Comparte este contenido
Descripción
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos, se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos los flujos de turistas a nivel nacional, creando visualizaciones de los turistas que se mueven entre las comunidades autónomas (CCAA) y provincias.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
Analizar los flujos de turistas nacionales nos permite observar ciertos movimientos ya muy conocidos, como, por ejemplo, que la provincia de Alicante es un destino muy popular del turismo veraniego. Además, este análisis es interesante para observar tendencias en el impacto económico que el turismo pueda tener, año tras año, en ciertas CCAA o provincias. El artículo sobre experiencias para la gestión de los flujos de visitantes en destinos turísticos ilustra el impacto de los datos en el sector.
3. Objetivo
El objetivo principal del ejercicio es crear visualizaciones interactivas en Python que permitan visualizar información compleja de manera comprensible y atractiva. Se cumplirá este objetivo usando un conjunto de datos abiertos que contiene información sobre flujos de turistas nacionales, planteando varias preguntas sobre los datos y contestándolas gráficamente. Podremos responder a preguntas como las que se plantean a continuación:
- ¿En qué CCAA hay más turismo procedente de la misma CA?
- ¿Cuál es la CA que más sale de su propia CA?
- ¿Qué diferencias hay entre los flujos de turistas a lo largo del año?
- ¿Cuál es la provincia valenciana que más turistas recibe?
La comprensión de las herramientas propuestas aportará al lector la capacidad para poder modificar el código contenido en el notebook que acompaña a este ejercicio para seguir explorando los datos por su cuenta y detectar más comportamientos interesantes a partir del conjunto de datos utilizado.
Para poder crear visualizaciones interactivas y contestar a las preguntas sobre los flujos de turistas, será necesario un proceso de limpieza y reformateado de datos que está descrito en el notebook que acompaña este ejercicio.
4. Recursos
Conjunto de datos
El conjunto de datos abiertos utilizado contiene información sobre los flujos de turistas en España a nivel de CCAA y provincias, indicando también los valores totales a nivel nacional. El conjunto de datos ha sido publicado por el Instituto Nacional de Estadística, a través de varios tipos de ficheros. Para el presente ejercicio utilizamos únicamente el fichero .csv separado por “;”. Los datos datan de julio de 2019 a marzo de 2024 (a la hora de redactar este ejercicio) y se actualizan mensualmente.
Número de turistas por CCAA y provincia de destino desagregados por PROVINCIA de origen
El conjunto de datos también se encuentra disponible para su descarga en este repositorio de Github.
Herramientas analíticas
Para la limpieza de los datos y la creación de las visualizaciones se ha utilizado el lenguaje de programación Python. El código creado para este ejercicio se pone a disposición del lector a través de un notebook de Google Colab.
Las librerías de Python que utilizaremos para llevar a cabo el ejercicio son:
- pandas: es una librería que se utiliza para el análisis y manipulación de datos.
- holoviews: es una librería que permite crear visualizaciones interactivas, combinando las funcionalidades de otras librerías como Bokeh y Matplotlib.
5. Desarrollo del ejercicio
Para visualizar los datos sobre flujos de turistas interactivamente crearemos dos tipos de diagramas, los diagramas de cuerdas y los diagramas de Sankey.
Los diagramas de cuerdas son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 1. Los nodos se sitúan en un círculo y las aristas simbolizan las relaciones entre los nodos del círculo. Estos diagramas suelen utilizarse para mostrar tipos de flujos, por ejemplo, flujos migratorios o monetarios. El volumen diferente de las aristas se visualiza de manera comprensible y refleja la importancia de un flujo o de un nodo. Por su forma de círculo, el diagrama de cuerdas es una buena opción para visualizar las relaciones entre todos los nodos de nuestro análisis (relación del tipo “varios a varios”).
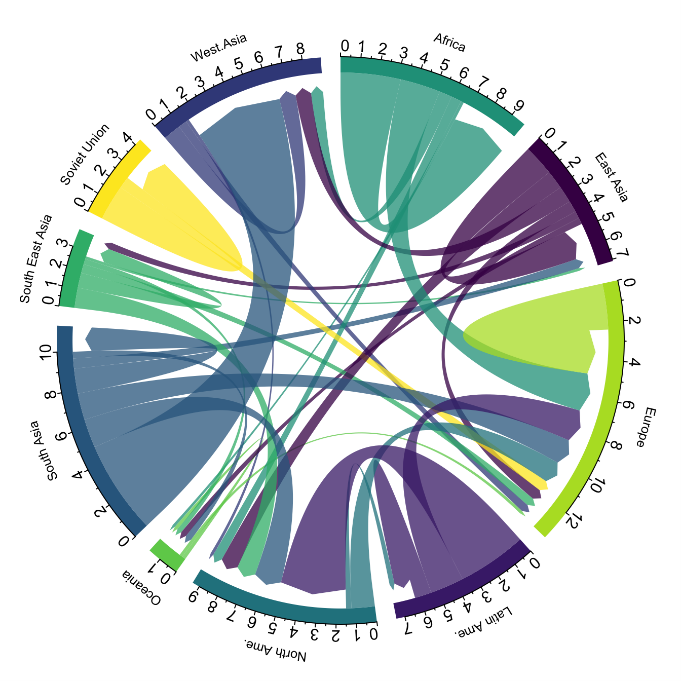
Figura 1. Diagrama de cuerdas (Migración global). Fuente.
Los diagramas de Sankey, igual que los diagramas de cuerdas, son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 2. Los nodos se representan en los márgenes de la visualización, estando las aristas entre los márgenes. Por esta agrupación lineal de los nodos, los diagramas de Sankey son mejores que los diagramas de cuerdas para análisis en los cuales queramos visualizar la relación entre:
- varios nodos y otros nodos (tipo varios a varios, o varios a pocos, o viceversa)
- varios nodos y un solo nodo (varios a uno, o viceversa)

Figura 2. Diagrama de Sankey (Migración interna Reino Unido). Fuente.
El ejercicio está dividido en 5 partes, siendo la parte 0 (“configuración inicial”) solo de montar el entorno de programación. A continuación, describimos las cinco partes y los pasos que se llevan a cabo.
5.1. Cargar datos
Este apartado podrás encontrarlo en el punto 1 del notebook.
En este parte cargamos el conjunto de datos para poder procesarlo en el notebook. Comprobamos el formato de los datos cargados y creamos un pandas.DataFrame que utilizaremos para el procesamiento de los datos en los siguientes pasos.
5.2. Exploración inicial de los datos
Este apartado podrás encontrarlo en el punto 2 del notebook.
En esta parte realizamos un análisis exploratorio de los datos para entender el formato del conjunto de datos que hemos cargado y para tener una idea más clara de la información que contiene. Mediante esta exploración inicial, podemos definir los pasos de limpieza que tenemos que llevar a cabo para poder crear las visualizaciones interactivas.
Si quieres aprender más sobre cómo abordar esta tarea, tienes a tu disposición esta guía introductoria sobre análisis exploratorio de datos.
5.3. Análisis del formato de los datos
Este apartado podrás encontrarlo en el punto 3 del notebook.
En esta parte resumimos las observaciones que hemos podido hacer durante la exploración inicial de los datos. Recapitulamos aquí las observaciones más importantes:
| Provincia de origen | Provincia de origen | CCAA y provincia de destino | CCAA y provincia de destino | CCAA y provincia de destino | Concepto turístico | Periodo | Total |
|---|---|---|---|---|---|---|---|
| Total Nacional | Total Nacional | Turistas | 2024M03 | 13.731.096 | |||
| Total Nacional | Ourense | Total Nacional | Andalucía | Almería | Turistas | 2024M03 | 373 |
Figura 3. Fragmento del conjunto de datos original.
Podemos observar en las columnas uno a cuatro que los orígenes de los flujos de turistas están desagregados por provincia mientras que, para los destinos, las provincias están agregadas por CCAA. Aprovecharemos el mapeado de las CCAA y de sus provincias que podemos extraer de la cuarta y quinta columna para agregar las provincias de origen por CCAA.
También podemos ver que la información contenida en la primera columna a veces es superflua, por lo cual, la combinaremos con la segunda columna. Además, hemos constatado que la quinta y sexta columna no aportan valor para nuestro análisis, por lo cual, las eliminaremos. Renombraremos algunas columnas para tener un pandas. DataFrame más comprensible.
5.4. Limpieza de los datos
Este apartado podrás encontrarlo en el punto 4 del notebook.
En esta parte llevamos a cabo los pasos necesarios para darle mejor formato a nuestros datos. Para ello aprovechamos varias funcionalidades que nos ofrece pandas, por ejemplo, para renombrar las columnas. También definimos una función reutilizable que necesitamos para concatenar los valores de la primera y segunda columna con el objetivo de no tener una columna que exclusivamente indique “Total Nacional” en todas las filas del pandas.DataFrame. Además, extraeremos de las columnas de destino un mapeado de CCAA a provincias que aplicaremos a las columnas de origen.
Queremos obtener una versión del conjunto de datos más comprimida con mayor transparencia de los nombres de las columnas y que no contenga información que no vamos a procesar. El resultado final del proceso de limpieza de datos es el siguiente:
| Origen | Provincia de origen | Destino | Provincia de destino | Periodo | Total |
|---|---|---|---|---|---|
| Total Nacional | Total Nacional | 2024M03 | 13731096.0 | ||
| Galicia | Ourense | Andalucía | Almería | 2024M03 | 373.0 |
Figura 4. Fragmento del conjunto de datos limpio.
5.5. Crear visualizaciones
Este apartado podrás encontrarlo en el punto 5 del notebook
En esta parte creamos nuestras visualizaciones interactivas utilizando la librería Holoviews. Para poder dibujar gráficos de cuerdas o de Sankey que visualicen el flujo de personas entre CCAA y CCAA y/o provincias, tenemos que estructurar la información de nuestros datos de tal forma que dispongamos de nodos y aristas. En nuestro caso, los nodos son los nombres de CCAA o provincia y las aristas, es decir, la relación entre los nodos, son el número de turistas. En el notebook definimos una función para obtener los nodos y aristas que podemos reutilizar para los diferentes diagramas que queramos realizar, cambiando el período de tiempo según la estación del año que nos interese analizar.
Vamos a crear primero un diagrama de cuerdas usando exclusivamente los datos sobre flujos de turistas de marzo de 2024. En el notebook, este diagrama de cuerdas es dinámico. Te animamos a probar su interactividad.
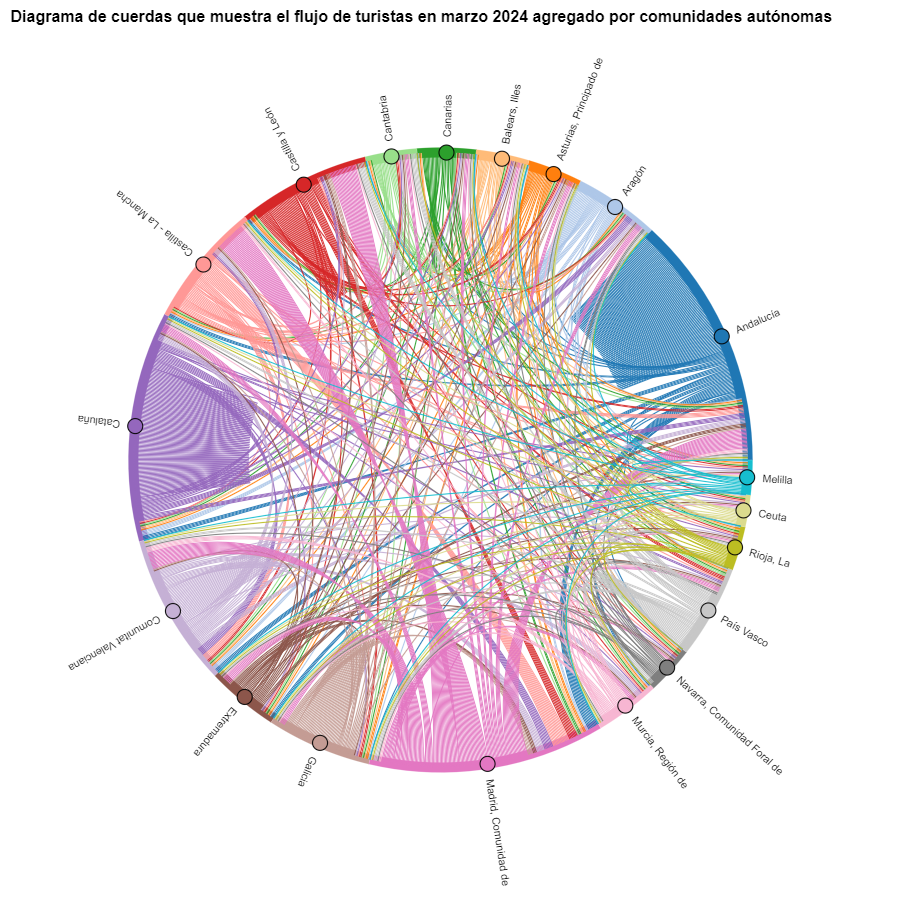
Figura 5. Diagrama de cuerdas que muestra el flujo de turistas en marzo 2024 agregado por comunidades autónomas.
En el diagrama de cuerdas se visualizan los flujos de turistas entre todas las CCAA. Cada CA tiene un color y los movimientos que hacen los turistas provenientes de esta CA se simbolizan con el mismo color. Podemos observar que los turistas de Andalucía y Cataluña viajan mucho dentro de sus propias CCAA. En cambio, los turistas de Madrid salen mucho de su propia CA.
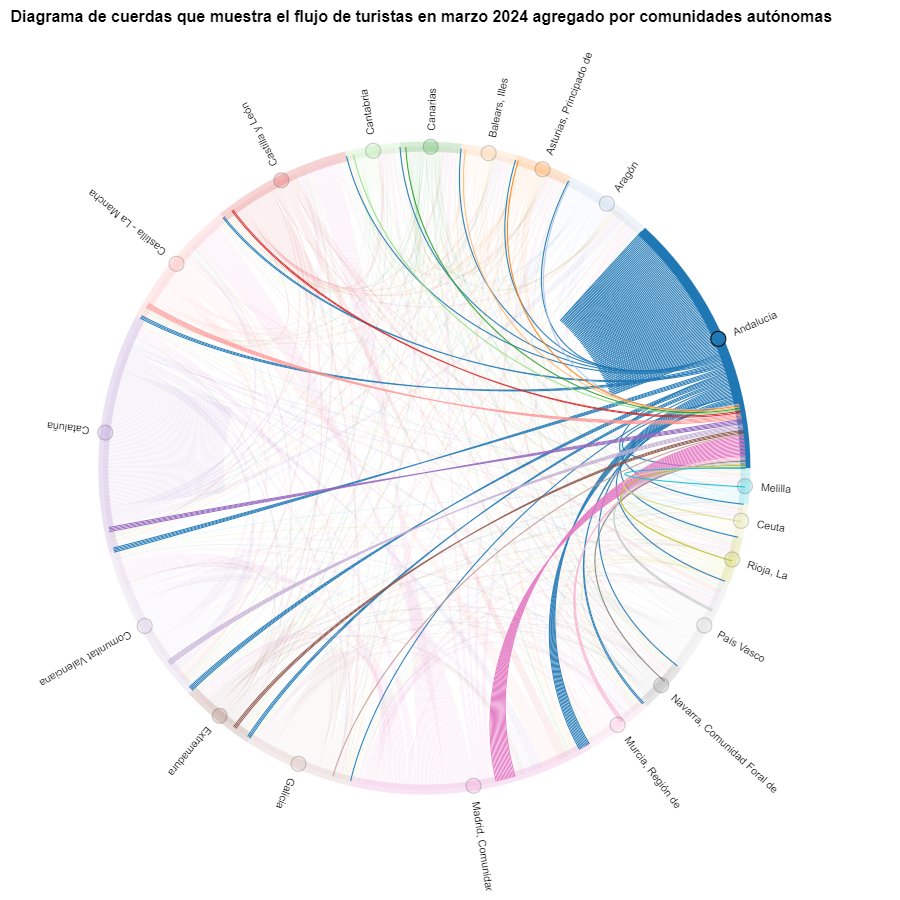
Figura 6. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de Andalucía en marzo 2024 agregado por comunidades autónomas.
Creamos otro diagrama de cuerdas utilizando la función que hemos creado y visualizamos los flujos de turistas en agosto de 2023.
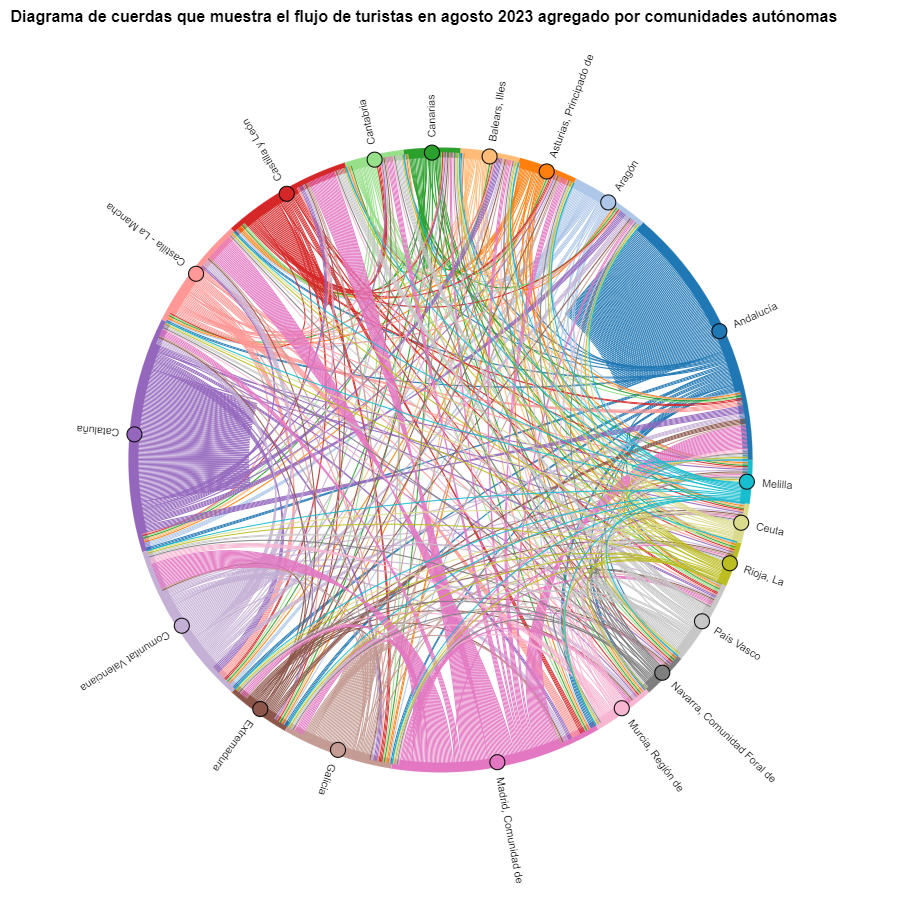
Figura 7. Diagrama de cuerdas que muestra el flujo de turistas en agosto 2023 agregado por comunidades autónomas.
Podremos observar que, a grandes rasgos, no cambian los movimientos de los turistas, solo que se intensifican los movimientos que ya hemos podido observar para marzo 2024.
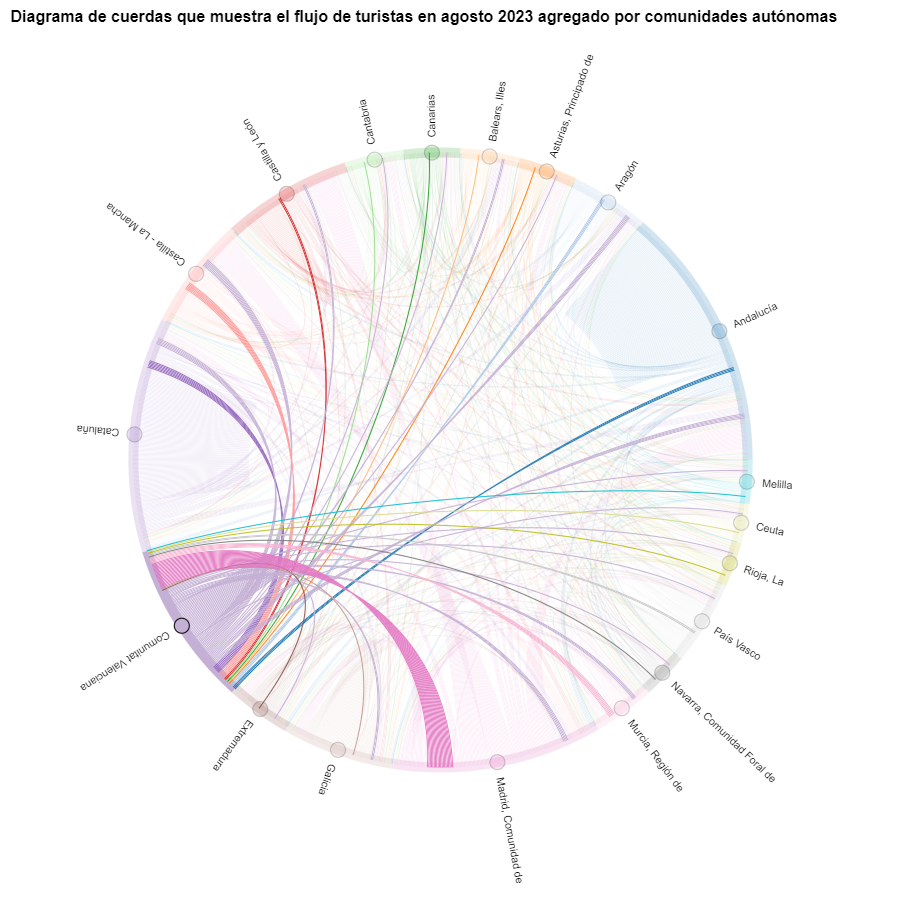
Figura 8. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de la Comunitat Valenciana en agosto 2023 agregado por comunidades autónomas.
El lector puede crear el mismo diagrama para otros períodos de tiempo, por ejemplo, para el verano del año 2020, con el fin de visualizar el impacto de la pandemia en el turismo veraniego, reutilizando la función que hemos creado.
Para los diagramas de Sankey nos vamos a centrar en la Comunitat Valenciana, ya que es un destino vacacional popular. Filtramos las aristas que hemos creado para el diagrama de cuerdas anterior de manera que solo contengan flujos que terminen en la Comunitat Valenciana. El mismo procedimiento se podría aplicar para estudiar cualquier otra CA o se podría invertir para analizar dónde van a veranear los valencianos. Visualizamos el diagrama de Sankey que, igual que los diagramas de cuerdas, es interactivo dentro del notebook. El aspecto visual quedaría así:
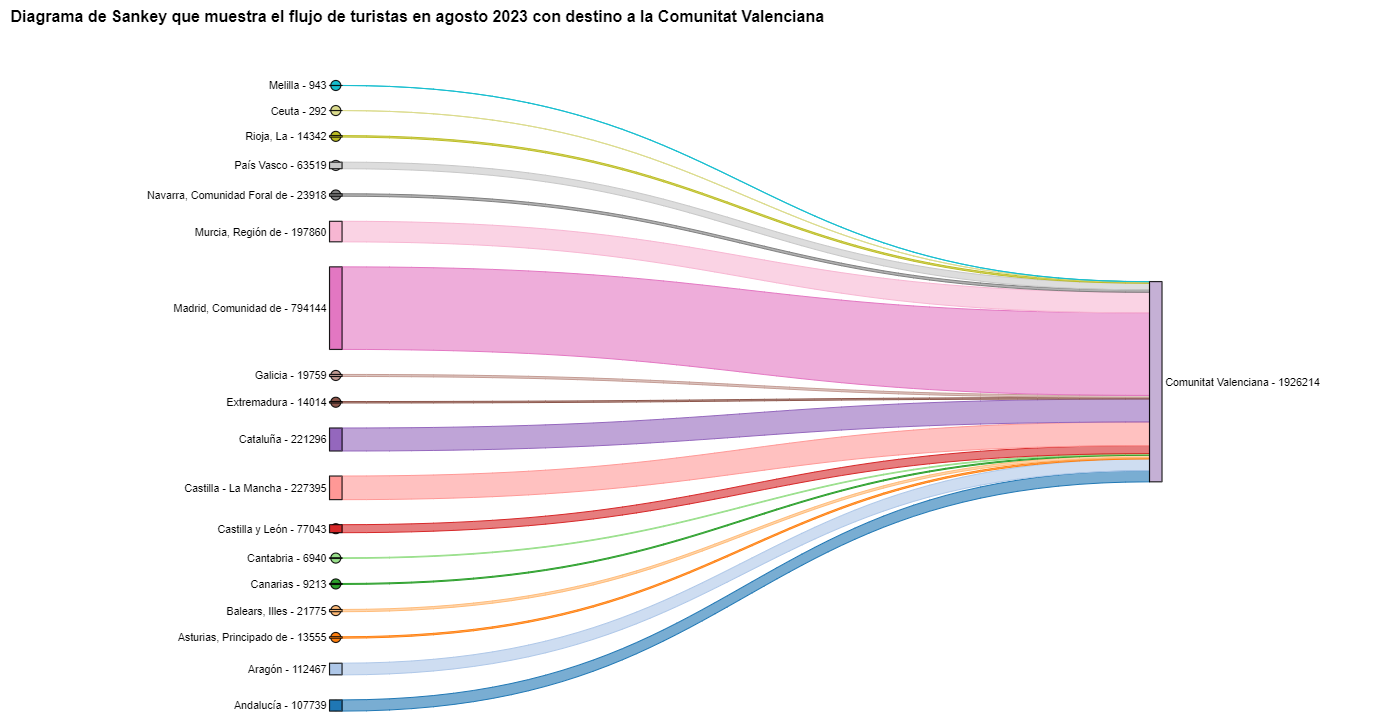
Figura 9. Diagrama de Sankey que muestra el flujo de turistas en agosto 2023 con destino a la Comunitat Valenciana.
Como ya hemos podido intuir por el diagrama de cuerdas de arriba, véase la figura 8 el mayor grupo de turistas que llegan a la Comunitat Valenciana proviene de Madrid. Vemos que también hay un elevado número de turistas que visitan la Comunitat Valenciana desde las CCAA vecinas como Murcia, Andalucía y Cataluña.
Para comprobar que estas tendencias se dan en las tres provincias de la Comunitat Valenciana, vamos a crear un diagrama de Sankey que muestre en el margen izquierdo todas las CCAA y en el margen derecho las tres provincias de la Comunitat Valenciana.
Para crear este diagrama de Sankey a nivel de provincias tenemos que filtrar nuestro pandas. DataFrame inicial para extraer de él las filas que contienen la información relevante. Los pasos en el notebook se pueden adaptar para realizar este análisis a nivel de provincias para cualquier otra CA. Aunque no estamos reutilizando la función que hemos usado anteriormente, también podemos cambiar el período de análisis.
El diagrama de Sankey que visualiza los flujos de turistas que llegaron en agosto de 2023 a las tres provincias valencianas quedaría así:
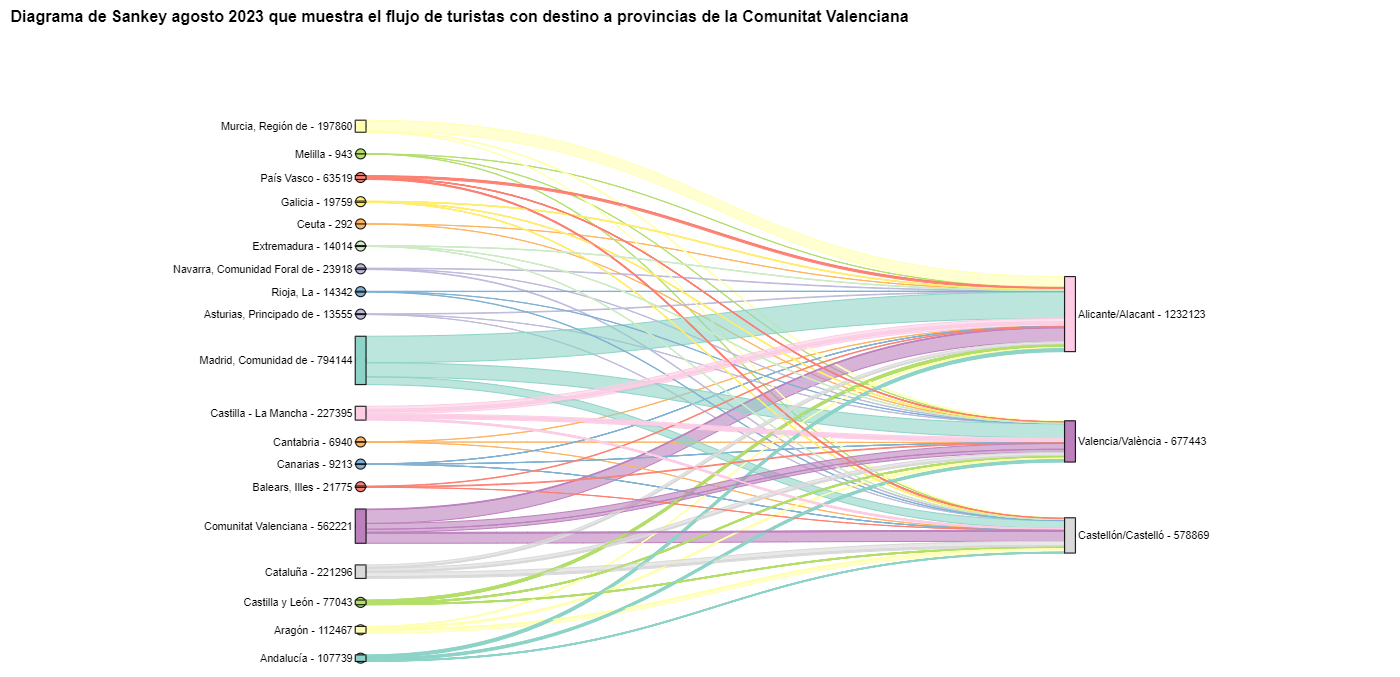
Figura 10. Diagrama de Sankey agosto 2023 que muestra el flujo de turistas con destino a provincias de la Comunitat Valenciana.
Podemos observar que, como ya suponíamos, el mayor número de turistas que llega a la Comunitat Valenciana en agosto proviene de la Comunidad de Madrid. Sin embargo, podemos comprobar que esto no es cierto para la provincia de Castellón, donde en agosto de 2023 la mayoría de los turistas fueron valencianos que se desplazaron dentro de su propia CA.
6. Conclusiones del ejercicio
Gracias a las técnicas de visualización empleadas en este ejercicio, hemos podido observar los flujos de turistas que se desplazan dentro del territorio nacional, enfocándonos en hacer comparaciones entre diversas épocas del año y tratando de identificar patrones. Tanto en los diagramas de cuerdas como en los diagramas de Sankey que hemos creado, hemos podido observar la afluencia de los turistas madrileños en las costas valencianas en verano. También hemos podido identificar las comunidades autónomas donde los turistas salen menos de su propia comunidad autónoma, como Cataluña y Andalucía.
7. ¿Quieres realizar el ejercicio?
Invitamos al lector a ejecutar el código contenido en el notebook de Google Colab que acompaña a este ejercicio para seguir con el análisis de los flujos de turistas. Dejamos aquí algunas ideas de posibles preguntas y de cómo se podrían contestar:
- El impacto de la pandemia: ya lo hemos mencionado brevemente arriba, pero una pregunta interesante sería medir el impacto que ha tenido la pandemia del coronavirus sobre el turismo. Podemos comparar los datos de los años anteriores con el 2020 y también analizar los años siguientes para detectar tendencias de estabilización. Visto que la función que hemos creado permite cambiar fácilmente el período de tiempo bajo análisis, te proponemos hacer este análisis por tu cuenta.
- Intervalos de tiempo: también es posible modificar la función que hemos estado usando de tal manera que no solo permita seleccionar un periodo de tiempo concreto, sino que también permita intervalos de tiempos.
- Análisis a nivel de provincias: igualmente, un lector avanzado con Pandas puede imponerse el reto de crear un diagrama de Sankey que visualice a qué provincias viajan los habitantes de una determinada región, por ejemplo, Ourense. Para no tener demasiadas provincias de destino que podrían hacer ilegible el diagrama de Sankey, se podrían visualizar solo las 10 más visitadas. Para obtener los datos para crear esta visualización, el lector tendría que jugar con los filtros que pone sobre el dataset y con el método de groupby de pandas, dejándose inspirar por el código ya ejecutado.
Esperamos que este ejercicio práctico te haya aportado conocimiento suficiente para desarrollar tus propias visualizaciones. Si tienes algún tema sobre ciencia de datos que quieras que tratemos próximamente, no dudes en proponer tu interés a través de nuestros canales de contacto.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Ejercicios de ciencia de datos”.