Entrevista
In recent years, artificial intelligence (AI) has gone from being a futuristic promise to becoming an everyday tool: today we live with language models, generative systems and algorithms capable of learning more and more tasks. But as their popularity grows, so does an essential question: how do we ensure that these technologies are truly reliable and trustworthy? Today we are going to explore that challenge with two invited experts in the field:
- David Escudero, director of the Artificial Intelligence Center of the University of Valladolid.
- José Luis Marín, senior consultant in strategy, innovation and digitalisation.
Listen to the podcast (availible in spanish) completo
Summary / Transcript of the interview
1. Why is it necessary to know how artificial intelligences work and evaluate this behavior?
Jose Luis Marín: It is necessary for a very simple reason: when a system influences important decisions, it is not enough that it seems to work well in an eye-catching demo, but we have to know when it gets it right, when it can fail and why. Right now we are already in a phase in which AI is beginning to be applied in such delicate issues as medical diagnoses, the granting of public aid or citizen care itself in many scenarios. For example, if we ask ourselves whether we would trust a system that operates like a black box and decides whether to grant us a grant, whether we are selected for an interview or whether we pass an exam without being able to explain to us how that decision was made, surely the answer would be that we would not trust it; And not because the technology is better or worse, but simply because we need to understand what is behind these decisions that affect us.
David Escudero: Indeed, it is not so much to understand how algorithms work internally, how the logic or mathematics behind all these systems works, but to understand or make users see that this type of system has degrees of reliability that have their limits, just like people. People can also make mistakes, they can fail at a certain time, but you have to give guarantees for users to use them with a certain level of security. Providing metrics on the performance of these algorithms and making them appear reliable to some degree is critical.
2. A concept that arises when we talk about these issues is that of explainable artificial intelligence . How would you define this idea and why is it so relevant now?
David Escudero: Explainable AI is a technicality that arises from the need for the system not only to offer decisions, not only to say whether a certain file has to be classified in a certain way or another, but to give the reasons that lead the system to make that decision. It's opening that black box. We talk about a black box because the user does not see how the algorithm works. It doesn't need it either, but it does at least give you some clues as to why the algorithm has made a certain decision or another, which is extremely important. Imagine an algorithm that classifies files to refer them to one administration or another. If the end user feels harmed, he needs to have a reason why this has been so, and he will ask for it; He can ask for it and he can demand it. And if from a technological point of view we are not able to provide that solution, artificial intelligence has a problem. In this sense, there are techniques that advance in providing not only solutions, but also in saying what are the reasons that lead an algorithm to make certain decisions.
Jose Luis Marín: I can't explain it much better than David has explained it. What we are really looking for with explainable artificial intelligence is to understand the reason for those answers or those decisions made by artificial intelligence algorithms. To simplify it a lot, I think that we are not really talking about anything other than applying the same standards as when those decisions are made by people, whom we also make responsible for the decisions. We need to be able to explain why a decision has been made or what rules have been followed, so that we can trust those decisions.
3. How is this need for explainability and rigorous evaluation being addressed? Which methodologies or frameworks are gaining the most weight? And what is the role of open data in them?
Jose Luis Marín: This question has many dimensions. I would say that several layers are converging here. On the one hand, specific explainability techniques such as LIME (Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations) or many others. I usually follow, for example, the catalog of reliable AI tools and metrics of the OECD's Observatory of Public Policies on Artificial Intelligence, because there progress in the domain is recorded quite well. But, on the other hand, we have broader evaluation frameworks, which do not only look at purely technical issues, but also issues such as biases, robustness, stability over time and regulatory compliance. There are different frameworks such as the NIST (National Institute of Standards and Technology) risk management framework, the impact assessment of the algorithms of the Government of Canada or our own AI Regulations. We are in a phase in which a lot of public and private initiatives are emerging that will help us to have better and better tools.
David Escudero: For research, it is still a fairly open field. There are methodologies, indeed, but new models based on neural networks have opened up a huge challenge. The artificial intelligence that had been developed in the years prior to the generative AI boom, to a large extent, was based on expert systems that accumulated a lot of knowledge rules about the domain. In this type of technology, explainability was given because, since what was done was to trigger a series of rules to make decisions, following backwards the order in which the rules had been applied, you had an explanation; But now with neural systems, especially with large models, where we are talking about billions and billions of parameters, these types of approximations have become impossible, unapproachable, and other types of methodologies are applied that are mainly based on knowing, when you train a machine learning model, what are the properties or attributes in the training that lead you to make one decision or another. Let's say, what are the weights of each of the properties they are using.
For example, if you're using a machine learning system to decide whether to advertise a certain car to a bunch of potential customers, the machine learning system is trained based on an experience. In the end, you are left with a neural model where it is very difficult to enter, but you can do it by analyzing the weight of each of the input variables that you have used to make that decision. For example, the person's income will be one of the most important attributes, but there may be other issues that lead you to very important considerations, such as biases. Imagine that one of the most important variables is the gender of the person. There you enter into a series of considerations that are delicate. In other types of algorithms, for example, that are based on images, an explainable AI algorithm can tell you which part of the image was most relevant. For example, if you are using an algorithm to, based on the image of a person's face - I am talking about a hypothetical, a future, which would also be an extreme case - decide whether that person is trustworthy or not. Then you could look at what traits of that person artificial intelligence is paying more attention to, for example, in the eyes or expression. This type of consideration is what AI would make explainable today: to know which are the variables or which are the input data of the algorithm that take on greater value when making decisions.
This brings me to another part of your question about the importance of data. The quality of the training data is absolutely important. This data, these explainable algorithms, can even lead you to derive conclusions that indicate that you need data of more or less quality, because it may be giving you some surprising result, which may indicate that some training or input data is deriving outputs and should not. Then you have to check your own input data. Have quality reference data like you can find in datos.gob.es. It is absolutely essential to be able to contrast the information that this type of system gives you.
José Luis Marín: I think open data is key in two dimensions. First, because they allow evaluations to be contrasted and replicated with greater independence. For example, when there are validation datasets that are public, it not only assesses who builds the system, but also that third parties can evaluate (universities, administrations or civil society itself). That openness of evaluation data is very important for AI to be verifiable and much less opaque. But I also believe that open data for training and evaluation also provides diversity and context. In any minority context in which we think, surely large systems have not paid the same attention to these aspects, especially commercial systems. Surely they have not been tested at the same level in majority contexts as in minority contexts and hence many biases or poor performances appear. So, open datasets can go a long way toward filling those gaps and correcting those problems.
I think that open data in explainable artificial intelligence fits very well, because deep down they share a very similar objective, related to transparency.
4. Another challenge we face is the rapid evolution in the artificial intelligence ecosystem. We started talking about the popularity of chatbots and LLMs, but we find that we are still moving towards agentic AI, systems capable of acting more autonomously. What do these systems consist of and what specific challenges do they pose from an ethical point of view?
David Escudero: Agent AI seems to be the big topic of 2026. It is not such a new term, but if last year we were talking about AI agents, now we are talking about agent AI as a new technology that coordinates different agents to solve more complex tasks. To simplify, if an agent serves you to carry out a specific activity, for example, to book a plane ticket, what the agent AI would do is: plan the trip, contrast different offers, book the plane, plan the outward trip, the stay, again the return and, finally, evaluate the entire activity. What the system based on agent AI does is coordinate different agents. In addition, with a nuance. When we talk about the word agéntica – which we don't have a very direct translation in Spanish – we think of a system that takes the initiative. In the end, it is no longer just you who, as a user, ask artificial intelligence for things, but AI is already capable of knowing how it can solve things. It will ask you for information when it needs it and will try to adapt to give you a final solution as a user, but more or less autonomously, making decisions in intermediate processes.
Here precision and explainability are fundamental because a very important challenge is opened again. If at any given moment one of these agents used by the agentic AI fails, the effect of summing errors can be created and in the end it ends up like the phone smashed. From one system to another, from one agent to another, information is passed and if that information is not as accurate as it should be, in the end the solution can be catastrophic. Then new elements are introduced that make the problem even more exciting from a technological point of view. But we also have to understand that it is absolutely necessary, because in the end we have to move from systems that provide a very specific solution for a very particular case to systems that combine the output of different systems to be a little more ambitious in the response given to possible users.
Jose Luis Marín: Indeed. The moment we go from a type of system that, in principle, we give the "ability to think" about the actions that should be done and tell us about them, to other systems that it is as if they have hands to interact with the digital world - and we begin to see systems that even interact with the physical world and can execute those actions, that do not stop at telling you or recommending them to you – very interesting opportunities open up. But the complexity of the evaluation is also multiplied. The problem is no longer just whether the answer is right or wrong, but it is beginning to be who controls what the system does, what margin of decision it has, who supervises it and, above all, who responds if something goes wrong, because we are not only talking about recommendations, we are talking about actions that sometimes may not be so easy to undo. This leads to new or at least more intense risks: if traceability is lost in the execution of actions that were not foreseen or that should not have occurred at a certain time; or there may be misuses of information, or many other risks. I believe that agentic AI requires even more governance and a much more careful design aligned with people's rights.
