Blog
La alfabetización en datos se ha convertido en un asunto crucial en la era digital. Este concepto se refiere a la capacidad de las personas para comprender el uso que se hace de los datos, así como para acceder a ellos, crearlos, analizarlos, utilizarlos o reutilizarlos, y comunicarlos.
Vivimos en un mundo donde los datos y los algoritmos influyen en decisiones cotidianas y en las oportunidades que tiene la gente para vivir bien. Su efecto se puede sentir en áreas que incluyen desde la publicidad y la oferta de empleo, hasta la justicia penal y las ayudas sociales. Por ello es fundamental comprender cómo se generan y utilizan los datos.
La alfabetización en datos puede implicar muchas áreas, pero nos vamos a centrar en su relación con los derechos digitales por una parte y la Inteligencia artificial (IA) por otro. Este artículo propone explorar la importancia de la alfabetización en datos para la ciudadanía, abordando sus implicaciones en la protección de los derechos individuales y colectivos y la promoción de una sociedad más informada y crítica en un contexto tecnológico donde la inteligencia artificial cobra cada vez más importancia.
El contexto de los derechos digitales
Cada vez hay más estudios que indican que una participación efectiva en la sociedad actual –impulsada por los datos y presidida por algoritmos— requiere de una alfabetización en datos. Los derechos civiles se traducen cada vez más en derechos digitales a medida que nuestra sociedad se vuelve más dependiente de las tecnologías y entornos digitales. Esta transformación se manifiesta de varias maneras:
- Por un lado, los derechos reconocidos en constituciones y declaraciones de derechos humanos se están adaptando explícitamente al contexto digital. Por ejemplo, la libertad de expresión ahora incluye la libertad de expresión en línea, y el derecho a la privacidad se extiende a la protección de datos personales en entornos digitales. Además, algunos derechos civiles tradicionales se están reinterpretando en el contexto digital. Una muestra de ello es el derecho a la igualdad y no discriminación, que ahora incluye la protección contra la discriminación algorítmica y contra los sesgos en sistemas de inteligencia artificial. Otro ejemplo es el derecho a la educación, que se extiende ahora también al derecho a la educación digital. La importancia de las habilidades digitales en la sociedad se reconoce en varios marcos legales y documentos, tanto a nivel nacional como internacional, como por ejemplo la Ley Orgánica 3/2018 de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD), en España. Por último, el derecho de acceso a Internet se está considerando cada vez más como un derecho fundamental, similar al acceso a otros servicios básicos.
- Por otro lado, están surgiendo derechos que abordan desafíos únicos del mundo digital, como el derecho al olvido (vigente en la Unión Europea y algunos otros países que han adoptado legislaciones similares1), que permite a las personas solicitar la eliminación de la información personal disponible en línea, bajo ciertas condiciones. Otro ejemplo puede ser el derecho a la desconexión digital (en vigor en varios países, principalmente en Europa2), que garantiza que los y las trabajadoras puedan desconectarse de dispositivos y comunicaciones laborales fuera del horario de trabajo. De la misma forma, existe el derecho a la neutralidad de Internet para asegurar un acceso equitativo a los contenidos en línea sin discriminación por parte de los proveedores de servicios, un derecho que también este derecho está establecido en varios países y regiones, aunque su implementación y alcance pueden variar. La UE tiene regulaciones que protegen la neutralidad de la red, incluido el Reglamento 2015/2120, que establece normas para salvaguardar el acceso abierto a Internet. La Ley de Protección de Datos española contempla la obligación de los proveedores de Internet de proporcionar una oferta transparente de servicios sin discriminación por motivos técnicos o económicos. Además, el derecho de acceso a Internet –relacionado con la neutralidad de la red— está reconocido como un derecho humano por la Organización de las Naciones Unidas (ONU).
Esta transformación de los derechos refleja la creciente importancia de las tecnologías digitales en todos los aspectos de nuestras vidas.
El contexto de la inteligencia artificial
La relación entre el desarrollo de la IA y los datos es fundamental y simbiótica, ya que los datos sirven como base para el desarrollo de la IA de varias maneras:
- Se utilizan datos para entrenar algoritmos de IA, lo que les permite aprender, detectar patrones, hacer predicciones y mejorar su rendimiento con el tiempo.
- La calidad y la cantidad de datos afectan directamente la precisión y la confiabilidad de los sistemas de IA. En general, los conjuntos de datos más diversos y completos conducen a modelos de IA de mejor rendimiento.
- La disponibilidad de datos en varios dominios puede permitir el desarrollo de sistemas de IA para diferentes casos de uso.
Por ello, la alfabetización de datos se ha vuelto cada vez más crucial en la era de la IA, ya que forma la base para aprovechar y comprender de manera eficaz las tecnologías de IA.
Además, el auge de los macrodatos y de los algoritmos ha transformado los mecanismos de participación, presentando tanto desafíos como oportunidades. Los algoritmos, aunque puedan estar diseñados para ser justos, a menudo reflejan los prejuicios de sus creadores o de los datos con los que se entrenan. Esto puede llevar a decisiones que afectan negativamente a grupos vulnerables.
En este sentido, se están llevando a cabo esfuerzos desde el punto de vista legislativo y académico para evitar que esto ocurra. Por ejemplo, la Ley de Inteligencia Artificial (AI Act) europea incluye garantías para evitar sesgos perjudiciales en la toma de decisiones algorítmica. Por ejemplo, clasifica los sistemas de IA según su nivel de riesgo potencial e impone requisitos más estrictos a aquellos de alto riesgo. Además, se exige el uso de datos de alta calidad para entrenar los algoritmos, minimizando los sesgos, y establece mantener documentación detallada sobre el desarrollo y funcionamiento de los sistemas, permitiendo auditorías y evaluaciones con supervisión humana. Asimismo, esta ley refuerza los derechos de las personas afectadas por decisiones de la IA, incluido el derecho a impugnar las decisiones tomadas y su explicabilidad, permitiendo a las personas afectadas entender cómo se llegó a una decisión.
La importancia de la alfabetización digital en ambos contextos
La alfabetización de datos ayuda a la ciudadanía a tomar decisiones informadas y entender todas las implicaciones de sus derechos digitales, que también se consideran, en muchos aspectos, como se ha referido anteriormente, derechos civiles universales. En este contexto, la alfabetización de datos sirve como un filtro crítico para una plena participación cívica que permita a la ciudadanía influir en las decisiones políticas y sociales. Es decir, quienes tienen el acceso a los datos y las habilidades y herramientas para navegar por la infraestructura de datos de manera efectiva pueden intervenir e influir de manera significativa en los procesos políticos y sociales, algo que promueve la Open Government Partnership.
Por otro lado, la alfabetización en datos permite a la ciudadanía cuestionar y entender estos procesos, fomentando una cultura de responsabilidad y transparencia en el uso de la IA. Asimismo, existen barreras para participar en entornos impulsados por datos. Una de estas barreras es la brecha digital (es decir, la privación del acceso a infraestructuras, conectividad y formación, entre otras) y, de hecho, la falta de alfabetización en datos. Por tanto, esta última se presenta como un concepto crucial para superar los desafíos que plantea la datificación de las relaciones humanas y la plataformización de los contenidos y servicios.
Recomendaciones para implementar una sociedad preparada
Parte de la solución para abordar los desafíos que propone el desarrollo de la tecnología digital es incluir la alfabetización en datos en los currículos educativos desde una edad temprana.
Esto debería abarcar:
- Conceptos básicos de datos: comprensión de qué son los datos, cómo se recopilan y se utilizan.
- Análisis crítico: adquisición de las habilidades para evaluar la calidad y la fuente de los datos e identificar sesgos en la información presentada. Se busca reconocer los potenciales sesgos que los datos puedan contener y que se puedan producir en el procesamiento de dichos datos, además de impulsar la capacidad para actuar en favor de la apertura de datos y su uso para el bien común.
- Derechos y regulaciones: información sobre los derechos de protección de datos y cómo las leyes europeas afectan al uso de la IA. Este ámbito abarcaría toda regulación presente y futura que afecte al uso de los datos y su implicación en tecnología como la IA.
- Aplicaciones prácticas: la posibilidad de crear, usar y reusar datos abiertos disponibles en los portales habilitados por gobiernos y administraciones públicas, para generar así proyectos y oportunidades que permitan a las personas trabajar con datos reales, promoviendo un aprendizaje activo, contextualizado y continuo.
Al educar sobre el uso y la interpretación de los datos, se fomenta una sociedad más crítica y capaz de demandar responsabilidad en el uso de la IA. Las nuevas leyes de protección de datos en Europa ofrecen un marco que, junto con la educación, puede ayudar a mitigar los riesgos asociados con el abuso algorítmico y promover un uso ético de la tecnología. En una sociedad datificada, en la que los datos desempeñan un papel fundamental, existe la necesidad de fomentar la alfabetización de datos en la ciudadanía desde edad temprana.
1. El derecho al olvido se estableció por primera vez en mayo de 2014 a raíz de una resolución del Tribunal de Justicia de la Unión Europea. Posteriormente, en 2018, se reforzó con el Reglamento General de Protección de Datos (RGPD), que lo incluye explícitamente en su artículo 17 como "derecho de supresión". En julio de 2015, Rusia aprobó una ley que permite a los ciudadanos solicitar la eliminación de enlaces en los buscadores rusos si la información "infringe la legislación rusa o si es falsa o se ha quedado obsoleta". Turquía ha establecido su propia versión del derecho al olvido, siguiendo un modelo similar al de la UE. Serbia también ha implementado una versión del derecho al olvido en su legislación. En España, la Ley Orgánica de Protección de Datos Personales (LOPD) regula el derecho al olvido, especialmente en lo que respecta a ficheros de morosos. En Estados Unidos, el derecho al olvido se considera incompatible con la Constitución, principalmente debido a la fuerte protección de la libertad de expresión. Sin embargo, existen algunas regulaciones relacionadas, como la Fair Credit Reporting Act de 1970, que permite en ciertas situaciones la eliminación de información antigua o caduca en informes crediticios.
2. Algunos países en los que se ha establecido este derecho incluyen España, regulado por el artículo 88 de la Ley Orgánica 3/2018 de Protección de Datos Personales; Francia, que, en 2017, se convirtió en el primer país en aprobar una ley sobre el derecho a la desconexión digital; Alemania, incluido en la Ley de Horarios de Trabajo y de Descanso (Arbeitszeitgesetz); Italia, dentro de la Ley 81/201, y Bélgica. Fuera de Europa, está, por ejemplo, en Chile.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
En el vertiginoso mundo de la Inteligencia Artificial (IA) Generativa, encontramos diversos conceptos que se han convertido en fundamentales para comprender y aprovechar el potencial de esta tecnología. Hoy nos centramos en cuatro: los Modelos de Lenguaje Pequeños (SLM, por sus siglas en inglés), los Modelos de Lenguaje Grandes (LLM), la Generación Aumentada por Recuperación (RAG) y el Fine-tuning. En este artículo, exploraremos cada uno de estos términos, sus interrelaciones y cómo están moldeando el futuro de la IA generativa.
Empecemos por el principio. Definiciones.
Antes de sumergirnos en los detalles, es importante entender brevemente qué representa cada uno de estos términos. Los dos primeros conceptos (SLM y LLM) que abordamos, son lo que se conoce cómo modelos del lenguaje. Un modelo de lenguaje es un sistema de inteligencia artificial que entiende y genera texto en lenguaje humano, como lo hacen los chatbots o los asistentes virtuales. Los siguientes dos conceptos (Fine Tuning y RAG), podríamos definirlos cómo técnicas de optimización de estos modelos del lenguaje previos. En definitiva, estás técnicas, con sus respectivos enfoques, que veremos más adelante, mejoran las respuestas y el contenido que devuelven al que pregunta. Vamos a por los detalles:
- SLM (Small Language Models): Modelos de lenguaje más compactos y especializados, diseñados para tareas específicas o dominios concretos.
- LLM (Large Language Models): Modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas.
- RAG (Retrieval-Augmented Generation): Una técnica que combina la recuperación de información relevante con la generación de texto para producir respuestas más precisas y contextualizadas.
- Fine-tuning: El proceso de ajustar un modelo pre-entrenado para una tarea o dominio específico, mejorando su rendimiento en aplicaciones concretas.
Ahora, profundicemos en cada concepto y exploremos cómo se interrelacionan en el ecosistema de la IA Generativa.
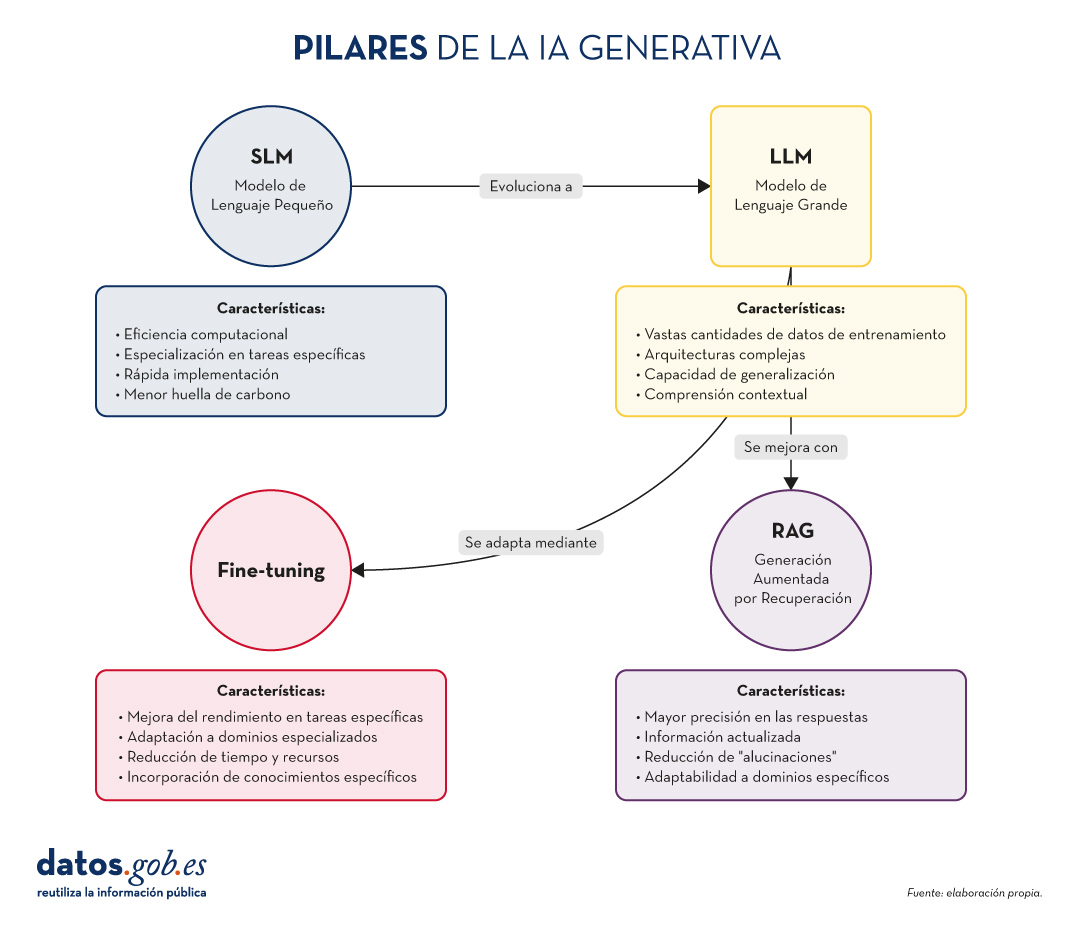
Figura 1. Pilares de la IA genrativa. Elaboración propia.
SLM: La potencia en la especialización
Mayor eficiencia para tareas concretas
Los Modelos de Lenguaje Pequeños (SLM) son modelos de IA diseñados para ser más ligeros y eficientes que sus contrapartes más grandes. Aunque tienen menos parámetros, están optimizados para tareas específicas o dominios concretos.
Características clave de los SLM:
- Eficiencia computacional: requieren menos recursos para su entrenamiento y ejecución.
- Especialización: se centran en tareas o dominios específicos, logrando un alto rendimiento en áreas concretas.
- Rápida implementación: ideal para dispositivos con recursos limitados o aplicaciones que requieren respuestas en tiempo real.
- Menor huella de carbono: al ser más pequeños, su entrenamiento y uso consumen menos energía.
Aplicaciones de los SLM:
- Asistentes virtuales para tareas específicas (por ejemplo, reserva de citas).
- Sistemas de recomendación personalizados.
- Análisis de sentimientos en redes sociales.
- Traducción automática para pares de idiomas específicos.
LLM: El poder de la generalización
La revolución de los Modelos de Lenguaje Grandes
Los LLM han transformado el panorama de la IA Generativa, ofreciendo capacidades sorprendentes en una amplia gama de tareas lingüísticas.
Características clave de los LLM:
- Vastas cantidades de datos de entrenamiento: se entrenan con enormes corpus de texto, abarcando diversos temas y estilos.
- Arquitecturas complejas: utilizan arquitecturas avanzadas, como Transformers, con miles de millones de parámetros.
- Capacidad de generalización: pueden abordar una amplia variedad de tareas sin necesidad de entrenamiento específico para cada una.
- Comprensión contextual: son capaces de entender y generar texto considerando contextos complejos.
Aplicaciones de los LLM:
- Generación de texto creativo (historias, poesía, guiones).
- Respuesta a preguntas complejas y razonamientos.
- Análisis y resumen de documentos extensos.
- Traducción multilingüe avanzada.
RAG: Potenciando la precisión y relevancia
La sinergia entre recuperación y generación
Como ya exploramos en nuestro artículo anterior, RAG combina la potencia de los modelos de recuperación de información con la capacidad generativa de los LLM. Sus aspectos fundamentales son:
Características clave de RAG:
- Mayor precisión en las respuestas.
- Capacidad de proporcionar información actualizada.
- Reducción de "alucinaciones" o información incorrecta.
- Adaptabilidad a dominios específicos sin necesidad de reentrenar completamente el modelo.
Aplicaciones de RAG:
- Sistemas de atención al cliente avanzados.
- Asistentes de investigación académica.
- Herramientas de fact-checking para periodismo.
- Sistemas de diagnóstico médico asistido por IA.
Fine-tuning: Adaptación y especialización
Perfeccionando modelos para tareas específicas
El fine-tuning es el proceso de ajustar un modelo pre-entrenado (generalmente un LLM) para mejorar su rendimiento en una tarea o dominio específico. Sus elementos principales son los siguientes:
Características clave del fine-tuning:
- Mejora significativa del rendimiento en tareas específicas.
- Adaptación a dominios especializados o nichos.
- Reducción del tiempo y recursos necesarios en comparación con el entrenamiento desde cero.
- Posibilidad de incorporar conocimientos específicos de la organización o industria.
Aplicaciones del fine-tuning:
- Modelos de lenguaje específicos para industrias (legal, médica, financiera).
- Asistentes virtuales personalizados para empresas.
- Sistemas de generación de contenido adaptados a estilos o marcas particulares.
- Herramientas de análisis de datos especializadas.
Pongamos algunos ejemplos
A muchos de los que estéis familiarizados con las últimas noticias en IA generativa os sonarán estos ejemplos que citamos a continuación.
SLM: La potencia en la especialización
Ejemplo: BERT para análisis de sentimientos
BERT (Bidirectional Encoder Representations from Transformers) es un ejemplo de SLM cuando se utiliza para tareas específicas. Aunque BERT en sí es un modelo de lenguaje grande, versiones más pequeñas y especializadas de BERT se han desarrollado para análisis de sentimientos en redes sociales.
Por ejemplo, DistilBERT, una versión reducida de BERT, se ha utilizado para crear modelos de análisis de sentimientos en X (Twitter). Estos modelos pueden clasificar rápidamente tweets como positivos, negativos o neutros, siendo mucho más eficientes en términos de recursos computacionales que modelos más grandes.
LLM: El poder de la generalización
Ejemplo: GPT-3 de OpenAI
GPT-3 (Generative Pre-trained Transformer 3) es uno de los LLM más conocidos y utilizados. Con 175 mil millones de parámetros, GPT-3 es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural sin necesidad de un entrenamiento específico para cada tarea.
Una aplicación práctica y conocida de GPT-3 es ChatGPT, el chatbot conversacional de OpenAI. ChatGPT puede mantener conversaciones sobre una gran variedad de temas, responder preguntas, ayudar con tareas de escritura y programación, e incluso generar contenido creativo, todo ello utilizando el mismo modelo base.
Ya a finales de 2020 introducimos en este espacio el primer post sobre GPT-3 como gran modelo del lenguaje. Para los más nostálgicos, podéis consultar el post original aquí.
RAG: Potenciando la precisión y relevancia
Ejemplo: El asistente virtual de Anthropic, Claude
Claude, el asistente virtual desarrollado por Anthropic, es un ejemplo de aplicación que utiliza técnicas RAG. Aunque los detalles exactos de su implementación no son públicos, Claude es conocido por su capacidad para proporcionar respuestas precisas y actualizadas, incluso sobre eventos recientes.
De hecho, la mayoría de asistentes conversacionales basados en IA generativa incorporan técnicas RAG para mejorar la precisión y el contexto de sus respuestas. Así, ChatGPT, la citada Claude, MS Bing y otras similares usan RAG.
Fine-tuning: Adaptación y especialización
Ejemplo: GPT-3 fine-tuned para GitHub Copilot
GitHub Copilot, el asistente de programación de GitHub y OpenAI, es un excelente ejemplo de fine-tuning aplicado a un LLM. Copilot está basado en un modelo GPT (posiblemente una variante de GPT-3) que ha sido específicamente ajustado (fine-tuned) para tareas de programación.
El modelo base se entrenó adicionalmente con una gran cantidad de código fuente de repositorios públicos de GitHub, lo que le permite generar sugerencias de código relevantes y sintácticamente correctas en una variedad de lenguajes de programación. Este es un claro ejemplo de cómo el fine-tuning puede adaptar un modelo de propósito general a una tarea altamente especializada.
Otro ejemplo: en el blog de datos.gob.es, también escribimos un post sobre aplicaciones que utilizaban GPT-3 como LLM base para construir productos concretos ajustados específicamente.
Interrelaciones y sinergias
Estos cuatro conceptos no operan de forma aislada, sino que se entrelazan y complementan en el ecosistema de la IA Generativa:
- SLM y LLM: Mientras que los LLM ofrecen versatilidad y capacidad de generalización, los SLM proporcionan eficiencia y especialización. La elección entre uno u otro dependerá de las necesidades específicas del proyecto y los recursos disponibles.
- RAG y LLM: RAG potencia las capacidades de los LLM al proporcionarles acceso a información actualizada y relevante. Esto mejora la precisión y utilidad de las respuestas generadas.
- Fine-tuning y LLM: El fine-tuning permite adaptar LLM genéricos a tareas o dominios específicos, combinando la potencia de los modelos grandes con la especialización necesaria para ciertas aplicaciones.
- RAG y Fine-tuning: Estas técnicas pueden combinarse para crear sistemas altamente especializados y precisos. Por ejemplo, un LLM con fine-tuning para un dominio específico puede utilizarse como componente generativo en un sistema RAG.
- SLM y Fine-tuning: El fine-tuning también puede aplicarse a SLM para mejorar aún más su rendimiento en tareas específicas, creando modelos altamente eficientes y especializados.
Conclusiones y futuro de la IA
La combinación de estos cuatro pilares está abriendo nuevas posibilidades en el campo de la IA Generativa:
- Sistemas híbridos: combinación de SLM y LLM para diferentes aspectos de una misma aplicación, optimizando rendimiento y eficiencia.
- RAG avanzado: implementación de sistemas RAG más sofisticados que utilicen múltiples fuentes de información y técnicas de recuperación más avanzadas.
- Fine-tuning continuo: desarrollo de técnicas para el ajuste continuo de modelos en tiempo real, adaptándose a nuevos datos y necesidades.
- Personalización a escala: creación de modelos altamente personalizados para individuos o pequeños grupos, combinando fine-tuning y RAG.
- IA Generativa ética y responsable: implementación de estas técnicas con un enfoque en la transparencia, la verificabilidad y la reducción de sesgos.
SLM, LLM, RAG y Fine-tuning representan los pilares fundamentales sobre los que se está construyendo el futuro de la IA Generativa. Cada uno de estos conceptos aporta fortalezas únicas:
- Los SLM ofrecen eficiencia y especialización.
- Los LLM proporcionan versatilidad y capacidad de generalización.
- RAG mejora la precisión y relevancia de las respuestas.
- El Fine-tuning permite la adaptación y personalización de modelos.
La verdadera magia ocurre cuando estos elementos se combinan de formas innovadoras, creando sistemas de IA Generativa más potentes, precisos y adaptables que nunca. A medida que estas tecnologías continúen evolucionando, podemos esperar ver aplicaciones cada vez más sofisticadas y útiles en una amplia gama de campos, desde la atención médica hasta la creación de contenido creativo.
El desafío para los desarrolladores e investigadores será encontrar el equilibrio óptimo entre estos elementos, considerando factores como la eficiencia computacional, la precisión, la adaptabilidad y la ética. El futuro de la IA Generativa promete ser fascinante, y estos cuatro conceptos estarán sin duda en el centro de su desarrollo y aplicación en los años venideros.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) está revolucionando la manera en que creamos y consumimos contenido. Desde la automatización de tareas repetitivas hasta la personalización de experiencias, la IA ofrece herramientas que están cambiando el panorama del marketing, la comunicación y la creatividad.
Estas inteligencias artificiales necesitan ser entrenadas con datos acordes a los objetivos, sobre los que no discurran derechos de autor. Por ello, los datos abiertos se alzan como una herramienta de gran utilidad de cara al futuro de la IA.
Para profundizar sobre esta temática, The Govlab ha publicado el informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI” (¿Una cuarta ola de datos abiertos? Explorando el espectro de escenarios para los datos abiertos y la IA generativa). En él se analiza la relación emergente entre los datos abiertos y la IA generativa, presentado diversos escenarios y recomendaciones. A continuación, se recogen sus claves.
El papel de los datos en la IA generativa
Los datos son la base fundamental de los modelos generativos de inteligencia artificial. Construir y entrenar dichos modelos requiere un gran volumen de datos, cuya escala y variedad está condicionada por los objetivos y los casos de uso del modelo.
El siguiente gráfico explica cómo los datos funcionan como una pieza clave tanto de entrada de un sistema de IA generativa, como de salida. Los datos se recopilan de diversas fuentes, incluyendo portales de datos abiertos, con el fin de entrenar un modelo de IA de propósito general. Este modelo, posteriormente, será adaptado para realizar funciones específicas y diferentes tipos de análisis, que generan, a su vez, nuevos datos, que pueden utilizarse para seguir entrenando modelos.

Figura 1. El Rol de los datos abiertos en la IA generativa, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
5 escenarios donde convergen los datos abiertos y la Inteligencia artificial
Con el fin de ayudar a los proveedores de datos abiertos a “preparar” dichos datos para la IA generativa, The Govlab ha definido cinco escenarios que resumen cinco formas distintas en las que los datos abiertos y la IA generativa pueden cruzarse. Estos escenarios pretenden ser un punto de partida, que se irá ampliando en el futuro, en base a los casos de uso disponibles.
| Escenario | Función | Requisitos de calidad | Necesidades de metadatos | Ejemplo |
|---|---|---|---|---|
| Preentrenamiento (Pretraining) | Entrenamiento de las capas fundacionales de un modelo de IA generativa con grandes cantidades de datos abiertos. | Alto volumen de datos, diversos y representativos del dominio de aplicación y uso no estructurado. | Información clara sobre la fuente de los datos. | Los datos del proyecto Harmonized Landsat Sentinel-2 (HLS) de la NASA se utilizaron para entrenar el modelo fundacional geoespacial watsonx.ai. |
| Adaptación (Adaptation) | Perfeccionamiento de un modelo preentrenado con datos abiertos específicos para tareas concretas, utilizando técnicas de fine-tuning or RAG. | Datos tabulares y/o no estructurados de alta precisión y relevancia para la tarea objetivo, con una distribución equilibrada. | Metadatado centrado en la anotación y procedencia de los datos para aportar enriquecimiento contextual. | Partiendo del modelo LLaMA 70B, el Gobierno de Francia creó LLaMandement, un modelo de lenguaje grande perfeccionado para el análisis y la redacción de resúmenes de proyectos jurídicos. Para ello usaron datos de SIGNALE, la plataforma legislativa del Gobierno francés. |
| Inferencia y generación de hechos relevantes (Inference and Insight Generation) | Extracción de información y patrones a partir de datos abiertos mediante un modelo entrenado de IA generativa. | Datos tabulares de alta calidad, completos y coherentes. | Metadatado descriptivo de los métodos de recogida de datos, información de origen y control de versiones. | Wobby es una interfaz generativa que acepta consultas en lenguaje natural y produce respuestas en forma de resúmenes y visualizaciones, utilizando conjuntos de datos de distintas oficinas como Eurostat o el Banco Mundial. |
| Incremento de datos (Data Augmentation) | Aprovechamiento de los datos abiertos para generar datos sintéticos o proporcionar ontologías para extender la cantidad de datos de entrenamiento. | Datos tabulares y/o no estructurados que sean una representación cercana a la realidad, asegurando el cumplimiento de consideraciones éticas. | Transparencia sobre el proceso de generación y posibles sesgos. | Un equipo de investigadores adaptó el modelo Synthea de EE.UU. para incluir datos demográficos y hospitalarios de Australia. Utilizando este modelo, el equipo pudo generar aproximadamente 117.000 historiales médicos sintéticos específicos, aplicados a su región. |
| Exploración abierta (Open-Ended Exploration) | Exploración y descubrimiento de nuevos conocimientos y patrones en datos abiertos mediante modelos generativos. | Datos tabulares y/o no estructurados, diversos y completos. | Información clara sobre fuentes y derechos de autor, comprensión de posibles sesgos y limitaciones, identificación de entidades. | NEPAccess es un piloto para desbloquear el acceso datos relacionados con la Ley Nacional de Política Medioambiental (NEPA) de EE.UU. mediante un modelo generativo de IA. Incluirá funciones para redactar evaluaciones de impacto ambiental, análisis de datos, etc. |
Figura 2. Cinco escenarios donde convergen los datos abiertos y la Inteligencia artificial, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
Puedes leer el detalle de estos escenarios en el informe, donde se explican más ejemplos. Además, The Govlab también ha puesto en marcha un observatorio donde recopila ejemplos de intersecciones entre datos abiertos e inteligencia artificial generativa (los incluidos en el informe junto con otros adicionales). Cualquier usuario puede proponer nuevos casos a través de este formulario. Dichos ejemplos se utilizarán para continuar estudiando este campo y mejorar los escenarios actualmente definidos.
Entre los casos que se pueden ver en la web, encontramos una empresa española: Tendios. Se trata de una compañía de software como servicio que ha desarrollado un chatbot para ayudar en el análisis de licitaciones y concursos públicos con el fin de facilitar la concurrencia. Esta herramienta está entrenada con documentos públicos de licitaciones gubernamentales.
Recomendaciones para publicadores de datos
Para extraer el máximo potencial de IA generativa, mejorando su eficiencia y eficacia, el informe destaca que los proveedores de datos abiertos deben hacer frente a algunos retos, como la mejora de la gobernanza y la gestión de los datos. En este sentido, recogen cinco recomendaciones:
- Mejorar la transparencia y la documentación. A través del uso de estándares, diccionarios de datos, vocabularios, plantillas de metadatos, etc. se ayudará a aplicar prácticas de documentación sobre el linaje, la calidad, las consideraciones éticas y el impacto de los resultados.
- Mantener la calidad y la integridad. Se necesita formación y procesos rutinarios que aseguren la calidad, incluida la validación automatizada o manual, así como herramientas para actualizar los conjuntos de datos rápidamente cuando sea necesario. Además, son necesarios mecanismos para informar y abordar problemas que puedan surgir relacionados con los datos, a fin de impulsar la transparencia y facilitar la creación de una comunidad en torno a los conjuntos de datos abiertos.
- Fomentar la interoperabilidad y los estándares. Implica adoptar y promover normas internacionales de datos, con especial foco en los datos sintéticos y los contenidos generados por IA.
- Mejorar la accesibilidad y la facilidad de uso. Supone la mejora de los portales de datos abiertos mediante algoritmos de búsqueda inteligentes y herramientas interactivas. También es imprescindible establecer un espacio compartido donde los publicadores de los datos y los usuarios puedan intercambiar opiniones y manifestar necesidades, con el fin de hacer coincidir oferta y demanda.
- Abordar las consideraciones éticas. Proteger a los titulares de los datos es de máxima prioridad al hablar de datos abiertos e IA generativa. Se necesitan comités éticos y directrices éticas exhaustivas en torno a la recopilación, el intercambio y el uso de datos abiertos, así como tecnologías avanzadas de preservación de la intimidad.
Estamos ante un campo en continua evolución que necesita de actualización constante por parte de los publicadores de datos. Estos deben proporcionar conjuntos de datos adecuados tanto técnica como éticamente, para que los sistemas de IA generativa puedan alcanzar todo su potencial.
Noticia
La transformación digital se ha convertido en un pilar fundamental para el desarrollo económico y social de los países en el siglo XXI. En España, este proceso ha cobrado una relevancia especial en los últimos años, impulsado por la necesidad de adaptarse a un entorno global cada vez más digitalizado y competitivo. La pandemia de COVID-19 actuó como un catalizador, acelerando la adopción de tecnologías digitales en todos los sectores de la economía y la sociedad.
Sin embargo, la transformación digital no solo implica la incorporación de nuevas tecnologías, sino también un cambio profundo en la forma en que las organizaciones operan y se relacionan con sus clientes, empleados y socios. En este contexto, España ha realizado importantes avances, situándose como uno de los países líderes en Europa en varios aspectos de la digitalización.
A continuación, se presentan algunos de los informes más destacados que analizan este fenómeno y sus implicaciones.
Informe sobre el estado de la Década Digital 2024
El informe sobre el estado de la Década Digital 2024 examina la evolución de las políticas europeas dirigidas a alcanzar los objetivos y metas acordados para el éxito de la transformación digital. Para ello evalúa el grado de cumplimiento en base a diversos indicadores, incluidos en cuatro grupos: infraestructura digital, transformación digital de los negocios, habilidades digitales y servicios públicos digitales.
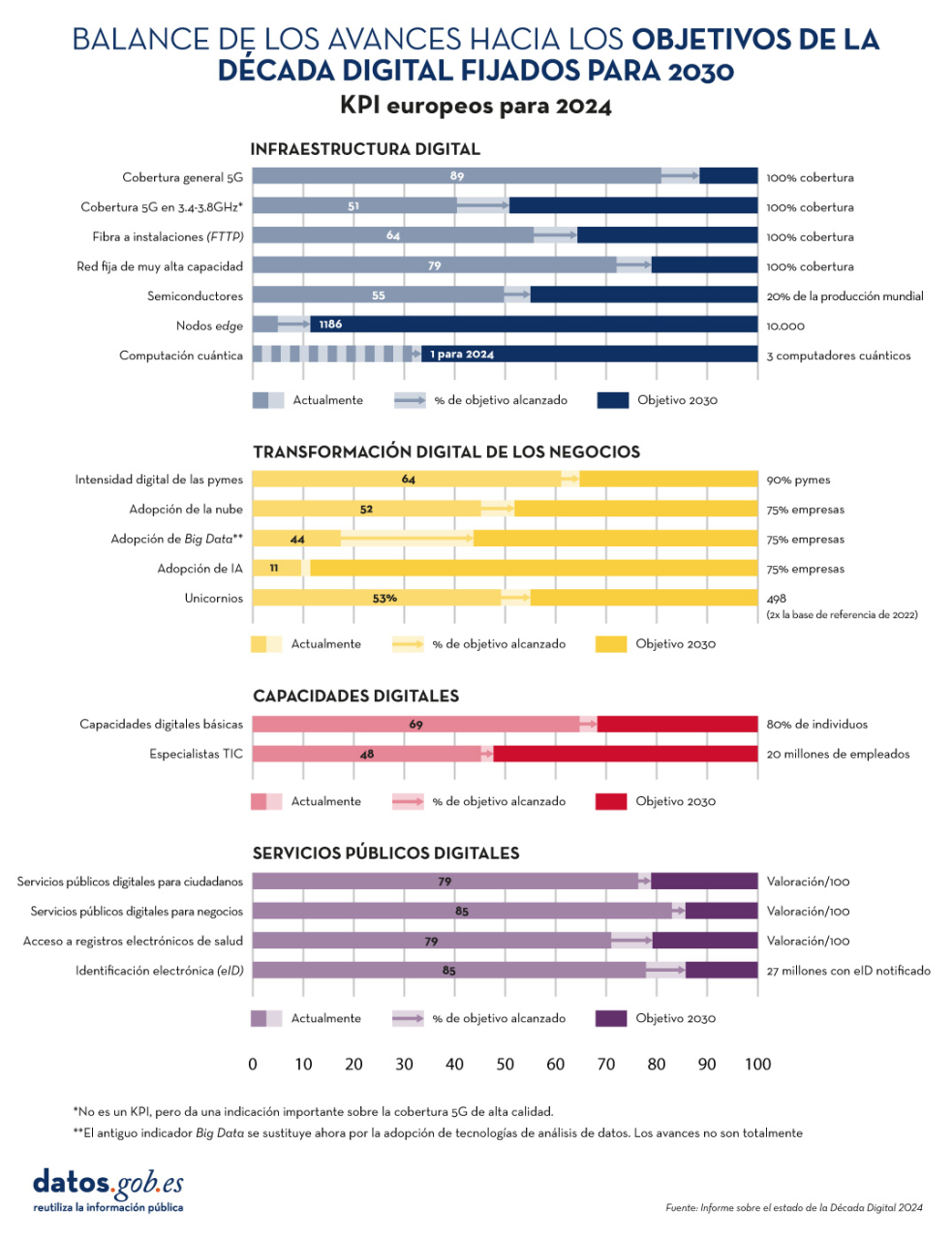
Figura 1. Balance de los avances hacia los objetivos de la Década Digital fijados para 2030, "Informe sobre el Estado de la Década Digital 2024", Comisión Europea.
En los últimos años, la Unión Europea (UE) ha mejorado considerablemente su actuación mediante la aprobación de medidas reguladoras -con 23 nuevos avances legislativos, que incluyen, entre otros, el Reglamento de gobernanza de datos y el Reglamento de datos- para dotarse de un marco de gobernanza global: el Programa de política de la Década Digital para 2030.
El documento incluye una evaluación de las hojas de ruta estratégicas de los diversos países de la Unión. En el caso de España, se destacan dos principales fortalezas:
- El avance en el uso de inteligencia artificial por parte de las empresas (9,2% frente al 8,0% europeo), donde el crecimiento anual de España (9,3%) es cuatro veces superior al de la UE (2,6%).
- La gran cantidad de ciudadanos con capacidades digitales básicas (66,2%), frente al promedio europeo (55,6%).
Por otro lado, los principales retos a superar son la adopción de los servicios en la nube (27,2% versus 38,9% de la UE) y el número de especialistas en tecnologías de la información y la comunicación o TIC (4,4% frente al 4,8% europeo).
En la siguiente imagen se puede observar la previsión en España de evolución de los indicadores clave analizados para 2024, en comparación con las metas fijadas por la UE para 2030.
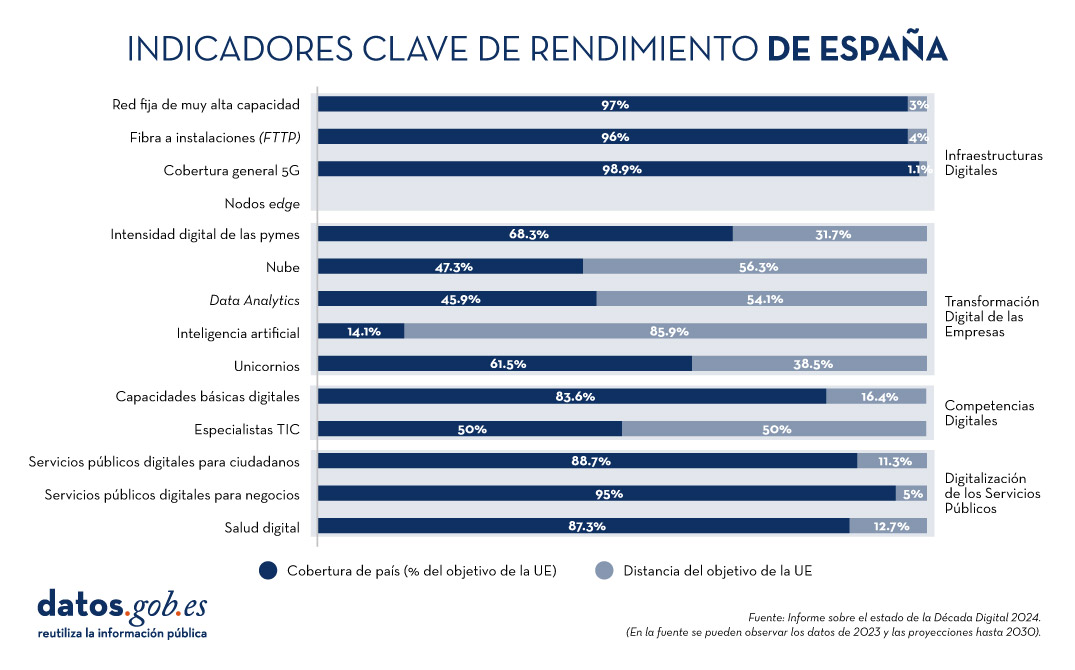
Figura 2. Indicadores clave de rendimiento de España, "Informe sobre el Estado de la Década Digital 2024", Comisión Europea.
Se espera que España alcance el 100% en prácticamente todos los indicadores para 2030. Para ello, el país tiene previsto asignar un presupuesto estimado de 26.700 millones de euros (1,8 % del PIB), sin tener en cuenta inversiones privadas. Esta hoja de ruta demuestra el compromiso para alcanzar los objetivos y metas de la Década Digital.
Además de la inversión, para conseguir el objetivo, en el informe se recomienda focalizar esfuerzos en tres áreas: la adopción de tecnologías avanzadas (IA, análisis de datos, nube) por parte de pymes; la digitalización y promoción del uso de servicios públicos; y la atracción y retención de especialistas TIC a través del diseño de planes de incentivos.
European Innovation Scoreboard 2024
El European Innovation Scoreboard realiza de manera anual una evaluación comparativa de los avances en investigación e innovación en diversos países, no solo europeos. El informe clasifica a las regiones en cuatro grupos de innovación que van de más a menos: Líderes en innovación, Innovadores fuertes, Innovadores moderados e Innovadores emergentes.
España se encuentra liderando el grupo de Innovadores moderados, con un rendimiento del 89,9% del promedio de la UE. Esto representa una mejora en comparación con años anteriores y supera el promedio de otros países de su misma categoría, que es del 84,8%. Nuestro país se sitúa por encima de la media comunitaria en tres indicadores: digitalización, capital humano y financiación y soporte. Por otro lado, las áreas en las que más debe mejorar son el empleo en innovación, la inversión empresarial y la innovación en pymes. Todo ello se recoge el siguiente gráfico:

Figura 3. Bloques que componen el índice sintético de la innovación en España, European Innovation Scorecard 2024 (adaptado de la Fundación COTEC).
Informe de la Sociedad Digital en España 2023
La Fundación Telefónica también realiza de manera periódica un informe donde se analizan los principales cambios y tendencias que está experimentando nuestro país a raíz de la revolución tecnológica.
La edición actualmente disponible es la de 2023. En él se destaca que “España sigue profundizando en su proceso de transformación digital a buen ritmo y ocupa un puesto destacado en este aspecto entre los países europeos”, resaltando sobre todo el área de conectividad. No obstante, siguen existiendo brechas digitales, principalmente por motivo de edad.
También se avanza en la relación de los ciudadanos con las administraciones digitales: el 79,7 % de las personas de entre 16 y 74 años utilizaron en 2022 páginas web o aplicaciones móviles de alguna administración. Por otro lado, el tejido empresarial español avanza en su digitalización, incorporando herramientas digitales, sobre todo en el ámbito del marketing. No obstante, aún queda margen de mejora en aspectos de análisis de macrodatos y la aplicación de inteligencia artificial, actividades que actualmente han implementado, en general, solo las grandes empresas.
Informe sobre el talento en inteligencia artificial y datos
IndesIA, una asociación que promueve el uso de la inteligencia artificial y el Big Data en España, ha realizado un análisis cuantitativo y cualitativo del mercado de talento en datos e inteligencia artificial en 2024 en nuestro país.
De acuerdo con el informe, el mercado de talento de datos e inteligencia artificial representa casi un 19% del total de profesionales TIC de nuestro país. En total, son 145.000 profesionales (+2,8% de 2023), de los cuales solo el 32% son mujeres. Aun así, existe un gap entre oferta y demanda, sobre todo en ingenieros de procesamiento del lenguaje natural. Para resolver esta situación el informe analiza seis áreas de mejora: estrategia y planificación de plantillas, identificación de talento, activación de talento, engagement, formación y desarrollo, y cultura data-driven.
Otros informes de interés
La Fundación COTEC también realiza de manera periódica diversos informes sobre la materia. En su web encontramos documentos sobre la ejecución presupuestaria de la I+D en el sector público, la percepción social de la innovación o el mapa del Talento autonómico.
Por su parte, la Fundación Orange en España y la consultora Nae han realizado un informe para analizar la evolución digital en los últimos 25 años, el mismo periodo que lleva en nuestro país dicha Fundación. El informe destaca que, entre 2013 y 2018, el sector digital ha contribuido en unos 7.500 millones de euros anuales al PIB del país.
En definitiva, todos ellos destacan la situación de España entre los líderes europeos a nivel de transformación digital, pero con la necesidad de avanzar en innovación. Para ello, no solo es necesario impulsar las inversiones económicas, sino también promover un cambio cultural que fomente la creatividad. Una mentalidad más abierta y colaborativa permitirá a las empresas, administraciones y a la sociedad en general adaptarse rápidamente a los cambios tecnológicos y aprovechar las oportunidades que estos brindan para asegurar un futuro próspero para España.
¿Conoces más informes sobre la materia? Déjanos un comentario o escríbenos a dinamizacion@datos.gob.es.
Blog
Marcos éticos generales
La ausencia de un marco ético, común y unificado para el uso de la inteligencia artificial en el mundo es solo aparente y, en cierto modo, un mito. Existen multitud de cartas, manuales y conjuntos de normas supranacionales que recogen principios de uso ético, si bien algunos de ellos han tenido que actualizarse con la aparición de nuevas herramientas y usos. La guía de la OCDE de estándares éticos para el uso de la inteligencia artificial, publicada en 2019 pero actualizada en 2024, incluye principios basados en valores y también recomendaciones para los responsables de políticas públicas. El Observatorio Global de Ética y Gobernanza de la IA de la UNESCO publicó en 2021 un material llamado Recomendación sobre la ética de la IA, adoptado en el mismo año por 193 países, y basado en cuatro principios básicos: los derechos humanos, la justicia social, la diversidad e inclusividad, y el respeto al ecosistema ambiental. También en 2021 la OMS recogía específicamente un documento de Ética y gobernanza de la IA para la salud, donde indicaba la necesidad de establecer responsabilidades para las organizaciones en el uso de la IA cuando esta afectase a pacientes y a trabajadores sanitarios. Sin embargo, diversas entidades y sectores a distintos niveles han tomado la iniciativa de establecer sus propias normativas y guías éticas, más ajustadas a su contexto. Por ejemplo, en febrero de 2024, el Ministerio de Cultura en España elaboraba una guía de buenas prácticas para establecer, entre otras directrices, que no podrían ser galardonadas las obras creadas exclusivamente con IA generativa.
Por tanto, el reto no está en la ausencia de guías éticas globales, sino en la excesiva globalidad de estos marcos. Con el legítimo objetivo de que resistan el paso del tiempo, sean válidos para la situación específica de cualquier país del mundo y se mantengan operativos ante nuevas disrupciones, estos estándares generales acaban recurriendo a conceptos que ya conocemos, como los que podemos leer en esta otra guía ética del Foro Económico Mundial: explicabilidad, transparencia, fiabilidad, robustez, privacidad, seguridad. Conceptos demasiado altos, predecibles, y que casi siempre miran la IA desde el punto de vista del desarrollador y no del usuario.
Manifiestos de los medios
En esta línea, los grandes grupos de comunicación han invertido sus esfuerzos en desarrollar principios éticos específicos para el uso de la IA en la creación y difusión de contenidos, que constituye por ahora un vacío significativo en los grandes marcos e incluso en el propio Reglamento europeo. Estos esfuerzos se han materializado en ocasiones de manera individual, en forma de manifiesto, pero también en un nivel superior como colectivo. Entre los manifiestos más relevantes destacan el de Le Figaro, en el que su redacción establece que no publicará ningún artículo o contenido visual generado con IA, o el de The Guardian que, actualizado en 2023, afirma que la IA es una herramienta habitual en las redacciones, pero únicamente como asistencia para asegurar la calidad de su trabajo. Por su parte, los medios españoles no han emitido manifiestos propios, pero sí han apoyado diferentes iniciativas colectivas. El Grupo Prisa, por ejemplo, aparece en la lista de organizaciones que suscriben el Manifiesto por una IA responsable y sostenible, publicado por Forética en 2024. También son interesantes las declaraciones de los responsables de innovación y estrategia digital de El País, El Español, El Mundo y RTVE que encontramos en una entrevista publicada en Fleet Street en abril de 2023. Ante la pregunta de si existen en sus medios líneas rojas específicas en el uso de la IA, todos declaran tener una actitud abierta de exploración y no haber delimitado demasiado el uso. Tan solo RTVE, se desmarca con una afirmación: “Entendemos que es algo complementario y para ayudarnos. Cualquier cosa que haga un periodista no queremos que la haga una IA. Tiene que estar bajo nuestro control”.
Principios globales del periodismo
En el contexto editorial encontramos por tanto un panorama de normativas múltiples en tres niveles posibles: manifiestos propios de cada medio, iniciativas colectivas del sector y la adhesión a códigos éticos generales a nivel nacional. En este escenario, a finales de 2023 la News Media Alliance publicaba los Principios globales de la IA en el periodismo, un documento firmado por grupos editoriales a nivel internacional que recoge, a modo de decálogo, 12 principios éticos fundamentales divididos en 8 bloques:

Figura 1. Principios globales de la IA en el periodismo, News Media Alliance.
Cuando los revisamos en profundidad, encontramos en ellos algunos de los grandes conflictos que están marcando el desarrollo de la inteligencia artificial moderna, conexiones con el Reglamento Europeo de IA y reivindicaciones que son constantes por parte de los creadores de contenido:
- Bloque 1: Propiedad intelectual. Es el primer bloque y el más completo, desarrollado específicamente en cuatro principios éticos complementarios. Aunque parece el principio más evidente, está orientado a poner el foco en uno de los principales conflictos de la IA moderna: el uso indiscriminado de contenido publicado en internet (texto, imagen, vídeo, música) para entrenar modelos de aprendizaje sin consultar ni remunerar a los autores. El primer principio ético manifiesta el deber, por parte de los desarrolladores de sistemas de IA, de respetar las restricciones o limitaciones impuestas por los titulares de derechos de autor sobre el acceso y uso de los contenidos. El segundo expresa la capacidad de estos autores y grupos editoriales para negociar una remuneración justa por el uso de su propiedad intelectual. El tercero, legitima el copyright como base suficiente ante la ley para proteger los contenidos de un autor. El cuarto reclama reconocer y respetar los mercados existentes para la concesión de licencias, esto es: crear contratos, acuerdos y modelos de mercado eficientes para que los sistemas de IA puedan entrenarse con contenido de calidad, pero legítimo, autorizado y licenciado.
- Bloque 2: Transparencia. El segundo bloque es una continuación lógica del anterior, y aboga por la transparencia en el funcionamiento, una característica que aporta valor tanto a los autores de contenido como a los usuarios de los sistemas IA. Este principio coincide con la obligación central que el Reglamento Europeo establece para los sistemas de IA generativa: deben ser transparentes desde un principio y declarar con qué contenidos han entrenado, con qué procedimientos los han conseguido y en qué medida cumplen con los derechos de propiedad intelectual de los autores. Esta transparencia es esencial para que los creadores y grupos editoriales puedan hacer valer sus derechos, y se establece además que este principio deba cumplirse con carácter universal, independientemente de la jurisdicción en la que se realicen el entrenamiento o las pruebas.
- Bloque 3: Responsabilidad. En inglés accountability, una palabra que recoge la capacidad para rendir cuentas sobre una acción. El principio expresa que los desarrolladores y operadores de sistemas de IA deben ser responsables de los resultados (outputs) generados por sus sistemas, por ejemplo, en el caso de atribuir contenidos a los autores que no son reales, o si contribuyen a la desinformación o a socavar la confianza en la ciencia o los valores democráticos.
- Bloque 4: Calidad e integridad. La base del principio es que los contenidos generados por IA deben ser precisos, correctos y completos, y no deben distorsionar las obras originales. Sin embargo, sobre esta idea superficial se construye una más ambiciosa: la de que los grupos editoriales y de comunicación deben ser garantes de esta calidad e integridad, y por tanto proveedores oficiales de los desarrolladores y proveedores de sistemas de IA. El argumento fundamental es que la calidad del contenido para el entrenamiento definirá la calidad de los resultados del sistema.
- Bloque 5: Justicia. La palabra fairness en español puede traducirse también como equidad o imparcialidad. El principio recoge en su titular que el uso de IA no debe crear injusticias en los mercados, prácticas anticompetitivas o competencia desleal, lo que quiere decir que no debe permitirse su uso para fomentar abusos de dominio ni excluir a rivales del mercado. Este principio no va orientado a regular la competencia entre los desarrolladores de IA, sino entre estos y los proveedores de contenido: el texto, la música o las imágenes generadas con IA no deberían competir nunca en igualdad de condiciones con el contenido generado por los autores.
- Bloque 6: Seguridad. Se compone de dos principios éticos. Redundando en los anteriores, el primer principio de seguridad establece que los sistemas de IA generativa deben ser confiables en cuanto a las fuentes de información que utilizan y promueven, las cuales no deben alterar ni representar de manera incorrecta los contenidos, preservando su integridad original. Lo contrario podría traducirse en un debilitamiento de la confianza del público en las obras originales, en los autores e incluso en los grandes grupos de comunicación. Este principio aplica en gran medida a los nuevos motores de búsqueda asistidos por IA, como la nueva búsqueda en Google (SGE), el nuevo SearchGPT o el propio Copilot de Microsoft, que recopilan y refunden información de diferentes fuentes en un solo párrafo generado. El segundo punto unifica en un solo principio las problemáticas de privacidad de datos del usuario y, en apenas una frase, se refiere a los sesgos discriminatorios. Los desarrolladores deben poder explicar cómo, cuándo y para qué utilizan los datos de los usuarios, y deben asegurar que los sistemas no producen, multiplican o cronifican sesgos de discriminación a personas o colectivos.
- Bloque 7: Diseño ético. Se trata de un metaprincipio que engloba a todos los demás, y que establece que todos los principios deben incorporarse desde el diseño en todos los sistemas de IA, generativa o no. Históricamente se ha considerado la ética al final del proceso de desarrollo, como una cuestión secundaria o menor, por lo que el principio defiende que la ética debe ser una preocupación significativa y fundamental desde el mismo proceso de diseño del sistema. Tampoco puede relegarse la auditoría ética únicamente a aquellos casos en que los usuarios presentan una reclamación.
- Bloque 8: Desarrollo sostenible. Aparentemente es un principio global, de alto alcance, que establece que los sistemas de IA deben estar alineados con los valores humanos y operar de acuerdo con las leyes globales, con el fin de beneficiar a toda la humanidad y a las generaciones futuras. Sin embargo, en la última frase encontramos la orientación real del principio, una conexión con los grupos editoriales como proveedores de datos para los sistemas IA: “La financiación a largo plazo y otros incentivos para los proveedores de datos de entrada de alta calidad puede ayudar a alinear los sistemas con los objetivos sociales y extraer el conocimiento más importante, actualizado y procesable.”
El documento está firmado por 31 asociaciones de grupos editoriales de países como Dinamarca, Corea, Canadá, Colombia, Portugal, Brasil, Argentina, Japón o Suecia, por asociaciones a nivel europeo, como European Publishers Council o News Media Europe, y asociaciones a nivel mundial como WAN-IFRA (World Association of News Publishers). Entre los grupos españoles destacan la Asociación de Medios de Información (AMI) y la Asociación de Revistas (ARI).
La ética como instrumento
Los principios globales del periodismo promovidos por la News Media Alliance son particularmente precisos al proponer soluciones aterrizadas a dilemas éticos muy representativos de la situación actual, como es el uso del contenido de autor para la explotación comercial de los sistemas de IA. Son útiles a la hora de intentar establecer un marco ético sólido y, sobre todo, unificado y global que propone soluciones consensuadas. Al mismo tiempo, en el documento podemos percibir la ausencia de otros conflictos que afectan a la profesión y que también tendrían cabida en este decálogo. Es posible que la omnipresencia del conflicto de licenciamiento de datos, al que se hace referencia constante, haya dejado en un segundo plano otras inquietudes como la nueva velocidad de la desinformación, la capacidad de la investigación periodística para verificar contenido auténtico o el impacto de las fake news y los deepfakes en procesos democráticos. Los principios se han centrado en exponer las obligaciones que deberían tener las grandes tecnológicas en lo que respecta al uso de los contenidos, pero quizá sería esperable una extensión que abordase las responsabilidades éticas desde el punto de vista de los medios, como por ejemplo, en qué modelo ético debe basarse la integración de la IA en la actividad de las redacciones y cuál es la responsabilidad de los periodistas en este nuevo escenario. Por último, en el documento se pone de manifiesto una dualidad habitual: la canalización, a través de la propuesta ética, de la sugerencia de soluciones concretas que apuntan incluso a posibles acuerdos comerciales y de mercado. Es un reflejo claro de la capacidad potencial de la ética para ser mucho más que un marco moral, y convertirse en un instrumento multidimensional para orientar la toma de decisiones e influir en la creación de políticas públicas.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos meses hemos visto cómo los grandes modelos del lenguaje (LLM en sus siglas en inglés) que habilitan las aplicaciones de Inteligencia artificial generativa (GenAI) han ido mejorando en cuanto a su precisión y confiabilidad. Las técnicas de RAG (Retrieval Augmented Generation) nos han permitido utilizar toda la potencia de la comunicación en lenguaje natural (NLP) con las máquinas para explorar bases de conocimiento propias y extraer información procesada en forma de respuestas a nuestras preguntas. En este artículo profundizamos en las técnicas RAG con el objetivo de conocer mejor su funcionamiento y todas las posibilidades que nos ofrecen en el contexto de la IA generativa.
¿Qué son las técnicas RAG?
No es la primera vez que hablamos de las técnicas RAG. En este artículo ya introdujimos el tema, explicando de forma sencilla en qué consisten, cuáles son sus principales ventajas y qué beneficios aporta en el uso de la IA Generativa.
Recordemos por un momento sus principales claves. RAG, del inglés, Retrieval Augmented Generation, viene a traducirse cómo Generación Aumentada por Recuperación (de información). Es decir, RAG consiste en lo siguiente: cuando un usuario realiza una pregunta -normalmente en un interfaz conversacional-, la Inteligencia Artificial (IA), antes de proporcionar la respuesta directa -que podría dar haciendo uso de la base de conocimiento (fijo) con la que ha sido entrenada-, realiza un proceso de búsqueda y procesamiento de información en una base de datos específica proporcionada previamente, complementaria a la del entrenamiento. Cuando hablamos de una base de datos nos referimos a una base de conocimiento previamente preparada a partir de un conjunto de documentos que el sistema utilizará para proporcionar respuestas más precisas. De esta forma, cuando hacen uso de las técnicas RAG, las interfaces conversacionales producen respuestas más precisas y adaptadas a un contexto concreto.
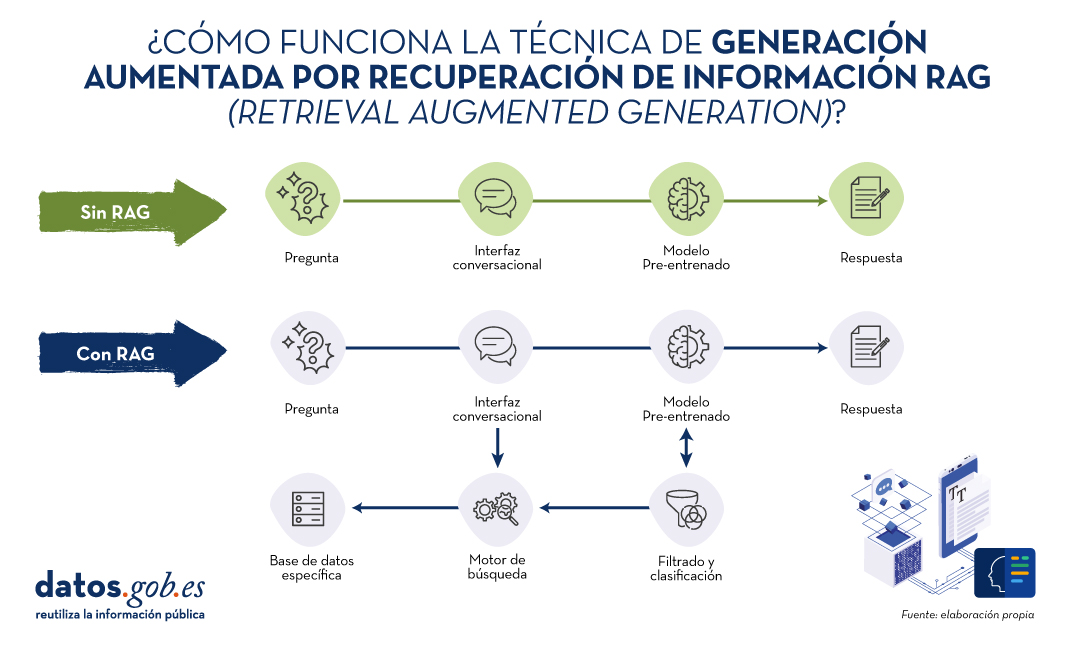
Fuente: Elaboración propia
Diagrama conceptual del funcionamiento de un asistente o interfaz conversacional sin hacer uso de RAG (arriba) y haciendo uso de RAG (abajo).
Haciendo un símil con el ámbito médico, podríamos decir que el uso de RAG es como si un médico, con amplia experiencia y, por lo tanto, altamente entrenado, además de los conocimientos adquiridos durante su formación académica y años de experiencia, tuviera acceso rápido y sin esfuerzo a los últimos estudios, análisis y bases de datos médicas al instante, antes de proporcionar un diagnóstico. La formación académica y los años de experiencia equivalen al entrenamiento del modelo grande del lenguaje (LLM) y el “mágico” acceso a los últimos estudios y bases de datos específicas pueden asimilarse a lo que proporciona las técnicas RAG.
Evidentemente, en el ejemplo que acabamos de poner, la buena práctica médica hace indispensables ambos elementos que el cerebro humano sabe combinar de forma natural, aunque no sin esfuerzo y tiempo, incluso disponiendo de las herramientas digitales actuales, que hacen más sencilla e inmediata la búsqueda de información.
RAG en detalle
Fundamentos de RAG
RAG combina dos fases para conseguir su objetivo: la recuperación y la generación. En la primera, se buscan documentos relevantes en una base de datos que contiene información pertinente a la pregunta planteada (por ejemplo, una base de datos clínicos o una base de conocimiento de preguntas y respuestas más habituales). En la segunda, se utiliza un LLM para generar una respuesta basada en los documentos recuperados. Este enfoque asegura que las respuestas no solo sean coherentes sino también precisas y respaldadas por datos verificables.
Componentes del Sistema RAG
A continuación, vamos a describir los componentes que utiliza un algoritmo de RAG para cumplir con su función. Para ello, en cada componente, vamos a explicar qué función cumple, qué tecnologías se utilizan para cumplir esta función y un ejemplo de la parte del proceso RAG en el que interviene ese componente.
1. Modelo de Recuperación:
- Función: Identifica y recupera documentos relevantes de una base de datos grande en respuesta a una consulta.
- Tecnología: Generalmente utiliza técnicas de recuperación de información (Information Retrieval en inglés o IR) como BM25 o modelos de recuperación basados en embeddings como Dense Passage Retrieval (DPR).
- Proceso: Dada una pregunta, el modelo de recuperación busca en una base de datos para encontrar los documentos más relevantes y los presenta como contexto para la generación de la respuesta.
2. Modelo de Generación:
- Función: Generar respuestas coherentes y contextualmente relevantes utilizando los documentos recuperados.
- Tecnología: Basado en algunos de los principales grandes modelos de Lenguaje (LLM) como GPT-3.5, T5, o BERT, Llama.
- Proceso: El modelo de generación toma la consulta del usuario y los documentos recuperados y utiliza esta información combinada para producir una respuesta precisa.
Proceso Detallado de RAG1
En detalle, un algoritmo RAG realiza las siguientes etapas:
1. Recepción de la pregunta. El sistema recibe una pregunta del usuario. Esta pregunta se procesa para extraer las palabras clave y entender la intención.
2. Recuperación de documentos. La pregunta se envía al modelo de recuperación.
- Ejemplo de Recuperación basada en embeddings:
- La pregunta se convierte en un vector de embeddings utilizando un modelo pre-entrenado.
- Este vector se compara con los vectores de documentos en la base de datos.
- Se seleccionan los documentos con mayor similitud.
- Ejemplo de BM25:
- Se tokeniza la pregunta y se comparan las palabras clave con los índices invertidos de la base de datos.
- Se recuperan los documentos más relevantes según una puntuación de relevancia.
3. Filtrado y clasificación. Los documentos recuperados se filtran para eliminar redundancias y clasificarlos según su relevancia. Pueden aplicarse técnicas adicionales como reranking utilizando modelos más sofisticados.
4. Generación de la respuesta. Los documentos filtrados se concatenan con la pregunta del usuario y se introducen en el modelo de generación. El LLM utiliza la información combinada para generar una respuesta que es coherente y directamente relevante a la pregunta. Por ejemplo, si utilizamos GPT-3.5 como LLM, la entrada al modelo incluye tanto la pregunta del usuario como fragmentos de los documentos recuperados. Finalmente, el modelo genera texto utilizando su capacidad para comprender el contexto de la información proporcionada.
En la siguiente sección vamos a ver algunas aplicaciones en las que la Inteligencia Artificial y los modelos grandes del lenguaje juegan un papel diferenciador y, en concreto, vamos a analizar cómo se benefician estos casos de usos de la aplicación de las técnicas RAG.
Ejemplos de casos de uso que se benefician sustancialmente de usar RAG frente a no usar RAG
1. Atención al Cliente en eCommerce
- Sin RAG:
- Un chatbot básico puede dar respuestas genéricas y potencialmente incorrectas sobre políticas de devolución.
- Ejemplo: Por favor, revise nuestra política de devoluciones en el sitio web.
- Con RAG:
- El chatbot accede a la base de datos de políticas actualizadas y proporciona una respuesta específica y precisa.
- Ejemplo: Puede devolver los productos dentro de 30 días desde la compra, siempre que estén en su embalaje original. Consulte más detalles [aquí].
2. Diagnóstico Médico
- Sin RAG:
- Un asistente virtual de salud podría ofrecer recomendaciones basadas solo en su entrenamiento previo, sin acceso a la información médica más reciente.
- Ejemplo: Es posible que tenga gripe. Consulte a su médico
- Con RAG:
- El asistente puede recuperar información de bases de datos médicas recientes y proporcionar un diagnóstico más preciso y actualizado.
- Ejemplo: Según los síntomas y los estudios recientes publicados en PubMed, podría estar enfrentando una infección viral. Consulte a su médico para un diagnóstico preciso.
3. Asistencia en Investigación Académica
- Sin RAG:
- Un investigador recibe respuestas limitadas a lo que el modelo ya sabe, lo que puede no ser suficiente para temas altamente especializados.
- Ejemplo: Los modelos de crecimiento económico son importantes para entender la economía.
- Con RAG:
- El asistente recupera y analiza artículos académicos relevantes, proporcionando información detallada y precisa.
- Ejemplo: Según el estudio de 2023 en 'Journal of Economic Growth', el modelo XYZ ha mostrado un 20% más de precisión en la predicción de tendencias económicas en mercados emergentes.
4. Periodismo
- Sin RAG:
- Un periodista recibe información genérica que puede no estar actualizada ni ser precisa.
- Ejemplo: La inteligencia artificial está cambiando muchas industrias.
- Con RAG:
- El asistente recupera datos específicos de estudios y artículos recientes, ofreciendo una base sólida para el artículo.
- Ejemplo: Según un informe de 2024 de 'TechCrunch', la adopción de IA en el sector financiero ha aumentado en un 35% en el último año, mejorando la eficiencia operativa y reduciendo costos.
Por supuesto, para la mayoría de los usuarios que hemos experimentado los interfaces conversacionales más accesibles, como ChatGPT, Gemini o Bing, podemos constatar que las respuestas suelen ser completas y bastante precisas cuando se trata de preguntas de ámbito general. Esto es porque estos agentes hacen uso de métodos RAG y otras técnicas avanzadas para proporcionar las respuestas. Sin embargo, no hay que remontarse mucho tiempo atrás en el que los asistentes conversacionales, como Alexa, Siri u OK Google, proporcionaban respuestas extremadamente simples y muy similares a las que explicamos en los ejemplos anteriores cuando no se hace uso de RAG.
Conclusiones
Las técnicas de Generación Aumentada por Recuperación (RAG) mejora la precisión y relevancia de las respuestas de los modelos de lenguaje al combinar recuperación de documentos y generación de texto. Utilizando métodos de recuperación como BM25 o DPR y modelos avanzados de lenguaje, RAG proporciona respuestas más contextualizadas, actualizadas y precisas. En la actualidad, RAG es la clave para el desarrollo exponencial de la IA en el ámbito de los datos privados de empresas y organizaciones. En los próximos meses se espera una adopción masiva de RAG en diversas industrias, optimizando la atención al cliente, diagnósticos médicos, investigación académica y periodismo, gracias a su capacidad para integrar información relevante y actual en tiempo real.
1. Para entender mejor esta sección, recomendamos al lector la lectura de este trabajo previo en el que explicamos de forma didáctica los fundamentos del procesamiento del lenguaje natural y cómo enseñamos a leer a las máquinas.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El pasado mes de julio comenzó la décima legislatura del Parlamento Europeo, un nuevo ciclo institucional que abarcará el periodo 2024-2029. La Presidenta de la Comisión Europea, Ursula von der Leyen, fue elegida para un segundo mandato, tras presentar al Parlamento Europeo sus Orientaciones Políticas para la próxima Comisión Europea 2024-2029.
Estas orientaciones establecen las prioridades que guiarán las políticas europeas en los próximos años. Entre los objetivos generales, encontramos que se invertirán esfuerzos en:
- Facilitar los negocios y fortalecer el mercado único.
- Descarbonizar y reducir los precios de la energía.
- Hacer que la investigación y la innovación sean los motores de la economía.
- Impulsar la productividad mediante la difusión de la tecnología digital.
- Invertir masivamente en competitividad sostenible.
- Subsanar la brecha en materia de capacidades y mano de obra.
En este artículo, nos vamos a centrar en desgranar el punto 4, centrado en combatir la insuficiente difusión de las tecnologías digitales. El desconocimiento de las posibilidades tecnológicas al alcance de la ciudadanía limita la capacidad de desarrollar nuevos servicios y modelos de negocio competitivos a nivel mundial.
Impulsar la productividad con la difusión de la tecnología digital
El mandato anterior estuvo marcado por la aprobación de nuevas regulaciones encaminadas a impulsar una economía digital justa y competitiva a través de un mercado único digital, donde la tecnología se situase al servicio de las personas. Ahora, es el momento de poner el foco en la aplicación y el cumplimiento de las leyes digitales adoptadas.
Una de las normativas de más reciente aprobación ha sido el Reglamento de Inteligencia Artificial (IA), un marco de referencia para el desarrollo de cualquier sistema IA. En esta norma, el foco estaba puesto en garantizar la seguridad y fiabilidad de la inteligencia artificial, evitando sesgos a través de diversas medidas entre las que se encontraba una gobernanza sólida de datos.
Una vez que ya contamos con este marco, ha llegado el momento de impulsar el uso de esta tecnología en pro de la innovación. Para ello, en este nuevo ciclo, se fomentarán los siguientes aspectos:
- Factorías de inteligencia artificial. Se trata de ecosistemas abiertos que ofrecen una infraestructura de servicios de supercomputación de inteligencia artificial. De esta forma se ponen grandes capacidades tecnológicas a disposición de empresas emergentes y comunidades de investigación.
- Estrategia de uso de la inteligencia artificial. Se busca impulsar usos industriales en diversos sectores, incluyendo la prestación de servicios públicos en áreas como la atención sanitaria. Para elaborar esta estrategia se contará con la visión de la industria y la sociedad civil.
- Consejo europeo de investigación sobre inteligencia artificial. Este organismo ayudará a poner en común los recursos de la Unión Europea (UE), facilitando el acceso a los mismos.
Pero para que sea posible desarrollar estas medidas, primero es necesario garantizar el acceso a datos de calidad. Estos datos no solo favorecen el entrenamiento de los sistemas IA y el desarrollo de productos y servicios tecnológicos de vanguardia, sino que también ayudan a la toma de decisiones informada y a la elaboración de estrategias políticas y económicas más certeras. Como dice el propio documento “el acceso a los datos no solo es un motor importante de la competitividad que representa casi el 4 % del PIB de la UE, sino que también es esencial para la productividad y las innovaciones sociales, desde la medicina personalizada hasta el ahorro de energía”.
Para mejorar el acceso a los datos de las empresas europeas y mejorar su capacidad competitiva con respecto a los grandes actores tecnológicos mundiales, la Unión Europea apuesta por la “mejora del acceso a los datos abiertos”, garantizando, al mismo tiempo, la más estricta protección de datos.
La revolución de los datos europea
“Europa necesita una revolución de los datos”. Así de tajante se muestra la Presidenta ante la situación actual. Por ello, una de las medidas en las que se trabajará es en una nueva Estrategia de datos de la Unión Europea. Esta estrategia se basará en las normas existentes actualmente. Es previsible que se tome como referencia la actual estrategia, entre cuyas líneas de acción se encuentra el fomento del intercambio de información a través de la creación de un mercado único de datos donde los datos puedan fluir entre países y sectores económicos de la UE.
En este marco seguirán muy presentes los avances legislativos que vimos en la última legislatura:
- Directiva (UE) 2019/1024 relativa a los datos abiertos y la reutilización de la información del sector público, que establece el marco jurídico para la reutilización de la información del sector público, puesta a disposición del público como datos abiertos, incluyendo el fomento de los datos de alto valor.
- Reglamento (UE) 2022/868 relativo a la gobernanza europea de datos (DGA en sus siglas en inglés), que regula el intercambio seguro y voluntario de conjuntos de datos que están bajo el poder de organismos públicos sobre los que concurren derechos de terceros, así como los servicios de intermediación de datos y su cesión altruista.
- Reglamento (UE) 2023/2854 sobre normas armonizadas para un acceso justo a los datos y su utilización (Data Act), que impulsa reglas armonizadas relativas al acceso y uso equitativo de los datos en el marco de la Estrategia Europea.
Con todo ello, se busca garantizar un “marco simplificado, claro y coherente para que las empresas y las administraciones compartan datos sin fisuras y a gran escala, respetando al mismo tiempo normas estrictas de privacidad y seguridad”.
Además de intensificar la inversión en tecnologías punteras, como la supercomputación, el internet de las cosas o la computación cuántica, la Unión Europea tiene entre sus planes continuar impulsando el acceso a datos de calidad que ayuden a generar un ecosistema tecnológico sostenible y solvente, capaz de competir con las grandes empresas mundiales. En este espacio iremos informando de las medidas tomadas con este fin.
Blog
La publicación el viernes 12 de julio de 2024 del Reglamento de Inteligencia Artificial (RIA o AIA en sus siglas en inglés) abre una nueva etapa en el marco regulatorio europeo y global. La norma se caracteriza por tratar de conjugar dos almas. De un lado se trata de asegurar que la tecnología no genere riesgos sistémicos para la democracia, la garantía de nuestros derechos y el ecosistema socioeconómico en su conjunto. De otro lado, se busca un enfoque orientado al desarrollo de producto de modo que responda a los altos estándares de fiabilidad, seguridad y cumplimiento normativo definidos por la Unión Europea.
Ámbito de aplicación de la norma
La norma permite diferenciar entre sistemas de bajo y medio riesgo, sistemas de alto riesgo y modelos de IA de uso general. Para calificar los sistemas, el RIA define criterios relacionados con el sector regulado por la Unión Europea (Anexo I) y define el contenido y alcance de aquellos sistemas que por su naturaleza y finalidad podrían generar riesgos (Anexo III). Los modelos son altamente dependientes del volumen de datos, sus capacidades y la carga operacional.
El RIA solo afecta a los dos últimos casos: sistemas de alto riesgo y modelos de IA de uso general. Los sistemas de alto riesgo exigen la evaluación de la conformidad a través de organismos notificados. Estos son entidades ante las que se presentan evidencias de que el desarrollo se ajusta al RIA. En este sentido, los modelos están sujetos a fórmulas de control por la Comisión que aseguran la prevención de riesgos sistémicos. No obstante, estamos ante un marco normativo flexible que favorece la investigación, relajando su aplicación en entornos de experimentación, así como mediante el despliegue de sandboxes para el desarrollo.
La norma establece una serie de “requisitos de los sistemas de IA de alto riesgo” (sección segunda del capítulo tercero) que deberían constituir un marco de referencia para el desarrollo de cualquier sistema e inspirar los códigos de buenas prácticas, normas técnicas y esquemas de certificación. Entre ellos, ocupa un lugar central el artículo 10 sobre “datos y gobernanza de datos”. Este proporciona indicaciones muy precisas sobre las condiciones de diseño de los sistemas de IA, particularmente cuando supongan tratar datos personales o cuando se proyecten sobre personas físicas.
Esta gobernanza debería considerarse por quienes proporcionen la infraestructura básica y/o los conjuntos de datos, gestionen espacios de datos o los llamados Digital Innovation Hubs, que ofrezcan servicios de soporte. En nuestro ecosistema, caracterizado por una alta prevalencia de PYMEs y/o equipos de investigación, la gobernanza de datos se proyecta sobre la calidad, seguridad y fiabilidad en sus acciones y resultados. Por ello es necesario asegurar los valores que el RIA impone a los conjuntos de datos de entrenamiento, validación y prueba en sistemas de alto riesgo y, en su caso, cuando se empleen técnicas que impliquen el entrenamiento de modelos de IA.
Estos valores pueden alinearse con los principios del artículo 5 del Reglamento General de Protección de Datos (RGPD) y los enriquecen y complementan. A ellos se añade el enfoque de riesgo y la protección de datos desde el diseño y por defecto. Relacionar unos y otros constituye un ejercicio sin duda interesante.
Garantizar el origen legítimo de los datos: Lealtad y licitud
Junto a la referencia común a la cadena de valor asociada a los datos, hay que referirse a una cadena de custodia que garantice la legalidad en los procesos de recogida de datos. El origen de los datos, particularmente en el caso de los datos personales, debe ser lícito, legítimo y su uso coherente con la finalidad original de su recogida. Por ello es indispensable una adecuada catalogación de los conjuntos de datos en origen que asegure una correcta descripción de su legitimidad y condiciones de uso.
Esta es una cuestión que afecta a los entornos de open data, a los organismos y servicios de acceso a datos detallados en el Reglamento de gobernanza de datos (DGA en sus siglas en inglés) o el Espacio Europeo de Datos de Salud (EHDS) y a buen seguro inspirará futuras regulaciones. Lo usual será combinar fuentes externas de datos con la información que maneja la PYME.
Minimización de los datos, exactitud y limitación de finalidad
El RIA ordena, de una parte, realizar una evaluación de la disponibilidad, la cantidad y la adecuación de los conjuntos de datos necesarios. De otra, exige que los conjuntos de datos de entrenamiento, validación y prueba sean pertinentes, suficientemente representativos y posean las propiedades estadísticas adecuadas. Esta tarea es muy relevante para los derechos de las personas o los colectivos afectados por el sistema. Además, en la mayor medida posible, carecerán de errores y estarán completos en vista de su finalidad prevista. RIA predica estas propiedades para cada conjunto de datos individualmente o para una combinación de estos.
Para la consecución de tales objetivos resulta necesario asegurar el despliegue de las técnicas adecuadas:
- Realizar las operaciones de tratamiento oportunas para la preparación de los datos, como la anotación, el etiquetado, la depuración, la actualización, el enriquecimiento y la agregación.
- Formular supuestos, en particular en lo que respecta a la información que se supone que miden y representan los datos. O, dicho en un lenguaje más coloquial, definir los casos de uso.
- Tener en cuenta, en la medida necesaria para la finalidad prevista, las características o elementos particulares del entorno geográfico, contextual, conductual o funcional específico en el que está previsto que se utilice el sistema de IA de alto riesgo.
Gestionar el riesgo: evitar el sesgo
En el ámbito de la gobernanza de los datos se atribuye un papel esencial a la evitación del sesgo cuando pueda generar riesgos para la salud y la seguridad de las personas, afectar negativamente a los derechos fundamentales o dar lugar a algún tipo de discriminación prohibida por el Derecho de la Unión, especialmente cuando las salidas de datos influyan en las informaciones de entrada de futuras operaciones. Para ello procede adoptar las medidas adecuadas para detectar, prevenir y mitigar posibles sesgos detectados.
El RIA habilita excepcionalmente el tratamiento de categorías especiales de datos personales siempre que ofrezcan las garantías adecuadas en relación con los derechos y las libertades fundamentales de las personas físicas. Pero impone condiciones adicionales:
- que el tratamiento de otros datos, como los sintéticos o los anonimizados, no permita efectuar de forma efectiva la detección y corrección de sesgos;
- que las categorías especiales de datos personales estén sujetas a limitaciones técnicas relativas a la reutilización de los datos personales y a medidas punteras en materia de seguridad y protección de la intimidad, incluida la seudonimización;
- que las categorías especiales de datos personales estén sujetas a medidas para garantizar que los datos personales tratados estén asegurados, protegidos y sujetos a garantías adecuadas, incluidos controles estrictos y documentación del acceso, a fin de evitar el uso indebido y garantizar que solo las personas autorizadas tengan acceso a dichos datos personales con obligaciones de confidencialidad adecuadas;
- que las categorías especiales de datos personales no se transmitan ni transfieran a terceros y que estos no puedan acceder de ningún otro modo a ellos;
- que las categorías especiales de datos personales se eliminen una vez que se haya corregido el sesgo o los datos personales hayan llegado al final de su período de conservación, si esta fecha es anterior;
- que los registros de las actividades de tratamiento con arreglo a los Reglamentos (UE) 2016/679 y (UE) 2018/1725 y la Directiva (UE) 2016/680 incluyan las razones por las que el tratamiento de categorías especiales de datos personales era estrictamente necesario para detectar y corregir sesgos, y por las que ese objetivo no podía alcanzarse mediante el tratamiento de otros datos.
Las previsiones normativas resultan extraordinariamente interesantes. RGPD, DGA o EHDS apuestan por tratar datos anonimizados. RIA establece una excepción en aquellos casos en los que se generan conjuntos de datos inadecuados o de baja calidad desde el punto de vista del sesgo.
Tanto los desarrolladores individuales, como los espacios de datos y los servicios de intermediación que proporcionen conjuntos de datos y/o plataformas para el desarrollo deben ser particularmente diligentes a la hora de definir su seguridad. Esta previsión es coherente con la exigencia de disponer de espacios seguros de procesamiento en EHDS, implica una apuesta por estándares certificables en seguridad, públicos o privados, y aconseja una relectura de la disposición adicional decimoséptima sobre tratamientos de datos en nuestra Ley orgánica de protección de datos en materia de seudonimización, en la medida en la que añade garantías éticas y jurídicas a las propiamente técnicas. Además, se subraya la necesidad de garantizar una adecuada trazabilidad en los usos. Adicionalmente será necesario integrar en el registro de actividades de tratamiento una mención específica a este tipo de usos y a su justificación.
Aplicar las lecciones aprendidas desde la protección de datos, desde el diseño y por defecto
El artículo 10 de RIA obliga a documentar las decisiones pertinentes relativas al diseño y a detectar lagunas o deficiencias pertinentes en los datos que impidan el cumplimiento del RIA y la forma de subsanarlas. En resumen, no basta con garantizar la gobernanza de datos, también es necesario proporcionar evidencia documental y mantener una actitud proactiva y vigilante durante todo el ciclo de vida de los sistemas de información.
Estas dos obligaciones integran la clave de bóveda del sistema. Y su lectura debería ser incluso mucho más amplia en la dimensión jurídica. Las lecciones aprendidas en el RGPD enseñan que existe una doble condición para la responsabilidad proactiva y la garantía de los derechos fundamentales. La primera es intrínseca y material: el despliegue de la ingeniería de la privacidad al servicio de la protección de datos desde el diseño y por defecto asegura el cumplimiento del RGPD. La segunda es contextual: los tratamientos de datos personales no se dan en el vacío, sino en un contexto amplio y complejo regulado por otros sectores del Ordenamiento.
La gobernanza de datos opera estructuralmente desde los cimientos a la bóveda de los sistemas de información basados en IA. Asegurar que exista, sea adecuada y funcional es esencial. Así lo ha entendido la Estrategia de Inteligencia Artificial 2024 del Gobierno de España que trata de dotar al país de esas palancas que dinamicen nuestro desarrollo.
RIA plantea un salto cualitativo y subraya el enfoque funcional desde el que deben leerse los principios de protección de datos subrayando la dimensión poblacional. Ello obliga a repensar las condiciones en las que se ha venido cumpliendo el RGPD en la Unión Europea. Urge abandonar los modelos basados en plantillas que la empresa de consultoría copia-pega. Es evidente que las listas de control y la estandarización son imprescindibles. Sin embargo, su efectividad es altamente dependiente del ajuste fino. Y ello obliga a apelar particularmente a los profesionales que soportan el cumplimiento de este objetivo a dedicar sus mayores esfuerzos para dotar de sentido profundo al cumplimiento del Reglamento de Inteligencia Artificial.
Puedes ver un resumen del reglamento en la siguiente infografía:

Puedes accerder a la versión accesible e interactiva aquí
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Estrategia de Inteligencia Artificial 2024 es el plan integral que establece un marco para acelerar el desarrollo y expansión de la inteligencia artificial (IA) en España. Esta estrategia fue aprobada, a propuesta del Ministerio para la Transformación Digital y de la Función Pública, por el Consejo de Ministros el 14 de Mayo de 2024 y viene a reforzar y acelerar la Estrategia Nacional de Inteligencia Artificial (ENIA), que comenzó a desplegarse en 2020.
La vertiginosa evolución de las tecnologías asociadas a la Inteligencia Artificial de estos últimos años justifica por sí sola, este refuerzo. Por ejemplo, según el AI Index Report de 2024 de la Universidad de Stanford, la inversión en IA se ha multiplicado por nueve desde 2022. El coste de entrenamiento de los modelos ha aumentado drásticamente, pero a cambio la IA está impulsando el progreso en ciencia, en medicina y en la productividad laboral en general. Por razones como estas, se pretende aprovechar al máximo el impacto de la IA en la economía y recoger los elementos positivos del trabajo en curso.
La nueva estrategia se articula en torno a tres ejes principales, que se desarrollarán a través de ocho líneas de acción. Estos ejes son:
- Reforzar las palancas claves para el desarrollo de la IA. Este eje se centra en potenciar la inversión en supercomputación, generar capacidades de almacenamiento en condiciones de sostenibilidad, desarrollar modelos y datos que constituyan una infraestructura pública de la IA y fomentar el talento especializado en IA.
- Facilitar la expansión de la IA en el sector público y privado, fomentando la innovación y la ciberseguridad. Este eje tiene como objetivos incorporar la IA en los procesos gubernamentales y empresariales, con un énfasis especial en las pymes, y desarrollar un marco de ciberseguridad robusto.
- Fomentar una IA transparente, ética y humanística. Este eje se centra en asegurar que el desarrollo y uso de la IA en España sea responsable y respetuoso con los derechos humanos, la igualdad, la privacidad y la no discriminación.
La siguiente infografía resumen los principales puntos de esta estrategia:

Haz clic para ampliar la infografía
La Estrategia de Inteligencia Artificial 2024 de España es un documento muy ambicioso que busca posicionar a nuestro país como líder en Inteligencia Artificial, expandiendo el uso de la IA robusta y responsable en el conjunto de la economía y en la administración pública. Con ello se podrá contribuir a que multiples áreas, como son la cultura o el diseño de ciudades, puedan beneficiarse de estos progresos.
La apertura y el acceso a datos de calidad son también fundamentales para el éxito de esta estrategia, ya que son parte de la materia prima necesaria para entrenar y evaluar modelos de IA que sean, además, inclusivos y socialmente justos, para que beneficien a toda la sociedad. Muy relacionadas con los datos abiertos, la estrategia dedica palancas específicas al impulso de la IA en el sector público y al desarrollo de corpus y modelos de lenguaje fundacionales y especializados. Esto incluye además el desarrollo de servicios comunes basados en modelos de IA y la implementación de un modelo de gobernanza de datos para asegurar la seguridad, calidad, interoperabilidad y reutilización de los datos manejados por la Administración General del Estado (AGE).
Los modelos fundacionales (Large Language Models o LLMs) son modelos de gran envergadura que se entrenarán a partir de grandes corpus de datos en castellano y lenguas cooficiales, garantizando así su aplicabilidad en una amplia variedad de contextos lingüísticos y culturales. Los modelos especializados (Small Language Models o SLMs), de menor tamaño, se desarrollarán con el objetivo de abordar con una menor demanda de recursos computacionales necesidades específicas dentro de sectores particulares.
Gobernanza común de datos de la AGE
La gobernanza de datos abiertos tendrá un papel crucial en la realización de los objetivos planteados, para, por ejemplo, conseguir un desarrollo eficiente de modelos de leguaje especializados. Con el objetivo de fomentar la creación de estos modelos y facilitar el desarrollo de aplicaciones para el ámbito público, la estrategia prevé un modelo de gobernanza uniforme para los datos, incluidos los corpus documentales de la Administración General del Estado, asegurando los estándares de seguridad, calidad, interoperabilidad y reutilización de todos los datos.
Esta iniciativa incluye la creación de un espacio de datos unificado que permita explotar conjuntos de datos sectoriales específicos para resolver casos de uso concretos de cada organismo. La gobernanza de datos garantizará la anonimización y privacidad de la información, así como el respeto a la normativa vigente durante todo el ciclo de vida de los datos.
Se desarrollará una estructura organizativa orientada al dato, con la Dirección General del Dato como elemento vertebrador. Además, se impulsará la Plataforma de datos de la AGE, la generación de catálogos de metadatos de los departamentos, el mapa de intercambios de datos y el fomento de la interoperabilidad. Todo ello con el fin de facilitar el despliegue de iniciativas de IA de mayor calidad y utilidad.
Desarrollar corpus y modelos de lenguaje fundacionales y especializados
Dentro de la palanca número tres, el documento reconoce que la base fundamental para el entrenamiento de los modelos de lenguaje son la cantidad y calidad de los datos disponibles, así como las licencias de uso que habilitan la posibilidad de utilizarlos.
La estrategia pone un énfasis especial en la creación de corpus lingüísticos que sean representativos y diversificados, incluyendo el castellano y las lenguas cooficiales como el catalán, euskera, gallego y valenciano. Estos corpus no solo deben ser extensos, sino también reflejar la variedad y riqueza cultural de las lenguas, lo que permitirá desarrollar modelos más precisos y adaptados a las necesidades locales.
Para lograrlo, se prevé la colaboración con instituciones académicas y de investigación, así como con la industria, para recopilar, limpiar y etiquetar grandes volúmenes de datos textuales. Además, se implementarán políticas que faciliten el acceso a estos datos a través de licencias abiertas que promuevan su reutilización y compartición.
La creación de modelos fundacionales se enfoca en desarrollar algoritmos de inteligencia artificial, entrenados sobre la base de estos corpus lingüísticos que reflejen la cultura y tradiciones de nuestras lenguas. Estos modelos se crearán en el marco del proyecto ALIA, extendiendo el trabajo iniciado con la pionera MarIA, y estarán diseñados para ser adaptables a una variedad de tareas de procesamiento del lenguaje natural. También se priorizará, siempre que sea posible, que estos modelos sean accesibles públicamente, permitiendo su uso tanto en el sector público como en el privado para generar el máximo valor económico posible.
En definitiva, la Estrategia Nacional de Inteligencia Artificial 2024 de España es un ambicioso plan que busca posicionar al país como un líder europeo en el desarrollo y uso de tecnologías de IA responsable, así como asegurar que estos avances tecnológicos se realicen de manera sostenible, beneficiando a toda la sociedad. El uso de datos abiertos y la gobernanza de los datos del sector público contribuyen también a esta estrategia, proporcionando bases fundamentales para el desarrollo de modelos de IA avanzados, éticos y eficientes que mejorarán los servicios públicos e impulsarán el crecimiento económico. Y, en definitiva, la competitividad de España en un escenario global en el que todos los países están haciendo un esfuerzo importante por impulsar la IA y recoger estos beneficios.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La equidad de datos es un concepto que enfatiza la importancia de considerar cuestiones de poder, sesgo y discriminación en la recopilación, el análisis y la interpretación de datos. Implica garantizar que los datos se recopilen, analicen y utilicen de manera justa, inclusiva y equitativa para todas las partes interesadas, en particular aquellas que históricamente han sido marginadas o excluidas. Aunque no hay un consenso sobre su definición, la equidad de datos tiene como objetivo abordar las desigualdades sistémicas y los desequilibrios de poder mediante la promoción de la transparencia, la rendición de cuentas y la propiedad comunitaria de los datos. También implica reconocer y corregir los legados de discriminación a través de datos y garantizar que los datos se utilicen para apoyar el bienestar y el empoderamiento de todos los individuos y comunidades. Por todo ello, la equidad de datos es un principio clave en la gobernanza de datos, relacionado con los impactos en individuos, grupos y ecosistemas
Para aclarar más sobre esta cuestión, el Foro Económico Mundial –una organización que reúne a líderes de las grandes empresas y personas expertas para tratar asuntos globales— publicó hace unos meses un informe breve titulado “Data Equity: Foundational Concepts for Generative AI” ("Equidad de datos: conceptos fundamentales para la IA generativa"), dirigido a la industria, la sociedad civil, academia y tomadores y tomadoras de decisión.
El objetivo del documento del Foro Económico Mundial es, primero, definir la equidad de los datos y demostrar su importancia en el desarrollo y la implementación de la IA generativa (conocida como genAI). En este informe, el Foro Económico Mundial identifica algunos desafíos y riesgos asociados con la falta de equidad de datos en el desarrollo de la IA, como el sesgo, la discriminación y los resultados injustos. Asimismo, pretende ofrecer orientación práctica y recomendaciones para lograr la equidad de datos, incluidas estrategias para la recopilación, el análisis y el uso de datos. Por otro lado, el Foro Económico Mundial dice querer, por un lado, fomentar la colaboración entre las partes interesadas de la industria, los gobiernos, el mundo académico y la sociedad civil para abordar las cuestiones de equidad de datos y promover el desarrollo de una IA justa e inclusiva, y por otro, influir sobre el futuro del desarrollo de la IA.
A continuación, se analizan algunas de las claves del informe.
Tipos de equidad de datos
El documento identifica cuatro clases principales de equidad de datos:
-
La equidad de representación se refiere a la inclusión justa y proporcional de diferentes grupos en los conjuntos de datos utilizados para entrenar modelos de genAI.
-
La equidad de recursos habla de la distribución ecuánime de los recursos (datos, infraestructura y conocimientos) necesarios para el desarrollo y uso de la genAI.
-
La equidad de acceso implica garantizar un acceso justo y no discriminatorio a las capacidades y beneficios de la genAI por parte de diferentes grupos.
- La equidad de resultados busca asegurar que los resultados y aplicaciones de la genAI no generen impactos desproporcionados o perjudiciales para grupos vulnerables.
Desafíos de equidad en la genAI
El documento destaca que los modelos de fundación, que son la base de muchas herramientas de genAI, presentan desafíos específicos de equidad de datos, ya que codifican sesgos y prejuicios presentes en los conjuntos de datos de entrenamiento y los pueden llegar a amplificar en sus resultados. En IA, un modelo de función se refiere a un programa o algoritmo que se basa en datos de entrenamiento para reconocer patrones y hacer predicciones o decisiones, lo que le permite hacer predicciones o decisiones basadas en nuevos datos de entrada.
Los principales retos en términos de justicia social con la inteligencia artificial (IA) incluyen el hecho de que los datos de entrenamiento pueden estar sesgados. Los modelos de IA generativa se entrenan en grandes conjuntos de datos que a menudo contienen sesgos y contenido discriminatorio, lo que puede conducir a la perpetuación del discurso de odio, la misoginia y el racismo. Luego, se pueden producir sesgos algorítmicos, que no solo reproducen estos sesgos iniciales, sino que pueden amplificarlos, aumentando las desigualdades sociales existentes y resultar en discriminación y trato injusto a los grupos estereotipados. Existen también preocupaciones sobre la privacidad, ya que la IA generativa se basa en algunos datos personales confidenciales, que pueden ser explotados y expuestos.
El uso cada vez más extenso de la IA generativa en diversos campos está ya provocando cambios laborales, ya que es más fácil, rápido o barato pedirle a una inteligencia artificial que cree una imagen o un texto –en realidad, basado en las creaciones humanas que existen en internet- que encargarlo a una persona experta. Esto puede exacerbar las desigualdades económicas.
Finalmente, la IA generativa tiene el potencial de intensificar la desinformación. La IA generativa se puede utilizar para crear deepfakes de alta calidad, que ya se están usando para difundir bulos y desinformación, algo que podría socavar los procesos e instituciones democráticos.
Brechas y posibles soluciones
Estos desafíos resaltan la necesidad de una cuidadosa consideración y regulación de la IA generativa para garantizar que se desarrolle y utilice de una manera que respete los derechos humanos y promueva la justicia social. Sin embargo, el documento no aborda la desinformación y solo menciona el género cuando habla de la “equidad de características” (feature equity), un componente de la equidad de datos. La equidad de características busca “garantizar una representación precisa de los individuos, grupos y comunidades representados por los datos, lo que requiere la inclusión de atributos como raza, género, ubicación e ingresos junto con otros datos” (pág. 4). Sin estos atributos, dice el documento, “a menudo resulta difícil identificar y abordar sesgos y desigualdades latentes”. No obstante, esas mismas características se pueden utilizar para discriminar contra las mujeres, por ejemplo.
Para abordar estos desafíos, se requiere el compromiso y la colaboración de diversas partes interesadas, como la industria, el gobierno, la academia y la sociedad civil, para desarrollar métodos y procesos que integren consideraciones de equidad de datos en todas las fases del desarrollo de la genAI. Este documento sienta las bases teóricas de lo que se puede entender como equidad de datos; sin embargo, queda mucho camino para ver cómo se pasa de la teoría a la práctica en regulación, hábitos y conocimiento.
Este documento enlaza con los pasos que ya se están llevando a cabo en Europa y España con la Ley de IA de la Unión Europea y la Estrategia IA del Gobierno de España, respectivamente. Precisamente, uno de los ejes de esta última (Eje 3) es fomentar una IA transparente, ética y humanística.
La estrategia española de IA es un documento más amplio que el del Foro Económico Mundial, que describe los planes del gobierno para el desarrollo y la adopción de tecnologías de inteligencia artificial general. La estrategia se centra en áreas como el desarrollo del talento, la investigación y la innovación, los marcos regulatorios y la adopción de la IA en los sectores público y privado, y se dirige principalmente a partes interesadas nacionales, como agencias gubernamentales, empresas e instituciones de investigación. Si bien la estrategia española de IA no menciona explícitamente la equidad de los datos, sí enfatiza la importancia de un desarrollo responsable y ético de la IA, que podría incluir consideraciones en torno a la equidad de los datos.
El informe del Foro Económico Mundial se puede encontrar aquí: Data Equity: Foundational Concepts for Generative AI | World Economic Forum (weforum.org)
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor