Documentación
1. Introducción
En la era de la información, la inteligencia artificial ha demostrado ser una herramienta invaluable para una variedad de aplicaciones. Una de las manifestaciones más increíbles de esta tecnología es GPT (Generative Pre-trained Transformer), desarrollado por OpenAI. GPT es un modelo de lenguaje natural que puede entender y generar texto, ofreciendo respuestas coherentes y contextualmente relevantes. Con la reciente introducción de Chat GPT-4, las capacidades de este modelo se han ampliado aún más, permitiendo una mayor personalización y adaptabilidad a diferentes temáticas.
En este post, te mostraremos cómo configurar y personalizar un asistente especializado en minerales críticos utilizando GPT-4 y fuentes de datos abiertas. Como ya mostramos en previas publicaciones, los minerales críticos son fundamentales para numerosas industrias, incluyendo la tecnología, la energía y la defensa, debido a sus propiedades únicas y su importancia estratégica. Sin embargo, la información sobre estos materiales puede ser compleja y dispersa, lo que hace que un asistente especializado sea particularmente útil.
El objetivo de este post es guiarte paso a paso desde la configuración inicial hasta la implementación de un asistente GPT que pueda ayudarte a resolver dudas y proporcionar información valiosa sobre minerales críticos en tu día a día. Además, exploraremos cómo personalizar aspectos del asistente, como el tono y el estilo de las respuestas, para que se adapte perfectamente a tus necesidades. Al final de este recorrido, tendrás una herramienta potente y personalizada que transformará la manera en que accedes y utilizas la información en abierto sobre minerales críticos.
Accede al repositorio del laboratorio de datos en Github.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
La transición hacia un futuro sostenible no solo implica cambios en las fuentes de energía, sino también en los recursos materiales que utilizamos. El éxito de sectores como baterías de almacenamiento de energía, aerogeneradores, paneles solares, electrolizadores, drones, robots, redes de transmisión de datos, dispositivos electrónicos o satélites espaciales, depende enormemente del acceso a las materias primas críticas para su desarrollo. Entendemos que un mineral es crítico cuando se cumplen los siguientes factores:
- Sus reservas mundiales son escasas
- No existen materiales alternativos que puedan ejercer su función (sus propiedades son únicas o muy singulares)
- Son materiales indispensables para sectores económicos clave de futuro, y/o su cadena de suministro es de elevado riesgo
Puedes aprender más sobre los minerales críticos en el post mencionado anteriormente.
3. Objetivo
Este ejercicio se centra en mostrar al lector cómo personalizar un modelo GPT especializado para un caso de uso concreto. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender cómo configurar y ajustar el modelo para resolver un problema real y relevante, como el asesoramiento experto en minerales críticos. Este enfoque práctico no solo mejora la comprensión de las técnicas de personalización de modelos de lenguaje, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
El asistente GPT especializado en minerales críticos estará diseñado para convertirse en una herramienta esencial para profesionales, investigadores y estudiantes. Su objetivo principal será facilitar el acceso a información precisa y actualizada sobre estos materiales, apoyar la toma de decisiones estratégicas y promover la educación en este campo. A continuación, se detallan los objetivos específicos que buscamos alcanzar con este asistente:
- Proporcionar información precisa y actualizada:
- El asistente debe ofrecer información detallada y precisa sobre diversos minerales críticos, incluyendo su composición, propiedades, usos industriales y disponibilidad.
- Mantenerse actualizado con las últimas investigaciones y tendencias del mercado en el ámbito de los minerales críticos.
- Asistir en la toma de decisiones:
- Proporcionar datos y análisis que puedan ayudar en la toma de decisiones estratégicas en la industria y la investigación sobre minerales críticos.
- Ofrecer comparativas y evaluaciones de diferentes minerales en función de su rendimiento, coste y disponibilidad.
- Promover la educación y la concienciación en torno a esta temática:
- Actuar como una herramienta educativa para estudiantes, investigadores y profesionales, ayudando a mejorar su conocimiento sobre los minerales críticos.
- Aumentar la conciencia sobre la importancia de estos materiales y los desafíos relacionados con su suministro y sostenibilidad.
4. Recursos
Para configurar y personalizar nuestro asistente GPT especializado en minerales críticos, es esencial disponer de una serie de recursos que faciliten la implementación y aseguren la precisión y relevancia de las respuestas del modelo. En este apartado, detallaremos los recursos necesarios que incluyen tanto las herramientas tecnológicas como las fuentes de información que serán integradas en la base de conocimiento del asistente.
Herramientas y Tecnologías
Las herramientas y tecnologías clave para desarrollar este ejercicio son:
- Cuenta de OpenAI: necesaria para acceder a la plataforma y utilizar el modelo GPT-4. En este post, utilizaremos la suscripción Plus de ChatGPT para mostrarte cómo crear y publicar un GPT personalizado. No obstante, puedes desarrollar este ejercicio de forma similar utilizando una cuenta gratuita de OpenAI y realizando el mismo conjunto de instrucciones a través de una conversación de ChatGPT estándar.
- Microsoft Excel: hemos diseñado este ejercicio de forma que cualquier persona sin conocimientos técnicos pueda desarrollarlo de principio a fin. Únicamente nos apoyaremos en herramientas ofimáticas como Microsoft Excel para realizar algunas adecuaciones de los datos descargados.
De forma complementaria, utilizaremos otro conjunto de herramientas que nos permitirán automatizar algunas acciones sin ser estrictamente necesaria su utilización:
- Google Colab: es un entorno de Python Notebooks que se ejecuta en la nube, permitiendo a los usuarios escribir y ejecutar código Python directamente en el navegador. Google Colab es especialmente útil para el aprendizaje automático, el análisis de datos y la experimentación con modelos de lenguaje, ofreciendo acceso gratuito a potentes recursos de computación y facilitando la colaboración y el intercambio de proyectos.
- Markmap: es una herramienta que visualiza mapas mentales de Markdown en tiempo real. Los usuarios escriben ideas en Markdown y la herramienta las renderiza como un mapa mental interactivo en el navegador. Markmap es útil para la planificación de proyectos, la toma de notas y la organización de información compleja visualmente. Facilita la comprensión y el intercambio de ideas en equipos y presentaciones.
Fuentes de Información
- Raw Materials Information System (RMIS): sistema de información sobre materias primas mantenido por el Joint Research Center de la Unión Europea. Proporciona datos detallados y actualizados sobre la disponibilidad, producción y consumo de materias primas en Europa.
- Catálogo de informes y datos de la Agencia Internacional de la Energía (IEA en sus siglas en inglés): ofrece un amplio catálogo de informes y datos relacionados con la energía, incluyendo estadísticas sobre producción, consumo y reservas de minerales energéticos y críticos.
- Base de datos de minerales del Instituto Geológico y Minero Español (BDMIN): contiene información detallada sobre los minerales y depósitos minerales en España, útil para obtener datos específicos sobre la producción y reservas de minerales críticos en el país.
Con estos recursos, estarás bien equipado para desarrollar un asistente GPT especializado que pueda proporcionar respuestas precisas y relevantes sobre minerales críticos, facilitando la toma de decisiones informadas en este campo.
5. Desarrollo del ejercicio
5.1. Construcción de la base de conocimiento
Para que nuestro asistente GPT especializado en minerales críticos sea verdaderamente útil y preciso, es esencial construir una base de conocimiento sólida y estructurada. Esta base de conocimiento será el conjunto de datos e información que el asistente utilizará para responder a las consultas. La calidad y relevancia de esta información determinarán la eficacia del asistente en proporcionar respuestas precisas y útiles.
Búsqueda de Fuentes de Datos
Comenzamos con la recopilación de fuentes de información que nutrirán nuestra base de conocimiento. No todas las fuentes de información son igualmente fiables. Es fundamental evaluar la calidad de las fuentes identificadas, asegurando que:
- La información esté actualizada: la relevancia de los datos puede cambiar con rapidez, especialmente en campos dinámicos como el de los minerales críticos.
- La fuente sea confiable y reconocida: es necesario utilizar fuentes de instituciones reconocidas y respetadas en el ámbito académico y profesional.
- Los datos sean completos y accesibles: es crucial que los datos sean detallados y que estén accesibles para su integración en nuestro asistente.
En nuestro caso, desarrollamos una búsqueda online en diferentes plataformas y repositorios de información tratando de seleccionar información perteneciente a diversas entidades reconocidas:
- Centros de investigación y universidades:
- Publican estudios y reportes detallados sobre la investigación y desarrollo de minerales críticos.
- Ejemplo: RMIS del Joint Research Center de la Unión Europea.
- Instituciones gubernamentales y organismos internacionales:
- Estas entidades suelen proporcionar datos exhaustivos y actualizados sobre la disponibilidad y el uso de minerales críticos.
- Ejemplo: Agencia Internacional de la Energía (IEA).
- Bases de datos especializadas:
- Contienen datos técnicos y específicos sobre depósitos y producción de minerales críticos.
- Ejemplo: Base de datos de Minerales del Instituto Geológico y Minero español (BDMIN).
Selección y preparación de la información
Nos centraremos ahora en la selección y preparación de la información existente en estas fuentes para asegurar que nuestro asistente GPT pueda acceder a datos precisos y útiles.
RMIS del Joint Research Center de la Unión Europea:
- Información seleccionada:
Seleccionamos el informe “Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU – A foresight study”. Se trata de un análisis de la cadena de suministro y la demanda de minerales en tecnologías y sectores estratégicos de la UE. Presenta un estudio detallado de las cadenas de suministro de materias primas críticas y pronostica la demanda de minerales hasta 2050.
- Preparación necesaria:
El formato del documento, PDF, permite la ingesta directa de la información por parte de nuestro asistente. No obstante, como se observa en la Figura 1, existe una tabla especialmente relevante en sus páginas 238-240 donde se analiza, para cada mineral, su riesgo de suministro, tipología (estratégico, crítico o no crítico) y las tecnologías clave que lo emplean. Decidimos, por ello, extraer esta tabla a un formato estructurado (CSV), de tal forma que dispongamos de dos piezas de información que pasarán a formar parte de nuestra base de conocimiento.

Figura 1: Tabla de minerales contenida en el PDF de JRC
Para extraer de forma programática los datos contenidos en esta tabla y transformarlos en un formato más fácilmente procesable, como CSV (comma separated values o valores separados por comas), utilizaremos un script de Python que podemos utilizar a través de la plataforma Google Colab (Figura 2).

Figura 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
A modo de resumen, este script:
- Se apoya en la librería de código abierto PyPDF2, capaz de interpretar información contenida en ficheros PDF.
- Primero, extrae en formato texto (cadena de caracteres) el contenido de las páginas del PDF donde se encuentra la tabla de minerales eliminando todo el contenido que no se corresponde con la propia tabla.
- Posteriormente, recorre, línea a línea, la cadena de caracteres convirtiendo los valores en columnas de una tabla de datos. Sabremos que un mineral es utilizado en una tecnología clave si en la columna correspondiente de dicho mineral encontramos un número 1 (en caso contrario contendrá un 0).
- Por último, exporta dicha tabla a un fichero CSV para su posterior utilización.
Agencia Internacional de la Energía (IEA):
- Información seleccionada:
Seleccionamos el informe “Global Critical Minerals Outlook 2024”. Este proporciona una visión general de los desarrollos industriales en 2023 y principios de 2024, y ofrece perspectivas a medio y largo plazo para la demanda y oferta de minerales clave para la transición energética. También evalúa los riesgos para la fiabilidad, sostenibilidad y diversidad de las cadenas de suministro de minerales críticos.
- Preparación necesaria:
El formato del documento, PDF, nos permite la ingesta directa de la información por parte de nuestro asistente virtual. No realizaremos en este caso ninguna adecuación de la información seleccionada.
Base de Datos de Minerales del Instituto Geológico y Minero Español (BDMIN)
- Información seleccionada:
En este caso, utilizamos el formulario para seleccionar los datos existentes en esta base de datos en cuanto a indicios y yacimientos del ámbito de la metalogenia, en particular seleccionamos aquellos con contenido de Litio.

Figura 3: Selección de conjunto de datos en BDMIN.
- Preparación necesaria:
Observamos cómo la herramienta web nos permite la visualización online y también la exportación de estos datos en varios formatos. Seleccionamos, por tanto, todos los datos a exportar y haciendo clic en esta opción, descargamos un fichero Excel con la información deseada.

Figura 4: Herramienta de visualización y descarga en BDMIN

Figura 5: Datos descargados BDMIN.
Todos los archivos que componen nuestra base de conocimiento se encuentran GitHub del proyecto, de tal forma que aquel lector que lo desee pueda saltarse la fase de descarga y preparación de la información.
5.2. Configuración y personalización del GPT para minerales críticos
Cuando hablamos de "crear un GPT," en realidad nos estamos refiriendo a la configuración y personalización de un modelo de lenguaje basado en GPT (Generative Pre-trained Transformer) para adaptarlo a un caso de uso específico. En este contexto, no estamos creando el modelo desde cero, sino ajustando cómo el modelo preexistente (como GPT-4 de OpenAI) interactúa y responde dentro de un dominio específico, en este caso, sobre minerales críticos.
En primer lugar, accedemos a la aplicación a través de nuestro navegador y, en caso de no tener una cuenta, seguimos el proceso de registro y login en la plataforma ChatGPT. Como indicamos con anterioridad, para realizar la creación de un GPT paso a paso será necesario disponer de una cuenta Plus. No obstante, aquellos lectores que no dispongan de dicha cuenta, podrán trabajar con una cuenta gratuita interactuando con ChatGPT a través de una conversación estándar.
Figura 6: Página de inicio de sesión y registro de ChatGPT.
Una vez iniciada la sesión, seleccionamos la opción "Explorar GPT", y posteriormente hacemos clic en "Crear" para comenzar el proceso de creación de nuestro GPT.

Figura 7: Creación de nuevo GPT.
En pantalla se nos mostrará la pantalla dividida de creación de un nuevo GPT: a la izquierda podremos conversar con el sistema para indicarle las características que debe tener nuestro GPT, mientras que a la izquierda podremos interactuar con nuestro GPT para validar que su comportamiento es el adecuado según vayamos avanzando en el proceso de configuración.

Figura 8: Pantalla de creación de nuevo GPT.
En el GitHub de este proyecto, podemos encontrar todos los prompts o instrucciones que utilizaremos para configurar y personalizar nuestro GPT y que deberemos introducir de forma secuencial en la pestaña "Crear", situada en la pestaña izquierda de nuestras pantallas, para completar los pasos que se detallan a continuación.
Los pasos que vamos a seguir para la creación del GPT son:
- En primer lugar, le indicaremos el objetivo y las consideraciones básicas a nuestro GPT para que pueda entender su modo de empleo.
Figura 9: Instrucciones básicas de nuevo GPT.
2. Posteriormente crearemos un nombre y una imagen que representen a nuestro GPT y lo hagan fácilmente identificable. En nuestro caso, lo denominaremos MateriaGuru.

Figura 10: Selección de nombre para nuevo GPT.

Figura 11: Creación de imagen para GPT.
3. A continuación, construiremos la base de conocimiento a partir de la información anteriormente seleccionada y preparada para nutrir los conocimientos de nuestro GPT.


Figura 12: Carga de información a la base de conocimiento de nuevo GPT.
4. Ahora, podemos personalizar aspectos conversacionales como su tono, el nivel de complejidad técnica de sus repuesta o si esperamos respuestas escuetas o elaboradas.
5. Por último, desde la pestaña "Configurar", podemos indicar los iniciadores de conversación deseados para que los usuarios que interactúen con nuestro GPT tengan algunas ideas para empezar la conversación de forma predefinida.

Figura 13: Pestaña Configurar GPT.
En la Figura 13 podemos también observar el resultado definitivo de nuestro entrenamiento, donde aparecen elementos clave como su imagen, nombre, instrucciones, iniciadores de conversación o documentos que forma parte de su base de conocimiento.
5.3. Validación y publicación de GPT
Antes de dar por bueno a nuestro nuevo asistente basado en GPT, procederemos a realizar una breve validación de su correcta configuración y aprendizaje respecto a la temática en torno a la que le hemos entrenado. Para ello, preparamos una batería de preguntas que le realizaremos para comprobar que responde de forma adecuada ante un escenario real de utilización.
| # | Pregunta | Respuesta |
|---|---|---|
| 1 | ¿Qué minerales críticos han experimentado una caída significativa en los precios en 2023? | Los precios de los minerales para baterías vieron particularmente grandes caídas con los precios del litio cayendo un 75% y los precios del cobalto níquel y grafito cayendo entre un 30% y un 45%. |
| 2 | ¿Qué porcentaje de la capacidad solar fotovoltaica (PV) mundial fue añadido por China en 2023? | China representó el 62% del aumento en la capacidad solar fotovoltaica global en 2023. |
| 3 | ¿Cuál es el escenario que proyecta que las ventas de autos eléctricos (EV) alcanzarán el 65% en 2030? | El escenario de emisiones netas cero (NZE) para 2050 proyecta que las ventas de autos eléctricos alcanzarán el 65% en 2030. |
| 4 | ¿Cuál fue el crecimiento de la demanda de litio en 2023? | La demanda de litio aumentó en un 30% en 2023. |
| 5 | ¿Qué país fue el mayor mercado de autos eléctricos en 2023? | China fue el mayor mercado de autos eléctricos en 2023 con 8.1 millones de ventas de autos eléctricos representando el 60% del total global. |
| 6 | ¿Cuál es el principal riesgo asociado con la concentración de mercado en la cadena de suministro de grafito para baterías? | Más del 90% del grafito de grado batería y el 77% de las tierras raras refinadas en 2030 se originan en China lo que representa un riesgo significativo para la concentración del mercado. |
| 7 | ¿Qué proporción de la capacidad mundial de producción de celdas de batería estaba en China en 2023? | China poseía el 85% de la capacidad de producción de celdas de batería en 2023. |
| 8 | ¿Cuánto aumentó la inversión en minería de minerales críticos en 2023? | La inversión en minería de minerales críticos creció un 10% en 2023. |
| 9 | ¿Qué porcentaje de la capacidad de almacenamiento de baterías en 2023 estaba compuesto por baterías de fosfato de hierro y litio (LFP)? | En 2023, las baterías LFP constituían aproximadamente el 80% del mercado total de almacenamiento de baterías. |
| 10 | ¿Cuál es el pronóstico para la demanda de cobre en un escenario de emisiones netas cero (NZE) para 2040? | En el escenario de emisiones netas cero (NZE) para 2040 se espera que la demanda de cobre tenga el mayor aumento en términos de volumen de producción. |
Figura 14: Tabla con batería de preguntas para la validación de nuestro GPT.
Valiéndonos de la parte de previsualización, situada a la derecha de nuestras pantallas, lanzamos la batería de preguntas y validamos que las respuestas se corresponden con aquellas esperadas.

Figura 15: Validación de respuestas GPT.
Por último, hacemos clic en el botón "Crear" para finalizar el proceso. Podremos seleccionar entre diferentes alternativas para restringir su utilización por parte de otros usuarios.

Figura 16: Publicación de nuestro GPT.
6. Escenarios de uso
En este apartado mostramos varios escenarios en los que podremos sacar partido a MateriaGuru en nuestro día a día. En el GitHub del proyecto podremos encontrar los prompts utilizados para replicar cada uno de ellos.
6.1. Consulta de información de minerales críticos
El escenario más típico de utilización de este tipo de GPTs es la asistencia para resolución de dudas relacionadas con la temática en cuestión, en este caso, los minerales críticos. A modo de ejemplo, hemos preparado una batería de cuestiones que el lector podrá plantear al GPT creado para comprender en mayor detalle la relevancia y situación actual de un material crítico como es el grafito a partir de los informes provistos a nuestro GPT.

Figura 17: Resolución de dudas de minerales críticos.
También podemos plantearle preguntas concretas sobre la información tabulada provista respecto a los yacimientos e indicios existentes en el territorio español.
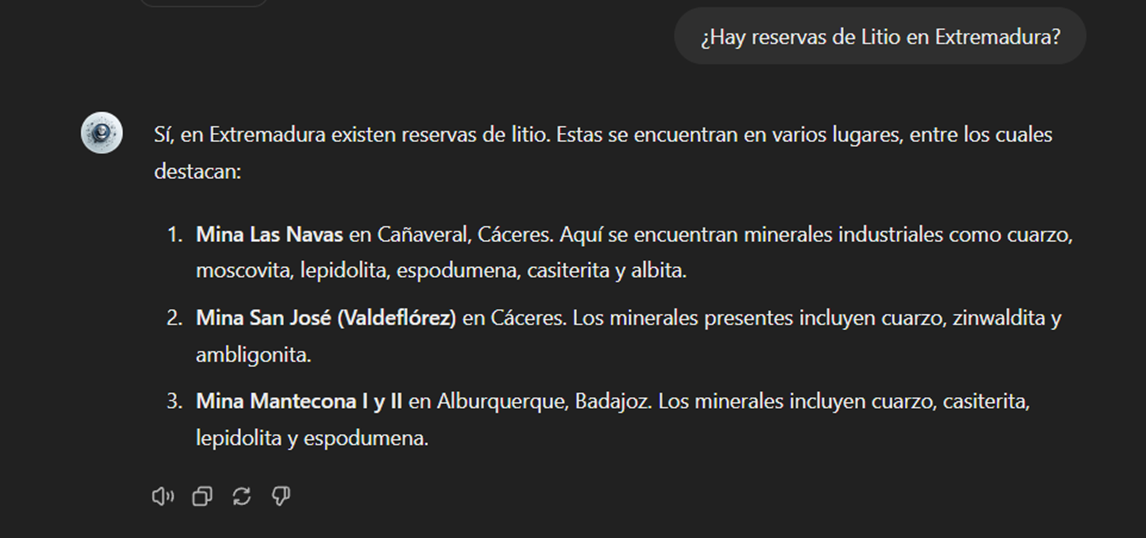
Figura 18: Reservas de litio en Extremadura.
6.2. Representación de visualizaciones de datos cuantitativos
Otro escenario común, es la necesidad de consultar información cuantitativa y realizar representaciones visuales para su mejor entendimiento. En este escenario, podemos observar cómo MateriaGuru es capaz de generar una visualización interactiva de la producción de grafito en toneladas de los principales países productores.

Figura 19: Generación de visualización interactiva con nuestro GPT.
6.3. Generación de mapas mentales para facilitar la comprensión
Por último, en línea con la búsqueda de alternativas para un mejor acceso y comprensión del conocimiento existente en nuestro GPT, plantearemos a MateriaGuru la construcción de un mapa mental que nos permita entender de una forma visual conceptos clave de los minerales críticos. Para ello, utilizamos la notación abierta Markmap (Markdown Mindmap), que nos permite definir mapas mentales utilizando notación markdown.

Figura 20: Generación de mapas mentales desde nuetro GPT.
Deberemos copiar el código generado e introducirlo en un visualizador de markmap para poder generar el mapa mental deseado. Facilitamos aquí una versión de este código generada por MateriaGuru.

Figura 21: Visualización de mapas mentales.
7. Resultados y conclusiones
En el ejercicio de construcción de un asistente experto utilizando GPT-4, hemos logrado crear un modelo especializado en minerales críticos. Este asistente proporciona información detallada y actualizada sobre minerales críticos, apoyando la toma de decisiones estratégicas y promoviendo la educación en este campo. Primero recopilamos información de fuentes confiables como el RMIS, la Agencia Internacional de la Energía (IEA), y el Instituto Geológico y Minero Español (BDMIN). Posteriormente, procesamos y estructuramos los datos adecuadamente para su integración en el modelo. Las validaciones demostraron que el asistente responde de manera precisa a preguntas relevantes del dominio, facilitando el acceso a su información.
De esta forma, el desarrollo del asistente especializado en minerales críticos ha demostrado ser una solución efectiva para centralizar y facilitar el acceso a información compleja y dispersa.
La utilización de herramientas como Google Colab y Markmap ha permitido una mejor organización y visualización de los datos, aumentando la eficiencia en la gestión del conocimiento. Este enfoque no solo mejora la comprensión y el uso de la información sobre minerales críticos, sino que también prepara a los usuarios para aplicar estos conocimientos en contextos reales.
La experiencia práctica adquirida en este ejercicio es directamente aplicable a otros proyectos que requieran la personalización de modelos de lenguaje para casos de uso específicos.
8. ¿Quieres realizar el ejercicio?
Si quieres replicar este ejercicio, accede a este repositorio donde encontrarás más información (las prompt utilizadas, el código generado por MateriaGuru, etc.)
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El verano supone para muchos la llegada de las vacaciones, una época en la que descansar o desconectar. Pero esos días libres también son una oportunidad para formarnos en diversas áreas y mejorar nuestras habilidades competitivas.
Para aquellos que quieran aprovechar las próximas semanas y adquirir nuevos conocimientos, las universidades españolas cuentan con una amplia oferta centrada en múltiples temáticas. En este artículo, recopilamos algunos ejemplos de cursos relacionados con la formación en datos.
Sistemas de Información Geográfica (SIG) con QGIS. Universidad de Alcalá de Henares (link no disponible).
El curso busca formar a los alumnos en las capacidades básicas en SIG para que puedan realizar procesos comunes como crear mapas para informes, descargar datos de un GPS, realizar análisis espaciales, etc. Cada estudiante tendrá la posibilidad de desarrollar su propio proyecto SIG con ayuda del profesorado. Está dirigido a estudiantes universitarios de cualquier disciplina, así como a profesionales interesados en aprender conceptos básicos para crear sus propios mapas o utilizar sistemas de información geográfica en sus actividades.
- Fecha y lugar: 27-28 de junio y 1-2 de julio en modalidad online.
Ciencia ciudadana aplicada a estudios de biodiversidad: de la idea a los resultados. Universidad Pablo de Olavide (Sevilla).
Este curso aborda todos los pasos necesarios para diseñar, implementar y analizar un proyecto de ciencia ciudadana: desde la adquisición de conocimientos básicos hasta sus aplicaciones en investigación y proyectos de conservación. Entre otras cuestiones, se realizará un taller sobre el manejo de datos de ciencia ciudadana, con el foco puesto en plataformas como Observation.org y GBIF. También se enseñará a utilizar herramientas de ciencia ciudadana para el diseño de proyectos de investigación. El curso está dirigido a un público amplio, especialmente investigadores, gestores de proyectos de conservación y estudiantes.
- Fecha y lugar: Del 1al 3 de julio de 2024 en modalidad online y presencial (Sevilla).
Big Data. Análisis de datos y aprendizaje automático con Python. Universidad Complutense de Madrid.
Este curso pretende que los alumnos adquieran una visión global del amplio ecosistema Big Data, sus retos y aplicaciones, centrándose en las nuevas maneras de obtener, gestionar y analizar datos. Durante el curso se presentará el lenguaje Python y se mostrarán distintas técnicas de aprendizaje automático para el diseño de modelos que permitan obtener información valiosa a partir de un conjunto de datos. Está dirigido a cualquier estudiante universitario, docente, investigador, etc. con interés en la temática, ya que no se requieren conocimientos previos.
- Fecha y lugar: Del 1 al 19 de julio de 2024 en Madrid.
Introducción a los Sistemas de Información Geográfica con R. Universidad de Santiago de Compostela.
Organizado por el Grupo de Trabajo de Cambio Climático y Riesgos Naturales de la Asociación Española de Geografía junto a la Asociación Española de Climatología, este curso introducirá al alumno en dos grandes áreas de gran interés: 1) el manejo del entorno R, mostrando las diferentes formas de gestión, manipulación y visualización de datos. 2) el análisis espacial, la visualización y el trabajo con archivos raster y vectoriales, abordando los principales métodos de interpolación geoestadística. Para participar, no se requieren conocimientos previos de Sistemas de Información Geográfica o del entorno R.
- Fecha y lugar: Del 2 al 5 de julio de 2024 en Santiago de Compostela.
Inteligencia Artificial y Grandes Modelos de Lenguaje: Funcionamiento, Componentes Clave y Aplicaciones. Universidad de Zaragoza.
A través de este curso, los alumnos podrán comprender los fundamentos y aplicaciones prácticas de la inteligencia artificial centrada en grandes modelos de lenguaje (Large Language Model o LLM en sus siglas en inglés). Se enseñará a utilizar bibliotecas y marcos de trabajo especializados para trabajar con LLM, y se mostrarán ejemplos de casos de uso y aplicaciones a través de talleres prácticos. Está dirigido a profesionales y estudiantes del sector de las tecnologías de la información y comunicaciones.
- Fecha y lugar: Del 3 al 5 de julio en Zaragoza.
Deep into Data Science. Universidad de Cantabria.
Este curso se centra en el estudio de grandes volúmenes de datos utilizando Python. El énfasis del curso se pone en el aprendizaje automático (Machine Learning en inglés), incluyendo sesiones sobre inteligencia artificial, redes neuronales o computación en la nube (Cloud Computing). Se trata de un curso técnico, que presupone conocimientos previos en ciencia y programación con Python.
- Fecha y lugar: Del 15 al 19 de julio de 2024 en Torrelavega.
Gestión de datos para el uso de inteligencia artificial en destinos turísticos. Universidad de Alicante.
Este curso se acerca al concepto de Destino Turístico Inteligente (DTI) y aborda la necesidad de disponer de una infraestructura tecnológica adecuada para garantizar su desarrollo sostenible, así como de realizar una gestión adecuada de los datos que permita la aplicación de técnicas de inteligencia artificial. Durante el curso se hablará de datos abiertos y espacios de datos, y su aplicación en el turismo. Está dirigido a todo tipo de público con interés en el uso de tecnologías emergentes en el ámbito del turismo.
- Fecha y lugar: Del 22 al 26 de julio de 2024 en Torrevieja.
Los retos de la transformación digital de sectores productivos desde la perspectiva de la inteligencia artificial y tecnologías de procesamiento de datos. Universidad de Extremadura.
Ya finalizado el verano, encontramos este curso donde se abordan los fundamentos de la transformación digital y su impacto en los sectores productivos a través de la exploración de tecnologías clave de procesamiento de datos, como Internet de las Cosas, Big Data, Inteligencia Artificial, etc. Durante las sesiones se analizarán casos de estudio y prácticas de implementación de estas tecnologías en diferentes sectores industriales. Todo ello sin dejar de lado los desafíos éticos, legales y de privacidad. Está dirigido a cualquier persona interesada en la materia, sin necesidad de conocimientos previos.
- Fecha y lugar: Del 17 al 19 de septiembre, en Cáceres.
Estos cursos son solo ejemplos que ponen de manifiesto la importancia que las capacidades relacionadas con datos están adquiriendo en las empresas españolas, y cómo eso se refleja en la oferta universitaria. ¿Conoces algún curso más, ofrecido por universidades públicas? Déjanoslo en comentarios.
Blog
La inteligencia artificial (IA) ha revolucionado diversos aspectos de la sociedad y nuestro entorno. Con avances tecnológicos cada vez más rápidos, la IA está transformando la forma en que se realizan las tareas diarias en diferentes sectores de la economía.
Por ello, el empleo es uno de estos sectores en los que más impacto genera. Entre las principales novedades, esta tecnología está introduciendo nuevos perfiles profesionales y modificando o transformando puestos de trabajo ya existentes. Ante este panorama, se plantean interrogantes sobre el futuro del empleo y cómo afectará a los trabajadores en el mercado laboral.
¿Cuáles son las principales cifras de la IA en el empleo?
El Fondo Monetario Internacional lo ha señalado recientemente: la Inteligencia Artificial afectará a un 40% de los puestos de trabajo en todo el mundo, tanto remplazando unos como complementando y creando otros nuevos.
La irrupción de la IA en el mundo laboral ha facilitado que algunas tareas que antes requerían de la intervención humana, ahora se realicen de forma más automática. Además, como advierte este mismo organismo internacional, frente a otros procesos de automatización vividos en décadas pasadas, la era de la IA viene también a transformar puestos de trabajo de alta preparación o cualificación (high skilled job).
Asimismo, este documento expone que el impacto de la IA en el trabajo será diferente según el nivel de desarrollo del país. Así, será mayor en el caso de economías avanzadas, donde se prevé que hasta 6 de cada 10 empleos se vean condicionados por esta tecnología. En el caso de economías emergentes, llegará hasta un 40% y, en países de bajos ingresos, se reflejará en un 26% de los empleos. Por su parte, la Organización Internacional del Trabajo (OIT), también advierte en su informe ‘Generative AI and Jobs: A global analysis of potential effects on job quantity and quality’ que los efectos de la llegada de la IA a los puestos administrativos afectarán en particular a las mujeres, debido a la alta tasa de empleo femenino en este sector laboral.
En el caso español, según cifras del pasado año, no sólo se observa la influencia de la IA en los puestos de trabajo, sino que aflora la dificultad de conseguir personas con formación especializada. Según el informe sobre el talento en inteligencia artificial elaborado por Indesia, el pasado año un 20% de las ofertas de empleo relacionadas con datos e Inteligencia Artificial no se cubrió por falta de profesionales con especialización.
Proyecciones a futuro
Aunque aún no existen cifras fidedignas que permitan ver cómo serán los próximos años, algunos organismos, como la OCDE, afirman que aún estamos en un estadio inicial del desarrollo de la IA en el mercado laboral, pero a las puertas de un avance a gran escala. Según su informe ‘Employment Outlook 2023’, “la adopción de la IA por parte de las empresas sigue siendo relativamente baja”, aunque advierte de que “los rápidos avances, incluidos los de la IA generativa (por ejemplo, ChatGPT), la caída de los costes y la creciente disponibilidad de trabajadores con conocimientos de IA sugieren que los países de la OCDE pueden estar al borde de una revolución de la IA”. Cabe destacar que la IA generativa es uno de los campos donde tienen un gran impacto los datos abiertos.
¿Y qué ocurrirá en España? Quizá todavía es pronto para apuntar cifras muy precisas, pero el informe elaborado el pasado año por Indesia ya advirtió de que la industria española demandará más de 90.000 profesionales del área de data e IA hasta 2025. Este mismo documento apunta además los desafíos que deberán acometer las compañías españolas, ya que la globalización y la intensificación del trabajo en remoto lleva a que las empresas nacionales estén compitiendo con compañías internacionales que ofrecen también empleo 100% a distancia, “con mejores condiciones salariales, proyectos más atractivos e innovadores y planes de carrera más retadores”, señala el informe.
¿Qué empleos está modificando la IA?
A pesar de que uno de los mayores temores de la llegada de esta tecnología al mundo laboral es la destrucción del empleo, las últimas cifras publicadas por la Organización Internacional del Trabajo (OIT), apuntan a un escenario bastante más halagüeño. En concreto, este organismo prevé que la IA complementará puestos de trabajo en lugar de destruirlos.
No hay excesiva unanimidad con respecto a cuáles serán los sectores más afectados. En su informe ‘The impact of AI on the workplace: Main findings from the OECD AI surveys of employers and workers’, la OCDE señala que industria manufacturera y la financiera son dos de las áreas más afectadas por la irrupción de la Inteligencia Artificial.
Por otro lado, Randstad ha publicado recientemente un informe sobre la evolución de los últimos dos años con una visión a futuro hasta 2033. El documento apunta que los sectores más afectados serán los empleos ligados al comercio, la hostelería y el transporte. Entre aquellos empleos que permanecerán sin apenas afección, se encuentran la agricultura, ganadería y pesca, las actividades asociativas, las industrias extractivas o la construcción. Y, por último, un tercer grupo, en el que se encuentran los sectores laborales en los que habrá creación de perfiles nuevos. En este caso, se encuentran las empresas de programación y consultoría, las científicas y técnicas, las telecomunicaciones y los medios de comunicación y las publicaciones.
Más allá de los desarrolladores de software, entre los nuevos puestos de trabajo que está trayendo la inteligencia artificial, encontraremos alguno que van desde expertos en procesamiento del lenguaje natural o ingenieros de AI Prompt (expertos en hacer las preguntas necesarias para conseguir que aplicaciones de IA generativa ofrezcan un resultado específico) hasta auditores de algoritmos o incluso artistas.
En definitiva, aunque todavía es pronto para señalar qué tipo de empleos exactos son los más influenciados, las organizaciones apuntan un dato: a mayor probabilidad de automatización de los procesos ligados al puesto de trabajo, existe una mayor afección de la IA a la hora de transformar o modificar ese perfil laboral.
Los retos de la IA en el mercado laboral
Uno de los organismos que más ha estudiado cuáles son los retos y repercusiones de la IA en el empleo es la OIT. En el plano de las necesidades, la OIT señala la necesidad de diseñar políticas que apoyen una transición ordenada, justa y consultiva. Para ello, apunta que la voz de los trabajadores, la capacitación y una protección social adecuada serán claves para gestionar la transición. “De lo contrario, se corre el riesgo de que sólo unos pocos países y participantes en el mercado bien preparados se beneficien de la nueva tecnología”, advierte el organismo.
Por su parte, la OCDE señala una serie de recomendaciones para que los gobiernos puedan acomodar esta nueva realidad laboral, entre las que se encuentra la necesidad de:
-
Establecer políticas concretas que garanticen la aplicación de principios clave para un uso fiable de la IA. A través de la puesta en marcha de estos mecanismos, la OCDE considera que se aprovechan los beneficios que la IA puede aportar al lugar de trabajo y, al mismo tiempo, se hace frente a los posibles riesgos para los derechos fundamentales y en favor del bienestar de los trabajadores.
-
Crear nuevas cualificaciones, mientras que otras cambiarán o quedarán obsoletas. Para ello, apunta a la formación, necesaria “tanto para los trabajadores poco cualificados como para los de más edad, pero también para los más cualificados”. Por ello, “los gobiernos deberían animar al empresariado a ofrecer más formación, integrar las competencias en IA en la educación y apoyar la diversidad en la mano de obra de la IA”.
En resumen, aunque las cifras todavía no permiten observar el panorama al completo, varios organismos internacionales sí coinciden en que la revolución de la IA está por llegar. También, apuntan la necesidad de acomodarse a este nuevo escenario a través de la formación interna en las empresas para poder hacer frente a las necesidades que plantea la tecnología. Por último, en materia gubernamental, organismos como la OIT señalan que es necesario asegurar que la transición en la revolución tecnológica sea justa y dentro de unos márgenes de usos fiables de la Inteligencia Artificial.
Blog
La transferencia de conocimiento humano hacia los modelos de aprendizaje automático es la base de toda la inteligencia artificial actual. Si queremos que los modelos de IA sean capaces de resolver tareas, primero tenemos que codificar y transmitirles tareas resueltas en un lenguaje formal que puedan procesar. Entendemos como tarea resuelta la información codificada en diferentes formatos, como el texto, la imagen, el audio o el vídeo. En el caso del procesamiento del lenguaje, y con el fin de conseguir sistemas con una alta competencia lingüística para que puedan comunicarse de manera ágil con nosotros, necesitamos trasladar a estos sistemas el mayor número posible de producciones humanas en texto. A estos conjuntos de datos los llamamos corpus.
Corpus: conjuntos de datos en texto
Cuando hablamos de los corpus, corpora (su plural latino) o datasets que se han utilizado para entrenar a los grandes modelos de lenguaje (LLMs por Large Language Models) como GPT-4, hablamos de libros de todo tipo, contenido escrito en páginas web, grandes repositorios de texto e información del mundo como Wikipedia, pero también producciones lingüísticas menos formales como las que escribimos en redes sociales, en reseñas públicas de productos o servicios, o incluso en correos electrónicos. Esta variedad permite que estos modelos de lenguaje puedan procesar y manejar texto en diferentes idiomas, registros y estilos.
Para las personas que trabajan en Procesamiento del Lenguaje Natural (PLN), ciencia e ingeniería de datos, son conocidos y habituales los grandes facilitadores como Kaggle o repositorios como Awesome Public Datasets en GitHub, que proporcionan acceso directo a la descarga de fuentes de datos públicas. Algunos de estos ficheros de datos han sido preparados para su procesamiento y están listos para analizar, mientras que otros se encuentran en un estado no estructurado, que requiere un trabajo previo de limpieza y ordenación antes de poder empezar a trabajar con ellos. Aunque también contienen datos numéricos cuantitativos, muchas de estas fuentes presentan datos en texto que pueden utilizarse para entrenar modelos de lenguaje.
El problema de la legitimidad
Una de las complicaciones que hemos encontrado en la creación de estos modelos es que los datos en texto que están publicados en internet y han sido recogidos mediante API (conexiones directas que permiten la descarga masiva de una web o repositorio) u otras técnicas, no siempre son de dominio público. En muchas ocasiones, tienen copyright: escritores, traductores, periodistas, creadores de contenido, guionistas, ilustradores, diseñadores y también músicos reclaman a las grandes tecnológicas un licenciamiento por el uso de sus contenidos en texto e imagen para entrenar modelos. Los medios de comunicación, en concreto, son actores enormemente impactados por esta situación, aunque su posicionamiento varía en función de su situación y de diferentes decisiones de negocio. Por ello es necesario que existan corpus abiertos que se puedan utilizar para estas tareas de entrenamiento, sin perjuicio de la propiedad intelectual.
Características idóneas para un corpus de entrenamiento
La mayoría de las características, que tradicionalmente han definido a un buen corpus en investigación lingüística, no han variado al utilizarse en la actualidad estos conjuntos de datos en texto para entrenar modelos de lenguaje.
- Sigue siendo beneficioso utilizar textos completos y no fragmentos, para asegurar su coherencia.
- Los textos deben ser auténticos, procedentes de la realidad lingüística y de situaciones naturales del lenguaje, recuperables y verificables.
- Es importante asegurar una diversidad amplia en la procedencia de los textos en cuanto a sectores de la sociedad, publicaciones, variedades locales de los idiomas y emisores o hablantes.
- Además del lenguaje general, debe incluirse una amplia variedad de lenguajes de especialidad, tecnicismos y textos específicos de diferentes áreas del conocimiento.
- El registro es fundamental en una lengua, por lo que debemos cubrir tanto el registro formal como el informal, en sus extremos y regiones intermedias.
- El lenguaje debe estar bien formado para evitar interferencias en el aprendizaje, por lo que es conveniente eliminar marcas de código, números o símbolos que correspondan a metadatos digitales y no a la formación natural del lenguaje.
Como recomendaciones específicas para los formatos de los archivos que van a formar parte de estos corpus, encontramos que los corpus de texto con anotaciones deben almacenarse en codificación UTF-8 y en formato JSON o CSV, no en PDF. Los corpus sonoros tienen como formato preferente WAV 16 bits, 16 KHz. (para voz) o 44.1 KHz (para música y audio). Los corpus en vídeo es conveniente recopilarlos en formato MPEG-4 (MP4), y las memorias de traducción en TMX o CSV.
El texto como patrimonio colectivo
Las bibliotecas nacionales en Europa están digitalizando activamente sus ricos depósitos de historia y cultura, asegurando el acceso público y la preservación. Instituciones como la Biblioteca Nacional de Francia o la British Library lideran con iniciativas que digitalizan desde manuscritos antiguos hasta publicaciones actuales en web. Este atesoramiento digital no solo protege el patrimonio contra el deterioro físico, sino que también democratiza el acceso para los investigadores y el público y, desde hace algunos años, también permite la recopilación de corpus de entrenamiento para modelos de inteligencia artificial.
Los corpus proporcionados de manera oficial por bibliotecas nacionales permiten que las colecciones de textos sirvan para crear tecnología pública al alcance de todos: un patrimonio cultural colectivo que genera un nuevo patrimonio colectivo, esta vez tecnológico. La ganancia es mayor cuando estos corpus institucionales sí están enfocados a cumplir con las leyes de propiedad intelectual, proporcionando únicamente datos abiertos y textos libres de restricciones de derechos de autor, con derechos prescritos o licenciados. Esto, unido al hecho esperanzador de que la cantidad de datos reales necesaria para entrenar modelos de lenguaje va reduciéndose a medida que avanza la tecnología, por ejemplo, con la generación de datos sintéticos o la optimización de determinados parámetros, indica que es posible entrenar grandes modelos de texto sin infringir las leyes de propiedad intelectual que operan en Europa.
En concreto, la Biblioteca Nacional de España está haciendo un gran esfuerzo de digitalización para poner sus valiosos repositorios de texto a disposición de la investigación, y en particular de las tecnologías del lenguaje. Desde que en 2008 se realizó la primera gran digitalización masiva de colecciones físicas, la BNE ha abierto el acceso a millones de documentos con el único objetivo de compartir y universalizar el conocimiento. En 2023, y gracias a la inversión procedente de los fondos de Recuperación, Transformación y Resiliencia de la Unión Europea, la BNE impulsa un nuevo proyecto de preservación digital en su Plan Estratégico 2023-2025, centrada en cuatro ejes:
- la digitalización masiva y sistemática de las colecciones,
- BNELab como catalizador de innovación y reutilización de datos en ecosistemas digitales,
- alianzas y nuevos entornos de cooperación,
- e integración y sostenibilidad tecnológica.
La alineación de estos cuatro ejes con las nuevas tecnologías de inteligencia artificial y procesamiento del lenguaje natural es más que notoria, ya que una de las principales reutilizaciones de datos es el entrenamiento de grandes modelos de lenguaje. Tanto los registros bibliográficos digitalizados como los índices de catalogación de la Biblioteca son materiales de valor para la tecnología del conocimiento.
Modelos de lenguaje en español
En el año 2020, y como una iniciativa pionera y relativamente temprana, en España se presentaba MarIA, un modelo de lenguaje impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación (BSC-CNS), a partir de los archivos de la Biblioteca Nacional de España. En este caso, el corpus estaba compuesto por textos procedentes de páginas web, que habían sido recopilados por la BNE desde el año 2009 y que habían servido para nutrir un modelo basado originalmente en GPT-2.
Han ocurrido muchas cosas entre la creación de MarIA y el anuncio en el Mobile World Congress de 2024 de la construcción de un gran modelo fundacional de lenguaje, entrenado específicamente en español y lenguas cooficiales. Este sistema será de código abierto y transparente, y únicamente utilizará en su entrenamiento contenido libre de derechos. Este proyecto es pionero a nivel europeo, ya que busca proporcionar desde las instituciones una infraestructura lingüística abierta, pública y accesible para las empresas. Al igual que MarIA, el modelo se desarrollará en el BSC-CNS, en un trabajo conjunto con la Biblioteca Nacional de España y otros actores como la Academia Española de la Lengua y la Asociación de Academias de la Lengua Española.
Además de las instituciones que pueden aportar colecciones lingüísticas o bibliográficas, existen muchas más instituciones en España que pueden proporcionar corpus de calidad que pueden servir también para el entrenamiento de modelos en español. El Estudio sobre datos reutilizables como recursos lingüísticos, publicado en 2019 en el marco del Plan de Tecnologías del Lenguaje, ya apuntaba a distintas fuentes: las patentes y los informes técnicos de la Oficina de Patentes y Marcas, tanto españolas como europeas, los diccionarios terminológicos del Centro de Terminología, o datos tan elementales como el padrón, del Instituto Nacional de Estadística, o los topónimos del Instituto Geográfico Nacional. Cuando hablamos de contenido audiovisual, que puede ser transcrito para su reutilización, contamos con el archivo en vídeo de RTVE A la carta, el Archivo Audiovisual del Congreso de los Diputados o los archivos de las diferentes televisiones autonómicas. El propio Boletín Oficial del Estado y sus materiales asociados son una fuente importante de información en texto que contiene conocimientos amplios sobre nuestra sociedad y su funcionamiento. Por último, en ámbitos específicos como la salud o la justicia, contamos con las publicaciones de la Agencia Española de Medicamentos y Productos Sanitarios, los textos de jurisprudencia del CENDOJ o las grabaciones de vistas judiciales del Consejo General del Poder Judicial.
Iniciativas europeas
En Europa no parece haber un precedente tan claro como MarIA o el próximo modelo basado en GPT en español, como proyectos impulsados a nivel estatal y entrenados con datos patrimoniales, procedentes de bibliotecas nacionales u organismos oficiales.
Sin embargo, en Europa hay un buen trabajo previo de disponibilidad de la documentación que podría utilizarse ahora para entrenar sistemas de IA de fundación europea. Un buen ejemplo es el proyecto Europeana, que busca digitalizar y hacer accesible el patrimonio cultural y artístico de Europa en conjunto. Es una iniciativa colaborativa que reúne contribuciones de miles de museos, bibliotecas, archivos y galerías, proporcionando acceso gratuito a millones de obras de arte, fotografías, libros, piezas de música y vídeos. Europeana cuenta con casi 25 millones de documentos en texto, que podrían ser la base para crear modelos fundacionales multilingües o competentes en las distintas lenguas europeas.
Existen también iniciativas no gubernamentales, pero con impacto global, como Common Corpus, que son la prueba definitiva de que es posible entrenar modelos de lenguaje con datos abiertos y sin infringir las leyes de derechos de autor. Common Corpus se liberó en marzo de 2024, y es el conjunto de datos más extenso creado para el entrenamiento de grandes modelos de lenguaje, con 500 mil millones de palabras procedentes de distintas iniciativas de patrimonio cultural. Este corpus es multilingüe y es el más grande hasta la fecha en inglés, francés, neerlandés, español, alemán e italiano.
Y finalmente, más allá del texto, es posible encontrar iniciativas en otros formatos como el audio, que también pueden servir para entrenar modelos de IA. En 2022, la Biblioteca Nacional de Suecia proporcionó un corpus sonoro de más de dos millones de horas de grabación procedentes de la radio pública local, podcasts y audiolibros. El objetivo del proyecto era generar un modelo basado en IA de transcripción de audio a texto competente en el idioma, que maximizase el número de hablantes para conseguir un dataset disponible para todos, diverso y democrático.
Hasta ahora, en la recopilación y la puesta a disposición de la sociedad de datos en texto era suficiente el sentido de lo colectivo y el patrimonio. Con los modelos de lenguaje, esta apertura consigue un beneficio mayor: el de crear y mantener una tecnología que aporte valor a las personas y a las empresas, alimentada y mejorada a partir de nuestras propias producciones lingüísticas.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Hoy, 23 de abril, se celebra el Día del Libro, una ocasión para resaltar la importancia de la lectura, la escritura y la difusión del conocimiento. La lectura activa promueve la adquisición de habilidades y el pensamiento crítico, al acercarnos a información especializada y detallada sobre cualquier tema que nos interese, incluido el mundo de los datos.
Por ello, queremos aprovechar la ocasión para mostrar algunos ejemplos de libros y manuales relacionados con los datos y tecnologías relacionadas que se pueden encontrar en la red de manera gratuita.
1. Fundamentos de ciencia de datos con R, editado por Gema Fernandez-Avilés y José María Montero (2024)
Accede al libro aquí.
- ¿De qué trata? El libro guía al lector desde el planteamiento de un problema hasta la realización del informe que contiene su solución. Para ello, explica una treintena de técnicas de ciencia de datos en el ámbito de la modelización, análisis de datos cualitativos, discriminación, machine learning supervisado y no supervisado, etc. En él se incluyen más de una docena de casos de uso en sectores tan dispares como la medicina, el periodismo, la moda o el cambio climático, entre otros. Todo ello, con un gran énfasis en la ética y en el fomento de la reproductibilidad de los análisis.
-
¿A quién va dirigido? Está dirigido a usuarios que quieran iniciarse en la ciencia de datos. Parte de preguntas básicas, como qué es la ciencia de datos, e incluye breves secciones con explicaciones sencillas sobre la probabilidad, la inferencia estadística o el muestreo, para aquellos lectores no familiarizados con estas cuestiones. También incluye ejemplos replicables para practicar.
-
Idioma: Español
2. Contar historias con datos, Rohan Alexander (2023).
Accede al libro aquí.
-
¿De qué trata? El libro explica una amplia gama de temas relacionados con la comunicación estadística y el modelado y análisis de datos. Abarca las distintas operaciones desde la recopilación de datos, su limpieza y preparación, hasta el uso de modelos estadísticos para analizarlos, prestando especial importancia a la necesidad de extraer conclusiones y escribir sobre los resultados obtenidos. Al igual que el libro anterior, también pone el foco en la ética y la reproductibilidad de resultados.
-
¿A quién va dirigido? Es perfecto para estudiantes y usuarios con conocimientos básicos, a los que dota de capacidades para realizar y comunicar de manera efectiva un ejercicio de ciencia de datos. Incluye extensos ejemplos de código para replicar y actividades a realizar a modo de evaluación.
-
Idioma: Inglés.
3. El gran libro de los pequeños proyectos con Python, Al Sweigart (2021)
Accede al libro aquí.
- ¿De qué trata? Es una colección de sencillos proyectos en Python para aprender a crear arte digital, juegos, animaciones, herramientas numéricas, etc. a través de un enfoque práctico. Cada uno de sus 81 capítulos explica de manera independiente un proyecto sencillo paso a paso -limitados a máximo 256 líneas de código-. Incluye una ejecución de muestra del resultado de cada programa, el código fuente y sugerencias de personalización.
-
¿A quién va dirigido? El libro está escrito para dos grupos de personas. Por un lado, aquellos que ya han aprendido los conceptos básicos de Python, pero todavía no están seguros de cómo escribir programas por su cuenta. Por otro, aquellos que se inician en la programación, pero son aventureros, cuentan con grandes dosis de entusiasmo y quieren ir aprendiendo sobre la marcha. No obstante, el mismo autor tiene otros recursos para principiantes con los que aprender conceptos básicos.
-
Idioma: Inglés.
4. Matemáticas para Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Accede al libro aquí.
-
¿De qué trata? La mayoría de libros sobre machine learning se centran en algoritmos y metodologías de aprendizaje automático, y presuponen que el lector es competente en matemáticas y estadística. Este libro pone en primer plano los fundamentos matemáticos de los conceptos básicos detrás del aprendizaje automático
-
¿A quién va dirigido? El autor asume que el lector tiene conocimientos matemáticos comúnmente aprendidos en las materias de matemáticas y física de la escuela secundaria, como por ejemplo derivadas e integrales o vectores geométricos. A partir de ahí, el resto de conceptos se explican de manera detallada, pero con un estilo académico, con el fin de ser precisos.
-
Idioma: Inglés.
5. Profundizando en el aprendizaje profundo, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, se actualiza continuamente)
Accede al libro aquí.
-
¿De qué trata? Los autores son empleados de Amazon que utilizan la biblioteca MXNet para enseñar Deep Learning. Su objetivo es hacer accesible el aprendizaje profundo, enseñando los conceptos básicos, el contexto y el código de forma práctica a través de ejemplos y ejercicios. El libro se divide en tres partes: conceptos preliminares, técnicas de aprendizaje profundo y temas avanzados centrados en sistemas y aplicaciones reales.
-
¿A quién va dirigido? Este libro está dirigido a estudiantes (de grado o posgrado), ingenieros e investigadores, que buscan un dominio sólido de las técnicas prácticas del aprendizaje profundo. Cada concepto se explica desde cero, por lo que no es necesario tener conocimientos previos de aprendizaje profundo o automático. No obstante, sí son necesario conocimientos de matemáticas y programación básicas, incluyendo álgebra lineal, cálculo, probabilidad y programación en Python.
-
Idioma: Inglés.
6. Inteligencia artificial y sector público: retos límites y medios, Eduardo Gamero y Francisco L. Lopez (2024)
Accede al libro aquí.
-
¿De qué trata? Este libro se centra en analizar los retos y oportunidades que presenta el uso de la inteligencia artificial en el sector público, especialmente cuando se usa como soporte a la toma de decisiones. Comienza explicando qué es la inteligencia artificial y cuáles son sus aplicaciones en el sector público, para pasar a abordar su marco jurídico, los medios disponibles para su implementación y aspectos ligados a la organización y gobernanza.
-
¿A quién va dirigido? Es un libro útil para todos aquellos interesados en la temática, pero especialmente para responsables políticos, trabajadores públicos y operadores jurídicos relacionados con la aplicación de la IA en el sector público.
-
Idioma: español
7. Introducción del analista de negocio a la analítica empresarial, Adam Fleischhacker (2024)
Accede al libro aquí.
-
¿De qué trata? El libro aborda un flujo de trabajo de análisis empresarial completo, que incluye la manipulación de datos, su visualización, el modelado de problemas empresariales, la traducción de modelos gráficos a código y la presentación de resultados ante las partes interesadas. El objetivo es aprender a impulsar cambios dentro de una organización gracias al conocimiento basado en datos, modelos interpretables y visualizaciones persuasivas.
-
¿A quién va dirigido? Según su autor, se trata de un contenido accesible para todos, incluso para principiantes en la realización de trabajos de análisis. El libro no asume ningún conocimiento del lenguaje de programación, sino que proporciona una introducción a R, RStudio y al “tidyverse”, una serie de paquetes de código abierto para la ciencia de datos.
-
Idioma: Inglés.
Te invitamos a ojear esta selección de libros. Asimismo, recordamos que solo se trata de una lista con ejemplos de las posibilidades de materiales que puedes encontrar en la red. ¿Conoces algún otro libro que quieras recomendar? ¡Indícanoslo en los comentarios o manda un email a dinamizacion@datos.gob.es!
Blog
La era de la digitalización en la que nos encontramos ha llenado nuestra vida diaria de productos de datos o productos basados en datos. En este post te descubrimos en qué consisten y te mostramos una de las tecnologías de datos clave para diseñar y construir este tipo de productos: GraphQL.
Introducción
Empecemos por el principio, ¿qué es un producto de datos? Un producto de datos es un contenedor digital (una pieza de software) que incluye, datos, metadatos y ciertas lógicas funcionales (qué y cómo manejo los datos). El objetivo de este tipo de productos es facilitar la interacción de los usuarios con un conjunto de datos. Algunos ejemplos son:
- Cuadro de mando de ventas: Los negocios online cuentan con herramientas para conocer la evolución de sus ventas, con gráficos que muestran las tendencias y rankings, para ayudar en la toma de decisiones
- Apps de recomendaciones: Los servicios de TV en streaming disponen de funcionalidades que muestran recomendaciones de contenidos basándose en los gustos históricos del usuario.
- Apps de movilidad. Las aplicaciones móviles de los nuevos servicios de movilidad (como Cabify, Uber, Bolt, etc.) combinan datos y metadatos de usuarios y conductores con algoritmos predictivos, como el cálculo dinámico del precio del viaje o la asignación óptima de conductor, con el fin de ofrecer una experiencia única al usuario.
- Apps de salud: Estas aplicaciones hacen un uso masivo de los datos capturados por gadgets tecnológicos (como el propio dispositivo, los relojes inteligentes, etc.) que se pueden integrar con otros datos externos como registros clínicos y pruebas diagnósticas.
- Monitoreo ambiental: Existen apps que capturan y combinan datos de servicios de predicción meteorológica, sistemas de calidad del aire, información de tráfico en tiempo real, etc. para emitir recomendaciones personalizadas a los usuarios (por ejemplo, la mejor hora para programar una sesión de entrenamiento, disfrutar al aire libre o viajar en coche).
Como vemos, los productos de datos nos acompañan en el día a día, sin que muchos usuarios se den siquiera cuenta. Pero, ¿cómo se captura esa gran cantidad de información heterogénea de diferentes sistemas tecnológicos y se combina para proporcionar interfaces y vías de interacción con el usuario final? Aquí es donde GraphQL se posiciona como una tecnología clave para acelerar la creación de productos de datos, al mismo tiempo que mejora considerablemente su flexibilidad y la capacidad de adaptación a las nuevas funcionalidades deseadas por los usuarios.
¿Qué es GraphQL?
GraphQL vio la luz en Facebook en 2012 y se liberó como Open Source en 2015. Puede definirse como un lenguaje y un intérprete de ese lenguaje, de forma que un desarrollador de productos de datos puede inventarse una forma de describir su producto en base a un modelo (una estructura de datos) que hace uso de los datos disponibles mediante APIs.
Antes de la aparición de GraphQL, teníamos (y tenemos) la tecnología REST, que utiliza el protocolo HTTPs para hacer preguntas y obtener respuestas en base a los datos. En 2021, introducimos un post donde presentamos la tecnológica y realizamos un pequeño ejemplo demostrativo sobre su funcionamiento. En él, explicamos REST API como la tecnología estándar que soporta el acceso a datos por programas informáticos. También destacamos cómo REST es una tecnología fundamentalmente diseñada para integrar servicios (como un servicio de autenticación o login).
De forma sencilla, podemos utilizar la siguiente analogía. Es como si REST fuera el mecanismo que nos da acceso a un diccionario completo. Es decir, si necesitamos buscar cualquier palabra, tenemos un método de acceso al diccionario que es la búsqueda alfabética. Es un mecanismo general para encontrar cualquier palabra disponible en el diccionario. Sin embargo, GraphQL nos permite, previamente, crear un modelo de diccionario para nuestro caso de uso (lo que conocemos como “modelo de datos”). Así por ejemplo, si nuestra aplicación final es un recetario, lo que hacemos es seleccionar un subconjunto de palabras del diccionario que estén relacionadas con recetas de cocina.
Para utilizar GraphQL los datos tienen que estar siempre disponibles mediante una API. GraphQL facilita una descripción completa y comprensible de los datos de dicha API, ofreciendo a los clientes (humanos o aplicación) la posibilidad de solicitar exactamente lo que necesitan. Tal y como citan en este post, GraphQL es como un API al que le añadimos una sentencia “Dónde” al estilo SQL.
A continuación, analizamos en detalle las virtudes de GraphQL cuando el foco se pone en el desarrollo de productos de datos.
Beneficios de usar GraphQL en productos de datos:
- Con GraphQL se optimiza de forma considerable la cantidad de datos y consultas sobre las APIs. Las APIs de acceso a determinados datos no están pensadas para un producto (o un caso de uso) específico sino como una especificación general de acceso (véase el ejemplo anterior del diccionario). Esto hace que, en muchas ocasiones, para acceder a un subconjunto de datos disponibles en un API, tengamos que realizar varias consultas encadenadas, descartando la mayor parte de información por el camino. GraphQL optimiza este proceso, puesto que define un modelo de consumo predefinido (aunque adaptable a futuro) por encima de una API técnica. Reducir la cantidad de datos solicitados impacta positivamente en la racionalización de recursos informáticos, como el ancho de banda o el almacenamiento transitorio (cachés), y mejora la velocidad de respuesta de los sistemas.
- Lo anterior, tiene un efecto inmediato sobre la estandarización de acceso a datos. El modelo definido gracias a GraphQL crea un estándar de consumo de datos para una familia de casos de uso. De nuevo, en el contexto de una red social, si lo que queremos es identificar conexiones entre personas, no nos interesa un mecanismo general de acceso a todas las personas de la red, sino un mecanismo que nos permita indicar aquellas personas con las que tengo algún tipo de conexión. Esta especie de filtro en el acceso a los datos, se puede pre-configurar gracias a GraphQL.
- Mejora de seguridad y rendimiento: A través de la definición precisa de consultas y la limitación de acceso a datos sensibles, GraphQL puede contribuir a una aplicación más segura y de mejor rendimiento.
Gracias a estas ventajas, el uso de este lenguaje representa una evolución significativa en la manera de interactuar con datos en aplicaciones web y móviles, ofreciendo ventajas claras sobre enfoques más tradicionales como REST.
La Inteligencia Artificial generativa. Un nuevo superhéroe en la ciudad.
Si el uso del lenguaje GraphQL para acceder a los datos de forma mucho más eficiente y estándar es una evolución significativa para los productos de datos, ¿qué pasará si podemos interactuar con nuestro producto en lenguaje natural? Esto es ahora posible gracias a la explosiva evolución en los últimos 24 meses de los LLMs (Modelos Grandes del Lenguaje) y la IA generativa.
La siguiente imagen muestra el esquema conceptual de un producto de datos, integrado con LLMS: un contenedor digital que incluye datos, metadatos y funciones lógicas que se expresan como funcionalidades para el usuario, junto con las últimas tecnologías para exponer información de forma flexible, como GraphQL y las interfaces conversacionales construidas sobre Modelos Grandes del Lenguaje (LLMs).

¿Cómo se pueden beneficiar los productos de datos de la combinación de GraphQLy el uso de los LLMs?
- Mejora de la experiencia de usuario. Mediante la integración de LLMs, las personas puedan hacer preguntas a los productos de datos usando lenguaje natural. Esto representa un cambio significativo en cómo interactuamos con los datos, haciendo que el proceso sea más accesible y menos técnico. De forma práctica sustituiremos los clicks por frases en el momento de pedir un taxi.
- Mejoras en la seguridad a lo largo de la cadena de interacción en el uso de un producto de datos. Para que esta interacción sea posible, se necesita un mecanismo que conecte de manera eficaz el backend (donde residen los datos) con el frontend (donde se hacen las preguntas). GraphQL se presenta como la solución ideal debido a su flexibilidad y capacidad para adaptarse a las necesidades cambiantes de los usuarios, ofreciendo un enlace directo y seguro entre los datos y las preguntas realizadas en lenguaje natural. Es decir, GraphQL puede pre-seleccionar los datos que se van a mostrar en una consulta, evitando así que la consulta general pueda hacer visibles algunos datos privados o innecesarios para una aplicación particular.
- Potenciando las consultas con Inteligencia Artificial: La inteligencia artificial no solo juega un papel en la interacción en lenguaje natural con el usuario. Se puede pensar en escenarios donde el propio modelo que se define con GraphQL esté asistido por la propia inteligencia artificial. Esto enriquecería las interacciones con los productos de datos, permitiendo una comprensión más profunda y una exploración más rica de la información disponible. Por ejemplo, le podemos pedir a una IA generativa (como ChatGPT) que tome estos datos del catálogo que se exponen como un API y que nos cree un modelo y un endpoint de GraphQL.
En definitiva, la combinación de GraphQL y los LLMs, supone una auténtica evolución en la forma en la que accedemos a los datos. La integración de GraphQL con los LLMs apunta hacia un futuro donde el acceso a los datos puede ser tan preciso como intuitivo, marcando un avance hacia sistemas de información más integrados, accesibles para todos y altamente reconfigurables para los diferentes casos de uso. Este enfoque abre la puerta a una interacción más humana y natural con las tecnologías de información, alineando la inteligencia artificial con nuestras experiencias cotidianas de comunicación usando productos de datos en nuestro día a día.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El proceso de modernización tecnológica en la Administración de Justicia en España se inició, en gran medida, en el año 2011. Ese año se aprobó la primera regulación que específicamente se destinaba a impulsar el uso de las tecnologías de la información y la comunicación. El objetivo de dicha regulación consistía, sustancialmente, en establecer las condiciones para reconocer la validez del uso de medios electrónicos en las actuaciones judiciales y, sobre todo, en dotar de seguridad jurídica a la tramitación procesal y a los actos de comunicación, incluyendo la presentación de escritos y la recepción de notificaciones de resoluciones. En este sentido, la legislación estableció un estatuto jurídico básico para quienes se relacionaran con la Administración de Justicia, especialmente para el caso de los profesionales. Asimismo, se dio carta de naturaleza legal a la presencia en Internet de la Administración de Justicia, fundamentalmente con la aparición de las sedes electrónicas y los puntos de acceso, admitiendo expresamente la posibilidad de que las actuaciones de realizaran de manera automatizada.
Sin embargo, al igual que sucede con la regulación legal del procedimiento administrativo común y el régimen jurídico del sector público de 2015, el modelo de gestión en que se inspiró estaba sustancialmente orientado a la generación, conservación y archivo de los documentos y los expedientes. Aunque ya se advertía una tímida consideración de los datos, lo cierto es que en gran medida adolecía de una excesiva generalidad en el alcance de la regulación, ya que se limitaba a reconocer y garantizar la seguridad, la interoperabilidad y la confidencialidad.
En este contexto, la aprobación del Real Decreto-ley 6/2023, de 19 de diciembre ha supuesto un hito muy relevante en este proceso, por cuanto incorpora importantes medidas que pretenden ir más allá de la mera modernización tecnológica. Entre otras cuestiones, intenta sentar las bases para abordar una efectiva transformación digital en este ámbito.
Hacia una orientación de la gestión basada en los datos
Aun cuando este nuevo marco normativo en gran medida consolida y actualiza la regulación anterior, supone un importante paso adelante a la hora de facilitar la transformación digital por cuanto establece algunas premisas esenciales sin las que sería imposible plantear este objetivo. En concreto, según se afirma con rotundidad en su Exposición de Motivos:
Desde la comprensión de la importancia capital de los datos en una sociedad contemporánea digital, se realiza una apuesta clara y decisiva por su empleo racional para lograr evidencia y certidumbre al servicio de la planificación y elaboración de estrategias que coadyuven a una mejor y más eficaz política pública de Justicia. […] De estos datos no se beneficiará únicamente la propia Administración, sino toda la ciudadanía mediante la incorporación en la Administración de Justicia del concepto de «dato abierto». Esta misma orientación al dato facilitará las denominadas actuaciones automatizadas, asistidas y proactivas.
En este sentido, se reconoce expresamente un principio general de orientación al dato, superando de este modo las restricciones de un modelo de gestión electrónica basada en los documentos y los expedientes como el que ha existido hasta ahora. Con ello se pretende no sólo alcanzar objetivos de mejora en la tramitación procesal sino, asimismo, facilitar su utilización para otras finalidades como la elaboración de cuadros de mando, la generación de actuaciones automatizadas, asistidas y proactivas, la utilización de sistemas de inteligencia artificial y su publicación en portales de datos abiertos.
¿Cómo se ha concretado este principio?
Las principales novedades de este marco regulatorio desde la perspectiva del principio de orientación al dato son las siguientes:
-
Con carácter general, los sistemas informáticos y de comunicación habrán de permitir el intercambio de información en formato de datos estructurados, debiendo facilitar su automatización y la integración en el expediente judicial. A tal efecto, se contempla la puesta en marcha de una plataforma de interoperabilidad de datos, que habrá de ser compatible con la Plataforma de Intermediación de Datos de la Administración General del Estado.
-
La interoperabilidad de datos entre los órganos judiciales y fiscales y, asimismo, los portales de datos se configuran como servicios electrónicos de la Administración de Justicia. Las concretas condiciones técnicas de prestación de tales servicios habrán de ser definidas a través del Comité técnico estatal de la Administración judicial electrónica (CTEAJE).
-
Con el fin, entre otros objetivos, de facilitar el impulso de la inteligencia artificial, la realización de actividades automatizadas, asistidas y proactivas, así como la publicación de información en portales de datos abiertos, se establece la exigencia de que todos los sistemas de información y comunicación aseguren que la gestión de la información incorpore metadatos y se basen en modelos de datos comunes e interoperables. Por lo que se refiere, en concreto, a las comunicaciones, la orientación al dato se proyecta asimismo en los canales electrónicos utilizados para su realización.
-
En la definición legal de expediente judicial, a diferencia de lo que sucede en el ámbito del procedimiento administrativo común, se incorpora una referencia explícita a los datos como una de las unidades básicas que lo integran.
-
Se incluye una regulación específica para el denominado Portal de datos de la Administración de Justicia, de manera que se consagra legalmente, por primera, vez la actual herramienta de acceso a datos en este ámbito. En concreto, además de establecer ciertos contenidos mínimos y asignar competencias a diversos órganos, se contempla la creación de un apartado específico sobre datos abiertos, así como un mandato a las Administraciones competentes para que sean automáticamente procesables e interoperables con el portal de datos abiertos del Estado. A este respecto, se declara de aplicación la normativa general ya existente para el resto del sector público, sin perjuicio de las singularidades que puedan contemplarse específicamente en la regulación procesal.

En definitiva, la nueva regulación supone un paso importante a la hora de articular el proceso de transformación digital de la Administración de Justicia a partir de un modelo de gestión basado en los datos. Sin embargo, las singularidades competenciales y organizativas propias de este ámbito requieren de un modelo de gobernanza singular. Por esta razón se ha contemplado un marco institucional de cooperación especifico cuyo eficaz funcionamiento resulta esencial para la puesta en marcha de las previsiones legales y, en definitiva, para abordar los retos, dificultades y oportunidades que plantean los datos abiertos y la reutilización de la información del sector público en el ámbito judicial. Unos retos que es necesario afrontar decididamente para que la modernización tecnológica de la Administración de Justicia facilite su efectiva transformación digital.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La estandarización es fundamental para mejorar la eficiencia y la interoperabilidad en el gobierno y la gestión de datos. La adopción de estándares proporciona un marco común para organizar, intercambiar e interpretar los datos, facilitando la colaboración y garantizando la consistencia y calidad de los mismos. Los estándares ISO, elaborados a nivel internacional y las normas UNE, desarrolladas específicamente para el mercado español, son ampliamente reconocidos en este ámbito. Ambos catálogos de buenas prácticas, aunque comparten objetivos similares, difieren en su alcance geográfico y enfoque de desarrollo, permitiendo a las organizaciones seleccionar las normas más adecuadas para sus necesidades y contexto específico.
Ante la publicación, hace unos meses, de las especificaciones UNE 0077, 0078, 0079, 0080, y 0081 sobre gobierno, gestión, calidad, madurez, y evaluación de calidad de datos, los usuarios pueden tener dudas sobre cómo se relacionan estas y las normas ISO que ya tienen implementadas en su organización. Con este post se busca contribuir a paliar estas dudas. Para ello, se presenta un resumen de los principales estándares relacionados con las TIC, poniendo el foco en dos de ellos: ISO 20000 sobre gestión del servicio, e ISO 27000, sobre seguridad y privacidad de la información, y se establece la relación entre estos y las especificaciones UNE.
Normas ISO más habituales relacionadas con el dato
Los estándares ISO tiene la gran ventaja de ser abiertos, dinámicos y agnósticos a las tecnologías subyacentes. Del mismo modo, se encargan de aunar las mejores prácticas consensuadas y decididas por distintos grupos de profesionales e investigadores en cada uno de los campos de actuación. Si ponemos el foco en los estándares relacionados con las TIC, ya existe un marco de estándares sobre gobierno, gestión y calidad de los sistemas de información donde destacan, entre otras:
A nivel de gobierno:
- ISO 38500 para el gobierno de TI.
A nivel de gestión:
- ISO 8000 para sistemas de gestión de datos y datos maestros.
- ISO 20000 para la gestión de los servicios.
- ISO 25000 para la calidad del producto generado (tanto software como datos).
- ISO 27000 e ISO 27701 para la gestión de la seguridad y privacidad de la información.
- ISO 33000 para la evaluación de procesos.
A estos estándares hay que sumar otros que también son de uso habitual en las empresas como:
- Sistema de gestión de calidad basado en ISO 9000
- Sistema de gestión medioambiental propuesto en ISO 14000
Estas normas se usan desde hace años para el gobierno y gestión de las TIC y tienen la gran ventaja de que, al basarse en los mismos principios, pueden usarse perfectamente de manera conjunta. Así, por ejemplo, es muy útil reforzar mutuamente la seguridad de los sistemas de información basados en la familia de normas ISO/IEC 27000 con la gestión de servicios basados en la familia de normas ISO/IEC 20000.
La relación entre las normas ISO y las especificaciones UNE sobre el dato
Las especificaciones UNE 0077, 0078, 0079, 0080 y 0081 complementan las normas ISO existentes sobre gobierno, gestión y calidad de datos al proporcionar directrices específicas y detalladas que se enfocan en los aspectos particulares del entorno español y las necesidades del mercado nacional.
Cuando se plantearon las especificaciones UNE 0077, 0078, 0079, 0080, y 0081, se basaron en los principales estándares ISO, con el fin de integrarse fácilmente en los sistemas de gestión ya disponibles en las organizaciones (mencionados anteriormente), como puede verse en la siguiente figura:

Figura 1. Relación de las especificaciones UNE con los diferentes estándares ISO para las TIC.
Ejemplo de aplicación de la norma UNE 0078
A continuación, se presenta un ejemplo para ver cómo se integran de una forma más clara las normas UNE y las ISO que muchas organizaciones ya tienen implantadas desde hace años, tomando como referencia la UNE 0078. Aunque todas las especificaciones UNE del dato se encuentran entrelazadas con la mayoría de las normas ISO de gobierno, gestión y calidad de TI, la especificación UNE 0078 de gestión de datos está más relacionada con los sistemas de gestión de seguridad de la información (ISO 27000) y gestión de los servicios de TI (ISO 20000). En la Tabla 1 se puede ver la relación para cada proceso con cada estándar ISO.
| Proceso UNE 0078: Gestión de Datos | Relacionado con ISO 20000 | Relacionado con ISO 27000 |
|---|---|---|
| (ProcDat) Procesamiento del dato | ||
| (InfrTec) Gestión de la infraestructura tecnológica | X | X |
| (ReqDat) Gestión de requisitos del dato | X | X |
| (ConfDat) Gestión de la configuración del dato | ||
| (DatHist) Gestión de datos histórico | X | |
| (SegDat) Gestión de la seguridad del dato | X | X |
| (Metdat) Gestión del metadato | X | |
| (ArqDat) Gestión de la arquitectura y diseño del metadato | X | |
| (CIIDat) Compartición, intermediación e integración del dato | X | |
| (MDM) Gestión del dato maestro | ||
| (RRHH) Gestión de recursos humanos | ||
| (CVidDat) Gestión del ciclo de vida del dato | X | |
| D(AnaDat) Análisis del dato esigualdad |
Figura 2. Relación de procesos de UNE 0078 con ISO 27000 e ISO 20000.
Relación de la norma UNE 0078 con ISO 20000
En cuanto a la interrelación ISO 20000-1 con la especificación UNE 0078 a continuación se presenta un caso de uso en el que una organización quiere poner a disposición datos relevantes para su consumo en toda la organización a través de distintos servicios. La implementación integrada de UNE 0078 e ISO 20000-1 permite a las organizaciones:
- Asegurar que los datos críticos para el negocio son gestionados y protegidos adecuadamente.
- Mejorar la eficiencia y efectividad de los servicios de TI, asegurando que la infraestructura tecnológica respalda las necesidades del negocio y de los usuarios finales
- Alinear la gestión de datos y la gestión de servicios de TI con los objetivos estratégicos de la organización, mejorando la toma de decisiones y la competitividad en el mercado
La relación entre ambas se manifiesta en cómo la infraestructura tecnológica gestionada según la UNE 0078 soporta la entrega y gestión de servicios de TI conforme a ISO 20000-1.
Para ello, es necesario contar, al menos, con:
- En primer lugar, para el caso de puesta a disposición de datos como un servicio, es necesario contar con una infraestructura de TI bien gestionada y segura. Esto es esencial, por un lado, para la implementación efectiva de procesos de gestión de servicios de TI, como los incidentes y problemas, y por otro, para asegurar la continuidad del negocio y la disponibilidad de los servicios de TI.
- En segundo lugar, una vez se dispone de la infraestructura, y se es consciente de que el dato va a ser dispuesto para su consumo en algún momento, es necesario gestionar los principios de compartición e intermediación de dicho dato. Para ello, en la especificación UNE 0078, se cuenta con el proceso de Compartición, intermediación e integración del dato. Su principal objetivo es habilitar su adquisición y/o entrega para su consumo o compartición, observando si fuese necesario el despliegue de mecanismos de intermediación, así como la integración del mismo. Este proceso de la UNE 0078 estaría relacionado con varios de los planteados en ISO 20000-1, tales como el proceso de Gestión de relaciones con el negocio, gestión de niveles de servicio, la gestión de la demanda y la gestión de la capacidad de los datos que son puestos a disposición.
Relación de la norma UNE 0078 con ISO 27000
Así mismo, la infraestructura tecnológica creada y gestionada para un objetivo específico debe asegurar unos mínimos en materia de seguridad y privacidad de datos, por lo tanto, será necesaria la implantación de buenas prácticas incluidas en ISO 27000 e ISO 27701 para gestionar la infraestructura desde la perspectiva de la seguridad y privacidad de la información, mostrando así un claro ejemplo de interrelación entre los tres sistemas de gestión: servicios, seguridad y privacidad de la información, y datos.
No solo es primordial que el dato sea puesto al servicio de las organizaciones y ciudadanos de una forma óptima, sino que es necesario además prestar especial atención a la seguridad del dato a lo largo de todo su ciclo de vida durante la puesta en servicio. Es en este punto donde el estándar ISO 27000 aporta todo su valor. El estándar ISO 27000, y en particular ISO 27001 cumple los siguientes objetivos:
- Especifica los requisitos para un sistema de gestión de seguridad de la información (SGSI).
- Se centra en la protección de la información contra accesos no autorizados, la integridad de los datos y la confidencialidad.
- Ayuda a las organizaciones a identificar, evaluar y gestionar los riesgos de seguridad de la información.
En esta línea, su interrelación con la especificación UNE 0078 de Gestión de Datos viene marcada a través del proceso de Gestión de seguridad del dato. A través de la aplicación de los distintos mecanismos de seguridad, se comprueba que la información manejada en los sistemas no tiene accesos no autorizados, manteniendo su integridad y confidencialidad a lo largo de todo el ciclo de vida del dato. Del mismo modo, se puede construir una terna en esta relación con el proceso de gestión de seguridad de datos de la especificación UNE 0078 y con el proceso de UNE 20000-1 de Operación SGSTI- Gestión de Seguridad de la Información.
A continuación, en la Figura 3 se presenta como la especificación UNE 0078 complementa a las actuales ISO 20000 e ISO 27000 aplicado al ejemplo comentado anteriormente.

Figura 3. Relación de procesos UNE 0078 con ISO 20000 e ISO 27000 aplicados al caso de compartición de datos.
A través de los casos anteriores se puede vislumbrar que la gran ventaja de la especificación UNE 0078 es que se integran perfectamente con los sistemas de gestión de seguridad y de gestión de servicios existentes en las organizaciones. Lo mismo ocurre con el resto de las normas UNE 0077, 0079, 0080, y 0081. Por lo tanto, si una organización que ya tiene implantados ISO 20000 o ISO 27000 quiere llevar a cabo iniciativas de gobierno, gestión y calidad de datos, se recomienda el alineamiento entre los distintos sistemas de gestión con las especificaciones UNE, puesto que se refuerzan mutuamente desde el punto de vista de la seguridad, de los servicios y de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras meses de novedades, no parece que el ritmo de los avances en materia de inteligencia artificial vaya a desacelerarse, sino más bien todo lo contrario. Hace pocas semanas, cuando se repasaban los últimos avances en este campo con motivo del cierre del 2023, se consideraba que la generación de video a partir de instrucciones de texto estaba aún en su infancia. Sin embargo, solo unas semanas después, hemos visto el anuncio de SORA. Con esta herramienta parece que ya está aquí la posibilidad de generar videos realistas, de hasta un minuto, a partir de descripciones textuales.
Cada día, las herramientas a las que vamos teniendo acceso se vuelven más sofisticadas y no deja de asombrarnos su capacidad para realizar tareas que antes parecían exclusivas de la mente humana. Nos hemos acostumbrado muy rápidamente a la generación de texto e imágenes a partir de instrucciones escritas y hemos incorporado estas herramientas a nuestro día a día, para potenciar y mejorar la forma en la que hacemos nuestros trabajos. Con cada nuevo avance, que empuja los límites un poco más lejos de lo que imaginábamos, las posibilidades nos acaban pareciendo infinitas.
Los avances en Inteligencia Artificial, potenciados por los datos abiertos y otras tecnologías como las asociadas a la Web, están ayudando a repensar el futuro de prácticamente todos los campos de nuestra actividad: desde las soluciones para abordar los desafíos del cambio climático, hasta la creación artística, ya sea música, literatura o pintura, pasando por el diagnóstico médico, la agricultura o la generación de confianza para impulsar la creación de valor social y económico.
En este artículo vamos a repasar los avances que impactan en un campo donde, en los próximos años, se producirán, probablemente, interesantes avances gracias a la combinación de inteligencia artificial y datos abiertos. Nos referimos al diseño y planificación de ciudades más inteligentes, sostenibles y habitables para todos sus habitantes.
Planificación y Gestión Urbana
La planificación y gestión urbana es complicada, porque es necesario prever, analizar y dar solución a innumerables interacciones de gran complejidad. Por ello, es razonable esperar importantes avances fruto del análisis de los datos que las ciudades abren cada vez con más frecuencia sobre movilidad, consumo de energía, climatología y contaminación, planificación y uso del suelo, etc. Las nuevas técnicas y herramientas que nos proporciona la inteligencia artificial generativa combinada, por ejemplo, con los agentes inteligentes permitirán una interpretación y simulación más profundas de las dinámicas urbanas.
En este sentido, esta nueva combinación de tecnologías podría ser utilizada por ejemplo para diseñar ciudades más eficientes, sostenibles y habitables, anticipando las necesidades futuras de la población y adaptándose dinámicamente a los cambios en tiempo real. Así, los nuevos modelos urbanos inteligentes se utilizarían para optimizar desde el flujo del tráfico, hasta la distribución de los recursos, gracias a la simulación del comportamiento a través de agentes inteligentes.

Figura 1: Imágenes generadas por Urbanistai.com
Urbanist.ai es uno de los primeros ejemplos de plataforma avanzada de análisis urbano, basada en inteligencia artificial generativa, que pretende transformar la forma en que se conciben actualmente las tareas de planificación urbana. Los servicios que provee actualmente ya permiten la transformación participativa de espacios urbanos a partir de imágenes, pero su ambición va más allá y prevén incorporar nuevas técnicas que redefinan la forma en la que se planifican las ciudades. Existe incluso una versión de UrbanistAI pensada para que los niños puedan introducirse en el mundo de la planificación urbana.
Si vamos un paso más allá, la generación de modelos de ciudades en tres dimensiones es algo que herramientas como InfiniCity ya han puesto a disposición de los usuarios. Aunque aún hay muchos retos que resolver, los resultados son francamente prometedores. Gracias estas tecnologías se podría abaratar sustancialmente la generación de gemelos digitales en los que realizar simulaciones que anticipen problemas antes de su construcción.
Datos disponibles
Sin embargo, como ocurre con otros avances basados en IA Generativa, estas cuestiones no serían posibles sin los datos y, muy especialmente, sin los datos abiertos. Todos los nuevos avances en IA usan una combinación de datos privados y públicos en su entrenamiento, pero en pocos casos se sabe con certeza cuál es el dataset de entrenamiento, ya que no se hace público. Los datos pueden provenir de una gran variedad de fuentes, como sensores IoT, registros gubernamentales o sistemas de transporte público, y son la base para proporcionar una visión integral de cómo funcionan las ciudades y cómo interactúan sus habitantes con el entorno urbano.
La creciente importancia de los datos abiertos para el entrenamiento de estos modelos se refleja en iniciativas como el Grupo de Trabajo sobre activos de datos de IA y Gobierno Abierto, puesto en marcha por el Departamento de Comercio de los Estados Unidos, y que se encargará de preparar los datos públicos abiertos para la Inteligencia Artificial. Esto significa que no sólo tengan formatos legibles por máquinas, sino que también cuenten con metadatos que sean comprensibles por máquinas. Con los datos abiertos enriquecidos por metadatos y organizados en formatos interpretables, podría conseguirse que los modelos de inteligencia artificial arrojasen resultados mucho más precisos.
Una fuente de datos básica y de larga trayectoria es OpenStreetmap (OSM), un proyecto colaborativo que pone a disposición de la comunidad un mapa libre y editable con datos geográficos abiertos a nivel global. Incluye información detallada sobre calles, plazas, parques, edificios, etc. que resulta crucial como base para el análisis de la movilidad urbana, la planificación del transporte o la gestión de infraestructuras. El inmenso coste de elaborar un recurso de estas características sólo está al alcance de las grandes compañías de tecnología, por lo que su valor es incalculable para todas las iniciativas que lo utilizan como base.

Figura 2: Imágenes de OpenStreetmap (OSM)
Otros conjuntos de datos más específicos como HoliCity, un activo de datos 3D con información estructural rica, que incluye 6.300 vistas del mundo real, están demostrando un gran valor. Por ejemplo, un reciente trabajo científico basado en este conjunto de datos ha demostrado que es posible que un modelo alimentado con millones de imágenes de calles pueda predecir características de un vecindario, como pueden ser el valor de las viviendas o las tasas de criminalidad.
En esta línea, Microsoft ha liberado una extensa colección de contornos de edificios generados automáticamente a partir de imágenes de satélite, cubriendo gran cantidad de países y regiones.

Figura 3: Imágenes de Urban Atlas.
Los Microsoft Building Footprints proporcionan una base detallada para el modelado 3D de ciudades, análisis de densidad urbana, planificación de infraestructuras y gestión de riesgos naturales, que ofrecen una visión precisa de la estructura física de las ciudades.
También disponemos de Urban Atlas, una iniciativa que ofrece un acceso gratuito y abierto a información detallada de uso y cobertura del suelo para más de 788 Áreas Urbanas Funcionales en Europa. Forma parte del programa Copernicus Land Monitoring Service, y proporciona una perspectiva muy valiosa sobre la distribución espacial de las características urbanas, incluyendo áreas residenciales, comerciales, industriales, áreas verdes y cuerpos de agua, mapas de árboles en las calles, mediciones de la altura de los bloques de edificios e, incluso, estimaciones de población.
Riesgos y consideraciones éticas
Sin embargo, no debemos perder de vista los riesgos que supone, al igual que en otros dominios, la incorporación de inteligencia artificial a la planificación y gestión de las ciudades, tal y como se analiza en el informe de Naciones Unidas sobre “Riesgos, Aplicaciones y Gobierno de la IA para las ciudades. Por ejemplo, las preocupaciones sobre la privacidad y la seguridad de la información personal que plantea la recopilación masiva de datos, o el riesgo de sesgos algorítmicos que pueden ahondar en las desigualdades ya existentes. Por ello, resulta fundamental garantizar que la recopilación y el uso de datos se realicen de manera ética y transparente, con un enfoque en la equidad y la inclusión.
Es por ello por lo que, a medida que el diseño de ciudades avanza en la adopción de la inteligencia artificial, el diálogo y la colaboración entre tecnólogos, planificadores urbanos, legisladores y la sociedad en general será clave para asegurar que el desarrollo de ciudades inteligentes se alinea con los valores de sostenibilidad, equidad e inclusión. Solo así podremos garantizar que las ciudades del futuro no solo sean más eficientes y tecnológicamente avanzadas, sino también más humanas y acogedoras para todos sus habitantes.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Unión Europea ha situado la transformación digital del sector público en el centro de su agenda política. A través de diversas iniciativas, encuadradas dentro del programa político la Década Digital, la UE busca impulsar la eficiencia de los servicios públicos y ofrecer una mejor experiencia a los ciudadanos. Un objetivo para el que es fundamental el intercambio de datos e información de manera ágil entre instituciones y países.
Es aquí donde cobra importancia la interoperabilidad y la busca de nuevas soluciones para impulsarla. Las tecnologías emergentes como la inteligencia artificial (IA), suponen grandes oportunidades en este campo, gracias a su capacidad para analizar y procesar enormes cantidades de datos.
Un informe para analizar el estado de la cuestión
Ante este contexto, la Comisión Europea ha publicado un extenso y exhaustivo informe titulado “Artificial Intelligence for Interoperability in the European Public Sector”, donde ofrece un análisis sobre cómo la IA ya están mejorando la interoperabilidad en el sector público europeo. El informe se divide en tres partes:
- Una revisión bibliográfica y política sobre las sinergias entre AI y la interoperabilidad. En ella se destaca el trabajo legislativo llevado a cabo por la UE. Se resalta la Ley sobre la Europa Interoperable que busca establecer una estructura de gobernanza e impulsar un ecosistema de soluciones reutilizables e interoperables para la administración pública. También se menciona la Ley de Inteligencia Artificial, diseñada para garantizar que los sistemas de IA utilizados en la UE sean seguros, transparentes, trazables, no discriminatorios y respetuosos con el medio ambiente.
- El informe continúa con un análisis cuantitativo de 189 casos de uso. Para seleccionar estos casos, se ha tenido en cuenta el inventario realizado en el informe “AI Watch. Panorama europeo del uso de la Inteligencia Artificial por el sector público” que incluye 686 ejemplos, actualizado a 720 recientemente.
- Un estudio cualitativo que profundiza en algunos de los casos anteriores. En concreto, se han caracterizado siete casos de uso (dos de e
sllos españoles), con un objetivo exploratorio. Es decir, se busca extraer conocimiento sobre los retos a afrontar de la interoperabilidad y cómo pueden ayudar las soluciones basadas en la IA a ello.
Conclusiones del estudio
La IA se está convirtiendo en una herramienta esencial para estructurar, conservar, normalizar y procesar los datos de la administración pública, mejorando la interoperabilidad dentro y fuera de la misma. Una tarea que ya realizan muchas organizaciones.
De entre todos los casos de uso de IA en el sector público analizados en el estudio, el 26% estaban relacionados con la interoperabilidad. Estas herramientas se utilizan para mejorar la interoperabilidad operando en diferentes niveles: técnico, semántico, jurídico y organizativo. Un mismo sistema de IA puede operar en distintas capas.
- La capa semántica de la interoperabilidad es la más relevante (91% de los casos). El uso de ontologías y taxonomías para crear un lenguaje común, combinado con la IA, puede ayudar a establecer la interoperabilidad semántica entre diferentes sistemas. Un ejemplo es el proyecto EPISA60, que se basa en procesamiento del lenguaje natural, utilizando reconocimiento de entidades y aprendizaje automático para explorar documentos digitales.
- En segundo lugar, se encuentra la capa organizativa, con un 35% de casos. Se destaca el uso de IA para la armonización de políticas, modelos de gobernanza y reconocimiento mutuo de datos, entre otros. En este sentido, el Ministerio de Justicia de Austria lanzó el proyecto JustizOnline que integra varios sistemas y procesos relacionados con la impartición de justicia.
- El 33% de los casos se centraba en la capa jurídica. En este caso se busca que el intercambio de datos se realice cumpliendo con los requisitos legales sobre protección de datos y privacidad. La Comisión Europea está elaborando un estudio para explorar cómo puede utilizarse la IA para verificar la transposición de la legislación de la UE por parte de los Estados miembros. Para ello se comparan distintos artículos de las leyes con ayuda de una IA.
- Por último, está la capa técnica, con un 21% de casos. En este campo, la IA puede ayudar al intercambio de datos de forma fluida y segura. Un ejemplo es el trabajo realizado en el centro de investigación belga VITO, basado en técnicas de codificación/decodificación y transporte de datos con IA.
En concreto, las tres acciones más comunes que los sistemas basados en IA realizan para impulsar la interoperabilidad de los datos son: detectar información (42%), estructurarla (22%) y clasificarla (16%). En la siguiente tabla, extraída del informe, se pueden ver todas las actividades detalladas:
Descarga aquí la versión accesible de la tabla
El informe también analiza el uso de IA en áreas concretas. Destaca su uso en “servicios públicos generales” (41%), seguido de “orden público y seguridad” (17%) y “asuntos económicos” (16%). Con respecto a sus beneficios, destaca la simplificación administrativa (59%), seguido de la evaluación de la eficacia y la eficiencia (35%) y la preservación de la información (27%).
Casos de uso de IA en España
En la tercera parte del informe se analizan en detalle casos de uso concretos de soluciones basadas en IA que han ayudado a mejorar la interoperabilidad del sector público. De las siete soluciones caracterizadas, dos son de España:
- Vulnerabilidad energética - evaluación automatizada del informe sobre pobreza energética. Cuando las empresas proveedoras de servicios de energía detectan impagos, antes de cortar el servicio deben consultar con el ayuntamiento para determinar si el usuario se encuentra en situación de vulnerabilidad social, en cuyo caso no se le pueden cortar los suministros. Los ayuntamientos reciben mensualmente listados de las compañías en diferentes formatos y tienen que pasar por un costoso proceso burocrático manual para validar si un ciudadano está en riesgo social o económico. Para solucionar este reto, la Administració Oberta de Catalunya (AOC) ha desarrollado una herramienta que automatiza el proceso de verificación de datos mejorando la interoperabilidad entre las empresas, los municipios y otras administraciones.
- Transcripciones automatizadas para agilizar los procedimientos judiciales. En el País Vasco, las transcripciones de juicios por parte de la administración se realizan revisando manualmente los vídeos de todas las sesiones. Por lo tanto, no es posible buscar fácilmente palabras, frases, etc. Esta solución convierte los datos de voz en texto automáticamente, lo que permite realizar búsquedas y ahorrar tiempo.
Recomendaciones
El informe finaliza con una serie de recomendaciones sobre lo que deberían hacer las administraciones públicas:
- Aumentar la concienciación interna sobre las posibilidades de la IA para mejorar la interoperabilidad. A través de la experimentación, podrán descubrir los beneficios y el potencial de esta tecnología.
- Enfocar la adopción de una solución IA como un proyecto complejo con implicaciones no solo técnicas, sino también organizativas, legales, éticas, etc.
- Crear las condiciones óptimas para una colaboración efectiva entre agencias públicas. Para ello es necesaria una comprensión común de los retos a afrontar, con el fin de facilitar el intercambio de datos y la integración de los diferentes sistemas y servicios.
- Promover el uso de ontologías y taxonomías uniformes y estandarizadas para crear un lenguaje común y una comprensión compartida de los datos que ayuden a establecer la interoperabilidad semántica entre sistemas.
- Evaluar las legislaciones actuales, tanto en las primeras etapas de experimentación como durante la implementación de una solución de IA, de manera regular. También se debe considerar la posibilidad de colaborar con actores externos para evaluar la adecuación del marco jurídico. En este sentido, el informe también incluye recomendaciones para las próximas actualizaciones políticas de la UE.
- Apoyar la mejora de las competencias de los especialistas en IA e interoperabilidad dentro de la administración pública. Se busca que las tareas críticas de supervisión de los sistemas de IA queden dentro de la organización.
La interoperabilidad es uno de los motores clave del gobierno digital, ya que permite el intercambio fluido de datos y procesos, fomentando la colaboración eficaz. La IA puede ayudar a automatizar tareas y procesos, reducir costes y mejorar la eficiencia. Por eso es recomendable impulsar su adopción por los organismos públicos de todos los niveles.