Noticia
El portal europeo de datos abiertos ha publicado el tercer volumen de su Observatorio de Casos de Uso (Use Case Observatory, en inglés), un informe que recopila la evolución de proyectos de reutilización de datos en toda Europa. Esta iniciativa pone de relieve los avances logrados en cuatro áreas: impacto económico, gubernamental, social y medioambiental.
El cierre de una investigación de tres años
Entre 2022 y 2025, el portal europeo de datos abiertos ha llevado a cabo un seguimiento sistemático de la evolución de diversos proyectos europeos. La investigación comenzó con una selección inicial de 30 iniciativas representativas, que fueron analizadas en profundidad para identificar su potencial de impacto.
Tras dos años, 13 proyectos continuaron en el estudio, entre los que se encontraban tres españoles: Planttes, Tangible Data y UniversiDATA-Lab. Se estudió su desarrollo a lo largo del tiempo para comprender cómo la reutilización de datos abiertos puede generar beneficios reales y sostenibles.
La publicación del volumen III en octubre de 2025 marca el cierre de esta serie de informes, tras el volumen I (2022) y el volumen II (2024). Este último documento ofrece una visión longitudinal, mostrando cómo los proyectos han madurado en tres años de observación y qué impactos concretos han generado en sus respectivos contextos.
Conclusiones comunes
Este tercer y último informe recopila una serie de conclusiones clave:
Impacto económico
Los datos abiertos impulsan el crecimiento y la eficiencia en todos los sectores. Contribuyen a la creación de empleo, tanto de forma directa como indirecta, facilitan procesos de contratación más inteligentes y estimulan la innovación en ámbitos como la planificación urbana y los servicios digitales.
El informe muestra el ejemplo de:
- Naar Jobs (Bélgica): una aplicación para la búsqueda de empleo cerca del domicilio de los usuarios y focalizada en las opciones de transporte disponible.
Esta aplicación demuestra cómo los datos abiertos pueden convertirse en un motor para el empleo regional y el desarrollo empresarial.
Impacto gubernamental
La apertura de datos fortalece la transparencia, la rendición de cuentas y la participación ciudadana.
A este campo pertenecen dos casos de uso analizados:
- Waar is mijn stemlokaal? (Holanda): plataforma para la búsqueda de colegios electorales.
- Statsregnskapet.no (Noruega): web para visualizar los ingresos y gastos del gobierno.
Ambos ejemplos evidencian cómo el acceso a la información pública empodera a los ciudadanos, enriquece el trabajo de los medios de comunicación y respalda la elaboración de políticas basadas en evidencia. Todo ello ayuda a reforzar los procesos democráticos y la confianza en las instituciones.
Impacto social
Los datos abiertos promueven la inclusión, la colaboración y el bienestar.
A este campo pertenecen las siguientes iniciativas analizadas:
- UniversiDATA-Lab (España): repositorio de datos universitarios que facilita aplicaciones analíticas.
- VisImE-360 (Italia): herramienta para mapear la discapacidad visual y orientar recursos sanitarios.
- Tangible Data (España): empresa centrada en realizar esculturas físicas que convierten datos en experiencias accesibles.
- EU Twinnings (Países Bajos): plataforma que compara regiones europeas para encontrar “ciudades gemelas”
- Open Food Facts (Francia): base de datos colaborativa sobre productos alimenticios.
- Integreat (Alemania): aplicación que centraliza información pública para apoyar la integración de migrantes.
Todos ellos muestran cómo las soluciones basadas en datos pueden amplificar la voz de los colectivos vulnerables, mejorar los resultados en salud y abrir nuevas oportunidades educativas. Incluso los efectos más pequeños, como la mejora en la vida de una sola persona, pueden resultar significativos y duraderos.
Impacto medioambiental
Los datos abiertos actúan como un poderoso facilitador de la sostenibilidad.
Al igual que pasaba con el impacto ambiental, en esta área encontramos un gran número de casos de uso:
- Digital Forest Dryads (Estonia): proyecto que emplea datos para monitorizar los bosques y fomentar su conservación.
- Air Quality in Cyprus (Chipre): plataforma que informa sobre la calidad del aire y apoya políticas ambientales.
- Planttes (España): aplicación de ciencia ciudadana que ayuda a personas con alergias al polen mediante el seguimiento de la fenología de plantas.
- Environ-Mate (Irlanda): herramienta que promueve hábitos sostenibles y conciencia ecológica.
Estas iniciativas ponen de relieve cómo la reutilización de datos contribuye a sensibilizar, impulsar cambios de comportamiento y permitir intervenciones específicas para proteger los ecosistemas y fortalecer la resiliencia climática.
El volumen III también señala retos comunes: la necesidad de financiación sostenible, la importancia de combinar datos institucionales con datos generados por la ciudadanía y la conveniencia de involucrar a los usuarios finales en todo el ciclo de vida de los proyectos. Además, subraya la importancia de la colaboración europea y la interoperabilidad transnacional para escalar el impacto.
En conjunto, el informe refuerza la relevancia de seguir invirtiendo en ecosistemas de datos abiertos como herramienta clave para afrontar desafíos sociales y promover una transformación inclusiva.
El impacto de los proyectos españoles en la reutilización de datos abiertos
Como hemos mencionado, tres de los casos de uso analizados en el Use Case Observatory tienen sello español. Estas iniciativas destacan por su capacidad de combinar innovación tecnológica con impacto social y medioambiental, y ponen de manifiesto la relevancia de España dentro del ecosistema europeo de datos abiertos. Su trayectoria demuestra cómo nuestro país contribuye activamente a transformar los datos en soluciones que mejoran la vida de las personas y refuerzan la sostenibilidad y la inclusión. A continuación, hacemos un zoom en lo que el informe dice sobre ellas.
Esta iniciativa de ciencia ciudadana ayuda a personas con alergias al polen mediante información en tiempo real sobre plantas alergénicas en floración. Desde su aparición en el Volumen I del Use Case Observatory, ha evolucionado como plataforma participativa en la que los usuarios aportan fotos y datos fenológicos para crear un mapa de riesgo personalizado. Este modelo participativo ha permitido mantener un flujo constante de información validada por investigadores y ofrecer mapas cada vez más completos. Con más de 1.000 descargas iniciales y unos 65.000 visitantes anuales en su web, es una herramienta útil para personas con alergias, educadores e investigadores.
El proyecto ha reforzado su presencia digital, con una creciente visibilidad gracias al apoyo de instituciones como la Universidad Autónoma de Barcelona y la Universidad de Granada, además de la promoción realizada por la empresa Thigis.
Entre sus retos figuran ampliar la cobertura geográfica más allá de Cataluña y Granada y sostener la participación y validación de datos. Por ello, de cara al futuro, busca extender su alcance territorial, fortalecer la colaboración con escuelas y comunidades, integrar más datos en tiempo real y mejorar sus capacidades predictivas.
A lo largo de este tiempo, Planttes se ha consolidado como un ejemplo de cómo la ciencia impulsada por la ciudadanía puede mejorar la salud pública y la conciencia ambiental, demostrando el valor de la ciencia ciudadana en la educación ambiental, la gestión de alergias y el seguimiento del cambio climático.
El proyecto transforma conjuntos de datos en esculturas físicas que representan retos globales como el cambio climático o la pobreza, integrando códigos QR y NFC para contextualizar la información. Reconocido en los EU Open Data Days 2025, Tangible Data ha inaugurado su instalación Tangible climate en el Museo Nacional de Ciencias Naturales de Madrid.
Tangible Data ha evolucionado en tres años desde un proyecto prototipo basado en esculturas 3D para visualizar datos de sostenibilidad hasta convertirse en una plataforma educativa y cultural que conecta los datos abiertos con la sociedad. El Volumen III del Use Case Observatory refleja su expansión en escuelas y museos, la creación de un programa educativo para estudiantes de 15 años y el desarrollo de experiencias interactivas con inteligencia artificial, consolidando su compromiso con la accesibilidad y el impacto social.
Entre sus retos destacan la financiación y la ampliación del programa educativo, mientras que sus objetivos futuros incluyen escalar las actividades escolares, exhibir esculturas de gran formato en espacios públicos y reforzar la colaboración con artistas y museos. En conjunto, sigue fiel a su misión de hacer los datos tangibles, inclusivos y accionables.
UniversiDATA-Lab es un repositorio dinámico de aplicaciones analíticas basadas en datos abiertos de universidades españolas, creado en 2020 como colaboración público-privada y actualmente integrado por seis instituciones. Su infraestructura unificada facilita la publicación y reutilización de datos en formatos estandarizados, reduciendo barreras y permitiendo que estudiantes, investigadores, empresas y ciudadanos accedan a información útil para la educación, la investigación y la toma de decisiones.
En los últimos tres años, el proyecto ha pasado de ser un prototipo a una plataforma consolidada, con aplicaciones activas como el visor de presupuestos y de jubilaciones, y un visor de contratación en fase beta. Además, organiza un datathon periódico que impulsa la innovación y proyectos con impacto social.
Entre sus retos destacan la resistencia interna en algunas universidades y la compleja anonimización de datos sensibles, aunque ha respondido con protocolos sólidos y un enfoque en la transparencia. De cara al futuro, busca ampliar su catálogo, sumar nuevas universidades y lanzar aplicaciones sobre cuestiones emergentes como abandono escolar, diversidad del profesorado o sostenibilidad, aspirando a convertirse en referente europeo en reutilización de datos abiertos en educación superior.
Conclusión
Como conclusión, el tercer volumen del Use Case Observatory confirma que los datos abiertos se han consolidado como una herramienta clave para impulsar la innovación, la transparencia y la sostenibilidad en Europa. Los proyectos analizados —y en particular las iniciativas españolas Planttes, Tangible Data y UniversiDATA-Lab— demuestran que la reutilización de la información pública puede traducirse en beneficios concretos para la ciudadanía, la educación, la investigación y el medio ambiente.
Blog
En todo entorno de gestión de datos (empresas, Administración pública, consorcios, proyectos de investigación), disponer de datos no basta: si no sabes qué datos tienes, dónde están, qué significan, quién los mantiene, con qué calidad, cuándo cambiaron o cómo se relacionan con otros datos, entonces el valor es muy limitado. Los metadatos —datos sobre los datos— son esenciales para:
-
Visibilidad y acceso: permitir que usuarios encuentren qué datos existen y puedan acceder.
-
Contextualización: saber qué significan los datos (definiciones, unidades, semántica).
-
Trazabilidad / linaje: entender de dónde vienen los datos y cómo han sido transformados.
-
Gobierno y control: conocer quién es responsable, qué políticas aplican, permisos, versiones, obsolescencia.
-
Calidad, integridad y consistencia: asegurar la fiabilidad de los datos mediante reglas, métricas y monitoreo.
-
Interoperabilidad: garantizar que diferentes sistemas o dominios puedan compartir datos, utilizando un vocabulario común, definiciones compartidas y relaciones explícitas.
En resumen, los metadatos son la palanca que convierte los datos “aislados” en un ecosistema de información gobernada. A medida que los datos crecen en volumen, diversidad y velocidad, su función va más allá de la simple descripción: los metadatos añaden contexto, permiten interpretar los datos y facilitan que puedan ser encontrados, accesibles, interoperables y reutilizables (FAIR).
