Blog
La inteligencia artificial (IA) está revolucionando la manera en que creamos y consumimos contenido. Desde la automatización de tareas repetitivas hasta la personalización de experiencias, la IA ofrece herramientas que están cambiando el panorama del marketing, la comunicación y la creatividad.
Estas inteligencias artificiales necesitan ser entrenadas con datos acordes a los objetivos, sobre los que no discurran derechos de autor. Por ello, los datos abiertos se alzan como una herramienta de gran utilidad de cara al futuro de la IA.
Para profundizar sobre esta temática, The Govlab ha publicado el informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI” (¿Una cuarta ola de datos abiertos? Explorando el espectro de escenarios para los datos abiertos y la IA generativa). En él se analiza la relación emergente entre los datos abiertos y la IA generativa, presentado diversos escenarios y recomendaciones. A continuación, se recogen sus claves.
El papel de los datos en la IA generativa
Los datos son la base fundamental de los modelos generativos de inteligencia artificial. Construir y entrenar dichos modelos requiere un gran volumen de datos, cuya escala y variedad está condicionada por los objetivos y los casos de uso del modelo.
El siguiente gráfico explica cómo los datos funcionan como una pieza clave tanto de entrada de un sistema de IA generativa, como de salida. Los datos se recopilan de diversas fuentes, incluyendo portales de datos abiertos, con el fin de entrenar un modelo de IA de propósito general. Este modelo, posteriormente, será adaptado para realizar funciones específicas y diferentes tipos de análisis, que generan, a su vez, nuevos datos, que pueden utilizarse para seguir entrenando modelos.

Figura 1. El Rol de los datos abiertos en la IA generativa, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
5 escenarios donde convergen los datos abiertos y la Inteligencia artificial
Con el fin de ayudar a los proveedores de datos abiertos a “preparar” dichos datos para la IA generativa, The Govlab ha definido cinco escenarios que resumen cinco formas distintas en las que los datos abiertos y la IA generativa pueden cruzarse. Estos escenarios pretenden ser un punto de partida, que se irá ampliando en el futuro, en base a los casos de uso disponibles.
| Escenario | Función | Requisitos de calidad | Necesidades de metadatos | Ejemplo |
|---|---|---|---|---|
| Preentrenamiento (Pretraining) | Entrenamiento de las capas fundacionales de un modelo de IA generativa con grandes cantidades de datos abiertos. | Alto volumen de datos, diversos y representativos del dominio de aplicación y uso no estructurado. | Información clara sobre la fuente de los datos. | Los datos del proyecto Harmonized Landsat Sentinel-2 (HLS) de la NASA se utilizaron para entrenar el modelo fundacional geoespacial watsonx.ai. |
| Adaptación (Adaptation) | Perfeccionamiento de un modelo preentrenado con datos abiertos específicos para tareas concretas, utilizando técnicas de fine-tuning or RAG. | Datos tabulares y/o no estructurados de alta precisión y relevancia para la tarea objetivo, con una distribución equilibrada. | Metadatado centrado en la anotación y procedencia de los datos para aportar enriquecimiento contextual. | Partiendo del modelo LLaMA 70B, el Gobierno de Francia creó LLaMandement, un modelo de lenguaje grande perfeccionado para el análisis y la redacción de resúmenes de proyectos jurídicos. Para ello usaron datos de SIGNALE, la plataforma legislativa del Gobierno francés. |
| Inferencia y generación de hechos relevantes (Inference and Insight Generation) | Extracción de información y patrones a partir de datos abiertos mediante un modelo entrenado de IA generativa. | Datos tabulares de alta calidad, completos y coherentes. | Metadatado descriptivo de los métodos de recogida de datos, información de origen y control de versiones. | Wobby es una interfaz generativa que acepta consultas en lenguaje natural y produce respuestas en forma de resúmenes y visualizaciones, utilizando conjuntos de datos de distintas oficinas como Eurostat o el Banco Mundial. |
| Incremento de datos (Data Augmentation) | Aprovechamiento de los datos abiertos para generar datos sintéticos o proporcionar ontologías para extender la cantidad de datos de entrenamiento. | Datos tabulares y/o no estructurados que sean una representación cercana a la realidad, asegurando el cumplimiento de consideraciones éticas. | Transparencia sobre el proceso de generación y posibles sesgos. | Un equipo de investigadores adaptó el modelo Synthea de EE.UU. para incluir datos demográficos y hospitalarios de Australia. Utilizando este modelo, el equipo pudo generar aproximadamente 117.000 historiales médicos sintéticos específicos, aplicados a su región. |
| Exploración abierta (Open-Ended Exploration) | Exploración y descubrimiento de nuevos conocimientos y patrones en datos abiertos mediante modelos generativos. | Datos tabulares y/o no estructurados, diversos y completos. | Información clara sobre fuentes y derechos de autor, comprensión de posibles sesgos y limitaciones, identificación de entidades. | NEPAccess es un piloto para desbloquear el acceso datos relacionados con la Ley Nacional de Política Medioambiental (NEPA) de EE.UU. mediante un modelo generativo de IA. Incluirá funciones para redactar evaluaciones de impacto ambiental, análisis de datos, etc. |
Figura 2. Cinco escenarios donde convergen los datos abiertos y la Inteligencia artificial, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
Puedes leer el detalle de estos escenarios en el informe, donde se explican más ejemplos. Además, The Govlab también ha puesto en marcha un observatorio donde recopila ejemplos de intersecciones entre datos abiertos e inteligencia artificial generativa (los incluidos en el informe junto con otros adicionales). Cualquier usuario puede proponer nuevos casos a través de este formulario. Dichos ejemplos se utilizarán para continuar estudiando este campo y mejorar los escenarios actualmente definidos.
Entre los casos que se pueden ver en la web, encontramos una empresa española: Tendios. Se trata de una compañía de software como servicio que ha desarrollado un chatbot para ayudar en el análisis de licitaciones y concursos públicos con el fin de facilitar la concurrencia. Esta herramienta está entrenada con documentos públicos de licitaciones gubernamentales.
Recomendaciones para publicadores de datos
Para extraer el máximo potencial de IA generativa, mejorando su eficiencia y eficacia, el informe destaca que los proveedores de datos abiertos deben hacer frente a algunos retos, como la mejora de la gobernanza y la gestión de los datos. En este sentido, recogen cinco recomendaciones:
- Mejorar la transparencia y la documentación. A través del uso de estándares, diccionarios de datos, vocabularios, plantillas de metadatos, etc. se ayudará a aplicar prácticas de documentación sobre el linaje, la calidad, las consideraciones éticas y el impacto de los resultados.
- Mantener la calidad y la integridad. Se necesita formación y procesos rutinarios que aseguren la calidad, incluida la validación automatizada o manual, así como herramientas para actualizar los conjuntos de datos rápidamente cuando sea necesario. Además, son necesarios mecanismos para informar y abordar problemas que puedan surgir relacionados con los datos, a fin de impulsar la transparencia y facilitar la creación de una comunidad en torno a los conjuntos de datos abiertos.
- Fomentar la interoperabilidad y los estándares. Implica adoptar y promover normas internacionales de datos, con especial foco en los datos sintéticos y los contenidos generados por IA.
- Mejorar la accesibilidad y la facilidad de uso. Supone la mejora de los portales de datos abiertos mediante algoritmos de búsqueda inteligentes y herramientas interactivas. También es imprescindible establecer un espacio compartido donde los publicadores de los datos y los usuarios puedan intercambiar opiniones y manifestar necesidades, con el fin de hacer coincidir oferta y demanda.
- Abordar las consideraciones éticas. Proteger a los titulares de los datos es de máxima prioridad al hablar de datos abiertos e IA generativa. Se necesitan comités éticos y directrices éticas exhaustivas en torno a la recopilación, el intercambio y el uso de datos abiertos, así como tecnologías avanzadas de preservación de la intimidad.
Estamos ante un campo en continua evolución que necesita de actualización constante por parte de los publicadores de datos. Estos deben proporcionar conjuntos de datos adecuados tanto técnica como éticamente, para que los sistemas de IA generativa puedan alcanzar todo su potencial.
Noticia
La transformación digital se ha convertido en un pilar fundamental para el desarrollo económico y social de los países en el siglo XXI. En España, este proceso ha cobrado una relevancia especial en los últimos años, impulsado por la necesidad de adaptarse a un entorno global cada vez más digitalizado y competitivo. La pandemia de COVID-19 actuó como un catalizador, acelerando la adopción de tecnologías digitales en todos los sectores de la economía y la sociedad.
Sin embargo, la transformación digital no solo implica la incorporación de nuevas tecnologías, sino también un cambio profundo en la forma en que las organizaciones operan y se relacionan con sus clientes, empleados y socios. En este contexto, España ha realizado importantes avances, situándose como uno de los países líderes en Europa en varios aspectos de la digitalización.
A continuación, se presentan algunos de los informes más destacados que analizan este fenómeno y sus implicaciones.
Informe sobre el estado de la Década Digital 2024
El informe sobre el estado de la Década Digital 2024 examina la evolución de las políticas europeas dirigidas a alcanzar los objetivos y metas acordados para el éxito de la transformación digital. Para ello evalúa el grado de cumplimiento en base a diversos indicadores, incluidos en cuatro grupos: infraestructura digital, transformación digital de los negocios, habilidades digitales y servicios públicos digitales.
