Blog
La European Open Science Cloud (EOSC) es una iniciativa de la Unión Europea que tiene como objetivo promover la ciencia abierta a través de la creación de una infraestructura digital de investigación abierta, colaborativa y sostenible. El objetivo principal de EOSC es el de proporcionar a los investigadores europeos un acceso más fácil a los datos, las herramientas y los recursos necesarios para poder llevar a cabo investigaciones de calidad.
EOSC en la agenda europea de investigación y datos
EOSC forma parte de las 20 acciones de la agenda 2022-2024 del Espacio Europeo de Investigación (ERA) y se reconoce como el espacio europeo de datos de ciencia, investigación e innovación, llamado a integrarse con otros espacios de datos sectoriales definidos en la estrategia europea para los datos. Entre los beneficios que se esperan obtener gracias a esta plataforma se encuentran:
-
Una mejora en la confianza, calidad y productividad de la ciencia europea.
- El desarrollo de nuevos productos y servicios innovadores.
- Una mejora en el impacto de la investigación a la hora de afrontar los mayores desafíos sociales.
La plataforma EOSC
EOSC es en realidad un proceso continuo que marca una hoja de ruta en la que todos los Estados Europeos participan, basándose en la idea central de que los datos de investigación son un bien público que debe estar disponible para todos los investigadores, independientemente de su ubicación o afiliación. Mediante este modelo se persigue que los resultados científicos cumplan con los Principios FAIR (Findable, Accesible, Interoperable, Reusable) para facilitar la reutilización, al igual que en cualquier otro espacio de datos.
No obstante, la parte más visible de ESCO es su plataforma que da acceso a millones de recursos aportados por cientos de proveedores de contenido. Dicha plataforma está diseñada para facilitar la búsqueda, el descubrimiento y la interoperabilidad de los datos y otros contenidos como recursos formativos, de seguridad, de análisis, herramientas, etc. Para ello, entre los elementos clave de la arquitectura prevista en EOSC encontramos dos componentes principales:
- EOSC Core: que proporciona todos los elementos básicos necesarios para descubrir, compartir, acceder y reutilizar recursos – autenticación, gestión de metadatos, métricas, identificadores persistentes, etc.
- EOSC Exchange: para asegurar que los servicios comunes y temáticos para la gestión y explotación de los datos estén disponibles a la comunidad científica.
A lo anterior hay que sumar el Framework de interoperabilidad de ESOC (EOSC-IF), un conjunto de políticas y directrices que habilitan la interoperabilidad entre distintos recursos y servicios y facilitan su posterior combinación.
En la actualidad la plataforma está disponible en 24 idiomas y se actualiza continuamente para añadir nuevos datos y servicios. Para los próximos siete años se prevé una inversión conjunta por parte de los socios de la Unión Europea de al menos 1.000 millones de euros para continuar con su desarrollo.
Participación en EOSC
La evolución de EOSC está siendo guiada por un organismo de coordinación tripartito formado por la propia Comisión Europea, los países participantes representados en la Junta Directiva de EOSC y la comunidad de investigación representada mediante la Asociación EOSC. Además, para poder formar parte de la comunidad ESCO tan sólo hay que seguir una serie de reglas mínimas de participación:
-
Todo el concepto de EOSC se basa en el principio general de apertura.
- Los recursos existentes en EOSC deben cumplir con los principios FAIR.
- Los servicios deben cumplir con la arquitectura y pautas de interoperabilidad de EOSC.
- EOSC sigue los principios de comportamiento ético e integridad en la investigación.
- Se espera que los usuarios de EOSC también contribuyan a EOSC.
- Los usuarios deben cumplir los términos y condiciones asociados a los datos que usen.
- Los usuarios de EOSC siempre citan las fuentes de los recursos que usen en su trabajo.
- La participación en EOSC está sujeta a las políticas y legislaciones aplicables.
EOSC en España
El Consejo Superior de Investigaciones Científicas (CSIC) de España fue uno de los 4 miembros fundadores de la asociación y actualmente es miembro encomendado de la misma, encargado de la coordinación a nivel nacional.
El CSIC lleva ya años trabajando en su repositorio de acceso abierto DIGITAL.CSIC como paso previo a su futura integración en EOSC. Dentro de su trabajo en ciencia abierta podemos señalar por ejemplo la adopción de los Current Research Information System (CRIS), sistemas de información diseñados para ayudar a las instituciones de investigación a recopilar, organizar y gestionar datos sobre su actividad investigadora: investigadores, proyectos, publicaciones, patentes, colaboraciones, financiación, etc.
Los CRIS son ya de por sí herramientas importantes a la hora de ayudar a las instituciones a rastrear y administrar su producción científica, promoviendo la transparencia y el acceso abierto a la investigación. Pero, además, pueden también desempeñar un papel relevante como fuentes de información que alimentan la EOSC, ya que los datos recopilados en los CRIS pueden ser también fácilmente compartidos y utilizados a través de la EOSC.
El camino hacia la ciencia abierta
La colaboración entre los CRIS y la EOSC tiene el potencial de mejorar significativamente la accesibilidad y la reutilización de los datos de investigación, pero hay también otras acciones de transición que se pueden adoptar en el camino hacia la producción de una ciencia cada vez más abierta:
-
Garantizar la calidad de los metadatos para facilitar el intercambio abierto de datos.
- Divulgar los principios FAIR entre la comunidad investigadora.
- Promover y desarrollar estándares comunes para facilitar la interoperabilidad.
- Fomentar la utilización de repositorios abiertos.
- Contribuir compartiendo recursos con el resto de la comunidad.
Todo ello ayudará a impulsar la ciencia abierta, aumentando la eficiencia, transparencia y replicabilidad de las investigaciones.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la era digital, los avances tecnológicos han transformado el sector de la investigación médica. Uno de los factores que contribuyen al desarrollo tecnológico en este ámbito son los datos y, en especial, los datos abiertos. La apertura y disponibilidad de la información que se obtiene de investigaciones sanitarias aporta múltiples beneficios a la comunidad científica. Los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas.
La relevancia de este tipo de datos también se manifiesta en la intención prioritaria de constituir el proyecto de espacio europeo de datos sanitarios (EEDS), el primer espacio común de datos de la UE que surge de la Estrategia Europea de Datos y una de las prioridades de la Comisión para el período 2019-2025. Tal y como plantea la Comisión Europea en su propuesta, el EEDS este espacio contribuirá a promover un mejor intercambio y acceso a diferentes tipos de datos sanitarios, no solo para apoyar la prestación de asistencia médica sino también para la investigación sanitaria y la elaboración de políticas en el ámbito de la salud.
Sin embargo, el tratamiento de este tipo de datos debe de ser adecuado, debido a la información sensible que albergan. Los datos personales relativos a la salud están considerados como una categoría especial por la Agencia Española de Protección de Datos (AEPD) y una brecha de datos personales, especialmente, en el sector de la salud, tiene un alto impacto personal y social.
Para evitar estos riesgos, los datos médicos se pueden anonimizar garantizando el cumplimiento normativo y de los derechos fundamentales y, así, proteger la privacidad de los pacientes. La Guía básica de anonimización elaborada por la AEPD a partir de la Personal Data Protection Commission Singapore (PDPC) define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
Una vez se realiza ese proceso, los datos médicos pueden contribuir a la investigación sobre enfermedades, lo que se traduce en mejoras en la eficacia de tratamientos y en el desarrollo de tecnologías de asistencia médica. Además, los datos abiertos en el sector salud permiten que los científicos compartan información, resultados y hallazgos de manera rápida y accesible, fomentando así la colaboración y la replicabilidad de los estudios.
En este sentido, existen diversas instituciones que comparten sus datos anonimizados para contribuir a la investigación sanitaria y el desarrollo de la ciencia. Una de ellas es la Fundación FISABIO (Fundación para el Fomento de la Investigación Sanitaria y Biomédica de la Comunitat Valenciana) que se ha convertido en un referente en el campo de la medicina gracias a su compromiso con la apertura y compartición de datos médicos. Como parte de esta institución, ubicada en la Comunidad Valenciana, existe la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) que se dedica, entre otras tareas, al estudio y desarrollo de técnicas avanzadas de imagen médica para mejorar el diagnóstico y tratamiento de enfermedades.
Este grupo de investigación ha desarrollado diferentes proyectos sobre análisis de imagen médica. El resultado de todo su trabajo se publica bajo licencias de código abierto: desde el resultado de sus investigaciones hasta los repositorios de datos que emplean para entrenar modelos de inteligencia artificial y machine learning.
Para proteger los datos sensibles de los pacientes, también han desarrollado sus propias técnicas de anonimización y seudonimización de imágenes e informes médicos mediante un modelo de Procesamiento del Lenguaje Natural (NLP) por el que los datos anonimizados se pueden sustituir por valores sintéticos. Siguiendo su técnica, se puede borrar la información facial de resonancias magnéticas cerebrales empleando un software libre de deep learning.
BIMCV: Banco de imágenes médicas de la Comunidad Valenciana
Uno de los mayores hitos de la Conselleria de Sanidad Universal y Salud Pública, a través de la Fundación y el hospital San Juan de Alicante, es la creación y mantenimiento del Banco de Imágenes Médicas de la Comunidad Valenciana, BIMCV (por sus siglas en inglés, Medical Imaging Databank of the Valencia Region), un repositorio de conocimiento para lograr “avances tecnológicos en imágenes médicas y proporcionar servicios de cobertura tecnológica para apoyar proyectos de I+D”, tal y como explican en su web.
BIMCV se aloja en XNAT, una plataforma que contiene imágenes de código abierto para la investigación basada en imágenes, y que es accesible bajo previo registro y/o bajo demanda. Actualmente, el Banco de Imágenes Médicas de la Comunidad Valenciana incluye datos abiertos procedentes de investigaciones realizada en diversos centros sanitarios de la región: alberga datos de más de 90.000 sujetos recogidos en más de 150.000 sesiones.
Nuevo conjunto de datos de imágenes radiológicas
Recientemente, la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) ha publicado en abierto la tercera y última iteración de datos del proyecto BIMCV-COVID-19: iniciativa con la que liberaron datos de imagen de radiologías de tórax realizadas a pacientes con COVID-19, así como los modelos que habían entrenado para detección de diferentes patologías de Rx tórax, gracias al apoyo de la Conselleria de Innovación, la Conselleria de Sanidad y los Fondos de la Unión Europea REACT-UE. Todo ello, “para que pueda ser utilizado por empresas del sector o simplemente para investigación”, explica María de la Iglesia, directora de la Unidad. “Creemos que la reproducibilidad es de gran relevancia e importancia en el sector salud", añade. Los conjuntos de datos y el resultado de sus investigaciones se pueden consultar aquí.
Los hallazgos están mapeados en terminología estándar del Sistema Unificado de Lenguaje Médico (UMLS) (como propuesta de los resultados de la tesis doctoral de la Oncóloga e Ingeniera Informática Dra. Aurelia Bustos)y almacenados en alta resolución con etiquetas anatómicas en un formato de Estructura de Datos de Imágenes Médicas (MIDS). Entre la información almacenada, se encuentran datos demográficos del paciente, el tipo de proyección y los parámetros de adquisición del estudio de imagen, entre otros, todo ello anonimizado.
La contribución que este tipo de proyectos sobre datos abiertos aportan a la sociedad, no solo beneficia a los investigadores y profesionales de la salud, sino que también permite el desarrollo de soluciones que pueden tener un impacto relevante en la mejora de la atención médica. Una de ellas puede ser la IA generativa que proporciona interesantes resultados que los profesionales sanitarios, priorizando su criterio, pueden tomar en consideración para personalizar el diagnóstico y proponer un tratamiento más eficaz.
Por otro lado, la digitalización de los sistemas sanitarios ya es una realidad: impresión 3D, gemelos digitales aplicados a la medicina, consultas telemáticas o dispositivos médicos portátiles. En este contexto, la colaboración y compartición de datos médicos, siempre y cuando se garantice su protección, contribuye a impulsar la investigación e innovación en el sector. Es decir, las iniciativas de datos abiertos para la investigación médica estimulan este avance tecnológico en la salud.
Por todo ello, la Fundación FISABIO conjuntamente con el Centro de Investigación Príncipe Felipe en donde se ubica la plataforma que alberga BIMCV, se destaca como un ejemplo destacado al promover la apertura y compartición de datos en el campo de la medicina. A medida que avanza la era digital, es fundamental seguir fomentando la apertura de datos y promoviendo su uso responsable en la investigación médica, en beneficio de toda la sociedad.
Noticia
El próximo 2 de marzo, tendrá lugar la presentación del proyecto ‘Datos abiertos y mujeres’, impulsado por el Observatorio Valenciano de Datos Abiertos y Transparencia, fruto de la colaboración entre la Conselleria de Participació, Transparencia, Cooperación y Calidad Democrática de la Generalitat y la Universidad Politécnica de València.
El evento que ha sido organizado por la profesora de la Universidad de Sevilla, Lorena R. Romero-Domínguez y la técnica audiovisual de la Universidad Politécnica de Valencia, Lucía García Robledo, con el apoyo de Antonia Ferrer Sapena, directora del Observatorio, y Eloína Coll Aliaga, directora de la Càtedra de Governança de la Ciutat de València, se llevará a cabo en el Salón de actos de Rectorado en la Universitat Politècnica de València.
Desde un inicio, el objetivo de este proyecto ha sido poner el foco en el rol que distintas mujeres del sector profesional desempeñan en el contexto de los datos y, en especial, de los datos abiertos. Así, mediante una serie de entrevistas, las profesionales seleccionadas comparten el transcurso de su trayectoria, explican cómo han crecido profesionalmente en el mundo de los datos y, también, cómo han abordado algunos de los proyectos más significativos de sus carreras a este respecto.
Las entrevistas, que fueron grabadas meses atrás, están disponibles para su visionado desde el canal de Youtube del Observatorio, donde podemos ver cómo cada una de las profesionales interpeladas reflexiona sobre los retos más importantes que afronta el sector, prestando especial atención a la inclusión de la perspectiva de género en los datos.
Presentación del proyecto y mesa redonda con algunas de las protagonistas
En la sesión de presentación del próximo 2 de marzo, se contará con Andrés Gomis, Director General de Transparencia, Atención a la Ciudadanía y Buen Gobierno de la Conselleria de Participación, Transparencia, Cooperación y Calidad Democrática de la Generalitat Valenciana y Elisa Valía, Tenienta Alcalde Participación, Derechos e Innovación de la Democracia. Concejala de Transparéncia y Gobierno Abierto del Ajuntament de València.
Además, también tendrá lugar una mesa de redonda sobre los datos con perspectiva de género que estará moderada por Carmen Montalbá, profesora de la Universitat de València, y en la que participarán las siguientes profesionales cuyas entrevistas forman parte del proyecto:
- Lorena R. Romero, profesora de la Universidad de Sevilla y autora del proyecto.
- Ana Tudela, Cofundadora de Datadista y miembro de la Oxford Climate Journalism Network.
- Silvia Rueda, Directora Territorial en la Conselleria de Innovación, Universidades, Ciencia y Sociedad Digital.
Junto a las ponentes anteriores que estarán presentes en la mesa redonda, el proyecto ‘Datos abiertos y mujeres’ recoge también las entrevistas de Lourdes Muñoz Santamaría, Fundadora y Directora de la Iniciativa Barcelona Open Data; Laura Castro, Diseñadora de visualización de datos en Affective Advisory; Zynnia del Villar, Directora de Investigación de Ciencias de Datos en Data-Pop Alliance; Thais Ruiz de Alda, Fundadora y CEO de Digital Fems. Tech Advisor&Consultant Digital Business; Sonia Castro-García Muñoz, Coordinadora de datos.gob.es (Red.es); Ana Tudela, Cofundadora de Datadista y Eva Méndez Rodríguez, Profesora Titular y Vicerrectora Adjunta de Política Científica de la Universidad Carlos III.
En definitiva, ‘Datos abiertos y mujeres’ es un proyecto que surge de la necesidad de incentivar un debate sobre la incorporación de la perspectiva de género a los datos, una práctica prioritaria para establecer políticas públicas que sean eficientes para combatir las desigualdades que se plantean entre hombres y mujeres.
Precisamente por esta razón, en las entrevistas, se ofrece una gran diversidad de visiones sobre el papel de los datos en los distintos campos profesionales, entre los que destacan, el periodismo de datos, el ámbito científico-tecnológico, el administrativo o las organizaciones internacionales, entre otros.
Por último, las personas interesadas en asistir presencialmente a la presentación del proyecto deberán inscribirse previamente en este formulario y, una vez confirmada su asistencia, acudir al Salón de actos de Rectorado UPV, en el edificio 3ª.
Blog
Python, R, SQL, JavaScript, C++, HTML... Hoy en día podemos encontrar multitud de lenguajes de programación que nos permiten desarrollar programas de software, aplicaciones, páginas webs, etc. Cada uno tiene características únicas que lo diferencian del resto y que lo hacen más apropiado para determinadas tareas. Pero, ¿cómo sabemos cuándo y dónde utilizar cada lenguaje? En este artículo te damos algunas pistas.
Tipos de lenguajes de programación
Los lenguajes de programación son reglas sintácticas y semánticas que nos permiten ejecutar una serie de instrucciones. Según su nivel de complejidad, podemos hablar de distintos niveles:
- Lenguajes de bajo nivel: utilizan instrucciones básicas que la máquina interpreta directamente y que son difíciles de entender por las personas. Están diseñados a medida de cada hardware y no se pueden migrar, pero son muy eficaces, ya que aprovechan al máximo las características de cada máquina.
- Lenguajes de alto nivel: utilizan instrucciones claras usando un lenguaje natural, más entendible por los humanos. Estos lenguajes emulan nuestra forma de pensar y razonar, pero después deben ser traducidos a lenguaje máquina a través de traductores/intérpretes o compiladores. Se pueden migrar y no dependen del hardware.
En ocasiones también se habla de lenguajes de nivel medio para aquellos que, aunque funcionan como un lenguaje de bajo nivel, permiten cierto manejo abstracto independiente de la máquina.
Los lenguajes de programación más utilizados
En este artículo nos vamos a centrar en los lenguajes de alto nivel más utilizados en la ciencia de datos. Para ello nos vamos a fijar en esta encuesta, realizada por Anaconda en 2021, y en el artículo elaborado por KD Nuggets.
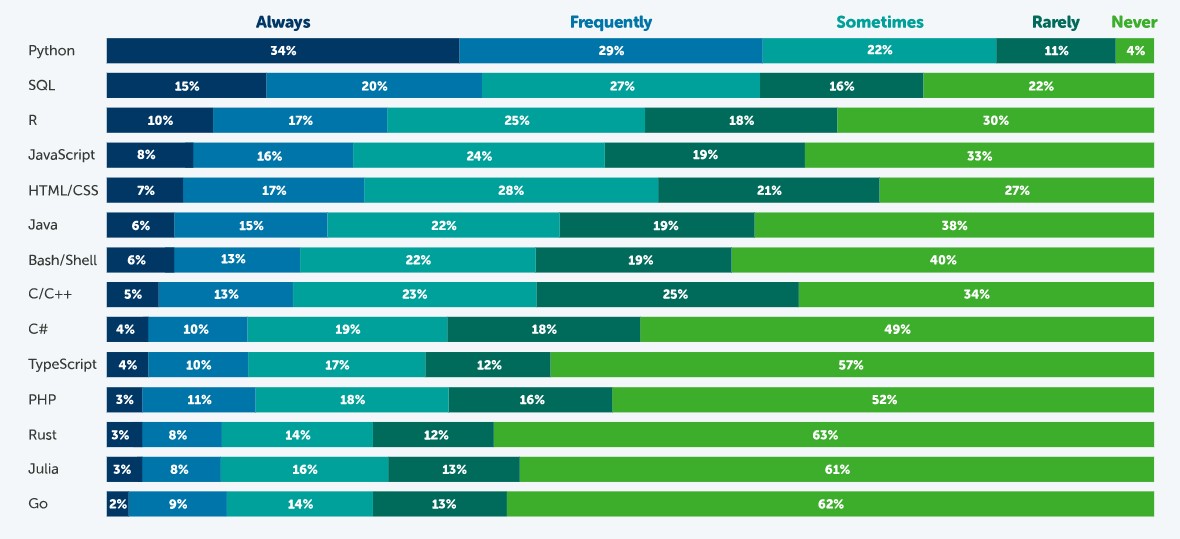
Fuente: Estado de la Ciencia de Datos en 2021, Anaconda.
Según esta encuesta, el lenguaje más popular es Python. El 63% de los encuestados – 3.104 científicos de datos, investigadores, estudiantes y profesionales del dato de todo el mundo- indicó que utiliza Python siempre o frecuentemente y solo un 4% indicó que nunca. Esto se debe a que es un lenguaje muy versátil, que se puede utilizar en las distintas tareas que existen a lo largo de un proyecto de ciencia de datos.
Un proyecto de ciencia de datos cuenta con distintas fases y tareas. Algunos lenguajes pueden ser utilizados para ejecutar distintas labores, pero con desigual rendimiento. La siguiente tabla, elaborada por KD Nuggets, muestra qué lenguaje es más recomendado para algunas de las tareas más populares:

Como vemos Python es el único lenguaje que resulta apropiado para todas las áreas analizadas por KD Nuggets, aunque existen otras opciones que también son muy interesantes, según la tarea a realizar, como veremos a continuación:
- Extracción y manipulación de datos. Estas tareas están dirigidas a obtener los datos y depurarlos con el fin de conseguir una estructura homogénea, sin datos incompletos, libre de errores y en el formato adecuado. Para ello se recomienda realizar un Análisis Exploratorio de Datos. SQL es el lenguaje de programación que más destaca con respecto a la extracción de datos, sobre todo cuando se trabaja con bases de datos relacionales. Es rápido en la recuperación de datos y cuenta con una sintaxis estandarizada, lo cual lo hace relativamente sencillo. Sin embargo, es más limitado a la hora de manipular datos. Una tarea en la que dan mejores resultados Python y R, dos programas que cuentan con una gran cantidad de librerías para estas tareas.
- Análisis estadístico y visualización de datos. Supone el tratamiento de los datos para encontrar patrones que luego se convierten en conocimiento. Existen distintos tipo de análisis según su propósito: conocer mejor nuestro entorno, realizar predicciones u obtener recomendaciones. El mejor lenguaje para ello es R, un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística. Python, Java y Julia son otras herramientas que dan un buen rendimiento en esta tarea, para la cual también se puede utilizar JavaScript. Los lenguajes anteriores permiten, además de realizar análisis, elaborar visualizaciones gráficas que facilitan la comprensión de la información.
- Modelización/aprendizaje automático (ML). Si queremos trabajar con machine learning y construir algoritmos, Python, Java, Java/JavaScript, Julia y TypeScript son las mejores opciones. Todas ellas simplifican la tarea de escribir código, aunque es necesario tener conocimientos amplios para poder trabajar con las diferentes técnicas de aprendizaje automático. Aquellos usuarios más expertos pueden trabajar con C/C++, un lenguaje de programación muy fácil de leer por máquinas, pero con mucho código, que puede ser difícil de aprender. Por el contrario, R puede ser una buena opción para aquellos menos expertos, aunque es más lento y poco apropiado para redes neuronales complejas.
- Despliegue de modelos. Una vez creado un modelo, es necesario su despliegue, teniendo en cuenta todos los requisitos necesarios para su entrada en producción en un entorno real. Para ello, los lenguajes más adecuados son Python, Java, JavaScript y C#, seguido de PHP, Rust, GoLang y, si trabajamos con aplicaciones básicas, HTML/CSS.
- Automatización. Aunque no todas las partes del trabajo de un científico de datos pueden automatizarse, hay algunas tareas tediosas y repetitivas cuya automatización agiliza el rendimiento. Python, por ejemplo, cuenta con una gran cantidad de librerías para la automatización de tareas de machine learning. Si trabajamos con aplicaciones móviles, entonces nuestra mejor opción será Java. Otras opciones son C# (especialmente útil para automatizar la construcción de modelos), Bash/Shell (para extracción y manipulación de datos) y R (para análisis estadísticos y visualizaciones).
En definitiva, el lenguaje de programación que utilicemos dependerá completamente de la tarea a realizar y de nuestras capacidades. No todos los profesionales de la ciencia de datos necesitan saber de todos los lenguajes, sino que deberán optar por profundizar en aquel más adecuado en base a su trabajo diario.
Algunos recursos adicionales para aprender más sobre estos lenguajes
En datos.gob.es hemos elaborado algunas guías y recursos que pueden ser de tu utilidad para aprender algunos de estos lenguajes:
- Informe sobre Herramientas de procesado y visualización de datos
- Cursos para aprender más sobre R
- Cursos para aprender más sobre Python
- Cursos online para aprender más sobre visualización de datos
- Comunidades de desarrolladores en R y Python
Contenido elaborado por el equipo de datos.gob.es.
Blog
Según el último análisis realizado por Gartner en septiembre de 2021, sobre las tendencias en materia de Inteligencia Artificial, los Chatbots son una de las tecnologías más cercanas a ofrecer una productividad efectiva en menos de 2 años. En la Figura 1, extraída de dicho informe, se observa que existen 4 tecnologías que han superado ampliamente el estado de sobre-expectativa (peak of inflated expectations) y comienzan ya a salir del canal de desilusión (trough of disillisionment), hacia estados de mayor madurez y estabilidad, incluyendo chatbots, búsqueda semántica, visión artificial y vehículos autónomos.
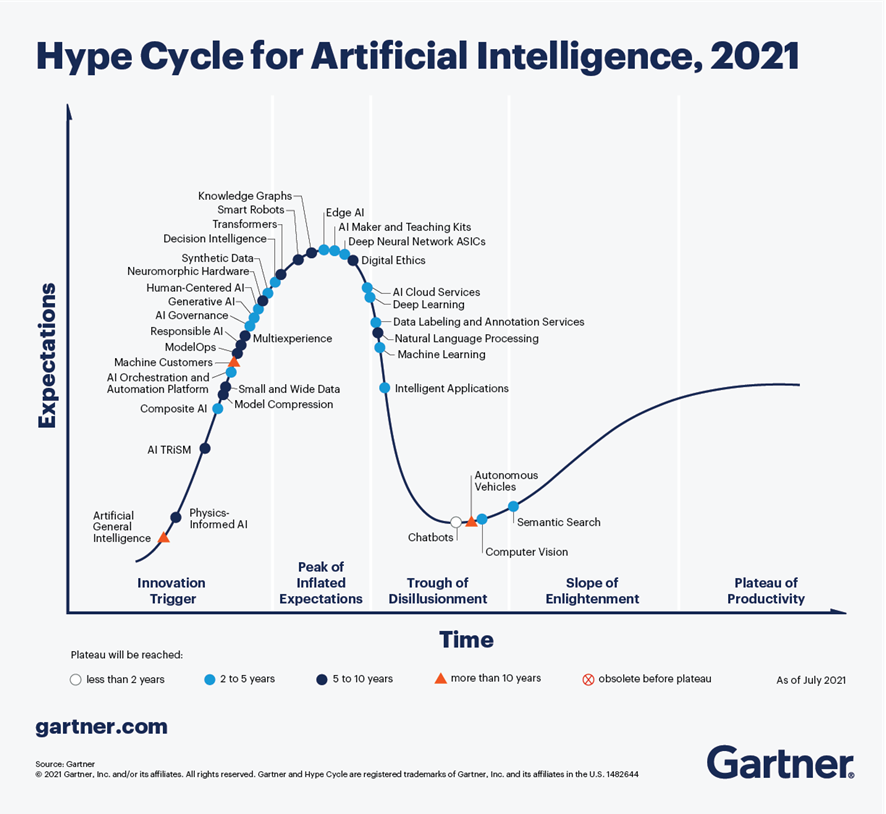
Figura 1 - Tendencias en IA para los próximos años.
En el caso concreto de los chatbots, existen grandes expectativas de productividad en los próximos años gracias a la madurez de las diferentes plataformas disponibles, tanto en opciones de Cloud Computing, como en proyectos de código abierto, es especial RASA o Xatkit. En la actualidad es relativamente sencillo desarrollar un chatbot o asistente virtual sin conocimientos de IA, mediante el uso de estas plataformas.
¿Cómo funciona un chatbot?
A modo de ejemplo, la Figura 2 muestra un diagrama de los diferentes componentes que habitualmente incluye un chatbot, en este caso enfocado en la arquitectura del proyecto RASA.
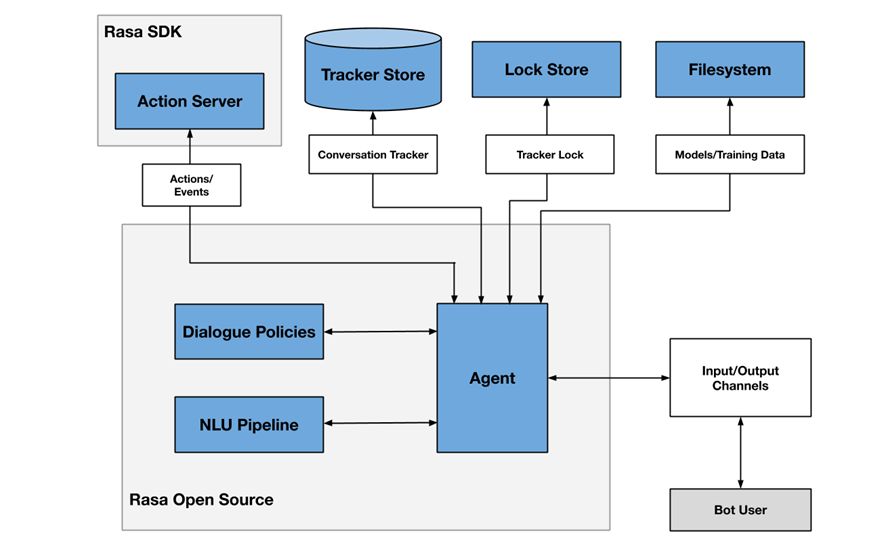
Figura 2 - Arquitectura del proyecto RASA
Uno de los componentes principales es el módulo agente (agent), que actúa a modo de controlador del flujo de datos y normalmente es la interfaz del sistema con los diferentes canales (input/output channels) ofrecidos a los usuarios, como aplicaciones de chat, redes sociales, aplicaciones web o móviles, etc.
El módulo de NLU (Natural Languge Understanding) se encarga de identificar la intención del usuario (qué quiere consultar o hacer), la extracción de entidades (de qué está hablando) y la generación de respuestas. Se considera un flujo (pipeline) porque intervienen varios procesos de diferente complejidad, en muchos casos incluso mediante el uso de modelos pre-entrenados de Inteligencia Artificial.
Finalmente, el módulo de gestión de conversaciones (dialogue policies) define cuál es el siguiente paso en una conversación, basándose en el contexto y el histórico de mensajes. Este módulo se integra con otros subsistemas como el almacén de conversaciones (tracker store) o el servidor que procesa las acciones necesarias para dar respuesta al usuario (action server).
Chatbots en portales de datos abiertos como mecanismo para localizar datos y acceder a información
Cada vez existen más iniciativas para empoderar a los ciudadanos en la consulta de datos abiertos mediante el uso de chatbots, empleando interfaces de lenguaje natural, aumentando así el valor neto que ofrecen dichos datos. El uso de chatbots permite automatizar la recopilación de datos a partir de la interacción con el usuario y responder de forma sencilla, natural y fluida, permitiendo la democratización de la puesta en valor de datos abiertos.
En el SOM Research Lab (Universitat Oberta de Catalunya) fueron pioneros en la aplicación de chatbots para mejorar el acceso de los ciudadanos a los datos abiertos a través de los proyectos Open Data for All y BODI (Bots para interactuar con datos abiertos – Interfaces conversacionales para facilitar el acceso a los datos públicos). Puedes encontrar más información sobre este último proyecto en este artículo.
También cabe destacar el chatbot de Aragón Open Data, del portal de datos abiertos del Gobierno de Aragón, cuyo objetivo es acercar la gran cantidad de datos disponibles a la ciudadanía, para que esta pueda aprovechar su información y valor, evitando cualquier barrera técnica o de conocimiento entre la consulta realizada y los datos abiertos existentes. Los dominios sobre los que ofrece información son:
- Información general sobre Aragón y su territorio
- Turismo y viajes en Aragón
- Transporte y agricultura
- Asistencia técnica o preguntas frecuentes en materia de sociedad de la información
Conclusiones
Estos son sólo algunos ejemplos del uso práctico de chatbots en la puesta en valor de datos abiertos y su potencial a corto plazo. En los próximos años veremos cada vez más ejemplos de asistentes virtuales en diferentes escenarios, tanto del ámbito de las administraciones públicas como en servicios privados, en especial enfocados a la mejora de la atención al usuario en aplicaciones de comercio electrónico y servicios surgidos de iniciativas de transformación digital.
Contenido elaborado por José Barranquero, experto en Ciencia de Datos y Computación Cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
La situación de pandemia que hemos vivido durante los últimos años ocasionó que una gran cantidad de eventos tuvieran que celebrarse de manera online. Fue el caso de las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE), cuyas ediciones de 2020 y 2021 tuvieron un formato virtual. Sin embargo, la situación ha cambiado y en este 2022 podremos volver a reunirnos para hablar de las últimas tendencias en información geográfica.
Sevilla será la sede de la JIIDE 2022
Sevilla ha sido la ciudad elegida para reunir a todos aquellos profesionales de la administración pública, el sector privado y el académico interesados en la información geográfica y que utilizan Infraestructuras de Datos Espaciales (IDE) en el ejercicio de sus actividades.
En concreto, la cita tendrá lugar del 25 al 27 de octubre en la Universidad de Sevilla. Puedes ver más información aquí.
Foco en la experiencia de usuario
El lema de este año es «Experiencia y evolución tecnológica: acercando la IDE a la ciudadanía». Con ello se quiere poner el énfasis en las nuevas tendencias tecnológicas y su uso para proporcionar al ciudadano soluciones que resuelvan problemas concretos, mediante la publicación y tratamiento de la información geográfica de forma normalizada, interoperable y abierta.
Durante tres días los asistentes podrán compartir experiencias y casos de uso sobre cómo utilizar técnicas de Big Data, Inteligencia Artificial o el Cloud Computing para mejorar la capacidad de análisis, el almacenamiento y la publicación web de grandes volúmenes de datos procedente de diversas fuentes, incluyendo sensores en tiempo real.
También se hablarán de las nuevas especificaciones y estándares que han surgido, así como de la evaluación que se está realizando de la Directiva INSPIRE.
Agenda ya disponible
Aunque aún quedan por confirmar algunas participaciones, el programa ya está disponible en la web de las Jornadas. Habrá unas 80 comunicaciones donde se mostrarán experiencias relativas a proyectos reales, 7 talleres técnicos donde compartir conocimientos concretos y una mesa redonda para promover el debate
Entre las ponencias encontramos algunas enfocadas en los datos abiertos. Es el caso del Ayuntamiento de Valencia que nos hablará de cómo utilizan datos abiertos para la obtención de la equidad ambiental en los barrios de la ciudad o la sesión dedicada a la “fototeca aérea Digital de Andalucía: un proyecto para la convergencia de las IDE y Open-Data”.
¿Cómo puedo asistir?
El evento es gratuito, pero para acudir es necesario registrarse a través de este formulario. En él es necesario indicar la jornada a la que se desea acudir.
De momento está abierto el registro para acudir presencialmente, pero en septiembre, se abrirá, en la web de las jornadas, la posibilidad de participar en las JIIDE de forma virtual.
Organizadores
Las Jornadas Ibéricas de Infraestructuras de Datos Espaciales (JIIDE) nacieron de la colaboración de la Direção-Geral do Território de Portugal, el Instituto Geográfico Nacional de España y el Govern d' Andorra. En esta ocasión se une como organizador el Instituto de Estadística y Cartografía de Andalucía y la Universidad de Sevilla.
Noticia
En los próximos días comenzará una época de sol, calor, playa y, en muchos casos, más tiempo libre, lo que convierte a esta estación en una oportunidad perfecta para ampliar nuestra formación sobre una gran variedad de temáticas, entre las que no puede faltar los datos, una materia transversal a los distintos sectores.
Cada vez son más los cursos relacionados con Big Data, ciencia, analítica e incluso periodismo de datos que encontramos en las ofertas estivales de los centros de formación. Existe un interés creciente por ampliar formación sobre estas materias debido a la alta demanda de perfiles profesionales con estas capacidades.
Bien seas estudiante o un/a profesional en activo, a continuación, te mostramos algunos ejemplos de cursos de verano que pueden ser de gran interés para ampliar tus conocimientos durante estas semanas:
Ciencia de datos
La Universidad de Castilla-La Mancha imparte el curso “Ciencia de datos: impacto en la sociedad”, el 22 y 23 de junio en el campus de Albacete, donde se hablará de las nuevas formas de formas de adquisición y uso de los datos fruto de los avances en tecnología e inteligencia artificial.
La Universidad de Deusto ofrecerá este verano una formación online sobre "Análisis de datos y machine learning aplicado". Este curso, que comenzará el próximo 27 de junio, te enseñará a dominar las principales tecnologías de análisis y procesamiento de grandes cantidades de datos, además de algunas técnicas para aumentar el valor de los datos analizados, fomentando una óptima toma de decisiones.
La Universidad de Alicante se centra en la inteligencia artificial con el curso “Introducción al Deep Learning” del 11 al 15 de julio de 2022, en modalidad presencial. El curso comenzará explicando conceptos básicos y el uso de paquetes básicos y avanzados como NumPy, Pandas, scikit-learn o tf.Keras, para luego continuar profundizando en redes neuronales.
La Universidad de Alcalá de Henares hablará de “Introducción al data science financiero con R” en un curso presencial del 20 al 24 de junio. El objetivo del curso es doble: familiarizar al alumno con el uso del lenguaje estadístico y mostrar algunas de las técnicas ligadas al cálculo estadístico avanzado, así como sus aplicaciones prácticas.
Datos abiertos
La Universidad Complutense de Madrid oferta, un año más, su curso "Big & Open Data. Análisis y programación con R y Python" del 4 al 22 de julio de 2022 (en horario de mañana de 9:00 a 14:00 horas, de lunes a viernes). En él se hablará del ciclo de vida del dato, ejemplos de casos de uso del Big Data o la ética aplicada a la gestión de datos masivos, entre otros temas.
Sistemas de Información Geográfica
Si eres un apasionado de los datos geográficos, la Universidad de Santiago imparte el curso “Introducción en sistemas de información geográfica y cartografía con el entorno R” del 5 al 8 de julio de 2022. En formato presencial y con 29 horas lectivas, busca introducir al alumno en el análisis espacial, la visualización y el trabajo con archivos raster y vectorial. Durante el curso se abordarán los principales métodos de interpolación geoestadística.
La Universidad de Alcalá de Henares, por su parte, impartirá el curso "Aplicaciones de los SIG a la Hidrología", del 6 al 8 de julio, también en formato presencial. Se trata de un curso práctico que abarca desde las distintas fuentes de datos hidro-meteorológicos hasta la realización de análisis de evapotranspiración y escorrentía, y obtención de resultados.
Periodismo de datos
El Institut de Formació Contínua – IL3 de la Universitat de Barcelona organizará del 4 al 7 de julio de 2022 el curso online en castellano "Bulos y periodismo de datos". Esta formación de 8 horas de duración te aportará los conocimientos necesarios para comprender, identificar y combatir el fenómeno de la desinformación. Además, conocerás las herramientas esenciales que se utilizan en el periodismo de datos, la verificación de datos (fact-checking) políticos y la investigación basada en peticiones de transparencia.
Protección de datos
La Universidad Internacional Menéndez Pelayo impartirá un curso sobre "Estrategias para la protección de datos ante los desafíos del entorno digital" los próximos 4, 5 y 6 de julio. El programa está dirigido a alumnos relacionados con el mundo empresarial, la prestación de servicios digitales, las administraciones públicas, investigadores e interesados en la materia. "Smart-cities y tratamiento de datos personales" o "el Comité Europeo de Protección de Datos y las iniciativas europeas del paquete digital" serán solo algunos de los temas que abordará este curso.
Otra de las formaciones relacionadas con la protección de datos que se impartirá durante los próximos meses será "¿Son nuestros datos realmente nuestros? Riesgos y garantías de la protección de datos personales en las sociedades digitales". La Universidad Internacional de Andalucía será la encargada de impartir este curso que se celebrará de manera presencial en Sevilla a partir del día 29 de agosto y en el que se abordará la situación actual de la protección de datos personales en el marco de la Unión Europea. A través de esta formación descubrirás cuáles son los beneficios y riesgos a los que se enfrenta el tratamiento de nuestros datos personales.
Además de esta formaciones específicas de verano, aquellos usuarios que lo deseen también pueden acudir a las grandes plataformas de cursos MOOC, como Coursera, EDX o Udacity, que ofrecen cursos interesantes de manera continua para que cualquier estudiante pueda comenzar su aprendizaje en el momento que precise.
Estos son solo algunos ejemplos de cursos que actualmente tienen matrícula abierta para este verano, aunque la oferta es muy amplia y variada. Además, cabe destacar que el verano aún no ha comenzado y que en las próximas semanas podrían surgir nuevas formaciones relacionados con el campo de los datos. Si conoces alguna más que sea de interés, no dudes en dejarnos un comentario aquí debajo o escribirnos a contacto@datos.gob.es
Blog
Durante la última década hemos visto como las instituciones nacionales e internacionales, así como los gobiernos de los países y las propias asociaciones empresariales alertaban sobre la escasez de perfiles tecnológicos y la amenaza que esto supone para la innovación y el crecimiento. No se trata de un problema exclusivamente europeo - y que por tanto afecta también a España-, sino que en mayor o menor medida se da en todo el mundo, y que ha sido agravado aún más por la reciente pandemia.
Cualquiera que lleve un tiempo de vida profesional, y no necesariamente en el mundo tecnológico, ha podido observar cómo la demanda de roles relacionados con la tecnología ha ido aumentando. No es más que la consecuencia de que las compañías de todo el mundo están haciendo grandes inversiones en digitalización para mejorar sus operaciones e innovar en sus productos, junto con la creciente presencia de la tecnología en todos los aspectos de nuestra vida.
Y dentro de los profesionales de la tecnología, durante los últimos años hay un grupo que se ha convertido en una especie de unicornio debido a su particular escasez, los científicos de datos y el resto de profesionales relacionados con los datos y la inteligencia artificial: ingenieros de datos, ingenieros de machine learning, especialistas en ingeniería artificial en todos los ámbitos, desde la gobernanza de datos hasta la propia configuración y despliegue de modelos de aprendizaje profundo, etc.
Este escenario es especialmente problemático para España donde los salarios son menos competitivos que en otros países de nuestro entorno y donde, de entrada, la proporción de trabajadores de IT está por debajo de la media de la UE. Por tanto, es previsible que las compañías españolas y las administraciones públicas, que también están implementando proyectos de este tipo, se enfrenten a crecientes dificultades para reclutar y retener el talento relacionado con la tecnología en general, y con los datos y la inteligencia artificial en particular.
Cuando existe un problema de oferta, la única solución sostenible a medio y largo plazo es aumentar la producción de aquello que escasea. En este caso la solución pasaría por incorporar al mercado laboral nuevos profesionales como único mecanismo para garantizar un mejor equilibrio entre oferta y demanda. Y así lo reconocen todas las estrategias y planes nacionales y europeos relacionadas con la digitalización, la inteligencia artificial y la propia reforma de los sistemas educativos, tanto superior como de formación profesional.
Las Estrategias españolas
La Estrategia Nacional de Inteligencia Artificial dedica uno de sus ejes a la promoción del desarrollo de capacidades digitales con el objetivo de poner todos los medios que garanticen que los trabajadores tengan un dominio adecuado de las habilidades digitales y capacidades para comprender y desarrollar tecnologías y aplicaciones de Inteligencia Artificial. El Gobierno español ha previsto una amplia gama de políticas de educación y formación cuya base es el Plan Nacional de competencias digitales, publicado en enero de 2021 y que está alineado con la Agenda Digital 2025.
Este plan incluye la analítica de datos y la inteligencia artificial como áreas de vanguardia tecnológica dentro de las competencias digitales especializadas, esto es, “necesarias para satisfacer la demanda laboral de especialistas en tecnologías digitales: personas que trabajan directamente en el diseño, implementación, operación y/o mantenimiento de sistemas digitales”.
En general, la estrategia nacional presenta acciones de política sobre educación y habilidades digitales para toda la población a lo largo de toda su vida. Aunque en muchos casos estas medidas están aún en fase de planificación y verán un impulso importante con el despliegue de los fondos de NextGenerationEU, ya tenemos algunos ejemplos pioneros como los programas de formación y orientación para el empleo para desempleados y jóvenes licitados el año pasado y recientemente adjudicados. En el caso de la formación para personas desempleadas ya se encuentran en ejecución actuaciones para como el programa Actualízate y el proyecto de formación para la adquisición de capacidades para la economía digital. Las acciones adjudicadas que están dirigidas a jóvenes está previsto que comiencen en el primer trimestre de 2022. En ambos casos el objetivo es la impartición de acciones formativas gratuitas dirigidas a la adquisición y mejora de competencias TIC, competencias personales y empleabilidad, en el ámbito de la transformación y la economía digital, así como la orientación y la inserción laboral. Entre estas competencias TIC, sin duda, las relacionadas con los datos y la inteligencia artificial tendrán un peso importante en los programas de formación.
El papel de las universidades
Por otra parte, las universidades de todo el mundo, y por supuesto las españolas, llevan ya un tiempo adaptando planes de estudio y creando nuevos programas formativos relacionados con los datos y la inteligencia artificial. La primera en adaptarse a la demanda fue la formación de posgrado, que, dentro del sistema de educación superior, es la más flexible y rápida de implementar. La primera hornada de profesionales con formación específica en datos e inteligencia artificial provenía de disciplinas diversas. Por ello, entre los veteranos de los equipos de datos de las empresas podemos encontrar diferentes disciplinas STEM, desde las matemáticas y la física hasta prácticamente cualquier ingeniería. En general, lo que tenían en común estos pioneros era haber cursado Másteres en Big Data, en ciencia de datos, en analítica de datos, etc. complementados con formaciones no regladas a través de MOOCs.
En la actualidad están comenzando a llegar ya al mercado laboral los primeros profesionales que han cursado los primeros grados en ciencia de datos o ingeniería de datos que reformaron las universidades pioneras - pero que en la actualidad están ya implantados en numerosas universidades españolas - . Estos profesionales tienen un grado de adaptación muy alto a las actuales necesidades del mercado laboral, por lo que están muy demandados entre las empresas.
Para las universidades, el principal reto pendiente es que los planes de estudios universitarios de cualquier disciplina incluyan conocimientos para trabajar con datos y para comprender cómo los datos apoyan la toma de decisiones. Esto será vital para apoyar el objetivo de la UE de que el 70% de los adultos tenga habilidades digitales básicas para 2025.
Grandes compañías tecnológicas desarrollando talento
Una idea del tamaño del problema que supone la escasez de estas competencias para la economía global es la implicación de gigantes tecnológicos como Google, Amazon o Microsoft en su solución. En los últimos años hemos observado como prácticamente todas ellas han lanzado materiales y programas gratuitos a gran escala para certificar personal en diferentes áreas de la tecnología, porque lo consideran una amenaza para su propio crecimiento, aunque no sean precisamente ellas las que tengan las mayores dificultades para reclutar el escaso talento existente. Su visión es que si el resto de compañías no son capaces de seguir el ritmo de la digitalización esto hará que su propio crecimiento se resienta y por eso hacen grandes inversiones en programas de certificación más allá de sus propias tecnologías, como por ejemplo el Certificado profesional de Soporte de TI de Google o el Programa especializado: Desarrollo de aplicaciones modernas con Python de AWS.
Otras compañías multinacionales están abordando la escasez de talento volviendo a capacitar a sus empleados en habilidades analíticas e inteligencia artificial. Para ello siguen diferentes estrategias, como incentivar que sus empleados cursen MOOC o crear planes de formación a medida con proveedores especializados del sector educativo. En algunos casos, también se incentiva a los empleados en roles no relacionados con los datos a participar en capacitaciones ligadas a la ciencia de datos, como la visualización o analítica de datos.
Aunque tardaremos aún en ver sus efectos debido a la elevada inercia que tienen todas estas medidas, sin duda se va en la dirección adecuada para mejorar la competitividad de unas empresas que necesitan seguir el elevado ritmo global de innovación que rodea la inteligencia artificial y todo lo referente con los datos. Por su parte los profesionales que sepan adaptarse a esta demanda vivirán un momento dulce los próximos años y podrán elegir con qué proyectos se comprometen sin preocuparse por las dificultades que, por desgracia, afectan al empleo en otras áreas de conocimiento y sectores de actividad.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La profesión del científico de datos está en auge. Según el Informe de Empleos Emergentes de LinkedIn de 2020, la demanda de especialistas en ciencia de datos creció un 46.8% con respecto al año anterior, siendo especialmente reclamado en sectores como la banca, las telecomunicaciones o la investigación. El informe también indica que entre las capacidades que demandan las empresas están “Machine Learning, R, Apache Spark, Python, Data Science, Big Data, SQL, Data Mining, Estadística y Hadoop”. Formarnos en este tipo de herramientas y capacidades es por tanto una notable ventaja competitiva en el ámbito laboral.
En este contexto, no es de extrañar que la oferta universitaria en estas materias no deje de crecer. Pero al mismo tiempo también surgen alternativas que permiten ampliar nuestros conocimientos de una forma lúdica.
Gamificación para aprender ciencia de datos
Una de las mejores formas de aprender nuevas habilidades, es a través del juego. La resolución de retos y casos reales nos permite poner a prueba nuestros conocimientos y ejercitar nuevas destrezas de una manera entretenida y motivadora. Es lo que se conoce como gamificación, una técnica de aprendizaje que aplica elementos del diseño de juego a contextos no lúdicos. En este caso hablamos de aprendizaje, pero también se puede aplicar al marketing o incluso a sectores como la salud y el bienestar, entre otros.
La gamificación es una técnica perfecta para adquirir capacidades relacionadas con los datos, que se pone de manifiesto a través de competiciones como hackathons o los concursos de aplicaciones e ideas – como nuestro Desafío Aporta-. Pero en los últimos años también han crecido las plataformas en la red que proponen competiciones abiertas en forma de retos a los usuarios.
Kaggle, un espacio de competiciones abiertas
De entre todas esas plataformas, la más conocida es Kaggle, que reúne a más de 7 millones de usuarios registrados de todo el mundo. Se trata de una plataforma gratuita que pone a disposición de los usuarios problemas a solucionar utilizando ciencia de datos, análisis predictivo o técnicas de machine learning, entre otros.
Hay problemas para principiantes, como predecir la supervivencia en el Titanic -un problema de clasificación binaria- o los precios de las viviendas, para el que es necesario usar técnicas avanzadas de regresión. Algunas competiciones parten directamente de empresas que buscan resolver un reto que se les resiste y optan por abrirlo a los usuarios de las plataformas, como hizo el Banco Santander. En ocasiones, puede haber cuantiosos premios en metálico para aquel usuario que encuentre la solución más acertada. Un ejemplo es la liga de Fútbol Americana, que busca predecir los golpes contra los cascos de los jugadores y premia con 100.000 dólares a quien lo logre .También hay empresas que crean específicamente concursos en los que los ganadores tienen la oportunidad de una entrevista con su equipo de ciencia de datos, como hizo Facebook, hace unos años. Kaggle es por tanto una buena fórmula para ampliar las posibilidades de encontrar un buen trabajo. Muchos reclutadores ponen su ojo en la plataforma a la hora de localizar nuevos talentos, prestando especial atención a los ganadores de las competiciones.
Además de competiciones, Kaggle ofrece otras funcionalidades:
- Un apartado para compartir datasets. Actualmente hay más de 50.000 conjuntos de datos públicos compartidos, que pueden ser utilizados de manera libre para practicar, resolver competiciones o entrenar algoritmos.
- Cursos gratuitos, que abarcan temas como Python, introducción al machine learning, análisis geoespacial o procesamiento del lenguaje natural. Están diseñados para introducir al usuario rápidamente en los temas esenciales y orientarle en la plataforma Kaggle. Una vez que se dispone de los conocimientos básicos, es el momento de participar en las competiciones.
- Notebooks, compartidos por los usuarios de Kaggle. Se trata del código, junto con tutoriales, que han utilizado los participantes en las competiciones para resolver diferentes problemas. Actualmente hay más de 500.000. Para poder ejecutarlos y practicar, Kaggle cuenta con un entorno computacional diseñado para facilitar la reproducción del trabajo de ciencia de datos.
- Un foro de discusión, donde resolver dudas y compartir feedback. Al registrase en Kaggle, no solo se obtienen numerosos recursos, sino que también te conviertes en parte de una comunidad de expertos. Estar presente en el foro es clave para ampliar conocimientos y conocer a otros usuarios, hacer equipo y enriquecerse con la experiencia de aquellos que dominan la materia en cuestión.
Kaggle utiliza un sistema de progresión con distintos tipos de usuario, según su nivel de rendimiento en cada área. Por un lado, existen 5 niveles de rendimientos: Novice, Contributor, Expert, Master y Grandmaster. Por otro, cuatro categorías de experiencia en ciencia de datos de Kaggle: Competiciones, Notebooks, Datasets y Discusión, que hacen referencia a la participación del usuario en cada área. El avance a través de los niveles de rendimiento se realiza de forma independiente dentro de cada categoría de experiencia, de tal forma que un mismo usuario puede ser Master en Competiciones, pero Novice en Discusión.
El éxito de Kaggle es tanto, que en 2017 fue adquirida por Google.
Si estás pensando en participar en alguna competición, tienes algunos consejos en este post, video y presentación.
Otras plataformas similares a Kaggle
Además de Kaggle, en la red también encontramos otras plataformas similares que albergan competiciones y retos relacionadas con los datos.
- DrivenData. Organiza retos online, que suelen durar entre 2 y 3 meses, algunos de ellas con premios económico. Un ejemplo de competición es la construcción de algoritmos de aprendizaje automático capaces de cartografiar inundaciones utilizando imágenes satélites de Sentinel-1. También disponen de un datalab donde ofrecen a las compañías sus servicios para construir soluciones relacionadas con los datos.
- Devpost. Ofrece un repositorio de hackathons a los que los usuarios se pueden apuntar, gran parte de ellos online. Incluye competiciones de empresas como Amazon o Microsoft. Alguna competición acumula hasta 5 millones de dólares a repartir en premios.
- Innocentive. Recoge retos de diversas organizaciones – algunos también con grandes cifras en premios-. Aunque tiene competiciones técnicas, también incluye retos teóricos o estratégicos en los que solo es necesaria una propuesta teórica.
- CrowdAnalytix. Con más de 25.000 usuarios, crowdAnalytix es una comunidad donde expertos en datos colaboran y compiten para customizar y optimizar algoritmos. Un ejemplo es esta competición, donde había que predecir la evolución de los cultivos utilizando imágenes satélite públicas.

Un buen perfil en Kaggle, o en el resto de plataformas que hemos visto, te ayudará a adquirir mayor experiencia y crear un buen portfolio de trabajos. También te hará más atractivo ante los reclutadores, aumentando tus posibilidades de conseguir un buen trabajo. Un buen desempeño en Kaggle demuestra habilidades de resolución de problemas y trabajo en equipo, que son algunas características necesarias para convertirse en un buen científico de datos.
Contenido elaborado por el equipo de datos.gob.es.
Blog
El mundo de la tecnología y los datos está en evolución constante. Estar a la última de las novedades y tendencias puede ser una tarea complicada. Por ello, son importantes los espacios de diálogo donde compartir conocimientos, dudas y recomendaciones.
¿Qué son las comunidades?
Las comunidades son canales abiertos a través de los cuales diferentes personas interesadas en una misma temática o tecnología se reúnen de forma física o virtual para aportar, preguntar, discutir y resolver temas relacionados con dicha tecnología. Comúnmente se crean a través de una plataforma en línea, aunque existen comunidades que organizan reuniones y eventos de manera periódica donde comparten experiencias, establecen objetivos y afianzan los lazos creados a través de la pantalla.
¿Cómo funcionan?
Muchas comunidades de desarrolladores utilizan plataformas de código abierto conocidas como GitHub o Stack Overflow, a través de las que almacenan y administran su código, además de compartir y debatir sobre temas relacionados.
Respecto a cómo se organizan, no todas las comunidades disponen de un organigrama como tal, algunas sí, pero no existe un parámetro que rija la organización de las comunidades de manera general. Sin embargo, sí pueden existir roles definidos en función de las habilidades y conocimientos de cada uno de sus miembros.
Las comunidades de desarrolladores como reutilizadores de datos
Existe un gran significativo número de comunidades que acercan los conocimientos sobre datos y sus tecnologías asociadas a diferentes grupos de usuarios. Algunas de ellas, están integradas por desarrolladores, que se reúnen para ampliar sus capacidades a través de webinars, concursos o proyectos. En ocasiones, estás actividades ayudan a impulsar la innovación y la transformación en el mundo de la tecnología y los datos, y pueden servir de escaparate para promover el uso de los datos abiertos.
A continuación, recogemos tres ejemplos de comunidades de desarrolladores relacionadas con los datos que pueden ser de tu interés si quieres ampliar tu conocimiento en este campo:
Hackathon Lovers
Desde su creación en 2013, esta comunidad de desarrolladores, diseñadores y emprendedores amantes de los hackathones, organizan encuentros para probar nuevas plataformas, APIs, productos, hardware, etc. Entre sus principales objetivos se encuentra el crear nuevos proyectos y aprender, a la vez que los usuarios se divierten y afianzan lazos con otros profesionales.
Las temáticas que abordan en sus eventos son variadas. En el hackathon #SerchathonSalud, se centraron en impulsar la formación e investigación en el campo de la salud a partir de las búsquedas bibliográficas en 3 bases de datos (PubMed, Embase, Cochrane). En otros eventos, se han focalizado en el uso de APIs concretas. Es el caso de #OpenApiHackathon, un evento de desarrollo sobre Open Banking y #hackaTrips, un hackathon para buscar ideas sobre turismo sostenible.
¿A través de qué canales puedes seguir sus novedades?
Hackathon Lovers está presente en las principales redes sociales como son Twitter y Facebook, además de YouTube, Github, Flickr y cuenta con un blog propio.
Comunidad R Hispano
Se creó en noviembre de 2011, en el seno de las III Jornadas de Usuarios de R celebradas en la Escuela de Organización Industrial en Madrid. Organizada a través de grupos locales de usuarios, su principal objetivo es el de fomentar el avance del conocimiento y el uso del lenguaje de programación en R, además del desarrollo de la profesión en todas sus vertientes, especialmente la investigadora, docente y empresarial.
Uno de sus principales campos es el de la formación de R y tecnologías asociadas a sus usuarios, en las que los datos abiertos tienen cabida. Respecto a las actividades que realizan, se encuentran eventos como:
- Congresos anuales: hasta ahora se han realizado once ediciones basadas en charlas y talleres con los asistentes con el software R como protagonista.
- Iniciativas locales: aunque la asociación es el principal promotor de los congresos anuales, el sentimiento de comunidad se forja gracias a grupos locales como los de Madrid, patrocinado por RConsortium, Canarias, que comunica aspectos como datos públicos y geográficos o Sevilla, que durante sus últimos hackatones han desarrollado varios paquetes vinculados a datos abiertos.
- Colaboración con grupos e iniciativas centradas en datos: como la UNED, Grupo de Periodismo de Datos, Grupo Machine Learning Spain o empresas como Kabel o Kernel Analytics.
- Colaboración con instituciones académicas españolas: como EOI, Universidad Francisco de Vitoria, ESIC, o K-School, entre otras.
- Relación con instituciones internacionales: como RConsortium o RStudio.
- Creación de paquetes centrado en datos en España: participación en ROpenSpain, una iniciativa para entusiastas de R y datos abiertos encaminada a crear paquetes de R de máxima calidad para la reutilización de datos españoles de interés general.
¿A través de qué canales puedes seguir sus novedades?
Esta comunidad está formada por más de 500 socios. El principal canal de comunicación para entrar en contacto con sus usuarios es Twitter, aunque sus grupos locales poseen cuentas propias, como es el caso de Málaga, Canarias o Valencia, entre otros.
R- Ladies Madrid
R-Ladies Madrid es una rama local de R-Ladies Global -un proyecto financiado por el R Consortium-Linux Foundation- que nace en 2016. Se trata de una comunidad open source desarrollada por mujeres que se apoyan y ayudan a crecer dentro del sector R.
La actividad principal de esta comunidad reside en la celebración de encuentros mensuales o meet ups donde ponentes mujeres comparten conocimientos y proyectos en los que trabajan, o enseñan funcionalidades relacionadas con R. Entre sus miembros encontramos desde profesionales que tienen R como herramienta principal de trabajo hasta aficionadas que buscan aprender y mejorar sus capacidades.
R-Ladies Madrid es muy activa dentro de la comunidad software y apoya diferentes iniciativas tecnológicas, desde la creación de grupos de trabajo open source hasta su participación en diferentes eventos tecnológicos. En algunos de sus grupos de trabajo utilizan datos abiertos, procedentes de fuentes como el BOE o Open Data NASA. Además, también han ayudado a montar un grupo de trabajo con datos sobre Covid-19. En años anteriores han organizado hackatones de género donde todos los equipos participantes estaban constituidos por un 50% mujeres y se proponía trabajar con datos de organizaciones sin ánimo de lucro.
¿A través de qué canales puedes seguir sus novedades?
R – Ladies Madrid está presente en Twitter, además de tener un grupo de Meetup.
Esta ha sido una primera aproximación, pero existen más comunidades de desarrolladores relacionadas con el mundo de los datos en nuestro país. Estas son fundamentales no solo para acercar los conocimientos teóricos y técnicos a los usuarios, sino también para impulsar la reutilización de los datos públicos a través de diversos proyectos como los que hemos visto. ¿Conoces alguna otra organización con fines similares? No dudes en escribirnos a dinamizacion@datos.gob.es o dejarnos toda la información en los comentarios.