Blog
Synthetic images are visual representations artificially generated by algorithms and computational techniques, rather than being captured directly from reality with cameras or sensors. They are produced from different methods, among which the antagonistic generative networks (Generative Adversarial NetworksGAN), the Dissemination models, and the 3D rendering techniques. All of them allow you to create images of realistic appearance that in many cases are indistinguishable from an authentic photograph.
When this concept is transferred to the field of Earth observation, we are talking about synthetic satellite images. These are not obtained from a space sensor that captures real electromagnetic radiation, but are generated digitally to simulate what a satellite would see from orbit. In other words, instead of directly reflecting the physical state of the terrain or atmosphere at a particular time, they are computational constructs capable of mimicking the appearance of a real satellite image.
The development of this type of image responds to practical needs. Artificial intelligence systems that process remote sensing data require very large and varied sets of images. Synthetic images allow, for example, to recreate areas of the Earth that are little observed, to simulate natural disasters – such as forest fires, floods or droughts – or to generate specific conditions that are difficult or expensive to capture in practice. In this way, they constitute a valuable resource for training detection and prediction algorithms in agriculture, emergency management, urban planning or environmental monitoring.
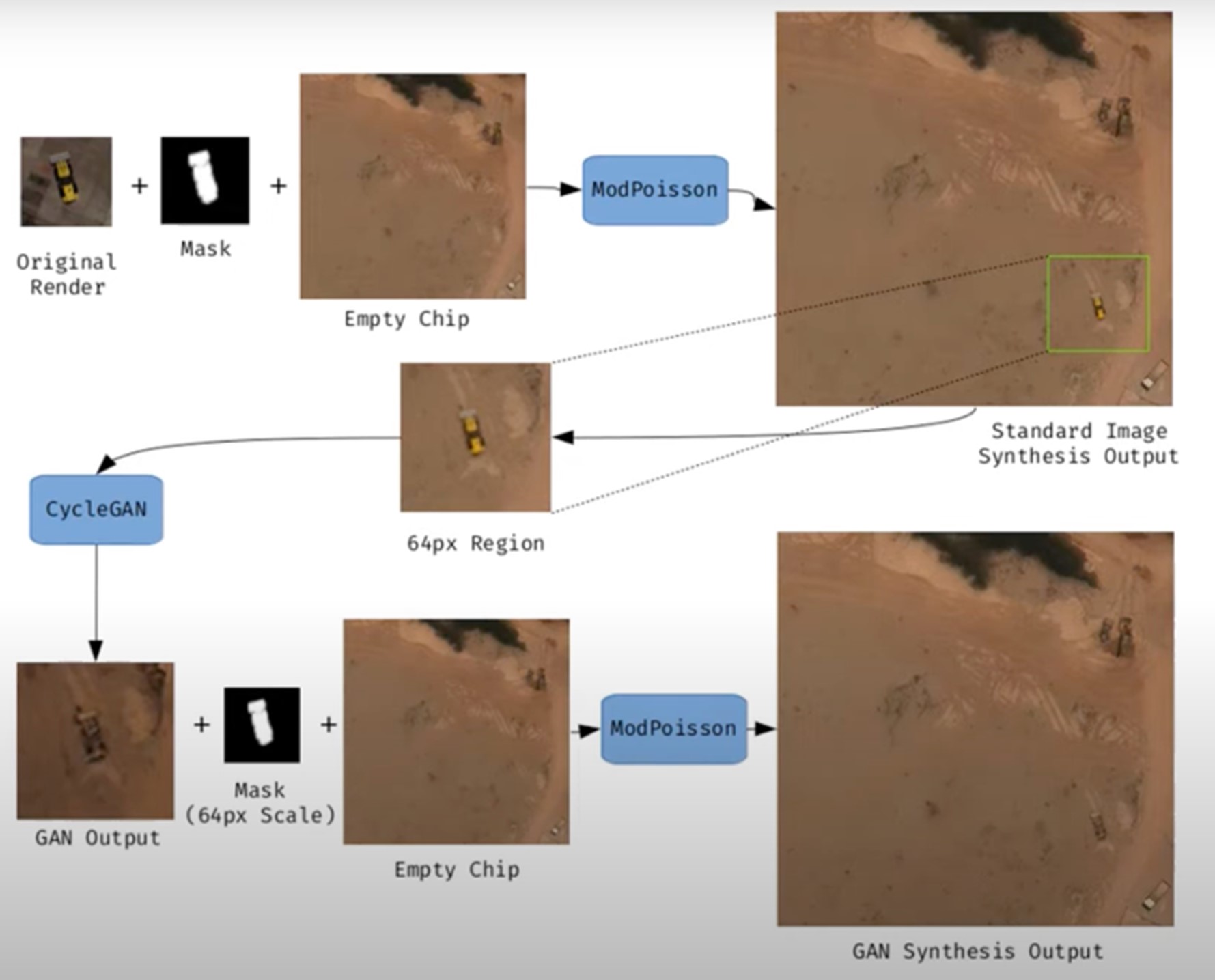
Figure 1. Example of synthetic satellite image generation.
Its value is not limited to model training. Where high-resolution images do not exist – due to technical limitations, access restrictions or economic reasons – synthesis makes it possible to fill information gaps and facilitate preliminary studies. For example, researchers can work with approximate synthetic images to design risk models or simulations before actual data are available.
However, synthetic satellite imagery also poses significant risks. The possibility of generating very realistic scenes opens the door to manipulation and misinformation. In a geopolitical context, an image showing non-existent troops or destroyed infrastructure could influence strategic decisions or international public opinion. In the environmental field, manipulated images could be disseminated to exaggerate or minimize the impacts of phenomena such as deforestation or melting ice, with direct effects on policies and markets.
Therefore, it is convenient to differentiate between two very different uses. The first is use as a support, when synthetic images complement real images to train models or perform simulations. The second is use as a fake, when they are deliberately presented as authentic images in order to deceive. While the former uses drive innovation, the latter threatens trust in satellite data and poses an urgent challenge of authenticity and governance.
Risks of satellite imagery applied to Earth observation
Synthetic satellite imagery poses significant risks when used in place of images captured by real sensors. Below are examples that demonstrate this.
A new front of disinformation: "deepfake geography"
The term deepfake geography has already been consolidated in the academic and popular literature to describe fictitious satellite images, manipulated with AI, that appear authentic, but do not reflect any existing reality. Research from the University of Washington, led by Bo Zhao, used algorithms such as CycleGAN to modify images of real cities—for example, altering the appearance of Seattle with non-existent buildings or transforming Beijing into green areas—highlighting the potential to generate convincing false landscapes.
One OnGeo Intelligence (OGC) platform article stresses that these images are not purely theoretical, but real threats affecting national security, journalism and humanitarian work. For its part, the OGC warns that fabricated satellite imagery, AI-generated urban models, and synthetic road networks have already been observed, and that they pose real challenges to public and operational trust.
Strategic and policy implications
Satellite images are considered "impartial eyes" on the planet, used by governments, media and organizations. When these images are faked, their consequences can be severe:
- National security and defense: if false infrastructures are presented or real ones are hidden, strategic analyses can be diverted or mistaken military decisions can be induced.
- Disinformation in conflicts or humanitarian crises: An altered image showing fake fires, floods, or troop movements can alter the international response, aid flows, or citizens' perceptions, especially if it is spread through social media or media without verification.
- Manipulation of realistic images of places: not only the general images are at stake. Nguyen et al. (2024) showed that it is possible to generate highly realistic synthetic satellite images of very specific facilities such as nuclear plants.
Crisis of trust and erosion of truth
For decades, satellite imagery has been perceived as one of the most objective and reliable sources of information about our planet. They were the graphic evidence that made it possible to confirm environmental phenomena, follow armed conflicts or evaluate the impact of natural disasters. In many cases, these images were used as "unbiased evidence," difficult to manipulate, and easy to validate. However, the emergence of synthetic images generated by artificial intelligence has begun to call into question that almost unshakable trust.
Today, when a satellite image can be falsified with great realism, a profound risk arises: the erosion of truth and the emergence of a crisis of confidence in spatial data.
The breakdown of public trust
When citizens can no longer distinguish between a real image and a fabricated one, trust in information sources is broken. The consequence is twofold:
- Distrust of institutions: if false images of a fire, a catastrophe or a military deployment circulate and then turn out to be synthetic, citizens may also begin to doubt the authentic images published by space agencies or the media. This "wolf is coming" effect generates skepticism even in the face of legitimate evidence.
- Effect on journalism: traditional media, which have historically used satellite imagery as an unquestionable visual source, risk losing credibility if they publish doctored images without verification. At the same time, the abundance of fake images on social media erodes the ability to distinguish what is real and what is not.
- Deliberate confusion: in contexts of disinformation, the mere suspicion that an image may be false can already be enough to generate doubt and sow confusion, even if the original image is completely authentic.
The following is a summary of the possible cases of manipulation and risk in satellite images:
|
Ambit |
Type of handling |
Main risk |
Documented example |
|---|---|---|---|
| Armed conflicts | Insertion or elimination of military infrastructures. | Strategic disinformation; erroneous military decisions; loss of credibility in international observation. | Alterations demonstrated in deepfake geography studies where dummy roads, bridges or buildings were added to satellite images. |
| Climate change and the environment | Alteration of glaciers, deforestation or emissions. | Manipulation of environmental policies; delay in measures against climate change; denialism. | Studies have shown the ability to generate modified landscapes (forests in urban areas, changes in ice) by means of GANs. |
| Gestión de emergencias | Creation of non-existent disasters (fires, floods). | Misuse of resources in emergencies; chaos in evacuations; loss of trust in agencies. | Research has shown the ease of inserting smoke, fire or water into satellite images. |
| Mercados y seguros | Falsification of damage to infrastructure or crops. | Financial impact; massive fraud; complex legal litigation. | Potential use of fake images to exaggerate damage after disasters and claim compensation or insurance. |
| Derechos humanos y justicia internacional | Alteration of visual evidence of war crimes. | Delegitimization of international tribunals; manipulation of public opinion. | Risk identified in intelligence reports: Doctored images could be used to accuse or exonerate actors in conflicts. |
| Geopolítica y diplomacia | Creation of fictitious cities or border changes. | Diplomatic tensions; treaty questioning; State propaganda | Examples of deepfake maps that transform geographical features of cities such as Seattle or Tacoma. |
Figure 2. Table showing possible cases of manipulation and risk in satellite images
Impact on decision-making and public policies
The consequences of relying on doctored images go far beyond the media arena:
- Urbanism and planning: decisions about where to build infrastructure or how to plan urban areas could be made on manipulated images, generating costly errors that are difficult to reverse.