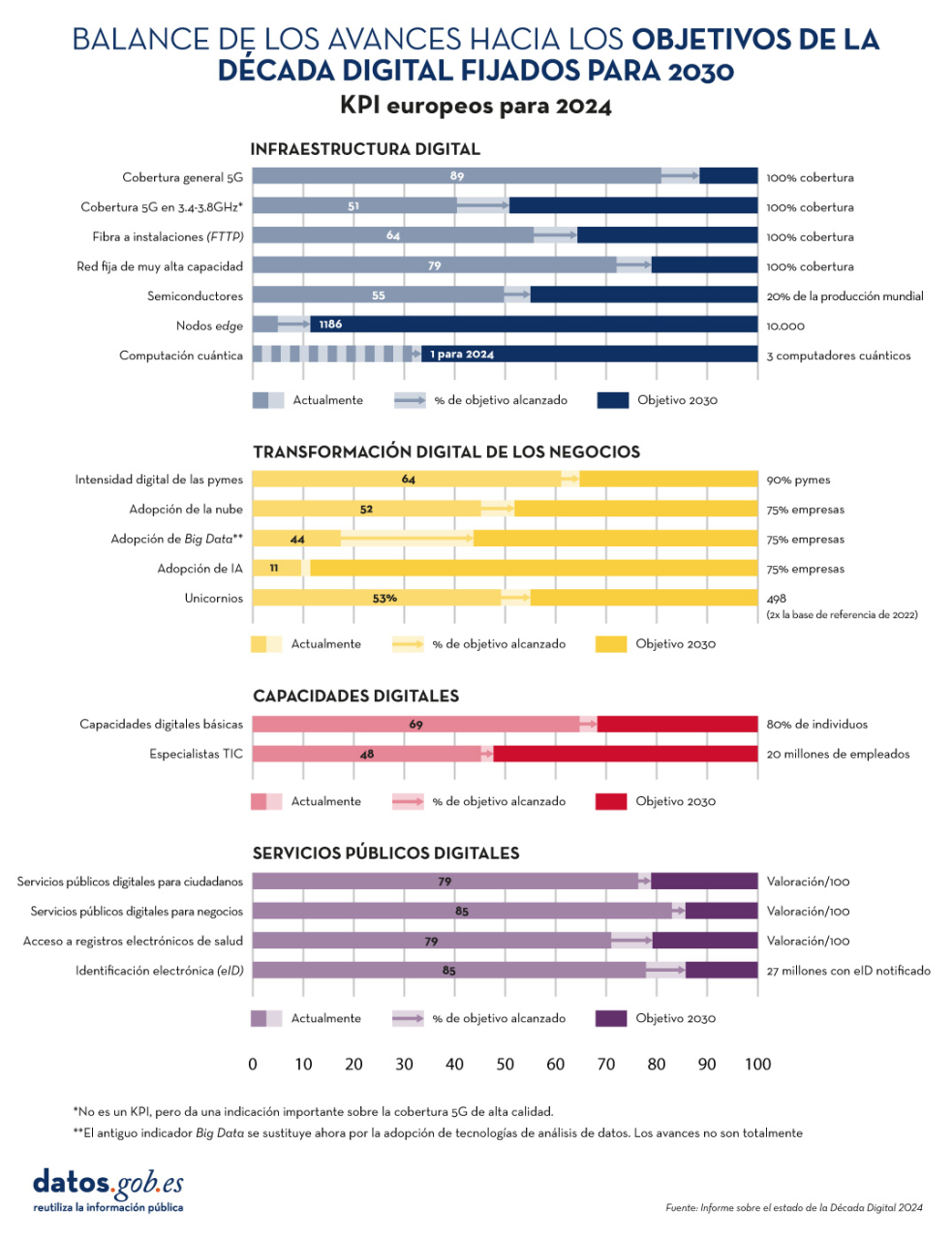
Figura 1. Balance de los avances hacia los objetivos de la Década Digital fijados para 2030, "Informe sobre el Estado de la Década Digital 2024", Comisión Europea.
En los últimos años, la Unión Europea (UE) ha mejorado considerablemente su actuación mediante la aprobación de medidas reguladoras -con 23 nuevos avances legislativos, que incluyen, entre otros, el Reglamento de gobernanza de datos y el Reglamento de datos- para dotarse de un marco de gobernanza global: el Programa de política de la Década Digital para 2030.
El documento incluye una evaluación de las hojas de ruta estratégicas de los diversos países de la Unión. En el caso de España, se destacan dos principales fortalezas:
- El avance en el uso de inteligencia artificial por parte de las empresas (9,2% frente al 8,0% europeo), donde el crecimiento anual de España (9,3%) es cuatro veces superior al de la UE (2,6%).
- La gran cantidad de ciudadanos con capacidades digitales básicas (66,2%), frente al promedio europeo (55,6%).
Por otro lado, los principales retos a superar son la adopción de los servicios en la nube (27,2% versus 38,9% de la UE) y el número de especialistas en tecnologías de la información y la comunicación o TIC (4,4% frente al 4,8% europeo).
En la siguiente imagen se puede observar la previsión en España de evolución de los indicadores clave analizados para 2024, en comparación con las metas fijadas por la UE para 2030.
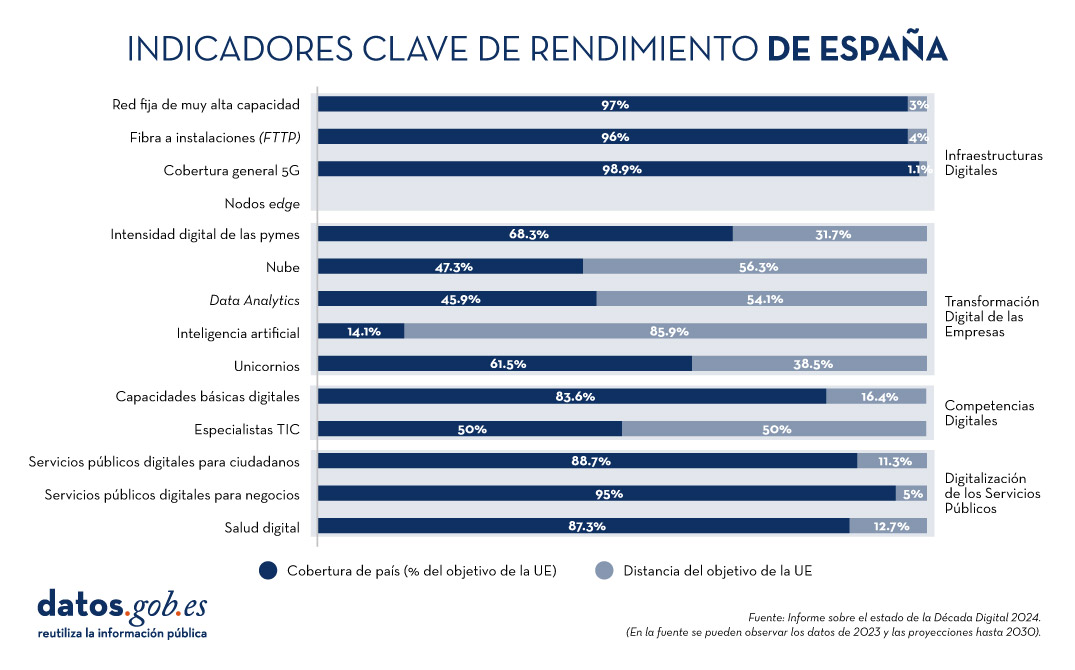
Figura 2. Indicadores clave de rendimiento de España, "Informe sobre el Estado de la Década Digital 2024", Comisión Europea.
Se espera que España alcance el 100% en prácticamente todos los indicadores para 2030. Para ello, el país tiene previsto asignar un presupuesto estimado de 26.700 millones de euros (1,8 % del PIB), sin tener en cuenta inversiones privadas. Esta hoja de ruta demuestra el compromiso para alcanzar los objetivos y metas de la Década Digital.
Además de la inversión, para conseguir el objetivo, en el informe se recomienda focalizar esfuerzos en tres áreas: la adopción de tecnologías avanzadas (IA, análisis de datos, nube) por parte de pymes; la digitalización y promoción del uso de servicios públicos; y la atracción y retención de especialistas TIC a través del diseño de planes de incentivos.
European Innovation Scoreboard 2024
El European Innovation Scoreboard realiza de manera anual una evaluación comparativa de los avances en investigación e innovación en diversos países, no solo europeos. El informe clasifica a las regiones en cuatro grupos de innovación que van de más a menos: Líderes en innovación, Innovadores fuertes, Innovadores moderados e Innovadores emergentes.
España se encuentra liderando el grupo de Innovadores moderados, con un rendimiento del 89,9% del promedio de la UE. Esto representa una mejora en comparación con años anteriores y supera el promedio de otros países de su misma categoría, que es del 84,8%. Nuestro país se sitúa por encima de la media comunitaria en tres indicadores: digitalización, capital humano y financiación y soporte. Por otro lado, las áreas en las que más debe mejorar son el empleo en innovación, la inversión empresarial y la innovación en pymes. Todo ello se recoge el siguiente gráfico:

Figura 3. Bloques que componen el índice sintético de la innovación en España, European Innovation Scorecard 2024 (adaptado de la Fundación COTEC).
Informe de la Sociedad Digital en España 2023
La Fundación Telefónica también realiza de manera periódica un informe donde se analizan los principales cambios y tendencias que está experimentando nuestro país a raíz de la revolución tecnológica.
La edición actualmente disponible es la de 2023. En él se destaca que “España sigue profundizando en su proceso de transformación digital a buen ritmo y ocupa un puesto destacado en este aspecto entre los países europeos”, resaltando sobre todo el área de conectividad. No obstante, siguen existiendo brechas digitales, principalmente por motivo de edad.
También se avanza en la relación de los ciudadanos con las administraciones digitales: el 79,7 % de las personas de entre 16 y 74 años utilizaron en 2022 páginas web o aplicaciones móviles de alguna administración. Por otro lado, el tejido empresarial español avanza en su digitalización, incorporando herramientas digitales, sobre todo en el ámbito del marketing. No obstante, aún queda margen de mejora en aspectos de análisis de macrodatos y la aplicación de inteligencia artificial, actividades que actualmente han implementado, en general, solo las grandes empresas.
Informe sobre el talento en inteligencia artificial y datos
IndesIA, una asociación que promueve el uso de la inteligencia artificial y el Big Data en España, ha realizado un análisis cuantitativo y cualitativo del mercado de talento en datos e inteligencia artificial en 2024 en nuestro país.
De acuerdo con el informe, el mercado de talento de datos e inteligencia artificial representa casi un 19% del total de profesionales TIC de nuestro país. En total, son 145.000 profesionales (+2,8% de 2023), de los cuales solo el 32% son mujeres. Aun así, existe un gap entre oferta y demanda, sobre todo en ingenieros de procesamiento del lenguaje natural. Para resolver esta situación el informe analiza seis áreas de mejora: estrategia y planificación de plantillas, identificación de talento, activación de talento, engagement, formación y desarrollo, y cultura data-driven.
Otros informes de interés
La Fundación COTEC también realiza de manera periódica diversos informes sobre la materia. En su web encontramos documentos sobre la ejecución presupuestaria de la I+D en el sector público, la percepción social de la innovación o el mapa del Talento autonómico.
Por su parte, la Fundación Orange en España y la consultora Nae han realizado un informe para analizar la evolución digital en los últimos 25 años, el mismo periodo que lleva en nuestro país dicha Fundación. El informe destaca que, entre 2013 y 2018, el sector digital ha contribuido en unos 7.500 millones de euros anuales al PIB del país.
En definitiva, todos ellos destacan la situación de España entre los líderes europeos a nivel de transformación digital, pero con la necesidad de avanzar en innovación. Para ello, no solo es necesario impulsar las inversiones económicas, sino también promover un cambio cultural que fomente la creatividad. Una mentalidad más abierta y colaborativa permitirá a las empresas, administraciones y a la sociedad en general adaptarse rápidamente a los cambios tecnológicos y aprovechar las oportunidades que estos brindan para asegurar un futuro próspero para España.
¿Conoces más informes sobre la materia? Déjanos un comentario o escríbenos a dinamizacion@datos.gob.es.
Noticia
El verano supone para muchos la llegada de las vacaciones, una época en la que descansar o desconectar. Pero esos días libres también son una oportunidad para formarnos en diversas áreas y mejorar nuestras habilidades competitivas.
Para aquellos que quieran aprovechar las próximas semanas y adquirir nuevos conocimientos, las universidades españolas cuentan con una amplia oferta centrada en múltiples temáticas. En este artículo, recopilamos algunos ejemplos de cursos relacionados con la formación en datos.
Sistemas de Información Geográfica (SIG) con QGIS. Universidad de Alcalá de Henares (link no disponible).
El curso busca formar a los alumnos en las capacidades básicas en SIG para que puedan realizar procesos comunes como crear mapas para informes, descargar datos de un GPS, realizar análisis espaciales, etc. Cada estudiante tendrá la posibilidad de desarrollar su propio proyecto SIG con ayuda del profesorado. Está dirigido a estudiantes universitarios de cualquier disciplina, así como a profesionales interesados en aprender conceptos básicos para crear sus propios mapas o utilizar sistemas de información geográfica en sus actividades.
- Fecha y lugar: 27-28 de junio y 1-2 de julio en modalidad online.
Ciencia ciudadana aplicada a estudios de biodiversidad: de la idea a los resultados. Universidad Pablo de Olavide (Sevilla).
Este curso aborda todos los pasos necesarios para diseñar, implementar y analizar un proyecto de ciencia ciudadana: desde la adquisición de conocimientos básicos hasta sus aplicaciones en investigación y proyectos de conservación. Entre otras cuestiones, se realizará un taller sobre el manejo de datos de ciencia ciudadana, con el foco puesto en plataformas como Observation.org y GBIF. También se enseñará a utilizar herramientas de ciencia ciudadana para el diseño de proyectos de investigación. El curso está dirigido a un público amplio, especialmente investigadores, gestores de proyectos de conservación y estudiantes.
- Fecha y lugar: Del 1al 3 de julio de 2024 en modalidad online y presencial (Sevilla).
Big Data. Análisis de datos y aprendizaje automático con Python. Universidad Complutense de Madrid.
Este curso pretende que los alumnos adquieran una visión global del amplio ecosistema Big Data, sus retos y aplicaciones, centrándose en las nuevas maneras de obtener, gestionar y analizar datos. Durante el curso se presentará el lenguaje Python y se mostrarán distintas técnicas de aprendizaje automático para el diseño de modelos que permitan obtener información valiosa a partir de un conjunto de datos. Está dirigido a cualquier estudiante universitario, docente, investigador, etc. con interés en la temática, ya que no se requieren conocimientos previos.
- Fecha y lugar: Del 1 al 19 de julio de 2024 en Madrid.
Introducción a los Sistemas de Información Geográfica con R. Universidad de Santiago de Compostela.
Organizado por el Grupo de Trabajo de Cambio Climático y Riesgos Naturales de la Asociación Española de Geografía junto a la Asociación Española de Climatología, este curso introducirá al alumno en dos grandes áreas de gran interés: 1) el manejo del entorno R, mostrando las diferentes formas de gestión, manipulación y visualización de datos. 2) el análisis espacial, la visualización y el trabajo con archivos raster y vectoriales, abordando los principales métodos de interpolación geoestadística. Para participar, no se requieren conocimientos previos de Sistemas de Información Geográfica o del entorno R.
- Fecha y lugar: Del 2 al 5 de julio de 2024 en Santiago de Compostela.
Inteligencia Artificial y Grandes Modelos de Lenguaje: Funcionamiento, Componentes Clave y Aplicaciones. Universidad de Zaragoza.
A través de este curso, los alumnos podrán comprender los fundamentos y aplicaciones prácticas de la inteligencia artificial centrada en grandes modelos de lenguaje (Large Language Model o LLM en sus siglas en inglés). Se enseñará a utilizar bibliotecas y marcos de trabajo especializados para trabajar con LLM, y se mostrarán ejemplos de casos de uso y aplicaciones a través de talleres prácticos. Está dirigido a profesionales y estudiantes del sector de las tecnologías de la información y comunicaciones.
- Fecha y lugar: Del 3 al 5 de julio en Zaragoza.
Deep into Data Science. Universidad de Cantabria.
Este curso se centra en el estudio de grandes volúmenes de datos utilizando Python. El énfasis del curso se pone en el aprendizaje automático (Machine Learning en inglés), incluyendo sesiones sobre inteligencia artificial, redes neuronales o computación en la nube (Cloud Computing). Se trata de un curso técnico, que presupone conocimientos previos en ciencia y programación con Python.
- Fecha y lugar: Del 15 al 19 de julio de 2024 en Torrelavega.
Gestión de datos para el uso de inteligencia artificial en destinos turísticos. Universidad de Alicante.
Este curso se acerca al concepto de Destino Turístico Inteligente (DTI) y aborda la necesidad de disponer de una infraestructura tecnológica adecuada para garantizar su desarrollo sostenible, así como de realizar una gestión adecuada de los datos que permita la aplicación de técnicas de inteligencia artificial. Durante el curso se hablará de datos abiertos y espacios de datos, y su aplicación en el turismo. Está dirigido a todo tipo de público con interés en el uso de tecnologías emergentes en el ámbito del turismo.
- Fecha y lugar: Del 22 al 26 de julio de 2024 en Torrevieja.
Los retos de la transformación digital de sectores productivos desde la perspectiva de la inteligencia artificial y tecnologías de procesamiento de datos. Universidad de Extremadura.
Ya finalizado el verano, encontramos este curso donde se abordan los fundamentos de la transformación digital y su impacto en los sectores productivos a través de la exploración de tecnologías clave de procesamiento de datos, como Internet de las Cosas, Big Data, Inteligencia Artificial, etc. Durante las sesiones se analizarán casos de estudio y prácticas de implementación de estas tecnologías en diferentes sectores industriales. Todo ello sin dejar de lado los desafíos éticos, legales y de privacidad. Está dirigido a cualquier persona interesada en la materia, sin necesidad de conocimientos previos.
- Fecha y lugar: Del 17 al 19 de septiembre, en Cáceres.
Estos cursos son solo ejemplos que ponen de manifiesto la importancia que las capacidades relacionadas con datos están adquiriendo en las empresas españolas, y cómo eso se refleja en la oferta universitaria. ¿Conoces algún curso más, ofrecido por universidades públicas? Déjanoslo en comentarios.
Blog
¿Qué es perfilado de datos?
El perfilado de datos es el conjunto de actividades y procesos destinados a determinar los metadatos sobre un conjunto concreto de datos. Este proceso, considerado como una técnica indispensable durante el análisis exploratorio de datos, incluye la aplicación de distintos estadísticos con el principal objetivo de determinar aspectos como el número de valores nulos, la cantidad de valores distintos en una columna, los tipos de datos y/o los patrones más frecuentes de los valores de los datos. Su objetivo final es proporcionar un entendimiento claro y detallado de la estructura, contenido y calidad de los datos, lo que es esencial antes de su uso en cualquier aplicación.
Tipos de perfilado de datos
Existen distintas alternativas en cuanto a los principios estadísticos a aplicar durante un perfilado de datos, así como su tipología. Para este artículo se ha realizado una revisión de varias aproximaciones de distintos autores. En base a ello, se decide centrar el artículo sobre la tipología de técnicas de perfilado de datos en tres categorías de alto nivel: perfilado de una columna, perfilado multicolumna y perfilado de dependencias. Para cada categoría se identifican posibles técnicas y usos, como veremos a continuación.

1. Perfilado de una columna
El perfilado de una columna se centra en analizar cada columna de un conjunto de datos de manera individual. Este análisis incluye la recopilación de estadísticas descriptivas como:
-
Conteo de valores distintos, para determinar el número exacto de registros únicos de una lista y poder clasificarlos. Por ejemplo, en el caso de un conjunto de datos que recoja las subvenciones otorgadas por un organismo público, esta tarea nos permitirá saber cuántos beneficiarios distintos hay para la columna de beneficiarios, y si alguno se repite.
-
Distribución de valores (frecuencia), que se refiere al análisis de la frecuencia con la que ocurren diferentes valores dentro de una misma columna. Esto se puede representar mediante histogramas que dividen los valores en intervalos y muestran cuántos valores se encuentran en cada intervalo. Por ejemplo, en una columna de edades, podríamos encontrar que 20 personas tienen entre 25-30 años, 15 personas tienen entre 30-35 años, etc.
-
Conteo de valores nulos o faltantes, lo que implica contar la cantidad de valores nulos o vacíos en cada columna de un conjunto de datos. Ayuda a determinar la completitud de los datos y puede señalar posibles problemas de calidad. Por ejemplo, en una columna de direcciones de correo electrónico, 5 de 100 registros podrían estar vacíos, indicando un 5% de datos faltantes.
- Longitud mínima, máxima y promedio de los valores (para columnas de texto), la cual está orientada a calcular cuál es la longitud de los valores en una columna de texto. Esto es útil para identificar valores inusuales y para definir restricciones de longitud en bases de datos. Por ejemplo, en una columna de nombres, podríamos encontrar que el nombre más corto tiene 3 caracteres, el más largo 20 caracteres, y el promedio es de 8 caracteres.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de anomalías: permite la identificación de valores inusuales o fuera de rango.
- Mejora de la preparación de datos: ayuda en la normalización y limpieza de datos antes de su uso en análisis más avanzados o en modelos de machine learning.
2. Perfilado multicolumna
El perfilado multicolumna analiza la relación entre dos o más columnas dentro del mismo conjunto de datos. Este tipo de perfilado puede incluir:
- Análisis de correlación, utilizado para identificar relaciones entre columnas numéricas en un conjunto de datos. Una técnica común es calcular correlaciones por pares entre todas las columnas numéricas para descubrir patrones de relación. Por ejemplo, en una tabla de investigadores, podríamos encontrar que la edad y el número de publicaciones están correlacionados, indicando que a medida que aumenta la edad de los investigadores y su categoría, también tiende a aumentar su número de publicaciones. Un coeficiente de correlación de Pearson podría cuantificar esta relación.
- Valores atípicos (outliers), lo cual implica identificar datos que se desvían significativamente de otros puntos de datos. Los outliers pueden indicar errores, variabilidad natural o puntos de datos interesantes que merecen una mayor investigación. Por ejemplo, en una columna de presupuestos para proyectos de I+D anuales, un valor de un millón de euros podría ser un outlier si la mayoría de los ingresos se encuentran entre 30.000 y 100.000 euros. Sin embargo, si se representa el importe en relación a la duración del proyecto, podría ser un valor normal si el proyecto de un millón tiene 10 veces la duración del de 100.000 euros.
- Detección de combinaciones de valores frecuentes, enfocada en encontrar conjuntos de valores que ocurren juntos con frecuencia en los datos. Se utilizan para descubrir asociaciones entre elementos, como en los datos de transacciones. Por ejemplo, en un conjunto de datos de compras, podríamos encontrar que los productos "pañales" y "leche de fórmula para bebés" se compran juntos frecuentemente. Un algoritmo de reglas de asociación podría generar la regla {pañales} → {leche de fórmula}, indicando que los clientes que compran pan también tienden a comprar mantequilla con una alta probabilidad.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de tendencias: permite identificar relaciones y correlaciones significativas entre columnas, lo que puede ayudar en la detección de patrones y tendencias.
- Mejora de la consistencia de datos: permite asegurar que existe integridad referencial y que se siguen, por ejemplo, formatos similares en tipos de datos entre los datos a través de múltiples columnas.
- Reducción de dimensionalidad: permite reducir el número de columnas que contienen datos redundantes o que están altamente correlacionadas.
3. Perfilado de dependencias
El perfilado de dependencias se enfoca en descubrir y validar relaciones lógicas entre diferentes columnas, como:
-
Descubrimiento de claves ajenas, que está orientado a establecer qué valores o combinaciones de valores de un conjunto de columnas también aparecen en el otro conjunto de columnas, un requisito previo para una clave foránea. Por ejemplo, en la tabla Investigador, la columna ProyectoID contiene los valores [101, 102, 101, 103]. Para establecer ProyectoID como clave ajena, verificamos que estos valores también están presentes en la columna ProyectoID de la tabla Proyecto [101, 102, 103]. Como todos los valores coinciden, ProyectoID en Investigador puede ser una clave ajena que referencia a ProyectoID en Proyecto.
- Dependencias funcionales, que establece relaciones en la que el valor de una columna depende del valor de otra. Así mismo, se usa para la validación de reglas específicas que deben cumplirse (por ejemplo, un valor de descuento no debe exceder el valor total).
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Mejora de la integridad referencial: permite asegurar que las relaciones entre tablas sean válidas y se mantengan correctas.
- Validación de consistencia entra valores: permite garantizar que los datos cumplen con determinadas restricciones o cálculos definidos por la organización.
- Optimización del repositorio de datos: permite mejorar la estructura y diseño de bases de datos mediante la validación y ajuste de dependencias.
Usos del perfilado de datos
Los estadísticos anteriormente citados pueden utilizarse en múltiples ámbitos en las organizaciones. Un caso de uso a destacar sería en iniciativas de ciencia de datos e ingeniería de datos donde permite comprender a fondo las características de un conjunto de datos antes de su análisis o modelado.
- Al generar estadísticas descriptivas, identificar valores atípicos y faltantes, descubrir patrones ocultos, identificar y corregir problemas, como valores nulos, duplicados e inconsistencias, el perfilado de datos facilita la limpieza y la preparación de datos, asegurando su calidad y consistencia.
- Además, es crucial para la detección temprana de problemas, como duplicados o errores, y para la validación de supuestos en proyectos de análisis predictivo.
- También es fundamental para la integración de datos provenientes de múltiples fuentes, garantizando su coherencia y compatibilidad.
- En el ámbito de gobierno, gestión y calidad de datos, el perfilado puede ayudar a establecer políticas y procedimientos sólidos, mientras que en el cumplimiento normativo asegura que los datos respeten con las regulaciones aplicables.
- Por último, en términos de gestión ayuda a optimizar los procesos de extracción, transformación y carga (Extract, Transform and Load o ETL en inglés), apoya la migración de datos entre sistemas y prepara conjuntos de datos para el machine learning y analíticas predictivas, mejorando la eficacia de los modelos y decisiones basadas en datos.
Diferencia entre perfilado de datos y evaluación de calidad de datos
En ocasiones, este término de perfilado de datos se confunde con la evaluación de calidad de datos.Mientras que el perfilado de datos se centra en descubrir y entender los metadatos y las características de los datos, la evaluación de calidad de datos va un paso más allá y se centra por ejemplo en analizar si los datos cumplen con ciertos requisitos o estándares de calidad predefinidos en la organización a través de las reglas de negocio. Así mismo, la evaluación de calidad de datos involucra verificar el valor de calidad para distintas características o dimensiones tales como las incluidas en la especificación UNE 0081: exactitud, completitud, consistencia o actualidad, etc., y asegurando que los datos sean aptos para su uso previsto en la organización: analítica, inteligencia artificial, inteligencia de negocio, etc.
Herramientas o soluciones para perfilado de datos
Por último, existen diversas soluciones (herramientas, librerías, o dependencias) open source destacadas para el perfilado de datos que facilitan el entendimiento de los datos. Entre ellas, destacan:
- Pandas Profiling e YData Profiling que ofrecen informes detallados y visualizaciones avanzadas en Python
- Great Expectations y Dataprep que permiten validar y preparar datos, asegurando su integridad en el ciclo de vida
- R dtables que permite la generación de informes detallados y visualizaciones para el análisis exploratorio y el perfilado de datos para el ecosistema R.
En resumen, el perfilado de datos es una parte importante en el análisis exploratorio de datos que permite obtener una comprensión detallada de la estructura, contenidos, etc. y que es recomendable tener en cuenta en iniciativas de análisis de datos. Es importante dedicar tiempo a esta actividad, contando con los recursos y herramientas necesarios, para tener un mejor conocimiento de los datos que se manejan y ser conscientes de que es una técnica más a utilizar como parte de la gestión de calidad de datos, y que puede ser utilizada como un paso previo a la evaluación de calidad de datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Noticia
El avance imparable de las TIC en las ciudades y territorios rurales, y el contexto social, económico y cultural que lo sustenta, exige habilidades y competencias que nos posicionan de manera ventajosa ante nuevos escenarios y entornos de innovación territorial. En este contexto, la Diputación Provincial de Badajoz ha sabido adaptarse y adelantarse a las circunstancias, y a partir del año 2018 puso en marcha la iniciativa “Badajoz Es Más – Smart Provincia”.
¿Qué es “Badajoz Es Más"?
El proyecto “Badajoz Es Más” es una iniciativa llevada a cabo por la Diputación Provincial de Badajoz cuyo objetivo es conseguir unos servicios más eficientes, mejorar la calidad de vida de sus ciudadanos y fomentar el emprendimiento y la innovación a través de las tecnologías y el gobierno del dato en una región integrada por 135 municipios. Se busca una transformación digital del territorio, que favorezcan la creación de oportunidades de negocio, de mejora social y de asentamiento de la población.
Tradicionalmente, los proyectos de “Smart Cities” han puesto sus esfuerzos en las ciudades, renovación de centros históricos, etc. Sin embargo, “Badajoz Es Más” está centrado en la transformación de las zonas rurales, los pueblos inteligentes y sus ciudadanos, poniendo el foco en los retos rurales como la despoblación de los municipios rurales, la brecha digital, la retención de talento o la dispersión de los servicios. Se quiere evitar los “silos” aislados y transformar estos retos en oportunidades mediante la mejora de la gestión de la información, a través de la explotación de los datos de una manera productiva y eficiente.

El ciudadano, en el Centro
El proyecto “Badajoz es Más” persigue llevar a cabo la transformación digital del territorio poniendo a disposición de los municipios, empresas y ciudadanos las nuevas tecnologías del IoT, Big Data, Inteligencia Artificial, etc. A continuación, se exponen las líneas maestras del proyecto.
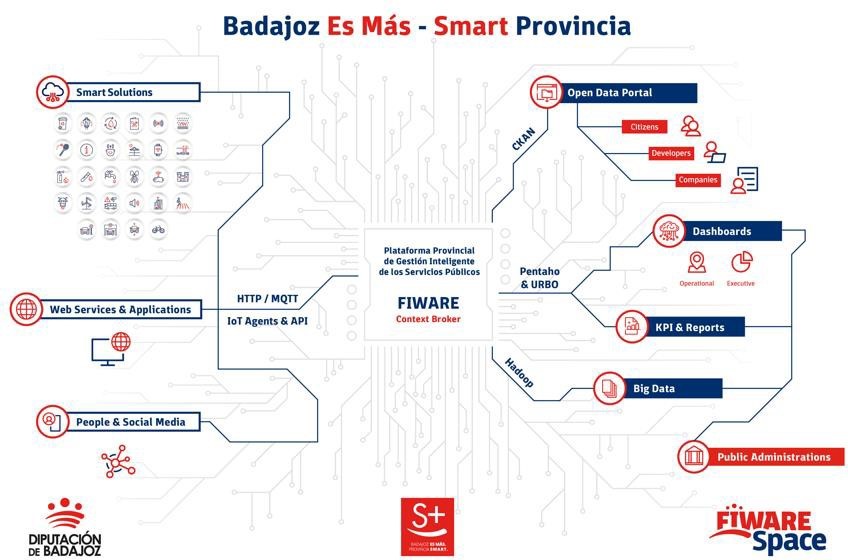
Plataforma Provincial de Gestión Inteligente de Servicios Públicos.
Es el componente nuclear de la iniciativa, ya que permite la integración de la información de cualquier dispositivo IoT, sistema de información o fuente de datos en un único lugar para su almacenamiento, visualización y análisis. En concreto, se recopilan datos de diversas fuentes: los diversos sensores de las soluciones inteligentes implantadas en la región, los servicios web y las aplicaciones, la información ofrecida por ciudadanos y redes sociales.
Toda la información se recolecta en una Plataforma horizontal y abierta, basada en el estándar de código abierto FIWARE, una iniciativa promovida por la Comisión Europea que aporta la capacidad de homogeneizar los datos (FIWARE Data Model) y favorecer su interoperabilidad. Construido siguiendo las directrices marcadas por AENOR (UNE 178104), cuenta con un módulo central Orion Context Broker (OCB) que permite administrar todo el ciclo de vida de la información. De esta forma, ofrece la capacidad de monitorizar y gestionar de forma centralizada un conjunto ampliable de servicios públicos a través de cuadros de mando internos.
La plataforma es “multientidad”, es decir permite proveer de información, conocimiento y servicios tanto a la propia Diputación Provincial como a su Municipios asociados (también conocidos como “Pueblos Inteligentes”). La visualización de los diferentes modelos de explotación de información procesados en los distintos niveles de la Plataforma se realiza sobre distintos cuadros de mando, que pueden dar servicio a un municipio o localidad concreta solo mostrando sus datos y servicios, o también disponer de una visión global de todos los servicios y datos a nivel de la Diputación de Badajoz.
Parte de la información recopilada en la plataforma se pone, también, a disposición de terceros a través de diversos canales:
- Portal de datos abiertos. Aquellos datos recopilados susceptibles de ser abiertos a terceros para su reutilización, se comparten a través de su portal de datos abiertos. En él podemos encontrar información tan diversa como datos en tiempo real sobre las playas de la región con bandera azul (se monitoriza la calidad del aire, del agua,la contaminación sonora, el aforo, etc.) o el flujo del tráfico, lo cual permite predecir los atascos.
- Portal para los ciudadanos Provincia Digital Badajoz. Este portal ofrece información sobre las soluciones implementadas actualmente en la provincia y sus datos en tiempo real de una forma amigable, con una experiencia de usuario sencilla que permite a aquellas personas sin conocimientos técnicos acceder conocer los proyectos desarrollados.
La siguiente gráfica muestra el ciclo de la información, desde su recolección, paso por la plataforma y distribución a los distintos canales. Todo ello bajo un fuerte gobierno del dato.
Servicios Públicos eficientes
Además de la implantación y puesta en marcha de la Plataforma Provincial de Gestión Inteligente de Servicios Públicos, este proyecto ya ha integrado distintos servicios o “verticales” existentes para:
- Comenzar a implantar estos nuevos servicios en la provincia y ser el ejemplo y la “punta de lanza” de esta transformación tecnológica.
- Mostrar los beneficios de la implantación de estas tecnologías para realizar una labor divulgativa y demostrativa con el ánimo de causar el impacto suficiente como para que de manera gradual los demás Ayuntamientos y organizaciones se vayan sumando a la iniciativa.
Actualmente se cuenta con más de 40 empresas enviando datos a la Plataforma Provincial, más de 60 fuentes de datos integradas, más de 800 dispositivos conectados, más del 500 transacciones por minuto… Cabe destacar que se trabaja para que los nuevos pliegos que se presentan lleven asociados una cláusula para que los datos provenientes de los diversos trabajos financiados con dinero público se viertan también a la plataforma.
La idea es poder realizar una gestión estandarizada, de tal forma que la solución que se ha implantado en un municipio sirva también para otro. De esta forma no solo se mejora la eficiencia, sino que también se pueden comparar los resultados entre municipios. Puede visualizar algunos de los servicios ya implantados en la Provincia, así que como sus Cuadros de Mando construidos desde la Plataforma Provincial en este vídeo.

Ecosistema de Innovación
Para conseguir que la iniciativa llegue su público objetivo, la Diputación Provincial de Badajoz ha desarrollado un ecosistema de innovación que sirve de punto de encuentro entre:
- Ciudadanos, que demandan estos servicios.
- Emprendedores y entidades educativas, que tienen interés en estas tecnologías.
- Empresas, que tienen la capacidad de implantar estas soluciones.
- Entidades públicas, que pueden poner en marcha este tipo de proyectos.
Se trata de facilitar y proveer las herramientas, conocimientos y asesoramiento necesario para que los proyectos que surjan de este encuentro puedan llevarse a cabo.
Este ecosistema tiene como elemento central un centro de innovación físico denominado FIWARE Space. FIWARE Space lleva a cabo labores como la organización de eventos para la divulgación de las tecnologías y conceptos Smart entre empresas y ciudadanos, talleres demostrativos y formativos, Hackathones con universidades y centros de estudio, etc. También cuenta con un Showroom para la exposición de soluciones, realiza Retos dotados económicamente y tiene presencia en congresos nacionales e internacionales.
Además, llevan a cabo labores de mentorización a empresas y entras entidades. En total, cerca de 40 empresas han sido mentorizadas por FIWARE Space, llegando a lanzar sus propias soluciones en varias ocasiones al Market de FIWARE, o proponiendo los modelos de datos generados como estándares para todo el ecosistema mundial. A estas empresas se les ofrece un servicio gratuito para que adquieran los conocimientos necesarios para trabajar de forma estandarizada, generando datos uniformes al resto de la región, y para conectar sus soluciones a la plataforma, ayudándoles y asesorándoles en los retos que puedan surgir.
Una de las claves de FIWARE Space es su carácter abierto, habiendo firmado multitud de acuerdos de colaboración y convenios con entidades tanto locales, como internacionales. Por ejemplo, se está trabajando en la normalización de modelos de datos avanzados para el turismo con el Instituto de Ciudades del Futuro (Argentina). Para aquellos que quieran más información, puede seguir la actividad de su centro a través de su blog semanal.

Próximos pasos: convergencia con Espacios de Datos y Gaia-X
Fruto del carácter colaborativo y abierto del proyecto, el concepto Espacio de Datos encaja perfectamente en la filosofía de “Badajoz es Más”. La Diputación de Badajoz cuentan actualmente con multitud de verticales con información interesante para su compartición (y futura explotación) de datos de forma confiable, soberana y segura. Como Entidad Pública, la comparación y obtención de otras fuentes de datos enriquecerá en gran medida al proyecto, aportando una visión externa imprescindible para su crecimiento. Gaia-X es la propuesta para la creación de una infraestructura de datos para Europa, y es el estándar hacía el que está convergiendo actualmente el proyecto “Badajoz es Más”, fruto de su colaboración con el hub Gaia-X España.
Noticia
Hoy, 23 de abril, se celebra el Día del Libro, una ocasión para resaltar la importancia de la lectura, la escritura y la difusión del conocimiento. La lectura activa promueve la adquisición de habilidades y el pensamiento crítico, al acercarnos a información especializada y detallada sobre cualquier tema que nos interese, incluido el mundo de los datos.
Por ello, queremos aprovechar la ocasión para mostrar algunos ejemplos de libros y manuales relacionados con los datos y tecnologías relacionadas que se pueden encontrar en la red de manera gratuita.
1. Fundamentos de ciencia de datos con R, editado por Gema Fernandez-Avilés y José María Montero (2024)
Accede al libro aquí.
- ¿De qué trata? El libro guía al lector desde el planteamiento de un problema hasta la realización del informe que contiene su solución. Para ello, explica una treintena de técnicas de ciencia de datos en el ámbito de la modelización, análisis de datos cualitativos, discriminación, machine learning supervisado y no supervisado, etc. En él se incluyen más de una docena de casos de uso en sectores tan dispares como la medicina, el periodismo, la moda o el cambio climático, entre otros. Todo ello, con un gran énfasis en la ética y en el fomento de la reproductibilidad de los análisis.
-
¿A quién va dirigido? Está dirigido a usuarios que quieran iniciarse en la ciencia de datos. Parte de preguntas básicas, como qué es la ciencia de datos, e incluye breves secciones con explicaciones sencillas sobre la probabilidad, la inferencia estadística o el muestreo, para aquellos lectores no familiarizados con estas cuestiones. También incluye ejemplos replicables para practicar.
-
Idioma: Español
2. Contar historias con datos, Rohan Alexander (2023).
Accede al libro aquí.
-
¿De qué trata? El libro explica una amplia gama de temas relacionados con la comunicación estadística y el modelado y análisis de datos. Abarca las distintas operaciones desde la recopilación de datos, su limpieza y preparación, hasta el uso de modelos estadísticos para analizarlos, prestando especial importancia a la necesidad de extraer conclusiones y escribir sobre los resultados obtenidos. Al igual que el libro anterior, también pone el foco en la ética y la reproductibilidad de resultados.
-
¿A quién va dirigido? Es perfecto para estudiantes y usuarios con conocimientos básicos, a los que dota de capacidades para realizar y comunicar de manera efectiva un ejercicio de ciencia de datos. Incluye extensos ejemplos de código para replicar y actividades a realizar a modo de evaluación.
-
Idioma: Inglés.
3. El gran libro de los pequeños proyectos con Python, Al Sweigart (2021)
Accede al libro aquí.
- ¿De qué trata? Es una colección de sencillos proyectos en Python para aprender a crear arte digital, juegos, animaciones, herramientas numéricas, etc. a través de un enfoque práctico. Cada uno de sus 81 capítulos explica de manera independiente un proyecto sencillo paso a paso -limitados a máximo 256 líneas de código-. Incluye una ejecución de muestra del resultado de cada programa, el código fuente y sugerencias de personalización.
-
¿A quién va dirigido? El libro está escrito para dos grupos de personas. Por un lado, aquellos que ya han aprendido los conceptos básicos de Python, pero todavía no están seguros de cómo escribir programas por su cuenta. Por otro, aquellos que se inician en la programación, pero son aventureros, cuentan con grandes dosis de entusiasmo y quieren ir aprendiendo sobre la marcha. No obstante, el mismo autor tiene otros recursos para principiantes con los que aprender conceptos básicos.
-
Idioma: Inglés.
4. Matemáticas para Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Accede al libro aquí.
-
¿De qué trata? La mayoría de libros sobre machine learning se centran en algoritmos y metodologías de aprendizaje automático, y presuponen que el lector es competente en matemáticas y estadística. Este libro pone en primer plano los fundamentos matemáticos de los conceptos básicos detrás del aprendizaje automático
-
¿A quién va dirigido? El autor asume que el lector tiene conocimientos matemáticos comúnmente aprendidos en las materias de matemáticas y física de la escuela secundaria, como por ejemplo derivadas e integrales o vectores geométricos. A partir de ahí, el resto de conceptos se explican de manera detallada, pero con un estilo académico, con el fin de ser precisos.
-
Idioma: Inglés.
5. Profundizando en el aprendizaje profundo, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, se actualiza continuamente)
Accede al libro aquí.
-
¿De qué trata? Los autores son empleados de Amazon que utilizan la biblioteca MXNet para enseñar Deep Learning. Su objetivo es hacer accesible el aprendizaje profundo, enseñando los conceptos básicos, el contexto y el código de forma práctica a través de ejemplos y ejercicios. El libro se divide en tres partes: conceptos preliminares, técnicas de aprendizaje profundo y temas avanzados centrados en sistemas y aplicaciones reales.
-
¿A quién va dirigido? Este libro está dirigido a estudiantes (de grado o posgrado), ingenieros e investigadores, que buscan un dominio sólido de las técnicas prácticas del aprendizaje profundo. Cada concepto se explica desde cero, por lo que no es necesario tener conocimientos previos de aprendizaje profundo o automático. No obstante, sí son necesario conocimientos de matemáticas y programación básicas, incluyendo álgebra lineal, cálculo, probabilidad y programación en Python.
-
Idioma: Inglés.
6. Inteligencia artificial y sector público: retos límites y medios, Eduardo Gamero y Francisco L. Lopez (2024)
Accede al libro aquí.
-
¿De qué trata? Este libro se centra en analizar los retos y oportunidades que presenta el uso de la inteligencia artificial en el sector público, especialmente cuando se usa como soporte a la toma de decisiones. Comienza explicando qué es la inteligencia artificial y cuáles son sus aplicaciones en el sector público, para pasar a abordar su marco jurídico, los medios disponibles para su implementación y aspectos ligados a la organización y gobernanza.
-
¿A quién va dirigido? Es un libro útil para todos aquellos interesados en la temática, pero especialmente para responsables políticos, trabajadores públicos y operadores jurídicos relacionados con la aplicación de la IA en el sector público.
-
Idioma: español
7. Introducción del analista de negocio a la analítica empresarial, Adam Fleischhacker (2024)
Accede al libro aquí.
-
¿De qué trata? El libro aborda un flujo de trabajo de análisis empresarial completo, que incluye la manipulación de datos, su visualización, el modelado de problemas empresariales, la traducción de modelos gráficos a código y la presentación de resultados ante las partes interesadas. El objetivo es aprender a impulsar cambios dentro de una organización gracias al conocimiento basado en datos, modelos interpretables y visualizaciones persuasivas.
-
¿A quién va dirigido? Según su autor, se trata de un contenido accesible para todos, incluso para principiantes en la realización de trabajos de análisis. El libro no asume ningún conocimiento del lenguaje de programación, sino que proporciona una introducción a R, RStudio y al “tidyverse”, una serie de paquetes de código abierto para la ciencia de datos.
-
Idioma: Inglés.
Te invitamos a ojear esta selección de libros. Asimismo, recordamos que solo se trata de una lista con ejemplos de las posibilidades de materiales que puedes encontrar en la red. ¿Conoces algún otro libro que quieras recomendar? ¡Indícanoslo en los comentarios o manda un email a dinamizacion@datos.gob.es!
Noticia
Entre el 2 de abril y el 16 de mayo se podrán presentar solicitudes en la sede electrónica del Ministerio para la Transformación Digital y de la Función Pública, para concurrir a la convocatoria de ayudas para la transformación digital de sectores productivos estratégicos. La Orden TDF/1461/2023, del 29 de diciembre, modificada por la Orden TDF/294/2024, regula ayudas por un total de 150 millones de euros para la creación de demostradores y casos de uso, como parte de una iniciativa más general de espacios de datos sectoriales, promovida por la Secretaría de Estado de Digitalización e Inteligencia Artificial y enmarcada en el Plan de Recuperación, Transformación y Resiliencia (PRTR). El objetivo es financiar el desarrollo de espacios de datos y el fomento de la innovación disruptiva en sectores estratégicos de la economía, acorde con las líneas estratégicas recogidas en la Agenda España Digital 2026.
Líneas, sectores y beneficiarios
La convocatoria actual incluye líneas de financiación para proyectos de desarrollo experimental en dos áreas de actuación complementarias: la creación de centros demostradores (desarrollo de plataformas tecnológicas de espacios de datos); y el fomento de casos de uso concretos de dichos espacios. Esta convocatoria se dirige a todos los sectores salvo al de turismo ya que este cuenta con una convocatoria propia. Podrán obtener la condición de beneficiarios las entidades únicas con personalidad jurídica propia, domicilio fiscal en la Unión Europea, y establecimiento o sucursal ubicado en España. En el caso de la línea destinada a centros demostradores deberán además tener carácter asociativo o representativo de las cadenas de valor de los sectores productivos en ámbitos territoriales, o con dominios científicos o tecnológicos.
Infografías-resumen
Las siguientes infografías muestra la información clave sobre esta convocatoria de ayudas:


¿Quieres más información?
- Acceso al portal de ayudas de la convocatoria desde en el siguiente enlace. En el portal encontrarás las bases reguladoras y la convocatoria, un resumen de su contenido, documentación y material divulgativo con presentaciones y vídeos, así como una completa lista de preguntas y respuestas. En el buzón de correo espaciosdedatos@digital.gob.es obtendrás ayuda sobre la convocatoria y el procedimiento de tramitación. Desde este portal se accede a la sede electrónica para poder hacer la solicitud
- Guía rápida para la convocatoria de ayudas en pdf + Infografías descargables (sobre el Programa de Datos Sectoriales y la Información Técnica)
- Enlace a otros documentos de interés:
- Información adicional sobre el concepto de espacio de datos
Noticia
El Centre de documentació i biblioteca del Institut Català d'Arqueologia Clàssica (ICAC) cuenta con el repositorio Open Science ICAC. Esta página web se configura como un espacio donde la ciencia se comparte de forma accesible e inclusiva. El espacio introduce recomendaciones y asesora sobre el proceso de la publicación de contenidos. También, sobre cómo poner a disposición los datos generados durante el proceso de investigación, de forma que sirvan a futuros trabajos de investigación.
La página web, además de ser un repositorio de textos de investigación científica, también es un lugar en el que encontrar herramientas y trucos a la hora de abordar el proceso de gestión de datos de investigación en cada una de sus fases: antes, durante y en el momento de la publicación.
- Antes de comenzar: recomienda crear un plan de gestión de datos para garantizar que la propuesta de investigación sea lo más sólida posible. El Plan de Gestión de Datos (PGD) es un documento metodológico que describe el ciclo de vida de los datos recogidos, generados y procesados durante un proyecto de investigación, una tesis doctoral, etc.
- Durante el proceso de investigación: en este punto señala la necesidad de unificar la nomenclatura de los documentos a generar antes de empezar a recopilar archivos o datos, para evitar una acumulación de contenido desorganizado que conducirá a datos extraviados o perdidos. Además, en este apartado se ofrece información sobre la estructura de directorios, nombres de carpetas y nombres de archivos, la creación de un archivo txt (README) que describa las nomenclaturas o el uso de nombres cortos y descriptivos como nombre del proyecto/acrónimo, fecha de creación del archivo, número de muestra o número de la versión. En la página web se pueden encontrar también recomendaciones sobre cómo estructurar cada uno de estos campos para que sean reutilizables y fácilmente buscables.
- Publicación de los datos de investigación: además de los propios resultados de la investigación en forma de tesis, tesina, paper... recomienda la publicación de los datos que se hayan ido generando con el propio proceso investigador. El propio ICAC señala que los datos de investigación siguen siendo valiosos una vez finalizado el proyecto de investigación para el que se generaron, y que compartir los datos puede abrir nuevas vías de investigación sin que los futuros investigadores tengan que recrear y recopilar datos idénticos. Por último, señala cómo, cuándo y qué tener en cuenta a la hora de publicar los datos de investigación.
Los contenidos gráficos para la mejora de la calidad de datos abiertos
Recientemente, el ICAC ha dado un paso más para incentivar unas buenas prácticas en el uso de datos abiertos. Para ello ha elaborado una serie de contenidos gráficos basándose en la “Guía práctica para la mejora de la calidad de datos abiertos”, elaborada por datos.gob.es. En concreto, el ente cultural ha elaborado cuatro infografías, en catalán e inglés, de fácil comprensión sobre buenas prácticas con datos abiertos en el trabajo con bases de datos y hojas de cálculo, textos y docs y formato CSV.
Todas las infografías surgidas de la adaptación de la guía están a disposición del público general y también del personal investigador del centro en Recercat, el repositorio de investigación de Cataluña. Próximamente también estará dentro de la web de Ciencia Abierta del Institut Català d'Arqueologia Clàssica (ICAC), Open Science ICAC.
Las infografías elaboradas por el ICAC repasan diversos aspectos. Las primeras, recogen las recomendaciones generales para garantizar la calidad de los datos abiertos, como el uso de codificación de caracteres estandarizados, tales como el UTF-8, o nombrar las columnas de forma correcta, utilizando solo letras en minúscula y evitando los espacios, siendo estos sustituidos por guiones. Entre las recomendaciones para generar datos de calidad, también recogen cómo mostrar la presencia de datos nulos o la carencia de datos o cómo gestionar la duplicidad de datos, de manera que se centralice la recogida de datos y su procesamiento en un único sistema de forma que, en caso de haber duplicidad, se puedan detectar de forma sencilla y puedan ser eliminados.
Las segundas abordan cómo establecer el formato de las cifras numéricas y de otros datos como las fechas, de manera que sigan el sistema estandarizado ISO, así como utilizar los puntos como decimales. En el caso de la información geográfica, tal y como recomienda la Guía, sus materiales también recogen la necesidad de reservar dos columnas para insertar la longitud y la latitud de los puntos geográficos utilizados.
La tercera temática de estas infografías se centra en la elaboración de buenas bases de datos u hojas de cálculo, de forma que sean fácilmente reutilizables y no generen problemas a la hora de trabajar con ellas. Entre las recomendaciones que destacan se encuentra la consistencia a la hora de generar nombres o códigos para cada ítem incluido en la recogida de datos, así como elaborar una guía de ayuda para las celdas que se encuentran codificadas, de manera que sean inteligibles para quienes necesiten reutilizarlas.
En el apartado de textos y documentos dentro de estas bases de datos, las infografías que ha elaborado el Institut Català d'Arqueologia Clàssica recogen algunas de las recomendaciones más importantes para crear textos y asegurarse de su conservación de la mejor forma posible. Entre ellas, señala la necesidad de guardar materiales adjuntos en los documentos de texto como pueden ser imágenes u hojas de cálculo de forma separada al documento de texto. De esta manera, se asegura que el documento conserva su calidad original, como la resolución de una imagen, por ejemplo.
Por último, la cuarta infografía que se ha puesto a disposición recoge las recomendaciones más importantes a la hora de trabajar con formato CSV (comma separated value) como crear un documento CSV para cada tabla y, en caso de trabajar con un documento con varias hojas de cálculo, ponerlas a disposición de forma independiente. También señala en este caso que cada fila en el documento CSV tiene el mismo número de columnas para que sean fácilmente trabajables y reutilizables, sin necesidad de realizar una limpieza posterior.
Como se mencionaba anteriormente, todas las infografías siguen las recomendaciones ya recogidas en la Guía práctica para la mejora de la calidad de datos abiertos.
La guía para la mejora de la calidad de datos abiertos
La “Guía práctica para la mejora de la calidad de datos abiertos” es un documento elaborado por datos.gob.es dentro de la Iniciativa Aporta y publicado en septiembre de 2022. El documento proporciona un compendio de directrices para actuar sobre cada una de las características que definen la calidad, impulsando su mejora. A su vez, esta guía toma como referente la guía para la calidad de datos de data.europe.eu, publicada en 2021 por la Oficina de Publicaciones de la Unión Europea y la completa para que tanto publicadores como reutilizadores de datos puedan seguir pautas que garanticen la calidad de los datos abiertos.

En resumen, la guía pretende ser un marco de referencia para todas las personas involucradas tanto en la generación como en la utilización de datos abiertos para que tengan un punto de partida que garantice la idoneidad de los datos tanto en su puesta a disposición como a la hora de evaluar si un conjunto de datos posee calidad suficiente para su reutilización en estudios, aplicaciones, servicios u otros.
Noticia
A finales de 2023, como recogió datos.gob.es, el ISTAC hizo públicos más de 500 activos semánticos, entre los que se incluían 404 clasificaciones o 100 esquemas de conceptos.
Todos estos recursos están disponibles en el Catálogo de Datos Abiertos de Canarias, un entorno en el que hay cabida tanto para recursos semánticos como estadísticos y que, por tanto, puede entrañar una dificultad extra para un usuario que busque únicamente activos semánticos.
Para facilitar la reutilización de estos conjuntos de datos con información tan relevante para la sociedad, el Instituto Canario de Estadística, con la colaboración de la Dirección General de Transformación Digital de los Servicios Públicos del Gobierno de Canarias, publicó el Banco de activos semánticos.
En este portal, el usuario puede realizar búsquedas de manera más sencilla proporcionando una palabra clave, identificador, nombre del conjunto de datos o institución que lo elabora y mantiene.

El Banco de activos semánticos del Instituto Canario de Estadística es una aplicación que sirve para explorar los recursos estructurales utilizados por el ISTAC. De esta forma es posible reutilizar los activos semánticos con los que trabaja el ISTAC, ya que hace uso directo de las API de eDatos, la infraestructura que vertebra el instituto de estadística canario.
El número de recursos a consultar crece enormemente respecto a los datos disponibles en el Catálogo, ya que, por un lado, incluye los DSD (Definiciones de las Estructuras de Datos), con los que se construyen las tablas de datos finales; y, por otro, porque incluye no solo los esquemas y clasificaciones, sino cada uno de los códigos, conceptos y elementos que los componen.
Esta herramienta es el equivalente de los mencionados Fusion Metadata Registry usados por SDMX, Eurostat o las Naciones Unidas; pero con un enfoque mucho más práctico y accesible sin perder funcionalidades avanzadas. El SDMX es el estándar de compartición de datos y metadatos en el que se basan las organizaciones ya mencionadas. El uso de este estándar en aplicaciones como la del ISTAC permite homogeneizar de manera sencilla todos los recursos asociados a los datos estadísticos que se van a publicar.
La publicación de datos bajo el estándar SDMX es un proceso más laborioso, ya que obliga a generar no solo los datos, sino también las claves de publicación, pero a la larga permite que se creen plantillas u operaciones estadísticas que permite compararlas con los datos de otro país o región.
La aplicación recién lanzada por el ISTAC permite navegar por todos los recursos estructurales del ISTAC, incluyendo las familias de clasificaciones o conceptos, de manera interconectada, por lo que opera como una red.
Funcionalidades del Banco de activos semánticos
La principal ventaja de esta nueva herramienta frente a los registros mencionados es la facilidad de uso. La cual, en este caso, se mide directamente por lo poco que cuesta encontrar un recurso específico.

Gracias a la búsqueda avanzada, se pueden filtrar recursos específicos por ID, nombre, descripción y mantenedor; a los que se agrega la opción de incluir solo los resultados que interesen, discriminando tanto por versión como por si son recomendados por el ISTAC o no.
Además, está pensado para que sea un gran banco interconectado, de tal manera que, entrando en un concepto, se recomienden clasificaciones, o que en un DSD estén enlazadas todas las representaciones de las dimensiones y atributos.

Estas características no solo diferencian al Banco de activos semánticos de otras herramientas similares, sino que suponen un paso adelante en materia de interoperabilidad y transparencia al no simplemente ofrecer los recursos semánticos sino también sus relaciones entre ellos.
El nuevo recurso del ISTAC cumple con lo dispuesto tanto a escala nacional con el Esquema Nacional de Interoperabilidad (artículo 10, activos semánticos), como a escala europea con el Marco Europeo de Interoperabilidad (artículo 3.4, interoperabilidad semántica). Ambos documentos defienden la necesidad y el valor de utilizar recursos comunes para el intercambio de información, máxima que se está implantando de manera transversal en el Gobierno de Canarias.
Píldora formativa
Para difundir este nuevo buscador de activos semánticos, el ISTAC ha publicado un breve vídeo explicativo del Banco y sus características, además de aportar pinceladas necesarias sobre SDMX. En este vídeo es posible conocer, de forma sencilla y en apenas unos minutos cómo utilizar y sacar el máximo provecho al nuevo Banco de Activos Semánticos del ISTAC a través de las búsquedas sencillas, complejas y cómo organizar los datos para que respondan a un análisis previo deseado.
En resumen, con el Banco de activos semánticos, el Instituto Canario de Estadística ha dado un paso significativo para facilitar la reutilización de sus activos semánticos. Esta herramienta que agrupa decenas de miles de recursos estructurales permite acceder de manera sencilla a una red interconectada que cumple con los estándares de interoperabilidad a nivel nacional y europeo.
Noticia
El Instituto Canario de Estadística (ISTAC) ha añadido a su catálogo más de 500 activos semánticos y más de 2100 cubos estadísticos. Esta inmensa cantidad de información representa lustros de trabajo del ISTAC en materia de normalización y adaptación a estándares internacionales punteros, que habilitan una mejor compartición de datos y metadatos entre productores y consumidores de información nacionales e internacionales.
El incremento de conjuntos de datos mejora no solo cuantitativamente el directorio de datos.canarias.es y datos.gob.es, sino que amplía los usos que éste ofrece gracias al tipo de información añadida.
Nuevos activos semánticos
Los recursos semánticos, a diferencia de los estadísticos, no presentan datos numéricos cuantificables, como pueden ser datos de desempleo o el PIB, sino que proporcionan homogeneidad y reproducibilidad.
Estos activos suponen un paso adelante en materia de interoperabilidad, según lo dispuesto tanto a escala nacional con el Esquema Nacional de Interoperabilidad (artículo 10, activos semánticos), como a escala europea con el Marco Europeo de Interoperabilidad (artículo 3.4, interoperabilidad semántica). En ambos documentos se expone la necesidad y el valor de utilizar recursos comunes para el intercambio de información, máxima que se está implantando de manera transversal en el Gobierno de Canarias. Estos activos semánticos ya se están usando en los formularios de la sede electrónica y se espera que en el futuro sean los activos semánticos que use todo el Gobierno de Canarias.
Concretamente en esta carga de datos hay 4 tipos de activos semánticos:
- Clasificaciones (404 cargadas): Listados de códigos que se utilizan para representar los conceptos asociados a las variables o categorías que forman parte de los conjuntos de datos normalizados, como por ejemplo la Clasificación Nacional de Actividades Económicas (CNAE), clasificaciones de países como la M49, o clasificaciones de sexo y edad.
- Esquemas de conceptos (100 cargados): Los conceptos son las definiciones de las variables en las que se desagregan los datos y que finalmente se representan con una o varias clasificaciones. Pueden ser transversales como “Edad”, “Lugar de nacimiento” y “Actividad de la empresa” o específicos para cada operación estadística como “Tipo de tareas del hogar” o “Índice de confianza del consumidor”.
- Esquemas de temas (2 cargados): Incorporan listas de temas que pueden corresponder a la clasificación temática de las operaciones estadísticas o al registro de temas INSPIRE.
- Esquemas de organizaciones (4 cargados): Se incluyen esquemas de entidades como unidades organizativas, universidades, agencias mantenedoras o proveedores de datos.
Todos estos tipos de recursos forman parte del estándar internacional SDMX (Statistical Data and Metadata Exchange), que se utiliza para el intercambio de datos y metadatos estadísticos. El estándar SDMX proporciona un formato y estructura común para facilitar la interoperabilidad entre diferentes organizaciones que producen, publican y utilizan datos estadísticos.

Este estándar es promovido por organizaciones como el Banco Central Europeo (BCE), Naciones Unidas, la Oficina Estadística de la Unión Europea (Eurostat), el Fondo Monetario Internacional (FMI) o la Organización para la Cooperación y el Desarrollo Económico (OCDE).
Con la inclusión de estos conjuntos de datos, datos.canarias.es y datos.gob.es entrarían a formar parte de un selecto grupo de organizaciones que también ponen a disposición de la sociedad diversos recursos estructurales para fines estadísticos en los siguientes registros públicos:
- SDMX Global Registry
- Euro SDMX Registry
- United Nations Statistical Division
- UNICEF Indicator Data Warehouse
- IMF SDMX Central
Nuevos recursos estadísticos
Dada la creciente necesidad de compartir, procesar y comparar datos, se hace indispensable la aplicación de estándares internacionales para la publicación e intercambio de datos y metadatos. El ISTAC se encuentra inmerso en un proceso de revisión y actualización de sus publicaciones para adaptarlas al estándar internacional SDMX, empezando por el análisis de la información publicada, pasando por la definición de activos semánticos y recursos estructurales en general, hasta llegar a la publicación de recursos estadísticos como los cubos o tablas de datos.
Como parte de este objetivo y tras años de trabajo armonizando y estandarizando datos, el ISTAC ha cargado en su catálogo 2196 cubos estadísticos que hacen uso de los activos semánticos antes descritos y que se basan en el estándar SDMX.
Esto permite mejorar el uso y compartición de datos tanto para el usuario de a pie como de manera programática gracias al uso estandarizado de recursos semánticos. En definitiva, la incorporación al catálogo de esta relevante información, supone un paso muy importante en la interoperabilidad de los datos y, por tanto, en su reutilización.