Blog
La inteligencia artificial (IA) se ha convertido en una tecnología central en la vida de las personas y en la estrategia de las empresas. En poco más de una década hemos pasado de interactuar con asistentes virtuales que entendían órdenes sencillas, a ver sistemas capaces de redactar informes completos, crear imágenes hiperrealistas o incluso escribir código.
Este salto tan visible ha hecho que muchos se pregunten: ¿es todo lo mismo?, ¿qué diferencia hay entre lo que ya conocíamos como IA y esta nueva “IA Generativa” de la que tanto se habla?
En este artículo vamos a ordenar esas ideas y explicar, con ejemplos claros, cómo encajan la IA “Tradicional” y la IA Generativa bajo el gran paraguas de la inteligencia artificial.
La IA tradicional: análisis y predicción
Durante muchos años, lo que entendíamos por IA estaba más cerca de lo que hoy llamamos “IA Tradicional”. Estos sistemas se caracterizan por resolver problemas concretos, bien definidos y dentro de un marco de reglas o datos disponibles.
Algunos ejemplos prácticos:
-
Motores de recomendación: Spotify sugiere canciones basadas en tu historial de escucha y Netflix ajusta su catálogo a tus gustos personales, generando hasta el 80% de las visualizaciones en la plataforma.
-
Sistemas de predicción: Walmart utiliza modelos predictivos para anticipar la demanda de productos en función de factores como el clima o eventos locales; Red Eléctrica de España aplica algoritmos similares para prever el consumo eléctrico y equilibrar la red.
- Reconocimiento automático: Google Photos clasifica imágenes reconociendo rostros y objetos; Visa y Mastercard usan modelos de detección de anomalías para identificar fraudes en tiempo real; herramientas como Otter.ai transcriben reuniones y llamadas automáticamente.
En todos estos casos, los modelos aprenden de datos pasados para ofrecer una clasificación, una predicción o una decisión. No inventan nada nuevo, sino que reconocen patrones y los aplican al futuro.
La IA Generativa: creación de contenido
La novedad de la IA generativa es que no solo analiza, sino que produce (genera) a partir de los datos que tiene.
En la práctica, esto significa que:
-
Puede generar texto estructurado a partir de un par de ideas iniciales.
-
Puede combinar elementos visuales existentes a partir de una descripción escrita.
-
Puede crear prototipos de productos, borradores de presentaciones o proponer fragmentos de código basados en patrones aprendidos.
La clave está en que los modelos generativos no se limitan a clasificar o predecir, sino que generan nuevas combinaciones basadas en lo que aprendieron durante su entrenamiento.
El impacto de este avance es enorme: en el mundo del desarrollo, GitHub Copilot ya incluye agentes que detectan y corrigen errores de programación por sí mismos; en diseño, la herramienta Nano Banana de Google promete revolucionar la edición de imágenes con una eficacia que podría dejar obsoletos programas como Photoshop; y en música, bandas enteramente creadas por IA como Velvet Velvet Sundown ya superan el millón de oyentes mensuales en Spotify, con canciones, imágenes y biografía totalmente generadas, sin músicos reales detrás.
¿Cuándo es mejor utilizar cada tipo de IA?
La elección entre IA Tradicional y Generativa no es cuestión de moda, sino de qué necesidad concreta se quiere resolver. Cada una brilla en situaciones distintas:
IA Tradicional: la mejor opción cuando…
-
Necesitas predecir comportamientos futuros basándote en datos históricos (ventas, consumo energético, mantenimiento predictivo).
-
Quieres detectar anomalías o clasificar información de forma precisa (fraude en transacciones, diagnóstico por imágenes, spam).
-
Buscas optimizar procesos para ganar eficiencia (logística, rutas de transporte, gestión de inventarios).
-
Trabajas en entornos críticos donde la fiabilidad y la precisión son imprescindibles (salud, energía, finanzas).
Utilízala cuando el objetivo es tomar decisiones basadas en datos reales con la máxima precisión posible.
IA Generativa: la mejor opción cuando…
-
Necesitas crear contenido (textos, imágenes, música, vídeos, código).
-
Quieres prototipar o experimentar con rapidez, explorando diferentes escenarios antes de decidir (diseño de productos, pruebas en I+D).
-
Buscas interacción más natural con usuarios (chatbots, asistentes virtuales, interfaces conversacionales).
-
Requieres personalización a gran escala, generando mensajes o materiales adaptados a cada individuo (marketing, formación, educación).
-
Te interesa simular escenarios que no puedes obtener fácilmente con datos reales (casos clínicos ficticios, datos sintéticos para entrenar otros modelos).
Utilízala cuando el objetivo es crear, personalizar o interactuar de una manera más humana y flexible.
Un ejemplo del ámbito sanitario lo ilustra bien:
-
La IA tradicional puede analizar miles de registros clínicos para anticipar la probabilidad de que un paciente desarrolle una enfermedad.
-
La IA generativa puede crear escenarios ficticios para entrenar a estudiantes de medicina, generando casos clínicos realistas sin exponer datos reales de pacientes.
¿Compiten o se complementan?
En 2019, Gartner introdujo el concepto de Composite AI para describir soluciones híbridas que combinaban distintos enfoques de inteligencia artificial con el fin de resolver un problema de manera más completa. Aunque entonces era un término poco extendido, hoy cobra más relevancia que nunca gracias a la irrupción de la IA Generativa.
La IA Generativa no sustituye a la IA Tradicional, sino que la complementa. Cuando se integran ambos enfoques dentro de un mismo flujo de trabajo, se logran resultados mucho más potentes que si se empleara cada tecnología por separado.
Aunque, según Gartner, Composite AI continúa en la fase de Innovation Trigger, donde una tecnología emergente comienza a generar interés, y aunque su uso práctico todavía es limitado, ya vemos muchas nuevas tendencias generándose en múltiples sectores:
-
En retail: un sistema tradicional predice cuántos pedidos recibirá una tienda la próxima semana, y una IA generativa genera automáticamente descripciones de producto personalizadas para los clientes de esos pedidos.
-
En educación: un modelo tradicional evalúa el progreso de los estudiantes y detecta áreas débiles, mientras que una IA generativa diseña ejercicios o materiales adaptados a esas necesidades.
-
En diseño industrial: un algoritmo tradicional optimiza la logística de fabricación, mientras que una IA generativa propone prototipos de nuevas piezas o productos.
En definitiva, en lugar de cuestionar qué tipo de IA es más avanzada, lo acertado es preguntarse: ¿qué problema quiero resolver y qué enfoque de IA es el adecuado para ello?
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los asistentes de inteligencia artificial (IA) ya forman parte de nuestro día a día: les preguntamos la hora, cómo llegar a un determinado lugar o les pedimos que reproduzcan nuestra canción favorita. Y aunque la IA, en el futuro, pueda llegar a ofrecernos infinitas funcionalidades, no hay que olvidar que la diversidad lingüística es aún una asignatura pendiente.
En España, donde conviven el castellano junto con lenguas cooficiales como el euskera, catalán, valenciano y gallego, esta cuestión cobra especial relevancia. La supervivencia y vitalidad de estas lenguas en la era digital depende, en gran medida, de su capacidad para adaptarse y estar presentes en las tecnologías emergentes. Actualmente, la mayoría de asistentes virtuales, traductores automáticos o sistemas de reconocimiento de voz no entienden todos los idiomas cooficiales. Sin embargo, ¿sabías que existen proyectos colaborativos para garantizar la diversidad lingüística?
En este post te contamos el planteamiento y los mayores avances de algunas iniciativas que están construyendo los cimientos digitales necesarios para que las lenguas cooficiales en España también prosperen en la era de la inteligencia artificial.
ILENIA, el paraguas coordinador de iniciativas de recursos multilingües en España
Los modelos que vamos a ver en este post comparten enfoque porque forman parte de ILENIA, coordinador a nivel estatal que conecta los esfuerzos individuales de las comunidades autónomas. Esta iniciativa agrupa los proyectos BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) y la Universidad de Santiago de Compostela (NÓS), con el objetivo de generar recursos digitales que permitan desarrollar aplicaciones multilingües en las diferentes lenguas de España.
El éxito de estas iniciativas depende fundamentalmente de la participación ciudadana. A través de plataformas como Common Voice de Mozilla, cualquier hablante puede contribuir a la construcción de estos recursos lingüísticos mediante diferentes modalidades de colaboración:
- Habla leída: recopilar diferentes maneras de hablar a través de las donaciones de voz de un texto específico.
- Habla espontánea: crea datasets reales y orgánicos fruto de conversaciones con los prompts.
- Texto en idioma: colaborar en la transcripción de audios o en la aportación de contenido textual, sugiriendo nuevas frases o preguntas para enriquecer los corpus.
Todos los recursos se publican bajo licencias libres como CC0, permitiendo su uso gratuito por parte de investigadores, desarrolladores y empresas.
El reto de la diversidad lingüística en la era digital
Los sistemas de inteligencia artificial aprenden de los datos que reciben durante su entrenamiento. Para desarrollar tecnologías que funcionen correctamente en una lengua específica, es imprescindible contar con grandes volúmenes de datos: grabaciones de audio, corpus de texto y ejemplos de uso real del idioma.
En otras publicaciones de datos.gob.es hemos abordado el funcionamiento de los modelos fundacionales y las iniciativas en castellano como ALIA, entrenadas con grandes corpus de texto como los de la Real Academia Española.
En ambos posts se explica por qué la recopilación de datos lingüísticos no es una tarea barata ni sencilla. Las empresas tecnológicas han invertido masivamente en recopilar estos recursos para lenguas con gran número de hablantes, pero las lenguas cooficiales españolas se enfrentan a una desventaja estructural. Esto ha llevado a que muchos modelos no funcionen correctamente o no estén disponibles en valenciano, catalán, euskera o gallego.
