Blog
El acceso a datos a través de API se ha convertido en una de las piezas clave del ecosistema digital actual. Administraciones públicas, organismos internacionales y empresas privadas publican información para que terceros puedan reutilizarla en aplicaciones, análisis o proyectos de inteligencia artificial. En esta situación, hablar de datos abiertos es, casi inevitablemente, hablar también de API.
Sin embargo, el acceso a una API rara vez es completamente libre e ilimitado. Existen restricciones, controles y mecanismos de protección que buscan equilibrar dos objetivos que, a primera vista, pueden parecer opuestos: facilitar el acceso a los datos y garantizar la estabilidad, seguridad y sostenibilidad del servicio. Estas limitaciones generan dudas frecuentes: ¿son realmente necesarias?, ¿van contra el espíritu de los datos abiertos?, ¿hasta qué punto pueden aplicarse sin cerrar el acceso?
Este artículo aborda cómo se gestionan estas limitaciones, por qué son necesarias y cómo encajan —lejos de lo que a veces se piensa— dentro de una estrategia coherente de datos abiertos.
Por qué es necesario limitar el acceso a una API
Una API no es simplemente un “grifo” de datos. Detrás suele haber infraestructura tecnológica, servidores, procesos de actualización, costes operativos y equipos responsables de que el servicio funcione correctamente.
Cuando un servicio de datos se expone sin ningún tipo de control, aparecen problemas bien conocidos:
- Saturación del sistema, provocada por un número excesivo de consultas simultáneas.
- Uso abusivo, intencionado o no, que degrade el servicio para otros usuarios.
- Costes descontrolados, especialmente cuando la infraestructura está desplegada en la nube.
- Riesgos de seguridad, como ataques automatizados o scraping masivo.
En muchos casos, la ausencia de límites no conduce a más apertura, sino a un deterioro progresivo del propio servicio.
Por este motivo, limitar el acceso no suele ser una decisión ideológica, sino una necesidad práctica para asegurar que el servicio sea estable, predecible y justo para todos los usuarios.
La API Key: control básico, pero efectivo
El mecanismo más habitual para gestionar el acceso es la API Key. Mientras que en algunos casos como la API del catálogo nacional de datos abiertos de datos.gob.es no se requiere ningún tipo de clave para poder acceder a la información publicada, otros catálogos solicitan una clave única que identifica a cada usuario o aplicación y que se incluye en cada llamada a la API.
Aunque desde fuera pueda parecer una simple formalidad, la API Key cumple varias funciones importantes. Permite identificar quién consume los datos, medir el uso real del servicio, aplicar límites razonables y actuar ante comportamientos problemáticos sin afectar al resto de usuarios.
En el contexto español existen ejemplos claros de plataformas de datos abiertos que funcionan así. La Agencia Estatal de Meteorología (AEMET), por ejemplo, ofrece acceso abierto a datos meteorológicos de alto valor, pero exige solicitar una API Key gratuita para consultas automatizadas. El acceso es libre y gratuito, pero no anónimo ni descontrolado.
Hasta aquí, el enfoque es relativamente conocido: identificación del consumidor y límites básicos de uso. Sin embargo, en muchas situaciones nos esto ya no es suficiente.
Cuando la API se convierte en un activo estratégico
Las plataformas líderes de gestión de API, como MuleSoft o Kong entre otros, fueron pioneras en implantar mecanismos avanzados de control y protección del acceso a las API. Su foco inicial estaba ligado a entornos empresariales complejos, donde múltiples aplicaciones, organizaciones y países consumen servicios de datos de forma intensiva y continuada.
Con el tiempo, muchas de estas prácticas han ido extendiéndose también a plataformas de datos abiertos. A medida que ciertos servicios de datos abiertos ganan relevancia y se convierten en dependencias clave para aplicaciones, investigaciones o modelos de negocio, los retos asociados a su disponibilidad y estabilidad se vuelven similares. La caída o degradación de servicios de datos abiertos de gran escala —como los relacionados con observación de la Tierra, clima o ciencia— puede tener un impacto significativo en múltiples sistemas que dependen de ellos.
En este sentido, la gestión avanzada del acceso deja de ser una cuestión exclusivamente técnica y pasa a formar parte de la propia sostenibilidad de un servicio que se vuelve estratégico. No se trata tanto de quién publica los datos, sino del papel que esos datos juegan dentro de un ecosistema más amplio de reutilización. Por ello, muchas plataformas de open data están adoptando, de forma progresiva, mecanismos ya probados en otros ámbitos, adaptándolos a sus principios de apertura y acceso público. A continuación, se detallan algunos de ellos.
Limitar el caudal: regular el ritmo, no el derecho de acceso
Una de las primeras capas adicionales es la limitación del caudal de uso, lo que habitualmente se conoce como rate limiting. En lugar de permitir un número ilimitado de llamadas, se define cuántas peticiones pueden realizarse en un intervalo de tiempo determinado.
La clave aquí no es impedir el acceso, sino regular el ritmo. Un usuario puede seguir utilizando los datos, pero se evita que una única aplicación monopolice los recursos. Este enfoque es habitual en las API de datos meteorológicos, movilidad o estadísticas públicas, donde muchos usuarios acceden simultáneamente.
Las plataformas más avanzadas van un paso más allá y aplican límites dinámicos, que se ajustan según la carga del sistema, el momento del día o el comportamiento histórico del consumidor. El resultado es un control más justo y flexible.
Contexto, origen y comportamiento: más allá del volumen
Otra evolución importante es dejar de mirar solo cuántas llamadas se hacen y empezar a analizar desde dónde y cómo se realizan. Aquí entran medidas como la restricción por direcciones IP, el control geográfico (geofencing) o la diferenciación entre entornos de prueba y producción.
En algunos casos, estas limitaciones responden a marcos regulatorios o licencias de uso. En otros, simplemente permiten proteger partes más sensibles del servicio sin cerrar el acceso general. Por ejemplo, una API puede ser accesible globalmente en modo consulta, pero limitar determinadas operaciones a situaciones muy concretas.
Las plataformas también analizan patrones de comportamiento. Si una aplicación empieza a realizar consultas repetitivas, incoherentes o muy distintas a su uso habitual, el sistema puede reaccionar automáticamente: reducir temporalmente el caudal, lanzar alertas o exigir un nivel adicional de validación. No se bloquea “porque sí”, sino porque el comportamiento deja de encajar con un uso razonable del servicio.
Medir impacto, no solo llamadas
Una tendencia especialmente relevante es dejar de medir únicamente el número de peticiones y empezar a considerar el impacto real de cada una. No todas las consultas consumen los mismos recursos: algunas transfieren grandes volúmenes de datos o ejecutan operaciones más costosas.
Un ejemplo claro en datos abiertos sería una API de movilidad urbana. Consultar el estado de una parada o el tráfico en un punto concreto implica pocos datos y un impacto limitado. En cambio, descargar de una sola vez todo el histórico de posiciones de vehículos de una ciudad durante varios años supone una carga mucho mayor para el sistema, aunque se realice en una única llamada.
Por este motivo, muchas plataformas introducen cuotas basadas en volumen de datos transferidos, tipo de operación o peso de la consulta. Esto evita situaciones en las que un uso aparentemente moderado genera una carga desproporcionada sobre el sistema.
¿Cómo encaja todo esto con el open data?
Llegados a este punto, surge inevitablemente la pregunta: ¿siguen siendo abiertos los datos cuando existen todas estas capas de control?
La respuesta depende menos de la tecnología y más de las reglas del juego. Los datos abiertos no se definen por la ausencia total de control técnico, sino por principios como el acceso no discriminatorio, la ausencia de barreras económicas, la claridad en las licencias y la posibilidad real de reutilización.
Solicitar una API Key, limitar el caudal o aplicar controles contextuales no contradice estos principios si se hace de forma transparente y equitativa. De hecho, en muchos casos es la única manera de garantizar que el servicio siga existiendo y funcionando correctamente a medio y largo plazo.
La clave está en el equilibrio: reglas claras, acceso gratuito, límites razonables y mecanismos pensados para proteger el servicio, no para excluir. Cuando este equilibrio se consigue, el control deja de percibirse como una barrera y pasa a ser parte natural de un ecosistema de datos abiertos, útiles y sostenibles.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
El Cabildo Insular de Tenerife ha convocado el II Concurso de Datos Abiertos: Desarrollo de APP, una iniciativa que premia la creación de aplicaciones web y móviles que aprovechen los conjuntos de datos disponibles en su portal datos.tenerife.es. Esta convocatoria representa una nueva oportunidad para desarrolladores, emprendedores y entidades innovadoras que quieran transformar información pública en soluciones digitales de valor para la sociedad. En este post, te contamos los detalles sobre la competición.
Un ecosistema en crecimiento: de las ideas a las aplicaciones
Esta iniciativa se enmarca en el proyecto de Datos Abiertos del Cabildo de Tenerife, que promueve la transparencia, la participación ciudadana y la generación de valor económico y social a través de la reutilización de información pública.
El Cabildo ha diseñado una estrategia en dos fases:
-
El I Concurso de Datos Abiertos: Ideas de Reutilización (ya celebrado) centrado en identificar propuestas creativas.
-
El II Concurso: Desarrollo de APP (convocatoria actual) que da continuidad al proceso y busca materializar ideas en aplicaciones funcionales.
Este enfoque progresivo permite construir un ecosistema de innovación que acompaña a los participantes desde la conceptualización hasta el desarrollo completo de soluciones digitales.
El objetivo es fomentar la creación de productos y servicios digitales que generen impacto social y económico, mientras se identifican nuevas oportunidades de innovación y emprendimiento en el ámbito de los datos abiertos.
Premios y dotación económica
Este concurso cuenta con una dotación total de 6.000 euros distribuidos en tres premios:
-
Primer premio: 3.000 euros
-
Segundo premio: 2.000 euros
-
Tercer premio: 1.000 euros
¿Quién puede participar?
La convocatoria está abierta a:
-
Personas físicas: desarrolladores individuales, diseñadores, estudiantes o cualquier persona interesada en la reutilización de datos abiertos.
-
Personas jurídicas: startups, empresas de tecnología, cooperativas, asociaciones u otras entidades.
Siempre y cuando presenten el desarrollo de una aplicación basada en datos abiertos del Cabildo de Tenerife. Una misma persona, física o jurídica, puede presentar tantas candidaturas como desee, tanto de forma individual como conjunta.
¿Qué tipo de aplicaciones se pueden presentar?
Las propuestas deben ser aplicaciones web o móviles que utilicen al menos un conjunto de datos del portal datos.tenerife.es. Algunas ideas que pueden servir de inspiración son:
-
Aplicaciones para optimizar el transporte y la movilidad en la isla.
-
Herramientas de visualización de datos turísticos o medioambientales.
-
Servicios de información ciudadana en tiempo real.
-
Soluciones para mejorar la accesibilidad y la participación social.
-
Plataformas de análisis de datos económicos o demográficos.
Criterios de evaluación: ¿qué valora el jurado?
El jurado evaluará las propuestas considerando los siguientes criterios:
-
Uso de datos abiertos: grado de aprovechamiento e integración de los conjuntos de datos disponibles en el portal.
-
Impacto y utilidad: valor que aporta la aplicación a la sociedad, capacidad para resolver problemas reales o mejorar servicios existentes.
-
Innovación y creatividad: originalidad de la propuesta y carácter innovador de la solución planteada.
-
Calidad técnica: solidez del código, buenas prácticas de programación, escalabilidad y mantenibilidad de la aplicación.
-
Diseño y usabilidad: experiencia de usuario (UX), diseño visual atractivo e intuitivo, garantía de accesibilidad digital en dispositivos Android e iOS.
¿Cómo participar?: plazos y forma de presentación:
Las solicitudes pueden presentarse hasta el 10 de marzo de 2026, tres meses desde la publicación de la convocatoria en el Boletín Oficial de la Provincia.
Sobre la documentación requerida, las propuestas deben presentarse en formato digital e incluir:
-
Descripción técnica detallada de la aplicación.
-
Memoria justificativa del uso de los datos abiertos.
-
Especificación de entornos tecnológicos utilizados.
-
Vídeo demostrativo del funcionamiento de la aplicación.
-
Código fuente completo.
-
Ficha técnica resumen.
Desde la institución organizadora recomiendan la presentación telemática a través de la Sede Electrónica del Cabildo de Tenerife, aunque también es posible la presentación presencial en los registros oficiales habilitados. Las bases completas y el modelo oficial de solicitud están disponibles en la Sede Electrónica del Cabildo.
Con esta segunda convocatoria, el Cabildo de Tenerife consolida su apuesta por la transparencia, la reutilización de información pública y la creación de un ecosistema de innovación digital. Iniciativas como esta demuestran cómo los datos abiertos pueden convertirse en catalizadores del emprendimiento, la participación ciudadana y el desarrollo económico local.
Noticia
En los últimos seis meses, el ecosistema de datos abiertos en España ha vivido una intensa actividad marcada por los avances normativos y estratégicos, la puesta en marcha de nuevas plataformas y funcionalidades en los portales de datos, o el lanzamiento de soluciones innovadoras basadas en la información pública.
En este artículo, repasamos algunos de esos avances, para que puedas estar al día. Te invitamos también a revisar el artículo sobre las novedades del primer semestre de 2025 para que puedas tener una visión general de lo que ha sucedido este año en el ecosistema de datos nacional.
Avances estratégicos, normativos y políticos de carácter transversal
La calidad, interoperabilidad y gobernanza de los datos se han situado en el centro de la agenda tanto nacional como europea, con iniciativas que buscan fomentar un marco sólido para aprovechar el valor de los datos como activo estratégico.
Una de las principales novedades ha sido el lanzamiento de un nuevo paquete digital por parte de la Comisión Europea con el fin de consolidar un ecosistema europeo de datos robusto, seguro y competitivo. Este paquete incluye un ómnibus digital para simplificar la aplicación del Reglamento de inteligencia artificial (IA). Además, se complementa con la nueva Estrategia Unión de Datos (Data Union Strategy) que se articula en torno a tres pilares:
- Ampliar el acceso a datos de calidad para impulsar la inteligencia artificial y la innovación.
- Simplificar el marco normativo existente para reducir barreras y burocracia.
- Proteger la soberanía digital europea frente a dependencias externas.
Su implementación se producirá de forma gradual durante los próximos meses. Será entonces cuando podamos ir apreciando sus efectos sobre nuestro país y el resto de territorios comunitarios.
La actividad en España también se ha visto -y se verá- marcada por el V Plan de Gobierno Abierto 2025-2029, aprobado el pasado octubre. Este plan cuenta con más de 200 iniciativas y aportaciones tanto de la sociedad civil como de administraciones, muchas de ellas relacionadas con la apertura y reutilización de datos. El compromiso de España con los datos abiertos también ha quedado patente en la adhesión a la Carta Internacional de Datos Abiertos, una iniciativa global que promueve la apertura y reutilización de datos públicos como herramientas para mejorar la transparencia, la participación ciudadana, la innovación y la rendición de cuentas.
Junto al impulso de la apertura de datos, también se ha trabajado en el desarrollo de espacios de compartición de datos. En este sentido, se presentó la normativa UNE 0087, que se suma a especificaciones UNE sobre datos y define por primera vez en España los principios y requisitos clave para crear y operar en espacios de datos, mejorando su interoperabilidad y gobernanza.
Más soluciones innovadoras basadas en datos
Los organismos españoles continúan aprovechando el potencial de los datos como motor de soluciones y políticas que optimizan la prestación de servicios a la ciudadanía. Algunos ejemplos son:
- El Ministerio de Sanidad y la iniciativa de ciencia ciudadana, Mosquito Alert, están utilizando inteligencia artificial y análisis de imágenes automatizado para mejorar la detección y seguimiento en tiempo real de mosquitos tigres y especies invasoras.
- La Fundación Valenciaport, junto a otras organizaciones europeas, ha lanzado una herramienta gratuita que permite evaluar los beneficios de instalar sistemas de energía eólica y fotovoltaica en los puertos.
- El Cabildo de la Palma apostó por una agricultura inteligente con la nueva web Smart Agro: los agricultores reciben recomendaciones de riego personalizadas según clima y ubicación. El Cabildo también ha puesto en marcha un visor para hacer seguimiento de la movilidad en la isla.
- El Ayuntamiento de Segovia ha implementado un gemelo digital que centraliza aplicaciones y datos geográficos de alto valor, permitiendo visualizar y analizar la ciudad en un entorno tridimensional interactivo. Mejora la gestión municipal y promueve la transparencia y la participación ciudadana.
- El Ayuntamiento de Vila-real ha lanzado una aplicación digital que integra transporte público, aparcamientos y puntos turísticos en tiempo real. El proyecto busca optimizar la movilidad urbana y fomentar la sostenibilidad mediante tecnología inteligente.
- El Ayuntamiento de Sant Boi ha lanzado un mapa interactivo elaborado con datos abiertos que centraliza información sobre transporte urbano, aparcamiento y opciones sostenibles en una única plataforma, con el fin de mejorar la movilidad urbana.
- Se ha inaugurado la Red Internacional de Investigación DataActive, una iniciativa financiada por el Consejo Superior de Deportes que busca impulsar el diseño de entornos urbanos activos mediante el uso de datos abiertos.
No solo los organismos públicos reutilizan los datos abiertos, desde las universidades también se trabaja en proyectos ligados a la innovación digital basados en información pública:
- Estudiantes de la Universitat de València han diseñado proyectos que utilizan IA y datos abiertos para prevenir desastres naturales.
- Investigadores de la Universidad de Castilla-La Mancha han demostrado que es viable reutilizar modelos de predicción de calidad del aire en distintas zonas de Madrid usando transfer learning.
Además de soluciones, los datos abiertos también sirven para dar forma a otros tipos de productos, incluso esculturas. Es el caso de “El esqueleto del cambio climático”, una figura que presentó el Museo Nacional de Ciencias Naturales, basada en datos sobre los cambios en la temperatura global desde 1880 hasta 2024.
Nuevos portales y funcionalidades para extraer valor de los datos
Las soluciones e innovaciones comentadas anteriormente son posibles gracias a la existencia de múltiples plataformas de apertura o compartición de datos que no dejan de incorporar nuevos conjuntos de datos y funcionalidades para extraerles valor. Algunas de las novedades que hemos visto a este respecto en los últimos meses son:
- El Observatorio Nacional de Tecnología y Sociedad (ONTSI) ha lanzado una nueva web. Una de sus novedades es Ontsi Data, una herramienta para elaborar informes con indicadores tanto de su portal como de terceros.
- El Consejo General del Notariado ha lanzado un Portal Estadístico de la Vivienda, una herramienta abierta con datos fiables y actualizados sobre el mercado inmobiliario en España.
- La Agencia Española de Seguridad Alimentaria y Nutrición (AESAN) ha inaugurado en su web un espacio de datos abiertos con microdatos sobre la composición de alimentos y bebidas comercializados en España.
- El Centro de Investigaciones Sociológicas (CIS) estrenó una web renovada, adaptada a cualquier dispositivo y con un buscador más potente para facilitar el acceso a sus estudios y datos.
- El Instituto Geográfico Nacional (IGN) ha presentado una nueva web del SIOSE, el Sistema de Información sobre Ocupación del Suelo de España, con un diseño más moderno, intuitivo y dinámico. Además, ha puesto a disposición de la ciudadanía una nueva versión de la Información Geográfica de Referencia de Redes de Transporte (IGR-RT), segmentada por provincias y modos de transporte, y disponible en Shapefile y GeoPackage.
- La Plataforma de Asesores AKIS, impulsada por el Ministerio de Agricultura, Pesca y Alimentación, ha puesto en marcha una nueva API de datos abiertos que permite a los usuarios registrados descargar y reutilizar contenidos relacionados con el sector agroalimentario en España.
- La Generalitat de Catalunya estrenó nueva web corporativa que centraliza aspectos clave sobre fondos europeos, contratación pública, transparencia y datos abiertos en un único punto. También ha lanzado una web donde recoge información sobre los sistemas de IA que utiliza.
- PortCastelló ha publicado sus Memorias 2024 en formato open data. Toda la gestión, tráficos, infraestructuras y datos económicos del puerto ahora son accesibles y reutilizables por cualquier ciudadano.
- Investigadores de la Universitat Oberta de Catalunya y del Instituto de Ciencias Fotónicas han creado una biblioteca abierta con datos de 140 biomoléculas. Un recurso pionero que impulsa la ciencia abierta y el uso de datos abiertos en biomedicina.
- También se presentó CitriData, un espacio federado de datos, modelos y servicios en la cadena de valor de los cítricos andaluces. Su objetivo es transformar el sector mediante el uso inteligente y colaborativo de los datos.
Otros organismos están inmersos en el desarrollo de sus novedades. Por ejemplo, próximamente veremos el nuevo Portal de Datos Abiertos de Aguas de Alicante, que permitirá un acceso público a información clave sobre la gestión del agua, fomentando el desarrollo de soluciones basadas en Big Data e IA.
Estos meses también se han presentado avances estratégicos ligados a mejorar la calidad y el uso de los datos, como el Modelo de Gobierno del Dato de la Generalitat Valenciana o la Hoja de Ruta para la Estrategia Provincial de inteligencia artificial de la diputación de Castellón.
Datos.gob.es también presentó una nueva plataforma dirigida a para optimizar tanto la publicación como el acceso a los datos. Si quieres conocer esta y otras novedades de la Iniciativa Aporta en el año 2025, te invitamos a leer este post.
Fomentando el uso de los datos a través de eventos, recursos y acciones ciudadanas
La segunda mitad del año 2025 fue la época elegida por gran cantidad de organismos públicos para lanzar concursos dirigidos a impulsar la reutilización de los datos que publican. Fue el caso de la Junta de Castilla y León, el Ayuntamiento Madrid, el Ayuntamiento de Valencia o la Diputación Foral de Bizkaia. También se ha participado desde nuestro país en eventos internacionales como el Desafío NASA Space Apps.
Entre los eventos donde se ha aprovecho para difundir el poder de los datos abiertos, destacan la Cumbre Global de Open Government Partnership (OGP), las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE), el Congreso Internacional de Transparencia y Gobierno Abierto o la 17ª Conferencia Internacional sobre Reutilización de la Información del Sector Público de ASEDIE, aunque hubo muchos más.
También se ha trabajado en informes que ponen de manifiesto el impacto de los datos en sectores concretos, como el Informe Cátedra DATAGRI 2025 de la Universidad de Córdoba, centrado en el sector agroalimentario. Otros documentos publicados buscan ayudar a mejorar la gestión de los datos, como “Fundamentos del Gobierno del Dato en el contexto de los espacios de datos", liderado por DAMA España, en colaboración con Gaia-X España.
La participación ciudadana también es fundamental para el éxito de la innovación basada en datos. En este sentido, hemos visto tanto actividades dirigidas a impulsar la publicación de datos como a mejorar los ya publicados o su reutilización:
- Desde la Iniciativa Barcelona Open Data se solicitó la ayuda ciudadana para elaborar un ranking de soluciones digitales basadas en datos abiertos para promover el envejecimiento saludable. También organizaron una actividad participativa para mejorar la app iCuida, dirigida a trabajadores del hogar y cuidados. Esta app permite buscar lavabos públicos, refugios climáticos y otros puntos de interés para el día a día de las cuidadoras.
- La Agencia Espacial Española lanzó una encuesta para conocer necesidades y usos de imágenes y datos de Observación de la Tierra en el marco de proyectos estratégicos como la Constelación Atlántica.
En conclusión, las actividades realizadas en el segundo semestre de 2025 ponen de manifiesto la consolidación del ecosistema de datos abiertos en España como un motor de innovación, transparencia y participación ciudadana. Los avances normativos y estratégicos, junto con la creación de nuevas plataformas y soluciones basadas en datos, muestran un compromiso firme por parte de las instituciones y la sociedad en aprovechar la información pública como recurso clave para el desarrollo sostenible, la mejora de servicios y la generación de conocimiento.
Como siempre, este artículo es solo una pequeña muestra de las actividades realizadas. Te invitamos a compartir otras actividades que conozcas a través de los comentarios.
Blog
Los datos abiertos son una pieza central de la innovación digital en torno a la inteligencia artificial ya que permiten, entre otras cosas, entrenar modelos o evaluar algoritmos de aprendizaje automático. Pero entre “descargar un CSV de un portal” y acceder a un conjunto de datos listo para aplicar técnicas de aprendizaje automático hay, todavía, un abismo.
Buena parte de ese abismo tiene que ver con los metadatos, es decir cómo se describen los conjuntos de datos (a qué nivel de detalle y con qué estándares). Si los metadatos se limitan a título, descripción y licencia, el trabajo de comprensión y preparación de datos se hace más complejo y tedioso para la persona que diseña el modelo de aprendizaje automático. Si, en cambio, se usan estándares que faciliten la interoperabilidad, como DCAT, los datos se vuelven más FAIR (Findable, Accessible, Interoperable, Reusable) y, por tanto, más fáciles de reutilizar. No obstante, es necesario metadatos adicionales para que los datos sean más fáciles de integrar en flujos de aprendizaje automático.
Este artículo realiza un itinerario por las diversas iniciativas y estándares necesarios para dotar a los datos abiertos de metadatos útiles para la aplicación de técnicas de aprendizaje automático.
DCAT como columna vertebral de los portales de datos abiertos
El vocabulario DCAT (Data Catalog Vocabulary) fue diseñado por la W3C para facilitar la interoperabilidad entre catálogos de datos publicados en la Web. Describe catálogos, conjuntos de datos y distribuciones, siendo la base sobre la que se construyen muchos portales de datos abiertos.
En Europa, DCAT se concreta en el perfil de aplicación DCAT-AP, recomendado por la Comisión Europea y ampliamente adoptado para describir conjuntos de datos en el sector público, por ejemplo, en España con DCAT-AP-ES. Con DCAT-AP se responde a preguntas como:
- ¿Qué conjuntos de datos existen sobre un tema concreto?
- ¿Quién los publica, bajo qué licencia y en qué formatos?
- ¿Dónde están las URL de descarga o las API de acceso?
El uso de un estándar como DCAT es imprescindible para descubrir conjuntos de datos, pero es necesario ir un paso más allá con el fin de saber cómo se utilizan en modelos de aprendizaje automático o qué calidad tienen desde la perspectiva de estos modelos.
MLDCAT-AP: aprendizaje automático en el catálogo de un portal de datos abiertos
MLDCAT-AP (Machine Learning DCAT-AP) es un perfil de aplicación de DCAT desarrollado por SEMIC y la comunidad Interoperable Europe, en colaboración con OpenML, que extiende DCAT-AP al dominio del aprendizaje automático.
MLDCAT-AP incorpora clases y propiedades para describir:
- Modelos de aprendizaje automático y sus características.
- Conjuntos de datos utilizados en el entrenamiento y la evaluación.
- Métricas de calidad obtenidas sobre los conjuntos de datos.
- Publicaciones y documentación asociadas a los modelos de aprendizaje automático.
- Conceptos relacionados con riesgo, transparencia y cumplimiento del contexto regulatorio europeo del AI Act.
Con ello, un catálogo basado en MLDCAT-AP ya no solo responde a “qué datos hay”, sino también a:
- ¿Qué modelos se han entrenado con este conjunto de datos?
- ¿Cuál ha sido el rendimiento de ese modelo según determinadas métricas?
- ¿Dónde se describe este trabajo (artículos científicos, documentación, etc.)?
MLDCAT-AP representa un gran avance en trazabilidad y gobernanza, pero se mantiene la definición de metadatos a un nivel que todavía no considera la estructura interna de los conjuntos de datos ni qué significan exactamente sus campos. Para eso, se necesita bajar a nivel de la propia estructura de la distribución de conjunto de datos.
Metadatos a nivel de estructura interna del conjunto de datos
Cuando se quiere describir qué hay dentro de las distribuciones de los conjuntos de datos (campos, tipos, restricciones), una iniciativa interesante es Data Package, parte del ecosistema de Frictionless Data.
Un Data Package se define por un archivo JSON que describe un conjunto de datos. En este archivo se incluyen no sólo metadatos generales (como el nombre, título, descripción o licencia) y recursos (es decir, los ficheros de datos con su ruta o una URL de acceso a su correspondiente servicio), sino también se define un esquema con:
- Nombres de campos.
- Tipos de datos (integer, number, string, date, etc.).
- Restricciones, como rangos de valores válidos, claves primarias y ajenas, etc.
Desde la óptica del aprendizaje automático, esto se traduce en la posibilidad de realizar una validación estructural automática antes de usar los datos. Además, también permite una documentación precisa de la estructura interna de cada conjunto de datos y mayor facilidad para compartir y versionar conjuntos de datos.
En resumen, mientras que MLDCAT-AP indica qué conjuntos de datos existen y cómo encajan en el ámbito de modelos de aprendizaje automático, Data Package especifica exactamente “qué hay” dentro de los conjuntos de datos.
Croissant: metadatos que preparan datos abiertos para aprendizaje automático
Aun con el concurso de MLDCAT-AP y de Data Package, faltaría conectar los conceptos subyacentes en ambas iniciativas. Por una parte, el ámbito del aprendizaje automático (MLDCAT-AP) y por otro el de las estructuras internas de los propios datos (Data Package). Es decir, se puede estar usando los metadatos de MLDCAT-AP y de Data Package pero para solventar algunas limitaciones que adolecen ambos, es necesario complementarlo. Aquí entra en juego Croissant, un formato de metadatos para preparar los conjuntos de datos para la aplicación de aprendizaje automático. Croissant está desarrollado en el marco de MLCommons, con participación de industria y academia.
Específicamente, Croissant se implementa en JSON-LD y se construye sobre schema.org/Dataset, un vocabulario para describir conjuntos de datos en la Web. Croissant combina los siguientes metadatos:
- Metadatos generales del conjunto de datos.
- Descripción de recursos (archivos, tablas, etc.).
- Estructura de los datos.
- Capa semántica sobre aprendizaje automático (separación de datos de entrenamiento/validación/test, campos objetivo, etc.)
Cabe destacar que Croissant está diseñado para que distintos repositorios (como Kaggle, HuggingFace, etc.) puedan publicar conjuntos de datos en un formato que las librerías de aprendizaje automático (TensorFlow, PyTorch, etc.) puedan cargar de forma homogénea. También existe una extensión de CKAN para usar Croissant en portales de datos abiertos.
Otras iniciativas complementarias
Merece la pena mencionar brevemente otras iniciativas interesantes relacionadas con la posibilidad de disponer de metadatos que permitan preparar a los conjuntos de datos para la aplicación de aprendizaje automático (“ML-ready datasets”):
- schema.org/Dataset: usado en páginas web y repositorios para describir conjuntos de datos. Es la base sobre la que se apoya Croissant y está integrado, por ejemplo, en las directrices de datos estructurados de Google para mejorar la localización de conjuntos de datos en buscadores.
- CSV on the Web (CSVW): conjunto de recomendaciones del W3C para acompañar ficheros CSV con metadatos en JSON (incluyendo diccionarios de datos), muy alineado con las necesidades de documentación de datos tabulares que luego se usan en aprendizaje automático.
- Datasheets for Datasets y Dataset Cards: iniciativas que permiten desarrollar una documentación narrativa y estructurada para describir el contexto, la procedencia y las limitaciones de los conjuntos de datos. Estas iniciativas son ampliamente adoptadas en plataformas como Hugging Face.
Conclusiones
Existen diversas iniciativas que ayudan a realizar una definición de metadatos adecuada para el uso de aprendizaje automático con datos abiertos:
- DCAT-AP y MLDCAT-AP articulan el nivel de catálogo, modelos de aprendizaje automático y métricas.
- Data Package describe y valida la estructura y restricciones de los datos a nivel de recurso y campo.
- Croissant conecta estos metadatos con el flujo de aprendizaje automático, describiendo cómo los conjuntos de datos son ejemplos concretos para cada modelo.
- Iniciativas como CSVW o Dataset Cards complementan las anteriores y son ampliamente utilizadas en plataformas como HuggingFace.
Estas iniciativas pueden usarse de manera combinada. De hecho, si se adoptan de forma conjunta, se permite que los datos abiertos dejen de ser simplemente “ficheros descargables” y se conviertan en una materia prima preparada para el aprendizaje automático, reduciendo fricción, mejorando la calidad y aumentando la confianza en los sistemas de IA construidos sobre ellos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El año 2025 ha supuesto un nuevo impulso para la Iniciativa Aporta y datos.gob.es, consolidando su papel como motor de innovación y referencia en el ecosistema de los datos abiertos en España. A lo largo de estos meses hemos reforzado nuestro compromiso con la apertura de la información pública, ampliando recursos y mejorando la experiencia de quienes reutilizan los datos para generar conocimiento, soluciones y oportunidades.
A continuación, y como siempre que llega el fin de año, recogemos algunos de los avances realizados en estos últimos doce meses, junto con el impacto generado.
Continúa el impulso internacional
Durante este año hemos continuado fortaleciendo la posición internacional de España en materia de datos abiertos, participando en iniciativas y foros que promueven la transparencia y la reutilización de la información pública a nivel global. La colaboración con organismos internacionales y la alineación con estándares europeos han permitido que nuestro país siga siendo un referente en la materia, contribuyendo activamente a la construcción de un ecosistema de datos más sólido y compartido. Algunos puntos a destacar son:
- La adhesión de nuestro país a la Carta Internacional de Datos Abiertos durante la IX Cumbre Global de la Alianza para el Gobierno Abierto en Vitoria-Gasteiz. Con este compromiso, el Gobierno reconoció al dato como un activo estratégico para diseñar políticas públicas y mejorar los servicios, consolidando la transparencia y la innovación digital.
