Noticia
El turismo es uno de los motores económicos de España. En 2022, supuso el 11,6% del Producto Interior Bruto (PIB), superando los 155.000 millones de euros, de acuerdo con el Instituto Nacional de Estadística (INE). Una cifra que creció hasta los 188.000 millones y el 12,8% del PIB en 2023, según Exceltur, asociación de empresas del sector. Además, España es un destino muy popular entre los extranjeros, situándose en el segundo puesto mundial y creciendo: este 2024 se espera alcanzar récord de visitantes internacionales, llegando a los 95 millones.
En este contexto, la Secretaría de Estado de Turismo (SETUR), alineada con las políticas europeas, está desarrollando actuaciones que pretenden crear nuevas herramientas tecnológicas para la Red de Destinos Turísticos Inteligentes, a través de SEGITTUR (Sociedad Mercantil Estatal parala Gestión de la Innovación y las Tecnologías Turísticas), ente encargado de impulsar la innovación (I+D+i) en esta industria. Para ello trabaja tanto con el sector público como con el privado, impulsando:
- Modelos de gestión sostenible y más competitivos.
- La gestión y creación de destinos inteligentes.
- La exportación de tecnología española al resto del mundo.
Todas ellas son actividades donde los datos -y el conocimiento que se puede extraer de ellos- tienen un gran papel. En este post, vamos a repasar algunas de las acciones que SEGITTUR lleva a cabo para impulsar la compartición y apertura de datos, así como su reutilización. El objetivo es ayudar no solo a la toma de decisiones, sino también al desarrollo de productos y servicios innovadores que continúen posicionando a nuestro país en los primeros puestos del turismo mundial.
Dataestur, un portal de datos abiertos
Dataestur es un espacio web que recoge en un único entorno datos abiertos del turismo nacional. Los usuarios pueden encontrar cifras procedentes de distintas fuentes de información, públicas y privadas.
Los datos están estructurados en seis categorías:
- General: llegadas de turistas internacionales, gasto turístico, encuesta de turismo de residentes, barómetro del turismo mundial, datos de cobertura banda ancha, etc.
- Economía: ingresos por turismo, aportación al PIB, empleo turístico (demandantes de empleo, paro y contratos), etc.
- Transporte: pasajeros aéreos, capacidad aérea programada, tráfico de pasajeros por puertos, trenes y carreteras, etc.
- Alojamientos: ocupación hotelera, precio de alojamientos e indicadores de rentabilidad del sector hotelero, etc.
- Sostenibilidad: calidad del aire, protección de la naturaleza, valores climatológicos, calidad del agua en las zonas de baño, etc.
- Conocimiento: informes de escucha activa, comportamiento y percepción del visitante, revistas científicas de turismo, etc.
Los datos están disponibles para su descarga vía API.
Dataestur forma parte de un proyecto más ambicioso en el que el análisis de los datos constituye la base para mejorar el conocimiento del turista, a través de acciones con un amplio alcance, como las que veremos a continuación.
Desarrollo de una Plataforma Inteligente de Destinos (PID)
Dentro del cumplimiento de los hitos marcados por los fondos Next Generation, y correspondiente al desarrollo del Plan de Transformación Digital de Destinos Turísticos, la Secretaría de Estado de Turismo, a través de SEGITTUR, está desarrollando una Plataforma Inteligente de Destinos (PID). Se trata de una plataforma-nodo que recoge la oferta de servicios turísticos y facilita la interoperabilidad de operadores públicos y privados. Gracias a esta plataforma se podrá proveer de servicios para integrar y relacionar datos de ambas fuentes, públicas y privadas.
Algunos de los retos del ecosistema turístico español a los que da respuesta la PID son:
- Potenciar la integración y desarrollo del ecosistema turístico (academia, emprendedores, empresa, etc.) en torno a la inteligencia del dato y garantizar el alineamiento tecnológico, la interoperabilidad y el lenguaje común.
- Promover el uso de la economía del dato para mejorar la generación, agregación y compartición de conocimiento en el sector turístico español, impulsando su transformación digital.
- Contribuir a una correcta gestión de los flujos turísticos y de los puntos de afluencia turística del espacio ciudadano, mejorando la respuesta a los problemas de la ciudadanía y ofreciendo información en tiempo real para la gestión turística.
- Generar un impacto notable en el turista, residentes y empresa, además del resto de agentes, potenciando la marca “país turismo sostenible” durante todo el ciclo de viaje (antes, durante y después).
- Establecer un marco de referencia para consensuar objetivos y métricas que impulsen la sostenibilidad y la reducción de la huella de carbono en la industria turística, fomentando prácticas sostenibles y la integración de tecnologías limpias.

Figura 1. Objetivos de la Plataforma Inteligente de Destinos (PID).
Nuevos casos de uso y metodologías para implementarlos
Para avanzar en la armonización de la gestión de datos, se han definido hasta 25 casos de uso que permiten a los distintos verticales del sector trabajar de manera coordinada. Estos verticales incluyen áreas como enoturismo, turismo termal, gestión de playas, hoteles proveedores de datos, indicadores de impacto, cruceros, turismo deportivo, etc.
Para implementar estos casos de uso, se sigue una metodología de 5 pasos que busca alinear las prácticas del sector con un enfoque más estructurado en torno a los datos:
- Identificar los problemas públicos a resolver.
- Identificar qué datos son necesarios disponer para poder resolverlos.
- Modelizar esos datos para definir una nomenclatura, definición y relaciones comunes.
- Definir qué tecnología hay que desplegar para poder capturar o generar dichos datos.
- Analizar qué capacidades de intervención, tanto públicas como privadas, se necesitan para resolver el problema.
Impulso de la interoperabilidad a través de una ontología común y un espacio de datos
Como resultado de esa definición de los 25 casos de uso se ha creado una ontología del turismo que esperan sirva como referencia mundial. La ontología tiene la vocación de generar un impacto significativo en el sector turístico, ofreciendo una serie de beneficios:
- Interoperabilidad: la ontología es esencial para establecer una estructura de datos homogénea y permitir una interoperabilidad global, lo que facilita la integración de información y el intercambio de datos entre plataformas y países. Al proporcionar un lenguaje común, definiciones y una estructura conceptual unificada, los datos pueden ser comparables y utilizables en cualquier parte del mundo. Los destinos turísticos y el tejido empresarial pueden comunicarse de manera más efectiva y ágil, impulsando una colaboración más estrecha.
- Transformación digital: al fomentar el desarrollo de tecnologías avanzadas, como la inteligencia artificial, las empresas turísticas, el ecosistema innovador o académico pueden analizar grandes volúmenes de datos de manera más eficiente. Esto es debido principalmente a la calidad de la información disponible y a que los sistemas comprenden mejor el contexto en el que operan.
- Competitividad turística: alineado con la cuestión anterior, la implementación de esta ontología contribuye a eliminar desigualdades en el uso y aplicación de la tecnología dentro del sector. Al facilitar el acceso a herramientas digitales avanzadas, tanto las instituciones públicas como las empresas privadas pueden tomar decisiones más informadas y estratégicas. Esto no solo eleva la calidad de los servicios ofrecidos, sino que también impulsa la productividad y competitividad del sector turístico español en un mercado global cada vez más exigente.
- Experiencia turística: gracias a la ontología, es posible ofrecer recomendaciones adaptadas a las preferencias individuales de cada viajero. Esto se logra mediante un perfilado más preciso basado en características demográficas y comportamentales, así como en las motivaciones específicas relacionadas con diferentes tipos de turismo. Al personalizar las ofertas y servicios, se mejora la satisfacción del cliente antes, durante y tras el viaje, y se fomenta una mayor fidelidad hacia los destinos turísticos.
- Gobernanza: el modelo ontológico está diseñado para evolucionar y adaptarse a medida que surgen nuevos casos de uso ante las demandas cambiantes del mercado. SEGITTUR está trabajando activamente en establecer un modelo de gobernanza que promueva la colaboración efectiva entre instituciones públicas y privadas, así como con el sector tecnológico.
Además, para resolver problemas complejos que requieren compartición de datos de diferentes fuentes, se ha creado la Plataforma de Innovación Abierta (PIA), un espacio de datos que facilita la colaboración entre los diferentes actores del ecosistema turístico, tanto públicos como privados. Esta plataforma permite compartir datos de manera segura y eficiente, potenciando la toma de decisiones basadas en datos. El PIA promueve un entorno colaborativo donde se comparten datos abiertos y privados para crear soluciones conjuntas que aborden desafíos específicos del sector, como la sostenibilidad, la personalización de la experiencia turístico o la gestión del impacto ambiental.
Impulso del consenso
Desde SEGITTUR también se están llevando a cabo diversas iniciativas para lograr el consenso necesario en la recopilación, gestión y análisis de datos relacionados con el turismo, a través de la colaboración entre actores públicos y privados. Para ello, en 2021 se creó el Ente Promotor de la Plataforma Inteligente de Destinos, que juega un papel fundamental al aglutinar a diversos actores para coordinar esfuerzos y acordar grandes líneas y directrices en el ámbito de los datos turísticos.
En resumen, España está avanzando en la recopilación, gestión y análisis de datos turísticos mediante la coordinación entre los actores públicos y privados, utilizando metodologías y herramientas avanzadas como la creación de ontologías, casos de uso y plataformas colaborativas como la PIA que aseguran una gestión eficiente y consensuada del sector.
Todo ello no solo está modernizando el sector turístico español, sino que también está sentando las bases para un futuro más inteligente, conectado y eficiente. Con su enfoque en la interoperabilidad, la transformación digital y la personalización de experiencias, España se posiciona como líder en innovación turística, lista para afrontar los desafíos tecnológicos del mañana.
Blog
La crisis climática y los desafíos ambientales actuales demandan respuestas innovadoras y efectivas. En este contexto, la iniciativa Destination Earth (DestinE) de la Comisión Europea es un proyecto pionero que tiene como objetivo desarrollar un modelo digital y altamente preciso de nuestro planeta.
A través de este gemelo digital de la Tierra se podrá monitorear y prevenir posibles desastres naturales, adaptar las estrategias de sostenibilidad y coordinar esfuerzos humanitarios, entre otras funciones. En este post, analizamos en qué consiste el proyecto y en qué estado se encuentra su desarrollo.
Características y componentes de Destination Earth
Alineado con el Pacto Verde Europeo y la Estrategia de Europa Digital, Destination Earth integra el modelado digital y las ciencias climáticas para ofrecer una herramienta que sea de utilidad a la hora de abordar retos ambientales. Para ello, cuenta con un enfoque orientado hacia la precisión, el detalle local y la rapidez en el acceso a la información.
En general, la herramienta permite:
- Monitorear y simular los desarrollos del sistema terrestre, que incluyen la tierra, el mar, la atmósfera y la biosfera, así como las intervenciones humanas.
- Anticipar desastres ambientales y crisis socioeconómicas, permitiendo así la salvaguarda de vidas y la prevención de recesiones económicas significativas.
- Generar y probar escenarios que promuevan un desarrollo más sostenible en el futuro.
Para llevar esto a cabo, DestinE se subdivide en tres componentes principales que son:
- Lago de datos:
- ¿Qué es? Un repositorio centralizado que permite almacenar datos de diversas fuentes, como la Agencia Espacial Europea (ESA), EUMETSAT y Copernicus, así como de los nuevos gemelos digitales.
- ¿Qué ofrece? Esta infraestructura permite el descubrimiento y acceso a datos, así como el procesamiento de grandes volúmenes de información en la nube.
- ·La Plataforma de DestinE:
- ¿Qué es? Un ecosistema digital que integra servicios, herramientas de toma de decisiones basadas en datos y una infraestructura de computación abierta en la nube, flexible y segura.
- ¿Qué ofrece? Los usuarios tienen acceso a información temática, modelos, simulaciones, pronósticos y visualizaciones que facilitarán una comprensión más profunda del sistema terrestre.
- Gemelos digitales e ingeniería:
- ¿Qué son? Son varias réplicas digitales que cubren diferentes aspectos del sistema terrestre. Ya están desarrollados los dos primeros, uno relacionado con la adaptación al cambio climático y, el otro, sobre eventos climáticos extremos.
- ¿Qué ofrecen? Estos gemelos ofrecen simulaciones multidecadales (variación de la temperatura) y pronósticos de alta resolución.
Descubre los servicios y contribuye a mejorar DestinE
La plataforma de DestinE ofrece un recopilatorio de aplicaciones y casos de uso desarrollados en el marco de la iniciativa, como, por ejemplo:
- Gemelo digital del turismo (Beta): permite revisar y anticipar la viabilidad de las actividades turísticas en función de las condiciones medioambientales y meteorológicas de su territorio.
- VizLab: ofrece una interfaz gráfica de usuario intuitiva y tecnologías avanzadas de renderizado en 3D para proporcionar una experiencia narrativa haciendo que conjuntos de datos complejos sean accesibles y comprensibles para un público amplio.
- miniDEA: es una app de visualización web interactiva y fácil de usar, basado en DEA, para previsualizar datos de DestinE.
- GeoAI: es una plataforma de IA geoespacial para casos de uso de observación de la Tierra.
- Global Fish Tracking System (GFTS): es un proyecto para ayudar a obtener información precisa sobre las poblaciones de peces para elaborar políticas de conservación basadas en datos.
- Planificación urbana más resiliente: es una solución que proporciona un índice de estrés térmico que permite a los planificadores urbanos conocer cuáles son las mejores prácticas de adaptación contra las temperaturas extremas en entornos urbanos.
- Monitoreo de la reserva de agua del Delta del Danubio: es un análisis exhaustivo y preciso basado en el lago de datos DestinE para informar sobre los esfuerzos de conservación del Delta del Danubio, una de las regiones con mayor biodiversidad de Europa.
Desde octubre de este año la plataforma de DestinE acepta registros, una posibilidad que permite explorar todo el potencial de la herramienta y acceder a recursos exclusivos. Esta opción sirve para recabar feedback y mejorar el sistema del proyecto.
Para convertirte en usuario y poder generar servicios, debes seguir estos pasos.
Hoja de ruta del proyecto:
La Unión Europea plantea una serie de hitos ubicados en el tiempo que marcarán el desarrollo de la iniciativa:
- 2022 – Lanzamiento oficial del proyecto.
- 2023 – Inicio del desarrollo de los principales componentes.
- 2024 – Desarrollo de todos los componentes del sistema. Puesta en marcha de la plataforma de DestinE y el lago de datos. Demostración.
- 2026 - Mejora del sistema DestinE, integración de gemelos digitales adicionales y servicios relacionados.
- 2030 - Réplica digital completa de la Tierra.
Destination Earth no solo representa un avance tecnológico, sino que también es una herramienta poderosa para la sostenibilidad y la resiliencia frente a los desafíos climáticos. Al proporcionar datos precisos y accesibles, DestinE permite tomar decisiones basadas en datos y crear estrategias de adaptación y mitigación efectivas.
Noticia
En el marco del mes europeo de concienciación sobre ciberseguridad, el portal europeo de datos, data.europa.eu, ha organizado un webinar centrado en la protección de datos abiertos. Este evento surge en un momento crítico donde las organizaciones, especialmente en el sector público, se enfrentan al desafío de equilibrar la transparencia y accesibilidad de los datos con la necesidad de protegerlos contra amenazas cibernéticas.
El seminario online contó con la participación de expertos en el campo de la ciberseguridad y la protección de datos, tanto desde el punto de vista privado como público.
En el panel de expertos se abordó la importancia que tiene la apertura de datos en la transparencia gubernamental y la innovación, así como los nuevos riesgos relacionados con brechas de datos, problemas de privacidad y otras amenazas de ciberseguridad. Los proveedores de datos, particularmente en el sector público, deben gestionar esta paradoja de hacer que los datos sean accesibles mientras garantizan su protección contra usos malintencionados.
Durante el evento, se identificaron diversas tácticas malintencionadas que utilizan algunos actores para comprometer la seguridad de los datos abiertos. Estas tácticas pueden producirse tanto antes como después de la publicación. Conocerlas es el primer paso para prevenirlas y contraatacarlas.
Amenazas prepublicación
Antes de que los datos sean puestos a disposición del público, estos pueden ser objeto de las siguientes amenazas:
- Ataques a la cadena de suministro: los atacantes pueden introducir de manera furtiva código malicioso en proyectos de datos abiertos, como librerías de uso común (Pandas, Numpy o módulos de visualización), aprovechando la confianza que se deposita en estos recursos. Esta técnica permite a los atacantes comprometer sistemas más grandes y recopilar información confidencial de manera gradual y difícil de detectar.
- Manipulación de la información: los datos pueden ser alterados de forma deliberada para presentar una imagen falsa o engañosa. Esto puede incluir la modificación de valores numéricos, la distorsión de tendencias o la creación de narrativas falsas. Estas acciones socavan la credibilidad de las fuentes de datos abiertos y pueden tener consecuencias significativas, especialmente en contextos donde los datos se utilizan para tomar decisiones importantes.
- Envenenamiento de datos (data poisoning): los atacantes pueden inyectar datos engañosos o incorrectos en los conjuntos de datos, especialmente aquellos utilizados para el entrenamiento de modelos de IA. Esto puede resultar en modelos que producen resultados inexactos o sesgados, llevando a fallos operacionales o decisiones empresariales erróneas.
Amenazas post-publicación
Una vez que los datos se han publicado, siguen siendo vulnerables a diversos ataques:
- Compromiso de la integridad de los datos: los atacantes pueden modificar los datos publicados, alterando archivos, bases de datos o incluso la transmisión de datos. Estas acciones pueden conducir a conclusiones erróneas y decisiones basadas en información falsa.
- Re-identificación y violación de la privacidad: los conjuntos de datos, aunque sean anónimos, pueden combinarse con otras fuentes de información para revelar la identidad de individuos. Esta práctica, conocida como ‘re-identificación’, permite a los atacantes reconstruir perfiles detallados de personas a partir de datos aparentemente anónimos. Esto representa una grave violación de la privacidad y puede exponer a las personas a riesgos como el fraude o la discriminación.
- Filtración de datos sensibles: las iniciativas de datos abiertos pueden exponer accidentalmente información sensible como registros médicos, información personal identificable (correos electrónicos, nombres, ubicaciones) o datos de empleo. Esta información puede ser vendida en mercados ilícitos como la dark web, o utilizarse para cometer fraude de identidad o discriminación.
Al hilo de estas amenazas, en el webinar se presentó un caso de estudio sobre cómo la desinformación cibernética aprovechó los datos abiertos durante la crisis energética y política asociada a la guerra de Ucrania en 2022. Los atacantes manipularon datos, generaron contenido falso con inteligencia artificial y amplificaron la desinformación en las redes sociales para crear confusión y desestabilizar los mercados.
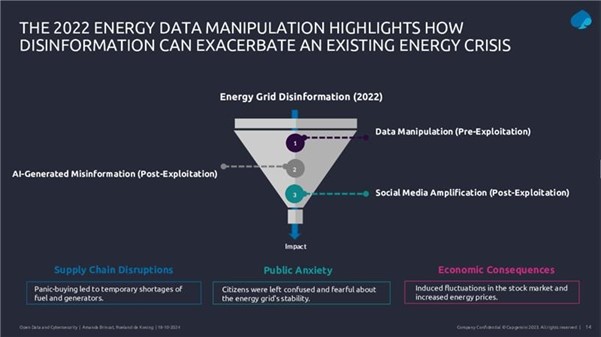
Figura 1. Diapositiva de la presentación del webinar ”Safeguarding open data: cybersecurity essentials and skills for data providers”
Estrategias de protección y gobierno de datos
En este contexto, la implementación de una estructura de gobernanza robusta emerge como elemento fundamental para la protección de datos abiertos. Este marco debe incorporar una gestión de calidad rigurosa que asegure la precisión y consistencia de los datos, junto con procedimientos efectivos de actualización y corrección. Los controles de seguridad deben ser exhaustivos, incluyendo:
- Medidas de protección técnicas.
- Procedimientos de verificación de integridad.
- Sistemas de monitoreo de accesos y modificaciones.
