Blog
La Unión Europea se encuentra a la vanguardia del desarrollo de la inteligencia artificial (IA) segura, ética y centrada en las personas. A través de un marco reglamentario sólido, basado en los derechos humanos y valores fundamentales, la UE está construyendo un ecosistema de IA que beneficia simultáneamente a la ciudadanía, las empresas y las administraciones públicas. Como parte de su compromiso por el correcto desarrollo de esta tecnología, la Comisión Europea ha propuesto un conjunto de acciones para impulsar su excelencia.
En este sentido, destaca una normativa pionera que establece un marco jurídico global: la Ley de IA. En ella, los modelos de inteligencia artificial se clasifican según su nivel de riesgo y se establecen obligaciones concretas para los proveedores relativas a los datos y su gobernanza. Paralelamente, el Plan Coordinado sobre la IA actualizado en 2021 establece una hoja de ruta para impulsar la inversión, armonizar políticas y fomentar la adopción de la IA en toda la UE.
España está alineada con Europa en esta materia y por ello cuenta con una estrategia para acelerar su desarrollo y expansión. Además, recientemente, se ha aprobado la trasposición de la ley IA, con el anteproyecto de ley para un uso ético, inclusivo y beneficioso de la inteligencia artificial.
Proyectos europeos que transforman sectores clave
En este contexto, la UE está financiando numerosos proyectos que utilizan tecnologías de inteligencia artificial para resolver desafíos en diversos ámbitos. A continuación, destacamos algunos de los más innovadores, algunos de ellos ya finalizados y otros en marcha:
Agricultura y sostenibilidad alimentaria
Proyectos actualmente en curso:
-
ANTARES: desarrolla tecnologías de sensores inteligentes y big data para ayudar a los agricultores a producir más alimentos de manera sostenible, beneficiando a la sociedad, los ingresos agrícolas y el medio ambiente.
Ejemplos de otros proyectos ya finalizados:
-
Pantheon: desarrolló un sistema de control y adquisición de datos, equivalente al industrial SCADA, para la agricultura de precisión en grandes huertos de avellanas, aumentando la producción, reduciendo insumos químicos y simplificando la gestión.
-
Trimbot2020: investigó tecnologías de robótica y visión para crear el primer robot de jardinería para exteriores, capaz de navegar por terrenos variados y recortar rosales, setos y topiarios.
Industria y manufactura
Proyectos actualmente en curso:
-
SERENA: aplica técnicas de IA para predecir necesidades de mantenimiento de equipos industriales, reduciendo costes y tiempo, y mejorando la productividad de los procesos de producción.
-
SecondHands: ha desarrollado un robot capaz de ofrecer ayuda proactiva a técnicos de mantenimiento, reconociendo la actividad humana y anticipando sus necesidades, lo que aumenta la eficiencia y productividad en entornos industriales.
Ejemplos de otros proyectos ya finalizados:
-
QU4LITY: combinó datos e IA para aumentar la sostenibilidad de la fabricación, proporcionando un modelo de fabricación de cero defectos basado en datos compartidos, amigable para las PYME, estandarizado y transformador.
-
KYKLOS 4.0: estudió cómo los sistemas ciberfísicos, la gestión del ciclo de vida del producto, la realidad aumentada y la IA pueden transformar la fabricación circular mediante siete proyectos piloto a gran escala.
Transporte y movilidad
Proyectos actualmente en curso
-
VI-DAS: proyecto de una empresa española que trabaja en sistemas avanzados de asistencia al conductor y ayudas a la navegación, combinando la comprensión del tráfico con la consideración del estado físico, mental y conductual del conductor para mejorar la seguridad vial.
-
PILOTING: adapta, integra y demuestra soluciones robóticas en una plataforma integrada para la inspección y mantenimiento de refinerías, puentes y túneles. Uno de sus focos es el impulso de la producción y acceso a datos de inspecciones.
Ejemplos de otros proyectos ya finalizados:
-
FABULOS: ha desarrollado y probado un sistema de transporte público local que utiliza minibuses autónomos, demostrando su viabilidad y promoviendo la introducción de tecnologías robóticas en la infraestructura pública.
Investigación en impacto social
Proyectos actualmente en curso:
-
HUMAINT: proporciona una comprensión multidisciplinaria del estado actual y evolución futura de la inteligencia de las máquinas y su impacto potencial en el comportamiento humano, enfocándose en capacidades cognitivas y socioemocionales.
-
AI Watch: monitorea la capacidad industrial, tecnológica y de investigación, las iniciativas políticas en los Estados miembros, la adopción y desarrollos técnicos de la IA y su impacto en la economía, sociedad y servicios públicos.
Ejemplos de otros proyectos ya finalizados:
-
TECHNEQUALITY: examinó las consecuencias sociales potenciales de la era digital, estudiando cómo la IA y los robots afectan al trabajo y cómo la automatización puede impactar de manera diferente a diversos grupos sociales.
Salud y bienestar
Proyectos actualmente en curso:
-
DeepHealth: desarrolla herramientas avanzadas para el procesamiento de imágenes médicas y modelos predictivos, facilitando el trabajo diario del personal sanitario sin necesidad de combinar múltiples herramientas.
-
BigO: recopila y analiza datos anónimos sobre patrones de comportamiento infantil y su entorno para extraer evidencias sobre factores locales involucrados en la obesidad infantil.
Ejemplos de otros proyectos ya finalizados:
-
PRIMAGE: ha creado una plataforma basada en la nube para apoyar la toma de decisiones relativa a tumores sólidos malignos, ofreciendo herramientas predictivas para su diagnóstico, pronóstico y seguimiento, mediante biomarcadores de imagen y simulación del crecimiento tumoral.
-
SelfBACK: proporcionó apoyo personalizado a pacientes con dolor lumbar a través de una aplicación móvil, utilizando datos recogidos por sensores para adaptar las recomendaciones a cada usuario.
-
EYE-RISK: desarrolló herramientas que predicen la probabilidad de desarrollar enfermedades oculares relacionadas con la edad y medidas para reducir este riesgo, incluyendo un panel diagnóstico para evaluar la predisposición genética.
-
Solve-RD: mejoró el diagnóstico de enfermedades raras mediante la agrupación de datos de pacientes y métodos genéticos avanzados.
El futuro de la IA en Europa
Estos ejemplos, tanto pasados como presentes, son casos de uso muy interesantes del desarrollo de la inteligencia artificial en Europa. No obstante, la apuesta de la UE por la IA también es a futuro. Y se refleja en un ambicioso plan de inversión: la Comisión planea invertir 1.000 millones de euros anuales en IA, procedentes de los programas Europa Digital y Horizonte Europa, con el objetivo de atraer más de 20.000 millones de euros de inversión total en IA al año durante esta década.
El desarrollo de una IA ética, transparente y centrada en el ser humano es ya un objetivo de la UE que va más allá del marco jurídico. Con un enfoque práctico, la Unión Europea financia proyectos que no solo impulsan la innovación tecnológica, sino que abordan retos sociales fundamentales, desde la salud hasta el cambio climático, construyendo un futuro más sostenible, inclusivo y próspero para todos los ciudadanos europeos.
Noticia
No hay duda de que la inteligencia artificial se ha convertido en un pilar fundamental de la innovación tecnológica. Hoy en día, mediante inteligencia artificial (IA) se pueden crear chatbots especializados en datos abiertos, aplicaciones que faciliten el trabajo profesional e incluso un gemelo digital de la Tierra para anticiparse a desastres naturales.
Las posibilidades son infinitas, sin embargo, el futuro de la IA también tiene retos a superar para que los modelos sean más inclusivos, accesibles y transparentes. En este sentido, la Unión Europea está desarrollando diversas iniciativas para conseguir avanzar en este campo.
Marco regulatorio europeo a favor de una IA más abierta y transparente
El planteamiento de la UE en materia de IA busca ofrecer a los ciudadanos la confianza necesaria para adoptar estas tecnologías y animar a las empresas a desarrollarlas. Para ello, el Reglamento Europeo de IA establece unas pautas de desarrollo de la inteligencia artificial alineadas con los valores europeos de privacidad, seguridad y diversidad cultural. Por otro lado, el Reglamento de Gobernanza de Datos (DGA) define que se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
Junto con la Ley de Inteligencia Artificial, la actualización del Plan Coordinado sobre la IA garantiza la seguridad y los derechos fundamentales de las personas y las empresas, reforzando al mismo tiempo la inversión y la innovación en todos los países de la UE. La Comisión también ha puesto en marcha un paquete de innovación en materia de inteligencia artificial para ayudar a las empresas emergentes y pymes europeas a que desarrollen una IA fiable que respete los valores y normas de la UE.
Otras instituciones también están trabajando en el impulso de una inteligencia impulsando los modelos de IA de código abierto como una solución muy interesante. Un informe reciente de Open Future y Open Source Initiative (OSI) define cómo debería ser la gobernanza de datos en los modelos de IA open source. Uno de los desafíos que destaca el informe es, precisamente, lograr un equilibrio entre apertura de datos y derechos sobre los mismos, conseguir más transparencia y evitar sesgos culturales. De hecho, los expertos en la materia Ricard Martínez y Carmen Torrijos debatieron sobre este tema en el pódcast de datos.gob.es.
El proyecto OpenEuroLLM
Con el objetivo de solventar los posibles desafíos y planteándose como una solución innovadora y abierta, la Unión Europea, a través del programa Europa Digital ha presentado A través de este proyecto de inteligencia artificial de código abierto se esperan crear modelos de lenguaje eficientes, transparentes y alineados con la normativa europea de IA.
El proyecto OpenEuroLLM tiene como meta principal el desarrollo de modelos de lenguaje de última generación que sirvan para una amplia variedad de aplicaciones tanto públicas como privadas. Entre los objetivos más destacados, podemos mencionar:
- Extender las capacidades multilingües de los modelos existentes: esto incluye no solo las lenguas oficiales de la Unión Europea, sino también otras lenguas que son de interés social y económico. Europa es un continente rico en diversidad lingüística, y el proyecto busca reflejar esa diversidad en los modelos de IA.
- Acceso sostenible a modelos fundamentales: los modelos desarrollados dentro del proyecto serán fáciles de acceder y estarán listos para ser ajustados a diversas aplicaciones. Esto no solo beneficiará a grandes empresas, sino también a pequeñas y medianas empresas (PYMES) que deseen integrar la IA en sus procesos sin enfrentar barreras tecnológicas.
- Evaluación de resultados y alineación con la normativa europea: los modelos serán evaluados de acuerdo con rigurosos estándares de seguridad y alineación con el Reglamento Europeo de IA y otros marcos regulatorios europeos. Esto garantizará que las soluciones de IA sean seguras y respetuosas con los derechos fundamentales.
- Transparencia y accesibilidad: una de las premisas del proyecto es compartir de manera abierta las herramientas, procesos y resultados intermedios de los procesos de entrenamiento. Esto permitirá que otros investigadores y desarrolladores puedan reproducir, mejorar y adaptar los modelos para sus propios propósitos.
- Fomento de la comunidad: OpenEuroLLM no se limita a la creación de modelos, sino que también tiene como objetivo construir una comunidad activa y comprometida, tanto en el sector público como en el privado, que pueda colaborar, compartir conocimientos y trabajar en conjunto para avanzar en la investigación de IA.
El Consorcio OpenEuroLLM: un proyecto colaborativo y multinacional
El proyecto OpenEuroLLM está siendo desarrollado por un consorcio de 20 instituciones europeas de investigación, empresas tecnológicas y centros de supercomputación, bajo la coordinación de la Universidad de Charles (República Checa) y la colaboración de Silo GenAI (Finlandia). El consorcio reúne a algunas de las instituciones y empresas líderes en el campo de la inteligencia artificial en Europa, creando una colaboración multinacional para desarrollar modelos de lenguaje de código abierto.
Entre las principales instituciones que participan en el proyecto se encuentran universidades de renombre como la Universidad de Helsinki (Finlandia) o la Universidad de Oslo (Noruega), así como empresas tecnológicas como Aleph Alpha Research (Alemania) o la empresa ilicitana prompsit (España), entre otras. Además, los centros de supercomputación como Barcelona Supercomputing Center (España) o SURF (Países Bajos) proporcionan la infraestructura necesaria para entrenar modelos a gran escala.
Diversidad lingüística, transparencia y conformidad con las normas de la UE
Uno de los mayores desafíos de la inteligencia artificial globalizada es la inclusión de múltiples idiomas y la preservación de las diferencias culturales. Europa, con su vasta diversidad lingüística, presenta un entorno único para abordar estos problemas. OpenEuroLLM se compromete a preservar esa diversidad y garantizar que los modelos de IA desarrollados sean sensibles a las variaciones lingüísticas y culturales de la región.
Como hemos visto al inicio del post, el desarrollo tecnológico debe ir de la mano de los valores éticos y responsables. En este sentido, una de las características clave del proyecto OpenEuroLLM es su enfoque en la transparencia. Los modelos, los datos, la documentación, el código de entrenamiento y las métricas de evaluación estarán completamente disponibles para el público. Esto permitirá que investigadores y desarrolladores puedan auditar, modificar y mejorar los modelos, garantizando un enfoque abierto y colaborativo.
