Publication date
25/10/2021
Update date
09/10/2024

Description
Data has occupied a fundamental place in our society in recent years. New technologies have enabled a data-driven globalization in which everything that happens in the world is interconnected. Using simple techniques, it is possible to extract value from them that was unimaginable just a few years ago. However, in order to make proper use of data, it is necessary to have good documentation, through a data dictionary.
What is a data dictionary?
It is common that when we talk about data dictionary, it is confused with business glossary or data vocabulary, however, they are different concepts.
While a business glossary, or data vocabulary, tries to give functional meaning to the indicators or concepts that are handled in a way that ensures that the same language is spoken, abstracting from the technical world, as explained in this article, a data dictionary tries to document the metadata most closely linked to its storage in the database. In other words, it includes technical aspects such as the type of data, format, length, possible values it can take and even the transformations it has undergone, without forgetting the definition of each field. The documentation of these transformations will automatically provide us with the lineage of the data, understood as the traceability throughout its life cycle. This metadata helps users to understand the data from a technical point of view in order to be able to use it properly. For this reason, each database should have its associated data dictionary.
For the completion of the metadata requested in a data dictionary, there are pre-designed guides and templates such as the following example provided by the U.S. Department of Agriculture.
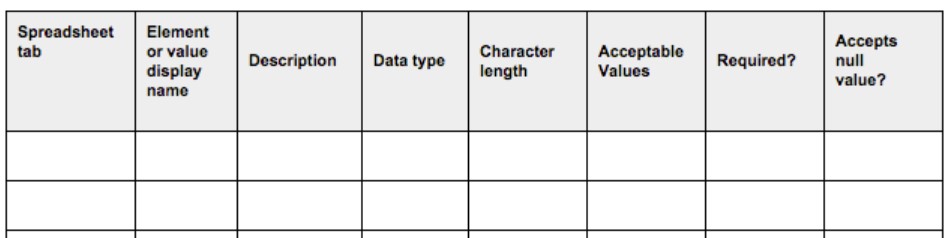
In addition, in order to standardize its content, taxonomies and controlled vocabularies are often used to encode values according to code lists.
Finally, a data catalog acts as a directory to locate information and make it available to users, providing all users with a single point of reference for accessing it. This is made possible by bridging functional and technical terms through the lineage.
Open data applicability
When we talk about open data, data dictionaries become even more important, as they are made available to third parties and their usability is much greater.
Each dataset should be published together with its data dictionary, describing the content of each column. Therefore, when publishing an open dataset, a URL to the document containing its data dictionary should also be published, regardless of its format. In cases where more than one Data Dictionary is required, due to the variety of the originating sources, as many as necessary should be added, generally one per database or table.
Unfortunately, however, it is easy to find datasets extracted directly from information systems without adequate preparation and without an associated data dictionary provided by the publishers. This may be due to several factors, such as a lack of knowledge of this type of tool that facilitates documentation, not knowing for sure how to create a dictionary, or simply assuming that the user knows the contents of the fields.
However, the consequences of publishing data without documenting them correctly may result in the user seeing data referring to unreadable acronyms or technical names, making it impossible to process them or even making inappropriate use of them due to ambiguity and misinterpretation of the contents.
To facilitate the creation of this type of documentation, there are standards and technical recommendations from some organizations. For example, the World Wide Web Consortium (W3C), the body that develops standards to ensure the long-term growth of the World Wide Web, has issued a model recommending how to publish tabular data such as CSV and metadata on the Web.
Interpreting published data
An example of a good data publication can be found in this dataset published by the National Statistics Institute (INE) and available at datos.gob.es, which indicates "the number of persons between 18 and 64 years of age according to the most frequent mother tongue and non-mother tongue languages they may use, by parental characteristics". For its interpretation, the INE provides all the necessary details for its understanding in a URL, such as the units of measurement, sources, period of validity, scope and the methodology followed for the preparation of these surveys. In addition, it provides self-explanatory functional names for each column to ensure the understanding of its meaning by any user outside the INE. All of this allows the user to know with certainty the information he/she is downloading for consumption, avoiding misunderstandings. This information is shared in the "related resources" section, designed for this purpose. This is a metadata describing the dct:references property.
Although this example may seem logical, it is not uncommon to find cases on the opposite side. For illustrative purposes, a fictitious example dataset is shown as follows:

In this case, a user who does not know the database will not know how to correctly interpret the meaning of the fields "TPCHE", "YFAB", "NUMC" ... However, if this table is associated with a data dictionary, we can relate the metadata to the set, as shown in the following image:

In this case, we have chosen to publish the data dictionary by means of a text document describing the fields, although there are many ways of publishing the dictionaries. It can be done following recommendations and standards, such as the one mentioned above by the W3C, by means of text files, as in this case, or even by means of Excel templates customized by the publisher itself. As a general rule, there is no one way that is better than another, but it must be adapted to the nature and complexity of the dataset in order to ensure its comprehension, planning the level of detail required depending on the final objective, the audience receiving the data and the needs of consumers, as explained in this post.
Open data is born with the aim of facilitating the reuse of information for everyone, but for such access to be truly useful, it cannot be limited only to the publication of raw datasets, but must be clearly documented for proper processing. The development of data dictionaries that include the technical details of the datasets that are published is essential for their correct reuse and the extraction of value from them.
Content prepared by Juan Mañes, expert in Data Governance.
The contents and views expressed in this publication are the sole responsibility of the author.
En la última imagen columna 4 aparece 100kms. Sólo indicar que las unidades de medida NO tienen plural, lo correcto sería 100km
Hola Manuel,
Gracias por tu comentario. Tienes razón, lo correcto sería 100km. Corregimos la errata.