Blog
La convergencia entre datos abiertos, inteligencia artificial y sostenibilidad medioambiental plantea uno de los principales desafíos para el modelo de transformación digital que se está impulsando a nivel europeo. Esta interacción se concreta principalmente en tres manifestaciones destacadas:
-
La apertura de datos de alto valor directamente relacionados con la sostenibilidad, que pueden ayudar al desarrollo de soluciones de inteligencia artificial orientadas a la mitigación del cambio climático y la eficiencia de recursos.
-
El impulso de los denominados algoritmos verdes en la reducción del impacto ambiental de la IA, que se ha de concretar tanto en el uso eficiente de la infraestructura digital como en la toma de decisiones sostenibles.
-
La apuesta por espacios de datos medioambientales, generando ecosistemas digitales donde se comparten datos que provienen de fuentes diversas para facilitar el desarrollo de proyectos y soluciones interoperables con impacto relevante desde la perspectiva medioambiental.
A continuación, profundizaremos en cada uno de estos puntos.
Datos de alto valor para la sostenibilidad
La Directiva (UE) 2019/1024 sobre datos abiertos y reutilización de la información del sector público introdujo por primera vez el concepto de conjuntos de datos de alto valor, definidos como aquellos con un potencial excepcional para generar beneficios sociales, económicos y medioambientales. Estos conjuntos deben publicarse de forma gratuita, en formatos legibles por máquina, mediante interfaces de programación de aplicaciones (API) y, cuando proceda, se han de poder descargar de forma masiva. A tal efecto se han identificado una serie de categorías prioritarias, entre los que se encuentran los datos medioambientales y relativos a la observación de la Tierra.
Se trata de una categoría especialmente relevante, ya que abarca tanto datos sobre clima, ecosistemas o calidad ambiental, así como los vinculados a la Directiva INSPIRE, que hacen referencia a áreas ciertamente diversas como hidrografía, lugares protegidos, recursos energéticos, uso del suelo, recursos minerales o, entre otros, los relativos a zonas de riesgos naturales, incluyendo también ortoimágenes.
Estos datos tienen una singular relevancia a la hora de monitorizar las variables relacionadas con el cambio climático, como puede ser el uso del suelo, la gestión de la biodiversidad teniendo en cuenta la distribución de especies, hábitats y lugares protegidos, el seguimiento de las especies invasoras o la evaluación de los riesgos naturales. Los datos sobre calidad del aire y contaminación son cruciales para la salud pública y ambiental, de manera que el acceso a los mismos permite llevar a cabo análisis exhaustivos sin duda relevantes para la adopción de políticas públicas orientadas a su mejora. La gestión de recursos hídricos también se puede optimizar mediante datos de hidrografía y monitoreo ambiental, de manera que su tratamiento masivo y automatizado constituye una premisa inexcusable para hacer frente al reto de la digitalización de la gestión del ciclo del agua.
La combinación con otros datos medioambientales de calidad facilita el desarrollo de soluciones de IA orientadas a desafíos climáticos específicos. En concreto, permiten entrenar modelos predictivos para anticipar fenómenos extremos (olas de calor, sequías, inundaciones), optimizar la gestión de recursos naturales o monitorizar en tiempo real indicadores ambientales críticos. También permite impulsar proyectos económicos de gran impacto, como puede ser el caso de la utilización de algoritmos de IA para implementar soluciones tecnológicas en el ámbito de la agricultura de precisión, posibilitando el ajuste inteligente de los sistemas de riego, la detección temprana de plagas o la optimización del uso de fertilizantes.
Algoritmos verdes y responsabilidad digital: hacia una IA sostenible
El entrenamiento y despliegue de sistemas de inteligencia artificial, particularmente de modelos de propósito general y grandes modelos de lenguaje, conlleva un consumo energético significativo. Según estimaciones de la Agencia Internacional de la Energía, los centros de datos representaron alrededor del 1,5 % del consumo mundial de electricidad en 2024. Esta cifra supone un crecimiento de alrededor de un 12 % anual desde 2017, más de cuatro veces más rápido que la tasa de consumo eléctrico total. Está previsto que el consumo eléctrico de los centros de datos se duplique hasta alcanzar unos 945 TWh en 2030.
Ante este panorama, los algoritmos verdes constituyen una alternativa que necesariamente ha de tenerse en cuenta a la hora de minimizar el impacto ambiental que plantea la implantación de la tecnología digital y, en concreto, la IA. De hecho, tanto la Estrategia Europea de Datos como el Pacto Verde Europeo integran explícitamente la sostenibilidad digital como pilar estratégico. Por su parte, España ha puesto en marcha un Programa Nacional de Algoritmos Verdes, enmarcado en la Agenda Digital 2026 y con una medida específica en la Estrategia Nacional de Inteligencia Artificial.
Uno de los principales objetivos del Programa consiste en fomentar el desarrollo de algoritmos que minimicen su impacto ambiental desde la concepción —enfoque green by design—, por lo que la exigencia de una documentación exhaustiva de los conjuntos de datos utilizados para entrenar modelos de IA —incluyendo origen, procesamiento, condiciones de uso y huella ambiental— resulta fundamental para dar cumplimiento a esta aspiración. A este respecto, la Comisión ha publicado una plantilla para ayudar a los proveedores de inteligencia artificial de propósito general a resumir los datos utilizados para el entrenamiento de sus modelos, de manera que se pueda exigir mayor transparencia que, por lo que ahora interesa, también facilitaría la trazabilidad y gobernanza responsable desde la perspectiva ambiental, así como la realización de ecoauditorías.
El Espacio de Datos del Pacto Verde Europeo (Green Deal)
Se trata de uno de los espacios de datos comunes europeos contemplados en la Estrategia Europea de Datos que se encuentra en un estado más avanzado, tal y como demuestran las numerosas iniciativas y eventos de divulgación que se han impulsado en torno al mismo. Tradicionalmente el acceso a la información ambiental ha sido uno de los ámbitos con una regulación más favorable, de manera que con el impulso de los datos de alto valor y la decida apuesta que supone la creación de un espacio europeo en esta materia se ha producido un avance cualitativo muy destacable que refuerza una tendencia ya consolidada en este ámbito.
En concreto, el modelo de los espacios de datos facilita la interoperabilidad entre datos abiertos públicos y privados, reduciendo barreras de entrada para startups y pymes en sectores como la gestión forestal inteligente, la agricultura de precisión o, entre otros muchos ejemplos, la optimización energética. Al mismo tiempo, refuerza la calidad de los datos disponibles para que las Administraciones Públicas lleven a cabo sus políticas públicas, ya que sus propias fuentes pueden contrastarse y compararse con otros conjuntos de datos. Finalmente, el acceso compartido a datos y herramientas de IA puede fomentar iniciativas y proyectos de innovación colaborativa, acelerando el desarrollo de soluciones interoperables y escalables.
Ahora bien, el ecosistema jurídico propio de los espacios de datos conlleva una complejidad inherente a su propia configuración institucional, ya que en el mismo confluyen varios sujetos y, por tanto, diversos intereses y regímenes jurídicos aplicables:
-
Por una parte, las entidades públicas, a las que en este ámbito les corresponde un papel de liderazgo especialmente reforzado.
-
Por otra las entidades privadas y la ciudanía, que no sólo pueden aportar sus propios conjuntos de datos, sino asimismo ofrecer desarrollos y herramientas digitales que pongan en valor los datos a través de servicios innovadores.
-
Y, finalmente, los proveedores de la infraestructura necesaria para la interacción en el seno del espacio.
En consecuencia, son imprescindibles modelos de gobernanza avanzados que hagan frente a esta complejidad reforzada por la innovación tecnológica y de manera especial la IA, ya que los planteamientos tradicionales propios de la legislación que regula el acceso a la información ambiental son ciertamente limitados para esta finalidad.
Hacia una convergencia estratégica
La convergencia de datos abiertos de alto valor, algoritmos verdes responsables y espacios de datos medioambientales está configurando un nuevo paradigma digital imprescindible para afrontar los retos climáticos y ecológicos en Europa que requiere un enfoque jurídico robusto y, al mismo tiempo flexible. Este singular ecosistema no solo permite impulsar la innovación y eficiencia en sectores clave como la agricultura de precisión o la gestión energética, sino que también refuerza la transparencia y la calidad de la información ambiental disponible para la formulación de políticas públicas más efectivas.
Más allá del marco normativo vigente resulta imprescindible diseñar modelos de gobernanza que ayuden a interpretar y aplicar de manera coherente regímenes legales diversos, que protejan la soberanía de los datos y, en definitiva, garanticen la transparencia y la responsabilidad en el acceso y reutilización de la información medioambiental. Desde la perspectiva de la contratación pública sostenible, es esencial promover procesos de adquisición por parte de las entidades públicas que prioricen soluciones tecnológicas y servicios interoperables basados en datos abiertos y algoritmos verdes, fomentando la elección de proveedores comprometidos con la responsabilidad ambiental y la transparencia en las huellas de carbono de sus productos y servicios digitales.
Solo partiendo de este enfoque se puede aspirar a que la innovación digital sea tecnológicamente avanzada y ambientalmente sostenible, alineando así los objetivos del Pacto Verde, la Estrategia Europea de Datos y el enfoque europeo en materia de IA
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El pasado mes de octubre España acogió la Cumbre Global OGP 2025, un evento de referencia internacional sobre el gobierno abierto. Más de 2.000 representantes de gobiernos, organizaciones de la sociedad civil y expertos/as de políticas públicas de todo el mundo se reunieron en Vitoria-Gasteiz para conversar sobre la importancia de mantener gobiernos abiertos, participativos y transparentes como pilares de la sociedad.
La ubicación elegida para este encuentro no fue casualidad: España lleva más de una década construyendo un modelo de gobierno abierto que la ha posicionado como referente internacional. En este artículo vamos a repasar algunos de los proyectos que se han puesto en marcha en nuestro país para transformar su Administración pública y acercarla a la ciudadanía.
El marco estratégico: planes de acción y compromisos internacionales
El gobierno abierto es una cultura de gobernanza que promueve los principios de transparencia, integridad, rendición de cuentas y participación de las partes interesadas en apoyo de la democracia y el crecimiento inclusivo.
La apuesta española por el gobierno abierto tiene un recorrido consolidado. Desde que España se unió a la Alianza para el Gobierno Abierto en 2011, el país ha desarrollado cinco planes de acción consecutivos que han ido ampliando y profundizando en las iniciativas de apertura gubernamental. Cada plan ha supuesto un avance respecto al anterior, incorporando nuevos compromisos y respondiendo a los desafíos emergentes de la sociedad digital.
El V Plan de Gobierno Abierto (2024-2028) representa la evolución de esta estrategia. Su proceso de elaboración incorporó una metodología de cocreación que involucró a múltiples actores de la sociedad civil, Administraciones públicas de todos los niveles y expertos en la materia. Este enfoque participativo facilitó que el plan respondiera a necesidades reales y contara con el respaldo de todos los sectores implicados.
Justicia 2030: la mayor transformación del sistema judicial en décadas
Bajo el lema “La mayor transformación de la Justicia en décadas”, el programa Justicia 2030 se plantea como una hoja de ruta para modernizar el sistema judicial español. Su objetivo es construir una justicia más accesible, eficiente, sostenible y centrada en las personas, mediante un modelo de cogobernanza que involucra a Administraciones públicas, operadores jurídicos y ciudadanía.
