Blog
Las imágenes sintéticas son representaciones visuales generadas de forma artificial mediante algoritmos y técnicas computacionales, en lugar de capturarse directamente de la realidad con cámaras o sensores. Se producen a partir de distintos métodos, entre los que destacan las redes generativas antagónicas (Generative Adversarial Networks, GAN), los modelos de difusión, y las técnicas de renderizado 3D. Todas ellas permiten crear imágenes de apariencia realista que en muchos casos resultan indistinguibles de una fotografía auténtica.
Cuando se traslada este concepto al campo de la observación de la Tierra, hablamos de imágenes satelitales sintéticas. Estas no se obtienen a partir de un sensor espacial que capta radiación electromagnética real, sino que se generan digitalmente para simular lo que vería un satélite desde la órbita. En otras palabras, en vez de reflejar directamente el estado físico del terreno o la atmósfera en un momento concreto, son construcciones computacionales capaces de imitar el aspecto de una imagen satelital real.
El desarrollo de este tipo de imágenes responde a necesidades prácticas. Los sistemas de inteligencia artificial que procesan datos de teledetección requieren conjuntos muy amplios y variados de imágenes. Las imágenes sintéticas permiten, por ejemplo, recrear zonas de la Tierra poco observadas, simular desastres naturales -como incendios forestales, inundaciones o sequías- o generar condiciones específicas que son difíciles o costosas de capturar en la práctica. De este modo, constituyen un recurso valioso para entrenar algoritmos de detección y predicción en agricultura, gestión de emergencias, urbanismo o monitorización ambiental.
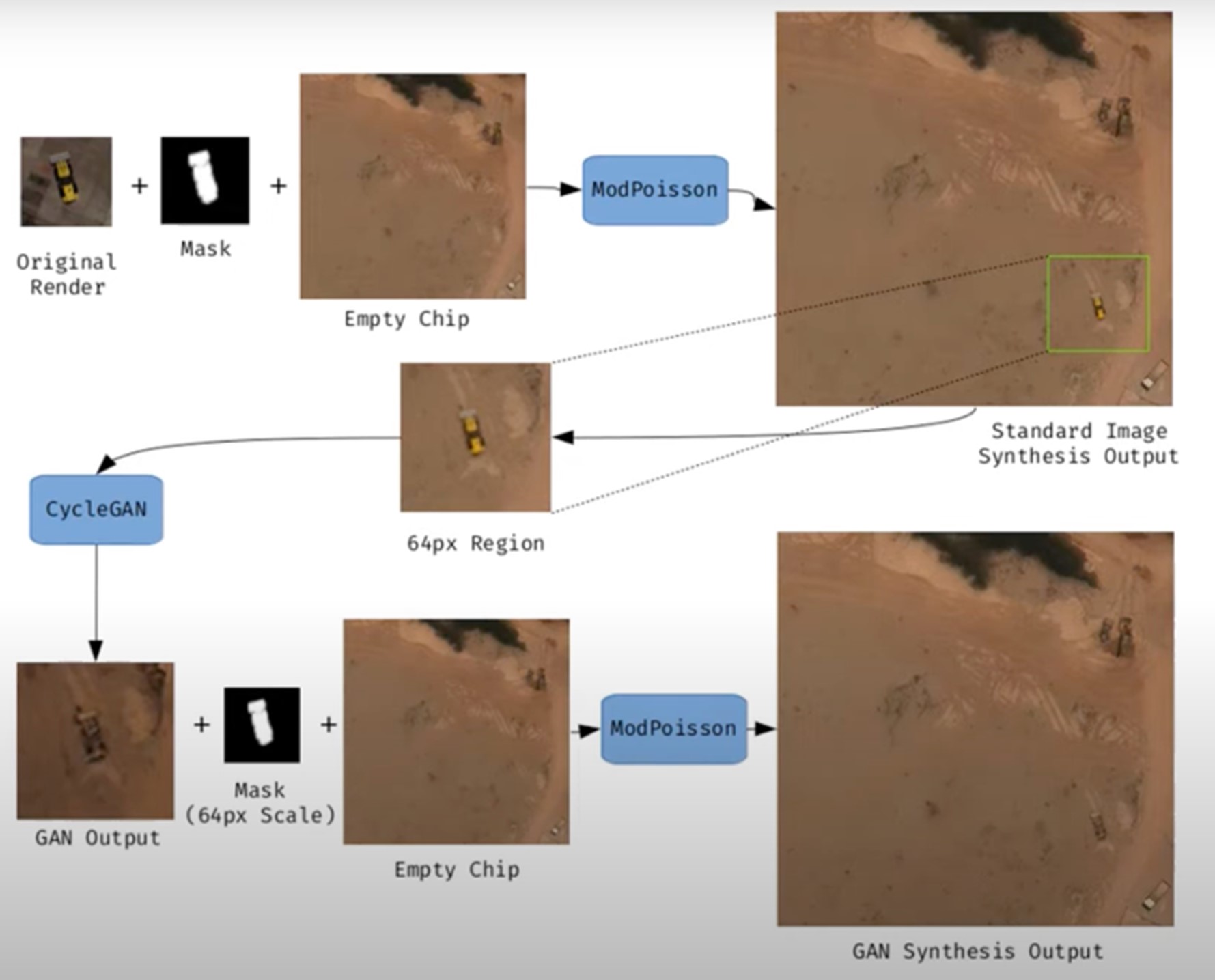
Figura 1. Ejemplo de generación de una imagen satelital sintética.
Su valor no se limita al entrenamiento de modelos. Allí donde no existen imágenes de alta resolución —por limitaciones técnicas, restricciones de acceso o motivos económicos—, la síntesis permite rellenar huecos de información y facilitar estudios preliminares. Por ejemplo, los investigadores pueden trabajar con imágenes sintéticas aproximadas para diseñar modelos de riesgo o simulaciones antes de disponer de datos reales.
Sin embargo, las imágenes satelitales sintéticas también plantean riesgos importantes. La posibilidad de generar escenas muy realistas abre la puerta a la manipulación y a la desinformación. En un contexto geopolítico, una imagen que muestre tropas inexistentes o infraestructuras destruidas podría influir en decisiones estratégicas o en la opinión pública internacional. En el terreno ambiental, se podrían difundir imágenes manipuladas para exagerar o minimizar impactos de fenómenos como la deforestación o el deshielo, con efectos directos en políticas y mercados.
Por ello, conviene diferenciar dos usos muy distintos. El primero es el uso como apoyo, cuando las imágenes sintéticas complementan a las reales para entrenar modelos o realizar simulaciones. El segundo es el uso como falsificación, cuando se presentan deliberadamente como imágenes auténticas con el fin de engañar. Mientras el primer uso impulsa la innovación, el segundo amenaza la confianza en los datos satelitales y plantea un reto urgente de autenticidad y gobernanza.
Riesgos de las imágenes satelitales aplicada a la observación de la Tierra
Las imágenes satelitales sintéticas plantean riesgos significativos cuando se utilizan en vez de imágenes captadas por sensores reales. A continuación, se detallan ejemplos que lo demuestran.
Un nuevo frente de desinformación: “deepfake geography”
El término deepfake geography ya se ha consolidado en la literatura académica y divulgativa para describir imágenes satelitales ficticias, manipuladas con IA, que parecen auténticas, pero no reflejan ninguna realidad existente. Una investigación de la Universidad de Washington, liderada por Bo Zhao, utilizó algoritmos como CycleGAN para modificar imágenes de ciudades reales -por ejemplo, alterando la apariencia de Seattle con edificios inexistentes o transformando Beijing en zonas verdes- lo que pone en evidencia el potencial para generar paisajes falsos convincentes.
Un artículo de la plataforma OnGeo Intelligence (OGC) subraya que estas imágenes no son puramente teóricas, sino amenazas reales que afectan a la seguridad nacional, el periodismo y el trabajo humanitario. Por su parte, el OGC advierte que ya se han observado imágenes satelitales fabricadas, modelos urbanos generados por IA y redes de carreteras sintéticas, y que representan desafíos reales a la confianza pública y operativa.
Implicaciones estratégicas y políticas
Las imágenes satelitales son consideradas "ojos imparciales" sobre el planeta, usadas por gobiernos, medios y organizaciones. Cuando estas imágenes se falsifican, sus consecuencias pueden ser graves:
- Seguridad nacional y defensa: si se presentan infraestructuras falsas o se ocultan otras reales, se pueden desviar análisis estratégicos o inducir decisiones militares equivocadas.
- Desinformación en conflictos o crisis humanitarias: una imagen alterada que muestre incendios, inundaciones o movimientos de tropas falsos puede alterar la respuesta internacional, los flujos de ayuda o la percepción de los ciudadanos, especialmente si se difunde por redes sociales o medios sin verificación.
- Manipulación de imágenes realistas de lugares: no solo las imágenes generales están en juego. Nguyen y colaboradores (2024) demostraron que es posible generar imágenes satelitales sintéticas altamente realistas de instalaciones muy específicas como plantas nucleares.
Crisis de confianza y erosión de la verdad
Durante décadas, las imágenes satelitales han sido percibidas como una de las fuentes más objetivas y fiables de información sobre nuestro planeta. Eran la prueba gráfica que permitía confirmar fenómenos ambientales, seguir conflictos armados o evaluar el impacto de desastres naturales. En muchos casos, estas imágenes se utilizaban como “evidencia imparcial”, difíciles de manipular y fáciles de validar. Sin embargo, la irrupción de las imágenes sintéticas generadas por inteligencia artificial ha empezado a poner en cuestión esa confianza casi inquebrantable.
Hoy en día, cuando una imagen satelital puede ser falsificada con gran realismo, surge un riesgo profundo: la erosión de la verdad y la aparición de una crisis de confianza en los datos espaciales.
La quiebra de la confianza pública
Cuando los ciudadanos ya no pueden distinguir entre una imagen real y una fabricada, se resquebraja la confianza en las fuentes de información. La consecuencia es doble:
- Desconfianza hacia las instituciones: si circulan imágenes falsas de un incendio, una catástrofe o un despliegue militar y luego resultan ser sintéticas, la ciudadanía puede empezar a dudar también de las imágenes auténticas publicadas por agencias espaciales o medios de comunicación. Este efecto “que viene el lobo” genera escepticismo incluso frente a pruebas legítimas.
- Efecto en el periodismo: los medios tradicionales, que han usado históricamente las imágenes satelitales como fuente visual incuestionable, corren el riesgo de perder credibilidad si publican imágenes adulteradas sin verificación. Al mismo tiempo, la abundancia de imágenes falsas en redes sociales erosiona la capacidad de distinguir qué es real y qué no.
- Confusión deliberada: en contextos de desinformación, la mera sospecha de que una imagen pueda ser falsa ya puede bastar para generar duda y sembrar confusión, aunque la imagen original sea completamente auténtica.
A continuación, se resumen los posibles casos de manipulación y riesgo en imágenes satelitales:
| Ámbito | Tipo de manipulación | Riesgo principal | Ejemplo documentado |
|---|---|---|---|
| Conflictos armados | Inserción o eliminación de infraestructuras militares. | Desinformación estratégica; decisiones militares erróneas; pérdida de credibilidad en observación internacional. | Alteraciones demostradas en estudios de deepfake geography donde se añadían carreteras, puentes o edificios ficticios en imágenes satelitales. |
| Cambio climático y medio ambiente | Alteración de glaciares, deforestación o emisiones. | Manipulación de políticas ambientales; retraso en medidas contra el cambio climático; negacionismo. | Estudios han mostrado la capacidad de generar paisajes modificados (bosques en zonas urbanas, cambios en el hielo) mediante GAN. |
| Gestión de emergencias | Creación de desastres inexistentes (incendios, inundaciones). | Mal uso de recursos en emergencias; caos en evacuaciones; pérdida de confianza en agencias. | Investigaciones han demostrado la facilidad de insertar humo, fuego o agua en imágenes satelitales. |
| Mercados y seguros | Falsificación de daños en infraestructuras o cultivos. | Impacto financiero; fraude masivo; litigios legales complejos. | Uso potencial de imágenes falsas para exagerar daños tras desastres y reclamar indemnizaciones o seguros. |
| Derechos humanos y justicia internacional | Alteración de pruebas visuales sobre crímenes de guerra. | Deslegitimación de tribunales internacionales; manipulación de la opinión pública. | Riesgo identificado en informes de inteligencia: imágenes adulteradas podrían usarse para acusar o exonerar a actores en conflictos. |
| Geopolítica y diplomacia | Creación de ciudades ficticias o cambios fronterizos. | Tensiones diplomáticas; cuestionamiento de tratados; propaganda estatal. | Ejemplos de deepfake maps que transforman rasgos geográficos de ciudades como Seattle o Tacoma. |
Figura 2. Tabla con los posibles casos de manipulación y riesgo en imágenes satelitales
Impacto en la toma de decisiones y políticas públicas
Las consecuencias de basarse en imágenes adulteradas van mucho más allá del terreno mediático:
- Urbanismo y planificación: decisiones sobre dónde construir infraestructuras o cómo planificar zonas urbanas podrían tomarse sobre imágenes manipuladas, generando errores costosos y de difícil reversión.
- Gestión de emergencias: si una inundación o un incendio se representan en imágenes falsas, los equipos de emergencia pueden destinar recursos a lugares equivocados, mientras descuidan zonas realmente afectadas.
- Cambio climático y medio ambiente: imágenes adulteradas de glaciares, deforestación o emisiones contaminantes podrían manipular debates políticos y retrasar la implementación de medidas urgentes.
- Mercados y seguros: aseguradoras y empresas financieras que confían en imágenes satelitales para evaluar daños podrían ser engañadas, con consecuencias económicas significativas.
En todos estos casos, lo que está en juego no es solo la calidad de la información, sino la eficacia y legitimidad de las políticas públicas basadas en esos datos.
El juego del gato y el ratón tecnológico
La dinámica de generación y detección de falsificaciones ya se conoce en otros ámbitos, como los deepfakes de vídeo o audio: cada vez que surge un método de generación más realista, se desarrolla un algoritmo de detección más avanzado, y viceversa. En el ámbito de las imágenes satelitales, esta carrera tecnológica tiene particularidades:
- Generadores cada vez más sofisticados: los modelos de difusión actuales pueden crear escenas de gran realismo, integrando texturas de suelo, sombras y geometrías urbanas que engañan incluso a expertos humanos.
- Limitaciones de la detección: aunque se desarrollan algoritmos para identificar falsificaciones (analizando patrones de píxeles, inconsistencias en sombras o metadatos), estos métodos no siempre son fiables cuando se enfrentan a generadores de última generación.
- Coste de la verificación: verificar de forma independiente una imagen satelital requiere acceso a fuentes alternativas o sensores distintos, algo que no siempre está al alcance de periodistas, ONG o ciudadanos.
- Armas de doble filo: las mismas técnicas usadas para detectar falsificaciones pueden ser aprovechadas por quienes las generan, perfeccionando aún más las imágenes sintéticas y haciendo más difícil diferenciarlas.
De la prueba visual a la prueba cuestionada
El impacto más profundo es cultural y epistemológico: lo que antes se asumía como una prueba objetiva ahora se convierte en un elemento sujeto a duda. Si las imágenes satelitales dejan de ser percibidas como evidencia fiable, se debilitan narrativas fundamentales en torno a la verdad científica, la justicia internacional y la rendición de cuentas política.
- En conflictos armados, una imagen de satélite que muestre posibles crímenes de guerra puede ser descartada bajo la acusación de ser un deepfake.
- En tribunales internacionales, pruebas basadas en observación satelital podrían perder peso frente a la sospecha de manipulación.
- En el debate público, el relativismo de “todo puede ser falso” puede usarse como arma retórica para deslegitimar incluso la evidencia más sólida.
Estrategias para garantizar autenticidad
La crisis de confianza en las imágenes satelitales no es un problema aislado del sector geoespacial, sino que forma parte de un fenómeno más amplio: la desinformación digital en la era de la inteligencia artificial. Así como los deepfakes de vídeo han puesto en cuestión la validez de pruebas audiovisuales, la proliferación de imágenes satelitales sintéticas amenaza con debilitar la última frontera de datos percibidos como objetivos: la mirada imparcial desde el espacio.
Garantizar la autenticidad de estas imágenes exige una combinación de soluciones técnicas y mecanismos de gobernanza, capaces de reforzar la trazabilidad, la transparencia y la responsabilidad en toda la cadena de valor de los datos espaciales. A continuación, se describen las principales estrategias en desarrollo.
Metadatos robustos: registrar el origen y la cadena de custodia
Los metadatos constituyen la primera línea de defensa frente a la manipulación. En imágenes satelitales, deben incluir información detallada sobre:
- El sensor utilizado (tipo, resolución, órbita).
- El momento exacto de la adquisición (fecha y hora, con precisión temporal).
- La localización geográfica precisa (sistemas de referencia oficiales).
- La cadena de procesado aplicada (correcciones atmosféricas, calibraciones, reproyecciones).
Registrar estos metadatos en repositorios seguros permite reconstruir la cadena de custodia, es decir, el historial de quién, cómo y cuándo ha manipulado una imagen. Sin esta trazabilidad, resulta imposible distinguir entre imágenes auténticas y falsificadas.
EJEMPLO: el programa Copernicus de la Unión Europea ya implementa metadatos estandarizados y abiertos para todas sus imágenes Sentinel, lo que facilita auditorías posteriores y confianza en el origen.
Firmas digitales y blockchain: garantizar la integridad
Las firmas digitales permiten verificar que una imagen no ha sido alterada desde su captura. Funcionan como un sello criptográfico que se aplica en el momento de adquisición y se valida en cada uso posterior.
La tecnología blockchain ofrece un nivel adicional de garantía: almacenar los registros de adquisición y modificación en una cadena inmutable de bloques. De esta manera, cualquier cambio en la imagen o en sus metadatos quedaría registrado y sería fácilmente detectable.
EJEMPLO: el proyecto ESA – Trusted Data Framework explora el uso de blockchain para proteger la integridad de datos de observación de la Tierra y reforzar la confianza en aplicaciones críticas como cambio climático y seguridad alimentaria.
Marcas de agua invisible: señales ocultas en la imagen
El marcado de agua digital consiste en incrustar señales imperceptibles en la propia imagen satelital, de modo que cualquier alteración posterior se pueda detectar automáticamente.
- Puede hacerse a nivel de píxel, modificando ligeramente patrones de color o luminancia.
- Se combina con técnicas criptográficas para reforzar su validez.
- Permite validar imágenes incluso si han sido recortadas, comprimidas o reprocesadas.
EJEMPLO: en el sector audiovisual, las marcas de agua se usa desde hace años en la protección de contenidos digitales. Su adaptación a imágenes satelitales está en fase experimental, pero podría convertirse en una herramienta estándar de verificación.
Estándares abiertos (OGC, ISO): confianza mediante interoperabilidad
La estandarización es clave para garantizar que las soluciones técnicas se apliquen de forma coordinada y global.
- OGC (Open Geospatial Consortium) trabaja en estándares para la gestión de metadatos, la trazabilidad de datos geoespaciales y la interoperabilidad entre sistemas. Su trabajo en API geoespaciales y metadatos FAIR (Findable, Accessible, Interoperable, Reusable) es esencial para establecer prácticas comunes de confianza.
- ISO desarrolla normas sobre gestión de la información y autenticidad de registros digitales que también pueden aplicarse a imágenes satelitales.
EJEMPLO: el OGC Testbed-19 incluyó experimentos específicos sobre autenticidad de datos geoespaciales, probando enfoques como firmas digitales y certificados de procedencia.
Verificación cruzada: combinar múltiples fuentes
Un principio básico para detectar falsificaciones es contrastar fuentes. En el caso de imágenes satelitales, esto implica:
- Comparar imágenes de diferentes satélites (ej. Sentinel-2 vs. Landsat-9).
- Usar distintos tipos de sensores (ópticos, radar SAR, hiperespectrales).
- Analizar series temporales para verificar la consistencia en el tiempo.
EJEMPLO: la verificación de daños en Ucrania tras el inicio de la invasión rusa en 2022 se realizó mediante la comparación de imágenes de varios proveedores (Maxar, Planet, Sentinel), asegurando que los hallazgos no se basaban en una sola fuente.
IA contra IA: detección automática de falsificaciones
La misma inteligencia artificial que permite crear imágenes sintéticas se puede utilizar para detectarlas. Las técnicas incluyen:
- Análisis forense de píxeles: identificar patrones generados por GAN o modelos de difusión.
- Redes neuronales entrenadas para distinguir entre imágenes reales y sintéticas en función de texturas o distribuciones espectrales.
- Modelos de inconsistencias geométricas: detectar sombras imposibles, incoherencias topográficas o patrones repetitivos.
EJEMPLO: investigadores de la Universidad de Washington y otros grupos han demostrado que algoritmos específicos pueden detectar falsificaciones satelitales con una precisión superior al 90% en condiciones controladas.
Experiencias actuales: iniciativas globales
Varios proyectos internacionales ya trabajan en mecanismos para reforzar la autenticidad:
- Coalition for Content Provenance and Authenticity (C2PA): una alianza entre Adobe, Microsoft, BBC, Intel y otras organizaciones para desarrollar un estándar abierto de procedencia y autenticidad de contenidos digitales, incluyendo imágenes. Su modelo se puede aplicar directamente al sector satelital.
- Trabajo del OGC: la organización impulsa el debate sobre confianza en datos geoespaciales y ha destacado la importancia de garantizar la trazabilidad de imágenes satelitales sintéticas y reales (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) en EE. UU. ha reconocido públicamente la amenaza de imágenes sintéticas en defensa y está impulsando colaboraciones con academia e industria para desarrollar sistemas de detección.
Hacia un ecosistema de confianza
Las estrategias descritas no deben entenderse como alternativas, sino como capas complementarias en un ecosistema de confianza:
|
Id |
Capas |
¿Qué aportan? |
|---|---|---|
| 1 | Metadatos robustos (origen, sensor, cadena de custodia) |
Garantizan trazabilidad |
| 2 | Firmas digitales y blockchain (integridad de datos) |
Aseguran integridad |
| 3 | Marcas de agua invisible (señales ocultas) |
Añade un nivel oculto de protección |
| 4 | Verificación cruzada (múltiples satélites y sensores) |
Valida con independencia |
| 5 | IA contra IA (detector de falsificaciones) |
Responde a amenazas emergentes |
| 6 | Gobernanza internacional (responsabilidad, marcos legales) |
Articula reglas claras de responsabilidad |
Figura 3. Capas para garantizar la confianza en las imágenes sintéticas satelitales
El éxito dependerá de que estos mecanismos se integren de manera conjunta, bajo marcos abiertos y colaborativos, y con la implicación activa de agencias espaciales, gobiernos, sector privado y comunidad científica.
Conclusiones
Las imágenes sintéticas, lejos de ser únicamente una amenaza, representan una herramienta poderosa que, bien utilizada, puede aportar un valor significativo en ámbitos como la simulación, el entrenamiento de algoritmos o la innovación en servicios digitales. El problema surge cuando estas imágenes se presentan como reales sin la debida transparencia, alimentando la desinformación o manipulando la percepción pública.
El reto, por tanto, es doble: aprovechar las oportunidades que ofrece la síntesis de datos visuales para avanzar en ciencia, tecnología y gestión, y minimizar los riesgos asociados al mal uso de estas capacidades, especialmente en forma de deepfakes o falsificaciones deliberadas.
En el caso particular de las imágenes satelitales, la confianza adquiere una dimensión estratégica. De ellas dependen decisiones críticas en seguridad nacional, respuesta a desastres, políticas ambientales y justicia internacional. Si la autenticidad de estas imágenes se pone en duda, se compromete no solo la fiabilidad de los datos, sino también la legitimidad de las decisiones basadas en ellos.
El futuro de la observación de la Tierra estará condicionado por nuestra capacidad de garantizar la autenticidad, transparencia y trazabilidad en toda la cadena de valor: desde la adquisición de los datos hasta su difusión y uso final. Las soluciones técnicas (metadatos robustos, firmas digitales, blockchain, marcas de agua, verificación cruzada e IA para detección de falsificaciones), combinadas con marcos de gobernanza y cooperación internacional, serán la clave para construir un ecosistema de confianza.
En definitiva, debemos asumir un principio rector sencillo pero contundente:
“Si no podemos confiar en lo que vemos desde el espacio, ponemos en riesgo nuestras decisiones en la Tierra.”
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los asistentes de inteligencia artificial (IA) ya forman parte de nuestro día a día: les preguntamos la hora, cómo llegar a un determinado lugar o les pedimos que reproduzcan nuestra canción favorita. Y aunque la IA, en el futuro, pueda llegar a ofrecernos infinitas funcionalidades, no hay que olvidar que la diversidad lingüística es aún una asignatura pendiente.
En España, donde conviven el castellano junto con lenguas cooficiales como el euskera, catalán, valenciano y gallego, esta cuestión cobra especial relevancia. La supervivencia y vitalidad de estas lenguas en la era digital depende, en gran medida, de su capacidad para adaptarse y estar presentes en las tecnologías emergentes. Actualmente, la mayoría de asistentes virtuales, traductores automáticos o sistemas de reconocimiento de voz no entienden todos los idiomas cooficiales. Sin embargo, ¿sabías que existen proyectos colaborativos para garantizar la diversidad lingüística?
En este post te contamos el planteamiento y los mayores avances de algunas iniciativas que están construyendo los cimientos digitales necesarios para que las lenguas cooficiales en España también prosperen en la era de la inteligencia artificial.
ILENIA, el paraguas coordinador de iniciativas de recursos multilingües en España
Los modelos que vamos a ver en este post comparten enfoque porque forman parte de ILENIA, coordinador a nivel estatal que conecta los esfuerzos individuales de las comunidades autónomas. Esta iniciativa agrupa los proyectos BSC-CNS (AINA), CENID (VIVES), HiTZ (NEL-GAITU) y la Universidad de Santiago de Compostela (NÓS), con el objetivo de generar recursos digitales que permitan desarrollar aplicaciones multilingües en las diferentes lenguas de España.
El éxito de estas iniciativas depende fundamentalmente de la participación ciudadana. A través de plataformas como Common Voice de Mozilla, cualquier hablante puede contribuir a la construcción de estos recursos lingüísticos mediante diferentes modalidades de colaboración:
- Habla leída: recopilar diferentes maneras de hablar a través de las donaciones de voz de un texto específico.
- Habla espontánea: crea datasets reales y orgánicos fruto de conversaciones con los prompts.
- Texto en idioma: colaborar en la transcripción de audios o en la aportación de contenido textual, sugiriendo nuevas frases o preguntas para enriquecer los corpus.
Todos los recursos se publican bajo licencias libres como CC0, permitiendo su uso gratuito por parte de investigadores, desarrolladores y empresas.
El reto de la diversidad lingüística en la era digital
Los sistemas de inteligencia artificial aprenden de los datos que reciben durante su entrenamiento. Para desarrollar tecnologías que funcionen correctamente en una lengua específica, es imprescindible contar con grandes volúmenes de datos: grabaciones de audio, corpus de texto y ejemplos de uso real del idioma.
En otras publicaciones de datos.gob.es hemos abordado el funcionamiento de los modelos fundacionales y las iniciativas en castellano como ALIA, entrenadas con grandes corpus de texto como los de la Real Academia Española.
En ambos posts se explica por qué la recopilación de datos lingüísticos no es una tarea barata ni sencilla. Las empresas tecnológicas han invertido masivamente en recopilar estos recursos para lenguas con gran número de hablantes, pero las lenguas cooficiales españolas se enfrentan a una desventaja estructural. Esto ha llevado a que muchos modelos no funcionen correctamente o no estén disponibles en valenciano, catalán, euskera o gallego.
No obstante, existen iniciativas colaborativas y de datos abiertos que permiten crear recursos lingüísticos de calidad. Se trata de los proyectos que varias comunidades autónomas han puesto en marcha marcando el camino hacia un futuro digital multilingüe.
Por un lado, el Proyecto Nós en Galicia crea recursos orales y conversacionales en gallego con todos los acentos y variantes dialectales para facilitar la integración a través de herramientas como GPS, asistentes de voz o ChatGPT. Un propósito similar el de Aina en Catalunya que además ofrece una plataforma académica y un laboratorio para desarrolladores o Vives en la Comunidad Valenciana. En el País Vasco también existe el proyecto Euskorpus que tiene como objetivo la constitución de un corpus de texto de calidad en euskera. Veamos cada uno de ellos.
Proyecto Nós, un enfoque colaborativo para el gallego digital
El proyecto ha desarrollado ya tres herramientas operativas: un traductor neuronal multilingüe, un sistema de reconocimiento de voz que convierte habla en texto, y una aplicación de síntesis de voz. Estos recursos se publican bajo licencias abiertas, garantizando su acceso libre y gratuito para investigadores, desarrolladores y empresas. Estas son sus características principales:
- Impulsado por: la Xunta de Galicia y la Universidad de Santiago de Compostela.
- Objetivo principal: crear recursos orales y conversacionales en gallego que capturen la diversidad dialectal y de acentos de la lengua.
- Cómo participar: el proyecto acepta contribuciones voluntarias tanto leyendo textos como respondiendo a preguntas espontáneas.
- Dona tu voz en gallego: https://doagalego.nos.gal
Aina, hacia una IA que entienda y hable catalán
Con un planteamiento similar al proyecto Nós, Aina busca facilitar la integración del catalán en los modelos de lenguaje de inteligencia artificial.
Se estructura en dos vertientes complementarias que maximizan su impacto:
- Aina Tech se centra en facilitar la transferencia tecnológica al sector empresarial, proporcionando las herramientas necesarias para traducir automáticamente al catalán webs, servicios y negocios en línea.
- Aina Lab impulsa la creación de una comunidad de desarrolladores a través de iniciativas como Aina Challenge, fomentando la innovación colaborativa en tecnologías del lenguaje en catalán. A través de esta convocatoria se han premiado 22 propuestas ya seleccionadas con un importe total de 1 millón para que ejecuten sus proyectos.
Las características del proyecto son:
- Impulsado por: la Generalitat de Catalunya en colaboración con el Barcelona Supercomputing Center (BSC-CNS)
- Objetivo principal: va más allá de la creación de herramientas, busca construir una infraestructura de IA abierta, transparente y responsable con el catalán.
- Cómo participar: puedes añadir comentarios, mejoras y sugerencias a través del buzón de contacto: https://form.typeform.com/to/KcjhThot?typeform-source=langtech-bsc.gitbook.io.
Vives, el proyecto colaborativo para IA en valenciano
Por otro lado, Vives recopila voces hablando en valenciano para que sirvan de entrenamiento a los modelos de IA.
- Impulsado por: el Centro de Inteligencia Digital de Alicante (CENID).
- Objetivo: busca crear corpus masivos de texto y voz, fomentar la participación ciudadana en la recolección de datos, y desarrollar modelos lingüísticos especializados en sectores como el turismo y el audiovisual, garantizando la privacidad de los datos.
- Cómo participar: puedes donar tu voz a través de este enlace: https://vives.gplsi.es/instruccions/.
Gaitu: inversión estratégica en la digitalización del euskera
En Euskera, podemos destacar Gaitu que busca recopilar voces hablando en euskera para poder entrenar los modelos de IA. Sus características son:
- Impulsado por: HiTZ, el centro vasco de tecnología de la lengua.
- Objetivo: desarrollar un corpus en euskera para entrenar modelos de IA.
- Cómo participar: puedes donar tu voz en euskera aquí https://commonvoice.mozilla.org/eu/speak.
Ventajas de construir y preservar modelos de lenguaje multilingües
Los proyectos de digitalización de las lenguas cooficiales trascienden el ámbito puramente tecnológico para convertirse en herramientas de equidad digital y preservación cultural. Su impacto se manifiesta en múltiples dimensiones:
- Para la ciudadanía: estos recursos garantizan que hablantes de todas las edades y niveles de competencia digital puedan interactuar con la tecnología en su lengua materna, eliminando barreras que podrían excluir a determinados colectivos del ecosistema digital.
- Para el sector empresarial: la disponibilidad de recursos lingüísticos abiertos facilita que empresas y desarrolladores puedan crear productos y servicios en estas lenguas sin asumir los altos costes tradicionalmente asociados al desarrollo de tecnologías lingüísticas.
- Para el tejido investigador, estos corpus constituyen una base fundamental para el avance de la investigación en procesamiento de lenguaje natural y tecnologías del habla, especialmente relevante para lenguas con menor presencia en recursos digitales internacionales.
El éxito de estas iniciativas demuestra que es posible construir un futuro digital donde la diversidad lingüística no sea un obstáculo sino una fortaleza, y donde la innovación tecnológica se ponga al servicio de la preservación y promoción del patrimonio cultural lingüístico.
Documentación
En el campo de la ciencia de datos, la capacidad de construir modelos predictivos robustos es fundamental. Sin embargo, un modelo no es solo un conjunto de algoritmos, es una herramienta que debe ser comprendida, validada y, en última instancia, útil para la toma de decisiones.
Gracias a la transparencia y accesibilidad de los datos abiertos, tenemos la oportunidad única de trabajar en este ejercicio con información real, actualizada y de calidad institucional que refleja problemáticas ambientales. Esta democratización del acceso permite no solo desarrollar análisis rigurosos con datos oficiales, sino también contribuir al debate público informado sobre políticas ambientales, creando un puente directo entre la investigación científica y las necesidades sociales.
En este ejercicio práctico, nos sumergiremos en el ciclo de vida completo de un proyecto de modelado, utilizando un caso de estudio real: el análisis de la calidad del aire en Castilla y León. A diferencia de los enfoques que se centran únicamente en la implementación de algoritmos, nuestra metodología se enfoca en:
- Carga y exploración inicial de los datos: identificar patrones, anomalías y relaciones subyacentes que guiarán nuestro modelado.
- Análisis exploratorio orientado al modelado: construir visualizaciones y realizar ingeniería de características para optimizar el modelado.
- Desarrollo y evaluación de modelos de regresión: construir y comparar múltiples modelos iterativos para entender cómo la complejidad afecta el rendimiento.
- Aplicación del modelo y conclusiones: utilizar el modelo final para simular escenarios y cuantificar el impacto de posibles políticas ambientales.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Arquitectura del Análisis
El núcleo de este ejercicio sigue un flujo estructurado en cuatro fases clave, como se ilustra en la Figura 1. Cada fase se construye sobre la anterior, desde la exploración inicial de los datos hasta la aplicación final del modelo.

Figura 1. Fases del proyecto de modelado predictivo.
Proceso de Desarrollo
1. Carga y exploración inicial de los datos
El primer paso es entender la materia prima de nuestro análisis: los datos. Utilizando un conjunto de datos de calidad del aire de Castilla y León, que abarca 24 años de mediciones, nos enfrentamos a desafíos comunes en el mundo real:
- Valores Faltantes: variables como el CO y el PM2.5 tienen una cobertura de datos limitada.
- Datos Anómalos: se detectan valores negativos y extremos, probablemente debidos a errores de los sensores.
A través de un proceso de limpieza y transformación, convertimos los datos brutos en un conjunto de datos limpio y estructurado, listo para el modelado.
2. Análisis exploratorio orientado al modelado
Una vez limpios los datos, buscamos patrones. El análisis visual revela una fuerte estacionalidad en los niveles de NO₂, con picos en invierno y valles en verano. Esta observación es crucial y nos lleva a la creación de nuevas variables (ingeniería de características), como componentes cíclicos para los meses, que permiten al modelo "entender" la naturaleza circular de las estaciones.

Figura 2. Variación estacional de los niveles de NO₂ en Castilla y León.
3. Desarrollo y evaluación de modelos de regresión
Con un conocimiento sólido de los datos, procedemos a construir tres modelos de regresión lineal de complejidad creciente:
- Modelo Base: utiliza solo los contaminantes como predictores.
- Modelo Estacional: añade las variables de tiempo.
- Modelo Completo: incluye interacciones y efectos geográficos.
La comparación de estos modelos nos permite cuantificar la mejora en la capacidad predictiva. El Modelo Estacional emerge como la opción óptima, explicando casi el 63% de la variabilidad del NO₂, un resultado notable para datos ambientales.
4. Aplicación del modelo y conclusiones
Finalmente, sometemos el modelo a un riguroso diagnóstico y lo utilizamos para simular el impacto de políticas ambientales. Por ejemplo, nuestro análisis estima que una reducción del 20% en las emisiones de NO podría traducirse en una disminución del 4.8% en los niveles de NO₂.

Figura 3. Rendimiento del modelo estacional. Los valores predichos se alinean bien con los valores reales.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Ciclo de vida de un proyecto de datos: desde la limpieza hasta la aplicación.
- Técnicas de regresión lineal: construcción, interpretación y diagnóstico.
- Manejo de datos temporales: captura de estacionalidad y tendencias.
- Validación de modelos: técnicas como la validación cruzada y temporal.
- Comunicación de resultados: cómo traducir hallazgos en insights accionables.
Conclusiones y Futuro
Este ejercicio demuestra el poder de un enfoque estructurado y riguroso en la ciencia de datos. Hemos transformado un conjunto de datos complejo en un modelo predictivo que no solo es preciso, sino también interpretable y útil.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades son numerosas:
- Incorporación de datos meteorológicos: variables como la temperatura y el viento podrían mejorar significativamente la precisión.
- Modelos más avanzados: explorar técnicas como los Modelos Aditivos Generalizados (GAM) u otros algoritmos de machine learning.
- Análisis espacial: investigar cómo varían los patrones de contaminación entre diferentes ubicaciones.
En resumen, este ejercicio no solo ilustra la aplicación de técnicas de regresión, sino que también subraya la importancia de un enfoque integral que combine el rigor estadístico con la relevancia práctica.
Blog
La participación ciudadana en la recopilación de datos científicos impulsa una ciencia más democrática, al involucrar a la sociedad en los procesos de I+D+i y reforzar la rendición de cuentas. En este sentido, existen diversidad de iniciativas de ciencia ciudadana puestas en marcha por entidades como CSIC, CENEAM o CREAF, entre otras. Además, actualmente, existen numerosas plataformas de plataformas de ciencia ciudadana que ayudan a cualquier persona a encontrar, unirse y contribuir a una gran diversidad de iniciativas alrededor del mundo, como por ejemplo SciStarter.
Algunas referencias en legislación nacional y europea
Diferentes normativas, tanto a nivel nacional como a nivel europeo, destacan la importancia de promover proyectos de ciencia ciudadana como componente fundamental de la ciencia abierta. Por ejemplo, la Ley Orgánica 2/2023, de 22 de marzo, del Sistema Universitario, establece que las universidades promoverán la ciencia ciudadana como un instrumento clave para generar conocimiento compartido y responder a retos sociales, buscando no solo fortalecer el vínculo entre ciencia y sociedad, sino también contribuir a un desarrollo territorial más equitativo, inclusivo y sostenible.
Por otro lado, la Ley 14/2011, de 1 de junio, de la Ciencia, la Tecnología y la Innovación, promueve “la participación de la ciudadanía en el proceso científico técnico a través, entre otros mecanismos, de la definición de agendas de investigación, la observación, recopilación y procesamiento de datos, la evaluación de impacto en la selección de proyectos y la monitorización de resultados, y otros procesos de participación ciudadana”.
A nivel europeo, el Reglamento (UE) 2021/695 que establece el Programa Marco de Investigación e Innovación “Horizonte Europa”, indica la oportunidad de desarrollar proyectos codiseñados con la ciudadanía, avalando la ciencia ciudadana como mecanismo de investigación y vía de difusión de resultados.
Iniciativas de ciencia ciudadana y planes de gestión de datos
El primer paso para definir una iniciativa de ciencia ciudadana suele ser establecer una pregunta de investigación que necesite de una recopilación de datos que pueda abordarse con la colaboración de la ciudadanía. Después, se diseña un protocolo accesible para que los participantes recojan o analicen datos de forma sencilla y fiable (incluso podría ser un proceso gamificado). Se deben preparar materiales formativos y desarrollar un medio de participación (aplicación, web o incluso papel). También se planifica cómo comunicar avances y resultados a la ciudadanía, incentivando su participación.
Al tratarse de una actividad intensiva en la recolección de datos, es interesante que los proyectos de ciencia ciudadana dispongan de un plan de gestión de datos que defina el ciclo de vida del dato en proyectos de investigación, es decir cómo se crean, organizan, comparten, reutilizan y preservan los datos en iniciativas de ciencia ciudadana. Sin embargo, la mayoría de las iniciativas de ciencia ciudadana no dispone de este plan: en este reciente artículo de investigación se encontró que sólo disponían de plan de gestión de datos el 38% de proyectos de ciencia ciudadana consultados.

Figura 1. Ciclo de vida del dato en proyectos de ciencia ciudadana Fuente: elaboración propia – datos.gob.es.
Por otra parte, los datos procedentes de la ciencia ciudadana solo alcanzan todo su potencial cuando cumplen los principios FAIR y se publican en abierto. Con el fin de ayudar a tener este plan de gestión de datos que hagan que los datos procedentes de iniciativas de ciencia ciudadana sean FAIR, es preciso contar con estándares específicos para ciencia ciudadana como PPSR Core.
Datos abiertos para ciencia ciudadana con el estándar PPSR Core
La publicación de datos abiertos debe considerarse desde etapas tempranas de un proyecto de ciencia ciudadana, incorporando el estándar PPSR Core como pieza clave. Como mencionábamos anteriormente, cuando se formulan las preguntas de investigación, en una iniciativa de ciencia ciudadana, se debe plantear un plan de gestión de datos que indique qué datos recopilar, en qué formato y con qué metadatos, así como las necesidades de limpieza y aseguramiento de calidad a partir de los datos que recolecte la ciudadanía, además de un calendario de publicación.
Luego, se debe estandarizar con PPSR (Public Participation in Scientific Research) Core. PPSR Core es un conjunto de estándares de datos y metadatos, especialmente diseñados para fomentar la participación ciudadana en procesos de investigación científica. Posee una arquitectura de tres capas a partir de un Common Data Model (CDM). Este CDM ayuda a organizar de forma coherente y conectada la información sobre proyectos de ciencia ciudadana, los conjuntos de datos relacionados y las observaciones que forman parte de ellos, de tal manera que el CDM facilita la interoperabilidad entre plataformas de ciencia ciudadana y disciplinas científicas. Este modelo común se estructura en tres capas principales que permiten describir de forma estructurada y reutilizable los elementos clave de un proyecto de ciencia ciudadana. La primera es el Project Metadata Model (PMM), que recoge la información general del proyecto, como su objetivo, público participante, ubicación, duración, personas responsables, fuentes de financiación o enlaces relevantes. En segundo lugar, el Dataset Metadata Model (DMM) documenta cada conjunto de datos generado, detallando qué tipo de información se recopila, mediante qué método, en qué periodo, bajo qué licencia y con qué condiciones de acceso. Por último, el Observation Data Model (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores). (ODM) se centra en cada observación individual realizada por los participantes de la iniciativa de ciencia ciudadana, incluyendo la fecha y el lugar de la observación y el resultado. Es interesante resaltar que este modelo de capas de PPSR-Core permite añadir extensiones específicas según el ámbito científico, apoyándose en vocabularios existentes como Darwin Core (biodiversidad) o ISO 19156 (mediciones de sensores).

Figura 2. Arquitectura de capas de PPSR CORE. Fuente: elaboración propia – datos.gob.es.
Esta separación permite que una iniciativa de ciencia ciudadana pueda federar automáticamente la ficha del proyecto (PMM) con plataformas como SciStarter, compartir un conjunto de datos (DMM) con un repositorio institucional de datos abiertos científicos, como aquellos agregados en RECOLECTA del FECYT y, al mismo tiempo, enviar observaciones verificadas (ODM) a una plataforma como GBIF sin redefinir cada campo.
Además, el uso de PPSR Core aporta una serie de ventajas para la gestión de los datos de una iniciativa de ciencia ciudadana:
- Mayor interoperabilidad: plataformas como SciStarter ya intercambian metadatos usando PMM, por lo que se evita duplicar información.
- Agregación multidisciplinar: los perfiles del ODM permiten unir conjuntos de datos de dominios distintos (por ejemplo, calidad del aire y salud) alrededor de atributos comunes, algo crucial para estudios multidisciplinares.
- Alineamiento con principios FAIR: los campos obligatorios del DMM son útiles para que los conjuntos de datos de ciencia ciudadana cumplan los principios FAIR.
Cabe destacar que PPSR Core permite añadir contexto a los conjuntos de datos obtenidos en iniciativas de ciencia ciudadana. Es una buena práctica trasladar el contenido del PMM a lenguaje entendible por la ciudadanía, así como obtener un diccionario de datos a partir del DMM (descripción de cada campo y unidad) y los mecanismos de transformación de cada registro a partir del ODM. Finalmente, se puede destacar iniciativas para mejorar PPSR Core, por ejemplo, a través de un perfil de DCAT para ciencia ciudadana.
Conclusiones
Planificar la publicación de datos abiertos desde el inicio de un proyecto de ciencia ciudadana es clave para garantizar la calidad y la interoperabilidad de los datos generados, facilitar su reutilización y maximizar el impacto científico y social del proyecto. Para ello, PPSR Core ofrece un estándar basado en niveles (PMM, DMM, ODM) que conecta los datos generados por la ciencia ciudadana con diversas plataformas, potenciando que estos datos cumplan los principios FAIR y considerando, de manera integrada, diversas disciplinas científicas. Con PPSR Core cada observación ciudadana se convierte fácilmente en datos abiertos sobre el que la comunidad científica pueda seguir construyendo conocimiento para el beneficio de la sociedad.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En un mundo cada vez más complejo, las decisiones públicas necesitan más que intuición: requieren evidencia científica. Aquí es donde entran en juego las iniciativas de I+P (Innovación + Política Pública): una intersección entre creatividad, conocimiento basado en datos y acción política.
En este artículo vamos a explicar este concepto, incluyendo ejemplos e información sobre programas de financiación.
¿Qué es I+P?
I+P no es una fórmula matemática, sino una práctica estratégica que combina el conocimiento científico, la investigación y la participación ciudadana para mejorar la formulación, implementación y evaluación de políticas públicas. No se trata únicamente de aplicar tecnología a lo público, sino de repensar cómo se toman las decisiones, cómo se formulan soluciones y cómo se involucra a la sociedad en estos procesos a través de la aplicación de metodologías científicas.
Esta idea nace del concepto “ciencia para las políticas públicas”, también conocida como “ciencia para la política” o “Science for Policy” (S4P) e implica la colaboración activa entre las administraciones públicas y la comunidad científica.
Las iniciativas de I+P promueven la evidencia empírica y la experimentación. Para ello, impulsan el uso de datos, tecnologías emergentes, pruebas piloto, metodologías ágiles y ciclos de retroalimentación que ayudan a diseñar políticas más eficientes y eficaces, centradas en las necesidades reales de la ciudadanía. Gracias a ello se facilita la toma de decisiones en tiempo real y la posibilidad de realizar ajustes ágiles ante situaciones que requieren respuestas rápidas. En definitiva, se trata de dar respuestas más creativas y acertadas a los retos de hoy en día, como pueden ser el cambio climático o la desigualdad digital, áreas donde las políticas tradicionales se pueden quedar cortas.
El siguiente visual resume estos y otros beneficios.

Fuente: Convocatoria de innovación pública de FECYT- adaptado por datos.gob.es.
Ejemplos de iniciativas de I+P
El uso de datos para la toma de decisiones políticas quedó patente durante la pandemia de COVID-19, donde los responsables políticos iban adaptando las medidas a tomar en base a los reportes de instituciones como la Organización Mundial de la Salud (OMS). Pero más allá de este tipo de acontecimientos extraordinarios, hoy en día encontramos iniciativas consolidadas que buscan cada vez más promover la innovación y la toma de decisiones fundamentada en datos científicos en el ámbito público de forma continua. Veamos dos ejemplos.
-
Informes periódicos de instituciones científicas para acercar el conocimiento científico a la toma de decisiones públicas
Los informes científicos sobre temas como el cambio climático, la resistencia bacteriana o la producción alimentaria son ejemplos de cómo la ciencia puede orientar decisiones políticas informadas.
La iniciativa Science4Policy del Consejo Superior de Investigaciones Científicas (CSIC) es un ejemplo de ello. Se trata de una colección de informes temáticos que presentan evidencias sólidas, generadas en sus centros de investigación, sobre problemas sociales relevantes. Cada informe incluye:
- Una introducción al problema y su impacto social.
- Información sobre la investigación desarrollada por el CSIC sobre el tema.
- Conclusiones y recomendaciones para políticas públicas.
Su objetivo principal es transformar el conocimiento científico en aportaciones accesibles para públicos no especializados, facilitando así decisiones informadas por parte de los poderes públicos.
-
Los laboratorios de innovación pública, un espacio para la creatividad basada en la ciencia
Los laboratorios de innovación pública o GovLabs son espacios experimentales que permiten a empleados públicos, científicos, expertos en diversas materias y ciudadanos co-crear políticas, prototipar soluciones y aprender de forma iterativa.
Un ejemplo es el Laboratorio de Innovación Pública (LIP) impulsado por el Instituto Nacional de Administración Pública (INAP), donde se han realizado pilotos sobre el uso de tecnologías para impulsar el puesto de trabajo de nueva generación, la colaboración intermunicipal para compartir talento o la descentralización de pruebas selectivas. Además, cuentan con un Catálogo de Recursos de Innovación donde se recopilan herramientas con licencias abiertas puestas en marcha por diversos organismos y que pueden servir de apoyo a los emprendedores públicos.
También cabe la pena destacar a la Red Española de Innovación Pública y Transferencia Científica, impulsada por la Fundación NovaGob. Es un espacio colaborativo que reúne a profesionales, administraciones públicas, universidades y organizaciones del tercer sector con el objetivo de transformar la gestión pública en España. A través de grupos de trabajo y repositorios de buenas prácticas, impulsa el uso de la inteligencia artificial, la simplificación administrativa y la mejora de la atención ciudadana.
También encontramos laboratorios de innovación pública a nivel regional, como, por ejemplo Govtechlab Madrid, un proyecto liderado por la Fundación para el Conocimiento madri+d que conecta startups y pymes digitales con instituciones públicas para resolver retos reales. Durante el curso 2023/2024, lanzaron 9 pilotos, por ejemplo, para recopilar y analizar la opinión de la ciudadanía para tomar mejores decisiones en el Ayuntamiento de Alcobendas, unificar la toma y gestión de datos en las inscripciones de las actividades del Área de Juventud del Ayuntamiento de Boadilla del Monte o proporcionar información veraz y actualizada de manera digital sobre el tejido comercial mostoleño.
El papel de los gobiernos e instituciones públicas
La innovación en política pública puede estar impulsada por una diversidad de actores: administraciones públicas abiertas al cambio, universidades y centros de investigación, startups cívicas y empresas tecnológicas, organizaciones de la sociedad civil o ciudadanos comprometidos.
La Comisión Europea, por ejemplo, desempeña un papel clave en el fortalecimiento del ecosistema de ciencia para la política en Europa, promoviendo el uso efectivo del conocimiento científico en la toma de decisiones a todos los niveles: europeo, nacional, regional y local. A través de programas como Horizonte Europa y la Agenda de Política del Espacio Europeo de Investigación 2025-2027, se impulsan acciones para desarrollar capacidades, compartir buenas prácticas y alinear la investigación con las necesidades sociales.
En España también encontramos acciones como la reciente convocatoria de financiación de la Fundación Española para la Ciencia y la Tecnología (FECYT), el Ministerio de Ciencia, Innovación y Universidades, y la Oficina Nacional de Asesoramiento Científico, cuyo objetivo es impulsar:
- Proyectos de investigación que generen nuevas evidencias científicas aplicables al diseño de políticas públicas (Categoría A).
- Actividades de asesoramiento científico y transferencia de conocimiento entre investigadores y responsables públicos (Categoría B).
Los proyectos pueden recibir hasta 100.000 euros (Categoría A) o 25.000 euros (Categoría B), cubriendo hasta el 90% del coste total. Pueden participar organismos de investigación, universidades, entidades sanitarias, centros tecnológicos, centros de I+D y otros actores que promuevan la transferencia de la I+D. El plazo para solicitar la ayuda finaliza el próximo 17 de septiembre de 2025. Para más información, se deben visitar las bases de la convocatoria o asistir a algunas sesiones formativas que se están realizando.
Conclusión
En un mundo donde los desafíos sociales, económicos y medioambientales son cada vez más complejos, necesitamos nuevas formas de pensar y actuar desde las instituciones públicas. Por ello, I+P no es una moda, es una necesidad que nos permite pasar del “creemos que funciona” al “sabemos que funciona”, fomentando una política más adaptativa, ágil y eficaz.
Blog
Durante los últimos años hemos visto avances espectaculares en el uso de la inteligencia artificial (IA) y, detrás de todos estos logros, siempre encontraremos un mismo ingrediente común: los datos. Un ejemplo ilustrativo y conocido por todo el mundo es el de los modelos de lenguaje utilizados por OpenAI para su famoso ChatGPT, como por ejemplo GPT-3, uno de sus primeros modelos que fue entrenado con más de 45 terabytes de datos, convenientemente organizados y estructurados para que resultaran de utilidad.
Sin suficiente disponibilidad de datos de calidad y convenientemente preparados, incluso los algoritmos más avanzados no servirán de mucho, ni a nivel social ni económico. De hecho, Gartner estima que más del 40% de los proyectos emergentes de agentes de IA en la actualidad terminarán siendo abandonados a medio plazo debido a la falta de datos adecuados y otros problemas de calidad. Por tanto, el esfuerzo invertido en estandarizar, limpiar y documentar los datos puede marcar la diferencia entre una iniciativa de IA exitosa y un experimento fallido. En resumen, el clásico principio de “basura entra, basura sale” en la ingeniería informática aplicado esta vez a la inteligencia artificial: si alimentamos una IA con datos de baja calidad, sus resultados serán igualmente pobres y poco fiables.
Tomando consciencia de este problema surge el concepto de AI Data Readiness o preparación de los datos para ser usados por la inteligencia artificial. En este artículo exploraremos qué significa que los datos estén "listos para la IA", por qué es importante y qué necesitaremos para que los algoritmos de IA puedan aprovechar nuestros datos de forma eficaz. Esto revierta en un mayor valor social, favoreciendo la eliminación de sesgos y el impulso de la equidad.
¿Qué implica que los datos estén "listos para la IA"?
Tener datos listos para la IA (AI-ready) significa que estos datos cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial. Esto incluye múltiples aspectos como la completitud de los datos, la ausencia de errores e inconsistencias, el uso de formatos adecuados, metadatos y estructuras homogéneas, así como proporcionar el contexto necesario para poder verificar que estén alineados con el uso que la IA les dará.
Preparar datos para la IA suele requerir de un proceso en varias etapas. Por ejemplo, de nuevo la consultora Gartner recomienda seguir los siguientes pasos:
- Evaluar las necesidades de datos según el caso de uso: identificar qué datos son relevantes para el problema que queremos resolver con la IA (el tipo de datos, volumen necesario, nivel de detalle, etc.), entendiendo que esta evaluación puede ser un proceso iterativo que se refine a medida que el proyecto de IA avanza.
- Alinear las áreas de negocio y conseguir el apoyo directivo: presentar los requisitos de datos a los responsables según las necesidades detectadas y lograr su respaldo, asegurando así los recursos requeridos para preparar los datos adecuadamente.
- Desarrollar buenas prácticas de gobernanza de los datos: implementar políticas y herramientas de gestión de datos adecuadas (calidad, catálogos, linaje de datos, seguridad, etc.) y asegurarnos de que incorporen también las necesidades de los proyectos de IA.
- Ampliar el ecosistema de datos: integrar nuevas fuentes de datos, romper potenciales barreras y silos que estén trabajando de forma aislada dentro de la organización y adaptar la infraestructura para poder manejar los grandes volúmenes y variedad de datos necesarios para el correcto funcionamiento de la IA.
- Garantizar la escalabilidad y cumplimiento normativo: asegurar que la gestión de datos pueda escalar a medida que crecen los proyectos de IA, manteniendo al mismo tiempo un marco de gobernanza sólido y acorde con los protocolos éticos necesarios y el cumplimiento de la normativa existente.
Si seguimos una estrategia similar a esta estaremos consiguiendo integrar los nuevos requisitos y necesidades de la IA en nuestras prácticas habituales de gobernanza del dato. En esencia, se trata simplemente de conseguir que nuestros datos estén preparados para alimentar modelos de IA con las mínimas fricciones posibles, evitando posibles contratiempos a posteriori durante el desarrollo de los proyectos.
Datos abiertos “preparados para IA”
En el ámbito de la ciencia abierta y los datos abiertos se han promovido desde hace años los principios FAIR. Estas siglas en inglés establecen que los datos deben localizables, accesibles, interoperables y reutilizables. Los principios FAIR han servido para guiar la gestión de datos científicos y datos abiertos para hacerlos más útiles y mejorar su uso por parte de la comunidad científica y la sociedad en general. Sin embargo, dichos principios no fueron diseñados para abordan las nuevas necesidades particulares asociadas al auge de la IA.
Se plantea por tanto en la actualidad la propuesta de extender los principios originales añadiendo un quinto principio de preparación (readiness) para la IA, pasando así del FAIR inicial a FAIR-R o FAIR². El objetivo sería precisamente el de hacer explícitos aquellos atributos adicionales que hacen que los datos estén listos para acelerar su uso responsable y transparente como herramienta necesaria para las aplicaciones de la IA de alto interés público.

¿Qué añadiría exactamente esta nueva R a los principios FAIR? En esencia, enfatiza algunos aspectos como:
- Etiquetado, anotado y enriquecimiento adecuado de los datos.
- Transparencia sobre el origen, linaje y tratamiento de los datos.
- Estándares, metadatos, esquemas y formatos óptimos para su uso por parte de la IA.
- Cobertura y calidad suficientes para evitar sesgos o falta de representatividad.
En el contexto de los datos abiertos, esta discusión es especialmente relevante dentro del discurso de la "cuarta ola" del movimiento de apertura de datos, a través del cual se argumenta que si los gobiernos, universidades y otras instituciones liberan sus datos, pero estos no se encuentran en las condiciones óptimas para poder alimentar a los algoritmos, se estaría perdiendo una oportunidad única para todo un nuevo universo de innovación e impacto social: mejoras en los diagnósticos médicos, detección de brotes epidemiológicos, optimización del tráfico urbano y de las rutas de transporte, maximización del rendimiento de las cosechas o prevención de la deforestación son sólo algunos ejemplos de las posibles oportunidades perdidas.
Además, de no ser así, podríamos entrar también en un largo “invierno de los datos”, en el que las aplicaciones positivas de la IA se vean limitadas por conjuntos de datos de mala calidad, inaccesibles o llenos de sesgos. En ese escenario, la promesa de una IA por el bien común se quedaría congelada, incapaz de evolucionar por falta de materia prima adecuada, mientras que las aplicaciones de la IA lideradas por iniciativas con intereses privados continuarían avanzando y aumentando el acceso desigual al beneficio proporcionado por las tecnologías.
Conclusión: el camino hacia IA de calidad, inclusiva y con verdadero valor social
En la era de la inteligencia artificial, los datos son tan importantes como los algoritmos. Tener datos bien preparados y compartidos de forma abierta para que todos puedan utilizarlos, puede marcar la diferencia entre una IA que aporta valor social y una que tan sólo es capaz de producir resultados sesgados.
Nunca podemos dar por sentada la calidad ni la idoneidad de los datos para las nuevas aplicaciones de la IA: hay que seguir evaluándolos, trabajándolos y llevando a cabo una gobernanza de estos de forma rigurosa y efectiva del mismo modo que se venía recomendado para otras aplicaciones. Lograr que nuestros datos estén listos para la IA no es por tanto una tarea trivial, pero los beneficios a largo plazo son claros: algoritmos más precisos, reducir sesgos indeseados, aumentar la transparencia de la IA y extender sus beneficios a más ámbitos de forma equitativa.
Por el contrario, ignorar la preparación de los datos conlleva un alto riesgo de proyectos de IA fallidos, conclusiones erróneas o exclusión de quienes no tienen acceso a datos de calidad. Abordar las asignaturas pendientes sobre cómo preparar y compartir datos de forma responsable es esencial para desbloquear todo el potencial de la innovación impulsada por IA en favor del bien común. Si los datos de calidad son la base para la promesa de una IA más humana y equitativa, asegurémonos de construir una base suficientemente sólida para poder alcanzar nuestro objetivo.
En este camino hacia una inteligencia artificial más inclusiva, alimentada por datos de calidad y con verdadero valor social, la Unión Europea también está avanzando con pasos firmes. A través de iniciativas como su estrategia de la Data Union, la creación de espacios comunes de datos en sectores clave como salud, movilidad o agricultura, y el impulso del llamado AI Continent y las AI factories, Europa busca construir una infraestructura digital donde los datos estén gobernados de forma responsable, sean interoperables y estén preparados para ser utilizados por sistemas de IA en beneficio del bien común. Esta visión no solo promueve una mayor soberanía digital, sino que refuerza el principio de que los datos públicos deben servir para desarrollar tecnologías al servicio de las personas y no al revés.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
La energía es el motor de nuestra sociedad, un recurso vital que impulsa nuestras vidas y la economía global. Sin embargo, el modelo energético tradicional se enfrenta a desafíos monumentales: la creciente demanda, la urgencia climática y la necesidad imperante de una transición hacia fuentes más limpias y sostenibles. En este panorama de transformación profunda, emerge un actor silencioso pero poderoso: los datos. No solo "tener datos" es importante, sino también la capacidad de gobernarlos adecuadamente para transformar el sector energético.
En este nuevo paradigma energético, los datos se han convertido en un recurso estratégico tan esencial como la propia energía. La clave no está solo en generar y distribuir electricidad, sino en entender, anticipar y optimizar su uso en tiempo real. Y para ello, es necesario captar el pulso digital del sistema energético a través de millones de puntos de medición y observación.
Así, antes de abordar cómo se gobiernan estos datos, conviene comprender de dónde provienen, qué tipo de información generan y cómo están transformando silenciosamente el funcionamiento de la red eléctrica.
El latido digital de la red: datos de contadores inteligentes y sensores
Imagina una red eléctrica que no solo distribuye energía, sino que también "escucha", "aprende" y "reacciona". Esta es la promesa de las redes inteligentes, o smart grids, un sistema que va mucho más allá de los cables y transformadores que vemos. Un smart grid es un sistema de distribución de electricidad que utiliza la tecnología digital para mejorar la eficiencia, la sostenibilidad y la seguridad de la red. En el corazón de esta revolución se encuentran los contadores inteligentes y una vasta red de sensores.
Los contadores inteligentes, también conocidos como Advanced Metering Infrastructure (AMI), son dispositivos que registran el consumo de electricidad de forma digital, a menudo, en intervalos de tiempo muy cortos (por ejemplo, cada 15 minutos o por hora), y transmiten estos datos a las compañías eléctricas a través de diversas tecnologías de comunicación, como redes celulares, WiFi, PLC (Power Line Communication) o radiofrecuencia (RF). Estos datos no se limitan a la cantidad total de energía consumida, sino que ofrecen un desglose detallado de patrones de consumo, niveles de voltaje, calidad de la energía e incluso la detección de fallos.
Pero la inteligencia de la red no recae solo en los contadores. Una miríada de sensores distribuidos por toda la infraestructura eléctrica monitorea variables críticas en tiempo real: desde la temperatura de los transformadores y el estado de los equipos hasta las condiciones ambientales y el flujo de energía en diferentes puntos de la red. Estos sensores actúan como los "ojos y oídos" del sistema, proporcionando una visión granular y dinámica del rendimiento de la red.
La magia ocurre en el flujo de estos datos. La información de los contadores y sensores viaja de forma bidireccional: desde el punto de consumo o generación hasta las plataformas de gestión de la empresa eléctrica y viceversa. Esta comunicación constante permite a las empresas de servicios públicos:
- Facturar con precisión
- Implementar programas de respuesta a la demanda
- Optimizar la distribución de energía
- Predecir y prevenir interrupciones
- Integrar de manera eficiente fuentes de energía renovable que por su naturaleza son intermitentes
Gobierno de datos: la columna vertebral de una red conectada
La mera recopilación de datos, por abundante que sea, no garantiza su valor. De hecho, sin una gestión adecuada, esta heterogeneidad de fuentes puede convertirse en una barrera insuperable para la integración y el análisis útil de la información. Aquí es donde entra en juego el gobierno del dato.
El gobierno del dato en el contexto de las redes inteligentes implica establecer un conjunto robusto de principios, procesos, roles y tecnologías para asegurar que los datos generados sean fiables, accesibles, útiles y seguros. Es la "regla de juego" que define cómo se capturan, almacenan, mantienen, usan, protegen y eliminan los datos a lo largo de todo su ciclo de vida.
¿Por qué es esto tan crucial?
- Interoperabilidad: una red inteligente no es un sistema monolítico, sino una constelación de dispositivos, plataformas y actores (generadores, distribuidores, consumidores, prosumidor, reguladores). Para que todos estos elementos "hablen el mismo idioma", la interoperabilidad es fundamental. El gobierno del dato establece estándares de nomenclatura, formatos, codificación y sincronización, permitiendo que la información fluya sin fricciones entre sistemas dispares. Sin ella, corremos el riesgo de crear silos de información fragmentados y costosos.
- Calidad: los algoritmos de inteligencia artificial y el aprendizaje automático, tan vitales para las redes inteligentes, son tan buenos como los datos con los que se alimentan. El gobierno del dato garantiza la exactitud, completitud y consistencia de los datos (y a futuro de la información y conocimiento) mediante la definición de reglas de negocio, la limpieza de duplicados y la gestión de errores en los datos. Datos de mala calidad pueden llevar a decisiones erróneas, ineficiencias operativas y resultados poco confiables.
- Seguridad: la interconexión de millones de dispositivos en una red inteligente expande exponencialmente la superficie de ataque para ciberdelincuentes. Un fallo en la seguridad de los datos podría tener consecuencias catastróficas, desde interrupciones masivas del suministro eléctrico hasta la vulneración de la privacidad de los usuarios. El gobierno del dato es el escudo que implementa controles de acceso robustos, protocolos de cifrado y auditorías de uso, salvaguardando la integridad y la confidencialidad de la información crítica. Adherirse a marcos de seguridad consolidados como ENS, ISO/IEC 27000, NIST, IEC 62443 y NERC CIP es fundamental.
En última instancia, un gobierno del dato efectivo convierte los datos en una infraestructura crítica, tan importante como los cables y las subestaciones, para la toma de decisiones, la optimización de recursos y la automatización inteligente.
Datos en acción: optimizando, anticipando y facilitando la transición energética
Gobernar los datos no es un fin en sí mismo, sino el medio para desbloquear un vasto potencial de eficiencia y sostenibilidad en el sector energético.
1. Optimización del consumo y eficiencia operativa
Los datos exactos, completos, consistentes, actuales y creíbles, así como en tiempo real permiten múltiples ventajas en la gestión energética:
-
Consumo a nivel de usuario: los contadores inteligentes empoderan a los ciudadanos y a las empresas al proporcionarles información detallada sobre su propio consumo. Esto les permite identificar patrones, ajustar sus hábitos y, en última instancia, reducir sus facturas de energía.
- Gestión de la demanda: las empresas de servicios públicos pueden utilizar los datos para implementar programas de respuesta a la demanda (DR, por sus siglas en inglés). Estos programas incentivan a los consumidores a reducir o trasladar su consumo de electricidad durante los períodos de alta demanda o de precios elevados, equilibrando así la carga en la red y evitando costosas inversiones en nueva infraestructura.
- Reducción de ineficiencias: la disponibilidad de datos precisos y bien integrados permite a las empresas eléctricas automatizar tareas, evitar procesos redundantes y reducir paradas no planificadas en sus sistemas. Por ejemplo, una planta de generación puede ajustar su producción en tiempo real basándose en el análisis de datos de rendimiento y demanda.
- Monitorización energética y control de emisiones: el seguimiento en tiempo real del consumo de energía, agua o emisiones de gases contaminantes revela ineficiencias ocultas y oportunidades de ahorro. Los cuadros de mando inteligentes, alimentados por datos gobernados, permiten a las plantas industriales y a las ciudades reducir sus costes y avanzar en sus objetivos de sostenibilidad ambiental.
2. Anticipación de la demanda y resiliencia de la red
Las redes inteligentes también pueden prever el futuro del consumo energético:
-
Predicción de la demanda: mediante el uso de algoritmos avanzados de inteligencia artificial y machine learning (como el análisis de series temporales o las redes neuronales), los datos históricos de consumo, combinados con factores externos como el clima, los días festivos o eventos especiales, permiten a las empresas eléctricas pronosticar la demanda con una precisión asombrosa. Esta anticipación es vital para optimizar la asignación de recursos, evitar sobrecargas y garantizar la estabilidad de la red.
- Mantenimiento predictivo: al combinar datos históricos de mantenimiento con información en tiempo real de sensores en equipos críticos, las empresas pueden anticipar fallos en las máquinas antes de que ocurran, programar el mantenimiento de forma proactiva y evitar costosas interrupciones inesperadas.
3. Facilitación de la transición energética
El gobierno del dato es un catalizador indispensable para la integración de energías renovables y la descarbonización:
- Integración de renovables: fuentes como la energía solar y eólica son intermitentes por naturaleza. Los datos en tiempo real sobre la generación, las condiciones meteorológicas y el estado de la red son fundamentales para gestionar esta variabilidad, balancear la carga y maximizar la inyección de energía limpia en la red.
- Gestión de Recursos Energéticos Distribuidos (RED): la proliferación de paneles solares en tejados, baterías de almacenamiento y vehículos eléctricos (que pueden cargar y descargar energía a la red) requiere una gestión de datos sofisticada. El gobierno del dato asegura la interoperabilidad necesaria para coordinar estos recursos de manera eficiente, transformándolos en "centrales eléctricas virtuales" que pueden apoyar la estabilidad de la red.
- Impulso a la economía circular: gracias a la trazabilidad total del ciclo de vida de un producto, desde su diseño hasta su reciclaje, los datos permiten identificar oportunidades de reutilización, valorización de materiales y diseño sostenible. Esto es crucial para cumplir con nuevos reglamentos de economía circular y el Pasaporte de Producto Digital (DPP, por sus siglas en inglés).
- Gemelos digitales: para que una réplica virtual de un proceso o sistema físico funcione, necesita alimentarse de datos precisos y coherentes. El gobierno del dato garantiza la sincronización entre el mundo físico y el virtual, permitiendo simulaciones fiables para optimizar el diseño de nuevas líneas de producción o la disposición de los elementos en una fábrica.
Beneficios tangibles para ciudadanos, empresas y administraciones
La inversión en gobierno del dato en redes inteligentes genera un valor significativo para todos los actores de la sociedad:
Para los ciudadanos
-
Ahorro en la factura de la luz: al tener acceso a datos de consumo en tiempo real y a tarifas flexibles (por ejemplo, con precios más bajos en horas valle), los ciudadanos pueden ajustar sus hábitos y reducir sus gastos de energía.
-
Empoderamiento y control: los ciudadanos pasan de ser meros consumidores a "prosumers", con la capacidad de generar su propia energía (por ejemplo, con paneles solares) e incluso inyectar el excedente en la red, siendo compensados por ello. Esto fomenta una participación y un mayor control sobre su consumo energético.
-
Mejor calidad de vida: una red más resiliente y eficiente significa menos interrupciones del suministro y una mayor fiabilidad, lo que se traduce en una mejor calidad de vida y servicios esenciales ininterrumpidos.
- Fomento de la sostenibilidad: al participar en programas de respuesta a la demanda y adoptar comportamientos de consumo más eficientes, los ciudadanos contribuyen directamente a la reducción de la huella de carbono y a la transición energética del país.
Para las empresas
- Optimización de operaciones y reducción de costes: las empresas pueden predecir la demanda, ajustar la producción y realizar un mantenimiento predictivo de su maquinaria, reduciendo pérdidas por fallos y optimizando el uso de recursos energéticos y materiales.
- Nuevos modelos de negocio: la disponibilidad de datos crea oportunidades para el desarrollo de nuevos servicios y productos. Esto incluye plataformas para el intercambio de energía, sistemas inteligentes de gestión energética para edificios y hogares, o la optimización de infraestructuras de carga para vehículos eléctricos.
- Reducción de pérdidas: una gestión de datos inteligente permite a las empresas eléctricas minimizar las pérdidas en la transmisión y distribución de energía, prevenir sobrecargas y aislar fallos de manera más rápida y eficiente.
- Mejora de la trazabilidad: en sectores regulados como la alimentación, automoción o farmacéutica, la trazabilidad completa del producto desde la materia prima hasta el cliente final no es solo un valor añadido, sino una obligación regulatoria. El gobierno del dato asegura que esta trazabilidad sea verificable y cumpla los estándares.
- Cumplimiento normativo: una gestión de datos robusta permite a las empresas cumplir con regulaciones cada vez más estrictas en materia de sostenibilidad, eficiencia energética y emisiones, así como con normativas de privacidad de datos (como el GDPR).
Para las Administraciones públicas
- Formulación de políticas energéticas inteligentes: los datos agregados y anonimizados de la red inteligente proporcionan a las Administraciones públicas información valiosa para diseñar políticas energéticas más efectivas, establecer objetivos de descarbonización ambiciosos y planificar estratégicamente el futuro energético del país.
- Planificación de infraestructuras: con una visión clara de los patrones de consumo y las necesidades futuras, las Administraciones pueden planificar de manera más eficiente las actualizaciones y expansiones de la red, así como la integración de recursos energéticos distribuidos como las micro-redes inteligentes.
- Impulso a la resiliencia urbana: la capacidad de gestionar y coordinar recursos energéticos distribuidos a nivel local, como en las micro-redes, mejora la resiliencia de las ciudades ante eventos extremos o fallos en la red principal.
- Promoción de la soberanía tecnológica y de datos: al fomentar la publicación de estos datos en portales de datos abiertos junto a la creación de espacios de datos nacionales y sectoriales, las Administraciones garantizan que el valor generado por los datos se quede en el país y en las empresas locales, impulsando la innovación y la competitividad a nivel internacional.
Retos y mejores prácticas en gobierno del dato de redes inteligentes
A pesar de los inmensos beneficios, la implementación de iniciativas de gobierno del dato efectivas en el sector energético presenta desafíos significativos:
- Heterogeneidad y complejidad de la integración de datos: los datos provienen de una multitud de fuentes dispares (contadores, sensores, SCADA, ERP, MES, sistemas de mantenimiento, etc.). Integrar y armonizar esta información es un reto técnico y organizacional considerable.
- Privacidad y cumplimiento normativo: los datos de consumo energético pueden revelar patrones de comportamiento altamente sensibles. Garantizar la privacidad del usuario y cumplir con regulaciones como el GDPR es un desafío constante que requiere marcos éticos y legales sólidos.
- Ciberseguridad: La interconexión masiva de dispositivos y sistemas expande la superficie de ataque, haciendo que las redes inteligentes sean objetivos atractivos para ciberataques sofisticados. La integración de sistemas heredados con nuevas tecnologías también puede crear vulnerabilidades.
- Calidad de datos: sin procesos robustos, la información puede ser inconsistente, incompleta o inexacta, lo que lleva a decisiones erróneas.
- Falta de estándares universales: la ausencia de prácticas y regulaciones de ciberseguridad uniformes en diferentes regiones puede reducir la eficacia de las medidas de seguridad.
- Resistencia al cambio y falta de cultura del dato: la implementación de nuevas políticas y procesos de gobierno del dato puede encontrar resistencia interna, y la falta de comprensión sobre la importancia de los datos a menudo obstaculiza los esfuerzos.
- Asignación de roles y recursos: definir claramente quién es responsable de qué aspecto del dato y asegurar los recursos financieros y humanos adecuados es fundamental para el éxito.
- Escalabilidad: a medida que el volumen y la variedad de datos crecen exponencialmente, la estructura de gobierno debe ser capaz de escalar eficientemente para evitar cuellos de botella y problemas de cumplimiento.
Para superar estos desafíos, la adopción de las siguientes mejores prácticas es esencial:
- Establecer un marco de gobierno sólido: definir principios, políticas, procesos y roles claros desde el principio, con el apoyo de las administraciones públicas y la alta dirección. Esto puede verse solventado con la implantación de los procesos de las UNE 0077 a 0080 que incluye la definición de los procesos de gobierno, gestión y calidad de datos, así como la definición de las estructuras organizativas.
- Garantizar la calidad de los datos: implementar metodologías y procesos de evaluación de calidad de datos, como la clasificación y catalogación de activos de datos, el control de calidad (validación, limpieza de duplicados) y la gestión del ciclo de vida del dato. Todo ello puede basarse en la implantación de un modelo de calidad siguiendo la UNE 0081.
- Priorizar la ciberseguridad y la privacidad: implementar marcos de seguridad robustos (ENS, ISO 27000, NIST, IEC 62443, NERC CIP), asegurar los dispositivos IoT, utilizar herramientas avanzadas de detección de amenazas (incluida la IA) y construir sistemas resilientes con segmentación de red y redundancia. Asegurar el cumplimiento de las regulaciones de privacidad de datos (como el GDPR).
- Fomentar la interoperabilidad mediante estándares: adoptar estándares abiertos para la comunicación y el intercambio de datos entre sistemas, como OPC UA o ISA-95.
- Invertir en tecnología y automatización: utilizar herramientas de gobierno del dato que permitan la detección y clasificación automática de datos, la aplicación de reglas de protección de datos, la automatización de la gestión de metadatos y la catalogación de datos. La automatización de tareas rutinarias mejora la eficiencia y reduce errores.
- Colaboración y compartición de información: fomentar el intercambio de información sobre amenazas y mejores prácticas entre empresas de servicios públicos, agencias gubernamentales y otras partes interesadas de la industria. En esta línea hay que destacar los más de 900 conjuntos de datos publicados en el catálogo de datos.gob.es del tema Energía, así como la creación de "Espacios de Datos" (como el Espacio de Datos Nacional de Energía o Industria en España) facilita la compartición segura y eficiente de datos entre organizaciones, impulsando la innovación y la competitividad sectorial.
- Monitoreo continuo y mejora: elgobierno del dato es un proceso continuo. Se deben establecer KPI para monitorear el progreso, evaluar el rendimiento y realizar mejoras basadas en la retroalimentación y los cambios regulatorios o estratégicos.
Conclusiones: un futuro conectado y sostenible
La energía y los datos están unidos en el futuro. Las redes inteligentes son la manifestación de esta simbiosis, y elgobierno del dato es la clave para desbloquear su potencial. Al transformar los datos de simples registros en activos estratégicos y una infraestructura crítica, podemos avanzar hacia un modelo energético más eficiente, sostenible y resiliente.
La colaboración entre empresas, ciudadanos y administraciones, impulsada por iniciativas como el Espacio de Datos Nacional de Industria en España, es fundamental para construir este futuro. Este espacio no solo busca mejorar la eficiencia industrial, sino también reforzar la soberanía tecnológica y de datos del país, asegurando que el valor generado por los datos beneficie a nuestras propias empresas, regiones y sectores. Al invertir en iniciativas degobierno del dato sólidas y en la creación de ecosistemas de datos compartidos, estamos invirtiendo en una industria más conectada, inteligente y preparada para los retos energéticos y climáticos del mañana.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
Imagina una máquina que pueda saber si estás feliz, preocupado o a punto de tomar una decisión, incluso antes de que tú lo sepas con claridad. Aunque suena a ciencia ficción, ese futuro ya está empezando a tomar forma. Gracias a los avances en neurociencia y tecnología, hoy podemos registrar, analizar e incluso predecir ciertos patrones de actividad cerebral. A los datos que se generan a partir de estos registros se les conoce como neurodatos.
En este artículo vamos a explicar este concepto, así como potenciales casos de uso, tomando como base el informe “TechDispatch sobre Neurodatos”, de la Agencia Española de Protección de Datos (AEPD).
¿Qué son los neurodatos y cómo se recolectan?
El término neurodatos se refiere a los datos que se recopilan directamente del cerebro y el sistema nervioso, mediante tecnologías como la electroencefalografía (EEG), la resonancia magnética funcional (fMRI), los implantes neuronales o incluso interfaces cerebro-computadora. En este sentido, su captación se ve impulsada por las neurotecnologías.
De acuerdo con la OCDE, las neurotecnologías se identifican con “dispositivos y procedimientos que se utilizan para acceder, investigar, evaluar, manipular y emular la estructura y función de los sistemas neuronales”. Las neurotecnologías pueden ser invasivas (si requieren interfaces cerebro-ordenador que se implanten quirúrgicamente en el cerebro) o no invasivas, con interfaces que se colocan fuera del cuerpo (como gafas o diademas).
Asimismo, existen dos formas habituales de recopilar los datos:
- Recolección pasiva, donde los datos se captan de manera habitual sin que el sujeto tenga que realizar ninguna actividad específica.
- Recolección activa, donde se recogen datos mientras los usuarios realizan una actividad concreta. Por ejemplo, pensar explícitamente en algo, responder preguntas, realizar tareas físicas o recibir determinados estímulos.
Posibles casos de uso
Una vez se han recolectado los datos en bruto, se procede a su almacenamiento y tratamiento. El tratamiento variará según la finalidad y el uso que se quiera dar a los neurodatos.
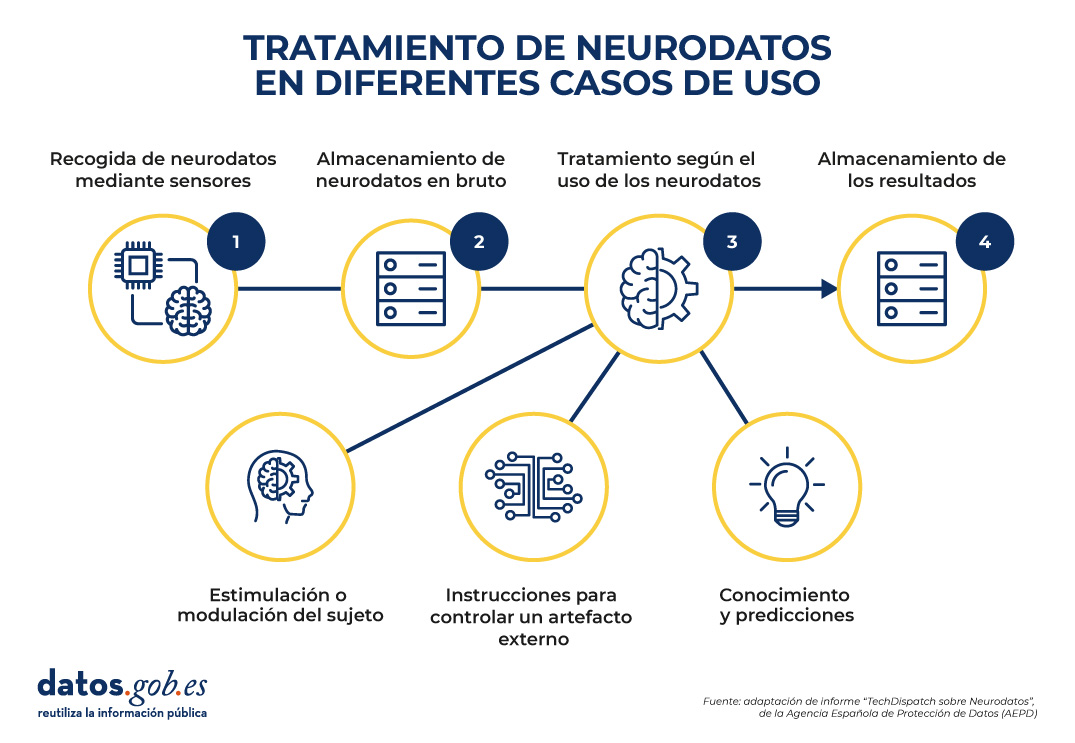
Figura 1. Estructura común para entender el tratamiento de neurodatos en diferentes casos de uso. Fuente: Informe “TechDispatch sobre Neurodatos”, de la Agencia Española de Protección de Datos (AEPD).
Como se puede ver en la imagen anterior, la Agencia Española de Protección de datos ha identificado 3 posibles finalidades:
-
Tratamiento de neurodatos para adquirir conocimiento directo y/o realizar predicciones.
Los neurodatos permiten descubrir patrones que decodifican la actividad cerebral en diversos sectores, como, por ejemplo:
- Salud: los neurodatos facilitan la investigación sobre el funcionamiento del cerebro y el sistema nervioso, lo que permite detectar signos de enfermedades neurológicas o mentales, realizar diagnósticos tempranos y predecir su comportamiento. Esto facilita el tratamiento personalizado desde etapas muy tempranas. Su impacto puede ser notable, por ejemplo, en la lucha contra el Alzheimer, la epilepsia o la depresión.
- Educación: a través de los estímulos cerebrales se puede analizar el rendimiento y los resultados del aprendizaje de los estudiantes. Por ejemplo, se puede medir la atención o el esfuerzo cognitivo del alumnado. Al cruzar estos datos con otros aspectos internos (como las preferencias del alumno) y externos (como las condiciones del aula o la metodología de enseñanza), se pueden tomar decisiones dirigidas a adaptar el ritmo de enseñanza.
- Marketing, economía y ocio: se puede analizar la respuesta cerebral ante ciertos estímulos para mejorar productos de ocio o campañas publicitarias. El objetivo es conocer las motivaciones y preferencias que impactan en la toma de decisiones. También se pueden utilizar en el ámbito laboral, para realizar un seguimiento de los empleados, conocer sus habilidades o determinar cómo funcionan ante la presión.
- Seguridad y vigilancia: los neurodatos se pueden usar para monitorizar factores que afectan a conductores o pilotos, como la somnolencia o la falta de atención, y así prevenir accidentes.
-
Tratamiento de neurodatos para controlar aplicaciones o dispositivos.
Al igual que en el estadio anterior, supone la recolección y análisis de información para la toma de decisiones, pero conlleva además una operación adicional: la generación de acciones a través de los impulsos mentales. Veamos varios ejemplos:
-
Ayudas ortopédicas o protésicas, implantes médicos o vida asistida por el entorno: gracias a tecnologías como las interfaces cerebro-computadora, es posible diseñar prótesis que respondan a la intención del usuario mediante la actividad cerebral. Además, los neurodatos pueden integrarse con sistemas inteligentes del hogar para anticipar necesidades, ajustar el entorno a los estados emocionales o cognitivos del usuario, e incluso emitir alertas ante signos tempranos de deterioro neurológico. Esto puede suponer una mejora de la autonomía de los pacientes y de su calidad de vida.
-
Robótica: se pueden interpretar las señales neuronales del usuario para controlar maquinaria, dispositivos de precisión o aplicaciones sin necesidad de utilizar las manos. Esto permite, por ejemplo, que una persona pueda manejar un brazo robótico o una herramienta quirúrgica simplemente con su pensamiento, lo cual es especialmente valioso en entornos donde se requiere precisión extrema o cuando el operador tiene movilidad reducida.
-
Videojuegos, realidad virtual y metaverso: dado que los neurodatos permiten controlar dispositivos de software, se pueden desarrollar interfaces cerebro-computadora que hagan posible manejar personajes o realizar acciones dentro de un juego, únicamente con la mente, sin necesidad de mandos físicos. Esto no solo incrementa la inmersión del jugador, sino que abre la puerta a experiencias más inclusivas y personalizadas.
- Defensa: los soldados pueden operar sistemas de armas, vehículos no tripulados, drones o robots de desactivación de explosivos en remoto, aumentando la seguridad personal y la eficiencia operativa en situaciones críticas.
-
Tratamiento de neurodatos para la estimulación o modulación del sujeto, logrando un neurofeedback.
En este caso, las señales del cerebro (salidas) se utilizan para generar nuevas señales que retroalimentan al cerebro (como entradas), lo que supone el control de las ondas cerebrales. Es el campo más complejo desde el punto de vista ético, ya que podrían generarse acciones de las que no es consciente el usuario. Algunos ejemplos son:
-
Psicología: los neurodatos tienen potencial para cambiar la forma en que el cerebro responde a ciertos estímulos. Se pueden utilizar, por tanto, como método de terapia para tratar el TDAH (Trastorno por Déficit de Atención e Hiperactividad), la ansiedad, la depresión, la epilepsia, el trastorno del espectro autista, el insomnio o la drogadicción, entre otros.
- Neuromejora: también se pueden utilizar para mejorar las capacidades cognitivas y afectivas en personas sanas. A través del análisis y estimulación personalizada de la actividad cerebral, es posible optimizar funciones como la memoria, la concentración, la toma de decisiones o la gestión emocional.
Retos éticos del uso de los neurodatos
Como hemos visto, aunque el potencial de los neurodatos es enorme, también plantea grandes retos éticos y legales. A diferencia de otros tipos de datos, los neurodatos pueden revelar aspectos profundamente íntimos de una persona, como sus deseos, emociones, miedos o intenciones. Esto abre la puerta a posibles usos indebidos, como la manipulación, la vigilancia encubierta o la discriminación basada en características neuronales. Además, se pueden recopilar en remoto y actuar sobre ellos sin que el sujeto sea consciente de la manipulación.
Esto ha generado un debate sobre la necesidad de nuevos derechos, como los neuroderechos, que buscan proteger la privacidad mental, la identidad personal y la libertad cognitiva. Desde diversas organizaciones internacionales, incluida la Unión Europea, se están tomando medidas para enfrentar estos desafíos y avanzar en la creación de marcos regulatorios y éticos que protejan los derechos fundamentales en el uso de tecnologías neurotecnológicas. Próximamente publicaremos un artículo que profundizará en estos aspectos.
En conclusión, los neurodatos suponen un avance muy prometedor, pero no exento de desafíos. Su capacidad para transformar sectores como la salud, la educación o la robótica es innegable, pero también lo son los desafíos éticos y legales que plantea su uso. A medida que avanzamos hacia un futuro donde mente y máquina están cada vez más conectadas, resulta crucial establecer marcos de regulación que garanticen la protección de los derechos humanos, en especial la privacidad mental y la autonomía individual. De esta forma podremos aprovechar todo el potencial de los neurodatos de manera justa, segura y responsable, en beneficio de toda la sociedad.
Documentación
La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
- Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
- Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
- Configuramos una base de datos MySQL externa como repositorio de metadatos.
- Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
- Creamos tablas estructuradas para representar rutas, autobuses o paradas.
- Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
- Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
- Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa comienza a estar presente en aplicaciones cotidianas que van desde agentes virtuales (o equipos de agentes virtuales) que nos resuelven dudas cuando llamamos a un centro de atención al cliente hasta asistentes inteligentes que redactan automáticamente resúmenes de reuniones o propuestas de informes en entornos de oficina.
Estas aplicaciones, gobernadas a menudo por modelos fundacionales de lenguaje (LLM), prometen revolucionar sectores enteros sobre la base de conseguir enormes ganancias en productividad. Sin embargo, su adopción conlleva nuevos retos ya que, a diferencia del software tradicional, un modelo de IA generativa no sigue reglas fijas escritas por humanos, sino que sus respuestas se basan en patrones estadísticos aprendidos tras procesar grandes volúmenes de datos. Esto hace que su comportamiento sea menos predecible y más difícil de explicar y que a veces ofrezca resultados inesperados, errores complicados de prever o respuestas que no siempre se alinean con las intenciones originales del creador del sistema.
Por ello, la validación de estas aplicaciones desde múltiples perspectivas como la ética, la seguridad o la consistencia es esencial para garantizar la confianza en los resultados de los sistemas que estamos creando en esta nueva etapa de transformación digital.
¿Qué hay que validar en los sistemas basados en IA generativa?
Validar los sistemas basados en IA generativa significa comprobar rigurosamente que cumplen ciertos criterios de calidad y responsabilidad antes de confiar en ellos para resolver tareas sensibles.
No se trata solo de verificar que “funcionan”, sino de asegurarse de que se comportan según lo esperado, evitando sesgos, protegiendo a los usuarios, manteniendo su estabilidad en el tiempo y cumpliendo las normas éticas y legales aplicables. La necesidad de una validación integral suscita un cada vez más amplio consenso entre expertos, investigadores, reguladores e industria: para desplegar IA de forma confiable se requieren estándares, evaluaciones y controles explícitos.
Resumimos cuatro dimensiones clave que deben verificarse en los sistemas basados en IA generativa para alinear sus resultados con las expectativas humanas:
- Ética y equidad: un modelo debe respetar principios éticos básicos y evitar perjudicar a personas o grupos. Esto implica detectar y mitigar sesgos en sus respuestas para no perpetuar estereotipos ni discriminación. También requiere filtrar contenido tóxico u ofensivo que pudiera dañar a los usuarios. La equidad se evalúa comprobando que el sistema ofrece un trato consistente a distintos colectivos demográficos, sin favorecer ni excluir indebidamente a nadie.
- Seguridad y robustez: aquí nos referimos tanto a la seguridad del usuario (que el sistema no genere recomendaciones peligrosas ni facilite actividades ilícitas) como a la robustez técnica frente a errores y manipulaciones. Un modelo seguro debe evitar instrucciones que lleven, por ejemplo, a conductas ilegales, rechazando esas solicitudes de manera fiable. Además, la robustez implica que el sistema resista ataques adversarios (como peticiones diseñadas para engañarlo) y que funcione de forma estable bajo distintas condiciones.
- Consistencia y fiabilidad: los resultados de la IA generativa deben ser consistentes, coherentes y correctos. En aplicaciones como las de diagnóstico médico o asistencia legal, no basta con que la respuesta suene convincente; debe ser cierta y precisa. Por ello se validan aspectos como la coherencia lógica de las respuestas, su relevancia respecto a la pregunta formulada y la exactitud factual de la información. También se comprueba su estabilidad en el tiempo (que ante dos peticiones similares se ofrezcan resultados equivalentes bajo las mismas condiciones) y su resiliencia (que pequeños cambios en la entrada no provoquen salidas sustancialmente diferentes).
- Transparencia y explicabilidad: para confiar en las decisiones de un sistema basado en IA, es deseable entender cómo y por qué las produce. La transparencia incluye proporcionar información sobre los datos de entrenamiento, las limitaciones conocidas y el rendimiento del modelo en distintas pruebas. Muchas empresas están adoptando la práctica de publicar “tarjetas del modelo” (model cards), que resumen cómo fue diseñado y evaluado un sistema, incluyendo métricas de sesgo, errores comunes y casos de uso recomendados. La explicabilidad va un paso más allá y busca que el modelo ofrezca, cuando sea posible, explicaciones comprensibles de sus resultados (por ejemplo, destacando qué datos influyeron en cierta recomendación). Una mayor transparencia y capacidad de explicación aumentan la rendición de cuentas, permitiendo que desarrolladores y terceros auditen el comportamiento del sistema.
Datos abiertos: transparencia y pruebas más diversas
Para validar adecuadamente los modelos y sistemas de IA, sobre todo en cuanto a equidad y robustez, se requieren conjuntos de datos representativos y diversos que reflejen la realidad de distintas poblaciones y escenarios.
Por otra parte, si solo las empresas dueñas de un sistema disponen datos para probarlo, tenemos que confiar en sus propias evaluaciones internas. Sin embargo, cuando existen conjuntos de datos abiertos y estándares públicos de prueba, la comunidad (universidades, reguladores, desarrolladores independientes, etc.) puede poner a prueba los sistemas de forma autónoma, funcionan así como un contrapeso independiente que sirve a los intereses de la sociedad.
Un ejemplo concreto lo dio Meta (Facebook) al liberar en 2023 su conjunto de datos Casual Conversations v2. Se trata de un conjunto de datos abiertos, obtenido con consentimiento informado, que recopila videos de personas de 7 países (Brasil, India, Indonesia, México, Vietnam, Filipinas y EE.UU.), con 5.567 participantes que proporcionaron atributos como edad, género, idioma y tono de piel.
El objetivo de Meta con la publicación fue precisamente facilitar que los investigadores pudiesen evaluar la imparcialidad y robustez de sistemas de IA en visión y reconocimiento de voz. Al expandir la procedencia geográfica de los datos más allá de EE.UU., este recurso permite comprobar si, por ejemplo, un modelo de reconocimiento facial funciona igual de bien con rostros de distintas etnias, o si un asistente de voz comprende acentos de diferentes regiones.
La diversidad que aportan los datos abiertos también ayuda a descubrir áreas descuidadas en la evaluación de IA. Investigadores del Human-Centered Artificial Intelligence (HAI) de Stanford pusieron de manifiesto en el proyecto HELM (Holistic Evaluation of Language Models) que muchos modelos de lenguaje no se evalúan en dialectos minoritarios del inglés o en idiomas poco representados, simplemente porque no existen datos de calidad en los benchmarks más conocidos.
La comunidad puede identificar estas carencias y crear nuevos conjuntos de prueba para llenarlos (por ejemplo, un conjunto de datos abierto de preguntas frecuentes en suajili para validar el comportamiento de un chatbot multilingüe). En este sentido, HELM ha incorporado evaluaciones más amplias precisamente gracias a la disponibilidad de datos abiertos, permitiendo medir no solo el rendimiento de los modelos en tareas comunes, sino también su comportamiento en otros contextos lingüísticos, culturales y sociales. Esto ha contribuido a visibilizar las limitaciones actuales de los modelos y a fomentar el desarrollo de sistemas más inclusivos y representativos del mundo real o modelos más adaptados a necesidades específicas de contextos locales como es el caso de modelo fundacional ALIA, desarrollado en España.
En definitiva, los datos abiertos contribuyen a democratizar la capacidad de auditar los sistemas de IA, evitando que el poder de validación resida solo en unos pocos. Permiten reducir los costes y barreras ya que un pequeño equipo de desarrollo puede probar su modelo con conjuntos abiertos sin tener que invertir grandes esfuerzos en recopilar datos propios. De este modo no solo se fomenta la innovación, sino que se consigue que soluciones de IA locales de pequeñas empresas estén sometidas también a estándares de validación rigurosos.
La validación de aplicaciones basadas en IA generativa es hoy una necesidad incuestionable para asegurar que estas herramientas operen en sintonía con nuestros valores y expectativas. No es un proceso trivial, requiere metodologías nuevas, métricas innovadoras y, sobre todo, una cultura de responsabilidad en torno a la IA. Pero los beneficios son claros, un sistema de IA rigurosamente validado será más confiable, tanto para el usuario individual que, por ejemplo, interactúa con un chatbot sin temor a recibir una respuesta tóxica, como para la sociedad en su conjunto que puede aceptar las decisiones basadas en estas tecnologías sabiendo que han sido correctamente auditadas. Y los datos abiertos contribuyen a cimentar esta confianza ya que fomentan la transparencia, enriquecen las pruebas con diversidad y hacen partícipe a toda la comunidad en la validación de los sistemas de IA..
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.