Entrevista
En los últimos años, la inteligencia artificial (IA) ha pasado de ser una promesa futurista a convertirse en una herramienta cotidiana: hoy convivimos con modelos de lenguaje, sistemas generativos y algoritmos capaces de aprender cada vez más tareas. Pero mientras su popularidad crece, también lo hace una pregunta esencial: ¿cómo garantizamos que estas tecnologías sean realmente fiables y dignas de confianza? Hoy vamos a explorar ese desafío con dos invitados expertos en la materia:
- David Escudero, director del Centro de Inteligencia Artificial de la Universidad de Valladolid.
- José Luis Marín, consultor senior en estrategia, innovación y digitalización.
Resumen / Transcripción de la entrevista
1. ¿Por qué es necesario conocer cómo funcionan las inteligencias artificiales y evaluar ese comportamiento?
Jose Luis Marín: Es necesario por una razón muy sencilla: cuando un sistema influye en decisiones importantes, no es suficiente con que parezca que funciona bien en una demo llamativa, sino que tenemos que saber cuándo acierta, cuándo puede fallar y por qué. Ahora mismo ya estamos en una fase en la que la IA se comienza a aplicar en cuestiones tan delicadas como los diagnósticos médicos, la concesión de ayudas públicas o la propia atención al ciudadano en muchísimos escenarios. Por ejemplo, si nos preguntamos si nos fiaríamos de un sistema que opera como una caja negra y que decide si nos conceden una ayuda, si nos seleccionan para una entrevista o si aprobamos un examen sin poder explicarnos cómo se ha tomado esa decisión, seguramente la respuesta sería que no nos fiaríamos; y no porque la tecnología sea mejor o peor, sino sencillamente porque necesitamos entender qué hay detrás de estas decisiones que nos afectan.
David Escudero: Efectivamente, no es tanto entender cómo funcionan los algoritmos internamente, cómo funciona la lógica o la matemática que hay detrás de todos estos sistemas, pero sí entender o hacer ver a los usuarios que este tipo de sistemas tienen unos grados de fiabilidad que tienen sus límites, igual que las personas. Las personas también se pueden equivocar, pueden fallar en un momento determinado, pero hay que dar garantías para que los usuarios los usen con cierto nivel de seguridad. Ofrecer métricas del rendimiento de estos algoritmos y hacer ver que son fiables hasta cierto grado es fundamental.
2. Un concepto que surge cuando hablamos de estas cuestiones es el de inteligencia artificial explicable ¿Cómo definiríais esta idea y por qué es tan relevante ahora?
David Escudero: IA explicable es un tecnicismo que surge por la necesidad de que el sistema, no solamente ofrezca decisiones, no solamente diga si determinado expediente tiene que ser clasificado de determinada forma o de otra, sino que dé las razones que le llevan al sistema a tomar esa decisión. Es abrir esa caja negra. Hablamos de caja negra porque el usuario no ve cómo funciona el algoritmo. Tampoco lo necesita, pero sí al menos darle unas claves de por qué el algoritmo ha tomado cierta decisión u otra, que es extremadamente importante. Imagínate un algoritmo que clasifica expedientes para derivar a una administración u otra. Si el usuario final se siente perjudicado, necesita tener una razón por la cual eso ha sido así, y la va a pedir; la puede pedir y la puede exigir. Y si desde un punto de vista tecnológico no somos capaces de darle esa solución, la inteligencia artificial tiene un problema. En ese sentido, existen técnicas que avanzan en aportar no solamente soluciones, sino en decir cuáles son las razones que llevan a un algoritmo para tomar determinadas decisiones.
Jose Luis Marín: Yo no puedo explicarlo mucho mejor de lo que lo ha explicado David. Realmente lo que buscamos con la inteligencia artificial explicable es entender el porqué de esas respuestas o de esas decisiones que toman los algoritmos de inteligencia artificial. Simplificándolo mucho, creo que en realidad no hablamos de otra cosa que no sea aplicar los mismos estándares que cuando esas decisiones las toman las personas, a las que además hacemos responsables de las decisiones. Necesitamos poder explicar por qué se ha tomado una decisión o qué reglas se han seguido, para poder confiar en esas decisiones.
3. ¿Cómo se está abordando esta necesidad de explicabilidad y evaluación rigurosa? ¿Qué metodologías o marcos están ganando más peso? ¿Y cuál es el papel de los datos abiertos en ellos?
Jose Luis Marín: Esta pregunta tiene muchas dimensiones. Diría que aquí están convergiendo varias capas. Por un lado, técnicas concretas de explicabilidad como LIME (Interpretable Model-agnostic Explanations) o SHAP (SHapley Additive exPlanations) u otras muchas. Yo suelo seguir, por ejemplo, el catálogo de herramientas y métricas de IA confiable del Observatorio de Políticas Públicas de Inteligencia Artificial de la OCDE, porque ahí se registran bastante bien los avances en el dominio. Pero, por otro lado, tenemos marcos más amplios de evaluación, que no miran solo cuestiones puramente técnicas, sino también cuestiones como los sesgos, la robustez, la estabilidad en el tiempo y el cumplimiento normativo. Ahí hay distintos frameworks como el de gestión del riesgo del NIST (National Institute of Standards and Technology), la evaluación de impacto de los algoritmos del Gobierno de Canadá o nuestro propio Reglamento de IA. Estamos en una fase en la que están surgiendo un montón de iniciativas públicas y privadas que nos irán ayudando a tener cada vez mejores herramientas.
David Escudero: Para la investigación es un campo bastante abierto todavía. Existen metodologías, efectivamente, pero los nuevos modelos basados en redes neuronales han abierto un desafío enorme. La inteligencia artificial que se venía desarrollando en los años anteriores al boom de la IA generativa, en buena medida, se basaba en sistemas expertos que acumulaban un montón de reglas de conocimiento sobre el dominio. En ese tipo de tecnología, la explicabilidad venía dada porque, como lo que se hacía era desencadenar una serie de reglas para tomar decisiones, siguiendo hacia atrás el orden en el que se habían aplicado las reglas, tenías una explicación; pero ahora con los sistemas neuronales, sobre todo con los modelos grandes, donde estamos hablando de miles y miles de millones de parámetros, ese tipo de aproximaciones han quedado imposibles, inabordables, y se aplican otro tipo de metodologías que están basadas principalmente en saber, cuándo entrenas un modelo de machine learning, cuáles son las propiedades o los atributos en el entrenamiento que te llevan a tomar unas u otras decisiones. Digamos, cuáles son los pesos de cada una de las propiedades que están utilizando.
Por ejemplo, si estás utilizando un sistema de machine learning para decidir si mandas publicidad sobre un determinado automóvil a un montón de potenciales clientes, el sistema de machine learning se entrena en base a una experiencia. Al final, te queda un modelo neuronal donde es muy difícil entrar, pero lo puedes hacer analizando el peso de cada una de las variables de entrada que has utilizado para tomar esa decisión. Por ejemplo, la renta de la persona será uno de los atributos más importantes, pero ahí pueden aparecer otras cuestiones que te llevan a consideraciones muy importantes, como pueden ser los sesgos. Imagínate que te sale que una de las variables más importantes es el género de la persona. Ahí entras en una serie de consideraciones que son delicadas. En otros tipos de algoritmos, por ejemplo, que se basen en imágenes, un algoritmo de IA explicable te puede decir qué parte de la imagen ha sido más relevante. Por ejemplo, si estás utilizando un algoritmo para, a partir de la imagen de la cara de una persona - estoy hablando de un hipotético, de un futurible, que además sería un caso extremo-, decidir si esa persona es confiable o no. Entonces podrías mirar en qué rasgos de esa persona se está fijando más la inteligencia artificial, por ejemplo, en los ojos o en la expresión. Ese tipo de consideraciones es lo que haría la IA explicable actualmente: saber cuáles son las variables o cuáles son los datos de entrada del algoritmo que toman mayor valor a la hora de tomar decisiones.
Esto me lleva a hablar de otra parte de tu pregunta sobre la importancia de los datos. La calidad de los datos de entrenamiento es absolutamente importante. Estos datos, estos algoritmos explicables, te pueden llevar incluso a derivar conclusiones que te indiquen que necesitas datos de más o menos calidad, porque te pueda estar dando algún resultado sorprendente, que puede indicar que algún dato de entrenamiento o entrada está derivando salidas y no debería. Entonces tienes que revisar tus propios datos de entrada. Tener datos de referencia de calidad como los que puedes encontrar en datos.gob.es. es absolutamente imprescindible para poder contrastar las informaciones que te va dando este tipo de sistemas.
José Luis Marín: Creo que los datos abiertos son clave en dos dimensiones. Primero porque permiten contrastar y replicar las evaluaciones con mayor independencia. Por ejemplo, cuando existen conjuntos de datos de validación que son públicos no solo evalúa quién construye el sistema, sino que también terceros podamos evaluar (las universidades, las administraciones o la propia sociedad civil). Esa apertura de los datos de evaluación es muy importante para que la IA sea verificable y mucho menos opaca. Pero además creo que los datos abiertos para el entrenamiento y la evaluación también aportan diversidad y contexto. En cualquier contexto minoritario en el que pensemos, seguramente los grandes sistemas no le han prestado la misma atención a estos aspectos, sobre todo los sistemas comerciales. Seguro que no han sido probados al mismo nivel en los contextos mayoritarios que en los minoritarios y de ahí que aparezcan muchos sesgos o malos funcionamientos. Entonces, los conjuntos de datos abiertos pueden contribuir en gran medida a cubrir esos gaps y corregir esos problemas.
Creo que los datos abiertos en la inteligencia artificial explicable encajan muy bien, porque en el fondo comparten un objetivo muy parecido, relacionado con la transparencia.
4. Otro reto que nos encontramos es la rápida evolución en el ecosistema de la inteligencia artificial. Hemos empezado hablando de la popularidad de los chatbots y LLM, pero nos encontramos con que seguimos avanzando, ahora hacia la IA agéntica, sistemas capaces de actuar de forma más autónoma. ¿En qué consisten estos sistemas y qué desafíos específicos plantean desde el punto de vista ético?
David Escudero: La IA agéntica parece que es el gran tema del 2026. No es un término tan nuevo, pero si el año pasado hablábamos de agentes IA, ahora estamos hablando de IA agéntica como una nueva tecnología que coordina diferentes agentes para resolver tareas más complejas. Por simplificar, si un agente te sirve para realizar una actividad concreta, por ejemplo, para reservar un billete de avión, la IA agéntica lo que haría es: planificar el viaje, contrastar diferentes ofertas, reservar el avión, planificar el viaje de ida, la estancia, de nuevo la vuelta y, finalmente, evaluar toda la actividad. El sistema basado en IA agéntica lo que hace es ir coordinando diferentes agentes. Además, con un matiz. Cuando hablamos de la palabra agéntica -que no tenemos una traducción en español muy directa-, pensamos en un sistema que toma la iniciativa. Al final ya no eres tú solamente el que, como usuario, le pides cosas a la inteligencia artificial, sino que la IA ya es capaz de saber cómo puede resolver cosas. Te pedirá información cuando la necesite e intentará adaptarse para darte una solución final a ti como usuario, pero de forma más o menos autónoma, tomando decisiones en procesos intermedios.
Aquí la precisión y la explicabilidad son fundamentales porque se abre de nuevo un desafío muy importante. Si en un momento dado uno de estos agentes que utiliza la IA agéntica falla, se puede crear el efecto de suma de errores y al final acaba como el teléfono escacharrado. De un sistema a otro, de un agente a otro, se va pasando información y si esa información no es tan precisa como debería ser, al final la solución puede ser catastrófica. Entonces se introducen nuevos elementos que hacen, desde un punto de vista tecnológico, más apasionante si cabe el problema. Pero también hay que entender que es absolutamente necesario, porque al final tenemos que avanzar de sistemas que den una solución muy concreta para un caso muy particular a sistemas que combinen la salida de diferentes sistemas para ser un poco más ambiciosos en la respuesta que se da a posibles usuarios.
