Noticia
The European open data portal has published the third volume of its Use Case Observatory, a report that compiles the evolution of data reuse projects across Europe. This initiative highlights the progress made in four areas: economic, governmental, social and environmental impact.
The closure of a three-year investigation
Between 2022 and 2025, the European Open Data Portal has systematically monitored the evolution of various European projects. The research began with an initial selection of 30 representative initiatives, which were analyzed in depth to identify their potential for impact.
After two years, 13 projects continued in the study, including three Spanish ones: Planttes, Tangible Data and UniversiDATA-Lab. Its development over time was studied to understand how the reuse of open data can generate real and sustainable benefits.
The publication of volume III in October 2025 marks the closure of this series of reports, following volume I (2022) and volume II (2024). This last document offers a longitudinal view, showing how the projects have matured in three years of observation and what concrete impacts they have generated in their respective contexts.
Common conclusions
This third and final report compiles a number of key findings:
Economic impact
Open data drives growth and efficiency across industries. They contribute to job creation, both directly and indirectly, facilitate smarter recruitment processes and stimulate innovation in areas such as urban planning and digital services.
The report shows the example of:
- Naar Jobs (Belgium): an application for job search close to users' homes and focused on the available transport options.
This application demonstrates how open data can become a driver for regional employment and business development.
Government impact
The opening of data strengthens transparency, accountability and citizen participation.
Two use cases analysed belong to this field:
- Waar is mijn stemlokaal? (Netherlands): platform for the search for polling stations.
- Statsregnskapet.no (Norway): website to visualize government revenues and expenditures.
Both examples show how access to public information empowers citizens, enriches the work of the media, and supports evidence-based policymaking. All of this helps to strengthen democratic processes and trust in institutions.
Social impact
Open data promotes inclusion, collaboration, and well-being.
The following initiatives analysed belong to this field:
- UniversiDATA-Lab (Spain): university data repository that facilitates analytical applications.
- VisImE-360 (Italy): a tool to map visual impairment and guide health resources.
- Tangible Data (Spain): a company focused on making physical sculptures that turn data into accessible experiences.
- EU Twinnings (Netherlands): platform that compares European regions to find "twin cities"
- Open Food Facts (France): collaborative database on food products.
- Integreat (Germany): application that centralizes public information to support the integration of migrants.
All of them show how data-driven solutions can amplify the voice of vulnerable groups, improve health outcomes and open up new educational opportunities. Even the smallest effects, such as improvement in a single person's life, can prove significant and long-lasting.
Environmental impact
Open data acts as a powerful enabler of sustainability.
As with environmental impact, in this area we find a large number of use cases:
- Digital Forest Dryads (Estonia): a project that uses data to monitor forests and promote their conservation.
- Air Quality in Cyprus (Cyprus): platform that reports on air quality and supports environmental policies.
- Planttes (Spain): citizen science app that helps people with pollen allergies by tracking plant phenology.
- Environ-Mate (Ireland): a tool that promotes sustainable habits and ecological awareness.
These initiatives highlight how data reuse contributes to raising awareness, driving behavioural change and enabling targeted interventions to protect ecosystems and strengthen climate resilience.
Volume III also points to common challenges: the need for sustainable financing, the importance of combining institutional data with citizen-generated data, and the desirability of involving end-users throughout the project lifecycle. In addition, it underlines the importance of European collaboration and transnational interoperability to scale impact.
Overall, the report reinforces the relevance of continuing to invest in open data ecosystems as a key tool to address societal challenges and promote inclusive transformation.
The impact of Spanish projects on the reuse of open data
As we have mentioned, three of the use cases analysed in the Use Case Observatory have a Spanish stamp. These initiatives stand out for their ability to combine technological innovation with social and environmental impact, and highlight Spain 's relevance within the European open data ecosystem. His career demonstrates how our country actively contributes to transforming data into solutions that improve people's lives and reinforce sustainability and inclusion. Below, we zoom in on what the report says about them.
This citizen science initiative helps people with pollen allergies through real-time information about allergenic plants in bloom. Since its appearance in Volume I of the Use Case Observatory, it has evolved as a participatory platform in which users contribute photos and phenological data to create a personalized risk map. This participatory model has made it possible to maintain a constant flow of information validated by researchers and to offer increasingly complete maps. With more than 1,000 initial downloads and about 65,000 annual visitors to its website, it is a useful tool for people with allergies, educators and researchers.
The project has strengthened its digital presence, with increasing visibility thanks to the support of institutions such as the Autonomous University of Barcelona and the University of Granada, in addition to the promotion carried out by the company Thigis.
Its challenges include expanding geographical coverage beyond Catalonia and Granada and sustaining data participation and validation. Therefore, looking to the future, it seeks to extend its territorial reach, strengthen collaboration with schools and communities, integrate more data in real time and improve its predictive capabilities.
Throughout this time, Planttes has established herself as an example of how citizen-driven science can improve public health and environmental awareness, demonstrating the value of citizen science in environmental education, allergy management, and climate change monitoring.
The project transforms datasets into physical sculptures that represent global challenges such as climate change or poverty, integrating QR codes and NFC to contextualize the information. Recognized at the EU Open Data Days 2025, Tangible Data has inaugurated its installation Tangible climate at the National Museum of Natural Sciences in Madrid.
Tangible Data has evolved in three years from a prototype project based on 3D sculptures to visualize sustainability data to become an educational and cultural platform that connects open data with society. Volume III of the Use Case Observatory reflects its expansion into schools and museums, the creation of an educational program for 15-year-old students, and the development of interactive experiences with artificial intelligence, consolidating its commitment to accessibility and social impact.
Its challenges include funding and scaling up the education programme, while its future goals include scaling up school activities, displaying large-format sculptures in public spaces, and strengthening collaboration with artists and museums. Overall, it remains true to its mission of making data tangible, inclusive, and actionable.
UniversiDATA-Lab is a dynamic repository of analytical applications based on open data from Spanish universities, created in 2020 as a public-private collaboration and currently made up of six institutions. Its unified infrastructure facilitates the publication and reuse of data in standardized formats, reducing barriers and allowing students, researchers, companies and citizens to access useful information for education, research and decision-making.
Over the past three years, the project has grown from a prototype to a consolidated platform, with active applications such as the budget and retirement viewer, and a hiring viewer in beta. In addition, it organizes a periodic datathon that promotes innovation and projects with social impact.
Its challenges include internal resistance at some universities and the complex anonymization of sensitive data, although it has responded with robust protocols and a focus on transparency. Looking to the future, it seeks to expand its catalogue, add new universities and launch applications on emerging issues such as school dropouts, teacher diversity or sustainability, aspiring to become a European benchmark in the reuse of open data in higher education.
Conclusion
In conclusion, the third volume of the Use Case Observatory confirms that open data has established itself as a key tool to boost innovation, transparency and sustainability in Europe. The projects analysed – and in particular the Spanish initiatives Planttes, Tangible Data and UniversiDATA-Lab – demonstrate that the reuse of public information can translate into concrete benefits for citizens, education, research and the environment.
Blog
In any data management environment (companies, public administration, consortia, research projects), having data is not enough: if you don't know what data you have, where it is, what it means, who maintains it, with what quality, when it changed or how it relates to other data, then the value is very limited. Metadata —data about data—is essential for:
-
Visibility and access: Allow users to find what data exists and can be accessed.
-
Contextualization: knowing what the data means (definitions, units, semantics).
-
Traceability/lineage: Understanding where data comes from and how it has been transformed.
-
Governance and control: knowing who is responsible, what policies apply, permissions, versions, obsolescence.
-
Quality, integrity, and consistency: Ensuring data reliability through rules, metrics, and monitoring.
-
Interoperability: ensuring that different systems or domains can share data, using a common vocabulary, shared definitions, and explicit relationships.
In short, metadata is the lever that turns "siloed" data into a governed information ecosystem. As data grows in volume, diversity, and velocity, its function goes beyond simple description: metadata adds context, allows data to be interpreted, and makes it findable, accessible, interoperable, and reusable (FAIR).
In the new context driven by artificial intelligence, this metadata layer becomes even more relevant, as it provides the provenance information needed to ensure traceability, reliability, and reproducibility of results. For this reason, some recent frameworks extend these principles to FAIR-R, where the additional "R" highlights the importance of data being AI-ready, i.e. that it meets a series of technical, structural and quality requirements that optimize its use by artificial intelligence algorithms.
Thus, we are talking about enriched metadata, capable of connecting technical, semantic and contextual information to enhance machine learning, interoperability between domains and the generation of verifiable knowledge.
From traditional metadata to "rich metadata"
Traditional metadata
In the context of this article, when we talk about metadata with a traditional use, we think of catalogs, dictionaries, glossaries, database data models, and rigid structures (tables and columns). The most common types of metadata are:
-
Technical metadata: column type, length, format, foreign keys, indexes, physical locations.
-
Business/Semantic Metadata: Field Name, Description, Value Domain, Business Rules, Business Glossary Terms.
-
Operational/execution metadata: refresh rate, last load, processing times, usage statistics.
-
Quality metadata: percentage of null values, duplicates, validations.
-
Security/access metadata: access policies, permissions, sensitivity rating.
-
Lineage metadata: Transformation tracing in data pipelines .
This metadata is usually stored in repositories or cataloguing tools, often with tabular structures or relational bases, with predefined links.
Why "rich metadata"?
Rich metadata is a layer that not only describes attributes, but also:
- They discover and infer implicit relationships, identifying links that are not expressly defined in data schemas. This allows, for example, to recognize that two variables with different names in different systems actually represent the same concept ("altitude" and "elevation"), or that certain attributes maintain a hierarchical relationship ("municipality" belongs to "province").
- They facilitate semantic queries and automated reasoning, allowing users and machines to explore relationships and patterns that are not explicitly defined in databases. Rather than simply looking for exact matches of names or structures, rich metadata allows you to ask questions based on meaning and context. For example, automatically identifying all datasets related to "coastal cities" even if the term does not appear verbatim in the metadata.
- They adapt and evolve flexibly, as they can be extended with new entity types, relationships, or domains without the need to redesign the entire catalog structure. This allows new data sources, models or standards to be easily incorporated, ensuring the long-term sustainability of the system.
- They incorporate automation into tasks that were previously manual or repetitive, such as duplication detection, automatic matching of equivalent concepts, or semantic enrichment using machine learning. They can also identify inconsistencies or anomalies, improving the quality and consistency of metadata.
- They explicitly integrate the business context, linking each data asset to its operational meaning and its role within organizational processes. To do this, they use controlled vocabularies, ontologies or taxonomies that facilitate a common understanding between technical teams, analysts and business managers.
- They promote deeper interoperability between heterogeneous domains, which goes beyond the syntactic exchange facilitated by traditional metadata. Rich metadata adds a semantic layer that allows you to understand and relate data based on its meaning, not just its format. Thus, data from different sources or sectors – for example, Geographic Information Systems (GIS), Building Information Modeling (BIM) or the Internet of Things (IoT) – can be linked in a coherent way within a shared conceptual framework. This semantic interoperability is what makes it possible to integrate knowledge and reuse information between different technical and organizational contexts.
This turns metadata into a living asset, enriched and connected to domain knowledge, not just a passive "record".
The Evolution of Metadata: Ontologies and Knowledge Graphs
The incorporation of ontologies and knowledge graphs represents a conceptual evolution in the way metadata is described, related and used, hence we speak of enriched metadata. These tools not only document the data, but connect them within a network of meaning, allowing the relationships between entities, concepts, and contexts to be explicit and computable.
In the current context, marked by the rise of artificial intelligence, this semantic structure takes on a fundamental role: it provides algorithms with the contextual knowledge necessary to interpret, learn and reason about data in a more accurate and transparent way. Ontologies and graphs allow AI systems not only to process information, but also to understand the relationships between elements and to generate grounded inferences, opening the way to more explanatory and reliable models.
This paradigm shift transforms metadata into a dynamic structure, capable of reflecting the complexity of knowledge and facilitating semantic interoperability between different domains and sources of information. To understand this evolution, it is necessary to define and relate some concepts:

Ontologies
In the world of data, an ontology is a highly organized conceptual map that clearly defines:
- What entities exist (e.g., city, river, road).
- What properties they have (e.g. a city has a name, town, zip code).
- How they relate to each other (e.g. a river runs through a city, a road connects two municipalities).
The goal is for people and machines to share the same vocabulary and understand data in the same way. Ontologies allow:
- Define concepts and relationships: for example, "a plot belongs to a municipality", "a building has geographical coordinates".
- Set rules and restrictions: such as "each building must be exactly on a cadastral plot".
- Unify vocabularies: if in one system you say "plot" and in another "cadastral unit", ontology helps to recognize that they are analogous.
- Make inferences: from simple data, discover new knowledge (if a building is on a plot and the plot in Seville, it can be inferred that the building is in Seville).
- Establish a common language: they work as a dictionary shared between different systems or domains (GIS, BIM, IoT, cadastre, urban planning).
In short: an ontology is the dictionary and the rules of the game that allow different geospatial systems (maps, cadastre, sensors, BIM, etc.) to understand each other and work in an integrated way.
Knowledge Graphs
A knowledge graph is a way of organizing information as if it were a network of concepts connected to each other.
-
Nodes represent things or entities, such as a city, a river, or a building.
-
The edges (lines) show the relationships between them, for example: "is in", "crosses" or "belongs to".
-
Unlike a simple drawing of connections, a knowledge graph also explains the meaning of those relationships: it adds semantics.
A knowledge graph combines three main elements:
-
Data: specific cases or instances, such as "Seville", "Guadalquivir River" or "Seville City Hall Building".
-
Semantics (or ontology): the rules and vocabularies that define what kinds of things exist (cities, rivers, buildings) and how they can relate to each other.
-
Reasoning: the ability to discover new connections from existing ones (for example, if a river crosses a city and that city is in Spain, the system can deduce that the river is in Spain).
In addition, knowledge graphs make it possible to connect information from different fields (e.g. data on people, places and companies) under the same common language, facilitating analysis and interoperability between disciplines.
In other words, a knowledge graph is the result of applying an ontology (the data model) to several individual datasets (spatial elements, other territory data, patient records or catalog products, etc.). Knowledge graphs are ideal for integrating heterogeneous data, because they do not require a previously complete rigid schema: they can be grown flexibly. In addition, they allow semantic queries and navigation with complex relationships. Here's an example for spatial data to understand the differences:
|
Spatial data ontology (conceptual model) |
Knowledge graph (specific examples with instances) |
|---|---|
|
|
|
|
Use Cases
To better understand the value of smart metadata and semantic catalogs, there is nothing better than looking at examples where they are already being applied. These cases show how the combination of ontologies and knowledge graphs makes it possible to connect dispersed information, improve interoperability and generate actionable knowledge in different contexts.
From emergency management to urban planning or environmental protection, different international projects have shown that semantics is not just theory, but a practical tool that transforms data into decisions.
Some relevant examples include:
- LinkedGeoData that converted OpenStreetMap data into Linked Data, linking it to other open sources.
- Virtual Singapore is a 3D digital twin that integrates geospatial, urban and real-time data for simulation and planning.
- JedAI-spatial is a tool for interconnecting 3D spatial data using semantic relationships.
- SOSA Ontology, a standard widely used in sensor and IoT projects for environmental observations with a geospatial component.
- European projects on digital building permits (e.g. ACCORD), which combine semantic catalogs, BIM models, and GIS data to automatically validate building regulations.
Conclusions
The evolution towards rich metadata, supported by ontologies, knowledge graphs and FAIR-R principles, represents a substantial change in the way data is managed, connected and understood. This new approach makes metadata an active component of the digital infrastructure, capable of providing context, traceability and meaning, and not just describing information.
Rich metadata allows you to learn from data, improve semantic interoperability between domains, and facilitate more expressive queries, where relationships and dependencies can be discovered in an automated way. In this way, they favor the integration of dispersed information and support both informed decision-making and the development of more explanatory and reliable artificial intelligence models.
In the field of open data, these advances drive the transition from descriptive repositories to ecosystems of interconnected knowledge, where data can be combined and reused in a flexible and verifiable way. The incorporation of semantic context and provenance reinforces transparency, quality and responsible reuse.
This transformation requires, however, a progressive and well-governed approach: it is essential to plan for systems migration, ensure semantic quality, and promote the participation of multidisciplinary communities.
In short, rich metadata is the basis for moving from isolated data to connected and traceable knowledge, a key element for interoperability, sustainability and trust in the data economy.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Evento
The Provincial Council of Bizkaia has launched the Data Journalism Challenge, a competition aimed at rewarding creativity, rigour and talent in the use of open data. This initiative seeks to promote journalistic projects that use the public data available on the Open Data Bizkaia platform to create informative content with a strong visual component. Whether through interactive graphics, maps, animated videos or in-depth reports, the goal is to transform data into narratives that connect with citizens.
Who can participate?
The call is open to individuals over 18 years of age, both individually and in teams of up to four members. Each participant may submit proposals in one or more of the available categories.
It is an opportunity of special relevance for students, entrepreneurs, developers, design professionals or journalists with an interest in open data.
Three categories to boost the use of open data
The competition is divided into three categories, each with its own approach and evaluation criteria:
-
Dynamic data representation: Projects that present data in an interactive, clear, and visually appealing way.
-
Data storytelling through animated video: audiovisual narratives that explain phenomena or trends using public data.
-
Reporting + Data: journalistic articles that integrate data analysis with research and depth of information.
