Blog
Open data has great potential to transform the way we interact with our cities. As they are available to all citizens, they allow the development of applications and tools that respond to urban challenges such as accessibility, road safety or citizen participation. Facilitating access to this information not only drives innovation, but also contributes to improving the quality of life in urban environments.
This potential becomes even more relevant if we consider the current context. Accelerated urban growth has brought with it new challenges, especially in the area of public health. According to data from the United Nations, it is estimated that by 2050 more than 68% of the world's population will live in cities. Therefore, the design of healthy urban environments is a priority in which open data is consolidated as a key tool: it allows planning more resilient, inclusive and sustainable cities, putting people's well-being at the center of decisions. In this post, we tell you what healthy urban environments are and how open data can help build and maintain them.
What are Healthy Urban Environments? Uses and examples
Healthy urban environments go beyond simply the absence of pollution or noise. According to the World Health Organization (WHO), these spaces must actively promote healthy lifestyles, facilitate physical activity, encourage social interaction, and ensure equitable access to basic services. As established in the Ministry of Health's "Guide to Planning Healthy Cities", these environments are characterized by three key elements:
-
Cities designed for walking: they must be spaces that prioritize pedestrian and cycling mobility, with safe, accessible and comfortable streets that invite active movement.
-
Incorporation of nature: they integrate green areas, blue infrastructure and natural elements that improve air quality, regulate urban temperature and offer spaces for recreation and rest.
-
Meeting and coexistence spaces: they have areas that facilitate social interaction, reduce isolation and strengthen the community fabric.
The role of open data in healthy urban environments
In this scenario, open data acts as the nervous system of smart cities, providing valuable information on usage patterns, citizen needs, and public policy effectiveness. Specifically, in the field of healthy urban spaces, data from:
-
Analysis of physical activity patterns: data on mobility, use of sports facilities and frequentation of green spaces reveal where and when citizens are most active, identifying opportunities to optimize existing infrastructure.
-
Environmental quality monitoring: urban sensors that measure air quality, noise levels, and temperature provide real-time information on the health conditions of different urban areas.
-
Accessibility assessment: public transport, pedestrian infrastructure and service distribution allow for the identification of barriers to access and the design of more inclusive solutions.
-
Informed citizen participation: open data platforms facilitate participatory processes where citizens can contribute local information and collaborate in decision-making.
The Spanish open data ecosystem has solid platforms that feed healthy urban space projects. For example, the Madrid City Council's Open Data Portal offers real-time information on air quality as well as a complete inventory of green areas. Barcelona also publishes data on air quality, including the locations and characteristics of measuring stations.
These portals not only store information, but structure it in a way that developers, researchers and citizens can create innovative applications and services.
Use Cases: Applications That Reuse Open Data
Several projects demonstrate how open data translates into tangible improvements for urban health. On the one hand, we can highlight some applications or digital tools such as:
-
AQI Air Quality Index: uses government data to provide real-time information on air quality in different Spanish cities.
-
GV Aire: processes official air quality data to generate citizen alerts and recommendations.
-
National Air Quality Index: centralizes information from measurement stations throughout the country.
-
Valencia Verde: uses municipal data to show the location and characteristics of parks and gardens in Valencia.
On the other hand, there are initiatives that combine multisectoral open data to offer solutions that improve the interaction between cities and citizens. For example:
-
Supermanzanas Program: uses maps showing air quality pollution levels and traffic data available in open formats such as CSV and GeoPackage from Barcelona Open Data and Barcelona City Council to identify streets where reducing road traffic can maximize health benefits, creating safe spaces for pedestrians and cyclists.
-
The DataActive platform: seeks to establish an international infrastructure in which researchers, public and private sports entities participate. The topics it addresses include land management, urban planning, sustainability, mobility, air quality and environmental justice. It aims to promote more active, healthy and accessible urban environments through the implementation of strategies based on open data and research.
Data availability is complemented by advanced visualization tools. The Madrid Spatial Data Infrastructure (IDEM) offers geographic viewers specialized in air quality and the National Geographic Institute (IGN) offers the national street map CartoCiudad with information on all cities in Spain.
Effective governance and innovation ecosystem
However, the effectiveness of these initiatives depends on new governance models that integrate multiple actors. To achieve proper coordination between public administrations at different levels, private companies, third sector organizations and citizens, it is essential to have quality open data.
Open data not only powers specific applications but creates an entire ecosystem of innovation. Independent developers, startups, research centers, and citizen organizations use this data to:
-
Develop urban health impact studies.
-
Create participatory planning tools.
-
Generate early warnings about environmental risks.
-
Evaluate the effectiveness of public policies.
-
Design personalized services according to the needs of different population groups.
Healthy urban spaces projects based on open data generate multiple tangible benefits:
-
Efficiency in public management: data makes it possible to optimize the allocation of resources, prioritize interventions and evaluate their real impact on citizen health.
-
Innovation and economic development: the open data ecosystem stimulates the creation of innovative startups and services that improve the quality of urban life, as demonstrated by the multiple applications available in datos.gob.es.
-
Transparency and participation: the availability of data facilitates citizen control and strengthens democratic decision-making processes.
-
Scientific evidence: Urban health data contributes to the development of evidence-based public policies and the advancement of scientific knowledge.
-
Replicability: successful solutions can be adapted and replicated in other cities, accelerating the transformation towards healthier urban environments.
In short, the future of our cities depends on our ability to integrate technology, citizen participation and innovative public policies. The examples analyzed demonstrate that open data is not just information; They are the foundation for building urban environments that actively promote health, equity, and sustainability.
Noticia
There is no doubt that artificial intelligence has become a fundamental pillar of technological innovation. Today, artificial intelligence (AI) can create chatbots specialised in open data, applications that facilitate professional work and even a digital Earth model to anticipate natural disasters.
The possibilities are endless, however, the future of AI also has challenges to overcome to make models more inclusive, accessible and transparent. In this respect, the European Union is developing various initiatives to make progress in this field.
European regulatory framework for a more open and transparent AI.
The EU's approach to AI seeks to give citizens the confidence to adopt these technologies and to encourage businesses to develop them. To this end, the European AI Regulation sets out guidelines for the development of artificial intelligence in line with European values of privacy, security and cultural diversity. On the other hand, the Data Governance Regulation (DGA) defines that broad access to data must be guaranteed without compromising intellectual property rights, privacy and fairness.
Together with the Artificial Intelligence Act, the update of the Coordinated Plan on AI ensures the security and fundamental rights of individuals and businesses, while strengthening investment and innovation in all EU countries. The Commission has also launched an Artificial Intelligence Innovation Package to help European start-ups and SMEs develop reliable AI that respects EU values and standards.
Other institutions are also working on boosting intelligence by pushing open source AI models as a very interesting solution. A recent report by Open Future and Open Source Initiative (OSI) defines what data governance should look like in open source AI models. One of the challenges highlighted in the report is precisely to strike a balance between open data and data rights, to achieve more transparency and to avoid cultural bias. In fact, experts in the field Ricard Martínez and Carmen Torrijos debated this issue in the pódcast of datos.gob.es.
The OpenEuroLLM project
With the aim of solving potential challenges and as an innovative and open solution, the European Union, through the Digital Europe programme has presented through this open source artificial intelligence project it is expected to create efficient, transparent language models aligned with European AI regulations.
The OpenEuroLLM project has as its main goal the development of state-of-the-art language models for a wide variety of public and private applications. Among the most important objectives, we can mention the following:
- Extend the multilingual capabilities of existing models: this includes not only the official languages of the European Union, but also other languages that are of social and economic interest. Europe is a continent rich in linguistic diversity, and the project seeks to reflect this diversity in AI models.
- Sustainable access to fundamental models: lthe models developed within the project will be easy to access and ready to be adjusted to various applications. This will not only benefit large enterprises, but also small and medium-sized enterprises (SMEs) that wish to integrate AI into their processes without facing technological barriers.
