Blog
La Comisión Europea ha presentado recientemente el documento en el que se establece una nueva Estrategia de la Unión en el ámbito de los datos. Entre otros ambiciosos objetivos, con esta iniciativa se pretende hacer frente a un reto trascendental en la era de la inteligencia artificial generativa: la insuficiente disponibilidad de datos en las condiciones adecuadas.
Desde la anterior Estrategia de 2020 hemos asistido a un importante avance normativo con el que se pretendía ir más allá de la regulación de 2019 sobre datos abiertos y reutilización de la información del sector público.
En concreto, por una parte, la Data Governance Act sirvió para impulsar una serie de medidas que tendían a facilitar el uso de los datos generados por el sector público en aquellos supuestos donde se vieran afectados otros derechos e intereses jurídicos —datos personales, propiedad intelectual.
Por otra, a través de la Data Act se avanzó, sobre todo, en la línea de impulsar el acceso a datos en poder de sujetos privados atendiendo a las singularidades del entorno digital.
El necesario cambio de enfoque en la regulación sobre acceso a datos.
A pesar de este importante esfuerzo regulatorio, por parte de la Comisión Europea se ha detectado una infrautilización de los datos que, además, con frecuencia se encuentran fragmentados en cuanto a las condiciones de su accesibilidad. Ello se debe, en gran parte, a la existencia de una importante diversidad regulatoria. Por ello se requieren medidas que faciliten la simplificación y la racionalización del marco normativo europeo sobre datos.
En concreto, se ha constatado que existe una fragmentación regulatoria que genera inseguridad jurídica y costes de cumplimiento desproporcionados debido a la complejidad del propio marco normativo aplicable. En concreto, el solapamiento entre el Reglamento General de Protección de Datos (RGPD), la Data Governance Act, la Data Act, la Directiva de datos abiertos y, asimismo, la existencia de regulaciones sectoriales específicas para algunos ámbitos concretos ha generado un complejo entramado normativo al que resulta arduo enfrentarse, sobre todo si pensamos en la competitividad de pequeñas y medianas empresas. Cada una de estas normas fue concebida para hacer frente a retos específicos que fueron abordados de manera sucesiva, por lo que resulta necesaria una visión de conjunto más coherente que resuelva posibles incoherencias y, en última instancia, facilite su aplicación práctica.
En este sentido, la Estrategia propone impulsar un nuevo instrumento legislativo —la propuesta de Reglamento denominado Ómnibus Digital—, con el que se pretende consolidar en una única norma las reglas relativas al mercado único europeo en el ámbito de los datos. En concreto, con esta iniciativa:
- Se fusionan las previsiones de la Data Governance Act en la regulación de la Data Act, eliminando así duplicidades.
- Se deroga el Reglamento sobre datos no personales, cuyas funciones se cubren igualmente a través de la Data Act;
- Se integran las normas sobre datos del sector público en la Data Act, ya que hasta ahora estaban incluidas tanto en la Directiva de 2019 como en la Data Governance Act.
Con esta regulación se consolida, por tanto, el protagonismo de la Data Act como normal general de referencia en la materia. Asimismo, se refuerza la claridad y la precisión de sus previsiones, con el objetivo de facilitar su función como instrumento normativo principal a través del cual se pretende impulsar la accesibilidad de los datos en el mercado digital europeo.
Modificaciones en materia de protección de datos personales
La propuesta Ómnibus Digital también incluye importantes novedades por lo que se refiere a la normativa sobre protección de datos de carácter personal, modificándose varios preceptos del Reglamento (UE) 1016/679 del Parlamento Europeo y del Consejo de 27 de abril de 2016, relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales.
Para que se puedan utilizar los datos personales —esto es, cualquier información referida a una persona física identificada o identificable— es necesario que concurra alguna de las circunstancias a que se refiere el artículo 6 del citado Reglamento, entre las que se encuentra el consentimiento del titular o la existencia de un interés legítimo por parte de quien vaya a tratar los datos.
El interés legítimo permite tratar datos personales cuando es necesario para un fin válido (mejorar un servicio, prevenir fraudes, etc.) y no afecta negativamente a los derechos de la persona.
Fuente: Guía sobre interés legítimo. ISMS Forum y Data Privacy Institute. Disponible aquí: guiaintereslegitimo1637794373.pdf
Respecto a la posibilidad de acudir al interés legítimo como base jurídica para entrenar las herramientas de inteligencia artificial, la actual regulación permite tratar datos personales siempre que no prevalezcan los derechos de los interesados titulares de dichos datos.
Sin embargo, dada la generalidad del concepto “interés legítimo”, a la hora de decidir cuándo se pueden utilizar los datos personales al amparo de esta cláusula no siempre existirá una certeza absoluta, habrá que analizar caso por caso: en concreto, será necesario llevar a cabo una actividad de ponderación de los bienes jurídicos en conflicto y, por tanto, su aplicación puede generar dudas razonables en muchos supuestos.
Aunque el Comité Europeo de Protección de Datos ha intentado establecer algunas pautas para concretar la aplicación del interés legítimo, lo cierto es que el uso de conceptos jurídicos abiertos e indeterminados no siempre permitirá llegar a respuestas claras y definitivas. Para facilitar la concreción de esta expresión en cada supuesto, la Estrategia alude como criterio a tener en cuenta el beneficio potencial que puede suponer el tratamiento para el propio titular de los datos y para la sociedad en general. Asimismo, dado que no será necesario el consentimiento del titular de los datos —y por tanto, no sería aplicable su revocación—, refuerza el derecho de oposición por parte del titular a que sus datos sean tratados y, sobre todo, garantiza una mayor transparencia respecto de las condiciones en que se van a tratar los datos. De este modo, al reforzar la posición jurídica del titular y aludir a dicho beneficio potencial, la Estrategia pretende facilitar la utilización del interés legítimo como base jurídica que permita utilizar los datos personales sin consentimiento del titular, pero con garantías adecuadas.
Otra de las principales medidas en materia de protección de datos se refiere a la distinción entre datos anónimos y seudonimizados. El RGPD define la seudonimización como un tratamiento de datos que, hasta ahora, hacía que ya no pudieran atribuirse a un interesado sin recurrir a información adicional, que se encuentra separada. Eso sí, los datos seudonimizados siguen siendo datos personales y, por tanto, sometidos a dicha regulación. En cambio, los datos anónimos no guardan relación con personas identificadas o identificables y, por tanto, su uso no estaría sometido al RGPD. En consecuencia, para saber si hablamos de datos anónimos o seudonimizados resulta esencial concretar si existe una “probabilidad razonable” de identificación del titular de los datos.
Ahora bien, las tecnologías actualmente disponibles multiplican el riesgo de reidentificación del titular de los datos, lo que afecta directamente a lo que podría considerarse razonable, generando una incertidumbre que incide negativamente en la innovación tecnológica. Por esta razón, la propuesta Ómnibus Digital, en la línea ya manifestada por el Tribunal de Justicia de la Unión Europea, pretende establecer las condiciones en las cuales los datos seudonimizados ya no se podrían considerar datos de carácter personal, facilitando así su uso. A tal efecto habilita a la Comisión Europea para que, a través de actos de implementación, pueda concretar tales circunstancias, en concreto teniendo en cuenta el estado de la técnica y, asimismo, ofreciendo criterios que permitan evaluar el riesgo de reidentificación en cada concreto supuesto.
La ampliación de los conjuntos de datos de alto valor
La Estrategia pretende también ampliar el catálogo de Datos de Alto Valor (HVD) que se contemplan en el Reglamento de Ejecución UE 2023/138. Se trata de conjuntos de datos con potencial excepcional para generar beneficios sociales, económicos y ambientales, ya que son datos de alta calidad, estructurados y fiables que están accesibles en condiciones técnicas, organizativas y semánticas muy favorables para su tratamiento automatizado. Actualmente se incluyen seis categorías (geoespacial, observación de la Tierra y medio ambiente, meteorología, estadística, empresas y movilidad), a las que se añadirían por parte de la Comisión, entre otros conjuntos, datos legales, judiciales y administrativos.
Oportunidad y reto
La Estrategia Europea de Datos representa un giro paradigmático ciertamente relevante: no sólo se trata de promover marcos normativos que faciliten en el plano teórico la accesibilidad de los datos sino, sobre todo, de hacerlos funcionar en su aplicación práctica, impulsando de esta manera las condiciones necesarias de seguridad jurídica que permitan dinamizar una economía de datos competitiva e innovadora.
Para ello resulta imprescindible, por una parte, evaluar la incidencia real de las medidas que se proponen a través del Ómnibus Digital y, por otra, ofrecer a las pequeñas y medianas empresas instrumentos jurídicos adecuados —guías prácticas, servicios de asesoramiento idóneos, cláusulas contractuales tipo…— para hacer frente al reto que para ellas supone el cumplimiento normativo en un contexto de enorme complejidad. Precisamente, esta dificultad requiere, por parte de las autoridades de control y, en general, de las entidades públicas, adoptar modelos de gobernanza de los datos avanzados y flexibles que se adapten a las singularidades que plantea la inteligencia artificial, sin que por ello se vean afectadas las garantías jurídicas.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autorR
Aplicación
Visor web que muestra en un único mapa los despliegues de fibra de todos los programas PEBA y UNICO, a partir de los datos disponibles en abierto. Cada área tiene el color de fondo del operador adjudicado, y el borde es de un color diferente para cada programa. Para el caso del plan PEBA 2013-2019, como los despliegues se asignan a entidades singulares de población, se muestra un marcador con la ubicación obtenida del CNIG. Además, cuando no se hace zoom sobre el mapa, se muestra un mapa de calor en el que se puede ver la distribución por zonas de los despliegues.
Esta visualización permite evitar tener que comparar en diferentes visores cartográficos si lo que nos interesa es ver qué operadores llegan a qué zonas o simplemente tener una visión global de qué despliegues quedan pendientes en mi zona, y además permite consultar aspectos como la fecha de finalización actualizada, que antes solamente estaban disponibles en los diferentes Excel de cada programa. También creo que podría ser útil de cara a análisis de cómo se reparten las zonas entre los diferentes programas (por ejemplo, si una zona cubierta en el UNICO 2021 luego tiene zonas cercanas en UNICO 2022 cubiertas por ejemplo por otro operador), o incluso posibles solapes (por ejemplo debido a zonas que quedaron sin ejecutar en anteriores programas)
Noticia
¿Sabías que España creó en 2023 la primera agencia estatal dedicada específicamente a la supervisión de la inteligencia artificial (IA)? Anticipándose incluso al Reglamento Europeo en esta materia, la Agencia Española de Supervisión de Inteligencia Artificial (AESIA) nació con el objetivo de garantizar el uso ético y seguro de la IA, fomentando un desarrollo tecnológico responsable.
Entre sus principales funciones está asegurar que tanto entidades públicas como privadas cumplan con la normativa vigente. Para ello promueve buenas prácticas y asesora sobre el cumplimiento del marco regulatorio europeo, motivo por el cual recientemente ha publicado una serie de guías para asegurar la aplicación consistente de la regulación europea de IA.
En este post profundizaremos en qué es la AESIA y conoceremos detalles relevantes del contenido de las guías.
¿Qué es la AESIA y por qué es clave para el ecosistema de datos?
La AESIA nace en el marco del Eje 3 de la Estrategia Española de IA. Su creación responde a la necesidad de contar con una autoridad independiente que no solo supervise, sino que oriente el despliegue de sistemas algorítmicos en nuestra sociedad.
A diferencia de otros organismos puramente sancionadores, la AESIA está diseñada como un Think & Do Tank de inteligencia, es decir, una organización que investiga y propone soluciones. Su utilidad práctica se divide en tres vertientes:
- Seguridad jurídica: proporciona marcos claros para que las empresas, especialmente las pymes, sepan a qué atenerse al innovar.
- Referente internacional: actúa como el interlocutor español ante la Comisión Europea, asegurando que la voz de nuestro ecosistema tecnológico sea escuchada en la elaboración de estándares europeos.
- Confianza ciudadana: garantiza que los sistemas de IA utilizados en servicios públicos o áreas críticas respeten los derechos fundamentales, evitando sesgos y promoviendo la transparencia.
Desde datos.gob.es, siempre hemos defendido que el valor de los datos reside en su calidad y accesibilidad. La AESIA complementa esta visión asegurando que, una vez que los datos se transforman en modelos de IA, su uso sea responsable. Por ello, estas guías son una extensión natural de los recursos que publicamos habitualmente sobre gobernanza y apertura de datos.
Recursos para el uso de la IA: guías y checklist
La AESIA ha publicado recientemente unos materiales de apoyo a la implementación y el cumplimiento de la normativa europea de Inteligencia Artificial y sus obligaciones aplicables. Aunque no tienen carácter vinculante ni sustituyen ni desarrollan la normativa vigente, proporcionan recomendaciones prácticas alineadas con los requisitos regulatorios a la espera de que se aprueben las normas armonizadas de aplicación para todos los Estados miembros.
Son el resultado directo del piloto español de Sandbox Regulatorio de IA. Este entorno de pruebas permitió a desarrolladores y autoridades colaborar en un espacio controlado para entender cómo aplicar la normativa europea en casos de uso reales.
Es fundamental destacar que estos documentos se publican sin perjuicio de las guías técnicas que la Comisión Europea está elaborando. De hecho, España está sirviendo de "laboratorio" para Europa: las lecciones aprendidas aquí proporcionarán una base sólida al grupo de trabajo de la Comisión, asegurando una aplicación consistente de la regulación en todos los Estados miembros.
Las guías están diseñadas para ser una hoja de ruta completa, desde la concepción del sistema hasta su vigilancia una vez está en el mercado.

Figura 1. Guías de AESIA para cumplir con la regulación. Fuente: Agencia Española de la Supervisión de la IA
- 01. Introductoria al Reglamento de IA: ofrece una visión general sobre las obligaciones, los plazos de aplicación y los roles (proveedores, desplegadores, etc.). Es el punto de partida esencial para cualquier organización que desarrolle o despliegue sistemas de IA.
- 02. Práctica y ejemplos: aterriza los conceptos jurídicos en casos de uso cotidianos (por ejemplo, ¿es mi sistema de selección de personal una IA de alto riesgo?). Incluye árboles de decisión y un glosario de términos clave del artículo 3 del Reglamento, ayudando a determinar si un sistema específico está regulado, qué nivel de riesgo tiene y qué obligaciones son aplicables.
- 03. Evaluación de conformidad: explica los pasos técnicos necesarios para obtener el "sello" que permite comercializar un sistema de IA de alto riesgo, detallando los dos procedimientos posibles según los Anexos VI y VII del Reglamento como valuación basada en control interno o evaluación con intervención de organismo notificado.
- 04. Sistema de gestión de la calidad: define cómo las organizaciones deben estructurar sus procesos internos para mantener estándares constantes. Abarca la estrategia de cumplimiento regulatorio, técnicas y procedimientos de diseño, sistemas de examen y validación, entre otros.
- 05. Gestión de riesgos: es un manual sobre cómo identificar, evaluar y mitigar posibles impactos negativos del sistema durante todo su ciclo de vida.
- 06. Vigilancia humana: detalla los mecanismos para que las decisiones de la IA sean siempre supervisables por personas, evitando la "caja negra" tecnológica. Establece principios como comprensión de capacidades y limitaciones, interpretación de resultados, autoridad para no usar el sistema o anular decisiones.
- 07. Datos y gobernanza de datos: aborda las prácticas necesarias para entrenar, validar y testear modelos de IA asegurando que los conjuntos de datos sean relevantes, representativos, exactos y completos. Cubre procesos de gestión de datos (diseño, recogida, análisis, etiquetado, almacenamiento, etc.), detección y mitigación de sesgos, cumplimiento del Reglamento General de Protección de Datos, linaje de datos y documentación de hipótesis de diseño, siendo de especial interés para la comunidad de datos abiertos y científicos de datos.
- 08. Transparencia: establece cómo informar al usuario de que está interactuando con una IA y cómo explicar el razonamiento detrás de un resultado algorítmico.
- 09. Precisión: define métricas apropiadas según el tipo de sistema para garantizar que el modelo de IA cumple su objetivo.
- 10. Solidez: proporciona orientación técnica sobre cómo garantizar que los sistemas de IA funcionan de manera fiable y consistente en condiciones variables.
- 11. Ciberseguridad: instruye sobre protección contra amenazas específicas del ámbito de IA.
- 12. Registros: define las medidas para cumplir con las obligaciones de registro automático de eventos.
- 13. Vigilancia poscomercialización: documenta los procesos para ejecutar el plan de vigilancia, documentación y análisis de datos sobre el rendimiento del sistema durante toda su vida útil.
- 14. Gestión de incidentes: describe el procedimiento para notificar incidentes graves a las autoridades competentes.
- 15. Documentación técnica: establece la estructura completa que debe incluir la documentación técnica (proceso de desarrollo, datos de entrenamiento/validación/prueba, gestión de riesgos aplicada, rendimiento y métricas, supervisión humana, etc.).
- 16. Manual de checklist de Guías de requisitos: explica cómo utilizar las 13 checklists de autodiagnóstico que permiten realizar evaluación del cumplimiento, identificar brechas, diseñar planes de adaptación y priorizar acciones de mejora.
Todas las guías están disponibles aquí y tienen una estructura modular que se adapta a diferentes niveles de conocimiento y necesidades empresariales.
La herramienta de autodiagnóstico y sus ventajas
En paralelo, la AESIA publica un material que facilita la traducción de requisitos abstractos en preguntas concretas y verificables, proporcionando una herramienta práctica para la evaluación continua del grado de cumplimiento.
Se trata de listas de verificación que permiten a una entidad evaluar su nivel de cumplimiento de forma autónoma.
La utilización de estas checklists proporciona múltiples beneficios a las organizaciones. En primer lugar, facilitan la identificación temprana de brechas de cumplimiento, permitiendo a las organizaciones tomar medidas correctivas antes de la comercialización o puesta en servicio del sistema. También promueven un enfoque sistemático y estructurado del cumplimiento normativo. Al seguir la estructura de los artículos del Reglamento, garantizan que ningún requisito esencial quede sin evaluar.
Por otro lado, facilitan la comunicación entre equipos técnicos, jurídicos y de gestión, proporcionando un lenguaje común y una referencia compartida para discutir el cumplimiento normativo. Y, por último, las checklists sirven como base documental para demostrar la debida diligencia ante las autoridades supervisoras.
Debemos entender que estos documentos no son estáticos. Están sujetos a un proceso permanente de evaluación y revisión. En este sentido, la AESIA continúa desarrollando su capacidad operativa y ampliando sus herramientas de apoyo al cumplimiento.
Desde la plataforma de datos abiertos del Gobierno de España, te invitamos a explorar estos recursos. El desarrollo de la IA debe ir de la mano con datos bien gobernados y supervisión ética.
Blog
Durante más de una década, las plataformas de datos abiertos han medido su impacto a través de indicadores relativamente estables: número de descargas, visitas a la web, reutilizaciones documentadas, aplicaciones o servicios creados en base a ellos, etc. Estos indicadores funcionaban bien en un ecosistema donde los usuarios - empresas, periodistas, desarrolladores, ciudadanos anónimos, etc. - accedían directamente a las fuentes originales para consultar, descargar y procesar los datos.
Sin embargo, el panorama ha cambiado radicalmente. La irrupción de los modelos de inteligencia artificial generativa ha transformado la forma en que las personas acceden a la información. Estos sistemas generan respuestas sin necesidad de que el usuario visite la fuente original, lo que está provocando una caída global del tráfico web en medios, blogs y portales de conocimiento.
En este nuevo contexto, medir el impacto de una plataforma de datos abiertos exige repensar los indicadores tradicionales para incorporar a las métricas ya utilizadas otras nuevas que capturen también la visibilidad e influencia de los datos en un ecosistema donde la interacción humana está cambiando.
Un cambio estructural: del clic a la consulta indirecta
El ecosistema web está experimentando una transformación profunda impulsada por el auge de los modelos de lenguaje de gran tamaño (LLM, por sus siglas en inglés). Cada vez más personas formulan sus preguntas directamente a sistemas como ChatGPT, Copilot, Gemini o Perplexity, obteniendo respuestas inmediatas y contextualizadas sin necesidad de recurrir a un buscador tradicional.
Al mismo tiempo, quienes continúan utilizando motores de búsqueda como Google o Bing también experimentan cambios relevantes derivados de la integración de la inteligencia artificial en estas plataformas. Google, por ejemplo, ha incorporado funciones como AI Overviews, que ofrece resúmenes generados automáticamente en la parte superior de los resultados, o el Modo IA, una interfaz conversacional que permite profundizar en una consulta sin navegar por enlaces. Esto genera un fenómeno conocido como Zero-Click: el usuario realiza una búsqueda en un motor como Google y obtiene la respuesta directamente en la propia página de resultados. En consecuencia, no tiene necesidad de hacer clic en ningún enlace externo, lo cual limita las visitas a las fuentes originales de las que está extraída la información.
Todo ello implica una consecuencia clave: el tráfico web deja de ser un indicador fiable de impacto. Una página web puede estar siendo extremadamente influyente en la generación de conocimiento sin que ello se traduzca en visitas.

Figura 1. Métricas para medir el impacto de los datos abiertos en la era de la IA. Fuente: elaboración propia.
Nuevas métricas para medir el impacto
Ante esta situación, las plataformas de datos abiertos necesitan nuevas métricas que capturen su presencia en este nuevo ecosistema. A continuación, se recogen algunas de ellas.
-
Share of Model (SOM): presencia en los modelos de IA
Inspirado en métricas del marketing digital, el Share of Model mide con qué frecuencia los modelos de IA mencionan, citan o utilizan datos procedentes de una fuente concreta. De esta forma, el SOM ayuda a ver qué conjuntos de datos concretos (empleo, clima, transporte, presupuestos, etc.) son utilizados por los modelos para responder preguntas reales de los usuarios, revelando qué datos tienen mayor impacto.
Esta métrica resulta especialmente valiosa porque actúa como un indicador de confianza algorítmica: cuando un modelo menciona una página web, está reconociendo su fiabilidad como fuente. Además, contribuye a aumentar la visibilidad indirecta, ya que el nombre de la web aparece en la respuesta incluso cuando el usuario no llega a hacer clic.
-
Análisis de sentimiento: tono de las menciones en IA
El análisis de sentimiento permite ir un paso más allá del Share of Model, ya que no solo identifica si un modelo de IA menciona una marca o dominio, sino cómo lo hace. Habitualmente, esta métrica clasifica el tono de la mención en tres categorías principales: positivo, neutro y negativo.
Aplicado al ámbito de los datos abiertos, este análisis ayuda a comprender la percepción algorítmica de una plataforma o conjunto de datos. Por ejemplo, permite detectar si un modelo utiliza una fuente como ejemplo de buenas prácticas, si la menciona de forma neutral como parte de una respuesta informativa o si la asocia a problemas, errores o datos desactualizados.
Esta información puede resultar útil para identificar oportunidades de mejora, reforzar la reputación digital o detectar posibles sesgos en los modelos de IA que afecten a la visibilidad de una plataforma de datos abiertos.
-
Categorización de prompts: en qué temas destaca una marca
Analizar las preguntas que hacen los usuarios permite identificar en qué tipos de consultas aparece con mayor frecuencia una marca. Esta métrica ayuda a entender en qué áreas temáticas -como economía, salud, transporte, educación o clima- los modelos consideran más relevante una fuente.
Para las plataformas de datos abiertos, esta información revela qué conjuntos de datos están siendo utilizados para responder preguntas reales de los usuarios y en qué dominios existe mayor visibilidad o potencial de crecimiento. También permite detectar oportunidades: si una iniciativa de datos abiertos quiere posicionarse en nuevas áreas, puede evaluar qué tipo de contenido falta o qué conjuntos de datos podrían reforzarse para aumentar su presencia en esas categorías.
-
Tráfico procedente de IA: clics desde resúmenes generados
Muchos modelos ya incluyen enlaces a las fuentes originales. Aunque muchos usuarios no hacen clic en dichos enlaces, algunos sí lo hacen. Por ello, las plataformas pueden empezar a medir:
- Visitas procedentes de plataformas de IA (cuando estas incluyen enlaces).
- Clics desde resúmenes enriquecidos en buscadores que integran IA.
Esto supone un cambio en la distribución del tráfico que llega a las webs desde los distintos canales. Mientras el tráfico orgánico —el que proviene de los motores de búsqueda tradicionales— está disminuyendo, empieza a crecer el tráfico referido desde los modelos de lenguaje.
Este tráfico será menor en cantidad que el tradicional, pero más cualificado, ya que quien hace clic desde una IA suele tener una intención clara de profundizar.
Es importante que se tengan en cuenta estos aspectos a la hora de fijar objetivos de crecimiento en una plataforma de datos abiertos.
-
Reutilización algorítmica: uso de datos en modelos y aplicaciones
Los datos abiertos alimentan modelos de IA, sistemas predictivos y aplicaciones automatizadas. Conocer qué fuentes se han utilizado para su entrenamiento sería también una forma de conocer su impacto. Sin embargo, pocas soluciones proporcionan de manera directa esta información. La Unión Europea está trabajando para promover la transparencia en este campo, con medidas como la plantilla para documentar los datos de entrenamiento de modelos de propósito general, pero su implantación -y la existencia de excepciones a su cumplimiento- hacen que el conocimiento sea aún limitado.
Medir el incremento de accesos a los datos mediante API podría dar una idea de su uso en aplicaciones para alimentar sistemas inteligentes. Sin embargo, el mayor potencial en este campo pasa por colaboración con empresas, universidades y desarrolladores inmersos en estos proyectos, para que ofrezcan una visión más realista del impacto.
Conclusión: medir lo que importa, no solo lo que es fácil de medir
La caída del tráfico web no significa una caída del impacto. Significa un cambio en la forma en que la información circula. Las plataformas de datos abiertos deben evolucionar hacia métricas que reflejen la visibilidad algorítmica, la reutilización automatizada y la integración en modelos de IA.
Esto no significa que las métricas tradicionales deban desaparecer. Conocer los accesos a la web, los conjuntos de datos más visitados o los más descargados sigue siendo una información de gran valor para conocer el impacto de los datos proporcionados a través de plataformas abiertas. Y también es fundamental monitorizar el uso de los datos a la hora de generar o enriquecer productos y servicios, incluidos los sistemas de inteligencia artificial. En la era de la IA, el éxito ya no se mide solo por cuántos usuarios visitan una plataforma, sino también por cuántos sistemas inteligentes dependen de su información y la visibilidad que ello otorga.
Por eso, integrar estas nuevas métricas junto a los indicadores tradicionales a través de una estrategia de analítica web y SEO * permite obtener una visión más completa del impacto real de los datos abiertos. Así podremos saber cómo circula nuestra información, cómo se reutiliza y qué papel juega en el ecosistema digital que hoy da forma a la sociedad.
*El SEO (Search Engine Optimization) es el conjunto de técnicas y estrategias destinadas a mejorar la visibilidad de un sitio web en los motores de búsqueda.
Blog
El contenido masivo y superficial generado por IA no es solo un problema, también es un síntoma. La tecnología amplifica un modelo de consumo que premia la fluidez y agota nuestra capacidad de atención.
Escuchamos entrevistas, pódcasts y audios de nuestra familia al 2x. Vemos vídeos recortados en highlights, y basamos decisiones y criterios en artículos e informes que solo hemos leído resumidos con IA. Consumimos información en modo ultrarrápido, pero a nivel cognitivo le damos la misma validez que cuando la consumíamos más despacio, e incluso la aplicamos en la toma de decisiones. Lo que queda afectado por este proceso no es la memoria básica de contenidos, que parece mantenerse según los estudios controlados, sino la capacidad de conectar esos conocimientos con los que ya teníamos y elaborar con ellos ideas propias. Más que la superficialidad, inquieta que esta nueva modalidad de pensamiento resulte suficiente en tantos contextos.
¿Qué es nuevo y qué no?
Podemos pensar que la IA generativa no ha hecho más que intensificar una dinámica antigua en la que la producción de contenido es infinita, pero nuestra capacidad de atención es la misma. No podemos engañarnos tampoco, porque desde que existe Internet la infinitud no es novedad. Si dijéramos que el problema es que hay demasiado contenido, estaríamos quejándonos de una situación en la que vivimos desde hace más de veinte años. Tampoco es nueva la crisis de autoridad de la información oficial o la dificultad para distinguir fuentes fiables de las que no lo son.
Sin embargo, el AI slop, que es la inundación de contenido digital generado con IA en Internet, aporta una lógica propia y consideraciones nuevas, como la ruptura del vínculo entre esfuerzo y contenido, o que todo lo que se genera es un promedio estadístico de lo que ya existía. Este flujo uniforme y descontrolado tiene consecuencias: detrás del contenido generado en masa puede haber una intención orquestada de manipulación, un sesgo algorítmico, voluntario o no, que perjudique a determinados colectivos o frene avances sociales, y también una distorsión de la realidad aleatoria e impredecible.
¿Pero cuánto de lo que leo es IA?
En 2025 se ha estimado que una gran parte del contenido online incorpora texto sintético: un análisis de Ahrefs de casi un millón de páginas web publicadas en la primera mitad del año detectó que el 74,2 % de las nuevas páginas contenían señales de contenido generado con IA. Una investigación de Graphite del mismo año cita que, solo durante el primer año de ChatGPT, un 39% de todo el contenido online estaba ya generado con IA. Desde noviembre de 2024 esa cifra se ha mantenido estable en torno al 52%, lo que significa que desde entonces el contenido IA supera en cantidad al contenido humano.
No obstante, hay dos preguntas que deberíamos hacernos cuando nos encontramos estimaciones de este tipo:
1. ¿Existe un mecanismo fiable para distinguir un texto escrito de un texto generado? Si la respuesta es no, por muy llamativas y coherentes que sean las conclusiones, no podemos darles valor, porque tanto podrían ser ciertas como no serlo. Es un dato cuantitativo valioso, pero que aún no existe.
Con la información que tenemos actualmente, podemos afirmar que los detectores de "texto generado por IA" fallan con la misma frecuencia con la que fallaría un modelo aleatorio, por lo que no podemos atribuirles fiabilidad. En un estudio reciente citado por The Guardian, los detectores acertaron si el texto estaba generado con IA o no en menos de un 40% de los casos. Por otro lado, ante el primer párrafo de El Quijote, también determinados detectores han devuelto un 86% de probabilidad de que el texto estuviera creado por IA.
2. ¿Qué significa que un texto está generado con IA? Por otro lado, no siempre el proceso es completamente automático (lo que llamamos copiar y pegar) sino que se dan muchos grises en la escala: la IA inspira, organiza, asiste, reescribe o expande ideas, y negar, deslegitimar o penalizar esta escritura sería ignorar una realidad instalada.
Los dos matices anteriores no anulan el hecho de que existe el AI slop, pero este no tiene por qué ser un destino inevitable. Existen maneras de mitigar sus efectos en nuestras capacidades.
¿Cuáles son los antídotos?
Podemos no contribuir a la producción de contenido sintético, pero no podemos desacelerar lo que está ocurriendo, así que el reto consiste en revisar los criterios y los hábitos mentales con los que abordamos tanto la lectura como la escritura de contenidos.
1. Prioriza lo que hace clic: una de las pocas señales fiables que nos quedan es esa sensación de clic en el momento en que algo conecta con un conocimiento previo, una intuición que teníamos difusa o una experiencia propia, y la reorganiza o la hace nítida. Solemos decir también que “resuena”. Si algo hace clic, merece la pena seguirlo, confirmarlo, investigarlo y elaborarlo brevemente a nivel personal.
2. Busca la fricción con datos: anclar el contenido en datos abiertos y fuentes contrastables introduce una fricción saludable frente al AI slop. Reduce, sobre todo, la arbitrariedad y la sensación de contenido intercambiable, porque los datos obligan a interpretar y poner en contexto. Es una manera de poner piedras en el río excesivamente fluido que supone la generación de lenguaje, y funciona cuando leemos y cuando escribimos.
3. ¿Quién se responsabiliza? el texto existe fácilmente ahora, la cuestión es por qué existe o qué quiere conseguir, y quién se hace cargo en última instancia de ese objetivo. Busca la firma de personas u organizaciones, no tanto por la autoría sino por la responsabilidad. Desconfía de las firmas colectivas, también en traducciones y adaptaciones.
4. Cambia el foco del mérito: evalúa tus inercias al leer, porque quizá un día aprendiste a dar mérito a textos que sonaban convincentes, utilizaban determinadas estructuras o subían a un registro concreto. Desplaza el valor a elementos no generables como encontrar una buena historia, saber formular una idea difusa o atreverse a dar un punto de vista en un contexto polémico.
En la otra cara de la moneda, también es un hecho que el contenido creado con IA entra con ventaja en el flujo, pero con desventaja en la credibilidad. Esto significa que el auténtico riesgo ahora es que la IA pueda llegar a crear contenido de alto valor, pero las personas hayamos perdido la capacidad de concentración para valorarlo. A esto hay que añadirle el prejuicio instalado de que, si es con IA, no es un contenido válido. Proteger nuestras capacidades cognitivas y aprender a diferenciar entre un contenido comprimible y uno que no lo es no es por tanto un gesto nostálgico, sino una habilidad que a la larga puede mejorar la calidad del debate público y el sustrato del conocimiento común.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Los agentes de IA (como los de Google ADK, LangChain, etc.) son "cerebros". Pero un cerebro sin "manos" no puede actuar en el mundo real (consultar APIs, buscar en bases de datos, etc.). Esas "manos" son las herramientas.
El desafío es: ¿cómo conectas el cerebro con las manos de forma estándar, desacoplada y escalable? La respuesta es el Model Context Protocol (MCP).
Como ejercicio práctico, construiremos un sistema de agente conversacional que permite explorar el Catálogo Nacional de datos abiertos albergado en datos.gob.es mediante preguntas en lenguaje natural, facilitando así el acceso a datos públicos.
En este ejercicio práctico, el objetivo principal es ilustrar, paso a paso, cómo construir un servidor de herramientas independiente que hable el protocolo MCP.
Para hacer este ejercicio tangible y no solo teórico, usaremos, FastMCP para construir el servidor. Para probar que nuestro servidor funciona, crearemos un agente simple con Google ADK que lo consuma. El caso de uso (consultar la API de datos.gob.es) ilustra esta conexión entre herramientas y agentes. El verdadero aprendizaje es la arquitectura, que podrías reutilizar para cualquier API o base de datos.
A continuación se muestran las tecnologías que usaremos y un esquema de cómo están realizados entre sí los diferentes componentes
- FastMCP (mcp.server.fastmcp): implementación ligera del protocolo MCP que permite crear servidores de herramientas con muy poco código mediante decoradores Python. Es el 'protagonista' del ejercicio.
- Google ADK (Agent Development Kit): framework para definir el agente de IA, su prompt y conectarlo a las herramientas. Es el 'cliente' que prueba nuestro servidor.
- FastAPI: para servir el agente como una API REST con interfaz web interactiva.
- httpx: para realizar llamadas asíncronas a la API externa de datos.gob.es.
- Docker y Docker Compose: para paquetizar y orquestar los dos microservicios, permitiendo que se ejecuten y comuniquen de forma aislada.

Figura 1. Arquitectura desacoplada con comunicación MCP.
El diagrama ilustra una arquitectura desacoplada dividida en cuatro componentes principales que se comunican mediante el protocolo MCP. Cuando el usuario realiza una consulta en lenguaje natural, el Agente ADK (basado en Google Gemini) procesa la intención y se comunica con el servidor MCP a través del Protocolo MCP, que actúa como intermediario estandarizado. El servidor MCP expone cuatro herramientas especializadas (buscar datasets, listar temáticas, buscar por temática y obtener detalles) que encapsulan toda la lógica de negocio para interactuar con la API externa de datos.gob.es. Una vez que las herramientas ejecutan las consultas necesarias y reciben los datos del catálogo nacional, el resultado se propaga de vuelta al agente, que finalmente genera una respuesta comprensible para el usuario, completando así el ciclo de comunicación entre el "cerebro" (agente) y las "manos" (herramientas).
Accede al repositorio del laboratorio de datos en GitHub
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
La arquitectura: servidor MCP y agente consumidor
La clave de este ejercicio es entender la relación cliente-servidor:
- El Servidor (Backend): es el protagonista de este ejercicio. Su único trabajo es definir la lógica de negocio (las "herramientas") y exponerlas al mundo exterior usando el "contrato" estándar de MCP. Es el responsable de encapsular toda la lógica de comunicación con la API de datos.gob.es.
- El Agente (Frontend): es el "cliente" o "consumidor" de nuestro servidor. Su rol en este ejercicio es probar que nuestro servidor MCP funciona. Lo usamos para conectarnos, descubrir las herramientas que el servidor ofrece y llamarlas.
- El Protocolo MCP: es el "lenguaje" o "contrato" que permite que el agente y el servidor se entiendan sin necesidad de conocer los detalles internos del otro.
Proceso de desarrollo
El núcleo del ejercicio se divide en tres partes: crear el servidor, crear un cliente para probarlo y ejecutarlos.
1. El servidor de herramientas (el backend con MCP)
Aquí es donde reside la lógica de negocio y el foco de este tutorial. En el archivo principal (server.py), definimos funciones Python simples y usamos el decorador @mcp.tool de FastMCP para exponerlas como 'herramientas' consumibles.
La description que añadimos al decorador es crucial, ya que es la documentación que cualquier cliente MCP (incluyendo nuestro agente ADK) leerá para saber cuándo y cómo usar cada herramienta.
Las herramientas que definiremos en el ejercicio son:
- buscar_datasets(titulo: str): para buscar datasets por palabras clave en el título.
- listar_tematicas(): para descubrir qué categorías de datos existen.
- buscar_por_tematica(tematica_id: str): para encontrar datasets de un tema específico.
-
obtener_detalle_dataset(dataset_id: str): para obtener la información completa de un dataset.
2. El agente consumidor (el frontend con Google ADK)
Una vez construido nuestro servidor MCP, necesitamos una forma de probarlo. Aquí es donde entra Google ADK. Lo usamos para crear un "agente consumidor" simple.
La magia de la conexión ocurre en el argumento tools. En lugar de definir las herramientas localmente, simplemente le pasamos la URL de nuestro servidor MCP. El agente, al iniciarse, consultará esa URL, leerá el "contrato" MCP y sabrá automáticamente qué herramientas tiene disponibles y cómo usarlas.
# Ejemplo de configuración en agent.py
root_agent = LlmAgent(
...
instruction="Eres un asistente especializado en datos.gob.es...",
tools=[
MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="http://mcp-server:8000/mcp",
),
)
]
)3. Orquestación con Docker Compose
Finalmente, para ejecutar nuestro Servidor MCP y el agente consumidor juntos, usamos docker-compose.yml. Docker Compose se encarga de construir las imágenes de cada servicio, crear una red privada para que se comuniquen (por eso el agente puede llamar a http://mcp-server:8000) y exponer los puertos necesarios.
Probando el servidor MCP en acción
Una vez que ejecutamos docker-compose up --build, podemos acceder a la interfaz web del agente (http://localhost:8080).
El objetivo de esta prueba no es solo ver si el bot responde bien, sino verificar que nuestro servidor MCP funciona correctamente y que el agente ADK (nuestro cliente de prueba) puede descubrir y usar las herramientas que este expone.
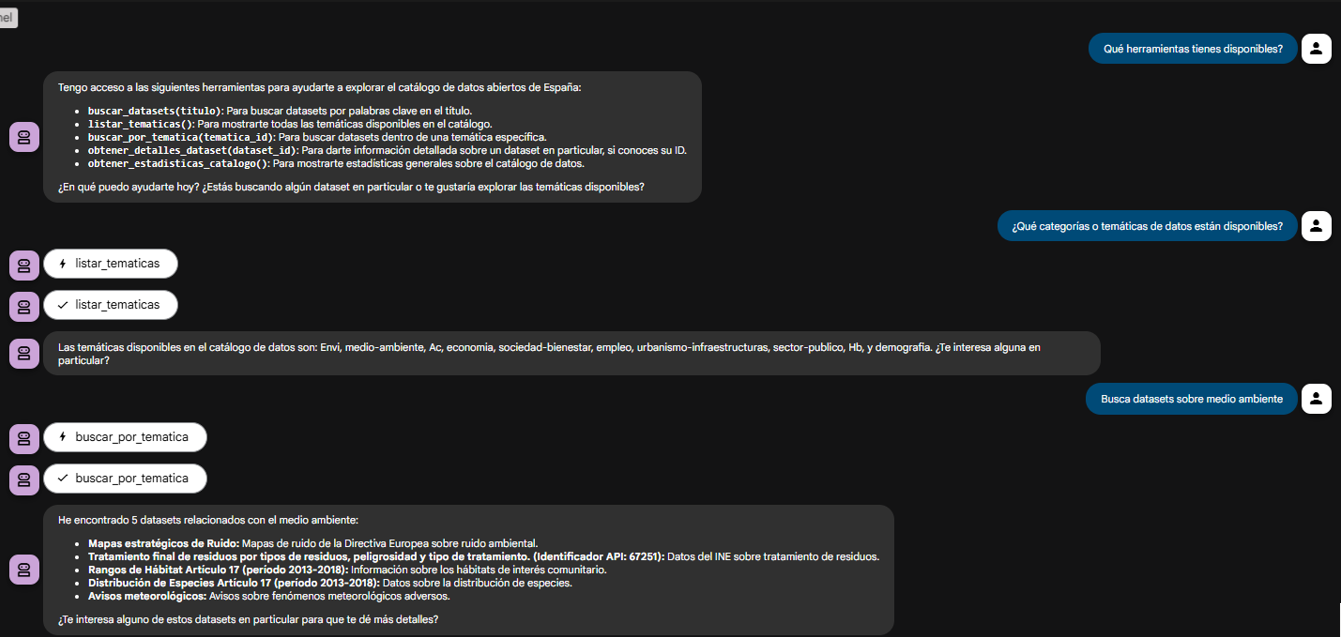
Figura 2. Pantalla del agente demostrando sus herramientas.
El verdadero poder del desacoplamiento se ve cuando el agente encadena lógicamente las herramientas que nuestro servidor le proveyó.
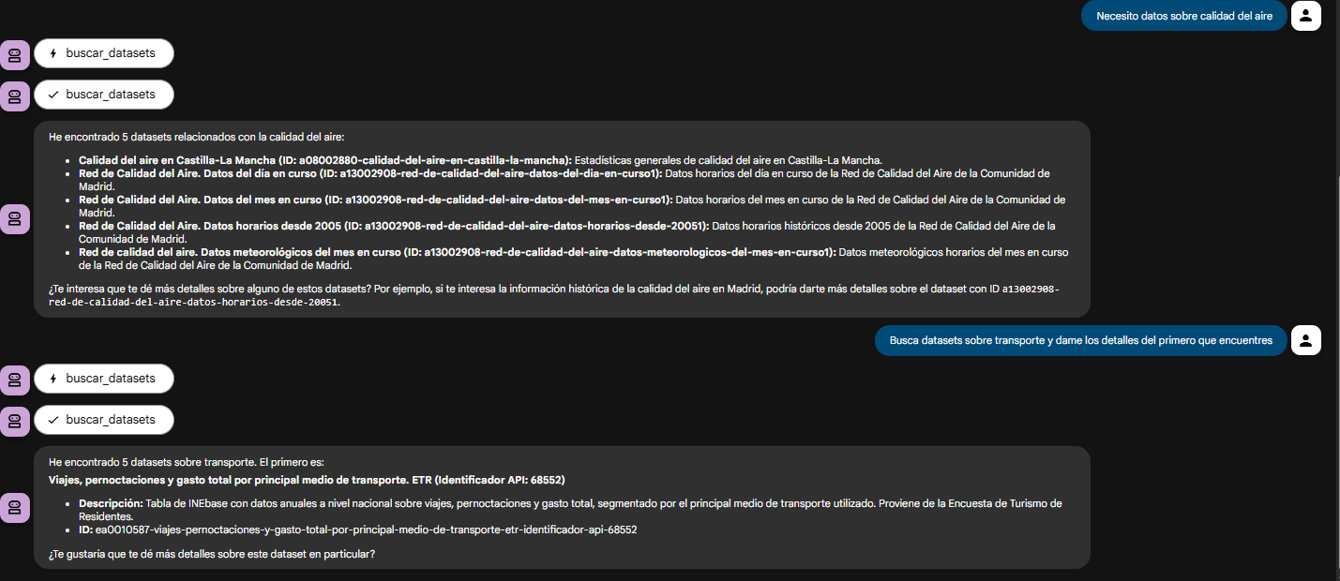
Figura 3. Pantalla del agente demostrando el uso conjunto de las herramientas.
¿Qué puedes aprender?
El objetivo de este ejercicio es aprender los fundamentos de una arquitectura de agentes moderna, centrándonos en el servidor de herramientas. En concreto:
- Cómo construir un servidor MCP: cómo crear un servidor de herramientas desde cero que hable MCP, usando decoradores como @mcp.tool.
- El patrón de una arquitectura desacoplada: el patrón fundamental de separar el 'cerebro' (LLM) de las 'herramientas' (lógica de negocio).
- Descubrimiento dinámico de herramientas: cómo un agente (en este caso, de ADK) puede conectarse dinámicamente a un servidor MCP para descubrir y consumir herramientas.
- Integración de API externas: el proceso de 'envolver' una API compleja (como la de datos.gob.es) en funciones simples dentro de un servidor de herramientas.
- Orquestación con Docker: cómo gestionar un proyecto de microservicios para desarrollo.
Conclusiones y futuro
Hemos construido un servidor de herramientas MCP robusto y funcional. El verdadero valor de este ejercicio es el cómo: una arquitectura escalable centrada en un servidor de herramientas que habla un protocolo estándar.
Esta arquitectura basada en MCP es increíblemente flexible. El caso de datos.gob.es es solo un ejemplo. Podríamos fácilmente:
- Cambiar el caso de uso: reemplazar el server.py por uno que conecte a una base de datos interna o a la API de Spotify, y cualquier agente que hable MCP (no solo ADK) podría consumirlo.
- Cambiar el "cerebro": cambiar el agente ADK por un agente de LangChain o cualquier otro cliente MCP, y nuestro servidor de herramientas seguiría funcionando sin cambios.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades se centran en mejorar el servidor MCP:
- Implementar más herramientas: añadir filtros por formato, publicador o fecha al servidor MCP.
- Integrar caché: usar Redis en el servidor MCP para cachear las respuestas de la API y mejorar la velocidad.
- Añadir persistencia: guardar el historial de chat en una base de datos (esto sí sería en el lado del agente).
Más allá de estas mejoras técnicas, esta arquitectura abre la puerta a múltiples aplicaciones en contextos muy diversos.
- Periodistas y académicos pueden disponer de asistentes de investigación que les ayuden a descubrir conjuntos de datos relevantes en segundos.
- Organizaciones de transparencia pueden construir herramientas de monitorización que detecten automáticamente nuevas publicaciones de datos de contratación pública o presupuestos.
- Consultoras y equipos de inteligencia de negocio pueden desarrollar sistemas que crucen información de múltiples fuentes gubernamentales para elaborar informes sectoriales.
- Incluso en el ámbito educativo, esta arquitectura sirve como base didáctica para enseñar conceptos avanzados de programación asíncrona, integración de API y diseño de agentes de IA.
El patrón que hemos construido —un servidor de herramientas desacoplado que habla un protocolo estándar— es la base sobre la que puedes desarrollar soluciones adaptadas a tus necesidades específicas, independientemente del dominio o la fuente de datos con la que trabajes.
Blog
Los datos abiertos son una pieza central de la innovación digital en torno a la inteligencia artificial ya que permiten, entre otras cosas, entrenar modelos o evaluar algoritmos de aprendizaje automático. Pero entre “descargar un CSV de un portal” y acceder a un conjunto de datos listo para aplicar técnicas de aprendizaje automático hay, todavía, un abismo.
Buena parte de ese abismo tiene que ver con los metadatos, es decir cómo se describen los conjuntos de datos (a qué nivel de detalle y con qué estándares). Si los metadatos se limitan a título, descripción y licencia, el trabajo de comprensión y preparación de datos se hace más complejo y tedioso para la persona que diseña el modelo de aprendizaje automático. Si, en cambio, se usan estándares que faciliten la interoperabilidad, como DCAT, los datos se vuelven más FAIR (Findable, Accessible, Interoperable, Reusable) y, por tanto, más fáciles de reutilizar. No obstante, es necesario metadatos adicionales para que los datos sean más fáciles de integrar en flujos de aprendizaje automático.
Este artículo realiza un itinerario por las diversas iniciativas y estándares necesarios para dotar a los datos abiertos de metadatos útiles para la aplicación de técnicas de aprendizaje automático.
DCAT como columna vertebral de los portales de datos abiertos
El vocabulario DCAT (Data Catalog Vocabulary) fue diseñado por la W3C para facilitar la interoperabilidad entre catálogos de datos publicados en la Web. Describe catálogos, conjuntos de datos y distribuciones, siendo la base sobre la que se construyen muchos portales de datos abiertos.
En Europa, DCAT se concreta en el perfil de aplicación DCAT-AP, recomendado por la Comisión Europea y ampliamente adoptado para describir conjuntos de datos en el sector público, por ejemplo, en España con DCAT-AP-ES. Con DCAT-AP se responde a preguntas como:
- ¿Qué conjuntos de datos existen sobre un tema concreto?
- ¿Quién los publica, bajo qué licencia y en qué formatos?
- ¿Dónde están las URL de descarga o las API de acceso?
El uso de un estándar como DCAT es imprescindible para descubrir conjuntos de datos, pero es necesario ir un paso más allá con el fin de saber cómo se utilizan en modelos de aprendizaje automático o qué calidad tienen desde la perspectiva de estos modelos.
MLDCAT-AP: aprendizaje automático en el catálogo de un portal de datos abiertos
MLDCAT-AP (Machine Learning DCAT-AP) es un perfil de aplicación de DCAT desarrollado por SEMIC y la comunidad Interoperable Europe, en colaboración con OpenML, que extiende DCAT-AP al dominio del aprendizaje automático.
MLDCAT-AP incorpora clases y propiedades para describir:
- Modelos de aprendizaje automático y sus características.
- Conjuntos de datos utilizados en el entrenamiento y la evaluación.
- Métricas de calidad obtenidas sobre los conjuntos de datos.
- Publicaciones y documentación asociadas a los modelos de aprendizaje automático.
- Conceptos relacionados con riesgo, transparencia y cumplimiento del contexto regulatorio europeo del AI Act.
Con ello, un catálogo basado en MLDCAT-AP ya no solo responde a “qué datos hay”, sino también a:
- ¿Qué modelos se han entrenado con este conjunto de datos?
- ¿Cuál ha sido el rendimiento de ese modelo según determinadas métricas?
- ¿Dónde se describe este trabajo (artículos científicos, documentación, etc.)?
MLDCAT-AP representa un gran avance en trazabilidad y gobernanza, pero se mantiene la definición de metadatos a un nivel que todavía no considera la estructura interna de los conjuntos de datos ni qué significan exactamente sus campos. Para eso, se necesita bajar a nivel de la propia estructura de la distribución de conjunto de datos.
Metadatos a nivel de estructura interna del conjunto de datos
Cuando se quiere describir qué hay dentro de las distribuciones de los conjuntos de datos (campos, tipos, restricciones), una iniciativa interesante es Data Package, parte del ecosistema de Frictionless Data.
Un Data Package se define por un archivo JSON que describe un conjunto de datos. En este archivo se incluyen no sólo metadatos generales (como el nombre, título, descripción o licencia) y recursos (es decir, los ficheros de datos con su ruta o una URL de acceso a su correspondiente servicio), sino también se define un esquema con:
- Nombres de campos.
- Tipos de datos (integer, number, string, date, etc.).
- Restricciones, como rangos de valores válidos, claves primarias y ajenas, etc.
Desde la óptica del aprendizaje automático, esto se traduce en la posibilidad de realizar una validación estructural automática antes de usar los datos. Además, también permite una documentación precisa de la estructura interna de cada conjunto de datos y mayor facilidad para compartir y versionar conjuntos de datos.
En resumen, mientras que MLDCAT-AP indica qué conjuntos de datos existen y cómo encajan en el ámbito de modelos de aprendizaje automático, Data Package especifica exactamente “qué hay” dentro de los conjuntos de datos.
Croissant: metadatos que preparan datos abiertos para aprendizaje automático
Aun con el concurso de MLDCAT-AP y de Data Package, faltaría conectar los conceptos subyacentes en ambas iniciativas. Por una parte, el ámbito del aprendizaje automático (MLDCAT-AP) y por otro el de las estructuras internas de los propios datos (Data Package). Es decir, se puede estar usando los metadatos de MLDCAT-AP y de Data Package pero para solventar algunas limitaciones que adolecen ambos, es necesario complementarlo. Aquí entra en juego Croissant, un formato de metadatos para preparar los conjuntos de datos para la aplicación de aprendizaje automático. Croissant está desarrollado en el marco de MLCommons, con participación de industria y academia.
Específicamente, Croissant se implementa en JSON-LD y se construye sobre schema.org/Dataset, un vocabulario para describir conjuntos de datos en la Web. Croissant combina los siguientes metadatos:
- Metadatos generales del conjunto de datos.
- Descripción de recursos (archivos, tablas, etc.).
- Estructura de los datos.
- Capa semántica sobre aprendizaje automático (separación de datos de entrenamiento/validación/test, campos objetivo, etc.)
Cabe destacar que Croissant está diseñado para que distintos repositorios (como Kaggle, HuggingFace, etc.) puedan publicar conjuntos de datos en un formato que las librerías de aprendizaje automático (TensorFlow, PyTorch, etc.) puedan cargar de forma homogénea. También existe una extensión de CKAN para usar Croissant en portales de datos abiertos.
Otras iniciativas complementarias
Merece la pena mencionar brevemente otras iniciativas interesantes relacionadas con la posibilidad de disponer de metadatos que permitan preparar a los conjuntos de datos para la aplicación de aprendizaje automático (“ML-ready datasets”):
- schema.org/Dataset: usado en páginas web y repositorios para describir conjuntos de datos. Es la base sobre la que se apoya Croissant y está integrado, por ejemplo, en las directrices de datos estructurados de Google para mejorar la localización de conjuntos de datos en buscadores.
- CSV on the Web (CSVW): conjunto de recomendaciones del W3C para acompañar ficheros CSV con metadatos en JSON (incluyendo diccionarios de datos), muy alineado con las necesidades de documentación de datos tabulares que luego se usan en aprendizaje automático.
- Datasheets for Datasets y Dataset Cards: iniciativas que permiten desarrollar una documentación narrativa y estructurada para describir el contexto, la procedencia y las limitaciones de los conjuntos de datos. Estas iniciativas son ampliamente adoptadas en plataformas como Hugging Face.
Conclusiones
Existen diversas iniciativas que ayudan a realizar una definición de metadatos adecuada para el uso de aprendizaje automático con datos abiertos:
- DCAT-AP y MLDCAT-AP articulan el nivel de catálogo, modelos de aprendizaje automático y métricas.
- Data Package describe y valida la estructura y restricciones de los datos a nivel de recurso y campo.
- Croissant conecta estos metadatos con el flujo de aprendizaje automático, describiendo cómo los conjuntos de datos son ejemplos concretos para cada modelo.
- Iniciativas como CSVW o Dataset Cards complementan las anteriores y son ampliamente utilizadas en plataformas como HuggingFace.
Estas iniciativas pueden usarse de manera combinada. De hecho, si se adoptan de forma conjunta, se permite que los datos abiertos dejen de ser simplemente “ficheros descargables” y se conviertan en una materia prima preparada para el aprendizaje automático, reduciendo fricción, mejorando la calidad y aumentando la confianza en los sistemas de IA construidos sobre ellos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Cuando se acaban de cumplir tres años desde que comenzó la aceleración del despliegue masivo de la Inteligencia Artificial con el lanzamiento de ChatGPT, un término nuevo emerge con fuerza: la IA agéntica (Agentic AI). En los últimos tres años hemos pasado de hablar de modelos de lenguaje (como por ejemplo, los LLM) y chatbots (o asistentes conversacionales) a diseñar los primeros sistemas capaces no solo de responder a nuestras preguntas, sino de actuar de forma autónoma para conseguir objetivos, combinando datos, herramientas y colaboraciones con otros agentes de IA o con personas humanas. Esto es, la conversación global sobre IA se está moviendo desde la capacidad para "conversar" hacia la capacidad para "actuar" de estos sistemas.
En el sector privado, informes recientes de grandes consultoras describen agentes de IA que resuelven de principio a fin incidencias de clientes, orquestan cadenas de suministro, optimizan inventarios en el sector retail o automatizan la elaboración de informes de negocio. En el sector público, esta conversación también comienza a tomar forma y cada vez más administraciones exploran cómo estos sistemas pueden ayudar a simplificar trámites o a mejorar la atención a la ciudadanía. Sin embargo, el despliegue parece que está siendo algo más lento porque lógicamente en la administración no solo debe tenerse en cuenta la excelencia técnica sino también el estricto cumplimiento del marco normativo, que en Europa lo marca el Reglamento de IA, para que los agentes autónomos sean, ante todo, aliados de la ciudadanía.
¿Qué es la IA agéntica (Agentic AI)?
Aunque se trate de un concepto reciente que aún está en evolución, varias administraciones y organismos empiezan a converger en una definición. Por ejemplo, el Gobierno del Reino Unido describe la IA agéntica como sistemas formados por agentes de IA que “pueden comportarse e interactuar de forma autónoma para lograr sus objetivos”. En este contexto un agente de IA sería una pieza especializada de software que puede tomar decisiones y operar de forma cooperativa o independiente para lograr los objetivos del sistema.
Podríamos pensar, por ejemplo, en un agente de IA en una administración local que recibe la solicitud de una persona para abrir un pequeño negocio. El agente, diseñado de acuerdo con el procedimiento administrativo correspondiente, comprobaría la normativa aplicable, consultaría datos urbanísticos y de actividad económica, verificaría requisitos, rellenaría borradores de documentos, propondría citas o trámites complementarios y prepararía un resumen para que el personal funcionario pudiera revisar y validar la solicitud. Esto es, no sustituiría la decisión humana, sino que automatizaría buena parte del trabajo que hay entre la solicitud realizada por el ciudadano y la resolución dictada por la administración.
Frente a un chatbot conversacional -que responde a una pregunta y, en general, termina ahí la interacción-, un agente de IA puede encadenar múltiples acciones, revisar resultados, corregir errores, colaborar con otros agentes de IA y seguir iterando hasta alcanzar la meta que se le ha definido. Esto no significa que los agentes autónomos decidan por su cuenta sin supervisión, sino que pueden hacerse cargo de buena parte de la tarea siempre siguiendo reglas y salvaguardas bien definidas.
Las características clave de un agente autónomo incluyen:
- Percepción y razonamiento: es la capacidad de un agente para comprender una solicitud compleja, interpretar el contexto y desglosar el problema en pasos lógicos que conduzcan a resolverlo.
- Planificación y acción: es la habilidad para ordenar esos pasos, decidir la secuencia en que se van a ejecutar y adaptar el plan cuando cambian los datos o aparecen nuevas restricciones.
- Uso de herramientas: un agente puede, por ejemplo, conectarse a diversas API, consultar bases de datos, catálogos de datos abiertos, abrir y leer documentos o enviar correos electrónicos según lo requieran las tareas que está intentando resolver.
- Memoria y contexto: es la capacidad del agente para mantener la memoria de las interacciones en procesos largos, recordando las acciones y respuestas pasadas y el estado actual de la solicitud que está resolviendo.
- Autonomía supervisada: un agente puede tomar decisiones dentro de unos límites previamente establecidos para avanzar hacia la meta sin necesidad de intervención humana en cada paso, pero permitiendo siempre la revisión y trazabilidad de las decisiones.
Podríamos resumir el cambio que supone con la siguiente analogía: si los LLM son el motor de razonamiento, los agentes de IA son sistemas que además de esa capacidad de “pensar” en las acciones que habría que hacer, tienen "manos" para interactuar con el mundo digital e incluso con el mundo físico y ejecutar esas mismas acciones.
El potencial de los agentes de IA en los servicios públicos
Los servicios públicos se organizan, en buena medida, alrededor de procesos de una cierta complejidad como son la tramitación de ayudas y subvenciones, la gestión de expedientes y licencias o la propia atención ciudadana a través de múltiples canales. Son procesos con muchos pasos, reglas y actores diferentes, donde abundan las tareas repetitivas y el trabajo manual de revisión de documentación.
Como puede verse en el eGovernment Benchmark de la Unión Europea, las iniciativas de administración electrónica de las últimas décadas han permitido avanzar hacia una mayor digitalización de los servicios públicos. Sin embargo, la nueva ola de tecnologías de IA, especialmente cuando se combinan modelos fundacionales con agentes, abre la puerta a un nuevo salto para automatizar y orquestar de forma inteligente buena parte de los procesos administrativos.
En este contexto, los agentes autónomos permitirían:
- Orquestar procesos de extremo a extremo como, por ejemplo, recopilar datos de distintas fuentes, proponer formularios ya cumplimentados, detectar incoherencias en la documentación aportada o generar borradores de resoluciones para su validación por el personal responsable.
- Actuar como “copilotos” de los empleados públicos, preparando borradores, resúmenes o propuestas de decisiones que luego se revisan y validan, asistiendo en la búsqueda de información relevante o señalando posibles riesgos o incidencias que requieren atención humana.
- Optimizar los procesos de atención ciudadana apoyando en tareas como la gestión de citas médicas, respondiendo consultas sobre el estado de expedientes, facilitando el pago de tributos o guiando a las personas en la elección del trámite más adecuado a su situación.
Diversos análisis sobre IA en el sector público apuntan a que este tipo de automatización inteligente, al igual que en el sector privado, puede reducir tiempos de espera, mejorar la calidad de las decisiones y liberar tiempo del personal para tareas de mayor valor añadido. Un informe reciente de PWC y Microsoft que explora el potencial de la IA agéntica para el sector público resume bien la idea, señalando que al incorporar la IA agéntica en los servicios públicos, los gobiernos pueden mejorar la capacidad de respuesta y aumentar la satisfacción ciudadana, siempre que existan las salvaguardas adecuadas.
Además, la implementación de agentes autónomos permite soñar con una transición desde una administración reactiva (que espera a que el ciudadano solicite un servicio) a una administración proactiva que se ofrece a hacer por nosotros parte de esas mismas acciones: desde avisarnos de que se ha abierto una ayuda para la que probablemente cumplamos los requisitos, hasta proponernos la renovación de una licencia antes de que caduque o recordarnos una cita médica.
Un ejemplo ilustrativo de esto último podría ser un agente de IA que, apoyado en datos sobre servicios disponibles y en la información que el propio ciudadano haya autorizado utilizar, detecte que se ha publicado una nueva ayuda para actuaciones de mejora de la eficiencia energética a través de la rehabilitación de viviendas y envíe un aviso personalizado a quienes podrían cumplir los requisitos. Incluso ofreciéndoles un borrador de solicitud ya pre-cumplimentado para su revisión y aceptación. La decisión final sigue siendo humana, pero el esfuerzo de buscar la información, entender las condiciones y preparar la documentación se podría reducir mucho.
El rol de los datos abiertos
Para que un agente de IA pueda actuar de forma útil y responsable necesita apalancarse sobre un entorno rico en datos de calidad y un sistema de gobernanza de datos sólido. Entre esos activos necesarios para desarrollar una buena estrategia de agentes autónomos, los datos abiertos tienen importancia al menos en tres dimensiones:
- Combustible para la toma de decisiones: los agentes de IA necesitan información sobre normativa vigente, catálogos de servicios, procedimientos administrativos, indicadores socioeconómicos y demográficos, datos de transporte, medio ambiente, planificación urbana, etc. Para ello, la calidad y estructura de los datos es de gran importancia ya que datos desactualizados, incompletos o mal documentados pueden llevar a los agentes a cometer errores costosos. En el sector público, esos errores pueden traducirse en decisiones injustas que en última instancia podrían llevar a la pérdida de confianza de la ciudadanía.
- Banco de pruebas para evaluar y auditar agentes: al igual que los datos abiertos son importantes para evaluar modelos de IA generativa, también pueden serlo para probar y auditar agentes autónomos. Por ejemplo, simulando expedientes ficticios con datos sintéticos basados en distribuciones reales para comprobar cómo actúa un agente en distintos escenarios. De este modo, universidades, organizaciones de la sociedad civil y la propia administración puedan examinar el comportamiento de los agentes y detectar problemas antes de escalar su uso.
- Transparencia y explicabilidad: los datos abiertos podrían ayudar a documentar de dónde proceden los datos que utiliza un agente, cómo se han transformado o qué versiones de los conjuntos de datos estaban vigentes cuando se tomó una decisión. Esta trazabilidad contribuye a la explicabilidad y la rendición de cuentas, especialmente cuando un agente de IA interviene en decisiones que afectan a los derechos de las personas o a su acceso a servicios públicos. Si la ciudadanía puede consultar, por ejemplo, los criterios y datos que se aplican para otorgar una ayuda, se refuerza la confianza en el sistema.
El panorama de la IA agéntica en España y en el resto del mundo
Aunque el concepto de IA agéntica es reciente, ya existen iniciativas en marcha en el sector público a nivel internacional y comienzan a abrirse paso también en el contexto europeo y español:
- La Government Technology Agency (GovTech) de Singapur ha publicado una guía Agentic AI Primer para orientar a desarrolladores y responsables públicos sobre cómo aplicar esta tecnología, destacando tanto sus ventajas como sus riesgos. Además, el gobierno está pilotando el uso de agentes en varios ámbitos para reducir la carga administrativa de los trabajadores sociales y apoyar a las empresas en procesos complejos de obtención de licencias. Todo ello en un entorno controlado (sandbox) para probar estas soluciones antes de escalarlas.
- El Gobierno de Reino Unido ha publicado una nota específica dentro de su documentación “AI Insights” para explicar qué es la IA agéntica y por qué es relevante para servicios gubernamentales. Además, ha anunciado una licitación para desarrollar un “GOV.UK Agentic AI Companion” que sirva de asistente inteligente para la ciudadanía desde el portal del gobierno.
- La Comisión Europea, en el marco de la estrategia Apply AI y de la iniciativa GenAI4EU, ha lanzado convocatorias para financiar proyectos piloto que introduzcan soluciones de IA generativa escalables y replicables en las administraciones públicas, plenamente integradas en sus flujos de trabajo. Estas convocatorias buscan precisamente acelerar el paso en la digitalización a través de IA (incluidos agentes especializados) para mejorar la toma de decisiones, simplificar procedimientos y hacer la administración más accesible.
En España, aunque la etiqueta “IA agéntica” todavía no se utiliza aún de forma amplia, ya se pueden identificar algunas experiencias que van en esa dirección. Por ejemplo, distintas administraciones están incorporando copilotos basados en IA generativa para apoyar a los empleados públicos en tareas de búsqueda de información, redacción y resumen de documentos, o gestión de expedientes, como muestran iniciativas de gobiernos autonómicos como el de Aragón y o entidades locales como el Ayuntamiento de Barcelona que empiezan a documentarse de forma pública.
El salto hacia agentes más autónomos en el sector público parece, por tanto, una evolución natural sobre la base de la administración electrónica existente. Pero esa evolución debe, al mismo tiempo, reforzar el compromiso con la transparencia, la equidad, la rendición de cuentas, la supervisión humana y el cumplimiento normativo que exige el Reglamento de IA y el resto del marco normativo y que deben guiar las actuaciones de la administración pública.
Mirando hacia el futuro: agentes de IA, datos abiertos y confianza ciudadana
La llegada de la IA agéntica ofrece de nuevo a la Administración pública nuevas herramientas para reducir la burocracia, personalizar la atención y optimizar sus siempre escasos recursos. Sin embargo, la tecnología es solo un medio, el fin último sigue siendo generar valor público reforzando la confianza de la ciudadanía.
En principio, España parte de una buena posición: dispone de una Estrategia de Inteligencia Artificial 2024 que apuesta por una IA transparente, ética y centrada en las personas, con líneas específicas para impulsar su uso en el sector público; cuenta con una infraestructura consolidada de datos abiertos; y ha creado la Agencia Española de Supervisión de la Inteligencia Artificial (AESIA) como organismo encargado de garantizar un uso ético y seguro de la IA, de acuerdo con el Reglamento Europeo de IA.
Estamos, por tanto, ante una nueva oportunidad de modernización que puede construir unos servicios públicos más eficientes, cercanos e incluso proactivos. Si somos capaces de adoptar la IA agéntica adecuadamente, los agentes que se desplieguen no serán una “caja negra” que actúa sin supervisión, sino “agentes públicos” digitales, transparentes y auditables, diseñados para trabajar con datos abiertos, explicar sus decisiones y dejar rastro de las acciones que realizan. Herramientas, en definitiva, inclusivas, centradas en las personas y alineadas con los valores del servicio público.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Empresa reutilizadora
Geomatico es una empresa especializada en el desarrollo de Sistemas de Información Geográfica (SIG) de código libre. Ofrecen mapas web a medida y dashboards SIG que añaden valor a los datos de sus clientes.
Blog
Las ciudades, las infraestructuras y el medio ambiente generan hoy un flujo constante de datos procedentes de sensores, redes de transporte, estaciones meteorológicas y plataformas de Internet of Things (IoT), entendidas como redes de dispositivos físicos (semáforos digitales, sensores de calidad de aire, etc.) capaces de medir y transmitir información a través de sistemas digitales. Este volumen creciente de información permite mejorar la prestación de servicios públicos, anticipar emergencias, planificar el territorio y responder a retos asociados al clima, la movilidad o la gestión de recursos.
El incremento de fuentes conectadas ha transformado la naturaleza del dato geoespacial. Frente a los conjuntos tradicionales —actualizados de forma periódica y orientados a cartografía de referencia o inventarios administrativos— los datos dinámicos incorporan la dimensión temporal como componente estructural. Una observación de calidad del aire, un nivel de ocupación de tráfico o una medición hidrológica no solo describen un fenómeno, sino que lo sitúan en un momento concreto. La combinación espacio-tiempo convierte a estas observaciones en elementos fundamentales para sistemas operativos, modelos predictivos y análisis basados en series temporales.
En el ámbito de los datos abiertos, este tipo de información plantea tanto oportunidades como requerimientos específicos. Entre las oportunidades se encuentran la posibilidad de construir servicios digitales reutilizables, de facilitar la supervisión en tiempo casi real de fenómenos urbanos y ambientales, y de fomentar un ecosistema de reutilización basado en flujos continuos de datos interoperables. La disponibilidad de datos actualizados incrementa además la capacidad de evaluación y auditoría de políticas públicas, al permitir contrastar decisiones con observaciones recientes.
No obstante, la apertura de datos geoespaciales en tiempo real exige resolver problemas derivados de la heterogeneidad tecnológica. Las redes de sensores utilizan protocolos, modelos de datos y formatos diferentes; las fuentes generan volúmenes elevados de observaciones con alta frecuencia; y la ausencia de estructuras semánticas comunes dificulta el cruce de datos entre dominios como movilidad, medio ambiente, energía o hidrología. Para que estos datos puedan publicarse y reutilizarse de manera consistente, es necesario un marco de interoperabilidad que normalice la descripción de los fenómenos observados, la estructura de las series temporales y las interfaces de acceso.
Los estándares abiertos del Open Geospatial Consortium (OGC) proporcionan ese marco. Definen cómo representar observaciones, entidades dinámicas, coberturas multitemporales o sistemas de sensores; establecen API basadas en principios web que facilitan la consulta de datos abiertos; y permiten que plataformas distintas intercambien información sin necesidad de integraciones específicas. Su adopción reduce la fragmentación tecnológica, mejora la coherencia entre fuentes y favorece la creación de servicios públicos basados en datos actualizados.
Interoperabilidad: el requisito básico para abrir datos dinámicos
Las administraciones públicas gestionan hoy datos generados por sensores de distinto tipo, plataformas heterogéneas, proveedores diferentes y sistemas que evolucionan de forma independiente. La publicación de datos geoespaciales en tiempo real exige una interoperabilidad que permita integrar, procesar y reutilizar información procedente de múltiples fuentes. Esta diversidad provoca inconsistencias en formatos, estructuras, vocabularios y protocolos, lo que dificulta la apertura del dato y su reutilización por terceros. Veamos qué aspectos de la interoperabilidad están afectados:
- La interoperabilidad técnica: se refiere a la capacidad de los sistemas para intercambiar datos mediante interfaces, formatos y modelos compatibles. En los datos en tiempo real, este intercambio requiere mecanismos que permitan consultas rápidas, actualizaciones frecuentes y estructuras de datos estables. Sin estos elementos, cada flujo dependería de integraciones ad hoc, aumentando la complejidad y reduciendo la capacidad de reutilización.
- La interoperabilidad semántica: los datos dinámicos describen fenómenos que cambian en periodos cortos —niveles de tráfico, parámetros meteorológicos, caudales, emisiones atmosféricas— y deben interpretarse de forma coherente. Esto implica contar con modelos de observación, vocabularios y definiciones comunes que permitan a aplicaciones distintas entender el significado de cada medición y sus unidades, condiciones de captura o restricciones. Sin esta capa semántica, la apertura de datos en tiempo real genera ambigüedad y limita su integración con datos procedentes de otros dominios.
- La interoperabilidad estructural: los flujos de datos en tiempo real tienden a ser continuos y voluminosos, lo que hace necesario representarlos como series temporales o conjuntos de observaciones con atributos consistentes. La ausencia de estructuras normalizadas complica la publicación de datos completos, fragmenta la información e impide consultas eficientes. Para proporcionar acceso abierto a estos datos, es necesario adoptar modelos que representen adecuadamente la relación entre fenómeno observado, momento de la observación, geometría asociada y condiciones de medición.
- La interoperabilidad en el acceso vía API: constituye una condición esencial para los datos abiertos. Las API deben ser estables, documentadas y basadas en especificaciones públicas que permitan consultas reproducibles. En el caso de datos dinámicos, esta capa garantiza que los flujos puedan ser consumidos por aplicaciones externas, plataformas de análisis, herramientas cartográficas o sistemas de monitorización que operan en contextos distintos al que genera el dato. Sin API interoperables, el dato en tiempo real queda limitado a usos internos.
En conjunto, estos niveles de interoperabilidad determinan si los datos geoespaciales dinámicos pueden publicarse como datos abiertos sin generar barreras técnicas.
Estándares OGC para publicar datos geoespaciales en tiempo real
La publicación de datos georreferenciados en tiempo real requiere mecanismos que permitan que cualquier usuario —administración, empresa, ciudadanía o comunidad investigadora— pueda acceder a ellos de forma sencilla, con formatos abiertos y a través de interfaces estables. El Open Geospatial Consortium (OGC) desarrolla un conjunto de estándares que permiten exactamente esto: describir, organizar y exponer datos espaciales de forma interoperable y accesible, que contribuyan a la apertura de datos dinámicos.
Qué es OGC y por qué sus estándares son relevantes
El OGC es una organización internacional que define reglas comunes para que distintos sistemas puedan entender, intercambiar y usar datos geoespaciales sin depender de tecnologías concretas. Estas reglas se publican como estándares abiertos, lo que significa que cualquier persona o institución puede utilizarlos. En el ámbito de los datos en tiempo real, estos estándares permiten:
- Representar lo que un sensor mide (por ejemplo, temperatura o tráfico).
- Indicar dónde y cuándo se hizo la observación.
- Estructurar series temporales.
- Exponer datos a través de API abiertas.
- Conectar dispositivos y redes IoT con plataformas públicas.
En conjunto, este ecosistema de estándares permite que los datos geoespaciales —incluyendo los generados en tiempo real— puedan publicarse y reutilizarse siguiendo un marco coherente. Cada estándar cubre una parte específica del ciclo del dato: desde la definición de las observaciones y los sensores, hasta la forma en la que se exponen los datos mediante API abiertas o servicios web. Esta organización modular facilita que administraciones y organizaciones seleccionen los componentes que necesitan, evitando dependencias tecnológicas y garantizando que los datos puedan integrarse entre plataformas distintas.
La familia OGC API: API modernas para acceder a datos abiertos
Dentro de OGC, la línea más reciente es la familia OGC API, un conjunto de interfaces web modernas diseñadas para facilitar el acceso a datos geoespaciales mediante URL y formatos como JSON o GeoJSON, habituales en el ecosistema de datos abiertos.
Estas API permiten:
- Obtener solo la parte del dato que interesa.
- Realizar búsquedas espaciales (“dame solo lo que está en esta zona”).
- Acceder a datos actualizados sin necesidad de software especializado.
- Integrarlos fácilmente en aplicaciones web o móviles.
En este informe: “Cómo utilizar las OGC API para potenciar la interoperabilidad de los datos geoespaciales”, ya te hablamos de algunas las API más populares del OGP. Mientras que el informe se centra en cómo utilizar las OGC API para la interoperabilidad práctica, este post amplía el foco explicando los modelos de datos subyacentes del OGC —como O&M, SensorML o Moving Features— que sustentan esa interoperabilidad.
A partir de esta base, este post pone el foco en los estándares que hacen posible ese intercambio fluido de información, especialmente en contextos de datos abiertos y en tiempo real. Los estándares más importantes en el contexto de datos abiertos en tiempo real son:
|
Estándar OGC |
Qué permite hacer |
Uso principal en datos abiertos |
|---|---|---|
|
Es una interfaz web abierta que permite acceder a conjuntos de datos formados por “entidades” con geometría, como sensores, vehículos, estaciones o incidentes. Utiliza formatos simples como JSON y GeoJSON y permite realizar consultas espaciales y temporales. Es útil para publicar datos que se actualizan con frecuencia, como movilidad urbana o inventarios dinámicos. |
Consultar entidades con geometría; filtrar por tiempo o espacio; obtener datos en JSON/GeoJSON. |
Publicación abierta de datos dinámicos de movilidad, inventarios urbanos, sensores estáticos. |
|
OGC API – Environmental Data Retrieval (EDR) Proporciona un método sencillo para recuperar observaciones ambientales y meteorológicas. Permite solicitar datos en un punto, una zona o un intervalo temporal, y es especialmente adecuado para estaciones meteorológicas, calidad del aire o modelos climáticos. Facilita el acceso abierto a series temporales y predicciones. |
Solicitar observaciones ambientales en un punto, zona o intervalo temporal. |
Datos abiertos de meteorología, clima, calidad del aire o hidrología. |
|
Es el estándar más utilizado para datos IoT abiertos. Define un modelo uniforme para sensores, lo que miden y las observaciones que producen. Está diseñado para manejar grandes volúmenes de datos en tiempo real y ofrece un modo claro para publicar series temporales, datos de contaminación, ruido, hidrología, energía o alumbrado. |
Gestionar sensores y sus series temporales; transmitir grandes volúmenes de datos IoT. |
Publicación de sensores urbanos (aire, ruido, agua, energía) en tiempo real. |
|
OGC API – Connected Systems |
Describir redes de sensores, dispositivos e infraestructuras asociadas. |
Documentar como dato abierto la estructura de sistemas IoT municipales. |
|
OGC Moving Features |
Representar objetos móviles mediante trayectorias espacio-tiempo. |
Datos abiertos de movilidad (vehículos, transporte, embarcaciones). |
|
WMS-T |
Visualizar mapas que cambian en el tiempo |
Publicación de mapas meteorológicos o ambientales multitemporales |
Tabla 1. Estándares OGC relevantes para datos geoespaciales en tiempo real
Modelos que estructuran observaciones y datos dinámicos
Además de las API, OGC define varios modelos conceptuales de datos que permiten describir de forma coherente observaciones, sensores y fenómenos que cambian en el tiempo:
- O&M (Observations & Measurements): modelo que define los elementos esenciales de una observación —fenómeno medido, instante, unidad y resultado— y que sirve como base semántica para datos de sensores y series temporales.
- SensorML: lenguaje que describe las características técnicas y operativas de un sensor, incluyendo su ubicación, calibración y proceso de observación.
- Moving Features: modelo que permite representar objetos móviles mediante trayectorias espacio-temporales (como vehículos, embarcaciones o fauna).
Estos modelos facilitan que diferentes fuentes de datos puedan interpretarse de forma uniforme y combinarse en análisis y aplicaciones.
El valor de estos estándares para los datos abiertos
El uso de los estándares OGC facilita la apertura de datos dinámicos porque:
- Proporciona modelos comunes que reducen la heterogeneidad entre fuentes.
- Facilita la integración entre dominios (movilidad, clima, hidrología).
- Evita dependencias de tecnología propietaria.
- Permite que el dato sea reutilizado en análisis, aplicaciones o servicios públicos.
- Mejora la transparencia, al documentar sensores, métodos y frecuencias.
- Asegura que los datos pueden ser consumidos directamente por herramientas comunes.
En conjunto, forman una infraestructura conceptual y técnica que permite publicar datos geoespaciales en tiempo real como datos abiertos, sin necesidad de desarrollar soluciones específicas para cada sistema.
Casos de uso de datos geoespaciales abiertos en tiempo real
Los datos georreferenciados en tiempo real ya se publican como datos abiertos en distintos ámbitos sectoriales. Estos ejemplos muestran cómo diferentes administraciones y organismos aplican estándares abiertos y API para poner a disposición del público datos dinámicos relacionados con movilidad, medio ambiente, hidrología y meteorología.
A continuación, se presentan varios dominios donde las Administraciones Públicas ya publican datos geoespaciales dinámicos utilizando estándares OGC.
Movilidad y transporte
Los sistemas de movilidad generan datos de forma continua: disponibilidad de vehículos compartidos, posiciones en tiempo casi real, sensores de paso en carriles bici, aforos de tráfico o estados de intersecciones semaforizadas. Estas observaciones dependen de sensores distribuidos y requieren modelos de datos capaces de representar variaciones rápidas en el espacio y en el tiempo.
Los estándares OGC desempeñan un papel central en este ámbito. En particular, OGC SensorThings API permite estructurar y publicar observaciones procedentes de sensores urbanos mediante un modelo uniforme –incluyendo dispositivos, mediciones, series temporales y relaciones entre ellos– accesible a través de una API abierta. Esto facilita que diferentes operadores y municipios publiquen datos de movilidad de forma interoperable, reduciendo la fragmentación entre plataformas.
El uso de estándares OGC en movilidad no solo garantiza compatibilidad técnica, sino que posibilita que estos datos se puedan reutilizar junto con información ambiental, cartográfica o climática, generando análisis multitemáticos para planificación urbana, sostenibilidad o gestión operativa del transporte.
Ejemplo:
El servicio abierto de Toronto Bike Share, que publica en formato SensorThings API el estado de sus estaciones de bicicletas y la disponibilidad de vehículos.
Aquí cada estación es un sensor y cada observación indica el número de bicicletas disponibles en un momento concreto. Este enfoque permite que analistas, desarrolladores o investigadores integren estos datos directamente en modelos de movilidad urbana, sistemas de predicción de demanda o paneles de control ciudadano sin necesidad de adaptaciones específicas.
Calidad del aire, ruido y sensores urbanos
Las redes de monitorización de calidad del aire, ruido o condiciones ambientales urbanas dependen de sensores automáticos que registran mediciones cada pocos minutos. Para que estos datos puedan integrarse en sistemas de análisis y publicarse como datos abiertos, es necesario disponer de modelos y API coherentes.
En este contexto, los servicios basados en estándares OGC permiten publicar datos procedentes de estaciones fijas o sensores distribuidos de forma interoperable. Aunque muchas administraciones utilizan interfaces tradicionales como OGC WMS para servir estos datos, la estructura subyacente suele apoyarse en modelos de observaciones derivados de la familia Observations & Measurements (O&M), que define cómo representar un fenómeno medido, su unidad y el instante de observación.
Ejemplo:
El servicio Defra UK-AIR Sensor Observation Service proporciona acceso a datos de mediciones de calidad del aire en tiempo casi real desde estaciones in situ en Reino Unido.
La combinación de O&M para la estructura del dato y API abiertas para su publicación facilita que estos sensores urbanos formen parte de ecosistemas más amplios que integran movilidad, meteorología o energía, permitiendo análisis urbanos avanzados o paneles ambientales en tiempo casi real.
Ciclo del agua, hidrología y gestión del riesgo
Los sistemas hidrológicos generan datos cruciales para la gestión del riesgo: niveles y caudales en ríos, precipitaciones, humedad del suelo o información de estaciones hidrometeorológicas. La interoperabilidad es especialmente importante en este dominio, ya que estos datos se combinan con modelos hidráulicos, predicción meteorológica y cartografía de zonas inundables.
Para facilitar el acceso abierto a series temporales y observaciones hidrológicas, varios organismos utilizan OGC API – Environmental Data Retrieval (EDR), una API diseñada para recuperar datos ambientales mediante consultas sencillas en puntos, áreas o intervalos temporales.
Ejemplo:
El USGS (United States Geological Survey), que documenta el uso de OGC API – EDR para acceder a series de precipitación, temperatura o variables hidrológicas.
Este caso muestra cómo EDR permite solicitar observaciones específicas por ubicación o fecha, devolviendo únicamente los valores necesarios para el análisis. Aunque los datos concretos de hidrología del USGS se sirven mediante su API propia, este caso demuestra cómo EDR encaja con la estructura de datos hidrometeorológicos y cómo se aplica en flujos operativos reales.
El empleo de estándares OGC en este ámbito permite que los datos hidrológicos dinámicos se integren con zonas inundables, ortoimágenes o modelos climáticos, creando una base sólida para sistemas de alerta temprana, planificación hidráulica y evaluación del riesgo.
Observación y predicción meteorológica
La meteorología es uno de los dominios con mayor producción de datos dinámicos: estaciones automáticas, radares, modelos numéricos de predicción, observaciones satelitales y productos atmosféricos de alta frecuencia. Para publicar esta información como datos abiertos, la familia de OGC API se está convirtiendo en un elemento clave, especialmente mediante OGC API – EDR, que permite recuperar observaciones o predicciones en ubicaciones concretas y en distintos niveles temporales.
Ejemplo:
El servicio NOAA OGC API – EDR, que proporciona acceso a datos meteorológicos y variables atmosféricas del National Weather Service (Estados Unidos).
Esta API permite consultar datos en puntos, áreas o trayectorias, facilitando la integración de observaciones meteorológicas en aplicaciones externas, modelos o servicios basados en datos abiertos.
El uso de OGC API en meteorología permite que datos procedentes de sensores, modelos y satélites puedan consumirse mediante una interfaz unificada, facilitando su reutilización para pronósticos, análisis atmosféricos, sistemas de soporte a la decisión y aplicaciones climáticas.
Buenas prácticas para publicar datos geoespaciales abiertos en tiempo real
La publicación de datos geoespaciales dinámicos requiere adoptar prácticas que garanticen su accesibilidad, interoperabilidad y sostenibilidad. A diferencia de los datos estáticos, los flujos en tiempo real presentan requisitos adicionales relacionados con la calidad de las observaciones, la estabilidad de las API y la documentación del proceso de actualización. A continuación, se presentan algunas prácticas recomendadas para administraciones y organizaciones que gestionan este tipo de datos.
- Formatos y API abiertas estables: el uso de estándares OGC —como OGC API, SensorThings API o EDR— facilita que los datos puedan consumirse desde múltiples herramientas sin necesidad de adaptaciones específicas. Las API deben ser estables en el tiempo, ofrecer versiones bien definidas y evitar dependencias de tecnologías propietarias. Para datos ráster o modelos dinámicos, los servicios OGC como WMS, WMTS o WCS siguen siendo adecuados para visualización y acceso programático.
- Metadatos compatibles con DCAT-AP y modelos OGC: la interoperabilidad de catálogos requiere describir los conjuntos de datos utilizando perfiles como DCAT-AP, complementado con metadatos geoespaciales y de observación basados en O&M (Observations & Measurements) o SensorML. Estos metadatos deben documentar la naturaleza del sensor, la unidad de medida, la frecuencia de muestreo y posibles limitaciones del dato.
- Políticas de calidad, frecuencia de actualización y trazabilidad: los datasets dinámicos deben indicar explícitamente su frecuencia de actualización, la procedencia de las observaciones, los mecanismos de validación aplicados y las condiciones bajo las cuales se generaron. La trazabilidad es esencial para que terceros puedan interpretar correctamente los datos, reproducir análisis e integrar observaciones procedentes de fuentes distintas.
- Documentación, límites de uso y sostenibilidad del servicio: la documentación debe incluir ejemplos de uso, parámetros de consulta, estructura de respuesta y recomendaciones para gestionar el volumen de datos. Es importante establecer límites razonables de consulta para garantizar la estabilidad del servicio y asegurar que la administración puede mantener la API a largo plazo.
- Aspectos de licencias para datos dinámicos: la licencia debe ser explícita y compatible con la reutilización, como CC BY 4.0 o CC0. Esto permite integrar datos dinámicos en servicios de terceros, aplicaciones móviles, modelos predictivos o servicios de interés público sin restricciones innecesarias. La consistencia en la licencia facilita también el cruce de datos procedentes de distintas fuentes.
Estas prácticas permiten que los datos dinámicos se publiquen de forma fiable, accesible y útil para toda la comunidad reutilizadora.
Los datos geoespaciales dinámicos se han convertido en una pieza estructural para comprender fenómenos urbanos, ambientales y climáticos. Su publicación mediante estándares abiertos permite que esta información pueda integrarse en servicios públicos, análisis técnicos y aplicaciones reutilizables sin necesidad de desarrollos adicionales. La convergencia entre modelos de observación, API OGC y buenas prácticas en metadatos y licencias ofrece un marco estable para que administraciones y reutilizadores trabajen con datos procedentes de sensores de forma fiable. Consolidar este enfoque permitirá avanzar hacia un ecosistema de datos públicos más coherente, conectado y preparado para usos cada vez más demandantes en movilidad, energía, gestión del riesgo y planificación territorial.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora