Blog
Los datos han ocupado un lugar fundamental en los últimos años en nuestra sociedad. Las nuevas tecnologías han permitido una globalización basada en el dato en la que todo lo que ocurre en el mundo está interconectado. Mediante sencillas técnicas es posible extraer de ellos un valor que resultaba inimaginable hace tan sólo algunos años. Sin embargo, para poder hacer un uso correcto de los datos, es necesario disponer de una buena documentación, a través de un diccionario de datos.
¿Qué es un diccionario de datos?
Es frecuente que cuando hablamos de diccionario de datos su significado se confunda con el de glosario de negocio o con el de vocabulario de datos, sin embargo, son conceptos distintos.
Mientras que un glosario de negocio, o vocabulario de datos, trata de dar significado funcional a los indicadores o conceptos que se manejan de forma que se garantice que se hable el mismo lenguaje, abstrayéndose del mundo técnico, tal y como se explica en este artículo, un diccionario de datos trata de documentar los metadatos más ligados a su almacenamiento en la base de datos. Es decir, incluye aspectos técnicos como el tipo de dato, formato, longitud, posibles valores que puede tomar e, incluso, transformaciones sufridas, sin olvidar la definición de cada campo. La documentación de estas transformaciones nos proporcionará automáticamente el linaje del dato, entendido como la trazabilidad a lo largo de su ciclo de vida. Estos metadatos ayudan a los usuarios a entender los datos desde el punto de vista técnico para poder explotarlos adecuadamente. Por este motivo, cada base de datos debería contar con su diccionario de datos asociado.
Para la cumplimentación de los metadatos solicitados en un diccionario de datos, existen guías y plantillas prediseñadas como el siguiente ejemplo proporcionado por el Departamento de Agricultura de los EEUU.
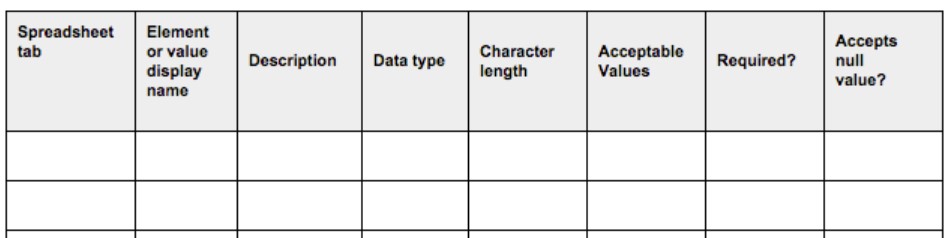
Además, para poder estandarizar su contenido, es frecuente el uso de taxonomías y vocabularios controlados para codificar los valores de acuerdo a listados de códigos.
Por último, un catálogo de datos, actúa como directorio para localizar la información y ponerla a disposición de los usuarios, proporcionando a todos los usuarios un único punto de referencia para el acceso a los mismos. Esto es posible gracias a los puentes trazados entre los términos funcionales y técnicos, a través del linaje.
Aplicabilidad en datos abiertos
Cuando hablamos de datos abiertos, los diccionarios de datos adquieren mayor importancia si cabe, ya que, al ponerse a disposición de terceros, su alcance de usabilidad es mucho mayor.
Cada conjunto de datos debería publicarse junto a su diccionario de datos que describa el contenido de cada columna. Por eso, cuando se publique un conjunto de datos abiertos, se debería publicar también una URL al documento que contenga su diccionario de datos, independientemente de su formato. En los casos que se requiera más de un Diccionario de Datos, debido a la variedad de las fuentes origen, deberá añadirse tantos como sean necesarios, generalmente uno por base de datos o tabla.
No obstante, desgraciadamente, es fácil encontrar conjuntos de datos extraídos directamente desde sistemas de información sin una adecuada preparación y sin un diccionario de datos asociado facilitado por los publicadores. Esto puede deberse a diversos factores, como el desconocimiento de este tipo de herramienta que facilita la documentación, el no saber con certeza cómo crear un diccionario, o simplemente, dar por hecho que el usuario conoce el contenido de los campos.
Sin embargo, las consecuencias de publicar datos sin documentarlos correctamente pueden provocar que el usuario vea datos referidos a siglas o nombres técnicos ilegibles, imposibilitando su tratamiento o, incluso, un uso inadecuado de los mismos debido a la ambigüedad y a la malinterpretación de los contenidos.
Para facilitar la creación de este tipo de documentación existen estándares y recomendaciones técnicas de algunos organismos. Por ejemplo, el World Wide Web Consortium (W3C), organismo que desarrolla los estándares que aseguren el crecimiento de la world wide web en el largo plazo, ha emitido un modelo en el que recomienda cómo publicar datos tabulares como CSV y metadatos en la web.
Interpretar los datos que se publican
Un ejemplo de una buena publicación de datos lo encontramos en este conjunto de datos publicado por el Instituto Nacional de Estadística (INE) y disponible en datos.gob.es, donde se indica “el número de personas entre 18 y 64 años de edad según idiomas maternos y no maternos más frecuentes que pueden usar, por características de los progenitores”. Para su interpretación, el INE aporta todos los detalles necesarios para su entendimiento en una URL, como las unidades de medida, las fuentes, periodo de validez, alcance y la metodología que sigue para la confección de estas encuestas. Además, proporciona nombres funcionales auto explicativos a cada columna para asegurar el entendimiento de su significado por parte de cualquier usuario ajeno al INE. Todo ello, permite al usuario conocer con certeza la información que descarga para su consumo, evitando malentendidos. Esta información se comparte en el apartado de “recursos relacionados”, pensado para este propósito. Se trata de un metadato que describe la propiedad dct:references.
Aunque este ejemplo pueda parecernos lógico, no es raro encontrar casos en el lado opuesto. A modo ilustrativo, se muestra un ejemplo ficticio de conjunto de datos de la siguiente forma:

En este caso, un usuario que desconozca la base de datos, no sabrá interpretar correctamente el significado de los campos “TPCHE”, “YFAB”, “NUMC” … Sin embargo, si esta tabla viene asociada con un diccionario de datos, podremos relacionar el metadato con el conjunto, tal y como se muestra en la siguiente imagen:

En este caso, se ha optado por la publicación del diccionario de datos mediante un documento de texto que describe los campos, aunque existen multitud de formas de publicar los diccionarios. Puede realizarse siguiendo recomendaciones y estándares, como la antes mencionada por el W3C, mediante archivos de texto, como en este caso, o incluso, mediante plantillas de Excel customizadas por el propio publicador. No existe una forma mejor que otra por regla general, sino que debe adaptarse a la naturaleza y complejidad del conjunto de datos con el objetivo de asegurar su comprensión, planificando el nivel de detalle necesario en función del objetivo final, la audiencia receptora de los datos y las necesidades de los consumidores, tal y como se explica en este post.
Los datos abiertos nacen con el objetivo de facilitar la reutilización de la información para todo el mundo, pero para que dicho acceso sea realmente útil, no puede limitarse únicamente a la publicación de conjuntos de datos en bruto, sino que deben estar claramente documentados para un correcto tratamiento. La elaboración de diccionarios de datos que incluyan los detalles técnicos de los conjuntos de datos que se publican, es fundamental para la correcta reutilización de los mismos y la extracción de valor a partir de ellos.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Cada individuo, organización o colectivo usa en su comunicación diaria un número de palabras habituales, que serían sus vocabularios personales. Cuanto mayor sea el número de vocablos que utilicemos, mayor será nuestra capacidad para comunicarnos, pero también puede suponer una barrera, al aumentar la dificultad para entendernos con otras personas que no estén familiarizadas con los mismos términos que nosotros. Esto mismo sucede en el mundo de los datos.
Para evitar equívocos, debemos utilizar un vocabulario controlado, que no es más que una lista definida de términos para organizar, categorizar o etiquetar sistemáticamente la información.
¿Qué es un vocabulario de datos?
Para una correcta implementación de una iniciativa de gobierno de datos, ya sean privados o públicos, debemos dotar al proceso de un business Glosary o vocabulario de referencia. Un vocabulario de referencia es un medio para poder compartir información y desarrollar y documentar definiciones de datos estándar, para reducir la ambigüedad y mejorar la comunicación. Estas definiciones deben ser claras, rigurosas en su redacción y explicar cualquier excepción, sinónimo o variante. Un ejemplo claro es EuroVoc, que cubre las actividades de la Unión Europea y, en particular, del Parlamento Europeo. Otro ejemplo es CIE10 que es el Manual de codificación de diagnósticos y procedimientos en el ámbito sanitario.
Los objetivos que persigue un vocabulario controlado son los siguientes:
- Permitir la comprensión común de los conceptos claves y de terminología, de forma precisa.
- Reducir el riesgo de que los datos sean mal utilizados debido a una comprensión inconsistente de los conceptos.
- Maximizar la capacidad de búsqueda, facilitando el acceso al conocimiento documentado.
- Impulsa la interoperabilidad y la reutilización de los datos, algo fundamental en el mundo del open data.
Los vocabularios varían en la complejidad de su desarrollo, desde listas simples o listas de selección, hasta anillos de sinónimos, taxonomías o los más complejos, tesauros y ontologías.
¿Cómo se crea un vocabulario?
A la hora de crear un vocabulario no se suele partir de cero, sino que se basa en ontologías y vocabularios preexistentes, lo que favorece la comunicación entre personas, agentes inteligentes y sistemas. Por ejemplo, Aragón Open Data ha desarrollado una ontologia llamada Estructura de Información Interoperable de Aragón EI2A que homogeniza estructuras, vocabularios y características, a través de la representación de entidades, propiedades y relaciones, para luchar contra la diversidad y heterogeneidad de datos existentes en la Administración aragonesa (datos de entidades locales que no siempre significan lo mismo). Para ello, se basa en propuestas como RDF Schema (un vocabulario general para el modelado de esquemas en RDF que se utiliza en la creación de otros Vocabularios), ISA Programme Person Core Vocabulary (destinado a describir personas) o OWL-Time (que describe conceptos temporales).
Un vocabulario debe ir acompañado de un diccionario de datos, que es donde se describen los datos en términos de negocio e incluye otras informaciones necesarias para usar los datos, como por ejemplo, detalles de su estructura o las restricciones de seguridad. Debido a que los vocabularios evolucionan con el tiempo, requieren un mantenimiento evolutivo. Como ejemplo, ANSI/NIZO Z39.19-2005 es un estándar que proporciona pautas para la construcción, formato y gestión de vocabularios controlados. También encontramos SKOS, una iniciativa de W3C que proporciona un modelo para representar la estructura básica y el contenido de esquemas conceptuales en cualquier tipo de vocabulario controlado.
Ejemplos de Vocabularios en ámbitos concretos creados en España
En el contexto español, con una estructura administrativa fragmentada, donde cada organismo comparte su información en abierto de manera individual, es necesario contar con reglas comunes que nos permitan homogeneizar los datos, facilitando su interoperabilidad y reutilización. Por suerte, encontramos distintas propuestas que nos ayudan en estas tareas.
A continuación, se recogen ejemplo de vocabularios creados en nuestro país para 2 sectores fundamentales para el futuro de la sociedad, como son la educación y las ciudades inteligentes.
Smart cities
Un ejemplo sobre la construcción de vocabularios de un dominio específico lo podemos encontrar en ciudades-abiertas.es, que es una iniciativa de varios ayuntamientos de España (A Coruña, Madrid, Santiago de Compostela y Zaragoza) y Red.es.
Entre otras acciones, dentro del marco del proyecto, se está trabajando en el desarrollo de un catálogo de vocabularios bien definidos y documentados, con ejemplos de utilización y disponibles en varios lenguajes de representación. En concreto, se están desarrollando 11 vocabularios correspondientes a una serie de conjuntos de datos seleccionados por los Ayuntamientos que no cuentan con un estándar definido. Un ejemplo de estos vocabularios es la Agenda municipal.
Estos vocabularios son generados utilizando el lenguaje estándar OWL, que es el acrónimo del inglés Web Ontology Language, un lenguaje de marcado para publicar y compartir datos usando ontologías en la Web. También se dispone de los correspondientes contextos para JSON-LD, N-triples, TTL y RDF/XML. En este video explicativo podemos ver como se definen estos vocabularios. Los vocabularios generados están disponibles en el repositorio de Github.
Educación
En el ámbito de las universidades, por su parte, encontramos la propuesta de contenidos de datos abiertos para universidades desarrollada por la comunidad UniversiDATA: Núcleo Común. En la versión 1.0 se ha identificado 42 datasets que toda Universidad debería publicar, como es el caso de la información relativa a Titulaciones, Matriculas o Licitaciones y contratos. De momento hay 11 disponibles, mientras que el resto se encuentran en proceso de elaboración.
Por ejemplo la UAM (Autónoma de Madrid), la URJC (Rey Juan Carlos) y la UCM (Complutense de Madrid), han publicado sus titulaciones siguiendo un mismo vocabulario.
Aunque se ha avanzado mucho en la creación y aplicación de vocabularios de datos en general, todavía queda terreno para avanzar en el campo de la investigación sobre vocabularios controlados para la publicación y consulta de datos en la Web, por ejemplo, en la construcción de Business Glosaries vinculados a los diccionarios de datos técnicos. La aplicación de buenas prácticas y la creación de vocabularios para la representación de metadatos que describan el contenido, la estructura, procedencia, calidad y uso de conjuntos de datos permitirá definir con mayor precisión las características que deben incorporar las plataformas de publicación de datos en la Web.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Una de las principales barreras para el despliegue de los datos enlazados (Linked Data) es la dificultad que tienen los editores de datos para determinar qué vocabularios usar para describir la semántica de los mismos. Estos vocabularios proporcionan el “pegamento semántico” (semantic glue) que permite que unos simples datos se conviertan en “datos con significado” (meaningful data).
Linked Open Vocabularies (LOV) es un catálogo de vocabularios disponibles para reutilizar con el objetivo de describir de datos en la Web. LOV recopila metadatos y visibiliza indicadores como la conexión entre diferentes vocabularios, el historial de versiones, las políticas de mantenimiento, junto con referencias pasadas y actuales (tanto a individuos como a organizaciones). El nombre de esta iniciativa (Linked Open Vocabularies - LOV) tiene su raíz en el término Linked Open Data - LOD.

El objetivo principal de LOV es ayudar a los editores de datos enlazados (Linked Data) y vocabularios a evaluar los recursos (vocabularios, clases, propiedades y agentes) ya disponibles y promover así la mayor reutilización posible, además de proporcionar una vía para que los editores añadan sus propias creaciones.
LOV comenzó en el año 2011 bajo el proyecto de investigación Datalift y albergado por Open Knowledge International (anteriormente conocida como Open Knowledge Foundation). Actualmente la iniciativa cuenta con el apoyo de un pequeño equipo de conservadores/revisores de datos y programadores.
Para facilitar la reutilización de los vocabularios bien documentados (con metadatos), se proporcionan varias formas de acceder a los datos:
-
Mediante un interfaz de usuario, con un entorno de navegación y búsquedas (la propia página web).
-
Mediante un SPARQL endpoint para realizar consultas al grafo de conocimiento.
-
Mediante un API REST.
-
Mediante un volcado de los datos, tanto de la base de conocimiento de LOV (en formato Notation3), como de la base de conocimiento más los propios vocabularios (en formato N-Quads).
Actualmente, el registro identifica y enumera:
-
621 vocabularios (vocabularios RDF -RDFS/OWL- definidos como esquemas (T-Box) para la descripción de Linked Data)
-
cerca de 60.000 términos (entre clases y propiedades)
-
Cerca de 700 agentes (creadores, contribuyentes o publicadores, y tanto personas como organizaciones)
Entre todos los vocabularios, 34 tiene algún término en idioma español, lo cual permite un amplio campo de trabajo para la comunidad en español.
LOV es un claro ejemplo de la importancia de documentar correctamente los vocabularios con metadatos. El valor de los metadatos radica en su capacidad para clasificar y organizar información de la manera más eficiente, proporcionando mayor inteligencia y conocimiento de superior calidad, lo que facilita e impulsa iniciativas de automatización, revisión de conformidades, colaboración, apertura de datos y mucho más.