5. Let's talk about real applications, where do you see the most potential and need for evaluation and explainability in the public sector?
Jose Luis Marín: I would say that the need for evaluation and explainability is greater where AI can influence decisions that affect people. The greater the impact on rights or opportunities or, even on trust in institutions, the greater this demand must be. If we think, for example, of areas such as health, social services, employment, education... In all of them, logically, the need for evaluation in the public sector is unavoidable.
In all cases, AI can be very useful in supporting decisions to achieve efficiencies in multiple scenarios. But we need to know very well how it behaves and what criteria are being used. This doesn't just affect the most complex systems. I think we have to look at the systems that at first may seem more or less sensitive at first glance, such as virtual assistants that we are already starting to see in many administrations or automatic translation systems... There is no final decision made by the AI, but a bad recommendation or a wrong answer can also have consequences for people. In other words, I think it does not depend so much on technological complexity as on the context of use. In the public sector, even a seemingly simple system can have a lot of impact.
David Escudero: I'll throw the rag at you to make another podcast about the concept that is also very fashionable, which is Human in the loop or Human on the loop. In the public sector we have a body of public officials who know their work very well and who can help. Human in the loop would be the role that the civil servant can play when it comes to generating data that can be useful for training systems, checking that the data with which systems can be trained is reliable, etc.; and Human on the loop would be the supervision of the decisions that artificial intelligence can make. The one who can review, who can know if that decision made by an automatic system is good or bad, is a public official.
In this sense, and also related to agentic AI, we have a project with the Spanish Foundation for Science and Technology to advise the Provincial Council of Valladolid on artificial intelligence tasks in the administration. And we see that many of the tasks that the civil servants themselves ask us do not have so much to do with AI, but with the interoperability of the services they already offer and that are automatic. Maybe in an administration they have a service developed by an automatic system, next to another service that offers them a form with results, but then they have to type in the data communicated by both services by hand. There we would also be talking about possibilities for the agency AI to intercommunicate. The challenge is to involve in this entire process the role of the civil servant as a watchdog that public functions are carried out rigorously.
Jose Luis Marín: The concept of Human in the loop is key in many of the projects we work on. In the end, it is the combination not only of technology, but of people who really know the processes and can supervise them and complement those actions that the Agent AI can perform. In any system of simple care, such supervision is already necessary in many cases, because a bad recommendation can also have many consequences, not only in the action of a complex system.
6. In closing, I'd like each of you to share a key idea about what we need to move towards a more trustworthy, assessable, and explainable AI.
David Escudero: I would point out, taking advantage of the fact that we are on the datos.gob.es podcast, the importance of data governance: to make sure that institutions, both public and private, are very concerned about the quality of the data, about having well-shared data that is representative, well documented and, of course, accessible. Data from public institutions is essential for citizens to have these guarantees and for companies and institutions to prepare algorithms that can use this information to improve services or provide guarantees to citizens. Data governance is critical.
Jose Luis Marín: If I had to summarise everything in a single idea, I would say that we are still a long way from assessment being a common practice. In AI systems we will have to make it mandatory within the development and deployment processes. Evaluating is not trying once and taking it for granted, it is necessary to continuously check how and where they can fail, what risks they introduce and if they are still appropriate when the context in which a certain system was designed has changed. I think we are still far from this.
Indeed, open data is key to contributing to this process. An AI is going to be more reliable the more we can observe it and improve it with shared criteria, not only with those of the organization that designs them. That is why open data provides transparency, can help us facilitate verification and build a more solid basis so that services are really aligned with the general interest.
David Escudero Mancebo: In that sense, I would also like to thank spaces like this that undoubtedly serve to promote that culture of data, quality and evaluation that is so necessary in our society. I think a lot of progress has been made, but that, without a doubt, there is still a long way to go and opening spaces for dissemination is very important.
Noticia
At the epicentre of global innovation that defines Mobile World Congress (MWC), a space has emerged where human talent takes centre stage: the Talent Arena.
The 2026 edition, promoted by Mobile World Capital Barcelona, brought together professionals, technology companies, training centres and emerging talent between 2 and 4 March with a common goal: to learn, connect and explore new opportunities in the digital field. At this event, Red.es actively participated with several sessions focused on one of the great current challenges: how to promote digital transformation through talent, training and innovation. Among them was the workshop "Open Data in Spain. From theory to practice with datos.gob.es", a session that focused on the strategic role of open data and its connection with emerging technologies such as artificial intelligence.
In this post we review the contents of the presentation that combined:
- A didactic look at the evolution, current state and future of open data in Spain
- A hands-on workshop on creating a conversational agent with MCP
What is open data? Evolution and milestones
The session began by establishing a fundamental pillar: the importance of open data in today's ecosystem. Beyond their technical definition – data that can be freely used, reused and shared by anyone, for any purpose – the talk underscored that their true power lies in the transformative impact they generate.
As addressed in the workshop, this data comes from multiple sources (public administrations, universities, companies and even citizens) and its openness allows:
- Promote institutional transparency, by facilitating access to public information.
- Encourage innovation, by enabling developers and businesses to create new services.
- Generate economic and social value, from the reuse of information in multiple sectors, such as health, education or the environment.
One of the key aspects of the workshop was to contextualize the historical evolution of open data. Although the first antecedents date back to the 50s and 60s, the modern concept of "open data" began to consolidate in the 90s. Subsequently, milestones such as the Memorandum on Transparency and Open Government (2007-2009) or the creation of the Open Government Partnership in 2011 marked a turning point at the international level.
In Spain, this development has been supported by a solid regulatory framework, such as Law 37/2007, which establishes key principles:
- Default opening of public data, especially high-value data.
- Creation of interoperable catalogs.
- Promotion of the reuse of information.
- Establishment of units responsible for data management.
The role of datos.gob.es: the national open data portal
At the heart of this ecosystem is datos.gob.es, the national open data portal, which acts as a unified access point to the public information available in Spain.
During the workshop, it was explained how this platform has evolved over time: from a few hundred datasets to hosting more than 100,000 today. It has also been incorporating new functionalities and adapting to international standards such as DCAT-AP and its national adaptation DCAT-AP-ES. These standards allow metadata to be structured in an interoperable way, facilitating integration between different catalogs.
Check here the Practical Guide to Implementing DCAT-AP-ES step by step
In addition, the data federation process in datos.gob.es was detailed , which ensures that data from different sources can be integrated in a consistent and accessible way.
Despite the progress, the presentation also addressed the remaining challenges:
- Data quality and updating.
- Standardization and interoperability.
- Security and access control, especially in AI-connected environments.
- Training of users, both technical and non-technical.

Figure 1. Photo taken during the Talent Arena presentation at the Mobile World Congress. The photo shows the slide from the presentation explaining the concept of open data. Source: own elaboration - datos.gob.es.
From data to intelligence: the leap to AI
One of the most innovative elements of the workshop was its practical approach, focused on the application of artificial intelligence to open data. This is where the Model Context Protocol (MCP) came into play, an open standard that allows you to connect language models (Large Language Model or LLM) with external data sources in real time.
The initial problem that the workshop had to answer is how AI models, on their own, do not have up-to-date access to information or external systems. This limits their usefulness in real contexts. One solution may be to develop an MCP that acts as a "bridge" between the model and data sources, enabling:
- Access up-to-date information.
- Execute actions on external systems.
- Integrate multiple data sources securely.
In simple words, it is about connecting the "brain" (the AI model) with the "tools" (databases, APIs, internal systems).
The exercise, which took place live in the Talent Arena, began with a simple example: creating a database of film preferences and developing an MCP that would allow it to be consulted using natural language.
From there, key concepts were introduced:
- Identification of the intention of the model.
- Function calling.
- Generation of natural language responses from structured data.
This approach allows us to abstract the technical complexity and bring the use of data closer to non-specialized profiles.
The next step was to apply this same approach to the datos.gob.es catalog. Through its API, it's possible. First, it allows you to search for datasets by title and filter by topic; then through the API you can obtain detailed information about a dataset and access catalog statistics.
The MCP developed in the workshop acted as an intermediary between the AI model and this API, allowing complex queries to be made using natural language.
This exercise combined a local database (SQLite) and the consumption of external data through an API, all integrated through an MCP server that allowed these functionalities to be exposed as accessible tools. The goal was to understand how to structure data, query it, and make it available to other AI systems or models in an organized way.
