Entrevista
Publicar datos abiertos siguiendo las buenas prácticas del linked data (datos enlazados) permite impulsar su reutilización. Datos y metadatos se describen utilizando estándares RDF que permiten representar relaciones entre entidades, propiedades y valores. De esta forma los conjuntos de datos se interconectan entre sí, independientemente del repositorio digital donde se encuentren, lo que facilita su contextualización y explotación.
Si hay un campo donde este tipo de datos son especialmente valorados es el de la investigación. Por ello no es de extrañar que cada vez más universidades empiecen a utilizar esta tecnología. Es el caso de la Universidad de Extremadura (UEX), que cuenta con un portal de investigación que recopila de forma automática la producción científica ligada a la institución. Adolfo Lozano, Director de la Oficina de transparencia y datos abiertos de la Universidad de Extremadura y colaborador en la elaboración de la “Guía práctica para la publicación de datos enlazados en RDF", nos cuenta cómo han puesto en marcha este proyecto.
Entrevista completa:
1. El portal de investigación de la Universidad de Extremadura es una iniciativa pionera en nuestro país. ¿Cómo surgió el proyecto?
El portal de investigación de la Universidad de Extremadura se ha lanzado hace aproximadamente un año, y ha tenido una magnífica acogida entre los investigadores de la UEX y de entidades externas que buscan las líneas de trabajo de nuestros investigadores.
Pero la iniciativa del portal de datos abiertos de la UEX comenzó en 2015, aplicando el conocimiento de nuestro grupo de investigación Quercus de la Universidad de Extremadura sobre representación semántica, y con la experiencia que teníamos en el portal de datos abiertos del Ayuntamiento de Cáceres. El impulso mayor lo ha tenido hace unos 3 años cuando el Vicerrectorado de Transformación Digital creó la Oficina de Transparencia y Datos abiertos de la UEX.
Desde el principio, teníamos claro que queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. Aunque supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos como práctica habitual, podemos decir que a medio plazo los beneficios de organizar así la información nos da un gran potencial para poder extraer y manejar la información para múltiples propósitos.
Queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. [...] supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos.
2. Uno de los primeros pasos en un proyecto de este tipo es seleccionar vocabularios que permitan conceptualizar y establecer relaciones semánticas entre los datos ¿existía un buen punto de partida o fue necesario crear un vocabulario ex-profeso para este contexto? ¿la disponibilidad de vocabularios de referencia constituye un freno para el desarrollo de la interoperabilidad de datos?
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets. Y además es una práctica que continúa conforme que se van incorporando nuevos conjuntos de datos.
En nuestro caso, hemos intentado reutilizar vocabularios lo más extendidos posible como foaf, schema, dublin core y también algunos específicos como vibo o bibo. Pero en muchos casos hemos tenido que definir términos propios en nuestra ontología porque no existían esos componentes. En nuestra opinión, cuando el proyecto Hércules de la CRUE-TIC esté operativo y se hayan definido los esquemas ontológicos genéricos para las universidades, va a mejorar mucho la intereoperabilidad entre nuestros datos, y sobre todo animará a otras universidades a crear sus portales de datos abiertos con estos modelos.
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets.
3. ¿Cómo se abordó el desarrollo de esta iniciativa, qué dificultades os encontrasteis y qué perfiles son necesarios para llevar a cabo un proyecto de este tipo?
En nuestra opinión, si se quiere hacer un portal que sea útil a medio plazo, está claro que se requiere un esfuerzo inicial para organizar la información. Quizás lo más complicado al principio es recopilar los datos que están dispersos en diferentes servicios de la Universidad en múltiples formatos, comprender en qué consisten, buscar la mejor forma de representación, y luego coordinar la forma de poder acceder a ellos de forma periódica para las actualizaciones.
En nuestro caso, hemos desarrollado scripts específicos para distintos formatos de fuentes datos, de diferentes Servicios de la UEX (como el Servicio de Informática, el Servicio de Transferencia, o desde servidores externos de publicaciones) y que los transforman en representación RDF. En este sentido, es imprescindible contar con Ingenieros Informáticos, especializados en representación semántica y con amplios conocimientos de RDF y SPARQL. Pero además, desde luego, se debe involucrar a diferentes servicios de la Universidad para coordinar este mantenimiento de la información.
4. ¿Cómo valora el impacto de la iniciativa? ¿Puede contarnos algunos casos de éxito de reutilización de los conjuntos de datos proporcionados?
Por los logs de consultas, sobre todo al portal de investigación, vemos que muchos investigadores utilizan el portal como punto de recogida de datos que usan para elaborar sus currículums. Además, sabemos que las empresas que necesitan algún desarrollo concreto, utilizan el portal para obtener el perfil de nuestros investigadores.
Pero, por otro lado es habitual que algunos usuarios (de dentro y fuera de la UEX) nos pidan consultas específicas a los datos del portal. Y curiosamente, en muchos casos, son los propios servicios de la Universidad que nos suministran los datos los que nos piden listados o gráficos específicos donde se enlacen y crucen con otros datasets del portal.
Al tener los datos enlazados, un profesor de la UEX está enlazado con la asignatura que imparte, el área de conocimiento, el departamento, el centro, pero también con su grupo de investigación, con cada una de sus publicaciones, los proyectos en los que participa, las patentes, etc. Las publicaciones están enlazadas con revistas y estas a su vez con sus índices de impacto.
Por otro lado, las asignaturas, están enlazadas con las titulaciones donde se imparten, los centros, y disponemos también de los números de matriculados por asignaturas, e índices de calidad y satisfacción de usuarios. De esta forma, se pueden realizar consultas e informes complejos manejando en conjunto toda esta información.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
Otro ejemplo, que hemos terminado este año, ha sido la memoria anual de investigación que se ha generado también automáticamente mediante consultas SPARQL. Estamos hablando de más de 1.500 páginas donde se expone toda la producción científica y de transferencia de la UEX, agrupada por institutos de investigación, grupos, centros y departamentos.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
5. ¿Cuáles son los planes de futuro de la Universidad de Extremadura en materia de datos abiertos?
Queda mucho por hacer. Por ahora estamos abordando en primer lugar aquellos temas que hemos considerado que eran más útiles para la comunidad universitaria, como son la producción científica y de transferencia, y la información académica de la UEX. Pero en el futuro cercano queremos desarrollar conjuntos de datos y aplicaciones relacionados con temas económicos (como contratos públicos, evolución del gastos, mesas de contratación) y administrativos (como el plan de organización docente, organigrama de Servicios, composiciones de órganos de gobierno, etc) para mejorar la transparencia de la institución.
Documentación
A la hora de publicar datos abiertos, es importante hacerlo siguiendo una serie de pautas que faciliten su reutilización, entre ellas, el uso de esquemas comunes, como formatos estándar, ontologías y vocabularios. De esta forma, los conjuntos de datos publicados por distintas organizaciones serán más homogéneos y los usuarios podrán extraer valor más fácilmente.
Una de las familias de formatos más recomendada para la publicación de datos abiertos es el RDF (Resource Description Framework). Se trata de un modelo estándar de intercambio de datos en la web recomendado por el World Wide Web Consortium, y destacado en los principios F.A.I.R. o el esquema de cinco estrellas en la publicación de datos abiertos.
Los RDFs son el fundamento de la web semántica, ya que permiten representar relaciones entre entidades, propiedades y valores, formando grafos. Así se interconectan datos y metadatos de manera automática, generando una red de datos enlazados que facilita su explotación por parte de los reutilizadores. Para ello también es necesario utilizar esquemas de datos consensuados (vocabularios u ontologías), con definiciones comunes que eviten malentendidos o ambigüedades.
Con el fin de promover el uso de este modelo, desde datos.gob.es ponemos a disposición de los usuarios la “Guía práctica para la publicación de datos enlazados”, elaborada con la colaboración del equipo del Ontology Engineering Group, del Departamento de Inteligencia Artificial de la ETSI Informáticos de la Universidad Politécnica de Madrid.
