Entrevista
In this episode we will discuss artificial intelligence and its challenges, based on the European Regulation on Artificial Intelligence that entered into force this year. Come and find out about the challenges, opportunities and new developments in the sector from two experts in the field:
- Ricard Martínez, professor of constitutional law at the Universitat de València where he directs the Chair of Privacy and Digital Transformation Microsoft University of Valencia.
- Carmen Torrijos, computational linguist, expert in AI applied to language and professor of text mining at the Carlos III University.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. It is a fact that artificial intelligence is constantly evolving. To get into the subject, I would like to hear about the latest developments in AI?
Carmen Torrijos: Many new applications are emerging. For example, this past weekend there has been a lot of buzz about an AI for image generation in X (Twitter), I don't know if you've been following it, called Grok. It has had quite an impact, not because it brings anything new, as image generation is something we have been doing since December 2023. But this is an AI that has less censorship, that is, until now we had a lot of difficulties with the generalist systems to make images that had faces of celebrities or had certain situations and it was very monitored from any tool. What Grok does is to lift all that up so that anyone can make any kind of image with any famous person or any well-known face. It is probably a passing fad. We will make images for a while and then it will pass.
And then there are also automatic podcast creation systems, such as Notebook LM. We've been watching them for a couple of months now and it's really been one of the things that has really surprised me in the last few months. Because it already seems that they are all incremental innovations: on top of what we already have, they give us something better. But this is something really new and surprising. You upload a PDF and it can generate a podcast of two people talking in a totally natural, totally realistic way about that PDF. This is something that Notebook LM, which is owned by Google, can do.
2. The European Regulation on Artificial Intelligence is the world's first legal regulation on AI, with what objectives is this document, which is already a reference framework at international level, being published?
Ricard Martínez: The regulation arises from something that is implicit in what Carmen has told us. All this that Carmen tells is because we have opened ourselves up to the same unbridled race that we experienced with the emergence of social media. Because when this happens, it's not innocent, it's not that companies are being generous, it's that companies are competing for our data. They gamify us, they encourage us to play, they encourage us to provide them with information, so they open up. They do not open up because they are generous, they do not open up because they want to work for the common good or for humanity. They open up because we are doing their work for them. What does the EU want to stop? What we learned from social media. The European Union has two main approaches, which I will try to explain very succinctly. The first approach is a systemic risk approach. The European Union has said: "I will not tolerate artificial intelligence tools that may endanger the democratic system, i.e. the rule of law and the way I operate, or that may seriously infringe fundamental rights". That is a red line.
The second approach is a product-oriented approach. An AI is a product. When you make a car, you follow rules that manage how you produce that car, and that car comes to market when it is safe, when it has all the specifications. This is the second major focus of the Regulation. The regulation says that you can be developing a technology because you are doing research and I almost let you do whatever you want. Now, if this technology is to come to market, you will catalogue the risk. If the risk is low or slight, you are going to be able to do a lot of things and, practically speaking, with transparency and codes of conduct, I will give you a pass. But if it's a high risk, you're going to have to follow a standardised design process, and you're going to need a notified body to verify that technology, make sure that in your documentation you've met what you have to meet, and then they'll give you a CE mark. And that's not the end of it, because there will be post-trade surveillance. So, throughout the life cycle of the product, you need to ensure that this works well and that it conforms to the standard.
On the other hand, a tight control is established with regard to big data models, not only LLM, but also image or other types of information, where it is believed that they may pose systemic risks.
In that case, there is a very direct control by the Commission. So, in essence, what they are saying is: "respect rights, guarantee democracy, produce technology in an orderly manner according to certain specifications".
Carmen Torrijos: Yes, in terms of objectives it is clear. I have taken up Ricard's last point about producing technology in accordance with this Regulation. We have this mantra that the US does things, Europe regulates things and China copies things. I don't like to generalise like that. But it is true that Europe is a pioneer in terms of legislation and we would be much stronger if we could produce technology in line with the regulatory standards we are setting. Today we still can't, maybe it's a question of giving ourselves time, but I think that is the key to technological sovereignty in Europe.
3. In order to produce such technology, AI systems need data to train their models. What criteria should the data meet in order to train an AI system correctly? Could open data sets be a source? In what way?
Carmen Torrijos: The data we feed AI with is the point of greatest conflict. Can we train with any dataset even if it is available? We are not talking about open data, but about available data.
Open data is, for example, the basis of all language models, and everyone knows this, which is Wikipedia. Wikipedia is an ideal example for training, because it is open, it is optimised for computational use, it is downloadable, it is very easy to use, there is a lot of language, for example, for training language models, and there is a lot of knowledge of the world. This makes it the ideal dataset for training an AI model. And Wikipedia is in the open, it is available, it belongs to everyone and it is for everyone, you can use it.
But can all the datasets available on the Internet be used to train AI systems? That is a bit of a doubt. Because the fact that something is published on the Internet does not mean that it is public, for public use, although you can take it and train a system and start generating profit from that system. It had a copyright, authorship and intellectual property. That I think is the most serious conflict we have right now in generative AI because it uses content to inspire and create. And there, little by little, Europe is taking small steps. For example, the Ministry of Culture has launched an initiative to start looking at how we can create content, licensed datasets, to train AI in a way that is legal, ethical and respectful of authors' intellectual property rights.
All this is generating a lot of friction. Because if we go on like this, we will turn against many illustrators, translators, writers, etc. (all creators who work with content), because they will not want this technology to be developed at the expense of their content. Somehow you have to find a balance in regulation and innovation to make both happen. From the large technological systems that are being developed, especially in the United States, there is a repeated idea that only with licensed content, with legal datasets that are free of intellectual property, or that the necessary returns have been paid for their intellectual property, it is not possible to reach the level of quality of AIs that we have now. That is, only with legal datasets alone we would not have ChatGPT at the level ChatGPT is at now.
This is not set in stone and does not have to be the case. We have to continue researching, that is, we have to continue to see how we can achieve a technology of that level, but one that complies with the regulation. Because what they have done in the United States, what GPT-4 has done, the great models of language, the great models of image generation, is to show us the way. This is as far as we can go. But you have done so by taking content that is not yours, that it was not permissible to take. We have to get back to that level of quality, back to that level of performance of the models, respecting the intellectual property of the content. And that is a role that I believe is primarily Europe's responsibility.
4. Another issue of public concern with regard to the rapid development of AI is the processing of personal data. How should they be protected and what conditions does the European regulation set for this?
Ricard Martínez: There is a set of conducts that have been prohibited essentially to guarantee the fundamental rights of individuals. But it is not the only measure. I attach a great deal of importance to an article in the regulation that we are probably not going to give much thought to, but for me it is key. There is an article, the fourth one, entitled AI Literacy, which says that any subject that is intervening in the value chain must have been adequately trained. You have to know what this is about, you have to know what the state of the art is, you have to know what the implications are of the technology you are going to develop or deploy. I attach great value to it because it means incorporating throughout the value chain (developer, marketer, importer, company deploying a model for use, etc.) a set of values that entail what is called accountability, proactive responsibility, by default. This can be translated into a very simple element, which has been talked about for two thousand years in the world of law, which is 'do no harm', the principle of non-maleficence.
With something as simple as that, "do no harm to others, act in good faith and guarantee your rights", there should be no perverse effects or harmful effects, which does not mean that it cannot happen. And this is precisely what the Regulation says in particular when it refers to high-risk systems, but it is applicable to all systems. The Regulation tells you that you have to ensure compliance processes and safeguards throughout the life cycle of the system. That is why it is so important to have robustness, resilience and contingency plans that allow you to revert, shut down, switch to human control, change the usage model when an incident occurs.
Therefore, the whole ecosystem is geared towards this objective of no harm, no rights, no harm. And there is an element that no longer depends on us, it depends on public policy. AI will not only infringe on rights, it will change the way we understand the world. If there are no public policies in the education sector that ensure that our children develop computational thinking skills and are able to have a relationship with a machine-interface, their access to the labour market will be significantly affected. Similarly, if we do not ensure the continuous training of active workers and also the public policies of those sectors that are doomed to disappear.
Carmen Torrijos: I find Ricard's approach of to train is to protect very interesting. Train people, inform people, get people trained in AI, not only people in the value chain, but everybody. The more you train and empower, the more you are protecting people.
When the law came out, there was some disappointment in AI environments and especially in creative environments. Because we were in the midst of the generative AI boom and generative AI was hardly being regulated, but other things were being regulated that we took for granted would not happen in Europe, but that have to be regulated so that they cannot happen. For example, biometric surveillance: Amazon can't read your face to decide whether you are sadder that day and sell you more stuff or get more advertising or a particular advertisement. I say Amazon, but it can be any platform. This, for example, will not be possible in Europe because it is forbidden by law, it is an unacceptable use: biometric surveillance.
Another example is social scoring, the social scoring that we see happening in China, where citizens are given points and access to public services based on these points. That is not going to be possible either. And this part of the law must also be considered, because we take it for granted that this is not going to happen to us, but when you don't regulate it, that's when it happens. China has installed 600 million TRF cameras, facial recognition technology, which recognise you with your ID card. That is not going to happen in Europe because it cannot, because it is also biometric surveillance. So you have to understand that the law perhaps seems to be slowing down on what we are now enraptured by, which is generative AI, but it has been dedicated to addressing very important points that needed to be covered in order to protect people. In order not to lose fundamental rights that we have already won.
Finally, ethics has a very uncomfortable component, which nobody wants to look at, which is that sometimes it has to be revoked. Sometimes it is necessary to remove something that is in operation, even that is providing a benefit, because it is incurring some kind of discrimination, or because it is bringing some kind of negative consequence that violates the rights of a collective, of a minority or of someone vulnerable. And that is very complicated. When we have become accustomed to having an AI operating in a certain context, which may even be a public context, to stop and say that this is discriminating against people, then this system cannot continue in production and has to be removed. This point is very complicated, it is very uncomfortable and when we talk about ethics, which we talk very easily about ethics, we must also think about how many systems we are going to have to stop and review before we can put them back into operation, however easy they make our lives or however innovative they may seem.
5. In this sense, taking into account all that the Regulation contains, some Spanish companies, for example, will have to adapt to this new framework. What should organisations already be doing to prepare? What should Spanish companies review in the light of the European regulation?
Ricard Martínez: This is very important, because there is a corporate business level of high capabilities that I am not worried about because these companies understand that we are talking about an investment. And just as they invested in a process-based model that integrated the compliance from the design for data protection. The next leap, which is to do exactly the same thing with artificial intelligence, I won't say that it is unimportant, because it is of relevant importance, but let's say that it is going down a path that has already been tried. These companies already have compliance units, they already have advisors, and they already have routines into which the artificial intelligence regulatory framework can be integrated as part of the process. In the end, what it will do is to increase risk analysis in one sense. It will surely force the design processes and also the design phases themselves to be modular, i.e., while in software design we are practically talking about going from a non-functional model to chopping up code, here there are a series of tasks of enrichment, annotation, validation of the data sets, prototyping that surely require more effort, but they are routines that can be standardised.
My experience in European projects where we have worked with clients, i.e. SMEs, who expect AI to be plug and play, what we have seen is a huge lack of capacity building. The first question you should ask yourself is not whether your company needs AI, but whether your company is ready for AI. This is an earlier and rather more relevant question. Hey, you think you can make a leap into AI, that you can contract a certain type of services, and we are realising that you don't even comply with the data protection regulation.
There is something, an entity called the Spanish Agency for Artificial Intelligence, AESIA, and there is a Ministry of Digital Transformation, and if there are no accompanying public policies, we may incur risky situations. Why? Because I have the great pleasure of training future entrepreneurs in artificial intelligence in undergraduate and postgraduate courses. When confronted with the ethical and legal framework, I won't say they want to die, but the world comes crashing down on them. Because there is no support, there is no accompaniment, there are no resources, or they cannot see them, that do not involve a round of investment that they cannot bear, or there are no guided models that help them in a way that is, I won't say easy, but at least usable.
Therefore, I believe that there is a substantial challenge in public policies, because if this combination does not happen, the only companies that will be able to compete are those that already have a critical mass, an investment capacity and an accumulated capital that allows them to comply with the standard. This situation could lead to a counterproductive outcome.
We want to regain European digital sovereignty, but if there are no public investment policies, the only ones who will be able to comply with the European standard are companies from other countries.
Carmen Torrijos: Not because they are from other countries but because they are bigger.
Ricard Martínez: Yes, not to mention countries.
6. We have talked about challenges, but it is also important to highlight opportunities. What positive aspects could you highlight as a result of this recent regulation?
Ricard Martínez: I am working on the construction, with European funding, of Cancer Image EU , which is intended to be a digital infrastructure for cancer imaging. At the moment, we are talking about a partnership involving 14 countries, 76 organisations, on the way to 93, to generate a medical imaging database of 25 million cancer images with associated clinical information for the development of artificial intelligence. The infrastructure is being built, it does not yet exist, and even so, at the Hospital La Fe in Valencia, research is already underway with mammograms of women who have undergone biennial screening and then developed cancer, to see if it is capable of training an image analysis model that is capable of preventively recognising that little spot that the oncologist or radiologist did not see and that later turned out to be a cancer. Does it mean you're getting chemotherapy five minutes later? No. It means they are going to monitor you, they are going to have an early reaction capability. And that the health system will save 200,000 euros. To mention just one opportunity.
On the other hand, opportunities must also be sought in other rules. Not only in the Artificial Intelligence Regulation. You have to go to Data Governance Act. It wants to counter the data monopoly held by US companies with a sharing of data from the public, private sectorand from the citizenry itself. With Data Act, which aims to empower citizens to retrieve their data and share it by consent. And finally with the European Health Data Space which aims to create ahealth data ecosystem to promote innovation, research and entrepreneurship. It is this ecosystem of data spaces that should be a huge generator of opportunity spaces.
And furthermore, I don't know whether they will succeed or not, but it aims to be coherent with our business ecosystem. That is to say, an ecosystem of small and medium-sized enterprises that does not have high data generation capabilities and what we are going to do is to build the field for them. We are going to create the data spaces for them, we are going to create the intermediaries, the intermediation services, and we hope that this ecosystem as a whole will allow European talent to emerge from small and medium-sized enterprises. Will it be achieved or not? I don't know, but the opportunity scenario looks very interesting.
Carmen Torrijos: If you ask for opportunities, all opportunities. Not only artificial intelligence, but all technological progress, is such a huge field that it can bring opportunities of all kinds. What needs to be done is to lower the barriers, which is the problem we have. And we also have barriers of many kinds, because we have technical barriers, talent barriers, salary barriers, disciplinary barriers, gender barriers, generational barriers, and so on.
We need to focus energies on lowering those barriers, and then I also think we still come from the analogue world and have little global awareness that both digital and everything that affects AI and data is a global phenomenon. There is no point in keeping it all local, or national, or even European, but it is a global phenomenon. The big problems we have come because we have technology companies that are developed in the United States working in Europe with European citizens' data. A lot of friction is generated there. Anything that can lead to something more global will always be in favour of innovation and will always be in favour of technology. The first thing is to lift the barriers within Europe. That is a very positive part of the law.
7. At this point, we would like to take a look at the state we are in and the prospects for the future. How do you see the future of artificial intelligence in Europe?
Ricard Martínez: I have two visions: one positive and one negative. And both come from my experience in data protection. If now that we have a regulatory framework, the regulatory authorities, I am referring to artificial intelligence and data protection, are not capable of finding functional and grounded solutions, and they generate public policies from the top down and from an excellence that does not correspond to the capacities and possibilities of research - I am referring not only to business research, but also to university research - I see a very dark future. If, on the other hand, we understand regulation in a dynamic way with supportive and accompanying public policies that generate the capacities for this excellence, I see a promising future because in principle what we will do is compete in the market with the same solutions as others, but responsive: safe, responsible and reliable.
Carmen: Yes, I very much agree. I introduce the time variable into that, don't I? Because I think we have to be very careful not to create more inequality than we already have. More inequality among companies, more inequality among citizens. If we are careful with this, which is easy to say but difficult to do, I believe that the future can be bright, but it will not be bright immediately. In other words, we are going to have to go through a darker period of adapting to change. Just as many issues of digitalisation are no longer alien to us, have already been worked on, we have already gone through them and have already regulated them, artificial intelligence also needs its time.
We have had very few years of AI, very few years of generative AI. In fact, two years is nothing in a worldwide technological change. And we have to give time to laws and we also have to give time for things to happen. For example, I give a very obvious example, the New York Times' complaint against Microsoft and OpenAI has not yet been resolved. It's been a year, it was filed in December 2023, the New York Times complains that they have trained AI systems with their content and in a year nothing has been achieved in that process. Court proceedings are very slow. We need more to happen. And that more processes of this type are resolved in order to have precedents and to have maturity as a society in what is happening, and we still have a long way to go. It's like almost nothing has happened. So, the time variable I think is important and I think that, although at the beginning we have a darker future, as Ricard says, I think that in the long term, if we keep clear limits, we can reach something brilliant.
Interview clips
1. What criteria should the data have to train an AI system?
2. What should Spanish companies review in light of the IA Regulation?
Noticia
Since last week, the Artificial Intelligence (AI) language models trained in Spanish, Catalan, Galician, Valencian and Basque, which have been developed within ALIA, the public infrastructure of AI resources, are now available. Through the ALIA Kit users can access the entire family of models and learn about the methodology used, related documentation and training and evaluation datasets. In this article we tell you about its key features.
What is ALIA?
ALIA is a project coordinated by the Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS). It aims to provide a public infrastructure of open and transparent artificial intelligence resources, capable of generating value in both the public and private sectors.
Specifically, ALIA is a family of text, speech and machine translation models. The training of artificial intelligence systems is computationally intensive, as huge volumes of data need to be processed and analysed. These models have been trained in Spanish, a language spoken by more than 600 million people worldwide, but also in the four co-official languages. The Real Academia Española (RAE) and the Asociación de Academias de la Lengua Española, which brings together the Spanish language institutions around the world, have collaborated in this project.
The MareNostrum 5, one of the most powerful supercomputers in the world, which is located at the Barcelona Supercomputing Center, has been used for the training. It has taken thousands of hours of work to process several billion words at a speed of 314,000 trillion calculations per second.
A family of open and transparent models
The development of these models provides an alternative that incorporates local data. One of ALIA's priorities is to be an open and transparent network, which means that users, in addition to being able to access the models, have the possibility of knowing and downloading the datasets used and all related documentation. This documentation makes it easier to understand how the models work and also to detect more easily where they fail, which is essential to avoid biases and erroneous results. Openness of models and transparency of data is essential, as it creates more inclusive and socially just models, which benefit society as a whole.
Having open and transparent models encourages innovation, research and democratises access to artificial intelligence, while ensuring that it is based on quality training data.
What can I find in ALIA Kit?
Through ALIA Kit, it is currently possible to access five massive language models (LLM) of general purpose, of which two have been trained with instructions from various open corpora. Also available are nine multilingual machine translation models, some of them trained from scratch, such as one for machine translation between Galician and Catalan, or between Basque and Catalan. In addition, translation models have been trained in Aranese, Aragonese and Asturian.
We also find the data and tools used to build and evaluate the text models, such as the massive CATalog textual corpus, consisting of 17.45 billion words (about 23 billion tokens), distributed over 34.8 million documents from a wide variety of sources, which have been largely manually reviewed.
To train the speech models, different speech corpora with transcription have been used, such as, for example, a dataset of the Valencian Parliament with more than 270 hours of recordings of its sessions. It is also possible to know the corpora used to train the machine translation models.
A freeAPI (from Python, Javascript or Curl) is also available through the ALIA Kit, with which tests can be carried out.
What can these models be used for?
The models developed by ALIA are designed to be adaptable to a wide range of natural language processing tasks. However, for specific needs it is preferable to use specialised models, which are more accurate and less resource-intensive.
As we have seen, the models are available to all interested users, such as independent developers, researchers, companies, universities or institutions. Among the main beneficiaries of these tools are developers and small and medium-sized enterprises, for whom it is not feasible to develop their own models from scratch, both for economic and technical reasons. Thanks to ALIA they can adapt existing models to their specific needs.
Developers will find resources to create applications that reflect the linguistic richness of Spanish and the co-official languages. For their part, companies will be able to develop new applications, products or services aimed at the broad international market offered by the Spanish language, opening up new business and expansion opportunities.
An innovative project financed with public funds
The ALIA project is fully publicly funded with the aim of fostering innovation and the adoption of value-generating technologies in both the public and private sectors. Having a public AI infrastructure democratises access to advanced technologies, allowing small businesses, institutions and governments to harness their full potential to innovate and improve their services. It also facilitates ethical oversight of AI development and encourages innovation.
ALIA is part of the Spain's Artificial Intelligence Strategy 2024, which aims to provide the country with the necessary capabilities to meet the growing demand for AI products and services and to boost the adoption of this technology, especially in the public sector and SMEs. Within Axis 1 of this strategy is the so-called Lever 3, which focuses on the generation of models and corpora for a public infrastructure of language models. With the publication of this family of models, advances in the development of artificial intelligence resources in Spain.
Blog
It is possible that our ability to be surprised by new generative artificial intelligence (AI) tools is beginning to wane. The best example is GPT-o1, a new language model with the highest reasoning ability achieved so far, capable of verbalising - something similar to - its own logical processes, but which did not arouse as much enthusiasm at its launch as might have been expected. In contrast to the previous two years, in recent months we have had less of a sense of disruption and have reacted less massively to new developments.
One possible reflection is that we do not need, for now, more intelligence in the models, but to see with our own eyes a landing in concrete uses that make our lives easier: how do I use the power of a language model to consume content faster, to learn something new or to move information from one format to another? Beyond the big general-purpose applications, such as ChatGPT or Copilot, there are free and lesser-known tools that help us think better, and offer AI-based capabilities to discover, understand and share knowledge.
Generate podcasts from a file: NotebookLM
The NotebookLM automated podcasts first arrived in Spain in the summer of 2024 and did raise a significant stir, despite not even being available in Spanish. Following Google's style, the system is simple: simply upload a PDF file as a source to obtain different variations of the content provided by Gemini 2.0 (Google's AI system), such as a summary of the document, a study guide, a timeline or a list of frequently asked questions. In this case, we have used a report on artificial intelligence and democracy published by UNESCO in 2024 as an example.
Figure 1. Different summary options in NotebookLM.
While the study guide is an interesting output, offering a system of questions and answers to memorise and a glossary of terms, the star of NotebookLM is the so-called "audio summary": a completely natural conversational podcast between two synthetic interlocutors who comment in a pleasant way on the content of the PDF.
Figure 2. Audio summary in NotebookLM.
The quality of the content of this podcast still has room for improvement, but it can serve as a first approach to the content of the document, or help us to internalise it more easily from the audio while we take a break from screens, exercise or move around.
The trick: apparently, you can't generate the podcast in Spanish, only in English, but you can try with this prompt: "Make an audio summary of the document in Spanish". It almost always works.
Create visualisations from text: Napkin AI
Napkin offers us something very valuable: creating visualisations, infographics and mind maps from text content. In its free version, the system only asks you to log in with an email address. Once inside, it asks us how we want to enter the text from which we are going to create the visualisations. We can paste it or directly generate with AI an automatic text on any topic.
Figure 3. Starting points in Napkin.ai.
In this case, we will copy and paste an excerpt from the UNESCO report which contains several recommendations for the democratic governance of AI. From the text it receives, Napkin.ai provides illustrations and various types of diagrams. We can find from simpler proposals with text organised in keys and quadrants to others illustrated with drawings and icons.
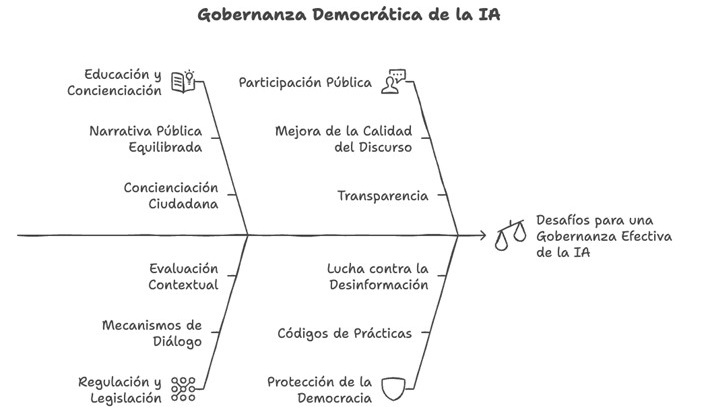
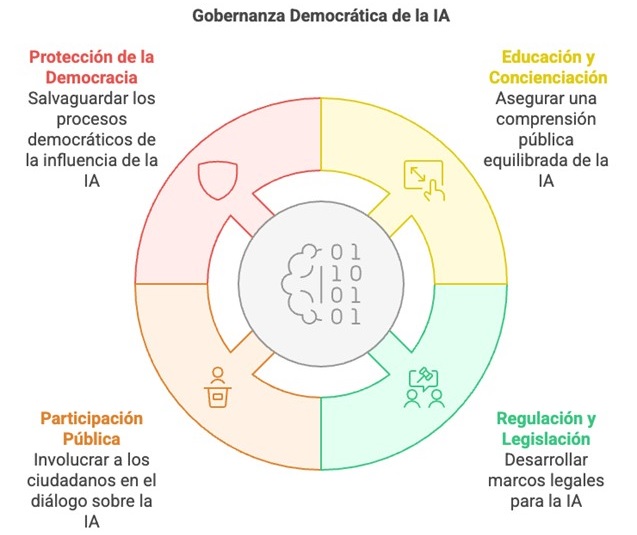
Figure 4. Proposed scheme in Napkin.ai.
Although they are far from the quality of professional infographics, these visualisations can be useful on a personal and learning level, to illustrate a post in networks, to explain concepts internally to our team or to enrich our own content in the educational field.
The trick: if you click on Stylesin each scheme proposal, you will find more variations of the scheme with different colours and lines. You can also modify the texts by simply clicking on them once you select a visualisation.
Automatic presentations and slides: Gamma
Of all the content formats that AI is capable of generating, slideshows are probably the least successful. Sometimes the designs are not too elaborate, sometimes we don't get the template we want to use to be respected, almost always the texts are too simple. The particularity of Gamma, and what makes it more practical than other options such as Beautiful.ai, is that we can create a presentation directly from a text content that we can paste, generate with AI or upload in a file.

Figure 5. Starting points for Gamma.
If we paste the same text as in the previous example, about UNESCO's recommendations for democratic governance of AI, in the next step Gamma gives us the choice between "free form" or "card by card". In the first option, the system's AI organises the content into slides while preserving the full meaning of each slide. In the second, it proposes that we divide the text to indicate the content we want on each slide.
Figure 6. Text automatically split into slides by Gamma.
We select the second option, and the text is automatically divided into different blocks that will be our future slides. By clicking on "Continue", we are asked to select a base theme. Finally, by clicking on "Generate", the complete presentation is automatically created.

Figure 7. Example of a slide created with Gamma.
Gamma accompanies the slides with AI-created images that keep a certain coherence with the content, and gives us the option of modifying the texts or generating different images. Once ready, we can export it directly to Power Point format.
A trick: in the "edit with AI" button on each slide we can ask it to automatically translate it into another language, correct the spelling or even convert the text into a timeline.
Summarise from any format: NoteGPT
The aim of NoteGPT is very clear: to summarise content that we can import from many different sources. We can copy and paste a text, upload a file or an image, or directly extract the information from a link, something very useful and not so common in AI tools. Although the latter option does not always work well, it is one of the few tools that offer it.
Figure 8. Starting points for NoteGPT.
In this case, we introduce the link to a YouTube video containing an interview with Daniel Innerarity on the intersection between artificial intelligence and democratic processes. On the results screen, the first thing you get on the left is the full transcript of the interview, in good quality. We can locate the transcript of a specific fragment of the video, translate it into different languages, copy it or download it, even in an SRT file of time-mapped subtitles.
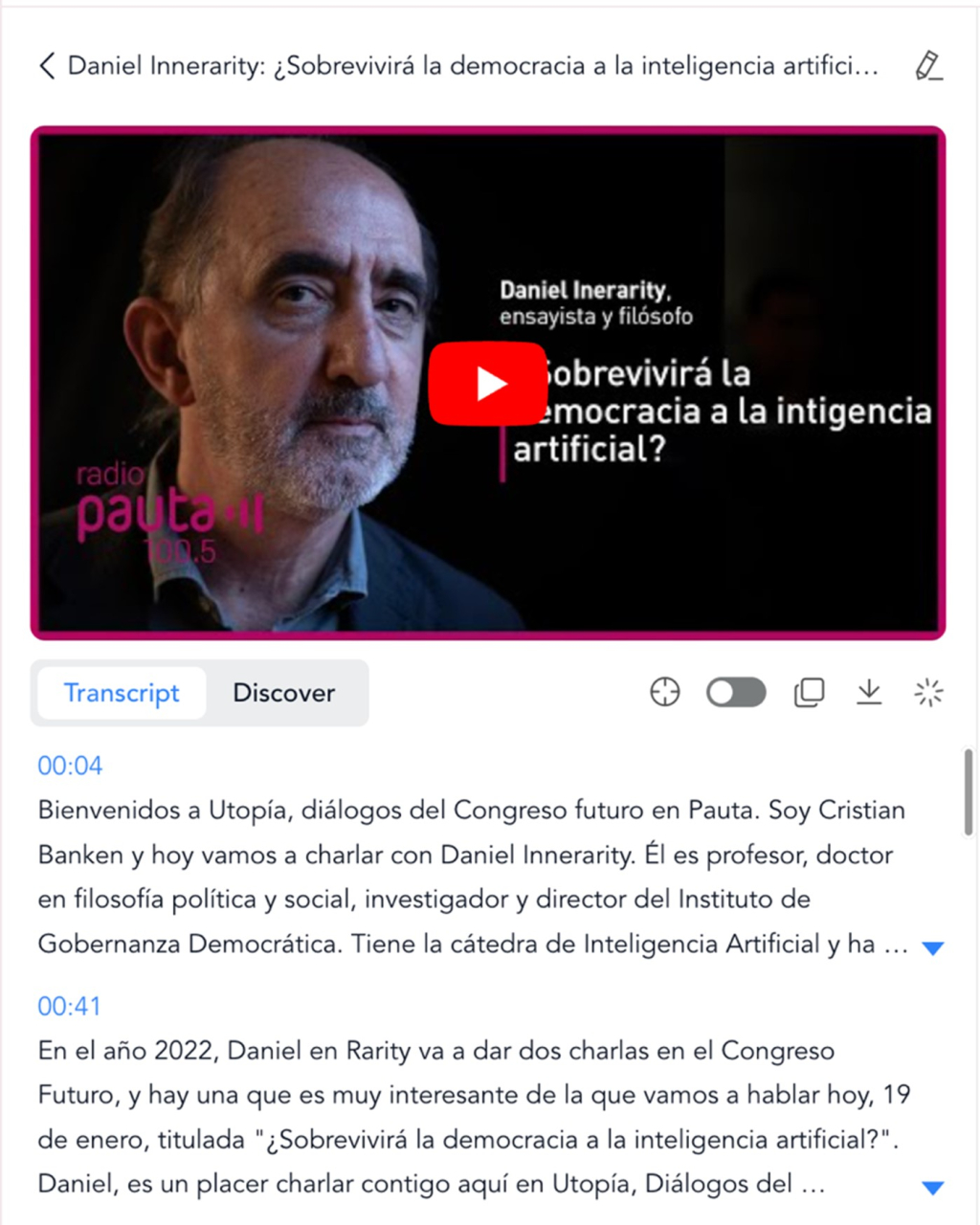
Figure 9. Example of transcription with minutes in NoteGPT
Meanwhile, on the right, we find the summary of the video with the most important points, sorted and illustrated with emojis. Also in the "AI Chat" button we can interact with a conversational assistant and ask questions about the content.
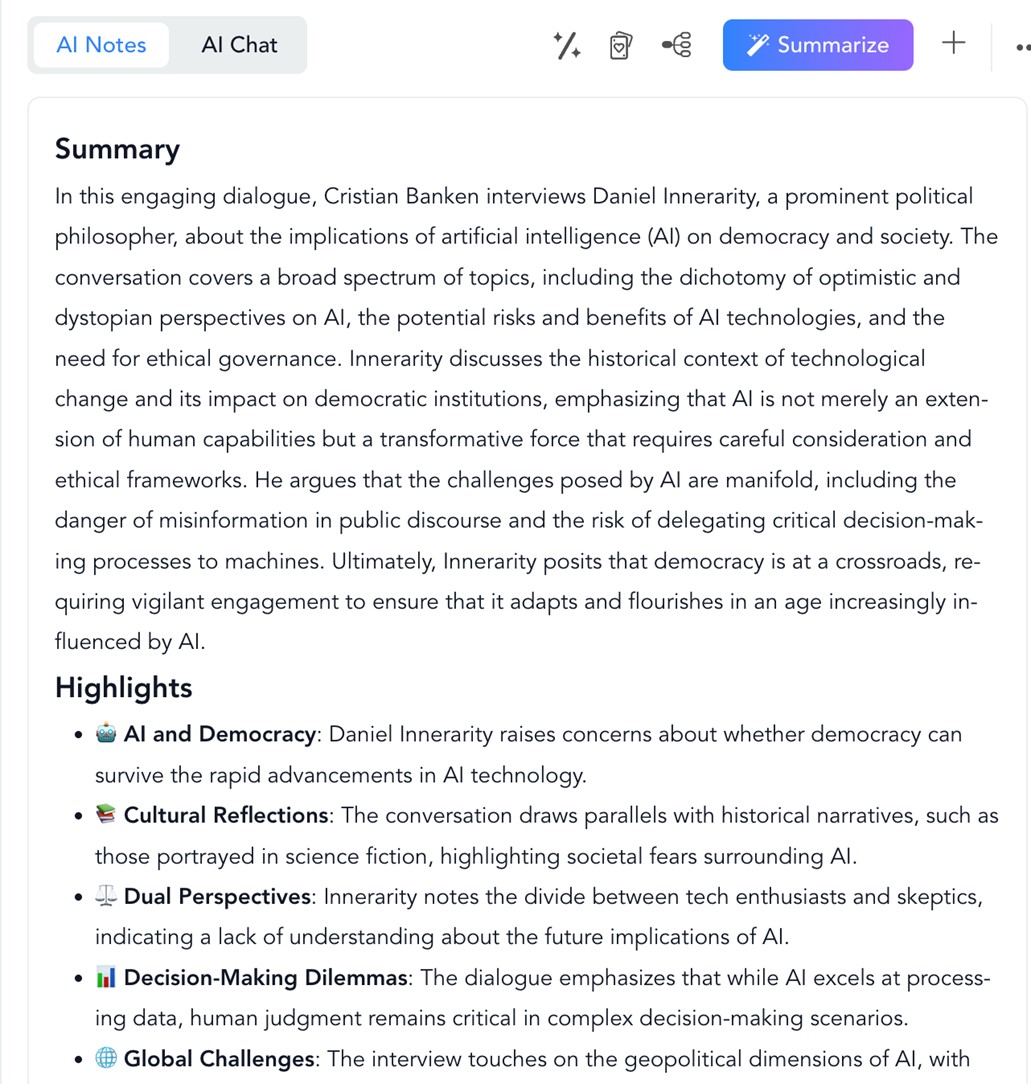
Figure 10. NoteGPT summary from a YouTube interview.
And although this is already very useful, the best thing we can find in NoteGPT are the flashcards, learning cards with questions and answers to internalise the concepts of the video.


Figure 11. NoteGPT learning card (question and answer).
A trick: if the summary only appears in English, try changing the language in the three dots on the right, next to "Summarize" and click "Summarize" again. The summary will appear in English below. In the case of flashcards, to generate them in English, do not try from the home page, but from "AI flashcards". Under "Create" you can select the language.
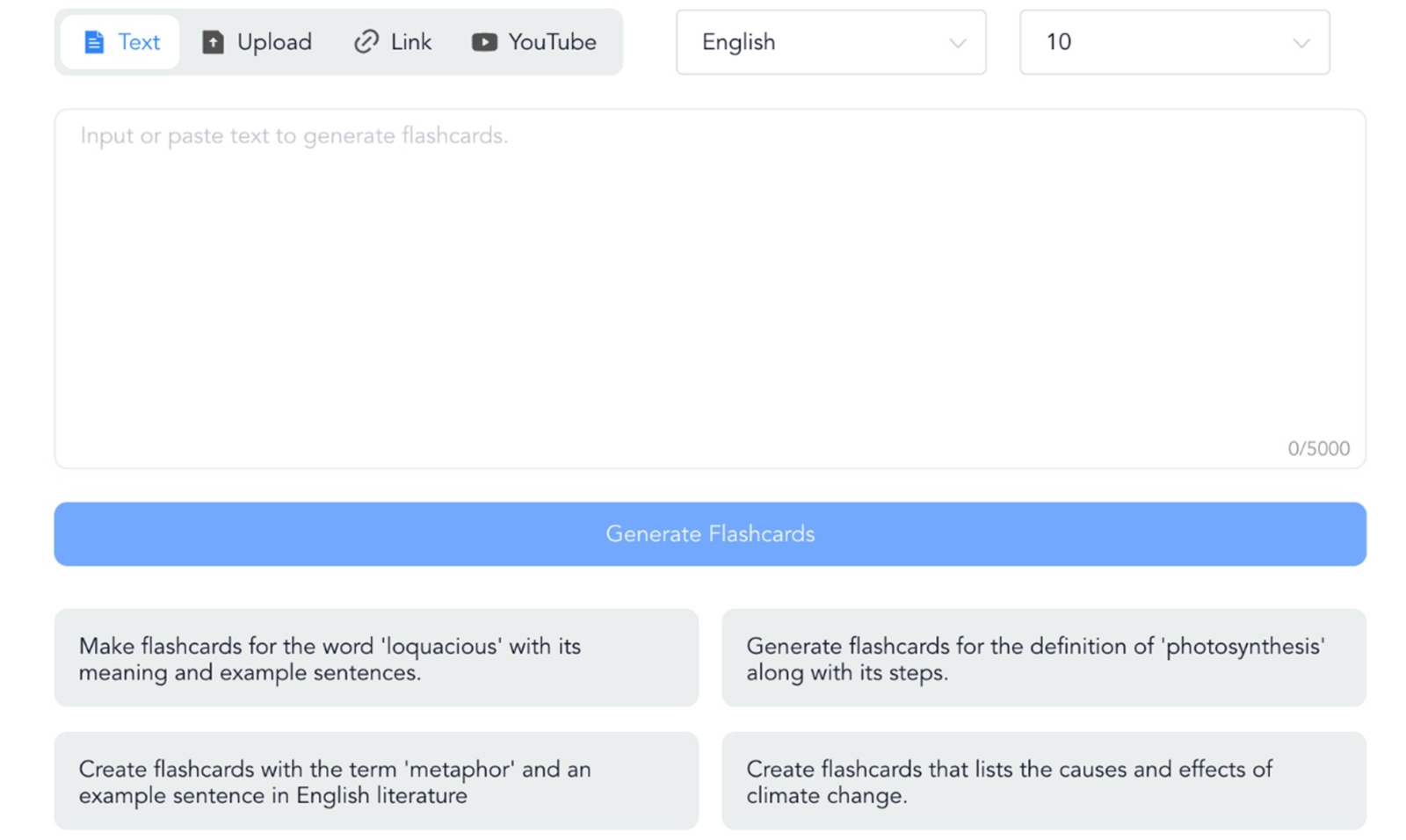
Figure 12. Creation of flashcards in NoteGPT.
Create videos about anything: Lumen5
Lumen5 makes it easy to create videos with AI by creating the script and images automatically from text or voice content. The most interesting thing about Lumen5 is the starting point, which can be a text, a document, simply an idea or also an existing audio recording or video.

Figure 13. Lumen5 options.
The system allows us, before creating the video and also once created, to change the format from 16:9 (horizontal) to 1:1 (square) or 9:16 (vertical), even with a special 9:16 option for Instagram stories.
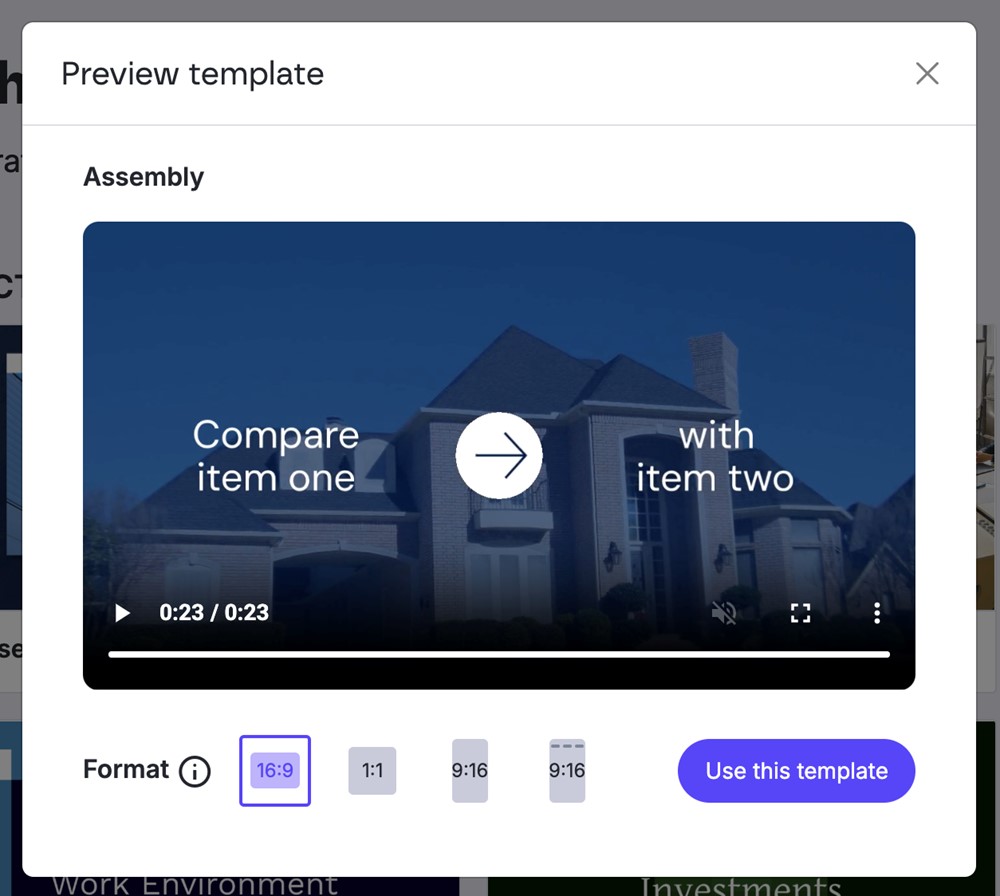
Figure 14. Video preview and aspect ratio options.
In this case, we will start from the same text as in previous tools: UNESCO's recommendations for democratic governance of AI. Select the starting option "Text on media", paste it directly into the box and click on "Compose script". The result is a very simple and schematic script, divided into blocks with the basic points of the text, and a very interesting indication: a prediction of the length of the video with that script, approximately 1 minute and 19 seconds.
An important note: the script is not a voice-over, but the text that will be written on the different screens. Once the video is finished, you can translate the whole video into any other language.

Figure 15. Script proposal in Lumen5.
Clicking on "Continue" will take you to the last opportunity to modify the script, where you can add new text blocks or delete existing ones. Once ready, click on "Convert to video" and you will find the story board ready to modify images, colours or the order of the screens. The video will have background music, which you can also change, and at this point you can record your voice over the music to voice the script. Without too much effort, this is the end result:
Figura 16. Resultado final de un vídeo creado con Lumen5.
From the wide range of AI-based digital products that have flourished in recent years, perhaps thousands of them, we have gone through just five examples that show us that individual and collaborative knowledge and learning are more accessible than ever before. The ease of converting content from one format to another and the automatic creation of study guides and materials should promote a more informed and agile society, not only through text or images but also through information condensed in files or databases.
It would be a great boost to collective progress if we understood that the value of AI-based systems is not as simple as writing or creating content for us, but to support our reasoning processes, objectify our decision-making and enable us to handle much more information in an efficient and useful way. Harnessing new AI capabilities together with open data initiatives may be key to the next step in the evolution of human thinking.
Content prepared by Carmen Torrijos, expert in AI applied to language and communication. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Language models are at the epicentre of the technological paradigm shift that has been taking place in generative artificial intelligence (AI) over the last two years. From the tools with which we interact in natural language to generate text, images or videos and which we use to create creative content, design prototypes or produce educational material, to more complex applications in research and development that have even been instrumental in winning the 2024 Nobel Prize in Chemistry, language models are proving their usefulness in a wide variety of applicationsthat we are still exploring.
Since Google's influential 2017 paper "Attention is all you need" describing the architecture of the Transformers, the technology underpinning the new capabilities that OpenAI popularised in late 2022 with the launch of ChatGPT, the evolution of language models has been more than dizzying. In just two years, we have moved from models focused solely on text generation to multimodal versions that integrate interaction and generation of text, images and audio.
This rapid evolution has given rise to two categories of language models: SLMs (Small Language Models), which are lighter and more efficient, and LLLMs (Large Language Models), which are heavier and more powerful. Far from considering them as competitors, we should analyse SLM and LLM as complementary technologies. While LLLMs offer general processing and content generation capabilities, SLMs can provide support for more agile and specialised solutions for specific needs. However, both share one essential element: they rely on large volumes of data for training and at the heart of their capabilities is open data, which is part of the fuel used to train these language models on which generative AI applications are based.
LLLM: power driven by massive data
The LLLMs are large-scale language models with billions, even trillions, of parameters. These parameters are the mathematical units that allow the model to identify and learn patterns in the training data, giving them an extraordinary ability to generate text (or other formats) that is consistent and adapted to the users' context. These models, such as the GPT family from OpenAI, Gemini from Google or Llama from Meta, are trained on immense volumes of data and are capable of performing complex tasks, some even for which they were not explicitly trained.
Thus, LLMs are able to perform tasks such as generating original content, answering questions with relevant and well-structured information or generating software code, all with a level of competence equal to or higher than humans specialised in these tasks and always maintaining complex and fluent conversations.
The LLLMs rely on massive amounts of data to achieve their current level of performance: from repositories such as Common Crawl, which collects data from millions of web pages, to structured sources such as Wikipedia or specialised sets such as PubMed Open Access in the biomedical field. Without access to these massive bodies of open data, the ability of these models to generalise and adapt to multiple tasks would be much more limited.
However, as LLMs continue to evolve, the need for open data increases to achieve specific advances such as:
- Increased linguistic and cultural diversity: although today's LLMs are multilingual, they are generally dominated by data in English and other major languages. The lack of open data in other languages limits the ability of these models to be truly inclusive and diverse. More open data in diverse languages would ensure that LLMs can be useful to all communities, while preserving the world's cultural and linguistic richness.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. This sometimes leads to responses that perpetuate stereotypes or inequalities. Incorporating more carefully selected open data, especially from sources that promote diversity and equality, is fundamental to building models that fairly and equitably represent different social groups.
- Constant updating: Data on the web and other open resources is constantly changing. Without access to up-to-date data, the LLMs generate outdated responses very quickly. Therefore, increasing the availability of fresh and relevant open data would allow LLMs to keep in line with current events[9].
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Open data allows independent developers, universities and small businesses to train and refine their own models without the need for costly data acquisitions. This democratises access to artificial intelligence and fosters global innovation.
To address some of these challenges, the new Artificial Intelligence Strategy 2024 includes measures aimed at generating models and corpora in Spanish and co-official languages, including the development of evaluation datasets that consider ethical evaluation.
SLM: optimised efficiency with specific data
On the other hand, SLMs have emerged as an efficient and specialised alternative that uses a smaller number of parameters (usually in the millions) and are designed to be lightweight and fast. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
For this, SLMs also rely on open data, but in this case, the quality and relevance of the datasets are more important than their volume, so the challenges they face are more related to data cleaning and specialisation. These models require sets that are carefully selected and tailored to the specific domain for which they are to be used, as any errors, biases or unrepresentativeness in the data can have a much greater impact on their performance. Moreover, due to their focus on specialised tasks, the SLMs face additional challenges related to the accessibility of open data in specific fields. For example, in sectors such as medicine, engineering or law, relevant open data is often protected by legal and/or ethical restrictions, making it difficult to use it to train language models.
The SLMs are trained with carefully selected data aligned to the domain in which they will be used, allowing them to outperform LLMs in accuracy and specificity on specific tasks, such as for example:
- Text autocompletion: a SLM for Spanish autocompletion can be trained with a selection of books, educational texts or corpora such as those to be promoted in the aforementioned AI Strategy, being much more efficient than a general-purpose LLM for this task.
- Legal consultations: a SLM trained with open legal datasets can provide accurate and contextualised answers to legal questions or process contractual documents more efficiently than a LLM.
- Customised education: ein the education sector, SLM trained with open data teaching resources can generate specific explanations, personalised exercises or even automatic assessments, adapted to the level and needs of the student.
- Medical diagnosis: An SLM trained with medical datasets, such as clinical summaries or open publications, can assist physicians in tasks such as identifying preliminary diagnoses, interpreting medical images through textual descriptions or analysing clinical studies.
Ethical Challenges and Considerations
We should not forget that, despite the benefits, the use of open data in language modelling presents significant challenges. One of the main challenges is, as we have already mentioned, to ensure the quality and neutrality of the data so that they are free of biases, as these can be amplified in the models, perpetuating inequalities or prejudices.
Even if a dataset is technically open, its use in artificial intelligence models always raises some ethical implications. For example, it is necessary to avoid that personal or sensitive information is leaked or can be deduced from the results generated by the models, as this could cause damage to the privacy of individuals.
The issue of data attribution and intellectual property must also be taken into account. The use of open data in business models must address how the original creators of the data are recognised and adequately compensated so that incentives for creators continue to exist.
Open data is the engine that drives the amazing capabilities of language models, both SLM and LLM. While the SLMs stand out for their efficiency and accessibility, the LLMs open doors to advanced applications that not long ago seemed impossible. However, the path towards developing more capable, but also more sustainable and representative models depends to a large extent on how we manage and exploit open data.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
The 2024 Best Cases Awards of the Public Sector Tech Watch observatory now have finalists. These awards seek to highlight solutions that use emerging technologies, such as artificial intelligence or blockchain, in public administrations, through two categories:
- Solutions to improve the public services offered to citizens (Government-to-Citizen or G2C).
- Solutions to improve the internal processes of the administrations themselves (Government-to-Government or G2G).
The awards are intended to create a mechanism for sharing the best experiences on the use of emerging technologies in the public sector and thus give visibility to the most innovative administrations in Europe.
Almost 60% of the finalist solutions are Spanish.
In total, 32 proposals have been received, 14 of which have been pre-selected in a preliminary evaluation. Of these, more than half are solutions from Spanish organisations. Specifically, nine finalists have been shortlisted for the G2G category -five of them Spanish- and five for G2C -three of them linked to our country-.The following is a summary of what these Spanish solutions consist of.
Solutions to improve the internal processes of the administrations themselves.
- Innovation in local government: digital transformation and GeoAI for data management (Alicante Provincial Council).
Suma Gestión Tributaria, of the Diputación de Alicante, is the agency in charge of managing and collecting the municipal taxes of the city councils of its province. To optimise this task, they have developed a solution that combines geographic information systems and artificial intelligence (machine learning and deep learning) to improve training in detection of properties that do not pay taxes. This solution collects data from multiple administrations and entities in order to avoid delays in the collection of municipalities.
- Regional inspector of public infrastructures: monitoring of construction sites (Provincial Council of Bizkaia and Interbiak).
The autonomous road inspector and autonomous urban inspector help public administrations to automatically monitor roads. These solutions, which can be installed in any vehicle, use artificial or computer vision techniques along with information from sensors to automatically check the condition of traffic signs, road markings, protective barriers, etc. They also perform early forecasting of pavement degradation, monitor construction sites and generate alerts for hazards such as possible landslides.
- Application of drones for the transport of biological samples (Centre for Telecommunications and Information Technologies -CTTI-, Generalitat de Catalunya).
This pilot project implements and evaluates a health transport route in the Girona health region. Its aim is to transport biological samples (blood and urine) between a primary health centre and a hospital using drones. As a result, the journey time has been reduced from 20 minutes with ground transport to seven minutes with the use of drones. This has improved the quality of the samples transported, increased flexibility in scheduling transport times and reduced environmental impact.
- Robotic automation of processes in the administration of justice (Ministry of the Presidency, Justice and Relations with the Courts).
Ministry of the Presidency, Justice and Relations with the Courts has implemented a solution for the robotisation of administrative processes in order to streamline routine, repetitive and low-risk work. To date, more than 25 process automation lines have been implemented, including the automatic cancellation of criminal records, nationality applications, automatic issuance of life insurance certificates, etc. As a result, it is estimated that more than 500,000 working hourshave been saved.
- Artificial intelligence in the processing of official publications (Official Gazette of the Province of Barcelona and Official Documentation and Publications Service, Barcelona Provincial Council).
CIDO (Official Information and Documentation Search Engine) has implemented an AI system that automatically generates summaries of official publications of the public administrations of Barcelona. Using supervised machine learning and neural networkstechniques, the system generates summaries of up to 100 words for publications in Catalan or Spanish. The tool allows the recording of manual modifications to improve accuracy.
Solutions to improve the public services offered to citizens
- Virtual Desk of Digital Immediacy: bringing Justice closer to citizens through digitalisation (Ministry of the Presidency, Justice and Relations with the Courts).
The Virtual Digital Immediacy Desktop (EVID) allows remote hearings with full guarantees of legal certainty using blockchain technologies. The solution integrates the convening of the hearing, the provision of documentation, the identification of the participants, the acceptance of consents, the generation of the document justifying the action carried out, the signing of the document and the recording of the session. In this way, legal acts can be carried out from anywhere, without the need to travel and in a simple way, making justice more inclusive, accessible and environmentally friendly. By the end of June 2024, more than 370,000 virtual sessions had been held through EVID.
- Application of Generative AI to make it easier for citizens to understand legal texts (Entitat Autònoma del Diari Oficial i Publicacions -EADOP-, Generalitat de Catalunya).
Legal language is often a barrier that prevents citizens from easily understanding legal texts. To remove this obstacle, the Government is making available to users of the Legal Portal of Catalonia and to the general public the summaries of Catalan law in simple language obtained from generative artificial intelligence. The aim is to have summaries of the more than 14,000 14,000 existing regulatory provisions adapted to clear communication available by the end of the year. The abstracts will be published in Catalan and Spanish, with the prospect of also offering a version in Aranesein the future.
- Emi - Intelligent Employment (Consellería de Emprego, Comercio e Emigración de la Xunta de Galicia).
Emi, Intelligent Employment is an artificial intelligence and big data tool that helps the offices of the Public Employment Service of Galicia to orient unemployed people towards the skills required by the labour market, according to their abilities. AI models make six-month projections of contracts for a particular occupation for a chosen geographical area. In addition, they allow estimating the probability of finding employment for individuals in the coming months.
You can see all the solutions presented here. The winners will be announced at the final event on 28 November. The ceremony takes place in Brussels, but can also be followed online. To do so, you need to register here.
Public Sector Tech Watch: an observatory to inspire new projects
Public Sector Tech Watch (PSTW), managed by the European Commission, is positioned as a "one-stop shop" for all those interested - public sector, policy makers, private companies, academia, etc. - in the latest technological developments to improve public sector performance and service delivery. For this purpose, it has several sections where the following information of interest is displayed:
- Cases: contains examples of how innovative technologies and their associated data are used by public sector organisations in Europe.
- Stories: presents testimonials to show the challenges faced by European administrations in implementing technological solutions.
If you know of a case of interest that is not currently monitored by PSTW, you can register it here. Successful cases are reviewed and evaluated before being included in the database.
Evento
From October 28 to November 24, registration will be open for submitting proposals to the challenge organized by the Diputación de Bizkaia. The goal of the competition is to identify initiatives that combine the reuse of available data from the Open Data Bizkaia portal with the use of artificial intelligence. The complete guidelines are available at this link, but in this post, we will cover everything you need to know about this contest, which offers cash prizes for the five best projects.
Participants must use at least one dataset from the Diputación Foral de Bizkaia or from the municipalities in the territory, which can be found in the catalog, to address one of the five proposed use cases:
-
Promotional content about tourist attractions in Bizkaia: Written promotional content, such as generated images, flyers, etc., using datasets like:
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Recreation areas
- Hotels in Euskadi – Open Data Euskadi
- Temperature predictions in Bizkaia – Weather API data
-
Boosting tourism through sentiment analysis: Text files with recommendations for improving tourist resources, such as Excel and PowerPoint reports, using datasets like:
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Recreation areas
- Hotels in Euskadi – Open Data Euskadi
- Google reviews API – this resource is paid with a possible free tier
-
Personalized tourism guides: Chatbot or document with personalized recommendations using datasets like:
- Tide table 2024
- Beaches of Bizkaia by municipality
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
- Bizkaibus
- Trails
- Hotels in Euskadi – Open Data Euskadi
- Temperature predictions in Bizkaia – Weather API data, resource with a free tier
-
Personalized cultural event recommendations: Chatbot or document with personalized recommendations using datasets like:
- Cultural agenda – BizkaiKOA
- Cultural agenda of Bizkaia
-
Waste management optimization: Excel, PowerPoint, and Word reports containing recommendations and strategies using datasets like:
- Urban waste
- Containers by municipality
How to participate?
Participants can register individually or in teams via this form available on the website. The registration period is from October 28 to November 24, 2024. Once registration closes, teams must submit their solutions on Sharepoint. A jury will pre-select five finalists, who will have the opportunity to present their project at the final event on December 12, where the prizes will be awarded. The organization recommends attending in person, but online attendance will also be allowed if necessary.
The competition is open to anyone over 16 years old with a valid ID or passport, who is not affiliated with the organizing entities. Additionally, multiple proposals can be submitted.
What are the prizes?
The jury members will select five winning projects based on the following evaluation criteria:
- Suitability of the proposed solution to the selected challenge.
- Creativity and innovation.
- Quality and coherence of the solution.
- Suitability of the Open Data Bizkaia datasets used.
The winning candidates will receive a cash prize, as well as the commitment to open the datasets associated with the project, to the extent possible.
- First prize: €2,000.
- Second prize: €1,000.
- Three prizes for the remaining finalists of €500 each.
One of the objectives of this challenge, as explained by the Diputación Foral de Bizkaia, is to understand whether the current dataset offerings meet demand. Therefore, if any participant requires a dataset from Bizkaia or its municipalities that is not available, they can propose that the institution make it publicly available, as long as the information falls within the competencies of the Diputación Foral de Bizkaia or the municipalities.
This is a unique event that will not only allow you to showcase your skills in artificial intelligence and open data but also contribute to the development and improvement of Bizkaia. Don’t miss the chance to be part of this exciting challenge. Sign up and start creating innovative solutions!
Blog
Natural language processing (NLP) is a branch of artificial intelligence that allows machines to understand and manipulate human language. At the core of many modern applications, such as virtual assistants, machine translation and chatbots, are word embeddings. But what exactly are they and why are they so important?
What are word embeddings?
Word embeddings are a technique that allows machines to represent the meaning of words in such a way that complex relationships between words can be captured. To understand this, let's think about how words are used in a given context: a word acquires meaning depending on the words surrounding it. For example, the word bank can refer to a financial institution or to a headquarters, depending on the context in which it is found.
The idea behind word embeddings is that each word is assigned a vector in a multi-dimensional space. The position of these vectors in space reflects the semantic closeness between the words. If two words have similar meanings, their vectors will be close. If their meanings are opposite or unrelated, they are distant in vector space.
To visualise this, imagine that words like lake, river and ocean would be close together in this space, while words like lake and building would be much further apart. This structure enables language processing algorithms to perform complex tasks, such as finding synonyms, making accurate translations or even answering context-based questions.
How are word embeddings created?
The main objective of word embeddings is to capture semantic relationships and contextual information of words, transforming them into numerical representations that can be understood by machine learning algorithms. Instead of working with raw text, machines require words to be converted into numbers in order to identify patterns and relationships effectively.
The process of creating word embeddings consists of training a model on a large corpus of text, such as Wikipedia articles or news items, to learn the structure of the language. The first step involves performing a series of pre-processing on the corpus, which includes tokenise the words, removing punctuation and irrelevant terms, and, in some cases, converting the entire text to lower case to maintain consistency.
The use of context to capture meaning
Once the text has been pre-processed, a technique known as "sliding context window" is used to extract information. This means that, for each target word, the surrounding words within a certain range are taken into account. For example, if the context window is 3 words, for the word airplane in the sentence "The plane takes off at six o'clock", the context words will be The, takes off, to.
The model is trained to learn to predict a target word using the words in its context (or conversely, to predict the context from the target word). To do this, the algorithm adjusts its parameters so that the vectors assigned to each word are closer in vector space if those words appear frequently in similar contexts.
How models learn language structure
The creation of word embeddings is based on the ability of these models to identify patterns and semantic relationships. During training, the model adjusts the values of the vectors so that words that often share contexts have similar representations. For example, if airplane and helicopter are frequently used in similar phrases (e.g. in the context of air transport), the vectors of airplane and helicopter will be close together in vector space.
As the model processes more and more examples of sentences, it refines the positions of the vectors in the continuous space. Thus, the vectors reflect not only semantic proximity, but also other relationships such as synonyms, categories (e.g., fruits, animals) and hierarchical relationships (e.g., dog and animal).
A simplified example
Imagine a small corpus of only six words: guitar, bass, drums, piano, car and bicycle. Suppose that each word is represented in a three-dimensional vector space as follows:
guitar [0.3, 0.8, -0.1]
bass [0.4, 0.7, -0.2]
drums [0.2, 0.9, -0.1]
piano [0.1, 0.6, -0.3]
car [0.8, -0.1, 0.6]
bicycle [0.7, -0.2, 0.5]
In this simplified example, the words guitar, bass, drums and piano represent musical instruments and are located close to each other in vector space, as they are used in similar contexts. In contrast, car and bicycle, which belong to the category of means of transport, are distant from musical instruments but close to each other. This other image shows how different terms related to sky, wings and engineering would look like in a vector space.

Figure 1. Examples of representation of a corpus in a vector space. Source: Adapted from “Word embeddings: the (very) basics”, by Guillaume Desagulier.
This example only uses three dimensions to illustrate the idea, but in practice, word embeddings usually have between 100 and 300 dimensions to capture more complex semantic relationships and linguistic nuances.
The result is a set of vectors that efficiently represent each word, allowing language processing models to identify patterns and semantic relationships more accurately. With these vectors, machines can perform advanced tasks such as semantic search, text classification and question answering, significantly improving natural language understanding.
Strategies for generating word embeddings
Over the years, multiple approaches and techniques have been developed to generate word embeddings. Each strategy has its own way of capturing the meaning and semantic relationships of words, resulting in different characteristics and uses. Some of the main strategies are presented below:
1. Word2Vec: local context capture
Developed by Google, Word2Vec is one of the most popular approaches and is based on the idea that the meaning of a word is defined by its context. It uses two main approaches:
- CBOW (Continuous Bag of Words): In this approach, the model predicts the target word using the words in its immediate environment. For example, given a context such as "The dog is ___ in the garden", the model attempts to predict the word playing, based on the words The, dog, is and garden.
- Skip-gram: Conversely, Skip-gram uses a target word to predict the surrounding words. Using the same example, if the target word is playing, the model would try to predict that the words in its environment are The, dog, is and garden.
The key idea is that Word2Vec trains the model to capture semantic proximity across many iterations on a large corpus of text. Words that tend to appear together have closer vectors, while unrelated words appear further apart.
2. GloVe: global statistics-based approach
GloVe, developed at Stanford University, differs from Word2Vec by using global co-occurrence statistics of words in a corpus. Instead of considering only the immediate context, GloVe is based on the frequency with which two words appear together in the whole corpus.
For example, if bread and butter appear together frequently, but bread and planet are rarely found in the same context, the model adjusts the vectors so that bread and butter are close together in vector space.
This allows GloVe to capture broader global relationships between words and to make the representations more robust at the semantic level. Models trained with GloVe tend to perform well on analogy and word similarity tasks.
3. FastText: subword capture
FastText, developed by Facebook, improves on Word2Vec by introducing the idea of breaking down words into sub-words. Instead of treating each word as an indivisible unit, FastText represents each word as a sum of n-grams. For example, the word playing could be broken down into play, ayi, ing, and so on.
This allows FastText to capture similarities even between words that did not appear explicitly in the training corpus, such as morphological variations (playing, play, player). This is particularly useful for languages with many grammatical variations.
4. Embeddings contextuales: dynamic sense-making
Models such as BERT and ELMo represent a significant advance in word embeddings. Unlike the previous strategies, which generate a single vector for each word regardless of the context, contextual embeddings generate different vectors for the same word depending on its use in the sentence.
For example, the word bank will have a different vector in the sentence "I sat on the park bench" than in "the bank approved my credit application". This variability is achieved by training the model on large text corpora in a bidirectional manner, i.e. considering not only the words preceding the target word, but also those following it.
Practical applications of word embeddings
ord embeddings are used in a variety of natural language processing applications, including:
- Named Entity Recognition (NER): allows you to identify and classify names of people, organisations and places in a text. For example, in the sentence "Apple announced its new headquarters in Cupertino", the word embeddings allow the model to understand that Apple is an organisation and Cupertino is a place.
- Automatic translation: helps to represent words in a language-independent way. By training a model with texts in different languages, representations can be generated that capture the underlying meaning of words, facilitating the translation of complete sentences with a higher level of semantic accuracy.
- Information retrieval systems: in search engines and recommender systems, word embeddings improve the match between user queries and relevant documents. By capturing semantic similarities, they allow even non-exact queries to be matched with useful results. For example, if a user searches for "medicine for headache", the system can suggest results related to analgesics thanks to the similarities captured in the vectors.
- Q&A systems: word embeddings are essential in systems such as chatbots and virtual assistants, where they help to understand the intent behind questions and find relevant answers. For example, for the question "What is the capital of Italy?", the word embeddings allow the system to understand the relationship between capital and Italy and find Rome as an answer.
- Sentiment analysis: word embeddings are used in models that determine whether the sentiment expressed in a text is positive, negative or neutral. By analysing the relationships between words in different contexts, the model can identify patterns of use that indicate certain feelings, such as joy, sadness or anger.
- Semantic clustering and similarity detection: word embeddings also allow you to measure the semantic similarity between documents, phrases or words. This is used for tasks such as grouping related items, recommending products based on text descriptions or even detecting duplicates and similar content in large databases.
Conclusion
Word embeddings have transformed the field of natural language processing by providing dense and meaningful representations of words, capable of capturing their semantic and contextual relationships. With the emergence of contextual embeddings , the potential of these representations continues to grow, allowing machines to understand even the subtleties and ambiguities of human language. From applications in translation and search systems, to chatbots and sentiment analysis, word embeddings will continue to be a fundamental tool for the development of increasingly advanced and humanised natural language technologies.
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Evento
On 11, 12 and 13 November, a new edition of DATAforum Justice will be held in Granada. The event will bring together more than 100 speakers to discuss issues related to digital justice systems, artificial intelligence (AI) and the use of data in the judicial ecosystem.The event is organized by the Ministry of the Presidency, Justice and Relations with the Courts, with the collaboration of the University of Granada, the Andalusian Regional Government, the Granada City Council and the Granada Training and Management entity.
The following is a summary of some of the most important aspects of the conference.
An event aimed at a wide audience
This annual forum is aimed at both public and private sector professionals, without neglecting the general public, who want to know more about the digital transformation of justice in our country.
The DATAforum Justice 2024 also has a specific itinerary aimed at students, which aims to provide young people with valuable tools and knowledge in the field of justice and technology. To this end, specific presentations will be given and a DATAthon will be set up. These activities are particularly aimed at students of law, social sciences in general, computer engineering or subjects related to digital transformation. Attendees can obtain up to 2 ECTS credits (European Credit Transfer and Accumulation System): one for attending the conference and one for participating in the DATAthon.
Data at the top of the agenda
The Paraninfo of the University of Granada will host experts from the administration, institutions and private companies, who will share their experience with an emphasis on new trends in the sector, the challenges ahead and the opportunities for improvement.
The conference will begin on Monday 11 November at 9:00 a.m., with a welcome to the students and a presentation of DATAthon. The official inauguration, addressed to all audiences, will be at 11:35 a.m. and will be given by Manuel Olmedo Palacios, Secretary of State for Justice, and Pedro Mercado Pacheco, Rector of the University of Granada.
From then on, various talks, debates, interviews, round tables and conferences will take place, including a large number of data-related topics. Among other issues, the data management, both in administrations and in companies, will be discussed in depth. It will also address the use of open data to prevent everything from hoaxes to suicide and sexual violence.
Another major theme will be the possibilities of artificial intelligence for optimising the sector, touching on aspects such as the automation of justice, the making of predictions. It will include presentations of specific use cases, such as the use of AI for the identification of deceased persons, without neglecting issues such as the governance of algorithms.
The event will end on Wednesday 13 at 17:00 hours with the official closing ceremony. On this occasion, Félix Bolaños, Minister of the Presidency, Justice and Relations with the Cortes, will accompany the Rector of the University of Granada.
A Datathon to solve industry challenges through data
In parallel to this agenda, a DATAthon will be held in which participants will present innovative ideas and projects to improve justice in our society. It is a contest aimed at students, legal and IT professionals, research groups and startups.
Participants will be divided into multidisciplinary teams to propose solutions to a series of challenges, posed by the organisation, using data science oriented technologies. During the first two days, participants will have time to research and develop their original solution. On the third day, they will have to present a proposal to a qualified jury. The prizes will be awarded on the last day, before the closing ceremony and the Spanish wine and concert that will bring the 2024 edition of DATAfórum Justicia to a close.
In the 2023 edition, 35 people participated, divided into 6 teams that solved two case studies with public data and two prizes of 1,000 euros were awarded.
How to register
The registration period for the DATAforum Justice 2024 is now open. This must be done through the event website, indicating whether it is for the general public, public administration staff, private sector professionals or the media.
To participate in the DATAthon it is necessary to register also on the contest site.
Last year's edition, focusing on proposals to increase efficiency and transparency in judicial systems, was a great success, with over 800 registrants. This year again, a large number of people are expected, so we encourage you to book your place as soon as possible. This is a great opportunity to learn first-hand about successful experiences and to exchange views with experts in the sector.
Blog
A digital twin is a virtual, interactive representation of a real-world object, system or process. We are talking, for example, about a digital replica of a factory, a city or even a human body. These virtual models allow simulating, analysing and predicting the behaviour of the original element, which is key for optimisation and maintenance in real time.
Due to their functionalities, digital twins are being used in various sectors such as health, transport or agriculture. In this article, we review the benefits of their use and show two examples related to open data.
Advantages of digital twins
Digital twins use real data sources from the environment, obtained through sensors and open platforms, among others. As a result, the digital twins are updated in real time to reflect reality, which brings a number of advantages:
- Increased performance: one of the main differences with traditional simulations is that digital twins use real-time data for modelling, allowing better decisions to be made to optimise equipment and system performance according to the needs of the moment.
- Improved planning: using technologies based on artificial intelligence (AI) and machine learning, the digital twin can analyse performance issues or perform virtual "what-if" simulations. In this way, failures and problems can be predicted before they occur, enabling proactive maintenance.
- Cost reduction: improved data management thanks to a digital twin generates benefits equivalent to 25% of total infrastructure expenditure. In addition, by avoiding costly failures and optimizing processes, operating costs can be significantly reduced. They also enable remote monitoring and control of systems from anywhere, improving efficiency by centralizing operations.
- Customization and flexibility: by creating detailed virtual models of products or processes, organizations can quickly adapt their operations to meet changing environmental demands and individual customer/citizen preferences. For example, in manufacturing, digital twins enable customized mass production, adjusting production lines in real time to create unique products according to customer specifications. On the other hand, in healthcare, digital twins can model the human body to customize medical treatments, thereby improving efficacy and reducing side effects.
- Boosting experimentation and innovation: digital twins provide a safe and controlled environment for testing new ideas and solutions, without the risks and costs associated with physical experiments. Among other issues, they allow experimentation with large objects or projects that, due to their size, do not usually lend themselves to real-life experimentation.
- Improved sustainability: by enabling simulation and detailed analysis of processes and systems, organizations can identify areas of inefficiency and waste, thus optimizing the use of resources. For example, digital twins can model energy consumption and production in real time, enabling precise adjustments that reduce consumption and carbon emissions.
Examples of digital twins in Spain
The following three examples illustrate these advantages.
GeDIA project: artificial intelligence to predict changes in territories
GeDIA is a tool for strategic planning of smart cities, which allows scenario simulations. It uses artificial intelligence models based on existing data sources and tools in the territory.
The scope of the tool is very broad, but its creators highlight two use cases:
- Future infrastructure needs: the platform performs detailed analyses considering trends, thanks to artificial intelligence models. In this way, growth projections can be made and the needs for infrastructures and services, such as energy and water, can be planned in specific areas of a territory, guaranteeing their availability.
- Growth and tourism: GeDIA is also used to study and analyse urban and tourism growth in specific areas. The tool identifies patterns of gentrification and assesses their impact on the local population, using census data. In this way, demographic changes and their impact, such as housing needs, can be better understood and decisions can be made to facilitate equitable and sustainable growth.
This initiative has the participation of various companies and the University of Malaga (UMA), as well as the financial backing of Red.es and the European Union.
Digital twin of the Mar Menor: data to protect the environment
The Mar Menor, the salt lagoon of the Region of Murcia, has suffered serious ecological problems in recent years, influenced by agricultural pressure, tourism and urbanisation.
To better understand the causes and assess possible solutions, TRAGSATEC, a state-owned environmental protection agency, developed a digital twin. It mapped a surrounding area of more than 1,600 square kilometres, known as the Campo de Cartagena Region. In total, 51,000 nadir images, 200,000 oblique images and more than four terabytes of LiDAR data were obtained.
Thanks to this digital twin, TRAGSATEC has been able to simulate various flooding scenarios and the impact of installing containment elements or obstacles, such as a wall, to redirect the flow of water. They have also been able to study the distance between the soil and the groundwater, to determine the impact of fertiliser seepage, among other issues.
Challenges and the way forward
These are just two examples, but they highlight the potential of an increasingly popular technology. However, for its implementation to be even greater, some challenges need to be addressed, such as initial costs, both in technology and training, or security, by increasing the attack surface. Another challenge is the interoperability problems that arise when different public administrations establish digital twins and local data spaces. To address this issue further, the European Commission has published a guide that helps to identify the main organisational and cultural challenges to interoperability, offering good practices to overcome them.
In short, digital twins offer numerous advantages, such as improved performance or cost reduction. These benefits are driving their adoption in various industries and it is likely that, as current challenges are overcome, digital twins will become an essential tool for optimising processes and improving operational efficiency in an increasingly digitised world.
Blog
Almost half of European adults lack basic digital skills. According to the latest State of the Digital Decade report, in 2023, only 55.6% of citizens reported having such skills. This percentage rises to 66.2% in the case of Spain, ahead of the European average.
Having basic digital skills is essential in today's society because it enables access to a wider range of information and services, as well as effective communication in onlineenvironments, facilitating greater participation in civic and social activities. It is also a great competitive advantage in the world of work.
In Europe, more than 90% of professional roles require a basic level of digital skills. Technological knowledge has long since ceased to be required only for technical professions, but is spreading to all sectors, from business to transport and even agriculture. In this respect, more than 70% of companies said that the lack of staff with the right digital skills is a barrier to investment.
A key objective of the Digital Decade is therefore to ensure that at least 80% of people aged 16-74 have at least basic digital skills by 2030.
Basic technology skills that everyone should have
When we talk about basic technological capabilities, we refer, according to the DigComp framework , to a number of areas, including:
- Information and data literacy: includes locating, retrieving, managing and organising data, judging the relevance of the source and its content.
- Communication and collaboration: involves interacting, communicating and collaborating through digital technologies taking into account cultural and generational diversity. It also includes managing one's own digital presence, identity and reputation.
- Digital content creation: this would be defined as the enhancement and integration of information and content to generate new messages, respecting copyrights and licences. It also involves knowing how to give understandable instructions to a computer system.
- Security: this is limited to the protection of devices, content, personal data and privacy in digital environments, to protect physical and mental health.
- Problem solving: it allows to identify and solve needs and problems in digital environments. It also focuses on the use of digital tools to innovate processes and products, keeping up with digital evolution.
Which data-related jobs are most in demand?
Now that the core competences are clear, it is worth noting that in a world where digitalisation is becoming increasingly important , it is not surprising that the demand for advanced technological and data-related skills is also growing.
According to data from the LinkedIn employment platform, among the 25 fastest growing professions in Spain in 2024 are security analysts (position 1), software development analysts (2), data engineers (11) and artificial intelligence engineers (25). Similar data is offered by Fundación Telefónica's Employment Map, which also highlights four of the most in-demand profiles related to data:
- Data analyst: responsible for the management and exploitation of information, they are dedicated to the collection, analysis and exploitation of data, often through the creation of dashboards and reports.
- Database designer or database administrator: focused on designing, implementing and managing databases. As well as maintaining its security by implementing backup and recovery procedures in case of failures.
- Data engineer: responsible for the design and implementation of data architectures and infrastructures to capture, store, process and access data, optimising its performance and guaranteeing its security.
- Data scientist: focused on data analysis and predictive modelling, optimisation of algorithms and communication of results.
These are all jobs with good salaries and future prospects, but where there is still a large gap between men and women. According to European data, only 1 in 6 ICT specialists and 1 in 3 science, technology, engineering and mathematics (STEM) graduates are women.
To develop data-related professions, you need, among others, knowledge of popular programming languages such as Python, R or SQL, and multiple data processing and visualisation tools, such as those detailed in these articles:
- Debugging and data conversion tools
- Data analysis tools
- Data visualisation tools
- Data visualisation libraries and APIs
- Geospatial visualisation tools
- Network analysis tools
The range of training courses on all these skills is growing all the time.
Future prospects
Nearly a quarter of all jobs (23%) will change in the next five years, according to the World Economic Forum's Future of Jobs 2023 Report. Technological advances will create new jobs, transform existing jobs and destroy those that become obsolete. Technical knowledge, related to areas such as artificial intelligence or Big Data, and the development of cognitive skills, such as analytical thinking, will provide great competitive advantages in the labour market of the future. In this context, policy initiatives to boost society's re-skilling , such as the European Digital Education Action Plan (2021-2027), will help to generate common frameworks and certificates in a constantly evolving world.
The technological revolution is here to stay and will continue to change our world. Therefore, those who start acquiring new skills earlier will be better positioned in the future employment landscape.