El plan se articula en torno a tres ejes estratégicos:
1. Accesibilidad y justicia centrada en las personas
Este eje busca garantizar que la justicia llegue a toda la ciudadanía, reduciendo brechas territoriales, sociales y digitales. Entre las principales medidas destacan:
- Accesos y atención presencial y digital: impulso de sedes judiciales más accesibles, tanto física como tecnológicamente, con servicios adaptados a colectivos vulnerables.
- Educación legal básica: iniciativas de alfabetización jurídica para la población general, favoreciendo la comprensión del sistema judicial.
- Justicia inclusiva: programas de mediación y justicia restaurativa, con especial atención a víctimas y grupos en situación de vulnerabilidad.
- Nuevas realidades sociales: adaptación del sistema judicial a los retos contemporáneos (violencia digital, delitos medioambientales, derechos digitales, etc.).
2. Eficiencia del servicio público de justicia
El programa defiende que la transformación tecnológica y organizativa es clave para una justicia más ágil y eficiente. Este segundo eje incorpora avances orientados a la gestión moderna y la digitalización:
- Oficinas de justicia en los municipios: creación de puntos de acceso a la justicia en localidades pequeñas, acercando los servicios judiciales al territorio.
- Reforma procesal y organizativa: actualización de la Ley de Enjuiciamiento Criminal y del marco procesal para mejorar la coordinación entre juzgados.
- Expediente judicial electrónico: consolidación del expediente digital y de las herramientas interoperables entre instituciones.
- Inteligencia artificial y datos judiciales: uso responsable de tecnologías avanzadas para mejorar la gestión de expedientes y la predicción de cargas de trabajo.
3. Justicia sostenible y cohesionada territorialmente
El tercer eje busca que la modernización judicial contribuya a los Objetivos de Desarrollo Sostenible (ODS) y a la cohesión territorial.
Las líneas principales son:
- Justicia ambiental y climática: promoción de mecanismos legales que favorezcan la protección medioambiental y la lucha contra el cambio climático.
- Cohesión territorial: coordinación con comunidades autónomas para garantizar igualdad de acceso a la justicia en todo el país.
- Colaboración institucional: fortalecimiento de la cooperación entre poderes públicos, entidades locales y sociedad civil.
El Portal de la Transparencia: el corazón del derecho a saber
Si Justicia 2030 representa la transformación del acceso a la justicia, el Portal de la Transparencia está pensado para garantizar el derecho ciudadano a la información pública. Esta plataforma digital, operativa desde 2014, centraliza la información sobre las organizaciones administrativas y permite a la ciudadanía ejercer su derecho de acceso a la información pública de manera sencilla y directa. Sus principales funciones son:
- Publicación proactiva de información sobre las actividades gubernamentales, presupuestos, contrataciones, subvenciones, convenios y decisiones administrativas, sin necesidad de que los ciudadanos lo soliciten.
- Sistema de solicitud de información para acceder a documentación no disponible públicamente, con plazos legalmente establecidos para la respuesta administrativa.
- Procesos participativos que permiten a los ciudadanos intervenir activamente en el diseño y evaluación de políticas públicas.
- Indicadores de transparencia que miden objetivamente el cumplimiento de las obligaciones de las diferentes administraciones, permitiendo comparaciones y fomentando la mejora continua.
Este portal se vertebra en tres derechos fundamentales:
- Derecho a saber: todo ciudadano puede acceder a información pública, ya sea a través de la consulta directa en el portal o ejerciendo formalmente su derecho de acceso cuando la información no esté disponible.
- Derecho a entender: la información debe presentarse de forma clara, comprensible y adaptada a diferentes públicos, evitando tecnicismos innecesarios y facilitando la interpretación.
- Derecho a participar: los ciudadanos pueden intervenir en la gestión de asuntos públicos mediante los mecanismos de participación ciudadana habilitados en la plataforma.
La plataforma cumple con la Ley 19/2013, de 9 de diciembre, de transparencia, acceso a la información pública y buen gobierno, una norma que supuso un cambio de paradigma, reconociendo el acceso a la información como un derecho fundamental del ciudadano y no como una concesión graciosa de la administración.
Consenso por una Administración Abierta: estrategia nacional de gobierno abierto
Otro proyecto que aboga por el gobierno abierto es el "Consenso por una Administración Abierta". Según este documento de referencia, no se trata únicamente de abrir datos o crear portales de transparencia, sino de transformar radicalmente la forma en que se diseñan e implementan las políticas públicas. Este consenso sustituye el modelo tradicional vertical, donde las administraciones deciden unilateralmente, por un diálogo permanente entre administraciones, operadores jurídicos y ciudadanía. El documento se estructura en cuatro ejes estratégicos:
1. Administración Abierta a las capacidades del sector público
- Desarrollo de un empleo público proactivo, innovador e inclusivo.
- Implementación responsable de sistemas de inteligencia artificial.
- Creación de espacios seguros y éticos de datos compartidos.
2. Administración Abierta a políticas públicas informadas por evidencias y a la participación:
- Desarrollo de mapas interactivos de políticas públicas.
- Evaluación sistemática basada en datos y evidencias.
- Incorporación de la voz ciudadana en todas las fases del ciclo de políticas públicas.
3. Administración Abierta a la ciudadanía:
- Evolución de "Mi Carpeta Ciudadana" hacia servicios más personalizados.
- Implementación de herramientas digitales como SomosGob.
- Simplificación radical de trámites y procedimientos administrativos.
4. Administración Abierta a la Transparencia, la Participación y la Rendición de Cuentas:
- Renovación completa del Portal de Transparencia.
- Mejora de los mecanismos de transparencia de la Administración General del Estado.
- Fortalecimiento de los sistemas de rendición de cuentas.

Figura 1: Consenso por una Administración abierta a. Fuente: elaboración propia
El Foro de Gobierno Abierto: espacio de diálogo permanente
Todos estos proyectos y compromisos necesitan un espacio institucional donde puedan discutirse, evaluarse y ajustarse continuamente. Esa es precisamente la función del Foro de Gobierno Abierto que funciona como un órgano de participación y diálogo integrado por representantes de la administración central, autonómica y local. Y lo conforman 32 miembros de la sociedad civil cuidadosamente seleccionados para garantizar la diversidad de perspectivas.
Esta composición equilibrada garantiza que todas las voces sean escuchadas en el diseño e implementación de las políticas de gobierno abierto. El Foro se reúne de manera periódica para evaluar el avance de los compromisos, identificar obstáculos y proponer nuevas iniciativas que respondan a los desafíos emergentes.
Su funcionamiento transparente y participativo, con actas públicas y procesos de consulta abiertos, lo convierte en un referente internacional de buenas prácticas en gobernanza colaborativa. El Foro no es simplemente un órgano consultivo, sino un espacio de codecisión donde se construyen consensos que posteriormente se traducen en políticas públicas concretas.
Hazlab: laboratorio de innovación para la participación ciudadana
Promovido por la Dirección General de Gobernanza Pública del Ministerio para la Transformación Digital y de la Función Pública, HazLab forma parte del Plan de Mejora de la Participación Ciudadana en los Asuntos Públicos, incluido en el Compromiso 3 del IV Plan de Gobierno Abierto de España (2020-2024).
HazLab es un espacio virtual diseñado para fomentar la colaboración entre la Administración, la ciudadanía, la academia, los profesionales y los colectivos sociales. Su propósito es impulsar una nueva forma de construir políticas públicas desde la innovación, el diálogo y la cooperación. En concreto hay tres áreas de trabajo:
- Espacios virtuales de colaboración, que facilitan el trabajo conjunto entre administraciones, expertos y ciudadanía.
- Proyectos de diseño y prototipado de servicios públicos, basados en metodologías participativas e innovadoras.
- Biblioteca de recursos, un repositorio con materiales audiovisuales, artículos, informes y guías sobre gobierno abierto, participación, integridad y transparencia.
El registro en HazLab es gratuito y permite participar en proyectos, eventos y comunidades de práctica. Además, la plataforma ofrece un manual de uso y un código de conducta para facilitar la participación responsable.
En conclusión, los proyectos de gobierno abierto que España está impulsando representan mucho más que iniciativas aisladas de modernización administrativa o actualizaciones tecnológicas. Constituyen un cambio cultural profundo en la concepción misma del servicio público, donde la ciudadanía deja de ser un mero receptor pasivo de servicios para convertirse en co-creadora activa de políticas públicas.
Blog
Vivimos rodeados de resúmenes generados por inteligencia artificial (IA). Tenemos la opción de generarlos desde hace meses, pero ahora se imponen en las plataformas digitales como el primer contenido que ven nuestros ojos al usar un buscador o abrir un hilo de emails. En plataformas como Microsoft Teams o Google Meet las reuniones por videollamada se transcriben y se resumen en actas automáticas para quien no ha podido estar presente, pero también para quien ha estado. Sin embargo, aquello que un modelo de lenguaje ha considerado importante, ¿es realmente lo importante para quien recibe el resumen?
En este nuevo contexto, la clave es aprender a recuperar el sentido detrás de tanta información resumida. Estas tres estrategias te ayudarán a transformar el contenido automático en una herramienta de comprensión y toma de decisiones.
1. Haz preguntas expansivas
Solemos resumir para reducir un contenido que no somos capaces de abarcar, pero corremos el riesgo de asociar breve con significativo, una equivalencia que no siempre se cumple. Por tanto, no deberíamos enfocarnos desde el inicio en resumir, sino en extraer información relevante para nosotros, nuestro contexto, nuestra visión de la situación y nuestra manera de pensar. Más allá del prompt básico “hazme un resumen”, esta nueva manera de enfocar un contenido que se nos escapa consiste en cruzar datos, conectar puntos y sugerir hipótesis, lo que llaman sensemaking o “construcción de sentido”. Y pasa, en primer lugar, por tener claro qué queremos saber.
Situación práctica:
Imaginemos una reunión larga a la que no hemos podido acudir. Esa tarde, recibimos en nuestro correo electrónico un resumen de los temas tratados. No siempre es posible, pero una buena práctica en este punto, si nuestra organización lo permite, es no quedarnos solo con el resumen: si está permitido, y siempre respetando las directrices de confidencialidad, sube la transcripción completa a un sistema conversacional como Copilot o Gemini y haz preguntas específicas:
-
¿Qué tema se repitió más o recibió más atención durante la reunión?
-
En una reunión anterior, la persona X usó este argumento. ¿Se usó de nuevo? ¿Lo discutió alguien? ¿Se dio por válido?
-
¿Qué premisas, suposiciones o creencias están detrás de esta decisión que se ha tomado?
-
Al final de la reunión, ¿qué elementos parecen más críticos para el éxito del proyecto?
-
¿Qué señales anticipan posibles retrasos o bloqueos? ¿Cuáles tienen que ver o podrían afectar a mi equipo?
Cuidado con:
Ante todo, revisa y confirma las atribuciones. Los modelos generativos son cada vez más precisos, pero tienen una gran capacidad para mezclar información real con información falsa o generada. Por ejemplo, pueden atribuir una frase a alguien que no la dijo, relacionar como causa-efecto ideas que en realidad no tenían conexión, y seguramente lo más importante: asignar tareas o responsabilidades de próximos pasos a alguien a quien no le corresponden.
2. Pide contenido estructurado
Los buenos resúmenes no son más cortos, sino más organizados, y el texto redactado no es el único formato al que podemos recurrir. Busca la eficacia y pide a los sistemas conversacionales que te devuelvan tablas, categorías, listas de decisiones o mapas de relaciones. La forma condiciona el pensamiento: si estructuras bien la información, la entenderás mejor y también la transmitirás mejor a otros, y por tanto irás más lejos con ella.
