Noticia
Los datos abiertos son un combustible fundamental en la innovación digital contemporánea, creando ecosistemas de información que democratizan el acceso al conocimiento y potencian el desarrollo de soluciones tecnológicas avanzadas.
Sin embargo, la mera disponibilidad de datos no es suficiente. La construcción de ecosistemas robustos y sostenibles requiere marcos normativos claros, principios éticos sólidos y metodologías de gestión que garanticen tanto la innovación como la protección de derechos fundamentales. Por ello, la documentación especializada que orienta estos procesos se convierte en un recurso estratégico para gobiernos, organizaciones y empresas que buscan participar responsablemente en la economía digital.
En este post, recopilamos informes recientes, elaborados por organizaciones de referencia tanto del ámbito público como privado, que ofrecen estas orientaciones clave. Estos documentos no solo analizan los desafíos actuales de los ecosistemas de datos abiertos, sino que proporcionan herramientas prácticas y marcos de trabajo concretos para su implementación efectiva.
Estado y evolución del mercado del open data
Conocer cómo es y qué cambios ha habido en el ecosistema de los datos abiertos a nivel europeo y nacional es importante para tomar decisiones informadas y adaptarse a las necesidades de la industria. En este sentido, la Comisión Europea publica, periódicamente, un informe sobre los mercados de datos, que se actualiza regularmente. La última versión es de diciembre de 2024, aunque periódicamente se van publicando casos de uso que ejemplifican el potencial de los datos en Europa (el último de febrero de 2025).
Por otro lado, desde una perspectiva regulatoria europea, el último informe anual sobre la implementación de la Ley de Mercados Digitales (DMA) aborda una visión integral de las medidas adoptadas para garantizar la equidad y competitividad en el sector digital. Este documento es interesante para comprender cómo se está configurando el marco normativo que afecta directamente a los ecosistemas de datos abiertos.
A nivel nacional, el informe sectorial de ASEDIE sobre la "Economía del Dato en su ámbito infomediario" 2025 proporciona evidencia cuantitativa del valor económico generado por los ecosistemas de datos abiertos en España.
La importancia de los datos abiertos en la IA
Está claro que la intersección entre datos abiertos e inteligencia artificial es una realidad que plantea desafíos éticos y normativos complejos que requieren respuestas colaborativas y multisectoriales. En este contexto, el desarrollo de marcos que guíen el uso responsable de la IA se convierte en una prioridad estratégica, especialmente cuando estas tecnologías se nutren de ecosistemas de datos públicos y privados para generar valor social y económico. Estos son algunos informes que abordan este objetivo:
- IA generativa y datos abiertos: directrices y buenas prácticas: el Departamento de Comercio de EE. UU. ha publicado una guía con principios y buenas prácticas sobre cómo aplicar inteligencia artificial generativa de forma ética y efectiva en el contexto de los datos abiertos. El documento ofrece pautas para optimizar la calidad y la estructura de los datos abiertos con el fin de hacerlos útiles para estos sistemas, incluyendo la transparencia y gobernanza.
- Guía de buenas prácticas para el uso de la inteligencia artificial ética: esta guía muestra un enfoque integral que combina principios éticos sólidos con preceptos normativos claros y aplicables. Además del marco teórico, la guía sirve de herramienta práctica para implementar sistemas de IA de manera responsable, considerando tanto los beneficios potenciales como los riesgos asociados. La colaboración entre actores públicos y privados garantiza que las recomendaciones sean tanto técnicamente viables como socialmente responsables.
- Enhancing Access to and Sharing of Data in the Age of AI: este análisis de la Organización para la Cooperación y el Desarrollo Económicos (OCDE) aborda uno de los principales obstáculos para el desarrollo de la inteligencia artificial: el acceso limitado a datos de calidad y modelos efectivos. A través de ejemplos, se identifican estrategias específicas que los gobiernos pueden implementar para mejorar significativamente el acceso y la compartición de datos y ciertos modelos de IA.
- A Blueprint to Unlock New Data Commons for AI: Open Data Policy Lab ha elaborado una guía práctica que se centra en la creación y gestión de bienes comunes de dato (data commons) específicamente diseñados para habilitar casos de uso de inteligencia artificial de interés público. La guía ofrece metodologías concretas sobre cómo gestionar datos de manera que se facilite la creación de estos bienes comunes de dato, incluyendo aspectos de gobernanza, sostenibilidad técnica y alineación con objetivos de interés público.
- Guía práctica sobre colaboraciones basadas en datos: la iniciativa Data for Children Collaborative ha publicado una guía paso a paso para desarrollar colaboraciones de datos efectivas, con un enfoque en impacto social. Incluye ejemplos reales, modelos de gobernanza y herramientas prácticas para impulsar alianzas sostenibles.
En resumen, estos informes definen el camino hacia ecosistemas de datos más maduros, éticos y colaborativos. Desde las cifras de crecimiento del sector infomediario español hasta los marcos regulatorios europeos, pasando por las guías prácticas para la implementación de IA responsable, todos estos documentos comparten una visión común: el futuro de los datos abiertos depende de nuestra capacidad para construir puentes entre el sector público y privado, entre la innovación tecnológica y la responsabilidad social.
Blog
Una de las misiones de la inteligencia artificial contemporánea es ayudarnos a encontrar, ordenar y digerir información, especialmente con la ayuda de los grandes modelos de lenguaje. Estos sistemas han llegado cuando más necesitamos gestionar un conocimiento que producimos y compartimos en masa, pero que después nos cuesta abarcar y consumir. Su valor radica en encontrar rápidamente las ideas y los datos que necesitamos, con el fin de que podamos dedicar nuestro esfuerzo y tiempo a pensar o, lo que es lo mismo, empezar a subir la escalera con uno o dos peldaños de ventaja.
Los sistemas basados en IA nos ayudan a navegar cualquier ecosistema de conocimiento, algo que es útil tanto en la investigación académica como en los estudios de tendencias en el mundo de la empresa. Las herramientas de IA analítica pueden analizar miles de papers para mostrarnos qué autores colaboran entre sí o cómo se agrupan los temas, creándonos a demanda un mapa interactivo y filtrable de la literatura. La IA generativa, la gran esperada, puede partir de una pregunta de investigación y devolvernos subcontenido útil como una síntesis o un contraste de enfoques. La primera nos muestra el terreno sobre el mapa, mientras que la segunda nos sugiere por dónde podemos avanzar.
Herramientas prácticas
Empezando por las más analíticas y dejando las mixtas o generativas para el final, recorremos cuatro herramientas prácticas para la investigación que integran la IA como funcionalidad, y una bola extra.
Es una herramienta basada sobre todo en la conexión entre autores, temas y artículos, que nos muestra redes de citas y nos permite crear el grafo completo de la literatura en torno a un tema. Como punto de partida, Inciteful nos pide el título o la URL de un paper, aunque también podemos simplemente buscar por nuestro tema de investigación. También existe la posibilidad de introducir los datos de dos artículos, para que nos enseñe cómo se conectan entre sí.
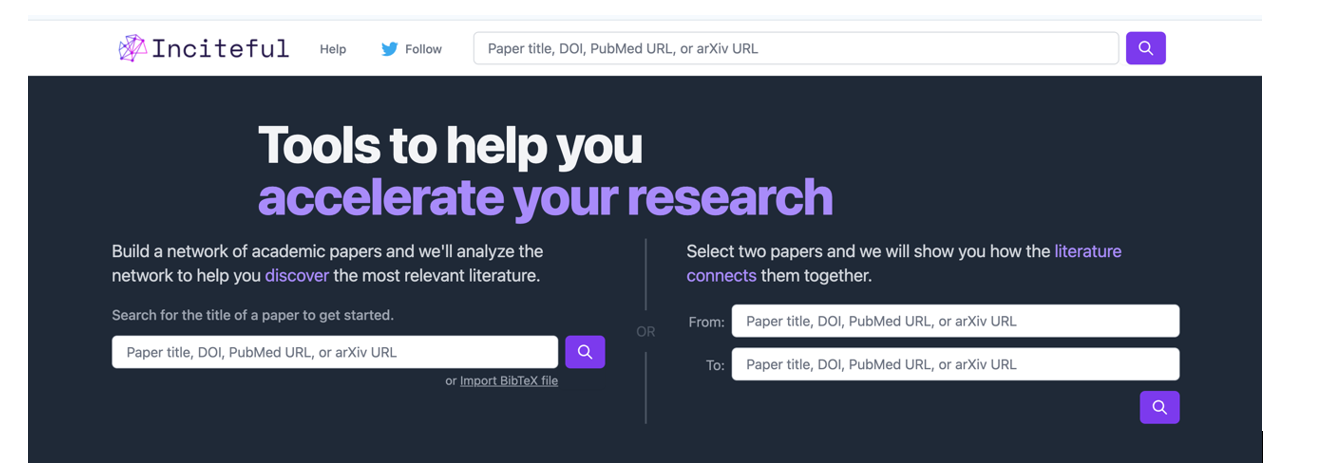
Figura 1. Captura de pantalla en Inciteful: pantalla inicial de búsqueda y conexión entre papers.
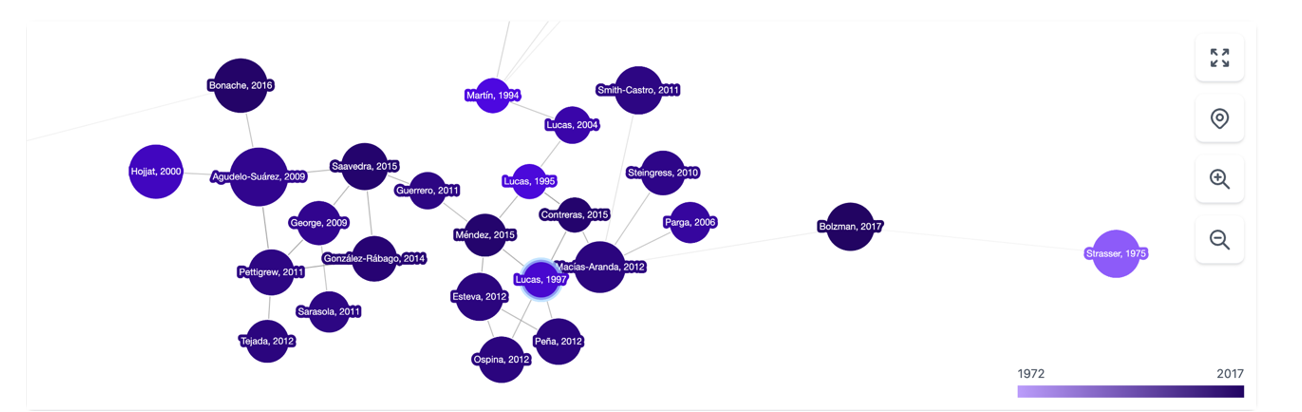
Figura 2. Captura de pantalla en Inciteful: red de nodos con artículos y autores.
En Scite, la integración de la IA es más evidente y práctica: ante una pregunta, crea una única respuesta resumen combinando la información de todas las referencias. La herramienta analiza la semántica de los papers para extraer cuál es la naturaleza de cada cita: cuántas citas lo apoyan (símbolo del check), lo cuestionan (interrogación) o solo lo mencionan (barra). Esto nos permite algo tan valioso como añadir contexto a las métricas de impacto de un artículo en nuestra bibliografía.
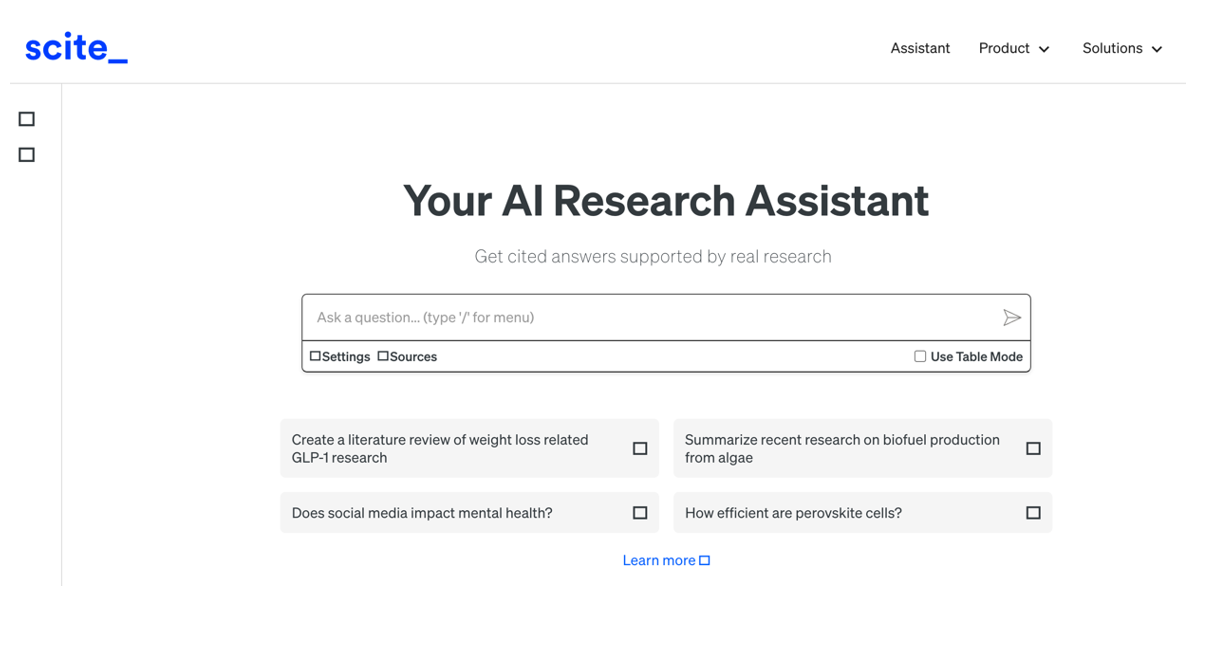
Figura 3. Captura de pantalla en Scite: pantalla inicial de búsqueda.

Figura 4. Captura de pantalla en Scite: valoración de las citas de un artículo.
Además de integrar las funcionalidades de las anteriores, se trata de un producto digital muy completo que no solo permite navegar de paper en paper en forma de red visual, sino que también hace posible establecer alertas sobre un tema o un autor al que seguimos y crear listas de papers. Además, el propio sistema sugiere qué otros papers te pueden interesar, todo en el estilo de un sistema de recomendación como los de Spotify o Netflix. También permite hacer listas públicas, como en Google Maps, y trabajar de forma colaborativa con otros usuarios.
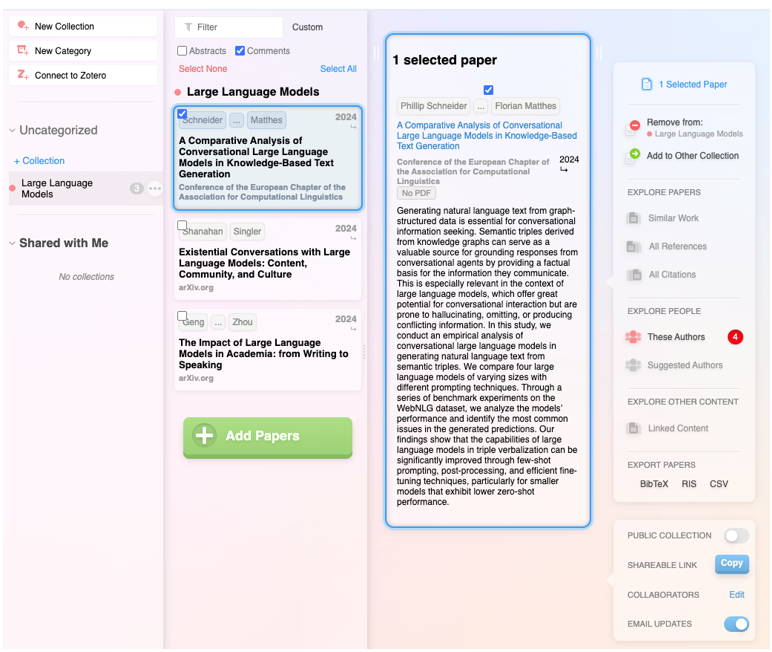
Figura 5. Captura de pantalla en Research Rabbit: lista personalizada de artículos.
Cuenta con el aval del gobierno británico, la Universidad de Stanford o la NASA, y está basada al cien por cien en IA generativa. Su funcionalidad estrella es la capacidad de hacer preguntas directas a un paper o a una colección de artículos, y finalmente obtener un informe dirigido a cuestiones concretas con todas las referencias. Aunque, en realidad, la característica más sorprendente es la capacidad de mejora de la pregunta inicial del usuario: la herramienta evalúa de forma instantánea la calidad de la pregunta y realiza sugerencias para hacerla más precisa o interesante.

Figura 6. Captura de pantalla en Elicit: sugerencias de mejora para la pregunta inicial.
Bola extra: Consensus
Lo que empezó como un humilde GPT personalizado dentro de la versión Plus de ChatGPT ha terminado siendo todo un producto digital para la investigación. A partir de una pregunta, intenta sintetizar el consenso científico en torno a esa temática, indicando si hay acuerdo o discrepancia entre los estudios. De una manera sencilla y visual muestra cuántos apoyan una afirmación, cuántos la ponen en duda y qué conclusiones predominan, además de proporcionar un pequeño informe para obtener una orientación rápida.
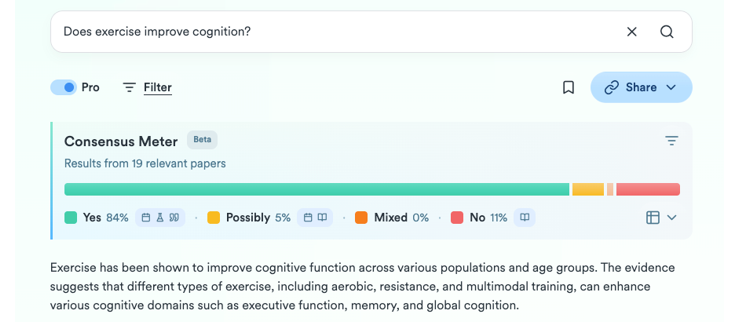
Figure 7. Screenshot on Consensus: impact metrics from a question.
El botón de la profundidad
En los últimos meses ha aparecido una nueva funcionalidad en las plataformas de los grandes modelos de lenguaje comerciales enfocada a la investigación en profundidad. En concreto, se trata de un botón con este mismo nombre, “investigación en profundidad” o “deep research”, que ya podemos encontrar en ChatGPT, versión Plus (con peticiones limitadas) o Pro, y en Gemini Advanced, aunque prometen que gradualmente se irá abriendo al uso gratuito y permiten algunas pruebas sin coste.
Figura 8. Captura de pantalla en ChatGPT Plus: botón Investigación en profundidad.
Figura 9. Captura de pantalla en Gemini Advanced: botón Deep Research.
Esta opción, que debemos activar antes de lanzar el prompt, funciona como un atajo: el modelo genera un informe sintético y organizado sobre el tema, reuniendo información clave, datos y contexto. Antes de iniciar la investigación, es posible que el sistema nos haga alguna pregunta adicional para centrar mejor la búsqueda.

Figura 10. Captura de pantalla en ChatGPT Plus: preguntas para acotar la investigación
Debemos tener en cuenta que, una vez resueltas estas dudas, el sistema inicia un proceso que puede tardar mucho más que una respuesta normal. En concreto, en ChatGPT Plus puede requerir hasta 10 minutos. Una barra de progreso nos va indicando el avance.
Figura 11. Captura de pantalla en ChatGPT Plus: inicio de la investigación y barra de progreso
Lo que obtenemos ahora es un informe completo, considerablemente preciso, incluyendo ejemplos y enlaces que nos pueden poner rápidamente en la pista de lo que estamos buscando.

Figura 12. Captura de pantalla de ChatGPT Plus: resultado de la investigación (fragmento).
Cierre
Las herramientas diseñadas para aplicar la IA a favor de la investigación no son infalibles ni definitivas, pueden todavía incurrir en errores y alucinaciones, pero no es menos cierto que la investigación con IA ya es un proceso radicalmente distinto a la investigación sin ella. La búsqueda asistida consiste, como prácticamente todo cuando hablamos de IA, en no desdeñar por imperfecto lo que puede ser útil, dedicar algo de tiempo a probar nuevos usos que pueden ahorrarnos muchas horas más adelante, y centrar su papel en lo que sí puede hacer para mantener nuestro enfoque en los siguientes pasos..
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El Índice de Tendencias del Trabajo 2024 sobre el Estado de la Inteligencia Artificial en el Trabajo y los informes de T-Systems e InfoJobs indican que un 78% de los trabajadores en España utilizan sus propias herramientas de IA en el ámbito laboral. Esta cifra aumenta al 80% en empresas de tamaño mediano. Además 1 de cada 3 trabajadores (32%) emplea herramientas de IA en su día a día laboral. El 75% de los trabajadores del conocimiento utiliza herramientas de IA generativa, y casi la mitad comenzó a hacerlo en los últimos seis meses. Curiosamente, la brecha generacional se reduce en este ámbito. Si bien el 85% de los empleados de la Generación Z (18 a 28 años) utilizan IA personalizada, resulta que más del 70% de los baby boomers (mayores de 58 años) también emplean estas herramientas. En realidad, esta tendencia parece ser confirmada desde distintos enfoques.
| Título del estudio | Fuente |
|---|---|
| 2024 Work Trend Index: AI at work is here. Now comes the hard part | Microsoft, LinkedIn |
| 2024 AI Adoption and Risk Report | Cyberhaven Labs |
| Generative AI''s fast and furious entry into Switzerland | Deloitte Switzerland |
| Bring Your Own AI: Balance Rewards and Risks (Webinar) | MITSloan |
| Lin, L. and Parker, K. (2025) U.S. workers are more worried than hopeful about future AI use in the Workplace | Pew Research Center |
Figura 1. Tabla de referencias sobre BYOAI
Este fenómeno se ha denominado BYOAI (Bring Your Own AI o Traer tu propia IA), por sus siglas en inglés. Se caracteriza porque la persona empleada suele utilizar algún tipo de solución abierta al uso libre como, por ejemplo, ChatGPT. La organización no ha contratado el servicio, el registro se ha producido con carácter privado por el usuario y el proveedor obviamente no asume ninguna responsabilidad legal. Si, por ejemplo, se utilizan las posibilidades que ofrece Notebook, Perplexity o DeepSeek es perfectamente posible que se carguen documentos confidenciales o protegidos.
Por otra parte, esto coincide, según datos de EuroStat, con la adopción de la IA en el sector empresarial. En 2024, el 13,5% de las empresas europeas (con 10 o más empleados) usaban alguna tecnología de IA, cifra que sube al 41% en grandes empresas y es especialmente alta en sectores como información y comunicación (48,7%), servicios profesionales, científicos y técnicos (30,5%). La tendencia a la adopción de la IA en el sector público también es creciente debido no sólo a las tendencias globales, sino probablemente a la adopción de estrategias de IA y al impacto positivo de los fondos Next Generation.
El deber legal de alfabetización en IA
En este contexto emergen preguntas de modo inmediato. Las primeras se refieren al fenómeno del uso no autorizado por las personas empleadas: ¿Ha emitido la persona delegada de protección de datos o la responsable de seguridad algún informe dirigido a la dirección de la organización? ¿Se ha autorizado este tipo de uso? ¿Se discutió el asunto en alguna reunión del Comité de Seguridad? ¿Se ha dirigido alguna circular informativa definiendo con precisión las reglas aplicables? Pero junto a estas emergen otras de carácter más general: ¿Qué nivel de formación poseen las personas? ¿Están capacitadas para emitir informes o tomar decisiones usando este tipo de herramientas?
El Reglamento de la Unión Europea sobre Inteligencia Artificial (RIA), con buen criterio, ha establecido un deber de alfabetización en IA que se impone a los proveedores y responsables del despliegue de este tipo de sistemas. A estos les corresponde adoptar medidas para garantizar que, en la mayor medida posible, su personal y demás personas que se encarguen en su nombre del funcionamiento y la utilización de sistemas de IA, tengan un nivel suficiente de alfabetización en materia de IA. Para ello es necesario tener en cuenta sus conocimientos técnicos, su experiencia, su educación y su formación. La formación debe integrarse en el contexto previsto de uso de los sistemas de IA y ajustarse al perfil de las personas o los colectivos en que se van a utilizar dichos sistemas.
A diferencia de lo que ocurre en el Reglamento General de Protección de Datos1, aquí la obligación se formula de forma expresa e imperativa. En el RGPD no existe ninguna referencia directa a esta materia, salvo al definir como función de la persona delegada de protección de datos la formación del personal que participa en las operaciones de tratamiento. Esta necesidad puede deducirse también de la obligación del encargado del tratamiento de garantizar que las personas autorizadas para tratar datos personales conozcan su deber de confidencialidad. Es obvio que el deber de responsabilidad proactiva, la protección de datos desde el diseño y por defecto y la gestión del riesgo conducen a formar a los usuarios de sistemas de información. Sin embargo, lo cierto es que el modo en el que esta formación se despliega no siempre es el adecuado. En muchas organizaciones o no existe, o es voluntaria o se basa en la firma de un conjunto de obligaciones de seguridad al acceder a un puesto de trabajo.
En el ámbito de los sistemas de información basados en inteligencia artificial la obligación de formar es innegociable y se impone de modo imperativo. El RIA prevé multas muy elevadas que especifica el Anteproyecto de ley para el buen uso y la gobernanza de la Inteligencia Artificial. Cuando se apruebe la futura Ley constituirá infracción grave el incumplimiento del artículo 26.2 del RIA, relativo a la necesidad de encomendar la supervisión humana del sistema a personas con la adecuada competencia, formación y autoridad.
Beneficios de formar en IA
Más allá de la coerción legal, formar a las personas constituye una decisión acertada y sin duda beneficiosa que debe leerse en positivo y concebirse como una inversión. De una parte, contribuye a adoptar medidas dirigidas a gestionar el riesgo que en el caso del BYOAI incluye fuga de datos, pérdida de propiedad intelectual, problemas de cumplimiento y ciberseguridad. Por otra parte, es necesario gestionar riesgos asociados al uso regular de la IA. Y en este sentido, resulta fundamental que los usuarios finales conozcan con mucho detalle los modos en los que la tecnología funciona, su papel de supervisión humana en el proceso de toma de decisiones y que adquieran la capacidad de identificar y reportar cualquier incidencia en el funcionamiento.
Sin embargo, la formación debe perseguir objetivos de alto nivel. Debería ser continua, combinando teoría, práctica y actualización permanente e incluir tanto aspectos técnicos como éticos, legales y de impacto social para promover una cultura de conocimiento y uso responsable de la IA en la organización. Sus beneficios para la dinámica de la actividad pública o privada son del más variado signo.
Con respecto a sus beneficios, la alfabetización en inteligencia artificial (IA) se ha convertido en un factor estratégico para transformar la toma de decisiones y promover la innovación en las organizaciones:
- Al dotar a los equipos de conocimientos sólidos sobre el funcionamiento y las aplicaciones de la IA, se facilita la interpretación de datos complejos y el uso de herramientas avanzadas, lo que permite identificar patrones y anticipar tendencias relevantes para el negocio.
- Este conocimiento especializado contribuye a minimizar errores y sesgos, ya que promueve decisiones fundamentadas en análisis rigurosos en lugar de intuiciones, y capacita para detectar posibles desviaciones en los sistemas automatizados. Además, la automatización de tareas rutinarias reduce la probabilidad de fallos humanos y libera recursos que pueden enfocarse en actividades estratégicas y creativas.
- La integración de la IA en la cultura organizacional impulsa una mentalidad orientada al análisis crítico y al cuestionamiento de las recomendaciones tecnológicas, promoviendo así una cultura basada en la evidencia. Este enfoque no solo fortalece la capacidad de adaptación ante los avances tecnológicos, sino que también facilita la detección de oportunidades para optimizar procesos, desarrollar nuevos productos y mejorar la eficiencia operativa.
- En el ámbito legal y ético, la alfabetización en IA ayuda a gestionar los riesgos asociados al cumplimiento normativo y a la reputación, ya que fomenta prácticas transparentes y auditables que generan confianza tanto en la sociedad como en los reguladores.
- Por último, comprender el impacto y las posibilidades de la IA disminuye la resistencia al cambio y favorece la adopción de nuevas tecnologías, acelerando la transformación digital y posicionando a la organización como líder en innovación y adaptación a los retos del entorno actual.

Figura 2. Beneficios de la alfabetización en IA. Fuente: elaboración propia
Buenas prácticas para una formación en IA exitosa
Las organizaciones deben reflexionar sobre su estrategia formativa para alcanzar estos objetivos. En este sentido, parece razonable compartir algunas lecciones aprendidas en materia de protección de datos. En primer lugar, es necesario señalar que toda formación se debe iniciar comprometiendo al equipo de dirección de la organización. El temor reverencial al Consejo de Administración, a la Corporación Local o al Gobierno de turno no debe existir. El nivel político de toda organización debería predicar con el ejemplo si realmente se quiere permear al conjunto de los recursos humanos. Y esta formación debe ser muy específica no sólo desde el punto de vista de la gestión del riesgo sino también desde un enfoque de oportunidad basada en una cultura de la innovación responsable.
Del mismo modo, y aunque pueda implicar costes adicionales, es necesario tener en cuenta no sólo a los usuarios de los sistemas de información basados en IA sino a todo el personal. Ello no sólo nos permitirá evitar los riesgos asociados al BYOAI sino establecer una cultura corporativa que facilite los procesos de implantación de la IA.
Finalmente, será indispensable adaptar la formación a los perfiles específicos: tanto a los usuarios de sistemas basados en IA, el personal técnico (TI) instrumental y los mediadores y habilitadores éticos y legales como a los oficiales de compliance o los responsables de la adquisición o licitación de productos y servicios.
Sin perjuicio de los contenidos que en buena lógica debe reunir este tipo de formación existen ciertos valores que deben inspirar los planes formativos. En primer lugar, no es ocioso recordar que se trata de una formación obligatoria y funcionalmente adaptada al puesto de trabajo. En segundo lugar, debe ser capaz de empoderar a las personas y comprometerlas con el uso de la IA. El enfoque legal de la UE se basa en el principio de responsabilidad y supervisión humana: el humano decide siempre. Y por tanto debe estar capacitado para tomar decisiones adecuadas al output que le proporciona la IA, para disentir del criterio de la máquina en un ecosistema que le ampare y le permita reportar incidentes y revisarlos.
Por último, existe un elemento que no se puede obviar bajo ninguna circunstancia: con independencia de que se traten o no datos personales, y de que la IA tenga por destino a los seres humanos, sus resultados siempre repercutirán directa o indirectamente en las personas o sobre la sociedad. Por tanto, el enfoque formativo debe integrar las implicaciones éticas, legales y sociales de la IA y comprometer a los usuarios con la garantía de los derechos fundamentales y la democracia.
1Reglamento (UE) 2024/1689 del Parlamento Europeo y del Consejo, de 13 de junio de 2024, por el que se establecen normas armonizadas en materia de inteligencia artificial y por el que se modifican los Reglamentos (CE) n.° 300/2008, (UE) n.° 167/2013, (UE) n.° 168/2013, (UE) 2018/858, (UE) 2018/1139 y (UE) 2019/2144 y las Directivas 2014/90/UE, (UE) 2016/797 y (UE) 2020/1828 (Reglamento de Inteligencia Artificial) (Texto pertinente a efectos del EEE)
Ricard Martínez Martínez, director de la Cátedra de Privacidad y Transformación Digital Microsoft-Universitat de Valencia
Blog
La evolución de la IA generativa está siendo vertiginosa: desde los primeros grandes modelos del lenguaje que nos impresionaron con su capacidad para reproducir la lecto-escritura de los humanos, pasando por las avanzadas técnicas de RAG (Retrieval-Augmented Generation) que mejoraron cuantitativamente la calidad de las respuestas proporcionadas y la aparición de agentes inteligentes, hasta llegar a una innovación que redefine nuestra relación con la tecnología: Computer use.
A finales del mes de abril del año 2020, tan solo un mes después de que comenzara un periodo inédito de confinamiento domiciliario de alcance mundial debido a la pandemia mundial del SAR-Covid19, difundíamos desde datos.gob.es los grandes modelos del lenguaje GPT-2 y GPT-3. OpenAI, fundada en 2015, había presentado prácticamente un año antes (febrero del 2019) un nuevo modelo del lenguaje que era capaz de generar texto escrito prácticamente indistinguible del creado por un humano. GPT-2 se había entrenado con un corpus (conjunto de textos preparados para entrenar modelos del lenguaje) de unos 40 GB (Gigabytes) de tamaño (unos 8 millones de páginas web), mientras que la última familia de modelos basados en GPT-4 se estima que han sido entrenados con corpus del tamaño de TB (Terabytes); mil veces más.
En este contexto, es importante hablar de dos conceptos:
- LLM (Large Language Models): son modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas. Hoy, disponemos de incontables herramientas basadas en estos LLM que, por campos de especialidad, son capaces de generar código de programación, imágenes y videos ultra-realistas y resolver problemas matemáticos complejos. Todas las grandes empresas y organizaciones del sector tecnológico-digital se han lanzado a integrar estas herramientas en sus diferentes productos de software y hardware, desarrollando casos de uso que resuelven u optimizan tareas y actividades concretas que previamente tenían alta intervención humana.
- Agentes: la experiencia de uso con los modelos de inteligencia artificial cada vez es más completa, de forma que le podemos pedir a nuestra interfaz no sólo respuestas a nuestras preguntas, sino también que realice tareas complejas que requieren integración con otras herramientas informáticas. Por ejemplo, no solo le preguntamos a un chatbot información sobre los mejores restaurantes de la zona, sino que le pedimos que busque disponibilidad de mesa para unas fechas concretas y realice una reserva por nosotros. Esta experiencia de uso extendida es lo que nos proporcionan los agentes de inteligencia artificial. Basados en los grandes modelos del lenguaje, estos agentes son capaces de interaccionar con el mundo exterior (al modelo) y “hablar” con otros servicios mediante API e interfaces de programación preparadas para tal fin.
Computer use
Sin embargo, la capacidad de los agentes para realizar acciones de forma autónoma depende de dos elementos clave: por un lado, su programación concreta -la funcionalidad que se les haya programado o configurado-; por otro lado, la necesidad de que el resto de programas estén preparados para “hablar” con estos agentes. Es decir, sus interfaces de programación han de estar listas para recibir instrucciones de estos agentes. Por ejemplo, la aplicación de reservas del restaurante ha de estar preparada, no solo para recepcionar formularios rellenados por un humano, sino también, peticiones realizadas por un agente que previamente ha sido invocado por un humano mediante lenguaje natural. Este hecho impone una limitación sobre el conjunto de actividades y/o tareas que podemos automatizar desde un interfaz conversacional. Es decir, el interfaz conversacional puede proporcionarnos respuestas casi infinitas a las cuestiones que le planteemos, pero encuentra grandes limitaciones para interactuar con el mundo exterior debido a la falta de preparación del resto de aplicaciones informáticas.
Aquí es donde entra Computer use. Con la llegada del modelo Claude 3.5 Sonnet, la empresa Anthropic ha introducido Computer use, una capacidad en fase beta que permite a la IA interactuar directamente con interfaces gráficas de usuario.
¿Cómo funciona Computer use?
Claude puede mover el cursor de tu ordenador como si fueras tú, hacer clic en botones y escribir texto, emulando la forma en que los humanos operamos con un ordenador. La mejor forma de entender cómo funciona Computer use en la práctica es viéndolo en acción. Aquí os dejamos un link directo al canal de YouTube de la sección específica de Computer use.

Figura 1. Captura del canal de YouTube de Anthropic, sección específica de Computer use.
¿Te animas a probarlo?
Si has llegado hasta aquí, no te puedes quedar sin probarlo con tus propias manos.
A continuación, te proponemos una sencilla guía para poder probar Computer use en un entorno aislado. Es importante tener en cuenta las recomendaciones de seguridad que Antrophic propone en sus guías de Computer use. Esta característica del modelo Claude Sonet puede realizar acciones sobre un ordenador y esto puede ser potencialmente peligroso, por lo que se recomienda revisar cuidadosamente la advertencia de seguridad de Computer use.
Toda la documentación oficial para desarrolladores se encuentra en el repositorio oficial de Github de Antrophic. En este post, nosotros hemos optado por ejecutar Computer use en un entorno de un contenedor de Docker. Es la forma más sencilla y segura de probarlo. Si no lo tienes ya, puedes seguir las sencillas guías oficiales para pre-instalarlo en tu sistema.
Para reproducir esta prueba os proponemos seguir este guion paso a paso:
- Antropic API Key. Para interactuar con Claude Sonet necesitas una cuenta de Antropic que puedes crear gratuitamente aquí. Una vez dentro, puedes ir a la sección de API Keys y crear una nueva para tu prueba
- Una vez tengas tu API Key, deberás de ejecutar este comando en tu terminal, sustituyendo tu clave donde indica “%your_api_key%”:

3. Si todo ha ido bien, verás estos mensajes en tu terminal y ya solo te queda abrir tu navegador y escribir esta url en la barra de navegación: http://localhost:8080/
Verás que se abre tu interfaz:

Figura 2. Interfaz de Computer use.
Ya puedes emplazar a explorar cómo funciona Computer use. Te sugerimos el siguiente prompt para empezar:
Te proponemos que empieces poco a poco. Por ejemplo, pídele que abra un navegador y busque algo. También puedes pedirle que te de información sobre tu ordenador o sistema operativo. Poco a poco, puedes ir pidiendo tareas más complejas. Nosotros hemos probado este prompt y tras varias pruebas hemos conseguido que Computer use realice la tarea completa.
Abre un navegador, navega hasta el catálogo de datos.gob.es, usa el buscador para localizar un conjunto de datos sobre: Seguridad ciudadana. Siniestralidad Tráfico. 2014; Localiza el fichero en formato csv; descárgalo y ábrelo con libre Office.
Potenciales usos en plataformas de datos como datos.gob.es
A la vista de esta primera versión experimental de Computer use parece que el potencial de la herramienta es muy alto. Podemos imaginar cuantas más cosas podemos hacer gracias a esta herramienta. Aquí os dejamos algunas ideas:
- Podríamos pedirle al sistema que realice una búsqueda completa de datasets relacionados con una temática concreta y que hiciera un resumen en un documento de los principales resultados. De esta manera, si por ejemplo escribimos un artículo sobre datos del tráfico en España, podríamos obtener de forma desatendida un listado con los principales datasets abiertos de datos de tráfico en España en el catálogo de datos.gob.es.
- De la misma forma, podríamos solicitar un resumen igual, pero en este caso, no de dataset, sino de artículos de la plataforma.
- Un ejemplo un poco más sofisticado sería pedirle a Claude, mediante el interfaz conversacional de Computer use que nos haga una serie de llamadas a la API de datos.gob.es para obtener información de ciertos datasets de forma programática. Para ello, abrimos un navegador y nos logueamos en una aplicación como Postman (recordemos en este punto que Computer use está en modo experimental y no nos permite introducir datos sensibles como credenciales de usuario en páginas web). A continuación le podemos pedimos que busque información sobre la API de datos.gob.es y ejecute una llamada http aprovechando que dicha API no requiere autenticación.
A través de estos sencillos ejemplos, esperamos haberte presentado una nueva aplicación de la IA generativa y que hayas entendido el cambio de paradigma que supone esta nueva capacidad. Si la máquina es capaz de emular el uso de un ordenador como lo hacemos los humanos, se abren nuevas oportunidades inimaginables para los próximos meses.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su auto
Blog
La enorme aceleración de la innovación en torno a la inteligencia artificial (IA) en estos últimos años gira, en gran medida, en torno al desarrollo de los llamados “modelos fundacionales”. También conocidos como modelos grandes (Large [X] Models o LxM), Los modelos fundacionales, según la definición del Center for Research on Foundation Models (CRFM) del Institute for Human-Centered Artificial Intelligence's (HAI) de la Universidad de Stanford son modelos que han sido entrenados con conjuntos de datos de gran tamaño y gran diversidad y que pueden adaptarse a realizar una amplia gama de tareas mediante técnicas como el ajuste fino (fine-tuning).
Precisamente es esta versatilidad y capacidad de adaptación lo que ha convertido a los modelos fundacionales en la piedra angular de las numerosas aplicaciones de la inteligencia artificial que están desarrollándose, ya que una única arquitectura base puede utilizarse en multitud de casos de uso con un esfuerzo adicional limitado.
Tipos de modelos fundacionales
La "X" en LxM puede sustituirse por varias opciones según el tipo de datos o tareas para las que el modelo está especializado. Los más conocidos por el público son los LLM (Large Language Models), que están en la base de aplicaciones como ChatGPT o Gemini, y que se centran en la comprensión y generación de lenguaje natural. Por su parte, los LVM (Large Vision Models), como DINOv2 o CLIP, están diseñados para interpretar imágenes y vídeos, reconocer objetos o generar descripciones visuales. También existen modelos como como Operator o Rabbit R1 que se encuentran en la categoría de LAM (Large Action Models) y que están orientados a ejecutar acciones a partir de instrucciones complejas.
A medida que han ido surgiendo regulaciones en distintas partes del mundo, también han aparecido otras definiciones que buscan establecer criterios y responsabilidades sobre estos modelos para fomentar la confianza y la seguridad. La definición más relevante para nuestro contexto es la establecida en el Reglamento de IA de la Unión Europea (AI Act), el cual los denomina “modelos de IA de uso general” y los distingue por su “capacidad de realizar de manera competente una amplia variedad de tareas diferenciadas” y porque “suelen entrenarse usando grandes volúmenes de datos y a través de diversos métodos, como el aprendizaje autosupervisado, no supervisado o por refuerzo”.
Modelos fundacionales en español y otras lenguas cooficiales
Históricamente, el inglés ha sido el idioma dominante en el desarrollo de los grandes modelos de IA, hasta el punto de que en torno al 90% de los tokens de entrenamiento de los grandes modelos actuales se han extraído de textos en inglés. Por ello resulta lógico que los modelos más conocidos, por ejemplo la familia GPT de OpenAI, Gemini de Google o Llama de Meta, sean más competentes respondiendo en inglés y presenten menor desempeño al usarlos en otros idiomas como el español.
Por tanto, la creación de modelos fundacionales en español, como ALIA, no es un simple ejercicio técnico o de investigación, sino que se trata de un movimiento estratégico para garantizar que la inteligencia artificial no haga aún más profundas las asimetrías lingüísticas y culturales que ya existen en las tecnologías digitales en general. El desarrollo de ALIA, impulsado por la Estrategia de Inteligencia Artificial 2024 de España, “partiendo del amplio alcance de nuestras lenguas, habladas por 600 millones de personas, tiene como objetivo facilitar el desarrollo de servicios y productos avanzados en tecnologías del lenguaje, ofreciendo una infraestructura marcada por la máxima transparencia y apertura”.
Este tipo de iniciativas no son exclusivas de España. Otros proyectos similares incluyen BLOOM, un modelo multilingüe de 176 mil millones de parámetros desarrollado por más de 1.000 investigadores de todo el mundo y que soporta 46 lenguas naturales y 13 lenguajes de programación. En China, Baidu ha desarrollado ERNIE, un modelo con fuerte capacidad en mandarín, mientras que en Francia el modelo PAGNOL se ha centrado en mejorar las capacidades en francés. Estos esfuerzos paralelos muestran una tendencia global hacia la "democratización lingüística" de la IA.
Desde principios de 2025, están disponibles los primeros modelos de lenguaje en las cuatro lenguas cooficiales, dentro del proyecto ALIA. En la familia de modelos ALIA destaca ALIA-40B, un modelo con 40.000 millones de parámetros, que es por el momento el modelo fundacional multilingüe público más avanzado de Europa y que fue entrenado durante más de 8 meses en el supercomputador MareNostrum 5, procesando 6,9 billones de tokens que equivaldrían a unos 33 terabytes de texto (¡unos 17 millones de libros!). Aquí se incluyen todo tipo de documentos oficiales y repositorios científicos en español, desde los diarios de sesiones del Congreso hasta repositorios científicos o boletines oficiales para asegurar la riqueza y calidad de su conocimiento.
Aunque se trata de un modelo multilingüe, el español y lenguas cooficiales tienen un peso muy superior al habitual en estos modelos, en torno al 20%, ya que el entrenamiento del modelo se diseñó específicamente para estas lenguas, reduciendo la relevancia del inglés y adaptando los tokens a las necesidades del español, catalán, euskera y gallego. Gracias a ello, ALIA “entiende” mejor nuestras expresiones locales y matices culturales que un modelo genérico entrenado mayoritariamente en inglés.
Aplicaciones de los modelos fundacionales en español y lenguas cooficiales
Aún es muy pronto para juzgar el impacto en sectores y aplicaciones concretas que puedan tener ALIA y otros modelos que puedan desarrollarse a partir de esta experiencia. Sin embargo, se espera que sirvan de base para mejorar multitud de aplicaciones y soluciones de Inteligencia Artificial:
- Administración pública y gobierno: ALIA podría dar vida a asistentes virtuales que atiendan a la ciudadanía las 24 horas en trámites como pagar impuestos, renovar el DNI, solicitar becas, etc. ya que está entrenado específicamente con la normativa española. De hecho, ya se anunció un piloto para la Agencia Tributaria usando ALIA, que tendría como objetivo agilizar gestiones internas.
- Educación: un modelo como ALIA podría ser también la base de tutores virtuales personalizados que orienten a estudiantes en español y lenguas cooficiales. Por ejemplo, asistentes que expliquen conceptos de matemáticas o historia en lenguaje sencillo y respondan preguntas del alumnado, adaptándose a su nivel ya que, al conocer bien nuestra lengua, serían capaces de aportar matices importantes en las respuestas y entender las dudas típicas de hablantes nativos en estos idiomas. También podrían ayudar a profesores, generando ejercicios o resúmenes de lecturas o asistiéndoles en la corrección de los trabajos de los alumnos.
- Salud: ALIA podría servir para analizar textos médicos y ayudar a profesionales de la salud con informes clínicos, historiales, folletos informativos, etc. Por ejemplo, podría revisar expedientes de pacientes para extraer elementos clave, o asistir a los profesionales en el proceso de diagnóstico. De hecho, el Ministerio de Sanidad planea una aplicación piloto con ALIA para mejorar la detección temprana de insuficiencias cardíacas en atención primaria.
- Justicia: en el ámbito jurídico, ALIA entendería términos técnicos y contextos del derecho español mucho mejor que un modelo no especializado ya que ha sido entrenada con vocabulario legal de documentos oficiales. Un asistente legal virtual basado en ALIA podría ser capaz de contestar consultas básicas del ciudadano como, por ejemplo, cómo iniciar un determinado trámite legal, citando la normativa aplicable. La administración de justicia podría beneficiarse también con unas traducciones automáticas de documentos judiciales entre lenguas cooficiales mucho más precisas.
Líneas futuras
El desarrollo de modelos fundaciones en español, al igual que en otros idiomas, comienza a considerarse fuera de Estados Unidos como una cuestión estratégica que contribuye a garantizar la soberanía tecnológica de los países. Por supuesto, será necesario seguir entrenando versiones más avanzadas (se apunta a modelos de hasta 175 mil millones de parámetros, que serían equiparables a los más potentes del mundo), incorporando nuevos datos abiertos, y afinando las aplicaciones. Desde la Dirección del Dato y la SEDIA se pretende continuar apoyando el crecimiento de esta familia de modelos, para mantenerla en vanguardia y asegurar su adopción.
Por otra parte, estos primeros modelos fundacionales en español y lenguas cooficiales se han centrado inicialmente en el lenguaje escrito, así que la siguiente frontera natural podría estar en la multimodalidad. Integrar la capacidad de gestionar imágenes, audio o vídeo en español junto con el texto multiplicaría sus aplicaciones prácticas ya que en la interpretación de imágenes en español es uno de los ámbitos donde se detectan mayores deficiencias en los grandes modelos genéricos.
También habrá que vigilar los aspectos éticos para asegurarse que estos modelos no perpetúen sesgos y sean útiles para todos los colectivos, incluyendo aquellos que hablan en distintas lenguas o que tienen diferentes niveles educativos. En este aspecto la Inteligencia Artificial Explicable (XAI) no es algo opcional, sino un requisito fundamental para garantizar su adopción responsable. La Agencia Nacional de Supervisión de la IA, la comunidad investigadora y la propia sociedad civil tendrán aquí un rol importante.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Unión Europea se encuentra a la vanguardia del desarrollo de la inteligencia artificial (IA) segura, ética y centrada en las personas. A través de un marco reglamentario sólido, basado en los derechos humanos y valores fundamentales, la UE está construyendo un ecosistema de IA que beneficia simultáneamente a la ciudadanía, las empresas y las administraciones públicas. Como parte de su compromiso por el correcto desarrollo de esta tecnología, la Comisión Europea ha propuesto un conjunto de acciones para impulsar su excelencia.
En este sentido, destaca una normativa pionera que establece un marco jurídico global: la Ley de IA. En ella, los modelos de inteligencia artificial se clasifican según su nivel de riesgo y se establecen obligaciones concretas para los proveedores relativas a los datos y su gobernanza. Paralelamente, el Plan Coordinado sobre la IA actualizado en 2021 establece una hoja de ruta para impulsar la inversión, armonizar políticas y fomentar la adopción de la IA en toda la UE.
España está alineada con Europa en esta materia y por ello cuenta con una estrategia para acelerar su desarrollo y expansión. Además, recientemente, se ha aprobado la trasposición de la ley IA, con el anteproyecto de ley para un uso ético, inclusivo y beneficioso de la inteligencia artificial.
Proyectos europeos que transforman sectores clave
En este contexto, la UE está financiando numerosos proyectos que utilizan tecnologías de inteligencia artificial para resolver desafíos en diversos ámbitos. A continuación, destacamos algunos de los más innovadores, algunos de ellos ya finalizados y otros en marcha:
Agricultura y sostenibilidad alimentaria
Proyectos actualmente en curso:
-
ANTARES: desarrolla tecnologías de sensores inteligentes y big data para ayudar a los agricultores a producir más alimentos de manera sostenible, beneficiando a la sociedad, los ingresos agrícolas y el medio ambiente.
Ejemplos de otros proyectos ya finalizados:
-
Pantheon: desarrolló un sistema de control y adquisición de datos, equivalente al industrial SCADA, para la agricultura de precisión en grandes huertos de avellanas, aumentando la producción, reduciendo insumos químicos y simplificando la gestión.
-
Trimbot2020: investigó tecnologías de robótica y visión para crear el primer robot de jardinería para exteriores, capaz de navegar por terrenos variados y recortar rosales, setos y topiarios.
Industria y manufactura
Proyectos actualmente en curso:
-
SERENA: aplica técnicas de IA para predecir necesidades de mantenimiento de equipos industriales, reduciendo costes y tiempo, y mejorando la productividad de los procesos de producción.
-
SecondHands: ha desarrollado un robot capaz de ofrecer ayuda proactiva a técnicos de mantenimiento, reconociendo la actividad humana y anticipando sus necesidades, lo que aumenta la eficiencia y productividad en entornos industriales.
Ejemplos de otros proyectos ya finalizados:
-
QU4LITY: combinó datos e IA para aumentar la sostenibilidad de la fabricación, proporcionando un modelo de fabricación de cero defectos basado en datos compartidos, amigable para las PYME, estandarizado y transformador.
-
KYKLOS 4.0: estudió cómo los sistemas ciberfísicos, la gestión del ciclo de vida del producto, la realidad aumentada y la IA pueden transformar la fabricación circular mediante siete proyectos piloto a gran escala.
Transporte y movilidad
Proyectos actualmente en curso
-
VI-DAS: proyecto de una empresa española que trabaja en sistemas avanzados de asistencia al conductor y ayudas a la navegación, combinando la comprensión del tráfico con la consideración del estado físico, mental y conductual del conductor para mejorar la seguridad vial.
-
PILOTING: adapta, integra y demuestra soluciones robóticas en una plataforma integrada para la inspección y mantenimiento de refinerías, puentes y túneles. Uno de sus focos es el impulso de la producción y acceso a datos de inspecciones.
Ejemplos de otros proyectos ya finalizados:
-
FABULOS: ha desarrollado y probado un sistema de transporte público local que utiliza minibuses autónomos, demostrando su viabilidad y promoviendo la introducción de tecnologías robóticas en la infraestructura pública.
Investigación en impacto social
Proyectos actualmente en curso:
-
HUMAINT: proporciona una comprensión multidisciplinaria del estado actual y evolución futura de la inteligencia de las máquinas y su impacto potencial en el comportamiento humano, enfocándose en capacidades cognitivas y socioemocionales.
-
AI Watch: monitorea la capacidad industrial, tecnológica y de investigación, las iniciativas políticas en los Estados miembros, la adopción y desarrollos técnicos de la IA y su impacto en la economía, sociedad y servicios públicos.
Ejemplos de otros proyectos ya finalizados:
-
TECHNEQUALITY: examinó las consecuencias sociales potenciales de la era digital, estudiando cómo la IA y los robots afectan al trabajo y cómo la automatización puede impactar de manera diferente a diversos grupos sociales.
Salud y bienestar
Proyectos actualmente en curso:
-
DeepHealth: desarrolla herramientas avanzadas para el procesamiento de imágenes médicas y modelos predictivos, facilitando el trabajo diario del personal sanitario sin necesidad de combinar múltiples herramientas.
-
BigO: recopila y analiza datos anónimos sobre patrones de comportamiento infantil y su entorno para extraer evidencias sobre factores locales involucrados en la obesidad infantil.
Ejemplos de otros proyectos ya finalizados:
-
PRIMAGE: ha creado una plataforma basada en la nube para apoyar la toma de decisiones relativa a tumores sólidos malignos, ofreciendo herramientas predictivas para su diagnóstico, pronóstico y seguimiento, mediante biomarcadores de imagen y simulación del crecimiento tumoral.
-
SelfBACK: proporcionó apoyo personalizado a pacientes con dolor lumbar a través de una aplicación móvil, utilizando datos recogidos por sensores para adaptar las recomendaciones a cada usuario.
-
EYE-RISK: desarrolló herramientas que predicen la probabilidad de desarrollar enfermedades oculares relacionadas con la edad y medidas para reducir este riesgo, incluyendo un panel diagnóstico para evaluar la predisposición genética.
-
Solve-RD: mejoró el diagnóstico de enfermedades raras mediante la agrupación de datos de pacientes y métodos genéticos avanzados.
El futuro de la IA en Europa
Estos ejemplos, tanto pasados como presentes, son casos de uso muy interesantes del desarrollo de la inteligencia artificial en Europa. No obstante, la apuesta de la UE por la IA también es a futuro. Y se refleja en un ambicioso plan de inversión: la Comisión planea invertir 1.000 millones de euros anuales en IA, procedentes de los programas Europa Digital y Horizonte Europa, con el objetivo de atraer más de 20.000 millones de euros de inversión total en IA al año durante esta década.
El desarrollo de una IA ética, transparente y centrada en el ser humano es ya un objetivo de la UE que va más allá del marco jurídico. Con un enfoque práctico, la Unión Europea financia proyectos que no solo impulsan la innovación tecnológica, sino que abordan retos sociales fundamentales, desde la salud hasta el cambio climático, construyendo un futuro más sostenible, inclusivo y próspero para todos los ciudadanos europeos.
Blog
La creciente adopción de sistemas de inteligencia artificial (IA) en ámbitos críticos como la administración pública, los servicios financieros o la atención sanitaria ha puesto en primer plano la necesidad de transparencia algorítmica. La complejidad de los modelos de IA que se utilizan para tomar decisiones como la concesión de un crédito o la realización de un diagnóstico médico, especialmente en lo que se refiere a algoritmos de aprendizaje profundo, a menudo da lugar a lo que comúnmente se conoce como el problema de la "caja negra", esto es, la dificultad de interpretar y comprender cómo y por qué un modelo de IA llega a una determinada conclusión. Los LLM o SLM que tanto utilizamos últimamente son un claro ejemplo de un sistema de caja negra donde ni los propios desarrolladores son capaces de prever sus comportamientos.
En sectores regulados, como el financiero o el sanitario, las decisiones basadas en IA pueden afectar significativamente la vida de las personas y, por tanto, no es admisible que generan dudas sobre su posible sesgo o atribución de responsabilidades. Por ello, los gobiernos han comenzado a desarrollar marcos normativos como el Reglamento de Inteligencia Artificial que exigen mayor explicabilidad y supervisión en el uso de estos sistemas con el fin adicional de generar confianza en los avances de la economía digital.
La inteligencia artificial explicable (conocida como XAI, del inglés explainable artificial intelligence) es la disciplina que surge como respuesta a este desafío, proponiendo métodos para hacer comprensibles las decisiones de los modelos de IA. Al igual que en otras áreas relacionados con la inteligencia artificial, como el entrenamiento de los LLM, los datos abiertos son un aliado importante de la inteligencia artificial explicable para construir mecanismos de auditoría y verificación de los algoritmos y sus decisiones.
¿Qué es la IA explicable (XAI)?
La IA explicable se refiere a métodos y herramientas que permiten a los humanos comprender y confiar en los resultados de los modelos de aprendizaje automático. Según el Instituto Nacional de Estándares y Tecnología (NIST) de EE. UU. son cuatro los principios clave de la Inteligencia Artificial Explicable de forma que se pueda garantizar que los sistemas de IA sean transparentes, comprensibles y confiables para los usuarios:
- Explicabilidad (Explainability): la IA debe proporcionar explicaciones claras y comprensibles sobre cómo llega a sus decisiones y recomendaciones.
- Justificabilidad (Meaningful): las explicaciones deben ser significativas y comprensibles para los usuarios.
- Precisión (Accuracy): la IA debe generar resultados precisos y confiables, y la explicación de estos resultados debe reflejar fielmente su desempeño.
- Límites del conocimiento (Knowledge Limits): la IA debe reconocer cuándo no tiene suficiente información o confianza en una decisión y abstenerse de emitir respuestas en esos casos.
A diferencia de los sistemas de IA tradicionales de "caja negra", que generan resultados sin revelar su lógica interna, XAI trabaja sobre la trazabilidad, interpretabilidad y responsabilidad de estas decisiones. Por ejemplo, si una red neuronal rechaza una solicitud de préstamo, las técnicas de XAI pueden destacar los factores específicos que influyeron en la decisión. De este modo, mientras un modelo tradicional simplemente devolvería una calificación numérica del expediente de crédito, un sistema XAI podría decirnos además algo como que "El historial de pagos (23%), la estabilidad laboral (38%) y el nivel de endeudamiento actual (32%) fueron los factores determinantes en la denegación del préstamo”. Esta transparencia es vital no solo para el cumplimiento normativo, sino también para fomentar la confianza del usuario y la mejora de los propios sistemas de IA.
Técnicas clave en XAI
El Catálogo de herramientas y métricas IA confiable del Observatorio de Políticas de Inteligencia Artificial de la OCDE (OECD.AI) recopila y comparte herramientas y métricas diseñadas para ayudar a los actores de la IA a desarrollar sistemas confiables que respeten los derechos humanos y sean justos, transparentes, explicables, robustos, seguros y confiables. Por ejemplo, dos metodologías ampliamente adoptadas en XAI son Local Interpretable Model-agnostic Explanations (LIME) y SHapley Additive exPlanations (SHAP).
- LIME aproxima modelos complejos con versiones más simples e interpretables para explicar predicciones individuales. Es una técnica en general útil para interpretaciones rápidas, pero no muy estable en la asignación de la importancia de las variables entre unos ejemplos y otros.
- SHAP cuantifica la contribución exacta de cada variable de entrada a una predicción utilizando principios de teoría de juegos. Se trata de una técnica más precisa y matemáticamente sólida, pero mucho más costosa computacionalmente.
Por ejemplo, en un sistema de diagnóstico médico, tanto LIME como SHAP podrían ayudarnos a interpretar que la edad y la presión arterial de un paciente fueron los principales factores que concluyeron en un diagnóstico de alto riesgo de infarto, aunque SHAP nos daría la contribución exacta de cada variable a la decisión.
Uno de los desafíos más importantes en XAI es encontrar el equilibrio entre la capacidad predictiva de un modelo y su explicabilidad. Por ello suelen utilizarse enfoques híbridos que integren métodos de explicación a posteriori de las decisiones tomadas con modelos complejos. Por ejemplo, un banco podría implementar un sistema de aprendizaje profundo para la detección de fraude, pero usar valores SHAP para auditar sus decisiones y garantizar que no se toman decisiones discriminatorias.
Los datos abiertos en la XAI
Existen, al menos, dos escenarios en los que se puede generar valor combinando datos abiertos con técnicas de inteligencia artificial explicable:
- El primero de ellos es el enriquecimiento y validación de las explicaciones obtenidas con técnicas XAI. Los datos abiertos permiten añadir capas de contexto a muchas explicaciones técnicas, algo que también es válido para la explicabilidad de los modelos de IA. Por ejemplo, si un sistema XAI indica que la contaminación atmosférica influyó en un diagnóstico de asma, vincular este resultado con conjuntos de datos abiertos de calidad del aire de las áreas de residencia de los pacientes permitiría validar si el resultado es correcto.
- La mejora del rendimiento de los propios modelos de IA es otra área en el que los datos abiertos aportan valor. Por ejemplo, si un sistema XAI identifica que la densidad de espacios verdes urbanos afecta significativamente los diagnósticos de riesgo cardiovascular, se podrían utilizar datos abiertos de urbanismo para mejorar la precisión del algoritmo.
Sería ideal que se pudiesen compartir como datos abiertos los conjuntos de datos de entrenamiento de los modelos de IA, de forma que fuese posible verificar el entrenamiento del modelo y replicar los resultados. En todo caso, lo que sí es posible es compartir de forma abierta son metadatos detallados sobre dichos entrenamientos como promueve la iniciativa Model Cards de Google, facilitando así explicaciones post-hoc de las decisiones de los modelos. En este caso se trata de un instrumento más orientado a los desarrolladores que a los usuarios finales de los algoritmos.
En España, en una iniciativa más dirigida a los ciudadanos, pero igualmente destinada a fomentar la transparencia en el uso de algoritmos de inteligencia artificial, la Administración Abierta de Cataluña ha comenzado a publicar fichas comprensibles para cada algoritmo de IA aplicado a los servicios de administración digital. Ya están disponibles algunas, como, por ejemplo, la de los Chatbots conversacionales de la AOC o la de la Videoidentificación para obtener el idCat Móvil.
Ejemplos reales de datos abiertos y XAI
Un artículo reciente publicado en Applied Sciences por investigadores portugueses ejemplifica la sinergia entre XAI y datos abiertos en el ámbito de la predicción de precios inmobiliarios en ciudades inteligentes. La investigación destaca cómo la integración de conjuntos de datos abiertos que abarcan características de propiedades, infraestructuras urbanas y redes de transporte, con técnicas de inteligencia artificial explicable, como el análisis SHAP, permite desentrañar los factores clave que influyen en los valores de las propiedades. Este enfoque pretende apoyar la generación de políticas de planificación urbana que respondan a las necesidades y tendencias evolutivas del mercado inmobiliario, promoviendo un crecimiento sostenible y equitativo de las ciudades.
Otro estudio realizado por investigadores de INRIA (Instituto francés de investigación en ciencias y tecnologías digitales), también sobre datos inmobiliarios, profundiza en los métodos y desafíos asociados a la interpretabilidad en el aprendizaje automático apoyándose en datos abiertos enlazados. El artículo analiza tanto técnicas intrínsecas, que integran la explicabilidad en el diseño del modelo, como métodos post hoc que permiten examinar y explicar las decisiones de sistemas complejos para fomentar la adopción de sistemas de IA transparentes, éticos y confiables.
A medida que la IA continúa evolucionando, las consideraciones éticas y las medidas regulatorias tienen un papel cada vez más relevante en la creación de un ecosistema de IA más transparente y confiable. La inteligencia artificial explicable y los datos abiertos están interconectados en su objetivo de fomentar la transparencia, la confianza y la responsabilidad en la toma de decisiones basadas en IA. Mientras que la XAI ofrece las herramientas para diseccionar la toma de decisiones de la IA, los datos abiertos proporcionan la materia prima no solo para el entrenamiento, sino para comprobar algunas explicaciones de la XAI y mejorar los rendimientos de los modelos. A medida que la IA continúa permeando en cada faceta de nuestras vidas, fomentar esta sinergia contribuirá a construir sistemas que no solo sean más inteligentes, sino también más justos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) de código abierto es una oportunidad para democratizar la innovación y evitar la concentración de poder en la industria tecnológica. Sin embargo, su desarrollo depende en gran medida de la disponibilidad de conjuntos de datos de alta calidad y de la implementación de marcos sólidos de gobernanza de datos. Un informe reciente de Open Future y la Open Source Initiative (OSI) analiza los desafíos y oportunidades en esta intersección, proponiendo soluciones para una gobernanza de datos equitativa y responsable. Puedes leer aquí el informe completo.
En este post, analizaremos las ideas más relevantes del documento, así como los consejos que ofrece para garantizar una correcta y efectiva gobernanza de datos en la inteligencia artificial open source y aprovechar todas sus ventajas.
Los retos de la gobernanza de datos en la IA
A pesar de la gran cantidad de datos disponibles en la web, su acceso y uso para entrenar modelos de IA plantean importantes desafíos éticos, legales y técnicos. Por ejemplo:
- Equilibrio entre apertura y derechos: en línea con el Reglamento de Gobernanza de Datos (DGA), se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
- Falta de transparencia y estándares de apertura: es importante que los modelos etiquetados como “abiertos” cumplan con criterios claros de transparencia en el uso de datos.
- Sesgos estructurales: muchos conjuntos de datos reflejan sesgos lingüísticos, geográficos y socioeconómicos que pueden perpetuar desigualdades en los sistemas de IA.
- Sostenibilidad ambiental: el uso intensivo de recursos para entrenar modelos de IA plantea desafíos de sostenibilidad que deben abordarse con prácticas más eficientes.
- Involucrar a más actores: actualmente, los desarrolladores y las grandes corporaciones dominan la conversación sobre IA, dejando fuera a comunidades afectadas y organizaciones públicas.
Una vez identificados los retos, el informe propone una estrategia para alcanzar el objetivo principal: una gobernanza de datos adecuada en los modelos de IA de código abiertos. Este enfoque está basado en dos pilares fundamentales.
Hacia un nuevo paradigma de gobernanza de datos
En la actualidad, el acceso y la gestión de los datos para entrenar modelos de IA están marcados por una creciente desigualdad. Mientras algunas grandes corporaciones tienen acceso exclusivo a vastos repositorios de datos, muchas iniciativas de código abierto y comunidades marginadas carecen de los recursos para acceder a datos representativos y de calidad. Para abordar este desequilibrio es necesario un nuevo enfoque en la gestión y uso de los datos en la IA de código abierto. El informe destaca dos cambios fundamentales en la manera en que se concibe la gobernanza de datos:
Por un lado, adoptar un enfoque de data commons que no es más que un modelo de acceso que garantiza el equilibrio entre la apertura de datos y la protección de derechos. Para ello, sería importante utilizar licencias innovadoras que permitan compartir datos sin explotación indebida. También es relevante crear estructuras de gobernanza que regulen el acceso y uso de datos. Y, por último, implementar mecanismos de compensación para comunidades cuyos datos son utilizados en inteligencia artificial.
Por otro lado, es necesario trascender la visión centrada en desarrolladores de IA e incluir a más actores en la gobernanza de datos, como:
- Propietarios de los datos y comunidades que generan contenido.
- Instituciones públicas que pueden promover estándares de apertura.
- Organizaciones de la sociedad civil que velen por la equidad y el acceso responsable a los datos.
Al adoptar estos cambios, la comunidad de IA podrá establecer un sistema más inclusivo, en el que los beneficios del acceso a datos se distribuyan de manera equitativa y respetuosa con los derechos de todas las partes interesadas. Según el informe, la implementación de estos modelos no solo aumentará la cantidad de datos disponibles para la IA de código abierto, sino que también fomentará la creación de herramientas más justas y sostenibles para la sociedad en su conjunto.
Consejos y estrategia
Para hacer efectiva una gobernanza de datos robusta en la IA de código abierto, el informe propone seis áreas de acción prioritarias:
- Preparación y trazabilidad de datos: mejorar la calidad y documentación de los conjuntos de datos.
- Mecanismos de licenciamiento y consentimiento: permitir a los creadores de datos definir su uso de manera clara.
- Custodia de datos: fortalecer la figura de intermediarios que gestionen datos de forma ética.
- Sostenibilidad ambiental: reducir el impacto del entrenamiento de IA con prácticas eficientes.
- Compensación y reciprocidad: garantizar que los beneficios de la IA lleguen a quienes contribuyen con datos.
- Intervenciones de política pública: promover regulaciones que incentiven la transparencia y el acceso equitativo a datos.

La inteligencia artificial de código abierto puede impulsar la innovación y la equidad, pero para lograrlo es necesario un enfoque de gobernanza de datos más inclusivo y sostenible. Adoptar modelos de datos comunes y ampliar el ecosistema de actores permitirá construir sistemas de IA más justos, representativos y responsables con el bien común.
El informe que publican Open Future y Open Source Initiative hace una llamada a la acción a desarrolladores, legisladores y sociedad civil para establecer normas compartidas y soluciones que equilibren la apertura de datos con la protección de derechos. Con una gobernanza de datos sólida, la IA de código abierto podrá cumplir su promesa de servir al interés público.
Blog
El concepto de data commons o bienes comunes de datos surge como un enfoque transformador para la gestión y el intercambio de datos que sirvan a fines colectivos y como alternativa al creciente número de macrosilos de datos de uso privado. Al tratar los datos como un recurso compartido, los data commons facilitan la colaboración, la innovación y el acceso equitativo a los mismos, enfatizando el valor comunal de los datos por encima de cualquier otra consideración. A medida que navegamos por las complejidades de la era digital —marcada en la actualidad por los rápidos avances en inteligencia artificial (IA) y el continuo debate sobre los retos en la gobernanza de datos— el papel que pueden jugar los data commons es ahora probablemente más importante que nunca.
¿Qué son los data commons?
Los data commons se refieren a un marco cooperativo donde los datos son recopilados, gobernados y compartidos entre todos los participantes de la comunidad mediante protocolos que promueven la apertura, la equidad, el uso ético y la sostenibilidad. Los data commons se diferencian de los modelos tradicionales de intercambio de datos, principalmente, por la prioridad que se da a la colaboración y la inclusión sobre el control unitario.
Otro objetivo común de los data commons es la creación de conocimiento colectivo que pueda ser utilizado por cualquiera para el bien de la sociedad. Esto los hace particularmente útiles a la hora de afrontar los grandes desafíos actuales, como los retos del medio ambiente, la interacción multilingüe, la movilidad, las catástrofes humanitarias, la preservación del conocimiento o los nuevos desafíos de la salud y la sanidad.
Además, también es cada vez más frecuente que estas iniciativas para compartir datos incorporen todo tipo de herramientas que faciliten su análisis e interpretación consiguiendo así democratizar no sólo la propiedad y el acceso a los datos, sino también su uso.
Por todo lo anterior, los data commons podrían considerarse hoy en día como una infraestructura digital pública crítica a la hora de aprovechar los datos y promover el bienestar social.
Principios de los data commons
Los data commons se construyen sobre una serie de principios simples que serán clave para su correcta gobernanza:
- Apertura y accesibilidad: los datos deben ser accesibles para todos los autorizados.
- Gobernanza ética: equilibrio entre la inclusión y la privacidad.
- Sostenibilidad: establecer mecanismos de financiación y recursos para mantener los datos como bienes comunes a lo largo del tiempo.
- Colaboración: fomentar que los participantes contribuyan con nuevos datos e ideas que habiliten su uso para el beneficio mutuo.
- Confianza: relaciones basadas en la transparencia y la credibilidad entre partícipes.
Además, si queremos asegurarnos también de que los data commons cumplan su papel como infraestructura digital de dominio público, deberemos garantizar otros requisitos mínimos adicionales como: existencia de identificadores únicos permanentes, metadatos documentados, acceso fácil a través de interfaces de programación de aplicaciones (API), portabilidad de los datos, acuerdos de intercambio de datos entre pares y capacidad de realizar operaciones sobre los mismos.
El importante papel de los data commons en la era de la Inteligencia Artificial
La innovación impulsada por la IA ha incrementado exponencialmente la demanda de conjuntos de datos diversos y de alta calidad, un bien relativamente escaso a gran escala que puede dar lugar a cuellos de botella en el desarrollo futuro de la tecnología y que, al mismo tiempo, hace de los data commons un facilitador muy relevante a la hora de conseguir una IA más equitativa. Al proporcionar conjuntos de datos compartidos gobernados por principios éticos, los data commons contribuyen a mitigar riesgos frecuentes como los sesgos, los monopolios de datos y el acceso desigual a los beneficios de la IA.
Además, la actual concentración de los desarrollos en el ámbito de la IA representa también un desafío para el interés público. En este contexto, los data commons cuentan con la llave necesaria para habilitar un conjunto de sistemas y aplicaciones de IA alternativos, públicos y orientados al interés general, que puedan contribuir a rebalancear esta concentración de poder actual. El objetivo de estos modelos sería demostrar cómo se pueden diseñar sistemas más democráticos, orientados al interés público y con propósitos bien definidos, basados en los principios y modelos de gobernanza de la IA pública.
Sin embargo, la era de la IA generativa también presenta nuevos desafíos para los data commons como, por ejemplo y quizás el más destacado, el riesgo potencial de una explotación descontrolada de los conjuntos de datos compartidos que podría dar lugar a nuevos desafíos éticos por el uso indebido de los datos y la vulneración de la privacidad.
Por otro lado, la falta de transparencia en cuanto al uso de los data commons por parte de la IA podría también acabar desmotivando a las comunidades que los gestionan poniendo en riesgo su continuidad. Esto se debe a la preocupación de que al final su contribución pueda estar beneficiando principalmente a las grandes plataformas tecnológicas, sin que haya ninguna garantía de un reparto más justo del valor y el impacto generados tal como se pretendía inicialmente."
Por todo lo anterior, organizaciones como Open Future abogan desde hace ya varios años por una Inteligencia Artificial que funcione como un bien común, gestionada y desarrollada como una infraestructura pública digital en beneficio de todos, evitando la concentración de poder y promoviendo la equidad y la transparencia tanto en su desarrollo como en su aplicación.
Para ello proponen una serie de principios que guíen la gobernanza de los bienes comunes de datos en su aplicación para el entrenamiento de la IA de forma que se maximice el valor generado para la sociedad y se minimicen las posibilidades de potenciales abusos por intereses comerciales:
- Compartir tantos datos como sea posible, pero manteniendo las restricciones que puedan resultar necesarias para preservar los derechos individuales y colectivos.
- Ser completamente transparente y proporcionar toda la documentación existente sobre los datos, así como sobre su uso, permitiendo además distinguir claramente entre datos reales y sintéticos.
- Respetar las decisiones tomadas sobre el uso de los datos por parte de las personas que han contribuido previamente a la creación de los datos, ya sea mediante la cesión de sus propios datos o a través de la elaboración de nuevos contenidos, incluyendo también el respeto hacia cualquier marco legal existente.
- Proteger el beneficio común en el uso de los datos y un uso sostenible de los mismos para poder asegurar una gobernanza adecuada a lo largo del tiempo, reconociendo siempre su naturaleza relacional y colectiva.
- Garantizar la calidad de los datos, lo que resulta crítico a la hora de conservar su valor como bien de interés común, especialmente teniendo en cuenta los potenciales riesgos de contaminación asociados a su uso por parte de la IA.
- Establecer instituciones fiables que se encarguen de la gobernanza de los datos y faciliten la participación por parte de toda la comunidad creada en torno a los datos, yendo así un paso más allá de los modelos existentes en la actualidad para los intermediarios de datos.
Casos de uso y aplicaciones
Existen en la actualidad múltiples ejemplos reales que nos ayudan a ilustrar el potencial transformador de los data commons:
-
Data commons sanitarios: proyectos como la iniciativa del National Institutes of Health en los Estados Unidos - NIH Common Fund para analizar y compartir grandes conjuntos de datos biomédicos, o el Cancer Research Data Commons del National Cancer Institute, demuestran cómo los data commons pueden contribuir a la aceleración de la investigación y la innovación en salud.
- Entrenamiento de la IA y machine learning: la evaluación de los sistemas de IA depende de conjuntos de datos de prueba rigurosos y estandarizados. Iniciativas como OpenML o MLCommons construyen conjuntos de datos abiertos, a gran escala y diversos, ayudando a la comunidad en general a ofrecer sistemas de IA más precisos y seguros.
- Data commons urbanos y de movilidad: las ciudades que aprovechan plataformas compartidas de datos urbanos mejoran la toma de decisiones y los servicios públicos mediante el análisis colectivo de datos, como es el caso de Barcelona Dades, que además de un amplio repositorio de datos abiertos integra y difunde datos y análisis sobre la evolución demográfica, económica, social y política de la ciudad. Otras iniciativas como el propio OpenStreetMaps pueden también contribuir a proporcionar datos geográficos de libre acceso.
- Preservación de la cultura y el conocimiento: con iniciativas tan relevantes en este campo como el proyecto de Common Voice de Mozilla para preservar y revitalizar los idiomas del mundo, o Wikidata, cuyo objetivo consiste en proporcionar un acceso estructurado a todos los datos provenientes de los proyectos de Wikimedia, incluyendo la popular Wikipedia.
Desafíos en los data commons
A pesar de su promesa y potencial como herramienta transformadora para los nuevos desafíos en la era digital, los data commons afrontan también sus propios desafíos:
- Complejidad en la gobernanza: llegar a conseguir un equilibrio correcto entre la inclusión, el control y la privacidad puede resultar una tarea delicada.
- Sostenibilidad: muchos de los data commons existentes libran una batalla continua para intentar asegurarse la financiación y los recursos que necesitan para mantenerse y garantizar su supervivencia a largo plazo.
- Problemas legales y éticos: abordar los retos relativos a los derechos de propiedad intelectual, la titularidad de datos y el uso ético siguen siendo aspectos críticos que todavía no se han resulto por completo.
- Interoperabilidad: asegurar la compatibilidad entre conjuntos de datos y plataformas es un obstáculo técnico persistente en casi cualquier iniciativa de compartición de datos, y los data commons no iban a ser la excepción.
El camino a seguir
Para desbloquear su pleno potencial, los data commons requieren de una acción colectiva y una apuesta decidida por la innovación. Las acciones clave incluyen:
- Desarrollar modelos de gobernanza estandarizados que consigan el equilibrio entre las consideraciones éticas y los requisitos técnicos.
- Aplicar el principio de reciprocidad en el uso de los datos, exigiendo a aquellos que se benefician de ellos compartir sus resultados de vuelta con la comunidad.
- Protección de datos sensibles mediante la anonimización, evitando que los datos puedan ser utilizados para vigilancia masiva o discriminación.
- Fomentar la inversión en infraestructura para apoyar el intercambio de datos escalable y sostenible.
- Promover la concienciación sobre los beneficios sociales de los data commons para impulsar la participación y la colaboración.
Los responsables políticos, investigadores y organizaciones civiles deberían trabajar juntos para crear un ecosistema en el que los data commons puedan prosperar, fomentando un crecimiento más equitativo en la economía digital y garantizando que los bienes comunes de datos puedan beneficiar a todos.
Conclusión
Los data commons pueden suponer una poderosa herramienta a la hora de democratizar el acceso a los datos y fomentar la innovación. En esta era definida por la IA y la transformación digital, nos ofrecen un camino alternativo hacia el progreso equitativo, sostenible e inclusivo. Al abordar sus desafíos y adoptar un enfoque de gobernanza colaborativa mediante la cooperación entre comunidades, investigadores y reguladores se podrá garantizar un uso equitativo y responsable de los datos.
De este modo se conseguirá que los data commons se conviertan en un pilar fundamental del futuro digital, incluyendo las nuevas aplicaciones de la Inteligencia Artificial, pudiendo servir además como herramienta habilitadora fundamental para algunas de las acciones clave que forman parte de la recién anunciada brújula Europea de competitividad, como la estrategia de la nueva Unión de Datos y la iniciativa de las Gigafábricas de IA.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Inteligencia Artificial (IA) ha dejado de ser un concepto futurista y se ha convertido en una herramienta clave en nuestra vida diaria. Desde las recomendaciones de películas o series en plataformas de streaming hasta los asistentes virtuales como Alexa o Google Assistant en nuestros dispositivos, la IA está en todas partes. Pero, ¿cómo se construye un modelo de IA? A pesar de lo que podría parecer, el proceso es menos intimidante si lo desglosamos en pasos claros y comprensibles.
Paso 1: definir el problema
Antes de empezar, necesitamos tener muy claro qué queremos resolver. La IA no es una varita mágica: diferentes modelos funcionarán mejor en diferentes aplicaciones y contextos por lo que es importante definir la tarea específica que deseamos ejecutar. Por ejemplo, ¿queremos predecir las ventas de un producto? ¿Clasificar correos como spam o no spam? Tener una definición clara del problema nos ayudará a estructurar el resto del proceso.
Además, debemos plantearnos qué tipo de datos tenemos y cuáles son las expectativas. Esto incluye determinar el nivel de precisión deseado y las limitaciones de tiempo o recursos disponibles.
Paso 2: recopilar los datos
La calidad de un modelo de IA depende directamente de la calidad de los datos utilizados para entrenarlo. Este paso consiste en recopilar y organizar los datos relevantes para nuestro problema. Por ejemplo, si queremos predecir ventas, necesitaremos datos históricos como precios, promociones o patrones de compra.
La recopilación de datos comienza identificando las fuentes relevantes, que pueden ser bases de datos internas, sensores, encuestas… Además de los datos propios de cada empresa, existe un amplio ecosistema de datos, tanto abiertos como propietarios, a los que podemos recurrir en busca de la construcción de modelos más potentes. Por ejemplo, el Gobierno de España habilita a través del portal datos.gob.es múltiples conjuntos de datos abiertos publicados por instituciones públicas. Por otro lado, la empresa Amazon Web Services (AWS) a través de su portal AWS Data Exchange permite el acceso y suscripción a miles de conjuntos de datos propietarios publicados y mantenidos por diferentes empresas y organizaciones.
En este punto también se debe considerar la cantidad de datos necesaria. Los modelos de IA suelen necesitar grandes volúmenes de información para aprender de manera efectiva. También es crucial que los datos sean representativos y no contengan sesgos que puedan afectar los resultados. Por ejemplo, si entrenamos un modelo para predecir patrones de consumo y solo usamos datos de un grupo limitado de personas, es probable que las predicciones no sean válidas para otros grupos con comportamientos diferentes.
Paso 3: preparar y explorar los datos
Una vez recopilados los datos, es hora de limpiarlos y normalizarlos. En muchas ocasiones, los datos en bruto pueden contener problemas como errores, duplicidades, valores faltantes, inconsistencias o formatos no estandarizados. Por ejemplo, podríamos encontrarnos con celdas vacías en un conjunto de datos de ventas o con fechas que no siguen un formato coherente. Antes de alimentar el modelo con estos datos, es fundamental adecuarlos para garantizar que el análisis sea preciso y confiable. Este paso no solo mejora la calidad de los resultados, sino que también asegura que el modelo pueda interpretar correctamente la información.
Una vez tenemos los datos limpios es fundamental realizar la ingeniería de características (feature engineering), un proceso creativo que puede marcar la diferencia entre un modelo básico y uno excelente. Esta fase consiste en crear nuevas variables que capturen mejor la naturaleza del problema que queremos resolver. Por ejemplo, si estamos analizando ventas online, además de usar el precio directo del producto, podríamos crear nuevas características como el ratio precio/media_categoría, los días desde la última promoción, o variables que capturen la estacionalidad de las ventas. La experiencia demuestra que contar con características bien diseñadas suele ser más determinante para el éxito del modelo que la elección del algoritmo en sí mismo.
En esta fase, también realizaremos un primer análisis exploratorio de los datos, buscando familiarizarnos con ellos y detectar posibles patrones, tendencias o irregularidades que puedan influir en el modelo. En esta guía podemos encontrar mayor detalle sobre cómo realizar un análisis exploratorio de datos.
Otra actividad típica de esta etapa es dividir los datos en conjuntos de entrenamiento, validación y prueba. Por ejemplo, si tenemos 10.000 registros, podríamos usar el 70% para entrenamiento, el 20% para validación y el 10% para pruebas. Esto permite que el modelo aprenda sin sobreajustarse a un conjunto de datos específico.
Para garantizar que nuestra evaluación sea robusta, especialmente cuando trabajamos con conjuntos de datos limitados, es recomendable implementar técnicas de validación cruzada (cross-validation). Esta metodología divide los datos en múltiples subconjuntos y realiza varias iteraciones de entrenamiento y validación. Por ejemplo, en una validación cruzada de 5 pliegues, dividimos los datos en 5 partes y entrenamos 5 veces, usando cada vez una parte diferente como conjunto de validación. Esto nos proporciona una estimación más fiable del rendimiento real del modelo y nos ayuda a detectar problemas de sobreajuste o variabilidad en los resultados.
Paso 4: seleccionar un modelo
Existen múltiples tipos de modelos de IA, y la elección depende del problema que deseemos resolver. Algunos ejemplos comunes son regresión, modelos de árboles de decisión, modelos de agrupamiento, modelos de series temporales o redes neuronales. En general, existen modelos supervisados, modelos no supervisados y modelos de aprendizaje por refuerzo. Podemos encontrar un mayor detalle en este post sobre cómo las maquinas aprenden.
A la hora de seleccionar un modelo, es importante tener en cuenta factores como la naturaleza de los datos, la complejidad del problema y el objetivo final. Por ejemplo, un modelo simple como la regresión lineal puede ser suficiente para problemas sencillos y bien estructurados, mientras que redes neuronales o modelos avanzados podrían ser necesarios para tareas como reconocimiento de imágenes o procesamiento del lenguaje natural. Además, también se debe considerar el balance entre precisión, tiempo de entrenamiento y recursos computacionales. Un modelo más preciso generalmente requiere configuraciones más complejas, como más datos, redes neuronales más profundas o parámetros optimizados. Aumentar la complejidad del modelo o trabajar con conjuntos de datos grandes puede alargar significativamente el tiempo necesario para entrenarlo. Esto puede ser un problema en entornos donde las decisiones deben tomarse rápidamente o los recursos son limitados y requerir hardware especializado, como GPUs o TPUs, y mayores cantidades de memoria y almacenamiento.
Hoy en día, muchas bibliotecas de código abiertas facilitan la implementación de estos modelos, como TensorFlow, PyTorch o scikit-learn.
Paso 5: entrenar el modelo
El entrenamiento es el corazón del proceso. Durante esta etapa, alimentamos el modelo con los datos de entrenamiento para que aprenda a realizar su tarea. Esto se logra ajustando los parámetros del modelo para minimizar el error entre sus predicciones y los resultados reales.
Aquí es clave evaluar constantemente el rendimiento del modelo con el conjunto de validación y realizar ajustes si es necesario. Por ejemplo, en un modelo de tipo red neuronal podríamos probar diferentes configuraciones de hiperparámetros como tasa de aprendizaje, número de capas ocultas y neuronas, tamaño del lote, número de épocas, o función de activación, entre otros.
Paso 6: evaluar el modelo
Una vez entrenado, es momento de poner a prueba el modelo utilizando el conjunto de datos de prueba que apartamos durante la fase de entrenamiento. Este paso es crucial para medir cómo se desempeña con datos que para el modelo son nuevos y garantiza que no esté “sobreentrenado”, es decir, que no solo funcione bien con los datos de entrenamiento, sino que sea capaz de aplicar el aprendizaje sobre nuevos datos que puedan generarse en el día a día.
Al evaluar un modelo, además de la precisión, también es común considerar:
- Confianza en las predicciones: evaluar cuán seguras son las predicciones realizadas.
- Velocidad de respuesta: tiempo que toma el modelo en procesar y generar una predicción.
- Eficiencia en recursos: medir cuánto uso de memoria y cómputo requiere el modelo.
- Adaptabilidad: cuán bien puede ajustarse el modelo a nuevos datos o condiciones sin necesidad de un reentrenamiento completo.
Paso 7: desplegar y mantener el modelo
Cuando el modelo cumple con nuestras expectativas, está listo para ser desplegado en un entorno real. Esto podría implicar integrar el modelo en una aplicación, automatizar tareas o generar informes.
Sin embargo, el trabajo no termina aquí. La IA necesita mantenimiento continuo para adaptarse a los cambios en los datos o en las condiciones del mundo real. Por ejemplo, si los patrones de compra cambian por una nueva tendencia, el modelo deberá ser actualizado.
Construir modelos de IA no es una ciencia exacta, es el resultado de un proceso estructurado que combina lógica, creatividad y perseverancia. Esto se debe a que intervienen múltiples factores, como la calidad de los datos, las elecciones en el diseño del modelo y las decisiones humanas durante la optimización. Aunque existen metodologías claras y herramientas avanzadas, la construcción de modelos requiere experimentación, ajustes y, a menudo, un enfoque iterativo para obtener resultados satisfactorios. Aunque cada paso requiere atención al detalle, las herramientas y tecnologías disponibles hoy en día hacen que este desafío sea accesible para cualquier persona interesada en explorar el mundo de la IA.
ANEXO I – Definiciones tipos de modelos
-
Regresión: técnicas supervisadas que modelan la relación entre una variable dependiente (resultado) y una o más variables independientes (predictores). La regresión se utiliza para predecir valores continuos, como ventas futuras o temperaturas, y puede incluir enfoques como la regresión lineal, logística o polinómica, dependiendo de la complejidad del problema y la relación entre las variables.
-
Modelos de árboles de decisión: métodos supervisados que representan decisiones y sus posibles consecuencias en forma de árbol. En cada nodo, se toma una decisión basada en una característica de los datos, dividiendo el conjunto en subconjuntos más pequeños. Estos modelos son intuitivos y útiles para clasificación y predicción, ya que generan reglas claras que explican el razonamiento detrás de cada decisión.
-
Modelos de agrupamiento: técnicas no supervisadas que agrupan datos en subconjuntos llamados clústeres, basándose en similitudes o proximidad entre los datos. Por ejemplo, se pueden agrupar clientes con hábitos de compra similares para personalizar estrategias de marketing. Modelos como k-means o DBSCAN permiten identificar patrones útiles sin necesidad de datos etiquetados.
-
Modelos de series temporales: diseñados para trabajar con datos ordenados cronológicamente, estos modelos analizan patrones temporales y realizan predicciones basadas en el historial. Se utilizan en casos como predicción de demanda, análisis financiero o meteorología. Incorporan tendencias, estacionalidad y relaciones entre los datos pasados y futuros.
-
Redes neuronales: modelos inspirados en el funcionamiento del cerebro humano, donde capas de neuronas artificiales procesan información y detectan patrones complejos. Son especialmente útiles en tareas como reconocimiento de imágenes, procesamiento de lenguaje natural y juegos. Las redes neuronales pueden ser simples o muy profundas (deep learning), dependiendo del problema y la cantidad de datos.
-
Modelos supervisados: estos modelos aprenden de datos etiquetados, es decir, conjuntos en los que cada entrada tiene un resultado conocido. El objetivo es que el modelo generalice para predecir resultados en datos nuevos. Ejemplos incluyen clasificación de correos en spam o no spam y predicciones de precios.
-
Modelos no supervisados: trabajan con datos sin etiquetas, buscando patrones ocultos, estructuras o relaciones dentro de los datos. Son ideales para tareas exploratorias donde no se conoce de antemano el resultado esperado, como segmentación de mercados o reducción de dimensionalidad.
- Modelo de aprendizaje por refuerzo: en este enfoque, un agente aprende interactuando con un entorno, tomando decisiones y recibiendo recompensas o penalizaciones según su desempeño. Este tipo de aprendizaje es útil en problemas donde las decisiones afectan un objetivo a largo plazo, como entrenar robots, jugar videojuegos o desarrollar estrategias de inversión.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.