





Datos Abiertos para el Mundo: Common Crawl Libera Petabytes de Información Web


Fecha de la noticia: 22-05-2024

Common Crawl desempeña un papel crucial en el universo de los datos abiertos, proporcionando acceso gratuito a una vasta colección de datos web. Este archivo, en constante crecimiento, permite a investigadores y desarrolladores explorar y analizar tendencias globales, entrenar modelos de inteligencia artificial y avanzar en la comprensión del amplio paisaje digital.
¿Qué es Common Crawl?
Common Crawl puede considerarse una plataforma tecnológica y de datos que ofrece un servicio de archivado y rastreo de datos web a gran escala. El tipo de dato que se almacena es particular, puesto que se trata de páginas webs completas incluyendo su código, sus imágenes y el resto de recursos que la componen. Funciona mediante el uso de robots de rastreo (robots de software) que navegan continuamente por Internet para capturar páginas web completas, que se almacenan y exponen públicamente de forma accesible en formatos estandarizados. De la misma manera que existen webs que almacenan el contenido de las series históricas de las cotizaciones de las principales bolsas del planeta o webs que historizan las variables ambientales de las diferentes regiones del mundo, Common Crawl captura y guarda las páginas webs que circulan por Internet a lo largo del tiempo.
Cabe destacar que Common Crawl es una organización sin ánimo de lucro fundada en 2011 por Gil Elbaz. Su sede principal está situada en San Francisco, en los Estados Unidos, y su misión persigue que investigadores, emprendedores y desarrolladores de todo el mundo obtengan acceso ilimitado a una gran cantidad de información, que les permita explorar, analizar y crear aplicaciones y servicios innovadores. En palabras de la propia organización:
“Los datos abiertos derivados de las exploraciones web pueden contribuir a la toma de decisiones informadas tanto a nivel individual como gubernamental. Los datos abiertos fomentan colaboraciones interdisciplinarias que pueden impulsar una mayor eficiencia y efectividad en la resolución de desafíos complejos, desde problemas ambientales hasta crisis de salud pública. En general, adoptar datos abiertos de exploraciones web enriquece a la sociedad con innovación, empoderamiento y colaboración”
“Al adoptar Datos Abiertos, fomentamos un ecosistema de conocimiento inclusivo y próspero, donde la inteligencia colectiva de la comunidad global puede llevar a descubrimientos transformadores y tener un impacto positivo en la sociedad”
Adaptado de https://commoncrawl.org
Potenciales usos de Common Crawl
La omnipresencia de la web hace que las aplicaciones prácticas de acceder a gran parte de la información disponible en sitios web de Internet sean prácticamente ilimitadas. No obstante, podemos destacar tres ejemplos:
- Investigación en Inteligencia Artificial y Aprendizaje Automático: Este es quizás el caso de aplicación más directo. En concreto, sabemos que GPT-3 fue entrenado con buena parte de los datos generados por Common Crawl. Investigadores y desarrolladores utilizan los vastos conjuntos de datos de texto de Common Crawl para entrenar modelos de procesamiento de lenguaje natural (NLP en sus siglas en inglés), lo que ayuda a mejorar la comprensión de máquinas sobre el lenguaje humano en aplicaciones como traducción automática, resumen de textos, y generación de contenido. Una derivada del mismo caso de uso es el análisis de sentimientos: los datos de Common Crawl permiten realizar análisis de sentimientos a gran escala, lo que es útil para entender opiniones públicas sobre diversos temas, desde productos hasta políticas.
- Desarrollo de Herramientas y Servicios Web: Cualquier tipo de producto de software, desde motores de búsqueda hasta herramientas educativas, se benefician de los datos puestos a disposición por la fundación Common Crawl. Estos datos son una fuente de incalculable valor para desarrolladores que trabajan en la mejora de algoritmos de búsqueda y procesamiento de la información.
- Estudios de Mercado y Competencia: Empresas de diferentes sectores utilizan los datos de Common Crawl para monitorizar tendencias en tiempo real, analizando la frecuencia y el contexto en que ciertos términos son mencionados en la web. De esta forma, generan análisis competitivos sobre su situación en el mercado respecto a sus competidores. Al tener acceso a información actualizada sobre cómo las compañías están presentando sus productos y servicios en la web, las empresas pueden realizar análisis competitivos de forma rutinaria y masiva.
Veamos de manera más detallada este último ejemplo. Supongamos que tenemos una idea para la creación de una nueva empresa, una start-up, sobre un modelo de negocio de aplicación móvil, ya sea para la venta de ropa de segunda mano, la entrega de comida o artículos a domicilio. En todo caso, cualquier emprendedor debe de analizar el mercado antes de lanzarse a la aventura de construir una nueva empresa, para detectar potenciales oportunidades.