La guía destaca una serie de buenas prácticas, consejos y flujos de trabajo para la creación de conjuntos de datos en RDF a partir de datos tabulares, de una forma eficiente y sostenible en el tiempo.
¿A quién va dirigida la guía?
La guía está dirigida a los responsables de los portales de datos abiertos y a aquellos que preparan los datos para su publicación en dichos portales. No es necesario tener conocimientos previos sobre RDF, vocabularios u ontologías, aunque sí es recomendable una base técnica sobre XML, YAML, SQL y algún lenguaje de programación de scripting, como Python.
¿Qué incluye la guía?
Tras una pequeña introducción, se abordan algunos conceptos teóricos necesarios (tripletas, URIs, vocabularios controlados de dominio, etc.), a la vez que se explica cómo se organiza la información en un RDF o cómo funcionan las estrategias de nombrado.
A continuación, se describen detalladamente los pasos a seguir para transformar un fichero de datos CSV que es el más habitual en los portales de datos abiertos en un conjunto de datos RDF normalizados en base al uso de vocabularios controlados y enriquecido con datos externos que mejoran la información de contexto de los datos de partida. Estos pasos son los siguientes:
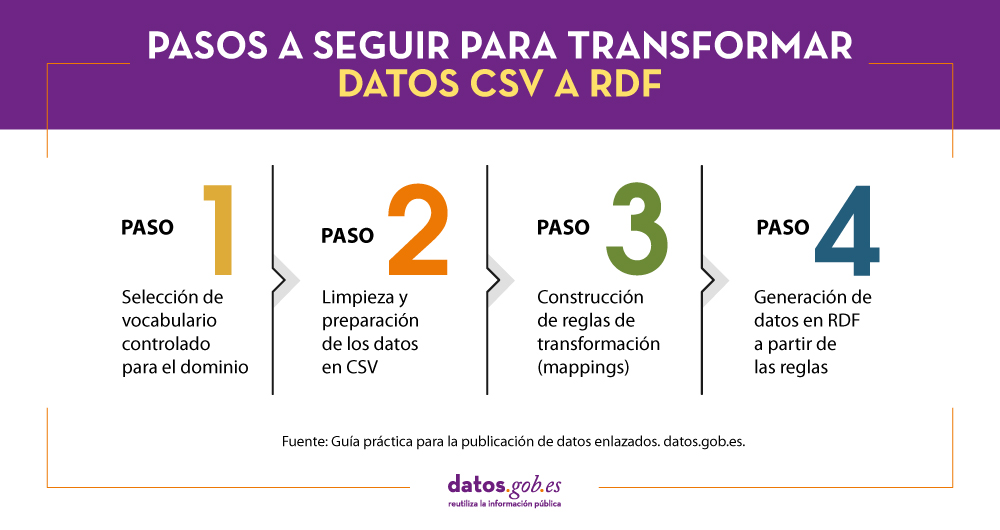
La guía finaliza con una sección orientada a perfiles más técnicos que implementa un ejemplo de uso de los datos en RDF generados utilizando algunas de las librerías de programación y bases de datos para almacenar tripletas más comunes para explotar datos en RDF.
Materiales adicionales
La guía práctica para la publicación de datos enlazados se complementa con una cheatsheet que resumen la información más importante de la guía y una serie de vídeos que ayudan a entender el conjunto de pasos llevados a cabo para la transformación de archivos CSV en RDF. Los vídeos se agrupan en dos series que se relacionan con los pasos explicados en la guía práctica:
1) Serie de vídeos explicativos para la preparación de datos en CSV utilizando OpenRefine. En esta serie se explican los pasos a realizar para preparar un archivo CSV para su posterior transformación en RDF:
- Vídeo 1: Pre-carga de los datos tabulares y creación de un proyecto OpenRefine.
- Vídeo 2: Modificación de valores en las columnas con funciones de transformación.
- Vídeo 3: Generación de valores para las listas controladas o SKOS.
- Vídeo 4: Enlazado de valores con fuentes externas (Wikidata) y descarga del archivo con las nuevas modificaciones.
2) Serie de vídeos explicativos para la construcción de reglas de transformación o mappings CSV a RDF. En esta serie se explican los pasos a realizar para transformar un archivo CSV en RDF mediante la aplicación de reglas de transformación.
- Vídeo 1: Descarga de la plantilla-básica para la creación de las reglas de transformación y creación del esqueleto del documento de reglas de transformación.
- Vídeo 2: Especificación de las referencias para cada propiedad y cómo añadir los valores reconciliados con Wikidata obtenidos a través de OpenRefine.
A continuación puedes descargarte la guía completa, así como la cheatsheet. Para ver los vídeos debes visitar nuestro canal de Youtube.
Noticia
Con gran frecuencia surgen noticias relacionadas con la propiedad intelectual, los derechos de autor y las licencias de las obras que se publican en Internet.
Y es que Internet se ha asociado a un gran espacio abierto, público y donde todo se comparte por todos. Pero esto no es así, y los contenidos en la red de redes también están sujetos a una legalidad y una propiedad intelectual.
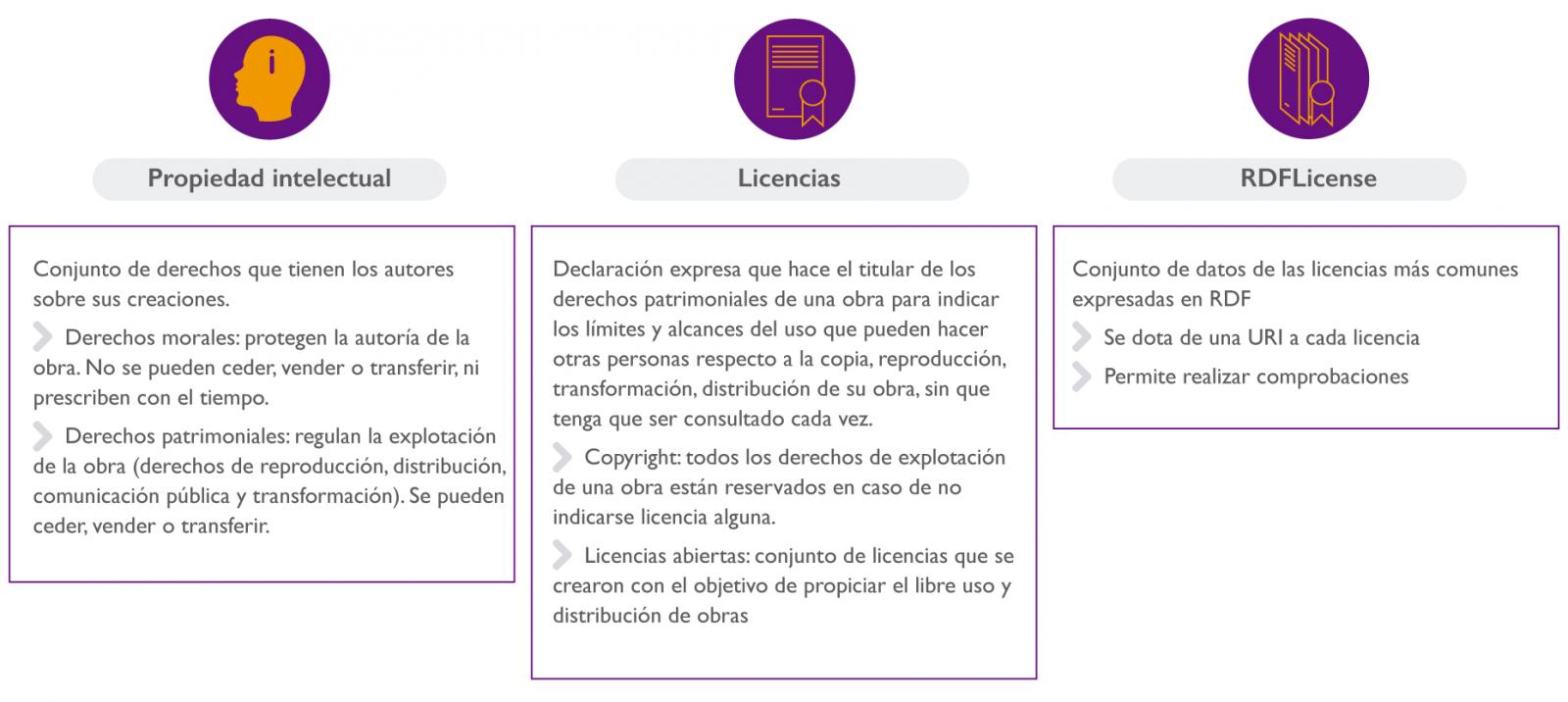
En primer lugar, hay que saber que cuando creas una obra (pintura, escrito, creación musical…), esta tiene una propiedad intelectual, que se podría definir como el conjunto de derechos que tienen los autores sobre sus creaciones.
El conjunto de los derechos de autor se dividen en:
-
Derechos morales: Sirven para proteger la autoría de la obra. Estos derechos no se pueden ceder, vender o transferir, ni prescriben con el tiempo.
-
Derechos patrimoniales: Sirven para regular la explotación de la obra (retribución por uso, reproducción, modificación...). Estos derechos sí se pueden ceder, vender o transferir. El conjunto de derechos de explotación está conformado por los derechos de reproducción, distribución, comunicación pública y transformación.
Por ello, si alguien quisiera usar una obra que he creado, tendría que pedirme permiso para poder hacerlo. Son las licencias las que nos proporcionan los mecanismos para explicitar los permisos que doy otros para el uso de mis obras, sin necesidad de que me pidan permiso cada vez que se quiera hacer uso de ella.
Más detalladamente, una licencia es una declaración expresa que hace el titular de los derechos patrimoniales de una obra para indicar los límites y alcances del uso que pueden hacer otras personas respecto a la copia, reproducción, transformación, distribución de su obra, sin que tenga que ser consultado cada vez.
Dentro del estado español es importante recordar dos cosas:
-
Cuando creas una obra, no es obligatorio registrarla ya que los derechos de autor quedan ligados al mismo con la simple creación de la obra.
-
En caso de no indicarse licencia alguna, por defecto, todos los derechos de explotación de una obra están reservados (copyright).
En contraposición al “todos los derechos reservados”, existen un conjunto de licencias denominadas “licencias abiertas” que se crearon con el objetivo de propiciar el libre uso y distribución de obras, pudiendo exigir que los concesionarios preserven las mismas libertades al distribuir sus copias y derivados.
La elección de una licencia es algo que puede llevar tiempo y que no es trivial. Por ello, existen páginas web que nos ayudan a la hora de escoger la licencia para nuestras obras y datos mediante asistentes, como por ejemplo la web Licentia, creada por el Institut National de Recherche en Informatique et en Automatique (INRIA), un centro de investigación francés especializado en Ciencias de la Computación, teoría de control y matemáticas aplicadas [enlace http://licentia.inria.fr/]
En el caso concreto del Linked Open Data, es conveniente enlazar los datos con sus licencias mediante URIs. Sobre este tema, hay un proyecto denominado RDFLicense [http://rdflicense.appspot.com/] que ha creado un conjunto de datos de las licencias más comunes expresadas en RDF. Con ello, no solo se dota de una URI a cada licencia, sino que además, al utilizar Open Digital Rights Language (ODRL) para describirlas, permite realizar inferencias de conocimiento y comprobaciones.
En conclusión, los datos abiertos necesitan dos cosas: datos y apertura. Y para la apertura de datos es fundamental que estos se encuentren explícitamente bajo una licencia abierta. Si los datos no están bajo una licencia abierta (y está bien explicitada), no son datos abiertos.