En el nuevo contexto impulsado por la inteligencia artificial, esta capa de metadatos adquiere una relevancia aún mayor, ya que proporciona la información de procedencia (provenance) necesaria para garantizar la trazabilidad, la fiabilidad y la reproducibilidad de los resultados. Por ello, algunos marcos recientes amplían estos principios hacia FAIR-R, donde la “R” adicional resalta la importancia de que los datos estén listos para la IA (AI-ready), es decir, que cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial.
Así, hablamos de metadatos enriquecidos, capaces de conectar información técnica, semántica y contextual para potenciar el aprendizaje automático, la interoperabilidad entre dominios y la generación de conocimiento verificable.
De los metadatos tradicionales a los “metadatos enriquecidos”
Metadatos tradicionales
En el contexto de este artículo, cuando hablamos de metadatos con un uso tradicional, pensamos en catálogos, diccionarios, glosarios, modelos de datos de base de datos, y estructuras rígidas (tablas y columnas). Los tipos de metadatos más comunes son:
-
Metadatos técnicos: tipo de columna, longitud, formato, claves foráneas, índices, ubicaciones físicas.
-
Metadatos de negocio / semánticos: nombre de campo, descripción, dominio de valores, reglas de negocio, términos del glosario empresarial.
-
Metadatos operativos / de ejecución: frecuencia de actualización, última carga, tiempos de procesamiento, estadísticas de uso.
-
Metadatos de calidad: porcentaje de valores nulos, duplicados, validaciones.
-
Metadatos de seguridad / acceso: políticas de acceso, permisos, clasificación de sensibilidad.
-
Metadatos de linaje: rastreo de transformación en los pipelines de datos.
Estos metadatos se almacenan usualmente en repositorios o herramientas de catalogación, muchas veces con estructuras tabulares o en bases relacionales, con vínculos predefinidos.
¿Por qué metadatos enriquecidos?
Los metadatos enriquecidos son aquella capa que no solo describe atributos, sino que:
- Descubren e infieren relaciones implícitas, identificando vínculos que no están expresamente definidos en los esquemas de datos. Esto permite, por ejemplo, reconocer que dos variables con nombres diferentes en sistemas distintos representan en realidad el mismo concepto (“altitud” y “elevación”), o que ciertos atributos mantienen una relación jerárquica (“municipio” pertenece a “provincia”).
- Facilitan consultas semánticas y razonamiento automatizado, permitiendo que los usuarios y las máquinas exploren relaciones y patrones que no están explícitamente definidos en las bases de datos. En lugar de limitarse a buscar coincidencias exactas de nombres o estructuras, los metadatos enriquecidos permiten formular preguntas basadas en significado y contexto. Por ejemplo, identificar automáticamente todos los conjuntos de datos relacionados con “ciudades costeras” aunque el término no aparezca literalmente en los metadatos.
- Se adaptan y evolucionan de manera flexible, ya que pueden ampliarse con nuevos tipos de entidades, relaciones o dominios sin necesidad de rediseñar toda la estructura del catálogo. Esto permite incorporar fácilmente nuevas fuentes de datos, modelos o estándares, garantizando la sostenibilidad del sistema a largo plazo.
- Incorporan automatización en tareas que antes eran manuales o repetitivas, como la detección de duplicidades, el emparejamiento automático de conceptos equivalentes o el enriquecimiento semántico mediante aprendizaje automático. También pueden identificar incoherencias o anomalías, mejorando la calidad y la coherencia de los metadatos.
- Integran de forma explícita el contexto de negocio, enlazando cada activo de datos con su significado operativo y su rol dentro de los procesos organizativos. Para ello utilizan vocabularios controlados, ontologías o taxonomías que facilitan un entendimiento común entre equipos técnicos, analistas y responsables de negocio.
- Favorecen una interoperabilidad más profunda entre dominios heterogéneos, que va más allá del intercambio sintáctico facilitado por los metadatos tradicionales. Los metadatos enriquecidos añaden una capa semántica que permite comprender y relacionar los datos en función de su significado, no solo de su formato. Así, datos procedentes de diferentes fuentes o sectores —por ejemplo, Sistemas de información Geográfica (GIS en inglés), Building Information Modeling (BIM) o Internet de las Cosas (IoT)— pueden vincularse de manera coherente dentro de un marco conceptual compartido. Esta interoperabilidad semántica es la que posibilita integrar conocimiento y reutilizar información entre contextos técnicos y organizativos diversos.
Esto convierte los metadatos en un activo vivo, enriquecido y conectado con el conocimiento del dominio, no solo un “registro” pasivo.

La evolución de los metadatos: ontologías y grafos de conocimiento
La incorporación de ontologías y grafos de conocimiento representa una evolución conceptual en la manera de describir, relacionar y aprovechar los metadatos, de ahí que hablemos de metadatos enriquecidos. Estas herramientas no solo documentan los datos, sino que los conectan dentro de una red de significado, permitiendo que las relaciones entre entidades, conceptos y contextos sean explícitas y computables.
En el contexto actual, marcado por el auge de la inteligencia artificial, esta estructura semántica adquiere un papel fundamental: proporciona a los algoritmos el conocimiento contextual necesario para interpretar, aprender y razonar sobre los datos de forma más precisa y transparente. Ontologías y grafos permiten que los sistemas de IA no solo procesen información, sino que entiendan las relaciones entre los elementos y puedan generar inferencias fundamentadas, abriendo el camino hacia modelos más explicativos y confiables.
Este cambio de paradigma transforma los metadatos en una estructura dinámica, capaz de reflejar la complejidad del conocimiento y de facilitar la interoperabilidad semántica entre distintos dominios y fuentes de información. Para comprender esta evolución conviene definir y relacionar algunos conceptos:
Ontologías
En el mundo de los datos, una ontología es un mapa conceptual muy organizado que define claramente:
- Qué entidades existen (ej. ciudad, río, carretera).
- Qué propiedades tienen (ej. una ciudad tiene nombre, población, código postal).
- Cómo se relacionan entre sí (ej. un río atraviesa una ciudad, una carretera conecta dos municipios).
El objetivo es que personas y máquinas compartan un mismo vocabulario y entiendan los datos de la misma manera. Las ontologías permiten:
- Definir conceptos y relaciones: por ejemplo, “una parcela pertenece a un municipio”, “un edificio tiene coordenadas geográficas”.
- Poner reglas y restricciones: como “cada edificio debe estar exactamente en una parcela catastral”.
- Unificar vocabularios: si en un sistema se dice “parcela” y en otro “unidad catastral”, la ontología ayuda a reconocer que son análogos.
- Hacer inferencias: a partir de datos simples, descubrir nuevo conocimiento (si un edificio está en una parcela y la parcela en Sevilla, se puede inferir que el edificio está en Sevilla).
- Establecer un lenguaje común: funcionan como un diccionario compartido entre distintos sistemas o dominios (GIS, BIM, IoT, catastro, urbanismo).
En resumen: una ontología es el diccionario y las reglas del juego que permiten que diferentes sistemas geoespaciales (mapas, catastro, sensores, BIM, etc.) se entiendan entre sí y puedan trabajar de manera integrada.
Grafos de conocimiento (Knowledge Graphs)
Un grafo de conocimiento es una forma de organizar información como si fuera una red de conceptos conectados entre sí.
-
Los nodos representan cosas o entidades, como una ciudad, un río o un edificio.
-
Las aristas (líneas) muestran las relaciones entre ellas, por ejemplo: “está en”, “atraviesa” o “pertenece a”.
-
A diferencia de un simple dibujo de conexiones, un grafo de conocimiento también explica el significado de esas relaciones: añade semántica.
Un grafo de conocimiento combina tres elementos principales:
-
Datos: los casos concretos o instancias, como “Sevilla”, “Río Guadalquivir” o “Edificio Ayuntamiento de Sevilla”.
-
Semántica (u ontología): las reglas y vocabularios que definen qué tipos de cosas existen (ciudades, ríos, edificios) y cómo pueden relacionarse entre sí.
-
Razonamiento: la capacidad de descubrir nuevas conexiones a partir de las existentes (por ejemplo, si un río atraviesa una ciudad y esa ciudad está en España, el sistema puede deducir que el río está en España).
Además, los grafos de conocimiento permiten conectar información de distintos ámbitos (por ejemplo, datos sobre personas, lugares y empresas) bajo un mismo lenguaje común, facilitando el análisis y la interoperabilidad entre disciplinas.
En otras palabras, un knowledge graph es el resultado de aplicar una ontología (el modelo de datos) a varios conjuntos de datos individuales (elementos espaciales, otros datos del territorio, registros de pacientes o productos de catálogo, etc.). Los grafos de conocimiento son ideales para integrar datos heterogéneos, porque no requieren un esquema rígido previamente completo: se pueden ir creciendo de forma flexible. Además, permiten consultas semánticas y navegación con relaciones complejas. A continuación, se pone un ejemplo para datos espaciales con los que entender las diferencias:
|
Ontología de datos espaciales (modelo conceptual) |
Grafo de conocimiento (ejemplos concretos con instancias) |
|---|---|
|
|
|
|
Casos de uso
Para entender mejor el valor de los metadatos inteligentes y los catálogos semánticos, nada mejor que mirar ejemplos donde ya se están aplicando. Estos casos muestran cómo la combinación de ontologías y grafos de conocimiento permite conectar información dispersa, mejorar la interoperabilidad y generar conocimiento accionable en distintos contextos.
Desde la gestión de emergencias hasta la planificación urbana o la protección del medio ambiente, diferentes proyectos internacionales han demostrado que la semántica no es solo teoría, sino una herramienta práctica que transforma datos en decisiones.
Algunos ejemplos relevantes incluyen:
- LinkedGeoData que convirtió datos de OpenStreetMap en Linked Data, enlazándolos con otras fuentes abiertas.
- Virtual Singapore un gemelo digital 3D que integra datos geoespaciales, urbanos y en tiempo real para simulación y planificación.
- JedAI-spatial una herramienta para interconectar datos espaciales en 3D mediante relaciones semánticas.
- SOSA Ontology, estándar ampliamente usado en proyectos de sensores e IoT para observaciones ambientales con componente geoespacial.
- Proyectos europeos de permisos digitales de construcción (ej. ACCORD), que combinan catálogos semánticos, modelos BIM y datos GIS para validar automáticamente normativas de construcción.
Conclusiones
La evolución hacia metadatos enriquecidos, apoyados en ontologías, grafos de conocimiento y principios FAIR-R, representa un cambio sustancial en la manera de gestionar, conectar y comprender los datos. Este nuevo enfoque convierte los metadatos en un componente activo de la infraestructura digital, capaz de aportar contexto, trazabilidad y significado, y no solo de describir información.
Los metadatos enriquecidos permiten aprender de los datos, mejorar la interoperabilidad semántica entre dominios y facilitar consultas más expresivas, donde las relaciones y dependencias pueden descubrirse de forma automatizada. De este modo, favorecen la integración de información dispersa y apoyan tanto la toma de decisiones informadas como el desarrollo de modelos de inteligencia artificial más explicativos y confiables.