Situación práctica:
En este caso, imaginemos que recibimos un informe largo sobre el avance de varios proyectos internos de nuestra empresa. El documento tiene muchas páginas con párrafos descriptivos de estado, feedback, fechas, imprevistos, riesgos y presupuestos. Leerlo todo línea por línea sería imposible y no retendríamos la información. La buena práctica aquí es pedir una transformación del documento que nos sea útil de verdad. Si es posible, sube el informe al sistema conversacional y solicita contenido estructurado de manera exigente y sin escatimar en detalles:
-
Organiza el informe en una tabla con las siguientes columnas: proyecto, responsable, fecha de entrega, estado, y una columna final que indique si ha ocurrido algún imprevisto o se ha materializado algún riesgo. Si todo va bien, imprime en esa columna “CORRECTO”.
-
Genera un calendario visual con los entregables, sus fechas de entrega y los responsables, que empiece el 1 de octubre de 2025 y termine el 31 de enero de 2026, en forma de diagrama de Gantt.
-
Quiero una lista en la que aparezcan exclusivamente el nombre de los proyectos, su fecha de inicio y su fecha de entrega. Ordena por la fecha de entrega, las más cercanas primero.
-
Del apartado de feedback de los clientes que encontrarás en cada proyecto, crea una tabla con los comentarios más repetidos y a qué áreas o equipos suelen hacer referencia. Colócalos en orden, de los que más se repiten a los que menos.
-
Dame la facturación de los proyectos que están en riesgo de no cumplir plazos, indica el precio de cada uno y el total.
Cuidado con:
La ilusión de veracidad y exhaustividad que nos va a proporcionar un texto limpio, ordenado, automático y con fuentes es enorme. Un formato claro, como una tabla, una lista o un mapa, puede dar una falsa sensación de precisión. Si los datos de origen son incompletos o erróneos, la estructura solo maquilla el error y tendremos más dificultades para verlo. Las producciones de la IA suelen ser casi perfectas. Como mínimo, y si el documento es muy extenso, haz comprobaciones aleatorias ignorando la forma y centrándote en el contenido.
3. Conecta los puntos
El sentido estratégico rara vez está en un texto aislado, y mucho menos en un resumen. El nivel avanzado en este caso consiste en pedir al chat multimodal que cruce fuentes, compare versiones o detecte patrones entre varios materiales o formatos, como por ejemplo la transcripción de una reunión, un informe interno y un artículo científico. Lo que interesa realmente ver son claves comparativas como los cambios evolutivos, las ausencias o las inconsistencias.
Situación práctica:
Imaginemos que estamos preparando una propuesta para un nuevo proyecto. Tenemos varios materiales: la transcripción de una reunión del equipo directivo, el informe interno del año anterior y un artículo reciente sobre tendencias del sector. En lugar de resumirlos por separado, puedes subirlos al mismo hilo de conversación o a un chat que hayas personalizado sobre el tema, y pedirle acciones más ambiciosas.
-
Compara estos tres documentos y dime qué prioridades coinciden en todos, aunque se expresen de maneras distintas.
-
¿Qué temas del informe interno no se han mencionado en la reunión? Genera una hipótesis para cada uno sobre por qué no se han tratado.
-
¿Qué ideas del artículo podrían reforzar o cuestionar las nuestras? Dame ideas fuerza de la investigación que no estén reflejadas en nuestro informe interno.
-
Busca artículos en prensa de los últimos seis meses que avalen las ideas fuerza del informe interno.
-
Encuentra fuentes externas que complementen la información ausente en estos tres documentos sobre el tema X y genera un informe panorámico con referencias.
Cuidado con:
Es muy habitual que los sistemas de IA simplifiquen de forma engañosa debates complejos, no porque tengan un objetivo oculto sino porque en el entrenamiento se les ha premiado siempre la sencillez y la claridad. Además, la generación automática introduce un riesgo de autoridad: como el texto se presenta con apariencia de precisión y neutralidad, asumimos que es válido y útil. Y, por si fuera poco, los resúmenes estructurados se copian y comparten rápido. Antes de reenviar, asegúrate de que el contenido está validado, sobre todo si contiene decisiones, nombres o datos sensibles.
Conclusión
Los modelos basados en IA pueden ayudarte a visualizar convergencias, lagunas o contradicciones y, a partir de ahí, formular hipótesis o líneas de acción. Se trata de encontrar con mayor agilidad eso tan valioso que llamamos insights. Ese es el paso del resumen al análisis: lo más importante no es comprimir la información, sino seleccionarla bien, relacionarla y conectarla con el contexto. Intensificar la exigencia desde el prompt es la manera más adecuada de trabajar con los sistemas IA, pero también nos exige un esfuerzo personal previo de análisis y aterrizaje.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La visualización de datos es una práctica fundamental para democratizar el acceso a la información pública. Sin embargo, crear gráficos efectivos va mucho más allá de elegir colores atractivos o utilizar las últimas herramientas tecnológicas. Como señala Alberto Cairo, experto en visualización de datos y docente de la academia del portal europeo de datos abiertos (data.europa.eu), “cada decisión de diseño debe ser deliberada: inevitablemente subjetiva, pero nunca arbitraria”. A través de una serie de tres webinar que puedes volver a ver aquí, el experto ofreció consejos innovadores para estar a la vanguardia de la visualización de datos.
Cuando trabajamos con visualización de datos, especialmente en el contexto de la información pública, es crucial desmontar algunos mitos arraigados en nuestra cultura profesional. Frases como "los datos hablan por sí mismos", "una imagen vale más que mil palabras" o "muestra, no cuentes" suenan bien, pero esconden una verdad incómoda: los gráficos no siempre comunican automáticamente.
La realidad es más compleja. Un/a profesional del diseño puede querer comunicar algo específico, pero los lectores pueden interpretar algo completamente diferente. ¿Cómo se puede superar la brecha entre intención y percepción en visualización de datos? En este post, ofrecemos algunas claves de la serie formativa.
Un marco estructurado para diseñar con propósito
En lugar de seguir "reglas" rígidas o aplicar plantillas predefinidas, en el curso se propone un marco de pensamiento basado en cinco componentes interrelacionados:
- Contenido: la naturaleza, origen y limitaciones de los datos
- Personas: la audiencia a la que nos dirigimos
- Intención: los propósitos que definimos
- Restricciones: las limitaciones que enfrentamos
- Resultados: cómo es recibido el gráfico
Este enfoque holístico nos obliga a preguntarnos constantemente: ¿qué necesitan realmente saber nuestros lectores? Por ejemplo, cuando comunicamos información sobre riesgos de huracanes o emergencias sanitarias, ¿es más importante mostrar trayectorias exactas o comunicar impactos potenciales? La respuesta correcta depende del contexto y, sobre todo, de las necesidades informativas de la ciudadanía.
El peligro de la agregación excesiva
Aún sin perder de vista el propósito es importante no caer en añadir demasiada información o presentar solo promedios. Imaginemos, por ejemplo, un conjunto de datos sobre seguridad ciudadana a nivel nacional: un promedio puede esconder que la mayoría de las localidades son muy seguras, mientras unas pocas con tasas extremadamente altas distorsionan el indicador nacional.
Como explica Claus O. Wilke en su libro "Fundamentals of Data Visualization", esta práctica puede ocultar patrones cruciales, valores atípicos y paradojas que son precisamente los más relevantes para la toma de decisiones. Para evitar este riesgo, en la formación se propone visualizar una gráfica como un sistema de capas que debemos construir cuidadosamente desde la base:
1. Codificación (Encoding)
- Es la base de todo: cómo traducimos datos en atributos visuales. Las investigaciones en percepción visual nos muestran que no todos los "canales visuales" son igual de efectivos. La jerarquía sería:
- Más efectivos: posición, longitud y altura
- Medianamente efectivos: ángulo, área y pendiente
- Menos efectivos: color, saturación y forma
¿Cómo ponemos esto en práctica? Pues, por ejemplo, para realizar comparaciones precisas, un gráfico de barras será casi siempre mejor opción que un gráfico circular. Sin embargo, como se matiza en los materiales formativos, "efectivo" no siempre significa "apropiado". Un gráfico circular puede ser perfecto cuando queremos expresar la idea de un "todo y sus partes", aunque las comparaciones precisas sean más difíciles.
2. Disposición (Arrangement)
El posicionamiento, orden y agrupación de los elementos afecta profundamente a la percepción. ¿Queremos que el lector compare entre categorías dentro de un grupo, o entre grupos? La respuesta determinará si organizamos nuestra visualización con barras agrupadas o apiladas, con paneles múltiples o en una única vista integrada.
3. Andamiaje (Scaffolding)
Los títulos, introducciones, anotaciones, escalas y leyendas son fundamentales. En datos.gob.es hemos visto cómo las visualizaciones interactivas pueden condensar información compleja, pero sin un andamiaje adecuado, la interactividad puede confundir más que aclarar.
El valor de una correcta escala
Uno de los aspectos técnicos más delicados —y a menudo más manipulables— de una visualización es la elección de la escala. Una simple modificación en el eje Y puede cambiar por completo la interpretación del lector: una tendencia suave puede parecer una crisis repentina, o un crecimiento sostenido puede pasar desapercibido.
Como se menciona en el segundo webinar de la serie, las escalas no son un detalle menor: son un componente narrativo. Decidir dónde empieza un eje, qué intervalos se usan o cómo se representan los periodos de tiempo implica hacer elecciones que afectan directamente la percepción de la realidad. Por ejemplo, si una gráfica de empleo comienza el eje Y en 90 % en lugar de 0 %, el descenso puede parecer dramático, aunque, en realidad, sea mínimo.
Por eso, las escalas deben ser honestas con los datos. Ser “honesto” no significa renunciar a decisiones de diseño, sino mostrar claramente qué decisiones se tomaron y por qué. Si existe una razón válida para empezar el eje Y en un valor distinto de cero, debe explicarse explícitamente en la gráfica o en su pie de texto. La transparencia debe prevalecer sobre el dramatismo.
La integridad visual no solo protege al lector de interpretaciones engañosas, sino que refuerza la credibilidad de quien comunica. En el ámbito de los datos públicos, esa honestidad no es opcional: es un compromiso ético con la verdad y con la confianza ciudadana.
Accesibilidad: visualizar para todos
Por otro lado, uno de los aspectos frecuentemente olvidado es la accesibilidad. Aproximadamente el 8 % de los hombres y el 0,5 % de las mujeres tienen algún tipo de daltonismo. Herramientas como Color Oracle permiten simular cómo se ven nuestras visualizaciones para personas con diferentes tipos de deficiencias en la percepción del color.
Además, en el webinar se mencionó el proyecto Chartability, una metodología para evaluar la accesibilidad de las visualizaciones de datos. En el sector público español, donde la accesibilidad web es un requisito legal, esto no es opcional: es una obligación democrática. Bajo esta premisa publicó la Federación Española de Municipios y Provincias publicó una Guía de Visualización de Datos para Entidades Locales.
Narrativa visual: cuando los datos cuentan historias
Una vez resueltas las cuestiones técnicas, podemos abordar el aspecto narrativo que cada día es más importante para comunicar correctamente. En este sentido, el curso plantea un método sencillo pero poderoso:
- Escribe una frase larga que resuma los puntos que quieres comunicar.
- Divide esa frase en componentes, aprovechando las pausas naturales.
- Transforma esos componentes en secciones de tu infografía.
Este enfoque narrativo es especialmente efectivo para proyectos como los que encontramos en data.europa.eu, donde se combinan visualizaciones con explicaciones contextuales para comunicar el valor de los conjuntos de datos de alto valor o en los ejercicios de visualización y ciencia de datos de datos de datos.gob.es.
El futuro de la visualización de datos también incluye aproximaciones más creativas y centradas en el usuario. Proyectos que incorporan elementos personalizados, que permiten a los lectores situarse en el centro de la información, o que utilizan técnicas narrativas para generar empatía, están redefiniendo lo que entendemos por "comunicación de datos".
Incluso emergen formas alternativas de "sensificación de datos": la fisicalización (crear objetos tridimensionales con datos) y la sonificación (traducir datos a sonido) abren nuevas posibilidades para hacer la información más tangible y accesible. La empresa española Tangible Data, de la que nos hacemos eco en datos.gob.es porque reutiliza conjuntos de datos abiertos, es prueba de ello.

Figura 1. Ejemplos de sensificación de datos. Fuente: https://data.europa.eu/sites/default/files/course/webinar-data-visualisation-episode-3-slides.pdf
A modo de conclusión, podemos resaltar que la integridad en el diseño no es un lujo: es un requisito ético. Cada gráfico que publicamos en plataformas oficiales influye en cómo los ciudadanos perciben la realidad y toman decisiones. Por eso, dominar herramientas técnicas como las bibliotecas y API de visualización, que se analizan en otros artículos del portal, es tan relevante.
La próxima vez que crees una visualización con datos abiertos, no te preguntes solo "¿qué herramienta uso?" o "¿qué gráfico se ve mejor?". Pregúntate: ¿qué necesita realmente saber mi audiencia? ¿Esta visualización respeta la integridad de los datos? ¿Es accesible para todos? Las respuestas a estas preguntas son las que transforman un gráfico bonito en una herramienta de comunicación verdaderamente efectiva.
Blog
La Inteligencia Artificial (IA) está convirtiéndose en uno de los principales motores del aumento de la productividad y la innovación tanto en el sector público como en el privado, siendo cada vez más relevante en tareas que van desde la creación de contenido en cualquier formato (texto, audio, video) hasta la optimización de procesos complejos a través de agentes de Inteligencia Artificial.
Sin embargo, los modelos avanzados de IA, y en particular los grandes modelos de lenguaje, exigen cantidades ingentes de datos para su entrenamiento, optimización y evaluación. Esta dependencia genera una paradoja: a la vez que la IA demanda más datos y de mayor calidad, la creciente preocupación por la privacidad y la confidencialidad (Reglamento General de Protección de Datos o RGPD), las nuevas reglas de acceso y uso de datos (Data Act), y los requisitos de calidad y gobernanza para sistemas de alto riesgo (Reglamento de IA), así como la inherente escasez de datos en dominios sensibles limitan el acceso a los datos reales.
En este contexto, los datos sintéticos pueden ser un mecanismo habilitador para conseguir nuevos avances, conciliando innovación y protección de la privacidad. Por una parte, permiten alimentar el progreso de la IA sin exponer información sensible, y cuando se combinan con datos abiertos de calidad amplían el acceso a dominios donde los datos reales son escasos o están fuertemente regulados.
¿Qué son los datos sintéticos y cómo se generan?
De forma sencilla, los datos sintéticos se pueden definir como información fabricada artificialmente que imita las características y distribuciones de los datos reales. La función principal de esta tecnología es reproducir las características estadísticas, la estructura y los patrones del dato real subyacente. En el dominio de las estadísticas oficiales existen casos como el del Censo de Estados Unidos que publica productos parcial o totalmente sintéticos como OnTheMap (movilidad de los trabajadores entre lugar de residencia y lugar trabajo) o el SIPP Synthetic Beta (microdatos socioeconómicos vinculados a impuestos y seguridad social).
La generación de datos sintéticos es actualmente un campo aún en desarrollo que se apoya en diversas metodologías. Los enfoques pueden ir desde métodos basados en reglas o modelado estadístico (simulaciones, bayesianos, redes causales), que imitan distribuciones y relaciones predefinidas, hasta técnicas avanzadas de aprendizaje profundo. Entre las arquitecturas más destacadas encontramos:
- Redes Generativas Adversarias (GAN): un modelo generativo, entrenado con datos reales, aprende a imitar sus características, mientras que un discriminador intenta distinguir entre datos reales y sintéticos. A través de este proceso iterativo, el generador mejora su capacidad para producir datos artificiales que son estadísticamente indistinguibles de los originales. Una vez entrenado, el algoritmo puede crear nuevos registros artificiales que son estadísticamente similares a la muestra original, pero completamente nuevos y seguros.
- Autoencoders Variacionales (VAE): Estos modelos se basan en redes neuronales que aprenden una distribución probabilística en un espacio latente de los datos de entrada. Una vez entrenado, el modelo utiliza esta distribución, para obtener nuevas observaciones sintéticas mediante el muestreo y decodificación de los vectores latentes. Los VAE son frecuentemente considerados una opción más estable y sencilla de entrenar en comparación con las GAN para la generación de datos tabulares.
- Modelos autorregresivos/jerárquicos y simuladores de dominio: utilizados, por ejemplo, en datos de historia clínica electrónica, que capturan dependencias temporales y jerárquicas. Los modelos jerárquicos estructuran el problema por niveles, primero muestrean variables de nivel superior y, después las de niveles inferiores condicionadas a las anteriores. Los simuladores de dominio codifican reglas del proceso y se calibran con datos reales, aportando control e interpretabilidad y garantizando el cumplimiento de reglas de negocio.
Puedes conocer más sobre los datos sintéticos y cómo se crean en esta infografía:
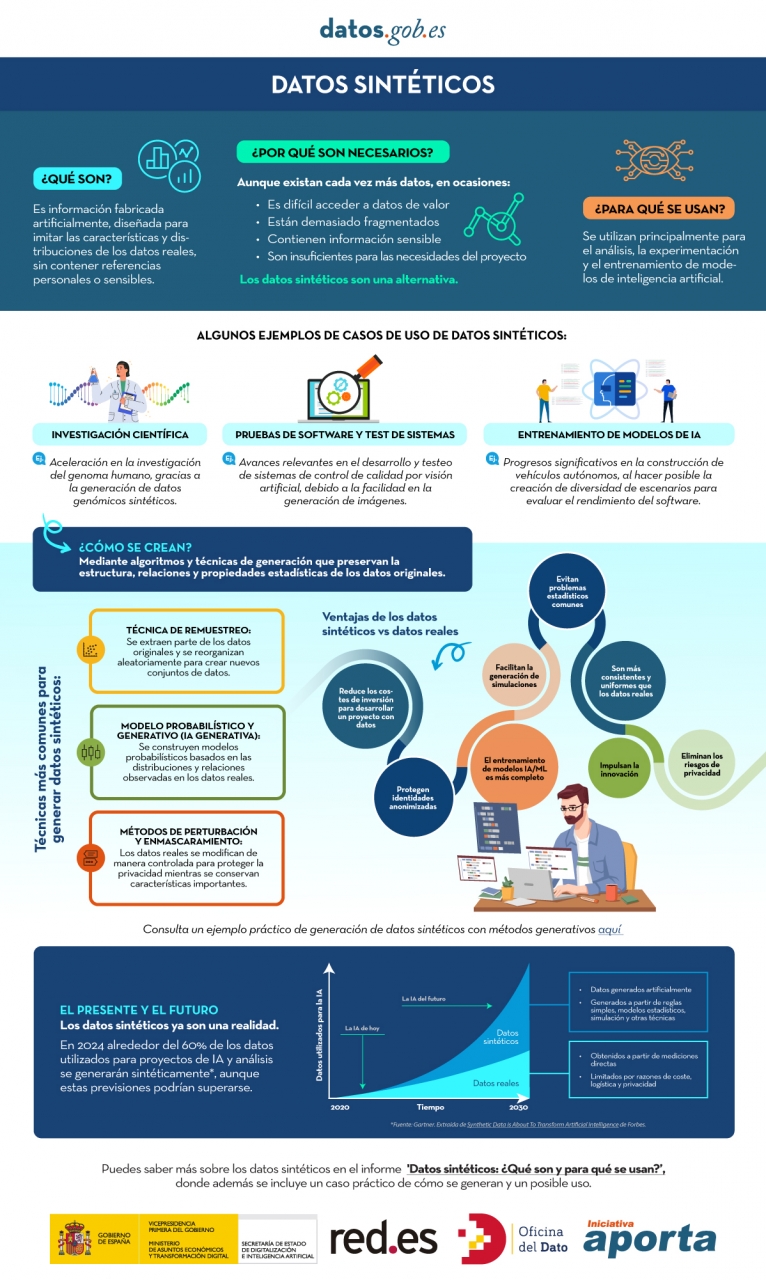
Figura 1. Infografía sobre datos sintéticos. Fuente: elaboración propia - datos.gob.es.
Si bien la generación sintética reduce inherentemente el riesgo de divulgación de datos personales, no lo elimina por completo. Sintético no significa automáticamente anónimo ya que, si los generadores se entrenan de forma inadecuada, pueden filtrarse trazas del conjunto real y ser vulnerables a ataques de inferencia de pertenencia (membership inference). De ahí que sea necesario utilizar Tecnologías de Mejora de la Privacidad (PET) como la privacidad diferencial y realizar evaluaciones de riesgo específicas. También el Supervisor Europeo de Protección de Datos (EDPS) ha subrayado la necesidad de realizar una evaluación de garantía de privacidad antes de que los datos sintéticos puedan ser compartidos, garantizando que el resultado no permita obtener datos personales reidentificables.
La Privacidad Diferencial (DP) es una de las tecnologías principales en este dominio. Su mecanismo consiste en añadir ruido controlado al proceso de entrenamiento o a los datos mismos, asegurando matemáticamente que la presencia o ausencia de cualquier individuo en el conjunto de datos original no altere significativamente el resultado final de la generación. El uso de métodos seguros, como el descenso de gradiente estocástico con privacidad diferencial (DP-SGD), garantiza que las muestras generadas no comprometan la privacidad de los usuarios que contribuyeron con sus datos al conjunto sensible.
¿Cuál es el papel de los datos abiertos?
Como es obvio, los datos sintéticos no aparecen de la nada, necesitan datos reales de alta calidad como semilla y, además, requieren buenas prácticas de validación. Por ello, los datos abiertos o los datos que no pueden abrirse por cuestiones relacionadas con la privacidad son, por una parte, una excelente materia prima para aprender patrones del mundo real y, por otra, una referencia independiente para verificar que lo sintético se parece a la realidad sin exponer a personas o empresas.
Como semilla de aprendizaje los datos abiertos de calidad, como los conjuntos de datos de alto valor, con metadatos completos, definiciones claras y esquemas estandarizados, aportan cobertura, granularidad y actualidad. Cuando ciertos conjuntos no pueden hacerse públicos por motivos de privacidad, pueden emplearse internamente con las adecuadas salvaguardas para producir datos sintéticos que sí podrían liberarse. En salud, por ejemplo, existen generadores abiertos como Synthea, que producen historias clínicas ficticias sin las restricciones de uso propias de los datos reales.
Por otra parte, frente a un conjunto sintético, los datos abiertos permiten actuar como patrón de verificación, para contrastar distribuciones, correlaciones y reglas de negocio, así como evaluar la utilidad en tareas reales (predicción, clasificación) sin recurrir a información sensible. En este sentido ya existen trabajos, como el del Gobierno de Gales con datos de salud, que han experimentado con distintos indicadores,. Entre ellos destacan la distancia de variación total (TVD), el índice de propensión (propensity score) y el desempeño en tareas de aprendizaje automático.
¿Cómo se evalúan los datos sintéticos?
La evaluación de los conjuntos de datos sintéticos se articula a través de tres dimensiones que, por su naturaleza, implican un compromiso:
- Fidelidad (Fidelity): mide lo cerca que está el dato sintético de replicar las propiedades estadísticas, correlaciones y la estructura de los datos originales.
- Utilidad (Utility): mide el rendimiento del conjunto de datos sintéticos en tareas posteriores de aprendizaje automático, como la predicción o la clasificación.
- Privacidad (Privacy): mide la efectividad con la que el dato sintético oculta la información sensible y el riesgo de que los sujetos de los datos originales puedan ser reidentificados.

Figura 2. Tres dimensiones para evaluar datos sintéticos. Fuente: elaboración propia - datos.gob.es.
El reto de gobernanza reside en que no es posible optimizar las tres dimensiones simultáneamente. Por ejemplo, aumentar el nivel de privacidad (inyectando más ruido mediante privacidad diferencial) inevitablemente puede reducir la fidelidad estadística y, en consecuencia, la utilidad para ciertas tareas. La elección de qué dimensión priorizar (máxima utilidad para investigación estadística o máxima privacidad) se convierte en una decisión estratégica que debe ser transparente y específica para cada caso de uso.
¿Datos abiertos sintéticos?
La combinación de datos abiertos y datos sintéticos ya puede considerarse algo más que una idea, ya que existen casos reales que demuestran su utilidad para acelerar la innovación y, al mismo tiempo, proteger la privacidad. Además de los ya citados OnTheMap o SIPP Synthetic Beta en Estados Unidos, también encontramos ejemplos en Europa y el resto del mundo. Por ejemplo, el Centro Común de Investigación (JRC) de la Comisión Europea ha analizado el papel de los datos sintéticos generados con IA en la formulación de políticas “AI Generated Synthetic Data in Policy Applications”, destacando su capacidad para acortar el ciclo de vida de las políticas públicas al reducir la carga de acceso a datos sensibles y habilitar fases de exploración y prueba más ágiles. También ha documentado aplicaciones de poblaciones sintéticas multipropósito para análisis de movilidad, energía o salud, reforzando la idea de que los datos sintéticos actúan como habilitador transversal.
En Reino Unido, el Office for National Statistics (ONS) llevó a cabo un Synthetic Data Pilot para entender la demanda de datos sintéticos. En el piloto se exploró la producción de herramientas de generación de microdatos sintéticos de alta calidad para requisitos específicos de los usuarios.
También en salud se observan avances que ilustran el valor de datos abiertos sintéticos para innovación responsable. El Departamento de Salud de la región de Australia Occidental ha impulsado un Synthetic Data Innovation Project y hackatones sectoriales donde se liberan conjuntos sintéticos realistas que permiten a equipos internos y externos probar algoritmos y servicios sin acceso a información clínica identificable, fomentando la colaboración y acelerando la transición de prototipos a casos de uso reales.
En definitiva, los datos sintéticos ofrecen una vía prometedora, aunque no suficientemente explorada, para el desarrollo de las aplicaciones de inteligencia artificial, ya que contribuyen al equilibrio entre el fomento de la innovación y la protección de la privacidad.
Los datos sintéticos no sustituyen a los datos abiertos, sino que se potencian mutuamente. En particular, representan una oportunidad para que las Administraciones públicas pueden ampliar su oferta de datos abiertos con versiones sintéticas de conjuntos sensibles para educación o investigación, y para facilitar que las empresas y desarrolladores independientes experimenten cumpliendo la regulación y puedan generar un mayor valor económico y social.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La educación tiene el poder de transformar vidas. Reconocida como un derecho fundamental por la comunidad internacional, constituye un pilar clave para el desarrollo humano y social. Sin embargo, según datos de la UNESCO, 272 millones de niños y jóvenes siguen sin acceso a la escuela, el 70% de los países destina menos del 4% de su PIB a la educación y aún son necesarios 69 millones de docentes más para lograr la educación primaria y secundaria universal en 2030. Ante este desafío global, los recursos educativos abiertos y las iniciativas de acceso libre se presentan como herramientas decisivas para fortalecer los sistemas de enseñanza, reducir desigualdades y avanzar hacia una educación inclusiva, equitativa y de calidad.
Los recursos educativos abiertos (REA) ofrecen tres beneficios principales: aprovechan las posibilidades de las tecnologías digitales para solucionar retos educativos comunes; actúan como catalizadores de innovación pedagógica y social al transformar la relación entre docentes, estudiantes y conocimiento; y contribuyen a mejorar el acceso equitativo a materiales educativos de alta calidad.
Qué son los recursos educativos abiertos (REA)
Según la UNESCO, los recursos educativos abiertos son "materiales de aprendizaje, enseñanza e investigación en cualquier formato y soporte que existen en el dominio público o están bajo derechos de autor y fueron liberados bajo una licencia abierta". El concepto, acuñado en el foro celebrado en París en el año 2002, tiene como característica fundamental que estos recursos permiten "su acceso sin coste, su reutilización, reorientación, adaptación y redistribución por parte de terceros".
Los REA abarcan una amplia variedad de formatos, desde cursos completos, libros de texto y programas curriculares hasta mapas, vídeos, pódcasts, aplicaciones multimedia, herramientas de evaluación, aplicaciones móviles, bases de datos e incluso simulaciones.
Los recursos educativos abiertos están constituidos por tres elementos que funcionan de manera inseparable:
- Contenidos educativos: incluyen todo tipo de material utilizable en el proceso de enseñanza-aprendizaje, desde objetos formales hasta recursos externos y sociales. Es aquí donde entrarían los datos abiertos, los cuales se pueden aprovechar para generar este tipo de recursos.
- Herramientas tecnológicas: software que permite desarrollar, utilizar, modificar y distribuir el contenido, incluyendo aplicaciones para la creación de contenidos y plataformas para comunidades de aprendizaje.
- Licencias abiertas: elemento diferenciador que respeta la propiedad intelectual mientras proporciona permisos para el uso, adaptación y redistribución de los materiales.
Por tanto, los REA se caracterizan principalmente por su accesibilidad universal, eliminando barreras económicas y geográficas que tradicionalmente limitan el acceso a la educación de calidad.
Innovación educativa y transformación pedagógica
La transformación pedagógica constituye uno de los principales impactos de los recursos educativos abiertos en el panorama educativo actual. Los REA no son simples contenidos digitales gratuitos, sino catalizadores de innovación que están redefiniendo los procesos de enseñanza-aprendizaje a nivel global.
Combinados con metodologías pedagógicas adecuadas y objetivos de aprendizaje bien diseñados, los REA ofrecen nuevas opciones de enseñanza innovadoras para lograr que tanto los docentes como los estudiantes asuman un papel más activo en el proceso educativo e incluso en la creación de contenidos. Fomentan competencias esenciales como el pensamiento crítico, la autonomía y la capacidad de “aprender a aprender”, superando los modelos tradicionales basados en la memorización.
La innovación educativa impulsada por los REA se materializa a través de herramientas tecnológicas abiertas que facilitan su creación, adaptación y distribución. Programas como eXeLearning permiten desarrollar contenidos educativos digitales de manera sencilla, mientras que LibreOffice e Inkscape ofrecen alternativas libres para la producción de materiales.
La interoperabilidad lograda mediante estándares abiertos, como IMS Global o SCORM, garantiza que estos recursos puedan integrarse en diferentes plataformas y, por tanto, la accesibilidad para todos los usuarios, incluidas personas con discapacidades.
Otra innovación prometedora para el futuro de los REA es la combinación de tecnologías descentralizadas como Nostr con herramientas de autoría como LiaScript. Este enfoque resuelve la dependencia de servidores centrales, permitiendo crear un curso completo y distribuirlo a través de una red abierta y resistente a la censura. El resultado es un único y permanente enlace (URI de Nostr) que encapsula todo el material, otorgando al creador la soberanía total sobre su contenido y garantizando su perdurabilidad. En la práctica, esto supone una revolución para el acceso universal al conocimiento. Los educadores comparten su trabajo con la seguridad de que el enlace será siempre válido, mientras que los estudiantes acceden al material de forma directa, sin necesidad de plataformas o intermediarios. Esta sinergia tecnológica es un paso fundamental para materializar la promesa de un ecosistema educativo verdaderamente abierto, resiliente y global, donde el conocimiento fluye sin barreras.
El potencial de los Recursos Educativos Abiertos se concreta gracias a las comunidades y proyectos que los desarrollan y difunden. Iniciativas institucionales, repositorios colaborativos y programas promovidos por organismos públicos y docentes aseguran que los REA sean accesibles, reutilizables y sostenibles.
Colaboración y comunidades de aprendizaje abiertas
La dimensión colaborativa representa uno de los pilares fundamentales que sostienen el movimiento de recursos educativos abiertos. Este enfoque trasciende fronteras y conecta a profesionales de la educación a nivel global.
Las comunidades educativas alrededor de los REA han generado espacios donde docentes comparten experiencias, acuerdan aspectos metodológicos y resuelven dudas sobre la aplicación práctica de estos recursos. La coordinación entre profesionales suele producirse en redes sociales o a través de canales digitales como Telegram, en los que participan tanto usuarios como creadores de contenidos. Este "claustro virtual" facilita la implementación efectiva de metodologías activas en el aula.
Más allá de los espacios surgidos por iniciativa de los propios docentes, distintos organismos e instituciones han promovido proyectos colaborativos y plataformas que facilitan la creación, el acceso y el intercambio de Recursos Educativos Abiertos, ampliando así su alcance e impacto en la comunidad educativa.
Proyectos y repositorios de REA en España
En el caso de España, los Recursos Educativos Abiertos cuentan con un ecosistema consolidado de iniciativas que reflejan la colaboración entre administraciones públicas, centros educativos, comunidades docentes y entidades culturales. Plataformas como Procomún, proyectos de creación de contenidos como EDIA (Educativo, Digital, Innovador y Abierto) o CREA (Creación de Recursos Educativos Abiertos), y repositorios digitales como Hispana muestran la diversidad de enfoques adoptados para poner a disposición de la ciudadanía recursos educativos y culturales en abierto. A continuación, te contamos un poco más sobre ellos:
- El Proyecto EDIA (Educativo, Digital, Innovador y Abierto), desarrollado por el Centro Nacional de Desarrollo Curricular en Sistemas no Propietarios (CEDEC), se centra en la creación de recursos educativos abiertos diseñados para integrarse en entornos que fomentan las competencias digitales y que se adaptan a metodologías activas. Los recursos se crean con eXeLearning, que facilita la edición, e incluyen plantillas, guías, rúbricas y todos los documentos necesarios para llevar al aula la propuesta didáctica.
