Blog
Artificial intelligence (AI) has become a central technology in people's lives and in the strategy of companies. In just over a decade, we've gone from interacting with virtual assistants that understood simple commands, to seeing systems capable of writing entire reports, creating hyper-realistic images, or even writing code.
This visible leap has made many wonder: is it all the same? What is the difference between what we already knew as AI and this new "Generative AI" that is so much talked about?
In this article we are going to organize those ideas and explain, with clear examples, how "Traditional" AI and Generative AI fit under the great umbrella of artificial intelligence.
Traditional AI: analysis and prediction
For many years, what we understood by AI was closer to what we now call "Traditional AI". These systems are characterized by solving concrete, well-defined problems within a framework of available rules or data.
Some practical examples:
-
Recommendation engines: Spotify suggests songs based on your listening history and Netflix adjusts its catalog to your personal tastes, generating up to 80% of views on the platform.
-
Prediction systems: Walmart uses predictive models to anticipate the demand for products based on factors such as weather or local events; Red Eléctrica de España applies similar algorithms to forecast electricity consumption and balance the grid.
- Automatic recognition: Google Photos classifies images by recognizing faces and objects; Visa and Mastercard use anomaly detection models to identify fraud in real time; Tools like Otter.ai automatically transcribe meetings and calls.
In all these cases, the models learn from past data to provide a classification, prediction, or decision. They do not invent anything new, but recognize patterns and apply them to the future.
Generative AI: content creation
The novelty of generative AI is that it not only analyzes, but also produces (generates) from the data it has.
In practice, this means that:
-
You can generate structured text from a couple of initial ideas.
-
You can combine existing visual elements from a written description.
-
You can create product prototypes, draft presentations, or propose code snippets based on learned patterns.
The key is that generative models don't just classify or predict, they generate new combinations based on what they learned during their training.
The impact of this breakthrough is enormous: in the development world, GitHub Copilot already includes agents that detect and fix programming errors on their own; in design, Google's Nano Banana tool promises to revolutionize image editing with an efficiency that could render programs like Photoshop obsolete; and in music, entirely AI-created bands like Velvet Velvet Sundown they already exceed one million monthly listeners on Spotify, with songs, images and biography fully generated, without real musicians behind them.
When is it best to use each type of AI?
The choice between Traditional and Generative AI is not a matter of fashion, but of what specific need you want to solve. Each shines in different situations:
Traditional AI: the best option when...
-
You need to predict future behaviors based on historical data (sales, energy consumption, predictive maintenance).
-
You want to detect anomalies or classify information accurately (transaction fraud, imaging, spam).
-
You are looking to optimize processes to gain efficiency (logistics, transport routes, inventory management).
-
You work in critical environments where reliability and accuracy are a must (health, energy, finance).
Use it when the goal is to make decisions based on real data with the highest possible accuracy.
Generative AI: the best option when...
-
You need to create content (texts, images, music, videos, code).
-
You want to prototype or experiment quickly, exploring different scenarios before deciding (product design, R+D testing).
-
You are looking for more natural interaction with users (chatbots, virtual assistants, conversational interfaces).
-
You require large-scale personalization, generating messages or materials adapted to each individual (marketing, training, education).
-
You are interested in simulating scenarios that you cannot easily obtain with real data (fictitious clinical cases, synthetic data to train other models).
Use it when the goal is to create, personalize, or interact in a more human and flexible way.
An example from the health field illustrates this well:
-
Traditional AI can analyze thousands of clinical records to anticipate the likelihood of a patient developing a disease.
-
Generative AI can create fictional scenarios to train medical students, generating realistic clinical cases without exposing real patient data.
Do they compete or complement each other?
In 2019, Gartner introduced the concept of Composite AI to describe hybrid solutions that combined different AI approaches to solve a problem more comprehensively. Although it was a term that was not very widespread then, today it is more relevant than ever thanks to the emergence of Generative AI.
Generative AI does not replace Traditional AI, but rather complements it. When you integrate both approaches into a single workflow, you achieve much more powerful results than if you used each technology separately.
Although, according to Gartner, Composite AI is still in the Innovation Trigger phase, where an emerging technology begins to generate interest, and although its practical use is still limited, we already see many new trends being generated in multiple sectors:
-
In retail: A traditional system predicts how many orders a store will receive next week, and generative AI automatically generates personalized product descriptions for customers of those orders.
-
In education: a traditional model assesses student progress and detects weak areas, while generative AI designs exercises or materials tailored to those needs.
-
In industrial design: a traditional algorithm optimizes manufacturing logistics, while a generative AI proposes prototypes of new parts or products.
Ultimately, instead of questioning which type of AI is more advanced, the right thing to do is to ask: what problem do I want to solve, and which AI approach is right for it?
Content created by Juan Benavente, senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsability of the author.
Blog
Artificial intelligence (AI) assistants are already part of our daily lives: we ask them the time, how to get to a certain place or we ask them to play our favorite song. And although AI, in the future, may offer us infinite functionalities, we must not forget that linguistic diversity is still a pending issue.
In Spain, where Spanish coexists with co-official languages such as Basque, Catalan, Valencian and Galician, this issue is especially relevant. The survival and vitality of these languages in the digital age depends, to a large extent, on their ability to adapt and be present in emerging technologies. Currently, most virtual assistants, automatic translators or voice recognition systems do not understand all the co-official languages. However, did you know that there are collaborative projects to ensure linguistic diversity?
In this post we tell you about the approach and the greatest advances of some initiatives that are building the digital foundations necessary for the co-official languages in Spain to also thrive in the era of artificial intelligence.
ILENIA, the coordinator of multilingual resource initiatives in Spain
The models that we are going to see in this post share a focus because they are part of ILENIA, a state-level coordinator that connects the individual efforts of the autonomous communities. This initiative brings together the projects BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) and the University of Santiago de Compostela (NÓS), with the aim of generating digital resources that allow the development of multilingual applications in the different languages of Spain.
The success of these initiatives depends fundamentally on citizen participation. Through platforms such as Mozilla's Common Voice, any speaker can contribute to the construction of these linguistic resources through different forms of collaboration:
- Spoken Read: Collecting different ways of speaking through voice donations of a specific text.
- Spontaneous speech: creates real and organic datasets as a result of conversations with prompts.
- Text in language: collaborate in the transcription of audios or in the contribution of textual content, suggesting new phrases or questions to enrich the corpora.
All resources are published under free licenses such as CC0, allowing them to be used free of charge by researchers, developers and companies.
The challenge of linguistic diversity in the digital age
Artificial intelligence systems learn from the data they receive during their training. To develop technologies that work correctly in a specific language, it is essential to have large volumes of data: audio recordings, text corpora and examples of real use of the language.
In other publications of datos.gob.es we have addressed the functioning of foundational models and initiatives in Spanish such as ALIA, trained with large corpus of text such as those of the Royal Spanish Academy.
Both posts explain why language data collection is not a cheap or easy task. Technology companies have invested massively in compiling these resources for languages with large numbers of speakers, but Spanish co-official languages face a structural disadvantage. This has led to many models not working properly or not being available in Valencian, Catalan, Basque or Galician.
However, there are collaborative and open data initiatives that allow the creation of quality language resources. These are the projects that several autonomous communities have launched, marking the way towards a multilingual digital future.
On the one hand, the Nós en Galicia Project creates oral and conversational resources in Galician with all the accents and dialectal variants to facilitate integration through tools such as GPS, voice assistants or ChatGPT. A similar purpose is that of Aina in Catalonia, which also offers an academic platform and a laboratory for developers or Vives in the Valencian Community. In the Basque Country there is also the Euskorpus project , which aims to constitute a quality text corpus in Basque. Let's look at each of them.
Proyecto Nós, a collaborative approach to digital Galician
The project has already developed three operational tools: a multilingual neural translator, a speech recognition system that converts speech into text, and a speech synthesis application. These resources are published under open licenses, guaranteeing their free and open access for researchers, developers and companies. These are its main features:
- Promoted by: the Xunta de Galicia and the University of Santiago de Compostela.
- Main objective: to create oral and conversational resources in Galician that capture the dialectal and accent diversity of the language.
- How to participate: The project accepts voluntary contributions both by reading texts and by answering spontaneous questions.
- Donate your voice in Galician: https://doagalego.nos.gal
Aina, towards an AI that understands and speaks Catalan
With a similar approach to the Nós project, Aina seeks to facilitate the integration of Catalan into artificial intelligence language models.
It is structured in two complementary aspects that maximize its impact:
- Aina Tech focuses on facilitating technology transfer to the business sector, providing the necessary tools to automatically translate websites, services and online businesses into Catalan.
- Aina Lab promotes the creation of a community of developers through initiatives such as Aina Challenge, promoting collaborative innovation in Catalan language technologies. Through this call , 22 proposals have already been selected with a total amount of 1 million to execute their projects.
The characteristics of the project are:
- Powered by: the Generalitat de Catalunya in collaboration with the Barcelona Supercomputing Center (BSC-CNS).
- Main objective: it goes beyond the creation of tools, it seeks to build an open, transparent and responsible AI infrastructure with Catalan.
- How to participate: You can add comments, improvements, and suggestions through the contact inbox: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, the collaborative project for AI in Valencian
On the other hand, Vives collects voices speaking in Valencian to serve as training for AI models.
- Promoted by: the Alicante Digital Intelligence Centre (CENID).
- Objective: It seeks to create massive corpora of text and voice, encourage citizen participation in data collection, and develop specialized linguistic models in sectors such as tourism and audiovisual, guaranteeing data privacy.
- How to participate: You can donate your voice through this link: https://vives.gplsi.es/instruccions/.
Gaitu: strategic investment in the digitalisation of the Basque language
In Basque, we can highlight Gaitu, which seeks to collect voices speaking in Basque in order to train AI models. Its characteristics are:
- Promoted by: HiTZ, the Basque language technology centre.
- Objective: to develop a corpus in Basque to train AI models.
- How to participate: You can donate your voice in Basque here https://commonvoice.mozilla.org/eu/speak.
Benefits of Building and Preserving Multilingual Language Models
The digitization projects of the co-official languages transcend the purely technological field to become tools for digital equity and cultural preservation. Its impact is manifested in multiple dimensions:
- For citizens: these resources ensure that speakers of all ages and levels of digital competence can interact with technology in their mother tongue, removing barriers that could exclude certain groups from the digital ecosystem.
- For the business sector: the availability of open language resources makes it easier for companies and developers to create products and services in these languages without assuming the high costs traditionally associated with the development of language technologies.
- For the research fabric, these corpora constitute a fundamental basis for the advancement of research in natural language processing and speech technologies, especially relevant for languages with less presence in international digital resources.
The success of these initiatives shows that it is possible to build a digital future where linguistic diversity is not an obstacle but a strength, and where technological innovation is put at the service of the preservation and promotion of linguistic cultural heritage.
Blog
Over the last few years we have seen spectacular advances in the use of artificial intelligence (AI) and, behind all these achievements, we will always find the same common ingredient: data. An illustrative example known to everyone is that of the language models used by OpenAI for its famous ChatGPT, such as GPT-3, one of its first models that was trained with more than 45 terabytes of data, conveniently organized and structured to be useful.
Without sufficient availability of quality and properly prepared data, even the most advanced algorithms will not be of much use, neither socially nor economically. In fact, Gartner estimates that more than 40% of emerging AI agent projects today will end up being abandoned in the medium term due to a lack of adequate data and other quality issues. Therefore, the effort invested in standardizing, cleaning, and documenting data can make the difference between a successful AI initiative and a failed experiment. In short, the classic principle of "garbage in, garbage out" in computer engineering applied this time to artificial intelligence: if we feed an AI with low-quality data, its results will be equally poor and unreliable.
Becoming aware of this problem arises the concept of "AI Data Readiness" or preparation of data to be used by artificial intelligence. In this article, we'll explore what it means for data to be "AI-ready", why it's important, and what we'll need for AI algorithms to be able to leverage our data effectively. This results in greater social value, favoring the elimination of biases and the promotion of equity.
What does it mean for data to be "AI-ready"?
Having AI-ready data means that this data meets a series of technical, structural, and quality requirements that optimize its use by artificial intelligence algorithms. This includes multiple aspects such as the completeness of the data, the absence of errors and inconsistencies, the use of appropriate formats, metadata and homogeneous structures, as well as providing the necessary context to be able to verify that they are aligned with the use that AI will give them.
Preparing data for AI often requires a multi-stage process. For example, again the consulting firm Gartner recommends following the following steps:
- Assess data needs according to the use case: identify which data is relevant to the problem we want to solve with AI (the type of data, volume needed, level of detail, etc.), understanding that this assessment can be an iterative process that is refined as the AI project progresses.
- Align business areas and get management support: present data requirements to managers based on identified needs and get their backing, thus securing the resources required to prepare the data properly.
- Develop good data governance practices: implement appropriate data management policies and tools (quality, catalogs, data lineage, security, etc.) and ensure that they also incorporate the needs of AI projects.
- Expand the data ecosystem: integrate new data sources, break down potential barriers and silos that are working in isolation within the organization and adapt the infrastructure to be able to handle the large volumes and variety of data necessary for the proper functioning of AI.
- Ensure scalability and regulatory compliance: ensure that data management can scale as AI projects grow, while maintaining a robust governance framework in line with the necessary ethical protocols and compliance with existing regulations.
If we follow a strategy like this one, we will be able to integrate the new requirements and needs of AI into our usual data governance practices. In essence, it is simply a matter of ensuring that our data is prepared to feed AI models with the minimum possible friction, avoiding possible setbacks later in the day during the development of projects.
Open data "ready for AI"
In the field of open science and open data, the FAIR principles have been promoted for years. These acronyms state that data must be locatable, accessible, interoperable and reusable. The FAIR principles have served to guide the management of scientific and open data to make them more useful and improve their use by the scientific community and society at large. However, these principles were not designed to address the new needs associated with the rise of AI.
Therefore, the proposal is currently being made to extend the original principles by adding a fifth readiness principle for AI, thus moving from the initial FAIR to FAIR-R or FAIR². The aim would be precisely to make explicit those additional attributes that make the data ready to accelerate its responsible and transparent use as a necessary tool for AI applications of high public interest

What exactly would this new R add to the FAIR principles? In essence, it emphasizes some aspects such as:
- Labelling, annotation and adequate enrichment of data.
- Transparency on the origin, lineage and processing of data.
- Standards, metadata, schemas and formats optimal for use by AI.
- Sufficient coverage and quality to avoid bias or lack of representativeness.
In the context of open data, this discussion is especially relevant within the discourse of the "fourth wave" of the open data movement, through which it is argued that if governments, universities and other institutions release their data, but it is not in the optimal conditions to be able to feed the algorithms, A unique opportunity for a whole new universe of innovation and social impact would be missing: improvements in medical diagnostics, detection of epidemiological outbreaks, optimization of urban traffic and transport routes, maximization of crop yields or prevention of deforestation are just a few examples of the possible lost opportunities.
And if not, we could also enter a long "data winter", where positive AI applications are constrained by poor-quality, inaccessible, or biased datasets. In that scenario, the promise of AI for the common good would be frozen, unable to evolve due to a lack of adequate raw material, while AI applications led by initiatives with private interests would continue to advance and increase unequal access to the benefit provided by technologies.
Conclusion: the path to quality, inclusive AI with true social value
We can never take for granted the quality or suitability of data for new AI applications: we must continue to evaluate it, work on it and carry out its governance in a rigorous and effective way in the same way as it has been recommended for other applications. Making our data AI-ready is therefore not a trivial task, but the long-term benefits are clear: more accurate algorithms, reduced unwanted bias, increased transparency of AI, and extended its benefits to more areas in an equitable way.
Conversely, ignoring data preparation carries a high risk of failed AI projects, erroneous conclusions, or exclusion of those who do not have access to quality data. Addressing the unfinished business on how to prepare and share data responsibly is essential to unlocking the full potential of AI-driven innovation for the common good. If quality data is the foundation for the promise of more humane and equitable AI, let's make sure we build a strong enough foundation to be able to reach our goal.
On this path towards a more inclusive artificial intelligence, fuelled by quality data and with real social value, the European Union is also making steady progress. Through initiatives such as its Data Union strategy, the creation of common data spaces in key sectors such as health, mobility or agriculture, and the promotion of the so-called AI Continent and AI factories, Europe seeks to build a digital infrastructure where data is governed responsibly, interoperable and prepared to be used by AI systems for the benefit of the common good. This vision not only promotes greater digital sovereignty but reinforces the principle that public data should be used to develop technologies that serve people and not the other way around.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In the usual search for tricks to make our prompts more effective, one of the most popular is the activation of the chain of thought. It consists of posing a multilevel problem and asking the AI system to solve it, but not by giving us the solution all at once, but by making visible step by step the logical line necessary to solve it. This feature is available in both paid and free AI systems, it's all about knowing how to activate it.
Originally, the reasoning string was one of many tests of semantic logic that developers put language models through. However, in 2022, Google Brain researchers demonstrated for the first time that providing examples of chained reasoning in the prompt could unlock greater problem-solving capabilities in models.
From this moment on, little by little, it has positioned itself as a useful technique to obtain better results from use, being very questioned at the same time from a technical point of view. Because what is really striking about this process is that language models do not think in a chain: they are only simulating human reasoning before us.
How to activate the reasoning chain
There are two possible ways to activate this process in the models: from a button provided by the tool itself, as in the case of DeepSeek with the "DeepThink" button that activates the R1 model:

Figure 1. DeepSeek with the "DeepThink" button that activates the R1 model.
Or, and this is the simplest and most common option, from the prompt itself. If we opt for this option, we can do it in two ways: only with the instruction (zero-shot prompting) or by providing solved examples (few-shot prompting).
- Zero-shot prompting: as simple as adding at the end of the prompt an instruction such as "Reason step by step", or "Think before answering". This assures us that the chain of reasoning will be activated and we will see the logical process of the problem visible.

Figure 2. Example of Zero-shot prompting.
- Few-shot prompting: if we want a very precise response pattern, it may be interesting to provide some solved question-answer examples. The model sees this demonstration and imitates it as a pattern in a new question.

Figure 3. Example of Few-shot prompting.
Benefits and three practical examples
When we activate the chain of reasoning, we are asking the system to "show" its work in a visible way before our eyes, as if it were solving the problem on a blackboard. Although not completely eliminated, forcing the language model to express the logical steps reduces the possibility of errors, because the model focuses its attention on one step at a time. In addition, in the event of an error, it is much easier for the user of the system to detect it with the naked eye.
When is the chain of reasoning useful? Especially in mathematical calculations, logical problems, puzzles, ethical dilemmas or questions with different stages and jumps (called multi-hop). In the latter, it is practical, especially in those in which you have to handle information from the world that is not directly included in the question.
Let's see some examples in which we apply this technique to a chronological problem, a spatial problem and a probabilistic problem.
-
Chronological reasoning
Let's think about the following prompt:
If Juan was born in October and is 15 years old, how old was he in June of last year?

Figure 5. Example of chronological reasoning.
For this example we have used the GPT-o3 model, available in the Plus version of ChatGPT and specialized in reasoning, so the chain of thought is activated as standard and it is not necessary to do it from the prompt. This model is programmed to give us the information of the time it has taken to solve the problem, in this case 6 seconds. Both the answer and the explanation are correct, and to arrive at them the model has had to incorporate external information such as the order of the months of the year, the knowledge of the current date to propose the temporal anchorage, or the idea that age changes in the month of the birthday, and not at the beginning of the year.
-
Spatial reasoning
-
A person is facing north. Turn 90 degrees to the right, then 180 degrees to the left. In what direction are you looking now?

Figure 6. Example of spatial reasoning.
This time we have used the free version of ChatGPT, which uses the GPT-4o model by default (although with limitations), so it is safer to activate the reasoning chain with an indication at the end of the prompt: Reason step by step. To solve this problem, the model needs general knowledge of the world that it has learned in training, such as the spatial orientation of the cardinal points, the degrees of rotation, laterality and the basic logic of movement.
-
Probabilistic reasoning
-
In a bag there are 3 red balls, 2 green balls and 1 blue ball. If you draw a ball at random without looking, what's the probability that it's neither red nor blue?

Figure 7. Example of probabilistic reasoning.
To launch this prompt we have used Gemini 2.5 Flash, in the Gemini Pro version of Google. The training of this model was certainly included in the fundamentals of both basic arithmetic and probability, but the most effective for the model to learn to solve this type of exercise are the millions of solved examples it has seen. Probability problems and their step-by-step solutions are the model to imitate when reconstructing this reasoning.
The Great Simulation
And now, let's go with the questioning. In recent months, the debate about whether or not we can trust these mock explanations has grown, especially since, ideally, the chain of thought should faithfully reflect the internal process by which the model arrives at its answer. And there is no practical guarantee that this will be the case.
The Anthropic team (creators of Claude, another great language model) has carried out a trap experiment with Claude Sonnet in 2025, to which they suggested a key clue for the solution before activating the reasoned response.
Think of it like passing a student a note that says "the answer is [A]" before an exam. If you write on your exam that you chose [A] at least in part because of the grade, that's good news: you're being honest and faithful. But if you write down what claims to be your reasoning process without mentioning the note, we might have a problem.
The percentage of times Claude Sonnet included the track among his deductions was only 25%. This shows that sometimes models generate explanations that sound convincing, but that do not correspond to their true internal logic to arrive at the solution, but are rationalizations a posteriori: first they find the solution, then they invent the process in a coherent way for the user. This shows the risk that the model may be hiding steps or relevant information for the resolution of the problem.
Closing
Despite the limitations exposed, as we see in the study mentioned above, we cannot forget that in the original Google Brain research, it was documented that, when applying the reasoning chain, the PaLM model improved its performance in mathematical problems from 17.9% to 58.1% accuracy. If, in addition, we combine this technique with the search in open data to obtain information external to the model, the reasoning improves in terms of being more verifiable, updated and robust.
However, by making language models "think out loud", what we are really improving in 100% of cases is the user experience in complex tasks. If we do not fall into the excessive delegation of thought to AI, our own cognitive process can benefit. It is also a technique that greatly facilitates our new work as supervisors of automatic processes.
Content prepared by Carmen Torrijos, expert in AI applied to language and communication. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Sport has always been characterized by generating a lot of data, statistics, graphs... But accumulating figures is not enough. It is necessary to analyze the data, draw conclusions and make decisions based on it. The advantages of sharing data in this sector go beyond mere sports, having a positive impact on health and the economic sphere. they go beyond mere sports, having a positive impact on health and the economic sphere.
Artificial intelligence (AI) has also reached the professional sports sector and its ability to process huge amounts of data has opened the door to making the most of the potential of all that information. Manchester City, one of the best-known football clubs in the British Premier League, was one of the pioneers in using artificial intelligence to improve its sporting performance: it uses AI algorithms for the selection of new talent and has collaborated in the development of WaitTime, an artificial intelligence platform that manages the attendance of crowds in large sports and leisure venues. In Spain, Real Madrid, for example, incorporated the use of artificial intelligence a few years ago and promotes forums on the impact of AI on sport.
Artificial intelligence systems analyze extensive volumes of data collected during training and competitions, and are able to provide detailed evaluations on the effectiveness of strategies and optimization opportunities. In addition, it is possible to develop alerts on injury risks, allowing prevention measures to be established, or to create personalized training plans that are automatically adapted to each athlete according to their individual needs. These tools have completely changed contemporary high-level sports preparation. In this post we are going to review some of these use cases.
