Blog
The convergence between open data, artificial intelligence and environmental sustainability poses one of the main challenges for the digital transformation model that is being promoted at European level. This interaction is mainly materialized in three outstanding manifestations:
-
The opening of high-value data directly related to sustainability, which can help the development of artificial intelligence solutions aimed at climate change mitigation and resource efficiency.
-
The promotion of the so-called green algorithms in the reduction of the environmental impact of AI, which must be materialized both in the efficient use of digital infrastructure and in sustainable decision-making.
-
The commitment to environmental data spaces, generating digital ecosystems where data from different sources is shared to facilitate the development of interoperable projects and solutions with a relevant impact from an environmental perspective.
Below, we will delve into each of these points.
High-value data for sustainability
Directive (EU) 2019/1024 on open data and re-use of public sector information introduced for the first time the concept of high-value datasets, defined as those with exceptional potential to generate social, economic and environmental benefits. These sets should be published free of charge, in machine-readable formats, using application programming interfaces (APIs) and, where appropriate, be available for bulk download. A number of priority categories have been identified for this purpose, including environmental and Earth observation data.
This is a particularly relevant category, as it covers both data on climate, ecosystems or environmental quality, as well as those linked to the INSPIRE Directive, which refer to certainly diverse areas such as hydrography, protected sites, energy resources, land use, mineral resources or, among others, those related to areas of natural hazards, including orthoimages.
These data are particularly relevant when it comes to monitoring variables related to climate change, such as land use, biodiversity management taking into account the distribution of species, habitats and protected sites, monitoring of invasive species or the assessment of natural risks. Data on air quality and pollution are crucial for public and environmental health, so access to them allows exhaustive analyses to be carried out, which are undoubtedly relevant for the adoption of public policies aimed at improving them. The management of water resources can also be optimized through hydrography data and environmental monitoring, so that its massive and automated treatment is an inexcusable premise to face the challenge of the digitalization of water cycle management.
Combining it with other quality environmental data facilitates the development of AI solutions geared towards specific climate challenges. Specifically, they allow predictive models to be trained to anticipate extreme phenomena (heat waves, droughts, floods), optimize the management of natural resources or monitor critical environmental indicators in real time. It also makes it possible to promote high-impact economic projects, such as the use of AI algorithms to implement technological solutions in the field of precision agriculture, enabling the intelligent adjustment of irrigation systems, the early detection of pests or the optimization of the use of fertilizers.
Green algorithms and digital responsibility: towards sustainable AI
Training and deploying AI systems, particularly general-purpose models and large language models, involves significant energy consumption. According to estimates by the International Energy Agency, data centers accounted for around 1.5% of global electricity consumption in 2024. This represents a growth of around 12% per year since 2017, more than four times faster than the rate of total electricity consumption. Data center power consumption is expected to double to around 945 TWh by 2030.
Against this backdrop, green algorithms are an alternative that must necessarily be taken into account when it comes to minimising the environmental impact posed by the implementation of digital technology and, specifically, AI. In fact, both the European Data Strategy and the European Green Deal explicitly integrate digital sustainability as a strategic pillar. For its part, Spain has launched a National Green Algorithm Programme, framed in the 2026 Digital Agenda and with a specific measure in the National Artificial Intelligence Strategy.
One of the main objectives of the Programme is to promote the development of algorithms that minimise their environmental impact from conception ( green by design), so the requirement of exhaustive documentation of the datasets used to train AI models – including origin, processing, conditions of use and environmental footprint – is essential to fulfil this aspiration. In this regard, the Commission has published a template to help general-purpose AI providers summarise the data used for the training of their models, so that greater transparency can be demanded, which, for the purposes of the present case, would also facilitate traceability and responsible governance from an environmental perspective. as well as the performance of eco-audits.
The European Green Deal Data Space
It is one of the common European data spaces contemplated in the European Data Strategy that is at a more advanced stage, as demonstrated by the numerous initiatives and dissemination events that have been promoted around it. Traditionally, access to environmental information has been one of the areas with the most favourable regulation, so that with the promotion of high-value data and the firm commitment to the creation of a European area in this area, there has been a very remarkable qualitative advance that reinforces an already consolidated trend in this area.
Specifically, the data spaces model facilitates interoperability between public and private open data, reducing barriers to entry for startups and SMEs in sectors such as smart forest management, precision agriculture or, among many other examples, energy optimization. At the same time, it reinforces the quality of the data available for Public Administrations to carry out their public policies, since their own sources can be contrasted and compared with other data sets. Finally, shared access to data and AI tools can foster collaborative innovation initiatives and projects, accelerating the development of interoperable and scalable solutions.
However, the legal ecosystem of data spaces entails a complexity inherent in its own institutional configuration, since it brings together several subjects and, therefore, various interests and applicable legal regimes:
-
On the one hand, public entities, which have a particularly reinforced leadership role in this area.
-
On the other hand, private entities and citizens, who can not only contribute their own datasets, but also offer digital developments and tools that value data through innovative services.
-
And, finally, the providers of the infrastructure necessary for interaction within the space.
Consequently, advanced governance models are essential to deal with this complexity, reinforced by technological innovation and especially AI, since the traditional approaches of legislation regulating access to environmental information are certainly limited for this purpose.
Towards strategic convergence
The convergence of high-value open data, responsible green algorithms and environmental data spaces is shaping a new digital paradigm that is essential to address climate and ecological challenges in Europe that requires a robust and, at the same time, flexible legal approach. This unique ecosystem not only allows innovation and efficiency to be promoted in key sectors such as precision agriculture or energy management, but also reinforces the transparency and quality of the environmental information available for the formulation of more effective public policies.
Beyond the current regulatory framework, it is essential to design governance models that help to interpret and apply diverse legal regimes in a coherent manner, that protect data sovereignty and, ultimately, guarantee transparency and responsibility in the access and reuse of environmental information. From the perspective of sustainable public procurement, it is essential to promote procurement processes by public entities that prioritise technological solutions and interoperable services based on open data and green algorithms, encouraging the choice of suppliers committed to environmental responsibility and transparency in the carbon footprints of their digital products and services.
Only on the basis of this approach can we aspire to make digital innovation technologically advanced and environmentally sustainable, thus aligning the objectives of the Green Deal, the European Data Strategy and the European approach to AI.
Content prepared by Julián Valero, professor at the University of Murcia and coordinator of the Innovation, Law and Technology Research Group (iDerTec). The content and views expressed in this publication are the sole responsibility of the author.
Blog
Last October, Spain hosted the OGP 2025 Global Summit, an international benchmark event on open government. More than 2,000 representatives of governments, civil society organisations and public policy experts from around the world met in Vitoria-Gasteiz to discuss the importance of maintaining open, participatory and transparent governments as pillars of society.
The location chosen for this meeting was no coincidence: Spain has been building an open government model for more than a decade that has positioned it as an international benchmark. In this article we are going to review some of the projects that have been launched in our country to transform its public administration and bring it closer to citizens.
The strategic framework: action plans and international commitments
Open government is a culture of governance that promotes the principles of transparency, integrity, accountability, and stakeholder participation in support of democracy and inclusive growth.
Spain's commitment to open government has a consolidated track record. Since Spain joined the Open Government Partnership in 2011, the country has developed five consecutive action plans that have been broadening and deepening government openness initiatives. Each plan has been an advance over the previous one, incorporating new commitments and responding to the emerging challenges of the digital society.
The V Open Government Plan (2024-2028) represents the evolution of this strategy. Its development process incorporated a co-creation methodology that involved multiple actors from civil society, public administrations at all levels and experts in the field. This participatory approach made it easier for the plan to respond to real needs and to have the support of all the sectors involved.
Justice 2030: the biggest transformation of the judicial system in decades
Under the slogan "The greatest transformation of Justice in decades", the Justice 2030 programme is proposed as a roadmap to modernise the Spanish judicial system. Its objective is to build a more accessible, efficient, sustainable and people-centred justice system, through a co-governance model that involves public administrations, legal operators and citizens.
The plan is structured around three strategic axes:
1. Accessibility and people-centred justice
This axis seeks to ensure that justice reaches all citizens, reducing territorial, social and digital gaps. Among the main measures are:
- Face-to-face and digital access and attention: promotion of more accessible judicial headquarters, both physically and technologically, with services adapted to vulnerable groups.
- Basic legal education: legal literacy initiatives for the general population, promoting understanding of the judicial system.
- Inclusive justice: mediation and restorative justice programmes, with special attention to victims and groups in vulnerable situations.
- New social realities: adaptation of the judicial system to contemporary challenges (digital violence, environmental crimes, digital rights, etc.).
2. Efficiency of the public justice service
The programme argues that technological and organisational transformation is key to a more agile and efficient justice. This second axis incorporates advances aimed at modern management and digitalization:
- Justice offices in the municipalities: creation of access points to justice in small towns, bringing judicial services closer to the territory.
- Procedural and organisational reform: updating the Criminal Procedure Law and the procedural framework to improve coordination between courts.
- Electronic judicial file: consolidation of the digital file and interoperable tools between institutions.
- Artificial intelligence and judicial data: responsible use of advanced technologies to improve file management and workload prediction.
3. Sustainable and territorially cohesive justice
The third axis seeks to ensure that judicial modernisation contributes to the Sustainable Development Goals (SDGs) and territorial cohesion.
The main lines are:
- Environmental and climate justice: promotion of legal mechanisms that favor environmental protection and the fight against climate change.
- Territorial cohesion: coordination with autonomous communities to guarantee equal access to justice throughout the country.
- Institutional collaboration: strengthening cooperation between public authorities, local entities and civil society.
The Transparency Portal: the heart of the right to know
If Justice 2030 represents the transformation of access to justice, the Transparency Portal is designed to guarantee the citizen's right to public information. This digital platform, operational since 2014, centralises information on administrative organisations and allows citizens to exercise their right of access to public information in a simple and direct way. Its main functions are:
- Proactive publication of information on government activities, budgets, contracts, grants, agreements and administrative decisions, without the need for citizens to request it.
- Information request system to access documentation that is not publicly available, with legally established deadlines for the administrative response.
- Participatory processes that allow citizens to actively participate in the design and evaluation of public policies.
- Transparency indicators that objectively measure compliance with the obligations of the different administrations, allowing comparisons and encouraging continuous improvement.
This portal is based on three fundamental rights:
- Right to know: every citizen can access public information, either through direct consultation on the portal or by formally exercising their right of access when the information is not available.
- Right to understand: information must be presented in a clear, understandable way and adapted to different audiences, avoiding unnecessary technicalities and facilitating interpretation.
- Right to participate: citizens can intervene in the management of public affairs through the citizen participation mechanisms enabled on the platform.
The platform complies with Law 19/2013, of 9 December, on transparency, access to public information and good governance, a regulation that represented a paradigm shift, recognising access to information as a fundamental right of the citizen and not as a gracious concession of the administration.
Consensus for Open Government: National Open Government Strategy
Another project advocating for open government is the "Consensus for Open Administration." According to this reference document, it is not only a matter of opening data or creating transparency portals, but of radically transforming the way in which public policies are designed and implemented. This consensus replaces the traditional vertical model, where administrations decide unilaterally, with a permanent dialogue between administrations, legal operators and citizens. The document is structured in four strategic axes:
1. Administration Open to the capacities of the public sector
- Development of proactive, innovative and inclusive public employment.
- Responsible implementation of artificial intelligence systems.
- Creating secure and ethical shared data spaces.
2. Administration Open to evidence-informed public policies and participation:
- Development of interactive maps of public policies.
- Systematic evaluation based on data and evidence.
- Incorporation of the citizen voice in all phases of the public policy cycle.
3. Administration Open to citizens:
- Evolution of "My Citizen Folder" towards more personalized services.
- Implementation of digital tools such as SomosGob.
- Radical simplification of administrative procedures and procedures.
4. Administration Open to Transparency, Participation and Accountability:
- Complete renovation of the Transparency Portal.
- Improvement of the transparency mechanisms of the General State Administration.
- Strengthening accountability systems.

Figure 1: Consensus on open government a. Source: own elaboration
The Open Government Forum: a space for permanent dialogue
All these projects and commitments need an institutional space where they can be continuously discussed, evaluated and adjusted. That is precisely the function of the Open Government Forum, which functions as a body for participation and dialogue made up of representatives of the central, regional and local administration. And it is made up of 32 members of civil society carefully selected to ensure diversity of perspectives.
This balanced composition ensures that all voices are heard in the design and implementation of open government policies. The Forum meets regularly to assess the progress of commitments, identify obstacles and propose new initiatives that respond to emerging challenges.
Its transparent and participatory operation, with public minutes and open consultation processes, makes it an international benchmark for good practices in collaborative governance. The Forum is not simply a consultative body, but a space of co-decision where consensus is built that is later translated into concrete public policies.
Hazlab: innovation laboratory for citizen participation
Promoted by the General Directorate of Public Governance of the Ministry for Digital Transformation and Public Function, HazLab is part of the Plan for the Improvement of Citizen Participation in Public Affairs, included in Commitment 3 of the IV Open Government Plan of Spain (2020-2024).
HazLab is a virtual space designed to promote collaboration between the Administration, citizens, academia, professionals and social groups. Its purpose is to promote a new way of building public policies based on innovation, dialogue and cooperation. Specifically, there are three areas of work:
- Virtual spaces for collaboration, which facilitate joint work between administrations, experts and citizens.
- Projects for the design and prototyping of public services, based on participatory and innovative methodologies.
- Resource Library, a repository with audiovisual materials, articles, reports and guides on open government, participation, integrity and transparency.
Registration in HazLab is free and allows you to participate in projects, events and communities of practice. In addition, the platform offers a user manual and a code of conduct to facilitate responsible participation.
In conclusion, the open government projects that Spain is promoting represent much more than isolated initiatives of administrative modernization or technological updates. They constitute a profound cultural change in the very conception of public service, where citizens cease to be mere passive recipients of services to become active co-creators of public policies.
Blog
We live surrounded by AI-generated summaries. We have had the option of generating them for months, but now they are imposed on digital platforms as the first content that our eyes see when using a search engine or opening an email thread. On platforms such as Microsoft Teams or Google Meet, video call meetings are transcribed and summarized in automatic minutes for those who have not been able to be present, but also for those who have been there. However, what a language model has considered important, is it really important for the person receiving the summary?
In this new context, the key is to learn to recover the meaning behind so much summarized information. These three strategies will help you transform automatic content into an understanding and decision-making tool.
1. Ask expansive questions
We tend to summarize to reduce content that we are not able to cover, but we run the risk of associating brief with significant, an equivalence that is not always fulfilled. Therefore, we should not focus from the beginning on summarizing, but on extracting relevant information for us, our context, our vision of the situation and our way of thinking. Beyond the basic prompt "give me a summary", this new way of approaching content that escapes us consists of cross-referencing data, connecting dots and suggesting hypotheses, which they call sensemaking. And it happens, first of all, to be clear about what we want to know.
Practical situation:
Imagine a long meeting that we have not been able to attend. That afternoon, we received in our email a summary of the topics discussed. It's not always possible, but a good practice at this point, if our organization allows it, is not to just stay with the summary: if allowed, and always respecting confidentiality guidelines, upload the full transcript to a conversational system such as Copilot or Gemini and ask specific questions:
-
Which topic was repeated the most or received the most attention during the meeting?
-
In a previous meeting, person X used this argument. Was it used again? Did anyone discuss it? Was it considered valid?
-
What premises, assumptions or beliefs are behind this decision that has been made?
-
At the end of the meeting, what elements seem most critical to the success of the project?
-
What signs anticipate possible delays or blockages? Which ones have to do with or could affect my team?
Beware of:
First of all, review and confirm the attributions. Generative models are becoming more and more accurate, but they have a great ability to mix real information with false or generated information. For example, they can attribute a phrase to someone who did not say it, relate ideas as cause and effect that were not really connected, and surely most importantly: assign tasks or responsibilities for next steps to someone who does not correspond.
2. Ask for structured content
Good summaries are not shorter, but more organized, and the written text is not the only format we can use. Look for efficiency and ask conversational systems to return tables, categories, decision lists or relationship maps. Form conditions thought: if you structure information well, you will understand it better and also transmit it better to others, and therefore you will go further with it.
Practical situation:
In this case, let's imagine that we received a long report on the progress of several internal projects of our company. The document has many pages with paragraphs descriptive of status, feedback, dates, unforeseen events, risks and budgets. Reading everything line by line would be impossible and we would not retain the information. The good practice here is to ask for a transformation of the document that is really useful to us. If possible, upload the report to the conversational system and request structured content in a demanding way and without skimping on details:
-
Organize the report in a table with the following columns: project, responsible, delivery date, status, and a final column that indicates if any unforeseen event has occurred or any risk has materialized. If all goes well, print in that column "CORRECT".
-
Generate a visual calendar with deliverables, their due dates, and assignees, starting on October 1, 2025 and ending on January 31, 2026, in the form of a Gantt chart.
-
I want a list that only includes the name of the projects, their start date, and their due date. Sort by delivery date, closest first.
-
From the customer feedback section that you will find in each project, create a table with the most repeated comments and which areas or teams they usually refer to. Place them in order, from the most repeated to the least.
-
Give me the billing of the projects that are at risk of not meeting deadlines, indicate the price of each one and the total.
Beware of:
The illusion of veracity and completeness that a clean, orderly, automatic text with fonts will provide us is enormous. A clear format, such as a table, list, or map, can give a false sense of accuracy. If the source data is incomplete or wrong, the structure only makes up the error and we will have a harder time seeing it. AI productions are usually almost perfect. At the very least, and if the document is very long, do random checks ignoring the form and focusing on the content.
3. Connect the dots
Strategic sense is rarely in an isolated text, let alone in a summary. The advanced level in this case consists of asking the multimodal chat to cross-reference sources, compare versions or detect patterns between various materials or formats, such as the transcript of a meeting, an internal report and a scientific article. What is really interesting to see are comparative keys such as evolutionary changes, absences or inconsistencies.
Practical situation:
Let's imagine that we are preparing a proposal for a new project. We have several materials: the transcript of a management team meeting, the previous year's internal report, and a recent article on industry trends. Instead of summarizing them separately, you can upload them to the same conversation thread or chat you've customized on the topic, and ask for more ambitious actions.
-
Compare these three documents and tell me which priorities coincide in all of them, even if they are expressed in different ways.
-
What topics in the internal report were not mentioned at the meeting? Generate a hypothesis for each one as to why they have not been treated.
-
What ideas in the article might reinforce or challenge ours? Give me ideas that are not reflected in our internal report.
-
Look for articles in the press from the last six months that support the strong ideas of the internal report.
-
Find external sources that complement the information missing in these three documents on topic X, and generate a panoramic report with references.
Beware of:
It is very common for AI systems to deceptively simplify complex discussions, not because they have a hidden purpose but because they have always been rewarded for simplicity and clarity in training. In addition, automatic generation introduces a risk of authority: because the text is presented with the appearance of precision and neutrality, we assume that it is valid and useful. And if that wasn't enough, structured summaries are copied and shared quickly. Before forwarding, make sure that the content is validated, especially if it contains sensitive decisions, names, or data.
AI-based models can help you visualize convergences, gaps, or contradictions and, from there, formulate hypotheses or lines of action. It is about finding with greater agility what is so valuable that we call insights. That is the step from summary to analysis: the most important thing is not to compress the information, but to select it well, relate it and connect it with the context. Intensifying the demand from the prompt is the most appropriate way to work with AI systems, but it also requires a previous personal effort of analysis and landing.
Content created by Carmen Torrijos, expert in AI applied to language and communication. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Data visualization is a fundamental practice to democratize access to public information. However, creating effective graphics goes far beyond choosing attractive colors or using the latest technological tools. As Alberto Cairo, an expert in data visualization and professor at the academy of the European Open Data Portal (data.europa.eu), points out, "every design decision must be deliberate: inevitably subjective, but never arbitrary." Through a series of three webinars that you can watch again here, the expert offered innovative tips to be at the forefront of data visualization.
When working with data visualization, especially in the context of public information, it is crucial to debunk some myths ingrained in our professional culture. Phrases like "data speaks for itself," "a picture is worth a thousand words," or "show, don't count" sound good, but they hide an uncomfortable truth: charts don't always communicate automatically.
The reality is more complex. A design professional may want to communicate something specific, but readers may interpret something completely different. How can you bridge the gap between intent and perception in data visualization? In this post, we offer some keys to the training series.
A structured framework for designing with purpose
Rather than following rigid "rules" or applying predefined templates, the course proposes a framework of thinking based on five interrelated components:
- Content: the nature, origin, and limitations of the data
- People: The audience we are targeting
- Intention: The Purposes We Define
- Constraints: The Constraints We Face
- Results: how the graph is received
This holistic approach forces us to constantly ask ourselves: what do our readers really need to know? For example, when communicating information about hurricane or health emergency risks, is it more important to show exact trajectories or communicate potential impacts? The correct answer depends on the context and, above all, on the information needs of citizens.
The danger of over-aggregation
Even without losing sight of the purpose, it is important not to fall into adding too much information or presenting only averages. Imagine, for example, a dataset on citizen security at the national level: an average may hide the fact that most localities are very safe, while a few with extremely high rates distort the national indicator.
As Claus O. Wilke explains in his book "Fundamentals of Data Visualization," this practice can hide crucial patterns, outliers, and paradoxes that are precisely the most relevant to decision-making. To avoid this risk, the training proposes to visualize a graph as a system of layers that we must carefully build from the base:
1. Encoding
- It's the foundation of everything: how we translate data into visual attributes. Research in visual perception shows us that not all "visual channels" are equally effective. The hierarchy would be:
- Most effective: position, length and height
- Moderately effective: angle, area and slope
- Less effective: color, saturation, and shape
How do we put this into practice? For example, for accurate comparisons, a bar chart will almost always be a better choice than a pie chart. However, as nuanced in the training materials, "effective" does not always mean "appropriate". A pie chart can be perfect when we want to express the idea of a "whole and its parts", even if accurate comparisons are more difficult.
2. Arrangement
- The positioning, ordering, and grouping of elements profoundly affects perception. Do we want the reader to compare between categories within a group, or between groups? The answer will determine whether we organize our visualization with grouped or stacked bars, with multiple panels, or in a single integrated view.
3. Scaffolding
Titles, introductions, annotations, scales and legends are fundamental. In datos.gob.es we've seen how interactive visualizations can condense complex information, but without proper scaffolding, interactivity can confuse rather than clarify.
The value of a correct scale
One of the most delicate – and often most manipulable – technical aspects of a visualization is the choice of scale. A simple modification in the Y-axis can completely change the reader's interpretation: a mild trend may seem like a sudden crisis, or sustained growth may go unnoticed.
As mentioned in the second webinar in the series, scales are not a minor detail: they are a narrative component. Deciding where an axis begins, what intervals are used, or how time periods are represented involves making choices that directly affect one's perception of reality. For example, if an employment graph starts the Y-axis at 90% instead of 0%, the decline may seem dramatic, even if it's actually minimal.
Therefore, scales must be honest with the data. Being "honest" doesn't mean giving up on design decisions, but rather clearly showing what decisions were made and why. If there is a valid reason for starting the Y-axis at a non-zero value, it should be explicitly explained in the graph or in its footnote. Transparency must prevail over drama.
Visual integrity not only protects the reader from misleading interpretations, but also reinforces the credibility of the communicator. In the field of public data, this honesty is not optional: it is an ethical commitment to the truth and to citizen trust.
Accessibility: Visualize for everyone
On the other hand, one of the aspects often forgotten is accessibility. About 8% of men and 0.5% of women have some form of color blindness. Tools like Color Oracle allow you to simulate what our visualizations look like for people with different types of color perception impairments.
In addition, the webinar mentioned the Chartability project, a methodology to evaluate the accessibility of data visualizations. In the Spanish public sector, where web accessibility is a legal requirement, this is not optional: it is a democratic obligation. Under this premise, the Spanish Federation of Municipalities and Provinces published a Data Visualization Guide for Local Entities.
Visual Storytelling: When Data Tells Stories
Once the technical issues have been resolved, we can address the narrative aspect that is increasingly important to communicate correctly. In this sense, the course proposes a simple but powerful method:
- Write a long sentence that summarizes the points you want to communicate.
- Break that phrase down into components, taking advantage of natural pauses.
- Transform those components into sections of your infographic.
This narrative approach is especially effective for projects like the ones we found in data.europa.eu, where visualizations are combined with contextual explanations to communicate the value of high-value datasets or in datos.gob.es's data science and visualization exercises.
The future of data visualization also includes more creative and user-centric approaches. Projects that incorporate personalized elements, that allow readers to place themselves at the center of information, or that use narrative techniques to generate empathy, are redefining what we understand by "data communication".
Alternative forms of "data sensification" are even emerging: physicalization (creating three-dimensional objects with data) and sonification (translating data into sound) open up new possibilities for making information more tangible and accessible. The Spanish company Tangible Data, which we echo in datos.gob.es because it reuses open datasets, is proof of this.

Figure 1. Examples of data sensification. Source: https://data.europa.eu/sites/default/files/course/webinar-data-visualisation-episode-3-slides.pdf
By way of conclusion, we can emphasize that integrity in design is not a luxury: it is an ethical requirement. Every graph we publish on official platforms influences how citizens perceive reality and make decisions. That is why mastering technical tools such as libraries and visualization APIs, which are discussed in other articles on the portal, is so relevant.
The next time you create a visualization with open data, don't just ask yourself "what tool do I use?" or "Which graphic looks best?". Ask yourself: what does my audience really need to know? Does this visualization respect data integrity? Is it accessible to everyone? The answers to these questions are what transform a beautiful graphic into a truly effective communication tool.
Blog
Artificial Intelligence (AI) is becoming one of the main drivers of increased productivity and innovation in both the public and private sectors, becoming increasingly relevant in tasks ranging from the creation of content in any format (text, audio, video) to the optimization of complex processes through Artificial Intelligence agents.
However, advanced AI models, and in particular large language models, require massive amounts of data for training, optimization, and evaluation. This dependence generates a paradox: at the same time as AI demands more and higher quality data, the growing concern for privacy and confidentiality (General Data Protection Regulation or GDPR), new data access and use rules (Data Act), and quality and governance requirements for high-risk systems (AI Regulation), as well as the inherent scarcity of data in sensitive domains limit access to actual data.
In this context, synthetic data can be an enabling mechanism to achieve new advances, reconciling innovation and privacy protection. On the one hand, they allow AI to be nurtured without exposing sensitive information, and when combined with quality open data, they expand access to domains where real data is scarce or heavily regulated.
What is synthetic data and how is it generated?
Simply put, synthetic data can be defined as artificially fabricated information that mimics the characteristics and distributions of real data. The main function of this technology is to reproduce the statistical characteristics, structure and patterns of the underlying real data. In the domain of official statistics, there are cases such as the United States Census , which publishes partially or totally synthetic products such as OnTheMap (mobility of workers between place of residence and workplace) or SIPP Synthetic Beta (socioeconomic microdata linked to taxes and social security).
The generation of synthetic data is currently a field still in development that is supported by various methodologies. Approaches can range from rule-based methods or statistical modeling (simulations, Bayesian, causal networks), which mimic predefined distributions and relationships, to advanced deep learning techniques. Among the most outstanding architectures we find:
- Generative Adversarial Networks (GANs): a generative model, trained on real data, learns to mimic its characteristics, while a discriminator tries to distinguish between real and synthetic data. Through this iterative process, the generator improves its ability to produce artificial data that is statistically indistinguishable from the originals. Once trained, the algorithm can create new artificial records that are statistically similar to the original sample, but completely new and secure.
- Variational Selfencoders (VAE): These models are based on neural networks that learn a probabilistic distribution in a latent space of the input data. Once trained, the model uses this distribution to obtain new synthetic observations by sampling and decoding the latent vectors. VAEs are often considered a more stable and easier option to train compared to GANs for tabular data generation.
- Autoregressive/hierarchical models and domain simulators: used, for example, in electronic medical record data, which capture temporal and hierarchical dependencies. Hierarchical models structure the problem by levels, first sampling higher-level variables and then lower-level variables conditioned to the previous ones. Domain simulators code process rules and calibrate them with real data, providing control and interpretability and ensuring compliance with business rules.
You can learn more about synthetic data and how it's created in this infographic:
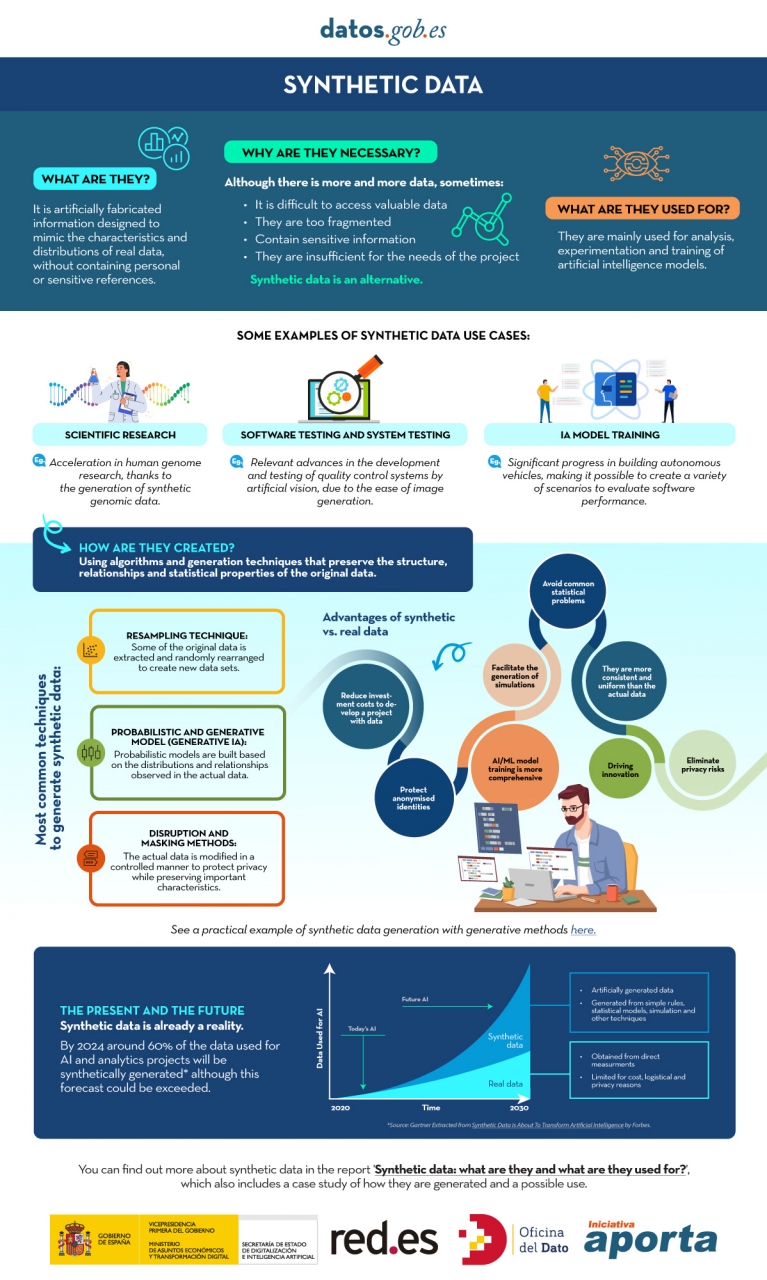
Figure 1. Infographic on synthetic data. Source: Authors' elaboration - datos.gob.es.
While synthetic generation inherently reduces the risk of personal data disclosure, it does not eliminate it entirely. Synthetic does not automatically mean anonymous because, if the generators are trained inappropriately, traces of the real set can leak out and be vulnerable to membership inference attacks. Hence, it is necessary to use Privacy Enhancing Technologies (PET) such as differential privacy and to carry out specific risk assessments. The European Data Protection Supervisor (EDPS) has also underlined the need to carry out a privacy assurance assessment before synthetic data can be shared, ensuring that the result does not allow re-identifiable personal data to be obtained.
Differential Privacy (PD) is one of the main technologies in this domain. Its mechanism is to add controlled noise to the training process or to the data itself, mathematically ensuring that the presence or absence of any individual in the original dataset does not significantly alter the final result of the generation. The use of secure methods, such as Stochastic Gradient Descent with Differential Privacy (DP-SGD), ensures that the samples generated do not compromise the privacy of users who contributed their data to the sensitive set.
What is the role of open data?
Obviously, synthetic data does not appear out of nowhere, it needs real high-quality data as a seed and, in addition, it requires good validation practices. For this reason, open data or data that cannot be opened for privacy-related reasons is, on the one hand, an excellent raw material for learning real-world patterns and, on the other, an independent reference to verify that the synthetic resembles reality without exposing people or companies.
As a seed of learning, quality open data, such as high-value datasets, with complete metadata, clear definitions and standardized schemas, provide coverage, granularity and timeliness. Where certain sets cannot be made public for privacy reasons, they can be used internally with appropriate safeguards to produce synthetic data that could be released. In health, for example, there are open generators such as Synthea, which produce fictitious medical records without the restrictions on the use of real data.
On the other hand, compared to a synthetic set, open data allows it to act as a verification standard, to contrast distributions, correlations and business rules, as well as to evaluate the usefulness in real tasks (prediction, classification) without resorting to sensitive information. In this sense, there are already works, such as that of the Welsh Government with health data, which have experimented with different indicators. These include total distance of change (TVD), propensity score and performance in machine learning tasks.
How is synthetic data evaluated?
The evaluation of synthetic datasets is articulated through three dimensions that, by their nature, imply a commitment:
- Fidelity: Measures how close the synthetic data is to replicating the statistical properties, correlations, and structure of the original data.
- Utility: Measures the performance of the synthetic dataset in subsequent machine learning tasks, such as prediction or classification.
- Privacy: measures how effectively synthetic data hides sensitive information and the risk that the subjects of the original data can be re-identified.
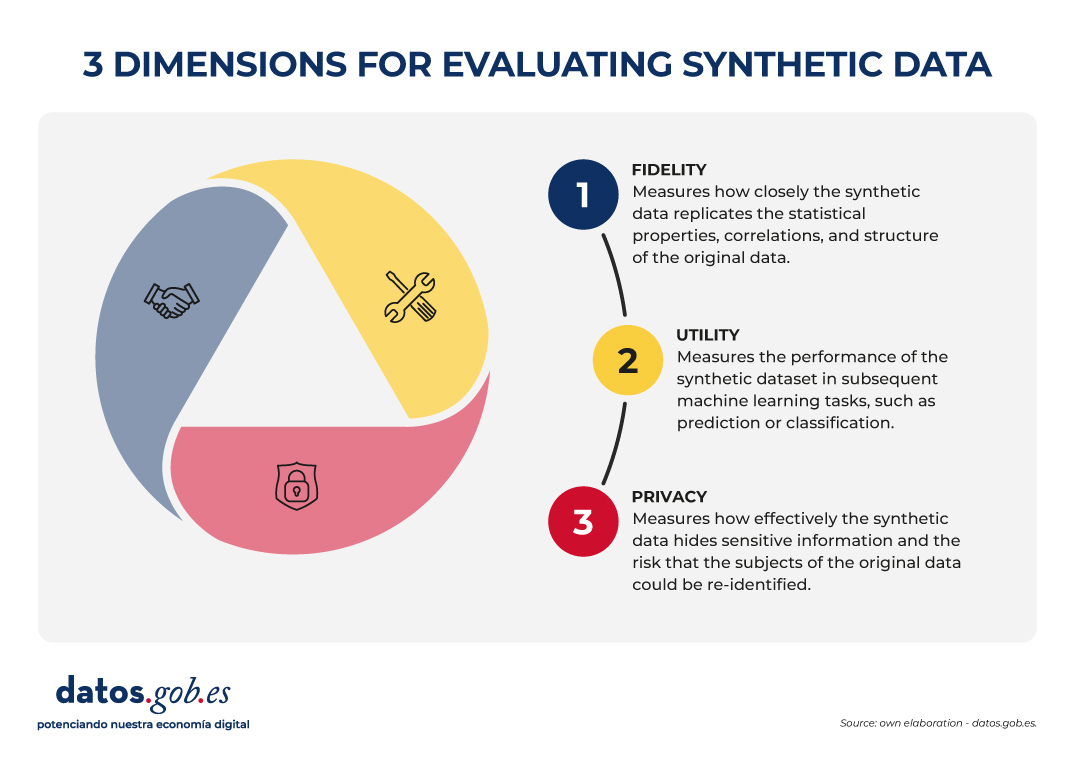
Figure 2. Three dimensions to evaluate synthetic data. Source: Authors' elaboration - datos.gob.es.
The governance challenge is that it is not possible to optimize all three dimensions simultaneously. For example, increasing the level of privacy (by injecting more noise through differential privacy) can inevitably reduce statistical fidelity and, consequently, usefulness for certain tasks. The choice of which dimension to prioritize (maximum utility for statistical research or maximum privacy) becomes a strategic decision that must be transparent and specific to each use case.
Synthetic open data?
The combination of open data and synthetic data can already be considered more than just an idea, as there are real cases that demonstrate its usefulness in accelerating innovation and, at the same time, protecting privacy. In addition to the aforementioned OnTheMap or SIPP Synthetic Beta in the United States, we also find examples in Europe and the rest of the world. For example, the European Commission's Joint Research Centre (JRC) has analysed the role of AI Generated Synthetic Data in Policy Applications, highlighting its ability to shorten the life cycle of public policies by reducing the burden of accessing sensitive data and enabling more agile exploration and testing phases. He has also documented applications of multipurpose synthetic populations for mobility, energy, or health analysis, reinforcing the idea that synthetic data act as a cross-sectional enabler.
In the UK, the Office for National Statistics (ONS) conducted a Synthetic Data Pilot to understand the demand for synthetic data. The pilot explored the production of high-quality synthetic microdata generation tools for specific user requirements.
Also in health , advances are observed that illustrate the value of synthetic open data for responsible innovation. The Department of Health of the Western Australian region has promoted a Synthetic Data Innovation Project and sectoral hackathons where realistic synthetic sets are released that allow internal and external teams to test algorithms and services without access to identifiable clinical information, fostering collaboration and accelerating the transition from prototypes to real use cases.
In short, synthetic data offers a promising, although not sufficiently explored, avenue for the development of artificial intelligence applications, as it contributes to the balance between fostering innovation and protecting privacy.
Synthetic data is not a substitute for open data, but rather enhances each other. In particular, they represent an opportunity for public administrations to expand their open data offering with synthetic versions of sensitive sets for education or research, and to make it easier for companies and independent developers to experiment with regulation and generate greater economic and social value.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Education has the power to transform lives. Recognized as a fundamental right by the international community, it is a key pillar for human and social development. However, according to UNESCO data, 272 million children and young people still do not have access to school, 70% of countries spend less than 4% of their GDP on education, and 69 million more teachers are still needed to achieve universal primary and secondary education by 2030. In the face of this global challenge, open educational resources and open access initiatives are presented as decisive tools to strengthen education systems, reduce inequalities and move towards inclusive, equitable and quality education.
Open educational resources (OER) offer three main benefits: they harness the potential of digital technologies to solve common educational challenges; they act as catalysts for pedagogical and social innovation by transforming the relationship between teachers, students and knowledge; and they contribute to improving equitable access to high-quality educational materials.
What are Open Educational Resources (OER)
According to UNESCO, open educational resources are "learning, teaching, and research materials in any format and support that exist in the public domain or are under copyright and were released under an open license." The concept, coined at the forum held in Paris in 2002, has as its fundamental characteristic that these resources allow "their access at no cost, their reuse, reorientation, adaptation and redistribution by third parties".
OER encompasses a wide variety of formats, from full courses, textbooks, and curricula to maps, videos, podcasts, multimedia applications, assessment tools, mobile apps, databases, and even simulations.
Open educational resources are made up of three elements that work inseparably:
- Educational content: includes all kinds of material that can be used in the teaching-learning process, from formal objects to external and social resources. This is where open data would come in, which can be used to generate this type of resource.
- Technological tools: software that allows content to be developed, used, modified and distributed, including applications for content creation and platforms for learning communities.
- Open licenses: differentiating element that respects intellectual property while providing permissions for the use, adaptation and redistribution of materials.
Therefore, OER are mainly characterized by their universal accessibility, eliminating economic and geographical barriers that traditionally limit access to quality education.
Educational innovation and pedagogical transformation
Pedagogical transformation is one of the main impacts of open educational resources in the current educational landscape. OER are not simply free digital content, but catalysts for innovation that are redefining teaching-learning processes globally.
Combined with appropriate pedagogical methodologies and well-designed learning objectives, OER offer innovative new teaching options to enable both teachers and students to take a more active role in the educational process and even in the creation of content. They foster essential competencies such as critical thinking, autonomy and the ability to "learn to learn", overcoming traditional models based on memorization.
Educational innovation driven by OER is materialized through open technological tools that facilitate their creation, adaptation and distribution. Programs such as eXeLearning allow you to develop digital educational content in a simple way, while LibreOffice and Inkscape offer free alternatives for the production of materials.
The interoperability achieved through open standards, such as IMS Global or SCORM, ensures that these resources can be integrated into different platforms and therefore accessibility for all users, including people with disabilities.
Another promising innovation for the future of OER is the combination of decentralized technologies like Nostr with authoring tools like LiaScript. This approach solves the dependency on central servers, allowing an entire course to be created and distributed over an open, censorship-resistant network. The result is a single, permanent link (URI de Nostr) that encapsulates all the material, giving the creator full sovereignty over its content and ensuring its durability. In practice, this is a revolution for universal access to knowledge. Educators share their work with the assurance that the link will always be valid, while students access the material directly, without the need for platforms or intermediaries. This technological synergy is a fundamental step to materialize the promise of a truly open, resilient and global educational ecosystem, where knowledge flows without barriers.
The potential of Open Educational Resources is realized thanks to the communities and projects that develop and disseminate them. Institutional initiatives, collaborative repositories and programmes promoted by public bodies and teachers ensure that OER are accessible, reusable and sustainable.
Collaboration and open learning communities
The collaborative dimension represents one of the fundamental pillars that support the open educational resources movement. This approach transcends borders and connects education professionals globally.
The educational communities around OER have created spaces where teachers share experiences, agree on methodological aspects and resolve doubts about the practical application of these resources. Coordination between professionals usually occurs on social networks or through digital channels such as Telegram, in which both users and content creators participate. This "virtual cloister" facilitates the effective implementation of active methodologies in the classroom.