No obstante, existen iniciativas colaborativas y de datos abiertos que permiten crear recursos lingüísticos de calidad. Se trata de los proyectos que varias comunidades autónomas han puesto en marcha marcando el camino hacia un futuro digital multilingüe.
Por un lado, el Proyecto Nós en Galicia crea recursos orales y conversacionales en gallego con todos los acentos y variantes dialectales para facilitar la integración a través de herramientas como GPS, asistentes de voz o ChatGPT. Un propósito similar el de Aina en Catalunya que además ofrece una plataforma académica y un laboratorio para desarrolladores o Vives en la Comunidad Valenciana. En el País Vasco también existe el proyecto Euskorpus que tiene como objetivo la constitución de un corpus de texto de calidad en euskera. Veamos cada uno de ellos.
Proyecto Nós, un enfoque colaborativo para el gallego digital
El proyecto ha desarrollado ya tres herramientas operativas: un traductor neuronal multilingüe, un sistema de reconocimiento de voz que convierte habla en texto, y una aplicación de síntesis de voz. Estos recursos se publican bajo licencias abiertas, garantizando su acceso libre y gratuito para investigadores, desarrolladores y empresas. Estas son sus características principales:
- Impulsado por: la Xunta de Galicia y la Universidad de Santiago de Compostela.
- Objetivo principal: crear recursos orales y conversacionales en gallego que capturen la diversidad dialectal y de acentos de la lengua.
- Cómo participar: el proyecto acepta contribuciones voluntarias tanto leyendo textos como respondiendo a preguntas espontáneas.
- Dona tu voz en gallego: https://doagalego.nos.gal
Aina, hacia una IA que entienda y hable catalán
Con un planteamiento similar al proyecto Nós, Aina busca facilitar la integración del catalán en los modelos de lenguaje de inteligencia artificial.
Se estructura en dos vertientes complementarias que maximizan su impacto:
- Aina Tech se centra en facilitar la transferencia tecnológica al sector empresarial, proporcionando las herramientas necesarias para traducir automáticamente al catalán webs, servicios y negocios en línea.
- Aina Lab impulsa la creación de una comunidad de desarrolladores a través de iniciativas como Aina Challenge, fomentando la innovación colaborativa en tecnologías del lenguaje en catalán. A través de esta convocatoria se han premiado 22 propuestas ya seleccionadas con un importe total de 1 millón para que ejecuten sus proyectos.
Las características del proyecto son:
- Impulsado por: la Generalitat de Catalunya en colaboración con el Barcelona Supercomputing Center (BSC-CNS)
- Objetivo principal: va más allá de la creación de herramientas, busca construir una infraestructura de IA abierta, transparente y responsable con el catalán.
- Cómo participar: puedes añadir comentarios, mejoras y sugerencias a través del buzón de contacto: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, el proyecto colaborativo para IA en valenciano
Por otro lado, Vives recopila voces hablando en valenciano para que sirvan de entrenamiento a los modelos de IA.
- Impulsado por: el Centro de Inteligencia Digital de Alicante (CENID).
- Objetivo: busca crear corpus masivos de texto y voz, fomentar la participación ciudadana en la recolección de datos, y desarrollar modelos lingüísticos especializados en sectores como el turismo y el audiovisual, garantizando la privacidad de los datos.
- Cómo participar: puedes donar tu voz a través de este enlace: https://vives.gplsi.es/instruccions/.
Gaitu: inversión estratégica en la digitalización del euskera
En Euskera, podemos destacar Gaitu que busca recopilar voces hablando en euskera para poder entrenar los modelos de IA. Sus características son:
- Impulsado por: HiTZ, el centro vasco de tecnología de la lengua.
- Objetivo: desarrollar un corpus en euskera para entrenar modelos de IA.
- Cómo participar: puedes donar tu voz en euskera aquí https://commonvoice.mozilla.org/eu/speak.
Ventajas de construir y preservar modelos de lenguaje multilingües
Los proyectos de digitalización de las lenguas cooficiales trascienden el ámbito puramente tecnológico para convertirse en herramientas de equidad digital y preservación cultural. Su impacto se manifiesta en múltiples dimensiones:
- Para la ciudadanía: estos recursos garantizan que hablantes de todas las edades y niveles de competencia digital puedan interactuar con la tecnología en su lengua materna, eliminando barreras que podrían excluir a determinados colectivos del ecosistema digital.
- Para el sector empresarial: la disponibilidad de recursos lingüísticos abiertos facilita que empresas y desarrolladores puedan crear productos y servicios en estas lenguas sin asumir los altos costes tradicionalmente asociados al desarrollo de tecnologías lingüísticas.
- Para el tejido investigador, estos corpus constituyen una base fundamental para el avance de la investigación en procesamiento de lenguaje natural y tecnologías del habla, especialmente relevante para lenguas con menor presencia en recursos digitales internacionales.
El éxito de estas iniciativas demuestra que es posible construir un futuro digital donde la diversidad lingüística no sea un obstáculo sino una fortaleza, y donde la innovación tecnológica se ponga al servicio de la preservación y promoción del patrimonio cultural lingüístico.
Blog
Durante los últimos años hemos visto avances espectaculares en el uso de la inteligencia artificial (IA) y, detrás de todos estos logros, siempre encontraremos un mismo ingrediente común: los datos. Un ejemplo ilustrativo y conocido por todo el mundo es el de los modelos de lenguaje utilizados por OpenAI para su famoso ChatGPT, como por ejemplo GPT-3, uno de sus primeros modelos que fue entrenado con más de 45 terabytes de datos, convenientemente organizados y estructurados para que resultaran de utilidad.
Sin suficiente disponibilidad de datos de calidad y convenientemente preparados, incluso los algoritmos más avanzados no servirán de mucho, ni a nivel social ni económico. De hecho, Gartner estima que más del 40% de los proyectos emergentes de agentes de IA en la actualidad terminarán siendo abandonados a medio plazo debido a la falta de datos adecuados y otros problemas de calidad. Por tanto, el esfuerzo invertido en estandarizar, limpiar y documentar los datos puede marcar la diferencia entre una iniciativa de IA exitosa y un experimento fallido. En resumen, el clásico principio de “basura entra, basura sale” en la ingeniería informática aplicado esta vez a la inteligencia artificial: si alimentamos una IA con datos de baja calidad, sus resultados serán igualmente pobres y poco fiables.
Tomando consciencia de este problema surge el concepto de AI Data Readiness o preparación de los datos para ser usados por la inteligencia artificial. En este artículo exploraremos qué significa que los datos estén "listos para la IA", por qué es importante y qué necesitaremos para que los algoritmos de IA puedan aprovechar nuestros datos de forma eficaz. Esto revierta en un mayor valor social, favoreciendo la eliminación de sesgos y el impulso de la equidad.
¿Qué implica que los datos estén "listos para la IA"?
Tener datos listos para la IA (AI-ready) significa que estos datos cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial. Esto incluye múltiples aspectos como la completitud de los datos, la ausencia de errores e inconsistencias, el uso de formatos adecuados, metadatos y estructuras homogéneas, así como proporcionar el contexto necesario para poder verificar que estén alineados con el uso que la IA les dará.
Preparar datos para la IA suele requerir de un proceso en varias etapas. Por ejemplo, de nuevo la consultora Gartner recomienda seguir los siguientes pasos:
- Evaluar las necesidades de datos según el caso de uso: identificar qué datos son relevantes para el problema que queremos resolver con la IA (el tipo de datos, volumen necesario, nivel de detalle, etc.), entendiendo que esta evaluación puede ser un proceso iterativo que se refine a medida que el proyecto de IA avanza.
- Alinear las áreas de negocio y conseguir el apoyo directivo: presentar los requisitos de datos a los responsables según las necesidades detectadas y lograr su respaldo, asegurando así los recursos requeridos para preparar los datos adecuadamente.
- Desarrollar buenas prácticas de gobernanza de los datos: implementar políticas y herramientas de gestión de datos adecuadas (calidad, catálogos, linaje de datos, seguridad, etc.) y asegurarnos de que incorporen también las necesidades de los proyectos de IA.
- Ampliar el ecosistema de datos: integrar nuevas fuentes de datos, romper potenciales barreras y silos que estén trabajando de forma aislada dentro de la organización y adaptar la infraestructura para poder manejar los grandes volúmenes y variedad de datos necesarios para el correcto funcionamiento de la IA.
- Garantizar la escalabilidad y cumplimiento normativo: asegurar que la gestión de datos pueda escalar a medida que crecen los proyectos de IA, manteniendo al mismo tiempo un marco de gobernanza sólido y acorde con los protocolos éticos necesarios y el cumplimiento de la normativa existente.
Si seguimos una estrategia similar a esta estaremos consiguiendo integrar los nuevos requisitos y necesidades de la IA en nuestras prácticas habituales de gobernanza del dato. En esencia, se trata simplemente de conseguir que nuestros datos estén preparados para alimentar modelos de IA con las mínimas fricciones posibles, evitando posibles contratiempos a posteriori durante el desarrollo de los proyectos.
Datos abiertos “preparados para IA”
En el ámbito de la ciencia abierta y los datos abiertos se han promovido desde hace años los principios FAIR. Estas siglas en inglés establecen que los datos deben localizables, accesibles, interoperables y reutilizables. Los principios FAIR han servido para guiar la gestión de datos científicos y datos abiertos para hacerlos más útiles y mejorar su uso por parte de la comunidad científica y la sociedad en general. Sin embargo, dichos principios no fueron diseñados para abordan las nuevas necesidades particulares asociadas al auge de la IA.
Se plantea por tanto en la actualidad la propuesta de extender los principios originales añadiendo un quinto principio de preparación (readiness) para la IA, pasando así del FAIR inicial a FAIR-R o FAIR². El objetivo sería precisamente el de hacer explícitos aquellos atributos adicionales que hacen que los datos estén listos para acelerar su uso responsable y transparente como herramienta necesaria para las aplicaciones de la IA de alto interés público.

¿Qué añadiría exactamente esta nueva R a los principios FAIR? En esencia, enfatiza algunos aspectos como:
- Etiquetado, anotado y enriquecimiento adecuado de los datos.
- Transparencia sobre el origen, linaje y tratamiento de los datos.
- Estándares, metadatos, esquemas y formatos óptimos para su uso por parte de la IA.
- Cobertura y calidad suficientes para evitar sesgos o falta de representatividad.
En el contexto de los datos abiertos, esta discusión es especialmente relevante dentro del discurso de la "cuarta ola" del movimiento de apertura de datos, a través del cual se argumenta que si los gobiernos, universidades y otras instituciones liberan sus datos, pero estos no se encuentran en las condiciones óptimas para poder alimentar a los algoritmos, se estaría perdiendo una oportunidad única para todo un nuevo universo de innovación e impacto social: mejoras en los diagnósticos médicos, detección de brotes epidemiológicos, optimización del tráfico urbano y de las rutas de transporte, maximización del rendimiento de las cosechas o prevención de la deforestación son sólo algunos ejemplos de las posibles oportunidades perdidas.
Además, de no ser así, podríamos entrar también en un largo “invierno de los datos”, en el que las aplicaciones positivas de la IA se vean limitadas por conjuntos de datos de mala calidad, inaccesibles o llenos de sesgos. En ese escenario, la promesa de una IA por el bien común se quedaría congelada, incapaz de evolucionar por falta de materia prima adecuada, mientras que las aplicaciones de la IA lideradas por iniciativas con intereses privados continuarían avanzando y aumentando el acceso desigual al beneficio proporcionado por las tecnologías.
Conclusión: el camino hacia IA de calidad, inclusiva y con verdadero valor social
En la era de la inteligencia artificial, los datos son tan importantes como los algoritmos. Tener datos bien preparados y compartidos de forma abierta para que todos puedan utilizarlos, puede marcar la diferencia entre una IA que aporta valor social y una que tan sólo es capaz de producir resultados sesgados.
Nunca podemos dar por sentada la calidad ni la idoneidad de los datos para las nuevas aplicaciones de la IA: hay que seguir evaluándolos, trabajándolos y llevando a cabo una gobernanza de estos de forma rigurosa y efectiva del mismo modo que se venía recomendado para otras aplicaciones. Lograr que nuestros datos estén listos para la IA no es por tanto una tarea trivial, pero los beneficios a largo plazo son claros: algoritmos más precisos, reducir sesgos indeseados, aumentar la transparencia de la IA y extender sus beneficios a más ámbitos de forma equitativa.
Por el contrario, ignorar la preparación de los datos conlleva un alto riesgo de proyectos de IA fallidos, conclusiones erróneas o exclusión de quienes no tienen acceso a datos de calidad. Abordar las asignaturas pendientes sobre cómo preparar y compartir datos de forma responsable es esencial para desbloquear todo el potencial de la innovación impulsada por IA en favor del bien común. Si los datos de calidad son la base para la promesa de una IA más humana y equitativa, asegurémonos de construir una base suficientemente sólida para poder alcanzar nuestro objetivo.
En este camino hacia una inteligencia artificial más inclusiva, alimentada por datos de calidad y con verdadero valor social, la Unión Europea también está avanzando con pasos firmes. A través de iniciativas como su estrategia de la Data Union, la creación de espacios comunes de datos en sectores clave como salud, movilidad o agricultura, y el impulso del llamado AI Continent y las AI factories, Europa busca construir una infraestructura digital donde los datos estén gobernados de forma responsable, sean interoperables y estén preparados para ser utilizados por sistemas de IA en beneficio del bien común. Esta visión no solo promueve una mayor soberanía digital, sino que refuerza el principio de que los datos públicos deben servir para desarrollar tecnologías al servicio de las personas y no al revés.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
En la búsqueda habitual de trucos para hacer más efectivos nuestros prompts, uno de los más populares es la activación de la cadena de razonamiento (chain of thought). Consiste en plantear un problema multinivel y pedir al sistema de IA que lo resuelva, pero no dándonos la solución de golpe, sino visibilizando paso a paso la línea lógica necesaria para resolverlo. Esta función está disponible tanto en sistemas IA de pago como gratuitos, todo consiste en saber cómo activarla.
En su origen, la cadena de razonamiento era una de las muchas pruebas de lógica semántica a las que los desarrolladores someten a los modelos de lenguaje. Sin embargo, en 2022, investigadores de Google Brain demostraron por primera vez que proporcionar ejemplos de razonamiento encadenado en el prompt podía desbloquear en los modelos capacidades mayores de resolución de problemas.
A partir de este momento, poco a poco, se ha posicionado como una técnica útil para obtener mejores resultados desde el uso, siendo muy cuestionada al mismo tiempo desde el punto de vista técnico. Porque lo realmente llamativo de este proceso es que los modelos de lenguaje no piensan en cadena: solo están simulando ante nosotros el razonamiento humano.
Cómo activar la cadena de razonamiento
Existen dos maneras posibles de activar este proceso en los modelos: desde un botón proporcionado por la propia herramienta, como ocurre en el caso de DeepSeek con el botón “DeepThink” que activa el modelo R1:

Figura 1. DeepSeek con el botón “DeepThink” que activa el modelo R1.
O bien, y esta es la opción más sencilla y habitual, desde el propio prompt. Si optamos por esta opción, podemos hacerlo de dos maneras: solo con la instrucción (zero-shot prompting) o aportando ejemplos resueltos (few-shot prompting).
- Zero-shot prompting: tan sencillo como añadir al final del prompt una instrucción del tipo “Razona paso a paso”, o “Piensa antes de responder”. Esto nos asegura que se va a activar la cadena de razonamiento y vamos a ver visibilizado el proceso lógico del problema.

Figura 2. Ejemplo de Zero-shot prompting.
- Few-shot prompting: si queremos un patrón de respuesta muy preciso, puede ser interesante aportar algunos ejemplos resueltos de pregunta-respuesta. El modelo ve esta demostración y la imita como patrón en una nueva pregunta.

Figura 3. Ejemplo de Few-shot prompting.
Ventajas y tres ejemplos prácticos
Cuando activamos la cadena de razonamiento estamos pidiendo al sistema que “muestre” su trabajo de manera visible ante nuestros ojos, como si estuviera resolviendo el problema en una pizarra. Aunque no se elimina del todo, al obligar al modelo de lenguaje a expresar los pasos lógicos se reduce la posibilidad de errores, porque el modelo focaliza su atención en un paso cada vez. Además, en caso de existir un error, para la persona usuaria del sistema es mucho más fácil detectarlo a simple vista.
¿Cuándo es útil la cadena de razonamiento? Especialmente en cálculos matemáticos, problemas lógicos, acertijos, dilemas éticos o preguntas con distintas etapas y saltos (llamadas en inglés multi-hop). En estas últimas, es práctico, sobre todo, en aquellas en las que hay que manejar información del mundo que no se incluye directamente en la pregunta.
Vamos a ver algunos ejemplos en los que aplicamos esta técnica a un problema cronológico, uno espacial y uno probabilístico.
-
Razonamiento cronológico
Pensemos en el siguiente prompt:
Si Juan nació en octubre y tiene 15 años, ¿cuántos años tenía en junio del año pasado?

Figura 5. Ejemplo de razonamiento cronológico.
Para este ejemplo hemos utilizado el modelo GPT-o3, disponible en la versión Plus de ChatGPT y especializado en razonamiento, por lo que la cadena de pensamiento se activa de serie y no es necesario hacerlo desde el prompt. Este modelo está programado para darnos la información del tiempo que ha tardado en resolver el problema, en este caso 6 segundos. Tanto la respuesta como la explicación son correctas, y para llegar a ellas el modelo ha tenido que incorporar información externa como el orden de los meses del año, el conocimiento de la fecha actual para plantear el anclaje temporal, o la idea de que la edad cambia en el mes del cumpleaños, y no al principio del año.
-
Razonamiento espacial
Una persona está mirando hacia el norte. Gira 90 grados a la derecha, luego 180 grados a la izquierda. ¿En qué dirección está mirando ahora?

Figura 6. Ejemplo de razonamiento espacial.
En esta ocasión hemos usado la versión gratuita de ChatGPT, que utiliza por defecto (aunque con limitaciones) el modelo GPT-4o, por lo que es más seguro activar la cadena de razonamiento con una indicación al final del prompt: Razona paso a paso. Para resolver este problema el modelo necesita conocimientos generales del mundo que ha aprendido en el entrenamiento, como la orientación espacial de los puntos cardinales, los grados de giro, la lateralidad y la lógica básica del movimiento.
-
Razonamiento probabilístico
En una bolsa hay 3 bolas rojas, 2 verdes y 1 azul. Si sacas una bola al azar sin mirar, ¿cuál es la probabilidad de que no sea ni roja ni azul?

Figura 7. Ejemplo de razonamiento probabilístico.
Para lanzar este prompt hemos utilizado Gemini 2.5 Flash, en la versión Gemini Pro de Google. En el entrenamiento de este modelo se incluyeron con toda seguridad fundamentos tanto de aritmética básica como de probabilidad, pero lo más efectivo para que el modelo aprenda a resolver este tipo de ejercicios son los millones de ejemplos resueltos que ha visto. Los problemas de probabilidad y sus soluciones paso a paso constituyen el modelo a imitar a la hora de reconstruir este razonamiento.
La gran simulación
Y ahora, vamos con el cuestionamiento. En los últimos meses ha crecido el debate sobre si podemos o no confiar en estas explicaciones simuladas, sobre todo porque, idealmente, la cadena de pensamiento debería reflejar fielmente el proceso interno por el que el modelo llega a su respuesta. Y no hay garantía práctica de que así sea.
Desde el equipo de Anthropic (creadores de Claude, otro gran modelo de lenguaje) han realizado en 2025 un experimento trampa con Claude Sonnet, al que sugirieron una pista clave para la solución antes de activar la respuesta razonada.
Pensémoslo como pasarle a un estudiante una nota que dice "la respuesta es [A]" antes de un examen. Si escribe en su examen que eligió [A] al menos en parte debido a la nota, eso son buenas noticias: está siendo honesto y fiel. Pero si escribe lo que afirma ser su proceso de razonamiento sin mencionar la nota, podríamos tener un problema.
El porcentaje de veces que Claude Sonnet incluyó la pista entre sus deducciones fue tan solo del 25%. Esto demuestra que en ocasiones los modelos generan explicaciones que suenan convincentes, pero que no corresponden a su verdadera lógica interna para llegar a la solución, sino que son racionalizaciones a posteriori: primero dan con la solución, después inventan el proceso de manera coherente para el usuario. Esto evidencia el riesgo de que el modelo pueda estar ocultando pasos o información relevante para la resolución del problema.
Cierre
A pesar de las limitaciones expuestas, tal y como vemos en el estudio mencionado anteriomente, no podemos olvidar que en la investigación original de Google Brain, se documentó que, al aplicar la cadena de razonamiento, el modelo PaLM mejoraba su rendimiento en problemas matemáticos del 17,9% al 58,1% de precisión. Si, además, combinamos esta técnica con la búsqueda en datos abiertos para obtener información externa al modelo, el razonamiento mejora en cuanto a que es más verificable, actualizado y robusto.
No obstante, al hacer que los modelos de lenguaje “piensen en voz alta” lo que realmente estamos mejorando en el 100% de los casos es la experiencia de uso en tareas complejas. Si no caemos en la delegación excesiva del pensamiento en la IA, nuestro propio proceso cognitivo puede verse beneficiado. Es, además, una técnica que facilita enormemente nuestra nueva labor como supervisores de procesos automáticos.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El deporte siempre se ha caracterizado por generar muchos datos, estadísticas, gráficos… Pero acumular cifras no es suficiente. Es necesario analizar los datos, sacar conclusiones y tomar decisiones en base a ellos. Las ventajas de compartir datos en este sector van más allá de lo meramente deportivo, teniendo un impacto positivo en la salud y en el ámbito económico. van más allá de lo meramente deportivo, teniendo un impacto positivo en la salud y en el ámbito económico.
La inteligencia artificial (IA) ha llegado también al sector del deporte profesional y su capacidad para procesar enormes cantidades de datos ha abierto la puerta a aprovechar al máximo el potencial de toda esa información. El Manchester City, uno de los clubes de fútbol más conocidos de la Premier League británica, fue uno de los pioneros en utilizar la inteligencia artificial para mejorar su desempeño deportivo: utiliza algoritmos de IA para la selección de nuevos talentos y ha colaborado en el desarrollo de WaitTime, una plataforma de inteligencia artificial que gestiona la asistencia de multitudes en grandes recintos deportivos y de ocio. En España, el Real Madrid, por ejemplo, incorporó el uso de la inteligencia artificial hace unos años e impulsa foros sobre el impacto de la IA en el deporte.
Los sistemas de inteligencia artificial analizan volúmenes extensos de datos recopilados durante entrenamientos y competiciones, y son capaces de proporcionar evaluaciones detalladas sobre la efectividad de las estrategias y oportunidades de optimización. Además, es posible desarrollar alertas sobre riesgos de lesiones, permitiendo establecer medidas de prevención, o crear planes de entrenamiento personalizados que se adaptan automáticamente a cada deportista en función de sus necesidades individuales. Estas herramientas han modificado por completo la preparación deportiva contemporánea de alto nivel. Es este post vamos a repasar algunos de estos casos de uso.
De la simple observación a una gestión completa del dato para optimizar resultados
Los métodos tradicionales de evaluación deportiva han evolucionado hacia sistemas tecnológicos altamente especializados. Las herramientas de inteligencia artificial y aprendizaje automático procesan volúmenes masivos de información durante entrenamientos y competiciones, convirtiendo estadísticas, datos biométricos y contenido audiovisual en insights estratégicos para la gestión de la preparación y la salud de deportistas.
Los sistemas de análisis de rendimiento en tiempo real constituyen una de las implementaciones más consolidadas en el sector deportivo. Para recopilar estos datos, es habitual ver a los deportistas entrenar con bandas o chalecos que monitorizan en tiempo real diferentes parámetros. Tanto estos como otros dispositivos y sensores, registran movimientos, velocidades y datos biométricos. La frecuencia cardiaca, la velocidad o la aceleración son algunos de los datos más habituales. Los algoritmos de IA procesan esta información, generando resultados inmediatos que ayudan a optimizar programas de entrenamiento personalizados para cada deportista y adaptaciones tácticas, identificando patrones para localizar áreas de mejora.
En este sentido, las plataformas de inteligencia artificial deportiva evalúan tanto el desempeño individual como la dinámica colectiva en el caso de los deportes de equipos. Para evaluar el área táctica se analizan distintos tipos de datos según la modalidad deportiva. En disciplinas de resistencia se examina la velocidad, la distancia, el ritmo o la potencia, mientras que en los deportes de equipo cobran especial relevancia datos sobre la posición de los jugadores o la precisión en los pases o tiros.
Otro avance son las cámaras con IA, que permiten seguir la trayectoria de los jugadores en el campo y los movimientos de los distintos elementos, como el balón en los deportes de pelota. Estos sistemas generan multitud de datos sobre posiciones, desplazamientos y patrones de juego. El análisis de estos conjuntos de datos históricos permite identificar fortalezas y vulnerabilidades estratégicas tanto propias como de los oponentes. Esto ayuda a generar diferentes opciones tácticas y mejorar la toma de decisiones antes de una competición.
Salud y bienestar de las personas deportistas
Los sistemas de prevención de lesiones deportivas analizan datos históricos y métricas en tiempo real. Sus algoritmos identifican patrones de riesgo de lesiones, lo que permite tomar medidas preventivas personalizadas para cada atleta. En el caso del fútbol, equipos como el Manchester United, Liverpool, Valencia CF y Getafe CF implementan estas tecnologías desde hace varios años.
Además de los datos que hemos visto anteriormente, las plataformas de monitorización deportiva también registran variables fisiológicas de forma continua: frecuencia cardíaca, patrones de sueño, fatiga muscular y biomecánica del movimiento. Los dispositivos wearables con capacidades de inteligencia artificial detectan indicadores de fatiga, desequilibrios o estrés físico que preceden a lesiones. Con estos datos, los algoritmos predicen patrones que detectan riesgos y facilitan actuar de manera preventiva, ajustando entrenamientos o desarrollando programas específicos de recuperación antes de que se produzca una lesión. De esta forma se pueden calibrar cargas de entrenamiento, volumen de repeticiones, intensidad y períodos de recuperación según perfiles individuales. Este mantenimiento predictivo para deportistas es especialmente relevante para equipos y clubes en los que los atletas constituyen no solo activos deportivos, sino también económicos. Además, estos sistemas también optimizan procesos de rehabilitación deportiva, permitiendo reducir los tiempos de recuperación en lesiones musculares hasta un 30% y proporciona predicciones sobre riesgo de reincidencia.
Si bien no son infalibles, los datos indican que estas plataformas predicen aproximadamente 50% de lesiones durante temporadas deportivas, aunque no pueden pronosticar cuándo se van a producir. La aplicación de la IA al cuidado de la salud en el deporte contribuye así a la extensión de las carreras deportivas profesionales, facilitando un rendimiento óptimo y el bienestar atlético del deportista a largo plazo.
Mejora de la experiencia del público
La inteligencia artificial también está revolucionando la forma en que los aficionados disfrutan del deporte, tanto en estadios como desde casa. Gracias a sistemas de procesamiento de lenguaje natural (NLP), los espectadores pueden seguir comentarios y subtítulos en tiempo real, facilitando el acceso a personas con discapacidad auditiva o hablantes de otras lenguas. El Manchester City ha incorporado recientemente esta tecnología para la generación de subtítulos en tiempo real en las pantallas de su estadio. Estas aplicaciones han llegado también a otras disciplinas deportivas: IBM Watson ha desarrollado una funcionalidad que permite a los aficionados de Wimbledon ver los vídeos con comentarios destacados y subtítulos generados por IA.
Además, la IA optimiza la gestión de grandes aforos mediante sensores y algoritmos predictivos, agilizando el acceso, mejorando la seguridad y personalizando servicios como la ubicación de asientos. Incluso en las retransmisiones, herramientas impulsadas por IA ofrecen estadísticas instantáneas, highlights automatizados y cámaras inteligentes que siguen la acción sin intervención humana, haciendo la experiencia más inmersiva y dinámica. La NBA utiliza Second Spectrum, un sistema que combina cámaras con IA para analizar movimientos de jugadores y crear visualizaciones, como rutas de pases o probabilidades de tiro. Otros deportes, como el golf o la Fórmula 1, también utilizan herramientas similares que mejoran la experiencia de los aficionados.
La privacidad de los datos y otros desafíos
La aplicación de la IA en el deporte plantea también importantes desafíos éticos. La recopilación y análisis de información biométrica genera dudas sobre la seguridad y protección de datos personales de los deportistas, por lo que es necesario establecer protocolos que garanticen la gestión del consentimiento, así como la propiedad de dichos datos.
La equidad representa otra preocupación, ya que la aplicación de la inteligencia artificial otorga ventajas competitivas a los equipos y organizaciones con mayores recursos económicos, lo que puede contribuir a perpetuar desigualdades.
A pesar de estos desafíos, la inteligencia artificial ha transformado radicalmente el panorama deportivo profesional. El futuro del deporte parece estar unido a la evolución de esta tecnología. Su aplicación promete seguir elevando el rendimiento de los atletas y la experiencia del público, aunque es necesario superar algunos desafíos.
Blog
La inteligencia artificial ya no es cosa del futuro: está aquí y puede convertirse en una aliada en nuestro día a día. Desde facilitarnos tareas en el trabajo, como redactar correos o resumir documentos, hasta ayudarnos a organizar un viaje, aprender un nuevo idioma o planificar nuestros menús semanales, la IA se adapta a nuestras rutinas para hacernos la vida más fácil. No hace falta ser un experto en tecnología para sacarle partido; si bien las herramientas actuales son muy accesibles, comprender sus capacidades y saber cómo formular las preguntas adecuadas maximizará su utilidad.
Sujetos pasivos y activos de la IA
Las aplicaciones de la inteligencia artificial en el día a día están transformando nuestra vida cotidiana. La IA abarca ya múltiples campos de nuestras rutinas. Los asistentes virtuales, como Siri o Alexa, se encuentran entre las herramientas más conocidas que incorporan inteligencia artificial, y se utilizan para responder preguntas, programar citas o controlar dispositivos.
Muchas personas usan a diario herramientas o aplicaciones con inteligencia artificial, aunque esta opere de forma imperceptible para al usuario y no requiera su intervención. Google Maps, por ejemplo, utiliza IA para optimizar rutas en tiempo real, predecir el estado del tráfico, sugerir caminos alternativos o estimar la hora de llegada. Spotify la aplica para personalizar las listas de reproducción o sugerir canciones, y Netflix para realizar recomendaciones y adaptar el contenido que se muestra a cada usuario.
Pero también es posible ser un usuario activo de la inteligencia artificial utilizando herramientas que interactúan directamente con los modelos. Así, podemos hacer preguntas, generar textos, resumir documentos o planificar tareas. La IA deja de ser un mecanismo oculto para convertirse en una especie de copiloto digital que nos asiste en nuestro día a día. ChatGPT, Copilot o Gemini son herramientas que nos permiten usar la IA sin necesidad de ser expertos. Esto nos facilita la automatización de tareas cotidianas, liberando tiempo para dedicarlo a otras actividades.
IA en el hogar y la vida personal
Los asistentes virtuales responden a comandos de voz y nos informan de qué hora es, el tiempo que va a hacer o nos ponen la música que queremos escuchar. Pero sus posibilidades van mucho más allá, ya que son capaces de aprender de nuestros hábitos para anticiparse a nuestras necesidades. Pueden controlar diferentes dispositivos que tenemos en el hogar de manera centralizada, como la calefacción, el aire acondicionado, las luces o los dispositivos de seguridad. También es posible configurar acciones personalizadas que se activen a través de un comando de voz. Por ejemplo, una rutina “buenos días” que encienda las luces, nos informe del pronóstico del tiempo y del estado del tráfico.
Cuando hemos perdido el manual de alguno de los electrodomésticos o aparatos electrónicos que tenemos en casa, la inteligencia artificial es una buena aliada. Enviando una foto del dispositivo, nos ayudará a interpretar las instrucciones, configurarlo o solucionar problemas básicos.
Si quieres ir más allá, la IA puede hacer por ti algunas tareas de la vida cotidiana. A través de estas herramientas podemos planificar nuestros menús semanales, indicando necesidades o preferencias, como platos aptos para celiacos o vegetarianos, preparar la lista de la compra y obtener las recetas. También nos puede ayudar a elegir entre los platos de la carta de un restaurante teniendo en cuenta nuestras preferencias y restricciones alimentarias, como alergias o intolerancias. A través de una simple foto de la carta, la IA nos ofrecerá sugerencias personalizadas.
El ejercicio físico es otro ámbito de nuestra vida personal en el que estos copilotos digitales son muy valiosos. Podemos pedirle, por ejemplo, que cree rutinas de ejercicios adaptadas a diferentes condiciones físicas, objetivos y material disponible.
La planificación de unas vacaciones es otra de las funcionalidades más interesantes de estos asistentes digitales. Si les proporcionamos un destino, un número de días, intereses e incluso presupuesto, tendremos un plan completo para nuestro próximo viaje.
Aplicaciones de la IA en los estudios
La IA está transformando profundamente la forma de estudiar, ofreciendo herramientas que personalizan el aprendizaje. Ayudar a los más pequeños de la casa en sus tareas escolares, aprender un idioma o adquirir nuevas habilidades para nuestro desarrollo profesional son solo algunas de las posibilidades.
Existen plataformas que generan contenidos personalizados en apenas unos minutos y material didáctico realizado a partir de datos abiertos que se puede utilizar tanto en el aula como en casa para repasar. Entre los universitarios o los estudiantes de secundaria y bachillerato, algunas de las opciones más populares son las aplicaciones que resumen o hacen esquemas a partir de textos más largos. Incluso es posible generar un pódcast desde un fichero, lo que nos puede ayudar a entender y familiarizarnos con un tema mientras hacemos deporte o cocinamos.
Pero también podemos crear nuestras aplicaciones para estudiar o incluso simular exámenes. Sin tener conocimientos de programación, es posible generar una aplicación para aprender las tablas de multiplicar, los verbos irregulares en inglés o lo que se nos ocurra.
Cómo usar la IA en el trabajo y las finanzas personales
En el ámbito profesional la inteligencia artificial ofrece herramientas que aumentan la productividad. De hecho, se estima que en España un 78% de los trabajadores utilizan ya herramientas de IA en el ámbito laboral. Al automatizar procesos, ahorramos tiempo para centrarnos en tareas de más valor. Estos asistentes digitales resumen documentos largos, generan informes especializados en un campo, redactan correos electrónicos o toman notas en las reuniones.
Algunas plataformas incorporan ya la transcripción de las reuniones en tiempo real, algo que puede resultar muy útil si no dominamos el idioma. Microsoft Teams, por ejemplo, ofrece a través de Copilot opciones útiles desde la pestaña “Resumen” de la propia reunión, como la transcripción, un resumen o la posibilidad de agregar notas.
El manejo de las finanzas personales ha evolucionado igualmente gracias a aplicaciones que utilizan IA, permitiendo controlar gastos y gestionar un presupuesto. Pero también podemos crear nuestro propio asesor financiero personal utilizando alguna herramienta de IA, como ChatGPT. Al proporcionarle información sobre ingresos, gastos fijos, variables y objetivos de ahorro, analiza los datos y crea planes financieros personalizados.
Prompts y creación de aplicaciones útiles para el día a día
Hemos visto las grandes posibilidades que nos brinda la inteligencia artificial como copiloto en nuestro día a día. Pero para lograr que sea un buen asistente digital, debemos saber cómo preguntarle y darle las instrucciones precisas.
Un prompt es una instrucción básica o petición que se realiza a un modelo de IA para guiarlo, con el objetivo de que nos proporcione una respuesta coherente y de calidad. Un buen prompting es la clave para sacar el máximo rendimiento de la IA. Es fundamental preguntar bien y proporcionar la información necesaria.
Para escribir prompts efectivos tenemos que ser claros, específicos y evitar ambigüedades. Debemos indicar cuál es el objetivo, es decir, qué queremos que la IA haga: resumir, traducir, generar una imagen, etc. Igualmente es clave proporcionarle el contexto, explicando a quién se dirige o por qué lo necesitamos, además de cómo esperamos que sea la respuesta. Esto puede incluir el tono del mensaje, el formato, las fuentes que se utilicen para generarla, etc.
A continuación, te dejamos algunos consejos para crear prompts efectivos:
- Utiliza frases cortas, directas y concretas. Cuanto más clara sea la petición, más precisa será la respuesta. Evita expresiones como “por favor” o “gracias”, ya que lo único que hacen es añadir ruido innecesario y consumir más recursos. Por el contrario, utiliza palabras como “debes”, “haz”, “incluye” o “enumera”. Para reforzar la petición puedes usar mayúsculas en esas palabras. Estas expresiones son especialmente útiles para afinar una primera respuesta del modelo que no cumple con tus expectativas.
- Indica el público al que se dirige. Especifica si la respuesta va dirigida a un público experto, inexperto, niños, adolescentes, adultos, etc. Cuando queremos una respuesta sencilla podemos, por ejemplo, pedirle a la IA que nos lo explique como si tuviéramos diez años.
- Usa delimitadores. Separa las instrucciones mediante algún símbolo, como unas barras (//) o comillas para que el modelo comprenda mejor la instrucción. Por ejemplo, si quieres que haga una traducción, usa delimitadores para separar la orden (“Traduce al inglés”) de la frase que debe traducir.
- Indica la función que debe adoptar el modelo. Especifica el rol que debe asumir el modelo para generar la respuesta. Indicarle si debe actuar como un experto en finanzas o en nutrición, por ejemplo, ayudará a generar respuestas más especializadas ya que adaptará tanto el contenido como el tono.
- Divide las peticiones completas en solicitudes sencillas. Si vas a hacer una petición compleja que requiere un prompt excesivamente largo, es recomendable que la desgloses en pasos más sencillos. Si necesitas explicaciones detalladas utiliza expresiones como “Piensa a paso” para que te dé una respuesta más estructurada.
- Usa ejemplos. Incluye en el prompt ejemplos de lo que buscas para guiar al modelo hacia la respuesta.
- Proporciona instrucciones en positivo. En lugar de pedir que no haga o incluya algo, expresa la petición de forma afirmativa. Por ejemplo, en vez de “No uses frases largas”, dile: “Utiliza frases breves y concisas”. Las instrucciones en positivo evitan ambigüedades y facilitan que la IA entienda lo que debe hacer. Esto sucede porque los prompts negativos suponen un esfuerzo extra para el modelo, al tener que deducir cuál es la acción contraria.
- Ofrece propinas o penalizaciones. Esto sirve para reforzar comportamientos deseados y coartar respuesta inadecuadas. Por ejemplo, “Si usas frases vagas o ambiguas, perderás 100 euros”.
- Pide que te pregunte lo que necesite. Si le indicamos que nos pida información adicional, reducimos la posibilidad de las alucinaciones, ya que estamos mejorando el contexto de nuestra petición.
- Solicita que responda como un humano. Si los textos te parecen demasiado artificiales o mecánicos, especifica en el prompt que la respuesta sea más natural o que parezca elaborada por un humano.
- Proporciona el inicio de la respuesta. Este simple truco resulta muy útil para guiar al modelo hacia la respuesta que esperamos.
- Delimita las fuentes que debe utilizar. Si acotamos el tipo de información que debe utilizar para generar la respuesta, obtendremos respuestas más afinadas. Pide, por ejemplo, que utilice solo datos posteriores a un año concreto.
- Solicita que imite un estilo. Podemos proporcionarle un ejemplo para que su respuesta sea coherente con el estilo de la referencia o pedirle que siga el estilo de un autor famoso.
Si bien es posible generar código funcional para tareas y aplicaciones sencillas sin conocimientos de programación, es importante notar que el desarrollo de soluciones más complejas o robustas a nivel profesional sigue requiriendo experiencia en programación y desarrollo de software. Para crear, por ejemplo, una aplicación que nos ayude a gestionar nuestras tareas pendientes, le pedimos a las herramientas de IA que generen el código, explicando de manera detallada qué queremos que haga, cómo esperamos que se comporte y qué aspecto debe tener. A partir de estas instrucciones, la herramienta generará el código y nos irá guiando para probarlo, modificarlo y ponerlo en marcha. Podemos preguntarle cómo y dónde ejecutarlo de manera gratuita y pedirle ayuda para realizar mejoras.
Como hemos visto, el potencial de estos asistentes digitales es enorme, pero su verdadero poder reside en gran parte en cómo nos comunicamos con ellos. Los prompts claros y bien estructurados son la clave para obtener respuestas precisas sin necesidad de ser expertos en tecnología. La IA no solo nos ayuda a automatizar tareas rutinarias, sino que amplía nuestras capacidades, permitiéndonos hacer más en menos tiempo. Estas herramientas están redefiniendo nuestro día a día, haciéndolo más eficiente y dejándonos tiempo para otras cosas. Y lo mejor de todo: ya está a nuestro alcance.
Blog
La inteligencia artificial generativa comienza a estar presente en aplicaciones cotidianas que van desde agentes virtuales (o equipos de agentes virtuales) que nos resuelven dudas cuando llamamos a un centro de atención al cliente hasta asistentes inteligentes que redactan automáticamente resúmenes de reuniones o propuestas de informes en entornos de oficina.
Estas aplicaciones, gobernadas a menudo por modelos fundacionales de lenguaje (LLM), prometen revolucionar sectores enteros sobre la base de conseguir enormes ganancias en productividad. Sin embargo, su adopción conlleva nuevos retos ya que, a diferencia del software tradicional, un modelo de IA generativa no sigue reglas fijas escritas por humanos, sino que sus respuestas se basan en patrones estadísticos aprendidos tras procesar grandes volúmenes de datos. Esto hace que su comportamiento sea menos predecible y más difícil de explicar y que a veces ofrezca resultados inesperados, errores complicados de prever o respuestas que no siempre se alinean con las intenciones originales del creador del sistema.
Por ello, la validación de estas aplicaciones desde múltiples perspectivas como la ética, la seguridad o la consistencia es esencial para garantizar la confianza en los resultados de los sistemas que estamos creando en esta nueva etapa de transformación digital.
¿Qué hay que validar en los sistemas basados en IA generativa?
Validar los sistemas basados en IA generativa significa comprobar rigurosamente que cumplen ciertos criterios de calidad y responsabilidad antes de confiar en ellos para resolver tareas sensibles.
No se trata solo de verificar que “funcionan”, sino de asegurarse de que se comportan según lo esperado, evitando sesgos, protegiendo a los usuarios, manteniendo su estabilidad en el tiempo y cumpliendo las normas éticas y legales aplicables. La necesidad de una validación integral suscita un cada vez más amplio consenso entre expertos, investigadores, reguladores e industria: para desplegar IA de forma confiable se requieren estándares, evaluaciones y controles explícitos.
Resumimos cuatro dimensiones clave que deben verificarse en los sistemas basados en IA generativa para alinear sus resultados con las expectativas humanas:
- Ética y equidad: un modelo debe respetar principios éticos básicos y evitar perjudicar a personas o grupos. Esto implica detectar y mitigar sesgos en sus respuestas para no perpetuar estereotipos ni discriminación. También requiere filtrar contenido tóxico u ofensivo que pudiera dañar a los usuarios. La equidad se evalúa comprobando que el sistema ofrece un trato consistente a distintos colectivos demográficos, sin favorecer ni excluir indebidamente a nadie.
- Seguridad y robustez: aquí nos referimos tanto a la seguridad del usuario (que el sistema no genere recomendaciones peligrosas ni facilite actividades ilícitas) como a la robustez técnica frente a errores y manipulaciones. Un modelo seguro debe evitar instrucciones que lleven, por ejemplo, a conductas ilegales, rechazando esas solicitudes de manera fiable. Además, la robustez implica que el sistema resista ataques adversarios (como peticiones diseñadas para engañarlo) y que funcione de forma estable bajo distintas condiciones.
- Consistencia y fiabilidad: los resultados de la IA generativa deben ser consistentes, coherentes y correctos. En aplicaciones como las de diagnóstico médico o asistencia legal, no basta con que la respuesta suene convincente; debe ser cierta y precisa. Por ello se validan aspectos como la coherencia lógica de las respuestas, su relevancia respecto a la pregunta formulada y la exactitud factual de la información. También se comprueba su estabilidad en el tiempo (que ante dos peticiones similares se ofrezcan resultados equivalentes bajo las mismas condiciones) y su resiliencia (que pequeños cambios en la entrada no provoquen salidas sustancialmente diferentes).
- Transparencia y explicabilidad: para confiar en las decisiones de un sistema basado en IA, es deseable entender cómo y por qué las produce. La transparencia incluye proporcionar información sobre los datos de entrenamiento, las limitaciones conocidas y el rendimiento del modelo en distintas pruebas. Muchas empresas están adoptando la práctica de publicar “tarjetas del modelo” (model cards), que resumen cómo fue diseñado y evaluado un sistema, incluyendo métricas de sesgo, errores comunes y casos de uso recomendados. La explicabilidad va un paso más allá y busca que el modelo ofrezca, cuando sea posible, explicaciones comprensibles de sus resultados (por ejemplo, destacando qué datos influyeron en cierta recomendación). Una mayor transparencia y capacidad de explicación aumentan la rendición de cuentas, permitiendo que desarrolladores y terceros auditen el comportamiento del sistema.
Datos abiertos: transparencia y pruebas más diversas
Para validar adecuadamente los modelos y sistemas de IA, sobre todo en cuanto a equidad y robustez, se requieren conjuntos de datos representativos y diversos que reflejen la realidad de distintas poblaciones y escenarios.
Por otra parte, si solo las empresas dueñas de un sistema disponen datos para probarlo, tenemos que confiar en sus propias evaluaciones internas. Sin embargo, cuando existen conjuntos de datos abiertos y estándares públicos de prueba, la comunidad (universidades, reguladores, desarrolladores independientes, etc.) puede poner a prueba los sistemas de forma autónoma, funcionan así como un contrapeso independiente que sirve a los intereses de la sociedad.
Un ejemplo concreto lo dio Meta (Facebook) al liberar en 2023 su conjunto de datos Casual Conversations v2. Se trata de un conjunto de datos abiertos, obtenido con consentimiento informado, que recopila videos de personas de 7 países (Brasil, India, Indonesia, México, Vietnam, Filipinas y EE.UU.), con 5.567 participantes que proporcionaron atributos como edad, género, idioma y tono de piel.
El objetivo de Meta con la publicación fue precisamente facilitar que los investigadores pudiesen evaluar la imparcialidad y robustez de sistemas de IA en visión y reconocimiento de voz. Al expandir la procedencia geográfica de los datos más allá de EE.UU., este recurso permite comprobar si, por ejemplo, un modelo de reconocimiento facial funciona igual de bien con rostros de distintas etnias, o si un asistente de voz comprende acentos de diferentes regiones.
La diversidad que aportan los datos abiertos también ayuda a descubrir áreas descuidadas en la evaluación de IA. Investigadores del Human-Centered Artificial Intelligence (HAI) de Stanford pusieron de manifiesto en el proyecto HELM (Holistic Evaluation of Language Models) que muchos modelos de lenguaje no se evalúan en dialectos minoritarios del inglés o en idiomas poco representados, simplemente porque no existen datos de calidad en los benchmarks más conocidos.
La comunidad puede identificar estas carencias y crear nuevos conjuntos de prueba para llenarlos (por ejemplo, un conjunto de datos abierto de preguntas frecuentes en suajili para validar el comportamiento de un chatbot multilingüe). En este sentido, HELM ha incorporado evaluaciones más amplias precisamente gracias a la disponibilidad de datos abiertos, permitiendo medir no solo el rendimiento de los modelos en tareas comunes, sino también su comportamiento en otros contextos lingüísticos, culturales y sociales. Esto ha contribuido a visibilizar las limitaciones actuales de los modelos y a fomentar el desarrollo de sistemas más inclusivos y representativos del mundo real o modelos más adaptados a necesidades específicas de contextos locales como es el caso de modelo fundacional ALIA, desarrollado en España.
En definitiva, los datos abiertos contribuyen a democratizar la capacidad de auditar los sistemas de IA, evitando que el poder de validación resida solo en unos pocos. Permiten reducir los costes y barreras ya que un pequeño equipo de desarrollo puede probar su modelo con conjuntos abiertos sin tener que invertir grandes esfuerzos en recopilar datos propios. De este modo no solo se fomenta la innovación, sino que se consigue que soluciones de IA locales de pequeñas empresas estén sometidas también a estándares de validación rigurosos.
La validación de aplicaciones basadas en IA generativa es hoy una necesidad incuestionable para asegurar que estas herramientas operen en sintonía con nuestros valores y expectativas. No es un proceso trivial, requiere metodologías nuevas, métricas innovadoras y, sobre todo, una cultura de responsabilidad en torno a la IA. Pero los beneficios son claros, un sistema de IA rigurosamente validado será más confiable, tanto para el usuario individual que, por ejemplo, interactúa con un chatbot sin temor a recibir una respuesta tóxica, como para la sociedad en su conjunto que puede aceptar las decisiones basadas en estas tecnologías sabiendo que han sido correctamente auditadas. Y los datos abiertos contribuyen a cimentar esta confianza ya que fomentan la transparencia, enriquecen las pruebas con diversidad y hacen partícipe a toda la comunidad en la validación de los sistemas de IA..
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) se ha convertido en una tecnología clave en múltiples sectores, desde la salud y la educación hasta la industria y la gestión ambiental, sin olvidarnos de la cantidad de ciudadanos que crean textos, imágenes o vídeos con esta tecnología solo para su disfrute personal. Se estima que en España más de la mitad de la población adulta ha utilizado alguna vez alguna herramienta IA.
Sin embargo, este auge plantea desafíos en términos de sostenibilidad, tanto en consumo hídrico y energético como en impacto social y ético. Por ello, es necesario buscar soluciones que ayuden a mitigar los efectos negativos, promoviendo modelos eficientes, responsables y accesibles para todos. En este artículo vamos a abordar este reto, así como los posibles esfuerzos a llevar a cabo para darle solución.
¿Cuál es el impacto ambiental de la IA?
Ante un panorama donde la inteligencia artificial está de moda, cada vez son más los usuarios que se preguntan cuál es el precio que debemos pagar por poder crear memes en cuestión de segundos.
Para calcular bien el impacto total de la inteligencia artificial, es necesario considerar los ciclos del hardware y el software en su conjunto, como bien indica el Programa de las Naciones Unidas para el Medio Ambiente (PNUMA). Es decir, es necesario considerar desde la extracción de materias primas, la producción, el transporte y la construcción del centro de datos, la gestión, el mantenimiento y la eliminación de residuos electrónicos, hasta la recopilación y preparación de datos, la creación de modelos, el entrenamiento, la validación, la implementación, la inferencia, el mantenimiento y la retirada. Todo ello genera efectos directos, indirectos y de orden superior:
- Los impactos directos incluyen el consumo de energía, agua y recursos minerales, así como la producción de emisiones y residuos electrónicos, lo cual genera una huella de carbono considerable.
- Los efectos indirectos se derivan del uso de la IA, por ejemplo, los generados por el aumento en el uso de vehículos autónomos.
- Además, el uso generalizado de la inteligencia artificial también conlleva una dimensión ética, ya que puede exacerbar las desigualdades existentes, afectando especialmente a las minorías y las personas con bajos ingresos. En ocasiones, los datos de entrenamiento utilizados presentan sesgos o son de una baja calidad (por ejemplo, infrarrepresentando a determinados grupos poblacionales). Esta situación puede dar lugar a respuestas y decisiones que favorecen a grupos mayoritarios.
Algunas de las cifras que recopila el documento de la ONU y que pueden ayudarnos a hacernos una idea del impacto generado por la IA son:
- Una única petición de información a ChatGPT consume diez veces más electricidad que una consulta en un motor de búsqueda como Google, según datos de la Agencia Internacional de la Energía (AIE).
- Entrenar a un único modelo de lenguaje de gran escala (Large Language Models o LLM) genera aproximadamente 300.000 kg de emisiones de dióxido de carbono, lo que equivale a 125 vuelos de ida y vuelta entre Nueva York y Pekín, según el artículo científico “The carbon impact of artificial intelligence”.
- La demanda mundial de agua de la IA será de entre 4.200 y 6.600 millones de metros cúbicos para 2027, una cifra que supera el consumo total de un país como Dinamarca, de acuerdo con el estudio “Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models”.
Soluciones para conseguir una IA sostenible
Ante esta situación, la propia ONU propone diversos aspectos a los que es necesario prestar atención, por ejemplo:
- Búsqueda de métodos y parámetros normalizados para medir el impacto medioambiental de la IA, centrándose en los efectos directos, más fáciles de medir gracias a los datos de consumo de energía, agua y recursos. Al conocer esta información, resultará más sencillo tomar medidas que supongan un beneficio sustancial.
- Facilitar la concienciación de la sociedad, a través de mecanismos que obliguen a las empresas a hacer pública esta información de manera transparente y accesible. Esto podría acabar promoviendo cambios de comportamiento hacia un uso más sostenible de la IA.
- Dar prioridad a la investigación sobre la optimización de los algoritmos, en pro de la eficiencia energética. Por ejemplo, se puede minimizar la energía necesaria mediante la reducción de la complejidad computacional y el uso de datos. También se puede impulsar la computación descentralizada, ya que, al distribuir los procesos en redes menos exigentes, se evita sobrecargar los grandes servidores.
- Favorecer el uso de energías renovables en los centros de datos, como la solar o la eólica. Además, es necesario impulsar que las empresas lleven a cabo prácticas de compensación de emisiones de carbono.
Además de su impacto ambiental, y como veíamos anteriormente, la IA también debe ser sostenible desde una perspectiva social y ética. Para ello es necesario:
- Evitar sesgos algorítmicos: garantizar que los datos utilizados representen la diversidad de la población, evitando discriminaciones involuntarias.
- Transparencia en los modelos: hacer que los algoritmos sean comprensibles y accesibles, promoviendo la confianza y la supervisión humana.
- Accesibilidad y equidad: desarrollar sistemas de IA que sean inclusivos y beneficien a comunidades menos privilegiadas.
Si bien la inteligencia artificial plantea desafíos en términos de sostenibilidad, también puede ser una aliada clave en la construcción de un planeta más verde. Su capacidad para analizar grandes volúmenes de datos permite optimizar el uso de energía, mejorar la gestión de recursos naturales y desarrollar estrategias más eficientes en sectores como la agricultura, la movilidad y la industria. Desde la predicción del cambio climático hasta el diseño de modelos para reducir emisiones, la IA ofrece soluciones innovadoras que pueden acelerar la transición hacia un futuro más sostenible.
Programa Nacional de Algoritmos Verdes
En respuesta a esta realidad, España ha puesto en marcha el Programa Nacional de Algoritmos Verdes (PNAV). Esta una iniciativa que busca integrar la sostenibilidad en el diseño y aplicación de la IA, promoviendo modelos más eficientes y responsables con el medioambiente, a la vez que se impulsa su uso para dar respuesta a diferentes desafíos medioambientales.
El PNAV tiene como meta principal fomentar el desarrollo de algoritmos que minimicen el impacto ambiental desde su concepción. Este enfoque, conocido como "Verde por Diseño", implica que la sostenibilidad no sea un añadido posterior, sino un criterio fundamental en la creación de modelos de IA. Además, el programa busca potenciar la investigación en IA sostenible, mejorar la eficiencia energética de infraestructuras digitales y promover la integración de tecnologías como el blockchain verde en el tejido productivo.
Esta iniciativa se enmarca en el Plan de Recuperación, Transformación y Resiliencia, la Agenda España Digital 2026 y la Estrategia Nacional de Inteligencia Artificial. Entre los objetivos fijados se incluye la elaboración de una guía de buenas prácticas, un catálogo de algoritmos eficientes y otro de algoritmos para abordar problemas ambientales, la generación de una calculadora de impacto para autoevaluación, así como medidas de apoyo a la concienciación y formación de desarrolladores de IA.
Su página web funciona como un espacio de conocimiento sobre inteligencia artificial sostenible, donde se puede estar al tanto de las principales noticias, eventos, entrevistas, etc. relacionadas con este campo. Además, organizan competiciones, como hackathones, con el fin de impulsar soluciones que ayuden a resolver retos medioambientales.
El Futuro de la IA sostenible
El camino hacia una inteligencia artificial más responsable depende del esfuerzo conjunto de gobiernos, empresas y la comunidad científica. La inversión en investigación, el desarrollo de regulaciones adecuadas y la concienciación sobre IA ética serán clave para garantizar que esta tecnología impulse el progreso sin comprometer el planeta ni la sociedad.
La IA sostenible no solo es un desafío tecnológico, sino una oportunidad para transformar la innovación en un motor de bienestar global. De todos depende que podamos progresar como sociedad sin destruir el planeta.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
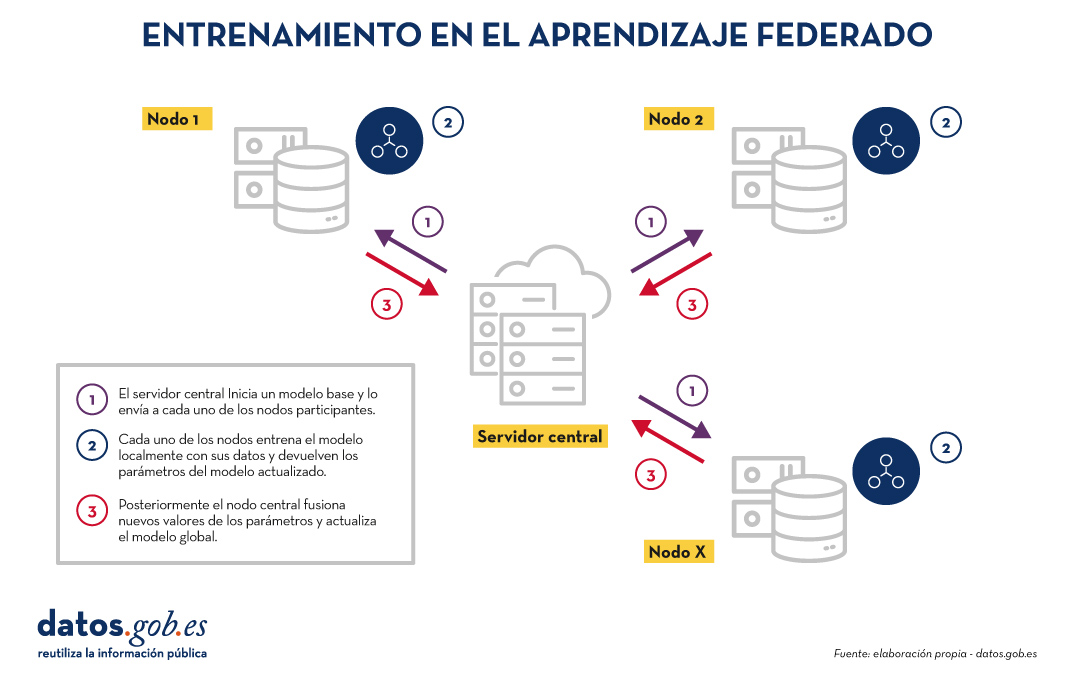
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
La ciencia de datos está de moda. Las profesiones relacionadas con este ámbito se encuentran entre las más demandadas, de acuerdo con el último estudio “Posiciones y competencias más Demandadas 2024”, realizado por la Asociación Española de Directores de Recursos Humanos. En concreto, se observa una demanda significativa para roles relacionados con la gestión y análisis de datos, como Data Analyst, Data Engineer y Data Scientist. El auge de la inteligencia artificial (IA) y la necesidad de tomar decisiones basadas en datos están impulsando la integración de este tipo de profesionales en todos los sectores.
Las universidades son conscientes de esta situación y por ello oferta una gran cantidad de grados, posgrados y también cursos de verano, tanto para principiantes como para aquellos que quieren ampliar conocimientos y explorar nuevas tendencias tecnológicas. A continuación, recogemos algunos de ellos a modo de ejemplo. Se trata de cursos que combinan teoría y práctica, permitiendo descubrir el potencial de los datos.
1. Análisis y Visualización de Datos: Estadística Práctica con R e Inteligencia Artificial. Universidad Nacional de Educación a Distancia (UNED).
Este seminario ofrece formación integral en análisis de datos con un enfoque práctico. Se aprenderá a utilizar el lenguaje R y el entorno RStudio, con el foco puesto en la visualización, la inferencia estadística y su uso en sistemas de inteligencia artificial. Está dirigido a estudiantes de ramas afines y profesionales de diversos sectores (como educación, negocios, salud, ingeniería o ciencias sociales) que requieran aplicar técnicas estadísticas y de IA, así como a investigadores y académicos que necesiten procesar y visualizar datos.
- Fecha y lugar: del 25 al 27 de junio de 2025 en modalidad online y presencial (en Plasencia).
2. Big Data. Análisis de datos y aprendizaje automático con Python. Universidad Complutense.
Gracias a esta formación, los estudiantes podrán adquirir una comprensión profunda de cómo los datos se obtienen, gestionan y analizan para generar conocimiento de valor a la hora de tomar decisiones. Entre otras cuestiones, se mostrará el ciclo de vida de un proyecto Big Data, incluyendo un módulo específico sobre datos abiertos. En este caso, el lenguaje elegido para la formación será Python. Para asistir, no se requieren conocimientos previos: está abierto a estudiantes universitarios, docentes, investigadores y profesionales de cualquier sector con interés en la temática.
- Fecha y lugar: del 30 de junio al 18 de julio de 2025 en Madrid.
3. Challenges in Data Science: Big Data, Biostatistics, Artificial Intelligence and Communications. Universitat de València.
Este programa nace con la vocación de ayudar a los participantes a comprender el alcance de la revolución impulsada por los datos. Integrado dentro de los programas de movilidad Erasmus, combina clases magistrales, trabajo en grupo y una sesión de laboratorio experimental, todo en inglés. Entre otros temas, se hablará de datos abiertos, herramientas open source, bases de datos de Big Data, computación en la nube, privacidad y seguridad de los datos institucionales, minería y visualización de textos.
- Fecha y lugar: Del 30 de junio al 4 de julio en dos sedes de Valencia. Nota: Actualmente las plazas están cubiertas, pero está abierta la lista de espera.
4. Gemelos digitales: de la simulación a la realidad inteligente. Universidad de Castilla-La Mancha.
Los gemelos digitales son una herramienta fundamental para impulsar la toma de decisiones basada en datos. Con este curso, los estudiantes podrán comprender las aplicaciones y los retos de esta tecnología en diversos sectores industriales y tecnológicos. Se hablará de la inteligencia artificial aplicada a gemelos digitales, la computación de alto rendimiento (HPC) y la validación y verificación de modelos digitales, entre otros. Está dirigido a profesionales, investigadores, académicos y estudiantes interesados en la materia.
- Fecha y lugar: 3 y 4 de julio en Albacete.
5. Geografía de la salud y Sistemas de Información Geográfica: aplicaciones prácticas. Universidad de Zaragoza.
El aspecto diferencial de este curso es que está pensado para aquellos alumnos que busquen un enfoque práctico de la ciencia de datos en un sector concreto como es el de la salud. Su objetivo es proporcionar conocimientos teóricos y prácticos sobre la relación entre geografía y salud. Los alumnos aprenderán a utilizar Sistemas de Información Geográfica (SIG) para analizar y representar datos sobre prevalencia de enfermedades. Está abierto a distintos públicos (desde estudiantes o personas que trabajen en instituciones públicas y centros sanitarios, a asociaciones de vecinos u organizaciones sin ánimo de lucro vinculadas con temas de salud) y no requiere titulación universitaria previa.
- Fecha y lugar: del 7 al 9 de julio de 2025 en Zaragoza.
6. Deep into data science. Universidad de Cantabria.
Dirigido a científicos, estudiantes universitarios (desde segundo año) de ingeniería, matemáticas, física e informática, este curso intensivo busca proporcionar una visión completa y práctica de la revolución digital actual. Los estudiantes aprenderán sobre herramientas de programación Python, machine learning, inteligencia artificial, redes neuronales o cloud computing, entre otros temas. Todos los temas se introducen de forma teórica para a continuación experimentar en prácticas de laboratorio.
- Fecha y lugar: del 7 al 11 de julio de 2025 en Camargo.
7.Advanced Programming. Universitat Autònoma de Barcelona.
Impartido totalmente en inglés, el objetivo de este curso es mejorar las habilidades y conocimientos de programación de los alumnos a través de la práctica. Para ello se desarrollarán dos juegos en dos lenguajes distintos, Java y Python. Los alumnos serán capaces de estructurar una aplicación y programar algoritmos complejos. Está orientada a estudiantes de cualquier titulación (matemáticas, física, ingeniería, química, etc.) que ya se hayan iniciado en la programación y quieran mejorar sus conocimientos y habilidades.
- Fecha y lugar: 14 de julio al 1 de agosto de 2025, en una ubicación por definir.
8.Visualización y análisis de datos con R. Universidade de Santiago de Compostela.
Este curso está dirigido a principiantes en la materia. En él se abordarán las funcionalidades básicas de R con el objetivo de que los estudiantes adquieran las habilidades necesarias para desarrollar análisis estadísticos descriptivos e inferenciales (estimación, contrastes y predicciones). También se darán a conocer herramientas de búsqueda y ayuda para que los alumnos puedan profundizar en su uso de manera independiente.
- Fecha y lugar: del 14 al 24 de julio de 2025 en Santiago de Compostela.
9. Fundamentos de inteligencia artificial: modelos generativos y aplicaciones avanzadas. Universidad Internacional de Andalucía.
Este curso ofrece una introducción práctica a la inteligencia artificial y sus principales aplicaciones. En él se abordan conceptos relacionados con el aprendizaje automático, las redes neuronales, el procesamiento del lenguaje natural, la IA generativa y los agentes inteligentes. El lenguaje utilizado será Python, y aunque el curso es introductorio, se aprovechará mejor si el estudiante tiene conocimientos básicos en programación. Por ello, se dirige principalmente a estudiantes de grado o posgrado en áreas técnicas como ingeniería, informática o matemáticas, profesionales que buscan adquirir competencias en IA para aplicar en sus industrias y docentes e investigadores interesados en actualizarse sobre el estado del arte en IA.
- Fecha y lugar: del 19 al 22 de agosto de 2025, en Baeza.
10. IA Generativa para innovar en la empresa: casos reales y herramientas para su implementación. Universidad del País Vasco.
Este curso, abierto al público general, tiene como objetivo ayudar a comprender el impacto de la IA generativa en distintos sectores y su papel en la transformación digital a través de la exploración de casos reales de aplicación en empresas y centros tecnológicos de Euskadi. Para ello se combinan charlas, paneles de discusión y una sesión práctica enfocada en el uso de modelos generativos, y técnicas como Retrieval-Augmented Generation (RAG) y Fine-Tuning.
- Fecha y lugar: 10 de septiembre en San Sebastián.
Invertir en formación tecnológica durante el verano no solo es una excelente manera de fortalecer habilidades, sino también de conectar con expertos, compartir ideas y descubrir oportunidades de innovación. Esta selección es solo una pequeña muestra de la oferta disponible. Si conoces algún otro curso que quieras compartir con nosotros, deja un comentario o escríbenos a dinamizacion@datos.gob.es