Noticia
Tourism is one of Spain's economic engines. In 2022, it accounted for 11.6% of Gross Domestic Product (GDP), exceeding €155 billion, according to the Instituto Nacional de Estadística (INE). A figure that grew to 188,000 million and 12.8% of GDP in 2023, according to Exceltur, an association of companies in the sector. In addition, Spain is a very popular destination for foreigners, ranking second in the world and growing: by 2024 it is expected to reach a record number of international visitors, reaching 95 million.
In this context, the Secretariat of State for Tourism (SETUR), in line with European policies, is developing actions aimed at creating new technological tools for the Network of Smart Tourist Destinations, through SEGITTUR (Sociedad Mercantil Estatal para la Gestión de la Innovación y las Tecnologías Turísticas), the body in charge of promoting innovation (R&D&I) in this industry. It does this by working with both the public and private sectors, promoting:
- Sustainable and more competitive management models.
- The management and creation of smart destinations.
- The export of Spanish technology to the rest of the world.
These are all activities where data - and the knowledge that can be extracted from it - play a major role. In this post, we will review some of the actions SEGITTUR is carrying out to promote data sharing and openness, as well as its reuse. The aim is to assist not only in decision-making, but also in the development of innovative products and services that will continue to position our country at the forefront of world tourism.
Dataestur, an open data portal
Dataestur is a web space that gathers in a unique environment open data on national tourism. Users can find figures from a variety of public and private information sources.
The data are structured in six categories:
- General: international tourist arrivals, tourism expenditure, resident tourism survey, world tourism barometer, broadband coverage data, etc.
- Economy: tourism revenues, contribution to GDP, tourism employment (job seekers, unemployment and contracts), etc.
- Transport: air passengers, scheduled air capacity, passenger traffic by ports, rail and road, etc.
- Accommodation: hotel occupancy, accommodation prices and profitability indicators for the hotel sector, etc.
- Sustainability: air quality, nature protection, climate values, water quality in bathing areas, etc.
- Knowledge: active listening reports, visitor behaviour and perception, scientific tourism journals, etc.
The data is available for download via API.
Dataestur is part of a more ambitious project in which data analysis is the basis for improving tourist knowledge, through actions with a wide scope, such as those we will see below.
Developing an Intelligent Destination Platform (IDP)
Within the fulfillment of the milestones set by the Next Generation funds, and corresponding to the development of the Digital Transformation Plan for Tourist Destinations, the Secretary of State for Tourism, through SEGITTUR, is developing an Intelligent Destination Platform (PID). It is a platform-node that brings together the supply of tourism services and facilitates the interoperability of public and private operators. Thanks to this platform it will be possible to provide services to integrate and link data from both public and private sources.
Some of the challenges of the Spanish tourism ecosystem to which the IDP responds are:
- Encourage the integration and development of the tourism ecosystem (academia, entrepreneurs, business, etc.) around data intelligence and ensure technological alignment, interoperability and common language.
- To promote the use of the data economy to improve the generation, aggregation and sharing of knowledge in the Spanish tourism sector, driving its digital transformation.
- To contribute to the correct management of tourist flows and tourist hotspots in the citizen space, improving the response to citizens' problems and offering real-time information for tourist management.
- Generate a notable impact on tourists, residents and companies, as well as other agents, enhancing the brand "sustainable tourism country" throughout the travel cycle (before, during and after).
- Establish a reference framework to agree on targets and metrics to drive sustainability and carbon footprint reduction in the tourism industry, promoting sustainable practices and the integration of clean technologies.

Figure 1. Objectives of the Intelligent Destination Platform (IDP).
New use cases and methodologies to implement them
To further harmonise data management, up to 25 use cases have been defined that enable different industry verticals to work in a coordinated manner. These verticals include areas such as wine tourism, thermal tourism, beach management, data provider hotels, impact indicators, cruises, sports tourism, etc.
To implement these use cases, a 5-step methodology is followed that seeks to align industry practices with a more structured approach to data:
- Identify the public problems to be solved.
- Identify what data are needed to be available to be able to solve them.
- Modelling these data to define a common nomenclature, definition and relationships.
- Define what technology needs to be deployed to be able to capture or generate such data.
- Analyse what intervention capacities, both public and private, are needed to solve the problem.
Boosting interoperability through a common ontology and data space
As a result of this definition of the 25 use cases, a ontology of tourism has been created, which they hope will serve as a global reference. The ontology is intended to have a significant impact on the tourism sector, offering a series of benefits:
- Interoperability: The ontology is essential to establish a homogeneous data structure and enable global interoperability, facilitating information integration and data exchange between platforms and countries. By providing a common language, definitions and a unified conceptual structure, data can be comparable and usable anywhere in the world. Tourism destinations and the business community can communicate more effectively and agilely, fostering closer collaboration.
- Digital transformation: By fostering the development of advanced technologies, such as artificial intelligence, tourism companies, the innovation ecosystem or academia can analyse large volumes of data more efficiently. This is mainly due to the quality of the information available and the systems' better understanding of the context in which they operate.
- Tourism competitiveness: Aligned with the previous question, the implementation of this ontology contributes to eliminating inequalities in the use and application of technology within the sector. By facilitating access to advanced digital tools, both public institutions and private companies can make more informed and strategic decisions. This not only raises the quality of the services offered, but also boosts the productivity and competitiveness of the Spanish tourism sector in an increasingly demanding global market.
- Tourist experience: Thanks to ontology, it is possible to offer recommendations tailored to the individual preferences of each traveller. This is achieved through more accurate profiling based on demographic and behavioural characteristics as well as specific motivations related to different types of tourism. By personalising offers and services, customer satisfaction before, during and after the trip is improved, and greater loyalty to tourist destinations is fostered.
- Governance: The ontology model is designed to evolve and adapt as new use cases emerge in response to changing market demands. SEGITTUR is actively working to establish a governance model that promotes effective collaboration between public and private institutions, as well as with the technology sector.
In addition, to solve complex problems that require the sharing of data from different sources, the Open Innovation Platform (PIA) has been created, a data space that facilitates collaboration between the different actors in the tourism ecosystem, both public and private. This platform enables secure and efficient data sharing, empowering data-driven decision making. The PIA promotes a collaborative environment where open and private data is shared to create joint solutions to address specific industry challenges, such as sustainability, personalisation of the tourism experience or environmental impact management.
Building consensus
SEGITTUR is also carrying out various initiatives to achieve the necessary consensus in the collection, management and analysis of tourism-related data, through collaboration between public and private actors. To this end, the Ente Promotor de la Plataforma Inteligente de Destinoswas created in 2021, which plays a fundamental role in bringing together different actors to coordinate efforts and agree on broad lines and guidelines in the field of tourism data.
In summary, Spain is making progress in the collection, management and analysis of tourism data through coordination between public and private actors, using advanced methodologies and tools such as the creation of ontologies, use cases and collaborative platforms such as PIA that ensure efficient and consensual management of the sector.
All this is not only modernising the Spanish tourism sector, but also laying the foundations for a smarter, more intelligent, connected and efficient future. With its focus on interoperability, digital transformation and personalisation of experiences, Spain is positioned as a leader in tourism innovation, ready to face the technological challenges of tomorrow.
Blog
Today's climate crisis and environmental challenges demand innovative and effective responses. In this context, the European Commission's Destination Earth (DestinE) initiative is a pioneering project that aims to develop a highly accurate digital model of our planet.
