Blog
Hace unas semanas, os contamos los distintos tipos de aprendizaje automático a través de una serie de ejemplos, y analizamos cómo elegir uno u otro en base a nuestros objetivos y a los conjuntos de datos disponibles para entrenar el algoritmo.
Ahora supongamos que contamos con un conjunto de datos ya etiquetado y que necesitamos entrenar un modelo de aprendizaje supervisado para resolver la tarea que nos ocupa. En este punto, necesitamos algún mecanismo que nos diga si el modelo ha aprendido correctamente o no. Eso es lo que vamos a tratar en este post, las métricas más utilizadas para evaluar la calidad de nuestros modelos.
La evaluación de modelos es un paso muy importante en la metodología de desarrollo de sistemas de aprendizaje automático. Ayuda a medir el rendimiento del modelo, es decir, cuantificar la calidad de las predicciones que ofrece. Para realizar este cometido utilizamos las métricas de evaluación, que dependen de la tarea de aprendizaje que apliquemos. Como vimos en el post anterior, dentro del aprendizaje supervisado existen dos tipos de tareas que difieren, principalmente, en el tipo de salida que ofrecen:
- Las tareas de clasificación, que producen como salida una etiqueta discreta, es decir, cuando la salida es una dentro de un conjunto finito.
- Las tareas de regresión, que producen como salida un valor real y continuo.
A continuación, te explicamos algunas de las métricas más utilizadas para evaluar el rendimiento de ambos tipos de tareas:
Evaluación de modelos de clasificación
Para poder entender mejor estas métricas, vamos a poner como ejemplo las predicciones de un modelo de clasificación para detectar enfermos de COVID. En la siguiente tabla podemos ver en la primera columna el identificador de ejemplo, en la segunda la clase que ha predicho el modelo, en la tercera la clase real y la cuarta columna indica si el modelo ha fallado en su predicción o no. En este caso, la clase positiva es “Si” y la clase negativa es “No”.
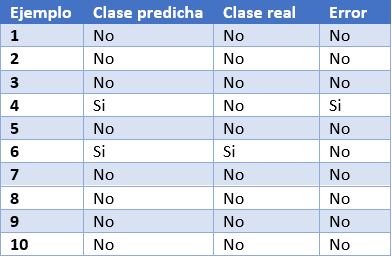
Algunos ejemplos de métricas de evaluación de modelos de clasificación son los siguientes:
- Matriz de confusión: es una herramienta ampliamente utilizada que permite inspeccionar y evaluar visualmente las predicciones de nuestro modelo. En cada fila se representa el número de predicciones de cada clase y en las columnas las instancias de la clase real.

La descripción de cada elemento de la matriz es la siguiente:
Verdadero positivo (VP): número de ejemplos positivos que el modelo predice como positivos. En el ejemplo que presentamos anteriormente, VP es 1 (del ejemplo 6).
Falso positivo (FP): número de ejemplos negativos que el modelo predice como positivos. En nuestro ejemplo, FP es igual a 1 (del ejemplo 4).
Falso negativo (FN): número de ejemplos positivos que el modelo predice como negativos. FN en el ejemplo sería 0.
Verdadero negativo (VN): número de ejemplos negativos que el modelo predice como negativos. En el ejemplo, VN es 8.
- Exactitud o accuracy: la fracción de predicciones que el modelo realizó correctamente. Se representa como un porcentaje o un valor entre 0 y 1. Es una buena métrica cuando tenemos un conjunto de datos balanceado, esto es, cuando el número de etiquetas de cada clase es similar. La exactitud de nuestro modelo de ejemplo es de 0.9, ya que ha acertado 9 predicciones de 10. Si nuestro modelo hubiese predicho siempre la etiqueta “No”, la exactitud sería de igualmente de 0.9, pero no resuelve nuestro problema de identificar enfermos de COVID.
- Recall o sensibilidad: indica la proporción de ejemplos positivos que están identificados correctamente por el modelo entre todos los positivos reales. Es decir, VP / (VP + FN). En nuestro ejemplo, el valor de sensibilidad sería 1 / (1 + 0) = 1. Si evaluásemos con esta métrica un modelo que siempre prediga la etiqueta positiva (“Si”) tendría una sensibilidad de 1, pero no sería un modelo demasiado inteligente. Aunque lo ideal para nuestro modelo de detección de COVID es maximizar la sensibilidad, esta métrica por sí sola no nos asegura que tengamos un buen modelo.
- Precision: esta métrica está determinada por la fracción de elementos clasificados correctamente como positivo entre todos los que el modelo ha clasificado como positivos. La fórmula es VP / (VP + FP). El modelo de ejemplo tendría una precisión de 1 / (1 + 1) = 0.5. Volvamos ahora al modelo que siempre predice la etiqueta positiva. En ese caso, la precisión del modelo es 1 / (1 + 9) = 0.1. Vemos como este modelo tenía una sensibilidad máxima, pero tiene una precisión muy pobre. En este caso necesitamos de las dos métricas para evaluar la calidad real del modelo.
- F1 score: combina las métricas Precision y Recall para dar un único resultado. Esta métrica es la más apropiada cuando tenemos conjuntos de datos no balanceados. Se calcula como la media armónica de Precision y Recal. La fórmula es F1 = (2 * precision * recall) / (precision + recall). Quizá te preguntes por qué la media armónica y no la simple. Esto es porque la media armónica hace que si una de las dos medidas es pequeña (aunque la otra sea máxima), el valor de F1 score va a ser pequeño.
Evaluación de modelos de regresión
A diferencia de los modelos de clasificación, en los modelos de regresión es casi imposible predecir el valor exacto, sino que más bien se busca estar lo más cerca posible del valor real, por lo que la mayoría de las métricas, con sutiles diferencias entre ellas, van a centrarse en medir eso: lo cerca (o lejos) que están las predicciones de los valores reales.