The full code is available as an attachment to this post in Python Notebook format.
This exercise is a sign of the enormous opportunities before us. The combination of open data and artificial intelligence can:
- Democratize access to information.
- Accelerate innovation.
- Improve decision-making in the public and private sectors.
In summary, the workshop "Open Data in Spain. From theory to practice with datos.gob.es" highlighted a fundamental idea: data, by itself, does not generate value. It is their use, interpretation and combination with other technologies that allows them to be transformed into knowledge and real solutions.
The evolution of open data in Spain shows that much progress has been made in recent years. However, the real potential is yet to be exploited, especially in its integration with technologies such as artificial intelligence. Events like Talent Arena 2026 serve precisely that: connecting ideas, sharing knowledge, and exploring new ways of doing things.
Noticia
On the occasion of Open Data Day 2026, the Open Knowledge Foundation (OKFN) held an online conference entitled "The Future of Open Data", an open-access event that brought together a diverse community of data professionals from governments, civil society organizations, universities, newsrooms and activist collectives. From datos.gob.es we follow the day live and share here a summary of the main ideas that marked the day.
Three approaches to understanding the role of open data in the age of AI
The conference was structured around three main thematic blocks:
- Navigating open data regulation in the public interest: interventions by representatives of academia, public policy makers and researchers from different countries who discussed the regulatory framework of open data in the current context of AI.
- Community Voices, Open Data, and AI: Short presentations of concrete projects from around the world exploring the intersection between open data and artificial intelligence, from tools for judicial analysis to citizen science dashboards.
- 20 years of CKAN: The future in the age of AI: reflections on the two decades of history of open data and CKAN, on the past, present and challenges to come.
Overall, the day combined political reflection, technical innovation and community vision, with voices from Spain, France, India, Ukraine, Kenya, the United States and Australia, among other countries. And the common thread of the event was the question that today runs through digital policy forums around the world: what is the role of open data in an ecosystem increasingly dominated by artificial intelligence?
Thematic block 1. A movement that was born out of activism
In its origins, the open data movement began in conversations between activists committed to transparency, accountability and access to public information to citizens.
This episode of the datos.gob.es podcast also discusses the origin of open data and its evolution
Today, however, the movement is more diversified because there are now more agents that influence, such as artificial intelligence. There is also a regulatory context that functions as a framework in the development of the open data movement.
The topic of regulation and governance was the backbone of the first session of the event, moderated by Renata Ávila, CEO of OKFN. The following participated in it:
- Jonathan Gray, author of the book Public Data Cultures (Polity, 2025) and professor at King's College London, presented his work as a reference source for reflecting on data as an open asset: how this openness is built and how it can help us respond to great collective challenges. His proposal is that public data is not simply technical information, but the result of cultural and political decisions about what we tell, how we tell it, and for whom.
- Renato Berrino Malaccorto, research manager of the Open Data Charter, stressed that the openness of data is fundamental for the ethical development of AI. Without open, auditable and quality data, it is not possible to build artificial intelligence systems that are accountable to citizens. At the same time, he pointed out that there is a real capacity gap: many organizations and governments lack the technical and human resources necessary to harness the potential of open data in this new context.
- Ruth del Campo, general director of data at the Ministry for Digital Transformation and Public Function of the Government of Spain, offered a very relevant institutional perspective for our context. He recalled that "The data economy is part of the economy", and underlined the boost that the Government is giving to initiatives such as datos.gob.es and Impulsa Data (aimed at modernizing internal management and feeding the Sectoral Data Spaces). He also stressed the importance of the data strategy incorporating AI ready principles, guaranteeing adequate resources – such as linguistic corpora – to train AI models efficiently and without generating new inequalities. Finally, he pointed out the need to simplify and harmonize data regulations, a process in which progress is already being made at the European level.
The panel's underlying message was clear: open data needs to be placed at the heart of the digital agenda, adequately resourced and explicitly connected to public AI strategies. AI of social interest cannot be built without open data; and open data without a vision of AI risks being relegated to irrelevance.
Thematic block 2. Lightning Talks: Projects That Demonstrate the Potential of Open Data
The second session of the day brought together short presentations of concrete projects that illustrated how open data and artificial intelligence can work together in the public interest. Some examples are:
- Ihor Samokhodskyi from the Ukrainian initiative Policy Genome presented an open data-based analysis tool for judicial practice that demonstrates how public information, combined with AI techniques, can contribute to transparency and the improvement of justice systems.
- Javier Conde, from the Polytechnic University of Madrid, presented the proposal he has developed together with his colleagues Andrés Muñoz-Arcentales and Álvaro Alonso to improve the integration of European open data in data spaces. This project facilitates the automatic generation of high-quality metadata, thus ensuring the interoperability and reuse of datasets. A directly relevant initiative for the improvement of portals such as datos.gob.es and its connection with data.europa.eu.
- Renu Kumari, from #semanticClimate and Frictionless Data (India), presented a project that works at the intersection between open climate data and semantic tools to make scientific literature and data on climate change more accessible, structured and reusable.
- Richard Muraya, from The Demography Project (Kenya), presented Uhai/Life, a citizen science dashboard that aggregates open data on natural resource use to provide insight into human and environmental well-being at the local scale. An example of how open data can empower communities to tell their own story, without relying on external narratives or institutions.
Figure 1. Presentation slide of one of the presentations of the event. Source: conference "The Future of Open Data" organized by OKFN.
- Finally, Sayantika Banik from DataJourney (India) showed an autonomous analytics assistant capable of transforming open datasets into easily understandable information.
Thematic block 3. Round table: 20 years of CKAN and the challenges of the future
The longest session of the day was also the most reflective: a round table to celebrate two decades of CKAN, the open data portal management tool born within OKFN and which today feeds hundreds of data portals around the world, including datos.gob.es. The panel was moderated by Jamaica Jones, CKAN/POSE community manager at the University of Pittsburgh. The following participated in this table:
- Rufus Pollock, founder of OKFN and Datopian, and co-founder of Life Itself, stressed the importance of keeping power in the hands of citizens and of betting on open source as a driver of economic development and shared knowledge. For Pollock, AI must be understandable and accessible to most, not just large corporations.
- Joel Natividad is Co-CEO and co-founder of datHere, a company specializing in open data solutions and analytics tools for the public sector. As a CKAN user for more than 15 years, he insisted on one idea: "We have always tried to learn how machines think, and now it is machines that are learning how humans think."
- Patricio Del Boca is Tech Lead and Open Activist at OKFN, where he leads the technical development of initiatives related to CKAN and open data infrastructures. He shared OKFN's next steps for 2026: building more community and developing use cases that demonstrate the practical value of open data in the current context.
- Andrea Borruso is an expert in Geographic Information Systems (GIS) and open data. As president of onData, an Italian non-profit association that promotes access to and reuse of public data, he highlighted data activism and citizen science as drivers of technological development that involve the community.
- Antonin Garrone of data.gouv.fr, France's national open data portal, brought to the table the perspective of an established portal that has spent years exploring how to integrate new technologies without losing sight of its public service mission.
- Steven De Costa is CEO of Link Digital, an Australian company specializing in the implementation and development of CKAN-based solutions, and Co-Steward of the CKAN project. His perspective combined technical vision with a concern to maintain an open and participatory governance model.
- Finally, Public AI research engineer Mohsin Yousufi insisted on the intersection between artificial intelligence, public data infrastructures, and technology policies, exploring how AI systems can be designed and governed to serve the public interest.
Final Thought: Open Data as Democratic Infrastructure
If there is one conclusion that ran through all the sessions of Open Data Day 2026, it is that open data is not in crisis, but at a decisive moment. The opportunities offered by artificial intelligence are real, but so are the risks. It is important to know them in order to know how to address them. Some of those that were mentioned are:
- Prevent public data from becoming the raw material of private systems without transparency or accountability.
- Preserve the political will to keep open data portals functional and updated.
- Bridging the digital skills and training gap to facilitate the participation of all countries and communities in the new AI ecosystem.
In the face of this, the message of the event was one of mobilization: it is necessary to vindicate open data as a democratic infrastructure, explicitly connect data policies with public AI strategies, and ensure that the benefits of artificial intelligence reach all citizens, and not only those who already have access to technological resources.
From datos.gob.es we will continue to work in that direction, and we celebrate the existence of spaces such as Open Data Day to remind us why we started and where we want to go.