Through this digital twin of the Earth it will be possible to monitor and prevent potential natural disasters, adapt sustainability strategies and coordinate humanitarian efforts, among other functions. In this post, we analyse what the project consists of and the state of development of the project.
Features and components of Destination Earth
Aligned with the European Green Pact and the Digital Europe Strategy, Destination Earth integrates digital modeling and climate science to provide a tool that is useful in addressing environmental challenges. To this end, it has a focus on accuracy, local detail and speed of access to information.
In general, the tool allows:
- Monitor and simulate Earth system developments, including land, sea, atmosphere and biosphere, as well as human interventions.
- To anticipate environmental disasters and socio-economic crises, thus enabling the safeguarding of lives and the prevention of significant economic downturns.
- Generate and test scenarios that promote more sustainable development in the future.
To do this, DestinE is subdivided into three main components :
- Data lake:
- What is it? A centralised repository to store data from a variety of sources, such as the European Space Agency (ESA), EUMETSAT and Copernicus, as well as from the new digital twins.
- What does it provide? This infrastructure enables the discovery and access to data, as well as the processing of large volumes of information in the cloud.
·The DestinE Platform:.
- What is it? A digital ecosystem that integrates services, data-driven decision-making tools and an open, flexible and secure cloud computing infrastructure.
- What does it provide? Users have access to thematic information, models, simulations, forecasts and visualisations that will facilitate a deeper understanding of the Earth system.
- Digital cufflinks and engineering:
- What are they? There are several digital replicas covering different aspects of the Earth system. The first two are already developed, one on climate change adaptation and the other on extreme weather events.
- WHAT DOES IT PROVIDE? These twins offer multi-decadal simulations (temperature variation) and high-resolution forecasts.
Discover the services and contribute to improve DestinE
The DestinE platform offers a collection of applications and use cases developed within the framework of the initiative, for example:
- Digital twin of tourism (Beta): it allows to review and anticipate the viability of tourism activities according to the environmental and meteorological conditions of its territory.
- VizLab: offers an intuitive graphical user interface and advanced 3D rendering technologies to provide a storytelling experience by making complex datasets accessible and understandable to a wide audience..
- miniDEA: is an interactive and easy-to-use DEA-based web visualisation app for previewing DestinE data.
- GeoAI: is a geospatial AI platform for Earth observation use cases.
- Global Fish Tracking System (GFTS): is a project to help obtain accurate information on fish stocks in order to develop evidence-based conservation policies.
- More resilient urban planning: is a solution that provides a heat stress index that allows urban planners to understand best practices for adapting to extreme temperatures in urban environments..
- Danube Delta Water Reserve Monitoring: is a comprehensive and accurate analysis based on the DestinE data lake to inform conservation efforts in the Danube Delta, one of the most biodiverse regions in Europe.
Since October this year, the DestinE platform has been accepting registrations, a possibility that allows you to explore the full potential of the tool and access exclusive resources. This option serves to record feedback and improve the project system.
To become a user and be able to generate services, you must follow these steps..
Project roadmap:
The European Union sets out a series of time-bound milestones that will mark the development of the initiative:
- 2022 - Official launch of the project.
- 2023 - Start of development of the main components.
- 2024 - Development of all system components. Implementation of the DestinE platform and data lake. Demonstration.
- 2026 - Enhancement of the DestinE system, integration of additional digital twins and related services.
- 2030 - Full digital replica of the Earth.
Destination Earth not only represents a technological breakthrough, but is also a powerful tool for sustainability and resilience in the face of climate challenges. By providing accurate and accessible data, DestinE enables data-driven decision-making and the creation of effective adaptation and mitigation strategies.
Noticia
As part of the European Cybersecurity Awareness Month, the European data portal, data.europa.eu, has organized a webinar focused on the protection of open data.This event comes at a critical time when organisations, especially in the public sector, face the challenge of balancing data transparency and accessibility with the need to protect against cyber threats.
The online seminar was attended by experts in the field of cybersecurity and data protection, both from the private and public sector.
The expert panel addressed the importance of open data for government transparency and innovation, as well as emerging risks related to data breaches, privacy issues and other cybersecurity threats. Data providers, particularly in the public sector, must manage this paradox of making data accessible while ensuring its protection against malicious use.
During the event, a number of malicious tactics used by some actors to compromise the security of open data were identified. These tactics can occur both before and after publication. Knowing about them is the first step in preventing and counteracting them.
Pre-publication threats
Before data is made publicly available, it may be subject to the following threats:
-
Supply chain attacks: attackers can sneak malicious code into open data projects, such as commonly used libraries (Pandas, Numpy or visualisation modules), by exploiting the trust placed in these resources. This technique allows attackers to compromise larger systems and collect sensitive information in a gradual and difficult to detect manner.
- Manipulation of information: data may be deliberately altered to present a false or misleading picture. This may include altering numerical values, distorting trends or creating false narratives. These actions undermine the credibility of open data sources and can have significant consequences, especially in contexts where data is used to make important decisions.
- Envenenamiento de datos (data poisoning): attackers can inject misleading or incorrect data into datasets, especially those used for training AI models. This can result in models that produce inaccurate or biased results, leading to operational failures or poor business decisions.
Post-publication threats
Once data has been published, it remains vulnerable to a variety of attacks:
-
Compromise data integrity: attackers can modify published data, altering files, databases or even data transmission. These actions can lead to erroneous conclusions and decisions based on false information.
- Re-identification and breach of privacy: data sets, even if anonymised, can be combined with other sources of information to reveal the identity of individuals. This practice, known as 're-identification', allows attackers to reconstruct detailed profiles of individuals from seemingly anonymous data. This represents a serious violation of privacy and may expose individuals to risks such as fraud or discrimination.
- Sensitive data leakage: open data initiatives may accidentally expose sensitive information such as medical records, personally identifiable information (emails, names, locations) or employment data. This information can be sold on illicit markets such as the dark web, or used to commit identity fraud or discrimination.
Following on from these threats, the webinar presented a case study on how cyber disinformation exploited open data during the energy and political crisis associated with the Ukraine war in 2022. Attackers manipulated data, generated false content with artificial intelligence and amplified misinformation on social media to create confusion and destabilise markets.
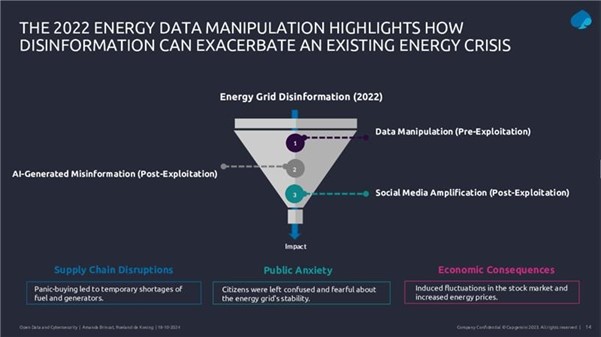
Figure 1. Slide from the webinar presentation "Safeguarding open data: cybersecurity essentials and skills for data providers".
Data protection and data governance strategies
In this context, the implementation of a robust governance structure emerges as a fundamental element for the protection of open data. This framework should incorporate rigorous quality management to ensure accuracy and consistency of data, together with effective updating and correction procedures. Security controls should be comprehensive, including:
- Technical protection measures.
- Integrity check procedures.
- Access and modification monitoring systems.