En el ámbito de los datos abiertos, estos avances impulsan la transición desde repositorios descriptivos hacia ecosistemas de conocimiento interconectado, donde los datos pueden combinarse y reutilizarse de manera flexible y verificable. La incorporación de contexto semántico y procedencia (provenance) refuerza la transparencia, la calidad y la reutilización responsable.
Esta transformación requiere, sin embargo, un enfoque progresivo y bien gobernado: es fundamental planificar la migración de sistemas, garantizar la calidad semántica, y promover la participación de comunidades multidisciplinares.
En definitiva, los metadatos enriquecidos son la base para pasar de datos aislados a conocimiento conectado y trazable, elemento clave para la interoperabilidad, la sostenibilidad y la confianza en la economía de los datos.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Evento
La Diputación Foral de Bizkaia ha lanzado el Reto del Periodismo de Datos, un concurso dirigido a premiar la creatividad, el rigor y el talento en el uso de datos abiertos. Esta iniciativa busca impulsar proyectos periodísticos que utilicen los datos públicos disponibles en la plataforma Open Data Bizkaia para crear contenidos informativos con un fuerte componente visual. Ya sea a través de gráficos interactivos, mapas, vídeos animados o reportajes profundos, el objetivo es transformar los datos en narrativas que conecten con la ciudadanía.
¿Quién puede participar?
La convocatoria está abierta a personas físicas mayores de 18 años, tanto de forma individual como en equipos de hasta cuatro integrantes. Cada participante podrá presentar propuestas en una o varias de las categorías disponibles.
Es una oportunidad de especial relevancia para estudiantes, personas emprendedoras, desarrolladoras y desarrolladores, profesionales del diseño o periodistas con interés en los datos abiertos.
Tres categorías para impulsar el uso de los datos abiertos
El concurso se divide en tres categorías, cada una con su propio enfoque y criterios de evaluación:
-
Representación dinámica de datos: proyectos que presenten datos de forma interactiva, clara y visualmente atractiva.
-
Data storytelling a través del vídeo de animación: narrativas audiovisuales que expliquen fenómenos o tendencias usando datos públicos.
-
Reportaje + Datos: artículos periodísticos que integren análisis de datos con investigación y profundidad informativa.
Como hemos mencionado previamente, todos los proyectos deben basarse en los datos públicos disponibles en la plataforma Open Data Bizkaia, que ofrece información sobre múltiples áreas: economía, medio ambiente, movilidad, salud, cultura, etc. Es una fuente rica y accesible para construir historias relevantes y bien fundamentadas.
Hasta 4.500 euros en premios
Para cada categoría se otorgarán los siguientes premios:
-
Primer lugar: 1.500 euros
-
Segundo lugar: 750 euros
Los premios estarán sujetos a las retenciones fiscales correspondientes. Dado que una misma persona puede presentar propuestas a varias categorías, y que estas serán evaluadas de manera independiente, es posible que un único participante gane más de un premio. Por tanto, un único participante podrá llevarse hasta 4.500 euros, si gana en las tres categorías.
¿Cuáles son los criterios de evaluación?
La concesión de los premios se realizará mediante el procedimiento de concurrencia competitiva. Todos los proyectos recibidos en el periodo habilitado para ello serán evaluados por el jurado, conforme a una serie de criterios específicos para cada categoría:
-
Representación dinámica de datos:
-
Claridad comunicativa (30%)
-
Interactividad (25%)
-
Diseño y usabilidad (20%)
-
Originalidad en la representación (15%)
-
Rigor y fidelidad de los datos (10%)
-
Data storytelling en vídeo de animación
-
Narrativa y guion (30%)
-
Creatividad visual e innovación técnica (25%)
-
Claridad informativa (20%)
-
Impacto emocional y estético (15%)
-
Uso riguroso y honesto de los datos (10%)
-
Reportaje + Datos
-
Calidad periodística y profundidad analítica (30%)
-
Integración narrativa de los datos (25%)
-
Originalidad en el enfoque y el formato (20%)
-
Diseño y experiencia de usuario (15%)
-
Transparencia y trazabilidad de las fuentes (10%)
¿Cómo se presentan las solicitudes?
El plazo para presentar los proyectos comenzó el 3 de noviembre y estará abierto hasta el 3 de diciembre de 2025 a las 23:59. Las solicitudes podrán presentarse de diversas maneras:
-
Electrónicamente, a través de la sede electrónica de Bizkaia, utilizando el código de trámite 2899.
-
Presencialmente, en el Registro General de la Oficina Laguntza (c/ Diputación, 7, Bilbao), en cualquier otro registro público o en las oficinas de Correos.
En el caso de proyectos grupales, se deberá presentar una única solicitud firmada por una persona representante. Esta persona asumirá la interlocución con la Dirección General organizadora, encargándose de los trámites y del cumplimiento de las obligaciones correspondientes.
La documentación que se debe presentar es:
-
El proyecto a evaluar.
-
El certificado de estar al corriente en las obligaciones tributarias.
-
El certificado de estar al corriente en las obligaciones con la Seguridad Social.
-
La ficha de domiciliación bancaria, solo en caso de que la persona solicitante se oponga que esta Administración compruebe los datos bancarios por sus propios medios.
Información de contacto
Para consultas o información adicional, se puede contactar con la Diputación Foral de Bizkaia. En concreto, con el Departamento de Administración Pública y Relaciones Institucionales, Sección de Asesoramiento Técnico c/ Gran Vía, 2 (48009) en la ciudad de Bilbao. También se atenderán dudas en el teléfono 944 068 000 y en el correo electrónico SAT@bizkaia.eus.
Este concurso representa una oportunidad para explorar el potencial del periodismo de datos y contribuir a una comunicación más transparente y accesible. Los proyectos presentados podrán de manifiesto el potencial de los datos abiertos para facilitar la comprensión de temas de interés público, de forma clara y sencilla.
Para más detalles, se recomienda leer la información disponible en su página web.

Noticia
El pasado 6 de octubre se aprobó el V Plan de Gobierno Abierto, una iniciativa que da continuidad al compromiso de las Administraciones públicas con la transparencia, la participación ciudadana y la rendición de cuentas. Este nuevo plan, que estará vigente hasta 2029, recoge 218 medidas agrupadas en 10 compromisos que afectan a los diversos niveles de la Administración.
En este artículo vamos a repasar las claves del Plan, centrándonos en aquellos compromisos relacionados con los datos y el acceso a la información pública.
Un documento fruto de la colaboración
El proceso de elaboración del V Plan de Gobierno Abierto se ha desarrollado de forma participativa y colaborativa, con el objetivo de recoger propuestas de distintos actores sociales. Para ello, se abrió una consulta pública en la que ciudadanos, organizaciones de la sociedad civil y representantes institucionales pudieron aportar ideas y sugerencias. También se desarrollaron una serie de talleres deliberativos. En total, se recibieron 620 aportaciones de la sociedad civil y más de 300 propuestas de ministerios, comunidades y ciudades autónomas, y representantes de las entidades locales.
Estas contribuciones se analizaron y se integraron en los compromisos del plan, que fueron posteriormente validados por el Foro de Gobierno Abierto. El resultado es un documento que refleja una visión compartida sobre cómo avanzar en transparencia, participación y rendición de cuentas en el conjunto de las Administraciones públicas.
10 líneas de acción principales con un papel destacado para los datos abiertos
Futo de ese trabajo colaborativo, se han fijado 10 líneas de acción. Los nueve primeros compromisos recogen iniciativas de la Administración General del Estado (AGE), mientras que el décimo agrupa las aportaciones de comunidades autónomas y entidades locales:
- Participación y espacio cívico.
- Transparencia y acceso a la información.
- Integridad y rendición de cuentas.
- Administración abierta.
- Gobernanza digital e inteligencia artificial.
- Apertura fiscal: cuentas claras y abiertas.
- Información veraz / ecosistema informativo.
- Difusión, formación y promoción del gobierno abierto.
- Observatorio de gobierno abierto.
- Estado abierto.

Figura 1. 10 líneas de acción del V Plan de Gobierno Abierto. Fuente: Ministerio de Inclusión, Seguridad Social y Migraciones.
Los datos y la información pública son un elemento clave en todos ellos. No obstante, la mayoría de medidas relacionadas con este campo las encontramos dentro de la línea de acción 2, donde se sitúa un apartado específico sobre apertura y reutilización de datos de la información pública. Entre las medidas previstas, se contempla:
- Modelo de gobernanza de datos: se propone crear un marco normativo que facilite el uso responsable y eficiente del dato público en la AGE. Incluye la regulación de órganos colegiados para el intercambio de datos, la aplicación de normativa europea y la creación de espacios institucionales para diseñar políticas públicas basadas en datos.
- Estrategia del dato para una administración centrada en el ciudadano: se busca establecer un marco estratégico para el uso ético y transparente de los datos en la Administración.
- Publicación de microdatos de encuestas electorales: se modificará la Ley Electoral para incluir la obligación de publicar los microdatos anonimizados de las encuestas electorales. Esto permite mejorar la fiabilidad de los estudios y facilitar el acceso abierto a datos individuales para su análisis.
- Apoyo a entidades locales en la apertura de datos: se ha lanzado un programa de ayudas para fomentar la apertura de datos homogéneos y de calidad en las entidades locales mediante convocatorias y/o convenios de colaboración. Además, se promoverá su reutilización mediante acciones de sensibilización, desarrollo de soluciones demostradoras y colaboración interadministrativa para impulsar la innovación pública.
- Apertura de datos en la Administración de Justicia: se continuarán publicando datos oficiales sobre justicia en portales públicos, con el objetivo de hacer la Administración de Justicia más transparente y accesible.
- Acceso e integración de información geoespacial de alto valor: se busca facilitar la reutilización de datos espaciales de alto valor en categorías como geoespacial, medio ambiente y movilidad. La medida incluye el desarrollo de mapas digitales, bases topográficas y una API para mejorar el acceso a esta información por parte de ciudadanos, administraciones y empresas.
- Datos abiertos del BORME: se trabajará para fomentar la publicación del contenido del Boletín Oficial del Registro Mercantil, especialmente la sección de empresarios, como datos abiertos en formatos legibles por máquina y accesibles mediante API.
- Bases de datos del Archivo Central de Hacienda: se impulsa la puesta a disposición pública de los registros del Archivo Central del Ministerio de Hacienda que no contengan datos personales ni estén sujetos a restricciones legales.
- Acceso seguro a datos públicos confidenciales para investigación e innovación: se quiere establecer un marco de gobernanza y entornos controlados que permitan a investigadores acceder de forma segura y ética a datos públicos sujetos a confidencialidad.
- Fomento del uso secundario del dato de salud: se continuará trabajando en el Espacio Nacional de Datos de Salud (ENDS), alineado con la normativa europea, para facilitar el uso de datos sanitarios con fines de investigación, innovación y políticas públicas. La medida incluye el fomento de infraestructuras técnicas, marcos normativos y garantías éticas para proteger la privacidad de los ciudadanos.
- Impulso de ecosistemas de datos para el progreso social: se busca promover espacios colaborativos de datos entre entidades públicas y privadas, bajo reglas claras de gobernanza. Estos ecosistemas ayudarán a desarrollar soluciones innovadoras que respondan a necesidades sociales, fomentando la confianza, la transparencia y el retorno justo de beneficios a la ciudadanía.