As we have previously mentioned, all projects must be based on the public data available on the Open Data Bizkaia platform, which offers information on multiple areas: economy, environment, mobility, health, culture, etc. It is a rich and accessible source for building relevant and well-grounded stories.
Up to 4,500 euros in prizes
For each category, the following prizes will be awarded:
-
First place: 1,500 euros
-
Second place: 750 euros
The prizes will be subject to the corresponding tax withholdings. Since the same person can submit proposals to several categories, and these will be evaluated independently, it is possible for a single participant to win more than one prize. Therefore, a single participant will be able to win up to 4,500 euros, if they win in all three categories.
What are the evaluation criteria?
The awards will be made through the competitive concurrence procedure. All the projects received in the period enabled for this will be evaluated by the jury, according to a series of specific criteria for each category:
-
Dynamic data representation:
-
Communicative clarity (30%)
-
Interactivity (25%)
-
Design and usability (20%)
-
Originality in representation (15%)
-
Rigor and fidelity of data (10%)
-
Data storytelling in animation video
-
Narrative and script (30%)
-
Visual creativity and technical innovation (25%)
-
Informational clarity (20%)
-
Emotional and aesthetic impact (15%)
-
Rigorous and honest use of data (10%)
-
Feature + Data
-
Journalistic quality and analytical depth (30%)
-
Narrative integration of data (25%)
-
Originality in approach and format (20%)
-
Design and user experience (15%)
-
Transparency and traceability of sources (10%)
How are applications submitted?
The deadline for submitting projects began on November 3 and will be open until December 3, 2025 at 11:59 p.m. Applications may be submitted in a variety of ways:
-
Electronically, through the electronic office of Bizkaia, using the procedure code 2899.
-
In person, at the General Registry of the Laguntza Office (c/ Diputación, 7, Bilbao), at any other public registry or at the Post Office.
In the case of group projects, a single application signed by a representative must be submitted. This person will assume the dialogue with the organizing General Directorate, taking care of the procedures and the fulfillment of the corresponding obligations.
The documentation that must be submitted is:
-
The project to be evaluated.
-
The certificate of being up to date with tax obligations.
-
The certificate of being up to date with Social Security obligations.
-
The direct debit form, only in the event that the applicant objects to this Administration checking the bank details by its own means.
Contact Information
For queries or additional information, please contact the Provincial Council of Bizkaia. Specifically, with the Department of Public Administration and Institutional Relations, Technical Advisory Section c/ Gran Vía, 2 (48009) in the city of Bilbao. Doubts will also be answered by calling 944 068 000 and by email SAT@bizkaia.eus.
This competition represents an opportunity to explore the potential of data journalism and contribute to more transparent and accessible communication. The projects presented will be able to highlight the potential of open data to facilitate the understanding of issues of public interest, in a clear and simple way.
For more details, it is recommended to read the information

Noticia
On October 6, the V Open Government Plan was approved, an initiative that gives continuity to the commitment of public administrations to transparency, citizen participation and accountability. This new plan, which will be in force until 2029, includes 218 measures grouped into 10 commitments that affect the various levels of the Administration.
In this article we are going to review the key points of the Plan, focusing on those commitments related to data and access to public information.
A document resulting from collaboration
The process of preparing the V Open Government Plan has been developed in a participatory and collaborative way, with the aim of collecting proposals from different social actors. To this end, a public consultation was opened in which citizens, civil society organizations and institutional representatives were able to contribute ideas and suggestions. A series of deliberative workshops were also held. In total, 620 contributions were received from civil society and more than 300 proposals from ministries, autonomous communities and cities, and representatives of local entities.
These contributions were analysed and integrated into the plan's commitments, which were subsequently validated by the Open Government Forum. The result is a document that reflects a shared vision on how to advance transparency, participation and accountability in the public administrations as a whole.
10 main lines of action with a prominent role for open data
As a result of this collaborative work, 10 lines of action have been established. The first nine commitments include initiatives from the General State Administration (AGE), while the tenth groups together the contributions of autonomous communities and local entities:
- Participation and civic space.
- Transparency and access to information.
- Integrity and accountability.
- Open administration.
- Digital governance and artificial intelligence.
- Fiscal openness: clear and open accounts.
- Truthful information / information ecosystem.
- Dissemination, training and promotion of open government.
- Open Government Observatory.
- Open state.

Figure 1. 10 lines of action of the V Open Government Plan. Source: Ministry of Inclusion, Social Security and Migration.
Data and public information are a key element in all of them. However, most of the measures related to this field are found within line of action 2, where there is a specific section on opening and reusing public information data. Among the measures envisaged, the following are contemplated:
- Data governance model: it is proposed to create a regulatory framework that facilitates the responsible and efficient use of public data in the AGE. It includes the regulation of collegiate bodies for the exchange of data, the application of European regulations and the creation of institutional spaces to design public policies based on data.
- Data strategy for a citizen-centred administration: it seeks to establish a strategic framework for the ethical and transparent use of data in the Administration.
- Publication of microdata from electoral surveys: the Electoral Law will be amended to include the obligation to publish anonymized microdata from electoral surveys. This improves the reliability of studies and facilitates open access to individual data for analysis.
- Support for local entities in the opening of data: a grant program has been launched to promote the opening of homogeneous and quality data in local entities through calls and/or collaboration agreements. In addition, its reuse will be promoted through awareness-raising actions, development of demonstrator solutions and inter-administrative collaboration to promote public innovation.
- Openness of data in the Administration of Justice: official data on justice will continue to be published on public portals, with the aim of making the Administration of Justice more transparent and accessible.
- Access and integration of high-value geospatial information: the aim is to facilitate the reuse of high-value spatial data in categories such as geospatial, environment and mobility. The measure includes the development of digital maps, topographic bases and an API to improve access to this information by citizens, administrations and companies.
- Open data of the BORME: work will be done to promote the publication of the content of the Official Gazette of the Mercantile Registry, especially the section on entrepreneurs, as open data in machine-readable formats and accessible through APIs.
- Databases of the Central Archive of the Treasury: the public availability of the records of the Central Archive of the Ministry of Finance that do not contain personal data or are not subject to legal restrictions is promoted.
- Secure access to confidential public data for research and innovation: the aim is to establish a governance framework and controlled environments that allow researchers to securely and ethically access public data subject to confidentiality.
- Promotion of the secondary use of health data: work will continue on the National Health Data Space (ENDS), aligned with European regulations, to facilitate the use of health data for research, innovation and public policy purposes. The measure includes the promotion of technical infrastructures, regulatory frameworks and ethical guarantees to protect the privacy of citizens.
- Promotion of data ecosystems for social progress: it seeks to promote collaborative data spaces between public and private entities, under clear governance rules. These ecosystems will help develop innovative solutions that respond to social needs, fostering trust, transparency and the fair return of benefits to citizens.
- Enhancement of quality public data for citizens and companies: the generation of quality data will continue to be promoted in the different ministries and agencies, so that they can be integrated into the AGE's centralised catalogue of reusable information.
- Evolution of the datos.gob.es platform: work continues on the optimization of datos.gob.es. This measure is part of a continuous enrichment to address changing citizen needs and emerging trends.
In addition to this specific heading, measures related to open data are also included in other sections. For example, measure 3.5.5 proposes to transform the Public Sector Procurement Platform into an advanced tool that uses Big Data and Artificial Intelligence to strengthen transparency and prevent corruption. Open data plays a central role here, as it allows massive audits and statistical analyses to be carried out to detect irregular patterns in procurement processes. In addition, by facilitating citizen access to this information, social oversight and democratic control over the use of public funds are promoted.
Another example can be found in measure 4.1.1, where it is proposed to develop a digital tool for the General State Administration that incorporates the principles of transparency and open data from its design. The system would allow the traceability, conservation, access and reuse of public documents, integrating archival criteria, clear language and document standardization. In addition, it would be linked to the National Open Data Catalog to ensure that information is available in open and reusable formats.
The document not only highlights the possibilities of open data: it also highlights the opportunities offered by Artificial Intelligence both in improving access to public information and in the generation of open data useful for collective decision-making.
Promotion of open data in the Autonomous Communities and Cities
As mentioned above, the IV Open Government Plan also includes commitments made by regional bodies, which are detailed in line of action 10 on Open State, many of them focused on the availability of public data.
For example, the Government of Catalonia reports its interest in optimising the resources available for the management of requests for access to public information, as well as in publishing disaggregated data on public budgets in areas related to children or climate change. For its part, the Junta de Andalucía wants to promote access to information on scientific personnel and scientific production, and develop a Data Observatory of Andalusian public universities, among other measures. Another example can be found in the Autonomous City of Melilla, which is working on an Open Data Portal.
