Publication date
30/06/2021
Update date
20/06/2024

Description
The Hercules initiative was launched in November 2017, through an agreement between the University of Murcia and the Ministry of Economy, Industry and Competitiveness, with the aim of developing a Research Management System (RMS) based on semantic open data that offers a global view of the research data of the Spanish University System (SUE), to improve management, analysis and possible synergies between universities and the general public.
This initiative is complementary to UniversiDATA, where several Spanish universities collaborate to promote open data in the higher education sector by publishing datasets through standardised and common criteria. Specifically, a Common Core is defined with 42 dataset specifications, of which 12 have been published for version 1.0. Hercules, on the other hand, is a research-specific initiative, structured around three pillars:
- Innovative SGI prototype
- Unified knowledge graph (ASIO) 1],
- Data Enrichment and Semantic Analysis (EDMA)
The ultimate goal is the publication of a unified knowledge graph integrating all research data that participating universities wish to make public. Hercules foresees the integration of universities at different levels, depending on their willingness to replace their RMS with the Hercules RMS. In the case of external RMSs, the degree of accessibility they offer will also have an impact on the volume of data they can share through the unified network.
General organisation chart of the Hercule initiative
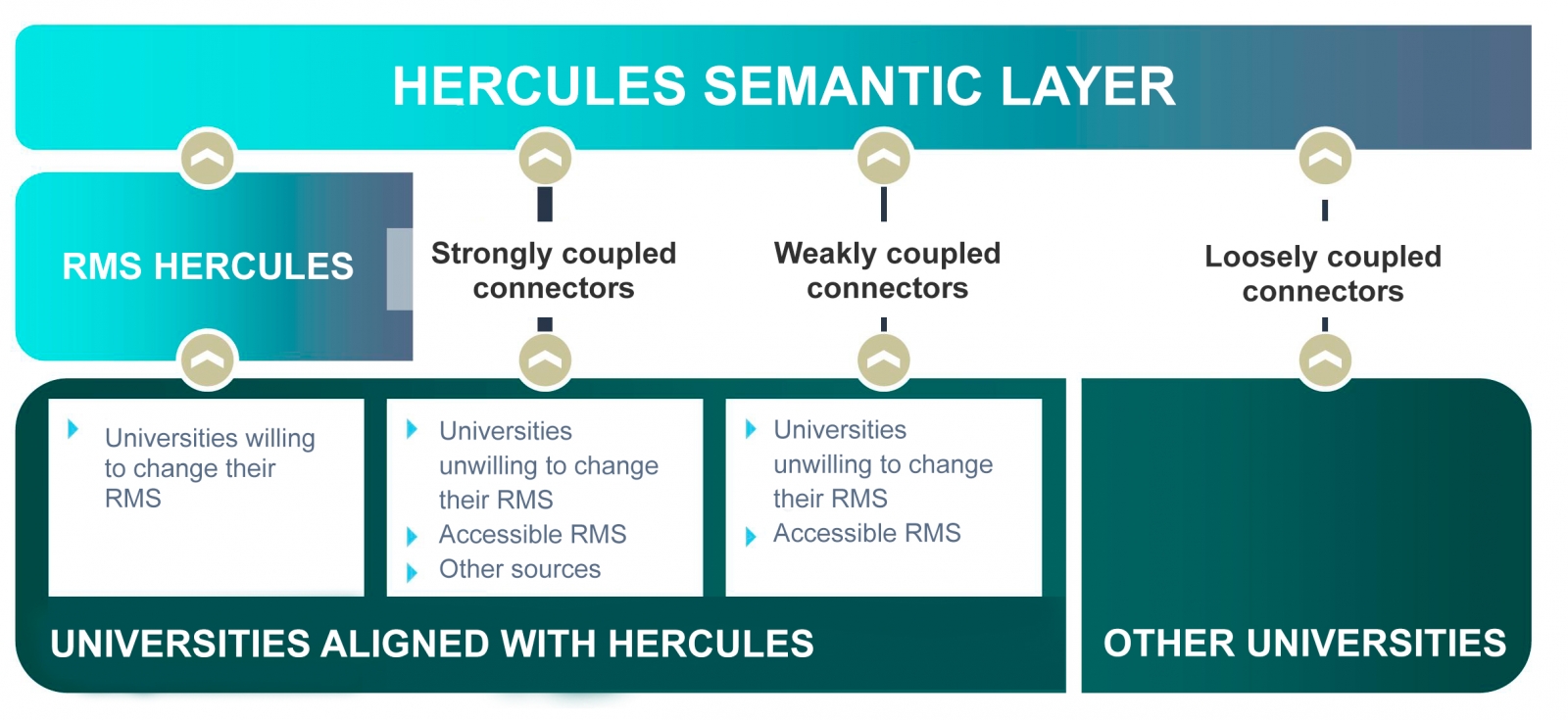
Within the Hercules initiative, the ASIO Project (Semantic Architecture and Ontology Infrastructure) is integrated. The purpose of this sub-project is to define an Ontology Network for Research Management (Ontology Infrastructure). An ontology is a formal definition that describes with fidelity and high granularity a particular domain of discussion. In this case, the research domain, which can be extrapolated to other Spanish and international universities (at the moment the pilot is being developed with the University of Murcia). In other words, the aim is to create a common data vocabulary.
Additionally, through the Semantic Data Architecture module, an efficient platform has been developed to store, manage and publish SUE research data, based on ontologies, with the capacity to synchronise instances installed in different universities, as well as the execution of distributed federated queries on key aspects of scientific production, lines of research, search for synergies, etc.
As a solution to this innovation challenge, two complementary lines have been proposed, one centralised (synchronisation in writing) and the other decentralised (synchronisation in consultation). The architecture of the decentralised solution is explained in detail in the following sections.
Domain Driven Design
The data model follows the Domain Driven Design approach, modelling common entities and vocabulary, which can be understood by both developers and domain experts. This model is independent of the database, the user interface and the development environment, resulting in a clean software architecture that can adapt to changes in the model.
This is achieved by using Shape Expressions (ShEx), a language for validating and describing RDF datasets, with human-readable syntax. From these expressions, the domain model is automatically generated and allows orchestrating a continuous integration (CI) process, as described in the following figure.
Continuous integration process using Domain Driven Design (just available in Spanish)
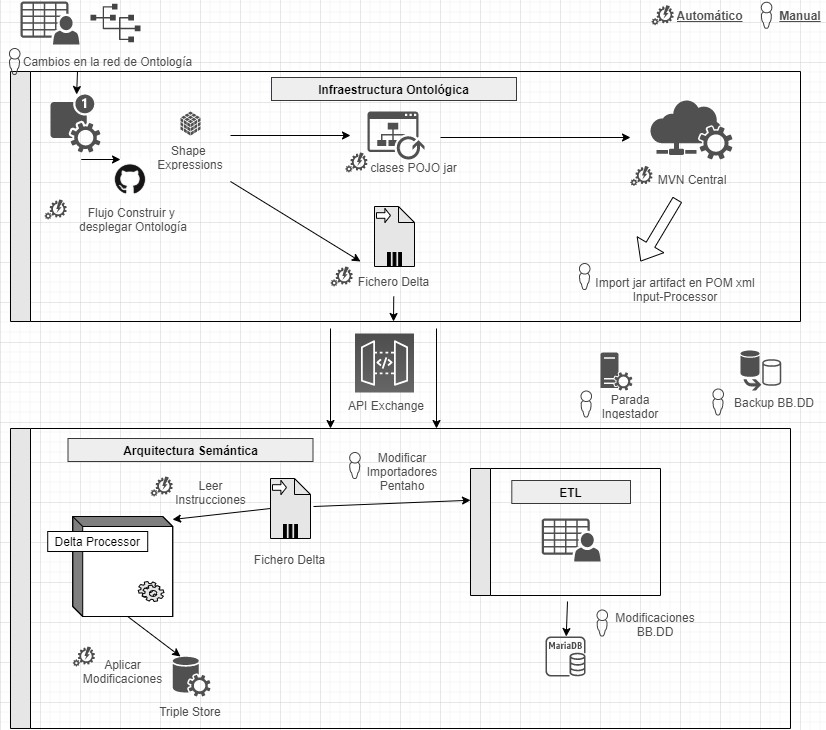
By means of a system based on version control as a central element, it offers the possibility for domain experts to build and visualise multilingual ontologies. These in turn rely on ontologies both from the research domain: VIVO, EuroCRIS/CERIF or Research Object, as well as general purpose ontologies for metadata tagging: Prov-O, DCAT, etc.
Linked Data Platform
The linked data server is the core of the architecture, in charge of rendering information about all entities. It does this by collecting HTTP requests from the outside and redirecting them to the corresponding services, applying content negotiation, which provides the best representation of a resource based on browser preferences for different media types, languages, characters and encoding.
All resources are published following a custom-designed persistent URI scheme. Each entity represented by a URI (researcher, project, university, etc.) has a series of actions to consult and update its data, following the patterns proposed by the Linked Data Platform (LDP) and the 5-star model.
This system also ensures compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) principles and automatically publishes the results of applying these metrics to the data repository.
Open data publication
The data processing system is responsible for the conversion, integration and validation of third-party data, as well as the detection of duplicates, equivalences and relationships between entities. The data comes from various sources, mainly the Hercules unified RMS, but also from alternative RMSs, or from other sources offering data in FECYT/CVN (Standardised Curriculum Vitae), EuroCRIS/CERIF and other possible formats.
The import system converts all these sources to RDF format and registers them in a specific purpose repository for linked data, called Triple Store, because of its capacity to store subject-predicate-object triples.
Once imported, they are organised into a knowledge graph, easily accessible, allowing advanced searches and inferences to be made, enhanced by the relationships between concepts.
Example of a knowledge network describing the ASIO project
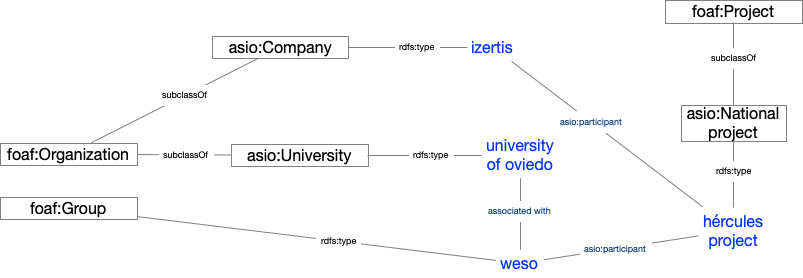
Results and conclusions
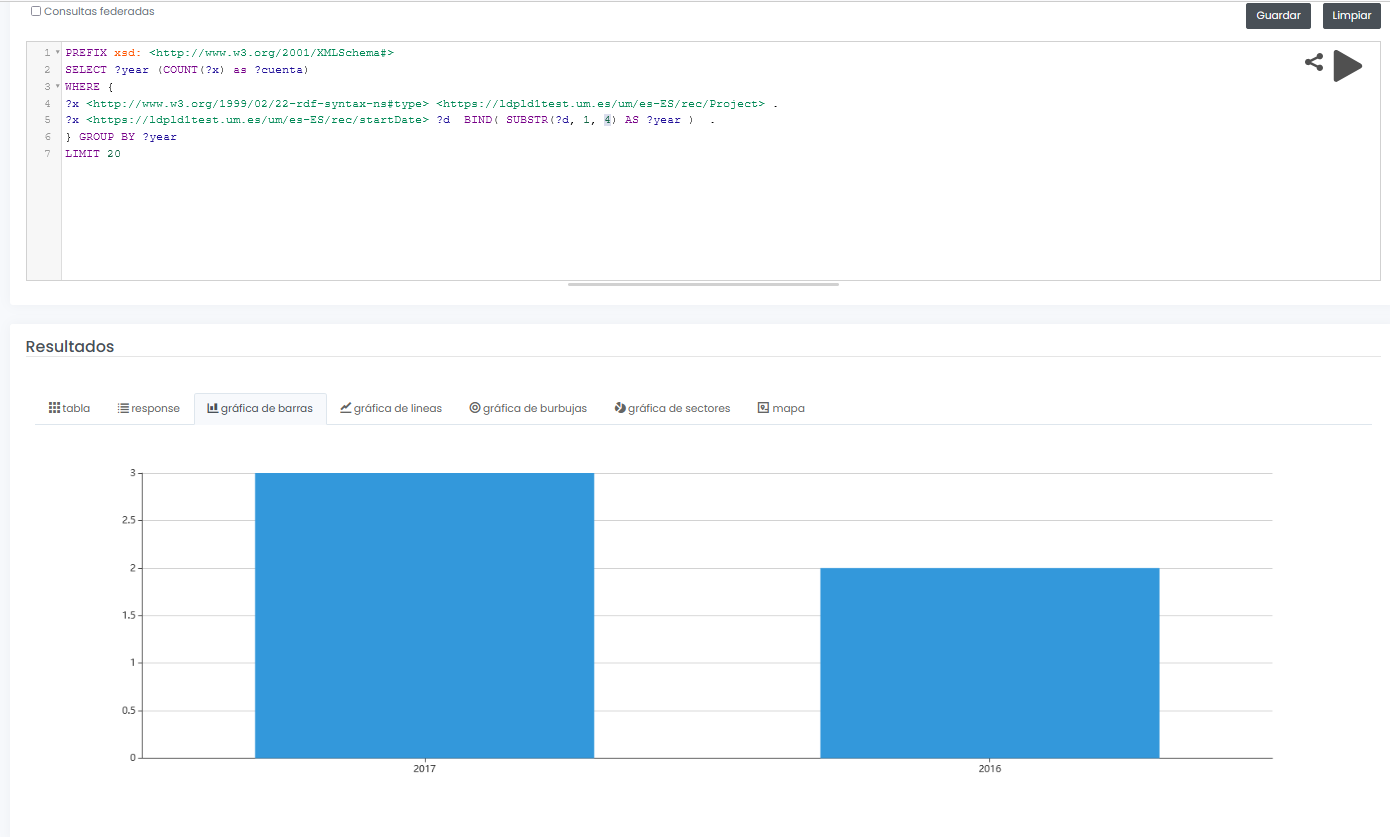
The final system not only allows to offer a graphical interface for interactive and visual querying of research data, but also to design SPARQL queries, such as the one shown below, even with the possibility to run the query in a federated way on all nodes of the Hercules network, and to display results dynamically in different types of graphs and maps.
In this example, a query is shown (with limited test data) of all available research projects grouped graphically by year:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
In short, ASIO offers a common framework for publishing linked open data, offered as open source and easily adaptable to other domains. For such adaptation, it would be enough to design a specific domain model, including the ontology and the import and validation processes discussed in this article.
Currently the project, in its two variants (centralised and decentralised), is in the process of being put into pre-production within the infrastructure of the University of Murcia, and will soon be publicly accessible.
[1 Graphs are a form of knowledge representation that allow concepts to be related through the integration of data sets, using semantic web techniques. In this way, the context of the data can be better understood, which facilitates the discovery of new knowledge.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Comments