- Puesta en valor del dato público de calidad para ciudadanos y empresas: se continuará impulsando la generación de datos de calidad en los diferentes ministerios y organismos, para que se integren en el catálogo centralizado de información reutilizable de la AGE.
- Evolución de la plataforma datos.gob.es: se continúa trabajando en la optimización de datos.gob.es,. Esta medida forma parte de un continuo enriquecimiento para hacer frente a las cambiantes necesidades ciudadanas y tendencias emergentes.
Además de en este epígrafe específico, también se incluyen medidas relacionadas con los datos abiertos en otros apartados. Por ejemplo, la medida 3.5.5 propone transformar la Plataforma de Contratación del Sector Público en una herramienta avanzada que utilice Big Data e Inteligencia Artificial para reforzar la transparencia y prevenir la corrupción. Los datos abiertos juegan aquí un papel central, ya que permiten realizar auditorías masivas y análisis estadísticos para detectar patrones irregulares en los procesos de contratación. Además, al facilitar el acceso ciudadano a esta información, se promueve la fiscalización social y el control democrático sobre el uso de fondos públicos.
Otro ejemplo lo encontramos en la medida 4.1.1, donde se propone desarrollar una herramienta digital para la Administración General del Estado que incorpore desde su diseño los principios de transparencia y dato abierto. El sistema permitiría la trazabilidad, conservación, acceso y reutilización de documentos públicos, integrando criterios archivísticos, lenguaje claro y normalización documental. Además, se vincularía con el Catálogo Nacional de Datos Abiertos para asegurar que la información esté disponible en formatos abiertos y reutilizables.
El documento no solo resalta las posibilidades de los datos abiertos: también destaca las oportunidades que ofrece la Inteligencia Artificial tanto en la mejora del acceso a la información pública como en la generación de datos abiertos útiles para la toma de decisiones colectivas.
Impulso de datos abiertos en las Comunidades y Ciudades Autónomas
Como se mencionó anteriormente, el IV Plan de Gobierno Abierto también incluye compromisos adquiridos por los organismos autonómicos, los cuales se detallan en la línea de acción 10 sobre Estado abierto, muchos de ellos centrados en la disponibilidad de datos públicos.
Por ejemplo, la Generalitat de Catalunya informa de su interés en optimizar los recursos disponibles para la gestión de solicitudes de acceso a la información pública, así como en publicar los datos desagregados de los presupuestos públicos en ámbitos relacionados con la infancia o el cambio climático. Por su parte, la Junta de Andalucía quiere potenciar el acceso a la información sobre personal científico y producción científica, y desarrollar un Observatorio de datos de las universidades públicas andaluzas, entre otras medidas. Otro ejemplo lo encontramos en la Ciudad Autónoma de Melilla, que está trabajando en un Portal de Datos Abiertos.
Con respecto a la Administración local, los compromisos se han fijado a través de la Federación Española de Municipios y Provincias (FEMP). Desde la Red de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP se propone que las administraciones públicas locales publiquen, como mínimo, a elegir entre los siguientes campos: callejero; presupuestos y ejecución presupuestaria; subvenciones; contratación y licitación pública; padrón municipal; censo de vehículos; contenedores de residuos y reciclajes; registro de asociaciones; agenda cultural; alojamientos turísticos; áreas empresariales e industriales; censo de empresas o agentes económicos.
Todas estas medidas ponen de manifiesto el interés por la apertura de datos en las instituciones españolas como herramienta clave para fomentar el gobierno abierto, impulsar servicios y productos alineados con las necesidades ciudadanas y optimizar la toma de decisiones.
Un sistema de seguimiento
El seguimiento del V Plan de Gobierno Abierto se basa en un sistema reforzado de rendición de cuentas y en el uso estratégico de la plataforma digital HazLab, donde se alojan cinco grupos de trabajo, uno de ellos centrado en la transparencia y el acceso a la información.
Cada iniciativa del Plan dispone además de una ficha de seguimiento con información sobre su ejecución, cronograma y resultados, actualizada periódicamente por las unidades responsables y publicada en el Portal de la Transparencia.
Conclusiones
En conjunto, el V Plan de Gobierno Abierto busca una Administración más transparente, participativa y orientada al uso responsable de los datos públicos. Muchas de las medidas incluidas tienen como objetivo reforzar la apertura informativa, la mejora de la gestión documental y el impulso a la reutilización de datos en sectores clave como la salud, la justicia o la contratación pública. Este enfoque no solo facilita el acceso ciudadano a la información, sino que también promueve la innovación, la rendición de cuentas y una cultura de gobernanza más abierta y colaborativa.
Blog
La Inteligencia Artificial (IA) está convirtiéndose en uno de los principales motores del aumento de la productividad y la innovación tanto en el sector público como en el privado, siendo cada vez más relevante en tareas que van desde la creación de contenido en cualquier formato (texto, audio, video) hasta la optimización de procesos complejos a través de agentes de Inteligencia Artificial.
Sin embargo, los modelos avanzados de IA, y en particular los grandes modelos de lenguaje, exigen cantidades ingentes de datos para su entrenamiento, optimización y evaluación. Esta dependencia genera una paradoja: a la vez que la IA demanda más datos y de mayor calidad, la creciente preocupación por la privacidad y la confidencialidad (Reglamento General de Protección de Datos o RGPD), las nuevas reglas de acceso y uso de datos (Data Act), y los requisitos de calidad y gobernanza para sistemas de alto riesgo (Reglamento de IA), así como la inherente escasez de datos en dominios sensibles limitan el acceso a los datos reales.
En este contexto, los datos sintéticos pueden ser un mecanismo habilitador para conseguir nuevos avances, conciliando innovación y protección de la privacidad. Por una parte, permiten alimentar el progreso de la IA sin exponer información sensible, y cuando se combinan con datos abiertos de calidad amplían el acceso a dominios donde los datos reales son escasos o están fuertemente regulados.
¿Qué son los datos sintéticos y cómo se generan?
De forma sencilla, los datos sintéticos se pueden definir como información fabricada artificialmente que imita las características y distribuciones de los datos reales. La función principal de esta tecnología es reproducir las características estadísticas, la estructura y los patrones del dato real subyacente. En el dominio de las estadísticas oficiales existen casos como el del Censo de Estados Unidos que publica productos parcial o totalmente sintéticos como OnTheMap (movilidad de los trabajadores entre lugar de residencia y lugar trabajo) o el SIPP Synthetic Beta (microdatos socioeconómicos vinculados a impuestos y seguridad social).
La generación de datos sintéticos es actualmente un campo aún en desarrollo que se apoya en diversas metodologías. Los enfoques pueden ir desde métodos basados en reglas o modelado estadístico (simulaciones, bayesianos, redes causales), que imitan distribuciones y relaciones predefinidas, hasta técnicas avanzadas de aprendizaje profundo. Entre las arquitecturas más destacadas encontramos:
- Redes Generativas Adversarias (GAN): un modelo generativo, entrenado con datos reales, aprende a imitar sus características, mientras que un discriminador intenta distinguir entre datos reales y sintéticos. A través de este proceso iterativo, el generador mejora su capacidad para producir datos artificiales que son estadísticamente indistinguibles de los originales. Una vez entrenado, el algoritmo puede crear nuevos registros artificiales que son estadísticamente similares a la muestra original, pero completamente nuevos y seguros.
- Autoencoders Variacionales (VAE): Estos modelos se basan en redes neuronales que aprenden una distribución probabilística en un espacio latente de los datos de entrada. Una vez entrenado, el modelo utiliza esta distribución, para obtener nuevas observaciones sintéticas mediante el muestreo y decodificación de los vectores latentes. Los VAE son frecuentemente considerados una opción más estable y sencilla de entrenar en comparación con las GAN para la generación de datos tabulares.
- Modelos autorregresivos/jerárquicos y simuladores de dominio: utilizados, por ejemplo, en datos de historia clínica electrónica, que capturan dependencias temporales y jerárquicas. Los modelos jerárquicos estructuran el problema por niveles, primero muestrean variables de nivel superior y, después las de niveles inferiores condicionadas a las anteriores. Los simuladores de dominio codifican reglas del proceso y se calibran con datos reales, aportando control e interpretabilidad y garantizando el cumplimiento de reglas de negocio.
Puedes conocer más sobre los datos sintéticos y cómo se crean en esta infografía:
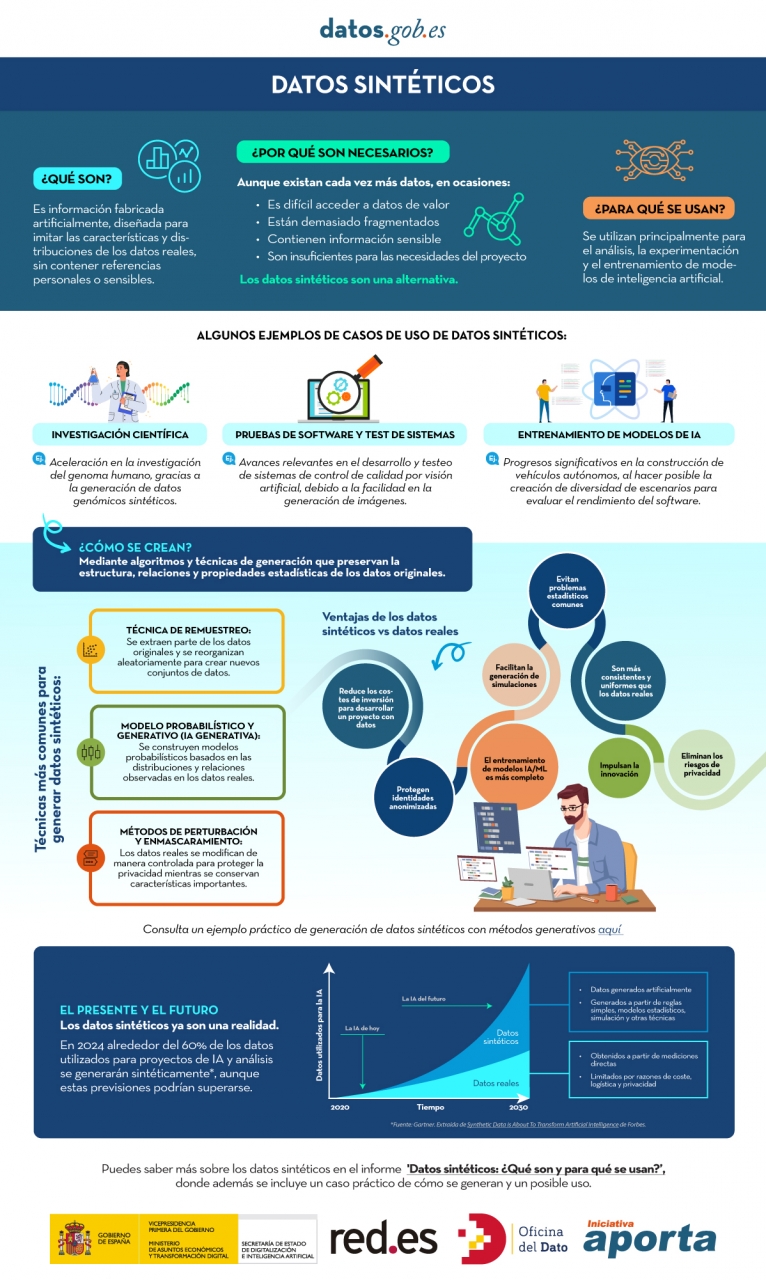
Figura 1. Infografía sobre datos sintéticos. Fuente: elaboración propia - datos.gob.es.
Si bien la generación sintética reduce inherentemente el riesgo de divulgación de datos personales, no lo elimina por completo. Sintético no significa automáticamente anónimo ya que, si los generadores se entrenan de forma inadecuada, pueden filtrarse trazas del conjunto real y ser vulnerables a ataques de inferencia de pertenencia (membership inference). De ahí que sea necesario utilizar Tecnologías de Mejora de la Privacidad (PET) como la privacidad diferencial y realizar evaluaciones de riesgo específicas. También el Supervisor Europeo de Protección de Datos (EDPS) ha subrayado la necesidad de realizar una evaluación de garantía de privacidad antes de que los datos sintéticos puedan ser compartidos, garantizando que el resultado no permita obtener datos personales reidentificables.
La Privacidad Diferencial (DP) es una de las tecnologías principales en este dominio. Su mecanismo consiste en añadir ruido controlado al proceso de entrenamiento o a los datos mismos, asegurando matemáticamente que la presencia o ausencia de cualquier individuo en el conjunto de datos original no altere significativamente el resultado final de la generación. El uso de métodos seguros, como el descenso de gradiente estocástico con privacidad diferencial (DP-SGD), garantiza que las muestras generadas no comprometan la privacidad de los usuarios que contribuyeron con sus datos al conjunto sensible.
¿Cuál es el papel de los datos abiertos?
Como es obvio, los datos sintéticos no aparecen de la nada, necesitan datos reales de alta calidad como semilla y, además, requieren buenas prácticas de validación. Por ello, los datos abiertos o los datos que no pueden abrirse por cuestiones relacionadas con la privacidad son, por una parte, una excelente materia prima para aprender patrones del mundo real y, por otra, una referencia independiente para verificar que lo sintético se parece a la realidad sin exponer a personas o empresas.
Como semilla de aprendizaje los datos abiertos de calidad, como los conjuntos de datos de alto valor, con metadatos completos, definiciones claras y esquemas estandarizados, aportan cobertura, granularidad y actualidad. Cuando ciertos conjuntos no pueden hacerse públicos por motivos de privacidad, pueden emplearse internamente con las adecuadas salvaguardas para producir datos sintéticos que sí podrían liberarse. En salud, por ejemplo, existen generadores abiertos como Synthea, que producen historias clínicas ficticias sin las restricciones de uso propias de los datos reales.
Por otra parte, frente a un conjunto sintético, los datos abiertos permiten actuar como patrón de verificación, para contrastar distribuciones, correlaciones y reglas de negocio, así como evaluar la utilidad en tareas reales (predicción, clasificación) sin recurrir a información sensible. En este sentido ya existen trabajos, como el del Gobierno de Gales con datos de salud, que han experimentado con distintos indicadores,. Entre ellos destacan la distancia de variación total (TVD), el índice de propensión (propensity score) y el desempeño en tareas de aprendizaje automático.
¿Cómo se evalúan los datos sintéticos?
La evaluación de los conjuntos de datos sintéticos se articula a través de tres dimensiones que, por su naturaleza, implican un compromiso:
- Fidelidad (Fidelity): mide lo cerca que está el dato sintético de replicar las propiedades estadísticas, correlaciones y la estructura de los datos originales.
- Utilidad (Utility): mide el rendimiento del conjunto de datos sintéticos en tareas posteriores de aprendizaje automático, como la predicción o la clasificación.
- Privacidad (Privacy): mide la efectividad con la que el dato sintético oculta la información sensible y el riesgo de que los sujetos de los datos originales puedan ser reidentificados.

Figura 2. Tres dimensiones para evaluar datos sintéticos. Fuente: elaboración propia - datos.gob.es.
El reto de gobernanza reside en que no es posible optimizar las tres dimensiones simultáneamente. Por ejemplo, aumentar el nivel de privacidad (inyectando más ruido mediante privacidad diferencial) inevitablemente puede reducir la fidelidad estadística y, en consecuencia, la utilidad para ciertas tareas. La elección de qué dimensión priorizar (máxima utilidad para investigación estadística o máxima privacidad) se convierte en una decisión estratégica que debe ser transparente y específica para cada caso de uso.
¿Datos abiertos sintéticos?
La combinación de datos abiertos y datos sintéticos ya puede considerarse algo más que una idea, ya que existen casos reales que demuestran su utilidad para acelerar la innovación y, al mismo tiempo, proteger la privacidad. Además de los ya citados OnTheMap o SIPP Synthetic Beta en Estados Unidos, también encontramos ejemplos en Europa y el resto del mundo. Por ejemplo, el Centro Común de Investigación (JRC) de la Comisión Europea ha analizado el papel de los datos sintéticos generados con IA en la formulación de políticas “AI Generated Synthetic Data in Policy Applications”, destacando su capacidad para acortar el ciclo de vida de las políticas públicas al reducir la carga de acceso a datos sensibles y habilitar fases de exploración y prueba más ágiles. También ha documentado aplicaciones de poblaciones sintéticas multipropósito para análisis de movilidad, energía o salud, reforzando la idea de que los datos sintéticos actúan como habilitador transversal.
En Reino Unido, el Office for National Statistics (ONS) llevó a cabo un Synthetic Data Pilot para entender la demanda de datos sintéticos. En el piloto se exploró la producción de herramientas de generación de microdatos sintéticos de alta calidad para requisitos específicos de los usuarios.
También en salud se observan avances que ilustran el valor de datos abiertos sintéticos para innovación responsable. El Departamento de Salud de la región de Australia Occidental ha impulsado un Synthetic Data Innovation Project y hackatones sectoriales donde se liberan conjuntos sintéticos realistas que permiten a equipos internos y externos probar algoritmos y servicios sin acceso a información clínica identificable, fomentando la colaboración y acelerando la transición de prototipos a casos de uso reales.
En definitiva, los datos sintéticos ofrecen una vía prometedora, aunque no suficientemente explorada, para el desarrollo de las aplicaciones de inteligencia artificial, ya que contribuyen al equilibrio entre el fomento de la innovación y la protección de la privacidad.
Los datos sintéticos no sustituyen a los datos abiertos, sino que se potencian mutuamente. En particular, representan una oportunidad para que las Administraciones públicas pueden ampliar su oferta de datos abiertos con versiones sintéticas de conjuntos sensibles para educación o investigación, y para facilitar que las empresas y desarrolladores independientes experimenten cumpliendo la regulación y puedan generar un mayor valor económico y social.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
España ha dado un paso más hacia la consolidación de una política pública basada en la transparencia y la innovación digital. A través de la Secretaría de Estado de Digitalización e Inteligencia Artificial del Ministerio para la Transformación Digital y de la Función Pública, el Gobierno de España ha firmado su adhesión a la Carta Internacional de Datos Abiertos, en el marco de la IX Cumbre Global de la Alianza para el Gobierno Abierto que se celebra estos días en Vitoria-Gasteiz.
Con esta adhesión se reconoce al dato como un activo estratégico para el diseño de políticas públicas y la mejora de los servicios. Además, se subraya la importancia de su apertura y reutilización, junto con el uso ético de la inteligencia artificial, como motores clave para la transformación digital y la generación de valor social y económico.
¿En qué consiste la Carta Internacional de Datos Abiertos?
La Carta Internacional de Datos Abiertos (conocida por el nombre en inglés Open Data Charter o las siglas ODC) es una iniciativa global que promueve la apertura y reutilización de datos públicos como herramientas para mejorar la transparencia, la participación ciudadana, la innovación y la rendición de cuentas. Esta iniciativa fue lanzada en 2015 y está respaldada por gobiernos, organizaciones y expertos. Su objetivo es guiar a las entidades públicas en la adopción de políticas de datos abiertos responsables, sostenibles y centradas en el impacto social, respetando los derechos fundamentales de las personas y comunidades. Para ello promueve seis principios:
-
Datos abiertos por defecto: los datos deben publicarse de forma proactiva, salvo que existan razones legítimas para restringirlos (como la privacidad o la seguridad).
-
Datos oportunos y comprensibles: los datos deben publicarse de forma completa, comprensible y rápida, con la frecuencia necesaria para ser de utilidad. También debe respetarse su formato original siempre que sea posible.
-
Datos accesibles y utilizables: los datos deben estar disponibles en formatos abiertos, legibles por máquina y sin barreras técnicas o legales para su reutilización. Asimismo, deben ser fáciles de encontrar.
-
Datos comparables e interoperables: las instituciones deben trabajar para asegurar que los datos sean precisos, relevantes y confiables, promoviendo estándares comunes que faciliten la interoperabilidad y el uso conjunto de diferentes fuentes.
-
Datos para mejorar la gobernanza y la participación ciudadana: los datos abiertos deben fortalecer la transparencia, la rendición de cuentas y permitir la participación informada de la sociedad civil.
-
Datos para el desarrollo inclusivo y la innovación: el acceso libre a los datos puede impulsar soluciones innovadoras, mejorar servicios públicos y fomentar el desarrollo económico inclusivo.
La Open Data Charter también ofrece recursos, guías e informes prácticos para apoyar a gobiernos y organizaciones en la aplicación de sus principios, adaptándolos a cada contexto. Así, los datos abiertos podrán impulsar reformas concretas con un impacto real.
España: una política consolidada de datos abiertos que nos sitúa como referente
La adhesión a la Carta Internacional de Datos Abiertos no es un punto de partida, sino un paso adelante en una estrategia consolidada que sitúa al dato como un activo fundamental para el avance del país. Desde hace años, España ya cuenta con un marco sólido de políticas y estrategias que han impulsado la apertura de datos como parte fundamental de la transformación digital:
- Marco normativo: España dispone de una base legal que garantiza la apertura de datos como norma general, donde destaca la Ley 37/2007 sobre reutilización de la información del sector público, la Ley 19/2013 de transparencia y la aplicación del Reglamento (UE) 2022/868 sobre gobernanza europea de datos. Este marco establece obligaciones claras para facilitar el acceso, la compartición y la reutilización de datos públicos en todo el ámbito estatal.
- Gobernanza institucional: la Dirección General del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial (SEDIA), tiene como misión dinamizar la gestión, compartición y el uso de los datos en diferentes sectores productivos de la economía y sociedad española. Entre otras cuestiones, lidera la coordinación de la política de datos abiertos en la Administración General del Estado.
- Iniciativas estratégicas y herramientas prácticas: la Iniciativa Aporta, promovida por el Ministerio para la Transformación Digital y de la Función Pública a través de la Entidad Pública Empresarial Red.es, fomenta la cultura del dato abierto y su reutilización social y económica desde 2009. Para ello cuenta con la plataforma datos.gob.es, que centraliza el acceso a cerca de 100.000 conjuntos y servicios de datos puestos a disposición de la ciudadanía por organismos públicos de todos los niveles de la administración. Mediante esta plataforma también se ofrecen múltiples recursos (noticias, análisis, infografías, guías e informes, materiales formativos, etc.) que ayudan a impulsar la cultura del dato.