You can watch the event video again here
Blog
"I'm going to upload a CSV file for you. I want you to analyze it and summarize the most relevant conclusions you can draw from the data". A few years ago, data analysis was the territory of those who knew how to write code and use complex technical environments, and such a request would have required programming or advanced Excel skills. Today, being able to analyse data files in a short time with AI tools gives us great professional autonomy. Asking questions, contrasting preliminary ideas and exploring information first-hand changes our relationship with knowledge, especially because we stop depending on intermediaries to obtain answers. Gaining the ability to analyze data with AI independently speeds up processes, but it can also cause us to become overconfident in conclusions.
Based on the example of a raw data file, we are going to review possibilities, precautions and basic guidelines to explore the information without assuming conclusions too quickly.
The file:
To show an example of data analysis with AI we will use a file from the National Institute of Statistics (INE) that collects information on tourist flows in Europe, specifically on occupancy in rural tourism accommodation. The data file contains information from January 2001 to December 2025. It contains disaggregations by sex, age and autonomous community or city, which allows comparative analyses to be carried out over time. At the time of writing, the last update to this dataset was on January 28, 2026.

Figure 1. Dataset information. Source: National Institute of Statistics (INE).
1. Initial exploration
For this first exploration we are going to use a free version of Claude, the AI-based multitasking chat developed by Anthropic. It is one of the most advanced language models in reasoning and analysis benchmarks, which makes it especially suitable for this exercise, and it is the most widely used option currently by the community to perform tasks that require code.
Let's think that we are facing the data file for the first time. We know in broad strokes what it contains, but we do not know the structure of the information. Our first prompt, therefore, should focus on describing it:
PROMPT: I want to work with a data file on occupancy in rural tourism accommodation. Explain to me what structure the file has: what variables it contains, what each one measures and what possible relationships exist between them. It also points out possible missing values or elements that require clarification.

Figure 2. Initial exploration of the data file with Claude. Source: Claude.
Once Claude has given us the general idea and explanation of the variables, it is good practice to open the file and do a quick check. The objective is to assess that, at a minimum, the number of rows, the number of columns, the names of the variables, the time period and the type of data coincide with what the model has told us.
If we detect any errors at this point, the LLM may not be reading the data correctly. If after trying in another conversation the error persists, it is a sign that there is something in the file that makes it difficult to read automatically. In this case, it is best not to continue with the analysis, as the conclusions will be very apparent, but will be based on misinterpreted data.
2. Anomaly management
Second, if we have discovered anomalies, it is common to document them and decide how to handle them before proceeding with the analysis. We can ask the model to suggest what to do, but the final decisions will be ours. For example:
- Missing values: if there are empty cells, we need to decide whether to fill them with an "average" value from the column or simply delete those rows.
- Duplicates: we have to eliminate repeated rows or rows that do not provide new information.
- Formatting errors or inconsistencies: we must correct these so that the variables are coherent and comparable. For example, dates represented in different formats.
- Outliers: if a number appears that does not make sense or is exaggeratedly different from the rest, we have to decide whether to correct it, ignore it or treat it as it is.

Figure 3. Example of missing values analysis with Claude. Source: Claude.
In the case of our file, for example, we have detected that in Ceuta and Melilla the missing values in the Total variable are structural, there is no rural tourism registered in these cities, so we could exclude them from the analysis.
Before making the decision, a good practice at this point is to ask the LLM for the pros and cons of modifying the data. The answer can give us some clue as to which is the best option, or indicate some inconvenience that we had not taken into account.

Figure 4. Claude's analysis on the possibility of eliminating or not securities. Source: Claude.
If we decide to go ahead and exclude the cities of Ceuta and Melilla from the analysis, Claude can help us make this modification directly on the file. The prompt would be as follows:
PROMPT: Removes all rows corresponding to Ceuta and Melilla from the file, so that the rest of the data remains intact. Also explain the steps you're following so they can review them.
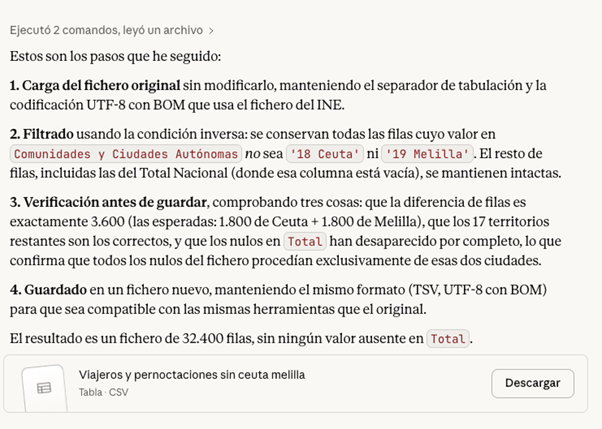
Figura 5. Step by step in the modification of data in Claude. Source: Claude.
At this point, Claude offers to download the modified file again, so a good checking practice would be to manually validate that the operation was done correctly. For example, check the number of rows in one file and another or check some rows at random with the first file to make sure that the data has not been corrupted.
3. First questions and visualizations
If the result so far is satisfactory, we can already start exploring the data to ask ourselves initial questions and look for interesting patterns. The ideal when starting the exploration is to ask big, clear and easy to answer questions with the data, because they give us a first vision.
PROMPT: It works with the file without Ceuta and Melilla from now on. Which have been the five communities with the most rural tourism in the total period?

Figure 6. Claude's response to the five communities with the most rural tourism in the period. Source: Claude.
Finally, we can ask Claude to help us visualize the data. Instead of making the effort to point you to a particular chart type, we give you the freedom to choose the format that best displays the information.
PROMPT: Can you visualize this information on a graph? Choose the most appropriate format to represent the data.
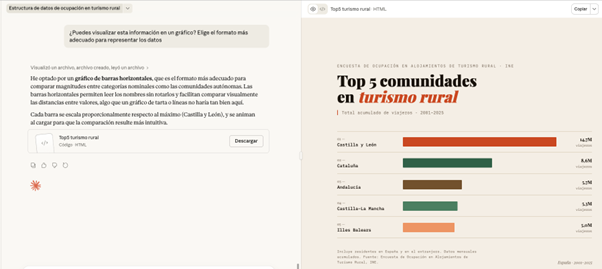
Figure 7. Graph prepared by Cloude to represent the information. Source: Claude.
Here, the screen unfolds: on the left, we can continue with the conversation or download the file, while on the right we can view the graph directly. Claude has generated a very visual and ready-to-use horizontal bar chart. The colors differentiate the communities and the date range and type of data are correctly indicated.
What happens if we ask you to change the color palette of the chart to an inappropriate one? In this case, for example, we are going to ask you for a series of pastel shades that are hardly different.
PROMPT: Can you change the color palette of the chart to this? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
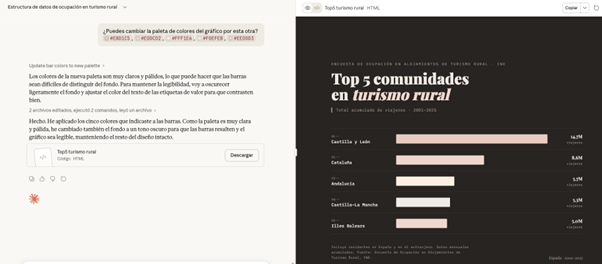
.Figure 8. Adjustments made to the graph by Claude to represent the information. Source: Claude.
Faced with the challenge, Claude intelligently adjusts the graphic himself, darkens the background and changes the text on the labels to maintain readability and contrast
All of the above exercise has been done with Claude Sonnet 4.6, which is not Anthropic's highest quality model. Its higher versions, such as Claude Opus 4.6, have greater reasoning capacity, deep understanding and finer results. In addition, there are many other tools for working with AI-based data and visualizations, such as Julius or Quadratic. Although the possibilities are almost endless in them, when we work with data it is still essential to maintain our own methodology and criteria.
Contextualizing the data we are analyzing in real life and connecting it with other knowledge is not a task that can be delegated; We need to have a minimum prior idea of what we want to achieve with the analysis in order to transmit it to the system. This will allow us to ask better questions, properly interpret the results and therefore make a more effective prompting.
Content created by Carmen Torrijos, expert in AI applied to language and communication. The content and views expressed in this publication are the sole responsibility of the author.
Evento
Every year, the international open knowledge advocacy organization Open Knowledge Foundation (OKFN) organizes Open Data Day (ODD), a framework initiative that will bring together activities around the world to demonstrate the value of open data. It is a meeting point for public administrations, civil society, universities, technology companies and citizens interested in the reuse of public information. It is, above all, an invitation to move from theory to practice: to open data, reuse it and turn it into concrete solutions.
From datos.gob.es, national open data portal, we join this celebration by also compiling other activities that put data and related technologies at the center. In this post we review some events that will be held during this month of March. Take note and write down the agenda!