En este caso, tenemos como ejemplo las predicciones de un modelo que determina el precio de relojes dependiendo de sus características. En la tabla mostramos el precio predicho por el modelo, el precio real, el error absoluto y el error elevado al cuadrado.
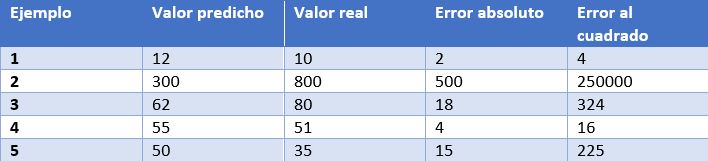
Algunas de las métricas de evaluación más comunes para los modelos de regresión son:
- Error medio absoluto: Es la media de las diferencias absolutas entre el valor objetivo y el predicho. Al no elevar al cuadrado, no penaliza los errores grandes, lo que la hace no muy sensible a valores anómalos, por lo que no es una métrica recomendable en modelos en los que se deba prestar atención a éstos. Esta métrica también representa el error en la misma escala que los valores reales. Lo más deseable es que su valor sea cercano a cero. Para nuestro modelo de cálculo de precios de relojes, el error medio absoluto es 107.8.
- Media de los errores al cuadrado (error cuadrático medio): Una de las medidas más utilizadas en tareas de regresión. Es simplemente la media de las diferencias entre el valor objetivo y el predicho al cuadrado. Al elevar al cuadrado los errores, magnifica los errores grandes, por lo que hay que utilizarla con cuidado cuando tenemos valores anómalos en nuestro conjunto de datos. Puede tomar valores entre 0 e infinito. Cuanto más cerca de cero esté la métrica, mejor. El error cuadrático medio del modelo de ejemplo es 50113.8. Vemos como en el caso de nuestro ejemplo se magnifican los errores grandes.
- Raíz cuadrada de la media del error al cuadrado: Es igual a la raíz cuadrada de la métrica anterior. La ventaja de esta métrica es que presenta el error en las mismas unidades que la variable objetivo, lo que la hace más fácil de entender. Para nuestro modelo este error es igual a 223.86.
- R cuadrado: también llamado coeficiente de determinación. Esta métrica difiere de las anteriores, ya que compara nuestro modelo con un modelo básico que siempre devuelve como predicción la media de los valores objetivo de entrenamiento. La comparación entre estos dos modelos se realiza en base a la media de los errores al cuadrado de cada modelo. Los valores que puede tomar esta métrica van desde menos infinito a 1. Cuanto más cercano a 1 sea el valor de esta métrica, mejor será nuestro modelo. El valor de R cuadrado para el modelo será de 0.455.
- R cuadrado ajustado. Una mejora de R cuadrado. El problema de la métrica anterior es que cada vez que se añaden más variables independientes (o variables predictoras) al modelo, R cuadrado se queda igual o mejora, pero nunca empeora, lo que puede llegar a confundirnos, ya que, porque un modelo utilice más variables predictoras que otro, no quiere decir que sea mejor. R cuadrado ajustado compensa la adición de variables independientes. El valor de R cuadrado ajustado siempre va a ser menor o igual al de R cuadrado, pero esta métrica mostrará mejoría cuando el modelo sea realmente mejor. Para esta medida no podemos hacer el cálculo para nuestro modelo de ejemplo porque, como hemos visto antes, depende del número de ejemplos y el número de variables utilizadas para entrenar dicho modelo.
Conclusión
A la hora de trabajar con algoritmos de aprendizaje supervisado es muy importante la elección de una métrica de evaluación correcta para nuestro modelo. Para los modelos de clasificación es muy importante prestar atención al conjunto de datos y comprobar si es balanceado o no. En los modelos de regresión hay que considerar los valores anómalos y si queremos penalizar errores grandes o no.
No obstante, generalmente, el dominio de negocio será el que nos guíe en la correcta elección de la métrica. Para un modelo de detección de enfermedades, como el que hemos visto, nos interesa que tenga una alta sensibilidad, pero también nos interesa que tenga un buen valor de precisión, por lo que F1-score sería una opción inteligente. Por otro lado, en un modelo para predecir la demanda de un producto (y por lo tanto de producción), donde un exceso de stock puede incurrir en un sobrecoste por almacenamiento de mercancía, quizás sea una buena idea utilizar la media de los errores al cuadrado para penalizar los errores grandes.
Contenido elaborado por Jose Antonio Sanchez, experto en Ciencia de datos y entusiasta de la Inteligencia Artificial .
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Los eventos son una opción perfecta para aprender más sobre aquellas cuestiones que teníamos pendientes. Como este año tenemos que mantener la tan mencionada distancia social, una de las mejores opciones son los seminarios online o también llamados Webinars. El éxito de este formato radica en que se trata de contenidos mayoritariamente gratuitos que puedes ver a distancia. Gracias a los webinars es posible formar parte de interesantes congresos con una gran afluencia de participantes o pequeñas charlas desde la comodidad de nuestro ordenador.
Estos eventos digitales están promovidos tanto desde empresas como de instituciones públicas. Por ejemplo, la Comisión Europea ha puesto en marcha dos citas de interés:
-
Conferencia Inspire 2020. Bajo el lema: “Bringing sustainability and digitalisation together” (Reuniendo la sostenibilidad y la digitalización), expertos europeos debatirán sobre cómo la digitalización puede ayudar a construir una Europa más sostenible, analizando también los riesgos medioambientales, económicos y sociales que conlleva. El evento se celebra del 3 al 11 de junio.
-
Empower your city with data. La Comisión Europea está llevando a cabo una serie de seminarios web sobre Context Broker, una API estándar que permite a los usuarios recopilar, integrar y contextualizar datos en tiempo real, y Big Data Test Infrastructure (BDTI), una infraestructura de prueba gratuita que ofrece plantillas de entorno virtual para explorar y experimentar con diversas fuentes de datos, herramientas de software y técnicas Big Data. Ya se han celebrado las dos primeras citas -cuya grabación está disponible en la web-, pero estás a tiempo de unirte en directo a las dos siguientes: el 4 o el 18 de junio.