- El impulso de DCAT-AP-ES a través de la puesta en marcha de una comunidad en GitHub, con recursos que facilitan su implementación. Este nuevo modelo de metadatos adopta las directrices del esquema europeo de intercambio de metadatos DCAT-AP, mejorando la interoperabilidad.
- La presencia de España, un año más, entre los países prescriptores en materia de datos abiertos, de acuerdo con el informe Open Data Maturity 2025, elaborado por data.europa.eu. Nuestro país reforzó su liderazgo mediante el desarrollo de políticas estratégicas, la modernización técnica y la innovación impulsada por la reutilización.
Una nueva plataforma con más datos y recursos
Otro de los hitos más destacados ha sido el estreno de la nueva plataforma de datos.gob.es, diseñada para optimizar tanto la publicación como el acceso a los datos. Con un aspecto renovado y una arquitectura de la información más clara, hemos conseguido que la navegación sea más intuitiva y funcional, facilitando que cualquier usuario pueda encontrar y aprovechar la información que necesita de manera más sencilla y eficiente.
A ello hay que sumar el crecimiento en volumen y diversidad de datos publicados en la plataforma. En 2025 hemos alcanzado casi 100.000 conjuntos de datos disponibles para su reutilización, lo que supone un incremento del 9% respecto al año anterior. Entre ellos destacan más de 300 datasets de alto valor, es decir, pertenecientes a categorías “cuya reutilización está asociada a considerables beneficios para la sociedad, el medio ambiente y la economía” de acuerdo con la Unión Europea. Estos conjuntos de datos, fundamentales para proyectos estratégicos, multiplican las posibilidades de análisis y sirven de base para innovaciones tecnologías, por ejemplo, ligadas a la inteligencia artificial.
Pero la Iniciativa Aporta no se limita a ofrecer datos: también acompaña a la comunidad con contenidos que ayudan a comprender y sacar el máximo partido de esta información. Durante este año hemos publicado más de un centenar de artículos de actualidad y análisis, además de infografías, pódcasts y vídeos que acercan temáticas complejas de forma clara y accesible. Asimismo, hemos ampliado nuestras guías y ejercicios prácticos, incorporando nuevas temáticas como el uso de la inteligencia artificial en aplicaciones conversacionales.
La reutilización de datos se refleja también en el aumento de casos de uso y modelos de negocio. En 2025 se han identificado decenas de soluciones, aplicaciones y empresas innovadoras basados en datos abiertos. Estos ejemplos muestran cómo la apertura de la información pública se traduce en beneficios tangibles para la sociedad y la economía.
Una comunidad en constante crecimiento
La comunidad que nos acompaña continúa creciendo y consolidándose. En el caso de las redes sociales, destaca nuestra presencia en LinkedIn, donde llegamos a profesionales y expertos en datos que comparten e interactúan con nuestro contenido de forma constante. Actualmente superamos los 17.000 seguidores (un 23 % más que en 2024). También se ha consolidado la apuesta en Instagram, con un crecimiento del 95 % (400 seguidores). Nuestro perfil en esta red social se puso en marcha en 2024 y desde entonces no deja de crecer, atrayendo a seguidores interesados en las oportunidades que ofrece la reutilización de datos públicos y privados. Por su parte, la comunidad de X (antiguo Twitter) se ha mantenido estable, en 20.700 seguidores.
A ello se suma el boletín de datos.gob.es, que se ha rediseñado y ya cuenta con más de 4.000 suscriptores, un reflejo del interés creciente por mantenerse al día en el ámbito de los datos. También hemos reforzado nuestros canales de atención, respondiendo a numerosas consultas y peticiones de organismos y ciudadanos. En concreto, se han atendido cerca de 2.000 interacciones a través de los distintos canales de soporte a publicadores, consultas generales y dinamización.
Todo este esfuerzo se traduce en un crecimiento sostenido del portal: en 2025 datos.gob.es ha recibido cerca de dos millones de visitas, con más de tres millones y medio de páginas vistas y un aumento significativo en el tiempo de permanencia de los usuarios. Estas cifras confirman que cada vez más personas encuentran en los datos abiertos un recurso valioso para sus proyectos y actividades.
Gracias por acompañarnos
En resumen, el balance de 2025 refleja un año de avances, aprendizajes y logros compartidos. Nada de esto sería posible sin la colaboración de la comunidad de datos en España, que impulsa con su participación y creatividad el universo de los datos abiertos. En 2026 seguiremos trabajando juntos para que los datos continúen siendo una palanca de innovación, transparencia y progreso.
Puedes ver más sobre nuestra actividad en la siguiente infografía:

Noticia
España vuelve a destacar en el panorama europeo de datos abiertos. El informe Open Data Maturity 2025 sitúa a nuestro país entre los líderes en la apertura y reutilización de información del sector público, consolidando una trayectoria ascendente en innovación digital.
El informe, elaborado anualmente por el portal europeo de datos, data.europa.eu, evalúa el grado de madurez de los datos abiertos en Europa. Para ello analiza varios indicadores, agrupados en cuatro dimensiones: política, portal, calidad e impacto. En la edición de este año han participado 36 países, incluidos los 27 Estados miembros de la Unión Europea (EU), tres países de la Asociación Europea de Libre Comercio (Islandia, Noruega y Suiza) y seis países candidatos (Albania, Bosnia y Herzegovina, Montenegro, Macedonia del Norte, Serbia y Ucrania).
Este año, España se sitúa en quinta posición entre los países de la Unión Europea y sexta del total de países analizados, empatada con Italia. En concreto se ha obtenido una puntuación total de 95,6%, muy por encima de la media de los países analizados (81,1%). Con este dato, España mejora su puntuación con respecto a 2024, cuando obtuvo un 94,8%.
España, entre los líderes europeos
Con esta posición, España se sitúa un año más entre los países prescriptores en materia de datos abiertos (trendsetters), es decir, aquellos que marcan tendencia y sirven de ejemplo de buenas prácticas a otros Estados. España comparte grupo con Francia, Lituania, Polonia, Ucrania, Irlanda, la ya mencionada Italia, Eslovaquia, Chipre, Portugal, Estonia y República Checa.
Los países de este grupo cuentan con políticas avanzadas de datos abiertos, alineadas con los progresos técnicos y políticos de la Unión Europea, incluyendo la publicación de conjuntos de datos de alto valor. Además, existe una coordinación sólida de las iniciativas relacionadas con los datos abiertos en todos los niveles de la administración. Sus portales nacionales ofrecen funciones completas y metadatos de calidad, con escasas limitaciones en publicación o uso. Esto lleva a que los datos publicados se puedan reutilizar más fácilmente para múltiples fines, contribuyendo a generar un impacto positivo en distintos ámbitos.
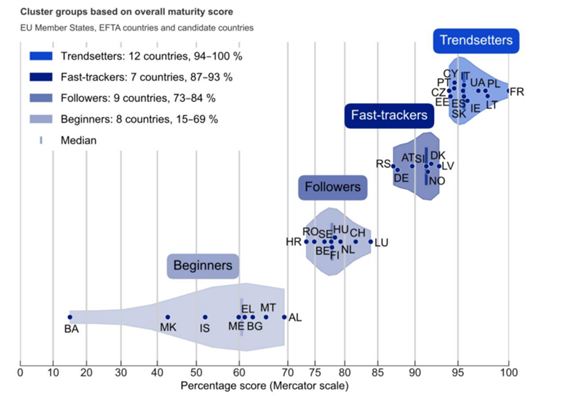
Figura 1. Países integrantes de los distintos clusters.
Las claves del avance de España
De acuerdo con el informe, España reforzó su liderazgo en materia de datos abiertos mediante el desarrollo de políticas estratégicas, la modernización técnica y la innovación impulsada por la reutilización. En concreto, las mejoras en el ámbito político son las que han impulsado el crecimiento de España:
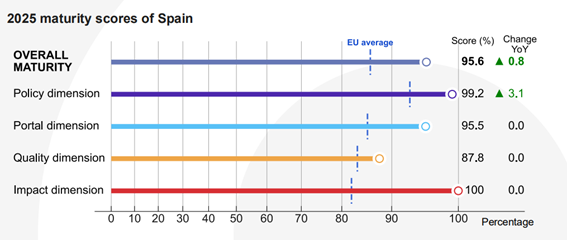
Figura 2. Puntuación de España en las distintas dimensiones junto con el crecimiento sobre el año anterior.
Tal y como se muestra en la imagen, la dimensión política ha alcanzado una puntuación de 99,2% frente al 96% del año pasado, destacando sobre la media europea que es del 93,1%. El motivo de este crecimiento es el avance en el marco normativo. En este sentido, el informe destaca la configuración del V Plan de Gobierno Abierto, desarrollado a través de un proceso de cocreación en el que participaron todos los grupos de interés. Este plan ha introducido nuevas iniciativas relacionadas con la gobernanza y la reutilización de datos abiertos. Otra cuestión destacada es que España impulsó la publicación de conjuntos de datos de alto valor, en consonancia con el Reglamento de Ejecución (UE) 2023/138.
El resto de dimensiones se mantienen estables, todas ellas con puntuaciones por encima de la media europea: en la dimensión portal se ha obtenido un 95,5% en comparación con el 85,45% europeo, mientras que la de calidad ha sido valorada con un 87,8% versus el 83.4% del resto de países analizados. El bloque de Impacto continúa siendo nuestra gran baza, con un 100% frente al 82.1% europeo. En esta dimensión continuamos posicionándonos como grandes líderes, gracias a una definición clara de reutilización, la medición sistemática del uso de datos y la existencia de ejemplos de impacto en los ámbitos gubernamental, social, ambiental y económico.
Aunque no se hayan producido grandes movimientos en la puntuación de estas dimensiones, el informe sí destaca hitos de España en todos los ámbitos. Por ejemplo, la plataforma datos.gob.es se sometió a un importante rediseño, que incluyó ajustes al perfil de metadatos DCAT-AP-ES, con el fin de mejorar la calidad e interoperabilidad. En este sentido, se publicó una guía de implementación específica y se consolidó una comunidad de aprendizaje y desarrollo a través de GitHub. Además, se mejoraron el motor de búsqueda y las herramientas de supervisión del portal, incluyendo el seguimiento de la reutilización externa a través de referencias de GitHub y análisis enriquecidos a través de cuadros de mando interactivos.
La implicación del sector infomediario ha sido clave a la hora de reforzar el liderazgo de España en datos abiertos. El informe destaca la importancia de actividades como el Encuentro Nacional de Datos Abiertos, con retos que se trabajan conjuntamente por parte de un equipo multidisciplinar con representantes de instituciones públicas, privadas y académicas, edición tras edición. A ello hay que sumar que la Federación Española de Municipios y Provincias identificó 80 conjuntos de datos esenciales en los que los gobiernos locales deben poner el foco a la hora de avanzar en la apertura de información, fomentando la coherencia y reutilización a nivel municipal.
La siguiente imagen muestra la puntuación específica de cada una de las subdimensiones analizadas:
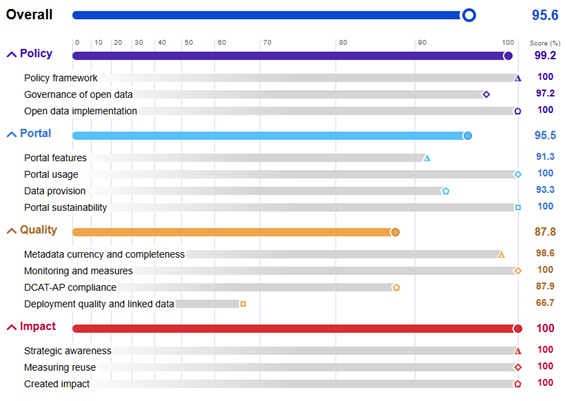
Figura 3. Puntuación de España en las distintas dimensiones y subcategorías.
Puedes ver el detalle del informe de España en la web del portal europeo.
Próximos pasos y retos comunes
El informe finaliza con una serie de recomendaciones concretas para cada grupo de países. Para el grupo de trendsetters, en el que se encuentra España, las recomendaciones no se centran tanto en alcanzar la madurez —ya lograda—, sino en profundizar y expandir su papel como referentes europeos. Algunas de las recomendaciones son:
- Consolidar ecosistemas temáticos (comunidades de proveedores y reutilizadores) y priorizar los datos de alto valor de forma sistemática.
- Alinear la acción local con la estrategia nacional, habilitando políticas “data-driven”.
- Cooperar con data.europa.eu y otros países para implementar y adaptar un marco de evaluación de impacto con métricas por dominios.
- Desarrollar perfiles de usuario y permitir sus contribuciones al portal nacional.
- Mejorar la calidad de datos y metadatos, y su localización, mediante herramientas de validación, inteligencia artificial y flujos centrados en el usuario.
- Aplicar estándares específicos de dominio para armonizar datasets y maximizar la interoperabilidad, calidad y reutilización.
- Ofrecer formación avanzada y certificada en normativa y alfabetización de datos.
- Colaborar internacionalmente en soluciones reutilizables, como software compartido u open source.
España ya trabaja en muchos de estos puntos para continuar mejorando su oferta de datos abiertos. El objetivo es que cada vez más reutilizadores puedan aprovechar de forma sencilla el potencial de la información pública para generar servicios y soluciones que generen un impacto positivo en toda la sociedad.
La posición alcanzada por España en este ranking europeo es fruto del trabajo de todas las iniciativas públicas, empresas, comunidades de usuarios y reutilizadores ligados a los datos abiertos, que impulsan un ecosistema que no deja de crecer. ¡Gracias por el esfuerzo!
Entrevista
En este pódcast hablamos de los datos de transporte y movilidad, un tema muy presente en nuestro día a día. Cada vez que consultamos una aplicación para saber cuánto tardará un autobús, estamos aprovechando los datos abiertos ligados al transporte. De la misma forma, cuando una administración realiza una planificación urbanística u optimiza flujos de tráfico, hace uso de datos de movilidad.
Para profundizar en los retos y oportunidades que hay detrás de la apertura de este tipo de datos por parte de las administraciones públicas españolas, contamos con dos invitadas de excepción:
- Tania Gullón Muñoz-Repiso, directora de la División de Estudios y Tecnología del Transporte del Ministerio de Transportes y Movilidad Sostenible. ¡Bienvenida, Tania!
- Alicia González Jiménez, subdirectora adjunta en la Subdirección General de Cartografía y Observación del Territorio del Instituto Geográfico Nacional. ¡Bienvenida, Alicia!
Resumen / Transcripción de la entrevista
1. Tanto el IGN como el Ministerio generan gran cantidad de datos relacionados con el transporte. De todos ellos, ¿nos podéis indicar qué datos y servicios se ponen a disposición de la ciudadanía como datos abiertos?
Alicia González: Por parte del Instituto Geográfico Nacional diría que todo, todo lo que producimos está a disposición de los usuarios, porque desde finales de 2015 la política de difusión que adoptó la Dirección General del Instituto Geográfico Nacional, a través del Organismo Autónomo Centro Nacional de Información Geográfica (CNIG), que es por donde se distribuyen todos los productos y servicios, es una política de datos abiertos, de forma que todo se distribuye bajo la licencia CCC BY 4.0, que ampara el uso libre y gratuito. Simplemente hay que hacer una atribución, una mención del origen de los datos. Entonces estamos hablando, en general, no solamente de transporte, sino de todo tipo de datos, de más de 100 productos que suponen más de dos millones y medio de ficheros que los usuarios demandan cada vez más. De hecho, en 2024 hemos llegado a tener hasta 20 millones de ficheros descargados, o sea que es muy demandada. Y concretamente en materia de redes de transporte, el conjunto fundamental de datos es la Información Geográfica de Referencia de Redes de Transportes (IGR-RT). Se trata de un conjunto de datos geoespacial multimodal que está compuesto por cinco redes de transporte que están continuas por todo el territorio nacional y además interconectadas. En concreto, contempla:
1. La red viaria que se compone de toda la red de carreteras, independientemente de su titular y que discurre por todo el territorio. Son más de 300 mil kilómetros de carretera que están además conectados a todos los callejeros, a la red viaria urbana de todos los núcleos de población. Es decir, tenemos un grafo viario que vertebra todo el territorio, , además de tener conectados los caminos que luego posteriormente se distribuyen y se difunden en el Mapa Topográfico Nacional.
2. La segunda red de mayor relevancia es la red de transporte por raíl. Contempla todos los datos de transporte ferroviario y además también de metro, tranvía y otros tipos de modos por rail.
3 y 4. En el ámbito marítimo y aéreo, las redes ya se limitan a lo que son las infraestructuras, de forma que contiene todos los puertos de la costa española y todas las infraestructuras de aeródromos, aeropuertos, helipuertos en la parte de aéreo.