Hoy en día, Internet es la mayor fuente de información del mundo, pero en este punto, el emprendedor conocedor de la existencia de Common Crawl puede aprovechar esta plataforma de datos abiertos para ganar ventaja frente a otros. ¿Cómo? Muy sencillo, una persona que no conozca esta plataforma iniciará un proceso de navegación manual buscando información del sector y el mercado en las webs de su potencial competencia. Entrará en esas webs y verá cómo sus competidores anuncian sus productos o servicios, qué tipo de palabras clave emplean y qué recursos web explotan con más frecuencia (videos, anuncios en redes sociales, promociones, servicios cruzados, etc.). Este proceso manual es lento y caro, en términos de tiempo consumido, puesto que depende de la pericia del emprendedor y del método que utilice para extraer la información de negocio que le interesa. Por el contrario, una persona que conozca la existencia de Common Crawl y disponga de ciertos conocimientos técnicos, podría utilizar los datos de Common Crawl para analizar las páginas web de sus competidores, extrayendo información clave como precios, descripciones de productos y estrategias de marketing de forma masiva y automática. Con esta información, la herramienta ofrecería a sus usuarios una visión comparativa del mercado, identificando qué productos son populares, cómo se posicionan los competidores en términos de precios y qué tácticas de promoción usan, sin necesidad de una costosa recolección manual de datos, como en el caso del primer emprendedor.
Entrando a fondo en Common Crawl
Common Crawl puede verse como un producto tecnológico que ofrece un servicio de archivado y rastreo de datos web a gran escala. Su propio nombre incluye la palabra Crawl que hace referencia a la palabra crawler (rastreador). En este contexto, los crawlers son robots de software - a veces conocidos como arañas web - cuya misión es navegar por la web simulando el comportamiento de un humano para posteriormente capturar determinados datos de las webs objetivo. Un caso de uso típico de estos robots es navegar por las webs para encontrar fallos en la navegación como, por ejemplo, enlaces rotos que no devuelven la página adecuada cuándo se pincha sobre ellos.
En este sentido, encontramos dos elementos clave de Common Crawl como plataforma tecnológica:
- Rastreadores (Crawlers) Web: Utiliza rastreadores automatizados que exploran la web para recopilar información. Estos rastreadores siguen enlaces de página a página, capturando el contenido HTML, los enlaces y otros elementos relevantes. Pese a que no es sencillo encontrar información técnica sobre los detalles del funcionamiento de Common Crawl, sabemos que su rastreador principal se denomina CCBot y está basado en el proyecto Apache Nut.
- Almacenamiento de Datos: Los datos recopilados se almacenan en ficheros WARC, WAT y WET. Estos archivos se alojan en Amazon S3, facilitando el acceso global a través de una plataforma de almacenamiento en la nube.
- WARC (Web ARChive): Contiene el contenido web completo, incluyendo HTML, imágenes y otros recursos multimedia.
- WAT (Web ARChive-Terse): Proporciona metadatos sobre el contenido del archivo WARC, como enlaces externos e internos y cabeceras HTTP.
- WET (Web ARChive Extracted Text): Contiene texto extraído de las páginas, eliminando todo el código HTML y otros formatos no textuales.
Para más información sobre cómo acceder a los conjuntos de datos, puedes consultar esta web.
Características técnicas de Common Crawl
Algunas de las principales características de Common crawl son:
- Volumen de Datos. Common Crawl captura más de 2.000 millones de páginas web en cada uno de sus rastreos mensuales, generando alrededor de 250 terabytes de datos. Estos rastreos acumulan petabytes de datos almacenados a lo largo del tiempo, representando una de las colecciones más grandes de datos web accesibles públicamente.
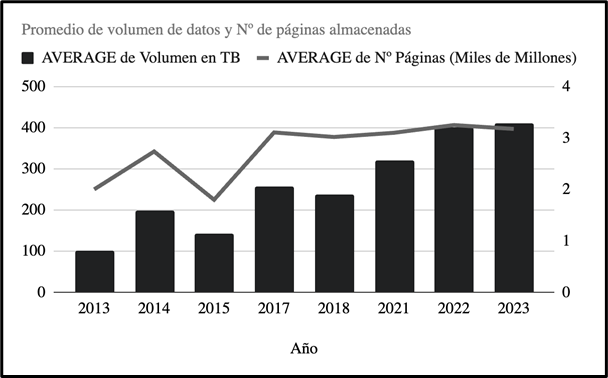
Evolución del volumen de datos almacenado por Common Crawl con el tiempo. Adaptado de la fuente original: https://en.wikipedia.org/wiki/Common_Crawl.
- Accesibilidad. Como veíamos anteriormente, los datos recogidos por Common Crawl están disponibles en Amazon S3 en el bucket "commoncrawl". Los usuarios pueden acceder a estos datos sin costo, aunque se aplican tarifas estándar de AWS para la transferencia de datos fuera de S3.
- Frecuencia de Actualización. La base de datos de Common Crawl se actualiza mensualmente. Cada rastreo mensual se planifica y ejecuta para capturar una instantánea amplia y representativa de la web.
- Diversidad. La colección de Common Crawl incluye páginas de más de 40 idiomas, abarcando una amplia variedad de temas y categorías. Esto hace que los datos sean excepcionalmente útiles para investigaciones que requieren una perspectiva global o para proyectos que necesitan datos en múltiples idiomas.
Conclusión
Common Crawl destaca como una herramienta de inestimable valor para el acceso a datos abiertos. Su capacidad para ofrecer petabytes de datos web de manera gratuita, no solo facilita la investigación en inteligencia artificial y el análisis de mercado, sino que también democratiza el acceso a la información, permitiendo a emprendedores y desarrolladores de todo el mundo innovar y crear soluciones efectivas para problemas complejos. Este modelo de datos abiertos no solo enriquece el conocimiento científico y tecnológico, sino que también impulsa la colaboración entre sectores y ámbitos sociales muy diferentes y la eficiencia en la resolución de desafíos globales. Las aplicaciones de los datos proporcionados por Common Crawls son, por lo tanto, inagotables y desde una perspectiva técnica, las herramientas de software involucradas en la plataforma tecnológica son apasionantes.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.












