Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
Captura del vídeo que muestra la interacción con el dashboard de la caracterización de la demanda de empleo y la contratación registrada en España disponible al final de este artículo
2. Objetivos
El objetivo principal de este post es realizar una visualización interactiva partiendo de datos abiertos. Para ello se han utilizado conjuntos de datos que contienen información relevante sobre la evolución de la demanda de empleo en España a lo largo de los últimos años. A partir de estos datos se determina el perfil que representa la demanda de empleo en nuestro país, estudiando específicamente cómo afecta la brecha de género al colectivo y la incidencia de variables como la edad, la prestación por desempleo o la región.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se han seleccionado conjuntos de datos publicados por el Servicio Público de Empleo Estatal (SEPE), coordinado por el Ministerio de Trabajo y Economía Social, que recogen series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presentan los demandantes de empleo. Estos datasets se encuentran disponibles en datos.gob.es con las siguientes características:
- Demandantes de empleo por municipio: contiene el número de demandantes de empleo desagregado por municipio, edad y sexo, desde 2006 hasta 2020.
- Gasto de prestaciones por desempleo por Provincia: serie temporal desde 2010 hasta 2020 sobre el gasto en prestaciones por desempleo, desagregado por provincia y el tipo de prestación.
- Contratos registrados por el Servicio Público de Empleo Estatal (SEPE) por municipio: estos conjuntos de datos contienen el número de contratos registrados tanto a demandantes como a no demandantes de empleo, desagregados por municipio, sexo y tipo de contrato, desde 2006 hasta 2020.
3.2. Herramientas
Para la realización de este análisis (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
RStudio es un entorno de desarrollo open source integrado para el lenguaje de programación R, dedicado al análisis estadístico y la creación de gráficos.
RMarkdown permite la realización de informes integrando texto, código y resultados dinámicos en un único documento.
Para la creación de los gráficos interactivos se ha utilizado la herramienta Kibana.
Kibana es una aplicación de código abierto que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstasg y Kibana) que proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch. Las principales ventajas de esta herramienta son:
- Presenta la información de manera visual a través de dashboards interactivos y personalizables mediante intervalos temporales, filtros facetados por rango, cobertura geoespacial, entre otros.
- Dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
- Cuenta con una versión gratuita para utilizar en tu propio ordenador y una versión enterprise que se desarrolla en un cloud propio de Elastic u otras infraestructuras en cloud como Amazon Web Service (AWS).
En la propia web de Elastic encontramos manuales de usuario para la descarga e instalación de la herramienta, o cómo crear gráficos o dashboards, entre otros. Además ofrece vídeos cortos en su canal de youtube y organiza webinars donde explican diversos aspectos relacionados con Elastic Stack.
Si quieres saber más sobre estas herramientas u otras que pueden ayudarte en el procesado de datos, puedes ver el informe \"Herramientas de procesado y visualización de datos\", actualizado recientemente.
4. Tratamiento de datos
Para la realización una visualización, es necesario preparar los datos de la forma adecuada realizando una serie de tareas que incluyen el preprocesado y el análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer la realidad de los datos a los que nos enfrentamos. El objetivo es identificar características de los datos y detectar las posibles anomalías o errores que pudieran afectar a la calidad de los resultados. Un tratamiento previo de los datos es esencial para que los análisis o las visualizaciones que se realicen posteriormente sean consistentes y efectivas.
Para favorecer el entendimiento de los lectores no especialistas en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo clik en \"Código\", no está diseñado para su eficiencia sino para su fácil comprensión, por lo que es posible que lectores más avanzados en este lenguaje de programación consideren una forma de codificar algunas funcionalidades de forma alternativa. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en cuenta en Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de RMarkdown. Una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
El paquete base de R, siempre disponible desde que abrimos la consola en RStudio, incorpora un amplio conjunto de funcionalidades para cargar datos de fuentes externas, llevar a cabo análisis estadísticos y obtener representaciones gráficas. No obstante, hay multitud de tareas para las que necesitamos recurrir a paquetes adicionales incorporando al entorno de trabajo las funciones y objetos definidos en ellas. Algunos de ellos ya están instalados en el sistema, pero otros será preciso descargarlos e instalarlos.
#Instalación de paquetes \r\n #El paquete dplyr presenta una colección de funciones para realizar de manera sencilla operaciones de manipulación de datos \r\n if (!requireNamespace(\"dplyr\", quietly = TRUE)) {install.packages(\"dplyr\")}\r\n #El paquete lubridate para el manejo de variables tipo fecha \r\n if (!requireNamespace(\"lubridate\", quietly = TRUE)) {install.packages(\"lubridate\")}\r\n#Carga de paquetes en el entorno de desarrollo \r\nlibrary (dplyr)\r\nlibrary (lubridate)\r\n4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros .CSV y .XLS. Debemos cargar en nuestro entorno de desarrollo todos los ficheros que nos interesan. El siguiente código muestra como ejemplo la carga de un único fichero .CSV en una tabla de datos para que la lectura de este post sea más comprensible.
Para agilizar el proceso de carga en el entorno de desarrollo, es necesario descargar en el directorio de trabajo los conjuntos de datos necesarios para esta visualización, que se encuentran disponibles en la cuenta de Github de datos.gob.es.
#Carga del datasets de demandantes de empleo por municipio de 2020. \r\n Demandantes_empleo_2020 <- \r\n read.csv(\"Conjuntos de datos/Demandantes de empleo por Municipio/Dtes_empleo_por_municipios_2020_csv.csv\",\r\n sep=\";\", skip = 1, header = T)\r\nUna vez que tenemos todos los conjuntos de datos cargados como tablas en el entorno de desarrollo, debemos unificarlos para así tener un único dataset que integre todos los años de la serie temporal, por cada una de las características relacionadas con los demandantes de empleo que se quiere analizar: número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados por el SEPE.
#Dataset de demandantes de empleo\r\nDatos_desempleo <- rbind(Demandantes_empleo_2006, Demandantes_empleo_2007, Demandantes_empleo_2008, Demandantes_empleo_2009, \r\n Demandantes_empleo_2010, Demandantes_empleo_2011,Demandantes_empleo_2012, Demandantes_empleo_2013,\r\n Demandantes_empleo_2014, Demandantes_empleo_2015, Demandantes_empleo_2016, Demandantes_empleo_2017, \r\n Demandantes_empleo_2018, Demandantes_empleo_2019, Demandantes_empleo_2020) \r\n#Dataset de gasto en prestaciones por desempleo\r\ngasto_desempleo <- rbind(gasto_2010, gasto_2011, gasto_2012, gasto_2013, gasto_2014, gasto_2015, gasto_2016, gasto_2017, gasto_2018, gasto_2019, gasto_2020)\r\n#Dataset de nuevos contratos a demandantes de empleo\r\nContratos <- rbind(Contratos_2006, Contratos_2007, Contratos_2008, Contratos_2009,Contratos_2010, Contratos_2011, Contratos_2012, Contratos_2013, \r\n Contratos_2014, Contratos_2015, Contratos_2016, Contratos_2017, Contratos_2018, Contratos_2019, Contratos_2020)b. Selección de variables
Una vez que tenemos las tablas con las tres series temporales (número de demandantes de empleo, gasto por desempleo y nuevos contratos registrados), crearemos una nueva tabla que incluirá las variables que interesan de cada una de ellas.
En primer lugar, agregaremos por provincia las tablas de demandantes de empleo (“datos_desempleo”) y contratos nuevos contratos registrados (“contratos”) para facilitar la visualización y que coincidan con la desagregación por provincia de la tabla de gasto en prestaciones por desempleo (“gasto_desempleo”). En este paso, seleccionamos únicamente las variables que interesen de los tres conjuntos de datos.
#Realizamos un group by al dataset de \"datos_desempleo\", agruparemos las variables numéricas que nos interesen, en función de varias variables categóricas\r\nDtes_empleo_provincia <- Datos_desempleo %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(total.Dtes.Empleo = (sum(total.Dtes.Empleo)), Dtes.hombre.25 = (sum(Dtes.Empleo.hombre.edad...25)), \r\n Dtes.hombre.25.45 = (sum(Dtes.Empleo.hombre.edad.25..45)), Dtes.hombre.45 = (sum(Dtes.Empleo.hombre.edad...45)),\r\n Dtes.mujer.25 = (sum(Dtes.Empleo.mujer.edad...25)), Dtes.mujer.25.45 = (sum(Dtes.Empleo.mujer.edad.25..45)),\r\n Dtes.mujer.45 = (sum(Dtes.Empleo.mujer.edad...45)))\r\n#Realizamos un group by al dataset de \"contratos\", agruparemos las variables numericas que nos interesen en función de las varibles categóricas.\r\nContratos_provincia <- Contratos %>% \r\n group_by(Código.mes, Comunidad.Autónoma, Provincia) %>%\r\n summarise(Total.Contratos = (sum(Total.Contratos)),\r\n Contratos.iniciales.indefinidos.hombres = (sum(Contratos.iniciales.indefinidos.hombres)), \r\n Contratos.iniciales.temporales.hombres = (sum(Contratos.iniciales.temporales.hombres)), \r\n Contratos.iniciales.indefinidos.mujeres = (sum(Contratos.iniciales.indefinidos.mujeres)), \r\n Contratos.iniciales.temporales.mujeres = (sum(Contratos.iniciales.temporales.mujeres)))\r\n#Seleccionamos las variables que nos interesen del dataset de \"gasto_desempleo\"\r\ngasto_desempleo_nuevo <- gasto_desempleo %>% select(Código.mes, Comunidad.Autónoma, Provincia, Gasto.Total.Prestación, Gasto.Prestación.Contributiva)En segundo lugar, procedemos a unir las tres tablas en una que será con la que trabajemos a partir de este punto.
Caract_Dtes_empleo <- Reduce(merge, list(Dtes_empleo_provincia, gasto_desempleo_nuevo, Contratos_provincia))
c. Transformación de variables
Una vez tengamos la tabla con las variables de interés para el análisis y la visualización, debemos transformar algunas de ellas a otros tipos más adecuados para futuras agregaciones.
#Transformación de una variable fecha\r\nCaract_Dtes_empleo$Código.mes <- as.factor(Caract_Dtes_empleo$Código.mes)\r\nCaract_Dtes_empleo$Código.mes <- parse_date_time(Caract_Dtes_empleo$Código.mes(c(\"200601\", \"ym\")), truncated = 3)\r\n#Transformamos a variable numérica\r\nCaract_Dtes_empleo$Gasto.Total.Prestación <- as.numeric(Caract_Dtes_empleo$Gasto.Total.Prestación)\r\nCaract_Dtes_empleo$Gasto.Prestación.Contributiva <- as.numeric(Caract_Dtes_empleo$Gasto.Prestación.Contributiva)\r\n#Transformación a variable factor\r\nCaract_Dtes_empleo$Provincia <- as.factor(Caract_Dtes_empleo$Provincia)\r\nCaract_Dtes_empleo$Comunidad.Autónoma <- as.factor(Caract_Dtes_empleo$Comunidad.Autónoma)d. Análisis exploratorio
Veamos qué variables y estructura presenta el nuevo conjunto de datos.
str(Caract_Dtes_empleo)\r\nsummary(Caract_Dtes_empleo)La salida de esta porción de código se omite para facilitar la lectura. Las características principales que presenta el conjunto de datos son:
- El rango temporal abarca desde enero de 2010 hasta diciembre de 2020.
- El número de columnas (variables) es de 17.
- Presenta dos variables categóricas (“Provincia” y “Comunidad.Autónoma”), una variable tipo fecha (“Código.mes”) y el resto son variables numéricas.
e. Detección y tratamiento de datos perdidos
Seguidamente analizaremos si el dataset presenta valores perdidos (NAs). El tratamiento o la eliminación de los NAs es esencial, ya que si no es así no será posible procesar adecuadamente las variables numéricas.
any(is.na(Caract_Dtes_empleo)) \r\n#Como el resultado es \"TRUE\", eliminamos los datos perdidos del dataset, ya que no sabemos cual es la razón por la cual no se encuentran esos datos\r\nCaract_Dtes_empleo <- na.omit(Caract_Dtes_empleo)\r\nany(is.na(Caract_Dtes_empleo))4.3. Creación de nuevas variables
Para realizar la visualización, vamos a crear una nueva variable a partir de dos variables que se encuentran en la tabla de datos. Esta acción es muy común en el análisis de datos ya que en ocasiones interesa trabajar con datos calculados (por ejemplo, la suma o la media de diferentes variables) en lugar de los datos de origen. En este caso vamos a calcular el gasto medio en prestaciones por desempleo para cada demandante de empleo. Para ello utilizaremos las variables de gasto total por prestación (“Gasto.Total.Prestación”) y el total de demandantes de empleo (“total.Dtes.Empleo”).
Caract_Dtes_empleo$gasto_desempleado <-\r\n (1000 * (Caract_Dtes_empleo$Gasto.Total.Prestación/\r\n Caract_Dtes_empleo$total.Dtes.Empleo))4.4. Guardar el dataset
Una vez que tenemos la tabla con las variables que nos interesan para los análisis y las visualizaciones, la guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos. Es importante utilizar la codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier herramienta.
write.csv(Caract_Dtes_empleo,\r\n file=\"Caract_Dtes_empleo_UTF8.csv\",\r\n fileEncoding= \"UTF-8\")5. Creación de la visualización sobre la caracterización de la demanda de empleo en España usando Kibana
El desarrollo de esta visualización interactiva se ha realizado usando Kibana en nuestro entorno local. Tanto para la descarga del software, como para la instalación del mismo, hemos recurrido al tutorial realizado por la propia compañía, Elastic.
A continuación se adjunta un vídeo tutorial donde se muestra todo el proceso de realización de la visualización. En el vídeo podrás ver la creación de un cuadro de mando (dashboard) con diferentes indicadores interactivos mediante la generación de representaciones gráficas de diferentes tipos. Los pasos para obtener el dashboard son los siguientes:
- Cargamos los datos en Elasticsearch y generamos un índice que nos permita interactuar con los datos desde Kibana. Este índice permite la búsqueda y gestión de datos en los archivos cargados, prácticamente en tiempo real.
- Generación de las siguientes representaciones gráficas:
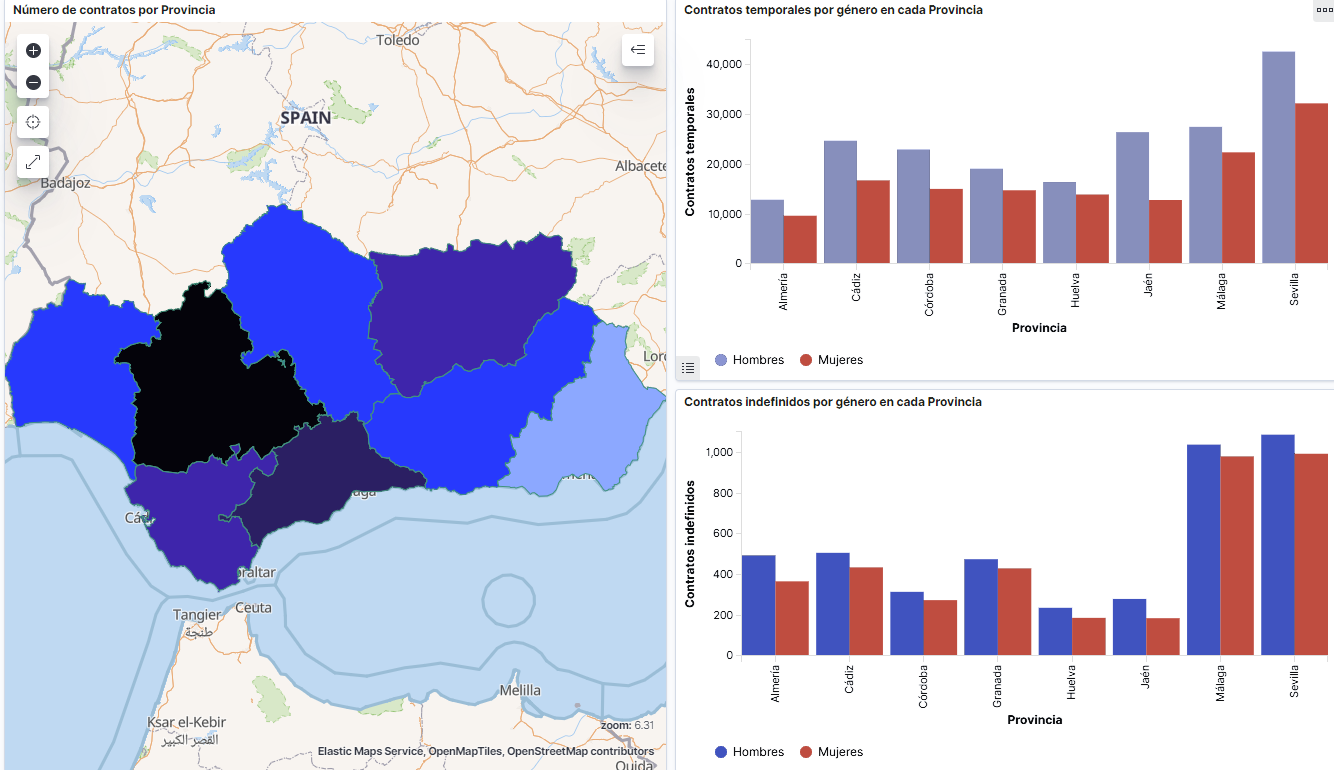
- Gráfico de líneas para representar la serie temporal sobre los demandantes de empleo en España desde 2006 hasta 2020.
- Gráfico de sectores de los demandantes de empleo desagregados por Provincia y Comunidad Autónoma.
- Mapa temático, mostrando el número de contratos nuevos registrados en cada Provincia del territorio. Para la creación de este visual es necesaria la descarga de un dataset de la georeferenciación de las Provincias publicado en el portal de datos abiertos Open Data Soft.
- Construcción del dashboard.
Seguidamente mostraremos un vídeo tutorial interactuando con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre el perfil de los demandantes de empleo en España en el periodo 2010 hasta 2020, se pueden obtener, entre otras, las siguientes conclusiones:
- Existen dos incrementos significativos en el número de demandantes de empleo. El primero aproximadamente en 2010, que coincide con la crisis económica. El segundo, mucho más pronunciado en 2020, que coincide con la crisis derivada de la pandemia.
- Se observa que existe una brecha de género en el colectivo de demandantes de empleo: el número de mujeres demandantes de empleo es mayor a lo largo de toda la serie temporal, principalmente en los grupos de edad de mayores de 25.
- A nivel regional, Andalucía, seguida de Cataluña y Comunidad Valenciana, son las Comunidades Autónomas con mayor número de demandantes de empleo. En contraste, Andalucía, es la Comunidad Autónoma con menor gasto por desempleo, mientras que Cataluña, es la que presenta mayor gasto por desempleo.
- Los contratos de tipo temporal son los prioritarios y las provincias que generan mayor número de contratos son Madrid y Barcelona, que coinciden con las provincias con mayor número de habitantes, mientras que en el lado opuesto, las provincias que menos número de contratos realizan son Soria, Ávila, Teruel o Cuenca, que coincide con las zonas más despobladas de España.
Esta visualización nos ha ayudado a sintetizar gran cantidad de información y darle sentido pudiendo obtener unas conclusiones y si fuera necesario tomar decisiones en función de los resultados. Esperemos que os haya gustado este nuevo post y volveremos para mostraros nuevas reutilizaciones de datos abiertos. ¡Hasta pronto!
Entrevista
R-Ladies es una comunidad software que tiene como objetivo visibilizar a las mujeres que trabajan o desarrollan proyectos o software utilizando R para ello. Es una rama local de R-Ladies Global, una comunidad open source que nace en 2016.
Sus organizadoras Inés Huertas, Leticia Martín-Fuertes y Elen Irazabal, nos han dedicado unos minutos para hablar de la actividad que realiza esta comunidad y de cómo impulsar la presencia de mujeres en los ámbitos tecnológicos.
Entrevista completa:
1. ¿Cómo nace R-Ladies?
R-Ladies Madrid nace a partir de una iniciativa internacional, pero también nace de una realidad local en España en aquel momento y es que se podían encontrar pocas chicas en los congresos o desarrollando paquetería en R, entonces nadie pensaba que fuera un problema hasta que en los primeros meetups comenzaron a aparecer muchas mujeres que acudían por primera vez a una comunidad y que no las veíamos en esos otros espacios por diferentes motivos. Aquello nos motivó a continuar con la comunidad, ya que en muchas ocasiones éramos la puerta de entrada a que pudieran participar en estas comunidades o congresos, etc.
2. ¿Qué ventajas y desventajas tiene R como lenguaje de programación frente a sus competidores?
R es uno de los primeros lenguajes de software libre que se utilizan en el mundo de los datos. Ha estado muy relacionado con la comunidad universitaria e investigadora que inicialmente alimentó gran parte de la paquetería que hoy en día tenemos. A día de hoy hay grandes empresas que trabajan por mejorar y mantener estos repositorios, porque el espectro de paquetería que puede encontrarse en R es muy amplio y cuenta con una potente comunidad detrás. Puedes encontrarte con desarrollos que abarcen desde paquetería de nicho de investigación como de biogenética, hasta paquetería menos específica para análisis generales.
3. El número de mujeres en ingenierías es de un 25% (mientras que el total de mujeres en el sistema universitario alcanza el 59%). En vuestra opinión, ¿cuáles son las razones detrás de esta situación?
Son diversos motivos pero si tenemos que elegir uno es la poca visibilidad a las mujeres dentro de las ingenierías. Se están haciendo actualmente grandes esfuerzos por dar visibilidad a las mujeres que desarrollan y trabajan con datos. En R-Ladies por ejemplo tenemos un directorio internacional donde puedes encontrar a mujeres para hablar en congresos a nivel mundial, pudiendo así crear modelos de referencia a otras mujeres que se animen a participar. Eso es lo que hacemos desde R-Ladies, damos visibilidad a mujeres que están trabajando con R.
De todas formas, y dada la revolución digital que estamos viviendo, lo que se está viendo es la unión entre las letras y las ciencias. Por ejemplo, en el campo de la Inteligencia Artificial, estamos viendo cómo afecta a áreas que anteriormente eran de letras, como la lingüística, el derecho, el marketing etc. Dada esta intersección, están apareciendo perfiles mixtos que, sin haber estudiado el grado de ingeniería, se dedican a aplicar aspectos técnicos al mundo no técnico. Por ejemplo, enseñar lenguaje natural a las máquinas.
El caso del derecho también es paradigmático, ya hay regulaciones que requieren de conocimientos técnicos para poder aplicarlas. De hecho, incluso el mundo técnico también puede interesarse del mundo de las letras, como por ejemplo, cómo afecta el derecho y la regulación a cómo funciona internet.
En definitiva, no hay que ver al mundo de la ciencia y de las letras como carreras laborales distintas sino que cada vez son más complementarias.
Se está viendo la unión entre las letras y las ciencias. Están apariendo perfiles mixtos que, sin haber estudiado el grado de ingeniería, se dedican a aplicar aspectos técnicos al mundo no técnico.
4. ¿Cómo ayudan Iniciativas como R-Ladies a impulsar la presencia de mujeres en el ámbito tecnológico?
Precisamente ayudando a crear Role Models. Apoyando a las mujeres para que no sufran el llamado “síndrome del impostor”. Dar una charla en tu tiempo libre sobre las cosas en las que trabajas o tienes interés es mucho más de lo que parece, para muchas de estas mujeres es un primer paso que puede ayudarlas a presentar un proyecto en su empresa o defender una propuesta ante un cliente.
5. ¿En qué proyectos están trabajando?
Actualmente con la pandemia hemos tenido que adaptarnos con un ciclo de talleres/charlas mensuales online durante 2020/2021 que no nos limita a estar físicamente en Madrid, por lo que contamos con speakers que de otra forma sería más complicado traer a Madrid. Además, hemos intentado hacer estos talleres mensuales de forma incremental, de tal forma que empezando en Septiembre hasta ahora hemos ido incrementando el nivel de la sesiones empezando desde los primeros pasos en R hasta acabar con la realización de un análisis de datos con Redes Neuronales. Además estamos alimentando con estas sesiones nuestro canal de YouTube, generando contenido en español sobre cómo utilizar R que está teniendo una gran acogida.
6. ¿Qué tipos de datos abiertos han utilizado en sus proyectos y con qué datos les gustaría trabajar?
Sobre la utilización de datos abiertos, alguno de los grupos de trabajo utiliza datos del BOE u Open Data NASA para desarrollo de proyectos. También ayudamos a montar un grupo de trabajo que trabaja con los datos del covid.
Nos gustaría poder trabajar con la jurisprudencia española. Sería muy interesante ver cómo en la historia de la democracia se han ido dictando distintas sentencias y la evolución de ellas a lo largo de todos estos años.
También nos gustaría poder trabajar con los corpus de referencia de la RAE, como el CREA, el CORDE o el CORPES XXI, que contienen textos de diversa índole, incluidos transcripciones orales, con los que se podrían hacer muchísimos análisis lingüísticos y servir como datos de entrenamiento para mejorar la presencia del español en el ámbito de la IA.
Sobre la utilización de datos abiertos, alguno de los grupos de trabajo utiliza datos del BOE u Open Data NASA para desarrollo de proyectos. También ayudamos a montar un grupo de trabajo que trabaja con los datos del covid.
7. Para terminar, ¿cómo pueden las personas interesadas seguir a R-Ladies y colaborar con vosotras?
¡Superfácil! Pueden escribirnos a madrid@rladies.org, apuntarse a nuestro Meetup o sencillamente por Twitter, en nuestra cuenta de @RladiesMad. ¡Todo el mundo es bienvenido!
Noticia
El verano ya está a la vuelta de la esquina y con él las merecidas vacaciones. Sin duda, esta época del año nos brinda tiempo para descansar, reencontrarnos con la familia y pasar ratos agradables con nuestros amigos.
Sin embargo, también resulta una magnífica oportunidad para aprovechar y mejorar nuestro conocimiento sobre datos y tecnología a través de los cursos que diferentes universidades ponen a nuestra disposición durante estas fechas. Ya seas estudiante o profesional en activo, este tipo de cursos pueden contribuir a aumentar tu formación, y ayudarte a adquirir ventajas competitivas dentro del mercado laboral.
A continuación, te mostramos varios ejemplos de cursos de verano de universidades españolas sobre estas temáticas. También hemos incluido alguna formación online, disponible todo el año, y que puede ser un excelente producto para aprender también en la época estival.
Cursos relacionados con los datos abiertos
Iniciamos nuestra recopilación con el curso de ‘Big & Open Data. Análisis y programación con R y Python’ impartido por la Universidad Complutense de Madrid. Se celebrará de manera presencial en la Fundación General UCM del 5 al 23 de julio, de lunes a viernes en horario de 9 a 14 horas. Este curso está dirigido a estudiantes universitarios, docentes, investigadores y profesionales que deseen ampliar y perfeccionar sus conocimientos sobre esta materia.
Análisis y visualización de datos
Si te interesa aprender el lenguaje R, la Universidad de Santiago de Compostela organiza dos cursos relacionados con esta materia, en el marco de su ‘Universidade de Verán’. El primero de ellos es ‘Introducción en sistemas de información geográfica y cartográfica con el Entorno R’, que se celebrará del 6 al 9 de julio en la Facultad de Geografía e Historia de Santiago de Compostela. Puedes consultar toda la información y el plan de estudios a través de este enlace.
El segundo es ‘Visualización y análisis de datos con R’, que tendrá lugar del 13 al 23 de julio en la Facultad de Matemáticas de la USC. En este caso, la universidad ofrece la posibilidad al alumnado de asistir en dos turnos (mañana y tarde). Como puedes comprobar en su programa, la estadística se erige como uno de los aspectos clave de esta formación.
Si tu campo son las ciencias sociales y quieres aprender a manejar los datos correctamente, el curso de la Universidad de Internacional de Andalucía (UNIA) ‘Técnicas de análisis de datos en Humanidades y Ciencias Sociales’ buscas aproximarse al uso de las nuevas técnicas estadísticas y espaciales en la investigación en estos campos. Se impartirá del 23 al 26 de agosto en modalidad presencial.
Big Data
El Big Data se coloca, cada día más, como uno de los elementos que más contribuyen al aceleramiento de la transformación digital. Si te interesa este campo, puedes optar por el curso ‘Big Data Geolocalizado: Herramientas para la captura, análisis y visualización’ que impartirá la Universidad Complutense de Madrid del 5 al 23 de julio en horario de 9 a 14 horas, de manera presencial en la Fundación General UCM.
Otra opción es el curso de ‘Big Data: fundamentos tecnológicos y aplicaciones prácticas’ organizado por la Universidad de Alicante que se celebrará del 19 al 23 de julio de manera online.
Inteligencia artificial
El Gobierno ha puesto en marcha recientemente el curso online ‘Elementos de IA’ en español con el objetivo de impulsar y perfeccionar la formación de la ciudadanía en inteligencia artificial. La Secretaría de Estado de Digitalización e Inteligencia Artificial será quien ponga en marcha este proyecto junto a la colaboración de la UNED, que se encargará de proporcionar el soporte técnico y académico de esta formación. Elementos de IA es un proyecto educativo masivo y abierto (MOOC) que tiene como objetivo acercar a los ciudadanos conocimientos y habilidades sobre Inteligencia Artificial y sus distintas aplicaciones. Puedes descubrir toda la información sobre este curso aquí. Y si quieres comenzar ya la formación, puedes inscribirte a través de este enlace. El curso es gratuito.
Otra formación interesante relacionada con este ámbito es el curso de ‘Introducción práctica a la inteligencia artificial y al deep learning’ que organiza la Universidad Internacional de Andalucía (UNIA). Se impartirá de manera presencial en la sede Antonio Machado de Baeza entre los días 17 y 20 de agosto de 2021. Entre sus objetivos, destaca el ofrecer a los alumnos una visión general de los modelos de procesamiento de datos basados en técnicas de inteligencia artificial y aprendizaje profundo, entre otros.
Estos son solo algunos ejemplos de cursos que actualmente tienen matrícula abierta, aunque hay muchos más ya que la oferta es amplia y variada. Además, hay que recordar que el inicio del verano aún no se ha producido y que en las próximas semanas podrían aparecer nuevos cursos relacionados con los datos. Si conoces alguno más que sea de interés, no dudes en dejarnos un comentario aquí debajo o escribirnos a contacto@datos.gob.es
Entrevista
R Hispano es una comunidad de usuarios y desarrolladores que nació en 2011, en el seno de las III Jornadas de Usuarios de R, con el objetivo de fomentar el avance del conocimiento y el uso del lenguaje de programación en R. Desde datos.gob.es hemos hablado con Emilio López Cano, presidente de R Hispano, para que nos cuente más sobre las actividades que realizan y el papel de los datos abiertos en ellas.
Entrevista completa
1. ¿Puede explicarnos de forma breve qué es la Comunidad R-Hispano?
Se trata de una asociación creada en España cuyo objetivo es el de promover el uso de R entre un público hispano. Hay muchos usuarios de R a nivel mundial e intentamos servir como punto de encuentro entre todos aquellos cuyo idioma principal es el español. Al tener como referencia un grupo más pequeño dentro de una comunidad tan grande, es más fácil entablar relaciones y conocer a personas a las que acudir cuando se quiere aprender más o compartir lo aprendido.
2. R nace como lenguaje ligado a la explotación estadística de los datos, sin embargo, se ha ido convirtiendo en una herramienta esencial de la Ciencia de Datos, ¿por qué tanta aceptación de este lenguaje por la comunidad?
Es verdad que muchos profesionales de la ciencia e ingeniería de datos tienden a utilizar lenguajes más genéricos como Python. Sin embargo, hay varios motivos por los que R se hace imprescindible en el “Stack” de los equipos que trabajan con datos. En primer lugar, R tiene su origen en el lenguaje S, que se diseñó en los años 70 específicamente para el análisis de datos, en el seno de los laboratorios Bell. Esto permite que personas con diferente formación informática pueda participar en proyectos complejos, centrándose en los métodos de análisis. En segundo lugar, R ha envejecido muy bien, y una amplia comunidad de usuarios, desarrolladores y empresas contribuyen al proyecto con paquetes y herramientas que extienden la funcionalidad de forma rápida hacia los métodos más innovadores con (relativa) sencillez y todo el rigor.
3. R Hispano funciona a través de numerosas iniciativas locales, ¿qué ventajas conlleva esta forma de organización?
En las actividades del día a día, sobre todo cuando teníamos encuentros presenciales, hace más de un año, es más cómodo coordinar a las personas de la manera más cercana posible. No tiene sentido que una persona en Madrid organice reuniones mensuales en Málaga, Sevilla o Canarias. Lo interesante de estos eventos es asistir regularmente, ir conociendo a los asistentes, entender lo que demanda el público y lo que se puede ofrecer. Eso, aparte de mimo y dedicación, requiere estar cerca porque, si no, no hay forma de establecer ese vínculo. Por eso nos ha parecido que es desde las propias ciudades como se tiene que mantener esa relación de día a día. Por otra parte, es la forma en la que la Comunidad de R se ha organizado en todo el mundo, con el éxito que todos conocemos.
4. ¿Consideráis las iniciativas de datos abiertos una valiosa fuente de información para el desarrollo de vuestros proyectos? ¿Algún ejemplo de reutilización destacable? ¿Qué aspectos consideráis mejorables de las iniciativas actuales?
Lo primero decir que R Hispano como tal no tiene proyectos. Sin embargo, muchos socios de R Hispano trabajan con datos abiertos en su ámbito profesional, ya sea académico o empresarial. Desde luego, es una fuente de información muy valiosa, con muchísimos ejemplos, como el análisis de los datos de la pandemia que todavía sufrimos, los datos de competiciones deportivas y rendimiento de deportistas, datos medioambientales, socioeconómicos, … No podemos destacar ninguno porque hay muchos muy interesantes que lo merecerían igualmente. En cuanto a las mejoras, todavía hay muchos repositorios de datos públicos que no los publican en formato “tratable” por los analistas. Un informe en PDF puede ser datos abiertos, pero desde luego no contribuyen a su difusión, análisis, y explotación por el bien de la sociedad. Todos los datos abiertos deberían estar tabulados en formatos que permitan la rápida importación a software, como por ejemplo R.
5. ¿Puede contarnos algunas de las actividades que llevan a cabo esas Iniciativas locales?
Varios grupos locales de R, tanto en España como Latam, colaboraron recientemente con la empresa de formación en tecnologías, UTad, en el evento “Encuentros en la fase R”. Celebrado en formato online con dos días de duración. Las jornadas de usuarios de R que celebramos cada año, normalmente las organiza alguno de los grupos locales de la sede. El grupo de Córdoba está organizando las próximas, aplazadas con motivo de la pandemia y de las que esperamos poder anunciar fechas pronto.
El Grupo de Usuarios de R de Madrid comenzó a funcionar como grupo local vinculado a la Comunidad R hispano hace más de quince años. Desde su origen mantiene una periodicidad mensual de reuniones anunciadas en la red social Meetup (patrocinado por parte de RConsortium, entidad, fundada y subvencionada por grandes compañías para favorecer el uso de R). La actividad se ha visto interrumpida por las limitaciones del Covid-19, pero todo el historial de las presentaciones se ha ido recopilando en este portal.
Desde el Grupo de R Canarias se han involucrado en la conferencia TabularConf, que tuvo lugar el 30 de enero, en formato online, con una agenda de una decena de ponencias sobre data science e inteligencia artificial. En el pasado el grupo canario realizó un encuentro de usuarios de R con comunicaciones sobre varios tópicos, incluidos modelización, tratamiento de datos geográficos, así como consultas a APIs de datos públicos, como datos.gob.es, con la librería opendataes. Otras librerías presentadas en un meetup que realizaron en 2020 son istacr o inebaseR, siempre apostando por el acceso a datos públicos.
En el Grupo Local de Sevilla, durante los hackatones celebrados en los últimos años, ha comenzado a desarrollar varios paquetes totalmente vinculados a datos abiertos.
-
Aire: Para obtener datos de calidad del aire en Andalucía (funciona, pero necesita algunos ajustes)
-
Aemet: Paquete de R para interaccionar con la API de AEMET (datos climáticos). Dimos los primeros pasos en un hackaton, luego Manuel Pizarro hizo un paquete totalmente funcional.
-
Andaclima: Paquete para obtener datos climáticos de estaciones agroclimáticas de la Junta de Andalucía
-
Datos.gob.es.r: Embrión de paquete para interaccionar con http://datos.gob.es. Realmente solo una exploración de ideas, nada funcional por ahora.
Sobre COVID-19 merece la pena destacar el desarrollo por parte de la UCLM, con la colaboración en un exmiembro de la Junta Directiva de la Comunidad R Hispano, de un panel de análisis de la COVID-19, con los casos que la Junta de Comunidades de Castilla-La Mancha presenta por municipio. Consiste en una herramienta interactiva para consultar la información sobre la incidencia y tasas por 100.000 habitantes.
6. Además, también colaboran con otros grupos e iniciativas.
Sí, colaboramos con otros grupos e iniciativas centradas en datos, como la UNED (Facultad de Ciencias), que durante un largo periodo de tiempo nos acogió como sede permanente. También destacaría nuestras actuaciones con:
-
Grupo de Periodismo de Datos. Presentaciones conjuntas con el grupo de Periodismo de Datos, compartiendo las bondades de R para sus análisis.
-
Una colaboración con el Grupo Machine Learning Spain que se tradujo en una presentación común en el Google Campus de Madrid.
-
Con grupos de otros lenguajes de datos, como Python.
-
Colaboraciones con empresas. En este punto destacamos el haber participado en dos eventos de Analítica Avanzada organizadas por Microsoft, así como el haber recibido pequeñas ayudas económicas de empresas como Kabel o Kernel Analytics (recientemente adquirida por Boston Consulting Group).
Estos son algunos ejemplos de presentaciones en el grupo de Madrid basadas en datos abiertos:
Además, diferentes socios de R-Hispano, también colaboran con instituciones académicas, en las que imparten diferentes cursos relacionados al análisis de Datos, fomentando especialmente el uso y análisis de datos abiertos, como por ejemplo la Facultad de Economía de la UNED, la Facultades de Estadística y de Turismo y Comercio de la UCM, la Universidad de Castilla-La Mancha, la EOI (asignatura específica sobre datos abiertos), la Universidad Francisco de Vitoria, la Escuela Superior de Ingeniería de Telecomunicaciones, el ESIC y la escuela K-School.
Por último, nos gustaría destacar el vínculo constante que se mantiene con diferentes entidades de relevancia del ecosistema R: con R-Consortium (https://www.r-consortium.org/) y RStudio (https://rstudio.com/). Es a través del R-Consortium donde hemos conseguido el reconocimiento del Grupo de Madrid como grupo estable y del que conseguimos el patrocinio para el pago de Meetup. Dentro de RStudio mantenemos diferentes contactos que nos han permitido igualmente conseguir patrocinios que han ayudado en las Jornadas de R, así como ponentes de la talla de Javier Luraschi (autor del paquete y libro sobre “sparklyr”) o Max Kuhn ( autor de paquetes como “caret” y de su evolución “tidymodels”).
7. A través de ROpenSpain algunos socios de RHispano han colaborado en la creación de paquetes en R que facilitan el uso de datos abiertos.
ROpenSpain es una comunidad de entusiastas de R, de los datos abiertos y la reproducibilidad que se reúne y organiza para crear paquetes de R de la máxima calidad para la explotación de datos españoles de interés general. Nace, con la inspiración de ROpenSci, en febrero de 2018 como organización de GitHub y dispone de un canal de colaboración en Slack. A enero de 2021, ROpenSpain agrupa los siguientes paquetes de R:
-
opendataes: Interactúa fácilmente con la API de datos.gob.es, que proporciona datos de las administraciones públicas de toda España.
-
MicroDatosEs: Permite importar a R varios tipos de ficheros de microdatos del INE: EPA, Censo, etc.
-
caRtociudad: Consulta la API de Cartociudad, que proporciona servicios de geolocalización, rutas, mapas, etc.
-
Siane: Para representar información estadística sobre los mapas del Instituto Geográfico Nacional.
-
airqualityES: Datos de calidad del aire en España de 2011 a 2018.
-
mapSpain: Para cargar mapas de municipios, provincias y CCAA. Incluye un plugin para leaflet.
-
MorbiditySpainR: Lee y manipula datos de la Encuesta de Morbilidad Hospitalaria
-
Spanish: Para el procesamiento de cierto tipo de información española: números, geocodificación catastral, etc.
-
BOE: Para el procesamiento del Boletín Oficial del Estado y del Boletín Oficial del Registro Mercantil.
-
istacbaser: Para consultar la API del Instituto Canario de Estadística.
-
CatastRo: Consulta la API del Catastro.
Algunos de estos paquetes se han presentado en eventos organizados por la Comunidad R Hispano.
8. Para terminar, ¿cómo pueden las personas interesadas seguir a R-Hispano y colaborar con vosotros?
Un elemento importante como nexo de unión en toda la comunidad de usuarios de R en español es la lista de ayuda R-Help-es:
-
Búsqueda: https://r-help-es.r-project.narkive.com/;
-
Suscripción: https://stat.ethz.ch/mailman/listinfo/r-help-es ).
Es una de las pocas listas de ayuda sobre R, activas e independiente de la principal en inglés R-Help que ha generado más de 12.800 entradas en sus más de 12 años de historia.
Además, se mantiene un gran nivel de actividad en las redes sociales que sirven como altavoz, palanca a través de las cuales se dan a conocer futuros eventos o diferentes noticias relacionadas con datos de interés para la comunidad. Podemos destacar las siguientes iniciativas en cada una de las plataformas:
-
Twitter: Presencia de la propia asociación R-Hispano; https://twitter.com/R_Hisp y participación en el hastag #rstatsES (R en Español) de diferentes colaboradores de R del ámbito nacional.
-
LinkedIn: En esta red profesional, “R” tiene presencia a través de la página de empresa https://www.linkedin.com/company/comunidad-r-hispano/. Además, multitud de socios de R-Hispano tanto de España como de Latam forman parte de esta red compartiendo recursos en abierto.
-
Canal de Telegram: Existe un canal de Telegram dónde se difunden con cierta periodicidad noticias de interés para la comunidad https://t.me/rhispano
Por último, en la página web de la asociación, http://r-es.org, se puede encontrar información sobre la asociación, así como la forma de hacerse socio/a (la cuota es, como R, gratuita).
Blog
Hasta hace relativamente poco tiempo, hablar de arte y datos en la misma conversación podía parecer algo extraño. Sin embargo, los recientes avances en ciencia de datos e inteligencia artificial parecen abrir la puerta a una nueva disciplina en la que ciencia, arte y tecnología se dan la mano.

La imagen en portada ha sido extraida del blog https://www.r-graph-gallery.com y ha sido creada originalmente por Marcus Volz en su página web.
La imágen de arriba podría ser una pintura abstracta creada por algún autor de arte moderno y expuesto en el MoMA de Nueva York. Sin embargo es una imagen creada con unas cuentas líneas de código R que utilizan algunas expresiones matemáticas complejas. A pesar de la espectacularidad de la figura resultante, la bella forma de los trazos no representa una forma real. Pero la capacidad de crear arte con los datos no se limita a generar formas abstractas. Las posibilidades de crear arte con código van mucho más allá y, a continuación, mostramos dos ejemplos.
Arte real y representación de plantas

Con menos de 100 líneas de código R podemos crear esta planta e infinitas variaciones de ella en cuanto a ramaje, simetría y complejidad. Sin ser un experto en plantas y algas estoy seguro de haber visto en multitud de ocasiones plantas y algas prácticamente igual que estas. Lejos de parecer extraño, con estas representaciones no hacemos sino intentar reproducir lo que la naturaleza crea de forma natural teniendo en cuenta las leyes de la física y las matemáticas. Las figuras que se muestran a continuación han sido creadas utilizando código R originalmente extraído del blog de Antonio Sánchez Chinchón.

Variaciones de plantas creadas artificialmente mediante código R y expresiones fractales
A modo de ejemplo, estos son los datos que forman algunas de las figuras expuestas anteriormente:
Fotografía y arte con datos
Pero no solamente es posible construir figuras abstractas o representaciones que imitan las formas de las plantas. Con la ayuda de las herramientas de datos e inteligencia artificial podemos imitar, e incluso, crear nuevas obras. En el siguiente ejemplo, obtenemos versiones simplificadas de fotografías, utilizando subconjuntos de píxeles de la fotografía original. Veamos este ejemplo con más detalle.
Tomamos una fotografía de un banco de imágenes abiertas, en este caso del sitio web Wikimedia Commons, como la siguiente:

By Finetooth - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=11692574
A continuación ejecutamos un algoritmo relativamente sencillo que genera formas poligonales alrededor de los principales píxeles de la imágen original. A parte de un tratamiento sencillo de imágenes para convertir esta fotografía en una imagen plana en blanco y negro, este algoritmo aplica un método matemático denominado diagrama de Voronoid. Cuando el subconjunto de datos (sobre el que aplicamos el diagrama de Voronoid) es pequeño, el resultado del tratamiento es pobre y apenas podemos distinguir la forma subyacente de la figura.

Sin embargo, a medida que vamos aumentando el subconjunto de puntos para reproducir la fotografía inicial, comenzamos a encontrar resultados fascinantes. Finalmente, con menos de un 20% de todos los puntos que componen la imagen original, obtenemos un resultado realmente bello y artístico como el de la siguiente figura. Este experimento está basado en el post original de Antonio Sánchez Chinchón en su blog Fronkostin.

La capacidad de generar arte con la potente combinación de matemáticas y códigos de programación es absolutamente potente. En el siguiente enlace es posible apreciar algunas de las obras más impresionantes que existen en esta modalidad de arte. El autor de este blog es Marcus Volz, investigador de la Universidad de Melburne. Marcus trabaja con R para generar las figuras en dos dimensiones y con Houdini para las obras en 3D y de animación.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿R vs Python? Mejor R y Python: Dos lenguajes, dos estilos. Un objetivo común: domesticar el dato.
Si la ciencia de datos fuera un deporte, R y Python llevan varias temporadas siendo los dos mejores equipos de la liga. Si eres un Data Scientist o estas cerca de esta disciplina científico-técnica, los dos lenguajes de programación que te vienen a la mente de inmediato son R y Python. Sin embargo, lejos de considerarlos lenguajes complementarios, la mayoría de las veces, terminamos comparando virtudes y defectos de ambos lenguajes como si de una competición se tratara. R y Python, son excelentes herramientas por derecho propio, pero a menudo se conciben como rivales. Tan solo basta con escribir la búsqueda R vs Python, en Google para obtener cientos de entradas que intentan decantar la balanza a favor de uno u otro. En buena parte, esto se debe a que las comunidades de ciencia del dato se han empeñado en dividirse en función del lenguaje de programación que usan. Podríamos decir que hay un equipo R y un equipo Python y la historia nos está enseñando que estos dos equipos están destinados a ser rivales eternos. Los hinchas de ambos equipos creen fervientemente que su elección de lenguaje es superior a la otra. Quizás en el fondo estos dos lenguajes no sea tan diferentes, pero parece que las personas que los usan si lo son.
Ambos lenguajes muestran una proyección y crecimiento espectacular en los últimos años, dejando a sus rivales clásicos muy por debajo en la mayoría de los rankings de lenguajes de programación para ciencia de datos.

Crecimiento de R y Python frente a sus competidores en lenguajes de programación para ciencia de datos.
Hay que tener en cuenta además que mientras que Python es un lenguaje de programación de propósito general (con muy buenas aptitudes para la ciencia de datos) R es un lenguaje de programación específico para esta disciplina, creado y diseñado desde su origen con una clara orientación hacia la matemática y la estadística.
Comunidades de R y Python
En España existen diferentes comunidades que agrupan a desarrolladores de uno y otro (mal interpretados) bandos.
R
La comunidad R Hispano congrega buena parte de los eventos relacionados con el mundo de R en nuestro país. La comunidad R Hispano organiza unas jornadas anuales que han ido creciendo en popularidad en los últimos años y en los que se pueden ver las últimas aplicaciones de R a problemas reales de ciencia de datos. Originalmente, fueron unas jornadas muy dirigidas al ámbito académico que poco a poco van dando entrada a aplicaciones procedentes del mundo empresarial y aplicado.
A nivel mundial, la R Foundation, es quien soporta y mantiene el proyecto de desarrollo de código R así como la que promueve el mayor evento mundial alrededor del código R - la conferencia UseR! que en 2019 será celebrada en Toulouse, Francia.
Existen grupos de usuarios de R (cientos en el mundo) en prácticamente todos los países desarrollados y varios de estos en países como EEUU, Canadá o Rusia. En este mapa interactivo se puede explorar la actividad de la comunidad R en todo el mundo. http://rapporter.net/custom/R-activity/
Hace unos años se inició un movimiento interesante en la comunidad de usuarios de R que dio como resultado la creación de unos grupos de usuarios compuestos por mujeres. Los denominados R-Ladies groups han crecido de forma importante poniendo de manifiesto la importancia de las mujeres en la ciencia y en particular en el campo de la ciencia de datos.
Python
De forma predecible, las comunidades de usuarios de R tienen su reflejo en las de Python y viceversa. Empezando por este último, la comunidad de usuarios de Python tiene su propia sub-comunidad PyLadies con el foco puesto en potenciar la presencia de la mujer en el desarrollo con código Python. De la misma forma, hubo un Python Hispano que lamentablemente ya no tiene actividad aunque podemos encontrar la web en el archivo de google. Por su parte, la asociación Python España lleva desde 2013 dando soporte organizativo a la conferencia PyConEs, la conferencia nacional sobre el lenguaje Python, y ayuda financiera a las comunidades locales.
A nivel mundial, de la misma forma que ocurre en R, la Python Software Foundation (PSF) es una organización dedicada al avance de la tecnología de código abierto relacionada con el lenguaje de programación Python. La PSF ofrece soporte a la comunidad de desarrollo de Python a través de los programas de ayudas económicas, el mantenimiento de infraestructuras tecnológicas (como los sitios web donde se aloja la documentación oficial así como los repositorios de librerías) y finalmente, la organización de la PyConUS, la conferencia de desarrollo de Python en Estados Unidos.
En definitiva, las comunidades alrededor del código abierto u open-source forman un modelo de desarrollo de software basado en la colaboración abierta y en la transparencia en los procesos. Estas comunidades garantizan el desarrollo de código abierto de mayor calidad, más confiable, con una mayor flexibilidad y un menor coste al aprovechar el poder colectivo para la generación de código, acabando así con el vendor lock-in de las empresas de software propietario.
Las comunidades de desarrollo de estos lenguajes - estándares de facto en el mundo de la ciencia de datos - tienen mucho que aportar a las comunidades de datos abiertos. Las organizaciones mantenedoras de los repositorios de datos abiertos pueden seguir el camino marcado por las comunidades open-source. Más allá de almacenar y poner a disposición conjuntos de datos abiertos a través de diferentes mecanismos, la potencia de la comunidad reside en los usuarios. El foco ha de ponerse en crear modelos de compromiso (engagement) que atraigan el talento de los desarrolladores y creadores de contenido alentados por el acceso sencillo y rápido a los datos con los que moldear el futuro digital.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En el mundo digital, los datos se convierten en un activo fundamental para las empresas. Gracias a ellos, pueden conocer mejor su entorno, negocio y competencia, y tomar decisiones oportunas en el momento adecuado.
En este contexto, no es de extrañar que cada vez más compañías busquen perfiles profesionales con capacidades digitales avanzadas. Trabajadores que sean capaces de buscar, encontrar, procesar y comunicar historias apasionantes sustentadas en los datos.
El informe "Cómo generar valor a partir de los datos: formatos, técnicas y herramientas para analizar datos abiertos" tiene como objetivo orientar a aquellos profesionales que deseen mejorar las competencias digitales destacadas anteriormente. En él se exploran diferentes técnicas para la extracción y el análisis descriptivo de los datos contenidos en los repositorios de datos abiertos.
El documento se estructura de la siguiente manera:
-
Formatos de datos. Explicación sobre los formatos de datos más habituales que se pueden encontrar en un repositorio de datos abiertos, prestando especial atención al csv y json.
-
Mecanismos de intercambio de datos a través de La Web. Recopilación de ejemplos prácticos que ilustran cómo extraer datos de interés de algunos de los repositorios con más populares de Internet.
-
Principales licencias. Se explican los factores que hay que tener en cuenta al trabajar con distintos tipos de licencias, orientando al lector hacia su identificación y reconocimiento.
-
Herramientas y tecnologías para el análisis de datos. Esta sección se vuelve ligeramente más técnica. En ella, se muestran diferentes ejemplos de extracción de información útil de los repositorios de datos abiertos, haciendo uso de algunos fragmentos cortos de código en diferentes lenguajes de programación.
-
Conclusiones. Se ofrece una visión tecnológica de futuro, con la mirada puesta en los más jóvenes, quienes constituirán la fuerza de trabajo del futuro.
El informe está orientado hacia un público general no especialista, aunque aquellos lectores familiarizados con el tratamiento e intercambio de datos en el mundo web se encontrarán con una lectura familiar y reconocible.
A continuación puedes descargar el texto completo, así como el resumen ejecutivo y una presentación resumen.
Nota: El código publicado pretende ser una guía para el lector, pero puede requerir de dependencias externas o configuraciones específicas para cada usuario que desee ejecutarlo.