Data against misinformation: celebrate Open Data Day with Open Data Barcelona Initiative
This meeting is part of the activities organized in Spain on the occasion of Open Data Day 2026, and is focused on the role of open data as a tool to strengthen the quality of public information and combat disinformation. The event will give visibility to projects that use open data to promote a more transparent democracy, encourage informed citizen participation and contribute to the development of responsible artificial intelligence based on reliable data.
- When? On Tuesday, March 10 at 5:30 p.m.
- Where? Ca l'Alier C/ de Pere IV, 362 in Barcelona
- Learn more
The future of Open Data: OKFN's anniversary
On the occasion of Open Data Day 2026, the Open Knowledge Foundation (OKFN) is organizing an online conference to bring together the open data community and celebrate two decades of CKAN, the tool that emerged from OKFN's work that today powers data portals around the world. The meeting will provide an opportunity to discuss the current role of open data and data infrastructures in the face of contemporary technical and political challenges. It is aimed at professionals from governments, civil society, the media, activist groups and all those interested in reflecting on the future of open data in a rapidly changing technological context, marked especially by the emergence of artificial intelligence tools.
- When? On Wednesday, March 11 from 11 a.m. to 4 p.m.
- Where? Online
- Learn more
Data as a public good: European webinar
Organized by the data.europa.eu academy in the framework of Open Data Day, this webinar addresses how open data can act as a public good to improve decision-making in all territories, especially in rural areas. Through case studies from the United Kingdom and Ireland, the session will show how open information can identify local needs, reduce territorial inequalities and design evidence-based public policies that ensure more equitable access to essential services.
- When? Friday, March 13 from 10 a.m. to 11.30 a.m.
- Where? Online event
- Learn more
Solid World: innovation in the sharing and reuse of scientific data
This event will explore how to model, analyze, and share research data using technologies from the Solid* ecosystem. The session will feature representatives from W3C and Open Data Institute to present the SpOTy project, a web application for organizing and analyzing linguistic data that has migrated from RDF to Solid to give researchers greater control over the sharing of their data, also addressing challenges of interoperability and responsible reuse of scientific information.
*The Solid Ecosystem is a set of technologies, standards, and tools that enable individuals and organizations to control their own data on the web and decide how, when, and with whom it is shared.
- When? Monday, March 23 from 5 p.m. to 6 p.m.
- Where? Online event
- Learn more
How to prepare public portals for the AI era
The thirteenth edition of the Data Centric AI cycle, organized by the Open Data Institute (ODI), will explore how public data portals must evolve to adapt to new ways of interacting with datasets. It will address the transformation of infrastructures such as data.gov.uk, plans for the National Data Library and the role of academic research in the design of new public data architectures, combining preparation for artificial intelligence with a user-centric approach and reflecting on the social context surrounding data and AI.
- When? Thursday, March 26 from 5 pm to 6 pm
- Where? Online event
- Learn more
Online events on open data in different sectors with Open Data Week
Open Data Week is an annual festival of events held every March in New York City and organized by the NYC Open Data team in conjunction with BetaNYC and Data Through Design. The week commemorates the anniversary of the city's first open data law, signed on March 7, 2012, and also coincides with Open Data Day, reinforcing its connection with the international open data movement. Some of the scheduled activities will be in virtual format.
- When? From 22 to 29 March
- Where? Some events can be followed in streaming
- Learn more
Data ethics keys for organizations
This session of the Data Ethics Professionals cycle organized by ODI will focus on the main lessons learned by organizations that have initiated processes of integrating data ethics into their structures and workflows. The seminar will address common challenges such as obtaining management support, the practical incorporation of ethical tools and frameworks, and the management of workloads in organizational transformation processes.
- When? On Monday, March 30 from 2 p.m. to 3 p.m.
- Where? Online
- Learn more
In short, the calendar for the coming weeks offers multiple opportunities to delve into the strategic value of open data and associated technologies. From local initiatives against disinformation to sectoral data spaces and European seminars on data as a public good, the ecosystem continues to grow and diversify. We encourage you to participate, share these calls and transfer the learnings to your organization. Because Open Data Day is just the starting point: true transformation is built throughout the year, connecting community, knowledge and action through open data.
These are some of the events that are scheduled for this month of March. In any case, don't forget to follow us on social networks so you don't miss any news about innovation and open data. We are on X and LinkedIn you can write to us if you need extra information.
Blog
La The European Commission has recently presented the document setting out a new EU Strategy in the field of data. Among other ambitious objectives, this initiative aims to address a transcendental challenge in the era of generative artificial intelligence: the insufficient availability of data under the right conditions.
Since the previous 2020 Strategy, we have witnessed an important regulatory advance that aimed to go beyond the 2019 regulation on open data and reuse of public sector information.
Specifically, on the one hand, the Data Governance Act served to promote a series of measures that tended to facilitate the use of data generated by the public sector in those cases where other legal rights and interests were affected – personal data, intellectual property.
On the other hand, through the Data Act, progress was made, above all, in the line of promoting access to data held by private subjects, taking into account the singularities of the digital environment.
The necessary change of focus in the regulation on access to data.
Despite this significant regulatory effort, the European Commission has detected an underuse of data , which is also often fragmented in terms of the conditions of its accessibility. This is due, in large part, to the existence of significant regulatory diversity. Measures are therefore needed to facilitate the simplification and streamlining of the European regulatory framework on data.
Specifically, it has been found that there is regulatory fragmentation that generates legal uncertainty and disproportionate compliance costs due to the complexity of the applicable regulatory framework itself. Specifically, the overlap between the General Data Protection Regulation (GDPR), the Data Governance Act, the Data Act, the Open Data Directive and, likewise, the existence of sectoral regulations specific to some specific areas has generated a complex regulatory framework which is difficult to face, especially if we think about the competitiveness of small and medium-sized companies. Each of these standards was designed to address specific challenges that were addressed successively, so a more coherent overview is needed to resolve potential inconsistencies and ultimately facilitate their practical implementation.
In this regard, the Strategy proposes to promote a new legislative instrument – the proposal for a Regulation called Digital Omnibus – which aims to consolidate the rules relating to the European single market in the field of data into a single standard. Specifically, with this initiative:
- The provisions of the Data Governance Act are merged into the regulation of the Data Act, thus eliminating duplications.
- The Regulation on non-personal data, whose functions are also covered by the Data Act, is repealed;
- Public sector data standards are integrated into the Data Act, as they were previously included in both the 2019 Directive and the Data Governance Act.
This regulation therefore consolidates the role of the Data Act as a general reference standard in the field. It also strengthens the clarity and precision of its forecasts, with the aim of facilitating its role as the main regulatory instrument through which it is intended to promote the accessibility of data in the European digital market.
Modifications in terms of personal data protection
The Digital Omnibus proposal also includes important new features with regard to the regulations on the protection of personal data, amending several provisions of Regulation (EU) 1016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data.
In order for personal data to be used – that is, any information referring to an identified or identifiable natural person – it is necessary that one of the circumstances referred to in Article 6 of the aforementioned Regulation is present, including the consent of the owner or the existence of a legitimate interest on the part of the person who is going to process the data.
Legitimate interest allows personal data to be processed when it is necessary for a valid purpose (improving a service, preventing fraud, etc.) and does not adversely affect the rights of the individual.
Source: Guide on legitimate interest. ISMS Forum and Data Privacy Institute. Available here: guiaintereslegitimo1637794373.pdf
Regarding the possibility of resorting to legitimate interest as a legal basis for training artificial intelligence tools, the current regulation allows the processing of personal data as long as the rights of the interested parties who own such data do not prevail.
However, given the generality of the concept of "legitimate interest", when deciding when personal data may be used under this clause , there will not always be absolute certainty, it will be necessary to analyse on a case-by-case basis: specifically, it will be necessary to carry out an activity of weighing the conflicting legal interests and, therefore, its application may give rise to reasonable doubts in many cases.
Although the European Data Protection Board has tried to establish some guidelines to specify the application of legitimate interest, the truth is that the use of open and indeterminate legal concepts will not always allow clear and definitive answers to be reached. To facilitate the specification of this expression in each case, the Strategy refers as a criterion to takeinto account the potential benefit that the processing may entail for the data subject and for society in general. Likewise, given that the consent of the owner of the data will not be necessary – and therefore, its revocation would not be applicable – it reinforces the right of opposition by the owner to the processing of their data and, above all, guarantees greater transparency regarding the conditions under which the data will be processed. Thus, by strengthening the legal position of the data subject and referring to this potential benefit, the Strategy aims to facilitate the use of legitimate interest as a legal basis for the use of personal data without the consent of the data subject, but with appropriate safeguards.