Además, son muchas las empresas que están aprovechando las nuevas tecnologías para difundir su conocimiento a través de diversas charlas. Este interés de las empresas pone de manifiesto las grandes oportunidades de negocio que hay detrás de los datos. A continuación, se recogen algunos ejemplos:
-
Intercambio de datos e innovación de IA. Cada jueves de junio el equipo de IBM Research e IBM Data Science y TI organizan un intercambio de ideas y debates sobre Inteligencia Artificial. Los expertos e investigadores de IBM Data e IA compartirán en el seminario nuevos enfoques, técnicas y perspectivas para facilitar la automatización, la predicción y la optimización de datos impulsada por la inteligencia Artificial. Los seminarios están totalmente abiertos a preguntas, de tal forma que podrás interactuar y charlar con los expertos.
-
What is the future of data strategy? El 25 de junio se celebra este seminario sobre los diferentes procesos de la gestión de datos. El objetivo es que los asistentes conozcan cuáles son las próximas tendencias que cambiarán el mundo de los datos, con el foco puesto en la visualización de datos.
-
CxO to CxO on scaling AI for growth and innovation – Michael Murray presidente y director de Wunderman Thompson Data, junto a Seth Dobrin vicepresidente de Datos e IA de IBM explorarán en este seminario online las futuras perspectivas de la Inteligencia Artificial y el crecimiento exponencial de estas nuevas tecnologías. El evento está ya disponible, solo tienes que registrarte para poder verlo.
-
The future of Data Management. En este evento de la firma de analistas Gartner, se discutirá de forma amplia sobre el futuro del mercado de gestión de datos. Dirigido a empresas, se mostrará cómo deben planificarse y organizarse para ser una organización data-driven y adelantarse a la competencia. Al igual que en el caso anterior, el evento ya está disponible bajo registro.
Esta es solo una pequeña selección de contenidos. ¿Conoces o estás organizando algún webinar sobre datos y nuevas tecnologías? Cuéntanoslo en los comentarios.
La ciencia de datos y la Inteligencia Artificial siguen a la vanguardia ofreciendo modelos y predicciones que nos ayudan a dar sentido y respuestas al mundo empresarial y también social. Gracias a estos webinars podemos comprobar cómo ambos se abren camino en nuestro día a día de una forma vertiginosa.
Blog
La ciencia de datos es un campo interdisciplinar que busca extraer conocimiento actuable a partir de conjuntos de datos, estructurados en bases de datos o no estructurados como textos, audios o vídeos. Gracias a la aplicación de nuevas técnicas, la ciencia de datos nos está permitiendo responder preguntas que no son fáciles de resolver a través de otros métodos. El fin último es diseñar acciones de mejora o corrección a partir del nuevo conocimiento que obtenemos.
El concepto clave en ciencia de datos es CIENCIA, y no tanto datos, ya que incluso se ha comenzado a hablar de un cuarto paradigma de la ciencia, añadiendo el enfoque basado en datos a los tradicionales teórico, empírico y computacional.
La ciencia de datos combina métodos y tecnologías que provienen de las matemáticas, la estadística y la informática, y entre las que encontramos el análisis exploratorio, el aprendizaje automático (machine learning), el aprendizaje profundo (deep learning), el procesamiento del lenguaje natural, la visualización de datos y el diseño experimental.
Dentro de la Ciencia de Datos, las dos tecnologías de las que más se está hablando son el Aprendizaje Automático (Machine Learning) y el Aprendizaje profundo (Deep Learning), ambas englobadas en el campo de la inteligencia artificial. En los dos casos se busca la construcción de sistemas que sean capaces de aprender a resolver problemas sin la intervención de un humano y que van desde los sistemas de predicción ortográfica o traducción automática hasta los coches autónomos o los sistemas de visión artificial aplicados a casos de uso tan espectaculares como las tiendas de Amazon Go.
En los dos casos los sistemas aprenden a resolver los problemas a partir de los conjuntos de datos que les enseñamos para entrenarlos en la resolución del problema, bien de forma supervisada cuando los conjuntos de datos de entrenamiento están previamente etiquetados por humanos, o bien de forma no supervisada cuando estos conjuntos de datos no están etiquetados.