La evaluación y gestión de riesgos requiere un enfoque sistemático que comience con una minuciosa identificación de datos sensibles y críticos. Esto implica no solo la catalogación de información crítica, sino también una evaluación detallada de su sensibilidad y valor estratégico. Un aspecto crucial es la identificación y exclusión de datos personales que pudieran permitir la identificación de individuos, implementando técnicas robustas de anonimización cuando sea necesario.
Para una protección efectiva, las organizaciones deben realizar análisis de riesgos exhaustivos que permitan identificar vulnerabilidades potenciales en sus sistemas y procesos de gestión de datos. Estos análisis deben conducir a la implementación de controles de seguridad sólidos y adaptados a las necesidades específicas de cada conjunto de datos. En este sentido, la implementación de acuerdos de compartición de datos establece términos claros y específicos para el intercambio de información con otras organizaciones, asegurando que todas las partes comprendan sus responsabilidades en materia de protección de datos.
Los expertos destacaron que la gobernanza de datos debe estructurarse mediante políticas y procedimientos bien definidos que garanticen una gestión efectiva y segura de la información. Esto incluye el establecimiento de roles y responsabilidades claras, procesos de toma de decisiones transparentes y mecanismos de supervisión y control. Los procedimientos de mitigación deben ser igualmente robustos, incluyendo protocolos de respuesta bien definidos, medidas preventivas efectivas y una actualización continua de las estrategias de protección.
Además, es fundamental mantener un enfoque proactivo en la gestión de la seguridad. Una estrategia que se anticipe a posibles amenazas y adapte las medidas de protección según evoluciona el panorama de riesgos. La formación continua del personal y la actualización regular de las políticas y procedimientos son elementos clave para mantener la efectividad de estas estrategias de protección. Todo esto debe realizarse manteniendo un equilibrio entre la necesidad de protección y el objetivo fundamental de los datos abiertos: su accesibilidad y utilidad para el público.
Aspectos legales y cumplimiento
Además, en el webinar se dio una explicación sobre el marco legal y regulatorio que rodea a los datos abiertos. Un punto crucial fue la distinción entre anonimización y seudoanonimización en el contexto del RGPD (Reglamento General de Protección de Datos).
Por un lado, los datos anonimizados no se consideran datos personales bajo el RGPD, porque es imposible identificar a los individuos. No obstante, la seudoanonimización mantiene la posibilidad de re-identificación si se combina con información adicional. Esta distinción es fundamental para las organizaciones que manejan datos abiertos, ya que determina qué datos pueden publicarse libremente y cuáles requieren protecciones adicionales.
Para ilustrar los riesgos de una inadecuada anonimización, en el webinar se presentó el caso de Netflix en 2006, cuando la empresa publicó un conjunto de datos supuestamente anonimizados para mejorar su algoritmo de recomendaciones. Sin embargo, investigadores pudieron “reidentificar” a usuarios específicos al combinar estos datos con información públicamente disponible en IMDb. Este caso demuestra cómo la combinación de diferentes conjuntos de datos puede comprometer la privacidad incluso cuando se han tomado medidas de anonimización.
En términos generales, se destacó el papel que tiene el Data Governance Act a la hora de proporcionar un marco de gobernanza horizontal para los espacios de datos, estableciendo la necesidad de compartir información de manera controlada y de acuerdo con las políticas y leyes aplicables. El Reglamento de Gobernanza de Datos es especialmente relevante para garantizar que la protección de datos, la ciberseguridad y los derechos de propiedad intelectual se respeten en el contexto de los datos abiertos.
El papel de la IA y la ciberseguridad en la seguridad de los datos
Las conclusiones del webinar se centraron en varios aspectos clave para el futuro de los datos abiertos. Un elemento fundamental fue la discusión sobre el papel de la inteligencia artificial y su impacto en la seguridad de los datos. Se destacó cómo la IA puede actuar como un multiplicador de amenazas cibernéticas, facilitando la creación de desinformación y el mal uso de datos abiertos.
Por otro lado, se enfatizó la importancia de implementar tecnologías de mejora de la privacidad (PET o Privacy Enhancing Technologies) como herramientas fundamentales para proteger los datos. Estas incluyen técnicas de anonimización y seudoanonimización, enmascaramiento de datos, computación que preserva la privacidad y diversos mecanismos de encriptación. Sin embargo, se subrayó que no basta con implementar estas tecnologías de manera aislada, sino que requieren una aproximación integral de ingeniería que considere su correcta implementación, configuración y mantenimiento.
La importancia de la formación
El webinar también enfatizó la importancia crítica de desarrollar habilidades específicas en ciberseguridad. El marco de habilidades cibernéticas de ENISA, presentado durante la sesión, identifica doce perfiles profesionales clave, incluyendo el Oficial de Política y Cumplimiento Legal en Ciberseguridad, el Implementador de Seguridad Cibernética y el Gestor de Riesgo en Ciberseguridad. Estos perfiles son esenciales para abordar los desafíos actuales en la protección de datos abiertos.
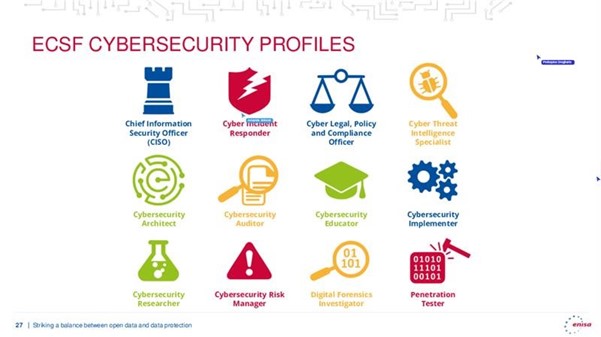
Figura 2. Diapositiva de la presentación del webinar "Safeguarding open data: cybersecurity essentials and skills for data providers”
En resumen, una recomendación clave que emergió del webinar fue la necesidad de que las organizaciones adopten un enfoque más proactivo en la gestión de datos abiertos. Esto incluye la implementación de evaluaciones de impacto regulares, el desarrollo de competencias técnicas específicas y la actualización continua de protocolos de seguridad. También se enfatizó la importancia de mantener la transparencia y la confianza pública mientras se implementan estas medidas de seguridad.
Blog
No hay duda de que los datos se han convertido en el activo estratégico para las organizaciones. Hoy en día, es esencial garantizar que las decisiones están fundamentadas en datos de calidad, independientemente del alineamiento que sigan: analítica de datos, inteligencia artificial o reporting. Sin embargo, asegurar repositorios de datos con altos niveles de calidad no es tarea fácil, dado que en muchos casos los datos provienen de fuentes heterogéneas donde los principios de calidad de datos no se han tenido en cuenta y no se dispone de contexto sobre el dominio.
Para paliar en la medida de lo posible esta casuística, en este artículo, exploraremos una de las bibliotecas más utilizadas en el análisis de datos: Pandas. Vamos a chequear cómo esta biblioteca de Python puede ser una herramienta eficaz para mejorar la calidad de los datos. También repasaremos la relación de alguna de sus funciones con las dimensiones y propiedades de calidad de datos incluidas en la especificación UNE 0081 de calidad de datos, y algunos ejemplos concretos de su aplicación en repositorios de datos con el objetivo de mejorar la calidad de los datos.
Utilizar de Pandas para Data Profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: es el proceso de análisis exploratorio que se realiza para entender las características fundamentales de los datos, como su estructura, tipos de datos, distribución de valores, y la presencia de valores faltantes o duplicados. El objetivo es obtener una imagen clara de cómo son los datos, sin necesariamente hacer juicios sobre su calidad.
- Evaluación de calidad de datos: implica la aplicación de reglas y estándares predefinidos para determinar si los datos cumplen con ciertos requisitos de calidad, como exactitud, completitud, consistencia, credibilidad o actualidad. En este proceso, se identifican errores y se determinan acciones para corregirlos. Una guía útil para la evaluación de calidad de datos es la especificación UNE 0081.
Consiste en explorar y analizar un conjunto de datos para obtener una comprensión básica de su estructura, contenido y características, antes de realizar un análisis más profundo o una evaluación de la calidad de los datos. El objetivo principal es obtener una visión general de los datos mediante el análisis de la distribución, los tipos de datos, los valores faltantes, las relaciones entre columnas y la detección de posibles anomalías. Pandas dispone de varias funciones para realizar este perfilado de datos.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
¿Qué es Pandas y cómo ayuda a asegurar la calidad de los datos?
Pandas es una de las bibliotecas más populares de Python para la manipulación y análisis de datos. Su capacidad para gestionar grandes volúmenes de información estructurada hace que sea una herramienta poderosa en la detección y corrección de errores en repositorios de datos. Con Pandas, se pueden realizar operaciones complejas de forma eficiente, desde limpieza hasta validación de datos, todas ellas son esenciales para mantener los estándares de calidad. A continuación, se indican algunos ejemplos para mejorar la calidad de los datos en repositorios con Pandas:
-
Detección de valores nulos o inconsistentes: uno de los errores más comunes en los datos son los valores faltantes o inconsistentes. Pandas permite identificar estos valores fácilmente mediante funciones como isnull() o dropna(). Esto es clave para la propiedad de completitud de los registros y la dimensión de consistencia de datos, ya que los valores faltantes en campos críticos pueden distorsionar los resultados de los análisis.
# Identificar valores nulos en un dataframe
df.isnull().sum()
- Normalización y estandarización de datos: los errores en la consistencia de nombres o códigos son comunes en grandes repositorios. Por ejemplo, en un conjunto de datos que contiene códigos de productos, es posible que algunos estén mal escritos o no sigan una convención estándar. Pandas ofrece funciones como merge() para realizar una comparación con una base de datos de referencia y corregir estos valores. Esta opción es clave para mantener la dimensión y propiedad de consistencia semántica de los datos.
# Sustitución de valores incorrectos utilizando una tabla de referencia
df = df.merge(codigos_productos, left_on='codigo_producto', right_on='codigo_ref', how= ‘left’)
- Validación de requisitos de datos: Pandas permite crear reglas personalizadas para validar la conformidad de los datos con ciertas normas. Por ejemplo, si un campo de edad solo debería contener valores enteros positivos, podemos aplicar una función para identificar y corregir valores que no cumplan con esta regla. De esta forma, se puede validar cualquier regla de negocio de cualquiera de las dimensiones y propiedades de calidad de datos.