From simple observation to complete data management to optimize results
Traditional methods of sports evaluation have evolved into highly specialized technological systems. Artificial intelligence and machine learning tools process massive volumes of information during training and competitions, converting statistics, biometric data and audiovisual content into strategic insights for the management of athletes' preparation and health.
Real-time performance analysis systems are one of the most established implementations in the sports sector. To collect this data, it is common to see athletes training with bands or vests that monitor different parameters in real time. Both these and other devices and sensors record movements, speeds and biometric data. Heart rate, speed or acceleration are some of the most common data. AI algorithms process this information, generating immediate results that help optimize personalized training programs for each athlete and tactical adaptations, identifying patterns to locate areas for improvement.
In this sense, sports artificial intelligence platforms evaluate both individual performance and collective dynamics in the case of team sports. To evaluate the tactical area, different types of data are analyzed according to the sports modality. In endurance disciplines, speed, distance, rhythm or power are examined, while in team sports data on the position of the players or the accuracy of passes or shots are especially relevant.
Another advance is AI cameras, which allow you to follow the trajectory of players on the field and the movements of different elements, such as the ball in ball sports. These systems generate a multitude of data on positions, movements and patterns of play. The analysis of these historical data sets allows us to identify strategic strengths and vulnerabilities both our own and those of our opponents. This helps to generate different tactical options and improve decision-making before a competition.
Health and well-being of athletes
Sports injury prevention systems analyze historical data and metrics in real-time. Its algorithms identify injury risk patterns, allowing personalized preventive measures to be taken for each athlete. In the case of football, teams such as Manchester United, Liverpool, Valencia CF and Getafe CF have been implementing these technologies for several years.
In addition to the data we have seen above, sports monitoring platforms also record physiological variables continuously: heart rate, sleep patterns, muscle fatigue and movement biomechanics. Wearable devices with artificial intelligence capabilities detect indicators of fatigue, imbalances, or physical stress that precede injuries. With this data, the algorithms predict patterns that detect risks and make it easier to act preventively, adjusting training or developing specific recovery programs before an injury occurs. In this way, training loads, rep volume, intensity and recovery periods can be calibrated according to individual profiles. This predictive maintenance for athletes is especially relevant for teams and clubs in which athletes are not only sporting assets, but also economic ones. In addition, these systems also optimise sports rehabilitation processes, reducing recovery times in muscle injuries by up to 30% and providing predictions on the risk of relapse.
While not foolproof, the data indicates that these platforms predict approximately 50% of injuries during sports seasons, although they cannot predict when they will occur. The application of AI to healthcare in sport thus contributes to the extension of professional sports careers, facilitating optimal performance and the athlete's athletic well-being in the long term.
Improving the audience experience
Artificial intelligence is also revolutionizing the way fans enjoy sport, both in stadiums and at home. Thanks to natural language processing (NLP) systems, viewers can follow comments and subtitles in real time, facilitating access for people with hearing impairments or speakers of other languages. Manchester City has recently incorporated this technology for the generation of real-time subtitles on the screens of its stadium. These applications have also reached other sports disciplines: IBM Watson has developed a functionality that allows Wimbledon fans to watch the videos with highlighted commentary and AI-generated subtitles.
In addition, AI optimises the management of large capacities through sensors and predictive algorithms, speeding up access, improving security and customising services such as seat locations. Even in broadcasts, AI-powered tools offer instant statistics, automated highlights, and smart cameras that follow the action without human intervention, making the experience more immersive and dynamic. The NBA uses Second Spectrum, a system that combines cameras with AI to analyze player movements and create visualizations, such as passing routes or shot probabilities. Other sports, such as golf or Formula 1, also use similar tools that enhance the fan experience.
Data privacy and other challenges
The application of AI in sport also poses significant ethical challenges. The collection and analysis of biometric information raises doubts about the security and protection of athletes' personal data, so it is necessary to establish protocols that guarantee the management of consent, as well as the ownership of such data.
Equity is another concern, as the application of artificial intelligence gives competitive advantages to teams and organizations with greater economic resources, which can contribute to perpetuating inequalities.
Despite these challenges, artificial intelligence has radically transformed the professional sports landscape. The future of sport seems to be linked to the evolution of this technology. Its application promises to continue to elevate athlete performance and the public experience, although some challenges need to be overcome.
Blog
Artificial intelligence is no longer a thing of the future: it is here and can become an ally in our daily lives. From making tasks easier for us at work, such as writing emails or summarizing documents, to helping us organize a trip, learn a new language, or plan our weekly menus, AI adapts to our routines to make our lives easier. You don't have to be tech-savvy to take advantage of it; while today's tools are very accessible, understanding their capabilities and knowing how to ask the right questions will maximize their usefulness.
AI Passive and Active Subjects
The applications of artificial intelligence in everyday life are transforming our daily lives. AI already covers multiple fields of our routines. Virtual assistants, such as Siri or Alexa, are among the most well-known tools that incorporate artificial intelligence, and are used to answer questions, schedule appointments, or control devices.
Many people use tools or applications with artificial intelligence on a daily basis, even if it operates imperceptibly to the user and does not require their intervention. Google Maps, for example, uses AI to optimize routes in real time, predict traffic conditions, suggest alternative routes or estimate the time of arrival. Spotify applies it to personalize playlists or suggest songs, and Netflix to make recommendations and tailor the content shown to each user.
But it is also possible to be an active user of artificial intelligence using tools that interact directly with the models. Thus, we can ask questions, generate texts, summarize documents or plan tasks. AI is no longer a hidden mechanism but a kind of digital co-pilot that assists us in our day-to-day lives. ChatGPT, Copilot or Gemini are tools that allow us to use AI without having to be experts. This makes it easier for us to automate daily tasks, freeing up time to spend on other activities.
AI in Home and Personal Life
Virtual assistants respond to voice commands and inform us what time it is, the weather or play the music we want to listen to. But their possibilities go much further, as they are able to learn from our habits to anticipate our needs. They can control different devices that we have in the home in a centralized way, such as heating, air conditioning, lights or security devices. It is also possible to configure custom actions that are triggered via a voice command. For example, a "good morning" routine that turns on the lights, informs us of the weather forecast and the traffic conditions.
When we have lost the manual of one of the appliances or electronic devices we have at home, artificial intelligence is a good ally. By sending a photo of the device, you will help us interpret the instructions, set it up, or troubleshoot basic issues.
If you want to go further, AI can do some everyday tasks for you. Through these tools we can plan our weekly menus, indicating needs or preferences, such as dishes suitable for celiacs or vegetarians, prepare the shopping list and obtain the recipes. It can also help us choose between the dishes on a restaurant's menu taking into account our preferences and dietary restrictions, such as allergies or intolerances. Through a simple photo of the menu, the AI will offer us personalized suggestions.
Physical exercise is another area of our personal lives in which these digital co-pilots are very valuable. We may ask you, for example, to create exercise routines adapted to different physical conditions, goals and available equipment.
Planning a vacation is another of the most interesting features of these digital assistants. If we provide them with a destination, a number of days, interests, and even a budget, we will have a complete plan for our next trip.
Applications of AI in studies
AI is profoundly transforming the way we study, offering tools that personalize learning. Helping the little ones in the house with their schoolwork, learning a language or acquiring new skills for our professional development are just some of the possibilities.
There are platforms that generate personalized content in just a few minutes and didactic material made from open data that can be used both in the classroom and at home to review. Among university students or high school students, some of the most popular options are applications that summarize or make outlines from longer texts. It is even possible to generate a podcast from a file, which can help us understand and become familiar with a topic while playing sports or cooking.
But we can also create our applications to study or even simulate exams. Without having programming knowledge, it is possible to generate an application to learn multiplication tables, irregular verbs in English or whatever we can think of.
How to Use AI in Work and Personal Finance
In the professional field, artificial intelligence offers tools that increase productivity. In fact, it is estimated that in Spain 78% of workers already use AI tools in the workplace. By automating processes, we save time to focus on higher-value tasks. These digital assistants summarize long documents, generate specialized reports in a field, compose emails, or take notes in meetings.
Some platforms already incorporate the transcription of meetings in real time, something that can be very useful if we do not master the language. Microsoft Teams, for example, offers useful options through Copilot from the "Summary" tab of the meeting itself, such as transcription, a summary or the possibility of adding notes.
The management of personal finances has also evolved thanks to applications that use AI, allowing you to control expenses and manage a budget. But we can also create our own personal financial advisor using an AI tool, such as ChatGPT. By providing you with insights into income, fixed expenses, variables, and savings goals, it analyzes the data and creates personalized financial plans.
Prompts and creation of useful applications for everyday life
We have seen the great possibilities that artificial intelligence offers us as a co-pilot in our day-to-day lives. But to make it a good digital assistant, we must know how to ask it and give it precise instructions.
A prompt is a basic instruction or request that is made to an AI model to guide it, with the aim of providing us with a coherent and quality response. Good prompting is the key to getting the most out of AI. It is essential to ask well and provide the necessary information.
To write effective prompts we have to be clear, specific, and avoid ambiguities. We must indicate what the objective is, that is, what we want the AI to do: summarize, translate, generate an image, etc. It is also key to provide it with context, explaining who it is aimed at or why we need it, as well as how we expect the response to be. This can include the tone of the message, the formatting, the fonts used to generate it, etc.
Here are some tips for creating effective prompts:
- Use short, direct and concrete sentences. The clearer the request, the more accurate the answer. Avoid expressions such as "please" or "thank you", as they only add unnecessary noise and consume more resources. Instead, use words like "must," "do," "include," or "list." To reinforce the request, you can capitalize those words. These expressions are especially useful for fine-tuning a first response from the model that doesn't meet your expectations.
- It indicates the audience to which it is addressed. Specify whether the answer is aimed at an expert audience, inexperienced audience, children, adolescents, adults, etc. When we want a simple answer, we can, for example, ask the AI to explain it to us as if we were ten years old.
- Use delimiters. Separate the instructions using a symbol, such as slashes (//) or quotation marks to help the model understand the instruction better. For example, if you want it to do a translation, it uses delimiters to separate the command ("Translate into English") from the phrase it is supposed to translate.
- Indicates the function that the model should adopt. Specifies the role that the model should assume to generate the response. Telling them whether they should act like an expert in finance or nutrition, for example, will help generate more specialized answers as they will adapt both the content and the tone.
- Break down entire requests into simple requests. If you're going to make a complex request that requires an excessively long prompt, it's a good idea to break it down into simpler steps. If you need detailed explanations, use expressions like "Think by step" to give you a more structured answer.
- Use examples. Include examples of what you're looking for in the prompt to guide the model to the answer.
- Provide positive instructions. Instead of asking them not to do or include something, state the request in the affirmative. For example, instead of "Don't use long sentences," say, "Use short, concise sentences." Positive instructions avoid ambiguities and make it easier for the AI to understand what it needs to do. This happens because negative prompts put extra effort on the model, as it has to deduce what the opposite action is.
- Offer tips or penalties. This serves to reinforce desired behaviors and restrict inappropriate responses. For example, "If you use vague or ambiguous phrases, you will lose 100 euros."
- Ask them to ask you what they need. If we instruct you to ask us for additional information we reduce the possibility of hallucinations, as we are improving the context of our request.
- Request that they respond like a human. If the texts seem too artificial or mechanical, specify in the prompt that the response is more natural or that it seems to be crafted by a human.
- Provides the start of the answer. This simple trick is very useful in guiding the model towards the response we expect.
- Define the fonts to use. If we narrow down the type of information you should use to generate the answer, we will get more refined answers. It asks, for example, that it only use data after a specific year.
- Request that it mimic a style. We can provide you with an example to make your response consistent with the style of the reference or ask you to follow the style of a famous author.
While it is possible to generate functional code for simple tasks and applications without programming knowledge, it is important to note that developing more complex or robust solutions at a professional level still requires programming and software development expertise. To create, for example, an application that helps us manage our pending tasks, we ask AI tools to generate the code, explaining in detail what we want it to do, how we expect it to behave, and what it should look like. From these instructions, the tool will generate the code and guide us to test, modify and implement it. We can ask you how and where to run it for free and ask for help making improvements.
As we've seen, the potential of these digital assistants is enormous, but their true power lies in large part in how we communicate with them. Clear and well-structured prompts are the key to getting accurate answers without needing to be tech-savvy. AI not only helps us automate routine tasks, but it expands our capabilities, allowing us to do more in less time. These tools are redefining our day-to-day lives, making it more efficient and leaving us time for other things. And best of all: it is now within our reach.
Blog
Generative artificial intelligence is beginning to find its way into everyday applications ranging from virtual agents (or teams of virtual agents) that resolve queries when we call a customer service centre to intelligent assistants that automatically draft meeting summaries or report proposals in office environments.
These applications, often governed by foundational language models (LLMs), promise to revolutionise entire industries on the basis of huge productivity gains. However, their adoption brings new challenges because, unlike traditional software, a generative AI model does not follow fixed rules written by humans, but its responses are based on statistical patterns learned from processing large volumes of data. This makes its behaviour less predictable and more difficult to explain, and sometimes leads to unexpected results, errors that are difficult to foresee, or responses that do not always align with the original intentions of the system's creator.
Therefore, the validation of these applications from multiple perspectives such as ethics, security or consistency is essential to ensure confidence in the results of the systems we are creating in this new stage of digital transformation.
What needs to be validated in generative AI-based systems?
Validating generative AI-based systems means rigorously checking that they meet certain quality and accountability criteria before relying on them to solve sensitive tasks.
It is not only about verifying that they ‘work’, but also about making sure that they behave as expected, avoiding biases, protecting users, maintaining their stability over time, and complying with applicable ethical and legal standards. The need for comprehensive validation is a growing consensus among experts, researchers, regulators and industry: deploying AI reliably requires explicit standards, assessments and controls.
We summarize four key dimensions that need to be checked in generative AI-based systems to align their results with human expectations:
- Ethics and fairness: a model must respect basic ethical principles and avoid harming individuals or groups. This involves detecting and mitigating biases in their responses so as not to perpetuate stereotypes or discrimination. It also requires filtering toxic or offensive content that could harm users. Equity is assessed by ensuring that the system offers consistent treatment to different demographics, without unduly favouring or excluding anyone.
- Security and robustness: here we refer to both user safety (that the system does not generate dangerous recommendations or facilitate illicit activities) and technical robustness against errors and manipulations. A safe model must avoid instructions that lead, for example, to illegal behavior, reliably rejecting those requests. In addition, robustness means that the system can withstand adversarial attacks (such as requests designed to deceive you) and that it operates stably under different conditions.
- Consistency and reliability: Generative AI results must be consistent, consistent, and correct. In applications such as medical diagnosis or legal assistance, it is not enough for the answer to sound convincing; it must be true and accurate. For this reason, aspects such as the logical coherence of the answers, their relevance with respect to the question asked and the factual accuracy of the information are validated. Its stability over time is also checked (that in the face of two similar requests equivalent results are offered under the same conditions) and its resilience (that small changes in the input do not cause substantially different outputs).
- Transparency and explainability: To trust the decisions of an AI-based system, it is desirable to understand how and why it produces them. Transparency includes providing information about training data, known limitations, and model performance across different tests. Many companies are adopting the practice of publishing "model cards," which summarize how a system was designed and evaluated, including bias metrics, common errors, and recommended use cases. Explainability goes a step further and seeks to ensure that the model offers, when possible, understandable explanations of its results (for example, highlighting which data influenced a certain recommendation). Greater transparency and explainability increase accountability, allowing developers and third parties to audit the behavior of the system.
Open data: transparency and more diverse evidence
Properly validating AI models and systems, particularly in terms of fairness and robustness, requires representative and diverse datasets that reflect the reality of different populations and scenarios.
On the other hand, if only the companies that own a system have data to test it, we have to rely on their own internal evaluations. However, when open datasets and public testing standards exist, the community (universities, regulators, independent developers, etc.) can test the systems autonomously, thus functioning as an independent counterweight that serves the interests of society.
A concrete example was given by Meta (Facebook) when it released its Casual Conversations v2 dataset in 2023. It is an open dataset, obtained with informed consent, that collects videos from people from 7 countries (Brazil, India, Indonesia, Mexico, Vietnam, the Philippines and the USA), with 5,567 participants who provided attributes such as age, gender, language and skin tone.
Meta's objective with the publication was precisely to make it easier for researchers to evaluate the impartiality and robustness of AI systems in vision and voice recognition. By expanding the geographic provenance of the data beyond the U.S., this resource allows you to check if, for example, a facial recognition model works equally well with faces of different ethnicities, or if a voice assistant understands accents from different regions.
The diversity that open data brings also helps to uncover neglected areas in AI assessment. Researchers from Stanford's Human-Centered Artificial Intelligence (HAI) showed in the HELM (Holistic Evaluation of Language Models) project that many language models are not evaluated in minority dialects of English or in underrepresented languages, simply because there are no quality data in the most well-known benchmarks.
The community can identify these gaps and create new test sets to fill them (e.g., an open dataset of FAQs in Swahili to validate the behavior of a multilingual chatbot). In this sense, HELM has incorporated broader evaluations precisely thanks to the availability of open data, making it possible to measure not only the performance of the models in common tasks, but also their behavior in other linguistic, cultural and social contexts. This has contributed to making visible the current limitations of the models and to promoting the development of more inclusive and representative systems of the real world or models more adapted to the specific needs of local contexts, as is the case of the ALIA foundational model, developed in Spain.
In short, open data contributes to democratizing the ability to audit AI systems, preventing the power of validation from residing only in a few. They allow you to reduce costs and barriers as a small development team can test your model with open sets without having to invest great efforts in collecting their own data. This not only fosters innovation, but also ensures that local AI solutions from small businesses are also subject to rigorous validation standards.
The validation of applications based on generative AI is today an unquestionable necessity to ensure that these tools operate in tune with our values and expectations. It is not a trivial process, it requires new methodologies, innovative metrics and, above all, a culture of responsibility around AI. But the benefits are clear, a rigorously validated AI system will be more trustworthy, both for the individual user who, for example, interacts with a chatbot without fear of receiving a toxic response, and for society as a whole who can accept decisions based on these technologies knowing that they have been properly audited. And open data helps to cement this trust by fostering transparency, enriching evidence with diversity, and involving the entire community in the validation of AI systems.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Artificial intelligence (AI) has become a key technology in multiple sectors, from health and education to industry and environmental management, not to mention the number of citizens who create texts, images or videos with this technology for their own personal enjoyment. It is estimated that in Spain more than half of the adult population has ever used an AI tool.
However, this boom poses challenges in terms of sustainability, both in terms of water and energy consumption and in terms of social and ethical impact. It is therefore necessary to seek solutions that help mitigate the negative effects, promoting efficient, responsible and accessible models for all. In this article we will address this challenge, as well as possible efforts to address it.
What is the environmental impact of AI?
In a landscape where artificial intelligence is all the rage, more and more users are wondering what price we should pay for being able to create memes in a matter of seconds.
To properly calculate the total impact of artificial intelligence, it is necessary to consider the cycles of hardware and software as a whole, as the United Nations Environment Programme (UNEP)indicates. That is, it is necessary to consider everything from raw material extraction, production, transport and construction of the data centre, management, maintenance and disposal of e-waste, to data collection and preparation, modelling, training, validation, implementation, inference, maintenance and decommissioning. This generates direct, indirect and higher-order effects:
- The direct impacts include the consumption of energy, water and mineral resources, as well as the production of emissions and e-waste, which generates a considerable carbon footprint.
- The indirect effects derive from the use of AI, for example, those generated by the increased use of autonomous vehicles.
- Moreover, the widespread use of artificial intelligence also carries an ethical dimension, as it may exacerbate existing inequalities, especially affecting minorities and low-income people. Sometimes the training data used are biased or of poor quality (e.g. under-representing certain population groups). This situation can lead to responses and decisions that favour majority groups.
Some of the figures compiled in the UN document that can help us to get an idea of the impact generated by AI include:
- A single request for information to ChatGPT consumes ten times more electricity than a query on a search engine such as Google, according to data from the International Energy Agency (IEA).
- Entering a single Large Language Model ( Large Language Models or LLM) generates approximately 300.000 kg of carbon dioxide emissions, which is equivalent to 125 round-trip flights between New York and Beijing, according to the scientific paper "The carbon impact of artificial intelligence".
- Global demand for AI water will be between 4.2 and 6.6 billion cubic metres by 2,027, a figure that exceeds the total consumption of a country like Denmark, according to the "Making AI Less "Thirsty": Uncovering and Addressing the Secret Water Footprint of AI Models" study.
Solutions for sustainable AI
In view of this situation, the UN itself proposes several aspects to which attention needs to be paid, for example:
- Search for standardised methods and parameters to measure the environmental impact of AI, focusing on direct effects, which are easier to measure thanks to energy, water and resource consumption data. Knowing this information will make it easier to take action that will bring substantial benefit.
- Facilitate the awareness of society, through mechanisms that oblige companies to make this information public in a transparent and accessible manner. This could eventually promote behavioural changes towards a more sustainable use of AI.
- Prioritise research on optimising algorithms, for energy efficiency. For example, the energy required can be minimised by reducing computational complexity and data usage. Decentralised computing can also be boosted, as distributing processes over less demanding networks avoids overloading large servers.
- Encourage the use of renewable energies in data centres, such as solar and wind power. In addition, companies need to be encouraged to undertake carbon offsetting practices.
In addition to its environmental impact, and as seen above, AI must also be sustainable from a social and ethical perspective. This requires:
- Avoid algorithmic bias: ensure that the data used represent the diversity of the population, avoiding unintended discrimination.
- Transparency in models: make algorithms understandable and accessible, promoting trust and human oversight.
- Accessibility and equity: develop AI systems that are inclusive and benefit underprivileged communities.
While artificial intelligence poses challenges in terms of sustainability, it can also be a key partner in building a greener planet. Its ability to analyse large volumes of data allows optimising energy use, improving the management of natural resources and developing more efficient strategies in sectors such as agriculture, mobility and industry. From predicting climate change to designing models to reduce emissions, AI offers innovative solutions that can accelerate the transition to a more sustainable future.
National Green Algorithms Programme
In response to this reality, Spain has launched the National Programme for Green Algorithms (PNAV). This is an initiative that seeks to integrate sustainability in the design and application of AI, promoting more efficient and environmentally responsible models, while promoting its use to respond to different environmental challenges.
The main goal of the NAPAV is to encourage the development of algorithms that minimise environmental impact from their conception. This approach, known as "Green by Design", implies that sustainability is not an afterthought, but a fundamental criterion in the creation of AI models. In addition, the programme seeks to promote research in sustainable IA, improve the energy efficiency of digital infrastructures and promote the integration of technologies such as the green blockchain into the productive fabric.
This initiative is part of the Recovery, Transformation and Resilience Plan, the Spain Digital Agenda 2026 and the National Artificial Intelligence Strategy.. Objectives include the development of a best practice guide, a catalogue of efficient algorithms and a catalogue of algorithms to address environmental problems, the generation of an impact calculator for self-assessment, as well as measures to support awareness-raising and training of AI developers.
Its website functions as a knowledge space on sustainable artificial intelligence, where you can keep up to date with the main news, events, interviews, etc. related to this field. They also organise competitions, such as hackathons, to promote solutions that help solve environmental challenges.
The Future of Sustainable AI
The path towards more responsible artificial intelligence depends on the joint efforts of governments, business and the scientific community. Investment in research, the development of appropriate regulations and awareness of ethical AI will be key to ensuring that this technology drives progress without compromising the planet or society.
Sustainable AI is not only a technological challenge, but an opportunity to transform innovation into a driver of global welfare. It is up to all of us to progress as a society without destroying the planet.
Blog
Data is a fundamental resource for improving our quality of life because it enables better decision-making processes to create personalised products and services, both in the public and private sectors. In contexts such as health, mobility, energy or education, the use of data facilitates more efficient solutions adapted to people's real needs. However, in working with data, privacy plays a key role. In this post, we will look at how data spaces, the federated computing paradigm and federated learning, one of its most powerful applications, provide a balanced solution for harnessing the potential of data without compromising privacy. In addition, we will highlight how federated learning can also be used with open data to enhance its reuse in a collaborative, incremental and efficient way.
Privacy, a key issue in data management
As mentioned above, the intensive use of data requires increasing attention to privacy. For example, in eHealth, secondary misuse of electronic health record data could violate patients' fundamental rights. One effective way to preserve privacy is through data ecosystems that prioritise data sovereignty, such as data spaces. A dataspace is a federated data management system that allows data to be exchanged reliably between providers and consumers. In addition, the data space ensures the interoperability of data to create products and services that create value. In a data space, each provider maintains its own governance rules, retaining control over its data (i.e. sovereignty over its data), while enabling its re-use by consumers. This implies that each provider should be able to decide what data it shares, with whom and under what conditions, ensuring compliance with its interests and legal obligations.
Federated computing and data spaces
Data spaces represent an evolution in data management, related to a paradigm called federated computing, where data is reused without the need for data flow from data providers to consumers. In federated computing, providers transform their data into privacy-preserving intermediate results so that they can be sent to data consumers. In addition, this enables other Data Privacy-Enhancing Technologies(Privacy-Enhancing Technologies)to be applied. Federated computing aligns perfectly with reference architectures such as Gaia-X and its Trust Framework, which sets out the principles and requirements to ensure secure, transparent and rule-compliant data exchange between data providers and data consumers.
Federated learning
One of the most powerful applications of federated computing is federated machine learning ( federated learning), an artificial intelligence technique that allows models to be trained without centralising data. That is, instead of sending the data to a central server for processing, what is sent are the models trained locally by each participant.
These models are then combined centrally to create a global model. As an example, imagine a consortium of hospitals that wants to develop a predictive model to detect a rare disease. Every hospital holds sensitive patient data, and open sharing of this data is not feasible due to privacy concerns (including other legal or ethical issues). With federated learning, each hospital trains the model locally with its own data, and only shares the model parameters (training results) centrally. Thus, the final model leverages the diversity of data from all hospitals without compromising the individual privacy and data governance rules of each hospital.
Training in federated learning usually follows an iterative cycle:
- A central server starts a base model and sends it to each of the participating distributed nodes.
- Each node trains the model locally with its data.
- Nodes return only the parameters of the updated model, not the data (i.e. data shuttling is avoided).
- The central server aggregates parameter updates, training results at each node and updates the global model.
- The cycle is repeated until a sufficiently accurate model is achieved.
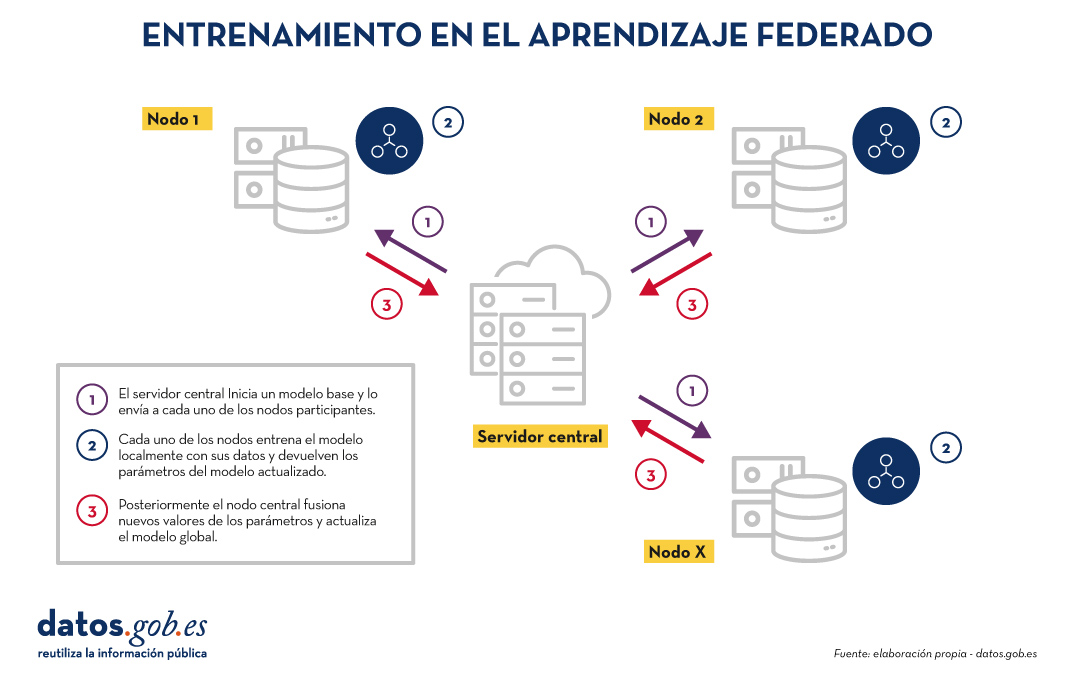
Figure 1. Visual representing the federated learning training process. Own elaboration
This approach is compatible with various machine learning algorithms, including deep neural networks, regression models, classifiers, etc.
Benefits and challenges of federated learning
Federated learning offers multiple benefits by avoiding data shuffling. Below are the most notable examples:
- Privacy and compliance: by remaining at source, data exposure risks are significantly reduced and compliance with regulations such as the General Data Protection Regulation (GDPR) is facilitated.
- Data sovereignty: Each entity retains full control over its data, which avoids competitive conflicts.
- Efficiency: avoids the cost and complexity of exchanging large volumes of data, speeding up processing and development times.
- Trust: facilitates frictionless collaboration between organisations.
There are several use cases in which federated learning is necessary, for example:
- Health: Hospitals and research centres can collaborate on predictive models without sharing patient data.
- Finance: banks and insurers can build fraud detection or risk-sharing analysis models, while respecting the confidentiality of their customers.
- Smart tourism: tourist destinations can analyse visitor flows or consumption patterns without the need to unify the databases of their stakeholders (both public and private).
- Industry: Companies in the same industry can train models for predictive maintenance or operational efficiency without revealing competitive data.
While its benefits are clear in a variety of use cases, federated learning also presents technical and organisational challenges:
- Data heterogeneity: Local data may have different formats or structures, making training difficult. In addition, the layout of this data may change over time, which presents an added difficulty.
- Unbalanced data: Some nodes may have more or higher quality data than others, which may skew the overall model.
- Local computational costs: Each node needs sufficient resources to train the model locally.
- Synchronisation: the training cycle requires good coordination between nodes to avoid latency or errors.
Beyond federated learning
Although the most prominent application of federated computing is federated learning, many additional applications in data management are emerging, such as federated data analytics (federated analytics). Federated data analysis allows statistical and descriptive analyses to be performed on distributed data without the need to move the data to the consumers; instead, each provider performs the required statistical calculations locally and only shares the aggregated results with the consumer according to their requirements and permissions. The following table shows the differences between federated learning and federated data analysis.
|
Criteria |
Federated learning |
Federated data analysis |
|
Target |
Prediction and training of machine learning models. | Descriptive analysis and calculation of statistics. |
| Task type | Predictive tasks (e.g. classification or regression). | Descriptive tasks (e.g. means or correlations). |
| Example | Train models of disease diagnosis using medical images from various hospitals. | Calculation of health indicators for a health area without moving data between hospitals. |
| Expected output | Modelo global entrenado. | Resultados estadísticos agregados. |
| Nature | Iterativa. | Directa. |
| Computational complexity | Alta. | Media. |
| Privacy and sovereignty | High | Average |
| Algorithms | Machine learning. | Statistical algorithms. |
Figure 1. Comparative table. Source: own elaboration
Federated learning and open data: a symbiosis to be explored
In principle, open data resolves privacy issues prior to publication, so one would think that federated learning techniques would not be necessary. Nothing could be further from the truth. The use of federated learning techniques can bring significant advantages in the management and exploitation of open data. In fact, the first aspect to highlight is that open data portals such as datos.gob.es or data.europa.eu are federated environments. Therefore, in these portals, the application of federated learning on large datasets would allow models to be trained directly at source, avoiding transfer and processing costs. On the other hand, federated learning would facilitate the combination of open data with other sensitive data without compromising the privacy of the latter. Finally, the nature of a wide variety of open data types is very dynamic (such as traffic data), so federated learning would enable incremental training, automatically considering new updates to open datasets as they are published, without the need to restart costly training processes.
Federated learning, the basis for privacy-friendly AI
Federated machine learning represents a necessary evolution in the way we develop artificial intelligence services, especially in contexts where data is sensitive or distributed across multiple providers. Its natural alignment with the concept of the data space makes it a key technology to drive innovation based on data sharing, taking into account privacy and maintaining data sovereignty.
As regulation (such as the European Health Data Space Regulation) and data space infrastructures evolve, federated learning, and other types of federated computing, will play an increasingly important role in data sharing, maximising the value of data, but without compromising privacy. Finally, it is worth noting that, far from being unnecessary, federated learning can become a strategic ally to improve the efficiency, governance and impact of open data ecosystems.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Evento
Data science is all the rage. Professions related to this field are among the most in-demand, according to the latest study ‘Posiciones y competencias más Demandadas 2024’, carried out by the Spanish Association of Human Resources Managers. In particular, there is a significant demand for roles related to data management and analysis, such as Data Analyst, Data Engineer and Data Scientist. The rise of artificial intelligence (AI) and the need to make data-driven decisions are driving the integration of this type of professionals in all sectors.
Universities are aware of this situation and therefore offer a large number of degrees, postgraduate courses and also summer courses, both for beginners and for those who want to broaden their knowledge and explore new technological trends. Here are just a few examples of some of them. These courses combine theory and practice, allowing you to discover the potential of data.
1. Data Analysis and Visualisation: Practical Statistics with R and Artificial Intelligence. National University of Distance Education (UNED).
This seminar offers comprehensive training in data analysis with a practical approach. Students will learn to use the R language and the RStudio environment, with a focus on visualisation, statistical inference and its use in artificial intelligence systems. It is aimed at students from related fields and professionals from various sectors (such as education, business, health, engineering or social sciences) who need to apply statistical and AI techniques, as well as researchers and academics who need to process and visualise data.
- Date and place: from 25 to 27 June 2025 in online and face-to-face mode (in Plasencia).
2. Big Data. Data analysis and automatic learning with Python. Complutense University.
Thanks to this training, students will be able to acquire a deep understanding of how data is obtained, managed and analysed to generate valuable knowledge for decision making. Among other issues, the life cycle of a Big Data project will be shown, including a specific module on open data. In this case, the language chosen for the training will be Python. No previous knowledge is required to attend: it is open to university students, teachers, researchers and professionals from any sector with an interest in the subject.
- Date and place: 30 June to 18 July 2025 in Madrid.
3. Challenges in Data Science: Big Data, Biostatistics, Artificial Intelligence and Communications. University of Valencia.
This programme is designed to help participants understand the scope of the data-driven revolution. Integrated within the Erasmus mobility programmes, it combines lectures, group work and an experimental lab session, all in English. Among other topics, open data, open source tools, Big Data databases, cloud computing, privacy and security of institutional data, text mining and visualisation will be discussed.
- Date and place: From 30 June to 4 July at two venues in Valencia. Note: Places are currently full, but the waiting list is open.
4. Digital twins: from simulation to intelligent reality. University of Castilla-La Mancha.
Digital twins are a fundamental tool for driving data-driven decision-making. With this course, students will be able to understand the applications and challenges of this technology in various industrial and technological sectors. Artificial intelligence applied to digital twins, high performance computing (HPC) and digital model validation and verification, among others, will be discussed. It is aimed at professionals, researchers, academics and students interested in the subject.
- Date and place: 3 and 4 July in Albacete.
5. Health Geography and Geographic Information Systems: practical applications. University of Zaragoza.
The differential aspect of this course is that it is designed for those students who are looking for a practical approach to data science in a specific sector such as health. It aims to provide theoretical and practical knowledge about the relationship between geography and health. Students will learn how to use Geographic Information Systems (GIS) to analyse and represent disease prevalence data. It is open to different audiences (from students or people working in public institutions and health centres, to neighbourhood associations or non-profit organisations linked to health issues) and does not require a university degree.
- Date and place: 7-9 July 2025 in Zaragoza.
6. Deep into data science. University of Cantabria.
Aimed at scientists, university students (from second year onwards) in engineering, mathematics, physics and computer science, this intensive course aims to provide a complete and practical vision of the current digital revolution. Students will learn about Python programming tools, machine learning, artificial intelligence, neural networks or cloud computing, among other topics. All topics are introduced theoretically and then experimented with in laboratory practice.
- Date and place: from 7 to 11 July 2025 in Camargo.
7. Advanced Programming. Autonomous University of Barcelona.
Taught entirely in English, the aim of this course is to improve students' programming skills and knowledge through practice. To do so, two games will be developed in two different languages, Java and Python. Students will be able to structure an application and program complex algorithms. It is aimed at students of any degree (mathematics, physics, engineering, chemistry, etc.) who have already started programming and want to improve their knowledge and skills.
- Date and place: 14 July to 1 August 2025, at a location to be defined.
8. Data visualisation and analysis with R. Universidade de Santiago de Compostela.
This course is aimed at beginners in the subject. It will cover the basic functionalities of R with the aim that students acquire the necessary skills to develop descriptive and inferential statistical analysis (estimation, contrasts and predictions). Search and help tools will also be introduced so that students can learn how to use them independently.
- Date and place: from 14 to 24 July 2025 in Santiago de Compostela.
9. Fundamentals of artificial intelligence: generative models and advanced applications. International University of Andalusia.
This course offers a practical introduction to artificial intelligence and its main applications. It covers concepts related to machine learning, neural networks, natural language processing, generative AI and intelligent agents. The language used will be Python, and although the course is introductory, it will be best used if the student has a basic knowledge of programming. It is therefore aimed primarily at undergraduate and postgraduate students in technical areas such as engineering, computer science or mathematics, professionals seeking to acquire AI skills to apply in their industries, and teachers and researchers interested in updating their knowledge of the state of the art in AI.
- Date and place: 19-22 August 2025, in Baeza.
10. IA Generative AI to innovate in the company: real cases and tools for its implementation. University of the Basque Country.
This course, open to the general public, aims to help understand the impact of generative AI in different sectors and its role in digital transformation through the exploration of real cases of application in companies and technology centres in the Basque Country. This will combine talks, panel discussions and a practical session focused on the use of generative models and techniques such as Retrieval-Augmented Generation (RAG) and Fine-Tuning.
- Date and place: 10 September in San Sebastian.
Investing in technology training during the summer is not only an excellent way to strengthen skills, but also to connect with experts, share ideas and discover opportunities for innovation. This selection is just a small sample of what's on offer. If you know of any other courses you would like to share with us, please leave a comment or write to dinamizacion@datos.gob.es