Risk assessment and risk management requires a systematic approach starting with a thorough identification of sensitive and critical data. This involves not only the cataloguing of critical information, but also a detailed assessment of its sensitivity and strategic value. A crucial aspect is the identification and exclusion of personal data that could allow the identification of individuals, implementing robust anonymisation techniques where necessary.
For effective protection, organisations must conduct comprehensive risk analyses to identify potential vulnerabilities in their data management systems and processes. These analyses should lead to the implementation of robust security controls tailored to the specific needs of each dataset. In this regard, the implementation of data sharing agreements establishes clear and specific terms for the exchange of information with other organisations, ensuring that all parties understand their data protection responsibilities.
Experts stressed that data governance must be structured through well-defined policies and procedures that ensure effective and secure information management. This includes the establishment of clear roles and responsibilities, transparent decision-making processes and monitoring and control mechanisms. Mitigation procedures must be equally robust, including well-defined response protocols, effective preventive measures and continuous updating of protection strategies.
In addition, it is essential to maintain a proactive approach to security management. A strategy that anticipates potential threats and adapts protection measures as the risk landscape evolves. Ongoing staff training and regular updating of policies and procedures are key elements in maintaining the effectiveness of these protection strategies. All this must be done while maintaining a balance between the need for protection and the fundamental purpose of open data: its accessibility and usefulness to the public.
Legal aspects and compliance
In addition, the webinar explained the legal and regulatory framework surrounding open data. A crucial point was the distinction between anonymization and pseudo-anonymization in the context of the GDPR (General Data Protection Regulation).
On the one hand, anonymised data are not considered personal data under the GDPR, because it is impossible to identify individuals. However, pseudo-anonymisation retains the possibility of re-identification if combined with additional information. This distinction is crucial for organisations handling open data, as it determines which data can be freely published and which require additional protections.
To illustrate the risks of inadequate anonymisation, the webinar presented the Netflix case in 2006, when the company published a supposedly anonymised dataset to improve its recommendation algorithm. However, researchers were able to "re-identify" specific users by combining this data with publicly available information on IMDb. This case demonstrates how the combination of different datasets can compromise privacy even when anonymisation measures have been taken.
In general terms, the role of the Data Governance Act in providing a horizontal governance framework for data spaces was highlighted, establishing the need to share information in a controlled manner and in accordance with applicable policies and laws. The Data Governance Regulation is particularly relevant to ensure that data protection, cybersecurity and intellectual property rights are respected in the context of open data.
The role of AI and cybersecurity in data security
The conclusions of the webinar focused on several key issues for the future of open data. A key element was the discussion on the role of artificial intelligence and its impact on data security. It highlighted how AI can act as a cyber threat multiplier, facilitating the creation of misinformation and the misuse of open data.
On the other hand, the importance of implementing Privacy Enhancing Technologies (PETs ) as fundamental tools to protect data was emphasized. These include anonymisation and pseudo-anonymisation techniques, data masking, privacy-preserving computing and various encryption mechanisms. However, it was stressed that it is not enough to implement these technologies in isolation, but that they require a comprehensive engineering approach that considers their correct implementation, configuration and maintenance.
The importance of training
The webinar also emphasised the critical importance of developing specific cybersecurity skills. ENISA's cyber skills framework, presented during the session, identifies twelve key professional profiles, including the Cybersecurity Policy and Legal Compliance Officer, the Cybersecurity Implementer and the Cybersecurity Risk Manager. These profiles are essential to address today's challenges in open data protection.
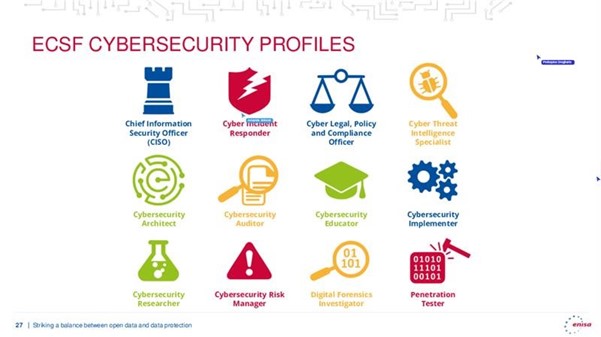
Figure 2. Slide presentation of the webinar " Safeguarding open data: cybersecurity essentials and skills for data providers".
In summary, a key recommendation that emerged from the webinar was the need for organisations to take a more proactive approach to open data management. This includes the implementation of regular impact assessments, the development of specific technical competencies and the continuous updating of security protocols. The importance of maintaining transparency and public confidence while implementing these security measures was also emphasised.
Blog
There is no doubt that data has become the strategic asset for organisations. Today, it is essential to ensure that decisions are based on quality data, regardless of the alignment they follow: data analytics, artificial intelligence or reporting. However, ensuring data repositories with high levels of quality is not an easy task, given that in many cases data come from heterogeneous sources where data quality principles have not been taken into account and no context about the domain is available.
To alleviate as far as possible this casuistry, in this article, we will explore one of the most widely used libraries in data analysis: Pandas. Let's check how this Python library can be an effective tool to improve data quality. We will also review the relationship of some of its functions with the data quality dimensions and properties included in the UNE 0081 data quality specification, and some concrete examples of its application in data repositories with the aim of improving data quality.
Using Pandas for data profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: is the process of exploratory analysis performed to understand the fundamental characteristics of the data, such as its structure, data types, distribution of values, and the presence of missing or duplicate values. The aim is to get a clear picture of what the data looks like, without necessarily making judgements about its quality.
- Data quality assessment: involves the application of predefined rules and standards to determine whether data meets certain quality requirements, such as accuracy, completeness, consistency, credibility or timeliness. In this process, errors are identified and actions to correct them are determined. A useful guide for data quality assessment is the UNE 0081 specification.
It consists of exploring and analysing a dataset to gain a basic understanding of its structure, content and characteristics, before conducting a more in-depth analysis or assessment of the quality of the data. The main objective is to obtain an overview of the data by analysing the distribution, types of data, missing values, relationships between columns and detection of possible anomalies. Pandas has several functions to perform this data profiling.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
What is Pandas and how does it help ensure data quality?
Pandas is one of the most popular Python libraries for data manipulation and analysis. Its ability to handle large volumes of structured information makes it a powerful tool in detecting and correcting errors in data repositories. With Pandas, complex operations can be performed efficiently, from data cleansing to data validation, all of which are essential to maintain quality standards. The following are some examples of how to improve data quality in repositories with Pandas:
1. Detection of missing or inconsistent values: One of the most common data errors is missing or inconsistent values. Pandas allows these values to be easily identified by functions such as isnull() or dropna(). This is key for the completeness property of the records and the data consistency dimension, as missing values in critical fields can distort the results of the analyses.
-
# Identify null values in a dataframe.
df.isnull().sum()
2. Data standardisation and normalisation: Errors in naming or coding consistency are common in large repositories. For example, in a dataset containing product codes, some may be misspelled or may not follow a standard convention. Pandas provides functions like merge() to perform a comparison with a reference database and correct these values. This option is key to maintaining the dimension and semantic consistency property of the data.
# Substitution of incorrect values using a reference table
df = df.merge(product_codes, left_on='product_code', right_on='ref_code', how= 'left')
3. Validation of data requirements: Pandas allows the creation of customised rules to validate the compliance of data with certain standards. For example, if an age field should only contain positive integer values, we can apply a function to identify and correct values that do not comply with this rule. In this way, any business rule of any of the data quality dimensions and properties can be validated.
# Identify records with invalid age values (negative or decimals)
age_errors = df[(df['age'] < 0) | (df['age'] % 1 != 0)])
4. Exploratory analysis to identify anomalous patterns: Functions such as describe() or groupby() in Pandas allow you to explore the general behaviour of your data. This type of analysis is essential for detecting anomalous or out-of-range patterns in any data set, such as unusually high or low values in columns that should follow certain ranges.
# Statistical summary of the data
df.describe()
#Sort by category or property
df.groupby()
5. Duplication removal: Duplicate data is a common problem in data repositories. Pandas provides methods such as drop_duplicates() to identify and remove these records, ensuring that there is no redundancy in the dataset. This capacity would be related to the dimension of completeness and consistency.
# Remove duplicate rows
df = df.drop_duplicates()
Practical example of the application of Pandas
Having presented the above functions that help us to improve the quality of data repositories, we now consider a case to put the process into practice. Suppose we are managing a repository of citizens' data and we want to ensure:
- Age data should not contain invalid values (such as negatives or decimals).
- That nationality codes are standardised.
- That the unique identifiers follow a correct format.
- The place of residence must be consistent.
With Pandas, we could perform the following actions:
1. Age validation without incorrect values:
# Identify records with ages outside the allowed ranges (e.g. less than 0 or non-integers)
age_errors = df[(df['age'] < 0) | (df['age'] % 1 != 0)])
2. Correction of nationality codes:
# Use of an official dataset of nationality codes to correct incorrect entries
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validation of unique identifiers:
# Check if the format of the identification number follows a correct pattern
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verification of consistency in place of residence:
# Detect possible inconsistencies in residency (e.g. the same citizen residing in two places at the same time).
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integration with a variety of technologies
Pandas is an extremely flexible and versatile library that integrates easily with many technologies and tools in the data ecosystem. Some of the main technologies with which Pandas is integrated or can be used are:
- SQL databases:
Pandas integrates very well with relational databases such as MySQL, PostgreSQL, SQLite, and others that use SQL. The SQLAlchemy library or directly the database-specific libraries (such as psycopg2 for PostgreSQL or sqlite3) allow you to connect Pandas to these databases, perform queries and read/write data between the database and Pandas.
- Common function: pd.read_sql() to read a SQL query into a DataFrame, and to_sql() to export the data from Pandas to a SQL table.
- REST and HTTP-based APIs:
Pandas can be used to process data obtained from APIs using HTTP requests. Libraries such as requests allow you to get data from APIs and then transform that data into Pandas DataFrames for analysis.
- Big Data (Apache Spark):
Pandas can be used in combination with PySpark, an API for Apache Spark in Python. Although Pandas is primarily designed to work with in-memory data, Koalas, a library based on Pandas and Spark, allows you to work with Spark distributed structures using a Pandas-like interface. Tools like Koalas help Pandas users scale their scripts to distributed data environments without having to learn all the PySpark syntax.
- Hadoop and HDFS:
Pandas can be used in conjunction with Hadoop technologies, especially the HDFS distributed file system. Although Pandas is not designed to handle large volumes of distributed data, it can be used in conjunction with libraries such as pyarrow or dask to read or write data to and from HDFS on distributed systems. For example, pyarrow can be used to read or write Parquet files in HDFS.
- Popular file formats:
Pandas is commonly used to read and write data in different file formats, such as:
- CSV: pd.read_csv()
- Excel: pd.read_excel() and to_excel().
- JSON: pd.read_json()
- Parquet: pd.read_parquet() for working with space and time efficient files.
- Feather: a fast file format for interchange between languages such as Python and R (pd.read_feather()).
- Data visualisation tools:
Pandas can be easily integrated with visualisation tools such as Matplotlib, Seaborn, and Plotly.. These libraries allow you to generate graphs directly from Pandas DataFrames.
- Pandas includes its own lightweight integration with Matplotlib to generate fast plots using df.plot().
- For more sophisticated visualisations, it is common to use Pandas together with Seaborn or Plotly for interactive graphics.
- Machine learning libraries:
Pandas is widely used in pre-processing data before applying machine learning models. Some popular libraries with which Pandas integrates are:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas supports these high-performance machine learning libraries, where DataFrames are used as input to train models.
- Jupyter Notebooks:
Pandas is central to interactive data analysis within Jupyter Notebooks, which allow you to run Python code and visualise the results immediately, making it easy to explore data and visualise it in conjunction with other tools.
- Cloud Storage (AWS, GCP, Azure):
Pandas can be used to read and write data directly from cloud storage services such as Amazon S3, Google Cloud Storage and Azure Blob Storage. Additional libraries such as boto3 (for AWS S3) or google-cloud-storage facilitate integration with these services. Below is an example for reading data from Amazon S3.
import pandas as pd
import boto3
#Create an S3 client
s3 = boto3.client('s3')
#Obtain an object from the bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Read CSV file from a DataFrame
df = pd.read_csv(obj['Body'])
10. Docker and containers:
Pandas can be used in container environments using Docker.. Containers are widely used to create isolated environments that ensure the replicability of data analysis pipelines .
In conclusion, the use of Pandas is an effective solution to improve data quality in complex and heterogeneous repositories. Through clean-up, normalisation, business rule validation, and exploratory analysis functions, Pandas facilitates the detection and correction of common errors, such as null, duplicate or inconsistent values. In addition, its integration with various technologies, databases, big dataenvironments, and cloud storage, makes Pandas an extremely versatile tool for ensuring data accuracy, consistency and completeness.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and point of view reflected in this publication is the sole responsibility of its author.
Evento
From October 28 to November 24, registration will be open for submitting proposals to the challenge organized by the Diputación de Bizkaia. The goal of the competition is to identify initiatives that combine the reuse of available data from the Open Data Bizkaia portal with the use of artificial intelligence. The complete guidelines are available at this link, but in this post, we will cover everything you need to know about this contest, which offers cash prizes for the five best projects.
Participants must use at least one dataset from the Diputación Foral de Bizkaia or from the municipalities in the territory, which can be found in the catalog, to address one of the five proposed use cases:
-
Promotional content about tourist attractions in Bizkaia: Written promotional content, such as generated images, flyers, etc., using datasets like:
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Recreation areas
- Hotels in Euskadi – Open Data Euskadi
- Temperature predictions in Bizkaia – Weather API data
-
Boosting tourism through sentiment analysis: Text files with recommendations for improving tourist resources, such as Excel and PowerPoint reports, using datasets like:
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Recreation areas
- Hotels in Euskadi – Open Data Euskadi
- Google reviews API – this resource is paid with a possible free tier
-
Personalized tourism guides: Chatbot or document with personalized recommendations using datasets like:
- Tide table 2024
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Hotels in Euskadi – Open Data Euskadi
- Temperature predictions in Bizkaia – Weather API data, resource with a free tier
-
Personalized cultural event recommendations: Chatbot or document with personalized recommendations using datasets like:
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
-
Waste management optimization: Excel, PowerPoint, and Word reports containing recommendations and strategies using datasets like:
- Urban waste
- Containers by municipality
How to participate?
Participants can register individually or in teams via this form available on the website. The registration period is from October 28 to November 24, 2024. Once registration closes, teams must submit their solutions on Sharepoint. A jury will pre-select five finalists, who will have the opportunity to present their project at the final event on December 12, where the prizes will be awarded. The organization recommends attending in person, but online attendance will also be allowed if necessary.
The competition is open to anyone over 16 years old with a valid ID or passport, who is not affiliated with the organizing entities. Additionally, multiple proposals can be submitted.
What are the prizes?
The jury members will select five winning projects based on the following evaluation criteria:
- Suitability of the proposed solution to the selected challenge.
- Creativity and innovation.
- Quality and coherence of the solution.
- Suitability of the Open Data Bizkaia datasets used.
The winning candidates will receive a cash prize, as well as the commitment to open the datasets associated with the project, to the extent possible.
- First prize: €2,000.
- Second prize: €1,000.
- Three prizes for the remaining finalists of €500 each.
One of the objectives of this challenge, as explained by the Diputación Foral de Bizkaia, is to understand whether the current dataset offerings meet demand. Therefore, if any participant requires a dataset from Bizkaia or its municipalities that is not available, they can propose that the institution make it publicly available, as long as the information falls within the competencies of the Diputación Foral de Bizkaia or the municipalities.
This is a unique event that will not only allow you to showcase your skills in artificial intelligence and open data but also contribute to the development and improvement of Bizkaia. Don’t miss the chance to be part of this exciting challenge. Sign up and start creating innovative solutions!
Blog
Open data can transform how we interact with our cities, offering opportunities to improve quality of life. When made publicly available, they enable the development of innovative applications and tools that address urban challenges, from accessibility to road safety and participation.
Real-time information can have positive impacts on citizens. For example, applications that use open data can suggest the most efficient routes, considering factors such as traffic and ongoing construction; information on the accessibility of public spaces can improve mobility for people with disabilities; data on cycling or pedestrian routes encourages greener and healthier modes of transport; and access to urban data can empower citizens to participate in decision-making about their city. In other words, citizen use of open data not only improves the efficiency of the city and its services, but also promotes a more inclusive, sustainable and participatory city.
To illustrate these ideas, this article discusses maps for "navigating" cities, made with open data. In other words, initiatives are shown that improve the relationship between citizens and their urban environment from different aspects such as accessibility, school safety and citizen participation. The first project is Mapcesible, which allows users to map and assess the accessibility of different locations in Spain. The second, Eskola BideApp, a mobile application designed to support safe school routes. And finally, maps that promote transparency and citizen participation in urban management. The first identifies noise pollution, the second locates available services in various areas within 15 minutes and the third displays banks in the city. These maps use a variety of public data sources to provide a detailed overview of different aspects of urban life.
The first initiative is a project of a large foundation, the second a collaborative and local proposal, and the third a personal project. Although they are based on very different approaches, all three have in common the use of public and open data and the vocation to help people understand and experience the city. The variety of origins of these projects indicates that the use of public and open data is not limited to large organisations.
Below is a summary of each project, followed by a comparison and reflection on the use of public and open data in urban environments.
Mapcesible, map for people with reduced mobility
Mapcessible was launched in 2019 to assess the accessibility of various spaces such as shops, public toilets, car parks, accommodation, restaurants, cultural spaces and natural environments.

Figure 1. Mapcesible. Source: https://mapcesible.fundaciontelefonica.com/intro
This project is supported by organizations such as the NGO Spanish Confederation of People with Physical and Organic Disabilities (COCEMFE) and the company ILUNION. It currently has more than 40,000 evaluated accessible spaces and thousands of users.

Figure 2. Mapcesible. Source: https://mapcesible.fundaciontelefonica.com/filters
Mapcesible uses open data as part of its operation. Specifically, the application incorporates fourteen datasets from official bodies, including the Ministry of Agriculture and Environment, city councils of different cities (including Madrid and Barcelona) and regional governments. This open data is combined with information provided by the users of the application, who can map and evaluate the accessibility of the places they visit. This combination of official data and citizen collaboration allows Mapcesible to provide up-to-date and detailed information on the accessibility of various spaces throughout Spain, thus benefiting people with reduced mobility.
Eskola BideAPP, application to define safe school routes.
Eskola BideAPP is an application developed by Montera34 - a team dedicated to data visualisation and the development of collaborative projects - in alliance with the Solasgune Association to support school pathways. Eskola BideAPP has served to ensure that boys and girls can access their schools safely and efficiently. The project mainly uses public data from the OpenStreetMap, e.g. geographical and cartographic data on streets, pavements, crossings, as well as data collected during the process of creating safe routes for children to walk to school in order to promote their autonomy and sustainable mobility.
The application offers an interactive dashboard to visualise the collected data, the generation of paper maps for sessions with students, and the creation of reports for municipal technicians. It uses technologies such as QGIS (a free and open source geographic information system) and a development environment for the R programming language, dedicated to statistical computing and graphics.
The project is divided into three main stages:
- Data collection through questionnaires in classrooms.
- Analysis and discussion of results with the children to co-design personalised routes.
- Testing of the designed routes.

Figure 3. Eskola BideaAPP. Photo by Julián Maguna (Solasgune). Source: https://montera34.com/project/eskola-bideapp/
Pablo Rey, one of the promoters of Montera34 together with Alfonso Sánchez, reports for this article that Eskola BideAPP, since 2019, has been used in eight municipalities, including Derio, Erandio, Galdakao, Gatika, Plentzia, Leioa, Sopela and Bilbao. However, it is currently only operational in the latter two. "The idea is to implement it in Portugalete at the beginning of 2025," he adds.
It''s worth noting the maps from Montera34 that illustrated the effect of Airbnb in San Sebastián and other cities, as well as the data analyses and maps published during the COVID-19 pandemic, which also visualized public data.In addition, Montera34 has used public data to analyse abstention, school segregation, minor contracts or make open data available to the public. For this last project, Montera34 has started with the ordinances of the Bilbao City Council and the minutes of its plenary sessions, so that they are not only available in a PDF document but also in the form of open and accessible data.
Mapas de Madrid sobre contaminación acústica, servicios y ubicación de bancos
Abel Vázquez Montoro has made several maps with open data that are very interesting, for example, the one made with data from the Strategic Noise Map (MER) offered by the Madrid City Council and land registry data. The map shows the noise affecting each building, facade and floor in Madrid.

Figure 4. Noise maps in Madrid. Source: https://madb.netlify.app/.
This map is organised as a dashboard with three sections: general data of the area visible on the map, dynamic 2D and 3D map with configurable options and detailed information on specific buildings. It is an open, free, non-commercial platform that uses free and open source software such as GitLab - a web-based Git repository management platform - and QGIS. The map allows the assessment of compliance with noise regulations and the impact on quality of life, as it also calculates the health risk associated with noise levels, using the attributable risk ratio (AR%).
15-minCity is another interactive map that visualises the concept of the "15-minute city" applied to different urban areas, i.e. it calculates how accessible different services are within a 15-minute walking or cycling radius from any point in the selected city.

Figure 5. 15-minCity. Source: https://whatif.sonycsl.it/15mincity/15min.php?idcity=9166
Finally, "Where to sit in Madrid" is another interactive map that shows the location of benches and other places to sit in public spaces in Madrid, highlighting the differences between rich (generally with more public seating) and poor (with less) neighbourhoods. This map uses the map-making tool, Felt, to visualise and share geospatial information in an accessible way. The map presents different types of seating, including traditional benches, individual seats, bleachers and other types of seating structures.

Figure 6. Where to sit in Madrid. Source: https://felt.com/map/Donde-sentarse-en-Madrid-TJx8NGCpRICRuiAR3R1WKC?loc=40.39689,-3.66392,13.97z
Its maps visualise public data on demographic information (e.g. population data by age, gender and nationality), urban information on land use, buildings and public spaces, socio-economic data (e.g. income, employment and other economic indicators for different districts and neighbourhoods), environmental data, including air quality, green spaces and other related aspects, and mobility data.
What do they have in common?
| Name | Promoter | Type of data used | Profit motive | Users | Characteristics |
|---|---|---|---|---|---|
| Mapcesible | Telefónica Foundation | Combines user-generated and public data (14 open data sets from government agencies) | Non-profit | More than 5.000 | Collaborative app, available on iOS and Android, more than 40,000 mapped accessible points. |
| Eskola BideAPP | Montera34 and Solasgune Association | Combines user-generated and public data (classroom questionnaires) and some public data. | Non-profit. | 4.185 | Focus on safe school routes, uses QGIS and R for data processing |
| Mapa Estratégico de Ruido (MER) | Madrid City Council | 2D and 3D geographic and visible area data | Non-profit | No data | It allows the assessment of compliance with noise regulations and the impact on quality of life, as it also calculates the associated health risk. |
| 15 min-City | Sony GSL | Geographic data and services | Non-profit | No data | Interactive map visualising the concept of the "15-minute city" applied to different urban areas. |
| MAdB "Dónde sentarse en Madrid" | Private | Public data (demographic, electoral, urban, socio-economic, etc.) | Non-profit | No data | Interactive maps of Madrid |
Figure 7. Comparative table of solutions
These projects share the approach of using open data to improve access to urban services, although they differ in their specific objectives and in the way information is collected and presented. Mapcesible, Eskola BideApp, MAdB and "Where to sit in Madrid" are of great value.
On the one hand, Mapcesible offers unified and updated information that allows people with disabilities to move around the city and access services. Eskola BideApp involves the community in the design and testing of safe routes for walking to school; this not only improves road safety, but also empowers young people to be active agents in urban planning. In the meantime, 15-min city, MER and the maps developed by Vázquez Montoro visualise complex data about Madrid so that citizens can better understand how their city works and how decisions that affect them are made.
Overall, the value of these projects lies in their ability to create a data culture, teaching how to value, interpret and use information to improve communities.
Content created by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy, and gender disinformation. The contents and viewpoints reflected in this publication are the sole responsibility of the author.
Evento
On 11, 12 and 13 November, a new edition of DATAforum Justice will be held in Granada. The event will bring together more than 100 speakers to discuss issues related to digital justice systems, artificial intelligence (AI) and the use of data in the judicial ecosystem.The event is organized by the Ministry of the Presidency, Justice and Relations with the Courts, with the collaboration of the University of Granada, the Andalusian Regional Government, the Granada City Council and the Granada Training and Management entity.
The following is a summary of some of the most important aspects of the conference.
An event aimed at a wide audience
This annual forum is aimed at both public and private sector professionals, without neglecting the general public, who want to know more about the digital transformation of justice in our country.
The DATAforum Justice 2024 also has a specific itinerary aimed at students, which aims to provide young people with valuable tools and knowledge in the field of justice and technology. To this end, specific presentations will be given and a DATAthon will be set up. These activities are particularly aimed at students of law, social sciences in general, computer engineering or subjects related to digital transformation. Attendees can obtain up to 2 ECTS credits (European Credit Transfer and Accumulation System): one for attending the conference and one for participating in the DATAthon.
Data at the top of the agenda
The Paraninfo of the University of Granada will host experts from the administration, institutions and private companies, who will share their experience with an emphasis on new trends in the sector, the challenges ahead and the opportunities for improvement.
The conference will begin on Monday 11 November at 9:00 a.m., with a welcome to the students and a presentation of DATAthon. The official inauguration, addressed to all audiences, will be at 11:35 a.m. and will be given by Manuel Olmedo Palacios, Secretary of State for Justice, and Pedro Mercado Pacheco, Rector of the University of Granada.
From then on, various talks, debates, interviews, round tables and conferences will take place, including a large number of data-related topics. Among other issues, the data management, both in administrations and in companies, will be discussed in depth. It will also address the use of open data to prevent everything from hoaxes to suicide and sexual violence.
Another major theme will be the possibilities of artificial intelligence for optimising the sector, touching on aspects such as the automation of justice, the making of predictions. It will include presentations of specific use cases, such as the use of AI for the identification of deceased persons, without neglecting issues such as the governance of algorithms.
The event will end on Wednesday 13 at 17:00 hours with the official closing ceremony. On this occasion, Félix Bolaños, Minister of the Presidency, Justice and Relations with the Cortes, will accompany the Rector of the University of Granada.
A Datathon to solve industry challenges through data
In parallel to this agenda, a DATAthon will be held in which participants will present innovative ideas and projects to improve justice in our society. It is a contest aimed at students, legal and IT professionals, research groups and startups.
Participants will be divided into multidisciplinary teams to propose solutions to a series of challenges, posed by the organisation, using data science oriented technologies. During the first two days, participants will have time to research and develop their original solution. On the third day, they will have to present a proposal to a qualified jury. The prizes will be awarded on the last day, before the closing ceremony and the Spanish wine and concert that will bring the 2024 edition of DATAfórum Justicia to a close.
In the 2023 edition, 35 people participated, divided into 6 teams that solved two case studies with public data and two prizes of 1,000 euros were awarded.
How to register
The registration period for the DATAforum Justice 2024 is now open. This must be done through the event website, indicating whether it is for the general public, public administration staff, private sector professionals or the media.
To participate in the DATAthon it is necessary to register also on the contest site.
Last year's edition, focusing on proposals to increase efficiency and transparency in judicial systems, was a great success, with over 800 registrants. This year again, a large number of people are expected, so we encourage you to book your place as soon as possible. This is a great opportunity to learn first-hand about successful experiences and to exchange views with experts in the sector.
Evento
In an increasingly information-driven world, open data is transforming the way we understand and shape our societies. This data are a valuable source of knowledge that also helps to drive research, promote technological advances and improve policy decision-making.
In this context, the Publications Office of the European Union organises the annual EU Open Data Days to highlight the role of open data in European society and all the new developments. The next edition will take place on 19-20 March 2025 at the European Conference Centre Luxembourg (ECCL) and online.
This event, organised by the data.europa.eu, europe's open data portal, will bring together data providers, enthusiasts and users from all over the world, and will be a unique opportunity to explore the potential of open data in various sectors. From success stories to new initiatives, this event is a must for anyone interested in the future of open data.
What are EU Open Data Days?
EU Open Data Days are an opportunity to exchange ideas and network with others interested in the world of open data and related technologies. This event is particularly aimed at professionals involved in data publishing and reuse, analysis, policy making or academic research.However, it is also open to the general public. After all, these are two days of sharing, learning and contributing to the future of open data in Europe.
What can you expect from EU Open Data Days 2025?
The event programme is designed to cover a wide range of topics that are key to the open data ecosystem, such as:
- Success stories and best practices: real experiences from those at the forefront of data policy in Europe, to learn how open data is being used in different business models and to address the emerging frontiers of artificial intelligence.
- Challenges and solutions: an overview of the challenges of using open data, from the perspective of publishers and users, addressing technical, ethical and legal issues.
- Visualising impact: analysis of how data visualisation is changing the way we communicate complex information and how it can facilitate better decision-making and encourage citizen participation.
- Data literacy: training to acquire new skills to maximise the potential of open data in each area of work or interest of the attendees.
An event open to all sectors
The EU Open Data Days are aimed at a wide audience: the public, the media, the general public and the general public.
- Private sector: data analytics specialists, developers and technology solution providers will be able to learn new techniques and trends, and connect with other professionals in the sector.
- Public sector: policy makers and government officials will discover how open data can be used to improve decision-making, increase transparency and foster innovation in policy design.
- Academia and education: researchers, teachers and students will be able to engage in discussions on how open data is fuelling new research and advances in areas as diverse as social sciences, emerging technologies and economics.
- Journalism and media: Data journalists and communicators will learn how to use data visualisation to tell more powerful and accurate stories, fostering better public understanding of complex issues.
Submit your proposal before 22 October
Would you like to present a paper at the EU Open Data Days 2025? You have until Tuesday 22 October to send your proposal on one of the above-mentioned themes. Papers that address open data or related areas are sought, such as data visualisation or the use of artificial intelligence in conjunction with open data.
The European data portal is looking for inspiring cases that demonstrate the impact of open data use in Europe and beyond. The call is open to participants from all over the world and from all sectors: from international, national and EU public organisations, to academics, journalists and data visualisation experts. Selected projects will be part of the conference programme, and presentations must be made in English.
Proposals should be between 20 and 35 minutes in length, including time for questions and answers. If your proposal is selected, travel and accommodation expenses (one night) will be reimbursed for participants from the academic sector, the public sector and NGOs.
For further details and clarifications, please contact the organising team by email: EU-Open-Data-Days@ec.europa.eu.
- Deadline for submission of proposals: 22 October 2024.
- Notification to selected participants: November 2024.
- Delivery of the draft presentation: 15 January 2025.
- Delivery of the final presentation: 18 February 2025.
- Conference dates: 19-20 March 2025.
The future of open data is now. The EU Open Data Days 2025 will not only be an opportunity to learn about the latest trends and practices in data use, but also to build a stronger and more collaborative community around open data. Registration for the event will open in late autumn 2024, we will announce it through our social media channels on TwitterlinkedIn and Instagram.
Blog
Citizen science is consolidating itself as one of the most relevant sources of most relevant sources of reference in contemporary research contemporary research. This is recognised by the Centro Superior de Investigaciones Científicas (CSIC), which defines citizen science as a methodology and a means for the promotion of scientific culture in which science and citizen participation strategies converge.
We talked some time ago about the importance importance of citizen science in society in society. Today, citizen science projects have not only increased in number, diversity and complexity, but have also driven a significant process of reflection on how citizens can actively contribute to the generation of data and knowledge.
To reach this point, programmes such as Horizon 2020, which explicitly recognised citizen participation in science, have played a key role. More specifically, the chapter "Science with and for society"gave an important boost to this type of initiatives in Europe and also in Spain. In fact, as a result of Spanish participation in this programme, as well as in parallel initiatives, Spanish projects have been increasing in size and connections with international initiatives.
This growing interest in citizen science also translates into concrete policies. An example of this is the current Spanish Strategy for Science, Technology and Innovation (EECTI), for the period 2021-2027, which includes "the social and economic responsibility of R&D&I through the incorporation of citizen science" which includes "the social and economic responsibility of I through the incorporation of citizen science".
In short, we commented some time agoin short, citizen science initiatives seek to encourage a more democratic sciencethat responds to the interests of all citizens and generates information that can be reused for the benefit of society. Here are some examples of citizen science projects that help collect data whose reuse can have a positive impact on society:
AtmOOs Academic Project: Education and citizen science on air pollution and mobility.
In this programme, Thigis developed a citizen science pilot on mobility and the environment with pupils from a school in Barcelona's Eixample district. This project, which is already replicable in other schoolsconsists of collecting data on student mobility patterns in order to analyse issues related to sustainability.
On the website of AtmOOs Academic you can visualise the results of all the editions that have been carried out annually since the 2017-2018 academic year and show information on the vehicles used by students to go to class or the emissions generated according to school stage.
WildINTEL: Research project on life monitoring in Huelva
The University of Huelva and the State Agency for Scientific Research (CSIC) are collaborating to build a wildlife monitoring system to obtain essential biodiversity variables. To do this, remote data capture photo-trapping cameras and artificial intelligence are used.
The wildINTEL project project focuses on the development of a monitoring system that is scalable and replicable, thus facilitating the efficient collection and management of biodiversity data. This system will incorporate innovative technologies to provide accurate and objective demographic estimates of populations and communities.
Through this project which started in December 2023 and will continue until December 2026, it is expected to provide tools and products to improve the management of biodiversity not only in the province of Huelva but throughout Europe.
IncluScience-Me: Citizen science in the classroom to promote scientific culture and biodiversity conservation.
This citizen science project combining education and biodiversity arises from the need to address scientific research in schools. To do this, students take on the role of a researcher to tackle a real challenge: to track and identify the mammals that live in their immediate environment to help update a distribution map and, therefore, their conservation.
IncluScience-Me was born at the University of Cordoba and, specifically, in the Research Group on Education and Biodiversity Management (Gesbio), and has been made possible thanks to the participation of the University of Castilla-La Mancha and the Research Institute for Hunting Resources of Ciudad Real (IREC), with the collaboration of the Spanish Foundation for Science and Technology - Ministry of Science, Innovation and Universities.
The Memory of the Herd: Documentary corpus of pastoral life.
This citizen science project which has been active since July 2023, aims to gather knowledge and experiences from sheperds and retired shepherds about herd management and livestock farming.
The entity responsible for the programme is the Institut Català de Paleoecologia Humana i Evolució Social, although the Museu Etnogràfic de Ripoll, Institució Milà i Fontanals-CSIC, Universitat Autònoma de Barcelona and Universitat Rovira i Virgili also collaborate.
Through the programme, it helps to interpret the archaeological record and contributes to the preservation of knowledge of pastoral practice. In addition, it values the experience and knowledge of older people, a work that contributes to ending the negative connotation of "old age" in a society that gives priority to "youth", i.e., that they are no longer considered passive subjects but active social subjects.
Plastic Pirates Spain: Study of plastic pollution in European rivers.
It is a citizen science project which has been carried out over the last year with young people between 12 and 18 years of age in the communities of Castilla y León and Catalonia aims to contribute to generating scientific evidence and environmental awareness about plastic waste in rivers.
To this end, groups of young people from different educational centres, associations and youth groups have taken part in sampling campaigns to collect data on the presence of waste and rubbish, mainly plastics and microplastics in riverbanks and water.
In Spain, this project has been coordinated by the BETA Technology Centre of the University of Vic - Central University of Catalonia together with the University of Burgos and the Oxygen Foundation. You can access more information on their website.
Here are some examples of citizen science projects. You can find out more at the Observatory of Citizen Science in Spain an initiative that brings together a wide range of educational resources, reports and other interesting information on citizen science and its impact in Spain. do you know of any other projects? Send it to us at dinamizacion@datos.gob.es and we can publicise it through our dissemination channels.
Blog
Data literacy has become a crucial issue in the digital age. This concept refers to the ability of people to understand how data is used, how it is accessed, created, analysed, used or reused, and communicated.
We live in a world where data and algorithms influence everyday decisions and the opportunities people have to live well. Its effect can be felt in areas ranging from advertising and employment provision to criminal justice and social welfare. It is therefore essential to understand how data is generated and used.
Data literacy can involve many areas, but we will focus on its relationship with digital rights on the one hand and Artificial Intelligence (AI) on the other. This article proposes to explore the importance of data literacy for citizenship, addressing its implications for the protection of individual and collective rights and the promotion of a more informed and critical society in a technological context where artificial intelligence is becoming increasingly important.
The context of digital rights
More and more studies studies increasingly indicate that effective participation in today's data-driven, algorithm-driven society requires data literacy indicating that effective participation in today's data-driven, algorithm-driven society requires data literacy. Civil rights are increasingly translating into digital rights as our society becomes more dependent on digital technologies and environments digital rights as our society becomes more dependent on digital technologies and environments. This transformation manifests itself in various ways:
- On the one hand, rights recognised in constitutions and human rights declarations are being explicitly adapted to the digital context. For example, freedom of expression now includes freedom of expression online, and the right to privacy extends to the protection of personal data in digital environments. Moreover, some traditional civil rights are being reinterpreted in the digital context. One example of this is the right to equality and non-discrimination, which now includes protection against algorithmic discrimination and against bias in artificial intelligence systems. Another example is the right to education, which now also extends to the right to digital education. The importance of digital skills in society is recognised in several legal frameworks and documents, both at national and international level, such as the Organic Law 3/2018 on Personal Data Protection and Guarantee of Digital Rights (LOPDGDD) in Spain. Finally, the right of access to the internet is increasingly seen as a fundamental right, similar to access to other basic services.
- On the other hand, rights are emerging that address challenges unique to the digital world, such as the right to be forgotten (in force in the European Union and some other countries that have adopted similar legislation1), which allows individuals to request the removal of personal information available online, under certain conditions. Another example is the right to digital disconnection (in force in several countries, mainly in Europe2), which ensures that workers can disconnect from work devices and communications outside working hours. Similarly, there is a right to net neutrality to ensure equal access to online content without discrimination by service providers, a right that is also established in several countries and regions, although its implementation and scope may vary. The EU has regulations that protect net neutrality, including Regulation 2015/2120, which establishes rules to safeguard open internet access. The Spanish Data Protection Act provides for the obligation of Internet providers to provide a transparent offer of services without discrimination on technical or economic grounds. Furthermore, the right of access to the internet - related to net neutrality - is recognised as a human right by the United Nations (UN).
This transformation of rights reflects the growing importance of digital technologies in all aspects of our lives.
The context of artificial intelligence
The relationship between AI development and data is fundamental and symbiotic, as data serves as the basis for AI development in a number of ways:
- Data is used to train AI algorithms, enabling them to learn, detect patterns, make predictions and improve their performance over time.
- The quality and quantity of data directly affect the accuracy and reliability of AI systems. In general, more diverse and complete datasets lead to better performing AI models.
- The availability of data in various domains can enable the development of AI systems for different use cases.
Data literacy has therefore become increasingly crucial in the AI era, as it forms the basis for effectively harnessing and understanding AI technologies.
In addition, the rise of big data and algorithms has transformed the mechanisms of participation, presenting both challenges and opportunities. Algorithms, while they may be designed to be fair, often reflect the biases of their creators or the data they are trained on. This can lead to decisions that negatively affect vulnerable groups.
In this regard, legislative and academic efforts are being made to prevent this from happening. For example, the EuropeanArtificial Intelligence Act (AI Act) includes safeguards to avoid harmful biases in algorithmic decision-making. For example, it classifies AI systems according to their level of potential risk and imposes stricter requirements on high-risk systems. In addition, it requires the use of high quality data to train the algorithms, minimising bias, and provides for detailed documentation of the development and operation of the systems, allowing for audits and evaluations with human oversight. It also strengthens the rights of persons affected by AI decisions, including the right to challenge decisions made and their explainability, allowing affected persons to understand how a decision was reached.
The importance of digital literacy in both contexts
Data literacy helps citizens make informed decisions and understand the full implications of their digital rights, which are also considered, in many respects, as mentioned above, to be universal civil rights. In this context, data literacy serves as a critical filter for full civic participation that enables citizens to influence political and social decisions full civic participation that enables citizens to influence political and social decisions. That is,those who have access to data and the skills and tools to navigate the data infrastructure effectively can intervene and influencepolitical and social processes in a meaningful way , something which promotes the Open Government Partnership.
On the other hand, data literacy enables citizens to question and understand these processes, fostering a culture of accountability and transparency in the use of AI. There arealso barriers to participation in data-driven environments. One of these barriers is the digital divide (i.e. deprivation of access to infrastructure, connectivity and training, among others) and, indeed, lack of data literacy. The latter is therefore a crucial concept for overcoming the challenges posed by datification datification of human relations and the platformisation of content and services.
Recommendations for implementing a preparedness partnership
Part of the solution to addressing the challenges posed by the development of digital technology is to include data literacy in educational curricula from an early age.
This should cover:
- Data basics: understanding what data is, how it is collected and used.
- Critical analysis: acquisition of the skills to evaluate the quality and source of data and to identify biases in the information presented. It seeks to recognise the potential biases that data may contain and that may occur in the processing of such data, and to build capacity to act in favour of open data and its use for the common good.
- Rights and regulations: information on data protection rights and how European laws affect the use of AI. This area would cover all current and future regulation affecting the use of data and its implication for technology such as AI.
- Practical applications: the possibility of creating, using and reusing open data available on portals provided by governments and public administrations, thus generating projects and opportunities that allow people to work with real data, promoting active, contextualised and continuous learning.
By educating about the use and interpretation of data, it fosters a more critical society that is able to demand accountability in the use of AI. New data protection laws in Europe provide a framework that, together with education, can help mitigate the risks associated with algorithmic abuse and promote ethical use of technology. In a data-driven society, where data plays a central role, there is a need to foster data literacy in citizens from an early age.
1The right to be forgotten was first established in May 2014 following a ruling by the Court of Justice of the European Union. Subsequently, in 2018, it was reinforced with the General Data Protection Regulation (GDPR)which explicitly includes it in its Article 17 as a "right of erasure". In July 2015, Russia passed a law allowing citizens to request the removal of links on Russian search engines if the information"violates Russian law or if it is false or outdated". Turkey has established its own version of the right to be forgotten, following a similar model to that of the EU. Serbia has also implemented a version of the right to be forgotten in its legislation. In Spain, the Ley Orgánica de Protección de Datos Personales (LOPD) regulates the right to be forgotten, especially with regard to debt collection files. In the United Statesthe right to be forgotten is considered incompatible with the Constitution, mainly because of the strong protection of freedom of expression. However, there are some related regulations, such as the Fair Credit Reporting Act of 1970, which allows in certain situations the deletion of old or outdated information in credit reports.
2Some countries where this right has been established include Spain, regulated by Article 88 of Organic Law 3/2018 on Personal Data Protection; France, which, in 2017, became the first country to pass a law on the right to digital disconnection; Germany, included in the Working Hours and Rest Time Act(Arbeitszeitgesetz); Italy, under Law 81/201; and Belgium. Outside Europe, it is, for example, in Chile.
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation. The contents and views reflected in this publication are the sole responsibility of the author.