Evento
Marzo se acerca y con ello una nueva edición del Open Data Day. Se trata de una celebración anual a nivel mundial que se organiza desde hace 12 años, impulsada por la fundación Open Knowledge a través de la Open Knowledge Network. Su objetivo es promover el uso de los datos abiertos en todos los países y culturas.
El tema central de este año es “Datos abiertos para abordar la policrisis”. El término policrisis hace referencia a una situación en la que existen diferentes riesgos en el mismo periodo temporal. Con esta temática se quiere poner el foco en los datos abiertos como herramienta para abordar, a través de su reutilización, desafíos globales como la pobreza y las múltiples desigualdades, la violencia y los conflictos, y los riegos climáticos y las catástrofes naturales.
Si hace varios años las actividades se limitaban a un único día, desde 2023 tenemos una semana para poder disfrutar de diversas conferencias, seminarios, talleres, etc. centradas en esta temática. En concreto, en 2025, las actividades relacionadas con el Open Data Day tendrán lugar del 1 al 7 de marzo.
A través de su página web puedes ver las diversas actividades que se realizarán a lo largo de la semana en todo el planeta. En este artículo repasamos algunas de las que puedes seguir desde España, bien porque se realizan en el territorio nacional o porque se pueden seguir online.
Open Data Day 2025: mujeres liderando datos abiertos para la igualdad
Iniciativa Barcelona Open Data organiza una sesión la tarde del 6 de marzo centrada en cómo los datos abiertos pueden ayudar a abordar los retos relacionados con la igualdad. La cita reunirá a mujeres expertas en tecnologías de datos y open data, para compartir conocimiento, experiencias y buenas prácticas tanto en la publicación como en la reutilización de datos abiertos en este campo.
El evento comenzará a las 17:30 con la bienvenida e introducción. A continuación, tendrán lugar dos mesas redondas y una entrevista:
- Mesa redonda 1. Instituciones publicadoras. Estrategia de datos con perspectiva de género para abordar la agenda feminista.
- Diálogo. Data lab. Construyendo la práctica feminista Tech Data.
- Mesa redonda 2. Reutilizadores/as. Proyectos basados en el uso de datos abiertos para abordar la agenda feminista.
La jornada terminará a las 19:40 con un cóctel y la oportunidad para los asistentes de conversar sobre los temas tratados y ampliar la red de contactos a través del networking.
¿Cómo lo puedes seguir? Se trata de un evento presencial, que se celebrará en Ca l’Alier, en la calle de Pere IV, 362 (Barcelona).
Las publicaciones científico-académicas de acceso abierto como herramientas para enfrentar la policrisis del siglo XXI: el rol clave de los editores
Organizada por un particular, el profesor Damián Molgaray, esta conferencia analiza el rol clave de los/as editores/as en las publicaciones científico-académicas de acceso abierto. La idea es que los participantes reflexionen sobre cómo el conocimiento abierto se posiciona como una herramienta fundamental para enfrentar los desafíos de la policrisis del siglo XXI, con el foco puesto en América Latina.
La cita será el 4 de marzo a las 11:00 de Argentina (15:00 en España peninsular).
¿Cómo lo puedes seguir? Se trata de un evento online a través de Google Meet.
WhoFundsThem
La organización mySociety mostrará los resultados de su último proyecto. Durante los últimos meses, un equipo de voluntarios ha recopilado datos de los intereses financieros de los 650 diputados de la Cámara de los Comunes del Reino Unido, a través de fuentes como el Registro de Intereses oficial, el Registro Mercantil, las participaciones de los diputados a los debates, etc. Eso datos, comprobados y verificados con los propios diputados mediante un sistema de “derecho de réplica”, se han transformado a un formato de fácil acceso, para que cualquier persona pueda entenderlos fácilmente, y se publicarán en el sitio web de seguimiento parlamentario TheyWorkForYou.
En este evento se presentará el proyecto y se analizarán las conclusiones. Se celebra en martes 4 a las 14:00 hora de Londres (15:00 en España peninsular).
¿Cómo lo puedes seguir? La sesión se puede seguir online, pero es necesario registrarse. El evento será en inglés.
Science on the 7th: A conversation on Open Data & Air Quality
El viernes 7 a las 9:00 EST – (15:00 en España peninsular) se podrá seguir online una conferencia sobre datos abiertos y calidad del aire. La sesión reunirá a diversos expertos para debatir los temas de actualidad en materia de calidad del aire y salud mundial, y se examinará la contaminación atmosférica procedente de fuentes clave, como las partículas, el ozono y la contaminación relacionada con el tráfico.
Esta iniciativa está organizada por Health Effects Institute, una corporación sin ánimo de lucro que proporciona datos científicos sobre los efectos de la contaminación atmosférica en la salud.
¿Cómo lo puedes seguir? La conferencia, que será en inglés, se puede ver a través de YouTube. No es necesario inscribirse.
Abierto el plazo para recibir nuevas propuestas de eventos
Los eventos anteriores son solo algunos ejemplos de las actividades que forman parte de esta celebración mundial, pero, como se mencionó anteriormente, puedes ver todas las acciones en la página web de la iniciativa.
Además, todavía está abierto el plazo para inscribir nuevos eventos. Si tienes una propuesta, puedes registrarla a través de este enlace.
Desde datos.gob.es te invitamos a unirte a esta semana de celebración, que sirve para reivindicar el poder de los datos abiertos para generar cambios positivos en nuestra sociedad. ¡No te lo pierdas!
Blog
La vivienda es una de las principales preocupaciones de los ciudadanos españoles, de acuerdo con el barómetro de enero de 2025 del Centro de Investigaciones Sociológicas (CIS). Para conocer la situación real del acceso a la vivienda, es necesario disponer de datos públicos, actualizados y de calidad, que permitan a todos los actores de este ecosistema realizar análisis y tomar decisiones informadas.
En este artículo vamos a repasar algunos ejemplos de datos abiertos disponibles, así como herramientas y soluciones que se han creado en base a ellos para acercar esta información a la ciudadanía.
Los datos abiertos pueden tener varios usos en este sector:
- Permitir a los organismos públicos conocer las necesidades de la ciudadanía y elaborar políticas acordes.
- Ayudar a particulares a encontrar viviendas para alquilar o comprar.
- Facilitar información a constructores y empresas para que desarrollen viviendas que den respuesta a esas necesidades.
Por ello, en este campo, los datos más utilizados incluyen aquellos que hacen referencia a las viviendas, pero también a aspectos demográficos y sociales, muchas veces con un alto componente geoespacial. Algunos de los datasets más populares en este sentido son el Índices de precios de consumo y vivienda del Instituto Nacional de Estadística (INE) o los datos del Catastro.
Diferentes organismos públicos han puesto a disposición de la ciudadanía espacios donde reúnen diversos datos relacionados con la vivienda. Es el caso del Ayuntamiento de Barcelona y su portal “Vivienda en datos”, un entorno que centraliza el acceso a información y datos de diversas fuentes, incluyendo datasets de su portal de datos abiertos.
Otro ejemplo es el portal de visualización de datos del Ayuntamiento de Madrid, donde se incluyen cuadros de mando con información sobre el número de inmuebles residenciales por distrito o barrio, así como su valor catastral, con acceso directo a la descarga de los datos utilizados.
Más ejemplos de organismos que también posibilitan el acceso a este tipo de información son la Junta de Castilla y León, el Gobierno Vasco o la Comunidad Valenciana. Además, aquellas personas que lo deseen pueden encontrar multitud de datos relacionados con la vivienda en el Catálogo Nacional de Datos Abiertos, albergado aquí, en datos.gob.es.
También cabe señalar que no solo los organismos públicos abren datos relacionados con esta materia. Hace unos meses, el portal inmobiliario idealista hizo público un conjunto de datos con información detallada de miles de viviendas en Madrid, Barcelona y Valencia. Está disponible como un paquete en R a través de Github.
Herramientas y soluciones para acercar esos datos a los ciudadanos
Datos como los anteriormente mencionados pueden ser reutilizados con múltiples fines, como mostramos en artículos anteriores y como podemos ver en esta nueva aproximación a los diversos casos de uso:
Periodismo de datos
Los medios de comunicación utilizan los datos abiertos sobre vivienda para ofrecer una visión más precisa de la situación del mercado inmobiliario, ayudando a los ciudadanos a comprender las dinámicas que afectan a los precios, la oferta y la demanda. Al acceder a datos sobre la evolución de los precios, la disponibilidad de viviendas o las políticas públicas relacionadas, los medios pueden generar reportajes e infografías que explican de manera accesible la situación y cómo estos factores impactan en la vida cotidiana de las personas. Estos artículos proporcionan información relevante a los ciudadanos, de forma sencilla, para tomar decisiones sobre su situación habitacional.
Un ejemplo es este artículo que permite visualizar, barrio a barrio, el precio del alquiler y el acceso a la vivienda según ingresos, para el cual se utilizaron datos abiertos del Ministerio de Vivienda y Agenda Urbana, el Catastro o el INE, entre otros. En la misma línea se mueve este artículo sobre el porcentaje de ingresos que se destina al alquiler.
Elaboración de informes y políticas
Los datos abiertos sobre vivienda son utilizados por organismos públicos como el Ministerio de Vivienda y Agenda Urbana en su Observatorio de Vivienda y Suelo, donde se generan boletines estadísticos electrónicos que integran datos disponibles en las principales fuentes estadísticas oficiales. El fin es realizar un seguimiento del sector desde diversas perspectivas y a lo largo de las distintas fases del proceso (mercado del suelo, productos edificados, accesibilidad y financiación, etc.). El Ministerio de Vivienda y Agenda Urbana también utiliza datos de diversas fuentes, como la Agencia Tributaria, el Catastro o el INE, para su Sistema Estatal de Referencia de Precios de Alquiler de Vivienda, que define rangos de valores de precios de alquiler de viviendas en zonas declaradas como tensionadas.
Oferta de servicios inmobiliarios
Los datos abiertos pueden ser valiosos para el sector de la construcción: la información abierta sobre el uso del suelo y los permisos se consultan antes de emprender trabajos de excavación y empezar a construir obras nuevas.
Además, algunas de las empresas que utilizan datos abiertos son sitios web inmobiliarios. Estos portales reutilizan conjuntos de datos abiertos para proporcionar a los usuarios precios comparables de las propiedades, estadísticas de delincuencia en los barrios o proximidad a instalaciones públicas educativas, sanitarias y recreativas. A ello ayudan, por ejemplo, herramientas como Location intelligence, que permite acceder a datos del padrón, precios de alquiler, características de la vivienda o planeamiento urbano. Los organismos públicos también pueden ayudar a este campo con sus propias soluciones, como Donde Vivo, del Gobierno de Aragón,que permite obtener un mapa interactivo y la información relacionada de los puntos de interés, centros educativos y sanitarios más cercanos así como información geoestadística del lugar donde vive.
También existen herramientas que ayudan a prever gastos futuros como, Urban3r, donde los usuarios pueden visualizar diferentes indicadores que les ayudan a conocer los datos de demanda energética de los edificios residenciales en su estado actual y tras someterlos a una rehabilitación energética, así como los costes estimados de estas intervenciones.Este es un campo donde las tecnologías disruptivas basadas en datos, como la inteligencia artificial, tendrán cada vez más protagonismo, al optimizar procesos y facilitar la toma de decisiones tanto para los compradores como para los proveedores de viviendas. A través del análisis de grandes volúmenes de datos, la IA puede predecir tendencias del mercado, identificar zonas con mayor demanda o proporcionar recomendaciones personalizadas según las necesidades de cada usuario. Algunas empresas ya han puesto en marcha chatbots, que responden a las preguntas de los usuarios, pero la IA puede ayudar incluso a crear proyectos para el desarrollo de viviendas económicas y sostenibles.
En resumen, nos encontramos en un campo donde las nuevas tecnologías van a hacer cada vez más fácil que los ciudadanos podamos conocer la oferta de viviendas, pero esta oferta debe estar alineada con las necesidades de los usuarios. Por ello es necesario continuar impulsando la apertura de datos de calidad, que ayuden a conocer la situación e impulsar políticas públicas y soluciones que facilitan el acceso a la vivienda.
Noticia
El Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas (SNPSAP) es una herramienta que contribuye a la transparencia, difusión y reutilización de datos relacionados con las subvenciones y ayudas públicas. Este sistema centraliza toda la información sobre convocatorias y concesiones de subvenciones y ayudas públicas aprobadas por la Administración General del Estado, las comunidades autónomas y las entidades locales.
Orígenes del proyecto
Hay que remontarse a 2014 para encontrar el inicio de este proyecto. Ese año se abordó una reforma de la Ley General de Subvenciones de 2003 (Ley 38/2003) con una enorme repercusión en dos aspectos significativos:
- Por una parte, la Base de Datos Nacional de Subvenciones, que había sido creada por la citada Ley en 2003, pasó a estar disponible para su consulta completa por los órganos gestores de subvenciones y ayudas de todas las administraciones públicas y aquellos otros legalmente autorizados.
- Por otra parte, se creó el Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas, como sitio web público, de acceso libre y sin restricciones para todos los ciudadanos. Con ello se daba cumplimiento a los requisitos de publicidad y transparencia de todas las subvenciones y ayudas públicas otorgadas en España, especialmente las convocatorias y las concesiones, con identificación de los beneficiarios de las mismas. Este espacio comenzó a funcionar el 1 de enero de 2015, ofreciendo datos de la administración del Estado. Al año siguiente se amplió a las administraciones autonómica y local, cubriendo de este modo todo el espectro del sector público.
Formatos de datos y funcionalidades iniciales
Desde su origen hubo una seria apuesta por la reutilización de los datos para la sociedad que los origina. Ya inicialmente el sitio web permitió descargar datos en diferentes formatos (CSV, XLSX y PDF) que permiten su reutilización, si bien limitando el tamaño de las descargas a 10.000 registros por cuestiones de rendimiento y capacidad técnica.
Además, desde el primer momento se dispuso de un mecanismo de suscripción de alertas. Un ciudadano o empresa podía -y puede- registrar tantas alertas como necesite para que el sistema le comunique automáticamente cuando se publique cualquier convocatoria de su interés, enviándole un enlace a la misma. Se suprimió así, de golpe, la tediosa necesidad de consultar diariamente las decenas de diarios oficiales que se publican en España para conocer las convocatorias de ayudas y subvenciones.
Un proyecto en constante evolución para hacer frente a su crecimiento
La evolución normativa en materia de ayudas y subvenciones en la Unión Europea, y la adhesión de España a la iniciativa Open Government Partnership de las Naciones Unidas, fueron modelando el crecimiento del sitio web en años sucesivos, incrementando la oferta de vistas de datos específicos (ayudas de Estado y de minimis, grandes beneficiarios, partidos políticos, etc.), que hicieron más fácil para el ciudadano y el reutilizador de datos el acceso a los mismos.
En los albores de la pandemia, el sistema soportaba ya 1,3 millones de visitas anuales, sirviendo 3,3 millones de páginas de concesiones y convocatorias. Esto suponía un reto a nivel de rendimiento, ya que se alcanzaron unos volúmenes nunca previstos en los diseños técnicos iniciales. Se hacía necesaria una reforma tecnológica profunda que fuera capaz de soportar la alta demanda de información y nivel de servicio.
La reforma se abordó, no solo desde el punto de vista tecnológico, sino recogiendo, además:
- Las novedades establecidas en el Real Decreto 130/2019 que regula la Base de Datos Nacional de Subvenciones.
- La necesidad socialmente demandada de habilitar un interfaz API-REST para descarga de información en formato reutilizable JSON que permitiera superar las limitaciones técnicas.
Características de la plataforma actual
El nuevo sitio web fue puesto en producción a finales de noviembre de 2023, ofreciendo múltiples vistas de convocatorias (520.000 a diciembre de 2024), concesiones (27.700.000), concesiones de ayudas de Estado (5.000.000), concesiones de minimis (3.190.000), planes estratégicos de subvenciones (1.341), infracciones muy graves (4), subvenciones a partidos (7.580), y subvenciones a grandes beneficiarios (145.000).
Toda esta información es accesible hoy a través de pantalla, descargable en formatos PDF, CSV, XSLX y del interfaz API-REST en formato JSON y XML, siendo libremente reutilizable por empresas infomediarias y ciudadanos, sin más restricciones que las establecidas en las leyes.
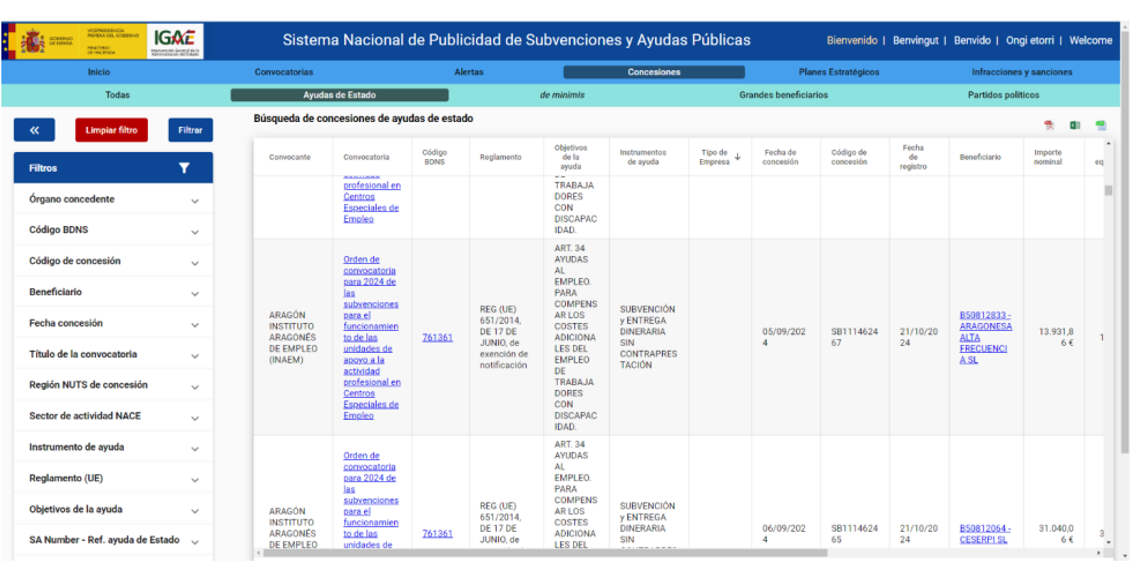
Figura 1. Captura de la web del Sistema Nacional de Publicidad de Subvenciones y ayudas Públicas (SNPSAP)
Desde su puesta en producción hace 11 meses, el nuevo sistema ha recibido 7,5 millones de visitas de ciudadanos y empresas. Y a través del interfaz API-REST se realizan miles de descargas diarias, contribuyendo poderosamente a la difusión de la información subvencional “en bruto” para su reutilización por la sociedad para todo tipo de análisis, estudios, etc. Además, diariamente se emiten de media 35.000 mensajes de correo electrónico de alerta a ciudadanos y empresas para informarr de nuevas convocatorias de ayudas.