With regard to the local administration, the commitments have been set through the Spanish Federation of Municipalities and Provinces (FEMP). The Network of Local Entities for Transparency and Citizen Participation of the FEMP proposes that local public administrations publish, at least, to choose from the following fields: street; budgets and budget execution; subsidies; public contracting and bidding; municipal register; vehicle census; waste and recycling containers; register of associations; cultural agenda; tourist accommodation; business areas and Industrial; Census of companies or economic agents.
All these measures highlight the interest in open data in Spanish institutions as a key tool to promote open government, promote services and products aligned with citizen needs and optimize decision-making.
A tracking system
The follow-up of the V Open Government Plan is based on a strengthened system of accountability and the strategic use of the HazLab digital platform, where five working groups are hosted, one of them focused on transparency and access to information.
Each initiative of the Plan also has a monitoring file with information on its execution, schedule and results, periodically updated by the responsible units and published on the Transparency Portal.
Conclusions
Overall, the V Open Government Plan seeks a more transparent, participatory Administration oriented to the responsible use of public data. Many of the measures included aim to strengthen the openness of information, improve document management and promote the reuse of data in key sectors such as health, justice or public procurement. This approach not only facilitates citizen access to information, but also promotes innovation, accountability, and a more open and collaborative culture of governance.
Blog
Artificial Intelligence (AI) is becoming one of the main drivers of increased productivity and innovation in both the public and private sectors, becoming increasingly relevant in tasks ranging from the creation of content in any format (text, audio, video) to the optimization of complex processes through Artificial Intelligence agents.
However, advanced AI models, and in particular large language models, require massive amounts of data for training, optimization, and evaluation. This dependence generates a paradox: at the same time as AI demands more and higher quality data, the growing concern for privacy and confidentiality (General Data Protection Regulation or GDPR), new data access and use rules (Data Act), and quality and governance requirements for high-risk systems (AI Regulation), as well as the inherent scarcity of data in sensitive domains limit access to actual data.
In this context, synthetic data can be an enabling mechanism to achieve new advances, reconciling innovation and privacy protection. On the one hand, they allow AI to be nurtured without exposing sensitive information, and when combined with quality open data, they expand access to domains where real data is scarce or heavily regulated.
What is synthetic data and how is it generated?
Simply put, synthetic data can be defined as artificially fabricated information that mimics the characteristics and distributions of real data. The main function of this technology is to reproduce the statistical characteristics, structure and patterns of the underlying real data. In the domain of official statistics, there are cases such as the United States Census , which publishes partially or totally synthetic products such as OnTheMap (mobility of workers between place of residence and workplace) or SIPP Synthetic Beta (socioeconomic microdata linked to taxes and social security).
The generation of synthetic data is currently a field still in development that is supported by various methodologies. Approaches can range from rule-based methods or statistical modeling (simulations, Bayesian, causal networks), which mimic predefined distributions and relationships, to advanced deep learning techniques. Among the most outstanding architectures we find:
- Generative Adversarial Networks (GANs): a generative model, trained on real data, learns to mimic its characteristics, while a discriminator tries to distinguish between real and synthetic data. Through this iterative process, the generator improves its ability to produce artificial data that is statistically indistinguishable from the originals. Once trained, the algorithm can create new artificial records that are statistically similar to the original sample, but completely new and secure.
- Variational Selfencoders (VAE): These models are based on neural networks that learn a probabilistic distribution in a latent space of the input data. Once trained, the model uses this distribution to obtain new synthetic observations by sampling and decoding the latent vectors. VAEs are often considered a more stable and easier option to train compared to GANs for tabular data generation.
- Autoregressive/hierarchical models and domain simulators: used, for example, in electronic medical record data, which capture temporal and hierarchical dependencies. Hierarchical models structure the problem by levels, first sampling higher-level variables and then lower-level variables conditioned to the previous ones. Domain simulators code process rules and calibrate them with real data, providing control and interpretability and ensuring compliance with business rules.
You can learn more about synthetic data and how it's created in this infographic:
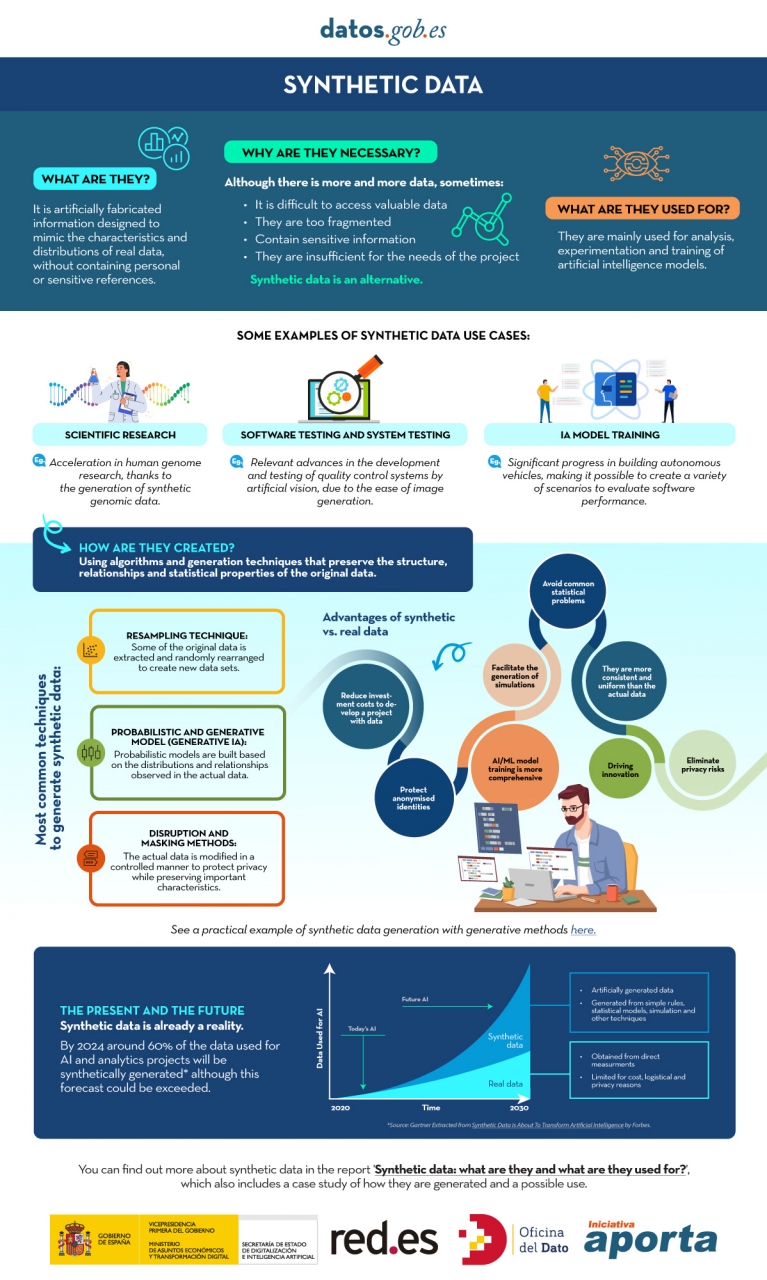
Figure 1. Infographic on synthetic data. Source: Authors' elaboration - datos.gob.es.
While synthetic generation inherently reduces the risk of personal data disclosure, it does not eliminate it entirely. Synthetic does not automatically mean anonymous because, if the generators are trained inappropriately, traces of the real set can leak out and be vulnerable to membership inference attacks. Hence, it is necessary to use Privacy Enhancing Technologies (PET) such as differential privacy and to carry out specific risk assessments. The European Data Protection Supervisor (EDPS) has also underlined the need to carry out a privacy assurance assessment before synthetic data can be shared, ensuring that the result does not allow re-identifiable personal data to be obtained.
Differential Privacy (PD) is one of the main technologies in this domain. Its mechanism is to add controlled noise to the training process or to the data itself, mathematically ensuring that the presence or absence of any individual in the original dataset does not significantly alter the final result of the generation. The use of secure methods, such as Stochastic Gradient Descent with Differential Privacy (DP-SGD), ensures that the samples generated do not compromise the privacy of users who contributed their data to the sensitive set.
What is the role of open data?
Obviously, synthetic data does not appear out of nowhere, it needs real high-quality data as a seed and, in addition, it requires good validation practices. For this reason, open data or data that cannot be opened for privacy-related reasons is, on the one hand, an excellent raw material for learning real-world patterns and, on the other, an independent reference to verify that the synthetic resembles reality without exposing people or companies.
As a seed of learning, quality open data, such as high-value datasets, with complete metadata, clear definitions and standardized schemas, provide coverage, granularity and timeliness. Where certain sets cannot be made public for privacy reasons, they can be used internally with appropriate safeguards to produce synthetic data that could be released. In health, for example, there are open generators such as Synthea, which produce fictitious medical records without the restrictions on the use of real data.
On the other hand, compared to a synthetic set, open data allows it to act as a verification standard, to contrast distributions, correlations and business rules, as well as to evaluate the usefulness in real tasks (prediction, classification) without resorting to sensitive information. In this sense, there are already works, such as that of the Welsh Government with health data, which have experimented with different indicators. These include total distance of change (TVD), propensity score and performance in machine learning tasks.
How is synthetic data evaluated?
The evaluation of synthetic datasets is articulated through three dimensions that, by their nature, imply a commitment:
- Fidelity: Measures how close the synthetic data is to replicating the statistical properties, correlations, and structure of the original data.
- Utility: Measures the performance of the synthetic dataset in subsequent machine learning tasks, such as prediction or classification.
- Privacy: measures how effectively synthetic data hides sensitive information and the risk that the subjects of the original data can be re-identified.
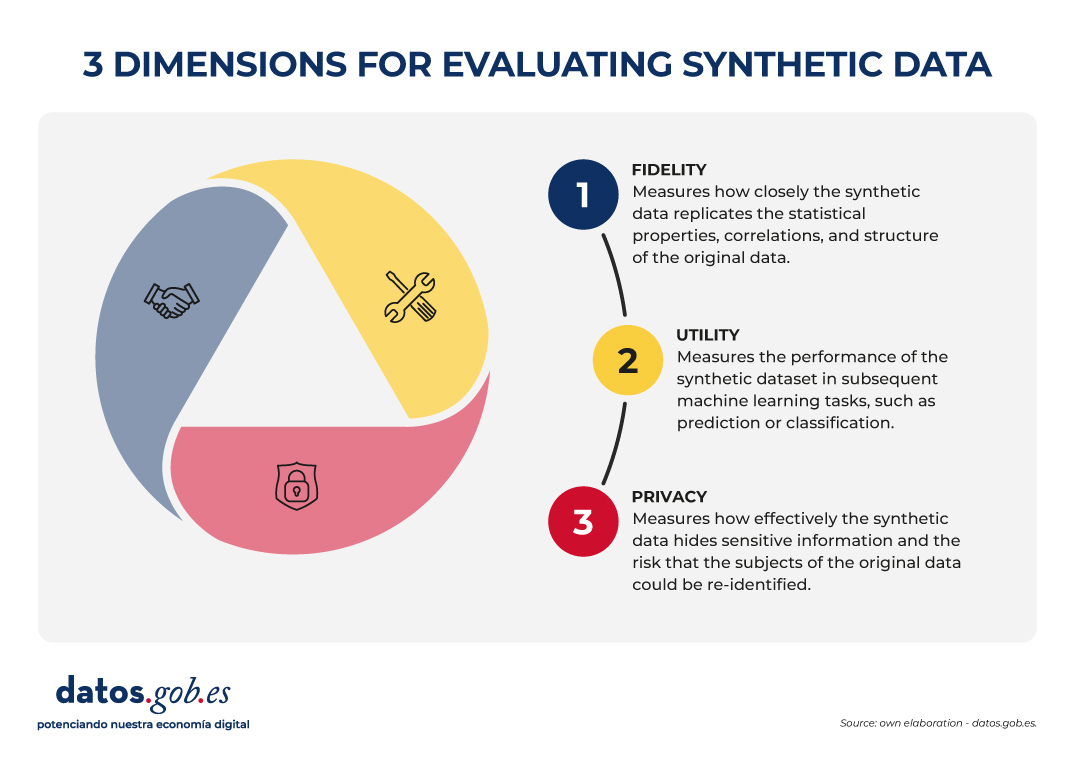
Figure 2. Three dimensions to evaluate synthetic data. Source: Authors' elaboration - datos.gob.es.
The governance challenge is that it is not possible to optimize all three dimensions simultaneously. For example, increasing the level of privacy (by injecting more noise through differential privacy) can inevitably reduce statistical fidelity and, consequently, usefulness for certain tasks. The choice of which dimension to prioritize (maximum utility for statistical research or maximum privacy) becomes a strategic decision that must be transparent and specific to each use case.
Synthetic open data?
The combination of open data and synthetic data can already be considered more than just an idea, as there are real cases that demonstrate its usefulness in accelerating innovation and, at the same time, protecting privacy. In addition to the aforementioned OnTheMap or SIPP Synthetic Beta in the United States, we also find examples in Europe and the rest of the world. For example, the European Commission's Joint Research Centre (JRC) has analysed the role of AI Generated Synthetic Data in Policy Applications, highlighting its ability to shorten the life cycle of public policies by reducing the burden of accessing sensitive data and enabling more agile exploration and testing phases. He has also documented applications of multipurpose synthetic populations for mobility, energy, or health analysis, reinforcing the idea that synthetic data act as a cross-sectional enabler.
In the UK, the Office for National Statistics (ONS) conducted a Synthetic Data Pilot to understand the demand for synthetic data. The pilot explored the production of high-quality synthetic microdata generation tools for specific user requirements.
Also in health , advances are observed that illustrate the value of synthetic open data for responsible innovation. The Department of Health of the Western Australian region has promoted a Synthetic Data Innovation Project and sectoral hackathons where realistic synthetic sets are released that allow internal and external teams to test algorithms and services without access to identifiable clinical information, fostering collaboration and accelerating the transition from prototypes to real use cases.
In short, synthetic data offers a promising, although not sufficiently explored, avenue for the development of artificial intelligence applications, as it contributes to the balance between fostering innovation and protecting privacy.
Synthetic data is not a substitute for open data, but rather enhances each other. In particular, they represent an opportunity for public administrations to expand their open data offering with synthetic versions of sensitive sets for education or research, and to make it easier for companies and independent developers to experiment with regulation and generate greater economic and social value.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Noticia
Spain has taken another step towards consolidating a public policy based on transparency and digital innovation. Through the General State Administration, the Government of Spain has signed its adhesion to the International Open Data Charter, within the framework of the IX Global Summit of the Open Government Partnership that is being held these days in Vitoria-Gasteiz.
With this adhesion, data is recognized as a strategic asset for the design of public policies and the improvement of services. In addition, the importance of its openness and reuse, together with the ethical use of artificial intelligence, as key drivers for digital transformation and the generation of social and economic value is underlined.
What is the International Open Data Charter?
The International Open Data Charter (ODC) is a global initiative that promotes the openness and reuse of public data as tools to improve transparency, citizen participation, innovation, and accountability. This initiative was launched in 2015 and is backed by governments, organizations and experts. Its objective is to guide public entities in the adoption of responsible, sustainable open data policies focused on social impact, respecting the fundamental rights of people and communities. To this end, it promotes six principles:
-
Open data by default: data must be published proactively, unless there are legitimate reasons to restrict it (such as privacy or security).
-
Timely and comprehensive data: data should be published in a complete, understandable and agile manner, as often as necessary to be useful. Its original format should also be respected whenever possible.
-
Accessible and usable data: data should be available in open, machine-readable formats and without technical or legal barriers to reuse. They should also be easy to find.
-
Comparable and interoperable data: institutions should work to ensure that data are accurate, relevant, and reliable, promoting common standards that facilitate interoperability and the joint use of different sources.
-
Data for improved governance and citizen engagement: open data should strengthen transparency, accountability, and enable informed participation of civil society.
-
Data for inclusive development and innovation: open access to data can drive innovative solutions, improve public services, and foster inclusive economic development.
The Open Data Charter also offers resources, guides and practical reports to support governments and organizations in applying its principles, adapting them to each context. Open data will thus be able to drive concrete reforms with a real impact.
Spain: a consolidated open data policy that places us as a reference model
Adherence to the International Open Data Charter is not a starting point, but a step forward in a consolidated strategy that places data as a fundamental asset for the country's progress. For years, Spain has already had a solid framework of policies and strategies that have promoted the opening of data as a fundamental part of digital transformation:
- Regulatory framework: Spain has a legal basis that guarantees the openness of data as a general rule, including Law 37/2007 on the reuse of public sector information, Law 19/2013 on transparency and the application of Regulation (EU) 2022/868 on European data governance. This framework establishes clear obligations to facilitate the access, sharing and reuse of public data throughout the state.
- Institutional governance: the General Directorate of Data, under the Secretary of State for Digitalisation and Artificial Intelligence (SEDIA), has the mission of boosting the management, sharing and use of data in different productive sectors of the Spanish economy and society. Among other issues, he leads the coordination of open data policy in the General State Administration.
- Strategic initiatives and practical tools: the Aporta Initiative, promoted by the Ministry for Digital Transformation and Public Service through the Public Business Entity Red.es, has been promoting the culture of open data and its social and economic reuse since 2009. To this end, the datos.gob.es platform centralises access to nearly 100,000 datasets and services made available to citizens by public bodies at all levels of administration. This platform also offers multiple resources (news, analysis, infographics, guides and reports, training materials, etc.) that help to promote data culture.
To continue moving forward, work is underway on the V Open Government Plan (2025–2029), which integrates specific commitments on transparency, participation, and open data within a broader open government agenda.
All this contributes to Spain positioning, year after year, as a European benchmark in open data.
Next steps: advancing an ethical data-driven digital transformation
Compliance with the principles of the International Open Data Charter will be a transparent and measurable process. SEDIA, through the General Directorate of Data, will coordinate internal monitoring of progress. The Directorate-General for Data will act as a catalyst, promoting a culture of sharing, monitoring compliance with the principles of the Charter and promoting participatory processes to collect input from citizens and civil society.
In addition to the opening of public data, it should be noted that work will continue on the development of an ethical and people-centred digital transformation through actions such as:
- Creation of sectoral data spaces: the aim is to promote the sharing of public and private data that can be combined in a secure and sovereign way to generate high-impact use cases in strategic sectors such as health, tourism, agribusiness or mobility, boosting the competitiveness of the Spanish economy.
-
Developing ethical and responsible AI: The national open data strategy is key to ensuring that algorithms are trained on high-quality, diverse and representative datasets, mitigating bias and ensuring transparency. This reinforces public trust and promotes a model of innovation that protects fundamental rights.
In short, Spain's adoption of the International Open Data Charter reinforces an already consolidated trajectory in open data, supported by a solid regulatory framework, strategic initiatives and practical tools that have placed the country as a benchmark in the field. In addition, this accession opens up new opportunities for international collaboration, access to expert knowledge and alignment with global standards. Spain is thus moving towards a more robust, inclusive data ecosystem that is geared towards social, economic and democratic impact.
Blog
Open data has great potential to transform the way we interact with our cities. As they are available to all citizens, they allow the development of applications and tools that respond to urban challenges such as accessibility, road safety or citizen participation. Facilitating access to this information not only drives innovation, but also contributes to improving the quality of life in urban environments.
This potential becomes even more relevant if we consider the current context. Accelerated urban growth has brought with it new challenges, especially in the area of public health. According to data from the United Nations, it is estimated that by 2050 more than 68% of the world's population will live in cities. Therefore, the design of healthy urban environments is a priority in which open data is consolidated as a key tool: it allows planning more resilient, inclusive and sustainable cities, putting people's well-being at the center of decisions. In this post, we tell you what healthy urban environments are and how open data can help build and maintain them.
What are Healthy Urban Environments? Uses and examples
Healthy urban environments go beyond simply the absence of pollution or noise. According to the World Health Organization (WHO), these spaces must actively promote healthy lifestyles, facilitate physical activity, encourage social interaction, and ensure equitable access to basic services. As established in the Ministry of Health's "Guide to Planning Healthy Cities", these environments are characterized by three key elements:
-
Cities designed for walking: they must be spaces that prioritize pedestrian and cycling mobility, with safe, accessible and comfortable streets that invite active movement.
-
Incorporation of nature: they integrate green areas, blue infrastructure and natural elements that improve air quality, regulate urban temperature and offer spaces for recreation and rest.
-
Meeting and coexistence spaces: they have areas that facilitate social interaction, reduce isolation and strengthen the community fabric.
The role of open data in healthy urban environments
In this scenario, open data acts as the nervous system of smart cities, providing valuable information on usage patterns, citizen needs, and public policy effectiveness. Specifically, in the field of healthy urban spaces, data from:
-
Analysis of physical activity patterns: data on mobility, use of sports facilities and frequentation of green spaces reveal where and when citizens are most active, identifying opportunities to optimize existing infrastructure.
-
Environmental quality monitoring: urban sensors that measure air quality, noise levels, and temperature provide real-time information on the health conditions of different urban areas.
-
Accessibility assessment: public transport, pedestrian infrastructure and service distribution allow for the identification of barriers to access and the design of more inclusive solutions.
-
Informed citizen participation: open data platforms facilitate participatory processes where citizens can contribute local information and collaborate in decision-making.
The Spanish open data ecosystem has solid platforms that feed healthy urban space projects. For example, the Madrid City Council's Open Data Portal offers real-time information on air quality as well as a complete inventory of green areas. Barcelona also publishes data on air quality, including the locations and characteristics of measuring stations.
These portals not only store information, but structure it in a way that developers, researchers and citizens can create innovative applications and services.
Use Cases: Applications That Reuse Open Data
Several projects demonstrate how open data translates into tangible improvements for urban health. On the one hand, we can highlight some applications or digital tools such as:
-
AQI Air Quality Index: uses government data to provide real-time information on air quality in different Spanish cities.
-
GV Aire: processes official air quality data to generate citizen alerts and recommendations.
-
National Air Quality Index: centralizes information from measurement stations throughout the country.
-
Valencia Verde: uses municipal data to show the location and characteristics of parks and gardens in Valencia.
On the other hand, there are initiatives that combine multisectoral open data to offer solutions that improve the interaction between cities and citizens. For example:
-
Supermanzanas Program: uses maps showing air quality pollution levels and traffic data available in open formats such as CSV and GeoPackage from Barcelona Open Data and Barcelona City Council to identify streets where reducing road traffic can maximize health benefits, creating safe spaces for pedestrians and cyclists.
-
The DataActive platform: seeks to establish an international infrastructure in which researchers, public and private sports entities participate. The topics it addresses include land management, urban planning, sustainability, mobility, air quality and environmental justice. It aims to promote more active, healthy and accessible urban environments through the implementation of strategies based on open data and research.
Data availability is complemented by advanced visualization tools. The Madrid Spatial Data Infrastructure (IDEM) offers geographic viewers specialized in air quality and the National Geographic Institute (IGN) offers the national street map CartoCiudad with information on all cities in Spain.
Effective governance and innovation ecosystem
However, the effectiveness of these initiatives depends on new governance models that integrate multiple actors. To achieve proper coordination between public administrations at different levels, private companies, third sector organizations and citizens, it is essential to have quality open data.
Open data not only powers specific applications but creates an entire ecosystem of innovation. Independent developers, startups, research centers, and citizen organizations use this data to:
-
Develop urban health impact studies.
-
Create participatory planning tools.
-
Generate early warnings about environmental risks.
-
Evaluate the effectiveness of public policies.
-
Design personalized services according to the needs of different population groups.
Healthy urban spaces projects based on open data generate multiple tangible benefits:
-
Efficiency in public management: data makes it possible to optimize the allocation of resources, prioritize interventions and evaluate their real impact on citizen health.
-
Innovation and economic development: the open data ecosystem stimulates the creation of innovative startups and services that improve the quality of urban life, as demonstrated by the multiple applications available in datos.gob.es.
-
Transparency and participation: the availability of data facilitates citizen control and strengthens democratic decision-making processes.
-
Scientific evidence: Urban health data contributes to the development of evidence-based public policies and the advancement of scientific knowledge.
-
Replicability: successful solutions can be adapted and replicated in other cities, accelerating the transformation towards healthier urban environments.
In short, the future of our cities depends on our ability to integrate technology, citizen participation and innovative public policies. The examples analyzed demonstrate that open data is not just information; They are the foundation for building urban environments that actively promote health, equity, and sustainability.
Blog
In recent years, open data initiatives have transformed the way in which both public institutions and private organizations manage and share information. The adoption of FAIR (Findable, Accessible, Interoperable, Reusable) principles has been key to ensuring that data generates a positive impact, maximizing its availability and reuse.
However, in contexts of vulnerability (such as indigenous peoples, cultural minorities or territories at risk) there is a need to incorporate an ethical framework that guarantees that the opening of data does not lead to harm or deepen inequalities. This is where the CARE principles (Collective Benefit, Authority to Control, Responsibility, Ethics), proposed by the Global Indigenous Data Alliance (GIDA), come into play, which complement and enrich the FAIR approach.
It is important to note that although CARE principles arise in the context of indigenous communities (to ensure indigenous peoples' effective sovereignty over their data and their right to generate value in accordance with their own values), these can be extrapolated to other different scenarios. In fact, these principles are very useful in any situation where data is collected in territories with some type of social, territorial, environmental or even cultural vulnerability.
This article explores how CARE principles can be integrated into open data initiatives generating social impact based on responsible use that does not harm vulnerable communities.
The CARE principles in detail
The CARE principles help ensure that open data initiatives are not limited to technical aspects, but also incorporate social, cultural and ethical considerations. Specifically, the four CARE principles are as follows:
-
Collective Benefit: data must be used to generate a benefit that is shared fairly between all parties involved. In this way, open data should support the sustainable development, social well-being and cultural strengthening of a vulnerable community, for example, by avoiding practices related to open data that only favour third parties.
-
Authority to Control: vulnerable communities have the right to decide how the data they generate is collected, managed, shared, and reused. This principle recognises data sovereignty and the need to respect one’s own governance systems, rather than imposing external criteria.
-
Responsibility: those who manage and reuse data must act responsibly towards the communities involved, recognizing possible negative impacts and implementing measures to mitigate them. This includes practices such as prior consultation, transparency in the use of data, and the creation of accountability mechanisms.
-
Ethics: the ethical dimension requires that the openness and re-use of data respects the human rights, cultural values and dignity of communities. It is not only a matter of complying with the law, but of going further, applying ethical principles through a code of ethics.
Together, these four principles provide a guide to managing open data more fairly and responsibly, respecting the sovereignty and interests of the communities to which that data relates.
CARE and FAIR: complementary principles for open data that transcend
The CARE and FAIR principles are not opposite, but operate on different and complementary levels:
-
FAIR focuses on making data consumption technically easier.
-
CARE introduces the social and ethical dimension (including cultural considerations of specific vulnerable communities).
The FAIR principles focus on the technical and operational dimensions of data. In other words, data that comply with these principles are easily locatable, available without unnecessary barriers and with unique identifiers, use standards to ensure interoperability, and can be used in different contexts for purposes other than those originally intended.
However, the FAIR principles do not directly address issues of social justice, sovereignty or ethics. In particular, these principles do not contemplate that data may represent knowledge, resources or identities of communities that have historically suffered exclusion or exploitation or of communities related to territories with unique environmental, social or cultural values. To do this, the CARE principles, which complement the FAIR principles, can be used, adding an ethical and community governance foundation to any open data initiative.
In this way, an open data strategy that aspires to be socially just and sustainable must articulate both principles. FAIR without CARE risks making collective rights invisible by promoting unethical data reuse. On the other hand, CARE without FAIR can limit the potential for interoperability and reuse, making the data useless to generate a positive benefit in a vulnerable community or territory.
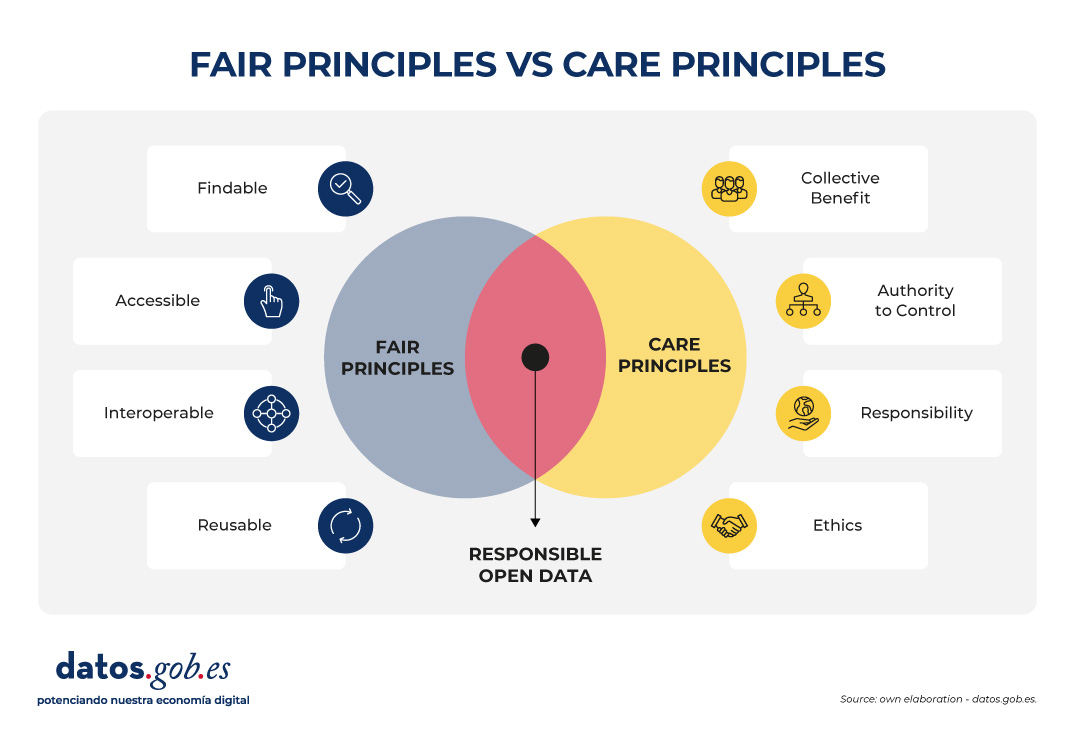
An illustrative example is found in the management of data on biodiversity in a protected natural area. While the FAIR principles ensure that data can be integrated with various tools to be widely reused (e.g., in scientific research), the CARE principles remind us that data on species and the territories in which they live can have direct implications for communities who live in (or near) that protected natural area. For example, making public the exact points where endangered species are found in a protected natural area could facilitate their illegal exploitation rather than their conservation, which requires careful definition of how, when and under what conditions this data is shared.
Let's now see how in this example the CARE principles could be met:
-
First, biodiversity data should be used to protect ecosystems and strengthen local communities, generating benefits in the form of conservation, sustainable tourism or environmental education, rather than favoring isolated private interests (i.e., collective benefit principle).
-
Second, communities living near or dependent on the protected natural area have the right to decide how sensitive data is managed, for example, by requiring that the location of certain species not be published openly or published in an aggregated manner (i.e., principle of authority).
-
On the other hand, the people in charge of the management of these protected areas of the park must act responsibly, establishing protocols to avoid collateral damage (such as poaching) and ensuring that the data is used in a way that is consistent with conservation objectives (i.e. the principle of responsibility).
-
Finally, the openness of this data must be guided by ethical principles, prioritizing the protection of biodiversity and the rights of local communities over economic (or even academic) interests that may put ecosystems or the populations that depend on them at risk (principle of ethics).
Notably, several international initiatives, such as Indigenous Environmental Data Justice related to the International Indigenous Data Sovereignty Movement and the Research Data Alliance (RDA) through the Care Principles for Indigenous Data Governance, are already promoting the joint adoption of CARE and FAIR as the foundation for more equitable data initiatives.
Conclusions
Ensuring the FAIR principles is essential for open data to generate value through its reuse. However, open data initiatives must be accompanied by a firm commitment to social justice, the sovereignty of vulnerable communities, and ethics. Only the integration of the CARE principles together with the FAIR will make it possible to promote truly fair, equitable, inclusive and responsible open data practices.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Open data from public sources has evolved over the years, from being simple repositories of information to constituting dynamic ecosystems that can transform public governance. In this context, artificial intelligence (AI) emerges as a catalytic technology that benefits from the value of open data and exponentially enhances its usefulness. In this post we will see what the mutually beneficial symbiotic relationship between AI and open data looks like.
Traditionally, the debate on open data has focused on portals: the platforms on which governments publish information so that citizens, companies and organizations can access it. But the so-called "Third Wave of Open Data," a term by New York University's GovLab, emphasizes that it is no longer enough to publish datasets on demand or by default. The important thing is to think about the entire ecosystem: the life cycle of data, its exploitation, maintenance and, above all, the value it generates in society.
What role can open data play in AI?
In this context, AI appears as a catalyst capable of automating tasks, enriching open government data (DMOs), facilitating its understanding and stimulating collaboration between actors.
Recent research, developed by European universities, maps how this silent revolution is happening. The study proposes a classification of uses according to two dimensions:
- Perspective, which in turn is divided into two possible paths:
- Inward-looking (portal): The focus is on the internal functions of data portals.
- Outward-looking (ecosystem): the focus is extended to interactions with external actors (citizens, companies, organizations).
- Phases of the data life cycle, which can be divided into pre-processing, exploration, transformation and maintenance.
In summary, the report identifies these eight types of AI use in government open data, based on perspective and phase in the data lifecycle.

Figure 1. Eight uses of AI to improve government open data. Source: presentation “Data for AI or AI for data: artificial intelligence as a catalyst for open government ecosystems”, based on the report of the same name, from EU Open Data Days 2025.
Each of these uses is detailed below:
1. Portal curator
This application focuses on pre-processing data within the portal. AI helps organize, clean, anonymize, and tag datasets before publication. Some examples of tasks are:
- Automation and improvement of data publication tasks.
- Performing auto-tagging and categorization functions.
- Data anonymization to protect privacy.
- Automatic cleaning and filtering of datasets.
- Feature extraction and missing data handling.
2. Ecosystem data retriever
Also in the pre-processing phase, but with an external focus, AI expands the coverage of portals by identifying and collecting information from diverse sources. Some tasks are:
- Retrieve structured data from legal or regulatory texts.
- News mining to enrich datasets with contextual information.
- Integration of urban data from sensors or digital records.
- Discovery and linking of heterogeneous sources.
- Conversion of complex documents into structured information.
3. Portal explorer
In the exploration phase, AI systems can also make it easier to find and interact with published data, with a more internal approach. Some use cases:
- Develop semantic search engines to locate datasets.
- Implement chatbots that guide users in data exploration.
- Provide natural language interfaces for direct queries.
- Optimize the portal's internal search engines.
- Use language models to improve information retrieval.
4. Ecosystem connector
Operating also in the exploration phase, AI acts as a bridge between actors and ecosystem resources. Some examples are:
- Recommend relevant datasets to researchers or companies.
- Identify potential partners based on common interests.
- Extract emerging themes to support policymaking.
- Visualize data from multiple sources in interactive dashboards.
- Personalize data suggestions based on social media activity.
5. Portal linker
This functionality focuses on the transformation of data within the portal. Its function is to facilitate the combination and presentation of information for different audiences. Some tasks are:
- Convert data into knowledge graphs (structures that connect related information, known as Linked Open Data).
- Summarize and simplify data with NLP (Natural Language Processing) techniques.
- Apply automatic reasoning to generate derived information.
- Enhance multivariate visualization of complex datasets.
- Integrate diverse data into accessible information products.
6. Ecosystem value developer
In the transformation phase and with an external perspective, AI generates products and services based on open data that provide added value. Some tasks are:
- Suggest appropriate analytical techniques based on the type of dataset.
- Assist in the coding and processing of information.
- Create dashboards based on predictive analytics.
- Ensure the correctness and consistency of the transformed data.
- Support the development of innovative digital services.
7. Portal monitor
It focuses on portal maintenance, with an internal focus. Their role is to ensure quality, consistency, and compliance with standards. Some tasks are:
- Detect anomalies and outliers in published datasets.
- Evaluate the consistency of metadata and schemas.
- Automate data updating and purification processes.
- Identify incidents in real time for correction.
- Reduce maintenance costs through intelligent monitoring.
8. Ecosystem engager
And finally, this function operates in the maintenance phase, but outwardly. It seeks to promote citizen participation and continuous interaction. Some tasks are:
- Predict usage patterns and anticipate user needs.
- Provide personalized feedback on datasets.
- Facilitate citizen auditing of data quality.
- Encourage participation in open data communities.
- Identify user profiles to design more inclusive experiences.
What does the evidence tell us?
The study is based on a review of more than 70 academic papers examining the intersection between AI and OGD (open government data). From these cases, the authors observe that:
- Some of the defined profiles, such as portal curator, portal explorer and portal monitor, are relatively mature and have multiple examples in the literature.
- Others, such as ecosystem value developer and ecosystem engager, are less explored, although they have the most potential to generate social and economic impact.
- Most applications today focus on automating specific tasks, but there is a lot of scope to design more comprehensive architectures, combining several types of AI in the same portal or across the entire data lifecycle.
From an academic point of view, this typology provides a common language and conceptual structure to study the relationship between AI and open data. It allows identifying gaps in research and guiding future work towards a more systemic approach.
In practice, the framework is useful for:
- Data portal managers: helps them identify what types of AI they can implement according to their needs, from improving the quality of datasets to facilitating interaction with users.
- Policymakers: guides them on how to design AI adoption strategies in open data initiatives, balancing efficiency, transparency, and participation.
- Researchers and developers: it offers them a map of opportunities to create innovative tools that address specific ecosystem needs.
Limitations and next steps of the synergy between AI and open data
In addition to the advantages, the study recognizes some pending issues that, in a way, serve as a roadmap for the future. To begin with, several of the applications that have been identified are still in early stages or are conceptual. And, perhaps most relevantly, the debate on the risks and ethical dilemmas of the use of AI in open data has not yet been addressed in depth: bias, privacy, technological sustainability.
In short, the combination of AI and open data is still a field under construction, but with enormous potential. The key will be to move from isolated experiments to comprehensive strategies, capable of generating social, economic and democratic value. AI, in this sense, does not work independently of open data: it multiplies it and makes it more relevant for governments, citizens and society in general.
Blog
We know that the open data managed by the public sector in the exercise of its functions is an invaluable resource for promoting transparency, driving innovation and stimulating economic development. At the global level, in the last 15 years this idea has led to the creation of data portals that serve as a single point of access for public information both in a country, a region or city.
However, we sometimes find that the full exploitation of the potential of open data is limited by problems inherent in its quality. Inconsistencies, lack of standardization or interoperability, and incomplete metadata are just some of the common challenges that sometimes undermine the usefulness of open datasets and that government agencies also point to as the main obstacle to AI adoption.
When we talk about the relationship between open data and artificial intelligence, we almost always start from the same idea: open data feeds AI, that is, it is part of the fuel for models. Whether it's to train foundational models like ALIA, to specialize small language models (SLMs) versus LLMs, or to evaluate and validate their capabilities or explain their behavior (XAI), the argument revolves around the usefulness of open data for artificial intelligence, forgetting that open data was already there and has many other uses.
Therefore, we are going to reverse the perspective and explore how AI itself can become a powerful tool to improve the quality and, therefore, the value of open data itself. This approach, which was already outlined by the United Nations Economic Commission for Europe (UNECE) in its pioneering 2022 Machine Learning for Official Statistics report , has become more relevant since the explosion of generative AI. We can now use the artificial intelligence available to increase the quality of datasets that are published throughout their entire lifecycle: from capture and normalization to validation, anonymization, documentation, and follow-up in production.
With this, we can increase the public value of data, contribute to its reuse and amplify its social and economic impact. And, at the same time, to improve the quality of the next generation of artificial intelligence models.
Common challenges in open data quality
Data quality has traditionally been a Critical factor for the success of any open data initiative, which is cited in numerous reports such as that of the European Commission "Improving data publishing by open data portal managers and owners”. The most frequent challenges faced by data publishers include:
-
Inconsistencies and errors: Duplicate data, heterogeneous formats, or outliers are common in datasets. Correcting these small errors, ideally at the data source itself, was traditionally costly and greatly limited the usefulness of many datasets.
-
Lack of standardization and interoperability: Two sets that talk about the same thing may name columns differently, use non-comparable classifications, or lack persistent identifiers to link entities. Without a common minimum, combining sources becomes an artisanal work that makes it more expensive to reuse data.
- Incomplete or inaccurate metadata: The lack of clear information about the origin, collection methodology, frequency of updating or meaning of the fields, complicates the understanding and use of the data. For example, knowing with certainty if the resource can be integrated into a service, if it is up to date or if there is a point of contact to resolve doubts is very important for its reuse.
- Outdated or outdated data: In highly dynamic domains such as mobility, pricing, or environmental data, an outdated set can lead to erroneous conclusions. And if there are no versions, changelogs, or freshness indicators, it's hard to know what's changed and why. The absence of a "history" of the data complicates auditing and reduces trust.
- Inherent biases: sometimes coverage is incomplete, certain populations are underrepresented, or a management practice introduces systematic deviation. If these limits are not documented and warned, analyses can reinforce inequalities or reach unfair conclusions without anyone noticing.
Where Artificial Intelligence Can Help
Fortunately, in its current state, artificial intelligence is already in a position to provide a set of tools that can help address some of these open data quality challenges, transforming your management from a manual and error-prone process to a more automated and efficient one:
- Automated error detection and correction: Machine learning algorithms and AI models can automatically and reliably identify inconsistencies, duplicates, outliers, and typos in large volumes of data. In addition, AI can help normalize and standardize data, transforming it for example into common formats and schemas to facilitate interoperability (such as DCAT-AP), and at a fraction of the cost it was so far.
- Metadata enrichment and cataloging: Technologies associated with natural language processing (NLP), including the use of large language models (LLMs) and small language models (SLMs), can help analyze descriptions and generate more complete and accurate metadata. This includes tasks such as suggesting relevant tags, classification categories, or extracting key entities (place names, organizations, etc.) from textual descriptions to enrich metadata.
- Anonymization and privacy: When open data contains information that could affect privacy, anonymization becomes a critical, but sometimes costly, task. Artificial Intelligence can contribute to making anonymization much more robust and to minimize risks related to re-identification by combining different data sets.
Bias assessment: AI can analyze the open datasets themselves for representation or historical biases. This allows publishers to take steps to correct them or at least warn users about their presence so that they are taken into account when they are to be reused. In short, artificial intelligence should not only be seen as a "consumer" of open data, but also as a strategic ally to improve its quality. When integrated with standards, processes, and human oversight, AI helps detect and explain incidents, better document sets, and publish trust-building quality evidence. As described in the 2024 Artificial Intelligence Strategy, this synergy unlocks more public value: it facilitates innovation, enables better-informed decisions, and consolidates a more robust and reliable open data ecosystem with more useful, more reliable open data with greater social impact.
In addition, a virtuous cycle is activated: higher quality open data trains more useful and secure models; and more capable models make it easier to continue raising the quality of data. In this way, data management is no longer a static task of publication and becomes a dynamic process of continuous improvement.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.