Blog
La alineación de la inteligencia artificial es un término establecido desde los años sesenta, según el que orientamos los objetivos de los sistemas inteligentes en la dirección exacta de los valores humanos. La llegada de los modelos generativos ha vuelto a poner de moda este concepto de alineación, que se vuelve más urgente cuanta más inteligencia y autonomía muestran los sistemas. Sin embargo, no hay alineamiento posible sin una definición anterior, consensuada y precisa de estos valores. El reto hoy es encontrar objetivos enriquecedores donde la aplicación de la IA tenga un efecto positivo y transformador en el conocimiento, la organización social y la convivencia.
El derecho a entender
En este contexto, uno de los grandes pilares de la IA actual, el procesamiento del lenguaje lleva años haciendo aportes de valor a la comunicación clara y, en concreto, al lenguaje claro. Veamos qué son estos conceptos:
- La comunicación clara, como disciplina, tiene como objetivo hacer la información accesible y comprensible para todas las personas, utilizando recursos de redacción, pero también visuales, de diseño, infografía, experiencia de usuario y accesibilidad.
- El lenguaje claro se enfoca en la composición de los textos, con técnicas para presentar las ideas de manera directa y concisa, sin excesos estilísticos ni omisiones de la información fundamental.
Ambos conceptos están estrechamente vinculados con el derecho a entender de las personas.
Antes de chatGPT: aproximaciones analíticas
Antes de la llegada de la IA generativa y la popularización de las capacidades GPT, la inteligencia artificial se aplicaba al lenguaje claro desde un punto de vista analítico, con diferentes técnicas de clasificación y búsqueda de patrones. La principal necesidad entonces era que un sistema pudiera evaluar si un texto era o no comprensible, pero no existía aún la expectativa de que ese mismo sistema pudiera reescribir nuestro texto de una manera más clara. Veamos un par de ejemplos:
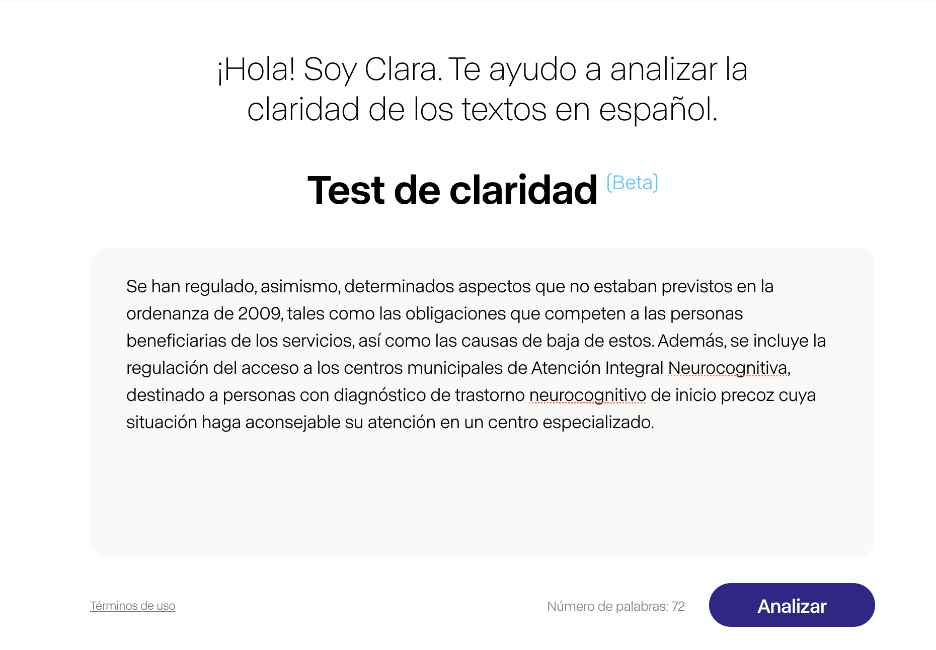
Este es el caso de Clara, un sistema de IA analítica disponible en abierto en versión beta. Clara es un sistema mixto: por un lado, ha aprendido qué patrones caracterizan a los textos claros y no claros a partir de la observación de un corpus de pares preparado por especialistas en Comunicación Clara. Por otro lado, maneja nueve métricas diseñadas por lingüistas computacionales para decidir si un texto cumple o no los requisitos mínimos de claridad, por ejemplo, el número medio de palabras por frase, los tecnicismos utilizados o la frecuencia de los conectores. Finalmente, Clara devuelve una puntuación en porcentaje para indicar si el texto escrito está más o menos cerca de ser un texto claro. Esto permite al usuario corregir el texto en función de las indicaciones de Clara y someterlo a evaluación de nuevo.

No obstante, otros sistemas analíticos han establecido una aproximación diferente, como Artext claro. Artext es más parecido a un editor de textos tradicional, y en él podemos redactar nuestro texto y activar una serie de revisiones, como los participios, las nominalizaciones verbales o el uso de la negación. Artext señala en color palabras o expresiones en nuestro texto y nos aconseja en un menú lateral qué tenemos que tener en cuenta al utilizarlas. El usuario puede reescribir el texto hasta que, en las diferentes revisiones, vayan desapareciendo las palabras y expresiones marcadas en color.
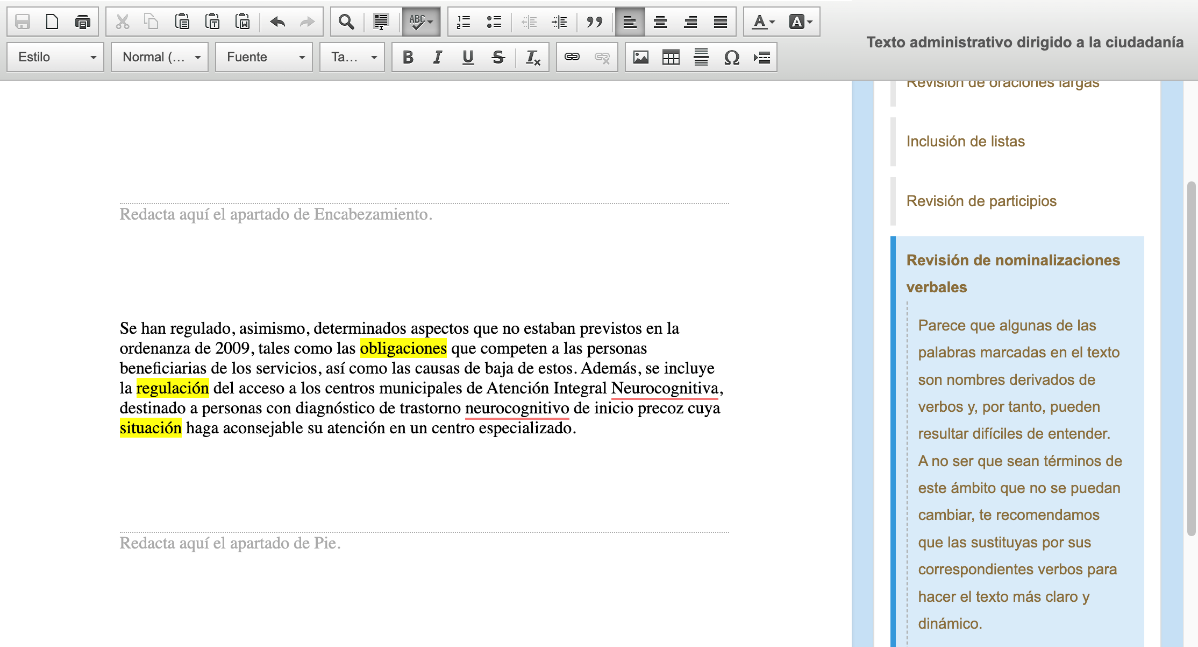
Tanto Clara como Artext están especializadas en textos administrativos y financieros, con el fin de ser de utilidad principalmente a la administración pública, las entidades financieras y otras fuentes de textos de difícil comprensión que impactan en la ciudadanía.
La revolución generativa
Las herramientas de IA analítica son útiles y muy valiosas si lo que queremos es evaluar un texto sobre el que necesitamos tener un mayor control. Sin embargo, tras la llegada de chatGPT en noviembre de 2022, las expectativas de los usuarios se sitúan más allá. No solo necesitamos un evaluador, sino que esperamos un traductor, un transformador automático de nuestro texto a una versión más clara. Insertamos la versión original del texto en el chat y, a través de una instrucción directa llamada prompt, le pedimos que lo transforme en un texto más claro y sencillo, comprensible por cualquier persona.

Si necesitamos mayor claridad, solo tenemos que repetir la instrucción y el texto vuelve a simplificarse ante nuestros ojos.

Utilizando IA generativa estamos reduciendo el esfuerzo cognitivo, pero también estamos perdiendo gran parte del control sobre el texto. Principalmente, no vamos a conocer cuáles son las modificaciones que se están realizando y por qué, por lo que podemos incurrir en la pérdida o alteración de información. Si queremos aumentar el control y seguir el rastro de los cambios, eliminaciones y añadidos que realiza chatGPT sobre el texto, podemos utilizar un plug-in como EditGPT, disponible como extensión para Google Chrome, que nos permite llevar un control de cambios similar al de Word en nuestras interacciones con el chat. No obstante, no llegaríamos a entender el fundamento de los cambios realizados, como sí haríamos con herramientas como Clara o Artext diseñadas por profesionales de la lengua. Una opción límite es pedirle al chat que nos justifique cada uno de estos cambios, pero la interacción se convertiría en farragosa, compleja y poco eficiente, sin contar con el entusiasmo excesivo con el que el modelo trataría de justificar sus correcciones.
Ejemplos de clarificación generativa
Más allá de la rapidez en la transformación, la IA generativa presenta otras ventajas frente a la analítica, como ciertos elementos que solo pueden identificarse con capacidades GPT. Por ejemplo, detectar en un texto si una sigla o acrónimo ha sido desarrollada previamente, o si un tecnicismo está explicado inmediatamente después de su aparición. Esto requiere un análisis semántico muy complejo para la IA analítica o los modelos basados en reglas. En cambio, un gran modelo de lenguaje es capaz de establecer una relación inteligente entre la sigla y su desarrollo, o entre el tecnicismo y su significado, reconocer si esta explicación existe en algún punto del texto, y además añadirla donde sea pertinente.

Datos abiertos para nutrir la clarificación
El acceso universal a los datos abiertos, y especialmente cuando estos se encuentran preparados para el tratamiento computacional, los hace imprescindibles para el entrenamiento de los grandes modelos lingüísticos. Enormes fuentes de información no estructurada como Wikipedia, el proyecto Common Crawl o Gutenberg permiten a los sistemas aprender el funcionamiento del lenguaje. Y, sobre esta base generalista, es posible ajustar los modelos con conjuntos de datos especializados para que sean más precisos en la tarea de clarificar texto.
En la aplicación de la inteligencia artificial generativa al lenguaje claro tenemos el ejemplo perfecto de un fin valioso, útil a la ciudadanía y positivo para el desarrollo social. Más allá de la fascinación que ha despertado, tenemos la oportunidad de utilizar su potencial en un caso de uso que favorece la igualdad y la inclusividad. La tecnología existe, solo nos falta recorrer el difícil camino de la integración.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Enseñar a los ordenadores a entender cómo hablan y escriben los humanos es un viejo desafío en el campo de la inteligencia artificial, conocido como procesamiento de lenguaje natural (PLN). Sin embargo, desde hace poco más de dos años, estamos asistiendo a la caída de este antiguo bastión con la llegada de los modelos grandes del lenguaje (LLM) y los interfaces conversacionales. En este post, vamos a tratar de explicar una de las técnicas clave que hace posible que estos sistemas nos respondan con relativa precisión a las preguntas que les hacemos.
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog, varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del RAG. En este post vamos a tratar de explicarlo de la forma más sencilla posible.
Los modelos grandes del lenguaje o Large Language Models (hay cosas que es mejor no traducir…) son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los LLM por sí solos no proporcionarán respuestas específicas o habrá una alta probabilidad de que alucinen y se inventen completamente la respuesta. Que los LLM alucinen significa que generan texto inexacto, sin sentido o desconectado. Este efecto plantea riesgos y desafíos potenciales para las organizaciones que utilizan estos modelos fuera del entorno doméstico o cotidiano del uso personal de los LLM. La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para ChatGPT, puede tener implicaciones profundas para la reputación de las empresas y la fiabilidad de los sistemas de IA.
¿Qué es un RAG?
Precisamente, las técnicas RAG se han desarrollado para mejorar la calidad de las respuestas en contextos específicos, como por ejemplo, en una disciplina concreta o en base a repositorios de conocimiento privados como bases de datos de empresas.
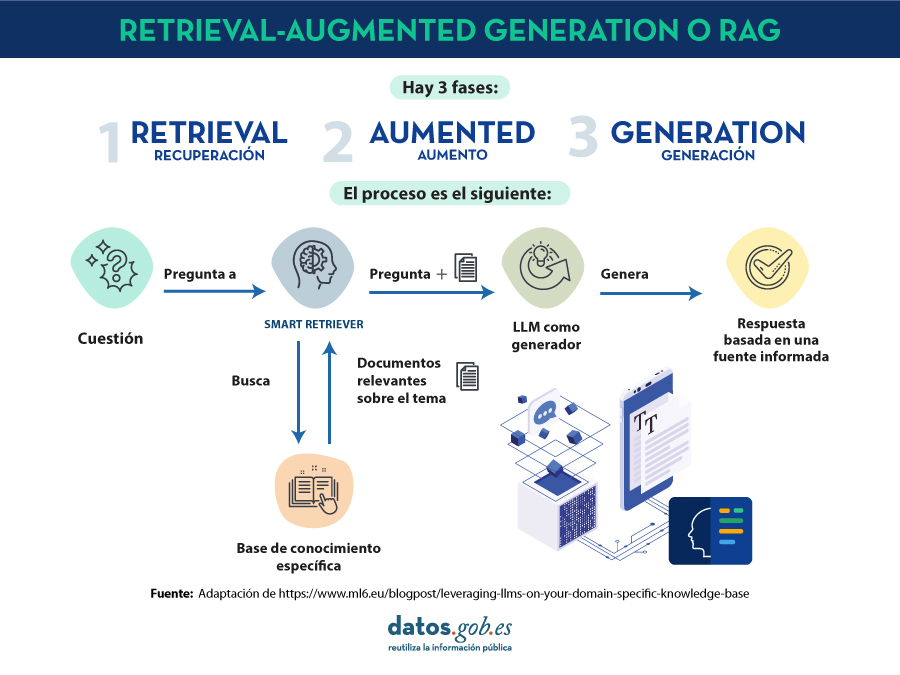
RAG es una técnica extra dentro de los marcos de trabajo de la inteligencia artificial, cuyo objetivo es recuperar hechos de una base de conocimientos externa para garantizar que los modelos de lenguaje devuelven información precisa y actualizada. Un sistema RAG típico (ver imágen) incluye un LLM, una base de datos vectorial (para almacenar convenientemente los datos externos) y una serie de comandos o preguntas. Es decir, de forma simplificada, cuándo hacemos una pregunta en lenguaje natural a un asistente cómo ChatGPT, lo que ocurre entre la pregunta y la respuesta es algo como:
- El usuario realiza la consulta, también denominada técnicamente prompt.
- El RAG se encarga de enriquecer ese prompt o pregunta con datos y hechos que ha obtenido de una base de datos externa que contiene información relevante relativa a la pregunta que ha realizado el usuario. A esta etapa se le denomina retrieval.
- El RAG se encarga de enviar el prompt del usuario enriquecido o aumentado al LLM que se encarga de generar una respuesta en lenguaje natural aprovechando toda la potencia del lenguaje humano que ha aprendido con sus datos de entrenamiento genéricos, pero también con los datos específicos proporcionados en la etapa de retrieval.
Entendiendo RAG con ejemplos
Pongamos un ejemplo concreto. Imagina que estás intentando responder una pregunta sobre dinosaurios. Un LLM generalista puede inventarse una respuesta perfectamente plausible, de forma que una persona no experta en la materia no la diferencia de una respuesta con base científica. Por el contrario, con el uso de RAG, el LLM buscaría en una base de datos de información sobre dinosaurios y recuperaría los hechos más relevantes para generar una respuesta completa.
Lo mismo ocurría si buscamos una información concreta en una base de datos privada. Por ejemplo, pensemos en un responsable de recursos humanos de una empresa. Éste desea recuperar información resumida y agregada sobre uno o varios empleados cuyos registros se encuentran en diferentes bases de datos de la empresa. Pensemos que podemos estar tratando de obtener información a partir de tablas salariales, encuestas de satisfacción, registros laborales, etc. Un LLM es de gran utilidad para generar una respuesta con un patrón humano. Sin embargo, es imposible que ofrezca datos coherentes y precisos puesto que nunca ha sido entrenado con esa información debido a su carácter privado. En este caso, RAG asiste al LLM para proporcionarle datos y contexto específico con el que poder devolver la respuesta adecuada.
De la misma forma, un LLM complementado con RAG sobre registros médicos podría ser un gran asistente en el ámbito clínico. También los analistas financieros se beneficiarían de un asistente vinculado a datos actualizados del mercado de valores. Prácticamente, cualquier caso de uso se beneficia de las técnicas RAG para enriquecer las capacidades de los LLM con datos de contexto específicos.
Recursos adicionales para entender mejor RAG
Cómo os podéis imaginar, tan pronto como nos asomamos por un momento a la parte más técnica de entender los LLM o RAG, las cosas se complican enormemente. En este post hemos tratado de explicar con palabras sencillas y ejemplos cotidianos cómo funciona la técnica de RAG para obtener respuestas más precisas y contextualizadas a las preguntas que le hacemos a un asistente conversacional como ChatGPT, Bard o cualquier otro. Sin embargo, para todos aquellos que tengáis ganas y fuerzas para profundizar en el tema, os dejamos una serie de recursos web disponibles para tratar de entender un poco más cómo se combinan los LLM con RAG y otras técnicas como la ingeniería de prompts para ofrecer las mejores apps de IA generativa posibles.
Videos introductorios:
Artículos de contenido de LLMs y RAG para principiantes:
- DEV - LLM for dummies
-
Digital Native - LLMs for Dummies
-
Hopsworks.ai - Retrieval Augmented Generation (RAG) for LLMs
-
Datalytyx - RAG For Dummies
¿Quieres pasar al siguiente nivel? Algunas herramientas para probar:
- LangChain. LangChain es un marco (framework) de desarrollo que facilita la construcción de aplicaciones usando LLMs, como GPT-3 y GPT-4. LangChain es para desarrolladores de software y permite integrar y gestionar varios LLMs, creando aplicaciones como chatbots y agentes virtuales. Su principal ventaja es simplificar la interacción y orquestación de LLMs para una amplia gama de aplicaciones, desde análisis de texto hasta asistencia virtual.
-
Hugging Face. Hugging Face es una plataforma con más de 350 mil modelos, 75 mil conjuntos de datos y 150 mil aplicaciones de demostración, todos ellos de código abierto y disponibles públicamente online donde la gente puede colaborar fácilmente y construir modelos de inteligencia artificial.
-
OpenAI. OpenAI es la plataforma más conocida en lo que a modelos de LLM e interfaces conversacionales se refiere. Los creadores de ChatGTP ponen a disposición de la comunidad de desarrolladores un conjunto de librerías para utilizar el API de OpenAI y poder crear sus propias aplicaciones utilizando los modelos GPT-3.5 y GPT- 4. Como ejemplo, os proponemos visitar la documentación de la librería de Python para entender cómo, con muy pocas líneas de código, podemos estar usando un LLM en nuestra propia aplicación. Aunque las interfaces conversacionales de OpenAI como ChatGPT, utilizan su propio sistema RAG, también podemos combinar los modelos GPT con nuestra propia RAG, como por ejemplo, lo que proponen en este artículo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El 8 de septiembre se celebró el webinar “Geospatial trends 2023: Opportunities for data.europa.eu”, organizado por la Data Europa Academy y centrado en las tendencias emergentes en el ámbto geoespacial. En concreto, la conferencia online abordó el concepto de GeoAI (Inteligencia Artificial Geoespacial), que consiste en la aplicación de inteligencia artificial (IA) combinada con datos geoespaciales.
A continuación, analizaremos cuáles han sido los desarrollos tecnológicos más punteros de 2023 en este ámbito, tomando como base el conocimiento aportado por los expertos participantes en dicho webinar.
¿Qué es el GeoAI?
El término GeoAI hace referencia, tal y como define Kyoung-Sook Kim, copresidente del Grupo de Trabajo de GeoAI del Open Geospatial Consortium (OGC), a: “un conjunto de métodos o entidades automatizadas que utilizan datos geoespaciales para percibir, construir (automatizar) y optimizar espacios en los que los humanos, así como todo lo demás, pueden continuar de manera segura y eficiente sus actividades geográficamente referenciadas\".
El GeoAI nos permite crear enormes oportunidades que hasta el momento no habían sido posibles como:
- Extraer datos geoespaciales enriquecidos con aprendizaje profundo: Permite automatizar la extracción, la clasificación y la detección de información de datos como imágenes, vídeos, nubes de puntos y texto.
- Realizar análisis predictivos con aprendizaje automático: Habilita la creación de modelos de predicción más precisos, detección de patrones y automatización de algoritmos espaciales.
- Mejorar la calidad, la uniformidad y la precisión de los datos: Simplifica los flujos de generación manual de datos mediante la automatización para mejorar la eficiencia y reducir los costes.
- Acelerar el tiempo de obtención de conocimiento de la situación: Ayuda a responder más rápidamente a las necesidades medioambientales y tomar decisiones más proactivas basadas en datos en tiempo real.
- Incorporar la inteligencia de ubicación en la toma de decisiones: Ofrece nuevas posibilidades en la toma de decisiones basadas en datos del estado actual de la zona que necesitamos gobernar o planificar.
Aunque esta tecnología ha cobrado protagonismo a lo largo del año 2023, ya se hablaba de ella en el informe sobre tendencias geoespaciales de 2022, donde se indicaba que la incorporación de inteligencia artificial a los datos espaciales supone una gran oportunidad en el mundo de los datos abiertos y en el sector geoespacial.
Casos de uso de GeoIA
El potencial de esta tecnología emergente quedó de manifiesto durante la conferencia Geospatial trends 2023. La sesión fue moderada por Inmaculada Farfan Velasco, quien trabaja como project manager en la Oficina de Publicaciones de la Unión Europea y está involucrada en la iniciativa de datos de la UE.
Durante el webinar, las empresas del sector GIS Con terra y 52ºNorth compartieron varios ejemplos prácticos para responder a la pregunta ¿Cuáles son las tendencias actuales en materia de datos geoespaciales? Todos los casos de usos presentados a tal fin tienen algo en común: el uso de GeoAI.
Los ejemplos presentados por parte de Con terra fueron:
- KINoPro: Un proyecto de investigación que utiliza GeoAI para predecir la actividad de la polilla \"black arches\" y su impacto en los abetos de los bosques alemanes. Se analiza una amplia gama de datos, desde la temperatura hasta la humedad del suelo, para prever la aparición de estas plagas y tomar medidas preventivas.
- Anomalía en la detección de torres de telefonía: Usa una red neuronal para la detección de las causas de las anomalías que se detectan en algunas torres y que puede arrojar una errónea localización en la posición de una llamada, dato crucial en las llamadas de emergencias para localizar la zona afectada.
- Análisis automatizado de áreas de construcción: Pretende detectar áreas de edificaciones destinadas a zonas industriales a partir del uso de datos de OpenData e imágenes satelitales. Para ello realiza dos modelos: uno de los cambios en el territorio y otro que predice si estos cambios se deben al uso de las edificaciones (uso industrial o comercial).
Por su parte, 52ºNorth presentó los siguientes casos de usos:
- MariData: Busca reducir las emisiones del transporte marítimo optimizando las operaciones de los barcos de carga. Utiliza GeoAI para calcular rutas óptimas, considerando factores como la posición del barco, los datos ambientales y las regulaciones de tráfico marítimo.
- KI:STE: Aplica tecnologías de inteligencia artificial en ciencias ambientales para obtener valor con un enfoque en la infraestructura y la gestión de datos. El proyecto KI:STE se centra en la interoperabilidad de datos, la ejecución de modelos en entornos diversos y la elaboración de distintos proyectos como son los siguientes:
- Vida silvestre: conceptos sensibles para la vida silvestre que clasifica las imágenes de Sentinel-2 en áreas (no) protegidas
- Emisiones biogénicas: métodos no supervisados para estimar las emisiones biogénicas a partir de la observación de la Tierra.
- Predicción de peligros: flujo de trabajo de mapeo de peligros que incorpora tanto modelos basados en la física como algoritmos de aprendizaje automático basados en fuentes de datos heterogéneas.
- Extremos hidrometeorológicos: métodos Al para fusionar modelos y reanálisis/observación para la cuantificación de extremos hidrometeorológicos .
- Variabilidad de las nubes: aprendizaje auto supervisado sobre datos de Meteosat.

Estos proyectos resaltan la importancia del GeoAI en diversas aplicaciones, desde la predicción de eventos ambientales hasta la optimización de rutas de transporte marítimo. Todos ellos ponen de manifiesto que esta tecnología se presenta como una herramienta crucial para abordar problemas complejos en la comunidad geoespacial.
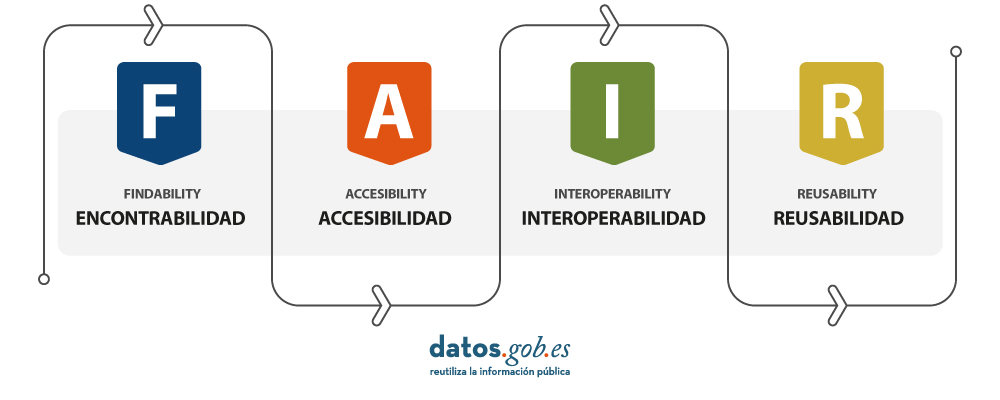
GeoAI no sólo representa una gran oportunidad para el sector espacial, sino que pondrá a prueba la importancia de disponer de datos abiertos que cumplan los principios FAIR. Estos principios (Encontrable, Accessible, Interoperable, Reusable) son fundamentales para los proyectos GeoAI, ya que garantizan un acceso a la información de manera transparente, eficiente y ética. Al adherirse a los principios FAIR, los conjuntos de datos se vuelven más accesibles para los investigadores y desarrolladores, alimentando la colaboración y la mejora constante de los modelos. Además, la transparencia y la capacidad de reutilizar datos abiertos contribuyen a generar confianza en los resultados obtenidos mediante proyectos de GeoAI.
Referencias
| Video de la conferencia | https://www.youtube.com/watch?v=YYiMQOQpk8A |
Documentación
En la era de los datos, nos enfrentamos al desafío de la escasez de datos de valor para la construcción de nuevos productos y servicios digitales. Aunque vivimos en una época en la que los datos están por todas partes, a menudo nos encontramos con dificultades para acceder a datos de calidad que nos permitan comprender procesos o sistemas desde una perspectiva basada en datos. La falta de disponibilidad, la fragmentación, la seguridad y la privacidad son solo algunas de las razones que dificultan el acceso a datos reales.
Sin embargo, los datos sintéticos han surgido como una solución prometedora a este problema. Los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible. Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales.
Los datos sintéticos son útiles en diversas situaciones donde la disponibilidad de datos reales es limitada o se requiere proteger la privacidad de las personas involucradas. Tienen aplicaciones en la investigación científica, pruebas de software y sistemas, y entrenamiento de modelos de inteligencia artificial. Permiten a los investigadores explorar nuevos enfoques sin acceder a datos sensibles, a los desarrolladores probar aplicaciones sin exponer datos reales y a los expertos en IA entrenar modelos sin la necesidad de recopilar todos los datos del mundo real que en ocasiones son, simplemente, imposibles de capturar en tiempos y costes asumibles.
Existen diferentes métodos para generar datos sintéticos, como el remuestreo, el modelado probabilístico y generativo, y los métodos de perturbación y enmascaramiento. Cada método tiene sus ventajas y desafíos, pero en general, los datos sintéticos ofrecen una alternativa segura y confiable para el análisis, la experimentación y el entrenamiento de modelos de inteligencia artificial.
Es importante destacar que el uso de datos sintéticos ofrece una solución viable para superar las limitaciones de acceso a datos reales y abordar preocupaciones de privacidad y seguridad. Los datos sintéticos permiten realizar pruebas, entrenar algoritmos y desarrollar aplicaciones sin exponer información confidencial. Sin embargo, es fundamental garantizar la calidad y la fidelidad de los datos sintéticos mediante evaluaciones rigurosas y comparaciones con los datos reales.
En este informe, abordamos de forma introductoria la disciplina de los datos sintéticos, ilustrando algunos casos de uso de valor para los diferentes tipos de datos sintéticos que se pueden generar. Los vehículos autónomos, la secuenciación de ADN o los controles de calidad en las cadenas de producción son solo algunos de los casos que detallamos en este informe. Además, hemos destacado el uso del software open-source SDV (Synthetic Data Vault), desarrollado en el entorno académico del MIT, que utiliza algoritmos de aprendizaje automático para crear datos sintéticos tabulares que imitan las propiedades y distribuciones de los datos reales. Desarrollamos un ejemplo práctico, en un entorno de Google Colab para generar datos sintéticos sobre clientes ficticios alojados en un hotel ficticio. Hemos seguido un flujo de trabajo que involucra la preparación de datos reales y metadatos, el entrenamiento del sintetizador y la generación de datos sintéticos basados en los patrones aprendidos. Además, hemos aplicado técnicas de anonimización para proteger los datos sensibles y hemos evaluado la calidad de los datos sintéticos generados.
En resumen, los datos sintéticos son una herramienta poderosa en la era de los datos, ya que nos permiten superar la escasez y la falta de disponibilidad de datos de valor. Con su capacidad para imitar los datos reales sin comprometer la privacidad, los datos sintéticos tienen el potencial de transformar la forma en que desarrollamos proyectos de inteligencia artificial y análisis. A medida que avanzamos en esta nueva era, es probable que los datos sintéticos desempeñen un papel cada vez más importante en la generación de nuevos productos y servicios digitales.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
En esta infografía se resume el concepto y sus principales aplicaciones:

Puedes descargarla en PDF aquí
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Blog
La tecnología digital y los algoritmos han revolucionado la forma en que vivimos, trabajamos y nos comunicamos. Si bien prometen eficiencia, precisión y conveniencia, estas tecnologías pueden exacerbar los prejuicios y las desigualdades sociales y crear nuevas formas de exclusión. Así, la invisibilización y la discriminación, que siempre han existido, cobran nuevas formas en la era de los algoritmos.
La falta de interés y de datos lleva a la invisibilización algorítmica, motivando que existan dos tipos de abandono algorítmico. El primero de ellos ocurre entre las personas desatendidas en el mundo, que incluye a los millones que no tienen un teléfono inteligente ni una cuenta bancaria y que, por ende, se encuentran al margen de la economía de plataformas y, para los algoritmos, no existen. El segundo tipo de abandono algorítimico incluye a individuos o grupos que son víctimas del fracaso del sistema algorítmico, como sucedió con SyRI (Systeem Risico Indicatie) en Países Bajos que señaló injustamente a unas 20.000 familias de origen socioeconómico bajo de cometer fraude fiscal, llevando a muchas a la ruina en 2021. El algoritmo, que fue declarado ilegal por un tribunal de La Haya meses más tarde, se aplicó en los barrios más pobres del país y bloqueó la posibilidad de muchas familias con más de una nacionalidad de percibir los beneficios sociales a los que tenían derecho por su condición socioeconómica.
Más allá del ejemplo en el sistema público neerlandés, la invisibilización y la discriminación también pueden originarse en el sector privado. Un ejemplo es el algoritmo de ofertas de trabajo de Amazon que mostró un sesgo contra las mujeres al aprender de datos históricos –es decir, datos incompletos al no incluir un universo amplio y representativo—, lo que llevó a Amazon a abandonar el proyecto. Otro ejemplo Apple Card, una tarjeta de crédito respaldada por Goldman Sachs, que también fue señalada cuando se descubrió que su algoritmo ofrecía límites de crédito más favorables a los hombres que a las mujeres.
En general, la invisibilidad y la discriminación algorítmica, en cualquier ámbito, puede derivar en un acceso desigual a los recursos y en una exacerbación de la exclusión social y económica.
Tomar decisiones basadas en algoritmos
Los datos y los algoritmos son componentes interconectados en el ámbito de la informática y el procesamiento de la información. Los datos sirven de base, pero pueden ser desestructurados, con excesiva variabilidad e incompletos. Los algoritmos son instrucciones o procedimientos diseñados para procesar y estructurar estos datos y extraer información, patrones o resultados significativos.
La calidad y relevancia de los datos impacta directamente en la efectividad de los algoritmos, ya que estos dependen de las entradas de datos para generar resultados. De ahí, el principio “basura entra basura sale”, que resume la idea de que, si entran datos de mala calidad, sesgados o inexactos en un sistema o proceso, el resultado también será de mala calidad o impreciso. Por su lado, los algoritmos bien diseñados pueden mejorar el valor de los datos al revelar relaciones ocultas o hacer predicciones.
Esta relación simbiótica subraya el papel fundamental que desempeñan tanto los datos como los algoritmos a la hora de impulsar los avances tecnológicos, permitir la toma de decisiones informadas y favorecer innovaciones.
La toma de decisiones algorítmica se refiere al proceso de utilizar conjuntos predefinidos de instrucciones o reglas para analizar datos y emitir predicciones que ayuden a decidir. Cada vez más, se aplica a decisiones que tienen que ver con el bienestar social y la oferta de servicios y productos comerciales a través de plataformas. Es ahí donde se puede encontrar la invisibilidad o la discriminación algorítmica.
Cada vez con más frecuencia, los sistemas de bienestar utilizan datos y algoritmos para ayudar en la toma de decisiones sobre asuntos como quién debe recibir asistencia y de qué tipo o quién presenta riesgos. Estos algoritmos consideran diferentes factores como ingresos, tamaño de la familia o de la vivienda, gastos, factores de riesgo, edad, sexo o género, que pueden incluir sesgos y omisiones.
Por eso el Relator Especial sobre la extrema pobreza y los derechos humanos, Philip Alston, advertía en un informe ante la Asamblea General de Naciones Unidas que la adopción sin cautelas de estos puede llevar a un bienestar social distópico. En dicho estado de bienestar distópico, los algoritmos se utilizan para reducir presupuestos, disminuir el número de personas beneficiarias, eliminar servicios, introducir formas exigentes e intrusivas de condicionalidad, modificar comportamientos, imponer sanciones y “revertir la noción de que el Estado debe rendir cuentas”.
Invisibilidad y discriminación algorítmicas: Dos conceptos opuestos
Aunque los datos y los algoritmos tienen mucho en común, la invisibilidad y la discriminación algorítmicas son dos conceptos opuestos. La invisibilidad algorítmica se refiere a lagunas en conjuntos de datos u omisiones en los algoritmos, que resultan en desatenciones en la aplicación de beneficios o servicios. Por el contrario, la discriminación algorítmica habla de puntos críticos que resaltan comunidades específicas o características sesgadas en conjuntos de datos, generando injusticia.
Es decir, la invisibilización algorítmica ocurre cuando individuos o grupos están ausentes en los conjuntos de datos, lo que hace imposible abordar sus necesidades. Por ejemplo, integrar en la toma de decisiones social datos sobre mujeres con discapacidad puede ser vital para la inclusión. A nivel mundial, las mujeres son más vulnerables a la invisibilización algorítmica que los hombres, ya que tienen menos acceso a la tecnología digital y dejan menos trazas digitales.
Los sistemas algorítmicos opacos que incorporan estereotipos pueden aumentar la invisibilización y la discriminación al ocultar, o bien apuntar, a personas o poblaciones vulnerables. Un sistema algorítmico opaco es aquel no permite el acceso a su funcionamiento.
Por otro lado, agregar o desagregar datos sin estudiar las consecuencias cuidadosamente puede resultar en omisiones u errores. Esto ilustra el doble filo de la contabilidad; es decir, la ambivalencia de la tecnología que cuantifica y cuenta, y que puede servir para mejorar la vida de las personas, pero también para perjudicarlas.
La discriminación puede surgir cuando las decisiones algorítmicas se basan en datos históricos, que normalmente incorporan asimetrías, estereotipos e injusticias, porque en el pasado existieron más desigualdades. El efecto de “basura entra basura sale” se produce si los datos están sesgados, como suele pasar con el contenido en línea. Asimismo, las bases de datos con sesgos o incompletas pueden ser incentivos de la discriminación algorítmica. Pueden aparecer sesgos de selección cuando los datos de reconocimiento facial, por ejemplo, se basan en rasgos de hombres blancos, mientras que las usuarias son mujeres de piel oscura, o en contenido en línea generado por una minoría de agentes, lo que dificulta la generalización.
Como se ve, abordar la invisibilidad y la discriminación algorítmica es un reto de primera magnitud que solo se podrá resolver con la concienciación y la colaboración de instituciones, organizaciones de campaña, empresas, e investigación.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
La UNESCO (Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura) es un organismo de las Naciones Unidas cuyo objeto es el de contribuir a la paz y a la seguridad en el mundo mediante la educación, la ciencia, la cultura y las comunicaciones. Para cumplir con su objetivo esta organización suele establecer guías y recomendaciones como la que ha publicado este 5 de Julio del 2023 titulado ‘Open data for AI: what now?’
Tras la pandemia del COVID-19 la UNESCO destaca una serie de lecciones aprendidas:
- Deben desarrollarse marcos normativos y modelos de gobernanza de datos, respaldados por infraestructuras, recursos humanos y capacidades institucionales suficientes para abordar los retos relacionados con los datos abiertos, con el fin de estar mejor preparados para las pandemias y otros retos mundiales.
- Es necesario especificar más la relación entre los datos abiertos y la IA, incluyendo qué características de los datos abiertos son necesarias para que sean "AI-Ready".
- Debe establecerse una política de gestión, colaboración e intercambio de datos para la investigación, así como para las instituciones gubernamentales que posean o procesen datos relacionados con la salud, al tiempo que se debe garantizar la privacidad de los datos mediante la anonimización.
- Los funcionarios públicos que manejan datos que son o pueden llegar a ser de utilidad para las pandemias pueden necesitar formación para reconocer la importancia de dichos datos, así como el imperativo de compartirlos.
- Deben recopilarse y recogerse tantos datos de alta calidad como sea posible. Los datos tienen que proceder de una variedad de fuentes creíbles, que, sin embargo, también deben ser éticas, es decir, no deben incluir conjuntos de datos con sesgos y contenido perjudicial, y tienen que recopilarse únicamente con consentimiento y no de forma invasiva para la privacidad. Además, las pandemias suelen ser procesos que evolucionan rápidamente, por lo que la actualización continua de los datos es esencial.
- Estas características de los datos son especialmente obligatorias para mejorar en el futuro las inadecuadas herramientas de diagnóstico y predicción de la IA. Es necesario realizar un esfuerzo para convertir los datos pertinentes en un formato legible por máquina, lo que implica la conservación de los datos recopilados, es decir, su limpieza y etiquetado.
- Debe abrirse una amplia gama de datos relacionados con las pandemias, adhiriéndose a los principios FAIR.
- El público objetivo de los datos abiertos relacionados con la pandemia incluye la investigación y el mundo académico, los responsables de la toma de decisiones en los gobiernos, el sector privado para el desarrollo de productos relevantes, pero también el público, todos los cuales deben ser informados sobre los datos disponibles.
- Las iniciativas de datos abiertos relacionadas con pandemias deberían institucionalizarse en lugar de formarse ad hoc, y por tanto deberían ponerse en marcha para la preparación ante futuras pandemias. Estas iniciativas también deberían ser integradoras y reunir a distintos tipos de productores y usuarios de datos.
- Asimismo, debería regularse el uso beneficioso de los datos relacionados con pandemias para las técnicas de aprendizaje automático de IA con el objetivo de evitar el uso indebido para el desarrollo de pandemias artificiales, es decir, armas biológicas, con la ayuda de sistemas de IA.
La UNESCO se basa en estas lecciones aprendidas para establecer unas Recomendaciones sobre la Ciencia Abierta facilitando el intercambio de datos, mejorando la reproducibilidad y la transparencia, promoviendo la interoperabilidad de los datos y las normas, apoyando la preservación de los datos y el acceso a largo plazo.
A medida que reconocemos cada vez más el papel de la Inteligencia Artificial (IA), la disponibilidad y el acceso a los datos son más cruciales que nunca, por ello la UNESCO lleva a cabo investigaciones en el ámbito de la IA para proporcionar conocimientos y soluciones prácticas que fomenten la transformación digital y construyan sociedades del conocimiento inclusivas.
Los datos abiertos son el principal objetivo de estas recomendaciones, ya que se consideran un requisito previo para la elaboración de planes, la toma de decisiones y las intervenciones con conocimiento de causa. Por ello, el informe afirma que los Estados miembros deben compartir los datos y la información, garantizando la transparencia y la rendición de cuentas, así como las oportunidades para que cualquiera pueda hacer uso de los datos.
La UNESCO ofrece una guía en la que pretende dar a conocer el valor de los datos abiertos y especifican los pasos concretos que los Estados miembros pueden dar para abrir sus datos. Son pasos prácticos, pero de alto nivel sobre cómo abrir datos, basándose en las directrices existentes. Se distinguen tres fases: preparación, apertura de los datos y seguimiento para su reutilización y sostenibilidad, y se presentan cuatro pasos para cada fase.
Es importante señalar que varios de los pasos pueden realizarse simultáneamente, es decir, no necesariamente de forma consecutiva.

Paso 1: Preparación
- Elaborar una política de gestión y puesta en común de datos: Una política de gestión y puesta en común de datos es un requisito importante previo a la apertura de los datos, ya que dicha política define el compromiso de los gobiernos de compartir los datos. El Instituto de Datos Abiertos sugiere los siguientes elementos de una política de datos abiertos:
- Una definición de datos abiertos, una declaración general de principios, un esquema de los tipos de datos y referencias a cualquier legislación, política u otra orientación pertinente.
- Se anima a los gobiernos a adherirse al principio "tan abierto como sea posible, tan cerrado como sea necesario". Si los datos no pueden abrirse por motivos legales, de privacidad o de otro tipo, por ejemplo, datos personales o sensibles, debe explicarse claramente.
Además, los gobiernos también deberían animar a los investigadores y al sector privado de sus países a desarrollar políticas de gestión e intercambio de datos que se adhieran a los mismos principios.
- Reunir y recopilar datos de alta calidad: Los datos existentes deben recopilarse y almacenarse en el mismo repositorio, por ejemplo, de varios departamentos gubernamentales donde pueden haber estado almacenados en silos. Los datos deben ser precisos y no estar desfasados. Además, los datos deben ser exhaustivos y no deben, por ejemplo, descuidar a las minorías o la economía informal. Los datos sobre las personas deben desglosarse cuando sea pertinente, incluso por ingresos, sexo, edad, raza, origen étnico, situación migratoria, discapacidad y ubicación geográfica.
- Desarrollar capacidades de datos abiertos: Estas capacidades se dirigen a dos grupos:
- Para los funcionarios públicos, incluye la comprensión de los beneficios de los datos abiertos potenciando y propiciando el trabajo que conlleva la apertura de los datos.
- Para los usuarios potenciales, incluye la demostración de las oportunidades de los datos abiertos, como su reutilización, y cómo tomar decisiones informadas.
- Preparar los datos para la IA: Si los datos no van a ser utilizados únicamente por humanos, sino que también pueden alimentar sistemas de IA, deben cumplir algunos criterios más para estar preparados para la IA.
- El primer paso en este sentido es preparar los datos en un formato legible por máquinas.
- Algunos formatos favorecen más que otros la legibilidad por parte de los sistemas de inteligencia artificial.
- Los datos también deben limpiarse y etiquetarse, lo que a menudo lleva mucho tiempo y, por tanto, es costoso.
- El éxito de un sistema de IA depende de la calidad de los datos de entrenamiento, incluida su coherencia y pertinencia. La cantidad necesaria de datos de entrenamiento es difícil de conocer de antemano y debe controlarse mediante comprobaciones de rendimiento. Los datos deben abarcar todos los escenarios para los que se ha creado el sistema de IA.
Paso 2: Abrir los datos
- Seleccionar los conjuntos de datos que se van a abrir: El primer paso para abrir los datos es decidir qué conjuntos de datos se van a abrir. Los criterios a favor de la apertura son:
- Si ha habido solicitudes previas de apertura de estos datos
- Si otros gobiernos han abierto estos datos y si ello ha dado lugar a usos beneficiosos de los datos.
La apertura de los datos no debe violar las leyes nacionales, como las leyes de privacidad de datos.
- Abrir los conjuntos de datos legalmente: Antes de abrir los conjuntos de datos, el gobierno correspondiente tiene que especificar exactamente en qué condiciones, en su caso, se pueden utilizar los datos. A la hora de publicar los datos, los gobiernos podrán optar por la licencia que mejor se adapte a sus objetivos, como son por ejemplo las licencias Creative Commons y Open. Para dar soporte a la selección de licencia la comisión europea pone a disposición JLA - Compatibility Checker, una herramienta que da apoyo para esta decisión
- Abrir los conjuntos de datos técnicamente: La forma más habitual de abrir los datos es publicarlos en formato electrónico para su descarga en un sitio web, además se debe contar con APIs para el consumo de estos datos, ya sea el del propio Gobierno o el de un tercero.
Los datos deben presentarse en un formato que permita su localización, accesibilidad, interoperabilidad y reutilización, cumpliendo así los principios FAIR.
Además, los datos también podrían publicarse en un archivo o repositorio de datos, que debería ser, según la Recomendación de la UNESCO, apoyado y mantenido por una institución académica, una sociedad académica, una agencia gubernamental u otra organización sin ánimo de lucro bien establecida y dedicada al bien común que permita el acceso abierto, la distribución sin restricciones, la interoperabilidad y la preservación y el archivo digital a largo plazo.
- Crear una cultura impulsada por los datos abiertos: La experiencia ha demostrado que, además de la apertura legal y técnica de los datos, hay que lograr al menos dos cosas más para alcanzar una cultura de datos abiertos:
- A menudo los departamentos gubernamentales no están acostumbrados a compartir datos y ha sido necesario crear una mentalidad y educarles en esta finalidad.
- Además, los datos deben convertirse, si es posible, en la base exclusiva para la toma de decisiones; en otras palabras, las decisiones deben estar basadas en los datos.
- Además se requieren cambios culturales por parte de todo el personal implicado, fomentando la divulgación proactiva de datos, lo que puede asegurar que los datos estén disponibles incluso antes de que se soliciten.
Paso 3: Seguimiento de la reutilización y la sostenibilidad
- Apoyar la participación ciudadana: Una vez abiertos los datos, deben ser descubiertos por los usuarios potenciales. Para ello hay que desarrollar una estrategia de promoción, que puede comprender anunciar la apertura de los datos en comunidades de datos abiertos y los canales de medios sociales pertinentes.
Otra actividad importante es la consulta y el compromiso tempranos con los usuarios potenciales, a los que, además de informar sobre los datos abiertos, se debe animar a utilizarlos y reutilizarlos y a seguir participando.
- Apoyar el compromiso internacional: Las asociaciones internacionales aumentarían aún más los beneficios de los datos abiertos, por ejemplo, mediante la colaboración sur-sur y norte-sur. Especialmente importantes son las asociaciones que apoyan y crean capacidades para la reutilización de los datos, ya sea mediante el uso de IA o sin ella.
- Apoyar la participación beneficiosa de la IA: Los datos abiertos ofrecen muchas oportunidades a los sistemas de IA. Para aprovechar todo el potencial de los datos, es necesario potenciar que los desarrolladores hagan uso de ellos y desarrollen sistemas de IA en consecuencia. Al mismo tiempo, hay que evitar el abuso de los datos abiertos para aplicaciones de IA irresponsables y perjudiciales. Una práctica recomendada es mantener un registro público de qué datos han utilizado los sistemas de IA y cómo lo han hecho.
- Mantener datos de alta calidad: Muchos datos quedan obsoletos rápidamente. Por lo tanto, los conjuntos de datos deben actualizarse con regularidad. El paso "Mantener datos de alta calidad" convierte esta directriz en un bucle, ya que enlaza con el paso "Reunir y recopilar datos de alta calidad".
Conclusiones
Estas directrices sirven como una llamada a la acción por parte de la UNESCO sobre la ética de la inteligencia artificial. Los datos abiertos son un requisito previo y necesario para el seguimiento y la consecución del desarrollo sostenible.
Debido a la magnitud de las tareas, los gobiernos no sólo deben adoptar la apertura de los datos, sino también crear condiciones favorables para una participación beneficiosa de la IA que cree nuevos conocimientos a partir de los datos abiertos, para una toma de decisiones basada en pruebas.
Si los Estados Miembros de la UNESCO siguen estas directrices y abren sus datos de manera sostenible, crean capacidades, así como una cultura impulsada por los datos abiertos, podremos conseguir un mundo en el que los datos no sólo sean más éticos, sino que las aplicaciones sobre estos datos sean más certeras y beneficiosas para la humanidad.
Referencias
https://www.unesco.org/en/articles/open-data-ai-what-now
Autor : Ziesche, Soenke , ISBN : 978-92-3-100600-5
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Según las previsiones de la Comisión Europea, en 2025 el volumen global de datos se habrá incrementado en un 530% y en ese contexto es clave garantizar la interoperabilidad y la reutilización de los datos. Así, la Unión Europea trabaja en la creación de un modelo digital que fomente el intercambio de datos y en el que se garantice la privacidad de las personas y la interoperabilidad de los datos.
La Estrategia Europea de Datos recoge la puesta en marcha de espacios de datos comunes e interoperables en sectores estratégicos. En este contexto, han surgido diferentes iniciativas en las que se debaten los procesos, estándares y herramientas adecuadas para la gestión e intercambio de datos, que sirven además para promover una cultura de información y reutilización. Una de estas iniciativas es SEMIC, la conferencia más importante sobre interoperabilidad a nivel europeo cuya edición de 2023 se celebra el próximo 18 de octubre en Madrid. Organizada por la Comisión Europea, esta edición cuenta con la colaboración de la Presidencia española del Consejo de la Unión Europea.
SEMIC 2023, que también se podrá seguir de manera virtual, se centra en ‘La Europa interoperable en la era de la IA’. Las sesiones abordarán los espacios de datos, la gobernanza digital, la garantía de calidad de los datos, la inteligencia artificial generativa y de propósito general o el derecho como código, entre otros aspectos. Además, se dará a conocer información sobre la propuesta de una Ley de Europa interoperable.
Talleres previos
Los asistentes tendrán la oportunidad de conocer casos de uso concretos en los que la interoperabilidad del sector público y la inteligencia artificial se han beneficiado mutuamente. Aunque SEMIC 2023 se celebrará el 18 de octubre, el día anterior se desarrollarán tres interesantes talleres a los que también se podrá asistir tanto de manera presencial como virtual.
- Inteligencia artificial en el diseño de políticas para la era digital y en la redacción de textos jurídicos. Este taller explorará cómo las herramientas impulsadas por la IA pueden ayudar a los responsables de la formulación de políticas públicas. Se abordarán diferentes herramientas, como el prototipo de análisis de políticas (SeTA) o las funcionalidades inteligentes para la redacción jurídica (LEOS).
- Grandes modelos lingüísticos en apoyo de la interoperabilidad. En esta sesión se explorarán los métodos y enfoques propuestos para el uso de grandes modelos lingüísticos y tecnología de IA en el contexto de la interoperabilidad semántica. Se centrará en el estado de LLM y su aplicación a la agrupación semántica, el descubrimiento de datos y la expansión de la terminología, entre otras aplicaciones que apoyan la interoperabilidad semántica.
- Registro europeo de modelos semánticos del sector público. En este taller se definirán acciones que permitan crear un punto de entrada para conectar las colecciones nacionales de activos semánticos.
Interacciones entre inteligencia artificial, interoperabilidad y semántica
El programa de la conferencia principal de SEMIC 2023 incluye mesas redondas y varias sesiones de trabajo que se desarrollarán de manera paralela. La primera sesión abordará la experiencia de Estonia, uno de los primeros países europeos que ha aplicado la IA en el sector público y pionero en interoperabilidad.
Por la mañana, se celebrará una interesante mesa redonda sobre el potencial de la inteligencia artificial para apoyar la interoperabilidad, en la que ponentes de diferentes Estados miembro de la Unión Europea presentarán casos de éxito y retos en relación con el despliegue de la IA en el sector público.
En la segunda mitad de la mañana se desarrollarán tres sesiones de manera paralela:
- Elaboración de políticas para la era digital y el derecho cómo código. En esta sesión se identificarán los principales retos y oportunidades en el ámbito de la IA y la interoperabilidad, teniendo como paradigma ‘el derecho como código’ y se prestará especial atención a la anotación semántica en la legislación.
- Interconexión de los espacios de datos. En este caso, se abordarán los principales retos y oportunidades en el desarrollo de los espacios de datos, prestando especial atención en las soluciones en materia de interoperabilidad. Igualmente, se tratarán las sinergias entre el Centro de apoyo a los espacios de datos (DSSC) y las especificaciones y herramientas DIGIT de la Comisión Europea.
- Servicios públicos automatizados. En esta sesión se hará una aproximación a la automatización del acceso a los servicios públicos con la ayuda de la IA y los chatbots.
Durante la tarde habrá tres nuevas sesiones paralelas:
- Grafos de conocimiento, semántica e IA. Se mostrará cómo la semántica tradicional se aprovecha de la IA.
- Calidad de los datos en la IA generativa y de propósito general. En esta sesión se hará un repaso de los principales problemas de calidad de los datos en la UE y se debatirá sobre las estrategias para superarlos.
- IA confiable para la interoperabilidad en el sector público. En este caso, se hablará sobre las oportunidades de utilizar la IA con fines de interoperabilidad en el sector público y los retos de transparencia y fiabilidad de los sistemas de IA.
También por la tarde tendrá lugar una mesa redonda sobre los próximos retos, en la que se abordarán las implicaciones tecnológicas, sociales y políticas de los avances en IA e interoperabilidad desde el punto de vista de las actuaciones políticas. Tras este panel, se celebrarán las conferencias de clausura.
La edición anterior, que tuvo lugar en Bruselas, congregó a más de 1.000 profesionales de 60 países tanto de manera presencial como virtual, por lo que SEMIC 2023 se presenta como una excelente oportunidad para conocer las últimas tendencias en interoperabilidad en la era de la inteligencia artificial.
Puedes apuntarte aquí: https://semic2023.eu/registration/
Blog
La segmentación de imágenes es un método que divide una imagen digital en subgrupos (segmentos) para reducir la complejidad de esta y, así, poder facilitar su procesamiento o análisis. La finalidad de la segmentación es asignar etiquetas a píxeles para identificar objetos, personas u otros elementos en la imagen.
La segmentación de las imágenes es clave para las tecnologías y algoritmos de visión artificial, pero también se utiliza hoy en día para muchas aplicaciones como, por ejemplo, el análisis de imágenes médicas, la visión de los vehículos autónomos, el reconocimiento y la detección de rostros o el análisis de imágenes satelitales, entre otras.
Segmentar una imagen es un proceso lento y costoso, por eso en lugar de procesar la imagen completa, una práctica común es la segmentación de imágenes mediante el enfoque de desplazamiento medio. Este procedimiento emplea una ventana desplazable que atraviesa progresivamente la imagen, calculando el promedio de los valores de píxeles contenidos en dicha región.
Este cálculo se efectúa con el propósito de establecer los píxeles que han de ser incorporados a cada uno de los segmentos delineados. Conforme la ventana avanza a lo largo de la imagen, lleva a cabo de manera iterativa una recalibración del cálculo para garantizar la idoneidad de cada uno de los segmentos resultantes.
A la hora de segmentar una imagen los factores o características que se tienen en cuenta son principalmente:
- El color: Los diseñadores gráficos tienen la posibilidad de emplear una pantalla de tonalidad verdosa con el fin de asegurar una uniformidad cromática en el fondo de la imagen. Esta práctica posibilita la automatización de la detección y sustitución del fondo durante la etapa de postprocesamiento.
- Bordes: La segmentación basada en bordes es una técnica que identifica los bordes de varios objetos en una imagen determinada. Estos se identifican en función de las variaciones de contraste, textura, color y saturación.
- Contraste: Se procesa la imagen distinguiendo entre una figura oscura y un fondo claro basándose en valores de alto contraste.
Estos factores se aplican en distintas técnicas de segmentación:
- Umbrales: Divide los píxeles en función de su intensidad en relación con un valor o umbral determinado. Este método es el más adecuado para segmentar objetos con mayor intensidad que otros objetos o fondos.
- Regiones: Consiste en dividir una imagen en regiones con características semejantes agregando los píxeles con características similares.
- Clústeres: Los algoritmos de agrupamiento son algoritmos de clasificación no supervisados que ayudan a identificar información oculta en las imágenes. El algoritmo divide las imágenes en grupos de píxeles con características similares, separando los elementos en grupos y agrupando elementos similares en estos grupos.
- Cuencas hidrográficas: Se trata de un proceso que transforma las imágenes a escala de grises, tratándolas como mapas topográficos, donde el brillo de los píxeles determina la altura. Esta técnica sirve para detectar líneas que forman crestas y cuencas. marcando las áreas entre las líneas divisorias de aguas.
El aprendizaje automático y el aprendizaje profundo (Deep learning) han mejorado estas técnicas, como la segmentación de clústeres, pero también han generado nuevos enfoques de segmentación que utilizan el entrenamiento de modelos para mejorar la capacidad de los programas a la hora de identificar características importantes. La tecnología de redes neuronales profundas es especialmente efectiva para las tareas de segmentación de imágenes.
En la actualidad encontramos distintos tipos de segmentación de imágenes, siendo las principales:
- Segmentación Semántica: La segmentación semántica de imágenes es un proceso que permite crear regiones dentro de una imagen y atribuir significado semántico a cada una de ellas. Estos objetos o también conocidas como clases semánticas, por ejemplo: coche, autobús, persona, árbol, etc., han sido previamente definidas mediante el entrenamiento de modelos en los que se clasifican y etiquetan estos objetos. El resultado es una imagen en lo que se han clasificado los pixeles en cada objeto o clase localizado.
- Segmentación de instancias: La segmentación de instancias combina el método de segmentación semántica (interpretando los objetos de una imagen) y la detección de objetos (al localizarlos dentro de la imagen). Como resultado de esta segmentación, se localizan los objetos, para que cada uno de ellos sea singularizado por medio de una ventana delimitadora (bounding box) y una máscara binaria, las cuales determinan qué píxeles de dicha ventana pertenecen al objeto localizado.
- Segmentación panóptica: Es el tipo más actual de segmentación. Se trata de una combinación de segmentación semántica y de instancias. Este método sí puede determinar la identidad de cada objeto porque esta técnica de segmentación localiza y distingue los diferentes objetos o instancias y asigna dos etiquetas a cada píxel de la imagen: una etiqueta semántica y una ID de instancia. De esta forma cada objeto es único.

En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.
El nuevo modelo de Meta: SAM
En abril del 2023, el departamento de investigación de Meta presentó un nuevo modelo de Inteligencia Artificial (IA) al que llamaron SAM (Segment Anything Model). Con SAM se puede realizar la segmentación de una imagen mediante tres formas:
- Seleccionando un punto en la imagen, se buscará y distinguirá el objeto que intersecta con ese punto y se buscará todos los objetos iguales encontrados en la imagen.
- Por ventana delimitadora o bounding box, sobre la imagen se dibuja un rectángulo y se identifican todos los objetos encontrados en esa área.
- Por palabras, mediante una consola se escribe una palabra y SAM puede identificar los objetos que coincidan con esa palabra u orden explícita tanto en imágenes o videos, incluso si ese dato no fue incluido en su entrenamiento.
SAM es un modelo flexible que fue entrenado con el conjunto de datos más grande hasta la fecha, llamado SA-1B y que cuenta con 11 millones de imágenes y 1.1 mil millones de máscaras en segmentación. Gracias a estos datos, SAM es capaz de detectar todo tipo de objetos sin necesidad de un entrenamiento adicional.
Por ahora, el modelo SAM y el conjunto de datos SA-1B está disponible para su uso no comercial y con fines de investigación. De este modo, los usuarios que suban sus imágenes tendrán que comprometerse a utilizarlo únicamente con fines de académicos. Para probarla, ingresa a este enlace de GitHub.
En agosto del 2023, el Grupo de Análisis de Imagen y Vídeo de la Academia China de las Ciencias, lanza una actualización de su modelo llamado FastSAM que reduce considerablemente el tiempo de procesado, se consigue una velocidad de ejecución 50 veces mayor, haciendo que el modelo sea más práctico de ejecutar que el modelo SAM original. Esta aceleración la consiguen habiendo entrenado el modelo con el 2% de los datos utilizados para entrenar SAM. FastSAM tiene menos requisitos computacionales que SAM, sin dejar de alcanzar una gran precisión.
SAMGEO: la versión que permite analizar datos geoespaciales
El paquete segment-geospatial desarrollado por Qiusheng Wu tiene como finalidad facilitar el uso de Segment Anything Model (SAM) para datos geoespaciales, para ello se he desarrollado los paquetes de Python segment-anything-py y segment-geospatial , que están disponibles en PyPI y conda-forge.
El objetivo es simplificar el proceso de aprovechamiento de SAM para el análisis de datos geoespaciales al permitir que los usuarios lo logren con un mínimo esfuerzo de codificación. A partir de estas librerías, se desarrolla el plugin de QGIS Geo-SAM y se desarrolla el uso del modelo en ArcGIS Pro.

Conclusiones
En definitiva, SAM supone una gran revolución no sólo por las posibilidades que abre a la hora de editar fotografías o extraer elementos de imágenes para collages o edición de video, sino también por las oportunidades de mejora que permiten aumentar la visión por computadora, a la hora de usar lentes de realidad aumentada o cascos de realidad virtual.
También SAM supone una revolución para la obtención de información espacial, mejorando la detención de objetos mediante imágenes satelitales y facilitando la detección de cambios en el territorio de forma rápida.
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La combinación e integración de los datos abiertos con la inteligencia artificial (IA) es un área de trabajo que cuenta con el potencial de lograr avances significativos en múltiples campos y conseguir mejoras en varios aspectos de nuestras vidas. El área de sinergia que más frecuentemente se menciona suele ser la utilización de los datos abiertos como datos de entrada para el entrenamiento de los algoritmos utilizados por la IA, ya que estos sistemas necesitan devorar grandes cantidades de datos para alimentar su funcionamiento. Esto convierte a los datos abiertos en un elemento ya de por sí esencial para el desarrollo de la IA, pero su utilización como datos de entrada conlleva además otras múltiples ventajas como una mayor igualdad de acceso a la tecnología o una mejora de la transparencia sobre el funcionamiento de los algoritmos.
Así pues, hoy en día podemos encontrar datos abiertos alimentando algoritmos para la aplicación de la IA en áreas tan variadas como la prevención de crímenes, el desarrollo del transporte público, la igualdad de género, la protección del medioambiente, la mejora de la sanidad o la búsqueda de ciudades más amigables y habitables. Todos ellos son ya objetivos más fácilmente alcanzables gracias a la adecuada combinación de ambas tendencias tecnológicas.
Sin embargo, como veremos a continuación, puestos a imaginar el futuro conjunto de los datos abiertos y la IA, el uso combinado de ambos conceptos puede dar lugar también a muchas otras mejoras en la forma en que trabajamos actualmente con los datos abiertos y a lo largo de todo el ciclo de vida de los mismos. Repasamos, paso a paso, cómo la inteligencia artificial puede enriquecer un proyecto con datos abiertos.
Utilizar la IA para descubrir fuentes y preparar conjuntos de datos
La inteligencia artificial puede ayudar ya desde los primeros pasos de nuestros proyectos de datos mediante el apoyo en la fase de descubrimiento e integración de diversas fuentes de datos, facilitando a las organizaciones encontrar y usar datos abiertos de relevancia para sus aplicaciones. Además, las tendencias futuras pueden incluir el desarrollo de estándares comunes de datos, marcos de metadatos y APIs para facilitar la integración de los datos abiertos con tecnologías de IA, lo que ampliaría aún más las posibilidades de automatizar la combinación de datos de diversas fuentes.
Además de la automatización en la búsqueda guiada de fuentes de datos, los procesos automáticos de la inteligencia artificial pueden ser de utilidad, al menos en parte, en el proceso de limpieza y preparación de los datos. De esta forma se puede mejorar la calidad de los datos abiertos al identificar y corregir los errores, rellenar los vacíos existentes en los datos y mejorar así su completitud. Esto contribuiría a liberar a los científicos y analistas de datos de ciertas tareas básicas y repetitivas para que puedan centrarse en otras tareas más estratégicas, como desarrollar nuevas ideas y hacer predicciones.
Técnicas innovadoras para el análisis de datos con IA
Una de las características de los modelos de IA es su facilidad para detectar patrones y conocimiento en grandes cantidades de datos. Técnicas de IA como el aprendizaje automático, el procesamiento del lenguaje natural y la visión por computador se pueden usar fácilmente para extraer nuevas perspectivas, patrones y conocimiento de los datos abiertos. Por otro lado, a medida que el desarrollo tecnológico continúa avanzando, podremos ver el desarrollo de técnicas de IA aún más sofisticadas y especialmente adaptadas para el análisis de datos abiertos, permitiendo a las organizaciones extraer todavía más valor de los mismos.
Paralelamente, las tecnologías de IA pueden ayudarnos a ir un paso más allá en el análisis de los datos facilitando y asistiendo en el análisis de datos colaborativo. Mediante este proceso, las múltiples partes interesadas pueden trabajar juntas en problemas complejos y darles respuesta a través de los datos abiertos. Esto daría lugar también a una mayor colaboración entre investigadores, formuladores de políticas públicas y comunidades de la sociedad civil a la hora de sacar el mayor provecho de los datos abiertos para abordar los desafíos sociales. Además, este tipo de análisis colaborativo también contribuiría a mejorar la transparencia y la inclusividad en los procesos de toma de decisiones.
La sinergia de la IA y los datos abiertos
En definitiva, la IA también se puede utilizar para automatizar muchas de las tareas involucradas en la presentación de los datos, como por ejemplo crear visualizaciones interactivas proporcionando simplemente instrucciones en lenguaje natural o una descripción de la visualización deseada.
Por otro lado, los datos abiertos permiten desarrollar aplicaciones que, combinadas con la inteligencia artificial, pueden resultar soluciones innovadoras. El desarrollo de nuevas aplicaciones impulsadas por los datos abiertos y la inteligencia artificial puede contribuir en diversos sectores como la atención sanitaria, finanzas, transporte o educación entre otros. Por ejemplo, se están utilizando chatbots para proporcionar servicio al cliente, algoritmos para tomar decisiones de inversión o coches autónomos, todos ellos impulsados por la IA. Lo que conseguiríamos además si estos servicios utilizaran los datos abiertos como fuente principal de datos sería una mayor calidad y veracidad, gracias a un mejor entrenamiento de los modelos de IA. Además, cuanta mayor sea la disponibilidad de los datos abiertos, mayor será también el número de personas que tendrán estas aplicaciones a su alcance.
Finalmente, la IA se puede utilizar también para analizar grandes volúmenes de datos abiertos e identificar nuevos patrones y tendencias que serían difíciles de detectar únicamente a través de la intuición humana. Esta información puede utilizarse luego para tomar mejores decisiones, como por ejemplo qué políticas llevar a cabo en un área determinada para poder obtener los cambios deseados.
Estas son solo algunas de las posibles tendencias futuras en la intersección de los datos abiertos y la inteligencia artificial, un futuro lleno de oportunidades pero al mismo tiempo no exento de riesgos. A medida que la IA continúa desarrollándose, podemos esperar ver aplicaciones aún más innovadoras y transformadoras de esta tecnología. Para ello será también necesaria una colaboración más cercana entre investigadores de inteligencia artificial y la comunidad de los datos abiertos a la hora de abrir nuevos conjuntos de datos y desarrollar nuevas herramientas para explotarlos. Esta colaboración es esencial para poder darle forma al futuro conjunto de los datos abiertos y la IA y garantizar que los beneficios de la IA estén disponibles para todos de forma justa y equitativa.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.