Blog
Since its origins, the open data movement has focused mainly on promoting the openness of data and promoting its reuse. The objective that has articulated most of the initiatives, both public and private, has been to overcome the obstacles to publishing increasingly complete data catalogues and to ensure that public sector information is available so that citizens, companies, researchers and the public sector itself could create economic and social value.
However, as we have taken steps towards an economy that is increasingly dependent on data and, more recently, on artificial intelligence – and in the near future on the possibilities that autonomous agents bring us through agentic artificial intelligence – priorities have been changing and the focus has been shifting towards issues such as improving the quality of published data.
It is no longer enough for the datasets to be published in an open data portal complying with good practices, or even for the data to meet quality standards at the time of publication. It is also necessary that this publication of the datasets meets service levels that transform the mere provision into an operational commitment that mitigates the uncertainties that often hinder reuse.
When a developer integrates a real-time transportation data API into their mobility app, or when a data scientist works on an AI model with historical climate data, they are taking a risk if they are uncertain about the conditions under which the data will be available. If at any given time the published data becomes unavailable because the format changes without warning, because the response time skyrockets, or for any other reason, the automated processes fail and the data supply chain breaks, causing cascading failures in all dependent systems.
In this context, the adoption of service level agreements (SLAs) could be the next step for open data portals to evolve from the usual "best effort" model to become critical, reliable and robust digital infrastructures.
What are an SLA and a Data Contract in the context of open data?
In the context of site reliability engineering (SRE), an SLA is a contract negotiated between a service provider and its customers in order to set the level of quality of the service provided. It is, therefore, a tool that helps both parties to reach a consensus on aspects such as response time, time availability or available documentation.
In an open data portal, where there is often no direct financial consideration, an SLA could help answer questions such as:
- How long will the portal and its APIs be available?
- What response times can we expect?
- How often will the datasets be updated?
- How are changes to metadata, links, and formatting handled?
- How will incidents, changes and notifications to the community be managed?
In addition, in this transition towards greater operational maturity, the concept, still immature, of the data contract (data contract) emerges. If the SLA is an agreement that defines service level expectations, the data contract is an implementation that formalizes this commitment. A data contract would not only specify the schema and format, but would act as a safeguard: if a system update attempts to introduce a change that breaks the promised structure or degrades the quality of the data, the data contract allows you to detect and block such an anomaly before it affects end users.
INSPIRE as a starting point: availability, performance and capacity
The European Union's Infrastructure for Spatial Information (INSPIRE) has established one of the world's most rigorous frameworks for quality of service for geospatial data. Directive 2007/2/EC, known as INSPIRE, currently in its version 5.0, includes some technical obligations that could serve as a reference for any modern data portal. In particular , Regulation (EC) No 976/2009 sets out criteria that could well serve as a standard for any strategy for publishing high-value data:
- Availability: Infrastructure must be available 99% of the time during normal operating hours.
- Performance: For a visualization service, the initial response should arrive in less than 3 seconds.
- Capacity: For a location service, the minimum number of simultaneous requests served with guaranteed throughput must be 30 per second.
To help comply with these service standards, the European Commission offers tools such as the INSPIRE Reference Validator. This tool helps not only to verify syntactic interoperability (that the XML or GML is well formed), but also to ensure that network services comply with the technical specifications that allow those SLAs to be measured.
At this point, the demanding SLAs of the European spatial data infrastructure make us wonder if we should not aim for the same for critical health, energy or mobility data or for any other high-value dataset.
What an SLA could cover on an open data platform
When we talk about open datasets in the broad sense, the availability of the portal is a necessary condition, but not sufficient. Many issues that affect the reuser community are not complete portal crashes, but more subtle errors such as broken links, datasets that are not updated as often as indicated, inconsistent formats between versions, incomplete metadata, or silent changes in API behavior or dataset column names.
Therefore, it would be advisable to complement the SLAs of the portal infrastructure with "data health" SLAs that can be based on already established reference frameworks such as:
- Quality models such as ISO/IEC 25012, which allows the quality of the data to be broken down into measurable dimensions such as accuracy (that the data represents reality), completeness (that necessary values are not missing) and consistency (that there are no contradictions between tables or formats) and convert them into measurable requirements.
- FAIR Principles, which stands for Findable, Accessible, Interoperable, and Reusable. These principles emphasize that digital assets should not only be available, but should be traceable using persistent identifiers, accessible under clear protocols, interoperable through the use of standard vocabularies, and reusable thanks to clear licenses and documented provenance. The FAIR principles can be put into practice by systematically measuring the quality of the metadata that makes location, access and interoperability possible. For example, data.europa.eu's Metadata Quality Assurance (MQA) service helps you automatically evaluate catalog metadata, calculate metrics, and provide recommendations for improvement.
To make these concepts operational, we can focus on four examples where establishing specific service commitments would provide a differential value:
- Catalog compliance and currency: The SLA could ensure that the metadata is always aligned with the data it describes. A compliance commitment would ensure that the portal undergoes periodic validations (following specifications such as DCAT-AP-ES or HealthDCAT-AP) to prevent the documentation from becoming obsolete with respect to the actual resource.
- Schema stability and versioning: One of the biggest enemies of automated reuse is "silent switching." If a column changes its name or a data type changes, the data ingestion flows will fail immediately. A service level commitment might include a versioning policy. This would mean that any changes that break compatibility would be announced at least notice, and preferably keep the previous version in parallel for a reasonable amount of time.
- Freshness and refresh frequency: It's not uncommon to find datasets labeled as daily but last actually modified months ago. A good practice could be the definition of publication latency indicators. A possible SLA would establish the value of the average time between updates and would have alert systems that would automatically notify if a piece of data has not been refreshed according to the frequency declared in its metadata.
- Success rate: In the world of data APIs, it's not enough to just receive an HTTP 200 (OK) code to determine if the answer is valid. If the response is, for example, a JSON with no content, the service is not useful. The service level would have to measure the rate of successful responses with valid content, ensuring that the endpoint not only responds, but delivers the expected information.
A first step, SLA, SLO, and SLI: measure before committing
Since establishing these types of commitments is really complex, a possible strategy to take action gradually is to adopt a pragmatic approach based on industry best practices. For example, in reliability engineering, a hierarchy of three concepts is proposed that helps avoid unrealistic compromises:
- Service Level Indicator (SLI): it is the measurable and quantitative indicator. It represents the technical reality at a given moment. Examples of SLI in open data could be the "percentage of successful API requests", "p95 latency" (the response time of 95% of requests) or the "percentage of download links that do not return error".
- Service Level Objective (SLO): this is the internal objective set for this indicator. For example: "we want 99.5% of downloads to work correctly" or "p95 latency must be less than 800ms". It is the goal that guides the work of the technical team.
- Service Level Agreement (SLA): is the public and formal commitment to those objectives. This is the promise that the data portal makes to its community of reusers and that includes, ideally, the communication channels and the protocols for action in the event of non-compliance.
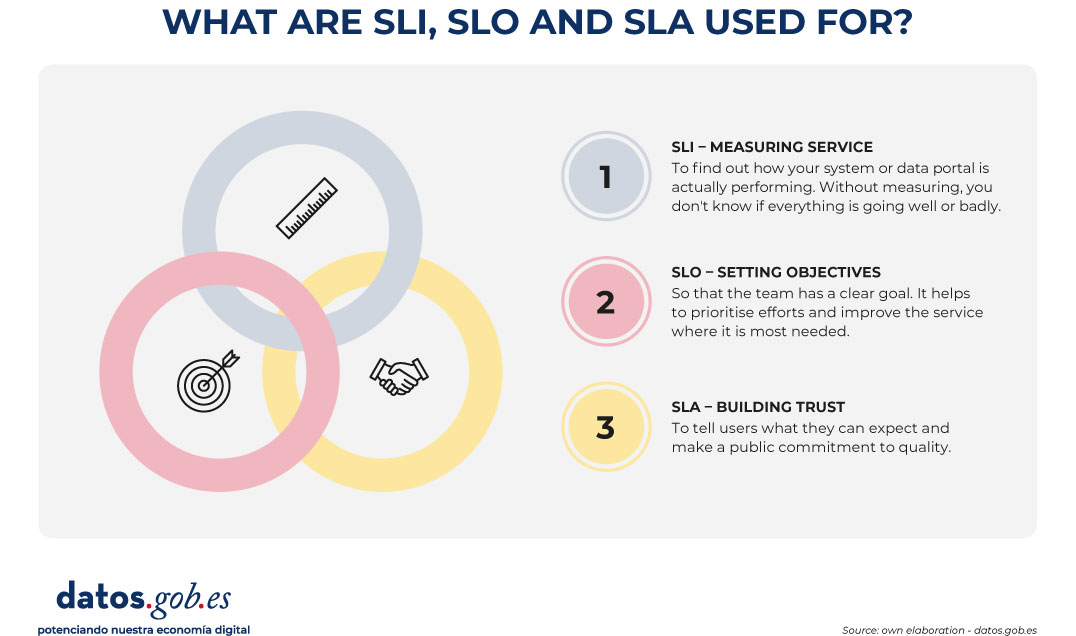
Figure 1. Visual to explain the difference between SLI, SLO and SLA. Source: own elaboration - datos.gob.es.