5. Y por último, la última red, que es mucho más modesta, son datos de carácter residual: el transporte por cable.
Está todo interconectado mediante relaciones de intermodalidad. Es un conjunto de datos que se genera a partir de fuentes oficiales. No podemos incorporar cualquier dato, tienen que ser siempre datos oficiales y se genera en el marco de cooperación del Sistema Cartográfico Nacional.
Al ser un conjunto de datos que es conforme con la Directiva INSPIRE tanto en su definición como en la forma por la que se difunde a través de servicios web estándar, también ha sido clasificado como un conjunto de datos de alto valor en la categoría de movilidad, conforme al Reglamento de ejecución de los datos de alto valor. Es un conjunto bastante importante y normalizado.
¿Cómo se puede localizar y acceder? Precisamente, al ser estándar, está catalogado en el catálogo de la IDE (Infraestructura de Datos espaciales), gracias a la descripción estándar de sus metadatos. También se puede localizar a través del catálogo oficial de datos y servicios INSPIRE (Servicios de Publicación de Información) o está accesible a través de portales tan relevantes como el portal de datos abiertos.
Una vez que lo tenemos localizado, ¿cómo puede acceder el usuario? ¿Cómo puede ver los datos? Hay varias vías. La más sencilla: consultar su visualizador. Ahí se muestran todos los datos y hay ciertas herramientas de consulta para facilitar su uso. Y después, por supuesto, a través del centro de descargas del CNIG. Ahí publicamos todos los datos de todas las redes y tiene gran demanda. Y luego la última vía es consultar los servicios web estándar que generamos, servicios de visualización y de descargas de distintas tecnologías. O sea que es un conjunto de datos que está a disposición de los usuarios para su reutilización.
Tania Gullón: En el Ministerio también compartimos muchos datos en abierto. A mí me gustaría, para no alargarnos mucho, comentar en especial cuatro grandes conjuntos de datos:
1. El primero sería el OTLE, el Observatorio del Transporte y la Logística en España, que es una iniciativa del Ministerio de Transportes, cuyo objetivo principal es proporcionar una visión global e integral de la situación del transporte y la logística en España. Se organiza en siete bloques: movilidad, socioeconomía, infraestructura, seguridad, sostenibilidad, transporte metropolitano y logística. Estos no son datos georreferenciados, sino que son datos estadísticos. El Observatorio pone a disposición del público datos, gráficos, mapas, indicadores y, no solo eso, sino que también ofrece informes anuales, monográficos, jornadas, etcétera. Y también de los observatorios que tenemos transfronterizos, que se hacen de forma colaborativa con Portugal y con Francia.
2. El segundo conjunto de datos que quiero mencionar es el NAP, el Punto de Acceso Nacional de Transporte Multimodal, que es una plataforma digital oficial gestionada por el Ministerio de Transportes, pero que se elabora de forma colaborativa entre las diferentes administraciones. Su objetivo es centralizar y publicar toda la información digitalizada sobre la oferta de transportes de viajeros en el territorio nacional de todos los modos de transporte. ¿Qué tenemos aquí? Todos los horarios, servicios, rutas, paradas de todos los servicios de transporte, del transporte por carretera, de los autobuses urbanos, interurbanos, rurales, discrecionales a demanda. Hay 116 conjuntos de datos. El de transporte ferroviario, los horarios de todos esos trenes, sus paradas, etcétera. También del transporte marítimo y del transporte aéreo. Y estos datos se van actualizando permanentemente en tiempo real. A día de hoy disponemos solo de los datos estáticos en formato GTFS (General Transit Feed Specification), también reutilizables y en un formato estándar útiles para el desarrollo posterior de aplicaciones de movilidad por los reutilizadores. Y aunque inicialmente este NAP se centró en datos estáticos, como esas rutas, horarios y paradas, se está avanzando hacia la incorporación también de datos dinámicos. De hecho, en diciembre ya tenemos además una obligación por una normativa europea que nos obliga a tener esos datos en tiempo real para, al final, mejorar toda esa planificación de transportes y la experiencia de usuario.
3. El tercer conjunto de datos es Hermes. Es el sistema de información geográfico de la red de transportes de interés general. ¿Cuál es su objetivo? Ofrecer una visión integral, en este caso georreferenciada. Aquí quiero hacer referencia a lo que ha comentado mi compañera Alicia, para que veáis cómo todos vamos colaborando unos con otros. No inventamos nada, sino que todo está proyectado sobre esos ejes de los viales, por ejemplo, de RT, la información geográfica de referencia de la red de transporte. Y lo que se hace es añadir todos esos parámetros técnicos, como un valor añadido para tener un sistema de información completo, integral, multimodal, de carreteras, ferrocarriles, puertos, aeropuertos, terminales ferroviarias y también vías navegables. Es un GIS (Sistema de Información Geográfica), con lo cual permite todo ese análisis, no solo descarga, consulta, con esos servicios web que ponemos al servicio de la ciudadanía en abierto, también en un catálogo de datos abiertos hecho con CKAN, que luego comentaré. Bueno, al final son más de 300 parámetros consultables. ¿De qué estamos hablando? Sobre cada tramo de carretera, se conoce la intensidad media de tráfico, la velocidad media, la capacidad de las infraestructuras, actuaciones planificadas también -no solo la red en servicio, sino también la red planificada, las actuaciones que tiene previstas hacer el Ministerio-, las titularidades de la vía, las longitudes, velocidades, accidentes... bueno, muchísimos parámetros, modos de acceso, proyectos cofinanciados, temas de combustibles alternativos, la red transeuropea de transportes, etcétera. Ese es el tercero de los conjuntos de datos.
4. El cuarto conjunto quizá es el más voluminoso porque son 16 GB al día. Es el proyecto que le llamamos Big Data Movilidad. Este proyecto es una iniciativa pionera que utiliza tecnologías Big Data y de inteligencia artificial para analizar en profundidad los patrones de movilidad en el país se basa principalmente en el análisis de los registros anonimizados de telefonía móvil de la población para obtener información detallada sobre todos los desplazamientos de las personas no individualizados, sino agregados a nivel de distrito censal. Desde 2020 se realiza un estudio diario de movilidad y se dan todos estos datos en abierto. Eso es la movilidad por horas, por origen / destino que nos permite monitorizar y evaluar la demanda de transportes para planificar mejoras en esas infraestructuras y servicios. Además, como se dan los datos en abierto, se puede utilizar para cualquier fin, para fines turísticos, para investigaciones…
2. ¿Cómo se generan y recopilan estos datos? ¿A qué retos hay que hacer frente en este proceso y cómo los solventáis?
Alicia González: Concretamente, en el ámbito de los productos que se generan tecnológicamente en entornos de sistema de información geográfica y bases de datos geoespaciales, al final se trata de proyectos en los que la base fundamental es la captura de datos y la integración de fuentes de referencia existentes. Cuando vemos que el titular tiene un dato, ese es el que hay que integrar. De una forma resumida, en los trabajos técnicos principales, se podrían identificar:
- Por un lado, la captura, es decir, cuando queremos almacenar un objeto geográfico hay que digitalizarlo, dibujarlo. ¿Sobre dónde? Sobre una base métrica adecuada como son las ortofotografías aéreas del Plan Nacional de Ortofotografía Aérea (PNOA), que también es otro conjunto de datos que está disponible y abierto. Bueno, nosotros cuando tenemos, por ejemplo, que dibujar o digitalizar una carretera, vamos trazándolo sobre esa imagen aérea que nos proporciona PNOA.
- Una vez que tenemos capturada esa componente geométrica, hay que dotarle de una atribución y no vale cualquier dato, tienen que ser fuentes oficiales. Entonces, tenemos que localizar quién es el titular de esa infraestructura o quién es el proveedor del dato oficial para detectar cuáles son los atributos, la caracterización que queremos darle a esa información, que en principio era solamente geométrica. Para eso hay que hacer una serie de procesos de validación de la fuente, detectar que no tiene incidencias y unos procesos que llamamos de integración, que son bastante complejos para garantizar que el resultado cumple lo que queremos.
- Y, por último, una fase fundamental en todos estos proyectos es el aseguramiento de la calidad geométrica y semántica. Es decir, hay que desarrollar y ejecutar una serie de controles de calidad que permitan validar el producto, el resultado final de esa integración y confirmar que cumple con los requisitos indicados en la especificación de producto.
En cuanto a retos, un desafío fundamental es la gobernanza de los datos, es decir, el resultado que se genera se alimenta de ciertas fuentes, pero al final se crea el resultado. Luego hay que definir bien el rol de cada proveedor que después quizá posteriormente sea usuario. Otro desafío en todo este proceso es la localización de proveedores de datos. A veces el responsable de esa infraestructura o del objeto que queramos almacenar en base de datos no publica la información de una forma estandarizada o es difícilmente localizable porque no está en un catálogo. A veces es complicado localizar la fuente oficial que necesitas para completar la información geográfica. Y ya mirando un poco al usuario, yo resaltaría que otro reto es el identificar, el tener la agilidad para identificar de una forma flexible y rápida los casos de uso que van cambiando con los usuarios, que nos van demandando, porque al final se trata de continuar siendo relevantes para la sociedad. Por finalizar, y porque el Instituto Geográfico es un entorno científico técnico y esta parte nos afecta mucho, otro desafío es la transformación digital, es decir, estamos trabajando en proyectos tecnológicos, luego tenemos que tener también bastante capacidad de gestión del cambio y adaptarnos a las nuevas tecnologías.
Tania Gullón: Respecto a cómo se generan y recopilan los datos y los retos que enfrentamos, por ejemplo, el NAP, del Punto de Acceso Nacional de Transporte multimodal, es una generación colaborativa, es decir, aquí los datos provienen de las propias comunidades autónomas, de los consorcios y de las empresas de transporte. El reto es que hay muchas comunidades autónomas que todavía no están digitalizadas, son muchas empresas… La digitalización del sector va lenta -va, pero va lenta-. Al final hay datos incompletos, datos duplicados. No está todavía bien definida la gobernanza. Nos pasa que, imaginaros, la empresa ALSA sube todos sus autobuses, pero tiene autobuses en todas las comunidades autónomas. Y si a la vez la comunidad autónoma sube sus datos, esos datos están duplicados. Es tan sencillo como eso. Es verdad que estamos empezando y todavía no está bien definida esa gobernanza, para que no sobren datos. Antes faltaban y ahora casi sobran.
En Hermes, el sistema de información geográfico, lo que se hace, como he dicho, es proyectarlo sobre la información de las redes de transporte, que es la oficial que ha comentado Alicia, y se integran datos de los diferentes gestores y administradores de infraestructuras, como son Adif, Puertos del Estado, AENA, la Dirección General de Carreteras, ENAIRE, etcétera. ¿Cuál es el principal reto - si tuviera que destacar, porque de esto nos podemos tirar hablando una hora-? Nos ha costado mucho, llevamos siete años con este proyecto y ha costado mucho porque, primero, la gente no se lo creía. No creían que iba a funcionar y no colaboraban. Al final todo esto es llamar a la puerta de Adif, de AENA y cambiar esa conciencia en la que los datos no pueden estar en un cajón, sino que hay que ponerlos todos al servicio del bien común. Y yo creo que eso es lo que nos ha costado un poco más. Además, está el tema de la gobernanza, que ya lo ha comentado Alicia. Vas a pedir un dato y en la propia organización no saben bien quién es el propietario de ese dato, porque quizá el dato de tráfico lo manejan diferentes departamentos. ¿Y quién es el propietario? Todo esto es muy importante.
Hemos de decir que justo Hermes ha sido el gran impulsor de las oficinas del Dato, de la oficina del Dato de Adif. Al final se han ido dando cuenta de que lo que necesitaban era poner orden en su casa, igual que en la casa de todos y en el Ministerio también, que se necesitan oficinas del Dato.
En el proyecto Big Data, ¿cómo se generan los datos? En este caso es completamente diferente. Es un proyecto pionero, más de nuevas tecnologías, en el que los datos se generan a partir de los registros anonimizados de telefonía móvil. Entonces, mediante la reconstrucción de toda esa gran cantidad de datos de Big Data, de los registros que hay en cada antena de España, con inteligencia artificial y con una serie de algoritmos, se reconstruyen y se hacen esas matrices. Luego, esos datos de esa muestra – al final tenemos una muestra de un 30 % de la población, de más de 13 millones de líneas móviles- se extrapola con datos abiertos del INE. Y luego, ¿qué hacemos también? Se calibra con fuentes externas, es decir, con fuentes de referencia cierta, como puede ser el billetaje de AENA, de los vuelos, los datos de Renfe, etc. Vamos calibrando ese modelo para poder generar esas matrices con calidad. Los retos: que es muy experimental. Para que os hagáis una idea, somos el único país que tiene todos estos datos. Entonces hemos ido abriendo brecha y aprendiendo por el camino. La dificultad es, otra vez, los datos. Esos datos para calibrar, nos cuesta Dios y ayuda encontrarlos y que nos los den con una periodicidad determinada y demás, porque esto va en tiempo real y necesitamos permanentemente ese flujo de datos. También la adaptación al usuario, que lo ha dicho Alicia. Nos debemos adaptar a lo que va demandando la sociedad y los reutilizadores de este Big Data. E irnos acompasando también, como ha dicho Alicia, a la tecnología, que no es lo mismo el dato de telefonía que hay ahora que el que había hace dos años. Y el gran reto del control de calidad. Pero bueno, aquí yo creo que le voy a dejar a Alicia, que es la súper experta, que nos explique qué mecanismos existen para garantizar que los datos sean fiables y actualizados y comparables. Y luego yo os doy mi visión, si te parece.
Alicia González: ¿Cómo se puede garantizar la fiabilidad, actualización y comparación? La fiabilidad no sé si se puede garantizar, pero creo que puede haber un par de indicadores que son especialmente relevantes. Uno, es el grado de conformidad de un conjunto de datos a la normativa que le atañe. En el ámbito de la información geográfica, la forma de trabajar es siempre normalizada, es decir, hay una familia de ISO 19100 de Información Geográfica/Geomática o la propia Directiva INSPIRE, que condiciona mucho la forma de trabajar y de publicar los datos. Y también, mirando en la administración pública, creo que el marchamo de oficialidad también debería de ser un garante de fiabilidad. Es decir, nosotros cuando tratamos los datos debemos hacerlo de una forma homogénea y sin sesgos, mientras que quizá, a lo mejor, una empresa privada pueda estar condicionada por ellos. Creo que esos dos parámetros son importantes, que pueden indicar fiabilidad.
En cuanto a grado de actualización y comparación de los datos, creo que esa información el usuario la deduce de los metadatos. Los metadatos al final son la carta de presentación de los conjuntos de datos. Entonces, si un conjunto de datos está correctamente y de forma veraz metadatado y además está hecho conforme a perfiles estándar -igual en el ámbito GEO, pues hablamos del perfil INPIRE o GeoDCAT-AP- , si distintos conjuntos de datos están definidos en sus metadatos conforme a estos perfiles normalizados, es mucho más fácil ver si son comparables y el usuario puede determinar y decidir si finalmente satisface sus requisitos de actualización y de comparabilidad con otro conjunto de datos.
Tania Gullón: Totalmente Alicia. Y si me permites complementar, nosotros, por ejemplo, en el Big Data hemos estado siempre muy empeñados en medir la calidad -más justo cuando son nuevas tecnologías que, al principio, la gente no se fiaba de qué resultados salen de todo esto-. Siempre intentando medir esta calidad - que, en este caso, es muy difícil porque son grandes conjuntos de datos-, desde el principio empezamos a diseñar unos procesos que tardan. Tarda siete horas el proceso de control de calidad diario de los datos, pero es verdad que al principio teníamos que detectar si se había caído alguna antena, si había ocurrido alguna cosa… Entonces hacemos un control con parámetros estadísticos y demás de consistencia interna y lo que detectamos aquí son las anomalías. Lo que estamos viendo es que el 90 % de las anomalías que salen son anomalías reales de movilidad. O sea, no ocurren errores en los datos, sino que son anomalías: ha habido una manifestación o ha habido un partido de fútbol. Son temas que distorsionan la movilidad. O ha habido una tormenta o una lluvia o cualquier cosa de estas. Y es importante no solo controlar esa calidad y ver si hay anomalías, sino que también creemos que es muy importante publicar esos criterios de calidad: el cómo estamos midiendo la calidad y sobre todo los resultados. Diariamente no solo damos el dato, sino que damos este metadato, que dice Alicia, de calidad, de cómo era la muestra ese día, de esos valores que se han obtenido de anomalías. Esto se da también en abierto: no solo el dato, sino el metadato. Y luego también publicamos las anomalías y el porqué de esos errores. Cuando se encuentran errores decimos “vale, es que ha habido una anomalía porque en el pueblo - no sé qué imaginaros, es toda España – del Casar era la fiesta de la torta del Casar”. Y ya está, se ha encontrado la anomalía y se publica.
¿Y cómo se mide otro parámetro de calidad: la exactitud temática? En este caso, comparando con fuentes de referencia cierta. Sabemos que la evolución respecto a sí mismo ya está muy controlada con esa consistencia lógica interna, pero también hay que compararlo con lo que ocurre en el mundo real. Lo hablaba antes con Alicia, decíamos “los datos son fiables, pero ¿cuál es la realidad de la movilidad? ¿Quién la conoce?” Al final tenemos algunas pistas, como en los billetajes de cuántos se han subido a los autobuses. Si tenemos ese dato, tenemos una pista, pero de la gente que va andando y de la gente que coge su coche y demás ¿cuál es la realidad? Es muy difícil tener un punto de comparación, pero sí que comparamos con todos los datos de AENA, de Renfe, de las concesiones de autobuses y se pasan todos esos controles para determinar cuánto nos desviamos de esa realidad que podemos conocer.
3. Todos estos datos sirven de base para desarrollar aplicaciones y soluciones, pero también son fundamentales a la hora de tomar decisiones y acelerar la implementación de los ejes centrales, por ejemplo, de la Estrategia de Movilidad Segura, Sostenible y Conectada o del Proyecto de Ley de Movilidad Sostenible. ¿Cómo se usan estos datos para tomar estas decisiones reales?
Tania Gullón: Si me permites, primero quiero hacer una introducción a esta estrategia y a la Ley en torno al dato para los que no lo conozcan. Uno de los ejes, el eje 5 de la Estrategia de Movilidad Segura Sostenible y Conectada 2030 del Ministerio es el de “Movilidad inteligente”. Y justo está centrado en esto y tiene como objetivo principal impulsar la digitalización, innovación y el uso de tecnologías avanzadas para mejorar esa eficiencia, sostenibilidad y experiencia de usuario en el sistema de transportes de España. Y justo una de las medidas de ese eje es la “facilitación de la Movilidad como Servicio (Mobility as a Service), Datos Abiertos y Nuevas Tecnologías”. O sea que justo aquí es donde se enmarcan todos estos proyectos que estamos comentando. De hecho, una submedida es impulsar la publicación de datos abiertos de movilidad, otra es el realizar análisis de flujos de movilidad y otra de las medidas, la última, es la creación de un espacio de datos integrado de movilidad. Me gustaría destacar -y aquí ya entronco con ese Proyecto de Ley que esperemos que pronto lo veamos aprobado- que la Ley, en el artículo 89 regula el Punto de Acceso Nacional, que también vemos cómo está metido en este instrumento legislativo. Y luego la Ley establece un instrumento digital clave para el Sistema Nacional de Movilidad Sostenible: fijaros la importancia que se la da al dato que en una ley de movilidad se ponga por escrito que este espacio de datos integrado de movilidad es un instrumento digital clave. Este espacio de datos es un ecosistema de compartición de datos confiable, materializado como la infraestructura digital gestionada por el Ministerio de Transportes y en coordinación con la SEDIA (la Secretaría de Estado de Digitalización e Inteligencia Artificial), cuyo objetivo es centralizar y estructurar la información sobre movilidad generada por administraciones públicas, operadores de transporte, gestores de infraestructuras, etc. y garantizar ese acceso abierto a todos estos datos para todas las administraciones bajo condiciones reglamentarias.
Alicia González: Yo en este caso quiero decir que cualquier toma de decisiones objetiva, por supuesto, se tiene que hacer a partir de datos que, como decíamos antes, tienen que ser fiables, actualizados y comparables. En este sentido, indicar que el IGN, el soporte fundamental que ofrece al Ministerio para el despliegue de la Estrategia de Movilidad Segura, Sostenible y Conectada, es la provisión de datos de servicios y análisis complejos de información geoespacial. Muchos de ellos, por supuesto, sobre el conjunto de datos que venimos hablando de redes de transporte.
En este sentido, mencionar como ejemplo los mapas de accesibilidad con los que contribuimos al eje 1 de la estrategia “Movilidad para todos”, en el que, a través de la Mesa de Movilidad Rural, se solicitó al IGN si podíamos generar unos mapas que representaran el coste en tiempo y en distancia que le cuesta a cualquier ciudadano, viviendo en cualquier núcleo de población, acceder a la infraestructura de transporte más cercana, empezando por red viaria. Es decir, cuánto le cuesta a un usuario en esfuerzo, tiempo y distancia, acceder desde su casa a la autopista o autovía más cercana y luego, por extensión, a cualquier carretera de la red básica. Hicimos ese análisis - por lo que decía que esta red vertebra todo el territorio, es continua - y esos resultados finalmente los publicamos vía web. Son datos también abiertos, cualquier usuario los puede consultar y, además, también los ofrecemos no solamente de forma numérica, sino representado en distintos tipos de mapas. Al final, esa visibilización geolocalizada del resultado aporta un valor fundamental y facilita, por supuesto, la toma de decisiones estratégicas en materia de planificación de infraestructuras.
Otro ejemplo a destacar que es posible gracias a la disponibilidad de datos abiertos, es el cálculo de indicadores de seguimiento de los Objetivos de Desarrollo Sostenible de la Agenda 2030. Actualmente, en colaboración con el Instituto Nacional de Estadística, estamos trabajando en el cálculo de varios de ellos, incluyendo uno asociado directamente a Transportes, que trata de hacer el seguimiento del objetivo 11, que es el de lograr que las ciudades sean más inclusivas, seguras, resilientes y sostenibles.
4. Hablando de esta toma de decisiones basada en datos, también existe cooperación a nivel de generación y reutilización de datos entre distintas administraciones públicas. ¿Nos podéis contar algún ejemplo de proyecto?
Tania Gullón: Yo te contesto también eso a la toma de decisiones basada en datos que antes me he ido por las ramas con el tema de la Ley. También se puede decir que todos esos datos de Big Data, Hermes y todo lo que hemos comentado están favoreciendo ese cambio del Ministerio y de las organizaciones hacia organizaciones basadas en datos, que significa que las decisiones se basan en ese análisis de datos objetivos. Cuando preguntas así por un ejemplo, es que tengo tantos que no sabría qué contarte. En el caso de los datos Big Data, se están utilizando para la planificación de infraestructuras desde hace unos años. Antes se hacía con encuestas y se dimensionaba porque ¿cuántos carriles pongo en una carretera? O algo muy básico, ¿cuánta frecuencia necesitamos en un tren? Pues eso, como no tengas datos de cuál va a ser la demanda, no puedes planificarlo. Esto se hace con los datos de Big Data, no solo el Ministerio sino, como están en abierto, los usan todas las administraciones, todos los ayuntamientos y todos los gestores de infraestructuras. Conocer las necesidades de movilidad de la población nos permite adecuar nuestras infraestructuras y nuestros servicios a esas necesidades reales. Por ejemplo, ahora se están estudiando los servicios de cercanías en Galicia. O imaginaros el soterramiento de la A-5. También se utilizan para emergencias, que no lo hemos comentado, pero también están siendo clave. Siempre nos damos cuenta de que cuando hay una emergencia, de repente todo el mundo piensa “datos, ¿dónde hay datos?, ¿dónde están los datos abiertos?”, pues han sido fundamentales. Os puedo contar, en el caso de la Dana, que es quizá el más reciente se quedaron gravemente afectadas varias líneas de tren de cercanías, se destrozaron las vías, y el 99 % de los vehículos de las personas que vivían en Paiporta, en Torrent, en toda la zona afectada, se quedaron inutilizados. Y el 1 % era porque no estaba en la zona de la Dana en ese momento. Entonces había que restablecer la movilidad cuanto antes, pues gracias a estos datos abiertos en una semana había unos autobuses haciendo unos servicios alternativos de transporte que se habían planificado con los datos de Big Data. O sea que fijaros el impacto sobre la población.
Hablando de emergencias, este proyecto nació justo por una emergencia, por el COVID. O sea, el estudio, este Big Data, nació en 2020 porque desde Presidencia de Gobierno se nos encargó monitorizar esa movilidad diariamente y darla en abierto. Y aquí enlazo con esa colaboración entre administraciones, organizaciones, empresas, universidades. Porque fijaros, estos datos de movilidad alimentaban los modelos epidemiológicos. Aquí trabajamos con el Instituto Carlos III, con el Barcelona Supercomputing Center, con estos institutos y centros de investigación que estaban empezando a dimensionar las camas de los hospitales para la segunda ola. Cuando todavía estábamos en la primera ola, no sabíamos ni lo que era una ola y ya nos estaban diciendo “ojo, porque va a haber una segunda ola, y con estos datos de movilidad y demás vamos a poder dimensionar cuántas camas se van a necesitar, según también el modelo epidemiológico”. Fijaos la reutilización tan importante. Estos datos, por ejemplo, de Big Data sabemos que los están utilizando miles de empresas, administraciones, centros de investigación, investigadores de todo el mundo. Además, nos llegan consultas de Alemania, de todos los países, porque en España yo somos un poco pioneros en esto de dar todos los datos en abierto. Estamos ahí creando escuela y no solo para transporte, sino para temas de turismo también, por ejemplo.
Alicia González: Nosotros, en el ámbito de la información geográfica, a nivel de cooperación, tenemos un instrumento específico que es el Sistema Cartográfico Nacional, que directamente promueve la coordinación en la actuación de las distintas administraciones en materia de información geográfica. No sabemos trabajar de otra forma que no sea cooperando. Y un ejemplo claro es el mismo conjunto del que venimos hablando: el conjunto de información geográfica de referencia de redes de transporte es el resultado de esta cooperación. Es decir, a nivel nacional lo impulsa y promueve el Instituto Geográfico, pero en su actualización, en su producción también participan agencias cartográficas autonómicas con diferente rango de colaboración. Incluso se llega a alcanzar el máximo de hacer coproducción de datos de ciertos subconjuntos en determinadas zonas. Además, una de las características de este producto es que se genera a partir de datos oficiales de otras fuentes. Es decir, ahí ya hay colaboración sí o sí. Hay cooperación porque hay una integración de datos, porque al final hay que rellenarlo con los datos oficiales. Y de partida, a lo mejor son datos que facilita INE, el Catastro, las propias agencias cartográficas, los callejeros locales… Pero, una vez que se ha conformado el resultado, como comentaba antes, el resultado tiene un valor añadido que es de interés para el propio proveedor original. Por ejemplo, este conjunto de datos se reutiliza internamente, en la casa, en el IGN: cualquier producto o servicio que precise de información de transporte se alimenta de este conjunto de datos. Ahí hay una reutilización interna, pero, además, en el ámbito de las administraciones públicas, en todos los niveles. En la estatal, pues, por ejemplo, en el Catastro, una vez que se ha generado el resultado, les es de interés para estudios de análisis de la delimitación del dominio público asociado a las infraestructuras, por ejemplo. O el propio Ministerio, como comentaba antes Tania. Hermes se generó a partir de un tratamiento de datos de RT, de los datos de redes de transporte. La Dirección General de Carreteras utiliza redes de transporte en su gestión interna para hacerse un mapa de tráfico, su gestión de catálogo, etcétera. Y en las propias comunidades autónomas, igualmente el resultado que se genera les es de utilidad en las agencias cartográficas o incluso a nivel local. Luego hay una reutilización cíclica continua, como tiene que ser, al final todo es dinero público y tiene que reutilizarse al máximo posible. Y en el ámbito privado, también se reutiliza y se generan servicios de valor añadido a partir de estos datos que se facilitan en múltiples casos de uso. Por no extenderme, simplemente eso: participamos facilitando datos sobre los que se generan servicios de valor añadido.
5. Y ya para terminar, podréis recapitular brevemente alguna idea que resalte el impacto en la vida cotidiana y el potencial comercial de estos datos para para los reutilizadores.
Alicia González: Muy brevemente, yo creo que el impacto fundamental en la vida cotidiana es que la distribución de datos abiertos ha permitido democratizar el acceso a los datos a todo el mundo, a empresas, pero también a ciudadanos; y, sobre todo, creo que ha sido fundamental en el ámbito académico, en el que seguramente, actualmente, es más fácil desarrollar ciertas investigaciones que en otros tiempos era más complejo. Y otro impacto en la vida cotidiana es la transparencia institucional que ello implica. Y en cuanto al potencial comercial de reutilizadores, reitero la idea anterior: la disponibilidad de datos impulsa la innovación y el incremento de soluciones de valor añadido. En este sentido, mirando una de las conclusiones del informe que se realizó en 2024 por ASEDIE; la Asociación de Empresas Infomediarias, sobre el impacto que tenían los datos geoespaciales que publica el CNIG en el sector privado, hubo un par de conclusiones bastante importantes. Una de ellas decía que cada vez que se libera un nuevo conjunto de datos se incentiva a los reutilizadores a generar soluciones de valor añadido y, además, les permite focalizar sus esfuerzos en ese desarrollo de innovación y no tanto en la captura del dato. Y también de ese informe se desprendía que desde la adopción de la política de datos abiertos que mencioné al principio, que se adoptó en 2015 por parte del IGN, el 75 % de las empresas encuestadas respondió que había podido ampliar de forma muy significativa el catálogo de productos y servicios basados en estos datos que son abiertos. Luego, yo creo que el impacto finalmente es enriquecedor para toda la sociedad.
Tania Gullón: yo suscribo todas las palabras de Alicia, totalmente de acuerdo. Y además, que los pequeños operadores de transporte y los ayuntamientos con menos recursos tengan a su disposición todos estos datos abiertos y gratuitos de calidad y el acceso a las herramientas digitales que les permitan competir en igualdad de condiciones. En el caso de las empresas o ayuntamientos, imaginaros poder planificar sus transportes y ser más eficientes. No solo les ahorra dinero, sino que ganan al final en el servicio al ciudadano. Y desde luego, el hecho de que en el sector público se tome las decisiones basadas en datos y se fomente ese ecosistema de compartición de datos, favoreciendo el desarrollo de aplicaciones de movilidad, por ejemplo, tiene un impacto directo en la vida cotidiana de las personas. O también el tema de las ayudas al transporte: el que se estudie con esos datos de demanda el impacto de las ayudas al transporte con datos de accesibilidad y demás. Se estudia quiénes son los más vulnerables y al final, ¿qué hace? Pues que las políticas sean cada vez más justas y esto, obviamente impacta en el ciudadano. Que las decisiones sobre cómo invertir el dinero de todos, de nuestros impuestos, el cómo invertirlo en infraestructuras o en ayudas o en servicios, se base en datos objetivos y no en intuiciones, sino en datos reales. Esto es lo más importante.
Clips de la entrevista
1. ¿Qué datos ofrece en abierto el Ministerio de Transportes y Movilidad Sostenible?
2. ¿Qué datos ofrece en abierto el Instituto Geográfico Nacional (IGN)?
Blog
Las ciudades, las infraestructuras y el medio ambiente generan hoy un flujo constante de datos procedentes de sensores, redes de transporte, estaciones meteorológicas y plataformas de Internet of Things (IoT), entendidas como redes de dispositivos físicos (semáforos digitales, sensores de calidad de aire, etc.) capaces de medir y transmitir información a través de sistemas digitales. Este volumen creciente de información permite mejorar la prestación de servicios públicos, anticipar emergencias, planificar el territorio y responder a retos asociados al clima, la movilidad o la gestión de recursos.
El incremento de fuentes conectadas ha transformado la naturaleza del dato geoespacial. Frente a los conjuntos tradicionales —actualizados de forma periódica y orientados a cartografía de referencia o inventarios administrativos— los datos dinámicos incorporan la dimensión temporal como componente estructural. Una observación de calidad del aire, un nivel de ocupación de tráfico o una medición hidrológica no solo describen un fenómeno, sino que lo sitúan en un momento concreto. La combinación espacio-tiempo convierte a estas observaciones en elementos fundamentales para sistemas operativos, modelos predictivos y análisis basados en series temporales.
En el ámbito de los datos abiertos, este tipo de información plantea tanto oportunidades como requerimientos específicos. Entre las oportunidades se encuentran la posibilidad de construir servicios digitales reutilizables, de facilitar la supervisión en tiempo casi real de fenómenos urbanos y ambientales, y de fomentar un ecosistema de reutilización basado en flujos continuos de datos interoperables. La disponibilidad de datos actualizados incrementa además la capacidad de evaluación y auditoría de políticas públicas, al permitir contrastar decisiones con observaciones recientes.
No obstante, la apertura de datos geoespaciales en tiempo real exige resolver problemas derivados de la heterogeneidad tecnológica. Las redes de sensores utilizan protocolos, modelos de datos y formatos diferentes; las fuentes generan volúmenes elevados de observaciones con alta frecuencia; y la ausencia de estructuras semánticas comunes dificulta el cruce de datos entre dominios como movilidad, medio ambiente, energía o hidrología. Para que estos datos puedan publicarse y reutilizarse de manera consistente, es necesario un marco de interoperabilidad que normalice la descripción de los fenómenos observados, la estructura de las series temporales y las interfaces de acceso.
Los estándares abiertos del Open Geospatial Consortium (OGC) proporcionan ese marco. Definen cómo representar observaciones, entidades dinámicas, coberturas multitemporales o sistemas de sensores; establecen API basadas en principios web que facilitan la consulta de datos abiertos; y permiten que plataformas distintas intercambien información sin necesidad de integraciones específicas. Su adopción reduce la fragmentación tecnológica, mejora la coherencia entre fuentes y favorece la creación de servicios públicos basados en datos actualizados.
Interoperabilidad: el requisito básico para abrir datos dinámicos
Las administraciones públicas gestionan hoy datos generados por sensores de distinto tipo, plataformas heterogéneas, proveedores diferentes y sistemas que evolucionan de forma independiente. La publicación de datos geoespaciales en tiempo real exige una interoperabilidad que permita integrar, procesar y reutilizar información procedente de múltiples fuentes. Esta diversidad provoca inconsistencias en formatos, estructuras, vocabularios y protocolos, lo que dificulta la apertura del dato y su reutilización por terceros. Veamos qué aspectos de la interoperabilidad están afectados:
- La interoperabilidad técnica: se refiere a la capacidad de los sistemas para intercambiar datos mediante interfaces, formatos y modelos compatibles. En los datos en tiempo real, este intercambio requiere mecanismos que permitan consultas rápidas, actualizaciones frecuentes y estructuras de datos estables. Sin estos elementos, cada flujo dependería de integraciones ad hoc, aumentando la complejidad y reduciendo la capacidad de reutilización.
- La interoperabilidad semántica: los datos dinámicos describen fenómenos que cambian en periodos cortos —niveles de tráfico, parámetros meteorológicos, caudales, emisiones atmosféricas— y deben interpretarse de forma coherente. Esto implica contar con modelos de observación, vocabularios y definiciones comunes que permitan a aplicaciones distintas entender el significado de cada medición y sus unidades, condiciones de captura o restricciones. Sin esta capa semántica, la apertura de datos en tiempo real genera ambigüedad y limita su integración con datos procedentes de otros dominios.
- La interoperabilidad estructural: los flujos de datos en tiempo real tienden a ser continuos y voluminosos, lo que hace necesario representarlos como series temporales o conjuntos de observaciones con atributos consistentes. La ausencia de estructuras normalizadas complica la publicación de datos completos, fragmenta la información e impide consultas eficientes. Para proporcionar acceso abierto a estos datos, es necesario adoptar modelos que representen adecuadamente la relación entre fenómeno observado, momento de la observación, geometría asociada y condiciones de medición.
- La interoperabilidad en el acceso vía API: constituye una condición esencial para los datos abiertos. Las API deben ser estables, documentadas y basadas en especificaciones públicas que permitan consultas reproducibles. En el caso de datos dinámicos, esta capa garantiza que los flujos puedan ser consumidos por aplicaciones externas, plataformas de análisis, herramientas cartográficas o sistemas de monitorización que operan en contextos distintos al que genera el dato. Sin API interoperables, el dato en tiempo real queda limitado a usos internos.
En conjunto, estos niveles de interoperabilidad determinan si los datos geoespaciales dinámicos pueden publicarse como datos abiertos sin generar barreras técnicas.
Estándares OGC para publicar datos geoespaciales en tiempo real
La publicación de datos georreferenciados en tiempo real requiere mecanismos que permitan que cualquier usuario —administración, empresa, ciudadanía o comunidad investigadora— pueda acceder a ellos de forma sencilla, con formatos abiertos y a través de interfaces estables. El Open Geospatial Consortium (OGC) desarrolla un conjunto de estándares que permiten exactamente esto: describir, organizar y exponer datos espaciales de forma interoperable y accesible, que contribuyan a la apertura de datos dinámicos.
Qué es OGC y por qué sus estándares son relevantes
El OGC es una organización internacional que define reglas comunes para que distintos sistemas puedan entender, intercambiar y usar datos geoespaciales sin depender de tecnologías concretas. Estas reglas se publican como estándares abiertos, lo que significa que cualquier persona o institución puede utilizarlos. En el ámbito de los datos en tiempo real, estos estándares permiten:
- Representar lo que un sensor mide (por ejemplo, temperatura o tráfico).
- Indicar dónde y cuándo se hizo la observación.
- Estructurar series temporales.
- Exponer datos a través de API abiertas.
- Conectar dispositivos y redes IoT con plataformas públicas.
En conjunto, este ecosistema de estándares permite que los datos geoespaciales —incluyendo los generados en tiempo real— puedan publicarse y reutilizarse siguiendo un marco coherente. Cada estándar cubre una parte específica del ciclo del dato: desde la definición de las observaciones y los sensores, hasta la forma en la que se exponen los datos mediante API abiertas o servicios web. Esta organización modular facilita que administraciones y organizaciones seleccionen los componentes que necesitan, evitando dependencias tecnológicas y garantizando que los datos puedan integrarse entre plataformas distintas.
La familia OGC API: API modernas para acceder a datos abiertos
Dentro de OGC, la línea más reciente es la familia OGC API, un conjunto de interfaces web modernas diseñadas para facilitar el acceso a datos geoespaciales mediante URL y formatos como JSON o GeoJSON, habituales en el ecosistema de datos abiertos.
Estas API permiten:
- Obtener solo la parte del dato que interesa.
- Realizar búsquedas espaciales (“dame solo lo que está en esta zona”).
- Acceder a datos actualizados sin necesidad de software especializado.
- Integrarlos fácilmente en aplicaciones web o móviles.
En este informe: “Cómo utilizar las OGC API para potenciar la interoperabilidad de los datos geoespaciales”, ya te hablamos de algunas las API más populares del OGP. Mientras que el informe se centra en cómo utilizar las OGC API para la interoperabilidad práctica, este post amplía el foco explicando los modelos de datos subyacentes del OGC —como O&M, SensorML o Moving Features— que sustentan esa interoperabilidad.
A partir de esta base, este post pone el foco en los estándares que hacen posible ese intercambio fluido de información, especialmente en contextos de datos abiertos y en tiempo real. Los estándares más importantes en el contexto de datos abiertos en tiempo real son:
|
Estándar OGC |
Qué permite hacer |
Uso principal en datos abiertos |
|---|---|---|
|
Es una interfaz web abierta que permite acceder a conjuntos de datos formados por “entidades” con geometría, como sensores, vehículos, estaciones o incidentes. Utiliza formatos simples como JSON y GeoJSON y permite realizar consultas espaciales y temporales. Es útil para publicar datos que se actualizan con frecuencia, como movilidad urbana o inventarios dinámicos. |
Consultar entidades con geometría; filtrar por tiempo o espacio; obtener datos en JSON/GeoJSON. |
Publicación abierta de datos dinámicos de movilidad, inventarios urbanos, sensores estáticos. |
|
OGC API – Environmental Data Retrieval (EDR) Proporciona un método sencillo para recuperar observaciones ambientales y meteorológicas. Permite solicitar datos en un punto, una zona o un intervalo temporal, y es especialmente adecuado para estaciones meteorológicas, calidad del aire o modelos climáticos. Facilita el acceso abierto a series temporales y predicciones. |
Solicitar observaciones ambientales en un punto, zona o intervalo temporal. |
Datos abiertos de meteorología, clima, calidad del aire o hidrología. |
|
Es el estándar más utilizado para datos IoT abiertos. Define un modelo uniforme para sensores, lo que miden y las observaciones que producen. Está diseñado para manejar grandes volúmenes de datos en tiempo real y ofrece un modo claro para publicar series temporales, datos de contaminación, ruido, hidrología, energía o alumbrado. |
Gestionar sensores y sus series temporales; transmitir grandes volúmenes de datos IoT. |
Publicación de sensores urbanos (aire, ruido, agua, energía) en tiempo real. |
|
OGC API – Connected Systems |
Describir redes de sensores, dispositivos e infraestructuras asociadas. |
Documentar como dato abierto la estructura de sistemas IoT municipales. |
|
OGC Moving Features |
Representar objetos móviles mediante trayectorias espacio-tiempo. |
Datos abiertos de movilidad (vehículos, transporte, embarcaciones). |
|
WMS-T |
Visualizar mapas que cambian en el tiempo |
Publicación de mapas meteorológicos o ambientales multitemporales |
Tabla 1. Estándares OGC relevantes para datos geoespaciales en tiempo real
Modelos que estructuran observaciones y datos dinámicos
Además de las API, OGC define varios modelos conceptuales de datos que permiten describir de forma coherente observaciones, sensores y fenómenos que cambian en el tiempo:
- O&M (Observations & Measurements): modelo que define los elementos esenciales de una observación —fenómeno medido, instante, unidad y resultado— y que sirve como base semántica para datos de sensores y series temporales.
- SensorML: lenguaje que describe las características técnicas y operativas de un sensor, incluyendo su ubicación, calibración y proceso de observación.
- Moving Features: modelo que permite representar objetos móviles mediante trayectorias espacio-temporales (como vehículos, embarcaciones o fauna).
Estos modelos facilitan que diferentes fuentes de datos puedan interpretarse de forma uniforme y combinarse en análisis y aplicaciones.
El valor de estos estándares para los datos abiertos
El uso de los estándares OGC facilita la apertura de datos dinámicos porque:
- Proporciona modelos comunes que reducen la heterogeneidad entre fuentes.
- Facilita la integración entre dominios (movilidad, clima, hidrología).
- Evita dependencias de tecnología propietaria.
- Permite que el dato sea reutilizado en análisis, aplicaciones o servicios públicos.
- Mejora la transparencia, al documentar sensores, métodos y frecuencias.
- Asegura que los datos pueden ser consumidos directamente por herramientas comunes.
En conjunto, forman una infraestructura conceptual y técnica que permite publicar datos geoespaciales en tiempo real como datos abiertos, sin necesidad de desarrollar soluciones específicas para cada sistema.
Casos de uso de datos geoespaciales abiertos en tiempo real
Los datos georreferenciados en tiempo real ya se publican como datos abiertos en distintos ámbitos sectoriales. Estos ejemplos muestran cómo diferentes administraciones y organismos aplican estándares abiertos y API para poner a disposición del público datos dinámicos relacionados con movilidad, medio ambiente, hidrología y meteorología.
A continuación, se presentan varios dominios donde las Administraciones Públicas ya publican datos geoespaciales dinámicos utilizando estándares OGC.
Movilidad y transporte
Los sistemas de movilidad generan datos de forma continua: disponibilidad de vehículos compartidos, posiciones en tiempo casi real, sensores de paso en carriles bici, aforos de tráfico o estados de intersecciones semaforizadas. Estas observaciones dependen de sensores distribuidos y requieren modelos de datos capaces de representar variaciones rápidas en el espacio y en el tiempo.
Los estándares OGC desempeñan un papel central en este ámbito. En particular, OGC SensorThings API permite estructurar y publicar observaciones procedentes de sensores urbanos mediante un modelo uniforme –incluyendo dispositivos, mediciones, series temporales y relaciones entre ellos– accesible a través de una API abierta. Esto facilita que diferentes operadores y municipios publiquen datos de movilidad de forma interoperable, reduciendo la fragmentación entre plataformas.
El uso de estándares OGC en movilidad no solo garantiza compatibilidad técnica, sino que posibilita que estos datos se puedan reutilizar junto con información ambiental, cartográfica o climática, generando análisis multitemáticos para planificación urbana, sostenibilidad o gestión operativa del transporte.
Ejemplo:
El servicio abierto de Toronto Bike Share, que publica en formato SensorThings API el estado de sus estaciones de bicicletas y la disponibilidad de vehículos.
Aquí cada estación es un sensor y cada observación indica el número de bicicletas disponibles en un momento concreto. Este enfoque permite que analistas, desarrolladores o investigadores integren estos datos directamente en modelos de movilidad urbana, sistemas de predicción de demanda o paneles de control ciudadano sin necesidad de adaptaciones específicas.
Calidad del aire, ruido y sensores urbanos
Las redes de monitorización de calidad del aire, ruido o condiciones ambientales urbanas dependen de sensores automáticos que registran mediciones cada pocos minutos. Para que estos datos puedan integrarse en sistemas de análisis y publicarse como datos abiertos, es necesario disponer de modelos y API coherentes.
En este contexto, los servicios basados en estándares OGC permiten publicar datos procedentes de estaciones fijas o sensores distribuidos de forma interoperable. Aunque muchas administraciones utilizan interfaces tradicionales como OGC WMS para servir estos datos, la estructura subyacente suele apoyarse en modelos de observaciones derivados de la familia Observations & Measurements (O&M), que define cómo representar un fenómeno medido, su unidad y el instante de observación.
Ejemplo:
El servicio Defra UK-AIR Sensor Observation Service proporciona acceso a datos de mediciones de calidad del aire en tiempo casi real desde estaciones in situ en Reino Unido.
La combinación de O&M para la estructura del dato y API abiertas para su publicación facilita que estos sensores urbanos formen parte de ecosistemas más amplios que integran movilidad, meteorología o energía, permitiendo análisis urbanos avanzados o paneles ambientales en tiempo casi real.
Ciclo del agua, hidrología y gestión del riesgo
Los sistemas hidrológicos generan datos cruciales para la gestión del riesgo: niveles y caudales en ríos, precipitaciones, humedad del suelo o información de estaciones hidrometeorológicas. La interoperabilidad es especialmente importante en este dominio, ya que estos datos se combinan con modelos hidráulicos, predicción meteorológica y cartografía de zonas inundables.
Para facilitar el acceso abierto a series temporales y observaciones hidrológicas, varios organismos utilizan OGC API – Environmental Data Retrieval (EDR), una API diseñada para recuperar datos ambientales mediante consultas sencillas en puntos, áreas o intervalos temporales.
Ejemplo:
El USGS (United States Geological Survey), que documenta el uso de OGC API – EDR para acceder a series de precipitación, temperatura o variables hidrológicas.
Este caso muestra cómo EDR permite solicitar observaciones específicas por ubicación o fecha, devolviendo únicamente los valores necesarios para el análisis. Aunque los datos concretos de hidrología del USGS se sirven mediante su API propia, este caso demuestra cómo EDR encaja con la estructura de datos hidrometeorológicos y cómo se aplica en flujos operativos reales.
El empleo de estándares OGC en este ámbito permite que los datos hidrológicos dinámicos se integren con zonas inundables, ortoimágenes o modelos climáticos, creando una base sólida para sistemas de alerta temprana, planificación hidráulica y evaluación del riesgo.
Observación y predicción meteorológica
La meteorología es uno de los dominios con mayor producción de datos dinámicos: estaciones automáticas, radares, modelos numéricos de predicción, observaciones satelitales y productos atmosféricos de alta frecuencia. Para publicar esta información como datos abiertos, la familia de OGC API se está convirtiendo en un elemento clave, especialmente mediante OGC API – EDR, que permite recuperar observaciones o predicciones en ubicaciones concretas y en distintos niveles temporales.
Ejemplo:
El servicio NOAA OGC API – EDR, que proporciona acceso a datos meteorológicos y variables atmosféricas del National Weather Service (Estados Unidos).
Esta API permite consultar datos en puntos, áreas o trayectorias, facilitando la integración de observaciones meteorológicas en aplicaciones externas, modelos o servicios basados en datos abiertos.
El uso de OGC API en meteorología permite que datos procedentes de sensores, modelos y satélites puedan consumirse mediante una interfaz unificada, facilitando su reutilización para pronósticos, análisis atmosféricos, sistemas de soporte a la decisión y aplicaciones climáticas.
Buenas prácticas para publicar datos geoespaciales abiertos en tiempo real
La publicación de datos geoespaciales dinámicos requiere adoptar prácticas que garanticen su accesibilidad, interoperabilidad y sostenibilidad. A diferencia de los datos estáticos, los flujos en tiempo real presentan requisitos adicionales relacionados con la calidad de las observaciones, la estabilidad de las API y la documentación del proceso de actualización. A continuación, se presentan algunas prácticas recomendadas para administraciones y organizaciones que gestionan este tipo de datos.
- Formatos y API abiertas estables: el uso de estándares OGC —como OGC API, SensorThings API o EDR— facilita que los datos puedan consumirse desde múltiples herramientas sin necesidad de adaptaciones específicas. Las API deben ser estables en el tiempo, ofrecer versiones bien definidas y evitar dependencias de tecnologías propietarias. Para datos ráster o modelos dinámicos, los servicios OGC como WMS, WMTS o WCS siguen siendo adecuados para visualización y acceso programático.
- Metadatos compatibles con DCAT-AP y modelos OGC: la interoperabilidad de catálogos requiere describir los conjuntos de datos utilizando perfiles como DCAT-AP, complementado con metadatos geoespaciales y de observación basados en O&M (Observations & Measurements) o SensorML. Estos metadatos deben documentar la naturaleza del sensor, la unidad de medida, la frecuencia de muestreo y posibles limitaciones del dato.
