Blog
En este post describimos paso a paso un ejercicio de ciencia de datos en el que tratamos de entrenar un modelo de deep learning con el objetivo de clasificar automáticamente imágenes médicas de personas sanas y enfermas.
El diagnóstico por radio-imagen existe desde hace muchos años en los hospitales de los países desarrollados, sin embargo, siempre ha existido una fuerte dependencia de personal altamente especializado. Desde el técnico que opera los instrumentos hasta el médico radiólogo que interpreta las imágenes. Con nuestras capacidades analíticas actuales, somos capaces de extraer medidas numéricas como el volumen, la dimensión, la forma y la tasa de crecimiento (entre otras) a partir del análisis de imagen. A lo largo de este post trataremos de explicarte, mediante un sencillo ejemplo, la potencia de los modelos de inteligencia artificial para ampliar las capacidades humanas en el campo de la medicina.
Este post explica el ejercicio práctico (sección Action) asociado al informe “Tecnologías emergentes y datos abiertos: introducción a la ciencia de datos aplicada al análisis de imagen”. Dicho informe introduce los conceptos fundamentales que permiten comprender cómo funciona el análisis de imagen, detallando los principales casos de aplicación en diversos sectores y resaltando el papel de los datos abiertos en su ejecución.
Proyectos previos
No podríamos haber preparado este ejercicio sin el trabajo y el esfuerzo previo de otros entusiastas de la ciencia de datos. A continuación, te dejamos una pequeña nota y las referencias a estos trabajos previos.
- Este ejercicio es una adaptación del proyecto original de Michael Blum sobre el desafío STOIC2021 - dissease-19 AI challenge. El proyecto original de Michael, partía de un conjunto de imágenes de pacientes con patología Covid-19, junto con otros pacientes sanos para hacer contraste.
- En una segunda aproximación, Olivier Gimenez utilizó un conjunto de datos similar al del proyecto original publicado en una competición de Kaggle. Este nuevo dataset (250 MB) era considerablemente más manejable que el original (280GB). El nuevo dataset contenía algo más de 1000 imágenes de pacientes sanos y enfermos. El código del proyecto de Olivier puede encontrarse en el siguiente repositorio.
Conjuntos de datos
En nuestro caso, inspirándonos en estos dos fantásticos proyectos previos, hemos construido un ejercicio didáctico apoyándonos en una serie de herramientas que facilitan la ejecución del código y la posibilidad de examinar los resultados de forma sencilla. El conjunto de datos original (de rayos-x de tórax) comprende 112.120 imágenes de rayos-X (vista frontal) de 30.805 pacientes únicos. Las imágenes se acompañan con las etiquetas asociadas de catorce enfermedades (donde cada imagen puede tener múltiples etiquetas), extraídas de los informes radiológicos asociados utilizando procesamiento de lenguaje natural (NLP). Partiendo del conjunto de imágenes médicas original hemos extraído (utilizando algunos scripts) una muestra más pequeña y acotada (tan solo personas sanas frente a personas con una sola patología) para facilitar este ejercicio. En particular, la patología escogida es el neumotórax.
Si quieres ampliar la información sobre el campo de procesamiento del lenguaje natural puedes consultar el siguiente informe que ya publicamos en su momento. Además, en el post 10 repositorios de datos públicos relacionados con la salud y el bienestar se cita al NIH como un ejemplo de fuente de datos sanitarios de calidad. En particular, nuestro conjunto de datos está disponible públicamente aquí.
Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.1.2) y RStudio (2022-02-3). Los pequeños scripts de ayuda a la descarga y ordenación de ficheros se han escrito en Python 3.
Acompañando a este post, hemos creado un cuaderno de Jupyter con el que poder experimentar de forma interactiva a través de los diferentes fragmentos de código que van desarrollando nuestro ejemplo. El objetivo de este ejercicio es entrenar a un algoritmo para que sea capaz de clasificar automáticamente una imagen de una radiografía de pecho en dos categorías (persona enferma vs persona no-enferma). Para facilitar la ejecución del ejercicio por parte de los lectores que así lo deseen, hemos preparado el cuaderno de Jupyter en el entorno de Google Colab que contiene todos los elementos necesarios para reproducir el ejercicio paso a paso. Google Colab o Collaboratory es una herramienta gratuita de Google que te permite programar y ejecutar código en Python (y también en R) sin necesidad de instalar ningún software adicional. Es un servicio online y para usarlo tan solo necesitas tener una cuenta de Google.
Flujo lógico del análisis de datos
Nuestro cuaderno de Jupyter, realiza las siguientes actividades diferenciadas que podrás seguir en el propio documento interactivo cuándo lo vayas ejecutando sobre Google Colab.
- Instalación y carga de dependencias.
- Configuración del entorno de trabajo
- Descarga, carga y pre-procesamiento de datos necesarios (imágenes médicas) en el entorno de trabajo.
- Pre-visualización de las imágenes cargadas.
- Preparación de los datos para entrenamiento del algoritmo.
- Entrenamiento del modelo y resultados.
- Conclusiones del ejercicio.
A continuación, hacemos un repaso didáctico del ejercicio, enfocando nuestras explicaciones en aquellas actividades que son más relevantes respecto al ejercicio de análisis de datos:
- Descripción del análisis de datos y entrenamiento del modelo
- Modelización: creación del conjunto de imágenes de entrenamiento y entrenamiento del modelo
- Analisis del resultado del entrenamiento
- Conclusiones
Descripción del análisis de datos y entrenamiento del modelo
Los primeros pasos que encontraremos recorriendo el cuaderno de Jupyter son las actividades previas al análisis de imágenes propiamente dicho. Como en todos los procesos de análisis de datos, es necesario preparar el entorno de trabajo y cargar las librerías necesarias (dependencias) para ejecutar las diferentes funciones de análisis. El paquete de R más representativo de este conjunto de dependencias es Keras. En este artículo ya comentamos sobre el uso de Keras como framework de Deep Learning. Adicionalmente también son necesarios los siguientes paquetes: httr; tidyverse; reshape2;patchwork.
A continuación, debemos descargar a nuestro entorno el conjunto de imágenes (datos) con el que vamos a trabajar. Como hemos comentado previamente, las imágenes se encuentran en un almacenamiento remoto y solo las descargamos en Colab en el momento de analizarlas. Tras ejecutar las secciones de código que descargan y descomprimen los ficheros de trabajo que contienen las imágenes médicas encontraremos dos carpetas (No-finding y Pneumothorax) que contienen los datos de trabajo.

Una vez que disponemos de los datos de trabajo en Colab, debemos cargarlas en la memoria del entorno de ejecución. Para ello hemos creado una función que verás en el cuaderno denominada process_pix(). Esta función, va a buscar las imágenes a las carpetas anteriores y las carga en memoria, además de pasarlas a escala de grises y normalizarlas todas a un tamaño de 100x100 pixels. Para no exceder los recursos que nos proporciona de forma gratuita Google Colab, limitamos la cantidad de imágenes que cargamos en memoria a 1000 unidades. Es decir, el algoritmo va a ser entrenado con 1000 imágenes, entre las que va usar para entrenamiento y las que va a usar para la validación posterior.
Una vez tenemos las imágenes perfectamente clasificadas, formateadas y cargadas en memoria hacemos una visualización rápida para verificar que son correctas.Obtenemos los siguientes resultados:

Obviamente, a ojos de un observador no experto no se ven diferencias significativas que nos permitan extraer ninguna conclusión. En los siguientes pasos veremos cómo el modelo de inteligencia artificial sí que tiene mejor ojo clínico que nosotros.
Modelización
Creación del conjunto de imágenes de entrenamiento
Como comentamos en los pasos previos, disponemos de un conjunto de 1000 imágenes de partida cargadas en el entorno de trabajo. Hasta este momento, tenemos clasificadas (por un especialista en rayos-x) aquellas imágenes de pacientes que presentan indicios de neumotórax (en la ruta "./data/Pneumothorax") y aquellos pacientes sanos (en la ruta "./data/No-Finding")
El objetivo de este ejercicio es, justamente, demostrar la capacidad de un algoritmo de asistir al especialista en la clasificación (o detección de signos de enfermedad en la imagen de rayos-x). Para esto, tenemos que mezclar las imágenes, para conseguir un conjunto homogéneo que el algoritmo tendrá que analizar y clasificar valiéndose solo de sus características. El siguiente fragmento de código, asocia un identificador (1 para personas enfermas y 0 para personas sanas) para, posteriormente, tras el proceso de clasificación del algoritmo, poder verificar aquellas que el modelo ha clasificado de forma correcta o incorrecta.

Bien, ahora tenemos un conjunto “df” uniforme de 1000 imágenes mezcladas con pacientes sanos y enfermos. A continuación, dividimos en dos este conjunto original. El 80% del conjunto original, lo vamos a utilizar para entrenar el modelo. Esto es, el algoritmo utilizará las características de las imágenes para crear un modelo que permita concluir si una imagen se corresponde con el identificador 1 o 0. Por otro lado, el 20% restante de la mezcla homogénea la vamos a utilizar para comprobar si el modelo, una vez entrenado, es capaz de tomar una imagen cualquiera y asignarle el 1 o el 0 (enfermo, no enfermo).

Entrenamiento del modelo
Listo, solo nos queda configurar el modelo y entrenar con el anterior conjunto de datos.
Antes de entrenar, veréis unos fragmentos de código que sirven para configurar el modelo que vamos a entrenar. El modelo que vamos a entrenar es de tipo clasificador binario. Esto significa que es un modelo que es capaz de clasificar los datos (en nuestro caso imágenes) en dos categorías (en nuestro caso sano o enfermo). El modelo escogido se denomina CNN o Convolutional Neural Network. Su propio nombre ya nos indica que es un modelo de redes neuronales y por lo tanto cae dentro de la disciplina de Deep Learning o aprendizaje profundo. Estos modelos se basan en capas de características de los datos que se van haciendo más profundas a medida que la complejidad del modelo aumenta. Os recordamos que el término deep hace referencia, justamente, a la profundidad del número de capas mediante las cuales estos modelos aprenden.
Nota: los siguientes fragmentos de código son los más técnicos del post. La documentación introductoria se puede encontrar aquí, mientras que toda la documentación técnica sobre las funciones del modelo está accesible aquí.
Finalmente, tras la configuración del modelo, estamos en disposición de entrenar el modelo. Como comentamos, entrenamos con el 80% de las imágenes y validamos el resultado con el 20% restante.

Resultado del entrenamiento
Bien, ya hemos entrenado nuestro modelo. ¿Y ahora qué? Las siguientes gráficas nos proporcionan una visualización rápida sobre cómo se comporta el modelo sobre las imágenes que hemos reservado para validar. Básicamente, estas figuras vienen a representar (la del panel inferior) la capacidad del modelo de predecir la presencia (identificador 1) o ausencia (identificador 0) de enfermedad (en nuestro caso neumotórax). La conclusión es que cuando el modelo entrenado con las imágenes de entrenamiento (aquellas de las que se sabe el resultado 1 o 0) se aplica al 20% de las imágenes de las cuales no se sabe el resultado, el modelo acierta aproximadamente en el 85% (0.87309) de las ocasiones.

En efecto, cuando solicitamos la evaluación del modelo para saber qué tan bien clasifica enfermedades el resultado nos indica la capacidad de nuestro modelo recién entrenado para clasificar de forma correcta el 0.87309 de las imágenes de validación.
Hacemos ahora algunas predicciones sobre imágenes de pacientes. Es decir, una vez entrenado y validado el modelo, nos preguntamos cómo va a clasificar las imágenes que le vamos a dar ahora. Como sabemos "la verdad" (lo que se denomina el ground truth) sobre las imágenes, comparamos el resultado de la predicción con la verdad. Para comprobar los resultados de la predicción (que variarán en función del número de imágenes que se usen en el entrenamiento) se utiliza lo que en ciencia de datos se denomina la matriz de confusión. La matriz de confusión:
- coloca en la posición (1,1) los casos que SÍ tenían enfermedad y el modelo clasifica como "con enfermedad"
- coloca en la posición (2,2), los casos que NO tenían enfermedad y el modelo clasifica como "sin enfermedad"
Es decir, estas son las posiciones en las que el modelo "acierta" en su clasificación.
En las posiciones contrarias, es decir, la (1,2) y la (2,1) son las posiciones en las que el modelo se "equivoca". Así, la posición (1,2) son los resultados que el modelo clasifica como CON enfermedad y la realidad es que eran pacientes sanos. La posición (2,1), justo lo contrario.
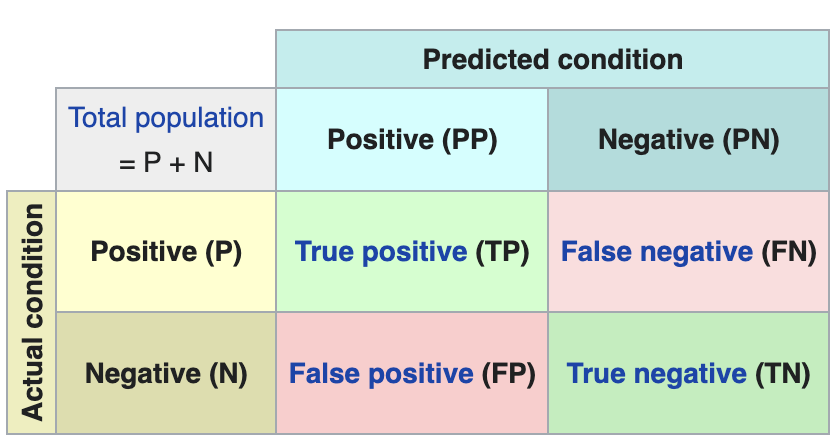
Ejemplo explicativo sobre cómo funciona la matriz de confusión. Fuente: wikipedia https://en.wikipedia.org/wiki/Confusion_matrix
En nuestro ejercicio, el modelo nos proporciona los siguientes resultados:


Es decir, 81 pacientes tenían esta enfermedad y el modelo los clasifica de forma correcta. De la misma forma, 91 pacientes estaban sanos y el modelo los clasifica, igualmente, de forma correcta. Sin embargo, el modelo clasifica cómo enfermos, 13 pacientes que estaban sanos. Y al contrario, el modelo clasifica cómo sanos a 12 pacientes que en realidad estaban enfermos. Cuando sumamos los aciertos del modelo 81+91 y lo dividimos sobre la muestra de validación total obtenemos el 87% de precisión del modelo.
Conclusiones
En este post te hemos guiado a través de un ejercicio didáctico que consiste en entrenar un modelo de inteligencia artificial para realizar clasificaciones de imágenes de radiografías de pecho con el objetivo de determinar automáticamente si una persona está enferma o sana. Por sencillez, hemos escogido pacientes sanos y pacientes que presentan un neumotórax (solo dos categorías) previamente diagnosticados por un médico. El viaje que hemos realizado nos ofrece una idea de las actividades y las tecnologías involucradas en el análisis automatizado de imágenes mediante inteligencia artificial. El resultado del entrenamiento nos ofrece un sistema de clasificación razonable para el screening automático con un 87% de precisión en sus resultados. Los algoritmos y las tecnologías avanzadas de análisis de imagen son y cada vez más serán, un complemento indispensable en múltiples ámbitos y sectores como, por ejemplo, la medicina. En los próximos años veremos cómo se consolidan los sistemas que, de forma natural, combinan habilidades de humanos y máquinas en procesos costosos, complejos o peligrosos. Los médicos y otros trabajadores verán aumentadas y reforzadas sus capacidades gracias a la inteligencia artificial. La combinación de fuerzas entre máquinas y humanos nos permitirá alcanzar cotas de precisión y eficiencia nunca vistas hasta la fecha. Esperamos que con este ejercicio os hayamos ayudado a entender un poco más cómo funcionan estas tecnologías. No olvides completar tu aprendizaje con el resto de materiales que acompañan este post.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Te presentamos un nuevo informe de la serie ‘Tecnologías emergentes y datos abiertos’, de la mano de Alejandro Alija. El objetivo de estos informes es ayudar al lector a entender cómo funcionan diversas tecnologías, cuál es el papel de los datos abiertos en ellas y qué impacto tendrán en nuestra sociedad. A esta serie pertenecen algunos monográficos sobre técnicas de análisis de datos como el análisis del lenguaje natural o la analítica predictiva. En este nuevo volumen de la serie se analizan los aspectos clave del análisis de datos aplicado a las imágenes y, a través de este ejercicio Inteligencia Artificial aplicada a la identificación y clasificación de enfermedades mediante radio imagen médica, se profundiza en la vertiente más práctica del monográfico.
El análisis de imágenes adopta diferentes nombres y formas de referirse a él. Algunos de los más comunes son visual analytics, computer vision o image processing. La importancia de este tipo de análisis presenta una gran relevancia actualmente, ya que muchas de las más modernas técnicas algorítmicas de inteligencia artificial han sido diseñadas concretamente con este objetivo. Algunas de sus aplicaciones las vemos en nuestro día a día, como la identificación de matrículas para acceder a un párking o la digitalización de texto escaneado para poder ser manipulado.
El informe introduce los conceptos fundamentales que permiten comprender cómo funciona el análisis de imagen, detallando los principales casos de aplicación en diversos sectores. Tras una breve introducción elaborada por el autor, que servirá como base para contextualizar la materia a tratar, se expone el informe completo, que sigue la estructura tradicional de la serie:
- Awareness. En la sección Awareness se explican los conceptos clave de las técnicas de análisis de imagen. A través de este apartado, los lectores pueden encontrar respuestas a cuestiones del tipo: ¿cómo se manipulan las imágenes como datos? o ¿cómo se clasifican las imágenes?, además de descubrir algunas de las aplicaciones más destacadas en el análisis de imagen.
- Inspire. La sección Inspire analiza detalladamente algunos de los principales casos de uso en sectores tan diferentes como la agricultura, la industria o el sector inmobiliario. También se incluyen ejemplos de aplicación en el campo de la medicina, donde el autor muestra algunos retos de especial importancia en este ámbito.
- Action: En este caso, la sección Action se ha publicado en formato notebook, de manera separada al informe teórico. En ella se muestra un ejemplo práctico de Inteligencia Artificial aplicada a la identificación y clasificación de enfermedades mediante radio imagen médica. En este post se incluye la explicación paso a paso del ejercicio realizado. El código fuente está disponible para que los lectores puedan aprender y experimentar por sí mismos el análisis inteligente de imágenes.
A continuación, puedes descargarte el informe -secciones Awareness e Inspire- en pdf y word (versión reutilizable).
Blog
La demanda de profesionales con habilidades relacionadas con la analítica de datos no deja de crecer y ya se estima que la industria solo en España necesitaría más de 90.000 profesionales en datos e inteligencia artificial para impulsar la economía. Formar profesionales que puedan llenar este hueco es un gran reto que está haciendo incluso grandes compañías tecnológicas como Google, Amazon o Microsoft estén proponiendo programas de formación especializado que en paralelo a los que propone el sistema educativo reglado. Y en este contexto los datos abiertos tienen un papel muy relevante en la formación práctica de estos profesionales, ya que con frecuencia, los datos abiertos son la única posibilidad para realizar ejercicios reales y no solo simulados.
Además, aunque aún no existe un corpus de investigación sólido al respecto, algunos trabajos ya sugieren efectos positivos derivados del uso de datos abiertos como herramienta en el proceso de enseñanza-aprendizaje de cualquier materia y no solo de las relacionadas con la analítica de datos. Algunos países europeos han reconocido ya este potencial y han desarrollado proyectos piloto para determinar la mejor forma de introducir datos abiertos en el currículo escolar.
En este sentido, los datos abiertos se pueden utilizar como una herramienta para la educación y la formación de varias maneras. Por ejemplo, los datos abiertos se pueden utilizar para desarrollar nuevos materiales de enseñanza y aprendizaje, para crear proyectos basados en datos del mundo real para estudiantes o para apoyar la investigación sobre enfoques pedagógicos efectivos. Además, los datos abiertos se pueden utilizar para crear oportunidades de colaboración entre educadores, estudiantes e investigadores con el fin de compartir mejores prácticas y colaborar en soluciones a desafíos comunes.
Proyectos basados en datos del mundo real
Una aportación clave de los datos abiertos es su autenticidad, ya que son una representación de la enorme complejidad e incluso de los defectos del mundo real a diferencia de las construcciones artificiales o los ejemplos de libros de texto que se basan en supuestos muchos más simples.
Un ejemplo interesante en este sentido es el que documentó la Universidad Simon Fraser de Canadá en su Máster en Edición donde la mayor parte de sus alumnos proceden de programas universitarios no STEM y que por tanto tenían unas capacidades limitadas en el manejo de datos. El proyecto está disponible como recurso educativo abierto en la plataforma OER Commons y su objetivo es que los estudiantes comprendan que las métricas y la medición son herramientas estratégicas importantes para comprender el mundo que nos rodea.
Al trabajar con datos del mundo real, los estudiantes pueden desarrollar habilidades de construcción de relatos e investigación, y pueden aplicar habilidades analíticas y colaborativas en el uso de datos para resolver problemas del mundo real. El caso de estudio realizado con la primera edición en la que se utilizó este OER basado en datos abiertos está documentado en el libro “Open Data as Open Educational Resources - Case studies of emerging practice”. En él se muestra que la oportunidad de trabajar con datos pertenecientes a su campo de estudio resultó esencial para mantener a los estudiantes comprometidos con el proyecto. Sin embargo, lidiar con el desorden de los datos del "mundo real" fue lo que les permitió obtener un aprendizaje valioso y nuevas habilidades prácticas.
Desarrollo de nuevos materiales de aprendizaje
Los conjuntos de datos abiertos tienen un gran potencial para ser utilizados en el desarrollo de recursos educativos abiertos (REA) que son materiales de enseñanza, aprendizaje e investigación en soporte digital de carácter gratuito, pues son publicados con una licencia abierta (Creative Commons) que permite su uso, adaptación y redistribución para usos no comerciales de acuerdo con la definición de la UNESCO.
En este contexto, si bien los datos abiertos no siempre son REA, podemos decir que se convierten en REA cuando se usan en contextos pedagógicos. Los datos abiertos cuando se utilizan como recurso educativo facilitan que los estudiantes aprendan y experimenten trabajando con los mismos conjuntos de datos que utilizan investigadores, gobiernos y sociedad civil. Son un componente clave para que los estudiantes desarrollen habilidades de análisis, estadísticas, científicas y de pensamiento crítico.
Es difícil estimar la presencia actual de los datos abiertos como parte de los REA pero no resulta difícil encontrar ejemplos interesantes dentro de las principales plataformas de recursos educativos abiertos. En la plataforma Procomún podemos encontrar interesantes ejemplos como Aprender Geografía a través de la evolución de los paisajes agrarios de España que construye sobre la plataforma ArcGIS Online de la Universidad Complutense de Madrid un Webmap para el aprendizaje de los paisajes agrarios en España. El recurso educativo emplea ejemplos concretos de distintas comunidades autónomas empleando fotografías o imágenes fijas geolocalizadas y datos propios integrados con datos abiertos. De este modo los estudiantes trabajan los conceptos no a través de una mera descripción en texto sino con recursos interactivos que favorecen además la mejora de sus competencias digitales y espaciales
En la plataforma OER Commons encontramos por ejemplo el recurso “De los datos abiertos al compromiso cívico” que está dirigido a públicos a partir de enseñanza secundaria con el objetivo de enseñar a interpretar cómo se gasta el dinero público en un área regional, local, o barrio determinado. Para ello se apoya en los conocidos proyectos para analizar presupuestos públicos “¿Dónde van mis impuestos?”, disponibles en muchas zonas del mundo como fruto de las políticas de transparencia de los poderes públicos. Este recurso que podría ser portado a España con facilidad ya que contamos con numerosos proyectos ¿Donde van mis impuestos?, como el mantenido por Fundación Civio.
Habilidades relacionadas con datos
Cuando nos referimos a la formación y educación en habilidades relacionadas con los datos, en realidad nos estamos refiriendo a un área de gran amplitud que además es muy difícil dominar en todas sus facetas. De hecho, lo habitual es que los proyectos relacionados con datos se aborden en equipos donde cada miembro desempeña un rol especializado en alguna de estas áreas. Por ejemplo, es habitual diferenciar al menos la limpieza y preparación de datos, el modelado de datos y la visualización de datos como las principales actividades que se realizan en un proyecto de ciencia datos e inteligencia artificial.
En todos los casos el uso de datos abiertos está ampliamente adoptado como recurso central de los proyectos que se proponen para la adquisición de cualquiera de estas habilidades. La muy conocida comunidad de ciencia de datos Kaggle organiza competiciones basadas en conjuntos de datos abiertos aportados a la comunidad y que constituyen un recurso esencial para el aprendizaje basado en proyectos reales de quienes quieren adquirir habilidades relacionadas con los datos. Existen otras propuestas basadas en suscripciones como Dataquest o ProjectPro pero en todos los casos utilizan para los proyectos que proponen conjuntos de datos reales obtenidos de los múltiples repositorios de datos abiertos de carácter general o repositorios específicos de un área de conocimiento.
Los datos abiertos, al igual que en otras áreas, aún no han desarrollado todo su potencial como herramienta para la educación y la formación. Sin embargo como puede verse en el programa de la última edición de la OER Conference 2022, cada vez son más los ejemplos en los que los datos abiertos tienen un papel central en la enseñanza, las nuevas prácticas educativas y la creación de nuevos recursos educativos para todo tipo de materias, conceptos y habilidades.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Quizás, uno de los usos más cotidianos de la inteligencia artificial que podemos experimentar en nuestro día a día sea mediante la interacción con sistemas de visión artificial e identificación de objetos. Desde el desbloqueo de nuestro smartphone, hasta la búsqueda por imágenes en Internet. Todos estas funcionalidades son posibles gracias a modelos de inteligencia artificial en el campo de la detección y clasificación de imágenes. En este post recopilamos algunos de los repositorios abiertos de imágenes más importantes, gracias a los cuales, hemos podido entrenar los modelos actuales de reconocimiento de imágenes.
Introducción
Volvamos por un momento a finales de 2017, principios del 2018. La posibilidad de desbloquear nuestros smartphones con algún tipo de lector de huella dactilar se ha extendido. Con mayor o menor acierto, la mayor parte de los fabricantes habían conseguido incluir el lector biométrico en sus terminales. El tiempo de desbloqueo, la facilidad de uso y la seguridad extra aportada eran excepcionales frente a los clásicos sistemas de contraseñas, patrones, etc. Como viene ocurriendo desde el año 2008, el líder indiscutible en innovación digital en terminales móviles - Apple - volvía a revolucionar el mercado incorporando un novedoso sistema de desbloqueo en el iPhone X mediante la imágen de nuestra cara. El denominado sistema FaceID escanea nuestra cara para desbloquear el terminal en décimas de segundo sin tener que utilizar las manos. La probabilidad de suplantación de identidad con este sistema era de 1 a 1.000.000; 20 veces más seguro que su predecesor el TouchID.
Valga esta pequeña historia sobre una funcionalidad cotidiana, para introducir un tema importante en el campo de la inteligencia artificial, y en particular del campo del procesamiento de imágenes por ordenador: los repositorios de imágenes de entrenamiento de modelos de IA. Hemos hablado mucho en este espacio sobre este campo de la inteligencia artificial. Pocos meses después del lanzamiento del FaceID, publicamos un post sobre IA, en el que mencionamos la clasificación de imágenes a nivel casi-humano como uno de los logros más importantes de la IA en los últimos años. Esto no sería posible sin la disponibilidad de bancos abiertos de imágenes anotadas[1] con los que poder entrenar modelos de reconocimiento y clasificación de imágenes. En este post listamos algunos de los repositorios de imágenes (de libre acceso) más importantes para el entrenamiento de modelos.
Lógicamente, no es lo mismo reconocer la matrícula de un vehículo a la entrada de un parking que identificar una enfermedad pulmonar en una imagen de rayos-x. Los bancos de imágenes anotadas son tan variados como las potenciales aplicaciones de IA que éstas habilitan.
Probablemente los 2 repositorios más conocidos de imágenes son MNIST e ImageNET.
- MNIST, es un conjunto de 70.000 imágenes en blanco y negro de números manuscritos normalizados en tamaño, listas para entrenar algoritmos de reconocimiento de números. El artículo original del profesor LeCun es del año 1998.
- ImageNET es una base de datos enorme de conceptos (palabras o conjuntos de palabras). Cada concepto con significado propio se denomina synset. Cada synset está representado por cientos o miles de imágenes. En la propia web de ImageNET se cita el proyecto como una herramienta indispensable para el reciente avance del Deep Learning y la visión por ordenador.
The project has been instrumental in advancing computer vision and deep learning research. The data is available for free to researchers for non-commercial use
El subconjunto más utilizado de ImageNet es el conjunto de datos de clasificación y localización de imágenes ImageNet Large Scale Visual Recognition Challenge ILSVRC. Este subconjunto de imágenes se utilizó desde 2010 hasta 2017 para las competiciones de detección de objetos y clasificación de imágenes a nivel mundial. Este conjunto de datos abarca 1000 clases de objetos y contiene más de un millón de imágenes de entrenamiento, 50.000 imágenes de validación y 100.000 imágenes de prueba. Este subconjunto está disponible en Kaggle.
Además de estos dos clásicos repositorios que ya forman parte de la historia del procesado de imágenes por inteligencia artificial, disponemos de algunos repositorios temáticos más actuales y variados. Estos son algunos ejemplos:
- Los tan molestos CAPTCHAs y reCAPTCHAs que encontramos en multitud de sitios web para verificar quienes estamos intentando acceder somos humanos son un buen ejemplo de inteligencia artificial aplicado al campo de la seguridad. Por supuesto, los CAPTCHAs también necesitan su propio repositorio para comprobar cuán efectivos son para evitar accesos no deseados. Te recomendamos leer este interesante artículo sobre la historia de estos compañeros de navegación por la web.
- Como hemos visto varias veces en el pasado, una de las aplicaciones más prometedoras de la IA en el campo de la imágenes es la de asistir a los médicos en el diagnóstico de enfermedades a partir de una prueba de imágen médica (rayos-x, tomografía computerizada, etc.) Para convertir esto en una realidad, no son pocos los esfuerzos en recopilar, anotar y poner a disposición de la comunidad investigadora repositorios de imágenes médicas anonimizadas y de calidad para entrenar modelos de detección de objetos, formas y patrones que puedan revelar una posible enfermedad. El 30% de todos los cánceres que padecen las mujeres en el mundo corresponde con el cáncer de mama. De ahí la importancia de contar con bancos de imágenes que faciliten el entrenamiento de modelos específicos.
- El diagnóstico de enfermedades basadas en la sangre a menudo implica la identificación y caracterización de muestras de sangre de pacientes. Los métodos automatizados (mediante imagen médica) para detectar y clasificar los subtipos de células sanguíneas tienen importantes aplicaciones médicas.
- Hace 3 años el Covid19 irrumpió en nuestras vidas poniendo a las sociedades desarrolladas patas arriba con esta pandemia de alcance mundial y consecuencias terribles en términos de pérdidas humanas y económicas. La comunidad científica al completo se volcó en dar solución en tiempo record para atajar las consecuencias del nuevo coronavirus. Fueron muchos los esfuerzos en la mejora del diagnóstico de la enfermedad. Algunas técnicas apostaron por el análisis de imagen asistidas por IA. Al mismo tiempo, las autoridades sanitarias incorporaron un elemento nuevo en nuestra rutina diaria - las mascarillas-. Todavía hoy en algunas situaciones la mascarilla sigue siendo de obligado uso, y durante estos 3 años hemos tenido que vigilar su adecuado uso en casi todo tipo de lugares. Tanto es así que en estos meses han proliferado los bancos de imágenes específicos para entrenar modelos de IA y visión artificial que detecten el uso de mascarillas de forma autónoma.
- Para ampliar información sobre repositorios abiertos relacionados con la salud y el bienestar, te dejamos este post que publicamos hace unos meses.
Además de estos curiosos ejemplos que hemos citado en este post, te animamos a explorar la sección de conjuntos de datos de Kaggle que incluyen imágenes como datos. Tan solo tienes 10.000 conjuntos para recorrer ;)
[1] Los repositorios de imágenes anotadas contienen, además de los ficheros de imágen (jpeg, tiff, etc.), unos ficheros descriptivos con los metadatos que identifican a cada imágen. Normalmente, estos ficheros (csv, JSON o XML) incluyen un identificador único para cada imágen además de unos campos que proporcionan información sobre el contenido de la imágen. Por ejemplo, el nombre del objeto que aparece en la imágen.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras varios meses de pruebas y entrenamientos de distinto tipo, el primer sistema masivo de Inteligencia Artificial de la lengua española es capaz de generar sus propios textos y resumir otros ya existentes. MarIA es un proyecto que ha sido impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación, a partir de los archivos web de la Biblioteca Nacional de España (BNE).
Hablamos de un avance muy importante en este ámbito, ya que se trata del primer sistema de inteligencia artificial experto en comprender y escribir en lengua española. Enmarcada dentro del Plan de Tecnologías del Lenguaje, esta herramienta pretende contribuir al desarrollo de una economía digital en español, gracias al potencial que los desarrolladores pueden encontrar en ella.
El reto de crear los asistentes del lenguaje del futuro
Los modelos de lenguaje al estilo de MarIA son la piedra angular sobre la que se sustenta el desarrollo del procesamiento del lenguaje natural, la traducción automática o los sistemas conversacionales, tan necesarios para comprender y replicar de forma automática una lengua. MarIA es un sistema de inteligencia artificial formado por redes neuronales profundas que han sido entrenadas para adquirir una comprensión de la lengua, de su léxico y de sus mecanismos para expresar el significado y escribir a nivel experto.
Gracias a este trabajo previo, los desarrolladores pueden crear herramientas relacionadas con el lenguaje y capaces de clasificar documentos, realizar correcciones o elaborar herramientas de traducción.
La primera versión de MarIA fue elaborada con RoBERTa, una tecnología que crea modelos del lenguaje del tipo “codificadores”, capaces de generar una interpretación que puede servir para categorizar documentos, encontrar similitudes semánticas en diferentes textos o detectar los sentimientos que se expresan en ellos.
Así, la última versión de MarIA ha sido desarrollada con GPT-2, una tecnología más avanzada que crea modelos generativos decodificadores y añade prestaciones al sistema. Gracias a estos modelos decodificadores, la última versión de MarIA es capaz de generar textos nuevos a partir de un ejemplo previo, lo que resulta muy útil a la hora de elaborar resúmenes, simplificar grandes cantidades de información, generar preguntas y respuestas e, incluso, mantener un diálogo.
Avances como los anteriores convierten a MarIA en una herramienta que, con entrenamientos adaptados a tareas específicas, puede ser de gran utilidad para desarrolladores, empresas y administraciones públicas. En esta línea, modelos similares que se han desarrollado en inglés son utilizados para generar sugerencias de texto en aplicaciones de escritura, resumir contratos o buscar informaciones concretas dentro de grandes bases de datos de texto para relacionarlas posteriormente con otras informaciones relevantes.
En otras palabras, además de redactar textos a partir de titulares o palabras, MarIA puede comprender no solo conceptos abstractos, sino también el contexto de los mismos.
Más de 135 mil millones de palabras al servicio de la inteligencia artificial
Para ser exactos, MarIA se ha entrenado con 135.733.450.668 de palabras procedentes de millones de páginas web que recolecta la Biblioteca Nacional y que ocupan un total de 570 Gigabytes de información. Para estos mismos entrenamientos, se ha utilizado el superordenador MareNostrum del Centro Nacional de Supercomputación de Barcelona y ha sido necesaria una potencia de cálculo de 9,7 trillones de operaciones (969 exaflops).
Teniendo en cuenta que uno de los primeros pasos para diseñar un modelo del lenguaje pasa por construir un corpus de palabras y frases que sirva como base de datos para entrenar al propio sistema, en el caso de MarIA, fue necesario realizar un cribado para eliminar todos los fragmentos de texto que no fuesen “lenguaje bien formado” (elementos numéricos, gráficos, oraciones que no terminan, codificaciones erróneas, etc.) y así entrenar correctamente a la IA.
Debido al volumen de información que maneja, MarIA se sitúa ya como el tercer sistema de inteligencia artificial experto en comprender y escribir con mayor número de modelos masivos de acceso abierto. Por delante solo están los modelos del lenguaje elaborados para el inglés y el mandarín. Esto ha sido posible principalmente por dos razones. Por un lado, debido al elevado nivel de digitalización en el que se encuentra el patrimonio de la Biblioteca Nacional y, por el otro, gracias a la existencia de un Centro de Supercomputación Nacional que cuenta con superordenadores como el MareNostrum 4.
El papel de los conjuntos de datos de la BNE
Desde que en 2014 lanzase su propio portal de datos abiertos (datos.bne.es), la BNE ha apostado por acercar los datos que están a su disposición y bajo su custodia: datos de las obras que conserva, pero también de autores, vocabularios controlados de materias y términos geográficos, entre otros.
En los últimos años, se ha desarrollado también la plataforma educativa BNEscolar, que busca ofrecer contenidos digitales del fondo documental de la Biblioteca Digital Hispánica y que pueden resultar de interés para la comunidad educativa.
Así mismo y para cumplir con los estándares internacionales de descripción e interoperabilidad, los datos de la BNE están identificados mediante URIs y modelos conceptuales enlazados, a través de tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables. Además, cuentan con un alto nivel de normalización.
Próximos pasos
Así y con el objetivo de perfeccionar y ampliar las posibilidades de uso de MarIA, se pretende que la versión actual dé lugar a otras especializadas en áreas de conocimiento más concretas. Teniendo en cuenta que se trata de un sistema de inteligencia artificial dedicado a comprender y generar texto, se torna fundamental que este sea capaz de desenvolverse con soltura ante léxicos y conjuntos de información especializada.
Para ello, el PlanTL continuará expandiendo MarIA para adaptarse a los nuevos desarrollos tecnológicos en procesamiento del lenguaje natural (modelos más complejos que el GPT-2 ahora implementado, entrenados con mayor cantidad de datos) y se buscará la forma de crear espacios de trabajo para facilitar el uso de MarIA por compañías y grupos de investigación.
Contenido elaborado por el equipo de datos.gob.es.
Evento
Los datos se han convertido en uno de los pilares del proceso de transformación digital de la sociedad, lo que interpela también a sectores como la justicia y la aplicación del derecho. Gracias a ellos, se ha conseguido mejorar el acceso a la información y la estadística, permitiendo que la toma de decisiones se base en cifras objetivas a las que poder aplicar nuevas técnicas como la automatización y la inteligencia artificial.
Así y con el objetivo de seguir ahondando en las ventajas derivadas del ecosistema de los datos, el próximo 17 y 18 de octubre, la Universidad de Salamanca organiza, en colaboración con el Ministerio de Justicia, un simposio sobre Justicia y Datos.
¿Cuáles serán las temáticas a abordar?
Durante las dos jornadas que durará el evento y a través de las distintas ponencias, se tratará de reflexionar sobre "el papel de los datos para el buen funcionamiento de los servicios públicos". Es decir, cómo pueden ayudar los datos abiertos a mejorar la eficiencia y la eficacia de estos de cara a la ciudadanía y los servicios ofrecidos a la misma.
En línea con esta idea, las cuestiones que formarán parte del simposio girarán en torno a los siguientes temas:
- Asistentes personalizados
- Analítica de Datos
- Diseño de Visualizaciones de Datos
- Gobernanza, Transparencia y Datos Abiertos
- IA – NLP
- IA – Otros
- Robotización
- Espacios compartidos de datos
- Capacitación en Datos, IA, RPA
Así, mientras la primera jornada estará formada por conferencias de personas relevantes del sector de la Justicia, el Derecho y el sector académico, en la segunda, se mostrarán las distintas iniciativas del sector tecnológico del ámbito internacional y del legal-tech relacionadas con los datos.
Igualmente, en salas simultáneas, se analizarán proyectos públicos y privados en los que se aplica la tecnología a los servicios de Justicia y del Derecho.
En conclusión, se trata de un evento que busca convertirse en un punto de encuentro para la innovación en el ámbito de la justicia. De forma que, a través del intercambio de experiencias y casos de éxito, entre la administración, instituciones y empresas privadas de cualquier ámbito sea posible orientar el uso de los datos a proveer y dar soluciones a problemas concretos.
¿Cómo puedo asistir?
La asistencia a las jornadas será gratuita y estas se desarrollarán en la Hospedería Arzobispo Fonseca de Salamanca. Para poder asistir, será necesario cumplimentar el siguiente formulario de inscripción. Asimismo, y al igual que sucede con otros eventos similares, este también será retransmitido online y en directo.
Blog
Según el último análisis realizado por Gartner en septiembre de 2021, sobre las tendencias en materia de Inteligencia Artificial, los Chatbots son una de las tecnologías más cercanas a ofrecer una productividad efectiva en menos de 2 años. En la Figura 1, extraída de dicho informe, se observa que existen 4 tecnologías que han superado ampliamente el estado de sobre-expectativa (peak of inflated expectations) y comienzan ya a salir del canal de desilusión (trough of disillisionment), hacia estados de mayor madurez y estabilidad, incluyendo chatbots, búsqueda semántica, visión artificial y vehículos autónomos.
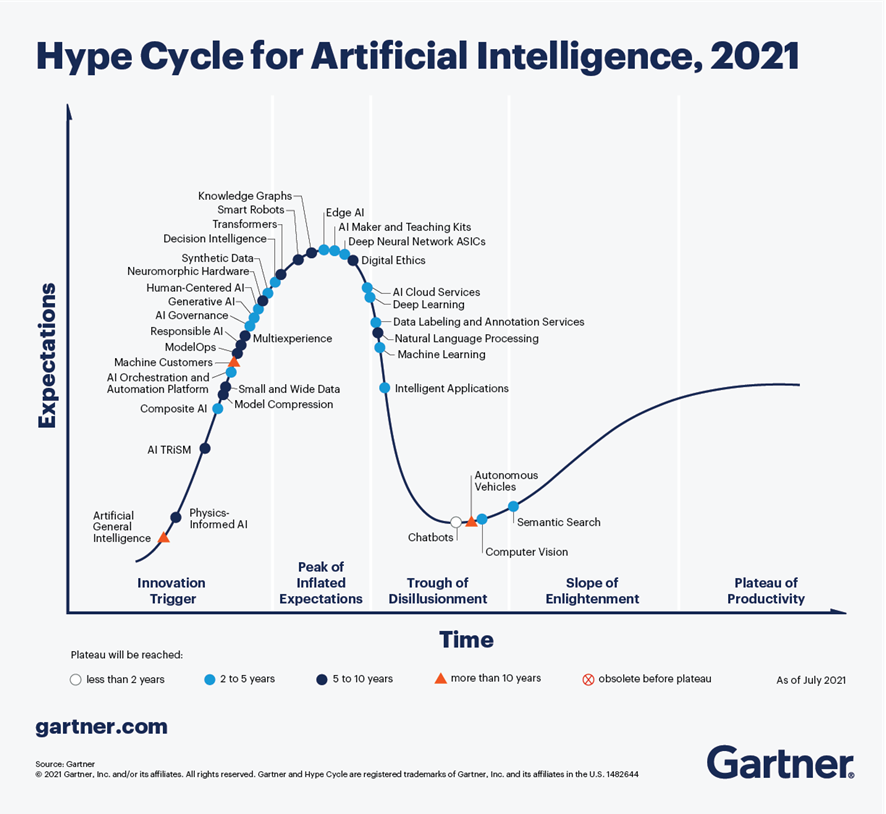
Figura 1 - Tendencias en IA para los próximos años.
En el caso concreto de los chatbots, existen grandes expectativas de productividad en los próximos años gracias a la madurez de las diferentes plataformas disponibles, tanto en opciones de Cloud Computing, como en proyectos de código abierto, es especial RASA o Xatkit. En la actualidad es relativamente sencillo desarrollar un chatbot o asistente virtual sin conocimientos de IA, mediante el uso de estas plataformas.
¿Cómo funciona un chatbot?
A modo de ejemplo, la Figura 2 muestra un diagrama de los diferentes componentes que habitualmente incluye un chatbot, en este caso enfocado en la arquitectura del proyecto RASA.
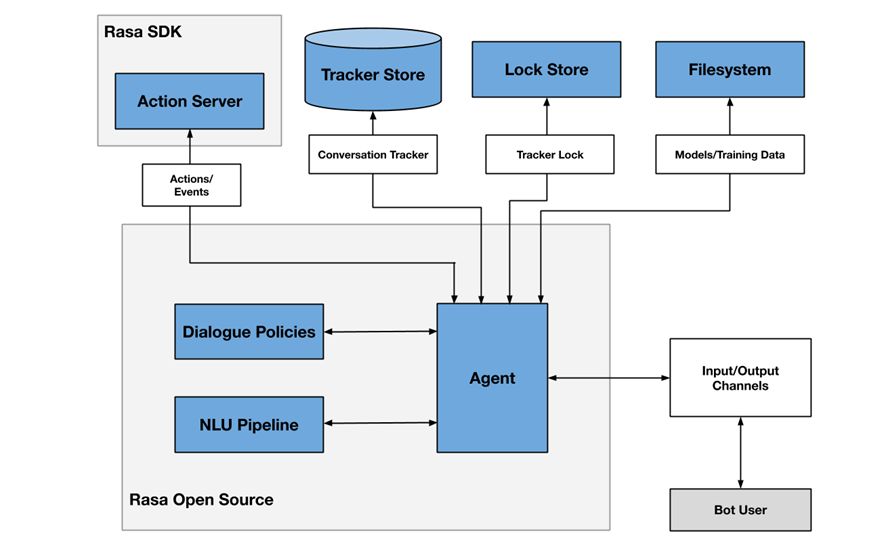
Figura 2 - Arquitectura del proyecto RASA
Uno de los componentes principales es el módulo agente (agent), que actúa a modo de controlador del flujo de datos y normalmente es la interfaz del sistema con los diferentes canales (input/output channels) ofrecidos a los usuarios, como aplicaciones de chat, redes sociales, aplicaciones web o móviles, etc.
El módulo de NLU (Natural Languge Understanding) se encarga de identificar la intención del usuario (qué quiere consultar o hacer), la extracción de entidades (de qué está hablando) y la generación de respuestas. Se considera un flujo (pipeline) porque intervienen varios procesos de diferente complejidad, en muchos casos incluso mediante el uso de modelos pre-entrenados de Inteligencia Artificial.
Finalmente, el módulo de gestión de conversaciones (dialogue policies) define cuál es el siguiente paso en una conversación, basándose en el contexto y el histórico de mensajes. Este módulo se integra con otros subsistemas como el almacén de conversaciones (tracker store) o el servidor que procesa las acciones necesarias para dar respuesta al usuario (action server).
Chatbots en portales de datos abiertos como mecanismo para localizar datos y acceder a información
Cada vez existen más iniciativas para empoderar a los ciudadanos en la consulta de datos abiertos mediante el uso de chatbots, empleando interfaces de lenguaje natural, aumentando así el valor neto que ofrecen dichos datos. El uso de chatbots permite automatizar la recopilación de datos a partir de la interacción con el usuario y responder de forma sencilla, natural y fluida, permitiendo la democratización de la puesta en valor de datos abiertos.
En el SOM Research Lab (Universitat Oberta de Catalunya) fueron pioneros en la aplicación de chatbots para mejorar el acceso de los ciudadanos a los datos abiertos a través de los proyectos Open Data for All y BODI (Bots para interactuar con datos abiertos – Interfaces conversacionales para facilitar el acceso a los datos públicos). Puedes encontrar más información sobre este último proyecto en este artículo.
También cabe destacar el chatbot de Aragón Open Data, del portal de datos abiertos del Gobierno de Aragón, cuyo objetivo es acercar la gran cantidad de datos disponibles a la ciudadanía, para que esta pueda aprovechar su información y valor, evitando cualquier barrera técnica o de conocimiento entre la consulta realizada y los datos abiertos existentes. Los dominios sobre los que ofrece información son:
- Información general sobre Aragón y su territorio
- Turismo y viajes en Aragón
- Transporte y agricultura
- Asistencia técnica o preguntas frecuentes en materia de sociedad de la información
Conclusiones
Estos son sólo algunos ejemplos del uso práctico de chatbots en la puesta en valor de datos abiertos y su potencial a corto plazo. En los próximos años veremos cada vez más ejemplos de asistentes virtuales en diferentes escenarios, tanto del ámbito de las administraciones públicas como en servicios privados, en especial enfocados a la mejora de la atención al usuario en aplicaciones de comercio electrónico y servicios surgidos de iniciativas de transformación digital.
Contenido elaborado por José Barranquero, experto en Ciencia de Datos y Computación Cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
La situación de pandemia que hemos vivido durante los últimos años ocasionó que una gran cantidad de eventos tuvieran que celebrarse de manera online. Fue el caso de las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE), cuyas ediciones de 2020 y 2021 tuvieron un formato virtual. Sin embargo, la situación ha cambiado y en este 2022 podremos volver a reunirnos para hablar de las últimas tendencias en información geográfica.
Sevilla será la sede de la JIIDE 2022
Sevilla ha sido la ciudad elegida para reunir a todos aquellos profesionales de la administración pública, el sector privado y el académico interesados en la información geográfica y que utilizan Infraestructuras de Datos Espaciales (IDE) en el ejercicio de sus actividades.
En concreto, la cita tendrá lugar del 25 al 27 de octubre en la Universidad de Sevilla. Puedes ver más información aquí.
Foco en la experiencia de usuario
El lema de este año es «Experiencia y evolución tecnológica: acercando la IDE a la ciudadanía». Con ello se quiere poner el énfasis en las nuevas tendencias tecnológicas y su uso para proporcionar al ciudadano soluciones que resuelvan problemas concretos, mediante la publicación y tratamiento de la información geográfica de forma normalizada, interoperable y abierta.
Durante tres días los asistentes podrán compartir experiencias y casos de uso sobre cómo utilizar técnicas de Big Data, Inteligencia Artificial o el Cloud Computing para mejorar la capacidad de análisis, el almacenamiento y la publicación web de grandes volúmenes de datos procedente de diversas fuentes, incluyendo sensores en tiempo real.
También se hablarán de las nuevas especificaciones y estándares que han surgido, así como de la evaluación que se está realizando de la Directiva INSPIRE.
Agenda ya disponible
Aunque aún quedan por confirmar algunas participaciones, el programa ya está disponible en la web de las Jornadas. Habrá unas 80 comunicaciones donde se mostrarán experiencias relativas a proyectos reales, 7 talleres técnicos donde compartir conocimientos concretos y una mesa redonda para promover el debate
Entre las ponencias encontramos algunas enfocadas en los datos abiertos. Es el caso del Ayuntamiento de Valencia que nos hablará de cómo utilizan datos abiertos para la obtención de la equidad ambiental en los barrios de la ciudad o la sesión dedicada a la “fototeca aérea Digital de Andalucía: un proyecto para la convergencia de las IDE y Open-Data”.
¿Cómo puedo asistir?
El evento es gratuito, pero para acudir es necesario registrarse a través de este formulario. En él es necesario indicar la jornada a la que se desea acudir.
De momento está abierto el registro para acudir presencialmente, pero en septiembre, se abrirá, en la web de las jornadas, la posibilidad de participar en las JIIDE de forma virtual.
Organizadores
Las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) nacieron de la colaboración de la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España y el Govern d' Andorra. En esta ocasión se une como organizador el Instituto de Estadística y Cartografía de Andalucía y la Universidad de Sevilla.
Noticia
La inteligencia artificial (IA) lleva ya varios años muy presente en nuestras vidas. Si bien no existe una definición exacta sobre ella, una descripción podría ser “la habilidad de una máquina de presentar las mismas capacidades que los seres humanos, como el razonamiento, el aprendizaje, la creatividad y la capacidad de planear”. Este proceso se realiza mediante la creación y la aplicación de algoritmos. Dicho de otra manera, la IA hace referencia a la capacidad que tienen los ordenadores, software y otras máquinas de pensar y actuar como lo harían los seres humanos.
La inteligencia artificial permite desarrollar diferentes casos de uso que facilitan la toma de decisiones o proporcionan soluciones a problemas complejos. Gracias a ello, esta inteligencia ha sido capaz, no solo de revolucionar el mundo empresarial sino también el ámbito social, con aplicaciones que van desde la rápida detección del cáncer hasta la lucha contra la deforestación del Amazonas, por nombrar algunos ejemplos.
Dadas todas estas ventajas, no es de extrañar que en los últimos años haya crecido la demanda de perfiles profesionales relacionados con este campo. Por ello, a continuación, te mostramos algunos ejemplos de cursos y formaciones de interés que podrían ayudarte a ampliar tu conocimiento sobre inteligencia artificial.
Cursos online
Elementos de IA
- Impartido por: Universidad de Helsinki y Reaktor
- Duración: 50 horas
- Idioma: Español
- Precio: Gratuito
Este proyecto educativo masivo y abierto (MOOC), al que ya se han inscrito más de 750.000 estudiantes, te ofrece la oportunidad de aprender qué es la inteligencia artificial, además de mostrarte cómo puede afectar a tu vida laboral y personal o cómo evolucionará en los próximos años.
Este curso, que ofrece a toda la ciudadanía la posibilidad de formarse y conocer de primera mano el funcionamiento y las oportunidades que ofrece la IA, ha sido promovido en nuestro país por la Secretaría de Estado de Digitalización e Inteligencia Artificial junto a la UNED.
Building AI
- Impartido por: Universidad de Helsinki y Reaktor
- Duración: 50 horas
- Idioma: Inglés
- Precio: Gratuito
Los creadores del curso anterior lanzaron tiempo más tarde esta otra formación con la pretensión de cerrar la brecha entre los cursos para principiantes como ‘Elementos de IA’ y la gran mayoría de oferta formativa sobre este campo que existe en el mercado, que suelen presentar un nivel más avanzado.
Este curso, que comienza donde termina el anterior, te ayudará a profundizar en elementos como el machine learning, las redes neuronales o algunas aplicaciones prácticas de la IA. Además, te ofrece la opción de plantear tu primer proyecto sobre inteligencia artificial e iniciarte en programación si lo deseas.
Programa especializado: Introducción a la inteligencia artificial
- Impartido por: Coursera (UNAM)
- Duración: 8 meses
- Idioma: Español
- Precio: Gratuito
Este curso está dirigido a personas que tienen interés en conocer más acerca de los diferentes desarrollos que se han ido generando durante los últimos años en el campo de la inteligencia artificial.
Si te decantas por esta formación aprenderás a implementar tecnología de IA con un propósito específico, a comparar la solución que has desarrollado con otras existentes o a reportar los resultados obtenidos en un ensayo estructurado.
Machine Learning Crash Course
- Impartido por: Google
- Duración: 15 horas
- Idioma: Inglés
- Precio: Gratuito
A través de este curso conocerás algunos conceptos clave como el estudio detallado del aprendizaje automático y darás tus primeros pasos con la API TensorFlow, entre otros.
Para poder cursarlo es recomendable contar con cierta experiencia en programación (preferiblemente en Python), conocimiento básico de aprendizaje automático, de estadística, álgebra lineal y cálculo.
Machine Learning
- Impartido por: Coursera (Stanford)
- Duración: 60 horas
- Idioma: Inglés (subtítulos en español)
- Precio: Gratuito (47€ si se desea solicitar certificado)
Se trata de un MOOC sobre machine learning creado por Andrew Ng, fundador del proyecto Google Brain en 2011 y de la plataforma de cursos online Coursera.
A través de este curso abordarás temas como el aprendizaje supervisado y no supervisado, el reconocimiento de patrones estadísticos o la aplicación de 'buenas prácticas' en este campo. Además, también aprenderás a aplicar algoritmos de aprendizaje a la construcción de robots inteligentes, entre otros muchos aspectos.
Másters
La oferta formativa que existe actualmente sobre inteligencia artificial no solo viene recogida a través de cursos. Cada vez son más las universidades y centros de estudio que ofrecen a sus alumnos programas especializados y másters universitarios relacionados con el campo de la IA. A continuación, te mostramos algunos ejemplos:
- Máster oficial en Seguridad Informática e IA, Universitat Rovira i Virgili (60 créditos ECTS, un año académico): su plan de estudios abarca temas de investigación relacionados con la protección de la información, la seguridad en las aplicaciones, el aprendizaje automático, o la modelización y resolución de problemas, entre otros.
- Máster universitario en Inteligencia Artificial, Universidad de Santiago de Compostela (USC) (90 créditos ECTS, 18 meses): ofrece a sus alumnos la posibilidad de ampliar sus conocimientos sobre aspectos como procesamiento del lenguaje natural, robótica, fundamentos de IA o ingeniería de datos.
- Máster Universitario en Sistemas Inteligentes y Aplicaciones Numéricas en Ingeniería, Universidad de Las Palmas de Gran Canaria (ULPGC) (60 créditos ECTS, 1 año académico): introduce al estudiante a las bases y fundamentos de algunas áreas punteras como el modelado computacional y la simulación numérica de problemas de ingeniería, el uso y desarrollo de sistemas inteligentes y autónomos, o los métodos de análisis e interpretación de datos.
- Máster en Inteligencia Artificial, Universitat Politécnica de catanlunya (90 créditos ECTS, 18 meses): ofrece una base sólida y conocimientos avanzados sobre inteligencia artificial. En este máster aprenderás conceptos clave sobre inteligencia computacional, visión artificial o los sistemas multiagente.
- Máster Universitario en Inteligencia Artificial Aplicada, Universidad Carlos III Madrid (60 créditos ECTS, 1 año académico): permite comprender los métodos y técnicas de IA más relevantes y aplicarlas para desarrollar soluciones apropiadas a diferentes tipos de problemas.
- Máster Universitario en Inteligencia Artificial, UNIR (60 créditos ECTS, 1 año académico): en este máster aprenderás técnicas de percepción computacional y visión artificial, razonamiento y planificación automática, machine learning y deep learning, Procesamiento del Lenguaje Natural, así como las tecnologías necesarias para implementarlas.
- Máster Universitario en Investigación en IA , Asociación Española para la Inteligencia Artificial (AEPIA) (60 créditos ECTS, un año académico): cuenta con tres especialidades: Aprendizaje y Ciencia de Datos, Inteligencia en la Web y Razonamiento y Planificación.
- Master en Inteligencia Artificial, Universidad Europea (30 créditos ECTS, 8 meses): dirigido a que los estudiantes adquieran una visión integradora de la Inteligencia Artificial y el dominio de técnicas avanzadas de Machine Learning y Optimización Computacional.
Esta ha sido tan solo una pequeña recopilación de formaciones relacionadas con el campo de la inteligencia artificial que esperamos pueda ser de tu interés. Si conoces algún otro curso o máster que quieras recomendar, no dudes en dejarnos un comentario o escribirnos un correo electrónico a dinamizacion@datos.gob.es.
Entrevista
La asociación AMETIC representa a empresas de todos los tamaños ligadas con la industria tecnológica digital española, un sector clave para el PIB nacional. Entre otras cuestiones, AMETIC busca impulsar un entorno favorable para el crecimiento de las empresas del sector, potenciando el talento digital y la creación y consolidación de nuevas empresas.
En datos.gob.es hemos hablado con Antonio Cimorra, Director de Transformación Digital y Tecnologías Habilitadoras de AMETIC, para reflexionar sobre el papel de los datos abiertos en la innovación y como base de nuevos productos, servicios e incluso modelos de negocio.
Entrevista completa:
1. ¿Cómo ayudan los datos abiertos a impulsar la transformación digital? ¿Qué tecnologías disruptivas son las más beneficiadas por la apertura de datos?
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad. Todas las industrias, administraciones publicas y la propia ciudadanía no hemos hecho más que comenzar a descubrir y utilizar el enorme potencial y utilidad que la utilización de los datos aporta a la mejora de la competitividad de las empresas, a la eficiencia y mejora de los servicios de las Administraciones Públicas y a las relaciones sociales y la calidad de vida de las personas.
2. Una de las áreas en las que trabajan desde AMETIC es la Inteligencia Artificial y el Big Data, entre cuyos objetivos está promover la creación de plataformas públicas de compartición de datos abiertos. ¿Podría explicarnos qué acciones llevan o han llevado a cabo para ello?
En AMETIC contamos con una Comisión de Inteligencia Artificial y Big Data en la que participan las principales empresas proveedoras de esta tecnología. Desde este ámbito, trabajamos en la definición de iniciativas y propuestas que contribuyen difundir su conocimiento entre los potenciales usuarios, con las consiguientes ventajas que supone su incorporación en los sectores público y privado. Son destacados ejemplos de las acciones en este ámbito la reciente presentación del Observatorio de Inteligencia Artificial de AMETIC, así como el AMETIC Artificial Intelligence Summit que en 2022 celebrará su quinta edición que pondrá foco en mostrar cómo la Inteligencia Artificial puede contribuir al cumplimiento de los Objetivos de Desarrollo Sostenible y a los Planes de Transformación a ejecutar con Fondos Europeos
3. Los datos abiertos pueden servir de base para desarrollar servicios y soluciones que den lugar a nuevas empresas. ¿Podría contarnos algún ejemplo de caso de uso llevado a cabo por sus asociados?
Los datos abiertos y muy particularmente la reutilización de la información del sector público son la base de desarrollo de un sinfín de aplicaciones e iniciativas emprendedoras tanto en empresas consolidadas de nuestro sector tecnológico como en otros muchos casos de pequeñas empresas o startups que encuentran en esta fuente de información el motor de desarrollo de nuevos negocios y acercamiento al mercado.
4. ¿Qué tipos de datos son los más demandados por las empresas a las que representan?
En la actualidad, todos los datos de actividad industrial y social cuentan con una importante demanda por las empresas, atendiendo a su gran valor en el desarrollo de proyectos y soluciones que vienen demostrando su interés y extensión en todos los ámbitos y tipología de organizaciones y usuarios en general.
5. También es fundamental contar con iniciativas de compartición de datos como GAIA-X, constituida sobre los valores de soberanía digital y disponibilidad de los datos. ¿Cómo han recibido las empresas la creación de un hub nacional?
El sector tecnológico ha recibido la creación del hub nacional de GAIA-X muy positivamente, entendiendo que nuestra aportación desde España a este proyecto europeo será de enorme valor para nuestras empresas de muy distintos ámbitos de actividad. Espacios de compartición de datos en sectores como el turismo, la sanidad, la movilidad, la industria, por poner algunos ejemplos, cuentan con empresas y experiencias españolas que son ejemplo y referencia a nivel europeo y mundial.
6. En este momento hay una gran demanda de profesionales relacionados con la captación, análisis y visualización de datos. Sin embargo, la oferta de profesionales, aunque va creciendo, continúa siendo limitada. ¿Qué habría que hacer para impulsar la capacitación en habilidades relacionadas con los datos y la digitalización?
La oferta de profesionales tecnológicos es uno de los mayores problemas para el desarrollo de nuestra industria local y para la transformación digital de la sociedad. Es una dificultad que podemos calificar como histórica, y que lejos de ir a menos, cada día es mayor en número de puestos y perfiles a cubrir. Es un problema a nivel mundial que evidencia que no existe una formula única o sencilla para solucionarlo, pero si podemos mencionar la importancia de que todos los agentes sociales y profesionales desarrollemos acciones conjuntas y en colaboración que permitan la capacitación digital de nuestra población desde edades tempranas y de ciclos y programas formativos y de grado especializados que se caractericen por su proximidad con lo que serán las carreras profesionales para lo que es necesario contar con la participación del sector empresarial
7. Durante los últimos años, has formado parte del jurado de las distintas ediciones del Desafío Aporta. ¿Cómo cree que contribuyen este tipo de acciones a impulsar negocios basados en datos?
El Desafío Aporta ha sido un ejemplo de apoyo y estímulo para la definición de muchos proyectos en torno a los datos abiertos y para el desarrollo de una industria propia que en estos últimos años ha venido creciendo de forma muy significativa con la puesta a disposición de datos de muy distintos colectivos, en muchos casos por parte de las Administraciones Públicas, y su posterior reutilización e incorporación a aplicaciones y soluciones de interés para muy distintos usuarios.
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad.
8. ¿Cuáles son las próximas acciones que van a llevar a cabo en AMETIC ligadas a la economía del dato?
Entre las acciones más destacadas de AMETIC en relación con la economía del dato cabría citar nuestra reciente incorporación al hub nacional de GAIA-X para el que hemos sido elegidos miembros de su junta directiva, y en donde representaremos e incorporaremos la visión y las aportaciones de la industria tecnológica digital en todos los espacios de datos que se constituyan, sirviendo de canal de participación de las empresas tecnológicas que desarrollan su actividad en nuestro país y que tienen que conformar la base de los proyectos y casos de uso que integrar en la red europea GAIA-X en colaboración con otros hubs nacionales.