Ventajas de SNPSAP
La difusión social y reutilización de toda esta información elimina asimetrías y fricciones en los mercados, y permite a los operadores y ciudadanos trabajar de modo más eficiente y productivo, redundando en mayores cotas de bienestar para la sociedad.
La publicación de datos en abierto permite a los ciudadanos y organizaciones, no solo conocer cómo se distribuyen los fondos públicos, sino también identificar nuevas oportunidades. Este sistema garantiza que todas las personas y organizaciones tengan el mismo acceso a la información, independientemente de su tamaño o recursos, contribuyendo a una distribución más equitativa de las ayudas públicas.
Blog
La captura de datos geoespaciales es esencial para entender nuestro entorno, tomar decisiones informadas y diseñar políticas efectivas en áreas como la planificación urbana, la gestión de recursos naturales o la respuesta ante emergencias. En el pasado, este proceso era principalmente manual y laborioso, basado en mediciones terrestres realizadas con herramientas como estaciones totales y niveles. Aunque estas técnicas tradicionales han evolucionado significativamente y siguen siendo ampliamente utilizadas, se han complementado con métodos automatizados y versátiles que permiten recopilar datos de manera más eficiente y detallada.
La novedad en el contexto actual no solo radica en los avances tecnológicos, que han mejorado la precisión y eficiencia en la recopilación de datos geoespaciales, sino también porque coincide con un cambio generalizado de mentalidad hacia la transparencia y la accesibilidad. Este enfoque ha impulsado la publicación de los datos obtenidos como recursos abiertos, facilitando su reutilización en aplicaciones como la planificación urbana, la gestión energética y la evaluación ambiental. La combinación de tecnología avanzada y una mayor conciencia sobre la importancia de compartir información marca un cambio significativo respecto a las técnicas tradicionales.
En este artículo, exploraremos algunos de los nuevos métodos de captura de datos, desde vuelos fotogramétricos con helicópteros y drones, hasta sistemas terrestres como el mobile mapping, que emplean sensores avanzados para generar modelos tridimensionales y mapas altamente precisos. Además, aprenderemos cómo estas tecnologías han potenciado la generación de datos abiertos, democratizando el acceso a información geoespacial clave para la innovación, la sostenibilidad y la colaboración pública-privada.
Fotogrametría áerea: helicópteros con sensores avanzados
En el pasado, la captura de datos geoespaciales desde el aire implicaba procesos largos y complejos. Las cámaras analógicas montadas en aviones generaban fotografías aéreas que debían procesarse manualmente para crear mapas bidimensionales. Aunque este enfoque fue innovador en su momento, también presentaba limitaciones, como una resolución más baja, tiempos prolongados de procesamiento y una mayor dependencia de las condiciones meteorológicas y de la luz diurna. Sin embargo, los avances tecnológicos han reducido estas restricciones, permitiendo incluso operaciones nocturnas o en condiciones climáticas adversas.
Hoy en día, la fotogrametría aérea ha dado un salto cualitativo gracias al uso de helicópteros equipados con sensores de última generación. Las cámaras digitales de alta resolución permiten capturar imágenes en múltiples ángulos, incluidas vistas oblicuas que ofrecen una perspectiva más completa del terreno. Además, la incorporación de sensores térmicos y tecnologías LiDAR (Light Detection and Ranging) añade una capa de detalle y precisión sin precedentes. Estos sistemas generan nubes de puntos y modelos tridimensionales que pueden integrarse directamente en software de análisis geoespacial, eliminando gran parte del procesamiento manual.
| Aspecto | Ventajas | Inconvenientes |
|---|---|---|
| Cobertura y flexibilidad | Permite cubrir grandes áreas y acceder a terrenos complejos. | Puede estar limitado a su uso en zonas con restricciones de espacio aéreo. Inaccesible a zonas subterráneas o de difícil acceso como túneles. |
| Tipos de datos | Captura datos visuales, térmicos y topográficos en un solo vuelo. | - |
| Precisión | Genera nubes de puntos y modelos 3D con alta precisión. | - |
| Eficiencia en grandes proyectos de datos | Permite cubrir áreas extensas donde los drones no tienen suficiente autonomía. | Coste operativo elevado comparado con otras tecnologías. |
| Impacto medioambiental y ruido | - | Genera ruido y mayor impacto ambiental, limitando su uso en áreas sensibles. |
| Condiciones climáticas | - | Depende del clima; condiciones adversas como viento y lluvia afectarán su operación. |
| Coste | - | Alto coste en comparación con drones o métodos terrestres. |
Figura 1. Tabla con ventajas e inconvenientes de la fotogrametría aérea con helicópteros.
Mobile mapping: de mochilas a integración BIM
El mobile mapping es una técnica de captura de datos geoespaciales que emplea vehículos equipados con cámaras, escáneres LiDAR, GPS y otros sensores avanzados. Esta tecnología permite recopilar información detallada mientras el vehículo se desplaza, siendo ideal para cartografiar áreas urbanas, redes viales y entornos dinámicos.
En el pasado, los levantamientos topográficos requerían mediciones estacionarias, lo que implicaba interrupciones del tráfico y un tiempo considerable para cubrir extensas áreas. En contraste, el mobile mapping ha revolucionado este proceso, permitiendo capturar datos de manera rápida, eficiente y con menor impacto en el entorno. Además, existen versiones portátiles de esta tecnología, como mochilas con escáneres robóticos, que permiten acceder a áreas peatonales o de difícil acceso.

Figura 2. Imagen captada con técnicas de mobile mapping.
| Aspecto | Ventajas | Inconvenientes |
|---|---|---|
| Rapidez | Captura datos mientras el vehículo se desplaza, reduciendo tiempos de operación. | Menor precisión en áreas con poca visibilidad para los sensores (por ejemplo, túneles). |
| Cobertura urbana | Ideal para entornos urbanos y redes viales complejas. | Es eficiente en áreas donde los vehículos pueden circular, pero su alcance es limitado como en terrenos rurales o inaccesibles. |
| Flexibilidad de implementación | Disponible en versiones portátiles (mochilas) para áreas peatonales o difíciles de alcanzar. | Los equipos portátiles suelen tener menor alcance que los sistemas vehiculares. |
| Integración con SIG y BIM | Facilita la generación de modelos digitales y su uso en planificación y análisis. | Requiere software avanzado para procesar grandes volúmenes de datos. |
| Impacto en el entorno | No requiere interrupciones del tráfico ni acceso exclusivo a áreas de trabajo. | Dependencia de condiciones ambientales óptimas, como luz adecuada y clima. |
| Accesibilidad | Accesible a zonas subterráneas o de difícil acceso como túneles. |
Figura 3. Tabla con ventajas e inconvenientes del mobile mapping.
El mobile mapping se presenta como una solución versátil y eficiente para capturar datos geoespaciales en movimiento, convirtiéndose en una herramienta clave para la modernización de los sistemas de gestión urbana y territorial.
HAPS y globos: nuevas alturas para la captura de información
Los HAPS (High-Altitude Platform Stations) y globos aerostáticos representan una alternativa innovadora y eficiente en la captura de datos geoespaciales desde grandes alturas. Estas plataformas, ubicadas en la estratosfera o a altitudes controladas, combinan características de los drones y los satélites, ofreciendo una solución intermedia que destaca por su versatilidad y sostenibilidad:
- Los HAPS, como los zepelines y aeronaves similares, operan en la estratosfera, a altitudes de entre 18 y 20 kilómetros, permitiendo una vista amplia y detallada del terreno.
- Los globos aerostáticos, por su parte, son ideales para estudios locales o temporales, gracias a su facilidad de despliegue y operación en altitudes más bajas.
Ambas tecnologías pueden equiparse con cámaras de alta resolución, sensores LiDAR, instrumentos térmicos y otras tecnologías avanzadas para la captura de datos.
| Aspecto | Ventajas | Inconvenientes |
|---|---|---|
| Cobertura | Amplia área de captura, especialmente con HAPS en la estratosfera. | Cobertura limitada en comparación con satélites en órbita. |
| Sostenibilidad | Menor impacto ambiental y huella energética en comparación con helicópteros o aviones. | Dependencia de condiciones meteorológicas para su despliegue y estabilidad. |
| Coste | Costos operativos más bajos que los satélites tradicionales | Mayor inversión inicial que drones o equipos terrestres. |
| Versatilidad | Ideal para proyectos temporales o de emergencia. | Limitada autonomía en globos aerostáticos. |
| Duración de operación | Los HAPS pueden operar por largos periodos (días o semanas). | Los globos aerostáticos tienen un tiempo de operación más corto. |
Figura 4. Tabla con ventajas e inconvenientes del HAPS y globos
Los HAPS y globos aerostáticos se presentan como herramientas clave para complementar tecnologías existentes como los drones y satélites, ofreciendo nuevas posibilidades en la recopilación de datos geoespaciales de manera sostenible, flexible y eficiente. A medida que estas tecnologías evolucionen, su adopción ampliará el acceso a datos cruciales para una gestión más inteligente del territorio y los recursos.
La tecnología satelital es una herramienta fundamental para la captura de datos geoespaciales a nivel global. España ha dado pasos significativos en este ámbito con el desarrollo y lanzamiento del satélite PAZ. Este satélite, diseñado inicialmente para fines de seguridad y defensa, ha demostrado un enorme potencial para aplicaciones civiles, como el monitoreo ambiental, la gestión de recursos naturales y la planificación urbana.