- Evaluation of results and alignment with European regulations: models will be evaluated according to rigorous safety standards and alignment with the European AI Regulation and other European regulatory frameworks. This will ensure that AI solutions are safe and respect fundamental rights.
- Transparency and accessibility: One of the premises of the project is to openly share the tools, processes and intermediate results of the training processes. This will allow other researchers and developers to reproduce, improve and adapt the models for their own purposes.
- Community building: OpenEuroLLM is not limited to modelling but also aims to build an active and engaged community, both in the public and private sector, that can collaborate, share knowledge and work together to advance AI research.
The OpenEuroLLM Consortium: a collaborative and multinational project
The OpenEuroLLM project is being developed by a consortium of 20 European research institutions , technology companies and supercomputing centres, under the coordination of Charles University (Czech Republic) and the collaboration of Silo GenAI (Finland). The consortium brings together some of the leading institutions and companies in the field of artificial intelligence in Europe, creating a multinational collaboration to develop open source language models.
The main institutions participating in the project include renowned universities such as University of Helsinki (Finland) and University of Oslo (Norway), as well as technology companies such as Aleph Alpha Research (Germany) or the company from Elche prompsit (Spain), among others. In addition, supercomputing centres such as the Barcelona Supercomputing Center (Spain) or SURF (The Netherlands) provide the infrastructure needed to train large-scale models.
Linguistic diversity, transparency and compliance with EU standards
One of the biggest challenges of globalised artificial intelligence is the inclusion of multiple languages and the preservation of cultural differences. Europe, with its vast linguistic diversity, presents a unique environment in which to address these issues. OpenEuroLLM is committed to preserving this diversity and ensuring that the AI models developed are sensitive to the linguistic and cultural variations of the region.
As we saw at the beginning of this post, technological development must go hand in hand with ethical and responsible values. In this respect, one of the key features of the OpenEuroLLM project is its focus on transparency. Models, data, documentation, training code and evaluation metrics will be fully available to the public. This will allow researchers and developers to audit, modify and improve the models, ensuring an open and collaborative approach.
In addition, the project is aligned with strict European AI regulations. OpenEuroLLM is designed to comply with the EU's AI Law , which sets stringent criteria to ensure safety, fairness and privacy in artificial intelligence systems.
Democratising access to AI
One of the most important achievements of OpenEuroLLLM is the democratisation of access to high-performance AI. Open source models will enable businesses, academic institutions and public sector organisations across Europe to have access to cutting-edge technology, regardless of their size or budget.
This is especially relevant for small and medium-sized enterprises (SMEs), which often face difficulties in accessing AI solutions due to high licensing costs or technological barriers. OpenEuroLLM will remove these barriers and enable companies to develop innovative products and services using AI, which will contribute to Europe's economic growth.
The OpenEuroLLM project is also an EU commitment to digital sovereignty that is strategically investing in the development of technological infrastructure that reduces dependence on global players and strengthens European competitiveness in the field of artificial intelligence. This is an important step towards artificial intelligence that is not only more advanced, but also fairer, safer and more responsible.
Blog
There is no doubt that digital skills training is necessary today. Basic digital skills are essential to be able to interact in a society where technology already plays a cross-cutting role. In particular, it is important to know the basics of the technology for working with data.
In this context, public sector workers must also keep themselves constantly updated. Training in this area is key to optimising processes, ensuring information security and strengthening trust in institutions.
In this post, we identify digital skills related to open data aimed at both publishing and using open data. Not only did we identify the professional competencies that public employees working with open data must have and maintain, we also compiled a series of training resources that are available to them.
Professional competencies for working with data
A working group was set up in 2024 National Open Data Gathering with one objective: to identify the digital competencies required of public administration professionals working with open data. Beyond conclusions of this event of national relevance, the working group defined profiles and roles needed for data opening, gathering information on their roles and the skills and knowledge required. The main roles identified were:
- Role responsible: has technical responsibility for the promotion of open data policies and organises activities to define policies and data models. Some of the skills required are:
- Leadership in promoting strategies to drive data openness.
- Driving the data strategy to drive openness with purpose.
- Understand the regulatory framework related to data in order to act within the law throughout the data lifecycle.
- Encourage the use of tools and processes for data management.
- Ability to generate synergies in order to reach a consensus on cross-cutting instructions for the entire organisation.
- Technical role of data entry technician (ICT profile): carries out implementation activities more closely linked to the management of systems, extraction processes, data cleansing, etc. EThis profile must have knowledge of, for example:
- How to structure the dataset, the metadata vocabulary, data quality, strategy to follow...
- Be able to analyse a dataset and identify debugging and cleaning processes quickly and intuitively.
- Generate data visualisations, connecting databases of different formats and origins to obtain dynamic and interactive graphs, indicators and maps.
- Master the functionalities of the platform, i.e. know how to apply technological solutions for open data management or know techniques and strategies to access, extract and integrate data from different platforms.
- Open data functional role (technician of a service): executes activities more related to the selection of data to be published, quality, promotion of open data, visualisation, data analytics, etc. For example:
- Handling visualisation and dynamisation tools.
- Knowing the data economy and knowing the information related to data in its full extent (generation by public administrations, open data, infomediaries, reuse of public information, Big Data, Data Driven, roles involved, etc.).
- To know and apply the ethical and personal data protection aspects that apply to the opening of data.
- Data use by public workers: this profile carries out activities on the use of data for decision making, basic data analytics, among others. In order to do so, it must have these competences:
- Navigation, search and filtering of data.
- Data assessment.
- Data storage and export
- Data analysis and exploitation.
In addition, as part of this challenge to increase capacities for open data, a list of free trainings and guides on open data and data analyticswas developed. We compile some of them that are available online and in open format.
| Institution | Resources | Link | Level |
|---|---|---|---|
| Knight Center for Journalism in the Americas | Data journalism and visualisation with free tools | https://journalismcourses.org/es/course/dataviz/ | Beginner |
| Data Europa Academy | Introduction to open data | https://data.europa.eu/en/academy/introducing-open-data | Beginner |
| Data Europa Academy | Understanding the legal side of open data | https://data.europa.eu/en/academy/understanding-legal-side-open-data | Beginner |
| Data Europa Academy | Improve the quality of open data and metadata | https://data.europa.eu/en/academy/improving-open-data-and-metadata-quality | Advanced |
| Data Europa Academy | Measuring success in open data initiatives | https://data.europa.eu/en/training/elearning/measuring-success-open-data-initiatives | Advanced |
| Escuela de Datos | Data Pipeline Course | https://escueladedatos.online/curso/curso-tuberia-de-datos-data-pipeline/ | Intermediate |
| FEMP | Strategic guidance for its implementation - Minimum data sets to be published | https://redtransparenciayparticipacion.es/download/guia-estrategica-para-su-puesta-en-marcha-conjuntos-de-datos-minimos-a-publicar/ | Intermediate |
| Datos.gob.es | Methodological guidelines for data opening | /es/conocimiento/pautas-metodologicas-para-la-apertura-de-datos | Beginner |
| Datos.gob.es | Practical guide to publishing open data using APIs |
/es/conocimiento/guia-practica-para-la-publicacion-de-datos-abiertos-usando-apis |
Intermediate |
| Datos.gob.es | Practical guide to publishing spatial data | /es/conocimiento/guia-practica-para-la-publicacion-de-datos-espaciales | Intermediate |
| Junta de Andalucía | Processing datasets with Open Refine | https://www.juntadeandalucia.es/datosabiertos/portal/tutoriales/usar-openrefine.html | Beginner |
Figure 1. Table of own elaboration with training resources. Source: https://encuentrosdatosabiertos.es/wp-content/uploads/2024/05/Reto-2.pdf
INAP''s continuing professional development training offer
The Instituto Nacional de Administración Pública (INAP) has a Training Activities Programme for 2025, framed in the INAP Learning Strategy 2025-2028.. This training catalogue includes more than 180 activities organised in different learning programmes, which will take place throughout the year with the aim of strengthening the competences of public staff in key areas such as open data management and the use of related technologies.
INAP''s 2025 training programme offers a wide range of courses aimed at improving digital skills and open data literacy. Some of the highlighted trainings include:
- Fundamentals and tools of data analysis.
- Introduction to Oracle SQL.
- Open data and re-use of information.
- Data analysis and visualisation with Power BI.
- Blockchain: technical aspects.
- Advanced Python programming.
These courses, aimed at different profiles of public employees, from open data managers to information management technicians, allow to acquire knowledge on data extraction, processing and visualisation, as well as on strategies for the opening and reuse of open data in the Public Administration. You can consult the full catalogue here..
Other training references
Some public administrations or entities offer training courses related to open data. For more information on its training offer, please see the catalogue with the programmed courses on offer.
- FEMP''s Network of Local Entities for Transparency and Citizen Participation: https://redtransparenciayparticipacion.es/.
- Government of Aragon: Aragon Open Data: https://opendata.aragon.es/informacion/eventos-de-datos-abiertos
- School of Public Administration of Catalonia (EAPC): https://eapc.gencat.cat/ca/inici/index.html#googtrans(ca|es
- Diputació de Barcelona: http://aplicacions.diba.cat/gestforma/public/cercador_baf_ens_locals
- Instituto Geográfico Nacional (IGN): https://cursos.cnig.es/
In short, training in digital skills, in general, and in open data, in particular, is a practice that we recommend at datos.gob.es. Do you need a specific training resource? Write to us in comments, we''ll read you!
Blog
Open source artificial intelligence (AI) is an opportunity to democratise innovation and avoid the concentration of power in the technology industry. However, their development is highly dependent on the availability of high quality datasets and the implementation of robust data governance frameworks. A recent report by Open Future and the Open Source Initiative (OSI) analyses the challenges and opportunities at this intersection, proposing solutions for equitable and accountable data governance. You can read the full report here.
In this post, we will analyse the most relevant ideas of the document, as well as the advice it offers to ensure a correct and effective data governance in artificial intelligence open source and take advantage of all its benefits.
The challenges of data governance in AI
Despite the vast amount of data available on the web, accessing and using it to train AI models poses significant ethical, legal and technical challenges. For example:
- Balancing openness and rights: In line with the Data Governance Regulation (DGA), broad access to data should be guaranteed without compromising intellectual property rights, privacy and fairness.
- Lack of transparency and openness standards: It is important that models labelled as "open" meet clear criteria for transparency in the use of data.
- Structural biases: Many datasets reflect linguistic, geographic and socio-economic biases that can perpetuate inequalities in AI systems.
- Environmental sustainability: the intensive use of resources to train AI models poses sustainability challenges that must be addressed with more efficient practices.
- Engage more stakeholders: Currently, developers and large corporations dominate the conversation on AI, leaving out affected communities and public organisations.
Having identified the challenges, the report proposes a strategy for achieving the main goal: adequate data governance in open source AI models. This approach is based on two fundamental pillars.
Towards a new paradigm of data governance
Currently, access to and management of data for training AI models is marked by increasing inequality. While some large corporations have exclusive access to vast data repositories, many open source initiatives and marginalised communities lack the resources to access quality, representative data. To address this imbalance, a new approach to data management and use in open source AI is needed. The report highlights two fundamental changes in the way data governance is conceived:
On the one hand, adopting a data commons approach which is nothing more than an access model that ensures a balance between data openness and rights protection.. To this end, it would be important to use innovative licences that allow data sharing without undue exploitation. It is also relevant to create governance structures that regulate access to and use of data. And finally, implement compensation mechanisms for communities whose data is used in artificial intelligence.
On the other hand, it is necessary to transcend the vision focused on AI developers and include more actors in data governance, such as:
- Data owners and content-generating communities.
- Public institutions that can promote openness standards.
- Civil society organisations that ensure fairness and responsible access to data.
By adopting these changes, the AI community will be able to establish a more inclusive system, in which the benefits of data access are distributed in a manner that is equitable and respectful of the rights of all stakeholders. According to the report, the implementation of these models will not only increase the amount of data available for open source AI, but will also encourage the creation of fairer and more sustainable tools for society as a whole.
Advice and strategy
To make robust data governance effective in open source AI, the report proposes six priority areas for action:
- Data preparation and traceability: Improve the quality and documentation of data sets.
- Licensing and consent mechanisms: allow data creators to clearly define their use.
- Data stewardship: strengthen the role of intermediaries who manage data ethically.
- Environmental sustainability: Reduce the impact of AI training with efficient practices.
- Compensation and reciprocity: ensure that the benefits of AI reach those who contribute data.
- Public policy interventions: promote regulations that encourage transparency and equitable access to data.

Open source artificial intelligence can drive innovation and equity, but to achieve this requires a more inclusive and sustainable approach to data governance. Adopting common data models and broadening the ecosystem of actors will build AI systems that are fairer, more representative and accountable to the common good.
The report published by Open Future and Open Source Initiative calls for action from developers, policymakers and civil society to establish shared standards and solutions that balance open data with the protection of rights. With strong data governance, open source AI will be able to deliver on its promise to serve the public interest.
Documentación
Public sector bodies must make their data available for re-use, making it accessible in the form of open data, as referred to in Spain's legislative framework. The first step for this is that each entity, at local, regional and state level, as well as bodies, entities and trading companies belonging to the institutional public sector, establishes a unit responsible for ensuring that their information is made available. This unit will be in charge of promoting that the information is updated and provided in the appropriate open formats. It should also coordinate information re-use activities, as well as promotion, awareness raising and training on open data, among other functions.
Once it has been determined who is responsible for ensuring open data, it is time to put in place a plan of measures to promote openness and reuse of open data, so that all the actions to be developed are carried out in an orderly, coordinated manner and subject to a viable agenda for openness.
In order to help the responsible units in this task, datos.gob.es has prepared a template for the formulation of the Plan. The aim is to provide guidance on the different elements that such a plan should contain in order to draw up a feasible roadmap for data openness, as well as to enable its monitoring and evaluation.
The following infographic lists the categories included in the template, together with a brief definition (Click on the image to access the infographic).
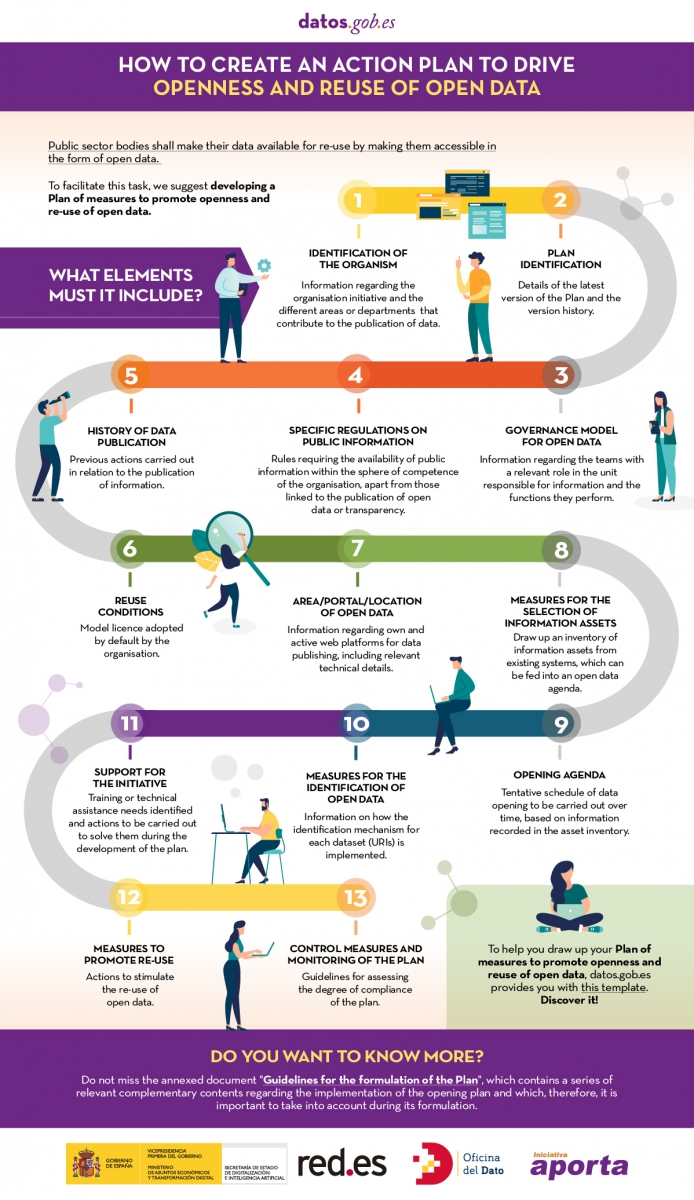
When drawing up the plan, it is important that each of these categories is completed in as much detail as possible. You can download the template document below, which details all of these elements.
A document has also been prepared with guidelines on important issues for the development of the open data initiative that should be taken into account when defining the plan of measures to promote openness and reuse of open data. This includes guidance on:
- Data governance
- The regulatory framework for open data
- The most common conditions for re-use
- High value data
- Metadata to consider
- Measurement indicators for the evaluation and monitoring of an open data initiative.
Click on the button below each document to download it.
Noticia
The National Open Data Meeting (ENDA, in its Spanish acronym) is an initiative born in 2022 from the joint effort of the Diputación de Barcelona, the Government of Aragón and the Diputación de Castellón. Its objective is to be a space for the exchange of ideas and reflections of the administrations to identify and elaborate concrete proposals in order to promote the reuse of quality open data that can bring concrete value in improving the living conditions of citizens.
An important peculiarity of the Encounters initiative is that it fosters an annual cycle of collaborative work, where challenges are posed and solutions are worked out together. These challenges, proposed by the organisers, are developed throughout the year by volunteers linked to the field of data, most of them belonging to the academic world and the public administration.
Three challenges have been worked on so far. The conclusions of the challenges worked on are presented during each annual event and the documentation generated is made public.
CHALLENGE 1.- Generate data exchanges and facilitate their opening up
At the first ENDA (held in Barcelona, November 2022) a vote was taken on which data should be prioritised for openness. Based on the results of this vote, the Challenge 1 working group made an effort to collect standards, regulations, data sources and data controllers, as well as cases of publication and re-use.
The objective of this challenge was to foster inter-administrative collaboration to generate data exchanges and facilitate their openness, identifying datasets to work on in order to boost their quality, the use of standards and their reusability.
- Material from Challenge 1: Encourage inter-administrative collaboration to generate data exchanges and facilitate their openness presented at the second ENDA (Zaragoza, September 2023)
CHALLENGE 2.- Increase capacities for data openness
Challenge 2 aimed to ensure that public sector workers develop the knowledge and skills needed to drive the dissemination of open data. The ultimate goal was to improve public policies by involving citizens and businesses in the whole process of opening up.
Therefore, the working group defined profiles and roles needed for data opening, collecting information on their functions and the skills and knowledge required.
In addition, a list of free training courses on open data and data analytics was compiled, linking these with the profiles for which they could be targeted.
- Document of the Challenge 2: Capabilities for opening data
CHALLENGE 3.- Measuring the impact of open data
Challenge 3 sought to address the need to understand the impact of open data. Therefore, throughout the year, work was carried out on a methodological proposal for a systematic mapping of initiatives that seek to measure the impact of open data.
At the third ENDA (Peñíscola, May 2024), a self-test for local authorities to measure the impact of the publication of open data was presented as a result of the working group.
- Document of the Challenge 3: Methodological proposal for a systematic mapping of initiatives that seek to measure the impact of open data
The answers to these challenges have been made possible through collaboration and joint work, resulting in concrete documents and tools that will be of great help to other public bodies that want to advance their open data strategy. In the coming years, work will continue on new challenges, with the aim of further boosting the openness of quality data and its re-use for the benefit of society as a whole.
Evento
Alicante will host the Gaia-X Summit 2023 on November 9 and 10, which will review the latest progress made by this initiative in promoting data sovereignty in Europe. Interoperability, transparency and regulatory compliance acquire a practical dimension through the exchange and exploitation of data articulated under a reliable cloud environment.
It will also address the relationships established with industry leaders, experts, companies, governments, academic institutions and various organisations, facilitating the exchange of ideas and experiences between the various stakeholders involved in the European digital transformation. The event will feature keynotes, interactive workshops and panel discussions, exploring the limitless possibilities of cooperative digital ecosystems, and a near future where data has become a high value-added asset.
This event is organised by the european association Gaia-X, in collaboration with the Spanish Gaia-X Hub. It also counts with the participation of the Data Office the project is being developed under the auspices of the Spanish Presidency of the Council of the European Union. The project is being developed under the auspices of the Spanish Presidency of the Council of the European Union.
The Gaia-X initiative aims to ensure that data is stored and processed in a secure and sovereign manner, respecting European regulations, and to foster collaboration between different and heterogeneous actors, such as companies, governments and organisations. Thus, Gaia-X promotes innovation promotes innovation and data-driven economic development in Europe. The open and collaborative relationship with the European Union is therefore essential for the achievement of its objectives.
Digital sovereignty: a Europe fit for the data age
As for Gaia-X, one of the major objectives of the European Union is to to promote digital sovereignty throughout the European Union. To this end, it promotes the development of key industries and technologies for its competitiveness and security, strengthens its trade relations and supply chains, and mitigates external dependencies, focusing on the reindustrialisation of its territory and on ensuring its strategic digital autonomy.
The concept of digital sovereignty encompasses different dimensions: technological, regulatory and socio-economic. The technology dimension refers to the hardware, software, cloud and network infrastructure used to access, process and store data. Meanwhile, the regulatory dimension refers to the rules that provide legal certainty to citizens, businesses and institutions operating in a digital environment. Finally, the socio-economic dimension focuses on entrepreneurship and individual rights in the new global digital environment. To make progress in all these dimensions, the EU relies on projects such as Gaia-X.
The initiative seeks to create federated, open, secure and transparent open, secure and transparent ecosystems, where data sets and services comply with a minimum set of common rules, thus allowing them to be reusable under environments of trust and transparency. In turn, this enables the creation of reliable, high-quality data ecosystems, with which European organisations will be able to drive their digitisation process, enhancing value chains across different industrial sectors. These value chains, digitally deployed on federated and trusted cloud environments ("Trusted Cloud"), are traceable and transparent, and thus serve to drive regulatory compliance and digital sovereignty efforts.
In short, this approach is based on building on and reinforcing values reflected in a developing regulatory framework that seeks to embed concepts such as trust and governance in data environments. This seeks to make the EU a leader in a society and economy where digitalisation is a vector for re-industrialisation and prosperity, but always within the framework of our defining values.
The full programme of the Summit is available on the official website of the European association: https://gaia-x.eu/summit-2023/agenda/.
Blog
Public administration is working to ensure access to open data, in order to empowering citizens in their right to information. Aligned with this objective, the European open data portal (data.europa.eu) references a large volume of data on a variety of topics.
However, although the data belong to different information domains or are in different formats, it is complex to exploit them together to maximise their value. One way to achieve this is through the use of RDF (Resource Description Framework), a data model that enables semantic interoperability of data on the web, standardised by the W3C, and highlighted in the FAIR principles. RDF occupies one of the top levels of the five-star schema for open data publishing, proposed by Tim Berners-Lee, the father of the web.
In RDF, data and metadata are automatically interconnected, generating a network of Linked Open Data (LOD) by providing the necessary semantic context through explicit relationships between data from different sources to facilitate their interconnection. This model maximises the exploitation potential of linked data.
It is a data sharing paradigm that is particularly relevant within the EU data space initiative explained in this post.
RDF offers great advantages to the community. However, in order to maximise the exploitation of linked open data it is necessary to know the SPARQL query language, a technical requirement that can hinder public access to the data.
An example of the use of RDF is the open data catalogues available on portals such as datos.gob.es or data.europa.eu that are developed following the DCAT standard, which is an RDF data model to facilitate their interconnection. These portals have interfaces to configure queries in SPARQL language and retrieve the metadata of the available datasets.
A new app to make interlinked data accessible: Vinalod.
Faced with this situation and with the aim of facilitating access to linked data, Teresa Barrueco, a data scientist and visualisation specialist who participated in the 2018 EU Datathon, the EU competition to promote the design of digital solutions and services related to open data, developed an application together with the European Publications Office.
The result is a tool for exploring LOD without having to be familiar with SPARQL syntax, called Vinalod: Visualisation and navigation of linked open data. The application, as its name suggests, allows you to navigate and visualise data structures in knowledge graphs that represent data objects linked to each other through the use of vocabularies that represent the existing relationships between them. Thus, through a visual and intuitive interaction, the user can access different data sources:
- EU Vocabularies. EU reference data containing, among others, information from Digital Europa Thesaurus, NUTS classification (hierarchical system to divide the economic territory of the EU) and controlled vocabularies from the Named Authority Lists.
- Who's Who in the EU. Official EU directory to identify the institutions that make up the structure of the European administration.
- EU Data. Sets and visualisations of data published on the EU open data portal that can be browsed according to origin and subject.
- EU publications. Reports published by the European Union classified according to their subject matter.
- EU legislation. EU Treaties and their classification.
The good news is that the BETA version of Vinalod is now available for use, an advance that allows for temporary filtering of datasets by country or language.
To test the tool, we tried searching for data catalogues published in Spanish, which have been modified in the last three months. The response of the tool is as follows:

And it can be interpreted as follows:

Therefore, the data.europa.eu portal hosts ("has catalog") several catalogues that meet the defined criteria: they are in Spanish language and have been published in the last three months. The user can drill down into each node ("to") and find out which datasets are published in each portal.
In the example above, we have explored the 'EU data' section. However, we could do a similar exercise with any of the other sections. These are: EU Vocabularies; Who's Who in the EU; EU Publications and EU Legislation.
All of these sections are interrelated, that means, a user can start by browsing the 'EU Facts', as in the example above, and end up in 'Who's Who in the EU' with the directory of European public officials.

As can be deduced from the above tests, browsing Vinalod is a practical exercise in itself that we encourage all users interested in the management, exploitation and reuse of open data to try out.
To this end, in this link we link the BETA version of the tool that contributes to making open data more accessible without the need to know SPARQL, which means that anyone with minimal technical knowledge can work with the linked open data.
This is a valuable contribution to the community of developers and reusers of open data because it is a resource that can be accessed by any user profile, regardless of their technical background. In short, Vinalod is a tool that empowers citizens, respects their right to information and contributes to the further opening of open data.
Documentación
In this article we compile a series of infographics aimed at both publishers and reusers working with open data. They show standards and good practices to facilitate both the publication and the processing of data.
Interoperability: the key to working with data from various sources
 |
Published: March 2026 Interoperability operates as a four-layer system: technical, semantic, organizational, and legal. All of these layers must function properly so that we can combine data from various sources seamlessly, without misunderstandings or surprises. |
How to publish open data on datos.gob.es
 |
Published: February 2026 This infographic outlines the recommended process for an agency to publish open data in the National Open Data Catalog hosted on datos.gob.es. The process is divided into five main phases: preliminary planning, agency and user registration, cataloging, federation, and maintenance. |
Technical guide: Data version control
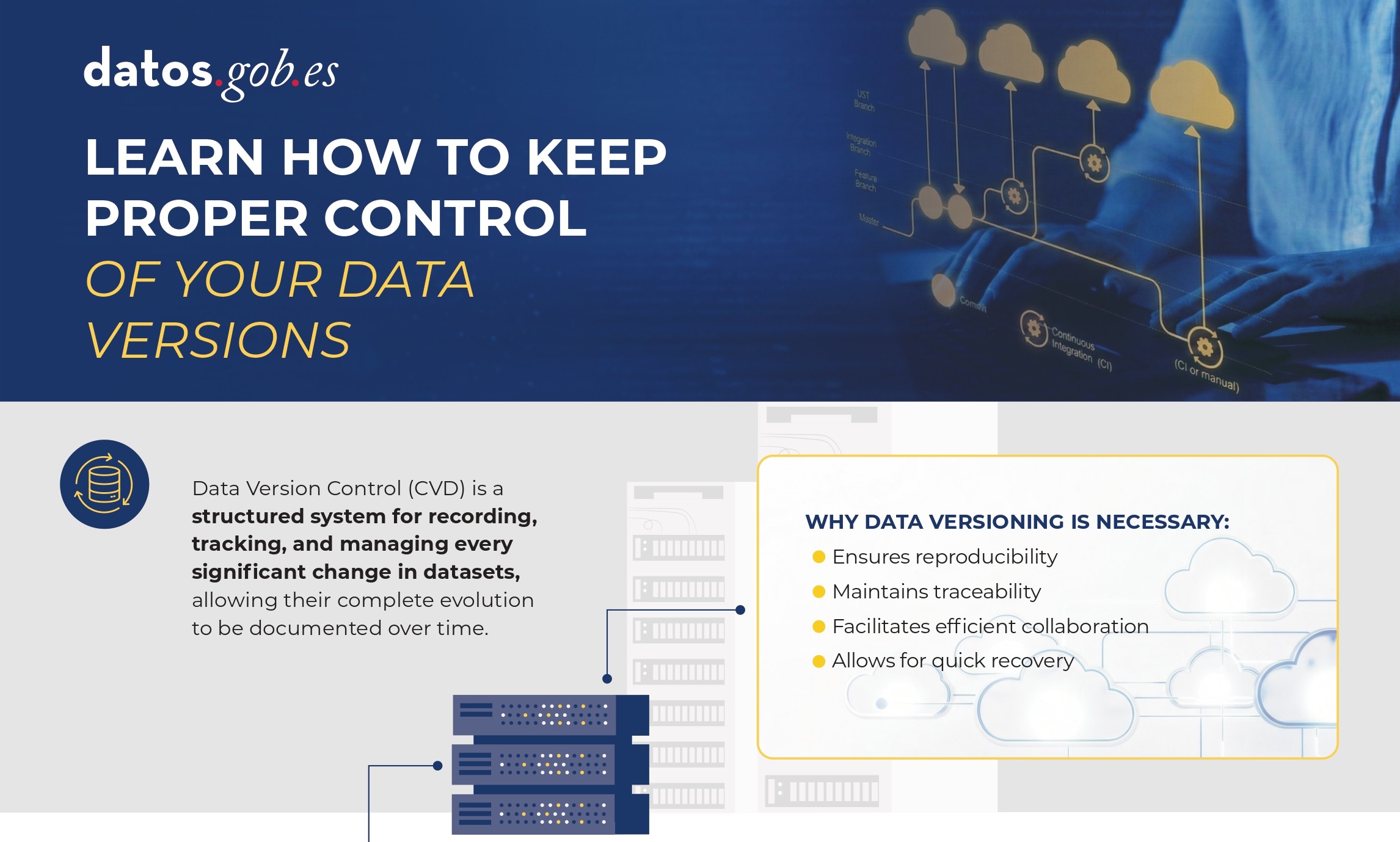 |
Published: January 2026 Data Version Control (DVC) allows you to record and document the complete evolution of a data set, facilitating collaboration, auditing, and recovery of previous versions. Without a clear system for managing these changes, it is easy to lose traceability. In this infographic, we explain how to implement DVC. |
DCAT-AP-ES: A step forward in open data interoperability
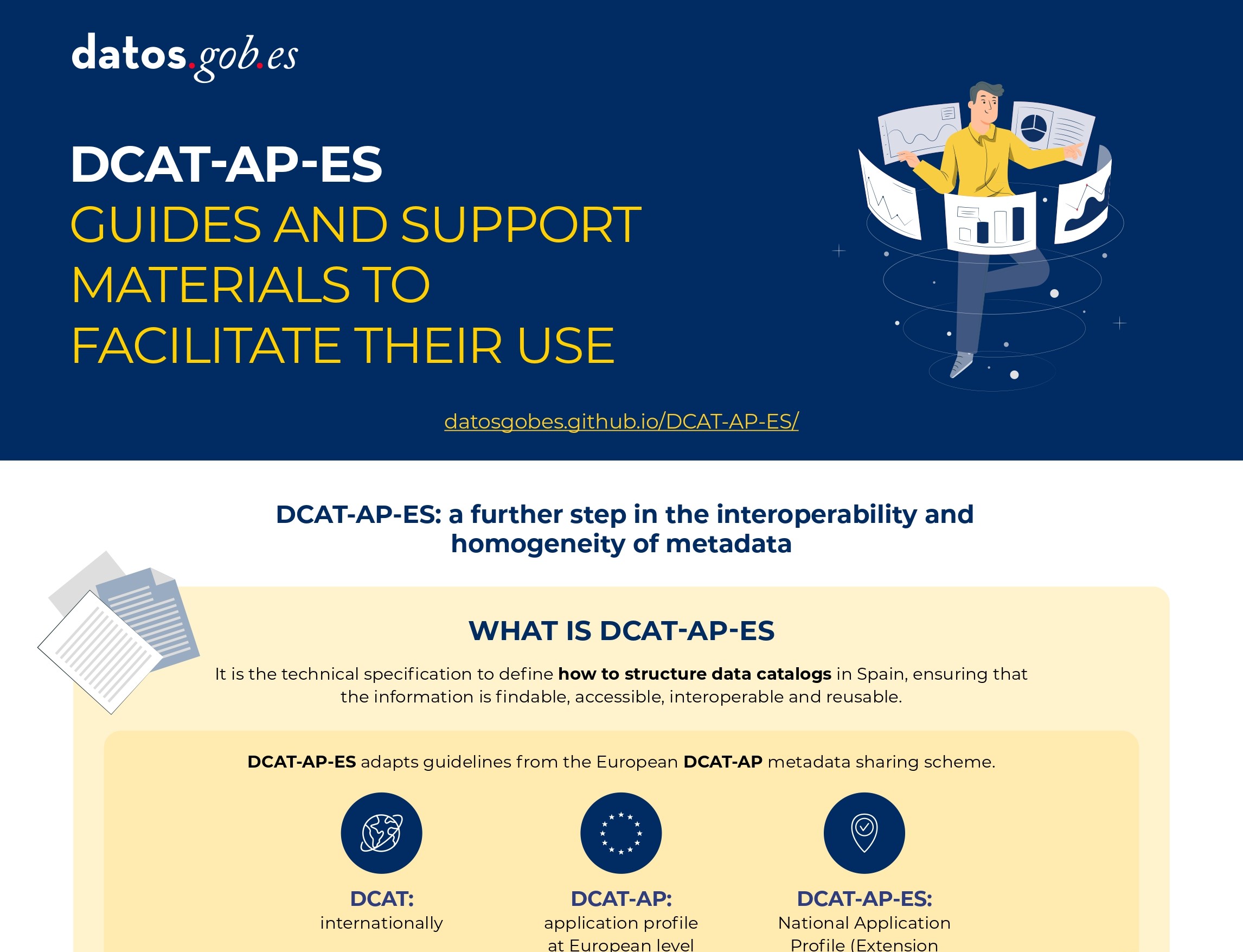 |
Published: august 2025 This new metadata model adopts the guidelines of the European metadata exchange schema DCAT-AP (Data Catalog Vocabulary-Application Profile) with some additional restrictions and adjustments.
|
Guide for the deployment of data portals. Good practices and recommendations
 |
Published: april 2025 This infographic summarizes best practices and recommendations for designing, developing and deploying open data portals at the municipal level. Specifically, it includes: strategic framework, general requirements and technical and functional guidelines. |
Data Act (DA)
 |
Published: February 2024 The Data Act is a European Union regulation to facilitate data accessibility in a horizontal way. In other words, it establishes principles and guidelines for all sectors, emphasizing fair access to data, user rights and the protection of personal data. Find out what its keys are in this infographic. A one-page version has also been created for easy printing: click here. |
Data Governance Act (DGA)
 |
Published: January 2024 The European Data Governance Act (DGA) is a horizontal instrument to regulate the reuse of data and promote its exchange under the principles and values of the European Union (EU). Find out what are its keys in this infographic. A one-page version has also been created to make printing easier: click here. |
The keys to the UNE data specifications
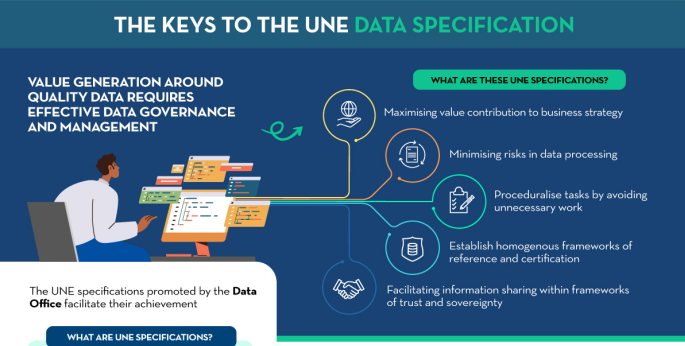 |
Published: September 2023 All types of institutions must have well-governed, managed data of adequate quality, requiring a common evaluation methodology. The following infographic summarizes the key aspects of the UNE Specifications on data and their main advantages. |
Main obligations of Law 37/2007
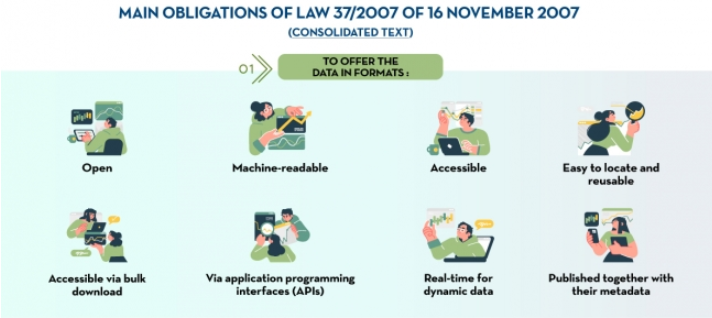 |
Published: March 2023 In accordance with the latest European Open Data Directive, Law 37/2007 has been amended to emphasize the concept of open data by design and by default. This infographic highlights the main changes in the legislation. |
How to create an action plan to drive openness and reuse of open data
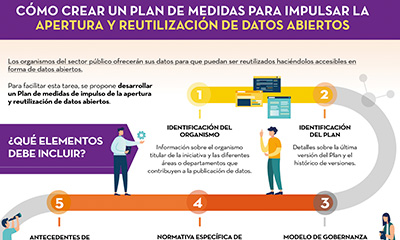 |
Published: November 2022 This infographic shows the different elements that should be included in a Plan of measures to promote openness and reuse of open data. The aim is that the units responsible for openness can draw up a feasible roadmap for open data, which also allows for its monitoring and evaluation. |
8 guides to improve data publication and processing
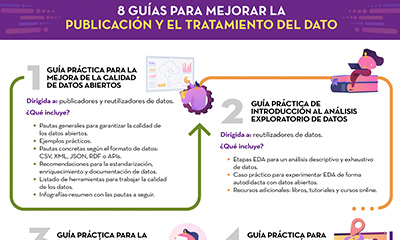 |
Published: October 2022 At datos.gob.es we have prepared different guides to help publishers and reusers when preparing data for publication and/or analysis. In this infographic we summarise the content of eight of them. |
General guidelines for quality assurance of open data
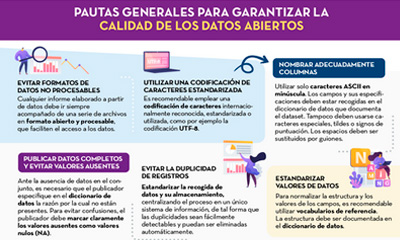 |
Published: September 2022 This infographic details general guidelines for ensuring the quality of open data, such as using standardised character encoding, avoiding duplicate records or incorporating variables with geographic information. |
Guidelines for quality assurance using specific data formats
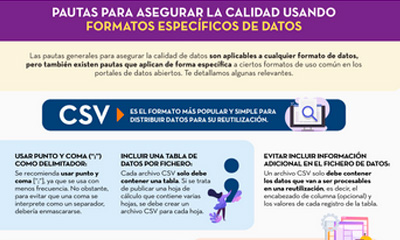 |
Published: September 2022 This infographic provides specific guidelines for ensuring the quality of open data according to the data format used. Specific guidelines have been included for CSV, XML, JSON, RDF and APIs. |
Technical standards for good data governance
 |
Published: May 2022 This infographic shows the standards to be taken into account for proper data governance, according to the Spanish Association for Standardisation (UNE). These standards are based on 4 principles: Governance, Management, Quality and Security and data privacy. |
APIs for open data access
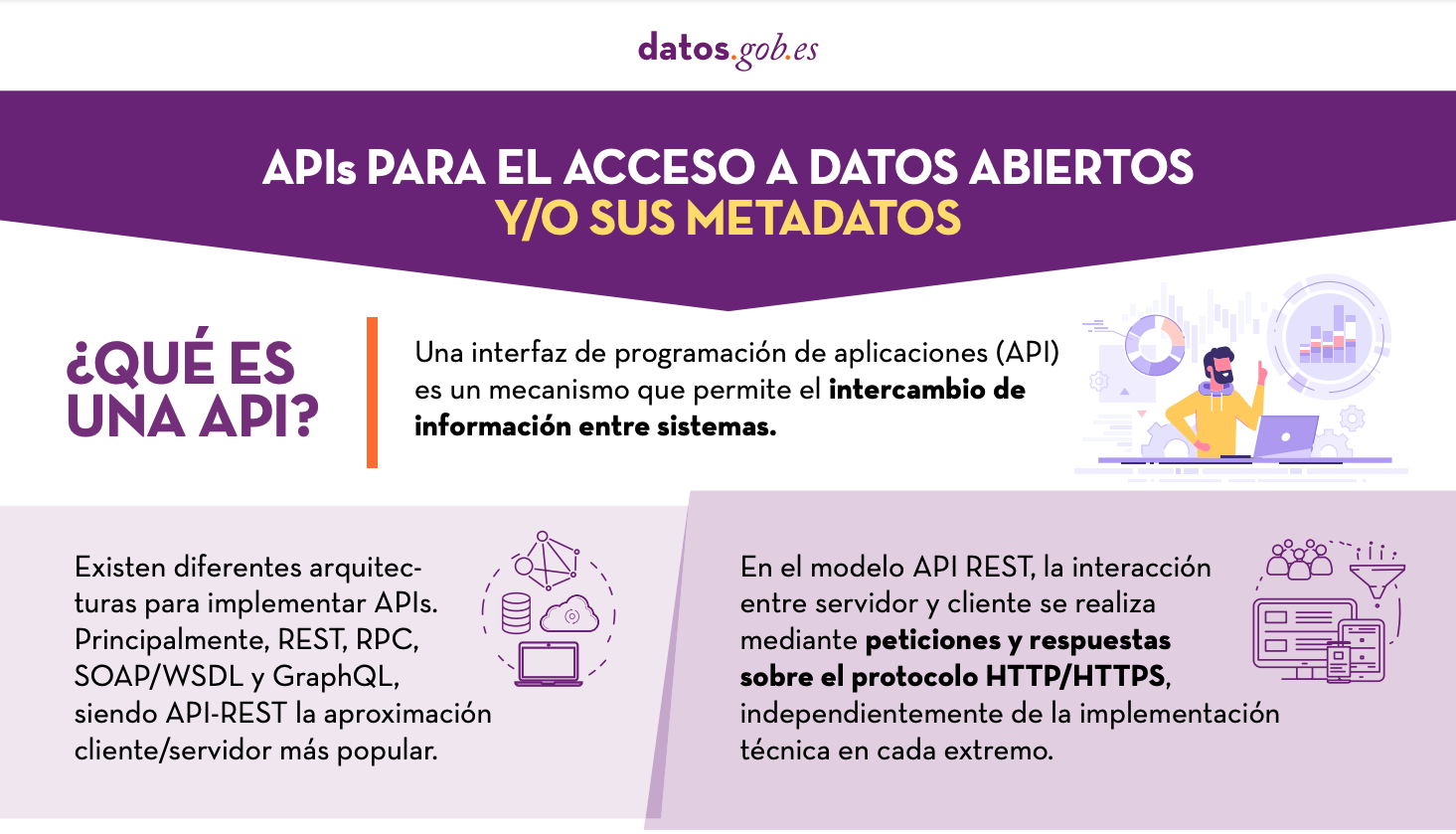 |
Published: January 2022 Many open data portals in Spain already have their own APIs to facilitate access to data and metadata. This infographic shows some examples at national, regional and local level, including information about the datos.gob.es API.. |
Blog
For a data space to function properly, it is necessary to have sufficient actors to cover a set of roles and a set of technological components. These elements enable a common governance framework to be established for secure data sharing, ensuring the sovereignty of the participants over their own data. This concept, data sovereignty, can be defined as the ability of the data owner to set the policies for the use and access of the data to be exchanged, and is the core element of a data space.
In this sense, the EU-funded report "Design Principles for Data Spaces" (April 2021) provides the fundamentals that data spaces should follow in order to act in accordance with EU values: decentralisation, openness, transparency, sovereignty and interoperability. The report was prepared by experts from 25 different companies, thus giving a consensus view with industry.
The following is a summary of some of the main contributions of the document, taking as a reference the article "Elements of a data space" published in the Boletic magazine of the Professional Association of Information Systems and Technologies. In this article, the elements of a data space are divided into two categories:
- Roles and domains
- Fundamental components
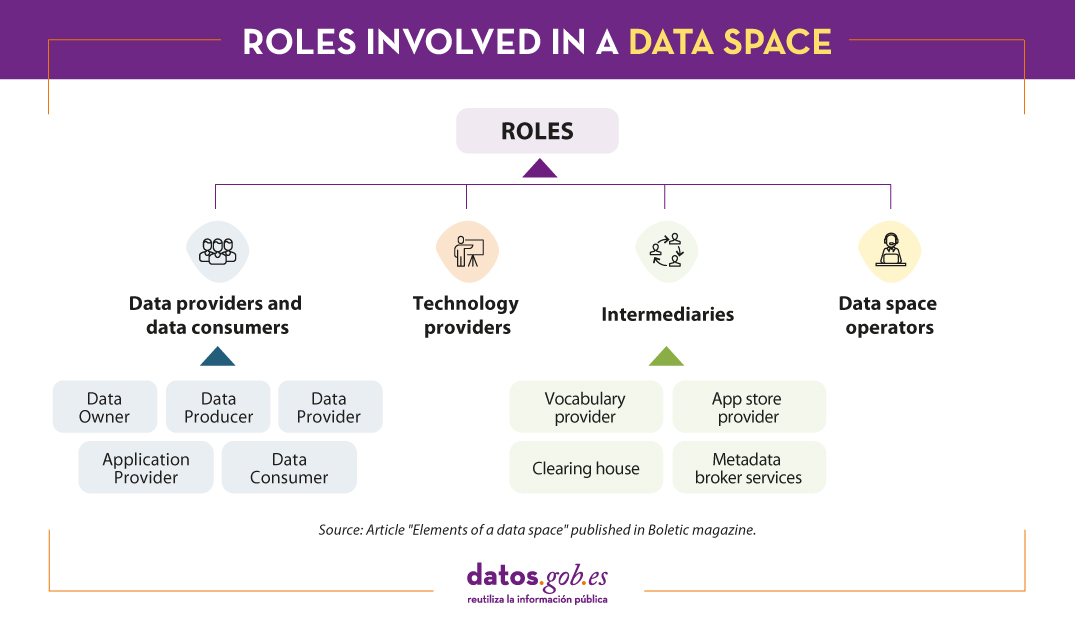
Roles
In a data space we can find different participants, each of them focused on a specific field of action. This is known as roles:
-
Data providers and data consumers
These are the participants who provide and interact with the data. Within this category there are several roles:
- Data Producer: Generates the data.
- Data Owner: The holder of the rights to access and use the data.
- Data Acquirer or Data Provider: Captures the data and offers it through the data space catalogue.
- Data Consumer: Accesses the data from the catalogue.
- Application Provider: Provides applications that allow working with the data offering added value (e.g. machine learning models, visualisations, cleansing processes, etc.).Intermediaries
-
Intermediaries
In this case we are talking about third parties that offer the services necessary for publishing, searching for resources and registering transactions. Some examples of services offered by intermediaries are:
- Vocabularies and ontologies, which allow information to be systematically organised, categorised or labelled, improving interoperability.
- Application stores, which list the tools offered by application providers, ensuring that they have passed a quality control process.
- Metadata broker services for the publication of a catalogue of resource offerings (data and applications) with as much information as possible.
- Orchestration services, allowing the automation of various activities.
- Clearing house, which allow to keep control of the operations carried out.
-
Technology providers
They provide components for the data space to operate correctly, making it a secure and trusted environment. Examples of these components are the connector - a fundamental element that we will see below -, user management systems or monitoring systems.
Brokerage services and applications do not fall into this category.
-
Data space operators
Focused on the management of the space, they carry out tasks such as the processing of requests or incidents, change control, software maintenance, etc. Among other things, they certify participants, exercise the governance of the data space and define the roadmap of functionalities.
All these roles are not exclusive, and the same user can adopt several roles.
Components of a data space
There are different approaches to the components that a data space should have. One can refer to Gaia-X and/or take as a reference the IDS-RAM architecture model (Reference Architecture model), characterised by an open, reliable and federated architecture for cross-sector data exchange.
In any case, at least the following blocks are necessary for carrying out the activity in a secure and controlled manner:
-
Components for accessing the data space: Connector
One of the main elements of data spaces is the connector, through which participants access the data space and the data. It is responsible for handling the data according to the usage policies defined by the owner of the access and usage rights, guaranteeing its sovereignty. To prevent malicious manipulation, connectors can be signed by a certificate provided by the data space governance, so as to guarantee their integrity and compliance with the usage rights established by the data owner.
-
Components for intermediation
They allow for the intermediation services mentioned above, the metadata broker, the app store, etc. Of all of them, the most fundamental is the resource catalogue. In addition to a list of the available offer, it is also the tool that allows the resource provider, its characteristics and conditions of use to be located.
-
Components for identity management and secure data exchange
These components ensure the identity of participants and the security of transactions. For this reason, participants are often required to present credentials (e.g. via X.509 certificates).
-
Data space management components
These are tools that allow the data space to operate normally, facilitating daily operations, management of participants (registration, deregistration, revocation, suspension), monitoring of the activity, etc.
How do all these elements interact?
All these roles and components interact with each other. First, the data provider registers its data offering in the catalogue, including relevant metadata such as usage policies. The data consumer searches the catalogue for datasets and applications of interest. Once located, he/she contacts the provider, communicating which resources he wants to acquire. In this process, further negotiation of terms and conditions may take place. Once an agreement is reached, the consumer can download the data.
The transaction must be registered by both the supplier and the consumer.
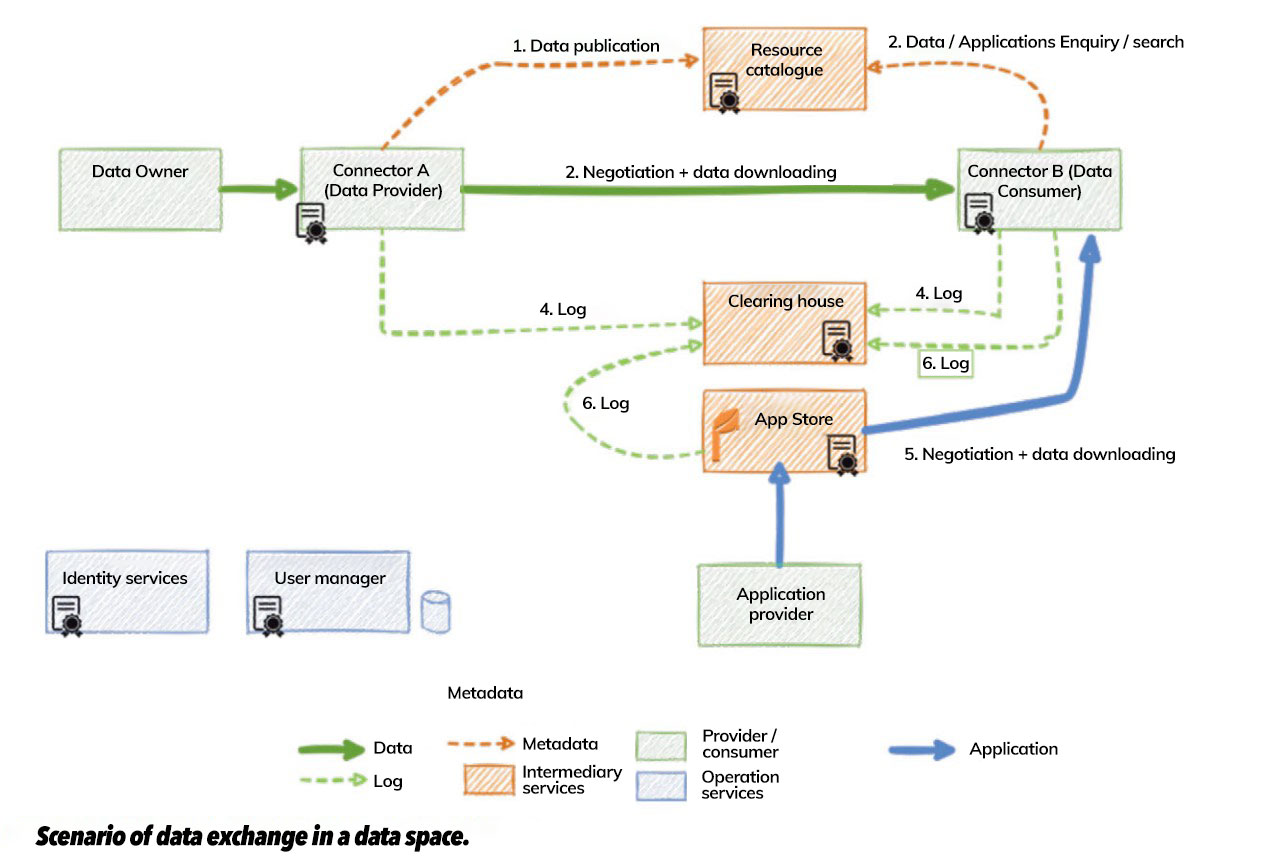
All these elements (roles, components and processes) allow data sharing in a secure and controlled manner, in a managed environment of trust. The aim is to enable European companies and organisations to exchange information, generating a European data market that will give rise to new products and services of value, boosting the European economy.
Content prepared by the datos.gob.es team.