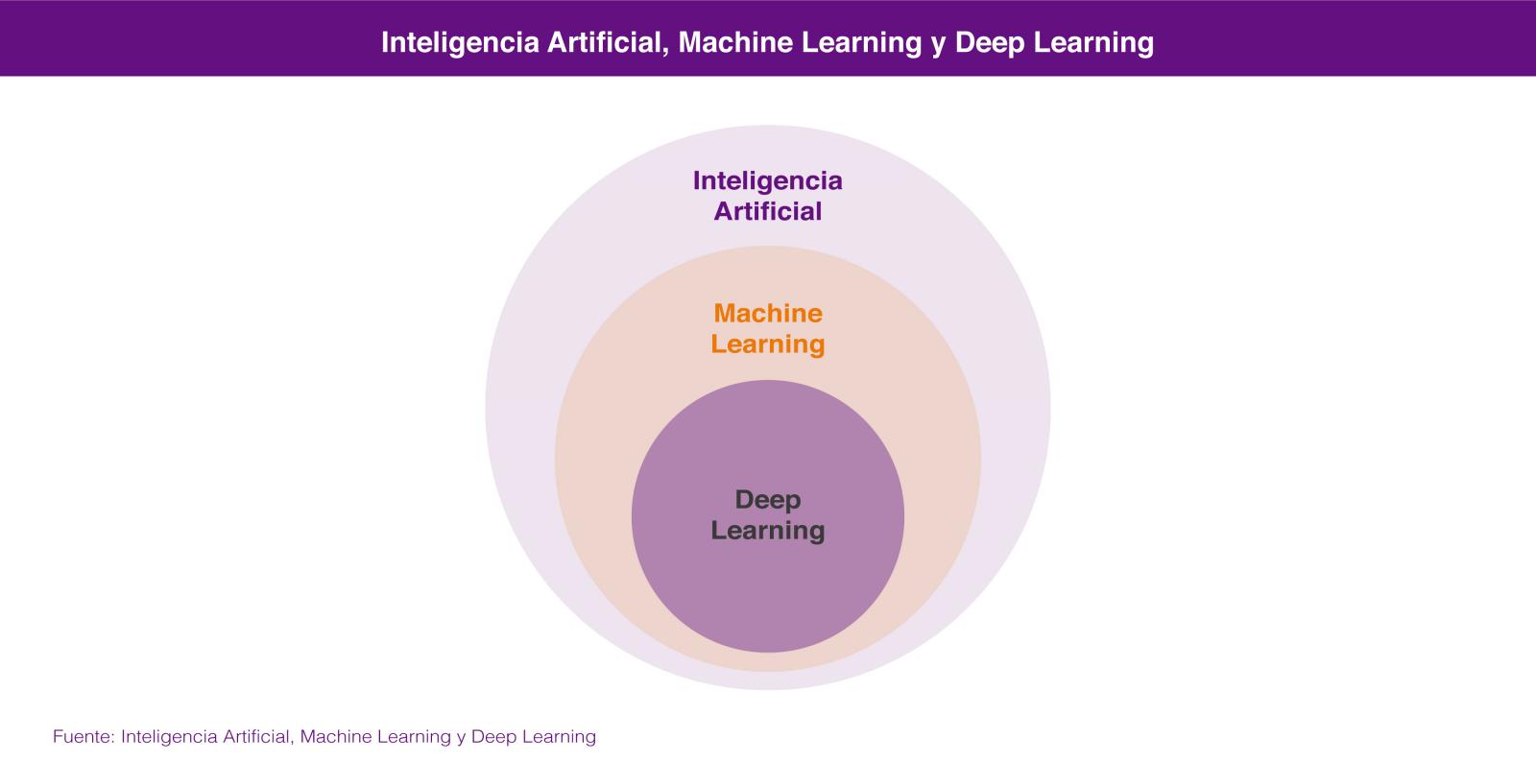
En realidad lo correcto es considerar el aprendizaje profundo como una parte del aprendizaje automático por lo que, si tenemos que buscar un atributo que nos permita diferenciarlas, éste sería su forma de aprender, que es completamente diferente. El aprendizaje automático se basa en algoritmos (redes bayesianas, máquinas de vectores de soporte, análisis de clusters, etc) que son capaces de descubrir patrones a partir de las observaciones incluidas en un conjunto de datos. En el caso del aprendizaje profundo se emplea un enfoque que está inspirado, salvando las distancias, en el funcionamiento de las conexiones de las neuronas del cerebro humano y existen también numerosas aproximaciones para diferentes problemas, como por ejemplo las redes neuronales convolucionales para reconocimiento de imágenes o las redes neuronales recurrentes para procesamiento del lenguaje natural.
La idoneidad de un enfoque u otro la marcará la cantidad de datos que tengamos disponibles para entrenar nuestro sistema de inteligencia artificial. En general podemos decir que para pequeñas cantidades de datos de entrenamiento, el enfoque basado en redes neuronales no ofrece un rendimiento superior al enfoque basado en algoritmos. El enfoque basado en algoritmos se suele estancar a partir de una cierta cantidad de datos, no siendo capaz de ofrecer una mayor precisión aunque le enseñemos más casos de entrenamiento. Sin embargo, a través del aprendizaje profundo podemos extraer un mejor rendimiento a partir de esa mayor disponibilidad de datos, ya que el sistema suele ser capaz de resolver el problema con una mayor precisión, cuanto más casos de entrenamiento tenga a su disposición.

Ninguna de estas tecnologías es nuevas en absoluto, ya que llevan décadas de desarrollo teórico. Sin embargo en los últimos años se han producido avances que han rebajado enormemente la barrera para trabajar con ellas: liberación de herramientas de programación que permiten trabajar a alto nivel con conceptos muy complejos, paquetes de software open source para administrar infraestructuras de gestión de datos, herramientas en la nube que permiten acceder a una potencia de computación casi sin límites y sin necesidad de administrar la infraestructura, e incluso formación gratuita impartida por algunos de los mejores especialistas del mundo.
Todo ello está contribuyendo a que capturemos datos a una escala sin precedentes y los almacenemos y procesemos a unos costes aceptables que permiten resolver problemas antiguos con enfoques novedosos. La inteligencia artificial está además al alcance de muchas más personas, cuya colaboración en un mundo cada vez más conectado están dando lugar a innovaciones que avanzan a un ritmo cada vez más veloz en todos los ámbitos: el transporte, la medicina, los servicios, la industria, etc.
Por algo el trabajo de científico de datos ha sido denominado el trabajo más sexy del siglo 21.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos años hemos ido descubriendo nuevas utilidades a las que aplicar la ciencia de datos, como la solución de problemas antiguos que ahora podemos resolver gracias a las nuevas técnicas y metodologías que están a nuestra disposición. La ciencia de datos se está configurando como una capacidad clave para la transformación digital y, por ello, compañías de todas las industrias y sectores están invirtiendo en la creación de equipos de ciencia de datos.
Este es quizá el motivo principal de la explosión de la demanda de trabajos relacionados con la ciencia de datos que estamos viviendo. Sirvan dos datos para ilustrar este crecimiento: en el periodo 2012-2017 se ha multiplicado hasta por diez en EE.UU. la demanda de estos profesionales y algunos estudios, como este de IBM, predicen un crecimiento del 28% hasta 2020. España no es una excepción a esta tendencia mundial: el mercado del Big Data crece un 30% cada año y ya en 2015 la demanda de talento Big Data creció un 93%, de acuerdo con un informe de Fundación Cotec para la Innovación.
Los roles más habituales en la configuración de un equipo de ciencia de datos son el científico de datos, el ingeniero de datos y el analista de negocio, todos ellos trabajando en la intersección de varias disciplinas: las matemáticas, la informática y por supuesto el conocimiento del problema de negocio.
-
El rol de científico de datos suele tener la responsabilidad de extraer conocimientos y diseñar productos basados en datos a partir de la exploración, la creación y la experimentación con modelos y visualizaciones. Para todo ello se suele apoyar en una combinación de técnicas estadísticas, matemáticas y de programación.
-
El rol de ingeniero de datos, por su parte, suele tener la misión de diseñar e implementar infraestructuras y software capaces de gestionar las necesidades de los proyectos de datos a la escala adecuada.
-
El rol de analista de negocio aporta al equipo conocimiento del problema de negocio, la correcta comprensión de los resultados derivados del análisis y modelado de los datos, así como la aplicación de los productos basados en datos que se hayan generado en los proyectos.
Normalmente encontramos desempeñando trabajos de ingeniero o científico de datos a profesionales con la formación más diversa: bien relacionados con las ciencias, como matemáticas, física o estadística, o bien con distintas ramas de la ingeniería como informática, telecomunicaciones, aeronáutica o industrial. Suelen ser personas que han decidido conducir su trayectoria profesional hacia la ciencia de datos formándose en los diferentes másteres de especialización de postgrado que ofrecen las universidades, MOOCs, o los cursos de formación no reglada que ofrecen las propias compañías para su propio personal o para captar talento.
La Universidad también está adaptándose a esta demanda del mercado para proporcionar una formación más específica y, además de los postgrados, comienzan a ser habituales los dobles grados combinando dos de estas disciplinas como la informática y la estadística. Incluso podemos encontrar ya titulaciones muy orientadas a la Ciencia de Datos como son el Grado en Ciencia e Ingeniería de Datos, el Grado en Ingeniería Matemática en Ciencia de Datos o el Grado en Ciencia e Ingeniería de Datos.
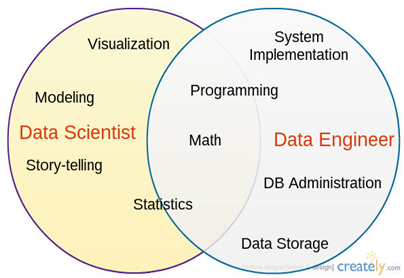
El rol de analista de negocio, también llamado analytics translator o data translator es mucho más singular, ya que debe combinar el conocimiento de negocio con una competencia técnica suficiente para comprender los problemas y enfoques de la ciencia de datos y así ser un interfaz eficaz entre el equipo y las expectativas del negocio.
La importancia y singularidad de este rol hace que las compañías estén optando por programas de formación interna a gran escala, de modo que personas que tienen un buen conocimiento de las operaciones y una cierta competencia técnica puedan conducir sus trayectorias profesionales en esta dirección.
Sin embargo no es una transición fácil por la tradicional separación entre la formación en ciencia o ingeniería, con muy pocas competencias relacionada con el negocio, y las disciplinas de negocio, que no incorporan prácticamente ninguna competencia técnica. En este sentido existe un amplio margen de mejora para que la formación universitaria ahonde en borrar estas líneas de separación, para conseguir que las personas adquieran formaciones más completas incorporando en mayor medida la economía, el marketing o la programación en disciplinas tradicionalmente ajenas a las mismas.
Como decía y demostraba Steve Jobs el valor se crea en la intersección entre la tecnología y las artes liberales.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La adopción comercial de cualquier nueva tecnología por parte de la industria y por tanto su incorporación a la cadena de valor de los negocios, en forma de innovaciones, sigue un ciclo que puede ser modelado de diferentes formas. Uno de los modelos más conocidos es el hype cycle que utiliza Gartner en sus publicaciones. En lo que se refiere a la inteligencia artificial y la ciencia de datos, la discusión actual se centra en si se ha alcanzado ya el pico de expectativas sobredimensionadas o si, por el contrario, seguiremos viendo como aumentan las promesas de nuevas y revolucionarias innovaciones.

A medida que se avanza en este ciclo lo habitual es que se produzcan nuevos avances en la tecnología (la aparición de nuevos algoritmos en el caso de la Inteligencia Artificial) o en el conocimiento de las posibilidades de aplicación comercial de estos avances (nuevos productos o productos mejorados en precio o funcionalidad). Y por supuesto cuantas más industrias y sectores se ven afectados, mayores son las expectativas que se generan.
Sin embargo los nuevos descubrimientos no se quedan sólo en el plano de la tecnología sino que es habitual que también se profundice en el estudio y comprensión del impacto económico, social, legal o ético derivado de las innovaciones que van llegando al mercado. Para cualquier negocio es esencial detectar y comprender lo antes posible cuál es el impacto que una nueva tecnología va a tener en su cadena de valor ya que de este modo podrá incorporarla entre sus capacidades antes que sus competidores y generar ventajas competitivas.
Una de las tesis más interesantes que se han publicado recientemente para modelar y comprender el impacto económico de la Inteligencia Artificial es la que propone el profesor Ajay Agrawal junto con Joshua Gans y Avi Goldfarb en su libro “Prediction Machines: The Simple Economics of Artificial Intelligence”. La premisa es muy sencilla ya que parte de establecer que desde un punto de vista meramente económico el propósito de la inteligencia artificial es reducir el coste de las predicciones.
Cuando se reduce el coste de una materia prima o tecnología, lo habitual es que la industria comience a utilizarla cada vez más, primero para los productos o servicios para los que fue ideada y más tarde para otros que se resolvían o fabricaban de otro modo. En ocasiones incluso termina afectando al valor de productos sustitutivos (que baja) y complementarios (que sube) o a otros elementos de la cadena de valor.
A pesar de que se trata de tecnologías muy complejas los autores han conseguido establecer un marco económico para entender la IA sorprendentemente sencillo. Pero pensemos en un caso concreto, familiar para todos nosotros, en el que el aumento de la precisión de las predicciones llevado al extremo podría significar, no sólo a automatizar una serie de tareas, sino a cambiar por completo las reglas de un negocio.
Como todos sabemos, Amazon utiliza Inteligencia Artificial para el sistema de recomendaciones de compra que ofrece a sus usuarios sugerencias de nuevos productos que podría interesarles adquirir. Tal y como mencionan los autores en su libro, la precisión de este sistema ronda el 5%. Esto quiere decir que los usuarios adquieren 1 de cada 20 productos que Amazon les sugieren, lo cual no está nada mal.
Si Amazon consiguiese aumentar la precisión de estas predicciones, digamos al 20%, es decir, si consiguiese que los usuarios adquiriesen 1 de cada 5 productos sugeridos, Amazon aumentaría sus beneficios enormemente y el valor de la compañía se dispararía aún más. Pero si nos imaginamos un sistema capaz de tener un precisión del 90% en las predicciones de compra de los usuarios, Amazon podría plantearse cambiar radicalmente su modelo de negocio y enviarnos los productos antes de que decidamos comprarlos ya que sólo devolveríamos 1 de cada 10. La IA no se limitaría a automatizar tareas o a mejorar nuestra experiencia de compra sino que cambiaría radicalmente la forma en la que entendemos la industria del comercio minorista.
Dado que el principal sustituto de las predicciones que nos proporciona la inteligencia artificial son las predicciones que realizamos los humanos, parece claro que nuestro valor como herramienta predictiva seguirá bajando. El avance de la ola de automatizaciones basadas en inteligencia artificial y ciencia de datos ya nos permite ver el comienzo de esta tendencia.
Por el contrario los datos de las compañías se convertirían en un activo cada vez más valioso, ya que son el principal producto complementario necesario para generar predicciones correctas. Asimismo, los datos públicos, necesarios para enriquecer los datos de las compañías, y así hacer posibles nuevos casos de uso también aumentarían su valor.
Siguiendo esta línea de razonamiento podríamos atrevernos a establecer métricas para medir el valor de los datos públicos allí donde se utilizasen. Tan sólo tendríamos que responder la pregunta: ¿cuánto mejora la precisión de una determinada predicción si enriquecemos el entrenamiento con determinamos datos abiertos? Estas mejoras tendrían un valor concreto que nos podría dar una idea del valor económico de un conjunto de datos públicos en un escenario determinado.
El repetido mantra “los datos son el nuevo petróleo” está pasando de ser una afirmación política o de marketing a estar sustentada por la ciencia económica ya que los datos no dejan de ser la materia prima necesaria e indispensable para hacer buenas y valiosas predicciones. Y parece claro que para que el coste de las predicciones siga bajando, el valor de los datos deberá aumentar. Simple economía.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Competir públicamente con tus colegas de profesión para solucionar un problema complejo basado en datos es una motivación irresistible para algunos. Casi tan tentador, como obtener relevancia en un campo de especialización tan emocionante y lucrativo como la ciencia de datos.
Las competiciones públicas para resolver problemas complejos, cuya materia prima de trabajo son datos públicamente disponibles, son una tendencia consolidada en el mundo de la ciencia de datos. Desde la predicción de terremotos hasta anticipar una rotura de stock en un gran centro de distribución son problemas basados en datos. Los nuevos métodos de machine learning y deep learning, así como la facilidad de acceso a potente tecnología de cálculo, han hecho posible que empresas y organizaciones de todo el mundo hayan abierto sus problemas de negocio a comunidades de científicos de datos que compiten entre sí para resolver el problema de la mejor forma posible a cambio de una recompensa económica.
Hace diez años que la, ahora todo poderosa y conocida, plataforma de vídeo en streaming Netflix, publicaba su Netflix Prize. El Premio Netflix fue una competición abierta que buscaba mejorar el algoritmo de filtrado colaborativo para predecir las calificaciones que los usuarios daban a las películas. El algoritmo se basa en las calificaciones anteriores sin ninguna otra información sobre los usuarios o las películas. El concurso estuvo abierto a cualquier persona que no tuviera vinculación estrecha con la compañía. El 21 de septiembre de 2009, se otorgó el gran premio de 1.000.000 $ al equipo Pragmatic Chaos de BellKor, que superó al algoritmo actual (en aquel entonces) de Netflix para predecir las calificaciones en más de un 10%.
El Premio Netflix abrió una nueva veta en el fértil campo de la ciencia de datos recompensando económicamente (con la nada desdeñable cantidad de 1M$) a aquellos equipos externos que fueran capaces de mejorar la clave de su negocio (su sistema de recomendaciones). Netflix, como muchas otras, era y es consciente de que el talento necesario para mejorar su, de por sí, sofisticado algoritmo, no se encontraba dentro de su organización si no fuera de ella.
A partir de ese momento, muchas otras competiciones similares se han abierto para solucionar toda clase de problemas basados en datos. Hasta han aparecido plataformas para gestionar este tipo de competiciones y crear una comunidad de talentosos científicos de datos alrededor de los mayores desafíos del mundo en materia de ciencia de datos. Quizás el sitio web Kaggle sea una de las plataformas de este tipo más populares para este tipo de competiciones. En el momento de escribir este artículo, existen en Kaggle 9 competiciones (activas) remuneradas por valor de 370.000 $. También hay competiciones no remuneradas económicamente (otras 9) que otorgan a los ganadores conocimiento y puntos (kudos) dentro de la propia plataforma para incentivar su uso continuado. Para cada competición, la plataforma gestiona los conjuntos de datos disponibles (datasets) así como los kernels - unos entornos de trabajo en la nube que permiten ejecutar los algoritmos de forma desatendida y reproducible por todos los participantes. Además, la plataforma establece las formas de valorar la competición así como los códigos éticos y las licencias de uso de los datos hospedados.
Además de su función como plataforma de competiciones públicas de datos, Kaggle y otras plataformas similares como ImageNet o KDD realizan una gran función como repositorios de datos abiertos. En la actualidad Kaggle registra más de 14.000 conjuntos de datos en diferentes formatos, listos para ser explotados y analizados por los científicos de datos más atrevidos del planeta. Kaggle documenta de forma extensa los conjuntos de datos disponibles en la plataforma. Los formatos de datos, comúnmente aceptados, son CSVs, JSON, SQLite, archivos comprimidos en formato ZIP y BigQuery (el formato SQL para BigData diseñado por Google). Las licencias más habituales para el uso y la redistribución de datos de la plataforma son Creative Commons, GPL y Open Database.
Plataformas como Kaggle son fantásticas. En mi opinión, el mayor beneficio de Kaggle es la capacidad de aprendizaje que ofrece, especialmente a los científicos de datos más jóvenes. En Kaggle puedes aprender mucho sobre el modelado de datos, quizás incluso mucho más de lo que normalmente se necesita en el 90% de los trabajos relacionados con Machine Learning. Aunque no hay que olvidar que, en vida real, un científico de datos necesita mucho más que conocimientos sobre modelado. Un buen científico de datos dedica el 10% de su tiempo al modelado. El 90% restante se divide entre otras habilidades técnicas en el manejo de datos y las llamadas habilidades blandas, como la capacidad de comunicación, síntesis, relación con colaboradores y liderazgo.
Recuerda, si quieres aprender mucho sobre machine learning en problemas reales, juega en Kaggle, pero no te olvides de entrenar y conocer las habilidades blandas.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Los datos son una de las principales fuerzas que mueven nuestro entorno económico y social. Los datos permiten tomar mejores decisiones en el momento y lugar adecuado, permiten realizar predicciones sobre cómo se van a comportar un mercado o conocer cuál ha sido el impacto de las últimas medidas implementadas. Por ello, cada vez más empresas y organismos buscan desarrollar una estrategia basada en datos, pero se encuentran con un problema: necesitan profesionales que sepan captar, integrar, analizar y extraer valor de las distintas fuentes de información, públicas y privadas.
La escasez de talento es uno de los principales retos a los que tienen que hacer frente las organizaciones a la hora de hablar de gestión y análisis de datos. Como ya indicaba el informe Generación de talento Big Data en España, realizado por la Fundación Cotec para la Innovación, existe una demanda creciente de profesionales especializados en materias como big data, ciencia de datos o arquitectura de datos, entre otros. Además, hacen falta profesionales que sepan moverse en un entorno de datos abiertos. La principal solución a este reto radica en la educación.
Los centros educativos son conscientes de esta situación y han incrementado la oferta formativa en torno a los datos. Muchos de los cursos, grados y posgrados que encontramos en la actualidad han incluido en su temario asignaturas centradas en los datos abiertos, como una fuente clave de conocimiento que, por sí solos o integrados junto con datos privados, puede ayudar a explicar y entender mejor el entorno, o ser utilizados como base para generar nuevos servicios y productos de valor añadido. A continuación se recogen algunos ejemplos:
-
La Universidad Politécnica de Cataluña ofrece el curso de formación continua semipresencial Mapas y Open Data: programación, organización y análisis de los Geodatos. Este curso, cuya próxima edición comienza el 12 de diciembre, forma parte del itinerario del máster Sistemas de Información Geográfica y del posgrado Tecnologías SIG. Durante la formación se analizarán los formatos, las técnicas de visualización y el tratamiento de las geometrías y geodatos en aplicaciones web. Está dirigido a cualquier profesional que quiera trabajar con datos, provengan de ámbitos sociales, como economía, política o periodismo, o de ámbitos científicos y tecnológicos.
-
El próximo 26 de octubre la Universidad Complutense de Madrid arranca su Máster Propio en Big Data y Business Analytics. Este master está centrado en el diseño, gestión, análisis y explotación de grandes volúmenes de datos para su implementación dentro de la estrategia empresarial y la toma de decisiones. Entre temas como machine learning, Python, Hadoop o Spark, se incluye un módulo centrado en las tendencias de gobierno abierto, así como las fuentes de datos y algoritmos abiertos. Al contrario que el ejemplo anterior, este master está dirigido a una audiencia de perfil técnico.
-
La Universidad de Alcalá también dedica un módulo de los Máster en Business Intelligence y data science y del Máster en Data Science a los distintos modelos de bases de datos y a la obtención de información procedente de fuentes públicas. Dirigido a estudiantes de perfil técnico, ambos masters buscan crear profesionales que quieran adquirir conocimientos de Big Data, Business Intelligence, Machine Learning, Business Analytics y visualización de datos como ventaja competitiva.
-
Por su parte, la Universidad de Salamanca ha puesto en marcha el Máster de Experto en Big Data con un módulo llamado Introducción a Big Data. Almacenamiento y Open Data, donde se señala la importancia de los datos abiertos y el mundo de posibilidades y aplicaciones que abre. Comienza el 15 de octubre.
-
Los datos abiertos también se han colado en la formación online. Además de los ya conocidos MOOCs, hoy podemos encontrar masters nacionales como el ofertado por Escuela de Organización industrial. El Master de Business Intelligence y Big Data que ofrece aborda la reutilización de datos abiertos públicos, la apertura de datos empresariales, el uso de APIs o el desarrollo de estrategias basadas en datos abiertos.
-
Por último, también se está incrementando la formación en áreas verticales concretas que utilizan datos, como el periodismo. Un ejemplo es el Master universitario en periodismo de investigación, datos y visualizaciones, de Universidad Internacional de La Rioja o Master de periodismo de datos del Centro Universitario Villanueva. Su objetivo es que los alumnos aprendan a transformar los datos y la información en historias visuales aplicando la estadística, minería de datos, infografía, diseño y la visualización.
Todos estos cursos ponen de manifiesto cómo las universidades están adaptando sus programas a los cambios tecnológicos vigentes, pero la reforma en la educación debe ir más allá. Los expertos también reclaman que se aumente la formación relacionada con estas materias en los estadios anteriores de la educación, tanto en primaria como en secundaria. De esta forma, se ayudará aún más a impulsar la generación del talento que el mercado reclama.
Noticia
European Data Science Academy (EDSA) es una plataforma de integración de cursos gratuitos que ofrece planes de estudios para la formación en ciencias de datos y en ciencias de la información. En concreto, ha diseñado currículos modulares adaptables, así como recursos de aprendizaje para aquellos que quieran formarse como científicos de los datos.
La era de los datos crece y se afianza de un modo imparable en todos los sectores y ámbitos. La recogida, almacenamiento y análisis de los datos se ha convertido en todo un desafío. Ante esta nueva realidad, European Data Science Academy ha diseñado este ciclo formativo sobre la Ciencia de Datos en el ámbito de la Unión Europea, con un enfoque abierto e innovador.
Los planes de estudios se basan en la experiencia que la EDSA tiene en Open University y eLearning a través de tres líneas educativas principales:
-
analizar las competencias específicas del sector para analistas de datos en los principales sectores industriales de Europa
-
desarrollar currículos modulares y adaptables para satisfacer las expectativas de la industria
-
impartir formación en ciencias de los datos apoyada en recursos de aprendizaje multiplataforma y multilingüe
 Los currículos y recursos de aprendizaje cuentan con la tutoría y evaluación constante de profesores expertos en pedagogía y ciencias de los datos. Entre las innovaciones que está llevando a cabo, destaca la monitorización de las tendencias en toda Europa para evaluar las demandas de habilidades y conocimientos específicos de Data Science. EDSA analiza dicha demanda, aprovechando la red de proveedores de datos europeos, consumidores e intermediarios para "tomar el pulso" al panorama de datos europeo.
Los currículos y recursos de aprendizaje cuentan con la tutoría y evaluación constante de profesores expertos en pedagogía y ciencias de los datos. Entre las innovaciones que está llevando a cabo, destaca la monitorización de las tendencias en toda Europa para evaluar las demandas de habilidades y conocimientos específicos de Data Science. EDSA analiza dicha demanda, aprovechando la red de proveedores de datos europeos, consumidores e intermediarios para "tomar el pulso" al panorama de datos europeo.
Asimismo, está entrevistando a profesionales de Data Science y utilizando herramientas automatizadas para extraer datos sobre empleos y noticias con el objetivo de generar un cuadro de mando que represente el panorama europeo de las ciencias de la información. Esta academia europea ha diseñado un currículo básico y ha elaborando materiales formativos de calidad multilingües y multimodales.
Su sistema de formación y aprendizaje se apoya en libros electrónicos, cursos y seminarios on line (MOOC), conferencias en video y formación presencial. Su objetivo es ofrecer estas iniciativas y materiales a lenguas europeas y ampliarlos para sectores específicos, principalmente a través de VideoLectures.NET y FutureLearn - la plataforma MOOC más grande de Europa, fundada por The Open University - para maximizar el alcance y la captación de dichos materiales.
Una de las innovaciones que ofrece European Data Science Academy y su plataforma formativa online es la utilización de herramientas de monitoreo y análisis para evaluar el progreso del alumno.
Más información: http://edsa-project.eu/
Noticia
Mejor iniciativa empresarial big data en España, mejor data scientist y mejor periodista de datos. La segunda edición de los premios Data Science Awards Spain 2017 convocada se estructura en tres categorías. Organizados por Synergic Partners, con el apoyo de Telefónica, Data Science Awards Spain 2017 se presenta como un concurso pero se define también como una oportunidad, networking, reconocimiento y certificación. Unos premios que persiguen el reconocimiento del talento analítico en España y que apuestan por descubrir las últimas tendencias dentro del mundo de Data Science.
El fenómeno del big data está irrumpiendo en todos los sectores y modelos de negocio y la gran mayoría de las empresas se están adaptando y reorganizando para convertirse en organizaciones data-driven. Las nuevas necesidades empresariales conllevan también cambios culturales y la adquisición de nuevas capacidades. La ciencia de datos emerge como profesión presente y futura: manejar, comprender y extraer conclusiones a partir de los datos. Junto a conocimientos técnicos y capacidad analítica, se precisa una visión más integral que ayude a comprender los datos y obtener valor de negocio.
Con esta filosofía se convocan y desarrollan estos premios, en sus tres modalidades a las que se puede optar hasta el próximo 30 de junio.
- Premio Mejor Iniciativa Empresarial Big Data en España: empresas pioneras en la adopción del Big Data. Se evaluarán las iniciativas más destacadas y se premiará la más innovadora y que combine un mejor balance entre el uso de la tecnología y la generación del valor de negocio.
- Premio Mejor Data Scientisten España: el objetivo de este premio es descubrir talento analítico en las tres especialidades de la ciencia de datos: Data Scientist, Data Engineer y Data Visualization. Se valorarán la innovación, la rigurosidad en la metodología y la aplicabilidad en el desarrollo de los retos.
- Premio Mejor Trabajo periodístico de Datos en España: el volumen de datos e información de la que disponemos hoy en día requiere una comunicación clara, fiable y objetiva. Este premio reconoce la labor de los periodistas pioneros en la comunicación basada en datos, donde la importancia de las fuentes, el tratamiento de datos, su análisis mediante herramientas Big Data, la claridad en la exposición y la visualización de los mismos es clave.
En una segunda fase, hasta el 15 de septiembre, los seleccionados podrán presentar sus proyectos que serán valorados por un jurado formado por grandes expertos nacionales e internacionales en Big Data. El fallo tendrá lugar el 25 de septiembre y la entrega de premios se celebrará en octubre en el marco de la Big Data Week de Madrid.