Evento
Events are a perfect option to learn more about those issues that we had pending. As this year we have to maintain the aforementioned social distance, one of the best options is online seminars or also called Webinars. The success of this format lies in the fact that it is mostly free content that you can see from a distance. Thanks to webinars, it is possible to take part in interesting conferences with a large number of participants or small talks from the comfort of our computer.
These digital events are promoted from both companies and public institutions. For example, the European Commission has launched two interesting appointments:
- Inspire 2020 Conference. Under the theme: “Bringing sustainability and digitalization together”, European experts will discuss how digitization can help build a more sustainable Europe, also analysing environmental, economic and social risks that entails. The event is held from June 3 to 11.
- Empower your city with data. The European Commission is conducting a series of webinars on Context Broker, a standard API that allows users to collect, integrate and contextualize data in real time, and Big Data Test Infrastructure (BDTI), a free testing infrastructure that offers Virtual environment templates to explore and experiment with various data sources, software tools and Big Data techniques. The first two appointments have already been held - the recording is available on the web - but you have time to join the next two webinars: June 4 or 18.
In addition, there are many companies that are taking advantage of new technologies to spread their knowledge through various talks. This interest from companies highlights the great business opportunities behind the data. Here are some examples:
- Data sharing and AI innovation. Every Thursday in June the team from IBM Research and IBM Data Science and IT organize an exchange of ideas and discussions on Artificial Intelligence. Experts and researchers from IBM Data and AI will share new approaches, techniques and perspectives to facilitate Artificial Intelligence-driven automation, prediction and data optimization at the seminar. The seminars are fully open to questions, so you can interact and chat with the experts.
- What is the future of data strategy? This seminar on the different processes of data management is held on June 25. The goal is for attendees to learn about the next trends that will change the world of data, with the focus on data visualization.
- CxO to CxO on scaling AI for growth and innovation - Michael Murray president and director of Wunderman Thompson Data, together with Seth Dobrin vice president of Data and AI of IBM will explore in this online seminar the future perspectives of Artificial Intelligence and the exponential growth of these new technologies. The event is already available, you just have to register to watch it.
- The future of Data Management. At this event by analyst firm Gartner, the future of the data management market will be discussed extensively. Aimed at companies, it will show how they should plan and organize to be a data-driven organization and stay ahead of the competition. As in the previous case, the event is already available under registration.
This is just a small selection of content. Do you know or are you organizing a webinar on data and new technologies? Tell us in the comments.
Data science and Artificial Intelligence remain at the forefront offering models and predictions that help us to understand the business and also social world. Thanks to these webinars, we can see how they both make their way in our day to day in a dizzying mode.
Blog
Data science is an interdisciplinary field that seeks to extract actuable knowledge from datasets, structured in databases or unstructured as texts, audios or videos. Thanks to the application of new techniques, data science is allowing for answering questions that are not easy to solve through other methods. The ultimate goal is to design improvement or correction actions based on the new knowledge.
The key concept in data science is SCIENCE, and not really data, considering that experts has even begun to speak about a fourth paradigm of science, including data-based approach together with the traditional theoretical, empirical and computational approachs.
Data science combines methods and technologies that come from mathematics, statistics and computer science. It include exploratory analysis, machine learning, deep learning, natural-language processing, data visualization and experimental design, among others.
Within Data Science, the two most talked-about technologies are Machine Learning and Deep Learning, both included in the field of artificial intelligence. In both cases, the objective is the construction of systems capable of learning to solve problems without the intervention of a human being, including from orthographic or automatic translation systems to autonomous cars or artificial vision systems applied to use cases as spectacular as the Amazon Go stores.
In both cases, the systems learn to solve problems from the datasets “we teach them” in order to train them to solve the problem, either in a supervised way - training datasets are previously labeled by humans-, or in a unsupervised way - these data sets are not labeled-.
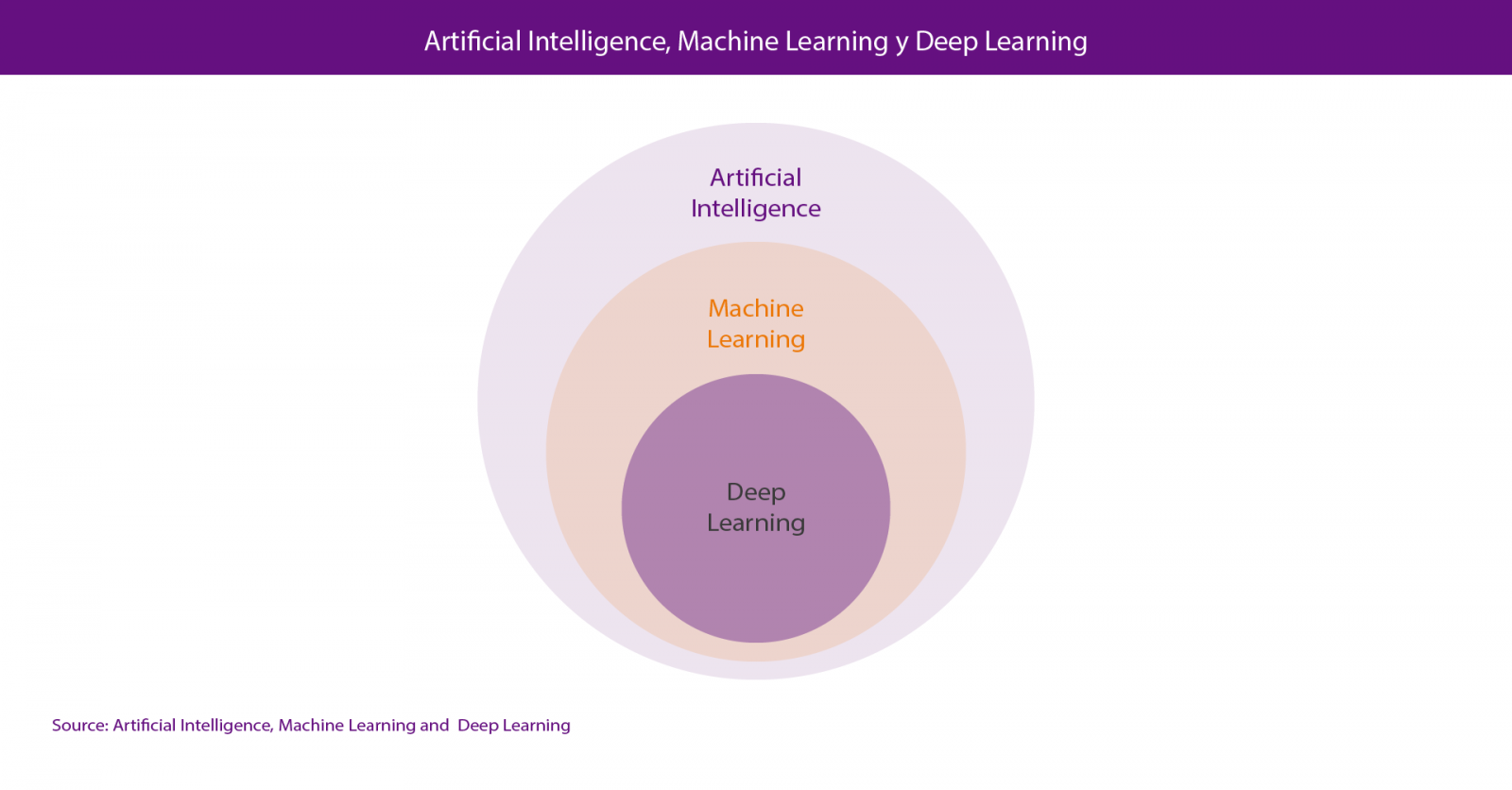
Actually, the correct point of view is to consider deep learning as a part of machine learning so, if we have to look for an attribute to differentiate both of them, we could consider their method of learning, which is completely different. Machine learning is based on algorithms (Bayesian networks, support vector machines, clusters analysis, etc.) that are able to discover patterns from the observations included in a dataset. In the case of deep learning, the approach is inspired, basically, in the functioning of human brain´s neurons and their connections; and there are also numerous approaches for different problems, such as convolutional neural networks for image recognition or recurrent neural networks for natural language processing.
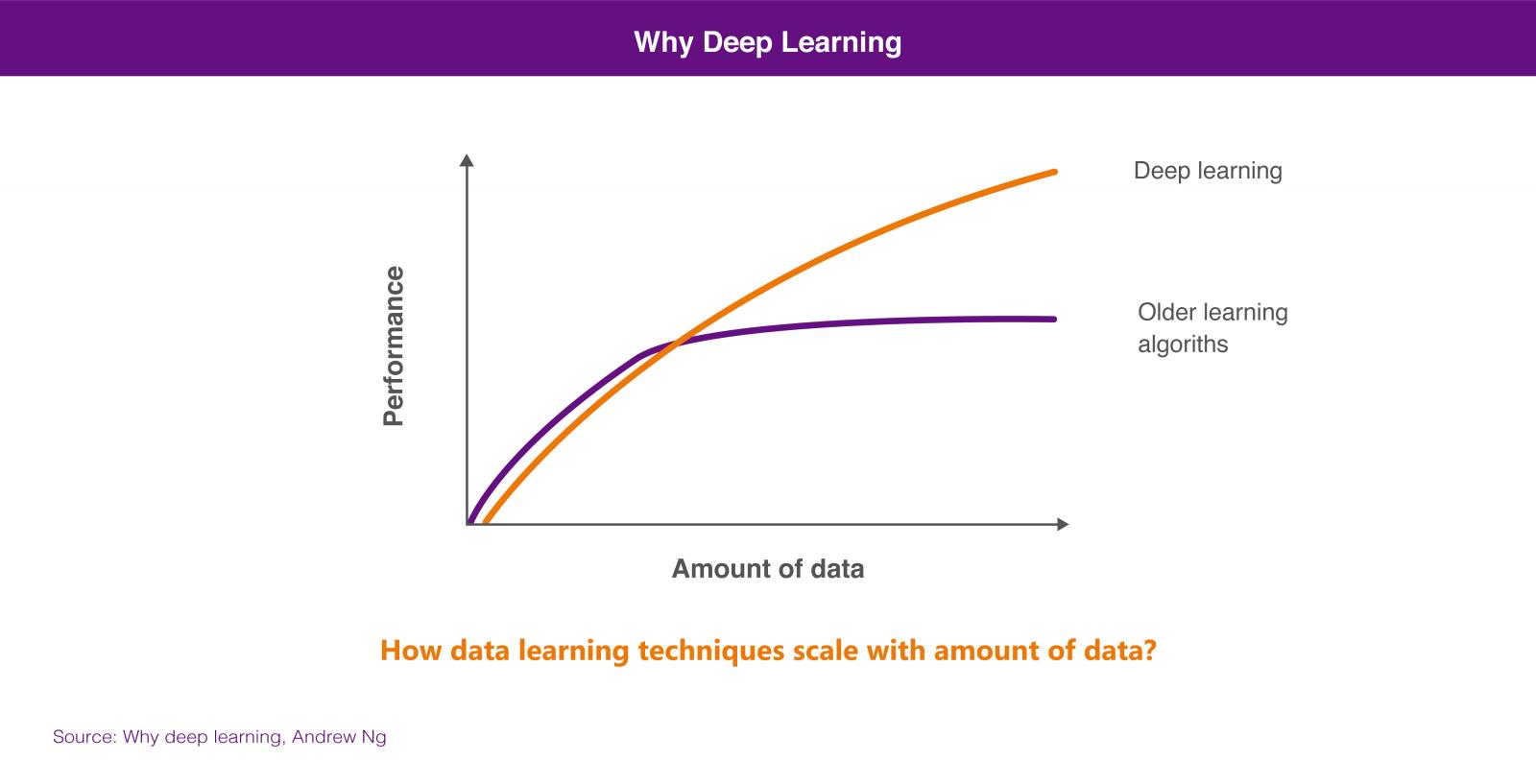
The suitability of one approach or another will rely on the amount of data we have available to train our artificial intelligence system. In general, we can affirm that, if we have a small amounts of training data, the neural network-based approach does not offer superior performance than the algorithm-based approach. The algorithm-based approach usually come to a standstill due to huge amount of data, not being able to offer greater precision although we teach more training cases. However, through deep learning we can have a better performance from this greater amount of data, because the system is usually able to solve the problem with greater precision, the more cases of training are available.
None of these technologies is new at all, considering that they have decades of theoretical development. However, in recent years new advances have greatly reduced their barriers: the opening of programming tools that allow high-level work with very complex concepts, open source software packages to run data management infrastructures, cloud tools that allow access to almost unlimited computing power and without the need to manage the infrastructure, and even free training given by some of the best specialists in the world.
All this issues are contributing to capture data on an unprecedented scale, and store and process data at acceptable costs that allow us to solve old problems with new approaches. Artificial intelligence is also available to many more people, whose collaboration in an increasingly connected world is giving rise to innovation, advancing increasingly faster in all areas: transport, medicine, services, manufacturing, etc.
For some reason, data scientist has been called the sexiest job of the 21st century.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
In recent years we have been discovering new field to apply data science, as the solution of old problems that we can now solve thanks to the new techniques and methodologies that are available. Data science is being configured as a key capability for digital transformation and, therefore, companies from all industries and sectors are investing in the creation of data science teams.
Perhaps, this is the main reason for the current explosion of demand for data science jobs. We will use two data to illustrate this growth: in the period 2012-2017 the demand of these professionals has multiplied up to ten in the USA, and some studies, like this one of IBM, predict a growth of 28% until 2020. Spain is not an exception to this global trend: Big Data market grows 30% each year and, already in 2015, the demand of Big Data talent grew by 93%, according to a Cotec Foundation report.
The most common roles in the configuration of a data science team are data scientist, data engineer and business analyst, all working at the intersection of several disciplines: mathematics, computer science and, of course, knowledge of the business problems.
- The data scientist role is usually responsible for extracting knowledge and designing products based on data from exploration, creation and experimentation with models and visualizations. For all this, he usually use a combination of statistical, mathematical and programming techniques.
- The data engineer role, on the other hand, usually has the mission of designing and implementing infrastructures and software capable of managing the needs of data projects at the appropriate scale.
- The business analyst role brings knowledge related to the business problem to the team: the correct understanding of the results derived from the analysis and modeling of the data, as well as the application of the data-based products generated in the projects.
Normally we find professionals that work as engineer or data scientist with the most diverse training: either related to the sciences, such as mathematics, physics or statistics, or related to different engineering branches such as computer science, telecommunications, aeronautics or industrial engineer. Usually, they are people who have decided to lead their career to data science learning different masters or postgraduate offered by universities, MOOCs, or non-regulated training courses offered by companies aimed at their own staff or to attract talent.
Universities are also adapting to this market demand in order to provide more specific training and, in addition to the postgraduate programs, double degrees are becoming common, combining two of these disciplines such as computer science and statistics. We can even find course oriented to data science such as the bachelor´s degree in Science and Data Engineering, the bachelor´s degree in Mathematical Engineering in Data Science or the Degree in Data Science and Engineering.
The business analyst role, also called analytics translator or data translator is much more unique, because he/she must combine business knowledge with sufficient technical competence to understand data science problems and approaches and, thus, be an effective interface between data science team and business expectations.
The importance and uniqueness of this role means that companies are opting for large-scale internal training programs, so that professionals with a good knowledge of operations and a certain technical competence can lead their professional careers in this direction.
However, it is not an easy transition due to the traditional separation between science or engineering training, with very few competences related to business, and business disciplines, without practically technical competence. In this sense, there is a wide margin for improvement, so that university training goes into erasing these separation lines, in order to get people to acquire more complete training incorporating economics, marketing or programming in disciplines traditionally unconnected.
As Steve Jobs said and demonstrated, best ideas emerge from the intersection of technology and the humanities.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
The commercial adoption of any new technology and, therefore, its incorporation into the business value chain follows a cycle that can be moulded in different ways. One of the best known models is the Gartner hype cycle. With regard to artificial intelligence and data science, the current discussion focuses on whether the peak of inflated expectations has already been reached or, on the contrary, we will continue to see how the promises of new and revolutionary innovations increase.
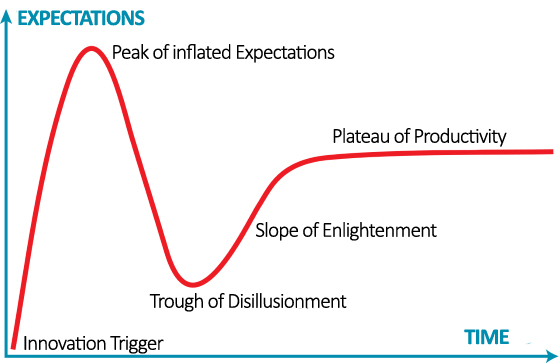
As we advance in this cycle, it is usual to find new advances in technology (new algorithms, in the case of Artificial Intelligence) or a great knowledge about their possibilities of commercial application (new products or products with better price or functionalities). And, of course, the more industries and sectors are affected, the higher expectations are generated.
However, the new discoveries do not only remain on the technological level, but it usually also go deeper into the study and understanding of the economic, social, legal or ethical impact derived from the innovations that are arriving on the market. For any business, it is essential to detect and understand as soon as possible the impact that a new technology will have on its value chain. This way, the company will be able to incorporate the technology into its capabilities before its competitors and generate competitive advantages.
One of the most interesting thesis recently published to model and understand the economic impact of Artificial Intelligence is the one proposed by Professor Ajay Agrawal with Joshua Gans and Avi Goldfarb in his book "Prediction Machines: The Simple Economics of Artificial Intelligence”. The premise is very simple: at the beginning, it establish that the purpose of artificial intelligence, from a merely economic point of view, is to reduce the cost of predictions.
When the cost of a raw material or technology is reduced, it is usual for the industry to increase their use, first applying this technology to the products or services it was designed for, and later, to other product or services that were manufactured in another way. Sometimes it even affects the value of substitute products (that fall) and complementary products (that rise), or other elements of the value chain.
Although these technologies are very complex, the authors were able to establish a surprisingly simple economic framework to understand the AI. But let's see a concrete case, familiar to all of us, in which the increase of the accuracy of the predictions, taken to the extreme, could mean not only to automate a series of tasks, but also to completely change the rules of a business .
As we all know, Amazon uses Artificial Intelligence for the purchase recommendation system that offers suggestions for new products. As mentioned by the authors in his book, the accuracy of this system is around 5%. This means that users acquire 1 out of every 20 products that Amazon suggests, which is not bad.
If Amazon is able to increase the accuracy of these predictions, let's say to 20%, that is, if users acquire 1 out of every 5 suggested products, Amazon would increase its profits enormously and the value of the company would skyrocket even more. But if we imagine a system capable of having a precision of 90% in the purchase predictions, Amazon could consider radically changing its business model and send us products before we decide to buy them, because we would only return 1 out of every 10. AI would not just automate tasks or improve our shopping experience, it would also radically change the way we understand the retail industry.
Given that the main substitute for AI predictions are human predictions, it seems clear that our value as a predictive tool will continue decreasing. The advance of the wave of automations based on artificial intelligence and data science already allows us to see the beginning of this trend.
On the contrary, company data would become an increasingly valuable asset, since they are the main complementary product necessary to generate correct predictions. Likewise, the public data necessary to enrich the companies data, and thus make possible new use cases, would also increase its value.
Following this line of reasoning, we could dare to establish metrics to measure the value of public data where they were used. We would only have to answer this question: how much improves the accuracy of a certain prediction if we enrich the training with determined open data? These improvements would have a concrete value that could give us an idea of the economic value of a public dataset in a specific scenario.
The repeated mantra "data is the new oil" is changing from being a political or marketing affirmation to being supported by economic science, because data are the necessary and indispensable raw material to make good and valuable predictions. And it seems clear that, to continue reducing the predictions cost, the data value should increase. Simple economy.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
Publicly competing with your colleagues to solve a complex problem based on data is an irresistible motivation for some people. Almost as tempting as gaining relevance in a field of expertise as exciting and lucrative as data science.
Public competitions to solve complex problems, whose raw material of work are public data, are a consolidated trend in the world of data science. The core is data-based problems, from predicting earthquakes to anticipating a stock break in a big distribution centre. The new methods of machine learning and deep learning, as well as the ease of access to powerful calculation technology, have made possible for companies and organizations around the world to open their business problems to communities of data scientists who compete with each other to solve the problem in the best possible way, in order to win an economic reward.
Ten years ago, the now powerful and well-known Netflix streaming video platform published its Netflix Prize. It was an open competition that sought to improve the collaborative filtering algorithm to predict the ratings users gave to movies. The algorithm is based on the previous ratings without any additional information about users or movies. The contest was open to anyone without close links with the company. On September 21, 2009, the grand prize of $ 1,000,000 was awarded to BellKor's Pragmatic Chaos which outperformed the current Netflix algorithm (at that time) to predict ratings passing the 10% mark.
The Netflix Award opened a new option in the fertile field of data science by financially rewarding (with the appreciable amount of $ 1M) to those external teams that were able to improve the key to their business (their recommendation system). Netflix, like many other companies, was and is aware that the talent needed to improve its sophisticated algorithm was not within the organization.
From that moment, many other similar competitions have been opened to solve all kinds of problems based on data. People have even create platforms to manage this type of competition and create a community of talented data scientists around the world's biggest data science challenges. Perhaps Kaggle website is one of the most popular platforms for this type of competitions. At the time of writing this article, there are 9 (active) competitions worth $ 370,000 in Kaggle. There are also competitions that are not economically remunerated (another 9) that give knowledge and points (kudos) within the platform itself to encourage their continued use. For each competition, the platform manages the available data sets as well as the kernels - work environments in the cloud that allow all participants to execute algorithms in an unattended and reproducible way. In addition, the platform establishes the ways to assess the competition as well as ethical codes and licenses for the use of hosted data.
In addition to its function as a platform for public data competitions, Kaggle and other similar platforms such as ImageNet or KDD perform high value function as open data repositories. Currently Kaggle records more than 14,000 data sets in different formats, ready to be exploited and analysed by the most daring data scientists on the planet. Kaggle documents data sets available on the platform extensively. The data formats commonly accepted are CSVs, JSON, SQLite, compressed files in ZIP format and BigQuery (the SQL format for BigData designed by Google). The most common licenses for data use and redistribution are Creative Commons, GPL and Open Database.
Platforms like Kaggle are fantastic. In my opinion, the greatest benefit of Kaggle is the learning capacity, especially to younger data scientists. In Kaggle you can learn a lot about data modelling, perhaps even much more than normally needed in the 90% of the jobs related to Machine Learning. Although we must not forget that, in real life, a data scientist needs much more than modelling knowledge. A good data scientist dedicates 10% of his time to modelling. The 90% remaining is divided among other technical skills in data management and “soft skills”, such as communication, synthesis, relationship with employees and leadership skills.
Remember, if you want to learn a lot about machine learning in real problems, play in Kaggle, but do not forget to train and learn soft skills.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Noticia
Data is one of the main forces that move our economic and social environment. The data allow us to make better decisions at the right time and place, make predictions about how a market will change or know the impact of the last measures . Therefore, more and more companies and organizations seek to develop a strategy based on data, but they find a problem: they need professionals who know how to capture, integrate, analyze and extract value from different sources of information, both public and private.
The shortage of talent is one of the main challenges that organizations have to face when talking about data management and analysis. As the report Generation of Big Data talent in Spain, carried out by the Fundación Cotec para la Innovación,already indicated, there is a growing demand for professionals specialized in fields such as big data, data science or data architecture, among others. In addition, organizations need professionals who know open data environment. The main solution to this challenge lies in education.
The educational centers are aware of this situation. Universities and schools have increased the offer around data. Many of these courses, degrees and postgraduate have included subjects focused on open data, as a key source of knowledge that, just alone or integrated with private data, can help better explain and understand the environment, or be used as a basis to generate new value-added services and products. Here we have some examples:
- The Technical University of Cataluña offers the continuous blended learning course Maps and Open Data: programming, organization and analysis of Geodata. This course, whose next edition begins on December 12, is part of the itinerary of the Master's Degree in Geographic Information Systems and the postgraduate GIS Technologies. During the course, students could learn about formats, visualization techniques and the treatment of geometries and geodata in web applications. The course is aimed at any professional who wants to work with data, from social areas such as economics, politics or journalism to scientific and technological fields.
- On October 26 the Complutense University of Madrid starts its own Master´s degree in Big Data and Business Analytics. This master is focused on the design, management, analysis and exploitation of large volumes of data for its implementation within the business strategy and decision making. Among topics such as machine learning, Python, Hadoop or Spark, they include a module focused on open government trends, as well as data sources and open algorithms. Unlike the previous example, this master is aimed at a technical profile audience.
- The University of Alcalá also dedicates a module of the Master´s degree in Business Intelligence and data science and of the Master´s degree in Data Science to the different models of databases and the obtaining of information from public sources. Aimed to technical students, both masters seek to create professionals who want to acquire knowledge of Big Data, Business Intelligence, Machine Learning, Business Analytics and data visualization as a competitive advantage.
- For its part, the University of Salamanca has launched the Master's Degree in Big Data with a module called Introduction to Big Data. Storage and Open Data, where the importance of open data and their world of possibilities and applications are pointed out. It starts on October 15.
- Open data has also leaked into online training. In addition to the well-known MOOCs, nowadays we can find national masters such as the Master´s degree in Business Intelligence and Big Data offered by Escuela de Organización industrial. This course address the reuse of public open data, the opening of business data, the use of APIs and the development of strategies based on open data.
- Finally, training in specific vertical areas that use data, such as journalism, is also increasing. An example is the Master's degree in research, visualizations and data journalism, from Internacional University of La Rioja or Master's degree in data journalism from University Center Villanueva. Its objective is learning how to transform data and information into visual stories by applying statistics, data mining, infographics, design and visualization.
All these courses show how universities are adapting their programs to the current technological changes, but the reform in education must go further. The experts also demand the increase of these subjects in the previous stages of education, both in primary and secondary education. In this way, it will help even more to boost the generation of the talent that the market demands.
Noticia
Best big data business initiative in Spain, best data scientist and best data reporter. The second edition of the Data Science Awards Spain 2017 is organized into three categories. Organized by Synergic Partners, with the support of Telefónica, Data Science Awards Spain 2017 is presented as a competition but is also an opportunity, networking, recognition and certification. Prizes that seek the recognition of analytical talent in Spain and that are committed to discovering the latest trends within the world of Data Science.
The big data phenomenon is breaking into all sectors and business models and the vast majority of companies are adapting and reorganizing to become data-driven organizations. New business needs also entail cultural changes and the acquisition of new skills. Data science emerges as a present and future profession: managing, understanding and drawing conclusions from data. Together with technical knowledge and analytical skills, a more comprehensive vision is needed to help understand data and obtain business value.
With this philosophy, these awards are announced and organised in three modalities which can be entered until the 30th of June.
- Best Business Initiative Big Data in Spain: companies pioneering the adoption of Big Data. The most outstanding initiatives will be evaluated and the most innovative and which achieves the best balance between the use of technology and the generation of business value will receive the award.
- Best Data Scientist Award in Spain: The aim of this award is to discover analytical talent in the three specialities of data science: Data Scientist, Data Engineer and Data Visualization. Innovation, methodological rigour and applicability in the carrying out challenges will be evaluated.
- Best Journalistic Data Work Award in Spain: the volume of data and information we have today requires clear, reliable and objective communication. This award recognizes the work of pioneering journalists in data-based communication, where the importance of sources, data processing, analysis using Big Data tools, clarity in the presentation and visualization thereof are key.
In a second phase, until September 15, those selected will be able to present their projects that will be assessed by a jury composed of major national and international experts in Big Data. The final decision will take place on September 25 and the awards ceremony will be held in October at the Big Data Week de Madrid.