Entrevista
En este episodio vamos a hablar de la inteligencia artificial y sus retos, tomando como base el Reglamento Europeo de Inteligencia Artificial que entró en vigor este año. Quédate para conocer los retos oportunidades y novedades del sector de la mano de dos expertos en la materia:
- Ricard Martínez, profesor de derecho constitucional de la Universitat de València en la que dirige la Cátedra de Privacidad y Transformación Digital Microsoft Universidad de Valencia.
- Carmen Torrijos, lingüista computacional, experta en IA aplicada al lenguaje y profesora de minería de texto en la Universidad Carlos III.
Resumen / Transcripción de la entrevista
1. Está claro que la inteligencia artificial está en continua evolución. Para entrar en materia, me gustaría que nos contarais ¿cuáles son los últimos avances en la IA?
Carmen Torrijos: Surgen muchas aplicaciones nuevas. Por ejemplo, este fin de semana pasado ha tenido mucho eco una IA de generación de imagen en X, en Twitter, no sé si lo habéis seguido, que se llama Grok. Ha tenido bastante impacto, no porque aporte nada nuevo, ya que la generación de imagen es algo que estamos haciendo desde diciembre de 2023. Pero esta es una IA que tiene menos censura, es decir, teníamos hasta ahora muchas dificultades con los sistemas generalistas para hacer imágenes que tuvieran caras de famosos o tuvieran situaciones determinadas y estaba muy vigilado desde cualquier herramienta. Grok lo que hace es levantar todo eso y que cualquiera pueda hacer cualquier tipo de imagen con cualquier persona famosa o con cualquier cara conocida. Es una moda seguramente muy pasajera. Haremos imágenes durante un tiempo y luego se nos pasará.
Y después tenemos también sistemas de creación de podcast automáticos, como Notebook LM. Ya llevamos un par de meses viéndolos y ha sido realmente una de las cosas que a mí, en los últimos meses, me ha sorprendido de verdad. Porque ya parece que todos son innovaciones incrementales: sobre lo que ya tenemos, nos dan algo mejor. Pero esto es algo realmente nuevo que sorprende. Tú subes un PDF y te puede generar un podcast de dos personas hablando de manera totalmente natural, totalmente realista, sobre ese PDF. Es algo que puede hacer Notebook LM que es de Google.
2. El Reglamento Europeo de Inteligencia Artificial es la primera norma jurídica del mundo sobre IA, ¿con qué objetivos se publica este documento que es ya un marco referencial a nivel internacional?
Ricard Martínez: El Reglamento surge por algo que está implícito en lo que Carmen nos ha contado. Todo esto que Carmen cuenta es porque nos hemos abierto a la misma carrera desenfrenada a la que nos abrimos con la aparición de las redes sociales. Porque cuando esto pasa, no es inocente, no es que las compañías sean generosas, es que las compañías están compitiendo por nuestros datos. Nos gamifican, nos animan a jugar, nos animan a proporcionarles información, por eso se abren. No se abren porque sean generosas, no se abren porque quieran trabajar para el bien común o para la humanidad. Se abren porque les estamos haciendo el trabajo. ¿Qué es lo que la Unión Europea quiere frenar? Lo que aprendimos con las redes sociales. La Unión Europea plantea dos grandes enfoques que voy a tratar de explicar de modo muy sucinto. El primer enfoque es un enfoque de riesgo sistémico. La Unión Europea ha dicho: “no voy a tolerar herramientas de inteligencia artificial que puedan poner en peligro el sistema democrático, es decir, el estado de derecho y mi modo de funcionamiento o que puedan vulnerar gravemente derechos fundamentales”. Eso es una línea roja.
El segundo enfoque es un enfoque de orientación a producto. Una IA es un producto. Cuando usted fabrica un coche, sigue unas reglas que gestionan cómo produce ese coche, y ese coche llega al mercado cuando es seguro, cuando tiene todas las especificaciones. Ese es el segundo gran enfoque del Reglamento. El Reglamento dice que puede usted estar desarrollando una tecnología porque usted está investigando y casi le dejo hacer lo que quiera. Ahora, si esta tecnología va a llegar al mercado, usted catalogará el riesgo. Si el riesgo es bajo o leve, usted va a poder hacer muchas cosas y, prácticamente, con transparencia y códigos de conducta, se lo voy a dar por bueno. Pero si es un riesgo alto, usted va a tener que seguir un proceso de diseño estandarizado, y va a necesitar que un órgano notificado verifique esa tecnología, se asegure que en su documentación usted ha cumplido lo que tiene que cumplir, y entonces le darán un sello CE. Y no acabamos aquí, porque va a haber vigilancia postcomercial. De modo que, a lo largo del ciclo de vida del producto, usted debe garantizar que esto funciona bien y que se ajusta a la norma.
Por otra parte, se establece un control férreo respecto de los grandes modelos de datos, no solo LLM, también puede ser de imagen o de otro tipo de información, cuando crea que pueden plantear riesgos sistémicos.
En ese caso, hay un control muy directo por parte de la Comisión. Por tanto, en el fondo, lo que están diciendo es: "respeten los derechos, garanticen la democracia, produzcan la tecnología de modo ordenado de acuerdo con ciertas especificaciones".
Carmen Torrijos: Sí, en cuanto a los objetivos está claro. Me he quedado con lo último que decía Ricard sobre producir tecnología de acuerdo a esta Regulación. Tenemos este mantra de que Estados Unidos hace cosas, Europa las regula y China las copia. A mí no me gusta nada generalizar así. Pero es verdad que Europa es pionera en materia de legislación y seríamos mucho más fuertes si pudiéramos producir tecnología acorde a los estándares regulatorios que estamos poniendo. Hoy por hoy todavía no podemos, quizás es una cuestión de darnos tiempo, pero creo que esa es la clave de la soberanía tecnológica en Europa.
3. Para poder producir esa tecnología, los sistemas de IA necesitan datos para entrenar sus modelos. ¿Qué criterios deberían cumplir los datos para poder entrenar correctamente un sistema de IA? ¿Los conjuntos de datos abiertos podrían ser una fuente? ¿De qué manera?
Carmen Torrijos: Los datos con los que alimentamos la IA son el punto de mayor conflicto. ¿Podemos entrenar con cualquier conjunto de datos incluso aunque estén disponibles? No vamos a hablar de datos abiertos, sino de datos disponibles.
Datos abiertos es, por ejemplo, la base de todos los modelos de lenguaje, y todo el mundo esto lo sabe, que es Wikipedia. Wikipedia es un ejemplo ideal para entrenar, porque es abierta, está optimizado para su uso computacional, es descargable, es muy fácil de usar, hay muchísimo lenguaje, por ejemplo, para entrenar modelos de lenguaje, y hay muchísimo conocimiento del mundo. Con lo cual es el conjunto de datos ideal para entrenar un modelo de IA. Y Wikipedia está en abierto, está disponible, es de todos y es para todos, se puede utilizar.
Ahora bien, ¿todos los conjuntos de datos que hay disponibles en Internet se pueden utilizar para entrenar sistemas de IA? Esa es un poco la duda. Porque el hecho de que algo esté publicado en Internet no quiere decir que sea público, de uso público, aunque tú puedas cogerlo y entrenar un sistema y empezar a generar lucro a partir de ese sistema. Tenía unos derechos de autor, una autoría y propiedad intelectual. Ese yo creo que es el conflicto más grave que tenemos ahora mismo en IA generativa porque utiliza contenidos para inspirarse y crear. Y ahí poco a poco Europa está dando pasitos. Por ejemplo, el Ministerio de Cultura ha lanzado una iniciativa para empezar a ver cómo podemos crear contenidos, conjuntos de datos licenciados, que permitan entrenar la IA de una manera legal, ética y con respecto a los derechos de propiedad intelectual de los autores.
Todo esto está generando muchísima fricción. Porque si seguimos así, nos ponemos en contra a muchos ilustradores, traductores, escritores, etc. (todos los creadores que trabajan con el contenido), porque no van a querer que se desarrolle esta tecnología a costa de sus contenidos. De alguna manera hay que encontrar el equilibrio en la regulación y en la innovación para que las dos cosas ocurran. Desde los grandes sistemas tecnológicos que se están desarrollando, sobre todo en Estados Unidos, se repite una idea que es que solo con contenidos licenciados, con conjuntos de datos legales que están libres de propiedad intelectual, o que se ha pagado los rendimientos necesarios por su propiedad intelectual, no se puede llegar al nivel de calidad de las IA's que tenemos ahora. Es decir, solamente con conjuntos de datos legales no hubiéramos tenido ChatGPT al nivel que está el ChatGPT.
Eso no está escrito en piedra y no tiene por qué ser así. Tenemos que seguir investigando, o sea, tenemos que seguir viendo cómo podemos lograr una tecnología de ese nivel, pero que cumpla con la regulación. Porque lo que han hecho en Estados Unidos, lo que ha hecho GPT-4, los grandes modelos del lenguaje, los grandes modelos de generación de imagen, es enseñarnos el camino. Esto es hasta dónde podemos llegar. Pero lo habéis hecho cogiendo contenido que no es vuestro, que no era lícito coger. Tenemos que conseguir volver a ese nivel de calidad, volver a ese nivel de rendimiento de los modelos, respetando la propiedad intelectual del contenido. Y eso es un papel que yo creo que corresponde principalmente a Europa
4. Otra de las cuestiones que le preocupa a la ciudadanía respecto al rápido desarrollo de la IA es el tratamiento de los datos personales. ¿Cómo deberían protegerse y qué condiciones establece el reglamento europeo para ello?
Ricard Martínez: Hay un conjunto de conductas que se han prohibido esencialmente para garantizar los derechos fundamentales de las personas. Pero no es la única medida. Yo le concedo muchísima importancia a un artículo en la norma al que seguramente no le vamos a dar muchas vueltas, pero para mí es clave. Hay un artículo, el cuarto, que en inglés se ha titulado AI Literacy, y en castellano “Formación en inteligencia artificial” que dice que cualquier sujeto que está interviniendo en la cadena de valor tiene que haber sido adecuadamente formado. Tiene que conocer de qué va esto, tiene que conocer cuál es el estado del arte, tiene que conocer cuáles son las implicaciones de la tecnología que va a desarrollar o que va a desplegar. Le concedo mucho valor porque significa incorporar en toda la cadena de valor (desarrollador, comercializador, importador, compañía que despliegue un modelo para su uso, etc.) un conjunto de valores que suponen lo que en inglés se llama accountability, responsabilidad proactiva, por defecto. Esto se puede traducir en un elemento que es muy sencillo, sobre el que se habla hace dos mil años en el mundo del derecho, que es el ‘no hacer daño’, es el principio de no maleficencia.
Con algo tan sencillo como eso, "no haga usted daño a los demás, actúe de buena y garantice sus derechos", no se deberían producir efectos perversos o efectos dañosos, lo cual no significa que no pueda suceder. Y precisamente eso lo dice el Reglamento muy particularmente cuando se refiere a los sistemas de riesgo alto, pero es aplicable a todos los sistemas. El Reglamento te dice que tienes que garantizar los procesos de cumplimiento y las garantías durante todo el ciclo de vida del sistema. De ahí que sea tan importante la robustez, la resiliencia y el disponer de planes de contingencia que te permiten revertir, paralizar, pasar a control humano, cambiar el modelo de uso cuando se produce algún incidente.
Por tanto, todo el ecosistema está dirigido a ese objetivo de no lesionar derechos, no causar perjuicios. Y hay un elemento que ya no depende de nosotros, depende de las políticas públicas. La IA no solo va a lesionar derechos, va a cambiar el modo en el que entendemos el mundo. Si no hay políticas públicas en el sector educativo que aseguren que nuestros niños y niñas desarrollen capacidades de pensamiento computacional y de ser capaces de tener una relación con una interfaz-máquina, su acceso al mercado de trabajo se va a ver significativamente afectado. Del mismo modo, si no aseguramos la formación continua de los trabajadores en activo y también las políticas públicas de aquellos sectores condenados a desaparecer.
Carmen Torrijos: Me parece muy interesante el enfoque de Ricard de formar es proteger. Formar a la gente, informar a la gente, que la gente tenga capacitación en IA, no solamente la gente que está en la cadena de valor, sino todo el mundo. Cuanto más formas y capacitas, más estás protegiendo a las personas.
Cuando salió la ley, hubo cierta decepción en los entornos IA y sobre todo en los entornos creativos. Porque estábamos en plena efervescencia de la IA generativa y no se estaba regulando apenas la IA generativa, pero se estaban regulando otras cosas que dábamos por hecho que en Europa no iban a pasar, pero que hay que regular para que no puedan pasar. Por ejemplo, la vigilancia biométrica: que Amazon no pueda leerte la cara para decidir si estás más triste ese día y venderte más cosas o sacarte más publicidad o una publicidad determinada. Digo Amazon, pero puede ser cualquier plataforma. Eso, por ejemplo, en Europa no se va a poder hacer porque está prohibido desde la ley, es un uso inaceptable: la vigilancia biométrica.
Otro ejemplo es la puntuación social, el social scoring que vemos que pasa en China, que se dan puntos a los ciudadanos y se accede a servicios públicos a partir de estos puntos. Eso tampoco se va a poder hacer. Y hay que contemplar también esta parte de la ley, porque damos muy por hecho que esto no nos va a ocurrir, pero cuando no lo regulas es cuando ocurre. China tiene instalados 600 millones de cámaras de TRF, de tecnología de reconocimiento facial, que te reconocen con tu DNI. Eso no va a pasar en Europa porque no se puede, porque también es vigilancia biométrica. Entonces hay que entender que la ley quizá parece que va más despacio en lo que ahora nos tiene embelesados que es la IA generativa, pero se ha dedicado a tratar puntos muy importantes que había que cubrir para proteger a las personas. Para no perder derechos fundamentales que ya teníamos ganados.
Por último, la ética tiene un componente muy incómodo, que nadie quiere mirar, que es que a veces hay que revocar. A veces hay que quitar algo que está en funcionamiento, incluso que está dando un beneficio, porque está incurriendo en algún tipo de discriminación, o porque está trayendo algún tipo de consecuencia negativa que viola a los derechos de un colectivo, de una minoría o de alguien vulnerable. Y eso es muy complicado. Cuando ya nos hemos acostumbrado a tener una IA funcionando en determinado contexto, que puede ser incluso un contexto público, parar y decir que esto está discriminando a personas, entonces este sistema no puede seguir en producción y hay que quitarlo. Ese punto es muy complicado, es muy incómodo y cuando hablamos de ética, que hablamos muy fácil de ética, hay que pensar también en cuántos sistemas vamos a tener que parar y revisar antes de poder volver a poner en funcionamiento, por muy fácil que nos hagan la vida o por muy innovadores que parezcan.
5. En este sentido, teniendo en cuenta todo lo que recoge el Reglamento, algunas empresas españolas, por ejemplo, tendrán que adaptarse a este nuevo marco. ¿Qué deberían estar haciendo ya las organizaciones para prepararse? ¿Qué deberían revisar las empresas españolas teniendo en cuenta el reglamento europeo?
Ricard Martínez: Esto es muy importante, porque hay un nivel corporativo empresarial de altas capacidades que a mí no me preocupa porque estas empresas entienden que estamos hablando de una inversión. Y del mismo modo que invirtieron en un modelo basado en procesos que integraba el compliance desde el diseño para protección de datos. El siguiente salto, que es hacer exactamente lo mismo con inteligencia artificial, no diré que carece de importancia, porque posee una importancia relevante, pero digamos que es recorrer un camino que ya se ensayó. Estas empresas ya tienen unidades de compliance, ya tienen asesores, y ya tienen unas rutinas en las que se puede integrar como una parte más del proceso el marco de referencia de la normativa de inteligencia artificial. Al final lo que va a hacer es crecer en un sentido el análisis de riesgos. Seguramente va a obligar a modular los procesos de diseño y también las propias fases de diseño, es decir, mientras que en un diseño de software prácticamente hablamos de pasar de un modelo no funcional a picar código, aquí hay una serie de labores de enriquecimiento, anotación, validación de los conjuntos de datos, prototipado que exigen seguramente más esfuerzo, pero son rutinas que se pueden estandarizar.
Mi experiencia en proyectos europeos en los que hemos trabajado con clientes, es decir, con las PYMES, que esperan que la IA sea plug and play, lo que hemos apreciado es una enorme falta de capacitación. Lo primero que deberías preguntarte no es si tu empresa necesita IA, sino si tu empresa está preparada para la IA. Es una pregunta previa y bastante más relevante. Oiga, usted cree que puede dar un salto a la IA, que puede contratar un determinado tipo de servicios, y nos estamos dando cuenta que es que usted ni siquiera cumple bien la norma de protección de datos.
Hay una cosa, una entidad que se llama Agencia Española de Inteligencia Artificial, AESIA y hay un Ministerio de Transformación Digital, y si no hay políticas públicas de acompañamiento, podemos incurrir en situaciones de riesgo. ¿Por qué? Porque yo tengo el enorme placer de formar en grados y posgrados a futuros emprendedores en inteligencia artificial. Cuando se enfrentan al marco ético y jurídico no diré que se quieren morir, pero se les cae el mundo encima. Porque no hay un soporte, no hay un acompañamiento, no hay recursos, o no los pueden ver, que no le supongan una ronda de inversión que no pueden soportar, o no hay modelos guiados que les ayuden de modo, no diré fácil, pero sí al menos usable.
Por lo tanto, creo que hay un reto sustancial en las políticas públicas, porque si no se da esa combinación, las únicas empresas que podrán competir son las que ya tienen una masa crítica, una capacidad inversora y un capital acumulado que les permite cumplir con la norma. Esta situación podría conducir a un resultado contraproducente.
Queremos recuperar la soberanía digital europea, pero si no hay políticas públicas de inversión, los únicos que van a poder cumplir la norma europea son las empresas de otros países.
Carmen Torrijos: No porque sean de otros países sino porque son más grandes.
Ricard Martínez: Sí, por no citar países.
6. Hemos hablado de retos, pero también es importante destacar oportunidades. ¿Qué aspectos positivos podríais destacar a raíz de esta regulación reciente?
Ricard Martínez: Yo trabajo en la construcción, con fondos europeos, de Cancer Image EU que pretende ser una infraestructura digital para la imagen de cáncer. En estos momentos, hablamos de un partenariado que engloba a 14 países, 76 organizaciones, camino de 93, para generar una base de datos de imagen médica con 25 millones de imágenes de cáncer con información clínica asociada para el desarrollo de inteligencia artificial. La infraestructura se está construyendo, todavía no existe, y aún así, en el Hospital La Fe, en Valencia, ya se está investigando con mamografías de mujeres que se han practicado el screening bienal y que después han desplegado cáncer, para ver si es capaz de entrenar un modelo de análisis de imagen que sea capaz de reconocer preventivamente esa manchita que el oncólogo o el radiólogo no vieron y que después acabó siendo un cáncer. ¿Significa que te van a poner quimioterapia cinco minutos después? No. Significa que te van a monitorizar, que van a tener una capacidad de reacción temprana. Y que el sistema de salud se va a ahorrar doscientos mil euros. Por mencionar alguna oportunidad.
Por otra parte, las oportunidades hay que buscarlas, además, en otras normas. No solo en el Reglamento de Inteligencia Artificial. Hay que irse a Data Governance Act, que quiere contrarrestar el monopolio de datos que tienen las empresas norteamericanas con una compartición de datos desde el sector público, privado y desde la propia ciudadanía. Con Data Act, que pretende empoderar a los ciudadanos para que puedan recuperar sus datos y compartirlos mediante consentimiento. Y finalmente con el European Health Data Space que quiere crear un ecosistema de datos de salud para promover la innovación, la investigación y el emprendimiento. Ese ecosistema de espacios de datos es el que debería ser un enorme generador de espacios de oportunidad.
Y además, yo no sé si lo van a conseguir o no, pero pretende ser coherente con nuestro ecosistema empresarial. Es decir, un ecosistema de pequeña y mediana empresa que no tiene altas capacidades en la generación de datos y lo que le vamos a hacer es a construirles el campo. Les vamos a crear los espacios de datos, les vamos a crear los intermediarios, los servicios de intermediación y esperemos que ese ecosistema en su conjunto permita que el talento europeo emerja desde la pequeña y media empresa. ¿Que se vaya a conseguir o no? No lo sé, pero el escenario de oportunidad parece muy interesante.
Carmen Torrijos: Si preguntas por oportunidades, oportunidades todas. No solamente la inteligencia artificial, sino todo el avance tecnológico, es un campo tan grande que puede traer oportunidades de todo tipo. Lo que hay que hacer es bajar las barreras, que ese es el problema que tenemos. Y barreras las tenemos también de muchos tipos, porque tenemos barreras técnicas, de talento, salariales, disciplinares, de género, generacionales, etc.
Tenemos que concentrar las energías en bajar esas barreras, y luego también creo que seguimos viniendo del mundo analógico y tenemos poca conciencia global de que tanto lo digital como todo lo que afecta a la IA y a los datos es un fenómeno global. No sirve de nada mantenerlo todo en lo local, o en lo nacional, o ni siquiera a nivel europeo, sino que es un fenómeno global. Los grandes problemas que tenemos vienen porque tenemos empresas tecnológicas que se desarrollan en Estados Unidos trabajando en Europa con datos de ciudadanos europeos. Ahí se genera muchísima fricción. Todo lo que pueda llevar a algo más global va a ir siempre en favor de la innovación y va a ir siempre en favor de la tecnología. Lo primero es levantar las barreras dentro de Europa. Esa es una parte muy positiva de la ley.
7. Llegados a este punto, nos gustaría realizar un repaso sobre el estado en el que nos encontramos y las perspectivas de futuro. ¿Cómo veis el futuro de la inteligencia artificial en Europa?
Ricard Martínez: Yo tengo dos visiones: una positiva y una negativa. Y las dos vienen de mi experiencia en protección de datos. Si ahora que tenemos un marco normativo, las autoridades reguladoras, me refiero desde inteligencia artificial y desde protección de datos, no son capaces de encontrar soluciones funcionales y aterrizadas, y generan políticas públicas desde arriba hacia abajo y desde una excelencia que no se corresponde con las capacidades y las posibilidades de la investigación -me refiero no solo a la investigación empresarial, también a la universitaria-, veo el futuro muy negro. Si por el contrario, entendemos de modo dinámico la regulación con políticas públicas de soporte y acompañamiento que generen las capacidades para esa excelencia, veo un futuro prometedor porque en principio lo que haremos será competir en el mercado con las mismas soluciones que los demás, pero responsive: seguras, responsables y confiables.
Carmen: Sí, yo estoy muy de acuerdo. Yo introduzco en eso la variable tiempo, ¿no? Porque creo que hay que tener mucho cuidado en no generar más desigualdad de la que ya tenemos. Más desigualdad entre empresas, más desigualdad entre la ciudadanía. Si tenemos cuidado con eso, que se dice fácil, pero se hace difícil, yo creo que el futuro puede ser brillante, pero no lo va a ser de manera inmediata. Es decir, vamos a tener que pasar por una época más oscura de adaptación al cambio. Igual que muchos temas de la digitalización ya no nos son ajenos, ya están trabajados, ya hemos pasado por ellos y ya los hemos regulado, la inteligencia artificial necesita su tiempo también.
Llevamos muy pocos años de IA, muy pocos años de IA generativa. De hecho, dos años no es nada en un cambio tecnológico a nivel mundial. Y tenemos que dar tiempo a las leyes y tenemos también que dar tiempo a que ocurran cosas. Por ejemplo, pongo un ejemplo muy evidente, la denuncia del New York Times a Microsoft y a OpenAI no se ha resuelto todavía. Llevamos un año, se interpuso en diciembre de 2023, el New York Times se queja de que han entrenado con sus contenidos los sistemas de IA y en un año no se ha conseguido llegar a nada en ese proceso. Los procesos judiciales son muy lentos. Necesitamos que ocurran más cosas. Y que se resuelvan más procesos de este tipo para tener precedentes y para tener madurez como sociedad en lo que está ocurriendo, y nos falta mucho. Es como que no ha pasado casi nada. Entonces, la variable tiempo creo que es importante y creo que, aunque al principio tengamos un futuro más negro, como dice Ricard, creo que a largo plazo, si mantenemos claros los límites, podemos llegar a algo brillante.
Clips de la entrevista
1. ¿Qué criterios deberían tener los datos para entrenar un sistema de IA?
2. ¿Qué deberían revisar las empresas españolas teniendo en cuenta el Reglamento de IA?
Noticia
Desde la semana pasada, ya están disponibles los modelos de lenguaje de inteligencia artificial (IA) entrenados en español, catalán, gallego, valenciano y euskera, que se han desarrollado dentro de ALIA, la infraestructura pública de recursos de IA. A través de ALIA Kit los usuarios pueden acceder a toda la familia de modelos y conocer la metodología utilizada, la documentación relacionada y los conjuntos de datos de entrenamiento y evaluación. En este artículo te contamos sus claves.
¿Qué es ALIA?
ALIA es un proyecto coordinado por el Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS). Su objetivo es proporcionar una infraestructura pública de recursos de inteligencia artificial abiertos y transparentes, capaces de generar valor tanto en el sector público como en el privado.
En concreto, ALIA es una familia de modelos de texto, voz y traducción automática. El entrenamiento de sistemas de inteligencia artificial demanda una gran cantidad de recursos computacionales, ya que es necesario procesar y analizar enormes volúmenes de datos. Estos modelos han sido entrenados en español, una lengua que hablan más de 600 millones de personas en todo el mundo, pero también en las cuatro lenguas cooficiales. Para ello, se ha contado con la colaboración de la Real Academia Española (RAE) y la Asociación de Academias de la Lengua Española, que agrupa a las entidades del español existentes en todo el mundo.
Para el entrenamiento se ha utilizado el MareNostrum 5, uno de los superordenadores más potentes del mundo, que se encuentra en el Barcelona Supercomputing Center. Han sido necesarias miles de horas de trabajo para tratar varios miles de millones de palabras a una velocidad de 314.000 billones de cálculos por segundo.
Una familia de modelos abiertos y transparentes
Con el desarrollo de estos modelos se proporciona una alternativa que incorpora datos locales. Una de las prioridades de ALIA es ser una red abierta y transparente, lo que significa que los usuarios, además de poder acceder a los modelos, tienen la posibilidad de conocer y descargar los conjuntos de datos utilizados y toda la documentación relacionada. Esta documentación facilita la comprensión del funcionamiento de los modelos y, además, detectar más fácilmente en qué fallan, algo fundamental para evitar sesgos y resultados erróneos. La apertura de los modelos y la transparencia de los datos son fundamentales, ya que crea modelos más inclusivos y socialmente justos, que benefician a la sociedad en su conjunto.
Contar con modelos abiertos y transparentes fomenta la innovación, la investigación y democratiza el acceso a la inteligencia artificial, asegurando además que se parte de datos de entrenamiento de calidad.
¿Qué puedo encontrar en ALIA Kit?
A través de ALIA Kit, es posible acceder actualmente a cinco modelos masivos de lenguaje (LLM) de propósito general, de los que dos han sido entrenados con instrucciones de varios corpus abiertos. Igualmente, están disponibles nueve modelos de traducción automática multilingüe, algunos de ellos entrenados desde cero, como uno de traducción automática entre el gallego y el catalán, o entre el euskera y el catalán. Además, se han entrenado modelos de traducción al aranés, el aragonés y el asturiano.
También encontramos los datos y herramientas utilizadas para elaborar y evaluar los modelos de texto, como el corpus textual masivo CATalog, formado por 17,45 mil millones de palabras (alrededor de 23.000 millones de tokens), distribuidos en 34,8 millones de documentos procedentes de una gran variedad de fuentes, que han sido revisados en buena parte manualmente.
Para entrenar los modelos de voz se han utilizado diferentes corpus de voz con transcripción, como, por ejemplo, un conjunto de datos de las Cortes Valencianas con más de 270 horas de grabación de sus sesiones. Igualmente, es posible conocer los corpus utilizados para el entrenamiento de los modelos de traducción automática.
A través del ALIA Kit también está disponible una API gratuita (desde Python, Javascript o Curl), con la que se pueden realizar pruebas.
¿Para qué se pueden usar estos modelos?
Los modelos desarrollados por ALIA están diseñados para ser adaptables a una amplia gama de tareas de procesamiento del lenguaje natural. Sin embargo, cuando se trata de necesidades específicas es preferible utilizar modelos especializados, que permiten obtener mayor precisión y consumen menos recursos.
Como hemos visto, los modelos están disponibles para todos los usuarios interesados, como desarrolladores independientes, investigadores, empresas, universidades o instituciones. Entre los principales beneficiarios de estas herramientas se encuentran los desarrolladores y las pequeñas y medianas empresas, para quienes no es viable desarrollar modelos propios desde cero, tanto por cuestiones económicas como técnicas. Gracias a ALIA pueden adaptar los modelos ya existentes a sus necesidades específicas.
Los desarrolladores encontrarán recursos para crear aplicaciones que reflejen la riqueza lingüística del castellano y de las lenguas cooficiales. Por su parte, las empresas podrán desarrollar nuevas aplicaciones, productos o servicios orientados al amplio mercado internacional que ofrece la lengua castellana, abriendo nuevas oportunidades de negocio y expansión.
Un proyecto innovador financiado con fondos públicos
El proyecto ALIA está financiado íntegramente con fondos públicos con el objetivo de impulsar la innovación y la adopción de tecnologías que generen valor tanto en el sector público como en el privado. Contar con una infraestructura de IA pública democratiza el acceso a tecnologías avanzadas, permitiendo que pequeñas empresas, instituciones y gobiernos aprovechen todo su potencial para innovar y mejorar sus servicios. Además, facilita el control ético del desarrollo de la IA y fomenta la innovación.
ALIA forma parte de la Estrategia de Inteligencia Artificial 2024 de España, que tiene entre sus objetivos dotar al país de las capacidades necesarias para hacer frente a una demanda creciente de productos y servicios IA e impulsar la adopción de esta tecnología, especialmente en el sector público y pymes. Dentro del eje 1 de dicha estrategia, se encuentra la llamada Palanca 3, que se centra en la generación de modelos y corpus para una infraestructura pública de modelos de lenguaje. Con la publicación de esta familia de modelos, se avanza en el desarrollo de recursos de inteligencia artificial en España.
Blog
Es posible que nuestra capacidad de sorpresa ante las nuevas herramientas de inteligencia artificial (IA) generativa esté empezando a mermar. El mejor ejemplo es GPT-o1, un nuevo modelo de lenguaje con la máxima habilidad de razonamiento lograda hasta ahora, capaz de verbalizar -algo similar a- sus propios procesos lógicos, pero que no despertó en su lanzamiento tanto entusiasmo como cabría esperar. A diferencia de los dos años anteriores, en los últimos meses hemos tenido menos sensación de disrupción y reaccionamos de manera menos masiva ante las novedades.
Una reflexión posible es que no necesitamos, por ahora, más inteligencia en los modelos, sino ver con nuestros propios ojos un aterrizaje en usos concretos que nos faciliten la vida: ¿cómo utilizo la potencia de un modelo de lenguaje para consumir contenido más rápido, para aprender algo nuevo o para trasladar información de un formato a otro? Más allá de las grandes aplicaciones de propósito general, como ChatGPT o Copilot, existen herramientas gratuitas y menos conocidas que nos ayudan a pensar mejor, y nos ofrecen capacidades basadas en IA para descubrir, entender y compartir conocimiento.
Generar pódcasts a partir de un fichero: NotebookLM
Los pódcasts automáticos de NotebookLM llegaron por primera vez a España en el verano de 2024 y sí levantaron un revuelo significativo, a pesar de no estar ni siquiera disponibles en español. Siguiendo el estilo de Google, el sistema es sencillo: basta con subir un fichero en PDF como fuente para obtener diferentes variaciones del contenido proporcionadas por Gemini 2.0 (el sistema de IA de Google), como un resumen del documento, una guía de estudio, una cronología o un listado de preguntas frecuentes. En este caso, hemos utilizado para el ejemplo un informe sobre inteligencia artificial y democracia publicado por la UNESCO en 2024.
Figura 1. Diferentes opciones de resumen en NotebookLM.
Si bien la guía de estudio es una salida interesante, que ofrece un sistema de preguntas y respuestas para memorizar y un glosario de términos, la estrella de NotebookLM es el llamado “resumen de audio”: un pódcast conversacional completamente natural entre dos interlocutores sintéticos que comentan de manera amena el contenido del PDF.
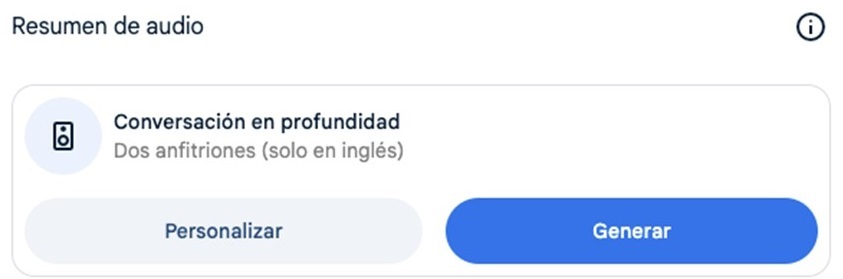
Figura 2. Resumen de audio en NotebookLM.
La calidad del contenido de este pódcast aún tiene margen de mejora, pero puede servirnos como un primer acercamiento al contenido del documento, o ayudarnos a interiorizarlo más fácilmente desde el audio mientras descansamos de las pantallas, hacemos ejercicio o nos desplazamos.
El truco: aparentemente, no se puede generar el pódcast en español, solo en inglés, pero puedes probar con este prompt: “Realiza un resumen de audio en español del documento”. Casi siempre funciona.
Crear visualizaciones a partir de un texto: Napkin AI
Napkin nos ofrece algo muy valioso: crear visualizaciones, infografías y mapas mentales a partir de un contenido en texto. En su versión gratuita, el sistema solo nos pide iniciar sesión con un correo electrónico. Una vez dentro, nos pregunta cómo queremos introducir el texto a partir del cual vamos a crear las visualizaciones. Podemos pegarlo o directamente generar con IA un texto automático sobre cualquier tema.
Figura 3. Puntos de partida en Napkin.ai.
En este caso, vamos a copiar y pegar un fragmento del informe de la UNESCO que recoge varias recomendaciones para la gobernanza democrática de la IA. A partir del texto que recibe, Napkin.ai nos ofrece ilustraciones y varios tipos de esquemas. Podemos encontrar desde propuestas más sencillas con texto organizado en llaves y cuadrantes hasta otras ilustradas con dibujos e iconos.
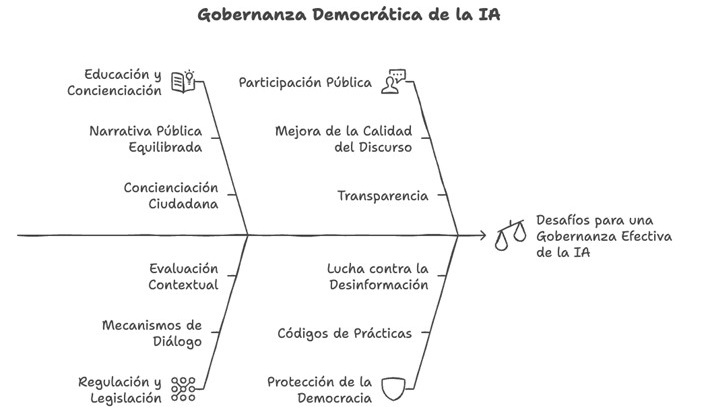
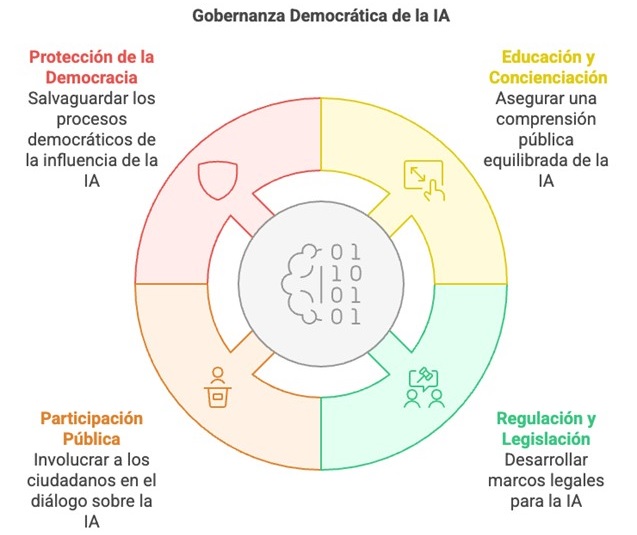
Figura 4. Propuesta de esquemas en Napkin.ai.
Aunque están muy lejos de la calidad de la infografía profesional, estas visualizaciones pueden servirnos a nivel personal y de aprendizaje, para ilustrar un post en redes, explicar conceptos internamente a nuestro equipo o enriquecer contenidos propios en el ámbito educativo.
El truco: si en cada propuesta de esquema haces clic en Styles, encontrarás más variaciones del esquema con colores y líneas diferentes. También puedes modificar los textos, simplemente haciendo clic en ellos una vez que seleccionas una visualización.
Presentaciones y diapositivas automáticas: Gamma
De todos los formatos de contenido que la IA es capaz de generar, las presentaciones con diapositivas es seguramente el menos logrado. En ocasiones los diseños no son demasiado elaborados, otras veces no conseguimos que la plantilla que queremos usar se respete, casi siempre los textos son demasiado simples. La particularidad de Gamma, y lo que la hace más práctica que otras opciones como Beautiful.ai, es que podemos crear una presentación directamente desde un contenido en texto que podemos pegar, generar con IA o subir en un archivo.

Figura 5. Puntos de partida para Gamma.
Si pegamos el mismo texto que en el ejemplo anterior, sobre las recomendaciones de la UNESCO para la gobernanza democrática de la IA, en el siguiente paso Gamma nos da a elegir entre “forma libre” o “tarjeta por tarjeta”. En la primera opción, la IA del sistema se encarga de organizar el contenido en diapositivas conservando el sentido completo de cada una. En la segunda, nos propone que dividamos el texto para indicar el contenido que queremos en cada diapositiva.
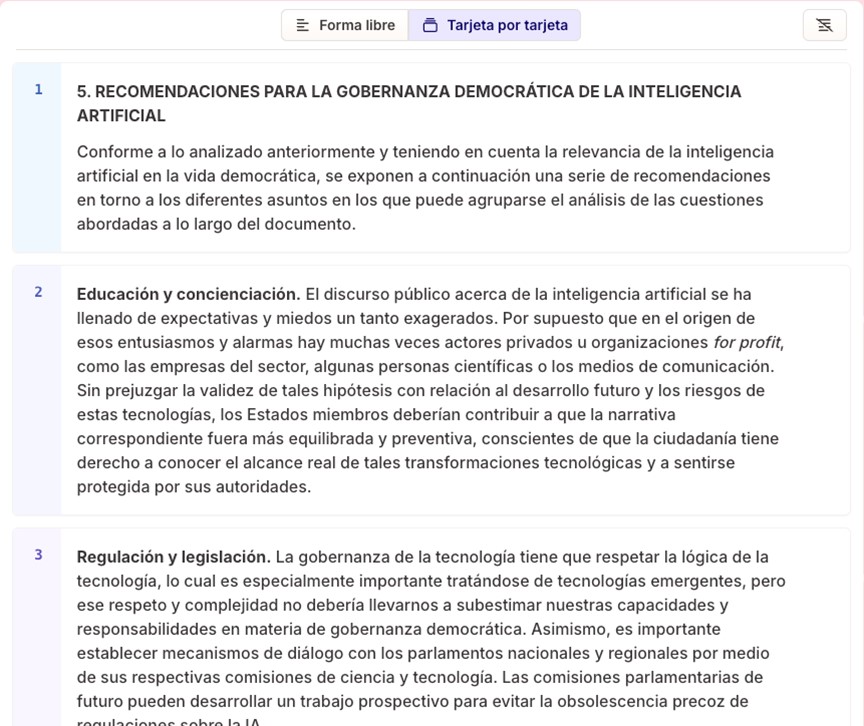
Figura 6. Texto dividido automáticamente en diapositivas por Gamma.
Seleccionamos la segunda opción, y el texto se divide automáticamente en diferentes bloques que serán nuestras diapositivas futuras. Pulsando en “Continuar”, nos pide que seleccionemos un tema de base. Por último, pulsando en “Generar”, se crea automáticamente la presentación completa.

Figura 7. Ejemplo de diapositiva creada con Gamma.
Gamma acompaña las diapositivas de imágenes creadas con IA que guardan cierta coherencia con el contenido, y nos da la opción de modificar los textos o de generar imágenes diferentes. Una vez lista, podemos exportarla directamente al formato Power Point.
Un truco: en el botón “editar con IA” de cada diapositiva podemos pedirle que la traduzca automáticamente a otro idioma, que corrija la ortografía o incluso que convierta el texto en una línea del tiempo.
Resumir desde cualquier formato: NoteGPT
El objetivo de NoteGPT es muy claro: resumir un contenido que podemos importar desde muchas fuentes diferentes. Podemos copiar y pegar un texto, subir un fichero o una imagen, o directamente extraer la información de un enlace, algo muy útil y no tan habitual en las herramientas de IA. Aunque esta última opción no siempre funciona bien, es una de las pocas herramientas que la ofrece.
Figura 8. Puntos de partida para NoteGPT.
En este caso, introducimos el enlace a un vídeo de YouTube que contiene una entrevista a Daniel Innerarity sobre la intersección entre la inteligencia artificial y los procesos democráticos. En la pantalla de resultados, lo primero que obtenemos a la izquierda es la transcripción completa de la entrevista, con buena calidad. Podemos localizar la transcripción de un fragmento concreto del vídeo, traducirla a distintos idiomas, copiarla o descargarla, incluso en un fichero SRT de subtítulos mapeados con los tiempos.
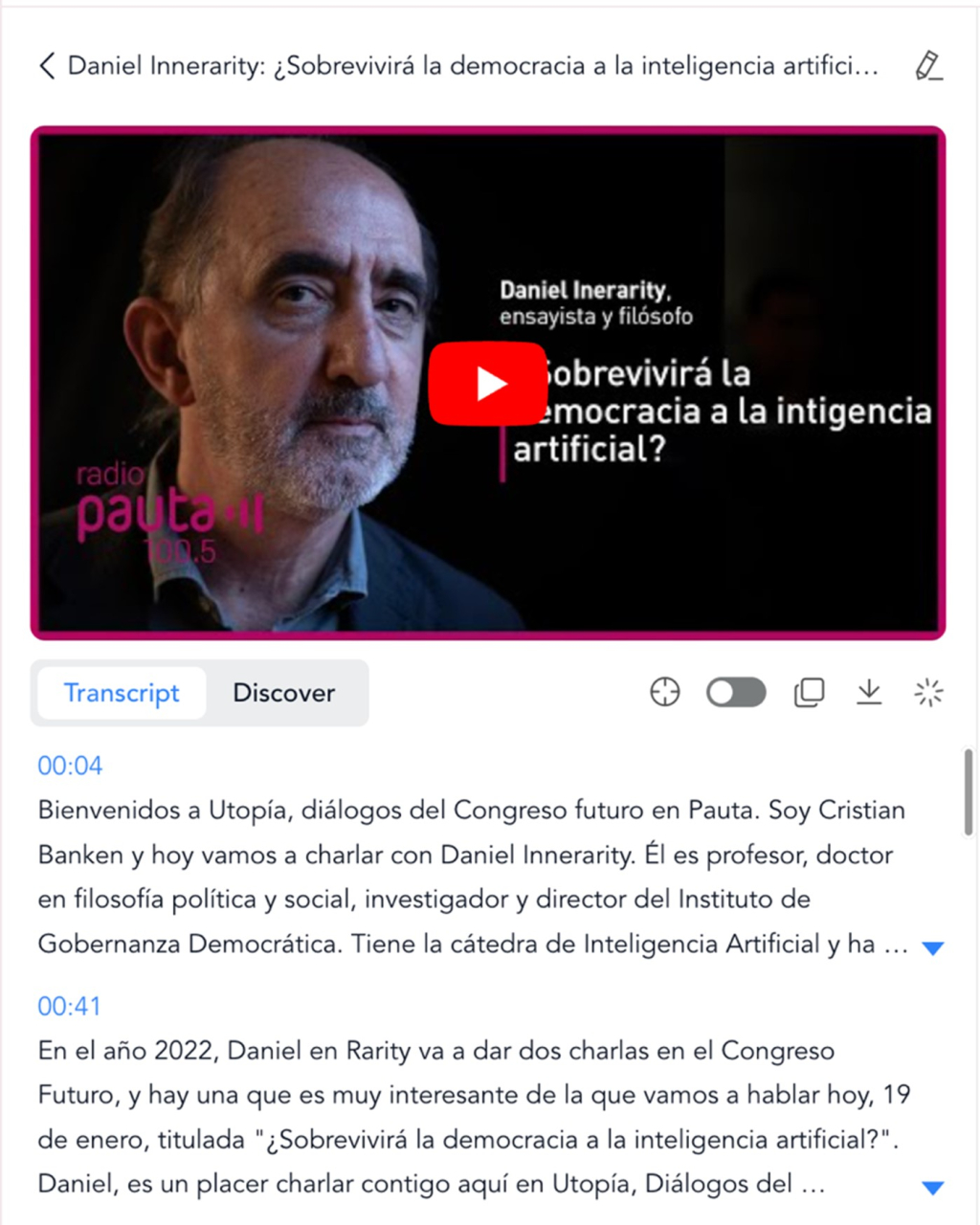
Figura 9. Ejemplo de transcripción con minutaje en NoteGPT.
Entre tanto, a la derecha encontramos el resumen del vídeo con los puntos más importantes, ordenados e ilustrados con emojis. También en el botón “AI Chat” podemos interactuar con un asistente conversacional y hacerle preguntas sobre el contenido.
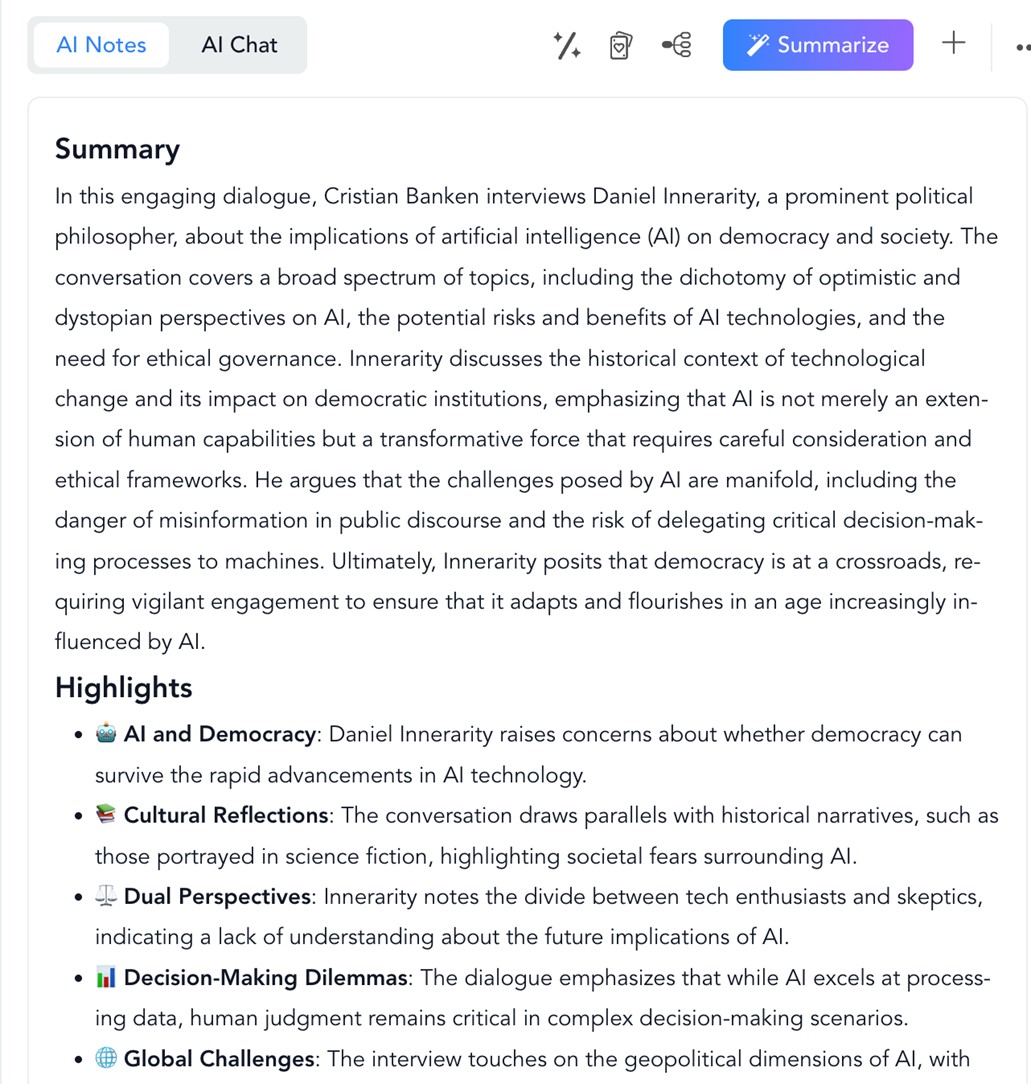
Figura 10. Resumen de NoteGPT a partir de una entrevista en YouTube.
Y aunque esto ya es muy útil, lo mejor que podemos encontrar en NoteGPT son las flashcards, tarjetas de aprendizaje con preguntas y respuestas para interiorizar los conceptos del vídeo.


Figura 11. Tarjetas de aprendizaje de NoteGPT (pregunta y respuesta).
Un truco: si el resumen solo aparece en inglés, prueba a cambiar el idioma en los tres puntos de la derecha, junto a “Summarize” y haz clic de nuevo en “Summarize”. El resumen aparecerá en español más abajo. En el caso de las flashcards, para generarlas en español no lo intentes desde la página de inicio, hazlo desde “AI flashcards”. En “Create” podrás seleccionar el idioma.
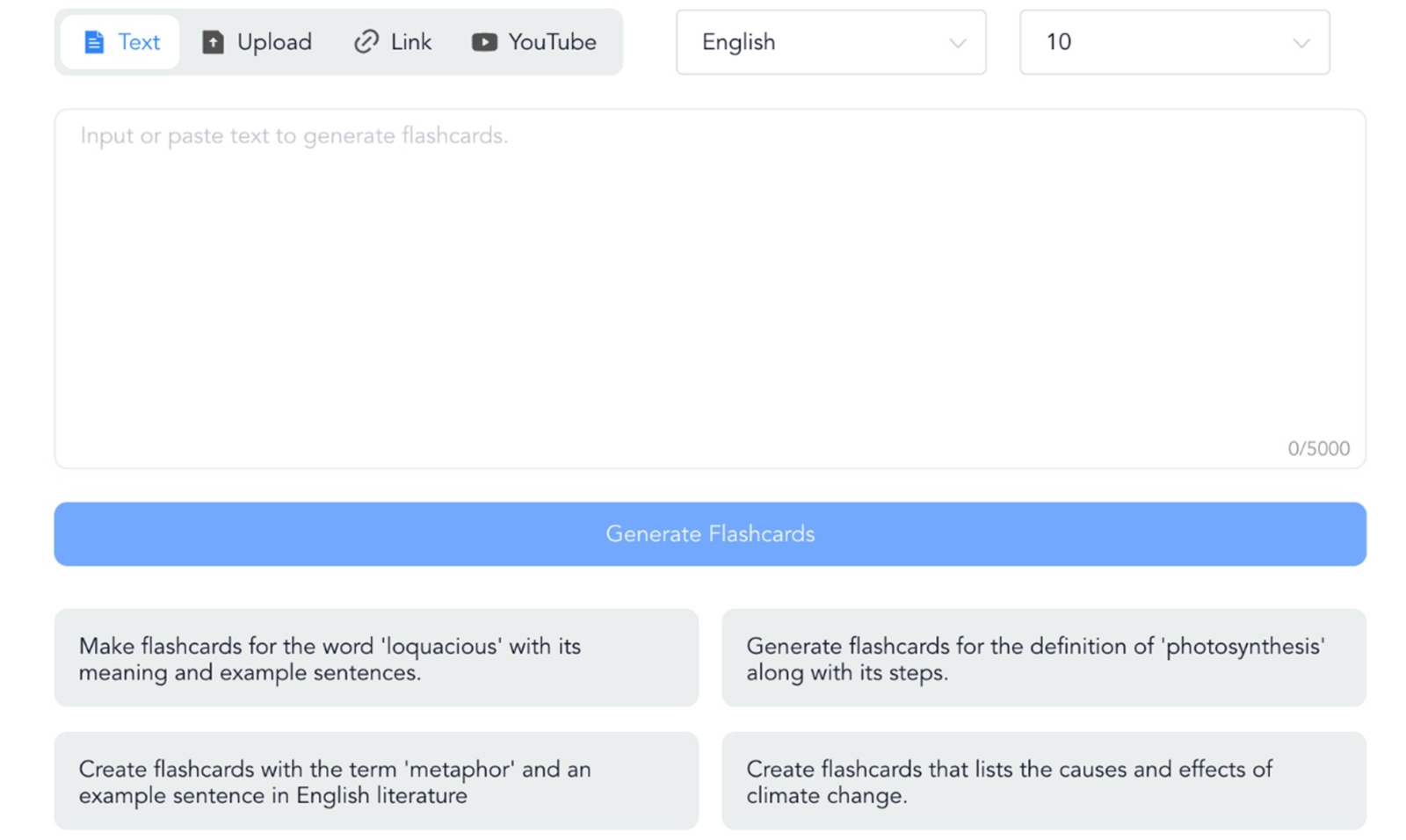
Figura 12. Creación de flashcards en NoteGPT.
Crea vídeos sobre cualquier cosa: Lumen5
Lumen5 facilita la creación de vídeos con IA permitiendo crear el guion y las imágenes automáticamente a partir de contenido en texto o en voz. Lo más interesante de Lumen5 es el punto de partida, que puede ser un texto, un documento, simplemente una idea o también una grabación en audio o un vídeo ya existente.

Figura 13. Opciones de Lumen5.
El sistema nos permite, antes de crear el vídeo y también una vez creado, cambiar el formato de 16:9 (horizontal) a 1:1 (cuadrado) o a 9:16 (vertical), incluso con una opción en 9:16 especial para stories de Instagram.
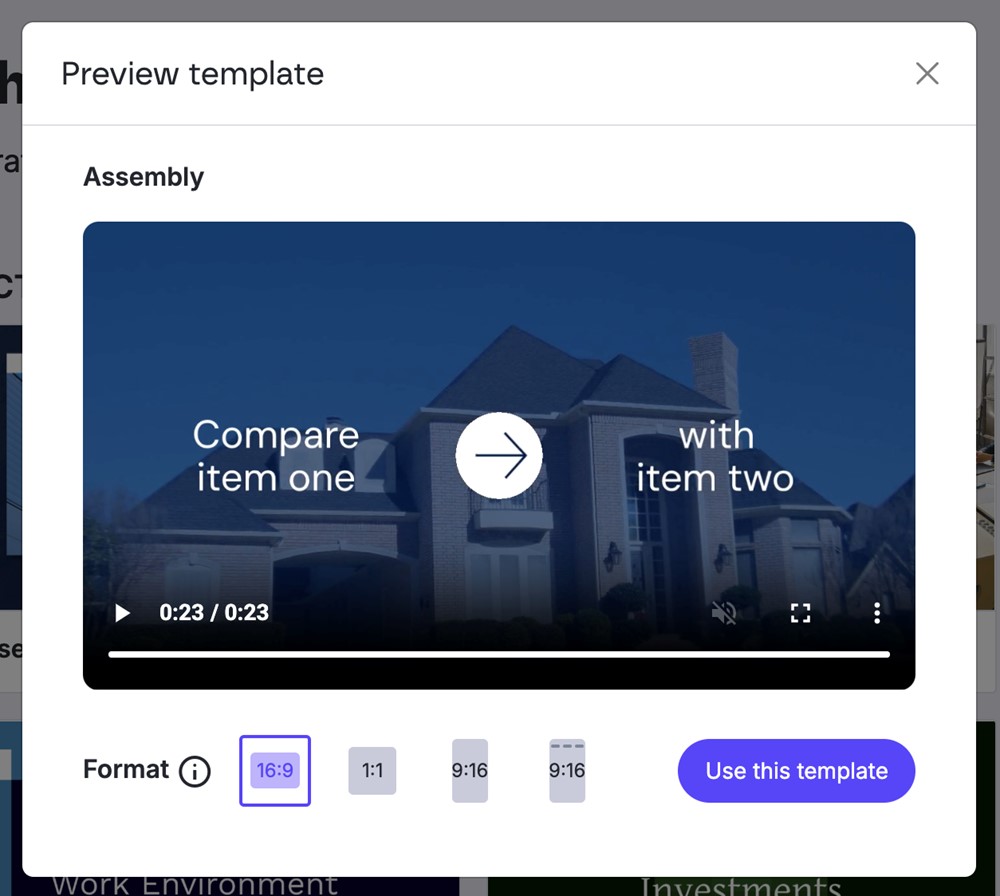
Figura 14. Previsualización del vídeo y opciones de relación de aspecto.
En este caso, vamos a partir del mismo texto que en herramientas anteriores: las recomendaciones de la UNESCO para una gobernanza democrática de la IA. Seleccionando la opción de partida “Text on media”, lo pegamos directamente en el cajetín y hacemos clic en “Compose script”. El resultado es un guion muy sencillo y esquemático, dividido en bloques con los puntos básicos del texto, y una indicación muy interesante: una predicción sobre la duración del vídeo con ese guion, aproximadamente 1 minuto y 19 segundos.
Una nota importante: el guion no es una locución sonora, sino el texto que aparecerá escrito en las diferentes pantallas. Una vez terminado el vídeo, puedes traducirlo entero a cualquier otro idioma.

Figura 15. Propuesta de guion en Lumen5.
Si hacemos clic en “Continue” llegaremos a la última oportunidad para modificar el guion, donde podremos añadir bloques de texto nuevos o eliminar los existentes. Una vez listo, hacemos clic en “Convert to video” y encontraremos el story board listo para modificar imágenes, colores o el orden de las pantallas. El vídeo tendrá música de fondo, que también puedes cambiar, y en este punto podrás grabar tu voz por encima de la música para locutar el guion. Sin demasiado esfuerzo, este es el resultado final:
Figura 16. Resultado final de un vídeo creado con Lumen5.
Del amplio abanico de productos digitales basados en IA que ha florecido en los últimos años, quizá miles de ellos, hemos recorrido solo cinco ejemplos que nos demuestran que el conocimiento y el aprendizaje individual y colaborativo son más accesibles que nunca. La facilidad para convertir contenido de un formato a otro y la creación automática de guías y materiales de estudio debería promover una sociedad más informada y ágil, no solo a través del texto o la imagen sino también de la información condensada en ficheros o bases de datos.
Supondría un gran impulso para el progreso colectivo que entendiéramos que el valor de los sistemas basados en IA no es tan simple como escribir o crear contenido por nosotros, sino apoyar nuestros procesos de razonamiento, objetivar nuestra toma de decisiones y permitirnos manejar mucha más información de una manera eficiente y útil. Aprovechar las nuevas capacidades IA junto con iniciativas de datos abiertos puede ser clave en el siguiente paso de la evolución del pensamiento humano.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los modelos de lenguaje se encuentran en el epicentro del cambio de paradigma tecnológico que está protagonizando la inteligencia artificial (IA) generativa en los últimos dos años. Desde las herramientas con las que interaccionamos en lenguaje natural para generar texto, imágenes o vídeos y que utilizamos para crear contenido creativo, diseñar prototipos o producir material educativo, hasta aplicaciones más complejas en investigación y desarrollo que incluso han contribuido de forma decisiva a la consecución del Premio Nobel de Química de 2024, los modelos de lenguaje están demostrando su utilidad en una gran variedad de aplicaciones, que por otra parte, aún estamos explorando.
Desde que en 2017 Google publicó el influyente artículo "Attention is all you need", donde se describió la arquitectura de los Transformers, tecnología que sustenta las nuevas capacidades que OpenAI popularizó a finales de 2022 con el lanzamiento de ChatGPT, la evolución de los modelos de lenguaje ha sido más que vertiginosa. En apenas dos años, hemos pasado de modelos centrados únicamente en la generación de texto a versiones multimodales que integran la interacción y generación de texto, imágenes y audio.
Esta rápida evolución ha dado lugar a dos categorías de modelos de lenguaje: los SLM (Small Language Models), más ligeros y eficientes, y los LLM (Large Language Models), más pesados y potentes. Lejos de considerarlos competidores, debemos analizar los SLM y LLM como tecnologías complementarias. Mientras los LLM ofrecen capacidades generales de procesamiento y generación de contenido, los SLM pueden proporcionar soporte a soluciones más ágiles y especializadas para necesidades concretas. Sin embargo, ambos comparten un elemento esencial: dependen de grandes volúmenes de datos para su entrenamiento y en el corazón de sus capacidades están los datos abiertos, que son parte del combustible que se utiliza para entrenar estos modelos de lenguaje en los que se basan las aplicaciones de IA generativa.
LLM: potencia impulsada por datos masivos
Los LLM son modelos de lenguaje a gran escala que cuentan con miles de millones, e incluso billones, de parámetros. Estos parámetros son las unidades matemáticas que permiten al modelo identificar y aprender patrones en los datos de entrenamiento, lo que les proporciona una extraordinaria capacidad para generar texto (u otros formatos) coherente y adaptado al contexto de los usuarios. Estos modelos, como la familia GPT de OpenAI, Gemini de Google o Llama de Meta, se entrenan con inmensos volúmenes de datos y son capaces de realizar tareas complejas, algunas incluso para las que no fueron explícitamente entrenados.
De este modo, los LLM son capaces de realizar tareas como la generación de contenido original, la respuesta a preguntas con información relevante y bien estructurada o la generación de código de software, todas ellas con un nivel de competencia igual o superior al de los humanos especializados en dichas tareas y siempre manteniendo conversaciones complejas y fluidas.
Los LLM se basan en cantidades masivas de datos para alcanzar su nivel de desempeño actual: desde repositorios como Common Crawl, que recopila datos de millones de páginas web, hasta fuentes estructuradas como Wikipedia o conjuntos especializados como PubMed Open Access en el campo biomédico. Sin acceso a estos corpus masivos de datos abiertos, la capacidad de estos modelos para generalizar y adaptarse a múltiples tareas sería mucho más limitada.
Sin embargo, a medida que los LLM continúan evolucionando, la necesidad de datos abiertos aumenta para conseguir progresos específicos como:
- Mayor diversidad lingüística y cultural: aunque los LLM actuales manejan múltiples idiomas, en general están dominados por datos en inglés y otros idiomas mayoritarios. La falta de datos abiertos en otras lenguas limita la capacidad de estos modelos para ser verdaderamente inclusivos y diversos. Más datos abiertos en idiomas diversos garantizarían que los LLM puedan ser útiles para todas las comunidades, preservando al mismo tiempo la riqueza cultural y lingüística del mundo.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. Esto, en ocasiones, genera respuestas que perpetúan estereotipos o desigualdades. Incorporar más datos abiertos cuidadosamente seleccionados, especialmente de fuentes que promuevan la diversidad y la igualdad, es fundamental para construir modelos que representen de manera justa y equitativa a diferentes grupos sociales.
- Actualización constante: los datos en la web y en otros recursos abiertos cambian constantemente. Sin acceso a datos actualizados, los LLM generan respuestas obsoletas muy rápidamente. Por ello, incrementar la disponibilidad de datos abiertos frescos y relevantes permitiría a los LLM mantenerse alineados con la actualidad.
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Los datos abiertos permiten que desarrolladores independientes, universidades y pequeñas empresas entrenen y afinen sus propios modelos sin necesidad de costosas adquisiciones de datos. De este modo se democratiza el acceso a la inteligencia artificial y se fomenta la innovación global.
Para solucionar algunos de estos retos, en la nueva Estrategia de Inteligencia Artificial 2024 se han incluido medidas destinadas a generar modelos y corpus en castellano y lenguas cooficiales, incluyendo también el desarrollo de conjuntos de datos de evaluación que consideran la evaluación ética.
SLM: eficiencia optimizada con datos específicos
Por otra parte, los SLM han emergido como una alternativa eficiente y especializada que utiliza un número más reducido de parámetros (generalmente en millones) y que están diseñados para ser ligeros y rápidos. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
Para ello, los SLM también dependen de datos abiertos, pero en este caso, la calidad y relevancia de los conjuntos de datos son más importantes que su volumen, por ello los retos que les afectan están más relacionados con la limpieza y especialización de los datos. Estos modelos requieren conjuntos que estén cuidadosamente seleccionados y adaptados al dominio específico para el que se van a utilizar, ya que cualquier error, sesgo o falta de representatividad en los datos puede tener un impacto mucho mayor en su desempeño. Además, debido a su enfoque en tareas especializadas, los SLM enfrentan desafíos adicionales relacionados con la accesibilidad de datos abiertos en campos específicos. Por ejemplo, en sectores como la medicina, la ingeniería o el derecho, los datos abiertos relevantes suelen estar protegidos por restricciones legales y/o éticas, lo que dificulta su uso para entrenar modelos de lenguaje.
Los SLM se entrenan con datos cuidadosamente seleccionados y alineados con el dominio en el que se utilizarán, lo que les permite superar a los LLM en precisión y especificidad en tareas concretas, como por ejemplo:
- Autocompletado de textos: un SLM para autocompletado en español puede entrenarse con una selección de libros, textos educativos o corpus como los que se impulsarán en la ya mencionada Estrategia de IA, siendo mucho más eficiente que un LLM de propósito general para esta tarea.
- Consultas jurídicas: un SLM entrenado con conjuntos de datos jurídicos abiertos pueden proporcionar respuestas precisas y contextualizadas a preguntas legales o procesar documentos contractuales de forma más eficaz que un LLM.
- Educación personalizada: en el sector educativo, SLM entrenados con datos abiertos de recursos didácticos pueden generar explicaciones específicas, ejercicios personalizados o incluso evaluaciones automáticas, adaptadas al nivel y las necesidades del estudiante.
- Diagnóstico médico: un SLM entrenado con conjuntos de datos médicos, como resúmenes clínicos o publicaciones abiertas, puede asistir a médicos en tareas como la identificación de diagnósticos preliminares, la interpretación de imágenes médicas mediante descripciones textuales o el análisis de estudios clínicos.
Desafíos y consideraciones éticas
No debemos olvidar que, a pesar de los beneficios, el uso de datos abiertos en modelos de lenguaje presenta desafíos significativos. Uno de los principales retos es, como ya hemos mencionado, garantizar la calidad y neutralidad de los datos para que estén libres de sesgos, ya que estos pueden amplificarse en los modelos, perpetuando desigualdades o prejuicios.
Aunque un conjunto de datos sea técnicamente abierto, su utilización en modelos de inteligencia artificial siempre plantea algunas implicaciones éticas. Por ejemplo, es necesario evitar que información personal o sensible se filtre o pueda deducirse de los resultados generados por los modelos, ya que esto podría causar daños a la privacidad de las personas.
También debe tenerse en cuenta la cuestión de la atribución y propiedad intelectual de los datos. El uso de datos abiertos en modelos comerciales debe abordar cómo se reconoce y compensa adecuadamente a los creadores originales de los datos para que sigan existiendo incentivos a los creadores.
Los datos abiertos son el motor que impulsa las asombrosas capacidades de los modelos de lenguaje, tanto en el caso de los SLM como de los LLM. Mientras que los SLM destacan por su eficiencia y accesibilidad, los LLM abren puertas a aplicaciones avanzadas que no hace mucho nos parecían imposibles. Sin embargo, el camino hacia el desarrollo de modelos más capaces, pero también más sostenibles y representativos, depende en gran medida de cómo gestionemos y aprovechemos los datos abiertos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Los premios 2024 Best Cases Award del observatorio Public Sector Tech Watch ya tienen finalistas. Estos premios buscan destacar soluciones que utilizan tecnologías emergentes, como inteligencia artificial o blockchain, en las administraciones públicas, a través de dos categorías:
- Soluciones para mejorar los servicios públicos que se ofrecen a los ciudadanos (Government-to-Citizen o G2C).
- Soluciones para mejorar los procesos internos de las propias administraciones (Government-to-Government o G2G).
Con estos premios se pretende generar un mecanismo para compartir las mejores experiencias sobre el uso de tecnologías emergentes en el sector público y así dar visibilidad a las administraciones más innovadoras de Europa.
Casi el 60% de las soluciones finalistas son españolas
En total, se han recibido 32 propuestas, 14 de las cuales han sido preseleccionadas en una evaluación previa. De ellas, más de la mitad son soluciones de organismos españoles. En concreto, se han preseleccionado nueve finalistas para la categoría G2G -cinco de ellas españolas- y cinco para G2C -tres de ellas ligadas a nuestro país-.
A continuación, se resumen en qué consisten estas soluciones españolas.
Soluciones para mejorar los procesos internos de las propias administraciones
- Innovación en el gobierno local: transformación digital y GeoAI para la gestión de datos (Diputación de Alicante).
Suma Gestión Tributaria, de la Diputación de Alicante, es el organismo encargado de gestionar y recaudar los tributos municipales de los ayuntamientos de su provincia. Para optimizar esta tarea, han desarrollado una solución que combina sistemas de información geográfica e inteligencia artificial (machine learning y deep learning) para mejorar la formación en detección de inmuebles que no tributan en los padrones. Esta solución recaba datos de múltiples administraciones y entidades con el objetivo de evitar retrasos en la recaudación de los ayuntamientos.
- Inspector autonómico de infraestructuras públicas: seguimiento de zonas de obras (Diputación Foral de Bizkaia e Interbiak).
El inspector autónomo de carreteras y el inspector autónomo urbano ayudan a las administraciones públicas a realizar un seguimiento automático de las carreteras. Estas soluciones, que se pueden instalar en cualquier vehículo, utilizan técnicas de visión artificial o por computadora junto a información procedente de sensores para comprobar de forma automática el estado de señales de tráfico, marcas viales, barreras de protección, etc. También realizan tareas de previsión temprana de la degradación del pavimento, monitorizan zonas de obras y generan alertas ante peligros, como posibles deslizamientos.
- Aplicación de drones para el transporte de muestras biológicas (Centro de Telecomunicaciones y Tecnologías de la Información -CTTI-, Generalitat de Catalunya).
Este proyecto piloto implementa y evalúa una ruta de transporte sanitario en la región sanitaria de Girona. Su objetivo es transportar muestras biológicas (sangre y orina) entre un centro de salud primaria y un hospital utilizando drones. Gracias a ello, el trayecto ha pasado de durar 20 minutos con el transporte terrestre a siete minutos con el uso de drones. Esto ha permitido mejorar la calidad de las muestras transportadas, aumentar la flexibilidad en la programación de los tiempos de transporte y reducir el impacto medioambiental.
- Automatización robótica de procesos en la administración de justicia (Ministerio de la Presidencia, Justicia y Relaciones con las Cortes).
Ministerio de la Presidencia, Justicia y Relaciones con las Cortes ha puesto en marcha una solución para la robotización de procesos administrativos con el fin de agilizar trabajos rutinarios, repetitivos y de bajo riesgo. Hasta la fecha, se han puesto en marcha más de 25 líneas de automatización de procesos, entre las que se encuentran la cancelación automática de antecedentes penales, las solicitudes de nacionalidad, la emisión automática de certificaciones de seguros de vida, etc. Gracias a ello se estima que se han ahorrado más de 500 mil horas de trabajo.
- Inteligencia artificial en el tratamiento de las publicaciones oficiales (Boletín Oficial de la Provincia de Barcelona y Servicio de Documentación y Publicaciones Oficiales, Diputación de Barcelona).
El CIDO (Buscador de Información y Documentación Oficial) ha implementado un sistema de IA que genera automáticamente resúmenes de publicaciones oficiales de las administraciones públicas de Barcelona. Utilizando técnicas de aprendizaje automático supervisado y redes neuronales, el sistema genera resúmenes de hasta 100 palabras para publicaciones en catalán o castellano. La herramienta permite el registro de modificaciones manuales para mejorar la precisión.
Soluciones para mejorar los servicios públicos que se ofrecen a los ciudadanos
- Escritorio Virtual de Inmediación Digital: acercar la Justicia a los ciudadanos a través de la digitalización (Ministerio de la Presidencia, Justicia y Relaciones con las Cortes).
El Escritorio Virtual de Inmediación Digital (EVID) permite realizar vistas a distancia con plenas garantías de seguridad jurídica utilizando tecnologías blockchain. La solución integra la convocatoria de la vista, la aportación de la documentación, la identificación de los participantes, la aceptación de consentimientos, la generación del documento justificativo de la actuación realizada, la firma de éste y la grabación de la sesión. De esta forma se pueden realizar actos jurídicos desde cualquier lugar, sin necesidad de desplazarse y de forma sencilla, haciendo que la justicia sea más inclusiva, accesible y ecológica. A finales de junio de 2024, se habían celebrado más de 370.000 sesiones virtuales a través de la EVID.
- Aplicación de la IA Generativa para facilitar a los ciudadanos la comprensión de los textos legales (Entitat Autònoma del Diari Oficial i Publicacions -EADOP-, Generalitat de Catalunya).
A menudo, el lenguaje jurídico es una barrera que impide a la ciudadanía entender fácilmente los textos legales. Para eliminar este obstáculo, el Govern pone a disposición de los usuarios del Portal Jurídico de Cataluña y de la población en general los resúmenes de normas de derecho catalán en lenguaje sencillo obtenidos a partir de la inteligencia artificial generativa. El objetivo es que, a finales de año, estén disponibles los resúmenes de las más de 14.000 disposiciones normativas vigentes adaptadas a la comunicación clara. Los resúmenes estarán editados en catalán y en castellano, con la perspectiva de ofrecer también en el futuro su versión en aranés.
- Emi - Empleo Inteligente (Consellería de Emprego, Comercio e Emigración de la Xunta de Galicia).
Emi, Empleo Inteligente es una herramienta de inteligencia artificial y big data que ayuda a las oficinas del Servicio Público de Empleo de Galicia a orientar a las personas desempleadas hacia las competencias que requiere el mercado laboral, en función de sus capacidades. Los modelos de IA realizan proyecciones a seis meses de los contratos de una ocupación concreta para una zona geográfica elegida. Además, permiten calcular la probabilidad de encontrar empleo de los individuos en los próximos meses.
Puedes ver todas las soluciones presentadas aquí. Los ganadores se anunciarán en el evento final que se celebrará el 28 de noviembre. La ceremonia se celebra en Bruselas, pero se podrá seguir también de manera online. Para ello es necesario registrarse aquí.
Public Sector Tech Watch: un observatorio para inspirar nuevos proyectos
Public Sector Tech Watch (PSTW), gestionado por la Comisión Europea, se posiciona como una “ventanilla única” para todos aquellos interesados -sector público, responsables políticos, empresas privadas, mundo académico, etc.- en los últimos avances tecnológicos para mejorar el funcionamiento del sector público y la prestación de servicios. Para ello cuenta con varias secciones donde se muestra la siguiente información de interés:
- Cases: contiene ejemplos de cómo utilizan tecnologías innovadores y sus datos asociados las organizaciones del sector público en Europa.
- Stories: presenta testimonios para mostrar los retos a los que se enfrentan las administraciones europeas en la aplicación de soluciones tecnológicas.
Si conoces algún caso de interés que actualmente no esté monitorizado por PSTW, puedes darlo de alta aquí. Los casos de éxito son revisados y evaluados antes de incluirse en la base de datos.
Evento
Desde el 28 de octubre y hasta el 24 de noviembre estará abierta la inscripción para presentar propuestas al reto de la Diputación de Bizkaia. El objetivo de la competición es identificar iniciativas que combinen la reutilización de datos disponibles en el portal Open Data Bizkaia con el uso de la inteligencia artificial. Las bases completas están disponibles en este enlace, pero, en este post, te contamos todo lo que tienes que saber sobre este concurso que ofrece premios en metálico para los cinco mejores proyectos.
Los participantes deberán utilizar al menos un dataset de la Diputación Foral de Bizkaia o de los ayuntamientos del territorio, que se pueden encontrar en el catálogo, para abordar uno de los cinco casos de uso propuestos:
- Contenido promocional sobre atractivos turísticos de Bizkaia: contenido promocional por escrito, como pueden ser imágenes generadas, flyers, etc. que utilicen datasets como:
- Playas de Bizkaia por municipio
- Agenda cultural – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Áreas de esparcimiento
- Hoteles de Euskadi – Open Data Euskadi
- Predicciones de la temperatura en Bizkaia – datos de Weather API
- Impulso del turismo a través del análisis de sentimientos: archivos de texto con recomendaciones para mejorar los recursos turísticos, como reportes en Excel y PowerPoint, etc. que utilicen datasets como:
- Playas de Bizkaia por municipio
- Agenda cultura – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Áreas de esparcimiento
- Hoteles de Euskadi – Open Data Euskadi
- Google reviews API – este recurso es de pago con posible capa gratuita
- Guías personalizadas para el turismo: Chatbot, documento con recomendaciones personalizadas que utilicen datasets como:
- Tabla de mareas 2024
- Playas de Bizkaia por municipio
- Agenda cultural – BizkaiKOA
- Agenda cultural de Bizkaia
- Bizkaibus
- Senderos
- Hoteles de Euskadi – Open Data Euskadi
- Predicciones de la temperatura en Bizkaia – datos de Weather API, recurso con capa gratuita
- Recomendación personalizada de eventos culturales: Chatbot, documento con recomendaciones personalizadas que utilicen datasets como:
- Agenda cultural - BizkaiKOA
- Agenda cultural de Bizkaia
- Optimización de la gestión de residuos: Reportes Excel, PowerPoint y Word que contengan recomendaciones y estrategias que utilicen datasets como:
- Residuos urbanos
- Contenedores por municipio
¿Cómo participar?
Los participantes podrán inscribirse de forma individual o en equipos a través de este formulario disponible en la web. El plazo de inscripción es del 28 de octubre al 24 de noviembre de 2024. Una vez cerrada la inscripción, los equipos deberán presentar sus soluciones en Sharepoint. Un jurado preseleccionará a cinco finalistas, quienes tendrán la oportunidad de presentar su proyecto en el evento final el 12 de diciembre, en el que se entregarán los premios. La organización recomienda asistir presencialmente, pero, si no es posible, también se permitirá la asistencia online.
La competición está abierta a cualquier persona mayor de 16 años con DNI o pasaporte en vigor, que no pertenezca a las entidades organizadoras. Además, se pueden presentar más de una propuesta.
¿Cuáles son los premios?
Los miembros del jurado elegirán cinco proyectos ganadores en base a los siguientes criterios de valoración:
- Adecuación de la solución propuesta al reto seleccionado.
- La creatividad y la innovación.
- Calidad y coherencia de la solución.
- Adecuación de datasets de Open Data Bizkaia utilizados.
Las candidaturas ganadoras recibirán un premio en metálico, así como el compromiso de abrir los datasets asociados al proyecto, en la medida en que sea posible.
- Primer premio: 2.000 €.
- Segundo premio: 1.000 €.
- Tres premios para el resto de finalistas de 500 € a cada uno.
Uno de los objetivos de este reto, tal y como explica la Diputación Foral de Bizkaia, es conocer si la oferta actual de datasets se ajusta a la demanda. Por este motivo, si alguna persona participante precisa de un conjunto de datos de Bizkaia o de sus ayuntamientos que no está disponible, puede proponer que la institución lo ponga a disposición del público. Siempre y cuando dicha información se ajuste a las competencias de la Diputación Foral de Bizkaia o de los ayuntamientos.
Este es un evento único que no solo te permitirá mostrar tus habilidades en inteligencia artificial y datos abiertos, sino que también contribuirás al desarrollo y mejora de Bizkaia. No dejes pasar la oportunidad de ser parte de este emocionante reto. ¡Inscríbete y empieza a crear soluciones innovadoras!
Blog
El procesamiento del lenguaje natural (NLP, por sus siglas en inglés) es una rama de la inteligencia artificial que permite a las máquinas comprender y manipular el lenguaje humano. En el núcleo de muchas aplicaciones modernas, como asistentes virtuales, sistemas de traducción automática y chatbots, se encuentran los word embeddings. Pero, ¿qué son exactamente y por qué son tan importantes?
¿Qué son los word embeddings?
Los word embeddings son una técnica que permite a las máquinas representar el significado de las palabras de manera que se puedan capturar relaciones complejas entre ellas. Para entenderlo, pensemos en cómo las palabras se usan en un contexto determinado: una palabra adquiere significado en función de las palabras que la rodean. Por ejemplo, la palabra banco podría referirse a una institución financiera o a un asiento, dependiendo del contexto en el que se encuentre.
La idea detrás de los word embeddings es que se asigna a cada palabra un vector en un espacio de varias dimensiones. La posición de estos vectores en el espacio refleja la cercanía semántica entre las palabras. Si dos palabras tienen significados similares, sus vectores estarán cercanos. Si sus significados son opuestos o no tienen relación, estarán distantes en el espacio vectorial.
Para visualizarlo, imaginemos que palabras como lago, río y océano estarían cerca entre sí en este espacio, mientras que palabras como lago y edificio estarían mucho más separadas. Esta estructura permite que los algoritmos de procesamiento de lenguaje puedan realizar tareas complejas, como encontrar sinónimos, hacer traducciones precisas o incluso responder preguntas basadas en contexto.
¿Cómo se crean los word embeddings?
El objetivo principal de los word embeddings es capturar relaciones semánticas y la información contextual de las palabras, transformándolas en representaciones numéricas que puedan ser comprendidas por los algoritmos de machine learning (aprendizaje automático). En lugar de trabajar con texto sin procesar, las máquinas requieren que las palabras se conviertan en números para poder identificar patrones y relaciones de manera efectiva.
El proceso de creación de word embeddings consiste en entrenar un modelo en un gran corpus de texto, como artículos de Wikipedia, para aprender la estructura del lenguaje. El primer paso implica realizar una serie de preprocesamientos en el corpus, que incluye tokenizar las palabras, eliminar puntuación y términos irrelevantes, y, en algunos casos, convertir todo el texto a minúsculas para mantener la consistencia.
El uso del contexto para capturar el significado
Una vez preprocesado el texto, se utiliza una técnica conocida como "ventana de contexto deslizante" para extraer información. Esto significa que, para cada palabra objetivo, se toman en cuenta las palabras que la rodean dentro de un cierto rango. Por ejemplo, si la ventana de contexto es de 3 palabras, para la palabra avión en la frase “El avión despega a las seis”, las palabras de contexto serán El, despega, a.
El modelo se entrena para aprender a predecir una palabra objetivo usando las palabras de su contexto (o a la inversa, predecir el contexto a partir de la palabra objetivo). Para ello, el algoritmo ajusta sus parámetros de manera que los vectores asignados a cada palabra se acerquen más en el espacio vectorial si esas palabras aparecen frecuentemente en contextos similares.
Cómo los modelos aprenden la estructura del lenguaje
La creación de los word embeddings se basa en la capacidad de estos modelos para identificar patrones y relaciones semánticas. Durante el entrenamiento, el modelo ajusta los valores de los vectores de manera que las palabras que suelen compartir contextos tengan representaciones similares. Por ejemplo, si avión y helicóptero se usan frecuentemente en frases similares (por ejemplo, en el contexto de transporte aéreo), los vectores de avión y helicóptero estarán cerca en el espacio vectorial.
A medida que el modelo procesa más y más ejemplos de frases, va afinando las posiciones de los vectores en el espacio continuo. De este modo, los vectores no solo reflejan la proximidad semántica, sino también otras relaciones como sinónimos, categorías (por ejemplo, frutas, animales) y relaciones jerárquicas (por ejemplo, perro y animal).
Un par de ejemplos simplificado
Imaginemos un pequeño corpus de solo seis palabras: guitarra, bajo, batería, piano, coche y bicicleta. Supongamos que cada palabra se representa en un espacio vectorial de tres dimensiones de la siguiente manera:
guitarra [0.3, 0.8, -0.1]
bajo [0.4, 0.7, -0.2]
batería [0.2, 0.9, -0.1]
piano [0.1, 0.6, -0.3]
coche [0.8, -0.1, 0.6]
bicicleta [0.7, -0.2, 0.5]
En este ejemplo simplificado, las palabras guitarra, bajo, batería y piano representan instrumentos musicales y están ubicadas cerca unas de otras en el espacio vectorial, ya que se utilizan en contextos similares. En cambio, coche y bicicleta, que pertenecen a la categoría de medios de transporte, se encuentran alejadas de los instrumentos musicales pero cercanas entre ellas. Esta otra imagen muestra cómo se verían distintos términos relacionados con cielo, alas e ingeniería en un espacio vectorial.

Figura1. Ejemplos de representación de un corpus en un espacio vectorial. Fuente: Adaptación de “Word embeddings: the (very) basics”, de Guillaume Desagulier.
Estos ejemplos solo utilizan tres dimensiones para ilustrar la idea, pero en la práctica, los word embeddings suelen tener entre 100 y 300 dimensiones para capturar relaciones semánticas más complejas y matices lingüísticos.
El resultado final es un conjunto de vectores que representan de manera eficiente cada palabra, permitiendo a los modelos de procesamiento de lenguaje identificar patrones y relaciones semánticas de forma más precisa. Con estos vectores, las máquinas pueden realizar tareas avanzadas como búsqueda semántica, clasificación de texto y respuesta a preguntas, mejorando significativamente la comprensión del lenguaje natural.
Estrategias para generar word embeddings
A lo largo de los años, se han desarrollado múltiples enfoques y técnicas para generar word embeddings. Cada estrategia tiene su forma de capturar el significado y las relaciones semánticas de las palabras, lo que resulta en diferentes características y usos. A continuación, se presentan algunas de las principales estrategias:
1. Word2Vec: captura de contexto local
Desarrollado por Google, Word2Vec es uno de los enfoques más conocidos y se basa en la idea de que el significado de una palabra se define por su contexto. Usa dos enfoques principales:
- CBOW (Continuous Bag of Words): en este enfoque, el modelo predice la palabra objetivo usando las palabras de su entorno inmediato. Por ejemplo, dado un contexto como "El perro está ___ en el jardín", el modelo intenta predecir la palabra jugando, basándose en las palabras El, perro, está y jardín.
- Skip-gram: A la inversa, Skip-gram usa una palabra objetivo para predecir las palabras circundantes. Usando el mismo ejemplo, si la palabra objetivo es jugando, el modelo intentaría predecir que las palabras en su entorno son El, perro, está y jardín.
La idea clave es que Word2Vec entrena el modelo para capturar la proximidad semántica a través de muchas iteraciones en un gran corpus de texto. Las palabras que tienden a aparecer juntas tienen vectores más cercanos, mientras que las que no están relacionadas aparecen más distantes.
2. GloVe: enfoque basado en estadísticas globales
GloVe, desarrollado en la Universidad de Stanford, se diferencia de Word2Vec al utilizar estadísticas globales de co-ocurrencia de palabras en un corpus. En lugar de considerar solo el contexto inmediato, GloVe se basa en la frecuencia con la que dos palabras aparecen juntas en todo el corpus.
Por ejemplo, si pan y mantequilla aparecen juntas con frecuencia, pero pan y planeta rara vez se encuentran en el mismo contexto, el modelo ajusta los vectores de manera que pan y mantequilla estén cerca en el espacio vectorial.
Esto permite que GloVe capture relaciones globales más amplias entre palabras y que las representaciones sean más robustas a nivel semántico. Los modelos entrenados con GloVe tienden a funcionar bien en tareas de analogía y similitud de palabras.
3. FastText: captura de sub-palabras
FastText, desarrollado por Facebook, mejora a Word2Vec al introducir la idea de descomponer las palabras en sub-palabras. En lugar de tratar cada palabra como una unidad indivisible, FastText representa cada palabra como una suma de n-gramas. Por ejemplo, la palabra jugando se podría descomponer en ju, uga, ando, etc.
Esto permite que FastText capture similitudes incluso entre palabras que no aparecieron explícitamente en el corpus de entrenamiento, como variaciones morfológicas (jugando, jugar, jugador). Esto es particularmente útil para lenguajes con muchas variaciones gramaticales.
4. Embeddings contextuales: captura de sentido dinámico
Modelos como BERT y ELMo representan un avance significativo en word embeddings. A diferencia de las estrategias anteriores, que generan un único vector para cada palabra independientemente del contexto, los embeddings contextuales generan diferentes vectores para una misma palabra según su uso en la frase.
Por ejemplo, la palabra banco tendrá un vector diferente en la frase "me senté en el banco del parque" que en "el banco aprobó mi solicitud de crédito". Esta variabilidad se logra entrenando el modelo en grandes corpus de texto de manera bidireccional, es decir, considerando no solo las palabras que preceden a la palabra objetivo, sino también las que la siguen.
Aplicaciones prácticas de los word embeddings
Los word embeddings se utilizan en una variedad de aplicaciones de procesamiento de lenguaje natural, como:
- Reconocimiento de Entidades Nombradas (NER, por sus siglas en inglés): permiten identificar y clasificar nombres de personas, organizaciones y lugares en un texto. Por ejemplo, en la frase "Apple anunció su nueva sede en Cupertino", los word embeddings permiten al modelo entender que Apple es una organización y Cupertino es un lugar.
- Traducción automática: ayudan a representar palabras de una manera independiente del idioma. Al entrenar un modelo con textos en diferentes lenguas, se pueden generar representaciones que capturan el significado subyacente de las palabras, facilitando la traducción de frases completas con un mayor nivel de precisión semántica.
- Sistemas de recuperación de información: en motores de búsqueda y sistemas de recomendación, los word embeddings mejoran la coincidencia entre las consultas de los usuarios y los documentos relevantes. Al capturar similitudes semánticas, permiten que incluso consultas no exactas se correspondan con resultados útiles. Por ejemplo, si un usuario busca "medicamento para el dolor de cabeza", el sistema puede sugerir resultados relacionados con analgésicos gracias a las similitudes capturadas en los vectores.
- Sistemas de preguntas y respuestas: los word embeddings son esenciales en sistemas como los chatbots y asistentes virtuales, donde ayudan a entender la intención detrás de las preguntas y a encontrar respuestas relevantes. Por ejemplo, ante la pregunta “¿Cuál es la capital de Italia?”, los word embeddings permiten que el sistema entienda las relaciones entre capital e Italia y encuentre Roma como respuesta.
- Análisis de sentimiento: los word embeddings se utilizan en modelos que determinan si el sentimiento expresado en un texto es positivo, negativo o neutral. Al analizar las relaciones entre palabras en diferentes contextos, el modelo puede identificar patrones de uso que indican ciertos sentimientos, como alegría, tristeza o enfado.
- Agrupación semántica y detección de similaridades: los word embeddings también permiten medir la similitud semántica entre documentos, frases o palabras. Esto se utiliza para tareas como agrupar artículos relacionados, recomendar productos basados en descripciones de texto o incluso detectar duplicados y contenido similar en grandes bases de datos.
Conclusión
Los word embeddings han transformado el campo del procesamiento de lenguaje natural al ofrecer representaciones densas y significativas de las palabras, capaces de capturar sus relaciones semánticas y contextuales. Con la aparición de embeddings contextuales, el potencial de estas representaciones sigue creciendo, permitiendo que las máquinas comprendan incluso las sutilezas y ambigüedades del lenguaje humano. Desde aplicaciones en sistemas de traducción y búsqueda, hasta chatbots y análisis de sentimiento, los word embeddings seguirán siendo una herramienta fundamental para el desarrollo de tecnologías cada vez más avanzadas y humanizadas en el campo del lenguaje natural.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Los próximos días 11, 12 y 13 de noviembre se celebra en Granada una nueva edición de DATAfórum Justicia. La cita reunirá a más de 100 ponentes para debatir sobre temas relacionados con los sistemas digitales de justicia, la inteligencia artificial (IA) y el uso del dato en el ecosistema judicial.
El evento está organizado por el Ministerio de Presidencia, Justicia y Relaciones con las Cortes, con la colaboración de la Universidad de Granada, la Junta de Andalucía, el Ayuntamiento de Granada y la entidad Formación y Gestión de Granada.
A continuación, se resumen algunos de los aspectos más importantes de estas jornadas.
Una cita dirigida a un público amplio
Este foro anual está dirigido tanto a profesionales del sector público, como del privado, sin dejar de lado al público general, que quiera saber más sobre la transformación digital de la justicia en nuestro país.
El DATAfórum Justicia 2024 cuenta, además, con un itinerario específico dirigido a estudiantes, cuyo objetivo es proporcionar a los jóvenes herramientas y conocimientos de valor en el ámbito de la justicia y la tecnología. Para ello, contarán con ponencias específicas y se pondrá en marcha un DATAthon. Estas actividades están especialmente dirigidas a estudiantes de derecho, ciencias sociales en general, ingenierías informáticas o materias relacionadas con la transformación digital. Los asistentes podrán obtener hasta 2 créditos ECTS (European Credit Transfer and Accumulation System o, en español, Sistema Europeo de Transferencia y Acumulación de Créditos): uno por asistir a las jornadas y otro por participar en el DATAthon.
Los datos, protagonistas de la agenda
El Paraninfo de la Universidad de Granada acogerá a expertos provenientes de la administración, instituciones y empresas privadas, que contarán su experiencia haciendo hincapié en las nuevas tendencias del sector, los retos que hay por delante y las oportunidades de mejora.
Las jornadas comenzarán el lunes 11 de noviembre a las 9:00 horas, con la bienvenida a los alumnos y la presentación del DATAthon. La inauguración oficial, dirigida a todas las audiencias, será a las 11:35 horas y correrá a cargo de Manuel Olmedo Palacios, Secretario de Estado de Justicia, y Pedro Mercado Pacheco, Rector de la Universidad de Granada.
A partir de entonces se sucederán diversas charlas, debates, entrevistas, mesas redondas y conferencias, entre las que encontramos un gran número de temáticas relacionadas con los datos. Entre otras cuestiones, se profundizará en la gestión del dato, tanto en administraciones como en empresas. También se abordará el uso de los datos abiertos para prevenir desde bulos hasta suicidios o la violencia sexual.
Otro tema con gran protagonismo será las posibilidades de la inteligencia artificial para optimizar el sector, tocando aspectos como la automatización de la justicia, la realización de predicciones. Se incluirán ponencias de casos de uso concretos, como la utilización de IA para la identificación de personas fallecidas, sin dejar de lado cuestiones como la gobernanza de algoritmos.
El evento finalizará el miércoles 13 a las 17:00 horas con la clausura oficial. En esta ocasión, Félix Bolaños, Ministro de la Presidencia, Justicia y Relaciones con las Cortes, acompañará al Rector de la Universidad de Granada.
Puedes ver la agenda completa aquí.
Un Datathon para resolver los retos del sector a través de los datos
En paralelo a esta agenda, se celebrará un DATAthon en el que los participantes presentarán ideas y proyectos innovadores para mejorar la justicia en nuestra sociedad. Se trata de un concurso destinado a estudiantes, profesionales del ámbito legal e informático, grupos de investigación y startups.
Los participantes se dividirán en equipos multidisciplinares para proponer soluciones a una serie de retos, planteados por la organización, utilizando tecnologías orientadas a la ciencia de datos. Durante las dos primeras jornadas los participantes dispondrán de tiempo para investigar y desarrollar su solución original. En la tercera jornada, deberán presentar una propuesta a un jurado cualificado. Los premios se entregarán el último día, antes de la clausura y del vino español y concierto que darán final a la edición 2024 del DATAfórum Justicia.
En la edición de 2023 participaron 35 personas, divididas en 6 equipos que resolvieron dos casos prácticos con datos de carácter público y se otorgaron dos premios de 1.000 euros.
Cómo inscribirse
El plazo de inscripción al DATAfórum Justicia 2024 ya está abierto. Debe realizarse a través de la web del evento, indicando si se trata de público general, personal de la administración pública, profesionales del sector privado o medios de comunicación.
Para participar en el DATAthon es necesario registrarse también en el site dedicado al concurso.
La edición del año pasado, centrada en propuestas para aumentar la eficiencia y transparencia en los sistemas judiciales, fue un gran éxito, con más de 800 inscritos. Este año se espera también una gran afluencia de público, así que te animamos a reservar tu plaza lo antes posible. Se trata de una gran oportunidad para conocer de primera mano experiencias exitosas y poder intercambiar opiniones con expertos en el sector.
Blog
Un gemelo digital es una representación virtual e interactiva de un objeto, sistema o proceso del mundo real. Hablamos, por ejemplo, de una réplica digital de una fábrica, una ciudad o incluso un cuerpo humano. Estos modelos virtuales permiten simular, analizar y predecir el comportamiento del elemento original, lo que es clave para la optimización y el mantenimiento en tiempo real.
Debido a sus funcionalidades, los gemelos digitales se están utilizando en diversos sectores como la salud, el transporte o la agricultura. En este artículo, repasamos las ventajas que aporta su uso y mostramos dos ejemplos relacionados con los datos abiertos.
Ventajas de los gemelos digitales
Los gemelos digitales utilizan fuentes de datos reales del entorno, obtenidos a través de sensores y plataformas abiertas, entre otros. Gracias a ello, los gemelos digitales se actualizan en tiempo real para reflejar la realidad, lo que aporta una serie de ventajas:
- Aumento del rendimiento: una de las principales diferencias con las simulaciones tradicionales es que los gemelos digitales utilizan datos en tiempo real para su modelización, lo que permite tomar decisiones más acertadas para optimizar el rendimiento de equipos y sistemas según las necesidades de cada momento.
- Mejora de la planificación: utilizando tecnologías basadas en inteligencia artificial (IA) y aprendizaje automático, el gemelo digital puede analizar problemas de rendimiento o realizar simulaciones virtuales de «qué pasaría si». De esta forma, se pueden predecir fallos y problemas antes de que ocurran, lo que permite un mantenimiento proactivo.
- Reducción de costes: la mejora en la gestión de datos gracias a un gemelo digital genera beneficios equivalentes al 25% del gasto total en infraestructuras. Además, al evitar fallos costosos y optimizar procesos, se pueden reducir significativamente los costes operativos. También permiten monitorear y controlar sistemas en remoto, desde cualquier lugar, mejorando la eficiencia al centralizar las operaciones.
- Personalización y flexibilidad: al crear modelos virtuales detallados de productos o procesos, las organizaciones pueden adaptar rápidamente sus operaciones para satisfacer las demandas cambiantes del entorno y las preferencias individuales de los clientes / ciudadanos. Por ejemplo, en la fabricación, los gemelos digitales permiten la producción personalizada en masa, ajustando las líneas de producción en tiempo real para crear productos únicos según las especificaciones del cliente. Por otro lado, en el ámbito de la salud, los gemelos digitales pueden modelar el cuerpo humano para personalizar tratamientos médicos, mejorando así la eficacia y reduciendo los efectos secundarios.
- Impulso de la experimentación e innovación: los gemelos digitales proporcionan un entorno seguro y controlado para probar nuevas ideas y soluciones, sin los riesgos y costes asociados a los experimentos físicos. Entre otras cuestiones, permiten experimentar con grandes objetos o proyectos que, por su tamaño, no suelen prestarse a la experimentación en la vida real.
- Mejora de la sostenibilidad: al permitir la simulación y el análisis detallado de procesos y sistemas, las organizaciones pueden identificar áreas de ineficiencia y desperdicio, optimizando así el uso de recursos. Por ejemplo, los gemelos digitales pueden modelar el consumo y la producción de energía en tiempo real, permitiendo ajustes precisos que reducen el consumo y las emisiones de carbono.
Ejemplos de gemelos digitales en España
A continuación, se muestran tres ejemplos que ponen de manifiesto estas ventajas.
Proyecto GeDIA: inteligencia artificial para predecir los cambios en los territorios
GeDIA es una herramienta para la planificación estratégica de ciudades inteligentes, que permite realiza simulaciones de escenarios. Para ellos utiliza modelos de inteligencia artificial basados en fuentes de datos y herramientas ya existentes en el territorio.
El alcance de la herramienta es muy amplio, pero sus creadores destacan dos casos de uso:
- Necesidades de infraestructuras futuras: la plataforma realiza análisis detallados considerando las tendencias, gracias a los modelos de inteligencia artificial. De esta forma, se pueden realizar proyecciones de crecimiento y planificar las necesidades de infraestructuras y servicios, como energía y agua, en áreas específicas de un territorio, garantizando su disponibilidad.
- Crecimiento y turismo: GeDIA también se utiliza para estudiar y analizar el crecimiento urbano y turístico en zonas concretas. La herramienta identifica patrones de gentrificación y evalúa su impacto en la población local, utilizando datos censales. De esta forma se pueden comprender mejor los cambios demográficos y su impacto, como las necesidades de vivienda, y tomar decisiones que faciliten el crecimiento equitativo y sostenible.
Esta iniciativa cuenta con la participación de diversas empresas y la Universidad de Málaga (UMA), así como el respaldo económico de Red.es y la Unión Europea.
Gemelo digital del Mar menor: datos para cuidar el medio ambiente
El Mar Menor, la laguna salada de la Región de Murcia, ha sufrido graves problemas ecológicos en los últimos años, influenciados por la presión agrícola, el turismo y la urbanización.
Para conocer mejor las causas y valorar posibles soluciones, TRAGSATEC, una entidad de protección ambiental de propiedad estatal, desarrolló un gemelo digital. Para ello mapeó un área circundante de más de 1.600 kilómetros cuadrados, conocida como la Región del Campo de Cartagena. En total se obtuvieron 51.000 imágenes nadirales, 200.000 imágenes oblicuas y más de cuatro terabytes de datos LiDAR.
Gracias a este gemelo digital, TRAGSATEC ha podido simular diversos escenarios de inundaciones y el impacto que tendría instalar elementos de contención u obstáculos, como un muro, que redirigieran el flujo del agua. También han podido estudiar la distancia entre el terreno y el agua subterránea, para determinar el impacto de la filtración de fertilizantes, entre otras cuestiones.
Retos y camino hacia el futuro
Estos son solo dos ejemplos, pero ponen de manifiesto el potencial de una tecnología cada vez más popular. No obstante, para que su implementación sea aun mayor es necesario hacer frente a algunos retos, como los costes iniciales, tanto en tecnología como en capacitación, o la seguridad, al aumentar la superficie de ataque. Otro de los retos a destacar son los problemas de interoperabilidad que surgen cuando las distintas administraciones públicas establecen gemelos digitales y espacios de datos locales. Para profundizar en esta problemática, la Comisión Europea ha publicado una guía que ayuda a identificar los principales retos organizativos y culturales de interoperabilidad, ofreciendo buenas prácticas para solventarlos.
En resumen, los gemelos digitales ofrecen numerosas ventajas, como la mejora del rendimiento o la reducción de costes. Estos beneficios están impulsando su adopción en diversas industrias y es probable que, a medida que se superen los retos actuales, los gemelos digitales se conviertan en una herramienta esencial para optimizar procesos y mejorar la eficiencia operativa en un mundo cada vez más digitalizado.
Blog
Casi la mitad de los adultos europeos carecen de competencias digitales básicas. De acuerdo con el último informe sobre el estado de la Década Digital, en 2023, solo el 55,6% de los ciudadanos declararon tener este tipo de capacidades. Este porcentaje crece al 66,2% en el caso de España, situado por delante de la media europea.
Tener capacidades digitales básicas es esencial en la sociedad actual, porque permite acceder a una mayor cantidad de información y servicios, así como comunicarse de manera efectiva en entornos online, facilitando una mayor participación en actividades cívicas y sociales. Y también supone una gran ventaja competitiva en el mundo laboral.
En Europa, más del 90% de las funciones profesionales requieren un nivel básico de conocimientos digitales. Hace mucho tiempo que el conocimiento tecnológico dejó de ser únicamente necesario para profesiones técnicas, sino que se está extendiendo a todos los sectores, desde las empresas hasta el transporte e incluso la agricultura. En este sentido, más del 70% de las empresas han afirmado que la falta de personal con las competencias digitales adecuadas es un obstáculo para la inversión.
Por ello, un objetivo clave de la Década Digital es garantizar que al menos el 80% de las personas de entre 16 y 74 años posean al menos competencias digitales básicas de aquí a 2030
Capacidades tecnológicas básicas que todos deberíamos tener
Cuando hablamos de capacidades tecnológicas básicas nos referimos, de acuerdo con el framework DigComp, a diversas áreas, entre las que se encuentran:
- Alfabetización informacional y de datos: incluye localizar, recuperar, gestionar y organizar datos, juzgando la pertinencia de la fuente y su contenido.
- Comunicación y colaboración: supone interactuar, comunicarse y colaborar a través de las tecnologías digitales teniendo en cuenta la diversidad cultural y generacional. También incluye la gestión de la propia presencia, identidad y reputación digitales.
- Creación de contenidos digitales: se definiría como la mejora e integración de información y contenidos para generar nuevos mensajes, respetando los derechos de autor y las licencias. También implica saber dar instrucciones comprensibles para un sistema informático.
- Seguridad: se circunscribe a la protección de dispositivos, contenidos, datos personales y la intimidad en los entornos digitales, para proteger la salud física y mental.
- Resolución de problemas: permite identificar y resolver necesidades y problemas en entornos digitales. También se enfoca en el uso de herramientas digitales para innovar procesos y productos, manteniéndose al día de la evolución digital.
¿Qué puestos de trabajo relacionados con datos son los más demandados?
Una vez que tenemos claro cuáles son las competencias básicas, cabe destacar que en un mundo donde cada vez cobra más importancia la digitalización no es de extrañar que también crezca la demanda de conocimientos tecnológicos avanzados y relacionados con los datos.
De acuerdo con los datos de la plataforma de empleo LinkedIn, entre las 25 profesiones que más crecen en España en 2024 encontramos analistas de seguridad (puesto 1), analistas de desarrollo de software (2), ingenieros de datos (11) e ingenieros de inteligencia artificial (25). Datos similares ofrece el Mapa del Empleo de Fundación Telefónica, que además destaca cuatro de los perfiles más demandados relacionados con los datos:
- Analista de datos: encargados de la gestión y aprovechamiento de la información, se dedican a la recopilación, análisis y explotación de los datos, para lo cual suelen recurrir a la creación de cuadros de mando e informes.
- Diseñador/a o administrador/a de bases de datos: enfocados en diseñar, implementar y gestionar bases de datos. Así como mantener su seguridad, ejecutando procedimientos de respaldo y recuperación de datos en caso de fallos.
- Ingeniero/a de datos: responsables del diseño e implementación de arquitecturas de datos e infraestructuras para captar, almacenar, procesar y acceder a los datos, optimizando su rendimiento y garantizando su seguridad.
- Científico/a de datos: centrado en el análisis de datos y modelado predictivo, la optimización de algoritmos y la comunicación de resultados.
Todos ellos son puestos con buenos salarios y expectativas de futuro, en los que sin embargo sigue existiendo una gran brecha entre hombres y mujeres. De acuerdo con datos europeos, sólo 1 de cada 6 especialistas en TIC y 1 de cada 3 licenciados en ciencias, tecnología, ingeniería y matemáticas (STEM) son mujeres.
Para desarrollar profesiones relacionadas con los datos, se necesitan, entre otros, conocimientos de lenguajes de programación populares como Python, R o SQL, y múltiples herramientas de procesado y visualización de datos, como las detalladas en estos artículos:
- Herramientas de depuración y conversión de datos
- Herramientas de análisis de datos
- Herramientas de visualización de datos
- Librerías y APIs de visualización de datos
- Herramientas de visualización geoespacial
- Herramientas de análisis de redes
Actualmente la oferta de formaciones sobre todas estas capacidades no deja de crecer.
Perspectivas de futuro
Casi una cuarta parte de todos los puestos de trabajo (23%) cambiarán en los próximos cinco años, de acuerdo con el Informe sobre el Futuro del Empleo 2023 del Foro Económico Mundial. Los avances tecnológicos crearán nuevos empleos, transformarán los existentes y destruirán aquellos que se queden anticuados. Los conocimientos técnicos, relacionados con áreas como la inteligencia artificial o el Big Data, y el desarrollo de habilidades cognitivas, como el pensamiento analítico, supondrán grandes ventajas competitivas en el mercado laboral del futuro. En este contexto, las iniciativas políticas para impulsar la recapacitación de la sociedad, como el Plan europeo de Acción de Educación Digital (2021-2027), ayudaran a generar marcos y certificados comunes en un mundo en constante evolución.
La revolución tecnológica ha venido para quedarse y continuará cambiando nuestro mundo. Por ello, quienes antes empiecen a adquirir nuevas capacidades, tendrán una posición más ventajosa en el panorama laboral futuro.