Tecnología satelital: el satélite PAZ y su futuro con PAZ-2
PAZ es un satélite de observación de la Tierra equipado con un radar de apertura sintética (SAR), que permite captar imágenes en alta resolución, independientemente de las condiciones meteorológicas o de luz.
El próximo lanzamiento de PAZ-2 (previsto para 2030) promete ampliar aún más las capacidades de observación de España. Este nuevo satélite, diseñado con mejoras tecnológicas, busca complementar las funciones de PAZ y aumentar la disponibilidad de datos para aplicaciones civiles y científicas. Entre las mejoras previstas, se incluyen:
- Mayor resolución de imágenes.
- Capacidad para monitorear áreas más extensas en menos tiempo.
- Incremento en la frecuencia de capturas para análisis más dinámicos.
| Aspecto | Ventajas | Desventajas |
|---|---|---|
| Cobertura global | Capacidad de capturar datos de cualquier parte del planeta. | Limitaciones en la resolución frente a tecnologías terrestres más detalladas. |
| Independiencia del clima | Los sensores SAR permiten capturas incluso en condiciones meteorológicas adversas.. | Dependencia de condiciones meteorológicas para su despliegue y estabilidad. |
| Frecuencia de datos | PAZ-2 mejorará la frecuencia de capturas, ideal para el monitoreo continuo. | Tiempo limitado en la vida útil del satélite. |
| Acceso a datos abiertos | Fomenta la reutilización en proyectos civiles y científicos. | Requiere infraestructura avanzada para procesar grandes volúmenes de datos. |
Figura 5. Tabla con ventajas e inconvenientes de la tecnología satelital PAZ y PAZ-2
Con PAZ y el próximo PAZ-2, España fortalece su posición en el ámbito de la observación satelital, abriendo nuevas oportunidades para la gestión eficiente del territorio, el análisis ambiental y el desarrollo de soluciones innovadoras basadas en datos geoespaciales. Estos satélites no solo son un avance tecnológico, sino también una herramienta estratégica para promover la sostenibilidad y la cooperación internacional en el acceso a datos.
Conclusión: retos y oportunidades en la gestión del dato
La evolución de las técnicas de captura de datos geoespaciales ofrece una oportunidad única para mejorar la precisión, accesibilidad y calidad de los datos, y en el caso concreto de datos abiertos, resulta fundamental para fomentar la transparencia y la reutilización de información pública. Sin embargo, este avance no puede entenderse sin analizar el papel que juegan las herramientas tecnológicas en dicho proceso.
Las innovaciones como el LiDAR en helicópteros, el Mobile Mapping, SAM, HAPS y satélites como PAZ y PAZ-2 no solo optimizan la obtención de datos, sino que también tienen un impacto directo en la calidad y disponibilidad de los datos.
En definitiva, estás herramientas tecnológicas generan información de alta calidad que puede ser puesta a disposición de los ciudadanos como datos abiertos, una situación que se está viendo impulsada por el cambio de mentalidad hacia la transparencia y la accesibilidad. Este equilibrio convierte a los datos abiertos y a las herramientas tecnológicas en elementos complementarios, esenciales para maximizar el valor social, económico y ambiental de los datos geoespaciales.
Puedes ver un resumen de estas técnicas y sus aplicaciones en la siguiente infografía:

Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Los EU Open Data Days 2025 son un evento esencial para todos los interesados en el mundo de los datos abiertos y la innovación en Europa y el mundo. Este encuentro, que se celebrará los días 19 y 20 de marzo de 2025, reunirá a expertos, profesionales, desarrolladores, investigadores y responsables de políticas públicas para compartir conocimientos, explorar nuevas oportunidades y abordar los retos a los que se enfrenta la comunidad de datos abiertos.
El evento, organizado por la Comisión Europea a través de data.europa.eu, tiene como objetivo principal promover la reutilización de datos abiertos. Los participantes tendrán la oportunidad de aprender sobre las últimas tendencias en el uso de los datos abiertos, descubrir nuevas herramientas y debatir sobre las políticas y normativas que están modelando el panorama digital en Europa.
¿Dónde y cuándo se celebra?
El evento se celebrará en el Centro Europeo de Convenciones de Luxemburgo, aunque también se podrá seguir online, con el siguiente horario:
- Miércoles 19 de marzo de 2025, de 13:30 a 18:30.
- Jueves 20 de marzo de 2025, de 9:00 a 15:30.
¿Qué temáticas se abordarán?
Ya está disponible la agenda del evento, donde encontramos distintas temáticas, como, por ejemplo:
- Historias de éxito y buenas prácticas: el evento contará con la presencia de profesionales que desarrollan su trabajo en la primera línea de la política de datos europea, para que cuenten su experiencia. Entre otras cuestiones, estos expertos proporcionarán una guía práctica para inventariar y abrir los datos del sector público de un país, abordarán el trabajo que implica la compilación de conjuntos de datos de alto valor o analizarán las perspectivas sobre la reutilización de datos en los modelos de negocio. También se explicarán buenas prácticas para contar con metadatos de calidad o mejorar la gobernanza de datos y su interoperabilidad.
- Foco en el uso de inteligencia artificial (IA): los datos abiertos ofrecen una fuente invaluable para el desarrollo y avance de la IA. Además, la IA puede optimizar la localización, gestión y uso de estos datos, ofreciendo herramientas que ayuden a agilizar procesos y extraer un mayor conocimiento. En este sentido, en el evento se abordará el potencial de la IA para transformar los ecosistemas de datos gubernamentales abiertos, fomentando la innovación, mejorando la gobernanza y potenciando la participación ciudadana. Los responsables del portal nacional de datos de Noruega contará cómo emplean un motor de búsqueda basado en IA para mejorar la localización de datos. Además, se explicarán los avances en espacios de datos lingüísticos y su uso en modelos de lenguaje, y se analizará cómo combinar de forma creativa los datos abiertos para lograr un impacto social.
- Aprendizaje sobre visualización de datos: los asistentes al evento podrán explorar cómo la visualización de datos está transformando la comunicación, la elaboración de políticas y la participación ciudadana. A través de diversos casos (como el árbol genealógico de 3.000 personas de la realeza europea o las relaciones del Patrimonio Cultural Inmaterial de la UNESCO) se mostrará cómo los procesos iterativos de diseño pueden descubrir patrones ocultos en redes complejas, aportando ideas sobre la narración y la comunicación de datos. También se abordará cómo influyen los elementos de diseño, como el color, la escala y el enfoque, en la percepción de los datos.
- Ejemplos y casos de uso: se mostrarán múltiples ejemplos de proyectos concretos basados en la reutilización de datos, en campos como la energía, el desarrollo urbano o el medio ambiente. Entre las experiencias que se compartirán, encontramos una empresa española, Tangible Data, que contará cómo las esculturas físicas de datos convierten conjuntos de datos complejos en experiencias accesibles y atractivas.
Estos son solo algunos de los temas a tratar, pero también se hablará de ciencia abierta, el papel de los datos abiertos en la transparencia y la rendición de cuentas, etc.
¿Por qué son tan importantes los EU Open Data Days?
El acceso a datos abiertos ha demostrado ser una herramienta poderosa para mejorar la toma de decisiones, impulsar la innovación y la investigación, y mejorar la eficiencia de las organizaciones. En un momento en el que la digitalización está avanzando rápidamente, la importancia de compartir y reutilizar datos se hace cada vez más crucial para enfrentar desafíos globales como el cambio climático, la salud pública o la justicia social.
Los EU Open Data Days 2025 son una oportunidad para explorar cómo los datos abiertos pueden aprovecharse para construir una Europa más conectada, innovadora y participativa.
Además, para aquellos que decidan asistir de forma presencial, el evento será también una oportunidad para establecer contactos con otros profesionales y organizaciones del sector, creando nuevas colaboraciones que pueden dar lugar a proyectos innovadores.
¿Cómo puedo asistir?
Para asistir presencialmente, es necesario inscribirse a través de este enlace. Sin embargo, no es necesario el registro para atender el evento de manera online.
Para cualquier consulta, se ha habilitado una dirección de correo donde se atenderán todas las dudas relativas al evento: EU-Open-Data-Days@ec.europa.eu.
Más información en la página web del evento.
Noticia
Impulsar la cultura del dato es un objetivo clave a nivel nacional que también comparten las administraciones autonómicas. Uno de los caminos para llevar a cabo este propósito es premiar aquellas soluciones que han sido desarrolladas con conjuntos de datos abiertos, una iniciativa que potencia su reutilización e impacto en la sociedad.
En esta misión, la Junta de Castilla y León y el Gobierno Vasco llevan años organizando concursos de datos abiertos, temática de la que hablamos en nuestro primer episodio del pódcast de datos.gob.es que puedes escuchar aquí.
En este post, repasamos cuáles han sido los proyectos premiados en las últimas ediciones de los concursos de datos abiertos de Euskadi y Castilla y León.
Premiados en el VIII Concurso de Datos Abiertos de Castilla y León
En la octava edición de esta competición anual, que suele abrir su plazo a finales de verano, se presentaron 35 candidaturas, de las cuales se han escogido 8 ganadores divididos en diferentes categorías.
Categoría Ideas: los participantes tenían que describir una idea para crear estudios, servicios, sitios web o aplicaciones para dispositivos móviles. Se repartían un primer premio de 1.500€ y un segundo premio de 500€.
- Primer premio: Guardianes Verdes de Castilla y León presentado por Sergio José Ruiz Sainz. Se trata de una propuesta para desarrollar una aplicación móvil que oriente a los visitantes de los parques naturales de Castilla y León. Los usuarios pueden acceder a información (como mapas interactivos con puntos de interés) a la vez que pueden contribuir con datos útiles de su visita, que enriquecen la aplicación.
- Segundo premio: ParkNature: sistema inteligente de gestión de aparcamientos en espacios naturales presentado por Víctor Manuel Gutiérrez Martín. Consiste en una idea para la crear una aplicación que optimice la experiencia de los visitantes de los espacios naturales de Castilla y León, mediante la integración en tiempo real de datos sobre aparcamientos y la conexión con eventos culturales y turísticos cercanos.
Categoría Productos y Servicios: premiaba estudios, servicios, sitios web o aplicaciones para dispositivos móviles, los cuales deben estar accesibles para toda la ciudadanía vía web mediante una URL. En esta categoría se repartieron un primer, segundo y tercer premio de 2.500€, 1.500€ y 500€, respectivamente, además de un premio específico de 1.500€ para estudiantes.
- Primer premio: AquaCyL de Pablo Varela Vázquez. Es una aplicación que ofrece información sobre las zonas de baño en la comunidad autónoma.
- Segundo premio: ConquistaCyL presentado por Markel Juaristi Mendarozketa y Maite del Corte Sanz. Es un juego interactivo pensado para hacer turismo en Castilla y León y aprender a través de un proceso gamificado.
- Tercer premio: Todo el deporte de Castilla y León presentado por Laura Folgado Galache. Es una app que presenta toda la información de interés asociada a un deporte según la provincia.
- Premio estudiantes: Otto Wunderlich en Segovia por Jorge Martín Arévalo. Es un repositorio fotográfico ordenado según tipo de monumentos y localización de las fotografías de Otto Wunderlich.
Categoría Recurso Didáctico: consistía en la creación de recursos didácticos abiertos nuevos e innovadores, que sirvieran de apoyo a la enseñanza en el aula. Estos recursos debían ser publicados con licencias Creative Commons. En esta categoría se otorgaba un único primer premio de 1.500€.
- Primer premio: StartUp CyL: Creación de empresas a través de la Inteligencia Artificial y Datos Abiertos presentado por José María Pérez Ramos. Es un chatbot que utiliza la API de ChatGPT para asistir en la creación de una empresa utilizando datos abiertos.
Categoría Periodismo de Datos: premiaba piezas periodísticas publicadas o actualizadas (de forma relevante), tanto en soporte escrito como audiovisual, y ofrecía un premio de 1.500€.
- Primer premio: Codorniz, perdiz y paloma torcaz son las especies más cazadas en Burgos, presentado por Sara Sendino Cantera, que analiza datos sobre la caza en Burgos.
Premiados de la 5ª edición del Concurso de Datos Abiertos de Open Data Euskadi
Como ya venía sucediendo en ediciones anteriores, el portal de datos abiertos de Euskadi abrió dos modalidades de premios: un concurso de ideas y otro de aplicaciones, cada uno de los cuales estaba dividido en varias categorías. En esta ocasión, se presentaron 41 candidaturas en el concurso de ideas y 30 para el de aplicaciones
Concurso de ideas: en esta modalidad se han repartido dos premios por categoría, el primero de 3.000€ y el segundo de 1.500€.
Categoría Sanitaria y Social
- Primer premio: Desarrollo de un Modelo de Predicción de Volumen de Pacientes que acudirán al Servicio de urgencias de Osakidetza de Miren Bacete Martínez. Propone el desarrollo de un modelo predictivo usando series temporales capaz de anticipar tanto el volumen de personas que acudirán a urgencias, como el nivel de gravedad de los casos.
- Segundo premio: Euskoeduca de Sandra García Arias. Es una propuesta de solución digital diseñada para brindar orientación académica y profesional personalizada a estudiantes, padres y tutores.
Categoría Medio ambiente y Sostenibilidad
- Primer premio: Baratzapp de Leire Zubizarreta Barrenetxea. La idea consiste en el desarrollo de un software que facilita y asiste en la planificación de un huerto mediante algoritmos que buscan potenciar el conocimiento relacionado con la huerta de autoconsumo, a la vez que integra, entre otras, la información climatológica, medioambiental y parcelaria de una manera personalizada para el usuario.
- Segundo premio: Euskal Advice de Javier Carpintero Ordoñez. El objetivo de esta propuesta es definir un recomendador turístico basado en inteligencia artificial.
Categoría General
- Primer premio: Lanbila de Hodei Gonçalves Barkaiztegi. Es una propuesta de app que utiliza IA generativa y datos abiertos para emparejar curriculum vitae con ofertas de empleo de forma semántica. Proporciona recomendaciones personalizadas, alertas proactivas de empleo y formación, y permite decisiones informadas a través de indicadores laborales y territoriales.
- Segundo premio: Desarrollo de un LLM para la consulta interactiva de Datos Abiertos del Gobierno Vasco de Ibai Alberdi Martín. La propuesta consiste en el desarrollo de un Modelo de Lenguaje a Gran Escala (LLM) similar a ChatGPT, entrenado específicamente con datos abiertos, enfocado en proporcionar una interfaz conversacional y gráfica que permita a los usuarios obtener respuestas precisas y visualizaciones dinámicas.
Concurso de aplicaciones: esta modalidad ha seleccionado un proyecto en la categoría de servicios web, premiado con 8.000€, y dos más en la Categoría General que han recibido un primer premio de 8.000€ y 5.000€ como segundo premio.
Categoría Servicios web
- Primer premio: Bizidata: Plataforma de visualización del uso de bicicletas en Vitoria-Gasteiz de Igor Díaz de Guereñu de los Ríos. Es una plataforma que visualiza, analiza y permite descargar datos del uso de bicicletas en Vitoria-Gasteiz, y explorar cómo factores externos, como la climatología y el tráfico, influyen en el uso de la bicicleta.
Categoría General
- Primer premio: Garbiñe AI de Beatriz Arenal Redondo. Es un asistente inteligente que combina la inteligencia artificial (IA) con datos abiertos de Open Data Euskadi para promover la economía circular y mejorar los ratios de reciclaje en Euskadi.
- Segundo premio: Vitoria-Gasteiz Businessmap de Zaira Gil Ozaeta. Es una herramienta de visualización interactiva basada en datos abiertos, diseñada para mejorar las decisiones estratégicas en el ámbito del emprendimiento y la actividad económica en Vitoria-Gasteiz.
Todas estas soluciones premiadas reutilizan conjuntos de datos abiertos del portal autonómico de Castilla y León o Euskadi, según el caso. Te animamos a que eches un vistazo a las propuestas que pueden inspirarte de cara a participar en la próxima edición de estos concursos. ¡Síguenos en redes sociales para no perderte las convocatorias de este año!
Noticia
Los últimos días del año siempre son un buen momento para echar la vista atrás y valorar los avances realizados. Si hace unas semanas hacíamos balance de lo sucedido en la iniciativa Aporta, ahora llega el momento de recopilar las novedades relacionadas con la compartición de datos, los datos abiertos y las tecnologías ligadas a ellos.
Hace seis meses, ya hicimos una primera recolección de hitos en el sector. En esta ocasión, vamos a resumir algunas de las innovaciones, mejoras y logros del último semestre del año.
Regulando e impulsando la inteligencia artificial
La inteligencia artificial (IA) continúa siendo uno de los campos donde cada día se aprecian nuevos avances. Se trata de un sector cuyo auge es relativamente nuevo y que necesita regulación. Por ello, la Unión Europea publicó el pasado julio el Reglamento de inteligencia artificial, una norma que marcará el entorno regulatorio europeo y global. Alineada con Europa, España ya presentó unos meses antes su nueva Estrategia de inteligencia artificial 2024, con el fin de establecer un marco para acelerar el desarrollo y expansión de la IA en España.
Por otro lado, en octubre, España asumió la copresidencia de Open Government Partnership (OGP). En su hoja de ruta está promover las ideas innovadoras, aprovechando las oportunidades que brindan los datos abiertos y la inteligencia artificial. Como parte del cargo, España organizará la próxima cumbre mundial de OGP en Vitoria.
Nuevas herramientas innovadoras basadas en datos
Los datos son el motor de una gran cantidad de herramientas tecnológicas disruptivas que pueden generar beneficios para toda la ciudadanía. Algunas de las puestas en marcha por organismos públicos durante estos últimos meses son:
- El Ministerio de Transportes y Movilidad Sostenible cumple un año más utilizando tecnología Big Data para analizar el tráfico de las carreteras y mejorar las inversiones y la seguridad vial. Este año han vuelto a compartir datos de movilidad diaria como ya hicieron durante la pandemia de COVID-19, también han desarrollado nuevas herramientas para facilitar la consulta y visualización de estos datos y se han abierto aplicaciones específicas para ayudar a la reutilización de los datos en el contexto de la gestión de la zona afectada por la DANA.
- El Principado de Asturias anuncia un plan para el uso de Inteligencia Artificial con el fin de acabar con los atascos durante el verano, a través de la elaboración de un gemelo digital.
- El Gobierno de Aragón presentó un nuevo sistema de inteligencia turística, que utiliza Big Data e IA para mejorar la toma de decisiones en el sector.
- La Región de Murcia ha lanzado "Murcia Business Insight" un aplicativo de business intelligence que permite realizar análisis dinámicos con datos sobre las empresas de la región: facturación, empleo, localización, sector de actividad, etc.
- El Ayuntamiento de Granada ha utilizado Inteligencia Artificial para mejorar el alcantarillado. El objetivo es conseguir una planificación y ejecución "más eficiente" del mantenimiento, con datos in situ.
