Entrevista
Publishing open data following the best practices of linked data allows to boost its reuse. Data and metadata are described using RDF standards that allow representing relationships between entities, properties and values. In this way, datasets are interconnected with each other, regardless of the digital repository where they are located, which facilitates their contextualization and exploitation.
If there is a field where this type of data is especially valued, it is research. It is therefore not surprising that more and more universities are beginning to use this technology. This is the case of the University of Extremadura (UEX), which has a research portal that automatically compiles the scientific production linked to the institution. Adolfo Lozano, Director of the Office of Transparency and Open Data at the University of Extremadura and collaborator in the preparation of the "Practical guide for the publication of linked data in RDF", tells us how this project was launched.
Full interview:
1. The research portal of the University of Extremadura is a pioneering initiative in our country. How did the project come about?
The research portal of the University of Extremadura has been launched about a year ago, and has had a magnificent reception among UEX researchers and external entities looking for the lines of work of our researchers.
But the UEX open data portal initiative started in 2015, applying the knowledge of our research group Quercus of the University of Extremadura on semantic representation, and with the experience we had in the open data portal of the City Council of Cáceres. The biggest boost came about 3 years ago when the Vice-Rectorate for Digital Transformation created the UEX Office of Transparency and Open Data.
From the beginning, we were clear that we wanted a portal with quality data, with the highest level of reusability, and where international standards would be applied. Although it was a considerable effort to publish all the datasets using ontological schemas, always representing the data in RDF, and linking the resources as usual practice, we can say that in the medium term the benefits of organizing the information in this way gives us great potential to extract and manage the information for multiple purposes.
We wanted a portal with quality data, with the highest level of reusability, and where international standards. [...] it was a considerable effort to publish all the datasets using ontological schemas, always representing the data in RDF, and linking the resources.
2. One of the first steps in a project of this type is to select vocabularies, that allow conceptualizing and establishing semantic relationships between data. Did you have a good starting point or did you need to develop a vocabulary ex-profeso for this context? Does the availability of reference vocabularies constitute a brake on the development of data interoperability?
One of the first steps in following ontology schemas in an open data portal is to identify the most appropriate terms to represent the classes, attributes and relationships that will configure the datasets. And it is also a practice that continues as new datasets are incorporated.
In our case, we have tried to reuse the most extended vocabularies as possible such as foaf, schema, dublin core and also some specific ones such as vibo or bibo. But in many cases we have had to define our own terms in our ontology because those components did not exist. In our opinion, when the CRUE-TIC Hercules project would be operational and the generic ontology schemas for universities would be defined, it will greatly improve the interoperability between our data, and above all it will encourage other universities to create their open data portals with these models.
One of the first steps in following ontology schemas in an open data portal is to identify the most appropriate terms to represent the classes, attributes and relationships that will configure the datasets.
3. How did you approach the development of this initiative, what difficulties did you encounter and what profiles are necessary to carry out a project of this type?
In our opinion, if you want to make a portal that is useful in the medium term, it is clear that an initial effort is required to organize the information. Perhaps the most complicated thing at the beginning is to collect the data that are scattered in different services of the University in multiple formats, understand what they consist of, find the best way to represent them, and then coordinate how to access them periodically for updates.
In our case, we have developed specific scripts for different data source formats, from different UEX Services (such as the IT Service, the Transfer Service, or from external publication servers) and that transform them into RDF representation. In this sense, it is essential to have Computer Engineers specialized in semantic representation and with extensive knowledge of RDF and SPARQL. In addition, of course, different services of the University must be involved to coordinate this information maintenance.
4. How do you assess the impact of the initiative? Can you tell us with some success stories of reuse of the provided datasets?
From the logs of queries, especially to the research portal, we see that many researchers use the portal as a data collection point that they use to prepare their resumes. In addition, we know that companies that need some specific development, use the portal to obtain the profile of our researchers.
But, on the other hand, it is common that some users (inside and outside the UEX) ask us for specific queries to the portal data. And curiously, in many cases, it is the University's own services that provide us with the data that ask us for specific lists or graphs where they are linked and crossed with other datasets of the portal.
By having the data linked, a UEX professor is linked to the subject he/she teaches, the area of knowledge, the department, the center, but also to his/her research group, to each of his/her publications, the projects in which he/she participates, the patents, etc. The publications are linked to journals and these in turn with their impact indexes.
On the other hand, the subjects are linked to the degrees where they are taught, the centers, and we also have the number of students enrolled in each subject, and quality and user satisfaction indexes. In this way, complex queries and reports can be made by handling all this information together.
As use cases, for example, we can mention that the Word documents of the 140 quality commissions of the degrees are automatically generated (including annual evolution graphs and lists) by means of queries to the opendata portal. This has saved dozens of hours of joint work for the members of these commissions.
Another example, which we have completed this year, is the annual research report, which has also been generated automatically through SPARQL queries. We are talking about more than 1,500 pages where all the scientific production and transfer of the UEX is exposed, grouped by research institutes, groups, centers and departments.
As use cases, for example, we can mention that the Word documents of the 140 quality commissions of the degrees are automatically generated (including annual evolution graphs and lists) by means of queries to the opendata portal. This has saved dozens of hours of joint work for the members of these commissions.
5. What are the future plans of the University of Extremadura in terms of open data?
Much remains to be done. For now we are addressing first of all those topics that we have considered to be most useful for the university community, such as scientific production and transfer, and academic information of the UEX. But in the near future we want to develop datasets and applications related to economic issues (such as public contracts, evolution of expenditure, hiring tables) and administrative issues (such as the teaching organization plan, organization chart of Services, compositions of governing bodies, etc.) to improve the transparency of the institution.
Documentación
It is important to publish open data following a series of guidelines that facilitate its reuse, including the use of common schemas, such as standard formats, ontologies and vocabularies. In this way, datasets published by different organizations will be more homogeneous and users will be able to extract value more easily.
One of the most recommended families of formats for publishing open data is RDF (Resource Description Framework). It is a standard web data interchange model recommended by the World Wide Web Consortium, and highlighted in the F.A.I.R. principles or the five-star schema for open data publishing.
RDFs are the foundation of the semantic web, as they allow representing relationships between entities, properties and values, forming graphs. In this way, data and metadata are automatically interconnected, generating a network of linked data that facilitates their exploitation by reusers. This also requires the use of agreed data schemas (vocabularies or ontologies), with common definitions to avoid misunderstandings or ambiguities.
In order to promote the use of this model, from datos.gob.es we provide users with the "Practical guide for the publication of linked data", prepared in collaboration with the Ontology Engineering Group team - Artificial Intelligence Department, ETSI Informáticos, Polytechnic University of Madrid-.
The guide highlights a series of best practices, tips and workflows for the creation of RDF datasets from tabular data, in an efficient and sustainable way over time.
Who is the guide aimed at?
The guide is aimed at those responsible for open data portals and those preparing data for publication on such portals. No prior knowledge of RDF, vocabularies or ontologies is required, although a technical background in XML, YAML, SQL and a scripting language such as Python is recommended.
What does the guide include?
After a short introduction, some necessary theoretical concepts (triples, URIs, controlled vocabularies by domain, etc.) are addressed, while explaining how information is organized in an RDF or how naming strategies work.
Next, the steps to be followed to transform a CSV data file, which is the most common in open data portals, into a normalized RDF dataset based on the use of controlled vocabularies and enriched with external data that enhance the context information of the starting data are described in detail. These steps are as follows:

The guide ends with a section oriented to more technical profiles that implements an example of the use of RDF data generated using some of the most common programming libraries and databases for storing triples to exploit RDF data.
Additional materials
The practical guide for publishing linked data is complemented by a cheatsheet that summarizes the most important information in the guide and a series of videos that help to understand the set of steps carried out for the transformation of CSV files into RDF. The videos are grouped in two series that relate to the steps explained in the practical guide:
1) Series of explanatory videos for the preparation of CSV data using OpenRefine. This series explains the steps to be taken to prepare a CSV file for its subsequent transformation into RDF:
- Video 1: Pre-loading tabular data and creating an OpenRefine project.
- Video 2: Modifying column values with transformation functions.
- Video 3: Generating values for controlled lists or SKOS.
- Video 4: Linking values with external sources (Wikidata) and downloading the file with the new modifications.
2) Series of explanatory videos for the construction of transformation rules or CSV to RDF mappings. This series explains the steps to be taken to transform a CSV file into RDF by applying transformation rules.
- Video 1: Downloading the basic template for the creation of transformation rules and creating the skeleton of the transformation rules document.
- Video 2: Specifying the references for each property and how to add the Wikidata reconciled values obtained through OpenRefine.
Below you can download the complete guide, as well as the cheatsheet. To watch the videos you must visit our Youtube channel.
Noticia
Usually news related to intellectual property, copyright and licenses for works published on the Internet arise.
Internet has been associated with a large open and public space, where everything is shared by all. But this is not the case, and contents on the web also subject to legality and intellectual property.
Firstly, we must know that when you create a work (painting, writing...), it has an intellectual property, which could be defined as the set of rights that authors have over their creations.
The set of copyrights are divided into:
- Moral rights: They serve to protect the authorship of the work. These rights can not be assigned, sold or transferred, nor do they prescribe over time.
- Patrimonial rights: They serve to regulate the exploitation of the work (retribution for use, reproduction, modification ...). These rights can be assigned, sold or transferred. The set of exploitation rights is made up of the rights of reproduction, distribution, public communication and transformation.
Therefore, if someone wants to use a work that I have created, he would have to ask for permission to do so. Licenses provide us with the mechanisms to make explicit the permissions that I give others for the use of my works, without needing to ask for permission whenever I want to use it.
In more detail, a license is an express declaration made by the owner of the economic rights of a work to indicate the limits and scope of the use that other people can make with respect to the copying, reproduction, transformation, distribution of their work, without having to be consulted each time.
Within the Spanish state it is important to take into account two aspects:
- When you create a piece of work, it is not mandatory to register it since the author's rights are linked to it with the simple creation of the work.
- If no license is indicated, by default, all exploitation rights of a work are reserved (copyright).
In contrast to the "all rights reserved", there is a set of licenses called "open licenses" that were created with the goal of promoting the free use and distribution of works, being able to demand that the concessionaires preserve the same freedoms when distributing their copies and derivatives.
The choice of a license is something that can take time, being not a trivial aspect. Therefore, there are web pages that help us when choosing the license for our works and data through attendees, such as the Licentia website, created by the Institut National de Recherche en Informatique et en Automatique (INRIA), a French research center specialized in Computer Science, control theory and applied mathematics [link http://licentia.inria.fr/]
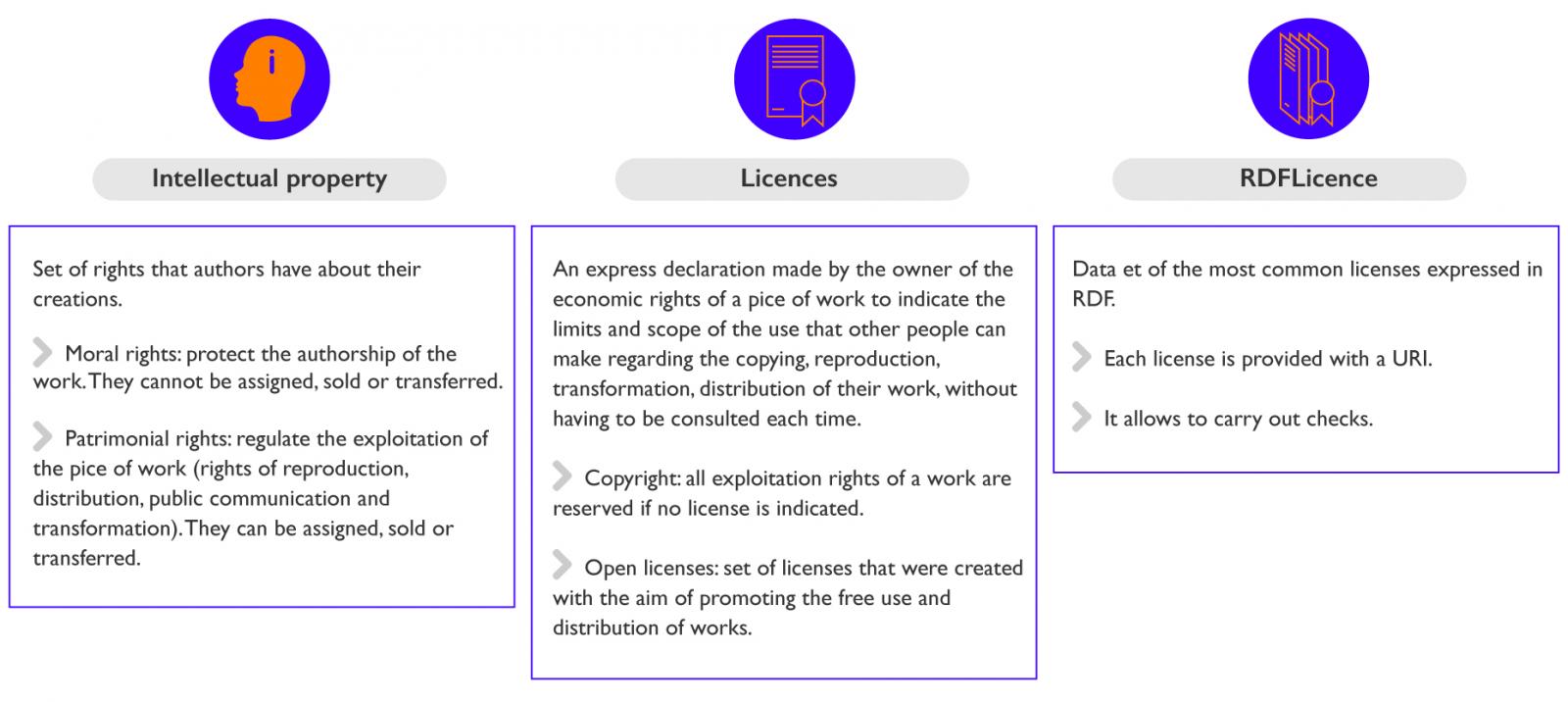
In the specific case of Linked Open Data, it is convenient to link the data with their licenses through URIs. On this topic, there is a project called RDFLicense [http://rdflicense.appspot.com/] that has created a data set of the most common licenses expressed in RDF. Thanks to this, not only each URI is provided with a URI, but also, when using Open Digital Rights Language (ODRL) to describe them, it allows to make knowledge inferences and verifications.
In conclusion, open data needs two things: data and openness. And for the data openess it is essential that they are explicitly under an open license. If the data is not under an open license, it is not open data.