# Identificar registros con valores de edad no válidos (negativos o decimales)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
- Análisis exploratorio para identificar patrones anómalos: funciones como describe() o groupby() en Pandas permiten explorar el comportamiento general de los datos. Este tipo de análisis es fundamental para detectar patrones anómalos o fuera de rango en cualquier conjunto de datos, como, por ejemplo, valores inusualmente altos o bajos en columnas que deberían seguir ciertos rangos.
# Resumen estadístico de los datos
df.describe()
#Ordenar según categoría o propiedad
df.groupby()
- Eliminación de duplicados: los datos duplicados son un problema común en los repositorios de datos. Pandas ofrece métodos como drop_duplicates() para identificar y eliminar estos registros, asegurando que no haya redundancia en el conjunto de datos. Esta capacidad estaría relacionada con la dimensión de completitud y consistencia.
# Eliminar filas duplicadas
df = df.drop_duplicates()
Ejemplo práctico de aplicación de Pandas
Una vez presentadas las funciones anteriores que nos sirven para mejorar la calidad de los repositorios de datos, planteamos un caso para poner en práctica el proceso. Supongamos que estamos gestionando un repositorio de datos de ciudadanos y queremos asegurarnos de:
- Que los datos de edad no contengan valores no válidos (como negativos o decimales?
- Que los códigos de nacionalidad estén estandarizados.
- Que los identificadores únicos sigan un formato correcto.
- Que el lugar de residencia sea coherente.
Con Pandas, podríamos realizar las siguientes acciones:
1. Validación de edades sin valores incorrectos
# Identificar registros con edades fuera de los rangos permitidos (por ejemplo, menores de 0 o no enteros)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
2. Corrección de códigos de nacionalidad
# Uso de un dataset oficial de códigos de nacionalidad para corregir los registros incorrectos
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validación de indentificadores únicos
# Verificar si el formato del número de identificación sigue un patrón correcto
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verificación de coherencia en lugar de residencia
# Detectar posibles inconsistencias en la residencia (por ejemplo, un mismo ciudadano residiendo en dos lugares al mismo tiempo)
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integración con diversidad de tecnologías
Pandas es una biblioteca extremadamente flexible y versátil que se integra fácilmente con muchas tecnologías y herramientas en el ecosistema de datos. Algunas de las principales tecnologías con las que Pandas tiene integración o se puede utilizar son:
-
Bases de datos SQL:
Pandas se integra muy bien con bases de datos relacionales como MySQL, PostgreSQL, SQLite, y otras que utilizan SQL. La biblioteca SQLAlchemy o directamente las bibliotecas específicas de cada base de datos (como psycopg2 para PostgreSQL o sqlite3) permiten conectar Pandas a estas bases de datos, realizar consultas y leer/escribir datos entre la base de datos y Pandas.
- Función común: pd.read_sql() para leer una consulta SQL en un DataFrame, y to_sql() para exportar los datos desde Pandas a una tabla SQL.
- APIs basadas en REST y HTTP:
Pandas se puede utilizar para procesar datos obtenidos de APIs utilizando solicitudes HTTP. Bibliotecas como requests permiten obtener datos de APIs y luego transformar esos datos en DataFrames de Pandas para su análisis.
- Big Data (Apache Spark):
Pandas se puede utilizar en combinación con PySpark, una API para Apache Spark en Python. Aunque Pandas está diseñado principalmente para trabajar con datos en memoria, Koalas, una biblioteca basada en Pandas y Spark, permite trabajar con estructuras distribuidas de Spark usando una interfaz similar a Pandas. Herramientas como Koalas ayudan a que los usuarios de Pandas puedan escalar sus scripts a entornos de datos distribuidos sin necesidad de aprender toda la sintaxis de PySpark.
- Hadoop y HDFS:
Pandas se puede utilizar junto con tecnologías de Hadoop, especialmente el sistema de archivos distribuido HDFS. Aunque Pandas no está diseñado para gestionar grandes volúmenes de datos distribuidos, puede utilizarse junto a bibliotecas como pyarrow o dask para leer o escribir datos desde y hacia HDFS en sistemas distribuidos. Por ejemplo, pyarrow se puede utilizar para leer o escribir archivos Parquet en HDFS.
- Formatos de archivos populares:
Pandas se utiliza comúnmente para leer y escribir datos en diferentes formatos de archivo, tales como:
- CSV: pd.read_csv()
- Excel: pd.read_excel() y to_excel()
- JSON: pd.read_json()
- Parquet: pd.read_parquet() para trabajar con archivos eficientes en espacio y tiempo.
- Feather: un formato de archivo rápido para intercambio entre lenguajes como Python y R (pd.read_feather()).
- Herramientas de visualización de datos:
Pandas se puede integrar fácilmente con herramientas de visualización como Matplotlib, Seaborn, y Plotly. Estas bibliotecas permiten generar gráficos directamente desde DataFrames de Pandas.
- Pandas incluye su propia integración ligera con Matplotlib para generar gráficos rápidos usando df.plot().
- Para visualizaciones más sofisticadas, es común usar Pandas junto a Seaborn o Plotly para gráficos interactivos.
- Bibliotecas de machine learning:
Pandas es ampliamente utilizado en el preprocesamiento de datos antes de aplicar modelos de machine learning. Algunas bibliotecas populares con las que Pandas se integra son:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas es compatible con estas bibliotecas de machine learning de alto rendimiento, donde los DataFrames se utilizan como entrada para entrenar modelos.
- Jupyter Notebooks:
Pandas es fundamental en el análisis de datos interactivo dentro de los Jupyter Notebooks, que permiten ejecutar código Python y visualizar los resultados de manera inmediata, lo que facilita la exploración de datos y su visualización en conjunto con otras herramientas.
- Cloud Storage (AWS, GCP, Azure):
Pandas se puede utilizar para leer y escribir datos directamente desde servicios de almacenamiento en la nube como Amazon S3, Google Cloud Storage y Azure Blob Storage. Bibliotecas adicionales como boto3 (para AWS S3) o google-cloud-storage facilitan la integración con estos servicios. A continuación, se muestra un ejemplo para leer datos desde Amazon S3.
import pandas as pd
import boto3
#Crear un cliente de S3
s3 = boto3.client('s3')
#Obtener un objeto del bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Leer el archivo CSV de un DataFrame
df = pd.read_csv(obj['Body'])
- Docker y contenedores:
Pandas se puede usar en entornos de contenedores utilizando Docker. Los contenedores son ampliamente utilizados para crear entornos aislados que aseguran la replicabilidad de los pipelines de análisis de datos.
En conclusión, el uso de Pandas es una solución eficaz para mejorar la calidad de los datos en repositorios complejos y heterogéneos. A través de funciones de limpieza, normalización, validación de reglas de negocio, y análisis exploratorio, Pandas facilita la detección y corrección de errores comunes, como valores nulos, duplicados o inconsistentes. Además, su integración con diversas tecnologías, bases de datos, entornos big data, y almacenamiento en la nube, convierte a Pandas en una herramienta extremadamente versátil para garantizar la exactitud, consistencia y completitud de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Evento
Desde el 28 de octubre y hasta el 24 de noviembre estará abierta la inscripción para presentar propuestas al reto de la Diputación de Bizkaia. El objetivo de la competición es identificar iniciativas que combinen la reutilización de datos disponibles en el portal Open Data Bizkaia con el uso de la inteligencia artificial. Las bases completas están disponibles en este enlace, pero, en este post, te contamos todo lo que tienes que saber sobre este concurso que ofrece premios en metálico para los cinco mejores proyectos.
Los participantes deberán utilizar al menos un dataset de la Diputación Foral de Bizkaia o de los ayuntamientos del territorio, que se pueden encontrar en el catálogo, para abordar uno de los cinco casos de uso propuestos:
- Contenido promocional sobre atractivos turísticos de Bizkaia: contenido promocional por escrito, como pueden ser imágenes generadas, flyers, etc. que utilicen datasets como:
- Playas de Bizkaia por municipio
- Agenda cultural – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Áreas de esparcimiento
- Hoteles de Euskadi – Open Data Euskadi
- Predicciones de la temperatura en Bizkaia – datos de Weather API
- Impulso del turismo a través del análisis de sentimientos: archivos de texto con recomendaciones para mejorar los recursos turísticos, como reportes en Excel y PowerPoint, etc. que utilicen datasets como:
- Playas de Bizkaia por municipio
- Agenda cultura – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Áreas de esparcimiento
- Hoteles de Euskadi – Open Data Euskadi
- Google reviews API – este recurso es de pago con posible capa gratuita
- Guías personalizadas para el turismo: Chatbot, documento con recomendaciones personalizadas que utilicen datasets como:
- Tabla de mareas 2024
- Playas de Bizkaia por municipio
- Agenda cultural – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Hoteles de Euskadi – Open Data Euskadi
- Predicciones de la temperatura en Bizkaia – datos de Weather API, recurso con capa gratuita
- Recomendación personalizada de eventos culturales: Chatbot, documento con recomendaciones personalizadas que utilicen datasets como:
- Agenda cultural - BizkaiKOA
- Agenda cultural de Bizkaia
- Optimización de la gestión de residuos: Reportes Excel, PowerPoint y Word que contengan recomendaciones y estrategias que utilicen datasets como:
- Residuos urbanos
- Contenedores por municipio
¿Cómo participar?
Los participantes podrán inscribirse de forma individual o en equipos a través de este formulario disponible en la web. El plazo de inscripción es del 28 de octubre al 24 de noviembre de 2024. Una vez cerrada la inscripción, los equipos deberán presentar sus soluciones en Sharepoint. Un jurado preseleccionará a cinco finalistas, quienes tendrán la oportunidad de presentar su proyecto en el evento final el 12 de diciembre, en el que se entregarán los premios. La organización recomienda asistir presencialmente, pero, si no es posible, también se permitirá la asistencia online.
La competición está abierta a cualquier persona mayor de 16 años con DNI o pasaporte en vigor, que no pertenezca a las entidades organizadoras. Además, se pueden presentar más de una propuesta.