- Políticas de calidad, frecuencia de actualización y trazabilidad: los datasets dinámicos deben indicar explícitamente su frecuencia de actualización, la procedencia de las observaciones, los mecanismos de validación aplicados y las condiciones bajo las cuales se generaron. La trazabilidad es esencial para que terceros puedan interpretar correctamente los datos, reproducir análisis e integrar observaciones procedentes de fuentes distintas.
- Documentación, límites de uso y sostenibilidad del servicio: la documentación debe incluir ejemplos de uso, parámetros de consulta, estructura de respuesta y recomendaciones para gestionar el volumen de datos. Es importante establecer límites razonables de consulta para garantizar la estabilidad del servicio y asegurar que la administración puede mantener la API a largo plazo.
- Aspectos de licencias para datos dinámicos: la licencia debe ser explícita y compatible con la reutilización, como CC BY 4.0 o CC0. Esto permite integrar datos dinámicos en servicios de terceros, aplicaciones móviles, modelos predictivos o servicios de interés público sin restricciones innecesarias. La consistencia en la licencia facilita también el cruce de datos procedentes de distintas fuentes.
Estas prácticas permiten que los datos dinámicos se publiquen de forma fiable, accesible y útil para toda la comunidad reutilizadora.
Los datos geoespaciales dinámicos se han convertido en una pieza estructural para comprender fenómenos urbanos, ambientales y climáticos. Su publicación mediante estándares abiertos permite que esta información pueda integrarse en servicios públicos, análisis técnicos y aplicaciones reutilizables sin necesidad de desarrollos adicionales. La convergencia entre modelos de observación, API OGC y buenas prácticas en metadatos y licencias ofrece un marco estable para que administraciones y reutilizadores trabajen con datos procedentes de sensores de forma fiable. Consolidar este enfoque permitirá avanzar hacia un ecosistema de datos públicos más coherente, conectado y preparado para usos cada vez más demandantes en movilidad, energía, gestión del riesgo y planificación territorial.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
Vivimos en una época en la que cada vez más fenómenos del mundo físico pueden observarse, medirse y analizarse en tiempo real. La temperatura de un cultivo, la calidad del aire de una ciudad, el estado de una presa, el flujo del tráfico o el consumo energético de un edificio ya no son datos que se revisan ocasionalmente: son flujos continuos de información que se generan segundo a segundo.
Esta revolución no sería posible sin los sistemas ciberfísicos (CPS), una tecnología que integra sensores, algoritmos y actuadores para conectar el mundo físico con el digital. Pero los CPS no sólo generan datos: también pueden alimentarse de datos abiertos, multiplicando su utilidad y permitiendo decisiones basadas en evidencia.
En este artículo exploraremos qué son los CPS, cómo generan datos masivos en tiempo real, qué retos plantea convertir esos datos en información pública útil, qué principios son esenciales para asegurar su calidad y trazabilidad, y qué ejemplos reales demuestran el potencial de su reutilización. Cerraremos con una reflexión sobre el impacto de esta combinación en la innovación, la ciencia ciudadana y el diseño de políticas públicas más inteligentes.
¿Qué son los sistemas ciberfísicos?
Un sistema ciberfísico es una integración estrecha entre componentes digitales —como software, algoritmos, comunicación y almacenamiento— y componentes físicos —sensores, actuadores, dispositivos IoT o máquinas industriales—. Su función principal es observar el entorno, procesar la información y actuar sobre él.
A diferencia de los sistemas tradicionales de monitorización, un CPS no se limita a medir: cierra un ciclo completo entre percepción, decisión y acción. Este ciclo se puede entender a través de tres elementos principales:
Figura 1. Ciclo de los sistemas ciberfísicos. Fuente: elaboración propia
Un ejemplo cotidiano que ilustra muy bien este ciclo completo de percepción, decisión y acción es el riego inteligente, cada vez más presente en la agricultura de precisión y en los sistemas domésticos de jardinería. En este caso, los sensores distribuidos por el terreno miden continuamente la humedad del suelo, la temperatura ambiente e incluso la radiación solar. Toda esa información fluye hacia la unidad de computación, que analiza los datos, los compara con umbrales previamente definidos o con modelos más complejos —por ejemplo, los que estiman la evaporación del agua o las necesidades hídricas de cada tipo de planta— y determina si realmente es necesario regar.
Cuando el sistema concluye que el suelo ha alcanzado un nivel de sequedad crítico, entra en juego el tercer elemento del CPS: los actuadores. Son ellos quienes abren las válvulas, activan la bomba de agua o regulan el caudal, y lo hacen durante el tiempo exacto necesario para devolver la humedad a niveles óptimos. Si las condiciones cambian —si empieza a llover, si la temperatura baja o si el suelo recupera humedad más rápido de lo esperado—, el propio sistema ajusta su comportamiento en consecuencia.
Todo este proceso ocurre sin intervención humana, de forma autónoma. El resultado es un uso más sostenible del agua, plantas mejor cuidadas y una capacidad de adaptación en tiempo real que solo es posible gracias a la integración de sensores, algoritmos y actuadores característica de los sistemas ciberfísicos.
Los CPS como fábricas de datos en tiempo real
Una de las características más relevantes de los sistemas ciberfísicos es su capacidad para generar datos de forma continua, masiva y con una resolución temporal muy alta. Esta producción constante puede apreciarse en múltiples situaciones del día a día:
- Una estación hidrológica puede registrar nivel y caudal cada minuto.
- Un sensor de movilidad urbana puede generar cientos de lecturas por segundo.
- Un contador inteligente registra el consumo eléctrico cada pocos minutos.
- Un sensor agrícola mide humedad, salinidad y radiación solar varias veces al día.
- Un dron cartográfico captura posiciones GPS decimétricas en tiempo real.
Más allá de estos ejemplos concretos, lo importante es comprender qué significa esta capacidad para el conjunto del sistema: los CPS se convierten en auténticas fábricas de datos, y en muchos casos llegan a funcionar como gemelos digitales del entorno físico que monitorizan. Esa equivalencia casi instantánea entre el estado real de un río, un cultivo, una carretera o una máquina industrial y su representación digital permite disponer de un retrato extremadamente preciso y actualizado del mundo físico, prácticamente al mismo tiempo que los fenómenos ocurren.
Esta riqueza de datos abre un enorme campo de oportunidades cuando se publica como información abierta. Los datos procedentes de CPS pueden impulsar servicios innovadores desarrollados por empresas, alimentar investigaciones científicas de alto impacto, potenciar iniciativas de ciencia ciudadana que complementen los datos institucionales, y reforzar la transparencia y la rendición de cuentas en la gestión de recursos públicos.
Sin embargo, para que todo ese valor llegue realmente a la ciudadanía y a la comunidad reutilizadora, es necesario superar una serie de retos técnicos, organizativos y de calidad que determinan la utilidad final del dato abierto. A continuación, analizamos cuáles son esos desafíos y por qué son tan importantes en un ecosistema cada vez más dependiente de información generada en tiempo real.
El reto: de datos en bruto a información pública útil
Que un CPS genere datos no significa que estos puedan publicarse directamente como datos abiertos. Antes de llegar a la ciudadanía y a las empresas reutilizadoras, la información necesita un trabajo previo de preparación, validación, filtrado y documentación. Las administraciones deben asegurarse de que esos datos son comprensibles, interoperables y fiables. Y en ese camino aparecen varios desafíos.
Uno de los primeros es la estandarización. Cada fabricante, cada sensor y cada sistema puede utilizar formatos distintos, diferentes frecuencias de muestreo o estructuras propias. Si no se armonizan esas diferencias, lo que obtenemos es un mosaico difícilmente integrable. Para que los datos sean interoperables se necesitan modelos comunes, unidades homogéneas, estructuras coherentes y estándares compartidos. Normativas como INSPIRE o los estándares de OGC (Open Geospatial Consortium) e IoT-TS son clave para que un dato generado en una ciudad pueda entenderse, sin transformación adicional, en otra administración o por cualquier reutilizador.
El siguiente gran reto es la calidad. Los sensores pueden fallar, quedarse congelados reportando siempre el mismo valor, generar lecturas físicamente imposibles, sufrir interferencias electromagnéticas o estar mal calibrados durante semanas sin que nadie lo note. Si esa información se publica tal cual, sin un proceso previo de revisión y limpieza, el dato abierto pierde valor e incluso puede inducir a errores. La validación —con controles automáticos y revisión periódica— es, por tanto, indispensable.
Otro punto crítico es la contextualización. Un dato aislado carece de significado. Un “12,5” no dice nada si no sabemos si son grados, litros o decibelios. Una medida de “125 ppm” no tiene utilidad si no conocemos qué sustancia se está midiendo. Incluso algo tan aparentemente objetivo como unas coordenadas necesita un sistema de referencia concreto. Y cualquier dato ambiental o físico solo puede interpretarse adecuadamente si se acompaña de la fecha, la hora, la ubicación exacta y las condiciones de captura. Todo esto forma parte de los metadatos, que son esenciales para que terceros puedan reutilizar la información sin ambigüedades.
También es fundamental abordar la privacidad y la seguridad. Algunos CPS pueden captar información que, directa o indirectamente, podría vincularse a personas, propiedades o infraestructuras sensibles. Antes de publicar los datos, es necesario aplicar procesos de anonimización, técnicas de agregación, controles de seguridad y evaluaciones de impacto que garanticen que el dato abierto no compromete derechos ni expone información crítica.
Por último, existen retos operativos como la frecuencia de actualización y la robustez del flujo de datos. Aunque los CPS generan información en tiempo real, no siempre es adecuado publicarla con la misma granularidad: en ocasiones es necesario agregarla, validar la coherencia temporal o corregir valores antes de compartirla. De igual modo, para que los datos sean útiles en análisis técnicos o en servicios públicos, deben llegar sin interrupciones prolongadas ni duplicados, lo que exige una infraestructura estable y mecanismos de supervisión.
Principios de calidad y trazabilidad necesarios para datos abiertos fiables
Superados estos retos, la publicación de datos procedentes de sistemas ciberfísicos debe apoyarse en una serie de principios de calidad y trazabilidad. Sin ellos, la información pierde valor y, sobre todo, pierde confianza.
El primero es la exactitud. El dato debe representar fielmente el fenómeno que mide. Esto requiere sensores correctamente calibrados, revisiones periódicas, eliminación de valores claramente erróneos y comprobación de que las lecturas se encuentran dentro de rangos físicamente posibles. Un sensor que marca 200 °C en una estación meteorológica o un contador que registra el mismo consumo durante 48 horas son señales de un problema que debe detectarse antes de la publicación.
El segundo principio es la completitud. Un conjunto de datos debe indicar cuándo hay valores perdidos, lagunas temporales o periodos en los que un sensor ha estado desconectado. Ocultar estos huecos puede llevar a conclusiones equivocadas, especialmente en análisis científicos o en modelos predictivos que dependen de la continuidad de la serie temporal.
El tercer elemento clave es la trazabilidad, es decir, la capacidad de reconstruir la historia del dato. Saber qué sensor lo generó, dónde está instalado, qué transformaciones ha sufrido, cuándo se capturó o si pasó por algún proceso de limpieza permite evaluar su calidad y fiabilidad. Sin trazabilidad, la confianza se erosiona y el dato pierde valor como evidencia.
La actualización adecuada es otro principio fundamental. La frecuencia con la que se publica la información debe adaptarse al fenómeno medido. Los niveles de contaminación atmosférica pueden necesitar actualizaciones cada pocos minutos; el tráfico urbano, cada segundo; la hidrología, cada minuto o cada hora según el tipo de estación; y los datos meteorológicos, con frecuencias variables. Publicar demasiado rápido puede generar ruido; demasiado lento, puede inutilizar el dato para ciertos usos.
El último principio es el de los metadatos enriquecidos. Los metadatos explican el dato: qué mide, cómo se mide, con qué unidad, qué precisión tiene el sensor, cuál es su rango operativo, dónde está ubicado, qué limitaciones tiene la medición y para qué se genera esa información. No son una nota al pie, sino la pieza que permite a cualquier reutilizador comprender el contexto y la fiabilidad del conjunto de datos. Con una buena documentación, la reutilización no solo es posible: se dispara.
Ejemplos: CPS que reutilizan datos públicos para ser más inteligentes
Además de generar datos, muchos sistemas ciberfísicos también consumen datos públicos para mejorar su desempeño. Esta retroalimentación convierte a los datos abiertos en un recurso central para el funcionamiento de los territorios inteligentes. Cuando un CPS integra información procedente de sensores propios con fuentes abiertas externas, su capacidad de anticipación, eficiencia y precisión aumenta de forma notable.
Agricultura de precisión: En el ámbito agrícola, los sensores instalados en el terreno permiten medir variables como la humedad del suelo, la temperatura o la radiación solar. Sin embargo, los sistemas de riego inteligente no dependen únicamente de esa información local: también incorporan predicciones meteorológicas de AEMET, mapas abiertos del IGN sobre pendiente o tipos de suelo y modelos climáticos publicados como datos públicos. Al combinar sus propias mediciones con estas fuentes externas, los CPS agrícolas pueden determinar con mucha mayor exactitud qué zonas del terreno necesitan agua, cuándo conviene sembrar y cuánta humedad debe mantenerse en cada cultivo. Esta gestión fina permite ahorros de agua y fertilizantes que, en algunos casos, superan el 30 %.
Gestión hídrica: Algo similar ocurre en la gestión del agua. Un sistema ciberfísico que controla una presa o un canal de riego necesita saber no solo qué está pasando en ese instante, sino qué puede ocurrir en las próximas horas o días. Por ello integra sus propios sensores de nivel con datos abiertos de aforos fluviales, predicciones de lluvia y nieve, e incluso información pública sobre caudales ecológicos. Con esta visión ampliada, el CPS puede anticipar inundaciones, optimizar el desembalse, responder mejor a fenómenos extremos o planificar el riego de forma sostenible. En la práctica, la combinación de datos propios y abiertos se traduce en una gestión más segura y eficiente del agua.
Impacto: innovación, ciencia ciudadana y decisiones basadas en datos
La unión entre sistemas ciberfísicos y datos abiertos genera un efecto multiplicador que se manifiesta en distintos ámbitos.
- Innovación empresarial: las empresas disponen de un terreno fértil para desarrollar soluciones basadas en información fiable y en tiempo real. A partir de datos abiertos y mediciones de CPS, pueden surgir aplicaciones de movilidad más inteligentes, plataformas de gestión hídrica, herramientas de análisis energético o sistemas predictivos para agricultura. El acceso a datos públicos reduce barreras de entrada y permite crear servicios sin necesidad de costosos datasets privados, acelerando la innovación y la aparición de nuevos modelos de negocio.
- Ciencia ciudadana: la combinación de CPS y datos abiertos también fortalece la participación social. Comunidades de vecinos, asociaciones o colectivos ambientales pueden desplegar sensores de bajo coste para complementar los datos públicos y entender mejor lo que ocurre en su entorno. Esto da lugar a iniciativas que miden el ruido en zonas escolares, monitorizan niveles de contaminación en barrios concretos, siguen la evolución de la biodiversidad o construyen mapas colaborativos que enriquecen la información oficial.
- Mejor toma de decisiones públicas: finalmente, los gestores públicos se benefician de este ecosistema de datos reforzado. La disponibilidad de mediciones fiables y actualizadas permite diseñar zonas de bajas emisiones, planificar de forma más efectiva el transporte urbano, optimizar redes de riego, gestionar situaciones de sequía o inundaciones o regular políticas energéticas basadas en indicadores reales. Sin datos abiertos que complementen y contextualicen la información generada por los CPS, estas decisiones serían menos transparentes y, sobre todo, menos defendibles ante la ciudadanía.
En resumen, los sistemas ciberfísicos se han convertido en una pieza esencial para entender y gestionar el mundo que nos rodea. Gracias a ellos podemos medir fenómenos en tiempo real, anticipar cambios y actuar de forma precisa y automatizada. Pero su verdadero potencial se despliega cuando sus datos se integran en un ecosistema de datos abiertos de calidad, capaz de aportar contexto, enriquecer decisiones y multiplicar usos.
La combinación de CPS y datos abiertos permite avanzar hacia territorios más inteligentes, servicios públicos más eficientes y una participación ciudadana más informada. Aporta valor económico, impulsa la innovación, facilita la investigación y mejora la toma de decisiones en ámbitos tan diversos como la movilidad, el agua, la energía o la agricultura.
Para que todo esto sea posible, es imprescindible garantizar la calidad, trazabilidad y estandarización de los datos publicados, así como proteger la privacidad y asegurar la robustez de los flujos de información. Cuando estas bases están bien asentadas, los CPS no solo miden el mundo: lo ayudan a mejorar, convirtiéndose en un puente sólido entre la realidad física y el conocimiento compartido.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La computación cuántica promete resolver en horas problemas que tomarían milenios a los superordenadores más potentes del mundo. Desde el diseño de nuevos fármacos hasta la optimización de redes de energía más sostenibles, esta tecnología transformará radicalmente nuestra capacidad para abordar los desafíos más complejos de la humanidad. Sin embargo, su verdadero potencial democratizador solo se materializará mediante la convergencia con los datos abiertos, permitiendo que investigadores, empresas y gobiernos de todo el mundo accedan tanto a la capacidad de cómputo cuántico en la nube como a los datasets públicos necesarios para entrenar y validar algoritmos cuánticos.