- El Ayuntamiento de Segovia y Visa han firmado un acuerdo de colaboración para desarrollar una herramienta online con datos reales, agregados y anónimos de los patrones de gasto de los titulares extranjeros de tarjetas Visa en la capital. Esta iniciativa ofrecerá información de interés que permitirá adaptar las estrategias para fomentar el turismo internacional.
También los investigadores y estudiantes de diversos centros han comunicado avances fruto del trabajo con datos:
- Investigadores del Centro de Regulación Genómica (CRG) de Barcelona, la Universidad del País Vasco (UPV/EHU), el Donostia International Physics Center (DIPC) y la Fundación Biofísica Bizkaia han entrenado un algoritmo para detectar alteraciones de tejidos en los estadios iniciales y mejorar el diagnóstico de cáncer.
- Investigadores del Consejo Superior de Investigaciones Científicas (CSIC) y KIDO Dynamics, han puesto en marcha un proyecto para extraer metadatos de las antenas móviles para comprender el flujo de personas en parajes naturales. El objetivo es la identificación y control del impacto del turismo.
- Una estudiante de la Universidad de Valladolid (UVa) ha diseñado un proyecto para mejorar la gestión y el análisis de los ecosistemas forestales en España a nivel local. Para ello, convierte los límites municipales a un formato de datos abiertos enlazados. Los resultados están disponibles para su reutilización.
Avances en espacios de datos
Desde el Ministerio para la Transformación Digital y de la Función Pública y, en concreto, desde la Secretaría de Estado de Digitalización e Inteligencia Artificial se continúa avanzando en la implementación de espacios de datos, a través de diversas acciones:
- Se ha presentado un Plan de Impulso de los Espacios de Datos Sectoriales para impulsar la compartición segura de los datos.
- Se ha puesto en marcha el desarrollo de Espacios de Datos para las Infraestructuras Urbanas Inteligentes (EDINT). Este proyecto, que se llevará a cabo a través de la Federación Española de Municipios y Provincias (FEMP), contempla la creación de un espacio de datos multisectorial que reunirá toda la información recopilada por las entidades locales.
- Se han lanzado ayudas, en el ámbito de la digitalización, para la transformación digital de los sectores productivos estratégicos mediante el desarrollo de productos y servicios tecnológicos para espacios de datos.
Funcionalidades que acercan los datos a los reutilizadores
Las plataformas de datos abiertos de los diversos organismos también han presentado novedades, ya sean nuevos conjuntos de datos, funcionalidades, estrategias o informes:
- El Ministerio para la Transición Ecológica y el Reto Demográfico ha lanzado una nueva aplicación para la visualización del Índice Nacional de Calidad del Aire (ICA) en tiempo real. Incluye recomendaciones sanitarias para la población general y la población sensible.
- La Junta de Andalucía ha publicado una “Guía para el diseño de Estudios Piloto de Políticas Públicas”. En ella propone una metodología para diseñar estudios piloto y un sistema de recogida de evidencias para la toma de decisiones.
- La Generalitat de Catalunya ha iniciado los pasos para implantar un nuevo modelo de gobierno del dato que permita mejorar las relaciones con la ciudadanía y las empresas.
- El Ayuntamiento de Madrid está implantando una nueva cartografía 3D y un mapa térmico. En el Blog IDEE (Infraestructura de Datos Espaciales de España) nos contaron cómo se ha creado este modelo 3D de la capital utilizando diversas tecnologías de captura de dato.
- El Instituto Canario de Estadística (ISTAC) ha publicado 6.527 mapas temáticos con indicadores laborales sobre Canarias en su catálogo de datos abiertos.
- Iniciativa Open Data y la Unión Democrática de Pensionistas y Jubilados de España, con apoyo del Ministerio de Derechos Sociales, Consumo y Agenda 2030, presentaron la primera web de Datos del Observatorio de Datos x Mayores. Su objetivo es facilitar el análisis del envejecimiento saludable en España y la toma decisiones estratégicas. La Iniciativa de Barcelona también puso en marcha un reto para identificar 50 datasets relacionados con el envejecimiento saludable, un proyecto que cuenta con el soporte de la Diputación de Barcelona.
- El Centro para el Desarrollo Tecnológico y la Innovación (CDTI) ha presentado un dashboard en fase beta con datos abiertos en formato explotable.
Además, se continúa trabajando para favorecer la apertura de datos desde diversas instituciones:
- Asedie y la Universidad Rey Juan Carlos (Madrid) han puesto en marcha el Observatorio Open Data Reuse para promover la reutilización de los datos abiertos. Ya cuenta con el compromiso del Ayuntamiento de Madrid y están buscando más instituciones que se unan a su Manifiesto.
- El Cabildo de Tenerife y la Universidad de La Laguna han desarrollado una Estrategia de Movilidad Sostenible en la Reserva de la Biosfera Macizo de Anaga. Se busca obtener datos en tiempo real para tomar medidas adaptadas a la demanda.
Concursos de datos y eventos para animar a utilizar datos abiertos
El verano fue la época elegida por distintos organismos públicos para lanzar concursos donde se buscaban productos y/o servicios basados en datos abiertos. Es el caso de:
- La Comunidad de Madrid celebró DATAMAD 2024 en la Universidad Rey Juan Carlos de Madrid. El evento incluía un taller sobre cómo reutilizar datos abiertos y un datathon.
- Más de 200 estudiantes de inscribieron al I Malackathon, organizado por la Universidad de Málaga, un concurso que premiaba los proyectos que usaban datos abiertos para plantear soluciones en la gestión de recursos hídricos.
- La Junta de Castilla y León celebró el VIII Concurso de Datos Abiertos, cuyos ganadores se conocieron en el mes de noviembre.
- También se lanzó el II Datathon de UniversiData. Han sido seleccionados 16 finalistas. Los ganadores se conocerán el 13 de febrero de 2025.
- El Cabildo de Tenerife también organizó su I Concurso de Datos Abiertos: Ideas de reutilización. Actualmente se encuentran valorando las candidaturas recibidas. Más adelante lanzarán su II Concurso de Datos Abiertos: Desarrollo de APP.
- El Gobierno de Euskadi llevó a cabo su V Concurso de datos abiertos. Ya se conocen los finalistas tanto de la categoría de Aplicaciones como de Ideas.
También en estos meses se han celebrado múltiples eventos, que se pueden ver online, como:
- El III Congreso GeoEuskadi y XVI Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE).
- DATAfórum Justicia 2024.
Otros ejemplos de eventos que se celebraron pero no están disponibles online son el III Congreso & XIV Jornadas de Usuarios de R, el Congreso de Innovación Pública Novagob 2024, DATAGRI 2024 o la Jornada Gobierno del Dato para Entidades Locales, entre otros.
Estos son solo algunos ejemplos de la actividad realizada durante los últimos seis meses en el ecosistema de datos de España. Te animamos a compartir otras experiencias que conozcas en los comentarios o a través de nuestra dirección de correo electrónico dinamizacion@datos.gob.es
Blog
Los modelos de lenguaje se encuentran en el epicentro del cambio de paradigma tecnológico que está protagonizando la inteligencia artificial (IA) generativa en los últimos dos años. Desde las herramientas con las que interaccionamos en lenguaje natural para generar texto, imágenes o vídeos y que utilizamos para crear contenido creativo, diseñar prototipos o producir material educativo, hasta aplicaciones más complejas en investigación y desarrollo que incluso han contribuido de forma decisiva a la consecución del Premio Nobel de Química de 2024, los modelos de lenguaje están demostrando su utilidad en una gran variedad de aplicaciones, que por otra parte, aún estamos explorando.
Desde que en 2017 Google publicó el influyente artículo "Attention is all you need", donde se describió la arquitectura de los Transformers, tecnología que sustenta las nuevas capacidades que OpenAI popularizó a finales de 2022 con el lanzamiento de ChatGPT, la evolución de los modelos de lenguaje ha sido más que vertiginosa. En apenas dos años, hemos pasado de modelos centrados únicamente en la generación de texto a versiones multimodales que integran la interacción y generación de texto, imágenes y audio.
Esta rápida evolución ha dado lugar a dos categorías de modelos de lenguaje: los SLM (Small Language Models), más ligeros y eficientes, y los LLM (Large Language Models), más pesados y potentes. Lejos de considerarlos competidores, debemos analizar los SLM y LLM como tecnologías complementarias. Mientras los LLM ofrecen capacidades generales de procesamiento y generación de contenido, los SLM pueden proporcionar soporte a soluciones más ágiles y especializadas para necesidades concretas. Sin embargo, ambos comparten un elemento esencial: dependen de grandes volúmenes de datos para su entrenamiento y en el corazón de sus capacidades están los datos abiertos, que son parte del combustible que se utiliza para entrenar estos modelos de lenguaje en los que se basan las aplicaciones de IA generativa.
LLM: potencia impulsada por datos masivos
Los LLM son modelos de lenguaje a gran escala que cuentan con miles de millones, e incluso billones, de parámetros. Estos parámetros son las unidades matemáticas que permiten al modelo identificar y aprender patrones en los datos de entrenamiento, lo que les proporciona una extraordinaria capacidad para generar texto (u otros formatos) coherente y adaptado al contexto de los usuarios. Estos modelos, como la familia GPT de OpenAI, Gemini de Google o Llama de Meta, se entrenan con inmensos volúmenes de datos y son capaces de realizar tareas complejas, algunas incluso para las que no fueron explícitamente entrenados.
De este modo, los LLM son capaces de realizar tareas como la generación de contenido original, la respuesta a preguntas con información relevante y bien estructurada o la generación de código de software, todas ellas con un nivel de competencia igual o superior al de los humanos especializados en dichas tareas y siempre manteniendo conversaciones complejas y fluidas.
Los LLM se basan en cantidades masivas de datos para alcanzar su nivel de desempeño actual: desde repositorios como Common Crawl, que recopila datos de millones de páginas web, hasta fuentes estructuradas como Wikipedia o conjuntos especializados como PubMed Open Access en el campo biomédico. Sin acceso a estos corpus masivos de datos abiertos, la capacidad de estos modelos para generalizar y adaptarse a múltiples tareas sería mucho más limitada.
Sin embargo, a medida que los LLM continúan evolucionando, la necesidad de datos abiertos aumenta para conseguir progresos específicos como:
- Mayor diversidad lingüística y cultural: aunque los LLM actuales manejan múltiples idiomas, en general están dominados por datos en inglés y otros idiomas mayoritarios. La falta de datos abiertos en otras lenguas limita la capacidad de estos modelos para ser verdaderamente inclusivos y diversos. Más datos abiertos en idiomas diversos garantizarían que los LLM puedan ser útiles para todas las comunidades, preservando al mismo tiempo la riqueza cultural y lingüística del mundo.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. Esto, en ocasiones, genera respuestas que perpetúan estereotipos o desigualdades. Incorporar más datos abiertos cuidadosamente seleccionados, especialmente de fuentes que promuevan la diversidad y la igualdad, es fundamental para construir modelos que representen de manera justa y equitativa a diferentes grupos sociales.
- Actualización constante: los datos en la web y en otros recursos abiertos cambian constantemente. Sin acceso a datos actualizados, los LLM generan respuestas obsoletas muy rápidamente. Por ello, incrementar la disponibilidad de datos abiertos frescos y relevantes permitiría a los LLM mantenerse alineados con la actualidad.
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Los datos abiertos permiten que desarrolladores independientes, universidades y pequeñas empresas entrenen y afinen sus propios modelos sin necesidad de costosas adquisiciones de datos. De este modo se democratiza el acceso a la inteligencia artificial y se fomenta la innovación global.
Para solucionar algunos de estos retos, en la nueva Estrategia de Inteligencia Artificial 2024 se han incluido medidas destinadas a generar modelos y corpus en castellano y lenguas cooficiales, incluyendo también el desarrollo de conjuntos de datos de evaluación que consideran la evaluación ética.
SLM: eficiencia optimizada con datos específicos
Por otra parte, los SLM han emergido como una alternativa eficiente y especializada que utiliza un número más reducido de parámetros (generalmente en millones) y que están diseñados para ser ligeros y rápidos. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
Para ello, los SLM también dependen de datos abiertos, pero en este caso, la calidad y relevancia de los conjuntos de datos son más importantes que su volumen, por ello los retos que les afectan están más relacionados con la limpieza y especialización de los datos. Estos modelos requieren conjuntos que estén cuidadosamente seleccionados y adaptados al dominio específico para el que se van a utilizar, ya que cualquier error, sesgo o falta de representatividad en los datos puede tener un impacto mucho mayor en su desempeño. Además, debido a su enfoque en tareas especializadas, los SLM enfrentan desafíos adicionales relacionados con la accesibilidad de datos abiertos en campos específicos. Por ejemplo, en sectores como la medicina, la ingeniería o el derecho, los datos abiertos relevantes suelen estar protegidos por restricciones legales y/o éticas, lo que dificulta su uso para entrenar modelos de lenguaje.
Los SLM se entrenan con datos cuidadosamente seleccionados y alineados con el dominio en el que se utilizarán, lo que les permite superar a los LLM en precisión y especificidad en tareas concretas, como por ejemplo:
- Autocompletado de textos: un SLM para autocompletado en español puede entrenarse con una selección de libros, textos educativos o corpus como los que se impulsarán en la ya mencionada Estrategia de IA, siendo mucho más eficiente que un LLM de propósito general para esta tarea.
- Consultas jurídicas: un SLM entrenado con conjuntos de datos jurídicos abiertos pueden proporcionar respuestas precisas y contextualizadas a preguntas legales o procesar documentos contractuales de forma más eficaz que un LLM.
- Educación personalizada: en el sector educativo, SLM entrenados con datos abiertos de recursos didácticos pueden generar explicaciones específicas, ejercicios personalizados o incluso evaluaciones automáticas, adaptadas al nivel y las necesidades del estudiante.
- Diagnóstico médico: un SLM entrenado con conjuntos de datos médicos, como resúmenes clínicos o publicaciones abiertas, puede asistir a médicos en tareas como la identificación de diagnósticos preliminares, la interpretación de imágenes médicas mediante descripciones textuales o el análisis de estudios clínicos.
Desafíos y consideraciones éticas
No debemos olvidar que, a pesar de los beneficios, el uso de datos abiertos en modelos de lenguaje presenta desafíos significativos. Uno de los principales retos es, como ya hemos mencionado, garantizar la calidad y neutralidad de los datos para que estén libres de sesgos, ya que estos pueden amplificarse en los modelos, perpetuando desigualdades o prejuicios.
Aunque un conjunto de datos sea técnicamente abierto, su utilización en modelos de inteligencia artificial siempre plantea algunas implicaciones éticas. Por ejemplo, es necesario evitar que información personal o sensible se filtre o pueda deducirse de los resultados generados por los modelos, ya que esto podría causar daños a la privacidad de las personas.
También debe tenerse en cuenta la cuestión de la atribución y propiedad intelectual de los datos. El uso de datos abiertos en modelos comerciales debe abordar cómo se reconoce y compensa adecuadamente a los creadores originales de los datos para que sigan existiendo incentivos a los creadores.
Los datos abiertos son el motor que impulsa las asombrosas capacidades de los modelos de lenguaje, tanto en el caso de los SLM como de los LLM. Mientras que los SLM destacan por su eficiencia y accesibilidad, los LLM abren puertas a aplicaciones avanzadas que no hace mucho nos parecían imposibles. Sin embargo, el camino hacia el desarrollo de modelos más capaces, pero también más sostenibles y representativos, depende en gran medida de cómo gestionemos y aprovechemos los datos abiertos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Ahora que el año llega a su fin es el momento perfecto para hacer una pausa y reflexionar sobre todo lo que hemos vivido y compartido desde Iniciativa Aporta. Este año ha estado lleno de desafíos, aprendizajes y logros que merecen ser celebrados.
Uno de los hitos que queremos compartir es que hemos alcanzado casi dos millones de visitas en la plataforma, lo que supone un crecimiento de un 15% con respecto a 2023. El interés por los datos y las tecnologías relacionadas también ha quedado patente en redes sociales: hemos superado los 14.000 seguidores en LinkedIn (+56%) y los 21.000 en X, el antiguo Twitter (+ 1,5%). Además, hemos querido aproximarnos a nuevas audiencias con el lanzamiento de nuestros perfiles en Instagram y Threads, y el rediseño del canal de YouTube.
Uno de nuestros objetivos es impulsar la apertura de los datos generados por el sector público para que puedan ser reutilizados por empresas y ciudadanos. Desde la Iniciativa Aporta proporcionamos apoyo técnico cualificado para ayudar a los organismos públicos a superar sus retos y poner a disposición de los usuarios datos de calidad, a través de auditorías, sesiones formativas y asesoramiento. Este trabajo ha dado sus frutos con los más 90.000 conjuntos de datos publicados en el Catálogo Nacional, un 18% más con respecto a 2023. Estos datasets se federan con el Portal Europeo de datos abiertos, data.europa.eu.
Pero no solo se trata de publicar datos, sino también de favorecer su uso. Para impulsar el conocimiento sobre los datos abiertos y estimular un mercado ligado a la reutilización de la información del sector público, desde la Iniciativa Aporta hemos desarrollado más de 120 artículos, 1.400 tuits y 250 publicaciones en LinkedIn con noticias, eventos o análisis del sector. En este sentido, hemos tratado de recoger las últimas tendencias sobre múltiples temáticas relacionadas con los datos como la inteligencia artificial, los espacios de datos o la ciencia abierta. Además:
- España se encuentra entre los países de la UE que marcan tendencia en materia de datos abiertos en 2024
- Hemos lanzado un nuevo formato de contenido: los pódcasts de datos.gob.es. El objetivo es que puedas profundizar en diversas temáticas a través de programas de audio que puedes escuchar en cualquier momento y lugar.
- Hemos reforzado la sección de infografías, con nuevos contenidos que resumen cuestiones complejas relacionadas con los datos, como diversas legislaciones o documentos estratégicos. Cada infografía presenta información detallada de forma visualmente atractiva, facilitando la asimilación de conceptos importantes y permitiéndote acceder rápidamente a los puntos clave.
- Hemos creado nuevos ejercicios de ciencia de datos, diseñados para guiarte paso a paso a través de conceptos clave y diversas técnicas de análisis para que puedas aprender de manera efectiva y práctica. Además, cada ejercicio incluye el código completo disponible en GitHub, permitiéndote replicar y experimentar por tu cuenta.
- Hemos publicado nuevas guías e informes enfocados en cómo aprovechar el potencial de los datos abiertos para impulsar la innovación y la transparencia. Cada documento incluye explicaciones claras y ejemplos prácticos para estar al tanto de las mejores prácticas y herramientas, asegurando que estés siempre a la vanguardia en el uso de tecnologías emergentes relacionadas con los datos.
