Fecha publicación
17/02/2022
Comparte este contenido

Descripción
Hoy en día las aplicaciones de Inteligencia Artificial (IA) están presentes en múltiples ámbitos de la vida cotidiana, desde televisores y altavoces inteligentes que son capaces de entender lo que les solicitamos, hasta sistemas de recomendación que nos ofrecen servicios y productos adaptados a nuestras preferencias.
Estas IA “aprenden” gracias a las diversas técnicas que existen, entre las que destacan el aprendizaje supervisado, no supervisado y el aprendizaje por refuerzo. En este artículo nos centraremos en el aprendizaje por refuerzo, que se enfoca principalmente en el método de prueba y error, de forma similar a cómo aprendemos los humanos y los animales en general.
La clave de este tipo de sistemas está en fijar correctamente los objetivos a largo plazo para encontrar una solución global óptima, sin focalizarse en exceso en las recompensas inmediatas, que no permiten realizar una exploración adecuada del conjunto de soluciones posibles.
Entornos de simulación como complemento a los conjuntos de datos abiertos
Al contrario que en otros tipos de aprendizaje, donde normalmente se aprende a partir de conjuntos de datos históricos, este tipo de técnicas requieren de entornos de simulación que permitan entrenar a un agente virtual mediante su interacción con un entorno, donde recibe recompensas o penalizaciones en función del estado y las acciones que realiza. Este ciclo entre agente y entorno puede verse en el siguiente diagrama:
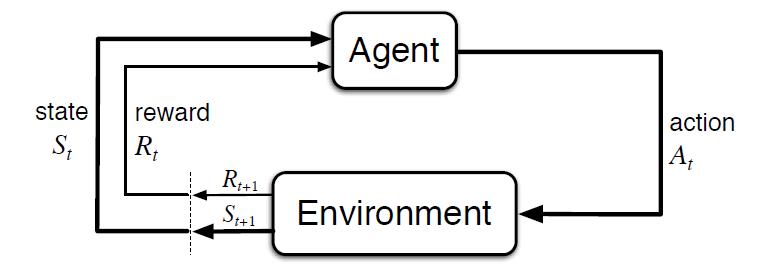
Figura 1 - Esquema de aprendizaje por refuerzo [Sutton & Barto, 2015]
Es decir, partiendo de un entorno simulado, con un estado inicial, el agente realiza una acción que genera un nuevo estado y una posible recompensa o penalización, que depende de los estados anteriores y la acción realizada. El agente aprende la mejor estrategia en este entorno simulado a partir de la experiencia, explorando el conjunto de estados, y siendo capaz de recomendar la mejor política de actuación si se configura de forma adecuada.
El ejemplo más conocido a nivel mundial fue el éxito conseguido por AlphaGo, al vencer al 18 veces campeón del mundo Lee Sedol en 2016. El Go es un juego ancestral, considerado una de las 4 artes básicas en la cultura China, junto con la música, la pintura y la caligrafía. Al contrario que con el ajedrez, el número de combinaciones de juego posibles es superior al número de átomos del Universo, siendo un problema imposible de resolver por algoritmos tradicionales.
Curiosamente, el avance tecnológico demostrado por AlphaGo al resolver un problema que se afirmaba fuera del alcance de una IA, quedó eclipsado un año después por su sucesor AlphaGo Zero. En esta versión sus creadores optaron por no emplear datos históricos, ni reglas heurísticas. AlphaGo Zero sólo emplea las posiciones del tablero y aprende por prueba y error jugando contra sí mismo.
Siguiendo esta innovadora estrategia de aprendizaje, en 3 días de ejecución consiguió superar a AlphaGo, y después de 40 días se convirtió en el mejor jugador de Go, acumulando miles de años de conocimiento en cuestión de días, y descubriendo incluso estrategias desconocidas hasta la fecha.
El impacto de este hito tecnológico abarca infinidad de ámbitos, pudiendo contar con soluciones de IA que aprendan a resolver problemas complejos desde la experiencia. Desde la gestión de recursos, la planificación de estrategias, o la calibración y optimización de sistemas dinámicos.
El desarrollo de soluciones en este ámbito está especialmente limitado por la necesidad de contar con entornos de simulación adecuados, siendo el componente más complejo de construir. Si bien existen múltiples repositorios donde se pueden obtener entornos de simulación abiertos que nos permitan probar este tipo de soluciones.
El referente más conocido es Open AI Gym, el cual incluye un extenso conjunto de librerías y entornos de simulación abiertos para el desarrollo y validación de algoritmos de aprendizaje por refuerzo. Entre otros incluye simuladores para el control básico de elementos mecánicos, aplicaciones de robótica y simuladores físicos, videojuegos ATARI en dos dimensiones, e incluso el aterrizaje de un módulo lunar. Además, permite integrar y publicar nuevos simuladores abiertos para el desarrollo de simuladores propios adaptados a nuestras necesidades que puedan ser compartidos con la comunidad:

Figura 2 - Ejemplos de entornos visuales de simulación ofrecidos por Open AI Gym
Otra referencia interesante es Unity ML Agents, donde también encontramos múltiples librerías y varios entornos de simulación, ofreciendo además la posibilidad de integrar nuestro propio simulador:

Figura 3 - Ejemplos de entornos visuales de simulación ofrecidos por Unity ML Agents
Posibles aplicaciones del aprendizaje por refuerzo en las administraciones públicas
Este tipo de aprendizaje se emplea especialmente en áreas como la robótica, la optimización de recursos o los sistemas de control, permitiendo definir políticas o estrategias óptimas de actuación en entornos concretos.
Uno de los ejemplos prácticos más conocidos, es el algoritmo de DeepMind empleado por Google para reducir un 40% el consumo de energía necesario para enfriar sus centros de datos en 2016, consiguiendo una reducción significativa en el consumo de energía durante su uso, como puede observarse en el siguiente gráfico (extraído del artículo anterior):
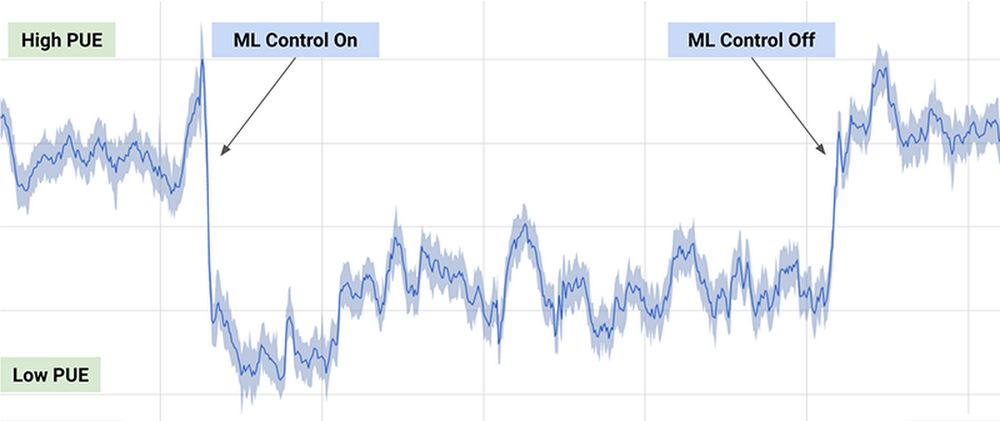
Figura 4 - Resultados del algoritmo de DeepMind sobre el consumo energético de los centros de datos de Google
El algoritmo empleado usa una combinación de técnicas de aprendizaje profundo y aprendizaje por refuerzo, junto con un simulador de propósito general para comprender sistemas dinámicos complejos que podría aplicarse en múltiples entornos como la transformación entre tipos de energía, el consumo de agua o la optimización de recursos en general.
Otras posibles aplicaciones en el ámbito público incluyen la búsqueda y recomendación de conjuntos de datos abiertos a través de chatbots, o la optimización de políticas públicas, como es el caso del proyecto europeo Policy Cloud, aplicado por ejemplo en el análisis de futuras estrategias de las diferentes denominaciones de origen de los vinos de Aragón.
En general, la aplicación de este tipo de técnicas podría optimizar el uso de recursos públicos mediante la planificación de políticas de actuación que reviertan en un consumo más sostenible, reduciendo la contaminación, los residuos y el gasto público.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Comentarios