Para seguir avanzando, se está trabajando en el V Plan de Gobierno Abierto (2025–2029), que integra compromisos específicos en transparencia, participación y apertura de datos dentro de una agenda más amplia de gobierno abierto.
Todo ello contribuye a que España se posicione, año tras año, como referente a nivel europeo en materia de datos abiertos.
Próximos pasos: avanzando en una transformación digital ética impulsada por los datos
El cumplimiento de los principios de la Carta Internacional de Datos Abiertos será un proceso transparente y medible. La SEDIA, a través de la Dirección General del Dato, coordinará un seguimiento interno de los avances. La Dirección General del Dato actuará como catalizador, impulsando la cultura de compartición, supervisando el cumplimiento de los principios de la Carta y promoviendo procesos participativos para recoger aportaciones de la ciudadanía y la sociedad civil.
Además de la apertura de datos públicos, cabe destacar que se continuará trabajando en el desarrollo de una transformación digital ética y centrada en las personas a través de acciones como:
- Creación de espacios de datos sectoriales: se busca impulsar la compartición de datos públicos y privados que podrán combinarse de forma segura y soberana para generar casos de uso de alto impacto en sectores estratégicos como la salud, el turismo, la agroindustria o la movilidad, impulsando la competitividad de la economía española.
-
Desarrollo de una inteligencia artificial ética y responsable: la estrategia de datos abiertos nacional es clave para garantizar que los algoritmos se entrenen con conjuntos de datos de alta calidad, diversos y representativos, mitigando sesgos y asegurando la transparencia. Con ello se refuerza la confianza ciudadana y se promueve un modelo de innovación que protege los derechos fundamentales.
En definitiva, la adopción por parte de España de la Carta Internacional de Datos Abiertos refuerza una trayectoria ya consolidada en materia de datos abiertos, respaldada por un marco normativo sólido, iniciativas estratégicas y herramientas prácticas que han situado al país como referente en la materia. Además, esta adhesión abre nuevas oportunidades de colaboración internacional, acceso a conocimiento experto y alineación con estándares globales. España avanza así hacia un ecosistema de datos más robusto, inclusivo y orientado al impacto social, económico y democrático.
Blog
Los datos abiertos tienen un gran potencial para transformar la forma en que interactuamos con nuestras ciudades. Al estar disponibles para toda la ciudadanía, permiten desarrollar aplicaciones y herramientas que dan respuesta a retos urbanos como la accesibilidad, la seguridad vial o la participación ciudadana. Facilitar el acceso a esta información no solo impulsa la innovación, sino que también contribuye a mejorar la calidad de vida en los entornos urbanos.
Este potencial cobra aún más relevancia si consideramos el contexto actual. El crecimiento urbano acelerado ha traído consigo nuevos desafíos, especialmente en materia de salud pública. Según datos de las Naciones Unidas, se estima que para 2050 más del 68% de la población mundial vivirá en ciudades. Por lo tanto, el diseño de entornos urbanos saludables es una prioridad en la que los datos abiertos se consolidan como una herramienta clave: permiten planificar ciudades más resilientes, inclusivas y sostenibles, poniendo el bienestar de las personas en el centro de las decisiones. En este post, te contamos qué son los entornos urbanos saludables y cómo pueden los datos abiertos ayudar a construirlos y mantenerlos.
¿Qué son los Entornos urbanos saludables? Usos y ejemplos
Los entornos urbanos saludables van más allá de la simple ausencia de contaminación o ruido. Según la Organización Mundial de la Salud (OMS), estos espacios deben promover activamente estilos de vida saludables, facilitar la actividad física, fomentar la interacción social y garantizar el acceso equitativo a servicios básicos. Como establece la "Guía para planificar ciudades saludables" del Ministerio de Sanidad, estos entornos se caracterizan por tres elementos clave:
-
Ciudades pensadas para caminar: deben ser espacios que prioricen la movilidad peatonal y ciclista, con calles seguras, accesibles y confortables que inviten al desplazamiento activo.
-
Incorporación de la naturaleza: integran zonas verdes, infraestructura azul y elementos naturales que mejoran la calidad del aire, regulan la temperatura urbana y ofrecen espacios de recreo y descanso.
-
Espacios de encuentro y convivencia: cuentan con áreas que facilitan la interacción social, reducen el aislamiento y fortalecen el tejido comunitario.
El papel de los datos abiertos en entornos urbanos saludables
En este escenario, los datos abiertos actúan como el sistema nervioso de las ciudades inteligentes, proporcionando información valiosa sobre patrones de uso, necesidades ciudadanas y efectividad de las políticas públicas. En concreto, en el ámbito de los espacios urbanos saludables son especialmente útiles los datos de:
-
Análisis de patrones de actividad física: los datos de movilidad, uso de instalaciones deportivas y frecuentación de espacios verdes revelan dónde y cuándo los ciudadanos son más activos, identificando oportunidades para optimizar la infraestructura existente.
-
Monitorización de la calidad ambiental: los sensores urbanos que miden la calidad del aire, los niveles de ruido y la temperatura proporcionan información en tiempo real sobre las condiciones de salubridad de diferentes áreas urbanas.
-
Evaluación de accesibilidad: el transporte público, la infraestructura peatonal y la distribución de servicios permiten identificar barreras al acceso y diseñar soluciones más inclusivas.
-
Participación ciudadana informada: las plataformas de datos abiertos facilitan procesos participativos donde los ciudadanos pueden contribuir con información local y colaborar en la toma de decisiones.
El ecosistema español de datos abiertos cuenta con sólidas plataformas que alimentan proyectos de espacios urbanos saludables. Por ejemplo, el Portal de Datos Abiertos del Ayuntamiento de Madrid ofrece información en tiempo real sobre la calidad del aire así como un inventario completo de zonas verdes. También Barcelona publica datos sobre calidad del aire, incluyendo las ubicaciones y características de las estaciones de medida.
Estos portales no solo almacenan información, sino que la estructuran de manera que desarrolladores, investigadores y ciudadanos puedan crear aplicaciones y servicios innovadores.
Casos de uso: aplicaciones que reutilizan datos abiertos
Varios proyectos demuestran cómo los datos abiertos se traducen en mejoras tangibles para la salud urbana. Por un lado, podemos destacar algunas aplicaciones o herramientas digitales como:
-
AQI Air Quality Index: utiliza datos gubernamentales para ofrecer información en tiempo real sobre la calidad del aire en diferentes ciudades españolas.
-
GV Aire: procesa datos oficiales de calidad atmosférica para generar alertas y recomendaciones ciudadanas.
-
Índice de Calidad del Aire Nacional: centraliza información de estaciones de medición de todo el país.
-
Valencia Verde: utiliza datos municipales para mostrar ubicación y características de parques y jardines de Valencia.
Por otro lado, existen iniciativas que combinan datos abiertos multisectoriales para ofrecer soluciones que mejoran la interacción entre urbe y ciudadanía. Por ejemplo:
-
Programa Supermanzanas: utiliza mapas que muestran los niveles de contaminación de calidad del aire y datos de tráfico disponibles en formatos abiertos como CSV y GeoPackage de Barcelona Open Data y el Ajuntament de Barcelona para identificar calles donde la reducción del tráfico rodado puede maximizar los beneficios para la salud, creando espacios seguros para peatones y ciclistas.
-
La plataforma DataActive: busca establecer una infraestructura internacional en la que participen investigadores, entidades deportivas públicas y privadas. Las temáticas que aborda incluyen la gestión del territorio, el urbanismo, la sostenibilidad, la movilidad, la calidad del aire y la justicia ambiental. Su objetivo es promover entornos urbanos más activos, saludables y accesibles mediante la implementación de estrategias basadas en el open data y la investigación.
La disponibilidad de datos se complementa con herramientas avanzadas de visualización. La Infraestructura de Datos Espaciales de Madrid (IDEM) ofrece visores geográficos especializados en calidad del aire y el Instituto Geográfico Nacional (IGN) ofrece el callejero nacional CartoCiudad con información de todas las ciudades de España.
Gobernanza efectiva y ecosistema de innovación
No obstante, la efectividad de estas iniciativas depende de nuevos modelos de gobernanza que integren múltiples actores. Para lograr una correcta coordinación entre administraciones públicas de diferentes niveles, empresas privadas, organizaciones del tercer sector y ciudadanía es esencial contar con datos abiertos de calidad.
Los datos abiertos no solo alimentan aplicaciones específicas, sino que crean un ecosistema completo de innovación. Desarrolladores independientes, startups, centros de investigación y organizaciones ciudadanas utilizan estos datos para:
-
Desarrollar estudios de impacto en salud urbana.
-
Crear herramientas de planificación participativa.
-
Generar alertas tempranas sobre riesgos ambientales.
-
Evaluar la efectividad de políticas públicas.
-
Diseñar servicios personalizados según las necesidades de diferentes grupos poblacionales.
Los proyectos de espacios urbanos saludables basados en datos abiertos generan múltiples beneficios tangibles:
-
Eficiencia en la gestión pública: los datos permiten optimizar la asignación de recursos, priorizar intervenciones y evaluar su impacto real sobre la salud ciudadana.
-
Innovación y desarrollo económico: el ecosistema de datos abiertos estimula la creación de startups y servicios innovadores que mejoran la calidad de vida urbana, como demuestran las múltiples aplicaciones disponibles en datos.gob.es.
-
Transparencia y participación: la disponibilidad de datos facilita el control ciudadano y fortalece los procesos democráticos de toma de decisiones.
-
Evidencia científica: los datos sobre salud urbana contribuyen al desarrollo de políticas públicas basadas en evidencia y al avance del conocimiento científico.
-
Replicabilidad: las soluciones exitosas pueden adaptarse y replicarse en otras ciudades, acelerando la transformación hacia entornos urbanos más saludables.
En definitiva, el futuro de nuestras ciudades depende de nuestra capacidad para integrar tecnología, participación ciudadana y políticas públicas innovadoras. Los ejemplos analizados demuestran que los datos abiertos no son solo información; son la base para construir entornos urbanos que promuevan activamente la salud, la equidad y la sostenibilidad.
Blog
En los últimos años, las iniciativas de datos abiertos han transformado la forma en que, tanto instituciones públicas como organizaciones privadas, gestionan y comparten la información. La adopción de los principios FAIR (Findable, Accessible, Interoperable, Reusable) ha sido clave para garantizar que los datos generen un impacto positivo, maximizando su disponibilidad y su reutilización.
Sin embargo, en contextos de vulnerabilidad (como pueblos indígenas, minorías culturales o territorios en situación de riesgo) surge la necesidad de incorporar un marco ético que garantice que la apertura de datos no derive en perjuicios ni profundice las desigualdades. Aquí es donde entran en juego los principios CARE (Collective Benefit, Authority to Control, Responsibility, Ethics), propuestos por el Global Indigenous Data Alliance (GIDA), que complementan y enriquecen el enfoque FAIR.
Es importante señalar que, aunque los principios CARE surgen en el contexto de las comunidades indígenas (para asegurar una soberanía efectiva de los pueblos indígenas sobre sus datos y su derecho a generar valor de acuerdo con sus propios valores), estos pueden extrapolarse a otros escenarios diferentes. De hecho, estos principios son muy útiles en cualquier situación donde los datos se recolecten en territorios con algún tipo de vulnerabilidad social, territorial, medioambiental o, incluso, cultural.
Este artículo explora cómo los principios CARE pueden integrarse en las iniciativas de datos abiertos generando un impacto social sobre la base de un uso responsable que no perjudique a comunidades vulnerables.
Los principios CARE en detalle
Los principios CARE ayudan a garantizar que las iniciativas de datos abiertos no se limiten a aspectos técnicos, sino que incorpore también consideraciones sociales, culturales y éticas. En concreto, los cuatro principios CARE son los siguientes:
- Collective Benefit (beneficio colectivo): los datos deben usarse para generar un beneficio que sean compartido de manera justa entre todas las partes involucradas. De esta manera, la apertura de datos debería apoyar el desarrollo sostenible, el bienestar social y el fortalecimiento cultural de una comunidad vulnerable, por ejemplo, evitando prácticas relacionadas con los datos abiertos que solo favorezcan a terceros.
-
Authority to Control (autoridad para controlar): las comunidades vulnerables tienen el derecho a decidir cómo se recopilan, gestionan, comparten y reutilizan los datos que generan. Este principio reconoce la soberanía de los datos y la necesidad de respetar sistemas de gobernanza propios, en lugar de imponer criterios externos.
-
Responsibility (responsabilidad): quienes gestionan y reutilizan los datos deben actuar con responsabilidad hacia las comunidades involucradas, reconociendo posibles impactos negativos y aplicando medidas para mitigarlos. Esto incluye prácticas como la consulta previa, la transparencia en el uso de los datos y la creación de mecanismos de rendición de cuentas.
-
Ethics (ética): la dimensión ética exige que la apertura y reutilización de los datos respete los derechos humanos, los valores culturales y la dignidad de las comunidades. No se trata únicamente de cumplir con la legalidad, sino de ir más allá, aplicando principios éticos a través de un código deontológico.
En conjunto, estos cuatro principios ofrecen una guía para gestionar los datos abiertos de manera más justa y responsable, respetando la soberanía y los intereses de las comunidades a las que esos datos se refieren.
CARE y FAIR: principios complementarios para datos abiertos que trascienden
Los principios CARE y FAIR no son opuestos, sino que operan en planos distintos y complementarios:
-
FAIR se centra en la facilitar técnicamente el consumo de datos.
-
CARE introduce la dimensión social y ética (incluso cultural considerando comunidades vulnerables concretas).
Los principios FAIR se enfocan en las dimensiones técnicas y operativas de los datos. Es decir, los datos que cumplen estos principios son fácilmente localizables, están disponibles sin barreras innecesarias y con identificadores únicos, usan estándares para asegurar la interoperabilidad y pueden utilizarse en distintos contextos para fines diferentes de los que fueron pensados en un principio.
No obstante, los principios FAIR no abordan directamente cuestiones de justicia social, soberanía ni ética. En particular, estos principios no contemplan que los datos pueden representar conocimientos, recursos o identidades de comunidades que históricamente han sufrido exclusión o explotación o de comunidades relacionadas con territorios con valores medioambientales, sociales o culturales únicos. Para ello, se pueden utilizar los principios CARE, que complementan a los principios FAIR, agregando una base ética y de gobernanza comunitaria a cualquier iniciativa de datos abiertos.
De esta forma, una estrategia de datos abiertos que aspire a ser socialmente justa y sostenible debe articular ambos principios. FAIR sin CARE corre el riesgo de invisibilizar derechos colectivos promoviendo una reutilización de datos poco ética. Por otro lado, CARE sin FAIR puede limitar el potencial de interoperabilidad y reutilización, haciendo los datos inservibles para generar un beneficio positivo en una comunidad o territorio vulnerable.

Un ejemplo ilustrativo se encuentra en la gestión de datos sobre biodiversidad en un área natural protegida. Mientras los principios FAIR aseguran que los datos puedan integrarse con diversas herramientas para ser ampliamente reutilizados (por ejemplo, en investigaciones científicas), los principios CARE recuerdan que los datos sobre especies y los territorios en los que habitan pueden tener implicaciones directas para las comunidades que viven en (o cerca de) esa área natural protegida. Por ejemplo, hacer públicos los puntos exactos donde se encuentran especies en peligro de extinción en un área natural protegida, podría facilitar su explotación ilegal en lugar de su conservación, lo que obliga a definir cuidadosamente cómo, cuándo y bajo qué condiciones se comparten esos datos.
Veamos ahora cómo en este ejemplo se podrían cumplir los principios CARE:
-
En primer lugar, los datos sobre biodiversidad deben usarse para proteger los ecosistemas y fortalecer a las comunidades locales, generando beneficios en forma de conservación, turismo sostenible o educación ambiental, en lugar de favorecer intereses privados aislados (es decir, principio de beneficio colectivo).
-
En segundo lugar, las comunidades que habitan cerca del área natural protegida o dependen de esos recursos tienen derecho a decidir cómo se gestionan los datos sensibles, por ejemplo, exigir que la ubicación de ciertas especies no se publique de forma abierta o se publique de manera agregada (es decir, principio de autoridad).
-
Por otra parte, las personas encargadas de la gestión de estas áreas protegidas del parque deben actuar con responsabilidad, estableciendo protocolos para evitar daños colaterales (como la caza furtiva) y garantizando que los datos se usen de manera coherente con los objetivos de conservación (esto es, principio de responsabilidad).
-
Finalmente, la apertura de estos datos debe guiarse por principios éticos, priorizando la protección de la biodiversidad y los derechos de las comunidades locales frente a intereses económicos (o incluso académicos) que puedan poner en riesgo los ecosistemas o las poblaciones que dependen de ellos (principio de ética).
Cabe destacar que varias iniciativas internacionales, como la justicia de datos ambientales indígenas relacionada con el International Indigenous Data Sovereignty Movement y el Research Data Alliance (RDA) a través del Care Principles for Indigenous Data Governance, ya promueven la adopción conjunta de CARE y FAIR como base de iniciativas de datos más equitativas.
Conclusiones
Garantizar los principios FAIR es esencial para que los datos abiertos generen valor a través de su reutilización. Sin embargo, las iniciativas de datos abiertos deben ir acompañadas de un compromiso firme con la justicia social, la soberanía de las comunidades vulnerables y la ética. Solo la integración de los principios CARE junto a los FAIR permitirá impulsar prácticas de datos abiertos verdaderamente justas, equitativas, inclusivas y responsables.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos de fuentes públicas han evolucionado a lo largo de estos años, pasando de ser simples repositorios de información a constituir ecosistemas dinámicos que pueden transformar la gobernanza pública. En este contexto, la inteligencia artificial (IA) emerge como una tecnología catalizadora que se beneficia del valor de los datos abiertos y potencia exponencialmente su utilidad. En este post veremos cómo es la relación simbiótica de mutuo beneficio entre la IA y los datos abiertos.
Tradicionalmente, el debate sobre datos abiertos se ha centrado en los portales: las plataformas en las que gobiernos publican información para que la ciudadanía, las empresas y las organizaciones puedan acceder a ella. Pero la llamada “Tercera Ola de Datos Abiertos”, término acuñado por el GovLab de la Universidad de Nueva York, enfatiza que ya no basta con publicar datasets a demanda o por defecto. Lo importante es pensar en el ecosistema completo: el ciclo de vida de los datos, su explotación, mantenimiento y, sobre todo, el valor que generan en la sociedad.
¿Qué función pueden tener los datos abiertos aplicados a la IA?
En este contexto, la IA aparece como un catalizador capaz de automatizar tareas, enriquecer los datos abiertos gubernamentales (OGD), facilitar su comprensión y estimular la colaboración entre actores.
Una investigación reciente, desarrollada por universidades europeas, mapea cómo está sucediendo esta revolución silenciosa. El estudio propone una clasificación de los usos según en dos dimensiones:
- Perspectiva, que a su vez se divide en dos posibles vías:
- Inward-looking (portal): el foco está en las funciones internas de los portales de datos.
- Outward-looking (ecosistema): el foco se amplía a las interacciones con actores externos (ciudadanos, empresas, organizaciones).
- Fases del ciclo de vida del dato, las cuales podemos dividir en pre-procesamiento, exploración, transformación y mantenimiento.
En resumen, el informe identifica estos ocho tipos de uso de la IA en los datos abiertos gubernamentales, que se producen al cruzar las perspectivas y las fases en el ciclo de vida del dato.

Figura 1. Ocho uso de la IA para mejorar los datos abiertos gubernamentales. Fuente: presentación "Data for AI or AI for data: artificial intelligence as a catalyser for open government ecosystems", basada en el informe del mismo nombre, de los EU Open Data Days 2025.
A continuación, se detalla cada uno de estos usos:
1. IA como depuradora (portal curator)
Esta aplicación se centra en el pre-procesamiento de datos dentro del portal. La IA ayuda a organizar, limpiar, anonimizar y etiquetar datasets antes de su publicación. Algunos ejemplos de tareas son:
- Automatización y mejora de las tareas de publicación de datos.
- Realización de funciones de etiquetado automático y categorización.
- Anonimización de datos para proteger la privacidad.
- Limpieza y filtrado automático de conjuntos de datos.
- Extracción de características y manejo de datos faltantes.
2. IA como recolectora de datos del ecosistema (ecosystem data retriever)
También en la fase de pre-procesamiento, pero con un enfoque externo, la IA amplía la cobertura de los portales al identificar y recopilar información de fuentes diversas. Algunas tareas son:
- Recuperar datos estructurados desde textos legales o normativos.
- Minería de noticias para enriquecer datasets con información contextual.
- Integración de datos urbanos procedentes de sensores o registros digitales.
- Descubrimiento y enlace de fuentes heterogéneas.
- Conversión de documentos complejos en información estructurada.
3. IA como exploradora del portal (portal explorer)
En la fase de exploración, los sistemas de IA también pueden facilitar la búsqueda e interacción con los datos publicados, con un enfoque más interno. Algunos casos de uso:
- Desarrollar buscadores semánticos para localizar conjuntos de datos.
- Implementar chatbots que guíen a los usuarios en la exploración de datos.
- Proporcionar interfaces de lenguaje natural para consultas directas.
- Optimizar los motores de búsqueda internos del portal.
- Utilizar modelos de lenguaje para mejorar la recuperación de información.
4. IA como recolectora de información en la web (ecosystem connector)
Operando también en la fase de exploración, la IA actúa como un puente entre actores y recursos del ecosistema. Algunos ejemplos son:
- Recomendar datasets relevantes a investigadores o empresas.
- Identificar socios potenciales a partir de intereses comunes.
- Extraer temas emergentes para apoyar la formulación de políticas.
- Visualizar datos de múltiples fuentes en paneles interactivos.
- Personalizar sugerencias de datos basadas en actividades en redes sociales.
5. IA que referencia el portal (portal linker)
Esta funcionalidad se enfoca en la transformación de datos dentro del portal. Su función es facilitar la combinación y presentación de información para distintos públicos. Algunas tareas son:
- Convertir datos en grafos de conocimiento (estructuras que conectan información relacionada, conocidas como Linked Open Data).
- Resumir y simplificar datos con técnicas de PLN (Procesamiento del Lenguaje Natural).
- Aplicar razonamiento automático para generar información derivada.
- Potenciar la visualización multivariante de datasets complejos.
- Integrar datos diversos en productos de información accesibles.
6. IA como desarrolladora de valor en el ecosistema (ecosystem value developer)
En la fase de transformación y con mirada externa, la IA genera productos y servicios basados en datos abiertos que aportan valor añadido. Algunas tareas son:
- Sugerir técnicas analíticas adecuadas según el tipo de conjunto de datos.
- Asistir en la codificación y procesamiento de información.
- Crear paneles de control basados en análisis predictivo.
- Garantizar la corrección y coherencia de los datos transformados.
- Apoyar el desarrollo de servicios digitales innovadores.
7. IA como supervisora del portal (portal monitor)
Se centra en el mantenimiento del portal, con un enfoque interno. Su papel es garantizar la calidad, consistencia y cumplimiento de estándares. Algunas tareas son:
- Detectar anomalías y valores atípicos en conjuntos de datos publicados.
- Evaluar la consistencia de metadatos y esquemas.
- Automatizar procesos de actualización y depuración de datos.
- Identificar incidencias en tiempo real para su corrección.
- Reducir costes de mantenimiento mediante monitorización inteligente.
8. IA como dinamizadora del ecosistema (ecosystem engager)
Y, por último, esta función opera en la fase de mantenimiento, pero hacia afuera. Busca promover la participación ciudadana y la interacción continua. Algunas tareas son:
- Predecir patrones de uso y anticipar necesidades de los usuarios.
- Proporcionar retroalimentación personalizada sobre datasets.
- Facilitar la auditoría ciudadana de la calidad de los datos.
- Incentivar la participación en comunidades de datos abiertos.
- Identificar perfiles de usuarios para diseñar experiencias más inclusivas.
¿Qué nos dice la evidencia?
El estudio se basa en una revisión de más de 70 artículos académicos que examinan la intersección entre IA y los datos abiertos gubernamentales (open government data u OGD). A partir de estos casos, los autores observan que:
- Algunos de los perfiles definidos, como portal curator, portal explorer y portal monitor, están relativamente maduros y cuentan con múltiples ejemplos en la literatura.
- Otros, como ecosystem value developer y ecosystem engager, están menos explorados, aunque son los que más potencial tienen para generar impacto social y económico.
- La mayoría de las aplicaciones actuales se centran en automatizar tareas concretas, pero hay un gran margen para diseñar arquitecturas más integrales, que combinen varios tipos de IA en un mismo portal o en todo el ciclo de vida del dato.
Desde un punto de vista académico, esta tipología aporta un lenguaje común y una estructura conceptual para estudiar la relación entre IA y datos abiertos. Permite identificar vacíos en la investigación y orientar futuros trabajos hacia un enfoque más sistémico.
En la práctica, el marco es útil para:
- Gestores de portales de datos: les ayuda a identificar qué tipos de IA pueden implementar según sus necesidades, desde mejorar la calidad de los datasets hasta facilitar la interacción con los usuarios.
- Responsables políticos: les orienta sobre cómo diseñar estrategias de adopción de IA en iniciativas de datos abiertos, equilibrando eficiencia, transparencia y participación.
- Investigadores y desarrolladores: les ofrece un mapa de oportunidades para crear herramientas innovadoras que atiendan necesidades específicas del ecosistema.
Limitaciones y próximos pasos de la sinergia entre IA y open data
Además de las ventajas, el estudio reconoce algunas asignaturas pendientes que, en cierta manera, sirven como hoja de ruta para el futuro. Para empezar, varias de las aplicaciones que se han identificado están todavía en fases tempranas o son conceptuales. Y, quizá lo más relevante, aún no se ha abordado en profundidad el debate sobre los riesgos y dilemas éticos del uso de IA en datos abiertos: sesgos, privacidad, sostenibilidad tecnológica.
En definitiva, la combinación de IA y datos abiertos es todavía un terreno en construcción, pero con un enorme potencial. La clave estará en pasar de experimentos aislados a estrategias integrales, capaces de generar valor social, económico y democrático. La IA, en este sentido, no funciona de manera independiente a los datos abiertos: los multiplica y los hace más relevantes para gobiernos, ciudadanía y sociedad en general.
Blog
Sabemos que los datos abiertos que gestiona el sector público en el ejercicio de sus funciones constituyen un recurso de gran valor para fomentar la transparencia, impulsar la innovación y estimular el desarrollo económico. A nivel global, en los últimos 15 años esta idea ha llevado a la creación de portales de datos que sirven como punto de acceso único para la información pública tanto de un país, como de una región o ciudad.
Sin embargo, en ocasiones nos encontramos que el pleno aprovechamiento del potencial de los datos abiertos se ve limitado por problemas inherentes a su calidad. Inconsistencias, falta de estandarización o interoperabilidad y metadatos incompletos son solo algunos de los desafíos comunes que a veces merman la utilidad de los conjuntos de datos abiertos y que las agencias gubernamentales además señalan como el principal obstáculo para la adopción de la IA.
Cuando hablamos de la relación entre datos abiertos e inteligencia artificial, casi siempre partimos de la misma idea: los datos abiertos alimentan a la IA, esto es, son parte del combustible de los modelos. Ya sea para entrenar modelos fundacionales como ALIA, para especializar modelos de lenguaje pequeños (SLM) frente a LLM, o para evaluar y validar sus capacidades o explicar su comportamiento (XAI), el argumento gira en torno a la utilidad de los datos abiertos para la inteligencia artificial, olvidando que los datos abiertos ya estaban ahí y tienen muchas otras utilidades.
Por ello, vamos a invertir la perspectiva y a explorar cómo la propia IA puede convertirse en una herramienta poderosa para mejorar la calidad y, por tanto, el valor de los propios datos abiertos. Este enfoque, que ya esbozó la Comisión Económica para Europa de las Naciones Unidas (UNECE) en su pionero informe Machine Learning for Official Statistics de 2022, adquiere una mayor relevancia desde la explosión de la IA generativa. Actualmente podemos utilizar la inteligencia artificial disponible para incrementar la calidad de los conjuntos de datos que se publican a lo largo de todo su ciclo de vida: desde la captura y la normalización hasta la validación, la anonimización, la documentación y el seguimiento en producción.
Con ello, podemos aumentar el valor público del dato, contribuir a que crezca su reutilización y a amplificar su impacto social y económico. Y, al mismo tiempo, a mejorar la calidad de la siguiente generación de modelos de inteligencia artificial.
Desafíos comunes en la calidad de los datos abiertos
La calidad de los datos ha sido tradicionalmente un factor crítico para el éxito de cualquier iniciativa de datos abiertos, que aparece citado en numerosos informes como el de Comisión Europea “Improving data publishing by open data portal managers and owners”. Los desafíos más frecuentes que enfrentan los publicadores de datos incluyen:
-
Inconsistencias y errores: en los conjuntos de datos, es frecuente la presencia de datos duplicados, formatos heterogéneos o valores atípicos. La corrección de estos pequeños errores, idealmente en la propia fuente de los datos, tenía tradicionalmente un coste elevado y limitaba enormemente la utilidad de numerosos conjuntos de datos.
-
Falta de estandarización e interoperabilidad: dos conjuntos que hablan de lo mismo pueden nombrar las columnas de forma diferente, usar clasificaciones no comparables o carecer de identificadores persistentes para enlazar entidades. Sin un mínimo común, combinar fuentes se convierte en un trabajo artesanal que encarece la reutilización de los datos.
- Metadatos incompletos o inexactos: la carencia de información clara sobre el origen, la metodología de recolección, la frecuencia de actualización o el significado de los campos, complica la comprensión y el uso de los datos. Por ejemplo, saber con certeza si se puede integrar el recurso en un servicio, si está al día o si existe un punto de contacto para resolver dudas es muy importante para su reutilización.
- Datos obsoletos o desactualizados: en dominios muy dinámicos como la movilidad, los precios o los datos de medio ambiente, un conjunto desactualizado puede generar conclusiones erróneas. Y si no hay versiones, registro de cambios o indicadores de frescura, es difícil saber qué ha variado y por qué. La ausencia de un “historial” de los datos complica la auditoría y reduce la confianza.
- Sesgos inherentes: a veces la cobertura es incompleta, ciertas poblaciones quedan infrarrepresentadas o una práctica administrativa introduce una desviación sistemática. Si estos límites no se documentan y advierten, los análisis pueden reforzar desigualdades o llegar a conclusiones injustas sin que nadie lo perciba.
Dónde puede ayudar la Inteligencia Artificial
Por fortuna, en su estado actual, la inteligencia artificial ya está en disposición de proporcionar un conjunto de herramientas que pueden contribuir a abordar algunos de estos desafíos de calidad de los datos abiertos, transformando su gestión de un proceso manual y propenso a errores en uno más automatizado y eficiente:
- Detección y corrección de errores automatizada: los algoritmos de aprendizaje automático y los modelos de IA pueden identificar automáticamente y con una gran fiabilidad inconsistencias, duplicados, valores atípicos y errores tipográficos en grandes volúmenes de datos. Además, la IA puede ayudar a normalizar y estandarizar datos, transformándolos por ejemplo a formatos y esquemas comunes para facilitar la interoperabilidad (como DCAT-AP), y con una fracción del coste que suponía hasta el momento.
- Enriquecimiento de metadatos y catalogación: las tecnologías asociadas al procesamiento de lenguaje natural (PLN), incluyendo el uso de modelos de lenguaje grandes (LLM) y pequeños (SLM), puede ayudar en la tarea de analizar descripciones y generar metadatos más completos y precisos. Esto incluye tareas como sugerir etiquetas relevantes, categorías de clasificación o extraer entidades clave (nombres de lugares, organizaciones, etc.) de descripciones textuales para enriquecer los metadatos.
- Anonimización y privacidad: cuando los datos abiertos contienen información que podría afectar a la privacidad, la anonimización se convierte en una tarea crítica, pero, en ocasiones, costosa. La Inteligencia Artificial puede contribuir a que la anonimización sea mucho más robusta y a minimizar riesgos relacionados con la re-identificación al combinar diferentes conjuntos de datos.
Evaluación de sesgos: la IA puede analizar los propios conjuntos de datos abiertos para detectar sesgos de representación o históricos. Esto permite a los publicadores tomar medidas para corregirlos o, al menos, advertir a los usuarios sobre su presencia para que sean tenidos en cuenta cuando vayan a reutilizarse. En definitiva, la inteligencia artificial no debe verse solo como “consumidora” de datos abiertos, sino también como una aliada estratégica para mejorar su calidad. Cuando se integra con estándares, procesos y supervisión humana, la IA ayuda a detectar y explicar incidencias, a documentar mejor los conjuntos y a publicar evidencias de calidad que refuerzan la confianza. Tal y como se describe en la Estrategia de Inteligencia Artificial 2024, esa sinergia libera más valor público: facilita la innovación, permite decisiones mejor informadas y consolida un ecosistema de datos abiertos más robusto y fiable con unos datos abiertos más útiles, más confiables y con mayor impacto social.
Además, se activa un ciclo virtuoso: datos abiertos de mayor calidad entrenan modelos más útiles y seguros; y modelos más capaces facilitan seguir elevando la calidad de los datos. De este modo la gestión del dato deja de ser una tarea estática de publicación y se convierte en un proceso dinámico de mejora continua.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.