Jose Luis Marín: Efectivamente. En el momento en el que pasamos de un tipo de sistemas a los que, en principio, les otorgamos la “capacidad de pensar” en las acciones que habría que hacer y nos las cuentan, a otros sistemas que es como si tuviesen manos para interactuar con el mundo digital - y empezamos a ver sistemas que incluso interactúan con el mundo físico y pueden ejecutar esas acciones, que no se quedan en decírtelas o recomendártelas-, se abren oportunidades muy interesantes. Pero también se multiplica la complejidad de la evaluación. El problema ya no es solo si la respuesta es correcta o incorrecta, sino que empieza a ser quién controla qué hace el sistema, qué margen de decisión tiene, quién lo supervisa y, sobre todo, quién responde si algo sale mal, porque no hablamos solo de recomendaciones, hablamos de acciones que a veces pueden no ser tan fácil deshacerlas. Esto hace que aparezcan riesgos nuevos o al menos más intensos: si se pierde esa trazabilidad en la ejecución de las acciones que no estaban previstas o que no tenían que haber ocurrido en un momento determinado; o puede haber usos indebidos de información, o muchos otros riesgos. Creo que la IA agéntica exige todavía más gobernanza y un diseño mucho más cuidadoso y alineado con los derechos de las personas.
5. Hablemos de aplicaciones reales, ¿Dónde veis más potencial y necesidad de evaluación y explicabilidad en el sector público?
Jose Luis Marín: Diría que la necesidad de evaluación y explicabilidad es mayor donde la IA pueda influir en las decisiones que afecten a las personas. Cuanto mayor sea el impacto en derechos o en oportunidades o, mismamente, en la confianza en las instituciones, mayor tiene que ser esa exigencia. Si pensamos, por ejemplo, en ámbitos como la sanidad, los servicios sociales, el empleo, la educación… En todos ellos lógicamente es ineludible esa necesidad de evaluación en el sector público.
En todos los casos, la IA puede ser muy útil para apoyar decisiones para conseguir eficiencias en múltiples escenarios. Pero necesitamos saber muy bien cómo se comporta y qué criterios se está utilizando. Esto no afecta solo a los sistemas más complejos. Creo que hay que fijarse en los sistemas que en principio nos puedan parecer más o menos sensibles a primera vista, como los asistentes virtuales que ya empezamos a ver en bastantes administraciones o los sistemas de traducción automática… Ahí no hay una decisión final que tome la IA, pero una mala recomendación o una respuesta errónea, también puede tener consecuencias para las personas. O sea, creo que no depende tanto de la complejidad tecnológica como del contexto de uso. En el sector público incluso un sistema aparentemente sencillo puede tener mucho impacto.
David Escudero: Os lanzo el trapo de hacer otro podcast sobre el concepto también muy de moda que es Human in the loop o Human on the loop. En el sector público tenemos un cuerpo de funcionarios públicos que conocen muy bien su trabajo y que pueden ayudar. Human in the loop sería el papel que puede tener el funcionario a la hora de generar datos que puedan ser útiles para entrenar sistemas, revisar que los datos con los que se pueden entrenar sistemas sean fiables, etc.; y Human on the loop sería la supervisión de las decisiones que pueda tomar una inteligencia artificial. Quien puede revisar, quien puede saber si esa decisión tomada por un sistema automático es buena o mala, es un funcionario público.
En ese sentido, y relacionado también con la IA agéntica, nosotros tenemos un proyecto con la Fundación Española de Ciencia y Tecnología para asesorar a la Diputación de Valladolid en tareas de inteligencia artificial en la administración. Y vemos que muchas de las tareas que nos piden los propios funcionarios no tienen tanto que ver con la IA, sino con la interoperabilidad de los propios servicios que ya ofrecen y que son automáticos. A lo mejor en una administración tienen un servicio desarrollado por un sistema automático, junto a otro servicio que les ofrece un formulario con resultados, pero después les toca teclear a mano los datos que comunican ambos servicios. Ahí estaríamos también hablando de posibilidades para la IA agéntica de intercomunicar. El desafío es implicar en todo ese proceso el papel del funcionario como velador de que las funciones públicas se hacen con rigor.
Jose Luis Marín: El concepto de Human in the loop es clave en muchos de los proyectos en los que trabajamos. Al final es la combinación no solo de tecnología, sino de las personas que conocen realmente los procesos y pueden supervisarlos y complementar esas acciones que puede realizar la IA agéntica. En cualquier sistema simplemente de atención ya es necesaria esa supervisión en muchos casos, porque una mala recomendación puede tener también muchas consecuencias, no solo en la acción de un sistema complejo.
6. Para cerrar, me gustaría que cada uno compartiera una idea clave sobre lo que necesitamos para avanzar hacia una IA más confiable, evaluable y explicable.
David Escudero: Apuntaría, aprovechando que estamos en el podcast de datos.gob.es, la importancia de la gobernanza del dato: asegurarse de que las instituciones, tanto públicas como privadas se preocupen mucho por la calidad del dato, por tener unos datos bien compartidos que sean representativos, que estén bien documentados y, por supuesto, que sean accesibles. Los datos de las instituciones públicas son fundamentales para que los ciudadanos tengan esas garantías y para que empresas e instituciones puedan preparar algoritmos que puedan utilizar esa información para mejorar servicios o dar garantías a los ciudadanos. La gobernanza del dato es fundamental.
Jose Luis Marín: Si yo tuviese que resumir todo en una sola idea, diría que todavía estamos muy lejos de que la evaluación sea una práctica habitual. En los sistemas de IA tendremos que convertirla en algo obligatorio dentro de los procesos de desarrollo y despliegue. Evaluar no es probar una vez y darlo por resuelto, hay que comprobar de forma continua cómo y dónde pueden fallar, qué riesgos introducen y si siguen siendo adecuados cuándo ha cambiado el contexto en el que se pensó un determinado sistema. Yo creo que aún estamos lejos de esto.
Efectivamente, los datos abiertos son clave para contribuir a este proceso. Una IA va a ser más confiable cuanto más podamos observarla y mejorarla con criterios compartidos, no solo con los de la organización que los diseñan. Por eso los datos abiertos aportan transparencia, pueden ayudarnos a facilitar la verificación y a construir una base más sólida para que realmente los servicios vayan alineados con el interés general.
David Escudero Mancebo: En ese sentido también agradecer espacios como este que sin duda sirven para potenciar esa cultura del dato, de la calidad y de la evaluación tan necesaria en nuestra sociedad. Creo que se ha avanzado muchísimo, pero que, sin duda, todavía queda y abrir espacios para la divulgación es muy importante.
Noticia
En el epicentro de la innovación global que define Mobile World Congress (MWC), ha surgido un espacio donde el talento humano cobra verdadero protagonismo: Talent Arena.
La edición de 2026, impulsada por Mobile World Capital Barcelona, reunió entre el 2 y 4 de marzo a profesionales, empresas tecnológicas, centros formativos y talento emergente con un objetivo común: aprender, conectar y explorar nuevas oportunidades en el ámbito digital. En esta cita, Red.es participó activamente con varias sesiones centradas en uno de los grandes retos actuales: cómo impulsar la transformación digital a través del talento, la formación y la innovación. Entre ellas, se encontraba el taller “Datos Abiertos en España. De la teoría a la práctica con datos.gob.es”, una sesión que puso el foco en el papel estratégico de los datos abiertos y su conexión con tecnologías emergentes como la inteligencia artificial.
En este post repasamos los contenidos de la ponencia que combinó:
- Una mirada didáctica sobre la evolución, el estado actual y el futuro de los datos abiertos en España
- Un taller práctico sobre la creación de un agente conversacional con MCP
¿Qué son los datos abiertos? Evolución e hitos
La sesión arrancó estableciendo un pilar fundamental: la importancia de los datos abiertos en el ecosistema actual. Más allá de su definición técnica -datos que pueden ser utilizados, reutilizados y compartidos libremente por cualquier persona, con cualquier fin- la charla subrayó que su verdadera potencia reside en el impacto transformador que generan.
Tal y como se abordó en el taller, estos datos provienen de múltiples fuentes (administraciones públicas, universidades, empresas e incluso la ciudadanía) y su apertura permite:
- Impulsar la transparencia institucional, al facilitar el acceso a la información pública.
- Fomentar la innovación, al permitir que desarrolladores y empresas creen nuevos servicios.
- Generar valor económico y social, a partir de la reutilización de la información en múltiples sectores, como la salud, la educación o el medio ambiente.
Uno de los aspectos clave del taller fue contextualizar la evolución histórica de los datos abiertos. Aunque los primeros antecedentes se remontan a las décadas de los 50 y 60, el concepto moderno de “datos abiertos” comenzó a consolidarse en los años 90. Posteriormente, hitos como el Memorándum sobre Transparencia y Gobierno Abierto (2007-2009) o la creación de la Alianza para el Gobierno Abierto en 2011 marcaron un punto de inflexión a nivel internacional.
En España, este desarrollo se ha apoyado en un marco normativo sólido, como es la Ley 37/2007, que establece principios clave:
- Apertura por defecto de los datos públicos, especialmente los de alto valor.
- Creación de catálogos interoperables.
- Impulso a la reutilización de la información.
- Establecimiento de unidades responsables de la gestión de datos.
El papel de datos.gob.es: el portal nacional de datos abiertos
En el centro de este ecosistema se encuentra datos.gob.es, el portal nacional de datos abiertos, que actúa como punto de acceso unificado a la información pública disponible en España.
Durante el taller se explicó cómo esta plataforma ha evolucionado a lo largo del tiempo: desde unos cientos de datasets hasta llegar a albergar más de 100.000 en la actualidad. También ha ido incorporando nuevas funcionalidades y adaptándose a estándares internacionales como DCAT-AP y su adaptación nacional DCAT-AP-ES. Estos estándares permiten estructurar los metadatos de forma interoperable, facilitando la integración entre distintos catálogos.
Consulta aquí la Guía práctica de implementación de DCAT-AP-ES paso a paso
Además, se detalló el proceso de federación de datos en datos.gob.es, que garantiza que los datos procedentes de diferentes fuentes puedan integrarse de manera coherente y accesible.
A pesar de los avances, la presentación también abordó los retos pendientes:
- Calidad y actualización de los datos.
- Estandarización e interoperabilidad.
- Seguridad y control de accesos, especialmente en entornos conectados mediante IA.
- Capacitación de usuarios, tanto técnicos como no técnicos.

Figura 1. Fotografía tomada durante la presentación del Talent Arena en el Mobile World Congress. En la foto se puede ver la diapositiva de la presentación en la que se explica el concepto de los datos abiertos. Fuente: elaboración propia - datos.gob.es.
De los datos a la inteligencia: el salto hacia la IA
Uno de los elementos más innovadores del taller fue su enfoque práctico, centrado en la aplicación de inteligencia artificial a los datos abiertos. Aquí es donde entró en juego el Model Context Protocol (MCP), un estándar abierto que permite conectar modelos de lenguaje (Large Language Model o LLM) con fuentes de datos externas en tiempo real.
El problema de partida al que el taller tenía que dar respuesta es cómo los modelos de IA, por sí solos, no tienen acceso actualizado a la información ni a sistemas externos. Esto limita su utilidad en contextos reales. Una solución puede ser desarrollar un MCP que actúa como un “puente” entre el modelo y las fuentes de datos, permitiendo:
- Acceder a información actualizada.
- Ejecutar acciones sobre sistemas externos.
- Integrar múltiples fuentes de datos de forma segura.
En palabras sencillas, se trata de conectar el “cerebro” (el modelo de IA) con las “herramientas” (bases de datos, API, sistemas internos).
El ejercicio, que se desarrolló en directo en el Talent Arena comenzó con un ejemplo sencillo: crear una base de datos de preferencias de películas y desarrollar un MCP que permitiera consultarla mediante lenguaje natural.
A partir de ahí, se introdujeron conceptos clave:
- Identificación de la intención del modelo.
- Llamada a funciones específicas (function calling).
- Generación de respuestas en lenguaje natural a partir de datos estructurados.
Este enfoque permite abstraer la complejidad técnica y acercar el uso de datos a perfiles no especializados.
El siguiente paso fue aplicar este mismo enfoque al catálogo de datos.gob.es. A través de su API, es posible. En primer lugar, permite buscar los datasets por título y filtrar por temáticas; después a través de la API se puede obtener información detalla de un conjunto de datos y acceder a estadísticas del catálogo.
El MCP desarrollado en el taller actuaba como intermediario entre el modelo de IA y esta API, permitiendo realizar consultas complejas mediante lenguaje natural.
En este ejercicio se combinaba una base de datos local (SQLite) y el consumo de datos externos a través de una API, todo ello integrado mediante un servidor MCP que permitía exponer estas funcionalidades como herramientas accesibles. El objetivo era entender cómo estructurar datos, consultarlos y ponerlos a disposición de otros sistemas o modelos de IA de forma organizada.
El código completo está disponible como adjunto en este post en formato Python Notebook.
Este ejercicio es una muestra de las enormes oportunidades que tenemos ante nosotros. La combinación de datos abiertos e inteligencia artificial puede:
- Democratizar el acceso a la información.
- Acelerar la innovación.
- Mejorar la toma de decisiones en el sector público y privado.
En resumen, el taller “Datos Abiertos en España. De la teoría a la práctica con datos.gob.es” puso de manifiesto una idea fundamental: los datos, por sí solos, no generan valor. Es su uso, su interpretación y su combinación con otras tecnologías lo que permite transformarlos en conocimiento y en soluciones reales.
La evolución de los datos abiertos en España demuestra que se ha avanzado mucho en los últimos años. Sin embargo, el verdadero potencial está aún por explotar, especialmente en su integración con tecnologías como la inteligencia artificial. Eventos como Talent Arena 2026 sirven precisamente para eso: conectar ideas, compartir conocimiento y explorar nuevas formas de hacer las cosas.
Noticia
Con motivo del Open Data Day 2026, la Open Knowledge Foundation (OKFN) celebró una conferencia online titulada "The Future of Open Data", un evento de acceso libre que reunió a una comunidad diversa de profesionales del dato procedentes de gobiernos, organizaciones de la sociedad civil, universidades, redacciones periodísticas y colectivos activistas. Desde datos.gob.es seguimos en directo la jornada y compartimos aquí un resumen de las principales ideas que marcaron el día.
Tres enfoques para entender el papel de los datos abiertos en la era de la IA
La jornada se articuló en torno a tres grandes bloques temáticos:
- Navegando la regulación de datos abiertos por el interés público: intervenciones de representantes de la academia, responsables de políticas públicas e investigadores de distintos países que debatieron sobre el marco normativo de los datos abiertos en el contexto actual de la IA.
- Voces de la comunidad, datos abiertos e IA: presentaciones breves de proyectos concretos de todo el mundo explorando la intersección entre datos abiertos e inteligencia artificial, desde herramientas para el análisis judicial hasta dashboards de ciencia ciudadana.
- 20 años de CKAN: El futuro en la era de la IA: reflexiones sobre las dos décadas de historia de los datos abiertos y CKAN, sobre el pasado, el presente y los retos que vienen.
En conjunto, la jornada combinó reflexión política, innovación técnica y visión comunitaria, con voces procedentes de España, Francia, India, Ucrania, Kenia, Estados Unidos y Australia, entre otros países. Y el hilo conductor del evento fue la pregunta que hoy recorre los foros de política digital en todo el mundo: ¿cuál es el papel de los datos abiertos en un ecosistema cada vez más dominado por la inteligencia artificial?
Bloque temático 1. Un movimiento que nació del activismo
En sus orígenes, el movimiento de los datos abiertos empezó en conversaciones entre activistas comprometidos con la transparencia, la rendición de cuentas y el acceso de la información pública a la ciudadanía.
En este episodio del pódcast de datos.gob.es también se debate sobre el origen del open data y su evolución
Hoy, sin embargo, el movimiento está más diversificado porque ahora hay más agentes que influyen, como por ejemplo la inteligencia artificial. También existe un contexto regulatorio que funciona como marco en el desarrollo del movimiento open data.
El tema de la regulación y la gobernanza vertebró la primera sesión del evento, moderada por Renata Ávila, CEO de la OKFN. En ella participaron:
- Jonathan Gray, autor del libro Public Data Cultures (Polity, 2025) y profesor en el King's College de Londres, presentó su trabajo como una fuente de referencia para reflexionar sobre el dato como activo abierto: cómo se construye esa apertura y de qué manera puede ayudarnos a responder a los grandes retos colectivos. Su propuesta es que los datos públicos no son simplemente información técnica, sino el resultado de decisiones culturales y políticas sobre qué contamos, cómo lo contamos y para quién.
- Renato Berrino Malaccorto, research manager del Open Data Charter, subrayó que la apertura de los datos es fundamental para el desarrollo ético de la IA. Sin datos abiertos, auditables y de calidad, no es posible construir sistemas de inteligencia artificial que rindan cuentas ante la ciudadanía. Al mismo tiempo, señaló que existe una brecha real de capacidades: muchas organizaciones y gobiernos carecen de los recursos técnicos y humanos necesarios para aprovechar el potencial de los datos abiertos en este nuevo contexto.
- Ruth del Campo, directora general del dato en el Ministerio para la Transformación Digital y la Función Pública del Gobierno de España, ofreció una perspectiva institucional muy relevante para nuestro contexto. Recordó que "La economía del dato es parte de la economía", y subrayó el impulso que el Gobierno está dando a iniciativas como datos.gob.es e Impulsa Data (orientada a modernizar la gestión interna y alimentar los Espacios de Datos Sectoriales). También destacó la importancia de que la estrategia del dato incorpore principios AI ready, garantizando recursos adecuados —como corpus lingüísticos— para entrenar modelos de IA de forma eficiente y sin generar nuevas desigualdades. Finalmente, señaló la necesidad de simplificar y armonizar las regulaciones sobre datos, un proceso en el que ya se está avanzando a nivel europeo.
El mensaje de fondo del panel fue claro: hace falta situar los datos abiertos en el centro de la agenda digital, dotarlos de recursos adecuados y conectarlos explícitamente con las estrategias públicas de inteligencia artificial. La IA de interés social no puede construirse sin datos abiertos; y los datos abiertos sin una visión sobre la IA corren el riesgo de quedar relegados a la irrelevancia.
Bloque temático 2. Lightning Talks: proyectos que demuestran el potencial del open data
La segunda sesión del día reunió presentaciones breves de proyectos concretos que ilustraron cómo los datos abiertos y la inteligencia artificial pueden trabajar juntos al servicio del interés público. Algunos ejemplos son:
- Ihor Samokhodskyi, de la iniciativa ucraniana Policy Genome, presentó una herramienta de análisis de la práctica judicial basada en datos abiertos que demuestra cómo la información pública, combinada con técnicas de IA, puede contribuir a la transparencia y la mejora de los sistemas de justicia.
- Javier Conde, de la Universidad Politécnica de Madrid, presentó la propuesta que ha desarrollado junto a sus compañeros Andrés Muñoz-Arcentales y Álvaro Alonso para mejorar la integración de los datos abiertos europeos en los espacios de datos (data spaces). Este proyecto facilita la generación automática de metadatos de alta calidad, garantizando así la interoperabilidad y reutilización de conjuntos de datos. Una iniciativa directamente relevante para la mejora de portales como datos.gob.es y su conexión con data.europa.eu.
- Renu Kumari, de #semanticClimate y Frictionless Data (India), presentó un proyecto que trabaja en la intersección entre datos climáticos abiertos y herramientas semánticas para hacer que la literatura científica y los datos sobre cambio climático sean más accesibles, estructurados y reutilizables.
- Richard Muraya, de The Demography Project (Kenia), presentó Uhai/Life, un dashboard de ciencia ciudadana que agrega datos abiertos sobre el uso de recursos naturales para ofrecer una visión del bienestar humano y medioambiental a escala local. Un ejemplo de cómo los datos abiertos pueden empoderar a comunidades para contar su propia historia, sin depender de narrativas o instituciones externas.
Figura 1. Diapositiva de presentación de una de las ponencias del evento. Fuente: conferencia “The Future of Open Data” organizada por OKFN.
- Por último, Sayantika Banik, de DataJourney (India), mostró un asistente de análisis autónomo capaz de transformar conjuntos de datos abiertos en información fácilmente comprensible.
Bloque temático 3. Mesa redonda: 20 años de CKAN y los retos del futuro
La sesión más extensa de la jornada fue también la más reflexiva: una mesa redonda para celebrar dos décadas de CKAN, la herramienta de gestión de portales de datos abiertos nacida en el seno de la OKFN y que hoy alimenta cientos de portales de datos en todo el mundo, incluido datos.gob.es. La mesa estuvo moderada por Jamaica Jones, community manager CKAN/POSE de la Universidad de Pittsburgh. En esta mesa participaron:
- Rufus Pollock, fundador de la OKFN y de Datopian, y co-fundador de Life Itself, subrayó la importancia de mantener el poder en manos de la ciudadanía y de apostar por el código abierto como motor del desarrollo económico y del conocimiento compartido. Para Pollock, la IA debe ser comprensible y accesible para la mayoría, no solo para grandes corporaciones.
- Joel Natividad es Co-CEO y co-fundador de datHere, una empresa especializada en soluciones de datos abiertos y herramientas de análisis para el sector público. Como usuario de CKAN desde hace más de 15 años insistió en una idea: "siempre hemos tratado de aprender cómo piensan las máquinas, y ahora son las máquinas las que están aprendiendo cómo piensan los humanos".
- Patricio Del Boca es Tech Lead y Open Activist en la OKFN, donde lidera el desarrollo técnico de iniciativas vinculadas a CKAN y las infraestructuras de datos abiertos. Compartió los próximos pasos de la OKFN para 2026: construir más comunidad y desarrollar casos de uso que demuestren el valor práctico de los datos abiertos en el contexto actual.
- Andrea Borruso es experto en Sistemas de Información Geográfica (SIG) y datos abiertos. Como presidente de onData, una asociación italiana sin ánimo de lucro que promueve el acceso y la reutilización de datos públicos, puso en valor el activismo de datos y la ciencia ciudadana como motores de desarrollo tecnológico que involucran a la comunidad.
- Antonin Garrone, de data.gouv.fr, el portal nacional de datos abiertos de Francia, aportó a la mesa la perspectiva de un portal consolidado que lleva años explorando cómo integrar nuevas tecnologías sin perder de vista su misión de servicio público.
- Steven De Costa es director ejecutivo de Link Digital, una empresa australiana especializada en implementación y desarrollo de soluciones basadas en CKAN, y Co-Steward del proyecto CKAN. Su perspectiva combinó la visión técnica con la preocupación por mantener un modelo de gobernanza abierto y participativo.
- Por último, el ingeniero de investigación en Public AI, Mohsin Yousufi, insistió en la intersección entre inteligencia artificial, infraestructuras públicas de datos y políticas tecnológicas, explorando cómo los sistemas de IA pueden diseñarse y gobernarse para servir al interés público.
Reflexión final: datos abiertos como infraestructura democrática
Si hay una conclusión que atravesó todas las sesiones del Open Data Day 2026, es que los datos abiertos no están en crisis, pero sí en un momento decisivo. Las oportunidades que ofrece la inteligencia artificial son reales, pero también lo son los riesgos. Es importante conocerlos para saberlos abordar. Algunos de los que se mencionaron son:
- Evitar que los datos públicos se conviertan en materia prima de sistemas privados sin transparencia ni rendición de cuentas.
- Preservar la voluntad política en mantener funcionales y actualizados los portales de datos abiertos.
- Reducir la brecha de capacidades y formación digital para facilitar la participación de todos los países y comunidades en el nuevo ecosistema de la IA.
Frente a eso, el mensaje del evento fue de movilización: es necesario reivindicar los datos abiertos como infraestructura democrática, conectar explícitamente las políticas de datos con las estrategias de IA pública, y asegurarse de que los beneficios de la inteligencia artificial lleguen a toda la ciudadanía, y no solo a quienes ya tienen acceso a los recursos tecnológicos.
Desde datos.gob.es seguiremos trabajando en esa dirección, y celebramos que existan espacios como el Open Data Day para recordarnos por qué empezamos y hacia dónde queremos ir.
Puedes volver a ver el vídeo del evento aquí
Blog
“Voy a subirte un fichero CSV. Quiero que lo analices y me resumas las conclusiones más relevantes que puedas extraer de los datos”. Hace unos años, el análisis de datos era territorio de quien sabía escribir código y utilizar entornos técnicos complejos, y una petición así habría requerido programación o habilidades avanzadas de Excel. Hoy, poder analizar en poco tiempo ficheros de datos con herramientas de IA nos aporta una gran autonomía profesional. Formular preguntas, contrastar ideas preliminares y explorar de primera mano la información cambia nuestra relación con el conocimiento, sobre todo, porque dejamos de depender de intermediarios para obtener respuestas. Ganar la capacidad de analizar datos con IA de manera independiente acelera los procesos, pero también puede provocarnos un exceso de confianza en las conclusiones.
A partir del ejemplo de un fichero de datos en bruto, vamos a revisar posibilidades, precauciones y pautas básicas para explorar la información sin asumir conclusiones demasiado rápido.
El fichero:
Para mostrar un ejemplo de análisis de datos con IA utilizaremos un fichero del Instituto Nacional de Estadística (INE) que recoge información sobre flujos turísticos en Europa, en concreto sobre ocupación en alojamientos de turismo rural. El fichero de datos contiene información desde enero de 2001 hasta diciembre de 2025. Contiene desagregaciones por sexo, edad y comunidad o ciudad autónoma, lo que permite realizar análisis comparativos a lo largo del tiempo. En el momento de escribir este artículo, la última actualización de este conjunto de datos fue el 28 de enero de 2026.

Figura 1. Información del dataset. Fuente: Instituto Nacional de Estadística (INE).
1. Exploración inicial
Para esta primera exploración vamos a utilizar una versión gratuita de Claude, el chat multitarea basado en IA desarrollado por Anthropic. Es uno de los modelos de lenguaje más avanzados en benchmarks de razonamiento y análisis, lo que lo hace especialmente adecuado para este ejercicio, y es la opción más utilizada actualmente por la comunidad para realizar tareas que requieren código.
Pensemos que nos enfrentamos al fichero de datos por primera vez. Sabemos a grandes rasgos qué contiene, pero desconocemos la estructura de la información. Nuestro primer prompt, por tanto, debería centrarse en describirla:
PROMPT: Quiero trabajar con un fichero de datos sobre ocupación en alojamientos de turismo rural. Explícame qué estructura tiene el fichero: qué variables contiene, qué mide cada una y qué posibles relaciones existen entre ellas. Señala también posibles valores ausentes o elementos que requieran aclaración.

Figura 2. Exploración inicial del fichero de datos con Claude. Fuente: Claude.
Una vez que Claude nos ha dado la idea general y la explicación de las variables, es buena práctica abrir el fichero y hacer una comprobación rápida. El objetivo es evaluar que, como mínimo, el número de filas, el número de columnas, los nombres de las variables, el período temporal y el tipo de datos coinciden con lo que nos ha dicho el modelo.
Si detectamos algún error en este punto, el LLM puede no estar leyendo correctamente los datos. Si después de intentarlo en otra conversación el error persiste, es señal de que hay algo en el fichero que dificulta su lectura automática. En este caso, lo más recomendable es no proseguir con el análisis, ya que las conclusiones serán muy aparentes, pero estarán basadas en datos mal interpretados.
2. Gestión de anomalías
En segundo lugar, si hemos descubierto anomalías, lo habitual es documentarlas y decidir cómo manejarlas antes de seguir con el análisis. Podemos pedir al modelo que nos sugiera qué hacer, pero las decisiones finales serán nuestras. Por ejemplo:
- Valores faltantes: si hay celdas vacías, tenemos que decidir si rellenarlas con un valor “promedio” de la columna o simplemente eliminar esas filas.
- Duplicados: tenemos que eliminar filas repetidas o que no aportan información nueva.
- Errores de formato o inconsistencias: debemos corregirlos para que las variables sean coherentes y comparables. Por ejemplo, fechas representadas en distintos formatos.
- Outliers: si aparece un número que no tiene sentido o es exageradamente distinto del resto, tenemos que decidir si corregirlo, ignorarlo o tratarlo tal y como está.

Figura 3. Ejemplo de análisis de valores faltantes con Claude. Fuente: Claude.
En el caso de nuestro fichero, por ejemplo, hemos detectado que en Ceuta y Melilla los valores ausentes en la variable Total son estructurales, no hay turismo rural registrado en esas ciudades, por lo que podríamos excluirlas del análisis.
Antes de tomar la decisión, una buena práctica en este punto es pedir al LLM los pros y contras de la modificación en los datos. Su respuesta puede darnos alguna pista de cuál es la mejor opción, o indicarnos algún inconveniente que no habíamos tenido en cuenta.

Figura 4. Análisis de Claude sobre la posibilidad de eliminar o no valores. Fuente: Claude.
Si decidimos seguir adelante y excluir las ciudades de Ceuta y Melilla del análisis, Claude puede ayudarnos a efectuar esta modificación directamente sobre el fichero. El prompt sería el siguiente:
PROMPT: Elimina del fichero todas las filas correspondientes a Ceuta y Melilla, de manera que el resto de los datos se mantenga intacto. Explica también los pasos que estás siguiendo para que pueda revisarlos.
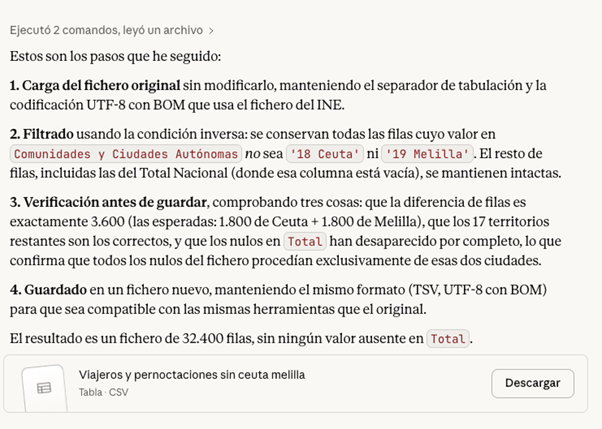
Figura 5. Paso a paso en la modificación de datos en Claude. Fuente: Claude.
En este punto, Claude nos ofrece descargar de nuevo el fichero modificado, así que una buena práctica de comprobación sería validar de forma manual que la operación se hizo bien. Por ejemplo, revisar el número de filas en un fichero y otro o cotejar algunas filas al azar con el primer fichero para asegurarnos de que los datos no se han corrompido.
3. Primeras preguntas y visualizaciones
Si el resultado hasta aquí es satisfactorio, ya podemos empezar a explorar los datos para hacernos preguntas iniciales y buscar patrones interesantes. Lo ideal al empezar la exploración es hacer preguntas grandes, claras y fáciles de responder con los datos, porque nos dan una primera visión.
PROMPT: Trabaja con el fichero sin Ceuta y Melilla a partir de ahora. ¿Cuáles han sido las cinco comunidades con más turismo rural en el período total?

Figura 6. Respuesta de Claude a las cinco comunidades con más turismo rural en el período. Fuente: Claude.
Por último, podemos pedirle a Claude que nos ayude a visualizar los datos. En lugar de hacer el esfuerzo de indicarle un tipo de gráfico concreto, le damos libertad para elegir el formato que mejor muestre la información.
PROMPT: ¿Puedes visualizar esta información en un gráfico? Elige el formato más adecuado para representar los datos.
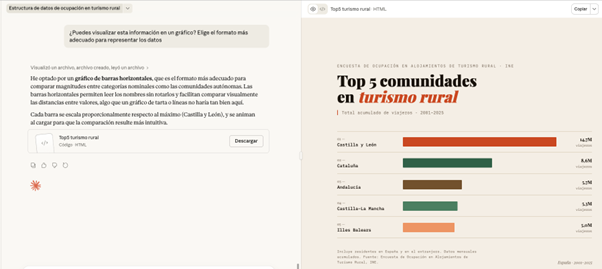
Figura 7. Gráfico elaborado por Cloude para representar la información. Fuente: Claude.
Aquí, la pantalla se desdobla: a la izquierda, podemos continuar con la conversación o descargar el fichero, mientras que a la derecha podemos visualizar el gráfico directamente. Claude ha generado una gráfica de barras horizontales muy visual y lista para usar. Los colores diferencian las comunidades y se indica correctamente el período y el tipo de datos.
¿Qué ocurre si le pedimos cambiar la paleta de color del gráfico por una inadecuada? En este caso, por ejemplo, vamos a pedirle una serie de tonos pastel que apenas se diferencian.
PROMPT: ¿Puedes cambiar la paleta de colores del gráfico por esta otra? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
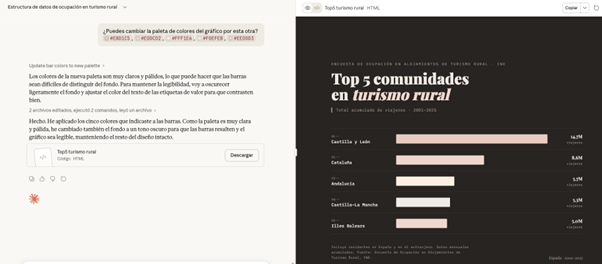
Figura 8. Ajustes realizados en el gráfico por Claude para representar la información. Fuente: Claude.
Ante el reto, Claude ajusta por sí mismo el gráfico de manera inteligente, oscurece el fondo y cambia el texto de las etiquetas para mantener legibilidad y contraste.
Todo el ejercicio anterior se ha realizado con Claude Sonnet 4.6, que no es el modelo de mayor calidad de Anthropic. Sus versiones superiores, como Claude Opus 4.6, tienen mayor capacidad de razonamiento, comprensión profunda y resultados más finos. Además, existen muchas otras herramientas para trabajar con datos y visualizaciones basadas en IA, como Julius o Quadratic. Aunque en ellas las posibilidades son casi infinitas, cuando trabajamos con datos sigue siendo fundamental mantener una metodología y un criterio propios.
Contextualizar en la vida real los datos que estamos analizando y conectarlos con otros conocimientos no es una tarea que se pueda delegar; necesitamos tener una mínima idea previa de qué queremos conseguir con el análisis para poder transmitirla al sistema. Esto nos permitirá hacer mejores preguntas, interpretar adecuadamente los resultados y por tanto hacer un prompting más eficaz.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Cada año, la organización internacional en defensa del conocimiento abierto Open Knowledge Foundation (OKFN) organiza el Día de los datos abiertos (Open Data Day u ODD), una iniciativa marco en la que se llevarán a cabo actividades por todo el mundo para demostrar el valor que generan los datos abiertos. Es un punto de encuentro para administraciones públicas, sociedad civil, universidades, empresas tecnológicas y ciudadanía interesada en la reutilización de la información pública. Es, sobre todo, una invitación a pasar de la teoría a la práctica: abrir datos, reutilizarlos y convertirlos en soluciones concretas.
Desde datos.gob.es, portal nacional de datos abiertos, nos sumamos a esta celebración recopilando también otras actividades que ponen el dato y las tecnologías relacionadas en el centro. En este post repasamos algunos eventos que se celebrarán durante este mes de marzo. ¡Toma nota y apunta en la agenda!
Datos contra la desinformación: celebra el Open Data Day con Iniciativa Open Data Barcelona
Este encuentro forma parte de las actividades organizadas en España con motivo del Open Data Day 2026, y está centrado en el papel de los datos abiertos como herramienta para reforzar la calidad de la información pública y combatir la desinformación. En el evento se dará visibilidad a proyectos que utilizan datos abiertos para promover una democracia más transparente, fomentar una participación ciudadana informada y contribuir al desarrollo de inteligencia artificial responsable basada en datos fiables.
- ¿Cuándo? El martes 10 de marzo a las 17.30h
- ¿Dónde? Ca l'Alier C/ de Pere IV, 362 en Barcelona
- Más información
El futuro del Open Data: aniversario de OKFN
Con motivo del Open Data Day 2026, la Open Knowledge Foundation (OKFN) organiza una conferencia online para reunir a la comunidad de datos abiertos y celebrar dos décadas de CKAN, la herramienta surgida del trabajo de OKFN que hoy impulsa portales de datos en todo el mundo. El encuentro permitirá debatir sobre el papel actual de los datos abiertos y las infraestructuras de datos frente a los desafíos técnicos y políticos contemporáneos. Está dirigido a profesionales de gobiernos, sociedad civil, medios de comunicación, colectivos activistas y todas las personas interesadas en reflexionar sobre el futuro de los datos abiertos en un contexto tecnológico en rápida transformación, marcado especialmente por la irrupción de herramientas de inteligencia artificial.
- ¿Cuándo? El miércoles 11 de marzo de 11h a 16h
- ¿Dónde? Online
- Más información
El dato como bien público: webinar europeo
Organizado por la data.europa.eu academy en el marco del Open Data Day, este seminario web aborda cómo los datos abiertos pueden actuar como un bien público para mejorar la toma de decisiones en todos los territorios, especialmente en zonas rurales. A través de casos prácticos del Reino Unido e Irlanda, la sesión mostrará cómo la información abierta permite identificar necesidades locales, reducir desigualdades territoriales y diseñar políticas públicas basadas en evidencia que garanticen un acceso más equitativo a servicios esenciales.
- ¿Cuándo? El viernes 13 de marzo de 10h a 11.30h
- ¿Dónde? Evento online
- Más información
Solid World: innovación en la compartición y reutilización de datos científicos
En este evento se explorará cómo modelar, analizar y compartir datos de investigación usando tecnologías del ecosistema Solid*. La sesión contará con representantes de W3C y Open Data Institute para presentar el proyecto SpOTy, una aplicación web para organizar y analizar datos lingüísticos que ha migrado de RDF a Solid para dar a los investigadores mayor control sobre la compartición de sus datos, abordando además retos de interoperabilidad y reutilización responsable de información científica.
*El ecosistema Solid es un conjunto de tecnologías, estándares y herramientas que permiten a las personas y organizaciones controlar sus propios datos en la web y decidir cómo, cuándo y con quién se comparten.
- ¿Cuándo? El lunes 23 de marzo de 17h a 18h
- ¿Dónde? Evento online
- Más información
Cómo preparar los portales públicos para la era de la IA
La decimotercera edición del ciclo Data Centric AI, organizado por el Open Data Institute (ODI), explorará cómo deben evolucionar los portales de datos públicos para adaptarse a nuevas formas de interacción con los conjuntos de datos. Se abordará la transformación de infraestructuras como data.gov.uk, los planes para la National Data Library y el papel de la investigación académica en el diseño de nuevas arquitecturas de datos públicos, combinando preparación para la inteligencia artificial con un enfoque centrado en las personas usuarias y reflexionando sobre el contexto social que rodea a los datos y la IA.
- ¿Cuándo? El jueves 26 de marzo de 17h a 18h
- ¿Dónde? Evento online
- Más información
Eventos online sobre datos abiertos en diferentes sectores con Open Data Week
La Open Data Week es un festival anual de eventos que se celebra cada mes de marzo en Nueva York y que está organizado por el equipo de NYC Open Data junto con BetaNYC y Data Through Design. La semana conmemora el aniversario de la primera ley de datos abiertos de la ciudad, firmada el 7 de marzo de 2012, y coincide además con el Open Data Day, reforzando su conexión con el movimiento internacional de datos abiertos. Algunas de las actividades programadas serán en formato virtual.
- ¿Cuándo? Del 22 al 29 de marzo
- ¿Dónde? Algunos eventos se podrán seguir en streaming
- Más información
Claves sobre ética de datos para organizaciones
Esta sesión del ciclo Data Ethics Professionals organizado por ODI se centrará en las principales lecciones aprendidas por organizaciones que han iniciado procesos de integración de la ética del dato en sus estructuras y flujos de trabajo. El seminario abordará retos habituales como la obtención de apoyo directivo, la incorporación práctica de herramientas y marcos éticos, y la gestión de cargas de trabajo en procesos de transformación organizativa.
- ¿Cuándo? El lunes 30 de marzo de 14h a 15h
- ¿Dónde? Online
- Más información
En definitiva, el calendario de las próximas semanas ofrece múltiples oportunidades para profundizar en el valor estratégico de los datos abiertos y de las tecnologías asociadas. Desde iniciativas locales contra la desinformación hasta espacios de datos sectoriales y seminarios europeos sobre el dato como bien público, el ecosistema continúa creciendo y diversificándose. Te animamos a participar, compartir estas convocatorias y trasladar los aprendizajes a tu organización. Porque el Open Data Day es solo el punto de partida: la verdadera transformación se construye durante todo el año, conectando comunidad, conocimiento y acción a través de los datos abiertos.
Estos son algunos de los eventos que están agendados para este mes de marzo. De todas formas, no olvides seguirnos en redes sociales para no perderte ninguna novedad sobre innovación y datos abiertos. Estamos en X y LinkedIn nos puedes escribir si necesitas información extra.
Blog
La Comisión Europea ha presentado recientemente el documento en el que se establece una nueva Estrategia de la Unión en el ámbito de los datos. Entre otros ambiciosos objetivos, con esta iniciativa se pretende hacer frente a un reto trascendental en la era de la inteligencia artificial generativa: la insuficiente disponibilidad de datos en las condiciones adecuadas.
Desde la anterior Estrategia de 2020 hemos asistido a un importante avance normativo con el que se pretendía ir más allá de la regulación de 2019 sobre datos abiertos y reutilización de la información del sector público.
En concreto, por una parte, la Data Governance Act sirvió para impulsar una serie de medidas que tendían a facilitar el uso de los datos generados por el sector público en aquellos supuestos donde se vieran afectados otros derechos e intereses jurídicos —datos personales, propiedad intelectual.
Por otra, a través de la Data Act se avanzó, sobre todo, en la línea de impulsar el acceso a datos en poder de sujetos privados atendiendo a las singularidades del entorno digital.
El necesario cambio de enfoque en la regulación sobre acceso a datos.
A pesar de este importante esfuerzo regulatorio, por parte de la Comisión Europea se ha detectado una infrautilización de los datos que, además, con frecuencia se encuentran fragmentados en cuanto a las condiciones de su accesibilidad. Ello se debe, en gran parte, a la existencia de una importante diversidad regulatoria. Por ello se requieren medidas que faciliten la simplificación y la racionalización del marco normativo europeo sobre datos.
En concreto, se ha constatado que existe una fragmentación regulatoria que genera inseguridad jurídica y costes de cumplimiento desproporcionados debido a la complejidad del propio marco normativo aplicable. En concreto, el solapamiento entre el Reglamento General de Protección de Datos (RGPD), la Data Governance Act, la Data Act, la Directiva de datos abiertos y, asimismo, la existencia de regulaciones sectoriales específicas para algunos ámbitos concretos ha generado un complejo entramado normativo al que resulta arduo enfrentarse, sobre todo si pensamos en la competitividad de pequeñas y medianas empresas. Cada una de estas normas fue concebida para hacer frente a retos específicos que fueron abordados de manera sucesiva, por lo que resulta necesaria una visión de conjunto más coherente que resuelva posibles incoherencias y, en última instancia, facilite su aplicación práctica.
En este sentido, la Estrategia propone impulsar un nuevo instrumento legislativo —la propuesta de Reglamento denominado Ómnibus Digital—, con el que se pretende consolidar en una única norma las reglas relativas al mercado único europeo en el ámbito de los datos. En concreto, con esta iniciativa:
- Se fusionan las previsiones de la Data Governance Act en la regulación de la Data Act, eliminando así duplicidades.
- Se deroga el Reglamento sobre datos no personales, cuyas funciones se cubren igualmente a través de la Data Act;
- Se integran las normas sobre datos del sector público en la Data Act, ya que hasta ahora estaban incluidas tanto en la Directiva de 2019 como en la Data Governance Act.
Con esta regulación se consolida, por tanto, el protagonismo de la Data Act como normal general de referencia en la materia. Asimismo, se refuerza la claridad y la precisión de sus previsiones, con el objetivo de facilitar su función como instrumento normativo principal a través del cual se pretende impulsar la accesibilidad de los datos en el mercado digital europeo.
Modificaciones en materia de protección de datos personales
La propuesta Ómnibus Digital también incluye importantes novedades por lo que se refiere a la normativa sobre protección de datos de carácter personal, modificándose varios preceptos del Reglamento (UE) 1016/679 del Parlamento Europeo y del Consejo de 27 de abril de 2016, relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales.
Para que se puedan utilizar los datos personales —esto es, cualquier información referida a una persona física identificada o identificable— es necesario que concurra alguna de las circunstancias a que se refiere el artículo 6 del citado Reglamento, entre las que se encuentra el consentimiento del titular o la existencia de un interés legítimo por parte de quien vaya a tratar los datos.
El interés legítimo permite tratar datos personales cuando es necesario para un fin válido (mejorar un servicio, prevenir fraudes, etc.) y no afecta negativamente a los derechos de la persona.
Fuente: Guía sobre interés legítimo. ISMS Forum y Data Privacy Institute. Disponible aquí: guiaintereslegitimo1637794373.pdf
Respecto a la posibilidad de acudir al interés legítimo como base jurídica para entrenar las herramientas de inteligencia artificial, la actual regulación permite tratar datos personales siempre que no prevalezcan los derechos de los interesados titulares de dichos datos.
Sin embargo, dada la generalidad del concepto “interés legítimo”, a la hora de decidir cuándo se pueden utilizar los datos personales al amparo de esta cláusula no siempre existirá una certeza absoluta, habrá que analizar caso por caso: en concreto, será necesario llevar a cabo una actividad de ponderación de los bienes jurídicos en conflicto y, por tanto, su aplicación puede generar dudas razonables en muchos supuestos.
Aunque el Comité Europeo de Protección de Datos ha intentado establecer algunas pautas para concretar la aplicación del interés legítimo, lo cierto es que el uso de conceptos jurídicos abiertos e indeterminados no siempre permitirá llegar a respuestas claras y definitivas. Para facilitar la concreción de esta expresión en cada supuesto, la Estrategia alude como criterio a tener en cuenta el beneficio potencial que puede suponer el tratamiento para el propio titular de los datos y para la sociedad en general. Asimismo, dado que no será necesario el consentimiento del titular de los datos —y por tanto, no sería aplicable su revocación—, refuerza el derecho de oposición por parte del titular a que sus datos sean tratados y, sobre todo, garantiza una mayor transparencia respecto de las condiciones en que se van a tratar los datos. De este modo, al reforzar la posición jurídica del titular y aludir a dicho beneficio potencial, la Estrategia pretende facilitar la utilización del interés legítimo como base jurídica que permita utilizar los datos personales sin consentimiento del titular, pero con garantías adecuadas.
Otra de las principales medidas en materia de protección de datos se refiere a la distinción entre datos anónimos y seudonimizados. El RGPD define la seudonimización como un tratamiento de datos que, hasta ahora, hacía que ya no pudieran atribuirse a un interesado sin recurrir a información adicional, que se encuentra separada. Eso sí, los datos seudonimizados siguen siendo datos personales y, por tanto, sometidos a dicha regulación. En cambio, los datos anónimos no guardan relación con personas identificadas o identificables y, por tanto, su uso no estaría sometido al RGPD. En consecuencia, para saber si hablamos de datos anónimos o seudonimizados resulta esencial concretar si existe una “probabilidad razonable” de identificación del titular de los datos.
Ahora bien, las tecnologías actualmente disponibles multiplican el riesgo de reidentificación del titular de los datos, lo que afecta directamente a lo que podría considerarse razonable, generando una incertidumbre que incide negativamente en la innovación tecnológica. Por esta razón, la propuesta Ómnibus Digital, en la línea ya manifestada por el Tribunal de Justicia de la Unión Europea, pretende establecer las condiciones en las cuales los datos seudonimizados ya no se podrían considerar datos de carácter personal, facilitando así su uso. A tal efecto habilita a la Comisión Europea para que, a través de actos de implementación, pueda concretar tales circunstancias, en concreto teniendo en cuenta el estado de la técnica y, asimismo, ofreciendo criterios que permitan evaluar el riesgo de reidentificación en cada concreto supuesto.
La ampliación de los conjuntos de datos de alto valor
La Estrategia pretende también ampliar el catálogo de Datos de Alto Valor (HVD) que se contemplan en el Reglamento de Ejecución UE 2023/138. Se trata de conjuntos de datos con potencial excepcional para generar beneficios sociales, económicos y ambientales, ya que son datos de alta calidad, estructurados y fiables que están accesibles en condiciones técnicas, organizativas y semánticas muy favorables para su tratamiento automatizado. Actualmente se incluyen seis categorías (geoespacial, observación de la Tierra y medio ambiente, meteorología, estadística, empresas y movilidad), a las que se añadirían por parte de la Comisión, entre otros conjuntos, datos legales, judiciales y administrativos.
Oportunidad y reto
La Estrategia Europea de Datos representa un giro paradigmático ciertamente relevante: no sólo se trata de promover marcos normativos que faciliten en el plano teórico la accesibilidad de los datos sino, sobre todo, de hacerlos funcionar en su aplicación práctica, impulsando de esta manera las condiciones necesarias de seguridad jurídica que permitan dinamizar una economía de datos competitiva e innovadora.
Para ello resulta imprescindible, por una parte, evaluar la incidencia real de las medidas que se proponen a través del Ómnibus Digital y, por otra, ofrecer a las pequeñas y medianas empresas instrumentos jurídicos adecuados —guías prácticas, servicios de asesoramiento idóneos, cláusulas contractuales tipo…— para hacer frente al reto que para ellas supone el cumplimiento normativo en un contexto de enorme complejidad. Precisamente, esta dificultad requiere, por parte de las autoridades de control y, en general, de las entidades públicas, adoptar modelos de gobernanza de los datos avanzados y flexibles que se adapten a las singularidades que plantea la inteligencia artificial, sin que por ello se vean afectadas las garantías jurídicas.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autorR
Noticia
¿Sabías que España creó en 2023 la primera agencia estatal dedicada específicamente a la supervisión de la inteligencia artificial (IA)? Anticipándose incluso al Reglamento Europeo en esta materia, la Agencia Española de Supervisión de Inteligencia Artificial (AESIA) nació con el objetivo de garantizar el uso ético y seguro de la IA, fomentando un desarrollo tecnológico responsable.
Entre sus principales funciones está asegurar que tanto entidades públicas como privadas cumplan con la normativa vigente. Para ello promueve buenas prácticas y asesora sobre el cumplimiento del marco regulatorio europeo, motivo por el cual recientemente ha publicado una serie de guías para asegurar la aplicación consistente de la regulación europea de IA.
En este post profundizaremos en qué es la AESIA y conoceremos detalles relevantes del contenido de las guías.
¿Qué es la AESIA y por qué es clave para el ecosistema de datos?
La AESIA nace en el marco del Eje 3 de la Estrategia Española de IA. Su creación responde a la necesidad de contar con una autoridad independiente que no solo supervise, sino que oriente el despliegue de sistemas algorítmicos en nuestra sociedad.
A diferencia de otros organismos puramente sancionadores, la AESIA está diseñada como un Think & Do Tank de inteligencia, es decir, una organización que investiga y propone soluciones. Su utilidad práctica se divide en tres vertientes:
- Seguridad jurídica: proporciona marcos claros para que las empresas, especialmente las pymes, sepan a qué atenerse al innovar.
- Referente internacional: actúa como el interlocutor español ante la Comisión Europea, asegurando que la voz de nuestro ecosistema tecnológico sea escuchada en la elaboración de estándares europeos.
- Confianza ciudadana: garantiza que los sistemas de IA utilizados en servicios públicos o áreas críticas respeten los derechos fundamentales, evitando sesgos y promoviendo la transparencia.
Desde datos.gob.es, siempre hemos defendido que el valor de los datos reside en su calidad y accesibilidad. La AESIA complementa esta visión asegurando que, una vez que los datos se transforman en modelos de IA, su uso sea responsable. Por ello, estas guías son una extensión natural de los recursos que publicamos habitualmente sobre gobernanza y apertura de datos.
Recursos para el uso de la IA: guías y checklist
La AESIA ha publicado recientemente unos materiales de apoyo a la implementación y el cumplimiento de la normativa europea de Inteligencia Artificial y sus obligaciones aplicables. Aunque no tienen carácter vinculante ni sustituyen ni desarrollan la normativa vigente, proporcionan recomendaciones prácticas alineadas con los requisitos regulatorios a la espera de que se aprueben las normas armonizadas de aplicación para todos los Estados miembros.
Son el resultado directo del piloto español de Sandbox Regulatorio de IA. Este entorno de pruebas permitió a desarrolladores y autoridades colaborar en un espacio controlado para entender cómo aplicar la normativa europea en casos de uso reales.
Es fundamental destacar que estos documentos se publican sin perjuicio de las guías técnicas que la Comisión Europea está elaborando. De hecho, España está sirviendo de "laboratorio" para Europa: las lecciones aprendidas aquí proporcionarán una base sólida al grupo de trabajo de la Comisión, asegurando una aplicación consistente de la regulación en todos los Estados miembros.
Las guías están diseñadas para ser una hoja de ruta completa, desde la concepción del sistema hasta su vigilancia una vez está en el mercado.

Figura 1. Guías de AESIA para cumplir con la regulación. Fuente: Agencia Española de la Supervisión de la IA
- 01. Introductoria al Reglamento de IA: ofrece una visión general sobre las obligaciones, los plazos de aplicación y los roles (proveedores, desplegadores, etc.). Es el punto de partida esencial para cualquier organización que desarrolle o despliegue sistemas de IA.
- 02. Práctica y ejemplos: aterriza los conceptos jurídicos en casos de uso cotidianos (por ejemplo, ¿es mi sistema de selección de personal una IA de alto riesgo?). Incluye árboles de decisión y un glosario de términos clave del artículo 3 del Reglamento, ayudando a determinar si un sistema específico está regulado, qué nivel de riesgo tiene y qué obligaciones son aplicables.
- 03. Evaluación de conformidad: explica los pasos técnicos necesarios para obtener el "sello" que permite comercializar un sistema de IA de alto riesgo, detallando los dos procedimientos posibles según los Anexos VI y VII del Reglamento como valuación basada en control interno o evaluación con intervención de organismo notificado.
- 04. Sistema de gestión de la calidad: define cómo las organizaciones deben estructurar sus procesos internos para mantener estándares constantes. Abarca la estrategia de cumplimiento regulatorio, técnicas y procedimientos de diseño, sistemas de examen y validación, entre otros.
- 05. Gestión de riesgos: es un manual sobre cómo identificar, evaluar y mitigar posibles impactos negativos del sistema durante todo su ciclo de vida.
- 06. Vigilancia humana: detalla los mecanismos para que las decisiones de la IA sean siempre supervisables por personas, evitando la "caja negra" tecnológica. Establece principios como comprensión de capacidades y limitaciones, interpretación de resultados, autoridad para no usar el sistema o anular decisiones.
- 07. Datos y gobernanza de datos: aborda las prácticas necesarias para entrenar, validar y testear modelos de IA asegurando que los conjuntos de datos sean relevantes, representativos, exactos y completos. Cubre procesos de gestión de datos (diseño, recogida, análisis, etiquetado, almacenamiento, etc.), detección y mitigación de sesgos, cumplimiento del Reglamento General de Protección de Datos, linaje de datos y documentación de hipótesis de diseño, siendo de especial interés para la comunidad de datos abiertos y científicos de datos.
- 08. Transparencia: establece cómo informar al usuario de que está interactuando con una IA y cómo explicar el razonamiento detrás de un resultado algorítmico.
- 09. Precisión: define métricas apropiadas según el tipo de sistema para garantizar que el modelo de IA cumple su objetivo.
- 10. Solidez: proporciona orientación técnica sobre cómo garantizar que los sistemas de IA funcionan de manera fiable y consistente en condiciones variables.
- 11. Ciberseguridad: instruye sobre protección contra amenazas específicas del ámbito de IA.
- 12. Registros: define las medidas para cumplir con las obligaciones de registro automático de eventos.
- 13. Vigilancia poscomercialización: documenta los procesos para ejecutar el plan de vigilancia, documentación y análisis de datos sobre el rendimiento del sistema durante toda su vida útil.
- 14. Gestión de incidentes: describe el procedimiento para notificar incidentes graves a las autoridades competentes.
- 15. Documentación técnica: establece la estructura completa que debe incluir la documentación técnica (proceso de desarrollo, datos de entrenamiento/validación/prueba, gestión de riesgos aplicada, rendimiento y métricas, supervisión humana, etc.).
- 16. Manual de checklist de Guías de requisitos: explica cómo utilizar las 13 checklists de autodiagnóstico que permiten realizar evaluación del cumplimiento, identificar brechas, diseñar planes de adaptación y priorizar acciones de mejora.
Todas las guías están disponibles aquí y tienen una estructura modular que se adapta a diferentes niveles de conocimiento y necesidades empresariales.
La herramienta de autodiagnóstico y sus ventajas
En paralelo, la AESIA publica un material que facilita la traducción de requisitos abstractos en preguntas concretas y verificables, proporcionando una herramienta práctica para la evaluación continua del grado de cumplimiento.
Se trata de listas de verificación que permiten a una entidad evaluar su nivel de cumplimiento de forma autónoma.
La utilización de estas checklists proporciona múltiples beneficios a las organizaciones. En primer lugar, facilitan la identificación temprana de brechas de cumplimiento, permitiendo a las organizaciones tomar medidas correctivas antes de la comercialización o puesta en servicio del sistema. También promueven un enfoque sistemático y estructurado del cumplimiento normativo. Al seguir la estructura de los artículos del Reglamento, garantizan que ningún requisito esencial quede sin evaluar.
Por otro lado, facilitan la comunicación entre equipos técnicos, jurídicos y de gestión, proporcionando un lenguaje común y una referencia compartida para discutir el cumplimiento normativo. Y, por último, las checklists sirven como base documental para demostrar la debida diligencia ante las autoridades supervisoras.
Debemos entender que estos documentos no son estáticos. Están sujetos a un proceso permanente de evaluación y revisión. En este sentido, la AESIA continúa desarrollando su capacidad operativa y ampliando sus herramientas de apoyo al cumplimiento.
Desde la plataforma de datos abiertos del Gobierno de España, te invitamos a explorar estos recursos. El desarrollo de la IA debe ir de la mano con datos bien gobernados y supervisión ética.
Blog
Durante más de una década, las plataformas de datos abiertos han medido su impacto a través de indicadores relativamente estables: número de descargas, visitas a la web, reutilizaciones documentadas, aplicaciones o servicios creados en base a ellos, etc. Estos indicadores funcionaban bien en un ecosistema donde los usuarios - empresas, periodistas, desarrolladores, ciudadanos anónimos, etc. - accedían directamente a las fuentes originales para consultar, descargar y procesar los datos.
Sin embargo, el panorama ha cambiado radicalmente. La irrupción de los modelos de inteligencia artificial generativa ha transformado la forma en que las personas acceden a la información. Estos sistemas generan respuestas sin necesidad de que el usuario visite la fuente original, lo que está provocando una caída global del tráfico web en medios, blogs y portales de conocimiento.
En este nuevo contexto, medir el impacto de una plataforma de datos abiertos exige repensar los indicadores tradicionales para incorporar a las métricas ya utilizadas otras nuevas que capturen también la visibilidad e influencia de los datos en un ecosistema donde la interacción humana está cambiando.
Un cambio estructural: del clic a la consulta indirecta
El ecosistema web está experimentando una transformación profunda impulsada por el auge de los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés). Cada vez más personas formulan sus preguntas directamente a sistemas como ChatGPT, Copilot, Gemini o Perplexity, obteniendo respuestas inmediatas y contextualizadas sin necesidad de recurrir a un buscador tradicional.
Al mismo tiempo, quienes continúan utilizando motores de búsqueda como Google o Bing también experimentan cambios relevantes derivados de la integración de la inteligencia artificial en estas plataformas. Google, por ejemplo, ha incorporado funciones como AI Overviews, que ofrece resúmenes generados automáticamente en la parte superior de los resultados, o el Modo IA, una interfaz conversacional que permite profundizar en una consulta sin navegar por enlaces. Esto genera un fenómeno conocido como Zero-Click: el usuario realiza una búsqueda en un motor como Google y obtiene la respuesta directamente en la propia página de resultados. En consecuencia, no tiene necesidad de hacer clic en ningún enlace externo, lo cual limita las visitas a las fuentes originales de las que está extraída la información.
Todo ello implica una consecuencia clave: el tráfico web deja de ser un indicador fiable de impacto. Una página web puede estar siendo extremadamente influyente en la generación de conocimiento sin que ello se traduzca en visitas.

Figura 1. Métricas para medir el impacto de los datos abiertos en la era de la IA. Fuente: elaboración propia.
Nuevas métricas para medir el impacto
Ante esta situación, las plataformas de datos abiertos necesitan nuevas métricas que capturen su presencia en este nuevo ecosistema. A continuación, se recogen algunas de ellas.
-
Share of Model (SOM): presencia en los modelos de IA
Inspirado en métricas del marketing digital, el Share of Model mide con qué frecuencia los modelos de IA mencionan, citan o utilizan datos procedentes de una fuente concreta. De esta forma, el SOM ayuda a ver qué conjuntos de datos concretos (empleo, clima, transporte, presupuestos, etc.) son utilizados por los modelos para responder preguntas reales de los usuarios, revelando qué datos tienen mayor impacto.
Esta métrica resulta especialmente valiosa porque actúa como un indicador de confianza algorítmica: cuando un modelo menciona una página web, está reconociendo su fiabilidad como fuente. Además, contribuye a aumentar la visibilidad indirecta, ya que el nombre de la web aparece en la respuesta incluso cuando el usuario no llega a hacer clic.
-
Análisis de sentimiento: tono de las menciones en IA
El análisis de sentimiento permite ir un paso más allá del Share of Model, ya que no solo identifica si un modelo de IA menciona una marca o dominio, sino cómo lo hace. Habitualmente, esta métrica clasifica el tono de la mención en tres categorías principales: positivo, neutro y negativo.
Aplicado al ámbito de los datos abiertos, este análisis ayuda a comprender la percepción algorítmica de una plataforma o conjunto de datos. Por ejemplo, permite detectar si un modelo utiliza una fuente como ejemplo de buenas prácticas, si la menciona de forma neutral como parte de una respuesta informativa o si la asocia a problemas, errores o datos desactualizados.
Esta información puede resultar útil para identificar oportunidades de mejora, reforzar la reputación digital o detectar posibles sesgos en los modelos de IA que afecten a la visibilidad de una plataforma de datos abiertos.
-
Categorización de prompts: en qué temas destaca una marca
Analizar las preguntas que hacen los usuarios permite identificar en qué tipos de consultas aparece con mayor frecuencia una marca. Esta métrica ayuda a entender en qué áreas temáticas -como economía, salud, transporte, educación o clima- los modelos consideran más relevante una fuente.
Para las plataformas de datos abiertos, esta información revela qué conjuntos de datos están siendo utilizados para responder preguntas reales de los usuarios y en qué dominios existe mayor visibilidad o potencial de crecimiento. También permite detectar oportunidades: si una iniciativa de datos abiertos quiere posicionarse en nuevas áreas, puede evaluar qué tipo de contenido falta o qué conjuntos de datos podrían reforzarse para aumentar su presencia en esas categorías.
-
Tráfico procedente de IA: clics desde resúmenes generados
Muchos modelos ya incluyen enlaces a las fuentes originales. Aunque muchos usuarios no hacen clic en dichos enlaces, algunos sí lo hacen. Por ello, las plataformas pueden empezar a medir:
- Visitas procedentes de plataformas de IA (cuando estas incluyen enlaces).
- Clics desde resúmenes enriquecidos en buscadores que integran IA.
Esto supone un cambio en la distribución del tráfico que llega a las webs desde los distintos canales. Mientras el tráfico orgánico —el que proviene de los motores de búsqueda tradicionales— está disminuyendo, empieza a crecer el tráfico referido desde los modelos de lenguaje.
Este tráfico será menor en cantidad que el tradicional, pero más cualificado, ya que quien hace clic desde una IA suele tener una intención clara de profundizar.
Es importante que se tengan en cuenta estos aspectos a la hora de fijar objetivos de crecimiento en una plataforma de datos abiertos.
-
Reutilización algorítmica: uso de datos en modelos y aplicaciones
Los datos abiertos alimentan modelos de IA, sistemas predictivos y aplicaciones automatizadas. Conocer qué fuentes se han utilizado para su entrenamiento sería también una forma de conocer su impacto. Sin embargo, pocas soluciones proporcionan de manera directa esta información. La Unión Europea está trabajando para promover la transparencia en este campo, con medidas como la plantilla para documentar los datos de entrenamiento de modelos de propósito general, pero su implantación -y la existencia de excepciones a su cumplimiento- hacen que el conocimiento sea aún limitado.
Medir el incremento de accesos a los datos mediante API podría dar una idea de su uso en aplicaciones para alimentar sistemas inteligentes. Sin embargo, el mayor potencial en este campo pasa por colaboración con empresas, universidades y desarrolladores inmersos en estos proyectos, para que ofrezcan una visión más realista del impacto.
Conclusión: medir lo que importa, no solo lo que es fácil de medir
La caída del tráfico web no significa una caída del impacto. Significa un cambio en la forma en que la información circula. Las plataformas de datos abiertos deben evolucionar hacia métricas que reflejen la visibilidad algorítmica, la reutilización automatizada y la integración en modelos de IA.
Esto no significa que las métricas tradicionales deban desaparecer. Conocer los accesos a la web, los conjuntos de datos más visitados o los más descargados sigue siendo una información de gran valor para conocer el impacto de los datos proporcionados a través de plataformas abiertas. Y también es fundamental monitorizar el uso de los datos a la hora de generar o enriquecer productos y servicios, incluidos los sistemas de inteligencia artificial. En la era de la IA, el éxito ya no se mide solo por cuántos usuarios visitan una plataforma, sino también por cuántos sistemas inteligentes dependen de su información y la visibilidad que ello otorga.
Por eso, integrar estas nuevas métricas junto a los indicadores tradicionales a través de una estrategia de analítica web y SEO * permite obtener una visión más completa del impacto real de los datos abiertos. Así podremos saber cómo circula nuestra información, cómo se reutiliza y qué papel juega en el ecosistema digital que hoy da forma a la sociedad.
*El SEO (Search Engine Optimization) es el conjunto de técnicas y estrategias destinadas a mejorar la visibilidad de un sitio web en los motores de búsqueda.
Noticia
Las administraciones públicas y, en concreto, las entidades locales se encuentran en un momento crucial de transformación digital. El desarrollo acelerado de la inteligencia artificial (IA) plantea tanto oportunidades extraordinarias como desafíos complejos que requieren una adaptación estructurada, ética y fundamentada. En este contexto, la Federación Española de Municipios y Provincias (FEMP) ha lanzado la Guía Práctica y Políticas de Uso de la Inteligencia Artificial en las Entidades Locales, un documento de referencia que aspira a funcionar como brújula para ayuntamientos, diputaciones y demás entidades locales en su camino hacia la adopción responsable de esta tecnología que avanza a pasos agigantados.
La guía parte de una idea clave: la IA no es solo una cuestión tecnológica, sino organizativa, jurídica, ética y cultural. Su implantación exige planificación, gobernanza y una visión estratégica adaptada al tamaño y madurez digital de cada entidad local. En este post, veremos algunas claves relevantes del documento.
En este vídeo puedes volver a ver la sesión de presentación de la Guía.
La guía parte de una idea clave: la IA no es solo una cuestión tecnológica, sino organizativa, jurídica, ética y cultural. Su implantación exige planificación, gobernanza y una visión estratégica adaptada al tamaño y madurez digital de cada entidad local. En este post, veremos algunas claves relevantes del documento.
Por qué una guía sobre IA para las entidades locales
Las administraciones locales llevan años persiguiendo la mejora continua de los servicios públicos, pero a menudo se han visto limitadas por la falta de recursos tecnológicos, la rigidez organizativa o la fragmentación de los datos. La IA abre una oportunidad inédita para superar muchas de estas barreras, porque permite:
- Automatizar procesos.
- Analizar grandes volúmenes de información.
- Anticipar necesidades ciudadanas.
- Personalizar la atención pública.
Sin embargo, junto a estas oportunidades surgen riesgos evidentes: pérdida de transparencia, sesgos discriminatorios, vulneraciones de la privacidad o una automatización acrítica de decisiones que afectan a derechos fundamentales. De ahí la necesidad de una guía que ayude a saber qué se puede hacer con IA, qué no se debe hacer y cómo hacerlo con garantías.
El 48% de las administraciones públicas utiliza la Inteligencia Artificial para agilizar la relación con el ciudadano
La guía se estructura en torno a varios ejes fundamentales que abordan las múltiples dimensiones de la implementación de IA en el ámbito local:
El marco jurídico: el Reglamento Europeo de IA como eje central
Uno de los pilares de la guía es el análisis del Reglamento Europeo de Inteligencia Artificial (RIA), la primera norma integral a nivel mundial que regula la IA con un enfoque basado en el riesgo, y que afecta de lleno a las entidades locales tanto si desarrollan sistemas de IA como si los utilizan o contratan.
En concreto, los distintos niveles de riesgo que reconoce la RIA son:
- Riesgo inadmisible: incluye prácticas prohibidas como la puntuación social, la manipulación subliminal o ciertos usos de biometría.
- Riesgo alto: abarca sistemas utilizados en ámbitos sensibles como la gestión de servicios públicos, el empleo, la educación, la seguridad o la toma de decisiones administrativas. Estos sistemas deben cumplir con una serie de requisitos estrictos, como por ejemplo la necesidad de supervisión humana o la trazabilidad de los datos.
- Riesgo específico de transparencia: se aplica a chatbots o contenidos generados por IA y se les impone principalmente obligaciones de información (por ejemplo, etiquetar los contenidos como generados por una IA).
- Riesgo mínimo: como filtros de correo no deseado o videojuegos basados en IA, sin obligaciones, aunque se recomienda adoptar códigos de conducta.
Un aspecto crucial es que, desde febrero de 2025, las entidades locales deben alfabetizar en IA a su personal, es decir, ofrecer formación para que quienes operan estos sistemas comprendan sus implicaciones técnicas, jurídicas y éticas. Además, deben revisar si alguno de sus sistemas incurre en las prácticas prohibidas por el RIA, como la manipulación subliminal o el social scoring (puntuación social).
Para las entidades locales, esto implica la necesidad de identificar qué sistemas de IA utilizan, evaluar su nivel de riesgo y cumplir con las obligaciones correspondientes.
IA, procedimiento administrativo y protección de datos
La guía recuerda que automatizar un proceso no equivale necesariamente a usar IA, pero que cuando se incorporan sistemas capaces de inferir, recomendar o decidir, el impacto jurídico es mucho mayor.
La incorporación de IA en procedimientos administrativos debe respetar principios como:
- Transparencia y explicabilidad de las decisiones.
- Identificación del órgano responsable.
- Posibilidad de impugnación.
- Supervisión humana efectiva.
Además, el uso de IA debe ser plenamente compatible con el Reglamento General de Protección de Datos (RGPD). Las entidades locales deben poder justificar las decisiones automatizadas, garantizar los derechos de las personas afectadas y extremar las precauciones cuando se tratan datos personales sensibles.
Gobernar los datos para gobernar la IA
La guía es tajante en un punto: no se puede implementar IA sin una sólida gobernanza de datos. La IA se alimenta de datos, y su calidad, disponibilidad y gestión ética determinarán el éxito o fracaso de cualquier iniciativa. El documento introduce el concepto de "dato único" y se refiere a la información unificada. En relación con esto, se ha visto que muchas organizaciones descubren deficiencias estructurales precisamente al intentar implementar IA, una idea que se abordó en el pódcast de datos.gob.es sobre datos e IA.
Para la gobernanza de datos en la IA en el contexto local, la guía define la importancia de:
- La privacidad desde el diseño.
- Valor estratégico de los datos.
- Responsabilidad ética institucional.
- Trazabilidad.
- Conocimiento compartido y gestión de la calidad.
Además, se recomienda la adopción de marcos internacionales reconocidos como DAMA-DMBOOK.
La guía también insiste en la importancia de la calidad, disponibilidad y correcta gestión de los datos para “garantizar un uso eficaz y responsable de la inteligencia artificial en nuestras administraciones locales". Para ello, es esencial:
• Adoptar estándares de interoperabilidad, como los ya existentes a nivel estatal y europeo.
• Utilizar APIs y sistemas de intercambio de datos seguros, que permitan compartir información de forma eficiente entre distintos organismos públicos.
• Aprovechar fuentes de datos abiertos, como las que proporciona el Portal de Datos Abiertos del Gobierno de España o las plataformas locales de datos públicos.
Cómo conocer el estado de madurez en IA
Otro de los aspectos más innovadores de la guía es la metodología FEMP.IA, que permite a las entidades locales autoevaluar su nivel de madurez organizativa para el despliegue de IA. Esta metodología distingue tres niveles progresivos que deberían adoptarse en orden:
- Nivel 1 - Administración Electrónica (AE): digitalización de áreas de negocio mediante soluciones corporativas basadas en el dato único.
- Nivel 2 - Robotización de Procesos Automatizados (RPA): automatización de procesos de gestión y actuaciones administrativas.
- Nivel 3 - Inteligencia Artificial: utilización de herramientas de análisis especializado que facilitan información obtenida automáticamente.
Esta aproximación gradual es fundamental, pues reconoce que no todas las entidades parten del mismo punto y que intentar saltar etapas puede resultar contraproducente.
La guía incide en que la IA debe verse como una herramienta de apoyo, no como un sustituto del juicio humano, especialmente en decisiones sensibles.
Requisitos para desplegar IA en una entidad local
El documento detalla de forma sistemática los requisitos necesarios para implantar IA con garantías:
- Normativos y éticos, asegurando el cumplimiento legal y el respeto a los derechos fundamentales.
- Organizativos, definiendo roles técnicos, jurídicos y de gobernanza.
- Tecnológicos, incluyendo infraestructura, integración con sistemas existentes, escalabilidad y ciberseguridad.
- Estratégicos, apostando por despliegues progresivos, pilotos y evaluación continua.
Más allá de la tecnología, la guía subraya la importancia de la ética, la transparencia y la confianza ciudadana. Todo ello es clave y apunta la idea de que el éxito no radica en avanzar rápido, sino en avanzar bien: con una base sólida, evitando improvisaciones y garantizando que la IA se aplique de manera ética, eficaz y orientada al interés general.
Asimismo, se destaca la relevancia de la colaboración público-privada y del intercambio de experiencias entre entidades locales, como vía para reducir riesgos, compartir conocimiento y optimizar recursos.
Casos reales y conclusiones
El documento se completa con numerosos casos de uso reales en ayuntamientos y diputaciones, que demuestran que la IA ya es una realidad tangible en ámbitos como la atención ciudadana, la gestión social, las licencias urbanísticas o los chatbots municipales.
En conclusión, la guía de la FEMP se presenta como un manual imprescindible para cualquier entidad local que quiera abordar la IA con responsabilidad. Su principal aportación no es solo explicar qué es la IA, sino ofrecer un marco práctico para implantarla con sentido, poniendo siempre en el centro a la ciudadanía, los derechos fundamentales y el buen gobierno.
Blog
El contenido masivo y superficial generado por IA no es solo un problema, también es un síntoma. La tecnología amplifica un modelo de consumo que premia la fluidez y agota nuestra capacidad de atención.
Escuchamos entrevistas, pódcasts y audios de nuestra familia al 2x. Vemos vídeos recortados en highlights, y basamos decisiones y criterios en artículos e informes que solo hemos leído resumidos con IA. Consumimos información en modo ultrarrápido, pero a nivel cognitivo le damos la misma validez que cuando la consumíamos más despacio, e incluso la aplicamos en la toma de decisiones. Lo que queda afectado por este proceso no es la memoria básica de contenidos, que parece mantenerse según los estudios controlados, sino la capacidad de conectar esos conocimientos con los que ya teníamos y elaborar con ellos ideas propias. Más que la superficialidad, inquieta que esta nueva modalidad de pensamiento resulte suficiente en tantos contextos.
¿Qué es nuevo y qué no?
Podemos pensar que la IA generativa no ha hecho más que intensificar una dinámica antigua en la que la producción de contenido es infinita, pero nuestra capacidad de atención es la misma. No podemos engañarnos tampoco, porque desde que existe Internet la infinitud no es novedad. Si dijéramos que el problema es que hay demasiado contenido, estaríamos quejándonos de una situación en la que vivimos desde hace más de veinte años. Tampoco es nueva la crisis de autoridad de la información oficial o la dificultad para distinguir fuentes fiables de las que no lo son.
Sin embargo, el AI slop, que es la inundación de contenido digital generado con IA en Internet, aporta una lógica propia y consideraciones nuevas, como la ruptura del vínculo entre esfuerzo y contenido, o que todo lo que se genera es un promedio estadístico de lo que ya existía. Este flujo uniforme y descontrolado tiene consecuencias: detrás del contenido generado en masa puede haber una intención orquestada de manipulación, un sesgo algorítmico, voluntario o no, que perjudique a determinados colectivos o frene avances sociales, y también una distorsión de la realidad aleatoria e impredecible.
¿Pero cuánto de lo que leo es IA?
En 2025 se ha estimado que una gran parte del contenido online incorpora texto sintético: un análisis de Ahrefs de casi un millón de páginas web publicadas en la primera mitad del año detectó que el 74,2 % de las nuevas páginas contenían señales de contenido generado con IA. Una investigación de Graphite del mismo año cita que, solo durante el primer año de ChatGPT, un 39% de todo el contenido online estaba ya generado con IA. Desde noviembre de 2024 esa cifra se ha mantenido estable en torno al 52%, lo que significa que desde entonces el contenido IA supera en cantidad al contenido humano.
No obstante, hay dos preguntas que deberíamos hacernos cuando nos encontramos estimaciones de este tipo:
1. ¿Existe un mecanismo fiable para distinguir un texto escrito de un texto generado? Si la respuesta es no, por muy llamativas y coherentes que sean las conclusiones, no podemos darles valor, porque tanto podrían ser ciertas como no serlo. Es un dato cuantitativo valioso, pero que aún no existe.
Con la información que tenemos actualmente, podemos afirmar que los detectores de "texto generado por IA" fallan con la misma frecuencia con la que fallaría un modelo aleatorio, por lo que no podemos atribuirles fiabilidad. En un estudio reciente citado por The Guardian, los detectores acertaron si el texto estaba generado con IA o no en menos de un 40% de los casos. Por otro lado, ante el primer párrafo de El Quijote, también determinados detectores han devuelto un 86% de probabilidad de que el texto estuviera creado por IA.
2. ¿Qué significa que un texto está generado con IA? Por otro lado, no siempre el proceso es completamente automático (lo que llamamos copiar y pegar) sino que se dan muchos grises en la escala: la IA inspira, organiza, asiste, reescribe o expande ideas, y negar, deslegitimar o penalizar esta escritura sería ignorar una realidad instalada.
Los dos matices anteriores no anulan el hecho de que existe el AI slop, pero este no tiene por qué ser un destino inevitable. Existen maneras de mitigar sus efectos en nuestras capacidades.
¿Cuáles son los antídotos?
Podemos no contribuir a la producción de contenido sintético, pero no podemos desacelerar lo que está ocurriendo, así que el reto consiste en revisar los criterios y los hábitos mentales con los que abordamos tanto la lectura como la escritura de contenidos.
1. Prioriza lo que hace clic: una de las pocas señales fiables que nos quedan es esa sensación de clic en el momento en que algo conecta con un conocimiento previo, una intuición que teníamos difusa o una experiencia propia, y la reorganiza o la hace nítida. Solemos decir también que “resuena”. Si algo hace clic, merece la pena seguirlo, confirmarlo, investigarlo y elaborarlo brevemente a nivel personal.
2. Busca la fricción con datos: anclar el contenido en datos abiertos y fuentes contrastables introduce una fricción saludable frente al AI slop. Reduce, sobre todo, la arbitrariedad y la sensación de contenido intercambiable, porque los datos obligan a interpretar y poner en contexto. Es una manera de poner piedras en el río excesivamente fluido que supone la generación de lenguaje, y funciona cuando leemos y cuando escribimos.
3. ¿Quién se responsabiliza? el texto existe fácilmente ahora, la cuestión es por qué existe o qué quiere conseguir, y quién se hace cargo en última instancia de ese objetivo. Busca la firma de personas u organizaciones, no tanto por la autoría sino por la responsabilidad. Desconfía de las firmas colectivas, también en traducciones y adaptaciones.
4. Cambia el foco del mérito: evalúa tus inercias al leer, porque quizá un día aprendiste a dar mérito a textos que sonaban convincentes, utilizaban determinadas estructuras o subían a un registro concreto. Desplaza el valor a elementos no generables como encontrar una buena historia, saber formular una idea difusa o atreverse a dar un punto de vista en un contexto polémico.
En la otra cara de la moneda, también es un hecho que el contenido creado con IA entra con ventaja en el flujo, pero con desventaja en la credibilidad. Esto significa que el auténtico riesgo ahora es que la IA pueda llegar a crear contenido de alto valor, pero las personas hayamos perdido la capacidad de concentración para valorarlo. A esto hay que añadirle el prejuicio instalado de que, si es con IA, no es un contenido válido. Proteger nuestras capacidades cognitivas y aprender a diferenciar entre un contenido comprimible y uno que no lo es no es por tanto un gesto nostálgico, sino una habilidad que a la larga puede mejorar la calidad del debate público y el sustrato del conocimiento común.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.