Blog
Access to data through APIs has become one of the key pieces of today's digital ecosystem. Public administrations, international organizations and private companies publish information so that third parties can reuse it in applications, analyses or artificial intelligence projects. In this situation, talking about open data is, almost inevitably, also talking about APIs.
However, access to an API is rarely completely free and unlimited. There are restrictions, controls and protection mechanisms that seek to balance two objectives that, at first glance, may seem opposite: facilitating access to data and guaranteeing the stability, security and sustainability of the service. These limitations generate frequent doubts: are they really necessary, do they go against the spirit of open data, and to what extent can they be applied without closing access?
This article discusses how these constraints are managed, why they are necessary, and how they fit – far from what is sometimes thought – within a coherent open data strategy.
Why you need to limit access to an API
An API is not simply a "faucet" of data. Behind it there is usually technological infrastructure, servers, update processes, operational costs and equipment responsible for the service working properly.
When a data service is exposed without any control, well-known problems appear:
- System saturation, caused by an excessive number of simultaneous queries.
- Abusive use, intentional or unintentional, that degrades the service for other users.
- Uncontrolled costs, especially when the infrastructure is deployed in the cloud.
- Security risks, such as automated attacks or mass scraping.
In many cases, the absence of limits does not lead to more openness, but to a progressive deterioration of the service itself.
For this reason, limiting access is not usually an ideological decision, but a practical necessity to ensure that the service is stable, predictable and fair for all users.
The API Key: basic but effective control
The most common mechanism for managing access is the API Key. While in some cases, such as the datos.gob.es National Open Data Catalog API , no key is required to access published information, other catalogs require a unique key that identifies each user or application and is included in each API call.
Although from the outside it may seem like a simple formality, the API Key fulfills several important functions. It allows you to identify who consumes the data, measure the actual use of the service, apply reasonable limits and act on problematic behavior without affecting other users.
In the Spanish context there are clear examples of open data platforms that work in this way. The State Meteorological Agency (AEMET), for example, offers open access to high-value meteorological data, but requires requesting a free API Key for automated queries. Access is free of charge, but not anonymous or uncontrolled.
So far, the approach is relatively familiar: consumer identification and basic limits of use. However, in many situations this is no longer enough.
When API becomes a strategic asset
Leading API management platforms, such as MuleSoft or Kong among others, were pioneers in implementing advanced mechanisms for controlling and protecting access to APIs. Its initial focus was on complex business environments, where multiple applications, organizations, and countries consume data services intensively and continuously.
Over time, many of these practices have also been extended to open data platforms. As certain open data services gain relevance and become key dependencies for applications, research, or business models, the challenges associated with their availability and stability become similar. The downfall or degradation of large-scale open data services—such as those related to Earth observation, climate, or science—can have a significant impact on multiple systems that depend on them.
In this sense, advanced access management is no longer an exclusively technical issue and becomes part of the very sustainability of a service that becomes strategic. It's not so much about who publishes the data, but the role that data plays within a broader ecosystem of reuse. For this reason, many open data platforms are progressively adopting mechanisms that have already been tested in other areas, adapting them to their principles of openness and public access. Some of them are detailed below.
Limiting the flow: regulating the pace, not the right of access
One of the first additional layers is the limitation of the flow of use, which is usually known as rate limiting. Instead of allowing an unlimited number of calls, it defines how many requests can be made in a given time interval.
The key here is not to prevent access, but to regulate the rhythm. A user can still use the data, but it prevents a single application from monopolizing resources. This approach is common in the Weather, Mobility, or Public Statistics APIs, where many users access it simultaneously.
More advanced platforms go a step further and apply dynamic limits, which are adjusted based on system load, time of day, or historical consumer behavior. The result is fairer and more flexible control.
Context, Origin, and Behavior: Beyond Volume
Another important evolution is to stop looking only at how many calls are made and start analyzing where and how they are made from. This includes measures such as restriction by IP addresses, geofencing, or differentiation between test and production environments.
In some cases, these limitations respond to regulatory frameworks or licenses of use. In others, they simply allow you to protect more sensitive parts of the service without shutting down general access. For example, an API can be globally accessible in query mode, but limit certain operations to very specific situations.
Platforms also analyze behavior patterns. If an application starts making repetitive, inconsistent queries or very different from its usual use, the system can react automatically: temporarily reduce the flow, launch alerts or require an additional level of validation. It is not blocked "just because", but because the behavior no longer fits with a reasonable use of the service.
Measuring impact, not just calls
A particularly relevant trend is to stop measuring only the number of requests and start considering the real impact of each one. Not all queries consume the same resources: some transfer large volumes of data or execute more expensive operations.
A clear example in open data would be an urban mobility API. Checking the status of a stop or traffic at a specific point involves little data and limited impact. On the other hand, downloading the entire vehicle position history of a city at once for several years is a much greater load on the system, even if it is done in a single call.
For this reason, many platforms introduce quotas based on the volume of data transferred, type of operation, or query weight. This avoids situations where seemingly moderate usage places a disproportionate load on the system.
How does all this fit in with open data?
At this point, the question inevitably arises: is data still open when all these layers of control exist?
The answer depends less on technology and more on the rules of the game. Open data is not defined by the total absence of technical control, but by principles such as non-discriminatory access, the absence of economic barriers, clarity in licensing, and the real possibility of reuse.
Requesting an API Key, limiting flow, or applying contextual controls does not contradict these principles if done in a transparent and equitable manner. In fact, in many cases it is the only way to guarantee that the service continues to exist and function correctly in the medium and long term.
The key is in balance: clear rules, free access, reasonable limits and mechanisms designed to protect the service, not to exclude. When this balance is achieved, control is no longer perceived as a barrier and becomes a natural part of an ecosystem of open, useful and sustainable data.
Content created by Juan Benavente, senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Evento
The Cabildo Insular de Tenerife has announced the II Open Data Contest: Development of APPs, an initiative that rewards the creation of web and mobile applications that take advantage of the datasets available on its datos.tenerife.es portal. This call represents a new opportunity for developers, entrepreneurs and innovative entities that want to transform public information into digital solutions of value for society. In this post, we tell you the details about the competition.
A growing ecosystem: from ideas to applications
This initiative is part of the Cabildo de Tenerife's Open Data project, which promotes transparency, citizen participation and the generation of economic and social value through the reuse of public information.
The Cabildo has designed a strategy in two phases:
-
The I Open Data Contest: Reuse Ideas (already held) focused on identifying creative proposals.
-
The II Contest: Development of PPPs (current call) that gives continuity to the process and seeks to materialize ideas in functional applications.
This progressive approach makes it possible to build an innovation ecosystem that accompanies participants from conceptualization to the complete development of digital solutions.
The objective is to promote the creation of digital products and services that generate social and economic impact, while identifying new opportunities for innovation and entrepreneurship in the field of open data.
Awards and financial endowment
This contest has a total endowment of 6,000 euros distributed in three prizes:
-
First prize: 3,000 euros
-
Second prize: 2,000 euros
-
Third prize: 1,000 euros
Who can participate?
The call is open to:
-
Natural persons: individual developers, designers, students, or anyone interested in the reuse of open data.
-
Legal entities: startups, technology companies, cooperatives, associations or other entities.
As long as they present the development of an application based on open data from the Cabildo de Tenerife. The same person, natural or legal, can submit as many applications as they wish, both individually and jointly.
What kind of applications can be submitted?
Proposals must be web or mobile applications that use at least one dataset from the datos.tenerife.es portal. Some ideas that can serve as inspiration are:
-
Applications to optimize transport and mobility on the island.
-
Tools for visualising tourism or environmental data.
-
Real-time citizen information services.
-
Solutions to improve accessibility and social participation.
-
Economic or demographic data analysis platforms.
Evaluation criteria: what does the jury assess?
The jury will evaluate the proposals considering the following criteria:
-
Use of open data: degree of exploitation and integration of the datasets available in the portal.
-
Impact and usefulness: value that the application brings to society, ability to solve real problems or improve existing services.
-
Innovation and creativity: originality of the proposal and innovative nature of the proposed solution.
-
Technical quality: code robustness, good programming practices, scalability and maintainability of the application.
-
Design and usability: user experience (UX), attractive and intuitive visual design, guarantee of digital accessibility on Android and iOS devices.
How to participate: deadlines and form of submission:
Applications can be submitted until March 10, 2026, three months from the publication of the call in the Official Gazette of the Province.
Regarding the required documentation, proposals must be submitted in digital format and include:
-
Detailed technical description of the application.
-
Report justifying the use of open data.
-
Specification of technological environments used.
-
Video demonstration of how the application works.
-
Complete source code.
-
Technical summary sheet.
The organising institution recommends electronic submission through the Electronic Office of the Cabildo de Tenerife, although it is also possible to submit it in person at the official registers enabled. The complete bases and the official application form are available at the Cabildo's Electronic Office.
With this second call, the Cabildo de Tenerife consolidates its commitment to transparency, the reuse of public information and the creation of a digital innovation ecosystem. Initiatives like this demonstrate how open data can become a catalyst for entrepreneurship, citizen participation, and local economic development.
Noticia
In the last six months, the open data ecosystem in Spain has experienced intense activity marked by regulatory and strategic advances, the implementation of new platforms and functionalities in data portals, or the launch of innovative solutions based on public information.
In this article, we review some of those advances, so you can stay up to date. We also invite you to review the article on the news of the first half of 2025 so that you can have an overview of what has happened this year in the national data ecosystem.
Cross-cutting strategic, regulatory and policy developments
Data quality, interoperability and governance have been placed at the heart of both the national and European agenda, with initiatives seeking to foster a robust framework for harnessing the value of data as a strategic asset.
One of the main developments has been the launch of a new digital package by the European Commission in order to consolidate a robust, secure and competitive European data ecosystem. This package includes a digital bus to simplify the application of the Artificial Intelligence (AI) Regulation. In addition, it is complemented by the new Data Union Strategy, which is structured around three pillars:
- Expand access to quality data to drive artificial intelligence and innovation.
- Simplify the existing regulatory framework to reduce barriers and bureaucracy.
- Protect European digital sovereignty from external dependencies.
Its implementation will take place gradually over the next few months. It will be then that we will be able to appreciate its effects on our country and the rest of the EU territories.
Activity in Spain has also been - and will be - marked by the V Open Government Plan 2025-2029, approved last October. This plan has more than 200 initiatives and contributions from both civil society and administrations, many of them related to the opening and reuse of data. Spain's commitment to open data has also been evident in its adherence to the International Open Data Charter, a global initiative that promotes the openness and reuse of public data as tools to improve transparency, citizen participation, innovation and accountability.
Along with the promotion of data openness, work has also been done on the development of data sharing spaces. In this regard, the UNE 0087 standard was presented, which is in addition to UNE specifications on data and defines for the first time in Spain the key principles and requirements for creating and operating in data spaces, improving their interoperability and governance.
More innovative data-driven solutions
Spanish bodies continue to harness the potential of data as a driver of solutions and policies that optimise the provision of services to citizens. Some examples are:
- The Ministry of Health and citizen science initiative, Mosquito Alert, are using artificial intelligence and automated image analysis to improve real-time detection and tracking of tiger mosquitoes and invasive species.
- The Valenciaport Foundation, together with other European organisations, has launched a free tool that allows the benefits of installing wind and photovoltaic energy systems in ports to be assessed.
- The Cabildo de la Palma opted for smart agriculture with the new Smart Agro website: farmers receive personalised irrigation recommendations according to climate and location. The Cabildo has also launched a viewer to monitor mobility on the island.
- The City Council of Segovia has implemented a digital twin that centralizes high-value applications and geographic data, allowing the city to be visualized and analyzed in an interactive three-dimensional environment. It improves municipal management and promotes transparency and citizen participation.
- Vila-real City Council has launched a digital application that integrates public transport, car parks and tourist spots in real time. The project seeks to optimize urban mobility and promote sustainability through smart technology.
- Sant Boi City Council has launched an interactive map made with open data that centralises information on urban transport, parking and sustainable options on a single platform, in order to improve urban mobility.
- The DataActive International Research Network has been inaugurated, an initiative funded by the Higher Sports Council that seeks to promote the design of active urban environments through the use of open data.
Not only public bodies reuse open data, universities are also working on projects linked to digital innovation based on public information:
- Students from the Universitat de València have designed projects that use AI and open data to prevent natural disasters.
- Researchers from the University of Castilla-La Mancha have shown that it is feasible to reuse air quality prediction models in different areas of Madrid using transfer learning.
In addition to solutions, open data can also be used to shape other types of products, including sculptures. This is the case of "The skeleton of climate change", a figure presented by the National Museum of Natural Sciences, based on data on changes in global temperature from 1880 to 2024.
New portals and functionalities to extract value from data
The solutions and innovations mentioned above are possible thanks to the existence of multiple platforms for opening or sharing data that do not stop incorporating new data sets and functionalities to extract value from them. Some of the developments we have seen in this regard in recent months are:
- The National Observatory of Technology and Society (ONTSI) has launched a new website. One of its new features is Ontsi Data, a tool for preparing reports with indicators from both its portal and third parties.
- The General Council of Notaries has launched a Housing Statistical Portal, an open tool with reliable and up-to-date data on the real estate market in Spain.
- The Spanish Agency for Food Safety and Nutrition (AESAN) has inaugurated on its website an open data space with microdata on the composition of food and beverages marketed in Spain.
- The Centre for Sociological Research (CIS) launched a renewed website, adapted to any device and with a more powerful search engine to facilitate access to its studies and data.
- The National Geographic Institute (IGN) has presented a new website for SIOSE, the Information System on Land Occupation in Spain, with a more modern, intuitive and dynamic design. In addition, it has made available to the public a new version of the Geographic Reference Information of Transport Networks (IGR-RT), segmented by provinces and modes of transport, and available in Shapefile and GeoPackage.
- The AKIS Advisors Platform, promoted by the Ministry of Agriculture, Fisheries and Food, has launched a new open data API that allows registered users to download and reuse content related to the agri-food sector in Spain.
- The Government of Catalonia launched a new corporate website that centralises key aspects of European funds, public procurement, transparency and open data in a single point. It has also launched a website where it collects information on the AI systems it uses.
- PortCastelló has published its 2024 Proceedings in open data format. All the management, traffic, infrastructures and economic data of the port are now accessible and reusable by any citizen.
- Researchers from the Universitat Oberta de Catalunya and the Institute of Photonic Sciences have created an open library with data on 140 biomolecules. A pioneering resource that promotes open science and the use of open data in biomedicine.
- CitriData, a federated space for data, models and services in the Andalusian citrus value chain, was also presented. Its goal is to transform the sector through the intelligent and collaborative use of data.
Other organizations are immersed in the development of their novelties. For example, we will soon see the new Open Data Portal of Aguas de Alicante, which will allow public access to key information on water management, promoting the development of solutions based on Big Data and AI.
These months have also seen strategic advances linked to improving the quality and use of data, such as the Data Government Model of the Generalitat Valenciana or the Roadmap for the Provincial Strategy of artificial intelligence of the Provincial Council of Castellón.
Datos.gob.es also introduced a new platform aimed at optimizing both publishing and data access. If you want to know this and other news of the Aporta Initiative in 2025, we invite you to read this post.
Encouraging the use of data through events, resources and citizen actions
The second half of 2025 was the time chosen by a large number of public bodies to launch tenders aimed at promoting the reuse of the data they publish. This was the case of the Junta de Castilla y León, the Madrid City Council, the Valencia City Council and the Provincial Council of Bizkaia. Our country has also participated in international events such as the NASA Space Apps Challenge.
Among the events where the power of open data has been disseminated, the Open Government Partnership (OGP) Global Summit, the Iberian Conference on Spatial Data Infrastructures (JIIDE), the International Congress on Transparency and Open Government or the 17th International Conference on the Reuse of Public Sector Information of ASEDIE stand out. although there were many more.
Work has also been done on reports that highlight the impact of data on specific sectors, such as the DATAGRI Chair 2025 Report of the University of Cordoba, focused on the agri-food sector. Other published documents seek to help improve data management, such as "Fundamentals of Data Governance in the context of data spaces", led by DAMA Spain, in collaboration with Gaia-X Spain.
Citizen participation is also critical to the success of data-driven innovation. In this sense, we have seen both activities aimed at promoting the publication of data and improving those already published or their reuse:
- The Barcelona Open Data Initiative requested citizen help to draw up a ranking of digital solutions based on open data to promote healthy ageing. They also organized a participatory activity to improve the iCuida app, aimed at domestic and care workers. This app allows you to search for public toilets, climate shelters and other points of interest for the day-to-day life of caregivers.
- The Spanish Space Agency launched a survey to find out the needs and uses of Earth Observation images and data within the framework of strategic projects such as the Atlantic Constellation.
In conclusion, the activities carried out in the second half of 2025 highlight the consolidation of the open data ecosystem in Spain as a driver of innovation, transparency and citizen participation. Regulatory and strategic advances, together with the creation of new platforms and solutions based on data, show a firm commitment on the part of institutions and society to take advantage of public information as a key resource for sustainable development, the improvement of services and the generation of knowledge.
As always, this article is just a small sample of the activities carried out. We invite you to share other activities that you know about through the comments.
Blog
Open data is a central piece of digital innovation around artificial intelligence as it allows, among other things, to train models or evaluate machine learning algorithms. But between "downloading a CSV from a portal" and accessing a dataset ready to apply machine learning techniques , there is still an abyss.
Much of that chasm has to do with metadata, i.e. how datasets are described (at what level of detail and by what standards). If metadata is limited to title, description, and license, the work of understanding and preparing data becomes more complex and tedious for the person designing the machine learning model. If, on the other hand, standards that facilitate interoperability are used, such as DCAT, the data becomes more FAIR (Findable, Accessible, Interoperable, Reusable) and, therefore, easier to reuse. However, additional metadata is needed to make the data easier to integrate into machine learning flows.
This article provides an overview of the various initiatives and standards needed to provide open data with metadata that is useful for the application of machine learning techniques.
DCAT as the backbone of open data portals
The DCAT (Data Catalog Vocabulary) vocabulary was designed by the W3C to facilitate interoperability between data catalogs published on the Web. It describes catalogs, datasets, and distributions, being the foundation on which many open data portals are built.
In Europe, DCAT is embodied in the DCAT-AP application profile, recommended by the European Commission and widely adopted to describe datasets in the public sector, for example, in Spain with DCAT-AP-ES. DCAT-AP answers questions such as:
- What datasets exist on a particular topic?
- Who publishes them, under what license and in what formats?
- Where are the download URLs or access APIs?
Using a standard like DCAT is imperative for discovering datasets, but you need to go a step further in order to understand how they are used in machine learning models or what quality they are from the perspective of these models.
MLDCAT-AP: Machine Learning in an Open Data Portal Catalog
MLDCAT-AP (Machine Learning DCAT-AP) is a DCAT application profile developed by SEMIC and the Interoperable Europe community, in collaboration with OpenML, that extends DCAT-AP to the machine learning domain.
MLDCAT-AP incorporates classes and properties to describe:
- Machine learning models and their characteristics.
- Datasets used in training and assessment.
- Quality metrics obtained on datasets.
- Publications and documentation associated with machine learning models.
- Concepts related to risk, transparency and compliance with the European regulatory context of the AI Act.
With this, a catalogue based on MLDCAT-AP no longer only responds to "what data is there", but also to:
- Which models have been trained on this dataset?
- How has that model performed by certain metrics?
- Where is this work described (scientific articles, documentation, etc.)?
MLDCAT-AP represents a breakthrough in traceability and governance, but the definition of metadata is maintained at a level that does not yet consider the internal structure of the datasets or what exactly their fields mean. To do this, it is necessary to go down to the level of the structure of the dataset distribution itself.
Metadata at the internal structure level of the dataset
When you want to describe what's inside the distributions of datasets (fields, types, constraints), an interesting initiative is Data Package, part of the Frictionless Data ecosystem.
A Data Package is defined by a JSON file that describes a set of data. This file includes not only general metadata (such as name, title, description or license) and resources (i.e. data files with their path or a URL to access their corresponding service), but also defines a schema with:
- Field names.
- Data types (integer, number, string, date, etc.).
- Constraints, such as ranges of valid values, primary and foreign keys, and so on.
From a machine learning perspective, this translates into the possibility of performing automatic structural validation before using the data. In addition, it also allows for accurate documentation of the internal structure of each dataset and easier sharing and versioning of datasets.
In short, while MLDCAT-AP indicates which datasets exist and how they fit into the realm of machine learning models, Data Package specifies exactly "what's there" within datasets.
Croissant: Metadata that prepares open data for machine learning
Even with the support of MLDCAT-AP and Data Package, it would be necessary to connect the underlying concepts in both initiatives. On the one hand, the field of machine learning (MLDCAT-AP) and on the other hand, that of the internal structures of the data itself (Data Package). In other words, the metadata of MLDCAT-AP and Data Package may be used, but in order to overcome some limitations that both suffer, it is necessary to complement it. This is where Croissant comes into play, a metadata format for preparing datasets for machine learning application. Croissant is developed within the framework of MLCommons, with the participation of industry and academia.
Specifically, Croissant is implemented in JSON-LD and built on top of schema.org/Dataset, a vocabulary for describing datasets on the Web. Croissant combines the following metadata:
- General metadata of the dataset.
- Description of resources (files, tables, etc.).
- Data structure.
- Semantic layer on machine learning (separation of training/validation/test data, target fields, etc.)
It should be noted that Croissant is designed so that different repositories (such as Kaggle, HuggingFace, etc.) can publish datasets in a format that machine learning libraries (TensorFlow, PyTorch, etc.) can load homogeneously. There is also a CKAN extension to use Croissant in open data portals.
Other complementary initiatives
It is worth briefly mentioning other interesting initiatives related to the possibility of having metadata to prepare datasets for the application of machine learning ("ML-ready datasets"):
- schema.org/Dataset: Used in web pages and repositories to describe datasets. It is the foundation on which Croissant rests and is integrated, for example, into Google's structured data guidelines to improve the localization of datasets in search engines.
- CSV on the Web (CSVW): W3C set of recommendations to accompany CSV files with JSON metadata (including data dictionaries), very aligned with the needs of tabular data documentation that is then used in machine learning.
- Datasheets for Datasets and Dataset Cards: Initiatives that enable the development of narrative and structured documentation to describe the context, provenance, and limitations of datasets. These initiatives are widely adopted on platforms such as Hugging Face.
Conclusions
There are several initiatives that help to make a suitable metadata definition for the use of machine learning with open data:
- DCAT-AP and MLDCAT-AP articulate catalog-level, machine learning models, and metrics.
- Data Package describes and validates the structure and constraints of data at the resource and field level.
- Croissant connects this metadata to the machine learning flow, describing how the datasets are concrete examples for each model.
- Initiatives such as CSVW or Dataset Cards complement the previous ones and are widely used on platforms such as HuggingFace.
These initiatives can be used in combination. In fact, if adopted together, open data is transformed from simply "downloadable files" to machine learning-ready raw material, reducing friction, improving quality, and increasing trust in AI systems built on top of it.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views expressed in this publication are the sole responsibility of the author.
Noticia
The year 2025 has been a new boost for the Aporta y datos.gob.es Initiative, consolidating its role as a driver of innovation and a benchmark in the open data ecosystem in Spain. Throughout these months we have reinforced our commitment to the opening of public information, expanding resources and improving the experience of those who reuse data to generate knowledge, solutions and opportunities.
Below, and as always when the end of the year arrives, we collect some of the progress made in the last twelve months, along with the impact generated.
International momentum continues
During this year we have continued to strengthen Spain's international position in open data, participating in initiatives and forums that promote transparency and the reuse of public information at a global level. Collaboration with international organizations and alignment with European standards have allowed our country to continue to be a benchmark in the field, actively contributing to the construction of a more solid and shared data ecosystem. Some points to highlight are:
- Our country's adherence to the International Open Data Charter during the IX Global Summit of the Open Government Partnership in Vitoria-Gasteiz. With this commitment, the Government recognized data as a strategic asset to design public policies and improve services, consolidating transparency and digital innovation.
- The promotion of DCAT-AP-ES through the launch of a community on GitHub, with resources that facilitate its implementation. This new metadata model adopts the guidelines of the European DCAT-AP metadata exchange scheme, improving interoperability.
- Spain's presence, once again, among the prescribing countries in terms of open data, according to the Open Data Maturity 2025 report, prepared by data.europa.eu. Our country strengthened its leadership through the development of strategic policies, technical modernization, and innovation driven by reuse.
A new platform with more data and resources
Another of the most outstanding milestones has been the premiere of the new datos.gob.es platform, designed to optimize both publication and access to data. With a renewed look and a clearer information architecture, we have made navigation more intuitive and functional, making it easier for any user to find and take advantage of the information they need in a simpler and more efficient way.
To this must be added the growth in volume and diversity of data published on the platform. By 2025 we have reached almost 100,000 datasets available for reuse, which is an increase of 9% compared to the previous year. Among them are more than 300 high-value datasets, that is, belonging to categories "whose reuse is associated with considerable benefits for society, the environment and the economy" according to the European Union. These datasets, which are essential for strategic projects, multiply the possibilities for analysis and serve as the basis for technological innovations, for example, linked to artificial intelligence.
But the Aporta Initiative is not limited to offering data: it also accompanies the community with content that helps to understand and make the most of this information. During this year we have published more than a hundred articles on current affairs and analysis, as well as infographics, podcasts and videos that approach complex topics in a clear and accessible way. We have also expanded our guides and practical exercises, incorporating new topics such as the use of artificial intelligence in conversational applications.
The reuse of data is also reflected in the increase in use cases and business models. By 2025, dozens of innovative solutions, applications, and companies based on open data have been identified. These examples show how the openness of public information translates into tangible benefits for society and the economy.
An ever-growing community
The community that accompanies us continues to grow and consolidate. In the case of social networks, our presence on LinkedIn stands out, where we reach professionals and data experts who share and interact with our content constantly. We currently have more than 17,000 followers (23% more than in 2024). The commitment to Instagram has also been consolidated, with a growth of 95% (400 followers). Our profile on this social network was launched in 2024 and since then it has not stopped growing, attracting followers interested in the opportunities offered by the reuse of public and private data. For its part, the X (formerly Twitter) community has remained stable, at 20,700 followers.
In addition, the datos.gob.es newsletter, which has been redesigned and already has more than 4,000 subscribers, a reflection of the growing interest in staying up to date in the field of data. We have also strengthened our service channels, responding to numerous queries and requests from organisations and citizens. Specifically, nearly 2,000 interactions have been attended through the different publisher support channels, general queries and dynamization.
All this effort translates into a sustained growth of the portal: in 2025 datos.gob.es has received nearly two million visits, with more than three and a half million page views and a significant increase in the time spent by users. These figures confirm that more and more people are finding open data a valuable resource for their projects and activities.
Thank you for joining us
In summary, the balance of 2025 reflects a year of progress, learning, and shared achievements. None of this would be possible without the collaboration of the data community in Spain, which promotes the universe of open data with its participation and creativity. In 2026 we will continue to work together so that data continues to be a lever for innovation, transparency and progress.

Noticia
Spain once again stands out in the European open data landscape. The Open Data Maturity 2025 report places our country among the leaders in the opening and reuse of public sector information, consolidating an upward trajectory in digital innovation.
The report, produced annually by the European data portal, data.europa.eu, assesses the degree of maturity of open data in Europe. To do this, it analyzes several indicators, grouped into four dimensions: policy, portal, quality and impact. This year's edition has involved 36 countries, including the 27 Member States of the European Union (EU), three European Free Trade Association countries (Iceland, Norway and Switzerland) and six candidate countries (Albania, Bosnia and Herzegovina, Montenegro, North Macedonia, Serbia and Ukraine).
This year, Spain is in fifth position among the countries of the European Union and sixth out of the total number of countries analysed, tied with Italy. Specifically, a total score of 95.6% was obtained, well above the average of the countries analysed (81.1%). With this data, Spain improves its score compared to 2024, when it obtained 94.8%.
Spain, among the European leaders
With this position, Spain is once again among the countries that prescribe open data (trendsetters), i.e. those that set trends and serve as an example of good practices to other States. Spain shares a group with France, Lithuania, Poland, Ukraine, Ireland, the aforementioned Italy, Slovakia, Cyprus, Portugal, Estonia and the Czech Republic.
The countries in this group have advanced open data policies, aligned with the technical and political progress of the European Union, including the publication of high-value datasets. In addition, there is strong coordination of open data initiatives at all levels of government. Its national portals offer comprehensive features and quality metadata, with few limitations on publication or use. This means that published data can be more easily reused for multiple purposes, helping to generate a positive impact in different areas.
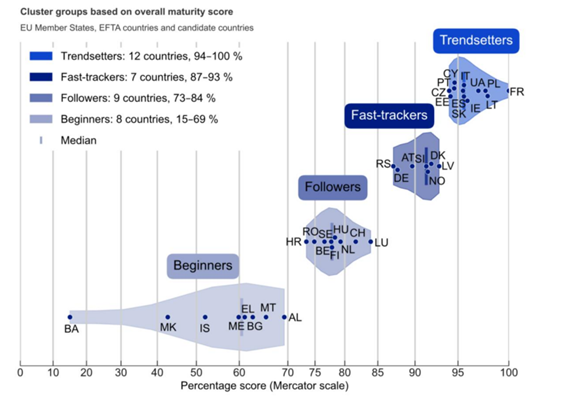
Figure 1. Member countries of the different clusters.
The keys to Spain's progress
According to the report, Spain strengthened its leadership in open data through strategic policy development, technical modernization, and reuse-driven innovation. In particular, improvements in the political sphere are what have boosted Spain's growth:
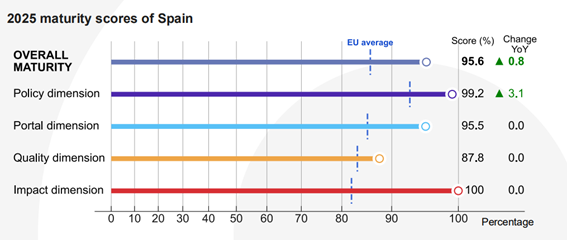
Figure 2. Spain's score in the different dimensions together with growth over the previous year.
As shown in the image, the political dimension has reached a score of 99.2% compared to 96% last year, standing out from the European average of 93.1%. The reason for this growth is the progress in the regulatory framework. In this regard, the report highlights the configuration of the V Open Government Plan, developed through a co-creation process in which all stakeholders participated. This plan has introduced new initiatives related to the governance and reuse of open data. Another noteworthy issue is that Spain promoted the publication of high-value datasets, in line with Implementing Regulation (EU) 2023/138.
The rest of the dimensions remain stable, all of them with scores above the European average: in the portal dimension, 95.5% has been obtained compared to 85.45% in Europe, while the quality dimension has been valued with 87.8% compared to 83.4% in the rest of the countries analysed. The Impact block continues to be our great asset, with 100% compared to 82.1% in Europe. In this dimension, we continue to position ourselves as great leaders, thanks to a clear definition of reuse, the systematic measurement of data use and the existence of examples of impact in the governmental, social, environmental and economic spheres.
Although there have not been major movements in the score of these dimensions, the report does highlight milestones in Spain in all areas. For example, the datos.gob.es platform underwent a major redesign, including adjustments to the DCAT-AP-ES metadata profile, in order to improve quality and interoperability. In this regard, a specific implementation guide was published and a learning and development community was consolidated through GitHub. In addition, the portal's search engine and monitoring tools were improved, including tracking external reuse through GitHub references and rich analytics through interactive dashboards.
The involvement of the infomediary sector has been key in strengthening Spain's leadership in open data. The report highlights the importance of activities such as the National Open Data Meeting, with challenges that are worked on jointly by a multidisciplinary team with representatives of public, private and academic institutions, edition after edition. In addition, the Spanish Federation of Municipalities and Provinces identified 80 essential data sets on which local governments should focus when advancing in the opening of information, promoting coherence and reuse at the municipal level.
The following image shows the specific score for each of the subdimensions analyzed:
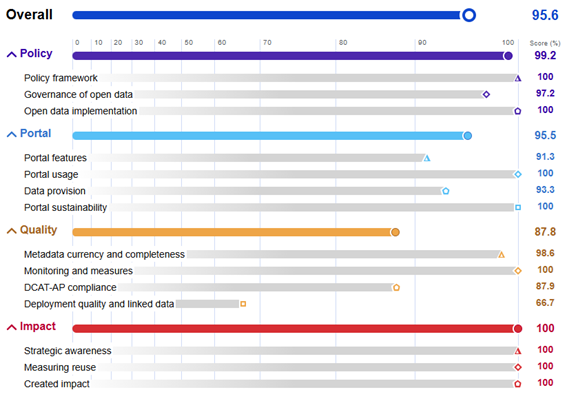
Figure 3. Spain's score in the different dimensions and subcategories.
You can see the details of the report for Spain on the website of the European portal.
Next steps and common challenges
The report concludes with a series of specific recommendations for each group of countries. For the group of trendsetters, in which Spain is located, the recommendations are not so much focused on reaching maturity – already achieved – but on deepening and expanding their role as European benchmarks. Some of the recommendations are:
- Consolidate thematic ecosystems (supplier and reuser communities) and prioritize high-value data in a systematic way.
- Align local action with the national strategy, enabling "data-driven" policies.
- Cooperate with data.europa.eu and other countries to implement and adapt an impact assessment framework with domain-by-domain metrics.
- Develop user profiles and allow their contributions to the national portal.
- Improve data and metadata quality and localization through validation tools, artificial intelligence, and user-centric flows.
- Apply domain-specific standards to harmonize datasets and maximize interoperability, quality, and reusability.
- Offer advanced and certified training in regulations and data literacy.
- Collaborate internationally on reusable solutions, such as shared or open source software.
Spain is already working on many of these points to continue improving its open data offer. The aim is for more and more reusers to be able to easily take advantage of the potential of public information to generate services and solutions that generate a positive impact on society as a whole.
The position achieved by Spain in this European ranking is the result of the work of all public initiatives, companies, user communities and reusers linked to open data, which promote an ecosystem that does not stop growing. Thank you for the effort!
Entrevista
In this podcast we talk about transport and mobility data, a topic that is very present in our day-to-day lives. Every time we consult an application to find out how long a bus will take, we are taking advantage of open data linked to transport. In the same way, when an administration carries out urban planning or optimises traffic flows, it makes use of mobility data.
To delve into the challenges and opportunities behind the opening of this type of data by Spanish public administrations, we have two exceptional guests:
- Tania Gullón Muñoz-Repiso, director of the Division of Transport Studies and Technology of the Ministry of Transport and Sustainable Mobility.
- Alicia González Jiménez, deputy director in the General Subdirectorate of Cartography and Observation of the Territory of the National Geographic Institute.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. Both the IGN and the Ministry generate a large amount of data related to transport. Of all of them, can you tell us which data and services are made available to the public as open data?
Alicia González: On the part of the National Geographic Institute, I would say that everything: everything we produce is available to users, because since the end of 2015 the dissemination policy adopted by the General Directorate of the National Geographic Institute, through the Autonomous Organism National Center for Geographic Information (CNIG), which is where all products and services are distributed, is an open data policy, so that everything is distributed under the CC BY 4.0 license, which protects free and open use. You simply have to make an attribution, a mention of the origin of the data. So we are talking, in general, not only about transport, but about all kinds of data, about more than 100 products that represent more than two and a half million files that users are increasingly demanding. In fact, in 2024 we have had up to 20 million files downloaded, so it is in high demand. And specifically in terms of transmission networks, the fundamental set of data is the Geographic Reference Information of Transport Networks (IGR-RT). It is a multimodal geospatial dataset that is composed of five transport networks that are continuous throughout the national territory and also interconnected. Specifically, it contemplates:
1. The road network that is made up of the entire road network, regardless of its owner and that runs throughout the territory. There are more than 300 thousand kilometers of road that are also connected to all the street maps, to the urban road network of all population centers. That is, we have a road graph that backbones the entire territory, in addition to having connected the roads that are later distributed and disseminated in the National Topographic Map.
2. The second most important network is the rail transport network. It includes all the data of rail transport and also of metro, tram and other types of modes by rail.
3 and 4. In the maritime and air field, the networks are already limited to infrastructures, so that they contain all the ports on the Spanish coast and all the infrastructures of aerodromes, airports, heliports in the air part.
5. And finally, the last network, which is much more modest, is residual data: cable transport.
Everything is interconnected through intermodal relationships. It is a set of data that is generated from official sources. We cannot incorporate just any data, it must always be official data and it is generated within the framework of cooperation of the National Cartographic System.
As a dataset that complies with the INSPIRE Directive both in its definition and in the way it is disseminated through standard web services, it has also been classified as a high-value dataset in the mobility category, in accordance with the High-Value Data Enforcement Regulation. It is a fairly important and normalized set.
How can it be located and accessed? Precisely, as it is standard, it is catalogued in the IDE (Spatial Data Infrastructure) catalogue, thanks to the standard description of its metadata. It can also be located through the official INSPIRE (Information Publication Services) data and services catalog or is accessible through portals as relevant as the open data portal.
Once we have located it, how can the user access it? How can they see the data? There are several ways. The easiest: check your visualizer. All the data is displayed there and there are certain query tools to facilitate its use. And then, of course, through the CNIG download centre. There we publish all the data from all the networks and it is in great demand. And then the last way is to consult the standard web services that we generate, visualization services and downloads of different technologies. In other words, it is a set of data that is available to users for reuse.
Tania Gullón: In the Ministry we also share a lot of open data. I would like, in order not to take too long, to comment in particular on four large sets of data:
1. The first would be the OTLE, the Observatory of Transport and Logistics in Spain, which is an initiative of the Ministry of Transport, whose main objective is to provide a global and comprehensive vision of the situation of transport and logistics in Spain. It is organized into seven blocks: mobility, socio-economy, infrastructure, security, sustainability, metropolitan transport and logistics. These are not georeferenced data, but statistical data. The Observatory makes data, graphs, maps, indicators available to the public and, not only that, but also offers annual reports, monographs, conferences, etc. And also of the observatories that we have cross-border, which are done collaboratively with Portugal and France.
2. The second set of data I want to mention is the NAP, the National Multimodal Transport Access Point, which is an official digital platform managed by the Ministry of Transport, but which is developed collaboratively between the different administrations. Its objective is to centralise and publish all the digitised information on the passenger transport offer in the national territory of all modes of transport. What do we have here? All schedules, services, routes, stops of all transport services, road transport, urban, intercity, rural, discretionary buses on demand. There are 116 datasets. The one of rail transport, the schedules of all those trains, their stops, etc. Also of maritime transport and air transport. And this data is constantly updated in real time. To date, we only have static data in GTFS (General Transit Feed Specification) format, which can also be reused and in a standard format that is useful for the further development of mobility applications by reusers. And while this NAP initially focused on static data, such as those routes, schedules, and stops, progress is being made toward incorporating dynamic data as well. In fact, in December we also have an obligation under European regulations that oblige us to have this data in real time to, in the end, improve all that transport planning and the user experience.
3. The third dataset is Hermes. It is the geographic information system of the general interest transport network. What is its objective? To offer a comprehensive vision, in this case georeferenced. Here I want to refer to what my colleague Alicia has commented, so that you can see how we are all collaborating with each other. We are not inventing anything, but everything is projected on those axes of the roads, for example, RT, the geographical reference information of the transport network. And what is done is to add all these technical parameters, as an added value to have a complete, comprehensive, multimodal information system for roads, railways, ports, airports, railway terminals and also waterways. It is a GIS (Geographic Information System), which allows all this analysis, not only downloading, consulting, with those open web services that we put at the service of citizens, but also in an open data catalog made with CKAN, which I will comment on later. Well, in the end there are more than 300 parameters that can be consulted. What are we talking about? For each section of road, the average traffic intensity, the average speed, the capacity of the infrastructures, planned actions are also known -not only the network in service, but also the planned network, the actions that the Ministry plans to carry out-, the ownership of the road, the lengths, speeds, accidents... well, many parameters, modes of access, co-financed projects, alternative fuels issues, the trans-European transport network, etc. That's the third of the datasets.
4. The fourth set is perhaps the largest because it is 16 GB per day. This is the project we call Big Data Mobility. This project is a pioneering initiative that uses Big Data and artificial intelligence technologies to analyze in depth the mobility patterns in the country is mainly based on the analysis of the anonymized mobile phone records of the population to obtain detailed information on all the movements of people not individualized, but aggregated at the census district level. Since 2020, a daily mobility study has been carried out and all this data is given openly. That is mobility by hours, by origin / destination that allows us to monitor and evaluate the demand for transport to plan improvements in those infrastructures and services. In addition, as data is given in open space, it can be used for any purpose, for tourism purposes, for research...
2. How is this data generated and collected? What challenges do you have to face in this process and how do you solve them?
Alicia González: Specifically, in the field of products that are technologically generated in geographic information system environments and geospatial databases, in the end these are projects in which the fundamental basis is the capture of data and the integration of existing reference sources. When we see that the headline has a piece of information, that is the one that must be integrated. In summary, in the main technical works, the following could be identified:
- On the one hand, capture, that is, when we want to store a geographical object we have to digitize it, draw it. Where? On an appropriate metric basis such as the aerial orthophotographs of the National Plan of Aerial Orthophotography (PNOA), which is also another dataset that is available and open. Well, when we have, for example, to draw or digitize a road, we trace it on that aerial image that PNOA provides us.
- Once we have captured that geometric component, we have to provide it with an attribution and not just any data will do, they have to be official sources. So, we have to locate who is the owner of that infrastructure or who is the provider of the official data to detect what the attributes are, the characterization that we want to give to that information, which in principle was only geometric. To do this, we have to carry out a series of source validation processes, detect that it does not have incidents and processes that we call integration, which are quite complex to guarantee that the result meets what we want.
- And finally, a fundamental phase in all these projects is the assurance of geometric and semantic quality. In other words, a series of quality controls must be developed and executed to validate the product, the final result of that integration and confirm that it meets the requirements indicated in the product specification.
In terms of challenges, a fundamental challenge is data governance, that is, the result that is generated is fed from certain sources, but in the end the result is created. Then you have to define the role of each provider that may later later be a user. Another challenge in this whole process is locating data providers. Sometimes the person responsible for that infrastructure or the object that we want to store in the database does not publish the information in a standardized way or it is difficult to locate because it is not in a catalog. Sometimes it is difficult to locate the official source you need to complete the geographical information. And looking a little at the user, I would highlight that another challenge is to identify, to have the agility to identify in a flexible and fast way the use cases that are changing with users, who are demanding us, because in the end it is about continuing to be relevant to society. Finally, and because the Geographic Institute is a scientific and technical environment and this part affects us a lot, another challenge is digital transformation, that is, we are working on technological projects, so we also have to have a lot of capacity to manage change and adapt to new technologies.
Tania Gullón: Regarding how data is generated and collected and the challenges we face, for example, the NAP, the National Access Point for Multimodal Transport, is a collaborative generation, that is, here the data comes from the autonomous communities themselves, from the consortia and from the transport companies. The challenge is that there are many autonomous communities that are not yet digitized, there are many companies... The digitalisation of the sector is going slowly – it is going, but it is going slowly. In the end there is incomplete data, duplicate data. Governance is not yet well defined. It happens to us that, imagine, the company ALSA raises all its buses, but it has buses in all the autonomous communities. And if at the same time the autonomous community uploads its data, that data is duplicated. It's as simple as that. It is true that we are just starting and that governance is not yet well defined, so that there is no excess data. Before they were missing and now there are almost too many.
In Hermes, the geographic information system, what is done, as I said, is to project it on the information of the transport networks, which is the official one that Alicia mentioned, and data from the different managers and administrators of infrastructures are integrated, such as Adif, Puertos del Estado, AENA, the General Directorate of Roads, ENAIRE, etc. What is the main challenge - if you had to stand out, because we can talk about this for an hour? It has cost us a lot, we have been working on this project for seven years and it has cost a lot because, first, people did not believe it. They didn't think it was going to work and they didn't collaborate. In the end, all this is knocking on the door of Adif, of AENA and changing that awareness in which data cannot be in a drawer, but must all be put at the service of the common good. And I think that's what has cost us a little more. In addition, there is the issue of governance, which Alicia has already commented on. You go to ask for a piece of information and in the organization itself they do not know who is the owner of that data, because perhaps the traffic data is handled by different departments. And who owns it? All this is very important.
We have to say that Hermes has been the great promoter of the Data offices, of the Adif Data office. In the end they have realized that what they needed was to put their house in order, as well as in everyone's house and in the Ministry as well, that Data offices are needed.
In the Big Data project, how is the data generated? In this case it is completely different. It is a pioneering project, more of new technologies, in which data is generated from anonymized mobile phone records. So, by reconstructing all that large amount of Big Data data, of the records that are in each antenna in Spain, with artificial intelligence and with a series of algorithms, these matrices are reconstructed and made. Then, those data from that sample – in the end we have a sample of 30% of the population, of more than 13 million mobile lines – is extrapolated with open data from the INE. And then, what do we do as well? It is calibrated with external sources, that is, with sources of certain reference, such as AENA ticketing, flights, Renfe data, etc. We calibrate this model to be able to generate these matrices with quality. The challenges: that it is very experimental. To give you an idea, we are the only country that has all this data. So we have been opening a gap and learning along the way. The difficulty is, again, the data. That data to calibrate, it is difficult for us to find it and to be given it with a certain periodicity and so on, because this goes in real time and we permanently need that flow of data. Also the adaptation to the user, as Alicia has said. We must adapt to what society and the reusers of this Big Data are demanding. And we must also keep pace, as Alicia said, with technology, which is not the same as the telephony data that exists now as it was two years ago. And the great challenge of quality control. But well, here I think I'm going to leave Alicia, who is the super expert, to explain to us what mechanisms exist to ensure that the data are reliable and updated and comparable. And then I will give you my vision, if you like.
Alicia González: How can reliability, updating and comparison be guaranteed? I don't know if reliability can be guaranteed, but I think there may be a couple of indicators that are especially relevant. One is the degree to which a set of data conforms to the regulations that concern it. In the field of geographic information, the way of working is always standardized, that is, there is a family of ISO 19100 on Geographic Information/Geomatics or the INSPIRE Directive itself, which greatly conditions the way of working and publishing data. And also, looking at the public administration, I think that the official seal should also be a guarantee of reliability. In other words, when we process data we must do so in a homogeneous and unbiased way, while perhaps, perhaps, a private company may be conditioned by them. I believe that these two parameters are important, that they can indicate reliability.
In terms of the degree of updating and comparison of the data, I believe that the user deduces this information from the metadata. The metadata at the end is the cover letter for the datasets. So, if a dataset is correctly and truthfully metadatad, and if it is also made according to standard profiles – the same in the GEO field, since we are talking about the INPIRE or GeoDCAT-AP profile – if different datasets are defined in their metadata according to these standardized profiles, it is much easier to see if they are comparable and the user can determine and decide if it finally satisfies their update and comparability with another dataset.
Tania Gullón: Totally Alicia. And if you allow me to add, we, for example, in Big Data have always been very committed to measuring quality – more so when they are new technologies that, at first, people did not trust the results that come out of all this. Always trying to measure this quality - which, in this case, is very difficult because they are large data sets - from the beginning we started designing processes that take time. The daily quality control process of the data takes seven hours, but it is true that at the beginning we had to detect if an antenna had fallen, if something had happened... Then we do a control with statistical parameters and other internal consistency and what we detect here are the anomalies. What we are seeing is that 90% of the anomalies that come out are real mobility anomalies. In other words, there are no errors in the data, but they are anomalies: there has been a demonstration or there has been a football match. These are issues that distort mobility. Or there's been a storm or a rain or anything like that. And it is important not only to control that quality and see if there are anomalies, but we also believe that it is very important to publish those quality criteria: how we are measuring quality and above all the results. Not only do we give the data on a daily basis, but we also give this metadata, which Alicia says, of quality, of what the sample was like that day, of those values that have been obtained from anomalies. This also occurs in the open: not only the data, but the metadata. And then we also publish the anomalies and the reason for those errors. When errors are found we say "okay, there has been an anomaly because in the town - I don't know what to imagine, it is all of Spain - del Casar was the festival of the Casar cake". And that's it, the anomaly has been found and it is published.
And how do you measure another quality parameter: thematic accuracy? In this case, comparing with sources of true reference. We know that evolution with respect to itself is already very controlled with that internal logical consistency, but we also have to compare it with what happens in the real world. I talked about it before with Alicia, we said "the data is reliable, but what is the reality of mobility? Who knows her?" In the end we have some clues, such as in the tickets of how many have boarded the buses. If we have that data, we have a clue, but of the people who walk and the people who take their cars and so on, what is the reality? It is very difficult to have a point of comparison, but we do compare it with all the data from AENA, Renfe, bus concessions and all these controls are passed to determine how far we deviate from that reality that we can know.
3. All this data serves as a basis for developing applications and solutions, but it is also essential when it comes to making decisions and accelerating the implementation of the central axes, for example, the Safe, Sustainable and Connected Mobility Strategy or the Sustainable Mobility Bill. How is this data used to make these real decisions?
Tania Gullón: If you will allow me, I would first like to introduce this strategy and the Law on data for those who do not know it. One of the axes, axis 5 of the Ministry's Safe, Sustainable and Connected Mobility Strategy 2030 is "Smart Mobility". And it is precisely focused on this and its main objective is to promote digitalisation, innovation and the use of advanced technologies to improve efficiency, sustainability and user experience in Spain's transport system. And precisely one of the measures of this axis is the "facilitation of Mobility as a Service, Open Data and New Technologies". In other words, this is where all these projects that we are commenting on are framed. In fact, one submeasure is to promote the publication of open mobility data, another is to carry out analysis of mobility flows and another of the measures, the last, is the creation of an integrated mobility data space. I would like to emphasize - and here I am already in line with this Bill that we hope we will soon see approved - that the Law, in Article 89, regulates the National Access Point, which we also see how it is included in this legislative instrument. And then the Law establishes a key digital instrument for the National Sustainable Mobility System: look at the importance given to the data that in a mobility law it is written that this integrated mobility data space is a key digital instrument. This data space is a reliable data sharing ecosystem, materialized as the digital infrastructure managed by the Ministry of Transport and in coordination with SEDIA (the Secretary of State for Digitalization and Artificial Intelligence), whose objective is to centralize and structure the information on mobility generated by public administrations, transport operators, infrastructure managers, etc. and guarantee that open access to all this data for all administrations under regulatory conditions.
Alicia González: In this case, I want to say that any objective decision-making, of course, has to be made based on data that, as we said before, has to be reliable, up-to-date and comparable. In this sense, it should be noted that the IGN, the fundamental support it offers to the Ministry for the deployment of the Safe, Sustainable and Connected Mobility Strategy, is the provision of service data and complex analysis of geospatial information. Many of them, of course, about the set of data that we have been talking about transport networks.
In this sense, we would like to mention as an example the accessibility maps with which we contribute to axis 1 of the "Mobility for all" strategy, in which, through the Rural Mobility Table, the IGN was asked if we could generate maps that represented the cost in time and distance that it costs any citizen. Living in any population centre, access to the nearest transport infrastructure, starting with the road network. In other words, how much it costs a user in terms of effort, time and distance, to access the nearest motorway or dual carriageway from their home and then, by extension, to any road in the basic network. We did that analysis - so I said that this network is the backbone of the entire territory, it is continuous - and we finally published those results via the web. They are also open data, any user can consult them and, in addition, we also offer them not only numerically, but also represented in different types of maps. In the end, this geolocated visibility of the result provides fundamental value and facilitates, of course, strategic decision-making in terms of infrastructure planning.
Another example to highlight that is possible thanks to the availability of open data is the calculation of monitoring indicators of the Sustainable Development Goals of the 2030 Agenda. Currently, in collaboration with the National Institute of Statistics, we are working on the calculation of several of them, including one directly associated with Transport, which seeks to monitor goal 11, which is to make cities more inclusive, safe, resilient and sustainable.
4. Speaking of this data-based decision-making, there is also cooperation at the level of data generation and reuse between different public administrations. Can you tell us about any examples of a project?
Tania Gullón: I also answer that to data-based decision-making, which I have previously beaten around the bush with the issue of the Law. It can also be said that all this Big Data data, Hermes and everything we have discussed is favouring this shift of the Ministry and organisations towards data-based organisations, which means that decisions are based on that analysis of objective data. When you ask like that for an example, I have so many that I wouldn't know what to tell you. In the case of Big Data data, it has been used for infrastructure planning for a few years now. Before, it was done with surveys and it was sized because how many lanes do I put on a road? Or something very basic, how often do we need on a train? Well, if you don't have data on what the demand is going to be, you can't plan it. This is done with Big Data data, not only by the Ministry but, as it is open, it is used by all administrations, all city councils and all infrastructure managers. Knowing the mobility needs of the population allows us to adapt our infrastructures and our services to these real needs. For example, commuter services in Galicia are now being studied. Or imagine the burying of the A-5. They are also used for emergencies, which we have not commented on, but they are also key. We always realize that when there is an emergency, suddenly everyone thinks "data, where is data, where is the open data?", because they have been fundamental. I can tell you, in the case of the Dana, which is perhaps the most recent, several commuter train lines were seriously affected, the tracks were destroyed, and 99% of the vehicles of the people who lived in Paiporta, in Torrent, in the entire affected area, were disabled. And 1% was because he was not in the Dana area at the time. So mobility had to be restored as soon as possible, because thanks to this open data in a week there were buses doing alternative transport services that had been planned with Big Data data. In other words, look at the impact on the population.
Speaking of emergencies, this project was born precisely because of an emergency, because of COVID. In other words, the study, this Big Data, was born in 2020 because the Presidency of the Government was in charge of monitoring this mobility on a daily basis and giving it openly. And here I link with that collaboration between administrations, organizations, companies, universities. Because look, these mobility data fed the epidemiological models. Here we work with the Carlos III Institute, with the Barcelona Supercomputing Center, with these institutes and research centers that were beginning to size hospital beds for the second wave. When we were still in the first wave, we didn't even know what a wave was and they were already telling us "be careful, because there is going to be a second wave, and with this mobility data and so on we will be able to measure how many beds are going to be needed, according to the epidemiological model". Look at the important reuse. We know that this data, for example, from Big Data is being used by thousands of companies, administrations, research centers, researchers around the world. In addition, we receive inquiries from Germany, from all countries, because in Spain we are a bit of a pioneer in this matter of giving all the data openly. We are there creating a school and not only for transportation, but for tourism issues as well, for example.
Alicia González: In the field of geographic information, at the level of cooperation, we have a specific instrument that is the National Cartographic System, which directly promotes coordination in the actions of the different administrations in terms of geographic information. We do not know how to work in any other way than by cooperating. And a clear example is the same set we have been talking about: the set of geographic reference information on transport networks is the result of this cooperation. That is to say, at the national level it is promoted and promoted by the Geographic Institute, but in its updating, regional cartographic agencies with different ranges of collaboration also participate in its production. The maximum is even reached for co-production of data from certain subsets in certain areas. In addition, one of the characteristics of this product is that it is generated from official data from other sources. In other words, there is already collaboration there no matter what. There is cooperation because there is an integration of data, because in the end it has to be filled in with the official data. And to begin with, perhaps it is data provided by INE, the Cadastre, the cartographic agencies themselves, the local street maps... But, once the result has been formed, as I mentioned before, the result has an added value that is of interest to the original supplier itself. For example, this dataset is reused internally, at home, in the IGN: any product or service that requires transport information is fed into this dataset. There is an internal reuse there, but also in the field of public administrations, at all levels. In the state sector, for example, in the Cadastre, once the result has been generated, it is of interest to them for studies to analyse the delimitation of the public domain associated with infrastructures, for example. Or the Ministry itself, as Tania commented before. Hermes was generated from RT data processing, from transport network data. The Directorate-General for Roads uses transport networks in its internal management to make a traffic map, its catalogue management, etc. And in the autonomous communities themselves, the result generated is also useful to them in cartographic agencies or even at the local level. Then there is a continuous cyclical reuse, as it should be, in the end everything is public money and it has to be reused as much as possible. And in the private sphere, it is also reused and value-added services are generated from this data that are provided in multiple use cases. Not to go on too long, simply that: we participate by providing data on which value-added services are generated.
5. And finally, you can briefly recap some ideas that highlight the impact on daily life and the commercial potential of this data for reusers.
Alicia González: Very briefly, I think that the fundamental impact on everyday life is that the distribution of open data has made it possible to democratize access to data for everyone, for companies, but also for citizens; and, above all, I think it has been fundamental in the academic field, where surely, currently, it is easier to develop certain investigations that in other times were more complex. And another impact on daily life is the institutional transparency that this implies. And as for the commercial potential of reusers, I reiterate the previous idea: the availability of data drives innovation and the increase of value-added solutions. In this sense, looking at one of the conclusions of the report that was carried out in 2024 by ASEDIE; the Association of Infomedia Companies, on the impact that the geospatial data published by the CNIG had on the private sector, there were a couple of quite important conclusions. One of them said that every time a new set of data is released, reusers are incentivized to generate value-added solutions and, in addition, it allows them to focus their efforts on this development of innovation and not so much on data capture. And it was also clear from that report that since the adoption of the open data policy that I mentioned at the beginning, which was adopted in 2015 by the IGN, 75% of the companies surveyed responded that they had been able to significantly expand the catalogue of products and services based on this open data. Then, I believe that the impact is ultimately enriching for society as a whole.
Tania Gullón: I subscribe to all of Alicia's words, I totally agree. And also, that small transport operators and municipalities with fewer resources have at their disposal all this open and free quality data and access to digital tools that allow them to compete on equal terms. In the case of companies or municipalities, imagine being able to plan their transport and be more efficient. Not only does it save them money, but they win in the end in the service to the citizen. And of course, the fact that in the public sector decisions are made based on data and this ecosystem of data sharing is encouraged, favouring the development of mobility applications, for example, has a direct impact on people's daily lives. Or also the issue of transport aid: the study of the impact of transport subsidies with accessibility data and so on. You study who are the most vulnerable and in the end, what do you do? Well, that policies are increasingly fairer and this obviously impacts the citizen. That decisions about how to invest everyone's money, our taxes, how to invest it in infrastructure or aid or services, should be based on objective data and not on intuitions, but on real data. This is the most important thing.
Interview clips
1. What data does the Ministry of Transport and Sustainable Mobility make publicly available?
2. What data does the National Geographic Institute (IGN) make publicly available?
Blog
Cities, infrastructures and the environment today generate a constant flow of data from sensors, transport networks, weather stations and Internet of Things (IoT) platforms, understood as networks of physical devices (digital traffic lights, air quality sensors, etc.) capable of measuring and transmitting information through digital systems. This growing volume of information makes it possible to improve the provision of public services, anticipate emergencies, plan the territory and respond to challenges associated with climate, mobility or resource management.
The increase in connected sources has transformed the nature of geospatial data. In contrast to traditional sets – updated periodically and oriented towards reference cartography or administrative inventories – dynamic data incorporate the temporal dimension as a structural component. An observation of air quality, a level of traffic occupancy or a hydrological measurement not only describes a phenomenon, but also places it at a specific time. The combination of space and time makes these observations fundamental elements for operating systems, predictive models and analyses based on time series.
In the field of open data, this type of information poses both opportunities and specific requirements. Opportunities include the possibility of building reusable digital services, facilitating near-real-time monitoring of urban and environmental phenomena, and fostering a reuse ecosystem based on continuous flows of interoperable data. The availability of up-to-date data also increases the capacity for evaluation and auditing of public policies, by allowing decisions to be contrasted with recent observations.
However, the opening of geospatial data in real time requires solving problems derived from technological heterogeneity. Sensor networks use different protocols, data models, and formats; the sources generate high volumes of observations with high frequency; and the absence of common semantic structures makes it difficult to cross-reference data between domains such as mobility, environment, energy or hydrology. In order for this data to be published and reused consistently, an interoperability framework is needed that standardizes the description of observed phenomena, the structure of time series, and access interfaces.
The open standards of the Open Geospatial Consortium (OGC) provide that framework. They define how to represent observations, dynamic entities, multitemporal coverages or sensor systems; establish APIs based on web principles that facilitate the consultation of open data; and allow different platforms to exchange information without the need for specific integrations. Its adoption reduces technological fragmentation, improves coherence between sources and favours the creation of public services based on up-to-date data.
Interoperability: The basic requirement for opening dynamic data
Public administrations today manage data generated by sensors of different types, heterogeneous platforms, different suppliers and systems that evolve independently. The publication of geospatial data in real time requires interoperability that allows information from multiple sources to be integrated, processed and reused. This diversity causes inconsistencies in formats, structures, vocabularies and protocols, which makes it difficult to open the data and reuse it by third parties. Let's see which aspects of interoperability are affected:
- Technical interoperability: refers to the ability of systems to exchange data using compatible interfaces, formats and models. In real-time data, this exchange requires mechanisms that allow for fast queries, frequent updates, and stable data structures. Without these elements, each flow would rely on ad hoc integrations, increasing complexity and reducing reusability.
- The Semantic interoperability: Dynamic data describe phenomena that change over short periods – traffic levels, weather parameters, flows, atmospheric emissions – and must be interpreted consistently. This implies having observation models, Vocabularies and common definitions that allow different applications to understand the meaning of each measurement and its units, capture conditions or constraints. Without this semantic layer, the opening of data in real time generates ambiguity and limits its integration with data from other domains.
- Structural interoperability: Real-time data streams tend to be continuous and voluminous, making it necessary to represent them as time series or sets of observations with consistent attributes. The absence of standardized structures complicates the publication of complete data, fragments information and prevents efficient queries. To provide open access to these data, it is necessary to adopt models that adequately represent the relationship between observed phenomenon, time of observation, associated geometry and measurement conditions.
- Interoperability in access via API: it is an essential condition for open data. APIs must be stable, documented, and based on public specifications that allow for reproducible queries. In the case of dynamic data, this layer guarantees that the flows can be consumed by external applications, analysis platforms, mapping tools or monitoring systems that operate in contexts other than the one that generates the data. Without interoperable APIs, real-time data is limited to internal uses.
Together, these levels of interoperability determine whether dynamic geospatial data can be published as open data without creating technical barriers.
OGC Standards for Publishing Real-Time Geospatial Data
The publication of georeferenced data in real time requires mechanisms that allow any user – administration, company, citizens or research community – to access them easily, with open formats and through stable interfaces. The Open Geospatial Consortium (OGC) develops a set of standards that enable exactly this: to describe, organize and expose spatial data in an interoperable and accessible way, which contributes to the openness of dynamic data.
What is OGC and why are its standards relevant?
The OGC is an international organization that defines common rules so that different systems can understand, exchange and use geospatial data without depending on specific technologies. These rules are published as open standards, which means that any person or institution can use them. In the realm of real-time data, these standards make it possible to:
- Represent what a sensor measures (e.g., temperature or traffic).
- Indicate where and when the observation was made.
- Structure time series.
- Expose data through open APIs.
- Connect IoT devices and networks with public platforms.
Together, this ecosystem of standards allows geospatial data – including data generated in real time – to be published and reused following a consistent framework. Each standard covers a specific part of the data cycle: from the definition of observations and sensors, to the way data is exposed using open APIs or web services. This modular organization makes it easier for administrations and organizations to select the components they need, avoiding technological dependencies and ensuring that data can be integrated between different platforms.
The OGC API family: Modern APIs for accessing open data
Within OGC, the newest line is family OGC API, a set of modern web interfaces designed to facilitate access to geospatial data using URLs and formats such as JSON or GeoJSON, common in the open data ecosystem.
Estas API permiten:
- Get only the part of the data that matters.
- Perform spatial searches ("give me only what's in this area").
- Access up-to-date data without the need for specialized software.
- Easily integrate them into web or mobile applications.
In this report: "How to use OGC APIs to boost geospatial data interoperability", we already told you about some of the most popular OGP APIs. While the report focuses on how to use OGC APIs for practical interoperability, this post expands the focus by explaining the underlying OGC data models—such as O&M, SensorML, or Moving Features—that underpin that interoperability.
On this basis, this post focuses on the standards that make this fluid exchange of information possible, especially in open data and real-time contexts. The most important standards in the context of real-time open data are:
|
OGC Standard |
What it allows you to do |
Primary use in open data |
|---|---|---|
|
OGC API – Features |
Query features with geometry; filter by time or space; get data in JSON/GeoJSON. |
Open publication of dynamic mobility data, urban inventories, static sensors. |
|
OGC API – Environmental Data Retrieval (EDR) |
Request environmental observations at a point, zone or time interval. |
Open data on meteorology, climate, air quality or hydrology. |
|
OGC SensorThings API |
Manage sensors and their time series; transmit large volumes of IoT data. |
Publication of urban sensors (air, noise, water, energy) in real time. |
|
OGC API – Connected Systems |
Describe networks of sensors, devices and associated infrastructures. |
Document the structure of municipal IoT systems as open data. |
|
OGC Moving Features |
Represent moving objects using space-time trajectories. |
Open mobility data (vehicles, transport, boats). |
|
WMS-T |
View maps that change over time. |
Publication of multi-temporal weather or environmental maps. |
Table 1. OGC Standards Relevant to Real-Time Geospatial Data
Models that structure observations and dynamic data
In addition to APIs, OGC defines several conceptual data models that allow you to consistently describe observations, sensors, and phenomena that change over time:
- O&M (Observations & Measurements): A model that defines the essential elements of an observation—measured phenomenon, instant, unity, and result—and serves as the semantic basis for sensor and time series data.
- SensorML: Language that describes the technical and operational characteristics of a sensor, including its location, calibration, and observation process.
- Moving Features: A model that allows mobile objects to be represented by means of space-time trajectories (such as vehicles, boats or fauna).
These models make it easy for different data sources to be interpreted uniformly and combined in analytics and applications.
The value of these standards for open data
Using OGC standards makes it easier to open dynamic data because:
- It provides common models that reduce heterogeneity between sources.
- It facilitates integration between domains (mobility, climate, hydrology).
- Avoid dependencies on proprietary technology.
- It allows the data to be reused in analytics, applications, or public services.
- Improves transparency by documenting sensors, methods, and frequencies.
- It ensures that data can be consumed directly by common tools.
Together, they form a conceptual and technical infrastructure that allows real-time geospatial data to be published as open data, without the need to develop system-specific solutions.
Real-time open geospatial data use cases
Real-time georeferenced data is already published as open data in different sectoral areas. These examples show how different administrations and bodies apply open standards and APIs to make dynamic data related to mobility, environment, hydrology and meteorology available to the public.
Below are several domains where Public Administrations already publish dynamic geospatial data using OGC standards.
Mobility and transport
Mobility systems generate data continuously: availability of shared vehicles, positions in near real-time, sensors for crossing in cycle lanes, traffic gauging or traffic light intersection status. These observations rely on distributed sensors and require data models capable of representing rapid variations in space and time.
OGC standards play a central role in this area. In particular, the OGC SensorThings API allows you to structure and publish observations from urban sensors using a uniform model – including devices, measurements, time series and relationships between them – accessible through an open API. This makes it easier for different operators and municipalities to publish mobility data in an interoperable way, reducing fragmentation between platforms.
The use of OGC standards in mobility not only guarantees technical compatibility, but also makes it possible for this data to be reused together with environmental, cartographic or climate information, generating multi-thematic analyses for urban planning, sustainability or operational transport management.
Example:
The open service of Toronto Bike Share, which publishes in SensorThings API format the status of its bike stations and vehicle availability.
Here each station is a sensor and each observation indicates the number of bicycles available at a specific time. This approach allows analysts, developers or researchers to integrate this data directly into urban mobility models, demand prediction systems or citizen dashboards without the need for specific adaptations.
Air quality, noise and urban sensors
Networks for monitoring air quality, noise or urban environmental conditions depend on automatic sensors that record measurements every few minutes. In order for this data to be integrated into analytics systems and published as open data, consistent models and APIs need to be available.
In this context, services based on OGC standards make it possible to publish data from fixed stations or distributed sensors in an interoperable way. Although many administrations use traditional interfaces such as OGC WMS to serve this data, the underlying structure is usually supported by observation models derived from the Observations & Measurements (O&M) family, which defines how to represent a measured phenomenon, its unit and the moment of observation.
Example:
The service Defra UK-AIR Sensor Observation Service provides access to near-real-time air quality measurement data from on-site stations in the UK.
The combination of O&M for data structure and open APIs for publication makes it easier for these urban sensors to be part of broader ecosystems that integrate mobility, meteorology or energy, enabling advanced urban analyses or environmental dashboards in near real-time.
Water cycle, hydrology and risk management
Hydrological systems generate crucial data for risk management: river levels and flows, rainfall, soil moisture or information from hydrometeorological stations. Interoperability is especially important in this domain, as this data is combined with hydraulic models, weather forecasting, and flood zone mapping.
To facilitate open access to time series and hydrological observations, several agencies use OGC API – Environmental Data Retrieval (EDR), an API designed to retrieve environmental data using simple queries at points, areas, or time intervals.
Example:
The USGS (United States Geological Survey), which documents the use of OGC API – EDR to access precipitation, temperature, or hydrological variable series.
This case shows how EDR allows you to request specific observations by location or date, returning only the values needed for analysis. While the USGS's specific hydrology data is served through its proprietary API, this case demonstrates how EDR fits into the hydrometeorological data structure and how it is applied in real operational flows.
The use of OGC standards in this area allows dynamic hydrological data to be integrated with flood zones, orthoimages or climate models, creating a solid basis for early warning systems, hydraulic planning and risk assessment.
Weather observation and forecasting
Meteorology is one of the domains with the highest production of dynamic data: automatic stations, radars, numerical prediction models, satellite observations and high-frequency atmospheric products. To publish this information as open data, the OGC API family is becoming a key element, especially through OGC API – EDR, which allows observations or predictions to be retrieved in specific locations and at different time levels.
Example:
The service NOAA OGC API – EDR, which provides access to weather data and atmospheric variables from the National Weather Service (United States).
This API allows data to be consulted at points, areas or trajectories, facilitating the integration of meteorological observations into external applications, models or services based on open data.
The use of OGC API in meteorology allows data from sensors, models, and satellites to be consumed through a unified interface, making it easy to reuse for forecasting, atmospheric analysis, decision support systems, and climate applications.
Best Practices for Publishing Open Geospatial Data in Real-Time
The publication of dynamic geospatial data requires adopting practices that ensure its accessibility, interoperability, and sustainability. Unlike static data, real-time streams have additional requirements related to the quality of observations, API stability, and documentation of the update process. Here are some best practices for governments and organizations that manage this type of data.
- Stable open formats and APIs: The use of OGC standards – such as OGC API, SensorThings API or EDR – makes it easy for data to be consumed from multiple tools without the need for specific adaptations. APIs must be stable over time, offer well-defined versions, and avoid dependencies on proprietary technologies. For raster data or dynamic models, OGC services such as WMS, WMTS, or WCS are still suitable for visualization and programmatic access.
- DCAT-AP and OGC Models Compliant Metadata: Catalog interoperability requires describing datasets using profiles such as DCAT-AP, supplemented by O&M-based geospatial and observational metadata or SensorML. This metadata should document the nature of the sensor, the unit of measurement, the sampling rate, and possible limitations of the data.
- Quality, update frequency and traceability policies: dynamic datasets must explicitly indicate their update frequency, the origin of the observations, the validation mechanisms applied and the conditions under which they were generated. Traceability is essential for third parties to correctly interpret data, reproduce analyses and integrate observations from different sources.
- Documentation, usage limits, and service sustainability: Documentation should include usage examples, query parameters, response structure, and recommendations for managing data volume. It is important to set reasonable query limits to ensure the stability of the service and ensure that management can maintain the API over the long term.
- Licensing aspects for dynamic data: The license must be explicit and compatible with reuse, such as CC BY 4.0 or CC0. This allows dynamic data to be integrated into third-party services, mobile applications, predictive models or services of public interest without unnecessary restrictions. Consistency in the license also facilitates the cross-referencing of data from different sources.
These practices allow dynamic data to be published in a way that is reliable, accessible, and useful to the entire reuse community.
Dynamic geospatial data has become a structural piece for understanding urban, environmental and climatic phenomena. Its publication through open standards allows this information to be integrated into public services, technical analyses and reusable applications without the need for additional development. The convergence of observation models, OGC APIs, and best practices in metadata and licensing provides a stable framework for administrations and reusers to work with sensor data reliably. Consolidating this approach will allow progress towards a more coherent, connected public data ecosystem that is prepared for increasingly demanding uses in mobility, energy, risk management and territorial planning.
Content created by Mayte Toscano, Senior Consultant in Technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Blog
We live in an age where more and more phenomena in the physical world can be observed, measured, and analyzed in real time. The temperature of a crop, the air quality of a city, the state of a dam, the flow of traffic or the energy consumption of a building are no longer data that are occasionally reviewed: they are continuous flows of information that are generated second by second.
This revolution would not be possible without cyber-physical systems (CPS), a technology that integrates sensors, algorithms and actuators to connect the physical world with the digital world. But CPS does not only generate data: it can also be fed by open data, multiplying its usefulness and enabling evidence-based decisions.
In this article, we will explore what CPS is, how it generates massive data in real time, what challenges it poses to turn that data into useful public information, what principles are essential to ensure its quality and traceability, and what real-world examples demonstrate the potential for its reuse. We will close with a reflection on the impact of this combination on innovation, citizen science and the design of smarter public policies.
What are cyber-physical systems?
A cyber-physical system is a tight integration between digital components – such as software, algorithms, communication and storage – and physical components – sensors, actuators, IoT devices or industrial machines. Its main function is to observe the environment, process information and act on it.
Unlike traditional monitoring systems, a CPS is not limited to measuring: it closes a complete loop between perception, decision, and action. This cycle can be understood through three main elements:
Figure 1. Cyber-physical systems cycle. Source: own elaboration
An everyday example that illustrates this complete cycle of perception, decision and action very well is smart irrigation, which is increasingly present in precision agriculture and home gardening systems. In this case, sensors distributed throughout the terrain continuously measure soil moisture, ambient temperature, and even solar radiation. All this information flows to the computing unit, which analyzes the data, compares it with previously defined thresholds or with more complex models – for example, those that estimate the evaporation of water or the water needs of each type of plant – and determines whether irrigation is really necessary.
When the system concludes that the floor has reached a critical level of dryness, the third element of CPS comes into play: the actuators. They are the ones who open the valves, activate the water pump or regulate the flow rate, and they do so for the exact time necessary to return the humidity to optimal levels. If conditions change—if it starts raining, if the temperature drops, or if the soil recovers moisture faster than expected—the system itself adjusts its behavior accordingly.
This whole process happens without human intervention, autonomously. The result is a more sustainable use of water, better cared for plants and a real-time adaptability that is only possible thanks to the integration of sensors, algorithms and actuators characteristic of cyber-physical systems.
CPS as real-time data factories
One of the most relevant characteristics of cyber-physical systems is their ability to generate data continuously, massively and with a very high temporal resolution. This constant production can be seen in many day-to-day situations:
- A hydrological station can record level and flow every minute.
- An urban mobility sensor can generate hundreds of readings per second.
- A smart meter records electricity consumption every few minutes.
- An agricultural sensor measures humidity, salinity, and solar radiation several times a day.
- A mapping drone captures decimetric GPS positions in real time.
Beyond these specific examples, the important thing is to understand what this capability means for the system as a whole: CPS become true data factories, and in many cases come to function as digital twins of the physical environment they monitor. This almost instantaneous equivalence between the real state of a river, a crop, a road or an industrial machine and its digital representation allows us to have an extremely accurate and up-to-date portrait of the physical world, practically at the same time as the phenomena occur.
This wealth of data opens up a huge field of opportunity when published as open information. Data from CPS can drive innovative services developed by companies, fuel high-impact scientific research, empower citizen science initiatives that complement institutional data, and strengthen transparency and accountability in the management of public resources.
However, for all this value to really reach citizens and the reuse community, it is necessary to overcome a series of technical, organisational and quality challenges that determine the final usefulness of open data. Below, we look at what those challenges are and why they are so important in an ecosystem that is increasingly reliant on real-time generated information.
The challenge: from raw data to useful public information
Just because a CPS generates data does not mean that it can be published directly as open data. Before reaching the public and reuse companies, the information needs prior preparation , validation, filtering and documentation. Administrations must ensure that such data is understandable, interoperable and reliable. And along the way, several challenges appear.
One of the first is standardization. Each manufacturer, sensor and system can use different formats, different sample rates or its own structures. If these differences are not harmonized, what we obtain is a mosaic that is difficult to integrate. For data to be interoperable, common models, homogeneous units, coherent structures, and shared standards are needed. Regulations such as INSPIRE or the OGC (Open Geospatial Consortium) and IoT-TS standards are key so that data generated in one city can be understood, without additional transformation, in another administration or by any reuser.
The next big challenge is quality. Sensors can fail, freeze always reporting the same value, generate physically impossible readings, suffer electromagnetic interference or be poorly calibrated for weeks without anyone noticing. If this information is published as is, without a prior review and cleaning process, the open data loses value and can even lead to errors. Validation – with automatic checks and periodic review – is therefore indispensable.
Another critical point is contextualization. An isolated piece of information is meaningless. A "12.5" says nothing if we don't know if it's degrees, liters or decibels. A measurement of "125 ppm" is useless if we do not know what substance is being measured. Even something as seemingly objective as coordinates needs a specific frame of reference. And any environmental or physical data can only be properly interpreted if it is accompanied by the date, time, exact location and conditions of capture. This is all part of metadata, which is essential for third parties to be able to reuse information unambiguously.
It's also critical to address privacy and security. Some CPS can capture information that, directly or indirectly, could be linked to sensitive people, property, or infrastructure. Before publishing the data, it is necessary to apply anonymization processes, aggregation techniques, security controls and impact assessments that guarantee that the open data does not compromise rights or expose critical information.
Finally, there are operational challenges such as refresh rate and robustness of data flow. Although CPS generates information in real time, it is not always appropriate to publish it with the same granularity: sometimes it is necessary to aggregate it, validate temporal consistency or correct values before sharing it. Similarly, for data to be useful in technical analysis or in public services, it must arrive without prolonged interruptions or duplication, which requires a stable infrastructure and monitoring mechanisms.
Quality and traceability principles needed for reliable open data
Once these challenges have been overcome, the publication of data from cyber-physical systems must be based on a series of principles of quality and traceability. Without them, information loses value and, above all, loses trust.
The first is accuracy. The data must faithfully represent the phenomenon it measures. This requires properly calibrated sensors, regular checks, removal of clearly erroneous values, and checking that readings are within physically possible ranges. A sensor that reads 200°C at a weather station or a meter that records the same consumption for 48 hours are signs of a problem that needs to be detected before publication.
The second principle is completeness. A dataset should indicate when there are missing values, time gaps, or periods when a sensor has been disconnected. Hiding these gaps can lead to wrong conclusions, especially in scientific analyses or in predictive models that depend on the continuity of the time series.
The third key element is traceability, i.e. the ability to reconstruct the history of the data. Knowing which sensor generated it, where it is installed, what transformations it has undergone, when it was captured or if it went through a cleaning process allows us to evaluate its quality and reliability. Without traceability, trust erodes and data loses value as evidence.
Proper updating is another fundamental principle. The frequency with which information is published must be adapted to the phenomenon measured. Air pollution levels may need updates every few minutes; urban traffic, every second; hydrology, every minute or every hour depending on the type of station; and meteorological data, with variable frequencies. Posting too quickly can generate noise; too slow, it can render the data useless for certain uses.
The last principle is that of rich metadata. Metadata explains the data: what it measures, how it is measured, with what unit, how accurate the sensor is, what its operating range is, where it is located, what limitations the measurement has and what this information is generated for. They are not a footnote, but the piece that allows any reuser to understand the context and reliability of the dataset. With good documentation, reuse isn't just possible: it skyrockets.
Examples: CPS that reuses public data to be smarter
In addition to generating data, many cyber-physical systems also consume public data to improve their performance. This feedback makes open data a central resource for the functioning of smart territories. When a CPS integrates information from its own sensors with external open sources, its anticipation, efficiency, and accuracy capabilities are dramatically increased.
Precision agriculture: In agriculture, sensors installed in the field allow variables such as soil moisture, temperature or solar radiation to be measured. However, smart irrigation systems do not rely solely on this local information: they also incorporate weather forecasts from AEMET, open IGN maps on slope or soil types, and climate models published as public data. By combining their own measurements with these external sources, agricultural CPS can determine much more accurately which areas of the land need water, when to plant, and how much moisture should be maintained in each crop. This fine management allows water and fertilizer savings that, in some cases, exceed 30%.
Water management: Something similar happens in water management. A cyber-physical system that controls a dam or irrigation canal needs to know not only what is happening at that moment, but also what may happen in the coming hours or days. For this reason, it integrates its own level sensors with open data on river gauging, rain and snow predictions, and even public information on ecological flows. With this expanded vision, the CPS can anticipate floods, optimize the release of the reservoir, respond better to extreme events or plan irrigation sustainably. In practice, the combination of proprietary and open data translates into safer and more efficient water management.
Impact: innovation, citizen science, and data-driven decisions
The union between cyber-physical systems and open data generates a multiplier effect that is manifested in different areas.
