Documentación
1. Introduction
In the information age, artificial intelligence has proven to be an invaluable tool for a variety of applications. One of the most incredible manifestations of this technology is GPT (Generative Pre-trained Transformer), developed by OpenAI. GPT is a natural language model that can understand and generate text, providing coherent and contextually relevant responses. With the recent introduction of Chat GPT-4, the capabilities of this model have been further expanded, allowing for greater customisation and adaptability to different themes.
In this post, we will show you how to set up and customise a specialised critical minerals wizard using GPT-4 and open data sources. As we have shown in previous publications critical minerals are fundamental to numerous industries, including technology, energy and defence, due to their unique properties and strategic importance. However, information on these materials can be complex and scattered, making a specialised assistant particularly useful.
The aim of this post is to guide you step by step from the initial configuration to the implementation of a GPT wizard that can help you to solve doubts and provide valuable information about critical minerals in your day to day life. In addition, we will explore how to customise aspects of the assistant, such as the tone and style of responses, to perfectly suit your needs. At the end of this journey, you will have a powerful, customised tool that will transform the way you access and use critical open mineral information.
Access the data lab repository on Github.
2. Context
The transition to a sustainable future involves not only changes in energy sources, but also in the material resources we use. The success of sectors such as energy storage batteries, wind turbines, solar panels, electrolysers, drones, robots, data transmission networks, electronic devices or space satellites depends heavily on access to the raw materials critical to their development. We understand that a mineral is critical when the following factors are met:
- Its global reserves are scarce
- There are no alternative materials that can perform their function (their properties are unique or very unique)
- They are indispensable materials for key economic sectors of the future, and/or their supply chain is high risk
You can learn more about critical minerals in the post mentioned above.
3. Target
This exercise focuses on showing the reader how to customise a specialised GPT model for a specific use case. We will adopt a "learning-by-doing" approach, so that the reader can understand how to set up and adjust the model to solve a real and relevant problem, such as critical mineral expert advice. This hands-on approach not only improves understanding of language model customisation techniques, but also prepares readers to apply this knowledge to real-world problem solving, providing a rich learning experience directly applicable to their own projects.
The GPT assistant specialised in critical minerals will be designed to become an essential tool for professionals, researchers and students. Its main objective will be to facilitate access to accurate and up-to-date information on these materials, to support strategic decision-making and to promote education in this field. The following are the specific objectives we seek to achieve with this assistant:
- Provide accurate and up-to-date information:
- The assistant should provide detailed and accurate information on various critical minerals, including their composition, properties, industrial uses and availability.
- Keep up to date with the latest research and market trends in the field of critical minerals.
- Assist in decision-making:
- To provide data and analysis that can assist strategic decision making in industry and critical minerals research.
- Provide comparisons and evaluations of different minerals in terms of performance, cost and availability.
- Promote education and awareness of the issue:
- Act as an educational tool for students, researchers and practitioners, helping to improve their knowledge of critical minerals.
- Raise awareness of the importance of these materials and the challenges related to their supply and sustainability.
4. Resources
To configure and customise our GPT wizard specialising in critical minerals, it is essential to have a number of resources to facilitate implementation and ensure the accuracy and relevance of the model''s responses. In this section, we will detail the necessary resources that include both the technological tools and the sources of information that will be integrated into the assistant''s knowledge base.
Tools and Technologies
The key tools and technologies to develop this exercise are:
- OpenAI account: required to access the platform and use the GPT-4 model. In this post, we will use ChatGPT''s Plus subscription to show you how to create and publish a custom GPT. However, you can develop this exercise in a similar way by using a free OpenAI account and performing the same set of instructions through a standard ChatGPT conversation.
- Microsoft Excel: we have designed this exercise so that anyone without technical knowledge can work through it from start to finish. We will only use office tools such as Microsoft Excel to make some adjustments to the downloaded data.
In a complementary way, we will use another set of tools that will allow us to automate some actions without their use being strictly necessary:
- Google Colab: is a Python Notebooks environment that runs in the cloud, allowing users to write and run Python code directly in the browser. Google Colab is particularly useful for machine learning, data analysis and experimentation with language models, offering free access to powerful computational resources and facilitating collaboration and project sharing.
- Markmap: is a tool that visualises Markdown mind maps in real time. Users write ideas in Markdown and the tool renders them as an interactive mind map in the browser. Markmap is useful for project planning, note taking and organising complex information visually. It facilitates understanding and the exchange of ideas in teams and presentations.
Sources of information
- Raw Materials Information System (RMIS): raw materials information system maintained by the Joint Research Center of the European Union. It provides detailed and up-to-date data on the availability, production and consumption of raw materials in Europe.
- International Energy Agency (IEA) Catalogue of Reports and Data: the International Energy Agency (IEA) offers a comprehensive catalogue of energy-related reports and data, including statistics on production, consumption and reserves of energy and critical minerals.
- Mineral Database of the Spanish Geological and Mining Institute (BDMIN in its acronym in Spanish): contains detailed information on minerals and mineral deposits in Spain, useful to obtain specific data on the production and reserves of critical minerals in the country.
With these resources, you will be well equipped to develop a specialised GPT assistant that can provide accurate and relevant answers on critical minerals, facilitating informed decision-making in the field.
5. Development of the exercise
5.1. Building the knowledge base
For our specialised critical minerals GPT assistant to be truly useful and accurate, it is essential to build a solid and structured knowledge base. This knowledge base will be the set of data and information that the assistant will use to answer queries. The quality and relevance of this information will determine the effectiveness of the assistant in providing accurate and useful answers.
Search for Data Sources
We start with the collection of information sources that will feed our knowledge base. Not all sources of information are equally reliable. It is essential to assess the quality of the sources identified, ensuring that:
- Information is up to date: the relevance of data can change rapidly, especially in dynamic fields such as critical minerals.
- The source is reliable and recognised: it is necessary to use sources from recognised and respected academic and professional institutions.
- Data is complete and accessible: it is crucial that data is detailed and accessible for integration into our wizard.
In our case, we developed an online search in different platforms and information repositories trying to select information belonging to different recognised entities:
- Research centres and universities:
- They publish detailed studies and reports on the research and development of critical minerals.
- Example: RMIS of the Joint Research Center of the European Union.
- Governmental institutions and international organisations:
- These entities usually provide comprehensive and up-to-date data on the availability and use of critical minerals.
- Example: International Energy Agency (IEA).
- Specialised databases:
- They contain technical and specific data on deposits and production of critical minerals.
- Example: Minerals Database of the Spanish Geological and Mining Institute (BDMIN).
Selection and preparation of information
We will now focus on the selection and preparation of existing information from these sources to ensure that our GPT assistant can access accurate and useful data.
RMIS of the Joint Research Center of the European Union:
- Selected information:
We selected the report "Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU - A foresight study". This is an analysis of the supply chain and demand for minerals in strategic technologies and sectors in the EU. It presents a detailed study of the supply chains of critical raw materials and forecasts the demand for minerals up to 2050.
- Necessary preparation:
The format of the document, PDF, allows the direct ingestion of the information by our assistant. However, as can be seen in Figure 1, there is a particularly relevant table on pages 238-240 which analyses, for each mineral, its supply risk, typology (strategic, critical or non-critical) and the key technologies that employ it. We therefore decided to extract this table into a structured format (CSV), so that we have two pieces of information that will become part of our knowledge base.

Figure 1: Table of minerals contained in the JRC PDF
To programmatically extract the data contained in this table and transform it into a more easily processable format, such as CSV(comma separated values), we will use a Python script that we can use through the platform Google Colab platform (Figure 2).

Figure 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
To summarise, this script:
- It is based on the open source library PyPDF2capable of interpreting information contained in PDF files.
- First, it extracts in text format (string) the content of the pages of the PDF where the mineral table is located, removing all the content that does not correspond to the table itself.
- It then goes through the string line by line, converting the values into columns of a data table. We will know that a mineral is used in a key technology if in the corresponding column of that mineral we find a number 1 (otherwise it will contain a 0).
- Finally, it exports the table to a CSV file for further use.
International Energy Agency (IEA):
- Selected information:
We selected the report "Global Critical Minerals Outlook 2024". It provides an overview of industrial developments in 2023 and early 2024, and offers medium- and long-term prospects for the demand and supply of key minerals for the energy transition. It also assesses risks to the reliability, sustainability and diversity of critical mineral supply chains.
- Necessary preparation:
The format of the document, PDF, allows us to ingest the information directly by our virtual assistant. In this case, we will not make any adjustments to the selected information.
Spanish Geological and Mining Institute''s Minerals Database (BDMIN)
- Selected information:
In this case, we use the form to select the existing data in this database for indications and deposits in the field of metallogeny, in particular those with lithium content.

Figure 3: Dataset selection in BDMIN.
- Necessary preparation:
We note how the web tool allows online visualisation and also the export of this data in various formats. Select all the data to be exported and click on this option to download an Excel file with the desired information.

Figure 4: Visualization and download tool in BDMIN

Figure 5: BDMIN Downloaded Data.
All the files that make up our knowledge base can be found at GitHub, so that the reader can skip the downloading and preparation phase of the information.
5.2. GPT configuration and customisation for critical minerals
When we talk about "creating a GPT," we are actually referring to the configuration and customisation of a GPT (Generative Pre-trained Transformer) based language model to suit a specific use case. In this context, we are not creating the model from scratch, but adjusting how the pre-existing model (such as OpenAI''s GPT-4) interacts and responds within a specific domain, in this case, on critical minerals.
First of all, we access the application through our browser and, if we do not have an account, we follow the registration and login process on the ChatGPT platform. As mentioned above, in order to create a GPT step-by-step, you will need to have a Plus account. However, readers who do not have such an account can work with a free account by interacting with ChatGPT through a standard conversation.
Figure 6: ChatGPT login and registration page.
Once logged in, select the "Explore GPT" option, and then click on "Create" to begin the process of creating your GPT.

Figure 7: Creation of new GPT.
The screen will display the split screen for creating a new GPT: on the left, we will be able to talk to the system to indicate the characteristics that our GPT should have, while on the left we will be able to interact with our GPT to validate that its behaviour is adequate as we go through the configuration process.

Figure 8: Screen of creating new GPT.
In the GitHub of this project, we can find all the prompts or instructions that we will use to configure and customise our GPT and that we will have to introduce sequentially in the "Create" tab, located on the left tab of our screens, to complete the steps detailed below.
The steps we will follow for the creation of the GPT are as follows:
- First, we will outline the purpose and basic considerations for our GPT so that you can understand how to use it.
Figure 9: Basic instructions for new GPT.
2. We will then create a name and an image to represent our GPT and make it easily identifiable. In our case, we will call it MateriaGuru.

Figure 10: Name selection for new GPT.

Figure 11: Image creation for GPT.
3.We will then build the knowledge base from the information previously selected and prepared to feed the knowledge of our GPT.


Figure 12: Uploading of information to the new GPT knowledge base.
4. Now, we can customise conversational aspects such as their tone, the level of technical complexity of their response or whether we expect brief or elaborate answers.
5. Lastly, from the "Configure" tab, we can indicate the conversation starters desired so that users interacting with our GPT have some ideas to start the conversation in a predefined way.

Figure 13: Configure GPT tab.
In Figure 13 we can also see the final result of our training, where key elements such as their image, name, instructions, conversation starters or documents that are part of their knowledge base appear.
5.3. Validation and publication of GPT
Before we sign off our new GPT-based assistant, we will proceed with a brief validation of its correct configuration and learning with respect to the subject matter around which we have trained it. For this purpose, we prepared a battery of questions that we will ask MateriaGuru to check that it responds appropriately to a real scenario of use.
| # | Question | Answer |
|---|---|---|
| 1 | Which critical minerals have experienced a significant drop in prices in 2023? | Battery mineral prices saw particularly large drops with lithium prices falling by 75% and cobalt, nickel and graphite prices falling by between 30% and 45%. |
| 2 | What percentage of global solar photovoltaic (PV) capacity was added by China in 2023? | China accounted for 62% of the increase in global solar PV capacity in 2023. |
| 3 | What is the scenario that projects electric car (EV) sales to reach 65% by 2030? | The Net Zero Emissions (NZE) scenario for 2050 projects that electric car sales will reach 65% by 2030. |
| 4 | What was the growth in lithium demand in 2023? | Lithium demand increased by 30% in 2023. |
| 5 | Which country was the largest electric car market in 2023? | China was the largest electric car market in 2023 with 8.1 million electric car sales representing 60% of the global total. |
| 6 | What is the main risk associated with market concentration in the battery graphite supply chain? | More than 90% of battery-grade graphite and 77% of refined rare earths in 2030 originate in China, posing a significant risk to market concentration. |
| 7 | What proportion of global battery cell production capacity was in China in 2023? | China owned 85% of battery cell production capacity in 2023. |
| 8 | How much did investment in critical minerals mining increase in 2023? | Investment in critical minerals mining grew by 10% in 2023. |
| 9 | What percentage of battery storage capacity in 2023 was composed of lithium iron phosphate (LFP) batteries? | By 2023, LFP batteries would constitute approximately 80% of the total battery storage market. |
| 10 | What is the forecast for copper demand in a net zero emissions (NZE) scenario for 2040? | In the net zero emissions (NZE) scenario for 2040, copper demand is expected to have the largest increase in terms of production volume. |
Figure 14: Table with battery of questions for the validation of our GPT.
Using the preview section on the right-hand side of our screens, we launch the battery of questions and validate that the answers correspond to those expected.

Figure 15: Validation of GPT responses.
Finally, click on the "Create" button to finalise the process. We will be able to select between different alternatives to restrict its use by other users.

Figure 16: Publication of our GPT.
6. Scenarios of use
In this section we show several scenarios in which we can take advantage of MateriaGuru in our daily life. On the GitHub of the project you can find the prompts used to replicate each of them.
6.1. Consultation of critical minerals information
The most typical scenario for the use of this type of GPTs is assistance in resolving doubts related to the topic in question, in this case, critical minerals. As an example, we have prepared a set of questions that the reader can pose to the GPT created to understand in more detail the relevance and current status of a critical material such as graphite from the reports provided to our GPT.

Figure 17: Resolution of critical mineral queries.
We can also ask you specific questions about the tabulated information provided on existing sites and evidence on Spanish territory.
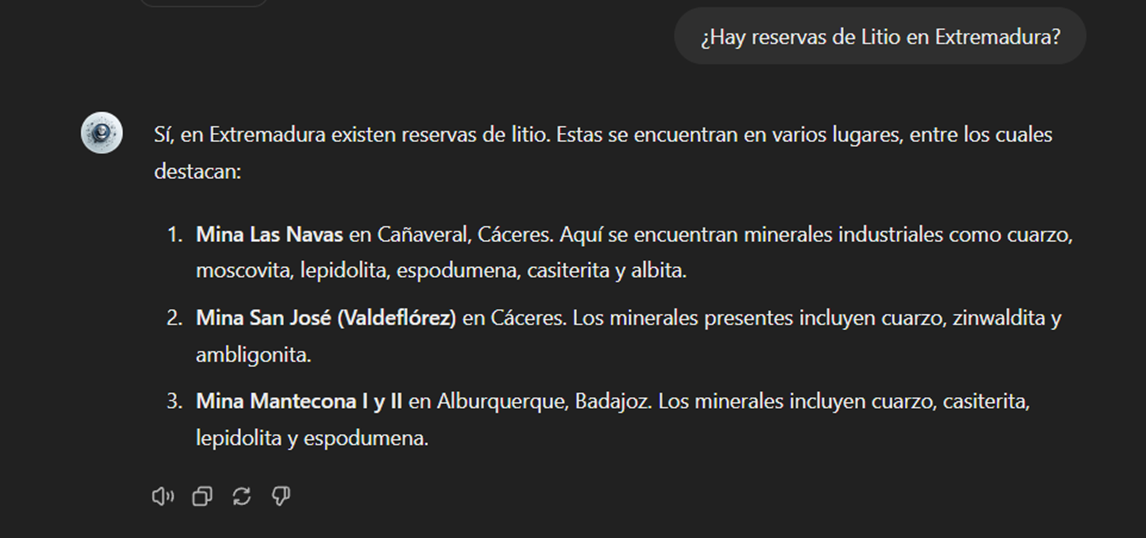
Figure 18: Lithium reserves in Extremadura.
6.2. Representation of quantitative data visualisations
Another common scenario is the need to consult quantitative information and make visual representations for better understanding. In this scenario, we can see how MateriaGuru is able to generate an interactive visualisation of graphite production in tonnes for the main producing countries.

Figure 19: Interactive visualisation generation with our GPT.
6.3. Generating mind maps to facilitate understanding
Finally, in line with the search for alternatives for a better access and understanding of the existing knowledge in our GPT, we will propose to MateriaGuru the construction of a mind map that allows us to understand in a visual way key concepts of critical minerals. For this purpose, we use the open Markmap notation (Markdown Mindmap), which allows us to define mind maps using markdown notation.

Figure 20: Generation of mind maps from our GPT
We will need to copy the generated code and enter it in a markmapviewer in order to generate the desired mind map. We facilitate here a version of this code generated by MateriaGuru.

Figure 21: Visualisation of mind maps.
7. Results and conclusions
In the exercise of building an expert assistant using GPT-4, we have succeeded in creating a specialised model for critical minerals. This wizard provides detailed and up-to-date information on critical minerals, supporting strategic decision making and promoting education in this field. We first gathered information from reliable sources such as the RMIS, the International Energy Agency (IEA), and the Spanish Geological and Mining Institute (BDMIN). We then process and structure the data appropriately for integration into the model. Validations showed that the wizard accurately answers domain-relevant questions, facilitating access to your information.
In this way, the development of the specialised critical minerals assistant has proven to be an effective solution for centralising and facilitating access to complex and dispersed information.
The use of tools such as Google Colab and Markmap has enabled better organisation and visualisation of data, increasing efficiency in knowledge management. This approach not only improves the understanding and use of critical mineral information, but also prepares users to apply this knowledge in real-world contexts.
The practical experience gained in this exercise is directly applicable to other projects that require customisation of language models for specific use cases.
8. Do you want to do the exercise?
If you want to replicate this exercise, access this this repository where you will find more information (the prompts used, the code generated by MateriaGuru, etc.)
Also, remember that you have at your disposal more exercises in the section "Step-by-step visualisations".
Content elaborated by Juan Benavente, industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
For many people, summer means the arrival of the vacations, a time to rest or disconnect. But those days off are also an opportunity to train in various areas and improve our competitive skills.
For those who want to take advantage of the next few weeks and acquire new knowledge, Spanish universities have a wide range of courses on a variety of subjects. In this article, we have compiled some examples of courses related to data training.
Geographic Information Systems (GIS) with QGIS. University of Alcalá de Henares (link not available).
The course aims to train students in basic GIS skills so that they can perform common processes such as creating maps for reports, downloading data from a GPS, performing spatial analysis, etc. Each student will have the possibility to develop their own GIS project with the help of the faculty. The course is aimed at university students of any discipline, as well as professionals interested in learning basic concepts to create their own maps or use geographic information systems in their activities.
- Date and place: June 27-28 and July 1-2 in online mode.
Citizen science applied to biodiversity studies: from the idea to the results. Pablo de Olavide University (Seville).
This course addresses all the necessary steps to design, implement and analyze a citizen science project: from the acquisition of basic knowledge to its applications in research and conservation projects. Among other issues, there will be a workshop on citizen science data management, focusing on platforms such as Observation.org y GBIF. It will also teach how to use citizen science tools for the design of research projects. The course is aimed at a broad audience, especially researchers, conservation project managers and students.
- Date and place: From July 1 to 3, 2024 in online and on-site (Seville).
Big Data. Data analysis and machine learning with Python. Complutense University of Madrid.
This course aims to provide students with an overview of the broad Big Data ecosystem, its challenges and applications, focusing on new ways of obtaining, managing and analyzing data. During the course, the Python language is presented, and different machine learning techniques are shown for the design of models that allow obtaining valuable information from a set of data. It is aimed at any university student, teacher, researcher, etc. with an interest in the subject, as no previous knowledge is required.
- Date and place: July 1 to 19, 2024 in Madrid.
Introduction to Geographic Information Systems with R. University of Santiago de Compostela.
Organized by the Working Group on Climate Change and Natural Hazards of the Spanish Association of Geography together with the Spanish Association of Climatology, this course will introduce the student to two major areas of great interest: 1) the handling of the R environment, showing the different ways of managing, manipulating and visualizing data. 2) spatial analysis, visualization and work with raster and vector files, addressing the main geostatistical interpolation methods. No previous knowledge of Geographic Information Systems or the R environment is required to participate.
- Date and place: July 2-5, 2024 in Santiago de Compostela
Artificial Intelligence and Large Language Models: Operation, Key Components and Applications. University of Zaragoza.
Through this course, students will be able to understand the fundamentals and practical applications of artificial intelligence focused on Large Language Model (LLM). Students will be taught how to use specialized libraries and frameworks to work with LLM, and will be shown examples of use cases and applications through hands-on workshops. It is aimed at professionals and students in the information and communications technology sector.
- Date and place: July 3 to 5 in Zaragoza.
Deep into Data Science. University of Cantabria.
This course focuses on the study of big data using Python. The emphasis of the course is on Machine Learning, including sessions on artificial intelligence, neural networks or Cloud Computing. This is a technical course, which presupposes previous knowledge in science and programming with Python.
- Date and place: From July 15 to 19, 2024 in Torrelavega.
Data management for the use of artificial intelligence in tourist destinations. University of Alicante.
This course approaches the concept of Smart Tourism Destination (ITD) and addresses the need to have an adequate technological infrastructure to ensure its sustainable development, as well as to carry out an adequate data management that allows the application of artificial intelligence techniques. During the course, open data and data spaces and their application in tourism will be discussed. It is aimed at all audiences with an interest in the use of emerging technologies in the field of tourism.
- Date and place: From July 22 to 26, 2024 in Torrevieja.
The challenges of digital transformation of productive sectors from the perspective of artificial intelligence and data processing technologies. University of Extremadura.
Now that the summer is over, we find this course where the fundamentals of digital transformation and its impact on productive sectors are addressed through the exploration of key data processing technologies, such as the Internet of Things, Big Data, Artificial Intelligence, etc. During the sessions, case studies and implementation practices of these technologies in different industrial sectors will be analyzed. All this without leaving aside the ethical, legal and privacy challenges. It is aimed at anyone interested in the subject, without the need for prior knowledge.
- Date and place: From September 17 to 19, in Cáceres.
These courses are just examples that highlight the importance that data-related skills are acquiring in Spanish companies, and how this is reflected in university offerings. Do you know of any other courses offered by public universities? Let us know in comments.
Blog
Artificial intelligence (AI) has revolutionised various aspects of society and our environment. With ever faster technological advances, AI is transforming the way daily tasks are performed in different sectors of the economy.
As such, employment is one of the sectors where it is having the greatest impact. Among the main developments, this technology is introducing new professional profiles and modifying or transforming existing jobs. Against this backdrop, questions are being asked about the future of employment and how it will affect workers in the labour market.
What are the key figures for AI in employment?
The International Monetary Fund has recently pointed out: Artificial Intelligence will affect 40% of jobs worldwide, both replacing some and complementing and creating new ones.
The irruption of AI in the world of work has made it easier for some tasks that previously required human intervention to be carried out more automatically. Moreover, as the same international organisation warns, compared to other automation processes experienced in past decades, the AI era is also transforming highly skilled jobs.
The document also states that the impact of AI on the workplace will differ according to the country's level of development. It will be greater in the case of advanced economies, where up to 6 out of 10 jobs are expected to be conditioned by this technology. In the case of emerging economies, it will reach up to 40% and, in low-income countries, it will be reflected in 26% of jobs. For its part, the International Labour Organisation (ILO) also warns in its report ‘Generative AI and Jobs: A global analysis of potential effects on job quantity and quality’ that the effects of the arrival of AI in administrative positions will particularly affect women, due to the high rate of female employment in this labour sector.
In the Spanish case, according to figures from last year, not only is the influence of AI on jobs observed, but also the difficulty of finding people with specialised training. According to the report on talent in artificial intelligence prepared by Indesia, last year 20% of job offers related to data and Artificial Intelligence were not filled due to a lack of professionals with specialisation.
Future projections
Although there are no reliable figures yet to see what the next few years will look like, some organisations, such as the OECD, say that we are still at an early stage in the development of AI in the labour market, but on the verge of a large-scale breakthrough. According to its ‘Employment Outlook 2023’ report, ‘business adoption of AI remains relatively low’, although it warns that ‘rapid advances, including in generative AI (e.g. ChatGPT), falling costs and the growing availability of AI-skilled workers suggest that OECD countries may be on the verge of an AI revolution’. It is worth noting that generative AI is one of the fields where open data is having a major impact.
And what will happen in Spain? Perhaps it is still too early to point to very precise figures, but the report produced last year by Indesia already warned that Spanish industry will require more than 90,000 data and AI professionals by 2025. This same document also points out the challenges that Spanish companies will have to face, as globalisation and the intensification of remote work means that national companies are competing with international companies that also offer 100% remote employment, ‘with better salary conditions, more attractive and innovative projects and more challenging career plans’, says the report.
What jobs is AI changing?
Although one of the greatest fears of the arrival of this technology in the world of work is the destruction of jobs, the latest figures published by the International Labour Organisation (ILO) point to a much more promising scenario. Specifically, the ILO predicts that AI will complement jobs rather than destroy them.
There is not much unanimity on which sectors will be most affected. In its report ‘The impact of AI on the workplace: Main findings from the OECD AI surveys of employers and workers', the OECD points out that manufacturing and finance are two of the areas most affected by the irruption of Artificial Intelligence.
On the other hand, Randstad has recently published a report on the evolution of the last two years with a vision of the future until 2033. The document points out that the most affected sectors will be jobs linked to commerce, hospitality and transport. Among those jobs that will remain largely unaffected are agriculture, livestock and fishing, associative activities, extractive industries and construction. Finally, there is a third group, which includes employment sectors in which new profiles will be created. In this case, we find programming and consultancy companies, scientific and technical companies, telecommunications and the media and publications.
Beyond software developers, the new jobs that artificial intelligence is bringing will include everything from natural language processing experts or AI Prompt engineers (experts in asking the questions needed to get generative AI applications to deliver a specific result) to algorithm auditors or even artists.
Ultimately, while it is too early to say exactly which types of jobs are most affected, organisations point to one thing: the greater the likelihood of automation of job-related processes, the greater the impact of AI in transforming or modifying that job profile.
The challenges of AI in the labour market
One of the bodies that has done most research on the challenges and impacts of AI on employment is the ILO. At the level of needs, the ILO points to the need to design policies that support an orderly, just and consultative transition. To this end, it notes that workers' voice, training and adequate social protection will be key to managing the transition. ‘Otherwise, there is a risk that only a few countries and well-prepared market participants will benefit from the new technology,’ it warns.
For its part, the OECD outlines a series of recommendations for governments to accommodate this new employment reality, including the need to:
-
Establish concrete policies to ensure the implementation of key principles for the reliable use of AI. Through the implementation of these mechanisms, the OECD believes that the benefits that AI can bring to the workplace are harnessed, while at the same time addressing potential risks to fundamental rights and workers' well-being.
-
Create new skills, while others will change or become obsolete. To this end, he points to training, which is needed ‘both for the low-skilled and older workers, but also for the high-skilled’. Therefore, ‘governments should encourage business to provide more training, integrate AI skills into education and support diversity in the AI workforce’.
In summary, although the figures do not yet allow us to see the full picture, several international organisations do agree that the AI revolution is coming. They also point to the need to adapt to this new scenario through internal training in companies to be able to cope with the needs posed by the technology. Finally, in governmental matters, organisations such as the ILO point out that it is necessary to ensure that the transition in the technological revolution is fair and within the margins of reliable uses of Artificial Intelligence.
Blog
The transfer of human knowledge to machine learning models is the basis of all current artificial intelligence. If we want AI models to be able to solve tasks, we first have to encode and transmit solved tasks to them in a formal language that they can process. We understand as a solved task information encoded in different formats, such as text, image, audio or video. In the case of language processing, and in order to achieve systems with a high linguistic competence so that they can communicate with us in an agile way, we need to transfer to these systems as many human productions in text as possible. We call these data sets the corpus.
Corpus: text datasets
When we talk about corpora (its Latin plural) or datasets that have been used to train Large Language Models (LLMs) such as GPT-4, we are talking about books of all kinds, content written on websites, large repositories of text and information in the world such as Wikipedia, but also less formal linguistic productions such as those we write on social networks, in public reviews of products or services, or even in emails. This variety allows these language models to process and handle text in different languages, registers and styles.
For people working in Natural Language Processing (NLP), data science and data engineering, great enablers like Kaggle or repositories like Awesome Public Datasets on GitHub, which provide direct access to download public datasets. Some of these data files have been prepared for processing and are ready for analysis, while others are in an unstructured state, which requires prior cleaning and sorting before they can be worked with. While also containing quantitative numerical data, many of these sources present textual data that can be used to train language models.
The problem of legitimacy
One of the complications we have encountered in creating these models is that text data that is published on the internet and has been collected via API (direct connections that allow mass downloading from a website or repository) or other techniques, are not always in the public domain. In many cases, they are copyrighted: writers, translators, journalists, content creators, scriptwriters, illustrators, designers and also musicians claim licensing fees from the big tech companies for the use of their text and image content to train models. The media, in particular, are actors greatly impacted by this situation, although their positioning varies according to their situation and different business decisions. There is therefore a need for open corpora that can be used for these training tasks, without prejudice to intellectual property.
Characteristics suitable for a training corpus
Most of the characteristics, which have traditionally have traditionally defined a good corpus in linguistic in linguistic research have not changed when these text datasets are now used to train language models.
- It is still beneficial to use whole texts rather than fragments to ensure coherence.
- Texts must be authentic, from linguistic reality and natural language situations, retrievable and verifiable.
- It is important to ensure a wide diversity in the provenance of texts in terms of sectors of society, publications, local varieties of languages and issuers or speakers.
- In addition to general language, a wide variety of specialised language, technical terms and texts specific to different areas of knowledge should be included.
- Register is fundamental in a language, so we must cover both formal and informal register, in its extremes and intermediate regions.
- Language must be well-formed to avoid interference in learning, so it is desirable to remove code marks, numbers or symbols that correspond to digital metadata and not to the natural formation of the language.
Like specific recommendations for the formats of the files that are to form part of these corpora to be part of these corpora, we find that text corpora with annotations should be stored in UTF-8 encoding and in JSON or CSV format, not in PDF. The preferred format of the sound corpus is WAV 16 bit, 16 KHz. (for voice) or 44.1 KHz (for music and audio). Video corpora should be compiled in MPEG-4 (MP4) format, and translation memories in TMX or CSV.
The text as a collective heritage
National libraries in Europe are actively digitising their rich repositories of history and culture, ensuring public access and preservation. Institutions such as the National Library of France or the British Library are leading the way with initiatives that digitise everything from ancient manuscripts to current web publications. This digital hoarding not only protects heritage from physical deterioration, but also democratises access for researchers and the public and, for some years now, also allows the collection of training corpora for artificial intelligence models.
The corpora provided officially by national libraries allow text collections to be used to create public technology available to all: a collective cultural heritage that generates a new collective heritage, this time a technologicalone. The gain is greatest when these institutional corpora do focus on complying with intellectual property laws, providing only open data and texts free of copyright restrictions, with prescribed or licensed rights. This, coupled with the encouraging fact that the amount of real data needed to train language models is hopefully decreasing as technology advances models is decreasing as technology advances, e.g. with the generation ofadvances, for example, with the generation of synthetic data or the optimisation of certain parameters, indicates that it is possible to train large text models without infringing on intellectual property laws operating in Europe.
In particular, the Biblioteca Nacional de España is making a major digitisation effort to make its valuable text repositories available for research, and in particular for language technologies. Since the first major mass digitisation of physical collections in 2008, the BNE has opened up access to millions of documents with the sole aim of sharing and universalising knowledge. In 2023, thanks to investment from the European Union's Recovery, Transformation and Resilience funds, the BNE is promoting a new digital preservation project in its Strategic Plan 2023-2025the plan focuses on four axes:
- the massive and systematic digitisation of collections,
- BNELab as a catalyst for innovation and data reuse in digital ecosystems,
- partnerships and new cooperation environments,
- and technological integration and sustainability.
The alignment of these four axes with new artificial intelligence and natural language processing technologies is more than obvious, as one of the main data reuses is the training of large language models. Both the digitised bibliographic records and the Library's cataloguing indexes are valuable materials for knowledge technology.
Spanish language models
In 2020, as a pioneering and relatively early initiative, in Spain the following was introduced MarIA a language model promoted by the Secretary of State for Digitalisation and Artificial Intelligence and developed by the National Supercomputing Centre (BSC-CNS), based on the archives of the National Library of Spain. In this case, the corpus was composed of texts from web pages, which had been collected by the BNE since 2009 and which had served to nourish a model originally based on GPT-2.
A lot has happened between the creation of MarIA and the announcement at the announcement at the 2024 Mobile World Congress of the construction of a great foundational language model, specifically trained in Spanish and co-official languages. This system will be open source and transparent, and will only use royalty-free content in its training. This project is a pioneer at European level, as it seeks to provide an open, public and accessible language infrastructure for companies. Like MarIA, the model will be developed at the BSC-CNS, working together with the Biblioteca Nacional de España and other actors such as the Academia Española de la Lengua and the Asociación de Academias de la Lengua Española.
In addition to the institutions that can provide linguistic or bibliographic collections, there are many more institutions in Spain that can provide quality corpora that can also be used for training models in Spanish. The Study on reusable data as a language resource, published in 2019 within the framework of the Language Technologies Plan, already pointed to different sources: the patents and technical reports of the Spanish and European Patent and Trademark Office, the terminology dictionaries of the Terminology Centre, or data as elementary as the census of the National Statistics Institute, or the place names of the National Geographic Institute. When it comes to audiovisual content, which can be transcribed for reuse, we have the video archive of RTVE A la carta, the Audiovisual Archive of the Congress of Deputies or the archives of the different regional television stations. The Boletín Oficial del Estado itself and its associated materials are an important source of textual information containing extensive knowledge about our society and its functioning. Finally, in specific areas such as health or justice, we have the publications of the Spanish Agency of Medicines and Health Products, the jurisprudence texts of the CENDOJ or the recordings of court hearings of the General Council of the Judiciary.
European initiatives
In Europe there does not seem to be as clear a precedent as MarIA or the upcoming GPT-based model in Spanish, as state-driven projects trained with heritage data, coming from national libraries or official bodies.
However, in Europe there is good previous work on the availability of documentation that could now be used to train European-founded AI systems. A good example is the europeana project, which seeks to digitise and make accessible the cultural and artistic heritage of Europe as a whole. It is a collaborative initiative that brings together contributions from thousands of museums, libraries, archives and galleries, providing free access to millions of works of art, photographs, books, music pieces and videos. Europeana has almost 25 million documents in text, which could be the basis for creating multilingual or multilingual competent foundational models in the different European languages.
There are also non-governmental initiatives, but with a global impact, such as Common Corpus which are the ultimate proof that it is possible to train language models with open data and without infringing copyright laws. Common Corpus was released in March 2024, and is the largest dataset created for training large language models, with 500 billion words from various cultural heritage initiatives. This corpus is multilingual and is the largest to date in English, French, Dutch, Spanish, German, Italian and French.
And finally, beyond text, it is possible to find initiatives in other formats such as audio, which can also be used to train AI models. In 2022, the National Library of Sweden provided a sound corpus of more than two million hours of recordings from local public radio, podcasts and audiobooks. The aim of the project was to generate an AI-based model of language-competent audio-to-text transcription that maximises the number of speakers to achieve a diverse and democratic dataset available to all.
Until now, the sense of collectivity and heritage has been sufficient in collecting and making data in text form available to society. With language models, this openness achieves a greater benefit: that of creating and maintaining technology that brings value to people and businesses, fed and enhanced by our own linguistic productions.
Content prepared by Carmen Torrijos, expert in AI applied to language and communication. The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
Today, 23 April, is World Book Day, an occasion to highlight the importance of reading, writing and the dissemination of knowledge. Active reading promotes the acquisition of skills and critical thinking by bringing us closer to specialised and detailed information on any subject that interests us, including the world of data.
Therefore, we would like to take this opportunity to showcase some examples of books and manuals regarding data and related technologies that can be found on the web for free.
1. Fundamentals of Data Science with R, edited by Gema Fernandez-Avilés and José María Montero (2024)
Access the book here.
- What is it about? The book guides the reader from the problem statement to the completion of the report containing the solution to the problem. It explains some thirty data science techniques in the fields of modelling, qualitative data analysis, discrimination, supervised and unsupervised machine learning, etc. It includes more than a dozen use cases in sectors as diverse as medicine, journalism, fashion and climate change, among others. All this, with a strong emphasis on ethics and the promotion of reproducibility of analyses.
- Who is it aimed at? It is aimed at users who want to get started in data science. It starts with basic questions, such as what is data science, and includes short sections with simple explanations of probability, statistical inference or sampling, for those readers unfamiliar with these issues. It also includes replicable examples for practice.
- Language: Spanish.
2. Telling stories with data, Rohan Alexander (2023).
Access the book here.
- What is it about? The book explains a wide range of topics related to statistical communication and data modelling and analysis. It covers the various operations from data collection, cleaning and preparation to the use of statistical models to analyse the data, with particular emphasis on the need to draw conclusions and write about the results obtained. Like the previous book, it also focuses on ethics and reproducibility of results.
- Who is it aimed at? It is ideal for students and entry-level users, equipping them with the skills to effectively conduct and communicate a data science exercise. It includes extensive code examples for replication and activities to be carried out as evaluation.
- Language: English.
3. The Big Book of Small Python Projects, Al Sweigart (2021)
Access the book here.
- What is it about? It is a collection of simple Python projects to learn how to create digital art, games, animations, numerical tools, etc. through a hands-on approach. Each of its 81 chapters independently explains a simple step-by-step project - limited to a maximum of 256 lines of code. It includes a sample run of the output of each programme, source code and customisation suggestions.
- Who is it aimed at? The book is written for two groups of people. On the one hand, those who have already learned the basics of Python, but are still not sure how to write programs on their own. On the other hand, those who are new to programming, but are adventurous, enthusiastic and want to learn as they go along. However, the same author has other resources for beginners to learn basic concepts.
- Language: English.
4. Mathematics for Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Access the book here.
- What is it about? Most books on machine learning focus on machine learning algorithms and methodologies, and assume that the reader is proficient in mathematics and statistics. This book foregrounds the mathematical foundations of the basic concepts behind machine learning
- Who is it aimed at? The author assumes that the reader has mathematical knowledge commonly learned in high school mathematics and physics subjects, such as derivatives and integrals or geometric vectors. Thereafter, the remaining concepts are explained in detail, but in an academic style, in order to be precise.
- Language: English.
5. Dive into Deep Learning, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, continually updated)
Access the book here.
- What is it about? The authors are Amazon employees who use the mXNet library to teach Deep Learning. It aims to make deep learning accessible, teaching basic concepts, context and code in a practical way through examples and exercises. The book is divided into three parts: introductory concepts, deep learning techniques and advanced topics focusing on real systems and applications.
- Who is it aimed at? This book is aimed at students (undergraduate and postgraduate), engineers and researchers, who are looking for a solid grasp of the practical techniques of deep learning. Each concept is explained from scratch, so no prior knowledge of deep or machine learning is required. However, knowledge of basic mathematics and programming is necessary, including linear algebra, calculus, probability and Python programming.
- Language: English.
6. Artificial intelligence and the public sector: challenges, limits and means, Eduardo Gamero and Francisco L. Lopez (2024)
Access the book here.
- What is it about? This book focuses on analysing the challenges and opportunities presented by the use of artificial intelligence in the public sector, especially when used to support decision-making. It begins by explaining what artificial intelligence is and what its applications in the public sector are, and then moves on to its legal framework, the means available for its implementation and aspects linked to organisation and governance.
- Who is it aimed at? It is a useful book for all those interested in the subject, but especially for policy makers, public workers and legal practitioners involved in the application of AI in the public sector.
- Language: Spanish
7. A Business Analyst’s Introduction to Business Analytics, Adam Fleischhacker (2024)
Access the book here.
- What is it about? The book covers a complete business analytics workflow, including data manipulation, data visualisation, modelling business problems, translating graphical models into code and presenting results to stakeholders. The aim is to learn how to drive change within an organisation through data-driven knowledge, interpretable models and persuasive visualisations.
- Who is it aimed at? According to the author, the content is accessible to everyone, including beginners in analytical work. The book does not assume any knowledge of the programming language, but provides an introduction to R, RStudio and the "tidyverse", a series of open source packages for data science.
- Language: English.
We invite you to browse through this selection of books. We would also like to remind you that this is only a list of examples of the possibilities of materials that you can find on the web. Do you know of any other books you would like to recommend? let us know in the comments or email us at dinamizacion@datos.gob.es!
Blog
The era of digitalisation in which we find ourselves has filled our daily lives with data products or data-driven products. In this post we discover what they are and show you one of the key data technologies to design and build this kind of products: GraphQL.
Introduction
Let's start at the beginning, what is a data product? A data product is a digital container (a piece of software) that includes data, metadata and certain functional logics (what and how I handle the data). The aim of such products is to facilitate users' interaction with a set of data. Some examples are:
- Sales scorecard: Online businesses have tools to track their sales performance, with graphs showing trends and rankings, to assist in decision making.
- Apps for recommendations: Streaming TV services have functionalities that show content recommendations based on the user's historical tastes.
- Mobility apps. The mobile apps of new mobility services (such as Cabify, Uber, Bolt, etc.) combine user and driver data and metadata with predictive algorithms, such as dynamic fare calculation or optimal driver assignment, in order to offer a unique user experience.
- Health apps: These applications make massive use of data captured by technological gadgets (such as the device itself, smart watches, etc.) that can be integrated with other external data such as clinical records and diagnostic tests.
- Environmental monitoring: There are apps that capture and combine data from weather forecasting services, air quality systems, real-time traffic information, etc. to issue personalised recommendations to users (e.g. the best time to schedule a training session, enjoy the outdoors or travel by car).
As we can see, data products accompany us on a daily basis, without many users even realising it. But how do you capture this vast amount of heterogeneous information from different technological systems and combine it to provide interfaces and interaction paths to the end user? This is where GraphQL positions itself as a key technology to accelerate the creation of data products, while greatly improving their flexibility and adaptability to new functionalities desired by users.
What is GraphQL?
GraphQL saw the light of day on Facebook in 2012 and was released as Open Source in 2015. It can be defined as a language and an interpreter of that language, so that a developer of data products can invent a way to describe his product based on a model (a data structure) that makes use of the data available through APIs.
Before the advent of GraphQL, we had (and still have) the technology REST, which uses the HTTPs protocol to ask questions and get answers based on the data. In 2021, we introduced a post where we presented the technology and made a small demonstrative example of how it works. In it, we explain REST API as the standard technology that supports access to data by computer programs. We also highlight how REST is a technology fundamentally designed to integrate services (such as an authentication or login service).
In a simple way, we can use the following analogy. It is as if REST is the mechanism that gives us access to a complete dictionary. That is, if we need to look up any word, we have a method of accessing the dictionary, which is alphabetical search. It is a general mechanism for finding any available word in the dictionary. However, GraphQL allows us, beforehand, to create a dictionary model for our use case (known as a "data model"). So, for example, if our final application is a recipe book, what we do is select a subset of words from the dictionary that are related to recipes.
To use GraphQL, data must always be available via an API. GraphQL provides a complete and understandable description of the API data, giving clients (human or application) the possibility to request exactly what they need. As quoted in this post, GraphQL is like an API to which we add a SQL-style "Where" statement.
Below, we take a closer look at GraphQL's strengths when the focus is on the development of data products.
Benefits of using GraphQL in data products:
- With GraphQL, the amount of data and queries on the APIs is considerably optimised . APIs for accessing certain data are not intended for a specific product (or use case) but as a general access specification (see dictionary example above). This means that, on many occasions, in order to access a subset of the data available in an API, we have to perform several chained queries, discarding most of the information along the way. GraphQL optimises this process, as it defines a predefined (but adaptable in the future) consumption model over a technical API. Reducing the amount of data requested has a positive impact on the rationalisation of computing resources, such as bandwidth or caches, and improves the speed of response of systems.
- This has an immediate effect on the standardisation of data access. The model defined thanks to GraphQL creates a data consumption standard for a family of use cases. Again, in the context of a social network, if what we want is to identify connections between people, we are not interested in a general mechanism of access to all the people in the network, but a mechanism that allows us to indicate those people with whom I have some kind of connection. This kind of data access filter can be pre-configured thanks to GraphQL.
- Improved safety and performance: By precisely defining queries and limiting access to sensitive data, GraphQL can contribute to a more secure and better performing application.
Thanks to these advantages, the use of this language represents a significant evolution in the way of interacting with data in web and mobile applications, offering clear advantages over more traditional approaches such as REST.
Generative Artificial Intelligence. A new superhero in town.
If the use of GraphQL language to access data in a much more efficient and standard way is a significant evolution for data products, what will happen if we can interact with our product in natural language? This is now possible thanks to the explosive evolution in the last 24 months of LLMs (Large Language Models) and generative AI.
The following image shows the conceptual scheme of a data product, intLegrated with LLMS: a digital container that includes data, metadata and logical functions that are expressed as functionalities for the user, together with the latest technologies to expose information in a flexible way, such as GraphQL and conversational interfaces built on top of Large Language Models (LLMs).

How can data products benefit from the combination of GraphQL and the use of LLMs?
- Improved user experience. By integrating LLMs, people can ask questions to data products using natural language, . This represents a significant change in how we interact with data, making the process more accessible and less technical. In a practical way, we will replace the clicks with phrases when ordering a taxi.
- Security improvements along the interaction chain in the use of a data product. For this interaction to be possible, a mechanism is needed that effectively connects the backend (where the data resides) with the frontend (where the questions are asked). GraphQL is presented as the ideal solution due to its flexibility and ability to adapt to the changing needs of users,offering a direct and secure link between data and questions asked in natural language. That is, GraphQl can pre-select the data to be displayed in a query, thus preventing the general query from making some private or unnecessary data visible for a particular application.
- Empowering queries with Artificial Intelligence: The artificial intelligence not only plays a role in natural language interaction with the user. One can think of scenarios where the very model that is defined with GraphQL is assisted by artificial intelligence itself. This would enrich interactions with data products, allowing a deeper understanding and richer exploration of the information available. For example, we can ask a generative AI (such as ChatGPT) to take this catalogue data that is exposed as an API and create a GraphQL model and endpoint for us.
In short, the combination of GraphQL and LLMs represents a real evolution in the way we access data. GraphQL's integration with LLMs points to a future where access to data can be both accurate and intuitive, marking a move towards more integrated information systems that are accessible to all and highly reconfigurable for different use cases. This approach opens the door to a more human and natural interaction with information technologies, aligning artificial intelligence with our everyday experiences of communicating using data products in our day-to-day lives.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The process of technological modernisation in the Administration of Justice in Spain began, to a large extent, in 2011. That year, the first regulation specifically aimed at promoting the use of information and communication technologies was approved. The aim of this regulation was to establish the conditions for recognising the validity of the use of electronic means in judicial proceedings and, above all, to provide legal certainty for procedural processing and acts of communication, including the filing of pleadings and the receipt of notifications of decisions. In this sense, the legislation established a basic legal status for those dealing with the administration of justice, especially for professionals. Likewise, the Internet presence of the Administration of Justice was given legal status, mainly with the appearance of electronic offices and access points, expressly admitting the possibility that the proceedings could be carried out in an automated manner.
However, as with the 2015 legal regulation of the common administrative procedure and the legal regime of the public sector, the management model it was inspired by was substantially oriented towards the generation, preservation and archiving of documents and records. Although a timid consideration of data was already apparent, it was largely too general in the scope of the regulation, as it was limited to recognising and ensuring security, interoperability and confidentiality.
In this context, the approval of Royal Decree-Law 6/2023 of 19 December has been a very important milestone in this process, as it incorporates important measures that aim to go beyond mere technological modernisation. Among other issues, it seeks to lay the foundations for an effective digital transformation in this area.
Towards a data-driven management orientation
Although this new regulatory framework largely consolidates and updates the previous regulation, it is an important step forward in facilitating the digital transformation as it establishes some essential premises without which it would be impossible to achieve this objective. Specifically, as stated in the Explanatory Memorandum:
From the understanding of the capital importance of data in a contemporary digital society, a clear and decisive commitment is made to its rational use in order to achieve evidence and certainty at the service of the planning and elaboration of strategies that contribute to a better and more effective public policy of Justice. [...] These data will not only benefit the Administration itself, but all citizens through the incorporation of the concept of "open data" in the Administration of Justice. This same data orientation will facilitate so-called automated, assisted and proactive actions.
In this sense, a general principle of data orientation is expressly recognised, thus overcoming the restrictions of a document- and file-based electronic management model as it has existed until now. This is intended not only to achieve objectives of improving procedural processing but also to facilitate its use for other purposes such as the development of dashboards, the generation of automated, assisted and proactive actions, the use of artificial intelligence systems and its publication in open data portals.
How has this principle been put into practice?
The main novelties of this regulatory framework from the perspective of the data orientation principle are the following:
- As a general rule, IT and communication systems shall allow for the exchange of information in structured data format, facilitating their automation and integration into the judicial file. To this end, the implementation of a data interoperability platform is envisaged, which will have to be compatible with the Data Intermediation Platform of the General State Administration.
- Data interoperability between judicial and prosecutorial bodies and data portals are set up as e-services of the administration of justice. The specific technical conditions for the provision of such services are to be defined through the State Technical Committee for e-Judicial Administration (CTEAJE).
- In order, among other objectives, to facilitate the promotion of artificial intelligence, the implementation of automated, assisted and proactive activities, as well as the publication of information in open data portals, a requirement is established for all information and communication systems to ensure that the management of information incorporate metadata and is based on common and interoperable data models. With regard to communications in particular, data orientation is also reflected in the electronic channels used for communications.
- In contrast to the common administrative procedure, the legal definition of court file incorporates an explicit reference to data as one of the basic units of the common administrative procedure.
- A specific regulation is included for the so-called Justice Administration Data Portal, so that the current data access tool in this area is legally enshrined for the first time. Specifically, in addition to establishing certain minimum contents and assigning competences to various bodies, it envisages the creation of a specific section on open data, as well as a mandate to the competent administrations to make them automatically processable and interoperable with the state open data portal. In this respect, the general regulations already existing for the rest of the public sector are declared applicable, without prejudice to the singularities that may be specifically contemplated in the procedural regulations.

In short, the new regulation is an important step in articulating the process of digital transformation of the Administration of Justice based on a data-driven management model. However, the unique competencies and organisational characteristics of this area require a unique governance model. For this reason, a specific institutional framework for cooperation has been envisaged, the effective functioning of which is essential for the implementation of the legal provisions and, ultimately, for addressing the challenges, difficulties and opportunities posed by open data and the re-use of public sector information in the judicial area. These are challenges that need to be tackled decisively so that the technological modernisation of the Justice Administration facilitates its effective digital transformation.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Standardisation is essential to improve efficiency and interoperability in governance and data management. The adoption of standards provides a common framework for organising, exchanging and interpreting data, facilitating collaboration and ensuring data consistency and quality. The ISO standards, developed at international level, and the UNE norms, developed specifically for the Spanish market, are widely recognised in this field. Both catalogues of good practices, while sharing similar objectives, differ in their geographical scope and development approach, allowing organisations to select the most appropriate standards for their specific needs and context.
With the publication, a few months ago, of the UNE 0077, 0078, 0079, 0080, and 0081 specifications on data governance, management, quality, maturity, and quality assessment, users may have questions about how these relate to the ISO standards they already have in place in their organisation. This post aims to help alleviate these doubts. To this end, an overview of the main ICT-related standards is presented, with a focus on two of them: ISO 20000 on service management and ISO 27000 on information security and privacy, and the relationship between these and the UNE specifications is established.
Most common ISO standards related to data
ISO standards have the great advantage of being open, dynamic and agnostic to the underlying technologies. They are also responsible for bringing together the best practices agreed and decided upon by different groups of professionals and researchers in each of the fields of action. If we focus on ICT-related standards, there is already a framework of standards on governance, management and quality of information systems where, among others, the following stand out:
At the government level:
- ISO 38500 for corporate governance of information technology.
At management level:
- ISO 8000 for data management systems and master data.
- ISO 20000 for service management.
- ISO 25000 for the quality of the generated product (both software and data).
- ISO 27000 and ISO 27701 for information security and privacy management.
- ISO 33000 for process evaluation.
In addition to these standards, there are others that are also commonly used in companies, such as:
- ISO 9000-based quality management system
- Environmental management system proposed in ISO 14000
These standards have been used for ICT governance and management for many years and have the great advantage that, as they are based on the same principles, they can be used perfectly well together. For example, it is very useful to mutually reinforce the security of information systems based on the ISO/IEC 27000 family of standards with the management of services based on the ISO/IEC 20000 family of standards.
The relationship between ISO standards and UNE data specifications
The UNE 0077, 0078, 0079, 0080 and 0081 specifications complement the existing ISO standards on data governance, management and quality by providing specific and detailed guidelines that focus on the particular aspects of the Spanish environment and the needs of the national market.
When the UNE 0077, 0078, 0079, 0080, 0080, and 0081 specifications were developed, they were based on the main ISO standards, in order to be easily integrated into the management systems already available in the organisations (mentioned above), as can be seen in the following figure:

Figure 1. Relation of the UNE specifications with the different ISO standards for ICT.
Example of application of standard UNE 0078
The following is an example of how the UNE and ISO standards that many organisations have already had in place for years can be more clearly integrated, taking UNE 0078 as a reference. Although all UNE data specifications are intertwined with most ISO standards on IT governance, management and quality, the UNE 0078 data management specification is more closely related to information security management systems (ISO 27000) and IT service management (ISO 20000). On Table 1 you can see the relationship for each process with each ISO standard.
| Process UNE 0078: Data Management | Related to ISO 20000 | Related to ISO 27000 |
|---|---|---|
| (ProcDat) Data processing | ||
| (InfrTec) Technology infrastructure management | X | X |
| (ReqDat) Data Requirements Management | X | X |
| (ConfDat) Data Configuration Management | ||
| (DatHist) Historical data management | X | |
| (SegDat) Data security management | X | X |
| (Metdat) Metadata management | X | |
| (ArqDat) Data architecture and design management | X | |
| (CIIDat) Sharing, brokering and integration of data | X | |
| (MDM) Master Data Management | | |
| (HR) Human resources management | ||
| (CVidDat) Data lifecycle management | X | |
| (AnaDat) Data analysis |
| Process UNE 0078: Data Management | Related to ISO 20000 | Related to ISO 27000 |
|---|---|---|
| (ProcDat) Data processing | ||
| (InfrTec) Technology infrastructure management | X | X |
| (ReqDat) Data Requirements Management | X | X |
| (ConfDat) Data Configuration Management | ||
| (DatHist) Historical data management | X | |
| (SegDat) Data security management | X | X |
|
(Metdat) Metadata management |
X | |
|
(ArqDat) Data architecture and design management |
X |
|
|
(CIIDat) Sharing, brokering and integration of data |
X |
|
|
(MDM) Master Data Management |
|
|
|
(HR) Human resources management |
|
|
|
(CVidDat) Data lifecycle management |
X |
|
|
(AnaDat) Data analysis |
|
Figure 2. Relationship of UNE 0078 processes with ISO 27000 and ISO 20000.
Relationship of the UNE 0078 standard with ISO 20000
Regarding the interrelation between ISO 20000-1 and the UNE 0078 specification, here you can find a use case in which an organisation wants to make relevant data available for consumption throughout the organisation through different services. The integrated implementation of UNE 0078 and ISO 20000-1 enables organisations:
- Ensure that business-critical data is properly managed and protected.
- Improve the efficiency and effectiveness of IT services, ensuring that the technology infrastructure supports the needs of the business and end users.
- Align data management and IT service management with the organisation''s strategic objectives, improving decision making and market competitiveness.
The relationship between the two is manifested in how the technology infrastructure managed according to UNE 0078 supports the delivery and management of IT services according to ISO 20000-1.
This requires at least the following:
- Firstly, in the case of making data available as a service, a well-managed and secure IT infrastructureis necessary. This is essential, on the one hand, for the effective implementation of IT service management processes, such as incident and problem management, and on the other hand, to ensure business continuity and availability of IT services.
- Secondly, once the infrastructure is in place, and it is known that the data will be made available for consumption at some point in time, the principles of sharing and brokering of that data need to be managed. For this purpose, the UNE 0078 specification includes the process of data sharing, intermediation and integration. Its main objective is to enable its acquisition and/or delivery for consumption or sharing, noting if necessary the deployment of intermediation mechanisms, as well as its integration. This UNE 0078 process would be related to several of the processes in ISO 20000-1, such as the Business Relationship Managementprocess, service level management, demand management and the management of the capacity of the data being made available.
Relationship of the UNE 0078 standard with ISO 27000
Likewise, the technological infrastructure created and managed for a specific objective must ensure minimum data security and privacy standards, therefore, the implementation of good practices included in ISO 27000 and ISO 27701 will be necessary to manage the infrastructure from the perspective of information security and privacy, thus showing a clear example of interrelation between the three management systems: services, information security and privacy, and data.
Not only is it essential that the data is made available to organisations and citizens in an optimal way, but it is also necessary to pay special attention to the security of the data throughout its entire lifecycle during commissioning. This is where the ISO 27000 standard brings its full value. The ISO 27000 standard, and in particular ISO 27001 fulfils the following objectives:
- It specifies the requirements for an information security management system (ISMS).
- It focuses on the protection of information against unauthorised access, data integrity and confidentiality.
- It helps organisations to identify, assess and manage information security risks.
In this line, its interrelation with the UNE 0078 Data Management specification is marked through the Data Security Management process. Through the application of the different security mechanisms, it is verified that the information handled in the systems is not subject to unauthorised access, maintaining its integrity and confidentiality throughout the data''s life cycle. Similarly, a triad can be built in this relationship with the data security management process of the UNE 0078 specification and with the UNE 20000-1 process of SGSTI Operation - Information Security Management.
The following figure presents how the UNE 0078 specification complements the current ISO 20000 and ISO 27000 as applied to the example discussed above.
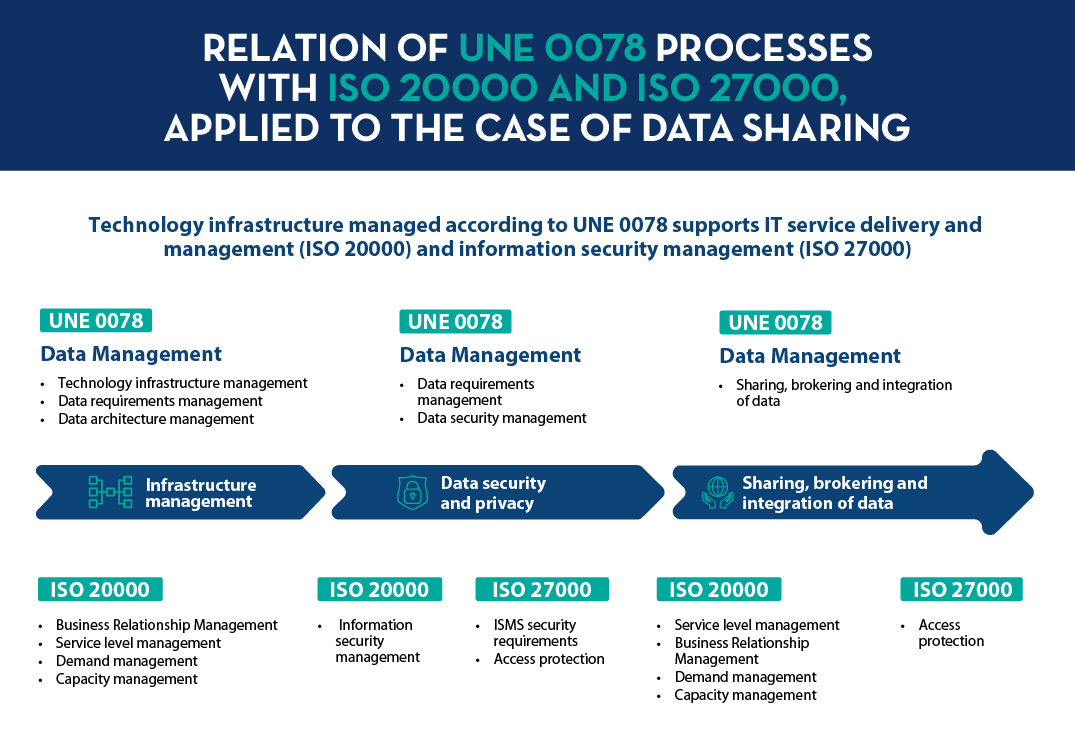
Figure 3. Relation of UNE 0078 processes with ISO 20000 and ISO 27000 applied to the case of data sharing.
Through the above cases, it can be seen that the great advantage of the UNE 0078 specification is that it integrates seamlessly with existing security management and service management systems in organisations. The same applies to the rest of the UNE standards 0077, 0079, 0080, and 0081. Therefore, if an organisation that already has ISO 20000 or ISO 27000 in place wants to implement data governance, management and quality initiatives, alignment between the different management systems with the UNE specifications is recommended, as they are mutually reinforcing from a security, service and data point of view.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
After months of new developments, the pace of advances in artificial intelligence does not seem to be slowing down - quite the contrary. A few weeks ago, when reviewing the latest developments in this field on the occasion of the 2023 deadline, video generation from text instructions was considered to be still in its infancy. However, just a few weeks later, we have seen the announcement of SORA. With this tool, it seems that the possibility to generate realistic videos, up to one minute long, from textual descriptions is here.
Every day, the tools we have access to become more sophisticated and we are constantly amazed by their ability to perform tasks that once seemed exclusive to the human mind. We have quickly become accustomed to generating text and images from written instructions and have incorporated these tools into our daily lives to enhance and improve the way we do our jobs. With each new development, pushing the boundaries a little further than we imagined, the possibilities seem endless.
Advances in Artificial Intelligence, powered by open data and other technologies such as those associated with the Web3, are helping to rethink the future of virtually every field of our activity: from solutions to address the challenges of climate change, to artistic creation, be it music, literature or painting[6], to medical diagnosis, agriculture or the generation of trust to drive the creation of social and economic value.
In this article we will review the developments that impact on a field where, in the coming years, interesting advances are likely to be made thanks to the combination of artificial intelligence and open data. We are talking about the design and planning of smarter, more sustainable and liveable cities for all their inhabitants.
Urban Planning and Management
Urban planning and management is complicated because countless complex interactions need to be anticipated, analysed and resolved. Therefore, it is reasonable to expect major breakthroughs from the analysis of the data that cities increasingly open up on mobility, energy consumption, climatology and pollution, planning and land use, etc. New techniques and tools provided by generative artificial intelligence combined, for example, with intelligent agents will allow a deeper interpretation and simulation of urban dynamics.
In this sense, this new combination of technologies could be used for example to design more efficient, sustainable and liveable cities, anticipating the future needs of the population and dynamically adapting to changes in real time. Thus, new smart urban models would be used to optimise everything from traffic flow to resource allocation by simulating behaviour through intelligent agents.

Figure 1: Images generated by Urbanistai.com
Urbanist.ai is one of the first examples of an advanced urban analytics platform, based on generative artificial intelligence, that aims to transform the way urban planning tasks are currently conceived. The services it currently provides already allow the participatory transformation of urban spaces from images, but its ambition goes further and it plans to incorporate new techniques that redefine the way cities are planned. There is even a version of UrbanistAI designed to introduce children to the world of urban planning.
Going one step further, the generation of 3D city models is something that tools such as InfiniCity have already made available to users. Although there are still many challenges to be overcome, the results are promising. These technologies could make it substantially cheaper to generate digital twins on which to run simulations that anticipate problems before they are built.
Available data
However, as with other developments based on Generative AI, these issues would not be possible without data, and especially not without open data. All new developments in AI use a combination of private and public data in their training, but in few cases is the training dataset known with certainty, as it is not made public. Data can come from a wide variety of sources, such as IoT sensors, government records or public transport systems, and is the basis for providing a holistic view of how cities function holistic view of how cities function and how and how their inhabitants interact with the urban environment.
The growing importance of open data in training these models is reflected in initiatives such as the Task Force on AI Data Assets and Open Government, launched by the US Department of Commerce, which will be tasked with preparing open public data for Artificial Intelligence. This means not only machine-readable formats, but also machine-understandable metadata. With open data enriched by metadata and organised in interpretable formats, artificial intelligence models could yield much more accurate results.
A long-established and basic data source is OpenStreetmap (OSM), a collaborative project that makes a free and editable map of open global geographic dataavailable to the community. It includes detailed information on streets, squares, parks, buildings, etc. which is crucial as a basis for urban mobility analysis, transport planning or infrastructure management. The immense cost of developing such a resource is only within the reach of large technology companies, making it invaluable to all initiatives that use it as a basis.

Figure 2: OpenStreetmap Images (OSM)
More specific datasets such as HoliCity, a 3D data asset with rich structural information, including 6,300 real-world views, are proving valuable. For example, recent scientific work based on this dataset has shown that it is possible for a model fed with millions of street images to predict neighbourhood characteristics, such as home values or crime rates.
Along these lines, Microsoft has released an extensive collection of building contours automatically generated from satellite imagery, covering a large number of countries and regions.

Figure 3: Urban Atlas Images (OSM)
Microsoft Building Footprints provide a detailed basis for 3D city modelling, urban density analysis, infrastructure planning and natural hazard management, giving an accurate picture of the physical structure of cities.
We also have Urban Atlas, an initiative that provides free and open access to detailed land use and land cover information for more than 788 Functional Urban Areas in Europe. It is part of the Copernicus Land Monitoring Serviceprogramme, and provides valuable insights into the spatial distribution of urban features, including residential, commercial, industrial, green areas and water bodies, street tree maps, building block height measurements, and even population estimates.
Risks and ethical considerations
However, we must not lose sight of the risks posed, as in other domains, by the incorporation of artificial intelligence into the planning and management of cities, as discussed in the UN report on "Risks, Applications and Governance of AI for Cities". For example, concerns about privacy and security of personal information raised by mass data collection, or the risk of algorithmic biases that may deepen existing inequalities. It is therefore essential to ensure that data collection and use is conducted in an ethical and transparent manner, with a focus on equity and inclusion.
This is why, as city design moves towards the adoption of artificial intelligence, dialogue and collaboration between technologists, urban planners, policy makers and society at large will be key to ensuring that smart city development aligns with the values of sustainability, equity and inclusion. Only in this way can we ensure that the cities of the future
are not only more efficient and technologically advanced, but also more humane and welcoming for all their inhabitants.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The European Union has placed the digital transformation of the public sector at the heart of its policy agenda. Through various initiatives under the Digital Decade policy programme, the EU aims to boost the efficiency of public services and provide a better experience for citizens. A goal for which the exchange of data and information in an agile manner between institutions and countries is essential.
This is where interoperability and the search for new solutions to promote it becomes important. Emerging technologies such as artificial intelligence (AI) offer great opportunities in this field, thanks to their ability to analyse and process huge amounts of data.
A report to analyse the state of play
Against this background, the European Commission has published an extensive and comprehensive report entitled "Artificial Intelligence for Interoperability in the European Public Sector", which provides an analysis of how AI is already improving interoperability in the European public sector. The report is divided into three parts:
- A literature and policy review on the synergies between IA and interoperability. It highlights the legislative work carried out by the EU. It highlights the Interoperable Europe Act which seeks to establish a governance structure and to foster an ecosystem of reusable and interoperable solutions for public administration. Mention is also made of the Artificial Intelligence Act, designed to ensure that AI systems used in the EU are safe, transparent, traceable, non-discriminatory and environmentally friendly.
- The report continues with a quantitative analysis of 189 use cases. These cases were selected on the basis of the inventory carried out in the report "AI Watch. European overview of the use of Artificial Intelligence by the public sector" which includes 686 examples, recently updated to 720.
- A qualitative study that elaborates on some of the above cases. Specifically, seven use cases have been characterised (two of them Spanish), with an exploratory objective. In other words, it seeks to extract knowledge about the challenges of interoperability and how AI-based solutions can help.
Conclusions of the study
AI is becoming an essential tool for structuring, preserving, standardising and processing public administration data, improving interoperability within and outside public administration. This is a task that many organisations are already doing.
Of all the AI use cases in the public sector analysed in the study, 26% were related to interoperability. These tools are used to improve interoperability by operating at different levels: technical, semantic, legal and organisational. The same AI system can operate at different layers.
- The semantic layer of interoperability is the most relevant (91% of cases). The use of ontologies and taxonomies to create a common language, combined with AI, can help establish semantic interoperability between different systems. One example is the EPISA60 project, which is based on natural language processing, using entity recognition and machine learning to explore digital documents.
- In second place is the organisational layer, with 35% of cases. It highlights the use of AI for policy harmonisation, governance models and mutual data recognition, among others. In this regard, the Austrian Ministry of Justice launched the JustizOnline project which integrates various systems and processes related to the delivery of justice.
- The 33% of the cases focused on the legal layer. In this case, the aim is to ensure that the exchange of data takes place in compliance with legal requirements on data protection and privacy. The European Commission is preparing a study to explore how AI can be used to verify the transposition of EU legislation by Member States. For this purpose, different articles of the laws are compared with the help of an AI.
- Lastly, there is the technical layer, with 21% of cases. In this field, AI can help the exchange of data in a seamless and secure way. One example is the work carried out at the Belgian research centre VITO, based on AI data encoding/decoding and transport techniques.
Specifically, the three most common actions that AI-based systems take to drive data interoperability are: detecting information (42%), structuring it (22%) and classifying it (16%). The following table, extracted from the report, shows all the detailed activities:

Download here the accessible version of the table
The report also analyses the use of AI in specific areas. Its use in "general public services" stands out (41%), followed by "public order and security" (17%) and "economic affairs" (16%). In terms of benefits, administrative simplification stands out (59%), followed by the evaluation of effectiveness and efficiency (35%) and the preservation of information (27%).
AI use cases in Spain
The third part of the report looks in detail at concrete use cases of AI-based solutions that have helped to improve public sector interoperability. Of the seven solutions characterised, two are from Spain:
- Energy vulnerability - automated assessment of the fuel poverty report. When energy service providers detect non-payments, they must consult with the municipality to determine whether the user is in a situation of social vulnerability before cutting off the service, in which case supplies cannot be cut off. Municipalities receive monthly listings from companies in different formats and have to go through a costly manual bureaucratic process to validate whether a citizen is at social or economic risk. To solve this challenge, the Administració Oberta de Catalunya (AOC) has developed a tool that automates the data verification process, improving interoperability between companies, municipalities and other administrations.
- Automated transcripts to speed up court proceedings. In the Basque Country, trial transcripts by the administration are made by manually reviewing the videos of all sessions. Therefore, it is not possible to easily search for words, phrases, etc. This solution converts voice data into text automatically, which allows you to search and save time.
Recommendations
The report concludes with a series of recommendations on what public administrations should do:
- Raise internal awareness of the possibilities of AI to improve interoperability. Through experimentation, they will be able to discover the benefits and potential of this technology.
- Approach the adoption of an AI solution as a complex project with not only technical, but also organisational, legal, ethical, etc. implications.
- Create optimal conditions for effective collaboration between public agencies. This requires a common understanding of the challenges to be addressed in order to facilitate data exchange and the integration of different systems and services.
- Promote the use of uniform and standardised ontologies and taxonomies to create a common language and shared understanding of data to help establish semantic interoperability between systems.
- Evaluate current legislation, both in the early stages of experimentation and during the implementation of an AI solution, on a regular basis. Collaboration with external actors to assess the adequacy of the legal framework should also be considered. In this regard, the report also includes recommendations for the next EU policy updates.
- Support the upgrading of the skills of AI and interoperability specialists within the public administration. Critical tasks of monitoring AI systems are to be kept within the organisation.
Interoperability is one of the key drivers of digital government, as it enables the seamless exchange of data and processes, fostering effective collaboration. AI can help automate tasks and processes, reduce costs and improve efficiency. It is therefore advisable to encourage their adoption by public bodies at all levels.