Además, el proyecto se alinea con las estrictas normativas europeas de IA. OpenEuroLLM está diseñado para cumplir con la Ley de IA de la UE, que establece criterios rigurosos para garantizar la seguridad, la equidad y la privacidad en los sistemas de inteligencia artificial.
Democratización del acceso a la IA
Uno de los logros más importantes de OpenEuroLLM es la democratización del acceso a la IA de alto rendimiento. Los modelos de código abierto permitirán que empresas, instituciones académicas y organizaciones del sector público de toda Europa tengan acceso a tecnología de vanguardia, independientemente de su tamaño o presupuesto.
Esto es especialmente relevante para las pequeñas y medianas empresas (PYMES), que a menudo enfrentan dificultades para acceder a soluciones de IA debido a los altos costos de licencias o las barreras tecnológicas. OpenEuroLLM eliminará estas barreras y permitirá que las empresas desarrollen productos y servicios innovadores utilizando IA, lo que contribuirá al crecimiento económico de Europa.
El proyecto OpenEuroLLM también es una apuesta de la UE por la soberanía digital que está invirtiendo de manera estratégica en el desarrollo de infraestructura tecnológica que reduzca la dependencia de actores globales y refuerce la competitividad europea en el ámbito de la inteligencia artificial. Este es un paso importante hacia una inteligencia artificial que no solo sea más avanzada, sino también más justa, segura y responsable.
Blog
La creciente adopción de sistemas de inteligencia artificial (IA) en ámbitos críticos como la administración pública, los servicios financieros o la atención sanitaria ha puesto en primer plano la necesidad de transparencia algorítmica. La complejidad de los modelos de IA que se utilizan para tomar decisiones como la concesión de un crédito o la realización de un diagnóstico médico, especialmente en lo que se refiere a algoritmos de aprendizaje profundo, a menudo da lugar a lo que comúnmente se conoce como el problema de la "caja negra", esto es, la dificultad de interpretar y comprender cómo y por qué un modelo de IA llega a una determinada conclusión. Los LLM o SLM que tanto utilizamos últimamente son un claro ejemplo de un sistema de caja negra donde ni los propios desarrolladores son capaces de prever sus comportamientos.
En sectores regulados, como el financiero o el sanitario, las decisiones basadas en IA pueden afectar significativamente la vida de las personas y, por tanto, no es admisible que generan dudas sobre su posible sesgo o atribución de responsabilidades. Por ello, los gobiernos han comenzado a desarrollar marcos normativos como el Reglamento de Inteligencia Artificial que exigen mayor explicabilidad y supervisión en el uso de estos sistemas con el fin adicional de generar confianza en los avances de la economía digital.
La inteligencia artificial explicable (conocida como XAI, del inglés explainable artificial intelligence) es la disciplina que surge como respuesta a este desafío, proponiendo métodos para hacer comprensibles las decisiones de los modelos de IA. Al igual que en otras áreas relacionados con la inteligencia artificial, como el entrenamiento de los LLM, los datos abiertos son un aliado importante de la inteligencia artificial explicable para construir mecanismos de auditoría y verificación de los algoritmos y sus decisiones.
¿Qué es la IA explicable (XAI)?
La IA explicable se refiere a métodos y herramientas que permiten a los humanos comprender y confiar en los resultados de los modelos de aprendizaje automático. Según el Instituto Nacional de Estándares y Tecnología (NIST) de EE. UU. son cuatro los principios clave de la Inteligencia Artificial Explicable de forma que se pueda garantizar que los sistemas de IA sean transparentes, comprensibles y confiables para los usuarios:
- Explicabilidad (Explainability): la IA debe proporcionar explicaciones claras y comprensibles sobre cómo llega a sus decisiones y recomendaciones.
- Justificabilidad (Meaningful): las explicaciones deben ser significativas y comprensibles para los usuarios.
- Precisión (Accuracy): la IA debe generar resultados precisos y confiables, y la explicación de estos resultados debe reflejar fielmente su desempeño.
- Límites del conocimiento (Knowledge Limits): la IA debe reconocer cuándo no tiene suficiente información o confianza en una decisión y abstenerse de emitir respuestas en esos casos.
A diferencia de los sistemas de IA tradicionales de "caja negra", que generan resultados sin revelar su lógica interna, XAI trabaja sobre la trazabilidad, interpretabilidad y responsabilidad de estas decisiones. Por ejemplo, si una red neuronal rechaza una solicitud de préstamo, las técnicas de XAI pueden destacar los factores específicos que influyeron en la decisión. De este modo, mientras un modelo tradicional simplemente devolvería una calificación numérica del expediente de crédito, un sistema XAI podría decirnos además algo como que "El historial de pagos (23%), la estabilidad laboral (38%) y el nivel de endeudamiento actual (32%) fueron los factores determinantes en la denegación del préstamo”. Esta transparencia es vital no solo para el cumplimiento normativo, sino también para fomentar la confianza del usuario y la mejora de los propios sistemas de IA.
Técnicas clave en XAI
El Catálogo de herramientas y métricas IA confiable del Observatorio de Políticas de Inteligencia Artificial de la OCDE (OECD.AI) recopila y comparte herramientas y métricas diseñadas para ayudar a los actores de la IA a desarrollar sistemas confiables que respeten los derechos humanos y sean justos, transparentes, explicables, robustos, seguros y confiables. Por ejemplo, dos metodologías ampliamente adoptadas en XAI son Local Interpretable Model-agnostic Explanations (LIME) y SHapley Additive exPlanations (SHAP).
- LIME aproxima modelos complejos con versiones más simples e interpretables para explicar predicciones individuales. Es una técnica en general útil para interpretaciones rápidas, pero no muy estable en la asignación de la importancia de las variables entre unos ejemplos y otros.
- SHAP cuantifica la contribución exacta de cada variable de entrada a una predicción utilizando principios de teoría de juegos. Se trata de una técnica más precisa y matemáticamente sólida, pero mucho más costosa computacionalmente.
Por ejemplo, en un sistema de diagnóstico médico, tanto LIME como SHAP podrían ayudarnos a interpretar que la edad y la presión arterial de un paciente fueron los principales factores que concluyeron en un diagnóstico de alto riesgo de infarto, aunque SHAP nos daría la contribución exacta de cada variable a la decisión.
Uno de los desafíos más importantes en XAI es encontrar el equilibrio entre la capacidad predictiva de un modelo y su explicabilidad. Por ello suelen utilizarse enfoques híbridos que integren métodos de explicación a posteriori de las decisiones tomadas con modelos complejos. Por ejemplo, un banco podría implementar un sistema de aprendizaje profundo para la detección de fraude, pero usar valores SHAP para auditar sus decisiones y garantizar que no se toman decisiones discriminatorias.
Los datos abiertos en la XAI
Existen, al menos, dos escenarios en los que se puede generar valor combinando datos abiertos con técnicas de inteligencia artificial explicable:
- El primero de ellos es el enriquecimiento y validación de las explicaciones obtenidas con técnicas XAI. Los datos abiertos permiten añadir capas de contexto a muchas explicaciones técnicas, algo que también es válido para la explicabilidad de los modelos de IA. Por ejemplo, si un sistema XAI indica que la contaminación atmosférica influyó en un diagnóstico de asma, vincular este resultado con conjuntos de datos abiertos de calidad del aire de las áreas de residencia de los pacientes permitiría validar si el resultado es correcto.
- La mejora del rendimiento de los propios modelos de IA es otra área en el que los datos abiertos aportan valor. Por ejemplo, si un sistema XAI identifica que la densidad de espacios verdes urbanos afecta significativamente los diagnósticos de riesgo cardiovascular, se podrían utilizar datos abiertos de urbanismo para mejorar la precisión del algoritmo.
Sería ideal que se pudiesen compartir como datos abiertos los conjuntos de datos de entrenamiento de los modelos de IA, de forma que fuese posible verificar el entrenamiento del modelo y replicar los resultados. En todo caso, lo que sí es posible es compartir de forma abierta son metadatos detallados sobre dichos entrenamientos como promueve la iniciativa Model Cards de Google, facilitando así explicaciones post-hoc de las decisiones de los modelos. En este caso se trata de un instrumento más orientado a los desarrolladores que a los usuarios finales de los algoritmos.
En España, en una iniciativa más dirigida a los ciudadanos, pero igualmente destinada a fomentar la transparencia en el uso de algoritmos de inteligencia artificial, la Administración Abierta de Cataluña ha comenzado a publicar fichas comprensibles para cada algoritmo de IA aplicado a los servicios de administración digital. Ya están disponibles algunas, como, por ejemplo, la de los Chatbots conversacionales de la AOC o la de la Videoidentificación para obtener el idCat Móvil.
Ejemplos reales de datos abiertos y XAI
Un artículo reciente publicado en Applied Sciences por investigadores portugueses ejemplifica la sinergia entre XAI y datos abiertos en el ámbito de la predicción de precios inmobiliarios en ciudades inteligentes. La investigación destaca cómo la integración de conjuntos de datos abiertos que abarcan características de propiedades, infraestructuras urbanas y redes de transporte, con técnicas de inteligencia artificial explicable, como el análisis SHAP, permite desentrañar los factores clave que influyen en los valores de las propiedades. Este enfoque pretende apoyar la generación de políticas de planificación urbana que respondan a las necesidades y tendencias evolutivas del mercado inmobiliario, promoviendo un crecimiento sostenible y equitativo de las ciudades.
Otro estudio realizado por investigadores de INRIA (Instituto francés de investigación en ciencias y tecnologías digitales), también sobre datos inmobiliarios, profundiza en los métodos y desafíos asociados a la interpretabilidad en el aprendizaje automático apoyándose en datos abiertos enlazados. El artículo analiza tanto técnicas intrínsecas, que integran la explicabilidad en el diseño del modelo, como métodos post hoc que permiten examinar y explicar las decisiones de sistemas complejos para fomentar la adopción de sistemas de IA transparentes, éticos y confiables.
A medida que la IA continúa evolucionando, las consideraciones éticas y las medidas regulatorias tienen un papel cada vez más relevante en la creación de un ecosistema de IA más transparente y confiable. La inteligencia artificial explicable y los datos abiertos están interconectados en su objetivo de fomentar la transparencia, la confianza y la responsabilidad en la toma de decisiones basadas en IA. Mientras que la XAI ofrece las herramientas para diseccionar la toma de decisiones de la IA, los datos abiertos proporcionan la materia prima no solo para el entrenamiento, sino para comprobar algunas explicaciones de la XAI y mejorar los rendimientos de los modelos. A medida que la IA continúa permeando en cada faceta de nuestras vidas, fomentar esta sinergia contribuirá a construir sistemas que no solo sean más inteligentes, sino también más justos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
No hay duda de que la formación en competencias digitales es necesaria hoy en día. Los conocimientos digitales básicos son fundamentales para poder interactuar en una sociedad en la que la tecnología ya juega un papel transversal. En concreto, es importante conocer aspectos básicos de la tecnología para trabajar con datos.
En este contexto, las trabajadoras y trabajadores del sector público también deben mantenerse en constante actualización. Capacitarse en este ámbito es clave para optimizar procesos, garantizar la seguridad de la información y fortalecer la confianza en las instituciones.
En este post, identificamos habilidades digitales relacionadas con los datos abiertos tanto dirigidas a la publicación como al uso de estos. No solo identificamos las competencias profesionales que deben tener y mantener los empleados públicos que trabajan con open data, también recopilamos una serie de recursos formativos que están a su disposición.
Competencias profesionales para trabajar con datos
En el Encuentro Nacional de Datos Abiertos de 2024 se constituyó un grupo de trabajo con un objetivo: identificar las competencias digitales que debían tener los profesionales de la administración pública que trabajasen con datos abiertos. Más allá de las conclusiones de este evento de relevancia nacional, el grupo de trabajo definió perfiles y roles necesarios para la apertura de datos, recogiendo información sobre sus funciones y las capacidades y conocimientos necesarios. Los principales roles identificados fueron:
- Rol responsable: tiene funciones de responsabilidad técnica en el impulso de políticas de datos abiertos y organiza actividades de definición de las políticas y modelos de datos. Algunos conocimientos necesarios son:
- Liderazgo en el impulso de estrategias para impulsar la apertura del dato.
- Impulsar la estrategia del dato para impulsar la apertura con propósito.
- Comprender el marco normativo relacionado con los datos para actuar dentro de la legalidad en todo el ciclo de vida del dato.
- Fomentar el uso de herramientas y procesos para la gestión del dato.
- Capacidad de generar sinergias para consensuar instrucciones transversales a toda la organización.
- Rol técnico de apertura de datos (perfil TIC): desarrolla actividades de ejecución más vinculadas con la gestión de los sistemas, los procesos de extracción, limpieza de datos, etc. Este perfil debe conocer, por ejemplo:
- Cómo estructurar el conjunto de datos, el vocabulario de metadatos, calidad del dato, estrategia a seguir...
- Ser capaz de analizar un conjunto de datos e identificar los procesos de depuración y limpieza de manera rápida e intuitiva.
- Generar visualizaciones de datos, conectando bases de datos de diferentes formatos y orígenes, y así obtener gráficos, indicadores y mapas dinámicos e interactivos.
- Dominar las funcionalidades de la plataforma, es decir, saber aplicar soluciones tecnológicas para la gestión de datos abiertos o conocer técnicas y estrategias para acceder, extraer e integrar datos de diferentes plataformas.
