Blog
Artificial intelligence (AI) is revolutionising the way we create and consume content. From automating repetitive tasks to personalising experiences, AI offers tools that are changing the landscape of marketing, communication and creativity.
These artificial intelligences need to be trained with data that are fit for purpose and not copyrighted. Open data is therefore emerging as a very useful tool for the future of AI.
The Govlab has published the report "A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI" to explore this issue in more detail. It analyses the emerging relationship between open data and generative AI, presenting various scenarios and recommendations. Their key points are set out below.
The role of data in generative AI
Data is the fundamental basis for generative artificial intelligence models. Building and training such models requires a large volume of data, the scale and variety of which is conditioned by the objectives and use cases of the model.
The following graphic explains how data functions as a key input and output of a generative AI system. Data is collected from various sources, including open data portals, in order to train a general-purpose AI model. This model will then be adapted to perform specific functions and different types of analysis, which in turn generate new data that can be used to further train models.
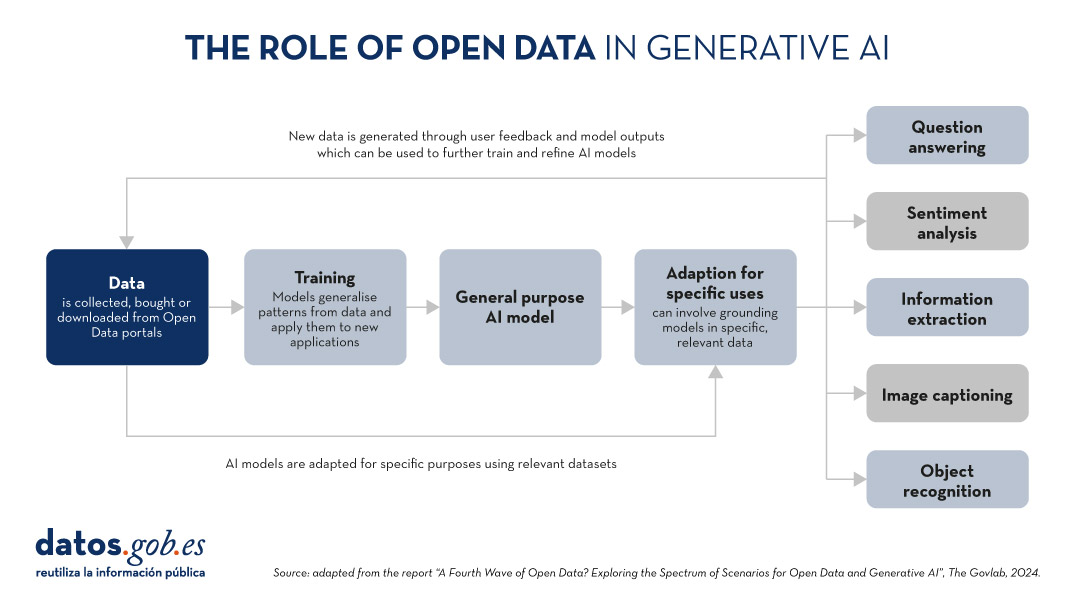
Figure 1. The role of open data in generative AI, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
5 scenarios where open data and artificial intelligence converge
In order to help open data providers ''prepare'' their data for generative AI, The Govlab has defined five scenarios outlining five different ways in which open data and generative AI can intersect. These scenarios are intended as a starting point, to be expanded in the future, based on available use cases.
| Scenario | Function | Quality requirements | Metadata requirements | Example |
|---|---|---|---|---|
| Pre-training | Training the foundational layers of a generative AI model with large amounts of open data. | High volume of data, diverse and representative of the application domain and non-structured usage. | Clear information on the source of the data. | Data from NASA''s Harmonized Landsat Sentinel-2 (HLS) project were used to train the geospatial foundational model watsonx.ai. |
| Adaptation | Refinement of a pre-trained model with task-specific open data, using fine-tuning or RAG techniques. | Tabular and/or unstructured data of high accuracy and relevance to the target task, with a balanced distribution. | Metadata focused on the annotation and provenance of data to provide contextual enrichment. | Building on the LLaMA 70B model, the French Government created LLaMandement, a refined large language model for the analysis and drafting of legal project summaries. They used data from SIGNALE, the French government''s legislative platform. |
| Inference and Insight Generation | Extracting information and patterns from open data using a trained generative AI model. | High quality, complete and consistent tabular data. | Descriptive metadata on the data collection methods, source information and version control. | Wobby is a generative interface that accepts natural language queries and produces answers in the form of summaries and visualisations, using datasets from different offices such as Eurostat or the World Bank. |
| Data Augmentation | Leveraging open data to generate synthetic data or provide ontologies to extend the amount of training data. | Tabular and/or unstructured data which is a close representation of reality, ensuring compliance with ethical considerations. | Transparency about the generation process and possible biases. | A team of researchers adapted the US Synthea model to include demographic and hospital data from Australia. Using this model, the team was able to generate approximately 117,000 region-specific synthetic medical records. |
| Open-Ended Exploration | Exploring and discovering new knowledge and patterns in open data through generative models. | Tabular data and/or unstructured, diverse and comprehensive. | Clear information on sources and copyright, understanding of possible biases and limitations, identification of entities. | NEPAccess is a pilot to unlock access to data related to the US National Environmental Policy Act (NEPA) through a generative AI model. It will include functions for drafting environmental impact assessments, data analysis, etc. |
Figure 2. Five scenarios where open data and Artificial Intelligence converge, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
You can read the details of these scenarios in the report, where more examples are explained. In addition, The Govlab has also launched an observatory where it collects examples of intersections between open data and generative artificial intelligence. It includes the examples in the report along with additional examples. Any user can propose new examples via this form. These examples will be used to further study the field and improve the scenarios currently defined.
Among the cases that can be seen on the web, we find a Spanish company: Tendios. This is a software-as-a-service company that has developed a chatbot to assist in the analysis of public tenders and bids in order to facilitate competition. This tool is trained on public documents from government tenders.
Recommendations for data publishers
To extract the full potential of generative AI, improving its efficiency and effectiveness, the report highlights that open data providers need to address a number of challenges, such as improving data governance and management. In this regard, they contain five recommendations:
- Improve transparency and documentation. Through the use of standards, data dictionaries, vocabularies, metadata templates, etc. It will help to implement documentation practices on lineage, quality, ethical considerations and impact of results.
- Maintaining quality and integrity. Training and routine quality assurance processes are needed, including automated or manual validation, as well as tools to update datasets quickly when necessary. In addition, mechanisms for reporting and addressing data-related issues that may arise are needed to foster transparency and facilitate the creation of a community around open datasets.
- Promote interoperability and standards. It involves adopting and promoting international data standards, with a special focus on synthetic data and AI-generated content.
- Improve accessibility and user-friendliness. It involves the enhancement of open data portals through intelligent search algorithms and interactive tools. It is also essential to establish a shared space where data publishers and users can exchange views and express needs in order to match supply and demand.
- Addressing ethical considerations. Protecting data subjects is a top priority when talking about open data and generative AI. Comprehensive ethics committees and ethical guidelines are needed around the collection, sharing and use of open data, as well as advanced privacy-preserving technologies.
This is an evolving field that needs constant updating by data publishers. These must provide technically and ethically adequate datasets for generative AI systems to reach their full potential.
Noticia
Digital transformation has become a fundamental pillar for the economic and social development of countries in the 21st century. In Spain, this process has become particularly relevant in recent years, driven by the need to adapt to an increasingly digitalised and competitive global environment. The COVID-19 pandemic acted as a catalyst, accelerating the adoption of digital technologies in all sectors of the economy and society.
However, digital transformation involves not only the incorporation of new technologies, but also a profound change in the way organisations operate and relate to their customers, employees and partners. In this context, Spain has made significant progress, positioning itself as one of the leading countries in Europe in several aspects of digitisation.
The following are some of the most prominent reports analysing this phenomenon and its implications.
State of the Digital Decade 2024 report
The State of the Digital Decade 2024 report examines the evolution of European policies aimed at achieving the agreed objectives and targets for successful digital transformation. It assesses the degree of compliance on the basis of various indicators, which fall into four groups: digital infrastructure, digital business transformation, digital skills and digital public services.

Figure 1. Taking stock of progress towards the Digital Decade goals set for 2030, “State of the Digital Decade 2024 Report”, European Commission.
In recent years, the European Union (EU) has significantly improved its performance by adopting regulatory measures - with 23 new legislative developments, including, among others, the Data Governance Regulation and the Data Regulation- to provide itself with a comprehensive governance framework: the Digital Decade Policy Agenda 2030.
The document includes an assessment of the strategic roadmaps of the various EU countries. In the case of Spain, two main strengths stand out:
- Progress in the use of artificial intelligence by companies (9.2% compared to 8.0% in Europe), where Spain's annual growth rate (9.3%) is four times higher than the EU (2.6%).
- The large number of citizens with basic digital skills (66.2%), compared to the European average (55.6%).
On the other hand, the main challenges to overcome are the adoption of cloud services ( 27.2% versus 38.9% in the EU) and the number of ICT specialists ( 4.4% versus 4.8% in Europe).
The following image shows the forecast evolution in Spain of the key indicators analysed for 2024, compared to the targets set by the EU for 2030.

Figure 2. Key performance indicators for Spain, “Report on the State of the Digital Decade 2024”, European Commission.
Spain is expected to reach 100% on virtually all indicators by 2030. 26.7 billion (1.8 % of GDP), without taking into account private investments. This roadmap demonstrates the commitment to achieving the goals and targets of the Digital Decade.
In addition to investment, to achieve the objective, the report recommends focusing efforts in three areas: the adoption of advanced technologies (AI, data analytics, cloud) by SMEs; the digitisation and promotion of the use of public services; and the attraction and retention of ICT specialists through the design of incentive schemes.
European Innovation Scoreboard 2024
The European Innovation Scoreboard carries out an annual benchmarking of research and innovation developments in a number of countries, not only in Europe. The report classifies regions into four innovation groups, ranging from the most innovative to the least innovative: Innovation Leaders, Strong Innovators, Moderate Innovators and Emerging Innovators.
Spain is leading the group of moderate innovators, with a performance of 89.9% of the EU average. This represents an improvement compared to previous years and exceeds the average of other countries in the same category, which is 84.8%. Our country is above the EU average in three indicators: digitisation, human capital and financing and support. On the other hand, the areas in which it needs to improve the most are employment in innovation, business investment and innovation in SMEs. All this is shown in the following graph:
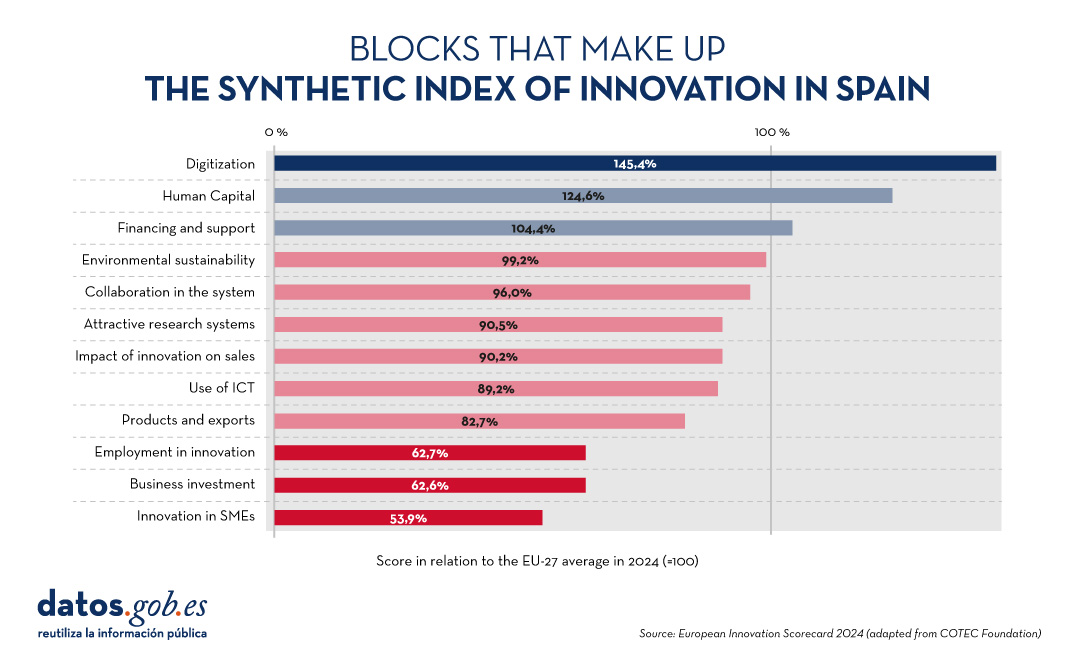
Figure 3. Blocks that make up the synthetic index of innovation in Spain, European Innovation Scorecard 2024 (adapted from the COTEC Foundation).
Spain's Digital Society Report 2023
The Telefónica Foundation also periodically publishes a report which analyses the main changes and trends that our country is experiencing as a result of the technological revolution.
The edition currently available is the 2023 edition. It highlights that "Spain continues to deepen its digital transformation process at a good pace and occupies a prominent position in this aspect among European countries", highlighting above all the area of connectivity. However, digital divides remain, mainly due to age.
Progress is also being made in the relationship between citizens and digital administrations: 79.7% of people aged 16-74 used websites or mobile applications of an administration in 2022. On the other hand, the Spanish business fabric is advancing in its digitalisation, incorporating digital tools, especially in the field of marketing. However, there is still room for improvement in aspects of big data analysis and the application of artificial intelligence, activities that are currently implemented, in general, only by large companies.
Artificial Intelligence and Data Talent Report
IndesIA, an association that promotes the use of artificial intelligence and Big Data in Spain, has carried out a quantitative and qualitative analysis of the data and artificial intelligence talent market in 2024 in our country.
According to the report, the data and artificial intelligence talent market represents almost 19% of the total number of ICT professionals in our country. In total, there are 145,000 professionals (+2.8% from 2023), of which only 32% are women. Even so, there is a gap between supply and demand, especially for natural language processing engineers. To address this situation, the report analyses six areas for improvement: workforce strategy and planning, talent identification, talent activation, engagement, training and development, and data-driven culture .
Other reports of interest
The COTEC Foundation also regularly produces various reports on the subject. On its website we can find documents on the budget execution of R&D in the public sector, the social perception of innovation or the regional talent map.
For their part, the Orange Foundation in Spain and the consultancy firm Nae have produced a report to analyse digital evolution over the last 25 years, the same period that the Foundation has been operating in Spain. The report highlights that, between 2013 and 2018, the digital sector has contributed around €7.5 billion annually to the country's GDP.
In short, all of them highlight Spain's position among the European leaders in terms of digital transformation, but with the need to make progress in innovation. This requires not only boosting economic investment, but also promoting a cultural change that fosters creativity. A more open and collaborative mindset will allow companies, administrations and society in general to adapt quickly to technological changes and take advantage of the opportunities they bring to ensure a prosperous future for Spain.
Do you know of any other reports on the subject? Leave us a comment or write to us at dinamizacion@datos.gos.es.
Noticia
For many people, summer means the arrival of the vacations, a time to rest or disconnect. But those days off are also an opportunity to train in various areas and improve our competitive skills.
For those who want to take advantage of the next few weeks and acquire new knowledge, Spanish universities have a wide range of courses on a variety of subjects. In this article, we have compiled some examples of courses related to data training.
Geographic Information Systems (GIS) with QGIS. University of Alcalá de Henares (link not available).
The course aims to train students in basic GIS skills so that they can perform common processes such as creating maps for reports, downloading data from a GPS, performing spatial analysis, etc. Each student will have the possibility to develop their own GIS project with the help of the faculty. The course is aimed at university students of any discipline, as well as professionals interested in learning basic concepts to create their own maps or use geographic information systems in their activities.
- Date and place: June 27-28 and July 1-2 in online mode.
Citizen science applied to biodiversity studies: from the idea to the results. Pablo de Olavide University (Seville).
This course addresses all the necessary steps to design, implement and analyze a citizen science project: from the acquisition of basic knowledge to its applications in research and conservation projects. Among other issues, there will be a workshop on citizen science data management, focusing on platforms such as Observation.org y GBIF. It will also teach how to use citizen science tools for the design of research projects. The course is aimed at a broad audience, especially researchers, conservation project managers and students.
- Date and place: From July 1 to 3, 2024 in online and on-site (Seville).
Big Data. Data analysis and machine learning with Python. Complutense University of Madrid.
This course aims to provide students with an overview of the broad Big Data ecosystem, its challenges and applications, focusing on new ways of obtaining, managing and analyzing data. During the course, the Python language is presented, and different machine learning techniques are shown for the design of models that allow obtaining valuable information from a set of data. It is aimed at any university student, teacher, researcher, etc. with an interest in the subject, as no previous knowledge is required.
- Date and place: July 1 to 19, 2024 in Madrid.
Introduction to Geographic Information Systems with R. University of Santiago de Compostela.
Organized by the Working Group on Climate Change and Natural Hazards of the Spanish Association of Geography together with the Spanish Association of Climatology, this course will introduce the student to two major areas of great interest: 1) the handling of the R environment, showing the different ways of managing, manipulating and visualizing data. 2) spatial analysis, visualization and work with raster and vector files, addressing the main geostatistical interpolation methods. No previous knowledge of Geographic Information Systems or the R environment is required to participate.
- Date and place: July 2-5, 2024 in Santiago de Compostela
Artificial Intelligence and Large Language Models: Operation, Key Components and Applications. University of Zaragoza.
Through this course, students will be able to understand the fundamentals and practical applications of artificial intelligence focused on Large Language Model (LLM). Students will be taught how to use specialized libraries and frameworks to work with LLM, and will be shown examples of use cases and applications through hands-on workshops. It is aimed at professionals and students in the information and communications technology sector.
- Date and place: July 3 to 5 in Zaragoza.
Deep into Data Science. University of Cantabria.
This course focuses on the study of big data using Python. The emphasis of the course is on Machine Learning, including sessions on artificial intelligence, neural networks or Cloud Computing. This is a technical course, which presupposes previous knowledge in science and programming with Python.
- Date and place: From July 15 to 19, 2024 in Torrelavega.
Data management for the use of artificial intelligence in tourist destinations. University of Alicante.
This course approaches the concept of Smart Tourism Destination (ITD) and addresses the need to have an adequate technological infrastructure to ensure its sustainable development, as well as to carry out an adequate data management that allows the application of artificial intelligence techniques. During the course, open data and data spaces and their application in tourism will be discussed. It is aimed at all audiences with an interest in the use of emerging technologies in the field of tourism.
- Date and place: From July 22 to 26, 2024 in Torrevieja.
The challenges of digital transformation of productive sectors from the perspective of artificial intelligence and data processing technologies. University of Extremadura.
Now that the summer is over, we find this course where the fundamentals of digital transformation and its impact on productive sectors are addressed through the exploration of key data processing technologies, such as the Internet of Things, Big Data, Artificial Intelligence, etc. During the sessions, case studies and implementation practices of these technologies in different industrial sectors will be analyzed. All this without leaving aside the ethical, legal and privacy challenges. It is aimed at anyone interested in the subject, without the need for prior knowledge.
- Date and place: From September 17 to 19, in Cáceres.
These courses are just examples that highlight the importance that data-related skills are acquiring in Spanish companies, and how this is reflected in university offerings. Do you know of any other courses offered by public universities? Let us know in comments.
Blog
What is data profiling?
Data profiling is the set of activities and processes aimed at determining the metadata about a particular dataset. This process, considered as an indispensable technique during exploratory data analysis, includes the application of different statistics with the main objective of determining aspects such as the number of null values, the number of distinct values in a column, the types of data and/or the most frequent patterns of data values. Its ultimate goal is to provide a clear and detailed understanding of the structure, content and quality of the data, which is essential prior to its use in any application.
Types of data profiling
There are different alternatives in terms of the statistical principles to be applied during data profiling, as well as their typology. For this article, a review of various approaches by different authors has been carried out. On this basis, it is decided to focus the article on the typology of data profiling techniques on three high-level categories: single-column profiling, multi-column profiling and dependency profiling. For each category, possible techniques and uses are identified, as discussed below.
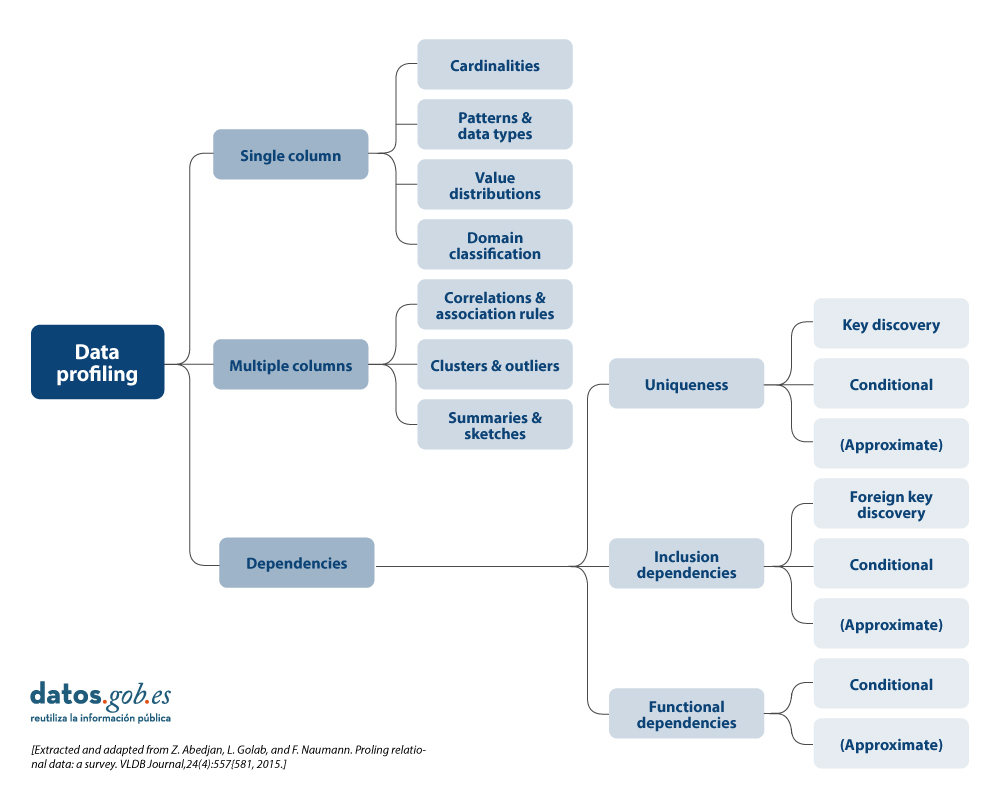
More detail on each of the categories and the benefits they bring is presented below.
1. Profiling of a column
Single-column profiling focuses on analysing each column of a dataset individually. This analysis includes the collection of descriptive statistics such as:
-
Count of distinct values, to determine the exact number of unique records in a list and to be able to sort them. For example, in the case of a dataset containing grants awarded by a public body, this task will allow us to know how many different beneficiaries there are for the beneficiaries column, and whether any of them are repeated.
-
Distribution of values (frequency), which refers to the analysis of the frequency with which different values occur within the same column. This can be represented by histograms that divide the values into intervals and show how many values are in each interval. For example, in an age column, we might find that 20 people are between 25-30 years old, 15 people are between 30-35 years old, and so on.
-
Counting null or missing values, which involves counting the number of null or empty values in each column of a dataset. It helps to determine the completeness of the data and can point to potential quality problems. For example, in a column of email addresses, 5 out of 100 records could be empty, indicating 5% missing data.
- Minimum, maximum and average length of values (for text columns), which is oriented to calculate what is the length of the values in a text column. This is useful for identifying unusual values and for defining length restrictions in databases. For example, in a column of names, we might find that the shortest name is 3 characters, the longest is 20 characters, and the average is 8 characters.
The main benefits of using this data profiling include:
- Anomaly detection: allows the identification of unusual or out-of-range values.
- Improved data preparation: assists in normalising and cleaning data prior to use in more advanced analytics or machine learningmodels.
2. Multi-column profiling
Multi-column profiling analyses the relationship between two or more columns within the same data set. This type of profiling may include:
-
Correlation analysis, used to identify relationships between numerical columns in a data set. A common technique is to calculate pairwise correlations between all numerical columns to discover patterns of relationships. For example, in a table of researchers, we might find that age and number of publications are correlated, indicating that as the age of researchers and their category increases, their number of publications tends to increase. A Pearson correlation coefficient could quantify this relationship.
- Outliers, which involves identifying data that deviate significantly from other data points. Outliers may indicate errors, natural variability or interesting data points that merit further investigation. For example, in a column of budgets for annual R&D projects, a value of one million euros could be an outlier if most of the income is between 30,000 and 100,000 euros. However, if the amount is represented in relation to the duration of the project, it could be a normal value if the 1 million project has 10 times the duration of the 100,000 euro project.
- Frequent value combination detection, focused on finding sets of values that occur together frequently in the data. They are used to discover associations between elements, as in transaction data. For example, in a shopping dataset, we might find that the products "nappies" and "baby formula" are frequently purchased together. An association rule algorithm could generate the rule {breads} → {formula milk}, indicating that customers who buy bread also tend to buy butter with a high probability.
The main benefits of using this data profiling include:
- Trend detection: allows the identification of significant relationships and correlations between columns, which can help in the detection of patterns and trends.
- Improved data consistency: ensures that there is referential integrity and that, for example, similar data type formats are followed between data across multiple columns.
- Dimensionality reduction: allows to reduce the number of columns containing redundant or highly correlated data.
3. Profiling of dependencies
Dependency profiling focuses on discovering and validating logical relationships between different columns, such as:
- Foreign key discovery, which is aimed at establishing which values or combinations of values from one set of columns also appear in the other set of columns, a prerequisite for a foreign key. For example, in the Investigator table, the ProjectID column contains the values [101, 102, 101, 103]. To set ProjectID as a foreign key, we verify that these values are also present in the ProjectID column of the Project table [101, 102, 103]. As all values match, ProjectID in Researcher can be a foreign key referring to ProjectID in Project.
- Functional dependencies, which establishes relationships in which the value of one column depends on the value of another. It is also used for the validation of specific rules that must be complied with (e.g. a discount value must not exceed the total value).
The main benefits of using this data profiling include:
- Improved referential integrity: ensures that relationships between tables are valid and maintained correctly.
- Consistency validation between values: allows to ensure that the data comply with certain constraints or calculations defined by the organisation.
- Data repository optimisation: allows to improve the structure and design of databases by validating and adjusting dependencies.
Uses of data profiling
The above-mentioned statistics can be used in many areas in organisations. One use case would be in data science and data engineering initiatives where it allows for a thorough understanding of the characteristics of a dataset prior to analysis or modelling.
- By generating descriptive statistics, identifying outliers and missing values, uncovering hidden patterns, identifying and correcting problems such as null values, duplicates and inconsistencies, data profiling facilitates data cleaning and data preparation, ensuring data quality and consistency.
- It is also crucial for the early detection of problems, such as duplicates or errors, and for the validation of assumptions in predictive analytics projects.
- It is also essential for the integration of data from multiple sources, ensuring consistency and compatibility.
- In the area of data governance, management and quality, profiling can help establish sound policies and procedures, while in compliance it ensures that data complies with applicable regulations.
- Finally, in terms of management, it helps optimiseExtract, Transform and Load ( ETL) processes, supports data migration between systems and prepares data sets for machine learning and predictive analytics, improving the effectiveness of data-driven models and decisions.
Difference between data profiling and data quality assessment
This term data profiling is sometimes confused with data quality assessment. While data profiling focuses on discovering and understanding the metadata and characteristics of the data, data quality assessment goes one step further and focuses for example on analysing whether the data meets certain requirements or quality standards predefined in the organisation through business rules. Likewise, data quality assessment involves verifying the quality value for different characteristics or dimensions such as those included in the UNE 0081 specification: accuracy, completeness, consistency or timeliness, etc., and ensuring that the data is suitable for its intended use in the organisation: analytics, artificial intelligence, business intelligence, etc.
Data profiling tools or solutions
Finally, there are several outstanding open source solutions (tools, libraries, or dependencies) for data profiling that facilitate the understanding of the data. These include:
- Pandas Profiling and YData Profiling offering detailed reporting and advanced visualisations in Python
- Great Expectations and Dataprep to validate and prepare data, ensuring data integrity throughout the data lifecycle
- R dtables that allows the generation of detailed reports and visualisations for exploratory analysis and data profiling for the R ecosystem.
In summary, data profiling is an important part of exploratory data analysis that provides a detailed understanding of the structure, contents, etc. and is recommended to be taken into account in data analysis initiatives. It is important to dedicate time to this activity, with the necessary resources and tools, in order to have a better understanding of the data being handled and to be aware that it is one more technique to be used as part of data quality management, and that it can be used as a step prior to data quality assessment
Content elaborated by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant The content and the point of view reflected in this publication are the sole responsibility of its author.
Noticia
The unstoppable advance of ICTs in cities and rural territories, and the social, economic and cultural context that sustains it, requires skills and competences that position us advantageously in new scenarios and environments of territorial innovation. In this context, the Provincial Council of Badajoz has been able to adapt and anticipate the circumstances, and in 2018 it launched the initiative "Badajoz Es Más - Smart Provincia".
What is "Badajoz Es Más"?
The project "Badajoz Is More" is an initiative carried out by the Provincial Council of Badajoz with the aim of achieving more efficient services, improving the quality of life of its citizens and promoting entrepreneurship and innovation through technology and data governance in a region made up of 135 municipalities. The aim is to digitally transform the territory, favouring the creation of business opportunities, social improvement andsettlement of the population.
Traditionally, "Smart Cities" projects have focused their efforts on cities, renovation of historic centres, etc. However, "Badajoz Es Más" is focused on the transformation of rural areas, smart towns and their citizens, putting the focus on rural challenges such as depopulation of rural municipalities, the digital divide, talent retention or the dispersion of services. The aim is to avoid isolated "silos" and transform these challenges into opportunities by improving information management, through the exploitation of data in a productive and efficient way.

Citizens at the Centre
The "Badajoz es Más" project aims to carry out the digital transformation of the territory by making available to municipalities, companies and citizens the new technologies of IoT, Big Data, Artificial Intelligence, etc. The main lines of the project are set out below.
Provincial Platform for the Intelligent Management of Public Services
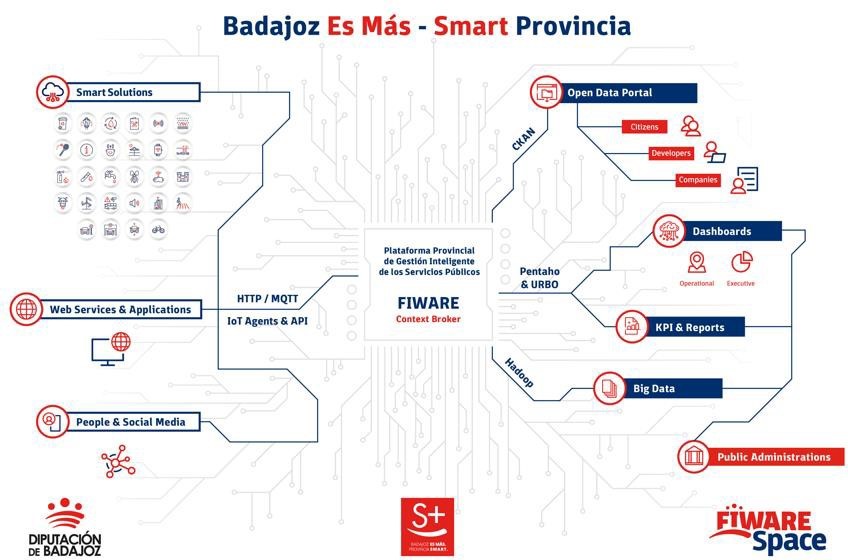
It is the core component of the initiative, as it allows for the integration of information from any IoT device, information system or data source in one place for storage, visualisation and in a single place for storage, visualisation and analysis. Specifically, data is collected from a variety of sources: the various sensors of smart solutions deployed in the region, web services and applications, citizen feedback and social networks.
All information is collected on a based on the open source standard FIWARE an initiative promoted by the European Commission that provides the capacity to homogenise data (FIWARE Data Model) and favour its interoperability. Built according to the guidelines set by AENOR (UNE 178104), it has a central module Orion Context Broker (OCB) which allows the entire information life cycleto be managed. In this way, it offers the ability to centrally monitor and manage a scalable set of public services through internal dashboards.
The platform is "multi-entity", i.e. it provides information, knowledge and services to both the Provincial Council itself and its associated Municipalities (also known as "Smart Villages"). The visualisation of the different information exploitation models processed at the different levels of the Platform is carried out on different dashboards, which can provide service to a specific municipality or locality only showing its data and services, or also provide a global view of all the services and data at the level of the Provincial Council of Badajoz.
Some of the information collected on the platform is also made available to third parties through various channels:
- Portal of open dopen data portal. Collected data that can be opened to third parties for reuse is shared through its open data portal. In it we can find information as diverse as real time data on the beaches with blue flags blue flag beaches in the region (air quality, water quality, noise pollution, capacity, etc. are monitored) or traffic flow, which makes it possible to predict traffic jams.
- Portal for citizens Digital Province Badajoz. This portal offers information on the solutions currently implemented in the province and their data in real time in a user-friendly way, with a simple user experience that allows non-technical people to access the projects developed.
The following graph shows the cycle of information, from its collection, through the platform and distribution to the different channels. All this under strong data governance.
Efficient public services
In addition to the implementation and start-up of the Provincial Platform for the Intelligent Management of Public Services, this project has already integrated various existing services or "verticals" for:
-
To start implementing these new services in the province and to be the example and the "spearhead" of this technological transformation.
- Show the benefits of the implementation of these technologies in order to disseminate and demonstrate them, with the aim of causing sufficient impact so that other local councils and organisations will gradually join the initiative.
There are currently more than 40 companies sending data to the Provincial Platform, more than 60 integrated data sources, more than 800 connected devices, more than 500 transactions per minute... It should be noted that work is underway to ensure that the new calls for tender include a clause so that data from the various works financed with public money can also be sent to the platform.
The idea is to be able to standardise management, so that the solution that has been implemented in one municipality can also be used in another. This not only improves efficiency, but also makes it possible to compare results between municipalities. You can visualise some of the services already implemented in the Province, as well as their Dashboards built from the Provincial Platform at this video.

Innovation Ecosystem
In order for the initiative to reach its target audience, the Provincial Council of Badajoz has developed an innovation ecosystem that serves as a meeting point for the Badajoz Provincial Council:
-
Citizens, who demand these services.
-
Entrepreneurs and educational entities, which have an interest in these technologies.
-
Companies, which have the capacity to implement these solutions.
- Public entities, which can implement this type of project.
The aim is to facilitate and provide the necessary tools, knowledge and advice so that the projects that emerge from this meeting can be carried out.
At the core of this ecosystem is a physical innovation centre called the FIWARE Space. FIWARE Space carries out tasks such as the organisation of events for the dissemination of Smart technologies and concepts among companies and citizens, demonstrative and training workshops, Hackathons with universities and study centres, etc. It also has a Showroom for the exhibition of solutions, organises financially endowed Challenges and is present at national and international congresses.
In addition, they carry out mentoring work for companies and other entities. In total, around 40 companies have been mentored by FIWARE Space, launching their own solutions on several occasions on the FIWARE Market, or proposing the generated data models as standards for the entire global ecosystem. These companies are offered a free service to acquire the necessary knowledge to work in a standardised way, generating uniform data for the rest of the region, and to connect their solutions to the platform, helping and advising them on the challenges that may arise.
One of the keys to FIWARE Space is its open nature, having signed many collaboration agreements and agreements with both local and international entities. For example, work on the standardisation of advanced data models for tourism is ongoing with the Future Cities Institute (Argentina). For those who would like more information, you can follow your centre's activity through its weekly blog.

Next steps: convergence with Data Spaces and Gaia-X
As a result of the collaborative and open nature of the project, the Data Space concept fits perfectly with the philosophy of "Badajoz is More". The Badajoz Provincial Council currently has a multitude of verticals with interesting information for sharing (and future exploitation) of data in a reliable, sovereign and secure way. As a Public Entity, comparing and obtaining other sources of data will greatly enrich the project, providing an external view that is essential for its growth. Gaia-X is the proposal for the creation of a data infrastructure for Europe, and it is the standard towards which the "Badajoz es Más" project is currently converging, as a result of its collaboration with the gaia-X Spain hub.
Noticia
Today, 23 April, is World Book Day, an occasion to highlight the importance of reading, writing and the dissemination of knowledge. Active reading promotes the acquisition of skills and critical thinking by bringing us closer to specialised and detailed information on any subject that interests us, including the world of data.
Therefore, we would like to take this opportunity to showcase some examples of books and manuals regarding data and related technologies that can be found on the web for free.
1. Fundamentals of Data Science with R, edited by Gema Fernandez-Avilés and José María Montero (2024)
Access the book here.
- What is it about? The book guides the reader from the problem statement to the completion of the report containing the solution to the problem. It explains some thirty data science techniques in the fields of modelling, qualitative data analysis, discrimination, supervised and unsupervised machine learning, etc. It includes more than a dozen use cases in sectors as diverse as medicine, journalism, fashion and climate change, among others. All this, with a strong emphasis on ethics and the promotion of reproducibility of analyses.
- Who is it aimed at? It is aimed at users who want to get started in data science. It starts with basic questions, such as what is data science, and includes short sections with simple explanations of probability, statistical inference or sampling, for those readers unfamiliar with these issues. It also includes replicable examples for practice.
- Language: Spanish.
2. Telling stories with data, Rohan Alexander (2023).
Access the book here.
- What is it about? The book explains a wide range of topics related to statistical communication and data modelling and analysis. It covers the various operations from data collection, cleaning and preparation to the use of statistical models to analyse the data, with particular emphasis on the need to draw conclusions and write about the results obtained. Like the previous book, it also focuses on ethics and reproducibility of results.
- Who is it aimed at? It is ideal for students and entry-level users, equipping them with the skills to effectively conduct and communicate a data science exercise. It includes extensive code examples for replication and activities to be carried out as evaluation.
- Language: English.
3. The Big Book of Small Python Projects, Al Sweigart (2021)
Access the book here.
- What is it about? It is a collection of simple Python projects to learn how to create digital art, games, animations, numerical tools, etc. through a hands-on approach. Each of its 81 chapters independently explains a simple step-by-step project - limited to a maximum of 256 lines of code. It includes a sample run of the output of each programme, source code and customisation suggestions.
- Who is it aimed at? The book is written for two groups of people. On the one hand, those who have already learned the basics of Python, but are still not sure how to write programs on their own. On the other hand, those who are new to programming, but are adventurous, enthusiastic and want to learn as they go along. However, the same author has other resources for beginners to learn basic concepts.
- Language: English.
4. Mathematics for Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Access the book here.
- What is it about? Most books on machine learning focus on machine learning algorithms and methodologies, and assume that the reader is proficient in mathematics and statistics. This book foregrounds the mathematical foundations of the basic concepts behind machine learning
- Who is it aimed at? The author assumes that the reader has mathematical knowledge commonly learned in high school mathematics and physics subjects, such as derivatives and integrals or geometric vectors. Thereafter, the remaining concepts are explained in detail, but in an academic style, in order to be precise.
- Language: English.
5. Dive into Deep Learning, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, continually updated)
Access the book here.
- What is it about? The authors are Amazon employees who use the mXNet library to teach Deep Learning. It aims to make deep learning accessible, teaching basic concepts, context and code in a practical way through examples and exercises. The book is divided into three parts: introductory concepts, deep learning techniques and advanced topics focusing on real systems and applications.
- Who is it aimed at? This book is aimed at students (undergraduate and postgraduate), engineers and researchers, who are looking for a solid grasp of the practical techniques of deep learning. Each concept is explained from scratch, so no prior knowledge of deep or machine learning is required. However, knowledge of basic mathematics and programming is necessary, including linear algebra, calculus, probability and Python programming.
- Language: English.
6. Artificial intelligence and the public sector: challenges, limits and means, Eduardo Gamero and Francisco L. Lopez (2024)
Access the book here.
- What is it about? This book focuses on analysing the challenges and opportunities presented by the use of artificial intelligence in the public sector, especially when used to support decision-making. It begins by explaining what artificial intelligence is and what its applications in the public sector are, and then moves on to its legal framework, the means available for its implementation and aspects linked to organisation and governance.
- Who is it aimed at? It is a useful book for all those interested in the subject, but especially for policy makers, public workers and legal practitioners involved in the application of AI in the public sector.
- Language: Spanish
7. A Business Analyst’s Introduction to Business Analytics, Adam Fleischhacker (2024)
Access the book here.
- What is it about? The book covers a complete business analytics workflow, including data manipulation, data visualisation, modelling business problems, translating graphical models into code and presenting results to stakeholders. The aim is to learn how to drive change within an organisation through data-driven knowledge, interpretable models and persuasive visualisations.
- Who is it aimed at? According to the author, the content is accessible to everyone, including beginners in analytical work. The book does not assume any knowledge of the programming language, but provides an introduction to R, RStudio and the "tidyverse", a series of open source packages for data science.
- Language: English.
We invite you to browse through this selection of books. We would also like to remind you that this is only a list of examples of the possibilities of materials that you can find on the web. Do you know of any other books you would like to recommend? let us know in the comments or email us at dinamizacion@datos.gob.es!
Noticia
Between 2 April and 16 May, applications for the call on aid for the digital transformation of strategic productive sectors may be submitted at the electronic headquarters of the Ministry for Digital Transformation and Civil Service. Order TDF/1461/2023, of 29 December, modified by Order TDF/294/2024, regulates grants totalling 150 million euros for the creation of demonstrators and use cases, as part of a more general initiative of Sectoral Data Spaces Program, promoted by the State Secretary for Digitalisation and Artificial Intelligence and framed within the Recovery, Transformation and Resilience Plan (PRTR). The objective is to finance the development of data spaces and the promotion of disruptive innovation in strategic sectors of the economy, in line with the strategic lines set out in the Digital Spain Agenda 2026.
Lines, sectors and beneficiaries
The current call includes funding lines for experimental development projects in two complementary areas of action: the creation of demonstration centres (development of technological platforms for data spaces); and the promotion of specific use cases of these spaces. This call is addressed to all sectors except tourism, which has its own call. Beneficiaries may be single entities with their own legal personality, tax domicile in the European Union, and an establishment or branch located in Spain. In the case of the line for demonstration centres, they must also be associative or representative of the value chains of the productive sectors in territorial areas, or with scientific or technological domains.
Infographic-summary
The following infographics show the key information on this call for proposals:


Would you like more information?
- Access to the grant portal for application proposals in the following link. On the portal you will find the regulatory bases and the call for applications, a summary of its content, documentation and informative material with presentations and videos, as well as a complete list of questions and answers. In the mailbox espaciosdedatos@digital.gob.es you will get help about the call and the application procedure. From this portal you can access the electronic office for the application.
- Quick guide to the call for proposals in pdf + downloadable Infographics (on the Sectoral Data Program and Technical Information)
- Link to other documents of interest:
- Additional information on the data space concept
Noticia
The Centre de documentació i biblioteca del Institut Català d'Arqueologia Clàssica (ICAC) has the repository Open Science ICAC. This website is a space where science is shared in an accessible and inclusive way. The space introduces recommendations and advises on the process of publishing content. Also, on how to make the data generated during the research process available for future research work.
The website, in addition to being a repository of scientific research texts, is also a place to find tools and tips on how to approach the research data management process in each of its phases: before, during and at the time of publication.
- Before you begin: create a data management plan to ensure that your research proposal is as robust as possible. The Data Management Plan (DMP) is a methodological document that describes the life cycle of the data collected, generated and processed during a research project, a doctoral thesis, etc.
- During the research process: at this point it points out the need to unify the nomenclature of the documents to be generated before starting to collect files or data, in order to avoid an accumulation of disorganised content that will lead to lost or misplaced data. In addition, this section provides information on directory structure, folder names and file names, the creation of a txt file (README) describing the nomenclatures or the use of short, descriptive names such as project name/acronym, file creation date, sample number or version number. Recommendations on how to structure each of these fields so that they are reusable and easily searchable can also be found on the website.
- Publication of research data: in addition to the results of the research itself in the form of a thesis, dissertation, paper, etc., it recommends the publication of the data generated by the research process itself. The ICAC itself points out that research data remains valuable after the research project for which it was generated has ended, and that sharing data can open up new avenues of research without future researchers having to recreate and collect identical data. Finally, it outlines how, when and what to consider when publishing research data.
Graphical content for improving the quality of open data
Recently, the ICAC has taken a further step to encourage good practice in the use of open data. To this end, it has developed a series of graphic contents based on the "Practical guide for the improvement of the quality of open data"produced by datos.gob.es. Specifically, the cultural body has produced four easy-to-understand infographics, in Catalan and English, on good practices with open data in working with databases and spreadsheets, texts and docs and CSV format.
All the infographics resulting from the adaptation of the guide are available to the general public and also to the centre's research staff at Recercat, Catalonia's research repository. Soon it will also be available on the Open Science website of the Institut Català d'Arqueologia Clàssica (ICAC)open Science ICAC.
The infographics produced by the ICAC review various aspects. The first ones contain general recommendations to ensure the quality of open data, such as the use of standardised character encoding, such as UTF-8, or naming columns correctly, using only lowercase letters and avoiding spaces, which are replaced by hyphens. Among the recommendations for generating quality data, they also include how to show the presence of null or missing data or how to manage data duplication, so that data collection and processing is centralised in a single system so that, in case of duplication, it can be easily detected and eliminated.
The latter deal with how to set the format of thenumerical figures and other data such as dates, so that they follow the ISO standardised system, as well as how to use dots as decimals. In the case of geographic information, as recommended by the Guide, its materials also include the need to reserve two columns for inserting the longitude and latitude of the geographic points used.
The third theme of these infographics focuses on the development of good databases or spreadsheets databases or spreadsheetsso that they are easily reusable and do not generate problems when working with them. Among the recommendations that stand out are consistency in generating names or codes for each item included in the data collection, as well as developing a help guide for the cells that are coded, so that they are intelligible to those who need to reuse them.
In the section on texts and documents within these databases, the infographics produced by the Institut Català d'Arqueologia Clàssica include some of the most important recommendations for creating texts and ensuring that they are preserved in the best possible way. Among them, it points to the need to save attachments to text documents such as images or spreadsheets separately from the text document. This ensures that the document retains its original quality, such as the resolution of an image, for example.
Finally, the fourth infographic that has been made available contains the most important recommendations for working with CSV format working with CSV format (comma separated value) format, such as creating a CSV document for each table and, in the case of working with a document with several spreadsheets, making them available independently. It also notes in this case that each row in the CSV document has the same number of columns so that they are easily workable and reusable, without the need for further clean-up.
As mentioned above, all infographics follow the recommendations already included in the Practical guide for improving the quality of open data.
The guide to improving open data quality
The "Practical guide for improving the quality of open data" is a document produced by datos.gob.es as part of the Aporta Initiative and published in September 2022. The document provides a compendium of guidelines for action on each of the defining characteristics of quality, driving quality improvement. In turn, this guide takes the data.europe.eu data quality guide, published in 2021 by the Publications Office of the European Union, as a reference and complements it so that both publishers and re-users of data can follow guidelines to ensure the quality of open data.

In summary, the guide aims to be a reference framework for all those involved in both the generation and use of open data so that they have a starting point to ensure the suitability of data both in making it available and in assessing whether a dataset is of sufficient quality to be reused in studies, applications, services or other.
Noticia
At the end of 2023, as reported by datos.gob.es, the ISTAC made public more than 500 semantic assets, including 404 classifications or 100 concept schemes.
All these resources are available in the Open Data Catalog of the Canary Islands, an environment in which there is room for both semantic and statistical resources and which, therefore, may involve an extra difficulty for a user looking only for semantic assets.
To facilitate the reuse of these datasets with information so relevant to society, the Canary Islands Statistics Institute, with the collaboration of the Directorate General for the Digital Transformation of Public Services of the Canary Islands Government, published the Bank of Semantic Assets.
In this portal, the user can perform searches more easily by providing a keyword, identifier, name of the dataset or institution that prepares and maintains it.

The Bank of semantic assets of the Canary Islands Statistics Institute is an application that serves to explore the structural resources used by the ISTAC. In this way it is possible to reuse the semantic assets with which the ISTAC works, since it makes direct use of the eDatos APIs, the infrastructure that supports the Canary Islands statistics institute.
The number of resources to be consulted increases enormously with respect to the data available in the Catalog, since, on the one hand, it includes the DSD (Data Structures Definitions), with which the final data tables are built; and, on the other hand, because it includes not only the schemes and classifications, but also each of the codes, concepts and elements that compose them.
This tool is the equivalent of the aforementioned Fusion Metadata Registry used by SDMX, Eurostat or the United Nations; but with a much more practical and accessible approach without losing advanced functionalities. SDMX is the data and metadata sharing standard on which the aforementioned organizations are based. The use of this standard in applications such as ISTAC's makes it possible to homogenize in a simple way all the resources associated with the statistical data to be published.
The publication of data under the SDMX standard is a more laborious process, as it requires the generation of not only the data but also the publication keys, but in the long run it allows the creation of templates or statistical operations that can be compared with data from another country or region.
The application recently launched by the ISTAC allows you to navigate through all the structural resources of the ISTAC, including families of classifications or concepts, in an interconnected way, so it operates as a network.
Functionalities of the Semantic Asset Bank
The main advantage of this new tool over the aforementioned registries is its ease of use. Which, in this case, is directly measured by how easy it is to find a specific resource.

Thanks to the advanced search, specific resources can be filtered by ID, name, description and maintainer; to which is added the option of including only the results of interest, discriminating both by version and by whether they are recommended by the ISTAC or not.
In addition, it is designed to be a large interconnected bank, so that, entering a concept, classifications are recommended, or that in a DSD all the representations of the dimensions and attributes are linked.

These features not only differentiate the Semantic Asset Bank from other similar tools, but also represent a step forward in terms of interoperability and transparency by not only offering semantic resources but also their relationships with each other.
The new ISTAC resource complies with the provisions both at national level with the National Interoperability Scheme (Article 10, semantic assets), and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents defend the need and value of using common resources for the exchange of information, a maxim that is being implemented transversally in the Government of the Canary Islands.
Training Pill
To disseminate this new search engine for semantic assets, the ISTAC has published a short video explaining the Bank and its features, as well as providing the necessary information about SDMX. In this video it is possible to know, in a simple way and in just a few minutes how to use and get the most out of the new Semantic Assets Bank of the ISTAC through simple and complex searches and how to organize the data to respond to a previous analysis.
In summary, with the Semantic Asset Bank, the Canary Islands Statistics Institute has taken a significant step towards facilitating the reuse of its semantic assets. This tool, which brings together tens of thousands of structural resources, allows easy access to an interconnected network that complies with national and European interoperability standards.
Noticia
The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.

The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.