Blog
Data literacy has become a crucial issue in the digital age. This concept refers to the ability of people to understand how data is used, how it is accessed, created, analysed, used or reused, and communicated.
We live in a world where data and algorithms influence everyday decisions and the opportunities people have to live well. Its effect can be felt in areas ranging from advertising and employment provision to criminal justice and social welfare. It is therefore essential to understand how data is generated and used.
Data literacy can involve many areas, but we will focus on its relationship with digital rights on the one hand and Artificial Intelligence (AI) on the other. This article proposes to explore the importance of data literacy for citizenship, addressing its implications for the protection of individual and collective rights and the promotion of a more informed and critical society in a technological context where artificial intelligence is becoming increasingly important.
The context of digital rights
More and more studies studies increasingly indicate that effective participation in today's data-driven, algorithm-driven society requires data literacy indicating that effective participation in today's data-driven, algorithm-driven society requires data literacy. Civil rights are increasingly translating into digital rights as our society becomes more dependent on digital technologies and environments digital rights as our society becomes more dependent on digital technologies and environments. This transformation manifests itself in various ways:
- On the one hand, rights recognised in constitutions and human rights declarations are being explicitly adapted to the digital context. For example, freedom of expression now includes freedom of expression online, and the right to privacy extends to the protection of personal data in digital environments. Moreover, some traditional civil rights are being reinterpreted in the digital context. One example of this is the right to equality and non-discrimination, which now includes protection against algorithmic discrimination and against bias in artificial intelligence systems. Another example is the right to education, which now also extends to the right to digital education. The importance of digital skills in society is recognised in several legal frameworks and documents, both at national and international level, such as the Organic Law 3/2018 on Personal Data Protection and Guarantee of Digital Rights (LOPDGDD) in Spain. Finally, the right of access to the internet is increasingly seen as a fundamental right, similar to access to other basic services.
- On the other hand, rights are emerging that address challenges unique to the digital world, such as the right to be forgotten (in force in the European Union and some other countries that have adopted similar legislation1), which allows individuals to request the removal of personal information available online, under certain conditions. Another example is the right to digital disconnection (in force in several countries, mainly in Europe2), which ensures that workers can disconnect from work devices and communications outside working hours. Similarly, there is a right to net neutrality to ensure equal access to online content without discrimination by service providers, a right that is also established in several countries and regions, although its implementation and scope may vary. The EU has regulations that protect net neutrality, including Regulation 2015/2120, which establishes rules to safeguard open internet access. The Spanish Data Protection Act provides for the obligation of Internet providers to provide a transparent offer of services without discrimination on technical or economic grounds. Furthermore, the right of access to the internet - related to net neutrality - is recognised as a human right by the United Nations (UN).
This transformation of rights reflects the growing importance of digital technologies in all aspects of our lives.
The context of artificial intelligence
The relationship between AI development and data is fundamental and symbiotic, as data serves as the basis for AI development in a number of ways:
- Data is used to train AI algorithms, enabling them to learn, detect patterns, make predictions and improve their performance over time.
- The quality and quantity of data directly affect the accuracy and reliability of AI systems. In general, more diverse and complete datasets lead to better performing AI models.
- The availability of data in various domains can enable the development of AI systems for different use cases.
Data literacy has therefore become increasingly crucial in the AI era, as it forms the basis for effectively harnessing and understanding AI technologies.
In addition, the rise of big data and algorithms has transformed the mechanisms of participation, presenting both challenges and opportunities. Algorithms, while they may be designed to be fair, often reflect the biases of their creators or the data they are trained on. This can lead to decisions that negatively affect vulnerable groups.
In this regard, legislative and academic efforts are being made to prevent this from happening. For example, the EuropeanArtificial Intelligence Act (AI Act) includes safeguards to avoid harmful biases in algorithmic decision-making. For example, it classifies AI systems according to their level of potential risk and imposes stricter requirements on high-risk systems. In addition, it requires the use of high quality data to train the algorithms, minimising bias, and provides for detailed documentation of the development and operation of the systems, allowing for audits and evaluations with human oversight. It also strengthens the rights of persons affected by AI decisions, including the right to challenge decisions made and their explainability, allowing affected persons to understand how a decision was reached.
The importance of digital literacy in both contexts
Data literacy helps citizens make informed decisions and understand the full implications of their digital rights, which are also considered, in many respects, as mentioned above, to be universal civil rights. In this context, data literacy serves as a critical filter for full civic participation that enables citizens to influence political and social decisions full civic participation that enables citizens to influence political and social decisions. That is,those who have access to data and the skills and tools to navigate the data infrastructure effectively can intervene and influencepolitical and social processes in a meaningful way , something which promotes the Open Government Partnership.
On the other hand, data literacy enables citizens to question and understand these processes, fostering a culture of accountability and transparency in the use of AI. There arealso barriers to participation in data-driven environments. One of these barriers is the digital divide (i.e. deprivation of access to infrastructure, connectivity and training, among others) and, indeed, lack of data literacy. The latter is therefore a crucial concept for overcoming the challenges posed by datification datification of human relations and the platformisation of content and services.
Recommendations for implementing a preparedness partnership
Part of the solution to addressing the challenges posed by the development of digital technology is to include data literacy in educational curricula from an early age.
This should cover:
- Data basics: understanding what data is, how it is collected and used.
- Critical analysis: acquisition of the skills to evaluate the quality and source of data and to identify biases in the information presented. It seeks to recognise the potential biases that data may contain and that may occur in the processing of such data, and to build capacity to act in favour of open data and its use for the common good.
- Rights and regulations: information on data protection rights and how European laws affect the use of AI. This area would cover all current and future regulation affecting the use of data and its implication for technology such as AI.
- Practical applications: the possibility of creating, using and reusing open data available on portals provided by governments and public administrations, thus generating projects and opportunities that allow people to work with real data, promoting active, contextualised and continuous learning.
By educating about the use and interpretation of data, it fosters a more critical society that is able to demand accountability in the use of AI. New data protection laws in Europe provide a framework that, together with education, can help mitigate the risks associated with algorithmic abuse and promote ethical use of technology. In a data-driven society, where data plays a central role, there is a need to foster data literacy in citizens from an early age.
1The right to be forgotten was first established in May 2014 following a ruling by the Court of Justice of the European Union. Subsequently, in 2018, it was reinforced with the General Data Protection Regulation (GDPR)which explicitly includes it in its Article 17 as a "right of erasure". In July 2015, Russia passed a law allowing citizens to request the removal of links on Russian search engines if the information"violates Russian law or if it is false or outdated". Turkey has established its own version of the right to be forgotten, following a similar model to that of the EU. Serbia has also implemented a version of the right to be forgotten in its legislation. In Spain, the Ley Orgánica de Protección de Datos Personales (LOPD) regulates the right to be forgotten, especially with regard to debt collection files. In the United Statesthe right to be forgotten is considered incompatible with the Constitution, mainly because of the strong protection of freedom of expression. However, there are some related regulations, such as the Fair Credit Reporting Act of 1970, which allows in certain situations the deletion of old or outdated information in credit reports.
2Some countries where this right has been established include Spain, regulated by Article 88 of Organic Law 3/2018 on Personal Data Protection; France, which, in 2017, became the first country to pass a law on the right to digital disconnection; Germany, included in the Working Hours and Rest Time Act(Arbeitszeitgesetz); Italy, under Law 81/201; and Belgium. Outside Europe, it is, for example, in Chile.
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
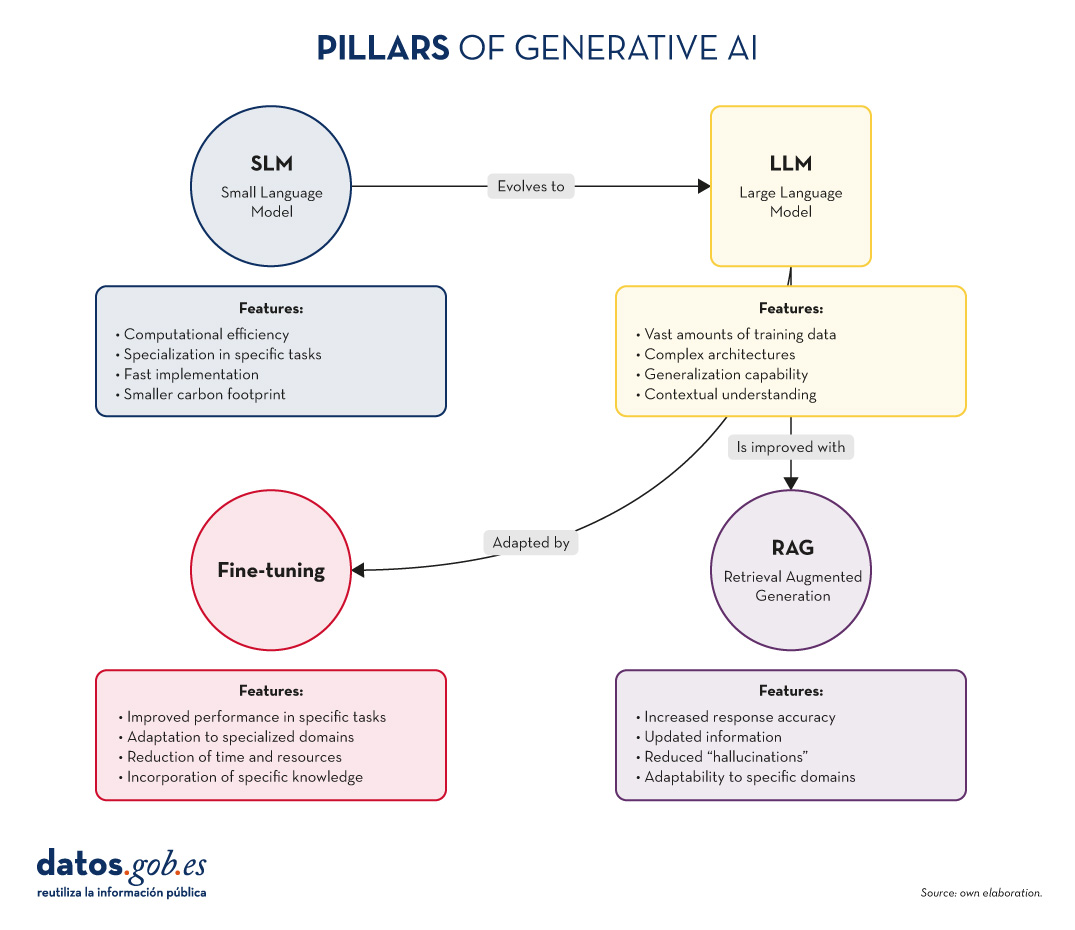
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Artificial intelligence (AI) is revolutionising the way we create and consume content. From automating repetitive tasks to personalising experiences, AI offers tools that are changing the landscape of marketing, communication and creativity.
These artificial intelligences need to be trained with data that are fit for purpose and not copyrighted. Open data is therefore emerging as a very useful tool for the future of AI.
The Govlab has published the report "A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI" to explore this issue in more detail. It analyses the emerging relationship between open data and generative AI, presenting various scenarios and recommendations. Their key points are set out below.
The role of data in generative AI
Data is the fundamental basis for generative artificial intelligence models. Building and training such models requires a large volume of data, the scale and variety of which is conditioned by the objectives and use cases of the model.
The following graphic explains how data functions as a key input and output of a generative AI system. Data is collected from various sources, including open data portals, in order to train a general-purpose AI model. This model will then be adapted to perform specific functions and different types of analysis, which in turn generate new data that can be used to further train models.
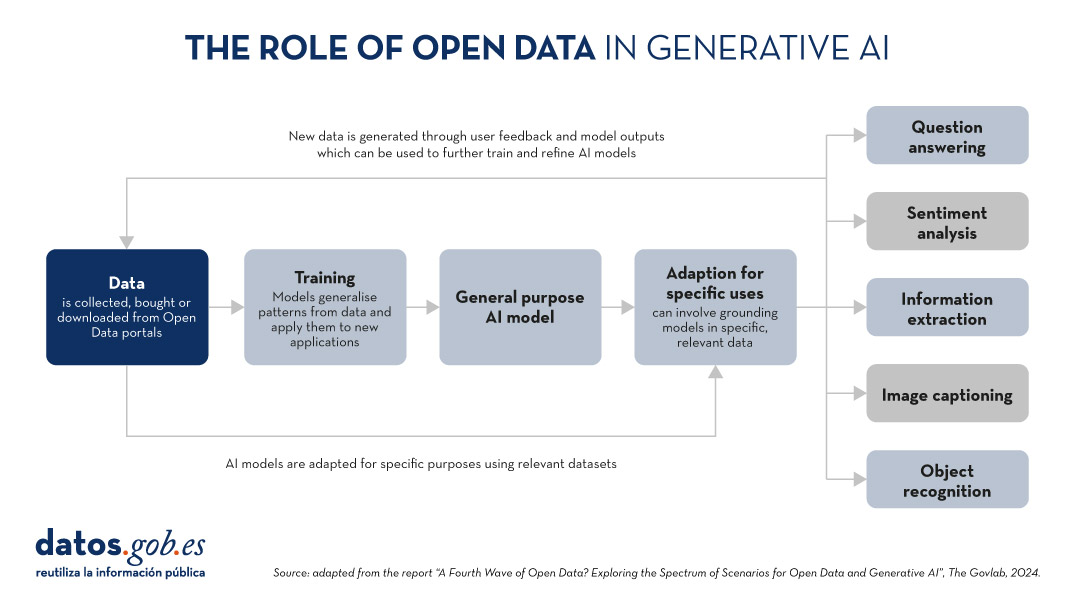
Figure 1. The role of open data in generative AI, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
5 scenarios where open data and artificial intelligence converge
In order to help open data providers ''prepare'' their data for generative AI, The Govlab has defined five scenarios outlining five different ways in which open data and generative AI can intersect. These scenarios are intended as a starting point, to be expanded in the future, based on available use cases.
| Scenario | Function | Quality requirements | Metadata requirements | Example |
|---|---|---|---|---|
| Pre-training | Training the foundational layers of a generative AI model with large amounts of open data. | High volume of data, diverse and representative of the application domain and non-structured usage. | Clear information on the source of the data. | Data from NASA''s Harmonized Landsat Sentinel-2 (HLS) project were used to train the geospatial foundational model watsonx.ai. |
| Adaptation | Refinement of a pre-trained model with task-specific open data, using fine-tuning or RAG techniques. | Tabular and/or unstructured data of high accuracy and relevance to the target task, with a balanced distribution. | Metadata focused on the annotation and provenance of data to provide contextual enrichment. | Building on the LLaMA 70B model, the French Government created LLaMandement, a refined large language model for the analysis and drafting of legal project summaries. They used data from SIGNALE, the French government''s legislative platform. |
| Inference and Insight Generation | Extracting information and patterns from open data using a trained generative AI model. | High quality, complete and consistent tabular data. | Descriptive metadata on the data collection methods, source information and version control. | Wobby is a generative interface that accepts natural language queries and produces answers in the form of summaries and visualisations, using datasets from different offices such as Eurostat or the World Bank. |
| Data Augmentation | Leveraging open data to generate synthetic data or provide ontologies to extend the amount of training data. | Tabular and/or unstructured data which is a close representation of reality, ensuring compliance with ethical considerations. | Transparency about the generation process and possible biases. | A team of researchers adapted the US Synthea model to include demographic and hospital data from Australia. Using this model, the team was able to generate approximately 117,000 region-specific synthetic medical records. |
| Open-Ended Exploration | Exploring and discovering new knowledge and patterns in open data through generative models. | Tabular data and/or unstructured, diverse and comprehensive. | Clear information on sources and copyright, understanding of possible biases and limitations, identification of entities. | NEPAccess is a pilot to unlock access to data related to the US National Environmental Policy Act (NEPA) through a generative AI model. It will include functions for drafting environmental impact assessments, data analysis, etc. |
Figure 2. Five scenarios where open data and Artificial Intelligence converge, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
You can read the details of these scenarios in the report, where more examples are explained. In addition, The Govlab has also launched an observatory where it collects examples of intersections between open data and generative artificial intelligence. It includes the examples in the report along with additional examples. Any user can propose new examples via this form. These examples will be used to further study the field and improve the scenarios currently defined.
Among the cases that can be seen on the web, we find a Spanish company: Tendios. This is a software-as-a-service company that has developed a chatbot to assist in the analysis of public tenders and bids in order to facilitate competition. This tool is trained on public documents from government tenders.
Recommendations for data publishers
To extract the full potential of generative AI, improving its efficiency and effectiveness, the report highlights that open data providers need to address a number of challenges, such as improving data governance and management. In this regard, they contain five recommendations:
- Improve transparency and documentation. Through the use of standards, data dictionaries, vocabularies, metadata templates, etc. It will help to implement documentation practices on lineage, quality, ethical considerations and impact of results.
- Maintaining quality and integrity. Training and routine quality assurance processes are needed, including automated or manual validation, as well as tools to update datasets quickly when necessary. In addition, mechanisms for reporting and addressing data-related issues that may arise are needed to foster transparency and facilitate the creation of a community around open datasets.
- Promote interoperability and standards. It involves adopting and promoting international data standards, with a special focus on synthetic data and AI-generated content.
- Improve accessibility and user-friendliness. It involves the enhancement of open data portals through intelligent search algorithms and interactive tools. It is also essential to establish a shared space where data publishers and users can exchange views and express needs in order to match supply and demand.
- Addressing ethical considerations. Protecting data subjects is a top priority when talking about open data and generative AI. Comprehensive ethics committees and ethical guidelines are needed around the collection, sharing and use of open data, as well as advanced privacy-preserving technologies.
This is an evolving field that needs constant updating by data publishers. These must provide technically and ethically adequate datasets for generative AI systems to reach their full potential.
Noticia
Digital transformation has become a fundamental pillar for the economic and social development of countries in the 21st century. In Spain, this process has become particularly relevant in recent years, driven by the need to adapt to an increasingly digitalised and competitive global environment. The COVID-19 pandemic acted as a catalyst, accelerating the adoption of digital technologies in all sectors of the economy and society.
However, digital transformation involves not only the incorporation of new technologies, but also a profound change in the way organisations operate and relate to their customers, employees and partners. In this context, Spain has made significant progress, positioning itself as one of the leading countries in Europe in several aspects of digitisation.
The following are some of the most prominent reports analysing this phenomenon and its implications.
State of the Digital Decade 2024 report
The State of the Digital Decade 2024 report examines the evolution of European policies aimed at achieving the agreed objectives and targets for successful digital transformation. It assesses the degree of compliance on the basis of various indicators, which fall into four groups: digital infrastructure, digital business transformation, digital skills and digital public services.

Figure 1. Taking stock of progress towards the Digital Decade goals set for 2030, “State of the Digital Decade 2024 Report”, European Commission.
In recent years, the European Union (EU) has significantly improved its performance by adopting regulatory measures - with 23 new legislative developments, including, among others, the Data Governance Regulation and the Data Regulation- to provide itself with a comprehensive governance framework: the Digital Decade Policy Agenda 2030.
The document includes an assessment of the strategic roadmaps of the various EU countries. In the case of Spain, two main strengths stand out:
- Progress in the use of artificial intelligence by companies (9.2% compared to 8.0% in Europe), where Spain's annual growth rate (9.3%) is four times higher than the EU (2.6%).
- The large number of citizens with basic digital skills (66.2%), compared to the European average (55.6%).
On the other hand, the main challenges to overcome are the adoption of cloud services ( 27.2% versus 38.9% in the EU) and the number of ICT specialists ( 4.4% versus 4.8% in Europe).
The following image shows the forecast evolution in Spain of the key indicators analysed for 2024, compared to the targets set by the EU for 2030.

Figure 2. Key performance indicators for Spain, “Report on the State of the Digital Decade 2024”, European Commission.
Spain is expected to reach 100% on virtually all indicators by 2030. 26.7 billion (1.8 % of GDP), without taking into account private investments. This roadmap demonstrates the commitment to achieving the goals and targets of the Digital Decade.
In addition to investment, to achieve the objective, the report recommends focusing efforts in three areas: the adoption of advanced technologies (AI, data analytics, cloud) by SMEs; the digitisation and promotion of the use of public services; and the attraction and retention of ICT specialists through the design of incentive schemes.
European Innovation Scoreboard 2024
The European Innovation Scoreboard carries out an annual benchmarking of research and innovation developments in a number of countries, not only in Europe. The report classifies regions into four innovation groups, ranging from the most innovative to the least innovative: Innovation Leaders, Strong Innovators, Moderate Innovators and Emerging Innovators.
Spain is leading the group of moderate innovators, with a performance of 89.9% of the EU average. This represents an improvement compared to previous years and exceeds the average of other countries in the same category, which is 84.8%. Our country is above the EU average in three indicators: digitisation, human capital and financing and support. On the other hand, the areas in which it needs to improve the most are employment in innovation, business investment and innovation in SMEs. All this is shown in the following graph:
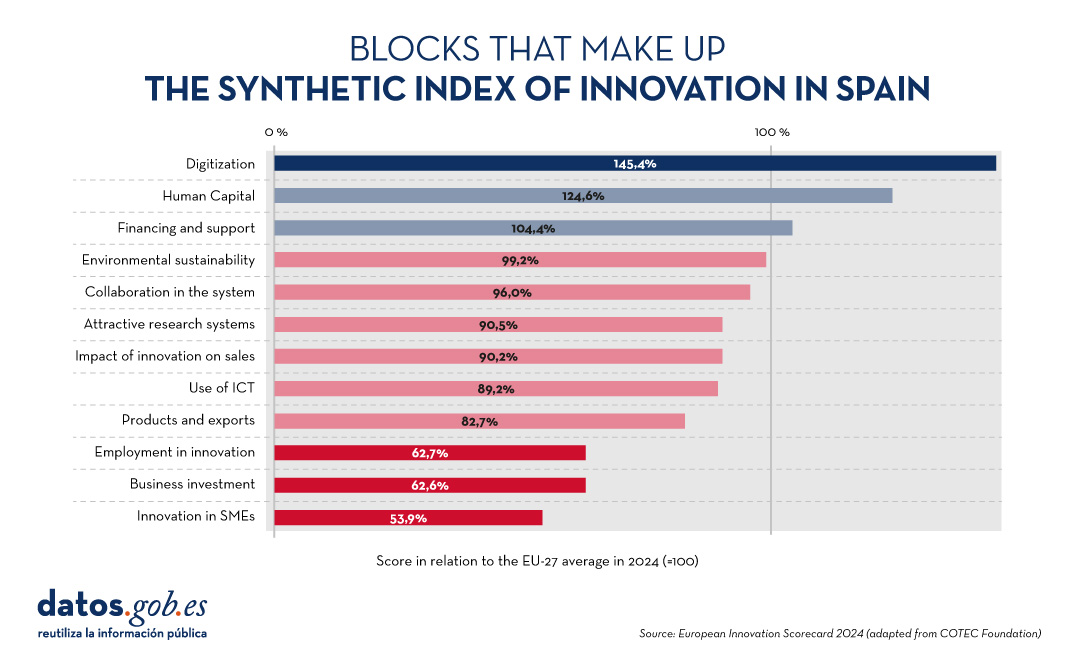
Figure 3. Blocks that make up the synthetic index of innovation in Spain, European Innovation Scorecard 2024 (adapted from the COTEC Foundation).
Spain's Digital Society Report 2023
The Telefónica Foundation also periodically publishes a report which analyses the main changes and trends that our country is experiencing as a result of the technological revolution.
The edition currently available is the 2023 edition. It highlights that "Spain continues to deepen its digital transformation process at a good pace and occupies a prominent position in this aspect among European countries", highlighting above all the area of connectivity. However, digital divides remain, mainly due to age.
Progress is also being made in the relationship between citizens and digital administrations: 79.7% of people aged 16-74 used websites or mobile applications of an administration in 2022. On the other hand, the Spanish business fabric is advancing in its digitalisation, incorporating digital tools, especially in the field of marketing. However, there is still room for improvement in aspects of big data analysis and the application of artificial intelligence, activities that are currently implemented, in general, only by large companies.
Artificial Intelligence and Data Talent Report
IndesIA, an association that promotes the use of artificial intelligence and Big Data in Spain, has carried out a quantitative and qualitative analysis of the data and artificial intelligence talent market in 2024 in our country.
According to the report, the data and artificial intelligence talent market represents almost 19% of the total number of ICT professionals in our country. In total, there are 145,000 professionals (+2.8% from 2023), of which only 32% are women. Even so, there is a gap between supply and demand, especially for natural language processing engineers. To address this situation, the report analyses six areas for improvement: workforce strategy and planning, talent identification, talent activation, engagement, training and development, and data-driven culture .
Other reports of interest
The COTEC Foundation also regularly produces various reports on the subject. On its website we can find documents on the budget execution of R&D in the public sector, the social perception of innovation or the regional talent map.
For their part, the Orange Foundation in Spain and the consultancy firm Nae have produced a report to analyse digital evolution over the last 25 years, the same period that the Foundation has been operating in Spain. The report highlights that, between 2013 and 2018, the digital sector has contributed around €7.5 billion annually to the country's GDP.
In short, all of them highlight Spain's position among the European leaders in terms of digital transformation, but with the need to make progress in innovation. This requires not only boosting economic investment, but also promoting a cultural change that fosters creativity. A more open and collaborative mindset will allow companies, administrations and society in general to adapt quickly to technological changes and take advantage of the opportunities they bring to ensure a prosperous future for Spain.
Do you know of any other reports on the subject? Leave us a comment or write to us at dinamizacion@datos.gos.es.
Blog
General ethical frameworks
The absence of a common, unified, ethical framework for the use of artificial intelligence in the world is only apparent and, in a sense, a myth. There are a multitude of supranational charters, manuals and sets of standards that set out principles of ethical use, although some of them have had to be updated with the emergence of new tools and uses. The OECD guide on ethical standards for the use of artificial intelligence, published in 2019 but updated in 2024, includes value-based principles as well as recommendations for policymakers. The UNESCO Global Observatory on Ethics and Governance of AI published in 2021 a material called Recommendation on the Ethics of AI adopted in the same year by 193 countries, and based on four basic principles: human rights, social justice, diversity and inclusiveness, and respect for the environmental ecosystem. Also in 2021, the WHO specifically included a document on Ethics and Governance of AI for Health in which they indicated the need to establish responsibilities for organisations in the use of AI when it affects patients and healthcare workers. However, various entities and sectors at different levels have taken the initiative to establish their own ethical standards and guidelines, more appropriate to their context. For example, in February 2024, the Ministry of Culture in Spain developed a good practice guide to establish, among other guidelines, that works created exclusively with generative AI would not be eligible for awards.
Therefore, the challenge is not the absence of global ethical guidelines, but the excessive globality of these frameworks. With the legitimate aim of ensuring that they stand the test of time, are valid for the specific situation of any country in the world and remain operational in the face of new disruptions, these general standards end up resorting to familiar concepts, such as those we can read in this other ethical guide from the World Economic Forum: explainability, transparency, reliability, robustness, privacy, security. Concepts that are too high, predictable, and almost always look at AI from the point of view of the developer and not the user.
Media manifestos
Along these lines, the major media groups have invested their efforts in developing specific ethical principles for the use of AI in the creation and dissemination of content, which for now constitutes a significant gap in the major frameworks and even in the European Regulation itself. These efforts have sometimes materialised individually, in the form of a manifesto, but also at a higher level as a collective. Among the most relevant manifestos are the one by Le Figaro, which editorial staff states that it will not publish any articles or visual content generated with AI, or that of The Guardian which, updated in 2023, states that AI is a common tool in newsrooms, but only to assist in ensuring the quality of their work. For their part, the Spanish media have not issued their own manifestos, but they have supported different collective initiatives. The Prisa Group, for example, appears in the list of organisations that subscribe to the Manifesto for Responsible and Sustainable AI, published by Forética in 2024. Also interesting are the statements of the heads of innovation and digital strategy at El País, El Español, El Mundo and RTVE that we found in an interview published on Fleet Street in April 2023. When asked whether there are any specific red lines in their media on the use of AI, they all stated that they are open-minded in their exploration and have not limited their use too much. Only RTVE, is not in the same position with a statement: "We understand that it is something complementary and to help us. Anything a journalist does, we don't want an AI to do. It has to be under our control.
Global principles of journalism
In the publishing context, therefore, we find a panorama of multiple regulations on three possible levels: manifestos specific to each medium, collective initiatives of the sector and adherence to general codes of ethics at national level. Against this backdrop, by the end of 2023 the News Media Alliance published the Global Principles for AI in Journalism, a document signed by international editorial groups that includes, in the form of a decalogue, 12 fundamental ethical principles divided into 8 blocks:

Figure 1. Global principles of AI in journalism, News Media Alliance.
When we review them in depth, we find in them some of the major conflicts that are shaping the development of modern artificial intelligence, connections with the European AI Regulation and claims that are constant on the part of content creators:
- Block 1: Intellectual property. It is the first and most comprehensive block, specifically developed in four complementary ethical principles. Although it seems the most obvious principle, it is aimed at focusing on one of the main conflicts of modern AI: the indiscriminate use of content published on the internet (text, image, video, music) to train learning models without consulting or remunerating the authors. The first ethical principle expresses the duty of AI system developers to respect restrictions or limitations imposed by copyright holders on access to and use of content. The second expresses the ability of these authors and publishing groups to negotiate fair remuneration for the use of their intellectual property. Third, it legitimises copyright as a sufficient basis in law to protect an author's content. The fourth calls for recognising and respecting existing markets for licensing, i.e. creating efficient contracts, agreements and market models so that AI systems can be trained with quality, but legitimate, authorised and licensed content.
- Block 2: Transparency. The second block is a logical continuation of the previous one, and advocates transparency in operation, a feature that brings value to both content authors and users of AI systems. This principle coincides with the central obligation that the European Regulation places on generative AI systems: they must be transparent from the outset and declare what content they have trained on, what procedures they have used to acquire it and to what extent they comply with the authors' intellectual property rights. This transparency is essential for creators and publishing groups to be able to enforce their rights, and it is further established that this principle must be universally adhered to, regardless of the jurisdiction in which the training or testing takes place.
- Block 3: Accountability. This word refers to the ability to be accountable for an action. The principle states that developers and operators of AI systems should be held accountable for the outputs generated by their systems, for example if they attribute content to authors that is not real, or if they contribute to misinformation or undermine trust in science or democratic values.
- Block 4: Quality and integrity. The basis of the principle is that AI-generated content must be accurate, correct and complete, and must not distort the original works. However, this superficial idea builds on a more ambitious one: that publishing and media groups should be guarantors of this quality and integrity, and thus official suppliers to AI system developers and providers. The fundamental argument is that the quality of the training content will define the quality of the outcomes of the system.
- Block 5: Fairness. The word fairness can also be translated as equity or impartiality. The principle states in its headline that the use of AI should not create market unfairness, anti-competitive practices or unfair competition, meaning that it should not be allowed to be used to promote abuses of dominance or to exclude rivals from the market. This principle is not aimed at regulating competition between AI developers, but between AI developers and content providers: AI-generated text, music or images should never compete on equal terms with author-generated content.
- Block 6: Safety. It is composed of two ethical principles. Building on the above, the first security principle states that generative AI systems must be reliable in terms of the information sources they use and promote, which must not alter or misrepresent the content, preserving its original integrity. The opposite could result in a weakening of the public's trust in original works, in authors and even in major media groups. This principle applies to a large extent to new AI-assisted search engines, such as the new Google Search (SGE), the new SearchGPT or Microsoft's own Copilot, which collect and recast information from different sources into a single generated paragraph. The second point unifies user data privacy issues into a single principle and, in just one sentence, refers to discriminatory bias. Developers must be able to explain how, when and for what purpose they use user data, and must ensure that systems do not produce, multiply or chronic biases that discriminate against individuals or groups.
- Block 7: By design. This is an overarching meta-principle, which states that all principles should be incorporated by design in all AI systems, generative or otherwise. Historically, ethics has been considered at the end of the development process, as a secondary or minor issue, so the principle argues that ethics should be a significant and fundamental concern from the very process of system design. Nor can ethical auditing be relegated only to cases where users file a complaint.
- Block 8: Sustainable development. It is apparently a global, far-reaching principle that AI systems should be aligned with human values and operate in accordance with global laws, in order to benefit all of humanity and future generations. However, in the last sentence we find the real orientation of the principle, a connection to publishing groups as data providers for AI systems: "Long-term funding and other incentives for providers of high-quality input data can help align systems with societal goals and extract the most relevant, up-to-date and actionable knowledge
The document is signed by 31 associations of publishing groups from countries such as Denmark, Korea, Canada, Colombia, Portugal, Brazil, Argentina, Japan or Sweden, by associations at European level, such as the European Publishers Council or News Media Europe, and associations at global level such as WAN-IFRA (World Association of News Publishers). The Spanish groups include the Asociación de Medios de Información (AMI) and the Asociación de Revistas (ARI).
Ethics as an instrument
The global principles of journalism promoted by the News Media Alliance are particularly precise in proposing grounded solutions to ethical dilemmas that are very representative of the current situation, such as the use of authored content for the commercial exploitation of AI systems. They are useful in trying to establish a solid and, above all, unified and global ethical framework that proposes consensual solutions. At the same time, other conflicts affecting the profession, which would also be included in this Decalogue, are conspicuously absent from the document. It is possible that the omnipresence of the constantly referenced data licensing conflict has overshadowed other concerns such as the new speed of disinformation, the ability of investigative journalism to verify authentic content, or the impact of fake news and deepfakes on democratic processes. The principles have focused on setting out the obligations that the big tech companies should have regarding the use of content, but perhaps an extension could be expected to address ethical responsibilities from the media's point of view, such as what ethical model the integration of AI into newsroom activity should be based on, and what the responsibility of journalists is in this new scenario. Finally, the document reveals a common duality: the channelling, through the ethical proposal, of the suggestion of concrete solutions that even point to possible trade and market agreements. It is a clear reflection of the potential capacity of ethics to be much more than a moral framework, and to become a multidimensional instrument to guide decision-making and influence the creation of public policy.
Content prepared by Carmen Torrijos, expert in AI applied to language and communication. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
In recent months we have seen how the large language models (LLMs ) that enable Generative Artificial Intelligence (GenAI) applications have been improving in terms of accuracy and reliability. RAG (Retrieval Augmented Generation) techniques have allowed us to use the full power of natural language communication (NLP) with machines to explore our own knowledge bases and extract processed information in the form of answers to our questions. In this article we take a closer look at RAG techniques in order to learn more about how they work and all the possibilities they offer in the context of generative AI.
What are RAG techniques?
This is not the first time we have talked about RAG techniques. In this article we have already introduced the subject, explaining in a simple way what they are, what their main advantages are and what benefits they bring in the use of Generative AI.
Let us recall for a moment its main keys. RAG is translated as Retrieval Augmented Generation . In other words, RAG consists of the following: when a user asks a question -usually in a conversational interface-, the Artificial Intelligence (AI), before providing a direct answer -which it could give using the (fixed) knowledge base with which it has been trained-, carries out a process of searching and processing information in a specific database previously provided, complementary to that of the training. When we talk about a database, we refer to a knowledge base previously prepared from a set of documents that the system will use to provide more accurate answers. Thus, when using RAGtechniques, conversational interfaces produce more accurate and context-specific responses.
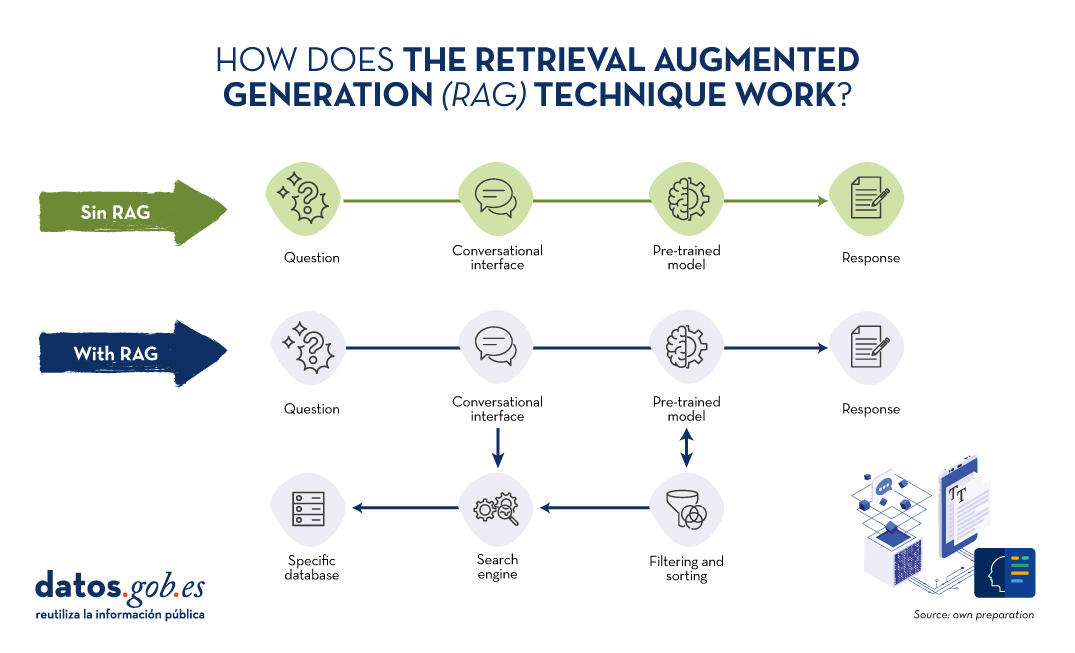
Source: Own preparation.
Conceptual diagram of the operation of a conversational interface or assistant without using RAG (top) and using RAG (bottom).
Drawing a comparison with the medical field, we could say that the use of RAG is as if a doctor, with extensive experience and therefore highly trained, in addition to the knowledge acquired during his academic training and years of experience, has quick and effortless access to the latest studies, analyses and medical databases instantly, before providing a diagnosis. Academic training and years of experience are equivalent to large language model (LLM) training and the "magic" access to the latest studies and specific databases can be assimilated to what RAG techniques provide.
Evidently, in the example we have just given, good medical practice makes both elements indispensable, and the human brain knows how to combine them naturally, although not without effort and time, even with today's digital tools, which make the search for information easier and more immediate.
RAG in detail
RAG Fundamentals
RAG combines two phases to achieve its objective: recovery and generation. In the first, relevant documents are searched for in a database containing information relevant to the question posed (e.g. a clinical database or a knowledge base of commonly asked questions and answers). In the second, an LLM is used to generate a response based on the retrieved documents. This approach ensures that responses are not only consistent but also accurate and supported by verifiable data.
Components of the RAG System
In the following, we will describe the components that a RAG algorithm uses to fulfil its function. For this purpose, for each component, we will explain what function it fulfils, which technologies are used to fulfil this function and an example of the part of the RAG process in which that component is involved.
- Recovery Model:
- Function: Identifies and retrieves relevant documents from a large database in response to a query.
- Technology: It generally uses Information Retrieval (IR) techniques such as BM25 or embedding-based retrieval models such as Dense Passage Retrieval (DPR).
- Process: Given a question, the retrieval model searches a database to find the most relevant documents and presents them as context for answer generation.
- Generation Model:
- Function: Generate coherent and contextually relevant answers using the retrieved documents.
- Technology: Based on some of the major Large Language Models (LLM) such as GPT-3.5, T5, or BERT, Llama.
- Process: The generation model takes the user's query and the retrieved documents and uses this combined information to produce an accurate response.
Detailed RAG Process
For a better understanding of this section, we recommend the reader to read this previous work in which we explain in a didactic way the basics of natural language processing and how we teach machines to read. In detail, a RAG algorithm performs the following steps:
- Reception of the question. The system receives a question from the user. This question is processed to extract keywords and understand the intention.
- Document retrieval. The question is sent to the recovery model.
- Example of Retrieval based on embeddings:
- The question is converted into a vector of embeddings using a pre-trained model.
- This vector is compared with the document vectors in the database.
- The documents with the highest similarity are selected.
- Example of BM25:
- The question is tokenised and the keywords are compared with the inverted indexes in the database.
- The most relevant documents are retrieved according to a relevance score.
- Example of Retrieval based on embeddings:
- Filtering and sorting. The retrieved documents are filtered to eliminate redundancies and to classify them according to their relevance. Additional techniques such as reranking can be applied using more sophisticated models.
- Response generation. The filtered documents are concatenated with the user's question and fed into the generation model. The LLM uses the combined information to generate an answer that is coherent and directly relevant to the question. For example, if we use GPT-3.5 as LLM, the input to the model includes both the user's question and fragments of the retrieved documents. Finally, the model generates text using its ability to understand the context of the information provided.
In the following section we will look at some applications where Artificial Intelligence and large language models play a differentiating role and, in particular, we will analyse how these use cases benefit from the application of RAGtechniques.
Examples of use cases that benefit substantially from using RAG vs. not using RAG
1. ECommerceCustomer Service
- No RAG:
- A basic chatbot can give generic and potentially incorrect answers about return policies.
- Example: Please review our returns policy on the website.
- With RAG:
- The chatbot accesses the database of updated policies and provides a specific and accurate response.
- Example: You may return products within 30 days of purchase, provided they are in their original packaging. See more details [here].
2. Medical Diagnosis
- No RAG:
- A virtual health assistant could offer recommendations based only on their previous training, without access to the latest medical information.
- Example: You may have the flu. Consult your doctor
- With RAG:
- The wizard can retrieve information from recent medical databases and provide a more accurate and up-to-date diagnosis.
- Example: Based on your symptoms and recent studies published in PubMed, you could be dealing with a viral infection. Consult your doctor for an accurate diagnosis.
3. Academic Research Assistance
- No RAG:
- A researcher receives answers limited to what the model already knows, which may not be sufficient for highly specialised topics.
- Example: Economic growth models are important for understanding the economy.
- With RAG:
- The wizard retrieves and analyses relevant academic articles, providing detailed and accurate information.
- Example: According to the 2023 study in the Journal of Economic Growth, the XYZ model has been shown to be 20% more accurate in predicting economic trends in emerging markets.
4. Journalism
- No RAG:
- A journalist receives generic information that may not be up to date or accurate.
- Example Artificial intelligence is changing many industries.
- With RAG:
- The wizard retrieves specific data from recent studies and articles, providing a solid basis for the article.
- Example: According to a 2024 report by 'TechCrunch', AI adoption in the financial sector has increased by 35% in the last year, improving operational efficiency and reducing costs.
Of course, for most of us who have experienced the more accessible conversational interfaces, such as ChatGPT, Gemini o Bing we can see that the answers are usually complete and quite precise when it comes to general questions. This is because these agents make use of AGN methods and other advanced techniques to provide the answers. However, it is not long before conversational assistants, such as Alexa, Siri u OK Google provided extremely simple answers and very similar to those explained in the previous examples when not making use of RAG.
Conclusions
Retrieval Augmented Generation (RAG) techniques improve the accuracy and relevance of language model answers by combining document retrieval and text generation. Using retrieval methods such as BM25 or DPR and advanced language models, RAG provides more contextualised, up-to-date and accurate responses.Today, RAG is the key to the exponential development of AI in the private data domain of companies and organisations. In the coming months, RAG is expected to see massive adoption in a variety of industries, optimising customer care, medical diagnostics, academic research and journalism, thanks to its ability to integrate relevant and current information in real time.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Noticia
The European Parliament's tenth parliamentary term started on July, a new institutional cycle that will run from 2024-2029. The President of the European Commission, Ursula von der Leyen, was elected for a second term, after presenting to the European Parliament her Political Guidelines for the next European Commission 2024-2029.
These guidelines set out the priorities that will guide European policies in the coming years. Among the general objectives, we find that efforts will be invested in:
- Facilitating business and strengthening the single market.
- Decarbonise and reduce energy prices.
- Make research and innovation the engines of the economy.
- Boost productivity through the diffusion of digital technology.
- Invest massively in sustainable competitiveness.
- Closing the skills and manpower gap.
In this article, we will explain point 4, which focuses on combating the insufficient diffusion of digital technologies. Ignorance of the technological possibilities available to citizens limits the capacity to develop new services and business models that are competitive on a global level.
Boosting productivity with the spread of digital technology
The previous mandate was marked by the approval of new regulations aimed at fostering a fair and competitive digital economy through a digital single market, where technology is placed at the service of people. Now is the time to focus on the implementation and enforcement of adopted digital laws.
One of the most recently approved regulations is the Artificial Intelligence (AI) Regulation, a reference framework for the development of any AI system. In this standard, the focus was on ensuring the safety and reliability of artificial intelligence, avoiding bias through various measures including robust data governance.
Now that this framework is in place, it is time to push forward the use of this technology for innovation. To this end, the following aspects will be promoted in this new cycle:
- Artificial intelligence factories. These are open ecosystems that provide an infrastructure for artificial intelligence supercomputing services. In this way, large technological capabilities are made available to start-up companies and research communities.
- Strategy for the use of artificial intelligence. It seeks to boost industrial uses in a variety of sectors, including the provision of public services in areas such as healthcare. Industry and civil society will be involved in the development of this strategy.
- European Research Council on Artificial Intelligence. This body will help pool EU resources, facilitating access to them.
But for these measures to be developed, it is first necessary to ensure access to quality data. This data not only supports the training of AI systems and the development of cutting-edge technology products and services, but also helps informed decision-making and the development of more accurate political and economic strategies. As the document itself states " Access to data is not only a major driver for competitiveness, accounting for almost 4% of EU GDP, but also essential for productivity and societal innovations, from personalised medicine to energy savings”.
To improve access to data for European companies and improve their competitiveness vis-à-vis major global technology players, the European Union is committed to "improving open access to data", while ensuring the strictest data protection.
The European data revolution
"Europe needs a data revolution. This is how blunt the President is about the current situation. Therefore, one of the measures that will be worked on is a new EU Data Strategy. This strategy will build on existing standards. It is expected to build on the existing strategy, whose action lines include the promotion of information exchange through the creation of a single data market where data can flow between countries and economic sectors in the EU.
In this framework, the legislative progress we saw in the last legislature will continue to be very much in evidence:
- Directive (EU) 2019/1024 on open data and re-use of public sector information, which establishes the legal framework for the re-use of public sector information, made available to the public as open data, including the promotion of high-value data.
- Regulation (EU) 2022/868 on European Data Governance (EDG), which regulates the secure and voluntary exchange of data sets held by public bodies over which third party rights concur, as well as data brokering services and the altruistic transfer of data.
- Regulation (EU) 2023/2854 on harmonised rules for fair access to and use of data (Data Act), which promotes harmonised rules on fair access and use of data in the framework of the European Strategy.
The aim is to ensure a "simplified, clear and coherent legal framework for businesses and administrations to share data seamlessly and at scale, while respecting high privacy and security standards".
In addition to stepping up investment in cutting-edge technologies, such as supercomputing, the internet of things and quantum computing, the EU plans to continue promoting access to quality data to help create a sustainable and solvent technological ecosystem capable of competing with large global companies. In this space we will keep you informed of the measures taken to this end.
Blog
The publication on Friday 12 July 2024 of the Artificial Intelligence Regulation (AIA) opens a new stage in the European and global regulatory framework. The standard is characterised by an attempt to combine two souls. On the one hand, it is about ensuring that technology does not create systemic risks for democracy, the guarantee of our rights and the socio-economic ecosystem as a whole. On the other hand, a targeted approach to product development is sought in order to meet the high standards of reliability, safety and regulatory compliance defined by the European Union.
Scope of application of the standard
The standard allows differentiation between low-and medium-risk systems, high-risk systems and general-purpose AI models. In order to qualify systems, the AIA defines criteria related to the sector regulated by the European Union (Annex I) and defines the content and scope of those systems which by their nature and purpose could generate risks (Annex III). The models are highly dependent on the volume of data, their capacities and operational load.
AIA only affects the latter two cases: high-risk systems and general-purpose AI models. High-risk systems require conformity assessment through notified bodies. These are entities to which evidence is submitted that the development complies with the AIA. In this respect, the models are subject to control formulas by the Commission that ensure the prevention of systemic risks. However, this is a flexible regulatory framework that favours research by relaxing its application in experimental environments, as well as through the deployment of sandboxes for development.
The standard sets out a series of "requirements for high-risk AI systems" (section two of chapter three) which should constitute a reference framework for the development of any system and inspire codes of good practice, technical standards and certification schemes. In this respect, Article 10 on "data and data governance" plays a central role. It provides very precise indications on the design conditions for AI systems, particularly when they involve the processing of personal data or when they are projected on natural persons.
This governance should be considered by those providing the basic infrastructure and/or datasets, managing data spaces or so-called Digital Innovation Hubs, offering support services. In our ecosystem, characterised by a high prevalence of SMEs and/or research teams, data governance is projected on the quality, security and reliability of their actions and results. It is therefore necessary to ensure the values that AIA imposes on training, validation and test datasets in high-risk systems, and, where appropriate, when techniques involving the training of AI models are employed.
These values can be aligned with the principles of Article 5 of the General Data Protection Regulation (GDPR) and enrich and complement them. To these are added the risk approach and data protection by design and by default. Relating one to the other is ancertainly interesting exercise.
Ensure the legitimate origin of the data. Loyalty and lawfulness
Alongside the common reference to the value chain associated with data, reference should be made to a 'chain of custody' to ensure the legality of data collection processes. The origin of the data, particularly in the case of personal data, must be lawful, legitimate and its use consistent with the original purpose of its collection. A proper cataloguing of the datasets at source is therefore indispensable to ensure a correct description of their legitimacy and conditions of use.
This is an issue that concerns open data environments, data access bodies and services detailed in the Data Governance Regulation (DGA ) or the European Health Data Space (EHDS) and is sure to inspire future regulations. It is usual to combine external data sources with the information managed by the SME.
Data minimisation, accuracy and purpose limitation
AIA mandates, on the one hand, an assessment of the availability, quantity and adequacy of the required datasets. On the other hand, it requires that the training, validation and test datasets are relevant, sufficiently representative and possess adequate statistical properties. This task is highly relevant to the rights of individuals or groups affected by the system. In addition, they shall, to the greatest extent possible, be error-free and complete in view of their intended purpose. AIA predicates these properties for each dataset individually or for a combination of datasets.
In order to achieve these objectives, it is necessary to ensure that appropriate techniques are deployed:
- Perform appropriate processing operations for data preparation, such as annotation, tagging, cleansing, updating, enrichment and aggregation.
- Make assumptions, in particular with regard to the information that the data are supposed to measure and represent. Or, to put it more colloquially, to define use cases.
- Take into account, to the extent necessary for the intended purpose, the particular characteristics or elements of the specific geographical, contextual, behavioural or functional environment in which the high-risk AI system is intended to be used.
Managing risk: avoiding bias
In the area of data governance, a key role is attributed to the avoidance of bias where it may lead to risks to the health and safety of individuals, adversely affect fundamental rights or give rise to discrimination prohibited by Union law, in particular where data outputs influence incoming information for future operations. To this end, appropriate measures should be taken to detect, prevent and mitigate possible biases identified.
The AIA exceptionally enables the processing of special categories of personal data provided that they offer adequate safeguards in relation to the fundamental rights and freedoms of natural persons. But it imposes additional conditions:
- the processing of other data, such as synthetic or anonymised data, does not allow effective detection and correction of biases;
- that special categories of personal data are subject to technical limitations concerning the re-use of personal data and to state-of-the-art security and privacy protection measures, including the pseudonymisation;
- that special categories of personal data are subject to measures to ensure that the personal data processed are secured, protected and subject to appropriate safeguards, including strict controls and documentation of access, to prevent misuse and to ensure that only authorised persons have access to such personal data with appropriate confidentiality obligations;
- that special categories of personal data are not transmitted or transferred to third parties and are not otherwise accessible to them;
- that special categories of personal data are deleted once the bias has been corrected or the personal data have reached the end of their retention period, whichever is the earlier;
- that the records of processing activities under Regulations (EU) 2016/679 and (EU) 2018/1725 and Directive (EU) 2016/680 include the reasons why the processing of special categories of personal data was strictly necessary for detecting and correcting bias, and why that purpose could not be achieved by processing other data.
The regulatory provisions are extremely interesting. RGPD, DGA or EHDS are in favour of processing anonymised data. AIA makes an exception in cases where inadequate or low-quality datasets are generated from a bias point of view.
Individual developers, data spaces and intermediary services providing datasets and/or platforms for development must be particularly diligent in defining their security. This provision is consistent with the requirement to have secure processing spaces in EHDS, implies a commitment to certifiable security standards, whether public or private, and advises a re-reading of the seventeenth additional provision on data processing in our Organic Law on Data Protection in the area of pseudonymisation, insofar as it adds ethical and legal guarantees to the strictly technical ones. Furthermore, the need to ensure adequate traceability of uses is underlined. In addition, it will be necessary to include in the register of processing activities a specific mention of this type of use and its justification.
Apply lessons learned from data protection, by design and by default
Article 10 of AIA requires the documentation of relevant design decisions and the identification of relevant data gaps or deficiencies that prevent compliance with AIA and how to address them. In short, it is not enough to ensure data governance, it is also necessary to provide documentary evidence and to maintain a proactive and vigilant attitude throughout the lifecycle of information systems.
These two obligations form the keystone of the system. And its reading should even be much broader in the legal dimension. Lessons learned from the GDPR teach that there is a dual condition for proactive accountability and the guarantee of fundamental rights. The first is intrinsic and material: the deployment of privacy engineering in the service of data protection by design and by default ensures compliance with the GDPR. The second is contextual: the processing of personal data does not take place in a vacuum, but in a broad and complex context regulated by other sectors of the law.
Data governance operates structurally from the foundation to the vault of AI-based information systems. Ensuring that it exists, is adequate and functional is essential. This is the understanding of the Spanish Government's Artificial Intelligence Strategy 2024 which seeks to provide the country with the levers to boost our development.
AIA makes a qualitative leap and underlines the functional approach from which data protection principles should be read by stressing the population dimension. This makes it necessary to rethink the conditions under which the GDPR has been complied with in the European Union. There is an urgent need to move away from template-based models that the consultancy company copies and pastes. It is clear that checklists and standardisation are indispensable. However, its effectiveness is highly dependent on fine tuning. And this calls particularly on the professionals who support the fulfilment of this objective to dedicate their best efforts to give deep meaning to the fulfilment of the Artificial Intelligence Regulation.
You can see a summary of the regulations in the following infographic:

You can access the accessible and interactive version here
Content prepared by Ricard Martínez, Director of the Chair of Privacy and Digital Transformation. Professor, Department of Constitutional Law, Universitat de València. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The Artificial Intelligence Strategy 2024 is the comprehensive plan that establishes a framework to accelerate the development and expansion of artificial intelligence (AI) in Spain. This strategy was approved, at the proposal of the Ministry for Digital Transformation and the Civil Service, by the Council of Ministers on 14 May 2024 and comes to reinforce and accelerate the National Artificial Intelligence Strategy (ENIA), which began to be deployed in 2020.
The dizzying evolution of the technologies associated with Artificial Intelligence in recent years justifies this reinforcement. For example, according to the AI Index Report for 2024 by Stanford University AI investment has increased nine-fold since 2022. The cost of training models has risen dramatically, but in return AI is driving progress in science, medicine and overall labour productivity in general. For reasons such as these, the aim is to maximise the impact of AI on the economy and to build on the positive elements of ongoing work.
The new strategy is built around three main axes, which will be developed through eight lines of action. These axes are:
- Strengthen the key levers for AI development. This axis focuses on boosting investment in supercomputing, building sustainable storage capacity, developing models and data to form a public AI infrastructure, and fostering AI talent .
- Facilitate the expansion of AI in the public and private sector, fostering innovation and cybersecurity. This axis aims to incorporate AI into government and business processes, with a special emphasis on SMEs, and to develop a robust cybersecurity framework .
- Promote transparent, ethical and humanistic AI. This axis focuses on ensuring that the development and use of AI in Spain is responsible and respectful of human rights, equality, privacy and non-discrimination.
The following infographic summarises the main points of this strategy:
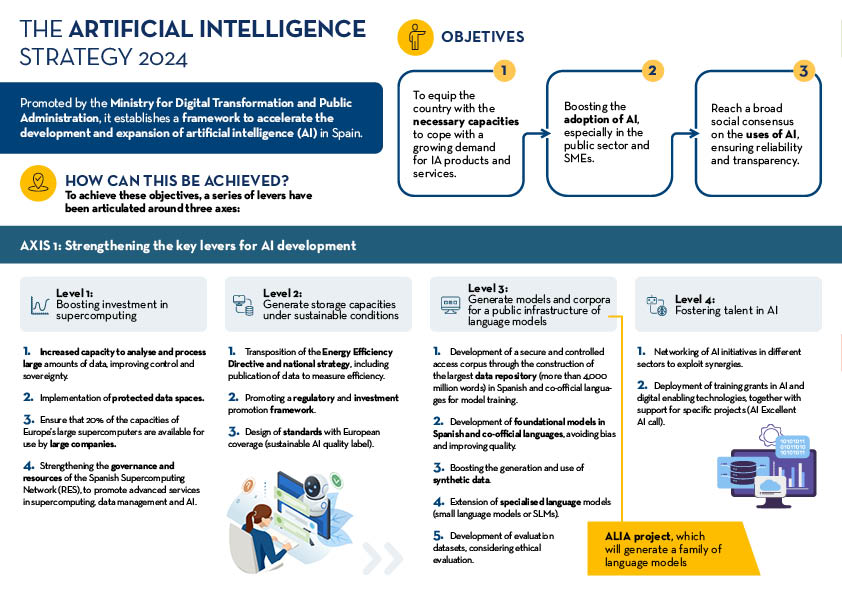
Go to click to enlarge the infographic
Spain's Artificial Intelligence Strategy 2024 is a very ambitious document that seeks to position our country as a leader in Artificial Intelligence, expanding the use of robust and responsible AI throughout the economy and in public administration. This will help to ensure that multiple areas such as culture or the city design can benefit from these developments.
Openness and access to quality data are also critical to the success of this strategy, as it is part of the raw material needed to train and evaluate AI models that are also inclusive and socially just so that they benefit society as a whole. Closely related to open data, the strategy dedicates specific levers to the promotion of AI in the public sector and the development of foundational and specialised corpora and language models . This also includes the development of common services based on AI models and the implementation of a data governance model to ensure the security, quality, interoperability and reuse of the data managed by the General State Administration (AGE, in Spanish acronyms).
The foundational models (Large Language Models or LLMs) are large-scale models that will be trained on large corpora of data in Spanish and co-official languages, thus ensuring their applicability in a wide variety of linguistic and cultural contexts. Smaller, specialised models (Small Language Models or SLMs) will be developed with the aim of addressing specific needs within particular sectors with a lower demand for computational resources.
Common data governance of the AGE
Open data governance will play a crucial role in the realisation of the stated objectives, e.g. to achieve an efficient development of specialised language models. With the aim of encouraging the creation of these models and facilitating the development of applications for the public sphere, the strategy foresees a uniform governance model for data, including the documentary corpus of the General State Administration, ensuring the standards of security, quality, interoperability and reusability of all data.
This initiative includes the creation of a unified data space to exploit sector-specific datasets to solve specific use cases for each agency. Data governance will ensure anonymisation and privacy of information and compliance with applicable regulations throughout the data lifecycle.
A data-driven organisational structure will be developed, with the Directorate-General for Data as the backbone. In addition, the AGE Data Platform, the generation of departmental metadata catalogues, the map of data exchanges and the promotion of interoperability will be promoted. The aim is to facilitate the deployment of higher quality and more useful AI initiatives.
Developing foundational and specialised corpora and language models
Within lever number three, the document recognises that the fundamental basis for training language models is the quantity and quality of available data, as well as the licenses that enable the possibility to use them.
The strategy places special emphasis on the creation of representative and diversified language corpora, including Spanish and co-official languages such as Catalan, Basque, Galician and Valencian. These corpora should not only be extensive, but also reflect the variety and cultural richness of the languages, which will allow for the development of more accurate models adapted to local needs.
To achieve this, collaboration with academic and research institutions as well as industry is envisaged to collect, clean and tag large volumes of textual data. In addition, policies will be implemented to facilitate access to this data through open licences that promote re-use and sharing.
The creation of foundational models focuses on developing artificial intelligence algorithms, trained on the basis of these linguistic corpora that reflect the culture and traditions of our languages. These models will be created in the framework of the ALIA project, extending the work started with the pioneering MarIA, and will be designed to be adaptable to a variety of natural language processing tasks. Priority will also be given, wherever possible, to making these models publicly accessible, allowing their use in both the public and private sectors to generate the maximum possible economic value.
In short, Spain's National Artificial Intelligence Strategy 2024 is an ambitious plan that seeks to position the country as a European leader in the development and use of responsible AI technologies, as well as to ensure that these technological advances are made in a sustainable manner, benefiting society as a whole. The use of open data and public sector data governance also contributes to this strategy, providing fundamental foundations for the development of advanced, ethical and efficient AI models that will improve public services and drive economic growth drive economic growth. And, in short, Spain's competitiveness in a global scenario in which all countries are making a major effort to boost AI and reap these benefits.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Data equity is a concept that emphasises the importance of considering issues of power, bias and discrimination in data collection, analysis and interpretation. It involves ensuring that data is collected, analysed and used in a way that is fair, inclusive and equitable to all stakeholders, particularly those who have historically been marginalised or excluded. Although there is no consensus on its definition, data equity aims to address systemic inequalities and power imbalances by promoting transparency, accountability and community ownership of data. It also involves recognising and redressing legacies of discrimination through data and ensuring that data is used to support the well-being and empowerment of all individuals and communities. Data equity is therefore a key principle in data governance, related to impacts on individuals, groups and ecosystems
To shed more light on this issue, the World Economic Forum - an organisation that brings together business leaders and experts to organisation that brings together leaders of major companies and experts to discuss global issues - published a short report entitled published a few months ago a short report entitled Data Equity: Foundational Concepts for Generative AI, aimed at industry, civil society, academia and decision-makers.
The aim of the World Economic Forum paper is, first, to define data equity and demonstrate its importance in the development and implementation of Generative AI (known as genAI). In this report, the World Economic Forum identifies some challenges and risks associated with data inequity in AI development, such as bias, discrimination and unfair outcomes. It also aims to provide practical guidance and recommendations for achieving data equity, including strategies for data collection, analysis and use. On the other hand, the World Economic Forum says it wants, on the one hand, to foster collaboration between stakeholders from industry, governments, academia and civil society to address data equity issues and promote the development of fair and inclusive AI, and on the other hand, to influence the future of AI development.
Some of the key findings of the report are discussed below.
Types of data equity
The paper identifies four main classes of data equity:
- Fairness of representation refers to the fair and proportional inclusion of different groups in the datasets used to train genAI models.
- Resource equity refers to the equitable distribution of resources (data, infrastructure and knowledge) necessary for the development and use of genAI.
- Equity of access means ensuring fair and non-discriminatory access to the capabilities and benefits of genAI by different groups.
- Equity of results seeks to ensure that genAI results and applications do not generate disproportionate or detrimental impacts on vulnerable groups.
Equity challenges in the genAI
The paper highlights that foundation models, which are the basis of many genAI tools, present specific data fairness challenges, as they encode biases and prejudices present in training datasets and can amplify them in their results. In AI, a function model refers to a program or algorithm that relies on training data to recognise patterns and make predictions or decisions, allowing it to make predictions or decisions based on new input data.
The main challenges in terms of social justice with artificial intelligence (AI) include thefact thattraining data may be biased. Generative AI models are trained on large datasets that often contain bias and discriminatory content, which can lead to the perpetuation of hate speech, misogyny and racism. Algorithmic biasescan then occur, which not only reproduce these initial biases, but can amplify them, increasing existing social inequalities and resulting in discrimination and unfair treatment of stereotyped groups. There are also privacy concerns, as generative AI relies on some sensitive personal data, which can be exploited and exposed.
The increasing use of generative AI in various fields is already causing job changes, as it is easier, quicker or cheaper to ask an artificial intelligence to create an image or text - in fact, based on human creations that exist on the internet - than to commission an expert to do so. This can exacerbate economic inequalities.
Finally, generative AI has the potential to intensify disinformation. Generative AI can be used to create high-quality deepfakes, which are already being used to spread hoaxes and misinformation, potentially undermining democratic processes and institutions.
Gaps and possible solutions
These challenges highlight the need for careful consideration and regulation of generative AI to ensure that it is developed and used in a way that respects human rights and promotes social justice. However, the document does not address misinformation and only mentions gender when talking about "feature equity", a component of data equity. Equity of characteristics seeks to "ensure accurate representation of the individuals, groups and communities represented by the data, which requires the inclusion of attributes such as race, gender, location and income along with other data" (p.4). Without these attributes, the paper says, "it is often difficult to identify and address latent biases and inequalities". However, the same characteristics can be used to discriminate against women, for example.
Addressing these challenges requires the engagement and collaboration of various stakeholders, such as industry, government, academia and civil society, to develop methods and processes that integrate data equity considerations into all phases of genAIdevelopment. This document lays the theoretical foundations of what can be understood as data equity; however, there is still a long way to go to see how to move from theory to practice in regulation, habits and knowledge.
This document links up with the steps already being taken in Europe and Spain with the European Union's AI Law y the IA Strategy of the Spanish Government respectively. Precisely, one of the axes of the latter (Axis 3) is to promote transparent, ethical and humanistic AI.
The Spanish AI strategy is a more comprehensive document than that of the World Economic Forum, outlining the government's plans for the development and adoption of general artificial intelligence technologies. The strategy focuses on areas such as talent development, research and innovation, regulatory frameworks and the adoption of AI in the public and private sectors, and targets primarily national stakeholders such as government agencies, businesses and research institutions. While the Spanish AI strategy does not explicitly mention data equity, it does emphasise the importance of responsible and ethical AI development, which could include data equity considerations.
The World Economic Forum report can be found here: Data Equity: Foundational Concepts for Generative AI | World Economic Forum (weforum.org)
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation. The contents and views reflected in this publication are the sole responsibility of its author.