- Rol funcional de apertura de datos (técnico de un servicio): ejecuta actividades más vinculadas con la selección de datos a publicar, la calidad, promoción de los datos abiertos, visualización, analítica de datos, etc. Por ejemplo:
- Manejar herramientas de visualización y dinamización.
- Conocer la economía del dato y conocer la información referente al dato en toda su extensión (generación por las AAPP, datos abiertos, infomediarios, reutilización de la información pública, Big Data, Data Driven, roles implicados, etc.).
- Conocer y aplicar los aspectos éticos y de protección de datos de carácter personal que aplican a la apertura de datos.
- Uso de datos por parte de los trabajadores públicos: este perfil lleva a cabo actividades sobre el uso de los datos para la toma de decisiones, analítica básica de datos, entre otros. Para ello, deberá tener estas competencias:
- Navegación, búsqueda y filtrado de datos.
- Evaluación de datos.
- Almacenamiento y explotación de datos.
- Análisis y explotación de datos.
Además, como parte de este reto para incrementar las capacidades para la apertura de datos, se elaboró un listado de formaciones y guías gratuitas en materia de datos abiertos y análisis de datos. Recopilamos algunas de ellas que están disponibles online y en formato abierto.
| Institución | Recurso | Enlace | Nivel |
|---|---|---|---|
| Centro Knight para el Periodismo en las Américas | Periodismo de datos y visualización con herramientas gratuitas | https://journalismcourses.org/es/course/dataviz/ | Principiante |
| Data Europa Academy | Introducción a los datos abiertos | https://data.europa.eu/en/academy/introducing-open-data | Principiante |
| Data Europa Academy | Comprender el lado legal de los datos abiertos | https://data.europa.eu/en/academy/understanding-legal-side-open-data | Principante |
| Data Europa Academy | Mejorar la calidad de los datos abiertos y los metadatos | https://data.europa.eu/en/academy/improving-open-data-and-metadata-quality | Avanzado |
| Data Europa Academy | Medir el éxito en las iniciativas de datos abiertos | https://data.europa.eu/en/training/elearning/measuring-success-open-data-initiatives | Avanzado |
| Escuela de Datos | Curso de tubería de datos – Data Pipeline | https://escueladedatos.online/curso/curso-tuberia-de-datos-data-pipeline/ | Intermedio |
| FEMP | Guía estratégica para su puesta en marcha – Conjuntos de datos mínimos a publicar | https://redtransparenciayparticipacion.es/download/guia-estrategica-para-su-puesta-en-marcha-conjuntos-de-datos-minimos-a-publicar/ | Intermedio |
| Datos.gob.es | Pautas metodológicas para la apertura de datos | /es/conocimiento/pautas-metodologicas-para-la-apertura-de-datos | Principiante |
| Datos.gob.es | Guía práctica para la publicación de datos abiertos usando APIs | /es/conocimiento/guia-practica-para-la-publicacion-de-datos-abiertos-usando-apis | Intermedio |
| Datos.gob.es | Guía práctica para la publicación de datos espaciales | /es/conocimiento/guia-practica-para-la-publicacion-de-datos-espaciales | Intermedio |
| Junta de Andalucía | Tratar conjuntos de datos con Open Refine | https://www.juntadeandalucia.es/datosabiertos/portal/tutoriales/usar-openrefine.html | Principiante |
Figura 1. Tabla de elaboración propia con recursos formativos. Fuente: https://encuentrosdatosabiertos.es/wp-content/uploads/2024/05/Reto-2.pdf
El Instituto Nacional de Administración Pública (INAP) cuenta con un Programa de Actividades Formativas para 2025, enmarcado en la Estrategia de Aprendizaje del INAP 2025-2028. Este catálogo formativo incluye más de 180 actividades organizadas en diferentes programas de aprendizaje, que se desarrollarán a lo largo del año con el objetivo de fortalecer las competencias del personal público en ámbitos clave como la gestión de datos abiertos y el uso de tecnologías relacionadas.
En el programa formativo de INAP para 2025 se ofrece una amplia variedad de cursos orientados a mejorar las capacidades digitales y la alfabetización en datos abiertos. Algunas de las formaciones destacadas incluyen:
- Fundamentos y herramientas del análisis de datos.
- Introducción a SQL de Oracle.
- Datos abiertos y reutilización de la información.
- Análisis y visualización de datos con Power BI.
- Blockchain: aspectos técnicos.
- Programación en Python avanzado.
Estos cursos, dirigidos a distintos perfiles de empleados públicos, desde responsables de datos abiertos hasta técnicos en gestión de información, permiten adquirir conocimientos sobre extracción, tratamiento y visualización de datos, así como sobre estrategias para la apertura y reutilización de datos abiertos en la Administración Pública. Puedes consultar el catálogo completo aquí.
Otras referencias formativas
Algunas administraciones públicas o entidades disponen de oferta de cursos de formación vinculadas a los datos abiertos. Para más información de su oferta formativa, se facilita el catálogo con la oferta de cursos programados.
- Red de entidades locales por la Transparencia y la Participación Ciudadana de la FEMP: https://redtransparenciayparticipacion.es/
- Gobierno de Aragón. Aragón Open Data: https://opendata.aragon.es/informacion/eventos-de-datos-abiertos
- Escuela de Administración Pública de Catalunya (EAPC): https://eapc.gencat.cat/ca/inici/index.html
- Diputació de Barcelona: http://aplicacions.diba.cat/gestforma/public/cercador_baf_ens_locals
- Instituto Geográfico Nacional (IGN): https://cursos.cnig.es/
En resumen, la formación en competencias digitales, en general, y en datos abiertos, en particular, es una práctica que recomendamos desde datos.gob.es. ¿Necesitas algún recurso formativo en específico? Escríbenos en comentarios, ¡te leemos!
Blog
La inteligencia artificial (IA) de código abierto es una oportunidad para democratizar la innovación y evitar la concentración de poder en la industria tecnológica. Sin embargo, su desarrollo depende en gran medida de la disponibilidad de conjuntos de datos de alta calidad y de la implementación de marcos sólidos de gobernanza de datos. Un informe reciente de Open Future y la Open Source Initiative (OSI) analiza los desafíos y oportunidades en esta intersección, proponiendo soluciones para una gobernanza de datos equitativa y responsable. Puedes leer aquí el informe completo.
En este post, analizaremos las ideas más relevantes del documento, así como los consejos que ofrece para garantizar una correcta y efectiva gobernanza de datos en la inteligencia artificial open source y aprovechar todas sus ventajas.
Los retos de la gobernanza de datos en la IA
A pesar de la gran cantidad de datos disponibles en la web, su acceso y uso para entrenar modelos de IA plantean importantes desafíos éticos, legales y técnicos. Por ejemplo:
- Equilibrio entre apertura y derechos: en línea con el Reglamento de Gobernanza de Datos (DGA), se debe garantizar un acceso amplio a los datos sin comprometer derechos de propiedad intelectual, privacidad y equidad.
- Falta de transparencia y estándares de apertura: es importante que los modelos etiquetados como “abiertos” cumplan con criterios claros de transparencia en el uso de datos.
- Sesgos estructurales: muchos conjuntos de datos reflejan sesgos lingüísticos, geográficos y socioeconómicos que pueden perpetuar desigualdades en los sistemas de IA.
- Sostenibilidad ambiental: el uso intensivo de recursos para entrenar modelos de IA plantea desafíos de sostenibilidad que deben abordarse con prácticas más eficientes.
- Involucrar a más actores: actualmente, los desarrolladores y las grandes corporaciones dominan la conversación sobre IA, dejando fuera a comunidades afectadas y organizaciones públicas.
Una vez identificados los retos, el informe propone una estrategia para alcanzar el objetivo principal: una gobernanza de datos adecuada en los modelos de IA de código abiertos. Este enfoque está basado en dos pilares fundamentales.
Hacia un nuevo paradigma de gobernanza de datos
En la actualidad, el acceso y la gestión de los datos para entrenar modelos de IA están marcados por una creciente desigualdad. Mientras algunas grandes corporaciones tienen acceso exclusivo a vastos repositorios de datos, muchas iniciativas de código abierto y comunidades marginadas carecen de los recursos para acceder a datos representativos y de calidad. Para abordar este desequilibrio es necesario un nuevo enfoque en la gestión y uso de los datos en la IA de código abierto. El informe destaca dos cambios fundamentales en la manera en que se concibe la gobernanza de datos:
Por un lado, adoptar un enfoque de data commons que no es más que un modelo de acceso que garantiza el equilibrio entre la apertura de datos y la protección de derechos. Para ello, sería importante utilizar licencias innovadoras que permitan compartir datos sin explotación indebida. También es relevante crear estructuras de gobernanza que regulen el acceso y uso de datos. Y, por último, implementar mecanismos de compensación para comunidades cuyos datos son utilizados en inteligencia artificial.
Por otro lado, es necesario trascender la visión centrada en desarrolladores de IA e incluir a más actores en la gobernanza de datos, como:
- Propietarios de los datos y comunidades que generan contenido.
- Instituciones públicas que pueden promover estándares de apertura.
- Organizaciones de la sociedad civil que velen por la equidad y el acceso responsable a los datos.
Al adoptar estos cambios, la comunidad de IA podrá establecer un sistema más inclusivo, en el que los beneficios del acceso a datos se distribuyan de manera equitativa y respetuosa con los derechos de todas las partes interesadas. Según el informe, la implementación de estos modelos no solo aumentará la cantidad de datos disponibles para la IA de código abierto, sino que también fomentará la creación de herramientas más justas y sostenibles para la sociedad en su conjunto.
Consejos y estrategia
Para hacer efectiva una gobernanza de datos robusta en la IA de código abierto, el informe propone seis áreas de acción prioritarias:
- Preparación y trazabilidad de datos: mejorar la calidad y documentación de los conjuntos de datos.
- Mecanismos de licenciamiento y consentimiento: permitir a los creadores de datos definir su uso de manera clara.
- Custodia de datos: fortalecer la figura de intermediarios que gestionen datos de forma ética.
- Sostenibilidad ambiental: reducir el impacto del entrenamiento de IA con prácticas eficientes.
- Compensación y reciprocidad: garantizar que los beneficios de la IA lleguen a quienes contribuyen con datos.
- Intervenciones de política pública: promover regulaciones que incentiven la transparencia y el acceso equitativo a datos.

La inteligencia artificial de código abierto puede impulsar la innovación y la equidad, pero para lograrlo es necesario un enfoque de gobernanza de datos más inclusivo y sostenible. Adoptar modelos de datos comunes y ampliar el ecosistema de actores permitirá construir sistemas de IA más justos, representativos y responsables con el bien común.
El informe que publican Open Future y Open Source Initiative hace una llamada a la acción a desarrolladores, legisladores y sociedad civil para establecer normas compartidas y soluciones que equilibren la apertura de datos con la protección de derechos. Con una gobernanza de datos sólida, la IA de código abierto podrá cumplir su promesa de servir al interés público.
Documentación
Introducción
En anteriores contenidos, hemos explorado a fondo el apasionante mundo de los Modelos Grandes de Lenguaje (LLM) y, en particular, las técnicas de Generación Aumentada por Recuperación (RAG) que están revolucionando la forma en que interactuamos con los agentes conversacionales. Este ejercicio marca un hito en nuestra serie, ya que no solo explicaremos los conceptos, sino que también te guiaremos paso a paso en la construcción de tu propio agente conversacional potenciado con RAG. Para ello, utilizaremos un notebook de Google Colab.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
A través de este notebook, construiremos un chat que utiliza RAG para mejorar sus respuestas, partiendo desde cero. El notebook guiará al usuario a través de todo el proceso:
- Instalación de dependencias.
- Configuración del entorno.
- Integración de una fuente de información en forma de post.
- Incorporación de dicha fuente a la base de conocimiento del chat utilizando técnicas RAG.
- Finalmente, podremos observar cómo la respuesta del modelo cambia antes y después de proporcionar el post y realizar una pregunta específica sobre su contenido.
Herramientas utilizadas
Antes de comenzar, es necesario introducir y explicar qué herramientas hemos utilizado y por qué hemos escogido estas. Para la construcción de esta aplicación RAG hemos utilizado 3 piezas de tecnología o herramientas: Google Colab, OpenAI y LangChain. Tanto Google Colab como OpenAI son viejos conocidos y los hemos utilizado varias veces en contenidos previos. Por eso, en esta sección, ponemos especial atención en explicar qué es LangChain puesto que es una nueva herramienta que no hemos utilizado en anteriores posts.
- Google Colab. Como es habitual en nuestros ejercicios, cuando son necesarios recursos de computación, así como un entorno de programación amigable, empleamos Google Colab, en la medida de lo posible. Google Colab nos garantiza que cualquier usuario que quiera reproducir el ejercicio lo pueda hacer sin complicaciones derivadas de la configuración de los entornos particulares de cada programador. Cabe destacar que adecuar este ejercicio inspirado en recursos previos disponibles en LangChain al entorno de Google Colab ha sido un reto.