- Business innovation: Companies have fertile ground to develop solutions based on reliable and real-time information. From open data and CPS measurements, smarter mobility applications, water management platforms, energy analysis tools, or predictive systems for agriculture can emerge. Access to public data lowers barriers to entry and allows services to be created without the need for expensive private datasets, accelerating innovation and the emergence of new business models.
- Citizen science: the combination of SCP and open data also strengthens social participation. Neighbourhood communities, associations or environmental groups can deploy low-cost sensors to complement public data and better understand what is happening in their environment. This gives rise to initiatives that measure noise in school zones, monitor pollution levels in specific neighbourhoods, follow the evolution of biodiversity or build collaborative maps that enrich official information.
- Better public decision-making: finally, public managers benefit from this strengthened data ecosystem. The availability of reliable and up-to-date measurements makes it possible to design low-emission zones, plan urban transport more effectively, optimise irrigation networks, manage drought or flood situations or regulate energy policies based on real indicators. Without open data that complements and contextualizes the information generated by the CPS, these decisions would be less transparent and, above all, less defensible to the public.
In short, cyber-physical systems have become an essential piece of understanding and managing the world around us. Thanks to them, we can measure phenomena in real time, anticipate changes and act in a precise and automated way. But its true potential unfolds when its data is integrated into a quality open data ecosystem, capable of providing context, enriching decisions and multiplying uses.
The combination of SPC and open data allows us to move towards smarter territories, more efficient public services and more informed citizen participation. It provides economic value, drives innovation, facilitates research and improves decision-making in areas as diverse as mobility, water, energy or agriculture.
For all this to be possible, it is essential to guarantee the quality, traceability and standardization of the published data, as well as to protect privacy and ensure the robustness of information flows. When these foundations are well established, CPS not only measure the world: they help it improve, becoming a solid bridge between physical reality and shared knowledge.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Quantum computing promises to solve problems in hours that would take millennia for the world's most powerful supercomputers. From designing new drugs to optimizing more sustainable energy grids, this technology will radically transform our ability to address humanity's most complex challenges. However, its true democratizing potential will only be realized through convergence with open data, allowing researchers, companies, and governments around the world to access both quantum computing power in the cloud and the public datasets needed to train and validate quantum algorithms.
Trying to explain quantum theory has always been a challenge, even for the most brilliant minds humanity has given in the last 2 centuries. The celebrated physicist Richard Feynman (1918-1988) put it with his trademark humor:
"There was a time when newspapers said that only twelve men understood the theory of relativity. I don't think it was ever like that [...] On the other hand, I think I can safely say that no one understands quantum mechanics."
And that was said by one of the most brilliant physicists of the twentieth century, Nobel Prize winner and one of the fathers of quantum electrodynamics. So great is the rarity of quantum behavior in the eyes of a human that, even Albert Einstein himself, in his now mythical phrase, said to Max Born, in a letter written to the German physicist in 1926, "God does not play dice with the universe" in reference to his disbelief about the probabilistic and non-deterministic properties attributed to quantum behavior. To which Niels Bohr - another titan of physics of the twentieth century - replied: "Einstein, stop telling God what to do."
Classical computing
If we want to understand why quantum mechanics proposes a revolution in computer science, we have to understand its fundamental differences from mechanics - and, therefore, - classical computing. Almost all of us have heard of bits of information at some point in our lives. Humans have developed a way of performing complex mathematical calculations by reducing all information to bits - the fundamental units of information with which a machine knows how to work -, which are the famous zeros and ones (0 and 1). With two simple values, we have been able to model our entire mathematical world. And why? Some will ask. Why base 2 and not 5 or 7? Well, in our classic physical world (in which we live day to day) differentiating between 0 and 1 is relatively simple; on and off, as in the case of an electrical switch, or north or south magnetization, in the case of a magnetic hard drive. For a binary world, we have developed an entire coding language based on two states: 0 and 1.
Quantum computing
In quantum computing, instead of bits, we use qubits. Qubits use several "strange" properties of quantum mechanics that allow them to represent infinite states at once between zero and one of the classic bits. To understand it, it's as if a bit could only represent an on or off state in a light bulb, while a qubit can represent all the light bulb's illumination intensities. This property is known as "quantum superposition" and allows a quantum computer to explore millions of possible solutions at the same time. But this is not all in quantum computing. If quantum superposition seems strange to you, wait until you see quantum entanglement. Thanks to this property, two "entangled" particles (or two qubits) are connected "at a distance" so that the state of one determines the state of the other. So, with these two properties we have information qubits, which can represent infinite states and are connected to each other. This system potentially has an exponentially greater computing capacity than our computers based on classical computing.
Two application cases of quantum computing
1. Drug discovery and personalized medicine. Quantum computers can simulate complex molecular interactions that are impossible to compute with classical computing. For example, protein folding – fundamental to understanding diseases such as Alzheimer's – requires analyzing trillions of possible configurations. A quantum computer could shave years of research to weeks, speeding up the development of new drugs and personalized treatments based on each patient's genetic profile.
2. Logistics optimization and climate change. Companies like Volkswagen already use quantum computing to optimize traffic routes in real time. On a larger scale, these systems could revolutionize the energy management of entire cities, optimizing smart grids that integrate renewables efficiently, or design new materials for CO2 capture that help combat climate change.
A good read recommended for a complete review of quantum computing here.
The role of open data (and computing resources)
The democratization of access to quantum computing will depend crucially on two pillars: open computing resources and quality public datasets. This combination is creating an ecosystem where quantum innovation no longer requires millions of dollars in infrastructure. Here are some options available for each of these pillars.
- Free access to real quantum hardware:
- IBM Quantum Platform: Provides free monthly access to quantum systems of more than 100 qubits for anyone in the world. With more than 400,000 registered users who have generated more than 2,800 scientific publications, it demonstrates how open access accelerates research. Any researcher can sign up for the platform and start experimenting in minutes.
- Open Quantum Institute (OQI): launched at CERN (the European Organization for Nuclear Research) in 2024, it goes further, providing not only access to quantum computing but also mentoring and educational resources for underserved regions. Its hackathon program in 2025 includes events in Lebanon, the United Arab Emirates, and other countries, specifically designed to mitigate the quantum digital divide.
- Public datasets for the development of quantum algorithms:
- QDataSet: Offers 52 public datasets with simulations of one- and two-qubit quantum systems, freely available for training quantum machine learning (ML) algorithms. Researchers without resources to generate their own simulation data can access its repository on GitHub and start developing algorithms immediately.
- ClimSim: This is a public climate-related modeling dataset that is already being used to demonstrate the first quantum ML algorithms applied to climate change. It allows any team, regardless of their budget, to work on real climate problems using quantum computing.
- PennyLane Datasets: is an open collection of molecules, quantum circuits, and physical systems that allows pharmaceutical startups without resources to perform expensive simulations and experiment with quantum-assisted drug discovery.
Real cases of inclusive innovation
The possibilities offered by the use of open data to quantum computing have been evident in various use cases, the result of specific research and calls for grants, such as:
- The Government of Canada launched in 2022 "Quantum Computing for Climate", a specific call for SMEs and startups to develop quantum applications using public climate data, demonstrating how governments can catalyze innovation by providing both data and financing for its use.
- The UK Quantum Catalyst Fund (£15 million) funds projects that combine quantum computing with public data from the UK's National Health Service (NHS) for problems such as optimising energy grids and medical diagnostics, creating solutions of public interest verifiable by the scientific community.
- The Open Quantum Institute's (OQI) 2024 report details 10 use cases for the UN Sustainable Development Goals developed collaboratively by experts from 22 countries, where the results and methodologies are publicly accessible, allowing any institution to replicate or improve these works).
- Red.es has opened an expression of interest aimed at agents in the quantum technologies ecosystem to collect ideas, proposals and needs that contribute to the design of the future lines of action of the National Strategy for Quantum Technologies 2025–2030, financed with 40 million euros from the ERDF Funds.
Current State of Quantum Computing
We are in the NISQ (Noisy Intermediate-Scale Quantum) era, a term coined by physicist John Preskill in 2018, which describes quantum computers with 50-100 physical qubits. These systems are powerful enough to perform certain calculations beyond the classical capabilities, but they suffer from incoherence, frequent errors that make them unviable in market applications.
IBM, Google, and startups like IonQ offer cloud access to their quantum systems, with IBM providing public access through the IBM Quantum Platform since 2016, being one of the first publicly accessible quantum processors connected to the cloud.
In 2019, Google achieved "quantum supremacy" with its 53-qubit Sycamore processor, which performed a calculation in about 200 seconds that would take about 10,000 years to a state-of-the-art classical supercomputer.
The latest independent analyses suggest that practical quantum applications may emerge around 2035-2040, assuming continued exponential growth in quantum hardware capabilities. IBM has committed to delivering a large-scale fault-tolerant quantum computer, IBM Quantum Starling, by 2029, with the goal of running quantum circuits comprising 100 million quantum gates on 200 logical qubits.

The Global Race for Quantum Leadership
International competition for dominance in quantum technologies has triggered an unprecedented wave of investment. According to McKinsey, until 2022 the officially recognized level of public investment in China (15,300 million dollars) exceeds that of the European Union (7,200 million dollars), the United States 1,900 million dollars) and Japan (1,800 million dollars) combined.
Domestically, the UK has committed £2.5 billion over ten years to its National Quantum Strategy to make the country a global hub for quantum computing, and Germany has made one of the largest strategic investments in quantum computing, allocating €3 billion under its economic stimulus plan.
Investment in the first quarter of 2025 shows explosive growth: quantum computing companies raised more than $1.25 billion, more than double the previous year, an increase of 128%, reflecting a growing confidence that this technology is approaching commercial relevance.
To end the section, a fantastic short interview with Ignacio Cirac, one of the "Spanish fathers" of quantum computing.
Quantum Spain Initiative
In the case of Spain, 60 million euros have been invested in Quantum Spain, coordinated by the Barcelona Supercomputing Center. The project includes:
- Installation of the first quantum computer in southern Europe.
- Network of 25 research nodes distributed throughout the country.
- Training of quantum talent in Spanish universities.
- Collaboration with the business sector for real-world use cases.
This initiative positions Spain as a quantum hub in southern Europe, crucial for not being technologically dependent on other powers.
In addition, Spain's Quantum Technologies Strategy has recently been presented with an investment of 800 million euros. This strategy is structured into 4 strategic objectives and 7 priority actions.
Strategic objectives:
- Strengthen R+D+I to promote the transfer of knowledge and facilitate research reaching the market.
- To create a Spanish quantum market, promoting the growth and emergence of quantum companies and their ability to access capital and meet demand.
- Prepare society for disruptive change, promoting security and reflection on a new digital right, post-quantum privacy.
- Consolidate the quantum ecosystem in a way that drives a vision of the country.
Priority actions:
- Priority 1: To promote Spanish companies in quantum technologies.
- Priority 2: Develop algorithms and technological convergence between AI and Quantum.
- Priority 3: Position Spain as a benchmark in quantum communications.
- Priority 4: Demonstrate the impact of quantum sensing and metrology.
- Priority 5: Ensure the privacy and confidentiality of information in the post-quantum world.
- Priority 6: Strengthening capacities: infrastructure, research and talent.
- Priority 7: Develop a solid, coordinated and leading Spanish quantum ecosystem in the EU.
Figure 1. Spain's quantum technology strategy. Source: Author's own elaboration
In short, quantum computing and open data represent a major technological evolution that affects the way we generate and apply knowledge. If we can build a truly inclusive ecosystem—where access to quantum hardware, public datasets, and specialized training is within anyone's reach—we will open the door to a new era of collaborative innovation with a major global impact.
Content created by Alejandro Alija, expert in Digital Transformation and Innovation. The content and views expressed in this publication are the sole responsibility of the author.