Tratar de explicar la teoría cuántica siempre ha supuesto un desafío, incluso para las mentes más brillantes que la humanidad ha dado en los últimos 2 siglos. El célebre físico Richard Feynman (1918-1988) lo expresó con su característico humor:
"Hubo un tiempo en que los periódicos decían que sólo doce hombres entendían la teoría de la relatividad. No creo que nunca fuera así [...] Por otro lado, creo que puedo decir con seguridad que nadie entiende la mecánica cuántica" Wikiquote.
Y eso lo dijo uno de los físicos más brillantes del siglo XX, premio Nobel y uno de los padres de la electrodinámica cuántica. Tan grande es la rareza del comportamiento cuántico a ojos de un humano que, hasta el mismísimo Albert Einstein en su ya mítica frase, le decía a Max Born, en una carta escrita al físico alemán en 1926 "Dios no juega a los dados con el universo" en referencia a su incredulidad sobre las propiedades probabilísticas y no deterministas que se le atribuyen al comportamiento cuántico. A lo que Niels Bohr - otro titán de la física del siglo XX - le respondió: "Einstein, deja de decirle a Dios qué hacer".
Computación clásica
Si queremos entender por qué la mecánica cuántica propone una revolución en la ciencia de la computación tenemos que entender sus diferencias fundamentales con la mecánica - y, por ende - computación clásica. Casi todos hemos oído hablar en algún momento de nuestra vida de los bits de información. Los humanos hemos desarrollado una forma de realizar cálculos matemáticos complejos reduciendo toda la información a bits - las unidades fundamentales de información con las que sabe trabajar una máquina -, que son los famosos ceros y unos (0 y 1). Con dos simples valores, hemos sido capaces de modelar todo nuestro mundo matemático. ¿Y esto por qué? se preguntará alguno. ¿Por qué en base 2 y no 5 o 7? Pues bien, en nuestro mundo físico clásico (en el que vivimos día a día) diferenciar entre 0 y 1 es relativamente sencillo; encendido y apagado, como en el caso de un interruptor eléctrico, o imanación norte o sur, en el caso de un disco duro magnético. Para un mundo binario, hemos desarrollado todo un lenguaje de codificación en base a dos estados: 0 y 1.
Computación cuántica
En computación cuántica en vez de bits, utilizamos los cúbits o qubits. Los qubits utilizan varias propiedades “extrañas” de la mecánica cuántica que les permite representar infinitos estados a la vez entre el cero y uno de los clásicos bits. Para entenderlo, es cómo si un bit solo pudiera representar un estado encendido o apagado en una bombilla, mientras que un qubit puede representar todas las intensidades de iluminación de la bombilla. Esta propiedad es conocida como “superposición cuántica” y permite que un ordenador cuántico explore millones de soluciones posibles al mismo tiempo. Pero esto no es todo en la computación cuántica. Si te parece extraña la superposición cuántica espera a ver el entrelazamiento cuántico (quantum entanglement). Gracias a esta propiedad, dos partículas (o dos qubits) “entrelazadas” están conectadas “a distancia” de forma que el estado de una determina el estado de la otra. Así que, con estas dos propiedades tenemos qubits de información, que pueden representar infinitos estados y están conectados entre ellos. Este sistema tiene potencialmente una capacidad de computación exponencialmente mayor que nuestros ordenadores basados en computación clásica.
Dos casos de aplicación de la computación cuántica
1. Descubrimiento de fármacos y medicina personalizada. Los ordenadores cuánticos pueden simular interacciones moleculares complejas que son imposibles de calcular con la computación clásica. Por ejemplo, el plegamiento de proteínas - fundamental para entender enfermedades como el Alzheimer - requiere analizar trillones de configuraciones posibles. Un ordenador cuántico podría reducir años de investigación a semanas, acelerando el desarrollo de nuevos medicamentos y tratamientos personalizados basados en el perfil genético de cada paciente.
2. Optimización logística y cambio climático. Empresas como Volkswagen ya utilizan computación cuántica para optimizar rutas de tráfico en tiempo real. A mayor escala, estos sistemas podrían revolucionar la gestión energética de ciudades enteras, optimizando redes eléctricas inteligentes que integren renovables de forma eficiente, o diseñar nuevos materiales para captura de CO2 que ayuden a combatir el cambio climático.
Una buena lectura recomendada para hacer un repaso completo por la computación cuántica aquí.
El papel de los datos (y los recursos de computación) abiertos
La democratización del acceso a la computación cuántica dependerá crucialmente de dos pilares: recursos de computación abiertos y datasets públicos de calidad. Esta combinación está creando un ecosistema donde la innovación cuántica ya no requiere millones de dólares en infraestructura. A continuación, vemos algunas opciones disponibles para cada uno de estos pilares.
- Acceso gratuito a hardware cuántico real:
- IBM Quantum Platform: ofrece acceso gratuito mensual a sistemas cuánticos de más de 100 qubits para cualquier persona en el mundo. Con más de 400.000 usuarios registrados que han generado más de 2.800 publicaciones científicas, demuestra cómo el acceso abierto acelera la investigación. Cualquier investigador puede registrarse en la plataforma y comenzar a experimentar en minutos.
- Open Quantum Institute (OQI): lanzado en CERN (la Organización Europea para la Investigación Nuclear) en 2024, va más allá, proporcionando no solo acceso a computación cuántica sino también mentorización y recursos educativos para regiones desatendidas. Su programa de hackathons en 2025 incluye eventos en Líbano, Emiratos Árabes Unidos y otros países, específicamente diseñados para mitigar la brecha digital cuántica.
- Datasets públicos para el desarrollo de algoritmos cuánticos:
- QDataSet: ofrece 52 conjuntos de datos públicos con simulaciones de sistemas cuánticos de uno y dos qubits, disponibles libremente para entrenar algoritmos de machine learning (ML) cuántico. Investigadores sin recursos para generar sus propios datos de simulación pueden acceder a su repositorio en GitHub y comenzar a desarrollar algoritmos inmediatamente.
- ClimSim: se trata de un dataset público de modelado relacionado con el clima que ya está siendo usado para demostrar los primeros algoritmos de ML cuántico aplicados al cambio climático. Permite a cualquier equipo, independientemente de su presupuesto, trabajar en problemas climáticos reales usando computación cuántica.
- PennyLane Datasets: es una colección abierta de moléculas, circuitos cuánticos y sistemas físicos que permite a las startups farmacéuticas sin recursos realizar simulaciones costosas y experimentar con el descubrimiento de fármacos asistido por computación cuántica.
Casos reales de innovación inclusiva
Las posibilidades que ofrece el uso de datos abiertos a la computación cuántica ha quedado patente en diversos casos de uso, fruto de investigaciones concretas y convocatorias de ayudas, como, por ejemplo:
- El Gobierno de Canadá lanzó en 2022 "Quantum Computing for Climate", una convocatoria específica para que PYMEs y startups desarrollen aplicaciones cuánticas usando datos climáticos públicos, demostrando cómo los gobiernos pueden catalizar innovación proporcionando tanto datos como financiación para su uso.
- UK Quantum Catalyst Fund (15 millones de libras) financia proyectos que combinan computación cuántica con datos públicos del sistema nacional de salud de Reino Unido (NHS) para problemas como la optimización de redes energéticas y diagnósticos médicos, creando soluciones de interés público verificables por la comunidad científica.
- El informe 2024 del Open Quantum Institute (OQI) detalla 10 casos de uso para los Objetivos de Desarrollo Sostenible de la ONU desarrollados colaborativamente por expertos de 22 países, donde los resultados y metodologías son públicamente accesibles, permitiendo que cualquier institución replique o mejore estos trabajos).
- Red.es ha abierto una manifestación de interés dirigida a agentes del ecosistema de tecnologías cuánticas para recopilar ideas, propuestas y necesidades que contribuyan al diseño de las futuras líneas de actuación de la Estrategia Nacional de Tecnologías Cuánticas 2025–2030, financiada con 40 millones de euros provenientes de los Fondos FEDER.

Estado actual de la computación cuántica
Estamos en la era NISQ (Noisy Intermediate-Scale Quantum), término acuñado por el físico John Preskill en 2018, que describe ordenadores cuánticos con 50-100 qubits físicos. Estos sistemas son suficientemente potentes para realizar ciertos cálculos más allá de las capacidades clásicas, pero sufren de decoherencia, errores frecuentes que los hacen poco viables en aplicaciones de mercado.
IBM, Google, y startups como IonQ ofrecen acceso cloud a sus sistemas cuánticos, con IBM proporcionando acceso público a través de IBM Quantum Platform desde 2016, siendo uno de los primeros procesadores cuánticos accesibles públicamente conectados a la nube.
En 2019, Google alcanzó la "supremacía cuántica" con su procesador Sycamore de 53 qubits, que realizó un cálculo en aproximadamente 200 segundos que tomaría aproximadamente 10.000 años a un superordenador clásico de última generación.
Los últimos análisis independientes sugieren que las aplicaciones cuánticas prácticas pueden emerger alrededor de 2035-2040, asumiendo un crecimiento exponencial continuo en las capacidades del hardware cuántico. IBM se ha comprometido a entregar un ordenador cuántico tolerante a fallos a gran escala, IBM Quantum Starling, para 2029, con el objetivo de ejecutar circuitos cuánticos que comprenden 100 millones de compuertas cuánticas en 200 qubits lógicos.
Para finalizar la sección, una fantástica entrevista corta a Ignacio Cirac, uno de los “padres españoles” de la computación cuántica.
La carrera global por el liderazgo cuántico
La competencia internacional por dominar las tecnologías cuánticas ha desencadenado una ola de inversiones sin precedentes. Según McKinsey, hasta 2022 el nivel reconocido oficialmente de inversión pública de China (15.300 millones de dólares) supera el de la Unión Europea (7.200 millones de dólares), Estados Unidos 1.900 millones de dólares) y Japón (1.800 millones de dólares) juntos.
A nivel doméstico, el Reino Unido ha comprometido 2.500 millones de libras durante diez años con su Estrategia Nacional Cuántica para hacer del país un hub global de innovación en esta tecnología, y Alemania ha realizado una de las inversiones estratégicas más grandes en computación cuántica, destinando 3.000 millones de euros bajo su plan de estímulo económico.
La inversión en el primer trimestre de 2025 muestra un crecimiento explosivo: las empresas de computación cuántica recaudaron más de 1.250 mil millones de dólares, más del doble que el año anterior, un aumento del 128%, reflejando una creciente confianza en que esta tecnología está acercándose a la relevancia comercial.
Iniciativa Quantum Spain
En el caso de España se han invertido 60 millones de euros en Quantum Spain, coordinado por el Barcelona Supercomputing Center. El proyecto incluye:
- Instalación del primer ordenador cuántico del sur de Europa.
- Red de 25 nodos de investigación distribuidos por todo el país.
- Formación de talento cuántico en universidades españolas.
- Colaboración con el sector empresarial para casos de uso reales.
Esta iniciativa posiciona a España como hub cuántico del sur de Europa, crucial para no depender tecnológicamente de otras potencias.
Además, muy recientemente se ha presentado la Estrategia de Tecnologías Cuánticas de España con una inversión de 800 millones de euros. Esta estrategia se estructura en 4 objetivos estratégicos y 7 acciones prioritarias.
Objetivos estratégicos:
- Reforzar la I+D+I para favorecer la transferencia de conocimiento y facilitar que la investigación llegue al mercado.
- Crear un mercado español cuántico, fomentando el crecimiento y aparición de empresas cuánticas y su capacidad de acceder a capital y de satisfacer la demanda.
- Preparar a la sociedad para un cambio disruptivo, fomentando la seguridad y la reflexión sobre un nuevo derecho digital, la privacidad postcuántica.
- Consolidar el ecosistema cuántico de manera que traccione una visión de país.
Acciones prioritarias:
- Prioridad 1: Potenciar las empresas españolas en tecnologías cuánticas.
- Prioridad 2: Desarrollar la algoritmia y convergencia tecnológica entre IA y Cuántica.
- Prioridad 3: Posicionar a España cómo un referente en comunicaciones cuánticas.
- Prioridad 4: Demostrar el impacto de la sensórica y metrología cuántica.
- Prioridad 5: Garantizar la privacidad y confidencialidad de la información en el mundo post cuántico.
- Prioridad 6: Reforzar las capacidades: infraestructuras, investigación y talento.
- Prioridad 7: Desarrollar un ecosistema español cuántico sólido, coordinado y líder en la UE.
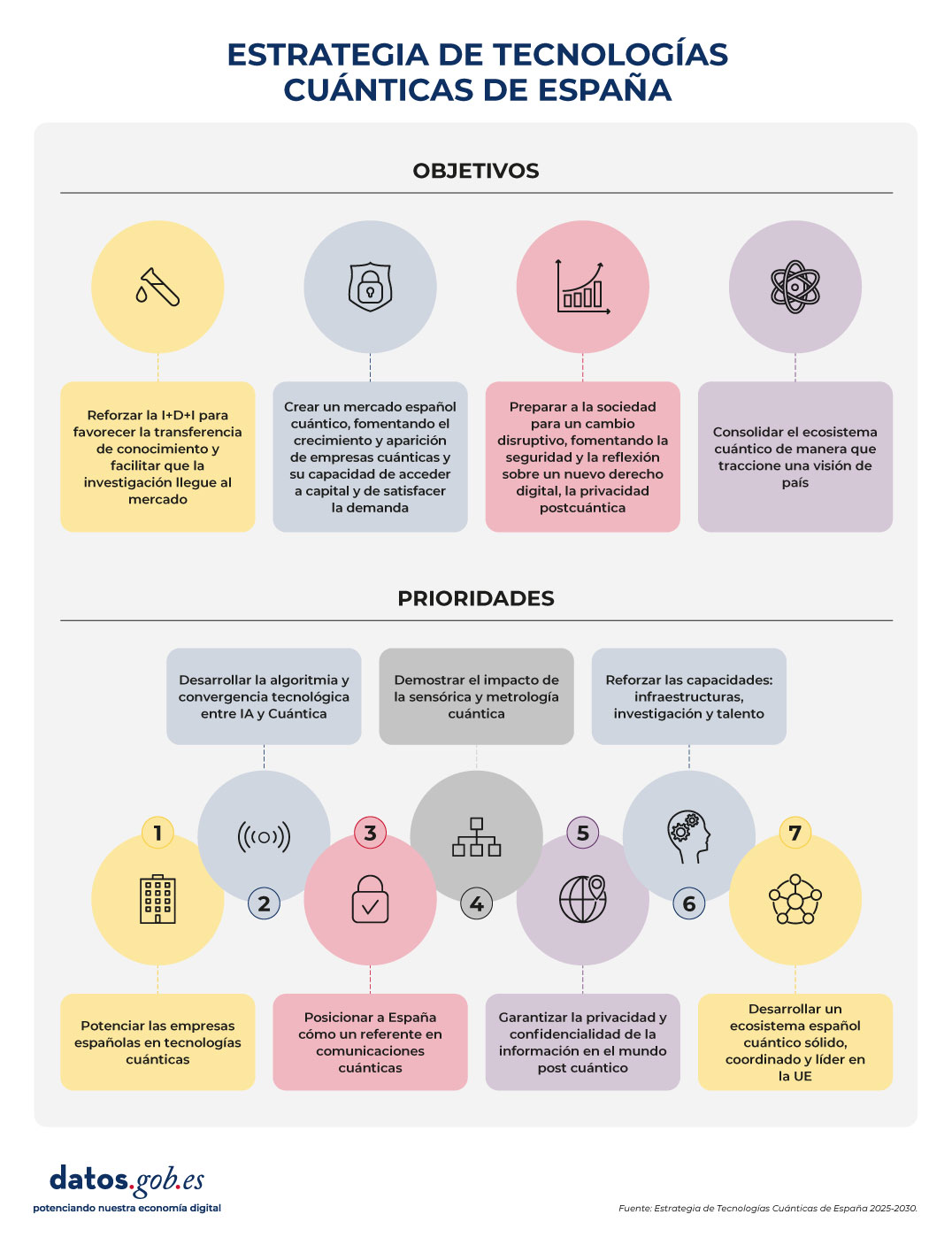
Figura 1. Estrategia de tecnologías cuánticas de España. Fuente: elaboración propia
En definitiva, la computación cuántica y los datos abiertos representan una gran evolución tecnológica que afecta a la forma en que generamos y aplicamos el conocimiento. Si somos capaces de construir un ecosistema verdaderamente inclusivo —donde el acceso a hardware cuántico, datasets públicos y formación especializada esté al alcance de cualquiera— abriremos la puerta a una nueva era de innovación colaborativa con un gran impacto global.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor