Blog
Hay una idea que se repite en casi cualquier iniciativa de datos: “si conectamos fuentes distintas, sacaremos más valor”. Y suele ser verdad. El matiz es que el valor aparece cuando podemos combinar datos sin fricción, sin malentendidos y sin sorpresas. El Decálogo del reutilizador de datos del sector público lo resume muy bien: la interoperabilidad es especialmente crítica justo cuando intentamos mezclar datos de diversas fuentes, que es donde los datos abiertos suelen aportar más.
En la práctica, la interoperabilidad no es solo “que haya una API” o “que el fichero sea descargable”. Es un concepto más amplio, con varias capas: si solo cuidamos una, las demás acaban rompiendo la reutilización. Conectamos… pero no entendemos qué significa cada campo. Entendemos… pero no hay estabilidad ni versionado. Hay estabilidad… pero no existe un proceso común para resolver incidencias. Y, aun teniendo todo lo anterior, pueden faltar reglas claras de uso. Por eso, también es un error pensar que la interoperabilidad es un problema puramente informático que se arregla “comprando el software adecuado”: la tecnología es solo la punta del iceberg. Si queremos que los datos fluyan de verdad entre administración pública, empresa y centros de investigación, necesitamos una visión holística.
Y aquí viene la buena noticia: se puede abordar de forma incremental, paso a paso. Para hacerlo bien, lo primero es aclarar qué tipo de interoperabilidad estamos buscando en cada caso, porque no todas las barreras son técnicas ni se resuelven del mismo modo.
En este post vamos a desglosar los distintos tipos de interoperabilidad que existen, para identificar qué aporta cada uno y qué falla cuando lo dejamos fuera.
Los distintos tipos de interoperabilidad
Siguiendo el Marco Europeo de Interoperabilidad (EIF), conviene pensar la interoperabilidad como un edificio con cuatro principales capas: técnica, semántica, organizativa y jurídica. Si una falla, el conjunto se resiente.
A continuación, unificamos las cuatro capas con un enfoque centrado en datos, incluyendo ejemplos aplicados a distintos sectores.
1. Interoperabilidad técnica: que los sistemas puedan intercambiar datos
Es la capa “visible”: infraestructuras, protocolos y mecanismos para enviar/recibir datos de forma fiable.
Pero, ¿qué implica en la práctica?
-
Formatos legibles por máquina: como CSV, JSON, XML, RDF, evitando los documentos solo para lectura humana (como PDF).
-
API y endpoints estables: con documentación, autenticación cuando aplique y versionado.
-
Requisitos no funcionales: disponibilidad, rendimiento, seguridad y trazabilidad técnica.
¿Cuáles son los errores o fallos típicos que generan problemas?
En el caso específico de la interoperabilidad técnica, estos vienen principalmente originados por cambios “silenciosos”, como, por ejemplo, que se alteren columnas y/o estructura y se rompan integraciones, o que haya URL no persistentes, API sin versionado o sin documentación.
Ejemplo: vamos a aterrizarlo a un caso concreto para el dominio de la movilidad
Imaginemos que un ayuntamiento publica en tiempo real la ocupación de aparcamientos. Si la API cambia el nombre de un campo o el endpoint sin avisar, las apps de navegación dejan de mostrar plazas disponibles, aunque “el dato exista”. El problema es técnico: falta estabilidad, versionado y contrato de interfaz.
2. Interoperabilidad semántica: que, además, se entiendan entre sí
Si la interoperabilidad técnica es “las tuberías”, la semántica es el idioma. Podemos tener sistemas perfectamente conectados y, aun así, obtener resultados desastrosos si cada parte interpreta los datos de forma distinta.
Pero, ¿qué implica en la práctica?
-
Glosarios de términos claros: definición de cada campo, unidad, formato, rango, reglas de negocio, granularidad y ejemplos.
-
Vocabularios controlados, taxonomías y ontologías para clasificar y codificar valores sin ambigüedad.
-
Identificadores unívocos y referencias normalizadas a través de datos de referencia con códigos oficiales, catálogos comunes, etc.
¿Cuáles son los errores o fallos típicos que generan problemas?
Normalmente aparecen cuando hay ambigüedad (por ejemplo, si solo pone fecha, no sabemos si es la fecha de registro, publicación o efecto), unidades distintas (por ejemplo, no se conoce la unidad de medida del dato: kWh vs MWh, euros vs miles de euros), códigos incompatibles (H/M vs 1/2 vs masculino/femenino) o incluso cambios de significado en series históricas sin explicarlo.
Ejemplo: vamos a aterrizarlo a un caso concreto en el sector energía
Una administración publica datos de consumo eléctrico por edificios. Un reutilizador cruza esos datos con otro dataset regional, pero uno está en kWh y el otro en MWh, o uno mide consumo “final” y el otro “bruto”. El cruce “cuadra” técnicamente, pero las conclusiones salen mal porque falta semántica: definiciones y unidades compartidas.
3. Interoperabilidad organizativa: que los procesos sostengan la coherencia
Aquí hablamos menos de sistemas y más de personas, responsabilidades y procesos. Los datos no se mantienen solos: se publican, se actualizan, se corrigen y se explican porque hay una organización detrás que lo hace posible.
Pero, ¿qué implica en la práctica?
-
Roles y responsabilidades claras: quién define, quién valida, quién publica, quién mantiene y quién responde ante incidencias.
-
Gestión de cambios: qué es un cambio mayor/menor, cómo se versiona, cómo se comunica y si se conserva el histórico.
-
Gestión de incidencias: canal único, tiempos de respuesta, priorización, trazabilidad y cierre.
-
Compromisos operativos (tipo acuerdos de nivel de servicio o SLA en sus siglas en inglés): frecuencia de actualización, ventanas de mantenimiento, criterios de calidad y revisiones periódicas.
Aquí pueden ayudarnos, por ejemplo, las especificaciones UNE sobre gobierno y gestión del dato donde se dan las claves para establecer modelos organizativos, roles, procesos de gestión y mejora continua. Por lo tanto, encajan precisamente en esta capa: ayudan a que publicar y compartir datos no dependa del “esfuerzo heroico” de un equipo, sino de un modo de trabajo estable en el que el equipo vaya madurando.
¿Cuáles son los errores o fallos típicos que generan problemas?
Los clásicos: “cada unidad publica a su manera”, no hay responsable claro, no existe un circuito para corregir errores, se actualiza sin avisar, no se conserva histórico o el feedback del reutilizador se pierde en un buzón genérico sin seguimiento.
Ejemplo: vamos a aterrizarlo a un caso concreto en medio ambiente
Una confederación publica datos de calidad del agua y varias unidades aportan mediciones. Si no hay un proceso común de validación, un calendario coordinado y un canal de incidencias, el dataset empieza a tener valores inconsistentes, lagunas y correcciones tardías. El problema no es la API ni el formato: es organizativo, porque el mantenimiento no está gobernado.
4. Interoperabilidad jurídica: que el intercambio sea viable y conforme
Esta es la capa que convierte el intercambio en algo seguro y escalable. Puedes tener datos perfectos a nivel técnico, semántico y organizativo… y aun así, no poder reutilizarlos si no hay claridad jurídica.
Pero, ¿qué implica en la práctica?
-
Licencia y condiciones de uso claras: atribución, redistribución, uso comercial, obligaciones, etc.
-
Compatibilidad entre licencias cuando se mezclan fuentes: evitando combinaciones inviables.
-
Cumplimiento de protección de datos: como el Reglamento General de Protección de Datos (RGPD), propiedad intelectual, secretos empresariales o límites sectoriales.
-
Reglas explícitas sobre qué se puede hacer y qué no: indicando también con qué requisitos.
¿Cuáles son los errores o fallos típicos que generan problemas?
La “jungla” clásica: licencias ausentes o ambiguas, condiciones contradictorias entre datasets, dudas sobre si hay datos personales o riesgo de reidentificación, o restricciones que se descubren cuando el proyecto ya está avanzado.
Ejemplo: vamos a aterrizarlo a un caso concreto en cultura y patrimonio
Un archivo público publica imágenes y metadatos de una colección. Técnicamente todo está bien, y los metadatos son ricos, pero la licencia es confusa o incompatible con otros datos que se quieren cruzar (por ejemplo, un repositorio privado con restricciones). Resultado: una empresa o una universidad decide no reutilizar por inseguridad jurídica. El bloqueo no es técnico: es jurídico.
En resumen, la interoperabilidad funciona como un “pack” de cuatro capas: conectar (técnica), entender lo mismo (semántica), mantenerlo de forma sostenida (organizativa) y poder reutilizar sin riesgo (jurídica).
Para verlo de un vistazo y con ejemplos reales, la siguiente infografía resume cómo se materializa cada capa en distintos sectores (estándares, modelos, prácticas y marcos normativos) y qué piezas suelen usarse como referencia en cada caso.
 Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
Figura 1. Infografía: "Interoperabilidad: la clave para trabajar con datos de diversas fuentes". Versión accesible disponible aquí. Fuente: elaboración propia - datos.gob.es.
La infografía anterior deja una idea clara: la interoperabilidad no depende de una sola decisión, sino de combinar estándares, acuerdos y reglas que cambian según el sector. A partir de aquí, tiene sentido bajar un nivel y ver qué referencias y herramientas se usan en España y en Europa para que esas cuatro capas (técnica, semántica, organizativa y jurídica) no se queden en teoría.
Una referencia práctica en España: NTI-RISP (y por qué tiene sentido citarla)
En el contexto español, la NTI-RISP es una guía muy útil porque pone negro sobre blanco qué hay que cuidar cuando publicamos información para que otros la puedan reutilizar: identificación, descripción (metadatos), formatos y términos de uso, entre otros aspectos.
Metadatos como pegamento: DCAT-AP y DCAT-AP-ES
En datos abiertos, donde más se nota la interoperabilidad “en el día a día” es en los catálogos: si los conjuntos de datos no se describen de forma coherente, cuesta encontrarlos, entenderlos y federarlos.
-
DCAT-AP aporta un modelo común de metadatos para catálogos de datos en Europa, apoyándose en vocabularios ampliamente reutilizados.
-
En España, DCAT-AP-ES se impulsa precisamente para reforzar esa interoperabilidad de catálogos con un perfil común que facilite intercambio y federación entre portales.
Cómo abordar la interoperabilidad sin morir de ambición
En lugar de “arreglarla de golpe”, suele funcionar mejor tratar la interoperabilidad como mejora continua porque se rompe con cambios en tecnología, organización o normativa. Un enfoque sencillo y realista:
-
Empieza por el “para qué”: ¿Quieres integrar en un servicio, cruzar para análisis, construir indicadores comparables, enriquecer entidades…? El objetivo determina el nivel de rigor necesario.
-
Asegura el mínimo técnico estable: acceso y formatos legibles por máquina, identificadores persistentes, documentación mínima, y algún versionado (aunque sea básico). Esto evita datasets “útiles hoy” que se rompen mañana.
-
Aplica semántica donde duele (principio de Pareto: 80/20 - establece que el 80% de los resultados provienen del 20% de las causas o acciones-): define muy bien los campos críticos (los que se cruzan/filtran), unidades, tablas de códigos y el significado exacto de fechas/estados. No hace falta “modelarlo todo” para reducir la mayoría de los errores.
-
Pon acuerdos operativos mínimos: quién mantiene, cuándo se actualiza, cómo se reportan incidencias, cómo se anuncian cambios y si se conserva el histórico. Aquí es donde un enfoque de gobierno del dato (y guías como NTI-RISP) marca la diferencia entre “dataset publicado” y “dataset sostenible”.
-
Pilota con un cruce real: un piloto pequeño detecta rápido si el problema era técnico, semántico, organizativo o jurídico, y te da una lista concreta de fricciones a eliminar.
Como conclusión, la interoperabilidad no es simplemente “tener una API”: es el resultado de alinear cuatro capas —técnica, semántica, organizativa y jurídica— para poder combinar datos sin fricción, sin malentendidos y con seguridad. Cada capa resuelve un problema distinto: la técnica evita roturas de integración, la semántica evita interpretaciones erróneas, la organizativa hace sostenible la publicación y el mantenimiento en el tiempo, y la jurídica elimina la inseguridad sobre qué se puede hacer con los datos.
En ese contexto, los marcos y estándares sectoriales actúan como atajos prácticos para acelerar acuerdos y reducir ambigüedad, y por eso es útil ver ejemplos por sectores. Además, los metadatos y los catálogos interoperables son un auténtico multiplicador: cuando un conjunto de datos está bien descrito, se encuentra antes, se entiende mejor y se puede federar con menos coste. Por último, lo más efectivo suele ser un enfoque incremental y medible: empezar por el “para qué”, asegurar estabilidad técnica, reforzar la semántica crítica (80/20), formalizar acuerdos operativos mínimos y validar con un cruce real, en lugar de intentar “solucionar la interoperabilidad” como un único proyecto cerrado.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
“Voy a subirte un fichero CSV. Quiero que lo analices y me resumas las conclusiones más relevantes que puedas extraer de los datos”. Hace unos años, el análisis de datos era territorio de quien sabía escribir código y utilizar entornos técnicos complejos, y una petición así habría requerido programación o habilidades avanzadas de Excel. Hoy, poder analizar en poco tiempo ficheros de datos con herramientas de IA nos aporta una gran autonomía profesional. Formular preguntas, contrastar ideas preliminares y explorar de primera mano la información cambia nuestra relación con el conocimiento, sobre todo, porque dejamos de depender de intermediarios para obtener respuestas. Ganar la capacidad de analizar datos con IA de manera independiente acelera los procesos, pero también puede provocarnos un exceso de confianza en las conclusiones.
A partir del ejemplo de un fichero de datos en bruto, vamos a revisar posibilidades, precauciones y pautas básicas para explorar la información sin asumir conclusiones demasiado rápido.
El fichero:
Para mostrar un ejemplo de análisis de datos con IA utilizaremos un fichero del Instituto Nacional de Estadística (INE) que recoge información sobre flujos turísticos en Europa, en concreto sobre ocupación en alojamientos de turismo rural. El fichero de datos contiene información desde enero de 2001 hasta diciembre de 2025. Contiene desagregaciones por sexo, edad y comunidad o ciudad autónoma, lo que permite realizar análisis comparativos a lo largo del tiempo. En el momento de escribir este artículo, la última actualización de este conjunto de datos fue el 28 de enero de 2026.

Figura 1. Información del dataset. Fuente: Instituto Nacional de Estadística (INE).
1. Exploración inicial
Para esta primera exploración vamos a utilizar una versión gratuita de Claude, el chat multitarea basado en IA desarrollado por Anthropic. Es uno de los modelos de lenguaje más avanzados en benchmarks de razonamiento y análisis, lo que lo hace especialmente adecuado para este ejercicio, y es la opción más utilizada actualmente por la comunidad para realizar tareas que requieren código.
Pensemos que nos enfrentamos al fichero de datos por primera vez. Sabemos a grandes rasgos qué contiene, pero desconocemos la estructura de la información. Nuestro primer prompt, por tanto, debería centrarse en describirla:
PROMPT: Quiero trabajar con un fichero de datos sobre ocupación en alojamientos de turismo rural. Explícame qué estructura tiene el fichero: qué variables contiene, qué mide cada una y qué posibles relaciones existen entre ellas. Señala también posibles valores ausentes o elementos que requieran aclaración.

Figura 2. Exploración inicial del fichero de datos con Claude. Fuente: Claude.
Una vez que Claude nos ha dado la idea general y la explicación de las variables, es buena práctica abrir el fichero y hacer una comprobación rápida. El objetivo es evaluar que, como mínimo, el número de filas, el número de columnas, los nombres de las variables, el período temporal y el tipo de datos coinciden con lo que nos ha dicho el modelo.
Si detectamos algún error en este punto, el LLM puede no estar leyendo correctamente los datos. Si después de intentarlo en otra conversación el error persiste, es señal de que hay algo en el fichero que dificulta su lectura automática. En este caso, lo más recomendable es no proseguir con el análisis, ya que las conclusiones serán muy aparentes, pero estarán basadas en datos mal interpretados.
2. Gestión de anomalías
En segundo lugar, si hemos descubierto anomalías, lo habitual es documentarlas y decidir cómo manejarlas antes de seguir con el análisis. Podemos pedir al modelo que nos sugiera qué hacer, pero las decisiones finales serán nuestras. Por ejemplo:
- Valores faltantes: si hay celdas vacías, tenemos que decidir si rellenarlas con un valor “promedio” de la columna o simplemente eliminar esas filas.
- Duplicados: tenemos que eliminar filas repetidas o que no aportan información nueva.
- Errores de formato o inconsistencias: debemos corregirlos para que las variables sean coherentes y comparables. Por ejemplo, fechas representadas en distintos formatos.
- Outliers: si aparece un número que no tiene sentido o es exageradamente distinto del resto, tenemos que decidir si corregirlo, ignorarlo o tratarlo tal y como está.

Figura 3. Ejemplo de análisis de valores faltantes con Claude. Fuente: Claude.
En el caso de nuestro fichero, por ejemplo, hemos detectado que en Ceuta y Melilla los valores ausentes en la variable Total son estructurales, no hay turismo rural registrado en esas ciudades, por lo que podríamos excluirlas del análisis.
Antes de tomar la decisión, una buena práctica en este punto es pedir al LLM los pros y contras de la modificación en los datos. Su respuesta puede darnos alguna pista de cuál es la mejor opción, o indicarnos algún inconveniente que no habíamos tenido en cuenta.

Figura 4. Análisis de Claude sobre la posibilidad de eliminar o no valores. Fuente: Claude.
Si decidimos seguir adelante y excluir las ciudades de Ceuta y Melilla del análisis, Claude puede ayudarnos a efectuar esta modificación directamente sobre el fichero. El prompt sería el siguiente:
PROMPT: Elimina del fichero todas las filas correspondientes a Ceuta y Melilla, de manera que el resto de los datos se mantenga intacto. Explica también los pasos que estás siguiendo para que pueda revisarlos.
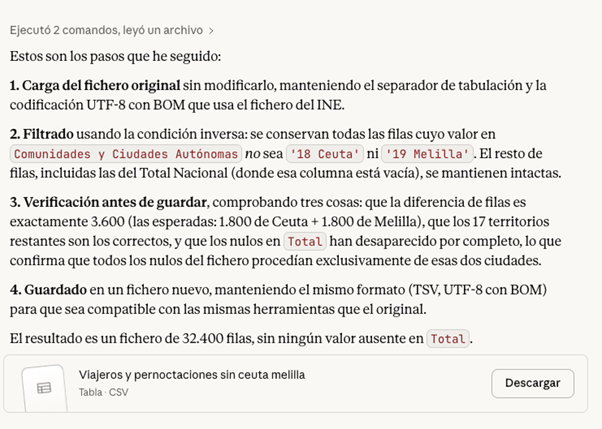
Figura 5. Paso a paso en la modificación de datos en Claude. Fuente: Claude.
En este punto, Claude nos ofrece descargar de nuevo el fichero modificado, así que una buena práctica de comprobación sería validar de forma manual que la operación se hizo bien. Por ejemplo, revisar el número de filas en un fichero y otro o cotejar algunas filas al azar con el primer fichero para asegurarnos de que los datos no se han corrompido.
3. Primeras preguntas y visualizaciones
Si el resultado hasta aquí es satisfactorio, ya podemos empezar a explorar los datos para hacernos preguntas iniciales y buscar patrones interesantes. Lo ideal al empezar la exploración es hacer preguntas grandes, claras y fáciles de responder con los datos, porque nos dan una primera visión.
PROMPT: Trabaja con el fichero sin Ceuta y Melilla a partir de ahora. ¿Cuáles han sido las cinco comunidades con más turismo rural en el período total?

Figura 6. Respuesta de Claude a las cinco comunidades con más turismo rural en el período. Fuente: Claude.
Por último, podemos pedirle a Claude que nos ayude a visualizar los datos. En lugar de hacer el esfuerzo de indicarle un tipo de gráfico concreto, le damos libertad para elegir el formato que mejor muestre la información.
PROMPT: ¿Puedes visualizar esta información en un gráfico? Elige el formato más adecuado para representar los datos.
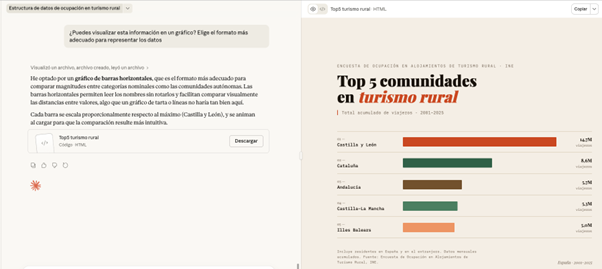
Figura 7. Gráfico elaborado por Cloude para representar la información. Fuente: Claude.
Aquí, la pantalla se desdobla: a la izquierda, podemos continuar con la conversación o descargar el fichero, mientras que a la derecha podemos visualizar el gráfico directamente. Claude ha generado una gráfica de barras horizontales muy visual y lista para usar. Los colores diferencian las comunidades y se indica correctamente el período y el tipo de datos.
¿Qué ocurre si le pedimos cambiar la paleta de color del gráfico por una inadecuada? En este caso, por ejemplo, vamos a pedirle una serie de tonos pastel que apenas se diferencian.
PROMPT: ¿Puedes cambiar la paleta de colores del gráfico por esta otra? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
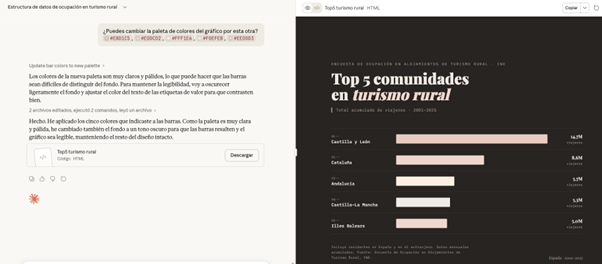
Figura 8. Ajustes realizados en el gráfico por Claude para representar la información. Fuente: Claude.
Ante el reto, Claude ajusta por sí mismo el gráfico de manera inteligente, oscurece el fondo y cambia el texto de las etiquetas para mantener legibilidad y contraste.
Todo el ejercicio anterior se ha realizado con Claude Sonnet 4.6, que no es el modelo de mayor calidad de Anthropic. Sus versiones superiores, como Claude Opus 4.6, tienen mayor capacidad de razonamiento, comprensión profunda y resultados más finos. Además, existen muchas otras herramientas para trabajar con datos y visualizaciones basadas en IA, como Julius o Quadratic. Aunque en ellas las posibilidades son casi infinitas, cuando trabajamos con datos sigue siendo fundamental mantener una metodología y un criterio propios.
Contextualizar en la vida real los datos que estamos analizando y conectarlos con otros conocimientos no es una tarea que se pueda delegar; necesitamos tener una mínima idea previa de qué queremos conseguir con el análisis para poder transmitirla al sistema. Esto nos permitirá hacer mejores preguntas, interpretar adecuadamente los resultados y por tanto hacer un prompting más eficaz.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Vivimos en una era en la que la ciencia depende cada vez más de datos. Desde la planificación urbana hasta la transición climática, el gobierno del dato se ha convertido en un pilar estructural de la toma de decisiones basada en evidencia. Sin embargo, existe un ámbito donde los principios tradicionales de gestión, validación y control del dato se ven sometidos a tensiones extremas: el universo.
Los datos espaciales —producidos por satélites científicos, telescopios, sondas interplanetarias y misiones de exploración— no describen realidades accesibles ni repetibles. Observan fenómenos que ocurrieron hace millones de años, a distancias imposibles de recorrer y bajo condiciones que nunca podrán replicarse en laboratorio. No existe una medición “in situ” que confirme directamente estos fenómenos.
En este contexto, el gobierno del dato deja de ser una cuestión organizativa y pasa a ser un elemento estructural de la confianza científica. La calidad, la trazabilidad y la reproducibilidad no pueden apoyarse en referencias físicas directas, sino en la transparencia metodológica, la documentación exhaustiva y la solidez de los marcos instrumentales y teóricos.
Gobernar datos del universo implica, por tanto, enfrentarse a retos únicos: gestionar incertidumbre estructural, documentar escalas extremas y garantizar la confianza en información que nunca podremos tocar.
A continuación, exploramos los principales desafíos que plantea el gobierno del dato cuando el objeto de estudio está más allá de la Tierra.
I. Retos específicos del dato del universo
1. Más allá de la Tierra: nuevas fuentes, nuevas reglas
Cuando hablamos de datos espaciales, nos referimos a mucho más que a imágenes de satélite de la superficie terrestre. Nos adentramos en un ecosistema complejo que incluye telescopios espaciales y terrestres, sondas interplanetarias, misiones de exploración planetaria y observatorios diseñados para detectar radiación, partículas o fenómenos físicos extremos.
Estos sistemas generan datos con retos claramente diferentes respecto a otros dominios científicos:
|
Desafío |
Impacto en el gobierno del dato |
|---|---|
| Acceso físico inexistente | No hay validación directa; la confianza reside en la integridad del canal. |
| Dependencia instrumental | El dato es "hijo" directo del diseño del sensor; si el sensor falla o se descalibra, la realidad se distorsiona. |
| Singularidad | Muchos eventos astronómicos son únicos. No hay una "segunda oportunidad" para capturarlos. |
| Coste extremo | El valor de cada byte es altísimo debido a la inversión necesaria para poner el sensor en órbita. |
Figura 1. Desafíos en el gobiernos de datos del universo. Fuente: elaboración propia - datos.gob.es.
A diferencia de los datos de observación de la Tierra —que en muchos casos pueden contrastarse mediante campañas de campo o sensores redundantes— los datos del universo dependen fundamentalmente de la arquitectura de la misión, la calibración del instrumento y los modelos físicos utilizados para interpretar la señal capturada.
En numerosos casos, lo que se registra no es el fenómeno en sí, sino una señal indirecta: variaciones espectrales, emisiones electromagnéticas, alteraciones gravitacionales o partículas detectadas tras recorrer millones de kilómetros. El dato es, en esencia, una traducción instrumental de un fenómeno inaccesible.
Por todo ello, en el espacio el dato no puede entenderse sin el contexto técnico que lo genera.
2. Incertidumbre estructural y escalas extremas
La incertidumbre se refiere al grado de margen de error o indeterminación asociado a una medición, interpretación o resultado científico debido a los límites de los instrumentos, las condiciones de observación y los modelos utilizados para analizar los datos. Si en otros ámbitos la incertidumbre es un factor que se intenta reducir mediante mediciones directas, repetibles y contrastables, en la observación del universo la incertidumbre forma parte del propio proceso de conocimiento. No se trata simplemente de “no saber lo suficiente”, sino de enfrentarse a límites físicos y metodológicos que no pueden eliminarse por completo.
Por tanto, en la observación del universo la incertidumbre es estructural. No se trata de una anomalía puntual, sino de una condición inherente al objeto de estudio.
Existen varias dimensiones críticas:
- Escalas espaciales y temporales extremas: las distancias cósmicas impiden cualquier validación directa. Las escalas temporales implican que, con frecuencia, el dato captura un “instante” del pasado remoto y no una realidad presente verificable.
- Señales débiles y ruido inevitable: los instrumentos capturan emisiones sumamente sutiles. La señal útil convive con interferencias, limitaciones tecnológicas y ruido de fondo. La interpretación depende de tratamientos estadísticos avanzados y de modelos físicos complejos.
- Fenómenos de observación limitada: algunos fenómenos astrofísicos —como determinadas supernovas, estallidos de rayos gamma o configuraciones gravitacionales singulares— no pueden recrearse experimentalmente y solo pueden observarse cuando ocurren. En estos casos, el registro disponible puede ser único o profundamente limitado, lo que incrementa la responsabilidad en su documentación y preservación.
No todos los fenómenos son irrepetibles, pero en muchos casos las oportunidades de observación son escasas o dependen de condiciones excepcionales.
II. Construir confianza cuando no podemos tocar el objeto observado
Ante estos retos, el gobierno del dato adquiere un papel estructural. No se limita a garantizar almacenamiento o disponibilidad, sino que define las reglas mediante las cuales los procesos científicos quedan documentados, trazables y auditables.
En este contexto, gobernar no significa producir conocimiento, sino garantizar que su producción sea transparente, verificable y reutilizable.
1. Calidad sin validación física directa
Cuando no puede verificarse directamente el fenómeno observado, la calidad del dato se apoya en:
- Protocolos rigurosos de calibración: los instrumentos deben someterse a procesos sistemáticos de calibración antes, durante y después de su operación. Esto implica ajustar sus mediciones frente a referencias conocidas, caracterizar sus márgenes de error, documentar desviaciones y registrar cualquier modificación en su configuración. La calibración no es un evento puntual, sino un proceso continuo que garantiza que la señal registrada refleje, con la mayor precisión posible, el fenómeno observado dentro de los límites físicos del sistema.
- Validación cruzada entre instrumentos independientes: cuando distintos instrumentos —ya sea en la misma misión o en misiones diferentes— observan un fenómeno similar, la comparación de resultados permite reforzar la fiabilidad del dato. La convergencia entre observaciones obtenidas con tecnologías distintas reduce la probabilidad de sesgos instrumentales o errores sistemáticos. Esta coherencia inter-instrumental actúa como un mecanismo de verificación indirecta.
- Repetición observacional cuando es posible: aunque no todos los fenómenos pueden repetirse, muchas observaciones sí pueden realizarse en diferentes momentos o bajo distintas condiciones. La repetición permite evaluar la estabilidad de la señal, identificar anomalías y estimar variabilidad natural frente a error de medición. La consistencia en el tiempo fortalece la robustez del resultado.
- Revisión por pares y consenso científico progresivo: los datos y sus interpretaciones son sometidos a evaluación por parte de la comunidad científica. Este proceso implica escrutinio metodológico, análisis crítico de supuestos y verificación de coherencia con el conocimiento existente. El consenso no surge de forma inmediata, sino a través de acumulación de evidencia y debate científico. La calidad, en este sentido, es también una construcción colectiva.
La calidad no es solo una propiedad técnica; es el resultado de un proceso documentado y auditable.
2. Trazabilidad científica completa
En el contexto espacial, el dato es inseparable del proceso técnico y científico que lo genera. No puede entenderse como un resultado aislado, sino como la culminación de una cadena de decisiones instrumentales, metodológicas y analíticas.
Por ello, la trazabilidad debe cubrir de forma explícita y documentada:
- Diseño y configuración del instrumento: es necesario conservar información sobre las características técnicas del instrumento que capturó la señal, por ejemplo, su arquitectura, capacidades de detección, límites de resolución y configuraciones operativas. Estas condiciones determinan qué tipo de señal puede registrarse y con qué precisión.
- Parámetros de calibración: deben registrarse los ajustes aplicados para asegurar que el instrumento opere dentro de los márgenes previstos, así como las modificaciones realizadas a lo largo del tiempo. Los parámetros de calibración influyen directamente en la interpretación de la señal obtenida.
- Versiones del software de procesamiento: el tratamiento del dato bruto depende de herramientas informáticas específicas. Conservar las versiones utilizadas permite comprender cómo se generaron los resultados y evitar ambigüedades si el software evoluciona.
- Algoritmos aplicados en la reducción de ruido: dado que las señales suelen estar acompañadas de interferencias o ruido de fondo, es esencial documentar los métodos empleados para filtrar, limpiar o transformar la información antes de su análisis. Estos algoritmos influyen en el resultado final.
- Supuestos científicos utilizados en la interpretación: la lectura del dato no es neutra: se apoya en marcos teóricos y modelos físicos aceptados en el momento del análisis. Registrar estos supuestos permite contextualizar las conclusiones y comprender posibles revisiones futuras.
- Transformaciones sucesivas del dato bruto al dato publicado: desde la señal original hasta el producto científico final, el dato atraviesa distintas fases de procesamiento, agregación y análisis. Cada transformación debe poder reconstruirse para entender cómo se llegó al resultado comunicado.
Sin trazabilidad exhaustiva, la reproducibilidad se debilita y la interpretabilidad futura se compromete. Cuando no es posible reconstruir el proceso completo que dio lugar a un resultado, su evaluación independiente se vuelve limitada y su reutilización científica pierde solidez.
3. Reproducibilidad a largo plazo
Las misiones espaciales pueden extenderse durante décadas, y sus datos pueden seguir siendo relevantes mucho después de que la misión haya finalizado. Además, la interpretación científica evoluciona con el tiempo: nuevos modelos, nuevas herramientas y nuevas preguntas pueden requerir volver a analizar información generada años atrás.
Por ello, los datos deben mantenerse interpretables incluso cuando los equipos originales ya no existen, los sistemas tecnológicos han cambiado o el contexto científico ha evolucionado.
Esto exige:
- Metadatos ricos y estructurados: la información contextual que acompaña al dato —sobre su origen, condiciones de adquisición, procesamiento y limitaciones— debe estar organizada de forma clara y normalizada. Sin metadatos suficientes, el dato pierde significado y se vuelve difícil de reinterpretar en el futuro.
- Identificadores persistentes: cada conjunto de datos debe poder localizarse y citarse de manera estable en el tiempo. Los identificadores persistentes permiten mantener la referencia incluso si cambian los sistemas de almacenamiento o las infraestructuras tecnológicas.
- Políticas de preservación digital robustas: la conservación a largo plazo requiere estrategias que contemplen la obsolescencia de formatos, la migración tecnológica y la integridad de los archivos. No basta con almacenar; es necesario asegurar que los datos sigan siendo accesibles y legibles con el paso del tiempo.
- Documentación accesible de los pipelines de procesamiento: el proceso que transforma el dato bruto en producto científico debe estar descrito de forma comprensible. Esto permite que investigadores futuros puedan reconstruir el análisis, verificar los resultados o aplicar nuevos métodos sobre los mismos datos originales.
La reproducibilidad, en este contexto, no significa repetir físicamente el fenómeno observado, sino poder reconstruir el proceso analítico que condujo a un resultado determinado. La gobernanza no solo gestiona el presente; garantiza la reutilización futura del conocimiento y preserva la capacidad de reinterpretar la información a la luz de nuevos avances científicos.
El siguiente visual resumen los tres desafíos:
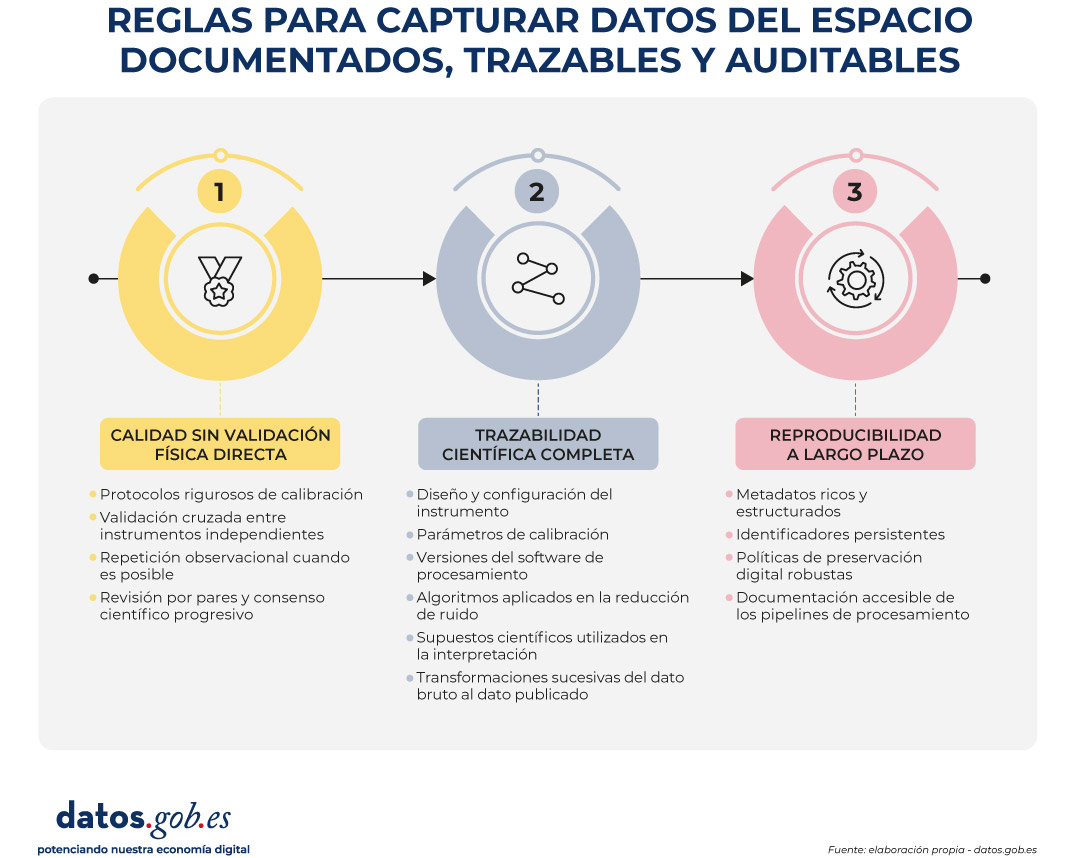
Figura 2. Reglas para capturar datos espaciales documentados, trazables y auditables. Fuente: elaboración propia - datos.gob.es.
Conclusión: gobernar lo que no podemos tocar
Los datos del universo nos obligan a repensar cómo entendemos y gestionamos la información. Estamos trabajando con realidades que no podemos visitar, tocar ni comprobar directamente. Observamos fenómenos que ocurren a distancias inmensas y en tiempos que superan la escala humana, a través de instrumentos altamente especializados que traducen señales complejas en datos interpretables.
En este contexto, la incertidumbre no es un error ni una debilidad, sino una característica natural del estudio del cosmos. La interpretación de los datos depende de modelos científicos que evolucionan con el tiempo, y la calidad no se basa en una verificación directa, sino en procesos rigurosos, bien documentados y revisados por la comunidad científica. La confianza, por tanto, no surge de la experiencia directa, sino de la transparencia, la trazabilidad y la claridad con la que se explican los métodos utilizados.
Gobernar datos espaciales no significa únicamente almacenarlos o ponerlos a disposición del público. Significa conservar toda la información que permite entender cómo se obtuvieron, cómo se procesaron y bajo qué supuestos fueron interpretados. Solo así pueden ser evaluados, reinterpretados y reutilizados en el futuro.
Más allá de la Tierra, el gobierno del dato no es un detalle técnico ni una tarea administrativa. Es el fundamento que sostiene la credibilidad del conocimiento humano sobre el universo y la base que permite que nuevas generaciones continúen explorando lo que aún no podemos alcanzar físicamente.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
La visualización de datos no es una disciplina reciente. Desde hace siglos, las personas han utilizado gráficos, mapas y esquemas para representar información compleja. Ejemplos clásicos como los mapas estadísticos del siglo XIX o los gráficos utilizados en la prensa muestran que la necesidad de “ver” los datos para entenderlos ha existido siempre.
Durante mucho tiempo, la creación de visualizaciones requería conocimientos especializados y acceso a herramientas profesionales, lo que limitaba su producción a perfiles muy concretos. Sin embargo, la revolución digital y tecnológica ha transformado profundamente este panorama. En la actualidad, cualquier persona con acceso a un ordenador y a datos puede crear visualizaciones. Las herramientas se han democratizado, muchas de ellas son gratuitas o de código abierto, y el trabajo de visualización se ha extendido más allá del diseño para integrarse en ámbitos como la estadística, la ciencia de datos, la investigación académica, la administración pública o la educación.
Hoy en día, la visualización de datos es una competencia transversal que permite a la ciudadanía explorar información pública, a las instituciones comunicar mejor sus políticas y a los reutilizadores generar nuevos servicios y conocimientos a partir de los datos abiertos. En este post presentamos algunas de las opciones más accesibles y utilizadas en visualización de datos.
Un ecosistema amplio y diverso de herramientas
El ecosistema de herramientas de visualización de datos es amplio y diverso, tanto en funcionalidades como en niveles de complejidad. Existen opciones pensadas para una primera exploración de los datos, otras orientadas al análisis en profundidad y algunas diseñadas para crear visualizaciones interactivas o narrativas digitales complejas.
Esta variedad permite adaptar la visualización a distintos contextos y objetivos: desde comprender un conjunto de datos de forma preliminar hasta publicar gráficos interactivos, paneles de control o mapas en la web.
La encuesta anual de la Data Visualization Society refleja esta diversidad y muestra cómo el uso de determinadas herramientas evoluciona con el tiempo, consolidando algunas opciones ampliamente conocidas y dando paso a nuevas soluciones que responden a necesidades emergentes. Estas son algunas de las herramientas que se mencionan en la encuesta, ordenadas según perfiles de uso.
Para la elaboración de este listado se ha tenido en cuenta los siguientes criterios:
- Grado de uso y madurez de la herramienta.
- Acceso libre, gratuito o con versiones abiertas.
- Utilidad para proyectos relacionados con datos públicos.
- Prioridad a herramientas abiertas o con versiones gratuitas.
Herramientas sencillas para empezar
Estas herramientas se caracterizan por contar con interfaces visuales, una curva de aprendizaje baja y la posibilidad de crear gráficos básicos de forma rápida. Son especialmente útiles para comenzar a explorar conjuntos de datos abiertos o para actividades de divulgación.
- Excel: es una de las herramientas más extendidas y conocidas. Permite realizar gráficos básicos y primeras exploraciones de datos de forma sencilla. Aunque no está diseñada específicamente para la visualización avanzada, sigue siendo una puerta de entrada habitual al trabajo con datos y su representación gráfica.
- Google Sheets: funciona como una alternativa gratuita y colaborativa a Excel. Su principal ventaja es la posibilidad de trabajar de forma compartida y publicar gráficos sencillos en línea, lo que facilita la difusión de visualizaciones básicas.
- Datawrapper: muy utilizada en comunicación pública y periodismo de datos. Permite crear gráficos claros, mapas y tablas interactivas sin necesidad de conocimientos técnicos. Es especialmente adecuada para explicar datos de forma comprensible a un público amplio.
- RAWGraphs: herramienta de software libre orientada a la exploración visual. Permite experimentar con tipos de gráficos menos habituales y descubrir nuevas formas de representar datos. Resulta especialmente útil en fases exploratorias.
- Canva: aunque su enfoque es más divulgativo que analítico, puede ser útil para crear piezas visuales sencillas que integren gráficos básicos con elementos de diseño. Es adecuada para la comunicación visual de resultados, no tanto para el análisis de datos.
Herramientas de análisis y exploración de datos
Este grupo de herramientas está orientado a perfiles que desean ir más allá de los gráficos básicos y realizar análisis más estructurados. Muchas de ellas son abiertas y están ampliamente consolidadas en el ámbito del análisis de datos.
- R: lenguaje de programación libre muy utilizado en estadística y análisis de datos. Dispone de un amplio ecosistema de paquetes que permiten trabajar con datos públicos de forma reproducible y transparente.
- Ggplot2: librería de visualización del lenguaje R. Es una de las herramientas más potentes para crear gráficos rigurosos y bien estructurados, tanto para análisis como para comunicación de resultados.
- Python (Matplotlib y Plotly): Python es uno de los lenguajes más utilizados en análisis de datos. Matplotlib permite crear gráficos estáticos personalizables, mientras que Plotly facilita la creación de visualizaciones interactivas. Juntas ofrecen un buen equilibrio entre potencia y flexibilidad.
- Apache Superset: plataforma de código abierto para análisis de datos y creación de paneles de control. Tiene un enfoque más institucional y escalable, lo que la hace adecuada para organizaciones que trabajan con grandes volúmenes de datos públicos.
Este bloque resulta especialmente relevante para reutilizadores de datos abiertos y perfiles técnicos intermedios que buscan combinar análisis y visualización de forma sistemática.
Herramientas para visualización interactiva y web
Estas herramientas permiten crear visualizaciones avanzadas para su publicación en entornos web. Aunque requieren mayores conocimientos técnicos, ofrecen una gran flexibilidad y posibilidades expresivas.
- D3.js: es uno de los referentes en visualización web. Se basa en estándares abiertos y permite un control total sobre la representación visual de los datos. Su flexibilidad es muy alta, aunque también lo es su complejidad.
En este ejercicio práctico puedes ver cómo se utiliza esta librería
- Vega y Vega-Lite: lenguajes declarativos para visualización que simplifican el uso de D3. Permiten definir gráficos de forma estructurada y reproducible, ofreciendo un buen equilibrio entre potencia y simplicidad.
- Observable: entorno interactivo muy ligado a D3 y Vega. Es especialmente útil para crear ejemplos educativos, prototipos y visualizaciones exploratorias que combinan código, texto y gráficos.
- Three.js y WebGL: tecnologías orientadas a visualizaciones avanzadas y en tres dimensiones. Su uso es más experimental y suele estar vinculado a proyectos de divulgación o investigación visual.
En este apartado conviene destacar que, aunque las barreras técnicas son mayores, estas herramientas permiten crear experiencias interactivas ricas que pueden resultar muy eficaces para comunicar datos públicos complejos.
Herramientas de cartografía y datos geoespaciales
La visualización geográfica es especialmente relevante en el ámbito de los datos abiertos, ya que una gran parte de la información pública tiene una dimensión territorial. En este campo, el software libre tiene un peso destacado y está muy alineado con el uso en administraciones públicas.
- QGIS: referente en software libre para sistemas de información geográfica (GIS). Es ampliamente utilizado en administraciones públicas y permite analizar y visualizar datos espaciales con gran detalle.
- ArcGIS: muy extendido en el ámbito institucional. Aunque no es software libre, su uso está muy consolidado y forma parte del ecosistema habitual de muchas organizaciones públicas.
- Mapbox: plataforma orientada a la creación de mapas web interactivos. Es muy utilizada en proyectos de visualización online y permite integrar datos geográficos en aplicaciones web.
- Leaflet: librería de código abierto muy popular para crear mapas interactivos en la web. Es ligera, flexible y ampliamente utilizada en proyectos de reutilización de datos abiertos geográficos.
Este conjunto de herramientas facilita la representación territorial de los datos y su reutilización en contextos locales, regionales o nacionales.
En conclusión, la elección de una herramienta de visualización depende en gran medida del objetivo que se persiga. No es lo mismo aprender y experimentar que analizar datos en profundidad o comunicar resultados a un público amplio. Por ello, resulta útil reflexionar previamente sobre el tipo de datos disponibles, el público al que se dirige la visualización y el mensaje que se quiere transmitir.
Apostar por herramientas accesibles y abiertas permite que más personas puedan explorar, interpretar y comunicar datos públicos. En este sentido, visualizar datos es también una forma de acercar la información a la ciudadanía y fomentar su reutilización.
Blog
En los últimos años, se ha puesto de manifiesto la necesidad de que la comunidad científica internacional disponga de mecanismos ágiles para compartir resultados de investigación con el fin de dar respuesta a desafíos como las pandemias, la crisis climática, la pérdida de biodiversidad o la transición energética. En este sentido, las tareas de I+D se han vuelto intensivas en el uso tanto de datos como de software especializado. Un ejemplo concreto se produjo durante la pandemia de COVID-19, cuando la compartición de datos habilitó la secuenciación rápida del genoma del SARS‑CoV‑2, resultando fundamental para el desarrollo de la vacuna de la COVID-19 en tiempo récord.
Es, por tanto, el momento de impulsar la ciencia abierta. Pero para que la ciencia abierta sea una realidad, es imprescindible evitar la fragmentación de los recursos de I+D. Más allá de las publicaciones científicas, es necesario conectar repositorios de datos distribuidos y promover herramientas software, que sean interoperables para facilitar la reutilización efectiva de los conjuntos de datos científicos.
En este contexto nace EOSC (European Open Science Cloud), una iniciativa europea que pretende conectar a la comunidad científica para hacer realidad la ciencia abierta y maximizar su impacto para la sociedad. EOSC ofrece al personal investigador en Europa un entorno multidisciplinar, abierto y de confianza donde poder publicar, descubrir y reutilizar datos, así como herramientas y servicios software en el ámbito científico.
¿Qué es EOSC? Acceso federado a recursos científicos
European Open Science Cloud es la iniciativa europea para crear un entorno abierto y de confianza donde la comunidad investigadora pueda publicar, descubrir y reutilizar datos científicos, así como servicios software de investigación. Su enfoque es federar y escalar recursos científicos en Europa, promoviendo la interoperabilidad entre disciplinas. La ambición de EOSC es acelerar las prácticas de ciencia abierta, aumentando la productividad científica y reforzando la reproducibilidad de la investigación de tal manera que se maximice su impacto en la sociedad. Para ello, EOSC se concibe como un “sistema de sistemas”, es decir, en lugar de centralizar todos los datos y servicios en una única plataforma, EOSC interconecta plataformas ya existentes (es decir, realiza una federación en lugar de una integración) como repositorios de datos, infraestructuras de investigación, o proveedores de servicios software científicos.
La Comisión Europea sitúa EOSC como el espacio común europeo para datos de I+D y lo alinea con el objetivo europeo de conseguir alcanzar una economía y sociedad basadas en datos. En términos de impacto, esto favorece los siguientes aspectos:
- Investigación colaborativa, no sólo dentro de una misma disciplina científica sino también entre disciplinas diferentes y diversos territorios.
- Reutilización y combinación de recursos científicos digitales (como conjuntos de datos o servicios software), así como el impulso de la ciencia ciudadana.
- Impacto en la sociedad a través de políticas basadas en evidencia, al mejorar la trazabilidad, disponibilidad e interoperabilidad de datos que sustentan decisiones públicas.
Para hacer EOSC una realidad, se construye un modelo federado basado en nodos que actúan como puntos de entrada coordinados. Sobre ellos se establecen políticas comunes y capacidades compartidas (por ejemplo, autenticación federada, catálogos y guías de interoperabilidad) que permiten la reutilización de datos y servicios. Este enfoque se concreta en la Federación EOSC, que conecta infraestructuras y comunidades para ofrecer un acceso y reutilización de recursos científicos más homogénea.
¿Qué es la Federación EOSC?
Según el EOSC Federation Handbook (documento de referencia que describe su estructura operativa, marco legal y de gobernanza, y operativa técnica), la Federación EOSC (EOSC Federation) es una red distribuida de nodos. Estos nodos están interconectados y son capaces de colaborar para compartir y gestionar conocimiento y recursos científicos (como conjuntos de datos, software y servicios) entre comunidades temáticas y geográficas, cumpliendo los principios FAIR. Es decir, es una red distribuida que habilita capacidades para desarrollar una ciencia abierta interoperable, segura y fiable a escala europea, entre disciplinas y fronteras.
Como veíamos, el elemento básico de esta federación son los EOSC Nodes (nodos EOSC) que funcionan como puntos de entrada para la comunidad científica a la federación. Se trata de plataformas operadas por organizaciones o consorcios de alcance territorial o temático, que integran:
- Un conjunto de capacidades esenciales para operar, como, por ejemplo, servicios de autenticación y acceso o catálogo de recursos.
- Un conjunto de recursos, como, por ejemplo, productos de datos de investigación.
Una parte de esos recursos se selecciona como Node Exchange, representando lo que el nodo comparte con la federación. Al agregarse las contribuciones de varios nodos, se constituyen el EOSC Exchange, es decir, la oferta global de recursos de la federación.
Para que todo ello funcione, se definen las Federating Capabilities como capacidades comunes (técnicas y también organizativas, como soporte a usuarios) que permiten que los servicios funcionen entre nodos y no como silos aislados. Estas capacidades se habilitan mediante servicios federadores operados por uno o varios nodos y se apoyan en interfaces y guías de interoperabilidad recogidas en el EOSC Interoperability Framework. La siguiente imagen representa gráficamente este proceso:
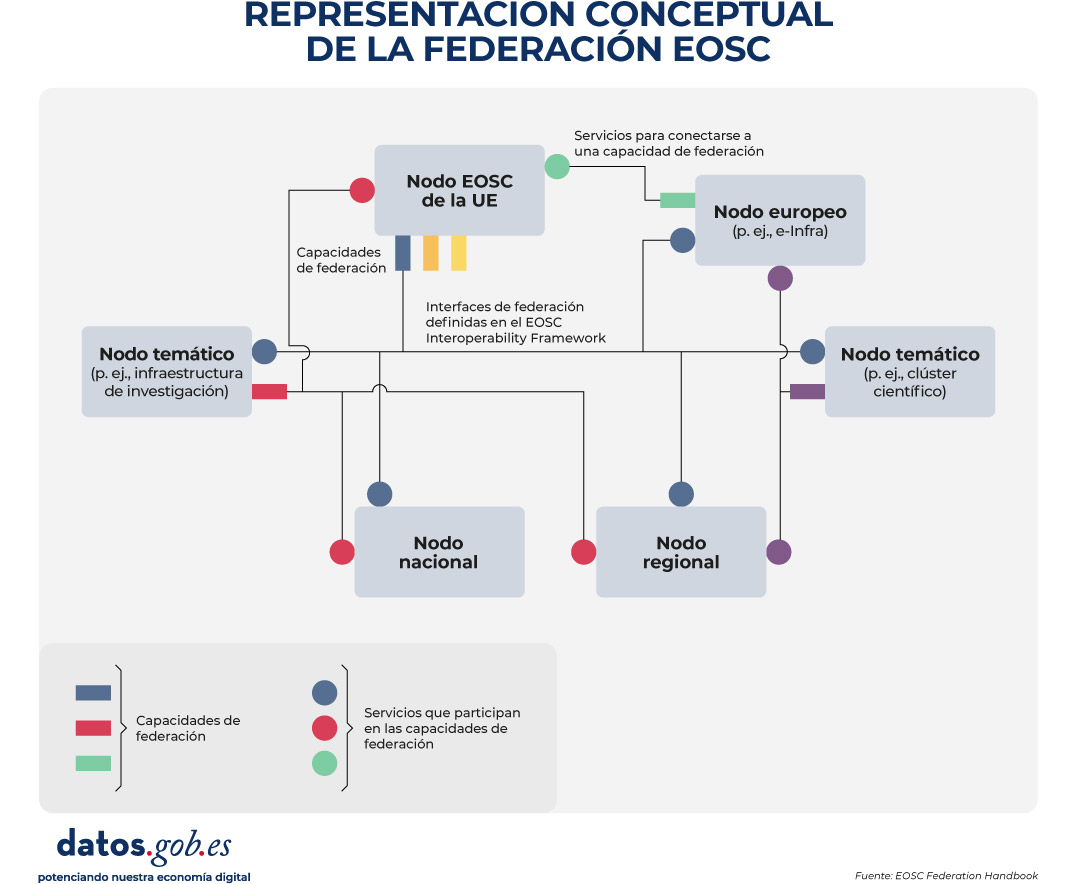
Figura 1. Representación conceptual de la Federación EOSC (fuente: EOSC Federation Handbook).
Existen dos capacidades federadas obligatorias: por una parte la infraestructura de autenticación y autorización (AAI) y, por otra, los catálogos de recursos que permiten a la comunidad científica descubrir y acceder a recursos ofrecidos por los nodos, no sólo manualmente sino por medio de servicios informáticos. Estas primeras capacidades se articulan en el EOSC EU Node.
EOSC EU Node: el primer nodo operativo
En este modelo federado, el EOSC EU Node (promovido por la Comisión Europea) es especialmente relevante como primer nodo de la Federación EOSC, proporcionando un conjunto inicial de datos, herramientas y servicios, y actuando como nodo de referencia para facilitar la interconexión de otros nodos.
Este nodo permite al personal investigador acceder con credenciales institucionales a capacidades como máquinas virtuales, recursos como GPUs, cuadernos interactivos, flujos científicos de trabajo en contenedores, almacenamiento, transferencia de datos y herramientas colaborativas, además de conectarse a un catálogo de recursos para descubrir resultados de investigación (conjuntos de datos científicos, publicaciones o servicios software especializados) procedentes de infraestructuras federadas.
Conclusiones
EOSC permite transformar recursos científicos dispersos en un ecosistema interoperable y reutilizable que permita a la comunidad científica desarrollar los objetivos de la ciencia abierta. La Federación EOSC, mediante nodos conectados y capacidades federadas (tales como AAI, catálogos o guías de interoperabilidad), facilita el acceso a datos FAIR, servicios y herramientas software, acelerando la colaboración científica y la reproducibilidad, además de permitir el impulso de propuestas de ciencia ciudadana e fomentar el impacto de los resultados científicos en la sociedad. Finalmente, cabe destacar que EOSC no sustituye lo que ya existe, sino que lo conecta, lo hace interoperable y lo proyecta a escala europea. En España avanza la definición de un nodo nacional para conectar capacidades existentes con la Federación EOSC. Por ello, la participación temprana de repositorios, infraestructuras, centros de investigación, universidades y proveedores de servicios será clave para construir una oferta representativa, definir prioridades y maximizar el impacto científico y social.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Las visualizaciones de datos actúan como puentes entre la información compleja y la comprensión humana. Un gráfico bien diseñado puede comunicar en segundos datos que llevaría minutos o incluso horas descifrar en formato tabular. Más aún, las visualizaciones interactivas permiten a cada usuario explorar los datos desde su propia perspectiva, filtrando, comparando y descubriendo insights personalizados.
Para alcanzar estos fines existen múltiples herramientas, algunas de las cuales hemos abordado en ocasiones anteriores. Hoy nos acercamos a un nuevo ejemplo: la librería gratuita D3.js. En este post te explicamos cómo permite generar visualizaciones de datos útiles y atractivas junto con la herramienta de código abierto Observable.
¿Qué es D3?
D3.js (Data-Driven Documents) es una biblioteca de JavaScript que permite crear visualizaciones de datos personalizadas en navegadores web. A diferencia de herramientas que ofrecen gráficos predefinidos, D3.js proporciona los elementos fundamentales para construir prácticamente cualquier tipo de visualización imaginable.
La biblioteca es completamente gratuita y de código abierto, publicada bajo licencia BSD, lo que significa que cualquier persona u organización puede utilizarla, modificarla y distribuirla sin restricciones. Esta característica ha contribuido a su adopción generalizada: medios de comunicación internacionales como The New York Times, The Guardian, Financial Times y locales como El País o el ABC utilizan D3.js para crear visualizaciones periodísticas que ayudan a contar historias con datos.
D3.js funciona manipulando el DOM (Document Object Model) del navegador. En términos prácticos, esto significa que toma información (por ejemplo, un archivo CSV con datos de población) y la transforma en elementos visuales (círculos, barras, líneas) que el navegador puede mostrar. La potencia de D3.js reside en su flexibilidad: no impone una forma específica de visualizar datos, sino que proporciona las herramientas para crear exactamente lo que se necesita.
¿Qué es Observable?
Observable es una plataforma web para crear y compartir código, especialmente diseñada para trabajar con datos y visualizaciones. Aunque ofrece un servicio freemium con algunas funcionalidades gratuitas y otras de pago, mantiene una filosofía de código abierto que resulta particularmente relevante para el trabajo con datos públicos.
La característica distintiva de Observable es su formato de "cuadernos computacionales" (notebooks). Similar a herramientas como Jupyter Notebooks en Python, un cuaderno de Observable combina código, visualizaciones y texto explicativo en un mismo documento interactivo. Cada celda del cuaderno puede contener código JavaScript que se ejecuta inmediatamente, mostrando resultados al instante. Esto crea un entorno de experimentación ideal para explorar datos.
Puedes verlo en la práctica en este ejercicio de ciencia de datos que hemos publicado en datos.gob.es
Observable se integra naturalmente con D3.js y otras bibliotecas de visualización. De hecho, el creador de D3.js, es también uno de los fundadores de Observable, por lo que ambas herramientas trabajan conjuntamente de manera fluida. Los cuadernos de Observable pueden compartirse públicamente, permitiendo que otros usuarios vean tanto el código como los resultados, los bifurquen (fork) para crear sus propias versiones, o los integren en sus propios proyectos.
Ventajas de la herramienta para trabajar con todo tipo de datos
Tanto D3.js como Observable presentan características que pueden resultar útiles para trabajar con datos, entre ellos, con datos abiertos:
- Transparencia y reproducibilidad: al publicar una visualización creada con estas herramientas es posible compartir tanto el resultado final como todo el proceso de transformación de datos. Cualquier persona puede inspeccionar el código, verificar los cálculos y reproducir los resultados. Esta transparencia resulta fundamental cuando se trabaja con información pública, donde la confianza y la verificabilidad son esenciales.
- Sin costes de licencia: tanto D3.js como la versión gratuita de Observable permiten crear y publicar visualizaciones sin necesidad de adquirir licencias de software. Esto elimina barreras económicas para organizaciones, periodistas, investigadores o ciudadanos que desean trabajar con datos abiertos.
- Formatos web estándar: las visualizaciones creadas funcionan directamente en navegadores web sin necesidad de plugins o software adicional. Esto facilita su integración en sitios web institucionales, artículos periodísticos o informes digitales, haciéndolas accesibles desde cualquier dispositivo.
- Comunidad y recursos: existe una amplia comunidad de usuarios que comparten ejemplos, tutoriales y soluciones a problemas comunes. Observable, en particular, alberga miles de cuadernos públicos que sirven como ejemplos y plantillas reutilizables.
- Flexibilidad técnica: a diferencia de herramientas con opciones predefinidas, estas bibliotecas permiten crear visualizaciones completamente personalizadas que se adapten exactamente a las necesidades específicas de cada conjunto de datos o historia que se quiera contar.
Es importante señalar que estas herramientas requieren conocimientos de programación, específicamente de JavaScript. Para personas sin experiencia en programación, existe una curva de aprendizaje que puede resultar pronunciada inicialmente. Otras herramientas como hojas de cálculo o software de visualización con interfaces gráficas pueden ser más apropiadas para usuarios que buscan resultados rápidos sin necesidad de escribir código.
Para quienes buscan alternativas open source con una curva de aprendizaje suave, existen herramientas basadas en interfaz visual que no requieren programar. Por ejemplo, RawGraphs permite crear visualizaciones complejas simplemente arrastrando y soltando archivos, mientras que Datawrapper es una opción excelente y muy intuitiva para generar gráficos y mapas listos para publicar.
Además, existen numerosas alternativas tanto de código abierto como comerciales para visualizar datos: Python con bibliotecas como Matplotlib o Plotly, R con ggplot2, Tableau Public, Power BI, entre muchas otras. En la sección didáctica de ejercicios de visualización y ciencia de datos de datos.gob.es puedes encontrar ejemplos prácticos de uso de algunas de ellas.
En resumen, la elección de herramientas debe basarse siempre en una evaluación de requisitos específicos, recursos disponibles y objetivos del proyecto. Lo importante es que los datos abiertos se transformen en conocimiento accesible, y existen múltiples caminos para lograr este objetivo. D3.js y Observable ofrecen uno de estos caminos, particularmente adecuado para quienes buscan combinar flexibilidad técnica con principios de apertura y transparencia. Si conoces alguna otra herramienta o te gustaría que profundizáramos en otra temática, háznosla llegar a través de nuestras redes sociales o en el formulario de contacto.
Blog
Desde sus orígenes el movimiento de datos abiertos se ha centrado fundamentalmente en el impulso de la apertura de los datos y en el fomento de su reutilización. El objetivo que ha articulado la mayoría de las iniciativas, tanto públicas como privadas, ha sido el de vencer los obstáculos para publicar catálogos de datos cada vez más completos y asegurar que la información del sector público estuviera disponible para que la ciudadanía, las empresas, los investigadores y el propio sector público pudieran crear valor económico y social.
Sin embargo, a medida que hemos ido dando pasos hacia una economía cada vez más dependiente de los datos y, más recientemente, de la inteligencia artificial -y en un futuro próximo de las posibilidades que nos traen los agentes autónomos a través de la inteligencia artificial agéntica-, las prioridades han ido cambiando y el foco ha ido girando hacia cuestiones como la mejora de la calidad de los datos publicados.
Ya no es suficiente con que los conjuntos de datos estén publicados en un portal de datos abiertos cumpliendo buenas prácticas, ni tan siquiera con que el dato cumpla unos estándares de calidad en el momento de su publicación. También es necesario que esta publicación de los conjuntos de datos cumpla con unos niveles de servicio que transformen la mera puesta a disposición en un compromiso operativo que mitigue las incertidumbres que, a menudo, obstaculizan la reutilización.
Cuando un desarrollador integra una API de datos de transporte en tiempo real en su app de movilidad, o cuando un científico de datos trabaja en un modelo de IA con datos climáticos históricos está asumiendo un riesgo si no tiene certeza sobre las condiciones en las que los datos estarán disponibles. Si en un momento dado los datos publicados dejan de estar disponibles porque cambia el formato sin previo aviso, porque el tiempo de respuesta se dispara o por cualquier otra razón, los procesos automatizados fallan y la cadena de suministro de datos se rompe, provocando fallos en cascada en todos los sistemas dependientes.
En este contexto, la adopción de acuerdos de nivel de servicio (ANS) también conocidos por su terminología en inglés, service level agreements (SLA), podrían ser el siguiente paso para que portales de datos abiertos evolucionen desde el habitual modelo “best effort” hasta convertirse en infraestructuras digitales críticas, fiables y robustas.
¿Qué son un ANS o SLA y un contrato de datos en el contexto de los datos abiertos?
En el contexto de la ingeniería de fiabilidad (site reliability engineering o SRE), un ANS es un contrato negociado entre un proveedor de servicios y sus clientes con objeto de fijar el nivel de calidad del servicio prestado. Es, por tanto, una herramienta que ayuda a ambas partes a llegar a un consenso en aspectos tales como el tiempo de respuesta, la disponibilidad horaria o la documentación disponible.
En un portal de datos abiertos, donde a menudo no existe una contraprestación económica directa, un ANS podría ayudar a responder preguntas como:
- ¿Cuánto tiempo estará disponible el portal y sus API?
- ¿Qué tiempos de respuesta podemos esperar?
- ¿Con qué frecuencia se actualizarán los conjuntos de datos?
- ¿Cómo se gestionan los cambios en metadatos, enlaces y formatos?
- ¿Cómo se gestionarán incidencias, cambios y avisos a la comunidad?
Adicionalmente, en esta transición hacia una mayor madurez operativa surge el concepto, aún inmaduro, del contrato de datos (data contract). Si el ANS es un acuerdo que define las expectativas de nivel de servicio, el contrato de datos es una implementación que formaliza este compromiso. Un contrato de datos no solo especificaría el esquema y el formato, sino que actuaría como una salvaguarda: si una actualización del sistema intenta introducir un cambio que rompa la estructura prometida o que degrade la calidad del dato, el contrato de datos permite detectar y bloquear dicha anomalía antes de que afecte a los usuarios finales.
INSPIRE como punto de partida: disponibilidad, rendimiento y capacidad
La infraestructura de la Unión Europea para la información espacial (INSPIRE) ha establecido uno de los marcos más rigurosos del mundo en cuanto a calidad de servicio para datos geoespaciales. La Directiva 2007/2/CE, conocida como INSPIRE, actualmente en su versión 5.0, incluye algunas obligaciones técnicas que podrían servir como referencia para cualquier portal de datos modernos. En particular el Reglamento (CE) nº 976/2009 establece criterios que bien podrían servir como patrón para cualquier estrategia de publicación de datos de alto valor:
- Disponibilidad: la infraestructura debe estar disponible el 99% del tiempo durante el horario de funcionamiento normal.
- Rendimiento: para un servicio de visualización la respuesta inicial debe llegar en menos de 3 segundos.
- Capacidad: para un servicio de localización el mínimo número de peticiones simultáneas servidas con rendimiento garantizado debe ser de 30 por segundo.
Para ayudar al cumplimiento de estos estándares de servicio, la Comisión Europea ofrece herramientas como el INSPIRE Reference Validator. Esta herramienta ayuda no solo a verificar la interoperabilidad sintáctica (que el XML o GML esté bien formado), sino también a asegurar que los servicios de red cumplen con las especificaciones técnicas que permiten medir esos ANS.
En este punto, los exigentes ANS de la infraestructura de datos espaciales europea nos hacen preguntarnos si no deberíamos aspirar a lo mismo para datos críticos de salud, energía o movilidad o para cualquier otro conjunto de datos de alto valor.
Qué podría cubrir un ANS en una plataforma de datos abiertos
Cuando hablamos de conjuntos de datos abiertos en sentido amplio, la disponibilidad del portal es una condición necesaria, pero no suficiente. Muchas incidencias que afectan a la comunidad de reutilizadores no son caídas completas del portal, sino errores más sutiles como enlaces rotos, conjuntos de datos que no se actualizan con la periodicidad indicada, formatos inconsistentes entre versiones, metadatos incompletos o cambios silenciosos en el comportamiento de las API o en los nombres de las columnas de los conjuntos de datos.
Por ello, convendría complementar los ANS propios de la infraestructura del portal con ANS de “salud del dato” que pueden basarse en marcos de referencia ya consolidados como:
- Modelos de calidad como ISO/IEC 25012, que permite desglosar la calidad del dato en dimensiones medibles como la exactitud (que el dato represente la realidad), la completitud (que no falten valores necesarios) y la consistencia (que no haya contradicciones entre tablas o formatos) y convertirlas en requisitos medibles.
- Principios FAIR, siglas de Findable (Localizable), Accessible (Accesible), Interoperable (Interoperable), y Reusable (Reutilizable). Estos principios enfatizan que los activos digitales no solo deben estar disponibles, sino que deben ser localizables mediante identificadores persistentes, accesibles bajo protocolos claros, interoperables mediante el uso de vocabularios estándar y reutilizables gracias a licencias claras y procedencia documentada. Los principios FAIR se pueden poner en práctica midiendo de forma sistemática la calidad de los metadatos que hacen posible la localización, el acceso y la interoperabilidad. Por ejemplo, el servicio Metadata Quality Assurance (MQA) de data.europa.eu ayuda a hacer una evaluación automática de los metadatos de los catálogos, a calcular métricas y a ofrecer recomendaciones de mejora.
Para convertir en operativos estos conceptos, podemos centrarnos en cuatro ejemplos donde establecer compromisos de servicio específicos aportaría un valor diferencial:
- Conformidad y vigencia del catálogo: el ANS podría garantizar que los metadatos estén siempre alineados con los datos que describen. Un compromiso de conformidad aseguraría que el portal se somete a validaciones periódicas (siguiendo especificaciones como DCAT-AP-ES o HealthDCAT-AP) para evitar que la documentación se volviese obsoleta respecto al recurso real.
- Estabilidad del esquema y versionado: uno de los mayores enemigos de la reutilización automatizada es el "cambio silencioso". Si una columna cambia de nombre o un tipo de dato varía, los flujos de ingesta de datos fallarán inmediatamente. Un compromiso de nivel de servicio podría incluir una política de versionado. Esto implicaría que cualquier cambio que rompiese la compatibilidad se anunciase con una antelación mínima y, preferiblemente, mantuviese la versión anterior en paralelo durante un tiempo prudencial.
- Frescura y frecuencia de actualización: no resulta infrecuente encontrar conjuntos de datos etiquetados como de actualización diaria pero cuya última modificación real fue hace meses. Una buena práctica podría ser la definición de indicadores de latencia de publicación. Un posible ANS establecería el valor del tiempo medio entre actualizaciones y contaría con sistemas de alerta que notificasen automáticamente si un dato no se ha refrescado según la frecuencia declarada en su metadato.
- Tasa de éxito: en el mundo de las API de datos, no es suficiente con recibir un código HTTP 200 (OK) para determinar si la respuesta es válida. Si la respuesta es, por ejemplo, un JSON sin contenido, el servicio no es útil. El nivel de servicio tendría que medir la tasa de respuestas exitosas y con contenido válido, asegurando que el endpoint no solo responde, sino que entrega la información esperada.
Un primer paso, SLA, SLO y SLI: medir antes de comprometer
Dado que establecer este tipo de compromisos es realmente complejo, una posible estrategia para pasar a la acción de forma gradual es adoptar un enfoque pragmático basado en las mejores prácticas de la industria. Por ejemplo, en la ingeniería de fiabilidad, se propone una jerarquía de tres conceptos que ayuda a evitar compromisos poco realistas:
- Indicador de Nivel de Servicio (SLI): es el indicador medible y cuantitativo. Representa la realidad técnica en un momento dado. Ejemplos de SLI en datos abiertos podrían ser el "porcentaje de peticiones exitosas a la API", la "latencia p95" (el tiempo de respuesta del 95% de las solicitudes) o el "porcentaje de enlaces de descarga que no devuelven error".
- Objetivo de Nivel de Servicio (SLO): es el objetivo interno que se marca sobre ese indicador. Por ejemplo: "queremos que el 99,5% de las descargas funcionen correctamente" o "la latencia p95 debe ser inferior a 800 ms". Es la meta que guía el trabajo del equipo técnico.
- Acuerdo de Nivel de Servicio (ANS o SLA): es el compromiso público y formal sobre esos objetivos. Es la promesa que el portal de datos hace a su comunidad de reutilizadores y que incluye, idealmente, los canales de comunicación y los protocolos de actuación en caso de incumplimiento.
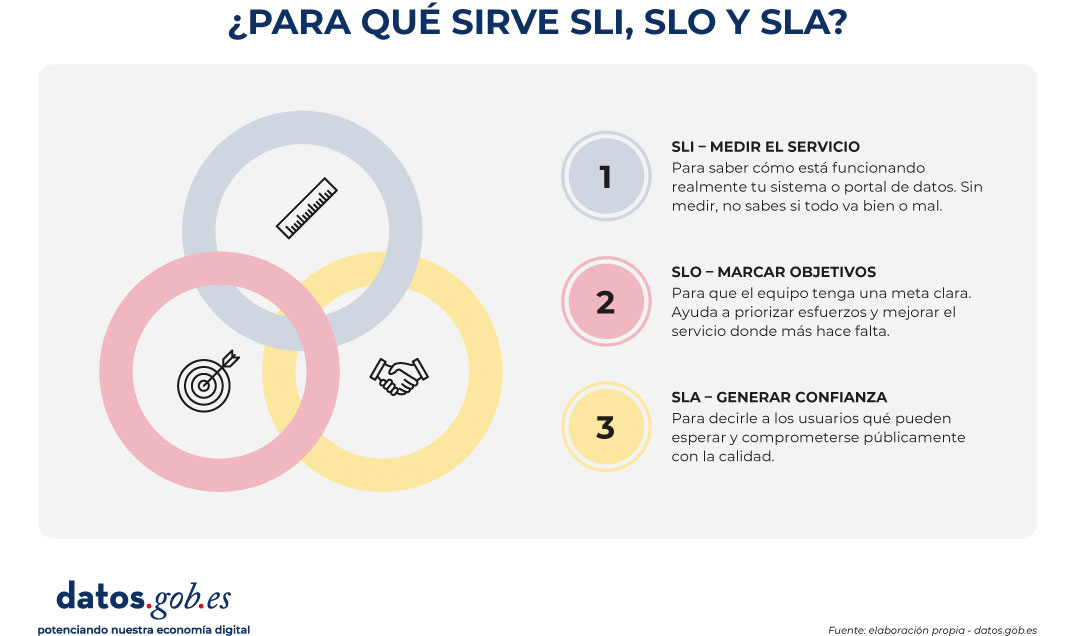
Figura 1. Visual elaborado para explicar la diferencia entre SLI, SLO y SLA. Fuente: elaboración propia - datos.gob.es.
Esta distinción es especialmente valiosa en el ecosistema de los datos abiertos debido a la naturaleza híbrida de un servicio en el que no solo se opera una infraestructura, sino que se gestiona el ciclo de vida de los datos.
En muchos casos, el primer paso podría ser no tanto publicar un ANS ambicioso de inmediato, sino empezar por definir sus SLI y observar sus SLO. Una vez que la medición estuviese automatizada y los niveles de servicio se estabilizasen y fuesen predecibles, sería el momento de convertirlos en un compromiso público (SLA).
En última instancia, la implementación de niveles de servicio en los datos abiertos podría tener un efecto multiplicador. No solo reduciría la fricción técnica para los desarrolladores y mejoraría la tasa de reutilización, sino que facilitaría la integración de los datos públicos en sistemas de IA y agentes autónomos. Los nuevos usos como la evaluación de sistemas de Inteligencia Artificial generativa, la generación y validación de conjuntos de datos sintéticos o incluso la propia mejora de la calidad de los datos abiertos se verían muy beneficiados.
Establecer un SLA de datos sería, por encima de todo, un potente mensaje: significaría que el sector público no solo publica los datos como un acto administrativo, sino que los opera como un servicio digital de alta disponibilidad, fiable, predecible y, en definitiva, preparado para los retos de la economía del dato.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
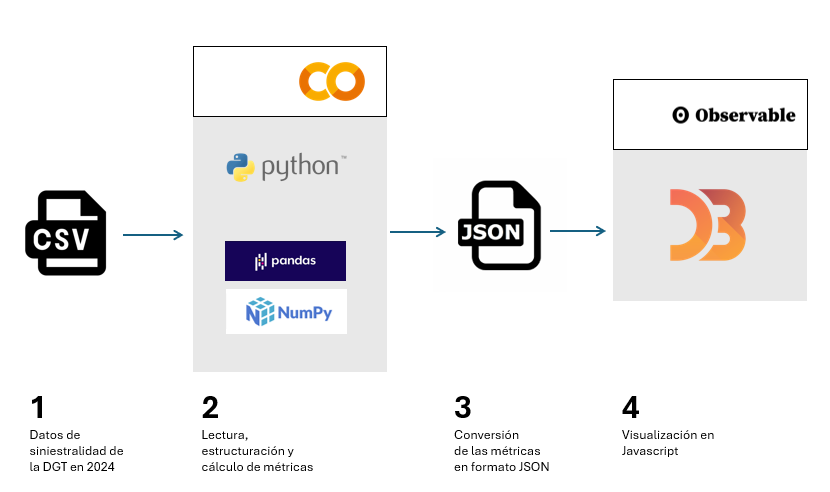
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de GoogleColab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
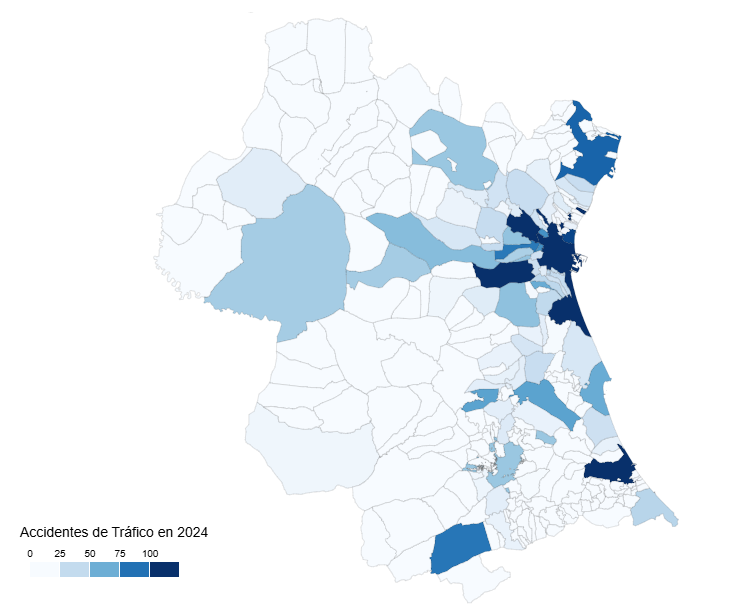
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
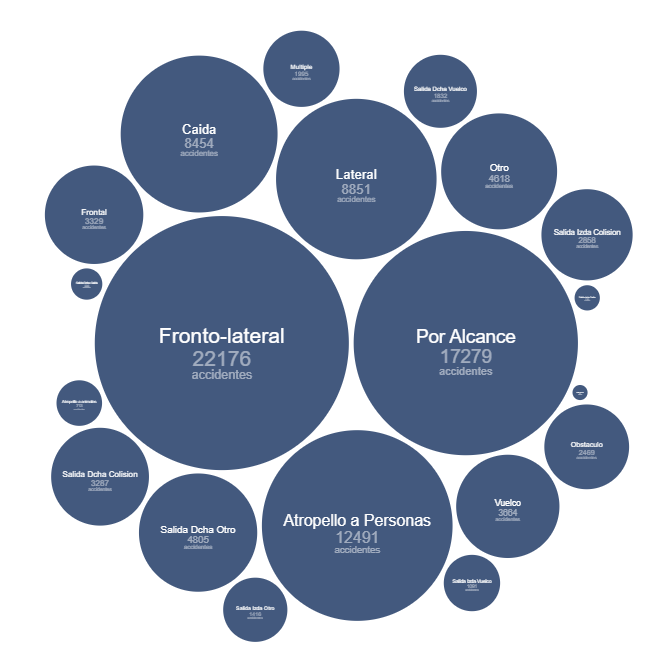
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
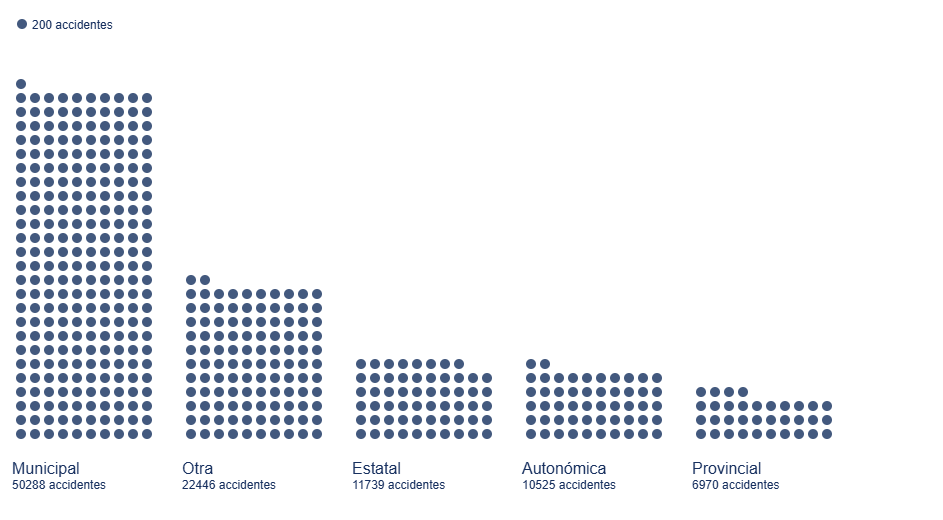
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
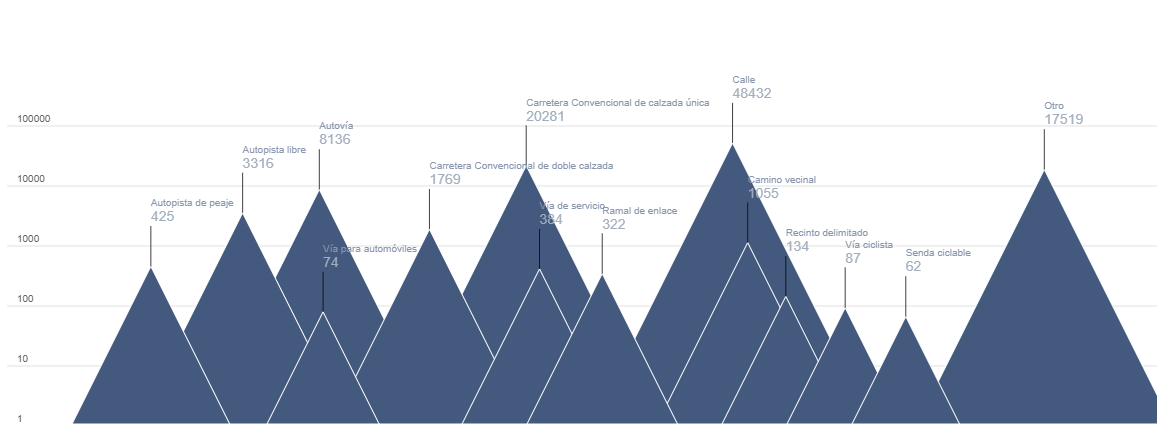
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Blog
La Comisión Europea ha presentado recientemente el documento en el que se establece una nueva Estrategia de la Unión en el ámbito de los datos. Entre otros ambiciosos objetivos, con esta iniciativa se pretende hacer frente a un reto trascendental en la era de la inteligencia artificial generativa: la insuficiente disponibilidad de datos en las condiciones adecuadas.
Desde la anterior Estrategia de 2020 hemos asistido a un importante avance normativo con el que se pretendía ir más allá de la regulación de 2019 sobre datos abiertos y reutilización de la información del sector público.
En concreto, por una parte, la Data Governance Act sirvió para impulsar una serie de medidas que tendían a facilitar el uso de los datos generados por el sector público en aquellos supuestos donde se vieran afectados otros derechos e intereses jurídicos —datos personales, propiedad intelectual.
Por otra, a través de la Data Act se avanzó, sobre todo, en la línea de impulsar el acceso a datos en poder de sujetos privados atendiendo a las singularidades del entorno digital.
El necesario cambio de enfoque en la regulación sobre acceso a datos.
A pesar de este importante esfuerzo regulatorio, por parte de la Comisión Europea se ha detectado una infrautilización de los datos que, además, con frecuencia se encuentran fragmentados en cuanto a las condiciones de su accesibilidad. Ello se debe, en gran parte, a la existencia de una importante diversidad regulatoria. Por ello se requieren medidas que faciliten la simplificación y la racionalización del marco normativo europeo sobre datos.
En concreto, se ha constatado que existe una fragmentación regulatoria que genera inseguridad jurídica y costes de cumplimiento desproporcionados debido a la complejidad del propio marco normativo aplicable. En concreto, el solapamiento entre el Reglamento General de Protección de Datos (RGPD), la Data Governance Act, la Data Act, la Directiva de datos abiertos y, asimismo, la existencia de regulaciones sectoriales específicas para algunos ámbitos concretos ha generado un complejo entramado normativo al que resulta arduo enfrentarse, sobre todo si pensamos en la competitividad de pequeñas y medianas empresas. Cada una de estas normas fue concebida para hacer frente a retos específicos que fueron abordados de manera sucesiva, por lo que resulta necesaria una visión de conjunto más coherente que resuelva posibles incoherencias y, en última instancia, facilite su aplicación práctica.
En este sentido, la Estrategia propone impulsar un nuevo instrumento legislativo —la propuesta de Reglamento denominado Ómnibus Digital—, con el que se pretende consolidar en una única norma las reglas relativas al mercado único europeo en el ámbito de los datos. En concreto, con esta iniciativa:
- Se fusionan las previsiones de la Data Governance Act en la regulación de la Data Act, eliminando así duplicidades.
- Se deroga el Reglamento sobre datos no personales, cuyas funciones se cubren igualmente a través de la Data Act;
- Se integran las normas sobre datos del sector público en la Data Act, ya que hasta ahora estaban incluidas tanto en la Directiva de 2019 como en la Data Governance Act.
Con esta regulación se consolida, por tanto, el protagonismo de la Data Act como normal general de referencia en la materia. Asimismo, se refuerza la claridad y la precisión de sus previsiones, con el objetivo de facilitar su función como instrumento normativo principal a través del cual se pretende impulsar la accesibilidad de los datos en el mercado digital europeo.
Modificaciones en materia de protección de datos personales
La propuesta Ómnibus Digital también incluye importantes novedades por lo que se refiere a la normativa sobre protección de datos de carácter personal, modificándose varios preceptos del Reglamento (UE) 1016/679 del Parlamento Europeo y del Consejo de 27 de abril de 2016, relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales.
Para que se puedan utilizar los datos personales —esto es, cualquier información referida a una persona física identificada o identificable— es necesario que concurra alguna de las circunstancias a que se refiere el artículo 6 del citado Reglamento, entre las que se encuentra el consentimiento del titular o la existencia de un interés legítimo por parte de quien vaya a tratar los datos.
El interés legítimo permite tratar datos personales cuando es necesario para un fin válido (mejorar un servicio, prevenir fraudes, etc.) y no afecta negativamente a los derechos de la persona.
Fuente: Guía sobre interés legítimo. ISMS Forum y Data Privacy Institute. Disponible aquí: guiaintereslegitimo1637794373.pdf
Respecto a la posibilidad de acudir al interés legítimo como base jurídica para entrenar las herramientas de inteligencia artificial, la actual regulación permite tratar datos personales siempre que no prevalezcan los derechos de los interesados titulares de dichos datos.
Sin embargo, dada la generalidad del concepto “interés legítimo”, a la hora de decidir cuándo se pueden utilizar los datos personales al amparo de esta cláusula no siempre existirá una certeza absoluta, habrá que analizar caso por caso: en concreto, será necesario llevar a cabo una actividad de ponderación de los bienes jurídicos en conflicto y, por tanto, su aplicación puede generar dudas razonables en muchos supuestos.
Aunque el Comité Europeo de Protección de Datos ha intentado establecer algunas pautas para concretar la aplicación del interés legítimo, lo cierto es que el uso de conceptos jurídicos abiertos e indeterminados no siempre permitirá llegar a respuestas claras y definitivas. Para facilitar la concreción de esta expresión en cada supuesto, la Estrategia alude como criterio a tener en cuenta el beneficio potencial que puede suponer el tratamiento para el propio titular de los datos y para la sociedad en general. Asimismo, dado que no será necesario el consentimiento del titular de los datos —y por tanto, no sería aplicable su revocación—, refuerza el derecho de oposición por parte del titular a que sus datos sean tratados y, sobre todo, garantiza una mayor transparencia respecto de las condiciones en que se van a tratar los datos. De este modo, al reforzar la posición jurídica del titular y aludir a dicho beneficio potencial, la Estrategia pretende facilitar la utilización del interés legítimo como base jurídica que permita utilizar los datos personales sin consentimiento del titular, pero con garantías adecuadas.
Otra de las principales medidas en materia de protección de datos se refiere a la distinción entre datos anónimos y seudonimizados. El RGPD define la seudonimización como un tratamiento de datos que, hasta ahora, hacía que ya no pudieran atribuirse a un interesado sin recurrir a información adicional, que se encuentra separada. Eso sí, los datos seudonimizados siguen siendo datos personales y, por tanto, sometidos a dicha regulación. En cambio, los datos anónimos no guardan relación con personas identificadas o identificables y, por tanto, su uso no estaría sometido al RGPD. En consecuencia, para saber si hablamos de datos anónimos o seudonimizados resulta esencial concretar si existe una “probabilidad razonable” de identificación del titular de los datos.
Ahora bien, las tecnologías actualmente disponibles multiplican el riesgo de reidentificación del titular de los datos, lo que afecta directamente a lo que podría considerarse razonable, generando una incertidumbre que incide negativamente en la innovación tecnológica. Por esta razón, la propuesta Ómnibus Digital, en la línea ya manifestada por el Tribunal de Justicia de la Unión Europea, pretende establecer las condiciones en las cuales los datos seudonimizados ya no se podrían considerar datos de carácter personal, facilitando así su uso. A tal efecto habilita a la Comisión Europea para que, a través de actos de implementación, pueda concretar tales circunstancias, en concreto teniendo en cuenta el estado de la técnica y, asimismo, ofreciendo criterios que permitan evaluar el riesgo de reidentificación en cada concreto supuesto.
La ampliación de los conjuntos de datos de alto valor
La Estrategia pretende también ampliar el catálogo de Datos de Alto Valor (HVD) que se contemplan en el Reglamento de Ejecución UE 2023/138. Se trata de conjuntos de datos con potencial excepcional para generar beneficios sociales, económicos y ambientales, ya que son datos de alta calidad, estructurados y fiables que están accesibles en condiciones técnicas, organizativas y semánticas muy favorables para su tratamiento automatizado. Actualmente se incluyen seis categorías (geoespacial, observación de la Tierra y medio ambiente, meteorología, estadística, empresas y movilidad), a las que se añadirían por parte de la Comisión, entre otros conjuntos, datos legales, judiciales y administrativos.
Oportunidad y reto
La Estrategia Europea de Datos representa un giro paradigmático ciertamente relevante: no sólo se trata de promover marcos normativos que faciliten en el plano teórico la accesibilidad de los datos sino, sobre todo, de hacerlos funcionar en su aplicación práctica, impulsando de esta manera las condiciones necesarias de seguridad jurídica que permitan dinamizar una economía de datos competitiva e innovadora.
Para ello resulta imprescindible, por una parte, evaluar la incidencia real de las medidas que se proponen a través del Ómnibus Digital y, por otra, ofrecer a las pequeñas y medianas empresas instrumentos jurídicos adecuados —guías prácticas, servicios de asesoramiento idóneos, cláusulas contractuales tipo…— para hacer frente al reto que para ellas supone el cumplimiento normativo en un contexto de enorme complejidad. Precisamente, esta dificultad requiere, por parte de las autoridades de control y, en general, de las entidades públicas, adoptar modelos de gobernanza de los datos avanzados y flexibles que se adapten a las singularidades que plantea la inteligencia artificial, sin que por ello se vean afectadas las garantías jurídicas.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autorR
Aplicación
Visor web que muestra en un único mapa los despliegues de fibra de todos los programas PEBA y UNICO, a partir de los datos disponibles en abierto. Cada área tiene el color de fondo del operador adjudicado, y el borde es de un color diferente para cada programa. Para el caso del plan PEBA 2013-2019, como los despliegues se asignan a entidades singulares de población, se muestra un marcador con la ubicación obtenida del CNIG. Además, cuando no se hace zoom sobre el mapa, se muestra un mapa de calor en el que se puede ver la distribución por zonas de los despliegues.
Esta visualización permite evitar tener que comparar en diferentes visores cartográficos si lo que nos interesa es ver qué operadores llegan a qué zonas o simplemente tener una visión global de qué despliegues quedan pendientes en mi zona, y además permite consultar aspectos como la fecha de finalización actualizada, que antes solamente estaban disponibles en los diferentes Excel de cada programa. También creo que podría ser útil de cara a análisis de cómo se reparten las zonas entre los diferentes programas (por ejemplo, si una zona cubierta en el UNICO 2021 luego tiene zonas cercanas en UNICO 2022 cubiertas por ejemplo por otro operador), o incluso posibles solapes (por ejemplo debido a zonas que quedaron sin ejecutar en anteriores programas)