Another major data protection measure concerns the distinction between anonymised and pseudonymised data. The GDPR defines pseudonymisation as data processing that, until now, could no longer be attributed to a data subject without recourse to additional, separate information. However, pseudonymised data is still personal data and, therefore, subject to this regulation. On the other hand, anonymous data does not relate to identified or identifiable persons and therefore its use would not be subject to the GDPR. Consequently, in order to know whether we are talking about anonymous or pseudo-nimized data, it is essential to specify whether there is a "reasonable probability" of identifying the owner of the data.
However, the technologies currently available multiply the risk of re-identification of the data subject, which directly affects what could be considered reasonable, generating uncertainty that has a negative impact on technological innovation. For this reason, the Digital Omnibus proposal, along the lines already stated by the Court of Justice of the European Union, aims to establish the conditions under which pseudonymised data could no longer be considered personal data, thus facilitating its use. To this end, it empowers the European Commission, through implementing acts, to specify such circumstances, in particular taking into account the state of the art and, likewise, offering criteria that allow the risk of re-identification to be assessed in each specific case.
Scaling High-Value Datasets
The Strategy also aims to expand the catalogue of High Value Data (HVD) provided for in Implementing Regulation (EU) 2023/138. These are datasets with exceptional potential to generate social, economic and environmental benefits, as they are high-quality, structured and reliable data that are accessible under technical, organisational and semantic conditions that are very favourable for automated processing. Six categories are currently included (geospatial, Earth observation and environment, meteorology, statistics, business and mobility), to which the Commission would add, among other things, legal, judicial and administrative data.
Opportunity and challenge
The European Data Strategy represents a paradigmatic shift that is certainly relevant: it is not only a matter of promoting regulatory frameworks that facilitate the accessibility of data at a theoretical level but, above all, of making them work in their practical application, thus promoting the necessary conditions of legal certainty that allow a competitive and innovative data economy to be energized.
To this end, it is essential, on the one hand, to assess the real impact of the measures proposed through the Digital Omnibus and, on the other, to offer small and medium-sized enterprises appropriate legal instruments – practical guides, suitable advisory services, standard contractual clauses, etc. – to face the challenge that regulatory compliance poses for them in a context of enormous complexity. Precisely, this difficulty requires, on the part of the supervisory authorities and, in general, of public entities, to adopt advanced and flexible data governance models that adapt to the singularities posed by artificial intelligence, without affecting legal guarantees.
Content prepared by Julián Valero, professor at the University of Murcia and coordinator of the Innovation, Law, and Technology Research Group (iDerTec). The content and views expressed in this publication are the sole responsibility of the author.
Noticia
Did you know that Spain created the first state agency specifically dedicated to the supervision of artificial intelligence (AI) in 2023? Even anticipating the European Regulation in this area, the Spanish Agency for the Supervision of Artificial Intelligence (AESIA) was born with the aim of guaranteeing the ethical and safe use of AI, promoting responsible technological development.
Among its main functions is to ensure that both public and private entities comply with current regulations. To this end, it promotes good practices and advises on compliance with the European regulatory framework, which is why it has recently published a series of guides to ensure the consistent application of the European AI regulation.
In this post we will delve into what the AESIA is and we will learn relevant details of the content of the guides.
What is AESIA and why is it key to the data ecosystem?
The AESIA was created within the framework of Axis 3 of the Spanish AI Strategy. Its creation responds to the need to have an independent authority that not only supervises, but also guides the deployment of algorithmic systems in our society.
Unlike other purely sanctioning bodies, the AESIA is designed as an intelligence Think & Do, i.e. an organisation that investigates and proposes solutions. Its practical usefulness is divided into three aspects:
- Legal certainty: Provides clear frameworks for businesses, especially SMEs, to know where to go when innovating.
- International benchmark: it acts as the Spanish interlocutor before the European Commission, ensuring that the voice of our technological ecosystem is heard in the development of European standards.
- Citizen trust: ensures that AI systems used in public services or critical areas respect fundamental rights, avoiding bias and promoting transparency.
Since datos.gob.es, we have always defended that the value of data lies in its quality and accessibility. The AESIA complements this vision by ensuring that, once data is transformed into AI models, its use is responsible. As such, these guides are a natural extension of our regular resources on data governance and openness.
Resources for the use of AI: guides and checklists
The AESIA has recently published materials to support the implementation and compliance with the European Artificial Intelligence regulations and their applicable obligations. Although they are not binding and do not replace or develop existing regulations, they provide practical recommendations aligned with regulatory requirements pending the adoption of harmonised implementing rules for all Member States.
They are the direct result of the Spanish AI Regulatory Sandbox pilot. This sandbox allowed developers and authorities to collaborate in a controlled space to understand how to apply European regulations in real-world use cases.
It is essential to note that these documents are published without prejudice to the technical guides that the European Commission is preparing. Indeed, Spain is serving as a "laboratory" for Europe: the lessons learned here will provide a solid basis for the Commission's working group, ensuring consistent application of the regulation in all Member States.
The guides are designed to be a complete roadmap, from the conception of the system to its monitoring once it is on the market.

Figure 1. AESIA guidelines for regulatory compliance. Source: Spanish Agency for the Supervision of Artificial Intelligence
- 01. Introductory to the AI Regulation: provides an overview of obligations, implementation deadlines and roles (suppliers, deployers, etc.). It is the essential starting point for any organization that develops or deploys AI systems.
- 02. Practice and examples: land legal concepts in everyday use cases (e.g., is my personnel selection system a high-risk AI?). It includes decision trees and a glossary of key terms from Article 3 of the Regulation, helping to determine whether a specific system is regulated, what level of risk it has, and what obligations are applicable.
- 03. Conformity assessment: explains the technical steps necessary to obtain the "seal" that allows a high-risk AI system to be marketed, detailing the two possible procedures according to Annexes VI and VII of the Regulation as valuation based on internal control or evaluation with the intervention of a notified body.
- 04. Quality management system: defines how organizations must structure their internal processes to maintain constant standards. It covers the regulatory compliance strategy, design techniques and procedures, examination and validation systems, among others.
- 05. Risk management: it is a manual on how to identify, evaluate and mitigate possible negative impacts of the system throughout its life cycle.
- 06. Human surveillance: details the mechanisms so that AI decisions are always monitorable by people, avoiding the technological "black box". It establishes principles such as understanding capabilities and limitations, interpretation of results, authority not to use the system or override decisions.
- 07. Data and data governance: addresses the practices needed to train, validate, and test AI models ensuring that datasets are relevant, representative, accurate, and complete. It covers data management processes (design, collection, analysis, labeling, storage, etc.), bias detection and mitigation, compliance with the General Data Protection Regulation, data lineage, and design hypothesis documentation, being of particular interest to the open data community and data scientists.
- 08. Transparency: establishes how to inform the user that they are interacting with an AI and how to explain the reasoning behind an algorithmic result.
- 09. Accuracy: Define appropriate metrics based on the type of system to ensure that the AI model meets its goal.
- 10. Robustness: Provides technical guidance on how to ensure AI systems operate reliably and consistently under varying conditions.
- 11. Cybersecurity: instructs on protection against threats specific to the field of AI.
- 12. Logs: defines the measures to comply with the obligations of automatic registration of events.
- 13. Post-market surveillance: documents the processes for executing the monitoring plan, documentation and analysis of data on the performance of the system throughout its useful life.
- 14. Incident management: describes the procedure for reporting serious incidents to the competent authorities.
- 15. Technical documentation: establishes the complete structure that the technical documentation must include (development process, training/validation/test data, applied risk management, performance and metrics, human supervision, etc.).
- 16. Requirements Guides Checklist Manual: explains how to use the 13 self-diagnosis checklists that allow compliance assessment, identifying gaps, designing adaptation plans and prioritizing improvement actions.
All guides are available here and have a modular structure that accommodates different levels of knowledge and business needs.
The self-diagnostic tool and its advantages
In parallel, the AESIA publishes material that facilitates the translation of abstract requirements into concrete and verifiable questions, providing a practical tool for the continuous assessment of the degree of compliance.
These are checklists that allow an entity to assess its level of compliance autonomously.
The use of these checklists provides multiple benefits to organizations. First, they facilitate the early identification of compliance gaps, allowing organizations to take corrective action prior to the commercialization or commissioning of the system. They also promote a systematic and structured approach to regulatory compliance. By following the structure of the rules of procedure, they ensure that no essential requirement is left unassessed.
On the other hand, they facilitate communication between technical, legal and management teams, providing a common language and a shared reference to discuss regulatory compliance. And finally, checklists serve as a documentary basis for demonstrating due diligence to supervisory authorities.
We must understand that these documents are not static. They are subject to an ongoing process of evaluation and review. In this regard, the EASIA continues to develop its operational capacity and expand its compliance support tools.