Beyond the spaces that have arisen at the initiative of the teachers themselves, different organizations and institutions have promoted collaborative projects and platforms that facilitate the creation, access and exchange of Open Educational Resources, thus expanding their reach and impact on the educational community.
OER projects and repositories in Spain
In the case of Spain, Open Educational Resources have a consolidated ecosystem of initiatives that reflect the collaboration between public administrations, educational centres, teaching communities and cultural entities. Platforms such as Procomún, content creation projects such as EDIA (Educational, Digital, Innovative and Open) or CREA (Creation of Open Educational Resources), and digital repositories such as Hispana show the diversity of approaches adopted to make educational and cultural resources available to citizens in open access. Here's a little more about them:
- The EDIA (Educational, Digital, Innovative and Open) Project, developed by the National Center for Curriculum Development in Non-Proprietary Systems (CEDEC), focuses on the creation of open educational resources designed to be integrated into environments that promote digital competences and that are adapted to active methodologies. The resources are created with eXeLearning, which facilitates editing, and include templates, guides, rubrics and all the necessary documents to bring the didactic proposal to the classroom.
- The Procomún network was born as a result of the Digital Culture in School Plan launched in 2012 by the Ministry of Education, Culture and Sport. This repository currently has more than 74,000 resources and 300 learning itineraries, along with a multimedia bank of 100,000 digital assets under the Creative Commons license and which, therefore, can be reused to create new materials. It also has a mobile application. Procomún also uses eXeLearning and the LOM-ES standard, which ensures a homogeneous description of the resources and facilitates their search and classification. In addition, it is a semantic web, which means that it can connect with existing communities through the Linked Open Data Cloud.
The autonomous communities have also promoted the creation of open educational resources. An example is CREA, a programme of the Junta de Extremadura aimed at the collaborative production of open educational resources. Its platform allows teachers to create, adapt and share structured teaching materials, integrating curricular content with active methodologies. The resources are generated in interoperable formats and are accompanied by metadata that facilitates their search, reuse and integration into different platforms.
There are similar initiatives, such as the REA-DUA project in Andalusia, which brings together more than 250 educational resources for primary, secondary and baccalaureate, with attention to diversity. For its part, Galicia launched the 2022-23 academic year cREAgal whose portal currently has more than 100 primary and secondary education resources. This project has an impact on inclusion and promotes the personal autonomy of students. In addition, some ministries of education make open educational resources available, as is the case of the Canary Islands.
Hispana, the portal for access to Spanish cultural heritage
In addition to these initiatives aimed at the creation of educational resources, others have emerged that promote the collection of content that was not created for an educational purpose but that can be used in the classroom. This is the case of Hispana, a portal for aggregating digital collections from Spanish libraries, archives and museums.
To provide access to Spanish cultural and scientific heritage, Hispana collects and makes accessible the metadata of digital objects, allowing these objects to be viewed through links to the pages of the owner institutions. In addition to acting as a collector, Hispana also adds the content of institutions that wish to do so to Europeana, the European digital library, which allows increasing the visibility and reuse of resources.
Hispana is an OAI-PMH repository, which means that it uses the Open Archives Initiative – Protocol for Metadata Harvesting, an international standard for the collection and exchange of metadata between digital repositories. Thus, Hispana collects the metadata of the Spanish archives, museums and libraries that exhibit their collections with this protocol and sends them to Europeana.
International initiatives and global cooperation
At the global level, it is important to highlight the role of UNESCO through the Dynamic Coalition on OER, which seeks to coordinate efforts to increase the availability, quality and sustainability of these assets.
In Europe, ENCORE+ (European Network for Catalysing Open Resources in Education) seeks to strengthen the European OER ecosystem. Among its objectives is to create a network that connects universities, companies and public bodies to promote the adoption, reuse and quality of OER in Europe. ENCORE+ also promotes interoperability between platforms, metadata standardization and cooperation to ensure the quality of resources.
In Europe, other interesting initiatives have been developed, such as EPALE (Electronic Platform for Adult Learning in Europe), an initiative of the European Commission aimed at specialists in adult education. The platform contains studies, reports and training materials, many of them under open licenses, which contributes to the dissemination and use of OER.
In addition, there are numerous projects that generate and make available open educational resources around the world. In the United States, OER Commons functions as a global repository of educational materials of different levels and subjects. This project uses Open Author, an online editor that makes it easy for teachers without advanced technical knowledge to create and customize digital educational resources directly on the platform.
Another outstanding project is Plan Ceibal, a public program in Uruguay that represents a model of technological inclusion for equal opportunities. In addition to providing access to technology, it generates and distributes OER in interoperable formats, compatible with standards such as SCORM and structured metadata that facilitate its search, integration into learning platforms and reuse by teachers.
Along with initiatives such as these, there are others that, although they do not directly produce open educational resources, do encourage their creation and use through collaboration between teachers and students from different countries. This is the case for projects such as eTwinning and Global Classroom.
The strength of OER lies in their contribution to the democratization of knowledge, their collaborative nature, and their ability to promote innovative methodologies. By breaking down geographical, economic, and social barriers, open educational resources bring the right to education one step closer to becoming a universal reality.
Blog
Open data from public sources has evolved over the years, from being simple repositories of information to constituting dynamic ecosystems that can transform public governance. In this context, artificial intelligence (AI) emerges as a catalytic technology that benefits from the value of open data and exponentially enhances its usefulness. In this post we will see what the mutually beneficial symbiotic relationship between AI and open data looks like.
Traditionally, the debate on open data has focused on portals: the platforms on which governments publish information so that citizens, companies and organizations can access it. But the so-called "Third Wave of Open Data," a term by New York University's GovLab, emphasizes that it is no longer enough to publish datasets on demand or by default. The important thing is to think about the entire ecosystem: the life cycle of data, its exploitation, maintenance and, above all, the value it generates in society.
What role can open data play in AI?
In this context, AI appears as a catalyst capable of automating tasks, enriching open government data (DMOs), facilitating its understanding and stimulating collaboration between actors.
Recent research, developed by European universities, maps how this silent revolution is happening. The study proposes a classification of uses according to two dimensions:
- Perspective, which in turn is divided into two possible paths:
- Inward-looking (portal): The focus is on the internal functions of data portals.
- Outward-looking (ecosystem): the focus is extended to interactions with external actors (citizens, companies, organizations).
- Phases of the data life cycle, which can be divided into pre-processing, exploration, transformation and maintenance.
In summary, the report identifies these eight types of AI use in government open data, based on perspective and phase in the data lifecycle.

Figure 1. Eight uses of AI to improve government open data. Source: presentation “Data for AI or AI for data: artificial intelligence as a catalyst for open government ecosystems”, based on the report of the same name, from EU Open Data Days 2025.
Each of these uses is detailed below:
1. Portal curator
This application focuses on pre-processing data within the portal. AI helps organize, clean, anonymize, and tag datasets before publication. Some examples of tasks are:
- Automation and improvement of data publication tasks.
- Performing auto-tagging and categorization functions.
- Data anonymization to protect privacy.
- Automatic cleaning and filtering of datasets.
- Feature extraction and missing data handling.
2. Ecosystem data retriever
Also in the pre-processing phase, but with an external focus, AI expands the coverage of portals by identifying and collecting information from diverse sources. Some tasks are:
- Retrieve structured data from legal or regulatory texts.
- News mining to enrich datasets with contextual information.
- Integration of urban data from sensors or digital records.
- Discovery and linking of heterogeneous sources.
- Conversion of complex documents into structured information.
3. Portal explorer
In the exploration phase, AI systems can also make it easier to find and interact with published data, with a more internal approach. Some use cases:
- Develop semantic search engines to locate datasets.
- Implement chatbots that guide users in data exploration.
- Provide natural language interfaces for direct queries.
- Optimize the portal's internal search engines.
- Use language models to improve information retrieval.
4. Ecosystem connector
Operating also in the exploration phase, AI acts as a bridge between actors and ecosystem resources. Some examples are:
- Recommend relevant datasets to researchers or companies.
- Identify potential partners based on common interests.
- Extract emerging themes to support policymaking.
- Visualize data from multiple sources in interactive dashboards.
- Personalize data suggestions based on social media activity.
5. Portal linker
This functionality focuses on the transformation of data within the portal. Its function is to facilitate the combination and presentation of information for different audiences. Some tasks are:
- Convert data into knowledge graphs (structures that connect related information, known as Linked Open Data).
- Summarize and simplify data with NLP (Natural Language Processing) techniques.
- Apply automatic reasoning to generate derived information.
- Enhance multivariate visualization of complex datasets.
- Integrate diverse data into accessible information products.
6. Ecosystem value developer
In the transformation phase and with an external perspective, AI generates products and services based on open data that provide added value. Some tasks are:
- Suggest appropriate analytical techniques based on the type of dataset.
- Assist in the coding and processing of information.
- Create dashboards based on predictive analytics.
- Ensure the correctness and consistency of the transformed data.
- Support the development of innovative digital services.
7. Portal monitor
It focuses on portal maintenance, with an internal focus. Their role is to ensure quality, consistency, and compliance with standards. Some tasks are:
- Detect anomalies and outliers in published datasets.
- Evaluate the consistency of metadata and schemas.
- Automate data updating and purification processes.
- Identify incidents in real time for correction.
- Reduce maintenance costs through intelligent monitoring.
8. Ecosystem engager
And finally, this function operates in the maintenance phase, but outwardly. It seeks to promote citizen participation and continuous interaction. Some tasks are:
- Predict usage patterns and anticipate user needs.
- Provide personalized feedback on datasets.
- Facilitate citizen auditing of data quality.
- Encourage participation in open data communities.
- Identify user profiles to design more inclusive experiences.
What does the evidence tell us?
The study is based on a review of more than 70 academic papers examining the intersection between AI and OGD (open government data). From these cases, the authors observe that:
- Some of the defined profiles, such as portal curator, portal explorer and portal monitor, are relatively mature and have multiple examples in the literature.
- Others, such as ecosystem value developer and ecosystem engager, are less explored, although they have the most potential to generate social and economic impact.
- Most applications today focus on automating specific tasks, but there is a lot of scope to design more comprehensive architectures, combining several types of AI in the same portal or across the entire data lifecycle.
From an academic point of view, this typology provides a common language and conceptual structure to study the relationship between AI and open data. It allows identifying gaps in research and guiding future work towards a more systemic approach.
In practice, the framework is useful for:
- Data portal managers: helps them identify what types of AI they can implement according to their needs, from improving the quality of datasets to facilitating interaction with users.
- Policymakers: guides them on how to design AI adoption strategies in open data initiatives, balancing efficiency, transparency, and participation.
- Researchers and developers: it offers them a map of opportunities to create innovative tools that address specific ecosystem needs.
Limitations and next steps of the synergy between AI and open data
In addition to the advantages, the study recognizes some pending issues that, in a way, serve as a roadmap for the future. To begin with, several of the applications that have been identified are still in early stages or are conceptual. And, perhaps most relevantly, the debate on the risks and ethical dilemmas of the use of AI in open data has not yet been addressed in depth: bias, privacy, technological sustainability.
In short, the combination of AI and open data is still a field under construction, but with enormous potential. The key will be to move from isolated experiments to comprehensive strategies, capable of generating social, economic and democratic value. AI, in this sense, does not work independently of open data: it multiplies it and makes it more relevant for governments, citizens and society in general.
Blog
We know that the open data managed by the public sector in the exercise of its functions is an invaluable resource for promoting transparency, driving innovation and stimulating economic development. At the global level, in the last 15 years this idea has led to the creation of data portals that serve as a single point of access for public information both in a country, a region or city.
However, we sometimes find that the full exploitation of the potential of open data is limited by problems inherent in its quality. Inconsistencies, lack of standardization or interoperability, and incomplete metadata are just some of the common challenges that sometimes undermine the usefulness of open datasets and that government agencies also point to as the main obstacle to AI adoption.
When we talk about the relationship between open data and artificial intelligence, we almost always start from the same idea: open data feeds AI, that is, it is part of the fuel for models. Whether it's to train foundational models like ALIA, to specialize small language models (SLMs) versus LLMs, or to evaluate and validate their capabilities or explain their behavior (XAI), the argument revolves around the usefulness of open data for artificial intelligence, forgetting that open data was already there and has many other uses.
Therefore, we are going to reverse the perspective and explore how AI itself can become a powerful tool to improve the quality and, therefore, the value of open data itself. This approach, which was already outlined by the United Nations Economic Commission for Europe (UNECE) in its pioneering 2022 Machine Learning for Official Statistics report , has become more relevant since the explosion of generative AI. We can now use the artificial intelligence available to increase the quality of datasets that are published throughout their entire lifecycle: from capture and normalization to validation, anonymization, documentation, and follow-up in production.
With this, we can increase the public value of data, contribute to its reuse and amplify its social and economic impact. And, at the same time, to improve the quality of the next generation of artificial intelligence models.
Common challenges in open data quality
Data quality has traditionally been a Critical factor for the success of any open data initiative, which is cited in numerous reports such as that of the European Commission "Improving data publishing by open data portal managers and owners”. The most frequent challenges faced by data publishers include:
-
Inconsistencies and errors: Duplicate data, heterogeneous formats, or outliers are common in datasets. Correcting these small errors, ideally at the data source itself, was traditionally costly and greatly limited the usefulness of many datasets.
-
Lack of standardization and interoperability: Two sets that talk about the same thing may name columns differently, use non-comparable classifications, or lack persistent identifiers to link entities. Without a common minimum, combining sources becomes an artisanal work that makes it more expensive to reuse data.
- Incomplete or inaccurate metadata: The lack of clear information about the origin, collection methodology, frequency of updating or meaning of the fields, complicates the understanding and use of the data. For example, knowing with certainty if the resource can be integrated into a service, if it is up to date or if there is a point of contact to resolve doubts is very important for its reuse.
- Outdated or outdated data: In highly dynamic domains such as mobility, pricing, or environmental data, an outdated set can lead to erroneous conclusions. And if there are no versions, changelogs, or freshness indicators, it's hard to know what's changed and why. The absence of a "history" of the data complicates auditing and reduces trust.
- Inherent biases: sometimes coverage is incomplete, certain populations are underrepresented, or a management practice introduces systematic deviation. If these limits are not documented and warned, analyses can reinforce inequalities or reach unfair conclusions without anyone noticing.
Where Artificial Intelligence Can Help
Fortunately, in its current state, artificial intelligence is already in a position to provide a set of tools that can help address some of these open data quality challenges, transforming your management from a manual and error-prone process to a more automated and efficient one:
- Automated error detection and correction: Machine learning algorithms and AI models can automatically and reliably identify inconsistencies, duplicates, outliers, and typos in large volumes of data. In addition, AI can help normalize and standardize data, transforming it for example into common formats and schemas to facilitate interoperability (such as DCAT-AP), and at a fraction of the cost it was so far.
- Metadata enrichment and cataloging: Technologies associated with natural language processing (NLP), including the use of large language models (LLMs) and small language models (SLMs), can help analyze descriptions and generate more complete and accurate metadata. This includes tasks such as suggesting relevant tags, classification categories, or extracting key entities (place names, organizations, etc.) from textual descriptions to enrich metadata.
- Anonymization and privacy: When open data contains information that could affect privacy, anonymization becomes a critical, but sometimes costly, task. Artificial Intelligence can contribute to making anonymization much more robust and to minimize risks related to re-identification by combining different data sets.
Bias assessment: AI can analyze the open datasets themselves for representation or historical biases. This allows publishers to take steps to correct them or at least warn users about their presence so that they are taken into account when they are to be reused. In short, artificial intelligence should not only be seen as a "consumer" of open data, but also as a strategic ally to improve its quality. When integrated with standards, processes, and human oversight, AI helps detect and explain incidents, better document sets, and publish trust-building quality evidence. As described in the 2024 Artificial Intelligence Strategy, this synergy unlocks more public value: it facilitates innovation, enables better-informed decisions, and consolidates a more robust and reliable open data ecosystem with more useful, more reliable open data with greater social impact.
In addition, a virtuous cycle is activated: higher quality open data trains more useful and secure models; and more capable models make it easier to continue raising the quality of data. In this way, data management is no longer a static task of publication and becomes a dynamic process of continuous improvement.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Artificial intelligence (AI) has become a central technology in people's lives and in the strategy of companies. In just over a decade, we've gone from interacting with virtual assistants that understood simple commands, to seeing systems capable of writing entire reports, creating hyper-realistic images, or even writing code.
This visible leap has made many wonder: is it all the same? What is the difference between what we already knew as AI and this new "Generative AI" that is so much talked about?
In this article we are going to organize those ideas and explain, with clear examples, how "Traditional" AI and Generative AI fit under the great umbrella of artificial intelligence.
Traditional AI: analysis and prediction
For many years, what we understood by AI was closer to what we now call "Traditional AI". These systems are characterized by solving concrete, well-defined problems within a framework of available rules or data.
Some practical examples:
-
Recommendation engines: Spotify suggests songs based on your listening history and Netflix adjusts its catalog to your personal tastes, generating up to 80% of views on the platform.
-
Prediction systems: Walmart uses predictive models to anticipate the demand for products based on factors such as weather or local events; Red Eléctrica de España applies similar algorithms to forecast electricity consumption and balance the grid.
- Automatic recognition: Google Photos classifies images by recognizing faces and objects; Visa and Mastercard use anomaly detection models to identify fraud in real time; Tools like Otter.ai automatically transcribe meetings and calls.
In all these cases, the models learn from past data to provide a classification, prediction, or decision. They do not invent anything new, but recognize patterns and apply them to the future.
Generative AI: content creation
The novelty of generative AI is that it not only analyzes, but also produces (generates) from the data it has.
In practice, this means that:
-
You can generate structured text from a couple of initial ideas.
-
You can combine existing visual elements from a written description.
-
You can create product prototypes, draft presentations, or propose code snippets based on learned patterns.
The key is that generative models don't just classify or predict, they generate new combinations based on what they learned during their training.
The impact of this breakthrough is enormous: in the development world, GitHub Copilot already includes agents that detect and fix programming errors on their own; in design, Google's Nano Banana tool promises to revolutionize image editing with an efficiency that could render programs like Photoshop obsolete; and in music, entirely AI-created bands like Velvet Velvet Sundown they already exceed one million monthly listeners on Spotify, with songs, images and biography fully generated, without real musicians behind them.
When is it best to use each type of AI?
The choice between Traditional and Generative AI is not a matter of fashion, but of what specific need you want to solve. Each shines in different situations:
Traditional AI: the best option when...
-
You need to predict future behaviors based on historical data (sales, energy consumption, predictive maintenance).
-
You want to detect anomalies or classify information accurately (transaction fraud, imaging, spam).
-
You are looking to optimize processes to gain efficiency (logistics, transport routes, inventory management).
-
You work in critical environments where reliability and accuracy are a must (health, energy, finance).
Use it when the goal is to make decisions based on real data with the highest possible accuracy.
Generative AI: the best option when...
-
You need to create content (texts, images, music, videos, code).
-
You want to prototype or experiment quickly, exploring different scenarios before deciding (product design, R+D testing).
-
You are looking for more natural interaction with users (chatbots, virtual assistants, conversational interfaces).
-
You require large-scale personalization, generating messages or materials adapted to each individual (marketing, training, education).
-
You are interested in simulating scenarios that you cannot easily obtain with real data (fictitious clinical cases, synthetic data to train other models).
Use it when the goal is to create, personalize, or interact in a more human and flexible way.
An example from the health field illustrates this well:
-
Traditional AI can analyze thousands of clinical records to anticipate the likelihood of a patient developing a disease.
-
Generative AI can create fictional scenarios to train medical students, generating realistic clinical cases without exposing real patient data.
Do they compete or complement each other?
In 2019, Gartner introduced the concept of Composite AI to describe hybrid solutions that combined different AI approaches to solve a problem more comprehensively. Although it was a term that was not very widespread then, today it is more relevant than ever thanks to the emergence of Generative AI.
Generative AI does not replace Traditional AI, but rather complements it. When you integrate both approaches into a single workflow, you achieve much more powerful results than if you used each technology separately.
Although, according to Gartner, Composite AI is still in the Innovation Trigger phase, where an emerging technology begins to generate interest, and although its practical use is still limited, we already see many new trends being generated in multiple sectors:
-
In retail: A traditional system predicts how many orders a store will receive next week, and generative AI automatically generates personalized product descriptions for customers of those orders.
-
In education: a traditional model assesses student progress and detects weak areas, while generative AI designs exercises or materials tailored to those needs.
-
In industrial design: a traditional algorithm optimizes manufacturing logistics, while a generative AI proposes prototypes of new parts or products.
Ultimately, instead of questioning which type of AI is more advanced, the right thing to do is to ask: what problem do I want to solve, and which AI approach is right for it?
Content created by Juan Benavente, senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsability of the author.
Noticia
From today, September 15, registration is open for one of the most important events in the geospatial sector in the Iberian Peninsula. The XVI Iberian Conference on Spatial Data Infrastructures (JIIDE 2025) will be held in Oviedo from 12 to 14 November 2025. This annual meeting represents a unique opportunity to explore the latest trends in spatial data reuse, especially in the context of the application of artificial intelligence to territorial knowledge.
Since its first edition in 2011, the JIIDEs have evolved as a result of collaboration between the Direção-Geral do Território de Portugal, the National Geographic Institute of Spain through the National Center for Geographic Information, and the Government of Andorra. In this sixteenth edition, the Ministry of Territorial Planning, Urban Planning, Housing and Citizens' Rights of the Principality of Asturias and the University of Oviedo also join, thus consolidating an initiative that brings together hundreds of professionals from the Public Administration, the private sector and the academic field every year.
For three days, experts with proven experience and technical knowledge in geographic information will share their most innovative developments, work methodologies and success stories in the management and reuse of spatial data.
Two axes: artificial intelligence and the INSPIRE and HVDS regulatory framework
The central theme of this edition, "AI and territory: exploring the new frontiers of spatial knowledge", reflects the natural evolution of the sector towards the incorporation of emerging technologies. Artificial intelligence, machine learning, and advanced analytics algorithms are radically transforming the way we process, analyze, and extract value from geospatial data.
This orientation towards AI is not accidental. The publication and use of geospatial data makes it possible to harness one of the most valuable digital assets for economic development, environmental monitoring, competitiveness, innovation and job creation. When this data is combined with artificial intelligence techniques, its potential multiplies exponentially.
The conference takes place at a particularly relevant time for the open data ecosystem. The INSPIRE Directive, together with Directive (EU) 2019/1024 on open data and re-use of public sector information, has established a regulatory framework that explicitly recognises the economic and social value of digital geospatial data.
The evolution in the publication of high-value datasets marks an important milestone in this process. These sets, characterized by their great potential for reuse, should be available free of charge, in machine-readable formats and through application programming interfaces (APIs). Geospatial data occupies a central position in this categorisation, underlining its strategic importance for the European open data ecosystem.
JIIDE 2025 will devote particular attention to presenting practical examples of re-use of these high-value datasets , both through the new OGC APIs and through traditional download services and established interoperable formats. This practical approach will allow attendees to learn about real cases of implementation and their tangible results.
Miscellaneous Program: Use Cases, AI, and Geospatial Data Reuse
You can also check the program here. Among the planned activities, there are sessions ranging from fundamental technical aspects to innovative applications that demonstrate the transformative potential of this data. The activities are organized into five main themes:
Spatial data structure and metadata.
Data management and publication.
Development of spatial software.
Artificial intelligence.
Cooperation between agents.
Some of the highlighted topics are project management and coordination, where corporate systems such as the SIG of the Junta de Andalucía or the SITNA of the Government of Navarra will be presented. Earth observation will also feature prominently, with presentations on the evolution of the National Plan for Aerial Orthophotography (APNOA) programme and advanced deep learning image processing techniques.
On the other hand, thematic visualisers also represent another fundamental axis, showing how spatial data can be transformed into accessible tools for citizens. From eclipse visualizers to tools for calculating the solar potential of rooftops, developments will be presented that demonstrate how the creative reuse of data can generate services of high social value.
Following the annual theme, the application of AI to geospatial data will be approached from multiple perspectives. Use cases will be presented in areas as diverse as the automatic detection of sports facilities, the classification of LiDAR point clouds, the identification of hazardous materials such as asbestos, or the optimization of urban mobility.
One of the most relevant sessions for the open data community will focus specifically on "Reuse and Open Government". This session will address the integration of spatial data infrastructures into open data portals, spatial data metadata according to the GeoDCAT-AP standard, and the application of data quality regulations.
Local governments play a key role in the generation and publication of spatial data. For this reason, the JIIDE 2025 will dedicate a specific session to the publication of local data, where municipalities such as Barcelona, Madrid, Bilbao or Cáceres will share their experiences and developments.
In addition to the theoretical sessions, the conferences include practical workshops on specific tools, methodologies and technologies. These workshops, lasting 45 minutes to an hour, allow attendees to experiment directly with the solutions presented. Some of them address the creation of custom web geoportals and others, for example, the implementation of OGC APIs, through advanced visualization techniques and metadata management tools.
Participate in person or online
The JIIDEs maintain their commitment to open participation, inviting both researchers and professionals to present their tools, technical solutions, work methodologies and success stories. In addition, the JIIDE 2025 will be held in hybrid mode, allowing both face-to-face participation in Oviedo and virtual monitoring.
This flexibility, maintained from the experiences of recent years, ensures that professionals throughout the Iberian territory and beyond can benefit from shared knowledge. Participation remains free, although prior registration is required for each session, roundtable or workshop.
Starting today, you can sign up and take advantage of this opportunity to learn and exchange experiences on geospatial data. Registration is available on the official website of the event: https://www.jiide.org/web/portal/inicio