- Emergency management: If a flood or fire is depicted in fake images, emergency teams can allocate resources to the wrong places, while neglecting areas that are actually affected.
- Climate change and the environment: Doctored images of glaciers, deforestation or polluting emissions could manipulate political debates and delay the implementation of urgent measures.
- Markets and insurance: Insurers and financial companies that rely on satellite imagery to assess damage could be misled, with significant economic consequences.
In all these cases, what is at stake is not only the quality of the information, but also the effectiveness and legitimacy of public policies based on that data.
The technological cat and mouse game
The dynamics of counterfeit generation and detection are already known in other areas, such as video or audio deepfakes: every time a more realistic generation method emerges, a more advanced detection algorithm is developed, and vice versa. In the field of satellite images, this technological career has particularities:
- Increasingly sophisticated generators: today's broadcast models can create highly realistic scenes, integrating ground textures, shadows, and urban geometries that fool even human experts.
- Detection limitations: Although algorithms are developed to identify fakes (analyzing pixel patterns, inconsistencies in shadows, or metadata), these methods are not always reliable when faced with state-of-the-art generators.
- Cost of verification: independently verifying a satellite image requires access to alternative sources or different sensors, something that is not always available to journalists, NGOs or citizens.
- Double-edged swords: The same techniques used to detect fakes can be exploited by those who generate them, further refining synthetic images and making them more difficult to differentiate.
From visual evidence to questioned evidence
The deeper impact is cultural and epistemological: what was previously assumed to be objective evidence now becomes an element subject to doubt. If satellite imagery is no longer perceived as reliable evidence, it weakens fundamental narratives around scientific truth, international justice, and political accountability.
- In armed conflicts, a satellite image showing possible war crimes can be dismissed under the accusation of being a deepfake.
- In international courts, evidence based on satellite observation could lose weight in the face of suspicion of manipulation.
- In public debate, the relativism of "everything can be false" can be used as a rhetorical weapon to delegitimize even the strongest evidence.
Strategies to ensure authenticity
The crisis of confidence in satellite imagery is not an isolated problem in the geospatial sector, but is part of a broader phenomenon: digital disinformation in the age of artificial intelligence. Just as video deepfakes have called into question the validity of audiovisual evidence, the proliferation of synthetic satellite imagery threatens to weaken the last frontier of perceived objective data: the unbiased view from space.
Ensuring the authenticity of these images requires a combination of technical solutions and governance mechanisms, capable of strengthening traceability, transparency and accountability across the spatial data value chain. The main strategies under development are described below.
Robust metadata: Record origin and chain of custody
Metadata is the first line of defense against manipulation. In satellite imagery, they should include detailed information about:
- The sensor used (type, resolution, orbit).
- The exact time of acquisition (date and time, with time precision).
- The precise geographical location (official reference systems).
- The applied processing chain (atmospheric corrections, calibrations, reprojections).
Recording this metadata in secure repositories allows the chain of custody to be reconstructed, i.e. the history of who, how and when an image has been manipulated. Without this traceability, it is impossible to distinguish between authentic and counterfeit images.
EXAMPLE: The European Union's Copernicus program already implements standardized and open metadata for all its Sentinel images, facilitating subsequent audits and confidence in the origin.
Digital signatures and blockchain: ensuring integrity
Digital signatures allow you to verify that an image has not been altered since it was captured. They function as a cryptographic seal that is applied at the time of acquisition and validated at each subsequent use.
Blockchain technology offers an additional level of assurance: storing acquisition and modification records on an immutable chain of blocks. In this way, any changes in the image or its metadata would be recorded and easily detectable.
EXAMPLE: The ESA – Trusted Data Framework project explores the use of blockchain to protect the integrity of Earth observation data and bolster trust in critical applications such as climate change and food security.
Invisible watermarks: hidden signs in the image
Digital watermarking involves embedding imperceptible signals in the satellite image itself, so that any subsequent alterations can be detected automatically.
- It can be done at the pixel level, slightly modifying color patterns or luminance.
- It is combined with cryptographic techniques to reinforce its validity.
- It allows you to validate images even if they have been cropped, compressed, or reprocessed.
EXAMPLE: In the audiovisual sector, watermarks have been used for years in the protection of digital content. Its adaptation to satellite images is in the experimental phase, but it could become a standard verification tool.
Open Standards (OGC, ISO): Trust through Interoperability
Standardization is key to ensuring that technical solutions are applied in a coordinated and global manner.
- OGC (Open Geospatial Consortium) works on standards for metadata management, geospatial data traceability, and interoperability between systems. Their work on geospatial APIs and FAIR (Findable, Accessible, Interoperable, Reusable) metadata is essential to establishing common trust practices.
- ISO develops standards on information management and authenticity of digital records that can also be applied to satellite imagery.
EXAMPLE: OGC Testbed-19 included specific experiments on geospatial data authenticity, testing approaches such as digital signatures and certificates of provenance.
Cross-check: combining multiple sources
A basic principle for detecting counterfeits is to contrast sources. In the case of satellite imagery, this involves:
- Compare images from different satellites (e.g. Sentinel-2 vs. Landsat-9).
- Use different types of sensors (optical, radar SAR, hyperspectral).
- Analyze time series to verify consistency over time.
EXAMPLE: Damage verification in Ukraine following the start of the Russian invasion in 2022 was done by comparing images from several vendors (Maxar, Planet, Sentinel), ensuring that the findings were not based on a single source.
AI vs. AI: Automatic Counterfeit Detection
The same artificial intelligence that allows synthetic images to be created can be used to detect them. Techniques include:
- Pixel Forensics: Identify patterns generated by GANs or broadcast models.
- Neural networks trained to distinguish between real and synthetic images based on textures or spectral distributions.
- Geometric inconsistencies models: detect impossible shadows, topographic inconsistencies, or repetitive patterns.
EXAMPLE: Researchers at the University of Washington and other groups have shown that specific algorithms can detect satellite fakes with greater than 90% accuracy under controlled conditions.
Current Experiences: Global Initiatives
Several international projects are already working on mechanisms to reinforce authenticity:
- Coalition for Content Provenance and Authenticity (C2PA): A partnership between Adobe, Microsoft, BBC, Intel, and other organizations to develop an open standard for provenance and authenticity of digital content, including images. Its model can be applied directly to the satellite sector.
- OGC work: the organization promotes the debate on trust in geospatial data and has highlighted the importance of ensuring the traceability of synthetic and real satellite images (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) in the US has publicly acknowledged the threat of synthetic imagery in defence and is driving collaborations with academia and industry to develop detection systems.
Towards an ecosystem of trust
The strategies described should not be understood as alternatives, but as complementary layers in a trusted ecosystem:
|
Id |
Layers |
Benefits |
|---|---|---|
| 1 | Robust metadata (source, sensor, chain of custody) |
Traceability guaranteed |
| 2 | Digital signatures and blockchain (data integrity) |
Ensuring integrity |
| 3 | Invisible watermarks (hidden signs) |
Add a hidden level of protection |
| 4 | Cross-check (multiple satellites and sensors) |
Validates independently |
| 5 | AI vs. AI (counterfeit detector) |
Respond to emerging threats |
| 6 | International governance (accountability, legal frameworks) |
Articulate clear rules of liability |
Figure 3. Layers to ensure confidence in synthetic satellite images
Success will depend on these mechanisms being integrated together, under open and collaborative frameworks, and with the active involvement of space agencies, governments, the private sector and the scientific community.
Conclusions
Synthetic images, far from being just a threat, represent a powerful tool that, when used well, can provide significant value in areas such as simulation, algorithm training or innovation in digital services. The problem arises when these images are presented as real without proper transparency, fueling misinformation or manipulating public perception.
The challenge, therefore, is twofold: to take advantage of the opportunities offered by the synthesis of visual data to advance science, technology and management, and to minimize the risks associated with the misuse of these capabilities, especially in the form of deepfakes or deliberate falsifications.
In the particular case of satellite imagery, trust takes on a strategic dimension. Critical decisions in national security, disaster response, environmental policy, and international justice depend on them. If the authenticity of these images is called into question, not only the reliability of the data is compromised, but also the legitimacy of decisions based on them.
The future of Earth observation will be shaped by our ability to ensure authenticity, transparency and traceability across the value chain: from data acquisition to dissemination and end use. Technical solutions (robust metadata, digital signatures, blockchain, watermarks, cross-verification, and AI for counterfeit detection), combined with governance frameworks and international cooperation, will be the key to building an ecosystem of trust.
In short, we must assume a simple but forceful guiding principle:
"If we can't trust what we see from space, we put our decisions on Earth at risk."
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Artificial intelligence (AI) assistants are already part of our daily lives: we ask them the time, how to get to a certain place or we ask them to play our favorite song. And although AI, in the future, may offer us infinite functionalities, we must not forget that linguistic diversity is still a pending issue.
In Spain, where Spanish coexists with co-official languages such as Basque, Catalan, Valencian and Galician, this issue is especially relevant. The survival and vitality of these languages in the digital age depends, to a large extent, on their ability to adapt and be present in emerging technologies. Currently, most virtual assistants, automatic translators or voice recognition systems do not understand all the co-official languages. However, did you know that there are collaborative projects to ensure linguistic diversity?
In this post we tell you about the approach and the greatest advances of some initiatives that are building the digital foundations necessary for the co-official languages in Spain to also thrive in the era of artificial intelligence.
ILENIA, the coordinator of multilingual resource initiatives in Spain
The models that we are going to see in this post share a focus because they are part of ILENIA, a state-level coordinator that connects the individual efforts of the autonomous communities. This initiative brings together the projects BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) and the University of Santiago de Compostela (NÓS), with the aim of generating digital resources that allow the development of multilingual applications in the different languages of Spain.
The success of these initiatives depends fundamentally on citizen participation. Through platforms such as Mozilla's Common Voice, any speaker can contribute to the construction of these linguistic resources through different forms of collaboration:
- Spoken Read: Collecting different ways of speaking through voice donations of a specific text.
- Spontaneous speech: creates real and organic datasets as a result of conversations with prompts.
- Text in language: collaborate in the transcription of audios or in the contribution of textual content, suggesting new phrases or questions to enrich the corpora.
All resources are published under free licenses such as CC0, allowing them to be used free of charge by researchers, developers and companies.
The challenge of linguistic diversity in the digital age
Artificial intelligence systems learn from the data they receive during their training. To develop technologies that work correctly in a specific language, it is essential to have large volumes of data: audio recordings, text corpora and examples of real use of the language.
In other publications of datos.gob.es we have addressed the functioning of foundational models and initiatives in Spanish such as ALIA, trained with large corpus of text such as those of the Royal Spanish Academy.
Both posts explain why language data collection is not a cheap or easy task. Technology companies have invested massively in compiling these resources for languages with large numbers of speakers, but Spanish co-official languages face a structural disadvantage. This has led to many models not working properly or not being available in Valencian, Catalan, Basque or Galician.
However, there are collaborative and open data initiatives that allow the creation of quality language resources. These are the projects that several autonomous communities have launched, marking the way towards a multilingual digital future.
On the one hand, the Nós en Galicia Project creates oral and conversational resources in Galician with all the accents and dialectal variants to facilitate integration through tools such as GPS, voice assistants or ChatGPT. A similar purpose is that of Aina in Catalonia, which also offers an academic platform and a laboratory for developers or Vives in the Valencian Community. In the Basque Country there is also the Euskorpus project , which aims to constitute a quality text corpus in Basque. Let's look at each of them.
Proyecto Nós, a collaborative approach to digital Galician
The project has already developed three operational tools: a multilingual neural translator, a speech recognition system that converts speech into text, and a speech synthesis application. These resources are published under open licenses, guaranteeing their free and open access for researchers, developers and companies. These are its main features:
- Promoted by: the Xunta de Galicia and the University of Santiago de Compostela.
- Main objective: to create oral and conversational resources in Galician that capture the dialectal and accent diversity of the language.
- How to participate: The project accepts voluntary contributions both by reading texts and by answering spontaneous questions.
- Donate your voice in Galician: https://doagalego.nos.gal
Aina, towards an AI that understands and speaks Catalan
With a similar approach to the Nós project, Aina seeks to facilitate the integration of Catalan into artificial intelligence language models.
It is structured in two complementary aspects that maximize its impact:
- Aina Tech focuses on facilitating technology transfer to the business sector, providing the necessary tools to automatically translate websites, services and online businesses into Catalan.
- Aina Lab promotes the creation of a community of developers through initiatives such as Aina Challenge, promoting collaborative innovation in Catalan language technologies. Through this call , 22 proposals have already been selected with a total amount of 1 million to execute their projects.
The characteristics of the project are:
- Powered by: the Generalitat de Catalunya in collaboration with the Barcelona Supercomputing Center (BSC-CNS).
- Main objective: it goes beyond the creation of tools, it seeks to build an open, transparent and responsible AI infrastructure with Catalan.
- How to participate: You can add comments, improvements, and suggestions through the contact inbox: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, the collaborative project for AI in Valencian
On the other hand, Vives collects voices speaking in Valencian to serve as training for AI models.
- Promoted by: the Alicante Digital Intelligence Centre (CENID).
- Objective: It seeks to create massive corpora of text and voice, encourage citizen participation in data collection, and develop specialized linguistic models in sectors such as tourism and audiovisual, guaranteeing data privacy.
- How to participate: You can donate your voice through this link: https://vives.gplsi.es/instruccions/.
Gaitu: strategic investment in the digitalisation of the Basque language
In Basque, we can highlight Gaitu, which seeks to collect voices speaking in Basque in order to train AI models. Its characteristics are:
- Promoted by: HiTZ, the Basque language technology centre.
- Objective: to develop a corpus in Basque to train AI models.
- How to participate: You can donate your voice in Basque here https://commonvoice.mozilla.org/eu/speak.
Benefits of Building and Preserving Multilingual Language Models
The digitization projects of the co-official languages transcend the purely technological field to become tools for digital equity and cultural preservation. Its impact is manifested in multiple dimensions:
- For citizens: these resources ensure that speakers of all ages and levels of digital competence can interact with technology in their mother tongue, removing barriers that could exclude certain groups from the digital ecosystem.
- For the business sector: the availability of open language resources makes it easier for companies and developers to create products and services in these languages without assuming the high costs traditionally associated with the development of language technologies.
- For the research fabric, these corpora constitute a fundamental basis for the advancement of research in natural language processing and speech technologies, especially relevant for languages with less presence in international digital resources.
The success of these initiatives shows that it is possible to build a digital future where linguistic diversity is not an obstacle but a strength, and where technological innovation is put at the service of the preservation and promotion of linguistic cultural heritage.
Documentación
In the field of data science, the ability to build robust predictive models is fundamental. However, a model is not just a set of algorithms; it is a tool that must be understood, validated, and ultimately useful for decision-making.
Thanks to the transparency and accessibility of open data, we have the unique opportunity to work in this exercise with real, updated, and institutional-quality information that reflects environmental issues. This democratization of access not only allows for the development of rigorous analyses with official data but also contributes to informed public debate on environmental policies, creating a direct bridge between scientific research and societal needs.
In this practical exercise, we will dive into the complete lifecycle of a modeling project, using a real case study: the analysis of air quality in Castile and León. Unlike approaches that focus solely on the implementation of algorithms, our methodology focuses on:
- Loading and initial data exploration: identifying patterns, anomalies, and underlying relationships that will guide our modeling.
- Exploratory analysis for modeling: building visualizations and performing feature engineering to optimize the model.
- Development and evaluation of regression models: building and comparing multiple iterative models to understand how complexity affects performance.
- Model application and conclusions: using the final model to simulate scenarios and quantify the impact of potential environmental policies.
Access the data laboratory repository on Github.
Run the data pre-processing code on Google Colab.
Analysis Architecture
The core of this exercise follows a structured flow in four key phases, as illustrated in Figure 1. Each phase builds on the previous one, from initial data exploration to the final application of the model.

Figure 1. Phases of the predictive modeling project.
Development Process
1. Loading and Initial Data Exploration
The first step is to understand the raw material of our analysis: the data. Using an air quality dataset from Castile and León, spanning 24 years of measurements, we face common real-world challenges:
- Missing Values: variables such as CO and PM2.5 have limited data coverage.
- Anomalous Data: negative and extreme values are detected, likely due to sensor errors.
Through a process of cleaning and transformation, we convert the raw data into a clean and structured dataset, ready for modeling.
2. Exploratory Analysis for Modeling
Once the data is clean, we look for patterns. Visual analysis reveals a strong seasonality in NO₂ levels, with peaks in winter and troughs in summer. This observation is crucial and leads us to create new variables (feature engineering), such as cyclical components for the months, which allow the model to "understand" the circular nature of the seasons.

Figure 2. Seasonal variation of NO₂ levels in Castile and León.
3. Development and Evaluation of Regression Models
With a solid understanding of the data, we proceed to build three linear regression models of increasing complexity:
- Base Model: uses only pollutants as predictors.
- Seasonal Model: adds time variables.
- Complete Model: includes interactions and geographical effects.
Comparing these models allows us to quantify the improvement in predictive capability. The Seasonal Model emerges as the optimal choice, explaining almost 63% of the variability in NO₂, a remarkable result for environmental data.
4. Model Application and Conclusions
Finally, we subject the model to a rigorous diagnosis and use it to simulate the impact of environmental policies. For example, our analysis estimates that a 20% reduction in NO emissions could translate into a 4.8% decrease in NO₂ levels.

Figure 3. Performance of the seasonal model. The predicted values align well with the actual values.
What can you learn?
This practical exercise allows you to learn:
- Data project lifecycle: from cleaning to application.
- Linear regression techniques: construction, interpretation, and diagnosis.
- Handling time-series data: capturing seasonality and trends.
- Model validation: techniques like cross-validation and temporal validation.
- Communicating results: how to translate findings into actionable insights.
Conclusions and Future
This exercise demonstrates the power of a structured and rigorous approach in data science. We have transformed a complex dataset into a predictive model that is not only accurate but also interpretable and useful.
For those interested in taking this analysis to the next level, the possibilities are numerous:
- Incorporation of meteorological data: variables such as temperature and wind could significantly improve accuracy.
- More advanced models: exploring techniques such as Generalized Additive Models (GAM) or other machine learning algorithms.
- Spatial analysis: investigating how pollution patterns vary between different locations.
In summary, this exercise not only illustrates the application of regression techniques but also underscores the importance of an integrated approach that combines statistical rigor with practical relevance.
Blog
Citizen participation in the collection of scientific data promotes a more democratic science, by involving society in R+D+i processes and reinforcing accountability. In this sense, there are a variety of citizen science initiatives launched by entities such as CSIC, CENEAM or CREAF, among others. In addition, there are currently numerous citizen science platform platforms that help anyone find, join and contribute to a wide variety of initiatives around the world, such as SciStarter.
Some references in national and European legislation
Different regulations, both at national and European level, highlight the importance of promoting citizen science projects as a fundamental component of open science. For example, Organic Law 2/2023, of 22 March, on the University System, establishes that universities will promote citizen science as a key instrument for generating shared knowledge and responding to social challenges, seeking not only to strengthen the link between science and society, but also to contribute to a more equitable, inclusive and sustainable territorial development.
On the other hand, Law 14/2011, of 1 June, on Science, Technology and Innovation, promotes "the participation of citizens in the scientific and technical process through, among other mechanisms, the definition of research agendas, the observation, collection and processing of data, the evaluation of impact in the selection of projects and the monitoring of results, and other processes of citizen participation."
At the European level, Regulation (EU) 2021/695 establishing the Framework Programme for Research and Innovation "Horizon Europe", indicates the opportunity to develop projects co-designed with citizens, endorsing citizen science as a research mechanism and a means of disseminating results.
Citizen science initiatives and data management plans
The first step in defining a citizen science initiative is usually to establish a research question that requires data collection that can be addressed with the collaboration of citizens. Then, an accessible protocol is designed for participants to collect or analyze data in a simple and reliable way (it could even be a gamified process). Training materials must be prepared and a means of participation (application, web or even paper) must be developed. It also plans how to communicate progress and results to citizens, encouraging their participation.
As it is an intensive activity in data collection, it is interesting that citizen science projects have a data management plan that defines the life cycle of data in research projects, that is, how data is created, organized, shared, reused and preserved in citizen science initiatives. However, most citizen science initiatives do not have such a plan: this recent research article found that only 38% of the citizen science projects consulted had a data management plan.

Figure 1. Data life cycle in citizen science projects Source: own elaboration – datos.gob.es.
On the other hand, data from citizen science only reach their full potential when they comply with the FAIR principles and are published in open access. In order to help have this data management plan that makes data from citizen science initiatives FAIR, it is necessary to have specific standards for citizen science such as PPSR Core.
Open Data for Citizen Science with the PPSR Core Standard
The publication of open data should be considered from the early stages of a citizen science project, incorporating the PPSR Core standard as a key piece. As we mentioned earlier, when research questions are formulated, in a citizen science initiative, a data management plan must be proposed that indicates what data to collect, in what format and with what metadata, as well as the needs for cleaning and quality assurance from the data collected by citizens. in addition to a publication schedule.
Then, it must be standardized with PPSR (Public Participation in Scientific Research) Core. PPSR Core is a set of data and metadata standards, specially designed to encourage citizen participation in scientific research processes. It has a three-layer architecture based on a Common Data Model (CDM). This CDM helps to organize in a coherent and connected way the information about citizen science projects, the related datasets and the observations that are part of them, in such a way that the CDM facilitates interoperability between citizen science platforms and scientific disciplines. This common model is structured in three main layers that allow the key elements of a citizen science project to be described in a structured and reusable way. The first is the Project Metadata Model (PMM), which collects the general information of the project, such as its objective, participating audience, location, duration, responsible persons, sources of funding or relevant links. Second, the Dataset Metadata Model (DMM) documents each dataset generated, detailing what type of information is collected, by what method, in what period, under what license and under what conditions of access. Finally, the Observation Data Model (ODM) focuses on each individual observation made by citizen science initiative participants, including the date and location of the observation and the result. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements). (ODM) focuses on each individual observation made by participants of the citizen science initiative, including the date and place of the observation and the outcome. It is interesting to note that this PPSR-Core layer model allows specific extensions to be added according to the scientific field, based on existing vocabularies such as Darwin Core (biodiversity) or ISO 19156 (sensor measurements).
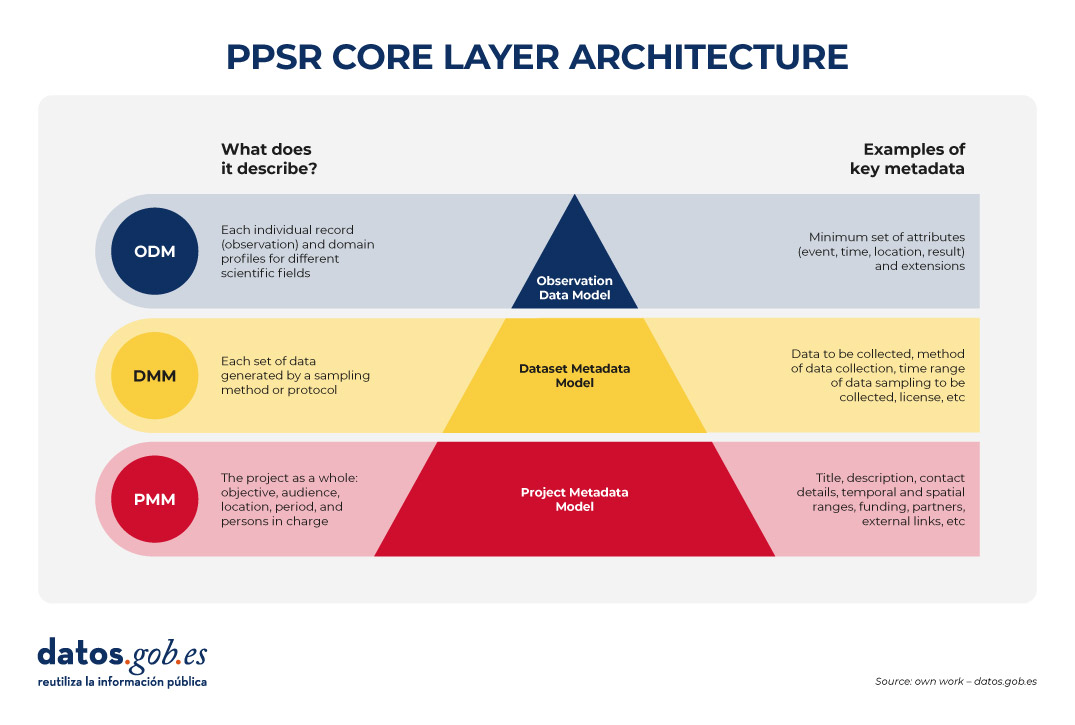
Figure 2. PPSR CORE layering architecture. Source: own elaboration – datos.gob.es.
This separation allows a citizen science initiative to automatically federate the project file (PMM) with platforms such as SciStarter, share a dataset (DMM) with a institutional repository of open scientific data, such as those added in FECYT's RECOLECTA and, at the same time, send verified observations (ODMs) to a platform such as GBIF without redefining each field.
In addition, the use of PPSR Core provides a number of advantages for the management of the data of a citizen science initiative:
- Greater interoperability: platforms such as SciStarter already exchange metadata using PMM, so duplication of information is avoided.
- Multidisciplinary aggregation: ODM profiles allow datasets from different domains (e.g. air quality and health) to be united around common attributes, which is crucial for multidisciplinary studies.
- Alignment with FAIR principles: The required fields of the DMM are useful for citizen science datasets to comply with the FAIR principles.
It should be noted that PPSR Core allows you to add context to datasets obtained in citizen science initiatives. It is a good practice to translate the content of the PMM into language understandable by citizens, as well as to obtain a data dictionary from the DMM (description of each field and unit) and the mechanisms for transforming each record from the MDG. Finally, initiatives to improve PPSR Core can be highlighted, for example, through a DCAT profile for citizen science.
Conclusions
Planning the publication of open data from the beginning of a citizen science project is key to ensuring the quality and interoperability of the data generated, facilitating its reuse and maximizing the scientific and social impact of the project. To this end, PPSR Core offers a level-based standard (PMM, DMM, ODM) that connects the data generated by citizen science with various platforms, promoting that this data complies with the FAIR principles and considering, in an integrated way, various scientific disciplines. With PPSR Core , every citizen observation is easily converted into open data on which the scientific community can continue to build knowledge for the benefit of society.

Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In an increasingly complex world, public decisions need more than intuition: they require scientific evidence. This is where I+P (Innovation + Public Policy) initiatives come into play: an intersection between creativity, data-driven knowledge, and policy action.
In this article we will explain this concept, including examples and information about funding programs.
What is I+P?
I+P is not a mathematical formula, but a strategic practice that combines scientific knowledge, research, and citizen participation to improve the formulation, implementation, and evaluation of public policies. It is not only a matter of applying technology to the public sphere, but of rethinking how decisions are made, how solutions are formulated and how society is involved in these processes through the application of scientific methodologies.
This idea stems from the concept of "science for public policy", also known as "science for policy" or "Science for Policy" (S4P) and implies active collaboration between public administrations and the scientific community.
I+P initiatives promote empirical evidence and experimentation. To this end, they promote the use of data, emerging technologies, pilot tests, agile methodologies and feedback loops that help design more efficient and effective policies, focused on the real needs of citizens. This facilitates real-time decision-making and the possibility of making agile adjustments in situations that require quick responses. In short, it is about providing more creative and accurate responses to today's challenges, such as climate change or digital inequality, areas where traditional policies can fall short.
The following visual summarizes these and other benefits.

Source: FECYT Call for Public Innovation - adapted by datos.gob.es.
Examples of R+P initiatives
The use of data for political decision-making was evident during the COVID-19 pandemic, where policymakers were adapting the measures to be taken based on reports from institutions such as the World Health Organization (WHO). But beyond these types of extraordinary events, today we find consolidated initiatives that increasingly seek to promote innovation and decision-making based on scientific data in the public sphere on an ongoing basis. Let's look at two examples.
-
Periodic reports from scientific institutions to bring scientific knowledge closer to public decision-making
Scientific reports on topics such as climate change, bacterial resistance or food production are examples of how science can guide informed policy decisions.
The Science4Policy initiative of the Spanish National Research Council (CSIC) is an example of this. It is a collection of thematic reports that present solid evidence, generated in its research centers, on relevant social problems. Each report includes:
- An introduction to the problem and its social impact.
- Information on the research carried out by the CSIC on the subject.
- Conclusions and recommendations for public policies.
Its main objective is to transform scientific knowledge into accessible contributions for non-specialized audiences, thus facilitating informed decisions by public authorities.
-
Public innovation laboratories, a space for science-based creativity
Public innovation labs or GovLabs are experimental spaces that allow public employees, scientists, experts in various fields and citizens to co-create policies, prototype solutions and learn iteratively.
An example is the Public Innovation Laboratory (LIP) promoted by the National Institute of Public Administration (INAP), where pilots have been carried out on the use of technologies to promote the new generation of jobs, intermunicipal collaboration to share talent or the decentralization of selective tests. In addition, they have an Innovation Resources Catalogue where tools with open licences launched by various organisations are compiled and can be used to support public entrepreneurs.
It is also worth highlighting the Spanish Network for Public Innovation and Scientific Transfer, promoted by the NovaGob Foundation. It is a collaborative space that brings together professionals, public administrations, universities and third sector organisations with the aim of transforming public management in Spain. Through working groups and repositories of good practices, it promotes the use of artificial intelligence, administrative simplification and the improvement of citizen service.
We also find public innovation laboratories at the regional level, such as Govtechlab Madrid, a project led by the madri+d Foundation for Knowledge that connects startups and digital SMEs with public institutions to solve real challenges. During the 2023/2024 academic year, they launched 9 pilots, for example, to collect and analyse the opinion of citizens to make better decisions in the Alcobendas City Council, unify the collection and management of data in the registrations of the activities of the Youth Area of the Boadilla del Monte City Council or provide truthful and updated information digitally on the commercial fabric of Mostoles.
The role of governments and public institutions
Innovation in public policy can be driven by a diversity of actors: public administrations open to change, universities and research centres, civic startups and technology companies, civil society organisations or committed citizens.
The European Commission, for example, plays a key role in strengthening the science-for-policy ecosystem in Europe, promoting the effective use of scientific knowledge in decision-making at all levels: European, national, regional and local. Through programmes such as Horizon Europe and the European Research Area Policy Agenda 2025-2027, actions are promoted to develop capacities, share good practices and align research with societal needs.
In Spain we also find actions such as the recent call for funding from the Spanish Foundation for Science and Technology (FECYT), the Ministry of Science, Innovation and Universities, and the National Office of Scientific Advice, whose objective is to promote:
- Research projects that generate new scientific evidence applicable to the design of public policies (Category A).
- Scientific advice and knowledge transfer activities between researchers and public officials (Category B).
Projects can receive up to €100,000 (Category A) or €25,000 (Category B), covering up to 90% of the total cost. Research organizations, universities, health entities, technology centers, R+D centers and other actors that promote the transfer of R+D can participate. The deadline to apply for the aid ends on September 17, 2025. For more information, you should visit the rules of the call or attend some training sessions that are being held.
Conclusion
In a world where social, economic and environmental challenges are increasingly complex, we need new ways of thinking and acting from public institutions. For this reason, R+P is not a fad, it is a necessity that allows us to move from "we think it works" to "we know it works", promoting a more adaptive, agile and effective policy.
Blog
Over the last few years we have seen spectacular advances in the use of artificial intelligence (AI) and, behind all these achievements, we will always find the same common ingredient: data. An illustrative example known to everyone is that of the language models used by OpenAI for its famous ChatGPT, such as GPT-3, one of its first models that was trained with more than 45 terabytes of data, conveniently organized and structured to be useful.
Without sufficient availability of quality and properly prepared data, even the most advanced algorithms will not be of much use, neither socially nor economically. In fact, Gartner estimates that more than 40% of emerging AI agent projects today will end up being abandoned in the medium term due to a lack of adequate data and other quality issues. Therefore, the effort invested in standardizing, cleaning, and documenting data can make the difference between a successful AI initiative and a failed experiment. In short, the classic principle of "garbage in, garbage out" in computer engineering applied this time to artificial intelligence: if we feed an AI with low-quality data, its results will be equally poor and unreliable.
Becoming aware of this problem arises the concept of "AI Data Readiness" or preparation of data to be used by artificial intelligence. In this article, we'll explore what it means for data to be "AI-ready", why it's important, and what we'll need for AI algorithms to be able to leverage our data effectively. This results in greater social value, favoring the elimination of biases and the promotion of equity.
What does it mean for data to be "AI-ready"?
Having AI-ready data means that this data meets a series of technical, structural, and quality requirements that optimize its use by artificial intelligence algorithms. This includes multiple aspects such as the completeness of the data, the absence of errors and inconsistencies, the use of appropriate formats, metadata and homogeneous structures, as well as providing the necessary context to be able to verify that they are aligned with the use that AI will give them.
Preparing data for AI often requires a multi-stage process. For example, again the consulting firm Gartner recommends following the following steps:
- Assess data needs according to the use case: identify which data is relevant to the problem we want to solve with AI (the type of data, volume needed, level of detail, etc.), understanding that this assessment can be an iterative process that is refined as the AI project progresses.
- Align business areas and get management support: present data requirements to managers based on identified needs and get their backing, thus securing the resources required to prepare the data properly.
- Develop good data governance practices: implement appropriate data management policies and tools (quality, catalogs, data lineage, security, etc.) and ensure that they also incorporate the needs of AI projects.
- Expand the data ecosystem: integrate new data sources, break down potential barriers and silos that are working in isolation within the organization and adapt the infrastructure to be able to handle the large volumes and variety of data necessary for the proper functioning of AI.
- Ensure scalability and regulatory compliance: ensure that data management can scale as AI projects grow, while maintaining a robust governance framework in line with the necessary ethical protocols and compliance with existing regulations.
If we follow a strategy like this one, we will be able to integrate the new requirements and needs of AI into our usual data governance practices. In essence, it is simply a matter of ensuring that our data is prepared to feed AI models with the minimum possible friction, avoiding possible setbacks later in the day during the development of projects.
Open data "ready for AI"
In the field of open science and open data, the FAIR principles have been promoted for years. These acronyms state that data must be locatable, accessible, interoperable and reusable. The FAIR principles have served to guide the management of scientific and open data to make them more useful and improve their use by the scientific community and society at large. However, these principles were not designed to address the new needs associated with the rise of AI.
Therefore, the proposal is currently being made to extend the original principles by adding a fifth readiness principle for AI, thus moving from the initial FAIR to FAIR-R or FAIR². The aim would be precisely to make explicit those additional attributes that make the data ready to accelerate its responsible and transparent use as a necessary tool for AI applications of high public interest

What exactly would this new R add to the FAIR principles? In essence, it emphasizes some aspects such as:
- Labelling, annotation and adequate enrichment of data.
- Transparency on the origin, lineage and processing of data.
- Standards, metadata, schemas and formats optimal for use by AI.
- Sufficient coverage and quality to avoid bias or lack of representativeness.
In the context of open data, this discussion is especially relevant within the discourse of the "fourth wave" of the open data movement, through which it is argued that if governments, universities and other institutions release their data, but it is not in the optimal conditions to be able to feed the algorithms, A unique opportunity for a whole new universe of innovation and social impact would be missing: improvements in medical diagnostics, detection of epidemiological outbreaks, optimization of urban traffic and transport routes, maximization of crop yields or prevention of deforestation are just a few examples of the possible lost opportunities.
And if not, we could also enter a long "data winter", where positive AI applications are constrained by poor-quality, inaccessible, or biased datasets. In that scenario, the promise of AI for the common good would be frozen, unable to evolve due to a lack of adequate raw material, while AI applications led by initiatives with private interests would continue to advance and increase unequal access to the benefit provided by technologies.
Conclusion: the path to quality, inclusive AI with true social value
We can never take for granted the quality or suitability of data for new AI applications: we must continue to evaluate it, work on it and carry out its governance in a rigorous and effective way in the same way as it has been recommended for other applications. Making our data AI-ready is therefore not a trivial task, but the long-term benefits are clear: more accurate algorithms, reduced unwanted bias, increased transparency of AI, and extended its benefits to more areas in an equitable way.
Conversely, ignoring data preparation carries a high risk of failed AI projects, erroneous conclusions, or exclusion of those who do not have access to quality data. Addressing the unfinished business on how to prepare and share data responsibly is essential to unlocking the full potential of AI-driven innovation for the common good. If quality data is the foundation for the promise of more humane and equitable AI, let's make sure we build a strong enough foundation to be able to reach our goal.
On this path towards a more inclusive artificial intelligence, fuelled by quality data and with real social value, the European Union is also making steady progress. Through initiatives such as its Data Union strategy, the creation of common data spaces in key sectors such as health, mobility or agriculture, and the promotion of the so-called AI Continent and AI factories, Europe seeks to build a digital infrastructure where data is governed responsibly, interoperable and prepared to be used by AI systems for the benefit of the common good. This vision not only promotes greater digital sovereignty but reinforces the principle that public data should be used to develop technologies that serve people and not the other way around.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Energy is the engine of our society, a vital resource that powers our lives and the global economy. However, the traditional energy model faces monumental challenges: growing demand, climate urgency, and the prevailing need for a transition to cleaner and more sustainable sources. In this panorama of profound transformation, a silent but powerful actor emerges: data. Not only is "having data" important, but also the ability to govern it properly to transform the energy sector.
In this new energy paradigm, data has become a strategic resource as essential as energy itself. The key is not only in generating and distributing electricity, but in understanding, anticipating and optimizing its use in real time. And to do this, it is necessary to capture the digital pulse of the energy system through millions of measurement and observation points.
So, before addressing how this data is governed, it's worth understanding where it comes from, what kind of information it generates, and how it's quietly transforming how the power grid works.
The digital heartbeat of the network: data from smart meters and sensors
Imagine an electric grid that not only distributes power, but also "listens," "learns," and "reacts." This is the promise of smart grids, a system that goes far beyond the cables and transformers we see. Asmart grid is an electricity distribution system that uses digital technology to improve grid efficiency, sustainability, and security. At the heart of this revolution are smart meters and a vast network of sensors.
Smart meters, also known as Advanced Metering Infrastructure (AMI), are devices that record electricity consumption digitally, often at very short intervals of time (e.g. every 15 minutes or per hour), and transmit this data to power companies via various communication technologies, such as cellular networks, WiFi, PLC (Power Line Communication) or radio frequency (RF). This data is not limited to the total amount of energy consumed, but offers a detailed breakdown of consumption patterns, voltage levels, power quality, and even fault detection.
But network intelligence doesn't just lie with the meters. A myriad of sensors distributed throughout the electrical infrastructure monitor critical variables in real time: from transformer temperature and equipment status to environmental conditions and power flow at different points on the grid. These sensors act as the "eyes and ears" of the system, providing a granular and dynamic view of network performance.
The magic happens in the flow of this data. The information from the meters and sensors travels bidirectionally: from the point of consumption or generation to the management platforms of the electricity company and vice versa. This constant communication allows utilities to:
- Check-in accurately
- Implement demand response programs
- Optimize power distribution
- Predict and prevent disruptions
- Efficiently integrate renewable energy sources that are intermittent by their nature
Data governance: the backbone of a connected network
The mere collection of data, however abundant, does not guarantee its value. In fact, without proper management, this heterogeneity of sources can become an insurmountable barrier to the integration and useful analysis of information. This is where data governance comes into play.
Data governance in the context of smart grids involves establishing a robust set of principles, processes, roles, and technologies to ensure that the data generated is reliable, accessible, useful, and secure. It's the "rule of the game" that defines how data is captured, stored, maintained, used, protected, and deleted throughout its entire lifecycle.
Why is this so crucial?
- Interoperability: A smart grid is not a monolithic system, but a constellation of devices, platforms, and actors (generators, distributors, consumers, prosumer, regulators). For all these elements to "speak the same language", interoperability is essential. Data governance sets standards for nomenclature, formats, encoding, and synchronization, allowing information to flow frictionlessly between disparate systems. Without it, we risk creating fragmented and costly information silos.
- Quality: Artificial intelligence algorithms and machine learning, so vital to smart grids, are only as good as the data they are fed with. Data governance ensures the accuracy, completeness, and consistency of data (and future information and knowledge) by defining business rules, cleaning up duplicates, and managing data errors. Poor quality data can lead to wrong decisions, operational inefficiencies, and unreliable results.
- Security: The interconnection of millions of devices in a smart network exponentially expands the attack surface for cybercriminals. A breach of data security could have catastrophic consequences, from massive power outages to breaches of user privacy. Data governance is the shield that implements robust access controls, encryption protocols, and usage audits, safeguarding the integrity and confidentiality of critical information. Adhering to consolidated security frameworks such as ENS, ISO/IEC 27000, NIST, IEC 62443, and NERC CIP is critical.
Ultimately, effective data governance turns data into critical infrastructure, as important as cables and substations, for decision-making, resource optimization, and intelligent automation.
Data in action: optimising, anticipating and facilitating the energy transition
Governing data is not an end in itself, but the means to unlock vast potential for efficiency and sustainability in the energy sector.
1. Optimisation of consumption and operational efficiency
Exact, complete, consistent, current, credible and real-time data enables multiple advantages in energy management:
- Consumption at the user level: smart meters empower citizens and businesses by providing them with detailed information about their own consumption. This allows them to identify patterns, adjust their habits, and ultimately reduce their energy bills.
- Demand management: Utilities can use data to implement demand response (DR) programs. These programs incentivize consumers to reduce or shift their electricity consumption during periods of high demand or high prices, thereby balancing the load on the grid and avoiding costly investments in new infrastructure.
- Reduced inefficiencies: The availability of accurate and well-integrated data allows utilities to automate tasks, avoid redundant processes, and reduce unplanned downtime in their systems. For example, a generation plant can adjust its production in real-time based on the analysis of performance and demand data.
- Energy monitoring and emission control: real-time monitoring of energy, water or polluting gas emissions reveals hidden inefficiencies and savings opportunities. Smart dashboards, powered by governed data, enable industrial plants and cities to reduce their costs and advance their environmental sustainability goals.
2. Demand anticipation and grid resilience
Smart grids can also foresee the future of energy consumption:
- Demand forecasting: By using advanced artificial intelligence and machine learning algorithms (such as time series analysis or neural networks), historical consumption data, combined with external factors such as weather, holidays, or special events, allow utilities to forecast demand with astonishing accuracy. This anticipation is vital to optimize resource allocation, avoid overloads, and ensure network stability.
- Predictive maintenance: By combining historical maintenance data with real-time information from sensors on critical equipment, companies can anticipate machine failures before they occur, proactively schedule maintenance, and avoid costly unexpected outages.
3. Facilitating the energy transition
Data governance is an indispensable catalyst for the integration of renewable energy and decarbonization:
- Integration of renewables: sources such as solar and wind energy are intermittent by nature. Real-time data on generation, weather conditions, and grid status are critical to managing this variability, balancing the load, and maximizing the injection of clean energy into the grid.
- Distributed Energy Resources (RED) Management: The proliferation of rooftop solar panels, storage batteries, and electric vehicles (which can charge and discharge energy to the grid) requires sophisticated data management. Data governance ensures the interoperability needed to coordinate these resources efficiently, transforming them into "virtual power plants" that can support grid stability.
- Boosting the circular economy: thanks to the full traceability of a product's life cycle, from design to recycling, data makes it possible to identify opportunities for reuse, recovery of materials and sustainable design. This is crucial to comply with new circular economy regulations and the Digital Product Passport (DPP).
- Digital twins: For a virtual replica of a physical process or system to work, it needs to be powered by accurate and consistent data. Data governance ensures synchronization between the physical and virtual worlds, enabling reliable simulations to optimize the design of new production lines or the arrangement of elements in a factory.
Tangible benefits for citizens, businesses and administrations
Investment in data governance in smart grids generates significant value for all actors in society:
For citizens
- Savings on electricity bills: by having access to real-time consumption data and flexible tariffs (for example, with lower prices in off-peak hours), citizens can adjust their habits and reduce their energy costs.
- Empowerment and control: citizens go from being mere consumers to "prosumers", with the ability to generate their own energy (for example, with solar panels) and even inject the surplus into the grid, being compensated for it. This encourages participation and greater control over their energy consumption.
- Better quality of life: A more resilient and efficient grid means fewer power interruptions and greater reliability, which translates into a better quality of life and uninterrupted essential services.
- Promoting sustainability: By participating in demand response programs and adopting more efficient consumption behaviors, citizens contribute directly to the reduction of the country's carbon footprint and energy transition.
For companies
- Optimization of operations and cost reduction: companies can predict demand, adjust production and perform predictive maintenance of their machinery, reducing losses due to failures and optimizing the use of energy and material resources.
- New business models: The availability of data creates opportunities for the development of new services and products. This includes platforms for energy exchange, intelligent energy management systems for buildings and homes, or the optimization of charging infrastructures for electric vehicles.
- Loss reduction: Intelligent data management allows utilities to minimize losses in power transmission and distribution, prevent overloads, and isolate faults faster and more efficiently.
- Improved traceability: in regulated sectors such as food, automotive or pharmaceuticals, the complete traceability of the product from the raw material to the end customer is not only an added value, but a regulatory obligation. Data governance ensures that this traceability is verifiable and meets standards.
- Regulatory compliance: Robust data management enables companies to comply with increasingly stringent regulations on sustainability, energy efficiency, and emissions, as well as data privacy regulations (such as GDPR).
For Public Administrations
- Smart energy policymaking: Aggregated and anonymised data from the smart grid provides public administrations with valuable information to design more effective energy policies, set ambitious decarbonisation targets and strategically plan the country's energy future.
- Infrastructure planning: with a clear view of consumption patterns and future needs, governments can more efficiently plan grid upgrades and expansions, as well as the integration of distributed energy resources such as smart microgrids.
- Boosting urban resilience: the ability to manage and coordinate locally distributed energy resources, such as in micro-grids, improves the resilience of cities to extreme events or failures in the main grid.
- Promotion of technological and data sovereignty: by encouraging the publication of this data in open data portals together with the creation of national and sectoral data spaces, Administrations ensure that the value generated by data stays in the country and in local companies, boosting innovation and competitiveness at an international level.
Challenges and best practices in smart grid data governance
Despite the immense benefits, implementing effective data governance initiatives in the energy sector presents significant challenges:
- Heterogeneity and complexity of data integration: Data comes from a multitude of disparate sources (meters, sensors, SCADA, ERP, MES, maintenance systems, etc.). Integrating and harmonizing this information is a considerable technical and organizational challenge.
- Privacy and compliance: Energy consumption data can reveal highly sensitive patterns of behavior. Ensuring user privacy and complying with regulations such as the GDPR is a constant challenge that requires strong ethical and legal frameworks.
- Cybersecurity: The massive interconnection of devices and systems expands the attack surface, making smart grids attractive targets for sophisticated cyberattacks. Integrating legacy systems with new technologies can also create vulnerabilities.
- Data quality: Without robust processes, information can be inconsistent, incomplete, or inaccurate, leading to erroneous decisions.
- Lack of universal standards: The absence of uniform cybersecurity practices and regulations across different regions can reduce the effectiveness of security measures.
- Resistance to change and lack of data culture: The implementation of new data governance policies and processes can encounter internal resistance, and a lack of understanding about the importance of data often hampers efforts.
- Role and resource allocation: Clearly defining who is responsible for which aspect of the data and securing adequate financial and human resources is critical to success.
- Scalability: As the volume and variety of data grows exponentially, the governance structure must be able to scale efficiently to avoid bottlenecks and compliance issues.
To overcome these challenges, the adoption of the following best practices is essential:
- Establish a strong governance framework: define clear principles, policies, processes and roles from the outset, with the support of public administrations and senior management. This can be solved with the implementation of the processes of UNE 0077 to 0080, which includes the definition of data governance, management and quality processes, as well as the definition of organizational structures.
- Ensure data quality: Implement data quality assessment methodologies and processes, such as data asset classification and cataloguing, quality control (validation, duplicate cleanup), and data lifecycle management. All this can be based on the implementation of a quality model following UNE 0081.
- Prioritize cybersecurity and privacy: Implement robust security frameworks (ENS, ISO 27000, NIST, IEC 62443, NERC CIP), secure IoT devices, use advanced threat detection tools (including AI), and build resilient systems with network segmentation and redundancy. Ensure compliance with data privacy regulations (such as GDPR).
- Promote interoperability through standards: adopt open standards for communication and data exchange between systems, such as OPC UA or ISA-95.
- Invest in technology and automation: Use data governance tools that enable automatic data discovery and classification, application of data protection rules, automation of metadata management, and cataloguing of data. Automating routine tasks improves efficiency and reduces errors.
- Collaboration and Information Sharing: Encourage the exchange of threat and best practice information among utilities, government agencies, and other industry stakeholders. In this regard, it is worth highlighting the more than 900 datasets published in the datos.gob.es catalogue on the subject of Energy, as well as the creation of "Data Spaces" (such as the National Data Space for Energy or Industry in Spain) facilitates the secure and efficient sharing of data between organisations, boosting innovation and sectoral competitiveness.
- Continuous monitoring and improvement: data governance is a continuous process. KPIs should be established to monitor progress, evaluate performance, and make improvements based on feedback and regulatory or strategic changes.
Conclusions: a connected and sustainable future
Energy and data are linked in the future. Smart grids are the manifestation of this symbiosis, and data governance is the key to unlocking its potential. By transforming data from simple records into strategic assets and critical infrastructure, we can move towards a more efficient, sustainable and resilient energy model.
Collaboration between companies, citizens and administrations, driven by initiatives such as the National Industry Data Space in Spain, is essential to build this future. This space not only seeks to improve industrial efficiency, but also to reinforce the country's technological and data sovereignty, ensuring that the value generated by data benefits our own companies, regions and sectors. By investing in strong data governance initiatives and building shared data ecosystems, we are investing in an industry that is more connected, smarter and ready for tomorrow's energy and climate challenges.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and the point of view reflected in this publication are the sole responsibility of its author.
Blog
Imagine a machine that can tell if you're happy, worried, or about to make a decision, even before you know clearly. Although it sounds like science fiction, that future is already starting to take shape. Thanks to advances in neuroscience and technology, today we can record, analyze, and even predict certain patterns of brain activity. The data that is generated from these records is known as neurodata.
In this article we will explain this concept, as well as potential use cases, based on the report "TechDispatch on Neurodata", of the Spanish Data Protection Agency (AEPD).
What is neurodata and how is it collected?
The term neurodata refers to data that is collected directly from the brain and nervous system, using technologies such as electroencephalography (EEG), functional magnetic resonance imaging (fMRI), neural implants, or even brain-computer interfaces. In this sense, its uptake is driven by neurotechnologies.
According to the OECD, neurotechnologies are identified with "devices and procedures that are used to access, investigate, evaluate, manipulate, and emulate the structure and function of neural systems." Neurotechnologies can be invasive (if they require brain-computer interfaces that are surgically implanted in the brain) or non-invasive, with interfaces that are placed outside the body (such as glasses or headbands).
There are also two common ways to collect data:
- Passive collection, where data is captured on a regular basis without the subject having to perform any specific activity.
- Active collection, where data is collected while users perform a specific activity. For example, thinking explicitly about something, answering questions, performing physical tasks, or receiving certain stimuli.
Potential use cases
Once the raw data has been collected, it is stored and processed. The treatment will vary according to the purpose and the intended use of the neurodata.
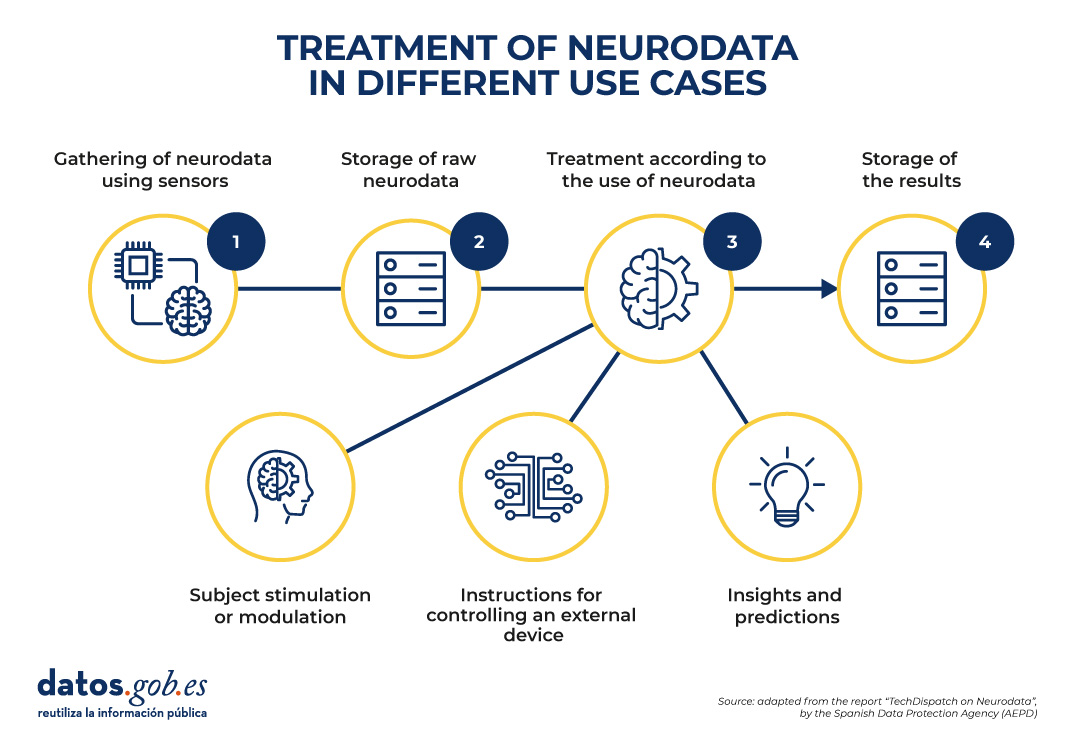
Figure 1. Common structure to understand the processing of neurodata in different use cases. Source: "TechDispatch Report on Neurodata", by the Spanish Data Protection Agency (AEPD).
As can be seen in the image above, the Spanish Data Protection Agency has identified 3 possible purposes:
-
Neurodata processing to acquire direct knowledge and/or make predictions.
Neurodata can uncover patterns that decode brain activity in a variety of industries, including:
-
Health: Neurodata facilitates research into the functioning of the brain and nervous system, making it possible to detect signs of neurological or mental diseases, make early diagnoses, and predict their behavior. This facilitates personalized treatment from very early stages. Its impact can be remarkable, for example, in the fight against Alzheimer's, epilepsy or depression.
-
Education: through brain stimuli, students' performance and learning outcomes can be analyzed. For example, students' attention or cognitive effort can be measured. By cross-referencing this data with other internal (such as student preferences) and external (such as classroom conditions or teaching methodology) aspects, decisions can be made aimed at adapting the pace of teaching.
-
Marketing, economics and leisure: the brain's response to certain stimuli can be analysed to improve leisure products or advertising campaigns. The objective is to know the motivations and preferences that impact decision-making. They can also be used in the workplace, to track employees, learn about their skills, or determine how they perform under pressure.
- Safety and surveillance: Neurodata can be used to monitor factors that affect drivers or pilots, such as drowsiness or inattention, and thus prevent accidents.
-
Neurodata processing to control applications or devices.
As in the previous stage, it involves the collection and analysis of information for decision-making, but it also involves an additional operation: the generation of actions through mental impulses. Let's look at several examples:
-
Orthopaedic or prosthetic aids, medical implants or environment-assisted living: thanks to technologies such as brain-computer interfaces, it is possible to design prostheses that respond to the user's intention through brain activity. In addition, neurodata can be integrated with smart home systems to anticipate needs, adjust the environment to the user's emotional or cognitive states, and even issue alerts for early signs of neurological deterioration. This can lead to an improvement in patients' autonomy and quality of life.
- Robotics: The user's neural signals can be interpreted to control machinery, precision devices or applications without the need to use hands. This allows, for example, a person to operate a robotic arm or a surgical tool simply with their thinking, which is especially valuable in environments where extreme precision is required or when the operator has reduced mobility.
- Video games, virtual reality and metaverse: since neurodata allows software devices to be controlled, brain-computer interfaces can be developed that make it possible to manage characters or perform actions within a game, only with the mind, without the need for physical controls. This not only increases player immersion, but opens the door to more inclusive and personalized experiences.
- Defense: Soldiers can operate weapons systems, unmanned vehicles, drones, or explosive ordnance disposal robots remotely, increasing personal safety and operational efficiency in critical situations.
-
Neurodata treatment for the stimulation or modulation of the subject, achieving neurofeedback.
In this case, signals from the brain (outputs) are used to generate new signals that feed back into the brain (such as inputs), which involves the control of brain waves. It is the most complex field from an ethical point of view, since actions could be generated that the user is not aware of. Some examples are:
-
Psychology: Neurodata has the potential to change the way the brain responds to certain stimuli. They can therefore be used as a therapy method to treat ADHD (Attention Deficit Hyperactivity Disorder), anxiety, depression, epilepsy, autism spectrum disorder, insomnia or drug addiction, among others.
- Neuroenhancement: They can also be used to improve cognitive and affective abilities in healthy people. Through the analysis and personalized stimulation of brain activity, it is possible to optimize functions such as memory, concentration, decision-making or emotional management.
Ethical challenges of the use of neurodata
As we have seen, although the potential of neurodata is enormous, it also poses great ethical and legal challenges. Unlike other types of data, neurodata can reveal deeply intimate aspects of a person, such as their desires, emotions, fears, or intentions. This opens the door to potential misuses, such as manipulation, covert surveillance, or discrimination based on neural features. In addition, they can be collected remotely and acted upon without the subject being aware of the manipulation.
This has generated a debate about the need for new rights, such as neurorights, which seek to protect mental privacy, personal identity and cognitive freedom. Various international organizations, including the European Union, are taking measures to address these challenges and advance in the creation of regulatory and ethical frameworks that protect fundamental rights in the use of neurotechnological technologies. We will soon publish an article that will delve into these aspects.
In conclusion, neurodata is a very promising advance, but not without challenges. Its ability to transform sectors such as health, education or robotics is undeniable, but so are the ethical and legal challenges posed by its use. As we move towards a future where mind and machine are increasingly connected, it is crucial to establish regulatory frameworks that ensure the protection of human rights, especially mental privacy and individual autonomy. In this way, we will be able to harness the full potential of neurodata in a fair, safe and responsible way, for the benefit of society as a whole.
Documentación
Data sharing has become a critical pillar for the advancement of analytics and knowledge exchange, both in the private and public sectors. Organizations of all sizes and industries—companies, public administrations, research institutions, developer communities, and individuals—find strong value in the ability to share information securely, reliably, and efficiently.
This exchange goes beyond raw data or structured datasets. It also includes more advanced data products such as trained machine learning models, analytical dashboards, scientific experiment results, and other complex artifacts that have significant impact through reuse. In this context, the governance of these resources becomes essential. It is not enough to simply move files from one location to another; it is necessary to guarantee key aspects such as access control (who can read or modify a given resource), traceability and auditing (who accessed it, when, and for what purpose), and compliance with regulations or standards, especially in enterprise and governmental environments.
To address these requirements, Unity Catalog emerges as a next-generation metastore, designed to centralize and simplify the governance of data and data-related resources. Originally part of the services offered by the Databricks platform, the project has now transitioned into the open source community, becoming a reference standard. This means that it can now be freely used, modified, and extended, enabling collaborative development. As a result, more organizations are expected to adopt its cataloging and sharing model, promoting data reuse and the creation of analytical workflows and technological innovation.

Figure 1. Image. Source: https://docs.unitycatalog.io/
Access the data lab repository on Github.
Run the data preprocessing code on Google Colab
Objectives
In this exercise, we will learn how to configure Unity Catalog, a tool that helps us organize and share data securely in the cloud. Although we will use some code, each step will be explained clearly so that even those with limited programming experience can follow along through a hands-on lab.
We will work with a realistic scenario in which we manage public transportation data from different cities. We’ll create data catalogs, configure a database, and learn how to interact with the information using tools like Docker, Apache Spark, and MLflow.
Difficulty level: Intermediate.

Figure 2: Unity catalogue schematic
Required Resources
In this section, we’ll explain the prerequisites and resources needed to complete this lab. The lab is designed to be run on a standard personal computer (Windows, macOS, or Linux).
We will be using the following tools and environments:
- Docker Desktop: Docker allows us to run applications in isolated environments called containers. A container is like a "box" that includes everything needed for the application to run properly, regardless of the operating system.
- Visual Studio Code: Our main working environment will be a Python Notebook, which we will run and edit using the widely adopted code editor Visual Studio Code (VS Code).
- Unity Catalog: Unity Catalog is a data governance tool that allows us to organize and control access to resources such as tables, data volumes, functions, and machine learning models. In this lab, we will use its open source version, which can be deployed locally, to learn how to manage data catalogs with permission control, traceability, and hierarchical structure. Unity Catalog acts as a centralized metastore, making data collaboration and reuse more secure and efficient.
- Amazon Web Services (AWS): AWS will serve as our cloud provider to host some of the lab’s data—specifically, raw data files (such as JSON) that we will manage using data volumes. We’ll use the Amazon S3 service to store these files and configure the necessary credentials and permissions so that Unity Catalog can interact with them in a controlled manner
Key Learnings from the Lab
Throughout this hands-on exercise, participants will deploy the application, understand its architecture, and progressively build a data catalog while applying best practices in organization, access control, and data traceability.
Deployment and First Steps
-
We clone the Unity Catalog repository and launch it using Docker.
-
We explore its architecture: a backend accessible via API and CLI, and an intuitive graphical user interface.
- We navigate the core resources managed by Unity Catalog: catalogs, schemas, tables, volumes, functions, and models.
Figure 2. Screenshot
What Will We Learn Here?
How to launch theapplication, understand its core components, and start interacting with it through different interfaces: the web UI, API, and CLI.
Resource Organization
-
We configure an external MySQL database as the metadata repository.
-
We create catalogs to represent different cities and schemas for various public services.

Figure 3. Screenshot
What Will We Learn Here?
How to structure data governance at different levels (city, service, dataset) and manage metadata in a centralized and persistent way.
Data Construction and Real-World Usage
-
We create structured tables to represent routes, buses, and bus stops.
-
We load real data into these tables using PySpark.
-
We set up an AWS S3 bucket as raw data storage (volumes).
- We upload JSON telemetry event files and govern them from Unity Catalog.
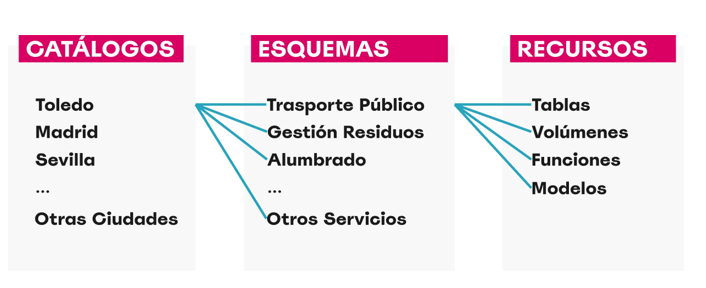
Figure 4. Diagram
What Will We Learn Here?
How to work with different types of data (structured and unstructured), and how to integrate them with external sources like AWS S3.
Reusable Functions and AI Models
-
We register custom functions (e.g., distance calculation) directly in the catalog.
-
We create and register machine learning models using MLflow.
- We run predictions from Unity Catalog just like any other governed resource.
Figure 5. Screenshot
What Will We Learn Here?
How to extend data governance to functions and models, and how to enable their reuse and traceability in collaborative environments.
Results and Conclusions
As a result of this hands-on lab, we gained practical experience with Unity Catalog as an open platform for the governance of data and data-related resources, including machine learning models. We explored its capabilities, deployment model, and usage through a realistic use case and a tool ecosystem similar to what you might find in an actual organization.
Through this exercise, we configured and used Unity Catalog to organize public transportation data. Specifically, you will be able to:
- Learn how to install tools like Docker and Spark.
- Create catalogs, schemas, and tables in Unity Catalog.
- Load data and store it in an Amazon S3 bucket.
- Implement a machine learning model using MLflow.
In the coming years, we will see whether tools like Unity Catalog achieve the level of standardization needed to transform how data resources are managed and shared across industries.
We encourage you to keep exploring data science! Access the full repository here
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Generative artificial intelligence is beginning to find its way into everyday applications ranging from virtual agents (or teams of virtual agents) that resolve queries when we call a customer service centre to intelligent assistants that automatically draft meeting summaries or report proposals in office environments.
These applications, often governed by foundational language models (LLMs), promise to revolutionise entire industries on the basis of huge productivity gains. However, their adoption brings new challenges because, unlike traditional software, a generative AI model does not follow fixed rules written by humans, but its responses are based on statistical patterns learned from processing large volumes of data. This makes its behaviour less predictable and more difficult to explain, and sometimes leads to unexpected results, errors that are difficult to foresee, or responses that do not always align with the original intentions of the system's creator.
Therefore, the validation of these applications from multiple perspectives such as ethics, security or consistency is essential to ensure confidence in the results of the systems we are creating in this new stage of digital transformation.
What needs to be validated in generative AI-based systems?
Validating generative AI-based systems means rigorously checking that they meet certain quality and accountability criteria before relying on them to solve sensitive tasks.
It is not only about verifying that they ‘work’, but also about making sure that they behave as expected, avoiding biases, protecting users, maintaining their stability over time, and complying with applicable ethical and legal standards. The need for comprehensive validation is a growing consensus among experts, researchers, regulators and industry: deploying AI reliably requires explicit standards, assessments and controls.
We summarize four key dimensions that need to be checked in generative AI-based systems to align their results with human expectations:
- Ethics and fairness: a model must respect basic ethical principles and avoid harming individuals or groups. This involves detecting and mitigating biases in their responses so as not to perpetuate stereotypes or discrimination. It also requires filtering toxic or offensive content that could harm users. Equity is assessed by ensuring that the system offers consistent treatment to different demographics, without unduly favouring or excluding anyone.
- Security and robustness: here we refer to both user safety (that the system does not generate dangerous recommendations or facilitate illicit activities) and technical robustness against errors and manipulations. A safe model must avoid instructions that lead, for example, to illegal behavior, reliably rejecting those requests. In addition, robustness means that the system can withstand adversarial attacks (such as requests designed to deceive you) and that it operates stably under different conditions.
- Consistency and reliability: Generative AI results must be consistent, consistent, and correct. In applications such as medical diagnosis or legal assistance, it is not enough for the answer to sound convincing; it must be true and accurate. For this reason, aspects such as the logical coherence of the answers, their relevance with respect to the question asked and the factual accuracy of the information are validated. Its stability over time is also checked (that in the face of two similar requests equivalent results are offered under the same conditions) and its resilience (that small changes in the input do not cause substantially different outputs).
- Transparency and explainability: To trust the decisions of an AI-based system, it is desirable to understand how and why it produces them. Transparency includes providing information about training data, known limitations, and model performance across different tests. Many companies are adopting the practice of publishing "model cards," which summarize how a system was designed and evaluated, including bias metrics, common errors, and recommended use cases. Explainability goes a step further and seeks to ensure that the model offers, when possible, understandable explanations of its results (for example, highlighting which data influenced a certain recommendation). Greater transparency and explainability increase accountability, allowing developers and third parties to audit the behavior of the system.
Open data: transparency and more diverse evidence
Properly validating AI models and systems, particularly in terms of fairness and robustness, requires representative and diverse datasets that reflect the reality of different populations and scenarios.
On the other hand, if only the companies that own a system have data to test it, we have to rely on their own internal evaluations. However, when open datasets and public testing standards exist, the community (universities, regulators, independent developers, etc.) can test the systems autonomously, thus functioning as an independent counterweight that serves the interests of society.
A concrete example was given by Meta (Facebook) when it released its Casual Conversations v2 dataset in 2023. It is an open dataset, obtained with informed consent, that collects videos from people from 7 countries (Brazil, India, Indonesia, Mexico, Vietnam, the Philippines and the USA), with 5,567 participants who provided attributes such as age, gender, language and skin tone.
Meta's objective with the publication was precisely to make it easier for researchers to evaluate the impartiality and robustness of AI systems in vision and voice recognition. By expanding the geographic provenance of the data beyond the U.S., this resource allows you to check if, for example, a facial recognition model works equally well with faces of different ethnicities, or if a voice assistant understands accents from different regions.
The diversity that open data brings also helps to uncover neglected areas in AI assessment. Researchers from Stanford's Human-Centered Artificial Intelligence (HAI) showed in the HELM (Holistic Evaluation of Language Models) project that many language models are not evaluated in minority dialects of English or in underrepresented languages, simply because there are no quality data in the most well-known benchmarks.
The community can identify these gaps and create new test sets to fill them (e.g., an open dataset of FAQs in Swahili to validate the behavior of a multilingual chatbot). In this sense, HELM has incorporated broader evaluations precisely thanks to the availability of open data, making it possible to measure not only the performance of the models in common tasks, but also their behavior in other linguistic, cultural and social contexts. This has contributed to making visible the current limitations of the models and to promoting the development of more inclusive and representative systems of the real world or models more adapted to the specific needs of local contexts, as is the case of the ALIA foundational model, developed in Spain.
In short, open data contributes to democratizing the ability to audit AI systems, preventing the power of validation from residing only in a few. They allow you to reduce costs and barriers as a small development team can test your model with open sets without having to invest great efforts in collecting their own data. This not only fosters innovation, but also ensures that local AI solutions from small businesses are also subject to rigorous validation standards.
The validation of applications based on generative AI is today an unquestionable necessity to ensure that these tools operate in tune with our values and expectations. It is not a trivial process, it requires new methodologies, innovative metrics and, above all, a culture of responsibility around AI. But the benefits are clear, a rigorously validated AI system will be more trustworthy, both for the individual user who, for example, interacts with a chatbot without fear of receiving a toxic response, and for society as a whole who can accept decisions based on these technologies knowing that they have been properly audited. And open data helps to cement this trust by fostering transparency, enriching evidence with diversity, and involving the entire community in the validation of AI systems.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.