Blog
Data has occupied a fundamental place in our society in recent years. New technologies have enabled a data-driven globalization in which everything that happens in the world is interconnected. Using simple techniques, it is possible to extract value from them that was unimaginable just a few years ago. However, in order to make proper use of data, it is necessary to have good documentation, through a data dictionary.
What is a data dictionary?
It is common that when we talk about data dictionary, it is confused with business glossary or data vocabulary, however, they are different concepts.
While a business glossary, or data vocabulary, tries to give functional meaning to the indicators or concepts that are handled in a way that ensures that the same language is spoken, abstracting from the technical world, as explained in this article, a data dictionary tries to document the metadata most closely linked to its storage in the database. In other words, it includes technical aspects such as the type of data, format, length, possible values it can take and even the transformations it has undergone, without forgetting the definition of each field. The documentation of these transformations will automatically provide us with the lineage of the data, understood as the traceability throughout its life cycle. This metadata helps users to understand the data from a technical point of view in order to be able to use it properly. For this reason, each database should have its associated data dictionary.
For the completion of the metadata requested in a data dictionary, there are pre-designed guides and templates such as the following example provided by the U.S. Department of Agriculture.
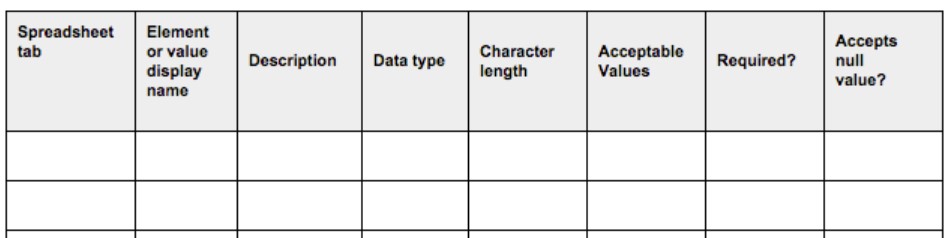
In addition, in order to standardize its content, taxonomies and controlled vocabularies are often used to encode values according to code lists.
Finally, a data catalog acts as a directory to locate information and make it available to users, providing all users with a single point of reference for accessing it. This is made possible by bridging functional and technical terms through the lineage.
Open data applicability
When we talk about open data, data dictionaries become even more important, as they are made available to third parties and their usability is much greater.
Each dataset should be published together with its data dictionary, describing the content of each column. Therefore, when publishing an open dataset, a URL to the document containing its data dictionary should also be published, regardless of its format. In cases where more than one Data Dictionary is required, due to the variety of the originating sources, as many as necessary should be added, generally one per database or table.
Unfortunately, however, it is easy to find datasets extracted directly from information systems without adequate preparation and without an associated data dictionary provided by the publishers. This may be due to several factors, such as a lack of knowledge of this type of tool that facilitates documentation, not knowing for sure how to create a dictionary, or simply assuming that the user knows the contents of the fields.
However, the consequences of publishing data without documenting them correctly may result in the user seeing data referring to unreadable acronyms or technical names, making it impossible to process them or even making inappropriate use of them due to ambiguity and misinterpretation of the contents.
To facilitate the creation of this type of documentation, there are standards and technical recommendations from some organizations. For example, the World Wide Web Consortium (W3C), the body that develops standards to ensure the long-term growth of the World Wide Web, has issued a model recommending how to publish tabular data such as CSV and metadata on the Web.
Interpreting published data
An example of a good data publication can be found in this dataset published by the National Statistics Institute (INE) and available at datos.gob.es, which indicates "the number of persons between 18 and 64 years of age according to the most frequent mother tongue and non-mother tongue languages they may use, by parental characteristics". For its interpretation, the INE provides all the necessary details for its understanding in a URL, such as the units of measurement, sources, period of validity, scope and the methodology followed for the preparation of these surveys. In addition, it provides self-explanatory functional names for each column to ensure the understanding of its meaning by any user outside the INE. All of this allows the user to know with certainty the information he/she is downloading for consumption, avoiding misunderstandings. This information is shared in the "related resources" section, designed for this purpose. This is a metadata describing the dct:references property.
Although this example may seem logical, it is not uncommon to find cases on the opposite side. For illustrative purposes, a fictitious example dataset is shown as follows:

In this case, a user who does not know the database will not know how to correctly interpret the meaning of the fields "TPCHE", "YFAB", "NUMC" ... However, if this table is associated with a data dictionary, we can relate the metadata to the set, as shown in the following image:

In this case, we have chosen to publish the data dictionary by means of a text document describing the fields, although there are many ways of publishing the dictionaries. It can be done following recommendations and standards, such as the one mentioned above by the W3C, by means of text files, as in this case, or even by means of Excel templates customized by the publisher itself. As a general rule, there is no one way that is better than another, but it must be adapted to the nature and complexity of the dataset in order to ensure its comprehension, planning the level of detail required depending on the final objective, the audience receiving the data and the needs of consumers, as explained in this post.
Open data is born with the aim of facilitating the reuse of information for everyone, but for such access to be truly useful, it cannot be limited only to the publication of raw datasets, but must be clearly documented for proper processing. The development of data dictionaries that include the technical details of the datasets that are published is essential for their correct reuse and the extraction of value from them.
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Each individual, organization or group uses a number of common words in their daily communication, which would be their personal vocabularies. The greater the number of words we use, the greater our ability to communicate, but it can also be a barrier, increasing the difficulty of understanding other people who are not familiar with the same terms as we are. The same is true in the world of data.
To avoid misunderstandings, we must use a controlled vocabulary, which is nothing more than a defined list of terms to systematically organize, categorize or label information.
What is a data vocabulary?
For a successful implementation of a data governance initiative, whether private or public, we must provide the process with a business Glosary or reference vocabulary. A reference vocabulary is a means of sharing information and developing and documenting standard data definitions to reduce ambiguity and improve communication. These definitions should be clear, rigorous in their wording and explain any exceptions, synonyms or variants. A clear example is EuroVoc, which covers the activities of the European Union and, in particular, the European Parliament. Another example is ICD10, which is the Coding Manual for Diagnoses and Procedures in Health Care.
The objectives of a controlled vocabulary are as follows:
- To enable common understanding of key concepts and terminology, in a precise manner.
- To reduce the risk of data being misused due to inconsistent understanding of concepts.
- Maximize searchability, facilitating access to documented knowledge.
- Drive interoperability and data reuse, which is critical in the open data world.
Vocabularies vary in the complexity of their development, from simple lists or selection lists, to synonym rings, taxonomies or the most complex, thesauri and ontologies.
How is a vocabulary created?
When creating a vocabulary, it does not usually start from scratch, but is based on pre-existing ontologies and vocabularies, which favors communication between people, intelligent agents and systems. For example, Aragón Open Data has developed an ontology called Interoperable Information Structure of Aragón EI2A that homogenizes structures, vocabularies and characteristics, through the representation of entities, properties and relationships, to fight against the diversity and heterogeneity of existing data in the Aragonese Administration (data from local entities that do not always mean the same thing). For this purpose, it is based on proposals such as RDF Schema (a general vocabulary for modeling RDF schemas that is used in the creation of other Vocabularies), ISA Programme Person Core Vocabulary (aimed at describing persons) or OWL-Time (describing temporal concepts).
A vocabulary must be accompanied by a data dictionary, which is where the data is described in business terms and includes other information needed to use the data, such as details of its structure or security restrictions. Because vocabularies evolve over time, they require evolutionary maintenance. As an example, ANSI/NIZO Z39.19-2005 is a standard that provides guidelines for the construction, formatting and management of controlled vocabularies. We also find SKOS, a W3C initiative that provides a model for representing the basic structure and content of conceptual schemas in any type of controlled vocabulary.
Examples of Vocabularies in specific fields created in Spain
In the Spanish context, with a fragmented administrative structure, where each agency shares its open information individually, it is necessary to have common rules that allow us to homogenize the data, facilitating its interoperability and reuse. Fortunately, there are various proposals that help us in these tasks.
The following are examples of vocabularies created in our country for two fundamental sectors for the future of society, such as education and smart cities.
Smart cities
An example of the construction of domain-specific vocabularies can be found in ciudades-abiertas.es, which is an initiative of several city councils in Spain (A Coruña, Madrid, Santiago de Compostela and Zaragoza) and Red.es.
Among other actions, within the framework of the project, they are working on the development of a catalog of well-defined and documented vocabularies, with examples of use and available in several representation languages. Specifically, 11 vocabularies are being developed corresponding to a series of datasets selected by the municipalities that do not have a defined standard. An example of these vocabularies is the Municipal Agenda.
These vocabularies are generated using the OWL standard language, which is the acronym for Web Ontology Language, a markup language for publishing and sharing data using ontologies on the Web. The corresponding contexts for JSON-LD, N-triples, TTL and RDF/XML are also available. In this explanatory video we can see how these vocabularies are defined. The generated vocabularies are available in the Github repository.
Education
In the field of universities, on the other hand, we find the proposal for open data content for universities developed by the UniversiDATA community: Common Core. In version 1.0, 42 datasets have been identified that every university should publish, such as information related to Degrees, Enrolments or Tenders and contracts. At the moment there are 11 available, while the rest are in the process of elaboration.
For example, the UAM (Autónoma de Madrid), the URJC (Rey Juan Carlos) and the UCM (Complutense de Madrid) have published their degrees following the same vocabulary.
Although much progress has been made in the creation and application of data vocabularies in general, there is still room for progress in the field of research on controlled vocabularies for publishing and querying data on the Web, for example, in the construction of Business Glosaries linked to technical data dictionaries. The application of best practices and the creation of vocabularies for the representation of metadata describing the content, structure, provenance, quality and use of datasets will help to define more precisely the characteristics that should be incorporated into Web data publishing platforms.
Content elaborated by David Puig, Graduate in Information and Documentation and responsible for the Master Data and Reference Group at DAMA ESPAÑA.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
One of the main barriers to the deployment of linked data is the difficulty that data editors have to determine which vocabularies to use to describe their semantics. These vocabularies provide the "semantic glue" that allows simple data to become "meaningful data".
Linked Open Vocabularies (LOV) is a catalog of vocabularies available for reuse with the aim of describing data on the Web. LOV collects metadata and makes visible indicators such as the connection among different vocabularies, version history, maintenance policies, together with past and current references (both to individuals and organizations). The name of this initiative (Linked Open Vocabularies - LOV) has its root in the term Linked Open Data - LOD.

The main goal of LOV is helping the editors of linked data and vocabularies to evaluate the resources (vocabularies, classes, properties and agents) already available and thus promote the highest possible reuse, appart from providing a way for the publishers to add their own creations.
LOV began in 2011 under the Datalift research project and hosted by Open Knowledge International (formerly known as Open Knowledge Foundation). Currently the initiative has the support of a small team of data curators / reviewers and programmers.
To facilitate the reuse of well-documented vocabularies (with metadata), several ways to access the data are provided:
- Through a user interface, with a browsing environment and searches (the web page itself).
- Through a SPARQL endpoint to make queries to the knowledge graph.
- Through a API REST.
- By means of a data dump, both from the knowledge base of LOV (in Notation3 format), as well as from the knowledge base plus the vocabularies themselves (in N-Quads) format).
Currently, the registry identifies and lists:
- 621 vocabularies (RDF vocabularies -RDFS / OWL- defined as schemas (T-Box) for the description of Linked Data)
- About 60,000 terms (between classes and properties).
- Nearly 700 agents (creators, contributors or publishers, and both people and organizations)
Among all the vocabularies, 34 has a term in Spanish, which allows a wide field of work for the Spanish community.
LOV is a clear example of the importance of correctly documenting vocabularies with metadata. The value of metadata lies in its ability to classify and organize information in the most efficient way, providing greater intelligence and knowledge of superior quality, which facilitates and drives automation initiatives, review of compliance, collaboration, open data and much more .