¿Cuáles son los premios?
Los miembros del jurado elegirán cinco proyectos ganadores en base a los siguientes criterios de valoración:
- Adecuación de la solución propuesta al reto seleccionado.
- La creatividad y la innovación.
- Calidad y coherencia de la solución.
- Adecuación de datasets de Open Data Bizkaia utilizados.
Las candidaturas ganadoras recibirán un premio en metálico, así como el compromiso de abrir los datasets asociados al proyecto, en la medida en que sea posible.
- Primer premio: 2.000 €.
- Segundo premio: 1.000 €.
- Tres premios para el resto de finalistas de 500 € a cada uno.
Uno de los objetivos de este reto, tal y como explica la Diputación Foral de Bizkaia, es conocer si la oferta actual de datasets se ajusta a la demanda. Por este motivo, si alguna persona participante precisa de un conjunto de datos de Bizkaia o de sus ayuntamientos que no está disponible, puede proponer que la institución lo ponga a disposición del público. Siempre y cuando dicha información se ajuste a las competencias de la Diputación Foral de Bizkaia o de los ayuntamientos.
Este es un evento único que no solo te permitirá mostrar tus habilidades en inteligencia artificial y datos abiertos, sino que también contribuirás al desarrollo y mejora de Bizkaia. No dejes pasar la oportunidad de ser parte de este emocionante reto. ¡Inscríbete y empieza a crear soluciones innovadoras!
Blog
Los datos abiertos pueden transformar cómo interactuamos con nuestras ciudades, ofreciendo oportunidades para mejorar la calidad de vida. Cuando se ponen a disposición del público, permiten el desarrollo de aplicaciones innovadoras y herramientas que abordan desafíos urbanos, desde la accesibilidad hasta la seguridad vial y la participación.
La información en tiempo real puede tener impactos positivos en la ciudadanía. Por ejemplo, aplicaciones que utilizan datos abiertos pueden sugerir las rutas más eficientes, considerando factores como el tráfico y las obras en curso; la información sobre la accesibilidad de espacios públicos puede mejorar la movilidad de personas con discapacidades; los datos sobre rutas ciclistas o peatonales animan a optar por modos de transporte más ecológicos y sanos, y el acceso a datos urbanos puede empoderar a la ciudadanía para participar en la toma de decisiones sobre su ciudad. En otras palabras, el empleo ciudadano de datos abiertos no solo mejora la eficiencia de la ciudad y sus servicios, sino que también promueve una ciudad más inclusiva, sostenible y participativa.
Para ilustrar estas ideas, en este artículo se abordan mapas para “navegar” ciudades, realizados con datos abiertos. Es decir, se muestran iniciativas que mejoran la relación de la ciudadanía con su entorno urbano desde diferentes aspectos como la accesibilidad, la seguridad escolar o la participación ciudadana. El primer proyecto es Mapcesible, que permite a usuarios y usuarias mapear y evaluar la accesibilidad de diferentes lugares en España. El segundo, Eskola BideApp, una aplicación móvil diseñada para apoyar los caminos escolares seguros. Y finalmente, unos mapas que fomentan la transparencia y la participación ciudadana en la gestión urbana. El primero identifica la contaminación acústica, el segundo ubica los servicios disponibles en varias áreas que se encuentran a un máximo de 15 minutos y el tercero visualiza los bancos que hay en la ciudad. Estos mapas utilizan diversas fuentes de datos públicos para ofrecer una visión detallada de diferentes aspectos de la vida urbana.
La primera iniciativa es un proyecto de una gran fundación, la segunda, una propuesta colaborativa y local, y la tercera, un proyecto personal. Aunque parten de planteamientos muy diferentes, las tres tienen en común el uso de datos públicos y abiertos y la vocación de ayudar a entender y vivir la ciudad. La variedad de orígenes de estos proyectos indica que el uso de datos públicos y abiertos no está limitado a grandes organizaciones.
A continuación, realizamos un resumen de cada proyecto, seguido de una comparación y una reflexión sobre el empleo de datos públicos y abiertos en entornos urbanos.
Mapcesible, mapa para personas con movilidad reducida
Mapcesible se lanzó en 2019 para evaluar la accesibilidad de diversos espacios como comercios, aseos públicos, estacionamientos, alojamientos, restaurantes, espacios culturales y entornos naturales.

Figura 1. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/intro
Este proyecto cuenta con el apoyo de organizaciones como la ONG Confederación Española de Personas con Discapacidad Física y Orgánica (COCEMFE) y la empresa ILUNION. Actualmente cuenta con más de 40.000 espacios accesibles evaluados y miles de usuarios y usuarias.

Figura 2. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/filters
Mapcesible utiliza datos abiertos como parte de su funcionamiento. Específicamente, la aplicación incorpora catorce conjuntos de datos de organismos oficiales, incluyendo del Ministerio de Agricultura y Medioambiente, ayuntamientos de diferentes ciudades (incluidos Madrid y Barcelona) y de los gobiernos autonómicos. Estos datos abiertos se combinan con la información aportada por las personas usuarias de la aplicación, que pueden mapear y evaluar la accesibilidad de los lugares que visitan. Esta combinación de datos oficiales y colaboración ciudadana permite a Mapcesible proporcionar información actualizada y detallada sobre la accesibilidad de diversos espacios en toda España, beneficiando así a las personas con movilidad reducida.
Eskola BideAPP, aplicación para definir trayectos escolares seguros
Eskola BideAPP es una aplicación desarrollada por Montera34 –un equipo que se dedica a la visualización de datos y el desarrollo de proyectos colaborativos— en alianza con la Asociación Solasgune para apoyar los caminos escolares. Eskola BideAPP ha servido para garantizar que los niños y las niñas puedan acceder a sus escuelas de manera segura y eficiente. El proyecto usa sobre todo datos públicos del callejero de OpenStreetMap, por ejemplo, datos geográficos y cartográficos de calles, aceras, cruces, así como datos recabados durante el proceso de creación de rutas seguras para que los niños y las niñas vayan andando a sus colegios con el objetivo de promover su autonomía y la movilidad sostenible.
La aplicación ofrece un panel de control interactivo para visualizar los datos recopilados, la generación de mapas en papel para sesiones con el alumnado, y la creación de informes para técnicos municipales. Utiliza tecnologías como QGIS (un sistema de información geográfica de software libre y de código abierto) y un entorno de desarrollo para el lenguaje de programación R, dedicado a la computación estadística y gráficos.
El proyecto se divide en tres etapas principales:
- Recolección de datos mediante cuestionarios en las aulas.
- Análisis y discusión de resultados con los niños para co-diseñar rutas personalizadas.
- Prueba de las rutas diseñadas.

Figura 3. Eskola BideaAPP. Foto de Julián Maguna (Solasgune). Fuente: https://montera34.com/project/eskola-bideapp/
Pablo Rey, uno de los promotores de Montera34 junto con Alfonso Sánchez, informa para este artículo de que Eskola BideAPP, desde 2019, se ha usado en ocho municipios, incluidos Derio, Erandio, Galdakao, Gatika, Plentzia, Leioa, Sopela y Bilbao. Sin embargo, ahora mismo sólo está operativa en los dos últimos mencionados. “La idea es implementarla en Portugalete a principios de 2025”, añade.
Merece la pena recordar los mapas de Montera34 que mostraban el “efecto” AirBnB en San Sebastián y en otras ciudades, y los análisis de datos y mapas publicados durante la epidemia de COVID-19, que también visualizaban datos públicos. Además, Montera34 ha usado datos públicos para analizar la abstención, segregación escolar, contratos menores o poner los datos abiertos a disposición del público. Para este último proyecto, Montera34 ha comenzado por las ordenanzas del ayuntamiento de Bilbao y las actas de sus plenos, de manera que no solo estén disponibles en un documento PDF sino en forma de datos abiertos y accesibles.
Mapas de Madrid sobre contaminación acústica, servicios y ubicación de bancos
Abel Vázquez Montoro ha realizado diversos mapas con datos abiertos que resultan muy interesantes, por ejemplo, el elaborado con datos del Mapa Estratégico de Ruido (MER) ofrecido por el Ayuntamiento de Madrid y datos del catastro. El mapa muestra el ruido que afecta a cada edificio, fachada y planta en Madrid.

Figura 4. Mapas del ruido en Madrid. Fuente: https://madb.netlify.app/
Este mapa se organiza como un dashboard con tres secciones: datos generales de la zona visible en el mapa, mapa dinámico en 2D y 3D con opciones configurables e información detallada de edificios específicos. Se trata de una plataforma abierta, gratuita y de uso no comercial que usa software libre y de código abierto como GitLab — una plataforma web de gestión de repositorios Git— y QGIS. El mapa permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado a los niveles de ruido, utilizando la proporción de riesgo atribuible (RA%).
15-minCity es otro mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas; es decir, calcula cuán accesibles son diferentes servicios dentro de un radio de 15 minutos a pie o en bicicleta desde cualquier punto de la ciudad seleccionada.

Figura 5. 15-minCity. Fuente: https://whatif.sonycsl.it/15mincity/15min.php?idcity=9166
Por último, "Dónde sentarse en Madrid" es otro mapa interactivo que expone la ubicación de bancos y otros lugares para sentarse en espacios públicos de Madrid, destacando las diferencias entre barrios ricos (generalmente con más asientos públicos) y pobres (con menos). Este mapa utiliza la herramienta para creación de mapas, Felt, para visualizar y compartir información geoespacial de forma accesible. El mapa presenta diferentes tipos de asientos, incluyendo bancos tradicionales, asientos individuales, gradas y otros tipos de estructuras para sentarse.

Figura 6. Dónde sentarse en Madrid. Fuente: https://felt.com/map/Donde-sentarse-en-Madrid-TJx8NGCpRICRuiAR3R1WKC?loc=40.39689,-3.66392,13.97z
Sus mapas visualizan datos públicos de información demográfica (por ejemplo, datos poblacionales distribuidos por edades, género y nacionalidades), información urbanística sobre el uso del suelo, edificaciones y espacios públicos, datos socioeconómicos (por ejemplo, renta, empleo y otros indicadores económicos de los diferentes distritos y barrios), datos medioambientales, incluyendo calidad del aire, zonas verdes y otros aspectos relacionados, y datos sobre la movilidad.