- Hemos ampliado el listado de ejemplos de aplicaciones y empresas que reutilizan datos abiertos. En el caso de las aplicaciones ya alcanzamos las 470 soluciones (37 más con respecto a 2023) y en el de empresas, 96 empresas (6 más respecto a 2023).
¡Gracias por este buen año! En 2025 continuaremos trabajando para impulsar la cultura del dato en organismos públicos, empresas y ciudadanos.
Puedes ver más sobre nuestra actividad en la siguiente infografía:

Blog
La capacidad de recopilar, analizar y compartir datos juega un papel crucial en el contexto de los desafíos globales a los que nos enfrentamos hoy en día como sociedad. Desde la contaminación y el cambio climático, pasando por la pobreza y las pandemias, hasta la movilidad sostenible y la falta de acceso a los servicios básicos. Los problemas globales exigen soluciones que puedan adaptarse a gran escala. Es ahí donde los datos abiertos pueden jugar un papel fundamental, ya que permiten que gobiernos, organizaciones y ciudadanos trabajen juntos de manera transparente, y facilitan el proceso hasta llegar a conseguir soluciones eficaces, innovadoras, adaptables y sostenibles.
El Banco Mundial como pionero en el uso integral de los datos abiertos
Uno de los ejemplos de buenas prácticas más relevantes que podemos encontrar a la hora de exprimir el potencial de los datos abiertos para afrontar los grandes desafíos globales es, sin duda, el caso del Banco Mundial, referente en el uso de los datos abiertos desde hace ya más de una década como herramienta fundamental para el desarrollo sostenible.
Desde el lanzamiento de su portal de datos abiertos en 2010, la institución ha llevado a cabo un completo proceso de transformación en cuanto al acceso y uso de los datos. Este portal, totalmente innovador en su día, se convirtió rápidamente en un modelo de referencia al ofrecer acceso libre y gratuito a una amplia gama de datos e indicadores que abarcan más de 250 economías. Además, su plataforma está en constante actualización y poco se parece en el presente a la versión inicial, ya que sigue mejorando continuamente y proporcionando nuevos conjuntos de datos y herramientas complementarias y especializadas con el objetivo de facilitar que los datos estén siempre accesibles y sean útiles para la toma de decisiones. Algunos ejemplos de esas herramientas serían:
- La Poverty and Inequality Platform (PIP): diseñada para monitorizar y analizar la pobreza y la desigualdad a nivel mundial. Con datos de más de 140 países, esta plataforma permite a los usuarios acceder a estadísticas actualizadas y comprender mejor las dinámicas del bienestar colectivo. También facilita la visualización de datos mediante gráficos interactivos y mapas, ayudando a los usuarios a obtener una comprensión clara y rápida de la situación en distintas regiones y a lo largo del tiempo.
- La Microdata Library: proporciona acceso a datos de encuestas y censos a nivel de hogar y empresa en diversos países. La biblioteca cuenta con más de 3.000 conjuntos de datos provenientes de estudios y encuestas realizadas tanto por el propio Banco, así como de otras organizaciones internacionales y agencias nacionales de estadística. Los datos están disponibles de forma gratuita y son totalmente accesibles para poder ser descargados y analizados.
- Los World Development Indicators (WDI): son una herramienta fundamental para poder seguir el progreso de la agenda de desarrollo global. Esta base de datos contiene una vasta colección de indicadores de desarrollo económico, social y ambiental, abarcando más de 200 países y territorios. Cuenta con datos que cubren áreas como pobreza, educación, salud, sostenibilidad ambiental, infraestructura y comercio. Los WDIs nos proporcionan un marco de referencia de confianza a la hora de analizar tendencias de desarrollo globales y regionales.


Figura 1. Capturas de los portales web Poverty and Inequality Platform (PIP), Microdata Library y World Development Indicators (WDI).
Un hito relevante que ha marcado la forma en la que el Banco Mundial hace uso de los datos ha sido la publicación del informe sobre el Desarrollo Mundial 2021, titulado "datos para mejorar nuestras vidas". Este informe se ha convertido en una publicación emblemática que explora el potencial transformador de los datos para abordar los grandes retos de la humanidad, mejorar los resultados de los esfuerzos invertidos en desarrollo y promover un crecimiento inclusivo y equitativo. A través del informe, la institución aboga por una nueva agenda social para los datos, incluyendo una gobernanza robusta, ética y responsable de los mismos, maximizando su valor para poder generar un beneficio económico y social significativo.
En el informe se examina cómo los datos pueden ser integrados en las políticas públicas y los programas de desarrollo para abordar los desafíos globales en áreas como educación, salud, infraestructuras o el cambio climático. Pero, además, supuso un antes y un después a la hora de reforzar el compromiso del Banco Mundial con los datos como motor de cambio a la hora de afrontar los grandes desafíos, adoptando desde entonces una nueva hoja de ruta con un enfoque del uso de los datos más innovador, transformador y orientado a la acción. Desde ese momento han venido pasando de la teoría a la práctica a través de sus propios proyectos, donde los datos se convierten en una herramienta fundamental durante todo el ciclo estratégico, como en los siguientes ejemplos:
- Datos abiertos y reducción del riesgo de desastres: en el informe "Bienes públicos digitales para la reducción del riesgo de desastres en un clima cambiante" se subraya cómo el acceso abierto a datos geoespaciales y meteorológicos facilita la toma de decisiones y una planificación estratégica más eficaz. También se hace referencia a herramientas como OpenStreetMap que permiten a las comunidades mapear en tiempo real áreas vulnerables. Esta democratización de los datos refuerza la respuesta ante emergencias y fomenta la resiliencia de las comunidades expuestas a los riesgos de inundaciones, sequías y huracanes.
- Datos abiertos ante los retos agroalimentarios: el informe "¿Qué se está cocinando?" muestra cómo los datos abiertos están revolucionando los sistemas agroalimentarios globales, haciéndolos más inclusivos, eficientes y sostenibles. En la agricultura, el acceso a datos abiertos sobre patrones climáticos, calidad del suelo y precios de mercado habilita a los pequeños agricultores para tomar decisiones informadas. Además, las plataformas que ofrecen datos geoespaciales abiertos sirven para fomentar la agricultura de precisión, permitiendo optimizar recursos clave como el agua y los fertilizantes, a la vez que se reducen costes y se minimiza el impacto ambiental.
- Optimización de los sistemas de transporte urbano: en Tanzania, el Banco Mundial ha respaldado un proyecto que utiliza los datos abiertos para mejorar el sistema de transporte público. La rápida urbanización de Dar es Salaam ha provocado una congestión de tráfico considerable en varias zonas, afectando tanto la movilidad urbana como la calidad del aire. Esta iniciativa aborda la congestión del tráfico mediante un sistema de información en tiempo real que mejora la movilidad y reduce el impacto ambiental. Este enfoque, basado en datos abiertos, no solo aumenta la eficiencia del transporte, sino que también contribuye a una mejor calidad de vida para los habitantes de la ciudad.
Predicando con el ejemplo
Por último, y dentro de esta misma visión integral, cabe destacar cómo este organismo internacional cierra el círculo de los datos abiertos a través de su utilización también como herramienta de transparencia y comunicación de sus propias actividades. Es por ello que entre las herramientas de datos destacadas de su catálogo podremos encontrar algunas como:
- Su portal de proyectos y operaciones: una herramienta que ofrece acceso detallado a los proyectos de desarrollo que la institución financia y ejecuta en todo el mundo. Este portal actúa como una ventana a todas sus iniciativas globales, proporcionando información sobre objetivos, financiación, resultados esperados y avances para los miles de proyectos del Banco.
- La plataforma Finances One: en la que centralizan todos sus datos financieros de interés público y los correspondientes a la cartera de proyectos de todas las entidades del grupo. Su objetivo es simplificar la presentación de información financiera, facilitando su análisis y compartición por parte de clientes y socios.
El impacto futuro de los datos abiertos en los grandes desafíos globales
Como hemos visto también anteriormente, la apertura de datos ofrece un potencial inmenso para avanzar en la agenda de desarrollo sostenible y poder así enfrentar los desafíos globales con mayor eficacia. El Banco Mundial ha venido demostrando cómo esta práctica puede evolucionar y adaptarse a los desafíos actuales. Su liderazgo en este ámbito ha servido como modelo para otras instituciones, mostrando el impacto positivo que los datos abiertos pueden tener en el desarrollo sostenible y a la hora de afrontar los grandes desafíos que afectan a la vida de millones de personas en todo el mundo.
No obstante, hay todavía un largo camino por recorrer, ya que es necesario seguir mejorando las políticas de transparencia y acceso a la información para que los datos puedan llegar a beneficiar al conjunto de la sociedad de forma más equitativa. Además, otro desafío clave es fortalecer las capacidades necesarias para maximizar el uso e impacto de estos datos, particularmente en los países en vías de desarrollo. Esto implica no solo ir más allá de facilitar el acceso, sino también trabajar en la alfabetización de datos y en el apoyo a la creación de las herramientas adecuadas que permitan que la información sea utilizada de manera efectiva.
El uso de datos abiertos está consiguiendo que cada vez más actores puedan participar en la creación de soluciones innovadoras y conseguir un cambio real. Todo ello da lugar a una nueva área de trabajo en expansión que, en las manos correctas y con el apoyo adecuado, puede desempeñar un papel crucial en la creación de un futuro más seguro, justo y sostenible para todos. Esperamos que sean muchas las organizaciones que sigan el ejemplo del Banco Mundial y adopten también un enfoque integral en el uso de los datos para afrontar los grandes retos de la humanidad.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.