Blog
Durante la última década hemos visto como las instituciones nacionales e internacionales, así como los gobiernos de los países y las propias asociaciones empresariales alertaban sobre la escasez de perfiles tecnológicos y la amenaza que esto supone para la innovación y el crecimiento. No se trata de un problema exclusivamente europeo - y que por tanto afecta también a España-, sino que en mayor o menor medida se da en todo el mundo, y que ha sido agravado aún más por la reciente pandemia.
Cualquiera que lleve un tiempo de vida profesional, y no necesariamente en el mundo tecnológico, ha podido observar cómo la demanda de roles relacionados con la tecnología ha ido aumentando. No es más que la consecuencia de que las compañías de todo el mundo están haciendo grandes inversiones en digitalización para mejorar sus operaciones e innovar en sus productos, junto con la creciente presencia de la tecnología en todos los aspectos de nuestra vida.
Y dentro de los profesionales de la tecnología, durante los últimos años hay un grupo que se ha convertido en una especie de unicornio debido a su particular escasez, los científicos de datos y el resto de profesionales relacionados con los datos y la inteligencia artificial: ingenieros de datos, ingenieros de machine learning, especialistas en ingeniería artificial en todos los ámbitos, desde la gobernanza de datos hasta la propia configuración y despliegue de modelos de aprendizaje profundo, etc.
Este escenario es especialmente problemático para España donde los salarios son menos competitivos que en otros países de nuestro entorno y donde, de entrada, la proporción de trabajadores de IT está por debajo de la media de la UE. Por tanto, es previsible que las compañías españolas y las administraciones públicas, que también están implementando proyectos de este tipo, se enfrenten a crecientes dificultades para reclutar y retener el talento relacionado con la tecnología en general, y con los datos y la inteligencia artificial en particular.
Cuando existe un problema de oferta, la única solución sostenible a medio y largo plazo es aumentar la producción de aquello que escasea. En este caso la solución pasaría por incorporar al mercado laboral nuevos profesionales como único mecanismo para garantizar un mejor equilibrio entre oferta y demanda. Y así lo reconocen todas las estrategias y planes nacionales y europeos relacionadas con la digitalización, la inteligencia artificial y la propia reforma de los sistemas educativos, tanto superior como de formación profesional.
Las Estrategias españolas
La Estrategia Nacional de Inteligencia Artificial dedica uno de sus ejes a la promoción del desarrollo de capacidades digitales con el objetivo de poner todos los medios que garanticen que los trabajadores tengan un dominio adecuado de las habilidades digitales y capacidades para comprender y desarrollar tecnologías y aplicaciones de Inteligencia Artificial. El Gobierno español ha previsto una amplia gama de políticas de educación y formación cuya base es el Plan Nacional de competencias digitales, publicado en enero de 2021 y que está alineado con la Agenda Digital 2025.
Este plan incluye la analítica de datos y la inteligencia artificial como áreas de vanguardia tecnológica dentro de las competencias digitales especializadas, esto es, “necesarias para satisfacer la demanda laboral de especialistas en tecnologías digitales: personas que trabajan directamente en el diseño, implementación, operación y/o mantenimiento de sistemas digitales”.
En general, la estrategia nacional presenta acciones de política sobre educación y habilidades digitales para toda la población a lo largo de toda su vida. Aunque en muchos casos estas medidas están aún en fase de planificación y verán un impulso importante con el despliegue de los fondos de NextGenerationEU, ya tenemos algunos ejemplos pioneros como los programas de formación y orientación para el empleo para desempleados y jóvenes licitados el año pasado y recientemente adjudicados. En el caso de la formación para personas desempleadas ya se encuentran en ejecución actuaciones para como el programa Actualízate y el proyecto de formación para la adquisición de capacidades para la economía digital. Las acciones adjudicadas que están dirigidas a jóvenes está previsto que comiencen en el primer trimestre de 2022. En ambos casos el objetivo es la impartición de acciones formativas gratuitas dirigidas a la adquisición y mejora de competencias TIC, competencias personales y empleabilidad, en el ámbito de la transformación y la economía digital, así como la orientación y la inserción laboral. Entre estas competencias TIC, sin duda, las relacionadas con los datos y la inteligencia artificial tendrán un peso importante en los programas de formación.
El papel de las universidades
Por otra parte, las universidades de todo el mundo, y por supuesto las españolas, llevan ya un tiempo adaptando planes de estudio y creando nuevos programas formativos relacionados con los datos y la inteligencia artificial. La primera en adaptarse a la demanda fue la formación de posgrado, que, dentro del sistema de educación superior, es la más flexible y rápida de implementar. La primera hornada de profesionales con formación específica en datos e inteligencia artificial provenía de disciplinas diversas. Por ello, entre los veteranos de los equipos de datos de las empresas podemos encontrar diferentes disciplinas STEM, desde las matemáticas y la física hasta prácticamente cualquier ingeniería. En general, lo que tenían en común estos pioneros era haber cursado Másteres en Big Data, en ciencia de datos, en analítica de datos, etc. complementados con formaciones no regladas a través de MOOCs.
En la actualidad están comenzando a llegar ya al mercado laboral los primeros profesionales que han cursado los primeros grados en ciencia de datos o ingeniería de datos que reformaron las universidades pioneras - pero que en la actualidad están ya implantados en numerosas universidades españolas - . Estos profesionales tienen un grado de adaptación muy alto a las actuales necesidades del mercado laboral, por lo que están muy demandados entre las empresas.
Para las universidades, el principal reto pendiente es que los planes de estudios universitarios de cualquier disciplina incluyan conocimientos para trabajar con datos y para comprender cómo los datos apoyan la toma de decisiones. Esto será vital para apoyar el objetivo de la UE de que el 70% de los adultos tenga habilidades digitales básicas para 2025.
Grandes compañías tecnológicas desarrollando talento
Una idea del tamaño del problema que supone la escasez de estas competencias para la economía global es la implicación de gigantes tecnológicos como Google, Amazon o Microsoft en su solución. En los últimos años hemos observado como prácticamente todas ellas han lanzado materiales y programas gratuitos a gran escala para certificar personal en diferentes áreas de la tecnología, porque lo consideran una amenaza para su propio crecimiento, aunque no sean precisamente ellas las que tengan las mayores dificultades para reclutar el escaso talento existente. Su visión es que si el resto de compañías no son capaces de seguir el ritmo de la digitalización esto hará que su propio crecimiento se resienta y por eso hacen grandes inversiones en programas de certificación más allá de sus propias tecnologías, como por ejemplo el Certificado profesional de Soporte de TI de Google o el Programa especializado: Desarrollo de aplicaciones modernas con Python de AWS.
Otras compañías multinacionales están abordando la escasez de talento volviendo a capacitar a sus empleados en habilidades analíticas e inteligencia artificial. Para ello siguen diferentes estrategias, como incentivar que sus empleados cursen MOOC o crear planes de formación a medida con proveedores especializados del sector educativo. En algunos casos, también se incentiva a los empleados en roles no relacionados con los datos a participar en capacitaciones ligadas a la ciencia de datos, como la visualización o analítica de datos.
Aunque tardaremos aún en ver sus efectos debido a la elevada inercia que tienen todas estas medidas, sin duda se va en la dirección adecuada para mejorar la competitividad de unas empresas que necesitan seguir el elevado ritmo global de innovación que rodea la inteligencia artificial y todo lo referente con los datos. Por su parte los profesionales que sepan adaptarse a esta demanda vivirán un momento dulce los próximos años y podrán elegir con qué proyectos se comprometen sin preocuparse por las dificultades que, por desgracia, afectan al empleo en otras áreas de conocimiento y sectores de actividad.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Los datos abiertos pueden ser la base de diversas tecnologías disruptivas, como la Inteligencia Artificial, que impliquen mejoras para la sociedad y la economía. En estas infografías se abordan tanto herramientas para trabajar con los datos, como ejemplos del uso de datos abiertos en estas nuevas tecnologías. Se irán publicando nuevos contenidos de manera periódica.
Decálogo del científico de datos
 |
Publicada: octubre 2025 Desde comprender el problema antes de mirar los datos, hasta visualizar para comunicar y mantenerse actualizado, este decálogo ofrece una visión completa del ciclo de vida de un proyecto de datos responsable y bien estructurado. |
Visualización de datos abiertos con herramientas open source
 |
Publicada: junio 2025 Esta infografía recopila herramientas de visualización de datos, el último paso del análisis exploratorio de datos. Es la segunda parte de la infografía sobre análisis de datos abiertos con herramientas open source. |
Análisis de datos abiertos con herramientas open source
 |
Publicada: marzo 2025 El AED consiste en aplicar un conjunto de técnicas estadísticas dirigidas a explorar, describir y resumir la naturaleza de los datos, de tal forma que podamos garantizar su objetividad e interoperabilidad. En esta infografía, recopilamos herramientas gratuitas para realizar los tres primeros pasos de un análisis de datos. |
Nuevas técnicas de captura de datos geoespaciales
 |
Publicada: enero 2025 La captura de datos geoespaciales es esencial para entender el entorno, tomar decisiones y diseñar políticas efectivas. En esta infografía, exploraremos nuevos métodos de captura de datos. |
Análisis Exploratorio de Datos (EDA)
 |
Publicada: noviembre 2024 En base a lo recogido en el informe “Guía Práctica de Introducción al Análisis Exploratorio de Datos”, se ha elaborado una infografía que resume de manera sencilla en qué consiste esta técnica, sus beneficios y cuáles son los pasos a seguir para realizarlo correctamente. |
Glosario de términos relacionados con nuevas tecnologías y datos
 |
Publicada: mayo 2024 Esta infografía se centra en términos sobre nuevas tecnologías relacionadas con los datos. |
Glosario de términos relacionados con datos abiertos
 |
Publicada: abril 2024 Esta infografía recoge la definición de diversos términos relacionados con los datos abiertos. |
Datos sintéticos
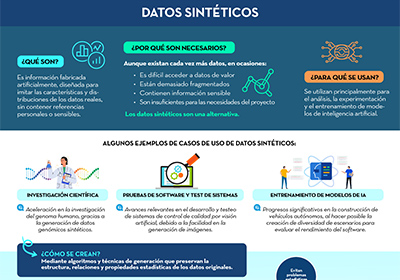 |
Publicada: octubre 2023 En base a lo recogido en el informe ''Datos sintéticos: ¿Qué son y para qué se usan?'', se ha elaborado una infografía que resume de manera sencilla las principales claves de los datos sintéticos y cómo permiten superar las limitaciones de los datos reales. |
Inteligencia artificial y datos abiertos
 |
Publicada: enero 2023 En esta infografía se detalla qué es la inteligencia artificial y cuál es el papel que juegan los datos abiertos dentro de la misma. Además, se ofrecen diferentes ejemplos de casos de uso de la inteligencia artificial. |
Tecnologías emergentes y datos abiertos: Analítica Predictiva
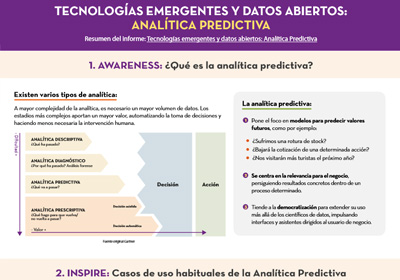 |
Publicada: abril 2021 Esta infografía es un resumen del informe Tecnologías emergentes y datos abiertos: Analítica Predictiva, de la serie “Awareness, Inspire, Action”. En ella se explica en qué consiste la analítica predictiva y sus casos de uso más habituales. También se muestra un ejemplo práctico, utilizando el conjunto de datos accidentes de tráfico en la ciudad de Madrid. |
4 retos del sector educativo a resolver con soluciones tecnológicas basadas en datos
 |
Publicada: agosto 2020 A través de una tecnología educativa innovadora basada en datos e inteligencia artificial se pueden abordar algunos de los desafíos a los que se enfrenta el sistema educativo, como la supervisión de pruebas de evaluación online, la identificación de problemas de comportamiento, la formación personalizada o la mejora del rendimiento en exámenes estandarizados. En esta infografía, resumen del informe “Tecnología educativa basada en datos para mejorar el aprendizaje en el aula y en el hogar”, se muestran algunos ejemplos. |
{kind=link}
Entrevista
Los datos abiertos no son solo cosa de las Administraciones públicas, cada vez más empresas también apuestan por ellos. Es el caso de Microsoft, quien ha proporcionado acceso a datos abiertos seleccionados en Azure pensados para el entrenamiento de modelos de Machine Learning. También colabora en el desarrollo de múltiples proyectos con el fin de impulsar el open data. En España, ha colaborado en el desarrollo de la plataforma HealthData 29, destinada a la publicación de datos en abierto para impulsar la investigación médica.
Hemos entrevistado a Belén Gancedo, Directora de Educación en Microsoft Ibérica y miembro del jurado en la III edición del Desafío Aporta, centrado en el valor de los datos para el sector educativo. Nos hemos reunido con ella para que nos hable de la importancia de la educación digital y de las soluciones innovadoras basadas en datos, así como de la importancia de los datos abiertos en el sector empresarial.
Entrevista completa:
1. ¿Qué retos del sector educativo, a los que urge dar respuesta, ha puesto de manifiesto la pandemia en España?
La tecnología se ha convertido en elemento imprescindible en la nueva forma de aprender y enseñar. Durante los últimos meses, marcados por la pandemia, hemos visto cómo se ha pasado en muy poco tiempo a un modelo de educación híbrido -presencial y en remoto-. Hemos visto ejemplos de centros que, en tiempo récord, en menos de 2 semanas, han tenido que acelerar los planes de digitalización que ya tenían en mente.
La tecnología ha pasado de ser un salvavidas temporal, que permitió dar clases en la peor etapa de la pandemia, a convertirse en una parte totalmente integrada de la metodología de enseñanza de muchos centros educativos. Según una encuesta reciente de YouGov encargada por Microsoft, el 71% de los educadores de Primaria y Secundaria señala que la tecnología les ha ayudado a mejorar su metodología y ha mejorado su capacidad de enseñar. Asimismo, el 82% del profesorado señala que, este último año, se ha acelerado el ritmo al que la tecnología ha impulsado la innovación en la enseñanza y el aprendizaje.
Antes de esta pandemia, de alguna forma, quienes veníamos dedicándonos a la educación, éramos quienes defendíamos la necesidad de transformar digitalmente el sector y los beneficios que la tecnología introducía en él. Sin embargo, lo vivido ha servido para que todo mundo sea consciente de los beneficios de la aplicación de la tecnología en el entorno educativo. En ese sentido ha habido un enorme avance. Nosotros hemos observado un gran incremento en el uso de nuestra herramienta Teams, que ya usan más de 200 millones de estudiantes, profesores y personal del sector educativo en todo el mundo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas. Los estudiantes son cada vez más diversos, y también lo son sus expectativas sobre el papel de la educación universitaria en su camino hacia el empleo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas
2. Cada vez hay más demanda de capacidades y competencias digitales relacionadas con los datos. En este sentido, se ha lanzado el Plan Nacional de Competencias Digitales, donde se incluye la digitalización de la educación y el desarrollo de las competencias digitales para el aprendizaje. ¿Qué cambios habría que hacer en los programas educativos de cara a impulsar la adquisición de conocimientos digitales por parte de los alumnos?
Sin duda, uno de los mayores retos a los que nos enfrentamos en la actualidad es la falta de capacitación y habilidades digitales. Según un estudio llevado a cabo por Microsoft y EY, el 57% de las compañías encuestadas esperan que la IA tenga un alto o muy alto impacto en las áreas de negocios que son “totalmente desconocidas para las compañías en la actualidad”.
Hay una clara oportunidad para que España lidere en Europa en talento digital, consolidándose como uno de los países más atractivos para atraer y retener este talento. Un reciente estudio de LinkedIn anticipa que en los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación. Sin embargo, hay un déficit de profesionales con habilidades y formación en competencias digitales. De acuerdo con los datos del Digital Economy and Society Index Report que publica anualmente la Comisión Europea, España se encuentra por debajo de la media europea en la mayoría de los indicadores que hacen referencia a las competencias digitales de los profesionales españoles.
Existe, por tanto, una demanda urgente de formar talento cualificado con capacidades digitales, gestión del dato, IA, machine learning… Los perfiles relacionados con la tecnología se encuentran entre los más difíciles de encontrar y, en un futuro próximo, los relacionados con la analítica de datos, la computación en la nube y el desarrollo de aplicaciones.
Para ello, es necesaria una adecuada formación, ya no solo en la forma de enseñar, sino también en el contenido curricular. Cualquier carrera, ya no solo las del ámbito STEM, necesitaría incluir materias relacionadas con la tecnología y la IA, que será la que defina el futuro. El uso de la IA llega a cualquier ámbito, no solo al tecnológico, por lo tanto, el alumnado de cualquier tipo de carrera -Derecho, Periodismo…- por poner algunos ejemplos de carreras no STEM, necesita formación cualificada en tecnología como la IA o la ciencia de datos, puesto que lo van a tener que aplicar en su futuro profesional.
Debemos apostar por las colaboraciones público-privadas e involucrar a la industria tecnológica, las administraciones públicas, la comunidad educativa, adecuando los contenidos curriculares de la Universidad a la realidad laboral- y las entidades del tercer sector, con el objetivo de impulsar la empleabilidad y el reciclaje profesional. De esta forma, se impulsará la capacitación de los profesionales en áreas como computación cuántica, Inteligencia Artificial, o analítica de datos y podremos aspirar al liderazgo digital.
En los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación.
3. Todavía hoy encontramos disparidad entre el número de hombre y mujeres que eligen ramas profesionales relacionadas con la tecnología. ¿Qué se necesita para impulsar el papel de la mujer en el ámbito tecnológico?
Según el Observatorio Nacional de Telecomunicaciones y Sociedad de la Información -ONTSI- (julio 2020), la brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos. El porcentaje de investigadoras en el sector de servicios TIC se reduce al 23,4%. Y en cuanto al porcentaje de graduados/as en STEM, España se sitúa en la posición 12 dentro de la UE, con una diferencia entre sexos de 17 puntos.
Sin duda, queda mucho camino por recorrer. Una de las principales barreras con las que se encuentran las mujeres en el sector de la tecnología y a la hora de emprender son los estereotipos y la tradición cultural. El entorno masculinizado de las carreras técnicas y los estereotipos sobre quienes se dedican a la tecnología las convierte en carreras poco atractivas para las mujeres.
La digitalización está dinamizando la economía y favoreciendo la competitividad empresarial, así como generando un incremento en la creación de empleo especializado. Quizá lo más interesante del impacto de la digitalización en el mercado laboral es que estos nuevos puestos de trabajo no se están creando sólo en la industria tecnológica, sino también en empresas de todos los sectores, que necesitan incorporar talento especializado y con habilidades digitales.
Por lo tanto, existe una demanda urgente de formar talento cualificado con capacidades digitales y este talento debe ser diverso. La mujer no puede quedar atrás. Es el momento de atajar la desigualdad de género, y alertar de esta enorme oportunidad a todos, con independencia de su género. Las carreras STEM son una opción ideal de futuro para cualquier persona, independientemente de su género.
Para favorecer la presencia femenina en el sector tecnológico, en pro de una era digital sin exclusión, en Microsoft hemos puesto en marcha diferentes iniciativas que buscan desterrar estereotipos y animar a las niñas y jóvenes a interesarse por la ciencia y la tecnología y hacerlas ver que ellas también pueden ser las protagonistas de la sociedad digital. Además de los Premios WONNOW que convocamos con CaixaBank, también participamos y colaboramos en muchas iniciativas, como los Premios Ada Byron junto a Universidad de Deusto, para ayudar a dar visibilidad al trabajo de mujeres en el ámbito STEM, para que sean referentes de las que están por venir.
La brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos
4. ¿Cómo pueden iniciativas como los hackathons, desafío o retos ayudar a impulsar la innovación basada en datos? ¿Cómo ha sido su experiencia en el III Desafío Aporta?
Este tipo de iniciativas son clave para ese cambio tan necesario. En Microsoft estamos constantemente organizando hackathons tanto a escala global, como regional y local, para innovar en distintas áreas prioritarias para la compañía como, por ejemplo, la educación.
Pero vamos más allá. También usamos estas herramientas en clase. Una de las apuestas de Microsoft son los proyectos Hacking STEM. Se trata de proyectos en los que se mezcla el concepto “maker” de aprender haciendo con la programación y la robótica, mediante el uso de materiales cotidianos. Además, están integrados por actividades que permiten a los docentes guiar a sus alumnos para construir y crear instrumentos científicos y herramientas basadas en proyectos para visualizar datos a través de la ciencia, la tecnología, la ingeniería y las matemáticas. Nuestros proyectos -tanto de Hacking STEM como de codificación y lenguaje computacional mediante el uso de herramientas gratuitas como Make Code- pretenden llevar la programación y la robótica a cualquier asignatura de forma transversal, y por qué no, aprender programación en una clase de latín o en una de biología.
Mi experiencia en el III Desafío Aporta ha sido fantástica porque me ha permitido conocer ideas y proyectos increíbles donde se hace realidad la utilidad de la cantidad de datos disponibles y se ponen al servicio de la mejora de la educación de todos. Ha habido muchísima participación y, además, con presentaciones muy cuidadas y trabajadas. La verdad es que me gustaría aprovechar esta oportunidad para dar las gracias a todos los que han participado y también dar la enhorabuena a los ganadores.
5. Hace un año Microsoft lanzó una campaña para impulsar la apertura de datos de cara a cerrar la brecha entre los países y empresas que tienen los datos necesarios para innovar y aquellos que no. ¿En qué ha consistido el proyecto? ¿Qué avances se han logrado?
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
Microsoft cree que se debe hacer más para ayudar a las organizaciones a compartir y colaborar en torno a los datos, de modo que las empresas y los gobiernos puedan utilizarlos para afrontar los retos que se les presentan, pues la capacidad de compartir datos conlleva enormes beneficios. Y no solo para el entorno empresarial, sino que también juegan un rol crítico a la hora de ayudarnos a entender y abordar grandes desafíos, como el cambio climático, o crisis sanitarias, como la pandemia COVID-19. Para aprovecharlos al máximo, es necesario desarrollar la capacidad de compartirlos de una forma segura y confiable, y permitir que puedan ser utilizados de manera efectiva.
Dentro de la iniciativa Open Data Campaign, Microsoft ha anunciado 5 grandes principios que guiarán cómo la propia compañía aborda la forma de compartir sus datos con otros:
- Abiertos – Trabajará para hacer que los datos relevantes sobre problemas sociales de gran envergadura se encuentren tan abiertos como sea posible.
- Utilizables– Invertirá en crear nuevas tecnologías y herramientas, mecanismos de gobernanza y políticas para que los datos puedan ser usados por todos.
- Impulsores – Microsoft ayudará a las organizaciones a generar valor a partir de sus datos y a desarrollar talento en IA para utilizarlos de manera efectiva.
- Seguros– Microsoft va a emplear controles de seguridad para garantizar que la colaboración en torno a datos sea segura a nivel operacional.
- Privados – Microsoft ayudará a las organizaciones a proteger la privacidad de los individuos en colaboraciones donde se compartan datos y que involucren información de identificación personal.
Seguimos avanzado en este sentido. El año pasado, Microsoft España, junto a Fundación 29, la Cátedra sobre la Privacidad y Transformación Digital Microsoft-Universitat de València y con el asesoramiento legal del despacho de abogados J&A Garrigues han creado la Guía “Health Data” que describe el marco técnico y legal para llevar a cabo la creación de un repositorio público de datos de los sistemas de Salud, y que estos puedan compartirse y utilizarse en entornos de investigación. Y LaLiga es una de las entidades que ha compartido, en junio de este año, sus datos anonimizados.
El Dato es el principio de todo. Y una de nuestras mayores responsabilidades como empresa de tecnología es ayudar a la conservación del ecosistema a gran escala, a nivel planetario. Para ello el mayor reto es consolidar no solo todos los datos disponibles, sino los algoritmos de inteligencia artificial que permitan acceder a ello y permitan tomar decisiones, crear modelos predictivos, escenarios con información actualizada desde múltiples fuentes. Por eso, Microsoft lanzó el concepto de Planetary Computer, basado en Open Data, para poner a disposición de científicos, biólogos, startups y empresas, de forma gratuita, más de 10 Petabytes de datos -y creciendo- de múltiples fuentes (biodiversidad, electrificación, forestación, biomasa, satélite), APIs, Entornos de Desarrollo y aplicaciones (modelo predictivo, etc.) para crear un mayor impacto para el planeta.
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
6. También ofrecen algunos conjuntos de datos en abierto a través de su iniciativa Azure Open Datasets. ¿Qué tipo de datos ofrecen? ¿Cómo los pueden utilizar los usuarios?
Esta iniciativa busca que las empresas mejoren la precisión de las predicciones de sus modelos de Machine Learning y reduzcan el tiempo de preparación de los datos, gracias a conjuntos de datos seleccionados de acceso público, listos para usar y a los que se puede acceder fácilmente desde los servicios de Azure.
Hay datos de todo tipo: salud y genómica, transporte, mano de obra y economía, población y seguridad, datos comunes… que se pueden utilizar de múltiples maneras. Y también es posible aportar datasets a la comunidad.
7. ¿Cuáles son los planes de futuro de Microsoft en relación con los datos abiertos?
Tras un año con la Opendata campaign, hemos tenido muchos aprendizajes y, en colaboración con nuestros partners, vamos a enfocarnos el próximo año a aspectos prácticos que hagan el proceso de la compartición de datos más sencilla. Acabamos de empezar a publicar materiales para que las organizaciones vean los aspectos prácticos de cómo empezar a compartir datos. Continuaremos identificando posibles colaboraciones para solventar retos sociales en temas de sostenibilidad, salud, equidad e inclusión. También queremos conectar a aquellos que están trabajando con datos o quieren explorar ese ámbito con las oportunidades que ofrecen las Certificaciones de Microsoft en Data e Inteligencia Artificial. Y, sobre todo, este tema requiere de un buen marco regulatorio y, para ello, es necesario que quienes definen las políticas se reúnan con la industria, la academia y la sociedad civil para desarrollar incentivos, infraestructuras y mecanismos que permitan compartir datos del sector público y privado -dentro y a través de fronteras organizacionales y nacionales,- siempre salvaguardando los derechos humanos, con el fin de hacer un uso efectivo de dichos datos en pro de la innovación.
Blog
La inteligencia artificial está cada vez más presente en nuestras vidas. Sin embargo, su presencia es cada vez más sutil e inadvertida. A medida que una tecnología madura y permea más en la sociedad, ésta se vuelve cada vez más transparente, hasta que se naturaliza por completo. La inteligencia artificial está recorriendo este camino rápidamente, y hoy, os lo contamos con un nuevo ejemplo.
Introducción
En este espacio de comunicación y divulgación hemos hablado muchas veces de inteligencia artificial (IA) y sus aplicaciones prácticas. En otras ocasiones, hemos comunicado informes monográficos y artículos sobre aplicaciones concretas de la IA en la vida real. Es evidente que este es un tema de máxima actualidad y repercusión en el sector de la tecnología, y es por esto que continuamos incidiendo en nuestra labor divulgativa sobre este campo.
En esta ocasión, os hablamos sobre los últimos avances en inteligencia artificial aplicada al campo del procesamiento de lenguaje natural. A principios del año 2020 publicamos un informe en el que citamos los trabajos de Paul Daugherty y James Wilson - Human + Machine - para explicar los tres estados en los que la IA colabora con las capacidades humanas. Daugherty y Wilson explican estos tres estados de colaboración entre máquinas (IA) y humanos de la siguiente forma (ver figura 1). En el primer estado, la IA se entrena con características genuinamente humanas como el liderazgo, la creatividad y los juicios de valor. El estado opuesto, es aquel en el que se destacan características donde las máquinas demuestran un mejor desempeño que los humanos. Hablamos de actividades repetitivas, precisas y continuas. Sin embargo, el estado más interesante es el intermedio. En este estado, los autores identifican actividades o características en las que los humanos y las máquinas realizan actividades híbridas, en las que se complementan mutuamente. En este estado intermedio, se distinguen, a su vez, dos etapas de madurez.
- En la primera etapa -la más inmadura- los humanos complementan a las máquinas. Disponemos de numerosos ejemplos de esta etapa en la actualidad. Los humanos enseñamos a las máquinas a conducir (coches autónomos) o a entender nuestro lenguaje (procesado del lenguaje natural).
- La segunda etapa de madurez se produce cuando la IA potencia o amplifica nuestras capacidades humanas. En palabras de Daugherty y Wilson, la IA nos da superpoderes a los humanos.

Figura 1: Estados de colaboración entre humanos y máquinas. Fuente original
En este post, te mostramos un ejemplo de este superpoder que nos devuelve la IA. El superpoder de resumir libros de decenas de miles de palabras a tan solo unos cientos. Los resúmenes resultantes son similares a cómo los haría un humano con la diferencia de que la IA lo hace en unos pocos segundos. Hablamos, en concreto, de los últimos avances que ha publicado la compañía OpenAI dedicada a la investigación en sistemas de inteligencia artificial.
Resumiendo libros como un humano
OpenAI define de forma similar el razonamiento de Daugherty y Wilson sobre los modelos de colaboración de la IA con los humanos. Los autores del último trabajo de OpenAI explican que, para implementar modelos de inteligencia artificial tan potentes que resuelvan problemas globales y genuinamente humanos, debemos asegurarnos de que los modelos de IA actúen alineados con las intenciones humanas. De hecho, este reto se conoce como el problema de alineamiento.
Los autores explican que: "Para probar técnicas de alineación escalables, entrenamos un modelo para resumir libros completos [...] Nuestro modelo funciona primero resumiendo pequeñas secciones de un libro, luego resumiendo esos resúmenes en un resumen de nivel superior, y así sucesivamente".
Veamos un ejemplo
Los autores han refinado el algoritmo GPT-3 para resumir libros completos basándose en una aproximación conocida como: descomposición recursiva de tareas acompañada con un refuerzo a partir de comentarios humanos. La técnica se denomina descomposición recursiva porque se fundamenta en realizar múltiples resúmenes de la obra completa (por ejemplo, un resumen por cada capítulo o sección) y, en iteraciones posteriores, ir realizando, a su vez, resúmenes de los resúmenes previos, cada vez con menor número de palabras. En la siguiente figura se explica el proceso de forma más visual.

Fuente original: https://openai.com/blog/summarizing-books/
Resultado final:

Fuente original: https://openai.com/blog/summarizing-books/
Como hemos citado en anteriores ocasiones, el algoritmo GPT-3 ha sido entrenado gracias al conjunto de libros digitalizados bajo el amparo del proyecto Gutenberg. El vasto repositorio del proyecto Gutenberg incluye hasta 60.000 libros en formato digital que, actualmente, son de dominio público en Estados Unidos. De la misma forma que se ha usado el proyecto Gutenberg para entrenar GPT-3 en inglés, se podrían haber usado otros repositorios de datos abiertos para entrenar el algoritmo en otros idiomas. En nuestro país, la Biblioteca Nacional cuenta con un portal de datos abiertos para explotar el catálogo disponible de obras bajo dominio público en español.
Los autores del trabajo afirman que la descomposición recursiva plantea ciertas ventajas con respecto a las aproximaciones más integrales que tratan de resumir el libro de una sola vez.
- La evaluación de la calidad de los resúmenes por humanos es más sencilla cuándo se trata de evaluar resúmenes de partes concretas de un libro que si se trata de la obra entera.
- Un resumen, trata siempre de identificar las partes clave de un libro o un capítulo de un libro, manteniendo los datos fundamentales y descartando aquellos que no aporten a la hora de entender el contenido. Evaluar este proceso para entender si realmente se han capturado esos detalles fundamentales es mucho más sencillo con esta aproximación basada en la descomposición del texto en unidades más pequeñas.
- Esta aproximación descompositiva mitiga las limitaciones que pueden existir cuándo las obras a resumir son muy grandes.
Además del ejemplo principal que hemos expuesto en este post sobre la obra de Shakespeare, Romeo y Julieta, los lectores pueden experimentar por ellos mismos cómo funciona esta IA en el explorador de resúmenes de openAI. Esta web, pone a disposición dos repositorios de libros (obras clásicas) abiertos sobre los que se puede experimentar la capacidad de resumir de esta IA navegando desde el resumen final del libro hacia los resúmenes anteriores en el proceso de descomposición recursiva.
Concluyendo, el procesamiento del lenguaje natural es una capacidad humana clave que está siendo reforzada por el desarrollo de la IA de forma espectacular en los últimos años. No solo OpenAI realiza contribuciones de calado en este campo. Otros gigantes tecnológicos, como Microsoft y NVIDIA, también están realizando grandes avances como se constata con el último anuncio de estas dos compañías y su nuevo modelo Megatron-Turing NLG. Este nuevo modelo muestra grandes avances en tareas como por ejemplo: la generación de texto predictivo o el entendimiento del lenguaje humano para interpretación de comandos de voz en asistentes personales. Con todo ello, no cabe duda que veremos a las máquinas hacer cosas increíbles en los próximos años.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Recientemente se ha hecho público un borrador de Reglamento sobre Inteligencia Artificial en el marco de la iniciativa de la Comisión Europea en este ámbito. Se trata de una normativa directamente relacionada con la propuesta sobre gobernanza de los datos, la Directiva de reutilización de la información del sector público y datos abiertos, así como otras iniciativas en el marco de la Estrategia europea de datos.
Esta medida es un importante paso adelante por cuanto supone que la Unión Europea dispondrá de un marco normativo uniforme que permitirá ir más allá de las iniciativas individuales adoptadas por cada uno de los Estados miembros que, como en el caso de España, han aprobado su propia estrategia al amparo de un Plan Coordinado que ha sido actualizado recientemente con el fin de impulsar el liderazgo global de la Unión Europea en la apuesta por un modelo de Inteligencia Artificial confiable.
¿Por qué un Reglamento?
A diferencia de la Directiva, el Reglamento de la Unión Europea es de aplicación directa en todos los Estados miembros, no siendo por tanto necesaria su transposición a través de la legislación propia de cada uno de ellos. Aunque las estrategias nacionales sirvieron para identificar los sectores más relevantes, así como promover el debate y la reflexión sobre las prioridades y objetivos a tener en cuenta, lo cierto es que existía un riesgo de fragmentación en el marco normativo ante la posibilidad de que cada uno de los Estados estableciera requisitos y garantías diferentes. En última instancia, esta potencial diversidad podría afectar negativamente a la seguridad jurídica que precisan los sistemas de Inteligencia Artificial y, sobre todo, impedir el objetivo de apostar por un enfoque equilibrado que permitiera articular un marco normativo confiable basado en los valores y derechos fundamentales de la Unión Europea en un escenario social y tecnológico global.
La importancia de los datos
En el Libro Blanco sobre Inteligencia Artificial se destacaba gráficamente la importancia de los datos con relación a la viabilidad de esta tecnología al afirmar rotundamente que “sin datos, no hay Inteligencia Artificial”. Esta es, precisamente, una de las razones que motivó que a finales de 2020 se promoviera un borrador de Reglamento sobre gobernanza de los datos en el que, entre otras medidas, se intenta afrontar los principales desafíos jurídicos que dificultan el acceso a los datos y su reutilización.
En este sentido, tal y como enfatiza el Plan Coordinado anteriormente citado, una condición previa y esencial para el adecuado funcionamiento de los sistemas de Inteligencia Artificial es la disponibilidad de datos de alta calidad, sobre todo por lo que se refiere a su diversidad y respeto de los derechos fundamentales. En concreto, partiendo de esta elemental premisa, es necesario garantizar que:
- Los sistemas de Inteligencia Artificial sean entrenados con conjuntos de datos suficientemente amplios, tanto por lo que se refiere a su cantidad como a la diversidad.
- Los conjuntos de datos objeto de tratamiento no generen situaciones discriminatorias o ilícitas que puedan afectar a los derechos y libertades.
- Se tengan en cuenta las exigencias y condiciones de la normativa sobre protección de datos de carácter personal, no sólo desde la perspectiva de su estricto cumplimiento sino, además, desde la perspectiva del principio de responsabilidad proactiva que obliga a ser capaz de demostrar el cumplimiento normativo en esta materia.
La importancia del acceso y la utilización de conjuntos de datos de alta calidad se ha destacado especialmente en el borrador de Reglamento, en particular por lo que se refiere a los denominados espacios comunes europeos de datos establecidos por la Comisión. La regulación europea pretende garantizar un acceso fiable, responsable y no discriminatorio que permita, sobre todo, el desarrollo de los sistemas de Inteligencia Artificial de alto riesgo con las garantías idóneas. Esta premisa adquiere una singular importancia en ciertos ámbitos como la salud, de manera que el entrenamiento de los algoritmos de Inteligencia Artificial pueda realizarse a partir de estándares ético-jurídicos elevados. En última instancia se pretende establecer unas condiciones óptimas por lo que respecta a las garantías de privacidad, seguridad, transparencia y que, sobre todo, aseguren una gobernanza institucional adecuada como base de la confianza en su correcto diseño y funcionamiento.
La clasificación del riesgo como eje de las obligaciones normativas
El Reglamento se articula a partir de la clasificación de los sistemas de Inteligencia Artificial teniendo en cuenta su nivel de riesgo, distinguiendo entre aquellos que suponen un riesgo inaceptable, lo que conllevan un riesgo mínimo y aquellos que, por el contrario, se consideran de nivel alto. Así, al margen de la prohibición excepcional de los primeros, el borrador establece que aquellos que se califiquen como de alto riesgo han de cumplir con ciertas garantías específicas, que serán voluntarias en el caso de los proveedores de sistemas que no tenga dicha consideración. ¿Cuáles son estas garantías?
- En primer lugar, se establece la obligación de implantar un modelo de gestión de la calidad de los datos que habrá de documentarse de forma sistemática y ordenada, uno de cuyos aspectos principales es el referido a los sistemas y procedimientos de gestión de datos, incluyendo su recogida, análisis, filtrado, agregación, etiquetado.
- En el caso de que se haga uso de técnicas que impliquen el entrenamiento de modelos con datos se exige que el desarrollo del sistema tenga lugar sobre la base de conjuntos de datos de entrenamiento, validación y prueba que cumplan ciertos estándares de calidad. En concreto, habrán de ser pertinentes, representativos, sin errores y completos, debiendo tener en cuenta, en la medida en que lo requiera la finalidad prevista, las características o elementos propios del entorno geográfico, conductual o funcional específico en el que se pretende utilizar el sistema de Inteligencia Artificial.
- Por otra parte, deberán tenerse en cuenta ciertas prácticas referidas a la gobernanza y gestión de datos, entre las que destacan la necesidad de realizar una evaluación previa de la disponibilidad, cantidad e idoneidad de los conjuntos de datos que se necesiten, así como analizar los posibles sesgos y lagunas por lo que se refiere a la carencia de los datos, en cuyo caso habrán de establecerse la forma en que se puede abordar dicha laguna.
En definitiva, en el caso de que el Reglamento siga su curso de tramitación y sea finalmente aprobado dispondremos de un marco regulador a nivel europeo que, desde las exigencias de respeto de los derechos y libertades, podría contribuir a la consolidación y futuro desarrollo de la Inteligencia Artificial no sólo desde la perspectiva de la competitividad industrial sino, además, conforme a unos estándares jurídicos acordes con los valores y principios en los que se fundamenta la Unión Europea.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El verano ya está a la vuelta de la esquina y con él las merecidas vacaciones. Sin duda, esta época del año nos brinda tiempo para descansar, reencontrarnos con la familia y pasar ratos agradables con nuestros amigos.
Sin embargo, también resulta una magnífica oportunidad para aprovechar y mejorar nuestro conocimiento sobre datos y tecnología a través de los cursos que diferentes universidades ponen a nuestra disposición durante estas fechas. Ya seas estudiante o profesional en activo, este tipo de cursos pueden contribuir a aumentar tu formación, y ayudarte a adquirir ventajas competitivas dentro del mercado laboral.
A continuación, te mostramos varios ejemplos de cursos de verano de universidades españolas sobre estas temáticas. También hemos incluido alguna formación online, disponible todo el año, y que puede ser un excelente producto para aprender también en la época estival.
Cursos relacionados con los datos abiertos
Iniciamos nuestra recopilación con el curso de ‘Big & Open Data. Análisis y programación con R y Python’ impartido por la Universidad Complutense de Madrid. Se celebrará de manera presencial en la Fundación General UCM del 5 al 23 de julio, de lunes a viernes en horario de 9 a 14 horas. Este curso está dirigido a estudiantes universitarios, docentes, investigadores y profesionales que deseen ampliar y perfeccionar sus conocimientos sobre esta materia.
Análisis y visualización de datos
Si te interesa aprender el lenguaje R, la Universidad de Santiago de Compostela organiza dos cursos relacionados con esta materia, en el marco de su ‘Universidade de Verán’. El primero de ellos es ‘Introducción en sistemas de información geográfica y cartográfica con el Entorno R’, que se celebrará del 6 al 9 de julio en la Facultad de Geografía e Historia de Santiago de Compostela. Puedes consultar toda la información y el plan de estudios a través de este enlace.
El segundo es ‘Visualización y análisis de datos con R’, que tendrá lugar del 13 al 23 de julio en la Facultad de Matemáticas de la USC. En este caso, la universidad ofrece la posibilidad al alumnado de asistir en dos turnos (mañana y tarde). Como puedes comprobar en su programa, la estadística se erige como uno de los aspectos clave de esta formación.
Si tu campo son las ciencias sociales y quieres aprender a manejar los datos correctamente, el curso de la Universidad de Internacional de Andalucía (UNIA) ‘Técnicas de análisis de datos en Humanidades y Ciencias Sociales’ buscas aproximarse al uso de las nuevas técnicas estadísticas y espaciales en la investigación en estos campos. Se impartirá del 23 al 26 de agosto en modalidad presencial.
Big Data
El Big Data se coloca, cada día más, como uno de los elementos que más contribuyen al aceleramiento de la transformación digital. Si te interesa este campo, puedes optar por el curso ‘Big Data Geolocalizado: Herramientas para la captura, análisis y visualización’ que impartirá la Universidad Complutense de Madrid del 5 al 23 de julio en horario de 9 a 14 horas, de manera presencial en la Fundación General UCM.
Otra opción es el curso de ‘Big Data: fundamentos tecnológicos y aplicaciones prácticas’ organizado por la Universidad de Alicante que se celebrará del 19 al 23 de julio de manera online.
Inteligencia artificial
El Gobierno ha puesto en marcha recientemente el curso online ‘Elementos de IA’ en español con el objetivo de impulsar y perfeccionar la formación de la ciudadanía en inteligencia artificial. La Secretaría de Estado de Digitalización e Inteligencia Artificial será quien ponga en marcha este proyecto junto a la colaboración de la UNED, que se encargará de proporcionar el soporte técnico y académico de esta formación. Elementos de IA es un proyecto educativo masivo y abierto (MOOC) que tiene como objetivo acercar a los ciudadanos conocimientos y habilidades sobre Inteligencia Artificial y sus distintas aplicaciones. Puedes descubrir toda la información sobre este curso aquí. Y si quieres comenzar ya la formación, puedes inscribirte a través de este enlace. El curso es gratuito.
Otra formación interesante relacionada con este ámbito es el curso de ‘Introducción práctica a la inteligencia artificial y al deep learning’ que organiza la Universidad Internacional de Andalucía (UNIA). Se impartirá de manera presencial en la sede Antonio Machado de Baeza entre los días 17 y 20 de agosto de 2021. Entre sus objetivos, destaca el ofrecer a los alumnos una visión general de los modelos de procesamiento de datos basados en técnicas de inteligencia artificial y aprendizaje profundo, entre otros.
Estos son solo algunos ejemplos de cursos que actualmente tienen matrícula abierta, aunque hay muchos más ya que la oferta es amplia y variada. Además, hay que recordar que el inicio del verano aún no se ha producido y que en las próximas semanas podrían aparecer nuevos cursos relacionados con los datos. Si conoces alguno más que sea de interés, no dudes en dejarnos un comentario aquí debajo o escribirnos a contacto@datos.gob.es
Blog
La inteligencia artificial está transformando las compañías, siendo los procesos de la cadena de suministro uno de los ámbitos que está obteniendo un mayor beneficio. Su gestión involucra a todas las actividades de administración de los recursos, incluyendo la adquisición de materiales, fabricación, almacenamiento y transporte desde el origen a su destino final.
Durante los últimos años, los sistemas empresariales se han ido modernizando y actualmente están respaldados por redes informáticas cada vez más omnipresentes. Dentro de estas redes, sensores, maquinas, sistemas, vehículos, dispositivos inteligentes y personas están interconectados y generando información continuamente. A ello hay que sumar el aumento de la capacidad computacional, que permite procesar estas grandes cantidades de datos generados de manera rápida y eficiente. Todos estos avances han contribuido a estimular la aplicación de las tecnologías de Inteligencia Artificial que ofrecen un mar de posibilidades.
En este artículo vamos a repasar algunas aplicaciones de Inteligencia Artificial en diferentes puntos de la cadena de suministro.
Implementaciones tecnológicas en las distintas fases de la cadena de suministro
Planificación
Según Gartner, la volatilidad en la demanda es uno de los aspectos que más preocupan a los empresarios. La crisis del COVID-19 ha puesto en evidencia la debilidad en la capacidad de planificación dentro de la cadena de suministro. Para poder organizar correctamente la producción, es necesario conocer las necesidades de los clientes. Esto se puede hacer a través de técnicas de análisis predictivo que nos permitan predecir de demanda, es decir, estimar una probable petición futura de un producto o un servicio. Este proceso sirve también como punto de partida para muchas otras actividades, como el almacenamiento, el envío, el precio del producto, la compra de materias primas, la planificación de la producción y otros procesos que tienen como objetivo satisfacer la demanda.
El acceso a datos en tiempo real permite desarrollar modelos de Inteligencia Artificial que toman ventaja de toda la información contextual para obtener así resultados más precisos, reduciendo el error de manera significativa comparado con métodos de previsión más tradicionales como pueden ser ARIMA o exponential smoothing.
La planificación de la producción es también un problema recurrente donde variables de diversa índole juegan un papel importante. Los sistemas de inteligencia artificial pueden manejar la información que implica los recursos materiales; la disponibilidad de recursos humanos (teniendo en cuenta turnos, vacaciones, bajas o asignaciones a otros proyectos) y sus habilidades; las máquinas disponibles y sus mantenimientos e información sobre el proceso de fabricación y sus dependencias para optimizar la planificación de la producción con la finalidad de cumplir satisfactoriamente los objetivos.
Producción
Dentro de las etapas del proceso productivo, una de las etapas más impulsadas por la aplicación de inteligencia artificial es el control de calidad y, más concretamente, la detección de defectos. Según la Comisión Europea, el 50% de la producción puede acabar como chatarra debido a los defectos, mientras que, en líneas de fabricación complejas, el porcentaje puede elevarse al 90%. Por otro lado, el control de calidad sin automatizar es un proceso caro, ya que es necesario entrenar a personas para que sean capaces de realizar las inspecciones de manera adecuada y, además, estas inspecciones manuales podrían causar cuellos de botella en la línea de producción, retrasando los tiempos de entrega. Unido a esto, los encargados de la inspección no aumentan en número a la vez que aumenta la producción.
En este escenario, la aplicación de algoritmos de visión por computador puede solventar todos estos problemas. Estos sistemas aprenden a partir de ejemplos de defectos y, de esta manera, pueden extraer patrones comunes para poder clasificar futuros defectos de producción. Las ventajas que aportan estos sistemas es que pueden conseguir la precisión de un humano o incluso mejor, ya que pueden procesar miles de imágenes en muy poco tiempo y son escalables.
Por otro lado, es muy importante asegurar la fiabilidad de la maquinaria y reducir las posibilidades de detención de la producción debido a averías. En este sentido, muchas empresas están apostando por sistemas de mantenimiento predictivo que son capaces de analizar los datos de monitorización para evaluar el estado de la maquinaria y programar un mantenimiento si es necesario.
Los datos abiertos pueden ayudar a la hora de entrenar estos algoritmos. Como ejemplo, la Nasa ofrece una colección de conjuntos de datos donados por varias universidades, organismos o empresas de utilidad para el desarrollo de algoritmos de predicción. En su mayoría, se trata de series temporales de datos desde un estado de funcionamiento normal hasta un estado fallido. En este artículo se muestra cómo se puede coger uno de estos conjuntos de datos concretos (Turbofan Engine Degradation Simulation Data Set, que incluye datos de sensores de 100 motores del mismo modelo) para realizar un análisis exploratorio y un modelo de regresión lineal de referencia.
Transporte
La optimización de rutas es uno de los elementos más críticos dentro de la planificación del transporte y la logística empresarial en general. Una planificación óptima asegura que la carga llega a tiempo, reduciendo el coste y la energía al mínimo posible. Hay muchas variables que intervienen en el proceso como, por ejemplo, picos de trabajo, incidencias en el tráfico, condiciones climáticas, etc. y ahí es donde la inteligencia artificial entra en juego. Un optimizador de rutas basado en inteligencia artificial es capaz combinar toda esta información para ofrecer la mejor ruta posible o modificarla en tiempo real dependiendo de las incidencias que ocurran durante el trayecto.
Las organizaciones de logística utilizan los datos de transporte y los mapas oficiales para optimizar las rutas en todos los medios de transporte, permitiendo evitar zonas con una gran congestión, mejorando la eficiencia y seguridad. De acuerdo con el estudio “Open Data impact Map”, los datos abiertos más demandados por estas empresas son aquellos relacionados directamente con los medios de transporte (rutas, horarios de transportes públicos, número de accidentes…), pero también datos geoespaciales, que les permitan planificar mejor sus viajes.
Asimismo, existen empresas que comparten sus datos en modelos B2B. Tal y como recoge el informe de la Fundación Cotec “Guía para la apertura y compartición de datos en el entorno empresarial”, la empresa española Primafrio, comparte datos con sus clientes como un elemento de valor en sus operaciones para la localización y posicionamiento de la flota y los productos (datos en tiempo real que pueden ser de utilidad para el cliente, como la matrícula del camión, la posición, el conductor, etc.) y para tareas de facturación o contabilidad. Como resultando, sus clientes han optimizado el tracking de los pedidos y su capacidad de adelantar la facturación.
Cerrando el apartado de transporte, uno de los objetivos de las empresas del sector logístico es asegurar que los bienes llegan a su destino en condiciones óptimas. Esto es especialmente crítico cuando trabajan con en empresas del sector alimentario. Por ello, es necesario monitorizar el estado de la carga durante el transporte. Controlar variables como la temperatura, localización o detectar impactos es crucial para saber cómo y cuándo se deterioró la carga y, así, poder realizar las acciones correctivas necesarias para evitar futuros problemas. Tecnologías como IoT, Blockchain e Inteligencia Artificial ya se están aplicando a en este tipo de soluciones, en ocasiones incluyendo el uso de datos abiertos.
Servicio al cliente
Ofrecer un buen servicio al cliente es fundamental para cualquier empresa. La implementación de asistentes conversacionales permite enriquecer la experiencia del cliente. Estos asistentes posibilitan a los usuarios interactuar con aplicaciones informáticas de forma conversacional, mediante texto, gráficos o voz. Por medio de técnicas de reconocimiento de voz y procesamiento de lenguaje natural, estos sistemas son capaces de interpretar la intención de los usuarios y realizar las acciones necesarias para responder a sus peticiones. De esta forma, los usuarios podrían interactuar con el asistente para hacer un seguimiento de su envío, modificar o realizar un pedido. En el entrenamiento de estos asistentes conversacionales es necesario utilizar datos de calidad, para conseguir un óptimo resultado.
En este artículo hemos visto sólo algunas de las aplicaciones de la inteligencia artificial a distintas fases de la cadena de suministro, pero su capacidad no sólo se reduce a éstas. Existen otras aplicaciones como el almacenamiento automatizado que utiliza Amazon en sus instalaciones, los precios dinámicos dependiendo de la demanda o la aplicación de inteligencia artificial en marketing, que sólo dan una idea de cómo la inteligencia artificial está revolucionando el consumo y la sociedad.
Contenido elaborado por Jose Antonio Sanchez, experto en Ciencia de datos y entusiasta de la Inteligencia Artificial .
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Ya ha llovido bastante desde que en 2012 se publicara aquel famoso artículo titulado "Data Scientist: The Sexiest Job of the 21st Century". Desde entonces el campo de la ciencia de datos se ha profesionalizado mucho. Se han desarrollado multitud de técnicas, frameworks y herramientas que aceleran el proceso de convertir datos brutos en información de valor. Una de estas técnicas se conoce cómo Auto ML o Machine Learning automático. En este artículo revisaremos las ventajas y características de este método.
En un proceso de ciencia de datos (data science), cualquier científico de datos (data scientist) suele utilizar un método de trabajo sistemático, según el cual va destilando los datos crudos hasta conseguir extraer información de valor para el negocio del cual parten esos datos. Existen varias definiciones del proceso de análisis de datos, aunque suelen ser todas muy similares con pequeñas variantes. En la siguiente figura mostramos un ejemplo de proceso o workflow de análisis de datos.

Cómo vemos, podemos distinguir tres etapas:
-
Importación y limpieza.
-
Exploración y modelado.
-
Comunicación.
Dependiendo del tipo de datos de origen y del resultado que busquemos alcanzar con estos datos, el proceso de modelado puede variar. Sin embargo, independientemente del modelo, el científico de datos debe de ser capaz de obtener un conjunto de datos limpios y preparados para servir como entrada al modelo. En este post vamos a centrarnos en la segunda etapa: exploración y modelado.
Una vez obtenidos estos datos limpios y libres de errores (tras su importación y limpieza en la etapa 1), el científico de datos debe de decidir qué transformaciones aplica a dichos datos, con el objetivo de que algunos datos derivados de los originales (en conjunto con los originales), sean los mejores indicadores del modelo subyacente al conjunto de datos. A estas transformaciones las denominamos características (en inglés, features).
El siguiente paso es dividir nuestro conjunto de datos en dos partes: una parte, por ejemplo, un 60% del conjunto total, servirá cómo conjunto de datos de entrenamiento. El 40% restante lo reservaremos para aplicar nuestro modelo, una vez entrenado. A este segundo lo denominamos subset de prueba o test. Este proceso de división de los datos de origen se realiza con la intención de evaluar la fiabilidad del modelo antes de aplicarlo sobre nuevos datos desconocidos para el modelo. Ahora se desarrolla un proceso iterativo en el que el científico de datos prueba varios tipos de modelos que cree que pueden funcionar sobre este conjunto de datos. Cada vez que aplica un modelo, observa y mide los parámetros matemáticos (cómo precisión y reproducibilidad) que expresan cuánto de bien el modelo es capaz de reproducir los datos de prueba. Además de probar diferentes tipos de modelos, el científico de datos puede variar el conjunto de datos de entrenamiento con nuevas transformaciones, calculando nuevas y diferentes características, con el fin de dar con algunas características que hagan que el modelo en cuestión se ajuste mejor a los datos.
Podemos imaginar que este proceso, repetido decenas o centenas de veces, es un gran consumidor de recursos tanto humanos como de cómputo. El científico de datos intenta realizar diferentes combinaciones de algoritmos, modelos, características y porcentajes de datos, en base a su experiencia y habilidad con las herramientas. Sin embargo, ¿qué pasaría si fuera un sistema el que llevará a cabo todas estas combinaciones por nosotros y diera, finalmente, con la mejor combinación? Precisamente para responder a esta herramienta se han creado los sistemas Auto ML.
En mi opinión, un sistema o herramienta de Auto ML no tiene el objetivo de sustituir al científico de datos, pero sí de complementarlo, ayudando a éste a ahorrar mucho tiempo en el proceso iterativo de probar diferentes técnicas y datos para alcanzar el mejor modelo. De forma general, podríamos decir que un sistema de Auto ML tiene (o tendría que) aportar los siguientes beneficios al científico de datos:
-
Sugerir las mejores técnicas de Machine Learning y generar automáticamente modelos optimizados (ajustando automáticamente los parámetros), habiendo probado una gran cantidad de conjuntos de datos de entrenamiento y test respectivamente.
-
Informar al científico de datos de aquellas características (recordar que son transformaciones de los datos originales) que tienen el mayor impacto en el resultado final del modelo.
-
Generar visualizaciones que permitan al científico de datos entender el resultado del proceso llevado a cabo por el Auto ML. Es decir, enseñar al usuario del Auto ML los indicadores clave del resultado del proceso.
-
Generar un entorno interactivo de simulación que permita a los usuarios explorar rápidamente el modelo para ver cómo funciona.
Para terminar, mencionamos algunos de los sistemas y herramientas Auto ML más conocidos, como H2O.ai, Auto-Sklearn y TPOT. Hay que destacar que estos tres sistemas cubren la totalidad del proceso de Machine Learning que veíamos al principio. Sin embargo, existen más soluciones y herramientas que cubren parcialmente alguno de los pasos del proceso completo. También existen artículos en los que se compara la eficacia de estos sistemas ante determinados problemas de machine learning sobre conjuntos de datos abiertos y accesibles.
En conclusión, estas herramientas proporcionan soluciones valiosas a problemas comunes de ciencia de datos y tienen la capacidad de mejorar drásticamente la productividad de los equipos de ciencia de datos. Sin embargo, la ciencia de datos sigue teniendo un componente importante de arte y no todos los problemas se resuelven con herramientas de automatización. Animamos a todos los alquimistas de algoritmos y artesanos de datos a seguir dedicando tiempo y esfuerzo en el desarrollo de nuevas técnicas y algoritmos que nos permitan convertir datos en valor de forma rápida y efectiva.
El objetivo de este post es explicar al público general, de forma sencilla y asequible, cómo las técnicas de auto ML pueden simplificar el proceso de análisis avanzado de datos. En ocasiones puede recurrirse a simplificaciones excesivas con el fin de no complicar en exceso el contenido de este post.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace unas semanas, os contamos los distintos tipos de aprendizaje automático a través de una serie de ejemplos, y analizamos cómo elegir uno u otro en base a nuestros objetivos y a los conjuntos de datos disponibles para entrenar el algoritmo.
Ahora supongamos que contamos con un conjunto de datos ya etiquetado y que necesitamos entrenar un modelo de aprendizaje supervisado para resolver la tarea que nos ocupa. En este punto, necesitamos algún mecanismo que nos diga si el modelo ha aprendido correctamente o no. Eso es lo que vamos a tratar en este post, las métricas más utilizadas para evaluar la calidad de nuestros modelos.
La evaluación de modelos es un paso muy importante en la metodología de desarrollo de sistemas de aprendizaje automático. Ayuda a medir el rendimiento del modelo, es decir, cuantificar la calidad de las predicciones que ofrece. Para realizar este cometido utilizamos las métricas de evaluación, que dependen de la tarea de aprendizaje que apliquemos. Como vimos en el post anterior, dentro del aprendizaje supervisado existen dos tipos de tareas que difieren, principalmente, en el tipo de salida que ofrecen:
- Las tareas de clasificación, que producen como salida una etiqueta discreta, es decir, cuando la salida es una dentro de un conjunto finito.
- Las tareas de regresión, que producen como salida un valor real y continuo.
A continuación, te explicamos algunas de las métricas más utilizadas para evaluar el rendimiento de ambos tipos de tareas:
Evaluación de modelos de clasificación
Para poder entender mejor estas métricas, vamos a poner como ejemplo las predicciones de un modelo de clasificación para detectar enfermos de COVID. En la siguiente tabla podemos ver en la primera columna el identificador de ejemplo, en la segunda la clase que ha predicho el modelo, en la tercera la clase real y la cuarta columna indica si el modelo ha fallado en su predicción o no. En este caso, la clase positiva es “Si” y la clase negativa es “No”.
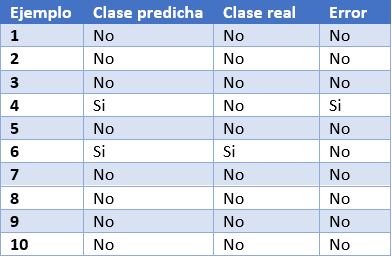
Algunos ejemplos de métricas de evaluación de modelos de clasificación son los siguientes:
- Matriz de confusión: es una herramienta ampliamente utilizada que permite inspeccionar y evaluar visualmente las predicciones de nuestro modelo. En cada fila se representa el número de predicciones de cada clase y en las columnas las instancias de la clase real.

La descripción de cada elemento de la matriz es la siguiente:
Verdadero positivo (VP): número de ejemplos positivos que el modelo predice como positivos. En el ejemplo que presentamos anteriormente, VP es 1 (del ejemplo 6).
Falso positivo (FP): número de ejemplos negativos que el modelo predice como positivos. En nuestro ejemplo, FP es igual a 1 (del ejemplo 4).
Falso negativo (FN): número de ejemplos positivos que el modelo predice como negativos. FN en el ejemplo sería 0.
Verdadero negativo (VN): número de ejemplos negativos que el modelo predice como negativos. En el ejemplo, VN es 8.
- Exactitud o accuracy: la fracción de predicciones que el modelo realizó correctamente. Se representa como un porcentaje o un valor entre 0 y 1. Es una buena métrica cuando tenemos un conjunto de datos balanceado, esto es, cuando el número de etiquetas de cada clase es similar. La exactitud de nuestro modelo de ejemplo es de 0.9, ya que ha acertado 9 predicciones de 10. Si nuestro modelo hubiese predicho siempre la etiqueta “No”, la exactitud sería de igualmente de 0.9, pero no resuelve nuestro problema de identificar enfermos de COVID.
- Recall o sensibilidad: indica la proporción de ejemplos positivos que están identificados correctamente por el modelo entre todos los positivos reales. Es decir, VP / (VP + FN). En nuestro ejemplo, el valor de sensibilidad sería 1 / (1 + 0) = 1. Si evaluásemos con esta métrica un modelo que siempre prediga la etiqueta positiva (“Si”) tendría una sensibilidad de 1, pero no sería un modelo demasiado inteligente. Aunque lo ideal para nuestro modelo de detección de COVID es maximizar la sensibilidad, esta métrica por sí sola no nos asegura que tengamos un buen modelo.
- Precision: esta métrica está determinada por la fracción de elementos clasificados correctamente como positivo entre todos los que el modelo ha clasificado como positivos. La fórmula es VP / (VP + FP). El modelo de ejemplo tendría una precisión de 1 / (1 + 1) = 0.5. Volvamos ahora al modelo que siempre predice la etiqueta positiva. En ese caso, la precisión del modelo es 1 / (1 + 9) = 0.1. Vemos como este modelo tenía una sensibilidad máxima, pero tiene una precisión muy pobre. En este caso necesitamos de las dos métricas para evaluar la calidad real del modelo.
- F1 score: combina las métricas Precision y Recall para dar un único resultado. Esta métrica es la más apropiada cuando tenemos conjuntos de datos no balanceados. Se calcula como la media armónica de Precision y Recal. La fórmula es F1 = (2 * precision * recall) / (precision + recall). Quizá te preguntes por qué la media armónica y no la simple. Esto es porque la media armónica hace que si una de las dos medidas es pequeña (aunque la otra sea máxima), el valor de F1 score va a ser pequeño.
Evaluación de modelos de regresión
A diferencia de los modelos de clasificación, en los modelos de regresión es casi imposible predecir el valor exacto, sino que más bien se busca estar lo más cerca posible del valor real, por lo que la mayoría de las métricas, con sutiles diferencias entre ellas, van a centrarse en medir eso: lo cerca (o lejos) que están las predicciones de los valores reales.
En este caso, tenemos como ejemplo las predicciones de un modelo que determina el precio de relojes dependiendo de sus características. En la tabla mostramos el precio predicho por el modelo, el precio real, el error absoluto y el error elevado al cuadrado.
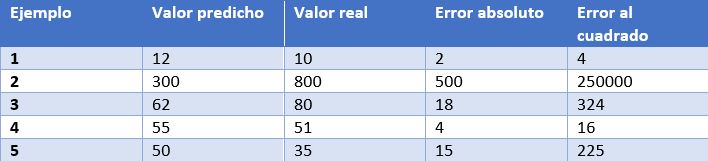
Algunas de las métricas de evaluación más comunes para los modelos de regresión son:
- Error medio absoluto: Es la media de las diferencias absolutas entre el valor objetivo y el predicho. Al no elevar al cuadrado, no penaliza los errores grandes, lo que la hace no muy sensible a valores anómalos, por lo que no es una métrica recomendable en modelos en los que se deba prestar atención a éstos. Esta métrica también representa el error en la misma escala que los valores reales. Lo más deseable es que su valor sea cercano a cero. Para nuestro modelo de cálculo de precios de relojes, el error medio absoluto es 107.8.
- Media de los errores al cuadrado (error cuadrático medio): Una de las medidas más utilizadas en tareas de regresión. Es simplemente la media de las diferencias entre el valor objetivo y el predicho al cuadrado. Al elevar al cuadrado los errores, magnifica los errores grandes, por lo que hay que utilizarla con cuidado cuando tenemos valores anómalos en nuestro conjunto de datos. Puede tomar valores entre 0 e infinito. Cuanto más cerca de cero esté la métrica, mejor. El error cuadrático medio del modelo de ejemplo es 50113.8. Vemos como en el caso de nuestro ejemplo se magnifican los errores grandes.
- Raíz cuadrada de la media del error al cuadrado: Es igual a la raíz cuadrada de la métrica anterior. La ventaja de esta métrica es que presenta el error en las mismas unidades que la variable objetivo, lo que la hace más fácil de entender. Para nuestro modelo este error es igual a 223.86.
- R cuadrado: también llamado coeficiente de determinación. Esta métrica difiere de las anteriores, ya que compara nuestro modelo con un modelo básico que siempre devuelve como predicción la media de los valores objetivo de entrenamiento. La comparación entre estos dos modelos se realiza en base a la media de los errores al cuadrado de cada modelo. Los valores que puede tomar esta métrica van desde menos infinito a 1. Cuanto más cercano a 1 sea el valor de esta métrica, mejor será nuestro modelo. El valor de R cuadrado para el modelo será de 0.455.
- R cuadrado ajustado. Una mejora de R cuadrado. El problema de la métrica anterior es que cada vez que se añaden más variables independientes (o variables predictoras) al modelo, R cuadrado se queda igual o mejora, pero nunca empeora, lo que puede llegar a confundirnos, ya que, porque un modelo utilice más variables predictoras que otro, no quiere decir que sea mejor. R cuadrado ajustado compensa la adición de variables independientes. El valor de R cuadrado ajustado siempre va a ser menor o igual al de R cuadrado, pero esta métrica mostrará mejoría cuando el modelo sea realmente mejor. Para esta medida no podemos hacer el cálculo para nuestro modelo de ejemplo porque, como hemos visto antes, depende del número de ejemplos y el número de variables utilizadas para entrenar dicho modelo.
Conclusión
A la hora de trabajar con algoritmos de aprendizaje supervisado es muy importante la elección de una métrica de evaluación correcta para nuestro modelo. Para los modelos de clasificación es muy importante prestar atención al conjunto de datos y comprobar si es balanceado o no. En los modelos de regresión hay que considerar los valores anómalos y si queremos penalizar errores grandes o no.
No obstante, generalmente, el dominio de negocio será el que nos guíe en la correcta elección de la métrica. Para un modelo de detección de enfermedades, como el que hemos visto, nos interesa que tenga una alta sensibilidad, pero también nos interesa que tenga un buen valor de precisión, por lo que F1-score sería una opción inteligente. Por otro lado, en un modelo para predecir la demanda de un producto (y por lo tanto de producción), donde un exceso de stock puede incurrir en un sobrecoste por almacenamiento de mercancía, quizás sea una buena idea utilizar la media de los errores al cuadrado para penalizar los errores grandes.
Contenido elaborado por Jose Antonio Sanchez, experto en Ciencia de datos y entusiasta de la Inteligencia Artificial .
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
2020 llega a su fin y en este año tan atípico nos va a tocar vivir unas Navidades diferentes, más tranquilas y con nuestro núcleo más cercano. ¿Qué mejor para disfrutar de esos momentos de calma que formarte y mejorar tus conocimientos sobre datos y nuevas tecnologías?
Tanto si estás buscando una lectura que te haga mejorar tu perfil profesional a la que dedicar tu tiempo libre en estas fechas tan especiales, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunas recomendaciones de libros sobre datos y tecnologías disruptivas que esperamos sean de tu interés. Hemos seleccionado libros en castellano e inglés, para que también puedas poner en práctica tu conocimiento de este idioma.
¡Toma nota porque todavía estás a tiempo de incluir alguno en tu carta a los Reyes Magos!
INTELIGENCIA ARTIFICIAL, naturalmente. Nuria Oliver, ONTSI, red.es (2020)
¿De qué trata?: Este libro es el primero de la nueva colección que publica el ONTSI llamada “Pensamiento para la sociedad digital”. Sus páginas ofrecen un breve recorrido por la historia de la inteligencia artificial, describiendo su impacto en la actualidad y abordando los retos que presenta desde diversos puntos de vista.
¿A quién va dirigido?: Esta dirigido especialmente a tomadores de decisiones, profesionales del sector público y privado, profesores y estudiantes universitarios, organizaciones del tercer sector, investigadores y medios de comunicación, pero también es una buena opción para lectores que quieran introducirse y acercarse al complejo mundo de la inteligencia artificial.
Artificial Intelligence: A Modern Approach, Stuart Russell
¿De qué trata?: Interesante manual que introduce al lector en el campo de la Inteligencia Artificial a través de una estructura ordenada y una redacción comprensible.
¿A quién va dirigido?: Este libro de texto es una buena opción para utilizar como documentación y referencia en diferentes cursos y estudios en Inteligencia Artificial a diferentes niveles. Para aquellos que quieran convertirse en expertos en la materia.
Situating Open Data: Global Trends in Local Contexts, Danny Lämmerhirt, Ana Brandusescu, Natalia Domagala – African Minds (Octubre 2020)
¿De qué trata?: Este libro proporciona varios relatos empíricos sobre las prácticas de datos abiertos, la implementación local de iniciativas globales y el desarrollo de nuevos ecosistemas de open data.
¿A quién va dirigido?: Será de gran interés para los investigadores y defensores de los datos abiertos y para quienes están en las administraciones gubernamentales o las asesoran en el diseño y la implementación de iniciativas efectivas de open data. Puedes descargar su versión en PDF a través de este enlace.
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (Springer Series in Statistics), Trevor Hustle, Jerome Friedman. – Springer (Mayo 2017)
¿De qué trata?: Este libro describe diversos conceptos estadísticos en una variedad de campos como la medicina, la biología, las finanzas y el marketing en un marco conceptual común. Si bien el enfoque es estadístico, el énfasis está en las definiciones más que en las matemáticas.
¿A quién va dirigido?: Es un recurso valioso para los estadísticos y cualquier persona interesada en la minería de datos en la ciencia o la industria. También puedes descargar su versión digital aquí.
Europa frente a EEUU y China: Prevenir el declive en la era de la inteligencia artificial, Luis Moreno, Andrés Pedreño – Kdp (2020)
¿De qué trata?: Este interesante libro aborda los motivos del retraso europeo respecto a la potencia que sí tienen EEUU y China, y sus consecuencias, pero sobre todo propone soluciones a la problemática que se expone en la obra.
¿A quién va dirigido?: Se trata de una reflexión para aquellos interesados en pensar acerca del cambio que Europa necesitaría, en palabras de su autor, “alejada cada vez más de la revolución que impone el nuevo paradigma tecnológico”.
¿De qué trata?: Este libro hace una llamada de atención acerca de la problemática que puede desencadenar el mal uso de los algoritmos y propone algunas ideas para no caer en errores.
¿A quién va dirigido?: En estas páginas no aparecen conceptos demasiado técnicos, ni hay fórmulas ni explicaciones complejas, aunque sí se tratan problemas densos que necesitan la atención del autor.
Data Feminism (Strong Ideas), Catherine D’Ignazio, Lauren F. Klein. MIT Press (2020)
¿De qué trata?: Estas páginas abordan una nueva forma de pensar sobre la ciencia de datos y su ética basada en las ideas del pensamiento feminista.
¿A quién va dirigido?: A todos/as aquellos/as que tienen interés en reflexionar sobre los sesgos integrados en los algoritmos de las herramientas digitales que utilizamos en todos los ámbitos de la vida.
Open Cities | Open Data: Collaborative Cities in the Information, Scott Hawken, Hoon Han, Chris Pettit – Palgrave Macmillan, Singapore (2020)
¿De qué trata?: Este libro explica la importancia de abrir los datos en las ciudades a través de una variedad de perspectivas críticas, y presenta estrategias, herramientas y casos de uso que facilitan tanto dicha apertura como su reutilización.
¿A quién va dirigido?: Perfecto para aquellos integrados en la cadena de valor del dato en las ciudades y quienes tienen que elaborar estrategias de open data en el marco de una ciudad inteligente, pero también para los ciudadanos preocupados por la privacidad y que quieran saber qué sucede -y qué puede suceder- con los datos que generan las ciudades.
Aunque nos encantaría incluirlos a todos en esta lista, son muchos los libros interesantes sobre datos y tecnología que llenan las estanterías de cientos de librerías y tiendas online. Si tienes alguna recomendación extra que nos quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Los miembros que formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones esta Navidad.