Evento
Son muchas las personas que aprovechan la época veraniega para actualizar sus conocimientos en alguna materia o adentrarse en nuevas disciplinas. La ciencia de datos y la inteligencia artificial generan cada vez mayor interés. El sector de la economía del dato genera 26.538 empleos en España, según el informe sobre la economía del dato en el ámbito infomediario que realiza ASEDIE.
La creciente demanda de competencias relacionadas con los datos y la inteligencia artificial se refleja también en la oferta formativa de las universidades. Los cursos están dirigidos tanto a estudiantes como a profesionales interesados en ampliar conocimientos, conocer nuevas herramientas o explorar tecnologías que están impulsando la transformación digital en ámbitos como la salud o la gestión pública.
A continuación, recogemos algunos ejemplos. Se trata de cursos que combinan teoría y práctica y permiten descubrir el potencial de los datos y la inteligencia artificial.
-
Políticas públicas y transformación digital de ciudades y territorios: una visión sistémica basada en datos
Universidad Pablo de Olavide
Este curso aborda el papel de los datos en la transformación de las ciudades y territorios, así como su contribución al diseño de políticas públicas más eficientes y sostenibles. Los participantes analizarán cómo la recopilación y el análisis de datos pueden apoyar la toma de decisiones y favorecer una mejor planificación de los servicios públicos. La formación está dirigida a profesionales de las administraciones públicas, responsables políticas, técnicos y gestores vinculados al desarrollo territorial, así como a investigadores y personas interesadas en las estrategias de gobernanza y transformación digital.
- Fecha y lugar: 25 y 26 de junio de 2026 en Carmona.
-
Análisis y Visualización de Datos: Estadística Práctica con R e Inteligencia Artificial
Universidad Nacional de Educación a Distancia (UNED)
Este seminario ofrece una formación práctica en análisis y visualización de datos, dos disciplinas que desempeñan un papel cada vez más importante en ámbitos como la salud, la educación, la economía o la informática. El programa aborda conceptos de inferencia estadística y enseña a trabajar con el lenguage R y el entorno RStudio. Además, los participantes podrán explorar las posibilidades que ofrecen herramientas de inteligencia artificial basadas en grandes modelos de lenguaje, como ChatGPT y GitHub Copilot, para facilitar tareas relacionadas con el análisis y la programación.
- Fecha y lugar: del 8 al 10 de julio de 2026 en modalidad online y presencial (en Plasencia).
-
Advanced Programming
Universitat Autònoma de Barcelona
Este programa está orientado a estudiantes de distintas disciplinas científicas y tecnológicas que ya cuentan con conocimientos básicos de programación y desean profundizar en esta materia. Con un enfoque eminentemente práctico, la formación permitirá reforzar las competencias en programación estructurada y programación orientada a objetos mediante lenguajes como C, Java y Python. A lo largo del curso los participantes desarrollarán diferentes proyectos, con el objetivo de poner en práctica conceptos como la gestión dinámica de memoria, las estructuras de datos o la creación de aplicaciones basada en objetos.
- Fecha y lugar: del 13 al 30 de julio de 2026. Ubicación por definir.
-
Introducción a la Ciencia de datos e IA
Universidad de Zaragoza
La Universidad de Zaragoza celebra la cuarta edición de este curso como una introducción estructurada a la ciencia de datos, en la que se abordan sus conceptos fundamentales, desde la recolección, limpieza y gestión de la información, hasta su análisis, visualización y la aplicación de algoritmos de machine learning e inteligencia artificial. El programa tiene además un enfoque práctico que permite a los participantes desarrollar un proyecto de IA bajo la supervisión de profesionales. El curso está dirigido a estudiantes universitarios de ciencias e ingeniería, alumnado de formación profesional vinculado a la programación y profesionales del sector de los datos y la informática.
- Fecha y lugar: del 15 al 17 de julio de 2026 en Jaca.
-
Herramientas de Visualización de Datos: Power BI, ShinyApps y Tableau
Universidad de Verano de Teruel (Universidad de Zaragoza)
La visualización de datos es una herramienta fundamental para transformar la información en conocimiento útil y facilitar la toma de decisiones. Este seminario ofrece una introducción a los principios del análisis visual y proporciona formación práctica en algunas de las plataformas más utilizadas en este ámbito, como son Power BI, Tableau y ShinyApps. Los participantes aprenderán a crear cuadros de mando interactivos y desarrollar aplicaciones para el análisis reproducible, entre otras cosas. La formación también aborda aspectos relacionados con el uso responsable de los datos y está dirigida tanto a profesionales como a investigadores interesados en mejorar sus competencias en visualización y análisis.
- Fecha y lugar: del 20 al 23 de julio de 2026 en Teruel.
-
Visualización y análisis de datos con R
Universidad de Santiago de Compostela
La Universidad de Santigo de Compostela organiza este curso una introducción al uso del lenguaje R para el tratamiento y análisis estadístico de datos. A lo largo de las distintas sesiones, los participantes adquirirán las habilidades necesarias para realizar análisis descriptivos e inferenciales (estimación, contrastes y predicciones). La formación está dirigida a estudiantes y profesionales de diferentes ámbitos interesados en incorporar métodos estadísticos al tratamiento de datos y proporciona recursos que permiten seguir profundizando de forma autónoma en las posibilidades de R.
- Fecha y lugar: del 20 a 24 de julio de 2026 en Santiago de Compostela.
-
Reto en Ciencia de Datos e Inteligencia Artificial aplicada al bienestar social de UNA-Europa
Universidad Complutense de Madrid
La Universidad Complutense de Madrid participa en esta iniciativa impulsada por la alianza universitaria UNA-Europa, cuyo objetivo es aplicar técnicas de datos e inteligencia artificial para abordar retos relacionados con el bienestar social. La formación está dirigida principalmente a estudiantes de doctorado e investigadores en las primeras etapas de su carrera, procedentes de diferentes disciplinas, interesados en explorar el potencial de la IA desde una perspectiva ética y responsable. A lo largo de tres jornadas, los participantes trabajarán sobre casos reales y participarán en actividades colaborativas inspiradas en formatos como los hackatones, prestando especial atención a cuestiones como la ética, los sesgos algorítmicos y los derechos humanos.
- Fecha y lugar: del 22 al 24 de julio de 2026 en San Lorenzo de El Escorial.
-
Teledetección desde satélite. Procesamiento digital de imágenes y aplicaciones copérnicus
Universidad de Verano de Teruel (Universidad de Zaragoza).
Los datos obtenidos mediante satélites de observación de la Tierra tienen aplicaciones cada vez más relevantes en ámbitos como el seguimiento del cambio climático o la gestión del territorio. Este curso profundiza en los fundamentos de la teledetección y en las técnicas de procesamiento digital de imágenes, utilizando información procedente de misiones como Landsat y de los satélites Sentinel del programa europeo Copernicus. La formación combina contenidos teóricos con ejercicios prácticos y permite explorar aplicaciones relacionadas con la desertificación o la monitorización de la superficie terrestre y marina, entre otras. Además, los participantes se familiarizarán con algunas de las herramientas empleadas para el tratamiento y análisis de datos geoespaciales.
- Fecha y lugar: del 27 al 30 de julio de 2026 en Teruel.
-
Fundamentos de Inteligencia Artificial: modelos generativos y aplicaciones avanzadas en Salud, visión artificial y lenguaje
Universidad Internacional de Andalucía
La inteligencia artificial está generando una creciente demanda de profesionales capaces de comprender y aplicar estas tecnologías. Este curso intensivo ofrece una introducción práctica a algunas de las principales áreas de la IA actual, con especial atención a los modelos generativos, las redes neuronales, el procesamiento del lenguaje natural y el aprendizaje profundo. Se abordarán aplicaciones avanzadas en campos como la salud y la visión artificial, así como tecnologías emergentes relacionadas con los agentes inteligentes. La formación está dirigida tanto a estudiantes y personal investigador, como a profesionales interesados en adquirir competencias en este ámbito.
- Fecha y lugar: del 18 al 21 de agosto de 2026 en Baeza.
10. Datos en el espacio científico: un viaje a la creación del conocimiento
Universidad Internacional Menéndez Pelayo
Este encuentro organizado, en colaboración con el CSIC, ofrecerá una visión integrada del ciclo de vida de los datos en el ámbito científico, desde su generación y tratamiento hasta su usabilidad y reutilización en entornos de investigación. El programa aborda cuestiones técnicas, normativas y éticas vinculadas a la gobernanza del dato, la interoperabilidad y su alineación con marcos europeos como el Espacio Europeo de Datos de Salud o el Data Act, e incluye reflexiones sobre la calidad y la seguridad de la información. El curso está dirigido principalmente a personal investigador, técnico y estudiantes de posgrado interesados en el análisis y aprovechamiento de datos científicos.
- Fecha y lugar: del 24 al 26 de agosto en Santander.
La ciencia de datos y la inteligencia artificial continúan ganando protagonismo en numerosos sectores, lo que hace cada vez más necesario adquirir nuevas competencias y mantenerse al día de los últimos avances. La programación de verano de las universidades españolas ofrece oportunidades para profundizar en estas materias desde diferentes perspectivas y niveles de especialización. Los cursos incluidos en esta selección constituyen solo algunos ejemplos de una oferta formativa cada vez más amplia y diversa.
Documentación
Introducción
En los últimos años hemos visto cómo la inteligencia artificial generativa ha dejado de ser una curiosidad técnica para convertirse en una herramienta cotidiana en el flujo de trabajo de los profesionales del dato. Sin embargo, sigue existiendo una pregunta importante: ¿cómo se traduce esta tecnología en un proceso real de análisis de datos abiertos?, ¿Qué cambia en la práctica cuando un analista trabaja "junto a" un modelo de lenguaje en lugar de hacerlo en solitario?
Este post documenta un ejercicio práctico realizado con datos publicados en el portal datos.gob.es: el análisis de precios de las más de 11.000 estaciones de servicio en España. A diferencia de otros ejercicios publicados en este espacio, el análisis no se ha realizado de forma manual línea por línea, sino que se ha llevado a cabo en un entorno agéntico: una interfaz conversacional apoyada en un modelo grande de lenguaje (LLM) y un sistema de codificación asistido por inteligencia artificial. En la práctica, esto significa que en lugar de escribir el código de análisis nosotros mismos, le describimos al sistema en lenguaje natural qué queremos obtener, y este lo implementa.
El objetivo de este post es doble. Por un lado, explicar el análisis propiamente dicho: qué preguntas nos hacemos sobre los datos, qué problemas técnicos encontramos y qué conclusiones extraemos. Por otro, reflexionar sobre el método: cómo se estructura un proceso de análisis cuando trabajamos con un copiloto de IA, qué patrones de interacción funcionan mejor y dónde están los límites de la asistencia automatizada.
Nota metodológica: para la realización de este ejercicio hemos empleado una metodología Spec Driven Development (SDD), que guía a la IA a través de un proceso estructurado con el objetivo de evitar que la conversación pierda el foco del ejercicio. La explicación detallada de esta metodología queda fuera del alcance del presente post, pero el lector encontrará en el repositorio especificaciones, planes técnicos y checklists que la documentan.
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
El proceso: un flujo clásico, asistido por IA
Antes de entrar en cada fase, conviene describir el esquema general del trabajo. El análisis sigue cinco etapas habituales en ciencia de datos —ingesta, limpieza, exploración, ingeniería de variables y análisis de impacto— pero introduciendo en cada una de ellas un patrón conversacional con la IA.
Ese patrón puede resumirse en cinco pasos:
- Describir el problema en lenguaje natural.
- Proponer una primera solución (lo hace la IA).
- Cuestionar los supuestos de esa propuesta (lo hace el analista humano).
- Refinar la solución hasta que sea robusta.
- Documentar el patrón para reutilizarlo en futuros proyectos.
A continuación, veremos, fase por fase, cómo se materializa este patrón en el análisis del precio de los combustibles. Cada apartado comienza explicando el reto conceptual, continúa describiendo cómo abordamos la resolución con la asistencia de la IA, y termina mostrando el código resultante y las lecciones aprendidas.
Fase 1: ingesta robusta de datos desde una API pública
El reto: API públicas que no siempre responden como se espera
Aviso para el lector: esta fase entra en cierto detalle técnico sobre integración de API, errores SSL y estrategias de respaldo. Si tu perfil es más analítico que de desarrollo, puedes hojear el bloque de código y centrarte en los apartados El enfoque y Reflexión, donde la idea de fondo —cómo diseñar una ingesta tolerante a fallos— se explica sin entrar en detalles de implementación.
La descarga de datos desde la API del Ministerio para la Transición Ecológica es conceptualmente sencilla: una petición HTTP GET a un endpoint conocido debería devolver un fichero JSON con aproximadamente 11.000 estaciones de servicio. En la práctica, sin embargo, las API públicas presentan dificultades habituales que cualquier analista termina encontrando antes o después:
- Certificados SSL caducados o mal configurados, que provocan errores del tipo SSLError.
- Bloqueo de IP procedentes de servidores en la nube (Google Colab, AWS, etc.), interpretadas como tráfico sospechoso.
- Servidores inestables, con tiempos de respuesta variables y timeouts esporádicos.
- Inconsistencias en la documentación, por ejemplo, cuando se describe una respuesta JSON pero el servidor devuelve XML.
La pregunta clave es: ¿cómo diseñamos un sistema de ingesta que tolere estos problemas en lugar de fallar al primer obstáculo?
El enfoque: una arquitectura de respaldos escalonados
En ingeniería de software, los sistemas críticos no dependen de un único componente. Cuando un canal falla, existe otro de respaldo (lo que en inglés se denomina fallback). Aplicar esta lógica a la ingesta de datos es especialmente útil cuando trabajamos con fuentes públicas sobre las que no tenemos control.
Para este ejercicio, diseñamos una estrategia de triple respaldo:
- Primer intento — requests con configuración permisiva: realizamos la petición HTTP con la librería estándar de Python, pero configurando un User-Agent que simula un navegador real y desactivando la verificación de SSL. Esto resuelve buena parte de los problemas de certificados.
- Segundo intento — curl desde la shell: si requests falla, invocamos curl como subproceso. La razón es que curl utiliza una pila TLS distinta a la de Python y no envía los mismos certificados, lo que permite sortear ciertos tipos de bloqueo.
- Tercer intento — datos de demostración: si todo lo anterior falla, generamos un conjunto sintético de 11.000 estaciones de servicio con distribuciones realistas. Esto garantiza que el notebook siempre sea ejecutable en un contexto educativo, aunque la API esté caída.
El razonamiento de fondo es sencillo: cada método sortea un tipo distinto de fallo de red, y su combinación proporciona robustez. A continuación, mostramos el código que implementa esta arquitectura.
El código resultante
El siguiente fragmento ilustra cómo se materializan los tres niveles de respaldo en una única función. Las cláusulas try/except permiten detectar el fallo de cada método y pasar automáticamente al siguiente:
def descargar_datos_api(url):
"""
Descarga datos con triple respaldo:
1. requests con verify=False (sortea problemas de SSL)
2. curl -k (pila TLS alternativa)
3. datos sintéticos (garantía de ejecución)
"""
# Intento 1: requests con cabeceras de navegador
try:
sesion = requests.Session()
sesion.headers.update({
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
})
response = sesion.get(url, timeout=45, verify=False)
return response.json()
except Exception as e_requests:
print(f"[Respaldo 1] requests ha fallado: {e_requests}")
# Intento 2: curl como subproceso
try:
resultado = subprocess.run(
["curl", "-s", "-k", url],
capture_output=True, timeout=45, text=True
)
return json.loads(resultado.stdout)
except Exception as e_curl:
print(f"[Respaldo 2] curl ha fallado: {e_curl}")
# Intento 3: datos sintéticos de demostración
print("[Respaldo 3] Utilizando datos de demostración")
return generar_datos_demo_gasolineras(11000)
Reflexión: dónde aporta valor la IA en esta fase
La iteración con la IA no produjo el código anterior de un solo intento. El proceso real fue más interesante: planteamos el problema ("la API a veces rechaza las peticiones, necesito respaldos"), la IA propuso una solución inicial, y el avance vino de cuestionar esa propuesta. La pregunta "¿por qué curl debería funcionar si requests ya ha fallado?" obligó al modelo a explicar las diferencias entre ambas pilas TLS, lo que a su vez nos permitió validar que la solución tenía fundamento técnico real, no era simplemente "probar lo mismo dos veces".
Una estimación razonable: resolver este problema mediante prueba y error puro habría llevado entre dos y tres horas de depuración. Con la iteración asistida, lo abordamos en aproximadamente treinta minutos.
Fase 2: limpieza con conocimiento de dominio
El reto: los datos reales nunca son perfectos
Una vez descargados los datos, comienza el trabajo menos visible pero más decisivo de cualquier análisis: la limpieza y preparación. La calidad del resultado final depende en gran medida del cuidado puesto en esta etapa. En el caso de los combustibles, las inconsistencias más habituales son:
- Variantes textuales no normalizadas: la marca "MOEVE" puede aparecer como "MOEVE", "Moeve" o "moeve" en distintos registros. Para una persona son obviamente la misma marca, pero en una agregación por groupby aparecen como tres categorías independientes.
- Coordenadas geográficas incorrectas: puntos situados fuera del territorio español (islas remotas, fragmentos de Marruecos, errores de captura).
- Separadores decimales inconsistentes: precios codificados como "1,349" con coma, que requieren conversión explícita antes de poder operar con ellos.
- Conversiones que introducen valores nulos: pd.to_numeric(..., errors='coerce') es muy útil, pero genera NaN silenciosos que pueden romper análisis posteriores.
La cuestión central de esta fase es: ¿cómo traducimos el conocimiento humano sobre el dominio en reglas de código?
El enfoque: validación organizada en capas
En lugar de limpiar "según va apareciendo", conviene organizar las reglas de validación en capas, cada una con una responsabilidad clara:
|
Capa |
Responsabilidad |
Ejemplo |
|---|---|---|
| Tipos | Conversión y coerción a tipos adecuados | Precio como float, fecha como datetime |
| Rangos | Valores dentro de límites razonables | Precio entre 0,5€ y 3,0€ por litro |
| Semántica | Coherencia con el dominio | Coordenadas dentro de España, marcas normalizadas |
Figura 1. Tabla de validación organizada en capas. Fuente: elaboración propia - datos.gob.es
La pregunta que cada capa debe responder es siempre la misma: ¿tiene sentido este valor en el contexto de las estaciones de servicio españolas? La novedad respecto a un flujo manual es que aquí describimos las reglas a la IA en lenguaje natural y dejamos que ella las traduzca a código pandas. Nosotros conservamos la responsabilidad de definir qué es válido y qué no.
El código resultante
El siguiente bloque implementa las tres capas de validación de forma secuencial. Conviene destacar que la lista de aliases de marcas (CEPSA → MOEVE) refleja conocimiento de negocio específico —el rebranding de CEPSA a MOEVE en 2023— que la IA no podría inferir por sí sola; es información que aporta el analista. Este es un ejemplo muy claro de aportación del conocimiento humano difícilmente alcanzable por la IA:
def validar_y_limpiar_carburantes(df):
# Capa 1: normalización de tipos
df['precio'] = (
df['precio'].astype(str)
.str.replace(',', '.')
.astype(float)
)
df['marca'] = df['marca'].str.upper().str.strip()
# Capa 2: validación de rangos
df = df[(df['precio'] >= 0.5) & (df['precio'] <= 3.0)]
df = df[
(df['latitud'] >= 27.5) & (df['latitud'] <= 43.8) &
(df['longitud'] >= -18.2) & (df['longitud'] <= 4.4)
]
# Capa 3: coherencia semántica (conocimiento de negocio)
aliases = {'CEPSA': 'MOEVE'} # Rebranding 2023
df['marca'] = df['marca'].map(lambda x: aliases.get(x, x))
# Auditoría de nulos
nulos = df[['precio', 'latitud', 'longitud', 'marca']].isnull().sum()
if nulos.sum() > 0:
print(f"Atención: se han detectado valores nulos:\n{nulos}")
return df.dropna(subset=['precio', 'latitud', 'longitud'])Reflexión: el reparto del trabajo entre la IA y el analista
Esta fase es especialmente reveladora del tipo de colaboración que la IA habilita. Las reglas más técnicas (conversión de tipos, detección de nulos, normalización de mayúsculas) son prácticamente automáticas: basta con describir el problema y el modelo propone una implementación correcta. En cambio, las reglas que dependen del dominio (que las islas Canarias tienen un sobrecoste logístico del 5%, que CEPSA y MOEVE son la misma marca tras la fusión, que un precio inferior a 0,5€ es probablemente un error de carga) deben ser especificadas por el analista humano.
La lección aprendida es importante: la calidad de la limpieza depende directamente del conocimiento de dominio que aporta el analista. La IA acelera la implementación, pero no inventa contexto. Por eso el patrón reutilizable es el mismo en cualquier proyecto: describe tu dominio con detalle, deja que la IA escriba las validaciones, y verifica tú mismo que los resultados son coherentes.
Fase 3: análisis exploratorio visual (EDA)
El reto: convertir números en intuiciones
Con 11.000 registros limpios ya en memoria, el siguiente paso es responder a las preguntas de negocio que motivaron el análisis. En este caso, formulamos cuatro preguntas concretas:
- ¿Qué provincias tienen los combustibles más caros?
- ¿Existe relación entre la ubicación geográfica (latitud y longitud) y el precio?
- ¿Hay diferencias significativas entre marcas?
- ¿Cómo se distribuyen los precios (media, mediana, valores atípicos)?
El reto técnico no es complejo —pandas y matplotlib resuelven cualquiera de estas preguntas— pero sí lo es el reto metodológico: elegir la visualización adecuada para cada pregunta. Una gráfica mal elegida puede ocultar tanto como una agregación incorrecta.
El enfoque: cada pregunta determina su gráfico
En análisis exploratorio existe una correspondencia natural entre el tipo de pregunta y la visualización más apropiada. Conviene tenerla presente antes de escribir una sola línea de código:
|
Pregunta |
Visualización adecuada |
Razón |
|---|---|---|
| ¿Ranking? | Gráfico de barras ordenado | Permite comparar valores ordenados |
| ¿Relación espacial? | Scatter con escala de color | Muestra correlación en dos dimensiones |
| ¿Distribución y atípicos? | Diagrama de caja (box plot) | Revela mediana, cuartiles y outliers |
| ¿Diferencias entre grupos? | Box plot o violin plot | Compara distribuciones simultáneamente |
Figura 2. Tabla de correspondencia natural entre el tipo de pregunta y la visualización más adecuada. Fuente: elaboración propia - datos.gob.es
El objetivo no es producir gráficos vistosos, sino gráficos que respondan a preguntas concretas. Esta es una idea aparentemente obvia, pero conviene recordarla: en la práctica, es frecuente que se generen visualizaciones por inercia, sin tener claro qué se quiere mostrar.
El código resultante
A continuación, mostramos uno de los gráficos como ejemplo, el ranking de precios por provincia. La estructura es siempre la misma: declaración del gráfico, configuración estética, y un breve comentario interpretando el resultado:
# Pregunta 1: ¿qué provincias son las más caras?
top_provincias = (
df.groupby('provincia')['precio']
.mean()
.sort_values(ascending=False)
.head(12)
)
fig, ax = plt.subplots(figsize=(12, 6))
top_provincias.plot(kind='bar', ax=ax, color='steelblue')
ax.set_title('Precio medio del combustible por provincia (Top 12)',
fontsize=14, fontweight='bold')
ax.set_ylabel('Precio (€/litro)')
ax.set_xlabel('Provincia')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# Hallazgo: las tres provincias más caras son insulares o costeras
# (Baleares, Canarias, Tarragona). Hipótesis: el coste logístico
# y la lejanía a los hubs de distribución elevan el precio.En el caso del scatter geográfico, aplicamos una segmentación adicional —península, Baleares y Canarias— para visualizar simultáneamente la ubicación y la insularidad. Esta segmentación reveló un patrón que ninguna agregación numérica había mostrado claramente: las estaciones insulares tienen precios sistemáticamente superiores, hallazgo probablemente atribuible a costes de transporte marítimo. El insight no emergió de un cálculo, sino de la visualización.
Reflexión: el punto ciego de la IA
Esta fase pone de manifiesto una limitación importante del modelo: la IA no ve el resultado gráfico. Puede sugerir el tipo de visualización adecuado, escribir el código correctamente y proponer una paleta de colores, pero no puede juzgar si la escala del eje es apropiada, si la densidad de puntos satura el gráfico o si los rótulos se solapan. Todas estas validaciones siguen siendo responsabilidad humana.
En la práctica, esto significa que la fase de EDA es la que requiere más iteración entre persona y máquina: la IA escribe, el analista observa, identifica un problema visual ("este eje no muestra bien la variación"), y describe la corrección ("ajusta el eje Y a [precio_min0.95, precio_max1.05]"). El patrón reutilizable es claro: una pregunta clara, un tipo de gráfico adecuado y una validación visual humana.
Fase 4: ingeniería de variables (feature engineering)
El reto: capturar variación con nuevas variables
El análisis exploratorio identifica patrones, pero rara vez los explica. Para entender qué factores influyen en el precio es necesario construir nuevas variables —features— que capturen hipótesis específicas sobre la dinámica del mercado. En este ejercicio formulamos tres hipótesis:
- Temporal: ¿Influye el día de la semana en el precio? ¿Es más caro repostar en fin de semana?
- Geográfica: ¿Influye la distancia a un hub económico (en este caso, Madrid)?
- Regional: ¿Existen diferencias estructurales entre el norte, el centro y el sur de España?
La ingeniería de variables consiste precisamente en traducir esas hipótesis en columnas calculadas que el resto del análisis pueda utilizar.
El enfoque: cada variable, una historia testable
Una buena variable debe contar una historia clara. No basta con calcular un número: hay que poder explicar qué pregunta intenta responder. En nuestro caso:
- es_fin_semana (0/1): ¿cambia el precio el sábado y el domingo?
- distancia_a_madrid (km): ¿se encarece el combustible al alejarse del hub logístico?
- region (norte/centro/sur): ¿hay brechas estructurales entre regiones?
Cada una de estas tres variables es, en realidad, una pregunta empírica disfrazada de columna. Si la variable no explica nada cuando la cruzamos con el precio, simplemente la descartamos.
El código resultante
Implementamos las tres variables en una única función. La más interesante técnicamente es la distancia a Madrid, que requiere la fórmula de Haversine para calcular distancias sobre la superficie terrestre teniendo en cuenta la curvatura del planeta:
from math import radians, cos, sin, asin, sqrt
def crear_features_carburantes(df):
# Variable temporal
df['es_fin_semana'] = (
df['fecha'].dt.dayofweek.isin([5, 6]).astype(int)
)
# Variable geográfica: distancia haversine a Madrid
madrid_lat, madrid_lon = 40.4168, -3.7038
def haversine(lat, lon):
lat, lon = radians(lat), radians(lon)
m_lat, m_lon = radians(madrid_lat), radians(madrid_lon)
dlat = lat - m_lat
dlon = lon - m_lon
a = sin(dlat/2)**2 + cos(m_lat) * cos(lat) * sin(dlon/2)**2
return 6371 * 2 * asin(sqrt(a)) # radio de la Tierra en km
df['distancia_a_madrid'] = df.apply(
lambda r: haversine(r['latitud'], r['longitud']), axis=1
)
# Variable regional
def region(lat):
if lat >= 42: return 'Norte'
if lat >= 39: return 'Centro'
return 'Sur'
df['region'] = df['latitud'].apply(region)
return dfReflexión: proponer variables con argumento, no solo con código
En esta fase la IA aporta un valor especialmente alto, pero no en lo que se podría pensar a primera vista. Lo verdaderamente útil no es que escriba la fórmula de Haversine —cualquier referencia técnica la contiene—, sino que proponga variables candidatas con argumentación detrás. Cuando le preguntamos "¿qué features podrían capturar la variación de precios?", la propuesta vino acompañada de razonamiento: Madrid se sugirió como hub porque es el mercado más eficiente y estable, y por tanto las desviaciones respecto a su precio funcionan como aproximación a la fricción logística.
Ese razonamiento es lo valioso: no la fórmula, sino la justificación. Trial-and-error puro habría llevado tres o cuatro horas explorando variables hasta encontrar las útiles; con la iteración asistida, llegamos a un conjunto razonado en aproximadamente cuarenta y cinco minutos.
Fase 5: análisis de impacto de las variables
El reto: cuantificar la contribución real
Construir variables es una cosa; demostrar que realmente explican algo es otra. En esta última fase del análisis evaluamos el impacto efectivo de cada una de las tres variables creadas, combinando dos enfoques: una medida numérica (correlación o diferencia de medias) y una representación visual que permita interpretar el resultado de un vistazo.
El enfoque: dos enfoques complementarios
Para cada variable, calculamos:
- Una medida numérica que cuantifica el efecto (correlación de Pearson para variables continuas; diferencia de medias para categóricas).
- Una representación visual que permite interpretar la magnitud del efecto y detectar relaciones no lineales.
El cruce de ambos enfoques es lo que da fiabilidad al resultado. Una correlación alta sin una visualización que la respalde puede ser engañosa (por ejemplo, si está dominada por outliers); una visualización sugestiva sin métrica puede llevar a sobreinterpretación.
El código resultante
Como ejemplo, mostramos el análisis de impacto de la distancia a Madrid. Primero calculamos la correlación, después segmentamos en cuartiles para hacer la relación visualmente interpretable:
# Medida numérica
correlacion = df['distancia_a_madrid'].corr(df['precio'])
print(f"Correlación (distancia a Madrid → precio): {correlacion:.3f}")
# Representación visual por cuartiles de distancia
df['cuartil_distancia'] = pd.qcut(
df['distancia_a_madrid'], q=4,
labels=['Q1 (cercano)', 'Q2', 'Q3', 'Q4 (lejano)']
)
precio_por_cuartil = df.groupby('cuartil_distancia')['precio'].mean()
fig, ax = plt.subplots(figsize=(10, 5))
precio_por_cuartil.plot(kind='bar', ax=ax, color='#2ecc71')
ax.set_title('Impacto geográfico: precio medio por cuartiles de distancia a Madrid')
ax.set_ylabel('Precio medio (€/litro)')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()El patrón emergente del análisis completo —comparando las tres variables— es que la distancia a Madrid es la más explicativa, seguida por la región, y por último por el efecto fin de semana, que en nuestro periodo de estudio resulta ser marginal. En conjunto, las tres variables explican aproximadamente el 60-70% de la variación de precios; el resto depende de factores como la marca específica, el tipo de estación (autopista, urbana, rural) y eventos puntuales del mercado.
Reflexión: no todas las variables impactan por igual
Una de las virtudes de este análisis estructurado es que revela cuáles de nuestras hipótesis iniciales se sostienen y cuáles no. En este caso, la hipótesis temporal (fin de semana) resultó ser mucho más débil de lo esperado, mientras que la hipótesis geográfica se confirmó con claridad. Sin este paso de cuantificación, habríamos podido seguir asumiendo que todas las variables aportan información valiosa.
Síntesis: las lecciones técnicas que nos llevamos
A lo largo de las cinco fases anteriores hemos ido acumulando soluciones a problemas concretos. La siguiente tabla resume las más reutilizables; cada una está documentada con mayor detalle en el directorio prompts del repositorio:
|
Fase |
Problema |
Solución |
Reutilizable en |
|---|---|---|---|
| Ingesta | Bloqueos SSL o de IP en APIs | Triple respaldo: request -> curl -> demo | Cualquier API pública |
| Ingesta | Documentación inconsistente | Validación de estructura + manejo de errores | APIs gubernamentales |
| Limpieza | Variantes textuales en marcas | .st.upper().str.trip() antes de agrupar | Cualquier agregación categórica |
| Limpieza | Coordenadas fuera de España | Bounding box [27.5-43.8, -18.2- 4.4] | Análisis geográficos en España |
| Limpieza | Rangos comprimidos en gráficos | ax.set_xlim(min*0.95, max*1.05) | Visualización con rangos estrechos |
| EDA | Elección de tipo de gráfico | Mapeo explícito pregunta -> gráfico | Cualquier EDA |
| Features | Variables sin justificación | Cada feature responde una hipótesis testable | Feature engineering en general |
| Análisis | Impacto no cuantificado | Métrica + visualización en paralelo | Cualquier análisis de impacto |
Figura 3. Tabla resumen de soluciones a problemas concretos. Fuente: elaboración propia - datos.gob.es
Reflexión final: qué hace que la IA sea un buen copiloto
Al cabo del ejercicio, podemos extraer algunas conclusiones generales sobre el uso de IA generativa como apoyo al análisis de datos. Las dividimos en dos planos: dónde aporta valor, y dónde no debe sustituir al criterio humano.
Donde la IA aporta valor de forma clara:
- Iteración rápida. El ciclo "describir problema – obtener solución – validar" se reduce de horas a minutos. Esto cambia cualitativamente la dinámica de trabajo: nos permite probar ideas que de otro modo descartaríamos por coste.
- Pensamiento lateral. La IA propone alternativas que un analista podría pasar por alto, como la idea de usar curl cuando requests falla. No siempre acierta, pero sí amplía el espacio de soluciones consideradas.
- Documentación articulada. La IA es especialmente buena explicando el porqué de una decisión técnica, no solo el qué. Esto facilita que el código resultante sea legible para personas no técnicas.
Donde el criterio humano sigue siendo imprescindible:
- Conocimiento de dominio. La IA no sabe que CEPSA y MOEVE son la misma marca, ni que Canarias tiene un sobrecoste logístico estructural. Esa información debe aportarla el analista.
- Validación estadística. La IA puede sugerir modelos, pero la validez estadística del análisis es responsabilidad humana.
- Lectura de gráficos. La IA no ve sus propias visualizaciones. El juicio sobre si una gráfica es legible, comunica lo que se pretende y respeta buenas prácticas visuales sigue siendo humano.
- Decisiones de negocio. Qué preguntar a los datos, qué considerar relevante, cómo comunicar los resultados a la organización: son decisiones que la IA puede apoyar, pero no sustituir.
En síntesis, la idea que resume mejor nuestra experiencia es la siguiente: la IA generativa funciona mejor cuando piensa con nosotros que cuando piensa por nosotros. El ejercicio que aquí presentamos no fue "pedir a Claude que hiciera el análisis", sino mantener una conversación estructurada en la que la IA proponía, el analista cuestionaba, la IA refinaba y el analista validaba. El resultado de esa conversación es un análisis más robusto, mejor documentado y más reutilizable que el que habríamos producido en solitario.
Cómo aprovechar este repositorio
El código completo, los prompts y la documentación están disponibles en el repositorio público del proyecto. Distintos perfiles pueden aprovecharlo de formas distintas:
- Si estudias análisis de datos: abre directamente el notebook en Google Colab y recorre cada celda en orden. Para cada visualización, consulta el prompt correspondiente en prompts/visualizacion/.
- Si trabajas como científico de datos: revisa specs/001-carburantes-ia/plan.md, donde están documentadas las decisiones arquitectónicas y las lecciones aprendidas. Los snippets de prompts/ son reutilizables tal cual en otros proyectos.
- Si te interesa la metodología de prompt engineering: el patrón "describe – cuestiona – refina – valida" está documentado caso por caso a lo largo de los prompts. Es replicable en cualquier dominio: finanzas, salud, marketing o cualquier análisis de datos abiertos.
Conclusión
El ejercicio que hemos presentado muestra que la IA generativa, utilizada con criterio, puede acelerar de manera notable el análisis de datos abiertos sin sacrificar rigor metodológico. Las cinco fases recorridas —ingesta, limpieza, exploración, ingeniería de variables y análisis de impacto— siguen siendo las mismas que en un flujo tradicional, pero la dinámica de trabajo cambia: pasamos de escribir código a describir intenciones y validar resultados.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
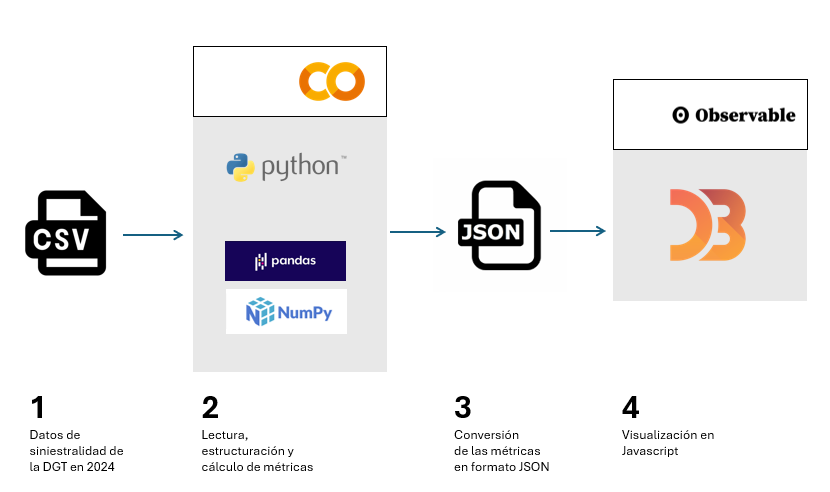
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
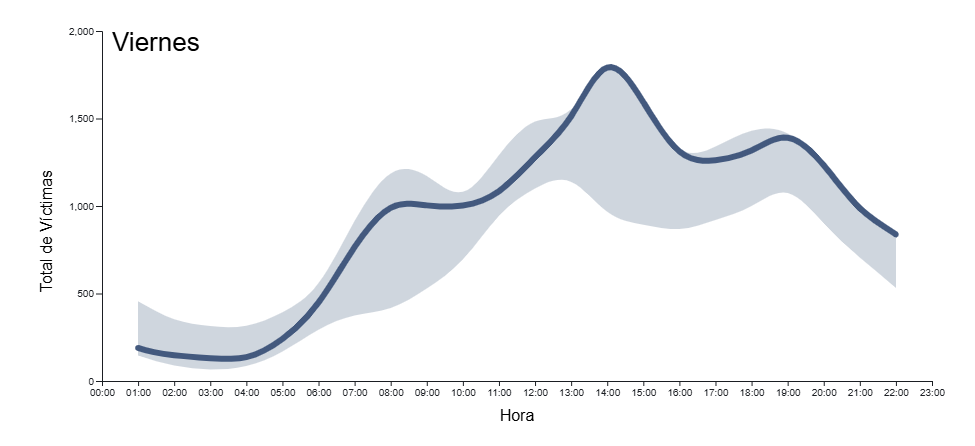
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
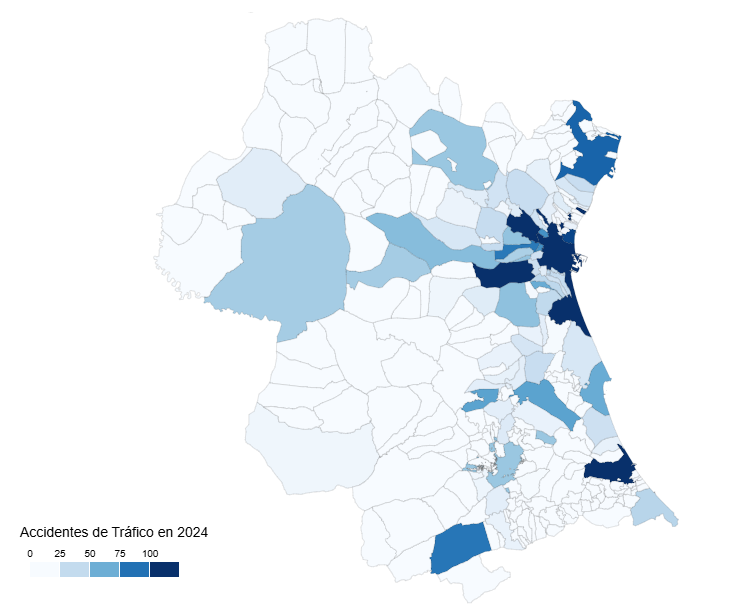
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
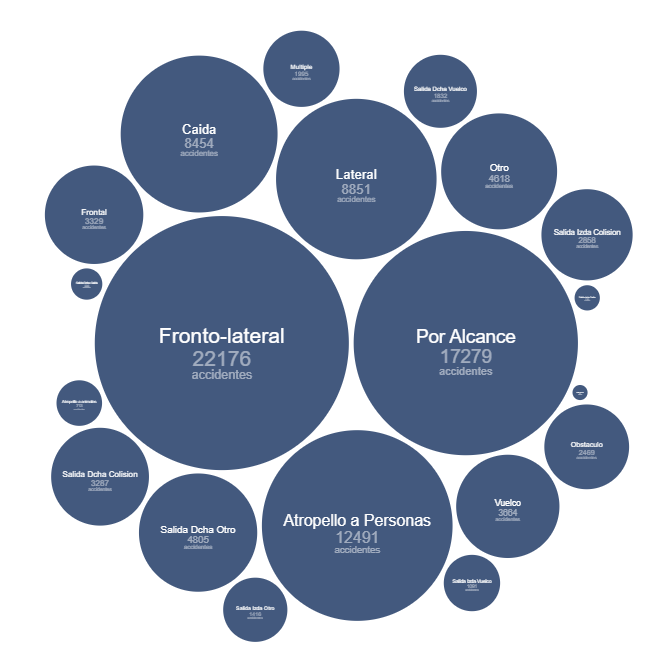
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
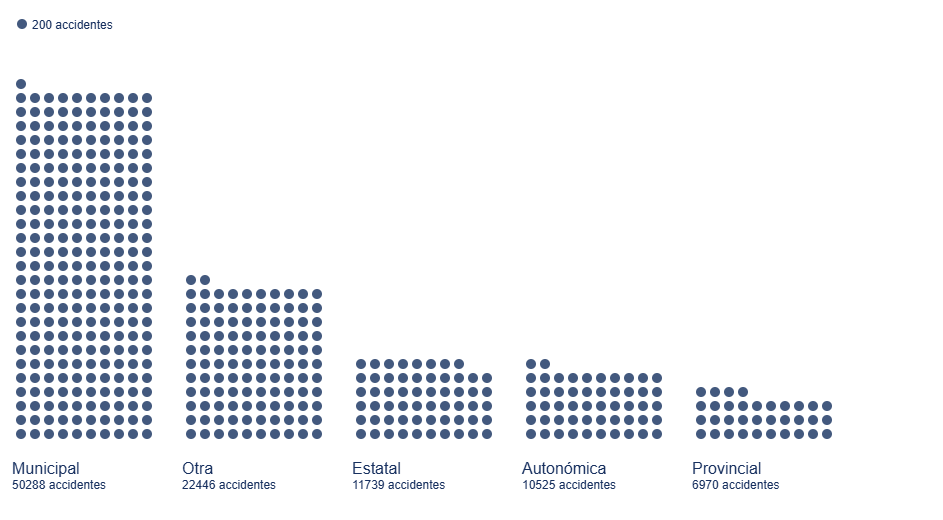
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
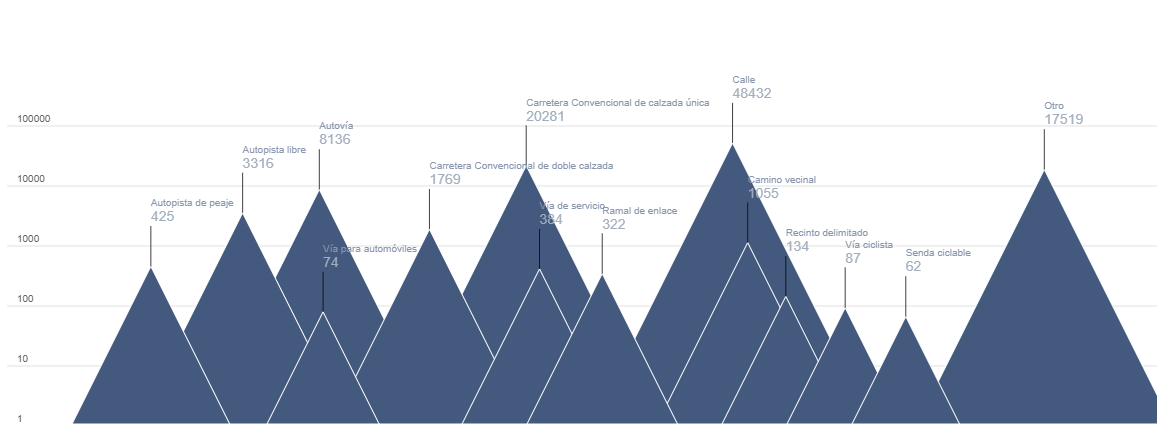
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Documentación
Los agentes de IA (como los de Google ADK, LangChain, etc.) son "cerebros". Pero un cerebro sin "manos" no puede actuar en el mundo real (consultar APIs, buscar en bases de datos, etc.). Esas "manos" son las herramientas.
El desafío es: ¿cómo conectas el cerebro con las manos de forma estándar, desacoplada y escalable? La respuesta es el Model Context Protocol (MCP).
Como ejercicio práctico, construiremos un sistema de agente conversacional que permite explorar el Catálogo Nacional de datos abiertos albergado en datos.gob.es mediante preguntas en lenguaje natural, facilitando así el acceso a datos públicos.
En este ejercicio práctico, el objetivo principal es ilustrar, paso a paso, cómo construir un servidor de herramientas independiente que hable el protocolo MCP.
Para hacer este ejercicio tangible y no solo teórico, usaremos, FastMCP para construir el servidor. Para probar que nuestro servidor funciona, crearemos un agente simple con Google ADK que lo consuma. El caso de uso (consultar la API de datos.gob.es) ilustra esta conexión entre herramientas y agentes. El verdadero aprendizaje es la arquitectura, que podrías reutilizar para cualquier API o base de datos.
A continuación se muestran las tecnologías que usaremos y un esquema de cómo están realizados entre sí los diferentes componentes
- FastMCP (mcp.server.fastmcp): implementación ligera del protocolo MCP que permite crear servidores de herramientas con muy poco código mediante decoradores Python. Es el 'protagonista' del ejercicio.
- Google ADK (Agent Development Kit): framework para definir el agente de IA, su prompt y conectarlo a las herramientas. Es el 'cliente' que prueba nuestro servidor.
- FastAPI: para servir el agente como una API REST con interfaz web interactiva.
- httpx: para realizar llamadas asíncronas a la API externa de datos.gob.es.
- Docker y Docker Compose: para paquetizar y orquestar los dos microservicios, permitiendo que se ejecuten y comuniquen de forma aislada.

Figura 1. Arquitectura desacoplada con comunicación MCP.
El diagrama ilustra una arquitectura desacoplada dividida en cuatro componentes principales que se comunican mediante el protocolo MCP. Cuando el usuario realiza una consulta en lenguaje natural, el Agente ADK (basado en Google Gemini) procesa la intención y se comunica con el servidor MCP a través del Protocolo MCP, que actúa como intermediario estandarizado. El servidor MCP expone cuatro herramientas especializadas (buscar datasets, listar temáticas, buscar por temática y obtener detalles) que encapsulan toda la lógica de negocio para interactuar con la API externa de datos.gob.es. Una vez que las herramientas ejecutan las consultas necesarias y reciben los datos del catálogo nacional, el resultado se propaga de vuelta al agente, que finalmente genera una respuesta comprensible para el usuario, completando así el ciclo de comunicación entre el "cerebro" (agente) y las "manos" (herramientas).
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
La arquitectura: servidor MCP y agente consumidor
La clave de este ejercicio es entender la relación cliente-servidor:
- El Servidor (Backend): es el protagonista de este ejercicio. Su único trabajo es definir la lógica de negocio (las "herramientas") y exponerlas al mundo exterior usando el "contrato" estándar de MCP. Es el responsable de encapsular toda la lógica de comunicación con la API de datos.gob.es.
- El Agente (Frontend): es el "cliente" o "consumidor" de nuestro servidor. Su rol en este ejercicio es probar que nuestro servidor MCP funciona. Lo usamos para conectarnos, descubrir las herramientas que el servidor ofrece y llamarlas.
- El Protocolo MCP: es el "lenguaje" o "contrato" que permite que el agente y el servidor se entiendan sin necesidad de conocer los detalles internos del otro.
Proceso de desarrollo
El núcleo del ejercicio se divide en tres partes: crear el servidor, crear un cliente para probarlo y ejecutarlos.
1. El servidor de herramientas (el backend con MCP)
Aquí es donde reside la lógica de negocio y el foco de este tutorial. En el archivo principal (server.py), definimos funciones Python simples y usamos el decorador @mcp.tool de FastMCP para exponerlas como 'herramientas' consumibles.
La description que añadimos al decorador es crucial, ya que es la documentación que cualquier cliente MCP (incluyendo nuestro agente ADK) leerá para saber cuándo y cómo usar cada herramienta.
Las herramientas que definiremos en el ejercicio son:
- buscar_datasets(titulo: str): para buscar datasets por palabras clave en el título.
- listar_tematicas(): para descubrir qué categorías de datos existen.
- buscar_por_tematica(tematica_id: str): para encontrar datasets de un tema específico.
-
obtener_detalle_dataset(dataset_id: str): para obtener la información completa de un dataset.
2. El agente consumidor (el frontend con Google ADK)
Una vez construido nuestro servidor MCP, necesitamos una forma de probarlo. Aquí es donde entra Google ADK. Lo usamos para crear un "agente consumidor" simple.
La magia de la conexión ocurre en el argumento tools. En lugar de definir las herramientas localmente, simplemente le pasamos la URL de nuestro servidor MCP. El agente, al iniciarse, consultará esa URL, leerá el "contrato" MCP y sabrá automáticamente qué herramientas tiene disponibles y cómo usarlas.
# Ejemplo de configuración en agent.py
root_agent = LlmAgent(
...
instruction="Eres un asistente especializado en datos.gob.es...",
tools=[
MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="http://mcp-server:8000/mcp",
),
)
]
)3. Orquestación con Docker Compose
Finalmente, para ejecutar nuestro Servidor MCP y el agente consumidor juntos, usamos docker-compose.yml. Docker Compose se encarga de construir las imágenes de cada servicio, crear una red privada para que se comuniquen (por eso el agente puede llamar a http://mcp-server:8000) y exponer los puertos necesarios.
Probando el servidor MCP en acción
Una vez que ejecutamos docker-compose up --build, podemos acceder a la interfaz web del agente (http://localhost:8080).
El objetivo de esta prueba no es solo ver si el bot responde bien, sino verificar que nuestro servidor MCP funciona correctamente y que el agente ADK (nuestro cliente de prueba) puede descubrir y usar las herramientas que este expone.
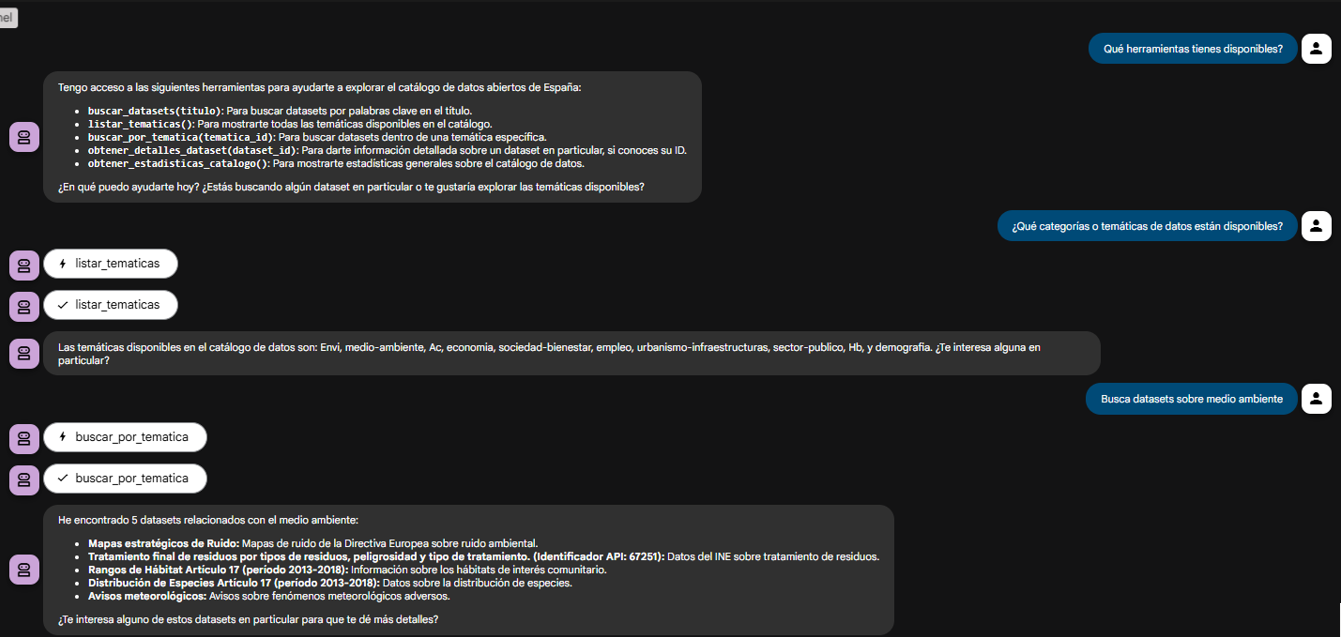
Figura 2. Pantalla del agente demostrando sus herramientas.
El verdadero poder del desacoplamiento se ve cuando el agente encadena lógicamente las herramientas que nuestro servidor le proveyó.
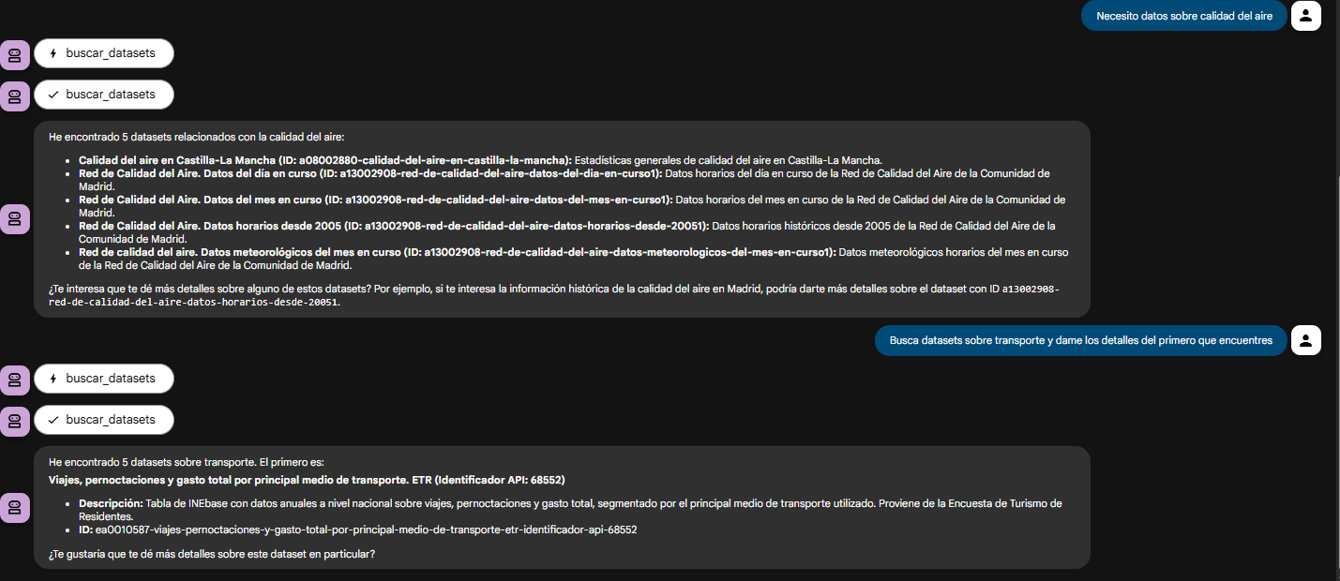
Figura 3. Pantalla del agente demostrando el uso conjunto de las herramientas.
¿Qué puedes aprender?
El objetivo de este ejercicio es aprender los fundamentos de una arquitectura de agentes moderna, centrándonos en el servidor de herramientas. En concreto:
- Cómo construir un servidor MCP: cómo crear un servidor de herramientas desde cero que hable MCP, usando decoradores como @mcp.tool.
- El patrón de una arquitectura desacoplada: el patrón fundamental de separar el 'cerebro' (LLM) de las 'herramientas' (lógica de negocio).
- Descubrimiento dinámico de herramientas: cómo un agente (en este caso, de ADK) puede conectarse dinámicamente a un servidor MCP para descubrir y consumir herramientas.
- Integración de API externas: el proceso de 'envolver' una API compleja (como la de datos.gob.es) en funciones simples dentro de un servidor de herramientas.
- Orquestación con Docker: cómo gestionar un proyecto de microservicios para desarrollo.
Conclusiones y futuro
Hemos construido un servidor de herramientas MCP robusto y funcional. El verdadero valor de este ejercicio es el cómo: una arquitectura escalable centrada en un servidor de herramientas que habla un protocolo estándar.
Esta arquitectura basada en MCP es increíblemente flexible. El caso de datos.gob.es es solo un ejemplo. Podríamos fácilmente:
- Cambiar el caso de uso: reemplazar el server.py por uno que conecte a una base de datos interna o a la API de Spotify, y cualquier agente que hable MCP (no solo ADK) podría consumirlo.
- Cambiar el "cerebro": cambiar el agente ADK por un agente de LangChain o cualquier otro cliente MCP, y nuestro servidor de herramientas seguiría funcionando sin cambios.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades se centran en mejorar el servidor MCP:
- Implementar más herramientas: añadir filtros por formato, publicador o fecha al servidor MCP.
- Integrar caché: usar Redis en el servidor MCP para cachear las respuestas de la API y mejorar la velocidad.
- Añadir persistencia: guardar el historial de chat en una base de datos (esto sí sería en el lado del agente).
Más allá de estas mejoras técnicas, esta arquitectura abre la puerta a múltiples aplicaciones en contextos muy diversos.
- Periodistas y académicos pueden disponer de asistentes de investigación que les ayuden a descubrir conjuntos de datos relevantes en segundos.
- Organizaciones de transparencia pueden construir herramientas de monitorización que detecten automáticamente nuevas publicaciones de datos de contratación pública o presupuestos.
- Consultoras y equipos de inteligencia de negocio pueden desarrollar sistemas que crucen información de múltiples fuentes gubernamentales para elaborar informes sectoriales.
- Incluso en el ámbito educativo, esta arquitectura sirve como base didáctica para enseñar conceptos avanzados de programación asíncrona, integración de API y diseño de agentes de IA.
El patrón que hemos construido —un servidor de herramientas desacoplado que habla un protocolo estándar— es la base sobre la que puedes desarrollar soluciones adaptadas a tus necesidades específicas, independientemente del dominio o la fuente de datos con la que trabajes.
Documentación
En el ecosistema del sector público, las subvenciones representan uno de los mecanismos más importantes para impulsar proyectos, empresas y actividades de interés general. Sin embargo, entender cómo se distribuyen estos fondos, qué organismos convocan ayudas más voluminosas o cómo varía el presupuesto según la región o los beneficiarios no es trivial cuando se trabaja con cientos de miles de registros.
En esta línea, presentamos un nuevo ejercicio práctico de la serie “Ejercicios de datos paso a paso”, en el que aprenderemos a explorar y modelar datos abiertos utilizando Apache Spark, una de las plataformas más extendidas para el procesamiento distribuido y el machine learning a gran escala.
En este laboratorio trabajaremos con datos reales del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas (BDNS) y construiremos un modelo capaz de predecir el rango de presupuesto de nuevas convocatorias en función de sus características principales.
Todo el código utilizado está disponible en el correspondiente repositorio de GitHub para que puedas ejecutarlo, entenderlo y adaptarlo a tus propios proyectos.
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
Contexto: ¿por qué analizar las subvenciones públicas?
La BDNS recoge información detallada sobre cientos de miles de convocatorias publicadas por distintas administraciones españolas: desde ministerios y consejerías autonómicas hasta diputaciones y ayuntamientos. Este conjunto de datos es una fuente extraordinariamente valiosa para:
-
analizar la evolución del gasto público,
-
entender qué organismos son más activos en ciertas áreas,
-
identificar patrones en los tipos de beneficiarios,
-
y estudiar la distribución presupuestaria según sector o territorio.
En nuestro caso, utilizaremos el dataset para abordar una pregunta muy concreta, pero de gran interés práctico:
¿Podemos predecir el rango de presupuesto de una convocatoria a partir de sus características administrativas?
Esta capacidad facilitaría tareas de clasificación inicial, apoyo a la toma de decisiones o análisis comparativos dentro de una administración pública.
Objetivo del ejercicio
El objetivo del laboratorio es doble:
- Aprender a manejar Spark de forma práctica:
- Cargar un dataset real de gran volumen
- Realizar transformaciones y limpieza
- Manipular columnas categóricas y numéricas
- Estructurar un pipeline de machine learning
2. Construir un modelo predictivo
Entrenaremos un clasificador capaz de estimar si una convocatoria pertenece a uno de estos rangos de presupuesto bajo (hasta 20 k€), medio (entre 20 y 150k€) o alto (superior a 150k€), basándonos para ello en variables como:
- Organismo concedente
- Comunidad Autónoma
- Tipo de beneficiario
- Año de publicación
- Descripciones administrativas
Recursos utilizados
Para completar este ejercicio empleamos:
Herramientas analíticas
- Python, lenguaje principal del proyecto
- Google Colab, para ejecutar Spark y crear Notebooks de forma sencilla
- PySpark, para el procesamiento de datos en las etapas de limpieza y modelado
- Pandas, para pequeñas operaciones auxiliares
- Plotly, para algunas visualizaciones interactivas
Datos
Dataset oficial del Sistema Nacional de Publicidad de Subvenciones (BDNS), descargado desde el portal de subvenciones del Ministerio de Hacienda.
Los datos utilizados en este ejercicio fueron descargados el 28 de agosto de 2025. La reutilización de los datos del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas está sujeta a las condiciones legales recogidas en https://www.infosubvenciones.es/bdnstrans/GE/es/avisolegal.
Desarrollo del ejercicio
El proyecto se divide en varias fases, siguiendo el flujo natural de un caso real de data science.
5.1. Volcado y transformación de datos
En este primer apartado vamos a descargar automáticamente el dataset de subvenciones desde la API del portal del Sistema Nacional de Publicidad de Subvenciones (BDNS). Posteriormente transformaremos los datos a un formato optimizado como Parquet (formato de datos columnar) para facilitar su exploración y análisis.
En este proceso utilizaremos algunos conceptos complejos, como:
-
Funciones asíncronas: permite procesar en paralelo dos o más operaciones independientes, lo que facilita hacer más eficiente el proceso.
-
Escritor rotativo: cuando se supera un límite de cantidad de información el fichero que se está procesando se cierra y se abre uno nuevo con un índice autoincremental (a continuación del anterior). Esto evita procesar ficheros demasiado grandes y mejora la eficiencia.
Figura 1. Captura de la API del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas
5.2. Análisis exploratorio
El objetivo de esta fase es obtener una primera idea de las características de los datos y de su calidad.
Analizaremos entre otros, aspectos como:
- Qué tipos de subvenciones tienen mayor número de convocatorias.
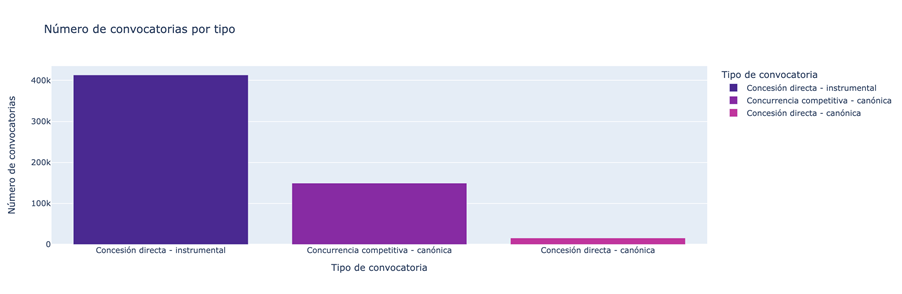
Figura 2. Tipos de subvenciones con mayor número de convocatorias.
- Cuál es la distribución de las subvenciones en función de su finalidad (i.e. Cultura, Educación, Fomento del empleo…).
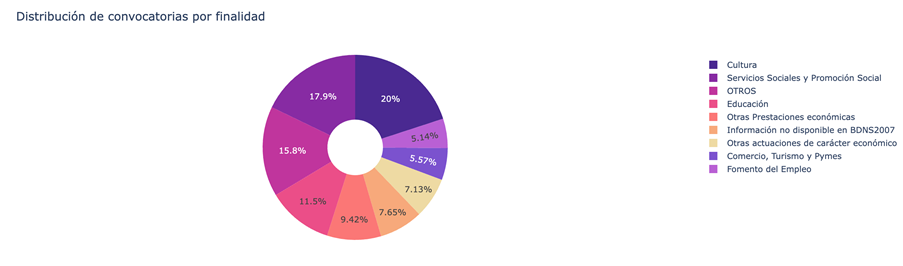
Figura 3. Distribución de las subvenciones en función de su finalidad.
- Qué finalidades agregan un mayor volumen presupuestario.
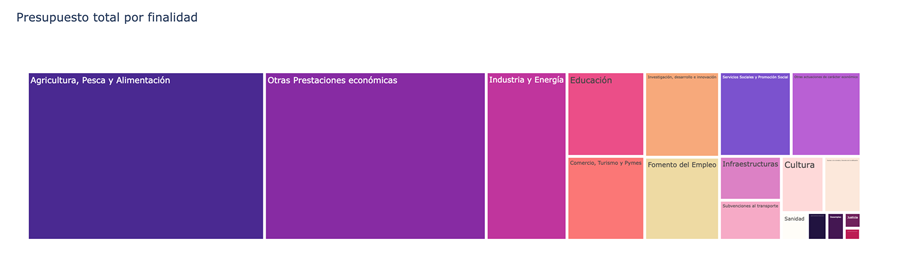
Figura 4. Finalidades con mayor volumen presupuestario.
5.3. Modelado: construcción del clasificador de presupuesto
Llegados a este punto, entramos en la parte más analítica del ejercicio: enseñar a una máquina a predecir si una nueva convocatoria tendrá un presupuesto bajo, medio o alto a partir de sus características administrativas. Para conseguirlo, diseñamos un pipeline completo de machine learning en Spark que nos permite transformar los datos, entrenar el modelo y evaluarlo de forma uniforme y reproducible.
Primero preparamos todas las variables —muchas de ellas categóricas, como el órgano convocante— para que el modelo pueda interpretarlas. Después combinamos toda esa información en un único vector que sirve como punto de partida para la fase de aprendizaje.
Con esa base construida, entrenamos un modelo de clasificación que aprende a distinguir patrones sutiles en los datos: qué organismos tienden a publicar convocatorias más voluminosas o cómo influyen elementos administrativos específicos en el tamaño de una ayuda.
Una vez entrenado, analizamos su rendimiento desde distintos ángulos. Evaluamos su capacidad para clasificar correctamente los tres rangos de presupuesto y analizamos su comportamiento mediante métricas como la accuracy o la matriz de confusión.
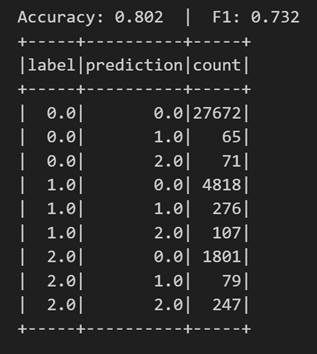
Figura 5. Métricas accuracy.
Pero no nos quedamos ahí: también estudiamos qué variables han tenido mayor peso en las decisiones del modelo, lo que nos permite entender qué factores parecen más determinantes a la hora de anticipar el presupuesto de una convocatoria.
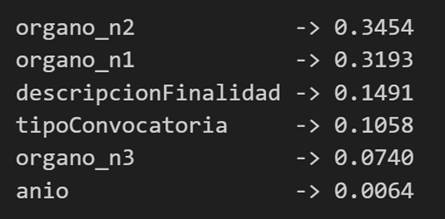
Figura 6. Variables que han tenido mayor peso en las decisiones del modelo.
Conclusiones del ejercicio
Este laboratorio nos permitirá comprobar cómo Spark simplifica el procesamiento y modelado de datos de gran volumen, especialmente útiles en entornos donde las administraciones generan miles de registros al año, y conocer mejor el sistema de subvenciones tras analizar algunos aspectos clave de la organización de estas convocatorias.
¿Quieres realizar el ejercicio?
Si te interesa profundizar en el uso de Spark y en el análisis avanzado de datos públicos, puedes acceder al repositorio y ejecutar el Notebook completo paso a paso.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En un mundo donde la inmediatez cobra cada vez más importancia, el comercio predictivo se ha convertido en una herramienta clave para anticipar comportamientos de consumo, optimizar decisiones y ofrecer experiencias personalizadas. Ya no se trata solo de reaccionar ante las necesidades del cliente, sino de predecir lo que quiere incluso antes de que lo sepa.
En este artículo vamos a explicar qué es el comercio predictivo y la importancia de los datos abiertos en ello, incluyendo ejemplos reales.
¿Qué es el comercio predictivo?
El comercio predictivo es una estrategia basada en el análisis de datos para anticipar las decisiones de compra de los consumidores. Utiliza algoritmos de inteligencia artificial y modelos estadísticos para identificar patrones de comportamiento, preferencias y momentos clave en el ciclo de consumo. Gracias a ello, las empresas pueden conocer información relevante sobre qué productos serán más demandados, cuándo y dónde se realizará una compra o qué clientes tienen mayor probabilidad de adquirir una determinada marca.
Esto es de gran importancia en un mercado como el actual, donde existe una saturación de productos y competencia. El comercio predictivo permite a las empresas ajustar inventarios, precios, campañas de marketing o la logística en tiempo real, convirtiéndose en una gran ventaja competitiva.
El papel de los datos abiertos en el comercio predictivo
Estos modelos se alimentan de grandes volúmenes de datos: históricos de compra, navegación web, ubicación o comentarios en redes sociales, entre otros. Pero cuanto más precisos y diversos sean los datos, más afinadas serán las predicciones. Aquí es donde los datos abiertos juegan un papel fundamental, ya que permiten añadir nuevas variables a tener en cuenta a la hora de definir el comportamiento del consumidor. Entre otras cuestiones, los datos abiertos pueden ayudarnos a:
- Enriquecer modelos de predicción con información externa como datos demográficos, movilidad urbana o indicadores económicos.
- Detectar patrones regionales que influyen en el consumo, como, por ejemplo, el impacto del clima en la venta de ciertos productos estacionales.
- Diseñar estrategias más inclusivas al incorporar datos públicos sobre hábitos y necesidades de distintos grupos sociales.
La siguiente tabla muestra ejemplos de conjuntos de datos disponibles en datos.gob.es que pueden servir para estas tareas, a nivel nacional, aunque muchas comunidades autónomas y ayuntamientos también publican este tipo de datos junto a otros también de interés.
| Conjunto de datos | Ejemplo | Posible uso |
|---|---|---|
| Padrón municipal por edad y sexo | Instituto Nacional de Estadística (INE) | Segmenta poblaciones por territorio, edad y género. Es útil para personalizar campañas en base a la población mayoritaria de cada municipio o prever la demanda por perfil demográfico. |
| Encuesta de presupuestos familiares | Instituto Nacional de Estadística (INE) | Ofrece información sobre el gasto medio por hogar en diferentes categorías. Puede ayudar a anticipar patrones de consumo por nivel socioeconómico. |
| Índice de precio de consumo (IPC) | Instituto Nacional de Estadística (INE) | Desagrega el IPC por territorio, midiendo cómo varían los precios de bienes y servicios en cada provincia española. Tiene utilidad para ajustar precios y estrategias de penetración de mercado. |
| Avisos meteorológicos en tiempo real | Ministerio para la Transición Ecológica y Reto Demográfico | Alerta de fenómenos meteorológicos adversos. Permite correlacionar clima con ventas de productos (ropa, bebidas, calefacción, etc.). |
| Estadísticas de educación y alfabetización digital | Instituto Nacional de Estadística (INE) | Ofrece información sobre el uso de Internet en los últimos 3 meses. Permite identificar brechas digitales y adaptar las estrategias de comunicación o formación. |
| Datos sobre estancias turísticas | Instituto Nacional de Estadística (INE) | Informa sobre la estancia media de turistas por comunidades autónomas. Ayuda a anticipar demanda en zonas con alta afluencia estacional, como productos locales o servicios turísticos. |
| Número de recetas y gasto farmacéutico | Mutualidad General de Funcionarios Civiles del Estado (MUFACE) | Ofrece información del consumo de medicamentos por provincia y subgrupos de edad. Facilita la estimación de ventas de otros productos sanitarios y de parafarmacia relacionados al estimar cuántos usuarios irán a la farmacia. |
Figura 1. Tabla comparativa. Fuente: elaboración propia -datos.gob.es.
Casos de uso reales
Desde hace años, ya encontramos empresas que están utilizando este tipo de datos para optimizar sus estrategias comerciales. Veamos algunos ejemplos:
- Uso de datos meteorológicos para optimizar el stock en grandes supermercados
Los grandes almacenes Walmart utilizan algoritmos de IA que incorporan datos meteorológicos (como olas de calor, tormentas o cambios de temperatura) junto a datos históricos de ventas, eventos y tendencias digitales, para prever la demanda a nivel granular y optimizar inventarios. Esto permite ajustar automáticamente el reabastecimiento de productos críticos según patrones climáticos anticipados. Además, Walmart menciona que su sistema considera “datos futuros” como patrones climáticos macro (“macroweather”), tendencias económicas y demografía local para anticipar la demanda y posibles interrupciones en la cadena de suministro.
La firma Tesco también utiliza datos meteorológicos públicos en sus modelos predictivos. Esto le permite anticipar patrones de compra, como que por cada aumento de 10°C en la temperatura, las ventas de barbacoa se incrementan hasta en un 300%. Además, Tesco recibe pronósticos meteorológicos locales hasta tres veces al día, conectándolos con datos sobre 18 millones de productos y el tipo de clientes de cada tienda. Esta información se comparte con sus proveedores para ajustar los envíos y mejorar la eficiencia logística.
- Uso de datos demográficos para decidir la ubicación de locales
Desde hace años Starbucks ha recurrido a la analítica predictiva para planificar su expansión. La compañía utiliza plataformas de inteligencia geoespacial, desarrolladas con tecnología GIS, para combinar múltiples fuentes de información —entre ellas datos abiertos demográficos y socioeconómicos como la densidad de población, el nivel de ingresos, los patrones de movilidad, el transporte público o la tipología de negocios cercanos— junto con históricos de ventas propias. Gracias a esta integración, puede predecir qué ubicaciones tienen mayor potencial de éxito, evitando la competencia entre locales y asegurando que cada nueva tienda se sitúe en el entorno más adecuado.
Domino's Pizza también utilizó modelos similares para analizar si la apertura de un nuevo local en un barrio de Londres tendría éxito y cómo afectaría a otras ubicaciones cercanas, considerando patrones de compra y características demográficas locales.
Este enfoque permite predecir flujos de clientes y maximizar la rentabilidad mediante decisiones de localización más informadas.
- Datos socioeconómicos para fijar precios en base a la demografía
Un ejemplo interesante lo encontramos en SDG Group, consultora internacional especializada en analítica avanzada para retail. La compañía ha desarrollado soluciones que permiten ajustar precios y promociones teniendo en cuenta las características demográficas y socioeconómicas de cada zona -como la base de consumidores, la ubicación o el tamaño del punto de venta-. Gracias a estos modelos es posible estimar la elasticidad de la demanda y diseñar estrategias de precios dinámicos adaptados al contexto real de cada área, optimizando tanto la rentabilidad como la experiencia de compra.
El futuro del comercio predictivo
El auge del comercio predictivo se ha visto impulsado por el avance de la inteligencia artificial y la disponibilidad de datos, tanto abiertos como privados. Desde la elección del lugar ideal para abrir una tienda hasta la gestión eficiente de inventarios, los datos públicos combinados con analítica avanzada permiten anticipar comportamientos y necesidades de los consumidores con una precisión cada vez mayor.
No obstante, aún quedan retos importantes por afrontar: la heterogeneidad de las fuentes de datos, que en muchos casos carecen de estándares comunes; la necesidad de contar con tecnologías e infraestructuras sólidas que permitan integrar la información abierta con los sistemas internos de las empresas; y, por último, el desafío de garantizar un uso ético y transparente, que respete la privacidad de las personas y evite la generación de sesgos en los modelos.
Superar estos retos será clave para que el comercio predictivo despliegue todo su potencial y se convierta en una herramienta estratégica para empresas de todos los tamaños. En este camino, los datos abiertos jugarán un papel fundamental como motor de innovación, transparencia y competitividad en el comercio del futuro.
Blog
Las imágenes sintéticas son representaciones visuales generadas de forma artificial mediante algoritmos y técnicas computacionales, en lugar de capturarse directamente de la realidad con cámaras o sensores. Se producen a partir de distintos métodos, entre los que destacan las redes generativas antagónicas (Generative Adversarial Networks, GAN), los modelos de difusión, y las técnicas de renderizado 3D. Todas ellas permiten crear imágenes de apariencia realista que en muchos casos resultan indistinguibles de una fotografía auténtica.
Cuando se traslada este concepto al campo de la observación de la Tierra, hablamos de imágenes satelitales sintéticas. Estas no se obtienen a partir de un sensor espacial que capta radiación electromagnética real, sino que se generan digitalmente para simular lo que vería un satélite desde la órbita. En otras palabras, en vez de reflejar directamente el estado físico del terreno o la atmósfera en un momento concreto, son construcciones computacionales capaces de imitar el aspecto de una imagen satelital real.
El desarrollo de este tipo de imágenes responde a necesidades prácticas. Los sistemas de inteligencia artificial que procesan datos de teledetección requieren conjuntos muy amplios y variados de imágenes. Las imágenes sintéticas permiten, por ejemplo, recrear zonas de la Tierra poco observadas, simular desastres naturales -como incendios forestales, inundaciones o sequías- o generar condiciones específicas que son difíciles o costosas de capturar en la práctica. De este modo, constituyen un recurso valioso para entrenar algoritmos de detección y predicción en agricultura, gestión de emergencias, urbanismo o monitorización ambiental.
Figura 1. Ejemplo de generación de una imagen satelital sintética.
Su valor no se limita al entrenamiento de modelos. Allí donde no existen imágenes de alta resolución —por limitaciones técnicas, restricciones de acceso o motivos económicos—, la síntesis permite rellenar huecos de información y facilitar estudios preliminares. Por ejemplo, los investigadores pueden trabajar con imágenes sintéticas aproximadas para diseñar modelos de riesgo o simulaciones antes de disponer de datos reales.
Sin embargo, las imágenes satelitales sintéticas también plantean riesgos importantes. La posibilidad de generar escenas muy realistas abre la puerta a la manipulación y a la desinformación. En un contexto geopolítico, una imagen que muestre tropas inexistentes o infraestructuras destruidas podría influir en decisiones estratégicas o en la opinión pública internacional. En el terreno ambiental, se podrían difundir imágenes manipuladas para exagerar o minimizar impactos de fenómenos como la deforestación o el deshielo, con efectos directos en políticas y mercados.
Por ello, conviene diferenciar dos usos muy distintos. El primero es el uso como apoyo, cuando las imágenes sintéticas complementan a las reales para entrenar modelos o realizar simulaciones. El segundo es el uso como falsificación, cuando se presentan deliberadamente como imágenes auténticas con el fin de engañar. Mientras el primer uso impulsa la innovación, el segundo amenaza la confianza en los datos satelitales y plantea un reto urgente de autenticidad y gobernanza.
Riesgos de las imágenes satelitales aplicada a la observación de la Tierra
Las imágenes satelitales sintéticas plantean riesgos significativos cuando se utilizan en vez de imágenes captadas por sensores reales. A continuación, se detallan ejemplos que lo demuestran.
Un nuevo frente de desinformación: “deepfake geography”
El término deepfake geography ya se ha consolidado en la literatura académica y divulgativa para describir imágenes satelitales ficticias, manipuladas con IA, que parecen auténticas, pero no reflejan ninguna realidad existente. Una investigación de la Universidad de Washington, liderada por Bo Zhao, utilizó algoritmos como CycleGAN para modificar imágenes de ciudades reales -por ejemplo, alterando la apariencia de Seattle con edificios inexistentes o transformando Beijing en zonas verdes- lo que pone en evidencia el potencial para generar paisajes falsos convincentes.
Un artículo de la plataforma OnGeo Intelligence (OGC) subraya que estas imágenes no son puramente teóricas, sino amenazas reales que afectan a la seguridad nacional, el periodismo y el trabajo humanitario. Por su parte, el OGC advierte que ya se han observado imágenes satelitales fabricadas, modelos urbanos generados por IA y redes de carreteras sintéticas, y que representan desafíos reales a la confianza pública y operativa.
Implicaciones estratégicas y políticas
Las imágenes satelitales son consideradas "ojos imparciales" sobre el planeta, usadas por gobiernos, medios y organizaciones. Cuando estas imágenes se falsifican, sus consecuencias pueden ser graves:
- Seguridad nacional y defensa: si se presentan infraestructuras falsas o se ocultan otras reales, se pueden desviar análisis estratégicos o inducir decisiones militares equivocadas.
- Desinformación en conflictos o crisis humanitarias: una imagen alterada que muestre incendios, inundaciones o movimientos de tropas falsos puede alterar la respuesta internacional, los flujos de ayuda o la percepción de los ciudadanos, especialmente si se difunde por redes sociales o medios sin verificación.
- Manipulación de imágenes realistas de lugares: no solo las imágenes generales están en juego. Nguyen y colaboradores (2024) demostraron que es posible generar imágenes satelitales sintéticas altamente realistas de instalaciones muy específicas como plantas nucleares.
Crisis de confianza y erosión de la verdad
Durante décadas, las imágenes satelitales han sido percibidas como una de las fuentes más objetivas y fiables de información sobre nuestro planeta. Eran la prueba gráfica que permitía confirmar fenómenos ambientales, seguir conflictos armados o evaluar el impacto de desastres naturales. En muchos casos, estas imágenes se utilizaban como “evidencia imparcial”, difíciles de manipular y fáciles de validar. Sin embargo, la irrupción de las imágenes sintéticas generadas por inteligencia artificial ha empezado a poner en cuestión esa confianza casi inquebrantable.
Hoy en día, cuando una imagen satelital puede ser falsificada con gran realismo, surge un riesgo profundo: la erosión de la verdad y la aparición de una crisis de confianza en los datos espaciales.
La quiebra de la confianza pública
Cuando los ciudadanos ya no pueden distinguir entre una imagen real y una fabricada, se resquebraja la confianza en las fuentes de información. La consecuencia es doble:
- Desconfianza hacia las instituciones: si circulan imágenes falsas de un incendio, una catástrofe o un despliegue militar y luego resultan ser sintéticas, la ciudadanía puede empezar a dudar también de las imágenes auténticas publicadas por agencias espaciales o medios de comunicación. Este efecto “que viene el lobo” genera escepticismo incluso frente a pruebas legítimas.
- Efecto en el periodismo: los medios tradicionales, que han usado históricamente las imágenes satelitales como fuente visual incuestionable, corren el riesgo de perder credibilidad si publican imágenes adulteradas sin verificación. Al mismo tiempo, la abundancia de imágenes falsas en redes sociales erosiona la capacidad de distinguir qué es real y qué no.
- Confusión deliberada: en contextos de desinformación, la mera sospecha de que una imagen pueda ser falsa ya puede bastar para generar duda y sembrar confusión, aunque la imagen original sea completamente auténtica.
A continuación, se resumen los posibles casos de manipulación y riesgo en imágenes satelitales:
| Ámbito | Tipo de manipulación | Riesgo principal | Ejemplo documentado |
|---|---|---|---|
| Conflictos armados | Inserción o eliminación de infraestructuras militares. | Desinformación estratégica; decisiones militares erróneas; pérdida de credibilidad en observación internacional. | Alteraciones demostradas en estudios de deepfake geography donde se añadían carreteras, puentes o edificios ficticios en imágenes satelitales. |
| Cambio climático y medio ambiente | Alteración de glaciares, deforestación o emisiones. | Manipulación de políticas ambientales; retraso en medidas contra el cambio climático; negacionismo. | Estudios han mostrado la capacidad de generar paisajes modificados (bosques en zonas urbanas, cambios en el hielo) mediante GAN. |
| Gestión de emergencias | Creación de desastres inexistentes (incendios, inundaciones). | Mal uso de recursos en emergencias; caos en evacuaciones; pérdida de confianza en agencias. | Investigaciones han demostrado la facilidad de insertar humo, fuego o agua en imágenes satelitales. |
| Mercados y seguros | Falsificación de daños en infraestructuras o cultivos. | Impacto financiero; fraude masivo; litigios legales complejos. | Uso potencial de imágenes falsas para exagerar daños tras desastres y reclamar indemnizaciones o seguros. |
| Derechos humanos y justicia internacional | Alteración de pruebas visuales sobre crímenes de guerra. | Deslegitimación de tribunales internacionales; manipulación de la opinión pública. | Riesgo identificado en informes de inteligencia: imágenes adulteradas podrían usarse para acusar o exonerar a actores en conflictos. |
| Geopolítica y diplomacia | Creación de ciudades ficticias o cambios fronterizos. | Tensiones diplomáticas; cuestionamiento de tratados; propaganda estatal. | Ejemplos de deepfake maps que transforman rasgos geográficos de ciudades como Seattle o Tacoma. |
Figura 2. Tabla con los posibles casos de manipulación y riesgo en imágenes satelitales
Impacto en la toma de decisiones y políticas públicas
Las consecuencias de basarse en imágenes adulteradas van mucho más allá del terreno mediático:
- Urbanismo y planificación: decisiones sobre dónde construir infraestructuras o cómo planificar zonas urbanas podrían tomarse sobre imágenes manipuladas, generando errores costosos y de difícil reversión.
- Gestión de emergencias: si una inundación o un incendio se representan en imágenes falsas, los equipos de emergencia pueden destinar recursos a lugares equivocados, mientras descuidan zonas realmente afectadas.
- Cambio climático y medio ambiente: imágenes adulteradas de glaciares, deforestación o emisiones contaminantes podrían manipular debates políticos y retrasar la implementación de medidas urgentes.
- Mercados y seguros: aseguradoras y empresas financieras que confían en imágenes satelitales para evaluar daños podrían ser engañadas, con consecuencias económicas significativas.
En todos estos casos, lo que está en juego no es solo la calidad de la información, sino la eficacia y legitimidad de las políticas públicas basadas en esos datos.
El juego del gato y el ratón tecnológico
La dinámica de generación y detección de falsificaciones ya se conoce en otros ámbitos, como los deepfakes de vídeo o audio: cada vez que surge un método de generación más realista, se desarrolla un algoritmo de detección más avanzado, y viceversa. En el ámbito de las imágenes satelitales, esta carrera tecnológica tiene particularidades:
- Generadores cada vez más sofisticados: los modelos de difusión actuales pueden crear escenas de gran realismo, integrando texturas de suelo, sombras y geometrías urbanas que engañan incluso a expertos humanos.
- Limitaciones de la detección: aunque se desarrollan algoritmos para identificar falsificaciones (analizando patrones de píxeles, inconsistencias en sombras o metadatos), estos métodos no siempre son fiables cuando se enfrentan a generadores de última generación.
- Coste de la verificación: verificar de forma independiente una imagen satelital requiere acceso a fuentes alternativas o sensores distintos, algo que no siempre está al alcance de periodistas, ONG o ciudadanos.
- Armas de doble filo: las mismas técnicas usadas para detectar falsificaciones pueden ser aprovechadas por quienes las generan, perfeccionando aún más las imágenes sintéticas y haciendo más difícil diferenciarlas.
De la prueba visual a la prueba cuestionada
El impacto más profundo es cultural y epistemológico: lo que antes se asumía como una prueba objetiva ahora se convierte en un elemento sujeto a duda. Si las imágenes satelitales dejan de ser percibidas como evidencia fiable, se debilitan narrativas fundamentales en torno a la verdad científica, la justicia internacional y la rendición de cuentas política.
- En conflictos armados, una imagen de satélite que muestre posibles crímenes de guerra puede ser descartada bajo la acusación de ser un deepfake.
- En tribunales internacionales, pruebas basadas en observación satelital podrían perder peso frente a la sospecha de manipulación.
- En el debate público, el relativismo de “todo puede ser falso” puede usarse como arma retórica para deslegitimar incluso la evidencia más sólida.
Estrategias para garantizar autenticidad
La crisis de confianza en las imágenes satelitales no es un problema aislado del sector geoespacial, sino que forma parte de un fenómeno más amplio: la desinformación digital en la era de la inteligencia artificial. Así como los deepfakes de vídeo han puesto en cuestión la validez de pruebas audiovisuales, la proliferación de imágenes satelitales sintéticas amenaza con debilitar la última frontera de datos percibidos como objetivos: la mirada imparcial desde el espacio.
Garantizar la autenticidad de estas imágenes exige una combinación de soluciones técnicas y mecanismos de gobernanza, capaces de reforzar la trazabilidad, la transparencia y la responsabilidad en toda la cadena de valor de los datos espaciales. A continuación, se describen las principales estrategias en desarrollo.
Metadatos robustos: registrar el origen y la cadena de custodia
Los metadatos constituyen la primera línea de defensa frente a la manipulación. En imágenes satelitales, deben incluir información detallada sobre:
- El sensor utilizado (tipo, resolución, órbita).
- El momento exacto de la adquisición (fecha y hora, con precisión temporal).
- La localización geográfica precisa (sistemas de referencia oficiales).
- La cadena de procesado aplicada (correcciones atmosféricas, calibraciones, reproyecciones).
Registrar estos metadatos en repositorios seguros permite reconstruir la cadena de custodia, es decir, el historial de quién, cómo y cuándo ha manipulado una imagen. Sin esta trazabilidad, resulta imposible distinguir entre imágenes auténticas y falsificadas.
EJEMPLO: el programa Copernicus de la Unión Europea ya implementa metadatos estandarizados y abiertos para todas sus imágenes Sentinel, lo que facilita auditorías posteriores y confianza en el origen.
Firmas digitales y blockchain: garantizar la integridad
Las firmas digitales permiten verificar que una imagen no ha sido alterada desde su captura. Funcionan como un sello criptográfico que se aplica en el momento de adquisición y se valida en cada uso posterior.
La tecnología blockchain ofrece un nivel adicional de garantía: almacenar los registros de adquisición y modificación en una cadena inmutable de bloques. De esta manera, cualquier cambio en la imagen o en sus metadatos quedaría registrado y sería fácilmente detectable.
EJEMPLO: el proyecto ESA – Trusted Data Framework explora el uso de blockchain para proteger la integridad de datos de observación de la Tierra y reforzar la confianza en aplicaciones críticas como cambio climático y seguridad alimentaria.
Marcas de agua invisible: señales ocultas en la imagen
El marcado de agua digital consiste en incrustar señales imperceptibles en la propia imagen satelital, de modo que cualquier alteración posterior se pueda detectar automáticamente.
- Puede hacerse a nivel de píxel, modificando ligeramente patrones de color o luminancia.
- Se combina con técnicas criptográficas para reforzar su validez.
- Permite validar imágenes incluso si han sido recortadas, comprimidas o reprocesadas.
EJEMPLO: en el sector audiovisual, las marcas de agua se usa desde hace años en la protección de contenidos digitales. Su adaptación a imágenes satelitales está en fase experimental, pero podría convertirse en una herramienta estándar de verificación.
Estándares abiertos (OGC, ISO): confianza mediante interoperabilidad
La estandarización es clave para garantizar que las soluciones técnicas se apliquen de forma coordinada y global.
- OGC (Open Geospatial Consortium) trabaja en estándares para la gestión de metadatos, la trazabilidad de datos geoespaciales y la interoperabilidad entre sistemas. Su trabajo en API geoespaciales y metadatos FAIR (Findable, Accessible, Interoperable, Reusable) es esencial para establecer prácticas comunes de confianza.
- ISO desarrolla normas sobre gestión de la información y autenticidad de registros digitales que también pueden aplicarse a imágenes satelitales.
EJEMPLO: el OGC Testbed-19 incluyó experimentos específicos sobre autenticidad de datos geoespaciales, probando enfoques como firmas digitales y certificados de procedencia.
Verificación cruzada: combinar múltiples fuentes
Un principio básico para detectar falsificaciones es contrastar fuentes. En el caso de imágenes satelitales, esto implica:
- Comparar imágenes de diferentes satélites (ej. Sentinel-2 vs. Landsat-9).
- Usar distintos tipos de sensores (ópticos, radar SAR, hiperespectrales).
- Analizar series temporales para verificar la consistencia en el tiempo.
EJEMPLO: la verificación de daños en Ucrania tras el inicio de la invasión rusa en 2022 se realizó mediante la comparación de imágenes de varios proveedores (Maxar, Planet, Sentinel), asegurando que los hallazgos no se basaban en una sola fuente.
IA contra IA: detección automática de falsificaciones
La misma inteligencia artificial que permite crear imágenes sintéticas se puede utilizar para detectarlas. Las técnicas incluyen:
- Análisis forense de píxeles: identificar patrones generados por GAN o modelos de difusión.
- Redes neuronales entrenadas para distinguir entre imágenes reales y sintéticas en función de texturas o distribuciones espectrales.
- Modelos de inconsistencias geométricas: detectar sombras imposibles, incoherencias topográficas o patrones repetitivos.
EJEMPLO: investigadores de la Universidad de Washington y otros grupos han demostrado que algoritmos específicos pueden detectar falsificaciones satelitales con una precisión superior al 90% en condiciones controladas.
Experiencias actuales: iniciativas globales
Varios proyectos internacionales ya trabajan en mecanismos para reforzar la autenticidad:
- Coalition for Content Provenance and Authenticity (C2PA): una alianza entre Adobe, Microsoft, BBC, Intel y otras organizaciones para desarrollar un estándar abierto de procedencia y autenticidad de contenidos digitales, incluyendo imágenes. Su modelo se puede aplicar directamente al sector satelital.
- Trabajo del OGC: la organización impulsa el debate sobre confianza en datos geoespaciales y ha destacado la importancia de garantizar la trazabilidad de imágenes satelitales sintéticas y reales (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) en EE. UU. ha reconocido públicamente la amenaza de imágenes sintéticas en defensa y está impulsando colaboraciones con academia e industria para desarrollar sistemas de detección.
Hacia un ecosistema de confianza
Las estrategias descritas no deben entenderse como alternativas, sino como capas complementarias en un ecosistema de confianza:
|
Id |
Capas |
¿Qué aportan? |
|---|---|---|
| 1 | Metadatos robustos (origen, sensor, cadena de custodia) |
Garantizan trazabilidad |
| 2 | Firmas digitales y blockchain (integridad de datos) |
Aseguran integridad |
| 3 | Marcas de agua invisible (señales ocultas) |
Añade un nivel oculto de protección |
| 4 | Verificación cruzada (múltiples satélites y sensores) |
Valida con independencia |
| 5 | IA contra IA (detector de falsificaciones) |
Responde a amenazas emergentes |
| 6 | Gobernanza internacional (responsabilidad, marcos legales) |
Articula reglas claras de responsabilidad |
Figura 3. Capas para garantizar la confianza en las imágenes sintéticas satelitales
El éxito dependerá de que estos mecanismos se integren de manera conjunta, bajo marcos abiertos y colaborativos, y con la implicación activa de agencias espaciales, gobiernos, sector privado y comunidad científica.
Conclusiones
Las imágenes sintéticas, lejos de ser únicamente una amenaza, representan una herramienta poderosa que, bien utilizada, puede aportar un valor significativo en ámbitos como la simulación, el entrenamiento de algoritmos o la innovación en servicios digitales. El problema surge cuando estas imágenes se presentan como reales sin la debida transparencia, alimentando la desinformación o manipulando la percepción pública.
El reto, por tanto, es doble: aprovechar las oportunidades que ofrece la síntesis de datos visuales para avanzar en ciencia, tecnología y gestión, y minimizar los riesgos asociados al mal uso de estas capacidades, especialmente en forma de deepfakes o falsificaciones deliberadas.
En el caso particular de las imágenes satelitales, la confianza adquiere una dimensión estratégica. De ellas dependen decisiones críticas en seguridad nacional, respuesta a desastres, políticas ambientales y justicia internacional. Si la autenticidad de estas imágenes se pone en duda, se compromete no solo la fiabilidad de los datos, sino también la legitimidad de las decisiones basadas en ellos.
El futuro de la observación de la Tierra estará condicionado por nuestra capacidad de garantizar la autenticidad, transparencia y trazabilidad en toda la cadena de valor: desde la adquisición de los datos hasta su difusión y uso final. Las soluciones técnicas (metadatos robustos, firmas digitales, blockchain, marcas de agua, verificación cruzada e IA para detección de falsificaciones), combinadas con marcos de gobernanza y cooperación internacional, serán la clave para construir un ecosistema de confianza.
En definitiva, debemos asumir un principio rector sencillo pero contundente:
“Si no podemos confiar en lo que vemos desde el espacio, ponemos en riesgo nuestras decisiones en la Tierra.”
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La ciencia de datos se ha consolidado como un pilar de la toma de decisiones basada en evidencias en sectores públicos y privados. En este contexto, surge la necesidad de una guía práctica y universal que trascienda modas tecnológicas y proporcione principios sólidos y aplicables. La presente guía ofrece un decálogo de buenas prácticas que acompaña al científico de datos a lo largo de todo el ciclo de vida de un proyecto, desde la conceptualización del problema hasta la evaluación ética del impacto.
- Comprender el problema antes de mirar los datos. La clave inicial es definir claramente el contexto, objetivos, restricciones e indicadores de éxito. Un framing sólido evita errores posteriores.
- Conocer los datos en profundidad. Más allá de las variables, implica analizar su origen, trazabilidad y posibles sesgos. La auditoría de datos es esencial para garantizar representatividad y fiabilidad.
- Cuidar la calidad. Sin datos limpios no hay ciencia. Técnicas de EDA, imputación, normalización y control de métricas de calidad permiten construir bases sólidas y reproducibles.
- Documentar y versionar. La reproducibilidad es condición científica. Notebooks, pipelines, control de versiones y prácticas de MLOps aseguran trazabilidad y replicabilidad de procesos y modelos.
- Elegir el modelo adecuado. No siempre gana la sofisticación: la decisión debe equilibrar rendimiento, interpretabilidad, costes y restricciones operativas.
- Medir con sentido. Las métricas deben alinearse con los objetivos. Validación cruzada, control del data drift y separación rigurosa de datos de entrenamiento, validación y test son imprescindibles para garantizar generalización.
- Visualizar para comunicar. La visualización no es un adorno, sino un lenguaje para comprender y persuadir. Storytelling con datos y diseño claro son herramientas críticas para conectar con audiencias diversas.
- Jugar en equipo. La ciencia de datos es colaborativa: requiere ingenieros de datos, expertos de dominio y responsables de negocio. El científico de datos debe actuar como facilitador y traductor entre lo técnico y lo estratégico.
- Mantenerse actualizado (y crítico). El ecosistema evoluciona constantemente. Es necesario combinar aprendizaje continuo con criterio selectivo, priorizando fundamentos sólidos frente a modas pasajeras.
- Ser ético. Los modelos tienen impacto real. Es imprescindible evaluar sesgos, proteger la privacidad, garantizar la explicabilidad y anticipar usos indebidos. La ética es brújula y condición de legitimidad.

Finalmente, el informe incluye un bonus-track sobre Python y R, destacando que ambos lenguajes son aliados complementarios: Python domina en producción y despliegue, mientras que R ofrece rigor estadístico y visualización avanzada. Conocer ambos multiplica la versatilidad del científico de datos.
El Decálogo del científico de datos constituye una guía práctica, atemporal y de aplicación transversal que ayuda a profesionales y organizaciones a convertir los datos en decisiones informadas, confiables y responsables. Su objetivo es reforzar la calidad técnica, la colaboración y la ética en una disciplina en plena expansión y con gran impacto social.
Para profundizar en el contenido del informe, hemos grabado un pódcast y una video-entrevista donde el autor nos cuenta las claves del Decálogo. Además, se ha elaborado una infografía y un resumen ejecutivo.
Escucha el pódcast con el autor
Mira la vídeo-entrevista con el autor
Descarga la infografía-resumen

Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su auto
Documentación
En el campo de la ciencia de datos, la capacidad de construir modelos predictivos robustos es fundamental. Sin embargo, un modelo no es solo un conjunto de algoritmos, es una herramienta que debe ser comprendida, validada y, en última instancia, útil para la toma de decisiones.
Gracias a la transparencia y accesibilidad de los datos abiertos, tenemos la oportunidad única de trabajar en este ejercicio con información real, actualizada y de calidad institucional que refleja problemáticas ambientales. Esta democratización del acceso permite no solo desarrollar análisis rigurosos con datos oficiales, sino también contribuir al debate público informado sobre políticas ambientales, creando un puente directo entre la investigación científica y las necesidades sociales.
En este ejercicio práctico, nos sumergiremos en el ciclo de vida completo de un proyecto de modelado, utilizando un caso de estudio real: el análisis de la calidad del aire en Castilla y León. A diferencia de los enfoques que se centran únicamente en la implementación de algoritmos, nuestra metodología se enfoca en:
- Carga y exploración inicial de los datos: identificar patrones, anomalías y relaciones subyacentes que guiarán nuestro modelado.
- Análisis exploratorio orientado al modelado: construir visualizaciones y realizar ingeniería de características para optimizar el modelado.
- Desarrollo y evaluación de modelos de regresión: construir y comparar múltiples modelos iterativos para entender cómo la complejidad afecta el rendimiento.
- Aplicación del modelo y conclusiones: utilizar el modelo final para simular escenarios y cuantificar el impacto de posibles políticas ambientales.
Accede al repositorio del laboratorio de datos en Github
Accede al notebook de Google Colab
Arquitectura del Análisis
El núcleo de este ejercicio sigue un flujo estructurado en cuatro fases clave, como se ilustra en la Figura 1. Cada fase se construye sobre la anterior, desde la exploración inicial de los datos hasta la aplicación final del modelo.

Figura 1. Fases del proyecto de modelado predictivo.
Proceso de Desarrollo
1. Carga y exploración inicial de los datos
El primer paso es entender la materia prima de nuestro análisis: los datos. Utilizando un conjunto de datos de calidad del aire de Castilla y León, que abarca 24 años de mediciones, nos enfrentamos a desafíos comunes en el mundo real:
- Valores Faltantes: variables como el CO y el PM2.5 tienen una cobertura de datos limitada.
- Datos Anómalos: se detectan valores negativos y extremos, probablemente debidos a errores de los sensores.
A través de un proceso de limpieza y transformación, convertimos los datos brutos en un conjunto de datos limpio y estructurado, listo para el modelado.
2. Análisis exploratorio orientado al modelado
Una vez limpios los datos, buscamos patrones. El análisis visual revela una fuerte estacionalidad en los niveles de NO₂, con picos en invierno y valles en verano. Esta observación es crucial y nos lleva a la creación de nuevas variables (ingeniería de características), como componentes cíclicos para los meses, que permiten al modelo "entender" la naturaleza circular de las estaciones.

Figura 2. Variación estacional de los niveles de NO₂ en Castilla y León.
3. Desarrollo y evaluación de modelos de regresión
Con un conocimiento sólido de los datos, procedemos a construir tres modelos de regresión lineal de complejidad creciente:
- Modelo Base: utiliza solo los contaminantes como predictores.
- Modelo Estacional: añade las variables de tiempo.
- Modelo Completo: incluye interacciones y efectos geográficos.
La comparación de estos modelos nos permite cuantificar la mejora en la capacidad predictiva. El Modelo Estacional emerge como la opción óptima, explicando casi el 63% de la variabilidad del NO₂, un resultado notable para datos ambientales.
4. Aplicación del modelo y conclusiones
Finalmente, sometemos el modelo a un riguroso diagnóstico y lo utilizamos para simular el impacto de políticas ambientales. Por ejemplo, nuestro análisis estima que una reducción del 20% en las emisiones de NO podría traducirse en una disminución del 4.8% en los niveles de NO₂.

Figura 3. Rendimiento del modelo estacional. Los valores predichos se alinean bien con los valores reales.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Ciclo de vida de un proyecto de datos: desde la limpieza hasta la aplicación.
- Técnicas de regresión lineal: construcción, interpretación y diagnóstico.
- Manejo de datos temporales: captura de estacionalidad y tendencias.
- Validación de modelos: técnicas como la validación cruzada y temporal.
- Comunicación de resultados: cómo traducir hallazgos en insights accionables.
Conclusiones y Futuro
Este ejercicio demuestra el poder de un enfoque estructurado y riguroso en la ciencia de datos. Hemos transformado un conjunto de datos complejo en un modelo predictivo que no solo es preciso, sino también interpretable y útil.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades son numerosas:
- Incorporación de datos meteorológicos: variables como la temperatura y el viento podrían mejorar significativamente la precisión.
- Modelos más avanzados: explorar técnicas como los Modelos Aditivos Generalizados (GAM) u otros algoritmos de machine learning.
- Análisis espacial: investigar cómo varían los patrones de contaminación entre diferentes ubicaciones.
En resumen, este ejercicio no solo ilustra la aplicación de técnicas de regresión, sino que también subraya la importancia de un enfoque integral que combine el rigor estadístico con la relevancia práctica.
Documentación
La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github
Accede al notebook de Google Colab
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
- Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
- Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
- Configuramos una base de datos MySQL externa como repositorio de metadatos.
- Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
- Creamos tablas estructuradas para representar rutas, autobuses o paradas.
- Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
- Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
- Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
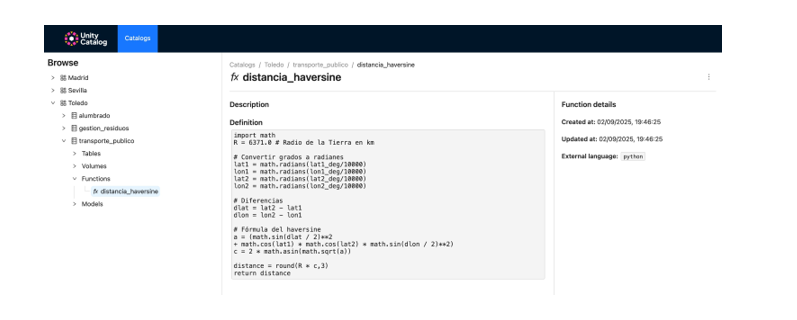
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.