- La red Procomún nació fruto del Plan de Cultura Digital en la Escuela puesto en marcha en 2012 por el Ministerio de Educación, Cultura y Deporte. Actualmente este repositorio cuenta con más de 74.000 recursos y 300 itinerarios de aprendizaje, junto a un banco multimedia de 100.000 activos digitales bajo la licencia Creative Commons y que, por tanto, se pueden reutilizar para crear nuevos materiales. Dispone, además, de una aplicación móvil. Procomún también utiliza eXeLearning y el estándar LOM-ES, lo que asegura una descripción homogénea de los recursos y facilita su búsqueda y clasificación. Además, es una web semántica, lo que supone que puede conectarse con comunidades existentes a través de la Linked Open Data Cloud.
Desde las comunidades autónomas también se ha promovido la creación de recursos educativos abiertos. Un ejemplo es CREA, un programa de la Junta de Extremadura orientado a la producción colaborativa de recursos educativos abiertos. Su plataforma permite al profesorado crear, adaptar y compartir materiales didácticos estructurados, integrando contenidos curriculares con metodologías activas. Los recursos se generan en formatos interoperables y se acompañan de metadatos que facilitan su búsqueda, reutilización e integración en distintas plataformas.
Existen iniciativas similares, como el proyecto REA-DUA en Andalucía, que aglutina más de 250 recursos educativos para primaria, secundaria y bachillerato, con atención a la diversidad. Por su parte, Galicia puso en marcha el curso 2022-23 cREAgal cuyo portal cuenta en la actualidad con más de 100 recursos de educación primaria y secundaria. Este proyecto incide en la inclusión y promueve la autonomía personal del alumnado. Además, desde algunas consejerías de educación se ponen a disposición recursos educativos abiertos, como es el caso de Canarias.
Hispana, el portal de acceso al patrimonio cultural español
Además de estas iniciativas orientadas a la creación de recursos educativos, han surgido otras que promueven la recopilación de contenidos que no fueron creados con un fin educativo pero que pueden ser utilizados en el aula. Es el caso de Hispana, un portal de agregación de fondos digitales de bibliotecas, archivos y museos españoles.
Para proporcionar acceso al patrimonio cultural y científico español, Hispana recolecta y hace accesibles los metadatos de los objetos digitales, permitiendo visualizar dichos objetos a través de enlaces que dirigen a las páginas de las instituciones propietarias. Además de actuar como recolector, Hispana también agrega el contenido de las instituciones que lo deseen a Europeana, la biblioteca digital europea, lo que permite aumentar la visibilidad y reutilización de los recursos.
Hispana es un repositorio OAI-PMH, lo que significa que utiliza el protocolo Open Archives Initiative – Protocol for Metadata Harvesting, un estándar internacional para la recolección e intercambio de metadatos entre repositorios digitales. Así, Hispana recolecta los metadatos de los archivos, museos y bibliotecas españoles que exponen sus fondos con este protocolo y los envía a Europeana.
Iniciativas internacionales y cooperación global
A nivel global es importante destacar el papel de la Unesco a través de la Coalición Dinámica sobre los REA, que busca coordinar esfuerzos para aumentar la disponibilidad, calidad y sostenibilidad de estos activos.
En Europa, ENCORE+ (European Network for Catalysing Open Resources in Education) busca fortalecer el ecosistema europeo de REA. Entre sus objetivos se encuentra crear una red que conecte universidades, empresas y organismos públicos para impulsar la adopción, reutilización y calidad de los REA en Europa. ENCORE+ promueve, además, la interoperabilidad entre plataformas, la estandarización de metadatos y la cooperación para garantizar la calidad de los recursos.
En Europa se han desarrollado otras iniciativas interesantes como EPALE (Electronic Platform for Adult Learning in Europe), una iniciativa de la Comisión Europea dirigida a los especialistas en educación para personas adultas. La plataforma contiene estudios, informes y materiales formativos, muchos de ellos bajo licencias abiertas, lo que contribuye a la difusión y uso de los REA.
Además, existen numerosos proyectos que generan y ponen a disposición recursos educativos abiertos en todo el mundo. En Estados Unidos, OER Commons funciona como un repositorio global de materiales educativos de diferentes niveles y materias. Este proyecto utiliza Open Author, un editor en línea que facilita que docentes sin conocimientos técnicos avanzados creen y personalicen recursos educativos digitales directamente en la plataforma.
Otro proyecto destacado es el Plan Ceibal, un programa público en Uruguay que representa un modelo de inclusión tecnológica para la igualdad de oportunidades. Además de proveer acceso a tecnología, genera y distribuye REA en formatos interoperables, compatibles con estándares como SCORM y metadatos estructurados que facilitan su búsqueda, integración en plataformas de aprendizaje y reutilización por parte del profesorado.
Junto a iniciativas como estas, existen otras que, aunque no producen recursos educativos abiertos de manera directa, sí fomentan su creación y uso mediante la colaboración entre docentes y estudiantes de diferentes países. Es el caso de proyectos como eTwinning y Global Classroom.
La fortaleza de los REA radica en su contribución a la democratización del conocimiento, su naturaleza colaborativa y su capacidad para impulsar metodologías innovadoras. Al derribar barreras geográficas, económicas y sociales, los recursos educativos abiertos hacen que el derecho a la educación esté un poco más cerca de convertirse en una realidad universal.
Blog
Los datos abiertos de fuentes públicas han evolucionado a lo largo de estos años, pasando de ser simples repositorios de información a constituir ecosistemas dinámicos que pueden transformar la gobernanza pública. En este contexto, la inteligencia artificial (IA) emerge como una tecnología catalizadora que se beneficia del valor de los datos abiertos y potencia exponencialmente su utilidad. En este post veremos cómo es la relación simbiótica de mutuo beneficio entre la IA y los datos abiertos.
Tradicionalmente, el debate sobre datos abiertos se ha centrado en los portales: las plataformas en las que gobiernos publican información para que la ciudadanía, las empresas y las organizaciones puedan acceder a ella. Pero la llamada “Tercera Ola de Datos Abiertos”, término acuñado por el GovLab de la Universidad de Nueva York, enfatiza que ya no basta con publicar datasets a demanda o por defecto. Lo importante es pensar en el ecosistema completo: el ciclo de vida de los datos, su explotación, mantenimiento y, sobre todo, el valor que generan en la sociedad.
¿Qué función pueden tener los datos abiertos aplicados a la IA?
En este contexto, la IA aparece como un catalizador capaz de automatizar tareas, enriquecer los datos abiertos gubernamentales (OGD), facilitar su comprensión y estimular la colaboración entre actores.
Una investigación reciente, desarrollada por universidades europeas, mapea cómo está sucediendo esta revolución silenciosa. El estudio propone una clasificación de los usos según en dos dimensiones:
- Perspectiva, que a su vez se divide en dos posibles vías:
- Inward-looking (portal): el foco está en las funciones internas de los portales de datos.
- Outward-looking (ecosistema): el foco se amplía a las interacciones con actores externos (ciudadanos, empresas, organizaciones).
- Fases del ciclo de vida del dato, las cuales podemos dividir en pre-procesamiento, exploración, transformación y mantenimiento.
En resumen, el informe identifica estos ocho tipos de uso de la IA en los datos abiertos gubernamentales, que se producen al cruzar las perspectivas y las fases en el ciclo de vida del dato.

Figura 1. Ocho uso de la IA para mejorar los datos abiertos gubernamentales. Fuente: presentación "Data for AI or AI for data: artificial intelligence as a catalyser for open government ecosystems", basada en el informe del mismo nombre, de los EU Open Data Days 2025.
A continuación, se detalla cada uno de estos usos:
1. IA como depuradora (portal curator)
Esta aplicación se centra en el pre-procesamiento de datos dentro del portal. La IA ayuda a organizar, limpiar, anonimizar y etiquetar datasets antes de su publicación. Algunos ejemplos de tareas son:
- Automatización y mejora de las tareas de publicación de datos.
- Realización de funciones de etiquetado automático y categorización.
- Anonimización de datos para proteger la privacidad.
- Limpieza y filtrado automático de conjuntos de datos.
- Extracción de características y manejo de datos faltantes.
2. IA como recolectora de datos del ecosistema (ecosystem data retriever)
También en la fase de pre-procesamiento, pero con un enfoque externo, la IA amplía la cobertura de los portales al identificar y recopilar información de fuentes diversas. Algunas tareas son:
- Recuperar datos estructurados desde textos legales o normativos.
- Minería de noticias para enriquecer datasets con información contextual.
- Integración de datos urbanos procedentes de sensores o registros digitales.
- Descubrimiento y enlace de fuentes heterogéneas.
- Conversión de documentos complejos en información estructurada.
3. IA como exploradora del portal (portal explorer)
En la fase de exploración, los sistemas de IA también pueden facilitar la búsqueda e interacción con los datos publicados, con un enfoque más interno. Algunos casos de uso:
- Desarrollar buscadores semánticos para localizar conjuntos de datos.
- Implementar chatbots que guíen a los usuarios en la exploración de datos.
- Proporcionar interfaces de lenguaje natural para consultas directas.
- Optimizar los motores de búsqueda internos del portal.
- Utilizar modelos de lenguaje para mejorar la recuperación de información.
4. IA como recolectora de información en la web (ecosystem connector)
Operando también en la fase de exploración, la IA actúa como un puente entre actores y recursos del ecosistema. Algunos ejemplos son:
- Recomendar datasets relevantes a investigadores o empresas.
- Identificar socios potenciales a partir de intereses comunes.
- Extraer temas emergentes para apoyar la formulación de políticas.
- Visualizar datos de múltiples fuentes en paneles interactivos.
- Personalizar sugerencias de datos basadas en actividades en redes sociales.
5. IA que referencia el portal (portal linker)
Esta funcionalidad se enfoca en la transformación de datos dentro del portal. Su función es facilitar la combinación y presentación de información para distintos públicos. Algunas tareas son:
- Convertir datos en grafos de conocimiento (estructuras que conectan información relacionada, conocidas como Linked Open Data).
- Resumir y simplificar datos con técnicas de PLN (Procesamiento del Lenguaje Natural).
- Aplicar razonamiento automático para generar información derivada.
- Potenciar la visualización multivariante de datasets complejos.
- Integrar datos diversos en productos de información accesibles.
6. IA como desarrolladora de valor en el ecosistema (ecosystem value developer)
En la fase de transformación y con mirada externa, la IA genera productos y servicios basados en datos abiertos que aportan valor añadido. Algunas tareas son:
- Sugerir técnicas analíticas adecuadas según el tipo de conjunto de datos.
- Asistir en la codificación y procesamiento de información.
- Crear paneles de control basados en análisis predictivo.
- Garantizar la corrección y coherencia de los datos transformados.
- Apoyar el desarrollo de servicios digitales innovadores.
7. IA como supervisora del portal (portal monitor)
Se centra en el mantenimiento del portal, con un enfoque interno. Su papel es garantizar la calidad, consistencia y cumplimiento de estándares. Algunas tareas son:
- Detectar anomalías y valores atípicos en conjuntos de datos publicados.
- Evaluar la consistencia de metadatos y esquemas.
- Automatizar procesos de actualización y depuración de datos.
- Identificar incidencias en tiempo real para su corrección.
- Reducir costes de mantenimiento mediante monitorización inteligente.
8. IA como dinamizadora del ecosistema (ecosystem engager)
Y, por último, esta función opera en la fase de mantenimiento, pero hacia afuera. Busca promover la participación ciudadana y la interacción continua. Algunas tareas son:
- Predecir patrones de uso y anticipar necesidades de los usuarios.
- Proporcionar retroalimentación personalizada sobre datasets.
- Facilitar la auditoría ciudadana de la calidad de los datos.
- Incentivar la participación en comunidades de datos abiertos.
- Identificar perfiles de usuarios para diseñar experiencias más inclusivas.
¿Qué nos dice la evidencia?
El estudio se basa en una revisión de más de 70 artículos académicos que examinan la intersección entre IA y los datos abiertos gubernamentales (open government data u OGD). A partir de estos casos, los autores observan que:
- Algunos de los perfiles definidos, como portal curator, portal explorer y portal monitor, están relativamente maduros y cuentan con múltiples ejemplos en la literatura.
- Otros, como ecosystem value developer y ecosystem engager, están menos explorados, aunque son los que más potencial tienen para generar impacto social y económico.
- La mayoría de las aplicaciones actuales se centran en automatizar tareas concretas, pero hay un gran margen para diseñar arquitecturas más integrales, que combinen varios tipos de IA en un mismo portal o en todo el ciclo de vida del dato.
Desde un punto de vista académico, esta tipología aporta un lenguaje común y una estructura conceptual para estudiar la relación entre IA y datos abiertos. Permite identificar vacíos en la investigación y orientar futuros trabajos hacia un enfoque más sistémico.
En la práctica, el marco es útil para:
- Gestores de portales de datos: les ayuda a identificar qué tipos de IA pueden implementar según sus necesidades, desde mejorar la calidad de los datasets hasta facilitar la interacción con los usuarios.
- Responsables políticos: les orienta sobre cómo diseñar estrategias de adopción de IA en iniciativas de datos abiertos, equilibrando eficiencia, transparencia y participación.
- Investigadores y desarrolladores: les ofrece un mapa de oportunidades para crear herramientas innovadoras que atiendan necesidades específicas del ecosistema.
Limitaciones y próximos pasos de la sinergia entre IA y open data
Además de las ventajas, el estudio reconoce algunas asignaturas pendientes que, en cierta manera, sirven como hoja de ruta para el futuro. Para empezar, varias de las aplicaciones que se han identificado están todavía en fases tempranas o son conceptuales. Y, quizá lo más relevante, aún no se ha abordado en profundidad el debate sobre los riesgos y dilemas éticos del uso de IA en datos abiertos: sesgos, privacidad, sostenibilidad tecnológica.
En definitiva, la combinación de IA y datos abiertos es todavía un terreno en construcción, pero con un enorme potencial. La clave estará en pasar de experimentos aislados a estrategias integrales, capaces de generar valor social, económico y democrático. La IA, en este sentido, no funciona de manera independiente a los datos abiertos: los multiplica y los hace más relevantes para gobiernos, ciudadanía y sociedad en general.
Blog
Sabemos que los datos abiertos que gestiona el sector público en el ejercicio de sus funciones constituyen un recurso de gran valor para fomentar la transparencia, impulsar la innovación y estimular el desarrollo económico. A nivel global, en los últimos 15 años esta idea ha llevado a la creación de portales de datos que sirven como punto de acceso único para la información pública tanto de un país, como de una región o ciudad.
Sin embargo, en ocasiones nos encontramos que el pleno aprovechamiento del potencial de los datos abiertos se ve limitado por problemas inherentes a su calidad. Inconsistencias, falta de estandarización o interoperabilidad y metadatos incompletos son solo algunos de los desafíos comunes que a veces merman la utilidad de los conjuntos de datos abiertos y que las agencias gubernamentales además señalan como el principal obstáculo para la adopción de la IA.
Cuando hablamos de la relación entre datos abiertos e inteligencia artificial, casi siempre partimos de la misma idea: los datos abiertos alimentan a la IA, esto es, son parte del combustible de los modelos. Ya sea para entrenar modelos fundacionales como ALIA, para especializar modelos de lenguaje pequeños (SLM) frente a LLM, o para evaluar y validar sus capacidades o explicar su comportamiento (XAI), el argumento gira en torno a la utilidad de los datos abiertos para la inteligencia artificial, olvidando que los datos abiertos ya estaban ahí y tienen muchas otras utilidades.
Por ello, vamos a invertir la perspectiva y a explorar cómo la propia IA puede convertirse en una herramienta poderosa para mejorar la calidad y, por tanto, el valor de los propios datos abiertos. Este enfoque, que ya esbozó la Comisión Económica para Europa de las Naciones Unidas (UNECE) en su pionero informe Machine Learning for Official Statistics de 2022, adquiere una mayor relevancia desde la explosión de la IA generativa. Actualmente podemos utilizar la inteligencia artificial disponible para incrementar la calidad de los conjuntos de datos que se publican a lo largo de todo su ciclo de vida: desde la captura y la normalización hasta la validación, la anonimización, la documentación y el seguimiento en producción.
Con ello, podemos aumentar el valor público del dato, contribuir a que crezca su reutilización y a amplificar su impacto social y económico. Y, al mismo tiempo, a mejorar la calidad de la siguiente generación de modelos de inteligencia artificial.
Desafíos comunes en la calidad de los datos abiertos
La calidad de los datos ha sido tradicionalmente un factor crítico para el éxito de cualquier iniciativa de datos abiertos, que aparece citado en numerosos informes como el de Comisión Europea “Improving data publishing by open data portal managers and owners”. Los desafíos más frecuentes que enfrentan los publicadores de datos incluyen:
-
Inconsistencias y errores: en los conjuntos de datos, es frecuente la presencia de datos duplicados, formatos heterogéneos o valores atípicos. La corrección de estos pequeños errores, idealmente en la propia fuente de los datos, tenía tradicionalmente un coste elevado y limitaba enormemente la utilidad de numerosos conjuntos de datos.
-
Falta de estandarización e interoperabilidad: dos conjuntos que hablan de lo mismo pueden nombrar las columnas de forma diferente, usar clasificaciones no comparables o carecer de identificadores persistentes para enlazar entidades. Sin un mínimo común, combinar fuentes se convierte en un trabajo artesanal que encarece la reutilización de los datos.
- Metadatos incompletos o inexactos: la carencia de información clara sobre el origen, la metodología de recolección, la frecuencia de actualización o el significado de los campos, complica la comprensión y el uso de los datos. Por ejemplo, saber con certeza si se puede integrar el recurso en un servicio, si está al día o si existe un punto de contacto para resolver dudas es muy importante para su reutilización.
- Datos obsoletos o desactualizados: en dominios muy dinámicos como la movilidad, los precios o los datos de medio ambiente, un conjunto desactualizado puede generar conclusiones erróneas. Y si no hay versiones, registro de cambios o indicadores de frescura, es difícil saber qué ha variado y por qué. La ausencia de un “historial” de los datos complica la auditoría y reduce la confianza.
- Sesgos inherentes: a veces la cobertura es incompleta, ciertas poblaciones quedan infrarrepresentadas o una práctica administrativa introduce una desviación sistemática. Si estos límites no se documentan y advierten, los análisis pueden reforzar desigualdades o llegar a conclusiones injustas sin que nadie lo perciba.
Dónde puede ayudar la Inteligencia Artificial
Por fortuna, en su estado actual, la inteligencia artificial ya está en disposición de proporcionar un conjunto de herramientas que pueden contribuir a abordar algunos de estos desafíos de calidad de los datos abiertos, transformando su gestión de un proceso manual y propenso a errores en uno más automatizado y eficiente:
- Detección y corrección de errores automatizada: los algoritmos de aprendizaje automático y los modelos de IA pueden identificar automáticamente y con una gran fiabilidad inconsistencias, duplicados, valores atípicos y errores tipográficos en grandes volúmenes de datos. Además, la IA puede ayudar a normalizar y estandarizar datos, transformándolos por ejemplo a formatos y esquemas comunes para facilitar la interoperabilidad (como DCAT-AP), y con una fracción del coste que suponía hasta el momento.
- Enriquecimiento de metadatos y catalogación: las tecnologías asociadas al procesamiento de lenguaje natural (PLN), incluyendo el uso de modelos de lenguaje grandes (LLM) y pequeños (SLM), puede ayudar en la tarea de analizar descripciones y generar metadatos más completos y precisos. Esto incluye tareas como sugerir etiquetas relevantes, categorías de clasificación o extraer entidades clave (nombres de lugares, organizaciones, etc.) de descripciones textuales para enriquecer los metadatos.
- Anonimización y privacidad: cuando los datos abiertos contienen información que podría afectar a la privacidad, la anonimización se convierte en una tarea crítica, pero, en ocasiones, costosa. La Inteligencia Artificial puede contribuir a que la anonimización sea mucho más robusta y a minimizar riesgos relacionados con la re-identificación al combinar diferentes conjuntos de datos.
Evaluación de sesgos: la IA puede analizar los propios conjuntos de datos abiertos para detectar sesgos de representación o históricos. Esto permite a los publicadores tomar medidas para corregirlos o, al menos, advertir a los usuarios sobre su presencia para que sean tenidos en cuenta cuando vayan a reutilizarse. En definitiva, la inteligencia artificial no debe verse solo como “consumidora” de datos abiertos, sino también como una aliada estratégica para mejorar su calidad. Cuando se integra con estándares, procesos y supervisión humana, la IA ayuda a detectar y explicar incidencias, a documentar mejor los conjuntos y a publicar evidencias de calidad que refuerzan la confianza. Tal y como se describe en la Estrategia de Inteligencia Artificial 2024, esa sinergia libera más valor público: facilita la innovación, permite decisiones mejor informadas y consolida un ecosistema de datos abiertos más robusto y fiable con unos datos abiertos más útiles, más confiables y con mayor impacto social.
Además, se activa un ciclo virtuoso: datos abiertos de mayor calidad entrenan modelos más útiles y seguros; y modelos más capaces facilitan seguir elevando la calidad de los datos. De este modo la gestión del dato deja de ser una tarea estática de publicación y se convierte en un proceso dinámico de mejora continua.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) se ha convertido en una tecnología central en la vida de las personas y en la estrategia de las empresas. En poco más de una década hemos pasado de interactuar con asistentes virtuales que entendían órdenes sencillas, a ver sistemas capaces de redactar informes completos, crear imágenes hiperrealistas o incluso escribir código.
Este salto tan visible ha hecho que muchos se pregunten: ¿es todo lo mismo?, ¿qué diferencia hay entre lo que ya conocíamos como IA y esta nueva “IA Generativa” de la que tanto se habla?
En este artículo vamos a ordenar esas ideas y explicar, con ejemplos claros, cómo encajan la IA “Tradicional” y la IA Generativa bajo el gran paraguas de la inteligencia artificial.
La IA tradicional: análisis y predicción
Durante muchos años, lo que entendíamos por IA estaba más cerca de lo que hoy llamamos “IA Tradicional”. Estos sistemas se caracterizan por resolver problemas concretos, bien definidos y dentro de un marco de reglas o datos disponibles.
Algunos ejemplos prácticos:
-
Motores de recomendación: Spotify sugiere canciones basadas en tu historial de escucha y Netflix ajusta su catálogo a tus gustos personales, generando hasta el 80% de las visualizaciones en la plataforma.
-
Sistemas de predicción: Walmart utiliza modelos predictivos para anticipar la demanda de productos en función de factores como el clima o eventos locales; Red Eléctrica de España aplica algoritmos similares para prever el consumo eléctrico y equilibrar la red.
- Reconocimiento automático: Google Photos clasifica imágenes reconociendo rostros y objetos; Visa y Mastercard usan modelos de detección de anomalías para identificar fraudes en tiempo real; herramientas como Otter.ai transcriben reuniones y llamadas automáticamente.
En todos estos casos, los modelos aprenden de datos pasados para ofrecer una clasificación, una predicción o una decisión. No inventan nada nuevo, sino que reconocen patrones y los aplican al futuro.
La IA Generativa: creación de contenido
La novedad de la IA generativa es que no solo analiza, sino que produce (genera) a partir de los datos que tiene.
En la práctica, esto significa que:
-
Puede generar texto estructurado a partir de un par de ideas iniciales.
-
Puede combinar elementos visuales existentes a partir de una descripción escrita.
-
Puede crear prototipos de productos, borradores de presentaciones o proponer fragmentos de código basados en patrones aprendidos.
La clave está en que los modelos generativos no se limitan a clasificar o predecir, sino que generan nuevas combinaciones basadas en lo que aprendieron durante su entrenamiento.
El impacto de este avance es enorme: en el mundo del desarrollo, GitHub Copilot ya incluye agentes que detectan y corrigen errores de programación por sí mismos; en diseño, la herramienta Nano Banana de Google promete revolucionar la edición de imágenes con una eficacia que podría dejar obsoletos programas como Photoshop; y en música, bandas enteramente creadas por IA como Velvet Velvet Sundown ya superan el millón de oyentes mensuales en Spotify, con canciones, imágenes y biografía totalmente generadas, sin músicos reales detrás.
¿Cuándo es mejor utilizar cada tipo de IA?
La elección entre IA Tradicional y Generativa no es cuestión de moda, sino de qué necesidad concreta se quiere resolver. Cada una brilla en situaciones distintas:
IA Tradicional: la mejor opción cuando…
-
Necesitas predecir comportamientos futuros basándote en datos históricos (ventas, consumo energético, mantenimiento predictivo).
-
Quieres detectar anomalías o clasificar información de forma precisa (fraude en transacciones, diagnóstico por imágenes, spam).
-
Buscas optimizar procesos para ganar eficiencia (logística, rutas de transporte, gestión de inventarios).
-
Trabajas en entornos críticos donde la fiabilidad y la precisión son imprescindibles (salud, energía, finanzas).
Utilízala cuando el objetivo es tomar decisiones basadas en datos reales con la máxima precisión posible.
IA Generativa: la mejor opción cuando…
-
Necesitas crear contenido (textos, imágenes, música, vídeos, código).
-
Quieres prototipar o experimentar con rapidez, explorando diferentes escenarios antes de decidir (diseño de productos, pruebas en I+D).
-
Buscas interacción más natural con usuarios (chatbots, asistentes virtuales, interfaces conversacionales).
-
Requieres personalización a gran escala, generando mensajes o materiales adaptados a cada individuo (marketing, formación, educación).
-
Te interesa simular escenarios que no puedes obtener fácilmente con datos reales (casos clínicos ficticios, datos sintéticos para entrenar otros modelos).
Utilízala cuando el objetivo es crear, personalizar o interactuar de una manera más humana y flexible.
Un ejemplo del ámbito sanitario lo ilustra bien:
-
La IA tradicional puede analizar miles de registros clínicos para anticipar la probabilidad de que un paciente desarrolle una enfermedad.
-
La IA generativa puede crear escenarios ficticios para entrenar a estudiantes de medicina, generando casos clínicos realistas sin exponer datos reales de pacientes.
¿Compiten o se complementan?
En 2019, Gartner introdujo el concepto de Composite AI para describir soluciones híbridas que combinaban distintos enfoques de inteligencia artificial con el fin de resolver un problema de manera más completa. Aunque entonces era un término poco extendido, hoy cobra más relevancia que nunca gracias a la irrupción de la IA Generativa.
La IA Generativa no sustituye a la IA Tradicional, sino que la complementa. Cuando se integran ambos enfoques dentro de un mismo flujo de trabajo, se logran resultados mucho más potentes que si se empleara cada tecnología por separado.
Aunque, según Gartner, Composite AI continúa en la fase de Innovation Trigger, donde una tecnología emergente comienza a generar interés, y aunque su uso práctico todavía es limitado, ya vemos muchas nuevas tendencias generándose en múltiples sectores:
-
En retail: un sistema tradicional predice cuántos pedidos recibirá una tienda la próxima semana, y una IA generativa genera automáticamente descripciones de producto personalizadas para los clientes de esos pedidos.
-
En educación: un modelo tradicional evalúa el progreso de los estudiantes y detecta áreas débiles, mientras que una IA generativa diseña ejercicios o materiales adaptados a esas necesidades.
-
En diseño industrial: un algoritmo tradicional optimiza la logística de fabricación, mientras que una IA generativa propone prototipos de nuevas piezas o productos.
En definitiva, en lugar de cuestionar qué tipo de IA es más avanzada, lo acertado es preguntarse: ¿qué problema quiero resolver y qué enfoque de IA es el adecuado para ello?
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Desde hoy, 15 de septiembre, están abiertas las inscripciones para uno de los eventos más importantes del sector geoespacial en la península ibérica. Las XVI Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE 2025) se celebrarán en Oviedo del 12 al 14 de noviembre de 2025. Este encuentro anual representa una oportunidad única para explorar las últimas tendencias en reutilización de datos espaciales, especialmente en el contexto de la aplicación de inteligencia artificial al conocimiento territorial.
Desde su primera edición en 2011, las JIIDE han evolucionado como resultado de la colaboración entre la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España a través del Centro Nacional de Información Geográfica, y el Gobierno de Andorra. En esta decimosexta edición se suman también la Consejería de Ordenación del Territorio, Urbanismo, Vivienda y Derechos Ciudadanos del Principado de Asturias y la Universidad de Oviedo, consolidando así una iniciativa que reúne cada año a centenares de profesionales de la Administración pública, el sector privado y el ámbito académico.
Durante tres días, expertos con acreditada experiencia y conocimiento técnico en información geográfica compartirán sus desarrollos más innovadores, metodologías de trabajo y casos de éxito en la gestión y reutilización de datos espaciales.
Dos ejes: la inteligencia artificial y el marco normativo INSPIRE y HVDS
El tema central de esta edición, "IA y territorio: explorando las nuevas fronteras del conocimiento espacial", refleja la evolución natural del sector hacia la incorporación de tecnologías emergentes. La inteligencia artificial, el aprendizaje automático y los algoritmos de análisis avanzado están transformando radicalmente la manera en que procesamos, analizamos y extraemos valor de los datos geoespaciales.
Esta orientación hacia la IA no es casual. La publicación y de los datos geoespaciales permite aprovechar uno de los activos digitales más valiosos para el desarrollo económico, la vigilancia medioambiental, la competitividad, la innovación y la creación de empleo. Cuando estos datos se combinan con técnicas de inteligencia artificial, su potencial se multiplica exponencialmente.
Las jornadas se desarrollan en un momento especialmente relevante para el ecosistema de datos abiertos. La Directiva INSPIRE, junto con la Directiva (UE) 2019/1024 sobre datos abiertos y reutilización de la información del sector público, ha establecido un marco regulatorio que reconoce explícitamente el valor económico y social de los datos geoespaciales digitales.
La evolución en la publicación de los conjuntos de datos de alto valor marca un hito importante en este proceso. Estos conjuntos, caracterizados por su gran potencial para la reutilización, deben estar disponibles de forma gratuita, en formatos legibles por máquinas y a través de interfaces de programación de aplicaciones (API). Los datos geoespaciales ocupan una posición central en esta categorización, lo que subraya su importancia estratégica para el ecosistema de datos abiertos europeo.
Las JIIDE 2025 dedicarán especial atención a presentar ejemplos prácticos de reutilización de estos conjuntos de datos de alto valor, tanto mediante las nuevas OGC API como a través de los servicios de descarga tradicionales y los formatos interoperables establecidos. Esta aproximación práctica permitirá a los asistentes conocer casos reales de implementación y sus resultados tangibles.
Programa diverso: casos de uso, IA y reutilización de datos geoespaciales
También puedes consultar el programa aquí. Entre las actividades previstas, hay sesiones que abarcan desde aspectos técnicos fundamentales hasta aplicaciones innovadoras que demuestran el potencial transformador de estos datos. Las actividades se organizan en cinco temáticas principales:
Estructura de datos espaciales y metadatos.
Gestión y publicación de datos.
Desarrollo de software espacial.
Inteligencia artificial.
Cooperación entre agentes.
Algunos de los temas destacados son la gestión de proyectos y coordinación, donde se presentarán sistemas corporativos como el SIG de la Junta de Andalucía o el SITNA del Gobierno de Navarra. La observación de la Tierra ocupará también un lugar prominente, con presentaciones sobre la evolución del programa del Plan Nacional de Ortofotografía Aérea (APNOA) y técnicas avanzadas de procesamiento de imágenes mediante deep learning.
Por otro lado, los visualizadores temáticos también representan otro eje fundamental, mostrando cómo los datos espaciales pueden transformarse en herramientas accesibles para la ciudadanía. Desde visualizadores de eclipses hasta herramientas para calcular el potencial solar de los tejados, se presentarán desarrollos que demuestran cómo la reutilización creativa de datos puede generar servicios de alto valor social.
Siguiendo la temática anual, la aplicación de IA a los datos geoespaciales se abordará desde múltiples perspectivas. Se presentarán casos de uso en áreas tan diversas como la detección automática de instalaciones deportivas, la clasificación de nubes de puntos LiDAR, la identificación de materiales peligrosos como el amianto, o la optimización de la movilidad urbana.
Una de las sesiones más relevantes para la comunidad de datos abiertos se centrará específicamente en "Reutilización y gobierno abierto". Esta sesión abordará la integración de las infraestructuras de datos espaciales en los portales de datos abiertos, los metadatos de datos espaciales según el estándar GeoDCAT-AP, y la aplicación de normativas de calidad del dato.
Las administraciones locales desempeñan un papel fundamental en la generación y publicación de datos espaciales. Por este motivo, las JIIDE 2025 dedicarán una sesión específica a la publicación de datos locales, donde municipios como Barcelona, Madrid, Bilbao o Cáceres compartirán sus experiencias y desarrollos.
Además de las sesiones teóricas, las jornadas incluyen talleres prácticos sobre herramientas, metodologías y tecnologías específicas. Estos talleres, de 45 minutos a una hora de duración, permiten a los asistentes experimentar directamente con las soluciones presentadas. Algunos de ellos abordan la creación de geoportales web personalizados y otros, por ejemplo, la implementación de API OGC, pasando por técnicas de visualización avanzada y herramientas de gestión de metadatos.
Participa de manera presencial u online
Las JIIDE mantienen su compromiso con la participación abierta, invitando tanto a investigadores como a profesionales a presentar sus herramientas, soluciones técnicas, metodologías de trabajo y casos de éxito. Además, las JIIDE 2025 se celebrarán en modalidad híbrida, permitiendo tanto la participación presencial en Oviedo como el seguimiento virtual.
Esta flexibilidad, mantenida desde las experiencias de los últimos años, garantiza que los profesionales de todo el territorio ibérico y más allá puedan beneficiarse del conocimiento compartido. La participación continúa siendo gratuita, aunque requiere registro previo en cada sesión, mesa redonda o taller.
Desde hoy mismo, puedes inscribirte y aprovechar esta oportunidad de aprendizaje e intercambio de experiencias sobre datos geoespaciales. Las inscripciones están disponibles en la web oficial del evento: https://www.jiide.org/web/portal/inicio