From the open data platform of the Government of Spain, we invite you to explore these resources. AI development must go hand in hand with well-governed data and ethical oversight.
Blog
For more than a decade, open data platforms have measured their impact through relatively stable indicators: number of downloads, web visits, documented reuses, applications or services created based on them, etc. These indicators worked well in an ecosystem where users – companies, journalists, developers, anonymous citizens, etc. – directly accessed the original sources to query, download and process the data.
However, the panorama has changed radically. The emergence of generative artificial intelligence models has transformed the way people access information. These systems generate responses without the need for the user to visit the original source, which is causing a global drop in web traffic in media, blogs and knowledge portals.
In this new context, measuring the impact of an open data platform requires rethinking traditional indicators to incorporate new ones to the metrics already used that also capture the visibility and influence of data in an ecosystem where human interaction is changing.

Figure 1. Metrics for measuring the impact of open data in the age of AI.
A structural change: from click to indirect consultation
The web ecosystem is undergoing a profound transformation driven by the rise of large language models (LLMs). More and more people are asking their questions directly to systems such as ChatGPT, Copilot, Gemini or Perplexity, obtaining immediate and contextualized answers without the need to resort to a traditional search engine.
At the same time, those who continue to use search engines such as Google or Bing are also experiencing relevant changes derived from the integration of artificial intelligence on these platforms. Google, for example, has incorporated features such as AI Overviews, which offers automatically generated summaries at the top of the results, or AI Mode, a conversational interface that allows you to drill down into a query without browsing links. This generates a phenomenon known as Zero-Click: the user performs a search on an engine such as Google and gets the answer directly on the results page itself. As a result, you don't need to click on any external links, which limits visits to the original sources from which the information is extracted.
All this implies a key consequence: web traffic is no longer a reliable indicator of impact. A website can be extremely influential in generating knowledge without this translating into visits.
New metrics to measure impact
Faced with this situation, open data platforms need new metrics that capture their presence in this new ecosystem. Some of them are listed below.
-
Share of Model (SOM): Presence in AI models
Inspired by digital marketing metrics, the Share of Model measures how often AI models mention, cite, or use data from a particular source. In this way, the SOM helps to see which specific data sets (employment, climate, transport, budgets, etc.) are used by the models to answer real questions from users, revealing which data has the greatest impact.
This metric is especially valuable because it acts as an indicator of algorithmic trust: when a model mentions a web page, it is recognizing its reliability as a source. In addition, it helps to increase indirect visibility, since the name of the website appears in the response even when the user does not click.
-
Sentiment analysis: tone of mentions in AI
Sentiment analysis allows you to go a step beyond the Share of Model, as it not only identifies if an AI model mentions a brand or domain, but how it does so. Typically, this metric classifies the tone of the mention into three main categories: positive, neutral, and negative.
Applied to the field of open data, this analysis helps to understand the algorithmic perception of a platform or dataset. For example, it allows detecting whether a model uses a source as an example of good practice, if it mentions it neutrally as part of an informative response, or if it associates it with problems, errors, or outdated data.
This information can be useful to identify opportunities for improvement, strengthen digital reputation, or detect potential biases in AI models that affect the visibility of an open data platform.
-
Categorization of prompts: in which topics a brand stands out
Analyzing the questions that users ask allows you to identify what types of queries a brand appears most frequently in. This metric helps to understand in which thematic areas – such as economy, health, transport, education or climate – the models consider a source most relevant.
For open data platforms, this information reveals which datasets are being used to answer real user questions and in which domains there is greater visibility or growth potential. It also allows you to spot opportunities: if an open data initiative wants to position itself in new areas, it can assess what kind of content is missing or what datasets could be strengthened to increase its presence in those categories.
-
Traffic from AI: clicks from digests generated
Many models already include links to the original sources. While many users don't click on such links, some do. Therefore, platforms can start measuring:
- Visits from AI platforms (when these include links).
- Clicks from rich summaries in AI-integrated search engines.
This means a change in the distribution of traffic that reaches websites from the different channels. While organic traffic—traffic from traditional search engines—is declining, traffic referred from language models is starting to grow.
This traffic will be smaller in quantity than traditional traffic, but more qualified, since those who click from an AI usually have a clear intention to go deeper.
It is important that these aspects are taken into account when setting growth objectives on an open data platform.
-
Algorithmic Reuse: Using Data in Models and Applications
Open data powers AI models, predictive systems, and automated applications. Knowing which sources have been used for their training would also be a way to know their impact. However, few solutions directly provide this information. The European Union is working to promote transparency in this field, with measures such as the template for documenting training data for general-purpose models, but its implementation – and the existence of exceptions to its compliance – mean that knowledge is still limited.
Measuring the increase in access to data through APIs could give an idea of its use in applications to power intelligent systems. However, the greatest potential in this field lies in collaboration with companies, universities and developers immersed in these projects, so that they offer a more realistic view of the impact.
Conclusion: Measure what matters, not just what's easy to measure
A drop in web traffic doesn't mean a drop in impact. It means a change in the way information circulates. Open data platforms must evolve towards metrics that reflect algorithmic visibility, automated reuse, and integration into AI models.
This doesn't mean that traditional metrics should disappear. Knowing the accesses to the website, the most visited or the most downloaded datasets continues to be invaluable information to know the impact of the data provided through open platforms. And it is also essential to monitor the use of data when generating or enriching products and services, including artificial intelligence systems. In the age of AI, success is no longer measured only by how many users visit a platform, but also by how many intelligent systems depend on its information and the visibility that this provides.
Therefore, integrating these new metrics alongside traditional indicators through a web analytics and SEO strategy * allows for a more complete view of the real impact of open data. This way we will be able to know how our information circulates, how it is reused and what role it plays in the digital ecosystem that shapes society today.
*SEO (Search Engine Optimization) is the set of techniques and strategies aimed at improving the visibility of a website in search engines.
Noticia
Public administrations and, specifically, local entities are at a crucial moment of digital transformation. The accelerated development of artificial intelligence (AI) poses both extraordinary opportunities and complex challenges that require structured, ethical, and informed adaptation. In this context, the Spanish Federation of Municipalities and Provinces (FEMP) has launched the Practical Guide and Policies for the Use of Artificial Intelligence in Local Entities, a reference document that aspires to function as a compass for city councils, provincial councils and other local entities on their way to the responsible adoption of this technology that is advancing by leaps and bounds.
The guide is based on a key idea: AI is not just a technological issue, but also an organisational, legal, ethical and cultural one. Its implementation requires planning, governance and a strategic vision adapted to the size and digital maturity of each local authority. In this post, we will look at some of the key points in the document.
In this video you can watch the presentation session of the Guide again.
The guide is based on a key idea: AI is not only a technological issue, but also an organizational, legal, ethical and cultural one. Its implementation requires planning, governance and a strategic vision adapted to the size and digital maturity of each local entity. In this post, we will look at some relevant keys to the document.
Why an AI guide for local authorities
Local administrations have been pursuing continuous improvement of public services for years, but have often been constrained by a lack of technological resources, organizational rigidity, or data fragmentation. AI opens up an unprecedented opportunity to overcome many of these barriers, because it makes it possible to:
- Automate processes.
- Analyze large volumes of information.
- Anticipate citizen needs.
- Personalize public attention.
However, along with these opportunities come obvious risks: loss of transparency, discriminatory biases, violations of privacy or uncritical automation of decisions that affect fundamental rights. Hence the need for a guide that helps to know what can be done with AI, what should not be done and how to do it with guarantees.
48% of public administrations use Artificial Intelligence to streamline the relationship with citizens
The guide is structured around several fundamental axes that address the multiple dimensions of AI implementation at the local level:
The legal framework: the European AI Regulation as a central axis
One of the pillars of the guide is the analysis of the European Artificial Intelligence Regulation (RIA), the first comprehensive standard worldwide that regulates AI with a risk-based approach, and which fully affects local entities whether they develop, use or contract AI systems.
Specifically, the different levels of risk recognized by the RIA are:
- Unacceptable risk: includes prohibited practices such as social punctuation, subliminal manipulation or certain uses of biometrics.
- High risk: covers systems used in sensitive areas such as the management of public services, employment, education, security or administrative decision-making. These systems must meet a number of strict requirements, such as the need for human supervision or data traceability.
- Specific transparency risk: This applies to chatbots or AI-generated content and is mainly imposed on them reporting obligations (e.g. labelling content as AI-generated).
- Minimal risk: such as spam filters or AI-based video games, with no obligations, although adopting codes of conduct is recommended.
Crucially, from February 2025, local authorities must make their staff AI literate, i.e. provide training for those who operate these systems to understand their technical, legal and ethical implications. In addition, they must review whether any of their systems incur in practices prohibited by the RIA, such as subliminal manipulation or social scoring .
For local authorities, this implies the need to identify which AI systems they use, assess their level of risk and comply with the corresponding obligations.
AI, administrative procedure and data protection
The guide recalls that automating a process does not necessarily equate to using AI, but that when systems capable of inferring, recommending or deciding are incorporated, the legal impact is much greater.
The incorporation of AI in administrative procedures must respect principles such as:
- Transparency and explainability of decisions.
- Identification of the responsible body.
- Possibility of challenge.
- Effective human supervision.
In addition, the use of AI must be fully compliant with the General Data Protection Regulation (GDPR). Local authorities should be able to justify automated decisions, guarantee the rights of affected individuals and exercise extreme caution when processing sensitive personal data.
Governing Data to Govern AI
The guide is blunt on one point: AI cannot be implemented without strong data governance. AI is powered by data, and its quality, availability, and ethical management will determine the success or failure of any initiative. The document introduces the concept of "single data" and refers to unified information. In relation to this, it has been seen that many organizations discover structural deficiencies precisely when trying to implement AI, an idea that was addressed in the datos.gob.es podcast on data and AI.
For data governance in AI in the local context, the guide defines the importance of:
- Privacy by design.
- Strategic value of data.
- Institutional ethical responsibility.
- Traceability.
- Shared knowledge and quality management.
In addition, the adoption of recognized international frameworks such as DAMA-DMBOOK is recommended.
The guide also insists on the importance of the quality, availability and correct management of data to "guarantee an effective and responsible use of artificial intelligence in our local administrations". To do this, it is essential to:
• Adopt interoperability standards, such as those already existing at national and European level.
• Use APIs and secure data exchange systems, which allow information to be shared efficiently between different public bodies.
• Leverage open data sources, such as those provided by the Spanish Government's Open Data Portal or local public data platforms.
How to know the maturity status in AI
Another of the most innovative aspects of the guide is the FEMP methodology. AI, which allows local entities to self-assess their level of organizational maturity for AI deployment. This methodology distinguishes three progressive levels that should be adopted in order:
- Level 1 - Electronic Administration (EA): digitalisation of business areas through corporate solutions based on single data.
- Level 2 - Robotization of Automated Processes (RPA): automation of management processes and administrative actions.
- Level 3 - Artificial Intelligence: use of specialized analysis tools that provide information obtained automatically.
This gradual approach is essential, as it recognizes that not all entities start from the same point and that trying to skip stages can be counterproductive.
The guide stresses that AI should be seen as a support tool, not as a substitute for human judgment, especially in sensitive decisions.
Requirements for deploying AI in a local entity
The document systematically details the requirements necessary to implement AI with guarantees:
- Normative and ethical, ensuring legal compliance and respect for fundamental rights.
- Organizational, defining technical, legal, and governance roles.
- Technological, including infrastructure, integration with existing systems, scalability, and cybersecurity.
- Strategic, betting on progressive deployments, pilots and continuous evaluation.
Beyond technology, the guide underlines the importance of ethics, transparency and public trust. All this is key and points to the idea that success does not lie in advancing quickly, but in advancing well: with a solid foundation, avoiding improvisations and ensuring that AI is applied ethically, effectively and oriented to the general interest.
Likewise, the relevance of public-private collaboration and the exchange of experiences between local entities is highlighted, as a way to reduce risks, share knowledge and optimize resources.
Real cases and conclusions
The document is completed with numerous real use cases in city councils and provincial councils, which demonstrate that AI is already a tangible reality in areas such as citizen service, social management, urban planning licenses or municipal chatbots.
In conclusion, the FEMP guide is presented as an essential manual for any local entity that wants to address AI responsibly. Its main contribution is not only to explain what AI is, but to offer a practical framework to implement it in a meaningful way, always putting citizenship, fundamental rights and good governance at the centre.
Blog
Massive, superficial AI-generated content isn't just a problem, it's also a symptom. Technology amplifies a consumption model that rewards fluidity and drains our attention span.
We listen to interviews, podcasts and audios of our family at 2x. We watch videos cut into highlights, and we base decisions and criteria on articles and reports that we have only read summarized with AI. We consume information in ultra-fast mode, but at a cognitive level we give it the same validity as when we consumed it more slowly, and we even apply it in decision-making. What is affected by this process is not the basic memory of contents, which seems to be maintained according to controlled studies, but the ability to connect that knowledge with what we already had and to elaborate our own ideas with it. More than superficiality, it is worrying that this new way of thinking is sufficient in so many contexts.
What's new and what's not?
We may think that generative AI has only intensified an old dynamic in which content production is infinite, but our attention spans are the same. We cannot fool ourselves either, because since the Internet has existed, infinity is not new. If we were to say that the problem is that there is too much content, we would be complaining about a situation in which we have been living for more than twenty years. Nor is the crisis of authority of official information or the difficulty in distinguishing reliable sources from those that are not.
However, the AI slop, which is the flood of AI-generated digital content on the Internet, brings its own logic and new considerations, such as breaking the link between effort and content, or that all that is generated is a statistical average of what already existed. This uniform and uncontrolled flow has consequences: behind the mass-generated content there may be an orchestrated intention of manipulation, an algorithmic bias, voluntary or not, that harms certain groups or slows down social advances, and also a random and unpredictable distortion of reality.
But how much of what I read is AI?
By 2025, it has been estimated that a large portion of online content incorporates synthetic text: an Ahrefs analysis of nearly one million web pages published in the first half of the year found that 74.2% of new pages contained signals of AI-generated content. Graphite research from the same year cites that, during the first year of ChatGPT alone, 39% of all online content was already generated with AI. Since November 2024, that figure has remained stable at around 52%, meaning that since then AI content outnumbers human content.
However, there are two questions we should ask ourselves when we come across estimates of this type:
1. Is there a reliable mechanism to distinguish a written text from a generated text? If the answer is no, no matter how striking and coherent the conclusions are, we cannot give them value, because they could be true or not. It is a valuable quantitative data, but one that does not yet exist.
With the information we currently have, we can say that "AI-generated text" detectors fail as often as a random model would, so we cannot attribute reliability to them. In a recent study cited by The Guardian, detectors were correct about whether the text was generated with AI or not in less than 40% of cases. On the other hand, in the first paragraph of Don Quixote, certain detectors have also returned an 86% probability that the text was created by AI.
2. What does it mean that a text is generated with AI? On the other hand, the process is not always completely automatic (what we call copying and pasting) but there are many grays in the scale: AI inspires, organizes, assists, rewrites or expands ideas, and denying, delegitimizing or penalizing this writing would be ignoring an installed reality.
The two nuances above do not cancel out the fact that the AI slop exists, but this does not have to be an inevitable fate. There are ways to mitigate its effects on our abilities.
What are the antidotes?
We may not contribute to the production of synthetic content, but we cannot slow down what is happening, so the challenge is to review the criteria and habits of mind with which we approach both reading and writing content.
1. Prioritize what clicks: one of the few reliable signals we have left is that clicking sensation at the moment when something connects with a previous knowledge, an intuition that we had diffused or an experience of our own, and reorganizes it or makes it clear. We also often say that it "resonates". If something clicks, it's worth following, confirming, researching, and briefly elaborating on a personal level.
2. Look for friction with data: anchoring content in open data and verifiable sources introduces healthy friction against the AI slop. It reduces, above all, arbitrariness and the feeling of interchangeable content, because the data force us to interpret and put it in context. It is a way of putting stones in the excessively fluid river that is the generation of language, and it works when we read and when we write.
3. Who is responsible? The text exists easily now, the question is why it exists or what it wants to achieve, and who is ultimately responsible for that goal. It seeks the signature of people or organizations, not so much for authorship but for responsibility. He is wary of collective signatures, also in translations and adaptations.
4. Change the focus of merit: evaluate your inertia when reading, because perhaps one day you learned to give merit to texts that sounded convincing, used certain structures or went up to a specific register. It shifts value to non-generatable elements such as finding a good story, knowing how to formulate a vague idea or daring to give a point of view in a controversial context.
On the other side of the coin, it is also a fact that content created with AI enters with an advantage in the flow, but with a disadvantage in credibility. This means that the real risk now is that AI can create high-value content, but people have lost the ability to concentrate on valuing it. To this we must add the installed prejudice that, if it is with AI, it is not valid content. Protecting our cognitive abilities and learning to differentiate between compressible and non-compressible content is therefore not a nostalgic gesture, but a skill that in the long run can improve the quality of public debate and the substrate of common knowledge.
Content created by Carmen Torrijos, expert in AI applied to language and communication. The content and views expressed in this publication are the sole responsibility of the author.