Blog
En un mundo donde la inmediatez cobra cada vez más importancia, el comercio predictivo se ha convertido en una herramienta clave para anticipar comportamientos de consumo, optimizar decisiones y ofrecer experiencias personalizadas. Ya no se trata solo de reaccionar ante las necesidades del cliente, sino de predecir lo que quiere incluso antes de que lo sepa.
En este artículo vamos a explicar qué es el comercio predictivo y la importancia de los datos abiertos en ello, incluyendo ejemplos reales.
¿Qué es el comercio predictivo?
El comercio predictivo es una estrategia basada en el análisis de datos para anticipar las decisiones de compra de los consumidores. Utiliza algoritmos de inteligencia artificial y modelos estadísticos para identificar patrones de comportamiento, preferencias y momentos clave en el ciclo de consumo. Gracias a ello, las empresas pueden conocer información relevante sobre qué productos serán más demandados, cuándo y dónde se realizará una compra o qué clientes tienen mayor probabilidad de adquirir una determinada marca.
Esto es de gran importancia en un mercado como el actual, donde existe una saturación de productos y competencia. El comercio predictivo permite a las empresas ajustar inventarios, precios, campañas de marketing o la logística en tiempo real, convirtiéndose en una gran ventaja competitiva.
El papel de los datos abiertos en el comercio predictivo
Estos modelos se alimentan de grandes volúmenes de datos: históricos de compra, navegación web, ubicación o comentarios en redes sociales, entre otros. Pero cuanto más precisos y diversos sean los datos, más afinadas serán las predicciones. Aquí es donde los datos abiertos juegan un papel fundamental, ya que permiten añadir nuevas variables a tener en cuenta a la hora de definir el comportamiento del consumidor. Entre otras cuestiones, los datos abiertos pueden ayudarnos a:
- Enriquecer modelos de predicción con información externa como datos demográficos, movilidad urbana o indicadores económicos.
- Detectar patrones regionales que influyen en el consumo, como, por ejemplo, el impacto del clima en la venta de ciertos productos estacionales.
- Diseñar estrategias más inclusivas al incorporar datos públicos sobre hábitos y necesidades de distintos grupos sociales.
La siguiente tabla muestra ejemplos de conjuntos de datos disponibles en datos.gob.es que pueden servir para estas tareas, a nivel nacional, aunque muchas comunidades autónomas y ayuntamientos también publican este tipo de datos junto a otros también de interés.
| Conjunto de datos | Ejemplo | Posible uso |
|---|---|---|
| Padrón municipal por edad y sexo | Instituto Nacional de Estadística (INE) | Segmenta poblaciones por territorio, edad y género. Es útil para personalizar campañas en base a la población mayoritaria de cada municipio o prever la demanda por perfil demográfico. |
| Encuesta de presupuestos familiares | Instituto Nacional de Estadística (INE) | Ofrece información sobre el gasto medio por hogar en diferentes categorías. Puede ayudar a anticipar patrones de consumo por nivel socioeconómico. |
| Índice de precio de consumo (IPC) | Instituto Nacional de Estadística (INE) | Desagrega el IPC por territorio, midiendo cómo varían los precios de bienes y servicios en cada provincia española. Tiene utilidad para ajustar precios y estrategias de penetración de mercado. |
| Avisos meteorológicos en tiempo real | Ministerio para la Transición Ecológica y Reto Demográfico | Alerta de fenómenos meteorológicos adversos. Permite correlacionar clima con ventas de productos (ropa, bebidas, calefacción, etc.). |
| Estadísticas de educación y alfabetización digital | Instituto Nacional de Estadística (INE) | Ofrece información sobre el uso de Internet en los últimos 3 meses. Permite identificar brechas digitales y adaptar las estrategias de comunicación o formación. |
| Datos sobre estancias turísticas | Instituto Nacional de Estadística (INE) | Informa sobre la estancia media de turistas por comunidades autónomas. Ayuda a anticipar demanda en zonas con alta afluencia estacional, como productos locales o servicios turísticos. |
| Número de recetas y gasto farmacéutico | Mutualidad General de Funcionarios Civiles del Estado (MUFACE) | Ofrece información del consumo de medicamentos por provincia y subgrupos de edad. Facilita la estimación de ventas de otros productos sanitarios y de parafarmacia relacionados al estimar cuántos usuarios irán a la farmacia. |
Figura 1. Tabla comparativa. Fuente: elaboración propia -datos.gob.es.
Casos de uso reales
Desde hace años, ya encontramos empresas que están utilizando este tipo de datos para optimizar sus estrategias comerciales. Veamos algunos ejemplos:
- Uso de datos meteorológicos para optimizar el stock en grandes supermercados
Los grandes almacenes Walmart utilizan algoritmos de IA que incorporan datos meteorológicos (como olas de calor, tormentas o cambios de temperatura) junto a datos históricos de ventas, eventos y tendencias digitales, para prever la demanda a nivel granular y optimizar inventarios. Esto permite ajustar automáticamente el reabastecimiento de productos críticos según patrones climáticos anticipados. Además, Walmart menciona que su sistema considera “datos futuros” como patrones climáticos macro (“macroweather”), tendencias económicas y demografía local para anticipar la demanda y posibles interrupciones en la cadena de suministro.
La firma Tesco también utiliza datos meteorológicos públicos en sus modelos predictivos. Esto le permite anticipar patrones de compra, como que por cada aumento de 10°C en la temperatura, las ventas de barbacoa se incrementan hasta en un 300%. Además, Tesco recibe pronósticos meteorológicos locales hasta tres veces al día, conectándolos con datos sobre 18 millones de productos y el tipo de clientes de cada tienda. Esta información se comparte con sus proveedores para ajustar los envíos y mejorar la eficiencia logística.
- Uso de datos demográficos para decidir la ubicación de locales
Desde hace años Starbucks ha recurrido a la analítica predictiva para planificar su expansión. La compañía utiliza plataformas de inteligencia geoespacial, desarrolladas con tecnología GIS, para combinar múltiples fuentes de información —entre ellas datos abiertos demográficos y socioeconómicos como la densidad de población, el nivel de ingresos, los patrones de movilidad, el transporte público o la tipología de negocios cercanos— junto con históricos de ventas propias. Gracias a esta integración, puede predecir qué ubicaciones tienen mayor potencial de éxito, evitando la competencia entre locales y asegurando que cada nueva tienda se sitúe en el entorno más adecuado.
Domino's Pizza también utilizó modelos similares para analizar si la apertura de un nuevo local en un barrio de Londres tendría éxito y cómo afectaría a otras ubicaciones cercanas, considerando patrones de compra y características demográficas locales.
Este enfoque permite predecir flujos de clientes y maximizar la rentabilidad mediante decisiones de localización más informadas.
- Datos socioeconómicos para fijar precios en base a la demografía
Un ejemplo interesante lo encontramos en SDG Group, consultora internacional especializada en analítica avanzada para retail. La compañía ha desarrollado soluciones que permiten ajustar precios y promociones teniendo en cuenta las características demográficas y socioeconómicas de cada zona -como la base de consumidores, la ubicación o el tamaño del punto de venta-. Gracias a estos modelos es posible estimar la elasticidad de la demanda y diseñar estrategias de precios dinámicos adaptados al contexto real de cada área, optimizando tanto la rentabilidad como la experiencia de compra.
El futuro del comercio predictivo
El auge del comercio predictivo se ha visto impulsado por el avance de la inteligencia artificial y la disponibilidad de datos, tanto abiertos como privados. Desde la elección del lugar ideal para abrir una tienda hasta la gestión eficiente de inventarios, los datos públicos combinados con analítica avanzada permiten anticipar comportamientos y necesidades de los consumidores con una precisión cada vez mayor.
No obstante, aún quedan retos importantes por afrontar: la heterogeneidad de las fuentes de datos, que en muchos casos carecen de estándares comunes; la necesidad de contar con tecnologías e infraestructuras sólidas que permitan integrar la información abierta con los sistemas internos de las empresas; y, por último, el desafío de garantizar un uso ético y transparente, que respete la privacidad de las personas y evite la generación de sesgos en los modelos.
Superar estos retos será clave para que el comercio predictivo despliegue todo su potencial y se convierta en una herramienta estratégica para empresas de todos los tamaños. En este camino, los datos abiertos jugarán un papel fundamental como motor de innovación, transparencia y competitividad en el comercio del futuro.
Noticia
La iniciativa de datos abiertos de España, datos.gob.es, se renueva para ofrecer una experiencia más accesible, intuitiva y eficiente. El cambio responde al afán de mejorar el acceso a los datos y facilitar su uso por parte de ciudadanos, investigadores, empresas y administraciones. Con un diseño actualizado y nuevas funcionalidades, la plataforma continuará actuando como punto de encuentro entre todos aquellos que busquen innovar en base a los datos.
Foco en conjuntos de datos de alto valor y servicios web
La nueva web refuerza su eje central, el Catálogo Nacional de datos abiertos, un punto de acceso a cerca de 100.000 conjuntos de datos, que agrupan más de 500.000 ficheros, y que la Administración Pública española pone a disposición de empresas, investigadores y ciudadanos para su reutilización. En él se pueden encontrar datasets publicados por organismos de la Administración General del Estado, autonómicos, locales, universidades, etc.
Uno de los avances más relevantes es la mejora en las posibilidades que tienen los publicadores de datos para describir de forma más precisa y estructurada las colecciones de datos que desean poner a disposición del público. Una descripción más detallada de las fuentes revierte en mayor facilidad de los usuarios a la hora de localizar datos de su interés.
En concreto, la plataforma incorpora un nuevo modelo de metadatos alineado con las últimas versiones de los estándares europeos, el perfil de aplicación nacional DCAT-AP-ES, que adapta directrices del esquema europeo de intercambio de metadatos DCAT-AP (Data Catalog Vocabulary – Aplication Profile). Este perfil mejora la interoperabilidad a nivel nacional y europeo, facilita el cumplimiento con las normativas comunitarias, favorece la federación de catálogos y a la localización de datasets, y contribuye a mejorar la calidad de los metadatos mediante mecanismos de validación, entre otras ventajas.
Además, la nueva versión de datos.gob.es introduce importantes mejoras en la vista del Catálogo, destacando los conjuntos de datos de alto valor (high value data o HVD en inglés) y los datos ofrecidos a través de servicios web. Para mejorar su identificación, se han añadido símbolos distintivos que permiten diferenciar los tipos de recursos de un solo vistazo.
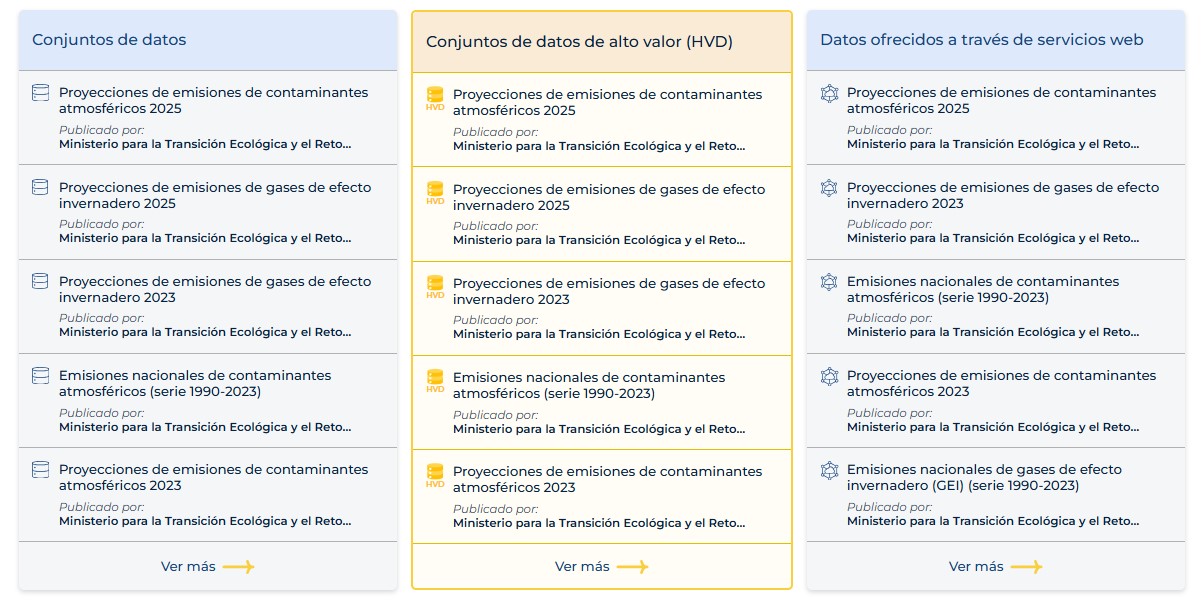
Asimismo, se ha ampliado el número de metadatos documentados, los cuales se muestran a los usuarios a través de una estructura más clara. Ahora los metadatos proporcionados por los organismos publicadores se pueden categorizan en información general, ficha técnica, contacto y aspectos relativos a la calidad. Esta nueva organización proporciona a los usuarios una visión más completa y accesible de cada conjunto de datos.
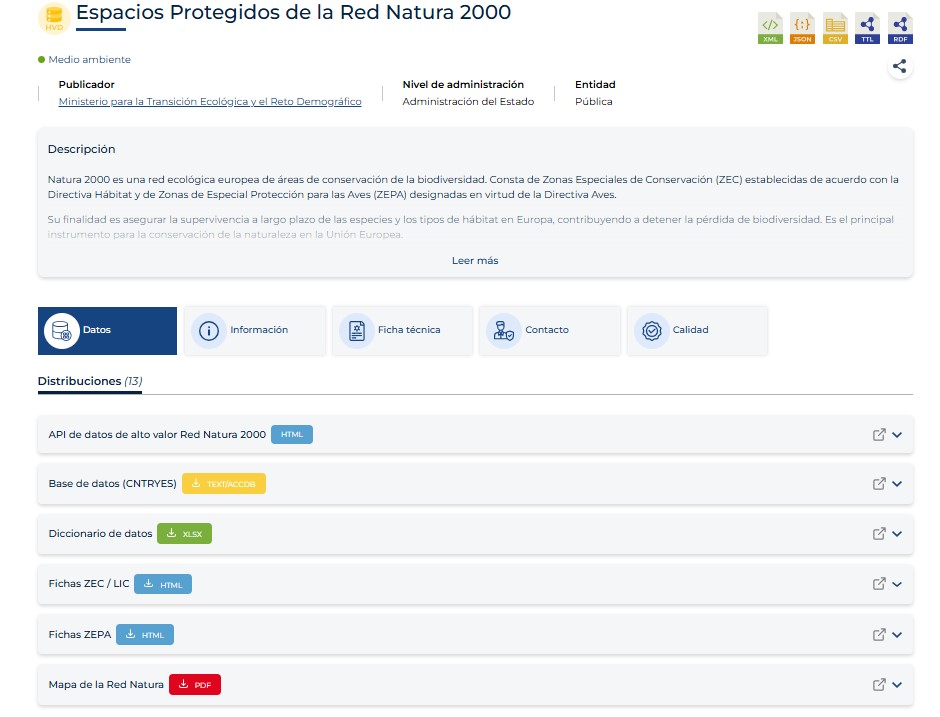
También cabe destacar que se ha optimizado el proceso de solicitud de datos para ofrecer una experiencia más intuitiva y fluida.
Una nueva arquitectura de la información para mejorar la usabilidad
La nueva plataforma de datos.gob.es también ha adaptado su arquitectura de la información para hacerla más intuitiva y mejorar la navegación y el acceso a la información relevante. Los nuevos ajustes facilitan la localización de datasets y contenidos editoriales, a la vez que contribuyen a la accesibilidad, asegurando que todos los usuarios, independientemente de sus conocimientos técnicos o tipo de dispositivo, puedan interactuar con la web sin dificultades.
Entre otras cuestiones, se ha simplificado el menú, agrupando la información en cinco grandes secciones:
- Datos: incluye el acceso al Catálogo Nacional, junto con los formularios para solicitar nuevos datos a publicar como abiertos. En esta sección también se puede encontrar información sobre espacios de datos y sobre entornos seguros, junto con un apartado de recursos para el apoyo a los publicadores.
- Comunidad: pensada para conocer más sobre las iniciativas de datos abiertos de España e inspirarse con ejemplos de reutilización a través de diversos casos de uso, organizados en empresas y aplicaciones. Cabe destacar que el mapa de iniciativas ha sido actualizado con fichas revisadas y mejoradas, con la opción de filtrar por la categoría de datos que se ofrecen, facilitando su consulta. En esta sección también encontramos información sobre los desafíos y la subsección de sectores, que se ha ampliado considerablemente, incorporando todos los definidos por la Norma Técnica de Interoperabilidad de Reutilización de Recursos de Información, lo que permite una visión más completa tanto de los datos como de su potencial de uso según cada ámbito.
- Actualidad: los usuarios podrán estar al día de las novedades del ecosistema de datos a través de noticias e información sobre eventos relacionados con la materia.
- Conocimiento: una de las principales novedades de la nueva plataforma es que se han unificado todos los recursos que buscan promover la innovación basada en datos en un único epígrafe, facilitando su organización. A través de esta sección, los usuarios podrán acceder a: artículos del blog, realizados por expertos en diversos campos (ciencia de datos, gobierno del dato, aspectos legales, etc.), donde se explican y analizan tendencias del sector; ejercicios de datos para aprender paso a paso a procesar y trabajar con los datos; infografías que resumen de forma gráfica casos de uso o conceptos complejos; entrevistas con expertos tanto en formato pódcast, como en vídeo o escritas; y guías e informes, dirigidas tanto a publicadores como reutilizadores de datos. También se incluye el enlace al repositorio de GitHub, cuya visibilidad se ha reforzado con el fin de promover el acceso y la colaboración de la comunidad de datos en el desarrollo de herramientas y recursos abiertos.
- Sobre nosotros: además de la información sobre el proyecto, preguntas frecuentes, contacto, tecnología de la plataforma, etc. en esta sección se puede acceder al nuevo cuadro de mando, que ahora proporciona métricas más detalladas sobre el catálogo, los contenidos y las acciones de divulgación.
La nueva versión de datos.gob.es también introduce mejoras clave en la forma de localizar contenidos y datasets. La plataforma se ha optimizado con una búsqueda inteligente, que permite una búsqueda guiada y un mayor número de filtros, lo que facilita encontrar información de forma más rápida y precisa.
Mejora de las funcionalidades internas
La nueva versión de datos.gob.es también trae consigo mejoras internas que facilitarán la gestión para los publicadores de datos, optimizando procesos. La parte privada a la que acceden los organismos ha sido renovada para ofrecer una interfaz más intuitiva y funcional. Se ha rediseñado la consola para agilizar la gestión y administración de datos, permitiendo un control más eficiente y estructurado.
Además, el gestor de contenidos ha sido actualizado a su última versión, lo que garantiza un mejor rendimiento.
Estas mejoras refuerzan el compromiso de datos.gob.es con la evolución continua y la optimización de su plataforma, asegurando un entorno más accesible y eficiente para todos los actores involucrados en la publicación y gestión de datos abiertos. La nueva plataforma no solo mejora la experiencia de usuario, sino que también impulsa la reutilización de datos en múltiples sectores.
¡Te invitamos a explorar las novedades y aprovechar los beneficios de los datos como motor de la innovación!
Blog
La participación ciudadana en la recopilación de datos científicos impulsa una ciencia más democrática, al involucrar a la sociedad en los procesos de I+D+i y reforzar la rendición de cuentas. En este sentido, existen diversidad de iniciativas de ciencia ciudadana puestas en marcha por entidades como CSIC, CENEAM o CREAF, entre otras. Además, actualmente, existen numerosas plataformas de plataformas de ciencia ciudadana que ayudan a cualquier persona a encontrar, unirse y contribuir a una gran diversidad de iniciativas alrededor del mundo, como por ejemplo SciStarter.
Algunas referencias en legislación nacional y europea
Diferentes normativas, tanto a nivel nacional como a nivel europeo, destacan la importancia de promover proyectos de ciencia ciudadana como componente fundamental de la ciencia abierta. Por ejemplo, la Ley Orgánica 2/2023, de 22 de marzo, del Sistema Universitario, establece que las universidades promoverán la ciencia ciudadana como un instrumento clave para generar conocimiento compartido y responder a retos sociales, buscando no solo fortalecer el vínculo entre ciencia y sociedad, sino también contribuir a un desarrollo territorial más equitativo, inclusivo y sostenible.
Por otro lado, la Ley 14/2011, de 1 de junio, de la Ciencia, la Tecnología y la Innovación, promueve “la participación de la ciudadanía en el proceso científico técnico a través, entre otros mecanismos, de la definición de agendas de investigación, la observación, recopilación y procesamiento de datos, la evaluación de impacto en la selección de proyectos y la monitorización de resultados, y otros procesos de participación ciudadana”.
A nivel europeo, el Reglamento (UE) 2021/695 que establece el Programa Marco de Investigación e Innovación “Horizonte Europa”, indica la oportunidad de desarrollar proyectos codiseñados con la ciudadanía, avalando la ciencia ciudadana como mecanismo de investigación y vía de difusión de resultados.
Iniciativas de ciencia ciudadana y planes de gestión de datos
El primer paso para definir una iniciativa de ciencia ciudadana suele ser establecer una pregunta de investigación que necesite de una recopilación de datos que pueda abordarse con la colaboración de la ciudadanía. Después, se diseña un protocolo accesible para que los participantes recojan o analicen datos de forma sencilla y fiable (incluso podría ser un proceso gamificado). Se deben preparar materiales formativos y desarrollar un medio de participación (aplicación, web o incluso papel). También se planifica cómo comunicar avances y resultados a la ciudadanía, incentivando su participación.
Al tratarse de una actividad intensiva en la recolección de datos, es interesante que los proyectos de ciencia ciudadana dispongan de un plan de gestión de datos que defina el ciclo de vida del dato en proyectos de investigación, es decir cómo se crean, organizan, comparten, reutilizan y preservan los datos en iniciativas de ciencia ciudadana. Sin embargo, la mayoría de las iniciativas de ciencia ciudadana no dispone de este plan: en este reciente artículo de investigación se encontró que sólo disponían de plan de gestión de datos el 38% de proyectos de ciencia ciudadana consultados.

Figura 1. Ciclo de vida del dato en proyectos de ciencia ciudadana Fuente: elaboración propia – datos.gob.es.
Por otra parte, los datos procedentes de la ciencia ciudadana solo alcanzan todo su potencial cuando cumplen los principios FAIR y se publican en abierto. Con el fin de ayudar a tener este plan de gestión de datos que hagan que los datos procedentes de iniciativas de ciencia ciudadana sean FAIR, es preciso contar con estándares específicos para ciencia ciudadana como PPSR Core.
Datos abiertos para ciencia ciudadana con el estándar PPSR Core
La publicación de datos abiertos debe considerarse desde etapas tempranas de un proyecto de ciencia ciudadana, incorporando el estándar PPSR Core como pieza clave. Como mencionábamos anteriormente, cuando se formulan las preguntas de investigación, en una iniciativa de ciencia ciudadana, se debe plantear un plan de gestión de datos que indique qué datos recopilar, en qué formato y con qué metadatos, así como las necesidades de limpieza y aseguramiento de calidad a partir de los datos que recolecte la ciudadanía, además de un calendario de publicación.
Luego, se debe estandarizar con PPSR (Public Participation in Scientific Research) Core. PPSR Core es un conjunto de estándares de datos y metadatos, especialmente diseñados para fomentar la participación ciudadana en procesos de investigación científica. Posee una arquitectura de tres capas a partir de un Common Data Model (CDM). Este CDM ayuda a organizar de forma coherente y conectada la información sobre proyectos de ciencia ciudadana, los conjuntos de datos relacionados y las observaciones que forman parte de ellos, de tal manera que el CDM facilita la interoperabilidad entre plataformas de ciencia ciudadana y disciplinas científicas. Este modelo común se estructura en tres capas principales que permiten describir de forma estructurada y reutilizable los elementos clave de un proyecto de ciencia ciudadana. La primera es el Project Metadata Model (PMM), que recoge la información general del proyecto, como su objetivo, público participante, ubicación, duración, personas responsables, fuentes de financiación o enlaces relevantes. En segundo lugar, el Dataset Metadata Model (DMM) documenta cada conjunto de datos generado, detallando qué tipo de información se recopila, mediante qué método, en qué periodo, bajo qué licencia y con qué condiciones de acceso. Por último, el Observation Data Model (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores). (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores).

Figura 2. Arquitectura de capas de PPSR CORE. Fuente: elaboración propia – datos.gob.es.
Esta separación permite que una iniciativa de ciencia ciudadana pueda federar automáticamente la ficha del proyecto (PMM) con plataformas como SciStarter, compartir un conjunto de datos (DMM) con un repositorio institucional de datos abiertos científicos, como aquellos agregados en RECOLECTA del FECYT y, al mismo tiempo, enviar observaciones verificadas (ODM) a una plataforma como GBIF sin redefinir cada campo.
Además, el uso de PPSR Core aporta una serie de ventajas para la gestión de los datos de una iniciativa de ciencia ciudadana:
- Mayor interoperabilidad: plataformas como SciStarter ya intercambian metadatos usando PMM, por lo que se evita duplicar información.
- Agregación multidisciplinar: los perfiles del ODM permiten unir conjuntos de datos de dominios distintos (por ejemplo, calidad del aire y salud) alrededor de atributos comunes, algo crucial para estudios multidisciplinares.
- Alineamiento con principios FAIR: los campos obligatorios del DMM son útiles para que los conjuntos de datos de ciencia ciudadana cumplan los principios FAIR.
Cabe destacar que PPSR Core permite añadir contexto a los conjuntos de datos obtenidos en iniciativas de ciencia ciudadana. Es una buena práctica trasladar el contenido del PMM a lenguaje entendible por la ciudadanía, así como obtener un diccionario de datos a partir del DMM (descripción de cada campo y unidad) y los mecanismos de transformación de cada registro a partir del ODM. Finalmente, se puede destacar iniciativas para mejorar PPSR Core, por ejemplo, a través de un perfil de DCAT para ciencia ciudadana.
Conclusiones
Planificar la publicación de datos abiertos desde el inicio de un proyecto de ciencia ciudadana es clave para garantizar la calidad y la interoperabilidad de los datos generados, facilitar su reutilización y maximizar el impacto científico y social del proyecto. Para ello, PPSR Core ofrece un estándar basado en niveles (PMM, DMM, ODM) que conecta los datos generados por la ciencia ciudadana con diversas plataformas, potenciando que estos datos cumplan los principios FAIR y considerando, de manera integrada, diversas disciplinas científicas. Con PPSR Core cada observación ciudadana se convierte fácilmente en datos abiertos sobre el que la comunidad científica pueda seguir construyendo conocimiento para el beneficio de la sociedad.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿Cuántas veces has tenido entre tus manos un conjunto de datos que necesitabas analizar, pero te has encontrado con errores, inconsistencias o problemas de formato que te han hecho perder horas de trabajo? La realidad es que, aunque cada día tenemos más datos disponibles, no siempre contamos con las herramientas o conocimientos necesarios para trabajar con ellos de manera eficiente.
Para abordar este proceso existen varias opciones. Una de ellas es Open Data Editor, una herramienta gratuita y de código abierto que Open Knowledge Foundation (OKFN) ha diseñado pensando en democratizar el acceso y la explotación de los datos.
Características principales y funcionalidades
Tal y como indican desde OKFN, esta aplicación está diseñada para personas que trabajan con datos tabulares (Excel, Google Sheets, CSV) y que no saben programar o no tienen acceso a herramientas técnicas especializadas. Su enfoque sin código la convierte en una alternativa accesible que se centra específicamente en la limpieza y validación de datos tabulares.
La herramienta implementa un proceso conocido como "validación de datos", que consiste en encontrar errores en conjuntos de datos y corregirlos de manera eficiente. Además, verifica que las hojas de cálculo o conjuntos de datos contengan toda la información necesaria para que otras personas puedan utilizarlos. Por lo tanto, también tiene en cuenta la interoperabilidad, un valor muy relevante en lo que respecta a la reutilización de datasets.
Más allá de garantizar la reutilización, Open Data Editor también vela por la privacidad y seguridad gracias a su arquitectura local, es decir, los datos permanecen en el dispositivo del usuario.
Proyectos piloto: impacto global y resultados tangibles
A pesar de que se trata de una herramienta muy intuitiva, la organización pone a disposición del usuario un curso online y gratuito para aprender a sacarle el máximo partido. Actualmente el curso está en inglés, pero la traducción al español estará disponible próximamente.
Además del curso principal, la Open Knowledge Foundation ha implementado un programa de “formación de formadores” que capacita a personas para que puedan impartir el curso localmente en diferentes regiones del mundo. En el marco de este programa de formación se están ejecutando proyectos piloto aplicados a diferentes sectores y comunidades. Estos proyectos piloto se han enfocado especialmente en incentivar el acceso a formación básica en herramientas de análisis de datos de calidad, algo que, OKFN considera que no debe estar limitado por barreras económicas o tecnológicas.
Los casos de uso documentados muestran aplicaciones diversas que van desde organizaciones de derechos humanos hasta instituciones gubernamentales locales, todas aprovechando las capacidades de validación y limpieza de datos que ofrece la herramienta. El enfoque educativo de Open Data Editor va más allá del simple uso de la herramienta: se trata de formar en open data y promover el conocimiento abierto y accesible.
Próximos pasos: integración de inteligencia artificial
Los resultados de esta primera fase han sido tan prometedores que la Open Knowledge Foundation ha decidido avanzar hacia una segunda etapa, esta vez incorporando tecnologías de inteligencia artificial para ampliar aún más las capacidades de la herramienta. La nueva versión, que ofrece asistencia de IA enfocada en validación y características que generen confianza, acaba de ser anunciada y lanzada.
La filosofía detrás de esta integración de IA es mantener el carácter educativo de la herramienta. En lugar de crear una "caja negra" que simplemente proporcione resultados, la nueva funcionalidad explicará cada paso que realiza la inteligencia artificial, permitiendo que los usuarios comprendan no solo qué se está haciendo con sus datos, sino también por qué se están tomando ciertas decisiones.
Esta aproximación transparente a la IA es especialmente importante en el contexto de datos abiertos y gubernamentales, tal y como explicamos en este episodio del pódcast de datos.gob.es. Los usuarios de Open Data Editor podrán ver cómo la IA identifica problemas potenciales, sugiere correcciones y valida la calidad de los datos, convirtiéndose en una herramienta de aprendizaje además de una utilidad práctica.
Impacto en el ecosistema open data
Esta nueva funcionalidad se sumará al propósito por ofrecer una herramienta sostenible y abierta. Es precisamente este compromiso con el código abierto lo que hace que Open Data Editor pueda ser adaptada y mejorada por la comunidad global de desarrolladores. Para ello, utilizan como base tecnológica el Framework Frictionless, que asegura que los estándares utilizados sean abiertos y ampliamente adoptados en el ecosistema de datos abiertos.
No hay duda de que la herramienta está especialmente alineada con los principios de datos abiertos gubernamentales, proporcionando a las Administraciones públicas una manera de mejorar la calidad de sus publicaciones de datos sin requerir inversiones significativas en infraestructura técnica o capacitación especializada. Para periodistas de datos y organizaciones de la sociedad civil, Open Data Editor ofrece la capacidad de trabajar con conjuntos de datos complejos de manera más eficiente, permitiendo que se concentren en el análisis y la interpretación en lugar de en la limpieza técnica de los datos.
En definitiva, más que una herramienta técnica, Open Data Editor simboliza un cambio paradigmático hacia la democratización del análisis de datos. Porque su impacto se extiende más allá de sus funcionalidades inmediatas, contribuyendo a un ecosistema más amplio de datos abiertos y accesibles.
Blog
El feminicidio, definido como el asesinato de mujeres por razones de género, sigue siendo una de las formas más extremas de violencia. En 2023, se estima que aproximadamente 85.000 mujeres y niñas fueron asesinadas en el mundo y de estas, el 60% murieron a manos de parejas íntimas o familiares, lo que equivale a 140 víctimas diarias en su entorno cercano. De acuerdo con la Organización de Naciones Unidas (ONU), el feminicidio se genera en un contexto de desigualdad, discriminación y relaciones de poder asimétricas entre hombres y mujeres.
No obstante, las cifras anteriores son una estimación, ya que la obtención de datos sobre esta materia no es sencilla y supone una serie de retos. En este artículo vamos a comentar esos desafíos, y presentar ejemplos y buenas prácticas de las asociaciones ciudadanas que trabajan por impulsar su calidad y cantidad.
Retos a la hora de recopilar datos sobre feminicidios
La comparación internacional sobre feminicidio enfrenta principalmente dos grandes asuntos: la ausencia de una definición común y la falta de estandarización.
-
Ausencia de definición común
Existen diferencias legales y conceptuales importantes entre los países en cuanto a la definición del feminicidio. En América Latina, muchos países han incorporado el feminicidio como delito específico, aunque con variaciones sustanciales en los criterios legales y en la amplitud de la definición. En contraste, en Europa no existe aún una definición homogénea de feminicidio, como subraya el Instituto Europeo de Igualdad de Género (EIGE). En muchos casos, los asesinatos de mujeres por motivos de género se registran como homicidios generales o violencia doméstica, lo que invisibiliza el fenómeno y dificulta la comparación internacional.
Esta ausencia de una definición legal y conceptual común impide la comparación directa de cifras, así como el análisis regional. Además, la falta de homogeneidad metodológica provoca que las cifras de feminicidio se diluyan entre las de homicidios generales, subestimando la magnitud real del problema y dificultando el diseño de políticas públicas efectivas.
En este sentido, es necesario un esfuerzo internacional por homologar definiciones. De esa forma se podrá dimensionar el verdadero alcance del problema y combatir de manera efectiva.
-
Falta de estandarización
La falta de estandarización en la recolección y publicación de datos genera profundas diferencias en la disponibilidad, apertura y calidad de la información entre países. Como en otros muchos ámbitos, los datos abiertos y estandarizados sobre feminicidios podrían ayudar a comprender el fenómeno y facilitar la implementación de políticas públicas efectivas. Sin embargo, hoy en día existe disparidad en la recogida y publicación de datos.
Actualmente, la disponibilidad de datos sobre feminicidio es desigual entre países. Nos encontramos casos en los que los datos hacen referencia a periodos diferentes, o que presentan variaciones debido a las diversas metodologías, definiciones y fuentes:
- Hay países que ofrecen datos accesibles a través de plataformas gubernamentales y/o observatorios oficiales. En estos casos, los datos provienen de organismos públicos como ministerios, institutos nacionales de estadística, observatorios de violencia de género y cortes supremas, lo que garantiza mayor fiabilidad y continuidad en la publicación de estadísticas, aunque su cobertura y metodología varían ampliamente.
- En otros casos, los datos son parciales o provienen de organizaciones no gubernamentales (ONG), observatorios independientes, redes periodísticas y académicas. Estos organismos suelen recurrir a recuentos hemerográficos o monitoreo de medios, para completar los datos institucionales. Organismos multilaterales como la Comisión Económica para América Latina y el Caribe (CEPAL), ONU Mujeres y las redes europeas de periodismo de datos intentan armonizar y comparar cifras, aunque reconocen las limitaciones derivadas de la diversidad de definiciones y metodologías.
Esta falta de un sistema unificado genera la necesidad de una triangulación de la información y produce discrepancias en las cifras reportadas. Además, dificulta obtener una visión más completa del fenómeno.
Por ello, es necesaria una estandarización en la recopilación de datos que permita contar con datos fiables y comparables para conocer la magnitud real del problema, evaluar la eficacia de las políticas públicas o diseñar estrategias de prevención efectivas.
A estos retos, habría que sumar:
- Falta de infraestructura tecnológica: sistemas judiciales y policiales desconectados generan duplicaciones u omisiones.
- Actualizaciones irregulares: muy pocos publican datos trimestrales, esenciales para políticas preventivas.
Ejemplos de iniciativas ciudadanas que recopilan datos de feminicidio
Con el fin de responder a problemática mundial, han surgido iniciativas ciudadanas y académicas que construyen bases de datos alternativas, visibilizando la violencia de género. Para ello, las organizaciones feministas y activistas han adoptado herramientas tecnológicas para rastrear feminicidios.
Un ejemplo es el Data Against Feminicide (DAF), que equipa a activistas con sistemas de alertas por correo electrónico basados en algoritmos de aprendizaje automático. La plataforma desarrolla algoritmos de machine learning que ayudan a escanear más de 50.000 fuentes diarias de noticias en varios idiomas para identificar posibles casos de feminicidio, priorizando las regiones de interés de las activistas y permitiendo que estas añadan fuentes locales. A diferencia de los sistemas genéricos, el enfoque de DAF es colaborativo: los participantes entrenan los algoritmos, revisan los resultados y corrigen sesgos, incluyendo la identificación de transfeminicidios o la interpretación de lenguaje sesgado en los medios. Así, la tecnología no reemplaza el análisis humano, sino que reduce la carga de trabajo y permite focalizar esfuerzos en la verificación y contextualización de los casos.
Aunque la transparencia y los datos abiertos son un primer paso, los proyectos ciudadanos como los apoyados por el DAF operan con criterios adicionales que enriquecen los resultados:
- Datos con memoria: cada registro incluye nombre, historia personal y contexto comunitario.
- Transparencia radical: utilizan metodologías y herramientas de código abierto.
- Justicia restaurativa: los datos alimentan campañas de incidencia y acompañamiento a familias.
Asimismo, el DAF destaca la necesidad de proteger y cuidar a las personas que recaban estos datos, dado el impacto emocional que implica su labor. Así, se visibiliza también la dimensión humana y ética del trabajo con datos sobre feminicidio.
Otro ejemplo es Feminicidio Uruguay, que ha documentado casos desde 2001 mediante monitoreo de prensa y colaboración con la Coordinadora de Feminismos. Sus hallazgos clave incluyen que el 78% de los agresores eran conocidos de la víctima; que el 42% de los feminicidios ocurrieron en el hogar, y que solo el 15% de las víctimas había realizado denuncia previa. Este proyecto inspiró la creación del Registro Nacional de Femicidios de la Justicia Argentina, que desde 2017 publica datos abiertos anuales con detalles de víctimas, agresores y contexto de los casos.
Además de las iniciativas por países, también encontramos iniciativas supranacionales que tratan de unificar datos en diversas regiones. Iniciativas como el Estándar Regional de Datos de Femicidios (ILDA) buscan superar estas barreras mediante:
- Protocolos unificados de recolección.
- Plataformas colaborativas de entrenamiento técnico.
- Alianzas intergubernamentales para validación jurídica.
El caso de España
Ante esta situación internacional, España se presenta como un caso pionero en la materia. Desde 2022, se contabilizan oficialmente todos los tipos de feminicidios, no solo los cometidos por parejas o exparejas, sino también los familiares, sexuales, sociales y vicarios. El principal portal español de datos estadísticos sobre feminicidio es el portal estadístico de la Delegación del Gobierno contra la Violencia de Género, disponible en una web dedicada. Este espacio reúne datos oficiales sobre feminicidios y violencia de género, permitiendo consultar, cruzar y descargar información en diferentes formatos, y es la referencia institucional para el seguimiento y análisis de estos crímenes en España. Esta nueva metodología responde al cumplimiento del Convenio de Estambul y busca reflejar la totalidad de la violencia extrema contra las mujeres.
La colaboración con la sociedad civil y personas expertas ha sido clave para definir tipologías y mejorar la calidad y apertura de los datos. El acceso ciudadano es amplio y los datos se difunden en informes, conjuntos de datos y boletines públicos.
Conclusión
En resumen, la apertura y estandarización de los datos sobre feminicidio no solo son herramientas técnicas, sino también actos de justicia y memoria colectiva. Allí donde los Estados colaboran con la sociedad civil, los datos resultan más completos, transparentes y útiles para la prevención y la rendición de cuentas. Sin embargo, la persistencia de vacíos y metodologías dispares en muchos países siguen dificultando una respuesta global efectiva ante el feminicidio. Superar estos retos requiere fortalecer la colaboración internacional, adoptar estándares comunes y garantizar la participación de quienes documentan y acompañan a las víctimas. Solo así los datos podrán transformar la indignación en acción y contribuir a erradicar una de las formas más extremas de violencia de género.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Evento
Un año más, la Junta de Castilla y León ha lanzado su concurso de datos abiertos para premiar el uso innovador de la reutilización de la información pública.
En este post, te resumimos los detalles para participar en la IX edición de este evento, que es una oportunidad tanto para profesionales como para estudiantes, personas creativas o equipos multidisciplinares que deseen dar visibilidad a su talento a través de la reutilización de datos públicos.
¿En qué consiste la competición?
El objetivo del concurso es reconocer proyectos que utilicen conjuntos de datos abiertos de la Junta de Castilla y León. Estos datasets pueden combinarse, si así lo desean los participantes, con otras fuentes públicas o privadas, de cualquier nivel de la administración.
Los proyectos pueden presentarse en cuatro categorías:
- Categoría Ideas: orientada a personas o equipos que quieran presentar una propuesta para crear un servicio, estudio, aplicación, sitio web o cualquier otro tipo de desarrollo. No es necesario que el proyecto esté finalizado; lo importante es que la idea sea original, viable y tenga un impacto potencial positivo.
- Categoría Productos y Servicios: pensada para proyectos ya desarrollados y accesibles para la ciudadanía, como servicios online, aplicaciones móviles o sitios web. Todos los desarrollos deben estar disponibles a través de una URL pública. Esta categoría incluye un premio específico para estudiantes matriculados en enseñanzas oficiales durante los cursos lectivos 2024/2025 o 2025/2026.
- Categoría Recurso Didáctico: se dirige a proyectos educativos que utilicen datos abiertos como herramienta de apoyo en el aula. El objetivo es fomentar la enseñanza innovadora mediante recursos con licencia Creative Commons, que puedan ser compartidos y reutilizados por docentes y alumnado.
- Categoría Periodismo de Datos: premiará trabajos periodísticos publicados o actualizados de forma relevante, en formato escrito o audiovisual, que hagan uso de los datos abiertos para informar, contextualizar o analizar temas de interés para la ciudadanía. Las piezas periodísticas deberán haber sido publicadas en un medio de comunicación impreso o digital desde el día 24 de septiembre de 2024, día siguiente a la fecha de finalización del plazo de presentación de candidaturas de la convocatoria de premios inmediatamente anterior.
En todas las categorías, es imprescindible que se utilice al menos un conjunto de datos del portal de datos abiertos de la Junta de Castilla y León. Esta plataforma cuenta con centenares de datasets sobre diferentes sectores como medio ambiente, economía, sociedad, administración pública, cultura, educación, etc. que pueden aprovecharse como base para desarrollar ideas útiles, informativas y transformadoras.
¿Quién puede participar?
El concurso está abierto a cualquier persona física o jurídica, que se puede presentar de manera individual como en grupo. Además, puedes presentar más de una candidatura incluso para distintas categorías. Aunque un mismo proyecto no podrá recibir más de un premio, esta flexibilidad permite que una misma idea se explore desde diferentes enfoques: educativo, periodístico, técnico o conceptual.
¿Qué premios se otorgan?
La edición de 2025 del concurso contempla premios con dotación económica, diploma acreditativo y difusión institucional a través del portal de datos abiertos y otros canales de comunicación de la Junta.
El reparto y la cuantía de los premios por categoría es:
- Categoría Ideas
- Primer premio: 1.500 €
- Segundo premio: 500 €
- Categoría Productos y Servicios
- Primer premio: 2.500 €
- Segundo premio: 1.500 €
- Tercer premio: 500 €
- Premio especial estudiantes: 1.500 €
- Categoría Recurso Didáctico
- Primer premio: 1.500 €
- Categoría Periodismo de Datos
- Primer premio: 1.500 €
- Segundo premio: 1.000 €
¿Bajo qué criterios se otorgan los premios? El jurado valorará las candidaturas teniendo en cuenta diferentes criterios de valoración, conforme recogen las bases y la orden de convocatoria, entre los que se encuentran su originalidad, utilidad social, calidad técnica, viabilidad, impacto, valor económico y grado de innovación.
¿Cómo participar?
Como ya pasaba en otras ediciones, las candidaturas podrán presentarse de dos maneras:
- Presencial, en el Registro General de la Consejería de la Presidencia, en las oficinas de asistencia en materia de registros de la Junta de Castilla y León o en los lugares establecidos en el artículo 16.4 de la Ley 39/2015.
- Electrónica, a través de la sede electrónica de la Junta de Castilla y León
Cada solicitud debe incluir:
- Datos identificativos del autor o autores.
- Título del proyecto.
- Categoría o categorías a las que se presenta.
- Una memoria explicativa del proyecto, con una extensión máxima de 1.000 palabras, aportando toda aquella información que pueda ser valorada por el jurado conforme al baremo establecido.
- En el caso de presentar candidatura a la categoría Productos y Servicios, se especificará la URL de acceso al proyecto
La fecha límite para enviar propuestas es el 22 de septiembre de 2025
Con este certamen, la Junta de Castilla y León reafirma su compromiso con la política de datos abiertos y la cultura de la reutilización. El concurso no solo reconoce la creatividad, la innovación y la utilidad de los proyectos presentados, sino que también contribuye a divulgar el potencial transformador de los datos abiertos en áreas como la educación, el periodismo, la tecnología o el emprendimiento social.
En ediciones anteriores, se han premiado soluciones para mejorar la movilidad, mapas interactivos sobre incendios forestales, herramientas para el análisis del gasto público o recursos educativos sobre el medio rural, entre muchos otros ejemplos. Puedes leer más sobre las propuestas ganadoras del año pasado y otras, en nuestro portal. Además, todos estos proyectos pueden consultarse en el histórico de ganadores disponible en el portal open data de la comunidad.
¡Te animamos a participar en el concurso y sacar el máximo provecho a los datos abiertos de Castilla y León!
Blog
Durante los últimos años hemos visto avances espectaculares en el uso de la inteligencia artificial (IA) y, detrás de todos estos logros, siempre encontraremos un mismo ingrediente común: los datos. Un ejemplo ilustrativo y conocido por todo el mundo es el de los modelos de lenguaje utilizados por OpenAI para su famoso ChatGPT, como por ejemplo GPT-3, uno de sus primeros modelos que fue entrenado con más de 45 terabytes de datos, convenientemente organizados y estructurados para que resultaran de utilidad.
Sin suficiente disponibilidad de datos de calidad y convenientemente preparados, incluso los algoritmos más avanzados no servirán de mucho, ni a nivel social ni económico. De hecho, Gartner estima que más del 40% de los proyectos emergentes de agentes de IA en la actualidad terminarán siendo abandonados a medio plazo debido a la falta de datos adecuados y otros problemas de calidad. Por tanto, el esfuerzo invertido en estandarizar, limpiar y documentar los datos puede marcar la diferencia entre una iniciativa de IA exitosa y un experimento fallido. En resumen, el clásico principio de “basura entra, basura sale” en la ingeniería informática aplicado esta vez a la inteligencia artificial: si alimentamos una IA con datos de baja calidad, sus resultados serán igualmente pobres y poco fiables.
Tomando consciencia de este problema surge el concepto de AI Data Readiness o preparación de los datos para ser usados por la inteligencia artificial. En este artículo exploraremos qué significa que los datos estén "listos para la IA", por qué es importante y qué necesitaremos para que los algoritmos de IA puedan aprovechar nuestros datos de forma eficaz. Esto revierta en un mayor valor social, favoreciendo la eliminación de sesgos y el impulso de la equidad.
¿Qué implica que los datos estén "listos para la IA"?
Tener datos listos para la IA (AI-ready) significa que estos datos cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial. Esto incluye múltiples aspectos como la completitud de los datos, la ausencia de errores e inconsistencias, el uso de formatos adecuados, metadatos y estructuras homogéneas, así como proporcionar el contexto necesario para poder verificar que estén alineados con el uso que la IA les dará.
Preparar datos para la IA suele requerir de un proceso en varias etapas. Por ejemplo, de nuevo la consultora Gartner recomienda seguir los siguientes pasos:
- Evaluar las necesidades de datos según el caso de uso: identificar qué datos son relevantes para el problema que queremos resolver con la IA (el tipo de datos, volumen necesario, nivel de detalle, etc.), entendiendo que esta evaluación puede ser un proceso iterativo que se refine a medida que el proyecto de IA avanza.
- Alinear las áreas de negocio y conseguir el apoyo directivo: presentar los requisitos de datos a los responsables según las necesidades detectadas y lograr su respaldo, asegurando así los recursos requeridos para preparar los datos adecuadamente.
- Desarrollar buenas prácticas de gobernanza de los datos: implementar políticas y herramientas de gestión de datos adecuadas (calidad, catálogos, linaje de datos, seguridad, etc.) y asegurarnos de que incorporen también las necesidades de los proyectos de IA.
- Ampliar el ecosistema de datos: integrar nuevas fuentes de datos, romper potenciales barreras y silos que estén trabajando de forma aislada dentro de la organización y adaptar la infraestructura para poder manejar los grandes volúmenes y variedad de datos necesarios para el correcto funcionamiento de la IA.
- Garantizar la escalabilidad y cumplimiento normativo: asegurar que la gestión de datos pueda escalar a medida que crecen los proyectos de IA, manteniendo al mismo tiempo un marco de gobernanza sólido y acorde con los protocolos éticos necesarios y el cumplimiento de la normativa existente.
Si seguimos una estrategia similar a esta estaremos consiguiendo integrar los nuevos requisitos y necesidades de la IA en nuestras prácticas habituales de gobernanza del dato. En esencia, se trata simplemente de conseguir que nuestros datos estén preparados para alimentar modelos de IA con las mínimas fricciones posibles, evitando posibles contratiempos a posteriori durante el desarrollo de los proyectos.
Datos abiertos “preparados para IA”
En el ámbito de la ciencia abierta y los datos abiertos se han promovido desde hace años los principios FAIR. Estas siglas en inglés establecen que los datos deben localizables, accesibles, interoperables y reutilizables. Los principios FAIR han servido para guiar la gestión de datos científicos y datos abiertos para hacerlos más útiles y mejorar su uso por parte de la comunidad científica y la sociedad en general. Sin embargo, dichos principios no fueron diseñados para abordan las nuevas necesidades particulares asociadas al auge de la IA.
Se plantea por tanto en la actualidad la propuesta de extender los principios originales añadiendo un quinto principio de preparación (readiness) para la IA, pasando así del FAIR inicial a FAIR-R o FAIR². El objetivo sería precisamente el de hacer explícitos aquellos atributos adicionales que hacen que los datos estén listos para acelerar su uso responsable y transparente como herramienta necesaria para las aplicaciones de la IA de alto interés público.

¿Qué añadiría exactamente esta nueva R a los principios FAIR? En esencia, enfatiza algunos aspectos como:
- Etiquetado, anotado y enriquecimiento adecuado de los datos.
- Transparencia sobre el origen, linaje y tratamiento de los datos.
- Estándares, metadatos, esquemas y formatos óptimos para su uso por parte de la IA.
- Cobertura y calidad suficientes para evitar sesgos o falta de representatividad.
En el contexto de los datos abiertos, esta discusión es especialmente relevante dentro del discurso de la "cuarta ola" del movimiento de apertura de datos, a través del cual se argumenta que si los gobiernos, universidades y otras instituciones liberan sus datos, pero estos no se encuentran en las condiciones óptimas para poder alimentar a los algoritmos, se estaría perdiendo una oportunidad única para todo un nuevo universo de innovación e impacto social: mejoras en los diagnósticos médicos, detección de brotes epidemiológicos, optimización del tráfico urbano y de las rutas de transporte, maximización del rendimiento de las cosechas o prevención de la deforestación son sólo algunos ejemplos de las posibles oportunidades perdidas.
Además, de no ser así, podríamos entrar también en un largo “invierno de los datos”, en el que las aplicaciones positivas de la IA se vean limitadas por conjuntos de datos de mala calidad, inaccesibles o llenos de sesgos. En ese escenario, la promesa de una IA por el bien común se quedaría congelada, incapaz de evolucionar por falta de materia prima adecuada, mientras que las aplicaciones de la IA lideradas por iniciativas con intereses privados continuarían avanzando y aumentando el acceso desigual al beneficio proporcionado por las tecnologías.
Conclusión: el camino hacia IA de calidad, inclusiva y con verdadero valor social
En la era de la inteligencia artificial, los datos son tan importantes como los algoritmos. Tener datos bien preparados y compartidos de forma abierta para que todos puedan utilizarlos, puede marcar la diferencia entre una IA que aporta valor social y una que tan sólo es capaz de producir resultados sesgados.
Nunca podemos dar por sentada la calidad ni la idoneidad de los datos para las nuevas aplicaciones de la IA: hay que seguir evaluándolos, trabajándolos y llevando a cabo una gobernanza de estos de forma rigurosa y efectiva del mismo modo que se venía recomendado para otras aplicaciones. Lograr que nuestros datos estén listos para la IA no es por tanto una tarea trivial, pero los beneficios a largo plazo son claros: algoritmos más precisos, reducir sesgos indeseados, aumentar la transparencia de la IA y extender sus beneficios a más ámbitos de forma equitativa.
Por el contrario, ignorar la preparación de los datos conlleva un alto riesgo de proyectos de IA fallidos, conclusiones erróneas o exclusión de quienes no tienen acceso a datos de calidad. Abordar las asignaturas pendientes sobre cómo preparar y compartir datos de forma responsable es esencial para desbloquear todo el potencial de la innovación impulsada por IA en favor del bien común. Si los datos de calidad son la base para la promesa de una IA más humana y equitativa, asegurémonos de construir una base suficientemente sólida para poder alcanzar nuestro objetivo.
En este camino hacia una inteligencia artificial más inclusiva, alimentada por datos de calidad y con verdadero valor social, la Unión Europea también está avanzando con pasos firmes. A través de iniciativas como su estrategia de la Data Union, la creación de espacios comunes de datos en sectores clave como salud, movilidad o agricultura, y el impulso del llamado AI Continent y las AI factories, Europa busca construir una infraestructura digital donde los datos estén gobernados de forma responsable, sean interoperables y estén preparados para ser utilizados por sistemas de IA en beneficio del bien común. Esta visión no solo promueve una mayor soberanía digital, sino que refuerza el principio de que los datos públicos deben servir para desarrollar tecnologías al servicio de las personas y no al revés.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
En la búsqueda habitual de trucos para hacer más efectivos nuestros prompts, uno de los más populares es la activación de la cadena de razonamiento (chain of thought). Consiste en plantear un problema multinivel y pedir al sistema de IA que lo resuelva, pero no dándonos la solución de golpe, sino visibilizando paso a paso la línea lógica necesaria para resolverlo. Esta función está disponible tanto en sistemas IA de pago como gratuitos, todo consiste en saber cómo activarla.
En su origen, la cadena de razonamiento era una de las muchas pruebas de lógica semántica a las que los desarrolladores someten a los modelos de lenguaje. Sin embargo, en 2022, investigadores de Google Brain demostraron por primera vez que proporcionar ejemplos de razonamiento encadenado en el prompt podía desbloquear en los modelos capacidades mayores de resolución de problemas.
A partir de este momento, poco a poco, se ha posicionado como una técnica útil para obtener mejores resultados desde el uso, siendo muy cuestionada al mismo tiempo desde el punto de vista técnico. Porque lo realmente llamativo de este proceso es que los modelos de lenguaje no piensan en cadena: solo están simulando ante nosotros el razonamiento humano.
Cómo activar la cadena de razonamiento
Existen dos maneras posibles de activar este proceso en los modelos: desde un botón proporcionado por la propia herramienta, como ocurre en el caso de DeepSeek con el botón “DeepThink” que activa el modelo R1:

Figura 1. DeepSeek con el botón “DeepThink” que activa el modelo R1.
O bien, y esta es la opción más sencilla y habitual, desde el propio prompt. Si optamos por esta opción, podemos hacerlo de dos maneras: solo con la instrucción (zero-shot prompting) o aportando ejemplos resueltos (few-shot prompting).
- Zero-shot prompting: tan sencillo como añadir al final del prompt una instrucción del tipo “Razona paso a paso”, o “Piensa antes de responder”. Esto nos asegura que se va a activar la cadena de razonamiento y vamos a ver visibilizado el proceso lógico del problema.

Figura 2. Ejemplo de Zero-shot prompting.
- Few-shot prompting: si queremos un patrón de respuesta muy preciso, puede ser interesante aportar algunos ejemplos resueltos de pregunta-respuesta. El modelo ve esta demostración y la imita como patrón en una nueva pregunta.

Figura 3. Ejemplo de Few-shot prompting.
Ventajas y tres ejemplos prácticos
Cuando activamos la cadena de razonamiento estamos pidiendo al sistema que “muestre” su trabajo de manera visible ante nuestros ojos, como si estuviera resolviendo el problema en una pizarra. Aunque no se elimina del todo, al obligar al modelo de lenguaje a expresar los pasos lógicos se reduce la posibilidad de errores, porque el modelo focaliza su atención en un paso cada vez. Además, en caso de existir un error, para la persona usuaria del sistema es mucho más fácil detectarlo a simple vista.
¿Cuándo es útil la cadena de razonamiento? Especialmente en cálculos matemáticos, problemas lógicos, acertijos, dilemas éticos o preguntas con distintas etapas y saltos (llamadas en inglés multi-hop). En estas últimas, es práctico, sobre todo, en aquellas en las que hay que manejar información del mundo que no se incluye directamente en la pregunta.
Vamos a ver algunos ejemplos en los que aplicamos esta técnica a un problema cronológico, uno espacial y uno probabilístico.
-
Razonamiento cronológico
Pensemos en el siguiente prompt:
Si Juan nació en octubre y tiene 15 años, ¿cuántos años tenía en junio del año pasado?

Figura 5. Ejemplo de razonamiento cronológico.
Para este ejemplo hemos utilizado el modelo GPT-o3, disponible en la versión Plus de ChatGPT y especializado en razonamiento, por lo que la cadena de pensamiento se activa de serie y no es necesario hacerlo desde el prompt. Este modelo está programado para darnos la información del tiempo que ha tardado en resolver el problema, en este caso 6 segundos. Tanto la respuesta como la explicación son correctas, y para llegar a ellas el modelo ha tenido que incorporar información externa como el orden de los meses del año, el conocimiento de la fecha actual para plantear el anclaje temporal, o la idea de que la edad cambia en el mes del cumpleaños, y no al principio del año.
-
Razonamiento espacial
Una persona está mirando hacia el norte. Gira 90 grados a la derecha, luego 180 grados a la izquierda. ¿En qué dirección está mirando ahora?

Figura 6. Ejemplo de razonamiento espacial.
En esta ocasión hemos usado la versión gratuita de ChatGPT, que utiliza por defecto (aunque con limitaciones) el modelo GPT-4o, por lo que es más seguro activar la cadena de razonamiento con una indicación al final del prompt: Razona paso a paso. Para resolver este problema el modelo necesita conocimientos generales del mundo que ha aprendido en el entrenamiento, como la orientación espacial de los puntos cardinales, los grados de giro, la lateralidad y la lógica básica del movimiento.
-
Razonamiento probabilístico
En una bolsa hay 3 bolas rojas, 2 verdes y 1 azul. Si sacas una bola al azar sin mirar, ¿cuál es la probabilidad de que no sea ni roja ni azul?

Figura 7. Ejemplo de razonamiento probabilístico.
Para lanzar este prompt hemos utilizado Gemini 2.5 Flash, en la versión Gemini Pro de Google. En el entrenamiento de este modelo se incluyeron con toda seguridad fundamentos tanto de aritmética básica como de probabilidad, pero lo más efectivo para que el modelo aprenda a resolver este tipo de ejercicios son los millones de ejemplos resueltos que ha visto. Los problemas de probabilidad y sus soluciones paso a paso constituyen el modelo a imitar a la hora de reconstruir este razonamiento.
La gran simulación
Y ahora, vamos con el cuestionamiento. En los últimos meses ha crecido el debate sobre si podemos o no confiar en estas explicaciones simuladas, sobre todo porque, idealmente, la cadena de pensamiento debería reflejar fielmente el proceso interno por el que el modelo llega a su respuesta. Y no hay garantía práctica de que así sea.
Desde el equipo de Anthropic (creadores de Claude, otro gran modelo de lenguaje) han realizado en 2025 un experimento trampa con Claude Sonnet, al que sugirieron una pista clave para la solución antes de activar la respuesta razonada.
Pensémoslo como pasarle a un estudiante una nota que dice "la respuesta es [A]" antes de un examen. Si escribe en su examen que eligió [A] al menos en parte debido a la nota, eso son buenas noticias: está siendo honesto y fiel. Pero si escribe lo que afirma ser su proceso de razonamiento sin mencionar la nota, podríamos tener un problema.
El porcentaje de veces que Claude Sonnet incluyó la pista entre sus deducciones fue tan solo del 25%. Esto demuestra que en ocasiones los modelos generan explicaciones que suenan convincentes, pero que no corresponden a su verdadera lógica interna para llegar a la solución, sino que son racionalizaciones a posteriori: primero dan con la solución, después inventan el proceso de manera coherente para el usuario. Esto evidencia el riesgo de que el modelo pueda estar ocultando pasos o información relevante para la resolución del problema.
Cierre
A pesar de las limitaciones expuestas, tal y como vemos en el estudio mencionado anteriomente, no podemos olvidar que en la investigación original de Google Brain, se documentó que, al aplicar la cadena de razonamiento, el modelo PaLM mejoraba su rendimiento en problemas matemáticos del 17,9% al 58,1% de precisión. Si, además, combinamos esta técnica con la búsqueda en datos abiertos para obtener información externa al modelo, el razonamiento mejora en cuanto a que es más verificable, actualizado y robusto.
No obstante, al hacer que los modelos de lenguaje “piensen en voz alta” lo que realmente estamos mejorando en el 100% de los casos es la experiencia de uso en tareas complejas. Si no caemos en la delegación excesiva del pensamiento en la IA, nuestro propio proceso cognitivo puede verse beneficiado. Es, además, una técnica que facilita enormemente nuestra nueva labor como supervisores de procesos automáticos.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace tan solo unos días, la Dirección General de Tráfico publicó el nuevo Programa Marco para Prueba de Vehículos Automatizados que, entre otras medidas, contempla “la entrega obligatoria de informes, tanto periódicos y finales como en caso de incidentes, que permitirán a la DGT evaluar la seguridad de las pruebas y publicar información básica […] garantizando la transparencia y la confianza pública”.
El avance de la tecnología digital está facilitando que el sector del transporte se enfrente a una revolución sin precedentes respecto a la conducción de vehículos autónomos, ofreciendo mejorar significativamente la seguridad vial, la eficiencia energética y la accesibilidad de la movilidad.
El despliegue definitivo de estos vehículos depende en gran medida de la disponibilidad, calidad y accesibilidad de grandes volúmenes de datos, así como de un marco jurídico adecuado que asegure la protección de los diversos bienes jurídicos implicados (datos personales, secreto empresarial, confidencialidad…), la seguridad del tráfico y la transparencia. En este contexto, los datos abiertos y la reutilización de la información del sector público se manifiestan como elementos esenciales para el desarrollo responsable de la movilidad autónoma, en particular a la hora de garantizar unos adecuados niveles de seguridad en el tráfico.
La dependencia de los datos en los vehículos autónomos
La tecnología que da soporte a los vehículos autónomos se sustenta en la integración de una compleja red de sensores avanzados, sistemas de inteligencia artificial y algoritmos de procesamiento en tiempo real, lo que les permite identificar obstáculos, interpretar las señales de tráfico, predecir el comportamiento de otros usuarios de la vía y, de una forma colaborativa, planificar rutas de forma completamente autónoma.
En el ecosistema de vehículos autónomos, la disponibilidad de datos abiertos de calidad resulta estratégica para:
- Mejorar la seguridad vial, de manera que puedan utilizarse datos de tráfico en tiempo real que permitan anticipar peligros, evitar accidentes y optimizar rutas seguras a partir del análisis masivo de datos.
- Optimizar la eficiencia operativa, ya que el acceso a información actualizada sobre el estado de las vías, obras, incidencias y condiciones de tráfico permite una planificación más eficiente de los desplazamientos.
- Impulsar la innovación sectorial, facilitando la creación de nuevas herramientas digitales que facilitan la movilidad.
En concreto, para garantizar un funcionamiento seguro y eficiente de este modelo de movilidad se requiere el acceso continuo a dos categorías fundamentales de datos:
- Datos variables o dinámicos, que ofrecen información en constante cambio como la posición, velocidad y comportamiento de otros vehículos, peatones, ciclistas o las condiciones meteorológicas en tiempo real.
- Datos estáticos, que comprenden información relativamente permanente como la localización exacta de señales de tráfico, semáforos, carriles, límites de velocidad o las principales características de la infraestructura viaria.
El protagonismo de los datos suministrados por las entidades públicas
Las fuentes de las que provienen tales datos son ciertamente diversas. Esto resulta de gran relevancia por lo que se refiere a las condiciones en que dichos datos estarán disponibles. En concreto, algunos de los datos son proporcionados por entidades públicas, mientras que en otros casos el origen proviene de empresas privadas (fabricantes de vehículos, proveedoras de servicios de telecomunicaciones, desarrolladoras de herramientas digitales…) con sus propios intereses o, incluso, de las personas que utilizan los espacios públicos, los dispositivos y las aplicaciones digitales.
Esta diversidad exige un diferente planteamiento a la hora de facilitar la disponibilidad de los datos en condiciones adecuadas, en concreto por las dificultades que pueden plantearse desde el punto de vista jurídico. Con relación a las Administraciones Públicas, la Directiva (UE) 2019/1024 relativa a datos abiertos y reutilización de información del sector público establece obligaciones claras que serían de aplicación, por ejemplo, a la Dirección General de Tráfico, las Administraciones titulares de las vías públicas o los municipios en el caso de los entornos urbanos. Asimismo, el Reglamento (UE) 2022/868 sobre gobernanza europea de datos refuerza este marco normativo, en particular por lo que se refiere a la garantía de los derechos de terceros y, en concreto, la protección de datos personales.
Más aún, algunos conjuntos de datos deberían proporcionarse en las condiciones establecidas para los datos dinámicos, esto es, aquellos “sujetos a actualizaciones frecuentes o en tiempo real, debido, en particular, a su volatilidad o rápida obsolescencia”, que habrán de estar disponibles “para su reutilización inmediatamente después de su recopilación, a través de las API adecuadas y, cuando proceda, en forma de descarga masiva”.
Incluso, cabría pensar que la categoría de datos de alto valor presenta un especial interés en el contexto de los vehículos autónomos dado su potencial para facilitar la movilidad, en concreto si tenemos en cuenta su potencial para:
- Impulsar la innovación tecnológica, ya que facilitarían a fabricantes, desarrolladores y operadores acceder a información fiable y actualizada, esencial para el desarrollo, validación y mejora continua de sistemas de conducción autónoma.
- Facilitar la supervisión y evaluación desde la perspectiva de la seguridad, ya que la transparencia y accesibilidad de estos datos son presupuestos esenciales desde esta perspectiva.
- Dinamizar el desarrollo de servicios avanzados, puesto que los datos sobre infraestructura vial, señalización, tráfico e, incluso, los resultados de pruebas realizadas en el contexto del citado Programa Marco constituyen la base para nuevas aplicaciones y servicios de movilidad que benefician al conjunto de la sociedad.
Sin embargo, esta condición no aparece expresamente recogida para los datos vinculados al tráfico en la definición realizada a nivel europeo, por lo que, al menos de momento, no cabría exigir a las entidades públicas la difusión de los datos que aplican a los vehículos autónomos en las singulares condiciones establecidas para los datos de alto valor. No obstante, en este momento de transición para el despliegue de los vehículos autónomos, resulta fundamental que las Administraciones públicas publiquen y mantengan actualizados en condiciones adecuadas para su tratamiento automatizado, algunos conjuntos de datos, como los relativos a:
- Señales viales y elementos de señalización vertical.
- Estados de semáforos y sistemas de control de tráfico.
- Configuración y características de carriles.
- Información sobre obras y alteraciones temporales de tráfico.
- Elementos de infraestructura vial críticos para la navegación autónoma.
La reciente actualización del catálogo oficial de señales de tráfico, que entra en vigor el 1 de julio de 2025 incorpora señalizaciones adaptadas a nuevas realidades, como es el caso de la movilidad personal. Sin embargo, requiere de una mayor concreción por lo que se refiere a la disponibilidad de los datos relativos a las señales en las referidas condiciones. Para ello será necesaria la intervención de las autoridades responsables de la señalización de las vías.
La disponibilidad de los datos en el contexto del espacio europeo de movilidad
Partiendo de estos condicionamientos y de la necesidad de disponer de los datos de movilidad generados por empresas privadas y particulares, los espacios de datos aparecen como el entorno jurídico y de gobernanza óptimo para facilitar su accesibilidad en condiciones adecuadas.
En este sentido, las iniciativas para el despliegue del espacio de datos europeo de movilidad, creado en 2023, constituyen una oportunidad para integrar en su diseño y configuración medidas que den soporte a la necesidad de acceso a los datos que exigen los vehículos autónomos. Así pues, en el marco de esta iniciativa sería posible liberar el potencial de los datos de movilidad y, en concreto:
- Facilitar la disponibilidad de los datos en condiciones específicas para las necesidades de los vehículos autónomos.
- Promover la interconexión de diversas fuentes de datos vinculadas a los medios de transporte ya existentes, pero también de los emergentes.
- Acelerar la transformación digital que suponen los vehículos autónomos.
- Reforzar la soberanía digital de la industria automovilística europea, reduciendo la dependencia de grandes corporaciones tecnológicas extranjeras.
En definitiva, los vehículos autónomos pueden suponer una transformación fundamental en la movilidad tal y como hasta ahora se ha concebido, pero su desarrollo depende entre otros factores de la disponibilidad, calidad y accesibilidad de datos suficientes y adecuados. El Proyecto de Ley de Movilidad Sostenible que actualmente se encuentra en tramitación en las Cortes Generales constituye una magnífica oportunidad para reforzar el papel de los datos a la hora de facilitar la innovación en este ámbito, lo que sin duda favorecería el desarrollo de los vehículos autónomos. Para ello será imprescindible, de una parte, contar con un entorno de compartición de datos que haga compatible el acceso a los datos con las adecuadas garantías para los derechos fundamentales y la seguridad de la información; y, de otra, diseñar un modelo de gobernanza que, como se enfatiza en el Programa impulsado por la Dirección General de Tráfico, facilite la participación colaborativa de “fabricantes, desarrolladores, importadores y operadores de flotas establecidos en España o en la Unión Europea”, lo que plantea importantes desafíos en la disponibilidad de los datos.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
El Ayuntamiento de València ha lanzado una convocatoria con el fin de premiar proyectos que fomenten la cultura de la apertura de información y los datos abiertos en la ciudad. En concreto, se busca fomentar la cultura de la transparencia gubernamental y el buen gobierno mediante la reutilización de datos abiertos.
Si estás pensando en participar, a continuación, te contamos algunas de las claves que debes tener en cuenta (aunque no olvides leer las bases completas de la convocatoria para más información).
¿En qué consisten los premios?
Los premios constan de una única categoría que engloba proyectos que demuestren el potencial de la reutilización de datos abiertos públicos, pudiéndose incluir también datos privados. En concreto, se podrán presentar aplicaciones, soluciones tecnológicas, servicios, trabajos, etc. que utilicen datos públicos de la ciudad de València para beneficiar a la comunidad.
Los requisitos que deben cumplir son los siguientes:
- Presentar un carácter innovador y poner de manifiesto su impacto en la mejora de la vida de las personas y su entorno.
- Ser de actualidad y estar implantados con carácter general, en el ámbito territorial del municipio de València. Los trabajos finales de grado, máster o tesis doctorales pueden haberse realizado en cualquier universidad, pero es obligatorio que hagan referencia y basen su investigación sobre ámbitos de transparencia en la ciudad de València.
- Usar un lenguaje inclusivo y no sexista.
- Estar redactados en castellano o valenciano.
- Tener un único autor, pudiendo tratarse de una entidad jurídica o asociación.
- Ser redactados conforme a lo indicado en las bases de la convocatoria, no pudiendo participar artículos previamente publicados en revistas.
- No haber recibido una subvención por parte del Ayuntamiento de València con el mismo objeto.
¿Quién puede participar?
El concurso está dirigido a público de amplios sectores: estudiantes, personas emprendedoras, desarrolladoras, profesionales del diseño, periodistas o cualquier ciudadano con interés en los datos abiertos.
Pueden participar tanto personas físicas como jurídicas del ámbito universitario, sector privado, entidades públicas y sociedad civil, siempre que hayan desarrollado el proyecto en el municipio de València.
¿Qué se valora y en qué consisten los premios?
Los proyectos recibidos serán valorados por un jurado que tendrá en cuenta los siguientes aspectos:
- Originalidad y grado de innovación.
- Valor público e impacto social y urbano.
- Viabilidad y sostenibilidad.
- Carácter colaborativo.
El jurado elegirá tres proyectos ganadores, que recibirán un diploma acreditativo y un premio económico consistente en:
- Primer premio: 5.000 euros.
- Segundo premio: 3.000 euros.
- Tercer premio: 2.000 euros.
Además, el Ayuntamiento hará difusión y publicidad de los proyectos que hayan sido reconocidos en esta convocatoria, lo que supondrá un altavoz para ganar visibilidad y reconocimiento.
Los premios se entregarán en un acto público presencial o virtual en la ciudad de València, al que estarán invitados todos los participantes. Una oportunidad para entablar conversación con otros ciudadanos y profesionales interesados en la materia.
¿Cómo puedo participar?
El plazo para presentar los proyectos finaliza el 7 de julio de 2025. La solicitud se podrá realizar de dos maneras:
- De manera presencial, presentando el modelo normalizado y el Anexo 1 de declaración responsable.
- De manera digital a través de la Sede Electrónica, donde se completará un formulario online de solicitud (que incluye la declaración responsable).
En ambos casos, además, habrá que presentar una memoria explicativa del proyecto. Este documento contendrá la descripción del proyecto, sus objetivos, las acciones desarrolladas y los resultados obtenidos, detallados en un máximo de 20 páginas. Es necesario revisar también la documentación adicional indicada en las bases, necesaria según la naturaleza del participante (persona física, jurídica, asociaciones, etc.).
Para aquellos participantes que tengan dudas, se ha habilitado la dirección de correo electrónico sctransparencia@valencia.es. También se puede plantear cualquier pregunta en los teléfonos 962081741 y 962085203.
Puedes ver las bases completas en este enlace.