
Description
In recent months we have seen how the large language models (LLMs ) that enable Generative Artificial Intelligence (GenAI) applications have been improving in terms of accuracy and reliability. RAG (Retrieval Augmented Generation) techniques have allowed us to use the full power of natural language communication (NLP) with machines to explore our own knowledge bases and extract processed information in the form of answers to our questions. In this article we take a closer look at RAG techniques in order to learn more about how they work and all the possibilities they offer in the context of generative AI.
What are RAG techniques?
This is not the first time we have talked about RAG techniques. In this article we have already introduced the subject, explaining in a simple way what they are, what their main advantages are and what benefits they bring in the use of Generative AI.
Let us recall for a moment its main keys. RAG is translated as Retrieval Augmented Generation . In other words, RAG consists of the following: when a user asks a question -usually in a conversational interface-, the Artificial Intelligence (AI), before providing a direct answer -which it could give using the (fixed) knowledge base with which it has been trained-, carries out a process of searching and processing information in a specific database previously provided, complementary to that of the training. When we talk about a database, we refer to a knowledge base previously prepared from a set of documents that the system will use to provide more accurate answers. Thus, when using RAGtechniques, conversational interfaces produce more accurate and context-specific responses.
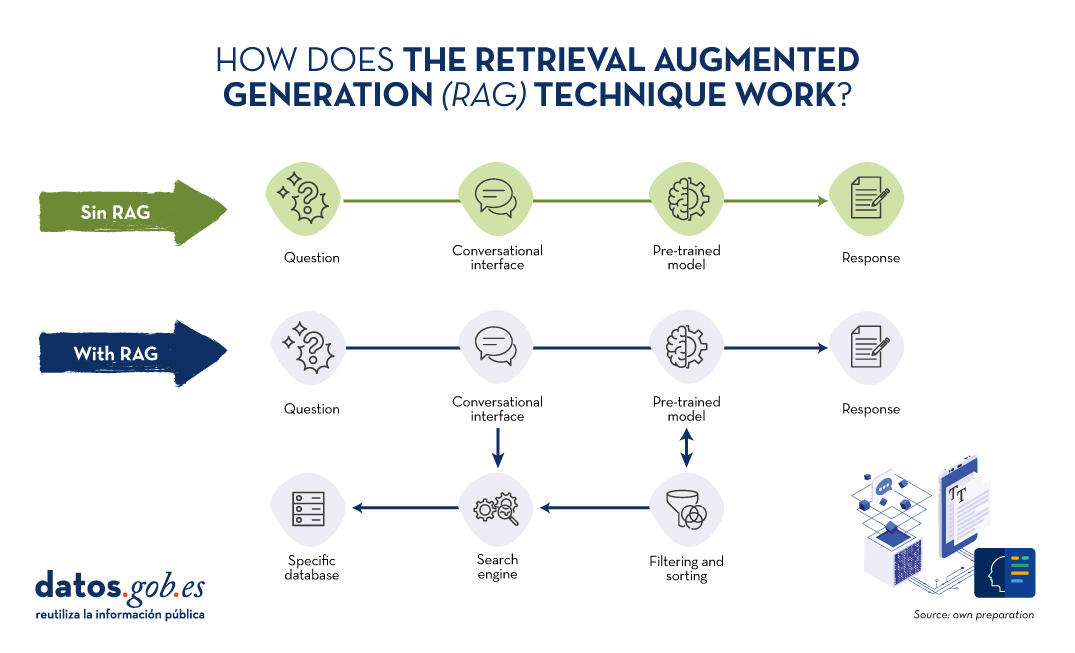
Source: Own preparation.
Conceptual diagram of the operation of a conversational interface or assistant without using RAG (top) and using RAG (bottom).
Drawing a comparison with the medical field, we could say that the use of RAG is as if a doctor, with extensive experience and therefore highly trained, in addition to the knowledge acquired during his academic training and years of experience, has quick and effortless access to the latest studies, analyses and medical databases instantly, before providing a diagnosis. Academic training and years of experience are equivalent to large language model (LLM) training and the "magic" access to the latest studies and specific databases can be assimilated to what RAG techniques provide.
Evidently, in the example we have just given, good medical practice makes both elements indispensable, and the human brain knows how to combine them naturally, although not without effort and time, even with today's digital tools, which make the search for information easier and more immediate.
RAG in detail
RAG Fundamentals
RAG combines two phases to achieve its objective: recovery and generation. In the first, relevant documents are searched for in a database containing information relevant to the question posed (e.g. a clinical database or a knowledge base of commonly asked questions and answers). In the second, an LLM is used to generate a response based on the retrieved documents. This approach ensures that responses are not only consistent but also accurate and supported by verifiable data.
Components of the RAG System
In the following, we will describe the components that a RAG algorithm uses to fulfil its function. For this purpose, for each component, we will explain what function it fulfils, which technologies are used to fulfil this function and an example of the part of the RAG process in which that component is involved.
- Recovery Model:
- Function: Identifies and retrieves relevant documents from a large database in response to a query.
- Technology: It generally uses Information Retrieval (IR) techniques such as BM25 or embedding-based retrieval models such as Dense Passage Retrieval (DPR).
- Process: Given a question, the retrieval model searches a database to find the most relevant documents and presents them as context for answer generation.
- Generation Model:
- Function: Generate coherent and contextually relevant answers using the retrieved documents.
- Technology: Based on some of the major Large Language Models (LLM) such as GPT-3.5, T5, or BERT, Llama.
- Process: The generation model takes the user's query and the retrieved documents and uses this combined information to produce an accurate response.
Detailed RAG Process
For a better understanding of this section, we recommend the reader to read this previous work in which we explain in a didactic way the basics of natural language processing and how we teach machines to read. In detail, a RAG algorithm performs the following steps:
- Reception of the question. The system receives a question from the user. This question is processed to extract keywords and understand the intention.
- Document retrieval. The question is sent to the recovery model.
- Example of Retrieval based on embeddings:
- The question is converted into a vector of embeddings using a pre-trained model.
- This vector is compared with the document vectors in the database.
- The documents with the highest similarity are selected.
- Example of BM25:
- The question is tokenised and the keywords are compared with the inverted indexes in the database.
- The most relevant documents are retrieved according to a relevance score.
- Example of Retrieval based on embeddings:
- Filtering and sorting. The retrieved documents are filtered to eliminate redundancies and to classify them according to their relevance. Additional techniques such as reranking can be applied using more sophisticated models.
- Response generation. The filtered documents are concatenated with the user's question and fed into the generation model. The LLM uses the combined information to generate an answer that is coherent and directly relevant to the question. For example, if we use GPT-3.5 as LLM, the input to the model includes both the user's question and fragments of the retrieved documents. Finally, the model generates text using its ability to understand the context of the information provided.
In the following section we will look at some applications where Artificial Intelligence and large language models play a differentiating role and, in particular, we will analyse how these use cases benefit from the application of RAGtechniques.
Examples of use cases that benefit substantially from using RAG vs. not using RAG
1. ECommerceCustomer Service
- No RAG:
- A basic chatbot can give generic and potentially incorrect answers about return policies.
- Example: Please review our returns policy on the website.
- With RAG:
- The chatbot accesses the database of updated policies and provides a specific and accurate response.
- Example: You may return products within 30 days of purchase, provided they are in their original packaging. See more details [here].
2. Medical Diagnosis
- No RAG:
- A virtual health assistant could offer recommendations based only on their previous training, without access to the latest medical information.
- Example: You may have the flu. Consult your doctor
- With RAG:
- The wizard can retrieve information from recent medical databases and provide a more accurate and up-to-date diagnosis.
- Example: Based on your symptoms and recent studies published in PubMed, you could be dealing with a viral infection. Consult your doctor for an accurate diagnosis.
3. Academic Research Assistance
- No RAG:
- A researcher receives answers limited to what the model already knows, which may not be sufficient for highly specialised topics.
- Example: Economic growth models are important for understanding the economy.
- With RAG:
- The wizard retrieves and analyses relevant academic articles, providing detailed and accurate information.
- Example: According to the 2023 study in the Journal of Economic Growth, the XYZ model has been shown to be 20% more accurate in predicting economic trends in emerging markets.
4. Journalism
- No RAG:
- A journalist receives generic information that may not be up to date or accurate.
- Example Artificial intelligence is changing many industries.
- With RAG:
- The wizard retrieves specific data from recent studies and articles, providing a solid basis for the article.
- Example: According to a 2024 report by 'TechCrunch', AI adoption in the financial sector has increased by 35% in the last year, improving operational efficiency and reducing costs.
Of course, for most of us who have experienced the more accessible conversational interfaces, such as ChatGPT, Gemini o Bing we can see that the answers are usually complete and quite precise when it comes to general questions. This is because these agents make use of AGN methods and other advanced techniques to provide the answers. However, it is not long before conversational assistants, such as Alexa, Siri u OK Google provided extremely simple answers and very similar to those explained in the previous examples when not making use of RAG.
Conclusions
Retrieval Augmented Generation (RAG) techniques improve the accuracy and relevance of language model answers by combining document retrieval and text generation. Using retrieval methods such as BM25 or DPR and advanced language models, RAG provides more contextualised, up-to-date and accurate responses.Today, RAG is the key to the exponential development of AI in the private data domain of companies and organisations. In the coming months, RAG is expected to see massive adoption in a variety of industries, optimising customer care, medical diagnostics, academic research and journalism, thanks to its ability to integrate relevant and current information in real time.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.


Comments