- OpenAI. Como proveedor del modelo grande del lenguaje (LLM) Chat GPT, OpenAI ofrece una variedad de modelos de lenguaje potentes, como GPT-4, GPT-4o, GPT-4o mini, etc. que se utilizan para procesar y generar texto en lenguaje natural. En este caso, el modelo de lenguaje de OpenAI se utiliza en la zona de generación de la respuesta, donde se combinan la pregunta del usuario y los documentos recuperados para producir una respuesta precisa.
- LangChain. Es un framework (conjunto de bibliotecas) de código abierto diseñado para facilitar el desarrollo de aplicaciones basadas en modelos de lenguaje de gran escala (LLM). Este framework es especialmente útil para integrar y gestionar flujos complejos que combinan múltiples componentes, como modelos de lenguaje, bases de datos vectoriales, y herramientas de recuperación de información, entre otros.
LangChain es ampliamente utilizado en el desarrollo de aplicaciones como:
- Sistemas de preguntas y respuestas (QA systems).
- Asistentes virtuales con conocimiento específico.
- Sistemas de generación de texto personalizados.
- Herramientas de análisis de datos basadas en lenguaje natural.
Características principales de LangChain
- Modularidad y flexibilidad. LangChain está diseñado con una arquitectura modular que permite a los desarrolladores conectar diferentes herramientas y servicios. Esto incluye modelos de lenguaje (como OpenAI, Hugging Face, o LLM locales) y bases de datos vectoriales (como Pinecone, ChromaDB o Weaviate). La La lista de modelos de chat con los que se puede interactuar a través de Langchain es muy amplia.
- Soporte para técnicas RAG (Recuperación Aumentada por Generación). Langhain facilita la implementación de técnicas RAG al permitir la integración directa de modelos de recuperación de información y generación de texto. Esto mejora la precisión de las respuestas al permitir que los LLM trabajen con conocimiento actualizado y específico.
- Optimización del manejo de prompts. Langhain ayuda a diseñar y gestionar prompts complejos de manera eficiente. Permite construir dinámicamente un contexto relevante que se trabaja con el modelo, optimizando el uso de tokens y asegurando que las respuestas sean precisas y útiles.
- Los tokens representan las unidades básicas que un modelo de IA utiliza para procesar texto. Un token puede ser una palabra completa, una parte de una palabra o un signo de puntuación. En la frase "¡Hola mundo!" existen, por ejemplo, cuatro tokens distintos: "¡", "Hola", "mundo", "!". El procesamiento de texto requiere más recursos computacionales a medida que aumenta el número de tokens. Las versiones gratuitas de modelos de IA, incluida la que usamos en este ejercicio, establecen límites en la cantidad de tokens procesables.
- Integración con múltiples fuentes de datos. El framework puede conectarse a diversas fuentes de datos, como bases de datos, API o documentos cargados por los usuarios. Esto lo hace ideal para construir aplicaciones que necesitan acceso a grandes volúmenes de información estructurada o no estructurada.
- Interoperabilidad con múltiples LLM. LangChain es agnóstico (se puede adaptar a varios proveedores de modelos de lenguaje) respecto al proveedor del modelo de lenguaje, lo que significa que puedes utilizar OpenAI, Cohere, Anthropic o incluso modelos de lenguaje alojados localmente.
Para terminar con esta sección, cabe destacar el carácter open source de Langhain, algo que facilita la colaboración y la innovación en el desarrollo de aplicaciones basadas en modelos de lenguaje. Además, LangChain nos aporta una increíble flexibilidad porque permite a los desarrolladores integrar fácilmente diferentes LLM, vectorizadores y hasta interfaces web finales en sus aplicaciones.
Exploración del ejercicio paso a paso
Introducción al Repositorio
El repositorio de Github que utilizaremos contiene todos los recursos necesarios para construir nuestra aplicación RAG. En su interior, encontrarás:
- README: este archivo proporciona una descripción general del proyecto, instrucciones de uso y recursos adicionales.
- Jupyter Notebook: el ejemplo lo hemos desarrollado usando un formato de Jupyter Notebook que ya hemos empleado en el pasado para codificar ejercicios prácticos combinando un documento de texto con fragmentos de código ejecutable en Google Colab. Aquí se encuentra la implementación detallada de la aplicación, incluyendo la carga y procesamiento de datos, la integración con modelos de lenguaje como GPT-44, la configuración de sistemas de recuperación de información y la generación de respuestas basadas en los datos recuperados.
Notebook: preparando el entorno
Antes de comenzar, es recomendable contar con los siguientes requisitos.
- Conocimientos básicos de Python y Procesamiento de Lenguaje Natural (PLN): si bien el notebook es autoexplicativo, una comprensión básica de estos conceptos facilitará el aprendizaje.
- Acceso a Google Colab: el notebook se ejecuta en este entorno, que nos proporciona la infraestructura necesaria.
- Cuentas activas en OpenAI y LangChain con claves de API válidas. Estos servicios son gratuitos y esenciales para la ejecución del notebook. Una vez que te registres en estos servicios, necesitarás generar una API Key para interactuar con los servicios. Deberás tener a mano esta clave para poder pegarla en el momento de ejecutar el fragmento de código correspondiente. Si necesitas ayuda para obtener estas claves, cualquier asistente conversacional como chatGPT o Google Gemini te pueden ayudar paso a paso a conseguir las claves. Si necesitas guía visual en youtube encontraras miles de tutoriales
- OpenAI API: https://openai.com/api/
- Lanchain API: https://www.langchain.com/
Explorando el Notebook: bloque por bloque
El notebook se divide en varios bloques, cada uno dedicado a una etapa específica del desarrollo de nuestra aplicación RAG. A continuación, describiremos cada bloque en detalle, incluyendo el código utilizado y su explicación.
Nota para el usuario. A continuación, vamos a ir reproduciendo bloques del código presentes en el notebook de Colab. Por claridad hemos dividido el código en unidades autocontenidas y hemos formateado el código para resaltar la sintaxis del lenguaje de programación Python. Además, las salidas que el Notebook proporciona, las hemos formateado y resaltado en formato JSON para que sean más legibles. Ha de tenerse en cuenta que este Notebook invoca API de modelos del lenguaje y por lo tanto, la respuesta del modelo cambia con cada ejecución. Esto hace que las salidas (las respuestas) que presentamos en este post puedan no ser exactamente iguales a las que el usuario reciba cuándo ejecute el Notebook en Colab
Bloque 1: instalación y configuración inicial
|
import os |
Es muy importante que ejecutes estas dos líneas al principio del ejercicio y luego ya no lo vuelvas a ejecutar más hasta que cierres y salgas de Google Colab.
|
%%capture |
|
!pip install langchain --quiet |
|
import getpass os.environ["LANGCHAIN_TRACING_V2"] = "true" |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de Langchain.
|
!pip install -qU langchain-openai |
|
import getpass |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de OpenAI.
En este primer bloque, hemos instalado las bibliotecas necesarias para nuestro proyecto. Algunas de las más relevantes son:
- openai: Para interactuar con la API de OpenAI y acceder a modelos como GPT-4.
- langchain: Un framework que simplifica el desarrollo de aplicaciones con LLM.
- langchain-text-splitters: Para dividir textos largos en fragmentos más pequeños que puedan ser procesados por los modelos de lenguaje.
- langchain-community: Una colección de herramientas y componentes adicionales para LangChain.
- langchain-openai: Para integrar LangChain con la API de OpenAI.
- langgraph: Para visualizar el flujo de trabajo de nuestra aplicación RAG.
- Además de instalar las bibliotecas, también configuramos las claves de API para OpenAI y LangChain, utilizando la función getpass.getpass() para introducirlas de forma segura.
Bloque 2: inicializamos la interacción con el LLM
A continuación, iniciamos la primera interacción programática (le pasamos nuestro primer prompt) con el modelo del lenguaje. Para comprobar que todo funciona le pedimos traducir una sencilla frase.
|
import getpass import os ] |
Si todo ha ido bien obtendremos una salida como esta:
|
{ |
Este bloque es una introducción básica a la utilización de un LLM para una tarea sencilla: la traducción. Se configura la clave de API de OpenAI y se instancia un modelo de lenguaje gpt-4o-mini utilizando ChatOpenAI.
Se definen dos mensajes:
- SystemMessage: Instrucción al modelo para traducir del inglés al italiano.
- HumanMessage: El texto que se desea traducir ("hi!").
Finalmente, se invoca al modelo con llm.invoke(messages) para obtener la traducción.
Bloque 3: creando Embeddings
Para entender el concepto del Embeddings aplicado al contexto del procesamiento del lenguaje natural recomendamos leer este post.
|
import getpass pip install -qU langchain-core from langchain_core.vectorstores import InMemoryVectorStore |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de OpenAI.
Este bloque se centra en la creación de embeddings (representaciones vectoriales de texto) que capturan su significado semántico. Utilizamos la clase OpenAIEmbeddings para acceder al modelo text-embedding-3-large de OpenAI, que genera embeddings de alta calidad.
Los embeddings se almacenarán en un InMemoryVectorStore, una estructura de datos en memoria que permite realizar búsquedas eficientes basadas en similitud semántica.
Bloque 4: implementando RAG
|
#RAG import bs4 from langchain_community.document_loaders import WebBaseLoader # Manten únicamente el título del post, los encabezados y el contenido del HTML bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://datos.gob.es/es/blog/slm-llm-rag-y-fine-tuning-pilares-de-la-ia…",) ) docs = loader.load() assert len(docs) == 1 print(f"Total characters: {len(docs.page_content)}") from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True, ) all_splits = text_splitter.split_documents(docs) print(f"Split blog post into {len(all_splits)} sub-documents.") document_ids = vector_store.add_documents(documents=all_splits) print(document_ids[:3]) |
Este bloque es el corazón de la implementación RAG. Comienza cargando el contenido de un post, utilizando WebBaseLoader y la URL del post sobre SLM, LLM, RAG y Fine-tuning.
Para preparar nuestro sistema de Recuperación Aumentada por Generación (RAG), comenzamos procesando el texto del post mediante técnicas de segmentación. Este paso inicial resulta fundamental, ya que dividimos el contenido en fragmentos más pequeños pero completos en significado. Utilizamos las herramientas de LangChain para realizar esta segmentación, asignando a cada fragmento un identificador único (id). Esta preparación previa nos permite posteriormente realizar búsquedas eficientes y precisas cuando el sistema necesite recuperar información relevante para responder a las consultas.
Se utiliza bs4.SoupStrainer para extraer solo las secciones relevantes del HTML. El texto del post se divide en fragmentos más pequeños con RecursiveCharacterTextSplitter, asegurando un solapamiento entre fragmentos para mantener el contexto. Estos fragmentos se añaden al vector_store creado en el bloque anterior, generando embeddings para cada uno.
Vemos que el resultado de uno de los fragmentos nos informa que ha dividido el documento en 21 sub-documentos.
|
Split blog post into 21 sub-documents. |
Los documentos tienen un identificador propio. Por ejemplo, los 3 primeros se identifican como:
|
["409f1bcb-1710-49b0-80f8-e45b7ca51a96", "e242f16c-71fd-4e7b-8b28-ece6b1e37a1c", "9478b11c-61ab-4dac-9903-f8485c4770c6"] |
Bloque 5: definiendo el Prompt y visualizando el flujo de trabajo
|
from langchain import hub prompt = hub.pull("rlm/rag-prompt") example_messages = prompt.invoke( {"context": "(context goes here)", "question": "(question goes here)"} ).to_messages() assert len(example_messages) == 1 print(example_messages.content) from langchain_core.documents import Document from typing_extensions import List, TypedDict class State(TypedDict): question: str context: List[Document] answer: str def retrieve(state: State): retrieved_docs = vector_store.similarity_search(state["question"]) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} from langgraph.graph import START, StateGraph graph_builder = StateGraph(State).add_sequence([retrieve, generate]) graph_builder.add_edge(START, "retrieve") graph = graph_builder.compile() from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png())) result = graph.invoke({"question": "What is Task Decomposition?"}) print(f"Context: {result["context"]}\n\n") print(f"Answer: {result["answer"]}") for step in graph.stream( {"question": "¿Cual es el futuro de la IA Generativa?"}, stream_mode="updates" ): print(f"{step}\n\n----------------\n") |
Este bloque define el prompt que se utilizará para interactuar con el LLM. Se utiliza un prompt predefinido de LangChain Hub (rlm/rag-prompt) que está diseñado para tareas RAG.
Se definen dos funciones:
- retrieve: busca en el vector_store los fragmentos más similares a la pregunta del usuario.
- generate: genera una respuesta utilizando el LLM, teniendo en cuenta el contexto proporcionado por los fragmentos recuperados.
Se utiliza langgraph para visualizar el flujo de trabajo RAG.
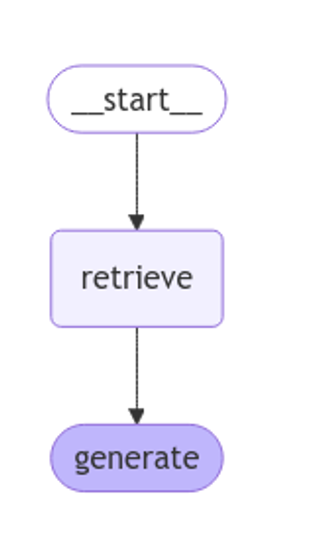
Figura 1: flujo de trabajo RAG. Elaboración propia.
Finalmente, se prueba el sistema con dos preguntas: una en inglés ("What is Task Decomposition?") y otra en español ("¿Cual es el futuro de la IA Generativa?").
La primera pregunta, "What is Task Decomposition?, está en inglés y es una pregunta genérica, sin relación con nuestro post de contenido. Por esto, pese a que el sistema, busca en su base de conocimiento previamente creada con la vectorización del documento (post) no encuentra relación entre la pregunta y este contexto.
Este texto puede variar con cada ejecución
|
Answer: No se menciona explícitamente el concepto de "Task Decomposition" en el contexto proporcionado. Por lo tanto, no tengo información sobre qué es Task Decomposition. |
|
Answer: Task Decomposition es un proceso que descompone una tarea compleja en subtareas más pequeñas y manejables. Esto permite abordar cada subtarea de manera independiente, facilitando su resolución y mejorando la eficiencia general. Aunque el contexto proporcionado no define explícitamente Task Decomposition, este concepto es común en la IA y optimización de tareas. |
Esta respuesta es la que proporciona el modelo del lenguaje sin ninguna base de conocimiento específica. Ahora bien, cuando preguntamos por algo que tiene que ver con el post que hemos cargado como base de conocimiento, la técnica RAG entra en funcionamiento y ejecuta los mecanismos secuenciales de retrieve y generate.
|
{ |
Cómo se ve en la respuesta, el sistema recupera 4 documentos (en el diagrama anterior, esto corresponde a la etapa de “Retrieve”) con sus correspondientes “id” (identificadores) cómo por ejemplo, el primer documento "id": "53962c40-c08b-4547-a74a-26f63cced7e8" que se corresponde con un fragmento del post original "title": "SLM, LLM, RAG y Fine-tuning: Pilares de la IA Generativa Moderna | datos.gob.es"
Con esos 4 fragmentos el sistema considera que tiene suficiente información relevante para proporcionar (en el diagrama anterior, la etapa “generate”) una respuesta satisfactoria a la pregunta.
|
{ |
Bloque 6: personalizando el prompt
|
from langchain_core.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don"t know the answer, just say that you don"t know, don"t try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template) |
Este bloque personaliza el prompt para que las respuestas sean más concisas y añadan una frase de cortesía al final. Se utiliza PromptTemplate para crear un nuevo prompt con las instrucciones deseadas.
Bloque 7: añadiendo metadatos y refinando la búsqueda
|
total_documents = len(all_splits) third = total_documents // 3 for i, document in enumerate(all_splits): if i < third: document.metadata["section"] = "beginning" elif i < 2 * third: document.metadata["section"] = "middle" else: document.metadata["section"] = "end" all_splits.metadata from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings) _ = vector_store.add_documents(all_splits) from typing import Literal from typing_extensions import Annotated class Search(TypedDict): """Search query.""" query: Annotated[str, ..., "Search query to run."] section: Annotated( Literal["beginning", "middle", "end"], ..., "Section to query.", ] class State(TypedDict): question: str query: Search context: List[Document] answer: str def analyze_query(state: State): structured_llm = llm.with_structured_output(Search) query = structured_llm.invoke(state["question"]) return {"query": query} def retrieve(state: State): query = state["query"] retrieved_docs = vector_store.similarity_search( query["query"], filter=lambda doc: doc.metadata.get("section") == query["section"], ) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate]) graph_builder.add_edge(START, "analyze_query") graph = graph_builder.compile() display(Image(graph.get_graph().draw_mermaid_png())) for step in graph.stream( {"question": "¿Cual es el furturo de la IA Generativa en palabras del autor?"}, stream_mode="updates", ): print(f"{step}\n\n----------------\n") |
En este bloque, se añaden metadatos a los fragmentos del post, dividiéndolos en tres secciones: "beginning", "middle" y "end". Esto permite realizar búsquedas más refinadas, limitando la búsqueda a una sección específica del post.
Se introduce una nueva función analyze_query que utiliza el LLM para determinar la sección del post más relevante para la pregunta del usuario. El flujo de trabajo RAG se actualiza para incluir esta nueva etapa.
Finalmente, se prueba el sistema con una pregunta en español ("¿Cuál es el futuro de la IA Generativa en palabras del autor?"), observando cómo el sistema utiliza la información de la sección "end" del post para generar una respuesta más precisa.
Veamos el resultado:

Figura 2: flujo de trabajo RAG. Elaboración propia.
|
{ ---------------- { |
|
{ |
Conclusiones
A través de este recorrido por el notebook de Google Colab, hemos experimentado de primera mano la construcción de un agente conversacional con RAG. Hemos aprendido a:
- Instalar las bibliotecas necesarias.
- Configurar el entorno de desarrollo.
- Cargar y procesar datos.
- Crear embeddings y almacenarlos en un vector_store.
- Implementar las etapas de recuperación y generación de RAG.
- Personalizar el prompt para obtener respuestas más específicas.
- Añadir metadatos para refinar la búsqueda.
Este ejercicio práctico te proporciona las herramientas y conocimientos necesarios para comenzar a explorar el potencial de RAG y desarrollar tus propias aplicaciones.
¡Anímate a experimentar con diferentes fuentes de información, modelos de lenguaje y prompts para crear agentes conversacionales cada vez más sofisticados!
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Los portales de datos abiertos son una fuente invaluable de información pública. Sin embargo, extraer insights significativos de estos datos puede resultar desafiante para usuarios sin conocimientos técnicos avanzados.
En este ejercicio práctico, exploraremos el desarrollo de una aplicación web que democratiza el acceso a estos datos mediante el uso de inteligencia artificial, permitiendo realizar consultas en lenguaje natural.
La aplicación, desarrollada utilizando el portal datos.gob.es como fuente de datos, integra tecnologías modernas como Streamlit para la interfaz de usuario y el modelo de lenguaje Gemini de Google para el procesamiento de lenguaje natural. La naturaleza modular permite que se pueda utilizar cualquier modelo de Inteligencia Artificial con mínimos cambios. El proyecto completo está disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en cuatro apartados principales e interconectados que trabajan para procesar las consultas de la persona usuaria:
- Generación del Contexto
- Analiza las características del dataset elegido.
- Genera una descripción detallada incluyendo dimensiones, tipos de datos y estadísticas.
- Crea una plantilla estructurada con guías específicas para la generación de código.
- Combinación de Contexto y Consulta
- Une el contexto generado con la pregunta de la persona usuaria creando el prompt que recibirá el modelo de inteligencia artificial.
- Generación de Respuesta
- Envía el prompt al modelo y obtiene el código Python que permite resolver la cuestión generada.
- Ejecución del Código
- Ejecuta de manera segura el código generado con un sistema de reintentos y correcciones automáticas.
- Captura y expone los resultados en el frontal de la aplicación.

Figura 1. Flujo de procesamiento de solicitudes
Proceso de desarrollo
El primer paso es establecer una forma de acceder a los datos públicos. El portal datos.gob.es ofrece vía API los datasets. Se han desarrollado funciones para navegar por el catálogo y descargar estos archivos de forma eficiente.
Figura 2. API de datos.gob
El segundo paso aborda la cuestión: ¿cómo convertir preguntas en lenguaje natural en análisis de datos útiles? Aquí es donde entra Gemini, el modelo de lenguaje de Google. Sin embargo, no basta con simplemente conectar el modelo; es necesario enseñarle a entender el contexto específico de cada dataset.
Se ha desarrollado un sistema en tres capas:
- Una función que analiza el dataset y genera una "ficha técnica" detallada.
- Otra que combina esta ficha con la pregunta del usuario.
- Y una tercera que traduce todo esto en código Python ejecutable.
Se puede ver en la imagen inferior como se desarrolla este proceso y, posteriormente, se muestran los resultados del código generado ya ejecutado.

Figura 3. Visualización del procesamiento de respuesta de la aplicación
Por último, con Streamlit, se ha construido una interfaz web que muestra el proceso y sus resultados al usuario. La interfaz es tan simple como elegir un dataset y hacer una pregunta, pero también lo suficientemente potente como para mostrar visualizaciones complejas y permitir la exploración de datos.
El resultado final es una aplicación que permite a cualquier persona, independientemente de sus conocimientos técnicos, realizar análisis de datos y aprender sobre el código ejecutado por el modelo. Por ejemplo, un funcionario municipal puede preguntar "¿Cuál es la edad media de la flota de vehículos?" y obtener una visualización clara de la distribución de edades.

Figura 4. Caso de uso completo. Visualizar la distribución de los años de matriculación de la flota automovilística del ayuntamiento de Almendralejo en 2018
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Integración de IA en Aplicaciones Web:
- Cómo comunicarse efectivamente con modelos de lenguaje como Gemini.
- Técnicas para estructurar prompts que generen código preciso.
- Estrategias para manejar y ejecutar código generado por IA de forma segura.
- Desarrollo Web con Streamlit:
- Creación de interfaces interactivas en Python.
- Manejo de estado y sesiones en aplicaciones web.
- Implementación de componentes visuales para datos.
- Trabajo con Datos Abiertos:
- Conexión y consumo de APIs de datos públicos.
- Procesamiento de archivos Excel y DataFrames.
- Técnicas de visualización de datos.
- Buenas Prácticas de Desarrollo:
- Estructuración modular de código Python.
- Manejo de errores y reintentos.
- Implementación de sistemas de feedback visual.
- Despliegue de aplicaciones web usando ngrok.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos públicos y los usuarios finales. A través del caso práctico desarrollado, hemos podido observar cómo la combinación de modelos de lenguaje avanzados con interfaces intuitivas permite democratizar el acceso al análisis de datos, transformando consultas en lenguaje natural en análisis significativos y visualizaciones informativas.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de modelos de lenguaje más avanzados que permitan análisis más sofisticados.
- Implementación de sistemas de aprendizaje que mejoren las respuestas basándose en el feedback del usuario.
- Integración con más fuentes de datos abiertos y formatos diversos.
- Desarrollo de capacidades de análisis predictivo y prescriptivo.
En resumen, este ejercicio no solo demuestra la viabilidad de democratizar el análisis de datos mediante la inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el acceso y análisis de datos públicos sea verdaderamente universal. La combinación de tecnologías modernas como Streamlit, modelos de lenguaje y técnicas de visualización abre un abanico de posibilidades para que organizaciones y ciudadanos aprovechen al máximo el valor de los datos abiertos.
Blog
La Inteligencia Artificial (IA) ha dejado de ser un concepto futurista y se ha convertido en una herramienta clave en nuestra vida diaria. Desde las recomendaciones de películas o series en plataformas de streaming hasta los asistentes virtuales como Alexa o Google Assistant en nuestros dispositivos, la IA está en todas partes. Pero, ¿cómo se construye un modelo de IA? A pesar de lo que podría parecer, el proceso es menos intimidante si lo desglosamos en pasos claros y comprensibles.
Paso 1: definir el problema
Antes de empezar, necesitamos tener muy claro qué queremos resolver. La IA no es una varita mágica: diferentes modelos funcionarán mejor en diferentes aplicaciones y contextos por lo que es importante definir la tarea específica que deseamos ejecutar. Por ejemplo, ¿queremos predecir las ventas de un producto? ¿Clasificar correos como spam o no spam? Tener una definición clara del problema nos ayudará a estructurar el resto del proceso.
Además, debemos plantearnos qué tipo de datos tenemos y cuáles son las expectativas. Esto incluye determinar el nivel de precisión deseado y las limitaciones de tiempo o recursos disponibles.
Paso 2: recopilar los datos
La calidad de un modelo de IA depende directamente de la calidad de los datos utilizados para entrenarlo. Este paso consiste en recopilar y organizar los datos relevantes para nuestro problema. Por ejemplo, si queremos predecir ventas, necesitaremos datos históricos como precios, promociones o patrones de compra.
La recopilación de datos comienza identificando las fuentes relevantes, que pueden ser bases de datos internas, sensores, encuestas… Además de los datos propios de cada empresa, existe un amplio ecosistema de datos, tanto abiertos como propietarios, a los que podemos recurrir en busca de la construcción de modelos más potentes. Por ejemplo, el Gobierno de España habilita a través del portal datos.gob.es múltiples conjuntos de datos abiertos publicados por instituciones públicas. Por otro lado, la empresa Amazon Web Services (AWS) a través de su portal AWS Data Exchange permite el acceso y suscripción a miles de conjuntos de datos propietarios publicados y mantenidos por diferentes empresas y organizaciones.
En este punto también se debe considerar la cantidad de datos necesaria. Los modelos de IA suelen necesitar grandes volúmenes de información para aprender de manera efectiva. También es crucial que los datos sean representativos y no contengan sesgos que puedan afectar los resultados. Por ejemplo, si entrenamos un modelo para predecir patrones de consumo y solo usamos datos de un grupo limitado de personas, es probable que las predicciones no sean válidas para otros grupos con comportamientos diferentes.
Paso 3: preparar y explorar los datos
Una vez recopilados los datos, es hora de limpiarlos y normalizarlos. En muchas ocasiones, los datos en bruto pueden contener problemas como errores, duplicidades, valores faltantes, inconsistencias o formatos no estandarizados. Por ejemplo, podríamos encontrarnos con celdas vacías en un conjunto de datos de ventas o con fechas que no siguen un formato coherente. Antes de alimentar el modelo con estos datos, es fundamental adecuarlos para garantizar que el análisis sea preciso y confiable. Este paso no solo mejora la calidad de los resultados, sino que también asegura que el modelo pueda interpretar correctamente la información.
Una vez tenemos los datos limpios es fundamental realizar la ingeniería de características (feature engineering), un proceso creativo que puede marcar la diferencia entre un modelo básico y uno excelente. Esta fase consiste en crear nuevas variables que capturen mejor la naturaleza del problema que queremos resolver. Por ejemplo, si estamos analizando ventas online, además de usar el precio directo del producto, podríamos crear nuevas características como el ratio precio/media_categoría, los días desde la última promoción, o variables que capturen la estacionalidad de las ventas. La experiencia demuestra que contar con características bien diseñadas suele ser más determinante para el éxito del modelo que la elección del algoritmo en sí mismo.
En esta fase, también realizaremos un primer análisis exploratorio de los datos, buscando familiarizarnos con ellos y detectar posibles patrones, tendencias o irregularidades que puedan influir en el modelo. En esta guía podemos encontrar mayor detalle sobre cómo realizar un análisis exploratorio de datos.
Otra actividad típica de esta etapa es dividir los datos en conjuntos de entrenamiento, validación y prueba. Por ejemplo, si tenemos 10.000 registros, podríamos usar el 70% para entrenamiento, el 20% para validación y el 10% para pruebas. Esto permite que el modelo aprenda sin sobreajustarse a un conjunto de datos específico.
Para garantizar que nuestra evaluación sea robusta, especialmente cuando trabajamos con conjuntos de datos limitados, es recomendable implementar técnicas de validación cruzada (cross-validation). Esta metodología divide los datos en múltiples subconjuntos y realiza varias iteraciones de entrenamiento y validación. Por ejemplo, en una validación cruzada de 5 pliegues, dividimos los datos en 5 partes y entrenamos 5 veces, usando cada vez una parte diferente como conjunto de validación. Esto nos proporciona una estimación más fiable del rendimiento real del modelo y nos ayuda a detectar problemas de sobreajuste o variabilidad en los resultados.
Paso 4: seleccionar un modelo
Existen múltiples tipos de modelos de IA, y la elección depende del problema que deseemos resolver. Algunos ejemplos comunes son regresión, modelos de árboles de decisión, modelos de agrupamiento, modelos de series temporales o redes neuronales. En general, existen modelos supervisados, modelos no supervisados y modelos de aprendizaje por refuerzo. Podemos encontrar un mayor detalle en este post sobre cómo las maquinas aprenden.
A la hora de seleccionar un modelo, es importante tener en cuenta factores como la naturaleza de los datos, la complejidad del problema y el objetivo final. Por ejemplo, un modelo simple como la regresión lineal puede ser suficiente para problemas sencillos y bien estructurados, mientras que redes neuronales o modelos avanzados podrían ser necesarios para tareas como reconocimiento de imágenes o procesamiento del lenguaje natural. Además, también se debe considerar el balance entre precisión, tiempo de entrenamiento y recursos computacionales. Un modelo más preciso generalmente requiere configuraciones más complejas, como más datos, redes neuronales más profundas o parámetros optimizados. Aumentar la complejidad del modelo o trabajar con conjuntos de datos grandes puede alargar significativamente el tiempo necesario para entrenarlo. Esto puede ser un problema en entornos donde las decisiones deben tomarse rápidamente o los recursos son limitados y requerir hardware especializado, como GPUs o TPUs, y mayores cantidades de memoria y almacenamiento.
Hoy en día, muchas bibliotecas de código abiertas facilitan la implementación de estos modelos, como TensorFlow, PyTorch o scikit-learn.
Paso 5: entrenar el modelo
El entrenamiento es el corazón del proceso. Durante esta etapa, alimentamos el modelo con los datos de entrenamiento para que aprenda a realizar su tarea. Esto se logra ajustando los parámetros del modelo para minimizar el error entre sus predicciones y los resultados reales.
Aquí es clave evaluar constantemente el rendimiento del modelo con el conjunto de validación y realizar ajustes si es necesario. Por ejemplo, en un modelo de tipo red neuronal podríamos probar diferentes configuraciones de hiperparámetros como tasa de aprendizaje, número de capas ocultas y neuronas, tamaño del lote, número de épocas, o función de activación, entre otros.
Paso 6: evaluar el modelo
Una vez entrenado, es momento de poner a prueba el modelo utilizando el conjunto de datos de prueba que apartamos durante la fase de entrenamiento. Este paso es crucial para medir cómo se desempeña con datos que para el modelo son nuevos y garantiza que no esté “sobreentrenado”, es decir, que no solo funcione bien con los datos de entrenamiento, sino que sea capaz de aplicar el aprendizaje sobre nuevos datos que puedan generarse en el día a día.
Al evaluar un modelo, además de la precisión, también es común considerar:
- Confianza en las predicciones: evaluar cuán seguras son las predicciones realizadas.
- Velocidad de respuesta: tiempo que toma el modelo en procesar y generar una predicción.
- Eficiencia en recursos: medir cuánto uso de memoria y cómputo requiere el modelo.
- Adaptabilidad: cuán bien puede ajustarse el modelo a nuevos datos o condiciones sin necesidad de un reentrenamiento completo.
Paso 7: desplegar y mantener el modelo
Cuando el modelo cumple con nuestras expectativas, está listo para ser desplegado en un entorno real. Esto podría implicar integrar el modelo en una aplicación, automatizar tareas o generar informes.
Sin embargo, el trabajo no termina aquí. La IA necesita mantenimiento continuo para adaptarse a los cambios en los datos o en las condiciones del mundo real. Por ejemplo, si los patrones de compra cambian por una nueva tendencia, el modelo deberá ser actualizado.
Construir modelos de IA no es una ciencia exacta, es el resultado de un proceso estructurado que combina lógica, creatividad y perseverancia. Esto se debe a que intervienen múltiples factores, como la calidad de los datos, las elecciones en el diseño del modelo y las decisiones humanas durante la optimización. Aunque existen metodologías claras y herramientas avanzadas, la construcción de modelos requiere experimentación, ajustes y, a menudo, un enfoque iterativo para obtener resultados satisfactorios. Aunque cada paso requiere atención al detalle, las herramientas y tecnologías disponibles hoy en día hacen que este desafío sea accesible para cualquier persona interesada en explorar el mundo de la IA.
ANEXO I – Definiciones tipos de modelos
-
Regresión: técnicas supervisadas que modelan la relación entre una variable dependiente (resultado) y una o más variables independientes (predictores). La regresión se utiliza para predecir valores continuos, como ventas futuras o temperaturas, y puede incluir enfoques como la regresión lineal, logística o polinómica, dependiendo de la complejidad del problema y la relación entre las variables.
-
Modelos de árboles de decisión: métodos supervisados que representan decisiones y sus posibles consecuencias en forma de árbol. En cada nodo, se toma una decisión basada en una característica de los datos, dividiendo el conjunto en subconjuntos más pequeños. Estos modelos son intuitivos y útiles para clasificación y predicción, ya que generan reglas claras que explican el razonamiento detrás de cada decisión.
-
Modelos de agrupamiento: técnicas no supervisadas que agrupan datos en subconjuntos llamados clústeres, basándose en similitudes o proximidad entre los datos. Por ejemplo, se pueden agrupar clientes con hábitos de compra similares para personalizar estrategias de marketing. Modelos como k-means o DBSCAN permiten identificar patrones útiles sin necesidad de datos etiquetados.
-
Modelos de series temporales: diseñados para trabajar con datos ordenados cronológicamente, estos modelos analizan patrones temporales y realizan predicciones basadas en el historial. Se utilizan en casos como predicción de demanda, análisis financiero o meteorología. Incorporan tendencias, estacionalidad y relaciones entre los datos pasados y futuros.
-
Redes neuronales: modelos inspirados en el funcionamiento del cerebro humano, donde capas de neuronas artificiales procesan información y detectan patrones complejos. Son especialmente útiles en tareas como reconocimiento de imágenes, procesamiento de lenguaje natural y juegos. Las redes neuronales pueden ser simples o muy profundas (deep learning), dependiendo del problema y la cantidad de datos.
-
Modelos supervisados: estos modelos aprenden de datos etiquetados, es decir, conjuntos en los que cada entrada tiene un resultado conocido. El objetivo es que el modelo generalice para predecir resultados en datos nuevos. Ejemplos incluyen clasificación de correos en spam o no spam y predicciones de precios.
-
Modelos no supervisados: trabajan con datos sin etiquetas, buscando patrones ocultos, estructuras o relaciones dentro de los datos. Son ideales para tareas exploratorias donde no se conoce de antemano el resultado esperado, como segmentación de mercados o reducción de dimensionalidad.
- Modelo de aprendizaje por refuerzo: en este enfoque, un agente aprende interactuando con un entorno, tomando decisiones y recibiendo recompensas o penalizaciones según su desempeño. Este tipo de aprendizaje es útil en problemas donde las decisiones afectan un objetivo a largo plazo, como entrenar robots, jugar videojuegos o desarrollar estrategias de inversión.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
En este episodio vamos a hablar de la inteligencia artificial y sus retos, tomando como base el Reglamento Europeo de Inteligencia Artificial que entró en vigor este año. Quédate para conocer los retos oportunidades y novedades del sector de la mano de dos expertos en la materia:
- Ricard Martínez, profesor de derecho constitucional de la Universitat de València en la que dirige la Cátedra de Privacidad y Transformación Digital Microsoft Universidad de Valencia.
- Carmen Torrijos, lingüista computacional, experta en IA aplicada al lenguaje y profesora de minería de texto en la Universidad Carlos III.
Resumen / Transcripción de la entrevista
1. Está claro que la inteligencia artificial está en continua evolución. Para entrar en materia, me gustaría que nos contarais ¿cuáles son los últimos avances en la IA?
Carmen Torrijos: Surgen muchas aplicaciones nuevas. Por ejemplo, este fin de semana pasado ha tenido mucho eco una IA de generación de imagen en X, en Twitter, no sé si lo habéis seguido, que se llama Grok. Ha tenido bastante impacto, no porque aporte nada nuevo, ya que la generación de imagen es algo que estamos haciendo desde diciembre de 2023. Pero esta es una IA que tiene menos censura, es decir, teníamos hasta ahora muchas dificultades con los sistemas generalistas para hacer imágenes que tuvieran caras de famosos o tuvieran situaciones determinadas y estaba muy vigilado desde cualquier herramienta. Grok lo que hace es levantar todo eso y que cualquiera pueda hacer cualquier tipo de imagen con cualquier persona famosa o con cualquier cara conocida. Es una moda seguramente muy pasajera. Haremos imágenes durante un tiempo y luego se nos pasará.
Y después tenemos también sistemas de creación de podcast automáticos, como Notebook LM. Ya llevamos un par de meses viéndolos y ha sido realmente una de las cosas que a mí, en los últimos meses, me ha sorprendido de verdad. Porque ya parece que todos son innovaciones incrementales: sobre lo que ya tenemos, nos dan algo mejor. Pero esto es algo realmente nuevo que sorprende. Tú subes un PDF y te puede generar un podcast de dos personas hablando de manera totalmente natural, totalmente realista, sobre ese PDF. Es algo que puede hacer Notebook LM que es de Google.
2. El Reglamento Europeo de Inteligencia Artificial es la primera norma jurídica del mundo sobre IA, ¿con qué objetivos se publica este documento que es ya un marco referencial a nivel internacional?
Ricard Martínez: El Reglamento surge por algo que está implícito en lo que Carmen nos ha contado. Todo esto que Carmen cuenta es porque nos hemos abierto a la misma carrera desenfrenada a la que nos abrimos con la aparición de las redes sociales. Porque cuando esto pasa, no es inocente, no es que las compañías sean generosas, es que las compañías están compitiendo por nuestros datos. Nos gamifican, nos animan a jugar, nos animan a proporcionarles información, por eso se abren. No se abren porque sean generosas, no se abren porque quieran trabajar para el bien común o para la humanidad. Se abren porque les estamos haciendo el trabajo. ¿Qué es lo que la Unión Europea quiere frenar? Lo que aprendimos con las redes sociales. La Unión Europea plantea dos grandes enfoques que voy a tratar de explicar de modo muy sucinto. El primer enfoque es un enfoque de riesgo sistémico. La Unión Europea ha dicho: “no voy a tolerar herramientas de inteligencia artificial que puedan poner en peligro el sistema democrático, es decir, el estado de derecho y mi modo de funcionamiento o que puedan vulnerar gravemente derechos fundamentales”. Eso es una línea roja.
El segundo enfoque es un enfoque de orientación a producto. Una IA es un producto. Cuando usted fabrica un coche, sigue unas reglas que gestionan cómo produce ese coche, y ese coche llega al mercado cuando es seguro, cuando tiene todas las especificaciones. Ese es el segundo gran enfoque del Reglamento. El Reglamento dice que puede usted estar desarrollando una tecnología porque usted está investigando y casi le dejo hacer lo que quiera. Ahora, si esta tecnología va a llegar al mercado, usted catalogará el riesgo. Si el riesgo es bajo o leve, usted va a poder hacer muchas cosas y, prácticamente, con transparencia y códigos de conducta, se lo voy a dar por bueno. Pero si es un riesgo alto, usted va a tener que seguir un proceso de diseño estandarizado, y va a necesitar que un órgano notificado verifique esa tecnología, se asegure que en su documentación usted ha cumplido lo que tiene que cumplir, y entonces le darán un sello CE. Y no acabamos aquí, porque va a haber vigilancia postcomercial. De modo que, a lo largo del ciclo de vida del producto, usted debe garantizar que esto funciona bien y que se ajusta a la norma.
Por otra parte, se establece un control férreo respecto de los grandes modelos de datos, no solo LLM, también puede ser de imagen o de otro tipo de información, cuando crea que pueden plantear riesgos sistémicos.
En ese caso, hay un control muy directo por parte de la Comisión. Por tanto, en el fondo, lo que están diciendo es: "respeten los derechos, garanticen la democracia, produzcan la tecnología de modo ordenado de acuerdo con ciertas especificaciones".
Carmen Torrijos: Sí, en cuanto a los objetivos está claro. Me he quedado con lo último que decía Ricard sobre producir tecnología de acuerdo a esta Regulación. Tenemos este mantra de que Estados Unidos hace cosas, Europa las regula y China las copia. A mí no me gusta nada generalizar así. Pero es verdad que Europa es pionera en materia de legislación y seríamos mucho más fuertes si pudiéramos producir tecnología acorde a los estándares regulatorios que estamos poniendo. Hoy por hoy todavía no podemos, quizás es una cuestión de darnos tiempo, pero creo que esa es la clave de la soberanía tecnológica en Europa.
3. Para poder producir esa tecnología, los sistemas de IA necesitan datos para entrenar sus modelos. ¿Qué criterios deberían cumplir los datos para poder entrenar correctamente un sistema de IA? ¿Los conjuntos de datos abiertos podrían ser una fuente? ¿De qué manera?
Carmen Torrijos: Los datos con los que alimentamos la IA son el punto de mayor conflicto. ¿Podemos entrenar con cualquier conjunto de datos incluso aunque estén disponibles? No vamos a hablar de datos abiertos, sino de datos disponibles.
Datos abiertos es, por ejemplo, la base de todos los modelos de lenguaje, y todo el mundo esto lo sabe, que es Wikipedia. Wikipedia es un ejemplo ideal para entrenar, porque es abierta, está optimizado para su uso computacional, es descargable, es muy fácil de usar, hay muchísimo lenguaje, por ejemplo, para entrenar modelos de lenguaje, y hay muchísimo conocimiento del mundo. Con lo cual es el conjunto de datos ideal para entrenar un modelo de IA. Y Wikipedia está en abierto, está disponible, es de todos y es para todos, se puede utilizar.
Ahora bien, ¿todos los conjuntos de datos que hay disponibles en Internet se pueden utilizar para entrenar sistemas de IA? Esa es un poco la duda. Porque el hecho de que algo esté publicado en Internet no quiere decir que sea público, de uso público, aunque tú puedas cogerlo y entrenar un sistema y empezar a generar lucro a partir de ese sistema. Tenía unos derechos de autor, una autoría y propiedad intelectual. Ese yo creo que es el conflicto más grave que tenemos ahora mismo en IA generativa porque utiliza contenidos para inspirarse y crear. Y ahí poco a poco Europa está dando pasitos. Por ejemplo, el Ministerio de Cultura ha lanzado una iniciativa para empezar a ver cómo podemos crear contenidos, conjuntos de datos licenciados, que permitan entrenar la IA de una manera legal, ética y con respecto a los derechos de propiedad intelectual de los autores.
Todo esto está generando muchísima fricción. Porque si seguimos así, nos ponemos en contra a muchos ilustradores, traductores, escritores, etc. (todos los creadores que trabajan con el contenido), porque no van a querer que se desarrolle esta tecnología a costa de sus contenidos. De alguna manera hay que encontrar el equilibrio en la regulación y en la innovación para que las dos cosas ocurran. Desde los grandes sistemas tecnológicos que se están desarrollando, sobre todo en Estados Unidos, se repite una idea que es que solo con contenidos licenciados, con conjuntos de datos legales que están libres de propiedad intelectual, o que se ha pagado los rendimientos necesarios por su propiedad intelectual, no se puede llegar al nivel de calidad de las IA's que tenemos ahora. Es decir, solamente con conjuntos de datos legales no hubiéramos tenido ChatGPT al nivel que está el ChatGPT.
Eso no está escrito en piedra y no tiene por qué ser así. Tenemos que seguir investigando, o sea, tenemos que seguir viendo cómo podemos lograr una tecnología de ese nivel, pero que cumpla con la regulación. Porque lo que han hecho en Estados Unidos, lo que ha hecho GPT-4, los grandes modelos del lenguaje, los grandes modelos de generación de imagen, es enseñarnos el camino. Esto es hasta dónde podemos llegar. Pero lo habéis hecho cogiendo contenido que no es vuestro, que no era lícito coger. Tenemos que conseguir volver a ese nivel de calidad, volver a ese nivel de rendimiento de los modelos, respetando la propiedad intelectual del contenido. Y eso es un papel que yo creo que corresponde principalmente a Europa
4. Otra de las cuestiones que le preocupa a la ciudadanía respecto al rápido desarrollo de la IA es el tratamiento de los datos personales. ¿Cómo deberían protegerse y qué condiciones establece el reglamento europeo para ello?
Ricard Martínez: Hay un conjunto de conductas que se han prohibido esencialmente para garantizar los derechos fundamentales de las personas. Pero no es la única medida. Yo le concedo muchísima importancia a un artículo en la norma al que seguramente no le vamos a dar muchas vueltas, pero para mí es clave. Hay un artículo, el cuarto, que en inglés se ha titulado AI Literacy, y en castellano “Formación en inteligencia artificial” que dice que cualquier sujeto que está interviniendo en la cadena de valor tiene que haber sido adecuadamente formado. Tiene que conocer de qué va esto, tiene que conocer cuál es el estado del arte, tiene que conocer cuáles son las implicaciones de la tecnología que va a desarrollar o que va a desplegar. Le concedo mucho valor porque significa incorporar en toda la cadena de valor (desarrollador, comercializador, importador, compañía que despliegue un modelo para su uso, etc.) un conjunto de valores que suponen lo que en inglés se llama accountability, responsabilidad proactiva, por defecto. Esto se puede traducir en un elemento que es muy sencillo, sobre el que se habla hace dos mil años en el mundo del derecho, que es el ‘no hacer daño’, es el principio de no maleficencia.
Con algo tan sencillo como eso, "no haga usted daño a los demás, actúe de buena y garantice sus derechos", no se deberían producir efectos perversos o efectos dañosos, lo cual no significa que no pueda suceder. Y precisamente eso lo dice el Reglamento muy particularmente cuando se refiere a los sistemas de riesgo alto, pero es aplicable a todos los sistemas. El Reglamento te dice que tienes que garantizar los procesos de cumplimiento y las garantías durante todo el ciclo de vida del sistema. De ahí que sea tan importante la robustez, la resiliencia y el disponer de planes de contingencia que te permiten revertir, paralizar, pasar a control humano, cambiar el modelo de uso cuando se produce algún incidente.
Por tanto, todo el ecosistema está dirigido a ese objetivo de no lesionar derechos, no causar perjuicios. Y hay un elemento que ya no depende de nosotros, depende de las políticas públicas. La IA no solo va a lesionar derechos, va a cambiar el modo en el que entendemos el mundo. Si no hay políticas públicas en el sector educativo que aseguren que nuestros niños y niñas desarrollen capacidades de pensamiento computacional y de ser capaces de tener una relación con una interfaz-máquina, su acceso al mercado de trabajo se va a ver significativamente afectado. Del mismo modo, si no aseguramos la formación continua de los trabajadores en activo y también las políticas públicas de aquellos sectores condenados a desaparecer.
Carmen Torrijos: Me parece muy interesante el enfoque de Ricard de formar es proteger. Formar a la gente, informar a la gente, que la gente tenga capacitación en IA, no solamente la gente que está en la cadena de valor, sino todo el mundo. Cuanto más formas y capacitas, más estás protegiendo a las personas.
Cuando salió la ley, hubo cierta decepción en los entornos IA y sobre todo en los entornos creativos. Porque estábamos en plena efervescencia de la IA generativa y no se estaba regulando apenas la IA generativa, pero se estaban regulando otras cosas que dábamos por hecho que en Europa no iban a pasar, pero que hay que regular para que no puedan pasar. Por ejemplo, la vigilancia biométrica: que Amazon no pueda leerte la cara para decidir si estás más triste ese día y venderte más cosas o sacarte más publicidad o una publicidad determinada. Digo Amazon, pero puede ser cualquier plataforma. Eso, por ejemplo, en Europa no se va a poder hacer porque está prohibido desde la ley, es un uso inaceptable: la vigilancia biométrica.
Otro ejemplo es la puntuación social, el social scoring que vemos que pasa en China, que se dan puntos a los ciudadanos y se accede a servicios públicos a partir de estos puntos. Eso tampoco se va a poder hacer. Y hay que contemplar también esta parte de la ley, porque damos muy por hecho que esto no nos va a ocurrir, pero cuando no lo regulas es cuando ocurre. China tiene instalados 600 millones de cámaras de TRF, de tecnología de reconocimiento facial, que te reconocen con tu DNI. Eso no va a pasar en Europa porque no se puede, porque también es vigilancia biométrica. Entonces hay que entender que la ley quizá parece que va más despacio en lo que ahora nos tiene embelesados que es la IA generativa, pero se ha dedicado a tratar puntos muy importantes que había que cubrir para proteger a las personas. Para no perder derechos fundamentales que ya teníamos ganados.
Por último, la ética tiene un componente muy incómodo, que nadie quiere mirar, que es que a veces hay que revocar. A veces hay que quitar algo que está en funcionamiento, incluso que está dando un beneficio, porque está incurriendo en algún tipo de discriminación, o porque está trayendo algún tipo de consecuencia negativa que viola a los derechos de un colectivo, de una minoría o de alguien vulnerable. Y eso es muy complicado. Cuando ya nos hemos acostumbrado a tener una IA funcionando en determinado contexto, que puede ser incluso un contexto público, parar y decir que esto está discriminando a personas, entonces este sistema no puede seguir en producción y hay que quitarlo. Ese punto es muy complicado, es muy incómodo y cuando hablamos de ética, que hablamos muy fácil de ética, hay que pensar también en cuántos sistemas vamos a tener que parar y revisar antes de poder volver a poner en funcionamiento, por muy fácil que nos hagan la vida o por muy innovadores que parezcan.
5. En este sentido, teniendo en cuenta todo lo que recoge el Reglamento, algunas empresas españolas, por ejemplo, tendrán que adaptarse a este nuevo marco. ¿Qué deberían estar haciendo ya las organizaciones para prepararse? ¿Qué deberían revisar las empresas españolas teniendo en cuenta el reglamento europeo?
Ricard Martínez: Esto es muy importante, porque hay un nivel corporativo empresarial de altas capacidades que a mí no me preocupa porque estas empresas entienden que estamos hablando de una inversión. Y del mismo modo que invirtieron en un modelo basado en procesos que integraba el compliance desde el diseño para protección de datos. El siguiente salto, que es hacer exactamente lo mismo con inteligencia artificial, no diré que carece de importancia, porque posee una importancia relevante, pero digamos que es recorrer un camino que ya se ensayó. Estas empresas ya tienen unidades de compliance, ya tienen asesores, y ya tienen unas rutinas en las que se puede integrar como una parte más del proceso el marco de referencia de la normativa de inteligencia artificial. Al final lo que va a hacer es crecer en un sentido el análisis de riesgos. Seguramente va a obligar a modular los procesos de diseño y también las propias fases de diseño, es decir, mientras que en un diseño de software prácticamente hablamos de pasar de un modelo no funcional a picar código, aquí hay una serie de labores de enriquecimiento, anotación, validación de los conjuntos de datos, prototipado que exigen seguramente más esfuerzo, pero son rutinas que se pueden estandarizar.
Mi experiencia en proyectos europeos en los que hemos trabajado con clientes, es decir, con las PYMES, que esperan que la IA sea plug and play, lo que hemos apreciado es una enorme falta de capacitación. Lo primero que deberías preguntarte no es si tu empresa necesita IA, sino si tu empresa está preparada para la IA. Es una pregunta previa y bastante más relevante. Oiga, usted cree que puede dar un salto a la IA, que puede contratar un determinado tipo de servicios, y nos estamos dando cuenta que es que usted ni siquiera cumple bien la norma de protección de datos.
Hay una cosa, una entidad que se llama Agencia Española de Inteligencia Artificial, AESIA y hay un Ministerio de Transformación Digital, y si no hay políticas públicas de acompañamiento, podemos incurrir en situaciones de riesgo. ¿Por qué? Porque yo tengo el enorme placer de formar en grados y posgrados a futuros emprendedores en inteligencia artificial. Cuando se enfrentan al marco ético y jurídico no diré que se quieren morir, pero se les cae el mundo encima. Porque no hay un soporte, no hay un acompañamiento, no hay recursos, o no los pueden ver, que no le supongan una ronda de inversión que no pueden soportar, o no hay modelos guiados que les ayuden de modo, no diré fácil, pero sí al menos usable.
Por lo tanto, creo que hay un reto sustancial en las políticas públicas, porque si no se da esa combinación, las únicas empresas que podrán competir son las que ya tienen una masa crítica, una capacidad inversora y un capital acumulado que les permite cumplir con la norma. Esta situación podría conducir a un resultado contraproducente.
Queremos recuperar la soberanía digital europea, pero si no hay políticas públicas de inversión, los únicos que van a poder cumplir la norma europea son las empresas de otros países.
Carmen Torrijos: No porque sean de otros países sino porque son más grandes.
Ricard Martínez: Sí, por no citar países.
6. Hemos hablado de retos, pero también es importante destacar oportunidades. ¿Qué aspectos positivos podríais destacar a raíz de esta regulación reciente?
Ricard Martínez: Yo trabajo en la construcción, con fondos europeos, de Cancer Image EU que pretende ser una infraestructura digital para la imagen de cáncer. En estos momentos, hablamos de un partenariado que engloba a 14 países, 76 organizaciones, camino de 93, para generar una base de datos de imagen médica con 25 millones de imágenes de cáncer con información clínica asociada para el desarrollo de inteligencia artificial. La infraestructura se está construyendo, todavía no existe, y aún así, en el Hospital La Fe, en Valencia, ya se está investigando con mamografías de mujeres que se han practicado el screening bienal y que después han desplegado cáncer, para ver si es capaz de entrenar un modelo de análisis de imagen que sea capaz de reconocer preventivamente esa manchita que el oncólogo o el radiólogo no vieron y que después acabó siendo un cáncer. ¿Significa que te van a poner quimioterapia cinco minutos después? No. Significa que te van a monitorizar, que van a tener una capacidad de reacción temprana. Y que el sistema de salud se va a ahorrar doscientos mil euros. Por mencionar alguna oportunidad.
Por otra parte, las oportunidades hay que buscarlas, además, en otras normas. No solo en el Reglamento de Inteligencia Artificial. Hay que irse a Data Governance Act, que quiere contrarrestar el monopolio de datos que tienen las empresas norteamericanas con una compartición de datos desde el sector público, privado y desde la propia ciudadanía. Con Data Act, que pretende empoderar a los ciudadanos para que puedan recuperar sus datos y compartirlos mediante consentimiento. Y finalmente con el European Health Data Space que quiere crear un ecosistema de datos de salud para promover la innovación, la investigación y el emprendimiento. Ese ecosistema de espacios de datos es el que debería ser un enorme generador de espacios de oportunidad.
Y además, yo no sé si lo van a conseguir o no, pero pretende ser coherente con nuestro ecosistema empresarial. Es decir, un ecosistema de pequeña y mediana empresa que no tiene altas capacidades en la generación de datos y lo que le vamos a hacer es a construirles el campo. Les vamos a crear los espacios de datos, les vamos a crear los intermediarios, los servicios de intermediación y esperemos que ese ecosistema en su conjunto permita que el talento europeo emerja desde la pequeña y media empresa. ¿Que se vaya a conseguir o no? No lo sé, pero el escenario de oportunidad parece muy interesante.
Carmen Torrijos: Si preguntas por oportunidades, oportunidades todas. No solamente la inteligencia artificial, sino todo el avance tecnológico, es un campo tan grande que puede traer oportunidades de todo tipo. Lo que hay que hacer es bajar las barreras, que ese es el problema que tenemos. Y barreras las tenemos también de muchos tipos, porque tenemos barreras técnicas, de talento, salariales, disciplinares, de género, generacionales, etc.
Tenemos que concentrar las energías en bajar esas barreras, y luego también creo que seguimos viniendo del mundo analógico y tenemos poca conciencia global de que tanto lo digital como todo lo que afecta a la IA y a los datos es un fenómeno global. No sirve de nada mantenerlo todo en lo local, o en lo nacional, o ni siquiera a nivel europeo, sino que es un fenómeno global. Los grandes problemas que tenemos vienen porque tenemos empresas tecnológicas que se desarrollan en Estados Unidos trabajando en Europa con datos de ciudadanos europeos. Ahí se genera muchísima fricción. Todo lo que pueda llevar a algo más global va a ir siempre en favor de la innovación y va a ir siempre en favor de la tecnología. Lo primero es levantar las barreras dentro de Europa. Esa es una parte muy positiva de la ley.
7. Llegados a este punto, nos gustaría realizar un repaso sobre el estado en el que nos encontramos y las perspectivas de futuro. ¿Cómo veis el futuro de la inteligencia artificial en Europa?
Ricard Martínez: Yo tengo dos visiones: una positiva y una negativa. Y las dos vienen de mi experiencia en protección de datos. Si ahora que tenemos un marco normativo, las autoridades reguladoras, me refiero desde inteligencia artificial y desde protección de datos, no son capaces de encontrar soluciones funcionales y aterrizadas, y generan políticas públicas desde arriba hacia abajo y desde una excelencia que no se corresponde con las capacidades y las posibilidades de la investigación -me refiero no solo a la investigación empresarial, también a la universitaria-, veo el futuro muy negro. Si por el contrario, entendemos de modo dinámico la regulación con políticas públicas de soporte y acompañamiento que generen las capacidades para esa excelencia, veo un futuro prometedor porque en principio lo que haremos será competir en el mercado con las mismas soluciones que los demás, pero responsive: seguras, responsables y confiables.
Carmen: Sí, yo estoy muy de acuerdo. Yo introduzco en eso la variable tiempo, ¿no? Porque creo que hay que tener mucho cuidado en no generar más desigualdad de la que ya tenemos. Más desigualdad entre empresas, más desigualdad entre la ciudadanía. Si tenemos cuidado con eso, que se dice fácil, pero se hace difícil, yo creo que el futuro puede ser brillante, pero no lo va a ser de manera inmediata. Es decir, vamos a tener que pasar por una época más oscura de adaptación al cambio. Igual que muchos temas de la digitalización ya no nos son ajenos, ya están trabajados, ya hemos pasado por ellos y ya los hemos regulado, la inteligencia artificial necesita su tiempo también.
Llevamos muy pocos años de IA, muy pocos años de IA generativa. De hecho, dos años no es nada en un cambio tecnológico a nivel mundial. Y tenemos que dar tiempo a las leyes y tenemos también que dar tiempo a que ocurran cosas. Por ejemplo, pongo un ejemplo muy evidente, la denuncia del New York Times a Microsoft y a OpenAI no se ha resuelto todavía. Llevamos un año, se interpuso en diciembre de 2023, el New York Times se queja de que han entrenado con sus contenidos los sistemas de IA y en un año no se ha conseguido llegar a nada en ese proceso. Los procesos judiciales son muy lentos. Necesitamos que ocurran más cosas. Y que se resuelvan más procesos de este tipo para tener precedentes y para tener madurez como sociedad en lo que está ocurriendo, y nos falta mucho. Es como que no ha pasado casi nada. Entonces, la variable tiempo creo que es importante y creo que, aunque al principio tengamos un futuro más negro, como dice Ricard, creo que a largo plazo, si mantenemos claros los límites, podemos llegar a algo brillante.
Clips de la entrevista
1. ¿Qué criterios deberían tener los datos para entrenar un sistema de IA?
2. ¿Qué deberían revisar las empresas españolas teniendo en cuenta el Reglamento de IA?
Noticia
Desde la semana pasada, ya están disponibles los modelos de lenguaje de inteligencia artificial (IA) entrenados en español, catalán, gallego, valenciano y euskera, que se han desarrollado dentro de ALIA, la infraestructura pública de recursos de IA. A través de ALIA Kit los usuarios pueden acceder a toda la familia de modelos y conocer la metodología utilizada, la documentación relacionada y los conjuntos de datos de entrenamiento y evaluación. En este artículo te contamos sus claves.
¿Qué es ALIA?
ALIA es un proyecto coordinado por el Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS). Su objetivo es proporcionar una infraestructura pública de recursos de inteligencia artificial abiertos y transparentes, capaces de generar valor tanto en el sector público como en el privado.
En concreto, ALIA es una familia de modelos de texto, voz y traducción automática. El entrenamiento de sistemas de inteligencia artificial demanda una gran cantidad de recursos computacionales, ya que es necesario procesar y analizar enormes volúmenes de datos. Estos modelos han sido entrenados en español, una lengua que hablan más de 600 millones de personas en todo el mundo, pero también en las cuatro lenguas cooficiales. Para ello, se ha contado con la colaboración de la Real Academia Española (RAE) y la Asociación de Academias de la Lengua Española, que agrupa a las entidades del español existentes en todo el mundo.
Para el entrenamiento se ha utilizado el MareNostrum 5, uno de los superordenadores más potentes del mundo, que se encuentra en el Barcelona Supercomputing Center. Han sido necesarias miles de horas de trabajo para tratar varios miles de millones de palabras a una velocidad de 314.000 billones de cálculos por segundo.
Una familia de modelos abiertos y transparentes
Con el desarrollo de estos modelos se proporciona una alternativa que incorpora datos locales. Una de las prioridades de ALIA es ser una red abierta y transparente, lo que significa que los usuarios, además de poder acceder a los modelos, tienen la posibilidad de conocer y descargar los conjuntos de datos utilizados y toda la documentación relacionada. Esta documentación facilita la comprensión del funcionamiento de los modelos y, además, detectar más fácilmente en qué fallan, algo fundamental para evitar sesgos y resultados erróneos. La apertura de los modelos y la transparencia de los datos son fundamentales, ya que crea modelos más inclusivos y socialmente justos, que benefician a la sociedad en su conjunto.
Contar con modelos abiertos y transparentes fomenta la innovación, la investigación y democratiza el acceso a la inteligencia artificial, asegurando además que se parte de datos de entrenamiento de calidad.
¿Qué puedo encontrar en ALIA Kit?
A través de ALIA Kit, es posible acceder actualmente a cinco modelos masivos de lenguaje (LLM) de propósito general, de los que dos han sido entrenados con instrucciones de varios corpus abiertos. Igualmente, están disponibles nueve modelos de traducción automática multilingüe, algunos de ellos entrenados desde cero, como uno de traducción automática entre el gallego y el catalán, o entre el euskera y el catalán. Además, se han entrenado modelos de traducción al aranés, el aragonés y el asturiano.
También encontramos los datos y herramientas utilizadas para elaborar y evaluar los modelos de texto, como el corpus textual masivo CATalog, formado por 17,45 mil millones de palabras (alrededor de 23.000 millones de tokens), distribuidos en 34,8 millones de documentos procedentes de una gran variedad de fuentes, que han sido revisados en buena parte manualmente.
Para entrenar los modelos de voz se han utilizado diferentes corpus de voz con transcripción, como, por ejemplo, un conjunto de datos de las Cortes Valencianas con más de 270 horas de grabación de sus sesiones. Igualmente, es posible conocer los corpus utilizados para el entrenamiento de los modelos de traducción automática.
A través del ALIA Kit también está disponible una API gratuita (desde Python, Javascript o Curl), con la que se pueden realizar pruebas.
¿Para qué se pueden usar estos modelos?
Los modelos desarrollados por ALIA están diseñados para ser adaptables a una amplia gama de tareas de procesamiento del lenguaje natural. Sin embargo, cuando se trata de necesidades específicas es preferible utilizar modelos especializados, que permiten obtener mayor precisión y consumen menos recursos.
Como hemos visto, los modelos están disponibles para todos los usuarios interesados, como desarrolladores independientes, investigadores, empresas, universidades o instituciones. Entre los principales beneficiarios de estas herramientas se encuentran los desarrolladores y las pequeñas y medianas empresas, para quienes no es viable desarrollar modelos propios desde cero, tanto por cuestiones económicas como técnicas. Gracias a ALIA pueden adaptar los modelos ya existentes a sus necesidades específicas.
Los desarrolladores encontrarán recursos para crear aplicaciones que reflejen la riqueza lingüística del castellano y de las lenguas cooficiales. Por su parte, las empresas podrán desarrollar nuevas aplicaciones, productos o servicios orientados al amplio mercado internacional que ofrece la lengua castellana, abriendo nuevas oportunidades de negocio y expansión.
Un proyecto innovador financiado con fondos públicos
El proyecto ALIA está financiado íntegramente con fondos públicos con el objetivo de impulsar la innovación y la adopción de tecnologías que generen valor tanto en el sector público como en el privado. Contar con una infraestructura de IA pública democratiza el acceso a tecnologías avanzadas, permitiendo que pequeñas empresas, instituciones y gobiernos aprovechen todo su potencial para innovar y mejorar sus servicios. Además, facilita el control ético del desarrollo de la IA y fomenta la innovación.
ALIA forma parte de la Estrategia de Inteligencia Artificial 2024 de España, que tiene entre sus objetivos dotar al país de las capacidades necesarias para hacer frente a una demanda creciente de productos y servicios IA e impulsar la adopción de esta tecnología, especialmente en el sector público y pymes. Dentro del eje 1 de dicha estrategia, se encuentra la llamada Palanca 3, que se centra en la generación de modelos y corpus para una infraestructura pública de modelos de lenguaje. Con la publicación de esta familia de modelos, se avanza en el desarrollo de recursos de inteligencia artificial en España.