Blog
La irrupción de la inteligencia artificial (IA) y, en particular ChatGPT, se ha convertido en uno de los principales temas de debate en los últimos meses. Esta herramienta ha eclipsado incluso otras tecnologías emergentes que habían adquirido un protagonismo en los más diversos ámbitos (jurídicos, económicos, sociales o culturales). Caso, por ejemplo, la web 3.0, el metaverso, la identidad digital descentralizada o los NFT y, en particular, las criptomonedas.
Resulta incuestionable la relación directa que existe entre este tipo de tecnología y la necesidad de disponer de datos suficientes y adecuados, siendo precisamente esta última dimensión cualitativa la que justifica que los datos abiertos estén llamados a desempeñar un papel de especial importancia. Aunque, al menos de momento, no es posible saber cuántos datos abiertos proporcionados por las entidades del sector público utiliza ChatGPT para entrenar su modelo, no hay duda de que los datos abiertos son una fuente especialmente significativa a la hora de mejorar su funcionamiento.
La regulación sobre el uso de los datos por la IA
Desde el punto de vista jurídico, la IA está despertando un especial interés por lo que se refiere a las garantías que deben respetarse a la hora de su aplicación práctica. Así, se están impulsando diversas iniciativas que pretenden regular específicamente las condiciones para proceder a su utilización, entre las que destaca la propuesta que está tramitando la Unión Europea, donde los datos son objeto de especial atención.
Ya en el ámbito estatal, hace unos meses se aprobó la Ley 15/2022, de 12 de julio, integral para la igualdad de trato y la no discriminación. Esta normativa exige a las Administraciones Públicas que favorezcan la implantación de mecanismos que contemplen garantías relativas a la minimización de sesgos, transparencia y rendición de cuentas, en concreto por lo que respecta a los datos utilizados para el entrenamiento de los algoritmos que se empleen para la toma de decisiones.
Por parte de las comunidades autónomas existe un creciente interés a la hora de regular el uso de los datos por parte de los sistemas de IA, reforzándose en algún caso las garantías relativas a la transparencia. También, a nivel municipal se están promoviendo protocolos para la implantación de la IA en los servicios municipales en los que las garantías aplicables a los datos, en particular desde la perspectiva de su calidad, se conciben como una exigencia prioritaria.
La posible colisión con otros derechos y bienes jurídicos: la protección de datos de carácter personal
Más allá de las iniciativas regulatorias, el uso de los datos en este contexto ha sido objeto de una especial atención por lo que se refiere a las condiciones jurídicas en que resulta admisible. Así, puede darse el caso de que los datos que se utilicen estén protegidos por derechos de terceros que impidan —o al menos dificulten— su tratamiento, tal y como sucede con la propiedad intelectual o, singularmente, la protección de datos de carácter personal. Esta inquietud constituye una de las principales motivaciones de la Unión Europea a la hora de promover el Reglamento de Gobernanza de Datos, regulación donde se plantean soluciones técnicas y organizativas que intentan compatibilizar la reutilización de la información con el respeto de tales bienes jurídicos.
Precisamente, la posible colisión con el derecho a la protección de datos de carácter personal ha motivado las principales medidas que se han adoptado en Europa respecto del uso de ChatGPT. En este sentido, el Garante per la Protezione dei Dati Personali ha acordado cautelarmente la limitación del tratamiento de datos de ciudadanos italianos, la Agencia Española de Protección de Datos ha iniciado de oficio actuaciones de inspección frente a OpenAI como responsable del tratamiento y, con una proyección supranacional, el Supervisor Europeo de Protección de Datos (EDPB) ha creado un grupo de trabajo específico.
La incidencia de la regulación sobre datos abiertos y reutilización
La regulación española sobre datos abiertos y reutilización de la información del sector público establece algunas previsiones que han de tenerse en cuenta por los sistemas de IA. Así, con carácter general, la reutilización será admisible si los datos se hubieren publicado sin sujeción a condiciones o, en el caso de que se fijen, cuando se ajuste a las establecidas a través de licencias u otros instrumentos jurídicos; si bien, cuando se definan, las condiciones han de ser objetivas, proporcionadas, no discriminatorias y estar justificadas por un objetivo de interés público.
Por lo que se refiere a las condiciones de reutilización de la información proporcionada por las entidades del sector público, su tratamiento sólo se permitirá si no se altera el contenido ni se desnaturaliza su sentido, debiéndose citar la fuente de la que se hubieren obtenido los datos y la fecha de su actualización más reciente.
Por otra parte, los conjuntos de datos de alto valor adquieren un especial interés para estos sistemas de IA caracterizados por la intensa reutilización de contenidos de terceros dado el carácter masivo de los tratamientos de datos que llevan a cabo y la inmediatez de las peticiones de información que formulan quienes las utilizan. En concreto, las condiciones establecidas legalmente para la puesta a disposición de estos conjuntos de datos de alto valor por parte de las entidades públicas determinan que existan muy pocas limitaciones y, asimismo, que se facilite enormemente su reutilización al tratarse de datos que han de estar disponibles de manera gratuita, ser susceptibles de tratamiento automatizado, suministrarse a través de API y proporcionarse en forma de descarga masiva, siempre que proceda.
En definitiva, teniendo en cuenta las particularidades de esta tecnología y, por tanto, las circunstancias tan singulares en las que tratan los datos, parece oportuno que las licencias y, en general, las condiciones en las que las entidades públicas permiten su reutilización sean revisadas y, en su caso, actualizadas para hacer frente a los retos jurídicos que se están empezando a plantear.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el proceso de análisis de datos y entrenamiento de modelos de aprendizaje automático, es fundamental contar con un conjunto de datos adecuado. Por lo tanto, surgen las preguntas: ¿cómo se deben preparar los conjuntos de datos para el aprendizaje automático y el análisis? ¿Cómo se puede confiar en que los datos conducirán a conclusiones sólidas y predicciones precisas?
Lo primero que hay que tener en cuenta al preparar los datos es saber el tipo de problema que se intenta resolver. Por ejemplo, si tu intención es crear un modelo de aprendizaje automático capaz de reconocer el estado emocional de alguien a partir de sus expresiones faciales, necesitarás un conjunto de datos con imágenes o vídeos de caras de personas. O, tal vez, el objetivo es crear un modelo que identifique los correos electrónicos no deseados. Para ello, se necesitarán datos en formato texto de correos electrónicos.
Además, los datos que se precisan también dependen del tipo de algoritmo que quieras utilizar. Los algoritmos de aprendizaje supervisado, como la regresión lineal o los árboles de decisión, requieren un campo que contenga el valor verdadero de un resultado para que el modelo aprenda de él. Además de este valor verdadero, denominado objetivo, requieren campos que contengan información sobre las observaciones, algo que se conoce como características. En cambio, los algoritmos de aprendizaje no supervisado, como la agrupación k-means o los sistemas de recomendación basados en el filtrado colaborativo, por lo general sólo necesitan características.
Sin embargo, encontrar los datos es sólo la mitad del trabajo. Los conjuntos de datos del mundo real pueden contener todo tipo de errores que pueden hacer que todo el trabajo resulte inútil si no se detectan y corrigen antes de empezar. En este post, vamos a presentar algunos de los principales obstáculos que puede haber en los conjuntos de datos para el aprendizaje automático y el análisis, así como conocer algunas maneras en que la plataforma de ciencia de datos colaborativa, Datalore, puede ayudar a detectarlos rápidamente y ponerles remedio.
¿Los datos son representativos de aquello que se quiere medir?
La mayoría de los conjuntos de datos para proyectos o análisis de aprendizaje automático no están diseñados específicamente para ese fin. A falta de un diccionario de metadatos o de una explicación sobre lo qué significan los campos del conjunto de datos, es posible que el usuario tenga que resolver la incógnita basándose en la información de la que dispone.
Una forma de determinar lo que miden las características de un conjunto de datos es comprobar sus relaciones con otras características. Si se supone que dos campos miden cosas similares, es de esperar que estén muy relacionados. Por el contrario, si dos campos miden cosas muy diferentes, es de esperar que no estén relacionados. Estas ideas se conocen como validez convergente y discriminante, respectivamente.
Otra cosa importante que hay que comprobar es si alguno de los rasgos está demasiado relacionado con el público objetivo. Si esto ocurre, puede indicar que este rasgo está accediendo a la misma información que el objetivo a predecir. Este fenómeno se conoce como “feature leakage” (fuga de características). Si se emplean estos datos, existe el riesgo de inflar artificialmente el rendimiento del modelo.
En este sentido, Datalore permite escanear rápidamente la relación entre variables continúas mediate el gráfico de correlación en la pestaña Visualizar para un DataFrame. Otra manera de comprobar estas relaciones es utilizando gráficos de barras o tabulaciones cruzadas, o medidas del tamaño del efecto como el coeficiente de determinación o la V de Cramér.
¿El conjunto de datos está correctamente filtrado y limpio?
Los conjuntos de datos pueden contener todo tipo de inconsistencias que pueden afectar negativamente a nuestros modelos o análisis. Algunos de los indicadores más importantes de datos sucios son:
- Valores inverosímiles: Esto incluye valores que están fuera de rango, como los negativos en una variable de recuento o frecuencias que son mucho más altas o más bajas de lo esperado para un campo en particular.
- Valores atípicos: Se trata de valores extremos, que pueden representar cualquier cosa, desde errores de codificación que se produjeron en el momento en que se escribieron los datos, hasta valores raros pero reales que se sitúan fuera del grueso de las demás observaciones.
- Valores perdidos: El patrón y la cantidad de datos que faltan determinan el impacto que tendrán, siendo los más graves los que están relacionados con el objetivo o las características.
Los datos sucios pueden mermar la calidad de sus análisis y modelos, en gran medida porque distorsionan las conclusiones o porque conducen a un rendimiento deficiente del modelo. La pestaña Estadísticas de Datalore permite comprobar fácilmente estos problemas, ya que muestra de un vistazo la distribución, el número de valores perdidos y la presencia de valores atípicos para cada campo. Datalore también facilita la exploración de los datos en bruto y permite realizar operaciones básicas de filtrado, ordenación y selección de columnas directamente en un DataFrame, exportando el código Python correspondiente a cada acción a una nueva celda.
¿Las variables están equilibradas?
Los datos desequilibrados se producen cuando los campos categóricos tienen una distribución desigual de observaciones entre todas las clases. Esta situación puede causar problemas importantes para los modelos y los análisis. Cuando se tiene un objetivo muy desequilibrado, se pueden crear modelos perezosos que aún pueden lograr un buen rendimiento simplemente prediciendo por defecto la clase mayoritaria. Pongamos un ejemplo extremo: tenemos un conjunto de datos en el que el 90% de las observaciones corresponden a una de las clases objetivo y el 10% a la otra. Si siempre predijéramos la clase mayoritaria para este conjunto de datos, seguiríamos obteniendo una precisión del 90%, lo que demuestra que, en estos casos, un modelo que no aprende nada de las características puede tener un rendimiento excelente.
Las características también se ven afectadas por el desequilibrio de clases. Los modelos funcionan aprendiendo patrones, y cuando las clases son demasiado pequeñas, es difícil para los modelos hacer predicciones para estos grupos. Estos efectos pueden agravarse cuando se tienen varias características desequilibradas, lo que lleva a situaciones en las que una combinación concreta de clases poco comunes sólo puede darse en un puñado de observaciones.
Los datos desequilibrados pueden rectificarse mediante diversas técnicas de muestreo. El submuestreo (undersampling, en inglés) consiste en reducir el número de observaciones en las clases más grandes para igualar la distribución de los datos, y el sobremuestreo (oversampling) consiste en crear más datos en las clases más pequeñas. Hay muchas formas de hacerlo. Algunos ejemplos incluyen el uso de paquetes Python como imbalanced-learn o servicios como Gretel. Las características desequilibradas también pueden corregirse mediante la ingeniería de características, cuyo objetivo es combinar clases dentro de un campo sin perder información.
En definitiva, ¿es representativo el conjunto de datos?
A la hora de crear un conjunto de datos, se tiene en mente un grupo objetivo o target para el cual deseas que tu modelo o análisis funcione. Por ejemplo, un modelo para predecir la probabilidad de que los hombres estadounidenses interesados en la moda compren una determinada marca. Este grupo objetivo es la población sobre la que se quiere poder hacer generalizaciones. Sin embargo, como no suele ser práctico recopilar información sobre todos los individuos que constituyen esta parte de la población, en su lugar se emplea un subconjunto denominado muestra.
A veces surgen problemas que hacen que los datos de la muestra para el modelo de aprendizaje automático y el análisis no representen correctamente el comportamiento de la población. Esto se denomina sesgo de los datos. Por ejemplo, es posible que la muestra no capte todos los subgrupos de la población, un tipo de sesgo denominado sesgo de selección.
Una forma de comprobar el sesgo es inspeccionar la distribución de los campos de sus datos y comprobar que tienen sentido basándose en lo que uno sabe sobre ese grupo de la población. El uso de la pestaña Estadísticas de Datalore permite escanear la distribución de las variables continuas y categóricas de un DataFrame.
¿Se está midiendo el rendimiento real de los modelos?
Una última cuestión que puede ponerle en un aprieto es la medición del rendimiento de sus modelos. Muchos modelos son propensos a un problema llamado sobreajuste que es cuando el modelo se ajusta tan bien a los datos de entrenamiento que no se generaliza bien a los nuevos datos. El signo revelador del sobreajuste es un modelo que funciona extremadamente bien con los datos de entrenamiento y su rendimiento es inferior con nuevos datos. La forma de tener esto en cuenta es dividir el conjunto de datos en varios conjuntos: un conjunto de entrenamiento para entrenar el modelo, un conjunto de validación para comparar el rendimiento de diferentes modelos y un conjunto de prueba final para comprobar cómo funcionará el modelo en el mundo real.
Sin embargo, crear una división limpia de entrenamiento-validación-prueba puede ser complicado. Un problema importante es la fuga de datos, por la que la información de los otros dos conjuntos de datos se filtra en el conjunto de entrenamiento. Esto puede dar lugar a problemas que van desde los obvios, como las observaciones duplicadas que terminan en los tres conjuntos de datos, a otros más sutiles, como el uso de información de todo el conjunto de datos para realizar el preprocesamiento de características antes de dividir los datos. Además, es importante que los tres conjuntos de datos tengan la misma distribución de objetivos y características, para que cada uno sea una muestra representativa de la población.
Para evitar cualquier problema, se debe dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba al principio de su trabajo, antes de realizar cualquier exploración o procesamiento. Para asegurarse de que cada conjunto de datos tiene la misma distribución de cada campo, se puede utilizar un método como train_test_split de scikit-learn, diseñado específicamente para crear divisiones representativas de los datos. Por último, es recomendable comparar las estadísticas descriptivas de cada conjunto de datos para comprobar si hay signos de fuga de datos o divisiones desiguales, lo que se hace fácilmente utilizando la pestaña Estadísticas de Datalore.
En definitiva, existen varios problemas que pueden ocurrir cuando se preparan los datos para el aprendizaje automático y el análisis y es importante saber cómo mitigarlos. Si bien esto puede ser una parte que consume mucho tiempo del proceso de trabajo, existen herramientas que pueden hacer que sea más rápido y fácil detectar problemas en una etapa temprana.
Contenido elaborado a partir del post de Jodie Burchell How to prepare your dataset for machine learning and analysis publicado en The JetBrains Datalore Blog
Blog
La crisis humanitaria que se originó tras el terremoto de Haití en 2010 fue el punto de partida de una iniciativa voluntaria para crear mapas que identificaran el nivel de daño y vulnerabilidad por zonas, y así, poder coordinar los equipos de emergencia. Desde entonces, el proyecto de mapeo colaborativo conocido como Hot OSM (OpenStreetMap) realiza una labor clave en situaciones de crisis y desastres naturales.
Ahora, la organización ha evolucionado hasta convertirse en una red global de voluntarios que aportan sus habilidades de creación de mapas en línea para ayudar en situaciones de crisis por todo el mundo. La iniciativa es un ejemplo de colaboración en torno a los datos para resolver problemas de la sociedad, tema que desarrollamos en este informe de datos.gob.es.
Hot OSM trabaja para acelerar la colaboración con organizaciones humanitarias y gubernamentales en torno a los datos, así como con comunidades locales y voluntarios de todo el mundo, para proporcionar mapas precisos y detallados de áreas afectadas por desastres naturales o crisis humanitarias. Estos mapas se utilizan para ayudar a coordinar la respuesta de emergencia, identificar necesidades y planificar la recuperación.
En su trabajo, Hot OSM prioriza la colaboración y el empoderamiento de las comunidades locales. La organización trabaja para garantizar que las personas que viven en las áreas afectadas tengan voz y poder en el proceso de mapeo. Esto significa que Hot OSM trabaja en estrecha colaboración con las comunidades locales para asegurarse de que se mapeen áreas importantes para ellos. De esta manera, se tienen en cuenta las necesidades de las comunidades a la hora de planificar respuesta de emergencia y la recuperación.
Labor didáctica de Hot OSM
Además de su trabajo en situaciones de crisis, Hot OSM dedica esfuerzos a la promoción del acceso a datos geoespaciales abiertos y libres, y trabaja en colaboración con otras organizaciones para construir herramientas y tecnologías que permitan a las comunidades de todo el mundo aprovechar el poder del mapeo colaborativo.
A través de su plataforma en línea, Hot OSM proporciona acceso gratuito a una amplia gama de herramientas y recursos para ayudar a los voluntarios a aprender y participar en la creación de mapas colaborativos. La organización también ofrece capacitación para aquellos interesados en contribuir a su trabajo.
Un ejemplo de proyecto de HOT es el trabajo que la organización realizó en el contexto del ébola en África Occidental. En 2014, un brote de ébola afectó a varios países de África Occidental, incluidos Sierra Leona, Liberia y Guinea. La falta de mapas precisos y detallados en estas áreas dificultó la coordinación de la respuesta de emergencia.
En respuesta a esta necesidad, HOT inició un proyecto de mapeo colaborativo que involucró a más de 3.000 voluntarios en todo el mundo. Los voluntarios utilizaron herramientas en línea para mapear áreas afectadas por el ébola, incluidas carreteras, pueblos y centros de tratamiento.
Este mapeo permitió a los trabajadores humanitarios coordinar mejor la respuesta de emergencia, identificar áreas de alto riesgo y priorizar la asignación de recursos. Además, el proyecto también ayudó a las comunidades locales a comprender mejor la situación y a participar en la respuesta de emergencia.
Este caso en África Occidental es solo un ejemplo del trabajo que HOT realiza en todo el mundo para ayudar en situaciones de crisis humanitarias. La organización ha trabajado en una variedad de contextos, incluidos terremotos, inundaciones y conflictos armados, y ha ayudado a proporcionar mapas precisos y detallados para la respuesta de emergencia en cada uno de estos contextos.
Por otro lado, la plataforma también está involucrada en zonas en las que no hay cobertura de mapas, como en muchos países africanos. En estas zonas los proyectos de ayuda humanitaria muchas veces tienen un gran reto en las primeras fases, ya que es muy difícil cuantificar qué población vive en una zona y donde está emplazada. Poder tener la ubicación esas personas y que muestre vías de acceso las “pone en el mapa” y permite que puedan llegar a acceder a los recursos.
En el artículo The evolution of humanitarian mapping within the OpenStreetMap community de Nature, podemos ver gráficamente algunos de los logros de la plataforma.
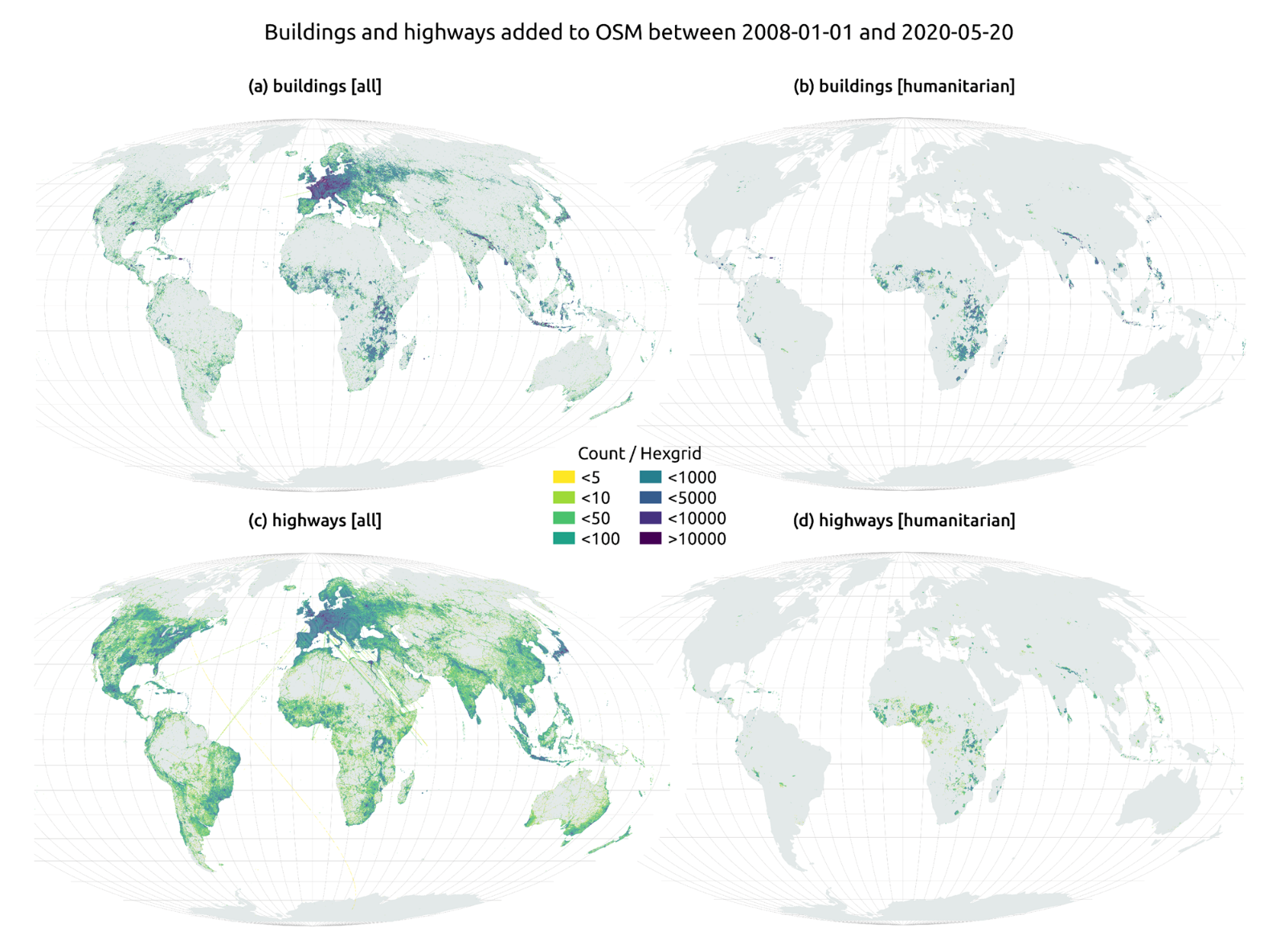
Como colaborar
Empezar a colaborar con Hot OSM es fácil, basta con ir a la página https://tasks.hotosm.org/explore y ver los proyectos abiertos que necesitan colaboración.
Esta pantalla nos permite una gran cantidad de opciones a la hora de buscar los proyectos, seleccionado por nivel de dificultad, organización, ubicación o intereses entre otros.
Para participar, basta con pulsar el botón Registrese.
Dar un nombre y un e-mail y en la siguiente pantalla:

Nos preguntará si tenemos creada una cuenta en Open Street Maps o queremos crear una.
Si queremos ver más en detalle el proceso, esta página nos lo pone muy fácil.
Una vez creado el usuario, en la página aprender encontramos ayuda de cómo participar en el proyecto.
Es importante destacar que las contribuciones de los voluntarios se revisan y validan y existe un segundo nivel de voluntarios, los validadores, que dan por bueno el trabajo de los principiantes. Durante el desarrollo de la herramienta, el equipo de HOT ha cuidado mucho que sea una aplicación sencilla de utilizar para no limitar su uso a personas con conocimientos informáticos.
Además, organizaciones como Cruz Roja o Naciones unidas organizan regularmente mapatones con el objetivo de reunir grupos de personas para proyectos específicos o enseñar a nuevos voluntarios el uso de la herramienta. Estas reuniones sirven, sobre todo, para quitar el miedo de los nuevos usuarios a “romper algo” y para que puedan ver cómo su labor de voluntariado sirve para cosas concretas y ayuda a otras personas.
Otra de las grandes fortalezas del proyecto es que está basado en software libre y permite la reutilización del mismo. En el repositorio Github del proyecto MissingMaps podemos encontrar el código y si queremos crear una comunidad basada en el software, la organización Missing Maps nos facilita el proceso y dará visibilidad a nuestro grupo.
En definitiva, Hot OSM es un proyecto de ciencia ciudadana y altruismo de datos que contribuye a aportar beneficios a la sociedad mediante la elaboración de mapas colaborativos muy útiles en situaciones de emergencia. Este tipo de iniciativas están alineadas con el concepto europeo de gobernanza de datos que busca impulsar el altruismo para facilitar voluntariamente el uso de los datos para el bien común.
Contenido elaborado por Santiago Mota, senior data scientist.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Continuamos con la serie de posts sobre Chat GPT-3. La expectación levantada por el sistema conversacional justifica con creces la publicación de varios artículos sobre sus características y aplicaciones. En este post, profundizamos sobre una de las últimas novedades publicadas por openAI relacionadas con Chat GPT-3. En este caso introducimos su API, es decir, su interfaz de programación con la que podemos integrar Chat GPT-3 en nuestras propias aplicaciones.
Introducción.
En nuestro último post sobre Chat GPT-3 realizamos un ejercicio de co-programación o programación asistida en el que le solicitamos a la IA que nos escribiera un programa sencillo, en lenguaje de programación R, para visualizar un conjunto de datos. Como vimos en el post, utilizamos la propia interfaz disponible de Chat GTP-3. La interfaz es muy minimalista y funcional, tan solo tenemos que preguntar a la IA en el cuadro de texto y ella nos contesta en el cuadro de texto posterior. Tal y como concluimos en el post, el resultado del ejercicio fue más que satisfactorio. Sin embargo, también detectamos algunos puntos de mejora. Por ejemplo, la interfaz estándar puede resultar un poco lenta. Para un ejercicio largo, con múltiples interacciones conversacionales con la IA (un diálogo largo), la interfaz tarda bastante en escribir las respuestas. Varios usuarios reportan la misma sensación y por eso algunos, como este desarrollador, han creado su propia interfaz con el asistente conversacional para mejorar su velocidad de respuesta.
Pero, ¿cómo es posible esto? La razón es sencilla, gracias al API de Chat GPT-3. En este espacio de divulgación hemos hablado mucho sobre las APIs en el pasado. No en vano, las APIs son los mecanismos estándar en el mundo de las tecnologías digitales para integrar servicios y aplicaciones. Cualquier app en nuestro smartphone hace uso de las APIs para mostrarnos los resultados. Cuando consultamos el tiempo, los resultados deportivos o el horario del transporte público, las apps hacen llamadas a las APIs de los servicios para consultar la información y mostrar los resultados.
El API de Chat GPT-3
Como cualquier otro servicio actual, openAI pone a disposición de sus usuarios una API con la que poder invocar (llamar) a sus diferentes servicios basados en el modelo entrenado de lenguaje natural GPT-3. Para usar el API, tan solo tenemos que iniciar sesión con nuestra cuenta en https://platform.openai.com y localizar el menú (superior derecha) View API Keys. Hacemos click en create a new secret key y ya tenemos nuestra nueva clave de acceso al servicio.

¿Qué hacemos ahora? Bien, para ilustrar lo que podemos hacer con esta nueva y flamante clave veamos algunos ejemplos:
Como decíamos en la introducción, podemos querer probar interfaces alternativas a Chat GPT-3 como https://www.typingmind.com/. Cuando accedemos a esta web, lo primero que debemos hacer es ingresar nuestra API Key.
Una vez dentro, hagamos un ejemplo y veamos cómo se comporta esta nueva interfaz. Preguntemos a Chat GPT-3 ¿Qué es datos.gob.es?
| Nota: Es importante notar que la mayoría de servicios no funcionarán si no activamos algún medio de pago en la web de OpenAI. Lo normal es que, si no hemos configurado una tarjeta de crédito, las llamadas al API devuelvan un mensaje de error similar a \"You exceeded your current quota, please check your plan and billing details”. |

Veamos ahora otra aplicación del API de Chat GPT-3.
Acceso programático con R para acceder a Chat GPT-3 de modo programático (o lo que es lo mismo, con algunas líneas de código en R tenemos acceso a la potencia conversacional del modelo GPT-3). Esta demostración está basada en el reciente post publicado en R Bloggers. Vamos a acceder a Chat GPT-3 de modo programático con el siguiente ejemplo.
| Nota: Notar que el API Key se ha ocultado por motivos de seguridad y privacidad |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

¿Nada mal verdad? Como dato curioso podemos ver que unas pocas llamadas al API de Chat GPT-3 han tenido el siguiente uso del API:

El uso del API se cotiza por tokens (algo similar a las palabras) y los precios públicos pueden consultarse aquí. En concreto el modelo que estamos utilizando tiene estos precios:

Para pequeñas pruebas y ejemplos, nos lo podemos permitir. En caso de aplicaciones empresariales para entornos productivos existe un modelo premium que permite tener un control de los costes sin depender tanto del uso.
Conclusión
Como no podía ser de otra manera, Chat GPT-3 habilita un API para proporcionar acceso programático a su motor conversacional. Este mecanismo permite la integración de aplicaciones y sistemas (es decir, todo lo que no son humanos) abriendo la puerta al despegue definitivo del Chat GPT-3 como modelo de negocio. Gracias a este mecanismo, el buscador Bing ahora integra Chat GPT-3 para respuestas a las búsquedas en modo conversacional. De la misma forma, Microsoft Azure acaba de anunciar la disponibilidad de Chat GPT-3 como un nuevo servicio de la nube pública. Sin lugar a dudas, en las próximas semanas veremos comunicaciones de todo tipo de aplicaciones, apps y servicios, conocidos y desconocidos, anunciando su integración con Chat GPT-3 para mejorar las interfaces conversacionales con sus clientes. Nos vemos en el próximo episodio, quién sabe sin con GPT-4.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Detrás de un asistente virtual de voz, la recomendación de una película en una plataforma de streaming o el desarrollo de algunas vacunas contra el covid-19 existen modelos de machine learning. Esta rama de la inteligencia artificial permite que los sistemas aprendan y mejoren su funcionamiento.
El machine learning (ML) o aprendizaje automático es uno de los campos que impulsa el avance tecnológico del presente y sus aplicaciones crecen cada día. Como ejemplos de soluciones desarrolladas con machine learning podemos mencionar DALL-E, el conjunto de modelos del lenguaje en español MarIA o incluso Chat GPT-3, herramienta de IA generativa que es capaz de crear contenido de todo tipo, como, por ejemplo, código para programar visualizaciones con datos del catálogo datos.gob.es.
Todas estas soluciones funcionan gracias a grandes repositorios de datos que hacen posible el aprendizaje de los sistemas. Entre estos, los datos abiertos juegan un papel fundamental para el desarrollo de la inteligencia artificial ya que pueden servir de entrenamiento para los modelos de aprendizaje automático.
Bajo esta premisa, sumado al esfuerzo permanente de las administraciones por la apertura de datos, existen organizaciones no gubernamentales y asociaciones que contribuyen desarrollando aplicaciones que usan técnicas de machine learning dirigidas a mejorar la vida de la ciudadanía. Destacamos tres de ellas:
ML Commons impulsa un sistema de aprendizaje automático mejor para todos
Esta iniciativa pretende mejorar el impacto positivo del aprendizaje automático en la sociedad y acelerar la innovación ofreciendo herramientas como conjuntos de datos, mejores prácticas y algoritmos abiertos. Entre sus miembros fundadores se encuentran empresas como Google, Microsoft, DELL, Intel AI, Facebook AI, entre otras.
Según ML Commons, en torno al 80% de las investigaciones realizadas en el ámbito del machine learning se basan en datos abiertos. Por lo tanto, los datos abiertos son vitales para acelerar la innovación en esta materia. Sin embargo, hoy en día, “la mayoría de los ficheros de datos públicos disponibles son pequeños, estáticos, tienen restricciones legales y no son redistribuibles”, tal y como asegura David Kanter, director de ML Commons.
En esta línea, las tecnologías innovadoras de ML necesitan grandes conjuntos de datos con licencias que permitan su reutilización, que puedan ser redistribuibles y que estén en continua mejora. Por ello, la misión de ML Commons es contribuir a mitigar esa brecha y para así impulsar la innovación en machine learning.
El principal objetivo de esta organización es crear una comunidad de datos abiertos para el desarrollo de aplicaciones machine learning. Su estrategia se basa en tres pilares:
En primer lugar, crear y mantener conjuntos de datos abiertos completos. Entre otros: The People’s Speech, con más de 30.000 horas de discurso en inglés para entrenar modelos de procesamiento del lenguaje natural (PLN), Multilingual Spoken Words, con más de 23 millones de expresiones en 50 idiomas diferentes o Dollar Street, con más de 38.000 imágenes de hogares de todo el mundo en situaciones socioeconómicas variadas. El segundo pilar consiste en impulsar buenas prácticas que faciliten la estandarización. Ejemplo de ello es el proyecto MLCube que propone estandarizar el proceso de contenedores para modelos ML para facilitar su uso compartido. Y, por último, realizar benchmarking en grupos de estudios para definir puntos de referencia para la comunidad desarrolladora e investigadora.
Aprovechar las ventajas y formar parte de la comunidad ML Commons es gratuito para las instituciones académicas y las empresas pequeñas (menos de diez trabajadores).
Datacommons sintetiza diferentes fuentes de datos abiertos en un único portal
Datacommons busca potenciar los flujos democráticos de datos dentro de la economía cooperativa y solidaria y tiene como objetivo principal ofrecer datos depurados, normalizados e interoperables.
La variedad de formato e información que ofrecen los portales públicos de datos abiertos puede llegar a ser un obstáculo para la investigación. El objetivo de Datacommons es compilar datos abiertos en una web enciclopédica que ordena todos los dataset mediante nodos. De esta manera, el usuario puede acceder a la fuente que más le interesa.
Esta plataforma, que fue diseñada con fines educativos y de investigación periodística, funciona como herramienta de referencia para navegar entre distintas fuentes de datos. El equipo de colaboradores trabaja para mantener la información actualizada e interactúa con la comunidad a través de su e-mail (support@datacommons.org) o foro de GitHub.
Papers with Code: el repositorio de materiales en abierto para alimentar modelos machine learning
Se trata de un portal que ofrece código, informes, datos, métodos y tablas de evaluación en formato abierto y gratuito. Todo el contenido de la web está bajo licencia CC-BY-SA, es decir, permite copiar, distribuir, exhibir y modificar la obra incluso con fines comerciales compartiendo las contribuciones realizadas con la misma licencia original.
Cualquier usuario puede contribuir aportando contenido e, incluso, participar en el canal de Slack de la comunidad que está moderado por responsables que protegen la política de inclusión definida por la plataforma.
A día de hoy, Papers with Code aloja 7806 conjuntos de datos que se pueden filtrar según formato (gráfico, texto, imagen, tabular etc.), tarea (detección de objeto, consultas, clasificación de imágenes etc.) o idioma. El equipo que mantiene Papers with Code pertenece al instituto de investigación de Meta.
El objetivo de ML Commons, Data Commons y Papers with Code es mantener y hacer crecer comunidades de datos abiertos que contribuyan al desarrollo de tecnologías innovadoras. Entre ellas, la inteligencia artificial (machine learning, deep learning etc.) con todas las posibilidades que su desarrollo puede llegar a ofrecer a la sociedad.
Como parte de este proceso, las tres organizaciones desarrollan un papel fundamental: ofrecen repositorios de datos en formato estándar y redistribuible para entrenar modelos machine learning. Son recursos útiles para realizar ejercicios académicos, impulsar la investigación y, al fin y al cabo, facilitar la innovación de tecnologías que cada día están más presentes en nuestra sociedad.
Blog
Hablar estos días de GPT-3 no es lo más original del mundo, lo sabemos. Toda la comunidad tecnológica está publicando ejemplos, realizando eventos y pronosticando el final del mundo del lenguaje y la generación de contenidos tal y cómo la conocemos actualmente. En este post, le pedimos a ChatGPT que nos eche una mano para programar un ejemplo de visualización de datos con R partiendo de un conjunto de datos abiertos disponible en datos.gob.es.
Introducción
Nuestro anterior post hablaba sobre Dall-e y la capacidad de GPT-3 para generar imágenes sintéticas partiendo de una descripción de lo que pretendemos generar en lenguaje natural. En este nuevo post, hemos realizado un ejercicio completamente práctico en el que le pedimos a la inteligencia artificial que nos ayude a realizar un sencillo programa en R que cargue un conjunto de datos abierto y genere algunas representaciones gráficas.
Hemos escogido un conjunto de datos abiertos de la plataforma datos.gob.es. En concreto, un conjunto de datos sencillos de uso de portales madrid.es. La descripción del repositorio explica que se incluye la información relativa a usuarios, sesiones y número de visitas a páginas de los siguientes portales del Ayuntamiento de Madrid: Portal Web municipal, Sede Electrónica, Portal de Transparencia, Portal de Datos Abiertos, Bibliotecas y Decide Madrid.
El fichero se puede descargar en formato .csv o .xslx y si lo pre-visualizamos tiene el siguiente aspecto:

Vale, comencemos a co-programar con ChatGPT!
Primero accedemos a la web y nos identificamos con nuestro usuario y contraseña. Es necesario estar registrado en el sitio web de openai.com para poder acceder a las capacidades de GPT-3, entre otras ChatGPT.
Iniciamos nuestra conversación:

Durante este ejercicio hemos intentado mantener una conversación de la misma forma que la tendríamos con un compañero de programación. Así que lo primero que hacemos es saludar y enunciar el problema que tenemos. Cuándo le pedimos a la IA que nos ayude a crear un pequeño programa en R que represente gráficamente unos datos, nos ofrece algunos ejemplos y ayuda con la explicación del programa:

Puesto que no tenemos datos, no podemos hacer nada práctico por el momento, así que le pedimos si nos ayuda a generar unos datos sintéticos.
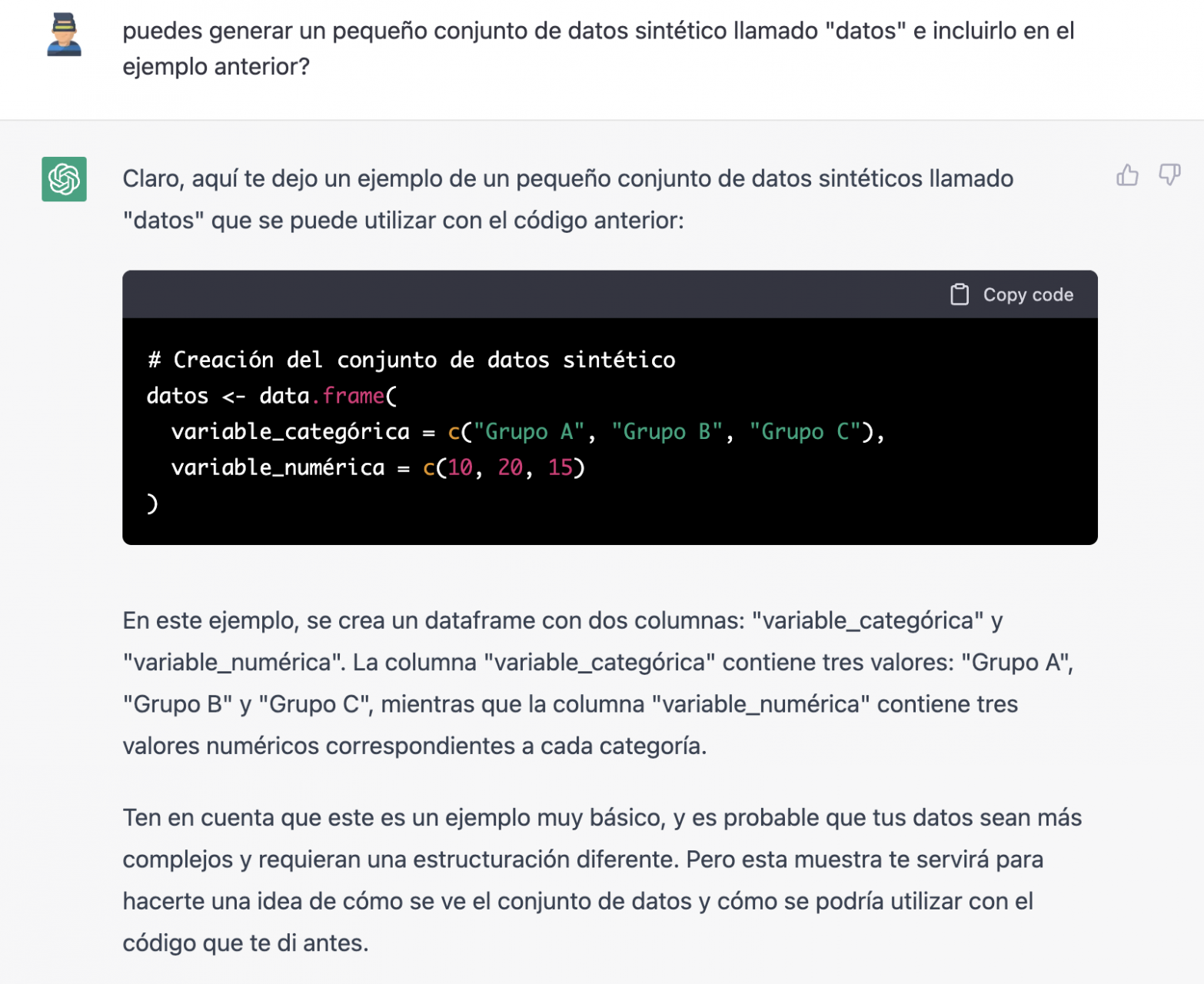
Como decimos, nos comportamos con la IA como lo haríamos con una persona (tiene buena pinta).

Una vez que parece que la IA responde con facilidad a nuestras preguntas, vamos con el siguiente paso, vamos a darle nosotros los datos. Y aquí empieza la magia… Hemos abierto el fichero de datos que nos hemos bajado de datos.gob.es y hemos copiado y pegado una muestra.
| Nota: ChatGPT no tiene conexión a Internet y por lo tanto no puede acceder a datos externos, así que lo único que podemos hacer es darle un ejemplo de los datos reales con los que queremos trabajar. |


Con los datos copiados y pegados tal cual se los hemos dado, nos escribe el código en R para cargarlos manualmente en un dataframe denominado “datos”. A continuación, nos proporciona el código de ggplot2 (la librería gráfica más conocida en R) para graficar los datos junto con una explicación del funcionamiento del código.

¡Genial! Es espectacular este resultado con un lenguaje totalmente natural y nada adaptado para hablar con una máquina. Veamos que pasa a continuación:
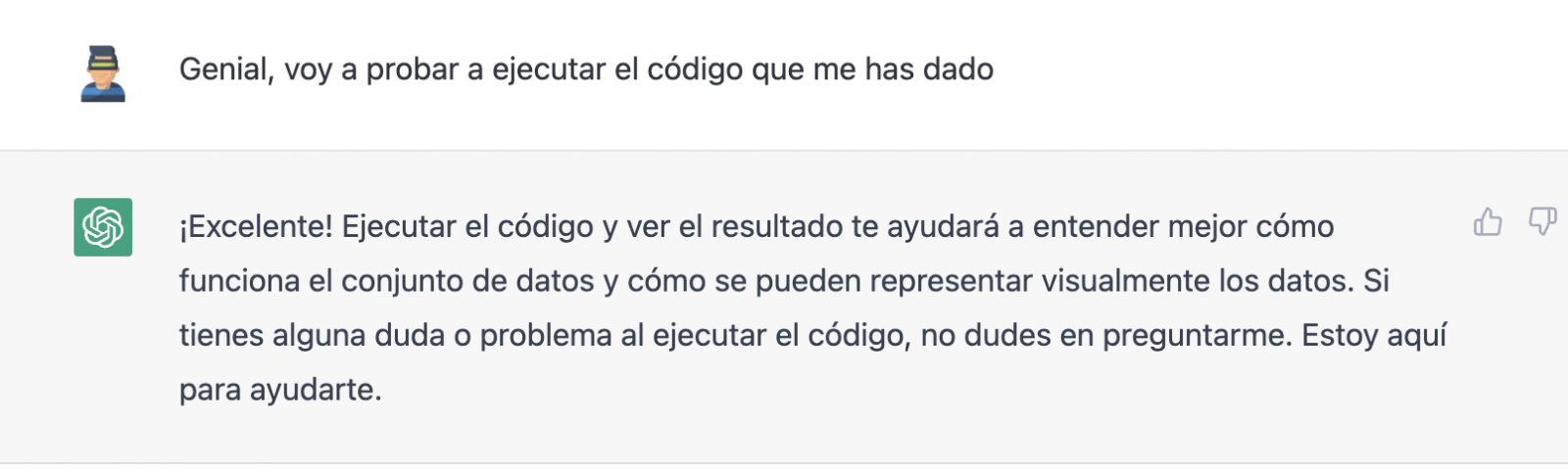
Pero resulta que al copiar y pegar el código en un entorno de RStudio comprobamos que este falla.

Así que le decimos lo que pasa y que nos ayude a solucionarlo.

Probamos de nuevo y ¡en este caso funciona!
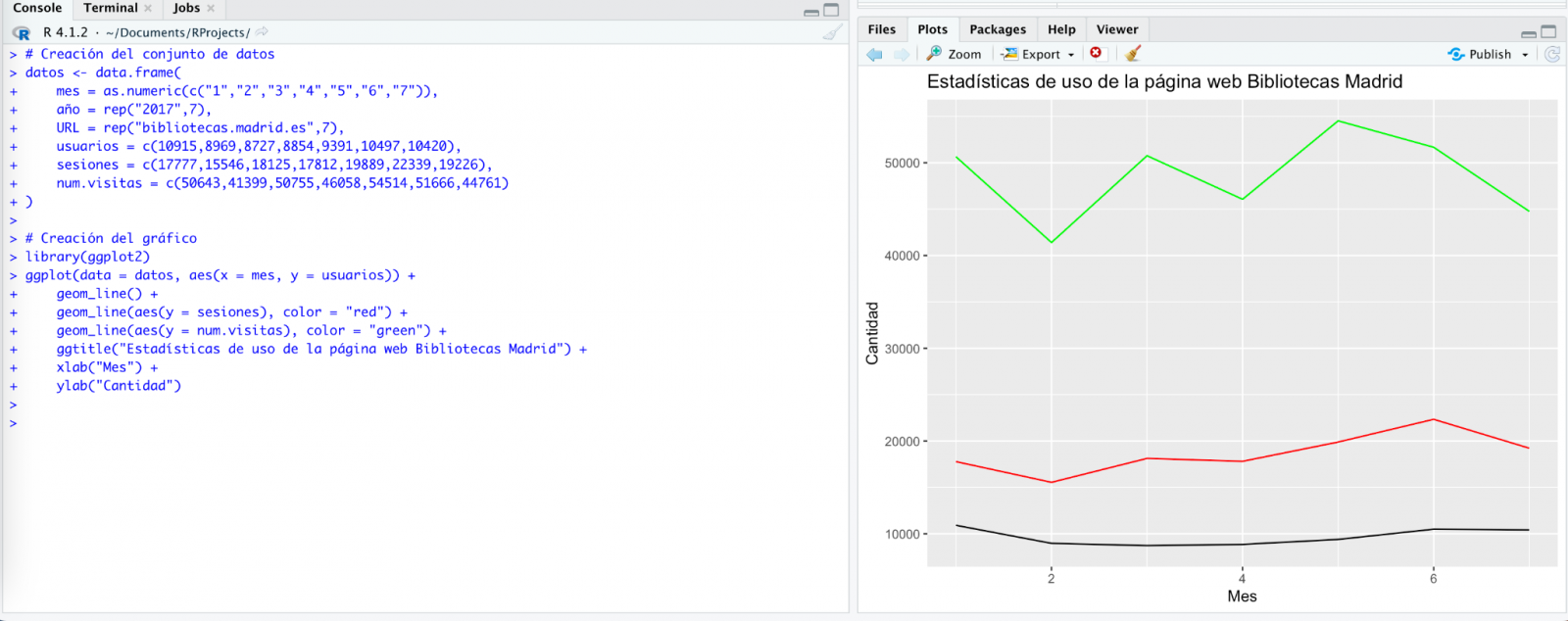
Sin embargo, el resultado es un poco tosco. Así que se lo decimos.

A partir de aquí (y tras varios intentos de copiar y pegar más y más filas de datos) la IA cambia ligeramente el enfoque y me proporciona instrucciones y código para cargar mi propio fichero de datos desde mi ordenador en lugar de introducir manualmente los datos en el código.

Le hacemos caso y copiamos un par de años de datos en un fichero de texto en nuestro ordenador. Fijaos, en lo que ocurre a continuación:
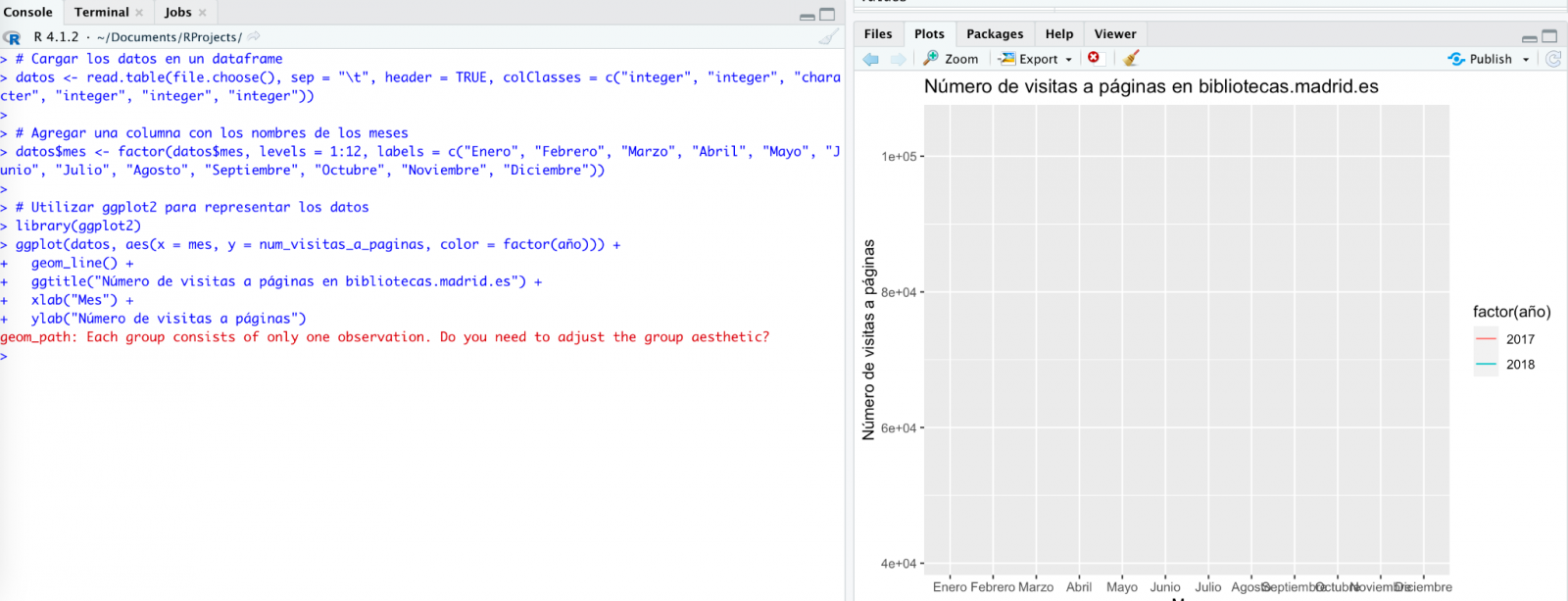

Probamos de nuevo:

Como veis, funciona, pero el resultado no es del todo acertado.
Y veamos lo que ocurre.

¡Por fin parece que ya nos ha entendido! Es decir, tenemos un gráfico de barras con las visitas a la web por mes, para los años 2017 (azul) y 2018 (rojo). Sin embargo, no me convencen ni el formato del título del eje ni tampoco se distingue bien la numeración del mismo eje.

Veamos el resultado ahora.

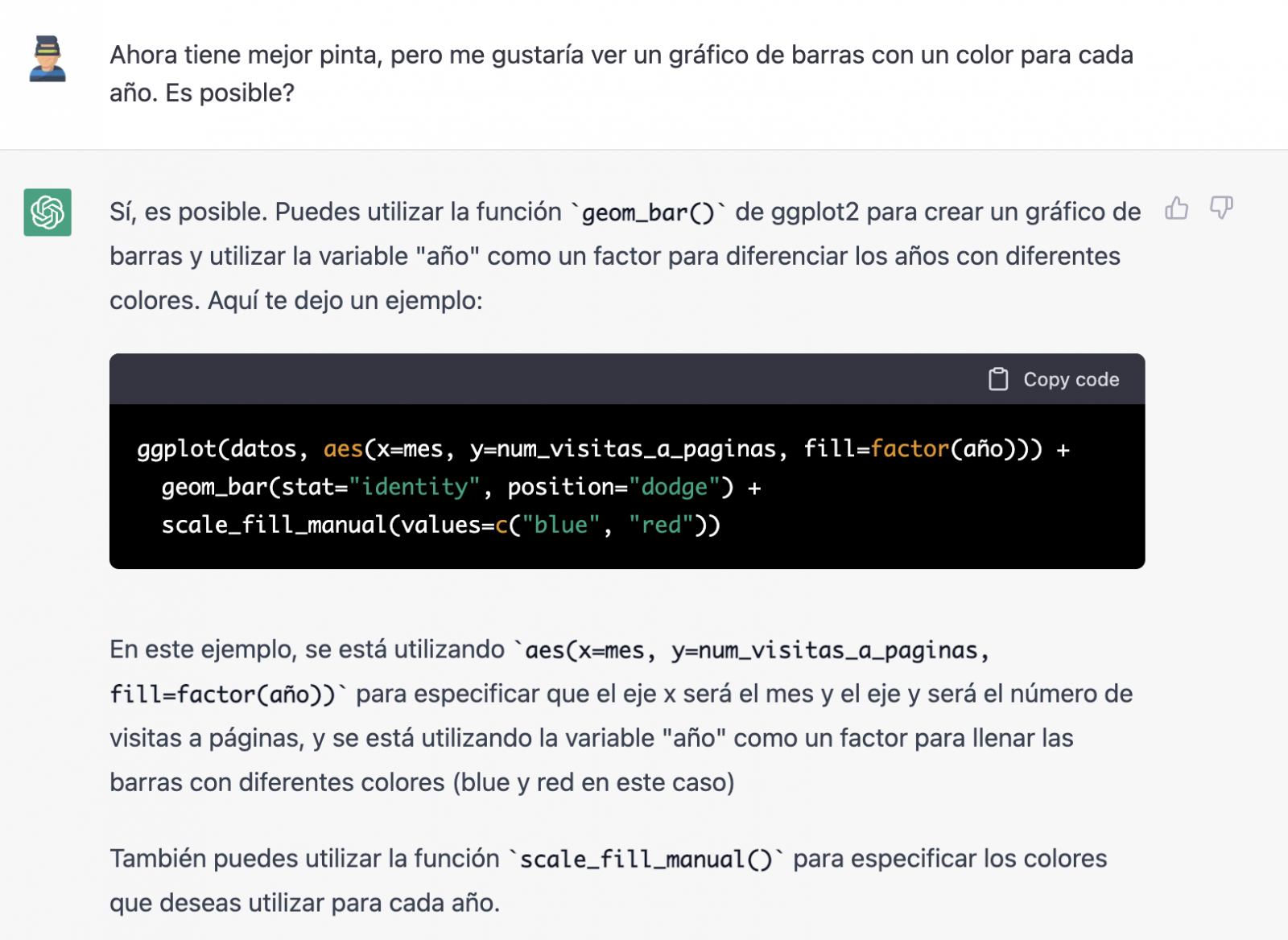
Tiene mucha mejor pinta, ¿verdad? Pero ¿qué tal si todavía le damos una vuelta de tuerca más?
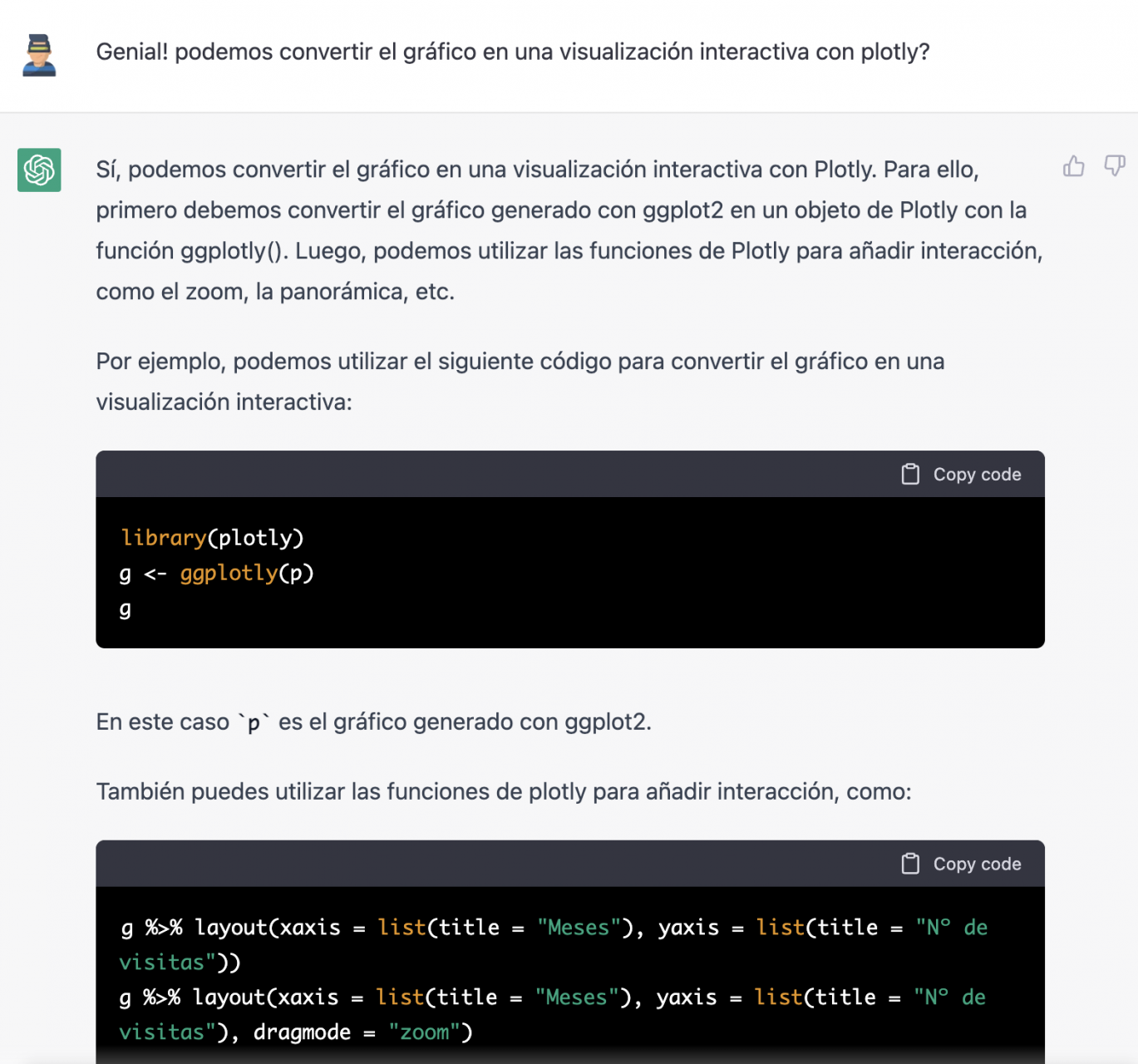
Sin embargo, se ha olvidado de decirnos que debemos instalar el paquete o librería plotly en R. Así que se lo recordamos.
Veamos el resultado:

Como podéis ver, ahora tenemos los controles del gráfico interactivo, de tal modo que podemos seleccionar un año concreto de la leyenda, hacer zoom, etc.
Conclusión
Puede que seas de esos escépticos, conservadores o prudentes que piensan que las capacidades demostradas por GPT-3 hasta el momento (ChatGPT, Dall-E2, etc) son todavía muy infantiles y poco prácticas en la vida real. Todas las consideraciones a este respecto son legítimas y, muchas, probablemente bien fundamentadas.
Sin embargo, algunos hemos pasado buena parte de la vida escribiendo programas, buscando documentación y ejemplos de código que pudiéramos adaptar o en los que inspirarnos; depurando errores, etc. Para todos nosotros (programadores, analistas, científicos, etc.) poder experimentar este nivel de interlocución con una inteligencia artificial en modo beta, puesta a disposición del público de forma gratuita y siendo capaz de demostrar esta capacidad de asistencia en la co-programación, es, sin duda, un salto cualitativo y cuantitativo en la disciplina de la programación.
No sabemos qué va a pasar, pero probablemente estemos a las puertas de un gran cambio de paradigma en la ciencia de la computación, hasta el punto que, quizás, haya cambiado para siempre la forma de programar y aún no nos hayamos dado cuenta.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa se refiere a la capacidad de una máquina para generar contenido original y creativo, como imágenes, texto o música, a partir de un conjunto de datos de entrada. En lo que se refiere a la generación de texto, estos modelos son accesibles, en formato experimental, desde hace un tiempo, pero comenzaron a generar interés a mediados de 2020 cuando Open AI, una organización dedicada a la investigación en el campo de la inteligencia artificial general, publicó el acceso a su modelo de lenguaje GPT-3 a través de una API.
La arquitectura de GPT-3 está compuesta por 175 mil millones de parámetros, mientras que la de su antecesor GPT-2 era de 1.500 millones de parámetros, esto es, más de 100 veces más. GPT-3 representa por tanto un cambio de escala enorme ya que además fue entrenado con un corpus de datos mucho mayor y un tamaño de los tokens mucho más grande, lo que le permitió adquirir una comprensión más profunda y compleja del lenguaje humano.
A pesar de que fue de 2022 cuando OpenAI anunció la apertura de chatGPT, que permite dotar de una interfaz conversacional a un modelo de lenguaje basado en una versión mejorada de GPT-3, no ha sido hasta los últimos dos meses cuando la noticia ha llamado masivamente la atención del público, gracias a la amplia cobertura mediática que trata de dar respuesta al incipiente interés general.
Y es que, ChatGPT no sólo es capaz de generar texto a partir de un conjunto de caracteres (prompt) como GPT-3, sino que responde a preguntas en lenguaje natural en varios idiomas que incluyen inglés, español, francés, alemán, italiano o portugués. Es precisamente este cambio en la interfaz de acceso, pasando de ser una API a un chatbot, lo que lo ha convertido a la IA en accesible para cualquier tipo de usuario.
Tanto es así que más de un millón de personas se registraron para usarlo en tan solo cinco días, lo que ha motivado la multiplicación de ejemplos en los que chatGPT produce código de software, ensayos de nivel universitario, poemas e incluso chistes. Eso sin tener en cuenta que ha sido capaz de sacar adelante un examen de selectividad de Historia o de aprobar el examen final del MBA de la prestigiosa Wharton School.
Todo esto ha puesto a la IA generativa en el centro de una nueva ola de innovación tecnológica que promete revolucionar la forma en que nos relacionamos con internet y la web a través de búsquedas vitaminadas por IA o navegadores capaces de resumir el resultado de estas búsquedas.
Hace tan solo unos días, conocíamos la noticia de que Microsoft trabaja en la implementación de un sistema conversacional dentro de su propio buscador, el cual ha sido desarrollado a partir del conocido modelo de lenguaje de Open AI y cuya noticia ha puesto en jaque a Google.
Y es que, como consecuencia de esta nueva realidad en la que la IA ha llegado para quedarse, los gigantes tecnológicos han ido un paso más allá en la batalla por aprovechar al máximo los beneficios que esta reporta. En esta línea, Microsoft ha presentado una nueva estrategia dirigida a optimizar al máximo la manera en la que nos relacionamos con internet, introduciendo la IA para mejorar los resultados ofrecidos por los buscadores de navegadores, aplicaciones, redes sociales y, en definitiva, todo el ecosistema de la web.
Sin embargo, aunque el camino en el desarrollo de los nuevos y futuros servicios ofrecidos por la IA de Open AI aún están por ver, avances como los anteriores ofrecen una pequeña pista de la guerra de navegadores que se avecina y que, probablemente, cambie en el corto plazo la manera de crear y hallar contenido en la web.
Los datos abiertos
GPT-3, al igual que otros modelos que han sido generados con las técnicas descritas en la publicación científica original de GTP-3, es un modelo de lenguaje pre-entrenado, lo que significa que ha sido entrenado con un gran conjunto de datos, en total unos 45 terabytes de datos de texto. Según este paper, el conjunto de datos de entrenamiento estaba compuesto en un 60% por datos obtenidos directamente de internet en los que están contenidos millones de documentos de todo tipo, un 22% del corpus WebText2 construido a partir de Reddit, y el resto con una combinación de libros (16%) y Wikipedia (3%).
Sin embargo, no se sabe cuántos datos abiertos utiliza GPT-3 exactamente, ya que OpenAI no proporciona detalles más específicos sobre el conjunto de datos utilizado para entrenar el modelo. Lo que sí podemos hacer son algunas preguntas al propio chatGPT que nos ayuden a extraer interesantes conclusiones sobre el uso que hace de los datos abiertos.
Por ejemplo, si le preguntamos a chatGPT cuál era la población de España entre 2015 y 2020 (no podemos pedirle datos más recientes), obtenemos una respuesta de este tipo:

Tal como podemos ver en la imagen superior, aunque la pregunta sea la misma, la respuesta puede variar tanto en la redacción como en la información que contiene. Las variaciones pueden ser aún mayores si realizamos la pregunta en diferentes días o hilos de conversación:
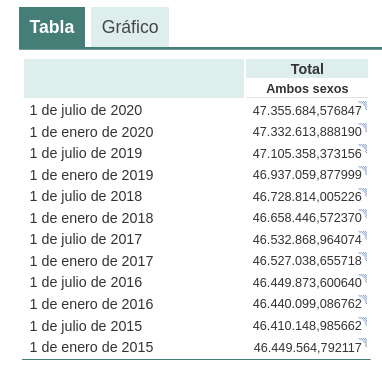
Pequeñas variaciones en la redacción del texto, generar la pregunta en diferentes momentos del hilo de conversación (recordemos que guarda el contexto) o en hilos o días diferentes puede conducir a resultados ligeramente diferentes. Además, la respuesta no es completamente precisa, tal y como nos advierte la propia herramienta si las comparamos con las series de población residente en España del propio INE, donde nos recomienda consultar. Los datos que idealmente habríamos esperado en la respuesta podrían obtenerse en un conjunto de datos abiertos del INE:
Este tipo de respuestas sugieren que los datos abiertos no se han empleado como una fuente autoritativa para responder preguntas de tipo factual, o al menos que aún no está completamente refinado el modelo en este sentido. Haciendo algunas pruebas básicas con preguntas sobre otros países hemos observado errores parecidos, por lo que no parece que se trate de un problema sólo con preguntas referentes a España.
Si hacemos preguntas algo más específicas como pedir la lista de los municipios de la provincia de Burgos que comienzan por la letra “G” obtenemos respuestas que no son completamente correctas, como es propio de una tecnología que todavía está en fase incipiente.
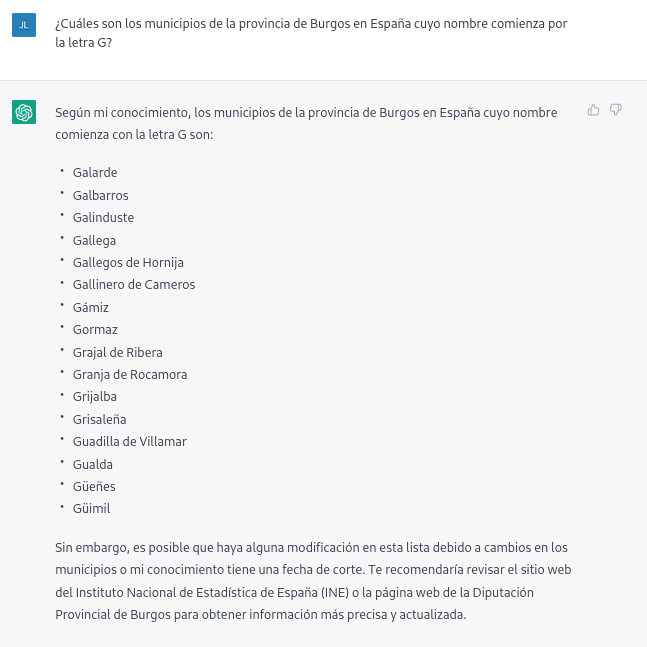
La respuesta correcta debería contener seis municipios: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán y Gumiel del Mercado. Sin embargo, la respuesta que hemos obtenido sólo contiene los cuatro primeros e incluye localidades de la provincia de Guadalajara (Gualda), municipios de la provincia de Valladolid (Gallegos de Hornija) o localidades de la provincia de Burgos que no son municipios (Galarde). En este caso, también podemos acudir a conjunto de datos abiertos para obtener la respuesta correcta.
A continuación, le preguntamos a ChatGPT por la lista de municipios que comienzan por la letra Z en la misma provincia. ChatGPT nos dice que nos hay ninguno, razonando la respuesta, cuando en realidad hay cuatro:
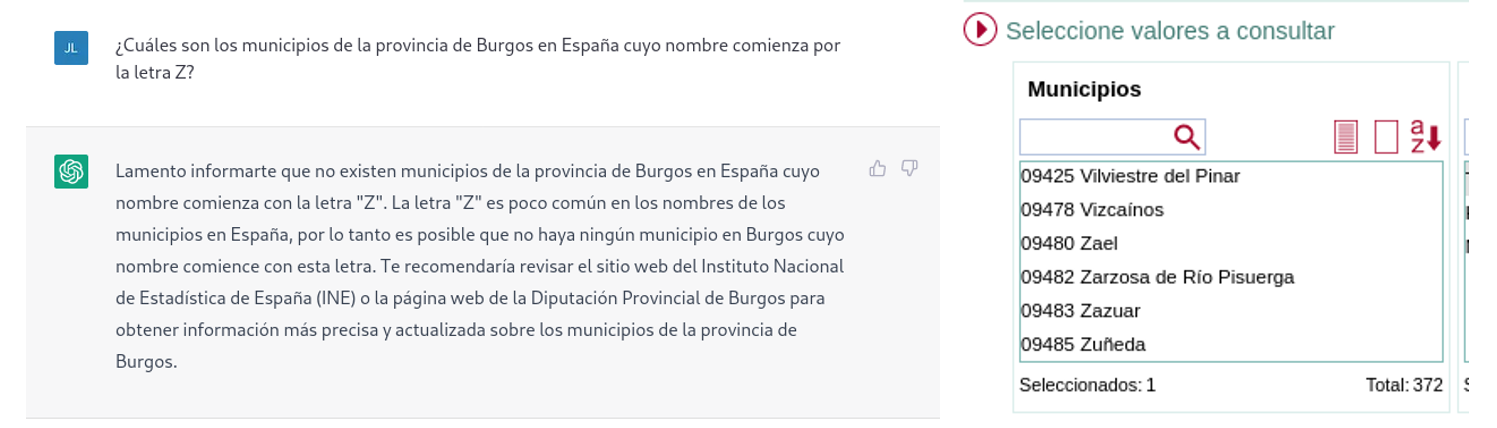
Como se deduce de los ejemplos anteriores, vemos cómo los datos abiertos sí pueden contribuir a la evolución tecnológica y, por ende, a mejorar el funcionamiento de la inteligencia artificial de Open AI. Sin embargo, dado el estado de madurez actual de la misma, aún es pronto para ver un empleo óptimo de estos, a la hora de dar respuesta a preguntas más complejas.
Por lo tanto, para que un modelo de inteligencia artificial generativa sea eficaz, es necesario que cuente con una gran cantidad de datos de alta calidad y diversidad, y los datos abiertos son una fuente de conocimiento valiosa para este fin.
Probablemente, en futuras versiones del modelo, podamos ver cómo los datos abiertos ya adquieren un peso mucho más importante en la composición del corpus de entrenamiento, logrando conseguir una mejora importante en la calidad de las respuestas de tipo factual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
A pesar de que parece un concepto novedoso, el término ‘inteligencia artificial’ ya se acuñó a mediados del pasado siglo. Sin embargo, su popularidad ha experimentado un aumento vertiginoso durante los últimos años gracias al incremento en los volúmenes de datos o la aplicación de algoritmos avanzados en situaciones cotidianas, entre otros aspectos.
La inteligencia artificial permite que las máquinas puedan aprender de la experiencia para realizar diversas tareas al estilo de los seres humanos. Para ello, sus técnicas de entrenamiento recurren con frecuencia al aprendizaje profundo o deep learning y al procesamiento del lenguaje natural (PLN), entre otras. Empleando estas tecnologías al servicio de la IA, las máquinas pueden ser entrenadas para llevar a cabo tareas muy específicas como el procesamiento de grandes cantidades de datos o el reconocimiento de patrones en estos.
¿Qué es la inteligencia artificial?
La Comisión Europea define la inteligencia artificial como la capacidad que presenta una máquina para imitar algunas de las características propias de la inteligencia del ser humano como son el aprendizaje, el razonamiento o la creatividad. Para ello las computadoras analizan la información disponible con el fin de alcanzar unos objetivos específicos.
La inteligencia artificial se encuentra formada a su vez por algunos subcampos basados en tecnologías como el Machine Learning o el Deep Learning. Ambas actividades tienen como fin la construcción de sistemas que tengan la capacidad de resolver problemas sin la necesidad de que un humano intervenga en ellos para solucionarlos.
¿Cuál es el papel que juegan los datos abiertos en la inteligencia artificial?
Para que la inteligencia artificial se desarrolle adecuadamente, los datos abiertos son sumamente importantes. Esto se debe a que sus algoritmos han de ser entrenados con datos de calidad que estén altamente disponibles, tal y como reflejan diversas estrategias y directrices de ámbito estatal y europeo como la Estrategia Nacional de Inteligencia Artificial, el Reglamento Europeo sobre Inteligencia Artificial o el Libro Blanco sobre Inteligencia Artificial.
Ejemplos de casos de uso de la inteligencia artificial
La aplicación de la inteligencia artificial permite que muchos campos puedan lograr mejoras en diversos procesos, servicios o aplicaciones . Algunos ejemplos son:
- Salud: la IA permite identificar diferentes patologías mediante el procesamiento de imágenes médicas, por ejemplo, a través de QMenta, que procesa y visualiza imágenes para realizar análisis de datos cerebrales.
- Medio ambiente: la IA permite realizar una gestión más eficiente de los bosques. Un ejemplo es Forecast, que ofrece herramientas para la toma de decisiones de gestores forestales.
- Economía: se utiliza la IA para optimizar la gestión de licitaciones, como sucede con la herramienta Arbatro Tender, diseñada para encontrar y elegir los concursos públicos más adecuados para cada empresa.
- Turismo: la IA permite el desarrollo de asistentes turísticos virtuales como Castilla y León Gurú, que presenta funciones avanzadas de PLN, detección de puntos de interés en imágenes y uso de contexto geolocalizado.
- Cultura: gracias a la IA es posible generar textos propios y resúmenes de otros ya existentes a través de procesamiento del lenguaje natural. MarIA ha sido la primera inteligencia artificial de la lengua española en lograrlo.
- Publicidad y redacción de contenidos: Sistemas de Inteligencia Artificial como Chat GPT permiten desarrollar textos a partir de peticiones concretas.
Como podemos observar, existen multitud de casos de uso que fusionan la inteligencia artificial y los datos abiertos para contribuir al progreso y bienestar de la sociedad. Te recomendamos que consultes esta práctica infografía en la que te ofrecemos más detalles, así como algunos artículos de interés como este sobre Dall-E para que puedas ampliar tu conocimiento.
Además, si deseas conocer más casos de uso relacionados, descubre el informe “Tecnologías emergentes y datos abiertos: Inteligencia Artificial”, que incluye un caso práctico paso a paso de reconocimiento y clasificación de imágenes.
Haz clic en la infografía para verla a tamaño real y poder acceder a los enlaces:
{kind=link}

Puedes ver la infografía en tamaño completo haciendo click aquí.
Blog
Llevamos años anunciando que la Inteligencia Artificial está viviendo uno de sus periodos más prolíficos y excitantes. Un momento en el que comienzan a verse aplicaciones y casos de uso donde la inteligencia humana se funde con la artificial. Algunas profesiones están cambiando para siempre. Los periodistas y escritores disponen ahora de herramientas de software que pueden escribir por ellos. Los creadores de contenido - imágenes o video - pueden pedirle a la máquina que, mediante una frase, que cree por ellos. En este post profundizamos en este último ejemplo. Hemos podido probar Dall-e 2 y nos hemos quedado de piedra con los resultados.
Introducción
Estos días, en la comunidad tecnológica del mundo entero, hay un murmullo de fondo, una excitación colectiva de todos los amantes de las tecnologías digitales y en particular de la inteligencia artificial. En varias ocasiones hemos mencionado en este espacio de comunicación las innovaciones de la compañía OpenAI. Hemos escrito varios artículos donde hablamos del algoritmo GPT-3 y de lo que es capaz en el campo del procesamiento del lenguaje natural. Recientemente, OpenAI ha ido eliminando las listas de espera (en las que muchos llevábamos tiempo inscritos) para permitirnos probar de forma limitada las capacidades del algoritmo GPT-3 implementado en diferentes tipos de aplicación.
Ejemplo de las múltiples aplicaciones de GPT-3 en el ámbito del lenguaje natural.
Recomendamos a nuestros lectores experimentar con la herramienta para completar texto, en la que con tan solo proporcionar una corta frase, la IA nos completa el texto con varios párrafos indistinguibles de la redacción de un humano. Los últimos días, están siendo frenéticos con multitud de personas probando la herramienta de Chat GPT-3. El nivel de naturalidad de la IA para mantener una conversación es, sencillamente, alucinante. Los resultados están impactando en casos de uso muy variados, como por ejemplo, la asistencia para programadores de software. Chat GPT-3 está siendo capaz de programar sencillas rutinas de código o algoritmos con tan solo describir en lenguaje natural lo que se quiere programar. Pero, el resultado impresiona más aún si caemos en que la IA es capaz de corregir sus propios errores de programación.
DALL-E
Dejando a un lado, las capacidades de generar lenguaje natural indistinguible del escrito por un humano, vamos al tema central de este post. Una de las aplicaciones más sorprendentes de la IA de OpenAI es la solución conocida cómo DALL-E. Qué mejor manera de presentar DALL-E que preguntarle a Chat GPT-3 qué es DALL-E.
La descripción más formal de DALL-E, de acuerdo con su propia web es:
DALL·E es una versión de GPT-3 entrenado con 12 mil millones de parámetros para generar imágenes a partir de descripciones de texto. DALL-E tiene un conjunto diverso de capacidades, incluida la creación de versiones antropomórficas de animales y objetos, la combinación de conceptos no relacionados de manera plausible, la representación de texto y la aplicación de transformaciones a imágenes existentes.
Actualmente existe una segunda versión del algoritmo DALL-E 2 capaz de generar imágenes más realistas y precisas con una resolución 4 veces mayor. La herramienta para probar DALL-E está disponible aquí https://labs.openai.com/. Para usarla es necesario crear previamente una cuenta en OpenAI que nos permitirá jugar con todas las herramientas de la compañía. Cuándo accedemos a la web de prueba podemos escribir nuestro propio texto o pedirle a la herramienta que genere descripciones aleatorias de imágenes en lenguaje natural para crear imágenes. Por ejemplo, haciendo clic sobre el botón Surprise me:

La web nos genera esta descripción aleatoria: an astronaut lounging in a tropical resort in space, pixel art
Y este es el resultado:

Repetimos: an expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula

Podemos asegurar que el ejercicio resulta algo adictivo y damos fe de que algunos nos hemos pasado horas del fin de semana jugando con las descripciones y esperando, una y otra vez, el asombroso resultado.
Sobre el entrenamiento de DALL-E 2
DALL-E 2 (arXiv:2204.06125) es una versión refinada del sistema original DALL-E (arXiv:2102.12092). Para entrenar el modelo original de DALL-E, que contiene 12 mil millones de parámetros, se utilizó un conjunto de 250 millones de pares de texto-imagen (públicamente disponibles en Internet). Este conjunto de datos es una mezcla de varios datasets previos compuesto por: Conceptual Captions de Google; los pares de texto e imagen de Wikipedia y un subconjunto filtrado de YFCC100M.
Curiosidades de DALL-E 2
Algunas curiosidades más allá de las pruebas que podemos hacer para generar nuestras propias imágenes. OpenAI ha creado un repositorio específico de Github en el que describe los riesgos y limitaciones de DALL-E. En el sitio se informa, por ejemplo, de que, por el momento, el uso de DALL-E está limitado para propósitos no comerciales. Así que no es posible hacer ningún uso comercial de las imágenes generadas. Es decir, no pueden ser vendidas, ni licenciadas bajo ningún supuesto. En este sentido, todas las imágenes generadas por DALL-E incluyen una marca distintiva que permite saber que han sido generadas con la IA. En el sitio de Github podemos encontrar ingente cantidad de información sobre la generación de contenido explícito, los riesgos relacionados con el sesgo que la IA pueda introducir en la generación de imágenes y los usos inadecuados de DALL-E cómo por ejemplo, el acoso, el bullying o la explotación de individuos.

En clave nacional, MarIA
En clave nacional, tras meses de pruebas y ajustes, ha visto la luz MarIA: la primera inteligencia artificial supermasiva, entrenada con datos abiertos procedentes de los archivos web de la Biblioteca Nacional de España (BNE) y gracias a los recursos de computación del Centro Nacional de Supercomputación. En relación con este post, MarIA ha sido entrenada haciendo uso del algoritmo GPT-2, del que hemos hablado mucho meses atrás en este espacio. Para realizar el entrenamiento de MarIA, se han utilizado 135 mil millones de palabras precedentes del banco documental de la Biblioteca Nacional con un volumen total de 570 Gigabytes de información.
Conclusiones
A medida que transcurren los días y las semanas desde la apertura general de las APIs y las herramientas de OpenIA, se suceden torrencialmente las publicaciones en todo tipo de medios, redes sociales y blogs especializados sobre las capacidades y posibilidades de Chat GPT-3 y DALL-E. No creo que en estos momentos nadie sea capaz de avanzar las potenciales aplicaciones comerciales, científicas y sociales de esta tecnología. Lo que está claro, es que muchos pensamos que OpenAI ha enseñado solo una muestra de lo que es capaz y parece que podemos estar a las puertas de un hito histórico en el desarrollo de la IA tras muchos años de sobreexpectación y promesas a medio cumplir. Seguiremos informando sobre los avances de GTP-3, pero por el momento, no nos queda más que seguir disfrutando, jugando y aprendiendo con las sencillas herramientas que tenemos a disposición!
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras varios meses de competición, el pasado 20 de octubre el concurso de datos abiertos organizado por la UE llegó a su fin. El EU Datathon es un certamen que brinda a los desarrolladores y científicos de datos la oportunidad de demostrar a través de su creatividad el potencial de los datos abiertos
Aunque en este post puedes conocer en detalle los proyectos que resultaron ganadores, en este caso queremos destacar la participación de dos desarrolladores españoles cuyas iniciativas fueron elegidas como semifinalistas entre las 156 propuestas presentadas en un inicio.
En una edición que batió récord de participación tanto en número de concursantes como de países de procedencia, Antonio Moneo y Manuel Jose García representaron a España con dos proyectos que brillaron por su carácter innovador a la hora de reutilizar datos abiertos.
Utilizar la Inteligencia Artificial para resolver de forma óptima las licitaciones públicas
Manuel José García es Doctor Ingeniero de Telecomunicaciónes por la Univerdidad de Oviedo y, actualmente, trabaja como científico de datos en la consultora tecnológica NTT Data. Tras hacerse con el primer premio en el concurso de Datos Abiertos de Euskadi en el año 2020, García decidió presentarse al hackathon europeo aprovechando el aprendizaje derivado de la investigación realizada en su tesis doctoral y que dio lugar al proyecto ’Detección de licitaciones irregulares en España mediante el análisis masivo de datos y la inteligencia artificial’.
“Se trata de una iniciativa que utiliza el Big Data y la Inteligencia Artificial (IA) para analizar los datos de las licitaciones públicas y recomendar de manera automática aquellas empresas que mejor puedan acometer la licitación. Para ello se crea un buscador de empresas que puedan llevar a cabo una licitación y se rellena un formulario describiendo los detalles que caracterizan al concurso público. A partir de ahí, el programa busca las empresas más aptas para llevar a cabo el proyecto”, describe Manuel Jose García, quien añade que la relación de empresas recomendadas por licitación se consigue gracias a que el modelo de IA se ha entrenado con el histórico de cientos de miles de licitaciones y empresas ganadoras del pasado, aprendiendo qué tipo de empresas ganan las licitaciones y que características tienen.
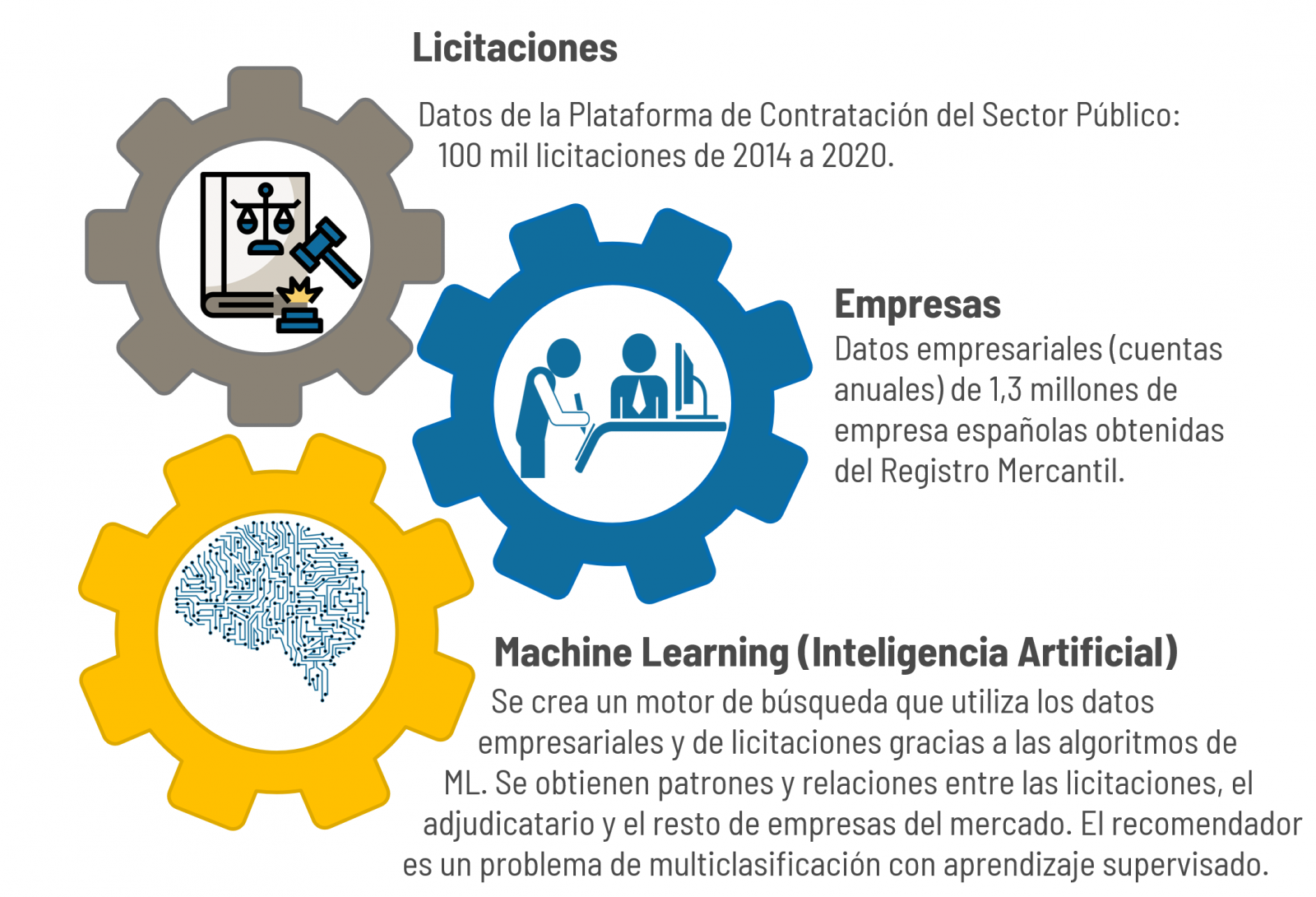
Un requisito indispensable para poder participar en el datathon europeo es utilizar información procedente de los catálogos de datos que tanto Europa como España a nivel nacional, autonómico y local ponen a disposición de la ciudadanía. En el caso concreto de Manuel José García, su proyecto se ha desarrollado recurriendo a los datos de las licitaciones públicas disponibles en las Plataformas de Contratación Pública.
“El proyecto se ha desarrollado utilizando dos tipos de fuentes de datos. Por un lado, los datos públicos y gratuitos de las licitaciones y, por el otro, los datos empresariales necesarios para buscar y caracterizar a las empresas presentes en el buscador. En particular, se han utilizado las cuentas anuales que las empresas deben presentar ante el Registro Mercantil. Estos datos son públicos pero de pago, estando en boga su gratuidad al ser datos gestionados por un ente público”, comenta el científico de datos.
De hecho es precisamente este punto relacionado con los datos del Registro Mercantil lo que supuso un reto para sacar adelante el proyecto: “Conseguir datos estructurados de licitaciones públicas es complicado, ya que el formato de datos en abierto de la Plataforma de Contratación de España es difícil de manejar. Además, es necesario hacer una limpieza profunda de los datos porque su calidad es baja”, apunta.
Bajo su criterio, si las administraciones públicas quieren fomentar la reutilización de datos abiertos, “Deben promover la cultura del dato. Es decir, ser conscientes de la importancia que tienen los datos que manejan y almacenan y, a su vez, ser proactivos para explotar esos datos y ponerlos a disposición de terceros”.
Arquitectura y datos abiertos para visibilizar los Objetivos de Desarrollo Sostenible
Además de ser Director de Gestión del Cambio y Análisis Avanzado en BBVA, Antonio Moneo también ha sido semifinalista de la última edición del datathon europeo gracias a un proyecto que fusiona el arte con la divulgación de los datos abiertos.
“Tangible Data (Datos Tangibles) es una iniciativa cuyo objetivo es convertir series de datos emblemáticas en esculturas físicas y, así, poder hacer tangibles problemas como el cambio climático, la desigualdad o la transparencia de nuestros gobiernos. En un contexto de exceso de información y creciente brecha digital, es fundamental apoyarnos en el entorno físico para explicar lo que pasa en el mundo”, explica Antonio Moneo y subraya que “representar los datos en una escultura permite presentar un desafío desde un punto de vista objetivo y respetuoso”.

A la hora de seleccionar los conjuntos de datos abiertos, Moneo tenía claro que quería visibilizar realidades y estadísticas relacionadas con los Objetivos de Desarrollo Sostenible para que su proyecto cumpliese el propósito social que le llevó a presentarse al datathon: “Utilizamos datos abiertos de fuentes fiables y adecuadamente licenciadas con criterios Creative Commons o MIT. En ocasiones hemos usado alguna fuente de datos privada, pero nuestro objetivo es poner en valor la información que ya está disponible. Además, solemos usar los datos tal cual están publicados y solo aplicamos algunas transformaciones como suavizaciones de las curvas con medias móviles que nos permiten hacer las esculturas más agradables al tacto y, por supuesto, técnicas para crear volúmenes en tres dimensiones que son la base para las esculturas”, relata.
Así, para llevar a cabo Tangible Data ha sido necesario, por un lado, construir una estructura física y, por el otro, hacer que esta invite al usuario a trasladarse al ámbito digital donde, al fin y al cabo, se encuentra la información que buscan visibilizar. “El primer paso es diseñar un modelo 3D en formato virtual que enviamos a producir localmente, apoyándonos en la red de FabLabs. Posteriormente, incluimos un código QR en la escultura que permite a la audiencia conocer en profundidad el significado de los datos que refleja la misma”, desglosa el impulsor del proyecto.
Elaborar un proyecto tan ambicioso tanto desde el punto de vista físico como desde la perspectiva divulgativa no es una tarea sencilla. Y es que, no solo se trata de sortear el diseño de la escultura como tal, sino también de dar con los datos necesarios para trasladar la realidad que se busca representar: “La comparabilidad es uno de los mayores retos que nos hemos encontrado porque, en muchos casos, los datos más relevantes para medir el entorno no son siempre comparables. A veces, encontramos datos a nivel regional, otras a nivel nacional o a nivel local, pero no siempre es posible encontrar toda la información que necesitas. Por ello, para solucionar este reto, hemos invertido más tiempo en buscar datos y, en muchos casos, se ha modificado la idea inicial sobre una escultura porque no encontrábamos datos de suficiente calidad”, desarrolla.
Igualmente, Moneo comenta que la otra gran dificultad que ha marcado el desarrollo del proyecto ha sido acceder a datos actualizados. “La actualización siempre es un tema crítico, pero en estos momentos lo es más. Las consecuencias del COVID, la guerra en Ucrania y la actual crisis energética dibujan un mundo muy distinto al que teníamos en 2015 cuando se firmaron los objetivos de desarrollo sostenible. Por ejemplo, se estima que como consecuencia de la pandemia, entre 70 y 150 millones de personas pasarán al segmento de pobreza extrema (menos de 1.9 dólares al día). Este cambio, que rompe la tendencia de las últimas tres décadas, todavía no está reflejado en las estadísticas del Banco Mundial, que se detienen en 2019. Por lo tanto, parece que datos muy relevantes reflejan una realidad distorsionada”, concluye.
Un balance positivo de su paso por el EU Datathon
A pesar de no haber llegado a la final que les hubiese permitido competir por una parte del premio total, que ascendía a 200.000 euros, los dos participantes coinciden en que su experiencia en el datathon ha sido más que positiva. Así, mientras Manuel José García considera que “la Comisión Europea debe seguir apostando por estas iniciativas para que la gente sea consciente del valor que tienen los datos y los retos que pueden llegar a resolver”, por su parte, Antonio Moneo apunta que “este tipo de acciones motivan a las agencias que impulsan los datos y a quienes están haciendo desarrollo para mejorar el impacto de los datos en la sociedad”.
Además, ambos participantes han conseguido despertar sus inquietudes profesionales gracias a este reto, a la par que han podido testear el potencial y la calidad de sus respectivos trabajos frente a expertos europeos en materia de datos.