This distinction is especially valuable in the open data ecosystem due to the hybrid nature of a service in which not only an infrastructure is operated, but the data lifecycle is managed.
In many cases, the first step might be not so much to publish an ambitious SLA right away, but to start by defining your SLIs and looking at your SLOs. Once measurement was automated and service levels stabilized and predictable, it would be time to turn them into a public commitment (SLA).
Ultimately, implementing service tiers in open data could have a multiplier effect. Not only would it reduce technical friction for developers and improve the reuse rate, but it would make it easier to integrate public data into AI systems and autonomous agents. New uses such as the evaluation of generative Artificial Intelligence systems, the generation and validation of synthetic datasets or even the improvement of the quality of open data itself would benefit greatly.
Establishing a data SLA would, above all, be a powerful message: it would mean that the public sector not only publishes data as an administrative act, but operates it as a digital service that is highly available, reliable, predictable and, ultimately, prepared for the challenges of the data economy.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Over the last few years we have seen spectacular advances in the use of artificial intelligence (AI) and, behind all these achievements, we will always find the same common ingredient: data. An illustrative example known to everyone is that of the language models used by OpenAI for its famous ChatGPT, such as GPT-3, one of its first models that was trained with more than 45 terabytes of data, conveniently organized and structured to be useful.
Without sufficient availability of quality and properly prepared data, even the most advanced algorithms will not be of much use, neither socially nor economically. In fact, Gartner estimates that more than 40% of emerging AI agent projects today will end up being abandoned in the medium term due to a lack of adequate data and other quality issues. Therefore, the effort invested in standardizing, cleaning, and documenting data can make the difference between a successful AI initiative and a failed experiment. In short, the classic principle of "garbage in, garbage out" in computer engineering applied this time to artificial intelligence: if we feed an AI with low-quality data, its results will be equally poor and unreliable.
Becoming aware of this problem arises the concept of "AI Data Readiness" or preparation of data to be used by artificial intelligence. In this article, we'll explore what it means for data to be "AI-ready", why it's important, and what we'll need for AI algorithms to be able to leverage our data effectively. This results in greater social value, favoring the elimination of biases and the promotion of equity.
What does it mean for data to be "AI-ready"?
Having AI-ready data means that this data meets a series of technical, structural, and quality requirements that optimize its use by artificial intelligence algorithms. This includes multiple aspects such as the completeness of the data, the absence of errors and inconsistencies, the use of appropriate formats, metadata and homogeneous structures, as well as providing the necessary context to be able to verify that they are aligned with the use that AI will give them.
Preparing data for AI often requires a multi-stage process. For example, again the consulting firm Gartner recommends following the following steps:
- Assess data needs according to the use case: identify which data is relevant to the problem we want to solve with AI (the type of data, volume needed, level of detail, etc.), understanding that this assessment can be an iterative process that is refined as the AI project progresses.
- Align business areas and get management support: present data requirements to managers based on identified needs and get their backing, thus securing the resources required to prepare the data properly.
- Develop good data governance practices: implement appropriate data management policies and tools (quality, catalogs, data lineage, security, etc.) and ensure that they also incorporate the needs of AI projects.
- Expand the data ecosystem: integrate new data sources, break down potential barriers and silos that are working in isolation within the organization and adapt the infrastructure to be able to handle the large volumes and variety of data necessary for the proper functioning of AI.
- Ensure scalability and regulatory compliance: ensure that data management can scale as AI projects grow, while maintaining a robust governance framework in line with the necessary ethical protocols and compliance with existing regulations.
If we follow a strategy like this one, we will be able to integrate the new requirements and needs of AI into our usual data governance practices. In essence, it is simply a matter of ensuring that our data is prepared to feed AI models with the minimum possible friction, avoiding possible setbacks later in the day during the development of projects.
Open data "ready for AI"
In the field of open science and open data, the FAIR principles have been promoted for years. These acronyms state that data must be locatable, accessible, interoperable and reusable. The FAIR principles have served to guide the management of scientific and open data to make them more useful and improve their use by the scientific community and society at large. However, these principles were not designed to address the new needs associated with the rise of AI.
Therefore, the proposal is currently being made to extend the original principles by adding a fifth readiness principle for AI, thus moving from the initial FAIR to FAIR-R or FAIR². The aim would be precisely to make explicit those additional attributes that make the data ready to accelerate its responsible and transparent use as a necessary tool for AI applications of high public interest

What exactly would this new R add to the FAIR principles? In essence, it emphasizes some aspects such as:
- Labelling, annotation and adequate enrichment of data.
- Transparency on the origin, lineage and processing of data.
- Standards, metadata, schemas and formats optimal for use by AI.
- Sufficient coverage and quality to avoid bias or lack of representativeness.
In the context of open data, this discussion is especially relevant within the discourse of the "fourth wave" of the open data movement, through which it is argued that if governments, universities and other institutions release their data, but it is not in the optimal conditions to be able to feed the algorithms, A unique opportunity for a whole new universe of innovation and social impact would be missing: improvements in medical diagnostics, detection of epidemiological outbreaks, optimization of urban traffic and transport routes, maximization of crop yields or prevention of deforestation are just a few examples of the possible lost opportunities.
And if not, we could also enter a long "data winter", where positive AI applications are constrained by poor-quality, inaccessible, or biased datasets. In that scenario, the promise of AI for the common good would be frozen, unable to evolve due to a lack of adequate raw material, while AI applications led by initiatives with private interests would continue to advance and increase unequal access to the benefit provided by technologies.
Conclusion: the path to quality, inclusive AI with true social value
We can never take for granted the quality or suitability of data for new AI applications: we must continue to evaluate it, work on it and carry out its governance in a rigorous and effective way in the same way as it has been recommended for other applications. Making our data AI-ready is therefore not a trivial task, but the long-term benefits are clear: more accurate algorithms, reduced unwanted bias, increased transparency of AI, and extended its benefits to more areas in an equitable way.
Conversely, ignoring data preparation carries a high risk of failed AI projects, erroneous conclusions, or exclusion of those who do not have access to quality data. Addressing the unfinished business on how to prepare and share data responsibly is essential to unlocking the full potential of AI-driven innovation for the common good. If quality data is the foundation for the promise of more humane and equitable AI, let's make sure we build a strong enough foundation to be able to reach our goal.
On this path towards a more inclusive artificial intelligence, fuelled by quality data and with real social value, the European Union is also making steady progress. Through initiatives such as its Data Union strategy, the creation of common data spaces in key sectors such as health, mobility or agriculture, and the promotion of the so-called AI Continent and AI factories, Europe seeks to build a digital infrastructure where data is governed responsibly, interoperable and prepared to be used by AI systems for the benefit of the common good. This vision not only promotes greater digital sovereignty but reinforces the principle that public data should be used to develop technologies that serve people and not the other way around.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
As tradition dictates, the end of the year is a good time to reflect on our goals and objectives for the new phase that begins after the chimes. In data, the start of a new year also provides opportunities to chart an interoperable and digital future that will enable the development of a robust data economy robust data economy, a scenario that benefits researchers, public administrations and private companies alike, as well as having a positive impact on the citizen as the end customer of many data-driven operations, optimising and reducing processing times. To this end, there is the European Data Strategy strategy, which aims to unlock the potential of data through, among others, the Data Act (Data Act), which contains a set of measures related to fair access to and use of data fair access to and use of data ensuring also that the data handled is of high quality, properly secured, etc.