¿Qué tienen en común?
| Nombre | Promotor/a | Tipo de datos usados | Afán de lucro | Usuarios/as | Características |
|---|---|---|---|---|---|
| Mapcesible | Fundación Telefónica. | Combina datos generados por usuarios/as y datos públicos (14 conjuntos de datos abiertos de organismos oficiales) | Sin ánimo de lucro. | Más de 5.000 | App colaborativa, disponible en iOS y Android, más de 40.000 puntos accesibles mapeados. |
| Eskola BideAPP | Montera34 y Asociación Solasgune. | Combina datos generados por usuarios/as y públicos (cuestionarios en aulas) y algunos datos abiertos. | Sin ánimo de lucro. | 4.185 | Enfocada en rutas escolares seguras, usa QGIS y R para procesamiento de datos |
| Mapa Estratégico de Ruido (MER) | Ayuntamiento de Madrid. | Datos geográficos y de zona visible en 2D y 3D | Sin ánimo de lucro. | No existen cifras públicas | Permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado |
| 15 min-City | Sony GSL | Servicios y datos geográficos. | Sin ánimo de lucro. | No existen cifras públicas | Mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas |
| MAdB "Dónde sentarse en Madrid" | Particular | Datos públicos (demográficos, electorales, urbanísticos, socioeconómicos, etc.) | Sin ánimo de lucro. | No existen cifras públicas | Mapas interactivos de Madrid |
Figura 7. Tabla comparativa de las soluciones
Estos proyectos comparten el enfoque de emplear datos abiertos para mejorar el acceso a los servicios urbanos, aunque difieren en sus objetivos específicos y en la forma de recopilar y presentar la información. Mapcesible, Eskola BideApp, MAdB y "Dónde sentarse en Madrid" tienen un gran valor.
Por un lado, Mapcesible ofrece información unificada y actualizada que permite a personas con discapacidad moverse por la ciudad y acceder a los servicios. Eskola BideApp involucra a la comunidad en el diseño y testeo de rutas seguras para ir caminando al colegio; esto no solo mejora la seguridad vial, sino que también empodera a los y las más jóvenes para que sean agentes activos en la planificación urbana. Entretanto, 15-min city, MER y los mapas desarrollados por Vázquez Montoro visualizan datos complejos sobre Madrid de manera que la ciudadanía pueden entender mejor cómo funciona su ciudad y cómo se toman las decisiones que les afectan.
En su conjunto, el valor de estos proyectos radica en su capacidad para crear una cultura de datos, enseñando a valorar, interpretar y utilizar la información para mejorar las comunidades.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Evento
Los próximos días 11, 12 y 13 de noviembre se celebra en Granada una nueva edición de DATAfórum Justicia. La cita reunirá a más de 100 ponentes para debatir sobre temas relacionados con los sistemas digitales de justicia, la inteligencia artificial (IA) y el uso del dato en el ecosistema judicial.
El evento está organizado por el Ministerio de Presidencia, Justicia y Relaciones con las Cortes, con la colaboración de la Universidad de Granada, la Junta de Andalucía, el Ayuntamiento de Granada y la entidad Formación y Gestión de Granada.
A continuación, se resumen algunos de los aspectos más importantes de estas jornadas.
Una cita dirigida a un público amplio
Este foro anual está dirigido tanto a profesionales del sector público, como del privado, sin dejar de lado al público general, que quiera saber más sobre la transformación digital de la justicia en nuestro país.
El DATAfórum Justicia 2024 cuenta, además, con un itinerario específico dirigido a estudiantes, cuyo objetivo es proporcionar a los jóvenes herramientas y conocimientos de valor en el ámbito de la justicia y la tecnología. Para ello, contarán con ponencias específicas y se pondrá en marcha un DATAthon. Estas actividades están especialmente dirigidas a estudiantes de derecho, ciencias sociales en general, ingenierías informáticas o materias relacionadas con la transformación digital. Los asistentes podrán obtener hasta 2 créditos ECTS (European Credit Transfer and Accumulation System o, en español, Sistema Europeo de Transferencia y Acumulación de Créditos): uno por asistir a las jornadas y otro por participar en el DATAthon.
Los datos, protagonistas de la agenda
El Paraninfo de la Universidad de Granada acogerá a expertos provenientes de la administración, instituciones y empresas privadas, que contarán su experiencia haciendo hincapié en las nuevas tendencias del sector, los retos que hay por delante y las oportunidades de mejora.
Las jornadas comenzarán el lunes 11 de noviembre a las 9:00 horas, con la bienvenida a los alumnos y la presentación del DATAthon. La inauguración oficial, dirigida a todas las audiencias, será a las 11:35 horas y correrá a cargo de Manuel Olmedo Palacios, Secretario de Estado de Justicia, y Pedro Mercado Pacheco, Rector de la Universidad de Granada.
A partir de entonces se sucederán diversas charlas, debates, entrevistas, mesas redondas y conferencias, entre las que encontramos un gran número de temáticas relacionadas con los datos. Entre otras cuestiones, se profundizará en la gestión del dato, tanto en administraciones como en empresas. También se abordará el uso de los datos abiertos para prevenir desde bulos hasta suicidios o la violencia sexual.
Otro tema con gran protagonismo será las posibilidades de la inteligencia artificial para optimizar el sector, tocando aspectos como la automatización de la justicia, la realización de predicciones. Se incluirán ponencias de casos de uso concretos, como la utilización de IA para la identificación de personas fallecidas, sin dejar de lado cuestiones como la gobernanza de algoritmos.
El evento finalizará el miércoles 13 a las 17:00 horas con la clausura oficial. En esta ocasión, Félix Bolaños, Ministro de la Presidencia, Justicia y Relaciones con las Cortes, acompañará al Rector de la Universidad de Granada.
Puedes ver la agenda completa aquí.
Un Datathon para resolver los retos del sector a través de los datos
En paralelo a esta agenda, se celebrará un DATAthon en el que los participantes presentarán ideas y proyectos innovadores para mejorar la justicia en nuestra sociedad. Se trata de un concurso destinado a estudiantes, profesionales del ámbito legal e informático, grupos de investigación y startups.
Los participantes se dividirán en equipos multidisciplinares para proponer soluciones a una serie de retos, planteados por la organización, utilizando tecnologías orientadas a la ciencia de datos. Durante las dos primeras jornadas los participantes dispondrán de tiempo para investigar y desarrollar su solución original. En la tercera jornada, deberán presentar una propuesta a un jurado cualificado. Los premios se entregarán el último día, antes de la clausura y del vino español y concierto que darán final a la edición 2024 del DATAfórum Justicia.
En la edición de 2023 participaron 35 personas, divididas en 6 equipos que resolvieron dos casos prácticos con datos de carácter público y se otorgaron dos premios de 1.000 euros.
Cómo inscribirse
El plazo de inscripción al DATAfórum Justicia 2024 ya está abierto. Debe realizarse a través de la web del evento, indicando si se trata de público general, personal de la administración pública, profesionales del sector privado o medios de comunicación.
Para participar en el DATAthon es necesario registrarse también en el site dedicado al concurso.
La edición del año pasado, centrada en propuestas para aumentar la eficiencia y transparencia en los sistemas judiciales, fue un gran éxito, con más de 800 inscritos. Este año se espera también una gran afluencia de público, así que te animamos a reservar tu plaza lo antes posible. Se trata de una gran oportunidad para conocer de primera mano experiencias exitosas y poder intercambiar opiniones con expertos en el sector.
Evento
En un mundo cada vez más impulsado por la información, los datos abiertos están transformando la manera en que entendemos y moldeamos nuestras sociedades. Estos datos son una fuente muy valiosa de conocimiento que, además, contribuye a impulsar la investigación, fomentar avances tecnológicos y mejorar la toma de decisiones políticas.
En este contexto, la Oficina de Publicaciones de la Unión Europea organiza cada año los EU Open Data Days para poner en valor el papel de los datos abiertos en la sociedad europea y destacar todas las novedades relacionadas con su desarrollo. La siguiente edición se llevará a cabo los días 19 y 20 de marzo de 2025 en el Centro de Conferencias Europeo de Luxemburgo (ECCL) y de forma online.
Este evento, organizado por el equipo de data.europa.eu, el portal europeo de datos abiertos, reunirá a proveedores de datos, entusiastas y usuarios de todo el mundo, y será una ocasión única para explorar el potencial del open data en diversos sectores. Desde historias de éxito hasta nuevas iniciativas, este evento es una cita obligada para cualquier persona interesada en el futuro de los datos abiertos.
¿Qué son los EU Open Data Days?
Los EU Open Data Days son una oportunidad para intercambiar ideas y hacer networking con otras personas interesadas en el mundo de los datos abiertos y sus tecnologías relacionadas. Este evento está especialmente dirigido a profesionales que se dediquen a la publicación y reutilización de datos, el análisis, la elaboración de políticas públicas o a la investigación académica. No obstante, también está abierto al público general. Al fin y al cabo, son dos jornadas para compartir, aprender y contribuir al futuro de los datos abiertos en Europa.
¿Qué puedes esperar de los EU Open Data Days 2025?
El programa del evento está diseñado para cubrir una amplia gama de temas que son clave en el ecosistema de datos abiertos, tales como:
- Historias de éxito y buenas prácticas: experiencias reales de quienes están en la primera línea de la política de datos en Europa, para conocer cómo se están utilizando los datos abiertos en diferentes modelos de negocio y abordar las fronteras emergentes de la inteligencia artificial.
- Desafíos y soluciones: repaso de los retos que presenta el uso de los datos abiertos, desde la perspectiva de editores y usuarios, abordando tanto los problemas técnicos como los éticos y legales.
- Visualización del impacto: análisis sobre cómo la visualización de datos está cambiando la forma en que comunicamos información compleja y cómo puede facilitar la toma de decisiones más acertadas, además de fomentar la participación ciudadana.
- Alfabetización en datos: formación para adquirir nuevas habilidades que maximicen el potencial de los datos abiertos en cada área de trabajo o interés de los asistentes.
Un evento abierto a todos los sectores
Los EU Open Data Days están dirigidos un público amplio:
- Sector privado: especialistas en análisis de datos, desarrolladores y proveedores de soluciones tecnológicas podrán aprender nuevas técnicas y tendencias, y conectar con otros profesionales del sector.
- Sector público: los responsables de políticas públicas y funcionarios gubernamentales descubrirán cómo los datos abiertos pueden ser utilizados para mejorar la toma de decisiones, aumentar la transparencia y fomentar la innovación en el diseño de políticas.
- Academia y educación: los investigadores, profesores y estudiantes podrán participar en discusiones sobre cómo los datos abiertos están alimentando nuevos estudios y avances en áreas tan diversas como las ciencias sociales, las tecnologías emergentes y la economía.
- Periodismo y medios de comunicación: los periodistas y comunicadores especializados en datos aprenderán cómo utilizar la visualización de datos para contar historias más poderosas y precisas, fomentando un mejor entendimiento de temas complejos por parte de la ciudadanía.
Presenta tu propuesta antes del 22 de octubre
¿Te gustaría presentar una ponencia en los EU Open Data Days 2025? Tienes hasta el próximo martes 22 de octubre para mandar tu propuesta sobre alguna de las temáticas mencionadas. Se buscan ponencias que aborden los datos abiertos o en áreas relacionadas, como la visualización de datos o el uso de la inteligencia artificial junto con datos abiertos.
Desde el portal de datos europeos están buscando casos inspiradores que demuestren el impacto del uso de datos abiertos en Europa y más allá. La convocatoria está abierta a participantes de todo el mundo y de todos los sectores: desde organizaciones públicas internacionales, nacionales y de la UE, hasta académicos, periodistas y expertos en visualización de datos. Los proyectos seleccionados formarán parte del programa de la conferencia, y las presentaciones deberán realizarse en inglés.
Las propuestas deberán tener una duración de entre 20 y 35 minutos, que incluirán tiempo para preguntas y respuestas. Si tu propuesta es elegida, los gastos de viaje y alojamiento (una noche) serán reembolsados para aquellos participantes provenientes del sector académico, el sector público y ONGs.
Para más detalles y aclaraciones, puedes ponerte en contacto con el equipo organizador a través del correo: EU-Open-Data-Days@ec.europa.eu.
- Fecha límite de presentación de propuestas: 22 de octubre de 2024.
- Notificación a los participantes seleccionados: noviembre de 2024.
- Entrega del borrador de la presentación: 15 de enero de 2025.
- Entrega de la presentación final: 18 de febrero de 2025.
- Fechas de la conferencia: 19-20 de marzo de 2025.
El futuro de los datos abiertos es ahora. Los EU Open Data Days 2025 no solo serán una oportunidad para aprender sobre las últimas tendencias y prácticas en el uso de datos, sino también para construir una comunidad más fuerte y colaborativa alrededor de los datos abiertos. El registro para el evento se abrirá a finales del otoño de 2024, lo anunciaremos a través de nuestras redes sociales en Twitter, LinkedIn e Instagram.
Blog
La ciencia ciudadana se está consolidando como una de las fuentes de referencia más relevantes en la investigación contemporánea. Así lo reconoce el Centro Superior de Investigaciones Científicas (CSIC) que define la ciencia ciudadana como una metodología y un medio para el fomento de la cultura científica en la que confluyen estrategias propias de la ciencia y de la participación ciudadana.
Ya hablamos hace un tiempo de la importancia que la ciencia ciudadana tenía en la sociedad. Hoy en día, los proyectos de ciencia ciudadana no solo han aumentado en número, diversidad y complejidad, sino que también han impulsado un significativo proceso de reflexión sobre cómo la ciudadanía puede contribuir activamente a la generación de datos y conocimiento.
Para llegar a este punto, programas como Horizonte 2020, que reconocía explícitamente la participación ciudadana en ciencia, han jugado un papel fundamental. Más en concreto, el capítulo "Ciencia con y para la sociedad” dio un importante empuje a este tipo de iniciativas en Europa y también en España. De hecho, a raíz de la participación española en dicho programa, así como en iniciativas paralelas, los proyectos españoles han ido aumentando su envergadura y las conexiones con iniciativas internacionales.
Este creciente interés por la ciencia ciudadana también se traduce en políticas concretas. Ejemplo de ello es la actual Estrategia Española de Ciencia, Tecnología e Innovación (EECTI), para el periodo 2021-2027 que incluye “la responsabilidad social y económica de la I+D+I a través de la incorporación de la ciencia ciudadana”.
En definitiva, comentamos hace un tiempo, las iniciativas de ciencia ciudadana buscan incentivar una ciencia más democrática, que responda a los intereses de toda la ciudadanía y que genere información que se pueda reutilizar en pro de la sociedad. A continuación, mostramos algunos ejemplos de proyectos de ciencia ciudadana que ayudan a recolectar datos cuya reutilización puede tener un impacto positivo en la sociedad:
Proyecto AtmOOs Academic: Educación y ciencia ciudadana sobre contaminación atmosférica y movilidad.
En este programa, Thigis desarrolló una prueba piloto de ciencia ciudadana sobre movilidad y medio ambiente con los alumnos de un colegio del distrito del Eixample de Barcelona. Este proyecto, que ya es replicable en otros centros educativos, consiste en recoger datos de patrones de movilidad del alumnado para analizar cuestiones relacionadas con la sostenibilidad.
En la web de AtmOOs Academic se pueden visualizar los resultados de todas las ediciones que llevan realizándose anualmente desde el curso 2017-2018 y muestran información sobre los vehículos que emplean los alumnos para ir a clase o las emisiones generadas según etapa escolar.
WildINTEL: Proyecto de investigación sobre el monitoreo de vida en Huelva
La Universidad de Huelva y la Agencia Estatal de Investigaciones Científicas (CSIC) colaboran para construir un sistema de monitoreo de vida silvestre para obtener las variables esenciales de biodiversidad. Para llevarlo a cabo, se utilizan cámaras de fototrampeo de captura remota de datos e inteligencia artificial.
El proyecto WildINTEL se centra en el desarrollo de un sistema de monitoreo que sea escalable y reproducible, facilitando así la recolección y gestión eficiente de datos sobre biodiversidad. Este sistema incorporará tecnologías innovadoras para proporcionar estimaciones demográficas precisas y objetivas de las poblaciones y comunidades.
A través de este proyecto, que empezó en diciembre de 2023 y seguirá ejecutándose hasta diciembre de 2026, se espera conseguir herramientas y productos para mejorar la gestión de la biodiversidad no solo en la provincia de Huelva sino en toda Europa.
IncluScience-Me: Ciencia ciudadana en el aula para impulsar la cultura científica y la conservación de la biodiversidad.
Este proyecto de ciencia ciudadana que combina educación y biodiversidad surge de la necesidad de abordar la investigación científica en las escuelas. Para ello, el alumnado toma el rol de persona investigadora para abordar un reto real: rastrear e identificar los mamíferos que habitan en sus entornos cercanos para ayudar a la actualización de un mapa de distribución y, por ende, a su conservación.
IncluScience-Me nace en la Universidad de Córdoba y, en concreto, en el Grupo de Investigación en Educación y Gestión de la Biodiversidad (Gesbio), y ha sido posible gracias a la participación de la Universidad de Castilla-La Mancha y el Instituto de Investigación en Recursos Cinegéticos de Ciudad Real (IREC), con la colaboración de la Fundación Española para la Ciencia y la Tecnología - Ministerio de Ciencia, Innovación y Universidades.
La Memoria del Rebaño: Corpus documental de la vida pastoril.
Este proyecto de ciencia ciudadana que lleva activo desde julio de 2023 tiene como objetivo recabar conocimientos y experiencias de pastores y pastoras, en activo y jubilados, sobre el manejo de rebaños y la actividad ganadera.
La entidad responsable del programa es el Institut Català de Paleoecología Humana i Evolució Social aunque también colaboran el Museu Etnogràfic de Ripoll, Institució Milà i Fontanals-CSIC, Universidad Autònoma de Barcelona y Universidad Rovira i Virgili.
A través del programa, se ayuda a interpretar el registro arqueológico y contribuye a conservar los conocimientos de la práctica pastoril. Además, pone en valor la experiencia y los conocimientos de las personas mayores, un trabajo que contribuye a acabar con la connotación negativa de la “vejez” en una sociedad que prima la “juventud”, es decir, que pasen de ser considerados sujetos pasivos a ser considerados sujetos sociales activos.
Plastic Pirates España: Estudio de la contaminación por plástico en ríos europeos.
Es un proyecto de ciencia ciudadana que se ha llevado a cabo durante el último año con jóvenes de entre 12 y 18 años de las comunidades de Castilla y León y Cataluña pretende contribuir a generar evidencias científicas y concienciación ambiental sobre los residuos plásticos en los ríos.
Para ello, grupos de jóvenes de diferentes centros educativos, asociaciones y agrupaciones juveniles, han participado en campañas de muestreo donde se recogen datos de la presencia de residuos y basuras, principalmente plásticos y microplásticos en las riberas y agua de los ríos.
En España este proyecto lo ha coordinado el Centro Tecnológico BETA de la Universidad de Vic - Universidad Central de Cataluña junto a la Universidad de Burgos y la Fundación Oxígeno. Puedes acceder a más información en su página web.
Estos son algunos ejemplos de proyectos de ciencia ciudadana. Puedes consultar más en el Observatorio de Ciencia Ciudadana en España, una iniciativa que recoge múltiples recursos didácticos, informes y más información de interés sobre la ciencia ciudadana y su impacto en España. ¿Conoces algún otro proyecto? Mándanoslo a dinamizacion@datos.gob.es y podemos darlo a conocer a través de nuestros canales de difusión.
Blog
La alfabetización en datos se ha convertido en un asunto crucial en la era digital. Este concepto se refiere a la capacidad de las personas para comprender el uso que se hace de los datos, así como para acceder a ellos, crearlos, analizarlos, utilizarlos o reutilizarlos, y comunicarlos.
Vivimos en un mundo donde los datos y los algoritmos influyen en decisiones cotidianas y en las oportunidades que tiene la gente para vivir bien. Su efecto se puede sentir en áreas que incluyen desde la publicidad y la oferta de empleo, hasta la justicia penal y las ayudas sociales. Por ello es fundamental comprender cómo se generan y utilizan los datos.
La alfabetización en datos puede implicar muchas áreas, pero nos vamos a centrar en su relación con los derechos digitales por una parte y la Inteligencia artificial (IA) por otro. Este artículo propone explorar la importancia de la alfabetización en datos para la ciudadanía, abordando sus implicaciones en la protección de los derechos individuales y colectivos y la promoción de una sociedad más informada y crítica en un contexto tecnológico donde la inteligencia artificial cobra cada vez más importancia.
El contexto de los derechos digitales
Cada vez hay más estudios que indican que una participación efectiva en la sociedad actual –impulsada por los datos y presidida por algoritmos— requiere de una alfabetización en datos. Los derechos civiles se traducen cada vez más en derechos digitales a medida que nuestra sociedad se vuelve más dependiente de las tecnologías y entornos digitales. Esta transformación se manifiesta de varias maneras:
- Por un lado, los derechos reconocidos en constituciones y declaraciones de derechos humanos se están adaptando explícitamente al contexto digital. Por ejemplo, la libertad de expresión ahora incluye la libertad de expresión en línea, y el derecho a la privacidad se extiende a la protección de datos personales en entornos digitales. Además, algunos derechos civiles tradicionales se están reinterpretando en el contexto digital. Una muestra de ello es el derecho a la igualdad y no discriminación, que ahora incluye la protección contra la discriminación algorítmica y contra los sesgos en sistemas de inteligencia artificial. Otro ejemplo es el derecho a la educación, que se extiende ahora también al derecho a la educación digital. La importancia de las habilidades digitales en la sociedad se reconoce en varios marcos legales y documentos, tanto a nivel nacional como internacional, como por ejemplo la Ley Orgánica 3/2018 de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD), en España. Por último, el derecho de acceso a Internet se está considerando cada vez más como un derecho fundamental, similar al acceso a otros servicios básicos.
- Por otro lado, están surgiendo derechos que abordan desafíos únicos del mundo digital, como el derecho al olvido (vigente en la Unión Europea y algunos otros países que han adoptado legislaciones similares1), que permite a las personas solicitar la eliminación de la información personal disponible en línea, bajo ciertas condiciones. Otro ejemplo puede ser el derecho a la desconexión digital (en vigor en varios países, principalmente en Europa2), que garantiza que los y las trabajadoras puedan desconectarse de dispositivos y comunicaciones laborales fuera del horario de trabajo. De la misma forma, existe el derecho a la neutralidad de Internet para asegurar un acceso equitativo a los contenidos en línea sin discriminación por parte de los proveedores de servicios, un derecho que también este derecho está establecido en varios países y regiones, aunque su implementación y alcance pueden variar. La UE tiene regulaciones que protegen la neutralidad de la red, incluido el Reglamento 2015/2120, que establece normas para salvaguardar el acceso abierto a Internet. La Ley de Protección de Datos española contempla la obligación de los proveedores de Internet de proporcionar una oferta transparente de servicios sin discriminación por motivos técnicos o económicos. Además, el derecho de acceso a Internet –relacionado con la neutralidad de la red— está reconocido como un derecho humano por la Organización de las Naciones Unidas (ONU).
Esta transformación de los derechos refleja la creciente importancia de las tecnologías digitales en todos los aspectos de nuestras vidas.
El contexto de la inteligencia artificial
La relación entre el desarrollo de la IA y los datos es fundamental y simbiótica, ya que los datos sirven como base para el desarrollo de la IA de varias maneras:
- Se utilizan datos para entrenar algoritmos de IA, lo que les permite aprender, detectar patrones, hacer predicciones y mejorar su rendimiento con el tiempo.
- La calidad y la cantidad de datos afectan directamente la precisión y la confiabilidad de los sistemas de IA. En general, los conjuntos de datos más diversos y completos conducen a modelos de IA de mejor rendimiento.
- La disponibilidad de datos en varios dominios puede permitir el desarrollo de sistemas de IA para diferentes casos de uso.
Por ello, la alfabetización de datos se ha vuelto cada vez más crucial en la era de la IA, ya que forma la base para aprovechar y comprender de manera eficaz las tecnologías de IA.
Además, el auge de los macrodatos y de los algoritmos ha transformado los mecanismos de participación, presentando tanto desafíos como oportunidades. Los algoritmos, aunque puedan estar diseñados para ser justos, a menudo reflejan los prejuicios de sus creadores o de los datos con los que se entrenan. Esto puede llevar a decisiones que afectan negativamente a grupos vulnerables.
En este sentido, se están llevando a cabo esfuerzos desde el punto de vista legislativo y académico para evitar que esto ocurra. Por ejemplo, la Ley de Inteligencia Artificial (AI Act) europea incluye garantías para evitar sesgos perjudiciales en la toma de decisiones algorítmica. Por ejemplo, clasifica los sistemas de IA según su nivel de riesgo potencial e impone requisitos más estrictos a aquellos de alto riesgo. Además, se exige el uso de datos de alta calidad para entrenar los algoritmos, minimizando los sesgos, y establece mantener documentación detallada sobre el desarrollo y funcionamiento de los sistemas, permitiendo auditorías y evaluaciones con supervisión humana. Asimismo, esta ley refuerza los derechos de las personas afectadas por decisiones de la IA, incluido el derecho a impugnar las decisiones tomadas y su explicabilidad, permitiendo a las personas afectadas entender cómo se llegó a una decisión.
La importancia de la alfabetización digital en ambos contextos
La alfabetización de datos ayuda a la ciudadanía a tomar decisiones informadas y entender todas las implicaciones de sus derechos digitales, que también se consideran, en muchos aspectos, como se ha referido anteriormente, derechos civiles universales. En este contexto, la alfabetización de datos sirve como un filtro crítico para una plena participación cívica que permita a la ciudadanía influir en las decisiones políticas y sociales. Es decir, quienes tienen el acceso a los datos y las habilidades y herramientas para navegar por la infraestructura de datos de manera efectiva pueden intervenir e influir de manera significativa en los procesos políticos y sociales, algo que promueve la Open Government Partnership.
Por otro lado, la alfabetización en datos permite a la ciudadanía cuestionar y entender estos procesos, fomentando una cultura de responsabilidad y transparencia en el uso de la IA. Asimismo, existen barreras para participar en entornos impulsados por datos. Una de estas barreras es la brecha digital (es decir, la privación del acceso a infraestructuras, conectividad y formación, entre otras) y, de hecho, la falta de alfabetización en datos. Por tanto, esta última se presenta como un concepto crucial para superar los desafíos que plantea la datificación de las relaciones humanas y la plataformización de los contenidos y servicios.
Recomendaciones para implementar una sociedad preparada
Parte de la solución para abordar los desafíos que propone el desarrollo de la tecnología digital es incluir la alfabetización en datos en los currículos educativos desde una edad temprana.
Esto debería abarcar:
- Conceptos básicos de datos: comprensión de qué son los datos, cómo se recopilan y se utilizan.
- Análisis crítico: adquisición de las habilidades para evaluar la calidad y la fuente de los datos e identificar sesgos en la información presentada. Se busca reconocer los potenciales sesgos que los datos puedan contener y que se puedan producir en el procesamiento de dichos datos, además de impulsar la capacidad para actuar en favor de la apertura de datos y su uso para el bien común.
- Derechos y regulaciones: información sobre los derechos de protección de datos y cómo las leyes europeas afectan al uso de la IA. Este ámbito abarcaría toda regulación presente y futura que afecte al uso de los datos y su implicación en tecnología como la IA.
- Aplicaciones prácticas: la posibilidad de crear, usar y reusar datos abiertos disponibles en los portales habilitados por gobiernos y administraciones públicas, para generar así proyectos y oportunidades que permitan a las personas trabajar con datos reales, promoviendo un aprendizaje activo, contextualizado y continuo.
Al educar sobre el uso y la interpretación de los datos, se fomenta una sociedad más crítica y capaz de demandar responsabilidad en el uso de la IA. Las nuevas leyes de protección de datos en Europa ofrecen un marco que, junto con la educación, puede ayudar a mitigar los riesgos asociados con el abuso algorítmico y promover un uso ético de la tecnología. En una sociedad datificada, en la que los datos desempeñan un papel fundamental, existe la necesidad de fomentar la alfabetización de datos en la ciudadanía desde edad temprana.
1. El derecho al olvido se estableció por primera vez en mayo de 2014 a raíz de una resolución del Tribunal de Justicia de la Unión Europea. Posteriormente, en 2018, se reforzó con el Reglamento General de Protección de Datos (RGPD), que lo incluye explícitamente en su artículo 17 como "derecho de supresión". En julio de 2015, Rusia aprobó una ley que permite a los ciudadanos solicitar la eliminación de enlaces en los buscadores rusos si la información "infringe la legislación rusa o si es falsa o se ha quedado obsoleta". Turquía ha establecido su propia versión del derecho al olvido, siguiendo un modelo similar al de la UE. Serbia también ha implementado una versión del derecho al olvido en su legislación. En España, la Ley Orgánica de Protección de Datos Personales (LOPD) regula el derecho al olvido, especialmente en lo que respecta a ficheros de morosos. En Estados Unidos, el derecho al olvido se considera incompatible con la Constitución, principalmente debido a la fuerte protección de la libertad de expresión. Sin embargo, existen algunas regulaciones relacionadas, como la Fair Credit Reporting Act de 1970, que permite en ciertas situaciones la eliminación de información antigua o caduca en informes crediticios.
2. Algunos países en los que se ha establecido este derecho incluyen España, regulado por el artículo 88 de la Ley Orgánica 3/2018 de Protección de Datos Personales; Francia, que, en 2017, se convirtió en el primer país en aprobar una ley sobre el derecho a la desconexión digital; Alemania, incluido en la Ley de Horarios de Trabajo y de Descanso (Arbeitszeitgesetz); Italia, dentro de la Ley 81/201, y Bélgica. Fuera de Europa, está, por ejemplo, en Chile.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor