Blog
En un mundo donde la inmediatez cobra cada vez más importancia, el comercio predictivo se ha convertido en una herramienta clave para anticipar comportamientos de consumo, optimizar decisiones y ofrecer experiencias personalizadas. Ya no se trata solo de reaccionar ante las necesidades del cliente, sino de predecir lo que quiere incluso antes de que lo sepa.
En este artículo vamos a explicar qué es el comercio predictivo y la importancia de los datos abiertos en ello, incluyendo ejemplos reales.
¿Qué es el comercio predictivo?
El comercio predictivo es una estrategia basada en el análisis de datos para anticipar las decisiones de compra de los consumidores. Utiliza algoritmos de inteligencia artificial y modelos estadísticos para identificar patrones de comportamiento, preferencias y momentos clave en el ciclo de consumo. Gracias a ello, las empresas pueden conocer información relevante sobre qué productos serán más demandados, cuándo y dónde se realizará una compra o qué clientes tienen mayor probabilidad de adquirir una determinada marca.
Esto es de gran importancia en un mercado como el actual, donde existe una saturación de productos y competencia. El comercio predictivo permite a las empresas ajustar inventarios, precios, campañas de marketing o la logística en tiempo real, convirtiéndose en una gran ventaja competitiva.
El papel de los datos abiertos en el comercio predictivo
Estos modelos se alimentan de grandes volúmenes de datos: históricos de compra, navegación web, ubicación o comentarios en redes sociales, entre otros. Pero cuanto más precisos y diversos sean los datos, más afinadas serán las predicciones. Aquí es donde los datos abiertos juegan un papel fundamental, ya que permiten añadir nuevas variables a tener en cuenta a la hora de definir el comportamiento del consumidor. Entre otras cuestiones, los datos abiertos pueden ayudarnos a:
- Enriquecer modelos de predicción con información externa como datos demográficos, movilidad urbana o indicadores económicos.
- Detectar patrones regionales que influyen en el consumo, como, por ejemplo, el impacto del clima en la venta de ciertos productos estacionales.
- Diseñar estrategias más inclusivas al incorporar datos públicos sobre hábitos y necesidades de distintos grupos sociales.
La siguiente tabla muestra ejemplos de conjuntos de datos disponibles en datos.gob.es que pueden servir para estas tareas, a nivel nacional, aunque muchas comunidades autónomas y ayuntamientos también publican este tipo de datos junto a otros también de interés.
| Conjunto de datos | Ejemplo | Posible uso |
|---|---|---|
| Padrón municipal por edad y sexo | Instituto Nacional de Estadística (INE) | Segmenta poblaciones por territorio, edad y género. Es útil para personalizar campañas en base a la población mayoritaria de cada municipio o prever la demanda por perfil demográfico. |
| Encuesta de presupuestos familiares | Instituto Nacional de Estadística (INE) | Ofrece información sobre el gasto medio por hogar en diferentes categorías. Puede ayudar a anticipar patrones de consumo por nivel socioeconómico. |
| Índice de precio de consumo (IPC) | Instituto Nacional de Estadística (INE) | Desagrega el IPC por territorio, midiendo cómo varían los precios de bienes y servicios en cada provincia española. Tiene utilidad para ajustar precios y estrategias de penetración de mercado. |
| Avisos meteorológicos en tiempo real | Ministerio para la Transición Ecológica y Reto Demográfico | Alerta de fenómenos meteorológicos adversos. Permite correlacionar clima con ventas de productos (ropa, bebidas, calefacción, etc.). |
| Estadísticas de educación y alfabetización digital | Instituto Nacional de Estadística (INE) | Ofrece información sobre el uso de Internet en los últimos 3 meses. Permite identificar brechas digitales y adaptar las estrategias de comunicación o formación. |
| Datos sobre estancias turísticas | Instituto Nacional de Estadística (INE) | Informa sobre la estancia media de turistas por comunidades autónomas. Ayuda a anticipar demanda en zonas con alta afluencia estacional, como productos locales o servicios turísticos. |
| Número de recetas y gasto farmacéutico | Mutualidad General de Funcionarios Civiles del Estado (MUFACE) | Ofrece información del consumo de medicamentos por provincia y subgrupos de edad. Facilita la estimación de ventas de otros productos sanitarios y de parafarmacia relacionados al estimar cuántos usuarios irán a la farmacia. |
Figura 1. Tabla comparativa. Fuente: elaboración propia -datos.gob.es.
Casos de uso reales
Desde hace años, ya encontramos empresas que están utilizando este tipo de datos para optimizar sus estrategias comerciales. Veamos algunos ejemplos:
- Uso de datos meteorológicos para optimizar el stock en grandes supermercados
Los grandes almacenes Walmart utilizan algoritmos de IA que incorporan datos meteorológicos (como olas de calor, tormentas o cambios de temperatura) junto a datos históricos de ventas, eventos y tendencias digitales, para prever la demanda a nivel granular y optimizar inventarios. Esto permite ajustar automáticamente el reabastecimiento de productos críticos según patrones climáticos anticipados. Además, Walmart menciona que su sistema considera “datos futuros” como patrones climáticos macro (“macroweather”), tendencias económicas y demografía local para anticipar la demanda y posibles interrupciones en la cadena de suministro.
La firma Tesco también utiliza datos meteorológicos públicos en sus modelos predictivos. Esto le permite anticipar patrones de compra, como que por cada aumento de 10°C en la temperatura, las ventas de barbacoa se incrementan hasta en un 300%. Además, Tesco recibe pronósticos meteorológicos locales hasta tres veces al día, conectándolos con datos sobre 18 millones de productos y el tipo de clientes de cada tienda. Esta información se comparte con sus proveedores para ajustar los envíos y mejorar la eficiencia logística.
- Uso de datos demográficos para decidir la ubicación de locales
Desde hace años Starbucks ha recurrido a la analítica predictiva para planificar su expansión. La compañía utiliza plataformas de inteligencia geoespacial, desarrolladas con tecnología GIS, para combinar múltiples fuentes de información —entre ellas datos abiertos demográficos y socioeconómicos como la densidad de población, el nivel de ingresos, los patrones de movilidad, el transporte público o la tipología de negocios cercanos— junto con históricos de ventas propias. Gracias a esta integración, puede predecir qué ubicaciones tienen mayor potencial de éxito, evitando la competencia entre locales y asegurando que cada nueva tienda se sitúe en el entorno más adecuado.
Domino's Pizza también utilizó modelos similares para analizar si la apertura de un nuevo local en un barrio de Londres tendría éxito y cómo afectaría a otras ubicaciones cercanas, considerando patrones de compra y características demográficas locales.
Este enfoque permite predecir flujos de clientes y maximizar la rentabilidad mediante decisiones de localización más informadas.
- Datos socioeconómicos para fijar precios en base a la demografía
Un ejemplo interesante lo encontramos en SDG Group, consultora internacional especializada en analítica avanzada para retail. La compañía ha desarrollado soluciones que permiten ajustar precios y promociones teniendo en cuenta las características demográficas y socioeconómicas de cada zona -como la base de consumidores, la ubicación o el tamaño del punto de venta-. Gracias a estos modelos es posible estimar la elasticidad de la demanda y diseñar estrategias de precios dinámicos adaptados al contexto real de cada área, optimizando tanto la rentabilidad como la experiencia de compra.
El futuro del comercio predictivo
El auge del comercio predictivo se ha visto impulsado por el avance de la inteligencia artificial y la disponibilidad de datos, tanto abiertos como privados. Desde la elección del lugar ideal para abrir una tienda hasta la gestión eficiente de inventarios, los datos públicos combinados con analítica avanzada permiten anticipar comportamientos y necesidades de los consumidores con una precisión cada vez mayor.
No obstante, aún quedan retos importantes por afrontar: la heterogeneidad de las fuentes de datos, que en muchos casos carecen de estándares comunes; la necesidad de contar con tecnologías e infraestructuras sólidas que permitan integrar la información abierta con los sistemas internos de las empresas; y, por último, el desafío de garantizar un uso ético y transparente, que respete la privacidad de las personas y evite la generación de sesgos en los modelos.
Superar estos retos será clave para que el comercio predictivo despliegue todo su potencial y se convierta en una herramienta estratégica para empresas de todos los tamaños. En este camino, los datos abiertos jugarán un papel fundamental como motor de innovación, transparencia y competitividad en el comercio del futuro.
Blog
Las imágenes sintéticas son representaciones visuales generadas de forma artificial mediante algoritmos y técnicas computacionales, en lugar de capturarse directamente de la realidad con cámaras o sensores. Se producen a partir de distintos métodos, entre los que destacan las redes generativas antagónicas (Generative Adversarial Networks, GAN), los modelos de difusión, y las técnicas de renderizado 3D. Todas ellas permiten crear imágenes de apariencia realista que en muchos casos resultan indistinguibles de una fotografía auténtica.
Cuando se traslada este concepto al campo de la observación de la Tierra, hablamos de imágenes satelitales sintéticas. Estas no se obtienen a partir de un sensor espacial que capta radiación electromagnética real, sino que se generan digitalmente para simular lo que vería un satélite desde la órbita. En otras palabras, en vez de reflejar directamente el estado físico del terreno o la atmósfera en un momento concreto, son construcciones computacionales capaces de imitar el aspecto de una imagen satelital real.
El desarrollo de este tipo de imágenes responde a necesidades prácticas. Los sistemas de inteligencia artificial que procesan datos de teledetección requieren conjuntos muy amplios y variados de imágenes. Las imágenes sintéticas permiten, por ejemplo, recrear zonas de la Tierra poco observadas, simular desastres naturales -como incendios forestales, inundaciones o sequías- o generar condiciones específicas que son difíciles o costosas de capturar en la práctica. De este modo, constituyen un recurso valioso para entrenar algoritmos de detección y predicción en agricultura, gestión de emergencias, urbanismo o monitorización ambiental.
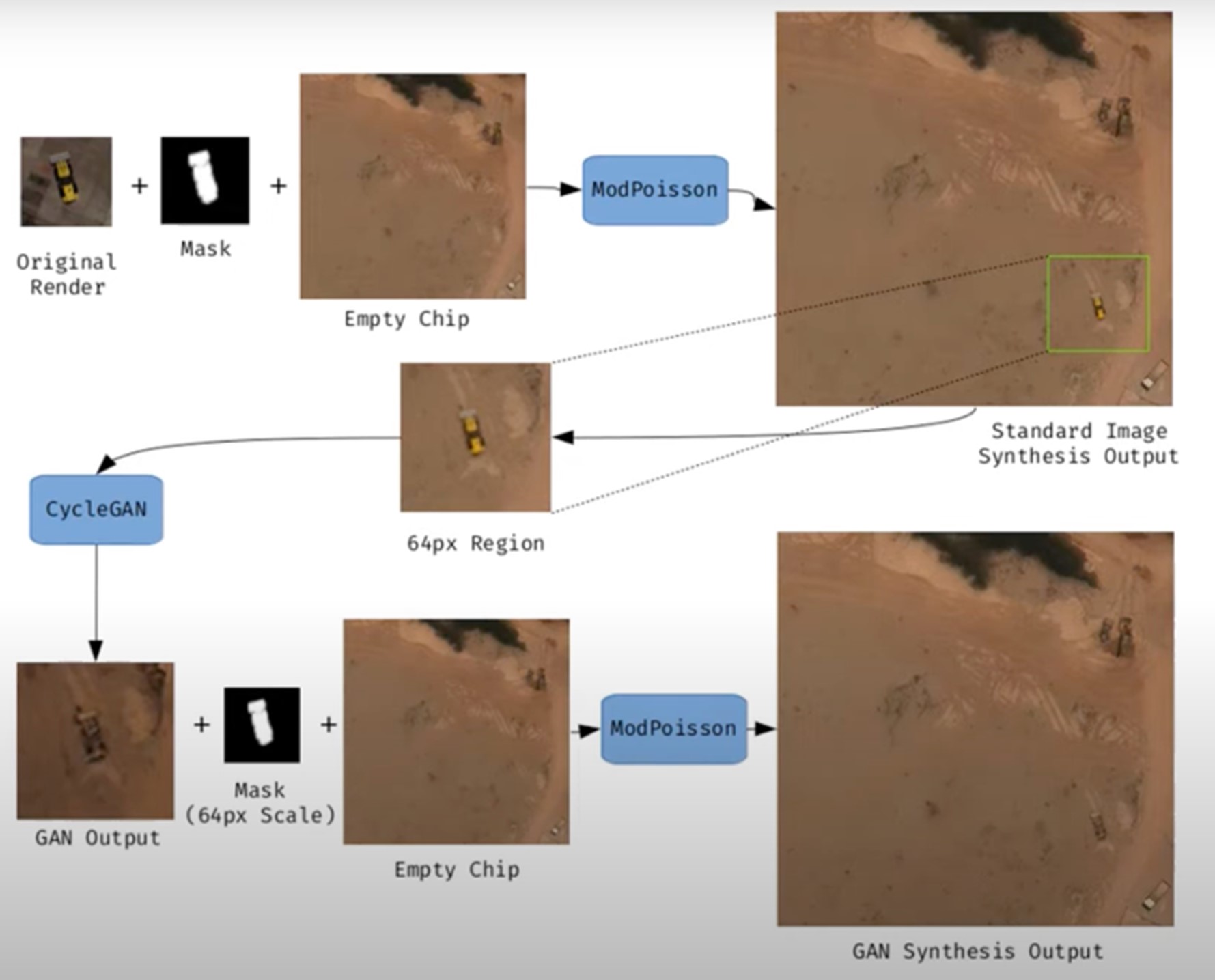
Figura 1. Ejemplo de generación de una imagen satelital sintética.
Su valor no se limita al entrenamiento de modelos. Allí donde no existen imágenes de alta resolución —por limitaciones técnicas, restricciones de acceso o motivos económicos—, la síntesis permite rellenar huecos de información y facilitar estudios preliminares. Por ejemplo, los investigadores pueden trabajar con imágenes sintéticas aproximadas para diseñar modelos de riesgo o simulaciones antes de disponer de datos reales.
Sin embargo, las imágenes satelitales sintéticas también plantean riesgos importantes. La posibilidad de generar escenas muy realistas abre la puerta a la manipulación y a la desinformación. En un contexto geopolítico, una imagen que muestre tropas inexistentes o infraestructuras destruidas podría influir en decisiones estratégicas o en la opinión pública internacional. En el terreno ambiental, se podrían difundir imágenes manipuladas para exagerar o minimizar impactos de fenómenos como la deforestación o el deshielo, con efectos directos en políticas y mercados.
Por ello, conviene diferenciar dos usos muy distintos. El primero es el uso como apoyo, cuando las imágenes sintéticas complementan a las reales para entrenar modelos o realizar simulaciones. El segundo es el uso como falsificación, cuando se presentan deliberadamente como imágenes auténticas con el fin de engañar. Mientras el primer uso impulsa la innovación, el segundo amenaza la confianza en los datos satelitales y plantea un reto urgente de autenticidad y gobernanza.
Riesgos de las imágenes satelitales aplicada a la observación de la Tierra
Las imágenes satelitales sintéticas plantean riesgos significativos cuando se utilizan en vez de imágenes captadas por sensores reales. A continuación, se detallan ejemplos que lo demuestran.
Un nuevo frente de desinformación: “deepfake geography”
El término deepfake geography ya se ha consolidado en la literatura académica y divulgativa para describir imágenes satelitales ficticias, manipuladas con IA, que parecen auténticas, pero no reflejan ninguna realidad existente. Una investigación de la Universidad de Washington, liderada por Bo Zhao, utilizó algoritmos como CycleGAN para modificar imágenes de ciudades reales -por ejemplo, alterando la apariencia de Seattle con edificios inexistentes o transformando Beijing en zonas verdes- lo que pone en evidencia el potencial para generar paisajes falsos convincentes.
Un artículo de la plataforma OnGeo Intelligence (OGC) subraya que estas imágenes no son puramente teóricas, sino amenazas reales que afectan a la seguridad nacional, el periodismo y el trabajo humanitario. Por su parte, el OGC advierte que ya se han observado imágenes satelitales fabricadas, modelos urbanos generados por IA y redes de carreteras sintéticas, y que representan desafíos reales a la confianza pública y operativa.
Implicaciones estratégicas y políticas
Las imágenes satelitales son consideradas "ojos imparciales" sobre el planeta, usadas por gobiernos, medios y organizaciones. Cuando estas imágenes se falsifican, sus consecuencias pueden ser graves:
- Seguridad nacional y defensa: si se presentan infraestructuras falsas o se ocultan otras reales, se pueden desviar análisis estratégicos o inducir decisiones militares equivocadas.
- Desinformación en conflictos o crisis humanitarias: una imagen alterada que muestre incendios, inundaciones o movimientos de tropas falsos puede alterar la respuesta internacional, los flujos de ayuda o la percepción de los ciudadanos, especialmente si se difunde por redes sociales o medios sin verificación.
- Manipulación de imágenes realistas de lugares: no solo las imágenes generales están en juego. Nguyen y colaboradores (2024) demostraron que es posible generar imágenes satelitales sintéticas altamente realistas de instalaciones muy específicas como plantas nucleares.
Crisis de confianza y erosión de la verdad
Durante décadas, las imágenes satelitales han sido percibidas como una de las fuentes más objetivas y fiables de información sobre nuestro planeta. Eran la prueba gráfica que permitía confirmar fenómenos ambientales, seguir conflictos armados o evaluar el impacto de desastres naturales. En muchos casos, estas imágenes se utilizaban como “evidencia imparcial”, difíciles de manipular y fáciles de validar. Sin embargo, la irrupción de las imágenes sintéticas generadas por inteligencia artificial ha empezado a poner en cuestión esa confianza casi inquebrantable.
Hoy en día, cuando una imagen satelital puede ser falsificada con gran realismo, surge un riesgo profundo: la erosión de la verdad y la aparición de una crisis de confianza en los datos espaciales.
La quiebra de la confianza pública
Cuando los ciudadanos ya no pueden distinguir entre una imagen real y una fabricada, se resquebraja la confianza en las fuentes de información. La consecuencia es doble:
- Desconfianza hacia las instituciones: si circulan imágenes falsas de un incendio, una catástrofe o un despliegue militar y luego resultan ser sintéticas, la ciudadanía puede empezar a dudar también de las imágenes auténticas publicadas por agencias espaciales o medios de comunicación. Este efecto “que viene el lobo” genera escepticismo incluso frente a pruebas legítimas.
- Efecto en el periodismo: los medios tradicionales, que han usado históricamente las imágenes satelitales como fuente visual incuestionable, corren el riesgo de perder credibilidad si publican imágenes adulteradas sin verificación. Al mismo tiempo, la abundancia de imágenes falsas en redes sociales erosiona la capacidad de distinguir qué es real y qué no.
- Confusión deliberada: en contextos de desinformación, la mera sospecha de que una imagen pueda ser falsa ya puede bastar para generar duda y sembrar confusión, aunque la imagen original sea completamente auténtica.
A continuación, se resumen los posibles casos de manipulación y riesgo en imágenes satelitales:
| Ámbito | Tipo de manipulación | Riesgo principal | Ejemplo documentado |
|---|---|---|---|
| Conflictos armados | Inserción o eliminación de infraestructuras militares. | Desinformación estratégica; decisiones militares erróneas; pérdida de credibilidad en observación internacional. | Alteraciones demostradas en estudios de deepfake geography donde se añadían carreteras, puentes o edificios ficticios en imágenes satelitales. |
| Cambio climático y medio ambiente | Alteración de glaciares, deforestación o emisiones. | Manipulación de políticas ambientales; retraso en medidas contra el cambio climático; negacionismo. | Estudios han mostrado la capacidad de generar paisajes modificados (bosques en zonas urbanas, cambios en el hielo) mediante GAN. |
| Gestión de emergencias | Creación de desastres inexistentes (incendios, inundaciones). | Mal uso de recursos en emergencias; caos en evacuaciones; pérdida de confianza en agencias. | Investigaciones han demostrado la facilidad de insertar humo, fuego o agua en imágenes satelitales. |
| Mercados y seguros | Falsificación de daños en infraestructuras o cultivos. | Impacto financiero; fraude masivo; litigios legales complejos. | Uso potencial de imágenes falsas para exagerar daños tras desastres y reclamar indemnizaciones o seguros. |
| Derechos humanos y justicia internacional | Alteración de pruebas visuales sobre crímenes de guerra. | Deslegitimación de tribunales internacionales; manipulación de la opinión pública. | Riesgo identificado en informes de inteligencia: imágenes adulteradas podrían usarse para acusar o exonerar a actores en conflictos. |
| Geopolítica y diplomacia | Creación de ciudades ficticias o cambios fronterizos. | Tensiones diplomáticas; cuestionamiento de tratados; propaganda estatal. | Ejemplos de deepfake maps que transforman rasgos geográficos de ciudades como Seattle o Tacoma. |
Figura 2. Tabla con los posibles casos de manipulación y riesgo en imágenes satelitales
Impacto en la toma de decisiones y políticas públicas
Las consecuencias de basarse en imágenes adulteradas van mucho más allá del terreno mediático:
- Urbanismo y planificación: decisiones sobre dónde construir infraestructuras o cómo planificar zonas urbanas podrían tomarse sobre imágenes manipuladas, generando errores costosos y de difícil reversión.
- Gestión de emergencias: si una inundación o un incendio se representan en imágenes falsas, los equipos de emergencia pueden destinar recursos a lugares equivocados, mientras descuidan zonas realmente afectadas.
- Cambio climático y medio ambiente: imágenes adulteradas de glaciares, deforestación o emisiones contaminantes podrían manipular debates políticos y retrasar la implementación de medidas urgentes.
- Mercados y seguros: aseguradoras y empresas financieras que confían en imágenes satelitales para evaluar daños podrían ser engañadas, con consecuencias económicas significativas.
En todos estos casos, lo que está en juego no es solo la calidad de la información, sino la eficacia y legitimidad de las políticas públicas basadas en esos datos.
El juego del gato y el ratón tecnológico
La dinámica de generación y detección de falsificaciones ya se conoce en otros ámbitos, como los deepfakes de vídeo o audio: cada vez que surge un método de generación más realista, se desarrolla un algoritmo de detección más avanzado, y viceversa. En el ámbito de las imágenes satelitales, esta carrera tecnológica tiene particularidades:
- Generadores cada vez más sofisticados: los modelos de difusión actuales pueden crear escenas de gran realismo, integrando texturas de suelo, sombras y geometrías urbanas que engañan incluso a expertos humanos.
- Limitaciones de la detección: aunque se desarrollan algoritmos para identificar falsificaciones (analizando patrones de píxeles, inconsistencias en sombras o metadatos), estos métodos no siempre son fiables cuando se enfrentan a generadores de última generación.
- Coste de la verificación: verificar de forma independiente una imagen satelital requiere acceso a fuentes alternativas o sensores distintos, algo que no siempre está al alcance de periodistas, ONG o ciudadanos.
- Armas de doble filo: las mismas técnicas usadas para detectar falsificaciones pueden ser aprovechadas por quienes las generan, perfeccionando aún más las imágenes sintéticas y haciendo más difícil diferenciarlas.
De la prueba visual a la prueba cuestionada
El impacto más profundo es cultural y epistemológico: lo que antes se asumía como una prueba objetiva ahora se convierte en un elemento sujeto a duda. Si las imágenes satelitales dejan de ser percibidas como evidencia fiable, se debilitan narrativas fundamentales en torno a la verdad científica, la justicia internacional y la rendición de cuentas política.
- En conflictos armados, una imagen de satélite que muestre posibles crímenes de guerra puede ser descartada bajo la acusación de ser un deepfake.
- En tribunales internacionales, pruebas basadas en observación satelital podrían perder peso frente a la sospecha de manipulación.
- En el debate público, el relativismo de “todo puede ser falso” puede usarse como arma retórica para deslegitimar incluso la evidencia más sólida.
Estrategias para garantizar autenticidad
La crisis de confianza en las imágenes satelitales no es un problema aislado del sector geoespacial, sino que forma parte de un fenómeno más amplio: la desinformación digital en la era de la inteligencia artificial. Así como los deepfakes de vídeo han puesto en cuestión la validez de pruebas audiovisuales, la proliferación de imágenes satelitales sintéticas amenaza con debilitar la última frontera de datos percibidos como objetivos: la mirada imparcial desde el espacio.
Garantizar la autenticidad de estas imágenes exige una combinación de soluciones técnicas y mecanismos de gobernanza, capaces de reforzar la trazabilidad, la transparencia y la responsabilidad en toda la cadena de valor de los datos espaciales. A continuación, se describen las principales estrategias en desarrollo.
Metadatos robustos: registrar el origen y la cadena de custodia
Los metadatos constituyen la primera línea de defensa frente a la manipulación. En imágenes satelitales, deben incluir información detallada sobre:
- El sensor utilizado (tipo, resolución, órbita).
- El momento exacto de la adquisición (fecha y hora, con precisión temporal).
- La localización geográfica precisa (sistemas de referencia oficiales).
- La cadena de procesado aplicada (correcciones atmosféricas, calibraciones, reproyecciones).
Registrar estos metadatos en repositorios seguros permite reconstruir la cadena de custodia, es decir, el historial de quién, cómo y cuándo ha manipulado una imagen. Sin esta trazabilidad, resulta imposible distinguir entre imágenes auténticas y falsificadas.
EJEMPLO: el programa Copernicus de la Unión Europea ya implementa metadatos estandarizados y abiertos para todas sus imágenes Sentinel, lo que facilita auditorías posteriores y confianza en el origen.
Firmas digitales y blockchain: garantizar la integridad
Las firmas digitales permiten verificar que una imagen no ha sido alterada desde su captura. Funcionan como un sello criptográfico que se aplica en el momento de adquisición y se valida en cada uso posterior.
La tecnología blockchain ofrece un nivel adicional de garantía: almacenar los registros de adquisición y modificación en una cadena inmutable de bloques. De esta manera, cualquier cambio en la imagen o en sus metadatos quedaría registrado y sería fácilmente detectable.
EJEMPLO: el proyecto ESA – Trusted Data Framework explora el uso de blockchain para proteger la integridad de datos de observación de la Tierra y reforzar la confianza en aplicaciones críticas como cambio climático y seguridad alimentaria.
Marcas de agua invisible: señales ocultas en la imagen
El marcado de agua digital consiste en incrustar señales imperceptibles en la propia imagen satelital, de modo que cualquier alteración posterior se pueda detectar automáticamente.
- Puede hacerse a nivel de píxel, modificando ligeramente patrones de color o luminancia.
- Se combina con técnicas criptográficas para reforzar su validez.
- Permite validar imágenes incluso si han sido recortadas, comprimidas o reprocesadas.
EJEMPLO: en el sector audiovisual, las marcas de agua se usa desde hace años en la protección de contenidos digitales. Su adaptación a imágenes satelitales está en fase experimental, pero podría convertirse en una herramienta estándar de verificación.
Estándares abiertos (OGC, ISO): confianza mediante interoperabilidad
La estandarización es clave para garantizar que las soluciones técnicas se apliquen de forma coordinada y global.
- OGC (Open Geospatial Consortium) trabaja en estándares para la gestión de metadatos, la trazabilidad de datos geoespaciales y la interoperabilidad entre sistemas. Su trabajo en API geoespaciales y metadatos FAIR (Findable, Accessible, Interoperable, Reusable) es esencial para establecer prácticas comunes de confianza.
- ISO desarrolla normas sobre gestión de la información y autenticidad de registros digitales que también pueden aplicarse a imágenes satelitales.
EJEMPLO: el OGC Testbed-19 incluyó experimentos específicos sobre autenticidad de datos geoespaciales, probando enfoques como firmas digitales y certificados de procedencia.
Verificación cruzada: combinar múltiples fuentes
Un principio básico para detectar falsificaciones es contrastar fuentes. En el caso de imágenes satelitales, esto implica:
- Comparar imágenes de diferentes satélites (ej. Sentinel-2 vs. Landsat-9).
- Usar distintos tipos de sensores (ópticos, radar SAR, hiperespectrales).
- Analizar series temporales para verificar la consistencia en el tiempo.
EJEMPLO: la verificación de daños en Ucrania tras el inicio de la invasión rusa en 2022 se realizó mediante la comparación de imágenes de varios proveedores (Maxar, Planet, Sentinel), asegurando que los hallazgos no se basaban en una sola fuente.
IA contra IA: detección automática de falsificaciones
La misma inteligencia artificial que permite crear imágenes sintéticas se puede utilizar para detectarlas. Las técnicas incluyen:
- Análisis forense de píxeles: identificar patrones generados por GAN o modelos de difusión.
- Redes neuronales entrenadas para distinguir entre imágenes reales y sintéticas en función de texturas o distribuciones espectrales.
- Modelos de inconsistencias geométricas: detectar sombras imposibles, incoherencias topográficas o patrones repetitivos.
EJEMPLO: investigadores de la Universidad de Washington y otros grupos han demostrado que algoritmos específicos pueden detectar falsificaciones satelitales con una precisión superior al 90% en condiciones controladas.
Experiencias actuales: iniciativas globales
Varios proyectos internacionales ya trabajan en mecanismos para reforzar la autenticidad:
- Coalition for Content Provenance and Authenticity (C2PA): una alianza entre Adobe, Microsoft, BBC, Intel y otras organizaciones para desarrollar un estándar abierto de procedencia y autenticidad de contenidos digitales, incluyendo imágenes. Su modelo se puede aplicar directamente al sector satelital.
- Trabajo del OGC: la organización impulsa el debate sobre confianza en datos geoespaciales y ha destacado la importancia de garantizar la trazabilidad de imágenes satelitales sintéticas y reales (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) en EE. UU. ha reconocido públicamente la amenaza de imágenes sintéticas en defensa y está impulsando colaboraciones con academia e industria para desarrollar sistemas de detección.
Hacia un ecosistema de confianza
Las estrategias descritas no deben entenderse como alternativas, sino como capas complementarias en un ecosistema de confianza:
|
Id |
Capas |
¿Qué aportan? |
|---|---|---|
| 1 | Metadatos robustos (origen, sensor, cadena de custodia) |
Garantizan trazabilidad |
| 2 | Firmas digitales y blockchain (integridad de datos) |
Aseguran integridad |
| 3 | Marcas de agua invisible (señales ocultas) |
Añade un nivel oculto de protección |
| 4 | Verificación cruzada (múltiples satélites y sensores) |
Valida con independencia |
| 5 | IA contra IA (detector de falsificaciones) |
Responde a amenazas emergentes |
| 6 | Gobernanza internacional (responsabilidad, marcos legales) |
Articula reglas claras de responsabilidad |
Figura 3. Capas para garantizar la confianza en las imágenes sintéticas satelitales
El éxito dependerá de que estos mecanismos se integren de manera conjunta, bajo marcos abiertos y colaborativos, y con la implicación activa de agencias espaciales, gobiernos, sector privado y comunidad científica.
Conclusiones
Las imágenes sintéticas, lejos de ser únicamente una amenaza, representan una herramienta poderosa que, bien utilizada, puede aportar un valor significativo en ámbitos como la simulación, el entrenamiento de algoritmos o la innovación en servicios digitales. El problema surge cuando estas imágenes se presentan como reales sin la debida transparencia, alimentando la desinformación o manipulando la percepción pública.
El reto, por tanto, es doble: aprovechar las oportunidades que ofrece la síntesis de datos visuales para avanzar en ciencia, tecnología y gestión, y minimizar los riesgos asociados al mal uso de estas capacidades, especialmente en forma de deepfakes o falsificaciones deliberadas.
En el caso particular de las imágenes satelitales, la confianza adquiere una dimensión estratégica. De ellas dependen decisiones críticas en seguridad nacional, respuesta a desastres, políticas ambientales y justicia internacional. Si la autenticidad de estas imágenes se pone en duda, se compromete no solo la fiabilidad de los datos, sino también la legitimidad de las decisiones basadas en ellos.
El futuro de la observación de la Tierra estará condicionado por nuestra capacidad de garantizar la autenticidad, transparencia y trazabilidad en toda la cadena de valor: desde la adquisición de los datos hasta su difusión y uso final. Las soluciones técnicas (metadatos robustos, firmas digitales, blockchain, marcas de agua, verificación cruzada e IA para detección de falsificaciones), combinadas con marcos de gobernanza y cooperación internacional, serán la clave para construir un ecosistema de confianza.
En definitiva, debemos asumir un principio rector sencillo pero contundente:
“Si no podemos confiar en lo que vemos desde el espacio, ponemos en riesgo nuestras decisiones en la Tierra.”
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La ciencia de datos se ha consolidado como un pilar de la toma de decisiones basada en evidencias en sectores públicos y privados. En este contexto, surge la necesidad de una guía práctica y universal que trascienda modas tecnológicas y proporcione principios sólidos y aplicables. La presente guía ofrece un decálogo de buenas prácticas que acompaña al científico de datos a lo largo de todo el ciclo de vida de un proyecto, desde la conceptualización del problema hasta la evaluación ética del impacto.
- Comprender el problema antes de mirar los datos. La clave inicial es definir claramente el contexto, objetivos, restricciones e indicadores de éxito. Un framing sólido evita errores posteriores.
- Conocer los datos en profundidad. Más allá de las variables, implica analizar su origen, trazabilidad y posibles sesgos. La auditoría de datos es esencial para garantizar representatividad y fiabilidad.
- Cuidar la calidad. Sin datos limpios no hay ciencia. Técnicas de EDA, imputación, normalización y control de métricas de calidad permiten construir bases sólidas y reproducibles.
- Documentar y versionar. La reproducibilidad es condición científica. Notebooks, pipelines, control de versiones y prácticas de MLOps aseguran trazabilidad y replicabilidad de procesos y modelos.
- Elegir el modelo adecuado. No siempre gana la sofisticación: la decisión debe equilibrar rendimiento, interpretabilidad, costes y restricciones operativas.
- Medir con sentido. Las métricas deben alinearse con los objetivos. Validación cruzada, control del data drift y separación rigurosa de datos de entrenamiento, validación y test son imprescindibles para garantizar generalización.
- Visualizar para comunicar. La visualización no es un adorno, sino un lenguaje para comprender y persuadir. Storytelling con datos y diseño claro son herramientas críticas para conectar con audiencias diversas.
- Jugar en equipo. La ciencia de datos es colaborativa: requiere ingenieros de datos, expertos de dominio y responsables de negocio. El científico de datos debe actuar como facilitador y traductor entre lo técnico y lo estratégico.
- Mantenerse actualizado (y crítico). El ecosistema evoluciona constantemente. Es necesario combinar aprendizaje continuo con criterio selectivo, priorizando fundamentos sólidos frente a modas pasajeras.
- Ser ético. Los modelos tienen impacto real. Es imprescindible evaluar sesgos, proteger la privacidad, garantizar la explicabilidad y anticipar usos indebidos. La ética es brújula y condición de legitimidad.

Finalmente, el informe incluye un bonus-track sobre Python y R, destacando que ambos lenguajes son aliados complementarios: Python domina en producción y despliegue, mientras que R ofrece rigor estadístico y visualización avanzada. Conocer ambos multiplica la versatilidad del científico de datos.
El Decálogo del científico de datos constituye una guía práctica, atemporal y de aplicación transversal que ayuda a profesionales y organizaciones a convertir los datos en decisiones informadas, confiables y responsables. Su objetivo es reforzar la calidad técnica, la colaboración y la ética en una disciplina en plena expansión y con gran impacto social.
Para profundizar en el contenido del informe, hemos grabado un pódcast y una video-entrevista donde el autor nos cuenta las claves del Decálogo. Además, se ha elaborado una infografía y un resumen ejecutivo.
Escucha el pódcast con el autor
Mira la vídeo-entrevista con el autor
Descarga la infografía-resumen

Contenido elaborado por Alejandro Alija, experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su auto
Noticia
El sector de los datos abiertos es muy activo. Para estar al día de todo lo que ocurre, desde datos.gob.es publicamos una recopilación de novedades como el desarrollo de nuevas aplicaciones tecnológicas, avances legislativos u otras noticias relacionadas.
Hace seis meses, ya hicimos la última recopilación del año 2024. En esta ocasión, vamos a resumir algunas innovaciones, mejoras y logros del primer semestre de 2025.
Marco normativo: nuevas regulaciones que transforman el panorama
Una de las novedades más significativas es la publicación del Reglamento relativo al Espacio Europeo de Datos de Salud por parte del Parlamento Europeo y el Consejo. Esta normativa establece un marco común para el intercambio seguro de datos sanitarios entre los estados miembro, facilitando tanto la investigación médica como la prestación de servicios sanitarios transfronterizos. Además, este hito representa un cambio paradigmático en la gestión de datos sensibles, demostrando que es posible conciliar la privacidad y protección de datos con la necesidad de compartir información para el bien común. Las implicaciones para el sistema sanitario español son considerables, ya que permitirá una mayor interoperabilidad con otros países europeos y facilitará el desarrollo de proyectos de investigación colaborativos.
Por otro lado, la entrada en vigor de la Ley Europea de IA establece normas claras para el desarrollo de esta tecnología, garantizando la seguridad, transparencia y respeto de los derechos humanos. Este tipo de normativas son especialmente relevantes en el contexto de datos abiertos, donde la transparencia algorítmica y la explicabilidad de los modelos de IA se convierten en requisitos esenciales.
En España, el compromiso con la transparencia se materializa en iniciativas como el nuevo Observatorio de Derechos Digitales, que cuenta con la participación de más de 150 entidades y 360 personas expertas. Esta plataforma se configura como un espacio de diálogo y seguimiento de las políticas digitales, contribuyendo a garantizar que la transformación digital respete los derechos fundamentales.
Innovaciones tecnológicas en España y el extranjero
Uno de los hitos más destacados en el ámbito tecnológico es el lanzamiento de ALIA, la infraestructura pública de recursos de inteligencia artificial. Esta iniciativa busca desarrollar modelos de lenguaje abiertos y transparentes que fomenten el uso del castellano y las lenguas cooficiales españolas en el ámbito de la IA.
ALIA no es solo una respuesta a la hegemonía de los modelos anglosajones, sino una apuesta estratégica por la soberanía tecnológica y la diversidad lingüística. Los primeros modelos ya disponibles han sido entrenados en español, catalán, gallego, valenciano y euskera, marcando un precedente importante en el desarrollo de tecnologías inclusivas y culturalmente sensibles.
Con relación a esta innovación, las aplicaciones prácticas de la inteligencia artificial se están multiplicando en diversos sectores. Por ejemplo, en el ámbito financiero, la Agencia Tributaria ha adoptado un compromiso ético en el diseño y uso de la inteligencia artificial. En este marco, la comunidad ha desarrollado incluso un chatbot virtual entrenado con datos propios que ofrece orientación legal en temas fiscales y tributarios.
En el sector sanitario, un grupo de radiólogos españoles está trabajando en un proyecto para la detección precoz de lesiones oncológicas utilizando IA, demostrando cómo la combinación de datos abiertos y algoritmos avanzados puede tener un impacto directo en la salud pública.
También combinando IA con datos abiertos se han desarrollado proyectos relacionados con la sostenibilidad medioambiental. Este modelo desarrollado en España combina IA y datos meteorológicos abiertos para predecir la producción de energía solar en los próximos 30 años, proporcionando información crucial para la planificación energética nacional.
Otro sector relevante en lo que respecta a la innovación tecnológica es el de las smart cities. En estos últimos meses, Las Palmas de Gran Canaria ha digitalizado sus mercados municipales combinando redes WiFi, dispositivos IoT, un gemelo digital y plataformas de datos abiertos. Esta iniciativa integral busca mejorar la experiencia del usuario y optimizar la gestión comercial, demostrando cómo la convergencia tecnológica puede transformar espacios urbanos tradicionales.
Zaragoza, por su parte, ha desarrollado un mapa de vulnerabilidad utilizando inteligencia artificial aplicada a datos abiertos, proporcionando una herramienta valiosa para la planificación urbana y las políticas sociales.
Otro caso relevante es el proyecto de la Iniciativa Open Data Barcelona, #iCuida, que destaca como un ejemplo innovador de reutilización de datos abiertos para mejorar la vida de las cuidadoras y trabajadoras del hogar. Esta aplicación demuestra cómo los datos abiertos pueden dirigirse a colectivos específicos y generar impacto social directo.
Por último, pero no menos importante, a nivel global, este semestre DeepSeek ha lanzado DeepSeek-R1, una nueva familia de modelos generativos especializados en razonamiento, publicando tanto los modelos como su metodología de entrenamiento completa en código abierto, contribuyendo al avance democrático de la IA.
Nuevos portales de datos abiertos y herramientas de mejora
En toda esta vorágine de innovación y tecnología, el panorama de los portales de datos abiertos se ha enriquecido con nuevas iniciativas sectoriales. El Colegio de Registradores Mercantiles y de la Propiedad de España ha presentado su plataforma de datos abiertos, permitiendo acceso inmediato a datos registrales sin esperar informes periódicos. Esta iniciativa representa un cambio significativo en la transparencia del sector registral.
En el ámbito sanitario, el portal 'I+Salud' del sistema sanitario público de Andalucía recoge y difunde desde un sitio único los recursos y datos sobre actividades y resultados de investigación, facilitando el acceso a información científica relevante.
Además de la disponibilidad de datos, hay un tratamiento que los hace más accesibles al público general: la visualización de datos. La Universidad de Granada ha desarrollado 'UGR en cifras', un espacio de acceso libre con sección de datos abiertos que facilita la exploración de estadísticas oficiales y se erige como pieza fundamental en la transparencia universitaria.
Por otro lado, IDENA, la nueva herramienta del Geoportal de Navarra, incorpora funcionalidades avanzadas para buscar, navegar, incorporar mapas, compartir datos y descargar información geográfica, siendo operativa en cualquier dispositivo.
Formación para el futuro: eventos y jornadas
El ecosistema formativo en este ecosistema se fortalece cada año con eventos como la Cumbre de Gestión del Dato (Data Management Summit) en Tenerife, que aborda la interoperabilidad en administraciones públicas y la inteligencia artificial. Otro evento de referencia en los datos abiertos que también se celebró en Canarias fue el Encuentro Nacional de Datos Abiertos.
Más allá de estos eventos, la innovación colaborativa también ha fomentado a través de hackathones especializados, como el dedicado a soluciones de IA generativa para la biodiversidad o el Merkle Datathon en Gijón. Estos eventos no solo generan soluciones innovadoras, sino que también crean comunidades de práctica y fomentan el talento emergente.
Un año más, los concursos de datos abiertos de Castilla y León y Euskadi han premiado proyectos que demuestran el potencial transformador de la reutilización de datos abiertos, inspirando nuevas iniciativas y aplicaciones.
Perspectiva internacional y tendencias globales: la cuarta ola de datos abiertos
Open Data Policy Lab habló en los EU Open Data Days de lo que se conoce como la "cuarta ola" de datos abiertos, estrechamente vinculada a la IA generativa. Esta evolución representa un salto cualitativo en la forma de procesar, analizar y utilizar los datos públicos, donde los modelos de lenguaje natural permiten interacciones más intuitivas y análisis más sofisticados.
En general, el panorama de datos abiertos en 2025 revela una transformación profunda del ecosistema, donde la convergencia entre inteligencia artificial, marcos normativos avanzados y aplicaciones especializadas está redefiniendo las posibilidades de la transparencia y la innovación pública.
Evento
La ciencia de datos está de moda. Las profesiones relacionadas con este ámbito se encuentran entre las más demandadas, de acuerdo con el último estudio “Posiciones y competencias más Demandadas 2024”, realizado por la Asociación Española de Directores de Recursos Humanos. En concreto, se observa una demanda significativa para roles relacionados con la gestión y análisis de datos, como Data Analyst, Data Engineer y Data Scientist. El auge de la inteligencia artificial (IA) y la necesidad de tomar decisiones basadas en datos están impulsando la integración de este tipo de profesionales en todos los sectores.
Las universidades son conscientes de esta situación y por ello oferta una gran cantidad de grados, posgrados y también cursos de verano, tanto para principiantes como para aquellos que quieren ampliar conocimientos y explorar nuevas tendencias tecnológicas. A continuación, recogemos algunos de ellos a modo de ejemplo. Se trata de cursos que combinan teoría y práctica, permitiendo descubrir el potencial de los datos.
1. Análisis y Visualización de Datos: Estadística Práctica con R e Inteligencia Artificial. Universidad Nacional de Educación a Distancia (UNED).
Este seminario ofrece formación integral en análisis de datos con un enfoque práctico. Se aprenderá a utilizar el lenguaje R y el entorno RStudio, con el foco puesto en la visualización, la inferencia estadística y su uso en sistemas de inteligencia artificial. Está dirigido a estudiantes de ramas afines y profesionales de diversos sectores (como educación, negocios, salud, ingeniería o ciencias sociales) que requieran aplicar técnicas estadísticas y de IA, así como a investigadores y académicos que necesiten procesar y visualizar datos.
- Fecha y lugar: del 25 al 27 de junio de 2025 en modalidad online y presencial (en Plasencia).
2. Big Data. Análisis de datos y aprendizaje automático con Python. Universidad Complutense.
Gracias a esta formación, los estudiantes podrán adquirir una comprensión profunda de cómo los datos se obtienen, gestionan y analizan para generar conocimiento de valor a la hora de tomar decisiones. Entre otras cuestiones, se mostrará el ciclo de vida de un proyecto Big Data, incluyendo un módulo específico sobre datos abiertos. En este caso, el lenguaje elegido para la formación será Python. Para asistir, no se requieren conocimientos previos: está abierto a estudiantes universitarios, docentes, investigadores y profesionales de cualquier sector con interés en la temática.
- Fecha y lugar: del 30 de junio al 18 de julio de 2025 en Madrid.
3. Challenges in Data Science: Big Data, Biostatistics, Artificial Intelligence and Communications. Universitat de València.
Este programa nace con la vocación de ayudar a los participantes a comprender el alcance de la revolución impulsada por los datos. Integrado dentro de los programas de movilidad Erasmus, combina clases magistrales, trabajo en grupo y una sesión de laboratorio experimental, todo en inglés. Entre otros temas, se hablará de datos abiertos, herramientas open source, bases de datos de Big Data, computación en la nube, privacidad y seguridad de los datos institucionales, minería y visualización de textos.
- Fecha y lugar: Del 30 de junio al 4 de julio en dos sedes de Valencia. Nota: Actualmente las plazas están cubiertas, pero está abierta la lista de espera.
4. Gemelos digitales: de la simulación a la realidad inteligente. Universidad de Castilla-La Mancha.
Los gemelos digitales son una herramienta fundamental para impulsar la toma de decisiones basada en datos. Con este curso, los estudiantes podrán comprender las aplicaciones y los retos de esta tecnología en diversos sectores industriales y tecnológicos. Se hablará de la inteligencia artificial aplicada a gemelos digitales, la computación de alto rendimiento (HPC) y la validación y verificación de modelos digitales, entre otros. Está dirigido a profesionales, investigadores, académicos y estudiantes interesados en la materia.
- Fecha y lugar: 3 y 4 de julio en Albacete.
5. Geografía de la salud y Sistemas de Información Geográfica: aplicaciones prácticas. Universidad de Zaragoza.
El aspecto diferencial de este curso es que está pensado para aquellos alumnos que busquen un enfoque práctico de la ciencia de datos en un sector concreto como es el de la salud. Su objetivo es proporcionar conocimientos teóricos y prácticos sobre la relación entre geografía y salud. Los alumnos aprenderán a utilizar Sistemas de Información Geográfica (SIG) para analizar y representar datos sobre prevalencia de enfermedades. Está abierto a distintos públicos (desde estudiantes o personas que trabajen en instituciones públicas y centros sanitarios, a asociaciones de vecinos u organizaciones sin ánimo de lucro vinculadas con temas de salud) y no requiere titulación universitaria previa.
- Fecha y lugar: del 7 al 9 de julio de 2025 en Zaragoza.
6. Deep into data science. Universidad de Cantabria.
Dirigido a científicos, estudiantes universitarios (desde segundo año) de ingeniería, matemáticas, física e informática, este curso intensivo busca proporcionar una visión completa y práctica de la revolución digital actual. Los estudiantes aprenderán sobre herramientas de programación Python, machine learning, inteligencia artificial, redes neuronales o cloud computing, entre otros temas. Todos los temas se introducen de forma teórica para a continuación experimentar en prácticas de laboratorio.
- Fecha y lugar: del 7 al 11 de julio de 2025 en Camargo.
7.Advanced Programming. Universitat Autònoma de Barcelona.
Impartido totalmente en inglés, el objetivo de este curso es mejorar las habilidades y conocimientos de programación de los alumnos a través de la práctica. Para ello se desarrollarán dos juegos en dos lenguajes distintos, Java y Python. Los alumnos serán capaces de estructurar una aplicación y programar algoritmos complejos. Está orientada a estudiantes de cualquier titulación (matemáticas, física, ingeniería, química, etc.) que ya se hayan iniciado en la programación y quieran mejorar sus conocimientos y habilidades.
- Fecha y lugar: 14 de julio al 1 de agosto de 2025, en una ubicación por definir.
8.Visualización y análisis de datos con R. Universidade de Santiago de Compostela.
Este curso está dirigido a principiantes en la materia. En él se abordarán las funcionalidades básicas de R con el objetivo de que los estudiantes adquieran las habilidades necesarias para desarrollar análisis estadísticos descriptivos e inferenciales (estimación, contrastes y predicciones). También se darán a conocer herramientas de búsqueda y ayuda para que los alumnos puedan profundizar en su uso de manera independiente.
- Fecha y lugar: del 14 al 24 de julio de 2025 en Santiago de Compostela.
9. Fundamentos de inteligencia artificial: modelos generativos y aplicaciones avanzadas. Universidad Internacional de Andalucía.
Este curso ofrece una introducción práctica a la inteligencia artificial y sus principales aplicaciones. En él se abordan conceptos relacionados con el aprendizaje automático, las redes neuronales, el procesamiento del lenguaje natural, la IA generativa y los agentes inteligentes. El lenguaje utilizado será Python, y aunque el curso es introductorio, se aprovechará mejor si el estudiante tiene conocimientos básicos en programación. Por ello, se dirige principalmente a estudiantes de grado o posgrado en áreas técnicas como ingeniería, informática o matemáticas, profesionales que buscan adquirir competencias en IA para aplicar en sus industrias y docentes e investigadores interesados en actualizarse sobre el estado del arte en IA.
- Fecha y lugar: del 19 al 22 de agosto de 2025, en Baeza.
10. IA Generativa para innovar en la empresa: casos reales y herramientas para su implementación. Universidad del País Vasco.
Este curso, abierto al público general, tiene como objetivo ayudar a comprender el impacto de la IA generativa en distintos sectores y su papel en la transformación digital a través de la exploración de casos reales de aplicación en empresas y centros tecnológicos de Euskadi. Para ello se combinan charlas, paneles de discusión y una sesión práctica enfocada en el uso de modelos generativos, y técnicas como Retrieval-Augmented Generation (RAG) y Fine-Tuning.
- Fecha y lugar: 10 de septiembre en San Sebastián.
Invertir en formación tecnológica durante el verano no solo es una excelente manera de fortalecer habilidades, sino también de conectar con expertos, compartir ideas y descubrir oportunidades de innovación. Esta selección es solo una pequeña muestra de la oferta disponible. Si conoces algún otro curso que quieras compartir con nosotros, deja un comentario o escríbenos a dinamizacion@datos.gob.es
Entrevista
¿Sabías que las habilidades de ciencia de datos están entre las más demandadas por las empresas? En este pódcast, te vamos a contar cómo puedes formarte en este campo, de manera autodidacta. Para ello, contaremos con dos expertos en ciencia de datos:
- Juan Benavente, ingeniero industrial e informático con más de 12 años de experiencia en innovación tecnológica y transformación digital. Además, lleva años formando a nuevos profesionales en escuelas tecnológicas, escuelas de negocio y universidades.
- Alejandro Alija, doctor en física, científico de datos y experto en transformación digital. Además de su amplia experiencia profesional enfocada en el Internet of Things (internet de las cosas), Alejandro también trabaja como profesor en diferentes escuelas de negocio y universidades.
Resumen / Transcripción de la entrevista
1. ¿Qué es la ciencia de datos? ¿Por qué es importante y para qué nos puede servir?
Alejandro Alija: La ciencia de datos podría definirse como una disciplina cuyo principal objetivo es entender el mundo, los procesos propios de un negocio y de la vida, analizando y observando los datos. En los últimos 20 años ha cobrado una relevancia excepcional debido a la explosión en la generación de datos, principalmente por la irrupción de internet y del mundo conectado.
Juan Benavente: El término ciencia de datos ha ido evolucionando desde su creación. Hoy, un científico de datos es la persona que está trabajando en el nivel más alto en análisis de datos, frecuentemente asociado con la construcción de algoritmos de machine learning o inteligencia artificial para empresas o sectores específicos, como predecir u optimizar la fabricación en una planta.
La profesión está evolucionando rápidamente, y probablemente en los próximos años se vaya fragmentando. Hemos visto aparecer nuevos roles como ingenieros de datos o especialistas en MLOps. Lo importante es que hoy cualquier profesional, independientemente de su área, necesita trabajar con datos. No cabe duda de que cualquier posición o empresa requiere análisis de datos, cada vez más avanzados. Da igual si estás en marketing, ventas, operaciones o en la universidad. Cualquiera hoy en día está trabajando con datos, manipulándolos y analizándolos. Si además aspiramos a la ciencia de datos, que sería el mayor nivel de expertise, estaremos en una posición muy beneficiosa. Pero, sin duda, recomendaría a cualquier profesional que tenga esto en radar.
2. ¿Cómo os iniciasteis en la ciencia de datos y qué hacéis para manteneros actualizados? ¿Qué estrategias recomendaríais tanto para principiantes como para perfiles más experimentados?
Alejandro Alija: Mi formación básica es en física, e hice mi doctorado en ciencia básica. En realidad, podría decirse que cualquier científico, por definición, es un científico de datos, porque la ciencia se basa en formular hipótesis y demostrarlas con experimentos y teorías. Mi relación con los datos comenzó temprano en la academia. Un punto de inflexión en mi carrera fue cuando empecé a trabajar en el sector privado, específicamente en una compañía de gestión medioambiental que se dedica a medir y observar la contaminación atmosférica. El medio ambiente es un campo que tradicionalmente es gran generador de datos, especialmente por ser un sector regulado donde las administraciones y empresas privadas están obligadas, por ejemplo, a registrar los niveles de contaminación atmosférica en determinadas condiciones. Encontré series históricas de hasta 20 años de antigüedad que estaban a mi disposición para analizar. A partir de ahí empezó mi curiosidad y me especialicé en herramientas concretas para analizar y entender lo que está ocurriendo en el mundo.
Juan Benavente: Yo me identifico con lo que ha comentado Alejandro porque tampoco soy informático. Me formé en ingeniería industrial y aunque la informática es uno de mis intereses, no fue mi base. A diferencia, hoy en día, sí veo que se están formando más especialistas desde la universidad. Actualmente, un científico de datos tiene muchas skills a la espalda como cuestiones de estadística, matemáticas y la capacidad de entender todo lo que pasa en el sector. Yo he ido adquiriendo estos conocimientos en base a la práctica. Sobre cómo mantenerse actualizado, yo creo que, en muchos casos, puedes estar en contacto con empresas que están innovando en este campo. También en eventos sectoriales o tecnológicos se puede aprender mucho. Yo empecé en las smart cities y he ido pasando por el mundo industrial hasta aprender poco a poco.
Alejandro Alija: Por añadir otra fuente en la que mantenerse actualizado. A parte de las que ha comentado Juan, creo que es importante identificar lo que llamamos outsiders, los fabricantes de tecnologías, los actores del mercado. Son una fuente de información muy útil para estar actualizado: identificar sus estrategias de futuros y por qué apuestan.
3. Pongámonos en el caso hipotético de que alguien con pocos o nulos conocimientos técnicos, quiera aprender ciencia de datos, ¿por dónde empieza?
Juan Benavente: En formación, me he encontrado perfiles muy diferentes: desde gente que acabe de salir de la carrera hasta perfiles que se han formado en ámbitos muy diferentes y encuentran en la ciencia de datos una oportunidad para transformarse y dedicarse a esto. Pensando en alguien que está empezando, creo que lo mejor es poner en práctica tus conocimientos. En proyectos en los que he trabajado definíamos la metodología en tres fases: una primera fase más de aspectos teóricos teniendo en cuenta matemáticas, programación y todo lo que necesita saber un científico de datos; una vez tengas esas bases, cuanto antes empieces a trabajar y practicar esos conocimientos, mejor. Creo que la habilidad agudiza el ingenio y, tanto para estar actualizado, como para formarte e ir adquiriendo conocimiento útil, cuanto antes entres en proyecto, mejor. Y más, hablando de un mundo que se actualiza tan recurrentemente. Estos últimos años, la aparición de la IA generativa ha supuesto otras oportunidades. En estas herramientas también hay oportunidades para nuevos perfiles que quieran formarse. Aunque no seas experto en programación tienes herramientas que te puedan ayudar a programar, y lo mismo te puede suceder en matemáticas o estadística.
Alejandro Alija: Por complementar un poco lo que dice Juan desde una perspectiva diferente. Creo que vale la pena destacar la evolución de la profesión de ciencia de datos. Recuerdo cuando se hizo famoso aquel paper en el que se hablaba de "la profesión más sexy del mundo", que se volvió muy viral, aunque luego las cosas se fueron ajustando. Los primeros pobladores del mundo de la ciencia de datos no venían tanto de ciencias de la computación o informática. Eran más los outsiders: físicos, matemáticos, con bases robustas en matemáticas y física, e incluso algunos ingenieros que por su trabajo y desarrollo profesional terminaban utilizando muchas herramientas del ámbito informático. Poco a poco se ha ido balanceando. Ahora es una disciplina que sigue teniendo esas dos vertientes: personas que vienen del mundo de la física y matemáticas hacia los datos más básicos, y personas que vienen con conocimientos de programación. Cada uno sabe lo que tiene que balancear de su caja de herramientas. Pensando en un perfil junior que esté empezando, creo que una cosa muy importante - y así lo vemos cuando damos clase - es la capacidad de programación. Diría que tener skills de programación no es solo un plus, sino un requisito básico para avanzar en esta profesión. Es verdad que algunas personas pueden desempeñarse bien sin muchas habilidades de programación, pero yo diría que un principiante necesita tener esas primeras skills de programación con un toolset básico. Estamos hablando de lenguajes como Python y R, que son los lenguajes de cabecera. No se trata de ser un gran codificador, pero sí de tener conocimientos básicos para poder arrancar. Luego, evidentemente, la formación específica sobre fundamentos matemáticos de la ciencia de datos es crucial. La estadística fundamental y la estadística más avanzada son complementos que, si se tienen, harán que la persona avance mucho más rápido en la curva de aprendizaje de la ciencia de datos. En tercer lugar, diría que la especialización en herramientas particulares es importante. Hay gente que se orienta más hacia la ingeniería de datos, otros hacia el mundo de los modelos. Lo ideal es especializarse en algunos frameworks y utilizarlos de manera conjunta, de la forma más óptima posible.
4. Además de como profesores, ambos trabajáis en empresas tecnológicas, ¿qué certificaciones técnicas son más valoradas en el sector empresarial y qué fuentes abiertas de conocimiento recomendáis para prepararse para ellas?
Juan Benavente: Personalmente, no es lo que más miro, pero creo que puede ser relevante, sobre todo para personas que están comenzando y que necesitan ayuda para estructurar su forma de aproximarse al problema y entenderlo. Recomiendo certificaciones de tecnologías que están en uso en cualquier empresa donde quieras acabar trabajando. Especialmente de proveedores de cloud computing y herramientas ampliamente extendidas de análisis de datos. Son certificaciones que recomendaría para alguien que quiere aproximarse a este mundo y necesita una estructura que le ayude. Cuando no tienes una base de conocimiento, puede ser un poco confuso entender por dónde empezar. Quizás deberías reforzar primero la programación o los conocimientos matemáticos, pero todo puede parecer un poco lioso. Donde sin duda te ayudan estas certificaciones es, además de reforzar conceptos, para garantizar que te mueves bien y conoces el ecosistema de herramientas típico con el que vas a trabajar mañana. No se trata solo de conceptos teóricos, sino de conocer los ecosistemas que te encontrarás cuando empieces a trabajar, ya sea fundando tu propia empresa o trabajando en una empresa establecida. Te facilita mucho conocer el ecosistema típico de herramientas. Llámalo Microsoft Computing, Amazon u otros proveedores de este tipo de soluciones. Así podrás centrarte más rápidamente en el trabajo en sí, y no tanto en todas las herramientas que lo rodean. Creo que este tipo de certificaciones son útiles, sobre todo para perfiles que se están acercando a este mundo con ilusión. Les ayudará tanto a estructurarse como a aterrizar bien en su destino profesional. Probablemente también se valoren en los procesos de selección.
Alejandro Alija: Si alguien nos escucha y quiere directrices más específicas, se podría estructurar en bloques. Hay una serie de cursos masivos en línea que, para mí, fueron un punto de inflexión. En mis comienzos, traté de inscribirme en varios de estos cursos en plataformas como Coursera, edX, donde incluso los propios fabricantes de tecnología son los que diseñan estos cursos. Creo que este tipo de cursos online masivos, que se pueden hacer de manera autoservicio, proporcionan una buena base inicial. Un segundo bloque serían los cursos y las certificaciones de los grandes proveedores de tecnología, como Microsoft, Amazon Web Services, Google y otras plataformas que son referentes en el mundo de los datos. Estas compañías tienen la ventaja de que sus rutas de aprendizaje están muy bien estructuradas, lo que facilita el crecimiento profesional dentro de sus propios ecosistemas. Se pueden ir combinando certificaciones de diferentes proveedores. Para una persona que quiera dedicarse a este campo, el camino va desde las certificaciones más sencillas hasta las más avanzadas, como ser un arquitecto de soluciones en el área de datos o un especialista en un servicio o producto específico de análisis de datos. Estos dos bloques de aprendizaje están disponibles en internet, la mayoría son abiertos y gratuitos o cercanos a la gratuidad. Más allá del conocimiento, lo que se valora es la certificación, especialmente en las compañías que buscan estos perfiles profesionales.
5. Además de la formación teórica, la práctica es clave, uno de los métodos más interesantes para aprender es replicar ejercicios paso a paso. En este sentido, desde datos.gob.es ofrecemos recursos didácticos, muchos de ellos desarrollados por vosotros como expertos en el proyecto, ¿nos podéis contar en qué consisten estos ejercicios? ¿Cómo se plantean?
Alejandro Alija: El planteamiento que siempre hicimos fue pensado para un público amplio, sin requisitos previos complejos. Queríamos que cualquier usuario del portal pudiera replicar los ejercicios, aunque es evidente que cuanto más conocimiento se tiene, más se puede aprovechar. Los ejercicios tienen una estructura bien definida: un apartado documental, generalmente un post de contenido o un informe que describe en qué consiste el ejercicio, qué materiales se necesitan, cuáles son los objetivos y qué se pretende conseguir. Además, acompañamos cada ejercicio con dos recursos adicionales. El primer recurso es un repositorio de código donde subimos los materiales necesarios, con una descripción breve y el código del ejercicio. Puede ser un notebook de Python, un Jupyter Notebook o un script simple, donde está el contenido técnico. Y luego otro elemento fundamental que creemos importante y que va dirigido a facilitar la ejecución de los ejercicios. En ciencia de datos y programación, los usuarios no especialistas suelen tener dificultades para configurar un entorno de trabajo. Un ejercicio en Python, por ejemplo, requiere tener instalado un entorno de programación, conocer las librerías necesarias y realizar configuraciones que para profesionales son triviales, pero para principiantes pueden ser muy complejas. Para mitigar esta barrera, publicamos la mayoría de nuestros ejercicios en Google Colab, una herramienta maravillosa y abierta. Google Colab es un entorno de programación web donde el usuario solo necesita un navegador para acceder. Básicamente, Google nos proporciona un ordenador virtual donde podemos ejecutar nuestros programas y ejercicios sin necesidad de configuraciones especiales. Lo importante es que el ejercicio esté listo para usarse y siempre lo verificamos en este entorno, lo que facilita enormemente el aprendizaje para usuarios principiantes o con menos experiencia técnica.
Juan Benavente: Sí, siempre planteamos un enfoque orientado para cualquier usuario, paso a paso, intentando que sea abierto y accesible. Se busca que cualquiera pueda ejecutar un ejercicio sin necesidad de configuraciones complejas, centrándose en temáticas lo más cercanas a la realidad que sea posible. Aprovechamos, muchas veces, datos abiertos publicados por entidades como la DGT u otros organismos para hacer análisis realistas. Hemos desarrollado ejercicios muy interesantes, como predicciones del mercado energético, análisis de materiales críticos para baterías y electrónica, que permiten aprender no solo tecnología, sino también sobre la temática específica. En seguida puedes ponerte manos a la obra, no solo aprender, sino además averiguar sobre la temática.
6. Para cerrar, nos gustaría que pudierais ofrecer un consejo más orientado a actitud que a conocimientos técnicos, ¿qué le diríais a alguien que esté empezando en ciencia de datos?
Alejandro Alija: En cuanto a un consejo de actitud para alguien que está empezando en ciencia de datos, sugiero ser valiente. No hay que preocuparse por no estar preparado, porque en este campo todo está por hacer y cualquier persona puede aportar valor. La ciencia de datos tiene múltiples vertientes: hay profesionales más cercanos al mundo de negocio que pueden aportar conocimientos valiosos, y otros más técnicos que necesitan comprender el contexto de cada área. Mi consejo es formarse con los recursos disponibles sin asustarse, porque, aunque el camino parezca complejo, las oportunidades son muy altas. Como consejo técnico, es importante tener sensibilidad hacia el desarrollo y uso de datos. Cuanta más comprensión se tenga de este mundo, más fluida será la aproximación a los proyectos.
Juan Benavente: Suscribo el consejo de ser valiente y añado una reflexión sobre la programación: mucha gente encuentra atractivo el concepto teórico, pero cuando llegan a la práctica y ven la complejidad de programar, algunos se desaniman por falta de conocimientos previos o expectativas diferentes. Es importante añadir los conceptos de paciencia y constancia. Al comenzar en este campo, te enfrentas a múltiples áreas que necesitas dominar: programación, estadística, matemáticas, y conocimiento específico del sector en el que trabajarás, ya sea marketing, logística u otro ámbito. La expectativa de convertirse en un experto rápidamente no es realista. Es una profesión que, aunque se puede comenzar sin miedo y colaborando con profesionales, requiere un recorrido y un proceso de aprendizaje. Hay que ser constante y paciente, gestionando las expectativas adecuadamente. La mayoría de las personas que llevan tiempo en este mundo coinciden en que no se arrepienten de dedicarse a la ciencia de datos. Es una profesión muy atractiva donde puedes aportar valor significativo, con un componente tecnológico importante. Sin embargo, el camino no siempre es directo. Habrá proyectos complejos, momentos de frustración cuando los análisis no arrojan los resultados esperados o cuando trabajar con datos resulta más desafiante de lo previsto. Pero mirando hacia atrás, son pocos los profesionales que se arrepienten de haber invertido tiempo y esfuerzo en formarse y desarrollarse en este campo. En resumen, los consejos fundamentales son: valentía para empezar, constancia en el aprendizaje y desarrollo de habilidades de programación.
Clips de la entrevista
1. ¿Merece la pena formarse en ciencia de datos?
2. ¿Cómo se plantean los ejercicios de ciencia de datos de datos.gob.es?
3. ¿Qué es la ciencia de datos? ¿Qué competencias son necesarias?
Blog
No hay duda de que los datos se han convertido en el activo estratégico para las organizaciones. Hoy en día, es esencial garantizar que las decisiones están fundamentadas en datos de calidad, independientemente del alineamiento que sigan: analítica de datos, inteligencia artificial o reporting. Sin embargo, asegurar repositorios de datos con altos niveles de calidad no es tarea fácil, dado que en muchos casos los datos provienen de fuentes heterogéneas donde los principios de calidad de datos no se han tenido en cuenta y no se dispone de contexto sobre el dominio.
Para paliar en la medida de lo posible esta casuística, en este artículo, exploraremos una de las bibliotecas más utilizadas en el análisis de datos: Pandas. Vamos a chequear cómo esta biblioteca de Python puede ser una herramienta eficaz para mejorar la calidad de los datos. También repasaremos la relación de alguna de sus funciones con las dimensiones y propiedades de calidad de datos incluidas en la especificación UNE 0081 de calidad de datos, y algunos ejemplos concretos de su aplicación en repositorios de datos con el objetivo de mejorar la calidad de los datos.
Utilizar de Pandas para Data Profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: es el proceso de análisis exploratorio que se realiza para entender las características fundamentales de los datos, como su estructura, tipos de datos, distribución de valores, y la presencia de valores faltantes o duplicados. El objetivo es obtener una imagen clara de cómo son los datos, sin necesariamente hacer juicios sobre su calidad.
- Evaluación de calidad de datos: implica la aplicación de reglas y estándares predefinidos para determinar si los datos cumplen con ciertos requisitos de calidad, como exactitud, completitud, consistencia, credibilidad o actualidad. En este proceso, se identifican errores y se determinan acciones para corregirlos. Una guía útil para la evaluación de calidad de datos es la especificación UNE 0081.
Consiste en explorar y analizar un conjunto de datos para obtener una comprensión básica de su estructura, contenido y características, antes de realizar un análisis más profundo o una evaluación de la calidad de los datos. El objetivo principal es obtener una visión general de los datos mediante el análisis de la distribución, los tipos de datos, los valores faltantes, las relaciones entre columnas y la detección de posibles anomalías. Pandas dispone de varias funciones para realizar este perfilado de datos.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
¿Qué es Pandas y cómo ayuda a asegurar la calidad de los datos?
Pandas es una de las bibliotecas más populares de Python para la manipulación y análisis de datos. Su capacidad para gestionar grandes volúmenes de información estructurada hace que sea una herramienta poderosa en la detección y corrección de errores en repositorios de datos. Con Pandas, se pueden realizar operaciones complejas de forma eficiente, desde limpieza hasta validación de datos, todas ellas son esenciales para mantener los estándares de calidad. A continuación, se indican algunos ejemplos para mejorar la calidad de los datos en repositorios con Pandas:
-
Detección de valores nulos o inconsistentes: uno de los errores más comunes en los datos son los valores faltantes o inconsistentes. Pandas permite identificar estos valores fácilmente mediante funciones como isnull() o dropna(). Esto es clave para la propiedad de completitud de los registros y la dimensión de consistencia de datos, ya que los valores faltantes en campos críticos pueden distorsionar los resultados de los análisis.
# Identificar valores nulos en un dataframe
df.isnull().sum()
- Normalización y estandarización de datos: los errores en la consistencia de nombres o códigos son comunes en grandes repositorios. Por ejemplo, en un conjunto de datos que contiene códigos de productos, es posible que algunos estén mal escritos o no sigan una convención estándar. Pandas ofrece funciones como merge() para realizar una comparación con una base de datos de referencia y corregir estos valores. Esta opción es clave para mantener la dimensión y propiedad de consistencia semántica de los datos.
# Sustitución de valores incorrectos utilizando una tabla de referencia
df = df.merge(codigos_productos, left_on='codigo_producto', right_on='codigo_ref', how= ‘left’)
- Validación de requisitos de datos: Pandas permite crear reglas personalizadas para validar la conformidad de los datos con ciertas normas. Por ejemplo, si un campo de edad solo debería contener valores enteros positivos, podemos aplicar una función para identificar y corregir valores que no cumplan con esta regla. De esta forma, se puede validar cualquier regla de negocio de cualquiera de las dimensiones y propiedades de calidad de datos.
# Identificar registros con valores de edad no válidos (negativos o decimales)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
- Análisis exploratorio para identificar patrones anómalos: funciones como describe() o groupby() en Pandas permiten explorar el comportamiento general de los datos. Este tipo de análisis es fundamental para detectar patrones anómalos o fuera de rango en cualquier conjunto de datos, como, por ejemplo, valores inusualmente altos o bajos en columnas que deberían seguir ciertos rangos.
# Resumen estadístico de los datos
df.describe()
#Ordenar según categoría o propiedad
df.groupby()
- Eliminación de duplicados: los datos duplicados son un problema común en los repositorios de datos. Pandas ofrece métodos como drop_duplicates() para identificar y eliminar estos registros, asegurando que no haya redundancia en el conjunto de datos. Esta capacidad estaría relacionada con la dimensión de completitud y consistencia.
# Eliminar filas duplicadas
df = df.drop_duplicates()
Ejemplo práctico de aplicación de Pandas
Una vez presentadas las funciones anteriores que nos sirven para mejorar la calidad de los repositorios de datos, planteamos un caso para poner en práctica el proceso. Supongamos que estamos gestionando un repositorio de datos de ciudadanos y queremos asegurarnos de:
- Que los datos de edad no contengan valores no válidos (como negativos o decimales?
- Que los códigos de nacionalidad estén estandarizados.
- Que los identificadores únicos sigan un formato correcto.
- Que el lugar de residencia sea coherente.
Con Pandas, podríamos realizar las siguientes acciones:
1. Validación de edades sin valores incorrectos
# Identificar registros con edades fuera de los rangos permitidos (por ejemplo, menores de 0 o no enteros)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
2. Corrección de códigos de nacionalidad
# Uso de un dataset oficial de códigos de nacionalidad para corregir los registros incorrectos
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validación de indentificadores únicos
# Verificar si el formato del número de identificación sigue un patrón correcto
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verificación de coherencia en lugar de residencia
# Detectar posibles inconsistencias en la residencia (por ejemplo, un mismo ciudadano residiendo en dos lugares al mismo tiempo)
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integración con diversidad de tecnologías
Pandas es una biblioteca extremadamente flexible y versátil que se integra fácilmente con muchas tecnologías y herramientas en el ecosistema de datos. Algunas de las principales tecnologías con las que Pandas tiene integración o se puede utilizar son:
-
Bases de datos SQL:
Pandas se integra muy bien con bases de datos relacionales como MySQL, PostgreSQL, SQLite, y otras que utilizan SQL. La biblioteca SQLAlchemy o directamente las bibliotecas específicas de cada base de datos (como psycopg2 para PostgreSQL o sqlite3) permiten conectar Pandas a estas bases de datos, realizar consultas y leer/escribir datos entre la base de datos y Pandas.
- Función común: pd.read_sql() para leer una consulta SQL en un DataFrame, y to_sql() para exportar los datos desde Pandas a una tabla SQL.
- APIs basadas en REST y HTTP:
Pandas se puede utilizar para procesar datos obtenidos de APIs utilizando solicitudes HTTP. Bibliotecas como requests permiten obtener datos de APIs y luego transformar esos datos en DataFrames de Pandas para su análisis.
- Big Data (Apache Spark):
Pandas se puede utilizar en combinación con PySpark, una API para Apache Spark en Python. Aunque Pandas está diseñado principalmente para trabajar con datos en memoria, Koalas, una biblioteca basada en Pandas y Spark, permite trabajar con estructuras distribuidas de Spark usando una interfaz similar a Pandas. Herramientas como Koalas ayudan a que los usuarios de Pandas puedan escalar sus scripts a entornos de datos distribuidos sin necesidad de aprender toda la sintaxis de PySpark.
- Hadoop y HDFS:
Pandas se puede utilizar junto con tecnologías de Hadoop, especialmente el sistema de archivos distribuido HDFS. Aunque Pandas no está diseñado para gestionar grandes volúmenes de datos distribuidos, puede utilizarse junto a bibliotecas como pyarrow o dask para leer o escribir datos desde y hacia HDFS en sistemas distribuidos. Por ejemplo, pyarrow se puede utilizar para leer o escribir archivos Parquet en HDFS.
- Formatos de archivos populares:
Pandas se utiliza comúnmente para leer y escribir datos en diferentes formatos de archivo, tales como:
- CSV: pd.read_csv()
- Excel: pd.read_excel() y to_excel()
- JSON: pd.read_json()
- Parquet: pd.read_parquet() para trabajar con archivos eficientes en espacio y tiempo.
- Feather: un formato de archivo rápido para intercambio entre lenguajes como Python y R (pd.read_feather()).
- Herramientas de visualización de datos:
Pandas se puede integrar fácilmente con herramientas de visualización como Matplotlib, Seaborn, y Plotly. Estas bibliotecas permiten generar gráficos directamente desde DataFrames de Pandas.
- Pandas incluye su propia integración ligera con Matplotlib para generar gráficos rápidos usando df.plot().
- Para visualizaciones más sofisticadas, es común usar Pandas junto a Seaborn o Plotly para gráficos interactivos.
- Bibliotecas de machine learning:
Pandas es ampliamente utilizado en el preprocesamiento de datos antes de aplicar modelos de machine learning. Algunas bibliotecas populares con las que Pandas se integra son:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas es compatible con estas bibliotecas de machine learning de alto rendimiento, donde los DataFrames se utilizan como entrada para entrenar modelos.
- Jupyter Notebooks:
Pandas es fundamental en el análisis de datos interactivo dentro de los Jupyter Notebooks, que permiten ejecutar código Python y visualizar los resultados de manera inmediata, lo que facilita la exploración de datos y su visualización en conjunto con otras herramientas.
- Cloud Storage (AWS, GCP, Azure):
Pandas se puede utilizar para leer y escribir datos directamente desde servicios de almacenamiento en la nube como Amazon S3, Google Cloud Storage y Azure Blob Storage. Bibliotecas adicionales como boto3 (para AWS S3) o google-cloud-storage facilitan la integración con estos servicios. A continuación, se muestra un ejemplo para leer datos desde Amazon S3.
import pandas as pd
import boto3
#Crear un cliente de S3
s3 = boto3.client('s3')
#Obtener un objeto del bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Leer el archivo CSV de un DataFrame
df = pd.read_csv(obj['Body'])
- Docker y contenedores:
Pandas se puede usar en entornos de contenedores utilizando Docker. Los contenedores son ampliamente utilizados para crear entornos aislados que aseguran la replicabilidad de los pipelines de análisis de datos.
En conclusión, el uso de Pandas es una solución eficaz para mejorar la calidad de los datos en repositorios complejos y heterogéneos. A través de funciones de limpieza, normalización, validación de reglas de negocio, y análisis exploratorio, Pandas facilita la detección y corrección de errores comunes, como valores nulos, duplicados o inconsistentes. Además, su integración con diversas tecnologías, bases de datos, entornos big data, y almacenamiento en la nube, convierte a Pandas en una herramienta extremadamente versátil para garantizar la exactitud, consistencia y completitud de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
El procesamiento del lenguaje natural (NLP, por sus siglas en inglés) es una rama de la inteligencia artificial que permite a las máquinas comprender y manipular el lenguaje humano. En el núcleo de muchas aplicaciones modernas, como asistentes virtuales, sistemas de traducción automática y chatbots, se encuentran los word embeddings. Pero, ¿qué son exactamente y por qué son tan importantes?
¿Qué son los word embeddings?
Los word embeddings son una técnica que permite a las máquinas representar el significado de las palabras de manera que se puedan capturar relaciones complejas entre ellas. Para entenderlo, pensemos en cómo las palabras se usan en un contexto determinado: una palabra adquiere significado en función de las palabras que la rodean. Por ejemplo, la palabra banco podría referirse a una institución financiera o a un asiento, dependiendo del contexto en el que se encuentre.
La idea detrás de los word embeddings es que se asigna a cada palabra un vector en un espacio de varias dimensiones. La posición de estos vectores en el espacio refleja la cercanía semántica entre las palabras. Si dos palabras tienen significados similares, sus vectores estarán cercanos. Si sus significados son opuestos o no tienen relación, estarán distantes en el espacio vectorial.
Para visualizarlo, imaginemos que palabras como lago, río y océano estarían cerca entre sí en este espacio, mientras que palabras como lago y edificio estarían mucho más separadas. Esta estructura permite que los algoritmos de procesamiento de lenguaje puedan realizar tareas complejas, como encontrar sinónimos, hacer traducciones precisas o incluso responder preguntas basadas en contexto.
¿Cómo se crean los word embeddings?
El objetivo principal de los word embeddings es capturar relaciones semánticas y la información contextual de las palabras, transformándolas en representaciones numéricas que puedan ser comprendidas por los algoritmos de machine learning (aprendizaje automático). En lugar de trabajar con texto sin procesar, las máquinas requieren que las palabras se conviertan en números para poder identificar patrones y relaciones de manera efectiva.
El proceso de creación de word embeddings consiste en entrenar un modelo en un gran corpus de texto, como artículos de Wikipedia, para aprender la estructura del lenguaje. El primer paso implica realizar una serie de preprocesamientos en el corpus, que incluye tokenizar las palabras, eliminar puntuación y términos irrelevantes, y, en algunos casos, convertir todo el texto a minúsculas para mantener la consistencia.
El uso del contexto para capturar el significado
Una vez preprocesado el texto, se utiliza una técnica conocida como "ventana de contexto deslizante" para extraer información. Esto significa que, para cada palabra objetivo, se toman en cuenta las palabras que la rodean dentro de un cierto rango. Por ejemplo, si la ventana de contexto es de 3 palabras, para la palabra avión en la frase “El avión despega a las seis”, las palabras de contexto serán El, despega, a.
El modelo se entrena para aprender a predecir una palabra objetivo usando las palabras de su contexto (o a la inversa, predecir el contexto a partir de la palabra objetivo). Para ello, el algoritmo ajusta sus parámetros de manera que los vectores asignados a cada palabra se acerquen más en el espacio vectorial si esas palabras aparecen frecuentemente en contextos similares.
Cómo los modelos aprenden la estructura del lenguaje
La creación de los word embeddings se basa en la capacidad de estos modelos para identificar patrones y relaciones semánticas. Durante el entrenamiento, el modelo ajusta los valores de los vectores de manera que las palabras que suelen compartir contextos tengan representaciones similares. Por ejemplo, si avión y helicóptero se usan frecuentemente en frases similares (por ejemplo, en el contexto de transporte aéreo), los vectores de avión y helicóptero estarán cerca en el espacio vectorial.
A medida que el modelo procesa más y más ejemplos de frases, va afinando las posiciones de los vectores en el espacio continuo. De este modo, los vectores no solo reflejan la proximidad semántica, sino también otras relaciones como sinónimos, categorías (por ejemplo, frutas, animales) y relaciones jerárquicas (por ejemplo, perro y animal).
Un par de ejemplos simplificado
Imaginemos un pequeño corpus de solo seis palabras: guitarra, bajo, batería, piano, coche y bicicleta. Supongamos que cada palabra se representa en un espacio vectorial de tres dimensiones de la siguiente manera:
guitarra [0.3, 0.8, -0.1]
bajo [0.4, 0.7, -0.2]
batería [0.2, 0.9, -0.1]
piano [0.1, 0.6, -0.3]
coche [0.8, -0.1, 0.6]
bicicleta [0.7, -0.2, 0.5]
En este ejemplo simplificado, las palabras guitarra, bajo, batería y piano representan instrumentos musicales y están ubicadas cerca unas de otras en el espacio vectorial, ya que se utilizan en contextos similares. En cambio, coche y bicicleta, que pertenecen a la categoría de medios de transporte, se encuentran alejadas de los instrumentos musicales pero cercanas entre ellas. Esta otra imagen muestra cómo se verían distintos términos relacionados con cielo, alas e ingeniería en un espacio vectorial.

Figura1. Ejemplos de representación de un corpus en un espacio vectorial. Fuente: Adaptación de “Word embeddings: the (very) basics”, de Guillaume Desagulier.
Estos ejemplos solo utilizan tres dimensiones para ilustrar la idea, pero en la práctica, los word embeddings suelen tener entre 100 y 300 dimensiones para capturar relaciones semánticas más complejas y matices lingüísticos.
El resultado final es un conjunto de vectores que representan de manera eficiente cada palabra, permitiendo a los modelos de procesamiento de lenguaje identificar patrones y relaciones semánticas de forma más precisa. Con estos vectores, las máquinas pueden realizar tareas avanzadas como búsqueda semántica, clasificación de texto y respuesta a preguntas, mejorando significativamente la comprensión del lenguaje natural.
Estrategias para generar word embeddings
A lo largo de los años, se han desarrollado múltiples enfoques y técnicas para generar word embeddings. Cada estrategia tiene su forma de capturar el significado y las relaciones semánticas de las palabras, lo que resulta en diferentes características y usos. A continuación, se presentan algunas de las principales estrategias:
1. Word2Vec: captura de contexto local
Desarrollado por Google, Word2Vec es uno de los enfoques más conocidos y se basa en la idea de que el significado de una palabra se define por su contexto. Usa dos enfoques principales:
- CBOW (Continuous Bag of Words): en este enfoque, el modelo predice la palabra objetivo usando las palabras de su entorno inmediato. Por ejemplo, dado un contexto como "El perro está ___ en el jardín", el modelo intenta predecir la palabra jugando, basándose en las palabras El, perro, está y jardín.
- Skip-gram: A la inversa, Skip-gram usa una palabra objetivo para predecir las palabras circundantes. Usando el mismo ejemplo, si la palabra objetivo es jugando, el modelo intentaría predecir que las palabras en su entorno son El, perro, está y jardín.
La idea clave es que Word2Vec entrena el modelo para capturar la proximidad semántica a través de muchas iteraciones en un gran corpus de texto. Las palabras que tienden a aparecer juntas tienen vectores más cercanos, mientras que las que no están relacionadas aparecen más distantes.
2. GloVe: enfoque basado en estadísticas globales
GloVe, desarrollado en la Universidad de Stanford, se diferencia de Word2Vec al utilizar estadísticas globales de co-ocurrencia de palabras en un corpus. En lugar de considerar solo el contexto inmediato, GloVe se basa en la frecuencia con la que dos palabras aparecen juntas en todo el corpus.
Por ejemplo, si pan y mantequilla aparecen juntas con frecuencia, pero pan y planeta rara vez se encuentran en el mismo contexto, el modelo ajusta los vectores de manera que pan y mantequilla estén cerca en el espacio vectorial.
Esto permite que GloVe capture relaciones globales más amplias entre palabras y que las representaciones sean más robustas a nivel semántico. Los modelos entrenados con GloVe tienden a funcionar bien en tareas de analogía y similitud de palabras.
3. FastText: captura de sub-palabras
FastText, desarrollado por Facebook, mejora a Word2Vec al introducir la idea de descomponer las palabras en sub-palabras. En lugar de tratar cada palabra como una unidad indivisible, FastText representa cada palabra como una suma de n-gramas. Por ejemplo, la palabra jugando se podría descomponer en ju, uga, ando, etc.
Esto permite que FastText capture similitudes incluso entre palabras que no aparecieron explícitamente en el corpus de entrenamiento, como variaciones morfológicas (jugando, jugar, jugador). Esto es particularmente útil para lenguajes con muchas variaciones gramaticales.
4. Embeddings contextuales: captura de sentido dinámico
Modelos como BERT y ELMo representan un avance significativo en word embeddings. A diferencia de las estrategias anteriores, que generan un único vector para cada palabra independientemente del contexto, los embeddings contextuales generan diferentes vectores para una misma palabra según su uso en la frase.
Por ejemplo, la palabra banco tendrá un vector diferente en la frase "me senté en el banco del parque" que en "el banco aprobó mi solicitud de crédito". Esta variabilidad se logra entrenando el modelo en grandes corpus de texto de manera bidireccional, es decir, considerando no solo las palabras que preceden a la palabra objetivo, sino también las que la siguen.
Aplicaciones prácticas de los word embeddings
Los word embeddings se utilizan en una variedad de aplicaciones de procesamiento de lenguaje natural, como:
- Reconocimiento de Entidades Nombradas (NER, por sus siglas en inglés): permiten identificar y clasificar nombres de personas, organizaciones y lugares en un texto. Por ejemplo, en la frase "Apple anunció su nueva sede en Cupertino", los word embeddings permiten al modelo entender que Apple es una organización y Cupertino es un lugar.
- Traducción automática: ayudan a representar palabras de una manera independiente del idioma. Al entrenar un modelo con textos en diferentes lenguas, se pueden generar representaciones que capturan el significado subyacente de las palabras, facilitando la traducción de frases completas con un mayor nivel de precisión semántica.
- Sistemas de recuperación de información: en motores de búsqueda y sistemas de recomendación, los word embeddings mejoran la coincidencia entre las consultas de los usuarios y los documentos relevantes. Al capturar similitudes semánticas, permiten que incluso consultas no exactas se correspondan con resultados útiles. Por ejemplo, si un usuario busca "medicamento para el dolor de cabeza", el sistema puede sugerir resultados relacionados con analgésicos gracias a las similitudes capturadas en los vectores.
- Sistemas de preguntas y respuestas: los word embeddings son esenciales en sistemas como los chatbots y asistentes virtuales, donde ayudan a entender la intención detrás de las preguntas y a encontrar respuestas relevantes. Por ejemplo, ante la pregunta “¿Cuál es la capital de Italia?”, los word embeddings permiten que el sistema entienda las relaciones entre capital e Italia y encuentre Roma como respuesta.
- Análisis de sentimiento: los word embeddings se utilizan en modelos que determinan si el sentimiento expresado en un texto es positivo, negativo o neutral. Al analizar las relaciones entre palabras en diferentes contextos, el modelo puede identificar patrones de uso que indican ciertos sentimientos, como alegría, tristeza o enfado.
- Agrupación semántica y detección de similaridades: los word embeddings también permiten medir la similitud semántica entre documentos, frases o palabras. Esto se utiliza para tareas como agrupar artículos relacionados, recomendar productos basados en descripciones de texto o incluso detectar duplicados y contenido similar en grandes bases de datos.
Conclusión
Los word embeddings han transformado el campo del procesamiento de lenguaje natural al ofrecer representaciones densas y significativas de las palabras, capaces de capturar sus relaciones semánticas y contextuales. Con la aparición de embeddings contextuales, el potencial de estas representaciones sigue creciendo, permitiendo que las máquinas comprendan incluso las sutilezas y ambigüedades del lenguaje humano. Desde aplicaciones en sistemas de traducción y búsqueda, hasta chatbots y análisis de sentimiento, los word embeddings seguirán siendo una herramienta fundamental para el desarrollo de tecnologías cada vez más avanzadas y humanizadas en el campo del lenguaje natural.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El verano supone para muchos la llegada de las vacaciones, una época en la que descansar o desconectar. Pero esos días libres también son una oportunidad para formarnos en diversas áreas y mejorar nuestras habilidades competitivas.
Para aquellos que quieran aprovechar las próximas semanas y adquirir nuevos conocimientos, las universidades españolas cuentan con una amplia oferta centrada en múltiples temáticas. En este artículo, recopilamos algunos ejemplos de cursos relacionados con la formación en datos.
Sistemas de Información Geográfica (SIG) con QGIS. Universidad de Alcalá de Henares (link no disponible).
El curso busca formar a los alumnos en las capacidades básicas en SIG para que puedan realizar procesos comunes como crear mapas para informes, descargar datos de un GPS, realizar análisis espaciales, etc. Cada estudiante tendrá la posibilidad de desarrollar su propio proyecto SIG con ayuda del profesorado. Está dirigido a estudiantes universitarios de cualquier disciplina, así como a profesionales interesados en aprender conceptos básicos para crear sus propios mapas o utilizar sistemas de información geográfica en sus actividades.
- Fecha y lugar: 27-28 de junio y 1-2 de julio en modalidad online.
Ciencia ciudadana aplicada a estudios de biodiversidad: de la idea a los resultados. Universidad Pablo de Olavide (Sevilla).
Este curso aborda todos los pasos necesarios para diseñar, implementar y analizar un proyecto de ciencia ciudadana: desde la adquisición de conocimientos básicos hasta sus aplicaciones en investigación y proyectos de conservación. Entre otras cuestiones, se realizará un taller sobre el manejo de datos de ciencia ciudadana, con el foco puesto en plataformas como Observation.org y GBIF. También se enseñará a utilizar herramientas de ciencia ciudadana para el diseño de proyectos de investigación. El curso está dirigido a un público amplio, especialmente investigadores, gestores de proyectos de conservación y estudiantes.
- Fecha y lugar: Del 1al 3 de julio de 2024 en modalidad online y presencial (Sevilla).
Big Data. Análisis de datos y aprendizaje automático con Python. Universidad Complutense de Madrid.
Este curso pretende que los alumnos adquieran una visión global del amplio ecosistema Big Data, sus retos y aplicaciones, centrándose en las nuevas maneras de obtener, gestionar y analizar datos. Durante el curso se presentará el lenguaje Python y se mostrarán distintas técnicas de aprendizaje automático para el diseño de modelos que permitan obtener información valiosa a partir de un conjunto de datos. Está dirigido a cualquier estudiante universitario, docente, investigador, etc. con interés en la temática, ya que no se requieren conocimientos previos.
- Fecha y lugar: Del 1 al 19 de julio de 2024 en Madrid.
Introducción a los Sistemas de Información Geográfica con R. Universidad de Santiago de Compostela.
Organizado por el Grupo de Trabajo de Cambio Climático y Riesgos Naturales de la Asociación Española de Geografía junto a la Asociación Española de Climatología, este curso introducirá al alumno en dos grandes áreas de gran interés: 1) el manejo del entorno R, mostrando las diferentes formas de gestión, manipulación y visualización de datos. 2) el análisis espacial, la visualización y el trabajo con archivos raster y vectoriales, abordando los principales métodos de interpolación geoestadística. Para participar, no se requieren conocimientos previos de Sistemas de Información Geográfica o del entorno R.
- Fecha y lugar: Del 2 al 5 de julio de 2024 en Santiago de Compostela.
Inteligencia Artificial y Grandes Modelos de Lenguaje: Funcionamiento, Componentes Clave y Aplicaciones. Universidad de Zaragoza.
A través de este curso, los alumnos podrán comprender los fundamentos y aplicaciones prácticas de la inteligencia artificial centrada en grandes modelos de lenguaje (Large Language Model o LLM en sus siglas en inglés). Se enseñará a utilizar bibliotecas y marcos de trabajo especializados para trabajar con LLM, y se mostrarán ejemplos de casos de uso y aplicaciones a través de talleres prácticos. Está dirigido a profesionales y estudiantes del sector de las tecnologías de la información y comunicaciones.
- Fecha y lugar: Del 3 al 5 de julio en Zaragoza.
Deep into Data Science. Universidad de Cantabria.
Este curso se centra en el estudio de grandes volúmenes de datos utilizando Python. El énfasis del curso se pone en el aprendizaje automático (Machine Learning en inglés), incluyendo sesiones sobre inteligencia artificial, redes neuronales o computación en la nube (Cloud Computing). Se trata de un curso técnico, que presupone conocimientos previos en ciencia y programación con Python.
- Fecha y lugar: Del 15 al 19 de julio de 2024 en Torrelavega.
Gestión de datos para el uso de inteligencia artificial en destinos turísticos. Universidad de Alicante.
Este curso se acerca al concepto de Destino Turístico Inteligente (DTI) y aborda la necesidad de disponer de una infraestructura tecnológica adecuada para garantizar su desarrollo sostenible, así como de realizar una gestión adecuada de los datos que permita la aplicación de técnicas de inteligencia artificial. Durante el curso se hablará de datos abiertos y espacios de datos, y su aplicación en el turismo. Está dirigido a todo tipo de público con interés en el uso de tecnologías emergentes en el ámbito del turismo.
- Fecha y lugar: Del 22 al 26 de julio de 2024 en Torrevieja.
Los retos de la transformación digital de sectores productivos desde la perspectiva de la inteligencia artificial y tecnologías de procesamiento de datos. Universidad de Extremadura.
Ya finalizado el verano, encontramos este curso donde se abordan los fundamentos de la transformación digital y su impacto en los sectores productivos a través de la exploración de tecnologías clave de procesamiento de datos, como Internet de las Cosas, Big Data, Inteligencia Artificial, etc. Durante las sesiones se analizarán casos de estudio y prácticas de implementación de estas tecnologías en diferentes sectores industriales. Todo ello sin dejar de lado los desafíos éticos, legales y de privacidad. Está dirigido a cualquier persona interesada en la materia, sin necesidad de conocimientos previos.
- Fecha y lugar: Del 17 al 19 de septiembre, en Cáceres.
Estos cursos son solo ejemplos que ponen de manifiesto la importancia que las capacidades relacionadas con datos están adquiriendo en las empresas españolas, y cómo eso se refleja en la oferta universitaria. ¿Conoces algún curso más, ofrecido por universidades públicas? Déjanoslo en comentarios.
Noticia
Hoy, 23 de abril, se celebra el Día del Libro, una ocasión para resaltar la importancia de la lectura, la escritura y la difusión del conocimiento. La lectura activa promueve la adquisición de habilidades y el pensamiento crítico, al acercarnos a información especializada y detallada sobre cualquier tema que nos interese, incluido el mundo de los datos.
Por ello, queremos aprovechar la ocasión para mostrar algunos ejemplos de libros y manuales relacionados con los datos y tecnologías relacionadas que se pueden encontrar en la red de manera gratuita.
1. Fundamentos de ciencia de datos con R, editado por Gema Fernandez-Avilés y José María Montero (2024)
Accede al libro aquí.
- ¿De qué trata? El libro guía al lector desde el planteamiento de un problema hasta la realización del informe que contiene su solución. Para ello, explica una treintena de técnicas de ciencia de datos en el ámbito de la modelización, análisis de datos cualitativos, discriminación, machine learning supervisado y no supervisado, etc. En él se incluyen más de una docena de casos de uso en sectores tan dispares como la medicina, el periodismo, la moda o el cambio climático, entre otros. Todo ello, con un gran énfasis en la ética y en el fomento de la reproductibilidad de los análisis.
-
¿A quién va dirigido? Está dirigido a usuarios que quieran iniciarse en la ciencia de datos. Parte de preguntas básicas, como qué es la ciencia de datos, e incluye breves secciones con explicaciones sencillas sobre la probabilidad, la inferencia estadística o el muestreo, para aquellos lectores no familiarizados con estas cuestiones. También incluye ejemplos replicables para practicar.
-
Idioma: Español
2. Contar historias con datos, Rohan Alexander (2023).
Accede al libro aquí.
-
¿De qué trata? El libro explica una amplia gama de temas relacionados con la comunicación estadística y el modelado y análisis de datos. Abarca las distintas operaciones desde la recopilación de datos, su limpieza y preparación, hasta el uso de modelos estadísticos para analizarlos, prestando especial importancia a la necesidad de extraer conclusiones y escribir sobre los resultados obtenidos. Al igual que el libro anterior, también pone el foco en la ética y la reproductibilidad de resultados.
-
¿A quién va dirigido? Es perfecto para estudiantes y usuarios con conocimientos básicos, a los que dota de capacidades para realizar y comunicar de manera efectiva un ejercicio de ciencia de datos. Incluye extensos ejemplos de código para replicar y actividades a realizar a modo de evaluación.
-
Idioma: Inglés.
3. El gran libro de los pequeños proyectos con Python, Al Sweigart (2021)
Accede al libro aquí.
- ¿De qué trata? Es una colección de sencillos proyectos en Python para aprender a crear arte digital, juegos, animaciones, herramientas numéricas, etc. a través de un enfoque práctico. Cada uno de sus 81 capítulos explica de manera independiente un proyecto sencillo paso a paso -limitados a máximo 256 líneas de código-. Incluye una ejecución de muestra del resultado de cada programa, el código fuente y sugerencias de personalización.
-
¿A quién va dirigido? El libro está escrito para dos grupos de personas. Por un lado, aquellos que ya han aprendido los conceptos básicos de Python, pero todavía no están seguros de cómo escribir programas por su cuenta. Por otro, aquellos que se inician en la programación, pero son aventureros, cuentan con grandes dosis de entusiasmo y quieren ir aprendiendo sobre la marcha. No obstante, el mismo autor tiene otros recursos para principiantes con los que aprender conceptos básicos.
-
Idioma: Inglés.
4. Matemáticas para Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Accede al libro aquí.
-
¿De qué trata? La mayoría de libros sobre machine learning se centran en algoritmos y metodologías de aprendizaje automático, y presuponen que el lector es competente en matemáticas y estadística. Este libro pone en primer plano los fundamentos matemáticos de los conceptos básicos detrás del aprendizaje automático
-
¿A quién va dirigido? El autor asume que el lector tiene conocimientos matemáticos comúnmente aprendidos en las materias de matemáticas y física de la escuela secundaria, como por ejemplo derivadas e integrales o vectores geométricos. A partir de ahí, el resto de conceptos se explican de manera detallada, pero con un estilo académico, con el fin de ser precisos.
-
Idioma: Inglés.
5. Profundizando en el aprendizaje profundo, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, se actualiza continuamente)
Accede al libro aquí.
-
¿De qué trata? Los autores son empleados de Amazon que utilizan la biblioteca MXNet para enseñar Deep Learning. Su objetivo es hacer accesible el aprendizaje profundo, enseñando los conceptos básicos, el contexto y el código de forma práctica a través de ejemplos y ejercicios. El libro se divide en tres partes: conceptos preliminares, técnicas de aprendizaje profundo y temas avanzados centrados en sistemas y aplicaciones reales.
-
¿A quién va dirigido? Este libro está dirigido a estudiantes (de grado o posgrado), ingenieros e investigadores, que buscan un dominio sólido de las técnicas prácticas del aprendizaje profundo. Cada concepto se explica desde cero, por lo que no es necesario tener conocimientos previos de aprendizaje profundo o automático. No obstante, sí son necesario conocimientos de matemáticas y programación básicas, incluyendo álgebra lineal, cálculo, probabilidad y programación en Python.
-
Idioma: Inglés.
6. Inteligencia artificial y sector público: retos límites y medios, Eduardo Gamero y Francisco L. Lopez (2024)
Accede al libro aquí.
-
¿De qué trata? Este libro se centra en analizar los retos y oportunidades que presenta el uso de la inteligencia artificial en el sector público, especialmente cuando se usa como soporte a la toma de decisiones. Comienza explicando qué es la inteligencia artificial y cuáles son sus aplicaciones en el sector público, para pasar a abordar su marco jurídico, los medios disponibles para su implementación y aspectos ligados a la organización y gobernanza.
-
¿A quién va dirigido? Es un libro útil para todos aquellos interesados en la temática, pero especialmente para responsables políticos, trabajadores públicos y operadores jurídicos relacionados con la aplicación de la IA en el sector público.
-
Idioma: español
7. Introducción del analista de negocio a la analítica empresarial, Adam Fleischhacker (2024)
Accede al libro aquí.
-
¿De qué trata? El libro aborda un flujo de trabajo de análisis empresarial completo, que incluye la manipulación de datos, su visualización, el modelado de problemas empresariales, la traducción de modelos gráficos a código y la presentación de resultados ante las partes interesadas. El objetivo es aprender a impulsar cambios dentro de una organización gracias al conocimiento basado en datos, modelos interpretables y visualizaciones persuasivas.
-
¿A quién va dirigido? Según su autor, se trata de un contenido accesible para todos, incluso para principiantes en la realización de trabajos de análisis. El libro no asume ningún conocimiento del lenguaje de programación, sino que proporciona una introducción a R, RStudio y al “tidyverse”, una serie de paquetes de código abierto para la ciencia de datos.
-
Idioma: Inglés.
Te invitamos a ojear esta selección de libros. Asimismo, recordamos que solo se trata de una lista con ejemplos de las posibilidades de materiales que puedes encontrar en la red. ¿Conoces algún otro libro que quieras recomendar? ¡Indícanoslo en los comentarios o manda un email a dinamizacion@datos.gob.es!