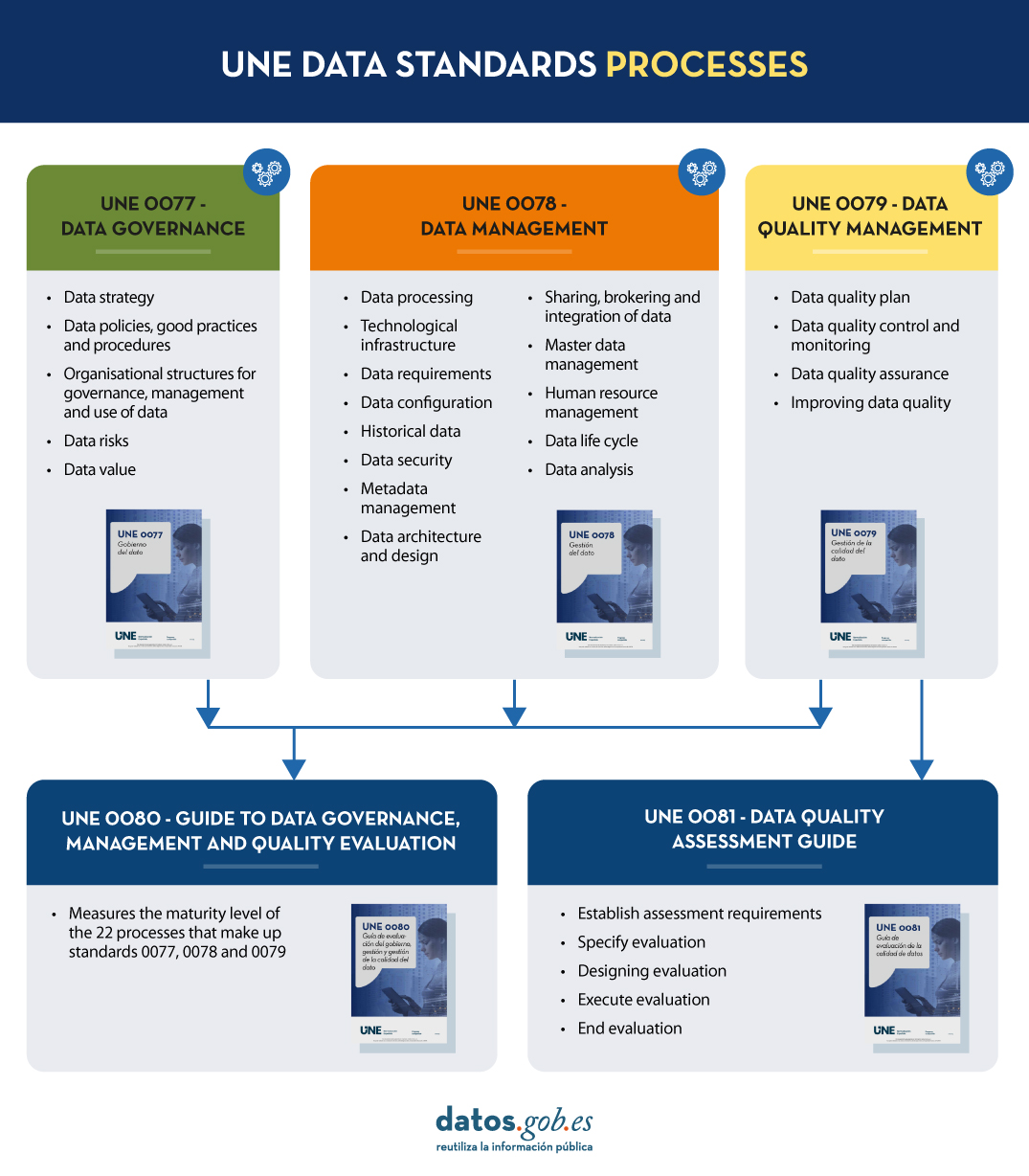
As a solution to this need, in the last year the uNE data specifications which are normative and informative resources for implementing common data governance, management and quality processes. These specifications, supported by the Data Officethese specifications, supported by the Data Office, establish standards for well-governed data (UNE 0077), managed (UNE 0078) and with adequate levels of quality (UNE 0079), thus allowing for sustainable growth in the organisation during the implementation of the different processes. In addition to these three specifications, the UNE 0080 specification defines a maturity assessment guide and process to measure the degree of implementation of data governance, management and quality processes. For its part, the UNE 0081 also establishes a process of evaluation of the data asset itself, i.e. of the data sets, regardless of their nature or typology; in short, its content is closely related to UNE 0079 because it sets out data quality characteristics. Adopting all of them can provide multiple benefits. In this post, we look at what they are and what the process would be like for each specification.
So, with an eye to the future, we set a New Year's resolution: the application of the UNE data specifications to an organisation.
What are the benefits of your application and how can I access them?
In today's era, where data governance and efficient data management have become a fundamental pillar of organisational success, the implementation of the uNE data specifications specifications emerge as a guiding light towards excellence, leading the way forward. These specifications describe rigorous standardised processes that offer organisations the possibility to build a robust and reliable structure for the management of their data and information throughout its lifecycle.
By adopting the UNE specifications, you not only ensure data quality and security, but also provide a solid and adequate basis for informed decision-making by enriching organisational processes with good data practices. Therefore, any organisation that chooses to embrace these regulations in the new year will be moving closer to innovation, efficiency and trust in data governance and management; as well as preparing to meet the challenges and opportunities that the digital future holds digital future. The application of UNE specifications is not only a commitment to quality, but a strategic investment that paves the way for sustainable success in an increasingly competitive and dynamic business environment because:
- Maximising value contribution to business strategy
- Minimises risks in data processing
- Optimise tasks by avoiding unnecessary work
- It establishes homogeneous frameworks for reference and certification
- Facilitates information sharing with trust and sovereignty
The content of the guides can be downloaded free of charge from the AENOR portal via the links below. Registration is required for downloading. The discount on the total price is applied at the time of checkout.
- SPECIFICATION UNE 0077:2023
- SPECIFICATION UNE 0078:2023
- SPECIFICATION UNE 0079:2023
- SPECIFICATION UNE 0080:2023
- SPECIFICATION UNE 0081:2023
From datos.gob.es we have echoed the content of the same and we have prepared different didactic resources such as this infographic or this explanatory video.
How do they apply to an organisation?
Once the decision has been taken to address the implementation of these specifications, a crucial question arises: what is the most effective way to do this? The answer to this question will depend on the initial situation (marked by an initial maturity assessment), the type of organisation and the resources available at the time of establishing the master plan or implementation plan. Nevertheless, at datos.gob.es, we have published a series of contents prepared by experts in technologies linked to the data economy datos.gob.es, we have published a series of contents elaborated by experts in technologies linked to the data economy that will accompany you in the process.
Before starting, it is important to know the different processes that make up each of the UNE data specifications. This image shows what they are.
Once the basics are understood, the series of contents 'Application of the UNE data specifications' deals with a practical exercise, broken down into three posts, on a specific use case: the application of these specifications to open data. As an example, a need is defined for the fictitious Vistabella Town Council: to make progress in the open publication of information on public transport and cultural events.
- In the first post of the series, the importance of using the UNE 0077 data using the UNE 0077 Data Governance Specification to establish approved mechanisms to support the openness and publication of open data. Through this first content, an overview of the processes necessary to align the organisational strategy in such a way as to achieve maximum transparency and quality of public services through the reuse of information is provided.
- The second article in the series takes a closer look at the uNE 0079 data quality management standard and its application in the context of open data and its application in the context of open data. This content underlines that the quality of open data goes beyond the FAIR principles fAIR principles principles and stresses the importance of assessing quality using objective criteria. Through the practical exercise, we explore how Vistabella Town Council approaches the UNE processes to improve the quality of open data as part of its strategy to enhance the publication of data on public transport and cultural events.
- Finally, the uNE 0078 standard on data management is explained in a third article presenting the Data Sharing, Intermediation and Integration (CIIDat) process for the publication of open data, combined with specific templates.
Together, these three articles provide a guide for any organisation to move successfully towards open publication of key information, ensuring consistency and quality of data. By following these steps, organisations will be prepared to comply with regulatory standards with all the benefits that this entails.
Finally, embracing the New Year's resolution to implement the UNE data specifications represents a strategic and visionary commitment for any organisation, which will also be aligned with the European Data Strategy and the European roadmap that aims to shape a world-leading digital future.
Blog
The new UNE 0081 Data Quality Assessment specification, focused on data as a product (datasets or databases), complements the UNE 0079 Data Quality Management specification, which we analyse in this article, and focuses on data quality management processes. Both standards 0079 and 0081 complement each other and address data quality holistically:
- The UNE 0079 standard refers to the processes, the activities that the organisation must carry out to guarantee the appropriate levels of quality of its data to satisfy the strategy that the organisation has set itself.
- On the other hand, UNE 0081 defines a data quality model, based on ISO/IEC 25012 and ISO/IEC 25024, which details the quality characteristics that data can have, as well as some applicable metrics. It also defines the process to be followed to assess the quality of a particular dataset, based on ISO/IEC 25040. Finally, the specification details how to interpret the results obtained from the evaluation, showing concrete examples of application.
How can an organisation make use of this specification to assess the quality level of its data?
To answer this question, we will use the example of the Vistabella Town Council, previously used in previous articles. The municipality has a number of data sets, the quality of which it wants to evaluate in order to improve them and provide a better service to citizens. The institution is aware that it works with many types of data (transactional, master, reference, etc.), so the first thing it does is to first identify the data sets that provide value and for which not having adequate levels of quality may have repercussions on the day-to-day work. Some criteria to follow when selecting these sets can be: data that provide value to the citizen, data resulting from a data integration process or master view of the data, critical data because they are used in several processes/procedures, etc.
The next step will be to determine at which point(s) in the lifecycle of the municipality's operational processes these data quality checks will be performed.
This is where the UNE 0081 specification comes into play. The evaluation is done on the basis of the "business rules" that define the requirements, data requirements or validations that the data must meet in order to provide value to the organisation. Some examples are shown below:
- Citizens' ID cards will have to comply with the specific syntax for this purpose (8 numbers and one letter).
- Any existing date in the system shall follow the notation DD-MM-YYYYYY.
- Records of documentation dated after the current date will not be accepted.
- Traceability of who has made a change to a dataset and when.
In order to systematically and comprehensively identify the business rules that data has to comply with at each stage of its lifecycle, the municipality uses a methodology based on BR4DQ.
The municipality then reviews all the data quality characteristics included in the specification, prioritises them, and determines a first set of data quality characteristics to be taken into account for the evaluation. For this purpose, and in this first stage, the municipality decided to stick exclusively to the 5 inherent characteristics of ISO 25012 defined within the specification. These are: accuracy, completeness, consistency, credibility and timeliness.
Similarly, for each of these first characteristics that have been agreed to be addressed, possible properties are identified. To this end, the municipality finally decided to work with the following quality model, which includes the following characteristics and properties:
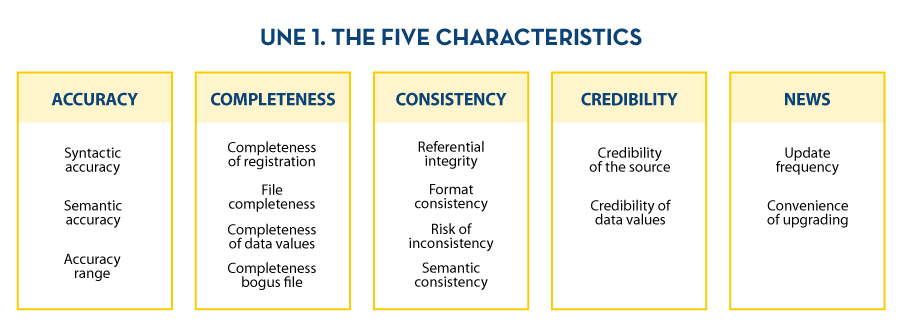
At this point, the municipality has identified the dataset to be assessed, as well as the business rules that apply to it, and which aspects of quality it will focus on (data quality model). Next, it is necessary to carry out data quality measurement through the validation of business rules. Values for the different metrics are obtained and computed in a bottom-up approach to determine the level of data quality of the repository
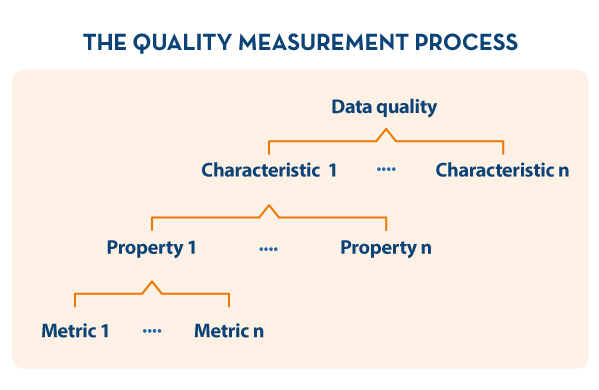
Definition of the evaluation process
In order to carry out the assessment in an appropriate way, it is decided to make use of the quality assessment process based on ISO 25024, indicated in the UNE 0081 specification (see below).
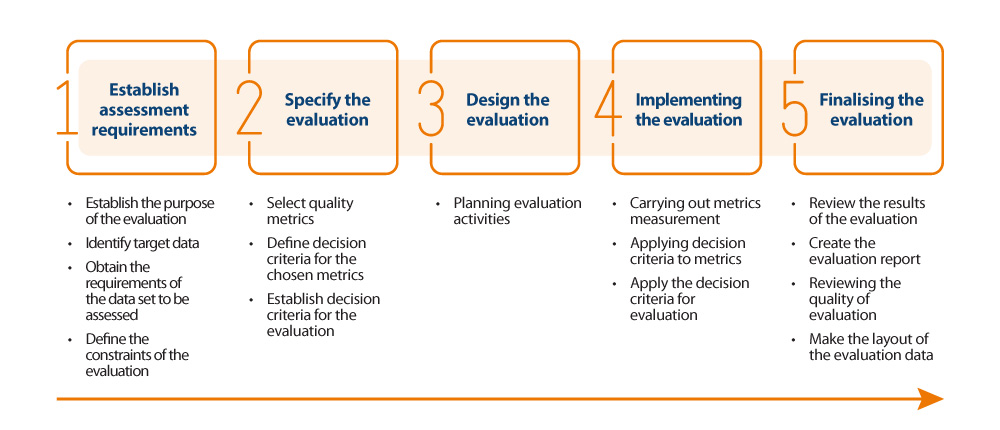
Implementation of the evaluation process
The following is a summary of the most noteworthy aspects carried out by the City Council during stage 4 of the evaluation process:
- Validation of the degree of compliance with each business rule by property: Having all the business rules classified by property, the degree of compliance with each of them is validated, thus obtaining a series of values for each of the metrics. This is run on each of the data sets to be evaluated.
As an example, for the syntactic accuracy property, two metrics are obtained:
- Number of records that comply with the syntactic correctness business rules: 826254
- Number of records that must comply with the syntactic correctness business rules: 850639
- Quantification of the value of the property: From these metrics, the value of the property is quantified and determined using the measurement function specified in the UNE 0081 specification. For the specific case of syntactic accuracy, it is determined that a record density of 97.1% complies with all syntactic accuracy rules.
- Calculation of the characteristic value: This is done by making use of the results of each of the data quality metrics associated with a property. To calculate it, and as specified in the UNE 0081 specification, it is decided to follow a weighted sum in which each property has the same weight. In the case of Accuracy, Syntactic Accuracy values are available: 97.1, Semantic accuracy: 95, and Accuracy range: 92.9. Computing these 3 scores, a value of 95 out of 100 was obtained for this characteristic.
- Shift from quantitative to qualitative value: In order to provide a final quality result, it is decided to use another weighted sum; in this case, all dimensions have the same weight. Based on the above aggregated results of the above characteristics: Accuracy: 95, Completeness: 87, Consistency: 90, Credibility: 88, News: 93, a quality level of 90 out of 100 is determined for the repository. Finally, it is necessary to move from this quantitative value of 0 to 100 to a qualitative value. In this particular example, using the percentage-based quality level function, it is concluded that the quality level of the repository, for the analysed property, is 4, or "Very Good".
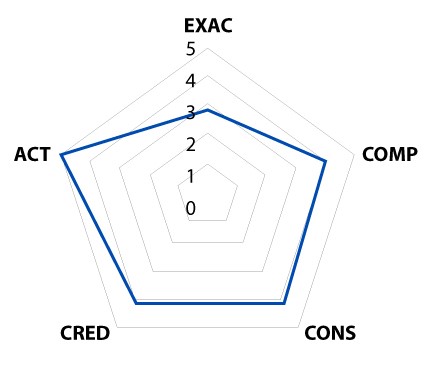
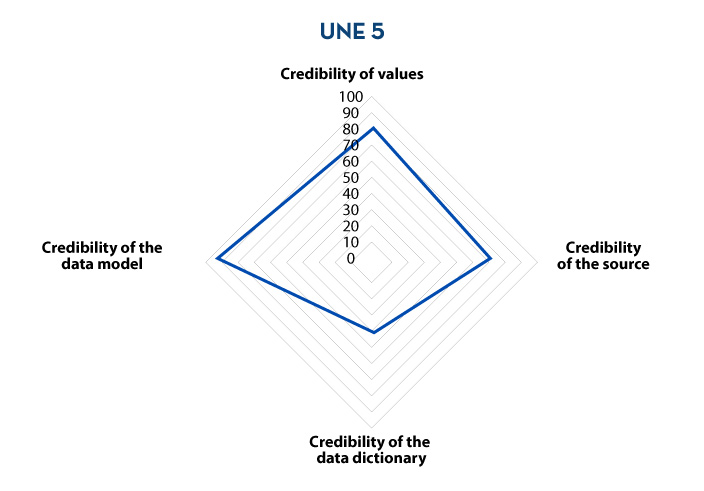
Results visualisation
Finally, once the evaluation of all the characteristics has been carried out, the municipality builds a series of data quality control dashboards with different levels of aggregation (characteristic, property, dataset and table/view) based on the results of the evaluation, so that the level of quality can be quickly consulted. For this purpose, results at different levels of aggregation are shown as an example.
As can be seen throughout the application example, there is a direct relationship between the application of this UNE 0081 specification, with certain parts of the 0078 specification, specifically with the data requirements management process, and with the UNE 0079specification, at least with the data planning and quality control processes. As a result of the evaluation, recommendations for quality improvement (corrective actions) will be established, which will have a direct impact on the established data processes, all in accordance with Deming's PDCA continuous improvement circle.
Once the example has been completed, and as an added value, it should be noted that it is possible to certify the level of data quality of organisational repositories. This will require a certification body to provide this data quality service, as well as an ISO 17025 accredited laboratory with the power to issue data quality assessment reports.
The content of this guide can be downloaded freely and free of charge from the AENOR portal through the link below by accessing the purchase section. Access to this family of UNE data specifications is sponsored by the Secretary of State for Digitalization and Artificial Intelligence, Directorate General for Data. Although the download requires prior registration, a 100% discount on the total price is applied at the time of finalizing the purchase. After finalizing the purchase, the selected standard or standards can be accessed from the customer area in “my products” section.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant.The content and the point of view reflected in this publication are the sole responsibility of its author.
Blog
Today, data quality plays a key role in today's world, where information is a valuable asset. Ensuring that data is accurate, complete and reliable has become essential to the success of organisations, and guarantees the success of informed decision making.
Data quality has a direct impact not only on the exchange and use within each organisation, but also on the sharing of data between different entities, being a key variable in the success of the new paradigm of data spaces. When data is of high quality, it creates an environment conducive to the exchange of accurate and consistent information, enabling organisations to collaborate more effectively, fostering innovation and the joint development of solutions.
Good data quality facilitates the reuse of information in different contexts, generating value beyond the system that creates it. High-quality data are more reliable and accessible, and can be used by multiple systems and applications, which increases their value and usefulness. By significantly reducing the need for constant corrections and adjustments, time and resources are saved, allowing for greater efficiency in the implementation of projects and the creation of new products and services.
Data quality also plays a key role in the advancement of artificial intelligence and machine learning. AI models rely on large volumes of data to produce accurate and reliable results. If the data used is contaminated or of poor quality, the results of AI algorithms will be unreliable or even erroneous. Ensuring data quality is therefore essential to maximise the performance of AI applications, reduce or eliminate biases and realise their full potential.
With the aim of offering a process based on international standards that can help organisations to use a quality model and to define appropriate quality characteristics and metrics, the Data Office has sponsored, promoted and participated in the generation of the specification UNE 0081 Data Quality Assessment that complements the already existing specification UNE 0079 Data Quality Management, focused more on the definition of data quality management processes than on data quality as such.
UNE Specification - Guide to Data Quality Assessment
The UNE 0081 specification, a family of international standards ISO/IEC 25000, makes it possible to know and evaluate the quality of the data of any organisation, making it possible to establish a future plan for its improvement, and even to formally certify its quality. The target audience for this specification, applicable to any type of organisation regardless of size or dedication, will be data quality officers, as well as consultants and auditors who need to carry out an assessment of data sets as part of their functions.
The specification first sets out the data quality model, detailing the quality characteristics that data can have, as well as some applicable metrics, and once this framework is defined, goes on to define the process to be followed to assess the quality of a dataset. Finally, the specification ends by detailing how to interpret the results obtained from the evaluation by showing some concrete examples of application.
Data quality model
The guide proposes a series of quality characteristics following those present in the ISO/IEC 25012 standard , classifying them between those inherent to the data, those dependent on the system where the data is hosted, or those dependent on both circumstances. The choice of these characteristics is justified as they encompass those present in other frameworks such as DAMA, FAIR, EHDS, IA Act and GDPR.
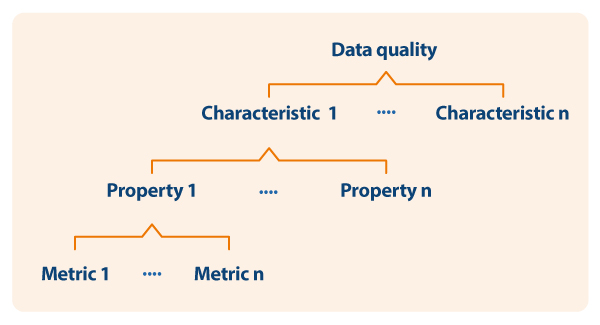
Based on the defined characteristics, the guide uses ISO/IEC 25024 to propose a set of metrics to measure the properties of the characteristics, understanding these properties as "sub-characteristics" of the characteristics.
Thus, as an example, following the dependency scheme, for the specific characteristic of "consistency of data format" its properties and metrics are shown, one of them being detailed


Process for assessing the quality of a data set
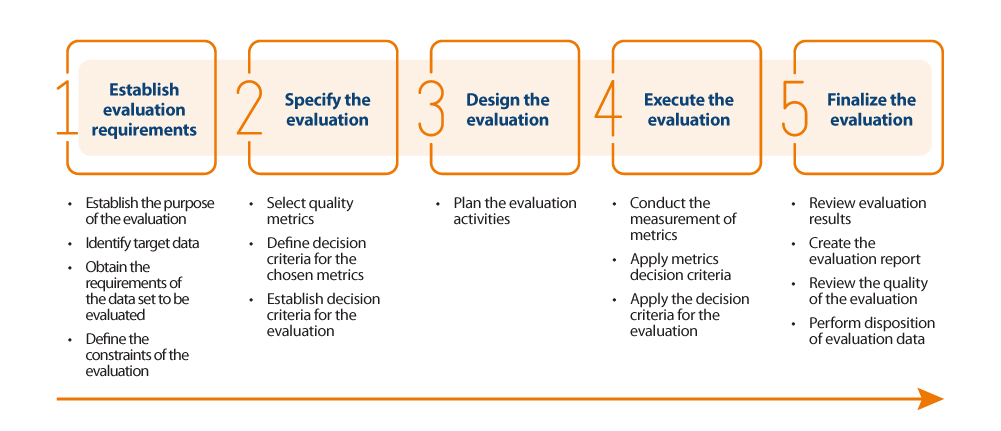
For the actual assessment of data quality, the guide proposes to follow the ISO/IEC 25040 standard, which establishes an assessment model that takes into account both the requirements and constraints defined by the organisation, as well as the necessary resources, both material and human. With these requirements, an evaluation plan is established through specific metrics and decision criteria based on business requirements, which allows the correct measurement of properties and characteristics and interpretation of the results.
Below is an outline of the steps in the process and its main activities:
Results of the quality assesment
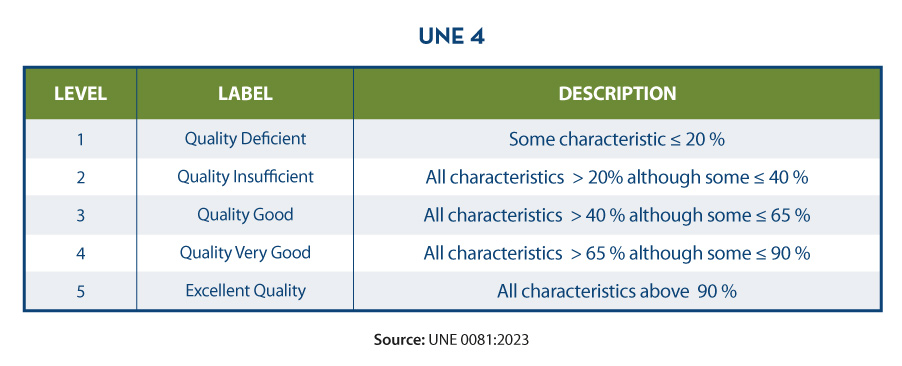
The outcome of the assessment will depend directly on the requirements set by the organisation and the criteria for compliance. The properties of the characteristics are usually evaluated from 0 to 100 based on the values obtained in the metrics defined for each of them, and the characteristics in turn are evaluated by aggregating the previous ones also from 0 to 100 or by converting them to a discrete value from 1 to 5 (1 poor quality, 5 excellent quality) depending on the calculation and weighting rules that have been established. In the same way that the measurement of the properties is used to obtain the measurement of their characteristics, the same happens with these characteristics, which by means of their weighted sum based on the rules that have been defined (being able to establish more weight to some characteristics than to others), a final result of the quality of the data can be obtained. For example, if we want to calculate the quality of data based on a weighted sum of their intrinsic characteristics, where, because of the type of business, we are interested in giving more weight to accuracy, then we could define a formula such as the following:
Data quality = 0.4*Accuracy + 0.15*Completeness + 0.15*Consistency + 0.15*Credibility + 0.15*Currentness
Assume that each of the quality characteristics has been similarly calculated on the basis of the weighted sum of their properties, resulting in the following values: Accuracy=50%, Completeness=45%, Consistency=35%, Credibility=100% and Currency=50%. This would result in data quality:
Data quality = 0.4*50% + 0.15*45% + 0.15*35% + 0.15*100% + 0.15*50% = 54.5%
Assuming that the organisation has established requirements as shown in the following table:

It could be concluded that the organisation as a whole has a data score of "3= Good Quality".
In summary, the assessment and improvement of the quality of the dataset may be as thorough and rigorous as necessary, and should be carried out in an iterative and constant manner so that the data is continuously increasing in quality, so that a minimum data quality is ensured or can even be certified. This minimum data quality can refer to improving data sets internal to an organisation, i.e. those that the organisation manages and exploits for the operation of its business processes; or it can be used to support the sharing of data sets through the new paradigm of data spaces generating new market opportunities. In the latter case, when an organisation wants to integrate its data into a data space for future brokering, it is desirable to carry out a quality assessment, labelling the dataset appropriately with reference to its quality (perhaps by metadata). Data of proven quality has a different utility and value than data that lacks it, positioning the former in a preferential position in the competitive market.
The content of this guide, as well as the rest of the UNE specifications mentioned, can be viewed freely and free of charge from the AENOR portal through the link below by accessing the purchase section and marking “read” in the dropdown where “pdf” is pre-selected. Access to this family of UNE data specifications is sponsored by the Secretary of State for Digitalization and Artificial Intelligence, Directorate General for Data. Although viewing requires prior registration, a 100% discount on the total price is applied at the time of finalizing the purchase. After finalizing the purchase, the selected standard or standards can be accessed from the customer area in the my products section.
https://tienda.aenor.com/norma-une-especificacion-une-0080-2023-n0071383
https://tienda.aenor.com/norma-une-especificacion-une-0079-2023-n0071118
https://tienda.aenor.com/norma-une-especificacion-une-0078-2023-n0071117
https://tienda.aenor.com/norma-une-especificacion-une-0077-2023-n0071116
Blog
Books are an inexhaustible source of knowledge and experiences lived by others before us, which we can reuse to move forward in our lives. Libraries, therefore, are places where readers looking for books, borrow them, and once they have used them and extracted from them what they need, return them. It is curious to imagine the reasons why a reader needs to find a particular book on a particular subject.
In case there are several books that meet the required characteristics, what might be the criteria that weigh most heavily in choosing the book that the reader feels best contributes to his or her task. And once the loan period of the book is over, the work of the librarians to bring everything back to an initial state is almost magical.
The process of putting books back on the shelves can be repeated indefinitely. Both on those huge shelves that are publicly available to all readers in the halls, and on those smaller shelves, out of sight, where books that for some reason cannot be made publicly available rest in custody. This process has been going on for centuries since man began to write and to share his knowledge among contemporaries and between generations.
In a sense, data are like books. And data repositories are like libraries: in our daily lives, both professionally and personally, we need data that are on the "shelves" of numerous "libraries". Some, which are open, very few still, can be used; others are restricted, and we need permissions to use them.
In any case, they contribute to the development of personal and professional projects; and so, we are understanding that data is the pillar of the new data economy, just as books have been the pillar of knowledge for thousands of years.
As with libraries, in order to choose and use the most appropriate data for our tasks, we need "data librarians to work their magic" to arrange everything in such a way that it is easy to find, access, interoperate and reuse data. That is the secret of the "data wizards": something they warily call FAIR principles so that the rest of us humans cannot discover them. However, it is always possible to give some clues, so that we can make better use of their magic:

- It must be easy to find the data. This is where the "F" in the FAIR principles comes from, from "findable". For this, it is important that the data is sufficiently described by an adequate collection of metadata, so that it can be easily searched. In the same way that libraries have a shingle to label books, data needs its own label. The "data wizards" have to find ways to write the tags so that the books are easy to locate, on the one hand, and provide tools (such as search engines) so that users can search for them, on the other. Users, for our part, have to know and know how to interpret what the different book tags mean, and know how the search tools work (it is impossible not to remember here the protagonists of Dan Brown's "Angels and Demons" searching in the Vatican Library).
- Once you have located the data you intend to use, it must be easy to access and use. This is the A in FAIR's "accessible". Just as you have to become a member and get a library card to borrow a book from a library, the same applies to data: you have to get a licence to access the data. In this sense, it would be ideal to be able to access any book without having any kind of prior lock-in, as is the case with open data licensed under CC BY 4.0 or equivalent. But being a member of the "data library" does not necessarily give you access to the entire library. Perhaps for certain data resting on those shelves guarded out of reach of all eyes, you may need certain permissions (it is impossible not to remember here Umberto Eco's "The Name of the Rose").
- It is not enough to be able to access the data, it has to be easy to interoperate with them, understanding their meaning and descriptions. This principle is represented by the "I" for "interoperable" in FAIR. Thus, the "data wizards" have to ensure, by means of the corresponding techniques, that the data are described and can be understood so that they can be used in the users' context of use; although, on many occasions, it will be the users who will have to adapt to be able to operate with the data (impossible not to remember the elvish runes in J.R.R. Tolkien's "The Lord of the Rings").
- Finally, data, like books, has to be reusable to help others again and again to meet their own needs. Hence the "R" for "reusable" in FAIR. To do this, the "data wizards" have to set up mechanisms to ensure that, after use, everything can be returned to that initial state, which will be the starting point from which others will begin their own journeys.
As our society moves into the digital economy, our data needs are changing. It is not that we need more data, but that we need to dispose differently of the data that is held, the data that is produced and the data that is made available to users. And we need to be more respectful of the data that is generated, and how we use that data so that we don't violate the rights and freedoms of citizens. So it can be said, we face new challenges, which require new solutions. This forces our "data wizards" to perfect their tricks, but always keeping the essence of their magic, i.e. the FAIR principles.
Recently, at the end of February 2023, an Assembly of these data wizards took place. And they were discussing about how to revise the FAIR principles to perfect these magic tricks for scenarios as relevant as European data spaces, geospatial data, or even how to measure how well the FAIR principles are applied to these new challenges. If you want to see what they talked about, you can watch the videos and watch the material at the following link: https://www.go-peg.eu/2023/03/07/go-peg-final-workshop-28-february-20203-1030-1300-cet/
Content prepared by Dr. Ismael Caballero, Lecturer at UCLM
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Ensuring data quality is an essential task for any open data initiative. Before publication, datasets need to be validated to check that they are free of errors, duplication, etc. In this way, their potential for re-use will grow.
Data quality is conditioned by many aspects. In this sense, the Aporta Initiative has developed the "Practical guide for improving the quality of open data", which provides a compendium of guidelines to act on the different characteristics that define quality and promote its improvement.
The guide includes a list of some free tools aimed at applying corrective measures on the data at source. In this article we share some examples. These tools are useful for working on specific aspects related to quality, so their usefulness will depend on the data you are working with and their characteristics.
This is a collection of online tools for format conversion and character encoding tasks. You can choose between different converters, but we highlight the tools for working with UTF8 encoding. This collection compiles a wide catalogue of programming tools, which offer conversion functionalities, encryption, password generation, editing and management of texts and images, date and time conversion, mathematical operations, etc.
All tools are free, without intrusive ads, and easy to use thanks to a simple user interface. In addition, each of them includes examples of use.
Managed by the Open Data Institute, this online tool allows you to check whether a CSV file is machine-readable and to verify the columns and types it should include. It also allows users to add schemas to data files. After analysis, it generates a report with the results and a tag that can be embedded in the data portal from which the evaluated dataset comes.
Although it is very easy to use (just upload the file to be verified and click on the validate button), the website includes a help section. It works well with files up to 100 Mb in size. It also offers a simple manual with guidelines on how to create a CSV file correctly and avoid the most common mistakes.
DenCode offers online encoding and decoding tools. Among the functionalities offered we can find this tool that helps publishers to convert date-type data to ISO 8601 format, which is the international standard that facilitates the homogenisation of this type of data and its interoperability.
The tool is very intuitive, as it is only necessary to type the date and time to be converted in the section provided for this purpose.
XML Escape / Unescape is an open source online tool used for "escaping" or masking special characters in XML and performing the reverse process. The tool removes traces of characters that could be misinterpreted.
As in the previous case, the tool is very intuitive. It is only necessary to copy and paste the fragment to be processed in the editor.
JSONLint is a validator and reformulator for JSON, which allows to check if the code is valid according to that specification. It has an editor where you can write or copy and paste the code, although you can also directly enter a url for validation. JSONLint will analyse the code to find and suggest the correction of errors, explaining the multiple reasons why they may occur. The tool can also be used as a compressor, thus reducing file size.
Its website includes information on good practices when working with the JSON format, as well as information on common errors.
Open Refine is a tool designed for data processing and enrichment: it allows you to clean data, transform their format and extend them with web services and external data. One of its main features is that it uses its own language, GREL (Google Refine Expression Language), which allows advanced debugging tasks to be carried out. It is available in more than 15 languages.
Its website offers several videos explaining how it works. It also has a documentation section with online courses, guides and FAQs. In addition, users can use its large community and discussion groups on Google, Gitter and Stackoverflow to solve doubts and share experiences.
OpenRefine allows to add different extensions. One of them allows transforming tabular data to an RDF schema through a SPARQL point. It allows to work with the following specific formats: TSV, CSV, SV, XLS, XLSX, JSON, XML, RDF as XML and Google sheet. The visual interface guides in the choice of predicates, the definition of data type mappings to RDF and the implementation of complex transformations using the GREL language.
The website includes information on how to use the tool, as well as use cases.
This tool allows JSON schemas to be generated and validated from JSON files. These schemas allow to describe existing data formats, providing clear and readable documentation for both humans and machines.
On the JSON Schema website, there are several training materials available, including examples, and information on different implementations. You can also learn more about JSON schema on their Github profile.
This is an online validation tool for the SHACL specification, the W3C standard for validating RDF graphs against a set of conditions expressed in SHACL. As with the previous tools, it is only necessary to cut and paste the code for its validation.
The tool provides some examples of use. In addition, all the code is available on github.
Swagger is a tool for editing and validating specifications that follow the OpenAPI standard. Although it has a paid version with more features, users can create a free account that will allow them to design APIS documentation in a fast and standardised way. This free version has intelligent error detection and syntax auto-completion functionalities.
Sphinx is an open source software for generating any kind of documentation on data. It allows creating hierarchical content structures and automatic indexes, as well as extending cross-references through semantic markup and automatic links for functions, classes, citations, glossary terms and similar pieces of information. It uses the reStructuredText markup language by default, and can read MyST markdown through third-party extensions.
Through its website you can access a large number of tutorials and guides. It also has a large community of users.
This is open source software for hosting and documenting data semantics, similar to the one above. It aims to simplify the generation of software documentation by automating the creation, version control and hosting of documentation.
It has an extensive tutorial on how to create a documentation project.
This tool allows to convert the words in a text into upper and/or lower case. The user only has to enter a text and the tool converts it into different formats: all uppercase, all lowercase, Title Case (where all important words start with uppercase, while minor terms, such as articles or prepositions, use lowercase) or AP-Style Title Case (where all terms start with uppercase).
This is just an example of some online tools that can help you work on data quality issues. If you want to recommend any other tool, you can leave us a comment or send a message to dinamizacion@datos.gob.es.
Content prepared by the datos.gob.es team.
Blog
Transforming data into knowledge has become one of the main objectives facing both public and private organizations today. But, in order to achieve this, it is necessary to start from the premise that the data processed is governed and of quality.
In this sense, the Spanish Association for Standardization (UNE) has recently published an article and report where different technical standards are collected that seek to guarantee the correct management and governance of an organization's data. Both materials are collected in this post , including an infographic-summary of the highlighted standards.
In the aforementioned reference articles, technical standards related to governance, management, quality, security and data privacy are mentioned. On this occasion we want to zoom in on those focused on data quality.
Quality management reference standards
As Lord Kelvin, a 19th-century British physicist and mathematician, said, “what is not measured cannot be improved, and what is not improved is always degraded”. But to measure the quality of the data and to be able to improve it, standards are needed to help us first homogenize said quality* . The following technical standards can help us with this:
ISO 8000 standard
The ISO ( International Organization for Standardization ) regulation has ISO 8000 as the international standard for the quality of transaction data, product data and business master data . This standard is structured in 4 parts: general concepts of data quality (ISO 8000-1, ISO 8000-2 and ISO 8000-8), data quality management processes (ISO 8000-6x), aspects related to the exchange of master data between organizations (parts 100 to 150) and application of product data quality (ISO 8000-311).
Within the ISO 8000-6X family , focused on data quality management processes to create, store and transfer data that support business processes in a timely and profitable manner, we find:
- ISO 8000-60 provides an overview of data quality management processes subject to a cycle of continuous improvement.
- ISO 8000-61 establishes a reference model for data quality management processes. The main characteristic is that, in order to achieve continuous improvement, the implementation process must be executed continuously following the Plan-Do-Check-Act cycle . In addition, implementation processes related to resource provisioning and data processing are included. As shown in the following image, the four stages of the implementation cycle must have input data, control information and support for continuous improvement, as well as the necessary resources to carry out the activities.
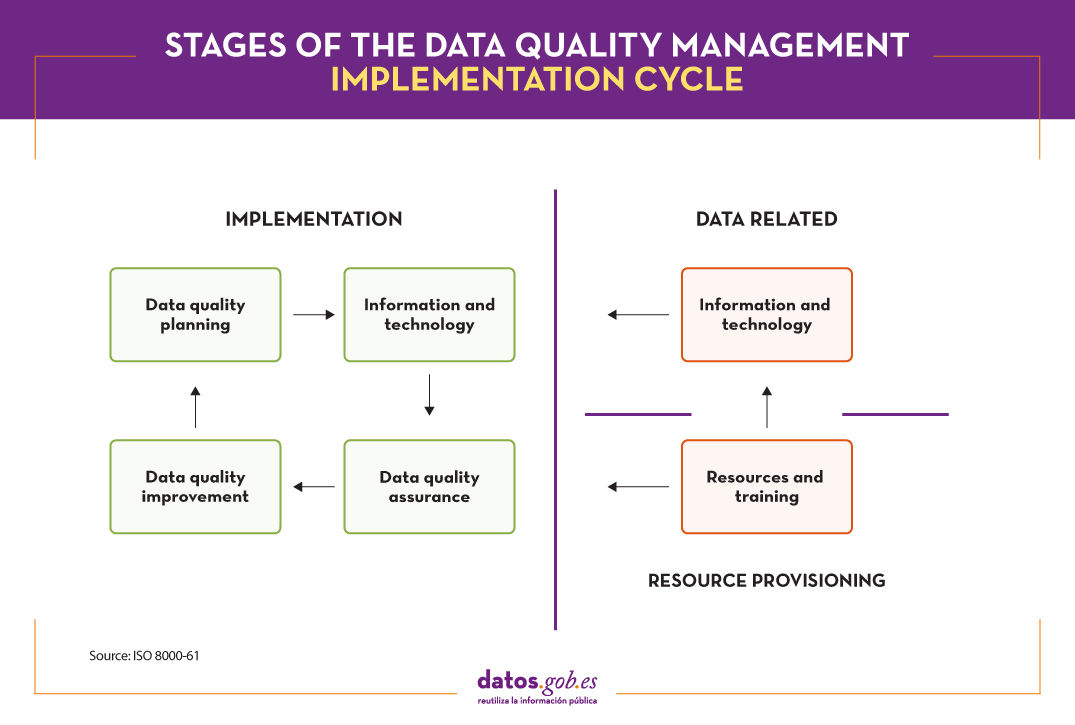
- For its part, ISO 8000-62 , the last of the ISO 8000-6X family, focuses on the evaluation of organizational process maturity . It specifies a framework for assessing the organization's data quality management maturity, based on its ability to execute the activities related to the data quality management processes identified in ISO 8000-61. . Depending on the capacity of the evaluated process, one of the defined levels is assigned.
ISO 25012 standard
Another of the ISO standards that deals with data quality is the ISO 25000 family , which aims to create a common framework for evaluating data quality.cinquality of the software product. Specifically, the ISO 25012 standard defines a general data quality model applicable to data stored in a structured way in an information system.
In addition, in the context of open data, it is considered a reference according to the set of good practices for the evaluation of the quality of open data developed by the pan-European network Share-PSI , conceived to serve as a guide for all public organizations to time to share information.
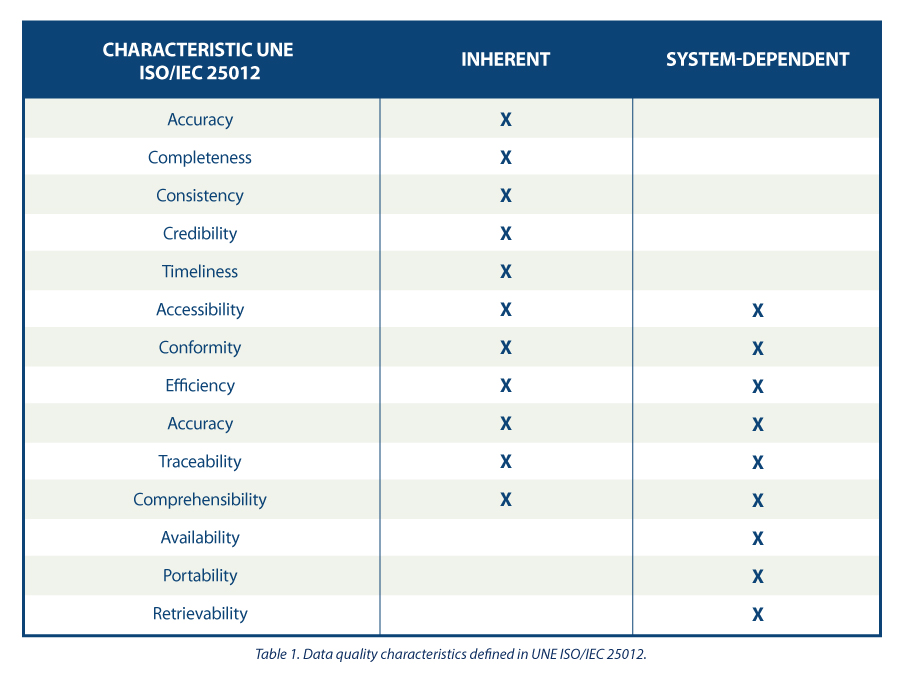
In this case, the quality of the data product is understood as the degree to which it satisfies the requirements previously defined in the data quality model through the following 15 characteristics.
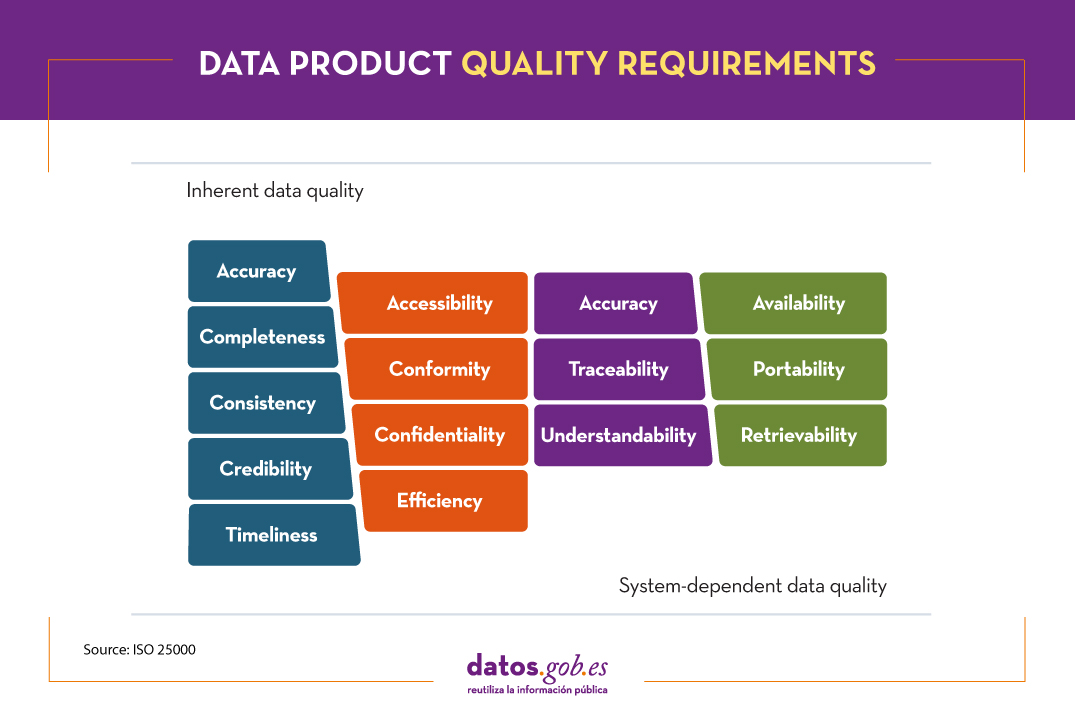
These quality characteristics or dimensions are mainly classified into two categories.
Inherent data quality relates to the intrinsic potential of data to meet defined needs when used under specified conditions. Is about:
- Accuracy : degree to which the data represents the true value of the desired attribute in a specific context, such as the closeness of the data to a set of values defined in a certain domain.
- Completeness – The degree to which the associated data has value for all defined attributes.
- Consistency : degree of consistency with other existing data, eliminating contradictions.
- Credibility – The degree to which the data has attributes that are considered true and credible in its context, including the veracity of the data sources.
- Up-to- dateness : degree of validity of the data for its context of use.
On the other hand, system-dependent data quality is related to the degree achieved through a computer system under specific conditions. Is about:
- Availability : degree to which the data has attributes that allow it to be obtained by authorized users.
- Portability : ability of data to be installed, replaced or deleted from one system to another, preserving the level of quality.
- Recoverability – The degree to which data has attributes that allow quality to be maintained and preserved even in the event of failures.
Additionally, there are characteristics or dimensions that can be encompassed both within " inherent" and "system-dependent" data quality . These are:
- Accessibility : possibility of access to data in a specific context by certain roles.
- Conformity : degree to which the data contains attributes based on established standards, regulations or references.
- Confidentiality : measures the degree of data security based on its nature so that it can only be accessed by the configured roles.
- Efficiency : possibilities offered by the data to be processed with expected performance levels in specific situations.
- Accuracy : Accuracy of the data based on a specific context of use.
- Traceability : ability to audit the entire life cycle of the data.
- Comprehensibility : ability of the data to be interpreted by any user, including the use of certain symbols and languages for a specific context.
In addition to ISO standards, there are other reference frameworks that establish common guidelines for quality measurement. DAMA International , for example, after analyzing the similarities of all the models, establishes 8 basic quality dimensions common to any standard: accuracy, completeness, consistency, integrity, reasonableness, timeliness, uniqueness, validity .
The need for continuous improvement
The homogenization of the quality of the data according to reference standards such as those described, allow laying the foundations for a continuous improvement of the information. From the application of these standards, and taking into account the detailed dimensions, it is possible to define quality indicators. Once they are implemented and executed, they will yield results that will have to be reviewed by the different owners of the data , establishing tolerance thresholds and thus identifying quality incidents in all those indicators that do not exceed the defined threshold.
To do this, different parameters will be taken into account, such as the nature of the data or its impact on the business, since a descriptive field cannot be treated in the same way as a primary key, for example.
From there, it is common to launch an incident resolution circuit capable of detecting the root cause that generates a quality deficiency in a data to extract it and guarantee continuous improvement.
Thanks to this, innumerable benefits are obtained, such as minimizing risks, saving time and resources, agile decision-making, adaptation to new requirements or reputational improvement.
It should be noted that the technical standards addressed in this post allow quality to be homogenized. For data quality measurement tasks per se, we should turn to other standards such as ISO 25024:2015 .
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.